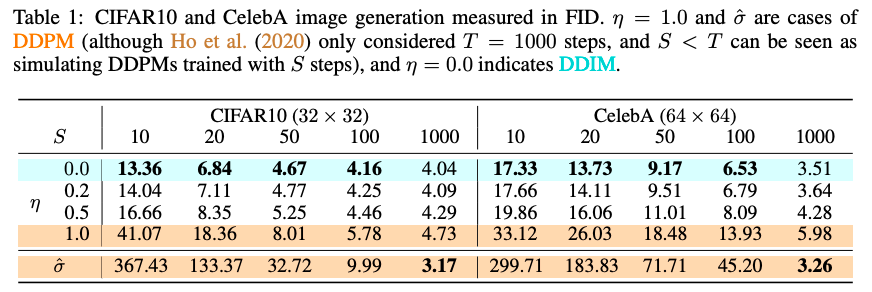
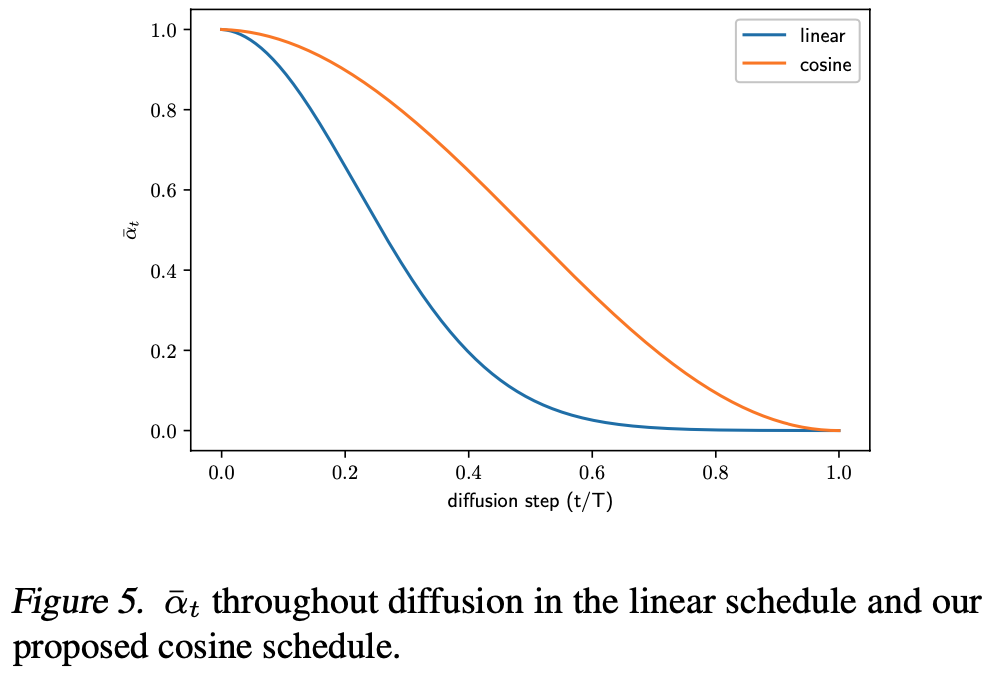
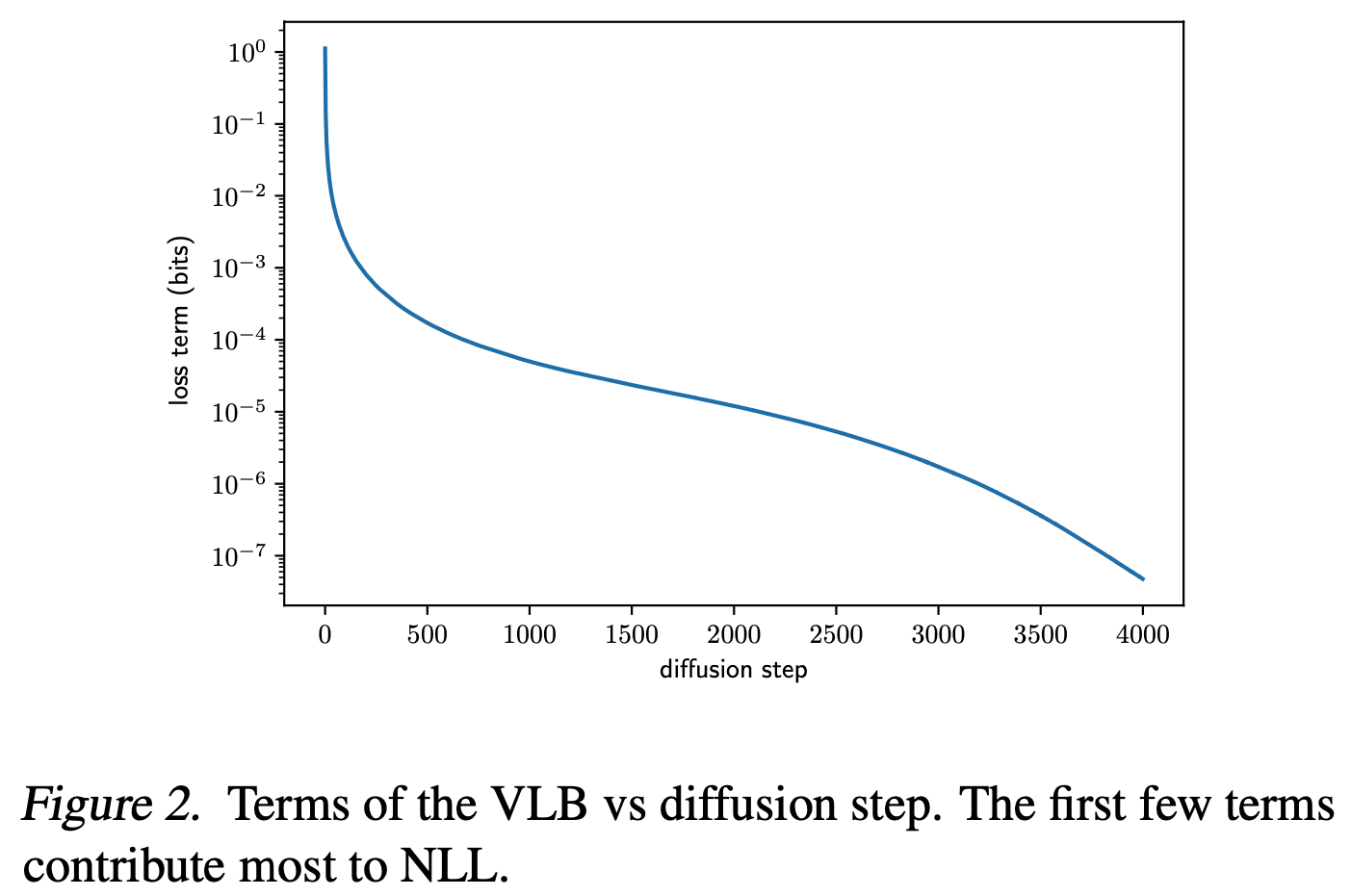
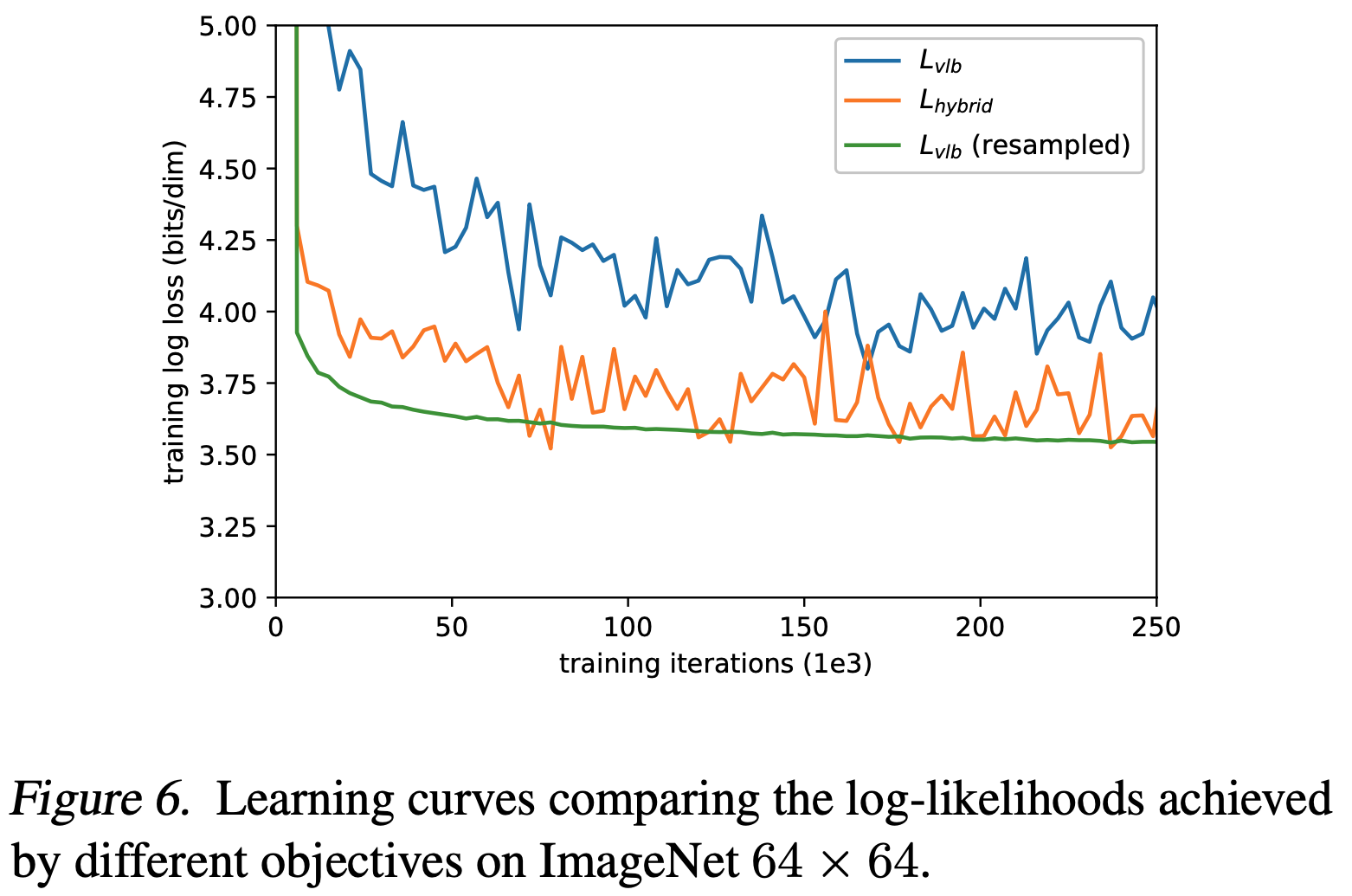
参考链接:https://www.cnblogs.com/flintlovesam/p/6677037.html
Shell中的${}、##和%%使用范例
假设我们定义了一个变量为:
1
file=/dir1/dir2/dir3/my.file.txt
可以用
${ }分别替换得到不同的值:1
2
3
4
5
6
7
8${file#*/}: # 删掉第一个 / 及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}: # 删掉最后一个 / 及其左边的字符串:my.file.txt
${file#*.}: # 删掉第一个 . 及其左边的字符串:file.txt
${file##*.}: # 删掉最后一个 . 及其左边的字符串:txt
${file%/*}: # 删掉最后一个 / 及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: # 删掉第一个 / 及其右边的字符串:(空值)
${file%.*}: # 删掉最后一个 . 及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: # 删掉第一个 . 及其右边的字符串:/dir1/dir2/dir3/my记忆的方法为:
%和#分别在$的右边和左边#是去掉左边(键盘上#在$的左边)%是去掉右边(键盘上%在$的右边)- 单一符号是最小匹配;两个符号是最大匹配
1
2${file:0:5}: # 提取最左边的 5 个字节:/dir1
${file:5:5}: # 提取第 5 个字节右边的连续5个字节:/dir2
也可以对变量值里的字符串作替换:
1
2${file/dir/path}: # 将第一个dir 替换为path:/path1/dir2/dir3/my.file.txt
${file//dir/path}: # 将全部dir 替换为 path:/path1/path2/path3/my.file.txt利用
${ }还可针对不同的变数状态赋值(沒设定、空值、非空值):1
2
3
4
5
6
7
8
9
10${file-my.file.txt} : # 假如 $file 沒有设定,則使用 my.file.txt 作传回值(空值及非空值時不作处理)
${file:-my.file.txt} : # 假如 $file 沒有設定或為空值,則使用 my.file.txt 作傳回值(非空值時不作处理)
${file+my.file.txt} : # 假如 $file 設為空值或非空值,均使用 my.file.txt 作傳回值(沒設定時不作处理)
${file:+my.file.txt} : # 若 $file 為非空值,則使用 my.file.txt 作傳回值(沒設定及空值時不作处理)
${file=my.file.txt} : # 若 $file 沒設定,則使用 my.file.txt 作傳回值,同時將 $file 賦值為 my.file.txt (空值及非空值時不作处理)
${file:=my.file.txt} : # 若 $file 沒設定或為空值,則使用 my.file.txt 作傳回值,同時將 $file 賦值為my.file.txt (非空值時不作处理)
${file?my.file.txt} : # 若 $file 沒設定,則將 my.file.txt 輸出至 STDERR(空值及非空值時不作处理)
${file:?my.file.txt} : # 若 $file 没设定或为空值,则将 my.file.txt 输出至 STDERR(非空值時不作处理)
${#var} # 可计算出变量值的长度
${#file} # 可得到 27 ,因为/dir1/dir2/dir3/my.file.txt 是27个字节
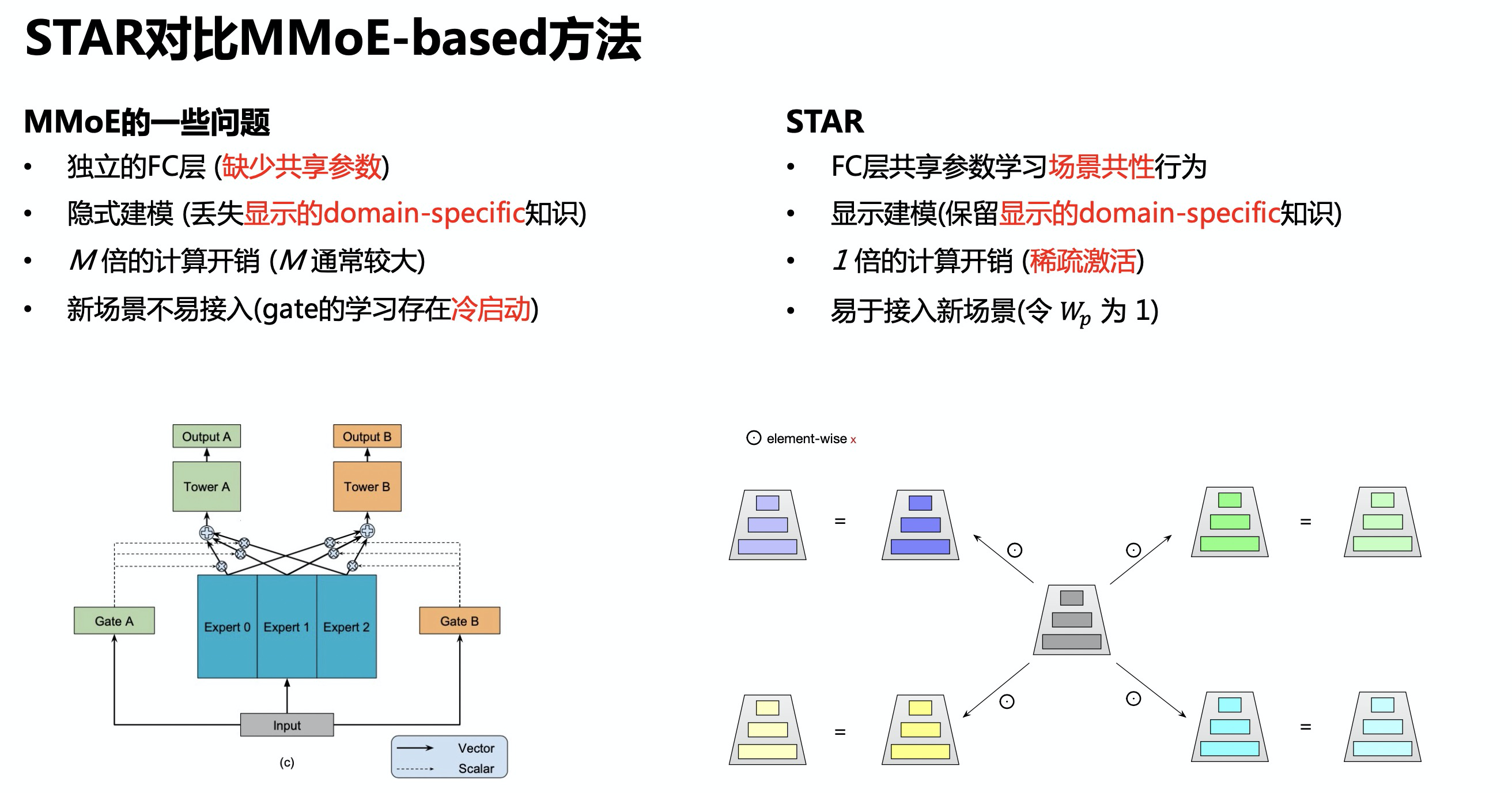
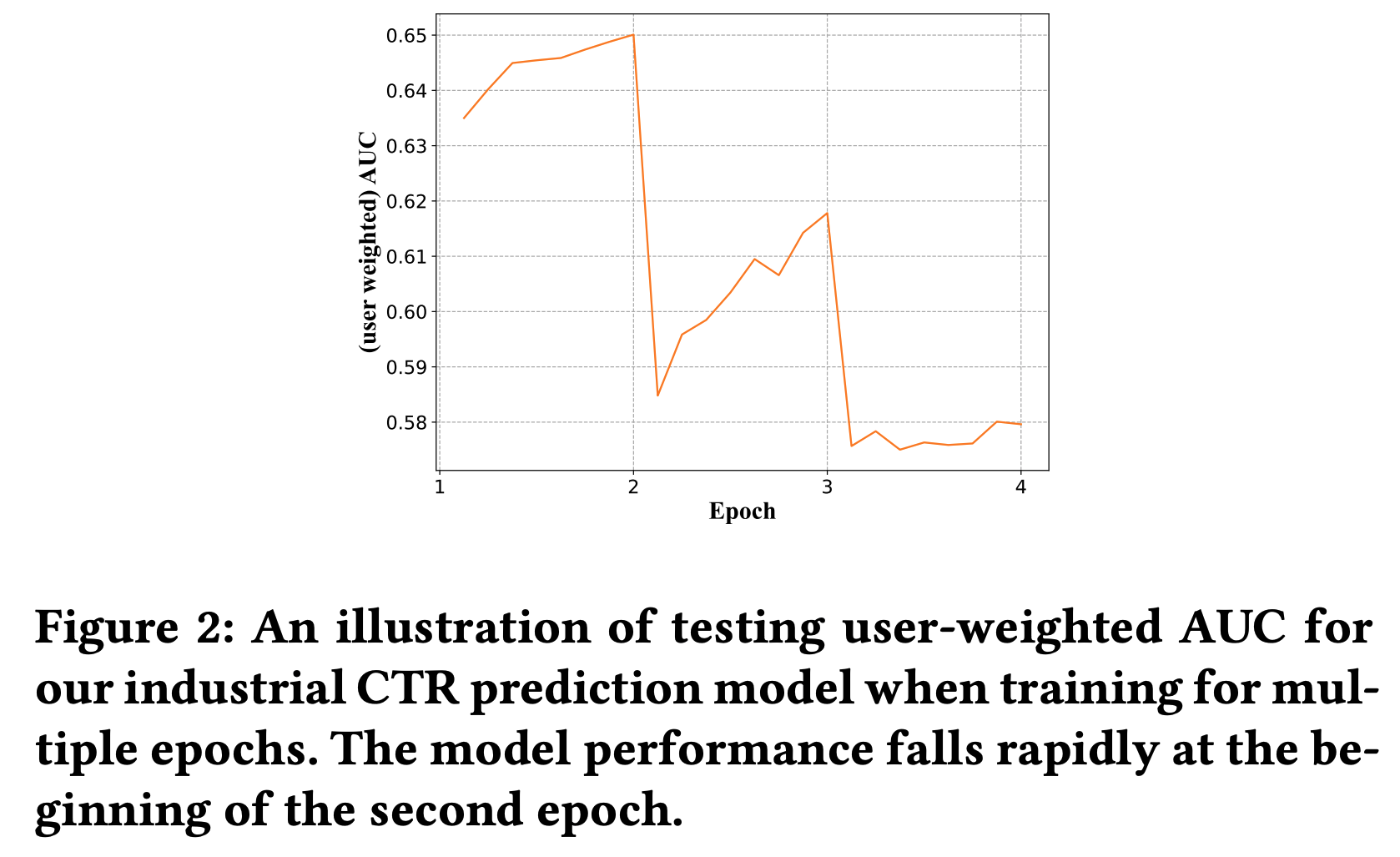

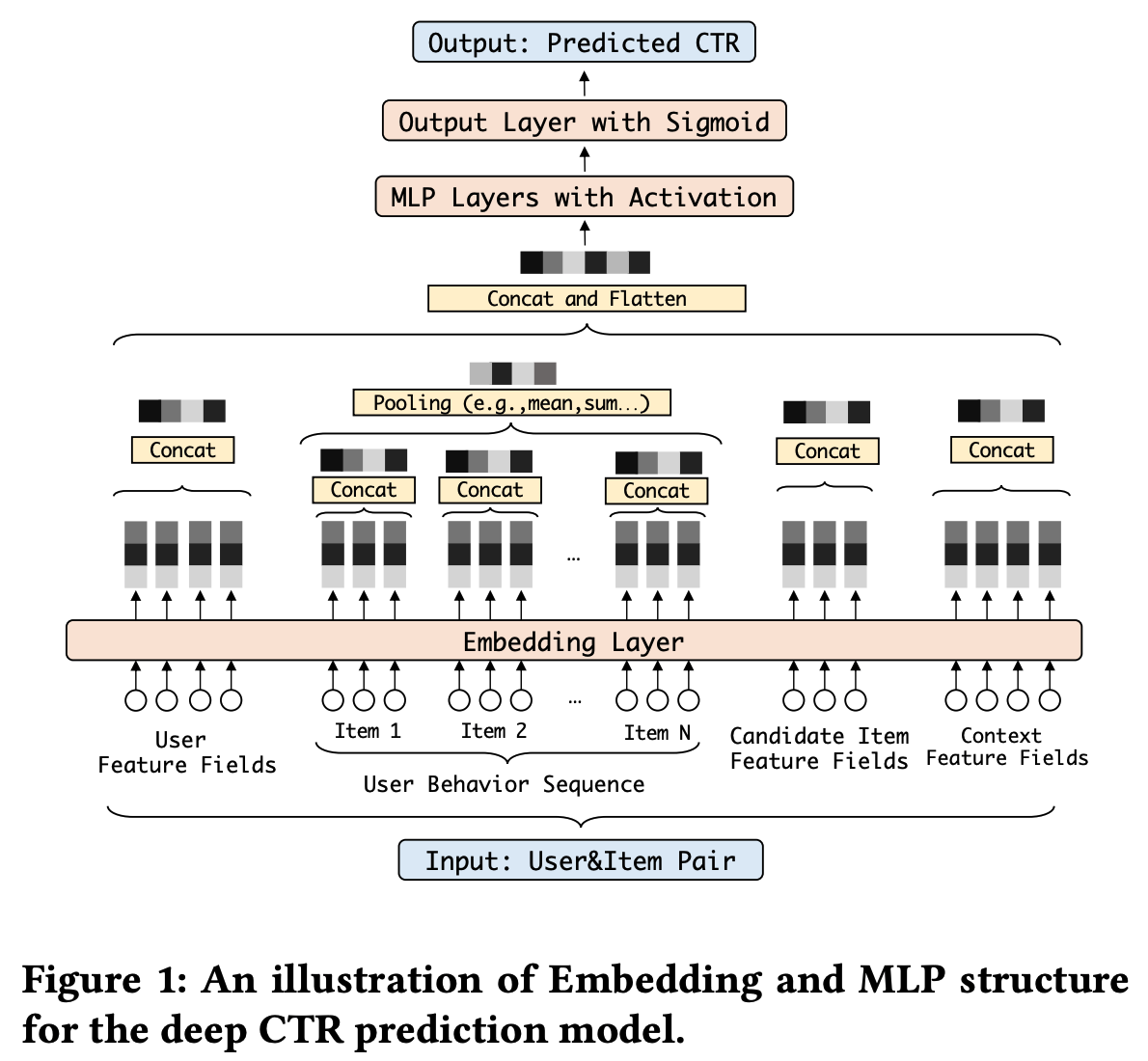
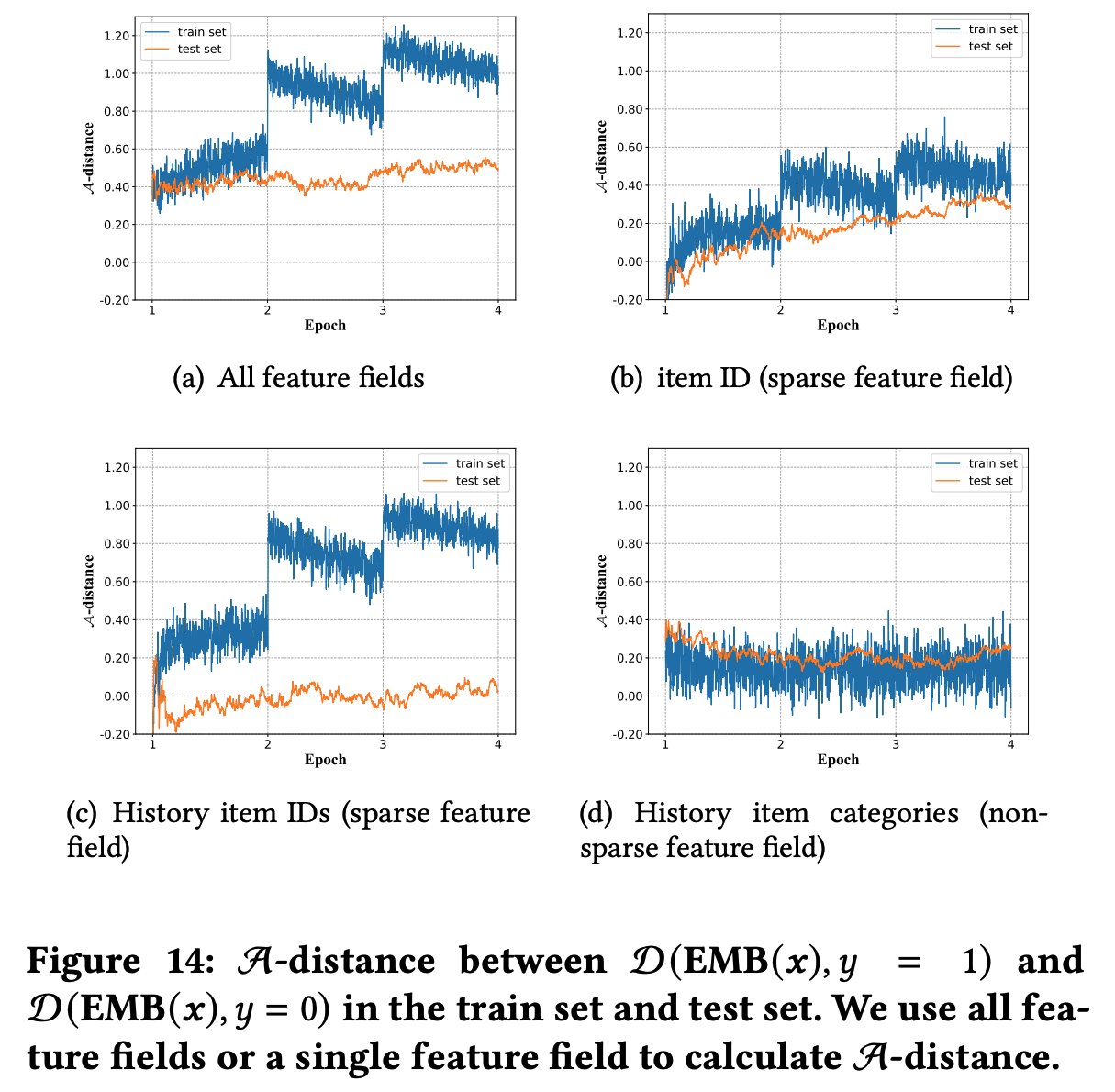
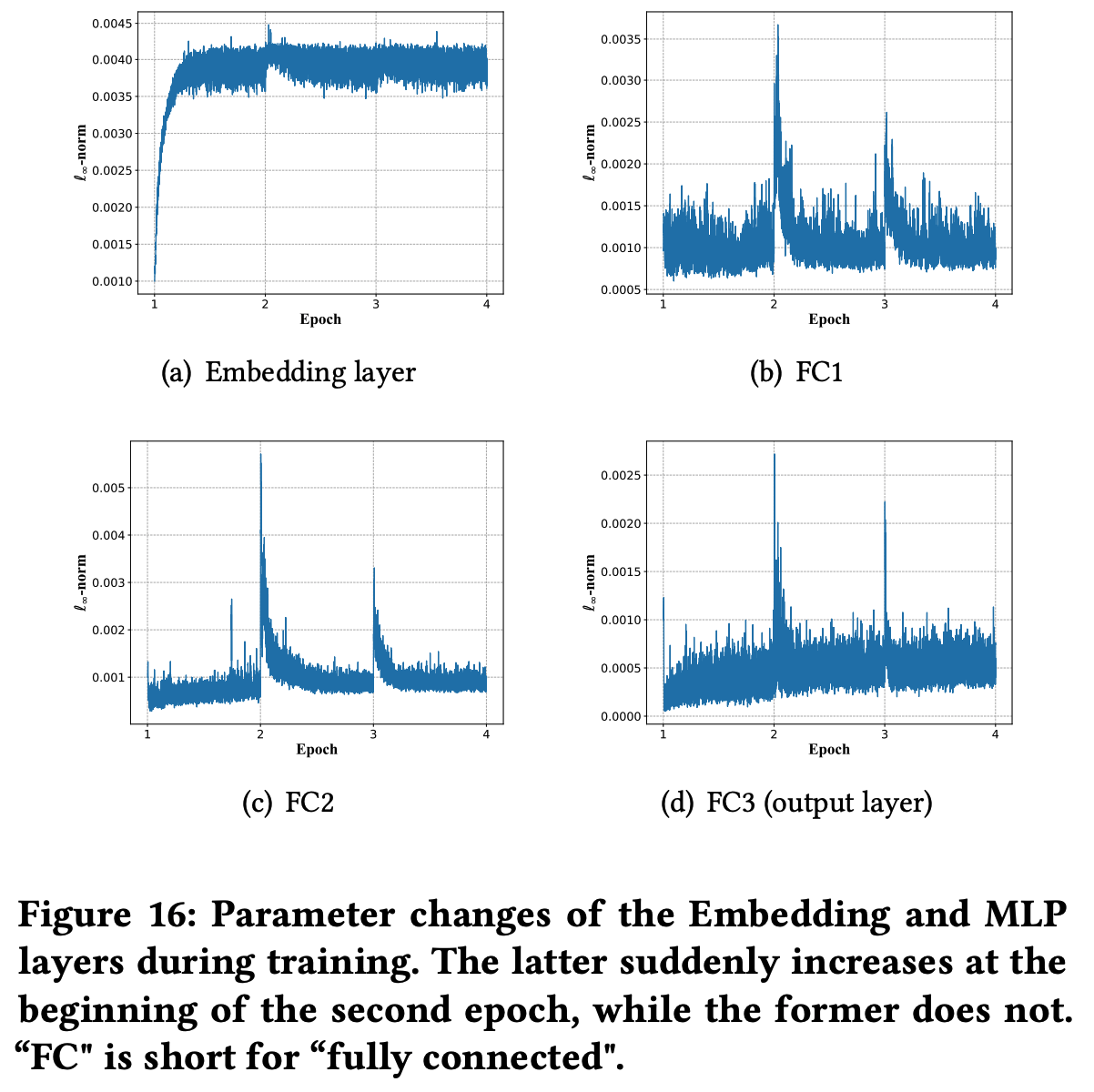
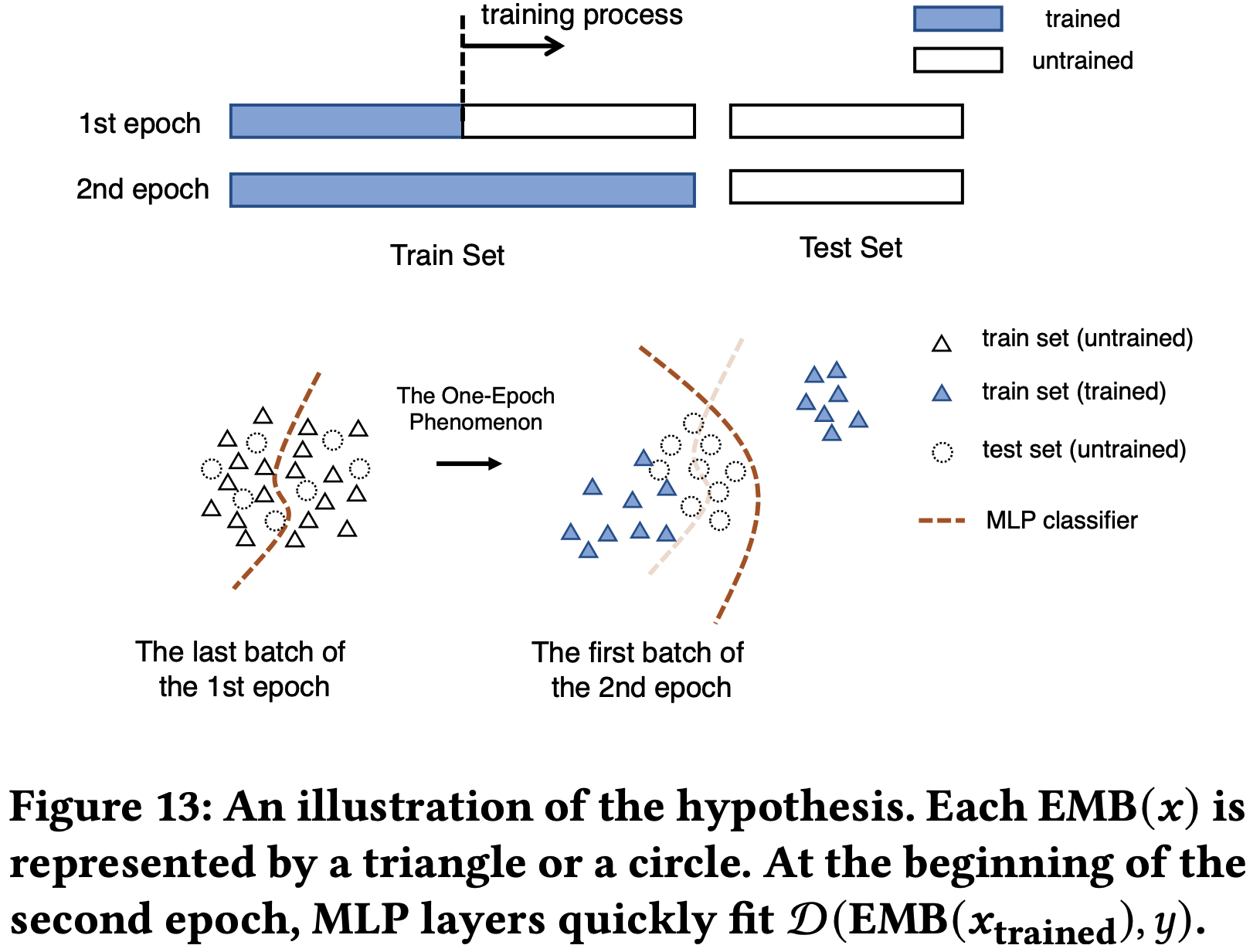
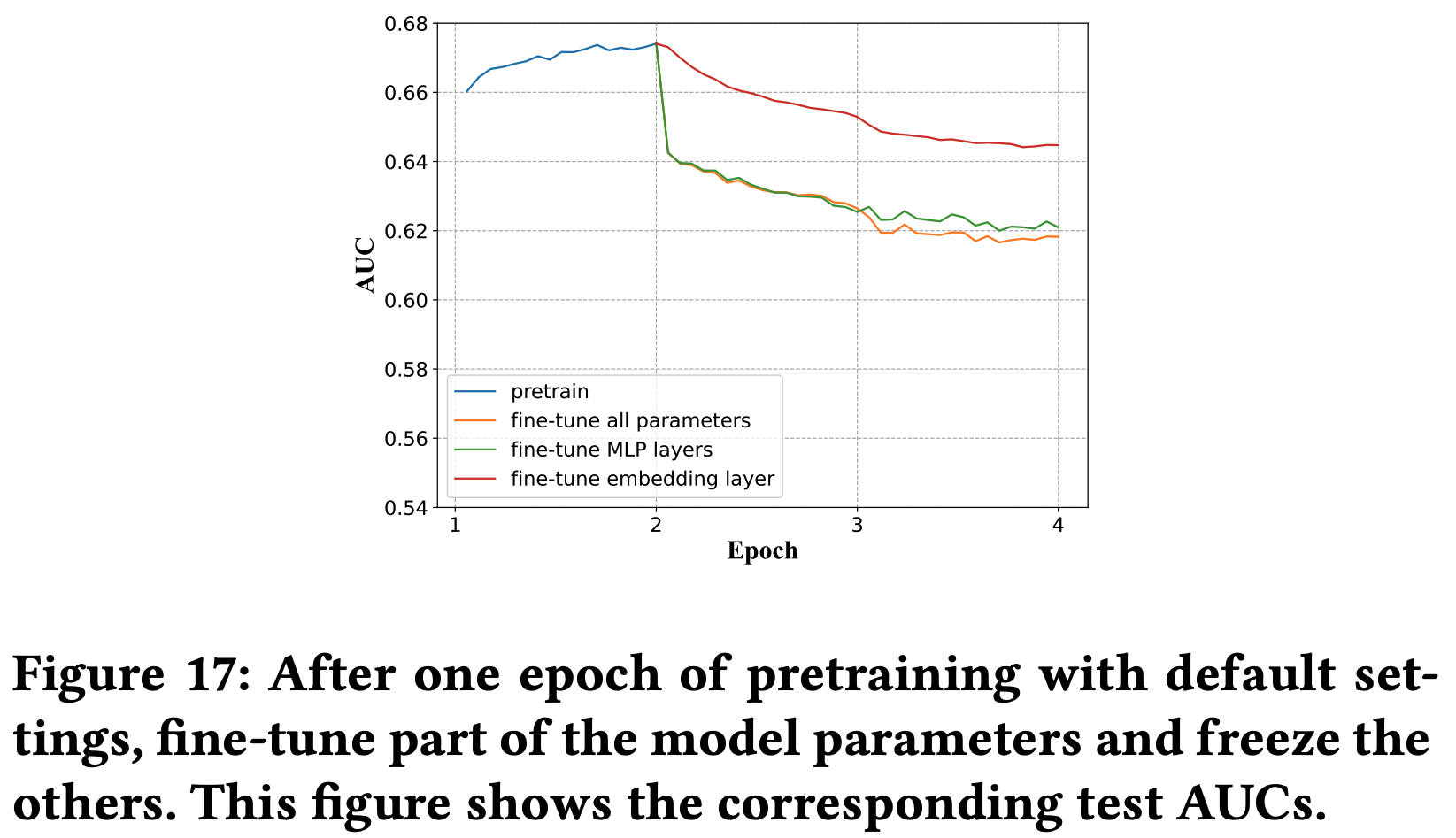
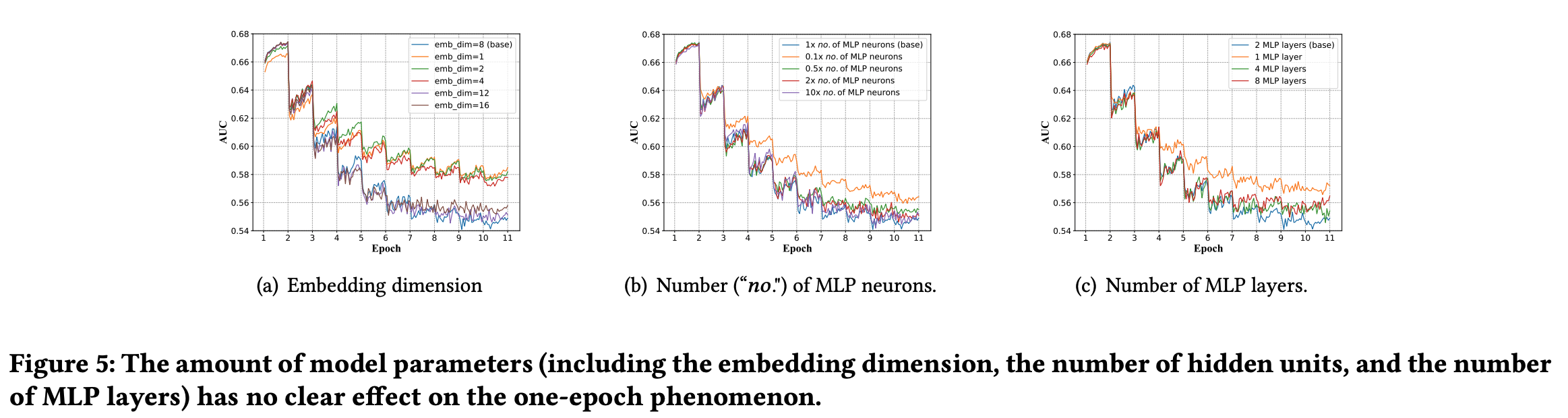
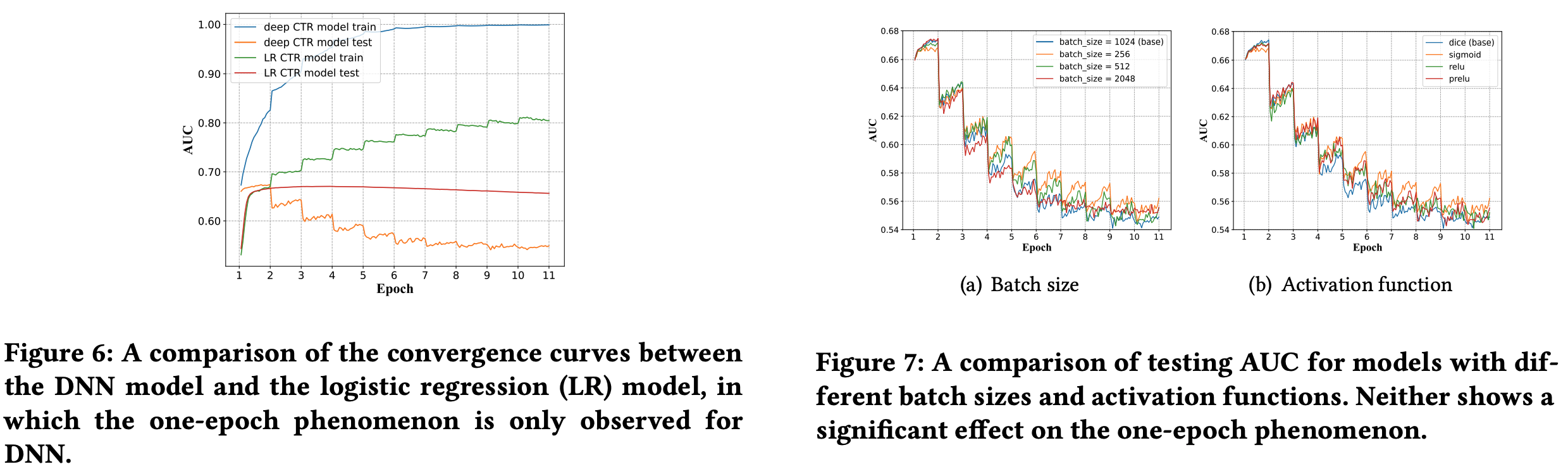
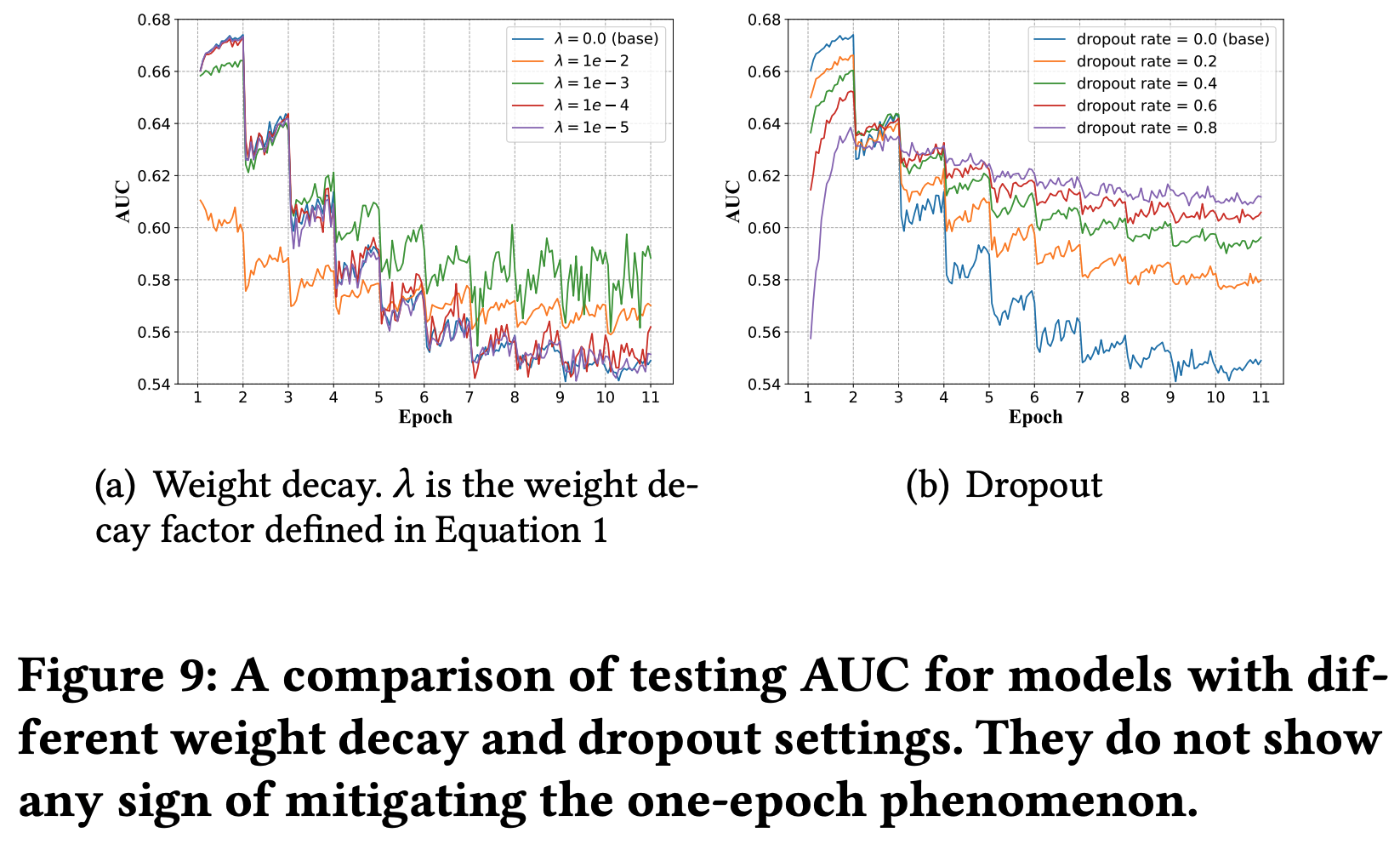
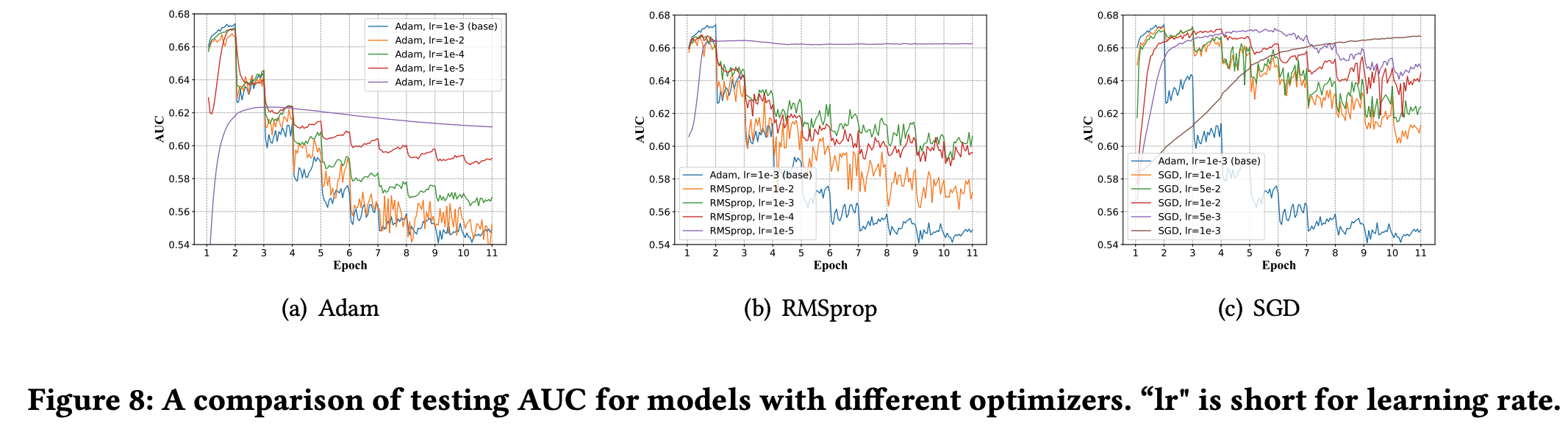
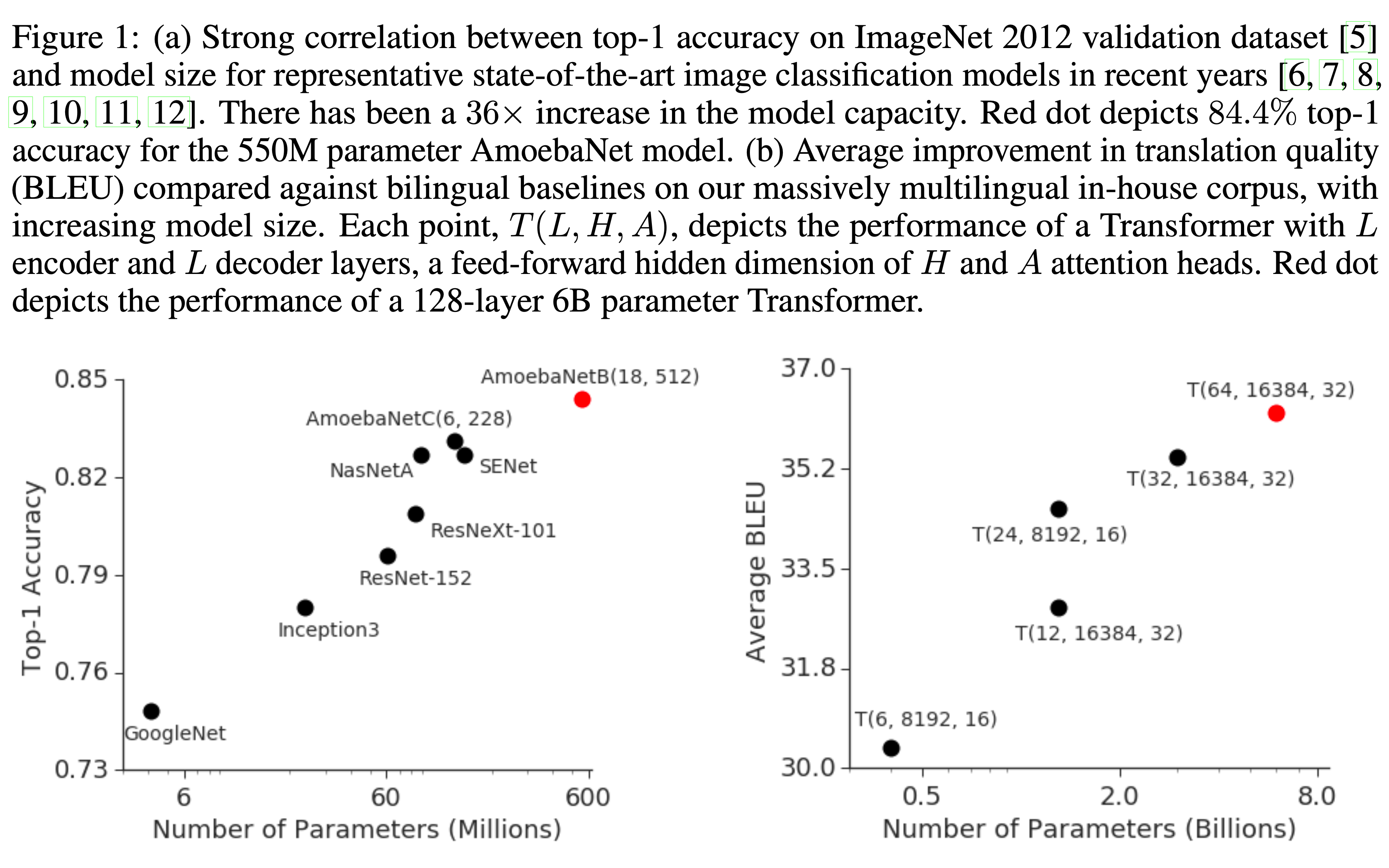
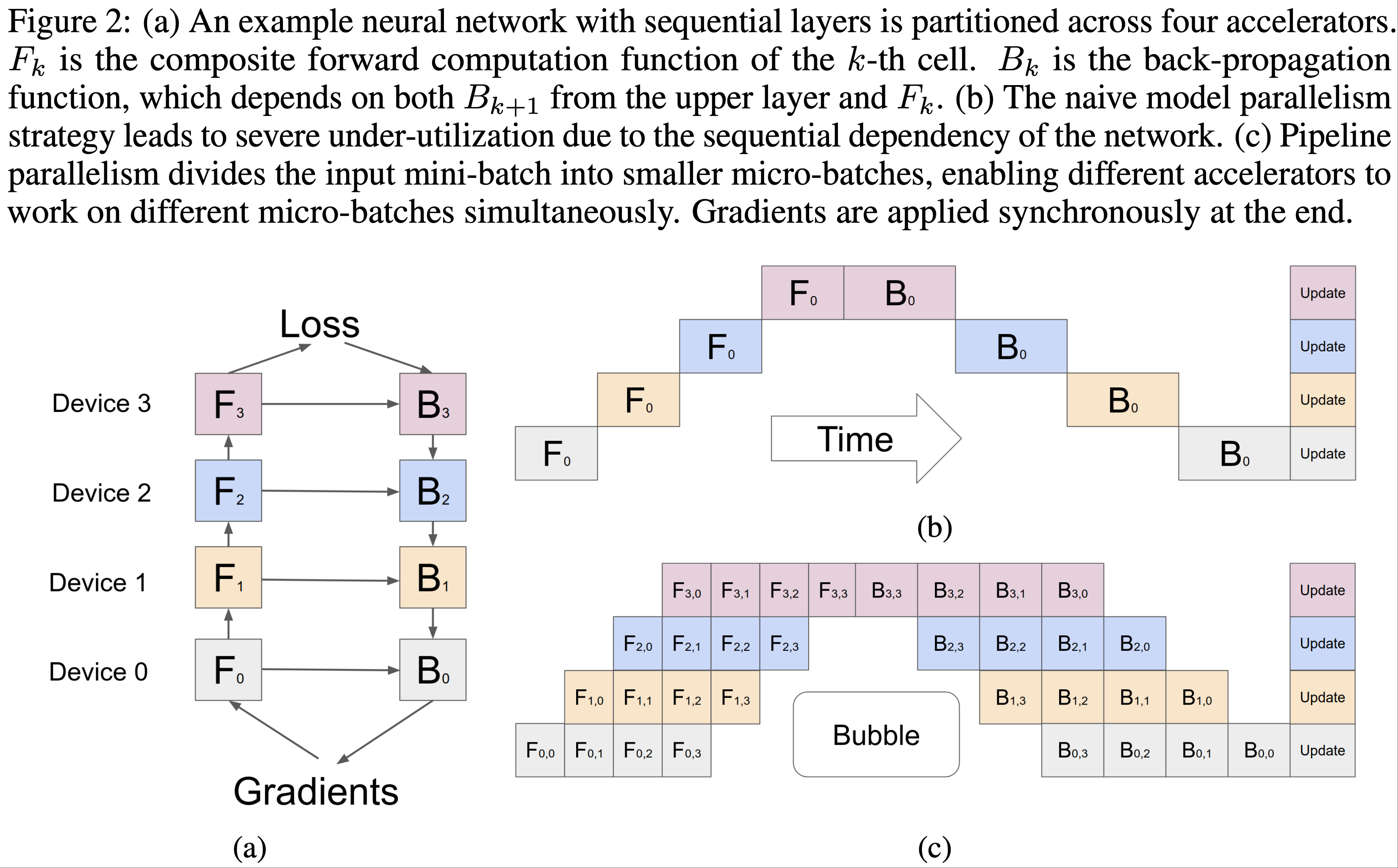
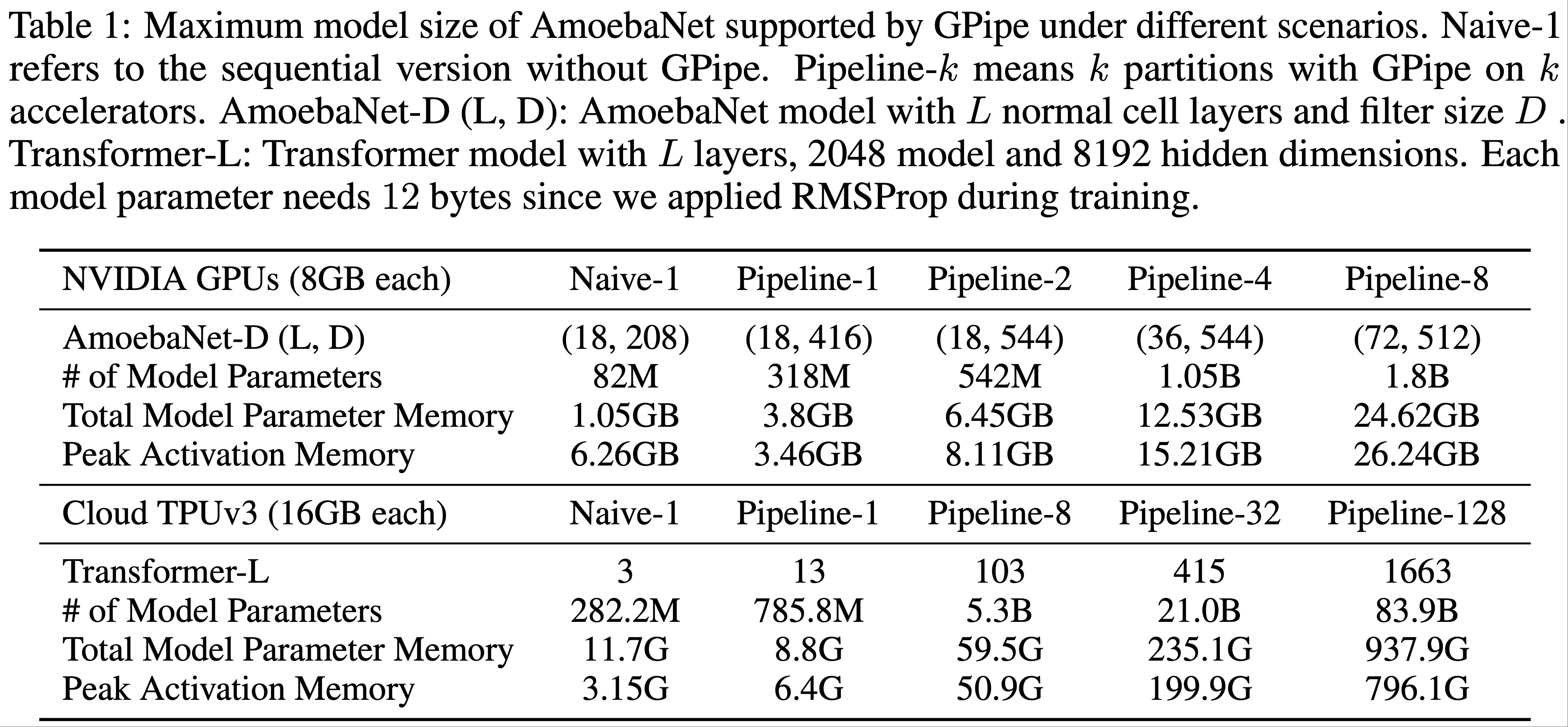
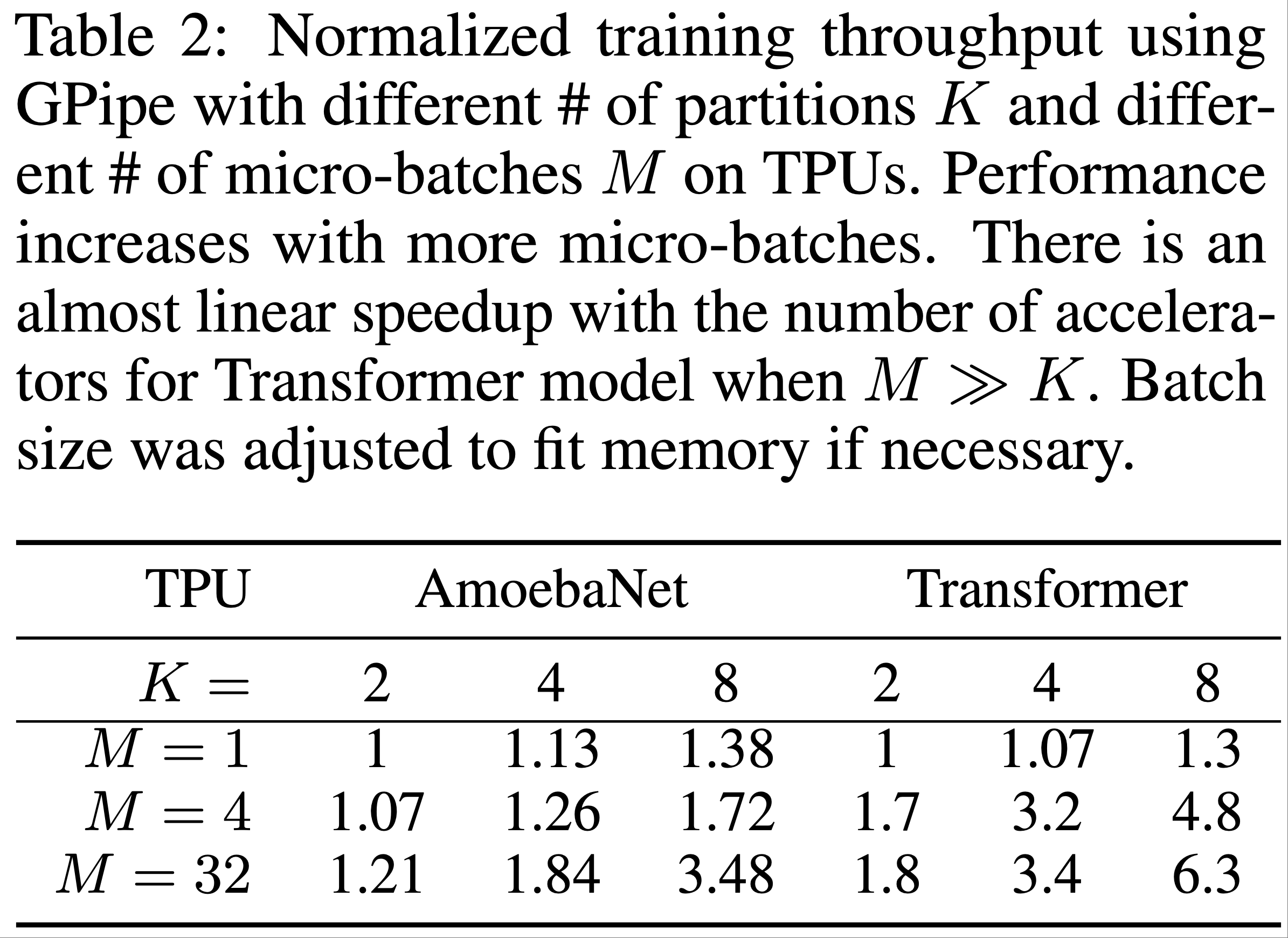
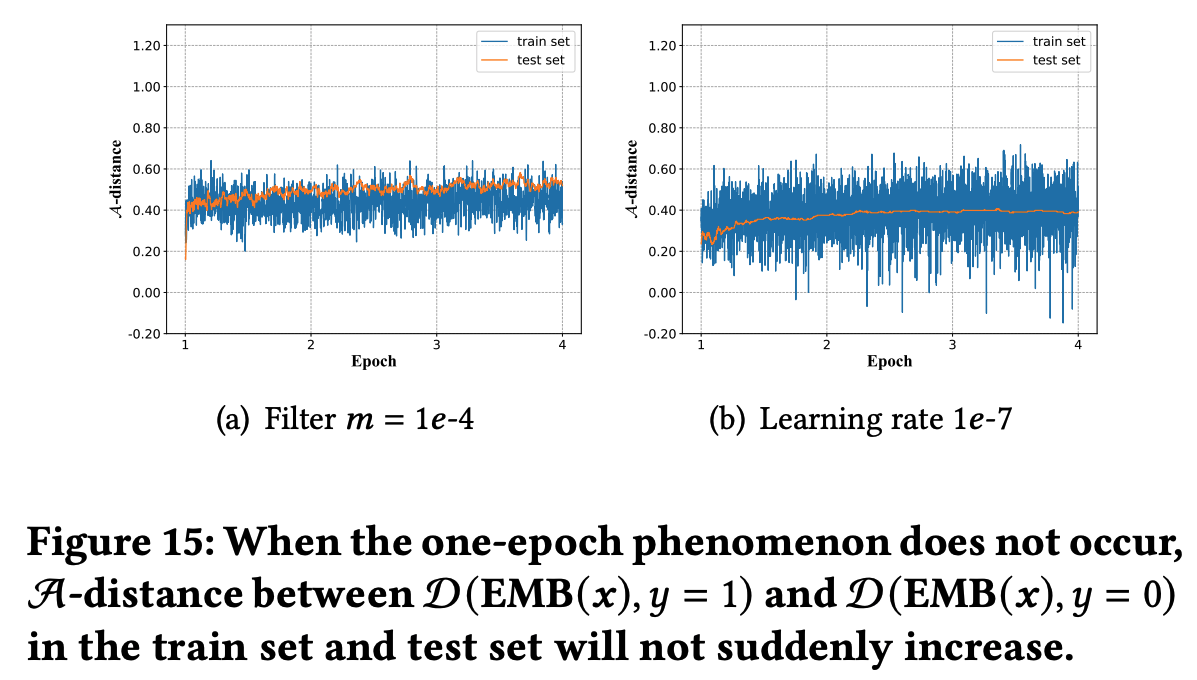 * 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了
* 问题:为什么稀疏反而收敛快?甚至一个 epoch 就能收敛
* 回答:文章没有给出详细解释,但个人理解为稀疏和收敛快不一定是严格矛盾的,可能是 Embedding 层参数更容易学习,但从文章给的实验结果看,一个 epoch 后 Embedding 层参数分布确实几乎收敛了