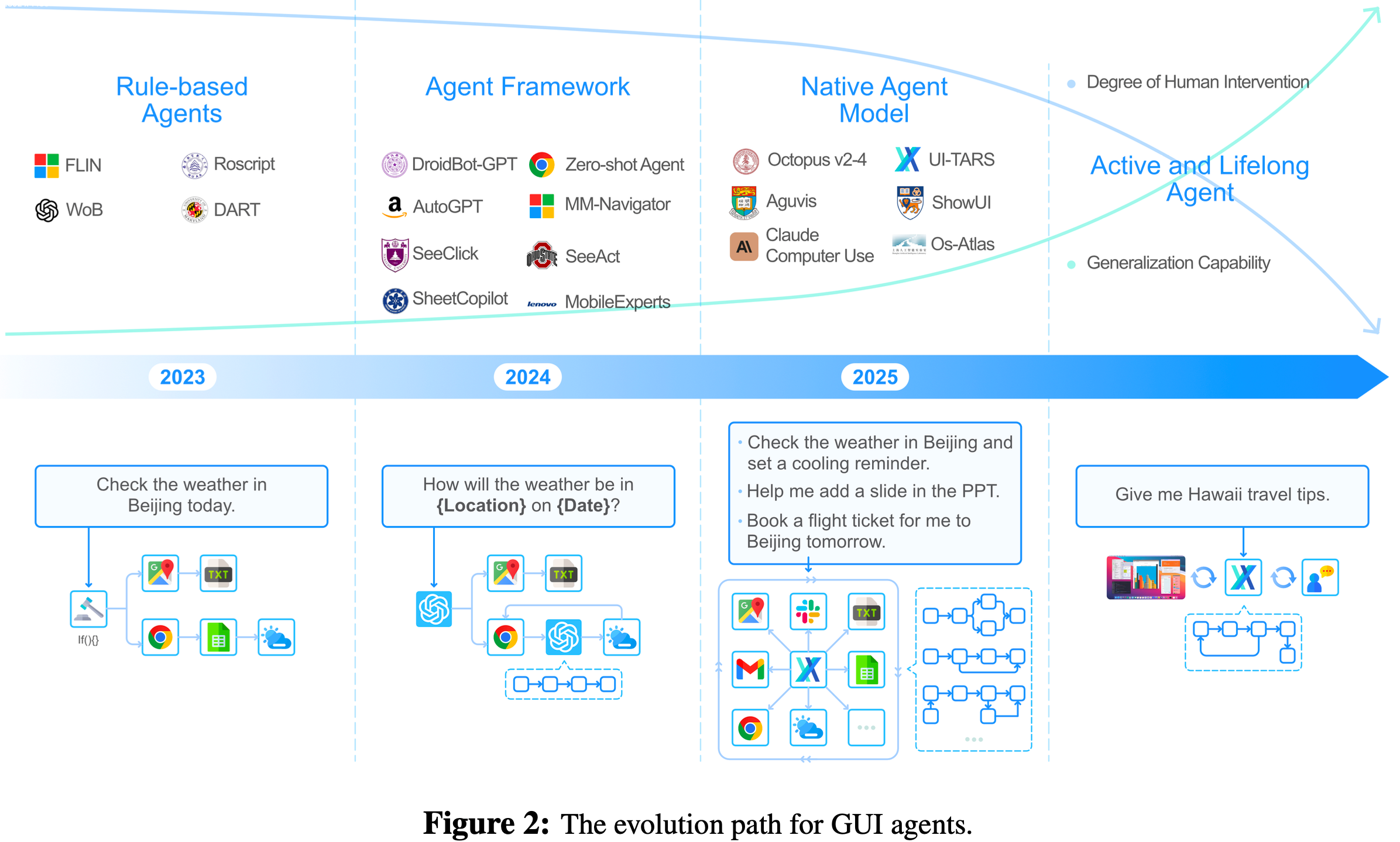
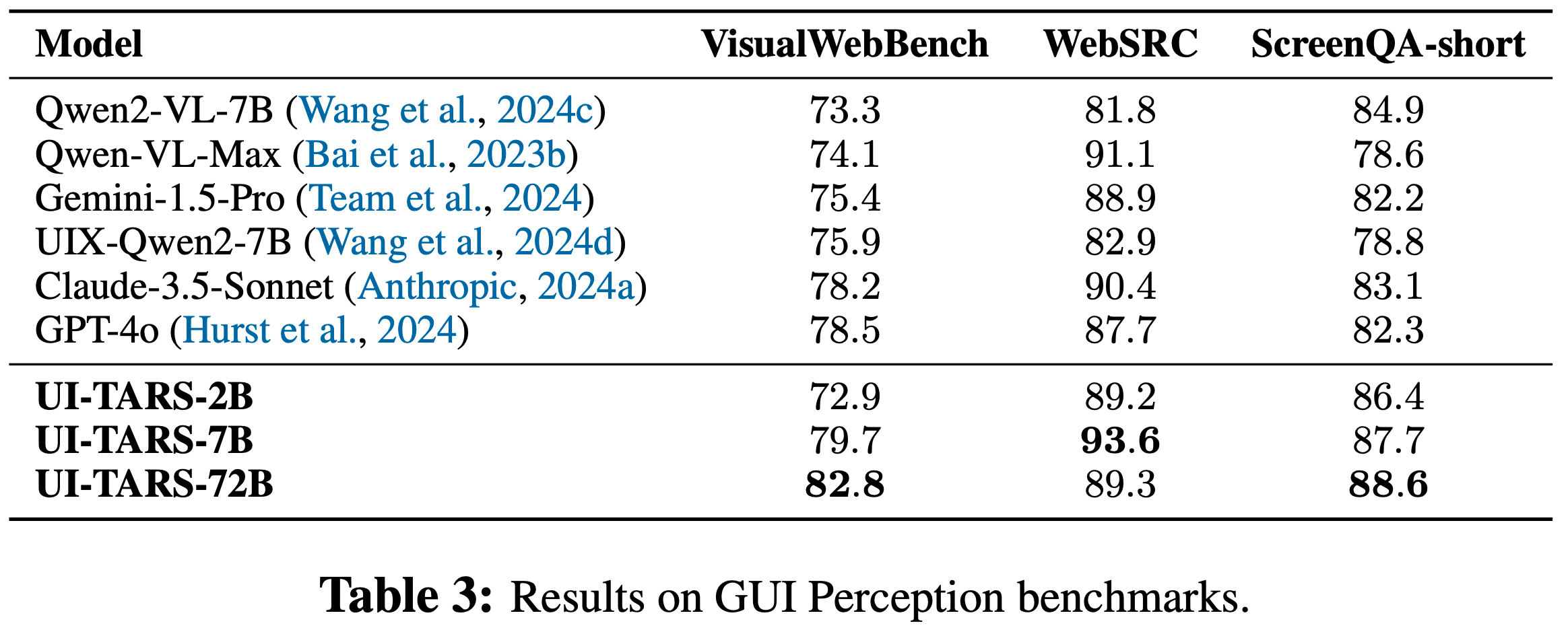
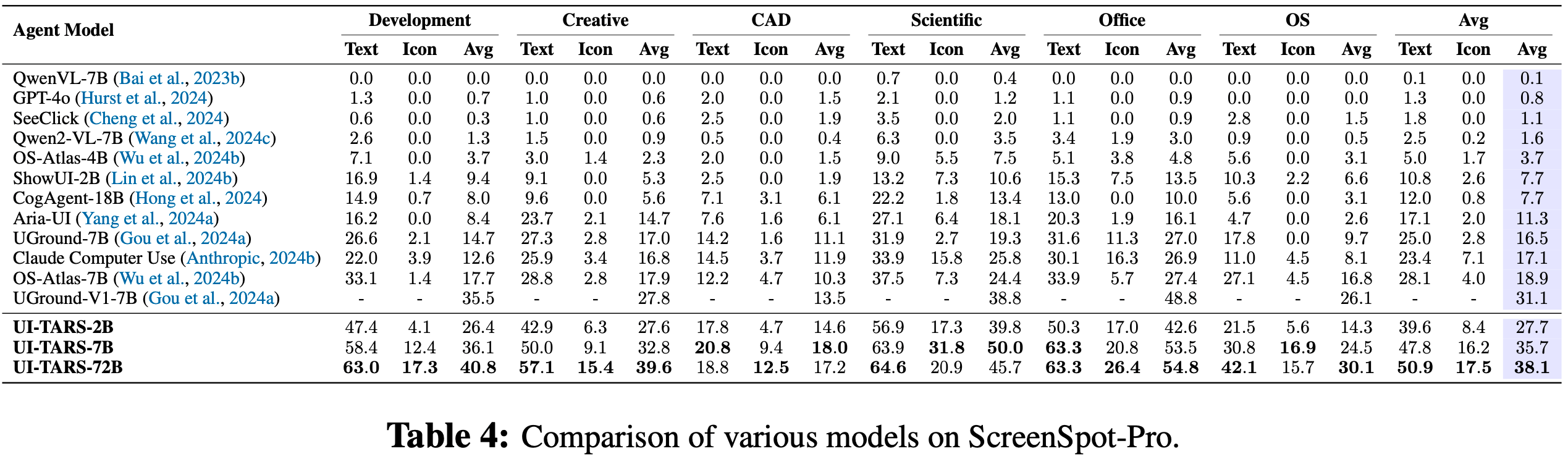
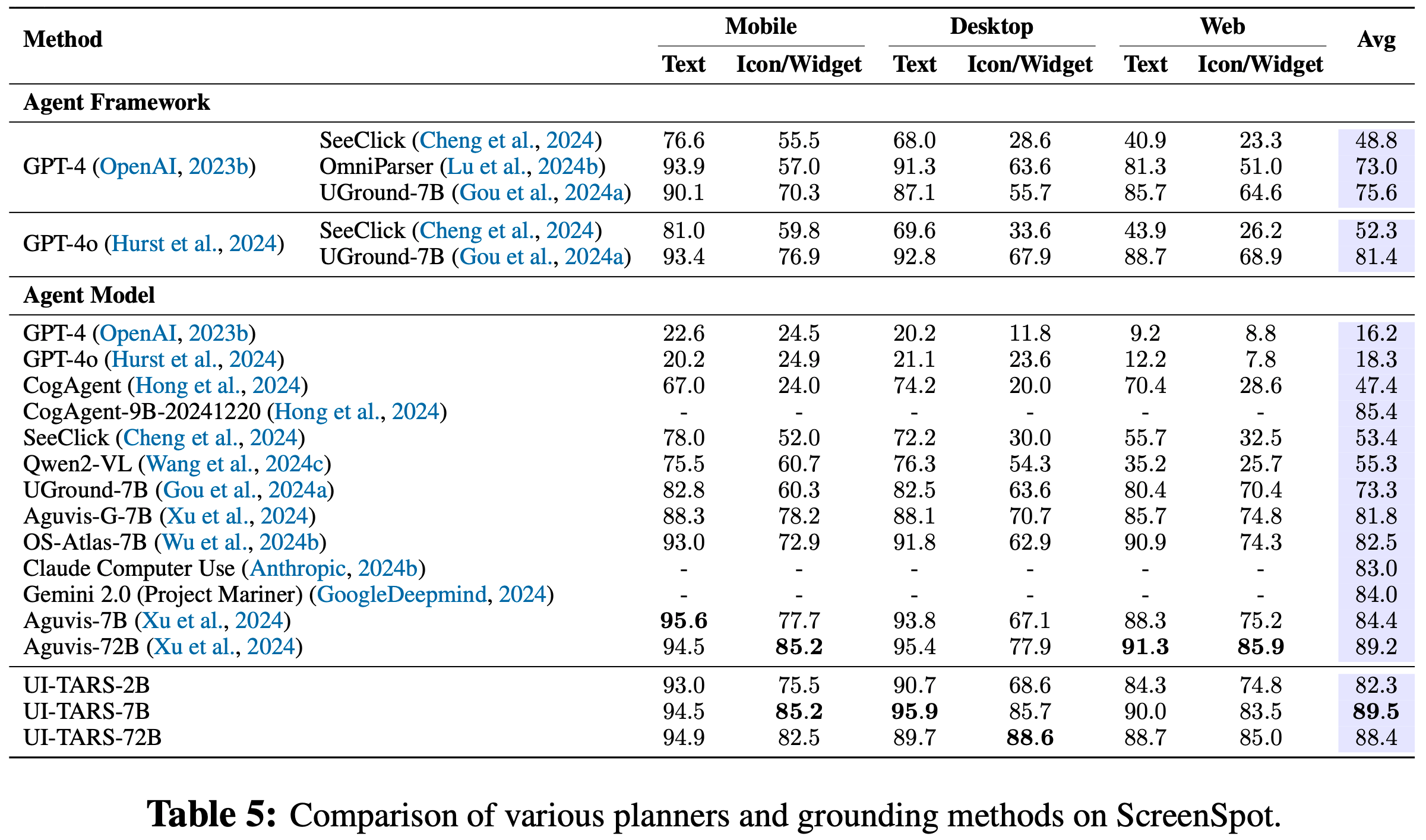
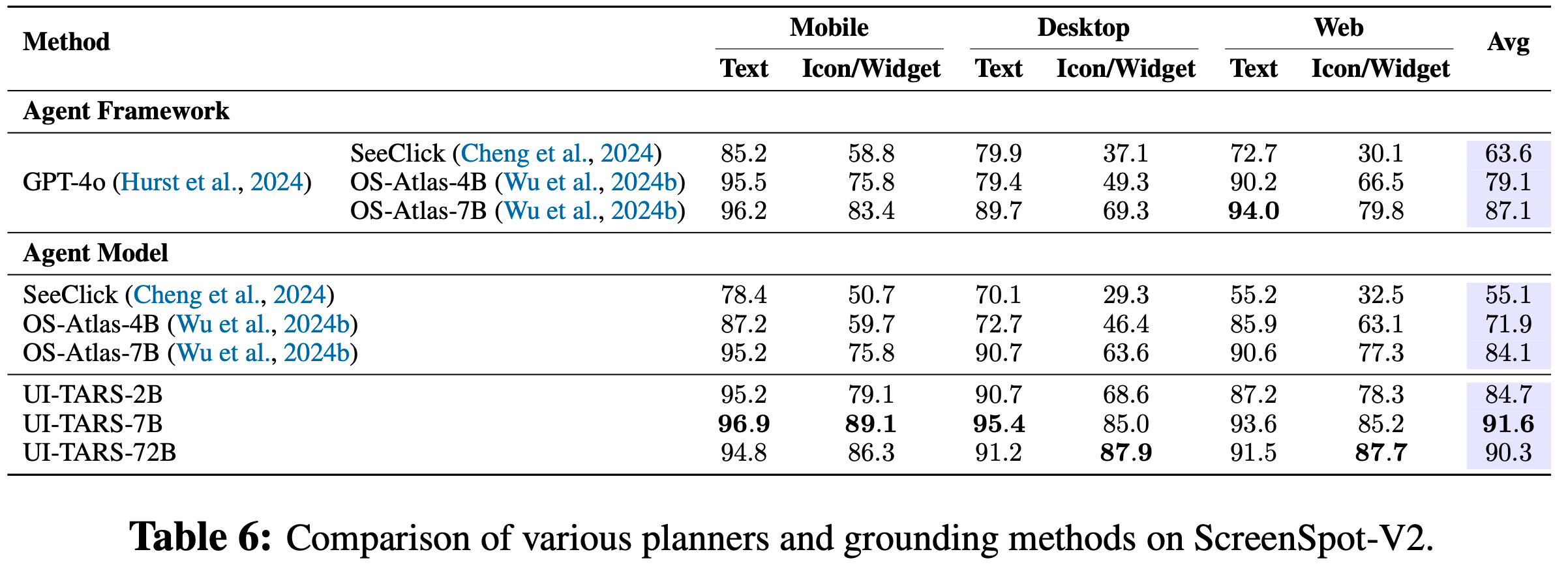
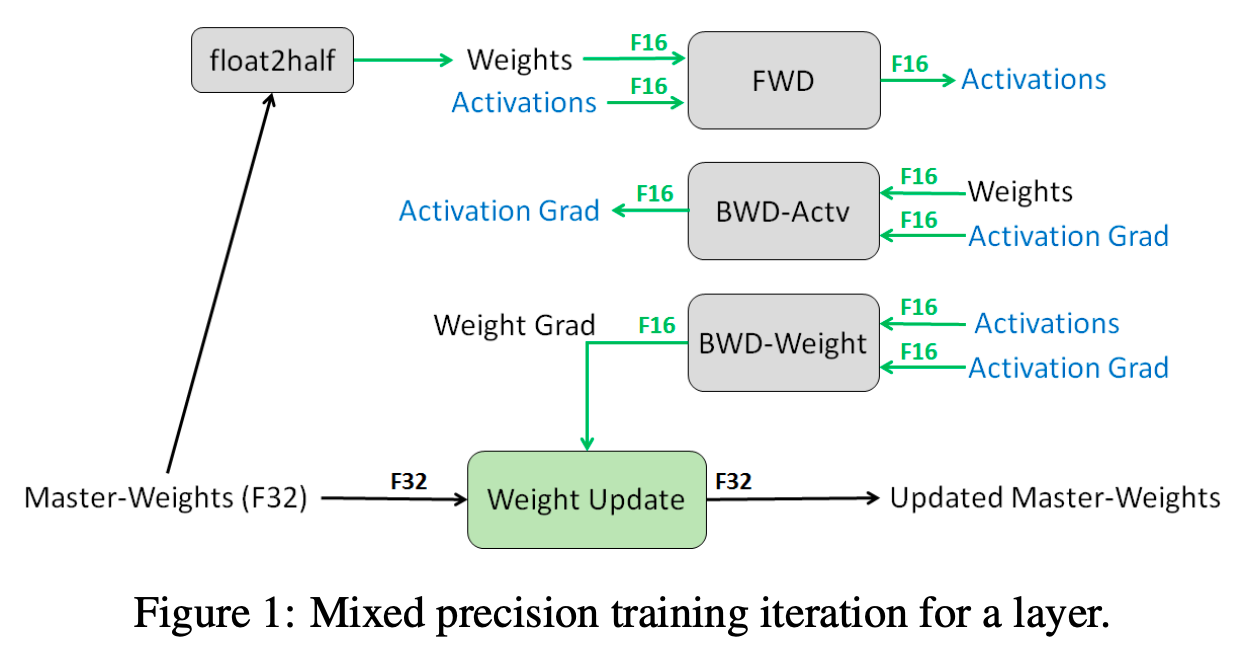
DCA 整体说明
- 双块注意力(Dual Chunk Attention, DCA)是一种无需训练的大语言模型长上下文扩展框架
- TLDR:通过将长序列的注意力计算分解为块内(Intra-Chunk)、块间(Inter-Chunk)和连续块(Successive-Chunk)三种注意力机制,有效捕捉短程和长程依赖关系
- DCA 可保证位置编码不会超过预训练 :通过重新设计相对位置矩阵 \( M \) 反映 tokens 间的真实相对位置,避免传统方法(如位置插值PI、NTK)对引入未见过的位置信息
- 保留预训练的位置编码,每个块的大小 \( s \) 小于模型预训练长度 \( c \),确保块内相对位置不超过预训练范围的降维损失
- DCA 可同时与 Flash Attention 结合实现高效计算
- 实验表明 DCA 在长上下文中的表现显著优于传统位置插值方法,如 PI 和 NTK-aware Scored RoPE
三大注意力机制
Intra-Chunk Attention(块内注意力)
- 作用 :处理同一块内的 tokens,捕捉短程依赖
- 位置编码 :块内查询和键的位置索引均为原序列索引对块大小取模,即:
$$
P_q^{\text{Intra} } = P_k = [0, 1, \dots, l-1] \mod s
$$- 其中,\( l \) 为序列长度,\( s \) 为块大小
- 相对位置矩阵 :同一块内的相对位置为查询与键的位置索引差:
$$
M[i][j] = P_q^{\text{Intra} }[i] - P_k[j] \quad (\text{where} \ \lfloor i/s \rfloor = \lfloor j/s \rfloor)
$$- 确保块内相对位置在 \([0, s-1]\) 范围内,与预训练一致,同一块内的 tokens 距离完全精确
Inter-Chunk Attention(块间注意力)
- 作用 :处理不同块间的 tokens,捕捉长程依赖
- 位置编码 :查询的位置索引统一设为预训练最大位置 \( c-1 \),键的位置索引为原块内索引,即:
$$
P_q^{\text{Inter} } = \underbrace{[c-1, c-1, \dots, c-1]}_{l \ \text{elements}}
$$ - 相对位置矩阵 :不同块间的相对位置为预训练最大位置与键的位置索引差:
$$
M[i][j] = c-1 - P_k[j] \quad (\text{when} \ \lfloor i/s \rfloor > \lfloor j/s \rfloor)
$$- 确保块间相对位置在 \([c-s, c-1]\) 范围内,避免超出预训练范围
Successive-Chunk Attention(连续块注意力)
- 作用 :处理相邻块间的 tokens,保留局部性(如相邻 tokens 的相对距离为1)
- 位置编码 :对当前块的前 \( w \) 个查询,位置索引设为前一块的末尾位置递增,即:
$$
P_q^{\text{Succ} } = [s, s+1, \dots, s+w-1, c-1, \dots, c-1]
$$- 其中 \( w = c - s \) 为局部窗口大小
- 显然:每个块前 \(w\) 个位置为递增索引
- 对所有的 chunk 上述连续块注意力编码都一样
- 相对位置矩阵 :相邻块间前 \( w \) 个查询的相对位置为真实距离,其余为块间注意力的固定值:
$$
M[i][j] =
\begin{cases}
(s + i’ ) - P_k[j], & \text{when} \ i’ < w \ (\text{前} \ w \ \text{个位置}) \\
c-1 - P_k[j], & \text{otherwise}
\end{cases}
$$- 确保相邻块的局部依赖关系(如 \( q_6 \) 与前一块的 \( k_5 \) 相对距离为1)
组合计算与归一化
- DCA 中不同块关系下的相对位置矩阵 \( M[i][j] \),表达式如下:
$$
M[i][j]=
\begin{cases}
P_{q}^{\text{Intra}}[i] - P_{k}[j], & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor = 0 \quad \text{同一块内}\\
P_{q}^{\text{Succ}}[i] - P_{k}[j], & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor = 1 \quad \text{相邻块间}\\
P_{q}^{\text{Inter}}[i] - P_{k}[j], & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor > 1 \quad \text{非相邻块间}
\end{cases}
$$- ( s ) 为块大小,( \lfloor i/s \rfloor ) 表示查询 ( i ) 所属的块索引,( \lfloor j/s \rfloor ) 表示键 ( j ) 所属的块索引
- 同一块内(索引差为0):使用块内注意力的位置索引 ( P_{q}^{\text{Intra}} ) 和 ( P_{k} ) 计算相对位置
- 相邻块间(索引差为1):使用连续块注意力的位置索引 ( P_{q}^{\text{Succ}} ) 计算相对位置,保留局部性
- 非相邻块间(索引差大于1):使用块间注意力的位置索引 ( P_{q}^{\text{Inter}} ) 计算相对位置,捕捉长程依赖
- 注意力权重计算 :根据 tokens 所属块的关系,选择对应的位置编码计算内积:
$$
q_i^\top k_j =
\begin{cases}
f(q, P_q^{\text{Intra} }[i])^\top f(k, P_k[j]), & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor = 0 \quad \text{同一块内} \\
f(q, P_q^{\text{Succ} }[i])^\top f(k, P_k[j]), & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor = 1 \quad \text{相邻块间} \\
f(q, P_q^{\text{Inter} }[i])^\top f(k, P_k[j]), & \text{if } \lfloor i / s \rfloor - \lfloor j / s \rfloor > 1 \quad \text{非相邻块间}
\end{cases}
$$- 其中 \( f \) 为RoPE位置编码函数
- 归一化 :通过Softmax对三种注意力的结果加权求和,确保数值稳定性:
$$
p_i = \text{softmax}\left( \left[ \frac{q_i^\top k_0}{\sqrt{d} }, \frac{q_i^\top k_1}{\sqrt{d} }, \dots, \frac{q_i^\top k_i}{\sqrt{d} } \right] \right)
$$- 其中 \( d \) 为隐藏层维度
DCA 的优势讨论
- 无需训练 :直接复用预训练模型的权重和位置编码,仅修改推理代码,避免昂贵的微调成本
- 高效扩展 :结合Flash Attention,显存占用和推理速度与原始模型相当,支持Llama2 70B处理超过100k tokens(PPL仅从5.24升至5.59)
- 正交兼容 :可与PI、NTK等位置编码方法结合,进一步扩展上下文(如从32k到192k)
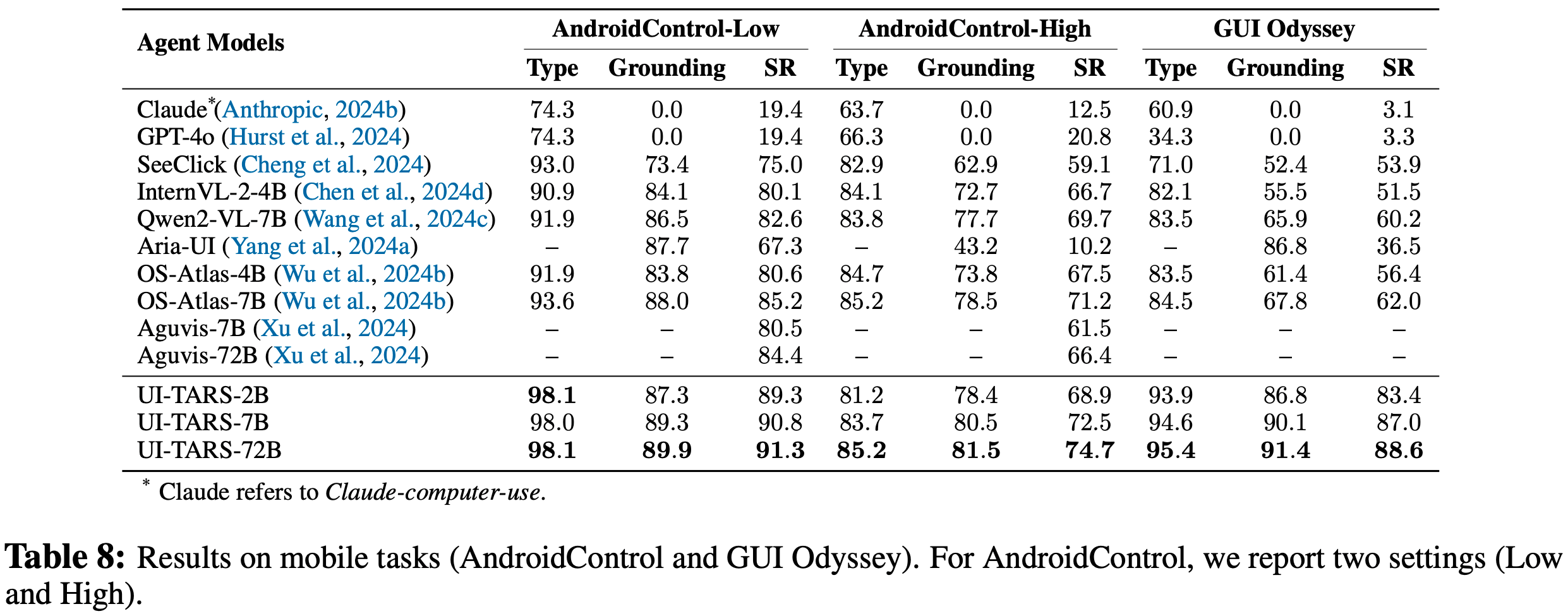
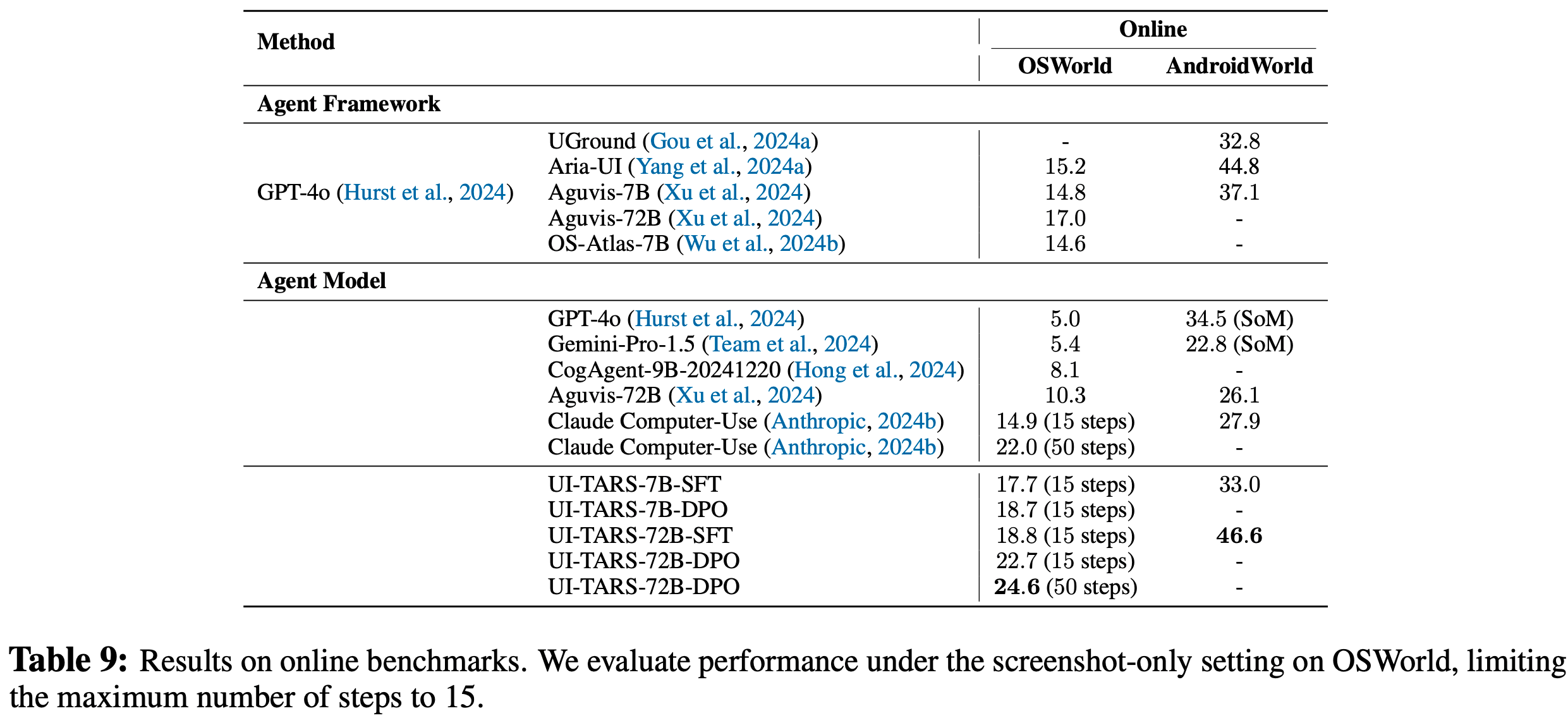
- 性能优势 :在长上下文任务(如语言建模、密钥检索、问答)中,性能接近或超过微调模型,例如Llama2 70B-DCA在零样本任务上达到GPT-3.5的94%性能
一些思考
- 问题:为什么只关注连续的块?仅一跳的块间是否可以设置一些特定的设计?
- 回答:在当前设定(不超出预训练位置编码)下,不可以,因为会超过预训练位置编码
- 补充:如果跳开不超出预训练位置编码的假设,将 DCA 和 PI 或 NTK 做融合(PI 或 NTK 主要修改的是为止编码的旋转角度,DCA 则仅在 Attention 相对位置设计上做文章,相当于重构了 Attention 的位置编码矩阵),理论上可以拿到更好的效果,论文中还对这种组合进行了实验,给出了结果
附录:相隔很远的 tokens 会被误编码为距离很近吗?
- 结论:在 DCA 中,相隔很远的 tokens 可能被编码为较大的相对距离,不会被误以为距离很近
- 其核心在于通过块间注意力和连续块注意力机制区分不同距离的依赖关系
- 块间相对位置的唯一性 :块间注意力中,查询的位置索引固定为预训练最大位置 \( c-1 \),键的位置索引为原块内索引(范围 \([0, s-1]\))。因此,不同块间的相对位置为:
$$
M[i][j] = c-1 - P_k[j] \quad (\text{块间}, \ i > j)
$$- 该值的范围为 \([c-s, c-1]\),每个块对应唯一的相对位置区间。例如,若预训练长度 \( c=10 \),块大小 \( s=6 \),则:
- 第1块的键位置为 \([0,5]\),块间相对位置为 \( 9-0=9, \ 9-1=8, \ \dots, \ 9-5=4 \)(区间 \([4,9]\))
- 第2块的键位置为 \([0,5]\),块间相对位置为 \( 9-0=9, \ \dots, \ 9-5=4 \)(同样区间 \([4,9]\))
- 该值的范围为 \([c-s, c-1]\),每个块对应唯一的相对位置区间。例如,若预训练长度 \( c=10 \),块大小 \( s=6 \),则:
- 补充问题 :不同块的键可能映射到相同的相对位置(如第1块的键5和第2块的键5,相对位置均为4),块间注意力主要用于捕捉“跨块”的全局依赖,而不区分具体是哪一块的键,如何保证长距离和更长距离的相对关系被识别到?
- 虽然不同块的键可能有相同的相对位置,但模型通过注意力权重自动学习跨块的依赖强度,例如较远的块(如第3块)的键会与查询形成相同的相对位置,但模型会根据上下文语义调整注意力权重,而非仅依赖位置编码
- 进一步理解:实际上,自回归模型自动带有位置编码信息,这里就全靠自回归模型自己悟了
附录:连续块注意力强化局部性的细节
- 相邻块的精确距离保留 :连续块注意力针对相邻块的前 \( w=c-s \) 个查询,设置递增的位置索引(如 \( s, s+1, \dots, s+w-1 \)),确保相邻块的局部tokens相对位置正确。例如:
- 第1块末尾的键5(位置5)与第2块开头的查询6(位置6),在连续块注意力中相对位置为 \( 6-5=1 \)(真实距离),而非块间注意力的 \( 9-5=4 \)
- 当 \( w=c-s \) 时,相邻块的前 \( w \) 个查询会覆盖前一块的全部键(如 \( c=10, s=6 \) 时,\( w=4 \),第2块前4个查询的位置为6、7、8、9,可与第1块的键0-5形成相对位置6-0=6、7-1=6等,但更接近真实距离)
- 效果* :通过保留相邻块的局部位置信息,模型能正确捕捉“邻近跨块”的短距离依赖(如对话中的连续句子),避免将相邻块的tokens 误判为远距离
附录:潜在局限性与实验验证
- 远距离块的位置歧义 :对于非相邻块(如第1块和第3块),它们的键在块间注意力中均映射到 \([c-s, c-1]\) 区间,可能导致位置编码的歧义(如第1块的键0和第3块的键0,相对位置均为 \( c-1-0 \))
- 实验结果 :
- 在密钥检索任务中,DCA 在 192k 上下文中仍能保持 90% 以上准确率,表明模型能区分不同块的全局位置(见论文图7)
- 语言建模任务中,DCA 的困惑度(PPL)增长缓慢(如 Llama2-70B 从 4k 到 100k+,PPL仅从 5.24 升至 5.59),说明位置编码的歧义对长程依赖的影响有限