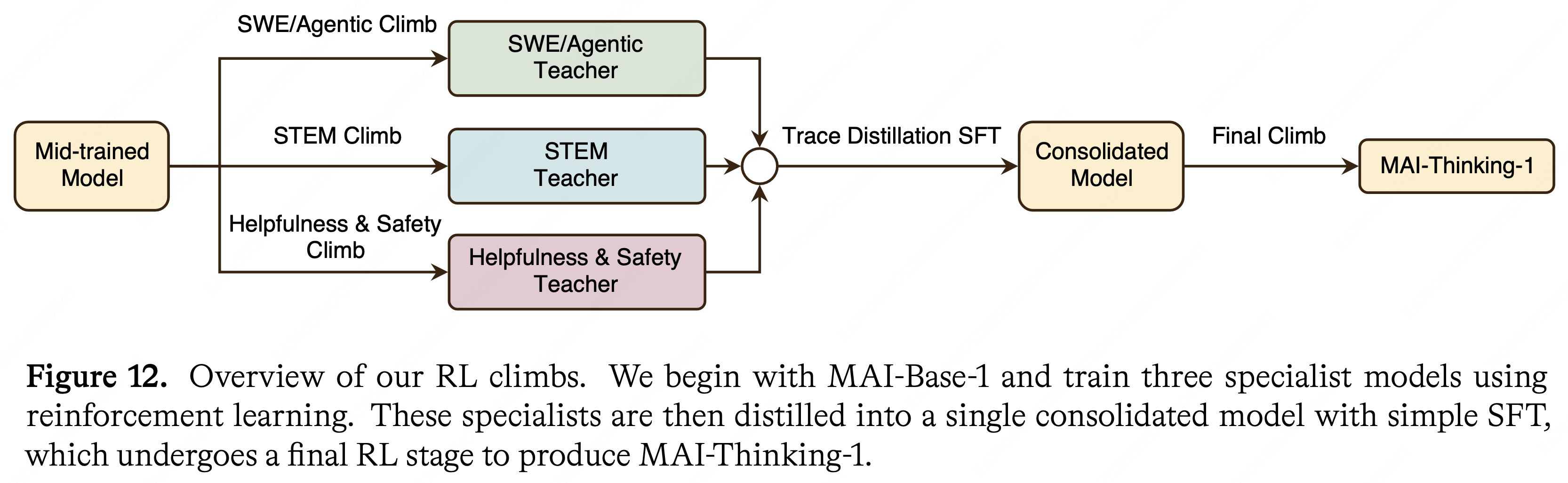
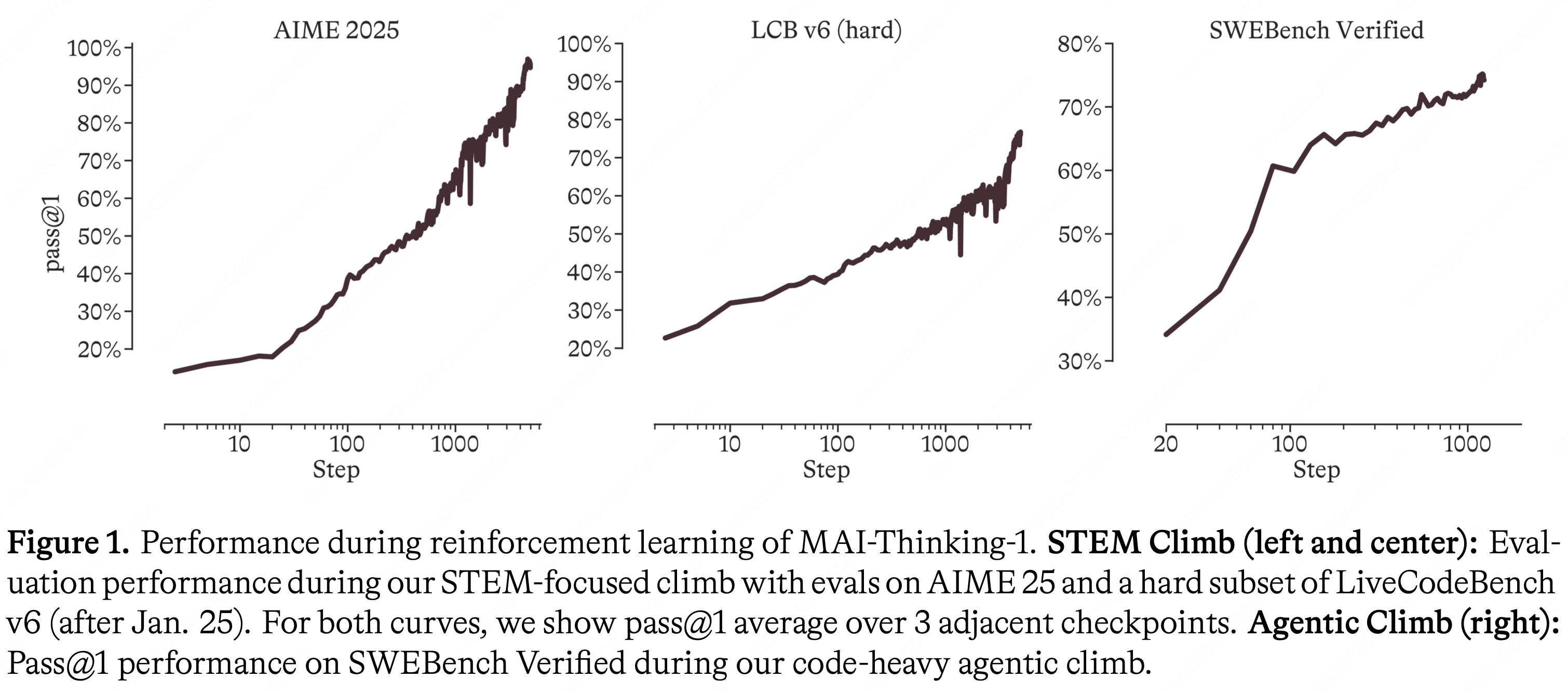
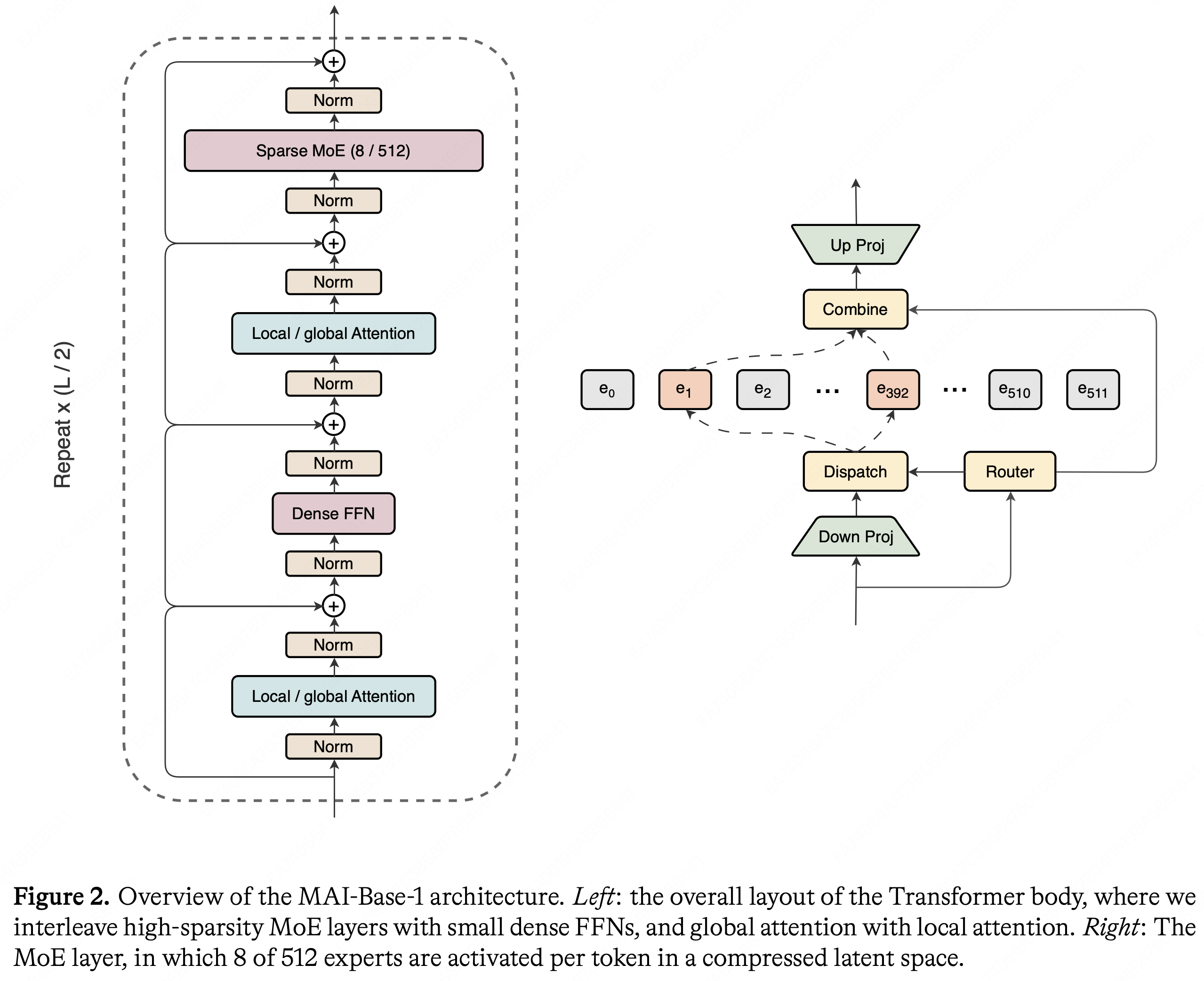
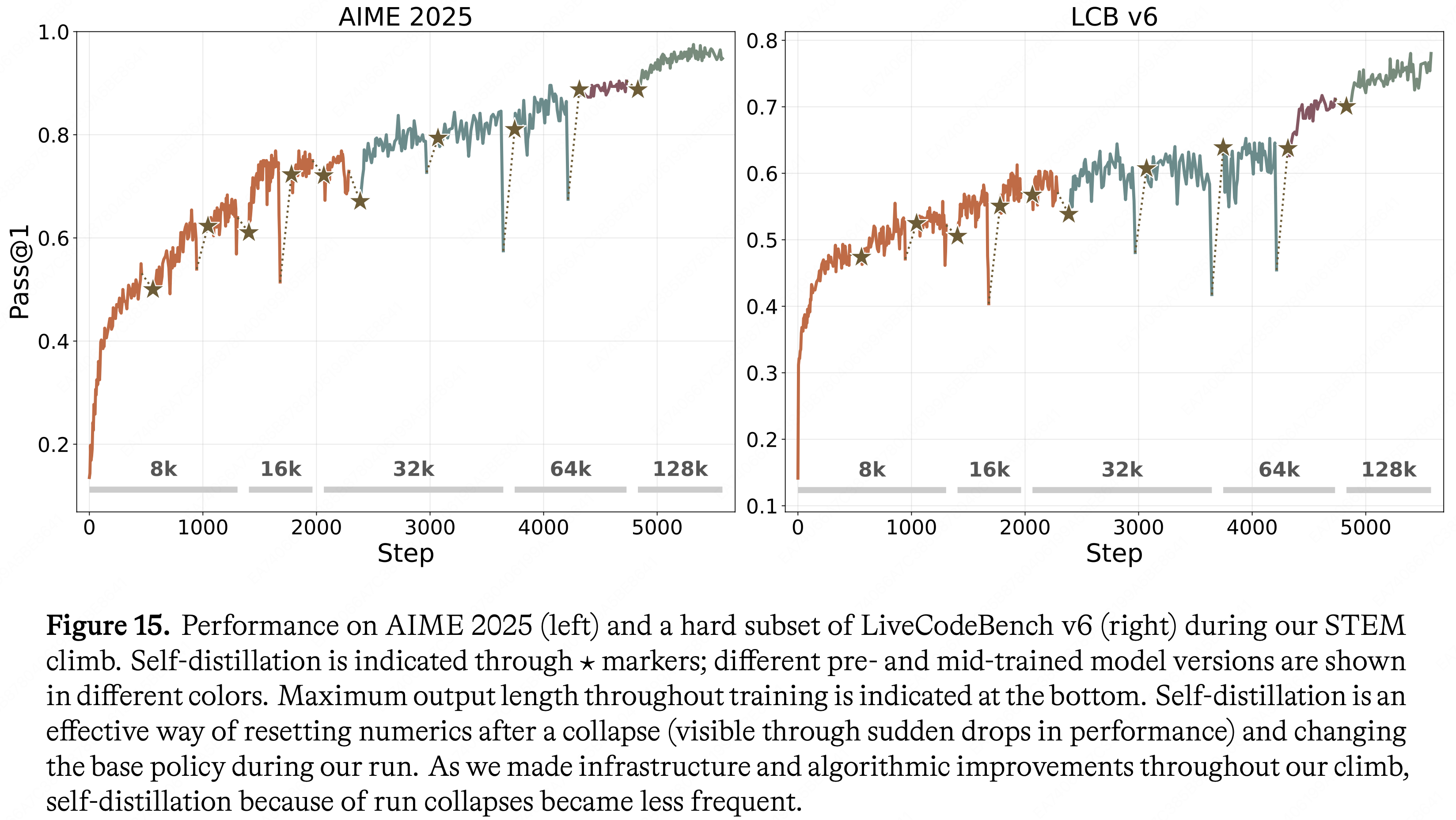
欢迎来到 Jiahong 的技术博客
包含操作系统、机器学习、深度学习、强化学习、NLP 和 LLM 等 计算机/AI 领域的学习笔记与实践总结
⭐ 论文解读 & 穿插个人评论/理解;⭐ 基础公式推导 & 数学原理分析;⭐ 实践技术思考 & 汇总整理;
📊 共计 659 篇技术文章 | 🏷️ 51 个分类领域
2017
66 篇
2018
122 篇
2019
102 篇
2020
48 篇
2021
33 篇
2022
40 篇
2023
34 篇
2024
50 篇
2025
127 篇
2026
36+ 篇
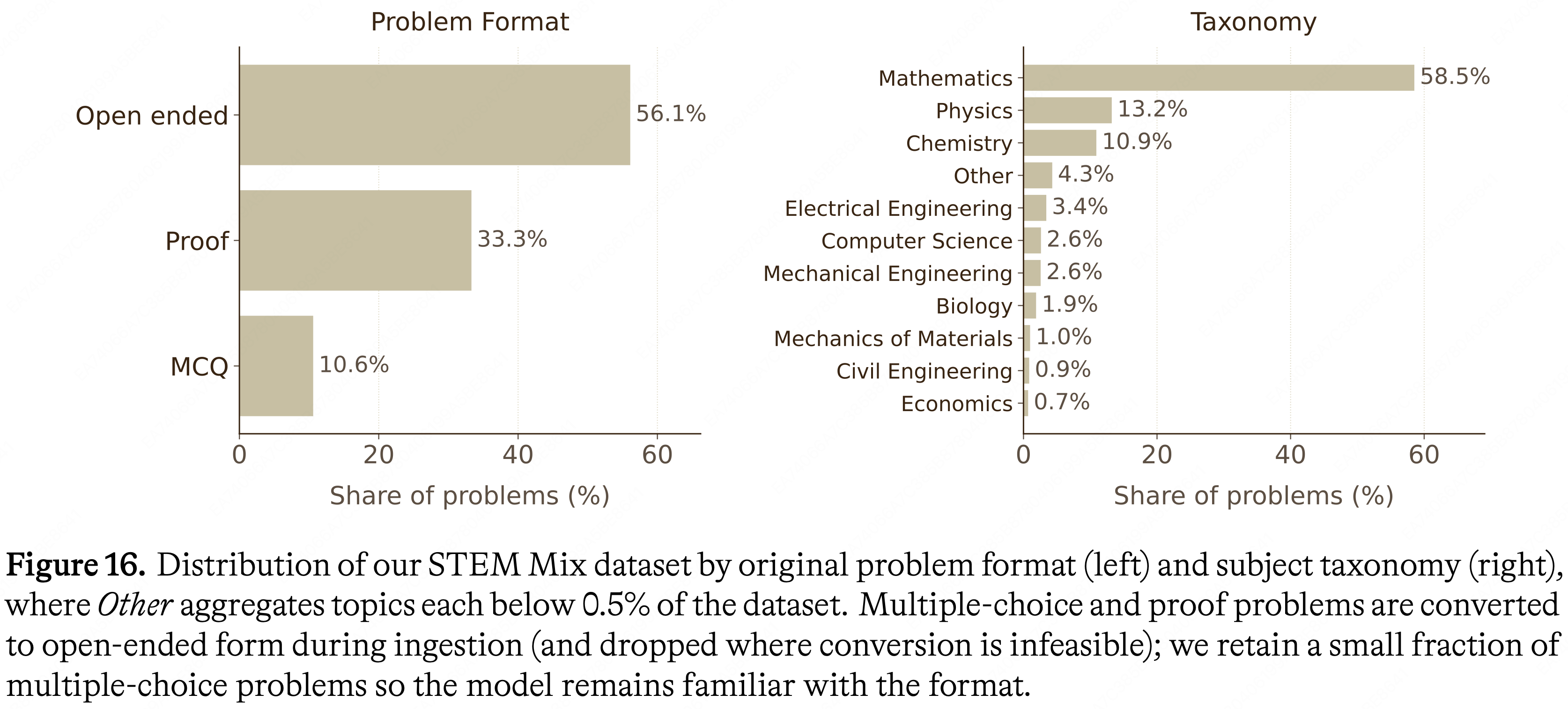
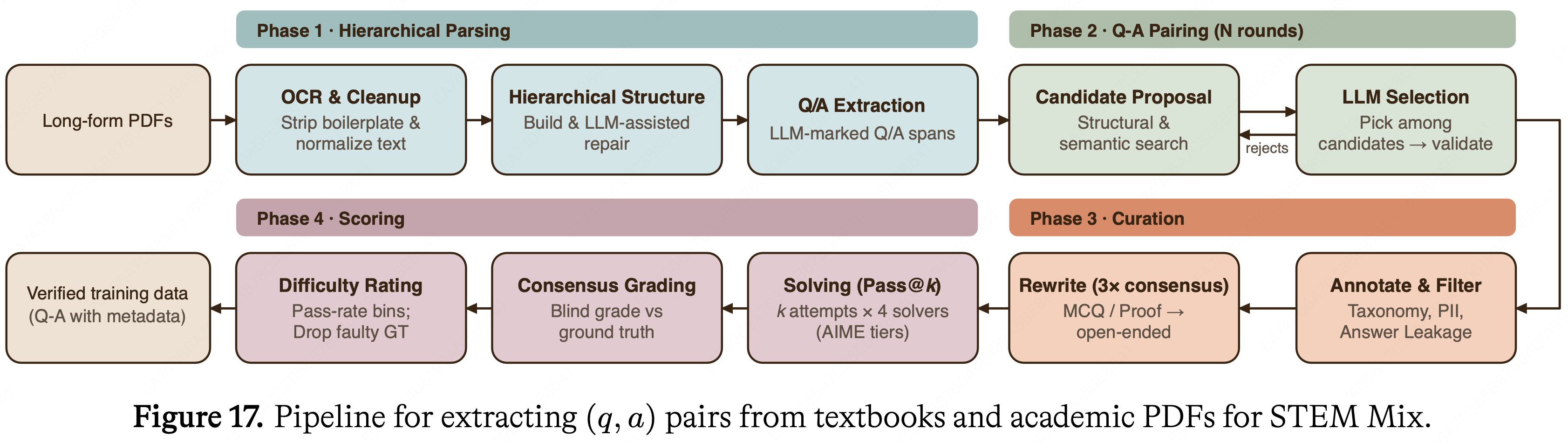
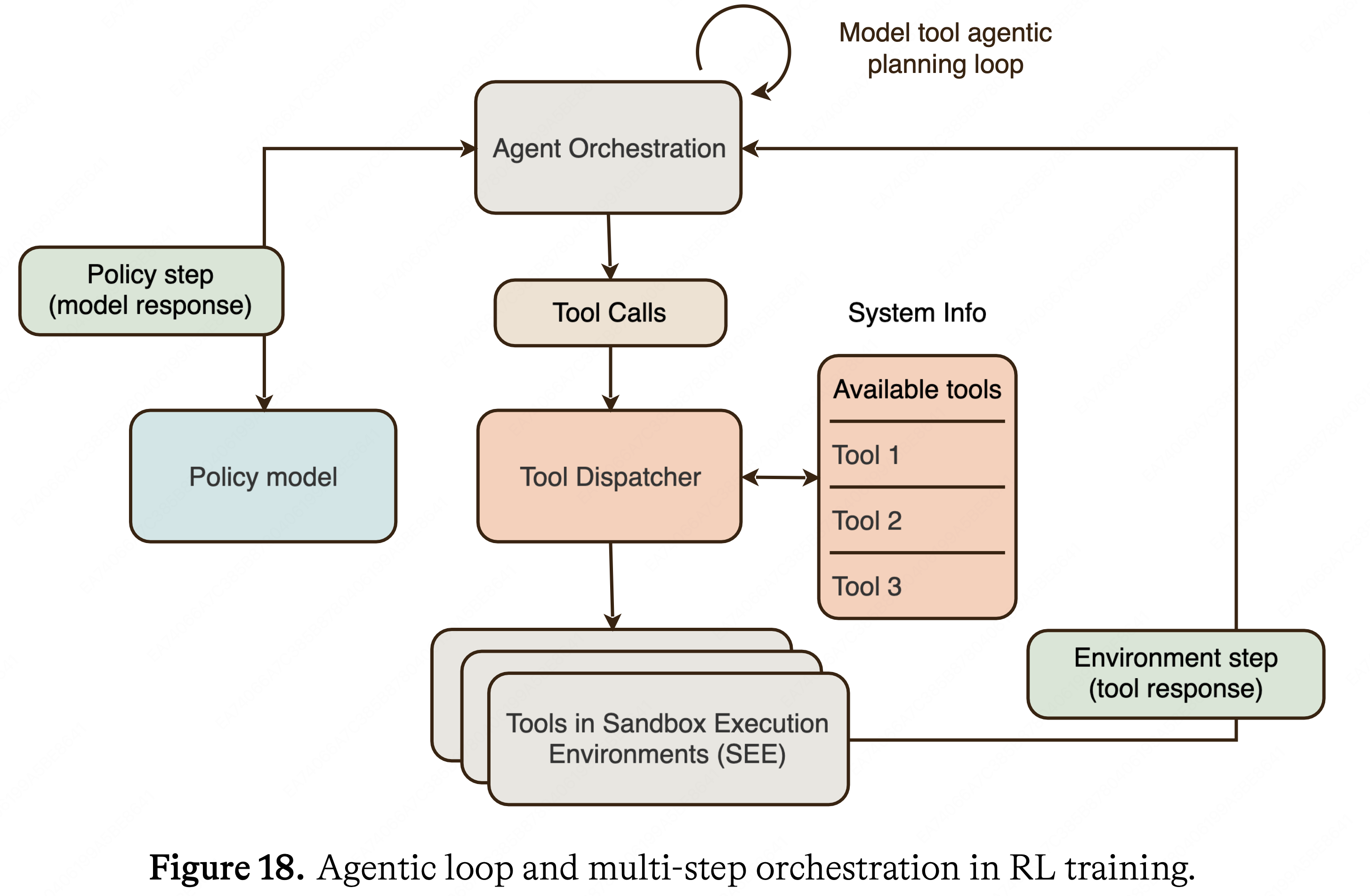
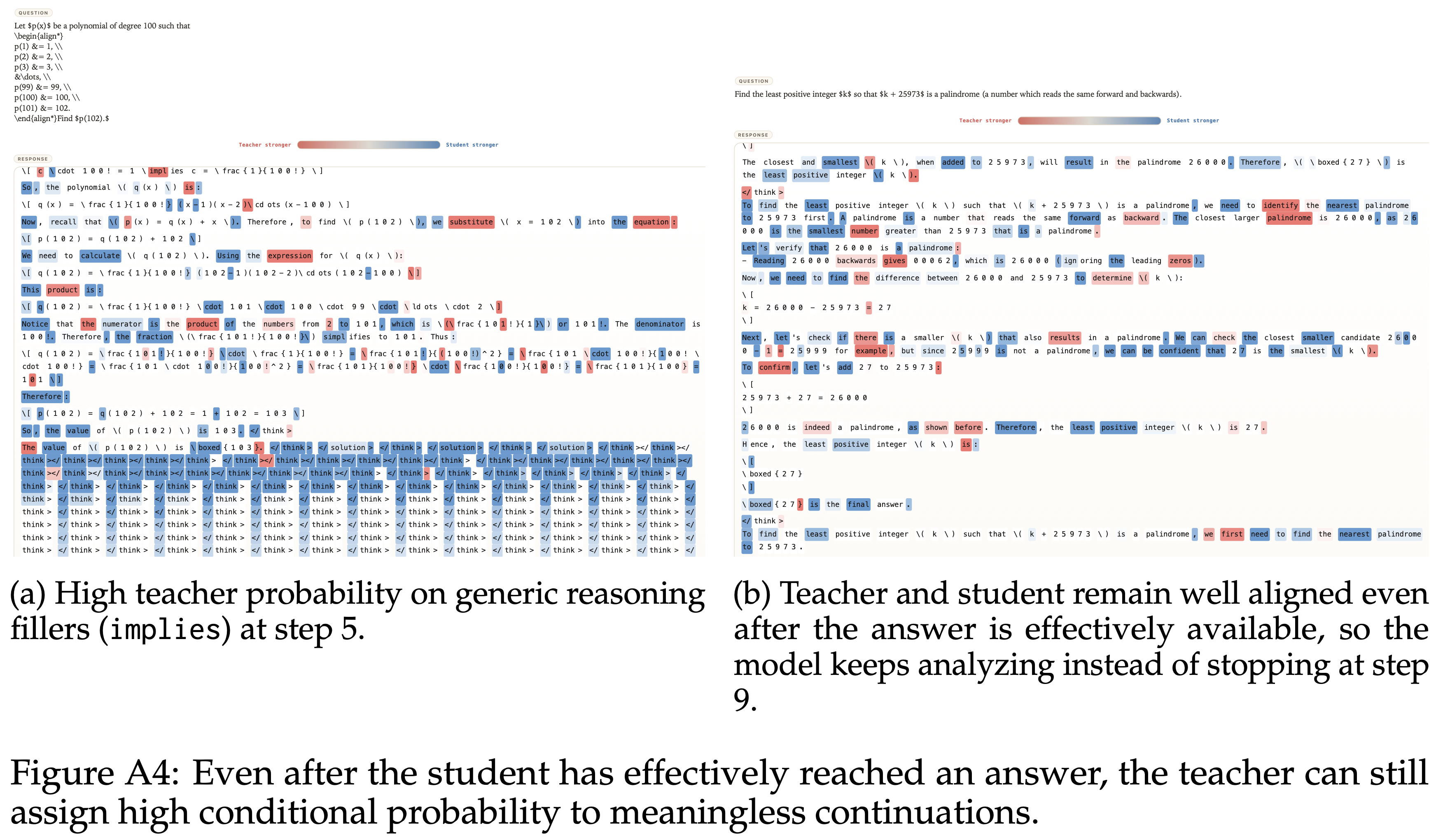
人工智能 & 机器学习
自然语言处理 (NLP)
📝 208 篇文章
LLM、BERT、Transformer、文本处理等
大语言模型 (LLM)
📝 188 篇文章
GPT、BERT、ChatGPT等大模型技术
强化学习 (RL)
📝 131 篇文章
Q-Learning、PPO、TRPO、策略梯度等
深度学习 (DL)
📝 92 篇文章
神经网络、CNN、RNN、Attention等
机器学习 (ML)
📝 50 篇文章
传统算法、特征工程、模型评估等
PyTorch
📝 28 篇文章
PyTorch框架使用与实践
TensorFlow
📝 9 篇文章
TensorFlow框架使用与实践
计算机视觉 (CV)
📝 10 篇文章
图像处理、目标检测、生成模型等
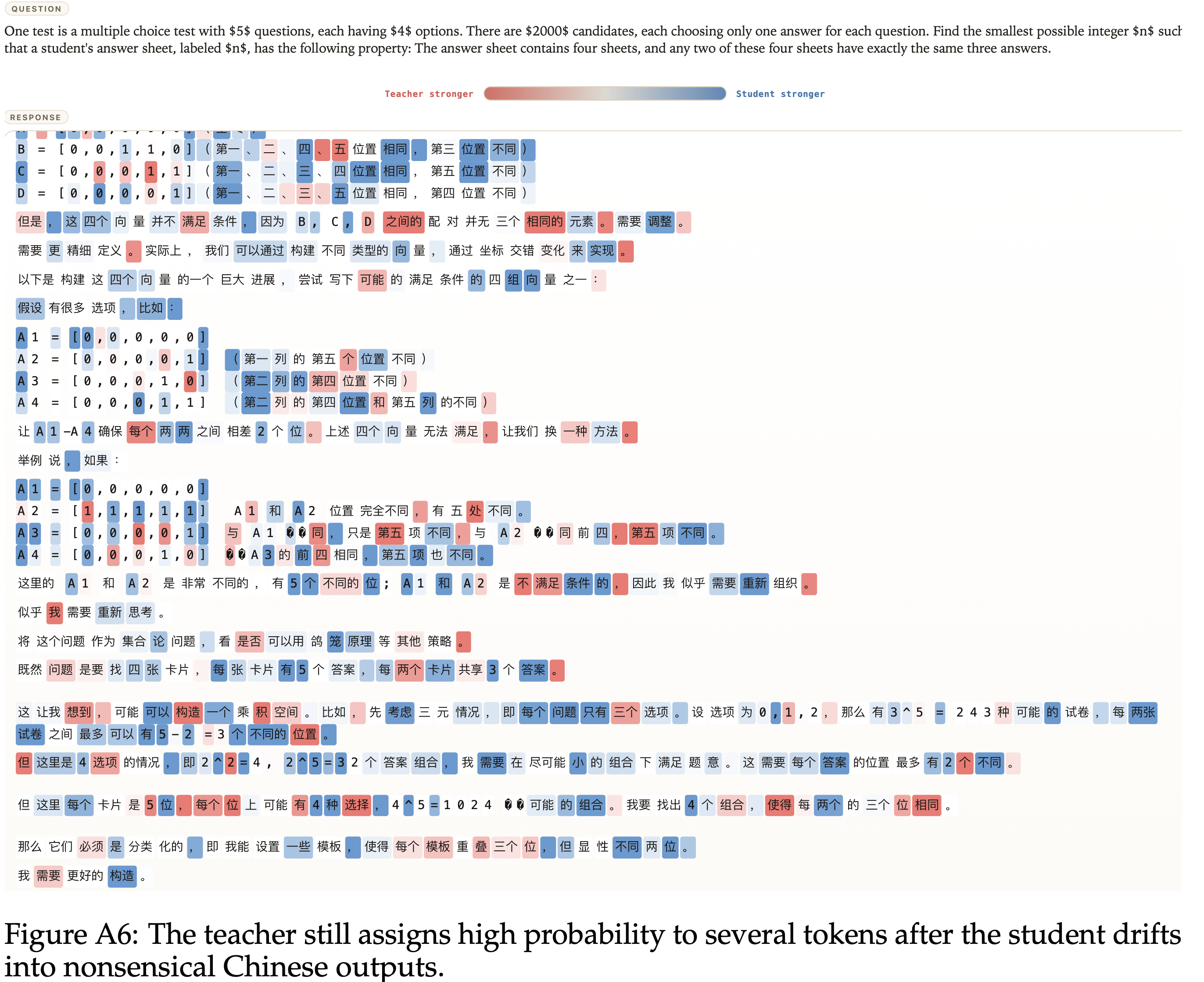
广告 & 推荐
计算广告 (CA)
📝 24 篇文章
广告系统、CTR预估、竞价策略、出价优化等
拍卖机制 (Auction)
📝 14 篇文章
拍卖理论、机制设计、竞价策略等
竞价与出价 (Bidding)
📝 9 篇文章
出价策略、自动出价、预算分配等
推荐系统 (RS)
📝 23 篇文章
协同过滤、深度推荐、排序策略等
编程语言
Python
📝 85 篇文章
Python语法、库使用、最佳实践
Java
📝 4 篇文章
Java编程与开发
Go
📝 3 篇文章
Go语言学习与实践
Scala
📝 1 篇文章
Scala函数式编程
Shell
📝 1 篇文章
Shell脚本编程
系统 & 运维
Linux
📝 29 篇文章
Linux系统、命令行工具使用
Docker
📝 5 篇文章
容器技术、镜像管理
Mac
📝 4 篇文章
macOS使用技巧
Ubuntu
📝 9 篇文章
Ubuntu 相关技术笔记
Centos
📝 6 篇文章
Centos 相关技术笔记
数学
开发工具
其他
其他
📝 44 篇文章
杂项笔记与技术分享
Regex
📝 1 篇文章
Regex 相关技术笔记
Anaconda
📝 4 篇文章
Anaconda 相关技术笔记
Numpy
📝 4 篇文章
Numpy 相关技术笔记
Jupyter
📝 6 篇文章
Jupyter 相关技术笔记
Ray
📝 2 篇文章
Ray 相关技术笔记
Pandas
📝 2 篇文章
Pandas 相关技术笔记
DataFrame
📝 1 篇文章
DataFrame 相关技术笔记
ACM
📝 1 篇文章
ACM 相关技术笔记
KG
📝 3 篇文章
KG 相关技术笔记
Neo4j
📝 1 篇文章
Neo4j 相关技术笔记
GR
📝 11 篇文章
GR 相关技术笔记
GBDT
📝 8 篇文章
GBDT 相关技术笔记
Sklearn
📝 3 篇文章
Sklearn 相关技术笔记
Hadoop
📝 1 篇文章
Hadoop 相关技术笔记
Hive
📝 1 篇文章
Hive 相关技术笔记
MySQL
📝 4 篇文章
MySQL 相关技术笔记
CPT
📝 5 篇文章
CPT 相关技术笔记
AI-Infra
📝 18 篇文章
AI-Infra 相关技术笔记
Megatron
📝 7 篇文章
Megatron 相关技术笔记
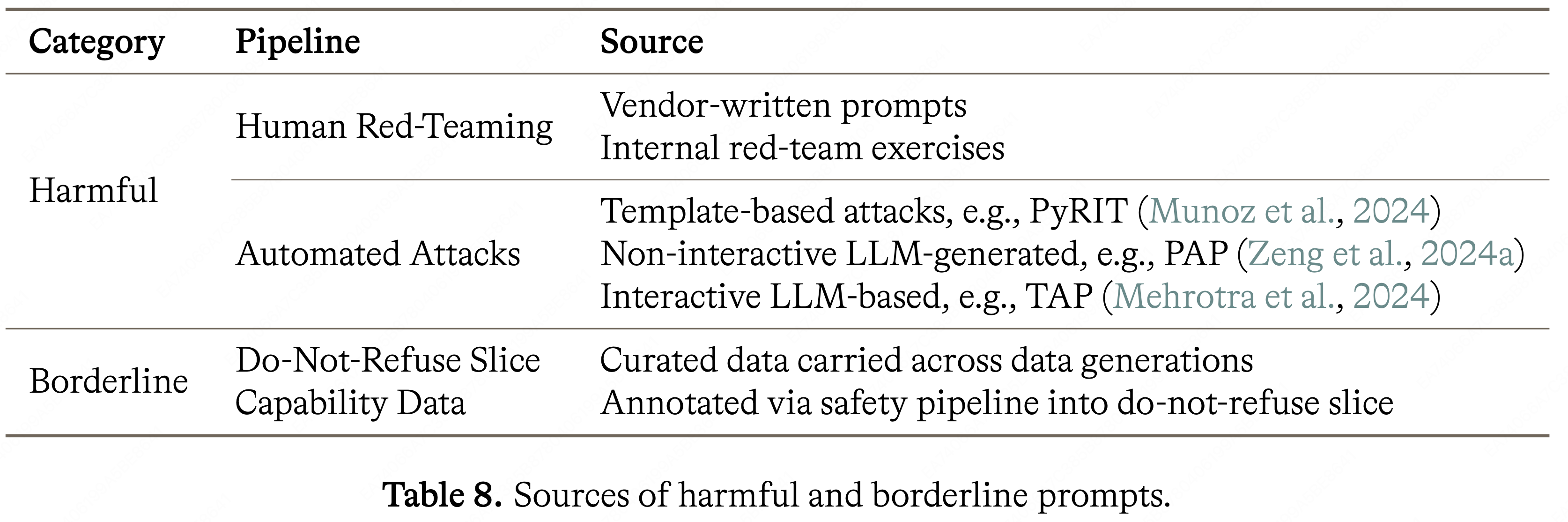
Rubrics
📝 14 篇文章
Rubrics 相关技术笔记
Rubric
📝 1 篇文章
Rubric 相关技术笔记
Agent
📝 1 篇文章
Agent 相关技术笔记
HuggingFace
📝 1 篇文章
HuggingFace 相关技术笔记
Spark
📝 2 篇文章
Spark 相关技术笔记
💡 提示:点击任意卡片即可查看该分类下的所有文章
📧 联系方式:JoeZJiahong@Foxmail.com | 🔗 GitHub: @JoeZJH