文本介绍DDIM(Denoising Diffusion Implicit Models)的理论介绍
- 参考链接:
DDPM为什么慢?
- 采样步数不能太小,否则单次破坏力度过大,不容易恢复?
- 不能跳步,否则不遵循马尔可夫过程
推导过程
核心是在DDPM的基础上,增加一些设定,解决马尔可夫性导致的无法跳步采样的问题
直观理解

放弃马尔可夫性假设后,我们假设分布 \(p(x_{t-1}|x_t, x_0)\) 服从高斯分布:
$$
\begin{align}
p(x_{t-1}|x_t, x_0) &\sim \mathcal{N}(kx_0+mx_t, \sigma^2) \\
x_{t-1} &= kx_0+mx_t + \sigma \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I})
\end{align}
$$在 \( x_t\) 加噪过程中有(详情参见DDPM推导):
$$ x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t} \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I})$$将 \(x_t\) 带入原始假设分布,并合并同类项有(下面的推导使用到两个高斯分布的混合):
$$
\begin{align}
x_{t-1} &= kx_0+m(\sqrt{\bar{\alpha}_t} x_0 + \sqrt{1-\bar{\alpha}_t} \epsilon’) + \sigma \epsilon, \ \text{where} \ \epsilon,\epsilon’ \sim \mathcal{N}(0,\boldsymbol{I}) \\
x_{t-1} &= (k+m\sqrt{\bar{\alpha}_t})x_0 + \sqrt{m^2(1-\bar{\alpha}_t) + \sigma^2}\epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I})
\end{align}
$$在 \( x_{t-1}\) 加噪过程中有(详情参见DDPM推导):
$$ x_{t-1} = \sqrt{\bar{\alpha}_{t-1}} x_0 + \sqrt{1-\bar{\alpha}_{t-1}} \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I})$$于是,对照两个等式,让对应项相等可得以下方程:
$$
\begin{align}
k+m\sqrt{\bar{\alpha}_t} &= \sqrt{\bar{\alpha}_{t-1}}\\
\sqrt{m^2(1-\bar{\alpha}_t) + \sigma^2} &= \sqrt{1-\bar{\alpha}_{t-1}}
\end{align}
$$解方程可得:
$$
\begin{align}
m &= \frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}} \\
k &= \sqrt{\bar{\alpha}_{t-1}} - \frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}}\sqrt{\bar{\alpha}_t}
\end{align}
$$将结果带回原始假设分布可得:
$$
\begin{align}
x_{t-1} &= (\sqrt{\bar{\alpha}_{t-1}} - \frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}}\sqrt{\bar{\alpha}_t})x_0+(\frac{\sqrt{1-\bar{\alpha}_{t-1}-\sigma^2}}{\sqrt{1-\bar{\alpha}_t}})x_t + \sigma \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I}) \\
x_{t-1} &= \sqrt{\bar{\alpha}_{t-1}}x_0 - \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2} \frac {x_t - \sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}} + \sigma \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I}) \\
\end{align}
$$由加噪过程中关系,用 \(x_t\) 表示 \(x_0\) 有(详情见DDPM推导):
$$
\begin{align}
x_0 = \frac{x_t - \sqrt{1-\bar{\alpha}_t} \epsilon_t}{\sqrt{\bar{\alpha}_t} } \\
\epsilon_t = \frac{x_t - \sqrt{\bar{\alpha}_t}x_0}{\sqrt{1-\bar{\alpha}_t}}
\end{align}
$$将上述结果带入上一步的结论可得:
$$ x_{t-1} = \sqrt{\bar{\alpha}_{t-1}}\frac{x_t - \sqrt{1-\bar{\alpha}_t} \epsilon_t}{\sqrt{\bar{\alpha}_t} } - \sqrt{1-\bar{\alpha}_{t-1}-\sigma^2} \epsilon_t + \sigma \epsilon, \ \epsilon \sim \mathcal{N}(0,\boldsymbol{I}) $$- 其中 \(\epsilon_t = \epsilon_\theta(x_t, t)\),为了跟许多论文对齐,我们后续也可以写成 \(\epsilon_t = \epsilon_\theta(x_t, t) = \epsilon_\theta^{(t)}(x_t)\)
至此,我们还差 \(\sigma\) 的值没有确定:
- 考虑上式可以写成:
$$
q_\sigma(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)
= \mathcal{N}(\mathbf{x}_{t-1}; \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \epsilon^{(t)}_\theta(\mathbf{x}_t), \sigma_t^2 \boldsymbol{I})
$$ - 且 \(q(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_{t-1}; \tilde{\boldsymbol{\mu}}(\mathbf{x}_t, \mathbf{x}_0), \tilde{\beta}_t \boldsymbol{I})\)
- 于是有:
$$ \tilde{\beta}_t = \sigma_t^2 = \frac{1 - \bar{\alpha}_{t-1}}{1 - \bar{\alpha}_t} \cdot \beta_t $$ - 实际实验时,可以改写为: \(\sigma_t^2 = \eta’ \cdot \tilde{\beta}_t\) 或直接使用 \(\sigma_t^2 = \eta \cdot \beta_t\),详情见论文实验部分
- 考虑上式可以写成:
推导过程中没有一定要求 \(x_{t-1}\) 是 \(x_t\) 的上一步,所以可以用 \(x_s\) 替换 \(x_{t-1}\):
$$q_{\sigma, s < t}(\mathbf{x}_s \vert \mathbf{x}_t, \mathbf{x}_0)
= \mathcal{N}(\mathbf{x}_s; \sqrt{\bar{\alpha}_s} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_s - \sigma_t^2} \epsilon^{(t)}_\theta(\mathbf{x}_t), \sigma_t^2 \boldsymbol{I})$$最后,我们可以得到推导结果:

- 当采样方差 \(\sigma\) 满足一定条件时,上面的式子会满足马尔可夫过程,即等价于DDPM(注:DDIM采样公式中, \(x_t\) 前面的系数展开以后和DDPM是是一样的)
图示跳步采样(生成)的原理:
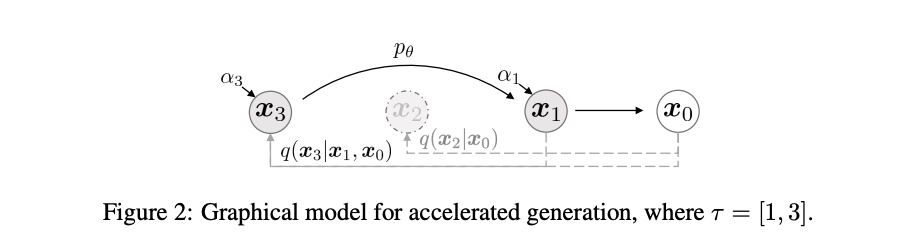
训练和推理
DDPM的训练和推理

DDIM的训练和推理
训练过程与DDPM基本一致,但DDIM只需要采样固定间隔的步数即可
- 如果已经有训练好的DDPM,可以直接用,因为DDPM的训练时间步包含了DDIM的训练时间步
推理过程

推理时,一般会设置 \(\sigma=0\),即DDIM是确定性的,这是DDIM中区别于DDPM的很大的点
实验结果
- 实验设置

- 结果展示
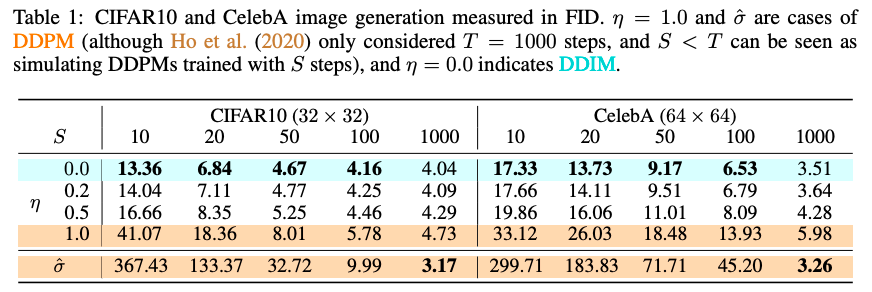
- 结果分析

- 从图中可以得出结论
- \(\sigma\) 越小( \(\eta\) 越小,方差越小),即方差越小,效果越好,DDIM最好(DDIM对应 \(\eta=0\) 且 \(\sigma=0\) )
- 当 \(T=1000\) 时(或者 \(T\) 非常大时),DDPM效果最好(DDPM对应 \(\eta=1\) 且 \(\sigma = \hat{\sigma}\) )
- 小节:当采样步数少时(即间隔大时),使用DDIM效果更好,DDPM效果非常差;当采样步数很大时,DDPM效果微微好于DDIM
代码亲测
各种 \(\alpha,\beta\) 的定义技巧:
1
2
3
4
5
6
7
8
9
10
11
12
13
14num_steps = 100
betas = torch.linspace(-6,6,num_steps)
betas = torch.sigmoid(betas)*(0.5e-2 - 1e-5)+1e-5 # beta逐步递增
alphas = 1-betas
print("alphas: %s" % alphas)
alphas_prod = torch.cumprod(alphas,0) # 连乘
alphas_bar = alphas_prod
alphas_prod_p = torch.cat([torch.tensor([1]).float(),alphas_prod[:-1]],0) # previous连乘
alphas_bar_sqrt = torch.sqrt(alphas_bar)
one_minus_alphas_bar_log = torch.log(1 - alphas_bar)
one_minus_alphas_bar_sqrt = torch.sqrt(1 - alphas_bar)
# 模型定义:model(x, t)
# 采样方式:torch.randn_like(x)实现细节(为了清晰表达,对原始采样公式有所修改):
$$
x_s = \sqrt{\bar{\alpha}_s}\left(\frac{x_k-\sqrt{1-\bar{\alpha}_k}\epsilon_{\theta}(x_k,k)}{\sqrt{\bar{\alpha}_k}}\right) + \sqrt{1-\bar{\alpha}_s-a_1\sigma_k^2}\epsilon_{\theta}(x_k,k) + a_2\sigma_k \epsilon
$$- 其中: \(\sigma_k^2 = \beta_t\)
- 注意: \(a_1,a_2\) 是新加的,拆开 \(a_1,a_2\) 的原因是实验发现两者可以设置不同值,且有以下现象:
- \(a_2=0,a_1=1.0\) 时,此时表示不采样,整个生成过程中没有添加随机值(除了初始样本为随机值外),不影响样本的生成质量,相对有随机值生成效果甚至更好
- \(a_1=0\) 时,无论 \(a_2\) 值为多少,生成的样本均是类似乱码的图
- \(a_1>0.5\) 时,无论 \(a_2\) 值是否为0,生成的样本均不错( \(a_1\) 的值不能太小,否则效果会不好)
亲测实验结果与论文有偏差的原因分析:
- 如果采样步数较少,效果也不好,但当采样间隔为2时,即跳一步采样,效果还可以(不如间隔为1)
- 采样步数越多,效果越好(与原始论文结果一样)
- 为什么本人实现的DDIM采样步数不能太少?(跳步10步时效果较差,与原始论文结果不一致)
- DDIM可能对模型要求很高,本人尝试环境中模型过于简单?训练样本过少?
- 为什么 \(a_1=0\) 时,效果非常差?
- 待解答
- 如果采样步数较少,效果也不好,但当采样间隔为2时,即跳一步采样,效果还可以(不如间隔为1)
DDIM对比DDPM
- DDIM训练流程与DDPM完全相同,只是推理(采样)过程不同
- DDIM主要解决DDPM采样慢的问题
- DDPM有符合马尔可夫假设,需要一步步采样,效率慢
- DDIM没有马尔可夫假设,可以跳步生成图片,且可以不采样(标准的DDIM就是不采样的,论文中,噪音的方差越小,得到的效果越好)
- DDIM中Implicit名字的来源是什么?
- Implicit的含义是表示“隐式的”,原论文的DDIM就是特指 \(\sigma_t=0\) 的情形,意思这是一个隐式的概率模型,因为跟其他选择所不同的是,此时从给定的 \(\boldsymbol{x}_T = \boldsymbol{z}\) 出发,得到的生成结果 \(\boldsymbol{x}_0\) 是不带随机性的生成扩散模型漫谈(四):DDIM = 高观点DDPM,科学空间
- 可以推导:在DDIM的结果中,如果方差 \(\sigma_t\) 取值满足一定条件时,跨度为1的DDIM采样过程会变成DDPM
一些问题和解答
- DDPM采样时不能去掉噪音,为什么DDIM可以?
- 回答:因为DDIM采样中,噪音的方差 \(\sigma\) 是通过实验发现效果比较好的
- 具体原因?
- 为什么DDPM和DDIM训练逻辑基本一致,但DDPM推断必须遵循马尔可夫性,而DDIM不需要?
- 回答:
- 训练时:DDIM和DDPM训练过程都遵循马尔可夫过程。DDIM可以按照一定间隔采样时间步,但实际上也是经过在满足马尔可夫过程的情况下推导出来的,DDPM和DDIM的训练采样公式都是因为方差可以累加实现跳跃采样的
- 推断时:因为DDPM的采样公式是在满足马尔可夫过程情况下推导出来的, 而DDIM的采样公式是在非马尔可夫过程情况下推导出来的,所以使用DDPM采样公式时,不能跳步;使用DDIM采样公式时(注意:实际上DDIM不采样,直接确定性生成),可以跳步
- 回答:
附录:其他快速推导方式
- 参考自:What are Diffusion Models?
$$
\begin{aligned}
\mathbf{x}_{t-1}
&= \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_{t-1}}\boldsymbol{\epsilon}_{t-1} & \\
&= \sqrt{\bar{\alpha}_{t-1}}\mathbf{x}_0 + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \boldsymbol{\epsilon}_t + \sigma_t\boldsymbol{\epsilon} & \\
&= \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \epsilon^{(t)}_\theta(\mathbf{x}_t) + \sigma_t\boldsymbol{\epsilon} \\
q_\sigma(\mathbf{x}_{t-1} \vert \mathbf{x}_t, \mathbf{x}_0)
&= \mathcal{N}(\mathbf{x}_{t-1}; \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \epsilon^{(t)}_\theta(\mathbf{x}_t), \sigma_t^2 \boldsymbol{I})
\end{aligned}
$$
附录:DDIM和ODE的关系
- 常微分方程(Ordinary Differential Equation,ODE)典型的形式表达如下:
$$ dy = f(x,y) dx $$ - 由之前的推导已经有:
$$\mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1} - \sigma_t^2} \epsilon^{(t)}_\theta(\mathbf{x}_t) + \sigma_t\boldsymbol{\epsilon}$$ - 此时令 \(\sigma_t = 0\),可得:
$$
\begin{align}
\mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1}} \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\end{align}
$$ - 经过变换有:
$$
\begin{align}
\frac{\mathbf{x}_{t-1}}{\sqrt{\bar{\alpha}_{t-1}}} = \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \frac{\sqrt{1 - \bar{\alpha}_{t-1}}}{\sqrt{\bar{\alpha}_{t-1}}} \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\frac{\mathbf{x}_{t-1}}{\sqrt{\bar{\alpha}_{t-1}}} = \frac{\mathbf{x}_t}{\sqrt{\bar{\alpha}_t}} - \frac{\sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} + \frac{\sqrt{1 - \bar{\alpha}_{t-1}}}{\sqrt{\bar{\alpha}_{t-1}}} \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\frac{\mathbf{x}_{t-1}}{\sqrt{\bar{\alpha}_{t-1}}} = \frac{\mathbf{x}_t}{\sqrt{\bar{\alpha}_t}} + \Big(\frac{\sqrt{1 - \bar{\alpha}_{t-1}}}{\sqrt{\bar{\alpha}_{t-1}}} - \frac{\sqrt{1 - \bar{\alpha}_t}}{\sqrt{\bar{\alpha}_t}}\Big) \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\end{align}
$$ - 当 \(T\) 足够大时,相邻距离 \(t-1\) 可以用 \(t-\Delta t\) 表示,于是有:
$$
\begin{align}
\frac{\mathbf{x}_{t-\Delta t}}{\sqrt{\bar{\alpha}_{t-\Delta t}}} = \frac{\mathbf{x}_t}{\sqrt{\bar{\alpha}_t}} + \Big(\frac{\sqrt{1 - \bar{\alpha}_{t-\Delta t}}}{\sqrt{\bar{\alpha}_{t-\Delta t}}} - \frac{\sqrt{1 - \bar{\alpha}_t}}{\sqrt{\bar{\alpha}_t}}\Big) \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\end{align}
$$ - 进一步作变量替换 \(\sigma = \frac{\sqrt{1-\bar{\alpha}}}{\sqrt{\bar{\alpha}}}\) 和 \(\bar{\mathbf{x}} = \frac{\mathbf{x}}{\sqrt{\bar{\alpha}}}\),则有:
$$
\begin{align}
\bar{\mathbf{x}}_{t-\Delta t} = \bar{\mathbf{x}}_{t} + \Big(\sigma_{t-\Delta t} - \sigma_{t}\Big) \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\end{align}
$$ - 进一步变换有:
$$
\begin{align}
\bar{\mathbf{x}}_{t} - \bar{\mathbf{x}}_{t-\Delta t} = \Big(\sigma_{t} - \sigma_{t-\Delta t}\Big) \epsilon^{(t)}_\theta(\mathbf{x}_t) \\
\end{align}
$$ - 写成微分形式有:
$$
\begin{align}
d \bar{\mathbf{x}}_{t} = \epsilon^{(t)}_\theta(\mathbf{x}_t) d\sigma_t \\
\end{align}
$$ - 进一步将 \(\epsilon^{(t)}_\theta(\mathbf{x}_t)\) 中的 \(\mathbf{x}_t\) 替换为 \(\bar{\mathbf{x}_t}\):
$$
\begin{align}
\bar{\alpha} &= \frac{1}{\sigma_t^2 + 1} \\
\mathbf{x}_t &= \bar{\mathbf{x}} \sqrt{\bar{\alpha}} = \frac{\bar{\mathbf{x}}_t}{\sqrt{\sigma_t^2 + 1}}
\end{align}$$ - 最终我们可以得到微分方程如下:
$$
\begin{align}
d \bar{\mathbf{x}}_{t} = \epsilon^{(t)}_\theta\Big(\frac{\bar{\mathbf{x}}_t}{\sqrt{\sigma_t^2 + 1}}\Big) d\sigma_t \\
\end{align}
$$ - 表达成时间的函数形式有:
$$
\begin{align}
d \bar{\mathbf{x}}(t) = \epsilon^{(t)}_\theta\Big(\frac{\bar{\mathbf{x}}(t)}{\sqrt{(\sigma(t))^2 + 1}}\Big) d\sigma(t) \\
\end{align}
$$ - 所以,在给定初始状态为 \(x_T \sim \mathcal{N}(0,\boldsymbol{I})\) 的情况下,求解 \(x_0\) 的过程 \(\mathbf{x}_{t-1} = \sqrt{\bar{\alpha}_{t-1}} \Big( \frac{\mathbf{x}_t - \sqrt{1 - \bar{\alpha}_t} \epsilon^{(t)}_\theta(\mathbf{x}_t)}{\sqrt{\bar{\alpha}_t}} \Big) + \sqrt{1 - \bar{\alpha}_{t-1}} \epsilon^{(t)}_\theta(\mathbf{x}_t)\) 可以等价于利用欧拉方法迭代求解常微分方程 \(d \bar{\mathbf{x}}(t) = \epsilon^{(t)}_\theta\Big(\frac{\bar{\mathbf{x}}(t)}{\sqrt{(\sigma(t))^2 + 1}}\Big) d\sigma(t)\) 离散点的过程,以下描述来自生成扩散模型漫谈(四):DDIM = 高观点DDPM:
而DDPM或者DDIM的迭代过程,对应于该常微分方程的欧拉方法。众所周知欧拉法的效率相对来说是最慢的,如果要想加速求解,可以用Heun方法、R-K方法等。也就是说,将生成过程等同于求解常微分方程后,可以借助常微分方程的数值解法,为生成过程的加速提供更丰富多样的手段
附录:欧拉方法
- 欧拉方法是求解常微分方程(Ordinary Differential Equation,ODE)数值解的一种基础且直观的方法。其核心思想是利用给定点处的斜率来预测下一个点的位置。这种方法特别适用于那些难以找到解析解或解析解过于复杂的问题
- (回顾)常微分长程典型的形式表达如下:
$$ dy = f(x,y) dx $$
欧拉方法的形式及推导
- 为了理解欧拉方法的工作原理,我们可以从泰勒展开的角度出发。假设我们有一个初值问题:
$$
\begin{cases}
y’(t) = f(t, y(t)), & t \in [a, b] \\
y(a) = y_0 & \text{; initial }
\end{cases}
$$ - 对于任意一点 \(t_n\),如果我们想要求得 \(t_{n+1} = t_n + h\) 处的 \(y_{n+1}\),可以通过对 \(y(t)\) 在 \(t_n\) 点进行一阶泰勒展开近似得到:
$$
y(t_{n+1}) \approx y(t_n) + hy’(t_n) = y(t_n) + hf(t_n, y(t_n))
$$ - 这里 \(h\) 是步长,即相邻两个时间点之间的距离。因此,欧拉方法的迭代公式可以写作(下面迭代公式的等号是赋值的意思)下面的形式:
$$
y_{n+1} = y_n + hf(t_n, y_n), \quad n=0, 1, 2, \ldots
$$- 这便是向前欧拉公式的定义。通过这种方式,我们可以递归地计算出后续各点的函数值
- 同理,欧拉公式也可以按照后项定义如下:
$$
y_{n} = y_{n+1} - hf(t_n, y_n), \quad n=0, 1, 2, \ldots
$$
欧拉方法求解函数离散点示例
- 使用欧拉方法解决实际问题时,首先需要确定的是微分方程的形式以及初始条件。然后选择合适的步长 \(h\) 并应用上述迭代公式逐步计算未来的值。例如,考虑一个简单的例子:
$$
y’(t) = \lambda y(t), \quad y(0) = 1
$$ - 如果我们设定 \(\lambda = -1\) 和 \(h = 0.1\),那么根据欧拉公式,我们可以写出如下代码片段来实现这个过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20import numpy as np
def euler_method(f, y0, t):
"""Simple implementation of Euler's method."""
y = np.zeros_like(t)
y[0] = y0
for i in range(1, len(t)):
y[i] = y[i-1] + (t[i] - t[i-1]) * f(t[i-1], y[i-1])
return y
def f(t, y):
return -1 * y
t = np.linspace(0, 5, 51) # 50 steps from 0 to 5
y0 = 1 # Initial condition
# Solve using Euler's method
y_euler = euler_method(f, y0, t)
print(y_euler[-1]) # Print the last computed value
其他扩展概念
- 与常微分方程对应的还有一个概念是随机微分方程(Stochastic Differential Equation,SDE),随机微分方程在常微分方程的基础上加入了随机过程作为其中一项,本质也是一个随机过程,示例如下:
$$\mathrm{d}X_t = \mu(t, X_t)\mathrm{d}t + \sigma(t, X_t)\mathrm{d}W_t$$ - 这里, \(\mu(t, X_t)\) 被称为漂移系数,表示系统的确定性变化趋势;而 \(\sigma(t, X_t)\) 是扩散系数,反映了系统受随机波动的影响程度; \(W_t\) 用来模拟不可预测的随机扰动。