Megatron Core 是什么?
- Megatron-Core,即 NVIDIA Megatron-Core,也称为 Megatron Core 或 MCore,是一个基于 PyTorch 的开源库,可在数千个 GPU 上以高速大规模训练大型模型
- Megatron-Core 提供了先进的模型并行技术
- 包括张量、序列、工作流、上下文和 MoE 专家并行等
- 用户可以灵活结合不同的模型并行技术以适应训练工作负载
- 还具备节省内存的功能,如激活重新计算、分布式优化器和分布式检查点等
- Megatron-Core 通过模块化和可组合的 API 提供可定制的基础模组,对于 Transformer 模型,它提供注意力机制、归一化层、嵌入技术等
- 借助 Megatron-Core(Mcore)规格系统,研究人员可以在 PyTorch 模型定义中轻松自定义所需抽象级别的子模块
- Megatron-Core 是 Megatron-LM 的子集,即:
- Megatron-LM 依赖 Megatron-Core 实现底层分布式逻辑;
- 开发者可以单独使用 Megatron-Core,而无需引入 Megatron-LM 的全部功能
ModuleSpec 类的使用
ModuleSpec是 Megatron-Core (Mcore) 引入的一个核心概念,旨在解决“如何在不修改底层代码的情况下灵活组合模型架构”的问题- 在传统的 PyTorch 开发中,如果你想把
LayerNorm换成RMSNorm,通常需要修改模型类的源码 - 在 Megatron-Core 中,模型结构与具体实现是解耦的
- 在传统的 PyTorch 开发中,如果你想把
- ModuleSpec 是什么?
ModuleSpec是一个配置容器,它告诉框架:“在这个位置,请使用这个类,并用这些参数初始化它”ModuleSpec允许用户通过配置文件或参数动态地“组装”模型,类似于乐高积木
ModuleSpec 的结构说明
ModuleSpec主要包含三个核心参数:module: 指定要实例化的类(例如TransformerLayer,SelfAttention)params: 一个字典,包含传递给该类__init__方法的静态参数(例如SelfAttention常用到的attn_mask_type)submodules: 指定该模块内部子模块的实现方式- 理解:
submodules允许递归地定义整个网络结构
- 理解:
使用 ModuleSpec 定义 GPT 模型示例
- 以一个简单的 Decoder-only Transformer GPT 模型定义为例
第一步:目标 GPT 类编写
- 自己写一个简单的 GPT 模型类(后续用在 ModuleSpec 中)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40class DiySimpleGPTModel(MegatronModule):# 定义一个简单的 GPT 模型,继承 MegatronModule
def __init__(
self,
config: ModelParallelConfig,
embeddings: MegatronModule, # 由 ModuleSpec 创建并注入的嵌入模块
decoder: MegatronModule, # 由 ModuleSpec 创建并注入的 TransformerBlock
output_layer: MegatronModule, # 由 ModuleSpec 创建并注入的输出层
):
super().__init__(config=config) # 调用父类构造函数,保存配置等
self.embeddings = embeddings # 把注入进来的嵌入模块保存为成员变量
self.decoder = decoder # 保存解码器(多层 Transformer)
self.output_layer = output_layer # 保存输出层(LMHead)
def forward( # forward 函数,用到上面定义的相关组件,后续这些组件会一个个定义
self,
input_ids: torch.Tensor, # 输入 token ids,形状 (batch, seq_len)
position_ids: torch.Tensor = None, # 位置 ids(可选)
attention_mask: torch.Tensor = None, # 注意力 mask(可选)
labels: torch.Tensor = None, # 训练时使用的标签(可选)
):
# 词嵌入 + 位置嵌入
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
# 通过多层 Transformer decoder
hidden_states = self.decoder(hidden_states, attention_mask=attention_mask)
# 输出层:hidden -> vocab logits
logits = self.output_layer(hidden_states=hidden_states)
# 如果没有 labels,说明不需要计算 Loss,直接返回 logits(推理模式)
if labels is None:
return logits # 返回 logits,形状 (batch, seq_len, vocab_size)
# 如果有 labels,计算交叉熵损失(Megatron 的训练模式)
loss_fn = nn.CrossEntropyLoss(ignore_index=-100) # 定义交叉熵损失,忽略 -100 标签
loss = loss_fn( # 计算损失
logits.view(-1, logits.size(-1)), # 仅保留最后一个维度,logits reshape 为 (batch*seq_len, vocab)
labels.view(-1), # labels reshape 为 (batch*seq_len),与 logits 对齐
)
return loss, logits # 同时返回 loss 和 logits
第二步:DiySimpleGPTModel 类的 ModuleSpec 定义
写一个完整的 GPT ModuleSpec
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82# 配置参数
num_layers = 12 # Transformer 层数(例如 GPT-2 small:12 层)
hidden_size = 768 # 隐层维度 d_model
num_attention_heads = 12 # 注意力头数
seq_length = 1024 # 最大序列长度
vocab_size = 50257 # 词表大小(例如 GPT-2 的 BPE vocab)
# 定义配置项 ModelParallelConfig
config = ModelParallelConfig(
num_layers=num_layers, # Transformer 层数
hidden_size=hidden_size, # 隐藏维度
num_attention_heads=num_attention_heads, # 注意力头数
max_position_embeddings=seq_length, # 最大位置编码长度
vocab_size=vocab_size, # 词表大小
)
# 定义单个 Transformer 层的 ModuleSpec
transformer_layer_spec = ModuleSpec( # 创建一个 ModuleSpec,描述单层 Transformer
module=TransformerLayer, # 指定使用 Megatron-Core 内的 TransformerLayer 类
submodules={ # 定义该 Transformer 层包含的子模块
"self_attention": ModuleSpec( # "self_attention" 与 TransformerLayer 类自身的属性名称相同
module=SelfAttention, # 使用 SelfAttention 模块
params={ # 传给 SelfAttention 构造函数的参数
"config": config, # 传入模型配置
"layer_number": 1, # 层号(可用于初始化不同随机种子等,这里简单写 1)
},
),
"mlp": ModuleSpec( # 前馈网络子模块的规格,注意:"mlp" 与 TransformerLayer 类自身的属性名称相同
module=MLP, # 使用 MLP 模块
params={ # 传给 MLP 的参数
"config": config, # 传入模型配置
},
),
},
params={ # 传给 TransformerLayer 自身的参数
"config": config,
"layer_number": 1,
},
)
# 定义嵌入层的 ModuleSpec
embeddings_spec = ModuleSpec( # 创建嵌入模块的 ModuleSpec
module=LanguageModelEmbedding, # 使用 LanguageModelEmbedding(词嵌入 + 位置嵌入)
params={
"config": config,
"rotary_pos_emb": RotaryPositionalEmbedding( # 传入 RoPE
config=config # RoPE 也需要配置对象
),
"use_position_embeddings": False, # 若想使用绝对位置编码,可以启用绝对位置嵌入,如果只想用 RoPE,设置 False
},
)
# 定义 Decoder(多层 TransformerBlock)的 ModuleSpec
decoder_spec = ModuleSpec( # 创建 decoder 的 ModuleSpec
module=TransformerBlock, # 使用 TransformerBlock(内部包含多层 TransformerLayer)
params={ # 构造函数参数
"config": config, # 传入配置
"layer_spec": transformer_layer_spec, # 指定“每一层”的结构(即上面的 transformer_layer_spec)
"num_layers": num_layers, # 总层数,理解:总层数 x 单层结构(transformer_layer_spec)= 整个 decoder 的结构
},
)
# 定义输出层的 ModuleSpec
output_layer_spec = ModuleSpec(
module=TransformerLanguageModelOutputLayer, # 使用标准语言模型作为输出层
params={ # 构造函数参数
"config": config, # 传入配置
},
)
# 定义完整 GPT 模型的 ModuleSpec(关键部分)
diy_simple_gpt_spec = ModuleSpec( # 创建整个 GPT 模型的 ModuleSpec
module=DiySimpleGPTModel, # 总模块使用我们自定义的 DiySimpleGPTModel 类
submodules={ # 声明该模型包含的子模块,注意名称与类对象名需要完全对齐,否则无法正确映射过去
"embeddings": embeddings_spec, # embeddings 子模块的规格
"decoder": decoder_spec, # decoder 子模块的规格
"output_layer": output_layer_spec, # output_layer 子模块的规格
},
params={ # 传给 DiySimpleGPTModel 构造函数的额外参数
"config": config, # 传入模型配置
},
)关键思路总结:
- 先构造
ModelParallelConfig - 撰写三个
ModuleSpec:embeddings_spec,decoder_spec,output_spec - 撰写总的
diy_simple_gpt_spec = ModuleSpec(...)指向DiySimpleGPTModel,使用上面定义的三个ModuleSpec来定义
- 先构造
第三步:用 ModuleSpec 实例化模型
- 用 ModuleSpec 实例化模型,尝试做一次推理和训练的前向过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 用 ModuleSpec 构建真正的模型实例
device = "cuda" if torch.cuda.is_available() else "cpu"
model = diy_simple_gpt_spec.build_module() # 调用 diy_simple_gpt_spec(ModuleSpec 对象)的 build_module(),自动递归构建模型
model = model.to(device)
# 构造一个 fake batch 做前向推理
batch_size = 2 # batch 大小
test_seq_len = 16 # 测试序列长度(可以小于 config 中的 max_length)
input_ids = torch.randint(
low=0, # 最小 token id
high=vocab_size, # 最大 token id(不含此值)
size=(batch_size, test_seq_len), # 张量形状为 (batch_size, seq_len)
device=device,
)
# 推理解码(不带 labels)
with torch.no_grad(): # 关闭梯度计算,加速推理
logits = model(input_ids=input_ids)
print("logits shape:", logits.shape) # 打印 logits 形状,应该是 (batch_size, seq_len, vocab_size)
# 训练模式(带 labels),用 input_ids 自回归做 labels
labels = input_ids[:, 1:]
input_ids = input_ids[:, :-1]
loss, logits = model(input_ids=input_ids, labels=labels)
print("loss:", loss.item())

")
")
")





/Algorithm1.png)
/Figure2.png)
/Figure3.png)
/Figure4.png)
/Figure6.png)
/Figure7.png)
/Figure8.png)
/Figure9.png)
/Figure10.png)
/Figure11.png)
/Figure12.png)
/Figure13.png)
/Figure14.png)
/Figure15.png)
/Figure16.png)
/Figure17.png)
/Figure18.png)
/Figure19.png)
/Table4.png)
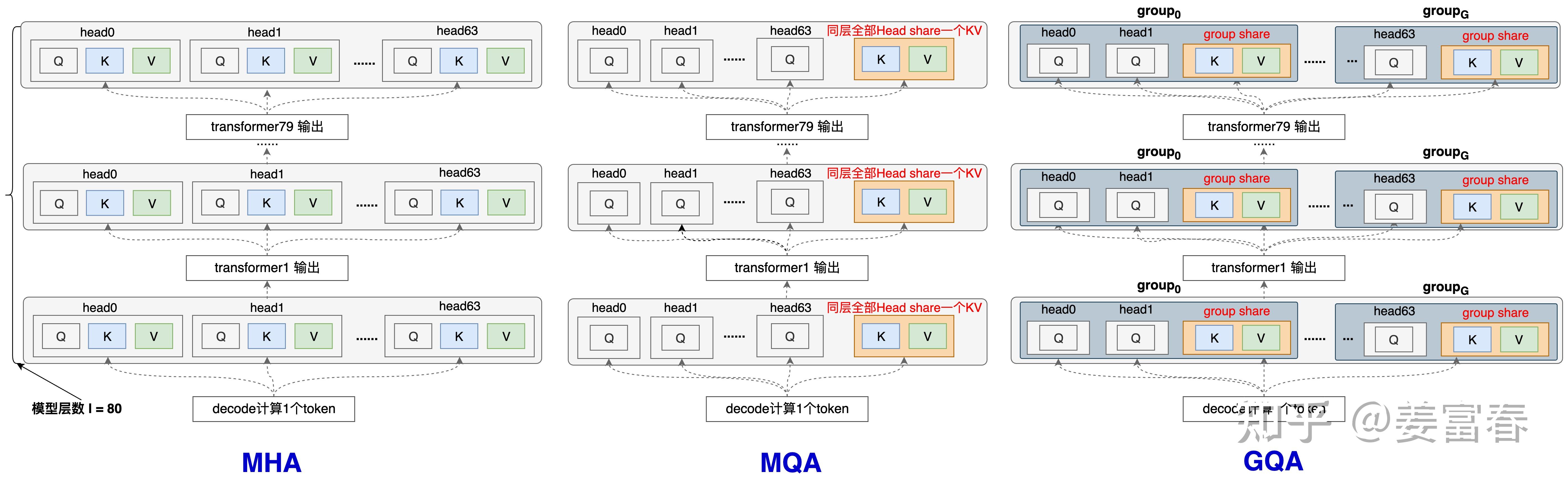
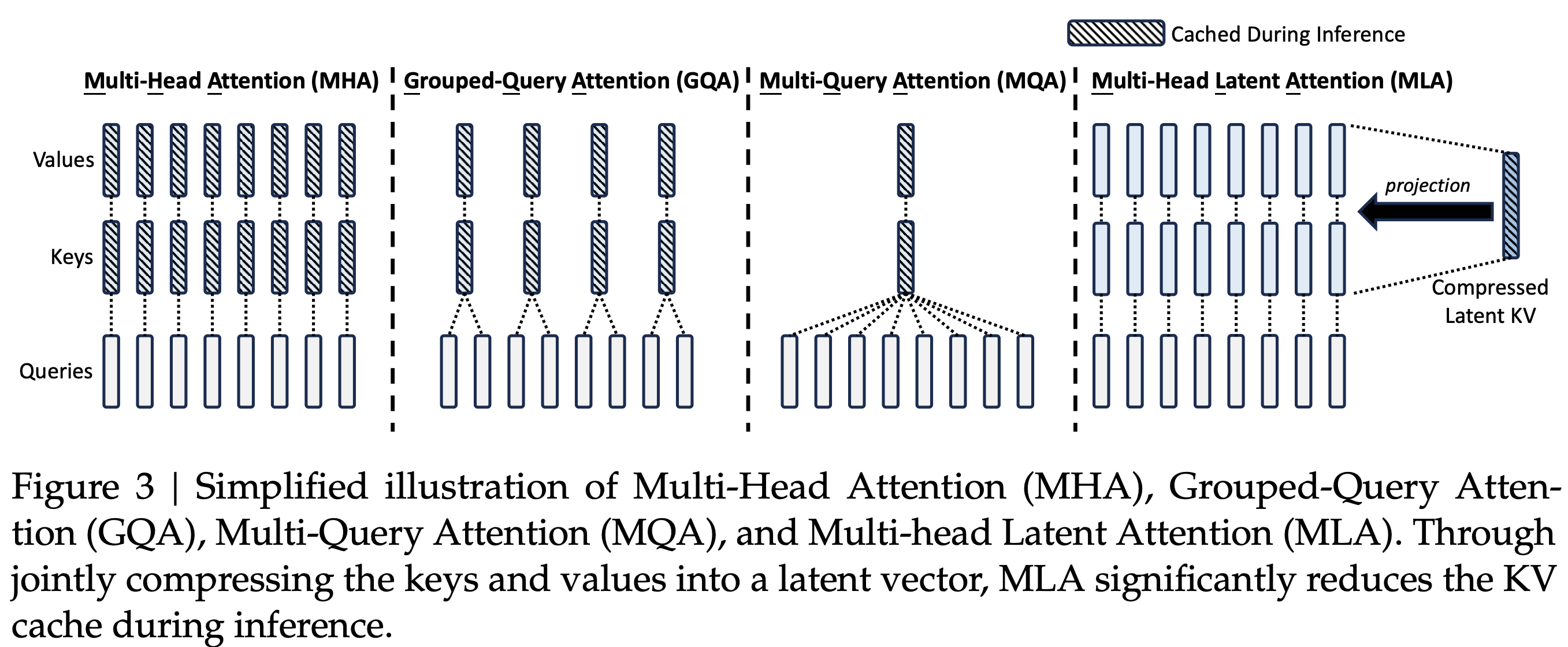
 * 核心,MLA 将 Q 和 K 拆开成 引入 RoPE 和 不引入 RoPE(NoPE)两部分,两者的 q 和 k 分别做 concat,本质是 qk 相乘以后做加法
* 核心,MLA 将 Q 和 K 拆开成 引入 RoPE 和 不引入 RoPE(NoPE)两部分,两者的 q 和 k 分别做 concat,本质是 qk 相乘以后做加法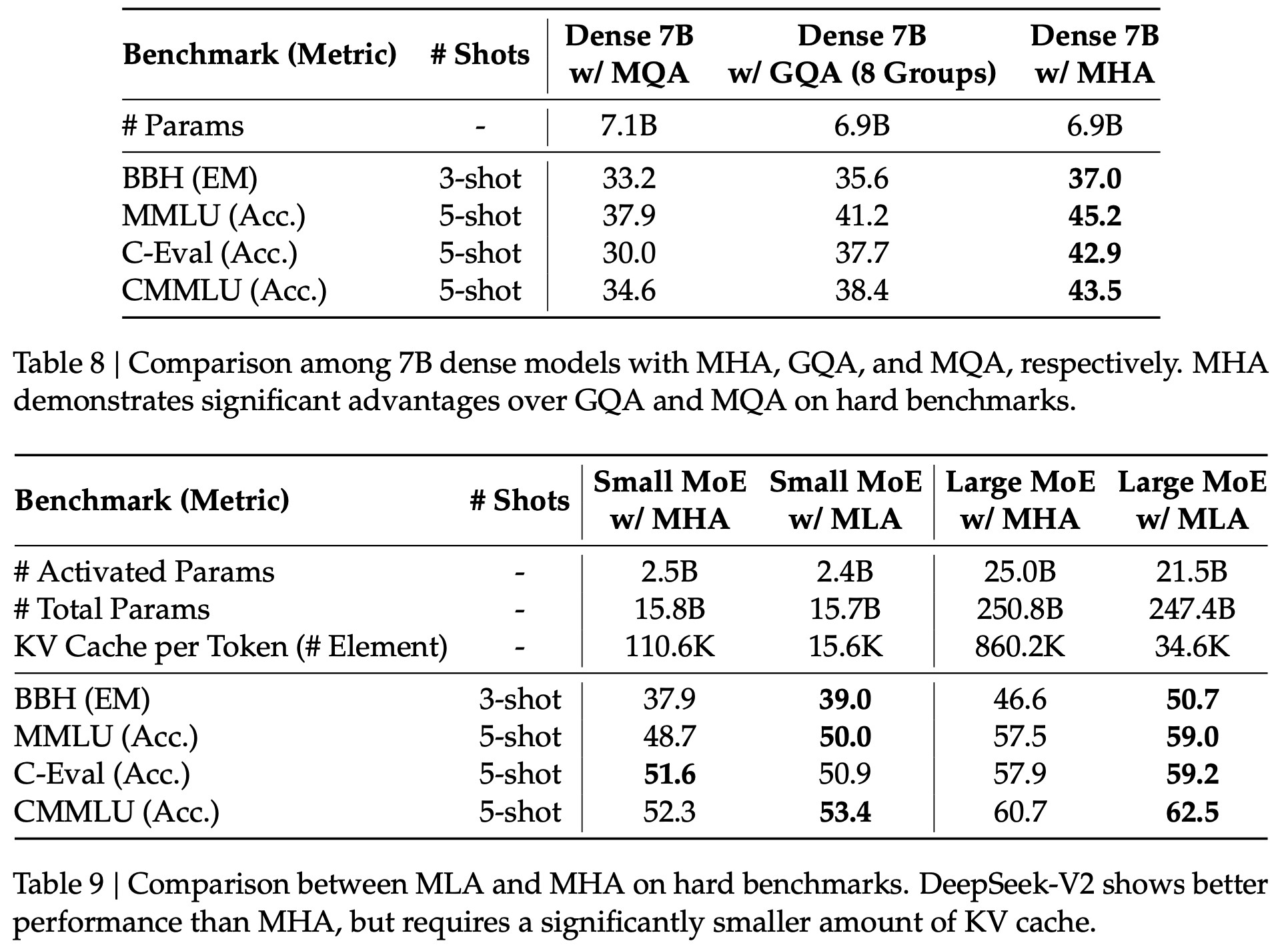

")
")