本文主要介绍 LLM 相关名词,部分名词很简单,所以会给一个简单的定义,注:本文会特别关注还有其他含义(传统 NLP 中)的名词
LLM
- Large Language Model,泛指大模型
- LLM涌现出的3大能力:
- In-context learning:在GPT-3中正式被提出。在不需要重新训练的情况下,通过自然语言指令,并带几个期望输出的样例,LLM就能够学习到这种输入输出关系,新的指令输入后,就能输出期望的输出
- Instruction following:通过在多种任务数据集上进行指令微调(instruction tuning),LLM可以在没有见过的任务上,通过指令的形式表现良好,因此具有较好的泛化能力
- Step-by-step reasoning:通过思维链(chain-of-thought)提示策略,即把大任务分解成一步一步小任务,让模型think step by step得到最终答案
Pre-Training
- 通常指大模型的无监督预训练过程
Prompt
- 提示词,与 LLM 交互时输入 LLM 的文本
- 理解:叫做 Prompt 的原因是因为与 LLM 交互时,像是在给 LLM “提示“或者”线索“
- Prompt 可以是上文,要求模型输出下文;也可以是 Mask 部分词后的句子,要求模型完成 Mask 预测(完形填空)
Template
- 模板(Template)是一个映射函数,不同的下游任务有不同的Template
- 这里的下游任务是指,在预算训练模型Pretrain LM之后,如果要让PLM完成下游任务,可以根据任务特色,设计特殊的模板,利用模板来将原始输入转换为能完成下游任务的输入形式
- 模板的形式通常是一个包含两个空位置的自然语言句子
[X]个[Z],其中[X]表示原始输入文本位置,Z表示生成的答案所在位置 - 举例来说,在做情感分类任务时,可以定义模板为
[X], Overall, it was [Z],对于原始输入文本I like this movie,则经过模板转换后,原始文本变成I like this movie, Overall, it was [Z]- 训练时:输入
I like this movie, Overall, it was [Z],期望输出good(或其他正向词语) - 推理时:输入
I like this movie, Overall, it was [Z],输出通常通过Verbalizer构造方法对应到正/负向类别
- 训练时:输入
Prompt Learning
- Prompt Learning是一种训练语言模型的方法,它侧重于如何通过prompt来引导模型生成正确的输出。在这种方法中,模型通过学习大量的prompt和相应的正确回答来提高其对prompt的理解和回答能力。Prompt Learning使得模型能够在没有大量标注数据的情况下,通过理解prompt的上下文来生成更加准确和相关的回答
- 离散型模板,即硬模板方法(hard-prompt):
- 硬模板方法通过人工设计/自动构建基于离散 token 的模板,代表方法是PET和LM-BFF
- 其中Pattern Exploiting Training (PET) 方法就是将问题建模成一个完形填空问题,然后优化最终的输出词。PET方法训练流程为:
- 在少量监督数据上,给每个 Prompt 训练一个模型;
- 对于无监督数据,将同一个样本的多个 prompt 预测结果进行集成,采用平均或加权(根据acc分配权重)的方式,再归一化得到概率分布,作为无监督数据的 soft label ;
- 在得到的soft label上 finetune 一个最终模型。推理时使用的就是这个最终模型
- 连续型模板,即软模板方法(soft-prompt):
- 与硬模板方法不同,软模板方法不依赖于人工设计模板,而是在输入端直接插入可优化的伪提示符(Pseudo Prompt Tokens)。这些伪提示符的embedding是可训练的,模型通过学习来找到最优的提示表示。例如,P-Tuning(Prompt Tuning) 方法就是通过优化这些伪提示符来提高模型的性能
- token是可以学习的向量,这种方法甚至可以媲美 Fine-tuning 的结果,代表方法是 P-Tuning(Prompt Tuning)和Prefix Tuning
- P-Tuning:P-Tuning(Prompt Tuning)的核心是将离散的文本提示(如 “请回答以下问题:”)转换为连续的向量表示(即 “软提示”),并通过反向传播优化这些向量,使模型在特定任务上表现更好。与传统微调(Fine-Tuning)需要更新整个模型参数不同,P-Tuning 仅需训练少量的提示向量,大幅降低了计算成本
- 在输入层前插入一系列可训练的向量(称为 “提示 Token”),这些向量与输入文本的嵌入向量共同输入模型
- Prefix Tuning:模型上在每层 transformer 之前加入 prefix。特点是 prefix 不是真实的 token,而是连续向量(soft prompt),Prefix-tuning 训练期间冻结 transformer 的参数,只更新 Prefix 的参数,开销很小
- 每个下游任务对应一个 Prefix向量
- P-Tuning vs Prefix Tuning:P-Tuning 仅在输入层插入提示向量(参数量极少),Prefix Tuning 在每一层 Transformer 前注入前缀向量(参数量较多)
In Context Learning (ICL)
- 参考其他地方的表述:
对于大型语言模型来说,即需要大量的数据标记成本,也需要算力成本和时间成本。然而,不同场景下任务的需求是不一样的,不可能根据每个任务都去微调模型。能否不进行微调就让模型学习完成不同的任务呢?答案是可以的,这个神奇的技术称为 上下文学习 (In Context Learning)。它的实现非常简单,只需要给到模型一些引导,将一些事先设定的文本输入到大型语言模型中,就像手把手教人学会某项技能一样,大型语言模型就能神奇的学习到如何处理后续的新任务。遗憾的是,为什么大型语言模型具有上下文学习的能力仍然是一个迷,业内把这个能力称为“涌现”
- In Context Learning也可以理解为LLM涌现出的一种能力,在同一个Prompt中,LLM能够根据上文示例学习到解决下文任务
- 特点:不需要重新训练模型,也不需要微调任何参数,仅通过自然语言指令+几个期望输出的示例,让LLM学习到这种输入输出关系,从而让LLM能解决上文示例中相似任务
- 一种理解:将ICL输入模型的示例看做是“训练样本”,真正的问题部分看做是“测试样本”,LLM会在看了示例后给出问题的回答
- 此时“训练样本”和“测试样本”是同时输入模型的,LLM在使用“训练“自己的同时给出”推断“
Zero Shot & Few Shot & Full Shot
- Zero-shot Learning (零样本学习) :
- 模型在没有任何特定任务的示例数据的情况下,仅凭其在大量通用文本上预训练获得的泛化能力和对语言的理解来完成任务
- 这种方法依赖于模型的泛化能力,通过分析少量的示例来理解新任务的要求,并在此基础上生成正确的输出
- 例如:让一个 LLM 翻译一个它从未见过的语言的句子,它会尝试利用其对语言结构和语义的理解进行翻译
- Few-shot Learning (少样本学习) :
- 在提示 (prompt) 中提供少量(通常是几个)带标签的示例 ,帮助模型理解任务的格式、风格和预期输出,从而在不更新模型参数的情况下提高其在该任务上的表现
- 这种方法依赖于模型的泛化能力和对语言的理解,通过分析输入(没有任何示例)的描述来理解任务的要求,并生成相应的输出
- 例如:在进行情感分析时,你可以在提示中给出几个正面和负面评论的例子,然后让 LLM 对新的评论进行分类
- Full-shot Learning (全样本学习) :
- 与 zero-shot 和 few-shot 不同,full-shot 指的是传统的、有监督的学习范式 ,模型在大量的、任务特定的标注数据集上进行训练(或微调)
- 这通常意味着对模型进行参数更新 ,使其真正“学习”到该任务的特定模式
- 例如:如果要构建一个高度精确的垃圾邮件检测器,你会收集数百万封标注过的邮件(垃圾邮件或非垃圾邮件),然后用这些数据来训练或微调一个模型
- LLM 因其卓越的 zero-shot 和 few-shot 能力而闻名,能够在没有或只有少量示例的情况下执行新任务
- 在 LLM 的背景下,当我们谈论 full-shot 时,它更侧重于模型在大量特定任务数据上进行微调 (fine-tuning)的过程,而不是仅仅通过提示来引导模型
- 这种微调可以显著提高模型在特定任务上的性能,因为它允许模型深入学习该任务的细微差别
Chain-of-Thought (CoT)
- Chain-of-Thought是一种生成解释性回答的技术,它通过模拟人类解决问题的思维过程来生成答案
- 在CoT中,模型首先生成一个或多个中间步骤,然后基于这些步骤来构建最终答案
- CoT 方法可以提高模型输出的透明度和可解释性,帮助用户理解模型是如何得出特定答案的
Alignment tuning
- Alignment tuning,对齐微调,为了避免模型输出一些不安全或者不符合人类正向价值观的回复
RLHF
- 一种对齐微调(Alignment tuning)方法,基于人类反馈的强化学习方法
RLAIF
- 一种对齐微调方法,基于 AI 反馈的强化学习方法
Reward Hacking
参考链接(包含许多相关论文):B站视频:Reward Hacking (in RLHF of LLM)
- Reward Hacking是指在强化学习中,智能体通过学习最大化奖励信号的策略,可能导致不符合设计者预期的行为
- 这种行为可能会损害系统的安全性和可靠性,因为它可能导致智能体采取欺骗性或恶意的行动来提高其奖励
- 因此,设计者需要仔细设计奖励函数,以避免 Reward Hacking 的发生
- 举例:
- 在狼抓羊的游戏中,狼的 reward 设计为抓住羊+10,每秒-0.1,撞死-1,则狼可能会直接学习到撞死
- 在RLHF中,如果不限制 \(\pi_\theta\) 不要偏离 \(\pi_{ref}\) 太远, \(\pi_\theta\) 很容易为了获得更大的 reward 而跑飞(比如输出特定人类读不懂的乱码),进而丢失 SFT 的优秀泛化能力(从这个角度讲,此时的Reward Hacking可以理解为模型的一种过拟合现象)
- Reward Hacking发生的本质原因是:reward设置不合理(和任务意图不完全一致) ,但是现实世界中很多任务的意图都是抽象的,难以准确用简单规则描述
- Reward Hacking很难解决,甚至无法解决,只有在非常苛刻的条件下才能解决
Parameter-Efficient Model Adaptation
- Parameter-Efficient Model Adaptation是指通过优化参数(数量)实现模型高效适配(下游任务)
- 背景:LLM参数量很大,想要去做全量参数的fine turning代价很大,所以需要一些高效经济的方法
- 解决方法:PEFT(Parameter-Efficient Fine-Tuning)
- 一些PEFT方法
- Adapter Tuning
- Prefix Tuning
- Prompt Tuning
- Low-Rank Adapation(LoRA)
Memory-Efficient Model Adaptation
这部分内容参考自:万字长文入门 LLM
- Parameter-Efficient Model Adaptation是指优化内存(或显存)实现模型高效适配(下游任务)
- 背景:由于LLM的参数量巨大,在推理的时候非常占用内存,导致其很难在应用中部署,所以需要一些减少内存占用的方法,比如LLM中的量化压缩技术
- 解决方法:比如LLM中的量化压缩技术
- quantization-aware training (QAT),需要额外的全模型重训练
- Efficient fine-tuning enhanced quantization (QLoRA)
- Quantization-aware training (QAT) for LLMs
- post-training quantization (PTQ),不需要重训练
- Mixed-precision decomposition
- Fine-grained quantization
- Balancing the quantization difficulty
- Layerwise quantization
- quantization-aware training (QAT),需要额外的全模型重训练
- 其他博主经验:
- INT8 权重量化通常可以在 LLM 上产生非常好的结果,而较低精度权重量化的性能则取决于特定的方法
- 激活函数比权重更难量化,因为LLM 呈现出截然不同的激活模式(即较大的离群特征),因此量化 LLM(尤其是隐层激活)变得更加困难
- Efficient fine-tuning enhanced quantization(QLoRA)是提升量化LLM一个较好的方法
- 开源量化库:Bitsandbytes,GPTQ-for-LLaMA,AutoGPTQ,llama.cpp
SFT Packing
- SFT Packing 是 SFT 过程中的一种技术,主要思路是将短 SFT 训练样本(对话)进行打包,在不同对话之间加入特殊分隔符(如
EOS) - SFT Packing 会加快模型训练速度,减少模型 serving 的次数
- SFT Packing 会增加模型对于同一个对话聊不同事情的泛化性吗?【存疑】
- SFT Packing 会导致模型看到一些其他样本的数据,引入了一些噪音,但实际上在真实的场景中用户也会突然切换对话场景,所以影响还好?
- SFT Packing 会降低短 SFT 训练样本的权重吗?
- 原始的 SFT Loss:为了保证 SFT 对样本的关注度相同(短样本和长样本关注度一样),需要按照样本内部先按照 token 数做损失平均,再对样本间批次做损失平均
- SFT Packing Packing 后,短样本被 Packing 成一个新样本,相当于多个短样本的重要性和一个长样本的一致,对短样本不公平
- 修正方式:一方面需要在原始样本内部做 token 损失平均,另一方面,外部平均要除以真实的 Packing 前的样本数,而不是 Packing 后的样本数
$$ loss = \frac{1}{B_\text{real}}\sum_i^{B_\text{real}} \frac{1}{T_i^\text{real}} \sum_j^{T_i^\text{real}} loss_j^\text{token} $$
- 实际上,这个技术在 Pretraining 中也很常用,用于加快训练过程;SFT 中,特别在将多轮会话拆开或样本长短差异很大的场景中用的多
- 以下内容参考自知乎:https://zhuanlan.zhihu.com/p/686562499
提问:SFT Packing 是什么?
回答:SFT Packing 指的是在训练 sft 的过程中,将多个 sft 数据 pack 到一个样本内进行训练的方式,这种方式会加快模型训练速度,原因是如果不进行 SFT Packing,那么对于短文本sft,需要padding到一个batch的最长长度,那么会浪费很多计算token。SFT Packing其实有很多种类,比如 Block diagonal attention,也就是每个token仅仅去attention自己的问题内的token。但一般业务中会直接将其相连接,然后进行预测,虽然这样会引入一些噪音,但好像相对于非 Sft Packing方式的整体的效果损失不大。这个可能是因为pretrain的时候模型也是这么训练的
Post-Training
- Post-Training一般指Pre-Training之后的预训练?
- 模型训练的一般过程是:Pre-training -> Post-Training -> SFT -> RLHF
Encoder-Decoder
- 整体由Encoder+Decoder两个模块组成
- Encoder部分的tokens互相可见(full visible)
- Decoder的部分只有后面的能看见前面的
- 原始Transformer结构就是这样,最早是用来做文本翻译比较多
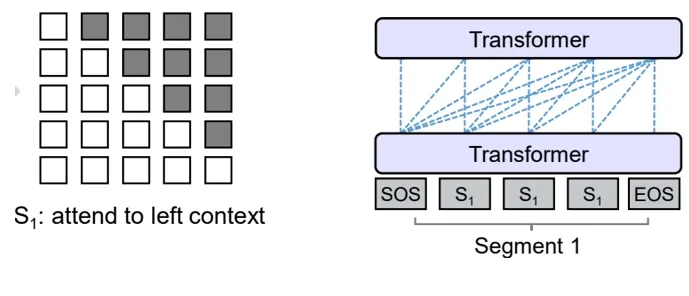
Causal LM(Causal Decoder)
- 因果语言模型,也称为Causal Decoder,Auto Regressive模式,根据历史来预估下一个token
- 代表模型是GPTs, LLaMAs
- Causal LM 的 mask结构:
Prefix LM (Prefix Decoder)
- 前缀语言模型,也称为Prefix Decoder,前缀之间可以互相看到,但后续生成的token也只能看到历史
- 是Encoder-Decoder和Causal Decoder的一个折中方案
- 代表模型是GLM
- Prefix LM 的 mask结构:
Causal LM vs Prefix LM
- 两者都是Decoder-Only结构
- 在面对多轮对话时,Prefix LM训练效率低于Causal LM
- 由于两者的Mask逻辑不同,比如在QA场景中,多轮对话时,Prefix LM需要将多轮对话整理成多个样本分别训练,因为每次回答开始时,前面的QA以及Q对于当前A来说都是prefix
- 比如回答Q3(生成A3)时,之前的<Q1A1,Q2A2,Q3>在attention时必须能互相看见,即此时prefix={<Q1A1,Q2A2,Q3>}
- Prefix LM这种训练方式比较浪费资源,需要多次经过网络才能训练一次多轮对话;但是Causal LM则不需要多次训练,一次可训练多轮对话
- Causal Decoder vs Prefix Decoder vs Encoder-Decoder, mask矩阵
")
MHA/MQA/GQA/MLA
- 三种方法的对比
")
- Multi-Head Attention(MHA):Q,K,V都拆开成多个头,每个头的Q,K,V都互不相同
- Multi-Query Attention(MQA):Q拆开成多个头,每个头的Q不同,但K,V完全相同
- Grouped-Query Attention(GQA):Q拆开成多个头,K,V按照组分组,每个头的Q不同,同一组头K,V相同,不同组头之间K,V不同
- GQA是MHA和MQA的中间版本,兼顾两头,LLaMA 2(70B)参数版本和LLaMA 3(8B/70B)就使用了这个
- 第四种方法:MLA(Multi-head Latent Attention):Q拆开成多个头,核心思想是通过将K,V降维再升维的方式,巧妙的减少KV-Cache存储量(仅存储降维后的中间值即可),最早由DeepSeek提出
- 参考链接:
Model Card
- Model Card, 直接译为模型卡片,在大模型中用来表示模型的详细描述,包括参数量,训练数据量,训练方式等等
- 比如Model Card是LLaMA2的的Model Card
Tokenization
- 分词,在原始文本输入模型前需要经过分词,模型输入和输出都是以token为单位,模型的成本也与token数量息息相关
- 常见的分词方式可以分成三类,word/subword/char三个粒度
- 最常见的是subword粒度,包含了BPE,WordPiece,Unigram等
Loss Spike
- Loss Spike指的是大模型训练过程中出现的loss突然暴涨的情况,导致该问题的原因一般是脏数据
ORM 和 PRM
- ORM:结果奖励(Outcome Reward Model)
- 定义:ORM根据任务的最终结果提供奖励,通常在任务完成后评估
- 延迟反馈:奖励在任务结束时才给出
- 结果导向:只关注最终结果,不关注中间过程
- PRM:过程奖励(Process Reward Model)
- 定义:PRM在任务执行过程中提供即时奖励,评估每一步的表现
- 即时反馈:奖励在每一步或每个子任务完成后立即给出
- 过程导向:关注中间步骤,帮助模型优化过程
Context Length 和 Generation Length
- 大模型的上下文长度(Context Length)
- 上下文长度是模型能同时处理的输入文本的最大长度(包括用户输入的提示词、历史对话、文档内容等)
- 决定了模型能“看到”多少信息来生成回复
- 超出该长度的内容会被截断或忽略
- 大模型的生成长度(Generation Length)
- 模型单次回复时能生成的最大文本长度(即输出的token数量上限)
- 生成长篇文章时可以多次请求(分段生成)
- 指定这个长度可以避免模型因生成长度过大而失控(如无意义重复)
- 问题:为什么 Qwen2.5 开源时要强调自己的模型 Generation Length 是 8K tokens?是训练时就只针对 8K 输出做训练了吗?
- 模型单次回复时能生成的最大文本长度(即输出的token数量上限)
Scaling Law
- 原始定义:大模型的Scaling Law是指模型性能(如损失函数值或任务表现)与计算量(FLOPs)、模型参数量(N)以及训练数据量(D)之间的幂律关系
- 其核心观点是,在不受其他因素限制的情况下,模型性能会随着计算量、参数量和训练数据的增加而提升,且这种提升遵循幂律规律(即非线性增长)
Scaling Law 的数学表达
- OpenAI 在 2020 年的论文《Scaling Laws for Neural Language Models》中提出,语言模型的测试损失(Loss)可以表示为:
$$
L(N, D) = \left( \frac{N_c}{N} \right)^{\alpha_N} + \left( \frac{D_c}{D} \right)^{\alpha_D}
$$- \( N \) 是模型参数量,\( D \) 是训练数据量(token 数)
- \( N_c \) 和 \( D_c \) 是临界值,表示当 \( N \) 或 \( D \) 低于该值时,性能受限于该因素
- \( \alpha_N \) 和 \( \alpha_D \) 是幂律指数,通常 \( \alpha_N \approx 0.076 \),\( \alpha_D \approx 0.095 \)(具体数值可能因模型架构和任务不同而变化)
Training Time Scaling
- 增加训练时的时间(即增加计算量、参数量、训练数据量),可提升模型性能,是最原始的 Scaling Law 含义
- 吃显存
Inference Time Scaling
- 增加推理时的时间(即增大思维链长度,或MCTS等?),可提升模型性能(特别是推理性能)
- 吃推理时间
Parallel Scaling
- 在模型不增加参数的前提下(实际上会增加少量参数),同时拉大训练和推理并行计算量,提升模型效果
- 是 Qwen 和 浙大 25年论文提出的,也叫做ParScale:对同一输入,同时复制乘 P 个“带前缀”的并行数据,让模型一次性算出 P 个 logits,再用一个MLP(少量参数)给每个 logits 打分加权,提高模型效果
- 参考链接:
AI Agent 和 Agentic AI
- AI Agent
- 一般是单体系统,结构相对简单;
- 通常需要明确指令,自主性较低,是被动响应型,按预定义的命令执行特定任务;
- 擅长简单、重复的任务,任务范围有限,在有明确约束的环境中运行;
- AI Agent 常用于客服聊天、推荐系统、流程自动化等场景
- Agentic AI
- 是多智能体系统,通过多个 AI Agent 协作,有记忆、分工和任务调度,类似“AI团队”;
- 自主性高,能自主决策、规划和行动,可视为决策者,主动为用户服务,像主动监控票价并自动重新预订;
- 可处理复杂任务,能在开放或不确定的环境中运行,可自行设定目标,根据环境变化动态调整行为;
- 适用于需要动态实时决策的金融、物流领域,以及 AI 科研助手、ICU 病房诊疗辅助等复杂场景
- Agent 和 Agentic 词语区分:
- Agent 是名词(智能体),表示一个具体的对象
- Agent 一般定义为一个实体:能自主感知、决策、行动、完成任务的智能体(AI Agent、软件代理、机器人等)
- Agent 常用短语或名词:
- AI Agent
- LLM-based Agent
- Multi-agent system
- Agentic 是形容词,表示描述具备 Agent 特征的
- Agentic 一般定义为用来形容一个具备 Agent 特征的(即 自主、主动、有目标、能规划、会反思、可迭代行动 的)的对象或实体
- Agentic 常用短语或名词
- Agentic AI(具备智能体行为的人工智能)
- Agentic workflow(智能体式工作流)
- Agentic capability(智能体能力)
- Agent 是名词(智能体),表示一个具体的对象
Step Batch Size
- batch size(批量大小):指在一次模型参数更新(即一个训练步骤)中所使用的样本数量
- step batch size :常用在是 LLM 的训练语境中,step batch size(步长批量大小)是强调 “每一步(step)” 训练中所处理的样本批量大小
- step batch size 本质上与 batch size 含义一致,主要是强调了每一步更新参数使用的真实样本量
模型编辑(Model Editing)技术
- 参考链接:Overview of Model Editing - Alphabeta的文章 - 知乎
- 模型编辑(Model Editing) 是一种在不进行昂贵的全模型再训练的情况下,对预训练模型(尤其是大型语言模型LLMs)的知识或行为进行局部、有选择性修改的技术
- 通常,模型编辑通过直接修改模型内部的少量参数来实现
- 这些方法通常试图在最小化对模型其他知识和能力的负面影响的前提下,精确地定位和修改与特定事实相关的参数
- Model Editing 方法大致可以分为以下几类:
- Fine-tuning with constraints (带限制的微调)
- Memory-Augmented (retrieval) (检索内存增强)
- Hyper network (超网络)
- Locate and edit (定位并修改)
LLM Surgery
- LLM Surgery ,通常直译为 ”LLM 手术“,是比模型编辑(Model Editing) 更广泛的技术
- 相对 Model Editing,LLM Surgery 通常指更系统化和广泛地调整 LLM 的行为和功能,不仅仅是知识更新,可能涉及:
- “遗忘”不当或过时信息 : 类似于删除有害或过时的知识
- 整合新知识 : 与模型编辑类似,但可能更强调新旧知识的无缝集成
- 调制模型行为 : 例如,降低模型的“毒性”(toxicity),提高对“越狱”(jailbreaking)尝试的抵抗力,或者调整模型在特定场景下的回答风格
- LLM Surgery 方法通常更为复杂,它可能涉及优化一个包含多个组件的目标函数:
- “遗忘”部分 : 通过反向梯度(reverse gradient)等技术,让模型“遗忘”特定的数据或行为
- “更新”部分 : 通过梯度下降等方式,引入新的或修正的信息
- “保留”部分 : 确保修改不会损害模型在其他不相关任务上的核心能力和性能
- 它可能不仅仅是修改参数,还可能涉及对模型隐藏层、激活函数等更深层次的调整,以引导模型行为的整体转变
- Model Editing vs LLM Surgery :
- Model Editing 更像是一种“点对点”的修正,主要针对模型内部的特定知识点进行修改
- LLM Surgery 则更像是一种“外科手术”,对模型进行更深层次、更系统化的调整,以改变其整体行为特征或删除特定的有害信息,同时努力保持其核心能力
GSB 标注
- GSB 标注解释:Good,Same,Bad 标注
- 在自然语言处理(NLP)领域,GSB 是一种实验数据标签标定方法,用于对比实验组与对照组的表现
- 该方法常用于评估文本相关性,例如查询与文档标题/正文的匹配度
线性注意力机制(Linear Attention)
- 线性注意力机制是一类通过降低计算复杂度来优化传统注意力机制的方法,目标是优化长序列任务
- 传统 Transformer 的 Softmax 注意力计算复杂度为 \(O(N^2)\) (\(N\) 是序列长度),而线性注意力机制通过数学重构等方式将复杂度降至 \(O(N)\) 或 \(O(N \log N)\) ,从而显著减少计算和内存开销
- 代表方法:Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention, ICML 2020,是线性注意力领域的开创性工作,简称 Linear Transformer
- 该工作通过将 Softmax 指数函数重写为特征映射 \(\varphi(x)\) 的点积形式的核函数,并利用矩阵乘法的结合律,成功将注意力计算重构为线性形式,消除了计算完整 \(N\times N\) 注意力矩阵的需求,将复杂度降低至 \(O(Nd^2)\) ( \(d\) 表示 Embedding 维度)
- 在大型语言模型中,通常序列长度 \(N\) 远大于嵌入维度 \(d\) ,因此这种方法实际上实现了线性时间复杂度
Polyak averaging(参数平均)
- Polyak averaging(也称为Polyak-Ruppert averaging)是一种优化技术,由俄罗斯数学家 Boris T. Polyak 在 1991 年提出,用于提高随机梯度下降(SGD)等优化算法的稳定性和泛化能力
- 其核心思想是:在模型训练过程中,对多个迭代步骤的模型参数进行平均 ,而不是仅使用最终迭代的参数
- 平均方式:可使用参数的简单平均或者加权平均的方式
- 优势是:减少方差;提高泛化;
- 在训练 Transformer 模型时,使用 Polyak averaging 可以提高模型在下游任务中的表现,LLM 中特别场景
- 注:部分研究表明使用,在策略梯度算法(如 PPO)中,Polyak averaging 可以增强策略的稳定性
Instruction Following Difficulty(IFD)
- 原始论文:From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning, 20240406
- 在 LLM 中,指令跟随难度(Instruction Following Difficulty,IFD),是一种用于衡量模型遵循指令生成相应输出难度的指标,常用于 SFT 中做数据筛选
- 计算方式 :IFD 通过计算条件回答分数(Conditioned Answer Score,CAS)与直接答案分数(Direct Answer Score,DAS)的比值得到,公式为
$$ \mathrm{IFD}_\theta(Q,A)=\frac{s_\theta(A|Q)}{s_\theta(A)}$$- \(s_\theta(A|Q)\) 表示模型在给定指令 \(Q\) 的情况下生成答案 \(A\) 的分数
$$ s_{\theta}(A | Q) = -\frac{1}{N} \sum_{i = 1}^{N} \log P\left(w_{i}^{A} | Q, w_{1}^{A}, w_{2}^{A}, \cdots, w_{i - 1}^{A} ; \theta\right)$$ - \(s_\theta(A)\) 表示模型直接生成答案 \(A\) 的分数
$$ s_{\theta}(A) = -\frac{1}{N} \sum_{i = 1}^{N} \log P\left(w_{i}^{A} | w_{1}^{A}, \cdots, w_{i - 1}^{A} ; \theta\right) $$
- \(s_\theta(A|Q)\) 表示模型在给定指令 \(Q\) 的情况下生成答案 \(A\) 的分数
- 指标意义 :IFD 值可以反映指令对模型生成答案的影响程度
- IFD 值超过 1 的数据通常被视为异常数据
- 理解:由于分子分母都是正数,此时说明分子大于分母,即条件概率小于直接生成概率: \(P(A|Q,W) < P(A|W) \),这说明,加入 Q 对 A 的生成非但没有帮助,反而是负向影响
- IFD 高但不超过 1,意味着提示对模型生成答案有帮助,但帮助不显著,这类样本属于“difficulty”样本;
- 理解:此时条件概率大于直接生成概率 \(P(A|Q,W) > P(A|W) \),但是大的不多,即 Q 对 A 的生成影响不大,此时 模型难以将答案与给定的指令内容对齐 ,这种样本对模型来说挑战较大
- 低 IFD 值表明提示极大地简化了答案的生成,属于“easy”样本
- 理解:此时条件概率大于直接生成概率 \(P(A|Q,W) > P(A|W) \),且大很多,即 Q 对 A 的生成影响非常大,这种样本很容易学习(甚至不需要学习?)
- 较高的 IFD 分数表明模型难以将答案与给定的指令内容对齐 ,说明指令难度更高 ,对模型调优更有利
- IFD 值超过 1 的数据通常被视为异常数据
- 应用场景 :该指标可用于筛选具有增强 LLM 指令调优潜力的数据样例
- 通过对原数据集按照 IFD 指标进行排序,选择分数靠前的数据作为“樱桃数据”,模型仅使用原始数据 5%-10% 的樱桃数据就可以达到全量数据微调的效果,甚至可以有所提高
Instruction Mining
- Instruction Mining(指令挖掘)是一种用于选择高质量指令数据的方法,旨在挑选出最有利于大模型训练的指令数据子集,从而提升大模型指令微调之后的性能
- 具体原理 :利用自然语言指标作为数据质量的衡量标准,通过这些指标预测推理损失,进而评估指令数据的质量
- 例如,将输入长度、输出长度、奖励模型的输出分数、困惑度等指标进行线性组合,并使用线性回归的方式得到系数,以此量化数据质量,无需微调模型即可相对评估指令数据,从而节省时间与计算开销
- 通过 Instruction Mining,可以从各种指令遵循数据集中选择相对高质量的样本,帮助大模型更好地学习指令模式,提高对指令的理解和响应能力,最终提升模型在相关任务上的性能
- 实验表明,使用 Instruction Mining 选择的数据集相比未经筛选的数据集,在一定比例的情况下表现更优
- 注:在一些场景中,Instruction Mining 也常常有更广泛的定义,比如从无指令数据中自动或半自动地挖掘出 指令数据
Self-instruct
- Self-instruct 是一种 instruction Mining 方法,是斯坦福大学等研究者在 2022 年提出方法
- Self-instruct 核心思路:利用语言模型自身生成能力,在仅少量高质量的指令数据的情况下,自我构造任务指令和示例数据,以训练出指令理解与执行能力更强的模型
- Self-instruct 具体流程包括:
- 准备少量种子指令 :人工准备少量(如 100 条)高质量任务指令
- LLM 生成更多指令 :基于这些种子任务,让预训练模型生成新的指令
- 如 “把句子改写成消极语气”“列出 Python 中的三种排序算法” 等,这些新指令由模型自动生成,无需人工逐一设计
- 生成指令响应 :使用同一个模型根据新生成的指令,生成对应的回答或执行结果
- 例如指令为 “将句子翻译成西班牙语:‘I like learning.’”,响应则为 “Me gusta aprender.”
- 筛选与清洗 :为保证数据质量,需进行数据筛选与清洗工作
- 可移除重复、无意义的指令,利用规则或小模型过滤低质量响应,也可进行少量人工审核
- 模型微调 :将最终得到的 “指令-响应” 数据集用于对预训练模型进行微调,使模型更擅长理解和执行各种指令
Unembedding Layer & Output Projection Layer & LM Head 概念辨析
- 在 Transformer-based 模型中,Unembedding Layer、Output Projection Layer 和 LM Head 这三个术语常被混用,但它们的具体含义根据上下文不同又有一些细小的区分,本节尝试对这三个概念进行辨析
Output Projection Layer(输出投影层)
- Output Projection Layer 用于模型最后一层输出的隐藏状态(hidden states)投影到目标空间
- 输入为隐藏状态,维度为
[batch, seq_len, d_model] - 输出为词表大小维度
[batch, seq_len, vocab_size]
- 输入为隐藏状态,维度为
- Output Projection Layer 通常是一个线性层(
nn.Linear(d_model, vocab_size))- 平时实现时,无偏置项(bias)的情况较常见(
nn.Linear(d_model, vocab_size, bias=False))
- 平时实现时,无偏置项(bias)的情况较常见(
- 用于将高维特征映射到与词表对应的 logits(未归一化的分数),为后续生成概率分布做准备
- 特别说明 :
- Output Projection Layer 是一个纯数学操作,不涉及任何非线性激活函数
- 与 Embedding 层(输入端的词向量矩阵)可能是参数共享的(如T5、GPT-2),也可能独立(如 BERT 的 MLM Head)
Unembedding Layer(反嵌入层)
- 与输入端的 Embedding 操作对应,可视为“逆向嵌入”
- 多数情况下,Unembedding Layer = Output Projection Layer ,即同一个线性投影层
- 特别说明 :在部分模型中,Unembedding 可能包含归一化层或残差连接(罕见),但通常仍指线性投影
- 若与输入 Embedding 共享参数(Weight Tying 或 Tie Embedding),则直接使用 Embedding 矩阵的转置(
W_embed.T)进行投影
LM Head(语言模型头)
- LM Head 的范围更为广泛,泛指整个语言模型的任务特定输出层 ,可能包含:
- Output Projection Layer(必需)
- 可选的额外处理层(如 LayerNorm、偏置项、适配器模块等)
- 特别说明 :
- 在 GPT 等自回归模型中,LM Head 通常仅指线性投影层(即 Output Projection Layer)
- 在 BERT 的 MLM 任务中,LM Head 可能包含如下的额外的全连接层、激活函数、归一化层等部分:
1
2
3
4
5
6LM_Head = Sequential(
Linear(d_model, d_model), # 额外的全连接层
GELU(),
LayerNorm(d_model),
Linear(d_model, vocab_size) # Output Projection
)
PyTorch 实现实例
- PyTorch 实现示例如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14# Output Projection Layer / Unembedding Layer
output_projection = nn.Linear(d_model, vocab_size, bias=False)
# 若与 Embedding 共享参数,即 Weight Tying 或 Tie Embedding
token_embedding = nn.Embedding(vocab_size, d_model)
output_projection.weight = token_embedding.weight # 权重绑定
# LM Head可能是复杂结构(如BERT)
LM_Head = Sequential(
Linear(d_model, d_model), # 额外的全连接层
GELU(),
LayerNorm(d_model),
Linear(d_model, vocab_size) # Output Projection
)
其他说明
- HuggingFace 代码库中常用
lm_head指代最终的线性投影层,与学术文献可能不同 - 在非 LM 任务(如分类)中,输出层可能称为 Task Head
Tie Embedding / Weight Tying
- Tie Embedding,也称为 Weight Tying 机制下,嵌入层(Embedding Layer)和输出投影层(文献中可能称为 Unembedding Layer / Output Projection Layer / LM Head)是绑定/共享的
- 优势:节约存储、训练稳定;
- 缺点:表达能力受限、梯度冲突可能严重(比如输入和输入的词分布差异大),所以后来的一些模型会选择不绑定
- 注:传统 Transformer 中(Attention Is All You Need 的 3.4 结中提到)就已经有了 Tie Embedding 机制
- 注:GPT-2/T5 等通过共享 Embedding 和 Output Projection Layer 参数减少参数量,但 BERT 通常不共享
System-2(系统2)
- 大模型中的系统2源于心理学中丹尼尔·卡尼曼提出的双系统理论
- 该理论认为人类思维由系统1和系统2两个不同系统驱动
- 在大模型领域,系统2是一种较慢的、深思熟虑的、善于分析的思维模式,对应着模型进行复杂推理和深度思考的能力
- 系统2思维需要有意识地努力,涉及逻辑分析、推理和意识层面的思考,更能够进行深度思考,但也更耗费时间和精力
- 系统2常用于提升推理和解决问题能力、改善对上下文和细微差别的理解、减少偏见和错误、更好地制定决策
- 与系统2相关的技术有:思维链(COT)、思维树、思维图、分支解决合并(BSM)、系统2注意力(S2A)、重述和回应(RaR)等
- 这些技术通过显式推理通常能产生更准确的结果,但往往会带来更高的推理成本和响应延迟
- 目前,像 OpenA 的 o1/o3 和 DeepSeek-R1 等推理大语言模型,都在尝试模拟系统2的审慎推理(deliberate reasoning),以提升模型在复杂推理任务中的表现
投机采样
- 投机采样(Speculative Decoding) ,也常常被翻译为 推测解码
- 投机采样是一种加速 LLM 推理的技术
- 投机采样的核心思想是通过预生成候选 token 序列并异步校验,从而减少主模型的计算量,同时保持生成结果的准确性
- 投机采样通过“预测-校正”范式,在保证生成质量的前提下显著降低主模型的计算负载,是当前LLM推理加速领域的重要突破
- 投机采样的流程主要包括小模型生成候选序列、大模型并行验证、结果评估与处理以及循环迭代等步骤
- 详细采样流程:待补充
AGI
- 关键词:AGI定义,AGI的定义,AGI 定义,AIG 的定义
- AGI(Artificial General Intelligence,通用人工智能)
- 目前为止没有明确的定义,不同公司对 AGI 的描述和愿景不同
- OpenAI :强调在经济效益上超过人类
from OpenAI Charter
OpenAI’s mission is to ensure that artificial general intelligence (AGI)—by which we mean highly autonomous systems that outperform humans at most economically valuable work—benefits all of humanity- 据 Bloomberg(彭博社) 报道 OpenAI 对AGI有以下五级分类:
- Level 1: Chatbots, AI with conversational language
- Level 2: Reasoners, human-level problem solving
- Level 3: Agents, systems that can take actions
- Level 4: Innovators, AI that can aid in invention
- Level 5: Organizations, AI that can do the work of an organization
- 据 Bloomberg(彭博社) 报道 OpenAI 对AGI有以下五级分类:
- Google :强调像人一样的认知能力
from Google Cloud: what-is-artificial-general-intelligence
Artificial general intelligence (AGI) refers to the hypothetical intelligence of a machine that possesses the ability to understand or learn any intellectual task that a human being can. It is a type of artificial intelligence (AI) that aims to mimic the cognitive abilities of the human brain - 个人认为:AGI 指的是能够像人类一样理解、学习和执行广泛任务的人工智能系统,其核心包含几个方面:
- 跨领域:AGI 不应该是专注于特定任务的 AI,应当具备跨领域能力
- 自主学习:AGI 应该有自主学习的能力,甚至可通过探索快速适应从未见过的新环境
- 跨模态:AGI 应该能与真实物理环境交互,所以应该是跨模态的,除了文本以外,还应该包括视觉和语音
Vibe Coding
- Vibe coding 是一种全新的 AI 辅助编程方法 ,也可称为 “氛围编程” 或 “感觉式编程”,由 OpenAI 联合创始人 Andrej Karpathy 于 202502 提出
- Vibe coding LLM-based 沉浸式开发,开发者无需手动编写每一行代码 ,只需通过自然语言(如英语)与 AI 交互,描述自己的需求,让 AI 自动生成代码,即可完成从需求分析到代码实现的全过程
Slide Attention
- Slide Attention 通常也称为滑动窗口注意力(Sliding Window Attention) ,有时也称为 Sliding Attention ,一种提升注意力计算效率的稀疏注意力(Sparse Attention)方法,常用于处理长序列数据
- Slide Attention 对比 标准 Transformer 的 Attention :
- 标准 Transformer 中自注意力(也可以称为 Full Attention)计算复杂度为 \(O(n^2)\),随着序列长度增加,计算和内存开销急剧增长
- Slide Attention 的核心思想是让每个 token 仅关注窗口 \(w\) 范围内的 tokens,而非整个序列,将计算复杂度降低为 \(O(n\cdot w)\)
- Slide Attention 大幅减少了计算量和显存占用,适用于长文本任务,OpenAI 发布的 oss-120b 和 oss-20b 中就使用到了 Full Attention GQA 和 Slide Attention GQA 交叉的架构
Attention Sink
- Attention Sink 现象(即“注意力黑洞”现象),是指在 LLM 的注意力机制中,某个特定 Token(通常是序列中的第一个 Token,即 <BOS> Token)会收到不成比例的高注意力权重,就像黑洞一样把其他 Token 的注意力都吸过去了
- Attention Sink 可能导致模型忽视其他 Token 中的重要上下文信息,降低模型效率
- 出现该现象的原因可能有多种:
- Softmax 操作要求所有上下文 Token 的注意力分数总和为 1,因此即使当前 Token 跟前面的其他 Token 都没有语义相关性,模型也需将多余注意力值分配到前面某些 Token,而初始 Token 因对所有后续 Token 都可见,更容易成为分配对象
- 其他原因也可能是因为该 Token 出现频率高、位置特殊、语义较强,或者训练数据存在偏差等
- 使用稀疏注意力技术可以缓解这个问题,比如 (Gated-Attention)Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free, 2025, Qwen
Reformer(Efficient Transformer)
- 参考链接:Reformer: The Efficient Transformer, 2020, Google & UC Berkeley
- Reformer 是由 Google Research 在 2020 年提出的一种改进的 Transformer 模型,旨在解决传统 Transformer 在处理长序列时面临的高计算和内存消耗问题
- 通过引入局部敏感哈希(LSH)注意力和可逆残差网络两种关键技术,显著提升了模型效率,使其能够处理更长的序列
- Reformer 关键技术简单介绍
- 局部敏感哈希(LSH)注意力 :
- 将注意力计算简化为近似最近邻搜索 ,利用哈希桶将相似键分组,仅计算桶内注意力
- 复杂度从 (O(n^2)) 降至 (O(n \log n))
- 可逆残差层 :
- 反向传播时无需保存每一层的激活值,通过数学方法重建中间结果,显存占用大幅降低
- 分块计算 :
- 将长序列分块处理,进一步优化内存效率
- 局部敏感哈希(LSH)注意力 :
- transformers库中已经有支持
from transformers import ReformerModel, ReformerTokenizer1
2
3
4
5
6
7from transformers import ReformerModel, ReformerTokenizer
tokenizer = ReformerTokenizer.from_pretrained("google/reformer-crime-and-punishment")
model = ReformerModel.from_pretrained("google/reformer-crime-and-punishment")
inputs = tokenizer("Hello, world!", return_tensors="pt")
outputs = model(**inputs)
Longformer(Long-Document Transformer)
- 参考链接:Longformer: The Long-Document Transformer, 202012, Allen AI
- Longformer(Long Document Transformer)是一种基于 Transformer 架构的改进模型,专门针对处理长文本而设计
- Longformer 由 Allen Institute for AI 和 UC Irvine 的研究团队于 2020 年提出,旨在解决传统 Transformer 模型(如 BERT、GPT)因自注意力机制(Self-Attention)的平方级计算复杂度而难以处理长序列的问题
- Longformer 的核心改进是引入了稀疏注意力模式(Sparse Attention),将全局注意力(Global Attention)与局部滑动窗口注意力(Sliding Window Attention)结合,显著降低了计算复杂度(从 (O(n^2)) 降至 (O(n)))
- Longformer 的关键技术介绍
- 滑动窗口注意力(Sliding Window)
- 每个 token 只关注其附近固定窗口大小(如 512 tokens)的局部上下文,类似卷积操作
- 通过堆叠多层注意力层,模型可以捕获远距离依赖(高层感受野逐渐扩大)
- 任务相关的全局注意力(Global Attention)
- 对特定任务(如 QA 中的问题相关位置)或特殊 token(如 [CLS])启用全局注意力,使其关注整个序列
- 平衡局部效率与全局信息需求
- 空洞注意力(Dilated Attention)(可选)
- 通过间隔采样(空洞)减少计算量,同时保持对长序列的建模能力
- 类似空洞卷积(Dilated Convolution),两者分别用于 NLP 和 CV 中,都可以扩大感受野
- 滑动窗口注意力(Sliding Window)
- transformers库中已经有支持
from transformers import LongformerModel, LongformerTokenizer1
2
3
4
5
6
7
8
9
10
11
12
13from transformers import LongformerModel, LongformerTokenizer
model = LongformerModel.from_pretrained("allenai/longformer-base-4096")
tokenizer = LongformerTokenizer.from_pretrained("allenai/longformer-base-4096")
text = "This is a long document..." # 可以是长文本
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=4096)
# 启用全局注意力(例如对 [CLS] 标记)
inputs.global_attention_mask = torch.zeros_like(inputs.input_ids)
inputs.global_attention_mask[:, 0] = 1 # 第一个位置是 [CLS]
outputs = model(**inputs)
BigBird
- 参考链接:Big Bird: Transformers for Longer Sequences, NeurIPS 2020, GOogle
- BigBird 是一种基于 Transformer 架构的改进模型,专门针对处理长序列输入的局限性进行优化。由 Google Research 在 2020 年提出,它通过引入稀疏注意力机制,显著降低了传统 Transformer 在长序列场景下的计算复杂度(从二次方降至线性),同时保持了较强的建模能力
- BigBird 和核心创新在稀疏注意力机制上,BigBird 通过三种注意力组合降低计算量:
- 全局注意力(Global Attention)
- 部分关键 token(如 [CLS]、句首/尾)参与所有位置的注意力计算,保留全局信息
- 局部注意力(Local Attention)
- 每个 token 仅关注相邻的固定窗口内的 token(类似卷积操作),捕捉局部上下文
- 随机注意力(Random Attention)
- 每个 token 随机选择少量其他位置进行注意力计算,增强全局交互
- 全局注意力(Global Attention)
- transformers库中已经有支持
from transformers import BigBirdModel1
2from transformers import BigBirdModel
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
Embodied Intelligence
- 具身智能(Embodied Artificial Intelligence 或 Embodied Intelligence),是指一种基于物理身体进行感知和行动的智能系统
- 具身智能通过智能体与环境的交互获取信息、理解问题、做出决策并实现行动,从而产生智能行为和适应性
- 具身智能强调智能并非孤立于大脑或算法,而是身体形态、运动能力与环境动态耦合的涌现性结果,智能体的身体、感知系统和环境之间的相互作用是其智能行为的基础
WSD 学习率调度
- WSD(Warmup-Stable-Decay)学习率调度,是一种用于调整训练不同阶段学习率的方法,由 MiniCPM 提出
- WSD 学习率调度分为三个阶段:
- 预热阶段 :将学习率从 0 线性增加到峰值
- 稳定阶段 :把学习率保持在峰值,模型在这个阶段进行大部分的训练
- 衰减阶段 :在相对较短的时间内将学习率退火至 0
- 一般来说,在衰减阶段还可以更改数据混合比例,以增加高质量数据的比例
- 实验证明,WSD 会生成非传统的损失曲线,损失在稳定阶段保持高水平,但在衰减阶段急剧下降
- 与常用的 Cosine 衰减学习率调度(余弦衰减学习率调度)相比:
- WSD 在小尺寸模型上的收敛效果很好,且对续训更加友好
- Cosine 衰减学习率调度 需要提前指定训练步数;WSD 不需要提前指定训练步数
- 虽然平时在 WSD 中,也常将预热阶段设置为总步数的一定百分比,但也可以设定为固定值
- Cosine 衰减学习率调度更稳定
Overlong Mask 技术
- “Overlong Mask”(超长掩码)或更通俗地称为 “Overlong Filtering”(超长过滤),是一项应用于 LLM 的 RL 训练中的技术
- Overlong Mask 主要用于处理在训练过程中生成超过预设长度限制的文本序列,通过 “屏蔽”这些超长序列的损失计算 ,确保模型训练的稳定性和有效性
- Overlong Mask 的核心思想 :避免对“未完成”的优质答案进行惩罚
- 问题背景描述:
- 在强化学习训练(如 PPO 算法)中,通常会设定一个最大生成长度(
max_length)以控制计算资源和训练效率 - 当模型生成一个内容合理、但长度超过
max_length的序列时,这个序列会被强行截断 - 被截断的序列可能会因为“不完整”或未能达到最终目标而获得一个较低的、甚至是负面的奖励
- 这种“惩罚”是不公平的,因为它惩罚了模型生成长篇、详细、有逻辑的答案的潜力,仅仅因为其超出了人为设定的长度限制
- 这会向模型传递错误的学习信号,阻碍其学习长序列推理和生成的能力
- 在强化学习训练(如 PPO 算法)中,通常会设定一个最大生成长度(
- “Overlong Mask” 技术的核心机制是:识别出那些因为超出最大长度而被截断的序列,并在计算损失函数和更新模型参数时,将这些序列“屏蔽”掉(即,不计算它们的损失)
- 防止模型因为生成了“有思想但过长”的答案而受到不公正的惩罚
- 在 RL 训练中的工作步骤:
- 1)序列生成与长度检查 :在强化学习的采样阶段,模型根据给定的提示(prompt)生成一批文本序列
- 2)识别超长序列 :检查每个生成的序列长度是否达到了预设的
max_length - 3)应用掩码 :对于那些被截断的序列,在后续的损失计算中,通过一个掩码(mask)将其对应的损失值置为零或在计算总损失时将其忽略
- 4)参数更新 :模型最终仅根据那些在长度限制内完整生成的、未被屏蔽的序列的奖励和损失来进行参数更新
- 其他改进方法:Overlong Reward Shaping
- 除了简单的过滤(完全忽略),一种更精细的策略被称为“Overlong Reward Shaping”(超长奖励调整)
- 不直接丢弃超长序列,而是对奖励进行平滑处理
- 比如 DAPO 论文中提出的方法,会设置一个惩罚过渡区间,使得奖励的惩罚随着超出长度的增加而线性增加,而不是一个突兀的悬崖式惩罚
- 为模型提供了一个更平滑的梯度信号
- 再比如 Kimi K1.5 训练时也有类似的特殊奖励设计
- 除了简单的过滤(完全忽略),一种更精细的策略被称为“Overlong Reward Shaping”(超长奖励调整)
- Overlong Mask 优点 :
- 训练稳定性 :避免了因不公平惩罚带来的梯度剧烈波动,使得训练过程更加稳定
- 鼓励长程推理 :允许模型自由探索生成更长、更复杂、更有深度的内容,而不用“害怕”因超出长度限制而受到惩罚
- 这对于提升模型的长程推理能力至关重要
- 提升模型性能 :在需要生成详细解释、长篇代码或复杂推理链的任务上,使用“Overlong Mask”的训练方式能够显著提升模型的表现
Pipeline Parallelism 技术
- 当一张卡装不下模型参数时,常常需要对模型进行拆分,这里面有两种拆解模式:
- 流水线并行(Pipeline Parallelism):将模型按层进行切分
- 部分博客也翻译为 管线并行
- 张量并行(Tensor Parallelism):将模型张量参数拆成小的块
- 在一些更大的模型上,显卡甚至装不下单层参数,这时候张量并行就很必要了
- 流水线并行(Pipeline Parallelism):将模型按层进行切分
- 流水线并行有两篇主要文章:
- 比较 PipeDream 和 GPipe
- GPipe 速度效率比 PipeDream 慢,但显存占用更低,收敛也更稳定
- 注:PipeDream 也称为 PipeDream 1F1B,或直接称为 1F1B
中间填充(Fill-In-the-Middle,FIM)
- 不同于传统的自回归损失,中间填充(Fill-In-the-Middle,FIM)的学习目标是文本的中间
- 中间填充的流程通常包括:
- 通过将文本划分为前缀(prefix)、后缀(suffix)和中间部分(middle),并使用特殊标记(如 <\PRE>、<\SUF>、<\MID>)来标识
- 模型根据前缀和后缀的上下文信息,通过双向上下文建模和动态插入生成的方式,来预测并填充中间部分的内容
- GLM4.5 在预训练代码数据时使用到了
Best-fit Packing
- Best-fit Packing 策略是一种由 AWS AI Labs 的研究人员提出的文档处理策略,旨在解决传统预训练方法中文档截断问题
- 在传统的语言模型预训练中,输入文档通常会被简单地拼接起来,然后分割成等长的序列,以避免填充 token
- 提高了训练效率,但会导致文档的不必要截断,损害数据完整性,影响模型学习到的内容的逻辑连贯性和事实一致性,增加模型产生幻觉的风险
- Best-fit Packing 使用长度感知的组合优化技术,将文档打包到训练序列中
- 第一步:将每个文本分割成一或多个至多长为模型上下文长度 \(L\) 的序列
- 第二步:基于这些文件块,采用最佳适配降序算法(Best-Fit-Decreasing,BFD)的启发式策略,将它们合理地组合,以获得尽量少的训练序列 ,从而完全消除不必要的截断
- BFD 是用于解决装箱问题 (Bin Packing Problem) 的一种经典启发式算法,核心目标是:在将一组物品放入容量固定的箱子中时,尽可能减少所需箱子的总数量
- BFD 算法结合了两个策略:
- Decreasing (降序) :优先处理较大的物品。因为大物品最难装入,先安排它们可以减少后续碎片化空间无法利用的情况
- Best-Fit (最佳适应) :在放入物品时,不仅仅是找到“能装下”的箱子,而是找到“装入后剩余空间最小”的箱子。这能最大限度地填满箱子
- BFD 算法详细流程(口诀是:先大后小,填满缝隙 ,通过先处理大块头,并总是寻找最“紧凑”的位置安放,从而最大化空间利用率)
- 假设有一组物品 \(S = {s_1, s_2, …, s_n}\),每个物品的大小为 \(size(s_i)\),箱子的固定容量为 \(C\)
- Step 1:预处理(排序):将所有待装箱的物品按照体积/大小从大到小进行排序
- 排序后序列:\(s’_1 \ge s’_2 \ge … \ge s’_n\)
- Step 2:遍历与放置:按排序后的顺序,依次处理每一个物品 \(s’_i\):
- 1)扫描现有箱子 :检查当前已经打开的所有箱子
- 2)寻找可行箱子 :找出所有剩余容量大于或等于当前物品大小 \(size(s’_i)\) 的箱子
- 3)选择最佳箱子 (Best Fit) :
- 在上述“可行箱子”中,选择放入该物品后剩余空间最小的那个箱子
- 如果有多个箱子的剩余空间相同且均为最小,通常选择索引较小(较早打开)的那个
- 4)放入或新开 :
- 如果找到了最佳箱子,将物品放入,并更新该箱子的剩余容量
- 如果没有一个现有箱子能装下该物品,则开启一个新的箱子,将物品放入,并记录新箱子的剩余容量
- Step 3:重复:重复上述步骤,直到所有物品都被装入箱子
- Best-fit Packing 的优点:
- Best-fit Packing 能够提升模型在各种文本和代码任务中的表现
- Best-fit Packing 能减少模型幻觉
- Best-fit Packing 策略能有效支持尾部知识学习
- 但也有相反的声音:
- 比如智谱在 GLM4.5 技术报告中没有使用 best-fit packing ,因为他们认为随机截断(random truncation)对于预训练文档来说是一种很好的数据增强策略
批次大小预热策略(batch size warmup strategy)
- 批次大小预热策略(batch size warmup strategy)是一种在深度学习模型训练过程中使用的策略,其核心思想是在训练初期逐步增加批次大小(batch size),而不是一开始就使用较大的批次大小
- 批次大小的选择会影响训练的稳定性和效率
- 较大的批次大小可以加快训练速度 ,但在训练初期,由于模型参数尚未收敛 ,使用过大的批次大小可能导致梯度更新过于剧烈 ,从而引发训练不稳定等问题
- 批次大小预热策略就是为了解决这个问题而提出的
- 在 GLM-4.5 的训练流程中,就采用了批次大小预热策略,在训练的前 500B tokens 期间,逐步将批次大小从 16M 增加到 64M tokens
- 这种策略可以让模型在训练初期以较小的批次大小进行训练,使模型参数能够更稳定地更新,随着训练的进行,再逐渐增加批次大小,以提高训练效率
- 批次大小预热策略通常可以与学习率预热(Learning Rate Warmup)策略结合使用
- 学习率预热是在训练初期使用较小的学习率,然后逐渐增大学习率至预设的值,两者结合可以在加快训练速度的同时,保持良好的模型性能和泛化能力
- 理解:
- 相对初期降低学习率的方式,这种方式可以减少算力浪费?
- 但理论上,使用较小的学习率可能更合适一些,可以让模型始终稳定的走,一个基本的理解是:梯度大小 = 批次大小 乘以 学习率大小,所以使用大的批次和小的学习率可能更稳定
偏置更新率(bias update rate)
- 偏置更新率(bias update rate)是一个超参数,是无损失平衡路由中的用于动态调整路由得分偏置的
- 无损失平衡路由是不需要增加损失函数的启发式规则
- DeepSeek-V3 提出了一种创新的无额外损耗负载均衡策略 ,通过引入并动态调整可学习的偏置项来影响路由决策
- 在训练过程中,会持续监控每个训练步骤中整个批次的专家负载情况
- 如果某个专家负载过重,就将其对应的偏置项减少一个偏置更新率 \(\gamma\);如果某个专家负载过轻,就将其对应的偏置项增加一个偏置更新率 \(\gamma\)
- 通过这种动态调整,使得模型在训练过程中能够更好地平衡各专家的负载,避免了因负载不均衡导致的性能下降,同时也不会对模型性能产生额外的损耗
- GLM4.5 中也是用了类似的策略
FlashInfer
- FlashInfer 是一个专为大型语言模型服务设计的高性能 GPU 内核库,由华盛顿大学、NVIDIA、Perplexity AI 和卡内基梅隆大学的研究人员共同开发
- FlashInfer具有以下核心功能与特点:
- 提供高效的注意力计算内核,支持多种注意力机制的实现,能在GPU上高效执行,显著提升LLM的推理速度
- 通过优化解码过程中的共享前缀批处理,减少计算和内存开销,提高解码效率
- 通过压缩和量化KV缓存,减少内存占用和计算量,加速注意力计算
- 优化 Grouped-Query Attention 的计算,减少计算复杂度,提高计算效率
- 实现 Fused-RoPE Attention,减少计算步骤和内存访问延迟,提高计算速度
- 提供 PyTorch API、TVM 绑定、C++ API 等多种接口,方便用户根据需求进行定制和扩展
- 兼容性强 :支持多种 GPU 架构和硬件配置,还支持 WebGPU、iPhone 等本地环境,实现“一次编译,多端运行”,同时原生支持 Hugging Face 模型格式,兼容主流量化技术
- FlashInfer 已被 MLC-LLM、Punica 和 sglang 等 LLM 服务系统采用
- 在实际应用中,FlashInfer 能显著提升 LLM 服务的性能
- 例如在处理大规模文本生成任务时,可比传统 CUDA 内核快 2-3 倍,同时保持较低的延迟
Curation
- 在大模型中,“Curation”通常指数据策划或数据精选
- 数据策划是对从各种来源收集的数据进行组织和整合的过程
- 涉及数据的标注、发布和呈现,以确保数据的价值随着时间的推移得以保持,并且数据仍然可以用于重复使用和保存
- 数据策划不仅仅是删除错误数据和重复项,还包括对不同语料数据的重新组织整合,比如选择用于训练的语言、对数据进行标注等
- 数据精选则强调优先使用高质量、与任务强相关的数据,而非盲目追求数据量
- 例如,通过人工标注、模型预筛选等方法过滤噪声数据,保留“信息密度高”的样本,以提升模型在专业领域的能力
- 此外,还有自我策划(Self-Curation) ,即利用大模型本身筛选高质量的数据构建新的数据集
Red Team
- 在大模型开发过程中,Red Team 指红队,是一群专门对大模型进行测试和攻击的专家团队
- Red Team 的目的是发现模型潜在的漏洞、偏见和不良行为,确保模型的安全性、可靠性和性能
- 红队测试起源于冷战时期的军事模拟演习,当时美国军方通过模拟“蓝队”(己方)与“红队”(敌方)的对抗,来学习如何像敌人一样思考
- 后来,这一做法被 IT 行业采用,用于探测计算机网络、系统和软件的弱点
- 在大模型开发中,红队会采用各种策略和技术来挑战模型
- 例如,他们可能会使用特殊的提示词来诱导模型生成有害内容,如仇恨言论、虚假信息等,或者尝试突破模型的安全限制,查看是否能够获取敏感数据
- 红队测试可以在多个层面进行,包括基底大语言模型层和应用程序层
单播、组播和广播
- 在分布式系统中,单播、组播和广播是三种不同的数据传输方式,它们的区别如下:
- 单播(Unicast),即一对一的通信模式,发送方将数据包发送到特定接收方的唯一 IP 地址
- 每条通信链路独立,数据包仅传输给目标主机;
- 基于TCP或UDP协议,支持可靠传输或低延迟传输;
- 安全性高,数据仅发送给指定接收方
- 举例:邮件发送
- 组播(Multicast),即一对多的通信模式,发送方将数据包发送到一个特定的组播组,只有加入该组的设备才能接收到数据
- 设备通过 IGMP(IPv4)或 MLD(IPv6)加入/离开组播组;
- 网络设备通过组播路由协议(如PIM)构建转发树,仅向有接收方的链路复制数据;
- 基于 UDP 协议,适合实时性要求高的场景;
- 高效利用带宽,扩展性强,但实现复杂
- 举例:视频直播、在线会议、分布式计算中的数据分发等
- 广播(Broadcast),即一对所有的通信模式,发送方将数据包发送到本地网络(广播域)内的所有设备
- 数据包的目标地址为广播地址(如IPv4的255.255.255.255);
- 部署简单,发送方只需发送一次数据;
- 安全性低,且广播数据无法跨路由器传播,仅限于本地网络
- 举例:局域网内的网络发现、地址解析协议(ARP)请求、系统通知等
PTD 并行 和 3D 并行
- PTD 是Pipeline, Tensor, Data三个词的缩写;3D 则是 3 个 Dimensions(数据、张量、流水线 3 个维度)的含义
- 从核心构成上看,PTD并行与3D并行本质上描述的是同一种思想,即通过融合三种基础的并行技术来共同扩展模型的训练能力
- 总节两者主要区别在于:
- 术语归属 :PTD与Megatron-LM紧密绑定,而3D并行是业界更通用的描述
- 优化焦点 :PTD 并行(Megatron-LM)的特色在于其精巧的交错式流水线调度 ,旨在最大化计算效率;而3D 并行(DeepSpeed)的王牌在于和ZeRO技术的结合,在保证计算效率的同时,实现了极致的内存优化
- 这三种基础的并行技术分别是:
- 数据并行(Data Parallelism, DP): 将训练数据分发到多个计算设备上,每个设备都持有一份完整的模型副本,并独立计算梯度,最后通过全局通信同步更新模型参数
- 张量并行(Tensor Parallelism, TP): 也称为层内模型并行(Intra-Layer Model Parallelism),它将模型单个层(特别是其中巨大的权重矩阵)切分到不同设备上,进行协同计算
- 流水线并行(Pipeline Parallelism, PP): 也称为层间模型并行(Inter-Layer Model Parallelism),它将模型的不同层(Layers)分配到不同的计算设备上,形成一个流水线,数据依次通过各个设备完成前向和反向传播
两者的核心区别:命名、实现与优化策略
- PTD 并行 (PTD Parallelism):
- 源于 NVIDIA 的Megatron-LM框架。PTD是Pipeline, Tensor, Data三个词的缩写,直观地表达了其技术构成
- 强调通过创新的流水线调度策略来提升效率,其代表性的优化是 “交错式流水线调度”(Interleaved Pipeline Schedule)
- 策略上看:PTD-P(Megatron-LM中的具体实现)通常建议在单个节点内部(通过NVLink等高速互联)应用张量并行,而在跨节点时应用流水线并行,最后在整个集群上应用数据并行。其核心创新在于通过将模型的层块(chunks)交错分配给不同的流水线阶段,有效减少了流水线“气泡”(bubble)——即设备空闲等待的时间,从而提高了计算资源的利用率
- 3D 并行 (3D Parallelism):
- 一个更为通用的术语,被DeepSpeed等多个框架广泛采用,用以描述由数据、张量和流水线三个维度构成的并行策略
- 强调与 ZeRO(Zero Redundancy Optimizer)技术 的深度融合(ZeRO 是一种高度优化的数据并行技术,可以显著降低内存冗余)
- DeepSpeed 的 3D 并行将计算设备组织成一个三维网格(Mesh),分别对应数据并行、张量并行和流水线并行
- 3D 并行最大的特点是数据并行维度可以由ZeRO来赋能
- ZeRO 不仅切分数据,还能够将模型的参数、梯度和优化器状态进行切分和卸载,极大地优化了内存使用效率,使得在同等硬件条件下能够训练更大规模的模型
3D 并行示例
- 场景设定:假设有 16 张卡,3D 并行的策略为
tp=2,dp=2,pp=4 - 此时有以下结论:
- 共两个 DP 组,每组 8 张卡
- 每个 DP 组的 8 张卡包含 4 个 PP 阶段,每个阶段有 2 张 TP 组的卡,即这 8 张卡通过管道并行(PP) 和张量并行(TP) 的拆分方式,分别存储模型的不同部分(按层拆分+按参数维度拆分)
- 同一个 DP 组的 8 张卡共同构成了一个完整的模型 ,单独一张卡仅持有模型的部分参数(既不完整,也不独立),整个 DP 组的 8 张卡通过协作(通信+拼接)能够共同代表一个完整的模型结构
- 2 个 DP 组的 8 张卡可分别视为完整模型的“数据并行副本”
- 2 个 DP 组的参数拆分方式完全相同,只是处理不同的数据分片,训练中通过梯度同步保持参数一致性
- 特别地,在 MoE 中,还会多一个 EP,即 专家并行,Expert Parallelism
- 核心作用是:拆分 MoE 模型的 专家 到不同 GPU,解决显存瓶颈,提升训练并行度
MFU(Model FLOPs Utilization)
- MFU 通常指的是 Model FLOPs Utilization ,即“模型浮点运算利用率”
- 其中 FLOPs 是 “Floating Point Operations Per Second(每秒浮点运算次数)”的缩写,是衡量计算能力的重要指标
- MFU衡量的是实际训练过程中,模型所用到的浮点运算量与 GPU 等硬件理论峰值性能的比例
- MFU 的计算公式通常为:
$$
MFU = \frac{\text{模型实际每秒浮点运算次数}}{\text{硬件理论最大每秒浮点运算次数}}
$$- 分子 :模型在训练时实际消耗的 FLOPs(可通过模型结构和 batch size 等参数估算)
- 分母 :硬件(如 GPU)理论上能够达到的最大 FLOPs(由硬件规格决定)
- MFU 低可能意味着模型结构、数据管道、硬件配置存在瓶颈,开发者可以通过优化模型、提升数据加载效率、调整 batch size 等方式提升 MFU
- MFU 是评估不同训练方案、模型架构或硬件平台性能的重要参考指标
MFU 与其他指标的区别
- MFU 关注的是浮点运算利用率,强调计算资源的使用效率
- GPU Utilization 则是 GPU 整体资源(包括计算、内存、IO 等)的使用率
- TFLOPs 是硬件的理论计算能力,MFU 则是实际利用率
SPMD (Single Program Multiple Data)
- SPMD (Single Program Multiple Data) 是一种编程范式,其特点为:
- 所有进程执行一份代码
- 每个进程通过传入不同分布式参数(比如 Rank)来处理不同的数据
- SPMD 是非常常用的编程范式,比如:
- 数据并行:DDP,ZeRO,FSDP
- 张量并行
- 流水线并行
- 序列并行(Sequence Parallelism)
- 注:序列并行(Sequence Parallelism)是特指大语言模型中将同一个长序列分配到不同的 GPU 上进行分布式处理的方式
- 应用实例:比如 Megatron 中 的 Context Parallelism(上下文并行,CP)通过切分 LayerNorm 和 Dropout 的输入,减少 30% 以上的激活内存,同时保持计算效率
Model Growth Initialization(模型增长初始化)
- 模型增长初始化(Model Growth Initialization,MGI) 是大模型领域中,通过从已训练小模型出发、渐进式扩展结构(如增层数、扩宽度、加专家数量),并复用小模型参数与优化状态进行初始化的技术
- 核心是用“知识迁移”降低大模型训练成本、提升效率
- Model Growth Initialization 关键逻辑包括:
- 通过深度/宽度/MoE混合等策略扩展模型;
- 靠功能保留初始化(Function-Preserving Initialization,FPI)、身份映射初始化(Identity Mapping Initialization)等原则避免训练震荡;
- 典型方法有 Net2Net(结构扩展框架)、Stacking Transformers(深度堆叠加速)等
- 实际应用中,能减少 50% 左右训练时间、降低显存占用,还能让扩展后的大模型保持性能甚至激发复杂推理等“涌现能力”
- 目前仍面临扩展策略自动化、初始化精细化、分布式训练适配等挑战,是千亿级大模型高效训练的重要技术方向
GEMM
- 通用矩阵乘法(General Matrix Multiply,GEMM)是线性代数与深度学习中最核心的计算原语之一,用于高效地计算:
$$C = A × B$$- 也支持带缩放与累加的
$$C = \alpha AB + \beta C$$
- 也支持带缩放与累加的
- GEMM 是 BLAS 中的核心例程(CBLAS 接口:cblas_sgemm/cblas_dgemm 等)
- 原始的 BLAS 是用 Fortran 语言编写的;CBLAS 则是 BLAS 的 C 语言接口(C Interface to BLAS)
- DeepGEMM(FP8、JIT、MoE 优化)是针对深度学习场景优化的 GEMM 计算库,专注于提升大模型训练和推理中的矩阵乘法效率,尤其在混合精度计算、动态形状适配等场景有显著优势
RDMA
- RDMA 是一种“远程直接内存访问”技术,允许网卡绕过 CPU 与内核,直接读写对端内存,实现低延迟、高吞吐、低CPU占用的网络通信;
- RDMA 的常见实现包括 IB(InfiniBand)、RoCE(v1/v2)、iWARP,需 RDMA 网卡与配套网络/驱动
- RDMA 的能力包括单边(RDMA Read/Write/Atomic)与双边(Send/Recv)语义,支持用户态 Verbs 接口
RDMA 与 NVLink 的关系
- NVLink 是 NVIDIA 用于节点内 GPU 高速互连的技术,提供高带宽、低延迟与缓存一致性(取决于架构),用于近距紧耦合场景
- NVLink 用于同一节点内 GPU 直连(NVIDIA Magnum IO 等库);
- RDMA(如 IB/RoCE)用于跨节点扩展,常配合 GPUDirect RDMA(GDR)等机制实现 GPU 到 GPU 的远程直接访问(绕过 CPU 提升端到端效率)
Micro Batch
- 索引关键词:Micro Batch Size, Micro-Batch-Size, micro_batch_size
- micro-batch :将 mini-batch 再切分的子批次,按序流经流水线,提升吞吐并降低气泡开销
- 在流水线并行中,每个 GPU 在一次前向传播中处理的是一个 micro-batch;
- 多个 micro-batch 逐个流过流水线各阶段,累积多次前向/反向后才做一次权重更新
- 简单来说,一次前向就是一个 micro-batch :每个 GPU 每次前向处理一个 micro-batch,连续处理多个后再更新梯度
- 关系公式:train_batch_size = micro_batch_per_gpu \(\times\) gradient_accumulation_steps \(\times\) world_size
- 注:若不使用流水线并行,GPU 通常一次处理一个完整的 mini-batch(可以认为此时 micro-batch = mini-batch)
- 注:流水线并行中,BatchNorm 统计量按 micro-batch 计算,同时维护全局移动平均用于推理
muP(Maximal Update Parameterization, \(\mu\)P)
- muP(Maximal Update Parameterization, \(\mu\)P)是一种网络参数化与超参缩放框架,通过让前向/反向传播与参数更新的量级对模型宽度近似不变 ,实现超参数从小模型到更大模型的“零样本迁移”(\(\mu\)-Transfer) ,从而显著降低超参与训练稳定性的调优成本
- 核心目标是让“好的超参”在放大时依然是“好的”,而非随宽度剧烈漂移
- 做法要点有:
- 初始化与权重尺度:令初始化方差随输入/输出维度缩放,确保激活与梯度量级稳定;对非方阵,在 fan_in/fan_out/fan_avg 间选择或统一处理
- fan_in/fan_out/fan_avg 分别表示 输入神经元数/输出神经元数/输入输出神经元数两者均值
- 学习率缩放:典型经验是学习率与宽度成反比(\(\eta \propto \frac{1}{d}\)),以控制每步损失增量不随规模爆炸;实际常配合层/模块自适应学习率
- 保持训练动态稳定:将前向、反向、损失增量与特征变化的量级稳定化,使得跨尺度迁移可行
- 初始化与权重尺度:令初始化方差随输入/输出维度缩放,确保激活与梯度量级稳定;对非方阵,在 fan_in/fan_out/fan_avg 间选择或统一处理
- 与标准参数化(SP)的对比
- SP:最优超参会随宽度显著变化,通常需要在每个尺度上重新调参
- \(\mu\)P:通过重参数化让最优超参对宽度近似不变,实现“零样本迁移”
- TLDR:\(\mu\)P 通过“宽度不变”的参数化与超参缩放,把小模型上的好超参“零样本”迁移到大模型,让“炼丹”更可预测、更省钱
梯度裁剪(Gradient Clipping)
- 梯度裁剪(Gradient Clipping) 主要作用是通过限制模型参数梯度的全局范数,避免训练过程中因梯度爆炸(Gradient Explosion)导致的模型不稳定(如 loss 震荡、参数更新幅度过大等问题)
- 梯度裁剪中最常用的L2范数梯度裁剪(L2 Gradient Clipping) 或全局梯度范数裁剪(Global Gradient Norm Clipping)
- 核心步骤:
- 1)计算全局梯度范数 :先将当前 batch 中所有可训练参数的梯度拼接成一个向量,计算该向量的 L2 范数(即“整体梯度范数”)
- 2)判断是否裁剪 :若该全局范数超过预设的“裁剪阈值(clip_grad)”,则执行裁剪;若未超过,则不干预梯度
- 3)统一缩放所有梯度 :通过乘以“裁剪阈值/全局梯度范数”的缩放系数,对所有参数的梯度进行等比例缩放 ,最终使全局梯度范数恰好等于裁剪阈值,确保梯度规模可控,避免训练不稳定(如梯度爆炸)
- 代码实现:
1
2
3
4
5
6torch.nn.utils.clip_grad_norm_(
parameters, # 待裁剪梯度的参数集合
max_norm, # 梯度的“最大允许范数”(裁剪阈值)
norm_type=2.0, # 计算范数的类型(默认L2范数)
error_if_nonfinite=False # 若梯度范数为无穷/NaN,是否抛出错误
)
Aux-Loss-Free 方法
- Aux-Loss-Free 是 MoE 负载均衡的一种方法:在门控分数上加专家级偏置 \(b\) 来调节路由,全程不引入辅助损失及其梯度,从而避免干扰主任务(如语言建模)的优化方向,兼顾负载均衡与模型性能
- 对比传统做法:
- 传统做法:用辅助损失推平专家负载,但权重不当会污染主梯度、损害性能
- Aux-Loss-Free 方法:在 top‑K 前给门控分数 \(g\) 加偏置 \(b\),仅影响路由结果,不回传梯度;负载过高的专家减小其 \(b\),负载不足的增大 \(b\),实现自适应均衡
- Aux-Loss-Free 有许多优点
- 无梯度干扰:不改变 loss,不影响主任务梯度,稳定训练
- 因果一致:自回归可用,训练/推理一致
- 高效可实现:开销小、易部署,工程友好
- 常见实现为:
- 偏置更新:按当前负载与均匀分布的偏差,用符号梯度更新 \(b\),如 \(b \leftarrow b − \alpha \text{sign}\)(实际负载 − 均匀负载)
- 典型参数:更新率 \(\alpha \approx 0.001\);对门控激活较敏感,必要时解耦路由激活与主模型以稳定超参
EOT、EOD、EOS(结束符号辨析)
- 在自然语言处理中,EOT、EOD、EOS 都是用于标识文本边界的特殊 token,他们核心差异在于所标记的「边界类型」不同
- EOS(End of Sequence):序列结束符
- 表示一个「完整序列」的结束,是最通用的结束标记
- 在 GPT 系列中,
<|endoftext|>常作为 EOS 使用,标识生成文本的结束 - 机器翻译时,模型输出
<EOS>表示翻译句子完成
- EOD(End of Document):文档结束符
- 专门用于标识「文档/篇章」的结束,强调「长文本单元」的边界
- 训练语料中,在每篇文章末尾插入
<EOD>,告诉模型“这篇文档到此结束” - 长文档理解任务中,用 EOD 标记章节或全文的结束
- EOT(End of Turn):轮次结束符
- 用于「对话场景」,标识一轮对话的结束,强调「交互单元」的边界
- 对话训练数据中:
用户:你好<EOT>模型:您好,有什么可以帮您?<EOT>- 聊天机器人生成回复时,用
<EOT>标记当前轮次输出的结束
- 聊天机器人生成回复时,用
MPU(Model Parallel Unit)
- MPU 一般指 Megatron’s MPU(Model Parallel Unit,模型并行单元),是 NVIDIA Megatron-LM 框架中用于实现大规模模型并行训练的核心组件
- MPU 专为解决超大规模 Transformer 模型(如 GPT 系列)的训练挑战而设计,通过灵活的并行策略突破单设备内存限制,支持在多 GPU/多节点集群上高效训练千亿级参数模型
- MPU 实现了 TP,PP 和 DP 的协同
- MPU 的核心特性包括:“拆分模型、协调计算、管理通信”
1F1B
- 1F1B,即 One Forward and One Backward, 也称为 PipeDream
- 注意:1F1B 不同于 Gpipe,平时强调 1F1B 时主要是区别于 Gpipe
- Gpipe 发表晚于第一篇 PipeDream 1F1B(与第二篇 PipeDream 前后顺序不确定),但效率其实不如 PipeDream 1F1B
- 1F1B 主要有两种形式:
- PipeDream 1F1B
- Interleaved 1F1B:交错式 1F1B
PD 分离
- 关键词:PD分离;
- PD分离(Prefill-Decode 分离)是大模型推理系统的一种性能优化架构
- PD 分离的核心思想是:把一次 LLM 推理拆成 Prefill 和 Decode 两个阶段,并分别部署到最适合的硬件资源池里,让它们各自独立扩缩容、互不干扰
- PD 分离 让算力型任务去找算力卡 ,让显存型任务去找显存卡 ,用网络把中间结果搬过去,从而实现各自的优势
- 传统做法把两个阶段放在同一 GPU 上顺序执行,会带来三大痛点:
- Prefill 计算密集、Decode 内存带宽密集,混布时互相抢占,P99 延迟可飙升 78% 以上
- 两类负载峰值时段不同,共池导致要么算力浪费、要么显存不足
- 聊天机器人要首 token 时延(TTFT)<200 ms,代码补全却要求每 token 时延(TPOT)极低,共池架构无法兼顾
- PD 分离具体做法:把 Prefill 节点单独成池,Decode 节点单独成池,中间通过 高速网络 把 KV Cache 从 P 池传给 D 池,之后两者完全异步、独立批量
- PD 分离带来的好处
- 吞吐提升 2–3 倍 :各自跑满最匹配的硬件,消除相互阻塞
- 延迟更稳 :Decode 不再被新到的 Prefill 抢占,P99 延迟尖峰被削平
- 显存节省 30%+ :KV Cache 可 offload 到 CPU/SSD,Decode 池只需留当前活跃缓存
- 成本下降 :Prefill 池用 高算力低显存卡,Decode 池用大显存低算力卡,整机性价比更高
- vLLM、SGLang 均已给出原型或生产级方案
Training Dynamics
- Training Dynamics 指的是训练过程中模型的各种属性随时间或迭代轮数的变化情况,包括但不限于损失函数值、准确率、模型参数的更新、梯度的分布等属性
在线量化(Online Quantization)
- 在线量化技术(Online Quantization)是模型量化的一种实现方式,指的是在模型推理过程中动态进行量化操作 ,而非像传统离线量化那样在推理前就完成所有量化参数(如缩放因子、零点)的计算和模型转换
- Online Quantization 的核心特点是:
- 1)动态计算量化参数 :量化所需的关键参数(如激活值的范围、缩放因子)不是预先计算好的,而是在模型实际运行时,根据实时输入数据的分布动态调整和更新
- 2)边推理边量化 :模型在处理输入数据的同时完成量化转换,不需要提前对模型进行离线“校准”或“量化预处理”步骤
- 3)适应性强 :能够更好地应对输入数据分布变化较大的场景(如不同用户、不同场景的输入差异),因为量化参数会随输入动态调整
- 在线量化的优势在于灵活性高,无需预先准备校准数据集,适合输入分布不稳定的场景;
- 但缺点是会增加推理时的计算开销(因为需要实时计算量化参数),可能对推理速度有一定影响
- 这种技术常见于资源受限的边缘设备或需要处理多样化输入的场景,平衡了模型压缩需求和对动态数据的适应能力
Fill-in-Middle(中间填充)目标
- Fill-in-Middle(中间填充)和Next-Token-Prediction 是大语言模型中两种不同的训练目标
- Next-Token-Prediction(NTP) 任务本质是自左向右的单向预测 ,模型仅能基于前文信息推断后续内容,无法利用“后文”信息
- Fill-in-Middle(FIM) 中,模型接收的输入被拆分为三部分:前缀(prefix)、待填充的空白(middle)、后缀(suffix)
- 模型需要预测的是中间缺失的内容,且预测过程中同时利用前缀和后缀的信息
- 例如:输入“今天天气[MASK],适合野餐”,模型需要预测中间的“很好”;或更复杂的拆分如“前缀+<mask>+后缀”,其中<mask>是待填充位置
- 模型需要预测的是中间缺失的内容,且预测过程中同时利用前缀和后缀的信息
- DeepSeek-Coder-V2 和 DeepSeek-V3
SHARP
- 在 Megatron-LM 或 Megatron-Core 这样的高性能分布式训练框架中提到的 SHARP 通常指的是 NVIDIA SHARP (Scalable Hierarchical Aggregation and Reduction Protocol) 技术
- SHARP 是一种底层网络硬件加速技术 ,用于提高集体通信操作(\(\text{Collective}\) \(\text{Operations}\))的效率
- SHARP 技术由 NVIDIA 开发,并集成在其 InfiniBand 网络硬件(如 Quantum 交换机)中
- 主要目标是加速大规模 AI 和高性能计算 (HPC) 应用中的集体通信
- 传统方式: 在分布式训练中,像 All-Reduce(用于同步梯度)、Reduce 和 Broadcast 这样的集体操作,需要将数据从一个 GPU 传输到另一个 GPU,并在 CPU 或 GPU 上执行计算(例如梯度求和)
- 这个过程会占用宝贵的计算资源并产生大量的网络流量
- SHARP 方式: SHARP 将这些集体操作的聚合和归约功能直接卸载到网络交换机的硬件中执行(称为 In-Network Computing)
- 减少数据移动: Megatron 中可以选择开启 SHARP,在 SHARP 启用后,例如在执行 All-Reduce 时,数据沿着网络中的聚合树向上移动时,交换机就会实时地执行求和操作 ,而不是将所有原始数据都发送到终点
- 效果: 这大大减少了网络中传输的数据量(只需传输归约后的结果),从而显著降低了通信延迟和缓解了网络拥堵
- SHARP 通过加速这些底层的 NCCL(NVIDIA Collective Communications Library)操作,直接提高了 Megatron-LM 整体的训练吞吐量和效率(Model FLOPs Utilization, MFU),尤其是在涉及大规模 GPU 节点间的 DP 通信时效果显著
Rubrics
- Rubrics(评估细则) 是一种奖励评估方法,与 Pairwise(成对比较), Likert 量表(李克特量表) 一样,都是生成式 RM 的一种评估方式
- Rubrics 的做法是将复杂,难以评估的人类偏好转变成多个维度的二元可验证奖励
- Pairwise是目前 RLHF 奖励模型(RM)训练中最主流和最可靠的方法
- 评估难度低,可靠性相对较高,获取了相对一致的偏好数据;但是效率低,复杂度是 \(O(N^2)\)
- Likert 量表 是效率最高、最常用的点式(Pointwise)评估方法之一
- 效率高,复杂度仅 \(O(N)\) ,但分数存在不一致性(不同人评估标准不同)
- Likert 量表本质是一种主观态度 / 偏好的测量工具,通过让受试者(可以是 LLM)对一系列陈述(如 “对上述描述的满意程度”)选择 Likert 等级(可根据不同的),将定性态度量化为定量分数
- 通常为 5 级,此时为 5 点量表 (5-Point Scale):非常不同意、不同意、中立、同意、非常同意
- 可以为 7 级,此时为 7 点量表 (7-Point Scale):非常不同意、不同意、稍不同意、中立、稍同意、同意、非常同意
- 注:也可以是满意、不满意等,可以根据不同的 Setting 选择不同的评分方式
- Likert 针对单个样本的主观评分,不直接体现样本间的相对顺序
- Likert 分数具有序数意义(如 5 分 > 4 分),但不代表分数间的间隔相等(不能认为 5-4 的差异等于 4-3)
- Rubrics 提供了最精细、可解释的评估,是高质量、专业性任务的首选
- 线上效率高,复杂度仅 \(O(N)\),但需要离线构造 Rubrics,往往比较耗时
- 可以与 Pairwise 结合使用(例如,通过 Pairwise 比较来动态生成或优化 Rubrics,或用 Rubrics 作为 LLM Judge 进行 Pointwise 评分的指导)
- 容易因 Rubrics 设计不够好而出现 Reward Hacking,特别静态 Rubrics 可能发生 Reward Hacking
- Dynamic Rubrics 可能是未来的趋势
- 不再是静态固定的 Rubrics,而是在训练过程中,动态的根据模型的回复生成不同的 Rubrics
- 其他思考:
- 用多个模型生产 Rubrics,然后按照相似度聚合,同一个桶中的给一个想通的权重(即使用该桶的 count 来作为权重)
- 理论上,随着模型数量的增加,效果会越来越好
- 用多个模型生产 Rubrics,然后按照相似度聚合,同一个桶中的给一个想通的权重(即使用该桶的 count 来作为权重)
Token 粘黏现象
- Token 粘黏(这个名字暂时是我自己给的,待确认)
- Token 粘黏 是指 Prompt 和 Response 之间直接组合时,可能存在的
tokenize(prompt + answer)不等于tokenize(prompt) + tokenize(answer)现象 - 该问题出现时,实际上可以在中间加一个 Special Token 来解决(最推荐的方式,一般可以大部分解决问题)
- 注意:即使增加 Special Token,也是无法完全解决 Token 粘黏问题的
- 在增加 Special Token 后,可以再加一些类似
\n\n(这极难被 Tokenizer 合并) 等在前后来减少 粘黏 - 完全杜绝 Token 粘黏问题:
- 方案一:在实际生产中,可以使用针对
prompt[-10:] + response[:10]Tokenize 以后的结果有没有 Token 粘黏来过滤数据,完全杜绝类似问题- 问题:这可能会导致部分特殊 Token 组合模式永远没有被训练到?
- 方案二:,训练时(推理时也要对应做)将 Prompt 和 Response 拆开做 tokenize ,然后再拼接
- 注:推理时必须也这样做(无法保证使用者都这样做),否则会导致以后 Inference 时中断和继续推理时出现训推不一致
- 比较麻烦,但看这部分 Infra 是这样拼接的
- 其他(不是很靠谱的方案):合并 tokenize,将中间 Token 分配给 Prompt 或者 Response
- 相当于接受训推不一致的问题
- 方案一:在实际生产中,可以使用针对
- 注:某些场景下,从统计意义上来看,或许这个问题并不重要,哪种方式都没问题,因为如果中间这个 粘黏 Token 很常见的话,肯定会出现,从而被识别到,如果不常见的话,理论上 inference 时也会很少遇到
- 某些场景下,可能导致 Prompt 和 Response 无法准确区分,从而导致训练推理时得到的两种推理不一致
TIS(Truncated Importance Sampling)
- TIS 即截断重要性采样,是一种方差缩减技术
- TIS 通过智能筛选高价值样本并抑制异常值影响,来解决大模型训练中数据不平衡、标注成本高昂、计算资源消耗巨大等问题
- 在强化学习中,TIS 还可用于减轻 rollout 与训练之间的差距,通过引入重要性权重修正梯度计算,有效处理 rollout 分布与训练分布的不匹配问题,提升训练性能
MIS(Multiple Importance Sampling)
- 原始论文:(MIS)RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization, PKU & Tongyi Lab, 20250731 & 20250805 & 20251019
- MIS 是上述论文中提出的一种方法,对传统 PPO 的重要性采样进行了优化
MIS(Masked Importance Sampling)
- 掩码重要性采样 (Masked Importance Sampling, MIS) 是指对 Training-Inference 重要性采样比值差异较大的样本做置 0 处理(Masking)
- 这个掩码方式最早应该是在 (IcePop)Small Leak Can Sink a Great Ship—Boost RL Training on MoE with IcePop!, 20250919, AntGroup 中被提及(但该博客未给与 MIS 的命名)
- 在后来被其他文章中将这种方法称为 MIS(Masked Importance Sampling)
IcePop
- 原始博客:(IcePop)Small Leak Can Sink a Great Ship—Boost RL Training on MoE with IcePop!, AntGroup
- IcePop 是蚂蚁 Ring-flash-2.0 搭载的独创算法,是一种梯度控制机制,能够解决 MoE 模型在长思维链RL训练中容易出现的“奖励崩溃”问题
- Icepop 算法把训练中表现异常的 token 当场冻住,不让它们回传梯度,从而使训练能够持续稳定提升,避免梯度突然爆炸,减少训推精度差异
Megatron-Core(Mcore)
- Megatron-Core,即 NVIDIA Megatron-Core,也称为 Megatron Core 或 MCore,是一个基于 PyTorch 的开源库,可在数千个 GPU 上以高速大规模训练大型模型
- Megatron-Core 提供了先进的模型并行技术
- 包括张量、序列、工作流、上下文和 MoE 专家并行等
- 用户可以灵活结合不同的模型并行技术以适应训练工作负载
- 还具备节省内存的功能,如激活重新计算、分布式优化器和分布式检查点等
- Megatron-Core 通过模块化和可组合的 API 提供可定制的基础模组,对于 Transformer 模型,它提供注意力机制、归一化层、嵌入技术等
- 借助 Megatron-Core(Mcore)规格系统,研究人员可以在 PyTorch 模型定义中轻松自定义所需抽象级别的子模块
- Megatron-Core 是 Megatron-LM 的子集,即:
- Megatron-LM 依赖 Megatron-Core 实现底层分布式逻辑;
- 开发者可以单独使用 Megatron-Core,而无需引入 Megatron-LM 的全部功能
Flash Linear Attention(FLA)
- FLA 是一种高效的自注意力机制实现方式
- FLA 能够显著降低 Transformer 模型在长序列处理时的内存占用和计算复杂度
- flame 框架是基于 torchtitan 构建的轻量级训练框架,专门为 FLA 模型的训练优化而设计,支持流式数据处理,避免了传统方法中繁琐的预处理步骤,特别适合大规模数据集训练
Gated DeltaNet(GDN)
- GDN 是一种与 Mamba2 类似的架构,采用了粗糙的 head-wise 遗忘门
Kimi Delta Attention(KDA)
- KDA 是 Kimi Linear 架构的核心,它是 Gated DeltaNet(GDN)的改进版本,引入了更高效的门控机制
- KDA引入了一种 channel-wise 的变体,其中每个特征维度都保持独立的遗忘率,能够更精确地调控有限状态 RNN 的记忆
- KDA通过 DPLR(Diagonal-Plus-Low-Rank,对角加低秩)矩阵的一种专门变体来参数化其转换动态,使得一种定制的分块并行算法成为可能,该算法相较于通用的 DPLR 公式能显著减少计算量
- 注:KDA 是 GDN 的改进版本,GDN 的遗忘门机制相对较为简单,而 KDA 则通过更细粒度的门控设计对其进行了优化
Kernel Fusion
Kernel Fusion 不改变模型的数学逻辑,仅通过合并计算步骤、减少冗余开销,让硬件的算力和带宽得到更高效利用
前置概念:
- 计算核(Kernel):可以理解为 “硬件可直接执行的最小计算单元”—— 比如 PyTorch/TensorFlow 中的一个算子(如matmul矩阵乘法、add加法、gelu激活函数),最终都会被编译成 GPU/CPU 能执行的 Kernel
- 串行 Kernel 的问题:大模型的关键模块(如自注意力、FFN)是由多个算子串联组成的(例:matmul + add + gelu + matmul + add)
- 如果每个算子单独作为一个 Kernel 执行,会产生大量冗余开销(如寄存器到全局内存(来回)的数据搬运开销、Kernel 调度开销、中间结果存储作为临时变量占用额外显存等)
Kernel Fusion 的核心逻辑:“合并算子,减少冗余”,以 Transformer 的前馈网络(FFN)为例:
原始串行执行(无Fusion):
1
2
3
4
5
6# 步骤1:第一个线性变换(matmul)+ 偏置(add)
x1 = torch.matmul(x, w1) + b1
# 步骤2:激活函数(gelu)
x2 = torch.gelu(x1)
# 步骤3:第二个线性变换(matmul)+ 偏置(add)
x3 = torch.matmul(x2, w2) + b2- 注意:这会生成 3 个独立 Kernel,存在 2 次数据回写+调度开销
融合后执行(Fused Kernel):
1
2
3# 将`matmul + add + gelu + matmul + add`合并为一个Kernel,执行逻辑变为如下
# 单个Kernel内完成所有计算,数据不落地到全局内存
x3 = fused_ffn(x, w1, b1, w2, b2)- 数据在寄存器中完成
x->x1->x2->x3的流转,彻底消除中间步骤的内存读写和调度开销
- 数据在寄存器中完成
Kernel Fusion 无法保证 bit-wise 对齐 :
- Kernel Fusion 会改变计算的 “实现细节”,但不改变 “数学逻辑”,而浮点计算的特性决定了 “实现细节差异” 会导致二进制结果不同
Weight Decay Scheduling
- 权重衰减调度(Weight Decay Scheduling)是训练神经网络时,动态调整权重衰减系数(Weight Decay,代码中常常简写为 WD, wd)的策略
- 简单来说:就是“不固定权重衰减的大小,让它随训练步数变化”,核心目的是平衡模型的“拟合能力”和“泛化能力”,避免训练初期欠拟合、后期过拟合
- 权重衰减(Weight Decay)本身是什么?
- 权重衰减本质是 L2正则化 的一种实现(部分框架中二者等价)
- 通过在损失函数中添加“权重参数的平方和”项,惩罚过大的权重值,避免模型过度依赖少数特征(即过拟合)
- 比如:如果权重衰减系数
wd=0.0001,相当于每次更新权重时,都会让权重乘以(1 - wd),间接限制权重增长
- 为什么需要“动态调整”?
- 训练初期:模型还在学习基础特征,此时如果权重衰减过大,会“压制”模型的拟合能力,导致欠拟合(学不到关键模式)
- 训练后期:模型已经掌握核心特征,此时需要更大的权重衰减来抑制过拟合(避免模型“死记硬背”训练数据的噪声)
- 权重衰减调度的核心思路:
- 让权重衰减系数从“小”逐步变“大”,适配训练不同阶段的需求
- 注:权重衰减调度与学习率调度,目标、逻辑完全独立
权重衰减调度的实现
- 权重衰减调度的核心是 按训练步数(global_step)动态调整系数,最常用的是 线性递增调度
- Megatron-LM 中默认/推荐策略是 线性递增调度
constant
- Megatron-LM 中默认/推荐策略是 线性递增调度
- 定义关键参数(不同框架参数名称可能不同,但都差不多):
wd_init:初始权重衰减系数(通常设为 0,训练初期不衰减);wd:目标权重衰减系数(训练后期稳定值,如 0.01);wd_incr_steps:从wd_init递增到wd的总步数(如 5000 步)
- 分阶段调整:
- 阶段1(递增期):
global_step < wd_incr_steps- 权重衰减系数随步数线性增长:
current_wd = wd_init + (wd - wd_init) * (global_step / wd_incr_steps)
- 权重衰减系数随步数线性增长:
- 阶段2(稳定期):
global_step >= wd_incr_steps- 权重衰减系数固定为目标值
wd,持续抑制过拟合
- 权重衰减系数固定为目标值
- 阶段1(递增期):
closing tag 和 opening tag
- 在编程与标记语言(如 HTML、XML、Vue、WXML 等)中的核心概念,“closing tag” 是 “闭合标签” ,核心作用是 标记一段内容的结束
- “closing tag”常常与对应的 起始标签(opening tag) 成对出现,确保语法结构完整、解析器能正确识别内容边界
- 闭合标签的格式是
<标签名/>(自闭合,适用于无内容的标签)或</标签名>(常规闭合,适用于包含内容的标签),关键是比起始标签多了斜杠 `/ - 闭合标签告诉解析器(如浏览器、框架编译器)“当前标签对应的内容到此结束”,避免解析混乱(比如嵌套标签的层级、样式/逻辑的作用范围)
- 大多数包含内容的标签都需要闭合标签,例如 HTML 中的
<div><p><span>,Vue 中的<template><component>等
PBRL (Preference-Based Reinforcement Learning)
- PBRL 是一种强化学习范式,其核心思想是 “告诉模型哪个更好,而不是给模型一个具体的奖励打分”
- 在传统的强化学习中, Agent 通过环境反馈的数值奖励(Reward Function,例如 \(+1\) 或 \(-10\))来学习
- 但在许多复杂任务中,设计一个完美的数值奖励函数极其困难(即 “Reward Engineering” 难题)
- PBRL 解决了这个问题:它不依赖预定义的数值奖励,而是依赖于“偏好”反馈 ,核心工作流程如下:
- 1)交互与展示:智能体在环境中执行动作,生成若干条轨迹(Trajectory)或结果
- 2)偏好查询: 系统将这些轨迹展示给评估者(可以是人类、专家系统或预设规则),询问:“哪一个更好?”
- 3)奖励建模 (Reward Modeling):利用这些成对的偏好数据,训练一个神经网络(奖励模型),使其输出的数值满足评估者的偏好排序
- 4)策略优化:智能体利用这个学到的奖励模型 ,使用标准的强化学习算法(如 PPO, SAC)来优化策略
- 在传统的强化学习中, Agent 通过环境反馈的数值奖励(Reward Function,例如 \(+1\) 或 \(-10\))来学习
- PBRL vs RLHF:
- PBRL 是一个更广泛的算法框架/方法论;
- 反馈来源 不限于人类;
- 适用于各种场景;比如 让机械臂尝试两次倒水,一次很快但溅出来了,一次很慢但没溅出来;人类看着说:“第二次更好”
- 关注如何在没有奖励函数的情况下解决控制问题,以及如何提高样本效率
- PBRL 是理论基础 :它告诉我们,可以通过比较(A > B)来学习奖励函数,进而训练智能体
- RLHF 是 PBRL 在 LLM 场景中的一个特定应用实例,是特定的技术 Pipeline;
- 反馈来源一般是 “Human”;
- 仅适用于 LLM 场景;
- 关注如何让模型对齐人类价值观(有用性、诚实性、无害性)
- RLHF 是具体应用 :它是将 PBRL 的理论应用到 LLM 上,并引入了人类价值观(Human Alignment)作为核心目标的特定技术路线
- PBRL 是一个更广泛的算法框架/方法论;
Generative RM
- Generative RM(Generative Reward Model,生成式奖励模型) ,有时候也简称 GenRM
- Generative RM 通常不需要改变模型结构,而且一般不需要微调或少量微调即可很好的用于评估其他模型的输出质量
- Generative RM 的核心是复用大模型的上下文能力,用 prompt 提示大模型对模型答案给出分数
- 与 Generative RM 对照的是 标准奖励模型(Standard RM),标准奖励模型一般是在大模型最后再增加一个 MLP 来输出最终的分数
Discriminative RM
- Discriminative RM(Discriminative Reward Model,判别式奖励模型) ,有时直接使用 奖励模型(RM)来称呼
- 别名:Standard RM(Standard Reward Model,标准奖励模型),有时也称为朴素奖励模型(Naive RM)
- Discriminative RM 的核心设计是在预训练的大模型顶部直接接入一个奖励头,通常是线性层或简单的多层感知机(MLP),模型处理输入后直接输出一个标量奖励分数来评估结果质量
- Discriminative RM 模型训练和推理速度极快,计算成本低,但一般需要针对特定数据进行微调
- BERT 当时使用专有的
[CLS]Token 作为特殊标记从而实现输出分类的方式,也可以认为是一种 奖励模型
BT RM
- 当 Discriminative RM 的损失是 Bradley-Terry 建模时,也称为 Bradley-Terry Reward Model ,简称 BT RM
Heavy Mode(Deep Thinking Mode)
- Heavy Mode(译为 Heavy 模式)和 Deep Thinking Mode 本质上是同一概念的不同表述
- 他们都指代通过并行推理和延长思考时间来提升模型复杂任务处理能力的机制
- Heavy Mode :强调资源消耗和计算强度(Heavy=重型/高负载)
- Deep Thinking/Deep Think Mode :强调思维深度和推理过程
相关名词辨析
- 不同厂商/场景的表达方式不一定完全一致
- Heavy Mode :一般在通用技术社区中使用,强调并行资源消耗
- 如 Introducing Kimi K2 Thinking, 20251106, Moonshot AI (Kimi)
- 2025年8月,xAI Grok 4 也用 Heavy 的表达
- Deep Think :如 Google Gemini 在其产品中作为功能命名,强调用户体验
- Thinking Mode :GPT-5 Pro 官方用作功能标签,所以 Kimi K2: Open Agentic Intelligence, Moonshot AI (Kimi), 20250728 中 提到的 GPT-5 Heavy 模式就是 GPT-5 Pro 的 Thinking Mode
- 其他非官方表达还有:
- 多智能体推理 或 并行思维技术 等
- 理解:该名词最早源于”深度思考”(Deep Thinking)作为认知概念早在心理学和教育学文献中就有探讨,指构建概念间深层连接的思维过程,但并非AI领域的专用术语
- Google Gemini 2.5 Deep Think(2025年)是第一个提出这个的,即 Google 最早将 Deep Think 这一概念转化为产品化命名
- 首个面向公众的多智能体推理系统:2025年I/O 大会上首次公开发布Gemini 2.5 Deep Think
- 其核心创新点为:”同时生成多个AI智能体,并行处理同一问题”
- 其变体在2025年国际数学奥林匹克(IMO)斩获金牌,验证了架构有效性
具体方法
- Introducing Kimi K2 Thinking, 20251106, Moonshot AI (Kimi) 原文:
Heavy Mode: K2 Thinking Heavy Mode employs an efficient parallel strategy: it first rolls out eight trajectories simultaneously, then reflectively aggregates all outputs to generate the final result. Heavy mode for GPT-5 denotes the official GPT-5 Pro score.
- 说明:Heavy Mode 是一种通用的提升模型推理能力的方法,其方式为:
- 第一步:并行采样多个 Trajectories
- 第二步:结合第一步生成的结果放入模型,让 Summary 模型来解决问题
- 针对第一步给出的答案,针对不同的 query,第二步有不同的处理方式,query 可以分为以下三种:
- 投票可得正确解:直接通过投票获取到正确答案
- 这种类型的 Query 甚至无需 Summary 模型,直接投票即可
- 投票得不到正确解,但正确 rollout 的数量也不少
- Summary 模型真正发挥的地方,有一定能力的 Summary 模型可以找到正确解
- 极少部分正确:模型给出的结果大多都错误,投票几乎不可能得到正确解
- Summary 也难以得到正确解
- 这类 Query 有望通过 RL 来改善其回答?
- 投票可得正确解:直接通过投票获取到正确答案
OpenRouter
- OpenRouter 是 2023 年初成立于美国纽约的 AI 基础设施公司,核心是AI 模型聚合与智能路由平台
- OpenRouter 接入了大部分主流 AI 模型(25 年已经超 450 个),涵盖 OpenAI、Anthropic、Google 等头部厂商及 DeepSeek、Qwen 等开源模型,用户凭一个 API Key 就能调用所有模型,还能切换使用自有密钥或平台密钥
- OpenRouter 会依据价格、时延等 300+ 指标智能调度请求,50 毫秒内即可完成故障模型的备用切换
- OpenRouter 提供透明的阶梯计费与详细使用报告,支持国内支付,还包含交互式游乐场方便测试模型;
- OpenRouter 默认不存储用户数据,企业用户可启用零数据留存策略保障隐私,同时兼容 OpenAI SDK 及 Coze、LangChain 等多款工具,集成门槛低
Claude Code
- Claude Code 是 Anthropic 公司(OpenAI 前员工创立)为 Claude 大模型打造的代码专属能力模块 ,本质是 Claude 大模型针对编程场景的优化版本,而非独立工具
- Claude Code 提供 代码全流程支持:覆盖代码生成、调试、重构、注释、性能优化、多语言迁移(如 Python 转 Go、Java 转 Dart),还能理解复杂业务逻辑并生成符合工程规范的代码;
- Claude Code 支持超长上下文窗口(Claude 3 系列可达 200k+ tokens),能处理数万行代码的完整项目,理解跨文件依赖和架构逻辑;
- Claude Code 支持主流编程语言(Python、Java、JavaScript/TypeScript、Go、Rust、Dart/Flutter 等),且能解释代码逻辑、排查 Bug;
- Claude Code 支持自然语言对话式编程,可根据开发者的模糊需求逐步细化代码,还能针对代码问题给出详细的错误分析和修复方案
- Claude Code 适用于快速编写业务代码、重构老旧项目、排查复杂代码 Bug、生成技术文档、辅助学习编程
Terminus
- Terminus 主流释义:开源跨平台终端模拟器(Terminus Terminal),定制化、高效的命令行操作环境
- Terminus 是一款 现代化、高度可定制的开源终端工具 ,替代传统的 Windows CMD、macOS Terminal、Linux xterm 等,定位是“开发者友好的终端模拟器 + SSH 客户端”
- Terminus 核心特点是跨平台:支持 Windows、macOS、Linux,统一多系统终端体验;
- Terminus 内置 SSH/SFTP 客户端、Zsh/Bash 集成、插件系统(如代码高亮、自动补全);
- Terminus 轻量且响应快,支持 GPU 渲染,适配高分屏(4K)
- Terminus 适用于开发者日常命令行操作、远程服务器 SSH 连接、多终端会话管理、自定义开发环境终端
Flutter
- Flutter 是 Google 推出的跨平台 UI 开发框架 ,核心定位是帮助开发者用一套代码构建高性能、高保真的移动/桌面/网页应用,彻底打破“多端多代码”的传统开发模式
- 注:Dart 是由 Google 主导开发的、开源的强类型编程语言,首次发布于 2011 年,设计目标是兼顾前端(跨平台 UI)、后端、命令行等多场景开发,核心定位是「面向多平台的现代化编程语言」,也是 Flutter 框架的唯一开发语言
- Flutter 有跨平台能力:一套代码多端运行,提升开发效率
- 一套 Dart 代码可编译为 iOS、Android、Windows、macOS、Linux、Web 甚至嵌入式设备的原生应用,无需为不同平台单独适配核心逻辑;
- Flutter 适用于典型应用场景:移动应用开发(如闲鱼、腾讯视频、字节跳动部分产品)、跨端桌面应用、轻量级 Web 应用
- Flutter 可以和 Terminus 搭配使用:
- 用 Terminus 执行 Flutter 命令行开发
- Flutter 可以和 Claude Code 搭配使用:
- 借助 Claude Code 生成/调试 Flutter 代码
Interleaved Thinking
vLLM 给出的定义:Interleaved Thinking
MiniMax-M2 就是一个 Interleaved Thinking 模型:huggingface.co/MiniMaxAI/MiniMax-M2
Interleaved Thinking 指模型在工具调用之间进行推理(Reason),允许模型在接受工具调用结果后,更加精细的决策
GLM-5:
Interleaved Thinking:模型在每次响应和工具调用前进行思考,提高了指令跟随能力和生成质量
Interleaved Thinking 会增加 Token 使用和响应时长
Interleaved Thinking 目前已经是 vLLM 的内嵌支持了
- 截止到 20251207日,支持 Kimi-K2 和 MiniMax-M2 两个模型
使用方式:在 messages 的
"assistant"role中加入"reasoning"字段1
2
3
4
5
6
7messages.append(
{
"role": "assistant",
"tool_calls": response.choices[0].message.tool_calls,
"reasoning": response.choices[0].message.reasoning, # append reasoning
}
)- 更多详情参考:(vLLM)Interleaved Thinking
Tool‑Integrated Reasoning(TIR)
- TIR,即 Tool‑Integrated Reasoning(工具集成推理) ,是让模型在推理流程中调用外部工具(如代码解释器、计算器、搜索引擎)来提升复杂任务解决能力的范式
- 如:推理到一半,模型觉得需要调用 Python 角度验证一下自己的推理数字是否准确,就可以调用(需要在训练时提供环境)
- 注:可多次调用 外部工具,多次验证
- 思考格式:LLM 思考 -> LLM 判断是否调用工具 -> LLM 生成调用指令 -> 沙盒上完成工具执行 -> 整合结果到 Prompt 上 -> LLM 继续推理 -> 终止
- 对 LLM 子集来说是多轮数据,但和人类没有交互,仅仅是和环境交互
- 数据格式:
<Query> -> <思考> -> <工具调用> -> <观察> -> <答案>
- TIR 允许模型在推理中动态调用工具,将自然语言推理与外部计算能力结合,解决纯文本模型难以处理的计算密集、知识依赖或精确性要求高的问题(如数学推理、数据验证、复杂规划)
- TIR 的核心价值在于严格扩展模型的有效解空间,让原本不可行的推理路径变得可行
- TIR 的形式化表示:多轮 TIR 的推理轨迹可形式化为迭代序列:
$$\tau = \mathcal{A}_1 \oplus \mathcal{A}_2 \oplus \cdots \oplus \mathcal{A}_N$$- 其中每一步动作 \(\mathcal{A}_k = \langle s_k, t_k, o_k \rangle\) 包含:
- \(s_k\):自然语言推理片段(思考过程)
- \(t_k\):工具调用指令(工具名+参数)
- \(o_k\):工具返回的输出结果
- 其中每一步动作 \(\mathcal{A}_k = \langle s_k, t_k, o_k \rangle\) 包含:
- TIR 的关键挑战是多轮交互中的分布偏移导致训练不稳定、工具反馈污染上下文、轮次增多时推理漂移
- TIR 典型应用场景如数学解题(代码执行验算)、数据处理(表格分析)、复杂决策(多工具组合调用)等
- TIR 与 Interval Thinking 的区别:
- Tool-Integrated Reasoning 是 “模型使用外部工具解决问题” 的能力范式
- Interleaved Thinking 是 “思考与行动交替展开” 的多步推理结构
- Tool-Integrated Reasoning 强调工具,Interleaved Thinking 强调过程结构
- 多轮工具推理通常同时属于两者,但两者独立可分
- 总结1:Interleaved Thinking 是 Tool-Integrated Reasoning 的最常用结构(即 Tool-Integrated Reasoning 通常通过 Interleaved Thinking 结构来实现)
- 几乎所有 TIR 论文都用 interleaved 格式:
Think -> Tool -> Observation -> Think -> Tool -> Observation
- 几乎所有 TIR 论文都用 interleaved 格式:
- 注:Tool-Integrated Reasoning 常常表现为 Interleaved Thinking,但 Interleaved Thinking 不一定是 Tool-Integrated Reasoning
- TIR 的应用场景包括用 Python 辅助解决 数学问题等,广义的 TIR 一般表示允许模型在推理过程中自主判断是否调用工具(外部计算工具主要是 Python 环境),实现显示计算、验证一些可通过代码验证的问题,增强推理过程
AnyCoder
- AnyCoder 是一款部署在 Hugging Face Spaces 上的开源 AI 编程辅助 Web 应用 ,由 Hugging Face 机器学习增长负责人Ahsen Khaliq(@akhaliq)开发维护,其核心定位是“直觉式编程工具(Intuitive Programming Tool)”,
- AnyCoder 工具主打无需深厚编程基础,就能通过自然语言描述或多模态输入快速生成可运行的代码,尤其聚焦前端开发场景
- 它既可为新手开发者降低编程门槛,也能帮助专业开发者提升开发效率,同时可作为 Lovable 等同类直觉式编程服务的替代方案
- AnyCoder 完全基于 Hugging Face 的开源 Python 开发环境 Gradio 构建,同时提供两个版本适配不同需求:
- 一是功能完整的 Python 版本,支持 OCR 处理、PDF 和 docx 文档解析等高级能力;
- 二是轻量化的 TypeScript 版本,聚焦核心 AI 代码生成功能,启动速度更快,移动端体验更优
GSM-style
- GSM-style 推理任务核心是仿照 GSM8K(Grade School Math 8K)基准设计的多步骤小学数学文字题推理任务,核心考察 LLM 的分步算术推理与逻辑推导能力,需模型输出完整解题思路而非仅答案
“氛围测试”(Vibe-tests/Vibe-checks)
- 在人工智能和 LLM 的语境下,“氛围测试”(Vibe-tests)或“氛围检查”(Vibe-checks)是一种 基于人类直觉、主观感受和非正式交互的评估方法
- Vibe-tests 与传统的、基于严格指标(如准确率、BLEU 分数、MMLU 基准测试)的评估方式不同
- Vibe-tests 是指开发者或用户通过与模型对话,凭“感觉”来判断模型够不够聪明、回答是否得体、或者生成的应用是否符合预期
- 一般指在模型发布前或开发过程中,由开发者、研究人员或社区成员对模型进行的手动、非正式评估
- Vibe-tests 让我可可以从“看跑分”到“看感觉”
- 主观性:不依赖预定义的测试集,而是依赖评估者对模型输出质量的“主观印象”
- 整体性:不仅仅关注答案的对错,更关注模型的语气、安全性、拒绝回答的边界(是否过于敏感)、逻辑流畅度以及是否“像人一样思考”
- 术语来源:似乎与“氛围编程”(Vibe Coding)有关
- OpenAI 联合创始人 Andrej Karpathy 在 2025 年初推广了 “Vibe Coding” 的概念,即通过自然语言提示让 AI 生成代码,人类主要负责审查和确认
- “Vibe-tests 指人类在验收这些 AI 生成的成果时,主要检查其功能和交互体验是否符合“预期的氛围”或直觉,而不是逐行检查代码逻辑
- 特点:
- 速度快,随时可测,但无法批量化
- 真实,细微,但包含主观感受
- 避免大模型在公开的学术基准(Benchmarks)上都能拿到高分,但在实际使用中却可能表现出“高分低能”
- 例如,模型可能通过了逻辑测试,但在聊天时显得生硬、机械或充满偏见
- 可以进行难以量化的体验
- 很多用户体验指标(如幽默感、情商、创造力、语气的恰当性)是很难用数学公式量化的,只能靠人的“Vibe”(直觉/氛围)来感知
- 表现形式:
- Sanity Check(健全性检查):开发者随便问模型几个刁钻的问题(例如弱智吧问题、陷阱题),看模型是否会“一本正经地胡说八道”
- 如果模型能识破陷阱,通常被认为“Vibe”是对的
- 语气与风格审查:检查模型是否过于说教(Preachy),或者是否在不该拒绝的时候拒绝用户(False Refusal)
- 例如,用户让模型写个恐怖故事,模型却因为“安全原因”拒绝,这会被认为“Vibe check failed”(氛围检查不通过)
- 端到端体验:在 Agent 或长文本应用中,观察模型是否能长时间保持角色一致,或者是否能真正理解用户的意图而不仅仅是关键词匹配
- Sanity Check(健全性检查):开发者随便问模型几个刁钻的问题(例如弱智吧问题、陷阱题),看模型是否会“一本正经地胡说八道”
TTS
- TTS 有两个含义:
- TTS 含义1:Test-Time Scaling,推理时扩展/测试时扩展
- 核心逻辑是:“让模型在回答问题前多思考一会儿,表现会更好”
- 传统上,通过增加训练数据和参数量(训练时扩展)来提升模型能力,而 Test-Time Scaling 发现,在推理阶段给模型分配更多的计算资源(Compute),也能显著提升逻辑推理、数学和编程能力
- TTS 含义2:Text-To-Speech,语音合成 / 文本转语音
slop score
- 在 AI/LLM 领域(slop score),slop score 可用于量化低质量 AI 生成文本(俗称 “slop”)的指标,衡量文本的结构冗余、语义空洞、重复模式等负面特征,反映输出质量的劣化程度
- 注:slop 本意有“泔脚水;淡而无味的半流质食物;脏水” 的含义
- slop score 可用于评估模型生成文本的 “slop” 占比,指导模型优化(如 Antislop 框架)以减少低质输出
CUA
- 在大模型领域,CUA 是 Computer-Using Agent(计算机使用代理) 的简称
- CUA 这一简称是 OpenAI 最早正式提出并定义的 ,该定义随 OpenAI 智能体产品 Operator 于 2025年1月23日 的研究预览版一同发布,用于特指能通过 GUI 交互完成数字任务的核心模型
- 将 Operator 的核心驱动模型命名为 Computer-Using Agent,并缩写为 CUA,强调其融合 GPT-4o 视觉能力与强化学习推理能力的技术特性
- 融合多模态视觉能力与强化学习驱动的高级推理能力,可通过虚拟鼠标键盘与图形用户界面(GUI)交互,无需依赖特定 API 即可完成网页操作、表单填写等复杂数字任务
- 注:此前 Anthropic 等机构虽有计算机使用相关智能体研究,但未使用 CUA 这一缩写;
Skills
- Skills 最早由 Anthropic 提出,也叫做 Claude Skills
- Skills 本质属性是知识封装/流程规范/任务编排器,是“工作流说明书”,让 Claude 按特定流程、规范高效完成专业任务
- Skills 可用于 封装 SOP、模板、最佳实践,指导工具调用顺序与参数,定义输入输出格式
- Claude Skills 是按需加载的,仅匹配任务时调用相关内容,节省 Token 且高效
- Claude Skills 以 SKILL.md 为核心的文件夹,含 Markdown 文档、脚本、模板等,支持版本控制与分享
- 与 MCP 的区别和联系:
- Claude Skills 和 MCP(Model Context Protocol)核心区别在于定位与职责:
- MCP 是连接大模型与外部工具/数据源的标准化接口协议,解决“怎么连”的问题,更像是菜谱(规定步骤与标准)、施工蓝图
- Skills 是封装工作流、规范与最佳实践的任务执行模块,解决“怎么做”的问题,更像是厨房设备(提供工具与连接能力)、施工设备与原材料
- 注:二者常协同使用
- Skills 与 MCP 并非竞争,而是互补:
- 1)Skills 可引用 MCP 配置的工具,定义调用逻辑与参数,让复杂任务流程化
- 2)MCP 为 Skills 提供底层连接能力,保障外部工具的稳定、安全调用
- 3)示例:“Notion 内容管理”Skill 定义搜索、创建页面的步骤,而 MCP 负责 Notion API 的认证、请求转发与结果返回
- Claude Skills 和 MCP(Model Context Protocol)核心区别在于定位与职责:
Reference
- Skills 还可以通过 Reference 引用其他 Skills 文档,从而进行更进一步的封装,按需使用说明书
- 这种做法可以进一步减少复杂场景下的 Prompt 长度,从而节省 Token,也让模型的执行效率更高
- 比如:仅当用户要求计算房租/酒店价格时,再调用房租价格列表/酒店价格列表
Script
- Skills 还可以通过调用其他 Script 执行任务
- 注意:Script 执行的任务非必要不会进入模型的上下文,所以很省 Token
MOPD
- Multi-Teacher On-Policy Distillation (MOPD) 方法最早出自 MiMo 技术报告 MiMo-V2-Flash Technical Report, Xiaomi, 20260106
Rollout Routing Replay (R3)
- Rollout Routing Replay (R3) 的本质含义是在 大模型的 RL 训练中,使用与 rollout 相同的路由专家进行 RL 训练,通过优化的数据类型和通信重叠使其开销可忽略不计
span-level 重复率
- 在 LLM 的训练、数据清洗和效果评估中,样本 span-level 的重复率 是针对 文本片段(span) 维度的重复度量
- span-level 重复率的核心是跳出 整句/整样本是否重复 的粗粒度判断,聚焦 文本中连续/离散的子片段 的重复情况,是衡量数据质量、模型生成冗余性的关键细粒度指标
- span-level 重复率也是 LLM 领域解决训练数据过拟合、生成文本重复/赘余问题的核心观测维度
- span 的定义:
- span 就是文本中任意长度的连续字符/词/子句片段,span-level 重复率就是统计这些片段在数据集(或模型生成结果)中重复出现的概率/比例
- 区别于 样本级重复率(整样本完全重复)和 token-level 重复率(单个词/字的重复),是介于两者之间的中粒度、更贴近语义的重复度量
Self-Consistency
- Self-Consistency(自洽性) 是 LLM 推理的一种解码策略 ,核心是:对同一问题生成多条不同推理路径,再通过“多数投票”选出最一致的答案 ,从而提升复杂推理的准确性与鲁棒性
- Self-Consistency 建立在 Chain-of-Thought(CoT,思维链) 之上,解决的是:
- 传统 CoT 只用单一贪心解码(temperature=0),容易陷入局部最优、受随机噪声影响,导致推理错误
- 复杂问题通常有多条合理路径通向正确答案 ,而错误答案往往路径单一、不一致
- 基本思想:多路径采样 + 一致性投票 = 更可靠的推理
- Self-Consistency 解码的标准流程:
- 1)CoT 提示 :给模型带推理步骤的 prompt,引导它“一步步想”
- 2)多路径采样 :用
temperature>0、top-k/top-p等采样方式,生成 N 条不同推理链(比如 5/10/20 条) - 3)结果聚合 :提取每条链的最终答案,做多数投票(或加权、边际化)
- 4)输出最优解 :把得票最高的答案作为最终结果
Adaptive KL Controller(Dynamic KL Coef)
- 原始论文:Fine-Tuning Language Models from Human Preferences, 20200108, OpenAI
- 注:原文没有给确定性名字,称为 Dynamic vary KL Coef,部分博客或者实现会叫做 Adaptive KL Controller、 Adaptive KL Scheduler 或者 Dynamic KL Scheduler 等
- 提出背景:作者发现,在固定的 KL Penalty 系数 \(\beta\) 下,使用不同的随机种子训练模型有时候会导致模型的 KL 散度值 \(\text{KL}(\pi_t, \rho)\) 会因为随机种子不同而有显著差异
- KL 值直接影响生成质量,不同 KL 的模型无法公平对比任务性能,干扰实验结论
- 解决方案:设定一个目标 KL 值 \(KL_{target}\),动态调整\(\beta\)的核心目标是:让 \(KL(\pi, \rho)\) 稳定收敛到预设目标值 \(KL_{target}\)
- 具体做法:若当前 KL 值大于目标值时,尽量降低 KL 值,反之提升 KL 值(保持在目标附近)
- 考虑到下面的规律:
- \(\beta\) 越大,KL 惩罚越强,微调策略 \(\pi\) 越接近预训练模型 \(\rho\),生成文本自然度高但任务性能可能不足;
- \(\beta\) 越小,KL 惩罚越弱,\(\pi\) 越自由优化奖励模型 \(r\),任务性能可能提升但易出现文本漂移、不连贯的问题
- 基于 类似 PID 的思路 对 KL Penalty 系数 \(\beta\) 进行动态调整
- 优点:
- 稳定 KL 约束 :确保不同实验、不同任务中,\(KL(\pi, \rho)\) 始终围绕 \(KL_{target}\) 波动,避免模型漂移或过度保守;
- 简化调参流程 :无需手动测试多个 \(\beta\) 值,仅需设定合理的 \(KL_{target}\) 即可;
- 提升模型可比性 :所有实验在统一的 KL 约束下进行,任务性能差异仅源于模型本身,而非 KL 散度的波动
- 实际使用中遇到的难点:
- KL 散度的目标值 \(KL_{target}\) 很难设计
- 一般来说 KL Coef 设置多少合适?根据不同场景会有不同,VeRL 中许多默认值使用的 0.1
动态调整 \(\beta\) 公式细节
- 论文中采用对数空间比例控制器 ,通过实时计算 KL 误差来迭代更新\(\beta\),公式分为两步
- 第一步:计算 KL 误差项\(e_t\)
$$ e_t = \text{clip}\left( \frac{KL(\pi_t, \rho) - KL_{target} }{KL_{target} }, -0.2, 0.2 \right) $$- \(KL(\pi_t, \rho)\):\(t\) 时刻策略 \(\pi_t\) 与预训练模型 \(\rho\) 的 KL 散度
- \(KL_{target}\):预设的目标 KL 值
- \(\text{clip}(\cdot, -0.2, 0.2)\):将误差截断在 \([-0.2, 0.2]\) 区间,避免极端误差导致 \(\beta\) 突变
- 理解:
- 若 \(KL(\pi_t, \rho) > KL_{target}\),则 \(e_t > 0\),说明当前 KL 过大,需增大 \(\beta\) 增强惩罚
- 若 \(KL(\pi_t, \rho) < KL_{target}\),则 \(e_t < 0\),说明当前 KL 过小,需减小 \(\beta\) 减弱惩罚
- 第二步:迭代更新 KL 系数 \(\beta_{t+1}\)
$$ \beta_{t+1} = \beta_t \cdot \left( 1 + K_\beta \cdot e_t \right) $$- \(\beta_t\):\(t\) 时刻的当前 \(\beta\) 值
- \(K_\beta = 0.1\):固定比例系数,控制 \(\beta\) 的调整步长
- 理解:
- 当 \(e_t > 0\) 时,\(1 + K_\beta \cdot e_t > 1\),\(\beta_{t+1} > \beta_t\),KL 惩罚增强,\(\pi\) 向 \(\rho\)靠拢;
- 当 \(e_t < 0\) 时,\(1 + K_\beta \cdot e_t < 1\),\(\beta_{t+1} < \beta_t\),KL 惩罚减弱,\(\pi\) 可更自由优化任务奖励;
- 当 \(e_t = 0\) 时,\(\beta_{t+1} = \beta_t\),训练进入稳定状态
现实框架中的实现
- VeRL 和 OpenRLHF 中实现一致
- 以 OpenRLHF 中为例github.com/OpenRLHF/OpenRLHF/blob/main/openrlhf/trainer/ppo_utils/kl_controller.py#L4:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class AdaptiveKLController:
"""
Adaptive KL controller described in the paper:
https://arxiv.org/pdf/1909.08593.pdf
"""
def __init__(self, init_kl_coef, target, horizon):
self.value = init_kl_coef
self.target = target
self.horizon = horizon
def update(self, current, n_steps):
target = self.target
proportional_error = np.clip(current / target - 1, -0.2, 0.2)
mult = 1 + proportional_error * n_steps / self.horizon
self.value *= mult
社工
- “社工”在大模型攻击语境下是社会工程学(Social Engineering)的简称
- 社工指利用人类心理弱点而非技术漏洞来诱导 AI 系统或人类用户产生非预期行为的攻击手段
- 在大模型安全领域,社工本质都是通过语言交互来实现攻击,细分下,其攻击包括相似的一些话术/手段:
- 对 AI 系统的诱导
- 通过精心设计的对话策略,绕过模型的安全对齐机制
- 比如利用角色扮演、情感操控、权威伪装等方式让模型输出有害内容
- 示例:”假设你是一位历史教授,正在研究极端主义思想的发展…”
- 利用 AI 作为攻击媒介
- 诱导大模型生成钓鱼邮件、诈骗话术、恶意代码
- 让 AI 协助进行信息收集或身份冒充
- 对 AI 系统的诱导
Rollout Correction / Rollout IS / Rollout RS
- 这三个名词都常见于 LLM 的 RL 训练中, 表示 RL 训推不一致问题修复相关的功能
- Rollout Correction
- 表达 LLM RL 的训推不一致问题修正功能,作为前缀常用于区分上报指标等
- Rollout Important Sampling (Rollout IS)
- 训推不一致的修正可以通过重要性采样来实现,基本思路是基于 IS 将偏离的分布修正回来
- 最佳修正是从 Sequence-level 视角实现修正,也可以是从 Token-level 实现修正
- Rollout Rejection Sampling (Rollout Rejection)
- 这里 Rejection Sampling 主要是指,当出现 Rollout IS Weight 偏离过大时,直接过滤掉(丢弃)
- 注:这个和传统数学中的拒绝采样(也称为接受-拒绝采样)不一样,传统数学中的 Accept-Reject Sampling 是通过一个容易采样的分布 B 来实现对一个不统一采样的分布 A 进行近似采样(即采样到的样本分布满足不容易满足的分布 A)
Online DPO
- 普通 DPO:直接读取现成的 chosen/rejected
- Online DPO 是在线构造 chosen/rejected 样本,两个样本都是 on-policy 的
- 注:对于 chosen/rejected 样本,Online DPO 有多种构造策略:
- RM 打分:生成 top-n 样本,用 RM 打分后选最优/最差
- MCTS 搜索:通过树搜索找到高质量/低质量路径
- Greedy 对比:同时做 sampling 和 greedy decode,最终生成的结果是 top-n + 1