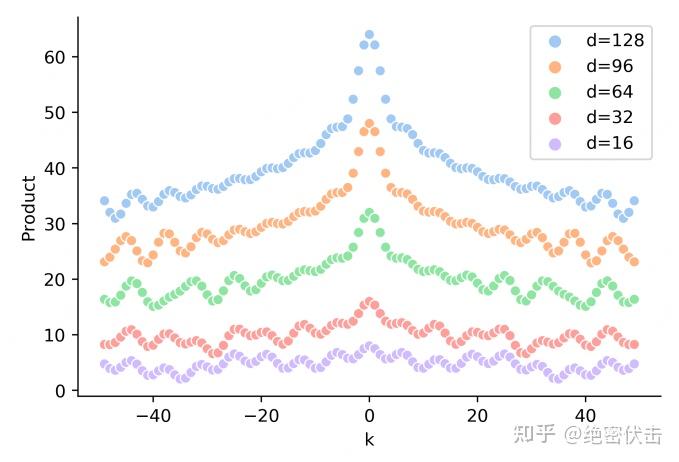
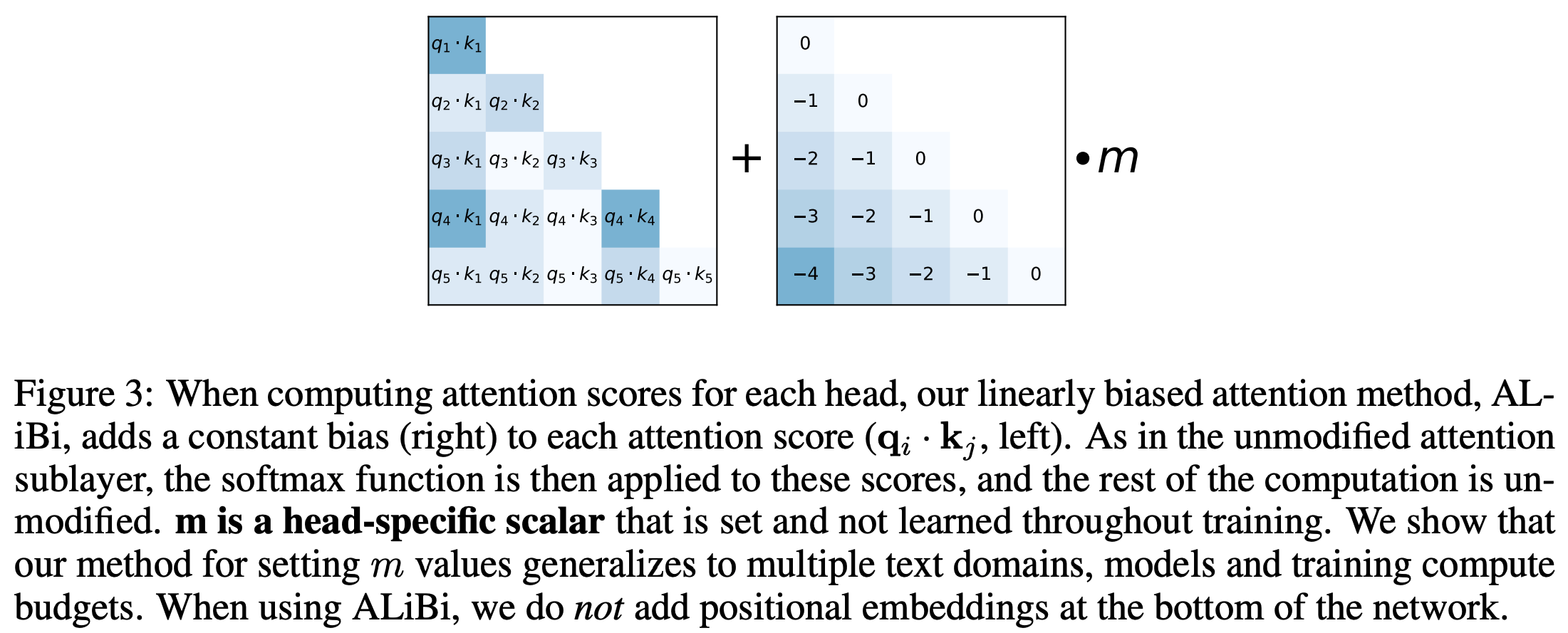
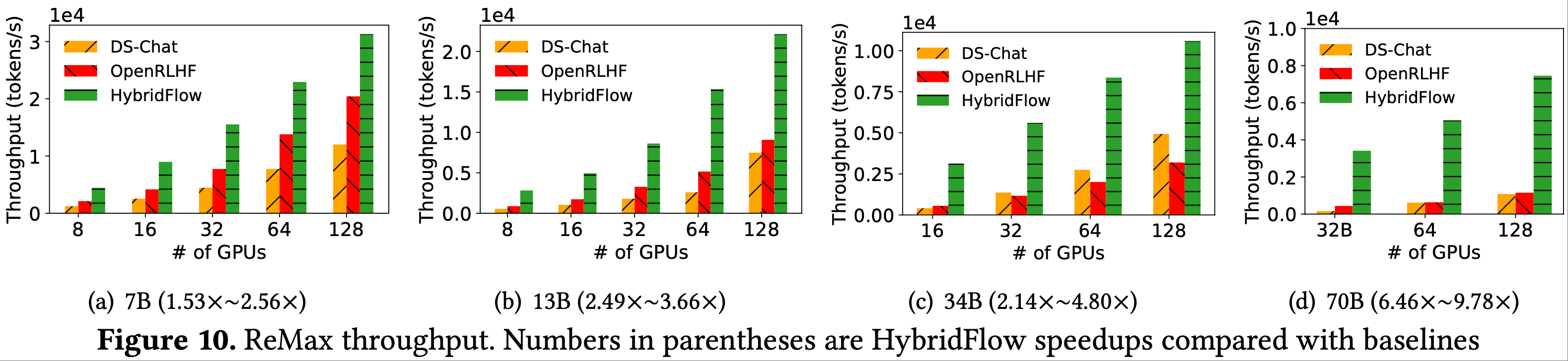
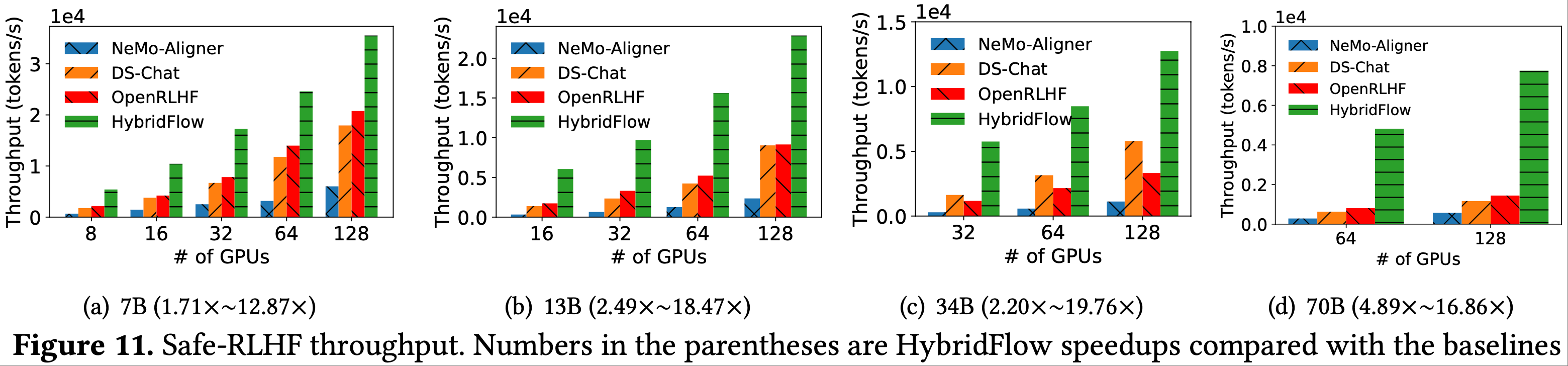
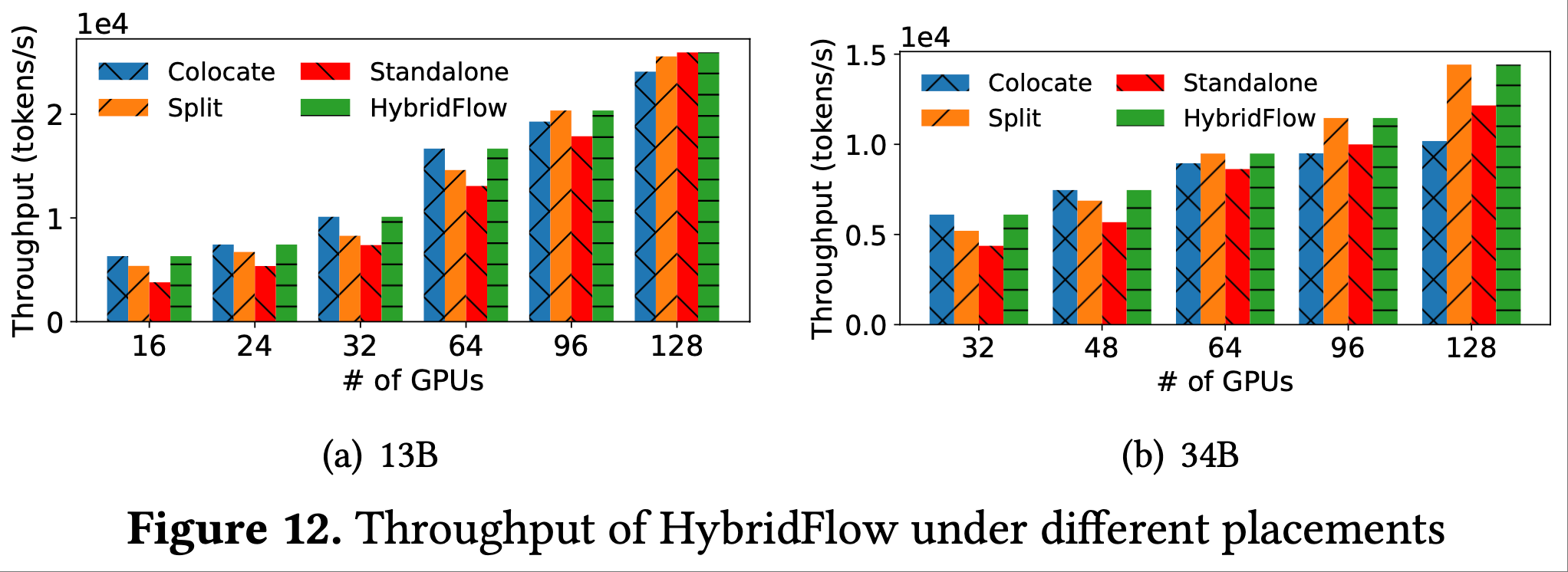
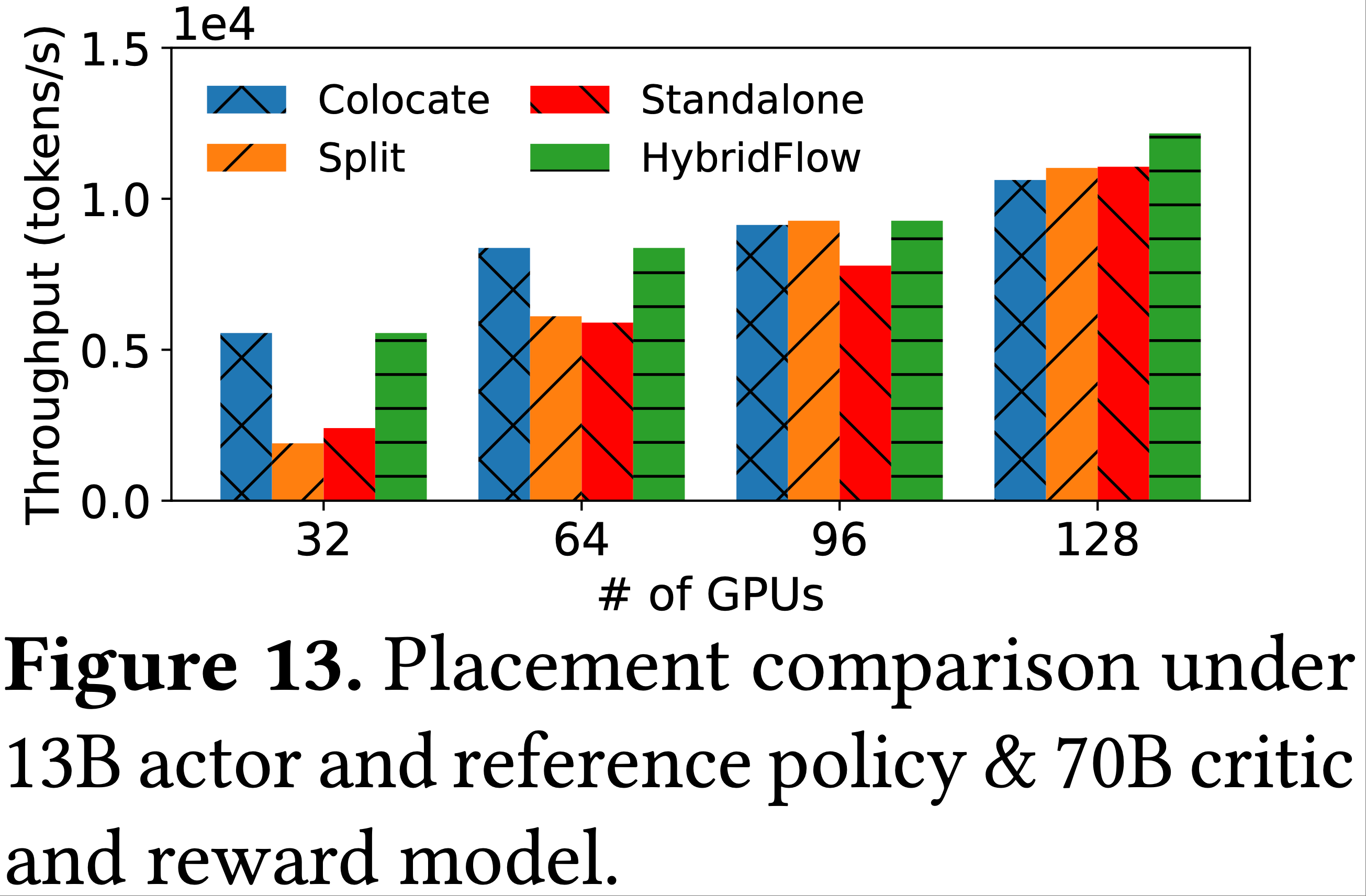
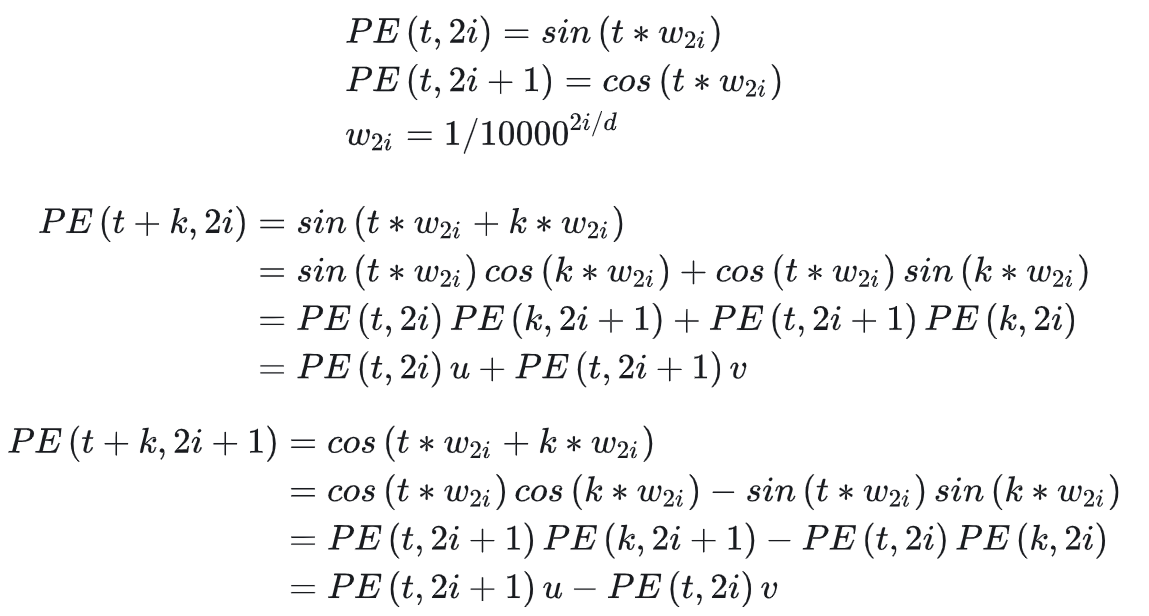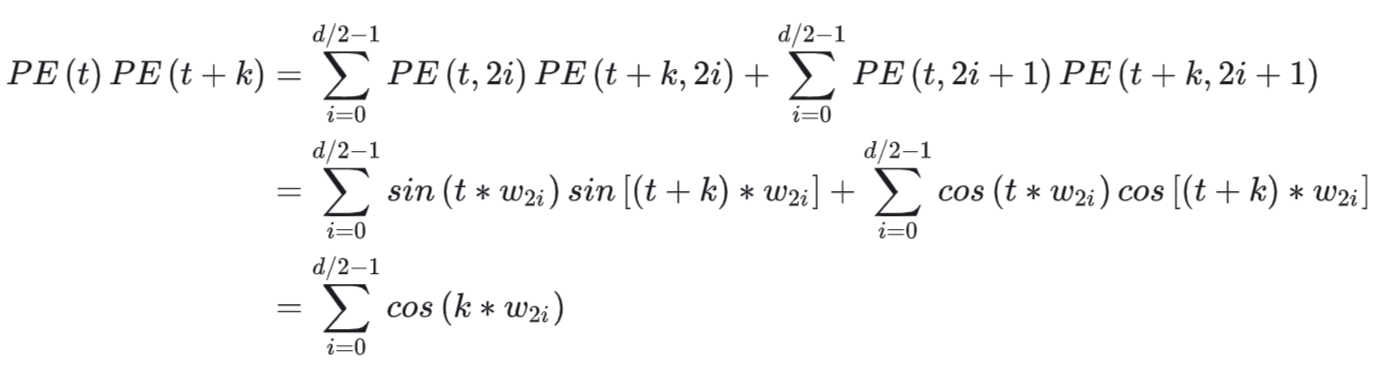Tulu3
- 原始论文:(Tulu3)Tülu 3: Pushing Frontiers in Open Language Model Post-Training
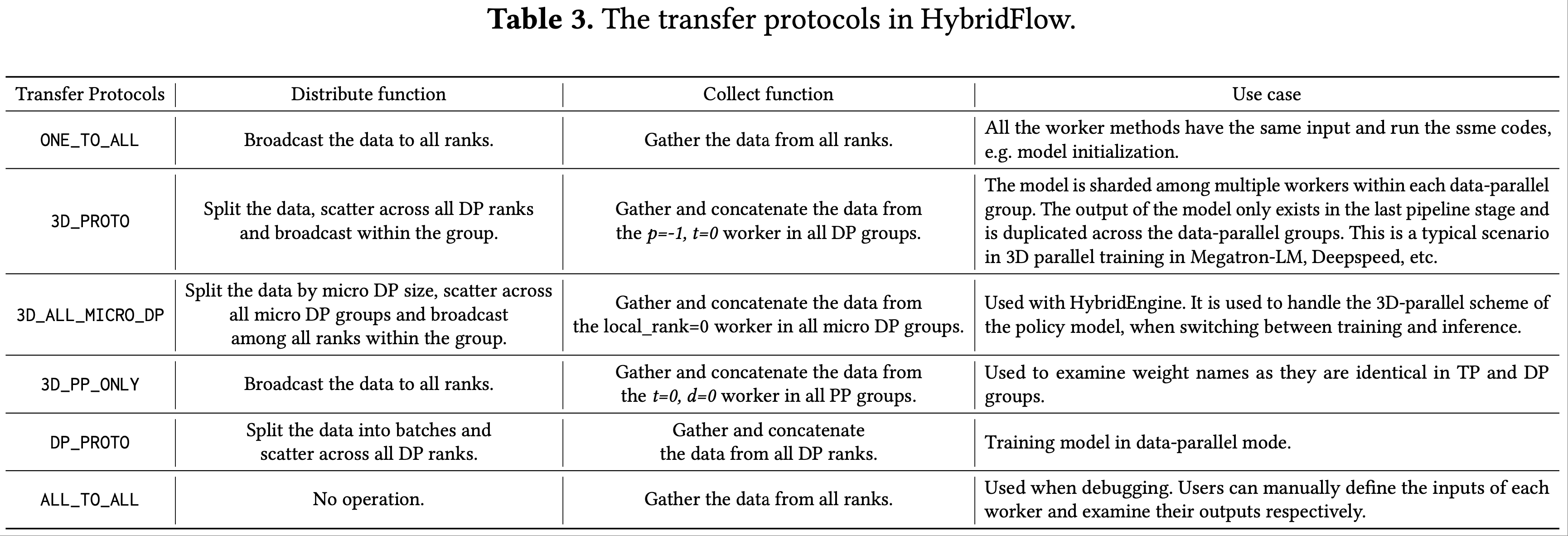
- Tulu3 数据集是艾伦人工智能研究所(Ai2)为训练Tulu3模型而创建的大规模多语言文本数据集
- Tulu3 数据集包含 939,344 个样本,覆盖多种语言和任务,数据来源广泛,包括 Coconot、Flan v2、No Robots 等
- Tulu3 数据集支持语言模型的训练和微调,特别是在多语言环境下,其结构包含标准的指令调整数据点,如 ID 等
- Tulu3 数据集的意义在于为研究人员和开发人员提供了丰富的语言资源,以增强和优化多语言人工智能模型的性能,可用于教育和研究目的,但需遵循特定的许可协议
lmarena-ai/arena-human-preference-140k
- HuggingFace:huggingface.co/datasets/lmarena-ai/arena-human-preference-140k
- Blog:A Deep Dive into Recent Arena Data, 20250731
- lmarena-ai/arena-human-preference-140k 数据集包含文本类别的用户投票(vote)数据,累计大约 14W 数据
- 每行代表一次投票,记录用户在特定对话场景下对两个模型(model_a 和 model_b)的评判结果,同时包含完整对话历史及元数据
- 核心字段说明如下:
id:每次投票/每行数据的唯一反馈IDevaluation_session_id:每次评估会话的唯一 ID,一个会话可包含多次独立投票/评估- 经测试,同一个
evaluation_session_id对应的模型可能不同,如何理解?
- 经测试,同一个
evaluation_order:当前投票的评估顺序(序号)winner:对决结果,取值为model_a(模型 A 获胜)model_b(模型 B 获胜)tie(平局)both_bad(两者均差)
conversation_a/conversation_b:当前评估轮次中两个模型对应的完整对话内容full_conversation:完整对话历史,包含上下文提示词及所有先前评估轮次的模型回复- 注意:每次投票后会重新采样模型,因此完整上下文中的响应模型会有所不同
- 问题:发现多轮数据中,两个模型的上下文是分离的,所以这部分训练时相当于是多轮信号
conv_metadata:聚合元数据(含格式标记、令牌计数),用于风格控制category_tag:标注标签,包括Math、创意写作(creative writing)、高难度提示词(hard prompts)、Instruction Following四类is_code:对话是否涉及代码(布尔值)
- 其他分析:
- 大部分数据是英语,约 51.8%
- 中文简体占比较少,仅 5%
- 中文繁体占比,仅 0.65%
- 注:这个数据集是用作 Reward Model 的优秀模型,也可以用于 SFT 和 DPO 等
- 用作 SFT 时,多轮数据也可以使用;用作 Reward Model 和 DPO 时,多轮数据暂无法使用