注:许多论文中没有使用粗体来表示多个 Token 组成的序列(比如 Question \(\mathbf{q}\)),为了方便理解,本文会尽量可以在一些地方使用粗体
注:本文包含 AI 辅助创作
- 参考链接:
GRPO
- Group Relative Policy Optimization, 简称 GRPO,一种用于在 LLM 中替代近端策略优化 PPO(Proximal Policy Optimization)的方法,可以理解为 PPO 的一种简化形式
- GRPO 相对 PPO 的核心改进点包括:
- 去除 Critic 网络,转而使用批量采样的样本均值和方差做归一化
- 将 PPO 奖励中的 KL 散度移除,并直接加到训练的目标函数中
从 PPO 到 GRPO
PPO是一种广泛用于LLMs强化学习微调阶段的Actor-Critic算法。具体来说,它通过最大化以下替代目标来优化LLMs:
$$
\mathcal{J}_{\textit{PPO}}(\theta)=\mathbb{E}_{q\sim P(Q),o\sim\pi_{\theta_{old}}(O|q)}\frac{1}{|o|}\sum_{t=1}^{|o|}\min\left[\frac{\pi_{\theta}(o_ {t}|q,o_{<t})}{\pi_{\theta_{old}}(o_{t}|q,o_{<t})}A_{t},\textrm{clip}\left( \frac{\pi_{\theta}(o_{t}|q,o_{<t})}{\pi_{\theta_{old}}(o_{t}|q,o_{<t})},1-\epsilon ,1+\epsilon\right)A_{t}\right],
$$- \(\pi_{\theta}\) 和 \(\pi_{\theta_{old}}\) 分别是当前和旧策略模型
- \(q,o\) 是从问题数据集和旧策略 \(\pi_{\theta_{old}}\) 中采样的问题和输出
- \(\epsilon\) 是PPO中用于稳定训练的剪裁相关超参数
- \(A_{t}\) 是优势函数 \(A^{\pi_\text{old}}_t\) 的简写,通过 GAE 计算,基于奖励 \(\{r_{\geq t}\}\) 和学习到的价值函数 \(V_{\psi}\)
- 注:一般实现时,只有最后一步 token 会有 Reward 反馈,其他位置 Reward 都是 0 ,通过折扣奖励的方式可以计算每个 token 对应 GAE
在 PPO 中,需要训练一个价值函数与策略模型并行,并且为了缓解奖励模型的过度优化问题,标准方法是在每个 token 的奖励中添加来自参考模型的每个 token 的KL惩罚(Ouyang et al., 2022),即:
$$
r_{t}=r_{\varphi}(q,o_{\leq t})-\beta\log\frac{\pi_{\theta}(o_{t}|q,o_{<t})}{\pi_{ref}(o_{t}|q,o_{<t})},
$$- 其中,\(r_{\varphi}\) 是奖励模型,\(\pi_{ref}\) 是参考模型(通常是初始的SFT模型),\(\beta\) 是KL惩罚的系数
由于PPO中使用的价值函数通常是另一个与策略模型大小相当的模型,这会带来大量的内存和计算负担。此外,在RL训练过程中,价值函数被用作计算优势的基线以减少方差。然而,在LLM的上下文中,通常只有最后一个token会被奖励模型分配一个奖励分数,这可能会使在每个token上准确训练价值函数变得复杂
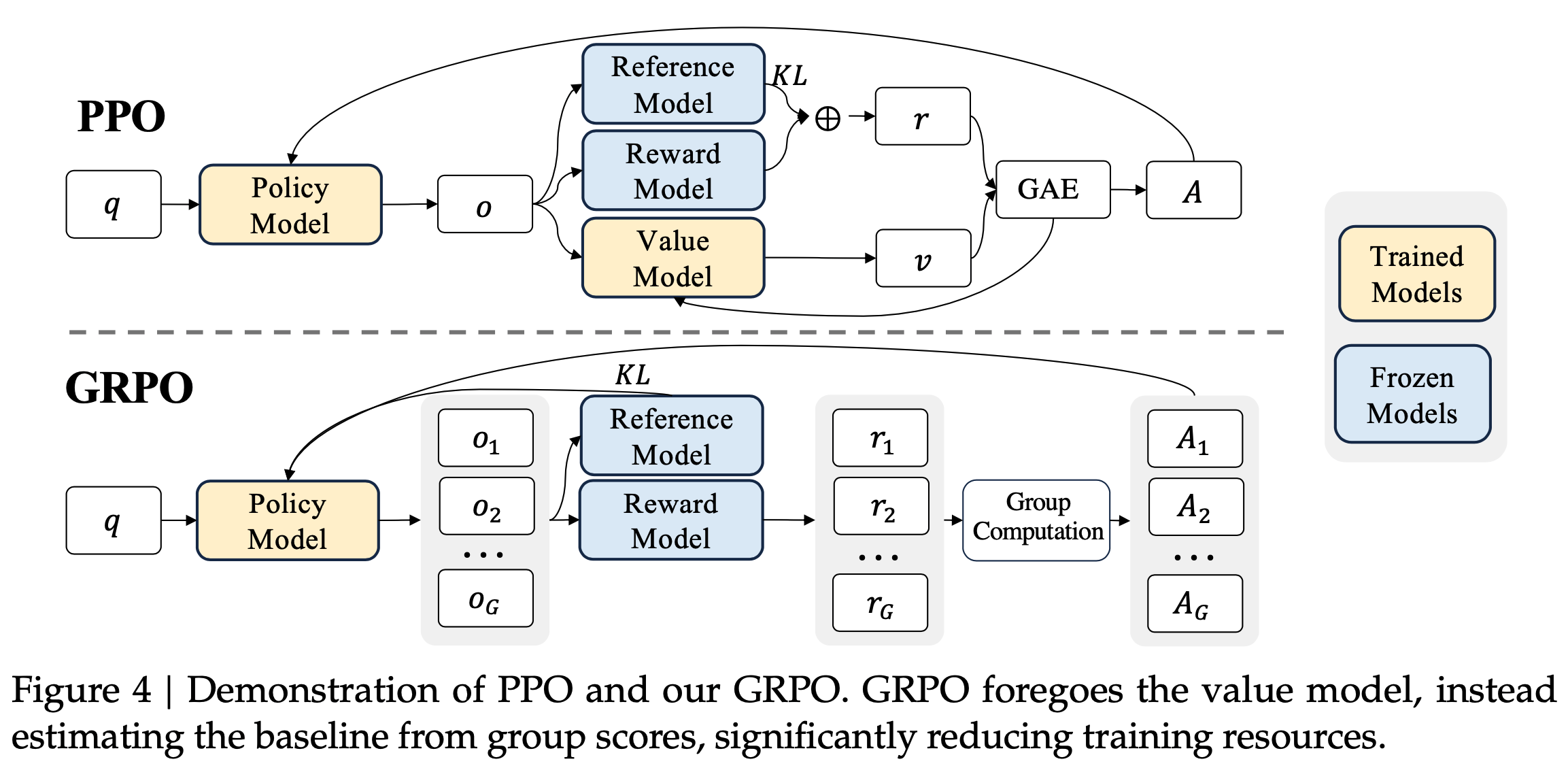
为了解决这个问题,如图4所示,作者提出了 GRPO ,它避免了PPO中额外的价值函数近似,而是使用对同一问题生成的多个采样输出的平均奖励作为基线。具体来说,对于每个问题 \(q\),GRPO从旧策略 \(\pi_{\theta_{old}}\) 中采样一组输出 \(\{o_{1},o_{2},\cdots,o_{G}\}\),然后通过最大化以下目标来优化策略模型(公式3):
$$
\begin{split}
\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}_{q\sim p(Q),\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)}\\
&\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|o_{t}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})}\hat{A}_{i,t},\text{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})},1-\epsilon,1+\epsilon\right)\hat{A}_{i,t}\right]-\beta\text{D}_{\text{KL}}\left[\pi_{\theta}||\pi_{ref}|\right) \right\},
\end{split}
$$- 其中,\(\epsilon\) 和 \(\beta\) 是超参数,\(\hat{A}_{i,t}\) 是基于组内输出的相对奖励计算的优势,具体细节将在后续小节中详细说明。GRPO通过组内相对奖励计算优势的方式,与奖励模型的比较性质非常契合,因为奖励模型通常是在同一问题的输出比较数据集上训练的
特别说明:GRPO 通过直接在损失函数中添加训练策略与参考策略之间的KL散度来进行正则化(与 PPO 在奖励中添加KL惩罚不同),避免了复杂化 \(\hat{A}_{i,t}\) 的计算
结果监督的 GRPO
- Outcome Supervision RL with GRPO,对应 ORM 模型
- 结果监督的GRPO具体步骤如下:
- 采样 :对于每个问题 \(q\),从旧策略模型 \(\pi_{\theta_{old}}\) 中采样一组输出
$$\{o_{1},o_{2},\cdots,o_{G}\}$$ - 评分 :使用奖励模型对这些输出进行评分,得到相应的 \(G\) 个奖励:
$$\mathbf{r}=\{r_{1},r_{2},\cdots,r_{G}\}$$ - 归一化&奖励分配 :这些奖励通过减去组平均值并除以组标准差进行归一化。结果监督在每个输出的末尾提供归一化的奖励,并将输出中所有 token 的优势 \(\hat{A}_{i,t}\) 设置为归一化的奖励,即:
$$\hat{A}_{i,t}=\overline{r}_{i}=\frac{r_{i}-\text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$$- 注:可以看到,结果监督下,GRPO 同一组的各个 token,奖励完全相同
- 最后:通过最大化公式(3)中定义的目标来优化策略
- 采样 :对于每个问题 \(q\),从旧策略模型 \(\pi_{\theta_{old}}\) 中采样一组输出
过程监督的 GRPO
- 说明:Process Supervision RL with GRPO,对应 PRM 模型,
- 结果监督仅在每个输出的末尾提供一个奖励,这可能不足以有效地监督复杂数学任务中的策略,根据Wang et al. (2023b),作者还探索了过程监督,它在每个推理步骤的末尾提供一个奖励,具体步骤如下:
- 采样 :给定问题 \(q\) 和 \(G\) 个采样输出
$$\{o_{1},o_{2},\cdots,o_{G}\}$$ - 评分 :过程奖励模型用于对输出的每个步骤进行评分,得到相应的奖励:
$$ \mathbf{R}=\{\{r_{1}^{\text{index}(1)},\cdots,r_{1}^{\text{index}(K_{1})}\},\cdots,\{r_{G}^{\text{index}(1)},\cdots,r_{G}^{\text{index}(K_{G})}\}\}$$- 其中 \(\text{index}(j)\) 是第 \(j\) 步的结束 token 索引,\(K_{i}\) 是第 \(i\) 个输出中的总步数
- 归一化 :作者还使用平均值和标准差对这些奖励进行归一化:
$$\tilde{r}_{i}^{\text{index}(j)}=\frac{r_{i}^{\text{index}(j)}-\text{mean}(\mathbf{R})}{\text{std}(\mathbf{R})}$$ - 奖励分配 :过程监督将每个 token 的优势计算为后续步骤的归一化奖励之和 ,即:
$$\hat{A}_{i,t}=\sum_{\text{index}(j)\geq t}\tilde{r}_{i}^{\text{index}(j)}$$ - 最后:通过最大化公式(3)中定义的目标 \(\mathcal{J}_{GRPO}(\theta)\) 来优化策略
- 采样 :给定问题 \(q\) 和 \(G\) 个采样输出
迭代式 GRPO
- 随着强化学习训练过程的进行,旧的奖励模型可能不足以监督当前的策略模型。因此,作者还探索了迭代式GRPO。如算法(1)所示,在迭代式GRPO中,作者基于策略模型的采样结果为奖励模型生成新的训练集,并通过包含10%历史数据的回放机制持续训练旧的奖励模型。然后,作者将参考模型设置为策略模型,并使用新的奖励模型持续训练策略模型

- 算法(1)中显示的公式(21)为:
$$
GC_{GRPO}(q, o, t, \pi_{\theta_{sm}}) = \hat{A}_{i,t} + \beta \left( \frac{\pi_{ref}(o_{i,t}|\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}|\mathbf{o}_{i,<t})} - 1 \right),
$$- 其中 \(\hat{A}_{i,t}\) 是基于组奖励分数计算的
DeepSeekMath-RL的训练与评估
- 作者基于DeepSeekMath-Instruct 7B进行强化学习。RL的训练数据是来自SFT数据的与GSM8K和MATH相关的链式思维(chain-of-thought)格式的问题,大约包含144K个问题。作者排除了其他SFT问题,以研究RL对在RL阶段缺乏数据的基准的影响。作者按照Wang et al. (2023b)的方法构建奖励模型的训练集
- 基于DeepSeekMath-Base 7B训练初始奖励模型,学习率为2e-5
- 对于GRPO,作者将策略模型的学习率设置为1e-6 ,KL系数为0.04
- 对于每个问题,作者采样64个输出
- 最大长度设置为1024
- 训练批次大小为1024
- 策略模型在每次探索阶段后仅进行一次更新。作者按照DeepSeekMath-Instruct 7B的基准评估DeepSeekMath-RL 7B。对于DeepSeekMath-RL 7B,GSM8K和MATH的链式思维推理可以被视为域内任务(因为训练主要是针对Math做Reward的),而所有其他基准可以被视为域外任务
- 注:GSM8K数据集是OpenAI创建的一个用于评估数学推理能力的数据集,包含8.5K个高质量的小学数学应用题,题目涵盖多种小学数学知识点,难度适中,且每个问题需要2-8个推理步骤。举例来说:“问题:小明有5个苹果,吃了2个,又买了4个,他现在有多少个苹果? 解答:5 - 2 + 4 = 7,所以小明现在有7个苹果。”
- 表5展示了使用链式思维和工具集成推理的开放和闭源模型在英语和中文基准上的表现。作者发现:1)DeepSeekMath-RL 7B在GSM8K和MATH上分别达到了88.2%和51.7%的准确率,使用链式思维推理。这一表现超过了所有7B到70B范围内的开源模型,以及大多数闭源模型。2)重要的是,DeepSeekMath-RL 7B仅从DeepSeekMath-Instruct 7B开始,在GSM8K和MATH的链式思维格式的指令调优数据上进行训练。尽管其训练数据的范围有限,但它在所有评估指标上均优于DeepSeekMath-Instruct 7B,展示了强化学习的有效性
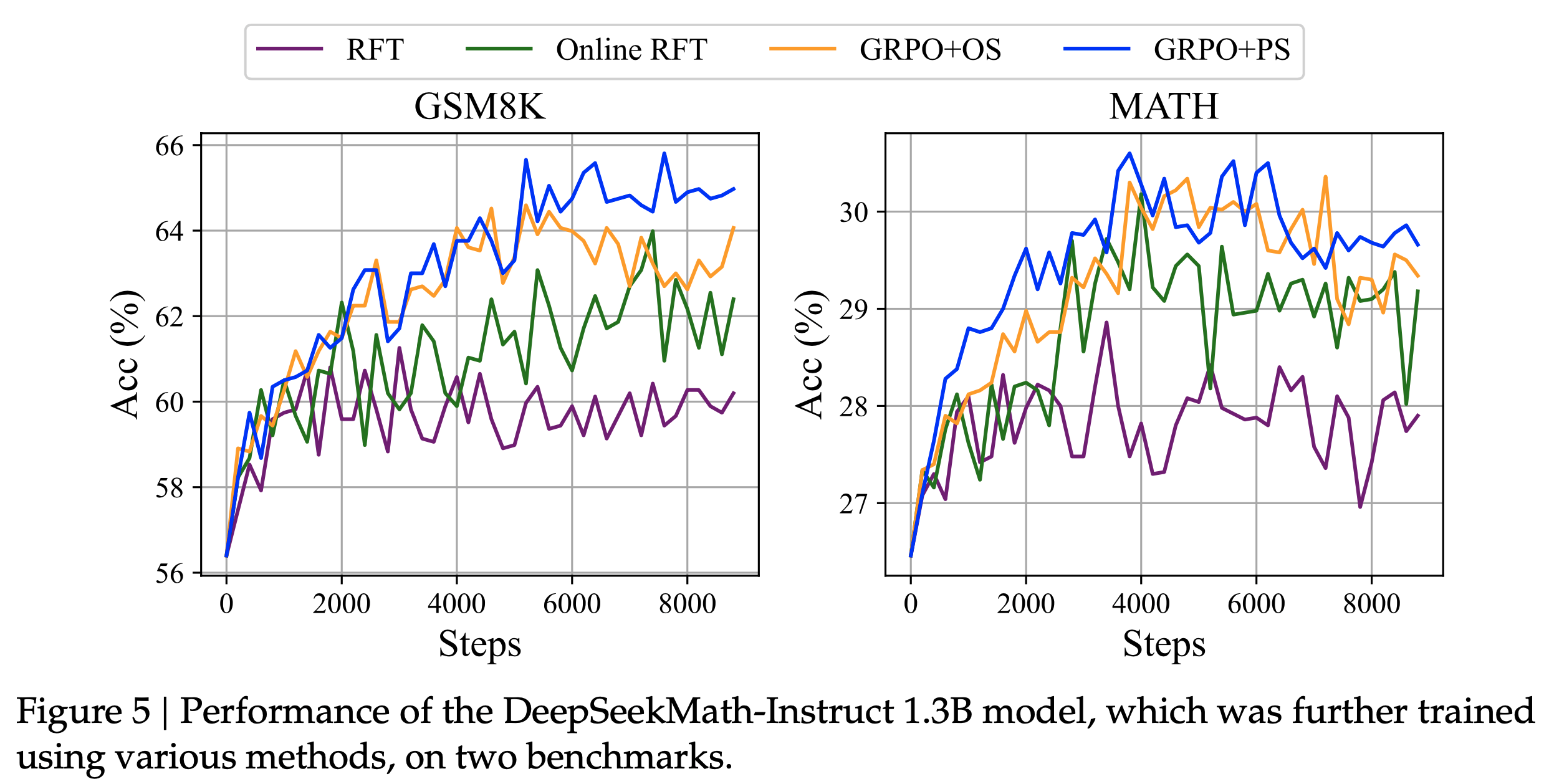
各种微调方法的比较
- 作者从强化学习的视角来看待LLMs的微调,对比了各种方法(包括SFT、RFT、在线RFT、DPO、PPO和GRPO)的数据来源和梯度系数(Gradient Coefficient)(算法和奖励函数)的详细推导
SFT
- 监督微调的目标是最大化以下目标函数:
$$
\mathcal{J}_{\textrm{SFT}}(\theta)=\mathbb{E}_{q,o\sim p_{sft}(Q ,O)}\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\log\pi_{\theta}(o_{t}|q,o_{<t})\right).
$$ - \(\mathcal{J}_{\textrm{SFT}}(\theta)\) 的梯度为:
$$
\nabla_{\theta}\mathcal{J}_{\textrm{SFT}}=\mathbb{E}_{q,o\sim p_{sft}(Q,O)}\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\nabla_{\theta}\log\pi_{\theta}(o_ {t}|q,o_{<t})\right).
$$ - 补充:LLMs做SFT时常用交叉熵损失函数:
$$\mathcal{L}(\theta) = -\frac{1}{|o|}\sum_{t=1}^{m} \log \pi_{\theta}(o_t | x, o_{<t})$$ - 训练数据来源 :用于SFT的数据集(通常是从各自领域真实场景收集得到的,也可以是其他优质大模型生成的)
- 奖励函数设计 :可以视为人类的选择
- 梯度系数(Gradient Coefficient) :始终设置为1
Rejection Sampling Fine-tuning, RFT
- 拒绝采样微调首先从监督微调的 LLM 中为每个问题采样多个输出,然后在具有正确答案的采样输出上训练 LLM。形式上,RFT 的目标是最大化以下目标函数:
$$
\mathcal{J}_{\textrm{RFT}}(\theta)=\mathbb{E}_{q\sim p_{sft}(Q),o\sim\pi_{sft}(O|q)}\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb{I}(o)\log\pi_{ \theta}(o_{t}|q,o_{<t})\right).
$$ - \(\mathcal{J}_{\textrm{RFT}}(\theta)\) 的梯度为:
$$
\nabla_{\theta}\mathcal{J}_{\textrm{RFT}}(\theta)=\mathbb{E}_{q\sim p_{sft}(Q),o\sim\pi_{sft}(O|q)}\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb{I}(o )\nabla_{\theta}\log\pi_{\theta}(o_{t}|q,o_{<t})\right).
$$ - 训练数据来源 :SFT 数据集中的问题,输出从 SFT 模型中采样
- 奖励函数设计 :规则(答案是否正确)
- 梯度系数(Gradient Coefficient) :
$$
GC_{\textrm{RFT}}(q,o,t)=\mathbb{I}(o)=\begin{cases}1&\text{the answer of \(o\) is correct}\\ 0&\text{the answer of \(o\) is not correct}\end{cases}
$$
Online Rejection Sampling Fine-tuning, Online RFT, 在线RFT
- 在线 RFT 和 RFT 的唯一区别在于,在线 RFT 的输出是从实时策略模型 \(\pi_{\theta}\) 中采样,而不是从 SFT 模型 \(\pi_{\theta_{sft}}\) 中采样。因此,在线 RFT 的梯度为:
$$
\nabla_{\theta}\mathcal{J}_{\textrm{OnRFT}}(\theta)=\mathbb{E}_{q\sim p_{sft}( Q),o\sim\pi_{\theta}(O|q)}\left(\frac{1}{|o|}\sum_{t=1}^{|o|}\mathbb{I}(o) \nabla_{\theta}\log\pi_{\theta}(o_{t}|q,o_{<t})\right).
$$
DPO
- DPO的目标是:
$$
\mathcal{J}_{DPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), \color{red}{(o^+, o^-) \sim \pi_{sft}(O|q)}} \Big[ \log \sigma \left( \beta \frac{1}{|o^+|} \sum_{t=1}^{|o^+|} \log \frac{\pi_\theta(o_t^+|q, o_{<t}^+)}{\pi_{ref}(o_t^+|q, o_{<t}^+)} - \beta \frac{1}{|o^-|} \sum_{t=1}^{|o^-|} \log \frac{\pi_\theta(o_t^-|q, o_{<t}^-)}{\pi_{ref}(o_t^-|q, o_{<t}^-)} \right)\Big].
$$- 注:\(\sigma(\cdot)\) 表示Sigmod函数 \(\sigma(x) = \frac{1}{1+e^{-x}}\)
- \(\mathcal{J}_{DPO}(\theta)\) 的梯度为:
$$
\nabla_\theta \mathcal{J}_{DPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), \color{red}{(o^+, o^-) \sim \pi_{sft}(O|q)}} \left( \frac{1}{|o^+|} \sum_{t=1}^{|o^+|} \color{blue}{GC_{DPO}(q, o, t)} \nabla_\theta \log \pi_\theta(o_t^+|q, o_{<t}^+) - \frac{1}{|o^-|} \sum_{t=1}^{|o^-|} \color{blue}{GC_{DPO}(q, o, t)} \nabla_\theta \log \pi_\theta(o_t^-|q, o_{<t}^-) \right).
$$ - 训练数据来源 :SFT数据集中的问题,输出从SFT模型中采样
- 奖励函数设计 :一般领域的人类偏好(在数学任务中可以是“规则”)
- 梯度系数(Gradient Coefficient) :
$$
GC_{DPO}(q, o, t) = \sigma \left( \beta \log \frac{\pi_\theta(o_t^-|q, o_{<t}^-)}{\pi_{ref}(o_t^-|q, o_{<t}^-)} - \beta \log \frac{\pi_\theta(o_t^+|q, o_{<t}^+)}{\pi_{ref}(o_t^+|q, o_{<t}^+)} \right).
$$ - DPO不同于其他训练方法,DPO的一个样本是同时包含了好和坏(对应正和负)两个子样本的,根RFT中的样本组织形式有根本区别,在RFT中,正负样本是独立的,负样本权重为0,正样本权重为1,而DPO中没有正负样本之分,只有样本对,上面的 \(GC_{DPO}(q, o, t) \) 就是样本对的系数
PPO
- PPO的目标是:
$$
\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), o \sim \pi_{\theta_{old}}(O|q)} \Big[\frac{1}{|o|} \sum_{t=1}^{|o|} \min \left( \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})} A_t, \text{clip} \left( \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})}, 1 - \epsilon, 1 + \epsilon \right) A_t \right)\Big].
$$ - 为了简化分析,假设模型在每次探索阶段后仅进行一次更新,从而确保 \(\pi_{\theta_{old}} = \pi_\theta\) ,在这种情况下,我们可以移除最小值和裁剪操作:
$$
\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), o \sim \pi_{\theta_{old}}(O|q)}\Big[ \frac{1}{|o|} \sum_{t=1}^{|o|} \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})} A_t\Big].
$$ - \(\mathcal{J}_{PPO}(\theta)\) 的梯度为:
$$
\nabla_\theta \mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), o \sim \pi_{\theta_{old}}(O|q)}\Big[\frac{1}{|o|} \sum_{t=1}^{|o|} A_t \nabla_\theta \log \pi_\theta(o_t|q, o_{<t})\Big].
$$- 这里的梯度中, \(\frac{1}{\pi_{\theta_{old}}(o_t|q, o_{ < t})}\) 部分被求导消掉了,详细求导过程见附录
- 训练数据来源 :SFT数据集中的问题,输出从策略模型中采样
- 奖励函数设计 :奖励模型
- 梯度系数(Gradient Coefficient) :
$$
GC_{PPO}(q, o, t, \pi_{\theta_{rm}}) = A_t,
$$- 其中 \(A_t\) 是通过广义优势估计(GAE)计算的,基于包含 Actor-Reference KL散度惩罚奖励 \(\{r_{\geq t}\}\) 和学习到的价值函数 \(V_\psi\)
- \(\pi_{\theta_{rm}}\) 中的 \(rm\) 表示简化版
GRPO
- GRPO原始目标是:
$$
\begin{split}
\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}_{q\sim p(Q),\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)}\\
&\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|o_{t}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})}\hat{A}_{i,t},\text{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})},1-\epsilon,1+\epsilon\right)\hat{A}_{i,t}\right]-\beta\text{D}_{\text{KL}}\left[\pi_{\theta}||\pi_{ref}|\right) \right\},
\end{split}
$$ - GRPO中使用了KL散度的近似形式,该形式可以进一步化简,Approximating KL Divergence —— 来自:Deepseek的RL算法GRPO解读 - AIQL的文章 - 知乎
- 估计形式为(注意以下式子中右边是左边的无偏梯度的前提是 \(o_{i,t} \sim \pi_\theta(\cdot \vert q,o_{i,< t})\),且此时 \(\pi_\theta(\cdot \vert q,o_{i,< t}) = \pi_{\theta_\text{old}}(\cdot \vert q,o_{i,< t})\) ),于是有:
$$
\mathbb{D}_\text{KL}[\pi_\theta\Vert\pi_{\text{ref}}] \approx \frac{\pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}\vert q,\mathbf{o}_{i,<t})} - \log \frac{\pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}\vert q,\mathbf{o}_{i,<t})} - 1, \quad o_{i,t} \sim \pi_\theta(\cdot \vert q,\mathbf{o}_{i,<t})
$$- 为了方便理解,这里给出直观解释 :上面的式子右边满足KL散度的基本特性
- 当两个分布足够接近时,第一项趋近于1,第二项趋近于0,整体趋近于0;
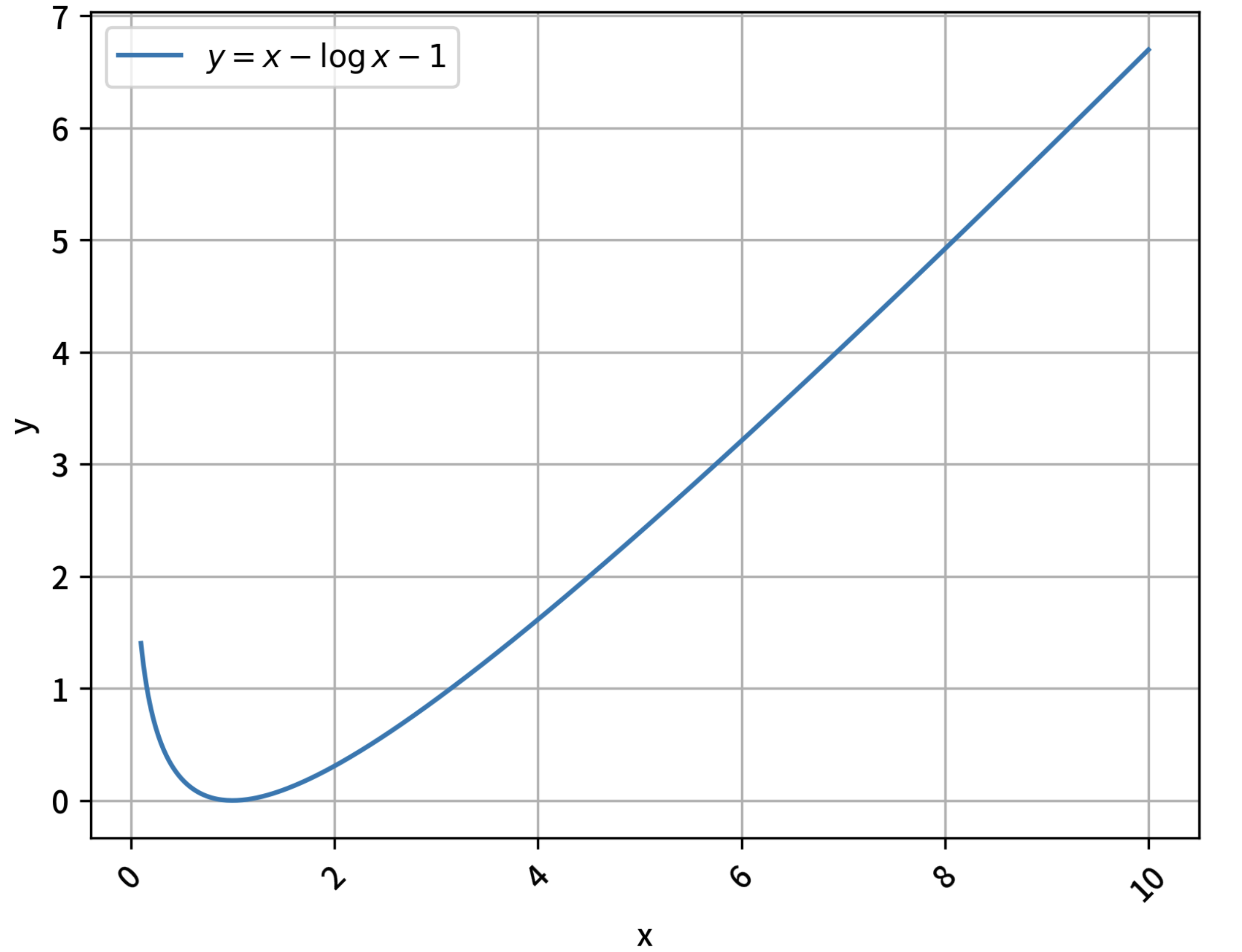
- 两个分布不相等时,上式右边取值总是大于0,可以通过求导证明:当 \(x>0\) 时,有 \(x - \log x - 1 \ge 0\)
- 为了方便理解,这里给出直观解释 :上面的式子右边满足KL散度的基本特性
- 估计形式为(注意以下式子中右边是左边的无偏梯度的前提是 \(o_{i,t} \sim \pi_\theta(\cdot \vert q,o_{i,< t})\),且此时 \(\pi_\theta(\cdot \vert q,o_{i,< t}) = \pi_{\theta_\text{old}}(\cdot \vert q,o_{i,< t})\) ),于是有:
- 最终,化简KL散度后,GRPO的目标是(假设 \(\pi_{\theta_{old}} = \pi_\theta\) 以简化分析):
$$
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), \{\mathbf{o}_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \frac{1}{G} \sum_{i=1}^G \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left( \frac{\pi_\theta(o_{i,t}|q, \mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, \mathbf{o}_{i,<t})} \hat{A}_{i,t} - \beta \left( \frac{\pi_{ref}(o_{i,t}|q, \mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}|q, \mathbf{o}_{i,<t})} - \log \frac{\pi_{ref}(o_{i,t}|q, \mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}|q, \mathbf{o}_{i,<t})} - 1 \right) \right).
$$ - \(\mathcal{J}_{GRPO}(\theta)\) 的梯度为:
$$
\nabla_\theta \mathcal{J}_{GRPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), \{\mathbf{o}_i\}_{i=1}^G \sim \pi_{\theta_{old}}(O|q)} \frac{1}{G} \sum_{i=1}^G \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \hat{A}_{i,t} + \beta \left( \frac{\pi_{ref}(o_{i,t}|\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}|\mathbf{o}_{i,<t})} - 1 \right) \right] \nabla_\theta \log \pi_\theta(o_{i,t}|q, \mathbf{o}_{i,<t}).
$$ - 训练数据来源 :SFT数据集中的问题,输出从策略模型中采样
- 奖励函数设计 :奖励模型
- 梯度系数(Gradient Coefficient) :
$$
GC_{GRPO}(q, o, t, \pi_{\theta_{sm}}) = \hat{A}_{i,t} + \beta \left( \frac{\pi_{ref}(o_{i,t}|\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}|\mathbf{o}_{i,<t})} - 1 \right),
$$- 其中 \(\hat{A}_{i,t}\) 是基于组奖励分数计算的,这里的 \(\hat{A}_{i,t}\) 不包含 Actor-Reference KL散度惩罚
- \(\beta \left( \frac{\pi_{ref}(o_{i,t}|o_{i, < t})}{\pi_\theta(o_{i,t}|o_{i, < t})} - 1 \right)\) 则是 Actor-Reference KL散度部分,用于控制当前策略不要偏离参考策略太远
- \(\pi_{\theta_{rm}}\) 中的 \(rm\) 表示简化版
附录:\(\mathcal{J}_{\text{PPO}}(\theta)\) 求导
前置假设:假设模型在每次探索阶段后仅进行一次更新,从而确保 \(\pi_{\theta_{old}} = \pi_\theta\)
对简化后的目标函数 \(\mathcal{J}_{\text{PPO}}(\theta)\) 关于参数 \(\theta\) 求导:
$$
\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim p_{sft}(Q), o \sim \pi_{\theta_{old}}(O|q)}\Big[ \frac{1}{|o|} \sum_{t=1}^{|o|} \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})} A_t\Big].
$$仅考虑期望内部的部分:对每个时间步 \(t\),应用对数导数技巧 \(\nabla_\theta\log \pi_\theta = \frac{\nabla_\theta \pi_\theta}{\pi_\theta}\)可得:
$$
\nabla_\theta \left( \frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} \right) = \frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} \nabla_\theta \log \pi_\theta(o_t|q, o_{<t}).
$$将梯度表达式代入期望,得到最终梯度:
$$
\nabla_\theta \mathcal{J}_{\text{PPO}}(\theta) = \mathbb{E}_{q \sim p_{\text{sft}}(Q), o \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{|o|} \sum_{t=1}^{|o|} \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{\text{old}}}(o_t|q, o_{<t})} A_t \nabla_\theta \log \pi_\theta(o_t|q, o_{<t}) \right].
$$结合此时的假设 \(\pi_{\theta_{old}} = \pi_\theta\),于是有最终导数如下:
$$
\nabla_\theta \mathcal{J}_{\text{PPO}}(\theta) = \mathbb{E}_{q \sim p_{\text{sft}}(Q), o \sim \pi_{\theta_{\text{old}}}(O|q)} \left[ \frac{1}{|o|} \sum_{t=1}^{|o|} A_t \nabla_\theta \log \pi_\theta(o_t|q, o_{<t}) \right]
$$
附录:GRPO 传统 RL 场景的应用前景讨论
- 一个有趣的对比:DeepSeek GRPO在简单控制系统上和PPO的对比 - 王兴兴的文章 - 知乎
对于整个系统中间过程和信息,比较清晰的问题(中间过程能被价值评价清晰),比如类似上面的控制系统(或者其他机器人系统),PPO还是最简单粗暴出效果很好的;但对于像DeepSeek用来搞数学RL推理,由于中间过程没法很好的描述和计算中间过程的价值,确实还是GRPO更快更方便(只看最终结果);
附录:为什么 GRPO 训练开始时,Loss 函数为 0,并且不降反增?
以下回答参考自:Open-R1 #239 issue: Why does the loss start at 0 when I train GRPO, and then possibly increase?
结论 :损失值从零开始逐渐增加是完全正常的,原因如下:
首先需要理解GRPO目标函数的数学表达:
$$
J_{\text{GRPO}}(\theta) = \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \min\left( \frac{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, \mathbf{o}_{i,<t})} \hat{A}_{i,t}, \text{clip}\left( \frac{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})}{\pi_{\theta_{\text{old}}}(o_{i,t} | q, \mathbf{o}_{i,<t})}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right) - \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}] \right].
$$- \( G \) 是每个提示的生成次数
- \( \mathbf{o}_i \) 是提示的第\( i \)次生成结果,\( |\mathbf{o}_i| \)表示其token数量
- \( q \) 是输入提示
- \( \pi_\theta \) 是策略模型
- \( \pi_{\theta_{\text{old}}} \) 是更新前的策略模型
- \( \pi_{\text{ref}} \) 是参考策略
- \( \hat{A}_{i,t} \) 是第\( i \)次生成中第\( t \)个token的优势估计(详见下文)
- \( \epsilon \) 和 \( \beta \) 是超参数
为简化说明,假设每次迭代只执行一次探索步骤(这是GRPO的标准实现)。此时\( \pi_{\theta_{\text{old}}} = \pi_\theta \),目标函数自然简化为(接下来的花间仅关心绝对值):
$$
\begin{align}
J_{\text{GRPO}}(\theta) &= \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \min\left( \frac{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})} \hat{A}_{i,t}, \text{clip}\left( \frac{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t} | q, \mathbf{o}_{i,<t})}, 1-\epsilon, 1+\epsilon \right) \hat{A}_{i,t} \right) - \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}] \right]. \\
&= \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \min\left( \hat{A}_{i,t}, \text{clip}(1, 1-\epsilon, 1+\epsilon) \hat{A}_{i,t} \right) - \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}] \right]. \\
&= \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \min\left( \hat{A}_{i,t}, \hat{A}_{i,t} \right) - \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}] \right].\\
&= \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \left[ \hat{A}_{i,t} - \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}] \right].\\
&= \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \hat{A}_{i,t} - \frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}].
\end{align}
$$注意优势函数 \(\hat{A}_{i,t}\) 实际上与 \( t \) 无关(在GRPO中,一个Response只有一个Reward,这个Reward是Response粒度的,不是token粒度的),因此:
$$
\frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \hat{A}_{i,t} = \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \hat{A}_i = \hat{A}_i.
$$此外,\( \hat{A}_t \)经过归一化处理意味着:
$$
\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \hat{A}_t = 0.
$$- 证明:这里的归一化处理是,对于一组给定的 \(G\) 个奖励 \(\mathbf{r}=\{r_{1},r_{2},\cdots,r_{G}\}\):
$$A_i = \frac{r-\text{mean}(\mathbf{r})}{\text{std}(\mathbf{r})}$$
- 证明:这里的归一化处理是,对于一组给定的 \(G\) 个奖励 \(\mathbf{r}=\{r_{1},r_{2},\cdots,r_{G}\}\):
因此最终可得:
$$
J_{\text{GRPO}}(\theta) = -\frac{1}{G} \sum_{i=1}^{G} \frac{1}{|\mathbf{o}_i|} \sum_{t=1}^{|\mathbf{o}_i|} \beta D_{\text{KL}}[\pi_\theta | \pi_{\text{ref}}].
$$从绝对值来看,损失等于平均KL散度乘以\( \beta \),由于参考策略与初始策略完全一致,这就是损失从零开始的原因。随着训练进行,策略会逐渐偏离初始参考策略,因此损失值会上升
附录:GRPO 中 KL 散度的近似为何与常规 RLHF 中不一样?
- 常规RLHF中,KL散度的近似为:
$$
\begin{align}
D_{\text{KL}}(\pi_{\theta_\text{old}}||\pi_{\theta}) &= \mathbb{E}_{a \sim \pi_{\theta_\text{old}}} \left[\log\frac{\pi_{\theta_\text{old}}(a|s)}{\pi_{\theta}(a|s)}\right] &\\
&\approx \frac{1}{N} \log\frac{\pi_{\theta_\text{old}}(a|s)}{\pi_{\theta}(a|s)} \\
&= \frac{1}{N} (\log \pi_{\theta_\text{old}}(a|s)- \log\pi_{\theta}(a|s))
\end{align}
$$ - GRPO中,KL散度的近似为(可参考Approximating KL Divergence):
$$
\mathbb{D}_\text{KL}[\pi_\theta\Vert\pi_{\text{ref}}] \approx \frac{\pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}\vert q,\mathbf{o}_{i,<t})} - \log \frac{\pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}\vert q,\mathbf{o}_{i,<t})} - 1, \quad o_{i,t} \sim \pi_\theta(\cdot \vert q,\mathbf{o}_{i,<t})
$$- 为了方便理解,这里给出上式的直观解释 :上面的式子右边满足KL散度的基本特性
- 当两个分布足够接近时,第一项趋近于1,第二项趋近于0,整体趋近于0;
- 两个分布不相等时,上式右边取值总是大于0,可以通过求导证明:当 \(x>0\) 时,有 \(x - \log x - 1 \ge 0\) 恒成立
- 为了方便理解,这里给出上式的直观解释 :上面的式子右边满足KL散度的基本特性
- 关于KL散度近似的更多讨论可参考:Math——KL散度的近似估计
GRPO 中 KL 近似的推导
- GRPO的近似式基于以下观察:
$$
D_{\text{KL}}(\pi_\theta \Vert \pi_{\text{ref}}) = \mathbb{E}_{a \sim \pi_\theta} \left[ \frac{\pi_{\text{ref}}(a|s)}{\pi_\theta(a|s)} - \log \frac{\pi_{\text{ref}}(a|s)}{\pi_\theta(a|s)} - 1 \right].
$$ - 推导思路 :
- 令\(x = \frac{\pi_{\text{ref}}(a|s)}{\pi_\theta(a|s)}\),当两个分布接近时,\(x \approx 1\)
- 对函数\(f(x) = x - \log x - 1\)在\(x=1\)处进行泰勒展开:
$$
f(x) \approx \frac{1}{2}(x-1)^2 + o((x-1)^2).
$$ - 此时,\(\mathbb{E}[f(x)]\)近似为KL散度的二阶项,可用于约束策略更新
- 此近似将KL散度转换为无需显式计算对数期望的形式,适用于从\(\pi_\theta\)采样的场景,同时保证在\(x \approx 1\)时近似准确
为什么不直接使用更简单的 KL 近似?
- 比如参考传统RLHF的思路来计算:
$$
\begin{align}
\mathbb{D}_\text{KL}[\pi_\theta\Vert\pi_{\text{ref}}] &= - \log \frac{\pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t})}{\pi_\theta(o_{i,t}\vert q,\mathbf{o}_{i,<t})} , \quad o_{i,t} \sim \pi_\theta(\cdot \vert q,o_{i, < t})\\
&=\log\pi_\theta(o_{i,t}\vert q,o_{i, < t}) - \log \pi_{\text{ref}}(o_{i,t}\vert q,\mathbf{o}_{i,<t}) , \quad o_{i,t} \sim \pi_\theta(\cdot \vert q,o_{i, < t})
\end{align}
$$ - 上面这个式子更简便也更准确,但是容易出现KL散度为负的情况,特别是对于采样次数不足的时候会更严重,传统的RLHF中就存在这个问题(这个问题也可以描述为方差大)
- k3估计的KL散度那么不好,为什么GRPO还要坚持用呢? - lym的文章 - 知乎中有详细实验发现,使用 \(k_1\) 估计会导致模型倾向于压低 token 的概率
- 但是在GRPO的KL散度近似中,两个分布不相等时,取值总是大于0(可以证明方差比上面的式子小),可以通过求导证明:当 \(x>0\) 时,有 \(x - \log x - 1 \ge 0\) 恒成立,最小值在 \(x=1,y=0\)处,其函数图像如下:
附录:为什么 GRPO 中要将 PPO 奖励中的 KL 散度挪出来?
- 实际上就是实验给的结论!
- 一些个人理解:
- KL 散度加到 Reward 上可能影响 GAE 的计算和稳定性
- KL 散度放到 Reward 上可能出现 Reward Hacking 现象,模型可能会倾向于只输出与参考模型相同的策略
- 特别地,在每个 Token 上都有 KL 散度反馈,但只有最后一个 Token 才会有 Reward 反馈
附录:GRPO 中损失的平均粒度有什么影响?
- GRPO :Sample-level 平均
$$
\begin{split}
\mathcal{J}_{\mathrm{GRPO} }(\theta) &=\mathbb{E}_{(\mathbf{q},\mathbf{a})\sim\mathcal{D},\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old} }(\cdot|q)} \\
&\left[\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|\mathbf{o}_i|}\Bigg{(}\min\Big{(}r_{i,t}(\theta)\hat{A}_{i,t},\mathrm{clip}\Big{(}r_{i,t}(\theta),1-\varepsilon,1+\varepsilon\Big{)}\hat{A}_{i,t}\Big{)}-\beta D_{\mathrm{KL} }(\pi_{\theta}|\pi_{\mathrm{ref} })\Bigg{)}\right],
\end{split}
$$- 其中
$$
r_{i,t}(\theta)=\frac{\pi_{\theta}(o_{i,t}\mid q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old} }(o_{i,t}\mid q,\mathbf{o}_{i,<t})}.
$$ - 从 token 视角看,\(\frac{1}{|\mathbf{o}_i|}\) 相当于是给不同 \(|\mathbf{o}_i|\) 中 token 加上了不同的权重
- 特别注意:一个容易理解的误区是认为 \(\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|\mathbf{o}_i|}\) 可保证整体的损失和是 token 均值,所以不同 \(|\mathbf{o}_i|\) 中 token 对 Loss 权重不变
- 这里理解有误,\(\sum_{t=1}^{|\mathbf{o}_i|}\) 只是损失函数累计到一起的动作(可以看做是一个 Batch 的多个样本一起更新模型), \(\color{red}{\frac{1}{|\mathbf{o}_i|}}\) 则是相当于给所有样本都加了一个权重 \(\color{red}{\frac{1}{|\mathbf{o}_i|}}\)
- 这个权重与 \(\color{red}{\mathbf{o}_i}\) 有关,对不同长度的 response 的 Token 是不公平的,此时,长序列的回复梯度会被缩小(不论正负都会被缩小)),导致模型会倾向于 简短的正确回答 和 较长的错误回答
- 其中
- DAPO :号称 Token-level 平均,本质是 Batch-level 平均(因为如果两个 batch 上采样到的 token 数量差异太大也会导致模型更关注短序列的 token)
$$
\begin{align}
\mathcal{J}_{\mathrm{GRPO} }(\theta) &=\mathbb{E}_{(\mathbf{q},\mathbf{a})\sim\mathcal{D},\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old} }(\cdot|q)} \\
&\left[\frac{1}{\color{red}{\sum_{i=1}^G|\mathbf{o}_i|}}\color{red}{\sum_{i=1}^{G}\sum_{t=1}^{|\mathbf{o}_i|}}\min\Big{(}r_{i,t}(\theta)\hat{A}_{i,t},~\mathrm{clip}\Big{(}r_{i,t}(\theta),1-\varepsilon_\text{low},1+\varepsilon_\text{high}\Big{)}\hat{A}_{i,t}\Big{)}\right] \\
\text{s.t.}\quad &0 < \left|\{\mathbf{o}_i \mid \texttt{is_equivalent}(a, \mathbf{o}_i)\}\right| < G
\end{align}
$$ - SimpleRL :方法与 DAPO 的处理完全一样(下面是原始论文中的写法,不带期望的形式,原始论文可参考:SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild, HKUST & TikTok Meituan, 20250524 & 202508076)
$$
\mathcal{J}_{\text{GRPO}}(\theta)=\underbrace{\frac{1}{\color{red}{\sum_{i=1}^{G}\left|o_{i}\right|}} \color{red}{\sum_{i=1}^{G} \sum_{t=1}^{\left|o_{i}\right|}} min \left[r_{i, t}(\theta) \hat{A}_{i}, clip\left(r_{i, t}(\theta) ; 1-\epsilon, 1+\epsilon\right) \hat{A}_{i}\right]}_{\text{Clipped policy update } }-\underbrace{\beta \mathbb{D}_{KL}\left[\pi_{\theta} | \pi_{ref }\right]}_{\text{KL penalty } }
$$ - Dr.GRPO :真正的 Token-level 平均 ,无论 batch 间的序列长度如何都可做到按照 token 平均
$$
\begin{split}
\mathcal{J}(\pi_{\theta}) &= \mathbb{E}_{\mathbf{q} \sim p_{Q}, \{\mathbf{o}_{i}\}_{i=1}^{G} \sim \pi_{\theta_{old} }(\cdot|\mathbf{q})} \\
&\quad \left[\frac{1}{G} \sum_{i=1}^{G} \sum_{t=1}^{|\mathbf{\mathbf{o}_i}|} \left\{\min \left[\frac{\pi_{\theta}(o_{i,t}|\mathbf{q}, \mathbf{o}_{i,<t})}{\pi_{\theta_{old} }(o_{i,t}|\mathbf{q}, \mathbf{o}_{i,<t})} \tilde{A}_{i,t}, \text{clip} \left(\frac{\pi_{\theta}(o_{i,t}|\mathbf{q}, \mathbf{o}_{i,<t})}{\pi_{\theta_{old} }(o_{i,t}|\mathbf{q}, \mathbf{o}_{i,<t})}, 1 - e, 1 + e \right) \tilde{A}_{i,t} \right]\right\}\right],
\end{split}
$$- 注意:没有 \(\color{red}{\frac{1}{|\mathbf{o}_i|}}\),实际实现时会除以一个
MAX_TOKEN(预设的最大生成长度)
- 注意:没有 \(\color{red}{\frac{1}{|\mathbf{o}_i|}}\),实际实现时会除以一个
- 实现中常用参数:
token-mean:按照正个 Batch 内部的整体 Token 粒度做平均dr_grpo:特殊的做法,常常单独命名,防止误解- Sequence 内部除以固定值(
NUM_MAX_TOKEN),再在 Batch 内部的 Sequence 之间求平均 - 本质可以理解为
seq-mean-fix:- 后面的
fix表示 Sequence 内部除以固定值 - 前面的
seq-mean表示 Batch 内部的 Sequence 之间求平均
- 后面的
- Sequence 内部除以固定值(
seq-mean-token-sum:- 后面的
token-sum表示 Sequence 内部的 Token 之间做求和 - 前面的
seq-mean表示 Batch 内部的 Sequence 之间求平均 - 整体看就是 Sequence 内部求和再对 Batch 内部(Sequence 之间)求平均
- 后面的
seq-mean-token-mean:- 后面的
token-mean表示 Sequence 内部的 Token 之间做平均 - 前面的
seq-mean表示 Batch 内部的 Sequence 之间求平均 - 整体看就是 Sequence 内部求平均再对 Batch 内部(Sequence 之间)求平均
- 后面的
附录:Off-policy 下 GRPO 中的 KL 散度损失项问题
整体说明
- GRPO 相对 PPO 有两个主要创新:
- 1)它放弃了传统的 Critic 模型,而是选择使用群体得分来估计价值基线
- 2)它不是在奖励中加入每个 token 的 KL 散度惩罚,而是通过将学习策略与参考策略之间的 KL 散度直接添加到损失函数中来规范学习过程
- 重点:在 Off-policy 场景中,不能简单地将奖励框架中的 KL 惩罚转移到作为正则化损失项
- 这需要在整个词汇表上计算 KL 项 ,而不仅仅是依赖于采样的轨迹
Theory recap
- PPO 中的损失函数定义如下:
$$
\mathcal{J}_{PPO}(\theta) = \mathbb{E}_{q \sim P(Q), o \sim \pi_{\theta_{old}}(O|q)} \Big[\frac{1}{|o|} \sum_{t=1}^{|o|} \min \left( \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})} A_t, \text{clip} \left( \frac{\pi_\theta(o_t|q, o_{<t})}{\pi_{\theta_{old}}(o_t|q, o_{<t})}, 1 - \epsilon, 1 + \epsilon \right) A_t \right)\Big].
$$- 在 PPO 设置中,\(\pi_{\theta_{\text{old}}}\) 和 \(\pi_{\text{ref}}\) 之间的 KL 散度被纳入奖励函数,表示为:
$$ R = r(q, o) - \text{KL}(\pi_{\theta_{\text{old}}}, \pi_{\text{ref}}) $$ - 在这个奖励函数中,没有任何项依赖于正在优化的策略 \(\pi_\theta\)
- 在精确损失函数的实现中,可以对这个奖励应用“detach”操作,在代码中有效地表示为
R = R.detach() - 这种分离可以防止损失计算中出现不可预测的行为
- 在 PPO 设置中,\(\pi_{\theta_{\text{old}}}\) 和 \(\pi_{\text{ref}}\) 之间的 KL 散度被纳入奖励函数,表示为:
- GRPO 的损失函数定义是:
$$
\begin{split}
\mathcal{J}_{GRPO}(\theta)&=\mathbb{E}_{q\sim p(Q),\{\mathbf{o}_i\}_{i=1}^{G}\sim\pi_{\theta_{old}}(O|q)}\\
&\frac{1}{G}\sum_{i=1}^{G}\frac{1}{|\mathbf{o}_i|}\sum_{t=1}^{|o_{t}|}\left\{\min\left[\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})}\hat{A}_{i,t},\text{clip}\left(\frac{\pi_{\theta}(o_{i,t}|q,\mathbf{o}_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q,\mathbf{o}_{i,<t})},1-\epsilon,1+\epsilon\right)\hat{A}_{i,t}\right]-\beta\text{D}_{\text{KL}}\left[\pi_{\theta}||\pi_{ref}|\right) \right\},
\end{split}
$$ - 注:两者都基于策略 \(\pi_{\theta_{\text{old}}}\) 采样轨迹,也就是说两种方法本质上都是 Off-policy 的
- 回顾 REINFORCE 算法 :
- REINFORCE 以 On-policy 方式运行,REINFORCE 的损失函数表示为:
$$ L = \mathbb{E}_{\pi_\theta}[R] $$ - 这是一个直接的目标,其中 \(R\) 代表 On-policy \(\pi_\theta\) 下获得的奖励(目标是最大化这个期望奖励)
- 该损失对应的梯度为:
$$ \nabla_\theta L = \nabla_\theta \mathbb{E}_{\pi_\theta}[R] $$ - 由于采样和优化都是相对于相同的策略分布 \(\pi_\theta\) 进行的,我们旨在计算该分布的梯度以更新参数 \(\theta\)
- 但这提出了一个挑战,因为直接评估期望通常是不可行的(非可微奖励(Non-differentiable Reward)):奖励函数可能不可微,或者可能是一个黑盒函数,这意味着其内部工作不可见,只能观察到输出(High-Dimensional Continuous Control Using Generalized Advantage Estimation)
- 为了处理这个问题,使用了一种称为得分函数估计器(score function estimator)或 REINFORCE 估计器(REINFORCE estimator)的通用梯度估计器
- 得分函数定义为:
$$ \nabla_\theta \log \pi_\theta = \frac{\nabla_\theta \pi_\theta}{\pi_\theta} $$
- 得分函数定义为:
- 利用这个得分函数,REINFORCE损失的梯度可以表示为:
$$ \nabla_\theta L = \mathbb{E}_{\pi_\theta}[R \cdot \nabla_\theta \log \pi_\theta] $$ - 在这里,梯度计算集中在对数概率项 \(\nabla_\theta \log \pi_\theta\) 上
- 这种公式有效地将寻找期望梯度(gradient of an expectation)的问题转化为梯度的期望(expectation of gradients) ,且梯度的期望可以通过从 \(\pi_\theta\) 中抽取的样本来估计
- 这是强化学习中的一个关键 Insight,因为它允许即使在奖励信号稀疏或随机的情况下也能优化策略
- REINFORCE 以 On-policy 方式运行,REINFORCE 的损失函数表示为:
- 为了理解 \(\pi_\theta\) 项在 GRPO 设置中的重要性,从 \(\pi_\theta\) 如何影响 KL 损失中的梯度计算开始
- 在 GRPO 的背景下,KL 散度以下列期望形式表示:
$$ \text{KL}(\pi_\theta | \pi_{\text{ref}}) = \mathbb{E}_{\pi_\theta}[\log \pi_\theta - \log \pi_{\text{ref}}] $$ - 在计算 GRPO 损失的梯度时,需要对两个组成部分进行微分:
- 1)与优势加权策略项相关的梯度,类似于 PPO
- 2)与 KL 散度项相关的梯度(GRPO 损失函数设计下独有的部分)
- 涉及 KL 散度的组成部分需要进行微分,因为它包含了明确依赖于策略参数 \(\theta\) 的项 \(\pi_\theta\)。这种依赖性在计算梯度时至关重要,因为:
- 对分布的微分(Differentiation Over the Distribution) :由于 \(\pi_\theta\) 代表了对动作的概率分布,\(\theta\) 的任何变化都会影响不同动作的概率分配
- 因此,推导梯度涉及考虑这些概率如何随参数更新而变化
- 梯度传播(Gradient Propagation) :KL 散度中的 \(\pi_\theta\) 项直接影响通过其向策略参数反向传播更新的梯度
- 与 PPO 场景不同,在 PPO 中奖励项(注:包含 KL 散度的奖励项)是分离的,(KL 散度)不会直接影响关于 \(\pi_\theta\) 的梯度,而在这里 \(\pi_\theta\) 主动参与梯度计算
- 对分布的微分(Differentiation Over the Distribution) :由于 \(\pi_\theta\) 代表了对动作的概率分布,\(\theta\) 的任何变化都会影响不同动作的概率分配
- 因此,强调 \(\pi_\theta\) 项至关重要,因为它将 KL 散度直接与策略参数联系起来,需要在梯度计算中予以考虑
- 在 GRPO 的背景下,KL 散度以下列期望形式表示:
从实现的视角看
PPO
以 OpenRLHF 仓库 为例:
在 PPO 中,为了计算奖励,需要添加 KL 项
- 如 openrlhf/models/utils.py 所示,其中 KL 在 trainer/ppo_utils/experience_maker.py 计算,下面的代码来自 openrlhf/models/utils.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def compute_approx_kl(
log_probs: torch.Tensor,
log_probs_base: torch.Tensor,
kl_estimator: str = "k1",
) -> torch.Tensor:
"""
Compute the approximate KL divergence between two distributions.
Schulman blog: http://joschu.net/blog/kl-approx.html
Args:
log_probs: Log probabilities of the new distribution.
log_probs_base: Log probabilities of the base distribution.
"""
if kl_estimator == "k1":
log_ratio = log_probs.float() - log_probs_base.float()
# The k2 estimator is the non negative kl approximation in
# http://joschu.net/blog/kl-approx.html
# The k2_loss is approximately equivalent to the
# one-step KL divergence penalty with the k1 estimator
# used in https://arxiv.org/pdf/2310.10505.
if kl_estimator == "k2":
log_ratio = log_probs.float() - log_probs_base.float()
log_ratio = log_ratio**2 / 2.0
# The k3 estimator is the non negative kl approximation in
# http://joschu.net/blog/kl-approx.html
if kl_estimator == "k3":
log_ratio = log_probs.float() - log_probs_base.float()
log_ratio = -log_ratio
log_ratio = log_ratio.exp() - 1 - log_ratio
log_ratio = log_ratio.clamp(min=-10, max=10)
return log_ratio
- 如 openrlhf/models/utils.py 所示,其中 KL 在 trainer/ppo_utils/experience_maker.py 计算,下面的代码来自 openrlhf/models/utils.py
值得注意的是,
action_log_probs和base_action_log_probs的形状是[batch_size, response_length]核心 :一个有趣的问题是,当计算 KL 散度时,应该在整个词汇表分布上计算,而不仅仅是采样的轨迹上
- 进一步引出问题思考:为什么在这种情况下可以省略
vocab_size维度?
- 进一步引出问题思考:为什么在这种情况下可以省略
回答问题:
- 回想一下,我们讨论过 PPO 中的奖励是定义为:
$$R = r(q, o) - \text{KL}(\pi_{\theta_{\text{old}}}, \pi_{\text{ref}})$$ - 将 PPO 损失重写为(简写):
$$\mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} A\right]$$ - 进一步忽略价值函数,这个表达式简化为
$$\mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} (r(q,o) - \text{KL}(\pi_{\theta_{\text{old}}}, \pi_{\text{ref}}))\right] = \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}} (r(q,o) - \mathbb{E}_{\pi_{\theta_\text{old}}}(\log \pi_{\theta_{\text{old}}} - \log \pi_{\text{ref}}))\right]$$ - 由于期望是在相同的分布 \(\pi_{\theta_\text{old}}\) 下取的,而不是在与我们正在优化的参数 \(\theta\) 无关的 \(\pi_\theta\) 下
- 因此只需计算 \(\pi_{\theta_{\text{old}}}\) 和 \(\pi_{\text{ref}}\) 的对数概率之间的差异就足够了(如Language Models are Few-Shot Learners, NIPS 2020 中所示)
- 在这种情况下省略
vocab_size维度是可行的- 理解:是因为做了采样,采样就相当于做了分布期望完整估计
- 回想一下,我们讨论过 PPO 中的奖励是定义为:
GRPO
- GRPO 中,KL 项被视为损失,特别是当 KL 散度表示为 \(\text{KL}(\pi_\theta || \pi_{\text{ref}})\) 时,不可能使用 \(\pi_\theta\) 和 \(\pi_{\text{ref}}\) 的对数概率之间的差异来近似这个 KL 损失
- 核心 :因为有必要在 \(\pi_\theta\) 下采样轨迹
- 同上,我们可以将 GRPO 目标化简表示为:
$$ \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}A - \text{KL}(\pi_\theta, \pi_{\text{ref}})\right] = \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}A - \mathbb{E}_{\pi_\theta}(\log\pi_\theta - \log\pi_{\text{ref}})\right] $$- 理解:上述的式子说明,内外层需要分别对 \(\pi_\theta\) 和 \(\pi_{\pi_\text{old}}\) 进行采样,而这两者对不齐
- 因此,当使用 KL 项作为损失时,必须保持
vocab_size维度- 问题:这跟
vocab_size有什么关系,主要还是同时需要两个不同的采样导致的吧? - 回答:有关系,需要对 \(\pi_\theta\) 采样的原因是无法全部列举 \(\pi_\theta\) 的 可能动作,如果是列举所有动作 (
vocab_size),则不再需要采样(理解:评估分布的期望有两种方式:1)采样 or 2)访问所有动作的概率计算期望)
- 问题:这跟
- 此外,重用上述代码中的
compute_approx_kl函数是不合适的(理解:这里是按照 \(\pi_{\pi_\text{old}}\) 采样的),因为这样做会导致:
$$ \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}A - \mathbb{E}_{\pi_{\theta_{\text{old}}}}(\log\pi_\theta - \log\pi_{\text{ref}})\right] $$- 因为我们实际上使用 \(\pi_{\theta_{\text{old}}}\) 进行采样,导致失去了 \(\pi_\theta\) 的导数信息
Ways to solve
- The critical implementation detail of KL loss in GRPO 博客作者在与 @Renbiao Liu 和 @Yiming Liu 讨论后,似乎有三种潜在的方法来解决这个问题:
- 1)遵循传统的 KL 损失(即重新通过 \(\pi_\theta\) 采样并计算 KL)
- 2)仅使用 GRPO 的 On-policy 版本
- 3)将 KL 散度重新加入奖励函数
遵循传统的 KL 损失
- 注:原始 GRPO 中使用的是 KL 散度的 K3 估计
$$ k_3 = (r-1) - \log r$$ - 本节使用传统的 KL 损失,传统 KL 损失可以推导如下:
$$
\begin{align}
&\nabla_\theta\mathbb{E}_{\pi_\theta}\left[\log\pi_\theta-\log\pi_\text{ref}\right] \\
=& \nabla_\theta\sum\pi_\theta (\log\pi_\theta-\log\pi_\text{ref}) \\
=& \sum\nabla_\theta\pi_\theta\cdot(\log\pi_\theta-\log\pi_\text{ref})+\pi_\theta\cdot\nabla_\theta(\log\pi_\theta-\log\pi_\text{ref}) \\
=& \sum\nabla_\theta\pi_\theta\cdot(\log\pi_\theta-\log\pi_\text{ref})+\pi_\theta\cdot\frac{\nabla_\theta\pi_\theta}{\pi_\theta}\\
=&\sum\pi_\theta\nabla_\theta\log\pi_\theta(\log\pi_\theta-\log\pi_\text{ref})+\sum\nabla_\theta\pi_\theta\\
=&\mathbb{E}_{\pi_\theta}\left[(\log\pi_\theta-\log\pi_\text{ref})\nabla_\theta\log\pi_\theta\right]
\end{align}
$$ - 理解:从上面可以看出,只需要对 \(\pi_{\theta}\) 采样就可以了,不再需要内层计算期望(也就没有内外层期望的概率分布不一致问题)
- 也就是说,可以通过基于样本的近似技术(如 On-policy 采样或重要性采样)或通过计算分布概率来进行梯度反向传播来优化它
- 问题:这里的 On-policy 采样是指真实使用当前策略去重新采样,也就是说 GRPO 迭代的每一步都需要重新采样并计算 KL?
- 然而,鉴于这些方法通常有一些缺点:
- 方式一:重新采样,依赖于额外的采样程序(除了从 \(\pi_{\theta_\text{old}}\) 采样外,还可能需要从每一步迭代后的 \(\pi_\theta\) 采样)
- 方式二:在 vocabulary size 上计算 KL 散度
- 它们并不特别实用或计算效率高
- 另一种近似方法可能涉及使用 top-K 软标签(soft labels)进行梯度反向传播,类似于知识蒸馏中使用的方法,尽管这尚未在 RL 场景中被证明是最佳选择
On-policy GRPO
- 在 GRPO 的 On-policy 版本中,原始损失函数可以重新表述为:
$$ \mathbb{E}_{\pi_{\theta}}\left[A-\mathbb{E}_{\pi_{\theta}}\left[\log\pi_\theta-\log\pi_\text{ref}\right]\right]=\mathbb{E}_{\pi_{\theta}}\left[A-(\log\pi_\theta-\log\pi_\text{ref}\right)] $$ - 相应的导数由下式给出:
$$ \mathbb{E}_{\pi_\theta}[(A-(\log\pi_\theta-\log\pi_\text{ref}))\cdot\nabla_\theta\log\pi_\theta] $$ - 因此,当 GRPO 完全 On-policy 时,它与之前使用的公式匹配:
$$ \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}A - \text{KL}(\pi_\theta, \pi_{\text{ref}})\right] = \mathbb{E}_{\pi_{\theta_{\text{old}}}}\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old}}}}A - \mathbb{E}_{\pi_\theta}(\log\pi_\theta - \log\pi_{\text{ref}})\right], $$- 在 On-policy 条件下,即 \(\pi_\theta = \pi_{\theta_{\text{old}}}\):
$$ \mathbb{E}_{\pi_{\theta}}\left[\frac{\pi_\theta}{\pi_{\theta}}A - \mathbb{E}_{\pi_\theta}(\log\pi_\theta - \log\pi_{\text{ref}})\right]=\mathbb{E}_{\pi_{\theta}}\left[A - (\log\pi_\theta - \log\pi_{\text{ref}})\right], $$
- 在 On-policy 条件下,即 \(\pi_\theta = \pi_{\theta_{\text{old}}}\):
Adding back to reward function(即将 KL 散度重新加入奖励函数)
- 从上面的推导可知,传统的 KL 散度损失可以化简为:
$$
\begin{align}
\nabla_\theta\mathbb{E}_{\pi_\theta}\left[\log\pi_\theta-\log\pi_\text{ref}\right] = \mathbb{E}_{\pi_\theta}\left[(\log\pi_\theta-\log\pi_\text{ref})\nabla_\theta\log\pi_\theta\right]
\end{align}
$$ - 在 Off-policy 场景中,KL 损失的为:
$$
\mathbb{E}_{\pi_\theta}\left[(\log\pi_\theta-\log\pi_\text{ref})\nabla_\theta\log\pi_\theta\right]=\mathbb{E}_{\pi_{\theta_\text{old} } }[\frac{\pi_{\theta} }{\pi_{\theta_\text{old} } }(\log\pi_\theta-\log\pi_{\text{ref} })\nabla_\theta\log\pi_\theta]
$$ - 如果此时忽略价值函数并应用此 KL 损失,则 GRPO 损失变为:
$$
\mathbb{E}_{\pi_{\theta_{\text{old} } } }\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old} } } } (r(q,o) - KL(\pi_{\theta}, \pi_{\text{ref} }))\right]
$$- 注:次数 KL 项应 detached(梯度不回传),这里的用法相当于 KL 散度本身就是奖励的一部分,不再通过梯度直接优化 KL 损失了
- 实际上,PPO 的推导过程中就使用到了重要性采样,同时考虑 KL 散度存在(使得相邻两步策略足够接近,所以可以使用近似策略)
$$
\begin{align}
\nabla_\theta J_{\text{PPO}}(\theta)
&= \mathbb{E}_{(s_t, a_t) \sim \pi_\theta} \left[ A_\theta(s_t, a_t) \nabla_\theta \log \pi_\theta(a_t|s_t) \right] \\
&= \mathbb{E}_{(s_t, a_t) \sim \pi_{\theta_\text{old}}} \left[ \frac{\pi_\theta(a_t|s_t) \pi_\theta(s_t)}{\pi_{\theta_\text{old}}(a_t|s_t)\pi_{\theta_\text{old}}(s_t)} A_{\theta}(s_t, a_t) \nabla_\theta \log \pi_\theta(a_t|s_t) \right] \\
&\approx \mathbb{E}_{(s_t, a_t) \sim \pi_{\theta_\text{old}}} \left[ \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_\text{old}}(a_t|s_t)} A_{\theta_\text{old}}(s_t, a_t) \nabla_\theta \log \pi_\theta(a_t|s_t) \right] \\
&= \mathbb{E}_{(s_t, a_t) \sim \pi_\theta} \left[ \frac{\nabla \pi_\theta(a_t|s_t)}{\pi_{\theta_\text{old}}(a_t|s_t)} A_{\theta_\text{old}}(s_t, a_t) \right]
\end{align}
$$- 注:\(\pi_\theta\) 和 \(\pi_\text{ref}\) 之间的 KL 散度可以通过 \(\pi_{\theta_\text{old} }\) 和 \(\pi_\text{ref}\) 之间的 KL 散度来近似
- 因此,GRPO 损失函数的一个进一步近似可以表示如下:
$$
\nabla_\theta\mathbb{E}_{\pi_{\theta_{\text{old} } } }\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old} } } } (r(q,o) - KL(\pi_{\theta}, \pi_{\text{ref} }))\right]\approx\nabla_\theta\mathbb{E}_{\pi_{\theta_{\text{old} } } }\left[\frac{\pi_\theta}{\pi_{\theta_{\text{old} } } } (r(q,o) - KL(\pi_{\theta_\text{old} }, \pi_{\text{ref} }))\right]
$$- 此时,这正是 Off-policy 版本的 PPO 的表达形式,两者很相似(注:但并不等价)
- 注:尽管上述 PPO 和 GRPO 的基本损失函数在 Off-policy 版本中看起来很相似,但两者的实际值不同:
- 此时 GRPO 的奖励是 Trajectory-level 奖励的总和减去 Token-level KL 散度,最终得到 Token-level 奖励
- 注意:这里是将 KL 散度放入 奖励 以后的 GRPO,原始的 GRPO 是 Trajectory-level 奖励
- PPO 中使用的是 Token-level 奖励和(potentially)Trajectory-level KL 散度
- 问题:原始的 PPO 中的 KL 散度是 Token-level 的,这里的 (potentially)Trajectory-level KL 散度 应该是在说某些场景中使用的 KL 散度奖励是 Trajectory-level 奖励
- 此时 GRPO 的奖励是 Trajectory-level 奖励的总和减去 Token-level KL 散度,最终得到 Token-level 奖励
- 注:尽管上述 PPO 和 GRPO 的基本损失函数在 Off-policy 版本中看起来很相似,但两者的实际值不同:
- 理解:这里与前面的 vanilla GRPO 公式不同
- 前面 KL 散度在 loss 上,不在奖励中,不能按照上面进行近似推导(KL 散度有梯度,且需要通过损失函数直接向后传递),所以之前存在问题;
- 现在这种推导虽然做了近似,但是是合理的(因为相邻两步的策略就应该比较近似才对,此时不需要直接通过 loss 进行 KL 散度梯度回传了)
- 问题:上面的推导中,将 KL 散度放入 GRPO 的奖励,同时不考虑 Advantage 的计算方式,确实 PPO 和 GRPO 就等价了啊,为什么还要绕一圈去证明?
- 回答:不是严格的等价,毕竟 GPRO 是整个样本粒度的所有 Token 相同的奖励(原始的 PPO RLHF 中,仅最后一个 Token 有奖励,然后通过 GAE 回传到每个 Token 上)
- 此时,这正是 Off-policy 版本的 PPO 的表达形式,两者很相似(注:但并不等价)
GRPO 核心要点
- GRPO 采用组优势归一化,而不是在整个经验回放缓冲区上进行优势归一化,这可以在某些基于规则的奖励设置中获得更好的性能
- 对于 GRPO 的 On-policy 变体,简单的实现就足够了,因为 \(\pi_{\theta_\text{old} }\) 与 \(\pi_\theta\) 是相同的
- 对于 GRPO 的 Off-policy 版本,将 KL 项加回奖励函数中更为实用,因为它可以节省计算资源和时间,使其再次几乎等同于 PPO(理解:这里的等同主要强调对 KL 散度的处理)
Potential Impact
- 这里研究的 KL 损失可能不会显著影响策略模型的收敛速度,因为当前研究表明强化学习算法倾向于接近 On-policy ,特别是对于推理型大语言模型
- 但随着 GRPO 变得更加 Off-policy ,这种差异可能会变得更加明显
- 这个问题可能普遍存在于许多开源代码库中,例如 OpenRLHF 和 verl
- 在 trl 代码库中,默认设置为 On-policy 版本,这可能已经足够
- 由于目前开源代码中尚未提供真正实现的 Off-policy GRPO,并且三种不同的实现方式尚未得到充分的实验和比较,因此 GRPO 不同实现方式之间的区别以及 GRPO 与 PPO 之间的性能差异仍然是需要持续讨论和考虑的课题
DeepSeek-V3.2 的补充
- DeepSeek-V3.2 中对 GRPO 的 KL 散度重新进行了推导,并给出了无偏的 KL 散度估计
- DeepSeek-V3.2 解决的问题本质就是本文提出的问题,但是解决的方法是通过在 KL 散度中增加重要性权重而得到无偏的 KL 散度估计
附录:记一次 GRPO 问题排查过程
- 问题描述:现实场景中发现过 GRPO 训练时,大部分 Step 的 GBS 内部 Advantage 均值微微大于 0 的情况(约 5e-3 量级)
问题分析
- 最终经过排查发现似乎是因为归一化时,全等的数据因为计算误差出现了均值不为 0 的情况(此时除以特别小的标准差以后得到的值较大)
- 表现为同一个 Group 内部归一化后的值相等(均值计算出现误差导致),且归一化后正值的概率大于负值的概率(不同原始值得到的正负误差是确定的,我们的场景更容易出现某个正误差的相同值,所以一直偏正)
torch.float32下的问题复现及torch.float64的问题修复1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77import torch
import numpy as np
# float32 时存在误差
print(f"\n=======\n数据类型 为 float32 时存在误差")
# values = [0.6666666865348816] * 8
values = [0.819531261920929] * 8
tensors = torch.tensor(values) # PyTorch 默认 是 float32
print(f"数据类型:{tensors.dtype}") # PyTorch 默认 是 float32
x1 = tensors.mean()
print(f"原始数值:{tensors[0].item()}")
print(f"均值数值:{x1.item()}")
print(f"原始数值-均值的结果:{(torch.tensor(values[0]) - x1).item()}")
# float32 时存在误差
print(f"\n=======\n数据类型 为 float32 时存在误差")
values = [0.6666666865348816] * 8
# values = [0.819531261920929] * 8
tensors = torch.tensor(values) # PyTorch 默认 是 float32
print(f"数据类型:{tensors.dtype}") # PyTorch 默认 是 float32
x1 = tensors.mean()
print(f"原始数值:{tensors[0].item()}")
print(f"均值数值:{x1.item()}")
print(f"原始数值-均值的结果:{(torch.tensor(values[0]) - x1).item()}")
# float64 时不存在误差
print(f"\n=======\n数据类型 为 float64 时不存在误差")
# values = [0.6666666865348816] * 8
values = [0.819531261920929] * 8
tensors = torch.tensor(values, dtype=torch.float64) # 切换回到 float64
print(f"数据类型:{tensors.dtype}")
x1 = tensors.mean()
print(f"原始数值:{tensors[0].item()}")
print(f"均值数值:{x1.item()}")
print(f"原始数值-均值的结果:{(torch.tensor(values[0]) - x1).item()}")
# float64 时不存在误差
print(f"\n=======\n数据类型 为 float64 时不存在误差")
values = [0.6666666865348816] * 8
# values = [0.819531261920929] * 8
tensors = torch.tensor(values, dtype=torch.float64) # 切换回到 float64
print(f"数据类型:{tensors.dtype}")
x1 = tensors.mean()
print(f"原始数值:{tensors[0].item()}")
print(f"均值数值:{x1.item()}")
print(f"原始数值-均值的结果:{(torch.tensor(values[0]) - x1).item()}")
# =======
# 数据类型 为 float32 时存在误差
# 数据类型:torch.float32
# 原始数值:0.819531261920929
# 均值数值:0.8195313215255737
# 原始数值-均值的结果:-5.960464477539063e-08
# =======
# 数据类型 为 float32 时存在误差
# 数据类型:torch.float32
# 原始数值:0.6666666865348816
# 均值数值:0.6666666269302368
# 原始数值-均值的结果:5.960464477539063e-08
# =======
# 数据类型 为 float64 时不存在误差
# 数据类型:torch.float64
# 原始数值:0.819531261920929
# 均值数值:0.819531261920929
# 原始数值-均值的结果:0.0
# =======
# 数据类型 为 float64 时不存在误差
# 数据类型:torch.float64
# 原始数值:0.6666666865348816
# 均值数值:0.6666666865348816
# 原始数值-均值的结果:0.0
解决方法
解决方法1:切换到精度更高的
torch.float64(PyTorch 默认为torch.float32)1
2
3
4
5original_dtype = rewards.dtype
rewards = rewards.to(dtype=torch.float64)
# 其他原始逻辑不变
advantages = advantages.to(dtype=original_dtype)
return advantages解决方法2:当 std 小于某个值时,其实组内 rewards 差异较小,索性将整体 advantages 置为 0
1
2
3
4if rewards_std < 1e-5: # 这个阈值可适当调整
advantages = torch.zeros_like(rewards)
else:
advantages = (rewards - rewards_mean) / (rewards_std + 1e-8)解决方法3:
- drop 这部分
rewards相同的样本(反正也不提供有效梯度)
- drop 这部分
解决方法4:
- 不使用
std或者使用 Batch 粒度的std(比如 使用 Dr.GRPO 等,可减少对误差的放大,这种情况依然会有较小误差,但几乎可以忽略) - 注:虽然 DeepSeek 自己最新的文章(DeepSeek-V3.2)没有除以
std,但现在大部分文章还是会使用 GRPO 的(Dr.GRPO 是在一些场景会好用一些,但没有确切证明他比 GRPO 好),比如最新的 GLM-5 就还是除以std的
- 不使用
修复后效果:
- 修复后,可以看到 Advantage 的均值严格在 0 附近波动(
[-1e-8, 1e-8]之间),远低于之前的1e-3量级,符合预期 - 修复后,特别是使用 mask std 过小的 Group 方式修复后,kl spike 大幅缩小
- 分析是因为被错误 Advantage 更新的 Token 变少了,特别是 mask std 过小的 Group 的实验组
- 修复后,kl 偏离程度更低(因为更新的 Token 变少了)
- float64 修复时可以做到下游分数相同或更高(因为丢弃的都是错误 Advantage 的 Token)
- 使用 mask std 过小的 Group 的实验组观察到训练的指标有一定下滑(因为更新的 Token 数量变少了)
- 修复后,可以看到 Advantage 的均值严格在 0 附近波动(
附录:GRPO 中 Advantage 归一化后的最大值是多少?
- 假设有一组数字 \(x_1, x_2, \dots, x_N\)
- 均值为:
$$ \mu = \frac{1}{N} \sum_{i=1}^N x_i $$ - 标准差(总体标准差格式)为:
$$ \sigma = \sqrt{\frac{1}{N} \sum_{i=1}^N (x_i - \mu)^2} $$ - 标准化后的数值 \(z_i\) 定义为:
$$ z_i = \frac{x_i - \mu}{\sigma} $$
- 均值为:
- 构建极端情况(构造最大的差值)
- 为了让某个 \(z_i\)(假设是 \(z_1\))达到最大值,需要让 \(x_1\) 尽可能远离均值,而让其余的 \(N-1\) 个数字尽可能集中
设 \(x_1 = a\),其余数字全部相等,即 \(x_2 = x_3 = \dots = x_N = b\)(且 \(a > b\))
- 为了让某个 \(z_i\)(假设是 \(z_1\))达到最大值,需要让 \(x_1\) 尽可能远离均值,而让其余的 \(N-1\) 个数字尽可能集中
- 计算均值和离差:
- 此时均值为:
$$ \mu = \frac{a + (N-1)b}{N} $$ - 计算 \(x_1\) 与均值的差:
$$ x_1 - \mu = a - \frac{a + (N-1)b}{N} = \frac{Na - a - (N-1)b}{N} = \frac{(N-1)(a-b)}{N} $$ - 计算其余 \(x_i (i > 1)\) 与均值的差:
$$ x_i - \mu = b - \frac{a + (N-1)b}{N} = \frac{Nb - a - Nb + b}{N} = \frac{-(a-b)}{N} $$
- 此时均值为:
- 计算标准差
- 方差 \(\sigma^2\) 的计算如下:
$$ \sigma^2 = \frac{1}{N} \left[ (x_1 - \mu)^2 + (N-1)(x_i - \mu)^2 \right] $$ - 代入离差:
$$ \sigma^2 = \frac{1}{N} \left[ \left( \frac{(N-1)(a-b)}{N} \right)^2 + (N-1) \left( \frac{-(a-b)}{N} \right)^2 \right] $$ - 提取公因子 \(\frac{(a-b)^2}{N^2}\):
$$
\begin{align}
\sigma^2 &= \frac{(a-b)^2}{N^3} \left[ (N-1)^2 + (N-1) \right] \\
\sigma^2 &= \frac{(a-b)^2}{N^3} \left[ (N-1)(N-1+1) \right] = \frac{(a-b)^2 (N-1)N}{N^3} = \frac{(a-b)^2(N-1)}{N^2}
\end{align}
$$ - 因此,标准差 \(\sigma\) 为:
$$ \sigma = \frac{(a-b)\sqrt{N-1} }{N} $$
- 方差 \(\sigma^2\) 的计算如下:
- 求出最大值 \(z_{max}\)
- 将结果代入 \(z_1\) 的公式:
$$ z_1 = \frac{x_1 - \mu}{\sigma} = \frac{\frac{(N-1)(a-b)}{N} }{\frac{(a-b)\sqrt{N-1} }{N} } $$ - 化简可消去 \((a-b)\),最终得:
$$ z_1 = \frac{N-1}{\sqrt{N-1} } = \sqrt{N-1} $$
- 将结果代入 \(z_1\) 的公式:
- 最终结果:
- 对于 \(N\) 个数字,经过 Z-score 归一化(标准化)后,任意一个数值的最大理论上限是:
$$ z_{max} = \sqrt{N-1} $$
- 对于 \(N\) 个数字,经过 Z-score 归一化(标准化)后,任意一个数值的最大理论上限是:
- 在 Z-score 中
- 当 \(N=2\) 时,最大值为 \(\sqrt{2-1} = 1\)
- 当 \(N=8\) 时,最大值为 \(\sqrt{7} \approx 2.6457\)
- 当 \(N=16\) 时,最大值为 \(\sqrt{15} \approx 3.873\)
- 当 \(N=100\) 时,最大值为 \(\sqrt{99} \approx 9.95\)
- 注:训练过程中,如果最大值超过这个值,则说明有问题
- 注:一般来说,N 越大时,出现极端值(其他值均相等)的概率越小,所以 N 越大的时候,实践统计的最大值和理论最大值之间的差距越大(但实际最大值和理论最大值都肯定是随着 N 的增大,单调增大的)
- 注:虽然在极端分布情况(即总能取到最大值场景)下,随着 N 增大,最大值是单调递增的,但是均值是单调递减的(也就是说如果训练模型的话,极端场景下 Token 的 Advantage 均值会单调递减,详情见后面的证明)
补充:其他归一化方式下的最大值情况
- 如果使用 Min-Max 归一化
$$ x’ = \frac{x - \min}{\max - \min}$$- 最大值恒等于 \(1\)
- 如果方差的估计是无偏的(即使用样本标准差,分母为 \(N-1\)),推导过程会略有不同,最终的最大值也会发生变化
- 无偏样本标准差 \(s\) 定义为:
$$ s = \sqrt{\frac{1}{N-1} \sum_{i=1}^N (x_i - \bar{x})^2} $$ - 当使用无偏估计的标准差进行归一化时,类似推导可得到,\(N\) 个数字中结果的最大值是:
$$ z_{max} = \frac{N-1}{\sqrt{N} } $$ - 使用 无偏样本标准差 \(s\) 时:
- 当 \(N=2\) 时,最大值为 \(\frac{2-1}{\sqrt{2} } = \frac{1}{\sqrt{2} } \approx 0.707\)
- 当 \(N=8\) 时,最大值为 \(\frac{8-1}{\sqrt{8} } = \frac{7}{\sqrt{8} } \approx 2.4749\)
- 无偏样本标准差 \(s\) 定义为:
补充 Insight:原始方差越小的数,归一化后的最大值越大
- 首先澄清一个数学前提:归一化(Z-score 标准化)具有“尺度不变性”
- 也就是说,如果把所有数字同时乘以 2(标准差也随之变为 2 倍),归一化后的结果是完全不变的
- 这里 “原始方差越小的数,归一化后的最大值越大”,准确的数学表述可以是:
- 在保持最大值与均值的距离(离差)不变的情况下,如果减小其他数据的离散程度(从而减小整体 std),归一化后的最大值会变大
- 证明过程(大致证明):
- 假设有一组数,其最大值为 \(x_{max}\),均值为 \(\mu\),标准差为 \(\sigma\),归一化后的最大值为:
$$ z_{max} = \frac{x_{max} - \mu}{\sigma} $$ - 归一化后的最大值大小,本质上取决于最大值的离差(\(x_{max}-\mu\))在整个标准差中所占的权重
- 如果原始数据 std 越小(意味着其余数据的波动越小),最大值就显得越像一个“离群点”(Outlier),其归一化后的得分就越高
- 反之,如果原始数据 std 很大(意味着大家都乱跳),那么即使某个数是最大的,它在概率分布中也不显得突出,归一化后的值自然就小了
- 假设有一组数,其最大值为 \(x_{max}\),均值为 \(\mu\),标准差为 \(\sigma\),归一化后的最大值为:
GRPO 中 Advantage 归一化后的绝对值的均值是多少?(影响训练的学习率)
- 补充描述:本节要求的是归一化(Z-score标准化)后数值绝对值的均值(即 \(\frac{1}{N}\sum_{i=1}^N |z_i|\) 或数学期望 \(E[|z|]\))
- TLDR:在不同原始分布情况下,得到的结论不同
原始分布一:极端分布情况
- 分布构建
- 设 \(x_1 = a\),其余 \(N-1\) 个样本 \(x_2 = x_3 = \dots = x_N = b\)(且 \(a > b\))
- 归一化后的值 \(z_i\)
- 根据您提供的推导,最大值 \(z_1\) 为:
$$ z_1 = \sqrt{N-1} $$ - 对于其余的 \(N-1\) 个样本
- 离差为
$$x_i - \mu = \frac{-(a-b)}{N}$$ - 标准差
$$\sigma = \frac{(a-b)\sqrt{N-1} }{N}$$ - 代入公式得:
$$ z_i = \frac{\frac{-(a-b)}{N} }{\frac{(a-b)\sqrt{N-1} }{N} } = \frac{-1}{\sqrt{N-1} } \quad (i > 1) $$
- 离差为
- 根据您提供的推导,最大值 \(z_1\) 为:
- 计算绝对值的均值
- 绝对值均值 \(M\) 的计算如下:
$$ M = \frac{1}{N} \sum_{i=1}^N |z_i| = \frac{1}{N} \left( |z_1| + (N-1)|z_i| \right) $$ - 代入 \(z_1\) 和 \(z_i\) 的绝对值:
$$ M = \frac{1}{N} \left( \sqrt{N-1} + (N-1)\frac{1}{\sqrt{N-1} } \right) $$
$$ M = \frac{1}{N} \left( \sqrt{N-1} + \sqrt{N-1} \right) = \frac{2\sqrt{N-1} }{N} $$
- 绝对值均值 \(M\) 的计算如下:
- 最终结果 :极端分布下,归一化后绝对值的均值为
$$\frac{2\sqrt{N-1} }{N}$$- 理解:随着 N 的变大,绝对值的均值在逐步降低
- 比如:如果在极端分布下,使用 Group Norm 的 Advantage 绝对值均值会比 Batch Norm 的大
- 具体数值示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import math
for N in [2, 4, 8, 16, 256, 1024, 2048, 2097152]:
mean_abs = (2 * math.sqrt(N - 1)) / N
print(f"N = {N:>8} | mean_abs = {mean_abs:.8f}")
# 可以看到,不同的 N 值下,均值的差异(学习率差异可以是几十倍,甚至几千倍)
# N = 2 | mean_abs = 1.00000000
# N = 4 | mean_abs = 0.86602540
# N = 8 | mean_abs = 0.66143783
# N = 16 | mean_abs = 0.48412292
# N = 256 | mean_abs = 0.12475562
# N = 1024 | mean_abs = 0.06246947
# N = 2048 | mean_abs = 0.04418338
# N = 2097152 | mean_abs = 0.00138107 (注:PPO Advantage 粒度做归一化时,样本数量可能非常大,但分布不会这么极端)
- 理解:随着 N 的变大,绝对值的均值在逐步降低
原始分布二:正态分布
- 分布构建
- 假设原始数据服从正态分布 \(x \sim \mathcal{N}(\mu, \sigma^2)\)
- 归一化后的分布
- 经过 Z-score 归一化后,\(z\) 服从标准正态分布,即 \(z \sim \mathcal{N}(0, 1)\)
- 其概率密度函数为:
$$ f(z) = \frac{1}{\sqrt{2\pi} } e^{-\frac{z^2}{2} } $$
- 计算绝对值的期望(均值)
- 求解 \(E[|z|]\),由于 \(f(z)\) 是偶函数,可化简为:
$$ E[|z|] = \int_{-\infty}^{\infty} |z| f(z) dz = 2 \int_{0}^{\infty} z \frac{1}{\sqrt{2\pi} } e^{-\frac{z^2}{2} } dz $$ - 设 \(u = \frac{z^2}{2}\),则 \(du = z dz\):
$$ E[|z|] = \sqrt{\frac{2}{\pi} } \int_{0}^{\infty} e^{-u} du = \sqrt{\frac{2}{\pi} } \left[ -e^{-u} \right]_0^\infty $$
$$ E[|z|] = \sqrt{\frac{2}{\pi} } (0 - (-1)) = \sqrt{\frac{2}{\pi} } $$
- 求解 \(E[|z|]\),由于 \(f(z)\) 是偶函数,可化简为:
- 最终结果 :正态分布下,归一化后绝对值的均值(期望)为
$$\sqrt{\frac{2}{\pi} } \approx 0.7979$$- 理解:此时的均值结果是固定值,平时的大部分情况下,都可以假定 归一化前的 Advantage 服从高斯分布或类似高斯分布
原始分布三:均匀分布
- 分布构建
- 假设原始数据服从连续均匀分布 \(x \sim U(a, b)\)
- 计算均值与标准差
- 均值 \(\mu = \frac{a+b}{2}\)
- 方差 \(\sigma^2 = \frac{(b-a)^2}{12}\),标准差 \(\sigma = \frac{b-a}{2\sqrt{3} }\)
- 归一化后的分布
- 归一化后的 \(z = \frac{x-\mu}{\sigma}\) 依然服从均匀分布
- 计算 \(z\) 的边界:
$$
\begin{align}
z_{max} &= \frac{b - \frac{a+b}{2} }{\frac{b-a}{2\sqrt{3} } } = \frac{\frac{b-a}{2} }{\frac{b-a}{2\sqrt{3} } } = \sqrt{3} \\
z_{min} &= -\sqrt{3}
\end{align}
$$ - 因此,\(z \sim U(-\sqrt{3}, \sqrt{3})\),其概率密度函数为 \(f(z) = \frac{1}{2\sqrt{3} }\)
- 计算绝对值的期望(均值)
- 求解 \(E[|z|]\),同样利用偶函数性质:
$$
\begin{align}
E[|z|] &= \int_{-\sqrt{3} }^{\sqrt{3} } |z| \frac{1}{2\sqrt{3} } dz = 2 \int_{0}^{\sqrt{3} } z \frac{1}{2\sqrt{3} } dz \\
&= \frac{1}{\sqrt{3} } \left[ \frac{z^2}{2} \right]_0^{\sqrt{3} } = \frac{1}{\sqrt{3} } \times \frac{3}{2} = \frac{\sqrt{3} }{2}
\end{align}
$$
- 求解 \(E[|z|]\),同样利用偶函数性质:
- 最终结果 :均匀分布下,归一化后绝对值的均值(期望)为
$$ \frac{\sqrt{3} }{2} \approx 0.8660$$
补充:真实场景说明
- 现象:在真实 PPO 训练场景中(Advantage Batch Norm),统计看到的 Advantage 的绝对值的均值约在
[0.78, 0.93]之间波动- 原因是因为分布在不断变化,不同分布下得到的 Advantage 绝对值的期望值是不一样的,故而训练过程中存在波动
- 同理:GRPO 训练过程中,Group 内归一化后的 Advantage 绝对值的均值也会存在波动
附录:GRPO 与 PPO 的对比
- 总结:
- GRPO 的主要优势:
- LLM RL 的动作空间太大了(几乎无法通过探索评估价值),所以之前在 传统 RL(通过探索估计价值的方式)上的一些假设已经失效,从而导致 LLM RL 中使用 Bandit 建模方式更佳(而不是传统 RL 中的 MDP 建模方式)
- GRPO 底层就是使用 Bandit 进行数学建模的,此时可以按照 Sequence-level 进行奖励估计了,不需要 Critic 了
- 注:Bandit 和 MDP 的主要区别
- Bandit 中:动作不会影响未来的状态 ,每次决策都是独立的(或者理解为单轮的),即一个回合,当前轨迹结束(此时获得奖励),下一次系统再给一个新的上下文,重新开始,目标就是遇到任意的上下文时,都能做一个最优动作最大化奖励
- MDP 中:智能体在状态 \(S_t\) 下采取动作 \(A_t\),不仅会获得一个即时奖励 \(R_t\),还会导致环境转移到一个新的状态 \(S_{t+1}\)
- GRPO 的主要劣势:
- 虽然从数学上看,建模更准确了,没有 PPO 的 Critic 以后,信用分配会出现问题,这本身会带来一些不足
- GRPO 的主要优势:
- PPO 试图教模型“每说一个 Token 都要考虑这句话最终能不能拿高分”(MDP),这太难且太耗算力
- GRPO 告诉模型“面对一个问题,策略给出几个不同的完整答案 (不关注中间奖励),RM 挑出相对最好的那个来强化策略”(Bandit)
- 省去了 Critic,也让 LLM 的强化学习变得更加高效和稳定
PPO 的建模方式:将 LLM 视作 MDP(Token 级别)
- PPO 是传统的强化学习算法,它天生是为解决 MDP 问题而设计的
- 当 PPO 被用于 LLM 时,它采用了Token 级别的 MDP 建模
- State:当前的 Prompt + 已经生成的所有 Token(即上文)
- Action:从词表中选择下一个 Token
- Transition :选定一个 Token 后,这个 Token 被拼接到上文中,形成新的状态 \(S_{t+1}\)
- Reward :通常在生成完最后一个 Token 时,由 Reward Model 给出一个总分;中间生成的 Token 奖励为 0
- PPO 建模带来的必然结果:必须要有 Critic
- 因为 PPO 把生成一句话看作是连续走几十上百步的 MDP 过程,而奖励只有在最后一步才发
- 为了知道“生成到一半的半句话到底好不好”,PPO 必须训练一个庞大的 Critic 模型 来预测每个中间状态的未来价值(即 \(V(S_t)\))
- 通过 Critic 算出的 Advantage,PPO 试图精确地告诉模型:“这句话得分低,是因为你生成的第 5 个 Token 不好,而不是第 10 个 Token 不好”
- 在 LLM 中,语言的组合是无穷的,Critic 极难准确预测“半句话”的最终得分,Critic 估算不准会导致更新方向错误
- 同时,多加载一个与 LLM 同等规模的 Critic 模型,会让显存和计算开销直接翻倍
- 因为 PPO 把生成一句话看作是连续走几十上百步的 MDP 过程,而奖励只有在最后一步才发
GRPO 的建模方式:将 LLM 视作 Contextual Bandit(Response 级别)
- GRPO 之所以能大获成功并大幅降低训练成本,其核心思想是 放弃了 Token 级别的 MDP 建模,转而采用了 Response(完整回答)级别的 Contextual Bandit 建模
- Context/State:用户输入的 Prompt
- Action:模型生成的一整段完整的 Response
- 状态转移:没有状态转移! 生成完一个回答后,这一轮交互直接结束,直接进入下一个 Prompt 的训练
- Reward:Reward Model 或规则校验器对这一整段回答给出的评分
GRPO 建模带来的巨大优势:彻底摒弃了 Critic
- 因为 GRPO 把问题变成了 Bandit,不存在“中间状态”,也不需要预测“未来收益”,所以 Critic 模型被彻底废弃了
- 既然没有 Critic 来计算 Advantage,GRPO 是如何判断动作好坏的呢?它巧妙地利用了 Bandit 中的相对比较思想:
- 1)Group 采样:对于同一个 Prompt,让当前的 LLM(Actor)生成多个不同的完整回答(例如采样 4 个或 8 个 Response)
- 2)Relative 优势:对这几个回答分别打分,然后在这一组内部进行标准化(Z-score)
- 得分高于组内平均分的回答,其 Advantage 为正;低于平均分的,Advantage 为负
- 3)Policy Optimization(策略更新) :把整段回答的 Advantage 赋予该回答中的每一个 Token,结合 KL 散度惩罚(防止偏离原始模型太远),直接更新 Actor 模型