注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- HybridFlow 是一个 RLHF 混合编程模型框架,能够灵活表示和高效执行各种 RLHF 算法,是 VeRL 的理论介绍
- 通过将不同 LLM 的分布式计算封装到原始 API 中,并隐藏节点间数据重分片的复杂性,允许用户用几行代码轻松构建 RLHF 数据流
- 论文的 3D-HybridEngine 确保了 actor 模型训练和生成的高效执行,实现了模型参数重分片的零内存冗余和显著降低的通信开销
- 论文有效的映射算法优化了 RLHF 数据流中模型的 GPU 分配和放置
- 大量实验表明,在各种模型大小和集群规模下,与 SOTA RLHF 系统相比,HybridFlow 实现了 \(1.53\times\) 到 \(20.57\times\) 的加速比
- HybridFlow 的代码已经开源(verl库)
- 思路介绍:
- 传统的 RL 可以建模为一个数据流
- 流中每个节点代表神经网络的计算,每条边表示神经网络(NN)之间的数据依赖关系
- RLHF 中的数据流很复杂
- 因为 RLHF 将每个节点扩展为分布式 LLM 训练或生成程序,并将每条边扩展为多对多组播(multicast)
- 传统的 RL 框架使用单一控制器来执行数据流,该控制器同时指导节点内计算和节点间通信’
- 在 RLHF 中,分布式节点内计算的控制调度开销较大,这种方式效率较低
- 现有的 RLHF 系统采用多控制器范式,但由于分布式计算和数据通信的嵌套,这种范式可能不够灵活
- 传统的 RL 可以建模为一个数据流
- 论文解决方案: HybridFlow
- HybridFlow 以混合方式结合了单控制器和多控制器范式 ,以实现 RLHF 数据流的灵活表示和高效执行
- 论文精心设计了一套分层 API
- 这些 API 解耦并封装了复杂 RLHF 数据流中的计算和数据依赖关系
- 支持高效的操作编排以实现 RLHF 算法
- 能将计算灵活映射到各种设备上
- 论文还设计了 3D-HybridEngine,用于在训练和生成阶段之间高效地对 actor 模型进行重分片,实现了零内存冗余并显著降低了通信开销
- 实验结果表明,与 SOTA 基线相比,使用 HybridFlow 运行各种 RLHF 算法时,吞吐量提升了 \(1.53\times \sim 20.57\times\)
Introduction and Discussion
- LLMs 已经彻底改变了各种 AI 应用,涵盖写作(2023)、搜索(2021)到编程(2023)等多个领域
- LLMs 经过了先经历了两个阶段:
- 大规模数据集上 NTP 预训练
- 在特定领域数据集上 SFT 训练 LLMs,使其能够遵循人类指令(2020)
- 两个阶段后,效果不错,但训练数据集中的有害和有偏见的内容可能仍然会误导 LLM 生成有毒和不受欢迎的内容
- RLHF 进一步将 LLM 与人类价值观对齐,从而构建有用且无害的 AI 应用(2022;2022)
- RLHF 基于传统的 RL 算法(2011;2017;1992),例如 PPO(2017)和 REINFORCE 算法(1992)
- 被广泛采用的基于 PPO 的 RLHF 系统通常包含四个 LLM(2022;2022):
- 一个 actor
- 一个 critic
- 一个参考策略网络(reference policy network)
- 一个奖励模型(reward model)
- 基于 PPO 的 RLHF 以迭代方式进行,每个迭代包含三个阶段:
- (1)使用 actor 模型根据一批 Prompt 生成响应;
- (2)通过 critic、参考策略和奖励模型的单次前向传播对生成的响应进行评分,从而准备训练数据;
- (3)通过前向和反向计算更新 actor 和 critic,以从人类偏好中学习
- 其他 RLHF 变体(2024;2023)遵循类似的阶段,但涉及不同数量的模型以及模型之间不同的数据依赖关系
- 传统 RL 可以建模为一个数据流(2021),它是一个有向无环图(directed acyclic graph, DAG):
- RL 数据流中的每个节点代表神经网络的计算(例如,actor 或critic网络,可能是 CNN 或 MLP);
- RL 数据流中的每条边表示神经网络计算之间的数据依赖关系(例如,critic 的输出被用作 actor 训练的输入(2017))
- RLHF 数据流更为复杂,涉及更复杂的模型(例如,用于 actor/critic/参考/奖励模型 的 LLMs),每个模型运行不同的计算,并且它们之间的数据依赖关系更加多样化(即,分布式模型分区之间的组播)
- RLHF 数据流中 LLM 的训练和生成需要分布式计算(例如,使用张量/管道/数据并行)(2023;2019)
- 因此,RLHF 数据流中的每个节点都是一个复杂的分布式程序,对应于相应 LLM 的分布式计算
- 由于工作负载不同,不同节点中的模型通常使用不同的并行策略
- 边表示数据重分片,这通常是一种多对多组播
- 因此,对复杂且资源密集的 RLHF 进行灵活表示和高效执行至关重要
- 传统 RL 框架,如 RLLib(2018)和 RLLib Flow(2021),采用分层单控制器范式来运行 RL 数据流
- 一个集中式控制器将数据流中的节点分配给不同的进程,并协调它们的执行顺序
- 每个节点进程可以进一步生成更多的工作进程来执行计算,这同样遵循单控制器范式
- 然而,它们仅提供数据并行训练的原语,并且仅限于大小最多为数百 MB 的神经网络(2018;2021)
- 在 RLHF 数据流中,每个节点对应一个具有多达数十亿个算子的 LLM,这些算子使用一些复杂的并行方式进行计算
- 将算子调度到分布式加速器的开销大,单控制器范式效率低下(2016;2022)
- 现有的 RLHF 系统采用多控制器范式来管理节点内计算和节点间数据重分片(2024;2023;2023)
- 每个控制器独立管理一个设备的计算,并使用多个点对点操作来协调不同节点之间的数据依赖关系
- 这种多控制器范式在执行 LLM 计算时引入的调度开销可忽略不计(详见第2.2节)
- 但由于缺乏中央控制,实现各种 RLHF 数据流缺乏灵活性,因为修改单个节点以适应不同的数据依赖关系需要更改所有依赖节点的实现 ,这阻碍了代码重用
- 为了解决这些局限性,论文提出了一个灵活高效的 RLHF 框架 HybridFlow
- HybridFlow 能够轻松表示和执行各种 RLHF 数据流,并实现高吞吐量
- 论文的核心发现是
- 在节点间层面(inter-node level)使用单控制器范式(single-controller paradigm)能够以最小的开销灵活表达各种数据依赖关系并轻松协调节点间数据重分片
- 在节点内计算(intra-node computation)中集成多控制器范式(multi-controller paradigm)则能显著提高计算效率
- 论文提出一种分层混合编程模型来生成 RLHF 数据流
- 在节点层面,提供了多个模型类,这些类将数据流中不同 LLM 的分布式计算(训练、推理和生成)封装到原语 API 中
- 这些 API 可以无缝支持现有 LLM 框架中的各种并行策略,包括 3D 并行(2019)、ZeRO(2020)和 PyTorch FSDP(2019),并在多控制器范式下执行分布式计算
- 在节点之间,设计了一套传输协议,在单控制器的协调下,向用户隐藏数据重分片的复杂性
- 在节点层面,提供了多个模型类,这些类将数据流中不同 LLM 的分布式计算(训练、推理和生成)封装到原语 API 中
- 这种编程模型抽象了分布式计算的复杂性,允许用户用几行代码实现 RLHF 数据流,并通过单控制器的单个进程运行 RLHF
- 还有效地解耦了节点内计算和节点间数据传输,允许在不更改数据流中其他模型代码的情况下独立优化每个模型
- actor 模型的训练和生成是 RLHF 数据流中的主要计算
- 论文进一步设计了 3D-HybridEngine ,以实现 actor 模型训练和生成的高效执行
- 在训练和生成阶段之间的模型参数重分片过程中实现零内存冗余并显著降低通信开销
- 论文的混合编程模型还支持将模型灵活放置在相同或不同的 GPU 设备集上
- 这能够提供一种有效的算法,针对任何 RLHF 数据流,优化具有不同模型大小和不同工作负载的模型的 GPU 分配和放置
- 论文在设计 HybridFlow 时的贡献总结如下:
- 论文提出了一种分层混合编程模型 ,用于方便地构建 RLHF 数据流
- 这种编程模型支持各种 RLHF 算法的节点内计算的高效分布式执行,以及灵活的节点间数据重分片和传输(第4节)
- 论文设计了 3D-HybridEngine ,它能高效执行 actor 模型的训练和生成 ,并在训练阶段和生成阶段之间实现零冗余过渡(第5节)
- 论文设计了一种有效的映射算法 ,用于自动确定 RLHF 数据流中每个节点(模型)的优化 GPU 分配和放置(第6节)
- 论文进行了大量实验,在各种 RLHF 算法、模型大小和集群规模下,将 HybridFlow 与 SOTA RLHF 系统(2024;2023;2023)进行比较
- 实验表明,HybridFlow 吞吐量提升了 \(1.53\times \sim 20.57\times\)
- 论文提出了一种分层混合编程模型 ,用于方便地构建 RLHF 数据流
Background and Motivation
Reinforcement Learning from Human Feedback
RLHF Workflow
- RLHF 使用一组人类排序的给定 Prompt 候选集,将 LLM 的语言空间与人类价值观对齐(2022;2024;2023;)
- 一个 RLHF 系统通常包含多个模型,例如一个 actor、一个 critic、一个参考策略(reference policy)和一个或多个奖励模型(reward model)
- actor 和参考策略各自是经过预训练/微调的 LLM(即正在接受 RLHF 训练的 LLM)
- critic 和奖励模型可以是在人类偏好数据集上微调的不同 LLM
- 其语言建模头被替换为标量输出头(2022;2022)
- RLHF 工作流程可分解为 3 个阶段(图 1),论文以 PPO 为例:
- 阶段 1(生成,Generation):actor 通过自回归生成(auto-regressive generation)根据一批 Prompt 生成响应
- 阶段 2(准备,Preparation):利用 Prompt 和生成的响应,critic 计算它们的价值(2015;2017),参考策略计算它们的参考对数概率,奖励模型计算它们的奖励(2022;2022),所有这些都通过各自模型的单次前向传播(forward pass)完成
- 阶段 3(学习/训练,Learning/Training):使用前一阶段产生的批量数据和损失函数(2022),通过 Adam 优化器(2017)更新 actor 和 critic
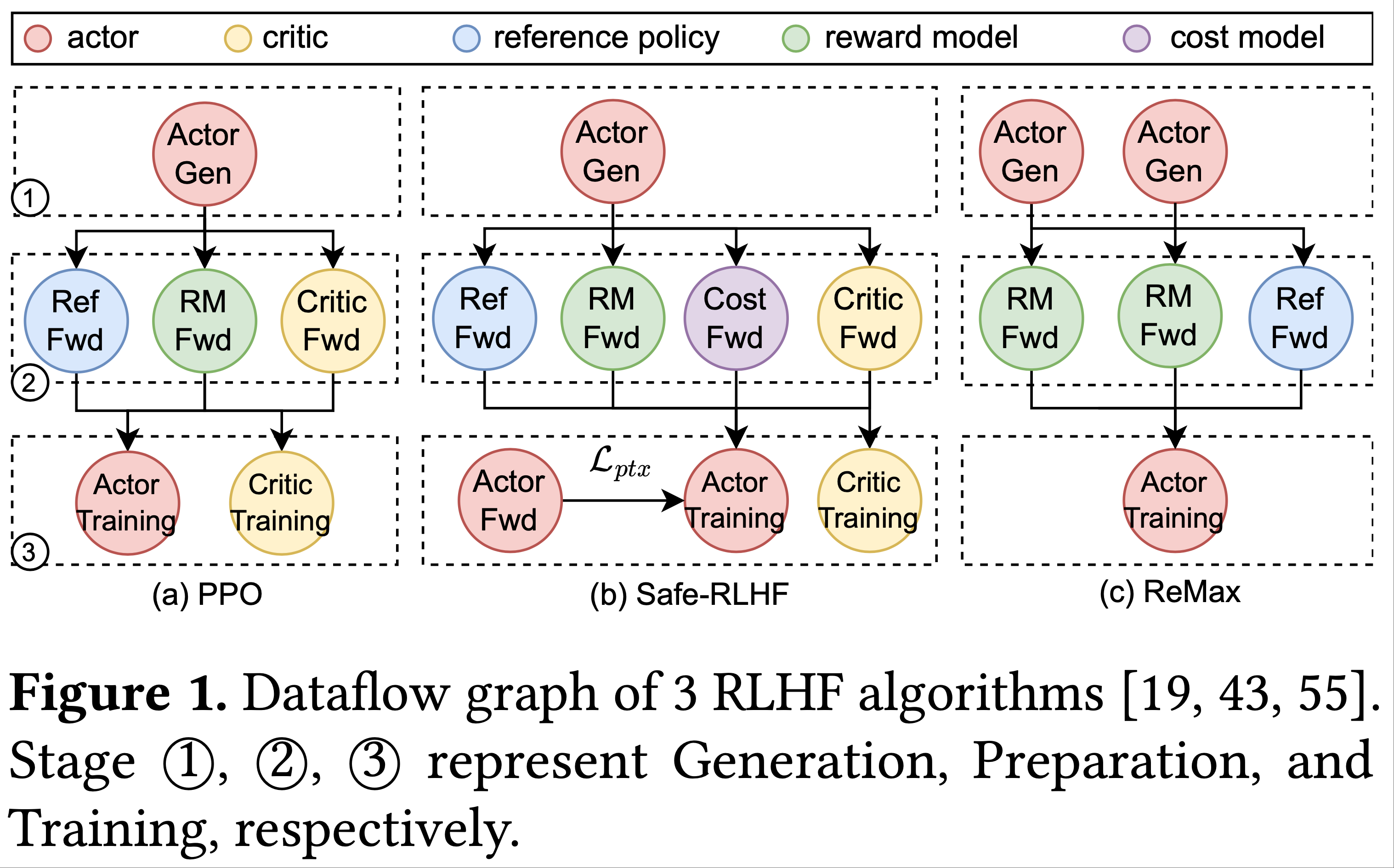
- 其他 RLHF 算法在很大程度上也遵循这 3 阶段工作流程(图 1(b)(c))
- Safe-RLHF(2024)引入了一个辅助预训练损失,遵循 PPO-ptx(2022),并包含一个额外的成本模型(cost model),以同时拟合人类偏好和安全标签
- ReMax(2023)需要额外的生成过程来减少方差,并在数据流中移除了 critic 模型
- 研究人员正在积极探索新的 RLHF 算法(2023;2024;2023),并将传统 RL 方法集成到 RLHF 领域(2023)
- 这些差异使得需要灵活表示 RLHF 数据流图,以适应不同的算法需求
Parallelism Strategies
- LLM 的训练和服务采用数据并行、管道并行和张量并行(2024;2023;2021)
- 在数据并行(data parallelism, DP)中
- 输入数据被分割为多个子集;每个子集由一个独立的设备(例如 GPU)处理(2018)
- ZeRO(2020)是一种内存优化的数据并行训练方案,通过在 GPU 间逐步分片优化器状态、梯度和模型参数
- 管道并行(pipeline parallelism, PP)(2019;2019)和张量并行(tensor parallelism, TP)(2019)将模型参数、梯度和优化器状态分布到多个 GPU 上
- 现代分布式训练框架如 Megatron-LM(2019)和 MegaScale(2024)采用 3D 并行或 PTD 并行(2021),其中 P、T、D 分别代表管道并行(PP)、张量并行(TP)和数据并行(DP)
- 在 3D 并行中,PP 大小表示模型训练中的管道阶段数,TP 大小指张量被分割成的分片数,DP 大小是模型副本数
- LLM 服务系统采用与训练类似的 3D 并行,但仅对模型参数和 KVCache 进行分片(2023;2024;2023)
- 现代分布式训练框架如 Megatron-LM(2019)和 MegaScale(2024)采用 3D 并行或 PTD 并行(2021),其中 P、T、D 分别代表管道并行(PP)、张量并行(TP)和数据并行(DP)
- RLHF 数据流中的 LLM 可能执行不同的计算,包括训练(一次前向传播、一次反向传播和模型更新)、推理(一次前向传播)和生成(多次前向传播的自回归生成)
- 具体来说,actor 模型执行训练和生成,critic 执行训练和推理,参考策略和奖励模型执行推理
- 可以对不同模型的不同计算采用不同的并行策略,以实现最优吞吐量
Programming Model for Distributed ML
Single-Controller
- 单控制器采用集中式控制器来管理分布式程序的整体执行流程
- 通过集中式控制逻辑,用户可以将数据流的核心功能构建为单个进程(图 2(b)),而控制器会自动生成分布式工作进程来执行计算
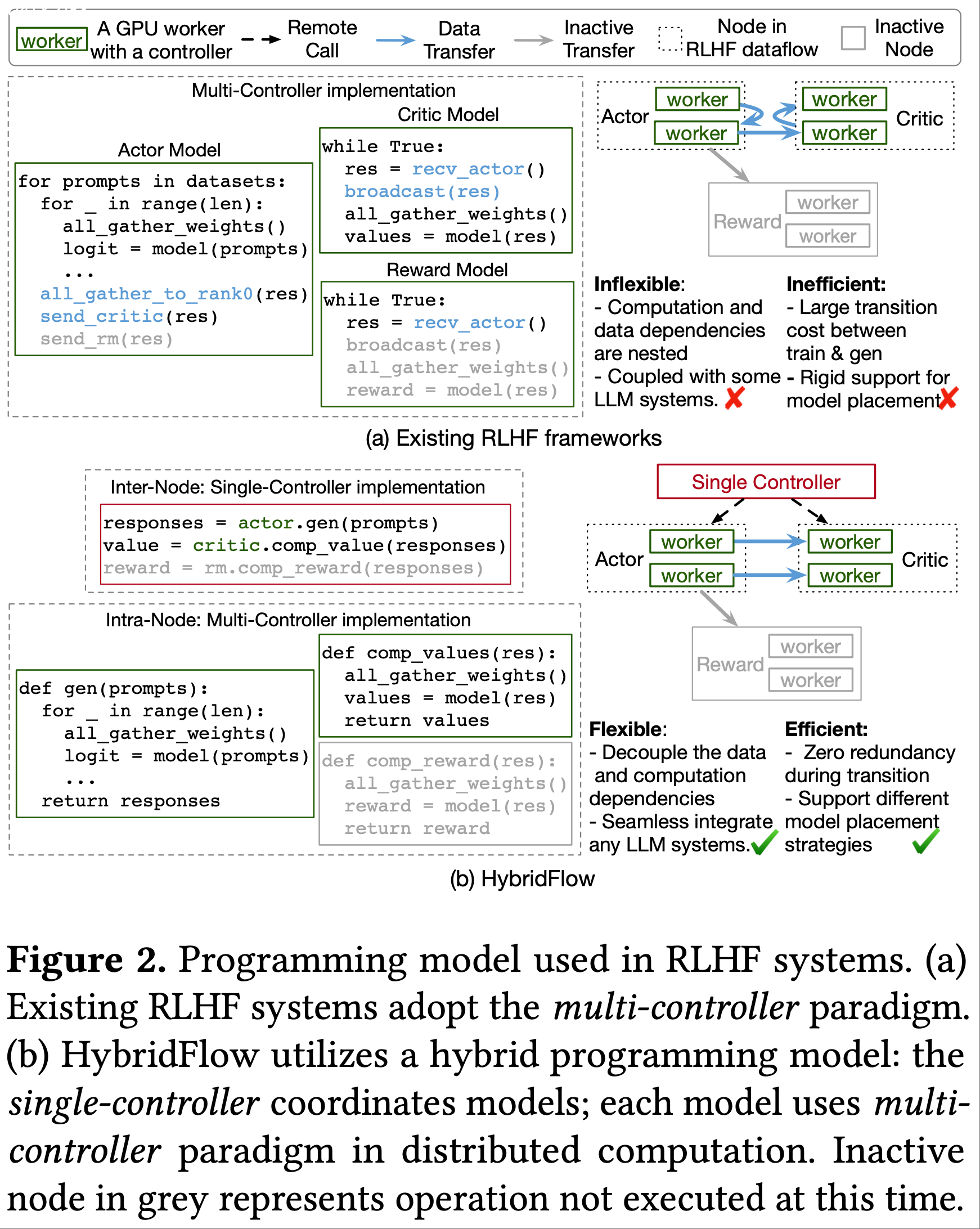
- 凭借对硬件和数据流图的全局视图,单控制器范式允许在数据流任务之间进行灵活且优化的资源映射和执行顺序协调
- 但当在大型集群上执行庞大的数据流图时,控制器向所有工作进程传递协调消息会导致显著的调度开销(2016;2022)
Multi-Controller
- 多控制器设计中,每个设备(即工作进程)都有自己的控制器
- SOTA 分布式 LLM 训练和服务系统采用多控制器范式,因为它具有可扩展性和低调度开销
- 控制消息主要通过快速 PCIe 链路从 CPU 传递到 GPU(2024;2023;2020;2019)
- 如图 2(a)中采用多控制器 RLHF 实现的示例所示
- 每个模型运行一个单独的程序
- 一个模型的所有工作进程执行相同的程序
- 每个工作进程仅拥有系统状态的局部视图,并且需要两个模型之间的点对点通信(蓝色代码和箭头)来协调模型执行顺序
- 要在多控制器架构中实现 RLHF 工作流程,用户必须在每个设备上运行的程序中复杂地集成集体通信、计算和点对点数据传输的代码
- 这导致计算和数据传输的代码深度嵌套,难以开发、维护和优化
- 在图 2(a)中,每个模型执行本地计算和 all_gather 操作(黑色代码),而 actor 模型必须显式管理向 critic 和奖励模型的发送操作,后者必须在其程序的精确点相应地实现接收操作
RLHF Characteristics
Heterogeneous model workloads(异构模型工作负载)
- RLHF 中的 actor、critic、参考和奖励模型可能在不同阶段执行训练、推理或生成,具有不同的内存占用(memory footprint)和计算需求
- 对于参考策略和奖励模型,由于它们仅执行前向传播计算,只需将模型参数存储在 GPU 内存中
- 对于 actor 和 critic,由于它们要进行模型训练,必须存储模型参数、梯度和优化器状态
- 此外,在 RLHF 中,一个小的 actor 模型(例如 7B 参数的预训练/微调 LLM)可以与更大的 critic 和奖励模型(例如 70B 参数的 LLM)配对,以实现更好的对齐(2022)
- 鉴于这种异构性,在 RLHF 运行期间,每个模型需要不同的并行策略和定制优化
Unbalanced computation between actor training and generation
- 在 RLHF 数据流中,actor 模型的训练和生成由两个节点表示(图 1),这两个节点通常占每个 RLHF 迭代的大部分工作负载(例如,使用 HybridFlow 时占总 RLHF 时间的 58.9%)
- actor 训练是计算密集型的(2021),通常需要更大的模型并行(model-parallel, MP)大小(即分割后的模型分区数),将工作负载分配到更多 GPU 上
- 例如 8 个 GPU 上的 7B 参数模型的 8 个分区
- 对 生成(generation) 使用相同的并行策略(例如相同的 MP 大小)可能会由于其内存密集型特性(2023)而导致 GPU 计算资源利用率不足
- 先前的研究表明,结合更大的 DP 大小和更小的 MP 大小(混合数据和模型并行)
- 例如将 7B 参数模型分割为两个部分并在 8 个 GPU 上复制四次,可以提高生成吞吐量(2023;2024)
- 先前的研究表明,结合更大的 DP 大小和更小的 MP 大小(混合数据和模型并行)
- 尽管对 actor 训练和生成使用不同的并行策略可能优化两个阶段的吞吐量 ,但在运行时两个阶段之间对 actor 模型权重进行重分片可能会产生显著的通信和内存开销
- 例如,对齐一个 70B 参数的 actor 模型需要在每个 RLHF 迭代中从训练阶段向生成阶段传输 140GB 的模型权重,当两个阶段在不同设备上时,这可能占用迭代时间的 36.4%(2023)
Diverse model placement requirements
- 根据模型的计算工作负载和数据依赖关系,需要对 RLHF 数据流中的模型进行策略性的设备放置
- 图 3 给出了一个模型放置计划和相应的 RLHF 执行流程示例
- 放置在不同设备集上的模型如果没有数据依赖关系,可以并行执行
- 放置在同一组 GPU 上的模型(称为共置模型,colocated models)共享 GPU 内存,并以分时方式顺序执行,因为如果共置的 LLM 并发执行,很容易发生内存不足(out-of-memory, OOM)错误
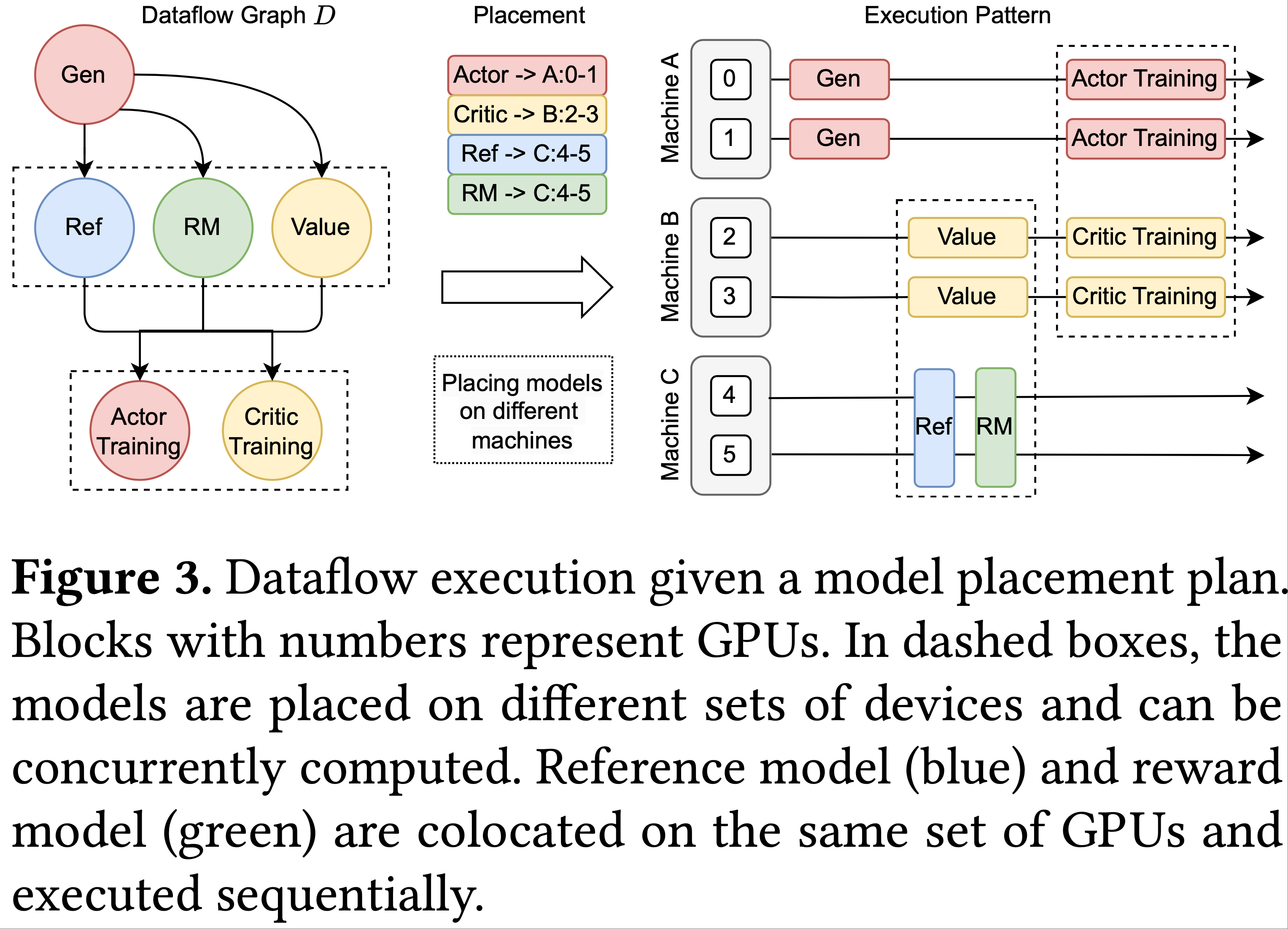
- 论文观察到一种折衷:将模型放置在不同设备上允许并行处理 ,但鉴于 RLHF 中的分阶段模型执行 ,可能不可避免地导致一些 GPU 空闲时间
- 在图 3 中,actor 和 critic 分开放置,并行执行训练,但在其他 RLHF 阶段,它们的 GPU 时间有 1/3 处于空闲状态
- 支持各种放置策略并最大化设备利用率对于在任何模型大小和集群规模下优化 RLHF 性能至关重要
Limitations of existing RLHF systems
Inflexible support for various RLHF dataflow graphs
- 现有的 RLHF 系统采用多控制器范式来实现数据流(2024;2023;)
- 要实现各种 RLHF 算法,用户必须处理和管理混合了集体通信、模型计算(可能使用各种分布式训练/服务框架)和点对点数据传输的代码
- 这种代码结构缺乏模块化/功能封装,使得 RLHF 系统与特定的 LLM 训练和服务框架紧密耦合
- 因此,用户需要逐个案例地实现和优化不同的 RLHF 数据流(2021),这阻碍了代码重用并增加了出错风险
- 现有的 RLHF 框架仅支持 PPO 算法
- 由于实现复杂性,支持的并行策略有限
- 例如,要在 DeepSpeed-Chat(2023)中为 LLM 训练和生成集成 3D 并行,可能需要重新实现整个系统,因为代码结构混乱
Inefficient RLHF execution
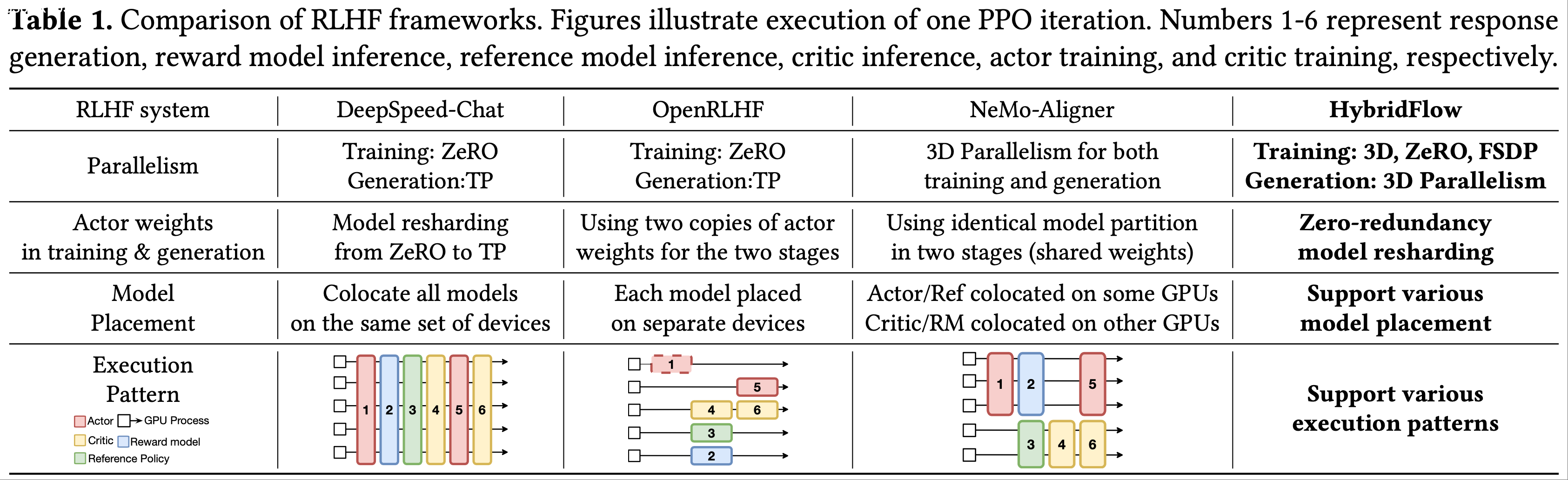
- 表 1 总结了现有 RLHF 系统采用的并行策略、模型放置和执行模式
- DeepSpeed-Chat(2023)和 OpenRLHF(2023)采用 ZeRO-3 进行 actor 训练,采用 TP 进行 actor 生成
- OpenRLHF 在不同设备上使用 actor 模型的不同副本进行训练和生成,导致内存使用冗余以及设备间频繁的权重同步
- DeepSpeed-Chat 在同一组设备上为训练和生成维护同一个 actor 模型副本,并在训练和生成之间对模型权重进行重分片(由于两个阶段使用不同的并行方式)
- 但对于大型模型,这可能仍然会产生大量的内存和通信开销(详见第 5.4 节)
- NeMo-Aligner(2024)在 actor 训练和生成中使用相同的 3D 并行配置,导致生成吞吐量较低(第 8.4 节)
- DeepSpeed-Chat(2023)和 OpenRLHF(2023)采用 ZeRO-3 进行 actor 训练,采用 TP 进行 actor 生成
- 现有 RLHF 框架仅限于一种模型放置计划,因此也仅限于一种 RLHF 执行模式,如表 1 所示
- 实现不同的放置非常困难,需要更改模型初始化的内部逻辑和节点间数据传输(如图 2 中蓝色部分所示)
- OpenRLHF 和 NeMo-Aligner 允许在准备和学习阶段进行并发模型计算;
- 在生成阶段,除了 actor 之外的模型都处于空闲状态,浪费了它们占用的 GPU
- DeepSpeed-Chat 将所有模型共置在同一组设备上,每个设备根据 RLHF 数据流顺序运行每个模型
- 由于模型之间的工作负载不平衡,这种放置方式可能导致资源利用率低下(第 8.3 节评估)
Design Considerations
- 为了解决现有系统的局限性,关键问题是:如何设计一种灵活高效的编程模型来实现 RLHF 数据流?
- 节点间使用单控制器 :单控制器设计在节点间层面特别有利
- 因为它在协调不同模型的分布式计算之间的数据传输、执行顺序和资源虚拟化方面具有灵活性(2022;2018)
- RLHF 数据流图通常只包含少数节点
- 与数据流中节点(模型)所需的分布式计算相比,从单控制器向不同节点调度控制消息的开销可以忽略不计
- 节点内使用多控制器 :多控制器范式以其向加速器调度算子的低延迟而闻名(2001),可用于每个模型的分布式计算
- 基于这些见解,论文提出了一种用于 RLHF 数据流实现的分层混合编程模型
- 论文的核心设计原则是以混合方式结合单控制器和多控制器范式
- 这种设计确保了 RLHF 数据流的灵活表达和高效执行,在节点间和节点内层面都保持较低的控制开销
- 如图 2(b)所示,这种范式解耦了节点内分布式计算和节点间数据传输,允许每个模型专注于本地计算,而无需管理节点间通信
HybridFlow Overview
- 图 4 展示了 HybridFlow 的架构,它由三个主要组件组成:
- 混合编程模型(Hybrid Programming Model)
- 3D 混合引擎(3D-HybridEngine)
- 自动映射算法(Auto-Mapping algorithm)
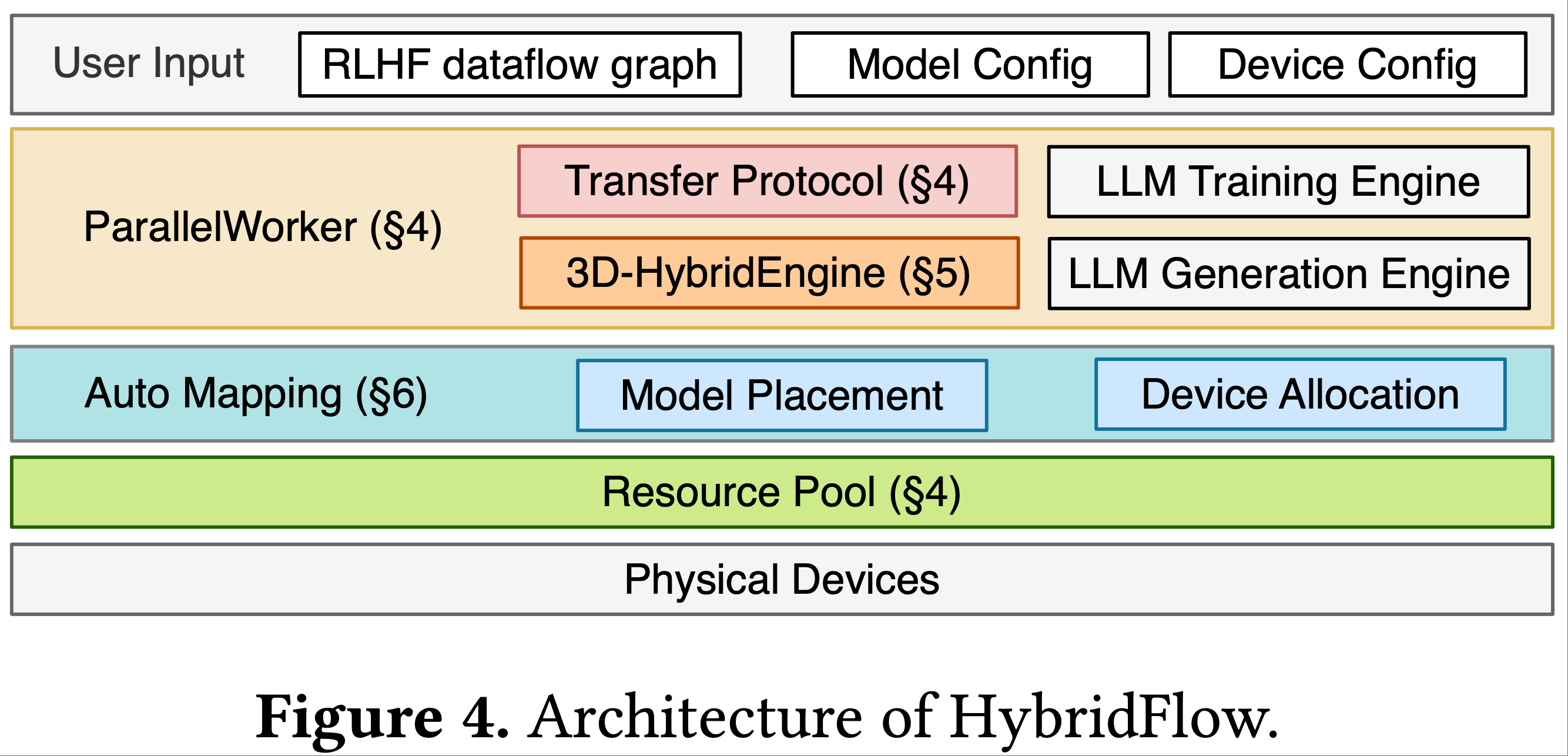
- 混合编程模型包含一组分层 API,用于灵活表达 RLHF 数据流并高效计算数据流中的模型(第4节)
- 3D 混合引擎专为 actor 模型的高效训练和生成而设计
- 允许在两个阶段使用不同的 3D 并行配置,并在两个阶段之间的过渡中实现零内存冗余和最小化通信开销(第5节)
- 自动映射算法确定每个模型的优化设备放置,以最大化 RLHF 的吞吐量(第6节)
- 论文的RLHF系统的工作流程如下
- 用户提供以下输入来启动RLHF系统:
- (i)模型规格,包括RLHF数据流中 actor/critic/参考策略/奖励模型 的架构和大小;
- (ii)数据流中模型的设备放置,通过在给定 GPU 集群配置下运行自动映射算法获得;
- (iii)每个模型在每个阶段运行的并行策略
- 例如 3D 并行的元组 \((p, t, d)\) ,其中 \(p\) 、 \(t\) 、 \(d\) 分别代表管道并行(PP)大小、张量并行(TP)大小和数据并行(DP)大小
- 单控制器程序接收这些输入,初始化 RLHF 数据流和虚拟化资源池中的模型,根据放置计划将操作/模型调度到设备,并调用设备上的多控制器运行的函数来执行每个模型的分布式计算
- 多控制器程序实现了ParallelWorker类:
- 它根据每个模型的并行策略在分配的设备之间构建模型的并行组,调用 3D 混合引擎进行 actor 训练和生成,并且可以与现有的 LLM 引擎(2023;2019;2020;)无缝集成,用于其他模型的训练、推理和生成
- 传输协议由单控制器程序协调,以支持具有不同并行策略的模型之间的数据(包括RLHF中的 Prompt 、响应和其他模型输出)重分片
- actor 在训练和生成之间的数据重分片由 3D 混合引擎处理
- 用户提供以下输入来启动RLHF系统:
Hybrid Programming Model
Hierarchical APIs
Intra-node: encapsulating distributed program(在节点内封装分布式程序)
- 针对不同 RLHF 阶段中每个模型的分布式计算,论文提供了一个基类 3DParallelWorker
- 给定分配的设备,它便于分布式模型权重初始化,并为每个模型建立 3D 并行组
- 一个并行组包括一组 GPU,用于承载模型的特定并行维度
- 例如张量并行(TP)中的不同张量分片和数据并行(DP)中的不同模型副本
- 图5(a)展示了使用论文的 API 初始化 actor 模型的过程,其他模型的初始化类似
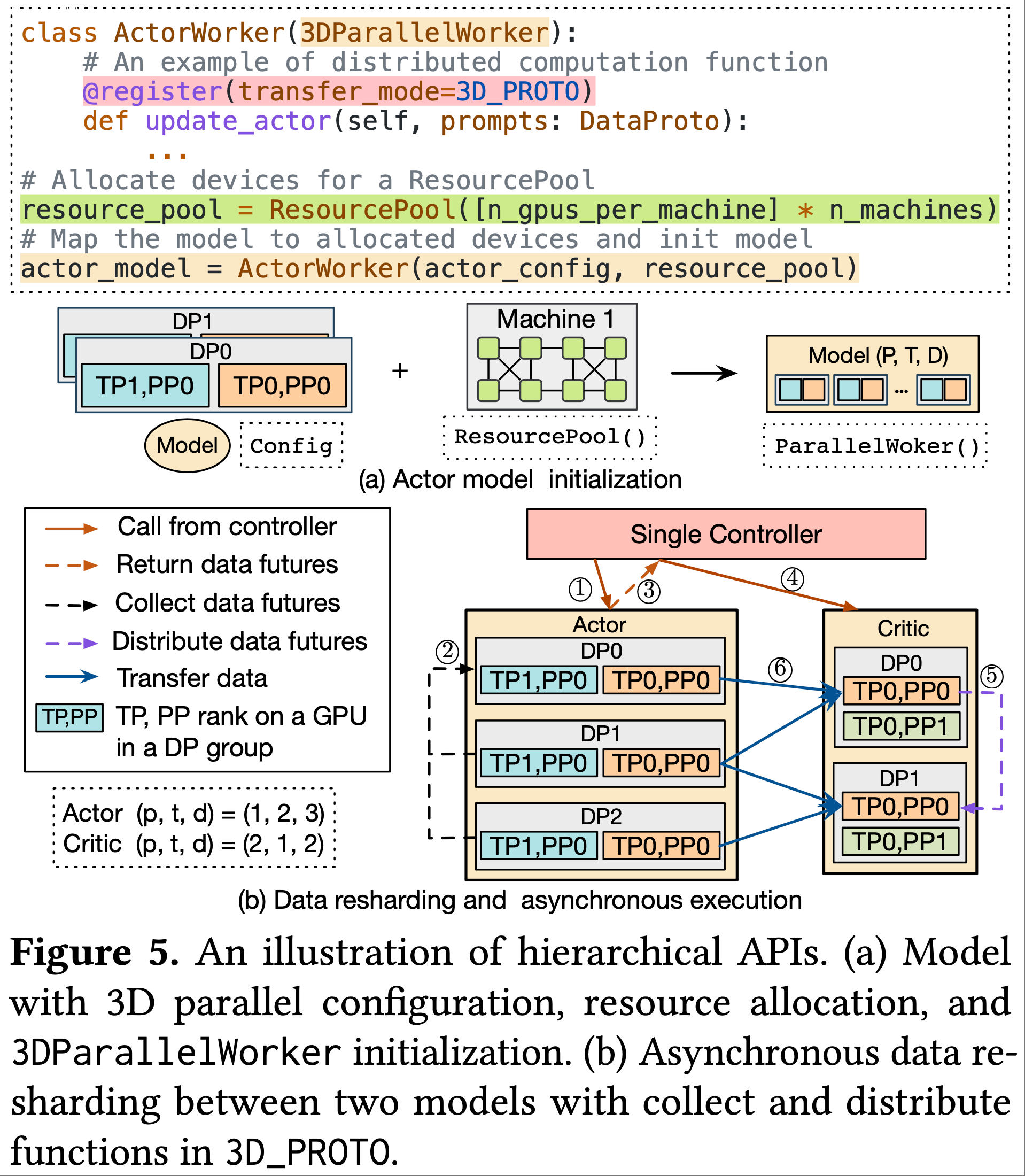
- 继承自 3DParallelWorker 类,分别提供了针对 actor、critic、参考模型和奖励模型 的几个模型类
- 这些模型类中的每一个都封装了实现模型的分布式前向和反向计算、自回归生成和优化器更新的 API,将分布式计算代码与其他模型的数据依赖关系解耦
- 这些 API 可以通过重用现有 LLM 系统的计算脚本轻松实现
- 例如,ActorWorker(actor 模型的类)的 update_actor 函数中涉及的计算类似于 Megatron-LM(2019)中的预训练脚本
- 一个模型类封装了实现各种 RLHF 算法的基本操作
- 例如 actor 模型类中的 generate_sequences(用于基于 Prompt 生成响应)和奖励模型类中的 compute_reward(用于通过前向传播评估响应)
- 更多 API 详见附录A
- 除了实现 3D 并行的基类 3DParallelWorker,论文还提供了 PyTorch FSDP(FSDPWorker)和 ZeRO(ZeROWorker)的基类,以及继承每个基类的相应模型类,以支持模型计算中的不同并行策略
- 图4 中的 ParallelWorker 表示这些基类之一
Inter-node: unifying data resharding implementation between models(在节点间,统一模型间的数据重分片实现)
- 采用不同并行策略的模型在不同设备上传输数据时,会涉及多对多组播
- 论文通过使用
@register将每个模型类中的每个操作与传输协议相关联,从而统一这种数据传输实现 - 每个传输协议由一个收集函数(collect function)和一个分发函数(distribute function)组成
- 用于根据每个模型的并行策略聚合输出数据和分发输入数据
- 在图5(a)的示例中,
update_actor操作注册到传输协议 3D_PROTO ,因为 actor 训练使用 3D 并行- 在 3D_PROTO 中
- 收集函数将每个 DP 组中相应模型函数的输出数据(例如,
update_actor返回的损失标量)收集到单控制器 - 分发函数将输入数据(例如,
update_actor的优势值)分发到注册函数的每个 DP 组
- 收集函数将每个 DP 组中相应模型函数的输出数据(例如,
- 通过源模型的输出收集函数和目标模型的输入分发函数,实现数据重分片
- 在 3D_PROTO 中
- 图5(b)展示了 actor(生成)和 critic(推理)之间的数据重分片,其中模型的计算采用不同的 3D 并行策略
- 单控制器使用 actor 的 3D_PROTO 中的收集函数收集数据 futures(步骤1-3),并将其发送到 critic(步骤4);
- 问题:这里的 数据 future 是指什么?是异步任务的 引用?
- critic 使用其 3D_PROTO 中的分发函数将接收到的数据 future 分发到每个 DP 组(步骤5)
- 然后,从 actor 到 critic 检索远程数据,critic 的每个 GPU 仅根据其 DP 排名获取所需的 actor 输出数据的本地批次(步骤6)
- 实际数据传输仅在 GPU 之间进行,避免了任何中央瓶颈
- 单控制器使用 actor 的 3D_PROTO 中的收集函数收集数据 futures(步骤1-3),并将其发送到 critic(步骤4);
- 论文提供了 8 种传输协议,包括 3D_PROTO、DP_PROTO、ONE_TO_ALL 等,涵盖了大多数数据重分片场景(详见附录B)
- 用户可以通过实现自定义的收集和分发函数进一步扩展传输协议
Facilitating flexible model placement(促进灵活的模型放置)
- 论文提供了一个
ResourcePool类,用于虚拟化一组 GPU 设备 - 当将
ResourcePool实例应用于模型类时(图5(a)),模型的分布式计算将映射到这些设备- 使用相同
ResourcePool实例的模型共置在同一组 GPU 上; - 当不同的
ResourcePool实例应用于它们的模型类时,模型放置在不同的 GPU 组上 - 论文假设不同的
ResourcePool实例之间没有重叠
- 使用相同
Asynchronous dataflow execution
- 当模型放置在不同的设备组上时,一旦输入可用,它们的执行会自动触发(2018)
- 在图5(b)中,控制器调用后立即返回来自 actor 的数据 future (步骤1-3);然后控制器启动对 critic 的新调用,并按照传输协议分发 future (步骤4-5)
- 当某些模型放置在同一设备组上时,它们会根据调用顺序顺序执行
- 借助论文的编程模型,HybridFlow 可以灵活支持各种分布式执行模式,而无需对 RLHF 算法的代码进行任何更改(图6)

Implementation of different RLHF algorithms
- 论文的 API 支持各种 RLHF 算法(数据流)的简化开发
- 用户可以通过几行代码将 RLHF 算法实现为在单控制器上运行的单进程程序,其中包括一系列原始 API 调用,以调用模型的分布式计算
- 图6 给出了 PPO、ReMax 和 Safe-RLHF 的示例
- 通过调用包括 compute_values 和 generate_sequences 在内的模型操作,PPO 可以仅用 8 行代码实现,这些操作在多控制器范式下在多个 GPU 上执行
- 为了适配 Safe-RLHF(它集成了一个额外的成本模型来评估安全偏好,以及 actor 的预训练损失),只需在 PPO 实现的基础上再添加 5 行代码
- 为了适配 ReMax,需要额外调用一次 actor 生成,并且可以删除与 critic 相关的代码
- 实现灵活性(Achieving flexible) :这种扩展灵活性对于研究人员探索不同的 RLHF 算法至关重要:
- 他们可以重用每个模型类中封装的分布式计算,并只需根据特定算法调整数值计算的代码
- 例如
compute_advantage中的 GAE(2018)和 KL 散度,以及 actor 和 critic 的损失函数 - 这种简化的开发归功于混合编程模型
- 例如
- 论文的模块化 API 设计简化了开发,促进了广泛的代码重用,并能够直接整合现有 LLM 训练/服务框架的代码库
- 论文还解耦了模型计算和模型间的数据传输
- 分布式框架的任何变化都不会影响 RLHF 算法的代码(图6),从而可以对每个模型的执行进行个性化优化(第5节)
- 支持具有不同工作负载的模型的灵活放置,能够将 RLHF 数据流优化映射到各种设备上(第6节)
- 他们可以重用每个模型类中封装的分布式计算,并只需根据特定算法调整数值计算的代码
3D-HybridEngine
- 论文设计了 3D 混合引擎(3D-HybridEngine),以支持 actor 模型的高效训练和生成,目标是显著提升 RLHF 的吞吐量
Parallel Groups
- 为了消除冗余的 actor 模型副本,论文建议将 actor 的训练和生成阶段部署在同一组设备上
- 即分配给 actor 的 \(N_a\) 个 GPU ,并在同一个 actor 模型权重副本上按顺序执行这两个阶段
- 尽管如此,actor 的训练和生成很可能采用不同的 3D 并行策略,即生成阶段通常需要比训练阶段更小的 TP 和 PP 大小 ,以及更大的 DP 大小(第2.3节)
- 在此背景下,3D 混合引擎能够在同一组设备上高效地在 actor 训练和生成之间进行模型参数重分片
- 用 \(p-t-d\) 表示为 actor 训练构建的 3D 并行组
- 对应于承载 \(p\) 个管道阶段(pipeline stages)、\(t\) 个张量分片(tensor shards)和 \(d\) 个模型副本的GPU集合(2021)
- 3D 混合引擎根据训练和生成阶段不同的 3D 并行策略,分别为 actor 的训练和生成构建不同的并行组
- 论文用 \(p_g\) 、 \(t_g\) 和 \(d_g\) 分别表示生成阶段中生成管道并行组(generation pipeline parallel group)、生成张量并行组(generation tensor parallel group)和微数据并行组(micro data parallel group)的大小
- \(d_g\) 表示生成阶段的模型副本数与训练阶段的比例 ,即训练阶段的每个 DP 副本会成为 \(d_g\) 个微 DP 副本 ,用于处理 \(d_g\) 个 Prompt 和响应的微批次
- 论文有 actor 的 GPU 总数 \(N_a = p \times t \times d = p_g \times t_g \times d_g \times d\) ,因此 \(d_g = \frac{pt}{p_g t_g}\)
- 微 DP 组仅在 actor 生成阶段使用,以实现更大的 DP 大小,从而充分利用设备
- 生成并行组表示为 \(p_g-t_g-d_g-d\)
- 问题:如何实现将训练时的一个 DP 副本,分散成生成时的 \(d_g\) 个微 DP 副本的?不需要重新拷贝的吗?
- 注:是需要对参数进行重新分区的,但是会对重新分区的配置进行优化?
- 问题:为什么生成时的 \(p_g \times t_g\) 可以变小些?
- 解答:因为生成时不需要存储梯度信息和优化器信息,还不需要存储每一层的激活值,所以可以将 \(p_g \times t_g\) 设置的小一些
3D-HybridEngine Workflow
- 在 RLHF 的第 \(i\) 次迭代的 actor 训练和第 \(i+1\) 次迭代的 actor 生成之间,需要根据两个阶段的并行组配置对 actor 模型参数进行重分片,并分发 Prompt 数据
- 在 RLHF 的第 \(i+1\) 次迭代中
- 3D 混合引擎收集在第 \(i\) 次迭代中更新的 actor 模型参数(图7中的步骤1),用于每个微 DP 组内的生成
- 然后,将批量 Prompt 加载到每个模型副本(步骤2),生成响应(RLHF 的生成阶段)
- 接着,3D 混合引擎在每个微 DP 组内对生成结果执行 all-gather 操作(步骤3),并根据 actor 训练的 3D 并行性对模型参数重新分区(步骤4)
- 在模型权重、Prompt 和响应正确分发后,计算 actor 模型的损失,并根据 RLHF 算法更新 actor 模型权重(步骤5)
- 即第 \(i+1\) 次迭代的 actor 训练阶段
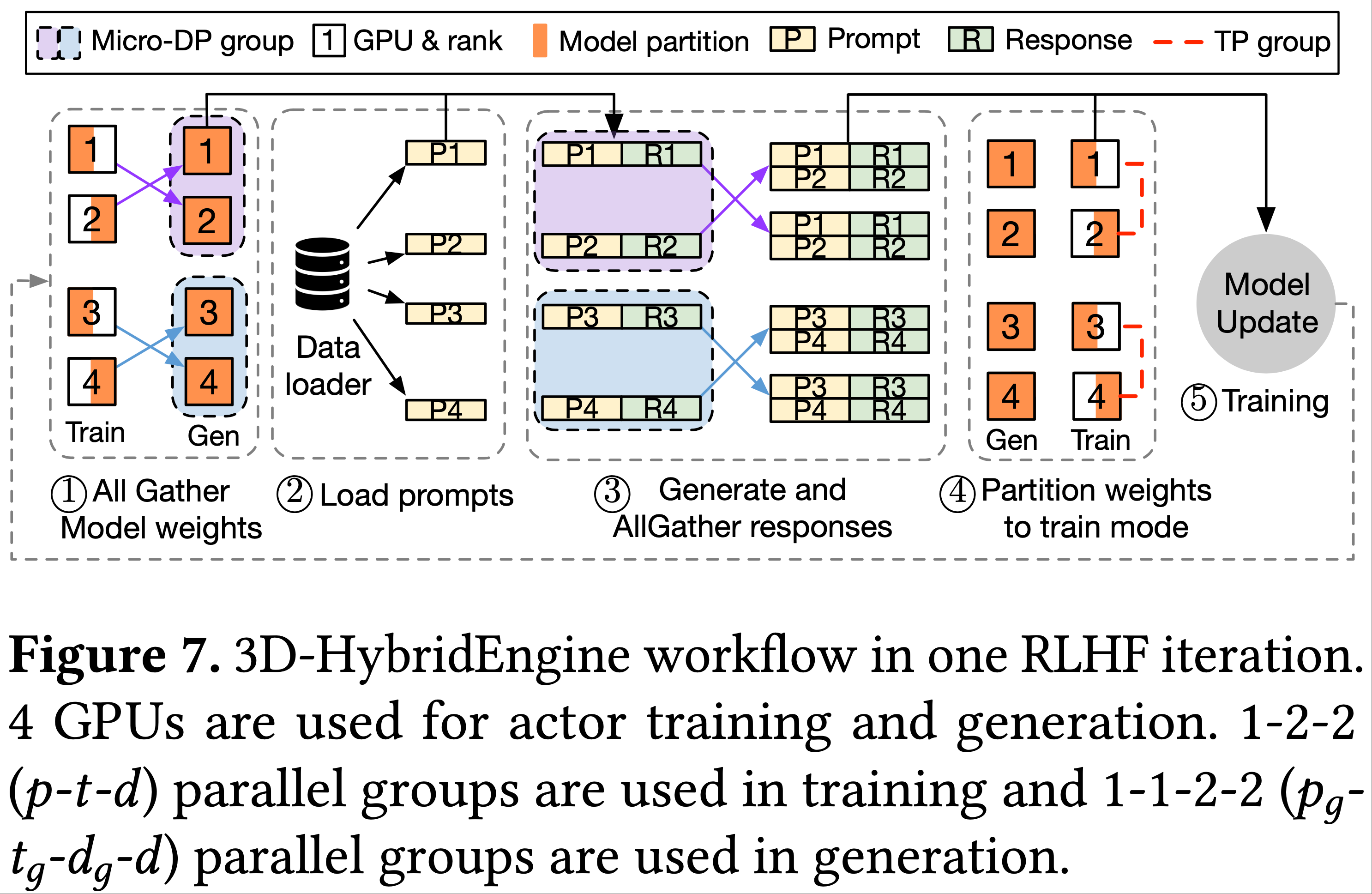
- 即第 \(i+1\) 次迭代的 actor 训练阶段
Zero redundancy model resharding
- 3D 并行中的并行组构建方法通常如下:
- PP 组和 TP 组通过将连续的排名分配给管道阶段和张量分片形成;
- DP 组通过按 PP 大小和 TP 大小的乘积确定的固定间隔选择排名构建
- 在图8(a)中,actor 训练使用 3D 并行组 1-4-2:
- 所有 GPU 组成一个 PP 组(为了说明清晰);
- TP 组为 [G1, G2, G3, G4]、[G5, G6, G7, G8]
- DP 组为 [G1, G5]、[G2, G6]、[G3, G7]、[G4, G8]
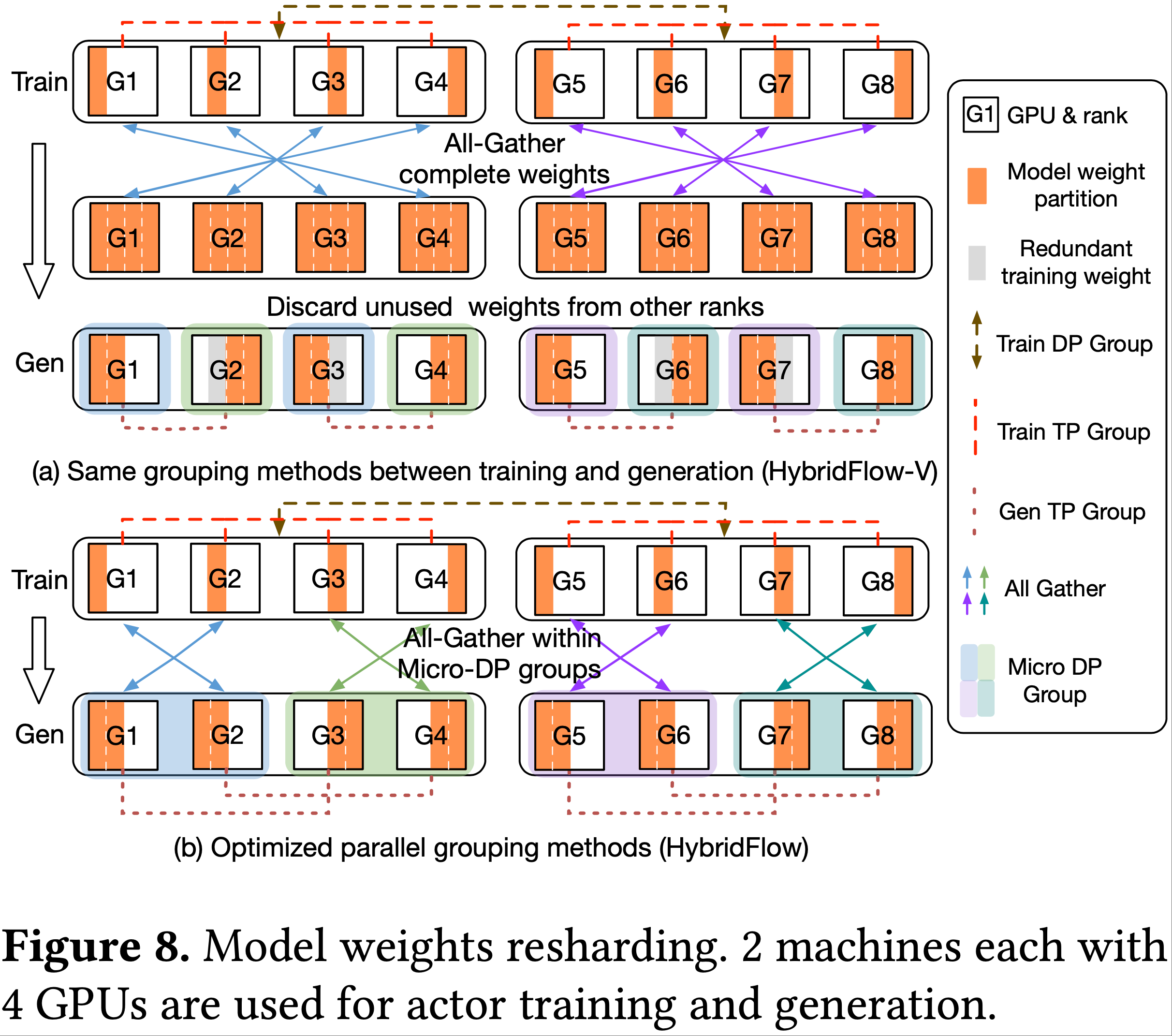
- 假设使用相同的并行组构建方法但采用不同的并行大小,例如图8(a)中生成阶段使用 1-2-2-2
- 在从训练到生成的过渡中,3D 混合引擎在模型并行组内应用 all-gather 操作聚合所有参数,然后根据设备所属的并行组在每个设备上仅保留模型权重的一个子集用于生成
- 在某些 GPU 上(如 G2、G3、G6、G7),训练和生成的模型权重之间没有重叠,并且还需要单独的内存来维护后续训练的权重(图8(a)中的灰色框)
- 当 3D 混合引擎在两个阶段使用上述常规并行组构建方法时,论文将该系统称为 HybridFlow-V
- 论文进一步为 3D 混合引擎设计了一种新的并行组构建方法,用于生成阶段,以消除权重存储的冗余,并最小化由于 actor 模型在训练和生成之间重分片导致的内存占用和通信开销
- 具体而言,论文通过按 \(\frac{t}{t_g}\) 和 \(\frac{p}{p_g}\) 确定的固定间隔选择排名来形成生成 TP 组和 PP 组,并沿着生成 TP 或 PP 维度按顺序分配排名来构建微 DP 组
- 在图8(b)中,生成阶段使用 1-2-2-2 并行组:
- 生成 TP 组为 [G1, G3]、[G2, G4]、[G5, G7]、[G6, G8];
- 微 DP 组为 [G1, G2]、[G3, G4]、[G5, G6]、[G7, G8]
- 这种生成并行组的策略性重排使得每个设备上的训练和生成模型权重能够重叠 ,从而在生成过程中重用训练权重 ,实现模型重分片的设备内存零冗余
- 注:主要是某一片参数重用,不是所有参数都能重用的,不论如何,参数的传输还是需要的
- 此外,3D 混合引擎并发执行多个 all-gather 操作(每个微 DP 组内一个),显著降低了通信开销
Transition overhead(过渡开销)
- 在表2 中,论文比较了不同 actor 引擎设计在训练和生成阶段之间过渡时的通信开销和内存占用
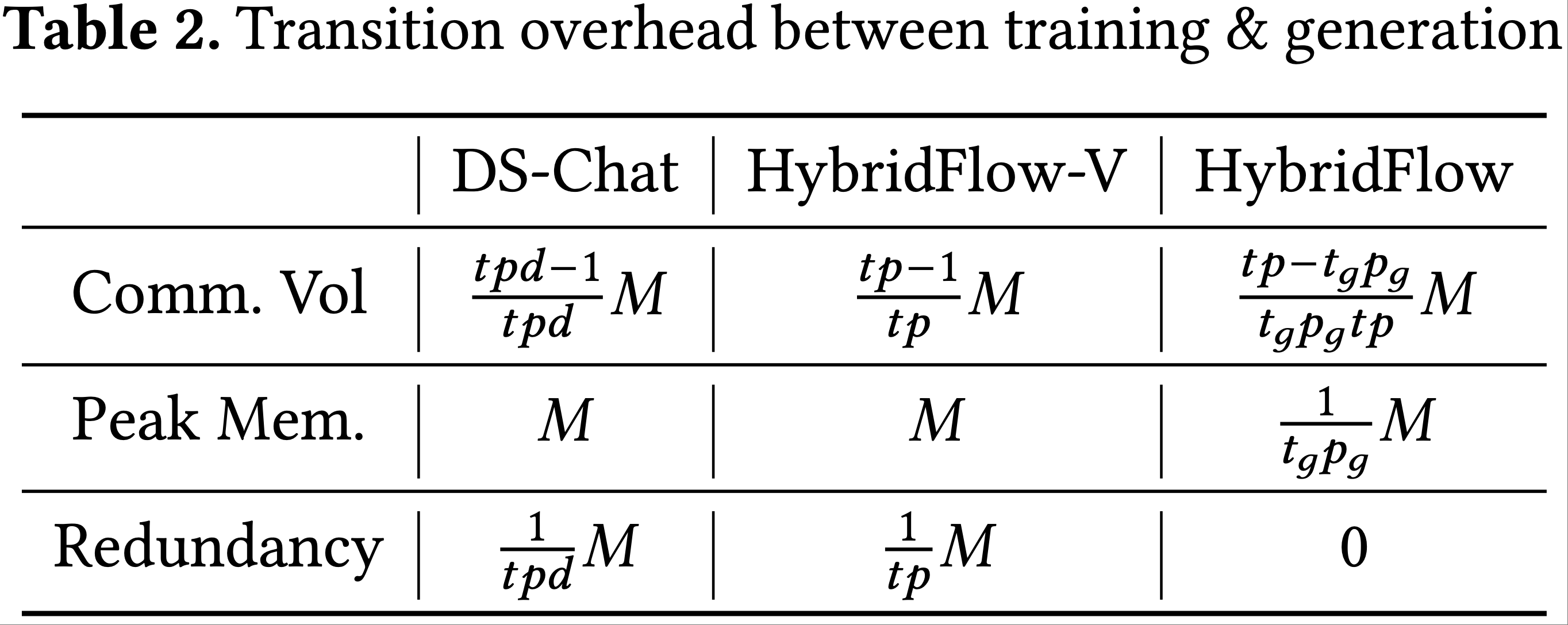
- 假设 actor 的模型大小为 \(M\),且有 \(N_a\) 个 GPU 用于其训练和生成
- DeepSpeed-Chat 中的 actor 引擎在过渡期间在所有 GPU 上执行 all-gather 操作;
- HybridFlow-V 在训练 TP 和 PP 组内执行此 all-gather 操作
- 这些操作的通信量计算如下(2007):
- DeepSpeed-Chat 为
$$ \frac{N_a-1}{N_a}M = \frac{t p d - 1}{t p d}M $$ - HybridFlow-V 为
$$ \frac{t p - 1}{t p}M $$ - 两种引擎在根据生成并行组划分模型状态之前,都会在每个 GPU 的内存中聚合所有模型参数,导致模型参数的峰值内存使用量为 \(M\)
- 由于它们无法在某些 GPU 上的生成过程中重用训练权重,这些 GPU 需要维护训练权重,分别导致 \(\frac{1}{t p d}\) 和 \(\frac{1}{t p}\) 的冗余内存消耗
- DeepSpeed-Chat 为
- 通过论文为生成阶段设计的并行组构建方法,HybridFlow 将 all-gather 操作限制在每个微 DP 组内
- 通信开销减少到
$$ \frac{d_g - 1}{t p}M = \frac{t p - t_g p_g}{t_g p_g t p}M $$ - 每个 GPU 只需收集其微 DP 组内的远程参数,并可以在生成过程中重用训练权重
- 因此,HybridFlow 中模型参数的峰值内存使用量正好与每个 GPU 在生成阶段的模型分区大小匹配 ,消除了 GPU 内存使用中的任何冗余
- 通信开销减少到
Auto Device Mapping
- 论文的混合编程模型要求用户输入以下配置,这些配置被称为 RLHF 数据流到给定设备的映射:
- (a)数据流中模型的设备放置;
- (b)每个模型在每个阶段运行的相应并行策略
- 论文为用户提供了一种高效算法(算法1),用于确定在给定设备集群上执行 RLHF 数据流的优化映射,以最小化每个 RLHF 迭代的端到端延迟

- 给定一个数据流 \(D\),论文首先在给定集群中探索模型的所有可能放置计划 \(\mathcal{P}\)(第3行)
- 例如,PPO 算法涉及 4 个模型,产生 15 种可能的放置(来自贝尔分区问题(1934;1964)),范围从所有模型放置在不同设备上的完全独立放置(如 OpenRLHF 的放置)到所有模型共置在同一组设备上的放置(如 DeepSpeed-Chat 的放置)
- 论文将共置在同一组 GPU 上的模型称为共置集(colocated set)
- 共置集中的模型可以在同一组 GPU 上采用不同的并行策略
- 论文根据共置模型的内存消耗确定分配给每个共置模型集的最小 GPU 数量 \(A_{min}\) ,确保不会出现内存不足错误(第9行)
- 接下来,从 \(A_{min}\) 中的最小 GPU 分配开始,论文枚举每个共置模型集的所有可行设备分配(第10-12行)
- 给定共置集的设备分配 \(A\) 和集合中模型的计算工作负载 \(W\),论文在
auto_parallel模块中探索每个模型的优化并行策略,以最小化模型执行延迟- 工作负载 \(W\) 包括每个模型的输入和输出形状以及计算(训练、推理或生成)
- 在
auto_parallel中,论文利用模拟器模块simu来估计不同并行策略的延迟,遵循先前的研究(2023;2024;2024;2024)(概述见附录C) d_cost模块通过遍历数据流图中的所有阶段并汇总所有阶段的延迟,来估计在给定模型放置和并行策略下 RLHF 数据流的端到端延迟(第17、25行)
- 对于同一共置集中在同一阶段涉及计算的模型(例如 actor 和 critic 在 RLHF 训练阶段都执行模型更新),它们的执行延迟会被累加(第32行)
- 对于不同共置集中的模型,它们在同一阶段的执行可以并行化,阶段延迟由不同集合之间的最大执行时间决定(第33行)
- 论文确定模型的最佳设备放置及其相应的并行策略 ,以实现每个 RLHF 迭代的最小执行时间(第18-23行)
- 算法1的复杂度为
$$ O(\frac{(N-1)!}{(k-1)!(N-k)!})$$- 其中 \(k\) 是数据流中模型的数量,\(N\) 是运行数据流的设备总数
- 这是为放置策略枚举所有可能设备分配的最坏情况复杂度(即独立放置),通过将 \(N\) 个设备分配给 \(k\) 个模型计算得出(称为整数分区问题(2004))
- 为了提高效率,论文缓存为每个模型在 \(A\) 个设备上确定的并行策略,以消除当模型在不同放置策略中放置在不同的 \(A\) 个 GPU 集上时对相同并行策略的冗余搜索
- 尽管论文在运行自动映射算法时假设 \(N\) 个同构 GPU,但算法1可以很容易地扩展到异构设备的模型映射优化,通过在
simu和auto_parallel模块中考虑异构设备(2024)
Implementation
- HybridFlow 由大约 12000 行 Python 代码(LoC)实现
Hybrid programming model
- 分层 API 用 1800 行代码实现
- 集中式单控制器构建在 Ray(2018)之上,并使用远程过程调用(Remote Process Calls, RPC)来协调不同模型的执行顺序,并按照数据流在模型之间传输数据
- 这些中间数据存储在 TensorDict(2019)中
- 在论文用于分布式计算的多控制器范式中,每个模型函数在不同设备上的独立进程中运行,控制消息从每个控制器的 CPU 进程传递到相应的 GPU
- 论文的实现支持 Megatron-LM、PyTorch FSDP 和 DeepSpeed 作为 LLM 训练和推理引擎,以及 vLLM 用于自回归生成
- 在 vLLM 中,论文用分布式管理器替换了集中式 KVCache 管理器,以与多控制器范式对齐
3D-HybridEngine
- 其主要逻辑在 Megatron-LM 和 vLLM 之上用 2400 行代码实现
- 论文在分开的内存缓冲区中存储训练和生成阶段的 actor 模型权重 ,在训练期间将生成权重卸载到 CPU 内存 ,在过渡期间将生成权重重新加载到 GPU 内存 ,并在生成中使用这两个缓冲区
- 理解:生成和训练两个阶段下,actor 模型权重有各自的缓冲区
- 论文使用 NCCL 通信原语(2017)在训练和生成之间的过渡期间收集和连接每个微 DP 组中的模型参数
- 论文在生成后将 KVCache 卸载到 CPU 内存,并在下一次迭代中重新加载到 GPU
- 问题:每一轮的 Prompt 数据是相同的吗?为什么要 缓存 KVCache
- 回答:每一轮的 Prompt 数据可能是相同的,Prompt 数据会被重复利用(多次生成和训练)
Auto-Mapping Algorithm
- 自动映射算法(Auto-Mapping Algorithm)用 1900 行代码实现,同时包含三个分别用于训练、推理和生成工作负载的模拟器
- 该算法在 CPU 上启动 RLHF 数据流之前运行,以生成用于数据流初始化的设备映射和并行策略
Evaluation
Experimental Setup
Testbed(测试平台)
- 论文在一个包含 16 台机器(128 个 GPU)的集群上部署 HybridFlow
- 每台机器配备 8 个 NVIDIA A100 80GB GPU,通过 600GB/s 的 NVLink 互连
- 机器间带宽为 200Gbps
- 论文的实验使用以下软件版本:CUDA 12.1、PyTorch 2.1.2、Megatron-core 0.6.0、NCCL 2.18.1 和 vLLM 0.3.1
Models and RLHF algorithms
- 论文运行 PPO(2017)、ReMax(2023)和 Safe-RLHF(2024)算法的 RLHF 数据流(图 1)
- PPO 是 RLHF 中最流行的算法之一(2022;2022),包括 actor、critic、参考策略和奖励模型
- 每个模型都是 Llama(2023)模型,大小从 7B 到 70B 参数不等
- Safe-RLHF 有一个额外的成本模型,其架构和大小与奖励模型相同,而 ReMax 则取消了 critic 模型
- 论文对 actor 和 critic 训练使用混合精度,即模型参数使用 BF16,梯度和优化器状态使用 FP32,所有实验均使用 Adam 优化器(2017)
- 模型推理和自回归生成使用 BF16
- 除非另有说明,否则实验结果均来自 PPO
Baselines
- 论文将 HybridFlow 与 SOTA RLHF 系统进行比较,包括 DeepSpeed-Chat(2023)v0.14.0、OpenRLHF(2023)v0.2.5 和 NeMo-Aligner(2024)v0.2.0(详见表 1)
- NeMo-Aligner 不支持 ReMax 算法
- 论文没有将 HybridFlow 与 Trlx(2023)、HuggingFace DDP(2019)和 Collosal-Chat(2023)等其他框架比较,因为它们的代表性较低,且比上述基线慢(如(2023)所报告)
- 论文使用 RLHF 吞吐量(tokens/秒)作为性能指标,计算方法是将全局批次中 Prompt 和响应的总 token 数除以一个 RLHF 迭代时间
- 所有报告的性能数据均为 10 次迭代预热后 5 次训练迭代的平均值
Datasets and hyperparameters
- 论文在 HuggingFace 的“Dahoas/ful-hh-rlhf”数据集(2022)上执行 RLHF,该数据集广泛用于 LLM 对齐(2023;2023)
- 由于基线系统在生成期间可能未集成连续批处理优化(2022),为了公平比较,论文强制所有要生成的响应长度相同
- 在每个实验中,输入 Prompt 长度和输出响应长度均为 1024,输入到 actor 模型的 Prompt 全局批次大小为 1024
- PPO 的 epoch 数为 1,每个 epoch 的 PPO 更新迭代次数为 8,与之前的 RLHF 研究一致(2024;2022;2023)
End-to-End performance
- 图 9、图 10 和 图 11 分别显示了运行 PPO、ReMax 和 Safe-RLHF 时的 RLHF 吞吐量
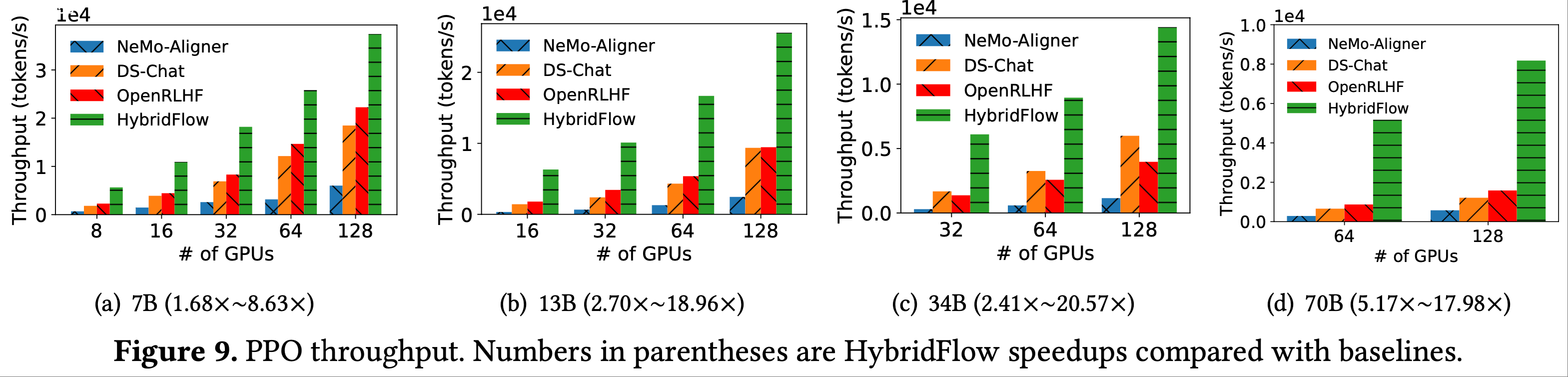
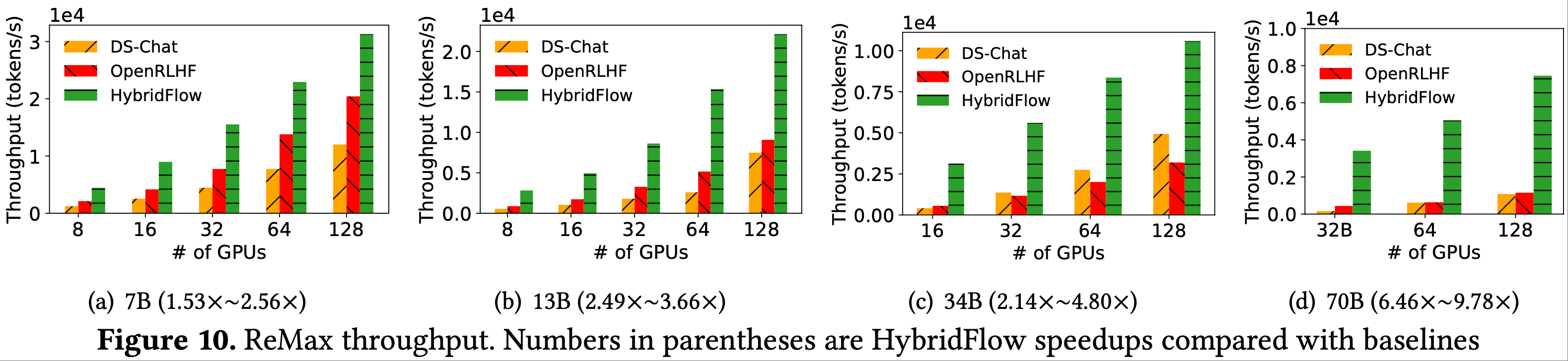
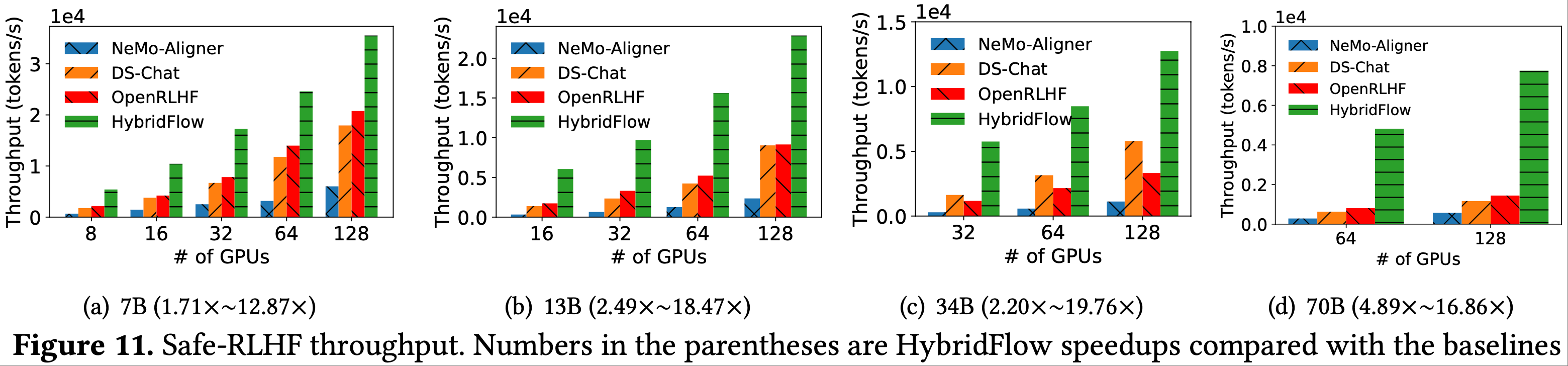
- 本组实验中的 actor、critic、参考模型和奖励模型大小相同,遵循先前的实践(2022;2022;2023)
- 不同模型大小的实验使用的 GPU 数量范围从运行 RLHF 而不出现 OOM 的最小 GPU 数量到 128 个 GPU
- 为了公平比较,论文在实验中未启用优化器状态卸载(2021)
Overall Performance
- 论文观察到,在所有模型规模上,HybridFlow 始终优于基线
- 在图 9 的 PPO 中
- HybridFlow 比 DeepSpeed-Chat、OpenRLHF 和 NeMo-Aligner 分别高出 \(3.67\times\) (最高 \(7.84\times\) )、 \(3.25\times\) (最高 \(5.93\times\) )和 \(12.52\times\) (最高 \(20.57\times\) )
- 这主要是因为 HybridFlow 通过使用不同的并行策略对模型进行分片,以适应各种计算工作负载,从而在所有 RLHF 阶段有效执行生成、推理和训练
- HybridFlow 在训练 70B 参数模型时实现了平均 \(9.64\times\) 的最高加速比
- 因为与 DeepSpeed-Chat 和 OpenRLHF 相比,HybridFlow 将过渡开销分别降低了高达 71.2% 和 89.1%,而后两者在使用 ZeRO-3 训练时也会产生大量的机器间通信
- 由于生成引擎中缺少 KVCache,NeMo-Aligner 的主要性能瓶颈在于生成阶段,该阶段占其 RLHF 迭代时间的比例高达 81.2%
- HybridFlow 比 DeepSpeed-Chat、OpenRLHF 和 NeMo-Aligner 分别高出 \(3.67\times\) (最高 \(7.84\times\) )、 \(3.25\times\) (最高 \(5.93\times\) )和 \(12.52\times\) (最高 \(20.57\times\) )
- 在图 10、11 中可以观察到类似的结果,验证了 HybridFlow 在运行各种 RLHF 算法时的效率
Scalability
- HybridFlow 在 8 个 GPU 上至少实现了 \(2.09\times\) 的加速比
- 随着 GPU 数量的增加,HybridFlow 在各种模型规模上的强扩展效率为 66.8%,计算方法是将最大规模下的吞吐量与最小规模下的吞吐量之比除以 GPU 数量的倍数(2007),取三种算法和所有模型规模的平均值
- 在固定全局批次大小的情况下扩展到大量 GPU 会导致每个工作进程的本地批次大小更小,可能导致 GPU 利用率不足
- 在 128 个 GPU 上运行 7B 参数模型时,HybridFlow 在 PPO、ReMax 和 Safe-RLHF 上仍分别比最佳基线 OpenRLHF 高出 \(1.68\times\) 、 \(1.53\times\) 和 \(1.71\times\)
- 这归因于 HybridFlow 能够为不同的模型和集群规模调整最佳放置策略,以最小化 RLHF 时间
- OpenRLHF 在更大的 GPU 集群中表现更好,但在较小的集群上效率较低
Model Placement
- 在本实验中,论文在 HybridFlow 中实现了 PPO 算法的各种模型放置,模型和集群设置与 8.2 节相同:
- (i)共置(colocate),即 DeepSpeed-Chat 中的放置策略;
- (ii)独立(standalone),即 OpenRLHF 中的放置策略;
- (iii)拆分(split),即 NeMo-Aligner 的共置放置(actor 和参考策略在同一组设备上,critic 和奖励模型在另一组上);
- (iv)hybridflow,即通过算法 1 获得的优化放置
Comparison of different model placements
- 图 12 显示,HybridFlow 在不同数量 GPU 下的优化放置有所不同
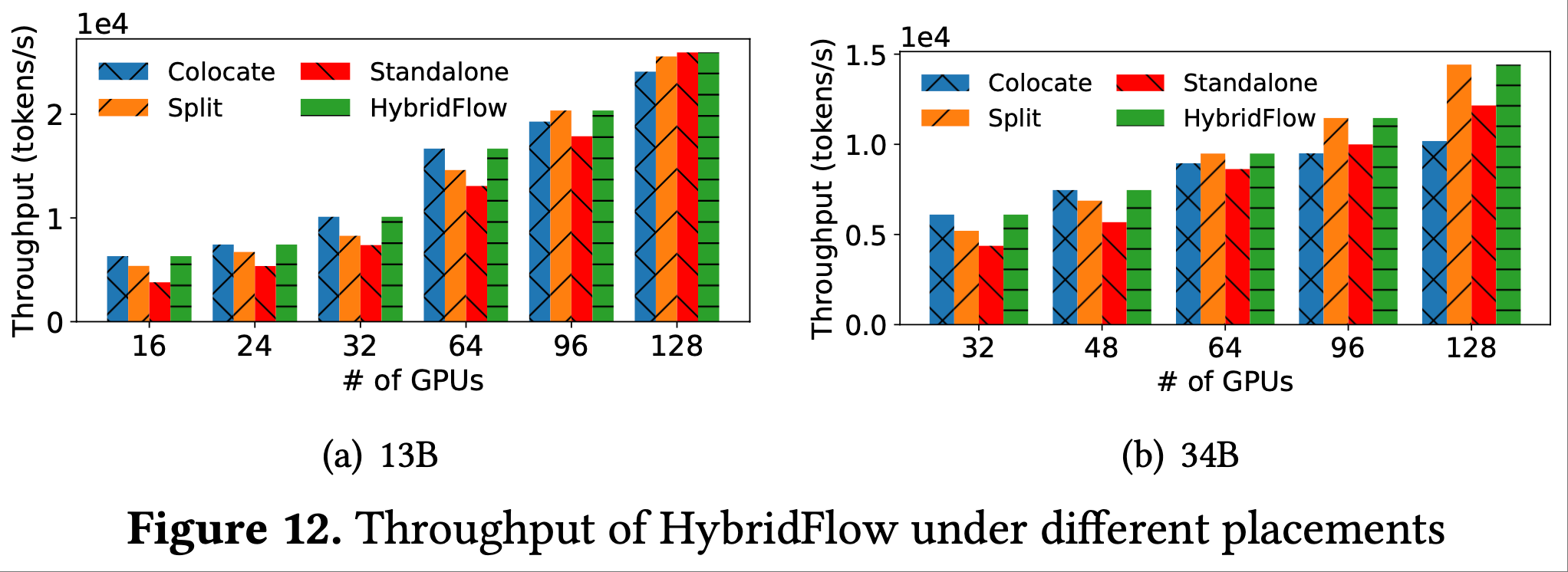
- 在 16 到 64 个 GPU 上,将所有模型共置在同一组设备上可获得最佳性能
- 对于 96 到 128 个 GPU 上的 34B 参数模型和 96 个 GPU 上的 13B 参数模型 ,拆分策略成为最优
- 拆分策略将 GPU 平均分配给两组模型,因为它们的大小相同
- 对于 128 个 GPU 上的 13B 参数模型,独立策略实现了最高吞吐量
- 在这种情况下,HybridFlow 为 actor 分配 64 个 GPU,为 critic 分配 32 个,为参考模型和奖励模型各分配 16 个
- 在较小的集群中,所有模型的计算都能充分利用 GPU 资源;
- 共置策略确保在不同 RLHF 阶段最大限度地利用 GPU
- 在较大的集群中,随着批次大小固定,共置放置下的 RLHF 吞吐量无法线性扩展,因为在更多 GPU 上,随着 DP 大小增大,计算与通信比会降低
- 在较大的集群中,独立和拆分策略将模型放置在不同设备上,每个模型使用更小的 DP 大小,有助于在同一阶段并行执行不同模型
- 在所有情况下,论文的算法 1 都能产生最佳放置,实现最高的训练吞吐量
Larger critic and reward model.
- 我们进一步评估了在运行 PPO 算法时的模型部署方案,此时采用 13B 参数的 actor 模型与参考策略(reference policy),并搭配 70B 参数的 critic 与奖励模型(更大的 critic 和奖励模型有望实现更优的对齐效果(2022))
- 图 13 显示
- 在 GPU 数量最多达 64 块的情况下,共置(colocate)策略仍以平均 44.8% 的优势优于其他策略
- 当使用 96 块 GPU 时,拆分(split)策略实现了更高的吞吐量
- 当扩展至 128 块 GPU 时,通过算法 1 得到的最优部署方案为:
- 将 actor、参考策略与奖励模型共置于 64 块 GPU 上,同时将剩余 64 块 GPU 分配给 critic
- 在 GPU 数量相同的情况下,actor 与参考策略的计算时间远短于 critic 与奖励模型;
- 将奖励模型与 actor、参考策略进行共置,能够减少 experience 准备阶段的 GPU 空闲时间
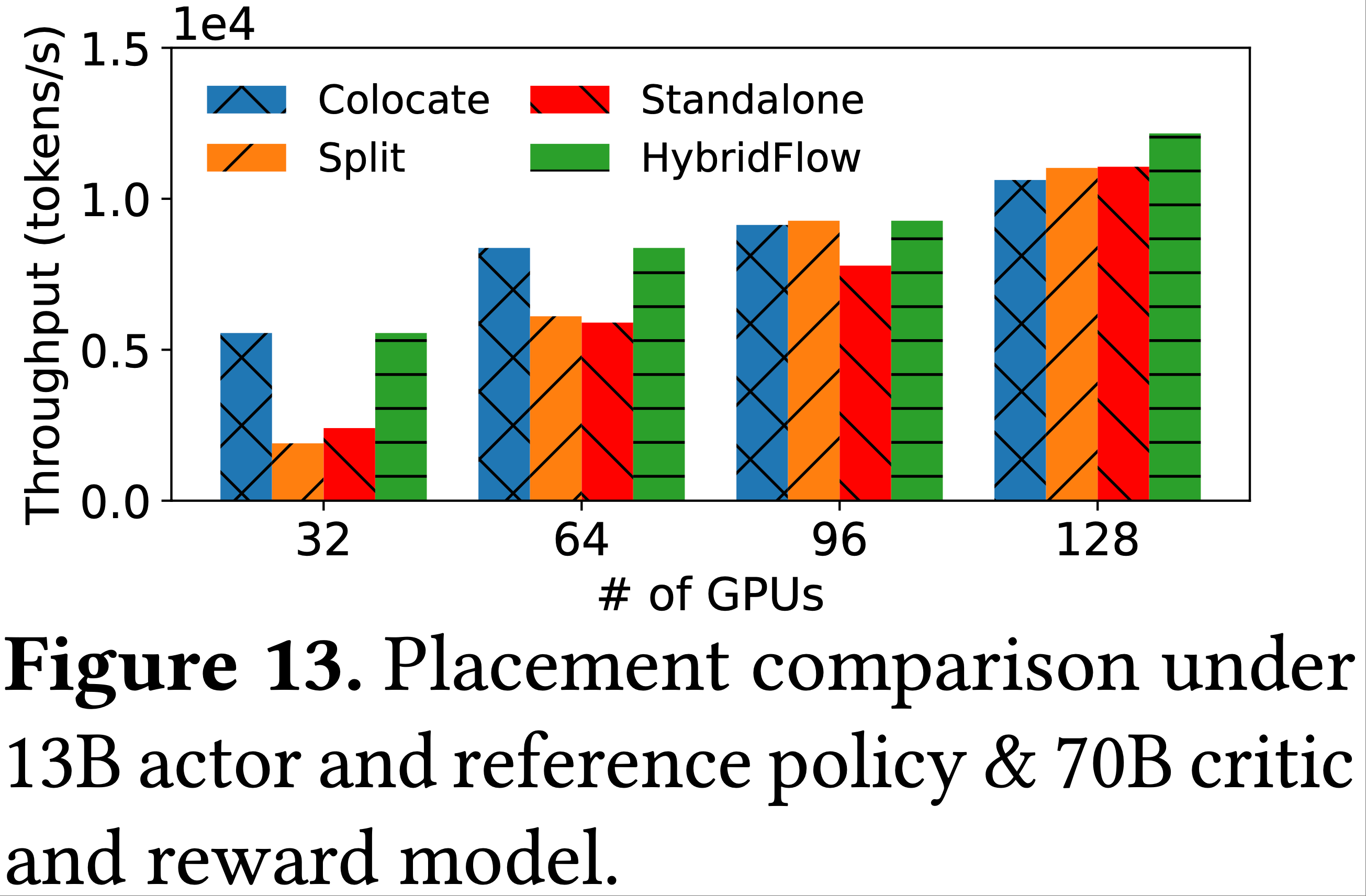
- 总体而言,大型集群中,在训练阶段将 actor 与 critic 分布在不同设备上进行并行执行,可实现更高的吞吐量
3D-HybridEngine
Transition time comparison
- 图 14 显示了在不同模型规模上 actor 训练和生成阶段之间的过渡时间,即从训练到生成的模型权重重分片时间,设置与 8.2 节相同
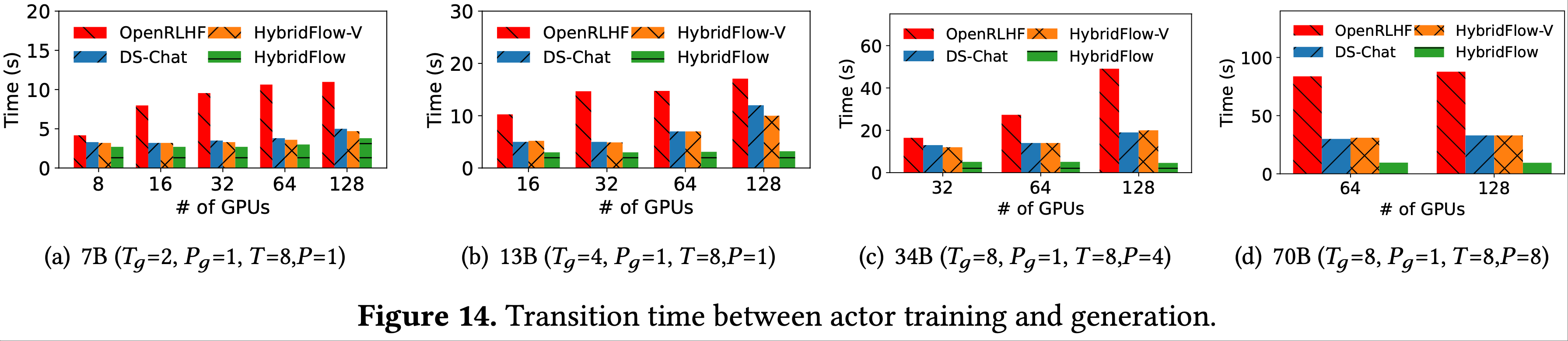
- OpenRLHF 的过渡时间包括不同设备上两个 actor 模型副本之间的权重同步时间
- HybridFlow 平均减少了 55.2%(11.7 秒)的过渡时间,在 70B 参数模型上最多减少了 89.1%(78.2 秒)的过渡开销,同时在不同集群规模上保持一致的开销
- 这归因于论文为生成阶段设计的新并行组构建方法(第 5.4 节)
- 在基线方法中,过渡期间必须收集所有模型参数,为了防止 OOM,需要多次逐层收集
- HybridFlow 在过渡期间实现了零内存冗余,每个微 DP 组只需一次 all-gather 操作
Transition and generation time
- 论文进一步验证了在 HybridFlow 中需要为 actor 训练和生成使用不同的并行大小
- 在本实验中,所有模型共置在同一组 GPU 上,生成的 KVCache 使用剩余的 GPU 内存(即尽力而为分配)
- 图 15 给出了在 16 个 GPU 上运行 RLHF 时 7B 和 13B 参数模型的过渡和生成时间
- 训练并行组为 1-8-2(遵循 p-t-d 约定),生成 TP 组大小 \(t_g\) 从 1 到 8 不等
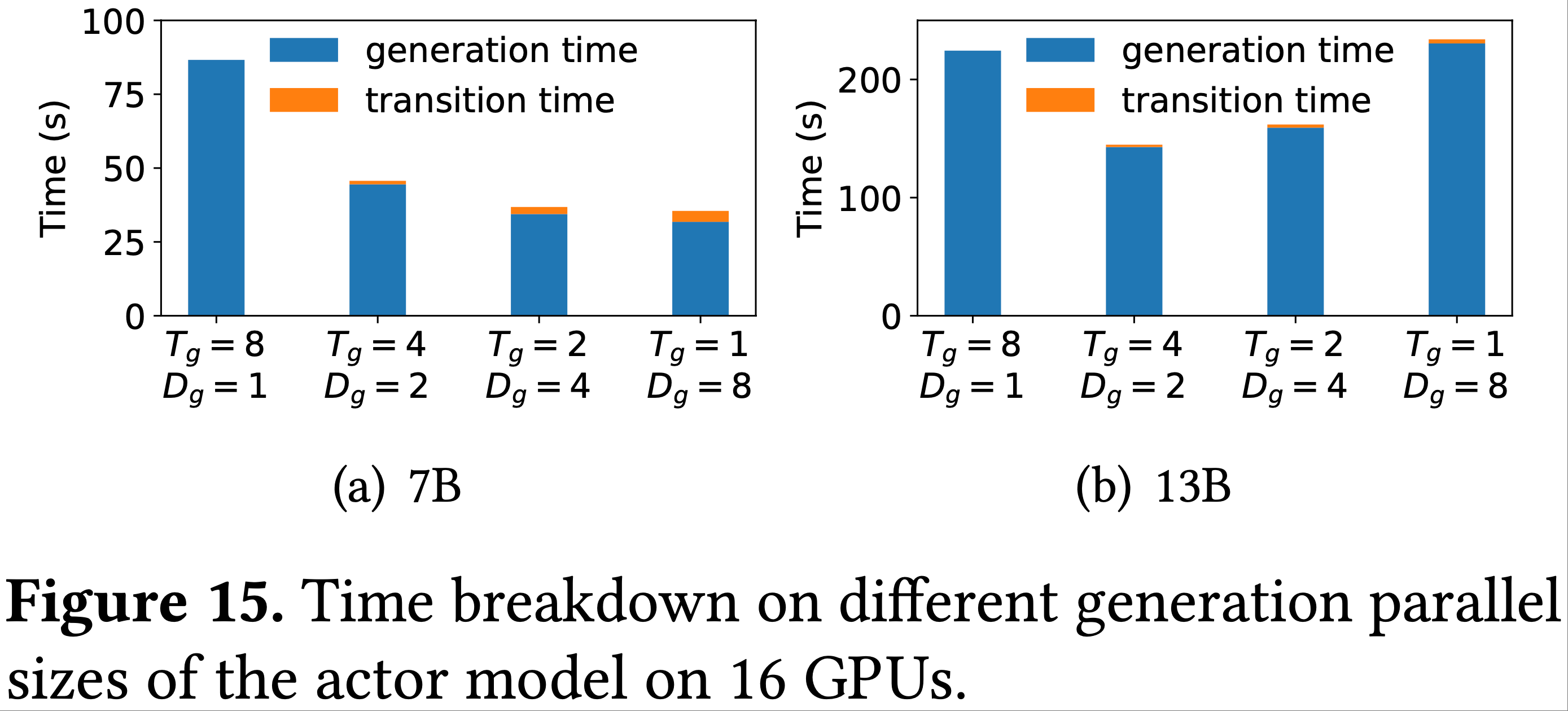
- 训练并行组为 1-8-2(遵循 p-t-d 约定),生成 TP 组大小 \(t_g\) 从 1 到 8 不等
- 生成 PP 组大小保持为 \(p_g=1\) ,微 DP 组大小 \(d_g\) 计算为 \(\frac{8}{t_g}\)
- 论文观察到
- 对于 7B 参数模型,使用较小的生成 TP 组大小 \(t_g=2\)
- 对于 13B 参数模型,使用 \(t_g=4\) ,分别减少了 60.3% 和 36.4% 的生成延迟
- 相反,遵循 NeMo-Aligner 的方法,使用与训练相同的 TP 大小( \(t_g=8\) ),会导致最大的生成延迟,因为 GPU 利用率不足
- 进一步减小 \(t_g\) 无法实现更高的加速比,因为较小的 \(t_g\) 需要每个 GPU 维护更大的 KVCache
Algorithm Runtime
- 图 16 显示了算法 1 的运行时间,该时间明显短于实际 RLHF 训练的天数
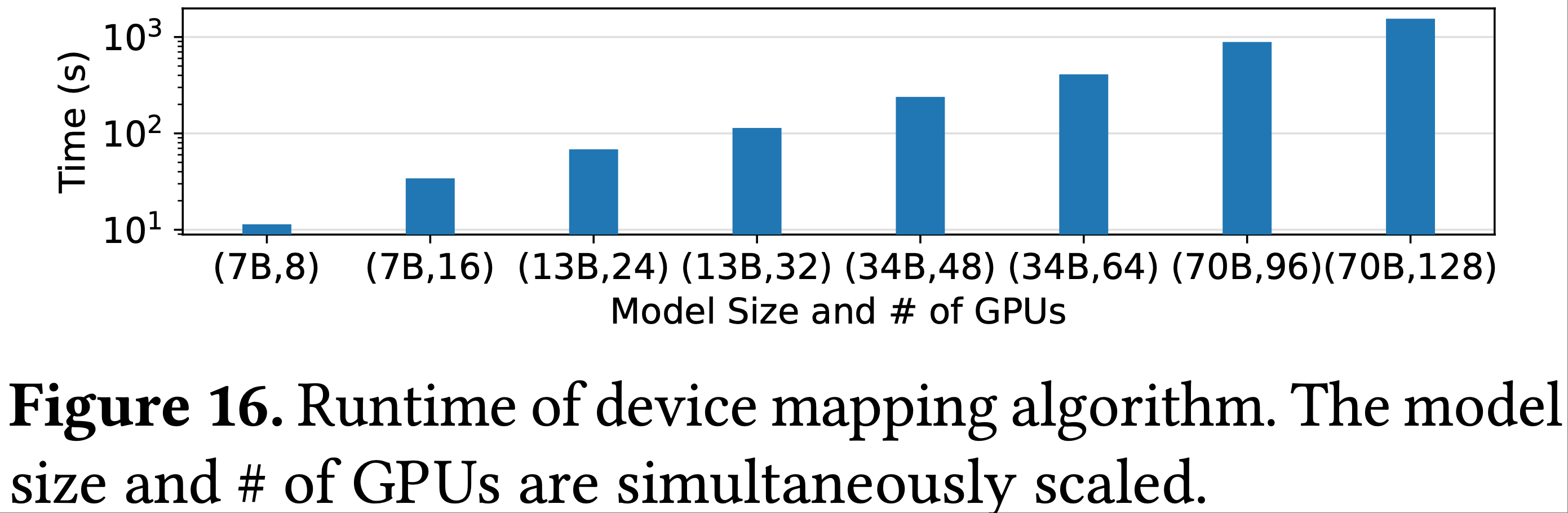
- 运行时间呈线性增长,表明设备映射算法在模型大小和集群大小方面具有良好的可扩展性
- 大部分运行时间用于估计每个模型并行策略的执行延迟
- 更大的模型有更多可用的并行策略,需要更多模拟来为每个放置计划确定最优策略
- 论文缓存模型的最优并行策略,以便在不同放置中重新应用,将最佳放置的搜索时间减少到最多半小时
Discussions
Fault Tolerance(容错能力)
- HybridFlow 与现有的容错方法(2020;2023;2021;)是正交的,并且已经集成了检查点机制(checkpointing)
- 可以通过 NCCL 错误检测故障,通过校验和检测静默数据损坏(silent-data-corruption)
- 论文的编程模型使单控制器能够通过 RPC 协调检查点操作,从而可以在每个 ParallelWorker 组内保存模型状态
- 这包括保存 actor/critic 模型的参数、数据加载器 ID(dataloader IDs)和随机数生成器(Random Number Generator, RNG)状态,以确保系统级一致性
- 此外,如果有足够多健康的模型副本可用,HybridFlow 还可以采用基于冗余的容错方法,例如广播参数和 CPU 检查点,以实现快速恢复(2023;2023)
Placement Insights
- 论文总结了 RLHF 训练中模型放置和 GPU 分配的三个主要见解
- 1)为 actor 模型分配更多 GPU 可以减少耗时的生成延迟,而生成延迟无法与其他模型并行化
- 2)当每个模型的计算都能充分利用 GPU 资源时,在相对小规模的集群上训练时,将所有模型共置是最有效的
- 3)当扩展到大规模集群(即强扩展)时,将 actor 和 critic 模型分布在不同设备上,以便在训练和准备阶段并行执行,有助于实现更高的吞吐量
Resource multiplexing(资源复用)
- HybridFlow 通过利用 GPU 计算的时间共享(time-sharing),支持模型在共享设备上的共置
- DNN 任务调度领域的最新研究已经开发了细粒度资源复用技术,主要旨在实现单个任务的服务级别目标(2020;2022;2022;2022;2021;2023;2023)
- 尽管
ResourcePool实现支持共置模型的并行执行,但如第 2.3 节所讨论的,HybridFlow 通常遵循顺序执行,以防止 GPU 资源竞争或 OOM 问题 - 在 RLHF 训练中应用 GPU 共享和异构资源面临着独特的挑战 ,因为它需要平衡计算工作负载并管理各种任务之间复杂的数据依赖关系
- 研究用于 RLHF 训练中 GPU 共享的细粒度自动映射算法,结合模型卸载优化和异构设备集成,将是未来研究的一个有前景的方向
From alignment to reasoning
- 在用于 LLM 对齐的 RLHF 中,奖励信号由奖励模型生成
- 除了对齐任务外,类似的算法(如 PPO 和 GRPO(2024))还可应用于其他领域,如代码生成和数学推理
- 对于这些任务,每个 Prompt 可能存在一个真实值(ground truth),这可以通过评估每个代码测试用例的输出值的正确性和验证数学结果的准确性来确定
- 因此,奖励模型可以被非神经网络奖励模块取代,例如用于评估生成代码的沙箱环境(2024)或用于验证数学结果的奖励函数(2021;2019)
- HybridFlow 可以通过将这些奖励模块包装为远程函数,并在单进程脚本中编排它们的执行,无缝集成这些奖励模块,为各种强化学习应用提供一个灵活高效的框架
Related Work
RL frameworks
- 已有许多强化学习框架,从用于小规模深度神经网络的通用强化学习系统设计(2017;2017;2017;2018;2018;2021)到专门为 LLM 优化的 RLHF 系统(2023;2024;2023;2023;2023)
- 论文在第 2 节中详细研究了密切相关的工作,并在本节中讨论更多强化学习框架
- 这些强化学习框架(2017;2017;2017;2018;2023)与最近的 RLHF 系统类似,使用多控制器框架的混合体来实现其算法。它们建立了多个长期运行的分布式程序,每个组件通过硬编码的数据同步来协调执行顺序
- Gear(2023)进一步优化了强化学习 pipeline 的经验回放(experience replay)部分
- 然而,所有这些框架都不支持 RLHF 中的 LLM 训练、推理和生成
LLM training and serving systems
- TorchDDP(2019)和 Horovod(2018)支持数据并行训练
- ByteScheduler(2019)和 DeepSpeed(2020)通过通信和内存优化扩展了数据并行性
- 许多系统(2021;2024;2021;2021;2019;2023;2022)通过模型并行性(如张量并行和管道并行)优化大型模型训练,将模型分布到多个设备上
- LLM 服务系统(2023;2023;2023;2023;2022;2024)也采用数据和模型并行性,通过连续批处理(2022)和分块预填充(2023)等专门优化来加速自回归生成
- 请注意,上述所有框架都采用多控制器范式来实现高效计算
Dataflow systems
- 像 MapReduce(2008)、Spark(2016)、Dryad(2007)和 Naiad(2013)这样的数据流系统在分析和机器学习工作负载中很流行,但它们缺乏对动态任务图的支持
- Ray(2018)在单个动态任务图中统一了任务并行和 actor 编程模型,并实现了可扩展的分布式调度器和全局控制存储,许多强化学习框架都采用了这一点(2018;2021)
- Pathways(2022)是一个用于 TPU 的闭源项目,旨在轻松表达单个 DNN 模型中复杂的并行模式和细粒度控制流,例如管道并行和具有稀疏计算的 MoE
- 它采用异步分布式数据流设计,尽管存在数据依赖关系,但仍能实现并行控制平面执行,减少了单控制器范式的调度开销
- 它主要关注单模型训练,需要对 DNN 模型的每个子网络进行复杂的编译
- HybridFlow 可以集成 Pathways 作为子模块,以实现 RLHF 数据流中模型的计算
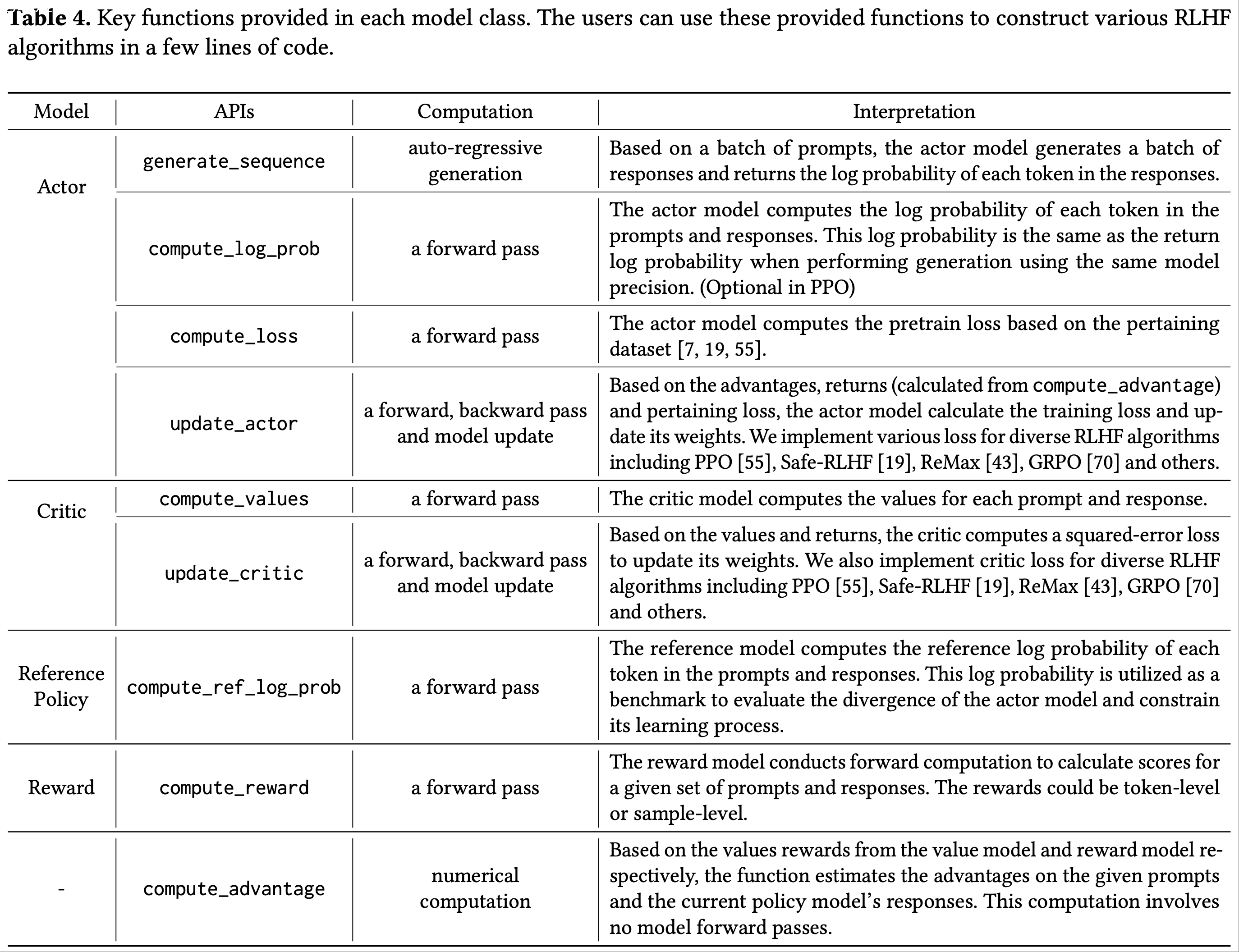
附录 A:Primitive APIs in HybridFlow
- 在 HybridFlow 中,论文通过继承 3DParallelWorker、FSDPWorker 和 ZeROWorker 实现了 RLHF 训练中每个模型的基本操作
- 这些模型类的函数旨在解耦分布式计算代码,并为用户提供 RLHF 中的基本操作
- 这种基本设计与现有的分布式推理和训练框架中的自回归生成、前向传播、反向传播和模型更新操作兼容
- 用户可以根据算法设计轻松定制 RLHF 训练数据流(通过调整提供函数中的数值计算),并受益于重用底层分布式计算实现
- 论文在表4 中说明了这些 API 的含义和实际计算
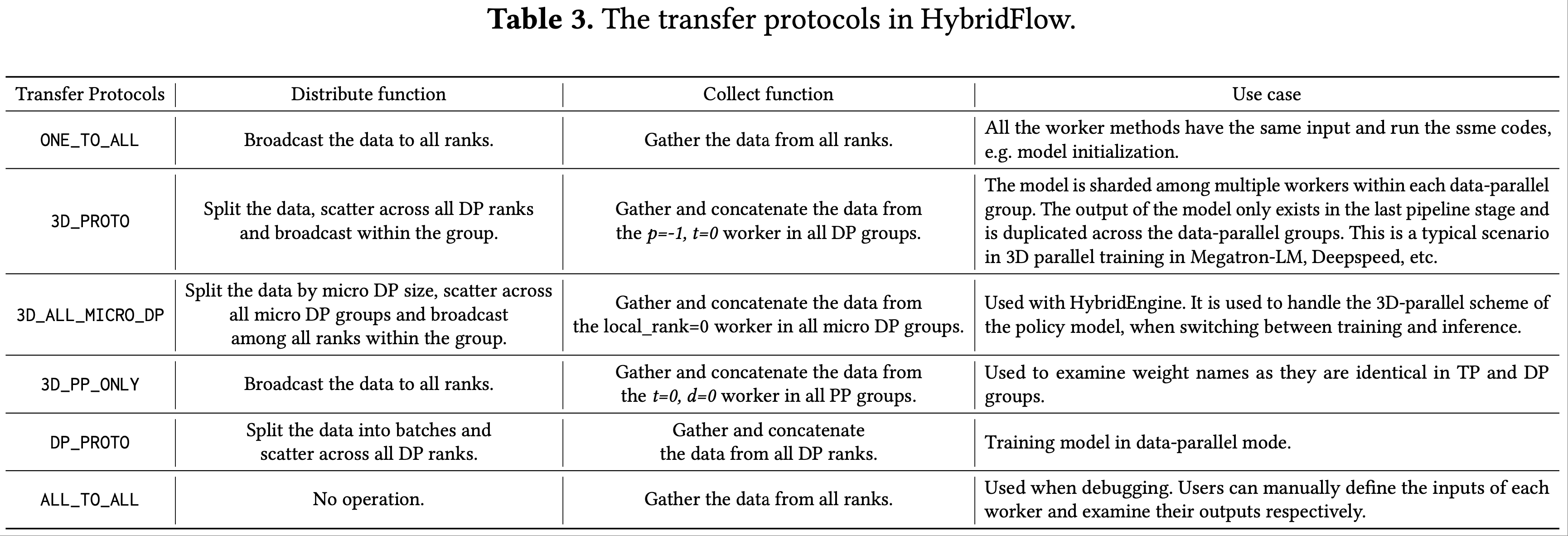
附录 B:Transfer Protocols
- 论文实现的传输协议涵盖了 RLHF 数据流中模型之间数据重分片的所有常见用例
- 用户可以利用这些预定义的协议生成任何 RLHF 数据流
- 此外,用户可以通过实现收集函数(collect function)和分发函数(distribute function)轻松定义自己的传输协议
- 传输协议解耦了复杂的数据重分片和分布式训练
- 论文用 \(p\) 、 \(t\) 、 \(d\) 分别表示工作进程在管道并行、张量并行和数据并行组中的排名
- 论文在表3 中说明了这些预定义的协议
附录 C:Auto-Parallelism Algorithm
- 算法2 概述了每个模型最优并行策略的搜索过程
- 从每个模型的最小模型并行大小开始(以防止与多个工作进程共置时出现内存不足),论文基于 GPU 数量和每台机器的 GPU 数量 \(U\) 枚举所有可行的并行配置
- \(U\) 的默认值设置为 8

- \(U\) 的默认值设置为 8
- 从每个模型的最小模型并行大小开始(以防止与多个工作进程共置时出现内存不足),论文基于 GPU 数量和每台机器的 GPU 数量 \(U\) 枚举所有可行的并行配置
- 论文使用
simu模块根据模型的工作负载估计每个模型的延迟- 该模块包括三个分别用于训练、推理和生成工作负载的模拟器,均为遵循先前研究的分析模型(2023;2024;2024;2024)
- 训练和推理工作负载是计算密集型的 ,而生成工作负载是内存密集型的
- 对于 actor 模型,论文首先找到训练的并行策略,并记录训练阶段的内存使用情况
- 在 actor 生成期间,使用批次大小和最大序列长度计算 KVCache 需求
- 如果生成阶段的模型并行大小无法同时容纳参数和 KVCache,论文会增大它
- 然后,论文通过比较延迟估计来寻找具有相应 KVCache 分配的最优策略
- 开发一个考虑可变 KVCache 大小的全面自回归生成模拟器,可以进一步增强 RLHF 研究中的自动映射过程