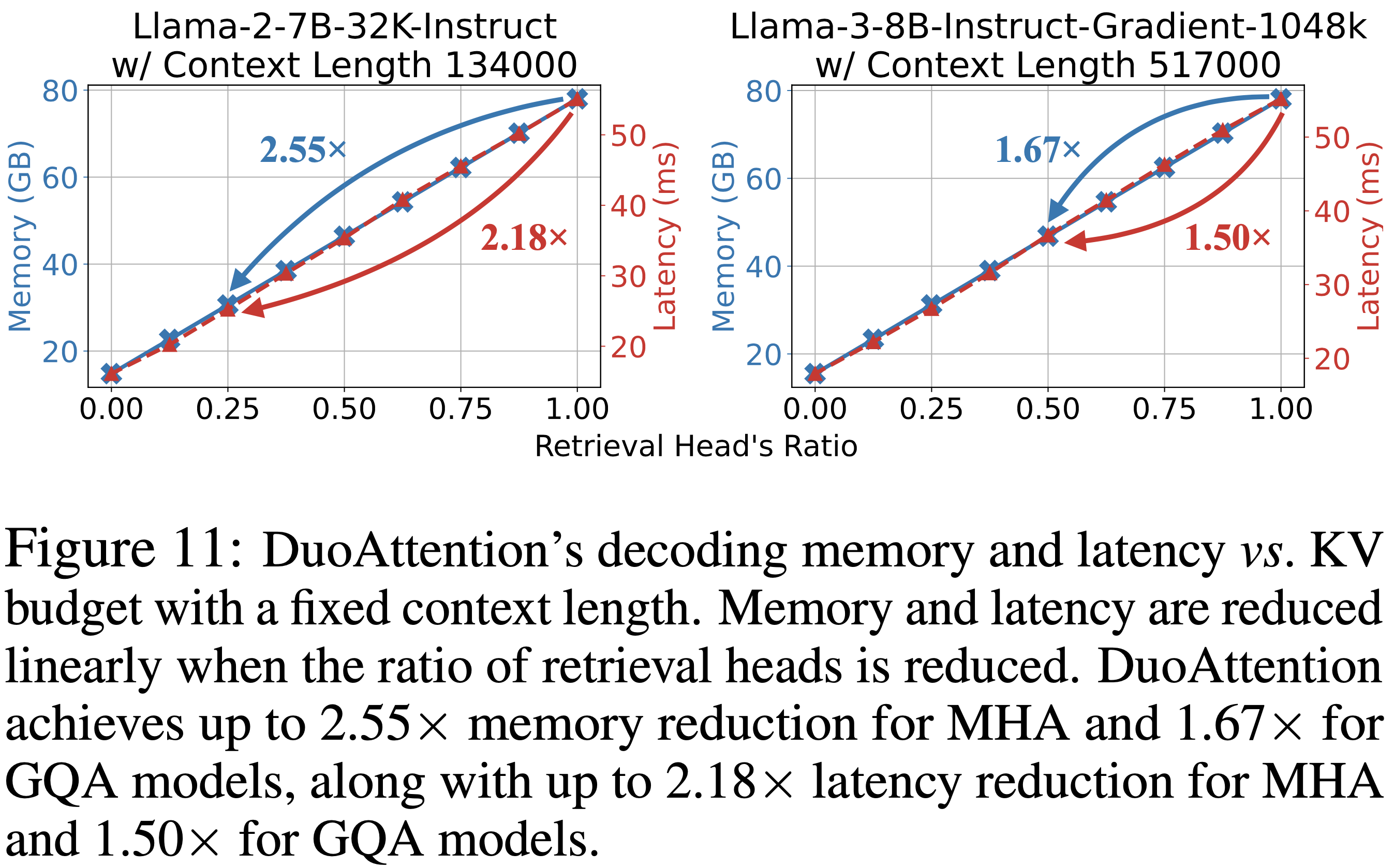
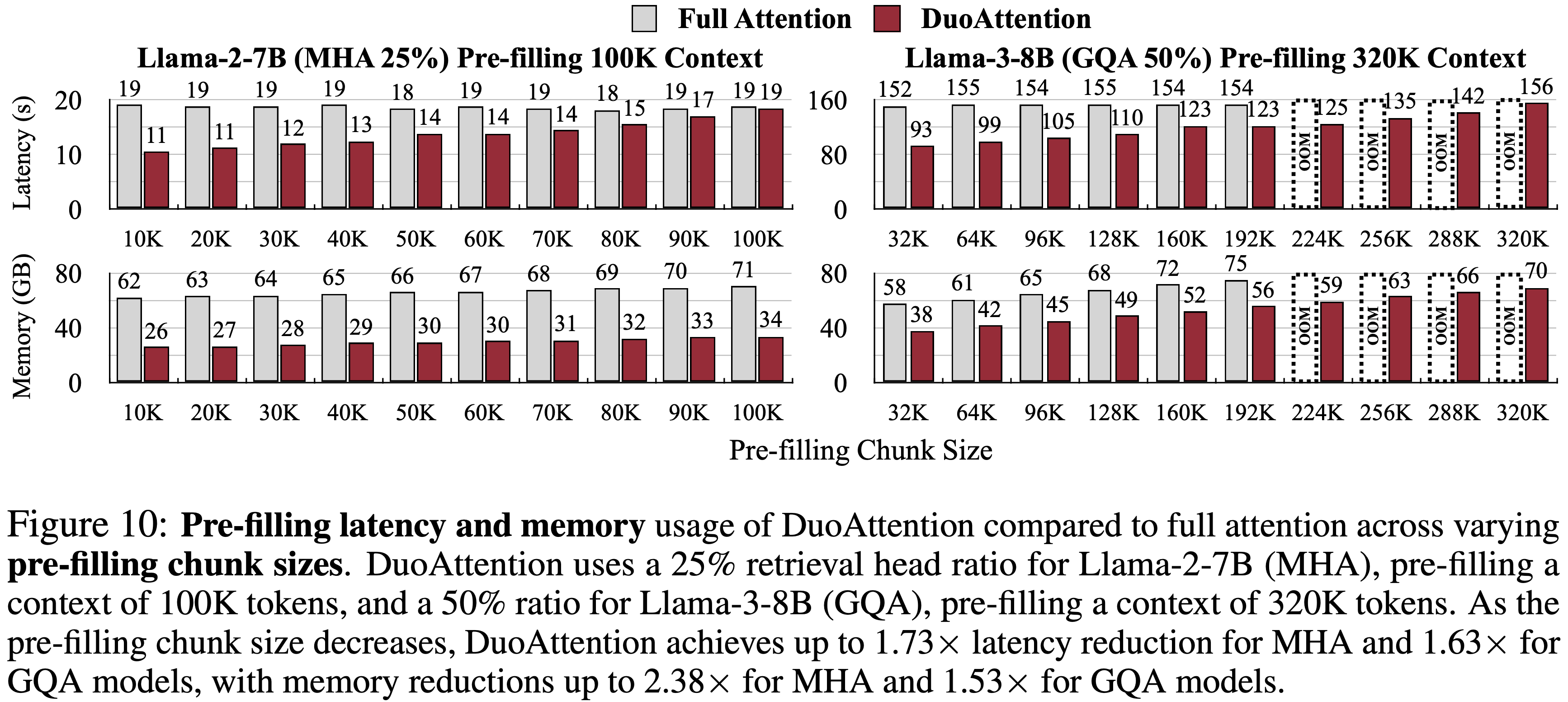
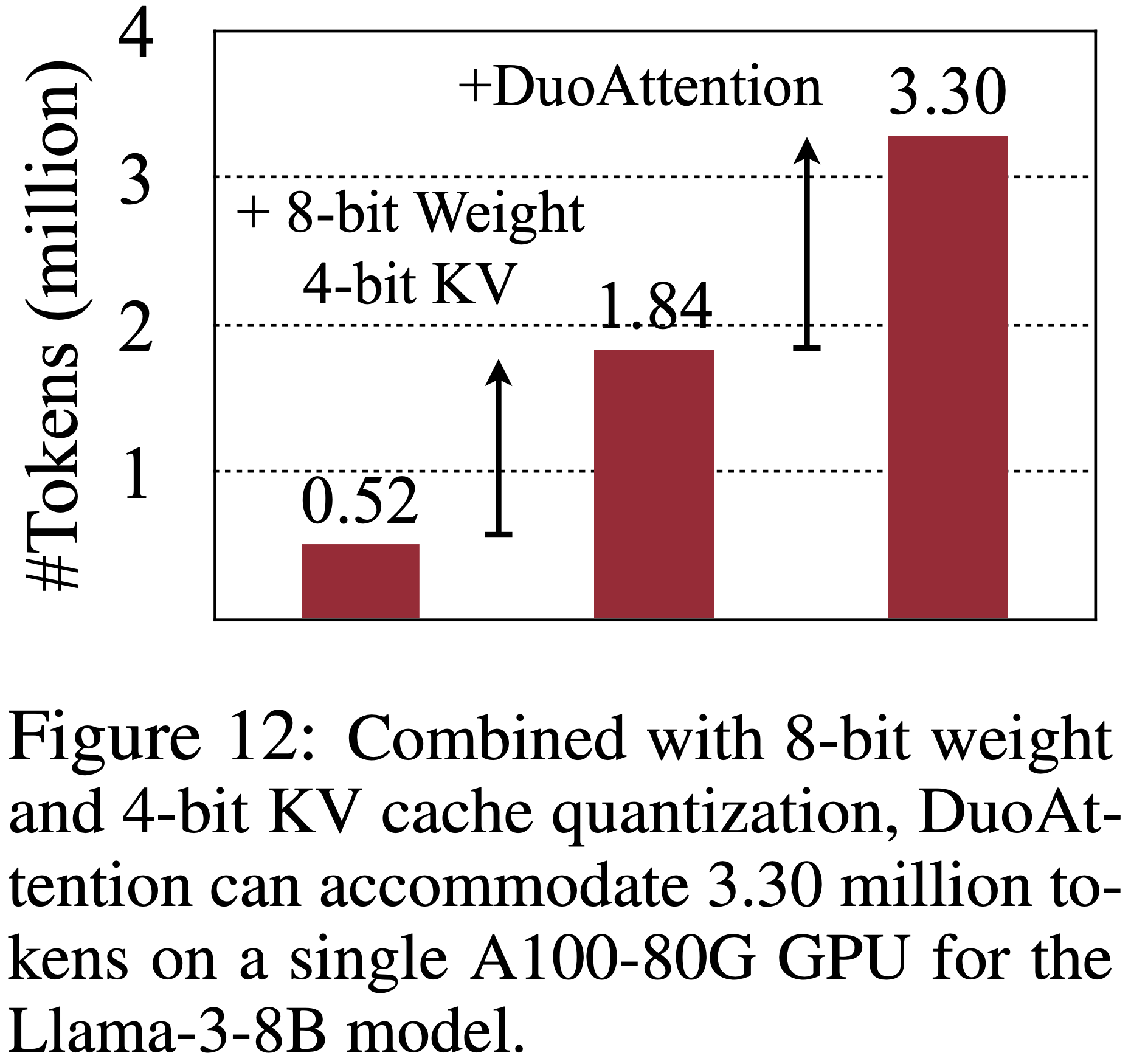
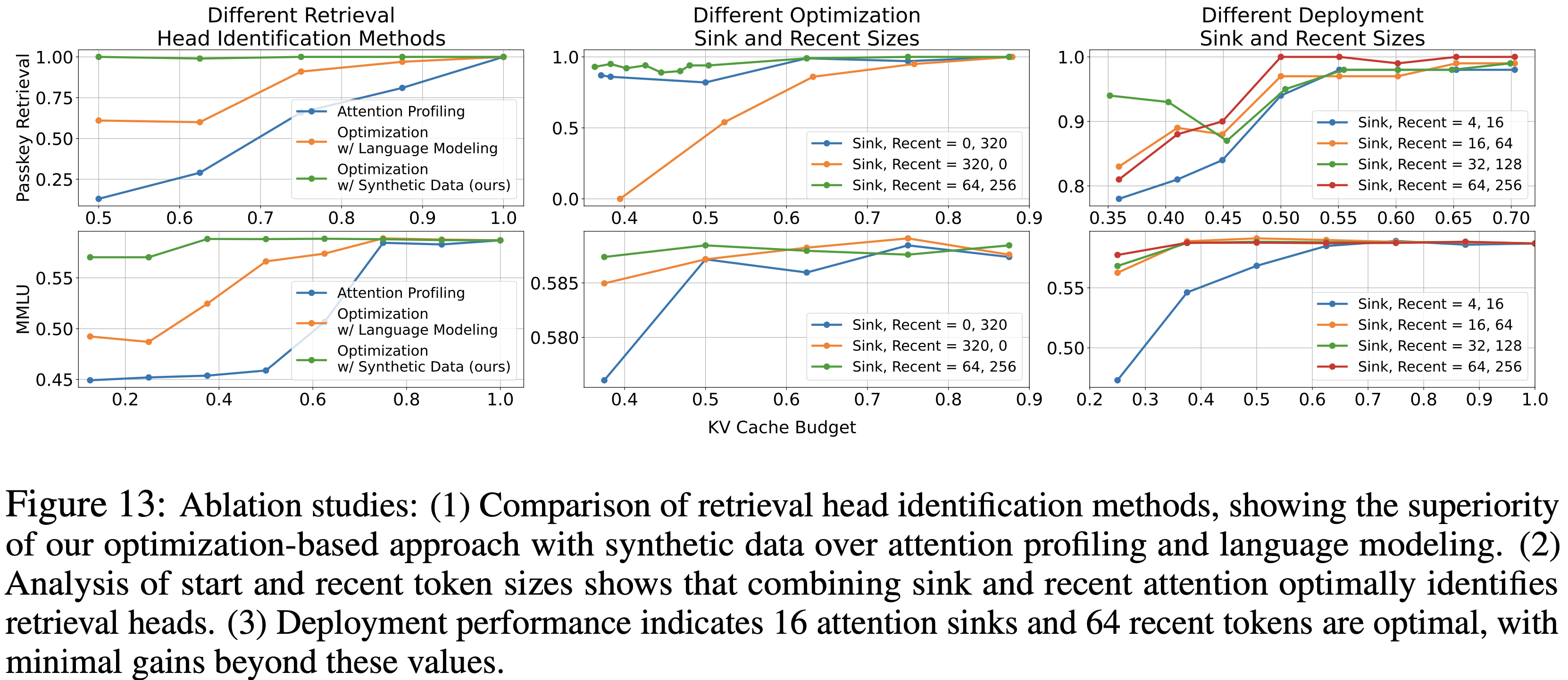
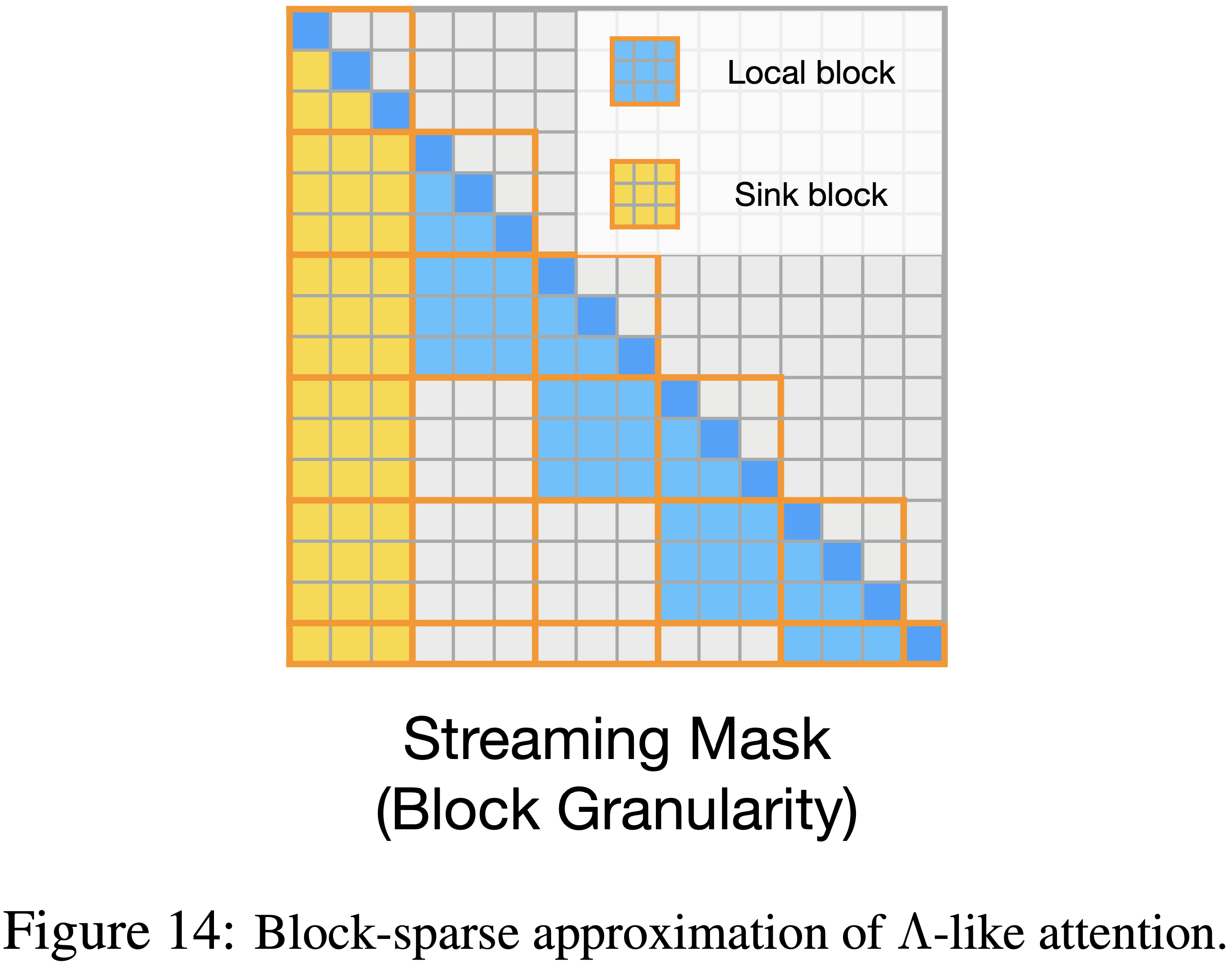
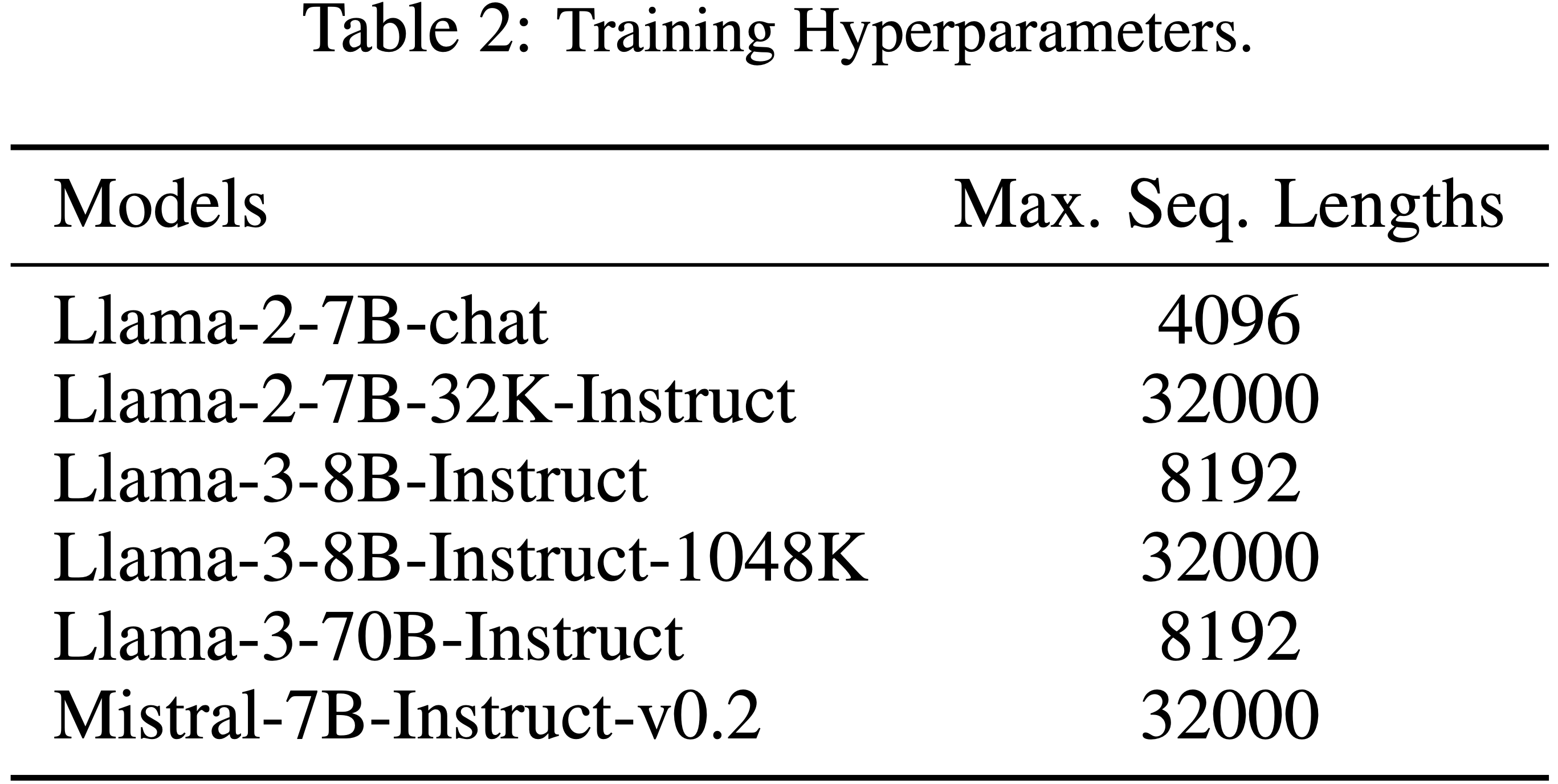
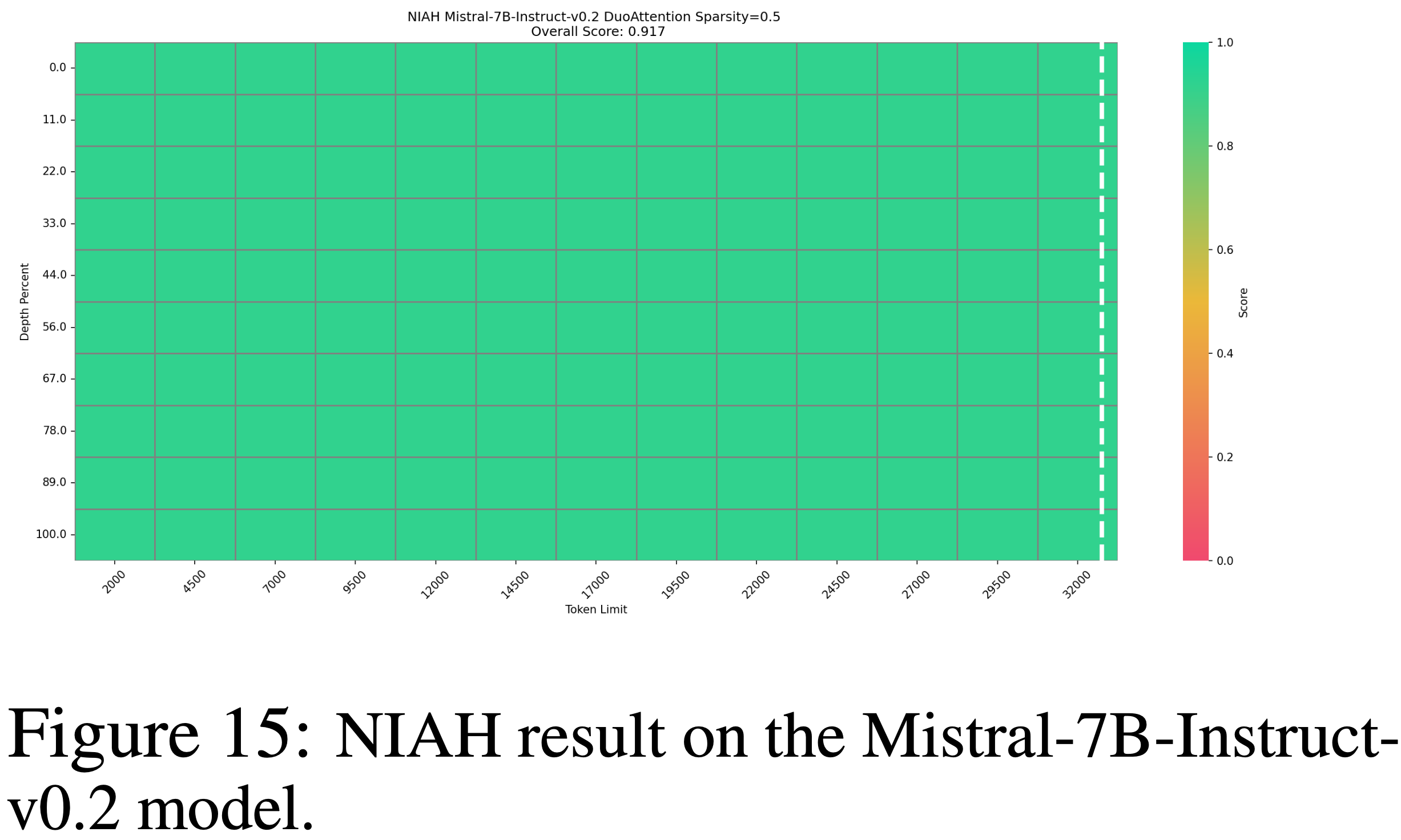
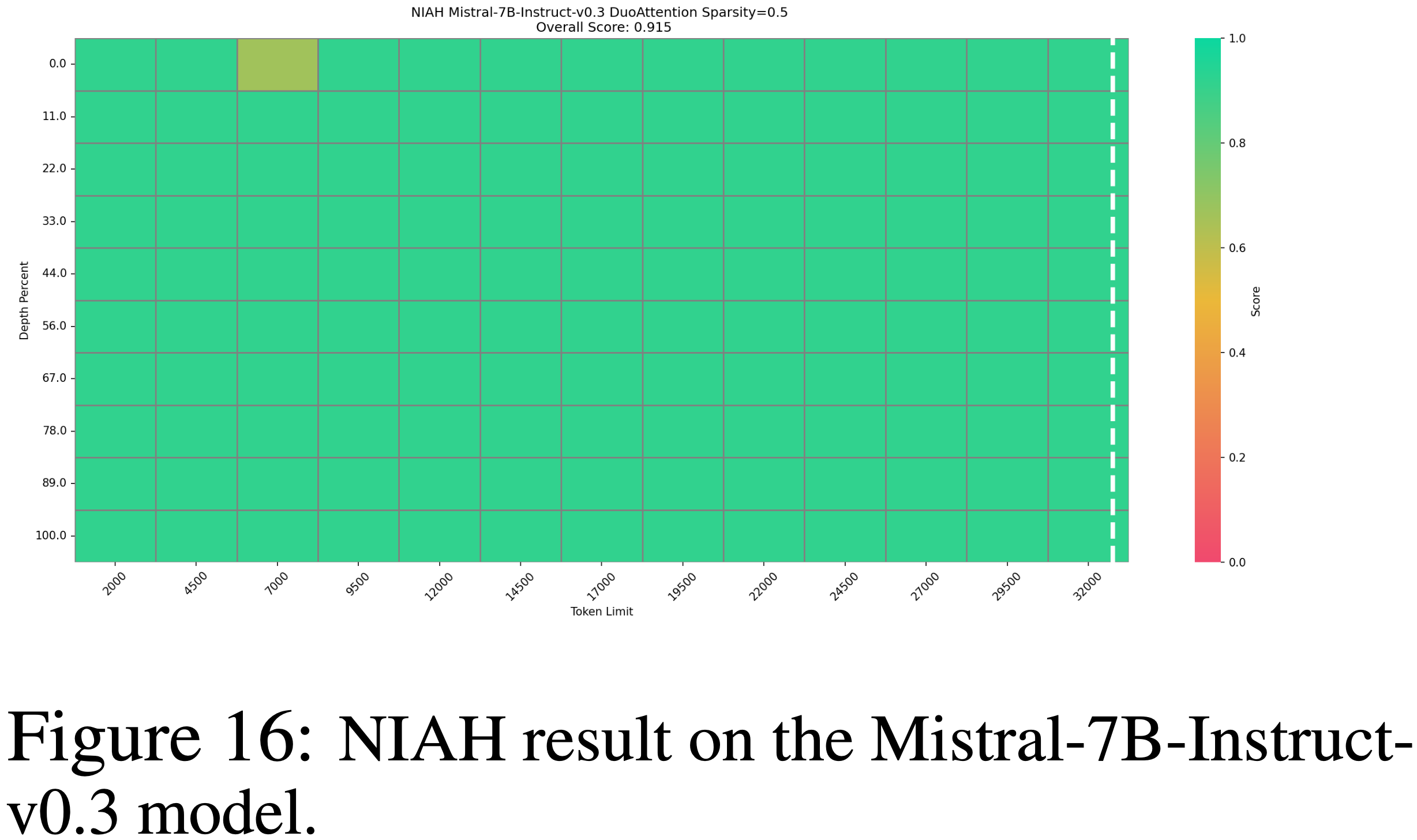
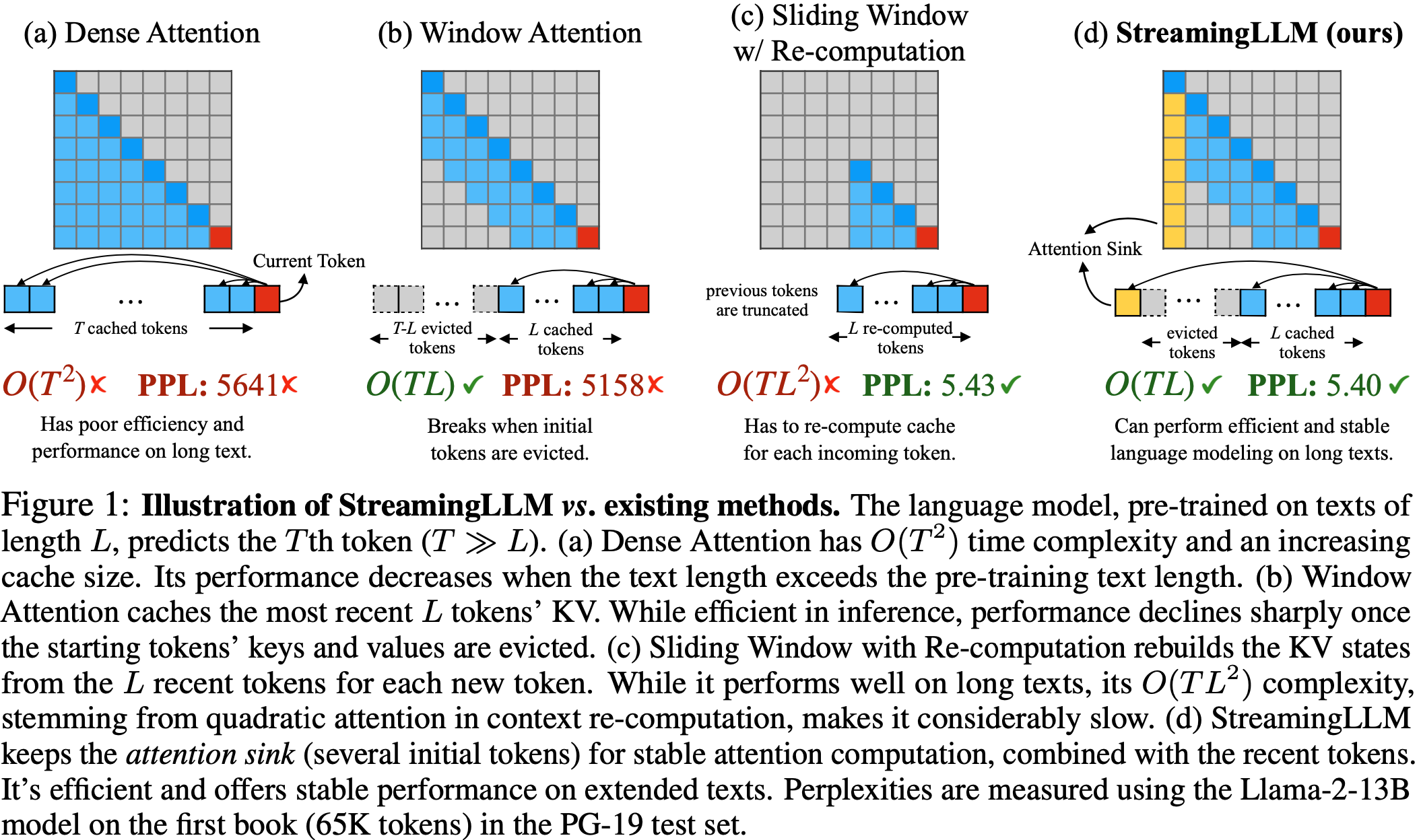
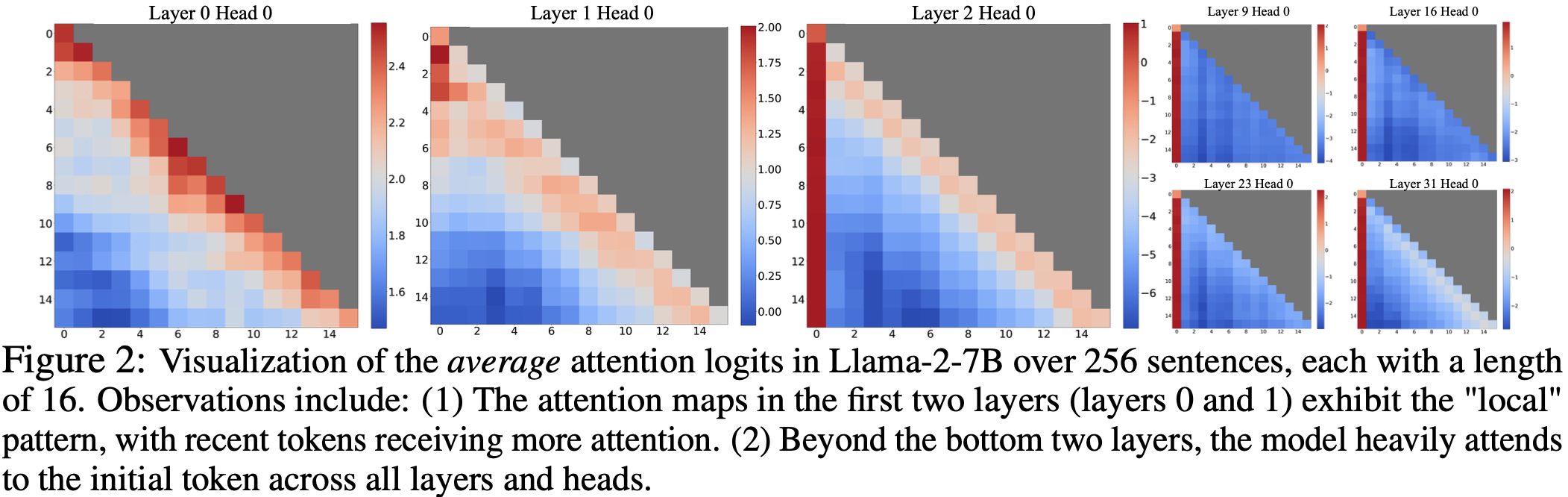
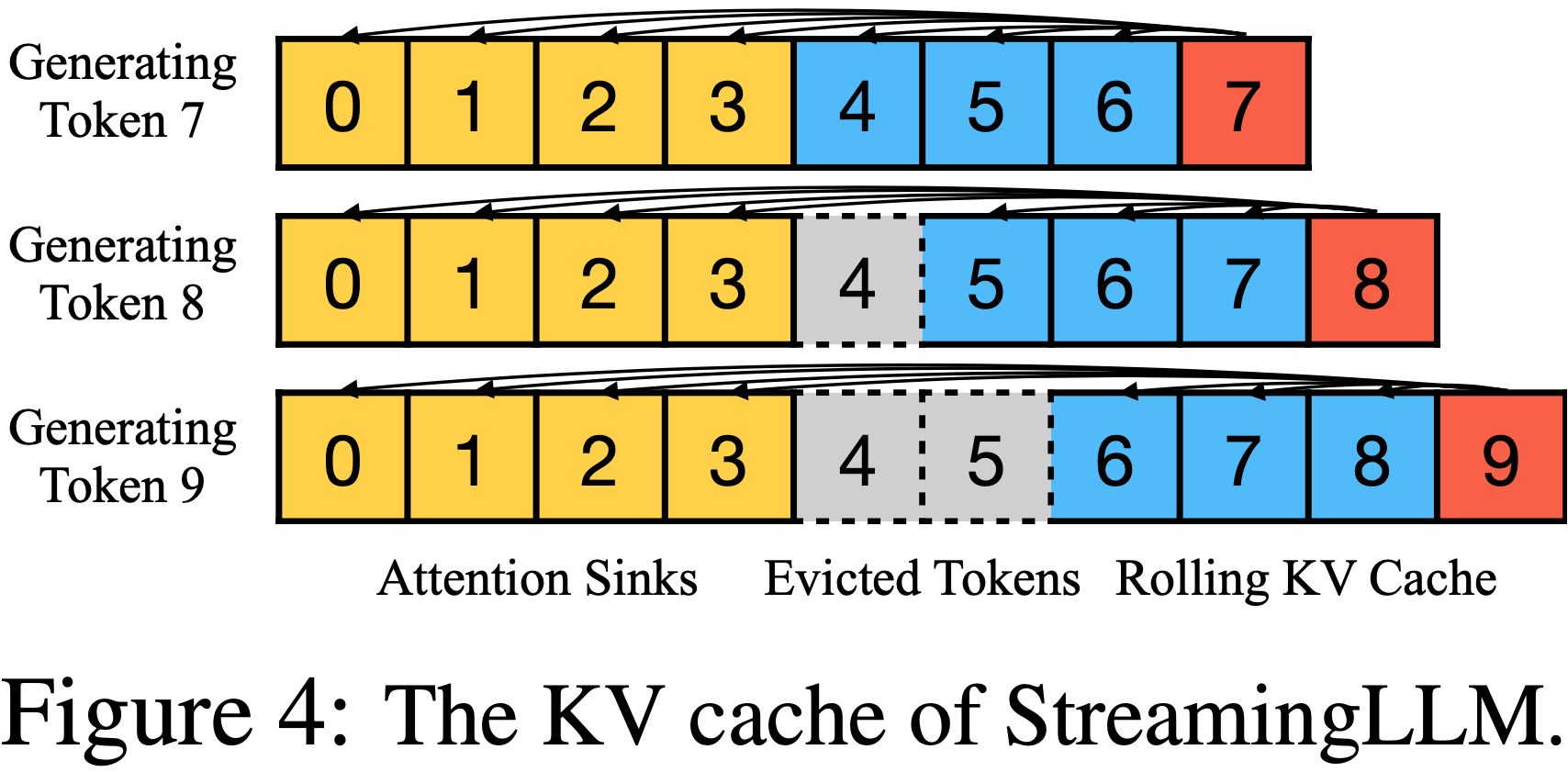
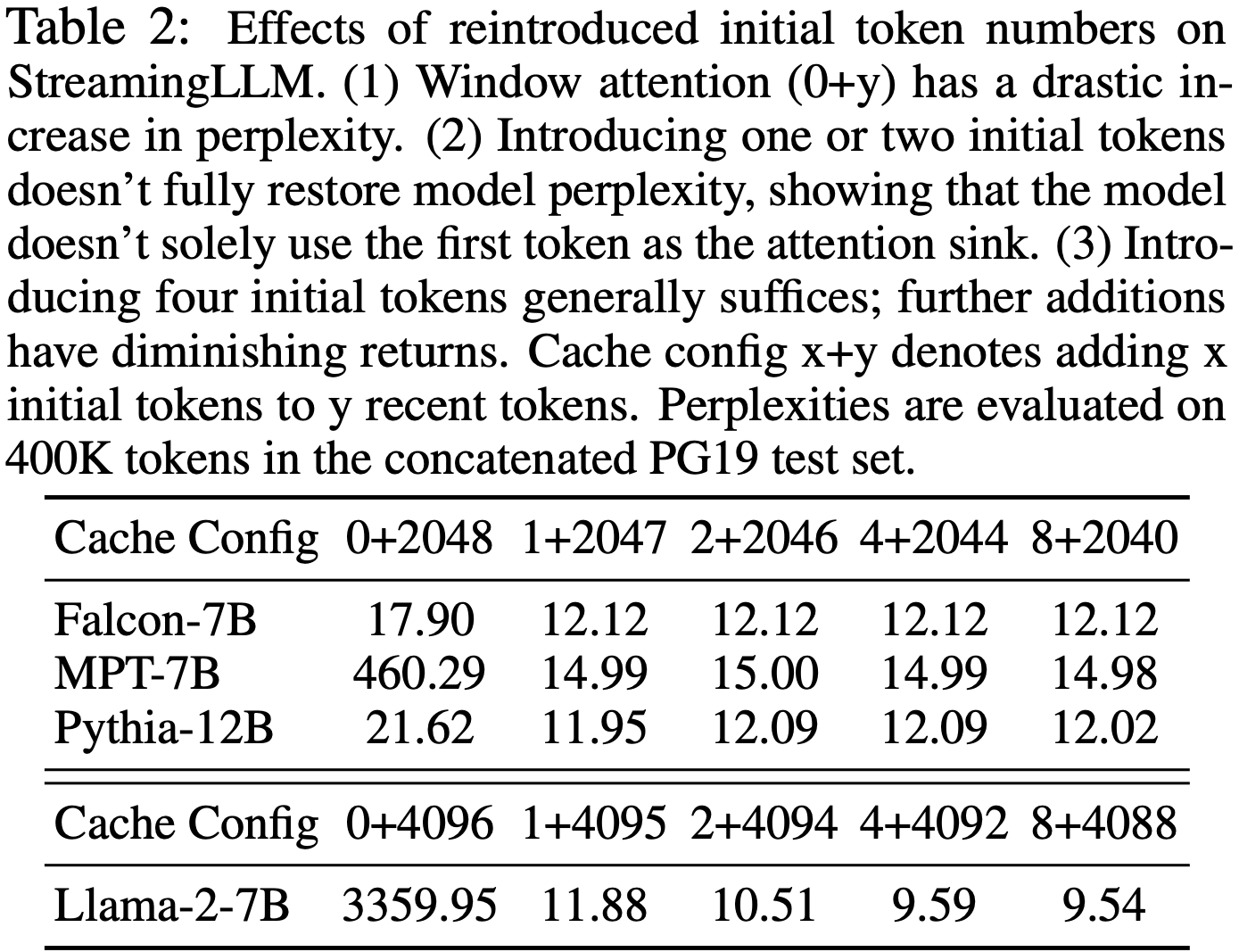
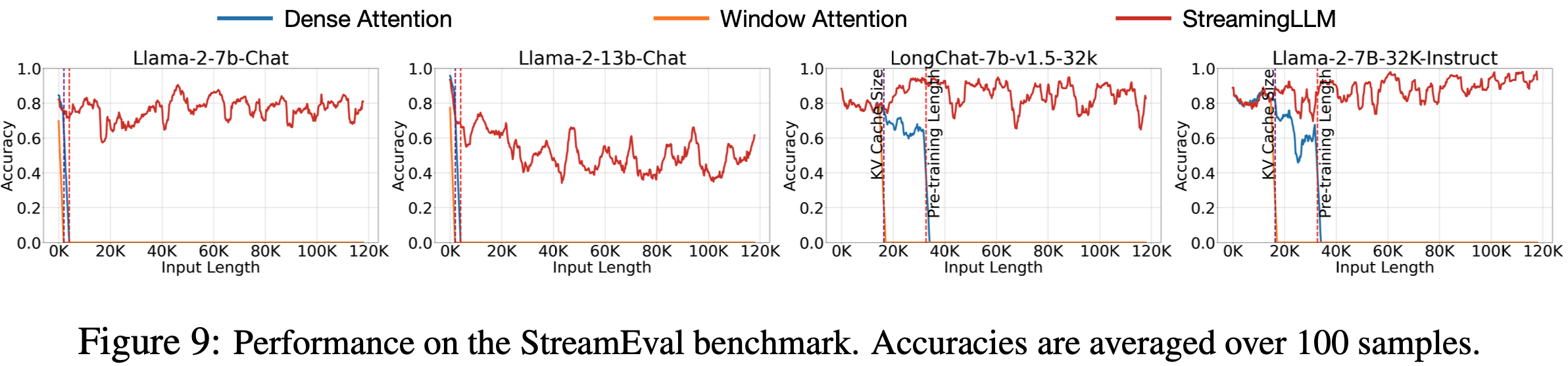
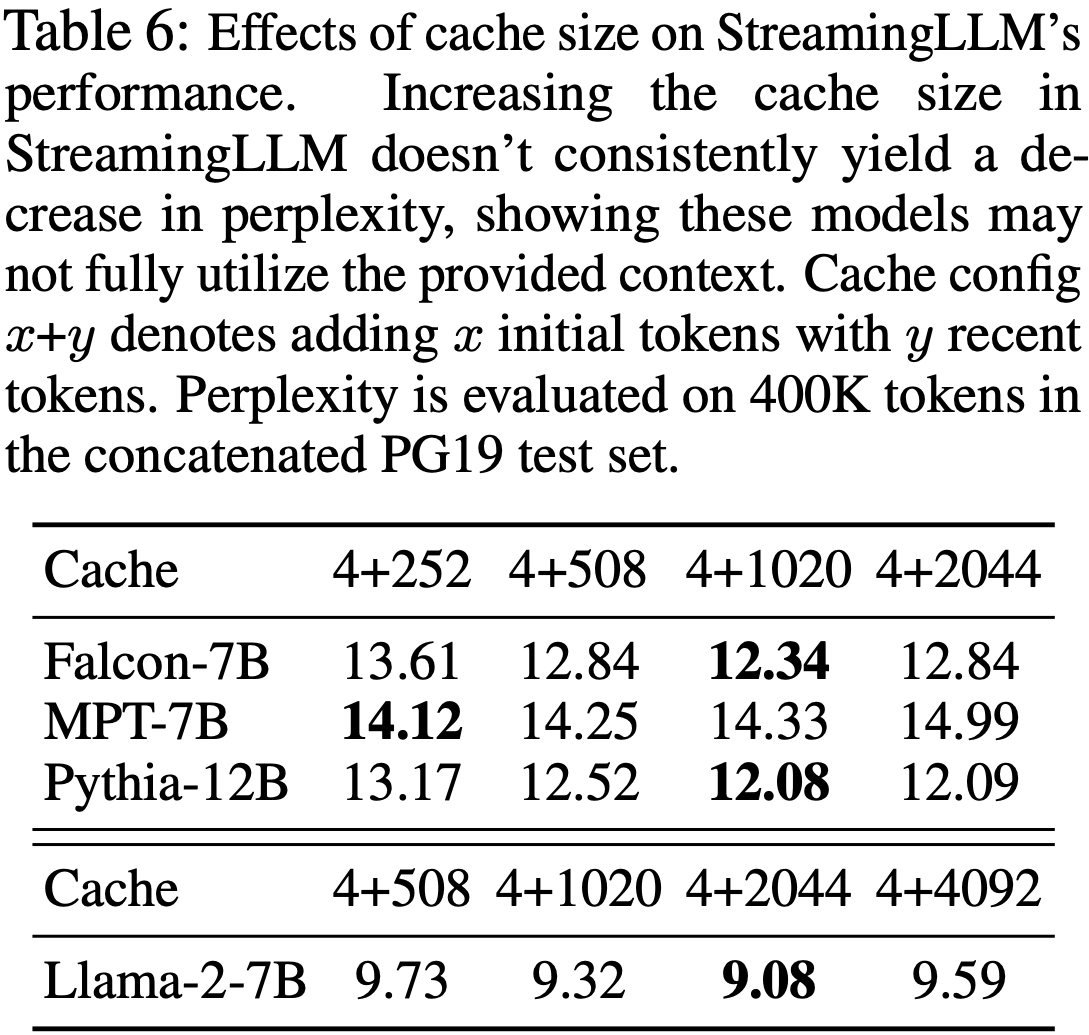
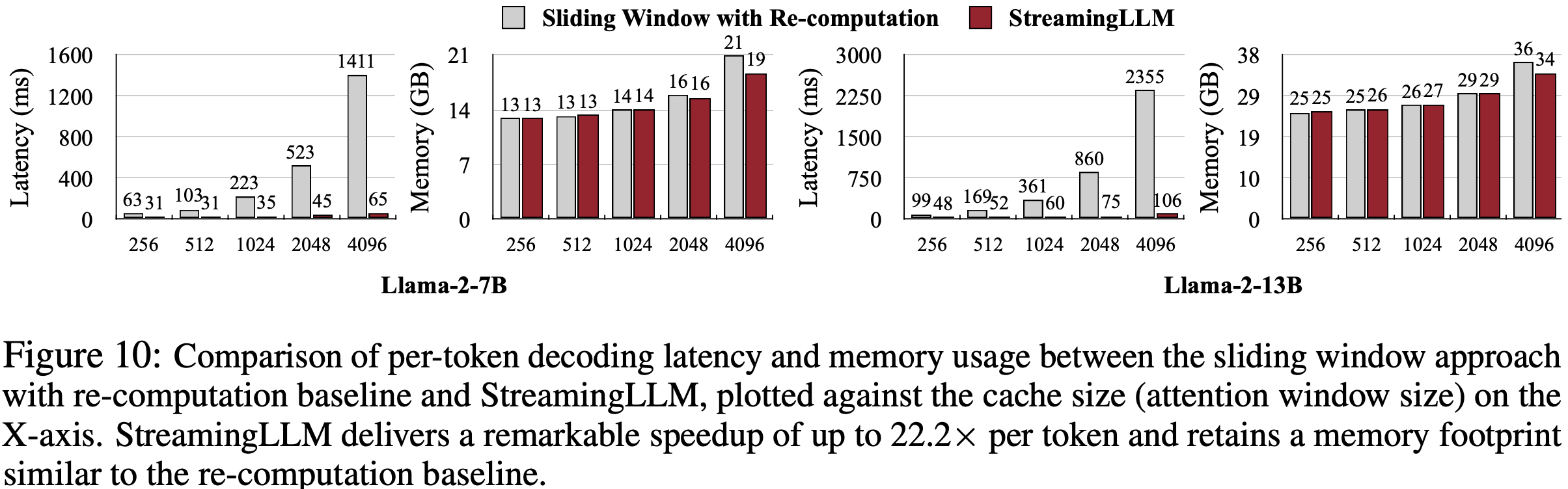
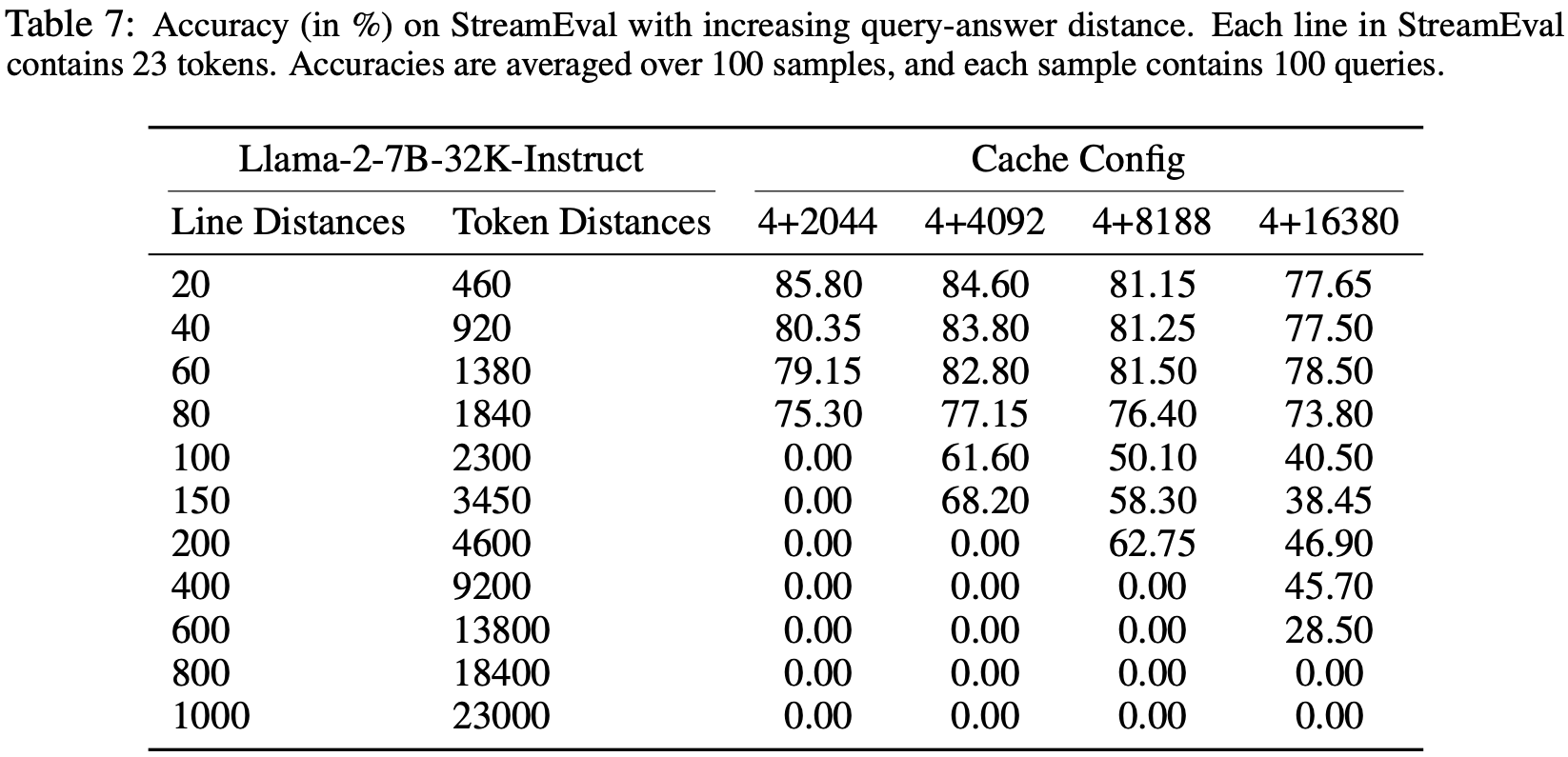
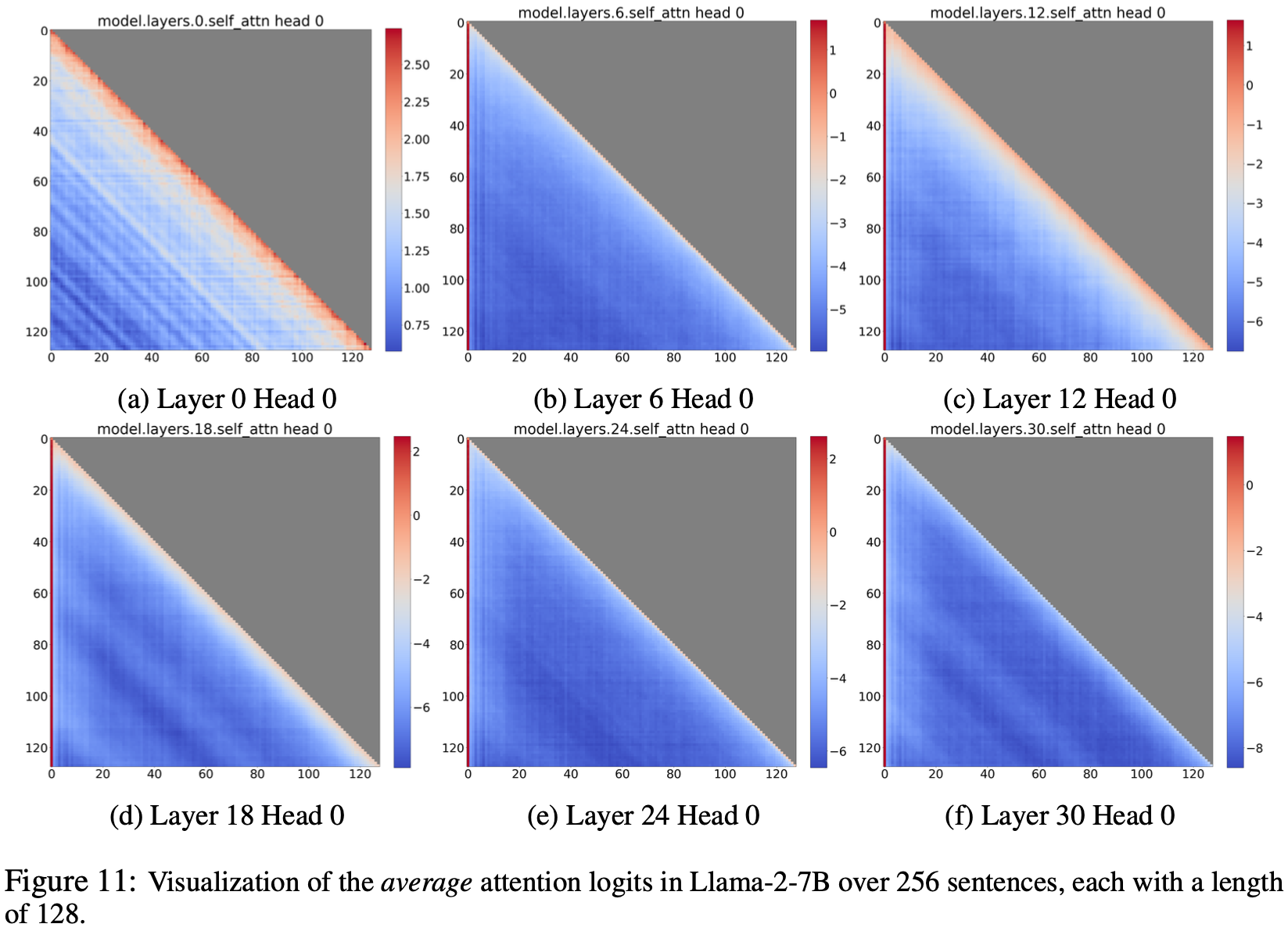
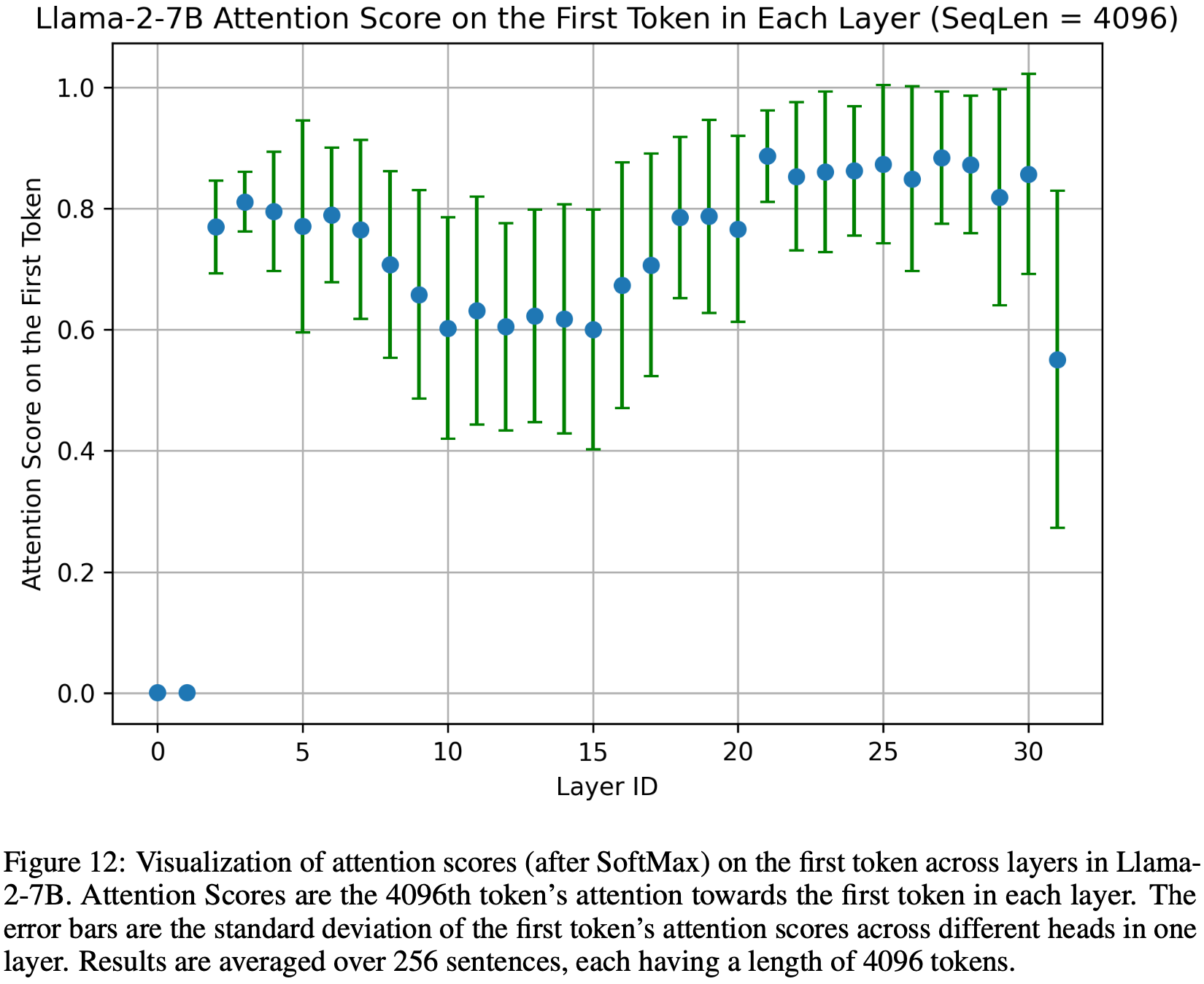
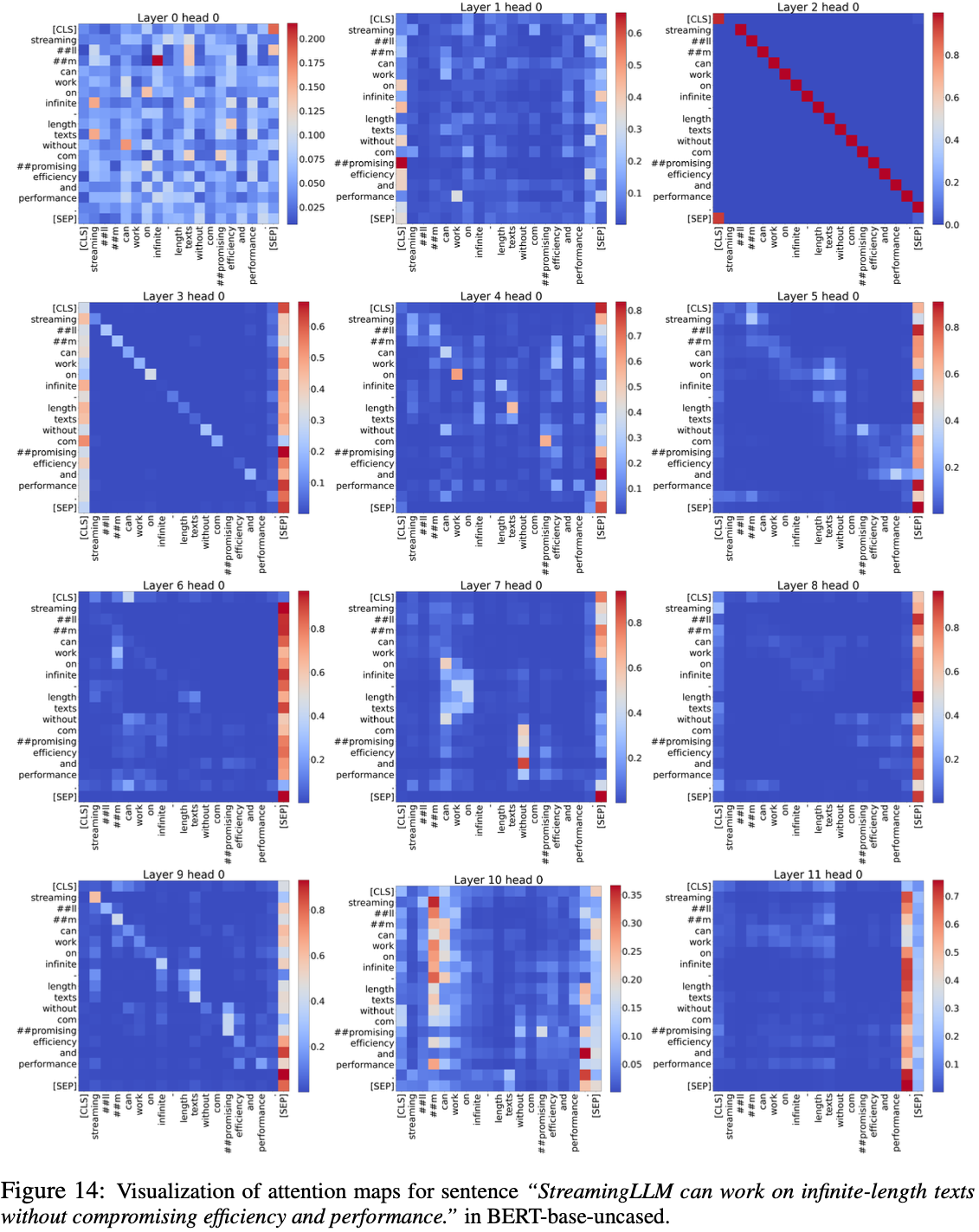
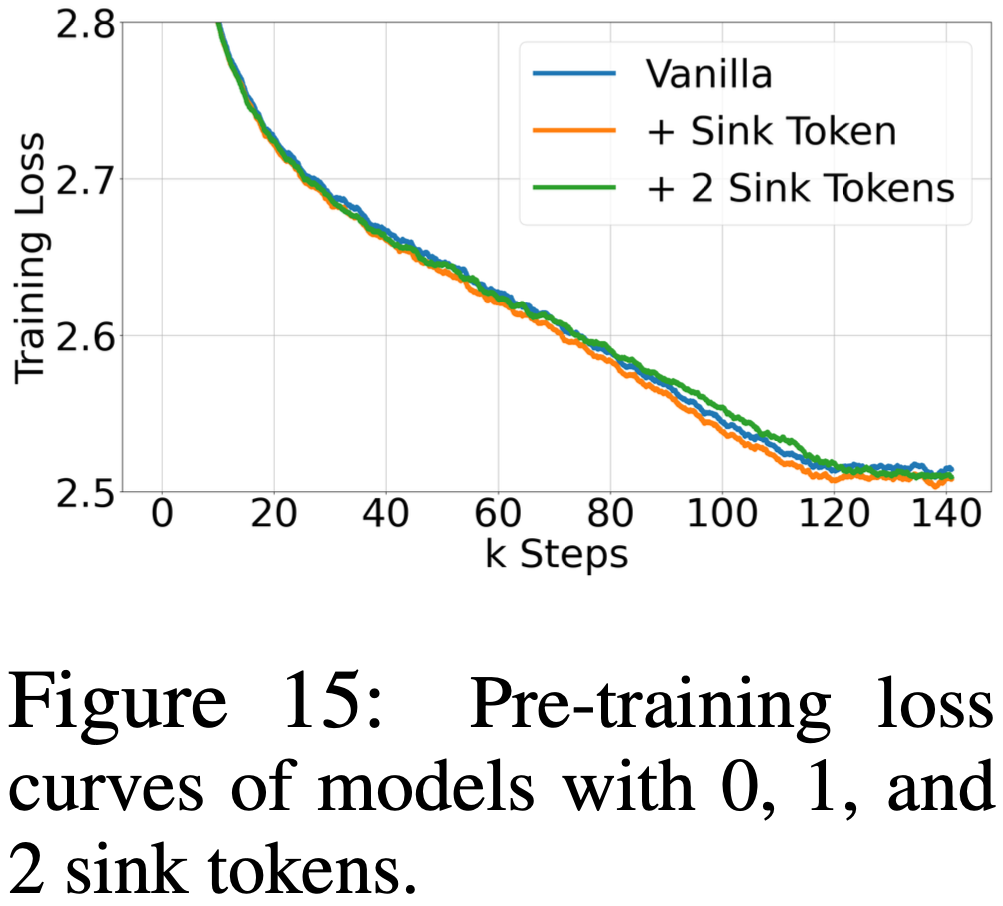
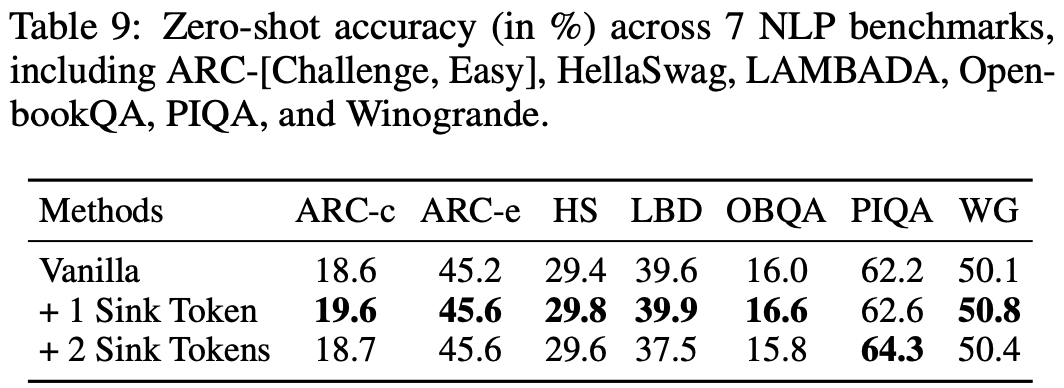
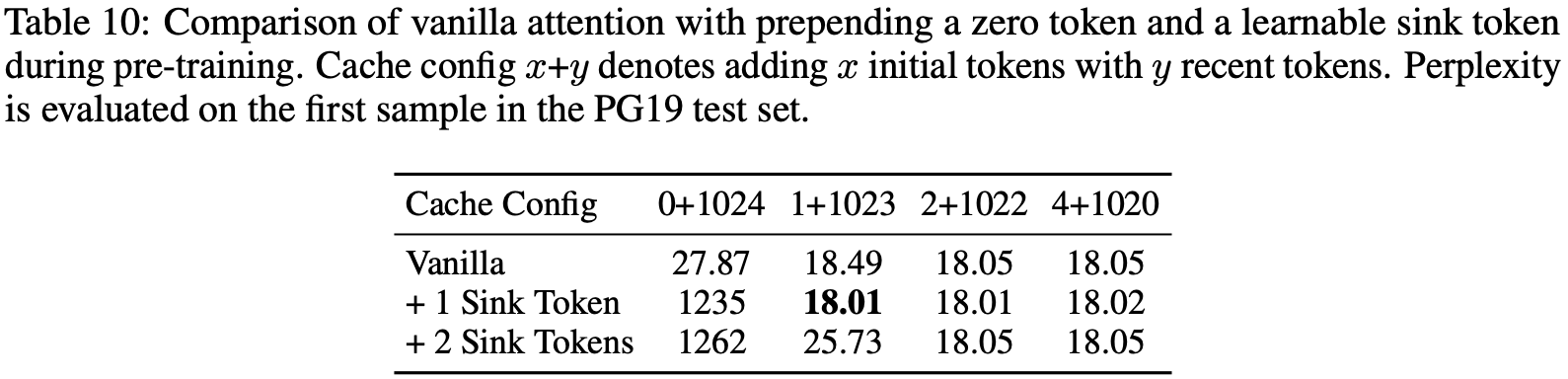
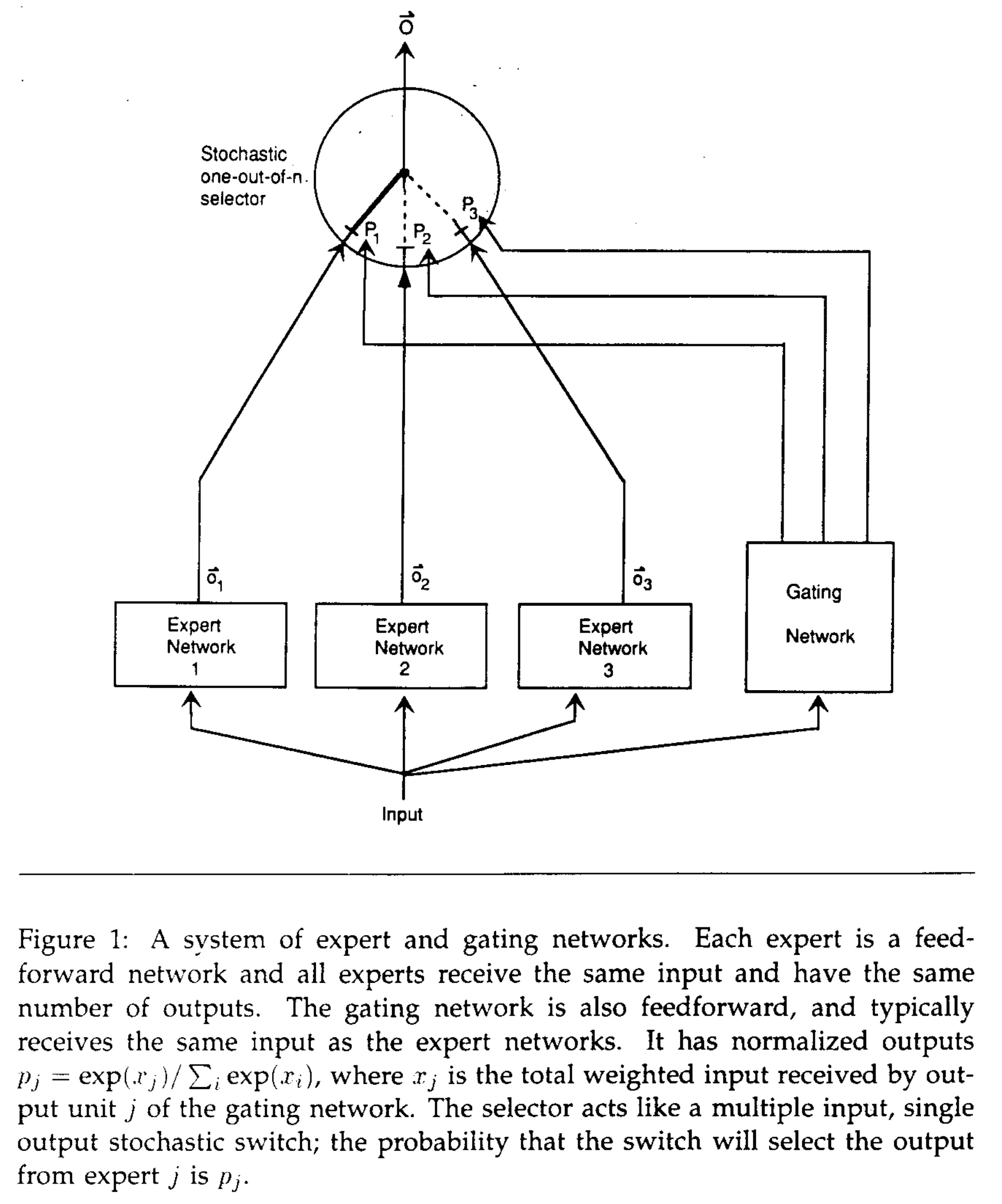
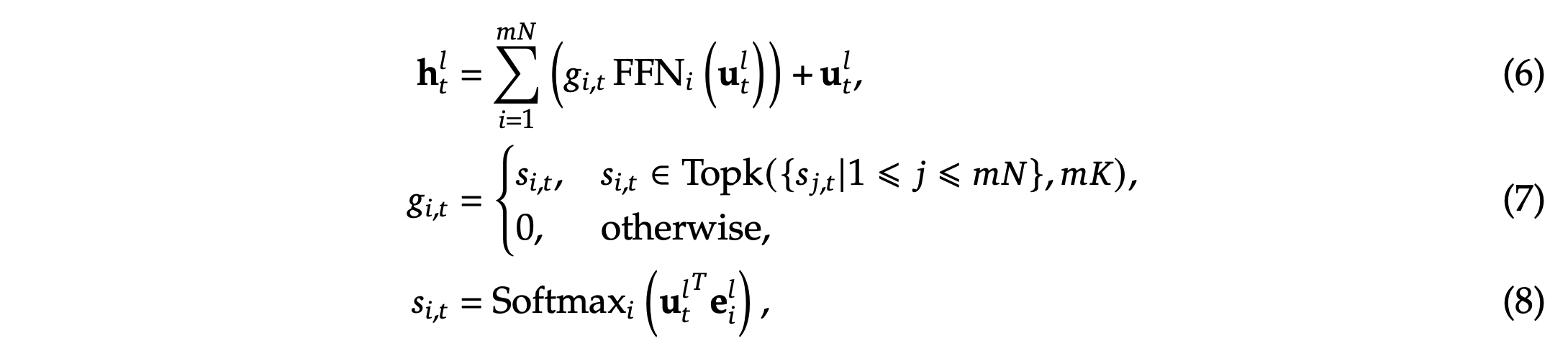整体说明
- FLOPS(Floating-Point Operations Per Second)和FLOPs(Floating-Point Operations)是衡量计算性能的两个相关但含义不同的术语
- FLOPs 是浮点运算次数 ,是模型复杂度的评估指标,用于评估一个模型的复杂度
- FLOPS 是每秒浮点运算次数 ,是硬件计算能力的单位,比如用于评估 GPU 性能
FLOPs(Floating-Point Operations)
- FLOPs 是 浮点运算次数 ,即模型或算法执行的总浮点计算量(如加、减、乘、除等操作数量)
- FLOPs 常用于衡量算法/模型的计算复杂度 ,举例:
- 矩阵乘法中,两个 \( n \times n \) 矩阵相乘需要 \( 2n^3 \) FLOPs(\( n \times n \)个数,每个数需要 \(n\) 次乘法和 \(n\) 次加法操作)
- 在深度学习中,FLOPs常用来估计模型的计算开销(如卷积层的计算量)
- 1 GFLOPs = 10亿次运算(算法复杂度)
- 注:”s” 为小写,表示复数(Operations)
- 用法:ResNet-50 模型约需 3.8 GFLOPs(38亿次浮点运算)处理一张图像
- 注意这里的十亿用的是 G,而不是 B,两者都有十亿的含义,但不同地方用不同的值
FLOPS(Floating-Point Operations Per Second)
- FLOPS 是每秒浮点运算次数 ,是硬件计算能力的单位
- FLOPS 常用于衡量处理器(如CPU/GPU)的理论峰值性能。例如:
- 1 FLOPS = 1次浮点运算/秒
- 1 TFLOPS(Tera-FLOPS)= \( 10^{12} \) 次浮点运算/秒
- 1 GFLOPS = 10亿次运算/秒(硬件速度)
- 注:”S” 为大写,代表 “Second”(每秒)
- 用法:NVIDIA A100 GPU的峰值性能为 312 TFLOPS
一些常见错误表达
- 错误的写法如 “Flops” 或 “flops” 可能导致歧义,建议严格区分大小写