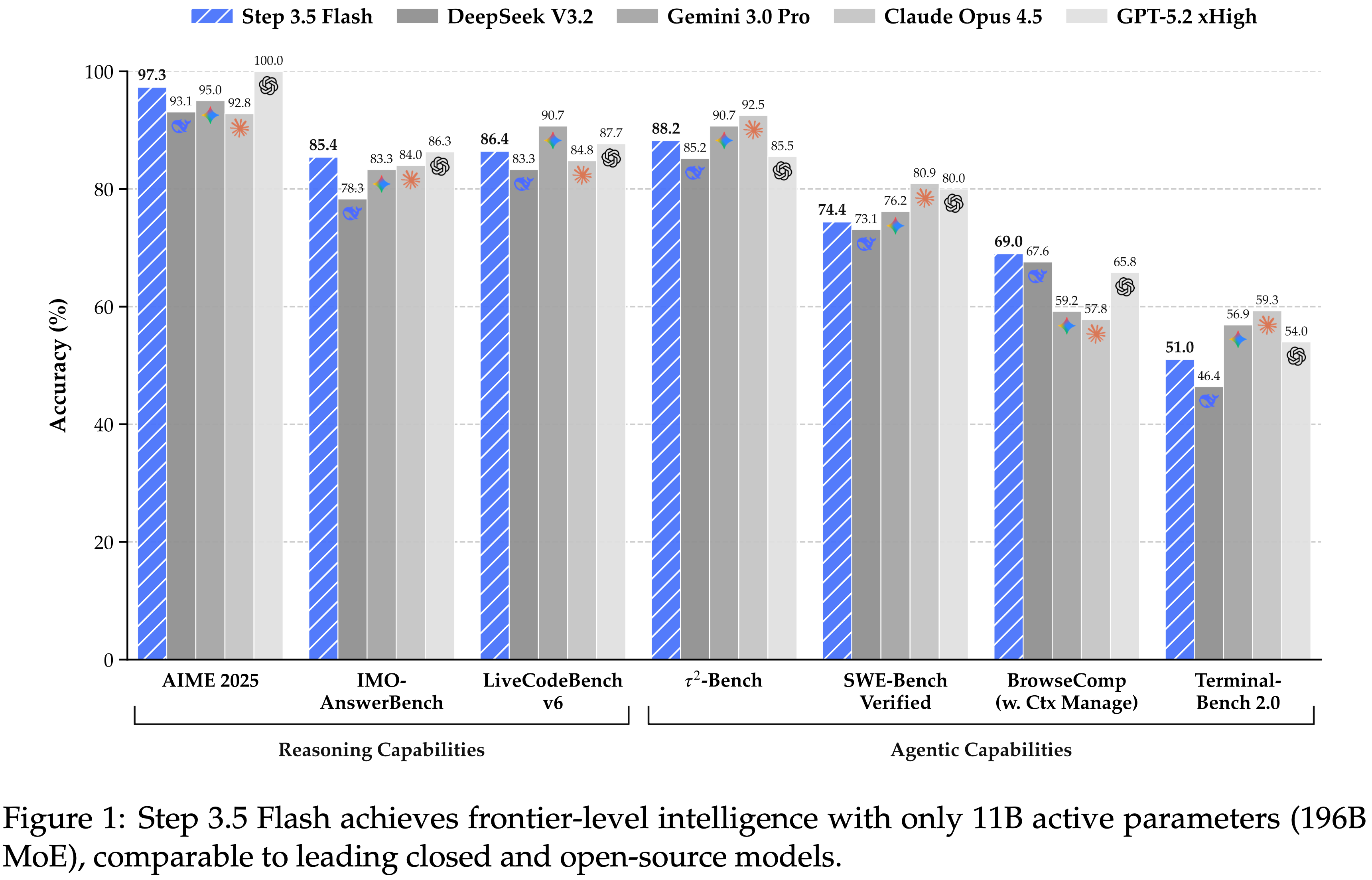
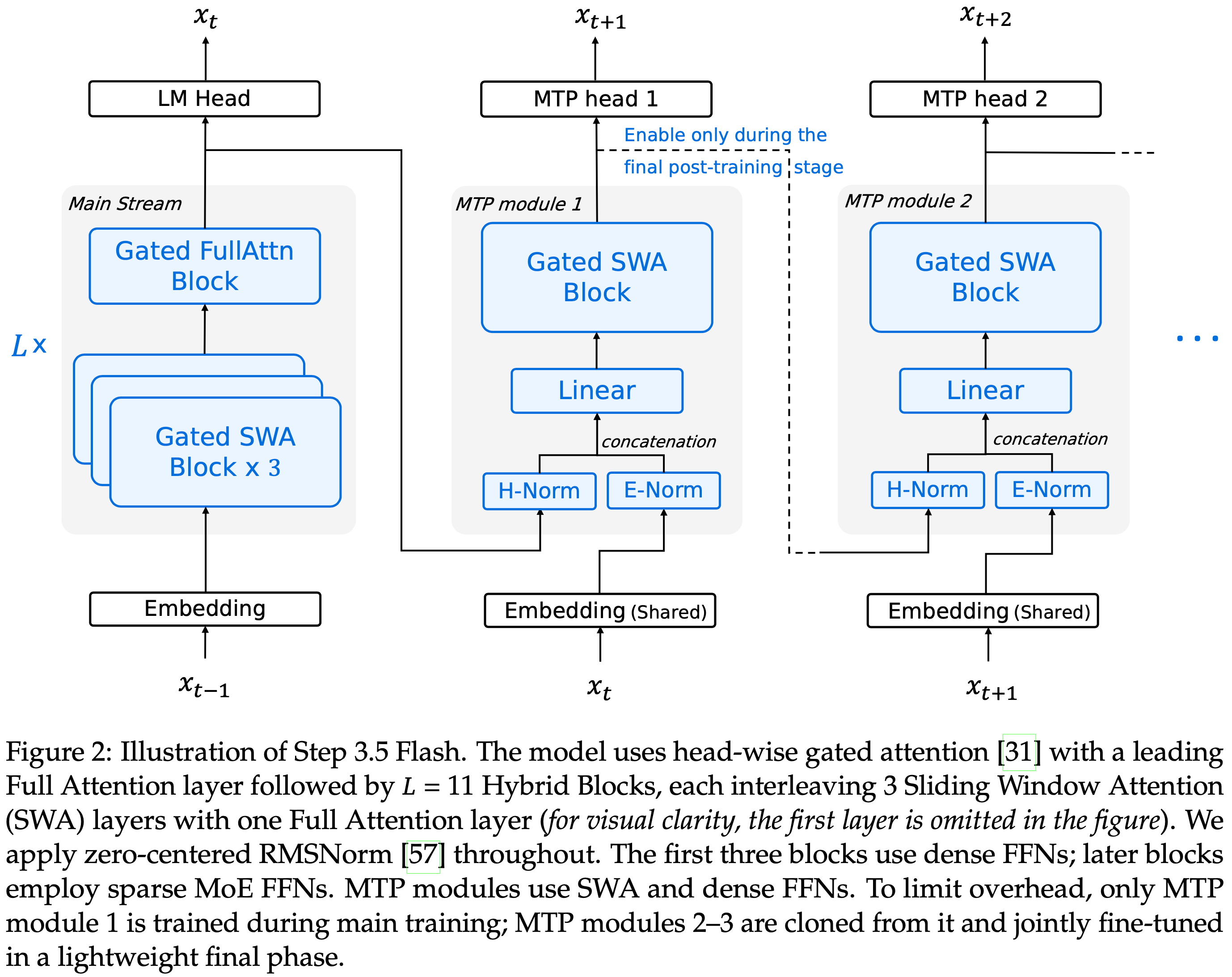
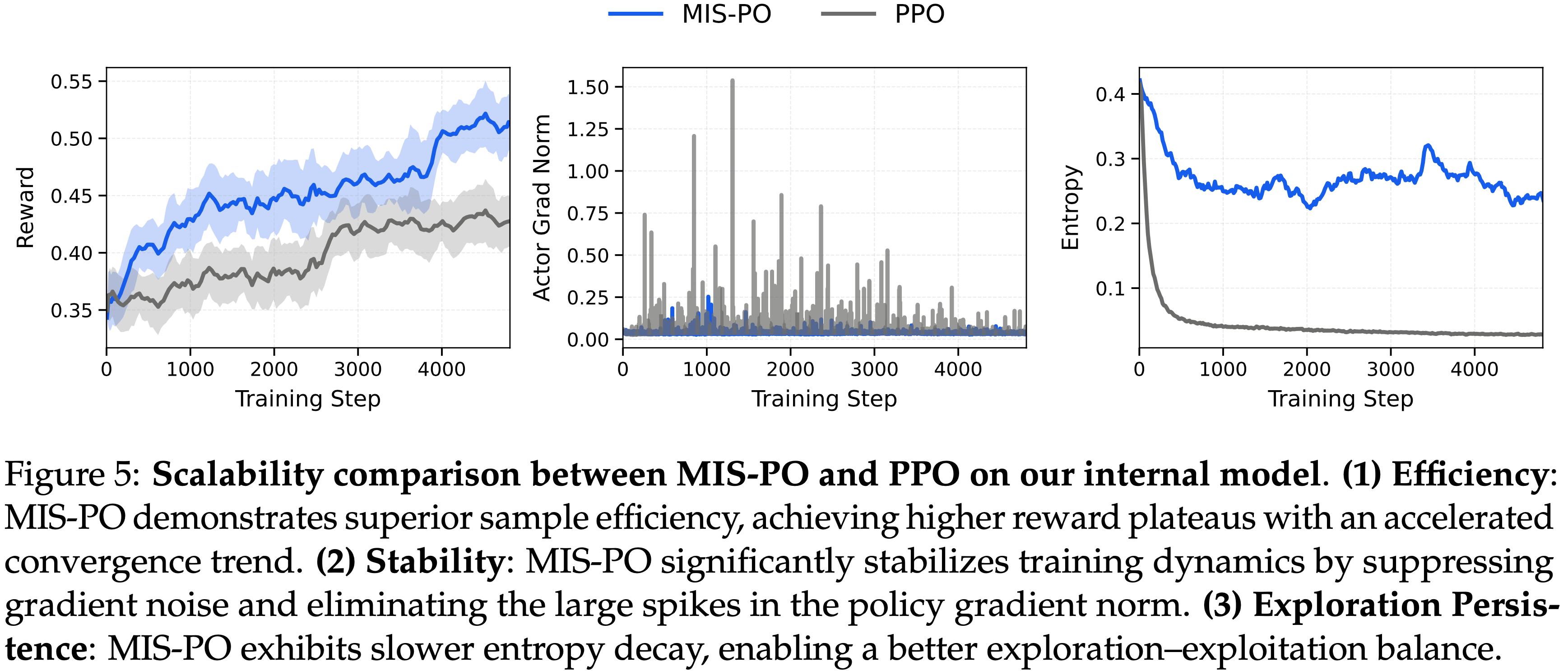
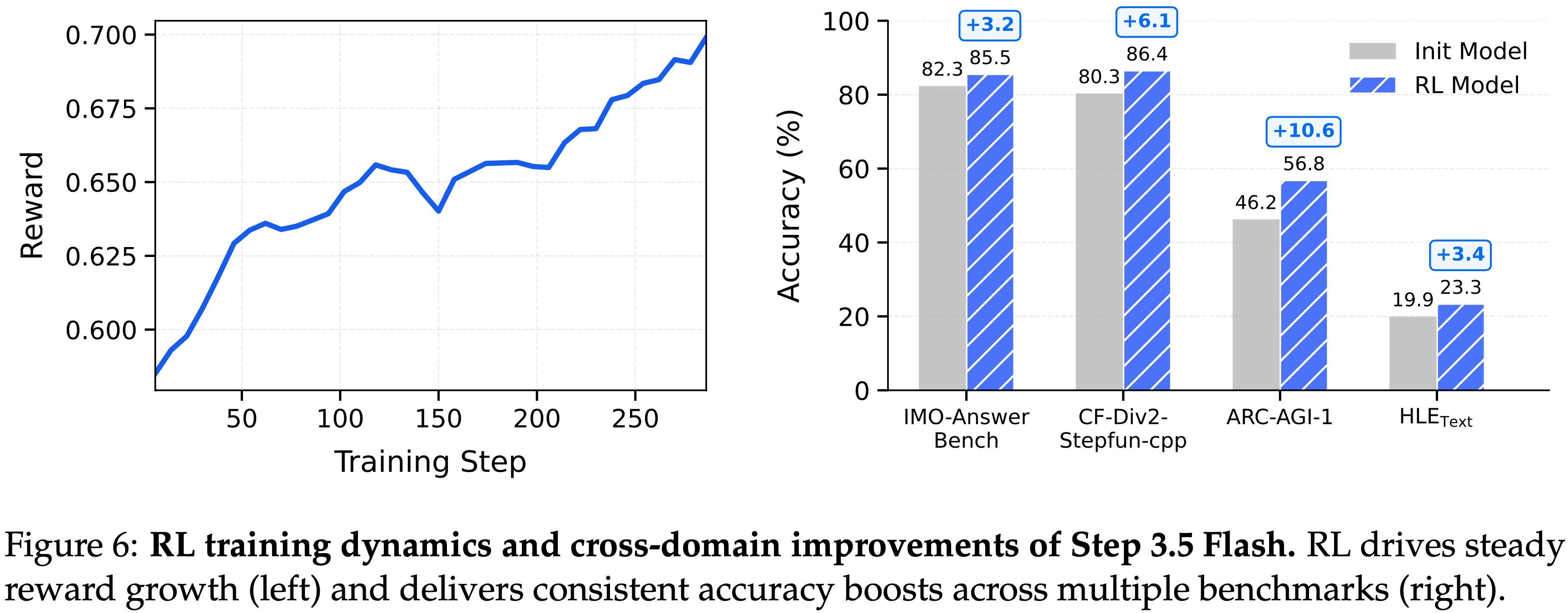
注:本文包含 AI 辅助创作
整体总结
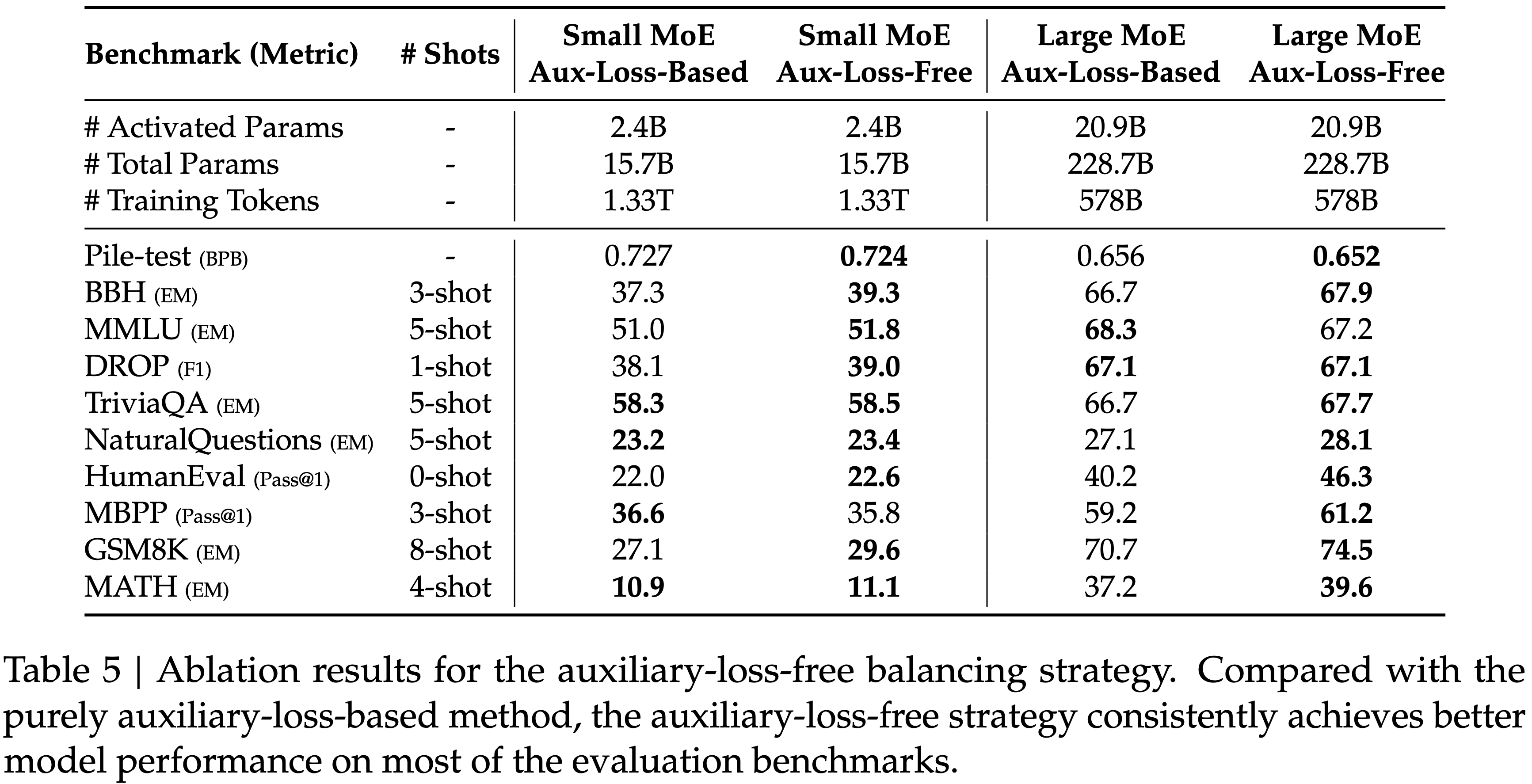
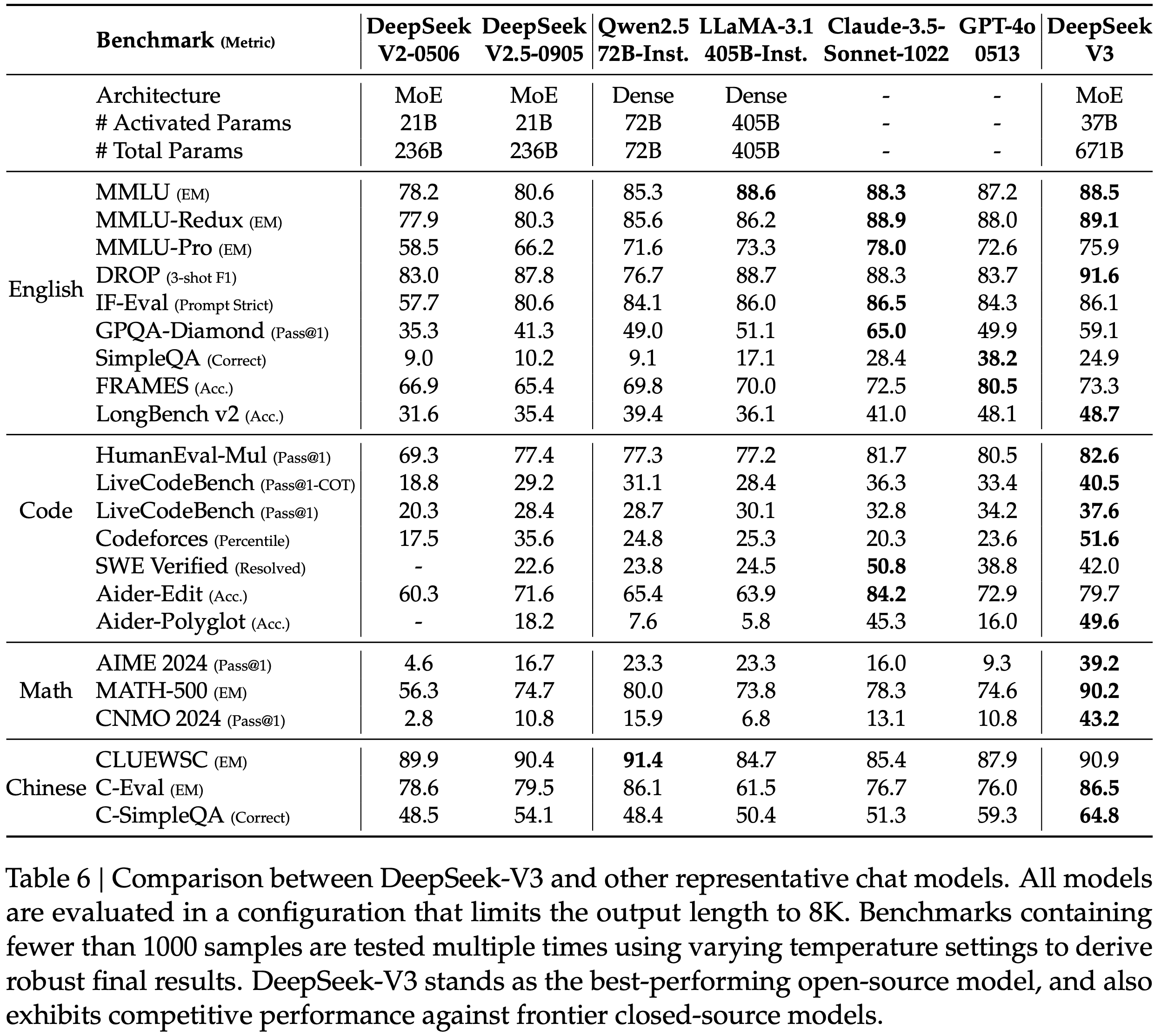
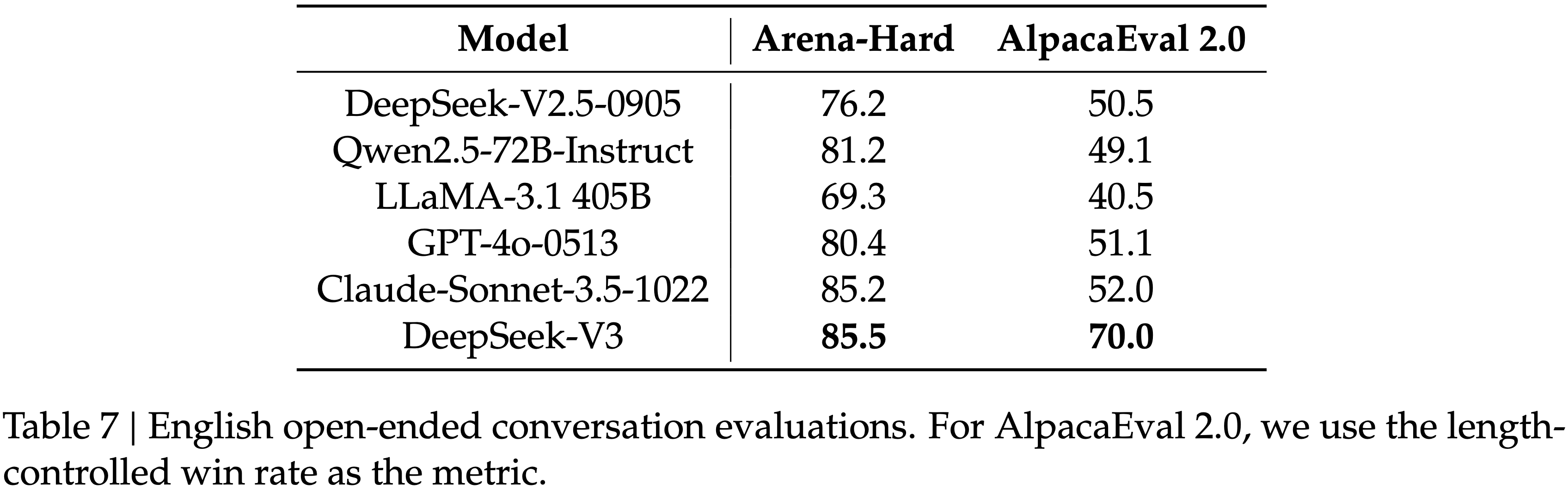
- 本文提出一种改进的 PPO 方法, VC-PPO(Value-Calibrated PPO)
- 核心贡献:
- Pretrained value:开始 RL 前先预训练价值网络
- Decoupled-GAE:计算 Advantage (for Actor 损失)时和 计算 Target Reward(for Critic 损失)时使用不同的 \(\lambda\)
Motivation
- LLM 在复杂推理任务(如数学、编程)中表现出色,尤其是通过生成长链思维(Long-CoT)来逐步推导答案
- OpenAI的o1、DeepSeek-R1等模型都采用了这种“推理时扩展”策略
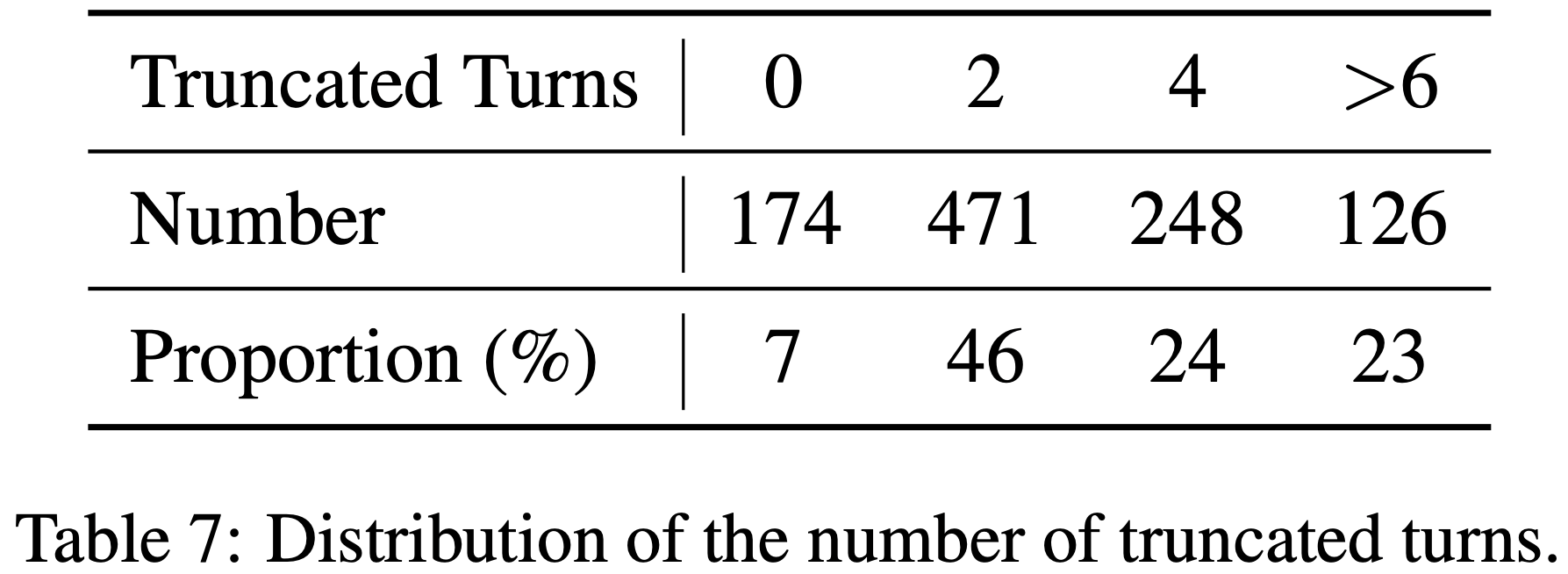
- 一个发现:在Long-CoT任务中,PPO经常失效 ,表现为:
- 模型输出长度迅速下降(注:通常是训练初期即开始大幅下降)
- 验证集性能大幅退化
- 无法有效利用长链思维
- 注:这些现象与 PPO 在传统 RL 任务中的成功形成鲜明对比
问题诊断:PPO 失效的两大原因简单描述
- 作者通过实验和分析,识别出 PPO 在 Long-CoT 任务中失效的两大根本原因
- 注:导致模型输出长度迅速下降的直接原因是:前置 Advantage 被高估,详情见本文后面补充的附录
Value/Critic Initialization Bias
- 在 RLHF 中,常用做法是用训练好的 奖励模型来初始化Value/Critic 模型
- 注:这种做法则源于奖励模型和价值模型之间的表面相似性,因为两个模型都旨在预测关于响应的标量信息
- 但奖励模型只在
<EOS>处提供评分,对前面的 token 没有监督信号,导致它对前置 token 的打分偏低 - 这种偏差在 GAE 中会被放大,导致前置 token 的 Advantage 被高估,进而促使模型倾向于生成短回答
奖励信号衰减(Reward Signal Decay)
- 在 GAE 中,当 \(\lambda < 1\) 时,来自
<EOS>的奖励信号会随传播距离指数衰减 - 在 Long-CoT 任务中,序列长度可达数千 token,前置 token 几乎接收不到任何奖励信号
- 这导致值模型无法有效学习,进而影响策略优化
- 注:传统 RLHF 中常常使用 \(\lambda = 0.95\)
- 这种做法源于传统的 RL 文献,其中 PPO 已在像 Mujoco 和 Atari 这样的环境中得到广泛测试
- 在这些环境中,奖励会在轨迹上累积,导致高方差的回报,因此,使用 \(\lambda < 1\) 方差降低是必要的
- 但这种方式会导致模型收敛缓慢
奖励信号衰减的数学推导
- 定义:
- \(V\):值函数
- \(r_t\):即时奖励
- \(\lambda\):GAE 平滑因子
- 在标准 GAE 中,优势估计为:
$$
\hat{A}_t = \sum_{l=0}^{T-t-1} \lambda^l \delta_{t+l}, \quad \delta_t = r_t + V(s_{t+1}) - V(s_t)
$$ - Critic 目标为回报的估值:
$$ R \approx V^{\text{target} }(s_t) = V_{old}(s_t) + A^{GAE}_t$$ - 展开即可得到:
$$
V^{\text{target} }(s_t) =
\begin{cases}
\sum_{l=0}^{T-t-1} \lambda^l (r_{t+l} + V(s_{t+l+1}) - V(s_{t+l})) + V(s_t), & \lambda < 1 \\
\sum_{l=0}^{T-t-1} r_{t+l}, & \lambda = 1
\end{cases}
$$- 上面式子的详细推导见:RL——强化学习中的方差与偏差 的 GAE 部分
- 当 \(\lambda=1\) 时, Critic 目标即为累积奖励,无偏且稳定
- 当 \(\lambda<1\) 时, Critic 目标引入了值函数自身的估计,可能不稳定
- 当长度太大时,可以看到最终的奖励 \(r_T\) 几乎被淹没了,需要逐步透传到 Critic,所以 Critic 收敛性本身也会变慢
模型输出长度迅速下降 的原因详细分析
- 现象描述:在标准的 PPO 训练中,模型本应生成长链思维(Long-CoT)来逐步推理答案
- 但在实验中,训练刚开始不久,模型输出的平均长度急剧下降 ,随之而来的是验证集性能的崩溃(如图 1 所示)
- 根据论文内容,可以得到一个清晰的因果链:
- 1)初始阶段 :Critic 模型对前置 token 的估计偏低(来自奖励模型初始化)
- 2)GAE 计算 :这种偏差被 GAE 放大,使前置 token 获得过高的优势值
- 3)策略更新 :PPO 鼓励高优势值的动作,即鼓励模型多输出前置 token,少输出后置 token
- 4)行为变化 :模型学会尽早结束生成,因为“早结束”意味着“多输出前置 token、少输出后置 token”
- 5)恶性循环 :输出变短后,训练数据中的长序列减少,值模型更难学习长序列的价值,进一步强化短输出倾向
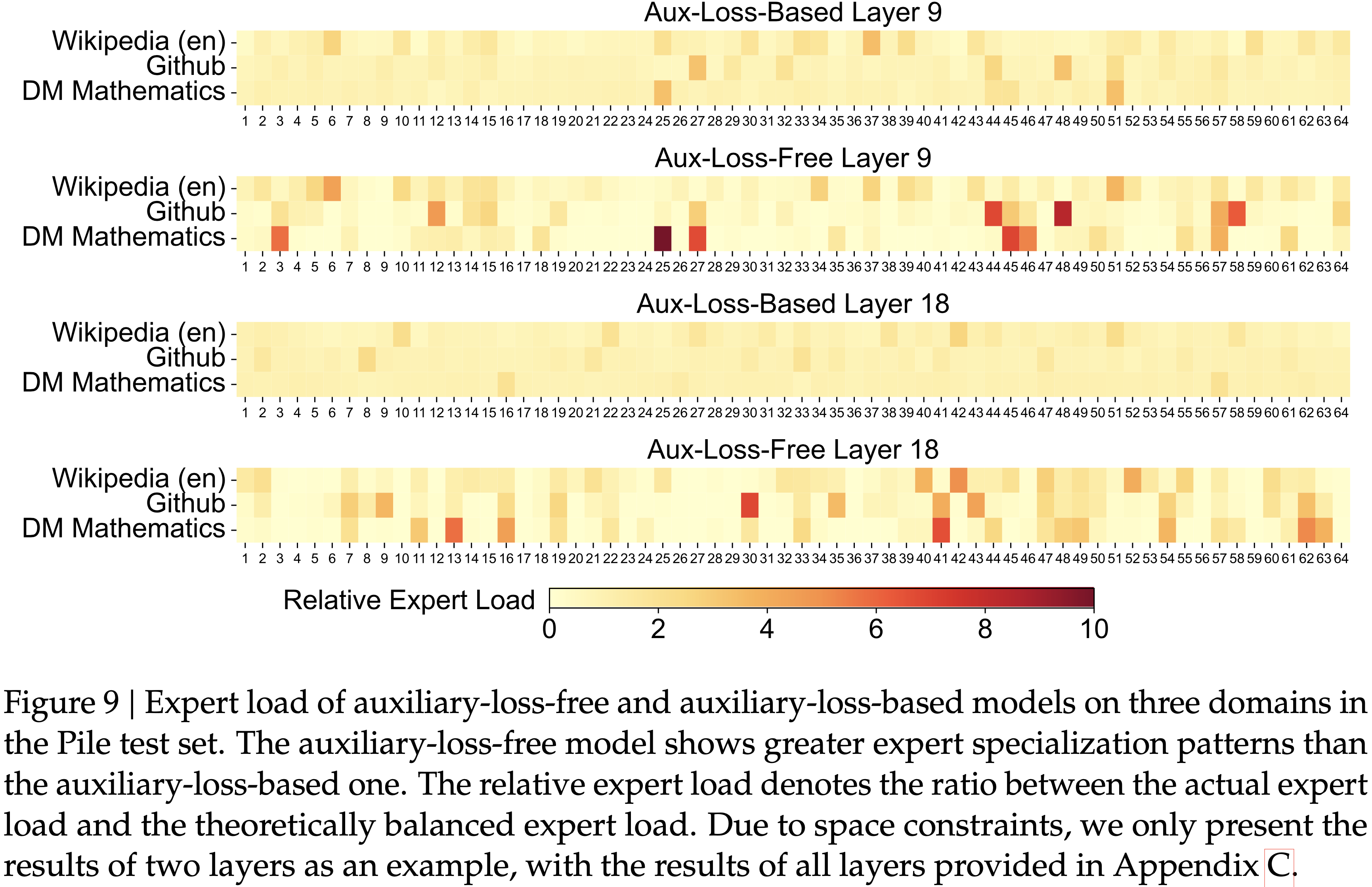
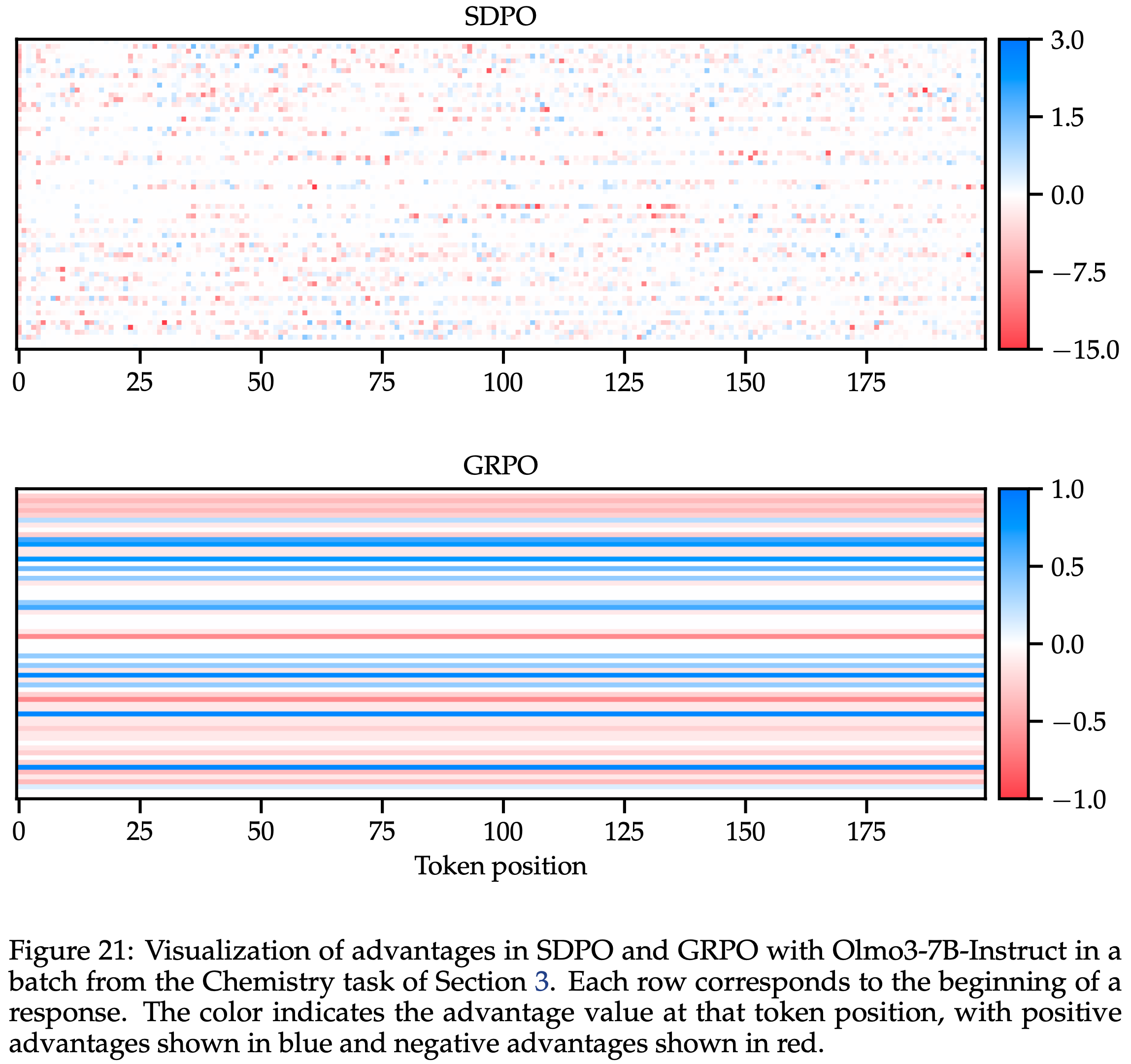
直接原因:前置 token 的优势被高估
- 通过分析优势值(Advantage)与token位置的关联(如图 2 所示)发现:
- 越靠前的 token,其优势值越高(正偏差越大);
- 这种偏差导致模型倾向于更早结束生成 ,因为前置 token 被“鼓励”输出,而后置 token 被“惩罚”或忽略
- 模型学会“尽早收尾”,从而输出长度急剧下降
根本原因之一:值初始化偏差
奖励模型的训练目标
- 奖励模型只在
token 处给出评分(如正确=1,错误=-1); - 它对前面的 token 没有直接的监督信号;
- 因此,奖励模型对前置 token 的评分偏低(因为信息不完整)
- 理解:这里不够严谨
- 其实需要看初始化值和大部分目标值的相对关系,本质应该是可能偏高也可能偏低才对
- 理解:这里不够严谨
值模型从奖励模型初始化
- 在 RLHF 中,常用做法是将训练好的奖励模型作为值模型的初始化;
- 这导致值模型在初始阶段也对前置token的预期回报估计偏低
偏差在 GAE 中被放大
- GAE 的优势估计公式为:
$$
\hat{A}_t = \sum_{l=0}^{T-t-1} \lambda^l \delta_{t+l}, \quad \delta_t = r_t + V(s_{t+1}) - V(s_t)
$$ - 由于前置token的 \(V(s_t)\) 被低估,而 \(V(s_{t+1})\) 相对较高(因为更接近
<EOS>),导致:- \(\delta_t\) 为正;
- 这些正偏差在累加过程中被放大,最终使前置token的优势值显著偏高
根本原因之二:奖励信号衰减
GAE 中的奖励传播机制
- 当 \(\lambda < 1\) 时(如默认的 0.95),来自
<EOS>的奖励信号会随传播距离指数衰减:
$$
\text{传播到第 } t \text{ 个 token 的奖励信号} = \lambda^{T-t} \cdot r_{}
$$
Long-CoT 任务的特点
- 序列长度 \(T\) 可能达到数千token;
- 前置 token 的 \(T-t\) 很大,\(\lambda^{T-t} \approx 0\);
- 前置 token 几乎接收不到任何来自最终答案的奖励信号
对 Critic 模型的影响
- 值模型难以学习到前置 token 的真实价值;
- 值估计进一步失真,加剧了前置 token 的优势偏差
解决方案:VC-PPO
- VC-PPO(Value-Calibrated PPO) 同时解决上述两个问题
创新1:Value-Pretraining
- 目的:解决值初始化偏差,使值模型在训练开始前就与初始策略对齐
- 方法流程
- Step 1: 固定策略模型 ,使用初始策略(如SFT后的模型)生成大量 Response
- Step 2: 使用 Monte-Carlo 回报(即 GAE \(\lambda=1.0\)) 作为值模型的目标,进行离线训练
- Step 3: 训练至值损失和解释方差(explained variance)收敛
- Step 4: 将该值模型作为后续 PPO 训练的初始值模型
- 实验效果
- 消除了前置 token 的优势偏差
- 保留了 Long-CoT 的模式,避免输出长度崩溃
创新2:Decoupled-GAE(解耦 GAE)
- 这是本文的核心创新点,目的是在策略优化和值函数优化中使用不同的 \(\lambda\) 值,以分别满足两者的不同需求
- 注:使用不同的 \(\lambda\) 值更新时,需要证明其策略梯度还能准确,下文会证明这个事情
背景问题描述
- 策略优化需要低方差 的梯度估计,因此希望使用较小的 \(\lambda\)(如 0.95);
- 但值函数优化需要无偏的目标 ,因此希望使用 \(\lambda=1.0\),避免奖励信号衰减;
- 传统 PPO 中,两者共用同一个 \(\lambda\),无法兼顾
方法流程
- Step 1: 策略优化使用 \(\lambda_{\text{actor} } < 1.0\)(如 0.95),以降低梯度方差
- Step 2: 值函数优化使用 \(\lambda_{\text{critic} } = 1.0\),以确保 Critic 目标无偏
- Step 3: 两者的 GAE 计算独立进行 ,互不干扰
- Algorithm1:
策略梯度的无偏性证明(待详细推导和理解)
- 作者进一步证明,即使值函数是用不同 \(\lambda\) 训练的,将其代入策略梯度中仍然无偏:
- 定义 n-step 回报为:
$$
G_{t:t+h} =
\begin{cases}
\sum_{l=0}^{h-1} r_{t+l} + \bar{V}(s_{t+h}), & t+h < T \\
\sum_{l=0}^{T-t-1} r_{t+l}, & t+h = T
\end{cases}
$$ - 则优势可写为:
$$
\hat{A}_t = (1-\lambda) \sum_{l=1}^{T-t-1} \lambda^{l-1} G_{t:t+l} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t)
$$ - 即,具有任意 \(\lambda\) 的策略梯度可以重写如下:
$$\begin{aligned} \mathbb{E}_t [\nabla_\theta \log \pi_\theta(a_t|s_t) A_t] &= \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t|s_t) \sum_{l=0}^{T-t-1} \lambda^l (r_{t+l} + \bar{V}(s_{t+l+1}) - \bar{V}(s_{t+l})) \right] \\ &= \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t|s_t) \left( (1-\lambda) \sum_{l=1}^{T-t-1} \lambda^{l-1} G_{t:t+l} + \lambda^{T-t-1} G_{t:T} - \bar{V}(s_t) \right) \right] \\ &= \mathbb{E}_t \left[ \nabla_\theta \log \pi_\theta(a_t|s_t) \left( (1-\lambda) \sum_{l=1}^{T-t-1} \lambda^{l-1} G_{t:t+l} + \lambda^{T-t-1} G_{t:T} \right) \right] \end{aligned} \tag{8}$$- 根据公式 8,代入任意价值函数不会给策略梯度引入额外的偏差
- 鉴于大型语言模型所需的大量时间和计算资源,使用较小的 \(\lambda\) 来加快策略的收敛是可取的
- 一个候选配置可以是 \(\lambda_{\text{policy}} = 0.95\) 和 \(\lambda_{\text{value}} = 1.0\)
- 论文中提到:使用任意值函数不会引入额外偏差
- 问题:这里并不是说明使用 Decoupled-GAE 前后的梯度一致,因为 \(G_{t:t+l}\) 中也包含了 \(\bar{V}(s_{t+l})\)
- 此时 Actor 更新时最大化的目标(Advantage)本身已经发生了改变,目标变成了 最大化新的 \(\lambda\) 下的 Critic 值
- 这里仅仅是证明了这 Actor 和 Critic 解耦的 \(\lambda\) 下,也有一个可以学习的目标值(形式上与原始的 策略梯度法/PPO 的结果是一样的)
- 注:这也就是说形式上本身是不冲突的,但没有说明两者的目标是完全等价的
- 问题:这里并不是说明使用 Decoupled-GAE 前后的梯度一致,因为 \(G_{t:t+l}\) 中也包含了 \(\bar{V}(s_{t+l})\)
实验
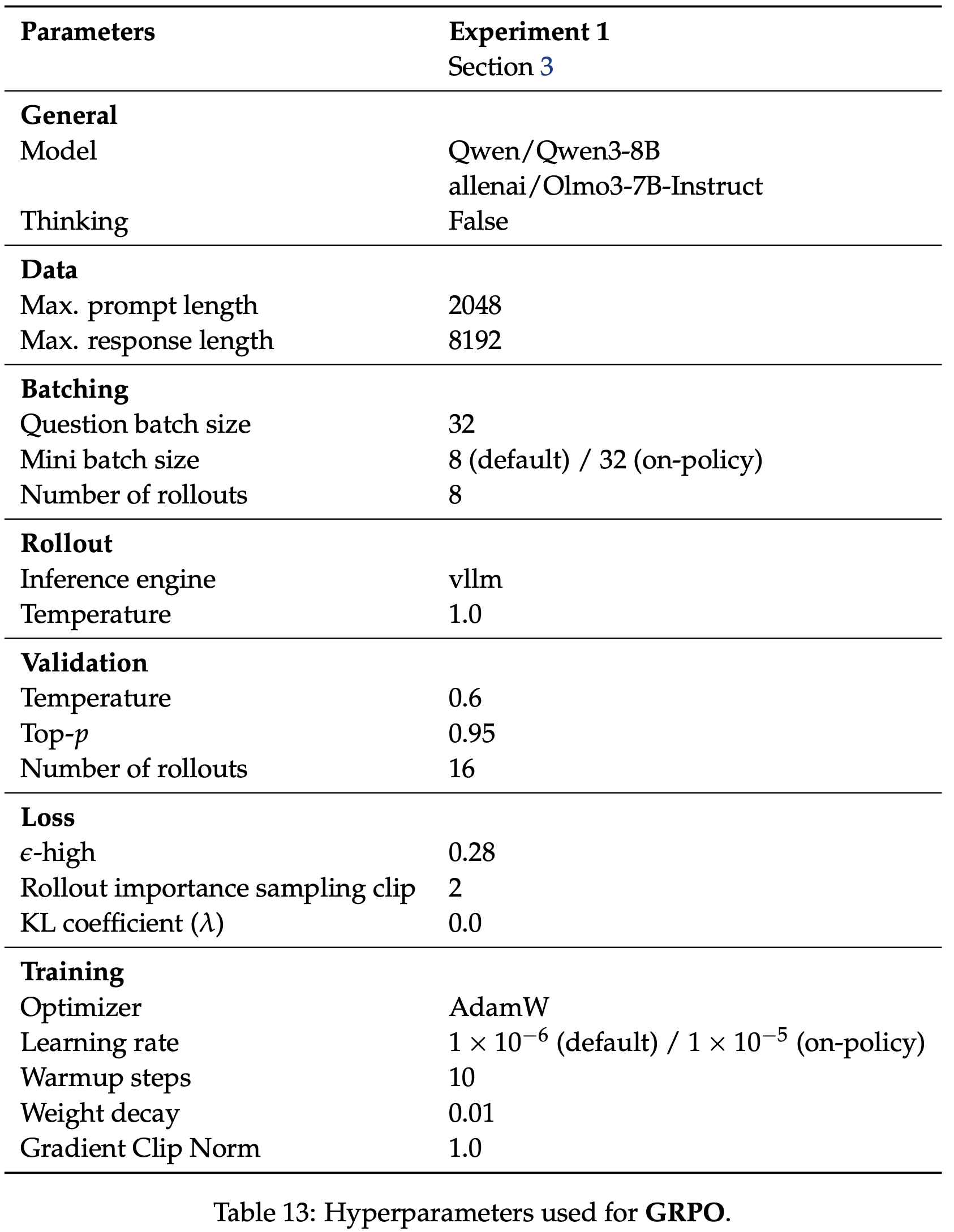
Setting
- 主要任务 :AIME、GPQA、Codeforces
- Base 模型型 :Qwen2.5 32B
- 冷启动 :使用少量 Long-CoT 格式样本进行 SFT
- 奖励 :规则驱动的答案匹配(正确=1,错误=-1)
- Baselines :PPO(\(\lambda=0.95\))和 GRPO(DeepSeek-R1 中使用)
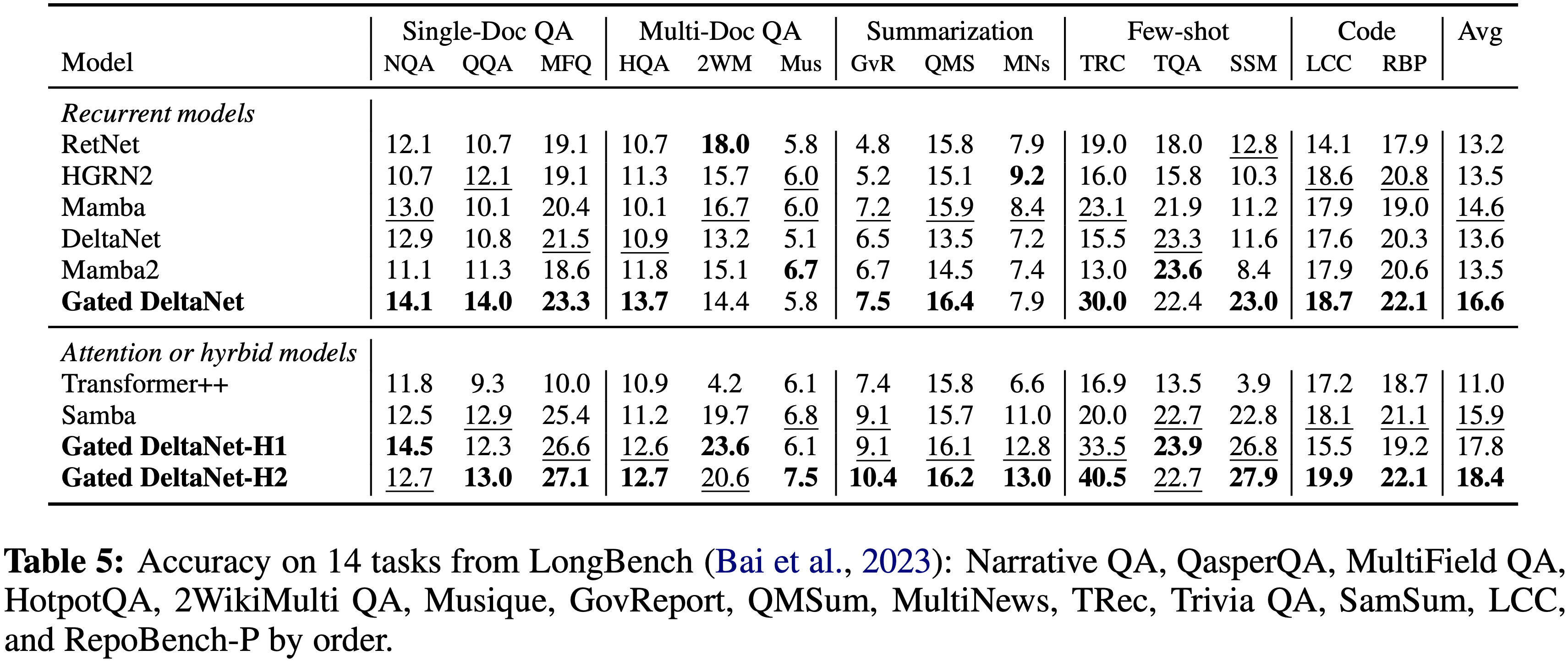
对照 GRPO
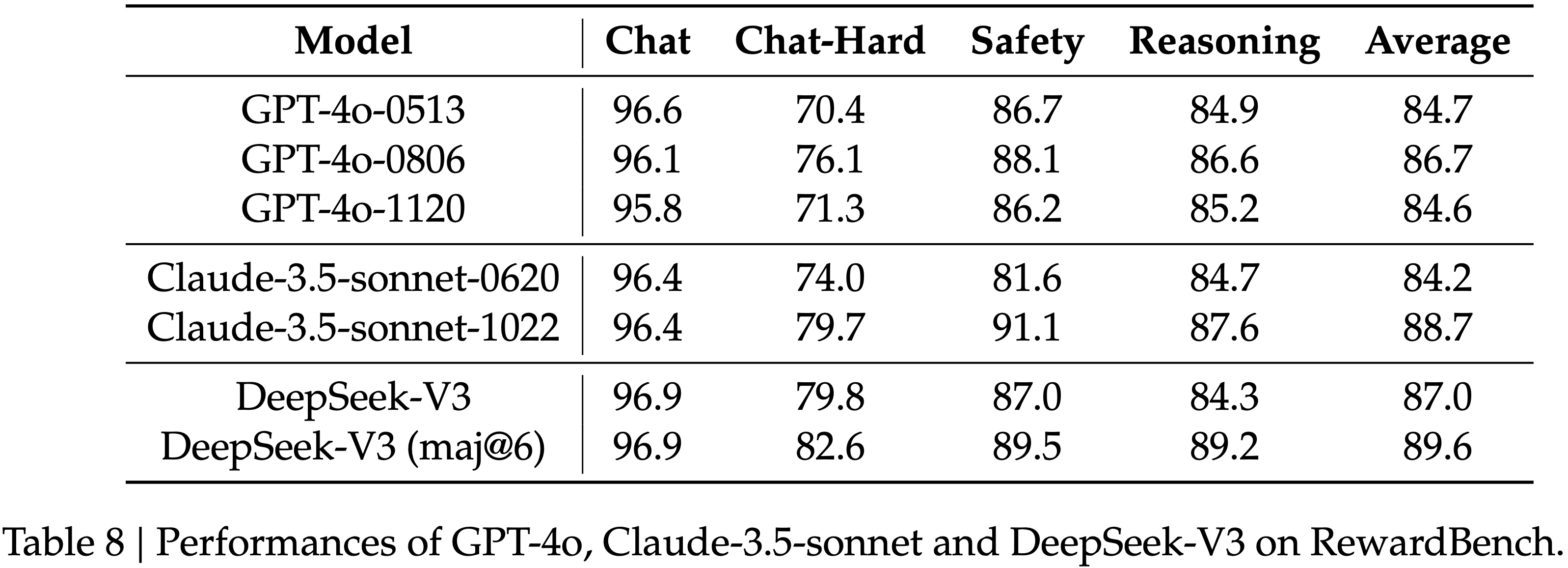
- VC-PPO vs GRPO
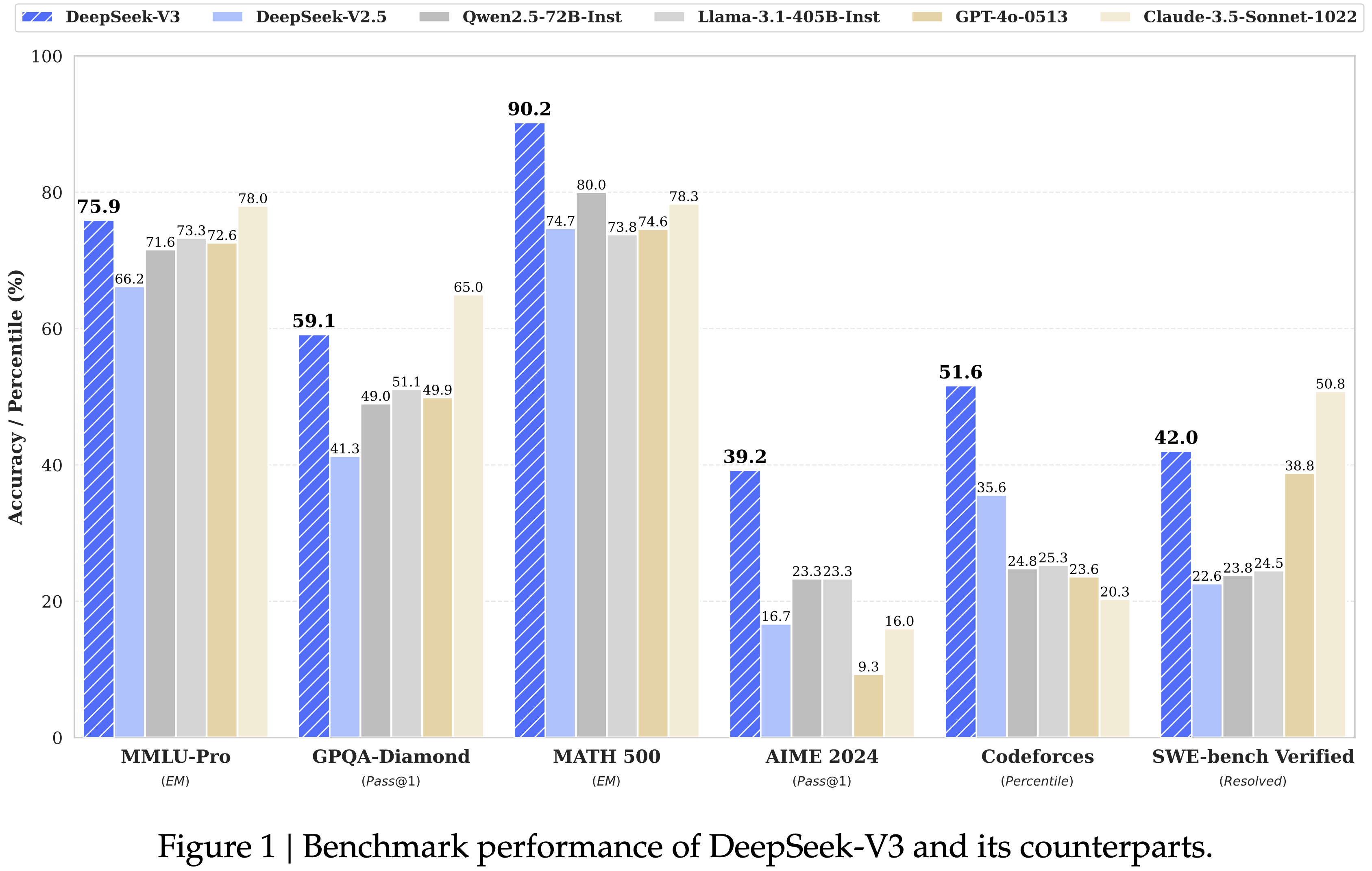
模型 AIME 2024 pass@1 GPQA pass@1 CodeForces pass@1 GRPO 38.9 49.4 12.6 VC-PPO 48.8 48.8 12.8 - VC-PPO 在 AIME 上显著优于 GRPO,达到 Qwen-32B 模型在该任务上的 SOTA
消融实验
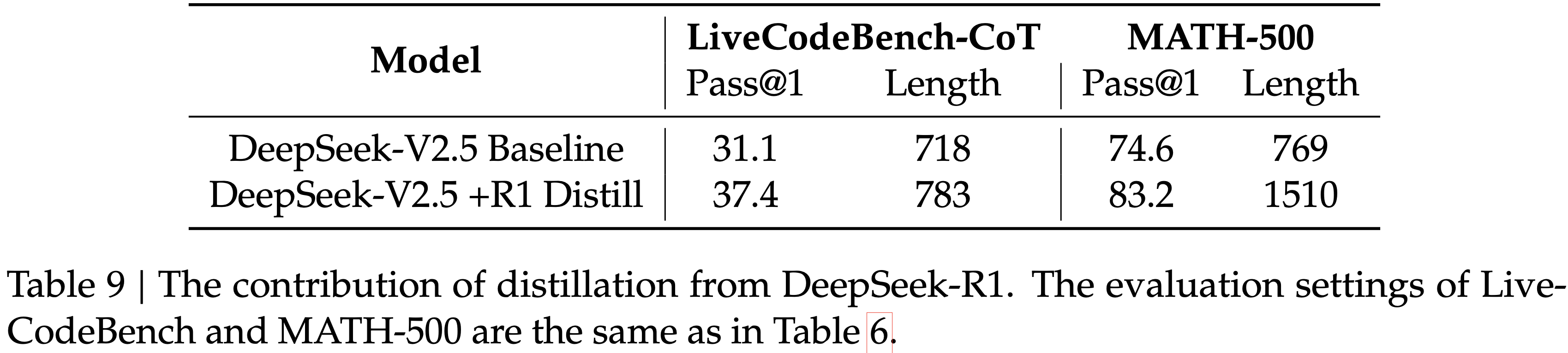
- 移除 Value-Pretraining :AIME pass@1 从 41.9 降至29.4
- 移除 Decoupled-GAE :AIME pass@1 降至 29.4
- \(\lambda_{\text{actor} }\) 调优 :\(\lambda=0.99\) 效果最佳,\(\lambda=1.0\) 效果最差
关键 Insight
- 值模型与策略的对齐至关重要 :尤其是在 Long-CoT 任务中,值模型必须充分理解策略的生成模式,否则会破坏 CoT 结构
- 值预训练不仅是值热身,更是知识注入 :它帮助模型理解哪些 token 更有价值,是提升性能的关键
- 值优化对噪声更鲁棒 :值模型可以使用 \(\lambda=1.0\) 的无偏目标,而策略需要 \(\lambda<1.0\) 来降低方差,二者解耦是合理的
附录:证明 score function 的梯度性质
- 核心思路:
- 概率和的梯度为 0
- 证明详情见:Math——KL中得分函数和路径梯度的理解

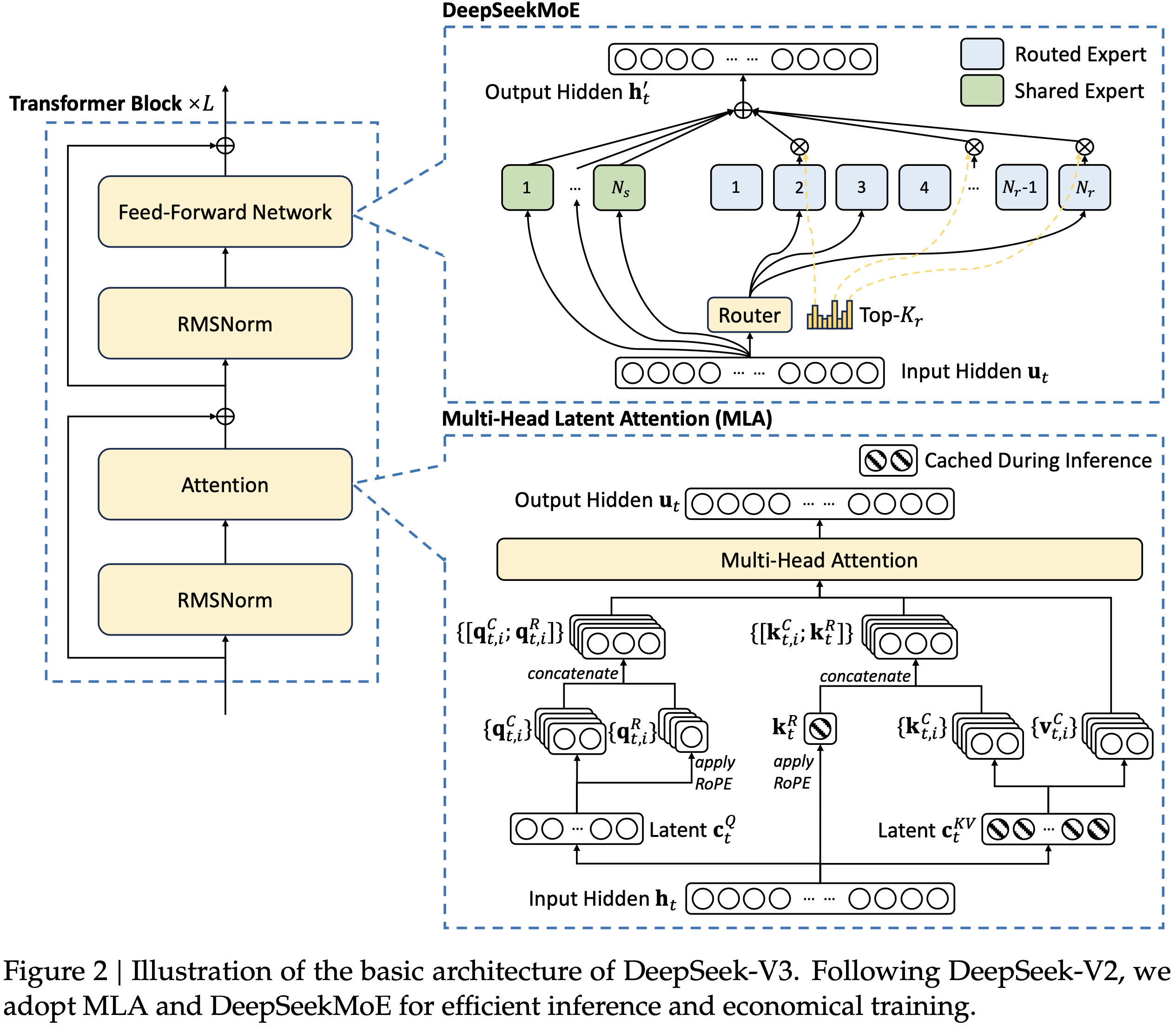
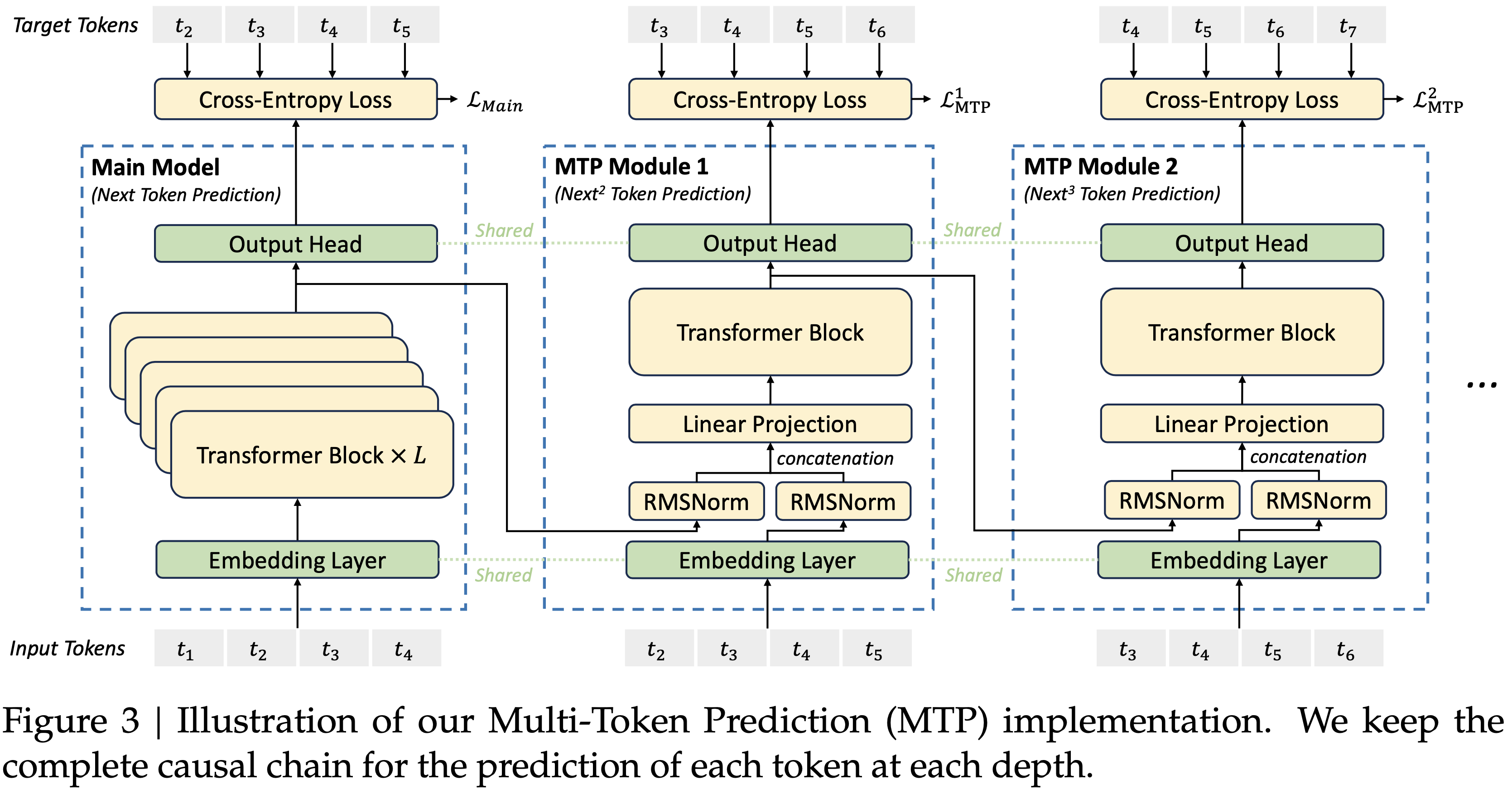
-MTP(Multi-token Prediction)的前世今生](https://zhuanlan.zhihu.com/p/18056041194)")









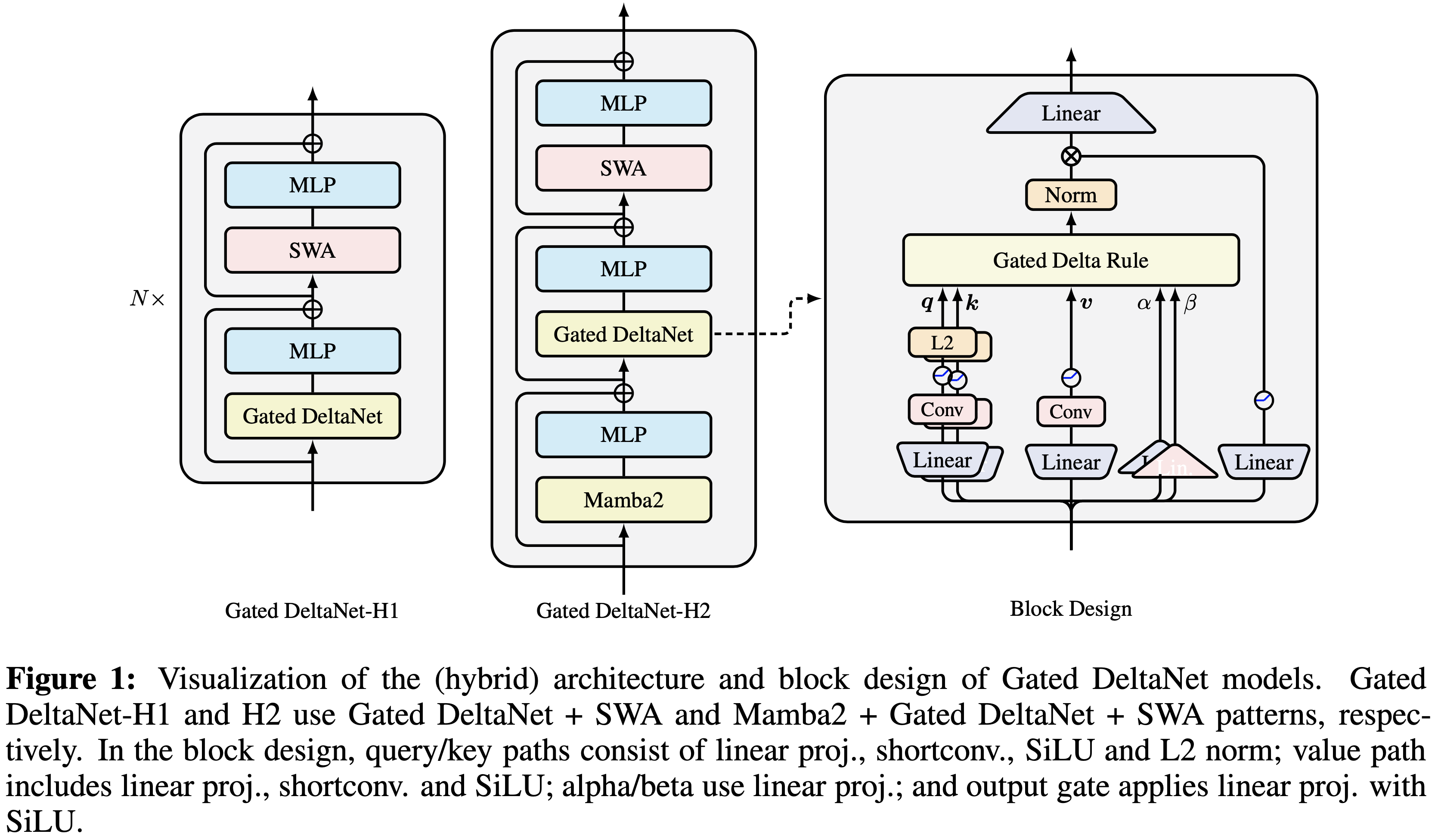
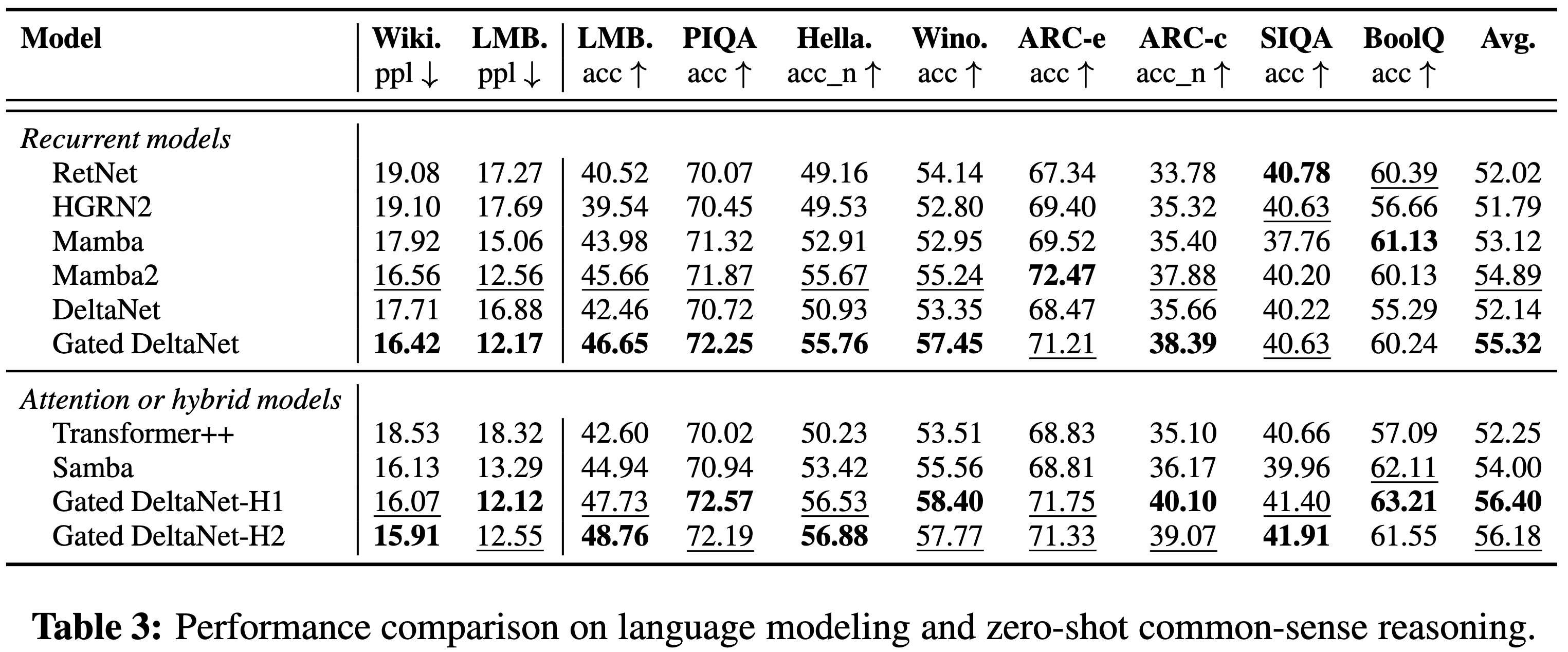
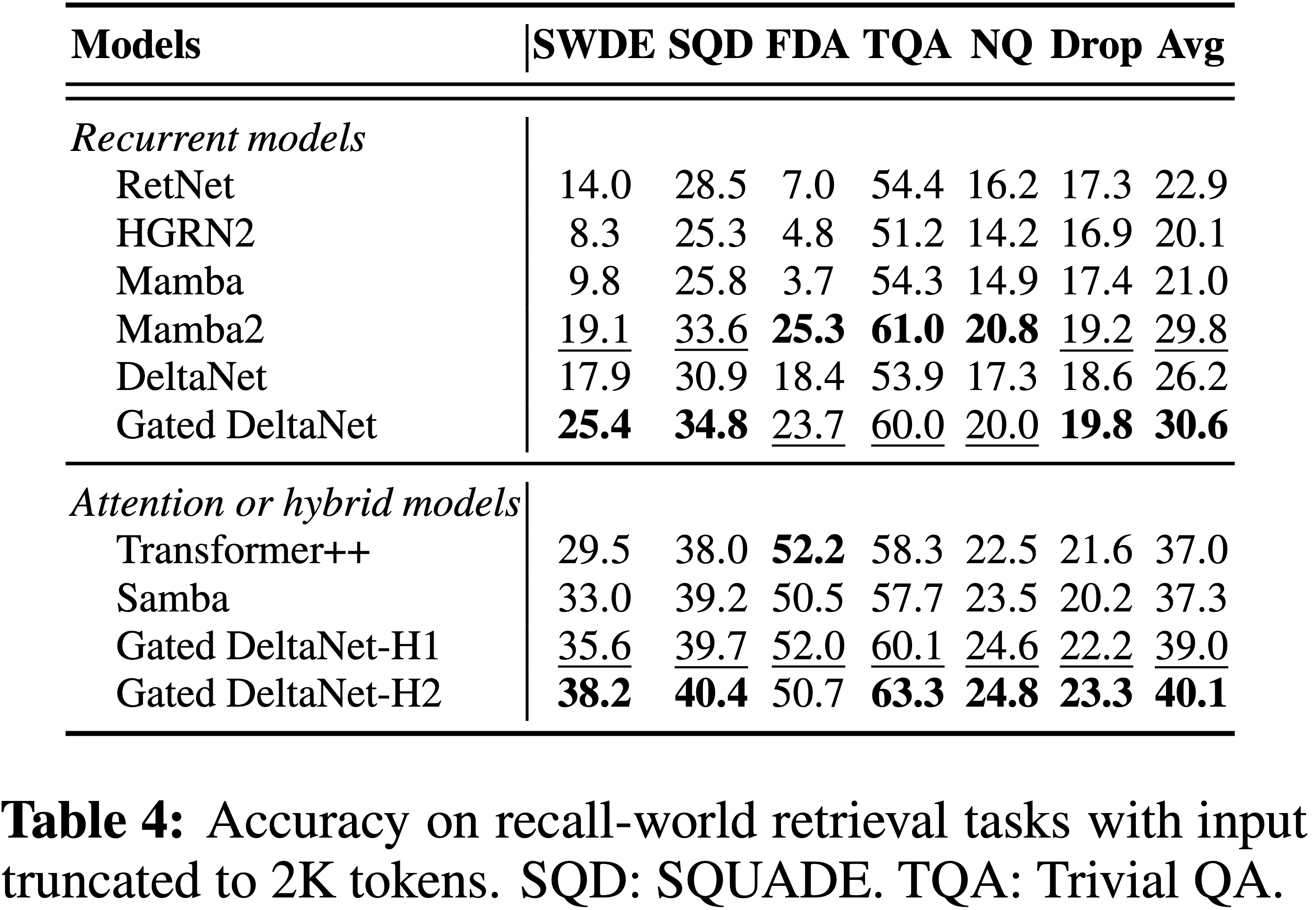
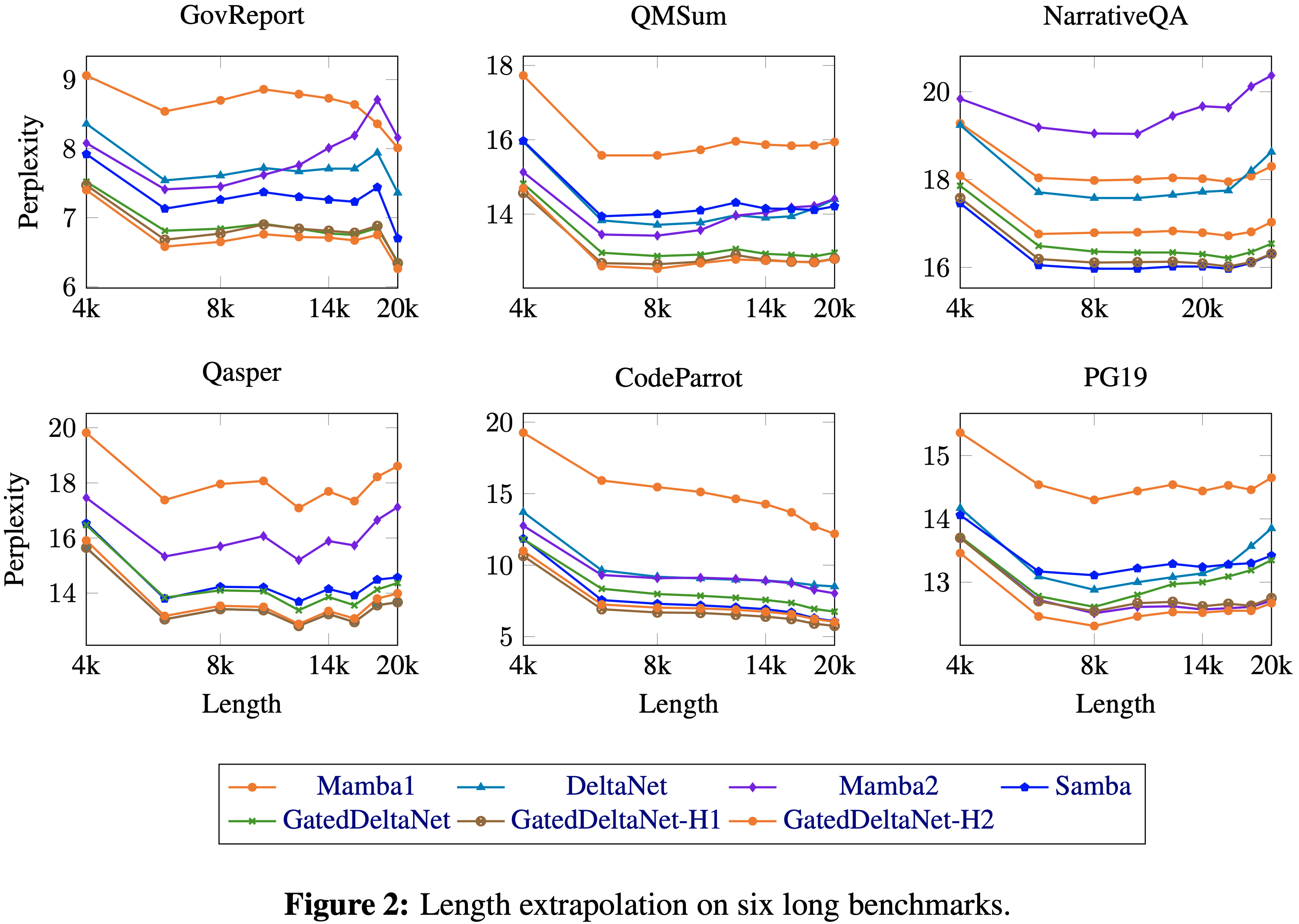
/EfficientAttention-Survey-Figure1.png)
/EfficientAttention-Survey-Table1.png)
/EfficientAttention-Survey-Figure2.png)
/EfficientAttention-Survey-Figure3.png)
/EfficientAttention-Survey-Figure4.png)






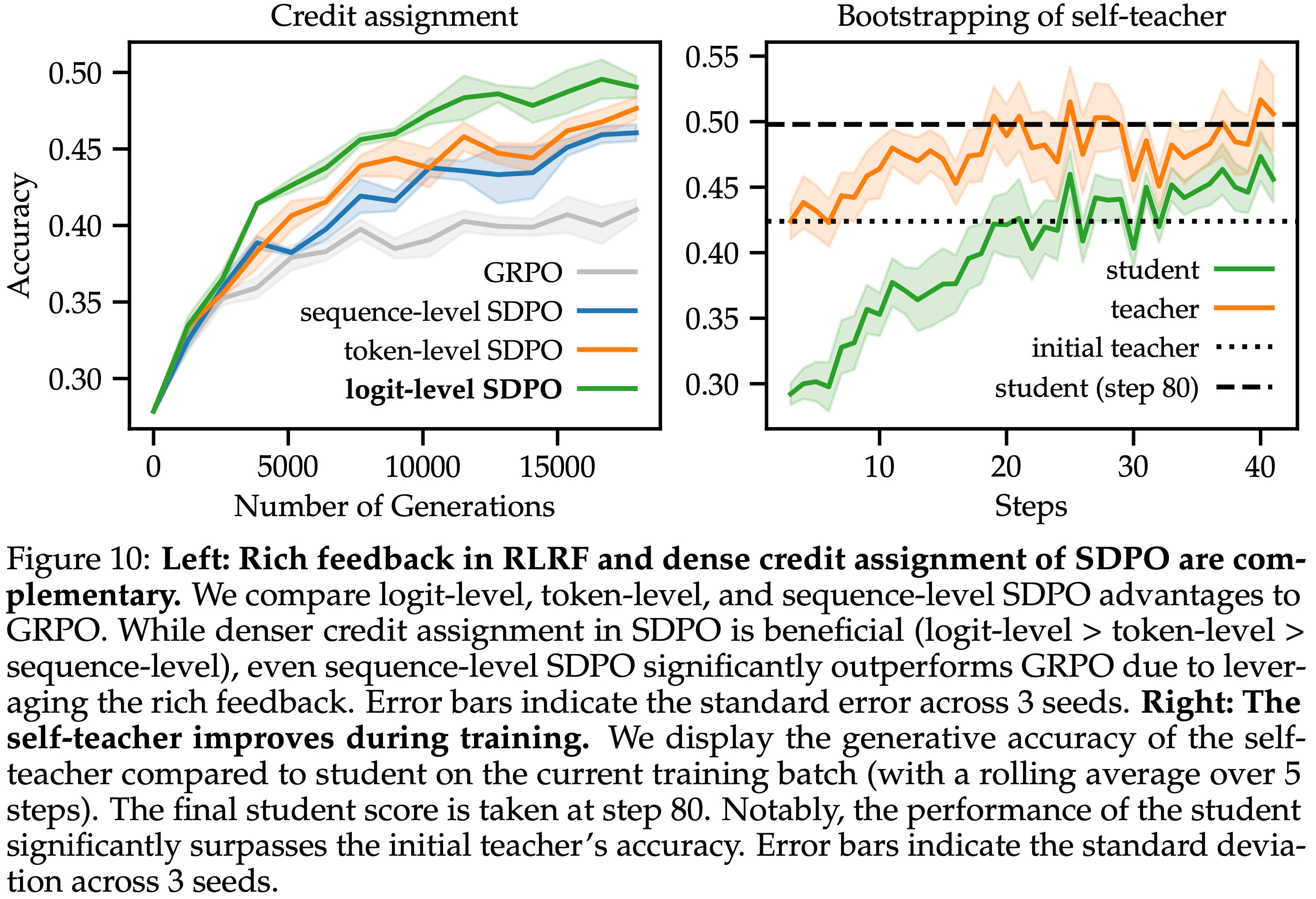
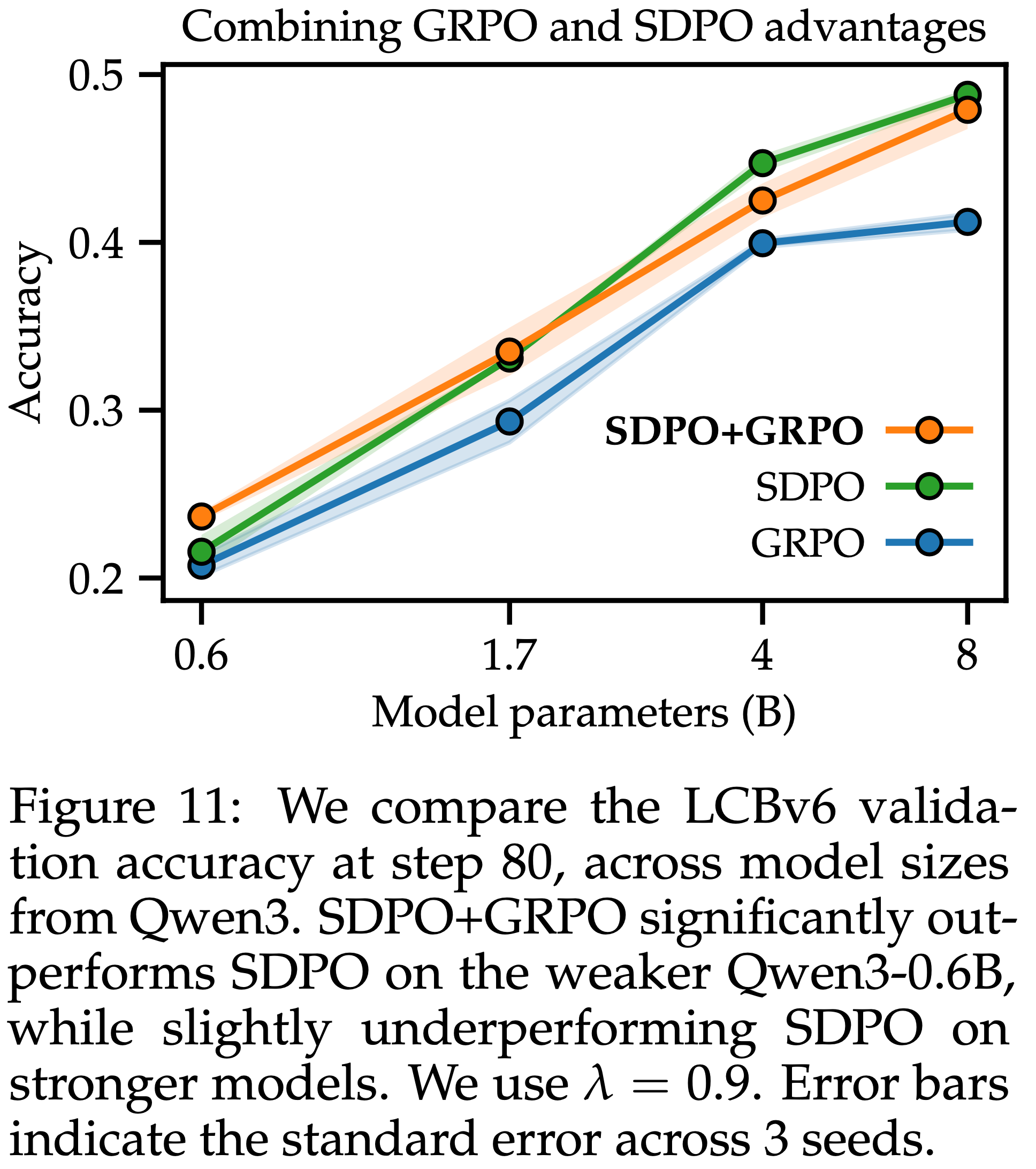

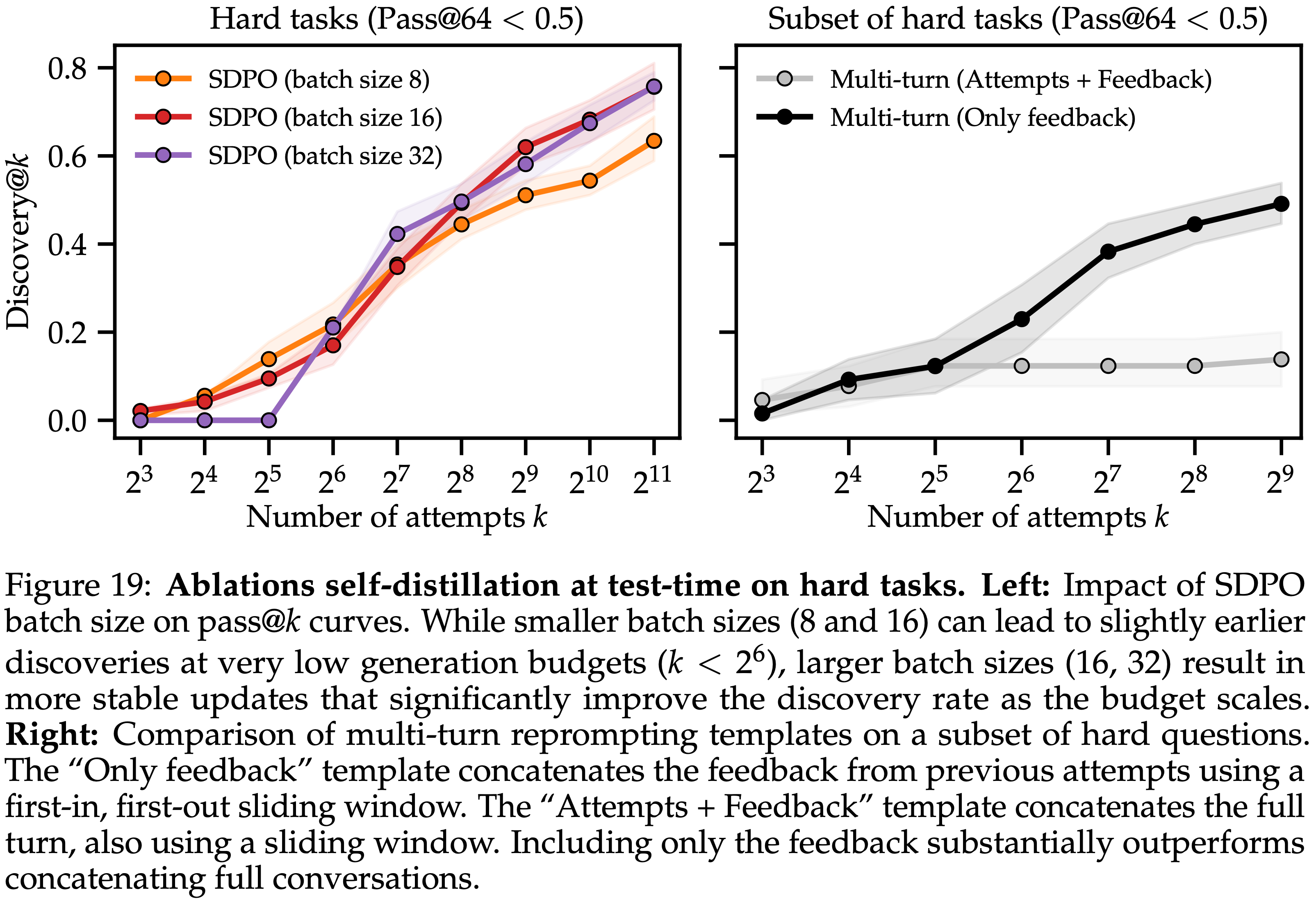
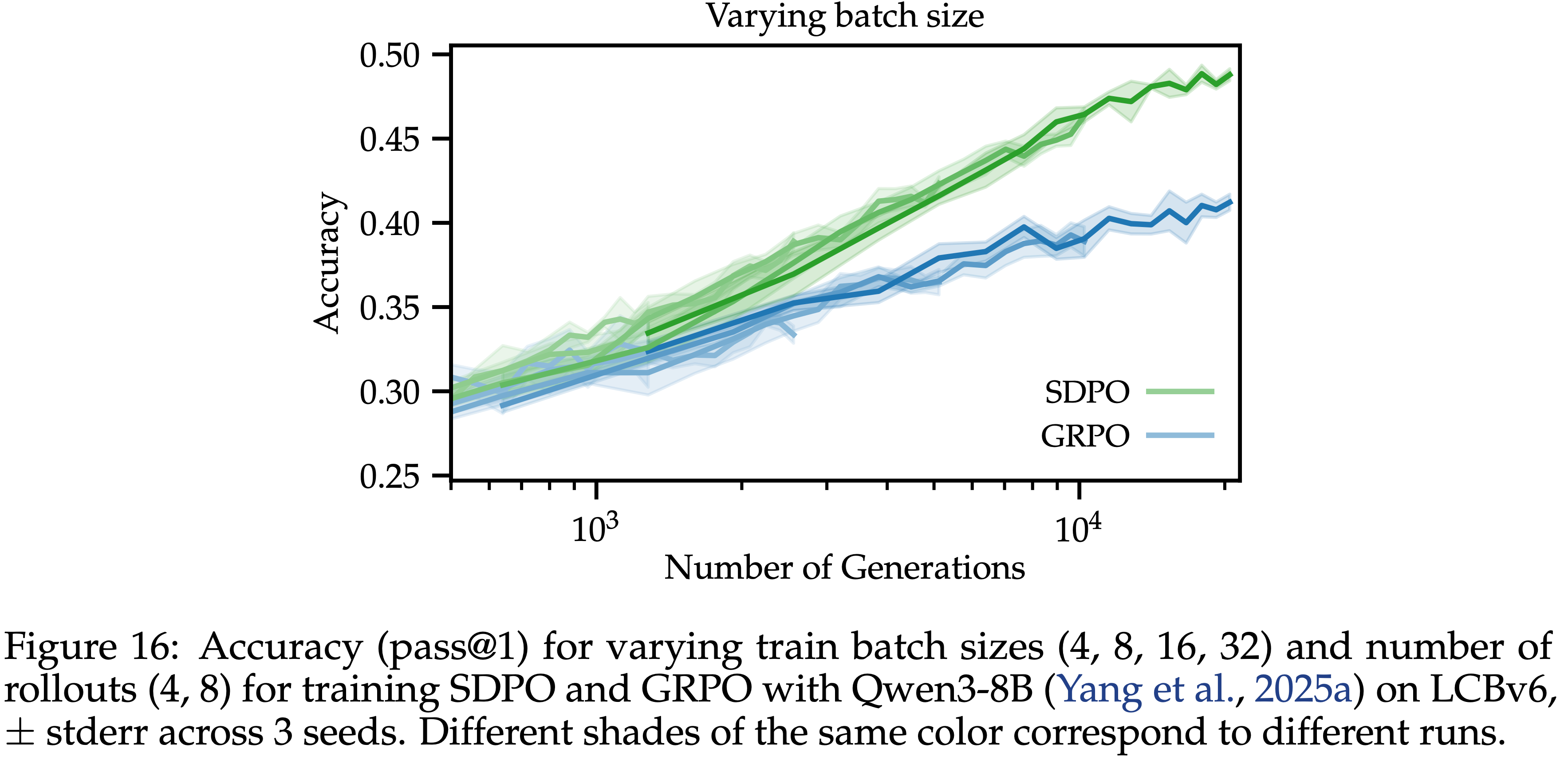
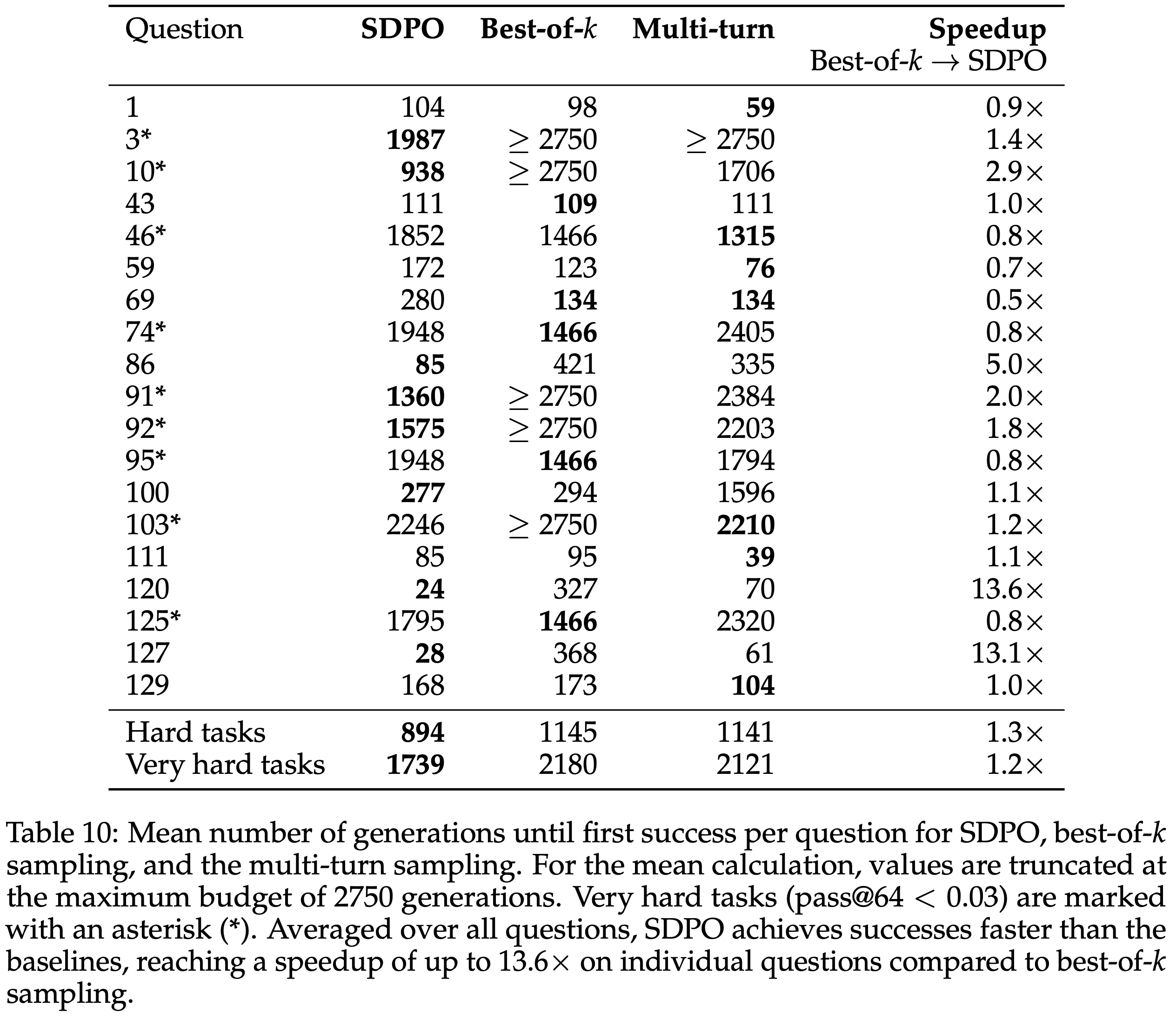
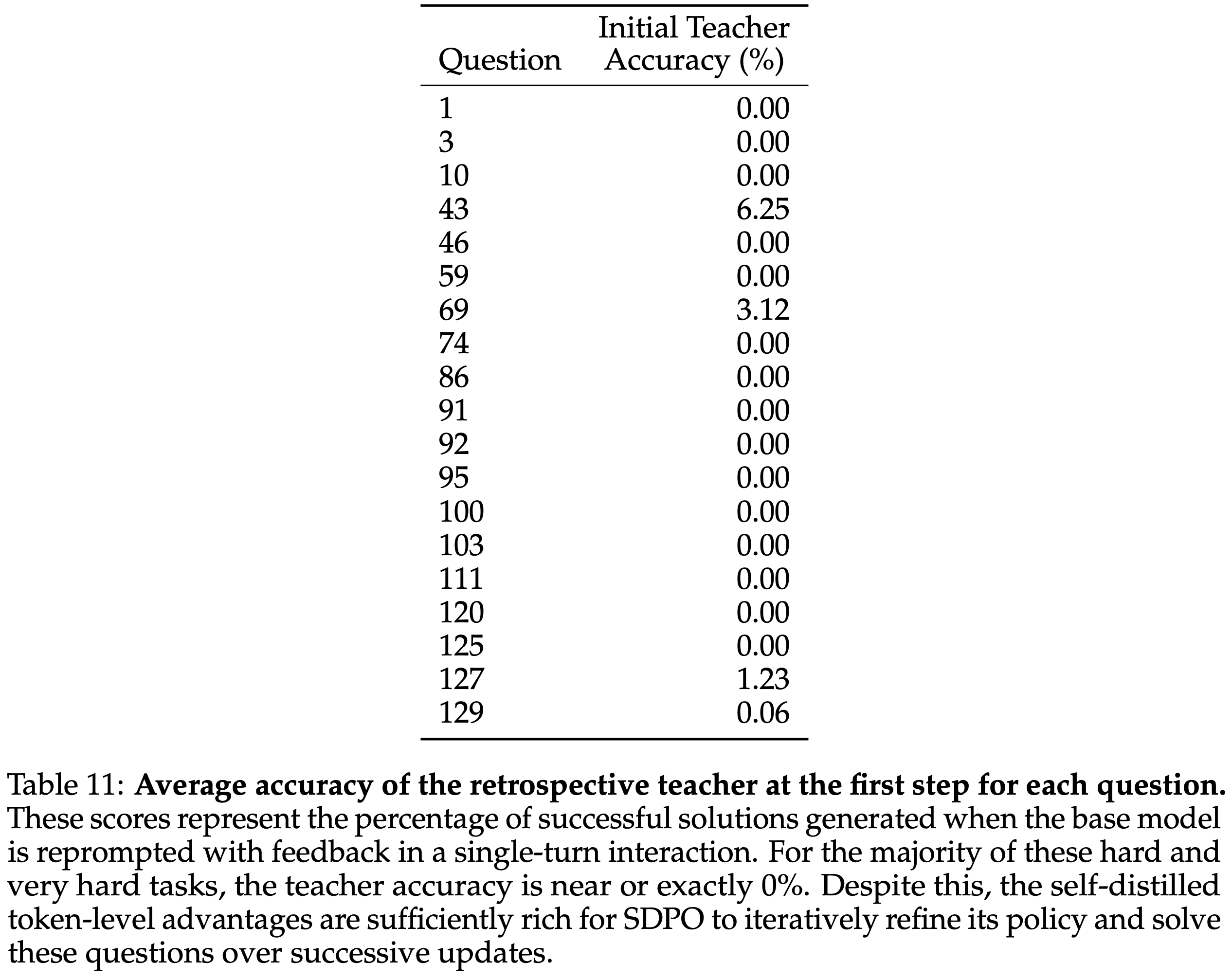


/Segment-Level-DPO-Figure1.png)
/Segment-Level-DPO-Figure6.png)
/Segment-Level-DPO-Figure2.png)
/Segment-Level-DPO-Table1.png)
/Segment-Level-DPO-Table2.png)
/Segment-Level-DPO-Figure3.png)
/Segment-Level-DPO-Figure4.png)
/Segment-Level-DPO-Table3.png)
/Segment-Level-DPO-Table4.png)
/Segment-Level-DPO-Figure5.png)
/Segment-Level-DPO-Table5.png)
/Segment-Level-DPO-Table6.png)
/Segment-Level-DPO-Table7.png)
/Segment-Level-DPO-Table8.png)
/Segment-Level-DPO-Figure7.png)
/Segment-Level-DPO-Figure8.png)
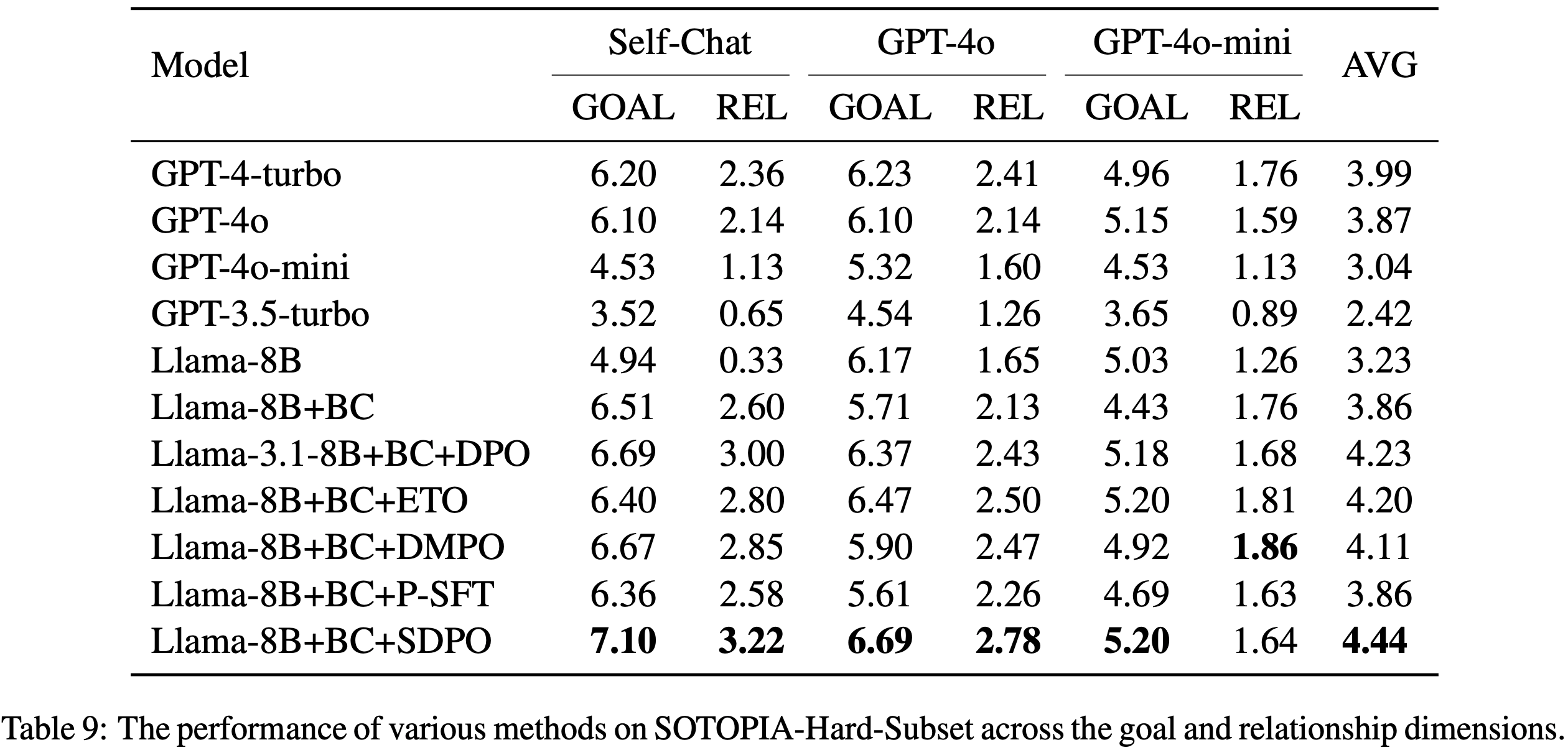
/Segment-Level-DPO-Table9.png)
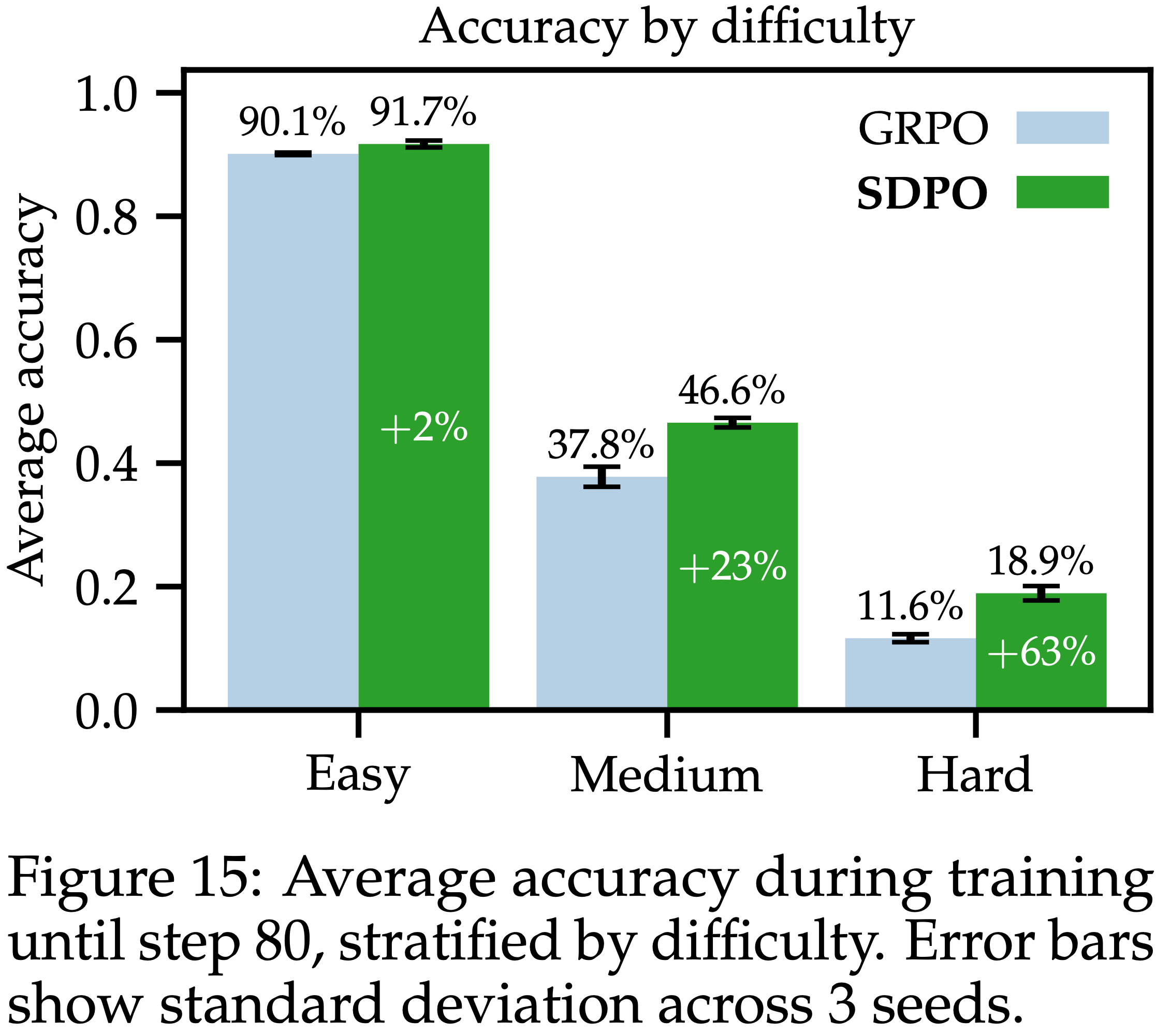
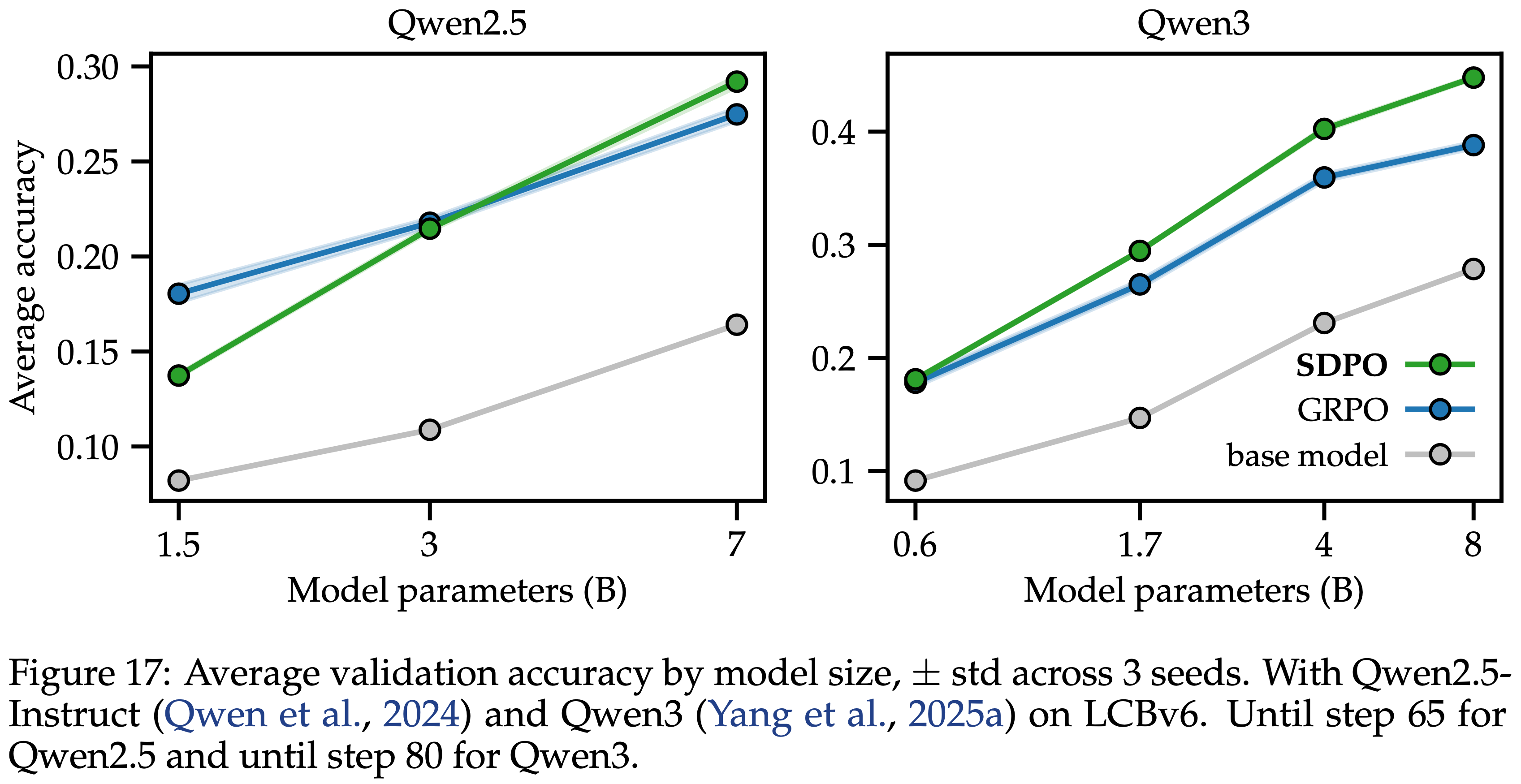
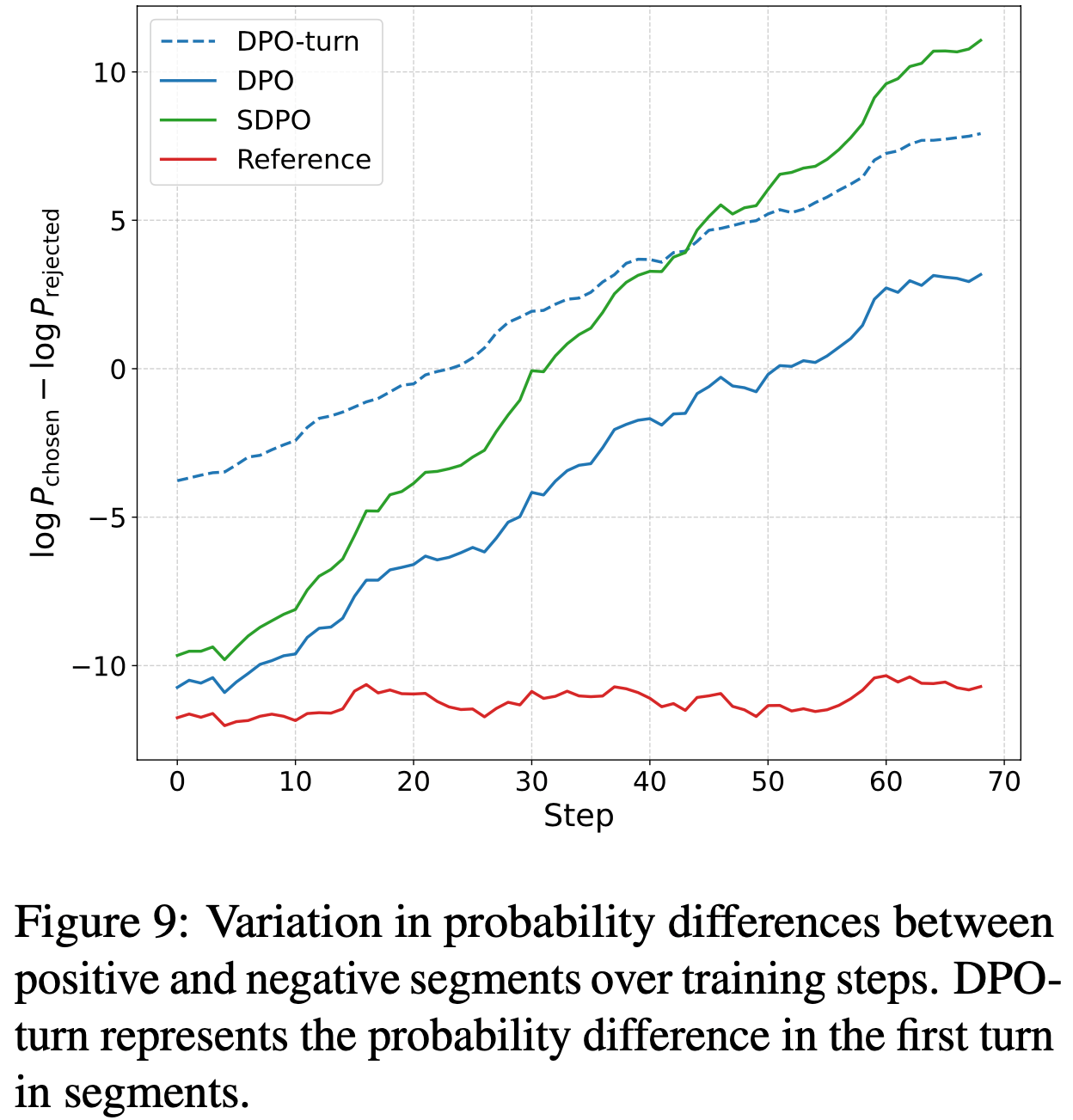
/Segment-Level-DPO-Figure9.png)