注:本文包含 AI 辅助创作
Paper Summary
- 整体总结:
- Step 3.5 Flash 是 MoE(196B-A11B),纯文本 的针对 Agentic 优化过的模型
- 最大优点是计算效率高(也是名字中 Flash 的来源),亲测速度确实还不错
- 交错使用 3:1 的 Sliding Window Attention(SWA)/Full Attention 和 Multi-Token Prediction(MTP-3)进行加速
- 提出 MIS-PO 算法
- 虽然使用了一种新的方式 MIS(Metropolis Independence Sampling)去描述 ,但本文 MIS(Metropolis Independence Sampling)的思路跟一些博客和文章中提到的 Masked Importance Sampling(MIS) 其实类似,并不是很创新
- 不同领域专家构建 + Self-Distillation 融合不同领域专家能力
- 在 Terminal-Bench 2.0 上达到 \(51.0%\),几乎与 GPT-5.2 xHigh 和 Gemini 3.0 Pro 等相当
- 注:本文中,作者经过评测认为 XML 的工具模板比 JSON 更好(去年还有争论,目前似乎慢慢成为共识)
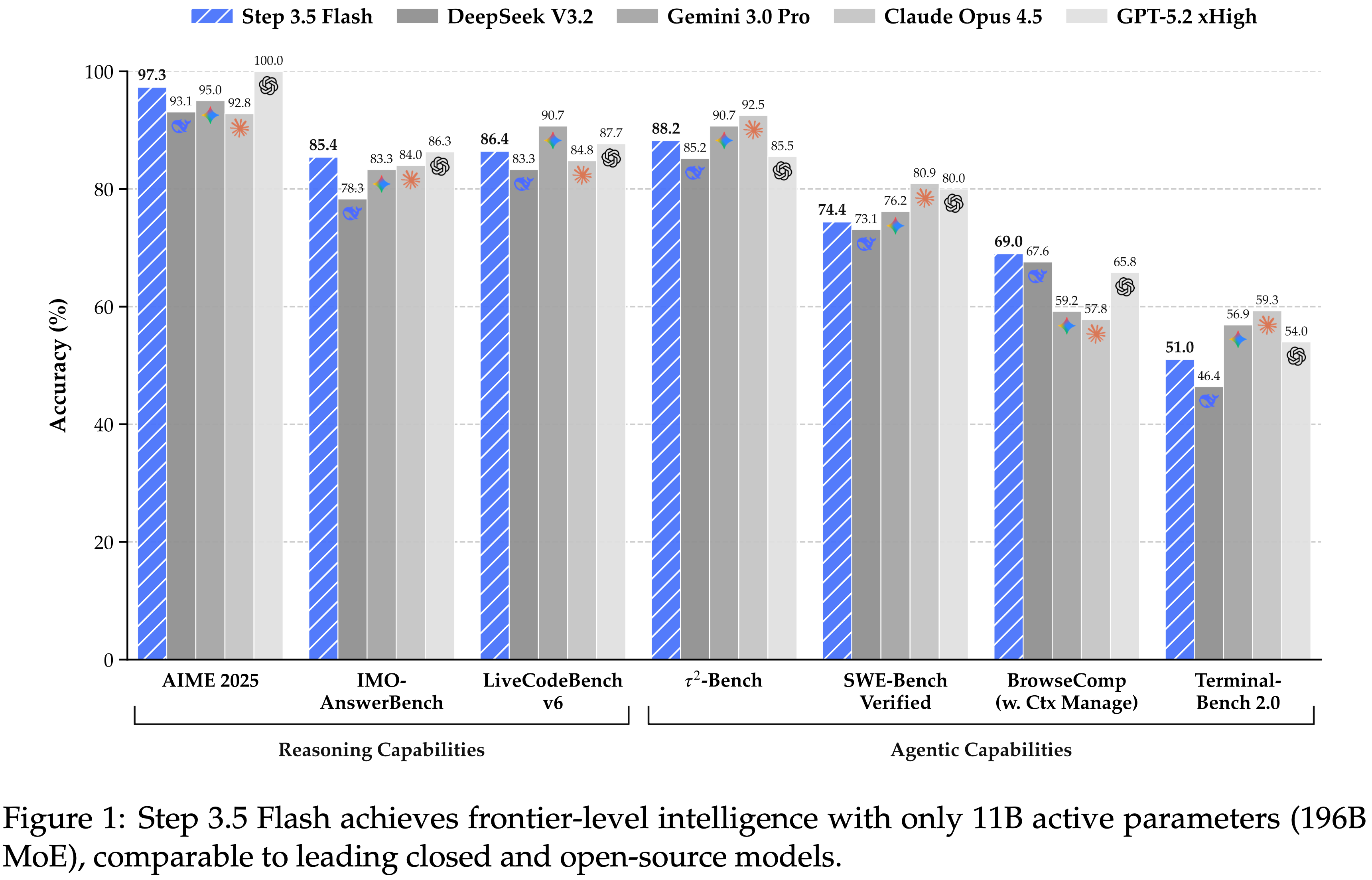
- 架构情况简单介绍
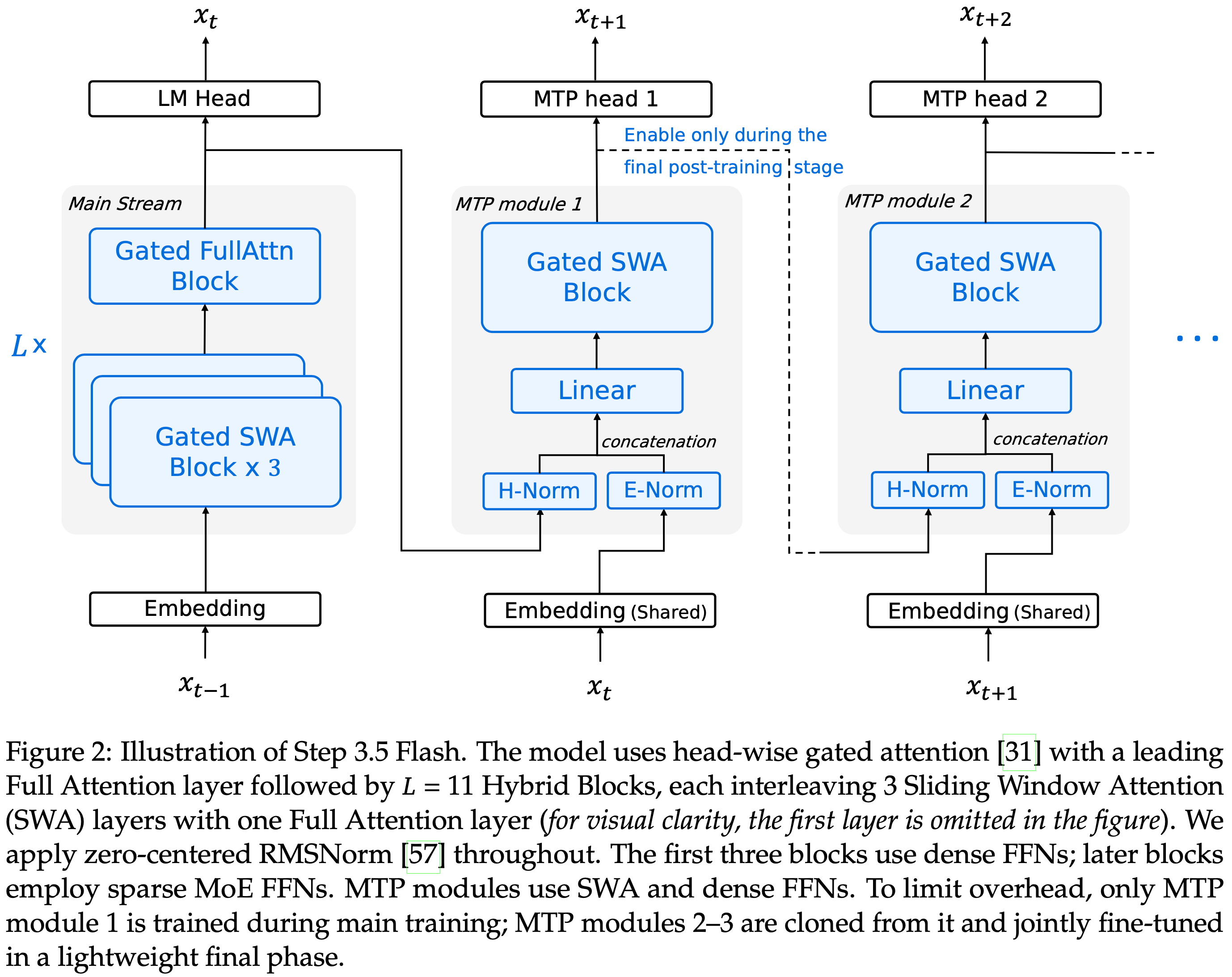
- 注:暂时重点对 Post-training 部分进行解读,后续有时间再补充其他部分
Post-Training
- 用于大规模 RL 的统一后训练方案
- 从一个统一 SFT 模型开始
- 结合可验证的奖励信号和人类偏好反馈,实现了持续的自改进,在 MoE 模型的大规模 Off-policy 训练期间也能保持稳定性
- 两阶段方案(类似 DeepSeek-V3.2):
- 第一步(构建专家模型):在 SFT 的基础上,训练数学、代码、STEM、工具使用、长上下文理解、人类偏好和 Agentic Reasoning 等领域的特定领域 RL
- 第二步(专家能力融合):使用 Self-Distillation 和可扩展 RL 将这些专门的专家蒸馏到一个通才模型中
- 通过在目标专业化和广泛综合之间系统地交替,实现了强大的泛化能力,而不会牺牲专家级的性能
Expert Model Construction and Self-Distillation
- SFT 阶段:采用 两阶段 SFT 流程 来构建用于后续 RL 的 Base
- 第一阶段执行大规模的多领域 SFT,涵盖数学、代码、STEM、逻辑、通用问答、Code Agent、工具使用、Search Agent 和长上下文理解
- 应用难度感知过滤和策略平衡来培养广泛的智能体行为
- 第二阶段通过注入 OOD 信号 来明确最大化推理密度,这些信号包括约 3 万条专家级化学轨迹和合成算术任务
- 这种对独特推理模式的有针对性暴露,仅在三个 Epoch 内就解锁了潜在能力,使模型具备了初始化后续特定领域 RL 阶段所需的复杂结构复杂性
- 第一阶段执行大规模的多领域 SFT,涵盖数学、代码、STEM、逻辑、通用问答、Code Agent、工具使用、Search Agent 和长上下文理解
- 特定领域 RL 阶段:针对特定领域分别进行 RL
- 专家能力合并:将不同的专家能力整合到一个统一的 Student 模型中,该模型从 Mid-train 检查点初始化 (注意:不是从 SFT 后的 ckpt 初始化)
- SFT 数据构造:
- 使用专家模型,在上面特定领域的 SFT 阶段使用的相同 Prompt 数据,重新 Rollout 得到 SFT 样本
- 给直接 RL 集成提供了一种更稳定、更高效的替代方案
- 使用专家模型,在上面特定领域的 SFT 阶段使用的相同 Prompt 数据,重新 Rollout 得到 SFT 样本
- 在构造数据时,采用拒绝采样来消除不良模式,如语言混杂或过度思考,从而将专家知识集中到单个 Student 模型中
- 通过建立这个高质量的 Base 模型,自蒸馏显著减轻了后续 RL 阶段的优化负担
- SFT 数据构造:
Hyper-Parameters
- 采用 Muon 优化器,进行 3% 的 warmup,并采用余弦衰减,学习率从 \(1.0 \times 10^{-5}\) 衰减到 \(5.0 \times 10^{-6}\)
- 冻结 MoE 路由器的权重,并像 Mid-training 一样禁用 EP 组平衡损失
- SFT 训练以 0.1 的 MTP 损失权重、32 的 Global batch size 和 128k 的 Global sequence length 进行
- 关于 ROPE,作者保持 \(\theta_{SWA} = 10,000\),并调整 \(\theta_{Full} = 5,000,000\) 以适应 128k 的上下文长度 (2023)
Scalable RL
- LLM RL 的目标是优化策略 \(\pi_{\theta}\) 以最大化轨迹 \(\tau = (s_0, a_0, \ldots , s_T)\) 上的终端奖励
- 其中 \(a_t\) 表示在状态 \(s_t\) 生成的 Token
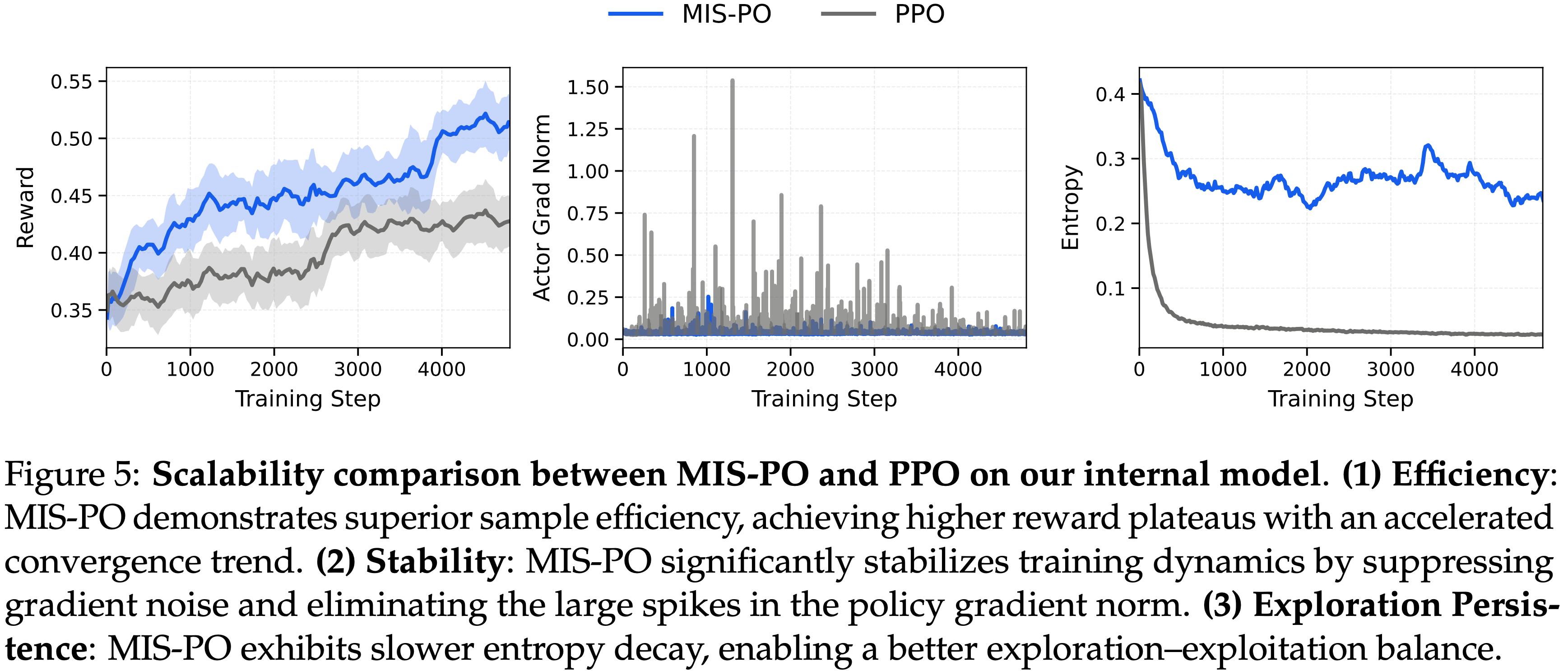
- 对于推理任务,由于极高的时间跨度和模型规模进一步放大了由高梯度方差引起的严重不稳定性(图 5 (2))
- 这种方差主要源于高吞吐量推理引擎和训练框架之间的基础设施差异,以及迭代更新固有的 Off-policy 偏差
- 在这种设置下,Importance Sampling 本质上是非稳定的,因为微小的 Token-level 概率偏移会累积成噪声梯度,阻碍收敛
MIS-Filtered Policy Optimization, MIS-PO
- 注意:这里的 MIS 名字来源不是之前其他文章中的 Masked IS
- 本文提出了 MIS-PO,一种受 Metropolis 独立性采样 (Metropolis Independence Sampling, MIS) (1953; 1970) 启发的方法
- 注:Metropolis Independence Sampling 是一种 MCMC 采样方法,详情见附录
- 将推理策略视为 Proposal distribution,训练策略视为目标分布,并将更新限制在那些与目标分布保持足够接近的样本上
- 与通过有界比率缩放梯度且通常遭受高方差影响的重要性采样不同,MIS-PO 应用二元掩码来过滤 Off-distribution 的样本,并将保留的轨迹视为有效的 On-policy ,从而显著降低梯度方差并实现稳定的优化
- 定义一个二元指示函数并将其应用于两个不同的粒度级别
$$\mathbb{I}(x) = \mathbb{1}[\rho_{\min}\leq x\leq \rho_{\max}]$$- 在 Token-level ,该函数过滤概率比率
$$x_{t} = \frac{\pi_{\theta_{\text{old} } }(a_{t}|s_{t})}{\pi_{\theta_{\text{vllm} } }(a_{t}|s_{t})}$$- 以抑制训练策略和推理策略之间的局部不匹配 (2025)
- 在 Trajectory-level ,将相同的指示函数应用于几何平均比率
$$\bar{\rho} (\tau) = (\prod_{t}x_{t})^{\frac{1}{T} }$$- 有效地丢弃那些已显著偏离目标分布的整个轨迹,这个思想类似 GSPO
- 重新制定的 Actor 损失用这些双级别离散掩码替代了连续的重要性权重:
$$\mathcal{L}_{actor} = -\mathbb{E}_{\tau \sim \pi_{\theta_{\text{vllm} } } }\left[\mathbb{I}(x_t)\cdot \mathbb{I}(\bar{\rho} (\tau))\cdot \log \pi_\theta (a_t|s_t)\cdot \hat{A}_t\right]. \tag{2}$$- 理解:
- 上述重要性权重有两级过滤(理论上稳定性是最高的)
- 可以看到,该目标函数将有效样本视为 On-policy (重要性采样的输出是一个二元的值,有梯度回传的 Token 也没有重要性采样比例修正)
- 论文中提到这在信任区域约束下显著降低了长时程推理任务的梯度方差
- 问题:对于 off-policy 的场景,即使已经做过 MIS 过滤了,是否也应该继续保留重要性权重以恢复采样差异呢?(至少在数学上保证准确)
- 图 5 展示了一个大约 5,000 个训练步骤的消融研究,其中 MIS-PO 在 Actor 梯度范数上表现出比 PPO 显著更低的噪声,表明了其改进的可扩展性
- 更多消融研究见附录 D.2.3
- 理解:
- 在 Token-level ,该函数过滤概率比率
- 为进一步稳定训练动态,采用了多种技术:
- 截断感知的价值引导 (Truncation-Aware Value Bootstrapping) (2026) :纠正由上下文长度截断引入的乐观奖励偏差
- 路由置信度 (Routing Confidence) 监控:预测特定于 MoE 架构的不稳定性
Truncation-Aware Value Bootstrapping
- 为截断的上下文轨迹分配零奖励会将截断与任务失败混为一谈
- 这种模糊性通过未能区分不完整和错误的结果来惩罚长链推理
- 为了解决这个问题,本文的做法是区分两者
- 将零奖励替换为对最终状态的价值引导估计 (bootstrapped value estimate)
- 将截断视为视野中断而不是终端失败
- 轨迹 \(\tau_{i}\) 的修改后奖励定义为:
$$\hat{R}_{i} = \left\{ \begin{array}{ll}V_{\phi}(s_{T}) & \text{if the response is truncated,}\\ R_{i} & \text{otherwise.} \end{array} \right. \tag{3}$$- 理解:可以看到
- 发生截断时,其奖励估计是截断状态的估计值,即 \(V_{\phi}(s_{T})\)
- 发生失败时,其分数正常表示为 \(R_i\),可能为 0 或 -1 等
- 理解:可以看到
- 作者的实践经验表明
- 这种截断感知的价值引导在截断率高达 20% 时也能稳定训练,防止了通常由不完整轨迹 (2025; 2025) 引发的奖励退化
- 消融研究证实,该技术对 Competition-level 基准测试特别有益,因为长时程推理使截断效应最为普遍
Routing Confidence as a Stability Proxy
- 一些之前的研究将 RL 稳定性与 MoE 路由一致性联系起来
- 在此基础上,作者提出将路由置信度 \((\Sigma_{k})\) 作为稳定性的代理
- 即激活专家的平均概率质量
- 理解:被激活专家的平均概率(每个专家都有一个概率)
- 较低的 \(\Sigma_{k}\) 意味着较高的路由不确定性,这会放大训练-推理不匹配
- 理解:较低的 \(\Sigma_{k}\) 意味着被激活的专家并不是概率非常大的,不确定性大(类似熵较高)
- 即激活专家的平均概率质量
- 通过初步实验,确定了一个明显的稳定性相变:
- 路由置信度低的模型是脆弱的,需要极端的稳定化措施
- 极端稳定化措施如:路由器重放 (Router Replay) (2025) 和 严格的 On-policy 更新 等
- 路由置信度高的模型保持鲁棒性,能够在没有复杂干预的情况下进行 Off-policy 训练
- 路由置信度低的模型是脆弱的,需要极端的稳定化措施
RL Training Dynamics
- 本文在图 6 中展示了 Step 3.5 Flash 的 RLVR 训练动态和下游评估改进
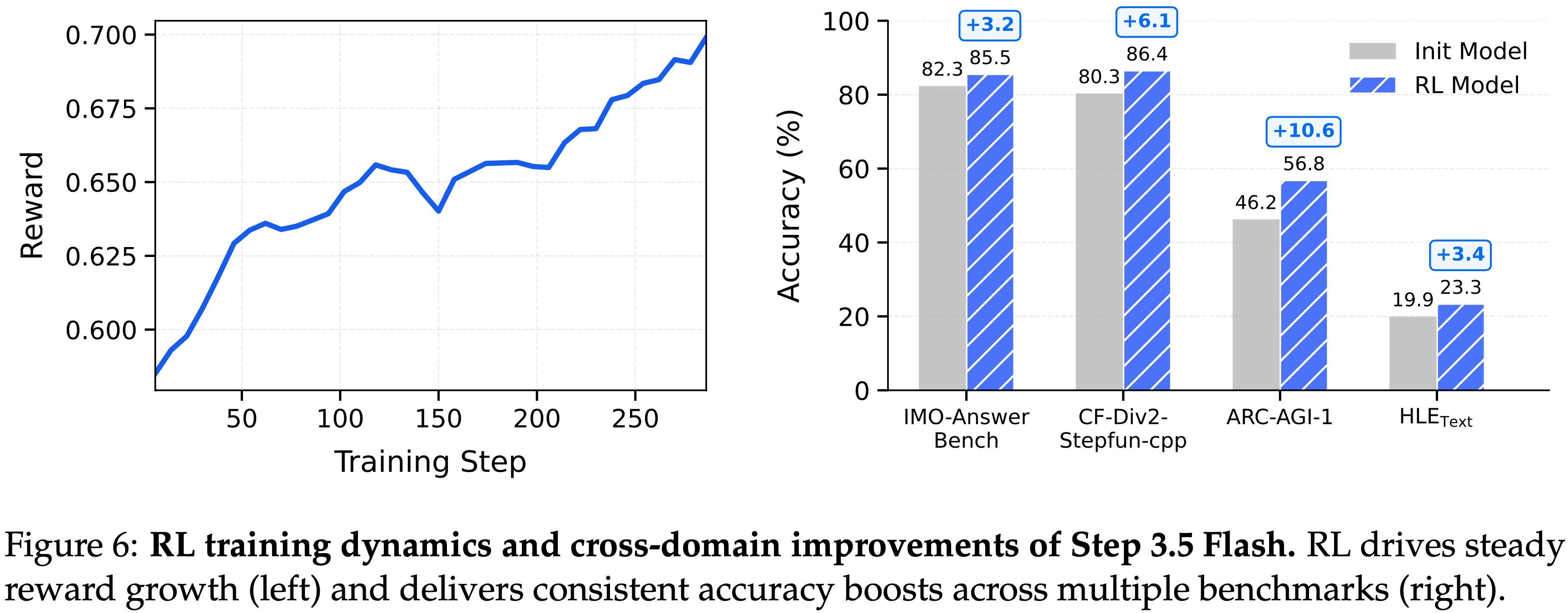
- 训练奖励的稳步上升表明了一个稳定且有效的学习过程
- Step 3.5 Flash 在不同的评估基准上实现了一致的性能提升
- IMO-AnswerBench (2025) 上显著提升了 \(+3.2%\)
- CF-Div2-Stepfun-cpp(附录 E.2.1:作者定制的 CodeForces Div.2 基准)上提升了 \(+6.1%\)
- ARC-AGI-1 (2019) 上提升了 \(+10.6%\)
- \(\text{HLE}_{\text{text} }\) (2025) 上提升了 \(+3.4%\)
Reward System
- 将 RL 框架解耦为 with Verifiable Rewards RL (RLVR) 和 with Non-verifiable Rewards RL(如 RLHF)
- 每个部分都由一个根据其监督特性量身定制的独特奖励支持
Verifiable Rewards
- 对于 RLVR,每个 Prompt 都与一个特定于任务的验证器配对,该验证器输出一个奖励
- 基于规则的检查器用于逻辑、指令遵循和代码任务
- 基于模型的验证器则用于 STEM 任务
- 在作者内部模型上进行的 450 步 RL 训练消融研究中
- 对 STEM 任务使用基于模型的验证器比直接使用普通的数学验证器平均高出 \(2.0%\)
- 更多细节见附录 D.2.2
Non-Verifiable Reward
- 使用 Pairwise GRM (2025) 来处理不可验证的任务,该模型根据固定参考来评估响应
- 理解:这里使用的是 Pairwise 的 GRM,应该是输入一个 Response 和 一个 Reference Response,然后融 GRM 评估 Response 的胜率是多少
- GenRM 是一个推理模型,输出一个置信度分数 ,指示一个 Response 获胜的可能性
- 该分数随后被转换为 Bradley-Terry 胜率 (1952),作为奖励信号
- Length Control 在 GenRM 中作为置信度分数惩罚进行建模 ,并传播到胜率奖励中,从而有效地抑制 RL 训练期间过度的长度增长
- 理解:这里应该是 Prompt GRM 评估 Response 胜率时也考虑 Length Control
- 通过对捏造的引用、过度自信的主张或语言不一致的 Response 分配零奖励来进一步确保鲁棒性
- 问题:这里是通过 GRM 直接判断的吗?
Agent Reward(待讨论)
- 搜索任务使用基于实体匹配分数的 LLM 进行评估
- 对于报告生成,基于 Rubric 的 LLM judge 评估研究查询、Rubric 规范和候选报告,产生三元判断(满意、部分满意、不满意)(2025)
- 由于中间类别经常与专家偏好不一致,本文将输出映射到非对称的二元奖励,从而产生更清晰的学习信号,并更快地收敛到符合专家行为的行为
- 问题:如何理解这里的 非对称的二元奖励
GenRM Training and MetaRM
- GenRM 初始化:使用 RM-Specific Prompts 微调本文的 SFT 模型来初始化
- GenRM RL 训练:使用精心挑选的 Pairwise 偏好数据,并采用类似于标量奖励模型公式的 logsigmoid 损失
- For 提高 GenRM 的鲁棒性
- 集成 MetaRM(一个额外的验证器)来惩罚表现出虚假推理 (即, 从有缺陷的逻辑中得出正确的偏好 )的 Response
- 当检测到此类存在问题的模式时,MetaRM 会降低奖励(避免模型陷入中间过程错误/结果正确的 Reward Hacking 模式)
- 在作者的内部模型上进行的 200 步 RL 训练消融研究中,MetaRM-augmented GenRM 在每个基准测试上都比普通 GenRM 高出 \(0.5% - 3%\)
- 注意:每个基准上都高
Hyper-Parameters
- 对于 Rollout
- 采样温度和 top-\(p\) 都设置为 1.0
- 最大序列长度为 128k 个 Token
- 每次生成
- 对推理任务:采样 256 个唯一的 Prompt,每个 Prompt 生成 16 个 Response
- 对人类偏好任务:采样 512 个唯一的 Prompt,每个 Prompt 生成 8 个 Response
- 对工具使用任务:采样 128 个唯一的 Prompt,每个 Prompt 生成 8 个 Response
- Rollout 后,完成的样本被划分成 mini-batch,并用于训练一个 Epoch
- 其中 Actor 使用 4 个 mini-batch,Critic 使用 12 个 mini-batch
- 优化使用 Muon 优化器进行,权重衰减为 0.1
- Actor 的学习率为 \(2\times 10^{-6}\), Warmup 步数为 20
- Critic 的学习率为 \(5\times 10^{-6}\),Warmup 步数为 50
- 遵循 ORZ (2025),将 \(\gamma\) 和 \(\lambda\) 都设置为 1
- 在最后阶段进一步采用了无偏的 KL 损失 (2025),系数为 0.001
- 对于公式 (2),Token-level 和 Trajectory-level 的掩码边界分别设置为
[0.5, 2]和[0.996, 1.001]- 理解:可以证明 Trajectory-level 下 几何平均的 Mask 权重 方差非常小(类似 GSPO 一样,需要设置非常小的过滤边界才能生效),其重要性采样系数几乎在 1 附近,而 Token-level 的权重则波动较大
Data Synthesis & Curation
- 整体说明:融合开源数据、合成数据和用户轨迹,构建了一个多样且难度均衡的 Prompt 池
- 使用统一的合成和策展流程,结合严格的全局过滤和特定领域的优化,以最大化推理密度
- 使用基于规则的启发式方法和基于模型的保真度检查相结合来确保数据质量
- 生成的数据集包含 871K 个样本(7.23B Token),详细的统计数据总结在表 3 中
General and Reasoning
- 本文的训练语料库聚合了来自不同开源社区的 Prompt、专家 Response 和合成数据
- 包括数学 (2025; 注:这里的开源数据集非常多)、编码 (2023; 2025; 2025) 以及科学与开放式问答 (2023; 2025; 2025; 2024)
- 为了最大化推理密度,本文采用了一个统一的流程,将严格的全局过滤与特定领域的优化相结合,通过基于规则的启发式方法和基于模型的保真度检查相结合来强制保证质量
- 对数学,通过专家引导的拒绝采样和合成的大数算术来确保数值稳定性
- 对编程,通过选择严谨的算法挑战来优先考虑离线可执行性,同时严格清除与 RAG 相关的幻觉
- 问题:如何理解这里与 RAG 相关的幻觉?
- 特别地, 本文减少了模型错误地声称可以访问外部搜索引擎或假装检索在线解决方案的倾向
- 此外,本文将科学数据限制在具有唯一、可确定答案的明确问题上
- 为了能够泛化到实际场景,本文还扩展了开源检查器,并使用一些现实世界的约束来增强样本
- 同时,作者从开源、合成和用户轨迹中收集通用 Prompt,形成一个多样且难度均衡的池
- 这个过程产生了一个包含数百万样本、达到十亿 Token-level 的高保真数据集
Generalized Tool Learning
- 本文提出了一个执行驱动的数据生成框架,用于在智能体中学习可靠的工具使用行为,解决了现有合成流程中的关键限制,如数据不一致、缺乏可验证性和模型幻觉
- 作者的方法不依赖于随机探索 (2025; 2025) 或基于模型的模拟 (2025; 2025),而是将工具使用行为分解为原子意图 (atomic intents),并使用有限状态机 (finite state machine, FSM) 对它们进行建模
- 明确地将抽象的工具调用逻辑与参数化的执行约束分离开来
- 数据通过一个 “采样-执行-验证” 循环与拒绝采样生成,所有候选轨迹都在真实环境中执行 ,并通过确定性反馈进行验证 ,从而确保保真度并消除幻觉行为
- 通过组合方式组合原子意图,该框架支持复杂、可控的工具使用场景的可扩展生成
- 使用此范式,本文构建了超过 10 万条高质量轨迹 ,总计数十亿个 Token,为基于工具的计划、推理和执行提供了精确的监督
Code Agents
- Code Agent 可以通过可验证环境构建和解决方案生成之间的闭环干预来自我改进,其中可执行的反馈不断优化这两种能力
- 本文作者将环境构建视为与错误修复和功能实现同等重要的第一类能力 (first-class capability),并在可验证的奖励信号下对其进行合成
- 为此,本文作者开发了一个专门的智能体流程,该流程从 SWE-factory (2026) 框架演变而来
- 结合了一个跨任务记忆池,用于检索历史构建成功案例作为 Few-shot 示例,以及一个循环检测机制,以防止冗余探索
- 该流程实现了 40% 的环境构建成功率,通过来自构建轨迹(包括 Shell 命令和错误恢复)的密集监督,形成了一个模型自我进化的正反馈循环
- 为了进一步提高信号质量,本文通过抽象和屏蔽那些对最终解决没有贡献的瞬态故障和冗余执行模式来规范化环境构建轨迹
- 得到的环境充当动态测试平台,利用执行反馈和单元测试生成高质量的合成数据,用于持续对齐的奖励信号
- 经验中观察到一种双向转移:
- 构建专业知识加速了编码性能,而在这些环境中编码进一步提高了构建准确性,如 DockSmith (2026) 所示
- 利用这个进化流程,作者精心挑选了 5 万个经过验证的环境,涵盖了超过 1.5 万个 GitHub 仓库和 20 多种编程语言
- 这个多样化的集合捕捉了广泛的现实世界场景,为训练通才 Code Agent 提供了坚实的基础
- 此外,作者还整合了几个著名的开源环境,包括 SWE-smith (2025)、SWE-Gym (2024)、R2E-Gym (2025)、SWE-rebench (2025) 和 SETA (2026)
Search and Research Agents
- 为了促进高级信息搜索,本文的流程集成了基于图和多文档合成 的方法来强制实现多跳推理
- 通过在知识图谱(例如,Wikidata5m (2021))上执行拓扑扩展并模拟跨网站浏览轨迹,生成了反映现实世界研究复杂性的数据
- 为了保证外部检索的必要性,针对 DeepSeek-R1 (2025) 验证生成的查询,系统地排除 了这个强大的推理模型无需工具交互即可解决的实例
- 生成的轨迹通过结构化的报告生成流程 (2025) 进行精炼
- 该流程强制执行严格的指令遵循和结构完整性
- 具体方法:
- 强制执行对预设研究计划的严格遵守,丢弃任何偏离该结构的轨迹
- 随后有效的输出通过基于模型的评判器和启发式规则进行迭代清洗,以解决诸如非正式写作、时间幻觉和混合语言等细微问题
- 这种端到端的方法在 RESEARCHUBRICS (2025) 基准测试上实现了业界领先的性能
Agent Infrastructure
Reasoning with Tool-Use Template Design
- 为了有效地将推理和智能体能力整合到一个基础模型中,确定思考过程和工具使用的适当模板至关重要
- 关于推理模板,作者评估了三种管理策略
- 每轮丢弃推理历史的方法 (2025) 虽然激励了独立生成,但在长时程任务(例如,超过 100 轮的编码会话)中会导致任务失败
- 保留完整的推理历史会带来高昂的上下文消耗,这会迅速耗尽模型的容量并阻止后续的工具调用
- 作者采用了一种选择性保留策略:仅为最近用户指令触发的工具使用轨迹保留推理痕迹
- 这种设计实现了推理连贯性和上下文效率之间的最佳权衡,这一做法与最新的前沿模型 (2025; 2025) 一致
- 关于工具使用模板,本文比较了流行的 JSON 和 XML 格式
- JSON 的严格语法,包括转义序列和分隔符,经常导致小型、训练不足的模型出现解析错误
- XML 格式允许平坦的字符串输出,语法开销显著更低
- 因此,本文选择 XML 格式以确保在复杂、真实的智能体编码场景中的鲁棒性
- 关于工具使用模板,本文比较了流行的 JSON 和 XML 格式
Scalable Code Agent Infrastructure
- 本文的集成架构侧重于可扩展的会话管理和跨框架泛化,以促进高吞吐量的智能体编码
- 其核心是一个专有的 Session-Router,它通过 Kubernetes 编排容器生命周期,并通过 Tmux 确保交互一致性
- 该架构支持数千个并发环境,具有无缝的状态持久性,无需手动配置特定于 Scaffold 的 Docker 配置
- 为了确保跨不同智能体工作流的高度泛化,本文训练模型适应广泛的交互框架,从学术标准(例如,OpenHands (2024)、SWE-agent (2024) 和 Terminus-2 (2026))到企业级协议(例如,KiloCode (2026)、RooCode (2026) 和 ClaudeCode (2026))
- 通过在训练期间让模型接触这些多样化的交互范式,有效地防止了它过拟合到特定的流程模式,确保无论底层执行环境如何,它都能保持鲁棒性
附录:Metropolis Independence Sampling (MIS) 介绍
- Metropolis Independence Sampling (MIS) 是一种马尔可夫链蒙特卡罗 (Markov Chain Monte Carlo, MCMC) 方法
- Metropolis Independence Sampling 是一种经典的 MCMC 方法,其核心在于使用独立于当前状态的提议分布进行采样
- Step 3.5 Flash 论文中的创新之处在于,将 MIS 的思想从概率采样领域迁移到强化学习的策略优化中 ,用二元过滤替代了传统的重要性采样权重,从而在保持有效学习信号的同时,极大地降低了梯度方差,为大规模 MoE 模型的稳定 RL 训练提供了新的有效范式
- 思路跟一些博客和文章中提到的 Masked IS 其实类似,并不是很创新
Metropolis Independence Sampling 方法的核心思想
- Metropolis Independence Sampling 的核心目标是从一个复杂的目标分布 \( \pi(x) \) 中采样,当直接采样困难时,通过构建一个马尔可夫链来间接生成服从该分布的样本
- Metropolis Independence Sampling 的基本框架是:
- 1)提议分布 (Proposal Distribution) \( q(x) \):一个易于采样的分布,用于生成候选样本
- 2)接受-拒绝机制 (Acceptance-Rejection Mechanism) :根据 Metropolis-Hastings 准则决定是否接受候选样本
- 注:独立性采样 意味着提议分布 \( q(x) \) 不依赖于当前状态 \( x^{(t)} \),即 \( q(x’ | x^{(t)}) = q(x’) \)
- 这与随机游走 Metropolis (Random Walk Metropolis) 形成对比,随机游走的提议分布依赖于当前位置
Metropolis-Hastings 接受概率
- 对于 MIS,接受概率简化为:
$$
\alpha(x^{(t)}, x’) = \min\left(1, \frac{\pi(x’) / q(x’)}{\pi(x^{(t)}) / q(x^{(t)})}\right)
$$- \( \pi(x) \) 是目标分布(未归一化的概率密度)
- \( q(x) \) 是提议分布
论文中 MIS-PO 的创新应用
- 在 Step 3.5 Flash 的 RL 框架中,作者将 MIS 的思想创造性地应用于策略优化,提出了 MIS-Filtered Policy Optimization (MIS-PO)
问题背景
- 在 RL 训练中,由于推理引擎和训练框架的分离,以及迭代更新的特性,会产生训练-推理策略不一致的问题
- 这导致传统的重要性采样 (Importance Sampling) 方法出现高方差和不稳定性,尤其是在 MoE 模型的长程推理任务中
MIS-PO 的核心创新
- 论文将 MIS 的思想进行了以下转化(MCMC 概念 -> MIS-PO 中的对应):
- 目标分布 \( \pi(x) \) -> 训练策略 \( \pi_{\theta} \)
- 提议分布 \( q(x) \) -> 推理策略 \( \pi_{\theta_{\text{vllm} } } \)(用于生成 Rollout 数据)
- 接受概率 \( \alpha \) -> 二元过滤函数 \( \mathbb{I}(x) \)
双重过滤机制
- MIS-PO 引入了两个层级的过滤(同时过滤):
- Token-level Filtering :
$$
x_t = \frac{\pi_{\theta_{\text{old} } }(a_t|s_t)}{\pi_{\theta_{\text{vllm} } }(a_t|s_t)}
$$- 通过阈值 \([\rho_{\min}, \rho_{\max}]\) 过滤单个令牌的概率比,抑制局部的分布不匹配
- Trajectory-level Filtering :
$$
\bar{\rho}(\tau) = \left(\prod_{t=0}^{T-1} x_t\right)^{\frac{1}{T} }
$$- 计算几何平均概率比,丢弃整个偏离目标分布过远的轨迹(类似 GSPO)
- Token-level Filtering :
- 最终的 Actor 损失函数
$$
\mathcal{L}_{\text{actor} } = -\mathbb{E}_{\tau \sim \pi_{\theta_{\text{vllm} } } }\left[\mathbb{I}(x_t)\cdot \mathbb{I}(\bar{\rho}(\tau))\cdot \log \pi_\theta (a_t|s_t)\cdot \hat{A}_t\right]
$$- 其中 \( \mathbb{I}(x) = \mathbb{1}[\rho_{\min} \leq x \leq \rho_{\max}] \) 是二元指示函数
MIS-PO 的优势
- 论文通过实验验证了 MIS-PO 相对于传统方法(如 PPO 和 GSPO)的显著优势:
- 1)更高的样本效率 :收敛速度更快,能够达到更高的奖励平台
- 2)更强的稳定性 :有效抑制了策略梯度范数的剧烈波动,消除了训练过程中的大幅尖峰
- 3)更好的探索-利用平衡 :熵值衰减更慢,保持了更持久的探索能力
- 4)对 MoE 架构更友好 :有效控制了训练-推理的分布漂移,解决了 MoE 模型在离策略 RL 训练中的关键稳定性问题