- 参考链接:
- 源码地址:github.com/volcengine/verl
- 官方教程文档:https://verl.readthedocs.io/
- DeepWiki 解读:deepwiki.com/volcengine/verl
- 官方公开讲座(青稞社区):verl 源码解读与 HybridFlow 编程范式讲解
- 字节跳动Seed官方解读:最高提升20倍吞吐量!豆包大模型团队发布全新 RLHF 框架,现已开源!
- 相关论文:HybridFlow: A Flexible and Efficient RLHF Framework, EuroSys 2025, HKU & ByteDance
- 其他解读:
- verl 参数速览 - Chayenne Zhao的文章 - 知乎
- 不错的系列文章:
- RLHF Infra — Verl 学习(一):Overview - swtheking的文章 - 知乎
- RLHF Infra — Verl 学习(二):Initialization - swtheking的文章 - 知乎
- RLHF Infra — Verl 学习(三):Sample Generation - swtheking的文章 - 知乎
- RLHF Infra — Verl 学习(四): Train Data Organize & Reward Model - swtheking的文章 - 知乎
- RLHF Infra — Verl 学习(五): Review Verl - swtheking的文章 - 知乎
- RLHF Infra — Verl 学习(六)Fully Async Policy Trainer - swtheking的文章 - 知乎
环境安装
- 参考链接:verl.readthedocs.io/en/latest/start/install
- 建议使用 docker 镜像安装方式,亲测本地直接安装坑很多,且安装后还会陆陆续续出现错误
- 特别注意:官方镜像加载后还需要执行本地安装
pip3 install --no-deps -e .- 不执行这一步会提示 verl 库找不到
- 建议将代码拉到本地 host 机器,然后用镜像挂载 host 路径
- 注:官方镜像可能缺失一些依赖包,比如我就遇到缺少 vllm 库,遇到这种情况直接安装即可
- 最新测试过可用的镜像为:
verlai/verl:base-verl0.5-cu126-cudnn9.8-torch2.7.0-fa2.7.4,仅需要自己安装一个 vllm 即可,还有个较小的包按需要安装1
2
3
4
5sudo docker create --gpus all --net=host --shm-size="10g" --cap-add=SYS_ADMIN -v ../verl:/workspace/verl -v ~/llm:/workspace/llm --name verl verlai/verl:base-verl0.5-cu126-cudnn9.8-torch2.7.0-fa2.7.4 sleep infinity
sudo docker start verl
sudo docker exec -it verl bash
cd verl && pip3 install --no-deps -e .
sudo docker stop verl
- 最新测试过可用的镜像为:
模型训练
- Quick Start 可参考:verl.readthedocs.io/en/latest/start/quickstart
- 多节点启动:verl.readthedocs.io/en/latest/start/multinode
源码阅读
verl 库的目标
- 将原始问题建模为一个有向图 DataFlow 问题
- 统一实现,让算法开发者仅需要考虑自身的代码优化即可
数据流的流向过程
- 原始论文的图片
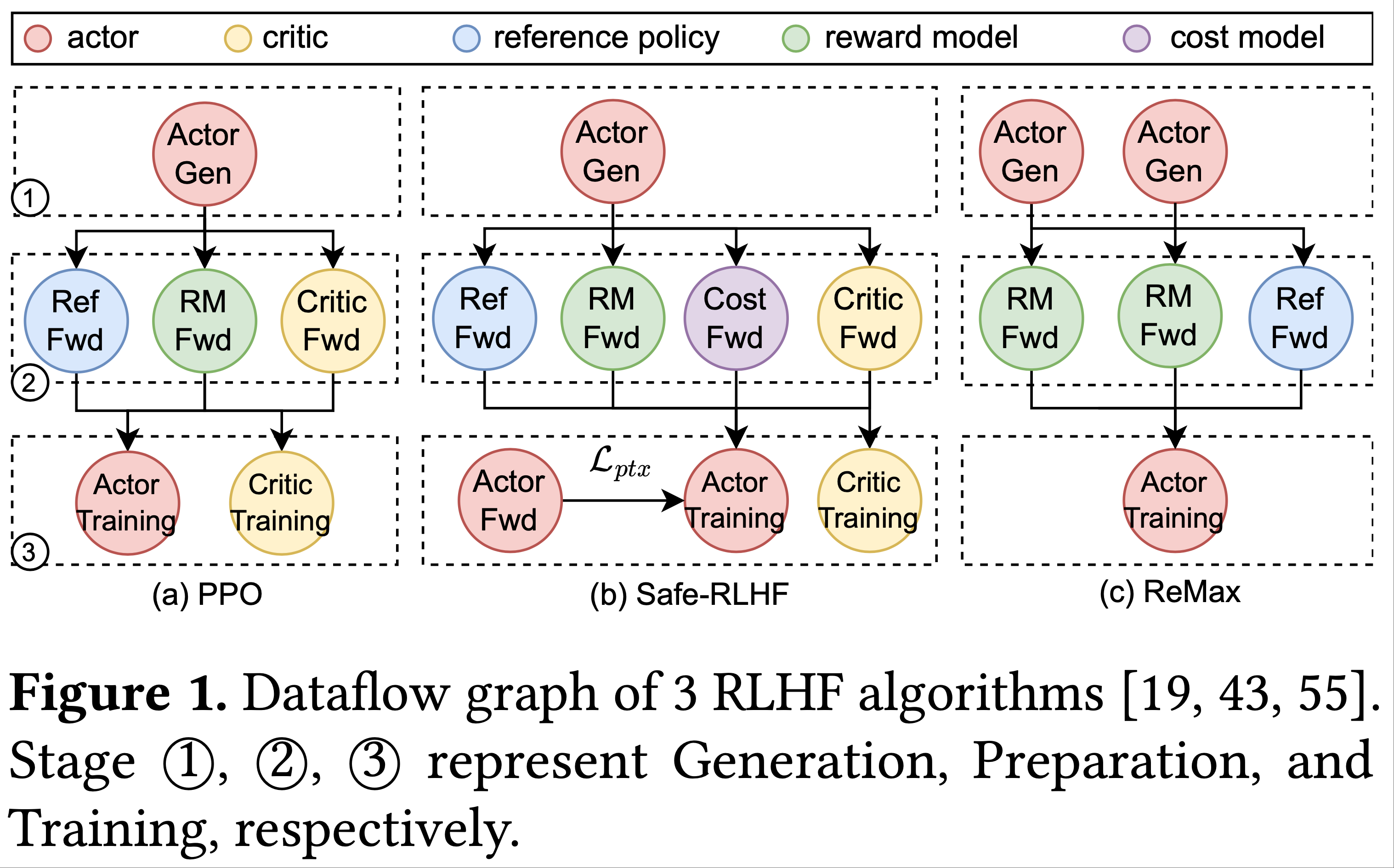
SPMD 的初始化
- 在
RayPPOTrainer.init_workers()内找到相关流程 - 对每个 资源池分别初始化(
for resource_pool, class_dict in self.resource_pool_to_cls.items():) - 每个资源池进行如下操作(
self.ray_worker_group_cls)- 进一步地,执行函数
self._init_with_resource_pool - for 循环依次处理每个 GPU(每个 GPU 启动一个进程),每个进程配置好对应的分别是环境变量
- 每个 GPU 对应一个 worker
- 进一步地,执行函数
数据的分发是如何实现的
- 每个 Worker 的函数都会接受来自上游的数据,处理数据并输出
- 注意传入每个 Worker 的数据已经是分布式处理过的,仅仅是 1/WORLD_SIZE,这里的数据分发是使用
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)定义的 @register是一个注解,用于实现数据分发过程和收集过程,dispatch_modee=Dispatch.DP_COMPUTE_PROTO会对应的绑定两个函数(分别负责分发和收集)
- 注意传入每个 Worker 的数据已经是分布式处理过的,仅仅是 1/WORLD_SIZE,这里的数据分发是使用
每个 Worker 的大致工作流程(Multi Controller 逻辑核心)
具体函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19def func_generator(self, method_name, dispatch_fn, collect_fn, execute_fn, blocking):
class Functor:
def __call__(this, *args, **kwargs):
args, kwargs = dispatch_fn(self, *args, **kwargs)
padding_count = kwargs.pop(_padding_size_key, 0)
output = execute_fn(method_name, *args, **kwargs)
if blocking:
output = ray.get(output)
output = collect_fn(self, output)
if padding_count > 0:
if isinstance(output, DataProto):
indices = [i for i in range(len(output))][:-padding_count]
output = output.select_idxs(indices)
elif isinstance(output, list):
output = output[:-padding_count]
return output
# use class type to pass the method_name to get a better observability
return type(method_name, (Functor,), {})()核心函数名为
func_generator,这个函数会接受5个参数method_name,dispatch_fn,collect_fn,execute_fn,blockingdispatch_fn负责 dispatch 参数execute_fn负责根据 dispatch 后的参数调用method_name函数(使用getattr方法实现)blocking决定在这里是否等待execute_fn执行完成collect_fn负责收集collect_fn函数返回的分组结果
注:原始代码中的
type(method_name, (Functor,), {})()表示:动态创建一个名为method_name、继承自Functor且无自定义属性的类,然后实例化该类,最终得到一个继承自Functor的实例对象
verl 编程接口
数据集修改(最简单)
保证数据集符合 verl 的格式即可,verl 要求数据是
.parquet格式,且包含下面 5 列prompt:是一个 message list,每个 message 是{"role":"...", "content": "..."}的格式data_source:数据来源,比如 gsm8k 来自openai/gsm8kability:数据分类,比如 gsm8k 属于math类reward_model:是一个字典,比如{'ground_truth': '72', 'style':'rule'}说明使用规则型 reward 模型extro_info:是一个字典,作为额外的信息在训练中使用,可以包含一些自定义信息,比如 PPO 官方示例中的 gsm8k 数据处理就是将 prompt 的answer放进去了,完整格式为:{'answer': '...', 'index': 0, 'question': '[原始问题]', 'split': 'train'}- 注:
extro_info的[原始问题]比 prompt 的content少一些模板内容
- 注:
注:支持 VLM 时,需要
images和videos这样的字段注:建议使用 pandas 加载数据后多看:
1
2import pandas as pd
df = pd.read_parquet(file_path)数据处理的参考模板见:
examples/data_preprocess/目录下,比如gsm8k数据集的处理文件是examples/data_preprocess/gsm8k.py特别地:还可以自定义数据类,通过参数将定义类的 Python 文件路径和类名传入并注册到 verl 中即可,详情见:verl 源码解读与 HybridFlow 编程范式讲解:40:06
自定义 Reward
reward fuction 的参数定义:
1
2
3
4
5custom_reward_function:
path: null # 指定源码路径
name: compute_score # 指定函数
reward_model:
reward_manager: naive # 指定 reward_manager 类 NaiveRewardManager可以通过参数传入,示例如下:
1
2
3--custom_reward_function.path=./examples/reward_fn/custom_reward_fn.py \
--custom_reward_function.name=compute_score \
--reward_model.reward_manager=naive函数定义可参考
NaiveRewardManager类的定义
自定义损失函数
- 全局搜索找到
.backward()函数调用的地方,这里就是损失定义的地方- 在这里可以修改函数
compute_policy_loss - 也可以添加其他损失项,比如 交叉熵损失
- 在这里可以修改函数
- verl 的损失函数定义方式和
llama_factory的模板类有点相似,是通过将 loss 注册到POLICY_LOSS_REGISTRY: dict[str, PolicyLossFn] = {}中实现的 - 可以通过修改
POLICY_LOSS_REGISTRY: dict[str, PolicyLossFn] = {}所在文件增加自己的损失函数
修改整个训练逻辑(最复杂)
- 核心是修改
fit函数 - DAPO 的实现类
RayDAPOTrainer就是继承RayPPOTrainer后实现的1
2
3
4
5
6
7
8class RayDAPOTrainer(RayPPOTrainer):
"""
Note that this trainer runs on the driver process on a single CPU/GPU node.
"""
def fit(self):
# ...
# DAPO 的 fit 实现
模型融合
训练完成模型是按照 GPU,以分片的形式存储的,所以需要进行模型融合
1
2
3
4python3 -m verl.model_merger merge \
--backend fsdp \
--local_dir checkpoints/verl_examples/gsm8k/global_step_410/actor \
--target_dir checkpoints/verl_examples/gsm8k/global_step_410/actor/huggingface- 将模型路径替换为目标路径
- 融合结果会存储到
target_dir下,即 huggingface 目录下,执行后会存贮model.safetensors文件和tokenizer.json文件
注:模型融合不一定需要安装
verl的所有的依赖,某些情况下,安装所有verl依赖是昂贵的,容易出错,建议简单安装(参考:官方安装说明)1
2
3
4
5# 安装底层框架依赖
USE_MEGATRON=0 bash scripts/install_vllm_sglang_mcore.sh # 仅使用 FSDP,不适用 Megatron(Megatron 安装容易出错)
# 安装 verl
pip install --no-deps -e . # 不安装依赖,在使用模型融合命令时遇到缺失的再安装,否则安装依赖容易出错
使用 verl 进行模型评估
评估分成生成回答和评估结果两个部分
生成回答
1
2
3
4
5
6
7
8
9
10
11python3 -m verl.trainer.main_generation \
trainer.nnodes=1 \
trainer.n_gpus_per_node=2 \
data.path=/path/to/test.parquet \
data.prompt_key=prompt \
data.batch_size=1024 \
data.n_samples=8 \
data.output_path=/path/to/output.parquet \
model.path=/path/to/model \
rollout.temperature=0.6 \
rollout.top_p=0.95- 注意:这里会为每个 Prompt 生成 8 个样本
- 路径替换为目标模型和目标输出文件名(注意:输出必须到文件名)
评估结果
1
2
3
4
5
6python3 -m recipe.r1.main_eval \
data.path=/path/to/output.parquet \
data.prompt_key=prompt \
data.response_key=responses \
custom_reward_function.path=./recipe/r1/reward_score.py \
custom_reward_function.name=reward_func- 注意:原始的
./recipe/r1/reward_score.py文件中不含有gsm8k数据集,只需要在数学类型中加入 “openai/gsm8k” 即可 - 执行该命令可能需要安装 math-verify 包,执行
pip install math-verify即可
- 注意:原始的
亲测:对
Qwen2.5-0.5B-Instruct模型在gsm8k上训练,从step=30到step=410(batch_size=256,epoch=15),测试集上的准确率从 0.45 提升至 0.53 左右
附录:如何传入多个数据集?
- 传入下面的参数?
1
2
3
4
5train_files="['$train_data_path1','$train_data_path2']"
test_files="['$valid_data_path1','$valid_data_path2']"
data.train_files="$train_files" \
data.val_files="$test_files" \
附录:其他注意事项或技巧
- 控制保留的
ckpt数量1
2trainer.max_actor_ckpt_to_keep=10
trainer.max_critic_ckpt_to_keep=10
附录:错误记录
HTTPRequestEntityTooLarge 错误
- 问题详情:HTTPRequestEntityTooLarge: Request Entity Too Large
- 原因:Ray 打包文件上传时上传了太多东西,导致实体过大,需要在
verl/trainer/runtime_env.yaml中增加需要移出的文件 至excludes- 一般都是
*.safetensors相关的文件导致
- 一般都是
- 详情参考:github.com/volcengine/verl/issues/696
NCCL 错误
表现是单机多卡没错误,多机多卡就会出现错误,错误信息为:
1
torch.distributed.DistBackendError: NCCL error in: /pytorch/torch/csrc/distributed/c10d/NCCLUtils.hpp:268, unhandled system error (run with NCCL_DEBUG=INFO for details), NCCL version 2.21.5
一般是 NCCL 相关的环境变量配置有问题,需要检查一下,被修改过后成功运行的参数包括
1
2
3
4NCCL_SOCKET_IFNAME
NCCL_SOCKET_IFNAME
NCCL_IB_DISABLE
NCCL_NET_GDR_LEVEL注:分布式训练中经常遇到 NCCL 相关的错误,下面是 NCCL 相关的官方错误说明:docs.nvidia.com/deeplearning/nccl/user-guide/docs/troubleshooting.html
附录:特殊参数说明和记录
log_prob_micro_batch_size_per_gpu:表示ref或rollout(actor)一次前向推理时的真实 样本数from https://verl.readthedocs.io/en/latest/examples/config.html#actor-rollout-reference-policy
The batch size for one forward pass in the computation of ref_log_prob. The value represent the local num per gpu.actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu表示ref_log_prob的配置actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu表示log_prob的配置- 注:
log_prob的计算是一个前向过程,但batch_size较大时显存会比较大,所以进一步进行拆分
- 注:更多 batch_size 相关介绍:
- 参考链接:聊聊verl中的batch_size
mini_batch,ppo_mini_batch_size(mini_batch_size) :一个mini_batch表示一次 PPO 参数更新micro_batch,ppo_micro_batch_size_per_gpu:一次前向/反向过程的批次大小,多个micro_batch会累加梯度,直到足够一次mini_batch再更新一次模型

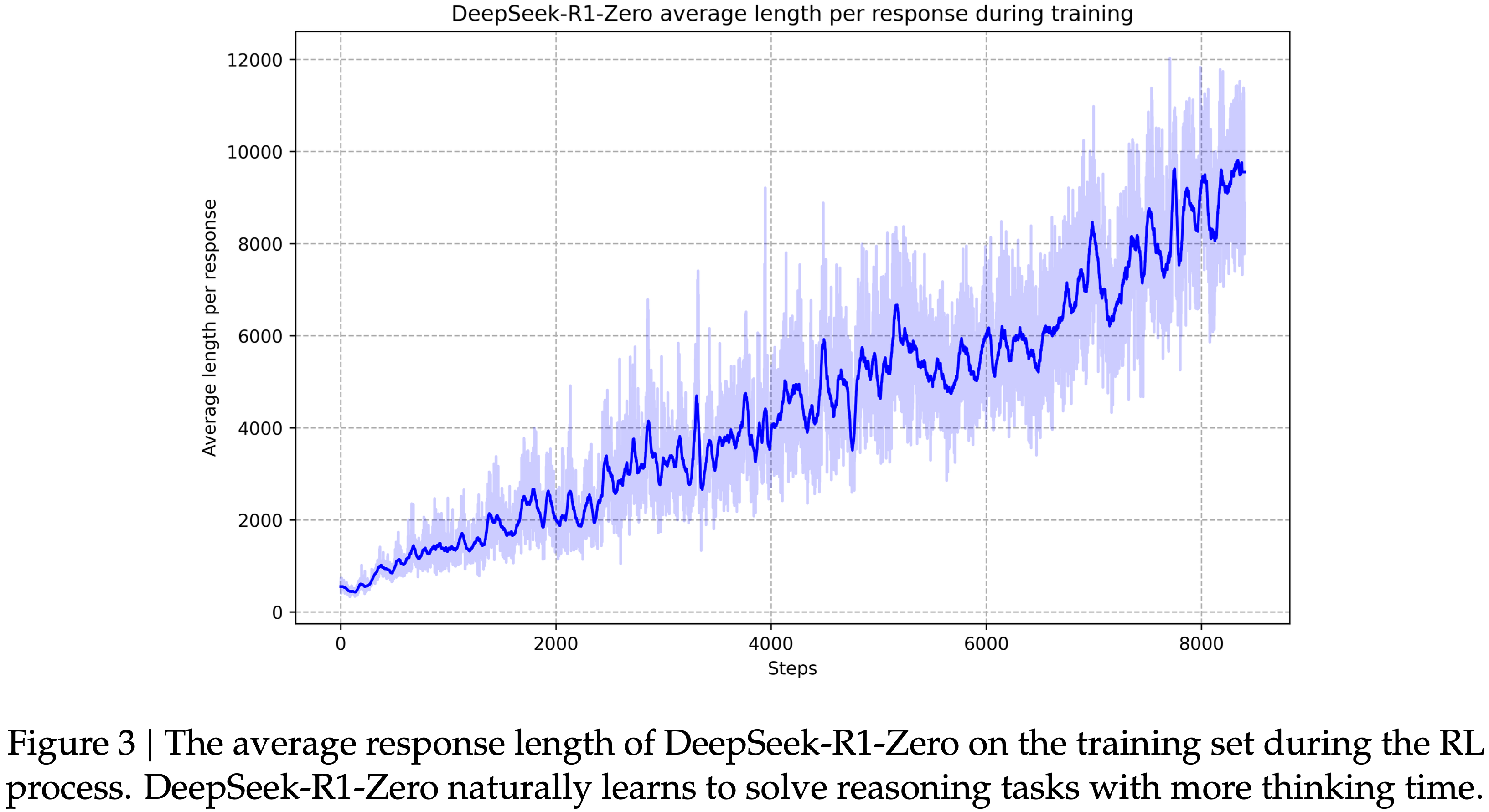


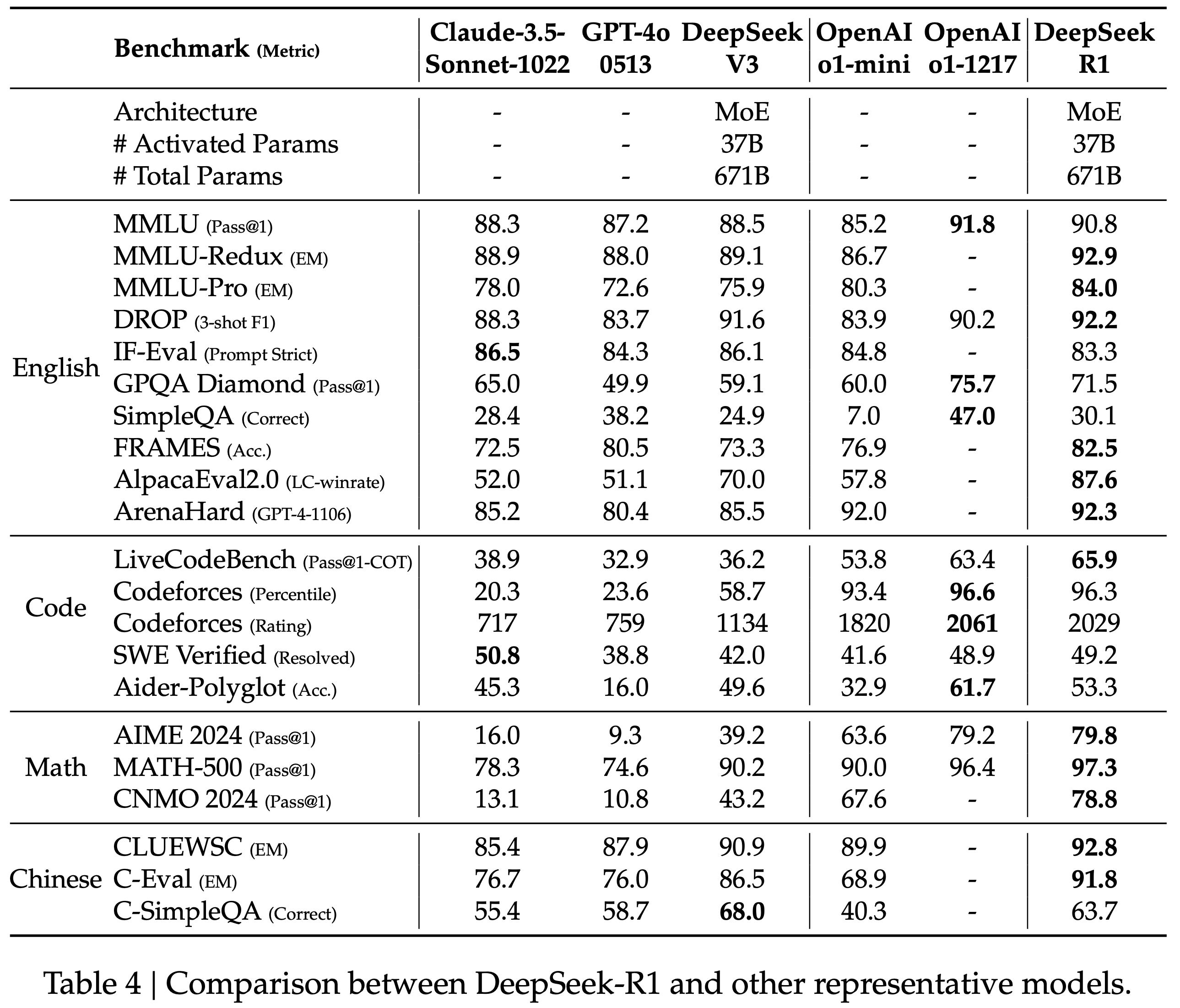
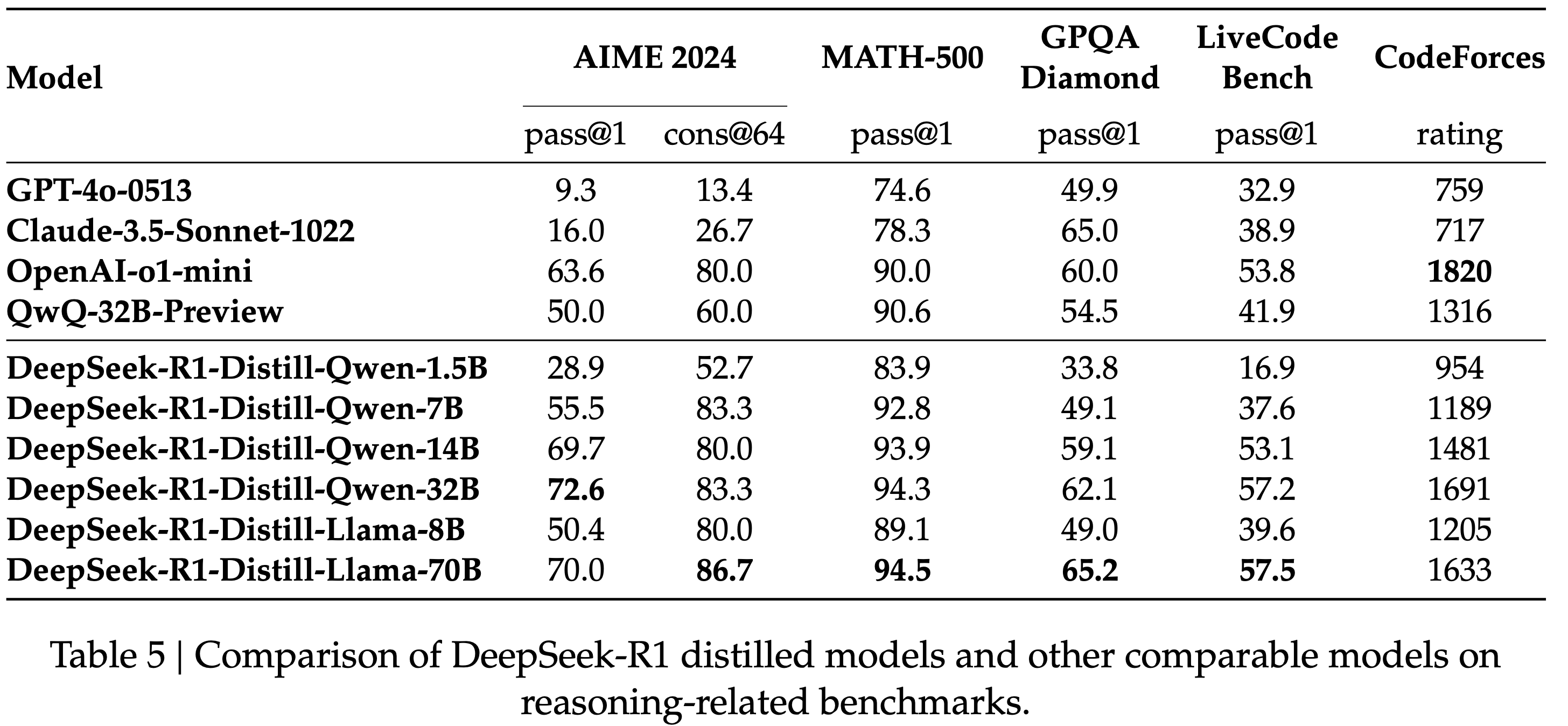
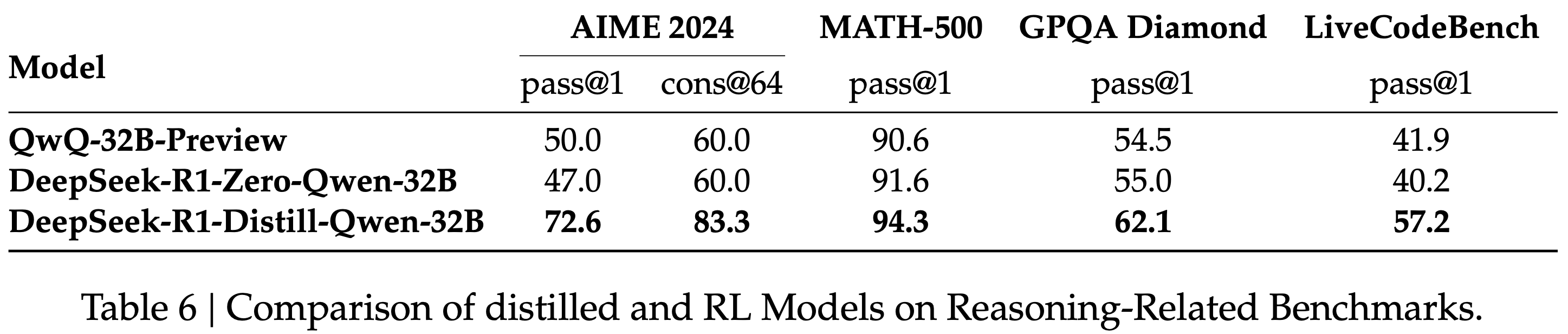











/MHA2MLA-Figure1.png)
/MHA2MLA-Figure2.png)
/MHA2MLA-Figure3.png)
/MHA2MLA-Figure4.png)
/MHA2MLA-Table1.png)
/MHA2MLA-Table2.png)
/MHA2MLA-Figure5.png)
/MHA2MLA-Table3.png)