注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 本论文首次对开源语言模型在不同任务上的性能进行了系统分析,将其性能与架构和数据等联系起来
- 但本文的分析存在一些不太严谨的地方,因为各个公司的实现方式可能是不一样的,比如基建或者各种配方的使用等
- 一般来说:语言模型能力的提升通常归因于模型规模或训练数据的增加
- 但在某些情况下:
- 使用精选数据训练的小模型或采用不同架构决策的模型 可以超越在更多 token 上训练的更大模型
- 引出问题:这是什么原因造成的呢?
- 为了量化这些设计选择的影响,论文对 92 个不同规模的开源预训练模型进行了元分析 (meta-analyze),这些模型包括:
- SOTA 开源权重模型
- 性能较差的模型(less performant models)
- 采用非常规设计决策的模型(less conventional design decisions)
- 论文发现:
- 通过纳入除模型大小和训练 token 数量之外的特征 ,论文预测下游任务性能的能力相对提高了 3-28%
- 注:这个提升是与仅使用规模特征相比
- 对模型设计决策的分析揭示了对数据构成的见解
- 例如代码占比在 15-25% 时语言任务和代码任务之间的权衡,以及网络数据对真实性 (truthfulness) 的负面影响
- 通过纳入除模型大小和训练 token 数量之外的特征 ,论文预测下游任务性能的能力相对提高了 3-28%
- 论文的框架为更系统地研究模型开发选择如何塑造最终能力奠定了基础
Introduction and Discussion
- 语言模型训练的效果关键取决于预训练 (pretraining) 期间所做的决策
- 例如,扩展数据 (scaling up data) 的有效性取决于其构成
- 理解:即使处理了一万亿个 token,如果它们全部由单词 “the” 组成,那也是无效的
- 研究发现,语言模型的性能可以通过 Scaling Laws (2020, 第 2 节) 进行相当准确的预测
- 即基于模型参数数量和训练所用 token 数量对模型性能进行外推
- 但仅基于这两个方面的扩展定律并不总能解释下游任务性能 (2024; 2024)
- 研究界在理解训练决策如何影响下游性能方面已经取得了进展,特别是在数据构成方面。例如,对照研究 (controlled studies) 表明
- 在代码数据上训练可以提高在某些推理基准测试上的性能 (2024; 2024);
- 数据的元特征 (meta-features),如年龄和毒性过滤器 (toxicity filters) 的使用,会影响许多问答 (QA) 任务的性能 (2024);
- 多语言数据的平衡会影响英语和其他语言的性能 (2023; 2025)
- 这些工作揭示了宝贵的见解,但它们往往只关注改变训练方案 (training recipe) 的单个方面,而保持其他方面不变
- 尽管严谨,但这在计算和开发时间上成本高昂
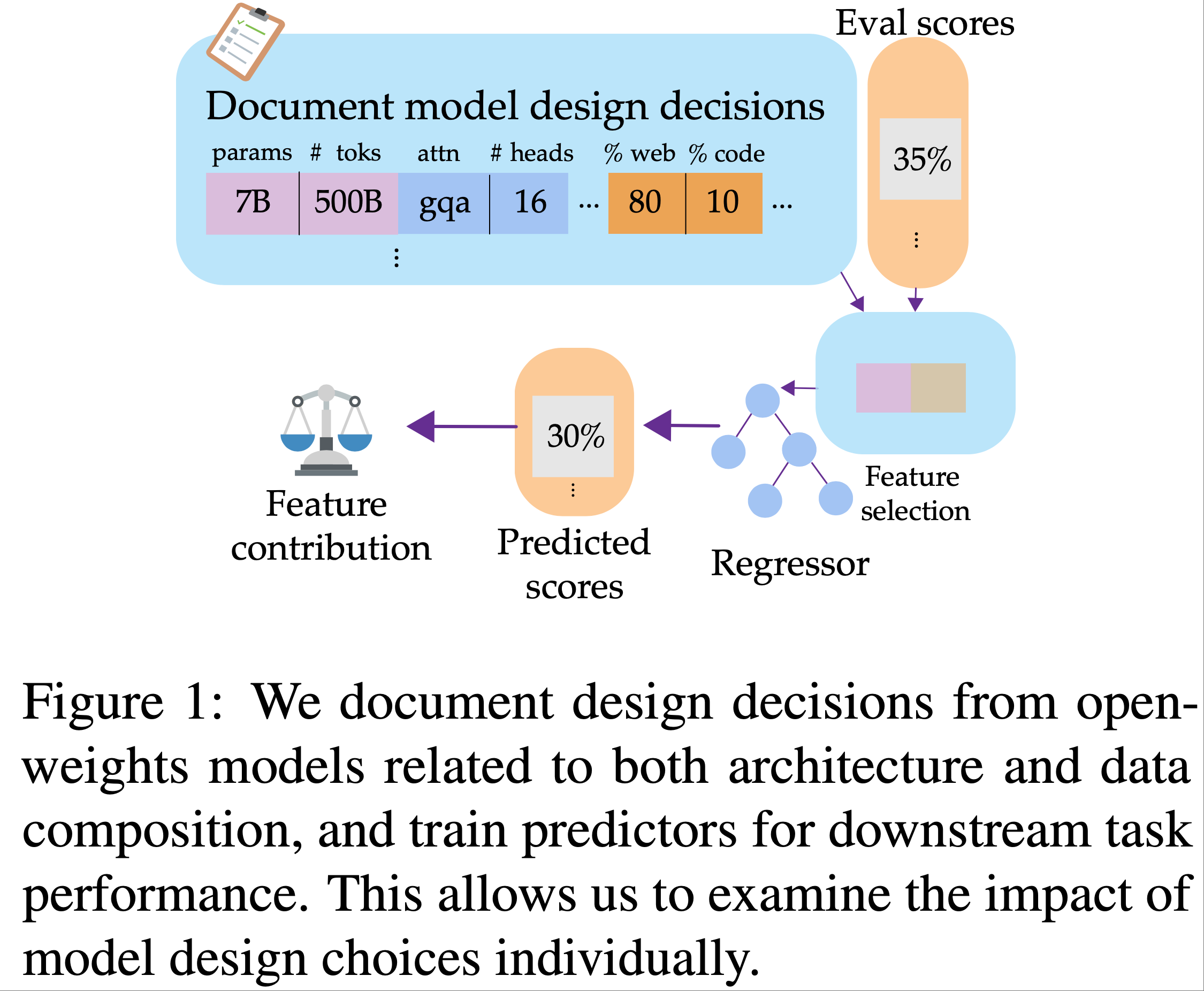
- 论文转而提出一个问题:论文能否利用过去来自开源语言模型的发现来检验训练决策如何共同影响下游性能?
- 为此,论文首先对来自不同系列的 92 个基础预训练 LM 的模型架构和数据相关的特征进行了 编目 (catalog) (章节3)
- 由此产生的模型特征数据库涵盖了 2019 年至 2024 年间发布的大多数主要的、原始的开源权重 Decoder-only 预训练模型
- 然后,论文开发了方法来 预测 这些模型在广泛基准测试上的性能
- 预测依据既包括传统的扩展因素,也包括架构决策和数据构成 (章节4)
- 具体来说,论文训练回归模型 (regression models)
- 模型输入:提取的特征
- 模型输出:预测基准测试结果
- 进一步使用模型可解释性技术 (model interpretability techniques) 来识别在做出这些预测时最显著的特征
- 论文在预测 12 个流行 LLM 基准测试的性能上评估了这种方法,并证明决定模型性能的 不仅仅是扩展 (not just scaling)
- 在所有基准测试上,包含所有特征的回归器 (regressor) 的性能都优于仅基于扩展模型特征的回归器 (章节5.1)
- 论文对特征重要性 (feature importance) 的分析揭示了数据领域 (data domains) 对任务性能的潜在影响,再次证实了经验性结果,例如预训练中使用代码的最佳比例 (章节5.2)
- 此外,论文发现从模型生成文本中提取的特征(例如问题相关词的频率或类似网络文本的比例),有助于预测各种基准测试的性能
- 这表明模型的生成模式可以反映其预训练数据中的潜在偏差 (underlying biases) ,进而影响下游性能
- 通过记录整个社区训练的开源模型并提取见解,论文为模型开发者提供了一个实用的资源,以从集体经验中学习
- 论文在 (章节8) 中讨论了这一点以及未来的工作
Scaling Laws
Definition
- 论文在此将扩展定律定义为语言模型系列的参数数量 \(N\) 和 token 数量 \(D\) 与收敛时期望的语言建模损失 \(L(N,D)\) 之间的关系
- 重要的是,这些定律通常是在保持所有其他因素不变的情况下进行研究的:
- 保持相同的模型架构、训练数据和模型参数
- 最初,Kaplan 等 (2020) 表明,在广泛的基于 Transformer 的模型中,这种关系可以表示为幂律 (power law):
$$L(N,D)=\left(\left(\frac{N_{c} }{N}\right)^{\frac{\alpha_{N} }{\theta_{D} } }+\frac{ D_{c} }{D}\right)^{\alpha_{D} }$$ - 后来,Hoffmann 等 (2022a) 提出了一个类似的定律,其拟合的系数不同,但同样基于幂律
- 但扩展定律并非绝对,其确切函数形式和拟合系数可能取决于架构类型、规模范围 (Pearce and Song, 2024) 或其他考虑因素,如推理成本 (inference costs)
- 更多讨论请参见 (章节7.2)
Maybe it’s Not Just Scaling?
- 参数数量和训练 token 数量真的是准确预测模型下游性能所需的全部吗?直觉上答案是否定的
- 模型训练涉及许多设计决策,所有这些都可能对模型性能产生影响
- 模型架构细节 (Model Architecture Details)
- 虽然大多数现代语言模型都遵循 Transformer 架构,但存在一些细节差异
- 例如,层归一化 (layer normalization) 的种类 (2019) 和位置 (2020),以及位置编码 (positional encoding) 的类型 (2021; 2022) 都会对模型性能产生显著差异
- 先前的工作,例如 Gu and Dao (2023),已经凭经验证明,在保持所有其他因素相等的情况下,做出更好架构决策的模型 (2023a) 优于做出更差决策的模型 (2017)
- 虽然大多数现代语言模型都遵循 Transformer 架构,但存在一些细节差异
- 数据构成 (Data Composition)
- 数据构成和质量在模型的最终质量中起着重要作用
- 例如,过去的工作表明,训练一定数量的代码可以提高英语推理任务的性能 (2023)
- 同样,有工作表明,筛选“教育”内容可以实现更高效的学习,并在基于知识的问答任务上获得更高的性能 (2023)
- 数据构成和质量在模型的最终质量中起着重要作用
- Task Setting
- 最后,所有上述因素与模型性能的衡量方式之间存在相互作用
- 虽然先前关于扩展定律的工作主要测量损失值,但下游用户通常关心的是任务性能,而不是预训练数据集上的验证损失 (validation loss)
- 尽管对于许多任务来说,两者之间通常存在相关性,但某些任务可能更难仅从模型的损失来预测 (2024)
- 此外,某些任务表现出异常的扩展行为,例如反向扩展 (inverse scaling) 或 U 型扩展 (U-shaped scaling) (2023; 2023; 2024),或者仅仅是更不可预测的性能 (2024)
- 论文提问:论文能否通过设计一套新的、不仅仅依赖于基于扩展的因素的“定律”来更有效地预测 LLM 的性能?
Building a Database of Publicly-Available Language Models
- 为了解决论文的研究问题,论文构建了一个包含 11M 到 110B 参数的公开可用语言模型的数据库(包括嵌入参数),仅限于不同的 Decoder-only 基础预训练模型
- 注:不同是指训练数据和架构的独特组合。在去重数据集上训练的模型被单独计数,但具有不同课程/初始化的变体不计入
- 本节描述了论文的纳入标准、模型特征化以及评估方法
Data Collection
- 为了确保论文的分析是一致的,论文应用了以下标准:
- Pretrained-only:
- 仅包含从头开始预训练的基础模型,排除了微调变体、合并模型以及经过额外后训练的模型
- Architecture:
- 仅包含基于 Transformer 的 Decoder-only 模型以保持一致性
- 排除了 MoE 或其他架构
- Publicly available information:
- 仅包含具有公开可用元数据的模型,这些元数据通过配置文件或论文记录
- 特别是,纳入需要总参数数量和训练所用总 token 数量这两个信息
- 模型和模型系列的完整列表可在附录A 中找到
Characterizing Models and Data
- 论文通过每个模型所做的架构选择以及其预训练数据的选择来表示每个模型
- 形式上,令 \(\mathcal{A}\) 为与模型架构相关的特征集合, \(\mathcal{D}\) 为与模型预训练数据集相关的特征集合
- 对于每个任务 \(T\) ,作者希望用预测值 \(\widehat{s_{T} }\) 来近似模型 \(M\) 的真实得分 \(s_{T}\) :
$$\widehat{s_{T} }(M)=f_{\theta}([\mathcal{A}_{M};\mathcal{D}_{M}]).$$ - 当 \(\mathcal{A}=\{\#\text{params}\}\) ,\(\mathcal{D}=\{\#\text{tokens}\}\) ,且 \(f_{\theta}\) 是幂律时,这就简化为典型的扩展定律
- 论文总共记录了 92 个开放模型,涵盖模型特征、高层数据集特征以及从该模型的无上下文生成中派生出的特征等维度
- 有关完整的特征集和定义,请参见附录B
Features from Model Documentation
- 论文首先通过阅读源论文/博客(如有,请参见附录A了解原始引用)以及在 Hugging Face Hub (2020) 上列出的数据来收集每个模型的信息
- Architectural Features:
- 这些特征捕获了决定模型结构的设计决策
- 例如,总参数(包括嵌入参数)、Transformer层数、嵌入和前馈维度,以及细节,例如使用的层归一化类型或注意力变体
- Data Features:
- 这些特征总结了预训练数据的组成
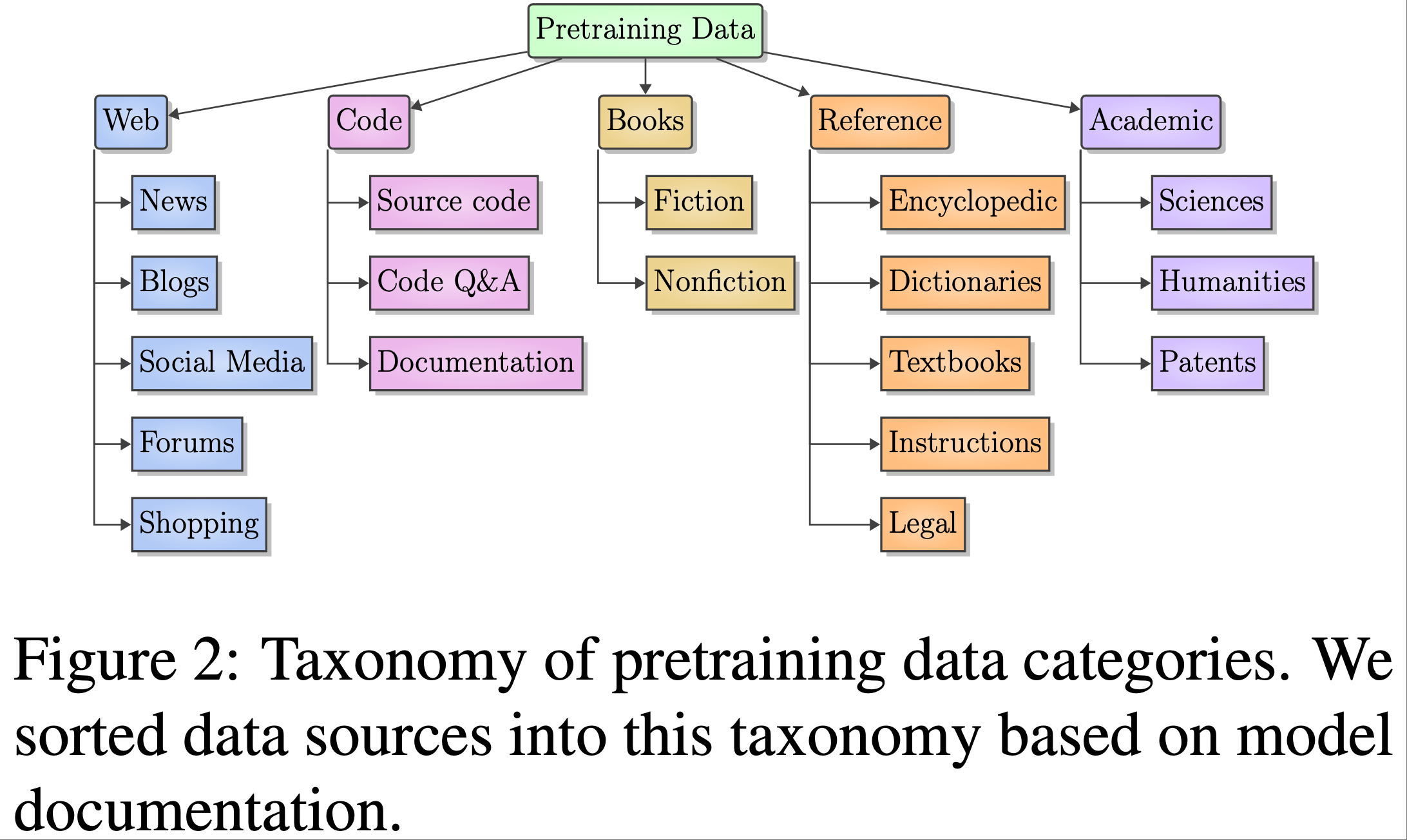
- 代表性示例包括训练所用的总 token 数以及来自图2中定义的各个领域的 token 百分比细分,以及英语 token 的比例
- 论文的预训练数据领域源自开放预训练数据集(2020; 2024)中常见的子领域
- 论文使用顶级领域(网络、代码、书籍、参考、学术),因为这往往是论文中描述数据组成的粒度
Exploring Data Composition via Generation
- 尽管许多模型记录了一些数据组成细节,但相对较少的模型发布了其完整的预训练语料库,导致论文研究中许多模型的这些值缺失
- 为了填补这些空白,论文探索了一种替代方法:
- 分析模型在无提示情况下生成的文本,以估计其训练数据的特征
- 论文假设模型的生成风格和内容反映了其训练数据的分布
- 对于每个模型,论文使用温度 \(T=0.8\) 和 top-p \(p=0.9\) 的核采样生成 5k-10k 个无上下文的生成文本(每个生成文本最多 256 个 token)
- 然后,论文使用标准 NLP 工具和基于 LM 的分类器从这些生成文本中提取语言学和领域特征
- 论文在附录E和F中验证了这种方法
- 论文还提取了 low-level 语言特征,例如每句词数(words per sentence)、成分树深度(constituency tree depth)和依存长度(dependency length)
- 论文的验证分析(附录G)表明:
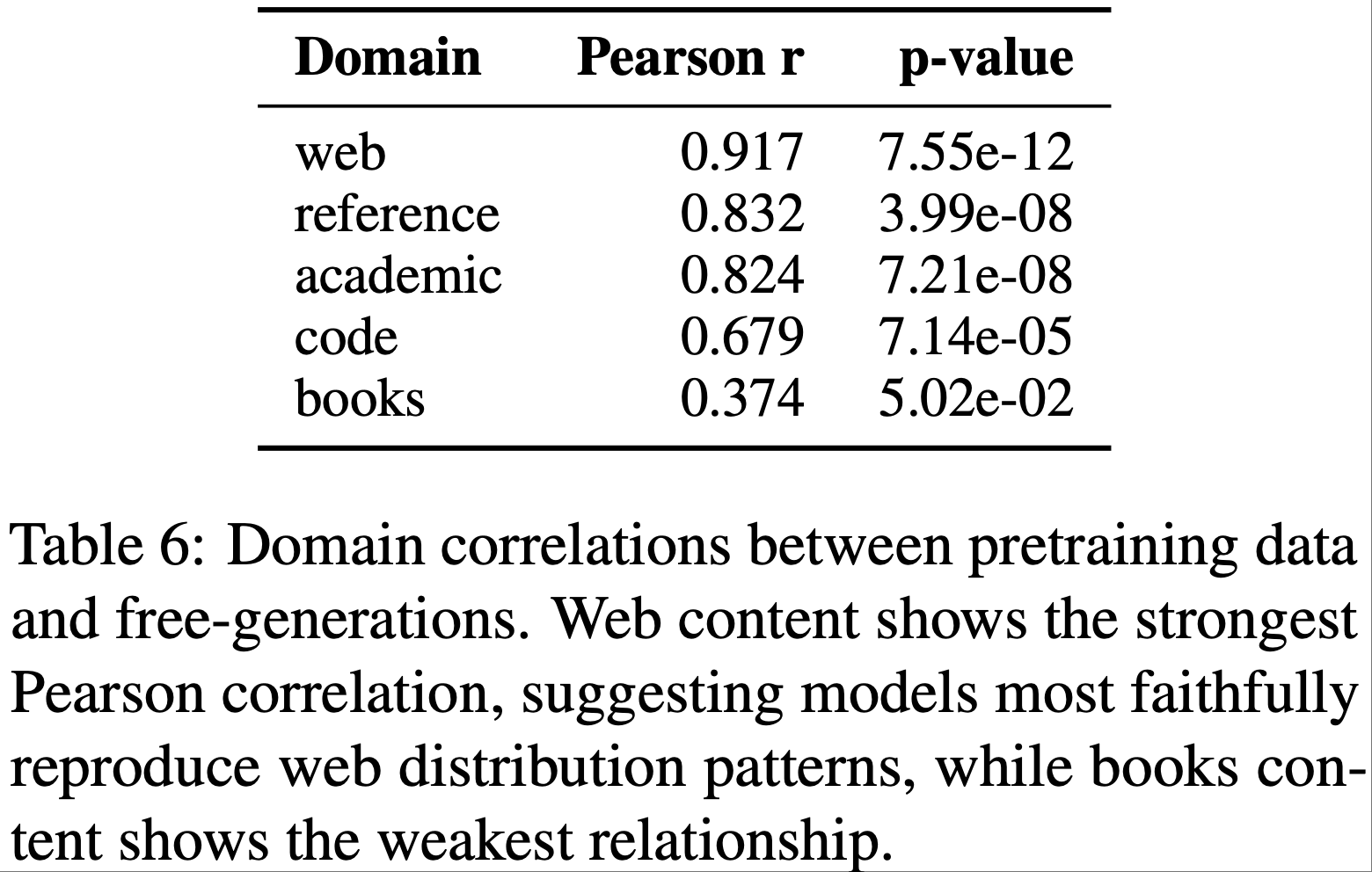
- 领域层级特征与实际预训练数据构成具有较强的相关性
- 例如,网页内容相关性:\(r = 0.916\),\(p = 7.55 \times 10^{-12}\)),
- low-level 风格特征的相关性较弱
- 领域层级特征与实际预训练数据构成具有较强的相关性
- 然而,所有特征的整体 Model-level 相关性表现强劲(通常 \(r > 0.8\))
- 这一结果支持我们将“自由生成内容”(free-generations)用作预训练数据构成的替代指标(proxies),同时也说明不能用自由生成特征替代预训练特征
- 论文的验证分析(附录G)表明:
- 注:一些关键术语补充说明:
- constituency tree depth(成分树深度) :句法分析中的核心概念,指“成分树”(用于表示句子句法结构的树形图,如主谓、动宾等成分的层级关系)从根节点到最深叶节点的路径长度,反映句子句法结构的复杂程度
- dependency length(依存长度) :依存句法分析中的指标,指句子中两个存在依存关系的词语(如中心词与修饰词)在文本序列中的距离,常用来衡量句子结构的线性复杂度
Evaluation Datasets and Metrics
- 为评估设计选择对推理能力的影响,我们在 Open LLM 排行榜(2024)的数据集上对模型进行了测评,这些数据集涵盖了推理能力的多个不同维度(见表 1)
- 其中,部分模型的测评结果直接从该排行榜获取;
- 对于未列入该排行榜的模型,我们使用 Eleuther LM 评估工具包(2023),在完全相同的设置下开展测评
- 此外,若某项任务或子任务存在多个版本,我们会对所有版本均进行测评,并通过求平均值得到该任务的整体得分
- 有关评估数据集及测评设置的完整列表,详见附录 C
- 对于评估数据集 \(T\) ,其中第 \(i\) 个样本是 \(y_{i}\) ,模型为 \(M\) ,论文如下定义 \(s_{T}(M)\) :
- 准确率(Accuracy) :对于大多数任务,论文使用未归一化的精确匹配准确率
$$ s_{T,\text{acc} }=\frac{1}{|T|}\sum_{i=1}^{|T|}\mathbb{I}\{y_{i}=\hat{y}_{i}\} $$- 对于 Humaneval,论文使用 pass@1,但为方便起见,将其与准确率任务归为一组
- Brier分数(Brier score) 对于较小模型难以达到非零准确率的任务,论文遵循(2023)的做法,使用多类 Brier 分数作为多项选择任务的替代连续指标(1950) (注意:对于 Brier 分数来说,值越低越好,多类 Brier 分数范围在 0-2 之间)
- 对于一个有 \(K\) 个类别的任务,令 \(p_{ik}\) 为样本 \(i\) 上类别 \(k\) 的预测概率。则
$$ s_{T,BS}=\frac{1}{|T|}\sum_{i=1}^{|T|}\sum_{k=1}^{K}(p_{ik}-\mathbb{I}\{y_{i}=k\})^{2} $$
- 对于一个有 \(K\) 个类别的任务,令 \(p_{ik}\) 为样本 \(i\) 上类别 \(k\) 的预测概率。则
异质性(Heterogeneity) in Task-specific Scaling
- 在加入其他因素之前,作者检查了所选任务之间沿 \(N\) 和 \(D\) 扩展的差异
- 论文为每个任务拟合了一个(2020)风格的定律
- 如图3所 示,论文看到不同的任务在遵循扩展趋势的程度以及它们各自的扩展轮廓上可能表现出显著差异
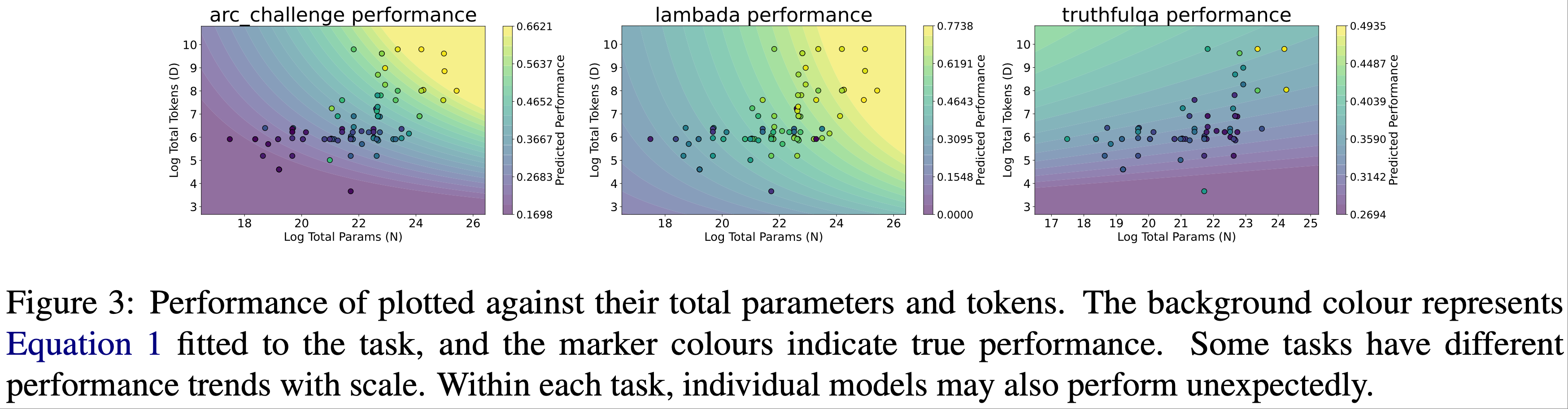
- 例如,TruthfulQA 似乎表现出 U 形扩展,而 Humaneval 有更多的“异常值”模型
- 任务的 \(R^{2}\) 值完整列表可在附录D 中找到
Predictive Modeling
- 接下来,给定论文的数据库,论文拟合一个回归器来尝试预测性能
- 在传统的扩展定律中,回归器是基于幂律拟合的
- 然而,论文现在要处理大量特征,其中一些可能无法通过简单的参数形式很好地捕捉
- 因此,论文遵循先前关于性能预测的工作(2020; 2021),利用基于 XGBoost (2016)的树形回归器
- 论文还试验了LightGBM (2017),发现其性能相似。结果见附录K
- 对于每个评估基准,训练一个模型 ,以基于架构特征 \(\mathcal{A}\) 和数据特征 \(\mathcal{D}\) 来预测该任务上的性能指标
- 理解:每个评估基准都有一个单独的 XGB 模型
- 对于每个任务设置,由于模型数量相对较少,论文执行 3 折交叉验证,并在每折的训练集上进行嵌套内部交叉验证
- 内部交叉验证在一小组超参数上进行网格搜索,允许模型随任务略有变化。更多细节请参见附录I
- Evaluation 为了评估预测器,论文使用所有模型和折迭的平均绝对误差(Mean Absolute Error)
- 对于一个有 \(N\) 个模型被评估的任务
$$ \text{MAE}_{T}=\frac{1}{|T|}\sum_{i=1}^{N}|s_{T}(M_{i})-\widehat{s_{T} }(M_{i})|$$ - 论文将扩展定律预测器以及全特征预测器相互比较,同时也与中位数基线(median baseline)(它只是为该折迭测试集中的每个模型预测训练集中模型的中位数得分)和对数线性基线(log-linear baseline)(它将一个对数线性函数拟合到参数数量和 token 数量)进行比较
- 对于一个有 \(N\) 个模型被评估的任务
- 迭代特征选择(Iterative Feature Selection) 由于完整的特征集非常大,论文根据哪个特征能最大程度地减少 MAE(在 5 个随机种子上平均),从完整集合中贪心地顺序选择特征
- 不断添加特征,直到观察到的减少量不再至少为 \(1\times 10^{-4}\)
- 论文开始时仅使用两个扩展定律特征,并将其称为扩展定律(scaling-laws) 模型,尽管它不具有传统幂律的形式
- 注:不具有传统幂律形式的解释:由于论文使用基于树的预测器来适应多样化的特征类型(包括非数值型特征),论文的方法优先考虑在观察到的界限(10M-100B 参数,50B-3T token)内进行插值,而不是外推(探索其他预测方法仍然是未来的工作)
- 然后,通过合并额外的架构或数据特征,我们可以直接量化这些额外特征带来的增量预测能力
- 论文将具有该组特征的模型称为全特征(all-features) 模型
- 在所有情况下,论文使用相同的超参数网格、相同的随机种子和分割来运行模型
- 显著性检验(Significance Testing) 由于基线之间的相对差异很小,论文在多个种子(50个)上测试两个预测器
- 然后,论文对每个种子的总体 MAE 值运行配对 \(t\) 检验,并使用错误发现率(1995)对跨任务的多重比较进行校正
Results
Predictor Performance
- 加入与规模无关的特征能持续提升基准测试性能
- 论文发现,在传统的扩展定律特征之外加入额外特征,能在多个基准测试上显著提升预测准确度,如表 2 所示
- 在所有评估案例中,全特征预测器均优于仅使用扩展定律的预测器,相对误差减少的幅度大约从 3%(MathQA)到 28%(Lambada)不等
- 值得注意的是,在语言建模和常识推理任务中观察到了最强的改进效果
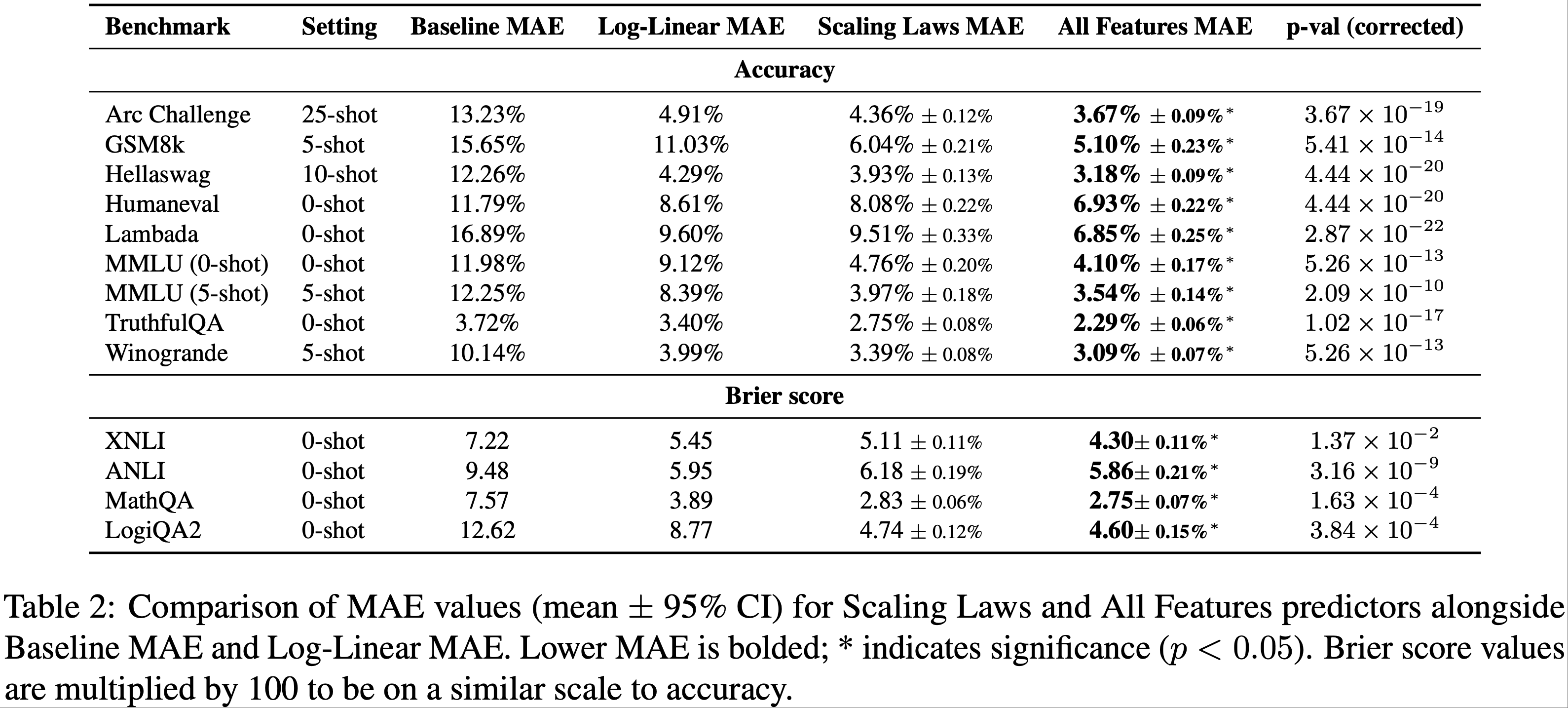
- 某些任务更强烈地依赖于非规模特征
- 这种改进模式表明,架构和训练数据特征,对于预测与特定数据“类型”更紧密相关的某些任务,其表现可能更具信息量
- 在代码生成任务(13% 的改进)和基于自然语言的推理任务(例如 Lambada,28% 的改进)上都观察到了巨大的改进
- 即使是领域较窄的任务,如数学推理(GSM8k,+16%)或知识密集型评估(MMLU,+11-14%),也看到了一致但更温和的增强
- 然而,使用 Brier 分数的基准测试显示出较小的改进(约 3-6%)
- 这可能是因为 Brier 分数本身对模型性能中的涌现效应敏感性较低,特定任务的选择限制了改进空间,或者是这两个因素共同作用的结果
What Features Does Task Performance Depend On?
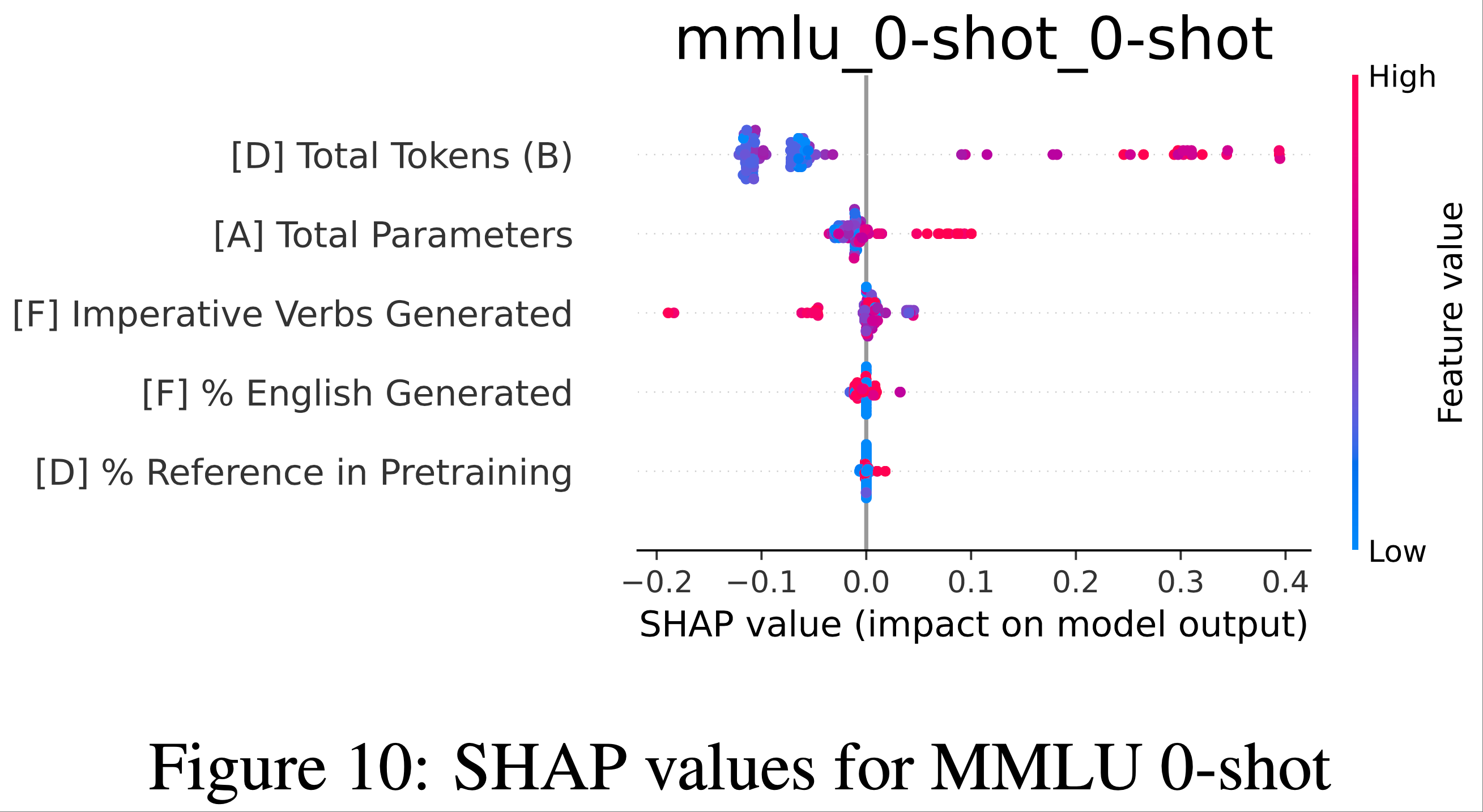
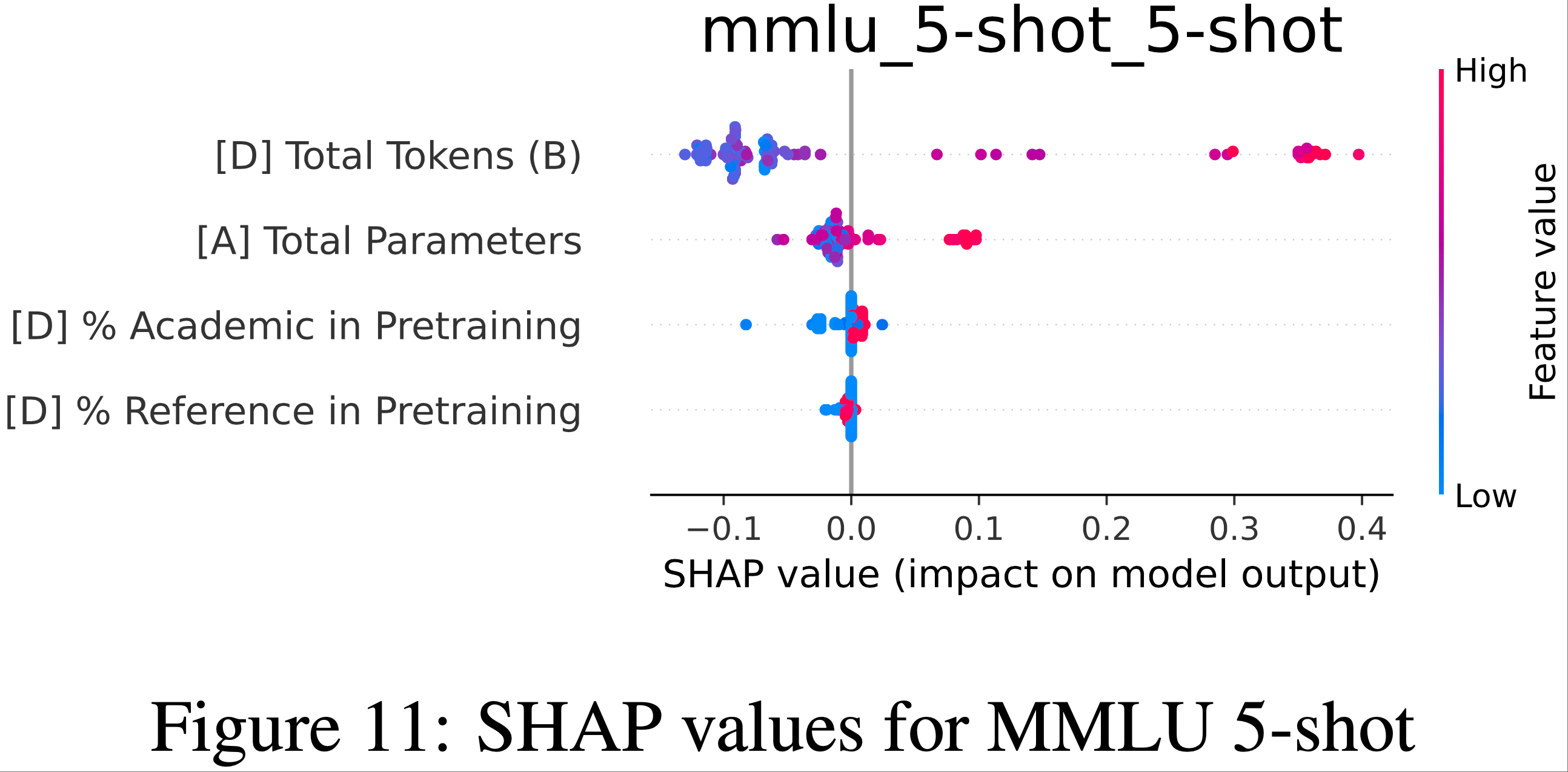
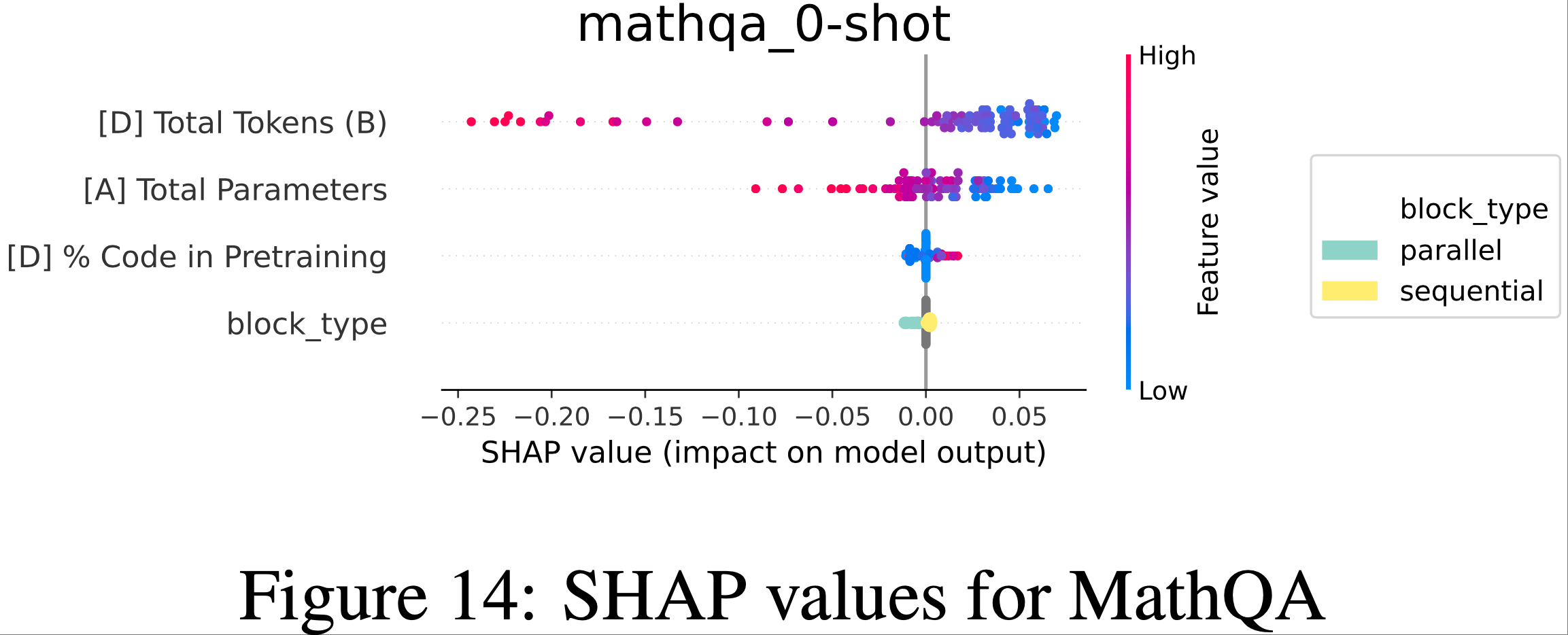
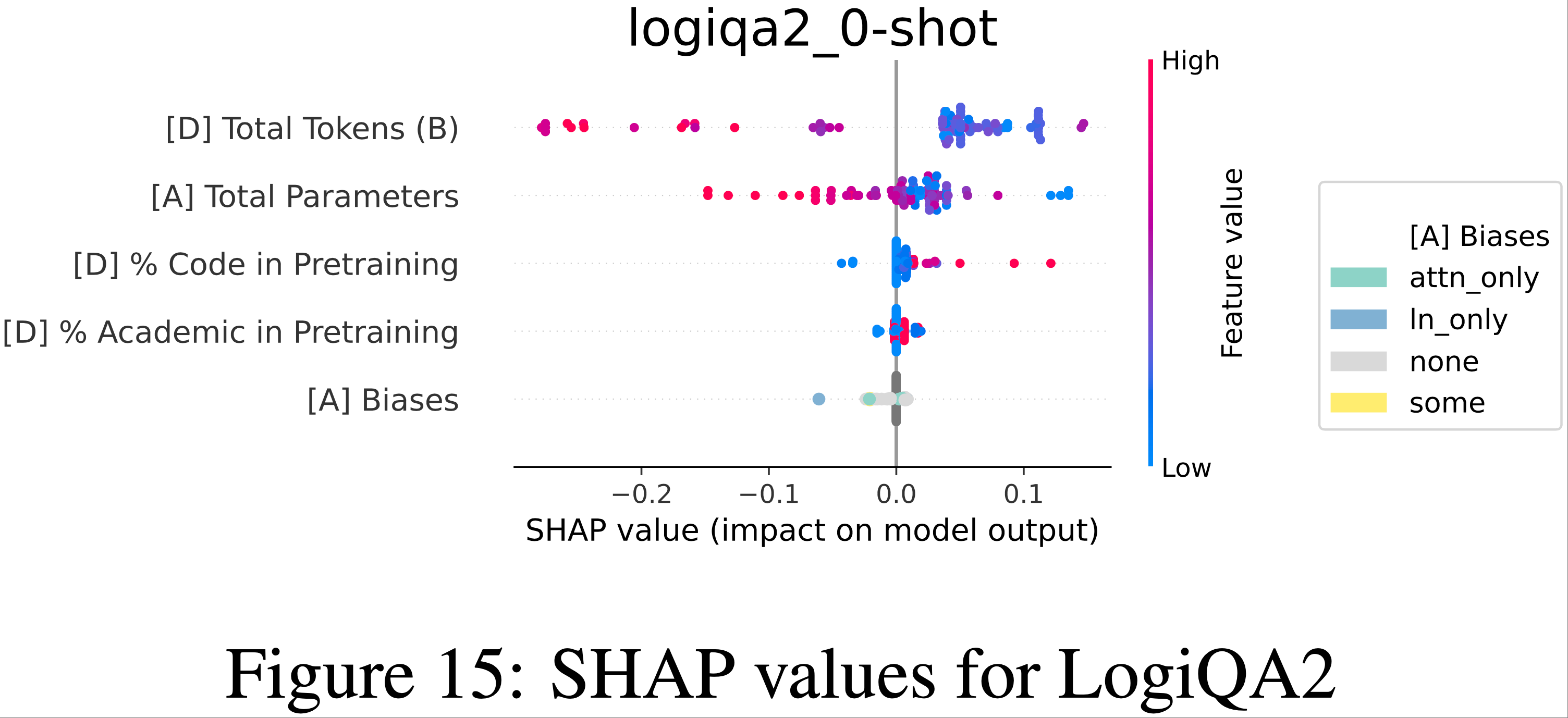
- 为了理解影响任务性能的因素,作者检查了 Shapley (1953) (SHAP) 值,这些值显示了特征值如何影响预测
- 注:SHAP Value(SHapley Additive exPlanations,沙普利可加解释)是一种基于合作博弈论的模型解释方法,核心目标是量化机器学习模型中每个特征对预测结果的贡献程度 ,让复杂模型(如随机森林、神经网络)的决策过程变得可解释
- “SHAP Value”:每个特征对这个 “收益” 的贡献值,即该特征让预测结果偏离基准值的程度(正值表示推动预测值升高 ,负值表示推动预测值降低)
- Arc Challenge、HumanEval、Winogrande 和 TruthfulQA 的结果如图 4 所示,其余基准测试的结果见附录 L
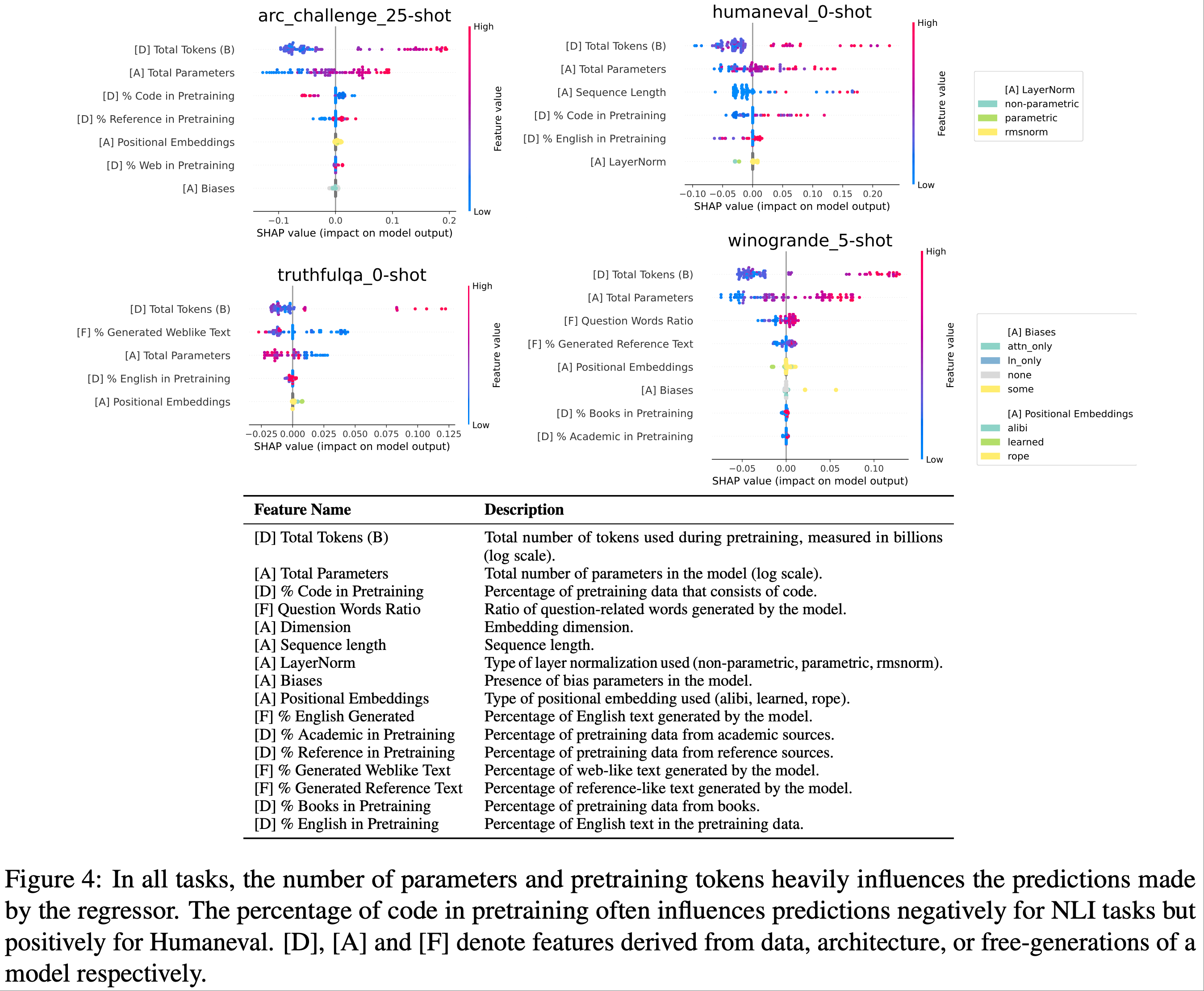
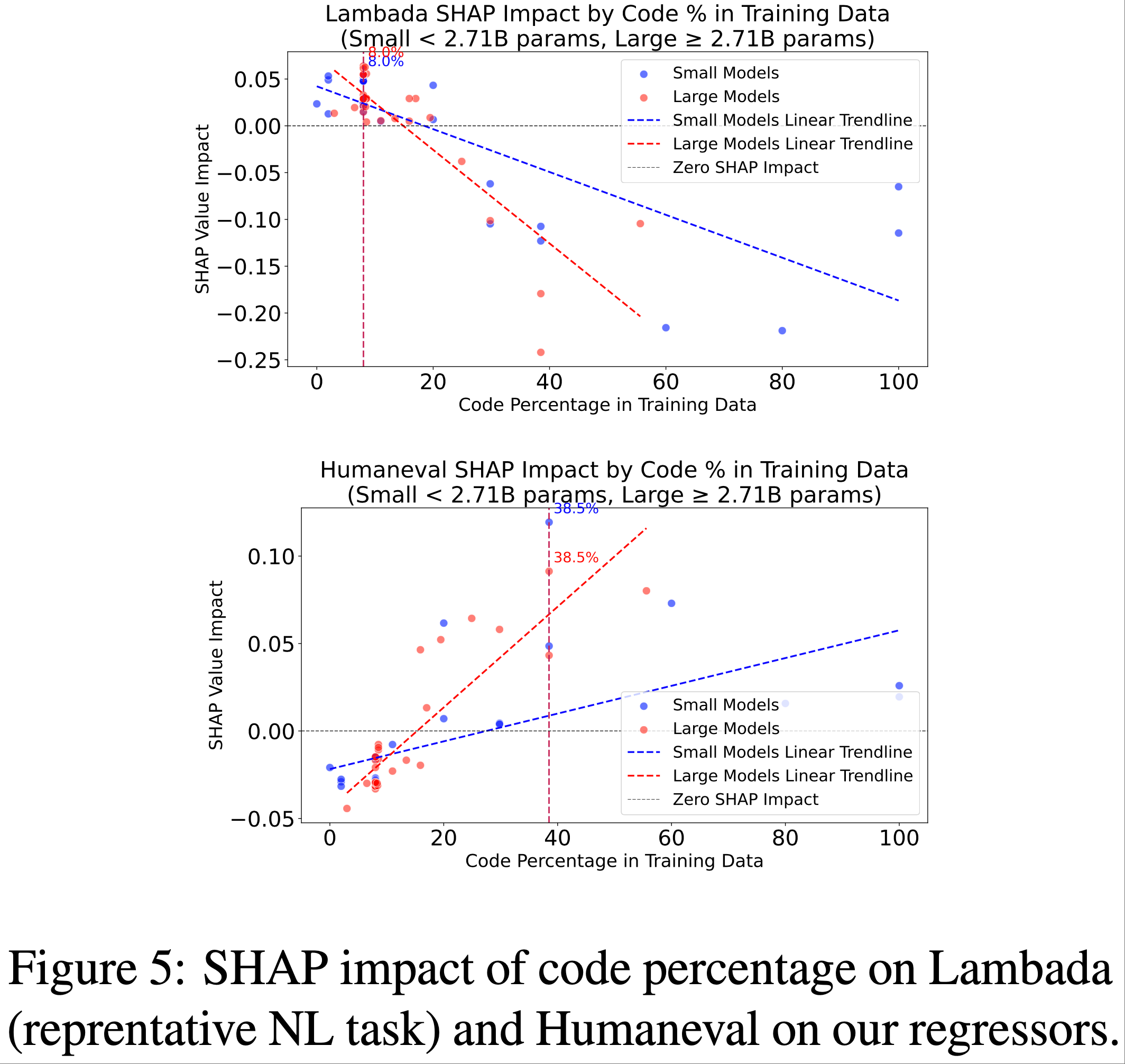
- 少量代码大有裨益,但过多则对自然语言推理(NLI)有害
- 预训练数据中代码的百分比是一个关键的非规模特征
- 较高的代码组成有益于 Humaneval 性能,但对包括 Arc Challenge、Hellaswag、Winogrande 和 Lambada 在内的自然语言推理任务产生负面影响
- 如图 5 所示,代码比例超过 20-25% 的模型在 Humaneval 上显示出增益,但在语言基准测试上受到惩罚
- 15-25% 的中等代码比例似乎能平衡这些相互竞争的需求
- 其他数据领域显示出任务特定的效应
- 从自由生成特征中,论文观察到最近使用合成数据训练的模型(Phi (2023)、SmoILM (2024))生成了更多疑问词,这表明训练数据中包含问答内容
- 类似参考书或包含大量问题的生成内容与 Arc Challenge 和 Winogrande 的更好性能相关,而类似网络文本的生成内容则与更差的 TruthfulQA 性能相关(图 4)
- 非规模的架构决策影响较小
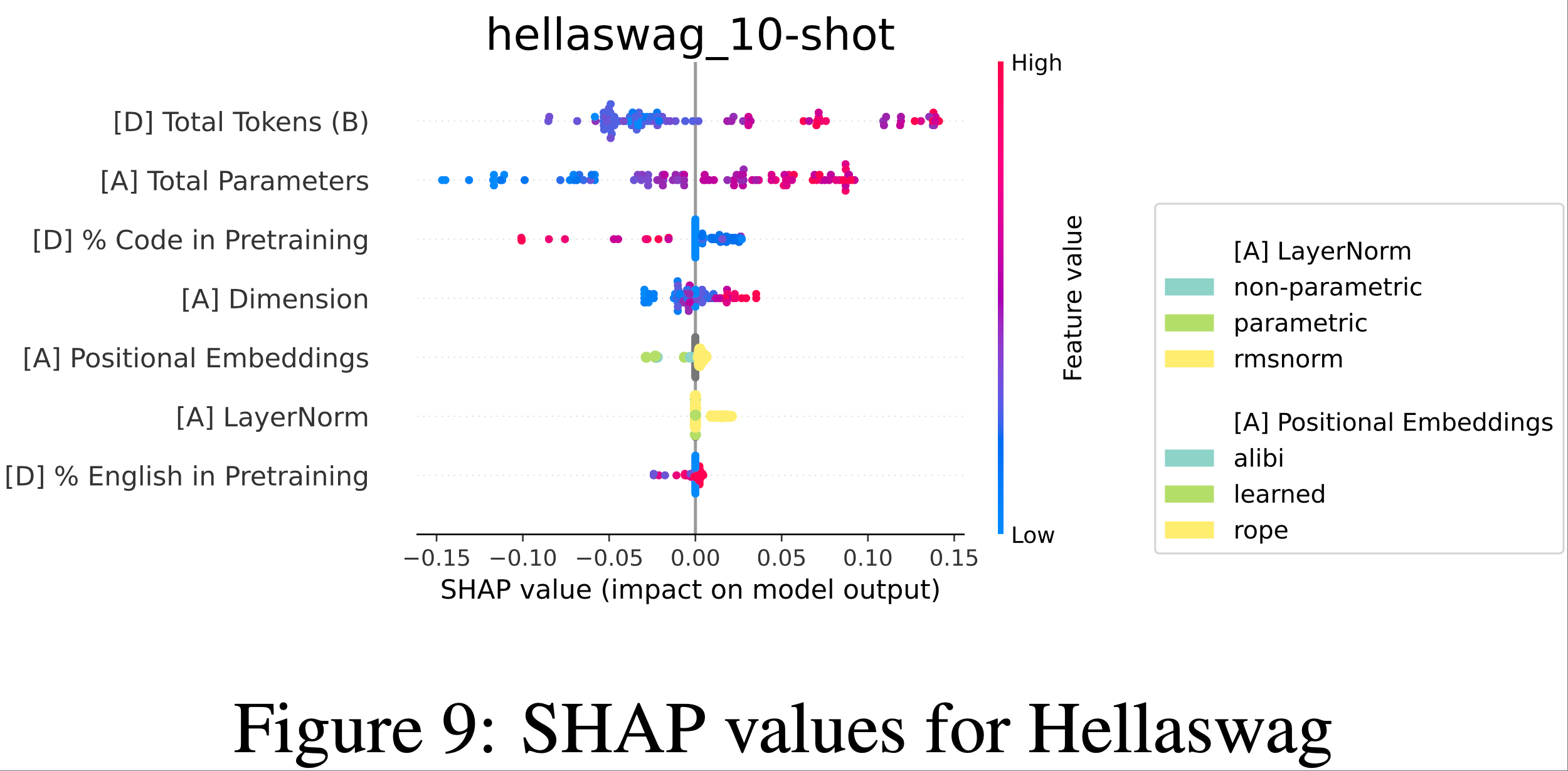
- 大多数高影响力特征是与数据相关的或与规模相关的架构特征(例如,维度)
- 在某些情况下,层归一化的类型和位置嵌入都被认为具有显著影响
Validating Performance Predictions with Confirmatory Experiments(验证性实验)
- 为了验证元分析的发现,论文还使用 Dolma 数据集上训练的 460M 参数模型进行了验证性的预训练实验
- 论文旨在验证两个关于数据分布的发现:
- (1) 当仅考虑自然语言推理时,约 8% 的代码比例是最优的 ,但在平衡代码和自然语言时,15-25% 可能是最佳比例;
- (2) TruthfulQA 性能随着网络数据比例的增加而降低
- 理解:网络数据的虚假信息多
- 由于这是一个小规模模型,准确度差异可能不显著,论文将相关数据集转换为基于损失的评估
- 由于计算限制,论文将每个检查点训练 10B 个 token,但使用按 100B token 运行规模调整的余弦学习率调度
- 详细信息和精确的损失图见附录 M
- 总体而言,在图 6 中,论文发现验证性运行在很大程度上验证了论文的元分析预测
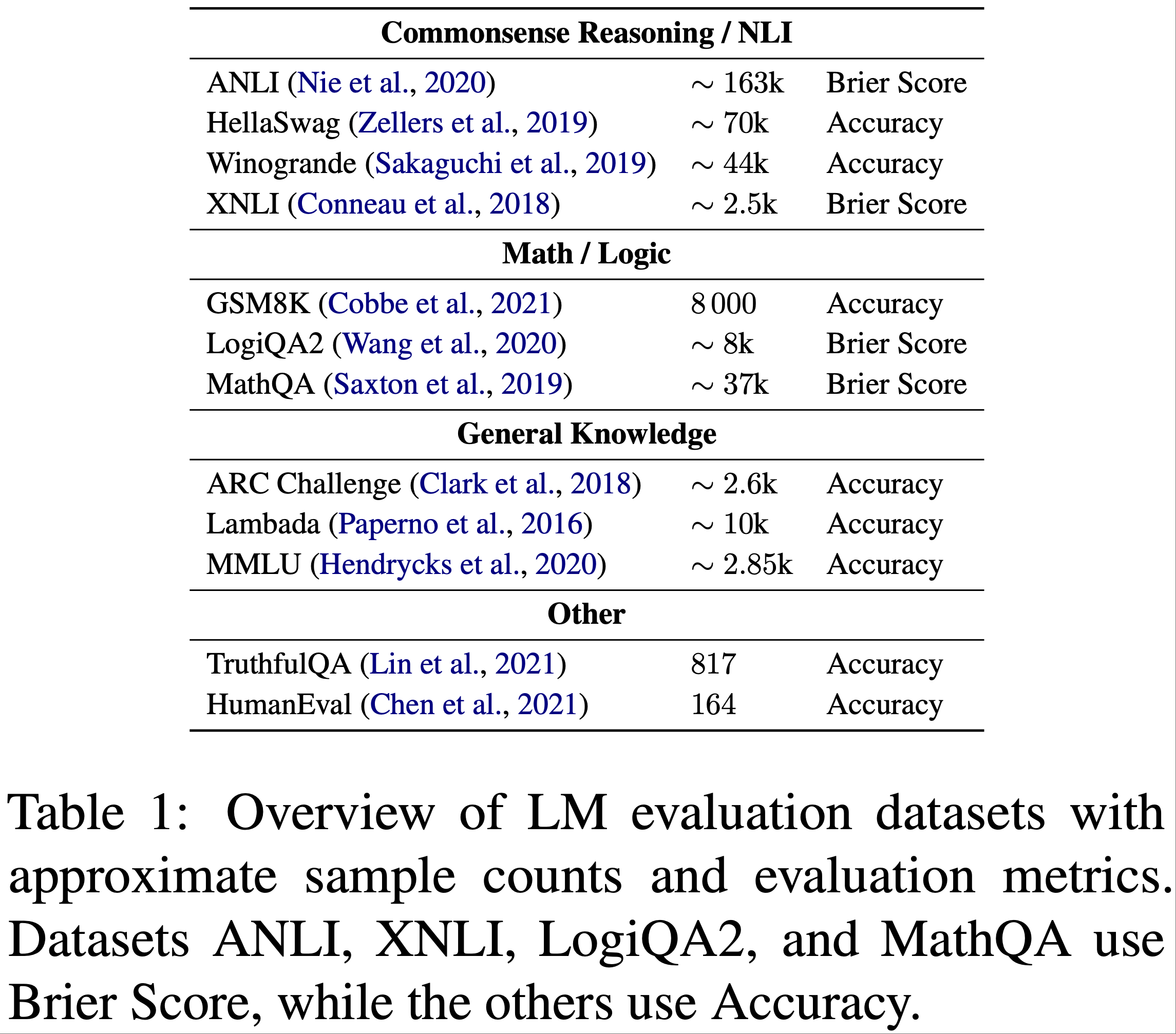
- 唯一不足:尽管准确度的趋势符合预期,但 TruthfulQA 的基于边际的损失在 50% 网络数据检查点上略低于 30% 检查点
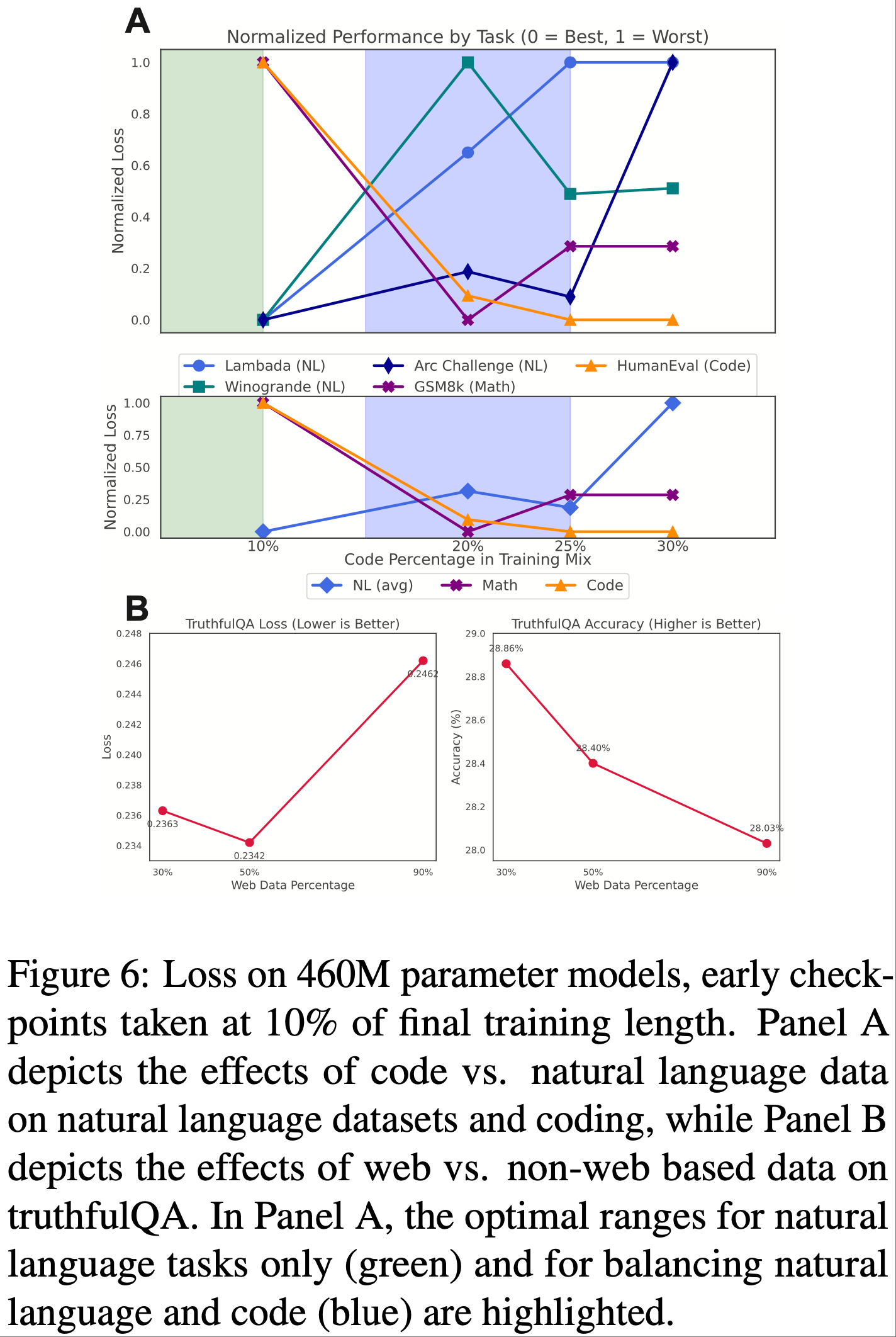
- 唯一不足:尽管准确度的趋势符合预期,但 TruthfulQA 的基于边际的损失在 50% 网络数据检查点上略低于 30% 检查点
- 这提供了初步证据,表明论文的分析方法可以用于先验地智能预测语言模型训练设计决策
Related Work
Empirical Data Composition Results
- 先前的研究已经探讨了预训练中代码数据的作用 (2023; 2024) 以及领域消融 (2024)
- 数据过滤可以在单纯扩展规模的基础上进一步提升性能 (2023; 2024)
- 论文的结果表明,代码数据在中等比例(最佳比例 15–25%)下能增强自然语言推理能力,这修正了先前 25% 的估计 (2024)
- 论文通过汇集现有模型的见解来识别有前景的测试方向,从而对实证消融研究进行了补充
Observational and Task-Specific Scaling Law Fitting(理解:观测性与任务特定的扩展定律拟合)
- 任务特定的扩展定律研究表明,参数分配会影响机器翻译的结果 (2021),而多任务处理对英语-目标语言对有益 (2023)
- 关于下游任务的研究强调了预训练数据与下游数据之间对齐的重要性 (2021; 2024)
- 各种研究探讨了数据重复 (2024)、多领域数据 (2024) 以及稀疏性 (2023)、精度 (2024) 和推理成本 (2022a) 等因素,而一些研究发现训练超参数具有稳定性 (DeepSeek-2024a)
- Ruan 等 (2024) 也使用开源模型的观测数据来预测任务性能,但他们是根据模型在其他任务上的表现来预测某一任务的性能
- 论文在识别性能的通用自然语言能力和编码能力两个方面得出了类似的结果,但论文的动机是将这些能力追溯到预训练决策
Pretraining Data Selection
- 领域混合在预训练中已被研究,其他工作将其表述为回归问题 (2024; 2025) 或在训练过程中使用代理模型来选择领域权重 (2023; 2023; 2024b; 2025)
- 相比之下,论文回顾性地分析了领域构成和训练决策如何影响跨任务的性能,这是在训练期间为单个模型优化数据权重的补充视角
Tracing Capabilities to Data
- 特定的语言模型能力已被关联到预训练数据中的模式
- 数值推理和句法规则学习的性能取决于训练数据中数字术语的频率 (2020; 2021)
- Ruis 等 (2024) 发现,对推理有影响的数据分散在众多文档中,并且与程序性内容相关
- 类似地,Chen 等 (2024) 观察到 “并行结构”与上下文学习能力密切相关
- 问题:这里的并行结构是什么?
- 论文目前关注更广泛的数据领域,但论文的框架可以通过更细粒度的任务或更精细的数据特征进行扩展
Future Work
- 展望未来,有几个明确的方向
- 首先,论文的数据库(章节3)可以随着新模型和基准测试的发布而进一步扩展,论文将发布代码和数据以帮助推动社区进行更系统的数据记录工作
- 其次,作者希望论文的工作将有助于发现在更受控环境中测试的假设
- 现有模型交织了许多设计决策,而进一步仅涉及单一变化轴的受控预训练实验可以进一步阐明每个特征的影响
- 最后,在论文的研究中,绝大多数预训练模型专注于密集 Transformer 架构,而混合专家 (2024a; DeepSeek-2024b) 和状态空间模型 (2023) 等替代架构也引起了显著的研究兴趣
- 如何恰当地对这些更多样化的模型架构进行特征化,并在性能预测中使用这些信息,是一个有趣的挑战,可能会揭示更多的见解
- 尽管预训练数据分析和选择迄今为止主要集中于实证发现,但通过大规模实证研究更好地理解训练如何影响模型能力,也可以促进可解释性实验和对学习表征的可能干预,其中受控的变化轴提供了案例研究
Limitations
- 论文当前的工作有几个局限性,可以在未来的工作中改进
- 第一,尽管论文记录了许多开源模型,但论文的样本量仍然有限,特别是对于较大(>50B)参数的模型
- 这限制了论文得出关于大型模型扩展行为的稳健结论的能力
- 而且论文拥有的模型在参数数量、数据大小和数据分布上并不均匀,某些规模范围和数据分布被过度代表
- 哪些模型被开源也可能存在选择效应,并且在不同的时间段,流行的架构决策或数据构成可能存在时间效应
- 第二,论文的方法论也带来了一些局限性
- 因为论文没有系统地训练所有论文自己的模型(尽管论文在附录 A 中有一些自己的模型),所以论文的分析本质上是观察性的
- 虽然我们可以观察到设计选择与性能之间的有趣关系,但要做出因果断言需要实验验证
- 此外,虽然基于树的回归器能有效捕捉复杂的特征交互,但它们限制了论文外推超出数据集中所见模型大小(参数和 token 数量)范围的能力
- 第三,论文注意到论文工作的范围也有局限性
- 论文专注于 Decoder-only 的基预训练密集 Transformer 模型,这排除了重要的架构变体,例如混合专家模型、非基于 Transformer 的架构以及经过后训练的模型
- 此外,论文主要检查英语模型,因为论文在这项工作中不关注多语言性
- 论文的特征集虽然广泛,但可能仍未捕捉到模型设计和训练的所有相关细节,特别是目前的优化细节
- 这些局限性为未来的工作指明了方向:
- 扩展数据库以包含更多样化的模型类型和语言覆盖范围;
- 开发更具针对性的函数形式,以便在输入异构特征集的同时实现更好的外推;
- 使用新的预训练模型进行有针对性的实验,以验证特定设计选择的影响
Ethical Considerations
- 在这项工作中,论文专注于理解模型为何在标准基准测试上表现良好,但并未关注其他重要的考量因素,例如安全性或社会偏见
- 而且论文的分析侧重于英语模型和基准测试
- 这一局限性反映但也可能强化了该领域现有的对英语的偏向,可能导致对其他语言有效架构的开发投入不足
附录 A:List of all models
- All models are listed in Table 3.

附录 B:List of all architectural and data features
B.1 Architectural Features
- (注意,本部分的特征是从官方文档(例如 Hugging Face 的模型/数据卡片或原始论文)中收集的)
- 总参数量 (Total parameters) :模型中的参数总数(包括嵌入参数)
- 注意,论文仅包含 Decoder-only 的密集模型
- 维度 (Dimension) :嵌入维度
- 头数 (Num heads) :注意力头的数量
- MLP 比率 (MLP ratio) :\(\frac{\text{FFN dimension} }{\text{Embedding dimension} }\) 的比率
- 位置嵌入 (Positional Embeddings) :位置嵌入的类型
- 这可以是非参数的(正弦或固定嵌入)、学习的(仅作为每个位置的向量学习)、rope (rope 嵌入) 或 alibi(技术上不是嵌入,但因其功能目的而包含在此)
- 层归一化 (LayerNorm) :应用的层归一化类型
- 这可以是非参数的(仅基于算术的归一化)、参数的(类似,但有一些可学习的参数,如扩展/偏置)和 RMSNorm(参数版本的简化版)
- 注意力变体 (Attention variant) :使用的注意力的大致类型
- 这可以是 full(普通注意力)、local(每个 Token 位置仅关注其周围的位置)、mqa(多查询注意力)或 gqa(分组查询注意力)
- 偏置 (Biases) :模型的某些部分是否存在偏置项
- 可以是 none(无偏置)、attn only(仅在注意力层中)、ln only(仅在层归一化中)
- 块类型 (Block type) :变压器块是否完全并行计算
- Sequential 表示不并行,而 parallel 表示在注意力或 FFN 层中存在某种并行性
- 激活函数 (Activation) :使用的激活函数
- 可以是 relu、gelu/gelu 变体、silu 或 swiglu
- 序列长度 (Sequence length) :序列长度
- 批次实例数 (Batch instances) :预训练期间使用的批次大小
B.2 Data Features
- (注意,本部分的特征是从官方文档(例如 Hugging Face 的模型/数据卡片或原始论文)中收集的)
- 总 Token 数 (B) (Total tokens (B)) :预训练期间使用的 Token 总数,以十亿计(转换为对数尺度)
- 预训练数据中网络数据百分比 (% Web in Pretraining) :来自通用网络来源的预训练数据百分比
- 预训练数据中代码百分比 (% Code in Pretraining) :由代码组成的预训练数据百分比
- 预训练数据中书籍百分比 (% Books in Pretraining) :来自书籍的预训练数据百分比
- 预训练数据中参考文献百分比 (% Reference in Pretraining) :来自参考文献来源的预训练数据百分比
- 预训练数据中学术内容百分比 (% Academic in Pretraining) :来自学术来源的预训练数据百分比
- 预训练数据中英文百分比 (% English in Pretraining) :预训练数据中英文文本的百分比
B.3 Freegen-derived Features
- 这些特征源自模型的生成文本
- 对于每个模型,提取 5-10k 个生成文本,并聚合以下指标(通过均值和标准差)
- 但二元组熵、教育分类器分数和领域分类是例外,因为它们是在所有生成文本上计算一次的
- 论文使用 Stanza (2020) 在按语言对生成文本进行分类后生成基于解析的特征
- 论文仅将 stanza 支持的语言包含在解析特征所基于的最终生成文本集中
B.3.1 生成长度和基本统计量 (Generation Length & Basic Statistics)
- 平均字符长度 (Mean Character Length) :每个生成文本的平均字符数(上限为 2048)
- 平均生成 Token 数 (Mean Tokens Generated) :每个生成文本的平均 Token 数
- 平均句子数 (Mean Sentences) :每个生成文本的平均句子数
- 平均词数 (Mean Words) :每个生成文本的平均词数
- 平均每句词数 (Mean Words per Sentence) :每个句子的平均词数
B.3.2 Constituency Parse Features
- 最深解析树平均深度 (Mean Depth of Deepest Parse Tree) :每个生成文本的平均最大选区树深度
- 解析树平均深度 (Mean Depth of Parse Trees) :所有句子/短语的平均选区树深度
- 词平均深度 (Mean Word Depth) :选区树内词的平均深度
- 词深度变异平均 (Mean Word Depth Variation) :跨句子/短语的词深度标准差的平均值
B.3.3 Dependency Parse Features
- 依存头距离 90% 分位数平均值 (Mean 90th-Percentile Dependency Head Distances) :对于每个生成文本,计算词与其依存头之间的线性距离的 90% 分位数,然后对这些值取平均
- 最大依存头距离平均值 (Mean Maximum Dependency Head Distances) :每个生成文本中任何词到其依存头的最大距离的平均值
- 依存头距离中位数平均值 (Mean Median Dependency Head Distances) :每个生成文本的依存头距离中位数的平均值
- 最大依存根距离平均值 (Mean Maximum Dependency Root Distances) :每个生成文本中任何词到句子根的最大距离的平均值
- 平均依存根距离平均值 (Mean Mean Dependency Root Distances) :每个生成文本中词到句子根的平均距离的平均值
- 依存根距离中位数平均值 (Mean Median Dependency Root Distances) :每个生成文本中词到句子根的距离中位数的平均值
B.3.4 Domain Classification Features
- 生成学术类文本百分比 (% Generated Academic-like Text) :被分类为学术类的生成文本百分比
- 生成书籍类文本百分比 (% Generated Books-like Text) :被分类为书籍类的生成文本百分比
- 生成代码类文本百分比 (% Generated Code-like Text) :被分类为代码类的生成文本百分比
- 生成参考类文本百分比 (% Generated Reference-like Text) :被分类为参考类的生成文本百分比
- 生成专业文本百分比 (% Generated Specialized Text) :被分类为专业类(例如,乐谱、象棋 PGN、生物医学数据)的生成文本百分比
- 生成网络类文本百分比 (% Generated Web-like Text) :被分类为网络类的生成文本百分比
B.3.5 Classifier and Language Metrics
- 教育分类器分数平均值 (Mean Educational Classifier Score) :教育分类器给出的平均分数
- 生成英文文本百分比 (% Generated English Text) :生成的英文文本的平均百分比
B.3.6 Lexical Diversity and Entropy Metrics
- 平均二元组熵 (Mean Bigram Entropy) :跨生成文本计算二元组的平均熵
- 型符比 (Type-Token Ratio) :唯一 Token 数与总 Token 数的平均比率
- 唯一 Token 数 (Unique Tokens) :每个生成文本的平均唯一 Token 数
B.3.7 Lexical and Stylistic Features
- 实词-功能词比率 (Content-Function Ratio) :实词(名词、动词、形容词、副词)与功能词的比率
- 疑问词比率 (Question Words Ratio) :每 10 万个词中疑问相关词(例如 how, what, why, when, where, who, which, whose)的比率
- 祈使词比率 (Imperative Words Ratio) :每 10 万个词中祈使词(例如 do, make, consider, take, use, ensure, check, build, apply, run, create, find, go, try, turn, start, stop, put, keep, leave, get, move)的比率
- 连词比率 (Conjunctions Ratio) :每 10 万个词中连词(例如 and, but, or, so, because, although, however, therefore, yet)的比率
- 指令词比率 (Instruction Words Ratio) :每 10 万个词中指令导向短语(例如 “Question:”, “Answer:”, “Instruction:”, “User:”, “Assistant:”, “Q:”, “A:”)的比率
- 数字比率 (Numbers Ratio) :生成文本中数字 Token 的比率
附录 C:List of all evaluations and settings
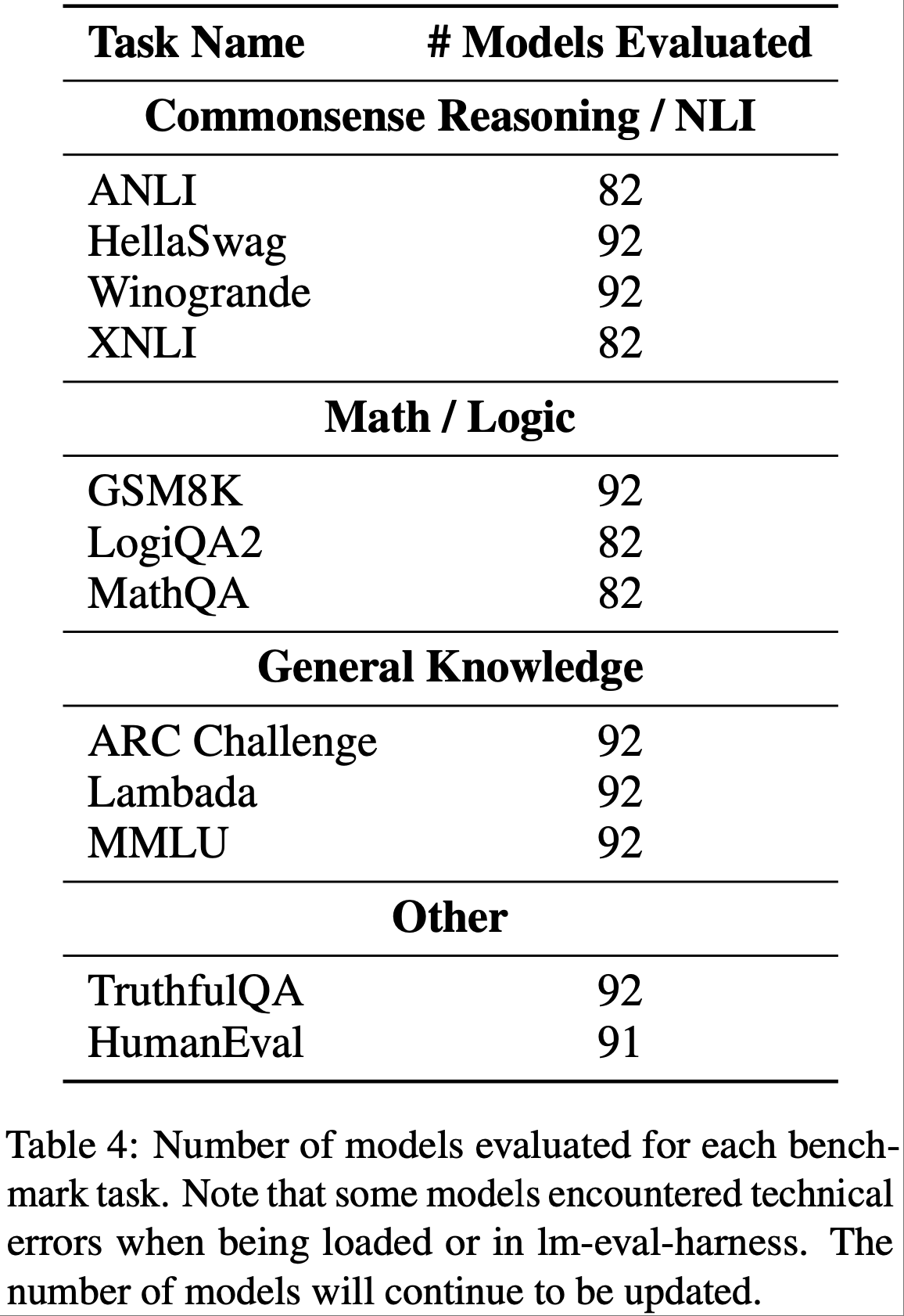
- 尽管论文理想情况下会评估模型和任务的全部组合,但论文发现由于一些模型与 LM Evaluation Harness 不兼容以及计算限制,论文无法在每個数据集上评估所有 92 个模型
- 论文在表 4 中列出了论文目前每个基准测试的评估数量,并将在数据库中继续补充评估结果
附录 D:Task Deviations from Kaplan-style Scaling Laws
- 表 5 记录了针对每个模型性能拟合幂律分布所得到的决定系数(\(R^2\) value)
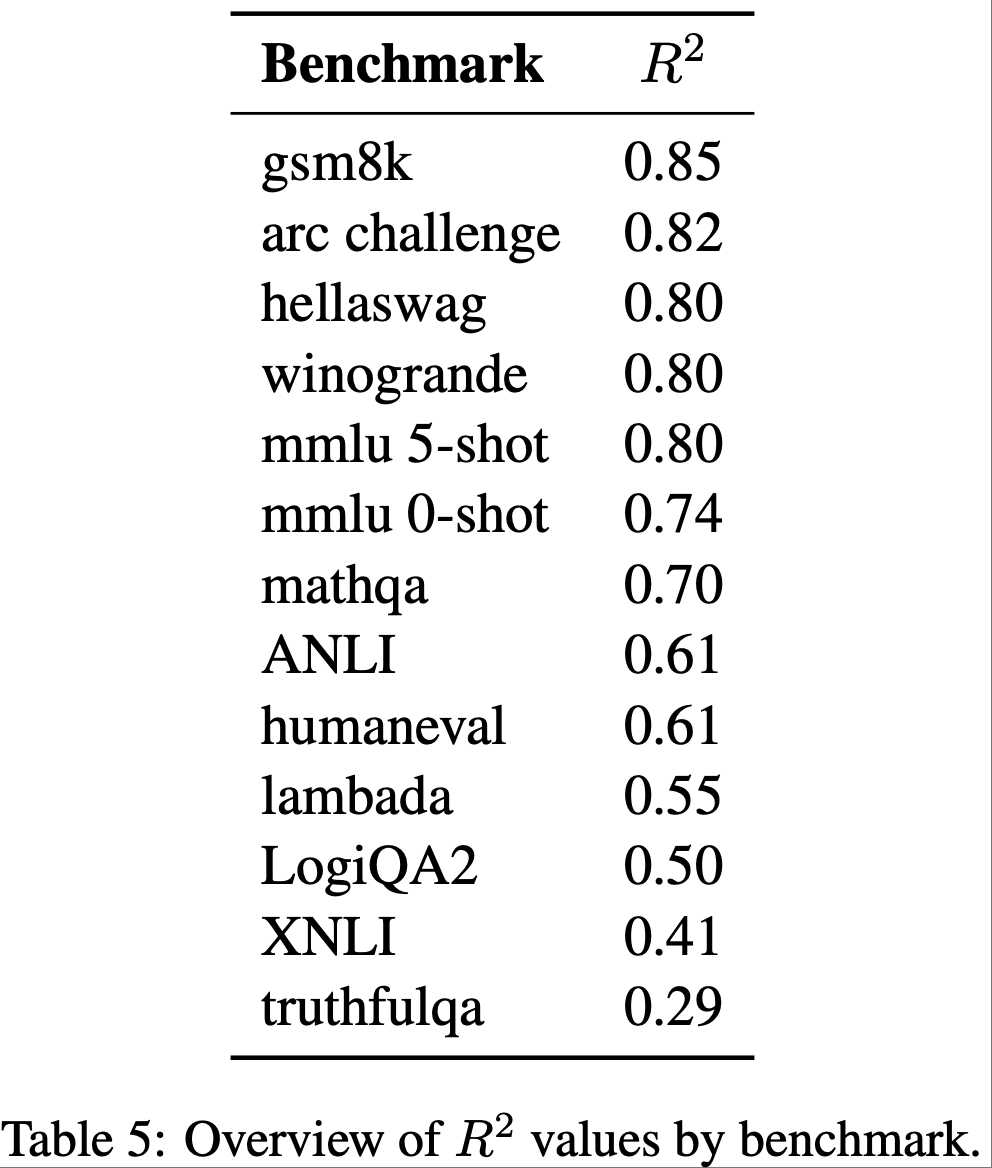
附录 E:Free-generation Domain Classification
- 论文使用 GPT-4o-mini 将模型生成文本分类到顶级领域
- 论文发现这种多阶段提示(清单 1,清单 2)在 Dolma 按领域采样的样本上具有合理的精确度 (2024),因此使用它对自由生成文本进行分类
附录 F:Domain Classifier Validation
- 为了验证基于 4o-mini 的分类器的可靠性,论文请论文的一位作者根据附录 E 中使用的相同标注标准,对来自三个预训练数据集(the Pile, the SmoILM corpus, 和 RefinedWeb)的 300 个选定样本进行标注
- 被模型或人类标注者标注为“unknown”或“incoherent”的样本被排除,因为这些样本不包含在领域混合的计算中
- 过滤后,论文分析了 258 个文本样本,发现人类标注者和模型的绝对一致率为 85.8%,Cohen’s \(\kappa\) 为 0.746,表明人类分类和模型分类之间具有高度一致性
附录 G:Free-generation Validation
- 为了验证论文的自由生成方法作为预训练数据组成的代理,论文分析了模型的自由生成特征与其预训练数据之间的相关性
- 对于在三个开放预训练数据集(the Pile, the SmoILM corpus, 和 Refinedweb)上训练的模型,论文比较了它们的自由生成特征与相同标注器和基于 LM 的分类器(附录 E)在预训练语料库随机采样的 100 万文档子集上产生的特征
- 由于成本原因,对于领域分类,每个语料库使用了 100 万中的 5000 个示例
- 这 100 万文档是通过水库采样均匀采样的
- 此外,论文计算了两个整体模型层面的相关性,它们衡量了每个模型的完整生成配置文件与其训练数据的匹配程度:
- 1)领域层面相关性 (Domain-level correlations): 对于每个领域类别(web, code, academic, books, reference),论文计算了模型文档记录的预训练数据中该领域的百分比与被分类到该类别的自由生成文本百分比之间的相关性
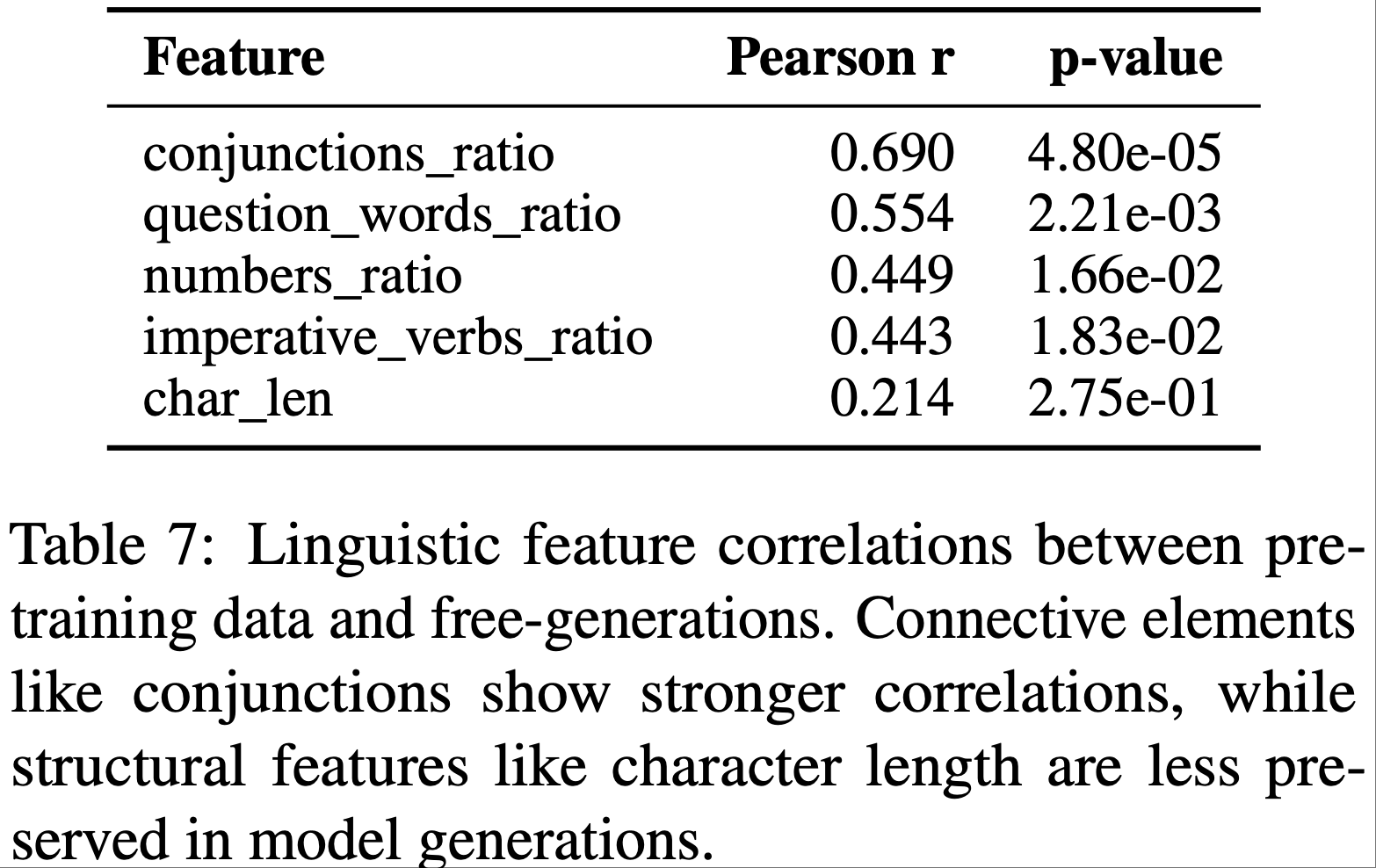
- 2)特征层面相关性 (Feature-level correlations): 对于语言特征(连词比率、祈使动词比率、疑问词比率、数字比率、字符长度),论文评估了自由生成中的每个特征与预训练数据中相应特征的相关性
- 这些模型层面的相关性明显高于单个特征的相关性,表明模型比任何单一维度都更好地保留了其训练数据的整体“指纹”
- 表6 和 表7
附录 H:Free-generation Examples
Llama-2-70B,网页风格(web-like):
给定斯蒂芬妮在与布雷克谢尔顿一起出席的活动上无法认出自己的第一首歌曲你创作和/或录制的第一首歌是什么?如果你再也没听过它,直到在参加一个大型乡村音乐活动时与数十万人进行Facetime视频通话,你会有什么感觉?这正是格温斯蒂芬妮本周在乡村电台研讨会活动上被授予荣誉时发生的事情。在纳什维尔,可以想象,当你拥有像她那样疯狂的职业生涯时,可能很难记住这些年所有的里程碑,但试想一下还要当场为所有人做到这一点。嗯,结果发现,双重才华的多莉帕顿原本要介绍格温是“一个打破壁垒的艺术家”,当时她引用了斯蒂芬妮第一首“乡村”歌曲的歌词……‘3000年’。外交辞令的“好声音”教练布雷克谢尔顿在她当时展示的视频中插话,问道“还有其他完成的工作吗……
phi-2,书籍风格(books-like): 太阳在傍晚的天空中明亮地闪烁,将温暖的光线投射在温馨的小厨房里,一对勤奋的父母正在那里准备一顿美味的饭菜。空气中充满了期待,他们开始了一次烹饪冒险,心中充满了爱和喜悦。他们卷起袖子,灵巧地挥舞着各种锋利的刀具,每把刀都是他们技能和精确度的延伸。就像艺术家拿着画笔一样,他们精巧地在食材中穿梭,与刀具共舞,如同舞伴。刀片的移动速度之快违背了日常动作的物理规律,优雅而有目的地在空中滑行。……
Qwen2-72B,参考(指令)风格(reference (instruct)-like): 儿童:家庭票(最多2名成人和2名儿童)23.00美元 (1)布莱克先生想和他的妻子以及两个儿子(他们都超过9岁)一起看电影,他应该支付多少?__ A.23美元 B.46美元 C.48美元 D.49美元 (2)布朗先生想和他5岁的双胞胎儿子一起看电影,他应该支付多少__。 A.18美元 B.23美元 C.28.5美元 D.32美元 (3)丽莎在这部电影中看不到雪。__ A.正确 B.错误 (4).简是一位数学老师,她有两个女儿(一个12岁,妹妹8岁)。她们想看电影。她应该支付多少?__ A.28.5美元 B.27美元 C.33美元 D.26.5美元 (5)迈克十六岁。今天是星期六,他想和他40岁的父母一起看电影。他们将为门票支付____。 A.22美元
OPT-6.7B,网页风格(web-like): 我不认为这是一个问题。这是一个陈述。我说养只狗吧,世界有狗更美好。我对自己说了完全一样的话。我不知道你为什么被踩了。因为reddit是一群讨厌狗的人
Codegen-16B-mono,代码风格(code-like):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22from typing import Optional
from fastapi import FastAPI
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
name: str
price: float
is_offer: Optional[bool] = None
def read_root():
return {"Hello": "World_from_ FastAPI"}
def read_item(item_id: int, q: Optional[str] = None):
return {"item_id": item_id, "q": q}
def update_item(item_id: int, item: Item):
return {"item_name": item.name, "item_id": item_id}Pythia-410M,学术风格(专利)(academic-like (patent)):
- 本发明涉及用于从发电站的废物流中去除固体废物材料的新的和改进的方法和设备,其中该固体废物材料计划在发电厂完工后进行处置。先前已经进行了各种尝试来从工厂的废物流中去除固体废物。这是真的,例如,对于污泥的排放,这些污泥通常被收集到一个污泥罐中,并在一个通常连接到工厂的敞开排水出口的清洗罐中被洗出工厂。这项现有技术由美国专利号3,623,579进行了讨论,该专利授予了G.R.Clark并描述了一种通过在罐中絮凝和絮凝并搅动固体以打破固体颗粒之间的键合来处理废物流以去除固体废物的方法。此外,美国专利号4,016,823描述了一种装置,该装置描述了一种方法,其中液体污水从废物流中和从污水处理厂中被去除,在那里要被去除的固体废物将被处理以生产用于沐浴浴缸或肥皂的氨净化水,并且其中来自废水处理厂的污水被去除到污水处理厂,在那里这些污水与水混合或作为肥料处理。…
附录 I:Appendix I XGBoost Settings
- 对于内部网格搜索,树的最大深度在[2,3,5]中,学习率在[0.01,0.1,0.3]中,树的数量在[50,100]中
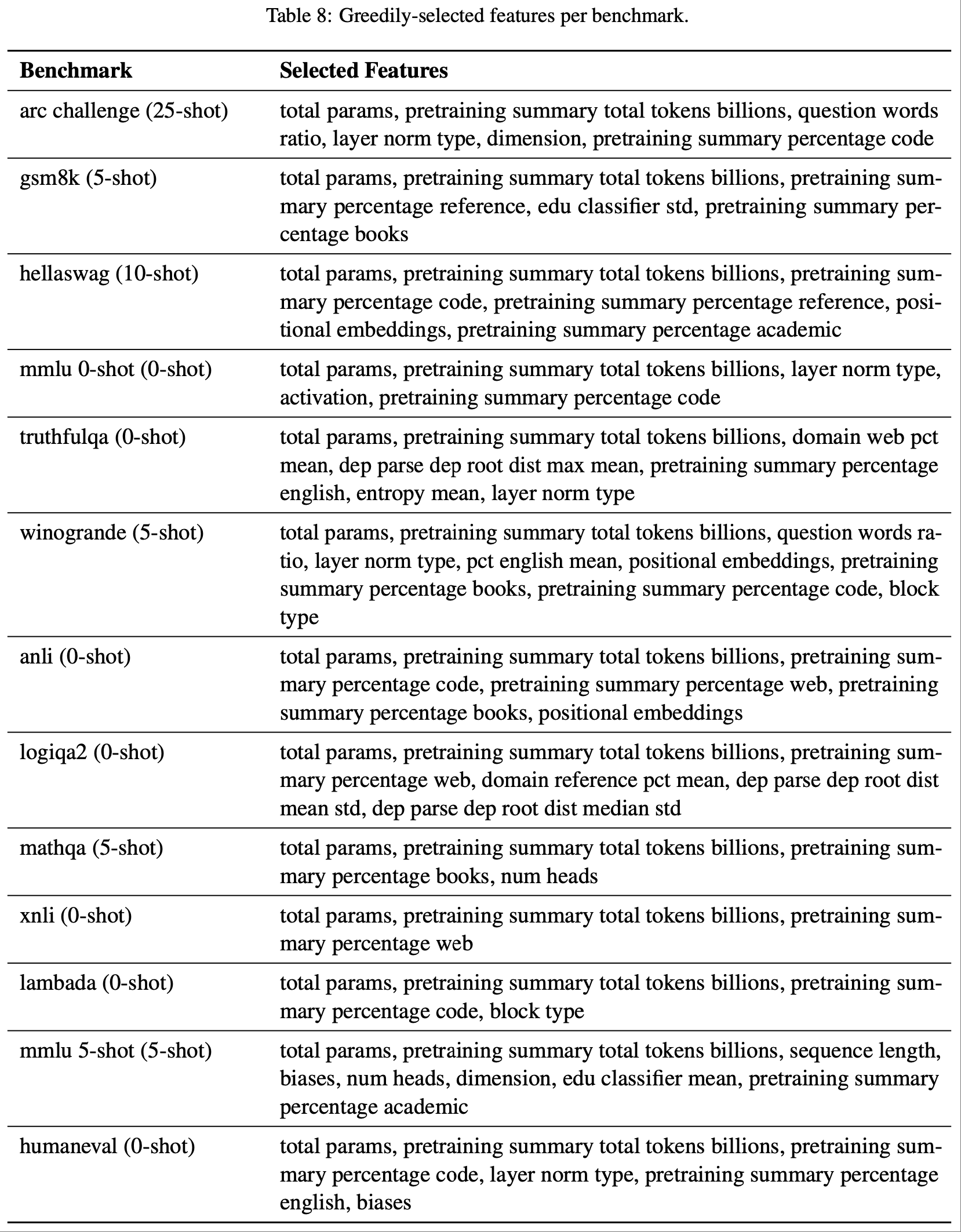
附录 J:Selected Features by Task
- 在表8中,论文展示了每个基准测试所选的特征
附录 K:LightGBM Results
- 表2的 LightGBM 版本可以在表9中找到
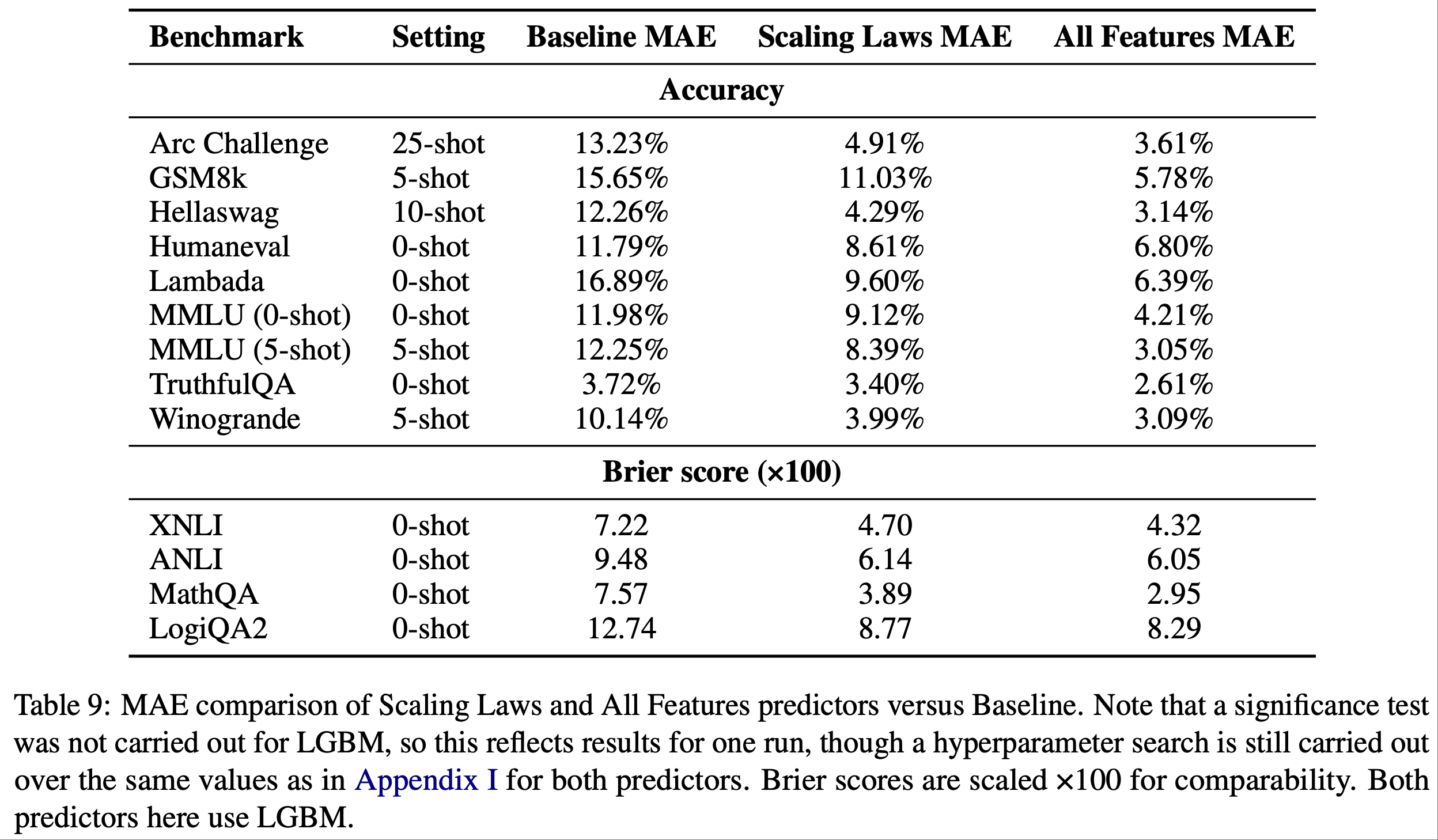
- 注意:未对 LGBM 进行显著性检验,因此这反映了一次运行的结果,尽管对两个预测器都仍在附录I的相同值上进行了超参数搜索
- Brier 分数扩展 ×100 以便比较
- 这里的两个预测器都使用 LGBM
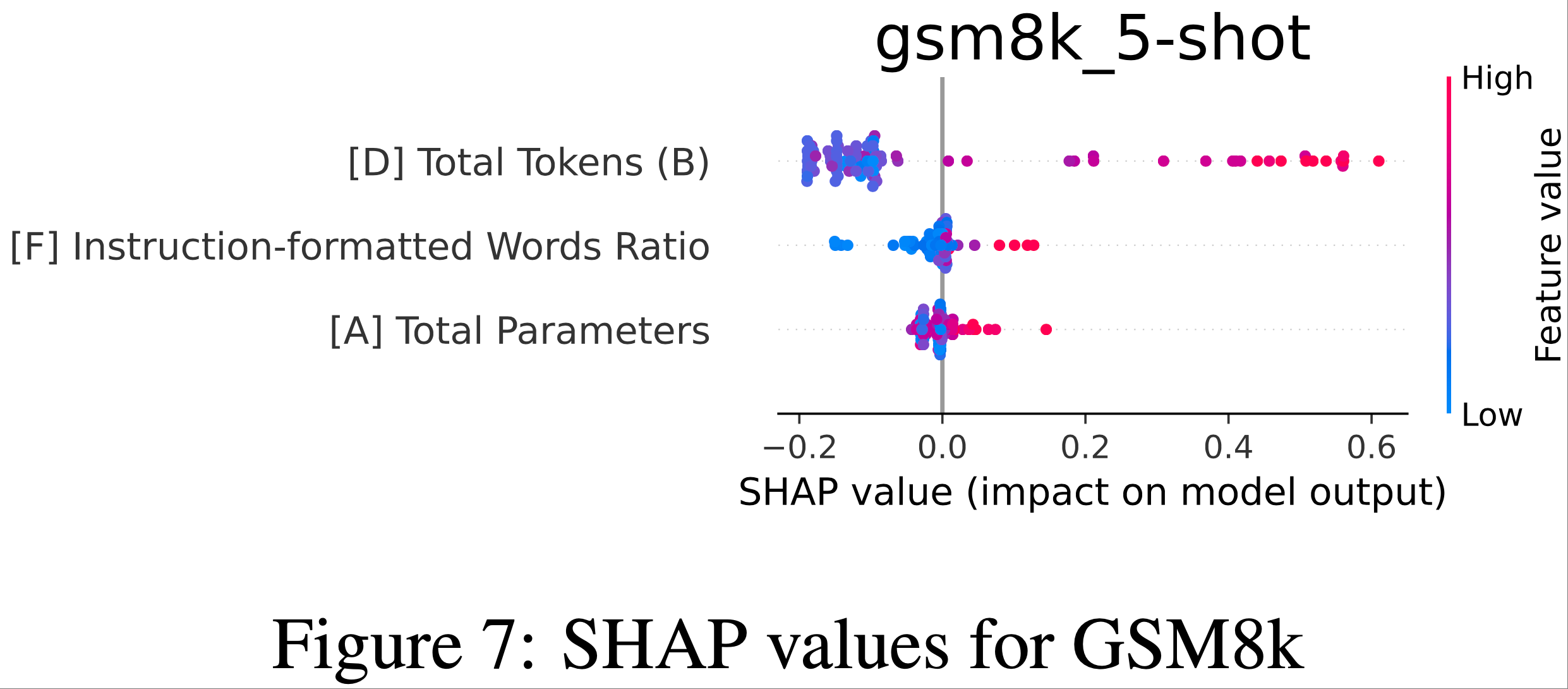
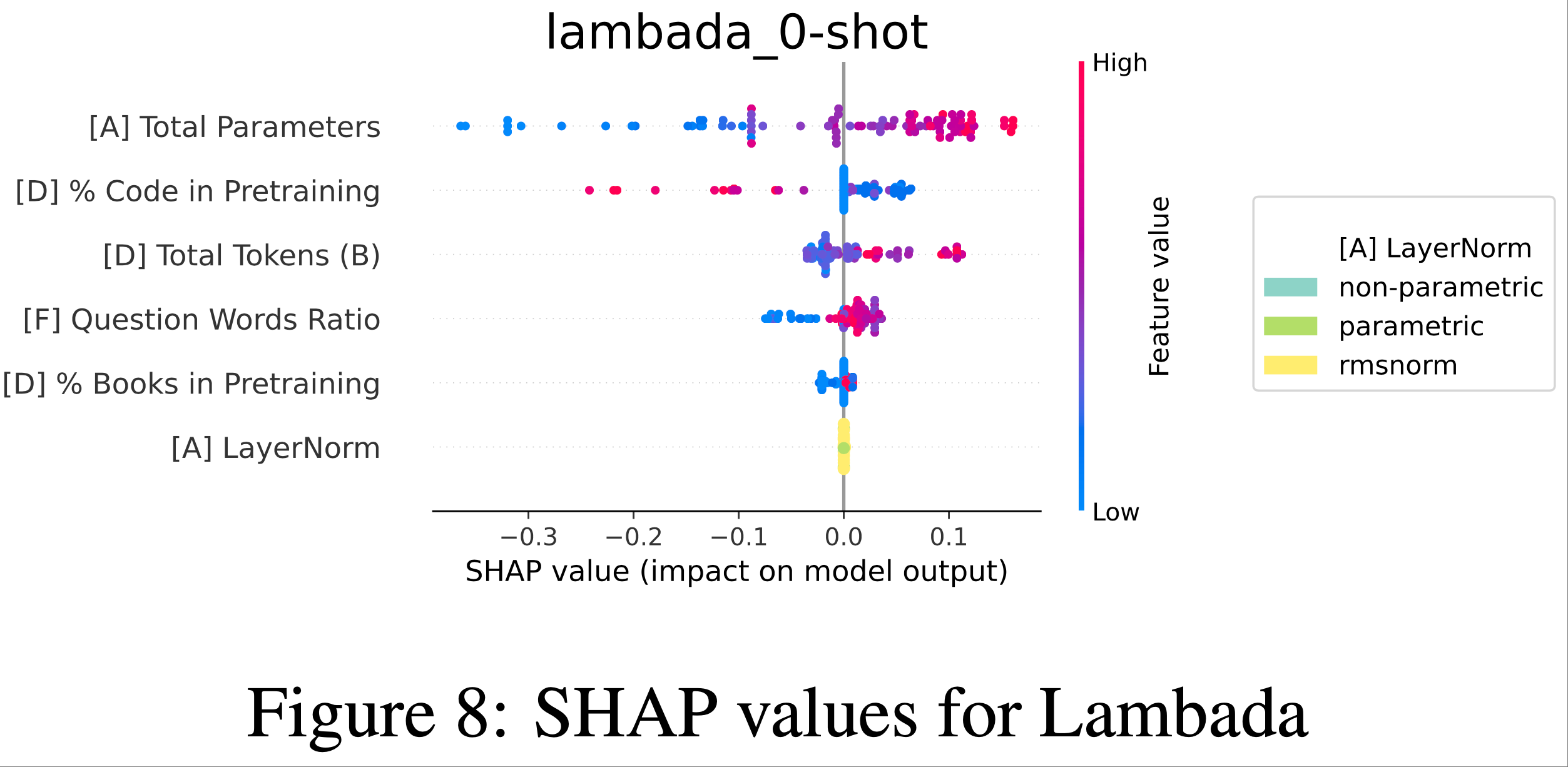
附录 L:SHAP Plots for remaining benchmarks
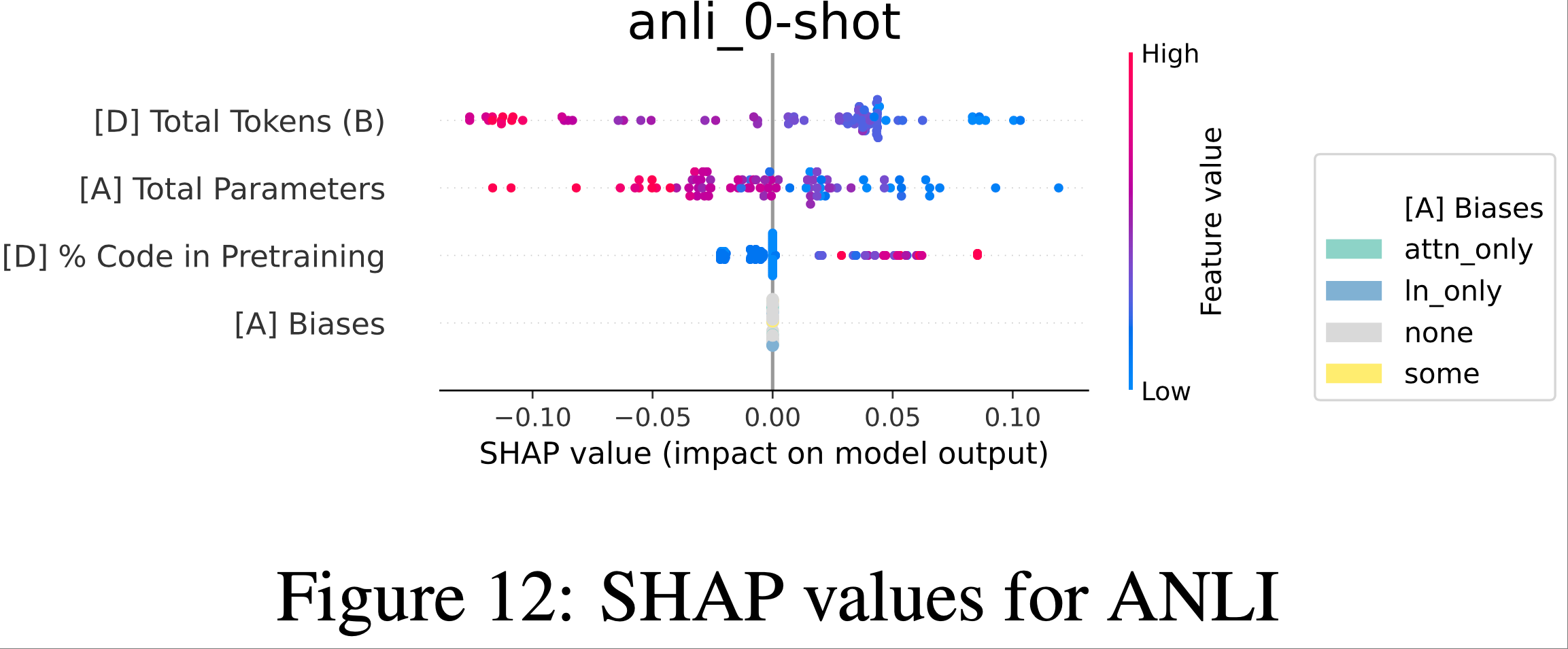
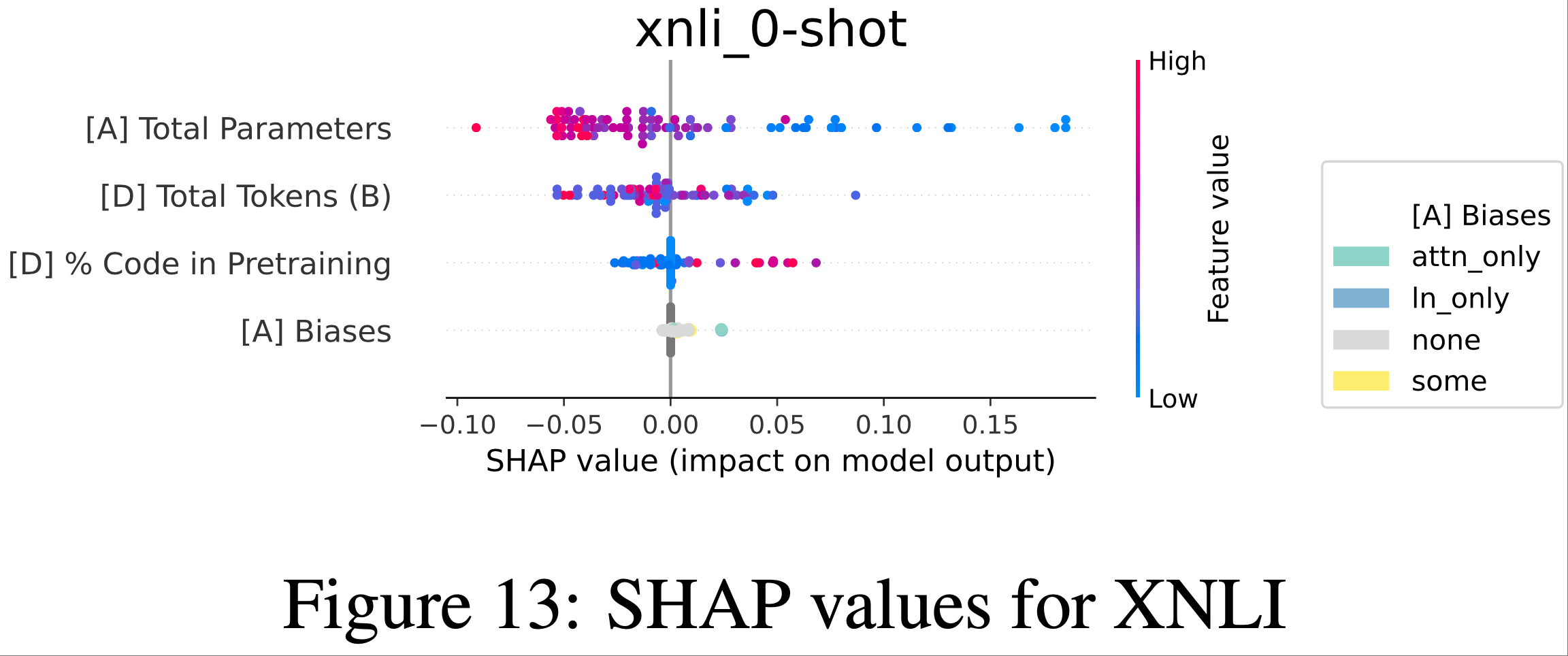
- 剩余基准测试的SHAP图可以在图7-图15中找到。请注意,对于Brier分数任务(ANLI,XNLI,MathQA,LogiQA2),分数越低越好
附录 M:Details on confirmatory pretraining runs
M.1 训练(Training)
对于论文的验证性实验,论文使用 Megatron-Deepspeed 库从头开始训练了 460M 参数的 Llama-2 架构模型
论文将训练 token 数量上限设为 10B,同时使用设置为 100B token 长度的余弦学习率调度(意味着每个检查点大约完成了“完整”预训练运行的 10%)
训练在每个检查点一个节点上进行,使用 8 个 H100 GPU
- 每个检查点大约需要 6 小时来训练
对于论文的数据混合,论文使用 Dolma v1 数据集的子集构建了各种混合
- 在网页与其他的实验中,论文固定了所有其他数据源的相对百分比,同时改变网页的百分比
训练配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20training:
num_layers: 14
num_attention_heads: 12
seq_length: 2048
num_kv_heads: 12
hidden_size: 1536
ffn_hidden_size: 4128
tune_steps: 1000
lr: 0.00015
min_lr: 1.0e-5
weight_decay: 1e-2
grad_clip: 1.0
lr_warmup_steps: 100
save_interval: 2000
eval_interval: 2000
train_epochs: 1
tp: 1
micro_batch_size: 16
global_batch_size: 512
seed: 42除了数据混合之外,所有实验都使用相同的超参数以确保公平比较
M.2 Evaluation
- 为了评估不同数据混合对模型性能的影响,论文在以下任务上评估了论文的模型:
- 1)自然语言推理(Natural language inference): Lambada, winogrande, arc challenge
- 2)Code Generation: Humaneval
- 3)Math: GSM8K
- 4)事实性(Factuality): TruthfulQA
- 注意,由于时间限制,论文没有选择完整的评估集
- 由于LM eval harness没有为所有任务实现困惑度/基于损失的评估,论文手动将多项选择任务转换为基于损失的指标,并在计算所有任务的损失时屏蔽提示或问题
M.3 转换为基于损失的指标(Conversion to Loss-Based Metrics)
- 为了确保跨不同任务和模型的一致评估,论文将各种基准测试数据集转换为基于损失的指标
- 这种方法允许在模型之间进行更直接的比较,并更清晰地解释改进
- 以下是论文为每种数据集类型实现损失计算的方式:
- 多项选择任务(ARC Challenge, Winogrande, HellaSwag, TruthfulQA): 对于这些数据集,论文计算了两个主要的基于损失的指标:
- 平均损失(Average Loss): 论文计算了正确答案的负归一化对数概率。对于每个问题,论文将输入格式化为“问题+答案选项”,然后为每个选项计算按token长度归一化的序列对数概率。正确答案的负对数概率被用作损失
- 基于边际的损失(Margin-based Loss): 特别是对于 TruthfulQA,论文计算了真实答案和非真实答案之间的边际。这被计算为最佳真实答案的对数概率与最佳非真实答案的对数概率之差的负值。损失越低表示区分真实和非真实信息的能力越好
- 生成任务(GSM8K, HumanEval, Lambda): 对于生成任务,论文计算:
- 回答损失(Answer Loss): 论文计算 solution Token 上的交叉熵损失
- 注:对 Lambada 任务,仅使用最后一个 word
- 所有对数概率均被序列长度归一化
- 回答损失(Answer Loss): 论文计算 solution Token 上的交叉熵损失
M.4 Full Results
- 表 10:代码与自然语言混合数据
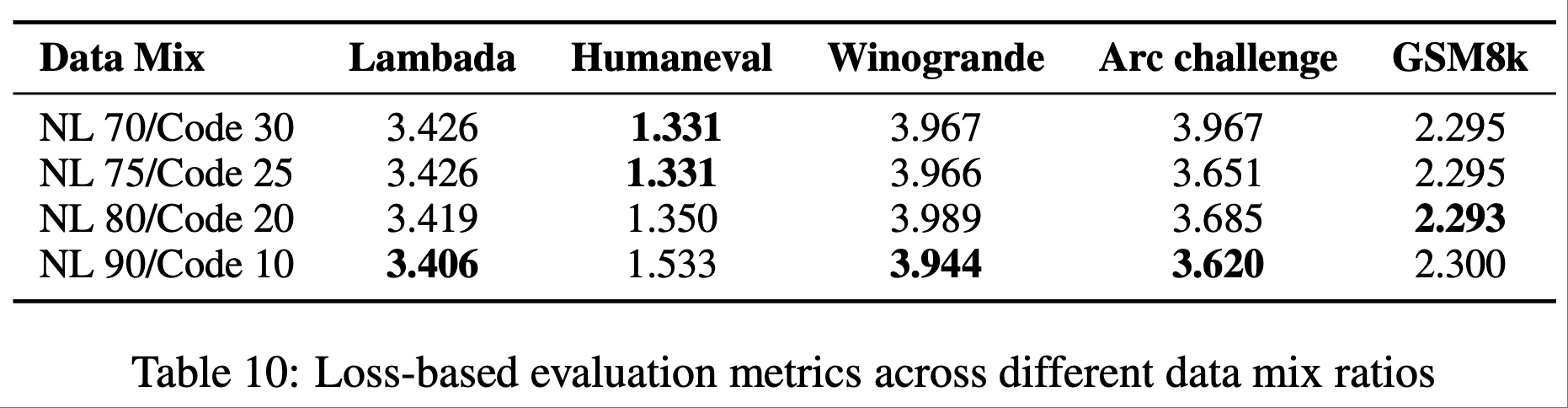
- 表 11:网络数据与其他数据混合的精确损失值