注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- LLM 在问答(QA)任务中经常产生幻觉(hallucination),一个关键但尚未充分探索的因素是问题的时间性:
- 即问题属于常青类(evergreen,答案随时间稳定)还是可变类(mutable,答案会变化)
- 本论文探讨了问题的常青性(evergreenness),即答案是否会随时间变化
- 论文测试了 LLM 检测常青性的能力,并展示了其在多个应用中的价值
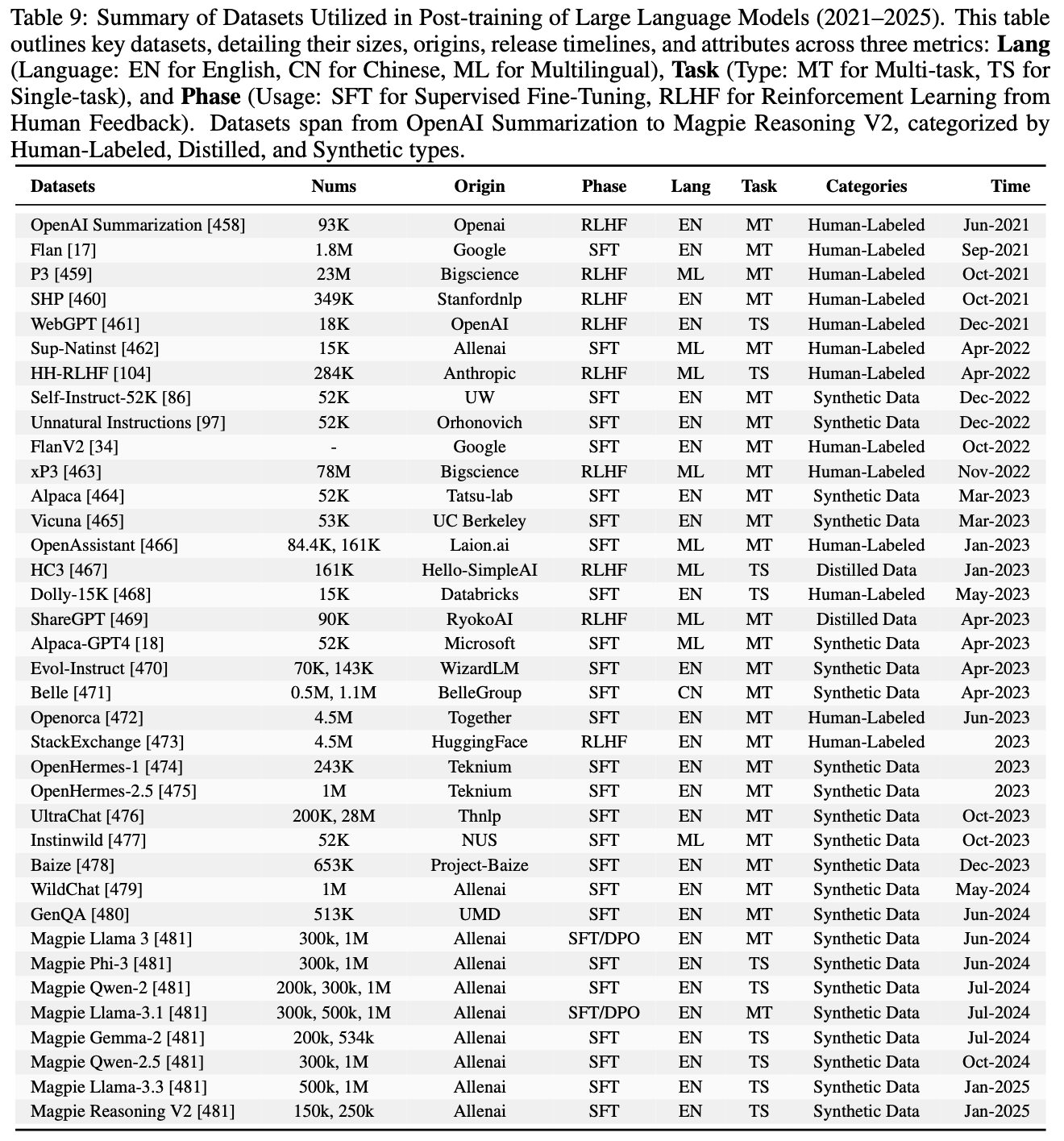
- 论文提出了 EverGreenQA ,这是首个支持多语言且带有常青标签的问答数据集,可用于评估和训练,包含 7 种语言的 4,757 个示例
- 利用 EverGreenQA 数据集,论文对现代大语言模型在常青问题分类任务上的表现进行了基准测试,并训练了 EG-E5 ,一个轻量级分类器,其性能优于大语言模型和此前训练的方法
- 论文进一步分析了大语言模型是否通过不确定性估计隐式编码了常青性 ,发现它们确实具备一定的能力 ,且模型规模越大,表现越好
- 论文展示了常青分类在三个应用中的实际价值:
- 改进自我知识估计(self-knowledge estimation):论文通过预测的常青概率增强了现有的不确定性估计方法 ,取得了稳定的改进
- 过滤问答数据集:论文展示了常青分类器有助于筛选高质量的问答数据集,支持更可靠和公平的评估
- 解释 GPT-4o 的检索行为:论文证明常青性是预测 GPT-4o 搜索行为的最佳指标,优于所有其他测试因素
Introduction and Discussion
- 大语言模型在问答任务中常因幻觉答案而表现不佳(2025)
- 为提高可信度,近期研究聚焦于:
- 估计模型的自我知识(self-knowledge),即识别自身已知与未知的能力(2023;2025)
- 通过检索增强生成(Retrieval-Augmented Generation, RAG)整合最新外部信息(2024;2024;2023)
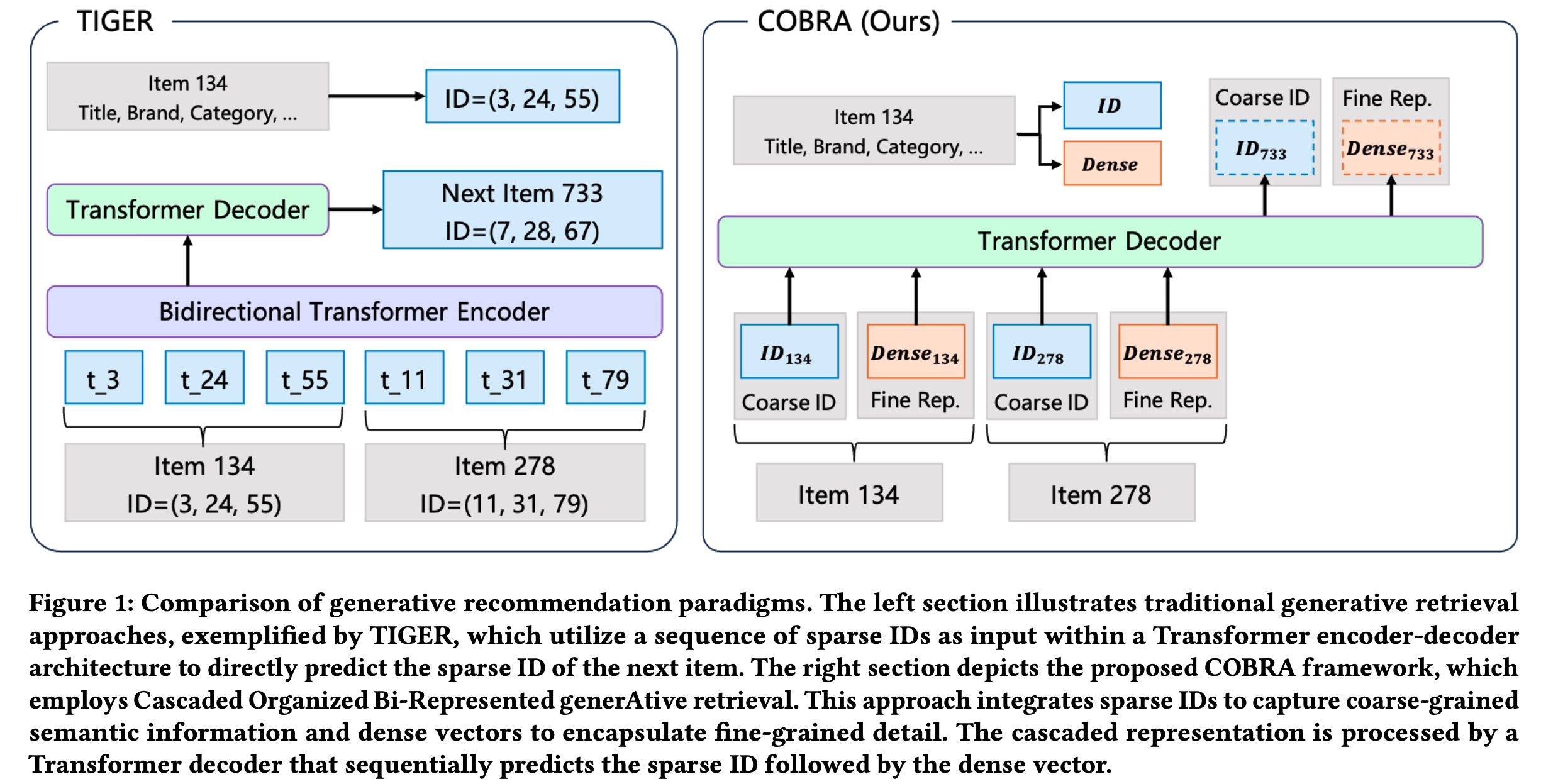
- 未充分探索 ,同时确是影响问题难度的关键因素是其是否为常青(evergreen)或可变(mutable)问题(2024a),即正确答案是否随时间稳定(如图 1 所示)
- 可变问题尤其具有挑战性,因为它们通常需要访问最新信息,而这些信息可能未包含在模型的固定参数化知识中
/EverGreenQA-Figure1.png)
- 可变问题尤其具有挑战性,因为它们通常需要访问最新信息,而这些信息可能未包含在模型的固定参数化知识中
- 常青性(evergreen-ness)具有实际重要性,但在评估和改进大语言模型行为时,它仍是一个未被充分探索的因素
- 现有研究大多局限于小规模、仅限英语的数据集,且主要关注问答准确性,很少探讨其更广泛的影响(2024;2024)
- 问题常青性在塑造大语言模型可靠性和可解释性中的作用仍未被充分研究
- 为填补这一空白,论文开展了关于问题常青性及其实际应用的全面研究
- 论文提出了 EverGreenQA ,这是首个多语言人工标注的常青感知问答数据集,包含适合模型训练的训练-测试划分
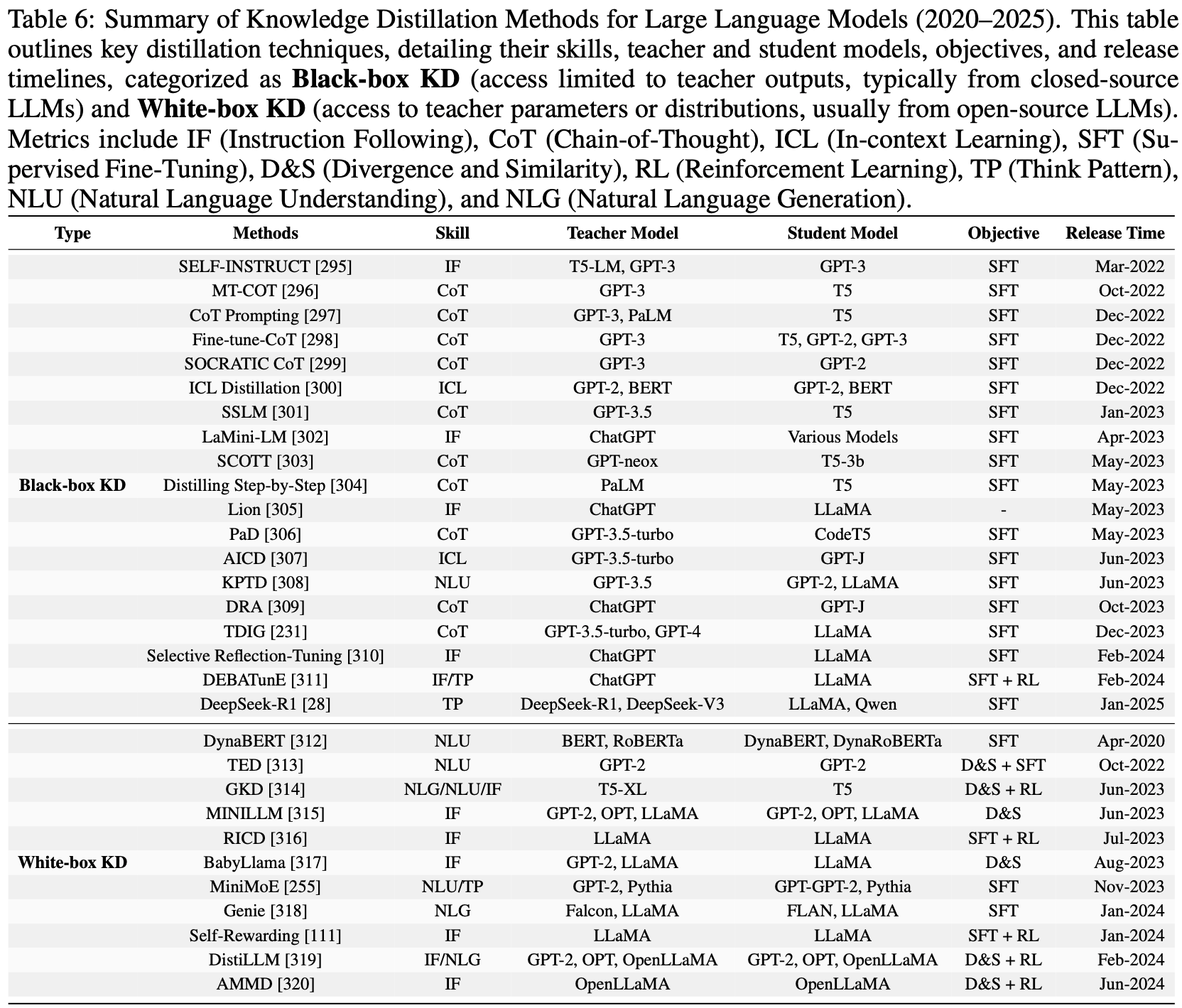
- 基于 EverGreenQA ,论文评估了 12 个现代大语言模型,判断它们是否通过显式(直接提示,through direct prompting)或隐式(基于不确定性的信号,via uncertainty-based signals)方式编码时间性知识
- 此外,论文还开发了 EG-E5 ,一个轻量级的,截止到当前最优的分类器,用于识别常青问题
- 论文展示了 EG-E5 在多个下游任务中的实用性:
- (1)改进自我知识估计
- (2)筛选问答数据集以支持更公平的评估
- (3)有效解释 GPT-4o 的黑盒检索行为
- 论文的贡献和发现如下:
- 1)构建了 EverGreenQA ,首个用于问题常青性分类的多语言数据集,涵盖 7 种语言,共 4,757 个样本
- 2)首次全面评估了大语言模型对问题常青知识的掌握情况,通过显式信号(提示)和隐式信号(不确定性估计)评估了 12 个模型
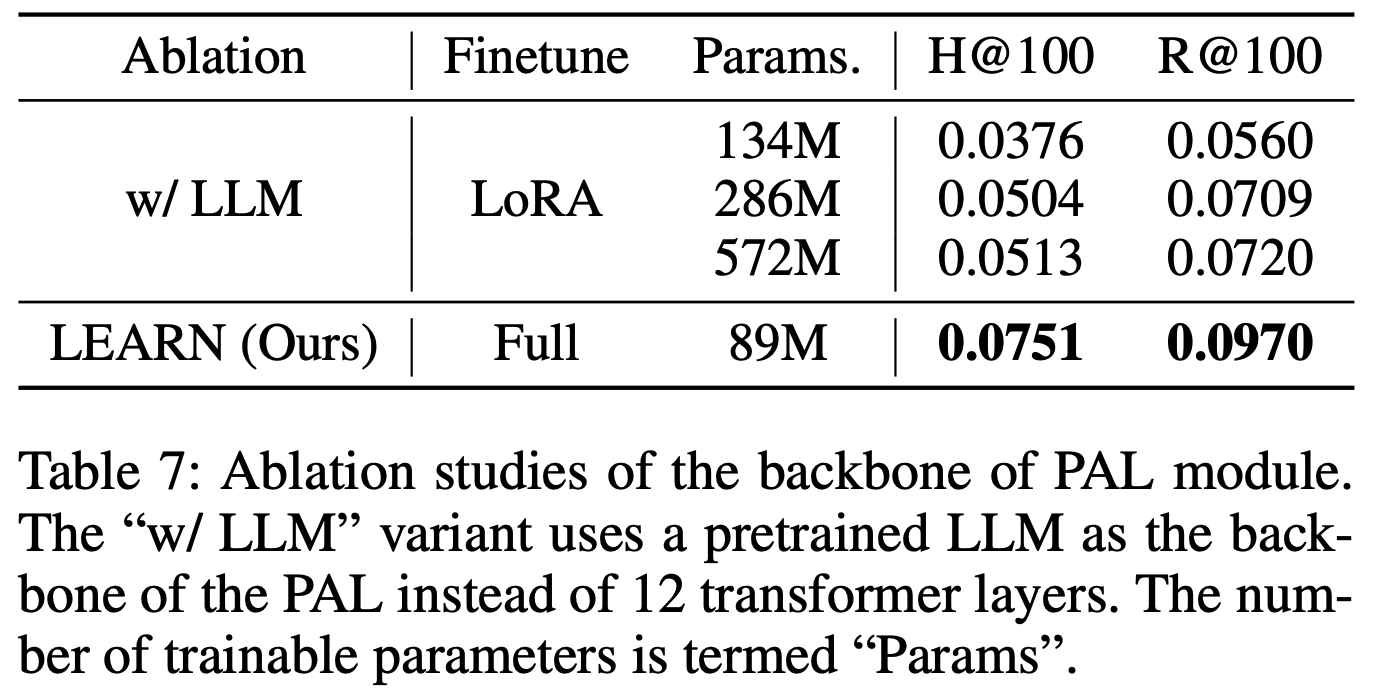
- 3)开发了 EG-E5 ,一个轻量级多语言分类器,用于识别常青问题,在此任务上达到当前最优性能,同时适用于低计算资源场景
- 4)展示了 EG-E5 在三个应用中的价值:
- (1)改进自我知识估计
- (2)筛选问答数据集以实现更公平的评估
- (3)有效解释 GPT-4o 的检索行为
- 论文发布了模型和数据以供进一步使用
EverGreenQA & EG-E5
Dataset Collection
- 论文构建了一个问答数据集,包含来自 AI 聊天助手的真实用户查询,每个问题标注为常青或可变,并提供对应的标准答案
- 所有问题均为事实性问题,并通过多轮内部 alpha 测试(internal alpha testing)手动验证以确保多样性和减少主题偏差
- 理解:Alpha Testing(α测试) 是软件开发过程中一种重要的内部测试阶段,主要用于在产品正式发布前,由开发团队或内部相关人员对软件进行系统性测试,目的是发现并修复主要的功能缺陷、性能问题和用户体验漏洞
- 补充:alpha 测试 和 beta 测试的区别如下:
维度 Alpha Testing Beta Testing 测试人员 内部团队/员工 外部真实用户 环境 开发/模拟环境 接近真实的生产环境 目的 修复核心缺陷,验证基本功能 收集用户反馈,优化体验 阶段 早于Beta,接近开发完成 晚于Alpha,接近正式发布
- 标签和标准答案由训练有素的语言学家团队手动分配,他们根据检索到的信息从头编写答案
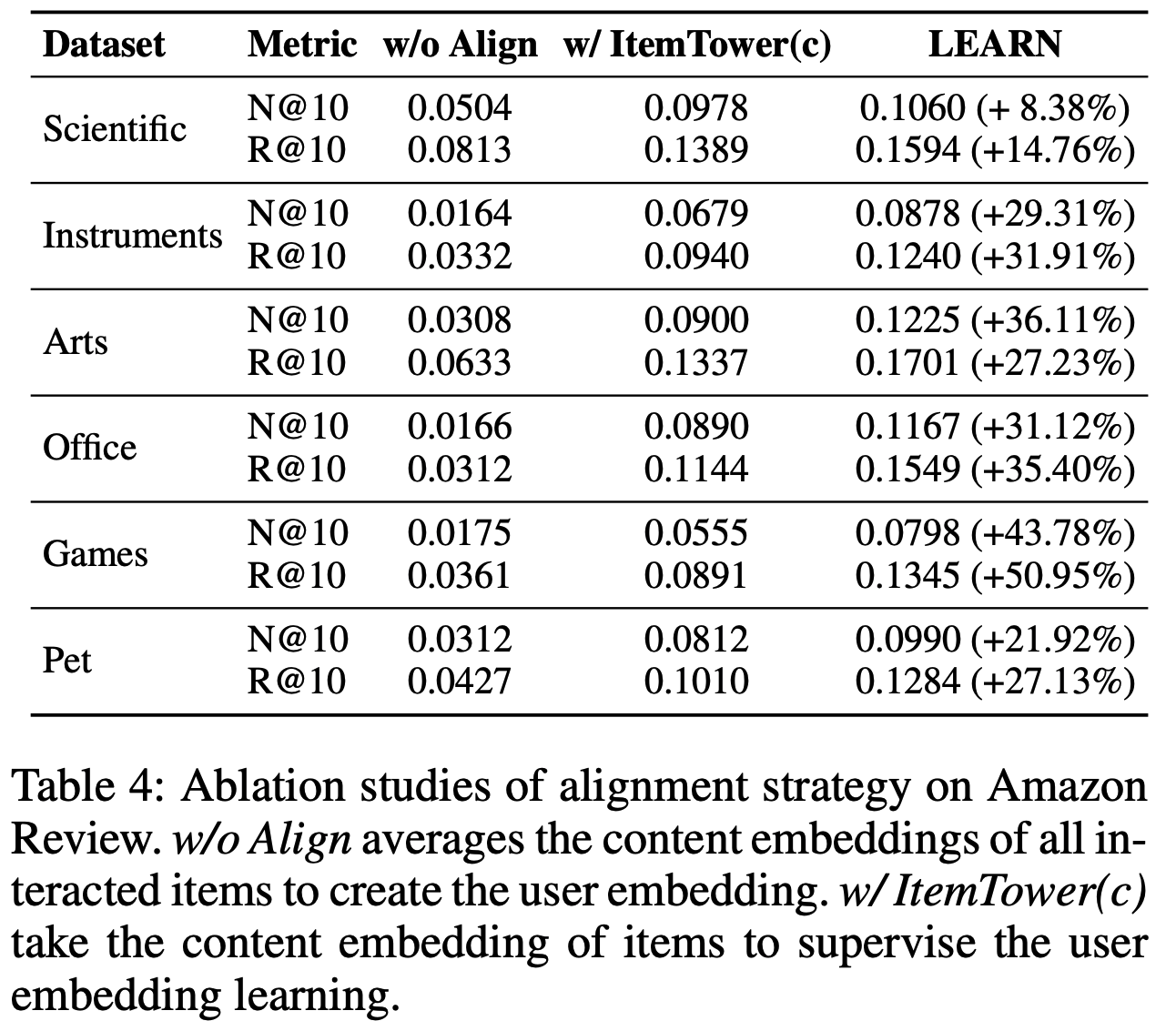
- 由于初始数据集中大多数问题为可变问题,为避免训练数据偏差,论文还生成了 1,449 个仅针对常青类的合成数据(这些附加数据同样经过语言学家验证)
- 最终数据集包含 4,757 个问题,其中 3,487 个用于训练,1,270 个保留用于测试
- 数据集构建和标注的详细信息见附录 F
Dataset Translation
- 论文使用 GPT-4.1 将问题从俄语翻译为英语,再从英语翻译为目标语言
- 此前研究表明,GPT-4.1 在多种语言(包括准确处理文化差异)上表现优异(2024)
- 完整翻译提示见附录 B
Dataset Validation
- 为评估翻译质量,论文为每种目标语言招募了人类评估员,均为母语者或具备高级语言水平(B2-C1 级)
- 论文从测试集中随机抽取 100 个问题(50 个可变,50 个常青)进行评估
- 英语、希伯来语、德语和阿拉伯语的翻译未发现错误,中文仅有两处轻微不准确
- 评估员指导见附录 C
EG-E5 Training
- 论文使用多语言数据集进行训练和测试
- 对于验证,论文使用了 FreshQA(2024)的开发集和测试集,将其快速变化和慢速变化类别合并为可变标签
- 为与多语言设置一致,FreshQA 数据被翻译为所有目标语言
- 论文尝试了多语言版本的 BERT(2019)、DeBERTaV3(2023)和 E5(2024)作为编码器
- 最佳性能由 E5-Large 模型实现,论文将其称为分类器 EverGreen-E5 (EG-E5)
- 超参数细节和消融实验结果见附录 A
Are LLMs Aware of Evergreenness?
- 在本节中,论文评估现代 LLM 是否能可靠地判断一个问题是否为常青问题(evergreen)
- 论文测试了12种不同架构的 LLM,完整细节见附录A
/EverGreenQA-Table10.png)
Verbalized Evergreen Awareness
- 为了评估LLM是否能显式识别常青问题,论文通过提示(prompting)让每个模型给出二元的“是/否”答案
- 论文还纳入了两种专门训练的方法:
- UAR (2024):一种基于 LLaMA2-13B 微调的模型,用于分类常青问题
- MULAN (2024):基于维基数据(Wikidata)中可变(mutable)和常青样本的分类器
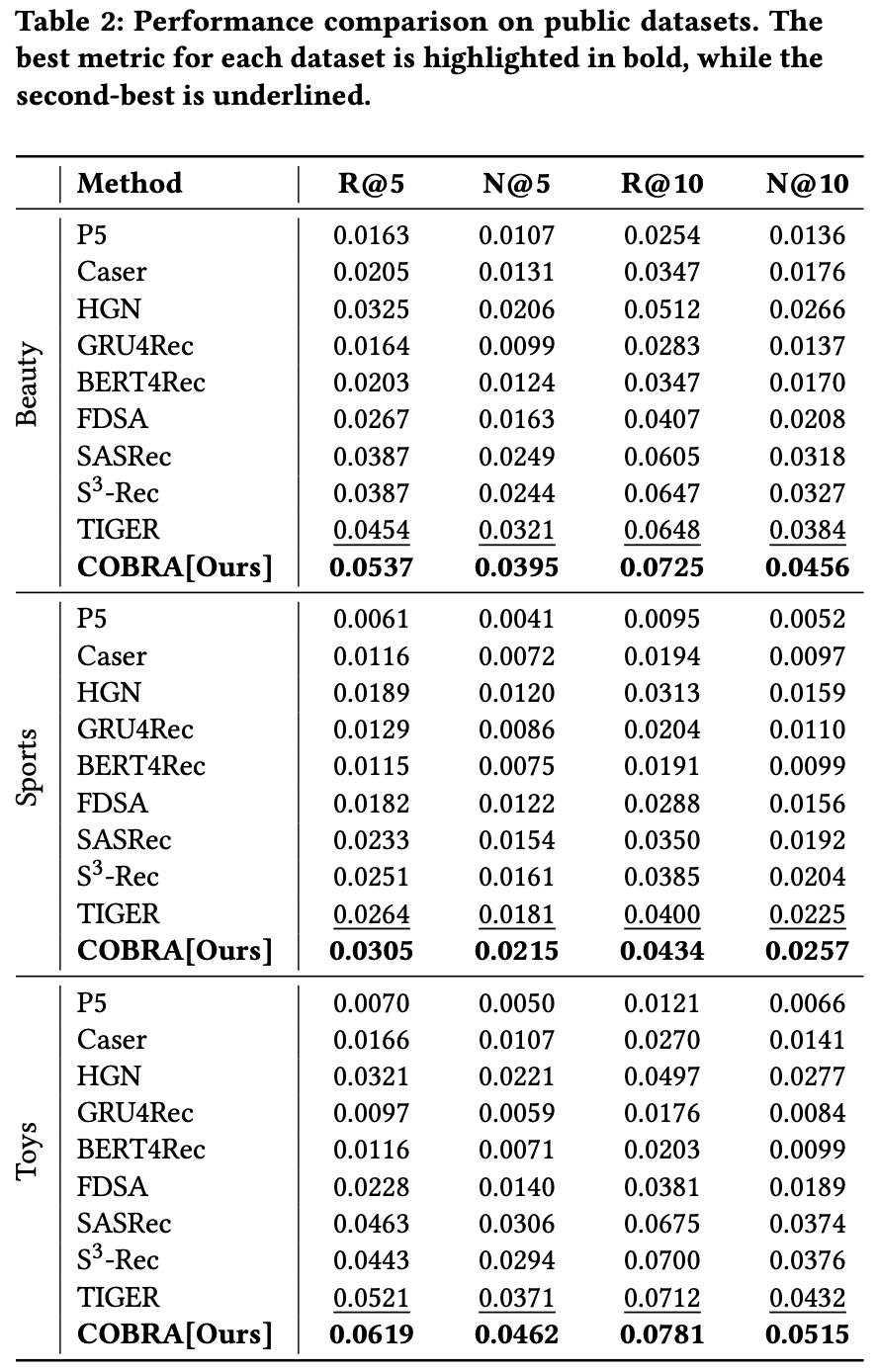
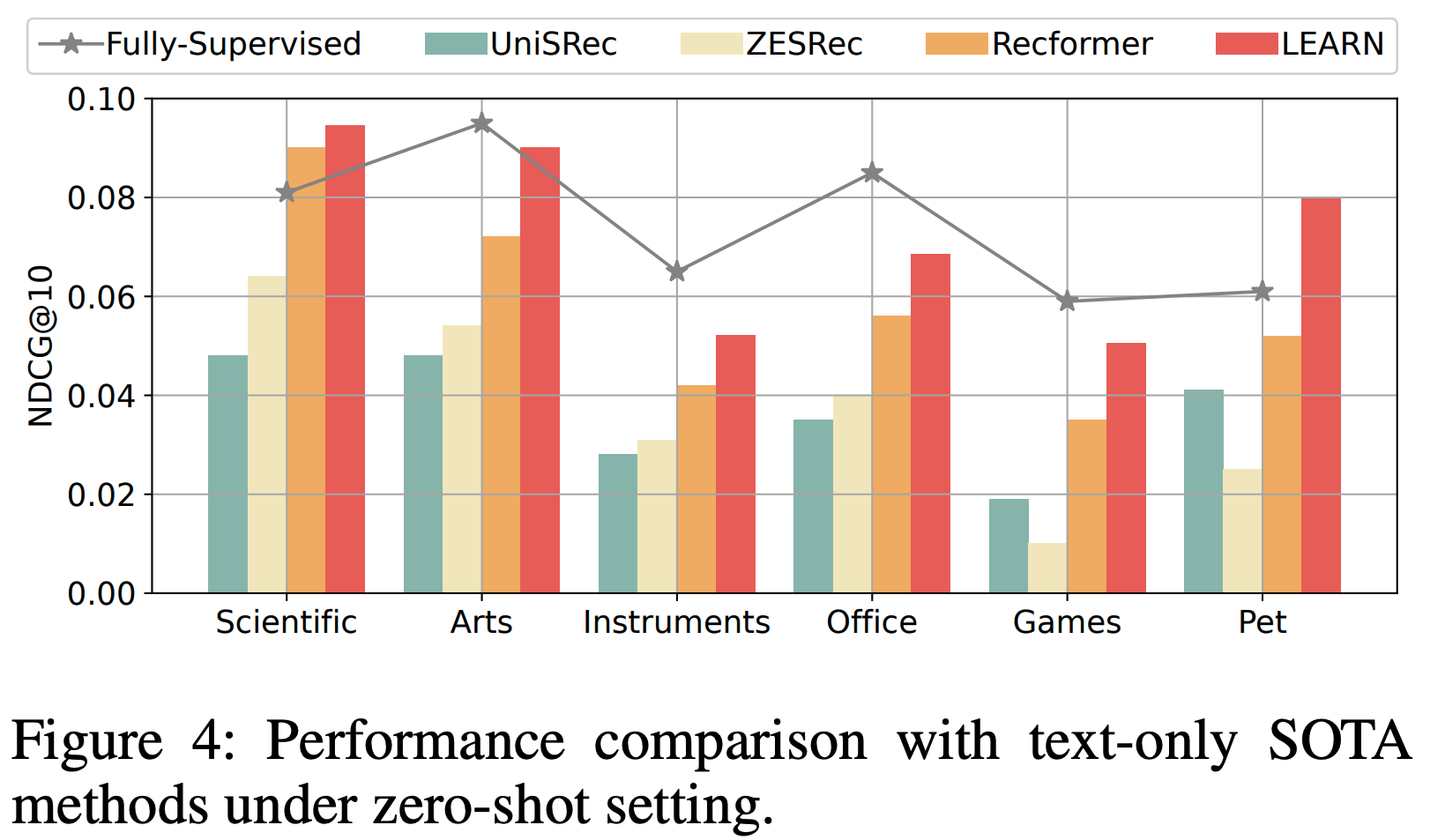
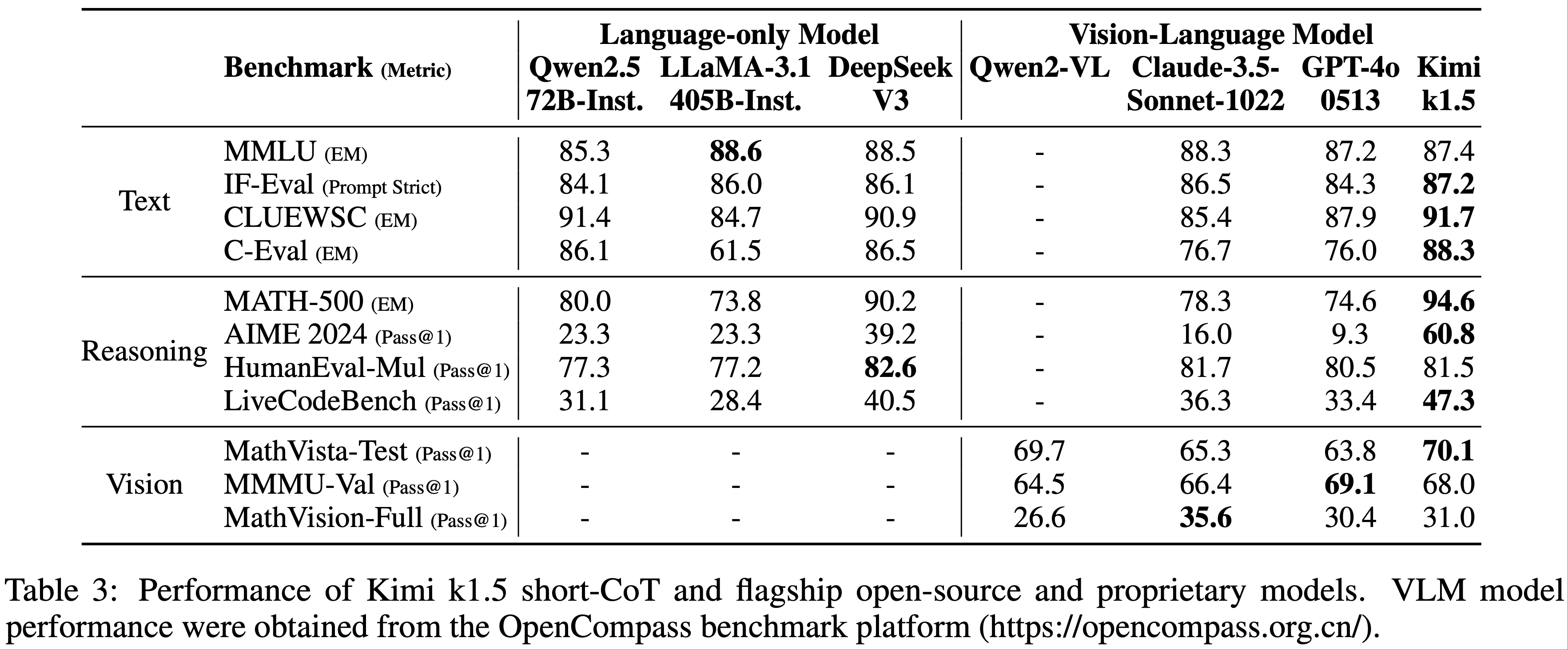
- 结果 :表2显示,论文提出的分类器 EG-E5 在所有语言中均表现最佳,显著优于通用LLM和专门训练的模型
- 在LLM中,LLaMA 3.1 70 和 Qwen 2.5 32B 表现最强,GPT-4.1稍逊一筹
/EverGreenQA-Table2.png "注:加权 F1 值通常是对每个类别的 F1 值进行加权平均,权重通常是每个类别的样本数量")
- 在LLM中,LLaMA 3.1 70 和 Qwen 2.5 32B 表现最强,GPT-4.1稍逊一筹
- 论文观察到不同语言的性能存在差异,但无明显差距,即使对于非拉丁语系(如阿拉伯语、中文、俄语)也是如此
- 基线方法 UAR 和 MULAN 的表现远逊于 LLM 和 EG-E5,这可能是因为它们对 QA 数据集的常青性假设过于简化
- Takeaway:EG-E5 超越了 few-shot LLMs 和之前的方法,这些方法较差原因是他们训练数据中包含非真实的假设
Internal Evergreen Awareness
- 论文进一步通过不确定性估计(uncertainty estimation)评估 LLM 是否隐式编码了问题的常青性信息
- 论文从测试集中抽样 400 个问题(200 个常青,200 个可变),并采用两种广泛使用的不确定性度量方法 (2024; 2025):
- 困惑度(Perplexity) :预测序列的逆概率,按长度归一化。对于 Token 序列 \(x_{1},\ldots,x_{T}\),定义为:
$$
\text{PPL} = \exp\left(-\frac{1}{T}\sum_{t=1}^{T}\log p(x_{t}\mid x_{ < t})\right)
$$ - 平均 Token 熵(Mean Token Entropy) :模型预测 Token 分布的平均熵:
$$
\text{Entropy} = -\frac{1}{T}\sum_{t=1}^{T}\sum_{w\in V}p_{t}(w)\log p_{t}(w)
$$- 其中 \(p_{t}(w)\) 是位置 \(t\) Token \(w\) 的预测概率,\(V\) 是词汇表
- 困惑度(Perplexity) :预测序列的逆概率,按长度归一化。对于 Token 序列 \(x_{1},\ldots,x_{T}\),定义为:
- 结果 :表3显示,大多数模型的不确定性与常青性仅呈现弱相关性(mild correlations),其中 Mistral 7B 和 Qwen 2.5 32B 的信号最强
/EverGreenQA-Table3.png "表3展示的数字是常青性(EG)和不确定性(UC,困惑度和熵越大越不确定)的相关性,数字越大越相关")
- 论文还发现一个微弱趋势:
- 更大规模的模型,(不确定性与)常青性的相关性更强,可能表明其对时间线索的内部依赖更强
- 困惑度和熵的表现无显著差异
- 总体而言,不确定性信号能捕捉部分时间信息 ,但明显弱于显式表达的判断
- 更多分析见附录E
- Takeaway:不确定性指标编码了常青性中的弱且不一致的信号,且在更大的模型中有微弱更强的趋势
Enhancing Self-Knowledge
- 本节评估结合问题常青性知识是否能改进自我知识(self-knowledge)估计,即模型识别自身知识边界并判断能否回答问题的能力 (2025; 2023)
- 这一能力被视为提升 LLM 可信度的关键因素
Task formulation
- 论文将自我知识估计定义为二分类任务,目标标签 \(y\in\{0,1\}\) 表示模型对输入 \(x\) 的答案是否正确
- 每种评估方法为输入分配一个实值自我知识分数 \(f(x)\in\mathbb{R}\)
Methods
- 论文使用 LLaMA3.1-8B-Instruct 和五种广泛采用的高性能不确定性估计器进行评估,这些方法代表不同的不确定性量化家族(如基于 logit 和一致性的方法):
- 最大 Token 熵(Max Token Entropy) :计算 Token-level 熵并取序列最大值作为最终分数 (2020)
- 平均 Token 熵(Mean Token Entropy) :类似上述方法,但通过平均 Token-level 熵值聚合序列 (2020)
- 词汇相似性(Lexical Similarity) :通过计算多响应间的平均词汇重叠估计不确定性,作为输出一致性的代理 (2020)
- SAR :结合熵与语义重要性加权,对序列调整后的熵值求和 (2023)
- EigValLaplacian :构建响应相似图,计算其拉普拉斯矩阵特征值和以量化响应多样性 (2023)
- 对于每种方法,论文评估结合常青问题预测概率(来自EG-E5分类器)的效果
- 最终自我知识分类器 \(f(x)\) 的训练使用标准机器学习模型,输入特征为不确定性估计指标(若适用则加入常青概率)
- 标准分类模型,包括:包括随机森林,决策树等
- 完整训练流程见附录D
Evaluation
- 论文采用文献中广泛使用的标准指标 (2024; 2025):
- AUROC :衡量模型基于 \(f(x)\) 区分正确答案与错误答案的能力,值越高表示可分性越强
- AUPRC :量化不同决策阈值下精确率与召回率的权衡,对不平衡数据集尤为重要
- 预测拒绝率(Prediction Rejection Ratio, PRR) :模拟拒绝最不确定的响应,追踪平均质量的提升,值越高表示不确定性与答案正确性的校准越好
Datasets
- 论文在 6 个 QA 数据集上评估方法,涵盖单跳(single-hop)和多跳(multi-hop)推理
- 单跳数据集包括 SQuAD v1.1 (2016)、Natural Questions (2019) 和 TriviaQA (2017),多跳数据集包括 MuSiQue (2022)、HotpotQA (2018) 和 2WikiMulti-HopQA (2020)
Results
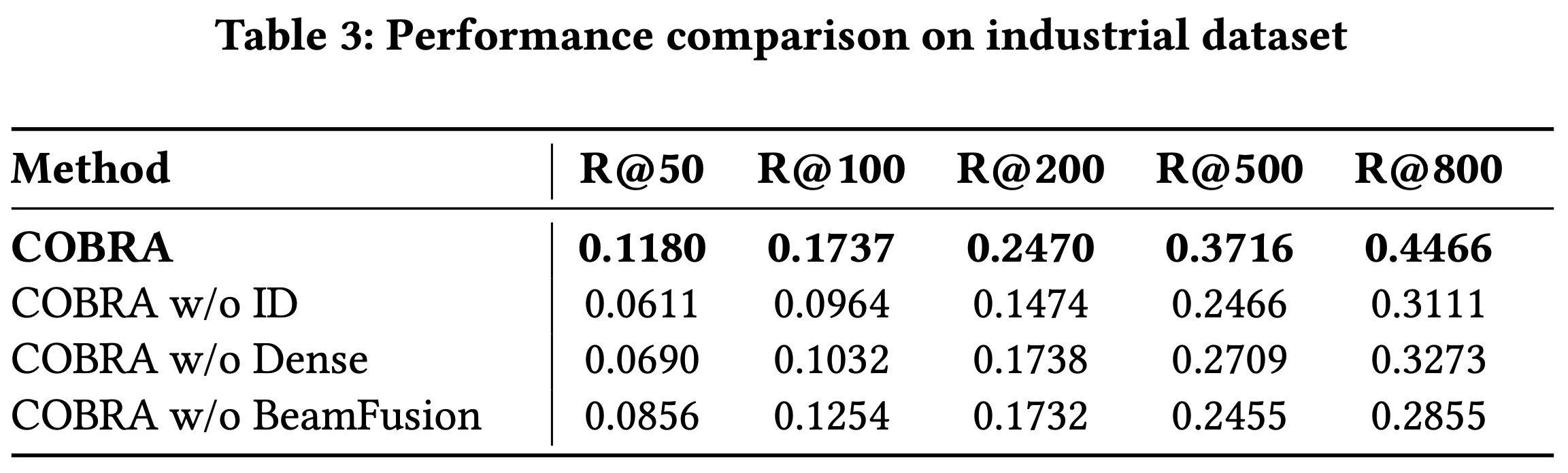
- 如表 4 所示,常青概率是改进自我知识识别的强信号
/EverGreenQA-Table4.png)
- 在 18 项评估中,16 项的最佳结果由常青特征单独或结合不确定性估计方法取得
- 此外,它能改进校准(PRR),对实际应用极具价值
- 值得注意的是,常青特征在 AUPRC 上表现突出,在 4 个数据集中排名第一,表明常青性是模型是否具备可靠知识的强指标
- 然而,论文也发现一致模式:常青性在 AUPRC 上得分高,但在 AUROC 上较低
- 这表明该特征虽能有效识别模型“知道答案”的情况,但对“不知道答案”的判别较弱(真阴性区分能力不足)
- 换言之,若问题是常青的,模型很可能正确回答;但若问题非常青,结果更难预测
- Takeaway:常青概率持续提升 self-knowledge 评估和校准(calibration),在 18 个设定下实现了 16 个 top 结果
- 问题:本节的 自我知识分类器 \(f(x)\) 的特征和 label 是什么?训练后的 \(f(x)\) 用来做什么?
Filtering QA with Evergreen
- 在本节中,论文展示了 Evergreen 分类在过滤 QA 数据集中的价值,通过排除可变问题(mutable questions),可以实现更公平的评估
- 论文使用了与第 5 节“自我知识”相同的模型设置
- QA 数据集理想情况下应仅包含 Evergreen 问题,这一点在 SimpleQA (2024a) 中得到了强调
- 为了实现这一目标,SimpleQA 依赖于人工标注者评估问题的 Evergreen 性
- 相比之下,EG-E5 支持自动化数据集整理,无需手动标注,从而促进了大规模 QA 语料库的构建
Popular QA Datasets Analysis
- 可变问题对公平的 QA 评估提出了严峻挑战:
- 过时的黄金答案(outdated gold answers)可能导致现代 LLM 的正确回答被误判为错误,尤其是在模型在不同时间被评估时
- 示例 :表 5 展示了六个数据集(见第 5.4 节)中的可变问题示例,这些问题的答案在 2025 年已与原参考答案不同
- 这些示例包括简单和复杂的查询,甚至来自最近发布的数据集如 MuSiQue (2022)
- 变化的性质多样:有些是可预测的(如奥运会主办城市、人口数据),有些是偶发的(如职位名称或配偶),还有一些是意外的(如君主、GDP 排名)
/EverGreenQA-Table5.png)
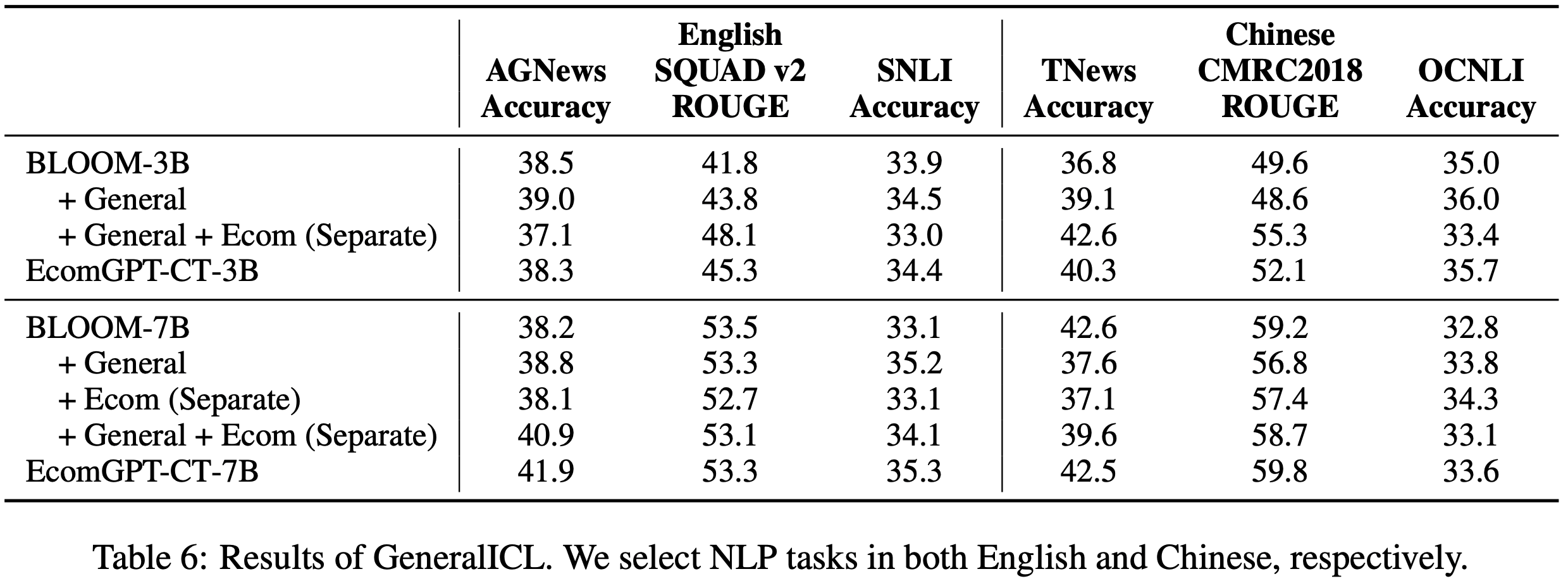
- 统计数据 :表 6 显示,可变问题仍然普遍存在,在 NQ 中占比高达 18%,平均占数据集的 10%
- 这一现象挑战了 QA 基准具有时间稳定性的普遍假设,并引发了对评估公平性的担忧
- 为确保可靠性,可变问题应被过滤掉,或者需要维护实时基准如 RealTimeQA (2024),尽管后者成本较高
/EverGreenQA-Table6.png)
- 错误的假设 :UAR (2024) 隐含假设数据集具有 Evergreen 性,而 MULAN (2024) 将许多问题视为不可变,但实际上某些关系(e.g., Wikidata’s P190, “sister cities”)可能会变化
- 这种不匹配可能解释了这些方法在面对时间漂移时实际效果有限的原因
- Takeaway:QA 基准包含可变问题,破坏了评估的公平性。过滤这些问题对可靠性评估非常重要
Filtered QA Performance
- 零样本性能 :如表 6 所示,模型在 Evergreen 问题上的准确率始终更高,在复杂任务中的相对差异高达 40%
- 这与预期一致,因为可变问题通常需要模型静态知识之外的实时信息
- RAG 的优势 :论文展示了模型在回答可变问题时通常更能从带有黄金上下文的 RAG 中受益,相对增益高达 30%
- 然而,在可变问题样本较少的数据集中,这种效果会减弱
Explaining GPT-4o Retrieval
- GPT-4o 通过内部的黑盒标准自主决定何时调用其检索系统
- 论文发现,问题的 Evergreen 性是这种行为的最强预测因子,这表明 GPT-4o 对外部搜索的使用与输入的时间性质密切相关
- 论文使用了与第 4.2 节相同的子集,并通过其网络接口查询 GPT-4o,记录是否触发了检索调用
- 除了 Evergreen 标签外,论文还评估了第 4.2 节中的几种基于不确定性的信号以及 EG-E5 ,以评估它们与 GPT-4o 检索决策的相关性
- 如表 7 所示,Evergreen 性和 EG-E5 预测比任何基于不确定性的信号都强得多(信息量是后者的两倍以上)
/EverGreenQA-Table7.png)
- 这表明 GPT-4o 可能在内部建模问题的时间性,或者其检索策略对时间性高度敏感
- Takeaway:常青性是 GPT-4o 的检索行为中最强的预测者(Predictor),表明检索和时序是强相关的
Error Analysis
- 论文从 EverGreenQA 数据集的测试部分中选取了样本,并对 EG-E5 分类器的错误进行了定性分析
- 表 8 展示了按原因分组的假阳性和假阴性示例
- 值得注意的是,分类器在涉及最高级表达时表现出较高的不确定性,有时将其标记为易变的,而其他时候则将“最”“最大”或“最健康”等趋势敏感短语误解为普遍固定的
/EverGreenQA-Table8.png)
- 值得注意的是,分类器在涉及最高级表达时表现出较高的不确定性,有时将其标记为易变的,而其他时候则将“最”“最大”或“最健康”等趋势敏感短语误解为普遍固定的
- 其他错误包括将活人的成就误分类为已故,以及错误地将稳定的地理或生物事实视为时间敏感的
- 有趣的是,假阴性的数量是假阳性的两倍
- 这表明分类器在判断问题是否涉及稳定事实时更为谨慎
- 在某些情况下,外部信息至关重要
- 例如,如果一个人已去世,所有关于他的问题都将是 Evergreen 的,但模型需要知道该人是否仍在世
- 类似地,关于最近年份(如 2023-2024)的问题也带来了挑战,因为模型缺乏对当前日期的感知
- 在其他情况下,模型在组织和区分其知识方面还有改进空间
- 例如,学习区分真正稳定的物理事实(如列支敦士登的面积)和更易变的事实(如天空中最亮的恒星),或区分已完成的历史事件(如法国大革命)和正在发展的动态(如即将举行的总统选举)
- 更多示例见附录 G
补充:Related Work
- 时间推理在问答任务中仍是一个基础性挑战,因为时间动态性常常使问题解释和答案检索变得复杂
- 时间敏感的问答任务得益于如 TimeQA(2021)等数据集的改进,该数据集包含 20,000 个需要时间推理的问题-答案对
- 尽管有帮助,但它仅涉及简单推理
- SituatedQA(Zhang 和 Choi,2021)通过将问题置于时间和空间上下文中,展示了语境的重要性
- StreamingQA 强调了时间适应的必要性,揭示了大语言模型在跟踪变化事实时的困难(2022)
- TemporalAlignmentQA (TAQA) (2024)通过提供 2000 年至 2023 年每年 20,000 个时间敏感问题及其答案,进一步增强了时间对齐的可能性
- MuLan(2024)根据变化率和事实类型对问题进行了区分
- FreshQA(2024)提出了一个专注于新鲜度敏感信息的基准,进一步说明了大语言模型在处理时间动态知识时的局限性
- 这些研究表明需要专门的时间推理方法(2024)
- 表 1 展示了数据集的对比
/EverGreenQA-Table1.png)
- 时间敏感的问答任务得益于如 TimeQA(2021)等数据集的改进,该数据集包含 20,000 个需要时间推理的问题-答案对
- 检索增强生成(RAG)方法,如 DRAGIN(2024)、IRCoT(2023)或 Rowen(2024),通过动态检索决策解决了时间敏感问答问题,但效果有限
- 动态检索决策需要自我知识估计
- 在问答系统被信任之前,它们需要知道自己不知道什么
- 大语言模型通常难以识别无法回答的问题(2023),但利用自我知识(self-knowledge)可以减少需要大量知识的任务中的错误(2023;2025)
- 问题:这里的 self-knowledge 是什么?是模型自己的内容知识吗?
- 基于检索的方法从外部解决了时间知识缺口(temporal knowledge gaps externally),另一种方向是更新大语言模型的内部知识
- 更新大语言模型的内部知识计算成本高昂,因为重新训练或编辑模型通常需要大量资源,且无法在实际中每天或每小时执行
- 诸如 LLM Surgery(2024)和参数高效微调(2024;2025)等技术试图使此类更新更实用,但仍面临大规模变更或事实幻觉的问题
Limitations
- 尽管论文的 EverGreenQA 数据集是首个多语言、人工标注的常青性基准测试,但其规模仍相对较小(3,278 个示例)
- 不过,它覆盖了 7 种语言的高质量数据,足以揭示模型行为的明确趋势
- 虽然论文涵盖了 7 种语言,但数据集并未覆盖所有主要语系,且在低资源语言环境中的表现仍有待探索
- 尽管如此,论文的选择包括了拉丁和非拉丁文字,能够进行有意义的多语言评估
- 论文对大语言模型的评估涵盖了 14 个不同规模和家族的模型,但主要聚焦于每个规模层级的代表性模型
- 扩展到更多指令调优或领域适配的变体可能会进一步推广研究结论
- 在基于不确定性的分析中,论文聚焦于五种代表性指标
- 尽管这些指标被广泛使用且足以得出强有力的结论,但引入更多最新或任务特定的指标可能会提供更多洞见
- 论文训练的常青分类器表现优异,但仅对其架构、训练过程和辅助数据的使用进行了有限的消融实验
- 探索更多模型变体或迁移学习策略可能会进一步提升鲁棒性
- 最后,尽管论文展示了常青分类的几种实际用途,但并未探索其在主动学习(active learning)、答案校准(answer calibration)或搜索重排序(search reranking)等任务中的潜力
- 这些有前景的方向留待未来工作
附录A Evergreen Testing Details
LLM 的文本参数
- 每个示例包含 5 个可变(mutable)和 5 个不可变(immutable)的样本
- 对于 LLaMA 3.1,采样参数如下:
- 温度(temperature)= 0.7
- top_p = 0.9
- 对于 Qwen 2.5:
- 温度 = 0.6
- top_p = 0.95
- top_k = 20
- min_p = 0
分类器参数
- 分类器模型训练参数如下:
- 所有模型训练了10个周期(epoch)
- 采用早停(early-stopping)策略
- 学习率(lr)= 4.6e-5
- 批量大小(batch size, bs)= 16
- 未使用额外数据集
- 论文为所有语言训练了一个统一模型
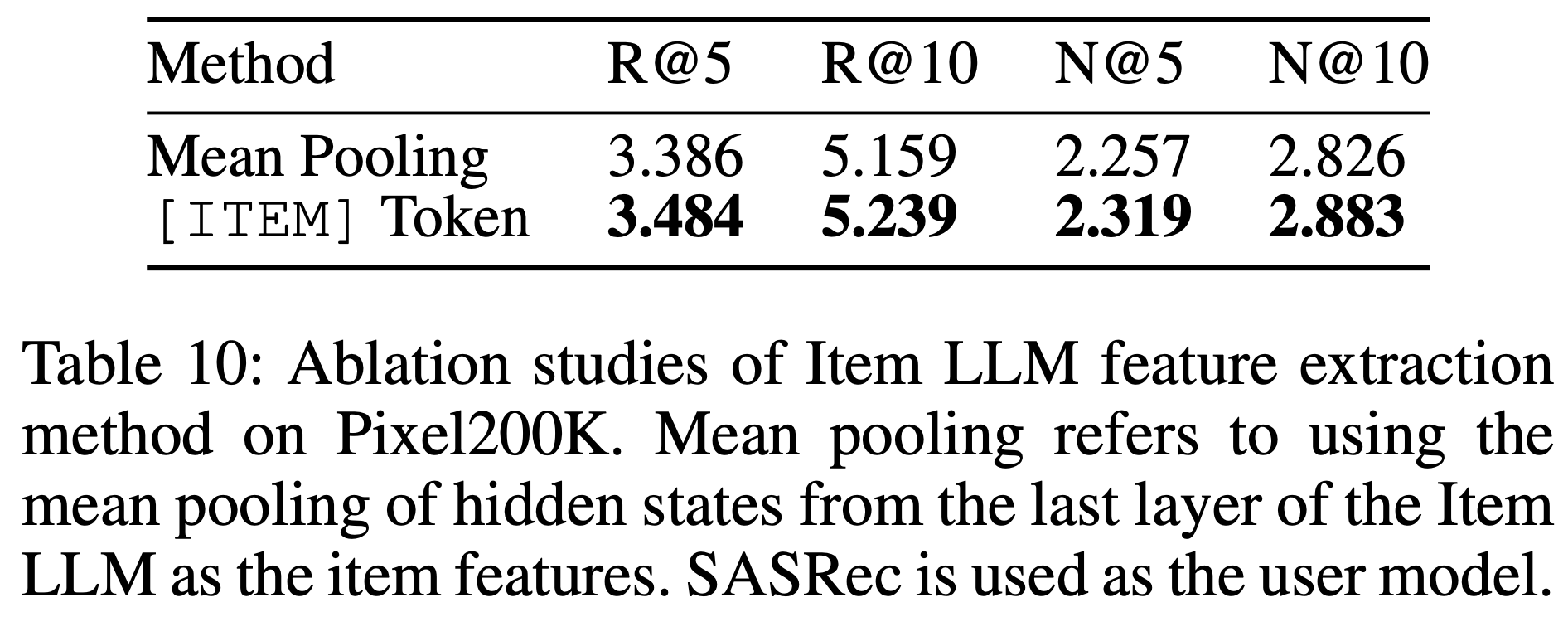
- 如表10 所示,multilingual-e5-large-instruct 表现最佳
- Evergreen Verbal Instruction
You are a helpful assistant. You help user to classify the questions based on the tem- porality. There are two classes: immutable and mutable. Immutable, in which the an- swer almost never changes. Mutable, in which the answer typically changes over the course of several years or less. Think about each question and in the end answer with Mutable or Immutable starting with ’Classi- fication:’
附录B Translation Prompt
- 翻译验证指令(Translation Validation Instruction) :将以下英文文本翻译为法语、德语、希伯来语、阿拉伯语和中文。以JSON格式提供翻译结果,键名为“French”、“German”、“Hebrew”、“Arabic”和“Chinese”
- Translation Validation Instruction :
Translate the following English text into French, German, Hebrew, Arabic and Chi- nese. Provide the translations as a JSON object with keys ’French’, ’German’, ’He- brew’, ’Arabic’, ’Chinese’.
- 论文使用GPT-4.1,温度参数(temperature)= 0.2,并添加标签
"response_format": "json_object"
附录C Validation Instructions
- 验证指令 :对每个翻译的问题,根据以下标准打分:
- 0 :翻译包含扭曲原意的错误
- 1 :翻译包含不影响整体含义的轻微错误
- Translation Validation Instruction:
For each translated question, assign a score according to the following criteria:
• 0 – the translation contains errors that distort the meaning.
• 1 – the translation contains minor er- rors that do not affect the overall mean- ing.
附录D Classifier for Self-Knowledge
- 论文探索了七种分类模型(使用scikit-learn (2013) 和CatBoost (2020)):
- 逻辑回归(Logistic Regression)
- k近邻(k-Nearest Neighbors)
- 多层感知机(Multilayer Perceptron)
- 决策树(Decision Tree)
- 随机森林(Random Forest)
- 梯度提升(Gradient Boosting)
- CatBoost
- 所有模型均使用标准化特征(StandardScaler)训练,超参数在训练数据的 100 个示例子集上优化,并在每个数据集上重复三次实验以确保鲁棒性
- 最终评估时,论文选择验证集上表现最佳的两个模型,使用 VotingClassifier 将其组合为软投票集成(soft-voting ensemble)
- 每个组件模型均使用调优后的超参数在全训练集上重新训练
超参数网格
- 逻辑回归 :C: [0.01, 0.1, 1],求解器(solver): [lbfgs, liblinear],类别权重(class_weight): [balanced, 0:1, 1:1, None],最大迭代次数(max_iter): [10000, 15000, 20000]
- k近邻 :n_neighbors: [5, 7, 9, 11, 13, 15],距离度量(metric): [euclidean, manhattan],算法(algorithm): [auto, ball_tree, kd_tree],权重(weights): [uniform, distance]
- 多层感知机 :隐藏层大小(hidden_layer_sizes): [(50), (100), (50,50), (100,50), (100,100)],激活函数(activation): [relu, tanh],求解器: [adam, sgd],alpha: [0.00001, 0.0001, 0.001, 0.01],学习率(learning_rate): [constant, adaptive],早停(early_stopping): True,最大迭代次数: [200, 500]
- 决策树 :最大深度(max_depth): [3, 5, 7, 10, None],最大特征数(max_features): [0.2, 0.4, sqrt, log2, None],分裂标准(criterion): [gini, entropy],分裂器(splitter): [best, random]
- CatBoost :迭代次数(iterations): [10, 50, 100, 200],学习率: [0.001, 0.01, 0.05],深度(depth): [3, 4, 5, 7, 9],bootstrap类型(bootstrap_type): [Bayesian, Bernoulli, MVS]
- 梯度提升 :n_estimators: [25, 35, 50],学习率: [0.001, 0.01, 0.05],最大深度: [3, 4, 5, 7, 9],最大特征数: [0.2, 0.4, sqrt, log2, None]
- 随机森林 :n_estimators: [25, 35, 50],最大深度: [3, 5, 7, 9, 11],最大特征数: [0.2, 0.4, sqrt, log2, None],bootstrap: [True, False],分裂标准: [gini, entropy],类别权重: [balanced, 0:1, 1:1, None]
附录E Predictive Analysis of Uncertainty for Temporality
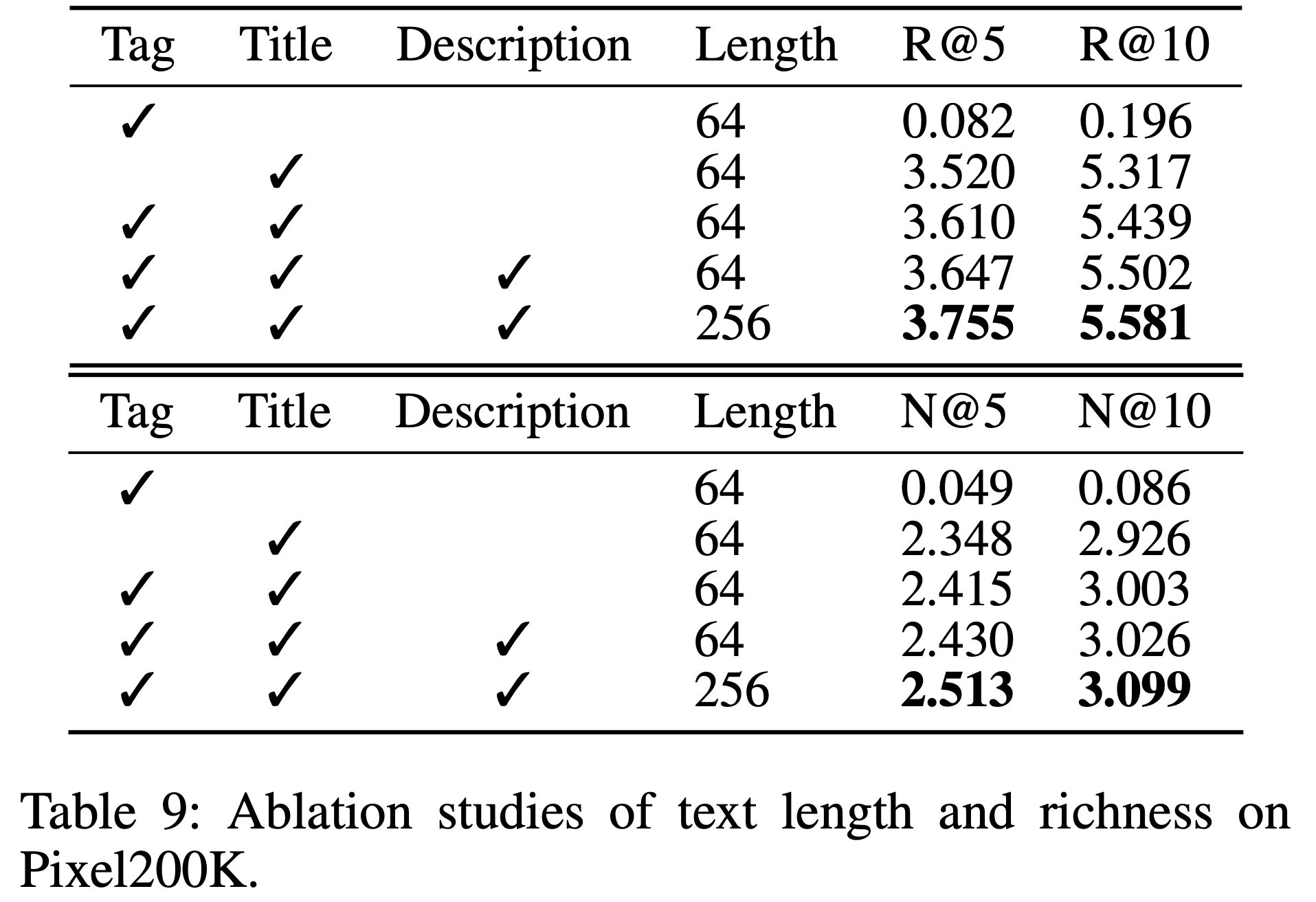
- 表9 报告了逻辑回归模型的 McFadden’s pseudo-\(R^2\) value , 该模型基于两种不确定性指标(困惑度(perplexity)和平均 Token 熵(mean token entropy))预测问题是否为常青(evergreen)
- 注:McFadden’s pseudo-\(R^2\) value 即麦克法登伪 \(R^2\) 值,是一种用于评价非线性模型,特别是逻辑回归模型等定性选择模型拟合优度的指标。该指标的取值范围是从 0 到小于 1,其值越接近 0,表明模型没有预测能力;值越接近 1,说明模型对数据的拟合效果越好,即模型能够解释因变量的变异程度越高
/EverGreenQA-Table9.png)
- 注:McFadden’s pseudo-\(R^2\) value 即麦克法登伪 \(R^2\) 值,是一种用于评价非线性模型,特别是逻辑回归模型等定性选择模型拟合优度的指标。该指标的取值范围是从 0 到小于 1,其值越接近 0,表明模型没有预测能力;值越接近 1,说明模型对数据的拟合效果越好,即模型能够解释因变量的变异程度越高
- 大多数模型的伪 pseudo-\(R^2\) 值低于 0.07,表明不确定性对常青分类的预测能力有限
- 唯一例外是 Phi-3-medium (128k),其困惑度得分最高(0.137),表明长上下文训练可能改善时间性不确定性的编码,但仍非常有限
- 两种不确定性指标无显著优劣,模型大小与预测性能也无明确相关性
- 结果表明,不确定性指标仅能捕捉有限的时间性信号,适合作为辅助特征而非独立预测器
附录F Dataset Collection Details
- 负责标注常青和可变标签(evergreen/mutable)及生成标准答案(golden answers)的语言学家团队均持有语言学学士以上学位,确保标注质量
- 每阶段标注均通过团队负责人验证以保证一致性
- 此外,为支持多样化应用,所有答案均转换为别名集合,具体流程见附录F.4
- 标注人员薪酬符合当地法规(注:这也太谨慎了)
Golden Answers Annotation
- 标准答案需完整且对用户有用
优质答案示例
- 问题 :谁被视为物理学的奠基人?
- 答案 :艾萨克·牛顿(Isaac Newton)被广泛认为是物理学的奠基人
- 注释 :问题为单数形式,而根据多数来源,牛顿是经典物理学的奠基人。尽管伽利略和笛卡尔也有贡献,但牛顿是最被广泛接受的答案
- 问题 :2000年意大利总统是谁?
答案 :Carlo Azeglio Ciampi 是意大利政治家,曾任意大利共和国第10任总统及总理
不完整答案示例
- 问题 :蜘蛛有牙齿吗?
- 答案 :是的,蜘蛛有牙齿
- 注释 :正确答案应为“蜘蛛没有牙齿,但有螯肢(chelicerae),可分泌消化酶。”
- 开放式列表问题(如“最高的山有哪些?”)需列出多个正确示例并注明非穷举
Evergreen-ness Annotation
- 常青性标准因领域而异
- 多数问题涉及已确立的事实或事件,但天文学等领域的新发现可能改变答案
- 政治领导人类问题(如“现任总统是谁?”)显然非常青
可变问题示例
- 1)最近一次日食是哪年?
- 2)哪个国家拥有最长铁路?
常青问题示例
- 1)罗马帝国分裂为哪两部分,何时发生?
- 2)梅西是谁?
Synthetic Data Generation
- 使用 GPT-4.1 生成并人工验证了 1,449 个额外问答对
- 过滤重复问题并改写常见模板(如“某人年龄”)
- 仿照 FreshQA 风格,生成常青和可变问题,后者进一步分为慢变(slow-changing)和快变(fast-changing)两类,以增强数据多样性
- 合成指令 :
- “请生成以下类型的问答对:慢变问题(答案通常几年内变化)、快变问题(答案一年内变化)、永不变问题(答案永不变化)。”
- Synthetic Instruction:
Can you generate different question-answer pair: slow-changing questions, in which the answer typically changes over the course of several years (up to 10); fast-changing question, in which the answer typically changes within a year or less; never-changing, in which the answer never changes.
Short-Answer Generation Prompt
- 简短答案生成器指令 :
- 给定一个事实性问题和完整(可能较长)答案 ,生成多个简洁且语义等价的答案变体
- 规则 :
- 1)每个变体必须事实正确且独立回答问题
- 2)尽量简短(约1–5词),同时保持无歧义
- 3)包含常见拼写、缩写、数字与罗马数字形式
- 4)不添加答案未明确包含的信息
- 5)返回如 JSON 对象:
{ "answers": ["变体1", "变体2", ...] }
- 示例 :
- 问题 :“英国国王是谁?”
- 答案 :“英国国王是查尔斯三世(Charles Philip Arthur George)。”,
["查尔斯3世", "国王是查尔斯3世", "Charles III"]
- 论文使用 GPT-4o(温度=0.2)并添加了 “response_format”: “json_object” 标签,从长 form 中生成简短 form 答案,便于比较 LLM 的性能
附录G Error Analysis Extended
- 表11 扩展了EG-E5分类器的错误模式分析,包括更多误分类示例
/EverGreenQA-Table11.png)
- 误报(False Positives) :
- 时间性表述误为固定历史事实(如“俄罗斯总统选举在哪年举行?”)
- 最高级假设为静态事实(如“最健康的茶是哪种?”)
- 漏报(False Negatives) :
- 最高级误为时间敏感(如“最古老的货币是什么?”)
- 生物地理事实误为频繁变化(如“列支敦士登的面积是多少?”)
- 完整示例见附录G
附录H License and Infrastructure
- 实验使用 1–2 块 NVIDIA A100 GPU,总计约 40 GPU 小时
- 模型遵循各自许可:LLaMA 3.1 (2024) 和 Gemma 2 (2024) 为自定义许可,Phi-3 (2024) 和 E5 为 MIT 许可,Qwen 2.5 (2024) 和 Mistral (2023) 为 Apache 2.0 许可
- GPT模型通过 API 或网页界面访问
- 数据集和分类器以 MIT 许可发布


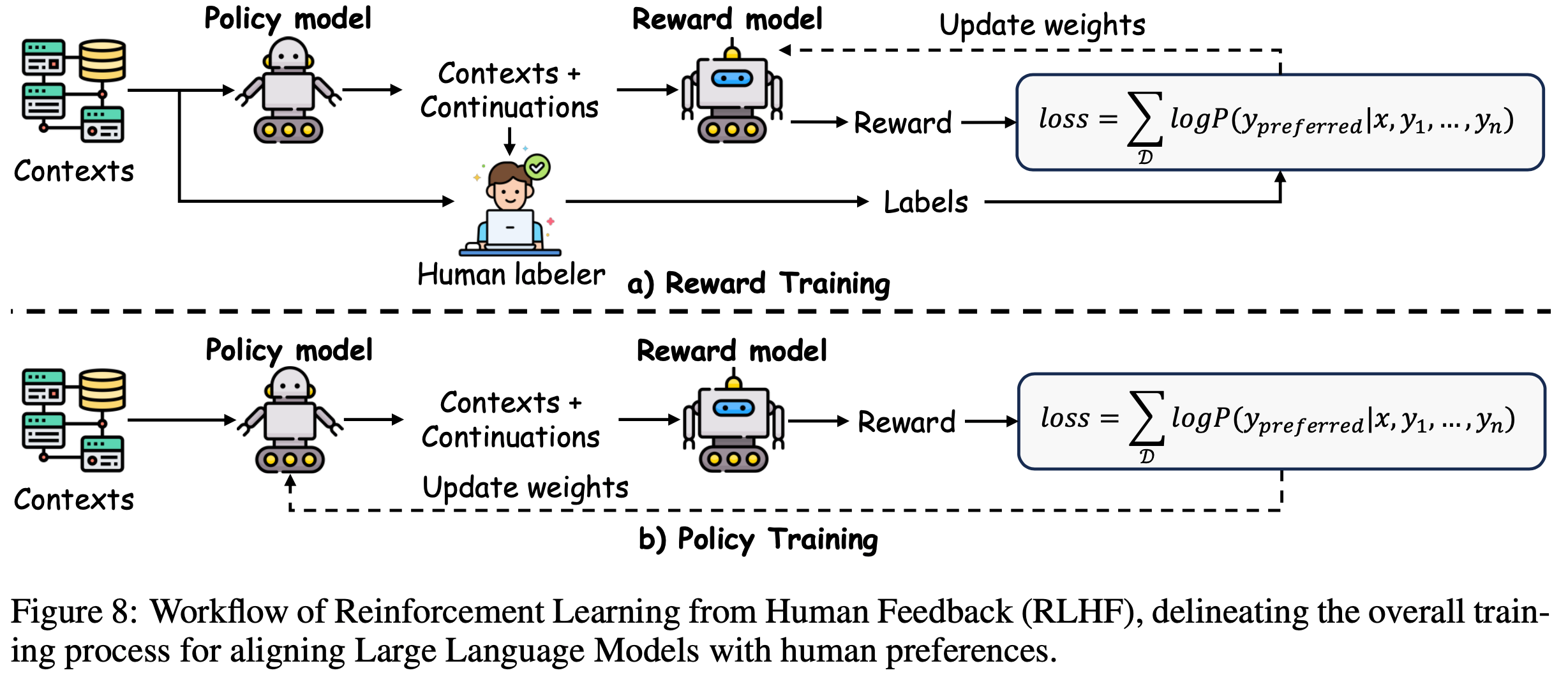
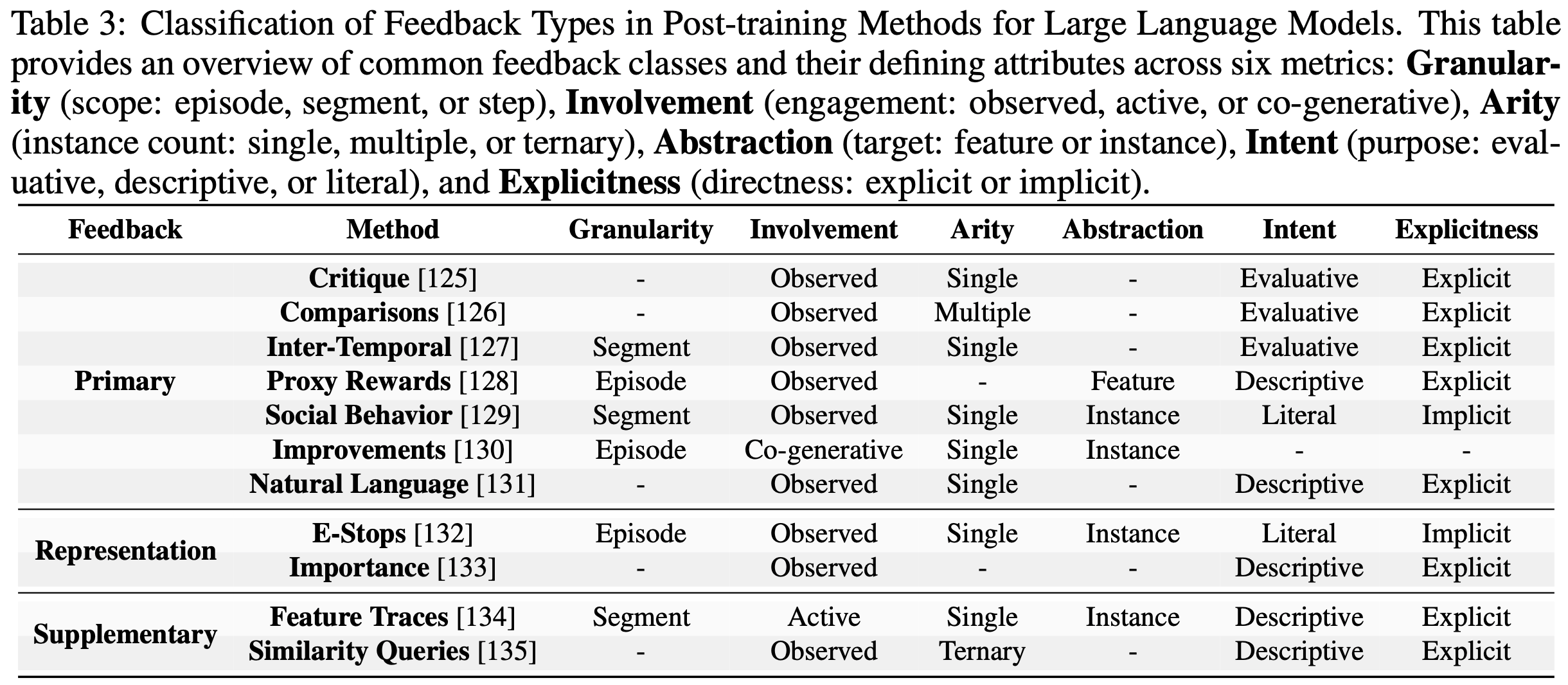
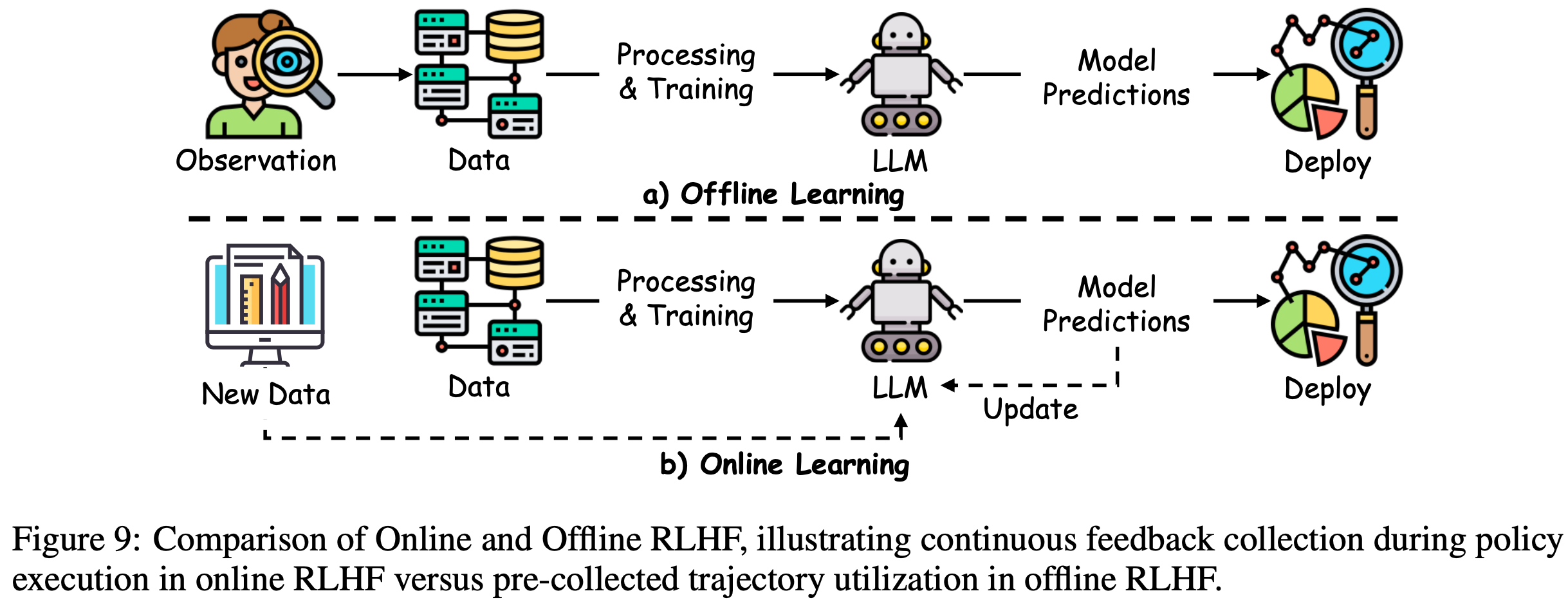
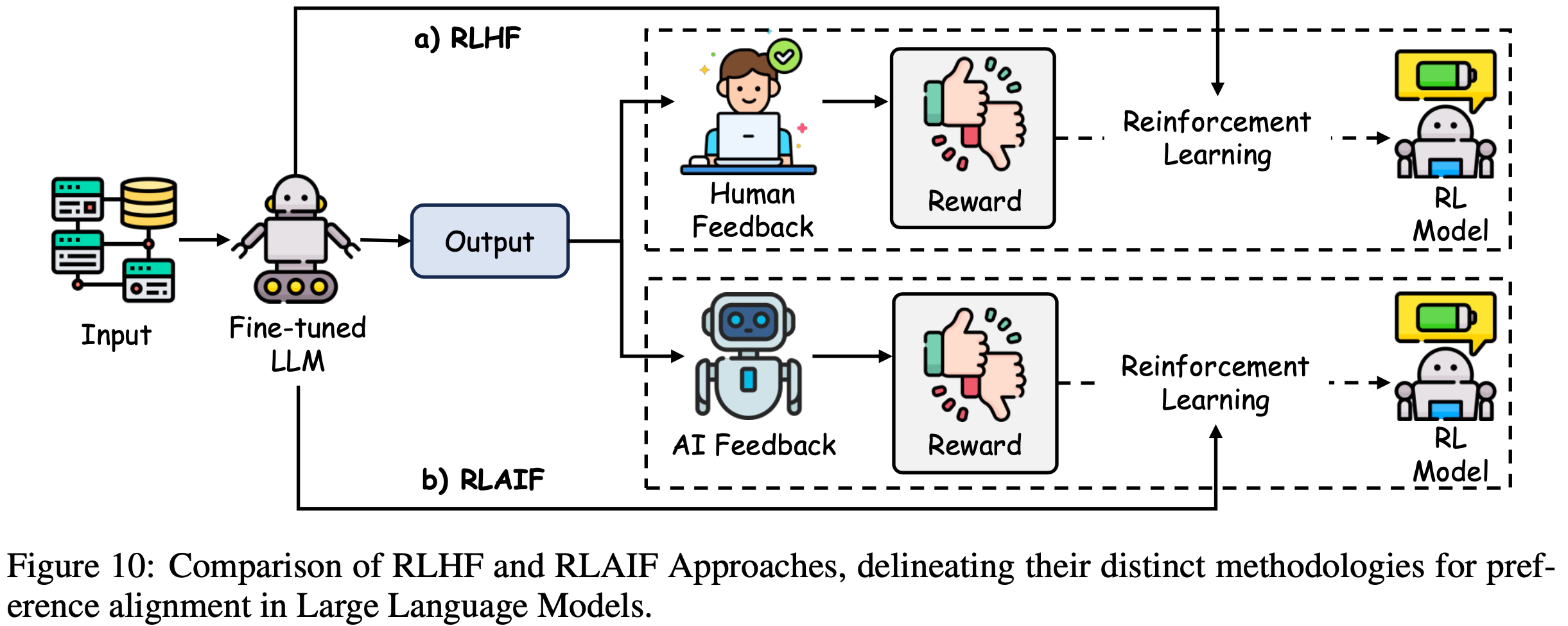


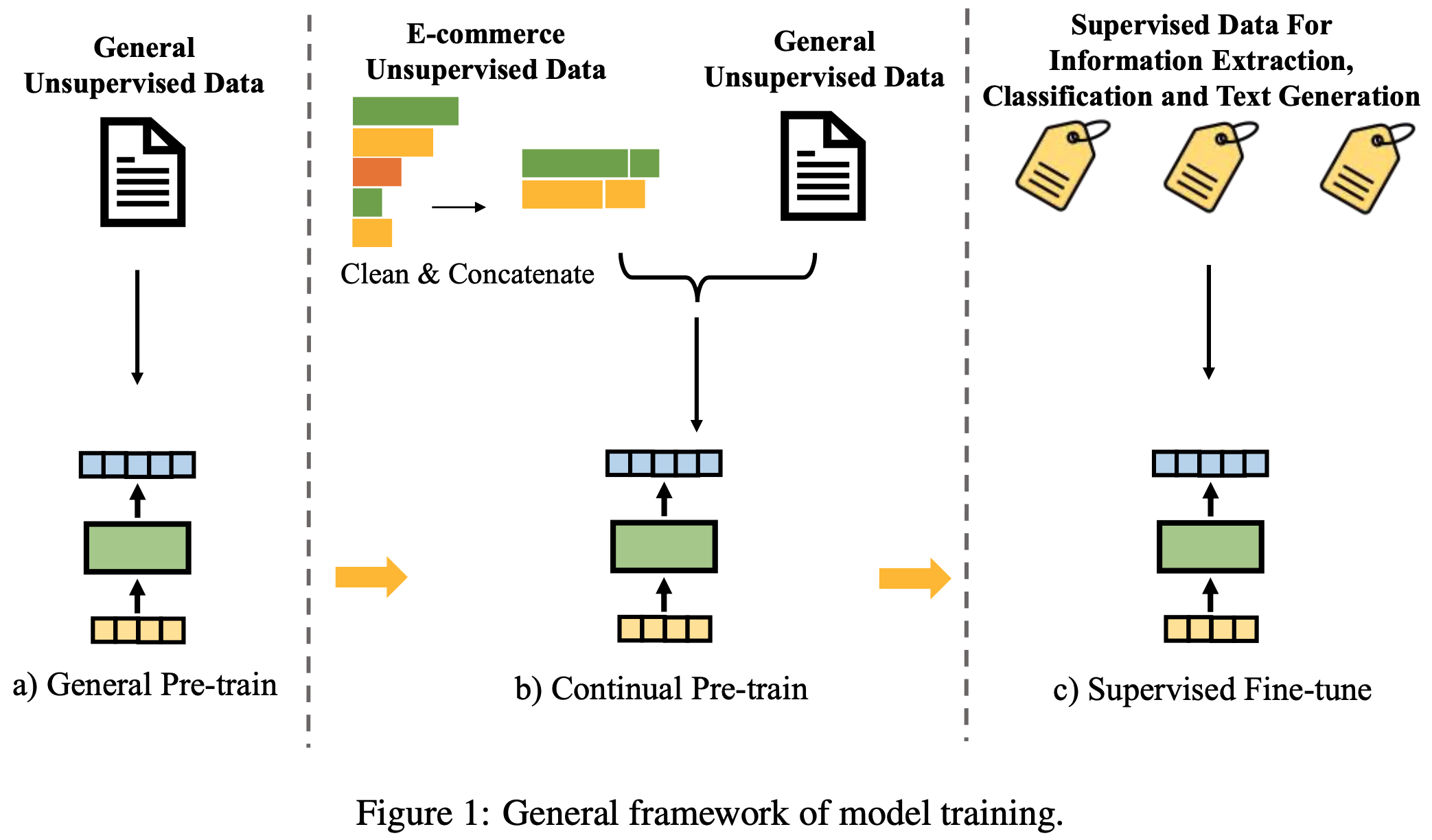
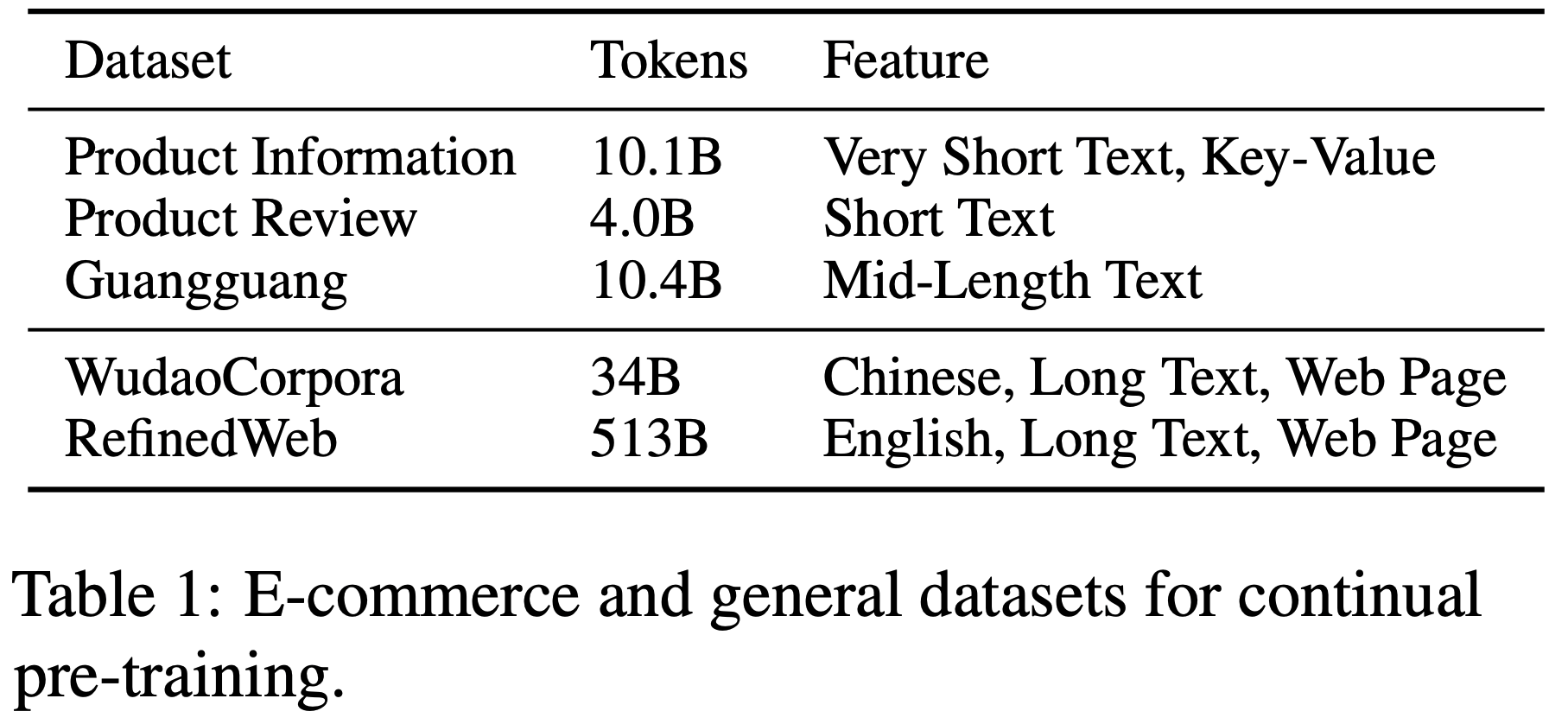
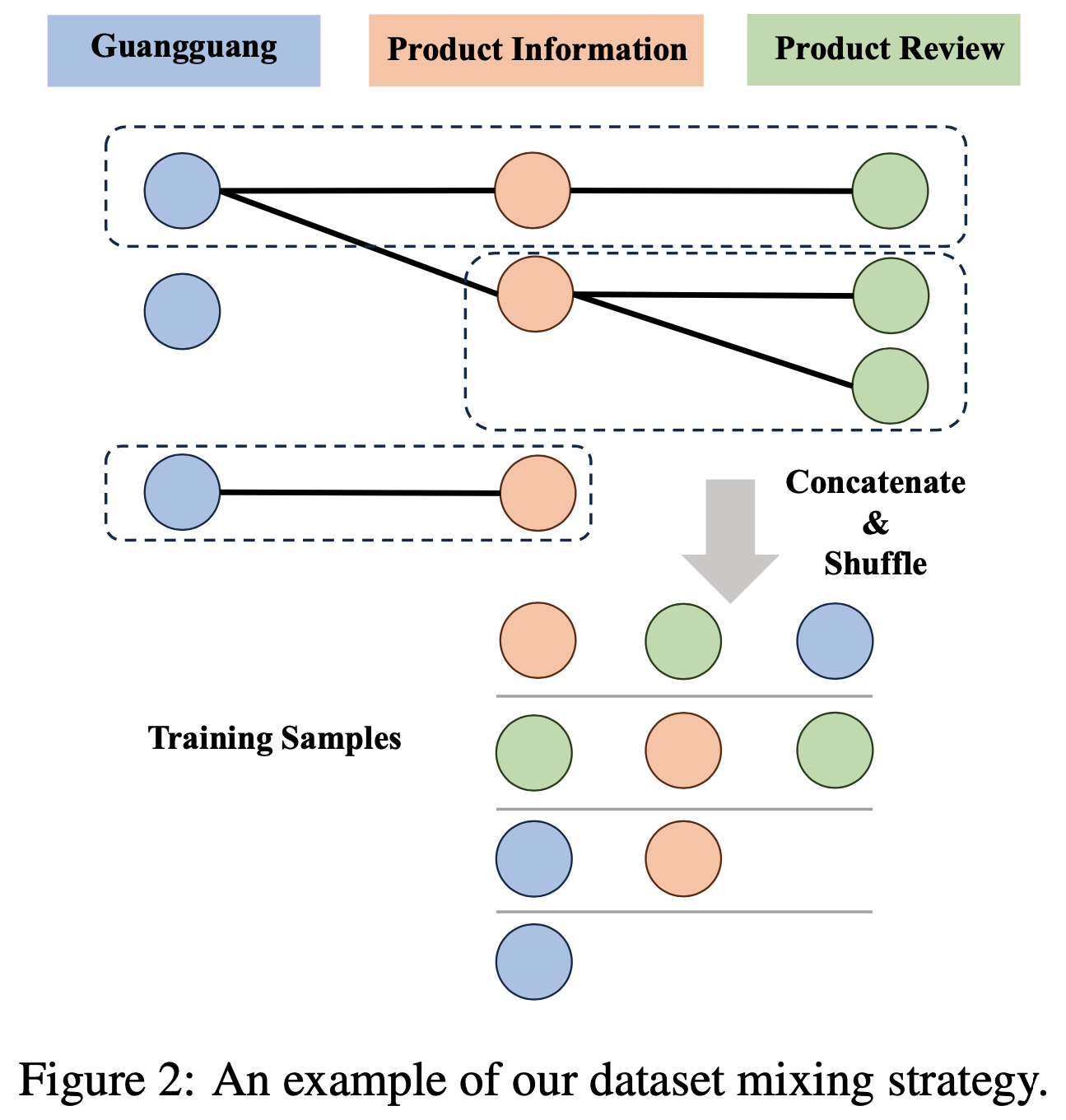
/FinPythia-Figure1.png)
/FinPythia-Table1.png)
/FinPythia-Table2.png)
/FinPythia-Table3.png)
/FinPythia-Table4.png)
/FinPythia-Figure2.png)
/FinPythia-Table5.png)
/FinPythia-Table6.png)
/Pile-Dataset.png "图片来源:[4个大语言模型训练中的典型开源数据集——华为云开发者联盟](https://zhuanlan.zhihu.com/p/680925832)")
/FinPythia-Figure3.png)
/FinPythia-Figure5.png)
/FinPythia-Figure4.png)
/FinPythia-Figure7.png)
/FinPythia-Figure6.png)
/FinPythia-Figure8.png)
/FinPythia-Figure9.png)