OneRec:Unifying Retrieve and Rank with Generative Recommender and Preference Alignment,本文主要是对论文OneRec的翻译,其中包含了一些总结和理解
- 参考链接:
整体思路说明
- 基于生成式检索的推荐系统介绍 :基于生成式检索(召回)的推荐系统(generative retrieval-based recommendation systems,GRs),通过自回归方式直接生成候选视频(注:论文针对短视频推荐场景,所以使用的是视频作为例子,实际上可以是任意 item),展现出巨大潜力
- 当前问题 :然而,现代推荐系统大多采用“检索-排序”(retrieve-and-rank)策略,生成模型仅在检索阶段作为选择器发挥作用
- 论文方案OneRec :用统一的生成模型取代传统的级联学习框架。具体而言,OneRec 包含以下核心组件:
- 1)Encoder-Decoder 结构 :编码用户历史行为序列,逐步解码用户可能感兴趣的视频。采用稀疏专家混合(MoE)技术,在不显著增加计算量的情况下扩展模型容量;
- 2)session 式生成方法 :与传统 next-item 预测不同,提出 session-wise 生成方式,相比依赖手工规则拼接生成结果的 point-by-point 生成更优雅且上下文连贯;
- 3)迭代偏好对齐模块 :结合直接偏好优化(Direct Preference Optimization,DPO)提升生成结果质量。与 NLP 中的DPO不同,推荐系统通常只有一次展示机会,无法同时获取正负样本。为此,论文设计奖励模型模拟用户生成行为,并根据在线学习特性定制采样策略,大量实验表明,少量DPO样本即可对齐用户兴趣偏好,显著提升生成质量
- OneRec已在快手主场景(日活数亿的短视频推荐平台)部署 ,观看时长提升1.6% ,实现了实质性突破
- 注:据论文所知,这是首个在真实场景中显著超越当前复杂且精心设计的推荐系统的端到端生成模型
更多相关讨论
- 推荐系统介绍 :为了平衡效率和有效性,大多数现代推荐系统采用级联排序策略。如图1(b)所示,一个典型的级联排序系统采用三阶段流程:召回、预排序和排序。每个阶段负责从接收到的 item 中选择前k个 item,并将结果传递到下一个阶段,共同平衡系统响应时间和排序准确性之间的权衡。尽管在实践中效率较高,但现有方法通常独立对待每个排序器,每个独立阶段的有效性成为后续排序阶段的上限,从而限制了整体排序系统的性能。尽管有各种努力通过实现排序器之间的交互来提高整体推荐性能,但它们仍然保持传统的级联排序范式
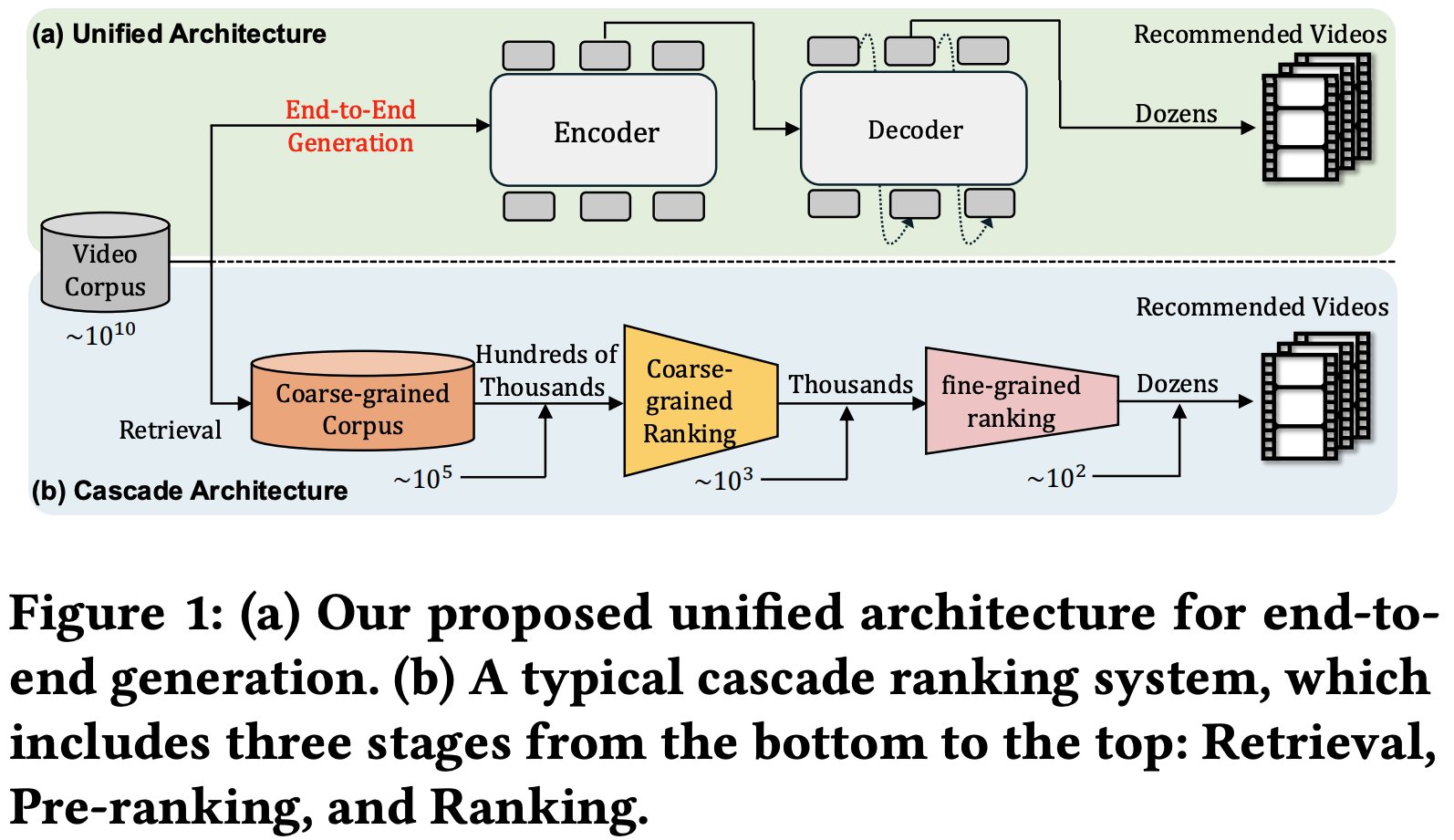
- 最近,基于生成式检索的推荐系统(GRs)[36, 45, 51]作为一种有前途的范式出现,它通过自回归序列生成方式直接生成候选 item 的标识符。通过使用对 item 语义进行编码的量化语义ID对 item 进行索引[24],推荐系统可以利用 item 内丰富的语义信息。GRs的生成特性使其适合通过 beam search 解码直接选择候选 item,并产生更多样化的推荐结果。然而,目前的生成模型仅在检索阶段充当选择器,因为其推荐准确性仍无法与精心设计的多级联排序器相媲美
- 为了应对上述挑战,论文提出了一种用于single-stage 推荐的统一端到端生成框架OneRec
- 首先 ,论文提出了一种 Encoder-Decoder 架构。从训练 LLM 时观察到的缩放定律中获得灵感,论文发现扩展推荐模型的容量也能持续提高性能。因此,论文基于MoE 结构扩展模型参数,这显著提高了模型表征用户兴趣的能力
- 其次 ,与传统的 point-by-point 预测 next-item 不同,论文提出了一种 session-wise 的列表生成方法,该方法考虑了每个 session 中 item 的相对内容和顺序。逐点生成方法需要 hand-craft 策略来确保生成结果的连贯性和多样性(coherence and diversity)。相比之下,session-wise 的学习过程使模型能够通过输入偏好数据自主学习最优的 session 结构
- 最后 ,论文探索使用直接偏好优化(DPO)进行偏好学习 ,以进一步提高生成结果的质量。为了构建偏好对,论文从 hard negative sampling[37]中获得灵感,从 beam search 结果中创建 self-hard rejected samples(而不是随机采样)。论文提出了一种迭代偏好对齐(IPA)策略 ,根据预训练奖励模型(RM)提供的分数对采样响应进行排序,确定最佳选择和最差拒绝(best-chosen and worst-rejected)的样本
- 论文在大规模工业数据集上的实验展示了所提方法的优越性。论文还进行了一系列消融实验,详细证明了每个模块的有效性
- 这项工作的主要贡献总结如下:
- OneRec框架提出 :为了克服级联排序的局限性,论文引入了 OneRec,这是一种 single-stage 生成式推荐框架。据论文所知,这是首批能够使用统一生成模型处理 item 推荐的工业解决方案之一,显著超越了传统的 multi-stage 排序流程
- session-wise 的生成方式 :论文通过 session-wise 的生成方式强调了模型容量和目标 item 上下文信息的必要性,这使得预测更加准确,并提高了生成 item 的多样性
- 迭代偏好对齐(IPA)策略 :论文提出了一种基于个性化奖励模型的新型 self-hard negative samples 选择策略。通过直接偏好优化,论文增强了 OneRec 在更广泛用户偏好范围内的泛化能力
- 大量的离线实验和在线A/B测试证明了它们的有效性和效率
OneRec框架整体方法
- 整体框架如下:
一些基本定义
- 用户特征 :输入为用户正向历史行为序列 \(\mathbf{\mathcal{H}}_u=\{\boldsymbol{v}^h_1,\boldsymbol{v}^h_2,…,\boldsymbol{v}^h_n\}\),其中 \(\boldsymbol{v}\) 表示用户实际观看或交互(likes/follows/shares,点赞/关注/分享)的视频,\(n\)为序列长度
- 输出 :视频列表构成的 session \(\mathcal{S}=\{\boldsymbol{v}_1,\boldsymbol{v}_2,…,\boldsymbol{v}_m\}\),\(m\) 为 session 内视频数
- 视频信息 :每个视频 \(\boldsymbol{v}_i\) 通过多模态嵌入 \(\boldsymbol{e}_i\in\mathbb{R}^d\) 描述,其分布与真实 user-item 行为对齐。基于预训练多模态表示,现有生成推荐框架[25,36]使用RQ-VAE[49]将嵌入编码为语义标记。但该方法因 code 分布不平衡(hourglass phenomenon,“沙漏现象”[23],表现为第二层编码过于集中)存在缺陷。论文采用多层级平衡量化机制(multi-level balanced quantitative mechanism),通过残差K-Means量化算法[27]转换 \(\boldsymbol{e}_i\):
- 第一层(\(l=1\))初始残差\(r^1_i=\boldsymbol{e}_i\)
- 每层 \(l\) 维护 codebook \(C_l=\{c^l_1,…,c^l_K\}\)(\(K\) 为 codebook 大小)
- 通过 \(\boldsymbol{s}^l_i=\arg\min_k|r^l_i-c^l_k|^2_2\) 生成最近中心节点索引,下一层残差 \(r^{l+1}_i=r^l_i-c^l_{s^l_i}\),即通过层级索引生成对应的 codebook tokens:
$$
\boldsymbol{s}^1_i = \arg\min_k|r^1_i-c^1_k|^2_2, \quad \boldsymbol{r}^2_i=r^1_i-c^1_{s^1_i} \\
\boldsymbol{s}^2_i = \arg\min_k|\boldsymbol{r}^2_i-c^2_k|^2_2, \quad \boldsymbol{r}^3_i=r^2_i-c^2_{s^2_i} \\
\vdots \\
\boldsymbol{s}^L_i = \arg\min_k|\boldsymbol{r}^L_i-c^L_k|^2_2
$$- 其中 \(L\) 为语义ID总层数
- 为构建平衡 codebook \(C_l=\{c^l_1,…,c^l_K\}\),采用算法1的平衡K-means进行 item 集划分。给定视频集 \(\mathcal{V}\),该算法将其划分为 \(K\) 个簇,每簇包含恰好 \(w=|\mathcal{V}|/K\) 个视频。迭代计算中,每个中心点依次分配 \(\mathbf{w}\) 个最近未分配视频(基于欧氏距离),随后用分配视频的均值向量重新校准中心点,直至簇分配收敛

- 算法1思路:
- 算法1中仅展示了第 \(l\) 层 codebook 的迭代过程
- 首先随机初始化 \(K\) 个中心点
- 内部循环 \(K\) 次,每一次中,使用最接近当前 \(c_k^l\) 的 \(w\) 个当前层的残差 \(\mathbf{r}^l\) 的均值来编码当前中心点 \(c_k^l\),同时移除已经参与均值计算的残差(确保每个中心点都刚好被K个残差)
- 整体循环以上步骤,直到算法收敛
session-wise 的列表生成
- 与传统仅预测 next video 的 point-wise 推荐方法不同,session-wise 的生成旨在根据用户的历史交互序列生成高价值的 session 列表,这使得推荐模型能够捕捉推荐列表中视频之间的依赖关系。具体而言,session 是指响应用户请求返回的一批短视频,通常包含5到10个视频。session 中的视频通常会综合考虑用户兴趣、连贯性和多样性等因素。论文设计了几项标准来识别高质量 session,包括:
- 用户在一个 session 中实际观看的短视频数量大于或等于5;
- 用户观看该 session 的总时长超过某个阈值;
- 用户表现出互动行为,例如点赞、收藏或分享视频;
- 这种方法确保论文的 session 模型能够从真实的用户参与模式中学习,并更准确地捕捉 session 列表中的上下文信息。因此,论文的 session 模型\(\mathcal{M}\)的目标可以形式化为:
$$
\mathcal{S} := \mathcal{M}(\mathcal{H}_u)
$$- 模型输入 :\(\mathcal{H}_u\) 通过语义ID表示( 长度为 \(n\) ):
$$
\mathcal{H}_u = \{(s^1_1, s^2_1, \cdots, s^L_1), (s^1_2, s^2_2, \cdots, s^L_2), \cdots, (s^1_n, s^2_n, \cdots, s^L_n)\}
$$ - 模型输出 :\(\mathcal{S}\) 也通过语义ID表示( 长度为 \(m\) ):
$$\mathcal{S} = \{(s^1_1, s^2_1, \cdots, s^L_1), (s^1_2, s^2_2, \cdots, s^L_2), \cdots, (s^1_m, s^2_m, \cdots, s^L_m)\}$$
- 模型输入 :\(\mathcal{H}_u\) 通过语义ID表示( 长度为 \(n\) ):
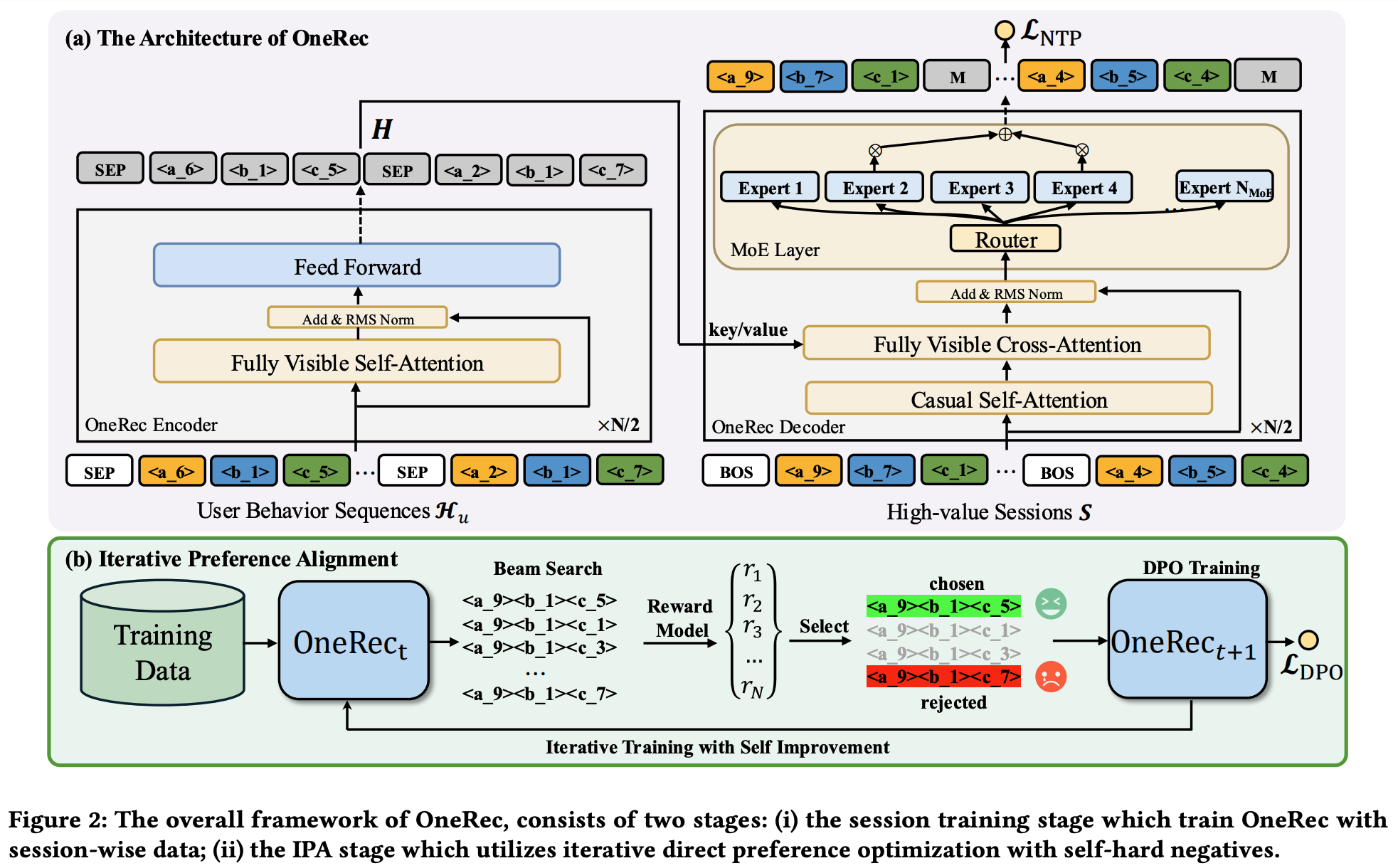
- 如 图2(a) 所示,与T5架构一致,论文的模型采用基于Transformer的框架,主要由两部分组成:用于建模用户历史交互的 encoder 和用于 session 列表生成的 decoder。具体来说,encoder 通过堆叠的(stacked)多头自注意力机制(multi-head self-attention,MHA)和前馈层(feed-forward layers)处理输入序列\(\mathcal{H}_u\)。论文将编码后的历史交互特征表示为\(\boldsymbol{H} = \text{Encoder}(\mathcal{H}_u)\)
- decoder 以目标 session 的语义ID为输入,并以自回归方式生成目标。为了以合理的经济成本训练更大的模型,论文在 decoder 的前馈神经网络(feed-forward neural networks,FNNs)中采用了Transformer语言模型中常用的MoE 架构 ,并将第\(l\)层的 FNN 替换为:
$$
\begin{split}
\mathbf{H}^{l+1}_t &= \sum_{i=1}^{N_{\text{MoE} } } \left(g_{i,t} \text{FFN}_i \left(\color{red}{\mathbf{H}^l_t} \right)\right) + \color{red}{\mathbf{H}^l_t}, \\
g_{i,t} &= \begin{cases}
\mathcal{S}_{i,t}, & \mathcal{S}_{i,t} \in \text{TopK}(\{\mathcal{S}_{j,t}|1 \leq j \leq N\}, K_{\text{MoE} }), \\
0, & \text{otherwise},
\end{cases} \\
\mathcal{S}_{i,t} &= \text{Softmax}_i \left({\mathbf{H}^{l}}^{\color{red}{T}}_t e^l_i \right),
\end{split}
$$- 其中,\(N_{\text{MoE} }\)表示专家总数,\(\text{FFN}_i(\cdot)\)是第\(i\)个专家的 FNN,\(g_{i,t}\)表示第\(i\)个专家的门控值。门控值\(g_{i,t}\)是稀疏的,即只有\(K_{\text{MoE} }\)个门控值为非零。这种稀疏性确保了MoE层的计算效率,每个 token 仅被分配到\(K_{\text{MoE} }\)个专家中进行计算
- 问题:和常规的MoE一样,由于先做了 softmax 再取的 TopK 系数,所有系数和小于1,这里不需要保证系数和为1吗?
- 回答:不需要,因为在每一个Transformer层中,FNN的结果和上一层的隐向量叠加后,都有LayerNorm存在(将每个token的隐向量分别归一化为均值为0,方差为1的向量),所以隐向量的值不会越来越小,在DeepSeek V3版本的公式中,会考虑在选择了TopK FNN后,再进行一次归一化(虽然不是softmax)
- 注意 :\({\mathbf{H}^{l}}^{\color{red}{T}}_t e^l_i\) 中的 \(\color{red}{T}\) 是矩阵转置的含义
- 修正 :这里的公式中表达有误,红色的 \(\mathbf{H}^l_t\) 在进入下一个 MoE(FNN)时,是需要整体经过 Self-Attention 编码的,即在更新前加一句 \(\color{blue}{\mathbf{H}^l_{1:T} = \text{Self-Att}(\mathbf{H}^l_{1:T}) + \mathbf{H}^l_{1:T}}\),详情见DeepSeekMoE的技术报告第2节(P4):DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
- 其中,\(N_{\text{MoE} }\)表示专家总数,\(\text{FFN}_i(\cdot)\)是第\(i\)个专家的 FNN,\(g_{i,t}\)表示第\(i\)个专家的门控值。门控值\(g_{i,t}\)是稀疏的,即只有\(K_{\text{MoE} }\)个门控值为非零。这种稀疏性确保了MoE层的计算效率,每个 token 仅被分配到\(K_{\text{MoE} }\)个专家中进行计算
- 在训练过程中,论文在编码(codes)的开头添加起始标记\(\boldsymbol{s}_{\text{[BOS]} }\)来构建 decoder 输入:
$$
\begin{split}
\bar{\boldsymbol{\mathcal{S}} } &= \{\boldsymbol{s}_{\text{[BOS]} }, \boldsymbol{s}^1_1, \boldsymbol{s}^2_1, \cdots, \boldsymbol{s}^L_1, \boldsymbol{s}_{\text{[BOS]} }, \boldsymbol{s}^1_2, \boldsymbol{s}^2_2, \cdots, \boldsymbol{s}^L_2, \cdots, \boldsymbol{s}_{\text{[BOS]} }, \boldsymbol{s}^1_m, \boldsymbol{s}^2_m, \cdots, \boldsymbol{s}^L_m\}
\end{split}
$$ - 论文使用交叉熵损失对目标 session 的语义ID进行 next token 预测。NTP(Next Token Prediction)损失\(\mathcal{L}_{\text{NTP} }\)定义为:
$$
\mathcal{L}_{\text{NTP} } = -\sum_{i=1}^m \sum_{j=1}^L \log P(\boldsymbol{s}^{j+1}_i \mid \left[\boldsymbol{s}_{\text{[BOS]} }, \boldsymbol{s}^1_1, \boldsymbol{s}^2_1, \cdots, \boldsymbol{s}^L_1, \cdots, \boldsymbol{s}_{\text{[BOS]} }, \boldsymbol{s}^1_i, \cdots, \boldsymbol{s}^j_i\right]; \Theta).
$$ - 在对 session 列表生成任务进行一定量的训练后,论文得到 seed 模型\(\mathcal{M}_t\)
基于奖励模型的迭代偏好对齐
- 上一小节总结 :上一小节中定义的高质量 session 提供了有价值的训练数据,使模型能够了解什么构成一个好的 session,从而确保生成视频的质量
- 本节内容 :在此基础上,论文旨在通过直接偏好优化(DPO)进一步提升模型的能力。在传统的 NLP 场景中,偏好数据是由人类明确标注的。然而,由于 user-item 交互数据的稀疏性,推荐系统中的偏好学习面临着独特的挑战,这就需要一个奖励模型(RM)。因此,论文引入了一个 session-wise 的奖励模型
- 其他内容 :此外,论文通过提出一种迭代直接偏好优化方法来改进传统的DPO,使模型能够自我提升,这将在后续章节中进行描述
奖励模型训练
- 论文用 \(R(\mathbf{u}, \mathcal{S})\) 表示奖励模型,它为不同的用户选择偏好数据。这里,输出 \(r\) 表示用户 \(\mathbf{u}\)(通常由用户行为表示)对 session \(\mathcal{S} = \{\mathbf{v}_1, \mathbf{v}_2, …, \mathbf{v}_m\}\) 的偏好所对应的奖励。为了使奖励模型具备对 session 进行排序的能力,论文首先提取 session \(\mathcal{S}\) 中每个 item \(\mathbf{v}_i\) 的目标感知表示 \(\mathbf{e}_i = \mathbf{v}_i \odot \mathbf{u}\),其中 \(\odot\) 表示目标感知操作(例如针对用户行为的目标注意力)。这样论文就得到了 session \(\mathcal{S}\) 的目标感知表示 \(\mathbf{h} = \{\mathbf{e}_1, \mathbf{e}_2, \cdots, \mathbf{e}_m\}\)。然后,session 中的 item 通过自注意力层相互作用,以融合不同 item 之间的必要信息:
$$\mathbf{h}_f = \text{SelfAttention}(\mathbf{hW}_{\mathcal{s}}^Q, \mathbf{hW}_{\mathcal{s}}^K, \mathbf{hW}_{\mathcal{s}}^V)$$- 问题:\(\mathbf{W}_{\mathcal{s}}^Q\) 中的下标 \(\mathcal{s}\) 是表达什么?为不同的 Session 做了不同的 Attention 权重吗?或是在强调这里是 Session 粒度的 Attention?
- 接下来,论文利用不同的塔对多目标奖励进行预测,并且使用丰富的推荐数据对奖励模型进行预训练:
$$\begin{aligned}
\hat{r}^{swt} = \text{Tower}^{swt}(\text{Sum}(\mathbf{h}_f)), &\hat{r}^{vtr} = \text{Tower}^{vtr}(\text{Sum}(\mathbf{h}_f)), \\
\hat{r}^{wtr} = \text{Tower}^{wtr}(\text{Sum}(\mathbf{h}_f)), &\hat{r}^{ltr} = \text{Tower}^{ltr}(\text{Sum}(\mathbf{h}_f)), \\
\text{where } \quad \text{Tower}(\cdot) &= \text{Sigmoid}(MLP(\cdot))
\end{aligned}$$- 问题:swt,wtr,vtr,ltr等分别表示什么?
- 回答:论文计算不同目标指标的平均奖励,包括 session 观看时间(session watch time,swt) 、观看概率(view probability,vtr)、关注概率(follow probability,wtr)和点赞概率(like probability,ltr),swt和vtr是观看时间指标 ,而wtr和ltr是交互指标
- 在得到每个 session 的所有估计奖励 \(\hat{r}^{swt}, …\) 和真实标签 \(y^{swt}, …\) 之后,论文直接最小化二元交叉熵损失来训练奖励模型。损失函数 \(\mathcal{L}_{RM}\) 定义如下:
$$\mathcal{L}_{RM} = -\sum_{swt, …}^{xtr} (y^{xtr} \log(\hat{r}^{xtr}) + (1 - y^{xtr})\log(1 - \hat{r}^{xtr}))$$
迭代偏好对齐(Iterative Preference Alignment,IPA)
基于预训练的奖励模型 \(R(\mathbf{u}, \mathcal{S})\) 和当前的OneRec模型 \(\mathcal{M}_t\),论文通过 beam search 为每个用户生成 \(N\) 个不同的响应:
$$\mathcal{S}_u^n \sim \mathcal{M}_t(\mathcal{H}_u) \quad \text{for all } u \in \mathcal{U} \text{ and } n \in [N]$$- 其中,论文用 \([N]\) 表示 \(\{1, 2, …, N\}\)
然后,论文基于奖励模型 \(R(\mathbf{u}, \mathcal{S})\) 为这些响应中的每一个计算奖励 \(r_u^n\):
$$r_u^n = R(\mathbf{u}, \mathcal{S}_u^n)$$接下来,论文通过选择奖励值最高的获胜响应 \((\mathcal{S}_u^w, \mathcal{H}_u)\) 和奖励值最低的失败响应 \((\mathcal{S}_u^l, \mathcal{H}_u)\) 来构建偏好对 \(D_t^{pairs} = (\mathcal{S}_u^w, \mathcal{S}_u^l, \mathcal{H}_u)\)。有了这些偏好对,论文现在可以训练一个新的模型 \(\mathcal{M}_{t+1}\),它从模型 \(\mathcal{M}_t\) 初始化,并使用结合了偏好对学习的DPO损失的损失函数进行更新。每个偏好对对应的损失如下:
$$\begin{aligned}
\mathcal{L}_{DPO} &= \mathcal{L}_{DPO}(\mathcal{S}_u^w, \mathcal{S}_u^l | \mathcal{H}_u) \\
&= -\log \sigma \left(\beta \log \frac{\mathcal{M}_{t+1}(\mathcal{S}_u^w | \mathcal{H}_u)}{\mathcal{M}_t(\mathcal{S}_u^w | \mathcal{H}_u)} - \beta \log \frac{\mathcal{M}_{t+1}(\mathcal{S}_u^l | \mathcal{H}_u)}{\mathcal{M}_t(\mathcal{S}_u^l | \mathcal{H}_u)}\right)
\end{aligned}$$- 注:上式和DPO的损失函数基本相同,对于给定的 \(\pi_{ref}\) 和数据集 \(D\) ,DPO是在优化语言模型 \(\pi_\theta\) 以最小化loss:
$$
Loss_{\text{DPO}}(\pi_\theta;\pi_{ref}) = - \mathbb{E}_{(x,y_w,y_l) \sim D}\left [ \log \sigma \left( \beta\log\frac{\pi_\theta(y_w|x)}{\pi_{ref}(y_w|x)} - \beta\log\frac{\pi_\theta(y_l|x)}{\pi_{ref}(y_l|x)} \right)\right ]
$$
- 注:上式和DPO的损失函数基本相同,对于给定的 \(\pi_{ref}\) 和数据集 \(D\) ,DPO是在优化语言模型 \(\pi_\theta\) 以最小化loss:
如算法2和图2(b)所示,整个过程涉及训练一系列模型 \(\mathcal{M}_t, …, \mathcal{M}_t\)。为了减轻 beam search 推理过程中的计算负担 ,论文仅随机采样 \(r_{DPO} = 1\%\) 的数据用于偏好对齐。对于每个后续模型 \(\mathcal{M}_{t+1}\),它从先前的模型 \(\mathcal{M}_t\) 初始化,并利用由 \(\mathcal{M}_t\) 生成的偏好数据 \(D_t^{pairs}\) 进行训练

对 随机采样 \(r_{DPO} = 1\%\) 的数据用于偏好对齐 的理解:
- DPO数据大小是固定的,总数据量一定,每轮迭代时均考虑采样部分数据用于DPO
- 随机采样的目的是,减少每轮迭代(\(\mathcal{M}_t \rightarrow \mathcal{M}_{t+1}\) 算是一轮迭代)的计算复杂度
- 问题:为什么不直接采样固定的比例,然后固定下来,后续每轮DPO迭代都用相同数据呢?
- 回答:为了数据的多样性和模型泛化性,类似于随机森林中每次采样部分样本训练一样
系统部署
- OneRec已在现实世界的工业场景中成功实现。为了平衡稳定性和性能,论文部署了 OneRec-1B 用于在线服务
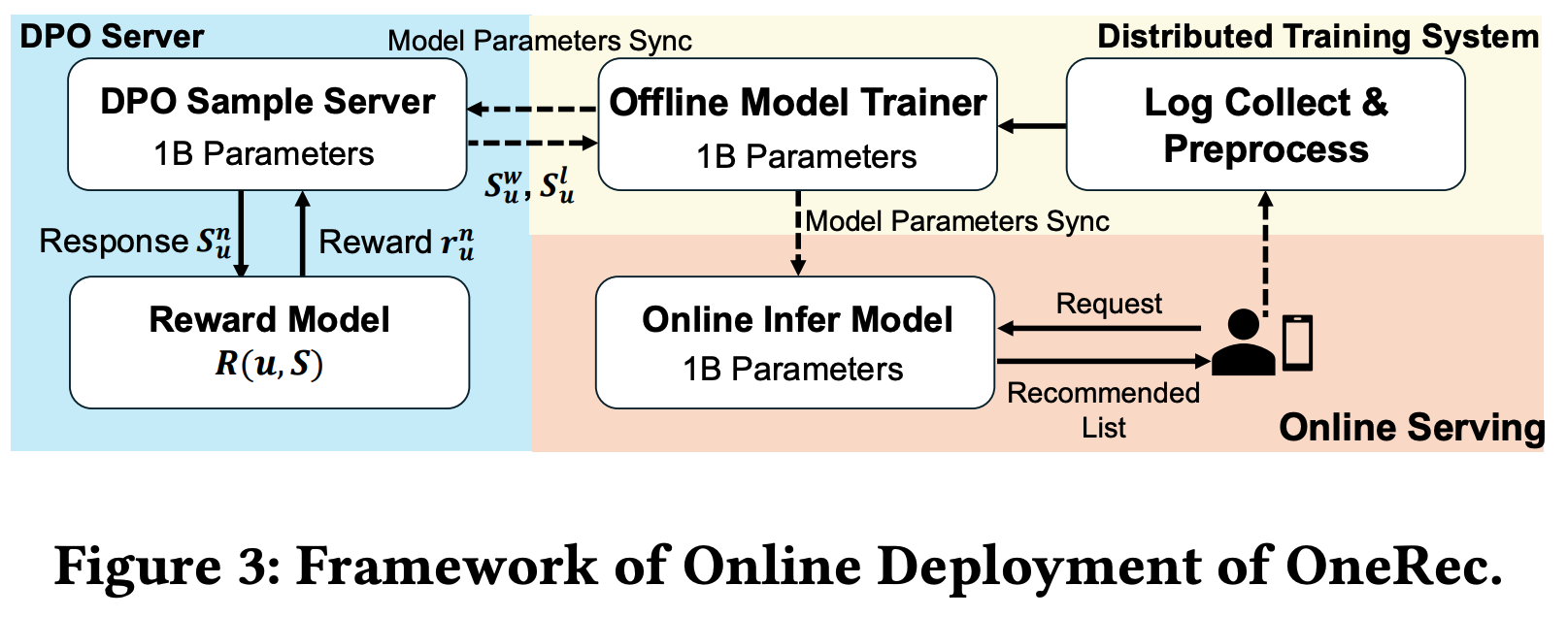
- 如图3所示,论文的部署架构由三个核心组件组成:
- 1)训练系统,
- 2)在线服务系统,
- 3)DPO样本服务器
- 种子模型训练 :该系统将收集到的交互日志作为训练数据,最初采用 next token 预测目标 \(\mathcal{L}_{NTP}\) 来训练种子模型
- DPO偏好对齐 :在收敛后,论文添加DPO损失 \(\mathcal{L}_{DPO}\) 进行偏好对齐,利用XLA和bfloat16混合精度训练来优化计算效率和内存利用率
- 注:XLA(Accelerated Linear Algebra)是一种专为优化线性代数计算而设计的编译器,主要用于深度学习框架(如TensorFlow、JAX等)中,以提升计算效率和资源利用率
- 参数部署 :训练好的参数被同步到在线推理模块和DPO采样服务器,用于实时服务和基于偏好的数据选择
- 为了提高推理效果,论文实施了两项关键优化 :
- 量化&KV缓存 :结合float16量化的键值缓存解码机制,以减少GPU内存开销;
- 量化&KV缓存 :以及 beam size 为 128 的 beam search 配置,以平衡生成质量和延迟
- MoE架构 :得益于MoE架构,在推理过程中只有13% 的参数被激活
相关实验
- 首先,论文在离线设置下将OneRec与逐点方法和几种DPO变体进行比较
- 然后,论文对提出的模块进行了一些消融实验,以验证OneRec的有效性
- 最后,论文将OneRec部署到线上并进行A/B测试,以进一步在快手平台上验证其性能
Experiment Setup
实现细节
- 论文使用Adam优化器训练模型,初始学习率为 \(2×10^{-4}\)
- 论文使用NVIDIA A800 GPU对OneRec进行优化
- 在整个训练过程中,DPO样本比率 \(r_{DPO}\) 设置为1%,并且论文通过 beam search 为每个用户生成 \(N = 128\) 个不同的响应;
- 语义标识符聚类过程为每个 codebook 层采用 \(K = 8192\) 个聚类,codebook 层数设置为 \(L = 3\);
- MoE 架构包含 \(N_{MoE} = 24\) 个专家,每次前向传递通过 top-\(k\) 选择激活 \(K_{MoE} = 2\) 个专家;
- 对于 session 建模,论文考虑 \(m = 5\) 个目标 session item,并采用 \(n = 256\) 个历史行为作为上下文
基线方法
- 论文采用以下具有代表性的推荐模型、DPO及其变体作为额外的比较基线,基线方法包括:
- SASRec[22]:采用单向Transformer架构来捕获 user-item 交互中的顺序依赖关系,用于 next item 预测
- BERT4Rec[40]:利用带有掩码语言建模的双向Transformer,通过序列重建来学习上下文 item 表示
- FDSA[50]:实现了双自注意力路径,以在异构推荐场景中联合建模 item 级转换和特征级转换模式
- TIGER[36]:利用分层语义标识符和生成式检索技术,通过自回归序列生成进行顺序推荐
- DPO[35]:通过隐式奖励建模,使用从人类反馈数据中导出的封闭形式奖励函数来形式化偏好优化
- IPO[1]:提出了一个有理论基础的偏好优化框架,绕过了标准DPO中固有的近似
- cDPO[30]:引入了一个考虑噪声偏好注释的鲁棒性感知变体,纳入了标签翻转率参数 \(\epsilon\)
- rDPO[5]:使用重要性采样开发了一个无偏损失估计器,以减少偏好优化中的方差
- CPO[47]:通过联合训练序列似然奖励和监督微调目标,将对比学习与偏好优化统一起来
- simPO[29]:通过采用序列级奖励裕度进行偏好优化,同时通过归一化概率平均消除参考模型依赖性
- S-DPO[4]:通过硬负采样(hard negative sampling)和多 item 对比学习,使DPO适用于推荐系统,以提高排名准确性
评估指标
- 论文使用几个关键指标来评估模型的性能。每个指标在评估模型输出的不同方面都有独特的作用,并且论文在每次迭代中对随机采样的测试用例集进行评估。为了估计每个特定 user-session 对的各种交互的概率,论文使用预训练的奖励模型来评估推荐 session 的价值。论文计算不同目标指标的平均奖励,包括 session 指标:
- 观看时间(session watch time,swt)
- 观看概率(view probability,vtr)
- 关注概率(follow probability,wtr)
- 点赞概率(like probability,ltr)
- swt和vtr是观看时间指标 ,而wtr和ltr是交互指标
离线性能
- 表1展示了OneRec与各种基线之间的全面比较。对于观看时间指标,论文主要关注 session 观看时间(swt),在交互指标中关注点赞概率(ltr)。论文的结果揭示了三个关键发现:
- 首先,所提出的 session-wise 的生成方法显著优于传统的基于点积的方法和像TIGER这样的逐点生成方法。与 TIGER-1B 相比,OneRec-1B在最大swt上提高了1.78%,在最大ltr上提高了3.36%。这证明了 session-wise 的建模在保持推荐之间的上下文连贯性方面的优势,而逐点方法在生成输出中难以平衡连贯性和多样性
- 其次,少量的DPO训练就能带来显著的提升。仅使用1% 的DPO训练比率(\(r_{DPO}\)),OneRec-1B + IPA在最大swt上比基础的 OneRec-1B 提高了4.04%,在最大ltr上提高了5.43%。这表明有限的DPO训练可以有效地使模型与期望的生成模式保持一致
- 第三,所提出的IPA策略优于各种现有的DPO变体。如表1所示,IPA比其他DPO实现具有更优的性能。值得注意的是,一些DPO基线甚至比未进行偏好对齐的 OneRec-1B 模型表现更差,这表明通过迭代挖掘自生成输出来进行偏好选择比其他方法更有效
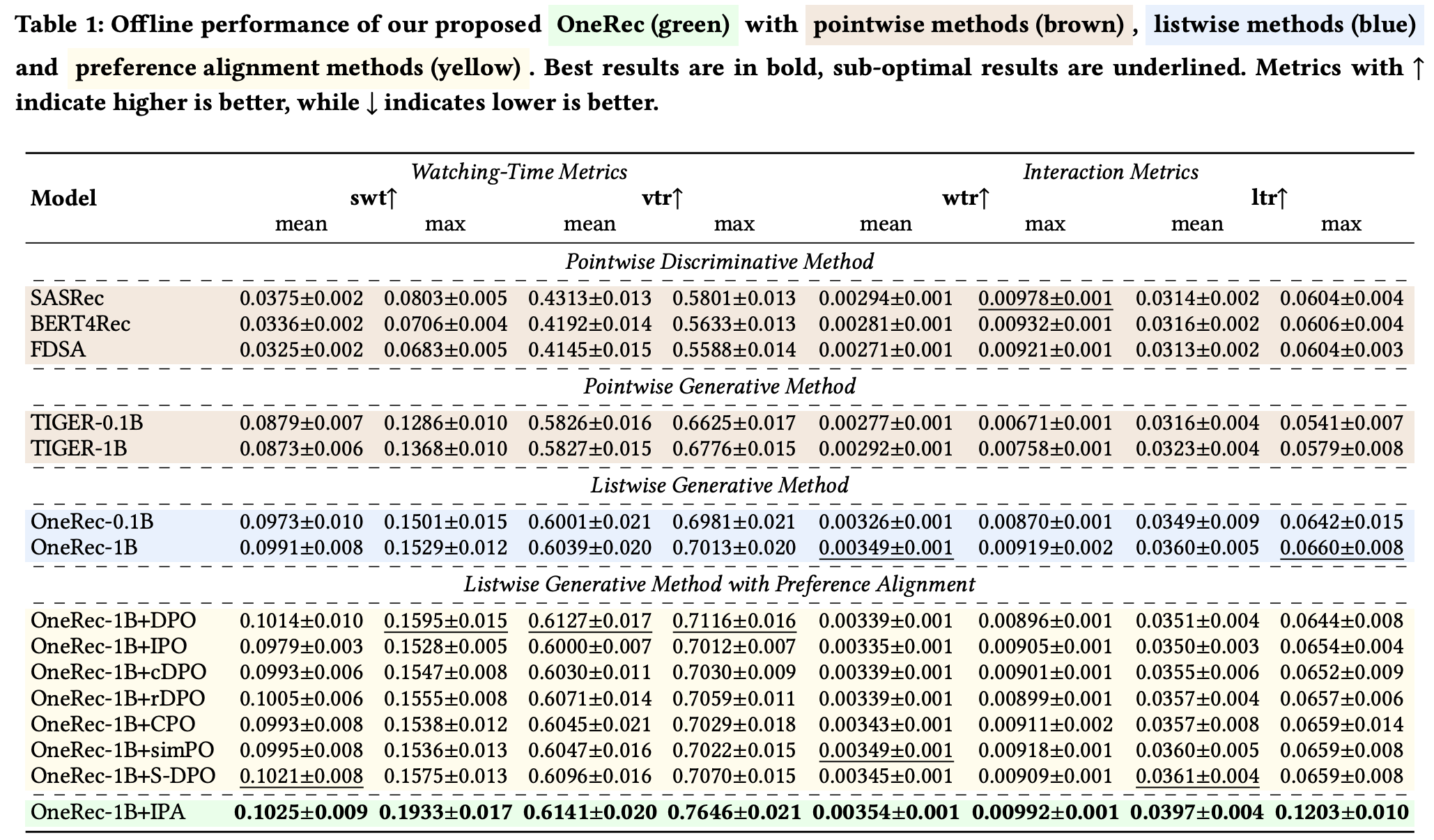
- 从表1可以观察到一些补充结论:
- DPO其实是一个不错的基线,且效果基本上优于其他DPO变体(包括IPO、cDPO、rDPO和CPO等),只有simPO和s-DPO在某些指标上能超过DPO
- 实验评估是离线的,基于奖励模型的,评估准确性取决于奖励模型
Ablation Study
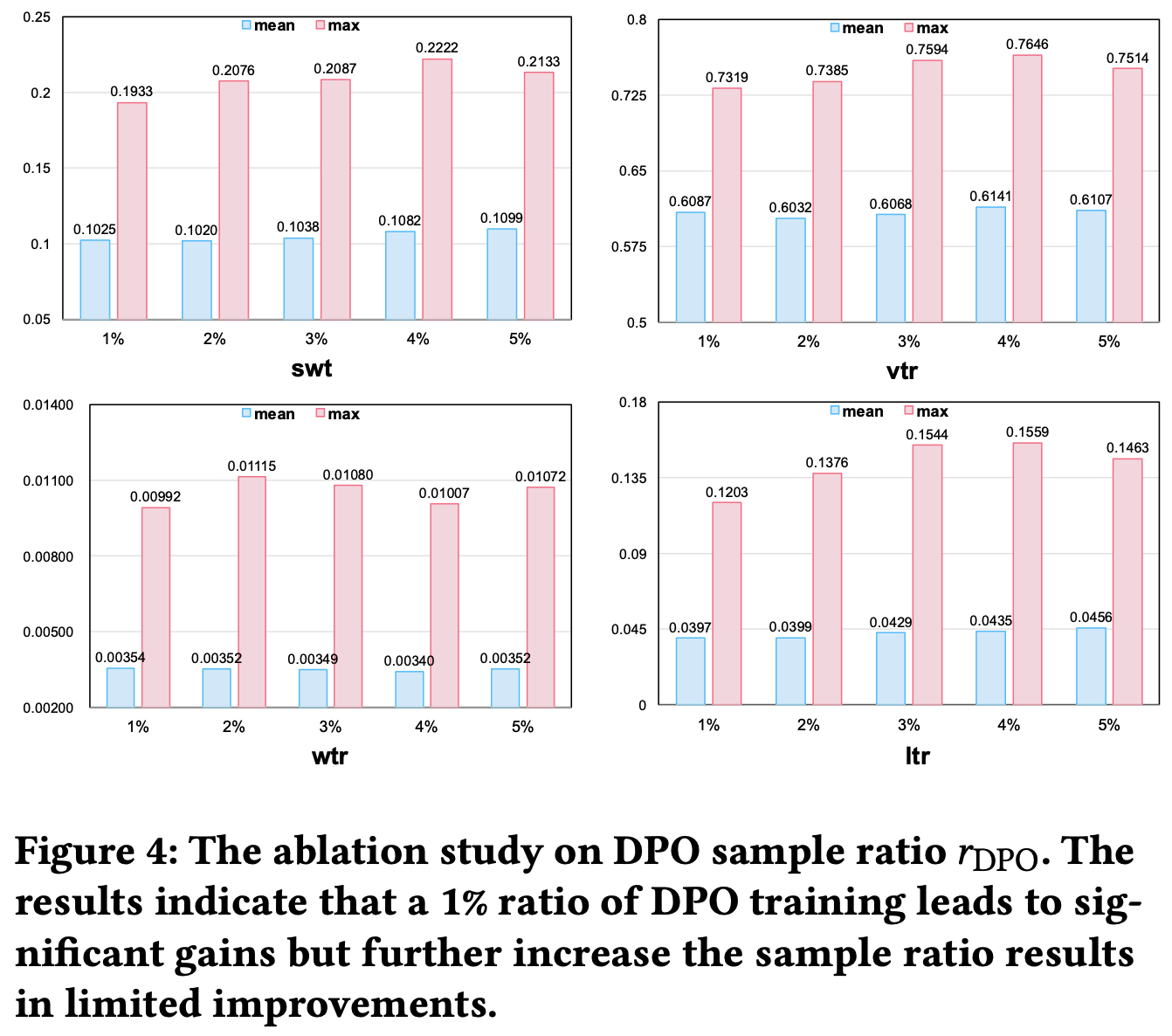
DPO样本比率消融
- 为了研究DPO训练中样本比率 \(r_{DPO}\) 的影响,论文将DPO样本比率从 1% 变化到 5%
- 如图4所示,消融结果表明,增加样本比率在多个评估目标上带来的性能提升微乎其微
- 效果 :尽管计算成本增加,但性能提升不显著(超过1% 基线)
- 算力 :在DPO样本服务器推理期间,样本比率与GPU资源利用率之间存在线性关系:5% 的样本比率比1% 的基线需要多5倍的GPU资源。这种缩放特性在计算效率和模型性能之间建立了明确的权衡
- 因此,在平衡计算效率和性能的最佳权衡后,论文在训练中应用 1% 的DPO样本比率,它在仅需要更高样本比率所需计算资源的 20% 的情况下,实现了观察到的最大性能的平均95%
模型缩放消融
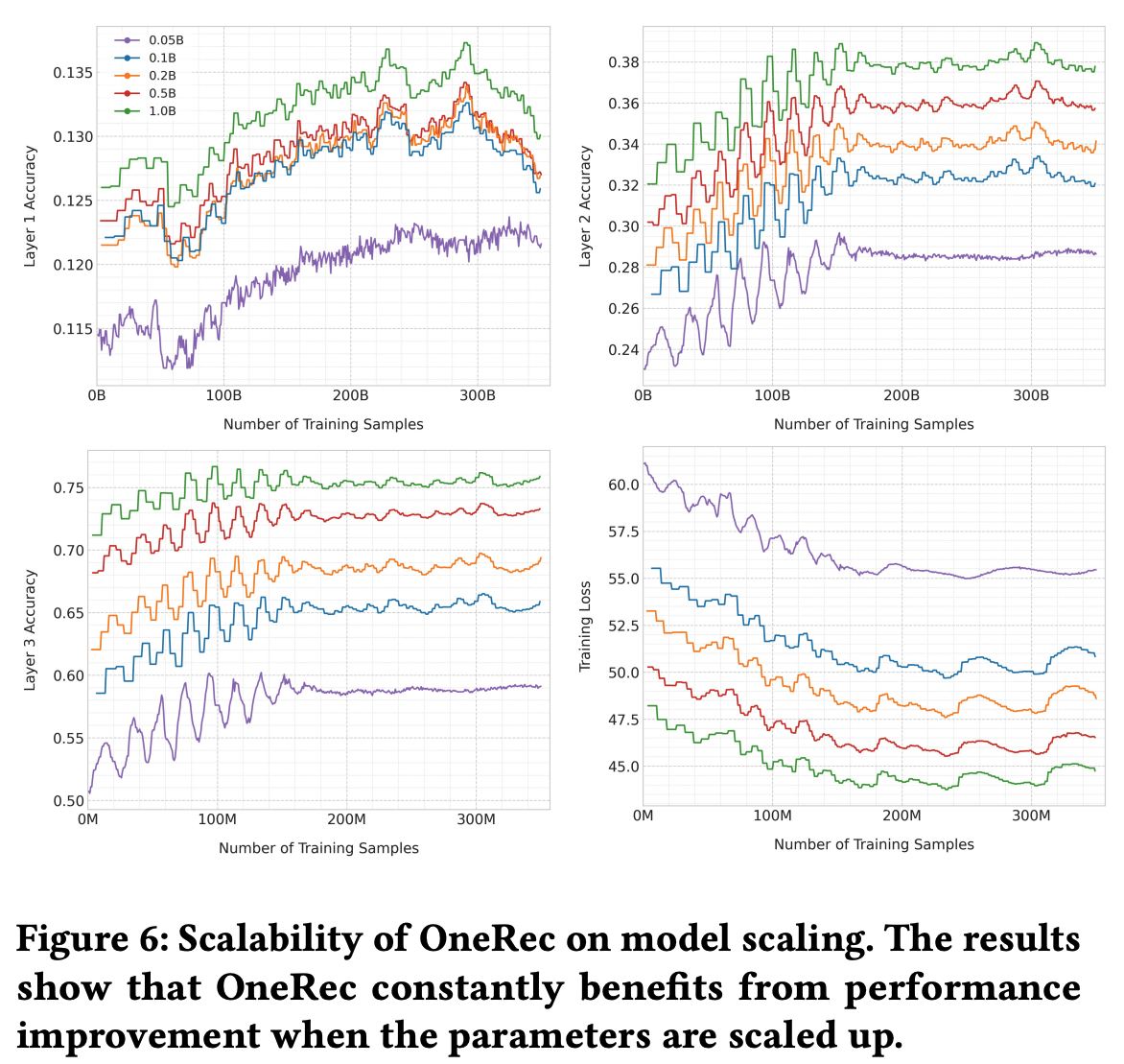
- 当模型规模增加时OneRec的性能表现(如图6所示):
- 将OneRec从0.05B扩展到1B实现了持续的精度提升,展示了一致的缩放特性
- 与 OneRec-0.05B 相比,OneRec-0.1B 在精度上实现了显著的最大 14.45% 的提升
- 在扩展到0.2B、0.5B和1B时,还可以分别实现 5.09%、5.70% 和5.69% 的额外精度提升
Prediction Dynamics of OneRec
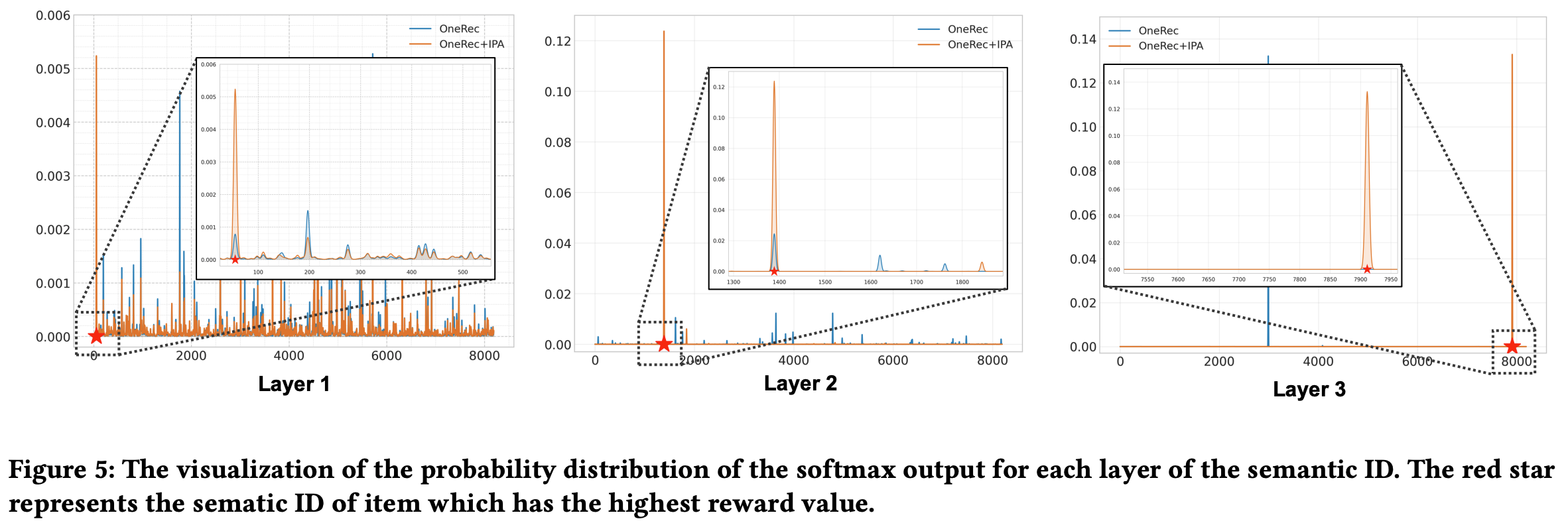
- 如图5所示,论文展示了不同层上 8192 个 code 的预测概率分布,其中红星表示奖励值最高的 item 的语义ID
- 与OneRec基线相比,OneRec+IPA 在预测分布上表现出显著的置信度转移,这表明论文提出的偏好对齐策略有效地鼓励基础模型产生更符合偏好的生成模式
- 理解 :OneRec+IPA 上模型输出更自信,更集中,熵更小
- 此外,论文观察到第一层的概率分布(熵 = 6.00)比后续层(第二层平均熵 = 3.71,第三层熵 = 0.048)具有更大的分散性,后续层的分布逐渐集中。这种分层不确定性的降低可以归因于自回归解码机制:初始层的预测继承了前序解码步骤中更高的不确定性,而后续层受益于积累的上下文信息,这些信息限制了决策空间
- 现象 :不论开始层输入分布如何,后续层都倾向于分布更集中
- 理解(TODO):后续层是属于第一层的残差,残差分布倾向于一致,所以后续层对应的SID都差不多?这里跟RQ-VAE中的沙漏现象是否相似?
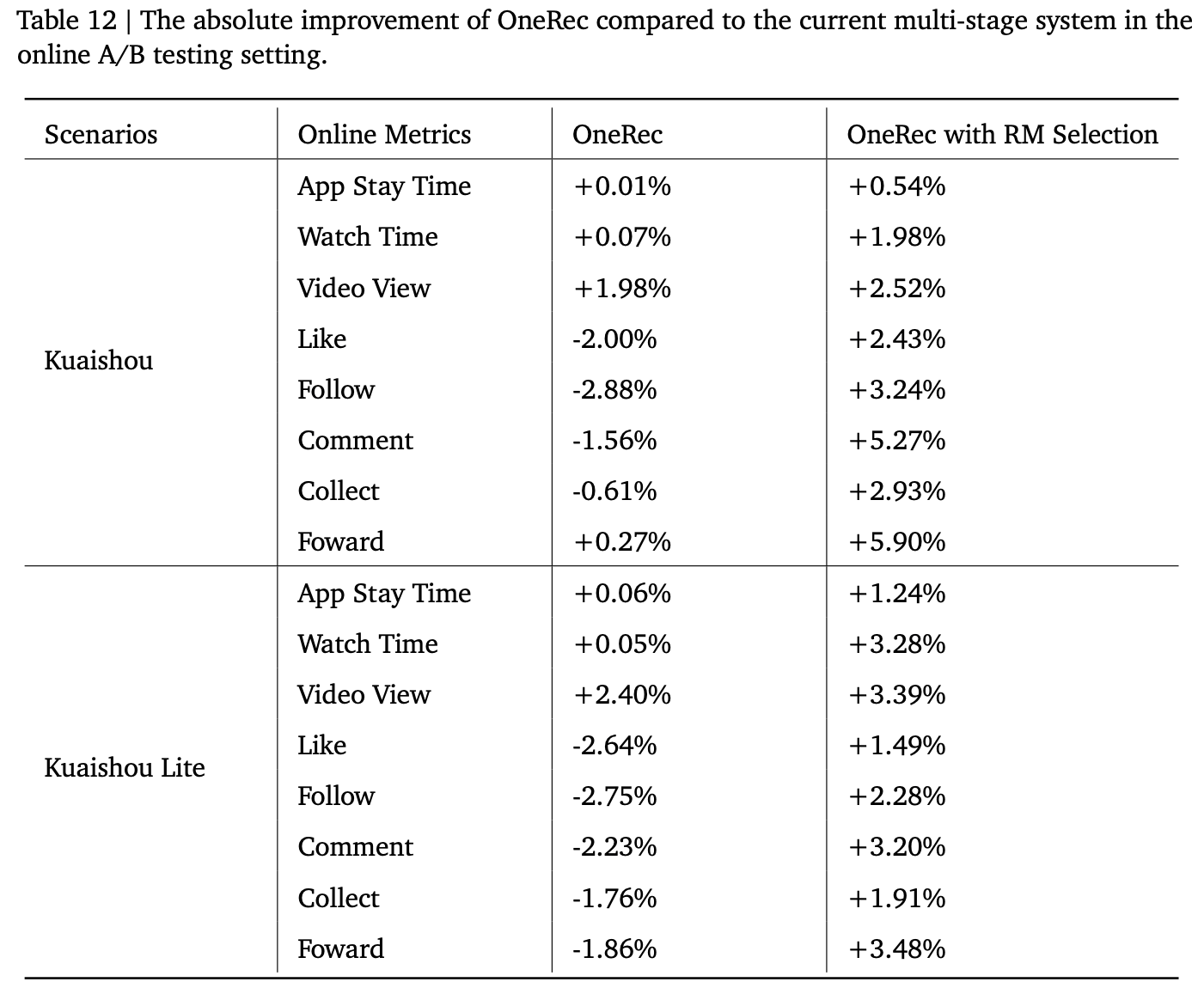
在线A/B测试
- 为了评估OneRec的在线性能,论文在快手主页面的视频推荐场景中进行了严格的在线A/B测试
- 线上流量划分 :论文将OneRec的性能与当前的 multi-stage 推荐系统进行比较,使用 1% 的主要流量进行实验
- 评估指标 :论文使用总观看时间来衡量用户观看视频的总时长,平均观看时长计算用户在推荐系统展示请求的 session 时每视频的平均观看时间
- 结论 :在线评估表明,OneRec在总观看时间上实现了1.68% 的提升,在平均观看时长上实现了6.56% 的提升,这表明OneRec实现了更好的推荐结果,并为平台带来了可观的收益增长

OneRec总结与讨论
- 在论文中,论文重点介绍了一种用于 single-stage 生成式推荐的工业解决方案。论文的解决方案有三个关键贡献:
- 第一,论文通过应用MoE架构,论文以高计算效率有效地扩展了模型参数,为大规模工业推荐提供了可扩展的蓝图
- 第二,论文发现以 session-wise 的生成方式对目标 item 的上下文信息进行建模的必要性,证明了上下文序列建模本质上比孤立的逐点方式更能捕捉用户偏好动态
- 第三,论文提出了一种迭代偏好对齐(IPA)策略,以提高OneRec在不同用户偏好模式下的泛化能力。广泛的离线实验和在线A/B测试验证了OneRec的有效性和效率
- 在线实验 :此外,论文对在线结果的分析表明,除了用户观看时间外,论文的模型在点赞等交互指标方面存在局限性
- 未来规划 :在未来的研究中,论文旨在增强端到端生成式推荐在多目标建模方面的能力,以提供更好的用户体验
补充:相关工作(直译,保留引用)
生成式推荐
- 近年来,随着生成模型的显著进展,生成式推荐受到越来越多的关注
- 传统基于嵌入的检索方法主要依赖双塔模型计算候选项排序分数,并利用高效的MIPS或ANN(2015; 2016)搜索系统检索Top-K相关项
- 生成式检索(GR)(2016)将数据库相关文档检索问题转化为序列生成任务,按序生成文档标记(如标题、ID或预训练语义ID)。GENRE(2019)首次采用Transformer架构进行实体检索,基于上下文自回归生成实体名称。DSI(2016)提出为文档分配结构化语义ID的概念,并训练 Encoder-Decoder 模型实现生成式文档检索。TIGER(2019)将该范式扩展至推荐系统,提出生成式 item 检索模型
- 除生成框架外,item 索引方法也备受关注。近期研究聚焦于语义索引技术(2017; 2019),旨在基于内容信息索引 item。例如,TIGER(2019)和LC-Rec(2019)对 item 标题和描述的文本嵌入应用残差量化(RQ-VAE)进行标记化;Recforest(2017)则通过层次化K均值聚类获取簇索引作为标记。EAGER(2019)等研究进一步探索将语义与协同信息共同融入标记化过程
语言模型的偏好对齐
- 在 LLM 的 post-training 阶段(2018), RLHF(2017; 2019)是主流方法,其通过奖励模型表征人类反馈,指导模型对齐人类价值观
- RLHF 存在不稳定和低效问题。直接偏好优化(DPO)(2024)通过闭式解推导最优策略,直接利用偏好数据优化模型。此外,多种改进方法被提出:
- IPO(2024)绕过DPO的两步近似,提出通用目标;
- cDPO(2024)引入超参数ε缓解噪声标签影响;
- rDPO(2024)设计原始二元交叉熵损失的无偏估计
- CPO(2024)、simDPO(2024)等变体也从不同角度优化DPO
- 与NLP中人类显式标注偏好数据不同,推荐系统的偏好学习面临 user-item 交互数据稀疏的独特挑战,相关研究仍处于探索阶段。不同于S-DPO(2024)为基于语言的推荐器整合多负例数据,论文训练奖励模型并基于其分数为用户定制个性化偏好数据
附录:OneRec 的一些讨论
OneRec 冷启动
- 用户冷启动:新用户没有历史行为序列怎么办?OneRec的冷起不好做吧?
- 商家冷启动:由于语义空间的存在,只要ID语义接近,理论上就能做到冷启动?
附录:OneRec Technical Report
- 参考链接:
- OneRec Technical Report, 20250616, Kuaishou:论文是一个技术报告,相对原始论文补充了很多细节,快40页
- 效果&成本双突破!快手提出端到端生成式推荐系统OneRec!,快手技术公众号
OneRec Technical Report 的整体说明
- 整体架构和 OneRec 相似,多了些细节和改进
- 论文暂时主要简单介绍一下与原始论文相比的重点改进
- 架构上,GPU利用率(MFU,模型浮点运算利用率)从 10% 提升至 训练23.7% 和 推理28.6% (快追上业内主流 AI 模型效能)
- Beam Search 从之前的 128 提升至 512,说明多采样才是硬道理
- 对模型生成的合法性给与格式奖励,可以缓解模型生成的高概率样本不符合规范的情况,这里的不符合规范指 RQ 编码后输出的 Token 空间可能是无意义的
- 使用了 RSFT + RL 的范式做训练,原始 OneRec 论文是抽取最好和最坏的样本做 DPO
- 提出了一种创新的 RL 方法,ECPO(Early Clipped GRPO),是对 GRPO 方法的一种改进
- 收益披露:
- 在快手主流量上已经承接了 25% 的QPS
- 在各种指标上均有涨幅,其中一些指标涨幅超过 5%
- 本地生活场景收益尤其明显(在本地生活场景已经 100% 流量推全)
除了短视频推荐的消费场景之外,OneRec在快手本地生活服务场景同样表现惊艳:AB对比实验表明该方案推动GMV暴涨21.01%、订单量提升17.89%、购买用户数增长18.58%,其中新客获取效率更实现23.02%的显著提升
- 题外话:未披露作者信息,是怕被挖人吧
对齐微调升级为 ECPO(Early Clipped GRPO)
- OneRec Technical Report 中使用的是 ECPO,原始 OneRec 论文用的是 DPO
- 具体来说,对于用户 \( u \),论文使用旧策略模型生成 \( G \) 个物品。每个物品与用户一起输入偏好奖励模型,得到 P-Score 作为奖励 \( r_i \)。优化目标如下:
$$
\mathcal{J}_{\text{ECPO}}(\theta) = \mathbb{E}_{u \sim P(U), \{o_i\}_{i=1}^G \sim \pi_{\theta_{old} } } \left[ \frac{1}{G} \sum_{i=1}^G \min \left( \frac{\pi_\theta(o_i|u)}{\color{red}{\pi’_{\theta_{old} }}(o_i|u)} A_i, \text{clip} \left( \frac{\pi_\theta(o_i|u)}{\color{red}{\pi’_{\theta_{old}} }(o_i|u)}, 1 - \epsilon, 1 + \epsilon \right) A_i \right) \right], \\
A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \ldots, r_G\})}{\text{std}(\{r_1, r_2, \ldots, r_G\})},\\
\color{red}{\pi’_{\theta_{old} }(o_i|u) = \max \left( \frac{\text{sg}(\pi_\theta(o_i|u))}{1 + \epsilon + \delta}, \pi_{\theta_{old} }(o_i|u) \right), \quad \delta > 0,}
$$- \(\text{sg}\) 表示停止梯度操作(stop gradient operation)
- \(\delta\) 是一个大于 0 的超参数
- 论文对 GRPO(Group Policy Relative Optimization)(2024) 进行了修改,使其训练过程更加稳定
- 如图 6 所示,在原始 GRPO 中,允许负优势(negative advantages)的策略比率(\(\pi_\theta / \pi_{\theta_{old} }\))较大,这容易导致梯度爆炸
- 因此,论文预先对具有较大比率的策略进行截断,以确保训练稳定性,同时仍允许相应的负优势生效
- \(\delta\) 越大,可容忍的策略比率越大,意味着可容忍的梯度越大,这可以根据实际需求确定
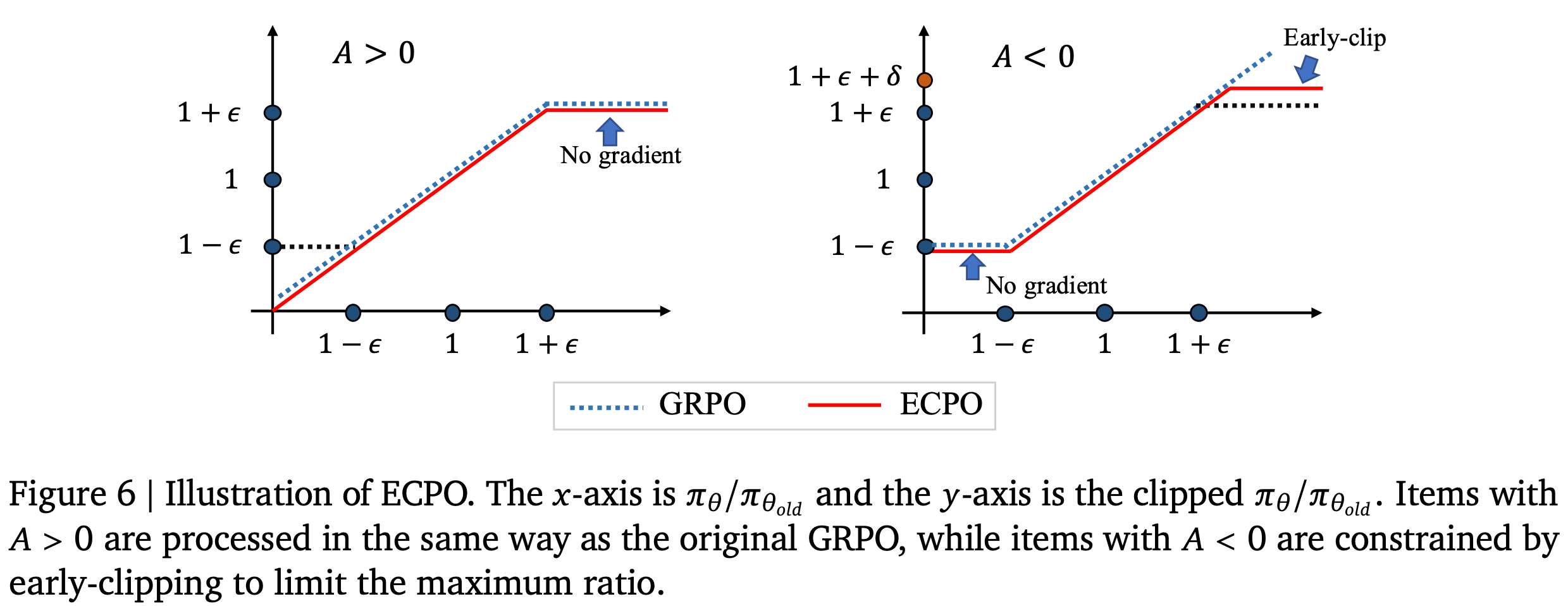
- 在 OneRec 中,论文将 \(\delta\) 设为 0.1,表示允许负优势的策略比率略微超过 \(1 + \epsilon\)
- 论文移除了 KL 散度损失(KL divergence loss),因为在 OneRec 中, RL 和 SFT 是一起训练的,SFT 损失确保了模型的稳定性
补充:对 ECPO 和 GRPO 的理解
- 当 advantage 为正时,ECPO 和 GRPO 等价(可以证明,都会在 \(1+\epsilon\) 处截断梯度)
- 当 advantage 为负时,ECPO 和 GRPO 不同:
- 若 \(\delta \to +\infty\),那么 ECPO 和 GRPO 依然等价
- 否则,相当于允许 \(1+\epsilon+\delta\) 样本的梯度更新,但是样本的更新比值是基于 \(1+\epsilon+\delta\) 的,而不是 \(\frac{\pi_\theta}{\pi_{\theta_\text{old}}}\),这相当于对梯度进行了一定限制
- 当 \(A\) 为负时,此时若 \(\frac{\pi_\theta}{\pi_{\theta_\text{old}}}\) 很大,则 \(\pi_{\theta_\text{old}}\) 很小
- 于是有取 \(\max\) 操作后 \(\pi’_{\theta_\text{old}} = \frac{\text{sg}(\pi_\theta)}{1+\epsilon+\delta}\),从而 Clip 结果是 \(1+\epsilon\)
- 经过 \(\min\) 的结果是 \(\frac{\pi_\theta \cdot (1+\epsilon + \delta)}{\text{sg}(\pi_{\theta})}\)
- 即梯度权重从原始的 \(\frac{1}{\pi_{\theta_\text{old}}}\) 变成了 \(\frac{\text{sg}(\pi_{\theta})}{1+\epsilon+\delta}\)
- 结论:不论 \(\pi_{\theta_\text{old}}\) 多小,都能稳稳控制梯度权重为 \(\frac{\text{sg}(\pi_{\theta})}{1+\epsilon+\delta}\),这个值是有限的,而 \(\frac{1}{\pi_{\theta_\text{old}}}\) 这个值可能是无限大
- 理解1:因为 \(\frac{\pi_\theta}{\pi_{\theta_\text{old}}}\) 的值可能是无穷大,这样可以缓解梯度爆炸的问题
- 理解2:为什么 advantage 为正时不需要过小的 \(\frac{1}{\pi_{\theta_\text{old}}}\) 限制呢?因为此时的 \(\frac{\pi_\theta}{\pi_{\theta_\text{old}}}\) 值最小也就是 0,不会造成梯度爆炸,最多造成梯度消失(其实这部分也可以关注一下)
Post-Training 中加入了 RSFT
- 在后训练中,除了使用了 ECPO 外,还引入了 RSFT(Reject Sampling Fine-Tuning)
- 具体来说:拒绝后 50% 的样本
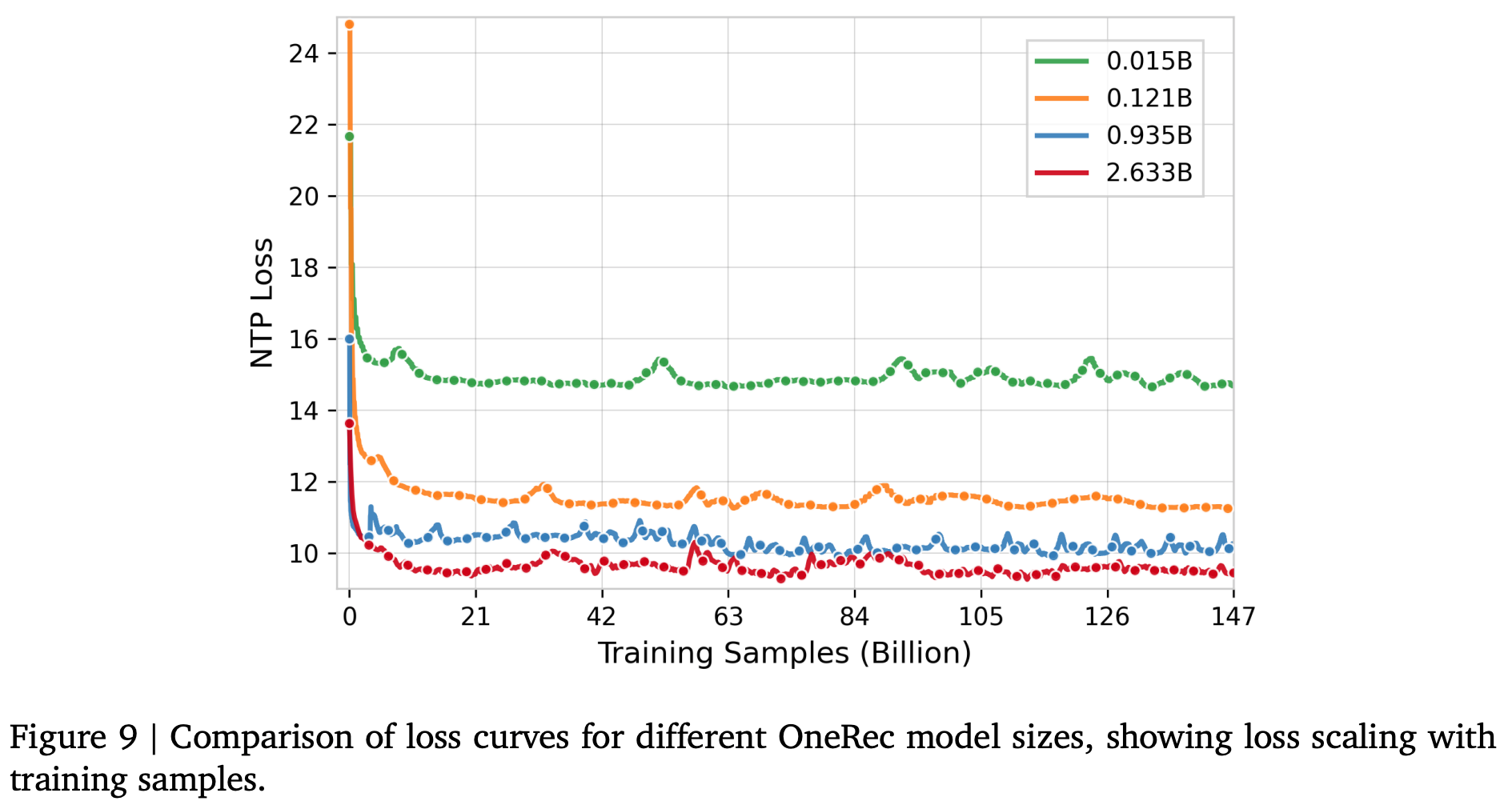
简单证明了存在 Scaling Law
- 仅仅在损失函数上证明了存在 Scaling Law
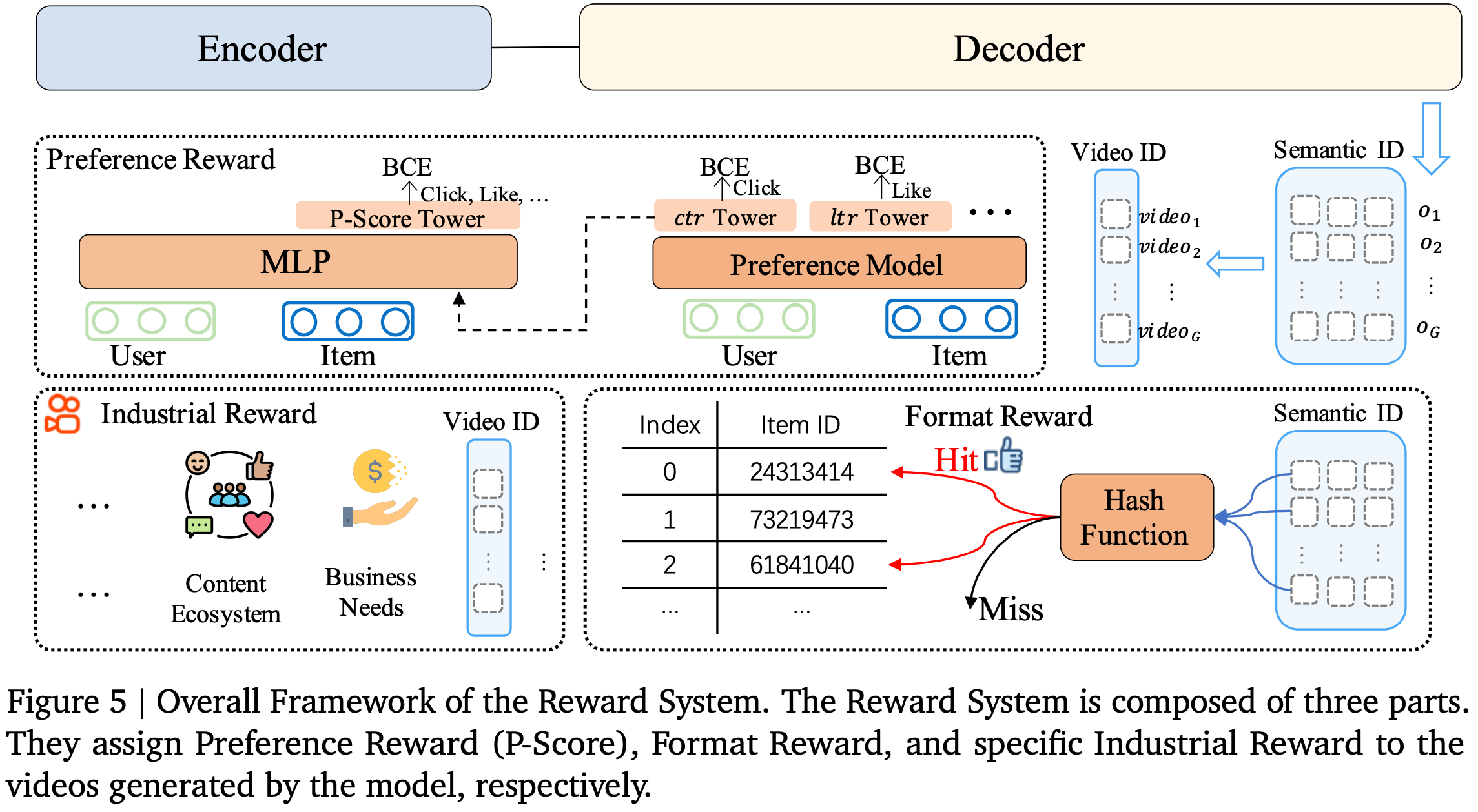
披露了更多 RM 细节
- Reward Model 细节披露
收益细节
- 线上 AB 测试收益披露