整体说明
- 当前推荐系统的特点 :
- 大规模推荐系统的特点在于其依赖高基数(high cardinality,注:也称为高维)、异构特征(heterogeneous features),并且需要每天处理数百亿用户行为
- 尽管大多数工业界的深度学习推荐模型(Deep Learning Recommendation Models,DLRMs)利用海量数据和数千个特征进行训练,却未能实现与计算资源的有效扩展(即增加了资源,效果得不到对应的提升)
- 论文方案一句话说明 :(受 Transformer 在语言和视觉领域成功的启发)
- 论文将推荐问题重新定义为生成式建模框架下的 Squential Transduction 任务(Generative Recommenders(GRs),生成式推荐器),并提出了一种新架构HSTU ,专为高基数、非平稳的流式推荐数据设计
- 注:论文的 Squential Transduction 和 Transduction Learning(直推式学习)没有直接关系(虽然二者名字很像);
- Transduction Learning(直推式学习) :利用训练数据和测试数据的整体信息,直接对见过的测试数据做出预测
- Inductive Learning(归纳式学习) :利用训练数据的信息,训练一个可以泛化到未见过的测试数据的通用的模型
- 从定义看,论文本质还是一个Inductive Learning(归纳式学习) ,学到的模型是要使用在未知数据场景的(包括未知用户、未知时间和未知商品)
- 效果和效率 :
- 离线效果 :在合成和公开数据集上,HSTU相比基线模型在 NDCG 指标上最高提升 65.8%
- 效率 :并且在处理 8192 长度序列时比基于 FlashAttention2 的 Transformer 快 5.3 倍至 15.2 倍
- 在线效果 :基于 HSTU 的生成式推荐器拥有1.5万亿参数,在线A/B测试中指标提升12.4%,已在拥有数十亿用户的互联网平台的多个场景中部署
- scaling law发现 :更重要的是,生成式推荐器的模型质量随训练计算量呈幂律增长(power-law),扩展范围达到GPT-3/LLaMa-2规模,这减少了未来模型开发所需的 carbon footprint(碳排放总和),并为推荐系统中的首个基础模型铺平了道路
- 理解:power-law说明模型的算力投入可以很高效的得到回报,所以不需要盲目增加很多计算资源,也就减少了碳排放
- 注意:论文的方法依然保留了推荐系统中的 Retrieval-Ranking 两阶段(Retrieval也称为召回或 Retrieval 阶段),只是分别将两阶段都使用生成式模型来建模了,对于召回阶段,甚至可以将生成式模型作为一个新的召回通道使用,作为对原始 DLRM 的一种补足
一些背景讨论
- 传统推荐系统 : SOTA 推荐方法主要基于深度学习推荐模型 (DLRM),其特点在于使用异构特征,包括数值特征(如 counters 和 ratios)、嵌入以及分类特征(如商品ID、用户ID等)
- 由于每分钟都有新内容和商品加入,特征空间具有极高的基数,通常达到十亿级别
- 为了利用这些数以万计的特征,DLRM 采用各种神经网络组合特征、转换中间表示并生成最终输出
- 尽管 DLRM 利用了大量人工设计的特征和海量数据进行训练,但工业界大多数 DLRM 的计算扩展性较差。这一显著限制至今仍未得到解决
- 论文的思路 :受 Transformer 在语言和视觉领域成功的启发,论文重新审视了现代推荐系统中的基础设计选择,但作者观察到:在十亿用户规模下,这需要克服三个挑战 :
- 推荐系统中的特征缺乏明确结构 :虽然在小规模场景中已探索过序列化方法(附录B详细讨论),但工业级 DLRM 中异构特征(包括高基数ID、交叉特征、计数器、比率等)起着关键作用
- 持续变化的十亿级词汇表 :与语言模型中十万级静态词汇表相比,十亿级动态词汇表带来了训练挑战,并由于需要考虑数万个目标感知(target-aware)候选而推高了推理成本
- 目标感知(target-aware)指生成用户表示或进行预测时,能够动态地结合当前候选内容(target item)的信息,从而更精准地建模用户与特定候选内容之间的交互
- 注:传统推荐系统(如DLRMs)中,target-aware通常指在特征交互阶段显式引入候选内容(target item)的信息
- 计算成本大 :(这是大规模序列模型落地的主要瓶颈),GPT-3使用数千个GPU在1-2个月内处理了总计3000亿 token。这一规模看似惊人,但与用户行为规模相比则相形见绌。最大规模的互联网平台每天服务数十亿日活用户,用户每天与数十亿帖子、图片和视频互动。用户序列长度可达 \(10^5\) 。因此,推荐系统每天需要处理的 token 数量比语言模型1-2个月处理的量高出几个数量级
- 一个特别重要的创新点 :在本工作中,论文将用户行为视为生成式建模中的新模态(在图片、文本和视频等多模态的基础上,增加一个模态叫做用户行为)。论文的 key insights 是:
- a)给定适当的新特征空间,工业级推荐系统中的核心排序和召回任务可被转化为生成式建模问题;
- b)这一范式使论文能够系统性地利用特征、训练和推理中的冗余(redundancies)来提高效率,基于这一新范式,论文部署的模型计算复杂度比之前最先进技术高出三个数量级(如图1所示),同时核心业务指标(英文中称为topline metrics)提升了12.4%
- 问题:如何理解”特征、训练和推理中的冗余(redundancies)“这句话?
- 问题:如何理解”特征、训练和推理中的冗余(redundancies)“这句话?
- 论文的贡献可总结如下:
- 第一 :提出生成式推荐器(Generative Recommenders,GRs) ,这一新范式将取代 DLRM
- 论文将 DLRM 中的异构特征空间序列化并统一(注:用户行为视为特定的一个新模态),当序列长度趋近无穷时,新方法可近似完整的 DLRM 特征空间。使得:
- 论文能将主要推荐问题(排序和召回)重新定义为GR中的纯 Squential Transduction 任务
- 论文模型训练能以序列化、生成式的方式进行,从而允许论文在相同计算量下处理多几个数量级的数据
- 论文将 DLRM 中的异构特征空间序列化并统一(注:用户行为视为特定的一个新模态),当序列长度趋近无穷时,新方法可近似完整的 DLRM 特征空间。使得:
- 第二 :解决训练和推理过程中的计算成本挑战 :
- 提出新结构 :提出新的 Squential Transduction 架构——分层 Squential Transduction 单元(Hierarchical Sequential Transduction Units,HSTU)。HSTU针对大规模非平稳词汇表修改了注意力机制 ,并利用推荐数据集特性实现比基于 FlashAttention2 的 Transformer 在 8192 长度序列上快5.3倍至15.2倍
- 提出新算法M-FALCON :通过新算法M-FALCON完全平摊计算成本,论文能在传统 DLRM 使用的相同推理预算下,服务复杂度高出285倍的GR模型,同时实现1.50-2.99倍的加速
- 第三 :验证所提技术在合成数据集、公开数据集以及在拥有数十亿日活用户的大型互联网平台多个场景中的部署效果
- 据论文所知,论文的工作首次展示了纯 Squential Transduction 架构(如HSTU)在生成式设置(GRs)中显著优于工业级大规模 DLRM。值得注意的是,论文不仅克服了传统 DLRM 中已知的扩展瓶颈,还进一步证明了扩展定律(scaling law)适用于推荐系统 ,这可能是推荐系统的”ChatGPT时刻“
- 第一 :提出生成式推荐器(Generative Recommenders,GRs) ,这一新范式将取代 DLRM
推荐作为 Squential Transduction 任务:从 DLRM 到GR
统一 DLRM 中的异构特征空间
- 现代 DLRM 模型通常使用大量分类(sparse)和数值(dense)特征进行训练。在GR中,论文将这些特征整合并编码为统一的时间序列 ,如图2所示
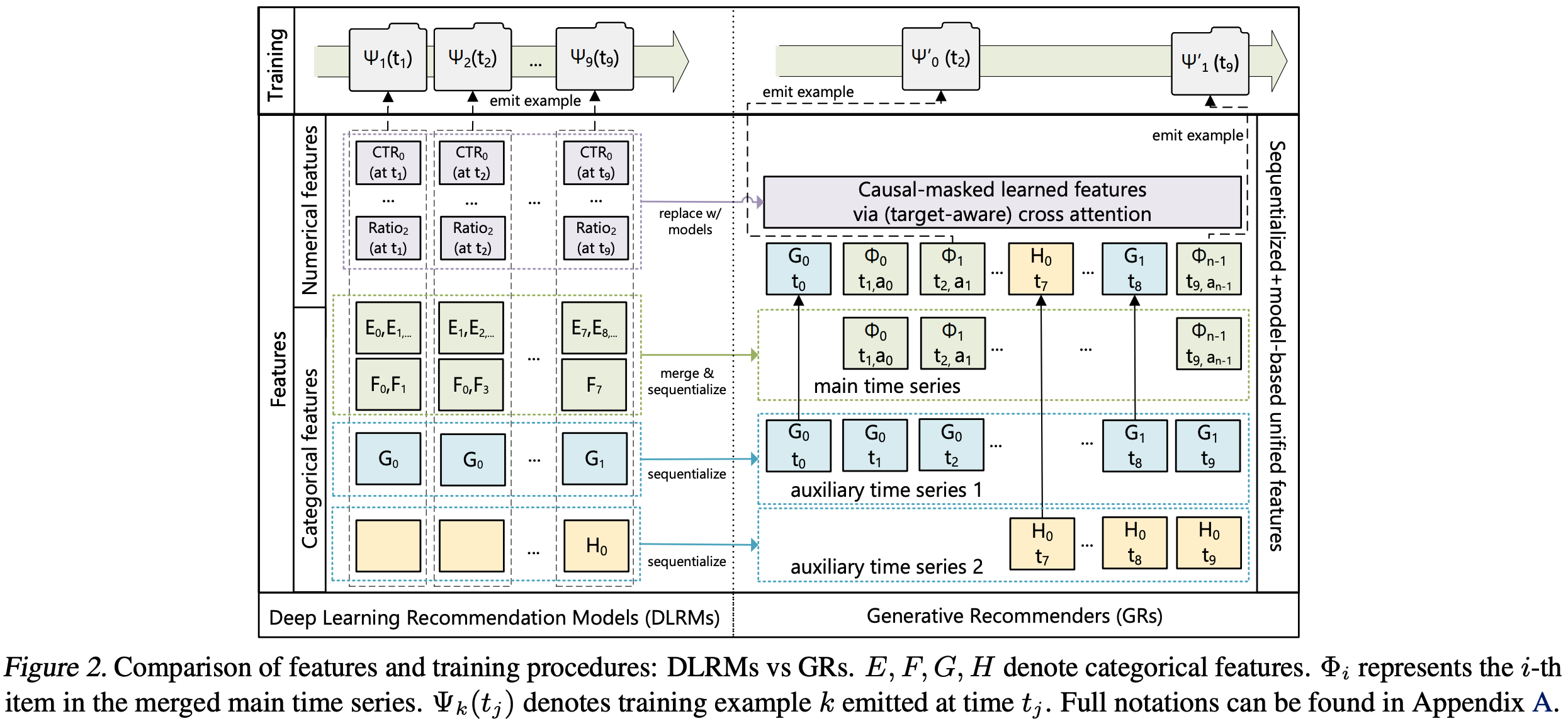
- 分类(sparse)特征 :这类特征的例子包括用户喜欢的商品、用户关注的某类别(如户外)创作者、用户语言、用户加入的社区、请求发起的城市等。论文按以下方式将这些特征序列化:
- 选择最长的时间序列(通常通过合并代表用户互动商品的特征)作为主时间序列
- 其余特征通常是随时间缓慢变化的序列(如人口统计信息或关注的创作者),论文通过保留每个连续段的最早条目(entry)来压缩这些时间序列,然后将结果合并到主时间序列中。由于这些时间序列变化非常缓慢,这种方法不会显著增加总体序列长度
- 理解:如图2所示,auxiliary time series 1 和 auxiliary time series 2 中,分别只有每个连续段的第一个entry被插入到 main time series 中(注:auxiliary time series 1 包含多个连续段,每个连续段的第一个 entry 都会保留并插入 main time series 中)
- 这部分写得不是很清晰,有点晦涩,原文介绍如下:
Categorical (‘sparse’) features. Examples of such features include items that user liked, creators in a category (e.g., Outdoors) that user is following, user languages, communities that user joined, cities from which requests were initiated, etc. We sequentialize these features as follows. We first select the longest time series, typically by merging the features that represent items user engaged with, as the main time series. The remaining features are generally time series that slowly change over time, such as demographics or followed creators. We compress these time series by keeping the earliest entry per consecutive segment and then merge the results into the main time series. Given these time series change very slowly, this approach does not significantly increase the overall sequence length.
- 数值(dense)特征 :这类特征的例子包括加权和衰减计数器、比率等(例如,某个特征可能代表用户过去对匹配特定主题商品的点击率(CTR))
- 与分类特征相比,这些特征变化更频繁 ,可能随每个(用户,商品)互动而变化,所以从计算和存储角度看,完全序列化这些特征并不可行
- 然而一个重要观察是:论文执行这些聚合所基于的分类特征(如商品主题、位置)在GR中已被序列化和编码。因此 ,给定足够强大的 Squential Transduction 架构与 target-aware 公式相结合,当增加GR中的总体序列长度和计算量时,论文可以移除数值特征 ,因为它们能被有效地捕捉
将排序和召回重新定义为 Squential Transduction 任务
- 给定按时间顺序排列的 \(n\) 个 token 列表 \(x_{0},x_{1},\ldots,x_{n-1}\) (\(x_{i}\in\mathbb{X}\)),观察到这些 token 的时间 \(t_{0},t_{1},\ldots,t_{n-1}\) ,Squential Transduction 任务将此输入序列映射到输出 token \(y_{0},y_{1},\ldots,y_{n-1}\) (\(y_{i}\in\mathbb{X}\cup\{\varnothing\}\)),其中 \(y_{i}=\varnothing\) 表示 \(y_{i}\) 未定义

- 论文用 \(\Phi_{i}\in\mathbb{X}_{c}\) (\(\mathbb{X}_{c}\subseteq\mathbb{X}\))表示系统向用户提供的内容(即历史上展示给用户看过的内容 ,如图片或视频)。由于不断有新内容产生 , \(\mathbb{X}_{c}\) 和 \(\mathbb{X}\) 是非平稳的。用户可以用某个行为 \(a_{i}\) (如点赞、跳过、视频完播+分享) \(a_{i}\in\mathbb{X}\) 来回应 \(\Phi_{i}\) 。论文用 \(n_{c}\) 表示用户互动过的内容总数
- 对 Retrieval 输入的理解:输入是 \(\{(\Phi_{0},a_0),(\Phi_{1},a_1),\cdots,(\Phi_{n_c-1},a_{n_c-1})\}\) ,表示历史上依次给用户分别展示了内容 \(\Phi_{i}\) 以后用户的行为 \(a_{i}\) 的元组序列
- 对 Retrieval 输出的理解:每个元组 \((\Phi_{i},a_i)\) 对应输出一个目标值 \(\Phi_{i}^{\prime}\) :
$$\Phi_{i}^{\prime}=
\begin{cases}
\Phi_{i}& \ a_i \ \text{ is positive}\\
\varnothing& \ \text{ otherwise}
\end{cases}$$ - 对 Ranking 输入的理解:如表1所示,对输入 \(x_i\) 的建模是, \(\{\Phi_{0},a_0,\Phi_{1},a_1,\cdots,\Phi_{n_c-1},a_{n_c-1}\}\) 是历史行为序列,表示历史上依次给用户分别展示了内容 \(\Phi_{i}\) 以后用户的行为 \(a_{i}\)
- 对 Ranking 输出的理解:如表1所示,输出和输入依次对应,输入为 \(\Phi_{i}\) 时预估目标是用户的行为 \(a_{i}\)
- 在因果自回归设置中,标准排序和 Retrieval 任务可定义为 Squential Transduction 任务(表1)。论文得出以下观察:
- 召回(Retrieval) :在推荐系统的召回阶段,论文学习 \(\Phi_{i+1}\in\mathbb{X}_{c}\) 上的分布 \(p(\Phi_{i+1}|u_{i})\) ,其中 \(u_{i}\) 是用户 \(i\) 的 token 表示。典型目标是选择 \(\arg\max_{\Phi\in\mathbb{X}_{c} }p(\Phi|u_{i})\) 以最大化某些奖励。这与标准自回归设置有两个不同:首先, \(x_{i}\) 的监督信号 \(y_{i}\) 不一定是 \(\Phi_{i+1}\) ,因为用户可能对 \(\Phi_{i+1}\) 做出负面回应。其次,当 \(x_{i+1}\) 代表非互动相关的分类特征(如人口统计信息)时, \(y_{i}\) 未定义
- 排序(Ranking) :GR中的 Ranking 任务带来独特挑战,因为工业推荐系统通常需要“目标感知”(target-aware)公式。在此设置中,目标 \(\Phi_{i+1}\) 与历史特征的”交互”(interaction)需要尽早发生,这在标准自回归设置中不可行(理解:不建模动作时,”交互”发生较晚)。论文通过表1中的交错排列商品和行为来解决这一问题,使得 Ranking 任务可被公式化为 \(p(a_{i+1}|\Phi_{0},a_{0},\Phi_{1},a_{1},\ldots,\Phi_{i+1})\) (在分类特征之前)。实践中论文使用小型神经网络将在 \(\Phi_{i+1}\) 的输出转换为多任务预测。重要的是,这使论文能在单次传递中对所有 \(n_{c}\) 次互动应用 target-aware 交叉注意力
- 补充:对论文 target-aware 实现方式的理解 :其实 Transformer 的 Attention 也有交叉功能,只要输入端有目标 item 和用户历史交互 item 即可,但论文所说的传统的自回归模型是指输入侧不包含目标 item 的情况,论文中,将动作也建模进去,则在输出对目标 item 的动作 token 时,自然就需要将目标 item 作为输入,从而也就实现了 target-aware 交叉注意力:
- 传统自回归模型预估目标为 : \(p(\Phi_{i+1}|\Phi_{0},\Phi_{1},\ldots,\Phi_{i})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列无交叉
- 注:此时动作 \(a_i\) 信息可能会作为额外表征加入到 \(\Phi_{i}\)中,所以 表述为 \(p(\Phi_{i}|(\Phi_{0}, a_{0}), …, (\Phi_{i - 1}, a_{i - 1}))\) 也可以
- 论文预估目标为 : \(p(a_{i+1}|\Phi_{0},a_{0},\Phi_{1},a_{1},\ldots,\Phi_{i+1})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列有交叉
- 传统自回归模型预估目标为 : \(p(\Phi_{i+1}|\Phi_{0},\Phi_{1},\ldots,\Phi_{i})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列无交叉
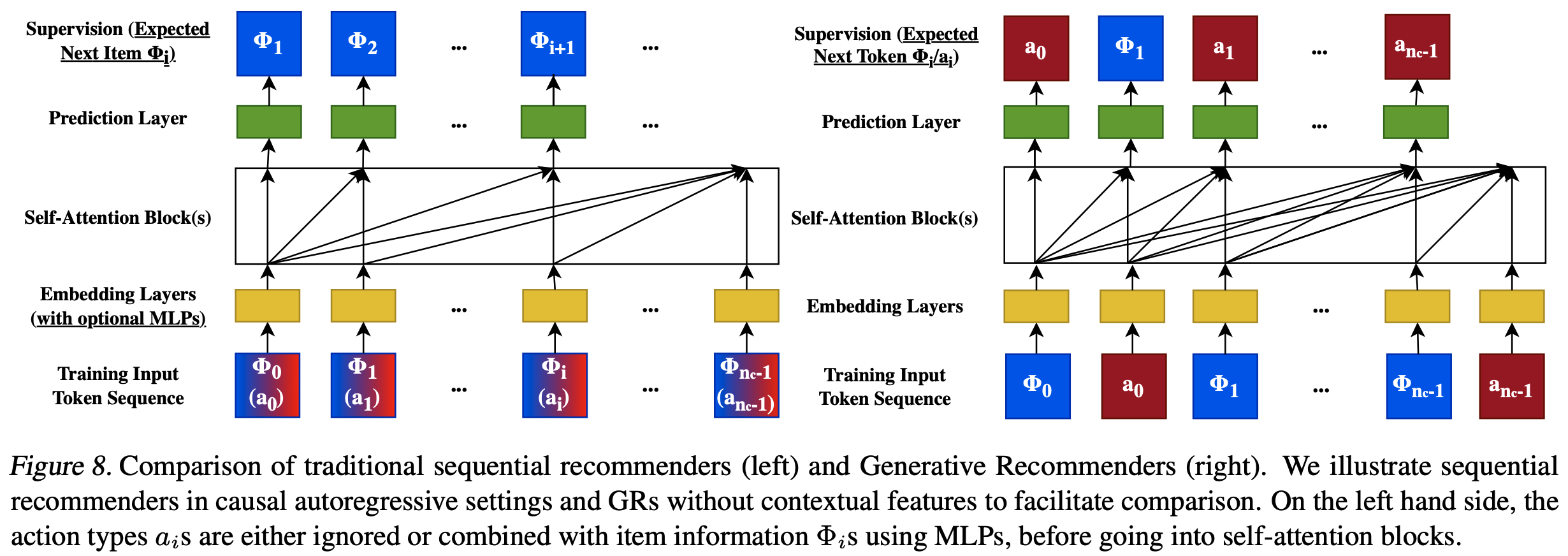
生成式训练
- 工业推荐系统通常在流式设置中训练,其中每个样本在可用时被顺序处理。在此设置中,基于自注意力的 Squential Transduction 架构(如 Transformer)的总计算需求量级为 \(\sum_{i}n_{i}(n_{i}^{2}d+n_{i}d_{ff}d)\) ,其中 \(n_{i}\) 是用户 \(i\) 的 token 数量, \(d\) 是嵌入维度,设 \(N=\max_{i}n_{i}\) ,总体时间复杂度降至 \(O(N^{3}d+N^{2}d^{2})\) ,这对推荐场景来说成本过高
- 注:更多对公示的理解看笔者补充的附录
- 为应对训练 Squential Transduction 模型处理长序列的挑战,论文从传统曝光级(impression-level)训练转向生成式训练,将计算复杂度降低 \(O(N)\) 因子,如图2顶部所示。这样做可将编码器成本平摊到多个目标上。具体来说,当论文以 \(s_{u}(n_{i})\) 的速率采样第 \(i\) 个用户时,总训练成本现在按 \(\sum_{i}s_{u}(n_{i})n_{i}(n_{i}^{2}d+n_{i}d^{2})\) 缩放,通过设 \(s_{u}(n_{i})\) 为 \(1/n_{i}\) 可降至 \(O(N^{2}d+Nd^{2})\) 。在工业级系统中实现此采样的一种方法是在用户请求或会话结束时发出训练样本,使得 \(\hat{s_{u} }(n_{i})\propto 1/n_{i}\)
- 理解:从「曝光级(impression-level)训练转向生成式训练」主要是强调从以前每个曝光都是一个样本,现在一个用户的所有行为组成一个样本
- 问题:这里对用户进行采样不会带来效果损失吗?模型看不到部分用户是OK的吗?
面向生成式推荐的高性能自注意力编码器(A High Performance Self-Attention Encoder for Generative Recommendations)
为了将生成式推荐系统(GRs)扩展至具有大规模非静态词表的工业级推荐场景,论文提出了一种新型编码器设计——分层序列转导单元(Hierarchical Sequential Transduction Unit, HSTU)
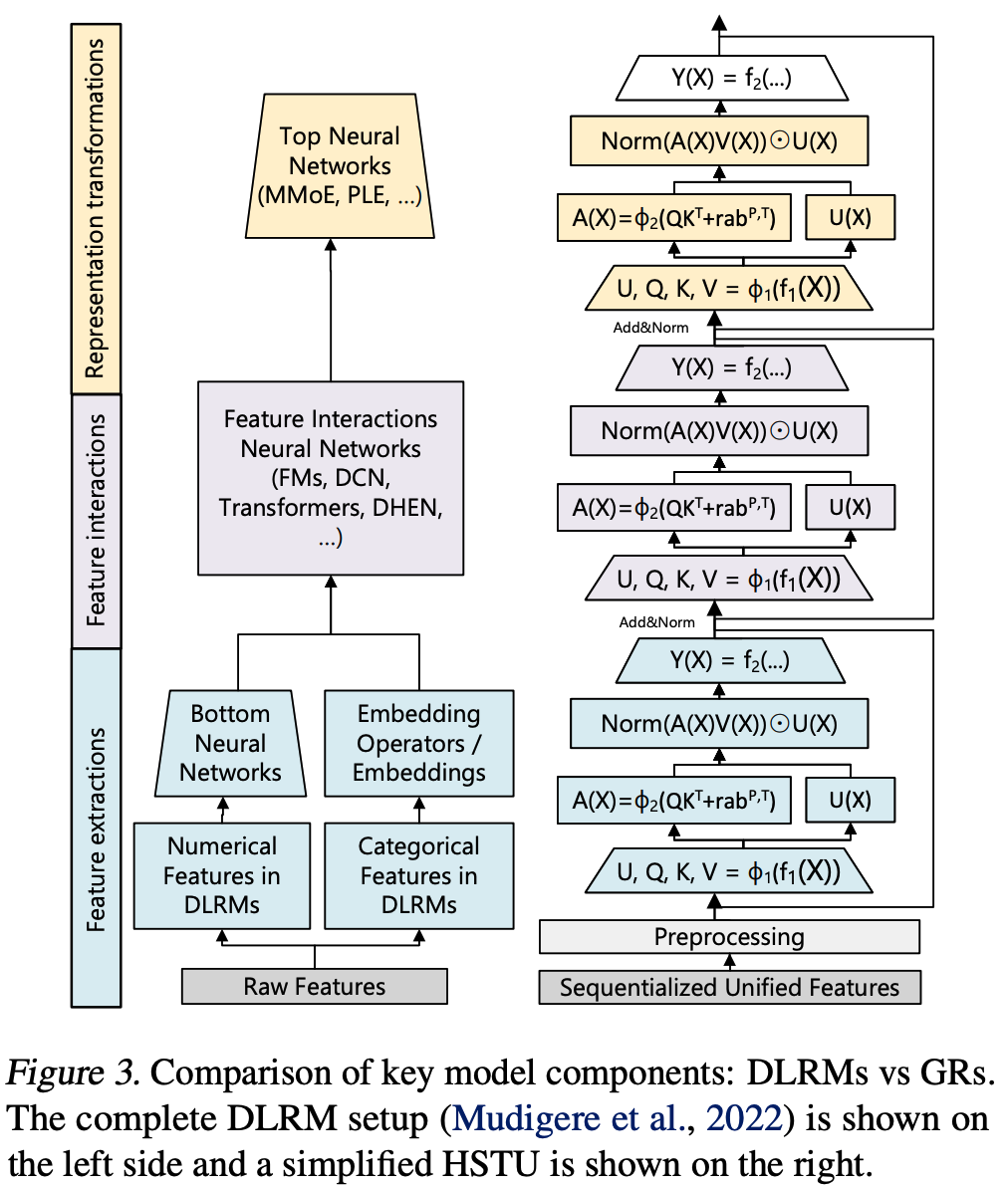
HSTU由多个通过残差连接堆叠的相同层构成,每层包含三个子层:Pointwise Projection(公式1)、Spatial Aggregation(公式2)和 Pointwise Transformation(公式3):
$$ U(X), V(X), Q(X), K(X) = \text{Split}(\phi_1(f_1(X))) \tag{1} $$
$$ A(X)V(X) = \phi_2\left(Q(X)K(X)^T + \text{rab}^{p,t}\right)V(X) \tag{2} $$
$$ Y(X) = f_2\left(\text{Norm}\left(A(X)V(X)\right) \odot U(X)\right) \tag{3} $$
- 其中:
- \( f_i(X) \) 表示多层感知机(MLP);为降低计算复杂度, \( f_1 \) 和 \( f_2 \) 使用单线性层 \( f_i(X) = W_i(X) + b_i \)
- 注:还通过融合内核批量处理查询 \( Q(X) \) 、键 \( K(X) \) 、值 \( V(X) \) 和门控权重 \( U(X) \) (即一次性将Q,K,V和Q映射都做完)
- \( \phi_1 \) 和 \( \phi_2 \) 为非线性激活函数,均采用SiLU(即Swish);
- Norm 表示 LayerNorm
- \( \text{rab}^{p,t} \) 为结合位置(\( p \))和时间(\( t \))信息的相对注意力偏置
- \( f_i(X) \) 表示多层感知机(MLP);为降低计算复杂度, \( f_1 \) 和 \( f_2 \) 使用单线性层 \( f_i(X) = W_i(X) + b_i \)
- HSTU的编码器设计允许用单一模块化块替代DLRMs中的异构模块。论文观察到DLRMs实际包含三个阶段:特征提取、特征交互和表征变换
- 1:特征提取(Feature Extraction)阶段通过池化操作获取类别特征的嵌入表示,其高级形式可泛化为成对注意力和 target-aware 池化
- 如 HSTU 层所实现,能够做到上述能力
- 2:特征交互(Feature Interaction)是DLRMs的核心,常用方法包括因子分解机及其神经网络变体、高阶特征交互等
- HSTU通过注意力池化特征直接与其他特征交互(即 \(\text{Norm}(A(X)V(X)) \odot U(X)\))替代传统特征交互模块
- 该设计源于学习型MLP难以近似点积的挑战(Rendle等, 2020; Zhai等, 2023a),由于SILU作用于 \(U(X)\),此结构也可视为SwiGLU(Shazeer, 2020)的变体
- 3:表征变换(Transformations of Representations)阶段通常采用 MoE 和路由机制处理异构用户群体,其核心思想是通过子网络 specialization 实现条件计算
- HSTU中的逐点乘积操作(Element-wise dot products)本质上能在归一化因子范围内模拟MoE的门控机制
- 1:特征提取(Feature Extraction)阶段通过池化操作获取类别特征的嵌入表示,其高级形式可泛化为成对注意力和 target-aware 池化
- 以上实现中可以看出,HSTU Layer 实现了类似 Transformer Layer 的功能
- \(X\) 是 HSTU 的输入, \(Y(X)\) 是 HSTU 的输出
- \(A(X)\) 为输入 \(X\) 的注意力向量(注:这里没有做归一化),是带位置偏置 \(\text{rab}^{p,t}\) 的 \(Q,K\) 内积
- HSTU的一层 与传统的 Transformer 相比,HSTU有以下不同:
- HSTU 增加了一个 \(U(X)\),跟Q,K,V的 projection 在同一层处理,\(U(X)\) 会作为一个 point-wise的向量与 HSTU Attention 的结果相乘
- HSTU 没有使用传统 Transformer 中的 Softmax Attention机制,放弃了 Attention 权重和为1的约束,文中提到,这能保留用户对 item 的动作强度信息(Softmax会使得这部分信息失真)
- HSTU 没有使用 FFN 层,这一层被 \(f_2\left(\text{Norm}\left(A(X)V(X)\right) \odot U(X)\right)\) 替换了,实现了将 MLP 替换为 point-wise 乘法,速度更快
- 理解1:这里更像是使用 \(U(X)\) 保留了原始特征,和 Attention 后的高阶交叉特征 point-wise 相乘,得到高阶交叉特征同时也保留低阶交叉;
- 理解2:这里的操作可以看做是 对 \(U(X)\) 进行加权,如前文所述,像是门网络/个性化加权机制实现对原始 Embedding \(U(X)\) 的加权(可类比于MoE的思想)
逐点聚合注意力(Pointwise aggregated attention)
- HSTU采用了一种新型的Pointwise aggregated attention(区别于传统的Softmax注意力)。其动机有二:
- 第一:与目标相关的历史数据点数量是用户偏好强度的关键特征,而Softmax归一化会削弱这一信息(Softmax的归一化会将强度信息也归一化为比例,这会使得绝对值失真)
- 第二:Softmax对噪声鲁棒,但在流式非静态词表场景中表现欠佳(频繁增加新的 item 会影响 Softmax)
- 实验表明,在合成数据(基于 Dirichlet 过程生成的非静态词表流式数据)中,逐点聚合注意力机制相比Softmax注意力可将Hit Rate@10提升高达44.7%(见表2)

利用算法增加稀疏性
- 在推荐系统中,用户历史序列的长度通常呈现偏态分布(skewed distribution,这里主要指大部分用户交互序列短,少部分用户交互序列长),导致输入序列具有稀疏性,尤其是在处理超长序列时。这种稀疏性可以被有效利用以显著提升编码器的效率。为此,论文开发了一种高效的GPU注意力核函数,其设计类似于[Dao等, 2022; Zhai等, 2023b],但实现了完全分组的注意力计算。这本质上将注意力计算转化为不同尺寸的分组GEMM(通用矩阵乘法)运算(详见附录G)。因此,HSTU中的自注意力变为内存受限(memory-bound)操作,其内存访问复杂度为 \(\Theta(\sum_{i}n_{i}^{2}d_{qk}^{2}R^{-1})\) ,其中 \(n_i\) 为样本 \(i\) 的序列长度, \(d_{qk}\) 为注意力维度, \(R\) 为寄存器大小。仅此一项改进即可带来2-5倍的吞吐量提升(详见第4.2节讨论)
- 论文进一步通过随机长度(Stochastic Length, SL)算法增加用户历史序列的稀疏性。推荐场景中用户历史序列的一个关键特征是用户行为在时间上具有重复性,这种重复性体现在用户交互历史的多尺度行为模式中。这为论文提供了在不损失模型质量的前提下人为增加稀疏性的机会,从而显著降低编码器计算成本(其复杂度为 \(\Theta(\sum_{i}n_{i}^{2})\))
- 问题:这种降低稀疏性的方式是有损的吧?此外,相同算力消耗下,随机长度是不是不如仅保留最近多个 item 的策略?
- 假设用户 \(j\) 的历史序列为 \((x_i)_{i=0}^{n_{c,j} }\) ,其中 \(n_{c,j}\) 为用户交互过的内容数量。令 \(N_c = \max_j n_{c,j}\) , \((x_{i_k})_{k=0}^L\) 为从1原始序列 \((x_i)_{i=0}^{n_{c,j} }\) 中选取的长度为 \(L\) 的子序列。SL算法按以下方式选择输入序列:
$$
\begin{align}
(x_i)_{i=0}^{n_{c,j} } \text{ if } n_{c,j} &\leq N_c^{\alpha/2}\\
(x_{i_k})_{k=0}^{N_c^{\alpha/2} } \text{ if } n_{c,j} &> N_c^{\alpha/2}, \text{w/ probability } 1 - N_c^{\alpha}/n_{c,j}^2\\
(x_i)_{i=0}^{n_{c,j} } \text{ if } n_{c,j} &> N_c^{\alpha/2}, \text{w/ probability } N_c^{\alpha}/n_{c,j}^2 \tag{4}
\end{align}
$$- 其中 “w/ probability xx” 是 “with probability”的简写,表示以 “xx” 概率采样
- \(N_c^{\alpha/2}\) 表示 \(N_c\) 的 \(\alpha/2\) 次方, \(\alpha\) 是一个调节采样比例的数字
- 公式4描述了Stochastic Length (SL)算法如何根据用户历史序列的长度(\(n_{c,j}\))动态调整子序列的采样策略:
- 如果序列长度 \(n_{c,j} \leq N_c^{\alpha/2}\) ,则:
- 直接使用完整序列
- 如果序列长度 \(n_{c,j} > N_c^{\alpha/2}\) ,则
- 以概率 \(1 - N_c^\alpha / n_{c,j}^2\) 选择长度为 \(N_c^{\alpha/2}\) 的子序列
- 以概率 \(N_c^\alpha / n_{c,j}^2\) 仍使用完整序列
- 如果序列长度 \(n_{c,j} \leq N_c^{\alpha/2}\) ,则:
- 该算法将注意力相关复杂度降低至 \(O(N_c^{\alpha}d) = O(N^{\alpha}d)\) ,其中 \(\alpha \in (1,2]\) 。关于子序列选择的更详细讨论见附录F.1。值得注意的是,将SL应用于训练能够实现高性价比的系统设计,因为训练的计算成本通常远高于推理
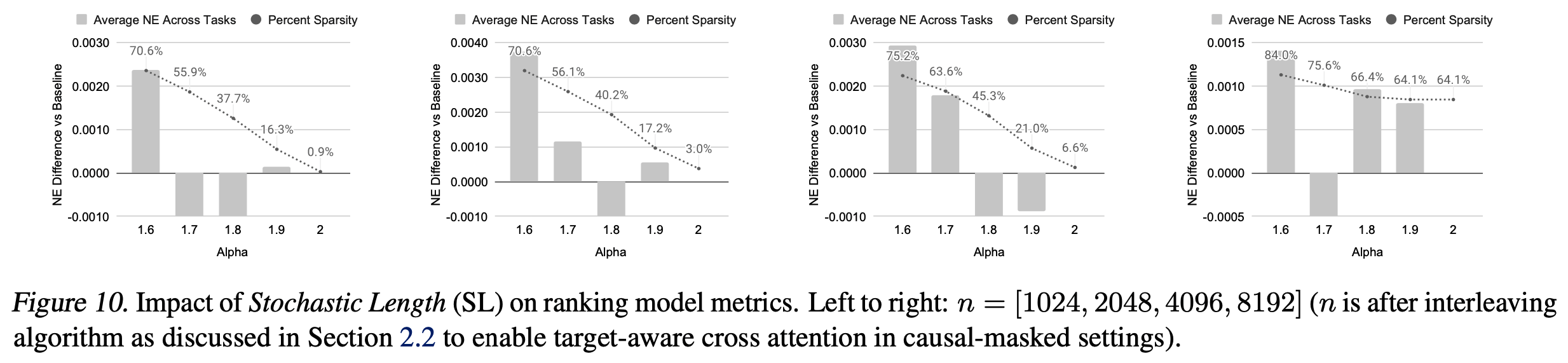
- 表3展示了在具有30天用户历史的典型工业规模配置下,不同序列长度和 \(\alpha\) 值对应的稀疏性(定义见附录F)。其中对模型质量影响可忽略的设置用下划线和蓝色标出。标为“ \(\alpha=2.0\) ”的行表示未应用SL时的基准稀疏性。更低的 \(\alpha\) 值适用于更长的序列,论文测试的最长序列长度为8,192
算法对序列sparse度的影响(如 \alpha=1.6 时sparse度达80.5%)")
最小化激活内存使用
- 在推荐系统中,使用大的 Batch Size 训练对提升训练吞吐量和模型质量至关重要(理解:大的 Batch Size 更容易得到准确的梯度),因此,激活内存的使用成为扩展的主要瓶颈,这与通常以小的 Batch Size 训练且以参数内存为主的大型语言模型形成鲜明对比
- 与 Transformer 相比,HSTU采用了一种简化且完全融合的设计,显著降低了激活内存的使用
- 首先,HSTU将注意力外的线性层数量从 6 个减少到 2 个,这与近期通过逐元素门控减少MLP计算的工作[Hua等, 2022; Zhai等, 2023b]一致
- 其次,HSTU将计算过程激进地融合为单一算子,包括公式(1)中的 \(\phi_1(f_1(\cdot))\) ,以及公式(3)中的层归一化、可选Dropout和输出MLP。这种简化设计将每层的激活内存使用量降低至 \(2d + 2d + 4hd_{qk} + 4hd_v + 2hd_v = 14d\) (以bfloat16格式存储)
- 理解:这里的减少线性层数量主要是通过移除传统的FFN来实现(传统的一个FFN包含两个线性层),HSTU总体仅保留两个线性层,即输入层和输出层
- 注:文章这里说的将线性层从 6 层降低到 2 层的表达应该是跳过了一些设计细节,比如网络结构中FFN的数量未明确
- 作为对比, Transformer 在注意力后使用前馈层和Dropout(中间状态为 \(3hd_v\)),随后是一个逐点前馈块,包含层归一化、线性层、激活函数、线性层和Dropout,中间状态为 \(2d + 4d_{ff} + 2d + 1d = 4d + 4d_{ff}\) 。这里论文假设 \(hd_v \geq d\) 且 \(d_{ff} = 4d\) [Vaswani等, 2017; Touvron等, 2023a]。因此,在考虑输入和输入层归一化(\(4d\))以及QKV投影后,总激活状态为 \(33d\) 。HSTU的设计使其能够扩展到比 Transformer 深2倍以上的网络
- 此外,用于表示词汇表的大规模原子ID也需要大量内存。对于包含100亿词汇、512维嵌入和Adam优化器的配置,仅存储嵌入和优化器状态(以fp32格式)就需要60TB内存。为缓解内存压力,论文采用了 row-wise AdamW 优化器并将优化器状态放置在DRAM中,从而将每个浮点数的HBM使用量从12字节减少到2字节
- 注:论文给的引用中没有详细介绍 row-wise AdamW 优化器
- HBM(High Bandwidth Memory,高带宽内存)和 DRAM(Dynamic Random Access Memory,动态随机存取存储器)都是计算机内存技术,HBM 将多个 DRAM 芯片堆叠在一起(HBM可以理解为更为昂贵的告诉内存),拥有比 DRAM 更高的数据传输性能
- 总结来看 :HSTU通过以下设计显著降低内存占用:
- 第一:将注意力外的线性层从6层减至2层,采用逐点门控减少MLP计算;
- 第二:将计算融合为单一算子(如公式1中的 \( \phi_1(f_1(\cdot)) \) 和公式3中的层归一化、Dropout及输出MLP);
- 第三:使用row-wise AdamW优化器,将优化器状态存储于DRAM,使每个浮点数在HBM的占用从12字节降至2字节
- 最终,与 Transformer 相比,HSTU的激活内存占用从每层33d降至14d(bfloat16),支持构建2倍更深的网络
通过成本分摊扩展推理规模
- 论文需要解决的最后一个挑战是推荐系统在服务时需要处理大量候选内容。论文主要关注 Ranking 任务 :
- 在Retrieval 任务(无需论文关注)中,编码器成本完全可以分摊,且已有高效的算法支持基于量化(quantization)、哈希(hashing)或分区(partitioning)的最大内积搜索(MIPS),以及基于束搜索或分层检索的 non-MIPS 场景
- MIPS 是 Maximum Inner Product Search(最大内积搜索)的缩写,主要用于高效地找到与给定查询向量内积最大的候选向量 ,在召回阶段,MIPS可以与量化、哈希或分区等技术结合使用,以提升效率
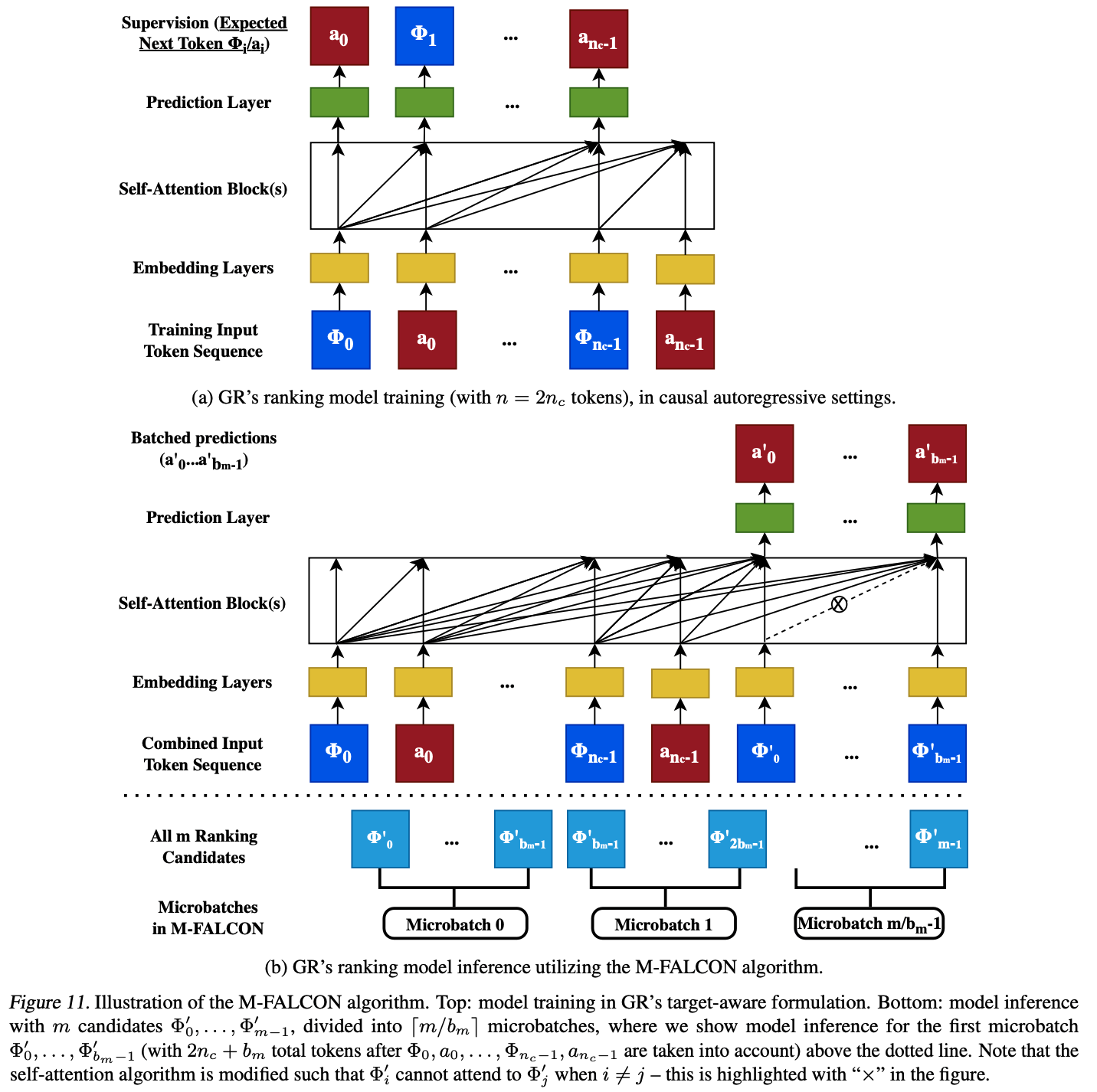
- 对于Ranking 任务 ,候选内容数量可能高达数万。论文提出了一种算法M-FALCON(Microbatched-Fast Attention Leveraging Cacheable Operations)(可译为微批次-快速注意力利用可缓存操作),用于在输入序列长度为 \(n\) 时对 \(m\) 个候选内容进行推理
- 批量推理 :在一次前向传播中,M-FALCON通过修改注意力掩码和 \(\text{rab}^{p,t}\) 偏置,使得 \(b_m\) 个候选内容的注意力操作完全一致,从而并行处理 \(b_m\) 个候选内容,此时原本的 \(b_m\) 次长度为 \(n\) 的推理转换为 1 次 \(b_m+n\) 的推理(注:这里有MTP的味道)
- 这将交叉注意力的计算成本从 \(O(b_m n^2 d)\) 降低到 \(O((n + b_m)^2 d) = O(n^2 d)\) (当 \(b_m\) 相对于 \(n\) 可视为小常数时)
- KV Caching机制 :论文还可以将全部 \(m\) 个候选内容划分为 \(\lceil m/b_m \rceil\) 个大小为 \(b_m\) 的微批次,以利用编码器级的KV缓存 ,从而在跨前向传播时降低成本,或在跨请求时最小化尾部延迟
- 关于M-FALCON方法的更多细节见附录H
- 批量推理 :在一次前向传播中,M-FALCON通过修改注意力掩码和 \(\text{rab}^{p,t}\) 偏置,使得 \(b_m\) 个候选内容的注意力操作完全一致,从而并行处理 \(b_m\) 个候选内容,此时原本的 \(b_m\) 次长度为 \(n\) 的推理转换为 1 次 \(b_m+n\) 的推理(注:这里有MTP的味道)
- 总体而言,M-FALCON使得模型复杂度能够与传统DLRM排序阶段的候选数量线性扩展。论文成功地在典型的排序配置中(见第4.3节)应用了复杂度高28倍的目标感知交叉注意力模型 ,同时在恒定推理预算下实现了1.5倍至3倍的吞吐量提升
- M-FALCON方法的整体结构图如下(From 附录):
Experiments
验证HSTU编码器的归纳假设
传统序列化设置
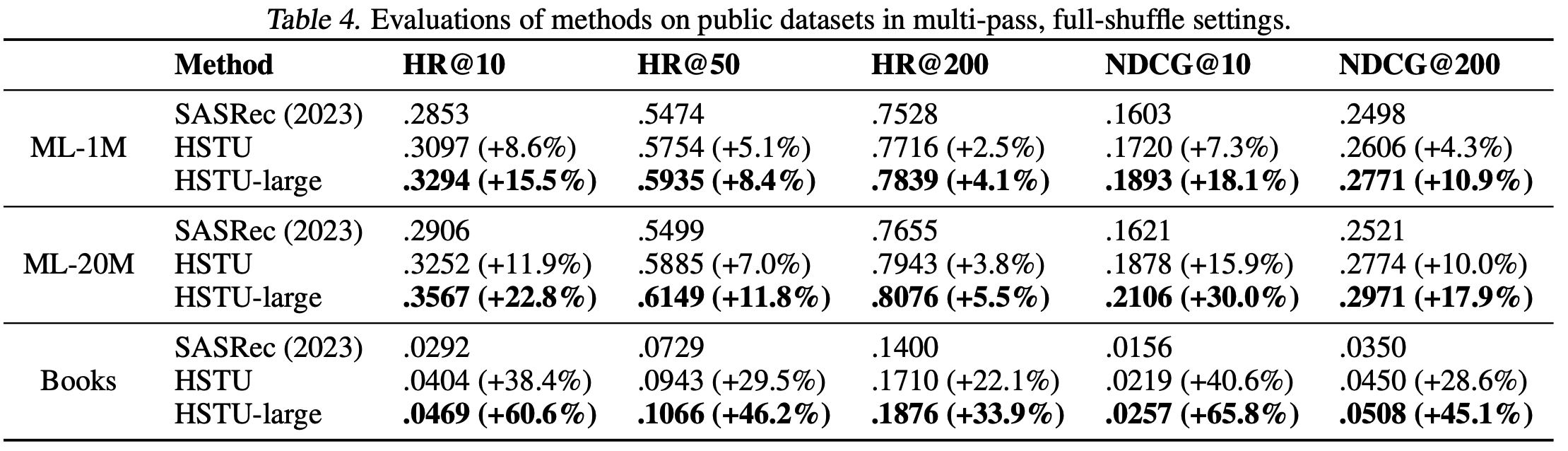
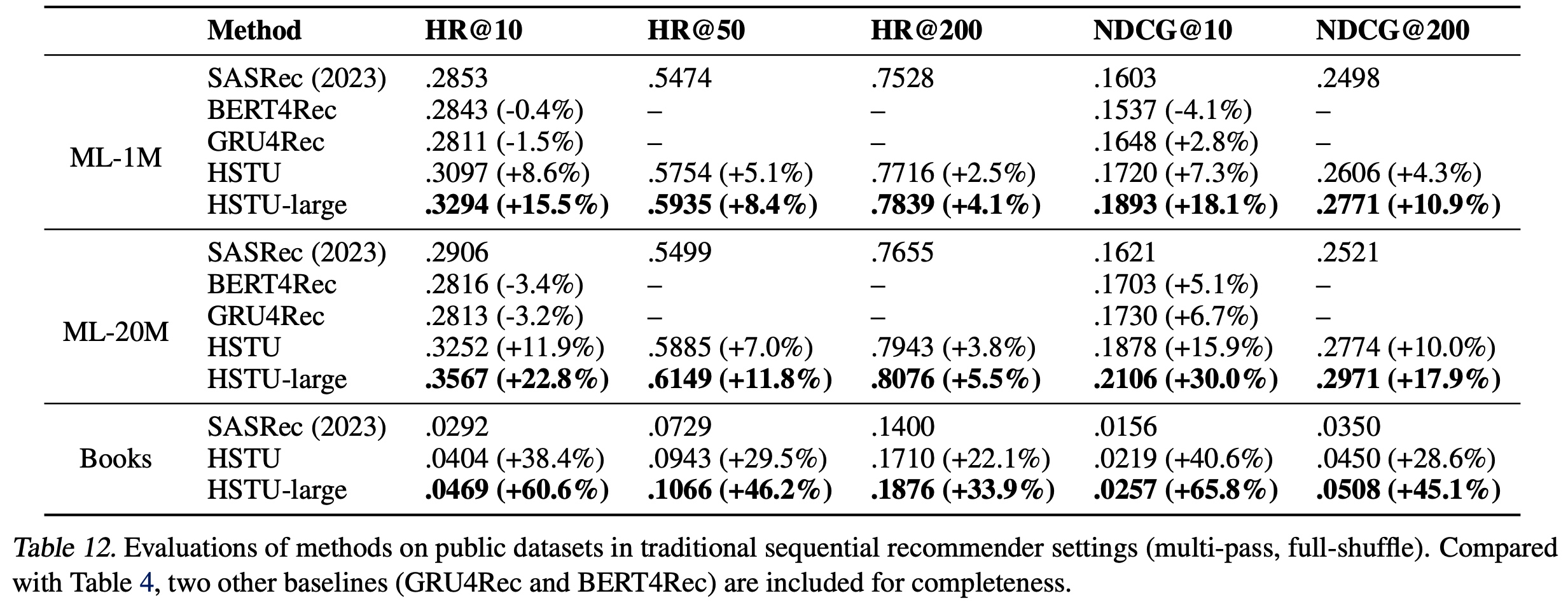
- 论文首先在两个流行的推荐数据集(MovieLens和Amazon Reviews)上评估HSTU的性能。实验遵循文献中的序列化推荐设置,包括完全打乱和多轮次训练。基线采用 SOTA Transformer 实现SASRec(Kang & McAuley, 2018)。与近期工作(Dallmann等, 2021; Zhai等, 2023a)一致,论文报告整个语料库的Hit Rate@K和NDCG@K
- 结果如表4所示。“SASRec (2023)”表示(Zhai等, 2023a)中报告的最佳SASRec配置。“HSTU”行使用与SASRec相同的配置(层数、头数等)。“HSTU-large”表示更大的HSTU编码器(层数4倍,头数2倍)。结果表明:
- a)HSTU因其针对推荐优化的设计,在相同配置下显著优于基线;
- b)HSTU在扩展后性能进一步提升
- 需要注意的是,此处使用的评估方法与工业级设置差异显著,因为完全打乱和多轮次训练在工业级流式设置中通常不实用(Liu等, 2022)
工业级流式设置
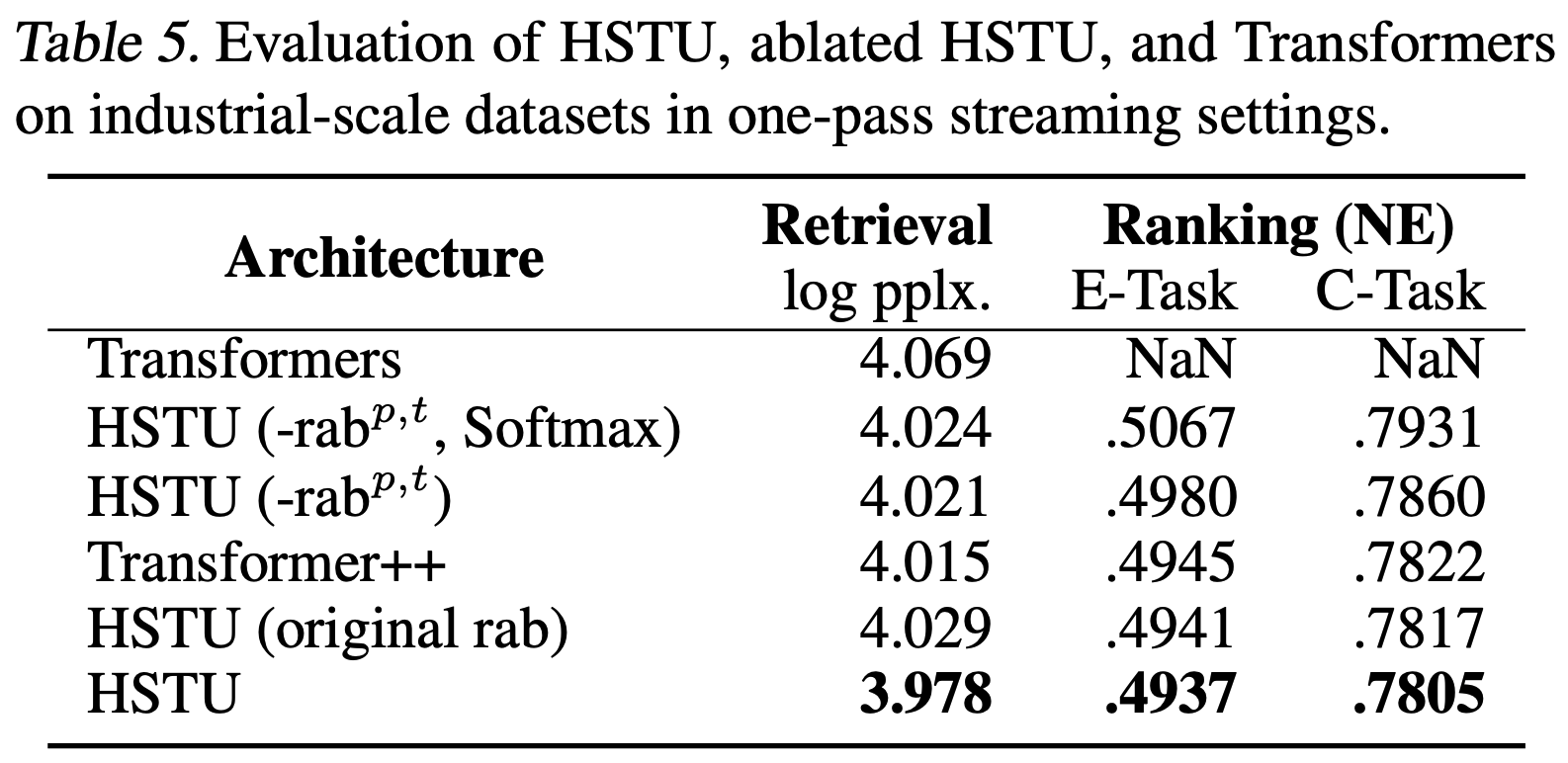
- 接下来,论文在工业级数据集的流式设置中比较HSTU、消融版HSTU和 Transformer 的性能。本节剩余部分中,论文报告排名的归一化熵(Normalized Entropy,NE)(详细定义见附录)。模型训练超过1000亿样本(DLRM等效),每个任务使用64-256块H100 GPU(!!!)。由于排名是多任务设置,论文报告主要互动事件(“E-Task”)和主要消费事件(“C-Task”)。在论文的上下文中,NE降低0.001通常意味着数十亿用户的顶层指标提升0.5%。对于 Retrieval 任务,由于设置与语言建模类似,论文报告对数困惑度。在小规模设置中固定编码器参数(排名任务: \(l=3\) , \(n=2048\) , \(d=512\) ; Retrieval 任务: \(l=6\) , \(n=512\) , \(d=256\)),并因资源限制对其他超参数进行网格搜索
- 结果如表5所示:
- 第一 :HSTU显著优于 Transformer,尤其是在排名任务中,这可能是由于点注意力机制和改进的相对注意力偏差
- 第二 :消融版HSTU与完整HSTU之间的差距验证了论文的设计有效性。Softmax版HSTU和 Transformer 的最佳学习率比其他模型低约10倍,这是为了训练稳定性。即使采用较低学习率和预归一化残差连接(Xiong等, 2020),标准 Transformer 在排名任务中仍频繁出现损失爆炸
- 第三 :HSTU优于LLM中流行的 Transformer 变体 Transformer ++(Touvron等, 2023b), Transformer ++ 使用了RoPE、SwiGLU等技术。总体而言,在此小规模设置中,HSTU在质量上表现更优,同时训练速度提升1.5-2倍,HBM使用减少50%
编码器效率
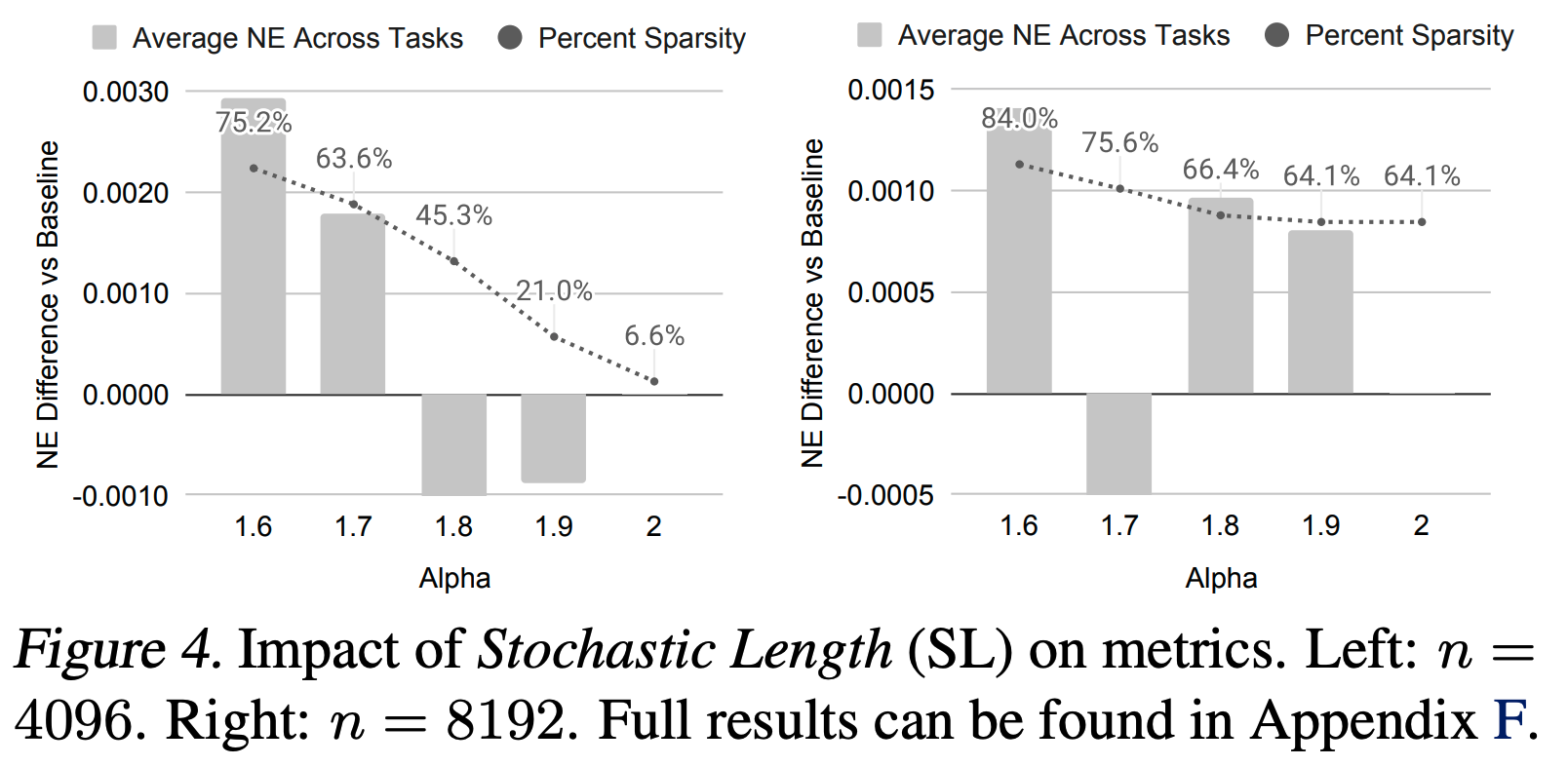
- 随机长度(Stochastic Length, SL)。图4和图5(a)展示了随机长度(SL)对模型指标的影响
- 当 \(\alpha=1.6\) 时,长度为 4096 的序列在大多数情况下被压缩为 776,移除了超过 80% 的 token。即使 sparse 率增加到 64%-84%,主要任务的NE下降不超过 0.002(0.2%)
- 以上这一证据表明,对于合适的 \(\alpha\) 值,SL 不会对模型质量产生负面影响,同时可以通过高 sparse 性降低训练成本。论文还在附录F.3中验证了 SL 显著优于现有的长度外推技术
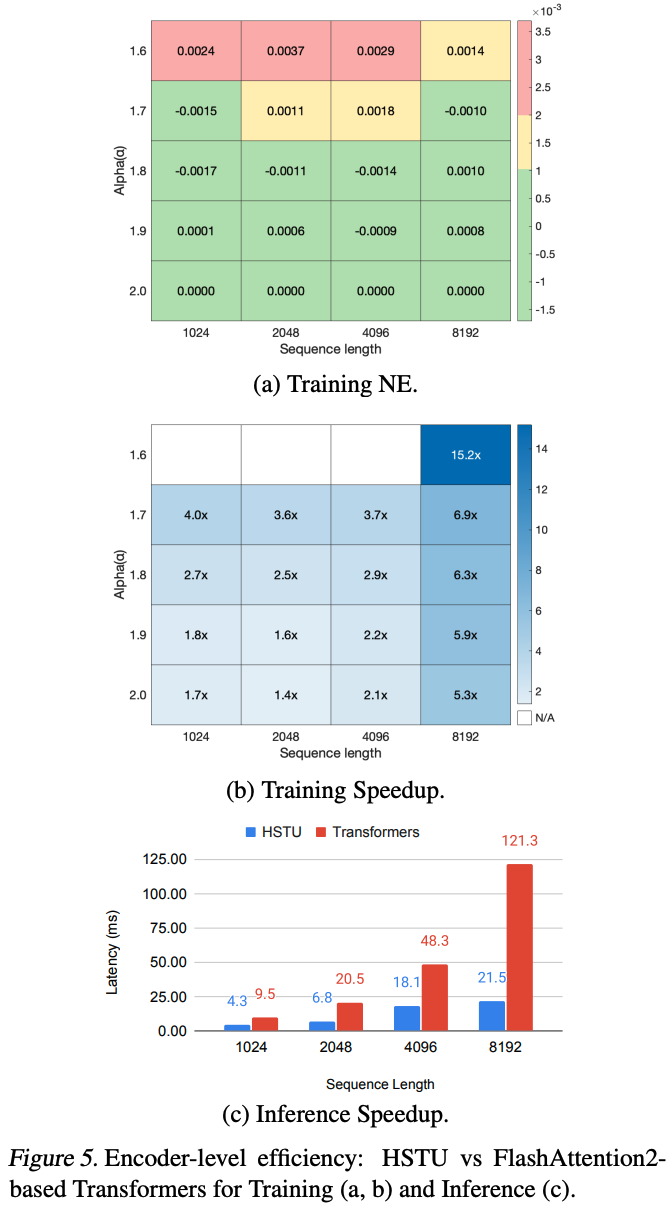
- 编码器效率。图5比较了HSTU和 Transformer 编码器在训练和推理设置中的效率
- 对于 Transformer,论文使用 SOTA FlashAttention-2(Dao, 2023)实现
- 考虑序列长度从 1,024 到 8,192,并在训练中应用随机长度(SL)
- 评估时,HSTU和 Transformer 使用相同配置(\(d=512\) , \(h=8\) , \(d_{qk}=64\)),并消融相对注意力偏差(如第4.1.2节所示,HSTU在不使用rab \(^{p,t}\) 时仍优于 Transformer)。在NVIDIA H100 GPU上以bfloat16比较编码器级性能。总体而言,HSTU在训练和推理中的效率分别比 Transformer 高15.2倍和5.6倍
- 此外,如第3.3节讨论的激活内存使用减少,使论文能够构建比 Transformer 深2倍以上的HSTU网络
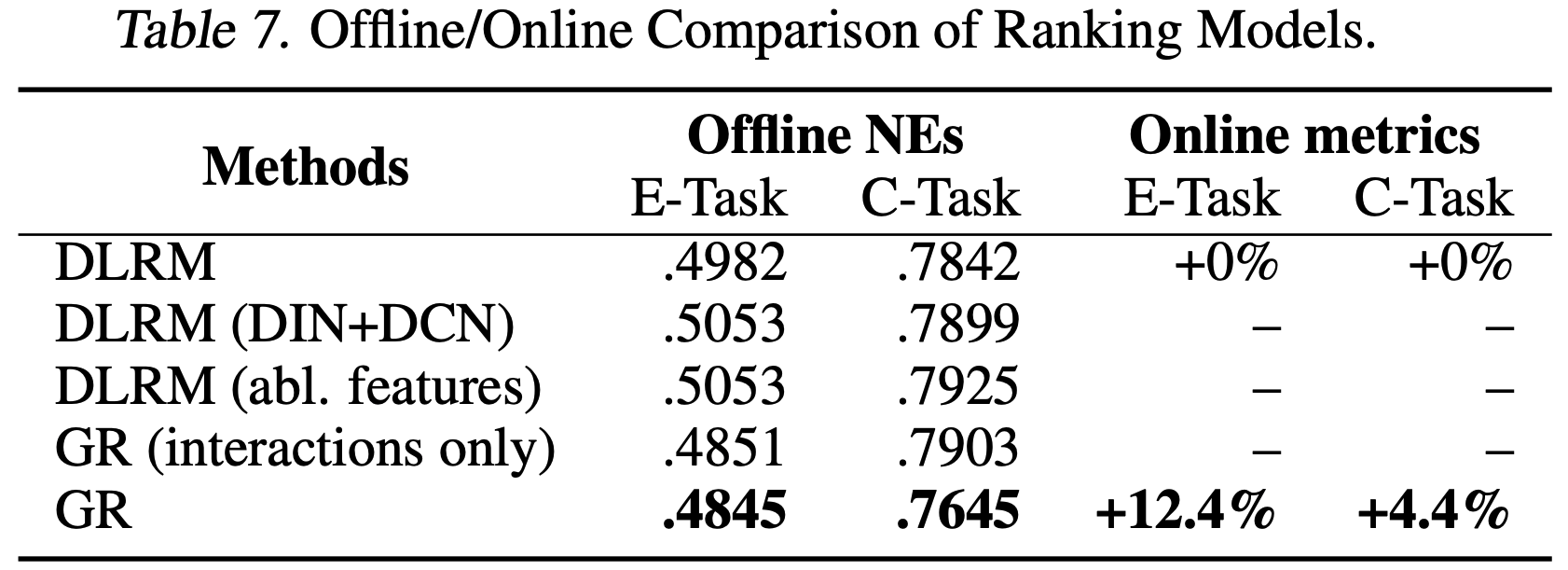
工业级流式设置中生成式推荐器(GR)与 DLRM 的比较
- 最后,论文比较了GR与 SOTA DLRM 基线在工业级流式设置中的端到端性能。论文的GR实现反映了生产中使用的典型配置,而 DLRM 设置则是数百人多年迭代的结果
- 由于推荐系统的召回阶段使用了多个生成器(理解:这里应该是指多路召回),论文报告了将 GR 作为新增召回通道(“new source”)和替换现有主要 DLRM 通道(“replace”)的在线结果。表6和表7显示,GR不仅在离线测试中显著优于 DLRM,还在A/B测试中带来了12.4%的提升
- 从表6中可知,作为一个召回通道加入能得到的更好的效果
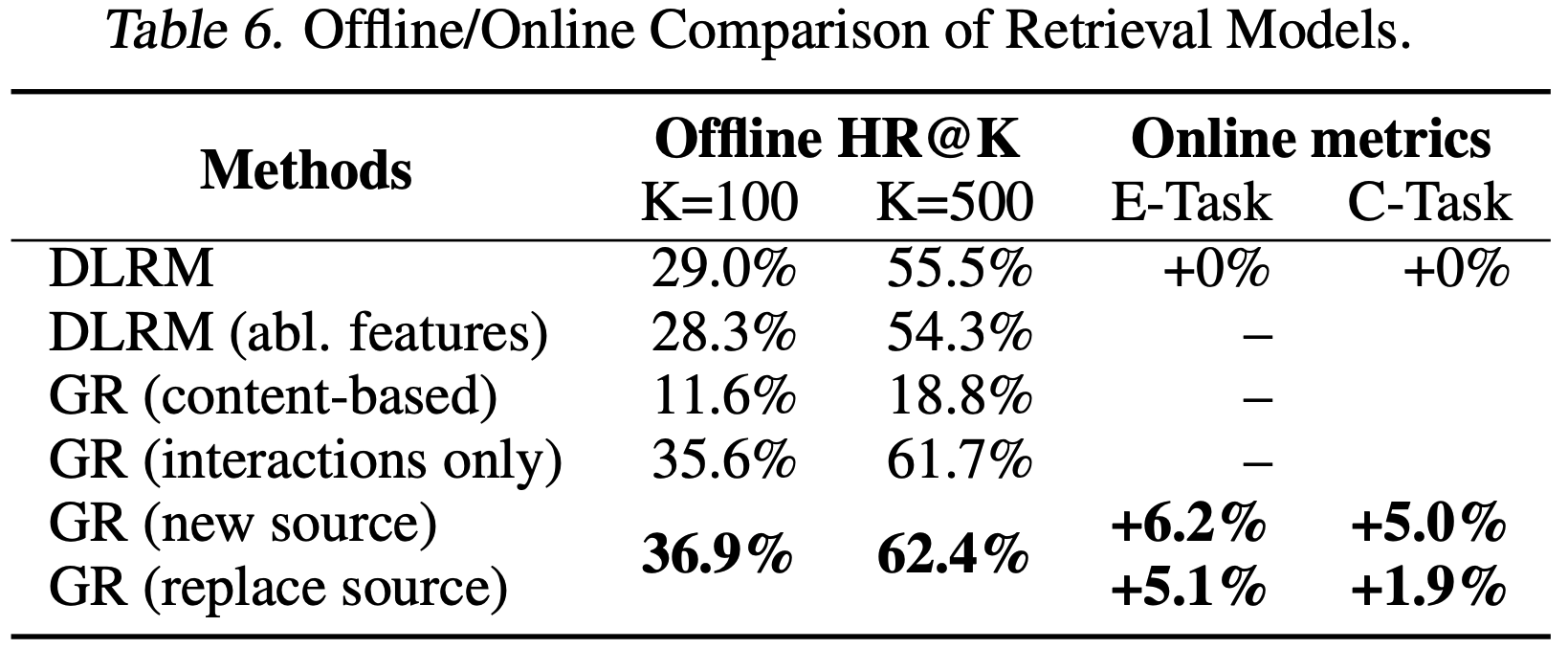
- 如第2节所述,GR基于原始分类互动特征构建,而 DLRM 通常使用更多手工特征(handcrafted features)。如果论文将GR使用的相同特征集提供给 DLRM (“DLRM(abl. features)”,消融特征),DLRM 的性能会显著下降,这表明GR通过其架构和统一特征空间可以有效地捕捉这些特征
- 论文进一步通过与传统序列推荐器设置的比较验证了第2.2节中的GR公式。传统设置仅考虑用户交互过的物品(Kang & McAuley, 2018),结果显示其性能显著下降(表6和表7中的“GR(interactions only)”行)。论文还包含了一个仅使用内容特征的GR基线(“GR(content-based)”)。内容基线与 DLRM /GR之间的巨大性能差距凸显了高基数用户行为的重要性
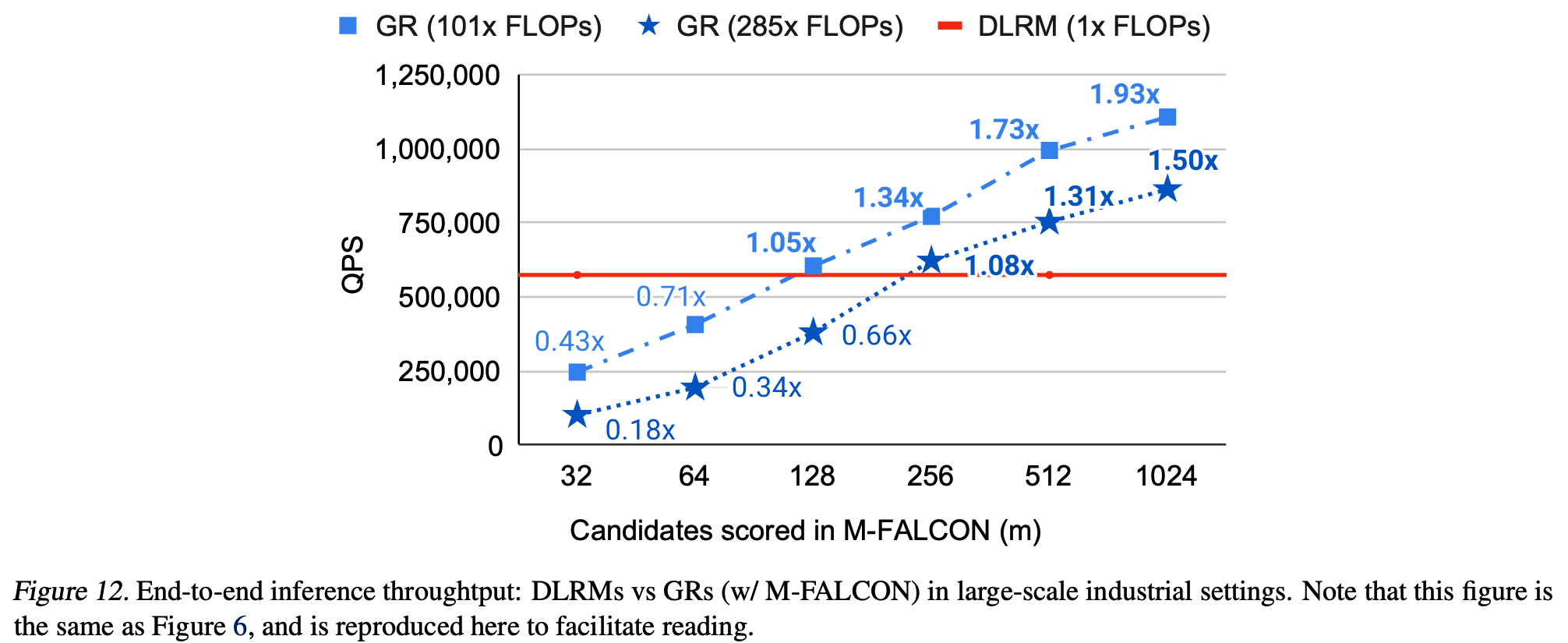
- 图6比较了GR与生产 DLRM 的效率。尽管GR模型的复杂度是 DLRM 的285倍(其中 \(285\times \text{FLOPs}\) 表示其复杂度是DLRM的285倍),但由于HSTU和第3.4节中的M-FALCON算法,论文在评分1024/16384个候选时实现了1.50倍/2.99倍的更高QPS
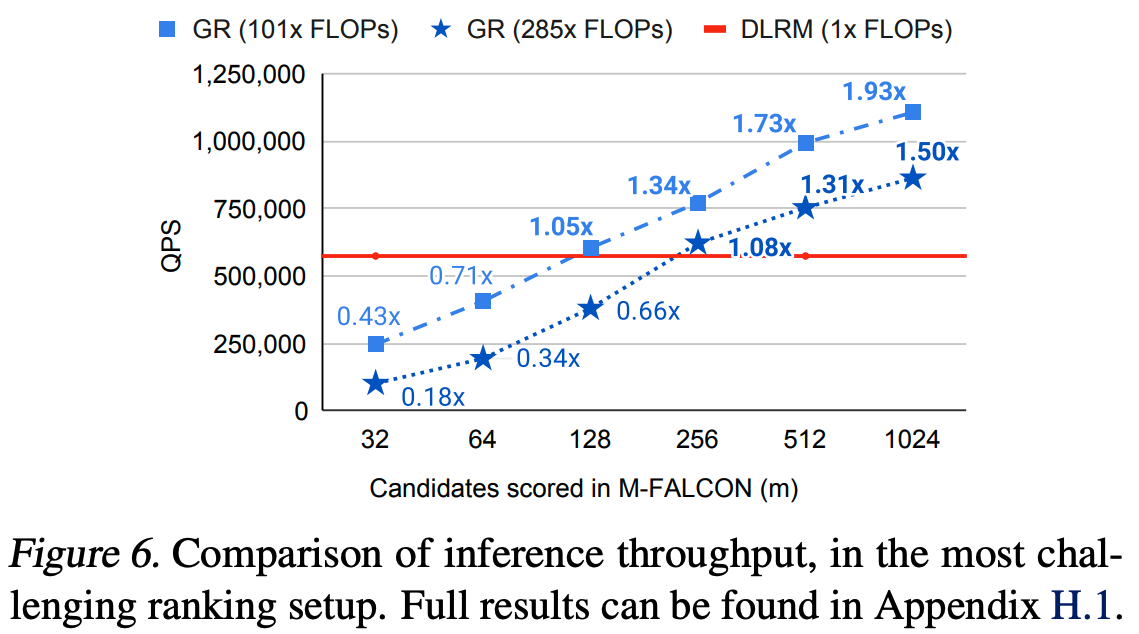
推荐系统的 scaling law
- 众所周知,在大规模工业设置中,DLRM 在特定计算和参数范围内会达到质量饱和(Zhao等, 2023)。论文比较了GR和 DLRM 的可扩展性以更好地理解这一现象
- 由于特征交互层对 DLRM 性能至关重要(Mudigere等, 2022),论文尝试了 Transformer (Vaswani等, 2017)、DHEN(Zhang等, 2022)以及论文生产设置中使用的带残差连接的DCN变体(He等, 2015)来扩展 DLRM 基线
- 对于召回基线,论文通过调整隐藏层大小、嵌入维度和层数来扩展模型
- 对于基于HSTU的生成式推荐器(GR),论文通过调整HSTU的超参数(如残差层数、序列长度、嵌入维度、注意力头数等)扩展模型,并调整 Retrieval 任务的负样本数量
- 结果如图7所示:
- 在低计算量区域,由于手工特征(handcrafted features)的存在,DLRM 可能优于GR,这验证了传统 DLRM 中特征工程的重要性
- 然而,GR在FLOPs方面表现出显著更好的可扩展性(scalability),而 DLRM 性能趋于饱和,这与先前的研究结果一致
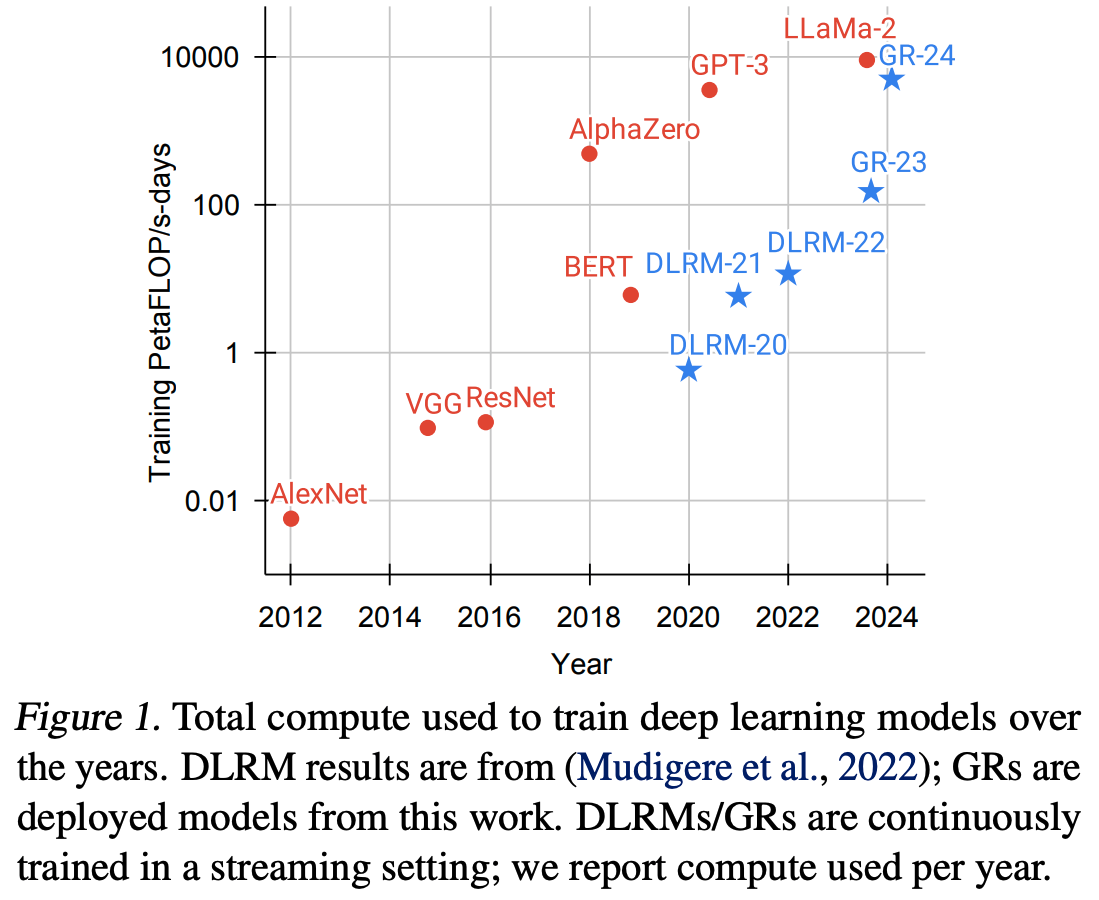
- 论文还观察到,GR在嵌入参数和非嵌入参数方面均具有更好的可扩展性,其模型参数达到 1,500B ,而 DLRM 在约 200B 参数时性能饱和(这个参数量的训练,Meta真够有钱!)
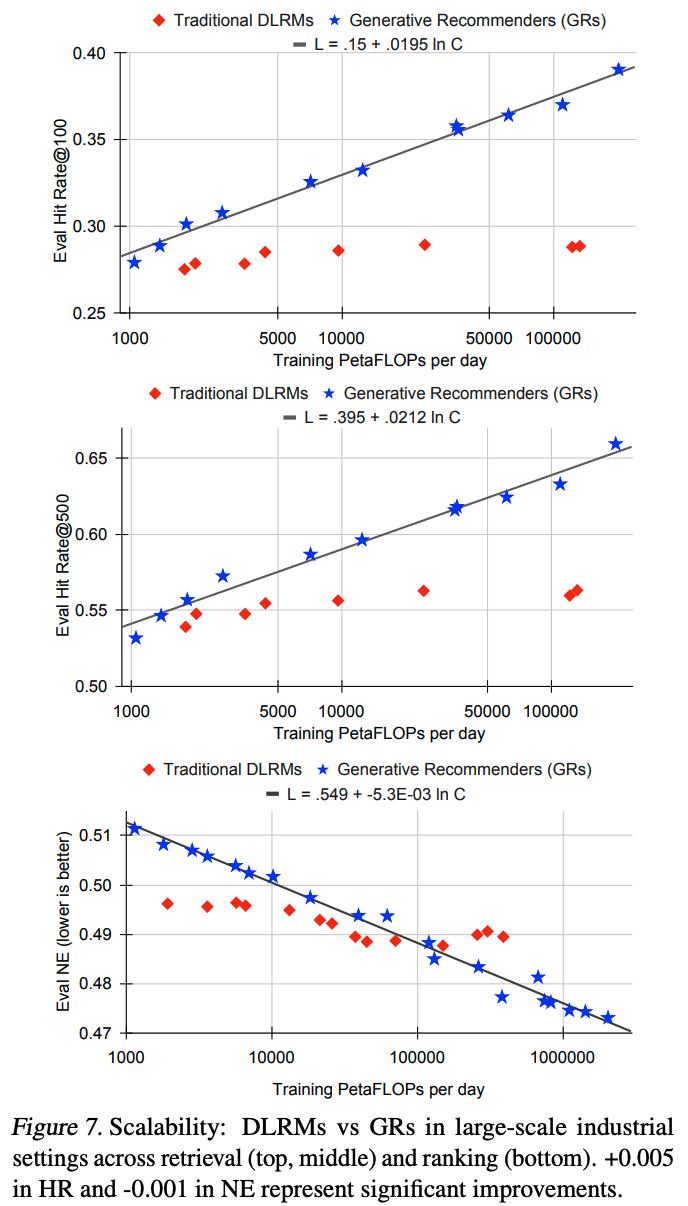
- 最后,论文的所有主要指标(包括 Retrieval 任务的 Hit Rate@100 和 Hit Rate@500,以及排名任务的NE)在适当的超参数下 ,随计算量的增加呈现幂律扩展(power law of compute used)
- 这一现象在三个数量级范围内均成立,直至论文测试的最大模型(序列长度8,192,嵌入维度1,024,24层HSTU)
- 此时,论文使用的总计算量(按365天标准化,因为论文采用标准流式训练设置)接近GPT-3(Brown等, 2020)和LLaMa-2(Touvron等, 2023b)的总训练计算量,如图1所示
- 与语言建模(Kaplan等, 2020)相比,序列长度在GR中扮演更重要的角色,因此需要同步扩展序列长度和其他参数
- 这或许是论文提出的方法最重要的优势,因为论文首次证明了 LLM 的 scaling law 可能也适用于大规模推荐系统
相关工作
传统序列推荐方法
- 先前关于序列推荐的研究将用户交互行为简化为单一同质的物品序列(Hidasi等,2016;Kang & McAuley,2018)。工业级应用中,序列方法主要作为深度推荐模型(DLRMs)的一部分,包括成对注意力(Zhou等,2018)或序列编码器(Chen等,2019;Xia等,2023)。为了提高效率,已有研究探索了多阶段注意力替代自注意力机制(Chang等,2023)。在 Retrieval 任务中,将ID表示为 token 序列的生成方法也有所探索(Zhuo等,2020)。附录B.1中对相关工作进行了更详细的讨论
高效注意力机制
- 由于自注意力机制的 \(O(n^2)\) 复杂度,高效注意力一直是研究热点,主要工作包括因子分解注意力(Child等,2019)、低秩近似(Katharopoulos等,2020)等。近期,针对序列转导任务的新架构也被提出(Gu等,2022;Hua等,2022)。HSTU的逐元素门控设计尤其受到FLASH(Hua等,2022)的启发。硬件感知的优化方法显著降低了内存使用(Rabe & Staats,2021;Korthikanti等,2022;Zhai等,2023b),并大幅缩短了实际运行时间(Dao等,2022)
长度外推技术
- 长度外推技术使模型能够在较短的序列上训练后泛化到更长的序列,但多数研究聚焦于微调或改进偏置机制(Press等,2022)。论文则通过在长度维度引入随机性,受深度维度随机性研究(Huang等,2016)的启发
大语言模型(LLMs)的应用
- 大语言模型的兴起促使研究者将推荐任务视为上下文学习(Silco等,2022)、指令微调(Bao等,2023)或基于预训练LLMs的迁移学习(Li等,2023)。LLMs中嵌入的世界知识可以迁移到下游任务(Cui等,2022),并在零样本或少样本场景中提升推荐效果。用户行为序列的文本表示也在中等规模数据集上展现出良好的扩展性(Shin等,2023)。然而,多数关于LLMs用于推荐的研究集中在低数据量场景;在大规模场景中,它们尚未在MovieLens等数据集上超越协同过滤方法(Hou等,2024)
整体总结
- 新范式提出 :论文提出了一种新范式:生成式推荐器(Generative Recommenders, GRs),将排序和 Retrieval 任务重新定义为序列直推式任务(Sequential Transduction Tasks),使其能够以生成式方式进行训练
- 注:最核心的创新点可能是将用户行为也视为一个像是图片、视频和文本类似的新模态
- 性能优化 :得益于新颖的HSTU编码器设计,其在8192长度的序列上比当前 SOTA Transformer 快5.3至15.2倍,同时结合了M-FALCON等新型训练和推理算法
- 实验 :通过GRs,论文部署了复杂度提升285倍的模型,同时减少了推理计算量。GRs和HSTU在生产环境中实现了12.4%的指标提升,并展现出比传统 DLRMs 更优的扩展性能
- 论文的结果验证了用户行为是生成式建模中一个尚未充分探索的模态——正如标题所言,Actions speak louder than words(行动胜于雄辩)
- 论文通过统一特征空间的简化设计,为推荐、搜索和广告领域的首个基础模型铺平了道路。GRs的完全序列化设置还支持端到端的生成式推荐框架。这两点使得推荐系统能够更全面地辅助用户
- 未来规划 :生成式推荐器的完全序列化特性有望进一步推动端到端推荐系统的发展,例如通过直接生成推荐序列而非传统的列表排序。作者相信,这一方向将为推荐系统带来更广阔的应用前景
附录(个人): Transformer 模型计算量评估
在原论文2.3节的公式 \(\sum_{i} n_{i}(n_{i}^{2}d + n_{i}d_{ff}d)\) 的来源解释如下
注: \(d_{ff}\) 表示 前馈神经网络(Feed-Forward Network, FFN)的隐藏层维度(即中间层的神经元数量),在原始 Transformer 中通常设为 \(d_{ff} = 4d\)
在 Transformer 或类似的自注意力架构(如HSTU)中,每个编码器层通常包含两个核心子层:
- 自注意力机制(Self-Attention):复杂度为 \(O(n_i^2 d)\) (与序列长度平方和嵌入维度相关)
- 自注意力的计算涉及三个主要步骤:
- 计算查询(Q)、键(K)、值(V)矩阵:复杂度为 \(O(n_i d^2)\) ,其中 \(n_i\) 是序列长度, \(d\) 是嵌入维度
- 计算注意力分数 \(QK^T\) :复杂度为 \(O(n_i^2 d)\)
- 加权求和 \(AV\) :复杂度为 \(O(n_i^2 d)\)
- 因此,自注意力的总复杂度为 \(O(n_i^2 d + n_i d^2)\) 。对于长序列(\(n_i \gg d\)),主导项为 \(O(n_i^2 d)\)
- 自注意力的计算涉及三个主要步骤:
- 前馈神经网络(FFN):复杂度为 \(O(n_i d_{ff} d)\) (与序列长度、嵌入维度和FFN隐藏层维度相关,)
- FFN的典型结构是:
$$
\text{FFN}(x) = W_2 \cdot \text{ReLU}(W_1 x + b_1) + b_2
$$- 其中:
- \(W_1 \in \mathbb{R}^{d \times d_{ff} }\) :将输入从 \(d\) 维映射到 \(d_{ff}\) 维(通常 \(d_{ff} = O(d)\) ,注意不是相等,一般是通常 \(d_{ff} = 4d\) 等)
- \(W_2 \in \mathbb{R}^{d_{ff} \times d}\) :将结果映射回 \(d\) 维
- 其中:
- 在 Transformer 中, \(d_{ff}\) 通常远大于 \(d\) (例如 \(d_{ff}=4d\)),这使得FFN成为计算瓶颈之一。HSTU通过点乘门控(如 \(U(X)\))替代了传统FFN(见式3),因此可能不再需要显式的 \(d_{ff}\) 参数。但在对比 Transformer 基线时,公式中仍保留了 \(d_{ff}\) 以反映传统架构的成本
- 自注意力机制(Self-Attention):复杂度为 \(O(n_i^2 d)\) (与序列长度平方和嵌入维度相关)
总计算复杂度
- 对于每个用户的序列,计算量为自注意力和前馈网络复杂度的总和:
$$
O(n_i^2 d + n_i d^2)
$$ - 若对所有用户求和,总计算量为:
$$
\sum_i n_i (n_i^2 d + n_i d^2)
$$ - 假设最大序列长度为 \(N = \max_i n_i\) ,则复杂度可简化为:
$$
O(N^3 d + N^2 d^2)
$$
- 对于每个用户的序列,计算量为自注意力和前馈网络复杂度的总和:
论文中的其他优化:论文提出通过生成式训练(generative training)对计算量进行优化:
- 通过调整用户采样率 \(s_u(n_i) \propto 1/n_i\) ,将总计算量降低为:
$$
\sum_i s_u(n_i) n_i (n_i^2 d + n_i d^2) \approx O(N^2 d + N d^2)
$$ - 这一优化将复杂度从三次方(\(N^3\))降至二次方(\(N^2\))
- 通过调整用户采样率 \(s_u(n_i) \propto 1/n_i\) ,将总计算量降低为:
附录(个人):关于NE的完整定义
- 参考原始论文:Practical Lessons from Predicting Clicks on Ads at Facebook
- NE(Normalized Cross Entropy,归一化交叉熵),也可更准确地称为Normalized Logarithmic Loss(归一化对数损失),其定义为平均每个展示的对数损失除以模型预测每个展示的 CTR 时的平均对数损失
- 假设给定的训练数据集有 \(N\) 个样本,则计算公式为:
$$NE=\frac{-\frac{1}{N} \sum_{i=1}^{n}\left(\frac{1+y_{i} }{2} log \left(p_{i}\right)+\frac{1-y_{i} }{2} log \left(1-p_{i}\right)\right)}{-(p * log (p)+(1-p) * log (1-p))} $$- \(y_{i} \in{-1,+1}\) 为真实标签
- \(p_{i}\) 为第 \(i\) 个样本的CTR预估值,其中 \(i = 1,2,\cdots,N\)
- \(p\) 平均经验点击率(基于统计的真实点击率)
- 该指标用于评估模型预测的好坏,其值越低,模型的预测效果越好
- 进行这种归一化处理的原因是,真实 CTR 预估值越接近0或1,就越容易获得更好的对数损失,而除以 真实 CTR 的熵可使 NE 对真实 CTR 不敏感
- 其他相关指标:Relative Information Gain (RIG)
$$ RIG = 1 − NE $$
附录A:符号说明
- 论文在下表中总结了论文使用的关键符号(对应原始论文的表8和表9)
符号 描述 \(\Psi_{k}(t_{j})\) Feature Logging 系统在 \(t_{j}\) 时刻发出的第 \(k\) 个 Training Example(\(k\) 是全局排序的)
在典型的深度推荐模型(DLRM)推荐系统中,用户消费某些内容 \(\Phi_{i}\) (通过诸如跳过、视频观看完成和分享等动作 \(a_{i}\) 做出响应)后,特征记录系统将元组 \((\Phi_{i}, a_{i})\) 与用于对 \(\Phi_{i}\) 进行排名的特征相结合,并发出 \((\Phi_{i}, a_{i}\) ,以及 \(\Phi_{i}\) 的特征) 作为 Training Example \(\Psi_{k}(t_{j})\)
如2.3节所述,DLRM和生成式推荐器(GRs)处理的 Training Example 数量不同,GRs中的 Example 数量通常少1 - 2个数量级\(n_{c}(n_{c,i})\) 与用户/样本 \(i\) 交互的内容数量 \(\Phi_{0}, …, \Phi_{n_{c}-1}\) 在推荐系统的上下文中,与用户交互的内容列表 \(a_{0}, …, a_{n_{c}-1}\) 与内容 \(\Phi_{i}\) 对应的用户动作列表
当所有预测事件都是 Binary 时,每个动作可以被视为一个 multi-hot vector 事件(如点赞、分享、评论、图片浏览、视频初始化、视频观看完成、隐藏等)\(E, F\) 图2中DLRM中的分类特征
\(E_{0}, E_{1}, …, E_{7}, E_{8}\) 和 \(F_{0}, F_{1}, …, F_{7}\) 表示在不同时间点通过特征提取(例如,最近喜欢的10张图片、用户过去点击的与当前候选内容最相似的50个网址等)从 \((\Phi_{0}, a_{0}, t_{0}), …, (\Phi_{n_{c}-1}, a_{n_{c}-1}, t_{n_{c}-1})\) 获得的转换结果
“merge & sequentialize” 表示获取原始参与系列 \((\Phi_{0}, a_{0}, t_{0}), …, (\Phi_{n_{c}-1}, a_{n_{c}-1}, t_{n_{c}-1})\) 的(虚拟)反向过程\(G, H\) 图2中DLRM中与 user-item 参与无关的分类特征。这些特征(例如人口统计信息或关注的创作者)被合并到主时间序列(用户参与的内容列表,例如 \(\Phi_{0}, a_{0}, …, \Phi_{n_{c}-1}, a_{n_{c}-1}\))中,如2.1节所述并在图2中说明 \(n(n_{i})\) Squential Transduction 任务中的 token 数量(对于用户或样本 \(i\))。虽然 \(O(n) = O(n_{c})\) ,但即使没有任何与非交互相关的分类特征, \(n\) 也可能与 \(n_{c}\) 不同;例如,见表1 \(x_{0}, …, x_{n - 1}\) Squential Transduction 任务中的输入 token 列表 \(y_{0}, …, y_{n - 1}\) Squential Transduction 任务中的输出 token 列表 \(t_{0}, …, t_{n - 1}\) 与观察到 \(x_{0}, …, x_{n - 1}\) 的时间对应的时间戳列表 \(\mathbb{X}, \mathbb{X}_{c}\) 所有输入/输出 token 的词汇表(\(\mathbb{X}\))及其内容子集(\(\mathbb{X}_{c}\)) \(N, N_{c}\) \(\max_{i}n_{i}\) , \(\max_{i}n_{c,i}\) \(u_{t}\) 在时间 \(t\) 的用户表示 \(s_{u}(n_{i}), \hat{s}_{u}(n_{i})\) 生成式训练(2.3节)中用于用户 \(i\) 的采样率 \(d\) 模型维度(嵌入维度) \(d_{qk}\) HSTU和 Transformer 中注意力维度的大小。这适用于公式(1)中的 \(Q(X)\) 和 \(K(X)\) \(d_{v}\) HSTU中 Value 维度的大小。对于 Transformer,论文通常有 \(d_{qk} = d_{v}\) \(d_{ff}\) Transformer pointwise 前馈层中(feedforward)的隐藏维度大小。HSTU不使用前馈层;见下面的 \(U(X)\) \(h\) 注意力头的数量 \(l\) HSTU中的层数。对于 Transformer,注意力层和逐点前馈层共同构成一层 \(Q(X), K(X), V(X)\) 根据公式(1)为给定输入 \(X\) 在HSTU中获得的查询、键、值(Query/Key/Value)。其定义与标准 Transformer 中的 \(Q, K, V\) 类似。 \(Q(X), K(X) \in \mathbb{R}^{h \times N \times d_{qk} }\) ,并且HSTU使用 \(U(X)\) (与 \(f_{2}(·)\) 一起)在公式(3)中 “门控” 注意力池化值(\(V(X)\)),这使得HSTU完全避免了前馈层。 \(U(X) \in \mathbb{R}^{h \times N \times d_{v} }\) \(A(X)\) 为输入 \(X\) 获得的注意力张量。 \(A(X) \in \mathbb{R}^{h \times N \times N}\) \(Y(X)\) HSTU层针对输入 \(X\) 的输出。 \(Y(X) \in \mathbb{R}^{d}\) \(Split(·)\) 将张量分割成块的操作。 \(Split(\phi_{1}(f_{1}(X))) \in \mathbb{R}^{N \times (2hd_{qk} + 2hd_{v})}\) ;论文通过分割较大的张量(并置换维度)获得 \(U(X), V(X)\) (两者形状均为 \(h \times N \times d_{v}\))、 \(Q(X), K(X)\) (两者形状均为 \(h \times N \times d_{qk}\)) \(rab^{p,t}\) 结合了位置(Raffel等,2020)和时间(基于观察到 token 的时间 \(t_{0}, …, t_{n - 1}\) ;一种可能的实现方式是对 \((t_{j} - t_{i})\) 应用某种分桶函数得到 \((i, j)\))信息的相对注意力偏差。在实践中,论文在一层内的不同注意力头之间共享 \(rab^{p,t}\) ,因此 \(rab^{p,t} \in \mathbb{R}^{1 \times N \times N}\) \(\alpha\) 控制HSTU中随机长度算法(3.2节)稀疏性的参数 \(R\) GPU上的寄存器大小,在3.2节讨论的HSTU算法的上下文中 \(m\) 推荐系统Ranking 阶段考虑的候选数量 \(b_{m}\) M-FALCON 算法(3.4节)中的微批次大小
附录B:生成式推荐器:背景与公式
- 许多读者可能对经典的深度学习推荐模型(DLRM)更为熟悉(Mudigere等,2022),因为自YouTube DNN时代起它就颇受欢迎(Covington等,2016),并且在每个大型在线内容和电子商务平台上都得到了广泛应用(Cheng等,2016;Zhou等,2018;Wang等,2021;Chang等,2023;Xia等,2023;Zhai等,2023a)。DLRM在异构特征空间上运行,使用各种神经网络,包括特征交互模块(Guo等,2017;Xiao等,2017;Wang等,2021)、顺序池化或目标感知成对注意力模块(Hidasi等,2016;Zhou等,2018;Chang等,2023)以及先进的多专家多任务模块(Ma等,2018;Tang等,2020)。因此,论文在第2节和第3节中通过将生成式推荐器(GRs)与经典DLRM进行明确对比,概述了GRs。在本节中,论文从经典的顺序推荐文献出发,为读者提供另一种视角
附录B.1:背景:学术界和工业界的顺序推荐
附录B.1.1:学术研究(传统顺序推荐设置)
- 循环神经网络(RNNs)最早在GRU4Rec(Hidasi等,2016)中应用于推荐场景。Hidasi等(2016)考虑了门控循环单元(GRUs),并将其应用于两个数据集,即RecSys Challenge 2015和VIDEO(一个专有数据集)。在这两种情况下,只有 positive 事件(点击的电子商务商品或用户观看至少一定时间的视频)被保留作为输入序列的一部分。论文进一步观察到,在由检索和Ranking 阶段组成的经典工业规模两阶段推荐系统设置中(Covington等,2016),Hidasi等(2016)解决的任务主要对应于检索任务
- 后来, Squential Transduction 架构的进步,特别是 Transformer (Vaswani等,2017),推动了推荐系统的类似进展。SASRec(Kang和McAuley,2018)首次在自回归设置中应用 Transformer。他们将评论或评分的存在视为 positive 反馈 ,从而将像亚马逊评论和MovieLens这样的经典数据集转换为 positive item 的序列,类似于GRU4Rec。采用二元交叉熵损失,其中正目标定义为下一个 “positive” item (回想一下,这本质上只是评论或评分的存在),负目标从 item 语料库 \(\mathbb{X}=\mathbb{X}_{c}\) 中随机采样
- 随后的大多数研究都基于与上述GRU4Rec(Hidasi等,2016)和SASRec(Kang和McAuley,2018)类似的设置,例如BERT4Rec(Sun等,2019)应用来自BERT(Devlin等,2019)的双向编码器设置,S3Rec(Zhou等,2020)引入明确的预训练阶段,等等
附录B.1.2:作为深度学习推荐模型(DLRM)一部分的工业应用
- 顺序方法,包括顺序编码器和成对注意力模块,由于能够作为DLRM的一部分增强用户表示,已在工业环境中得到广泛应用。DLRM通常使用相对较短的序列长度 ,例如BST(Chen等,2019)中为20,DIN(Zhou等,2018)中为1000,TransAct(Xia等,2023)中为100。论文观察到,论文中的8192比传统DLRM序列长度大 1-3 个数量级
- 尽管使用短序列长度,大多数DLRM仍能成功捕捉长期用户偏好。这可归因于两个关键方面:
- 第一 :现代DLRM中通常使用预计算的用户配置文件/嵌入或外部向量存储(Chang等,2023),这两者都有效地扩展了回顾窗口
- 理解,用户 Embedding 其实与用于历史长期用户偏好有关?
- 第二 :通常会采用大量的上下文、用户和 item 侧特征,并且使用各种异构网络,如因子分解机(FMs)、深度交叉网络(DCNs)、混合专家(MoEs)等,来转换表示并组合输出
- 理解:特征交叉能泛化到用户长期偏好?
- 第一 :现代DLRM中通常使用预计算的用户配置文件/嵌入或外部向量存储(Chang等,2023),这两者都有效地扩展了回顾窗口
- 与附录B.1.1中讨论的顺序设置相比,所有主要的工业界工作都在(用户/请求,候选 item)对上定义损失。在排名设置中,通常使用多任务二元交叉熵损失。在检索设置中,双塔设置(Covington等,2016)仍然是主导方法。最近的工作研究了将下一个推荐 item 表示为(子) token 序列上的概率分布,如OTM(Zhuo等,2020)和DR(Gao等,2021)(注意,在其他近期工作中,相同的设置有时被称为 “生成式召回”)。它们通常利用 beam search 从子 token 中解码 item。随着现代加速器(如GPU、定制ASIC和TPU)的普及,还提出并部署了先进的学习相似性函数,如混合逻辑(Zhai等,2023a),作为双塔设置和 beam search 的替代方案
- 从问题公式化的角度来看,考虑到模型架构、使用的特征和损失与附录B.1.1中讨论的学术顺序推荐研究有显著差异,作者认为上述所有工作都属于DLRM(Mudigere等,2022)的一部分。值得注意的是,在这项工作之前,工业界尚未成功应用完全顺序排名设置,特别是在每日活跃用户(DAU)达到数十亿规模的情况下
附录B.2:公式化表述:生成式推荐器(GRs)中作为序列转换任务的排序与检索
- 接下来,论文讨论传统序列推荐器设置和深度推荐模型(DLRM)设置中的三个局限性,以及生成式推荐器(GRs)如何从问题公式化的角度解决这些问题
- 问题1:忽略用户交互物品之外的特征 :以往的序列公式化表述仅考虑用户明确交互过的内容(物品) ,而在GRs出现之前,传统推荐系统会基于大量特征进行训练 ,以增强用户和内容的表征 ,GRs通过以下方式解决这一局限性:
- a)压缩其他分类特征并将其与主时间序列合并;
- b)如2.1节和图2所述,利用目标感知公式通过交叉注意力交互来捕捉数值特征。论文通过实验验证了这一点,结果表明,忽略这些特征的传统 “interactions only” 公式化表述会显著降低模型质量;实验结果可在表7和表6中标记为 “GR(interactions only)” 的行中找到,论文发现仅利用交互历史会导致检索的 HitRate@100 下降1.3%,排序的归一化熵(NE)下降2.6%(回想一下,如4.1.2节和4.3.1节所述,NE变化0.1% 即为显著变化)
- 问题2:用户表征在与目标无关的设置中计算 :大多数传统序列推荐器,包括GRU4Rec(2016)、SASRec(2018)、BERT4Rec(2019)、S3Rec(2020)等,都是以与目标无关的方式构建的。在这种方式中,对于目标物品 \(\Phi_{i}\) , \(\Phi_{0}, \Phi_{1}, …, \Phi_{i - 1}\) 被用作编码器输入来计算用户表征,然后用于进行预测。相比之下,工业环境中使用的大多数主要DLRM方法在构建所使用的序列模块时考虑了目标感知,能够将 “目标”(排序候选)信息整合到用户表征中。这些方法包括DIN(2018)(阿里巴巴)、BST(2019)(阿里巴巴)、TWIN(2023)(快手)和TransAct(2023)(Pinterest)
- 生成式推荐器(GRs)通过交错内容和动作序列(2.2节),在因果自回归设置中实现目标感知注意力机制 ,结合了两者的优点(序列推荐器和DLRM的优点)。论文在表10中对先前的工作和本工作进行了分类和对比
- 理解:(详情见前文对论文 target-aware 实现方式的理解),其实 Transformer 的 Attention 也有交叉功能,只要输入端有目标 item 和用户历史交互 item 即可,但论文所说的传统的自回归模型是指输入侧不包含目标 item 的情况,论文中,将动作也建模进去,则在输出对目标 item 的动作 token 时,自然就需要将目标 item 作为输入,从而也就实现了 target-aware 交叉注意力:
- 传统自回归模型预估目标为 : \(p(\Phi_{i+1}|\Phi_{0},\Phi_{1},\ldots,\Phi_{i})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列无交叉
- 注:此时动作 \(a_i\) 信息可能会作为额外表征加入到 \(\Phi_{i}\)中,所以 表述为 \(p(\Phi_{i}|(\Phi_{0}, a_{0}), …, (\Phi_{i - 1}, a_{i - 1}))\) 也可以
- 论文预估目标为 : \(p(a_{i+1}|\Phi_{0},a_{0},\Phi_{1},a_{1},\ldots,\Phi_{i+1})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列有交叉
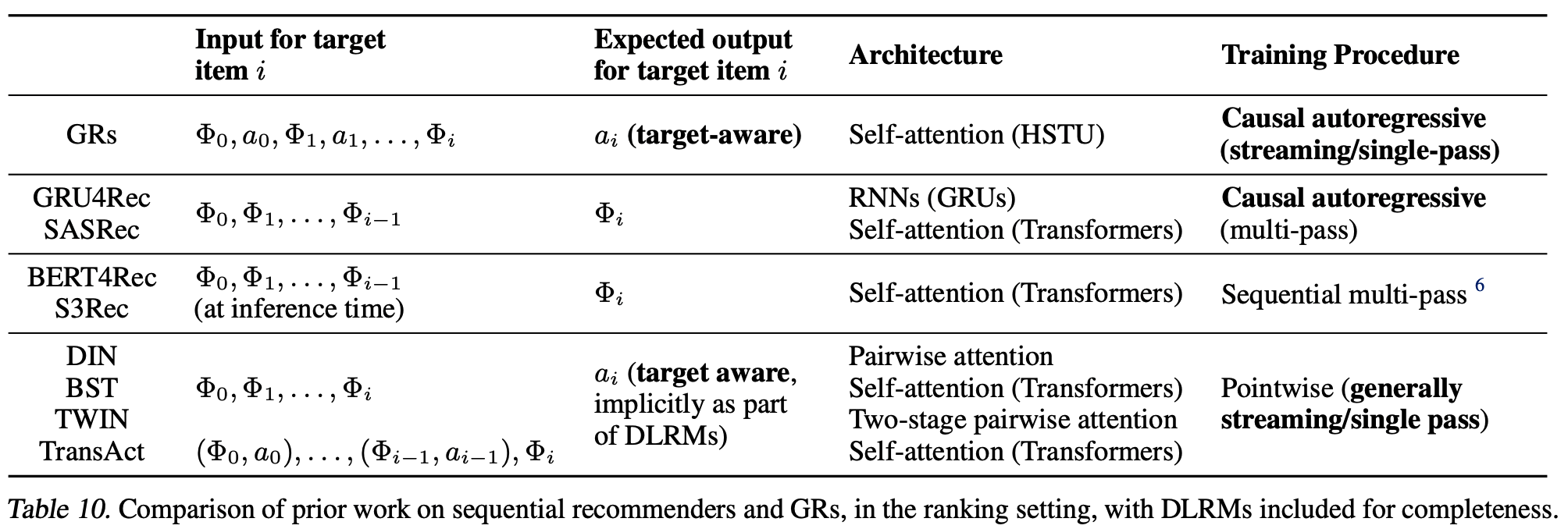
- 传统自回归模型预估目标为 : \(p(\Phi_{i+1}|\Phi_{0},\Phi_{1},\ldots,\Phi_{i})\),目标物品 \(\Phi_{i+1}\) 与其他历史序列无交叉
- 问题3:判别式公式限制了先前序列推荐器工作的适用性 :传统的序列推荐器本质上是判别式的。现有的序列推荐文献,包括GRU4Rec和SASRec等开创性工作,对 \(p(\Phi_{i}|\Phi_{0}, a_{0}, …, \Phi_{i - 1}, a_{i - 1})\) 进行建模(注:虽然这里传统这里输入中包含动作信息,但是实际上动作是作为额外的信息加入到 item 表征中的,不是单独将 action 作为一个 token,所以写成 \(p(\Phi_{i}|(\Phi_{0}, a_{0}), …, (\Phi_{i - 1}, a_{i - 1}))\) 更合适),即根据用户当前状态推荐下一个物品的条件分布
- 推荐系统中实际上存在两个概率过程 :
- 1)推荐系统向用户推荐内容 \(\Phi_{i}\) 的过程;
- 2)用户通过某些动作 \(a_{i}\) 对推荐内容 \(\Phi_{i}\) 做出反应的过程
- 生成式方法对推荐内容和用户动作序列的联合分布进行建模 ,如2.2节所述,即联合概率分布 \(p(\Phi_{0}, a_{0}, \Phi_{1}, a_{1}, …, \Phi_{n_{c}-1}, a_{n_{c}-1})\)(如表11(图8)所示,论文提出的生成式推荐器能够对这种分布进行建模):
- Next action token (\(a_{i}\)) prediction 任务正是 Ranking 任务(即表1中讨论的 GR Ranking 设定)
- Next content token (\(\Phi_{i}\)) prediction 任务对应 Retrieval 任务,目标是学习 next item

- 推荐系统中实际上存在两个概率过程 :
- 重要的是,这种公式化表述不仅能够对数据分布进行适当建模,还能够通过例如 beam search 直接采样要推荐给用户的物品序列。论文假设这将产生一种比传统列表式设置(例如DPP(2014)和RL(2018))更优越的方法,论文将此类系统的完整公式化表述和评估(在6节中简要讨论)留作未来的工作
附录C:评估:合成数据
- 如3.1节先前所述,标准的softmax注意力机制因其归一化因子,难以捕捉用户偏好的强度,而这对于用户表示学习至关重要。在推荐场景中,这一点很关键,因为系统可能不仅需要预测 item 的相对排序,还需要预测用户参与的强度(例如,未来对特定主题的 positive 行为数量)
- 为理解这种行为,论文构建了遵循狄利克雷过程(Dirichlet Process)的合成数据,该过程在动态词汇集上生成流式数据。狄利克雷过程捕捉了用户参与历史中 “富者更富”(rich gets richer) 的行为。论文设置合成实验如下:
- 论文将 20,000 个 item ID中的每一个随机分配到100个类别中的某一个
- 论文生成 1,000,000 条长度为 128 的记录,其中前90%用于训练,最后10%用于测试。为模拟流式训练设置,论文最初提供40%的 item ID,其余的以相等的间隔逐步提供;即在记录 500,000 时,可以采样的最大ID是 \((40% + 60% * 0.5) * 20,000 = 14,000\)
- 论文为每条记录从100个类别中随机选择最多5个类别,并为这5个类别随机采样一个先验 \(H_{c}\) 。按照狄利克雷过程,为每个位置顺序采样类别,具体如下:
- 对于 \(n>1\) :
- 以概率 \(\alpha / (\alpha + n - 1)\) ,从 \(H_{c}\) 中抽取类别 \(c\)
- 以概率 \(n_{c} / (\alpha + n - 1)\) ,抽取类别 \(c\) ,其中 \(n_{c}\) 是先前具有类别 \(c\) 的 item 数量
- 随机采样一个符合类别 \(c\) 且受流式约束的分配 item
- 其中 \(\alpha\) 从(1.0, 500.0)中均匀随机采样
- 对于 \(n>1\) :
- 结果见表2。由于此数据集没有时间戳,论文在HSTU中去除 \(rab^{p, t}\)。论文观察到,相对于标准 Transformer,HSTU的 HitRate@10 提高了100%以上。重要的是,将HSTU的逐点聚合注意力机制(Pointwise aggregated attention)替换为 Softmax(“HSTU w/ Softmax”)也会导致 HitRate 显著降低,这验证了类似逐点聚合注意力机制的重要性
附录D:评估:传统顺序推荐器设置
- 论文在4.1.1节的评估重点是将HSTU与 SOTA Transformer 基线SASRec进行比较,使用最新的训练方法。在本节中,论文进一步考虑另外两种替代方法
- 循环神经网络(RNNs)。论文考虑顺序推荐器的经典工作GRU4Rec(Hidasi等,2016),以帮助读者理解包括 Transformer 和HSTU在内的自注意力模型,在充分融入最新的建模和训练改进后,与传统RNNs相比如何
- 自监督顺序方法。论文考虑最受欢迎的工作BERT4Rec(Sun等,2019),以了解双向自监督(BERT4Rec通过完形填空目标利用)与单向因果自回归设置(如SASRec和HSTU)相比如何
- 结果见表12。论文重用Klenitskiy和Vasilev(2023)报告的BERT4Rec和GRU4Rec在ML-1M和ML-20M上的结果。由于使用了采样softmax损失,论文保持负样本数量不变(ML-1M、ML-20M为128,亚马逊图书为512),以确保方法之间的公平比较
- 结果证实,在使用采样softmax损失的传统顺序推荐设置中,SASRec仍然是最具竞争力的方法之一(Zhai等,2023a;Klenitskiy和Vasilev,2023),而HSTU显著优于所评估的 Transformer 、RNN和自监督双向 Transformer
附录E:评估:传统DLRM基线
- 第4节中使用的DLRM基线配置反映了数百名研究人员和工程师多年来的持续迭代,并且在部署HSTU/GR之前,是对拥有数十亿日活跃用户的大型互联网平台上生产配置的近似。本节对所使用的模型进行简要描述
排名设置
- 如(Mudigere等,2022)所述,基线排名模型采用了大约一千个密集特征和五十个稀疏特征。论文结合了各种建模技术,如 Mixture of Experts(Ma等,2018)、Deep & Cross Network 的变体(Wang等,2021)、各种顺序推荐模块,包括 target-aware pairwise 注意力(在工业设置中常用的一种变体可参见(Zhou等,2018)),以及特殊交互层上的残差连接(He等,2015;Zhang等,2022)。在 scaling law 部分(4.3.1节)的低FLOP区域,一些计算成本高的模块被简化、替换为其他 state-of-the-art 的变体,如DCN,以达到所需的FLOP
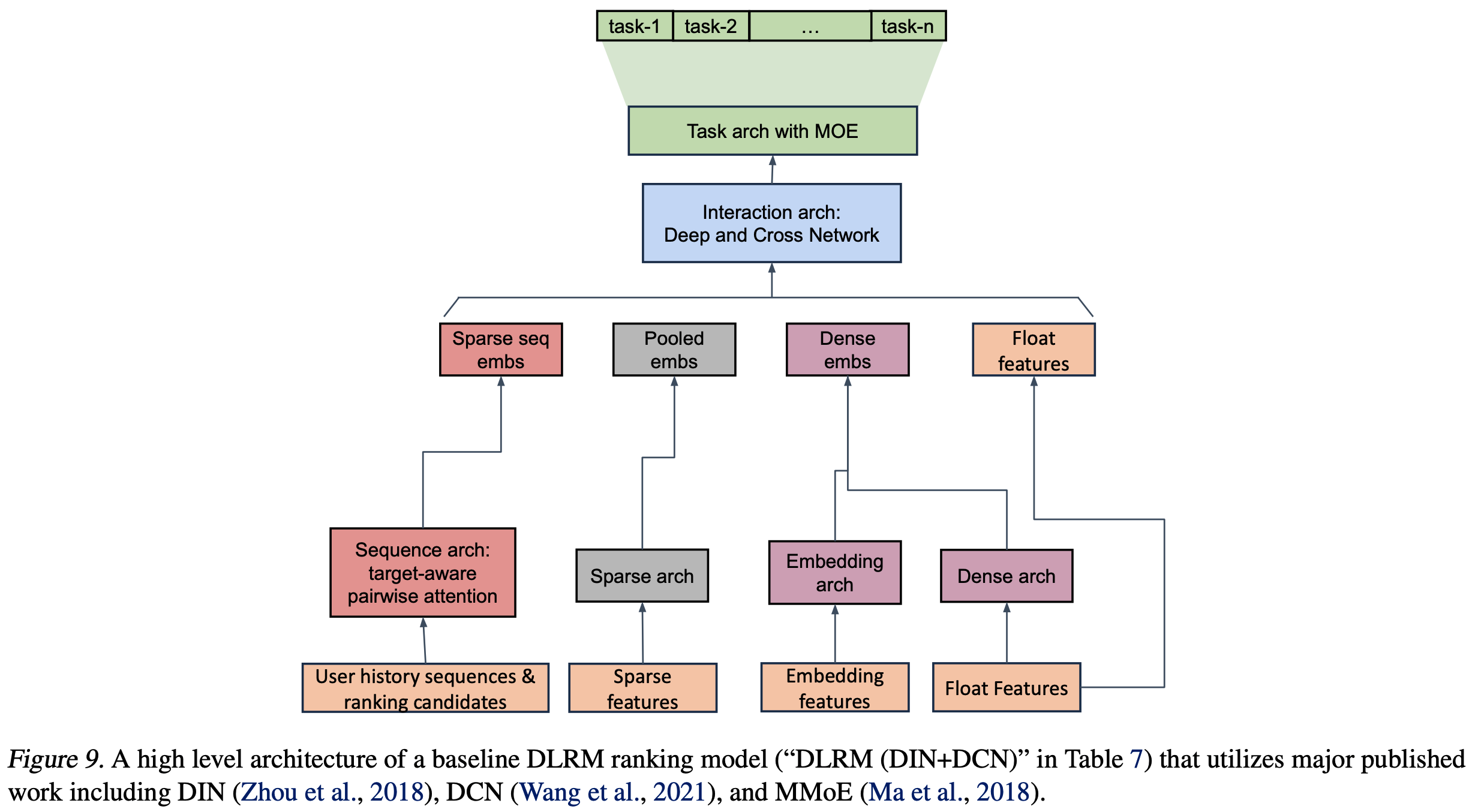
- 由于保密考虑,论文无法透露确切设置 ,但据论文所知,在充分纳入最新研究成果后,论文的基线代表了最优秀的DLRM方法之一。为验证这一说法并帮助读者理解,论文在表7中报告了基于相同特征,但仅利用主要已发表成果(包括DIN(Zhou等,2018)、DCN(Wang等,2021)和MMoE(Ma等,2018))的典型设置(“DLRM (DIN + DCN)”),并在图9中展示了组合架构。该设置在主要E任务的NE上比论文的生产DLRM设置低0.71%,在主要C任务的NE上低0.57%(0.1%的NE变化即具有显著性)
检索设置
- 基线检索模型采用标准的双塔神经检索设置(Covington等,2016),并结合了批内(in-batch)和批外(out-of-batch)采样。输入特征集包括高基数稀疏特征(如 item ID、用户ID)和低基数稀疏特征(如语言、主题、兴趣实体)。使用带有残差连接的前馈层堆栈(He等,2015)将输入特征压缩为用户和 item 嵌入
特征和序列长度
- DLRM基线中使用的特征,包括各种顺序编码器/成对注意力模块所利用的主要用户交互历史,是所有 GR 候选模型使用特征的严格超集(strict supersets)。这适用于论文中进行的所有研究,包括缩放研究(4.3.1节)中使用的特征
附录F:随机长度
附录F.1:子序列选择
- 在公式(4)中,论文从完整的用户历史中选择长度为 \(L\) 的子序列以增加稀疏性。论文的实证结果表明,精心设计子序列选择技术可以提高模型质量。论文计算一个指标 \(f_{i}=t_{n}-t_{i}\) ,它对应于用户与 item \(x_{i}\) 交互后经过的时间量。论文使用以下子序列选择方法进行离线实验:
- 贪心选择(Greedy Selection) - 从 \(S\) 中选择 \(L\) 个 \(f_{i}\) 值最小的 item,即保留最近交互的 item
- 随机选择(Random Selection) - 从 \(S\) 中随机选择 \(L\) 个 item
- 特征加权选择(Feature-Weighted Selection) - 根据加权分布 \(1 - f_{n, i} / (\sum_{j = 1}^{L}f_{j, i})\) 从 \(S\) 中选择 \(L\) 个 item(理解:对越近交互的样本,采样权重越大)
- 在离线实验中,特征加权子序列选择方法产生了最佳的模型质量,如表13所示

附录F.2:随机长度对序列稀疏性的影响
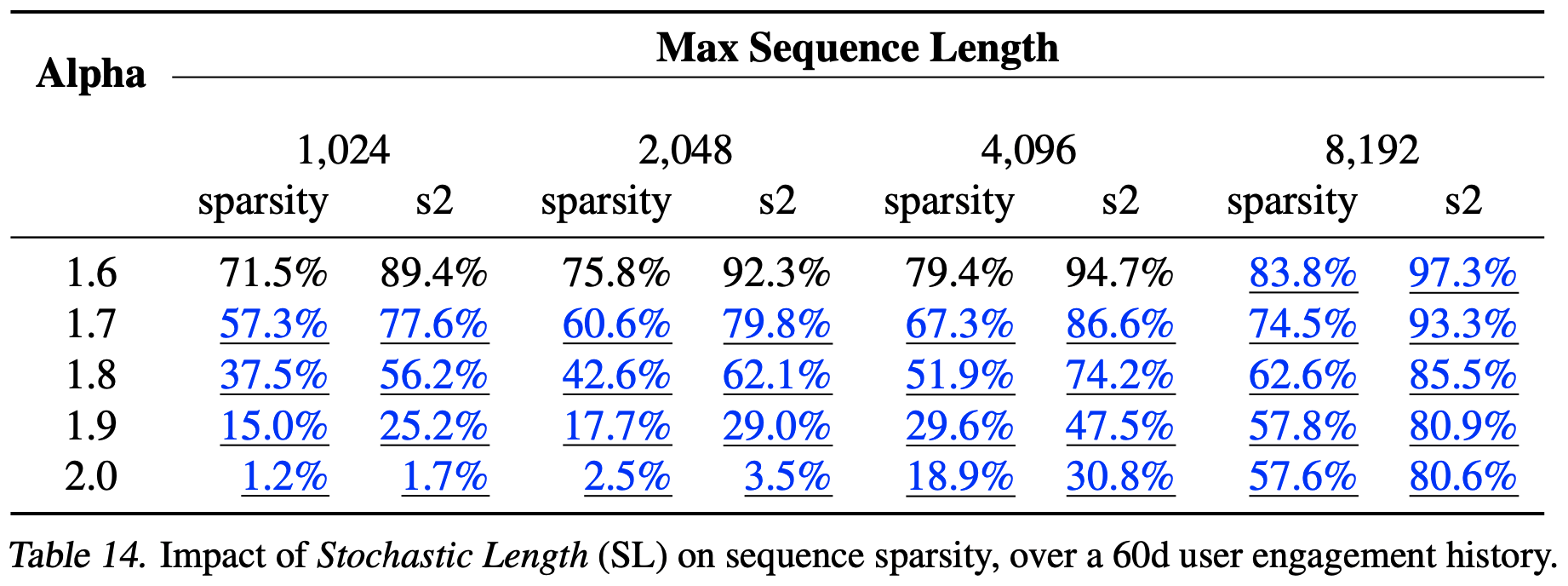
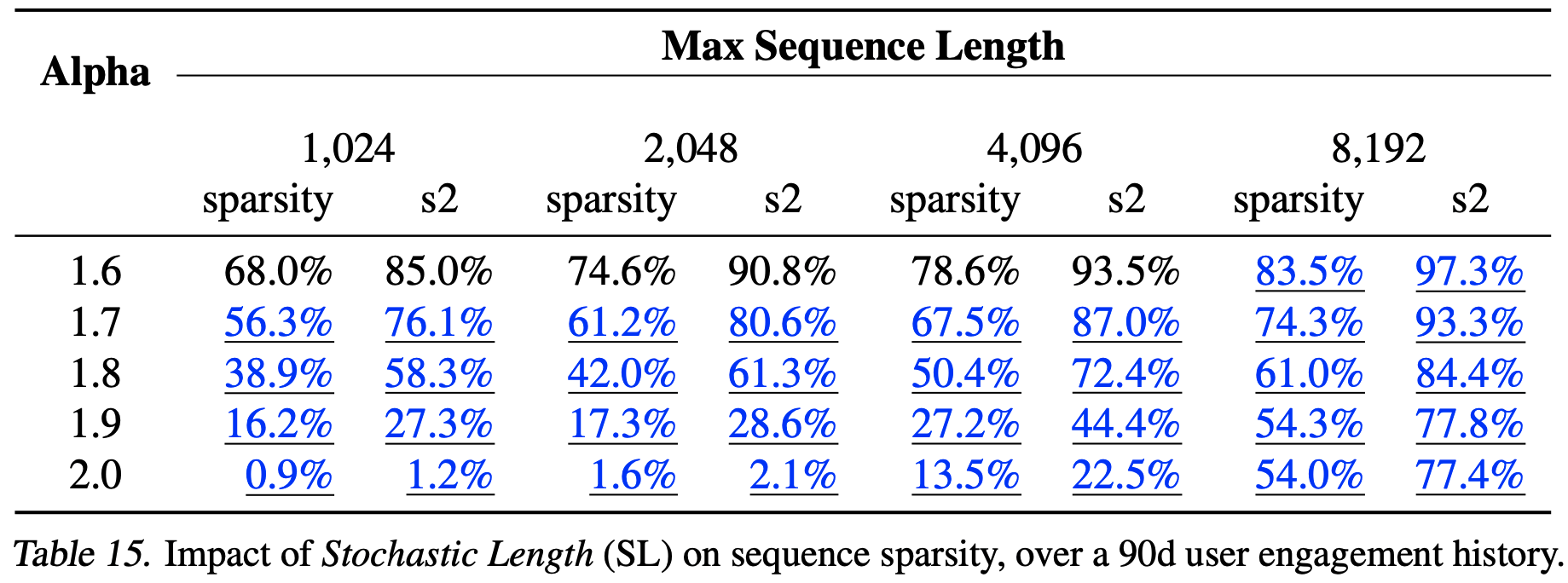
- 在表3中,论文展示了随机长度对具有30天用户参与历史的代表性工业规模配置中序列稀疏性的影响。序列稀疏性定义为1减去所有样本的平均序列长度与最大序列长度的比值。为了更好地描述稀疏注意力的计算成本,论文还定义了 \(s2\) ,它被定义为:1减去注意力矩阵的稀疏性(which is defined as one minus the sparsity of the attention matrix)。作为参考,论文在表14和表15中分别给出了60天和90天用户参与历史的结果
附录F.3:与序列长度外推技术的比较
- 论文进行了额外的研究,以验证随机长度与语言建模中使用的现有序列长度外推技术相比具有竞争力。许多现有方法通过修改旋转位置嵌入(RoPE)(Su等,2023)来进行序列长度外推。为了与现有方法进行比较,论文训练了一个没有相对注意力偏差和旋转嵌入的HSTU变体(HSTU - RoPE)
- 论文在HSTU-RoPE上评估以下序列长度外推方法:
- 零样本(Zero-Shot) - 应用NTK感知的RoPE(Peng等,2024),然后直接评估模型,不进行 Fine-tune
- 微调(Fine-tune) - 应用逐部分NTK(Peng等,2024)后,对模型进行1000步 Fine-tune
- 论文在HSTU(包括相对注意力偏差,无旋转嵌入)上评估以下序列长度外推方法:
- 零样本(Zero-Shot) - 根据最大训练序列长度夹紧相对位置偏差,直接评估模型(Raffel等,2020;Press等,2022)
- 微调(Fine-tune) - 根据最大训练序列长度夹紧相对位置偏差,在评估模型之前对模型进行1000步 Fine-tune
- 在表16中,论文报告了训练期间引入数据稀疏性的模型(随机长度、Zero-Shot、Fine-tune)与在完整数据上训练的模型之间的NE差异。论文将 Zero-Shot 和 Fine-tune 技术的稀疏性定义为训练期间的平均序列长度与评估期间的最大序列长度之比。所有 Zero-Shot 和 Fine-tune 模型都在1024序列长度的数据上进行训练,并在2048和4096序列长度的数据上进行评估。为了为这些技术找到合适的随机长度基线,论文选择了导致相同数据稀疏性指标的随机长度设置
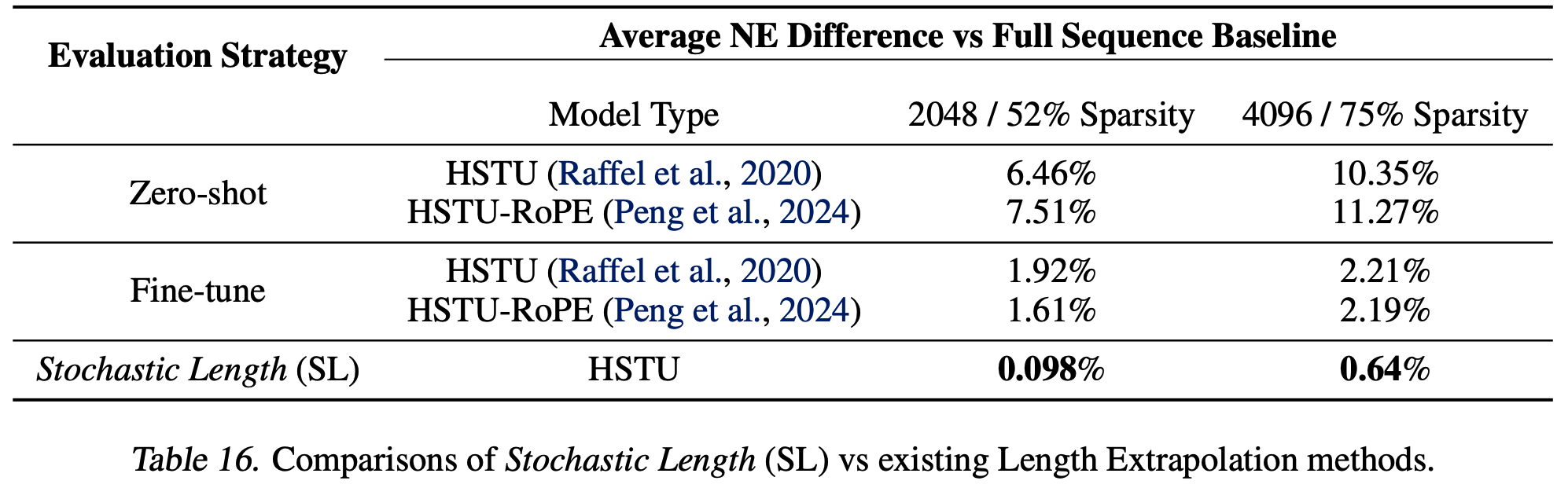
- 作者认为,Zero-Shot 和 Fine-tune 的序列长度外推方法不太适合处理高基数ID的推荐场景。从经验上看,论文观察到随机长度明显优于 Fine-tune 和 Zero-Shot 方法。作者认为这可能是由于论文的词表较大 ,Zero-Shot 和 Fine-tune 方法无法为较旧的ID学习良好的表示,这可能会损害它们充分利用较长序列中包含的信息的能力
附录G:稀疏分组通用矩阵乘法(GEMMs)和融合相对注意力偏差
- 论文提供3.2节中介绍的高效HSTU注意力内核的更多信息。论文的方法基于内存高效注意力(Rabe和Staats,2021)和FlashAttention(Dao等,2022),是一种内存高效的自注意力机制,它将输入划分为块,并避免在反向传播中具体化大的 \(h×N×N\) 中间注意力张量。通过利用输入序列的稀疏性,我们可以将注意力计算重新表述为一组具有不同形状的连续GEMM运算。论文实现了高效的GPU内核来加速此计算。相对注意力偏差的构建也因内存访问而成为瓶颈。为解决此问题,论文将相对偏差构建和分组GEMM运算融合到单个GPU内核中,并在反向传播中使用GPU的快速共享内存来累积梯度。尽管论文的算法在反向传播中需要重新计算注意力和相对偏差,但它比 Transformer 中使用的标准方法明显更快且内存使用更少
附录H:Microbatched-Fast Attention Leveraging Cacheable OperatioNs (M-FALCON)
- 在本节中,论文详细描述3.4节中讨论的 M-FALCON 算法
- M-FALCON 引入了三个关键思想
- 批量推理可应用于因果自回归设置 :GR中的排名任务以目标感知的方式制定,如2.2节所述。通常认为,在目标感知设置中,论文需要一次对一个 item 进行推理,对于 \(m\) 个候选 item 和长度为 \(n\) 的序列,成本为 \(O(mn^{2}d)\) 。但这里论文表明这不是最优解决方案;即使使用普通 Transformer,也可以修改自注意力中使用的注意力掩码以进行批量操作(“批量推理”),并将成本降低到 \(O((n + m)^{2}d)=O(n^{2}d)\)
- 图11给出了说明。这里,图11(a)和(b)都涉及因果自回归设置的注意力掩码矩阵。关键区别在于,图11(a)在因果训练中使用大小为 \(2n_{c}\) 的标准下三角矩阵,而图11(b)通过将 \(i, j≥2n_{c}\) 且 \(i≠j\) 的条目设置为 False 或 \(-\infty\) 来修改大小为 \(2n_{c}+b_{m}\) 的下三角矩阵,以防止目标位置 \(\Phi_{0}’, …, \Phi_{b_{m}-1}’\) 相互关注。很容易看出,通过这样做,自注意力块对 \(\Phi_{i}’, a_{i}’\) 的输出仅取决于 \(\Phi_{0}, a_{0}, …, \Phi_{n_{c}-1}, a_{n_{c}-1}\) ,而不取决于 \(\Phi_{j}’\) (\(i≠j\))。换句话说,通过使用修改后的注意力掩码对 \((2n_{c}+b_{m})\) 个 token 进行前向传递,论文现在可以获得与对 \((2n_{c}+1)\) 个 token 进行 \(b_{m}\) 次单独前向传递相同的最后 \(b_{m}\) 个 token 的结果,在第 \(i\) 次前向传递中, \(\Phi_{i}’\) 位于第 \(2n_{c}\) (基于0)位置,使用标准因果注意力掩码
- 微批次将批量推理扩展到大型候选集 :Ranking 阶段可能需要处理大量的排名候选 item ,多达数万个(Wang等,2020)。我们可以将总共 \(m\) 个候选 item 划分为 \(\lceil m / b_{m}\rceil\) 个大小为 \(b_{m}\) 的微批次,使得 \(O(b_{m}) = O(n)\) ,这在大多数实际推荐设置中,对于多达数万个候选 item ,保持了前面讨论的 \(O((n + m)^{2}d)=O(n^{2}d)\) 的运行时间
- 编码器级缓存可在请求内和请求间实现计算共享 :最后,键值缓存(Pope等,2022)可在请求内和请求间应用。例如,对于论文中介绍的HSTU模型(3节), \(K(X)\) 和 \(V(X)\) 在微批次内和/或请求间完全可缓存。对于缓存的前向传递,论文只需要为最后 \(b_{m}\) 个 token 计算 \(U(X), Q(X), K(X)\) 和 \(V(X)\) ,同时为包含 \(n\) 个 token 的序列化用户历史重用缓存的 \(K(X)\) 和 \(V(X)\) 。同样, \(f_{2}(Norm(A(X)V(X))\odot U(X))\) 只需要为 \(b_{m}\) 个候选 item 重新计算。这将缓存前向传递的计算复杂度降低到 \(O(b_{m}d^{2}+b_{m}nd)\) ,即使 \(b_{m}=n\) ,也比 \(O((n + b_{m})d^{2}+(n + b_{m})^{2}d)\) 提高了2 - 4倍
- 算法1说明了 M-FALCON 算法,有助于理解。论文注意到, M-FALCON 不仅适用于HSTU和GR,还广泛适用于其他基于自注意力架构的目标感知因果自回归设置的推理优化算法

附录H.1:推理吞吐量评估:使用 M-FALCON 的生成式推荐器(GRs)与DLRM的比较
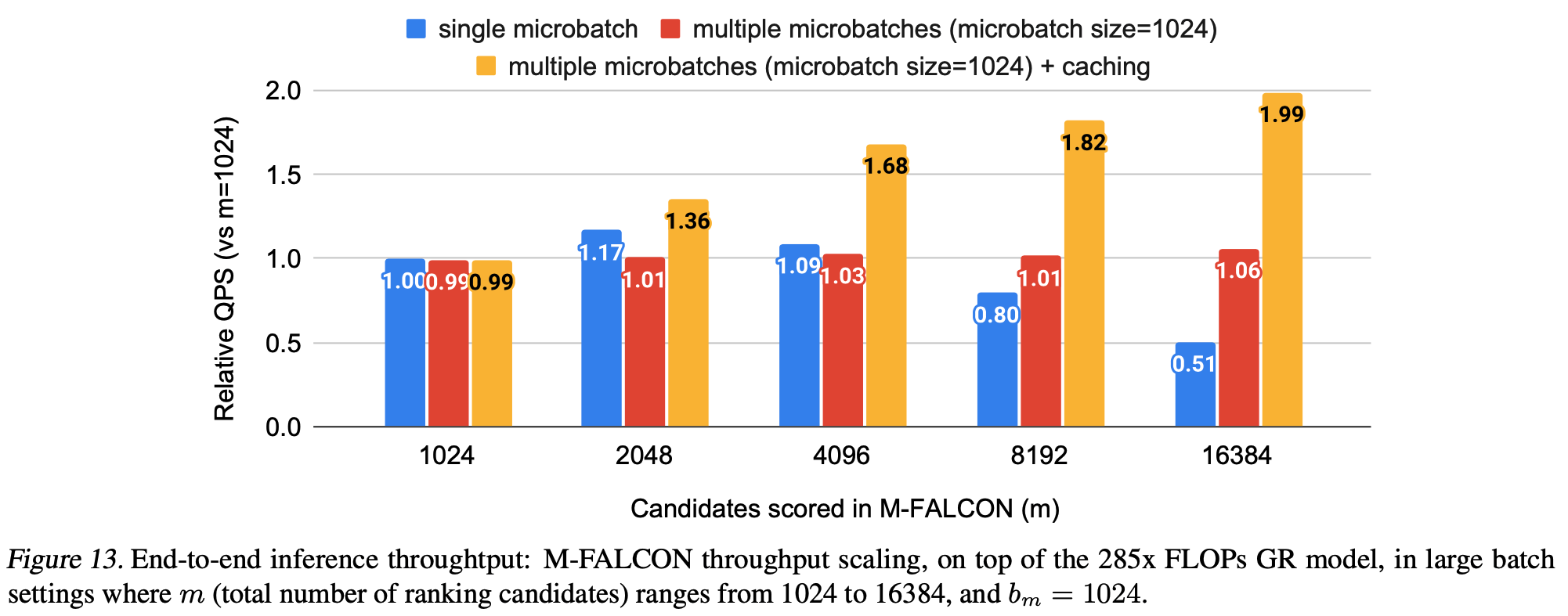
- 如3.4节所述, M-FALCON 在推理时并行处理 \(b_{m}\) 个候选 item ,以在所有 \(m\) 个候选 item 之间分摊计算成本。为理解论文的设计,论文在相同硬件设置下比较了GR和DLRM的吞吐量(即每秒评分的候选 item 数,QPS)
- 如图12和图13所示,由于批量推理实现了成本分摊,GR的吞吐量在一定区域内(在论文的案例研究中 \(m = 2048\))随Ranking 阶段候选 item 数 \((m)\) 呈次线性增长。这证实了批量推理在因果自回归设置中的关键性。由于注意力复杂度按 \(O((n + b_{m})^{2})\) 缩放,利用多个微批次本身就提高了吞吐量。缓存进一步消除了微批次之上的冗余线性和注意力计算。两者结合,相对于使用单个微批次的 \(b_{m}=m = 1024\) 基线,实现了高达1.99倍的额外加速,如图13所示。总体而言,凭借高效的HSTU编码器设计和利用 M-FALCON ,基于HSTU的生成式推荐器在大规模生产设置中的吞吐量比DLRM高出2.99倍,尽管GR在FLOP方面复杂285倍