注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:github.com/meituan-longcat/LongCat-Flash-Chat/blob/main/tech_report, 20250831, LongCat Team, Meituan
- LongCat Chat 在线体验: https://longcat.ai
- Hugging Face: https://huggingface.co/meituan-longcat
- Github: https://github.com/meituan-longcat
- 部署链接:LongCat-Flash Deployment Guide
Paper Summary
- LongCat-Flash 是一个 560B 参数的 MoE 模型,LongCat-Flash 采用了两种新颖的设计:
- (a) 零计算专家(Zero-computation Experts) :
- 能够实现动态计算预算分配,并根据上下文需求为每个 token 激活 18.6B 至 31.3B (平均 27B )参数,从而优化资源使用
- (b) 捷径连接的 MoE(Shortcut-connected MoE)
- 扩大了计算-通信重叠窗口,与同等规模的模型相比,在推理效率和吞吐量方面展现出显著提升
- (a) 零计算专家(Zero-computation Experts) :
- 论文为大型模型开发了一个全面的扩展框架,该框架结合了多个能力以实现稳定且可复现的训练:
- 超参数迁移(hyperparameter transfer)
- 模型增长初始化(model-growth initialization)
- 多管齐下的稳定性套件(multi-pronged stability suite)
- 确定性计算(deterministic computation)
- 利用可扩展架构设计和基础设施工作之间的协同作用,作者在 30 天内完成了超过 20T token 的模型训练,同时实现了超过 100 tokens/秒(TPS)的推理速度,每百万输出 token 的成本为 0.70 美元
- 训练过程:
- 在优化的混合数据上进行了大规模预训练
- 随后针对推理、代码和指令进行了有针对性的中期训练(mid-training)和Post-training
- 并进一步通过合成数据(synthetic data)和工具使用任务(tool use tasks)进行增强
- 作为一个 Non-thinking 的基础模型,LongCat-Flash 在其他领先模型中提供了极具竞争力的性能,并在智能体任务中表现出卓越的优势
Introduction and Discussion
- LLM 的快速发展已经证明了扩展模型规模和计算资源的有效性
- 尽管最近的一些进展引发了人们对潜在扩展放缓的担忧,但作者相信算法设计、底层系统优化和数据策略都在进一步推动可扩展智能前沿方面扮演着同样关键的角色
- 这需要在模型架构和训练策略上进行创新,以提高扩展的成本效益,同时需要一个系统性的数据策略来增强模型解决现实世界任务的能力
- LongCat-Flash 旨在沿着两个协同方向推进语言模型的前沿:计算效率(computational efficiency) 和 智能体能力(agentic capability)
- LongCat-Flash 在数万个加速器(Accelerators)上训练, 将架构创新与复杂的多阶段训练方法相结合,以打造可扩展且智能的模型
- 注意:使用的是 Accelerators 不一定是英伟达的 GPU!
- 论文的贡献涵盖了效率和智能体智能两个方面:
- 面向计算效率的可扩展架构设计(Scalable Architectural Design for Computational Efficiency)
- LongCat-Flash 的设计和优化遵循两个关键原则:高效的计算利用率 ,高效的训练和推理
- (1) 由于 并非所有 token 都是平等的 ,论文在 MoE 块中引入了 零计算专家(zero-computation experts) 机制,根据 token 的重要性为其动态分配计算预算,即基于上下文需求激活 18.6B 至 31.3B 参数(总共 560B )
- 为了确保一致的计算负载,论文采用了由 PID 控制器调整的专家偏置(expert bias) ,将每个 token 的平均激活参数维持在约 27B
- (2) 由于通信开销在 MoE 模型扩展过程中成为瓶颈,论文采用了 捷径连接的 MoE(Shortcut-connected MoE, ScMoE) (2024) 设计来扩大计算-通信重叠窗口
- 结合定制的基础设施优化,该设计使得能够在超过数万个加速器的大规模上进行训练,并实现高吞吐量和低延迟的推理
- 有效的模型扩展策略(Effective Model Scaling Strategy)
- 有效且高效地扩展模型规模仍然是策略设计中的一个关键挑战,为此,论文开发了一个全面的稳定性与扩展框架,用于稳健地训练大规模模型:
- (1) 论文成功地将超参数迁移策略应用于如此大的模型
- 通过利用具有理论保证的较小代理模型的结果来预测最优超参数配置
- (2) 论文使用基于精炼的半规模检查点的模型增长机制(model-growth mechanism based on a refined half-scale checkpoint)来初始化模型
- 与传统的初始化方法相比,实现了更好性能
- (3) 一个多管齐下的(multi-pronged)稳定性套件包含了:
- 原则性的路由器梯度平衡(principled router-gradient balancing)
- 用于抑制大规模激活的隐藏 z-loss (hidden z-loss to suppress massive activations)
- 精调的优化器配置(fine-tuned optimizer configurations)
- (4) 为了增强大规模集群训练的可靠性,论文引入了确定性计算(deterministic computation)
- 这保证了实验的精确可复现性,并能够在训练过程中检测静默数据损坏(Silent Data Corruption, SDC)
- 以上这些干预措施确保了 LongCat-Flash 的训练保持稳定,没有出现不可恢复的损失尖峰
- 面向智能体能力的多阶段训练流程(Multi-Stage Training Pipeline for Agentic Capability)
- 通过精心设计的流程,LongCat-Flash 被赋予了先进的智能体行为
- 最初的努力集中在构建一个更适合智能体后训练的基础模型上,论文设计了一个两阶段预训练数据融合策略(two-stage pretraining data fusion strategy)来浓缩(concentrate) reasoning-intensive 领域的数据
- 在中期训练期间,论文增强了推理和编码能力,同时将上下文长度扩展到 128k,以满足智能体后训练的要求
- 基于这个先进的基础模型,论文进行多阶段的后训练
- 认识到高质量、高难度的智能体任务训练问题的稀缺性,论文设计了一个多智能体合成框架 ,该框架在三个轴线上定义任务难度,即:
- 信息处理(information processing)
- 工具集复杂性(tool-set complexity)
- 用户交互(user interaction):使用专门的控制器来生成需要迭代推理和环境交互的复杂任务
- 受益于论文在可扩展架构设计、训练策略和基础设施工作之间的协同作用,LongCat-Flash 同时实现了高训练吞吐量和低推理延迟
- 在 30 天内完成了 560B 参数模型超过 20T token 的预训练 ,并在无需人工干预解决故障的情况下实现了 98.48% 的时间可用性
- 在推理期间,大规模部署效率在 H800 上超过每秒 100 个 token(TPS) ,每百万输出 token 的成本为 0.7 美元,与类似规模的模型相比,展现了卓越的性能
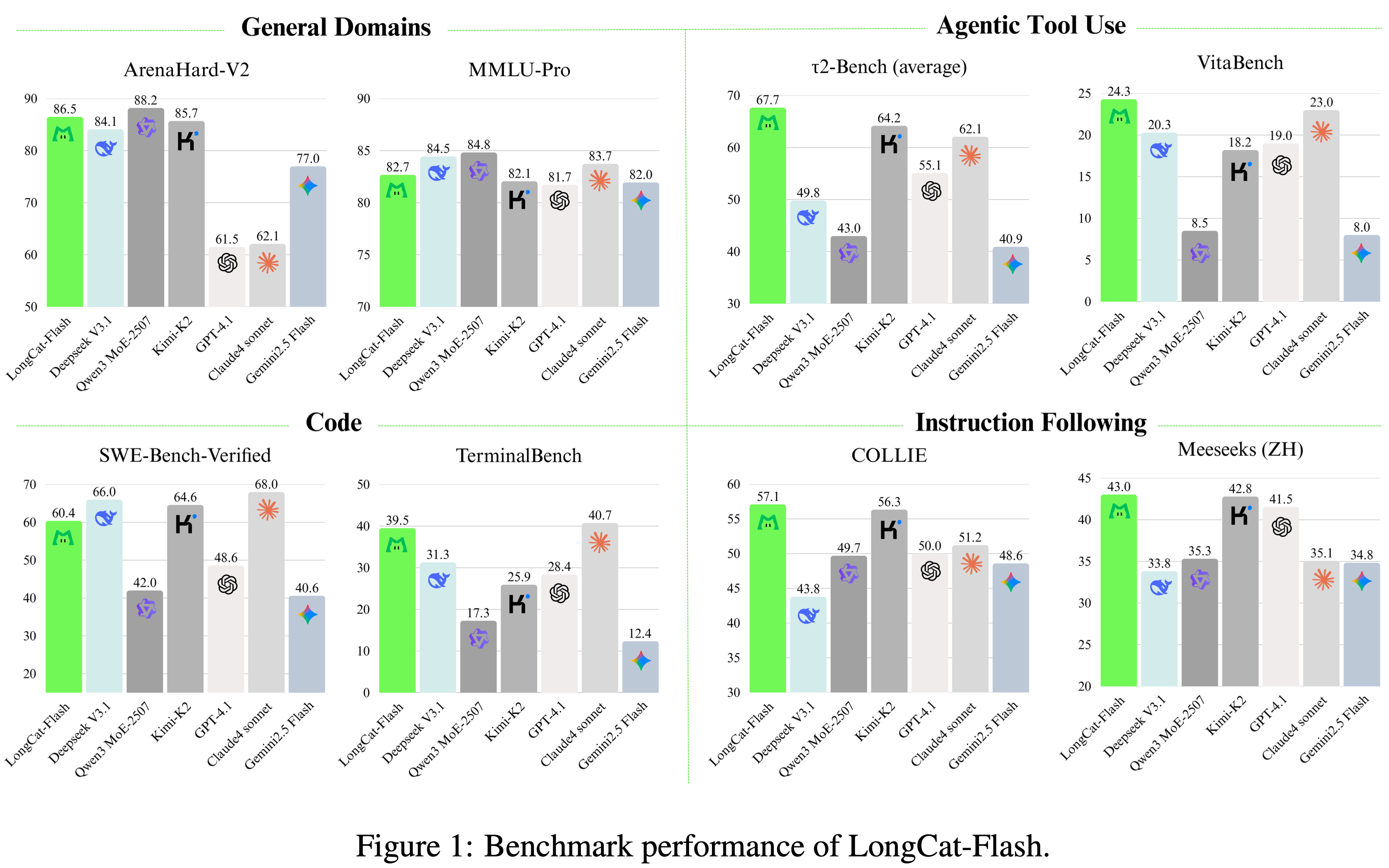
- 论文在各种基准测试中评估了 LongCat-Flash 的基础版本和指令调优版本,其概览总结在图 1 中
- 作为一个非思维模型,LongCat-Flash 实现了与 SOTA 非思维模型(包括 DeepSeek-V3.1 (2025) 和 Kimi-K2 (2025))相媲美的性能,同时使用了更少的参数并提供了更快的推理速度
- LongCat-Flash 得分展示了在通用领域、编码和智能体工具使用方面的强大能力:
- 在 ArenaHard-V2 上得分为 86.5
- 在 TerminalBench 上得分为 39.5
- 在 \(\tau^{2}\)-Bench 上得分为 67.7
- 为了减轻现有开源基准测试可能带来的污染(contamination)并增强评估信心,论文精心构建了两个新的基准测试:Meeseeks (2025) 和 VitaBench
- Meeseeks 通过迭代反馈框架模拟真实的人与 LLM 交互,以评估多轮指令遵循能力,LongCat-Flash 在该测试中取得了与前沿 LLMs 相当的成绩
- VitaBench 利用真实的商业场景来评估模型在处理复杂现实世界任务方面的熟练程度,LongCat-Flash 在其中提供了优于其他 LLMs 的性能
- 论文组织结构如下:
- 首先,详细介绍 LongCat-Flash 的架构和创新之处
- 然后,描述预训练和后训练过程,包括论文的训练策略、数据构建方法和评估结果
- 最后,讨论训练 LongCat-Flash 过程中的挑战和解决方案,以及利用其独特架构的优化推理和部署方法
Architecture
- LongCat-Flash 采用了一种新颖的 MoE 架构,包含两项关键创新(图 2):
- (1) MoE 块中引入了零计算专家(zero-computation experts)(2024) 以实现动态计算
- 允许 token 根据其上下文重要性消耗可变计算资源
- 且通过自适应专家偏置(adaptive expert bias)来调节平均计算负载
- (2) 每一层集成了两个多头潜在注意力(Multi-head Latent Attention, MLA)块 (2024a) 和多个异构前馈网络(Feed-Forward Network, FFN)块
- 采用了从第一个 MLA 输出到 MoE 块的快捷连接(shortcut connection)(2024)
- 为了进一步提升性能,论文通过方差对齐(variance alignment)改进了 MLA 和细粒度 FFN 专家
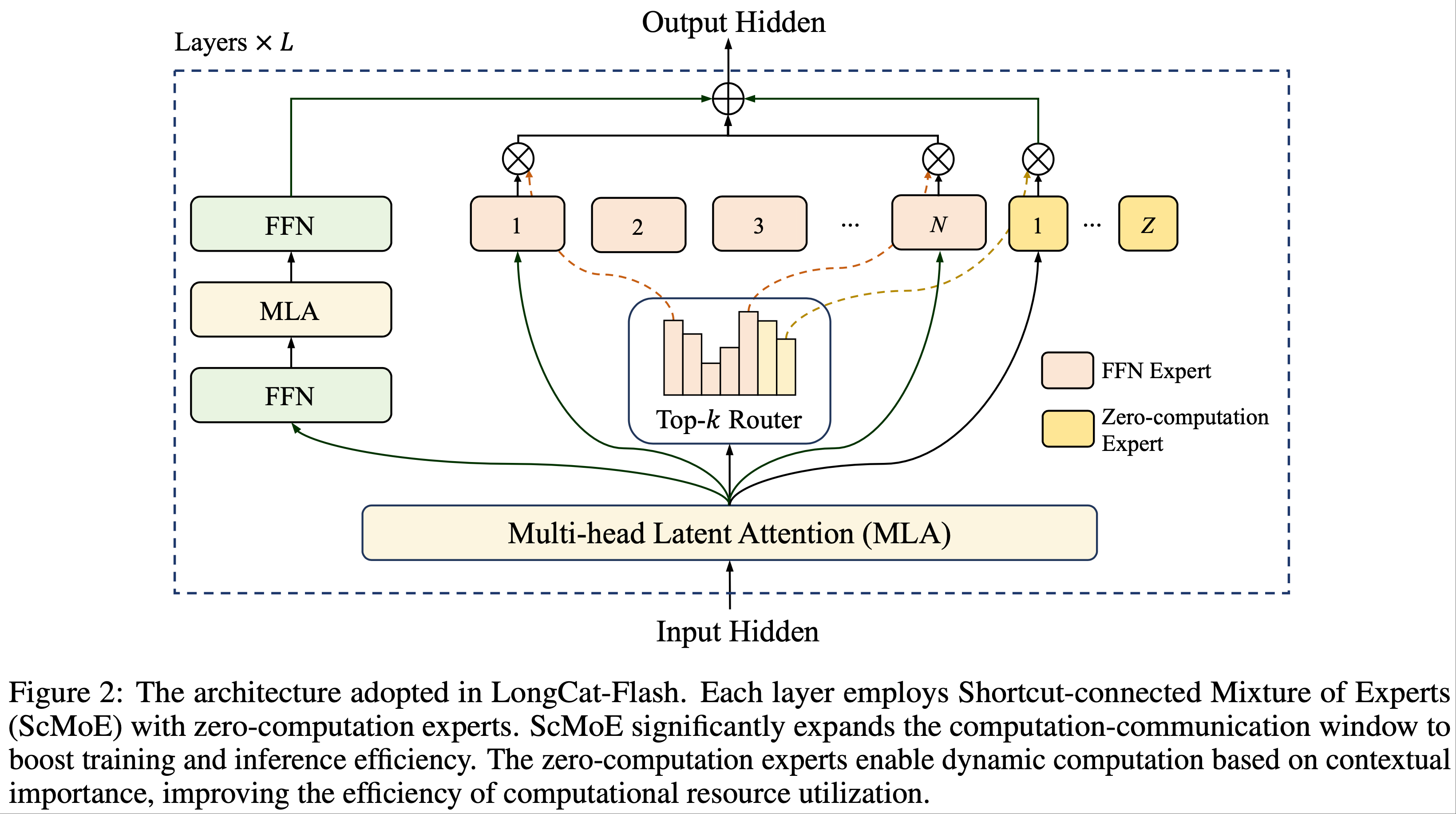
- (1) MoE 块中引入了零计算专家(zero-computation experts)(2024) 以实现动态计算
Zero-Computation Experts
- Next Token Prediction 展现出固有的计算异质性(computational heterogeneity)
- 困难的 token 可能需要更多资源来进行准确预测,而简单的 token 则需要可忽略的计算
- 注:这种现象也通过 投机采样(speculative decoding) 得到了经验性证据支持,其中小型草稿模型(draft model)能够可靠地预测大型模型对于大多数简单 token 的输出 (2023)
- 受现象启发,LongCat-Flash 提出了一种动态计算资源分配机制,通过零计算专家 (2024, 2024) 为每个 token 激活可变数量的 FFN 专家,从而能够根据上下文重要性更合理地分配计算
- 具体来说,LongCat-Flash 除了 \(N\) 个标准 FFN 专家外,还将其专家池扩展了 \(Z\) 个零计算专家
- 零计算专家简单地将其输入 \(x_{t}\) 作为输出返回,因此不引入额外的计算成本
- 令 \(x_{t}\) 为输入序列的第 \(t\) 个 token,LongCat-Flash 中的 MoE 模块可以公式化如下:
$$
\begin{align}
\text{MoE}(x_{t})&=\sum_{i=1}^{N+Z}g_{i}E_{i}(x_{t}), \\
g_{i}&=\begin{cases}
R(x_{t})_{i}, & \text{if } R(x_{t})_{i} \in \text{TopK}(R(x_{t})_{i}+b_{i} \mid 1\leq i\leq N+Z, K), \\
0, & \text{otherwise},
\end{cases} \\
E_{i}(x_{t})&=\begin{cases}
\text{FFN}_{i}(x_{t}), & \text{if } 1\leq i\leq N, \\
x_{t}, & \text{if } N < i\leq N+Z,
\end{cases} \tag{1}
\end{align}
$$- \(R\) 表示 softmax 路由器(router)
- \(b_{i}\) 是对应于第 \(i\) 个专家的专家偏置(expert bias)
- \(K\) 表示每个 token 选择的专家数量
- 问题: \(K\) 和 \(N+Z\) 有什么关系?\(\text{TopK}(R(x_{t})_{i}+b_{i} \mid 1\leq i\leq N+Z, K)\) 的具体含义是什么?
- 路由器将每个 token 分配给 \(K\) 个专家,其中激活的 FFN 专家数量根据上下文重要性因 token 而异
- 通过这种自适应分配机制,模型学会动态地将更多计算资源分配给具有更高上下文重要性的 token,从而在与图 2(a) 所示相同计算能力下实现更优的性能
Computational Budget Control
- 为了激励模型学习上下文相关的计算分配,对零计算专家的平均选择比率进行细粒度控制至关重要
- 没有显式约束时,模型倾向于未充分利用零计算专家(理解:即不选择零计算专家),导致资源使用效率低下
- 论文通过改进无辅助损失(aux-loss-free strategy)策略 (2024a) 中的专家偏置机制来实现这一点,引入了一个专家特定的偏置项,该偏置项根据最近的专家利用率动态调整路由分数 ,同时与语言模型(LM)训练目标解耦
- 对于对应于第 \(i\) 个专家的专家偏置 \(b_{i}\) ,它在每个步骤中按以下增量更新:
$$
\Delta b_{i}=\begin{cases}
\mu \left( \frac{K_{e} }{K} \cdot \frac{1}{N} - \frac{T_{i} }{T_{\text{all} } } \right), & \text{if } 1\leq i\leq N, \\
0, & \text{if } N < i\leq N+Z,
\end{cases}
\tag{2}
$$- \(\mu\) 表示偏置适应率(bias adaptation rate)
- \(T_{\text{all} }\) 表示全局批次(global batch)中的 token 数量
- \(T_{i}\) 表示路由到第 \(i\) 个专家的 token 数量
- \(K_{e}\) 表示期望激活的 FFN 专家数量,它小于每个 token 选择的专家数量 \(K\)
- 理解:
- 回顾:供包含 \(N\) 个标准 FFN 专家(非0计算专家),\(Z\) 个零计算专家
- \(\frac{1}{N}\) 表示绝对均衡情况下,每个非0计算专家需要负担的 Token 比例(所有 Token 比例)
- \(\frac{K_{e} }{K}\) 表示非0计算专家占选中的总专家数的比例(注意只有非 0 计算专家需要计算比例)
- \(\frac{K_{e} }{K}\frac{1}{N}\) 则表示绝对均匀情况下,每个非0计算专家需要负担的非0计算 Token 比例
- 注意:这里有点绕,实际上,路由到当前专家的 Token 都是命中了非 0 专家的部分
- \(\frac{T_{i} }{T_{\text{all} } }\) 表示当前专家(非0专家)被路由到的 Token 比例(路由到当前专家的都是非0专家路由)
- 最终,当所有非 0 专家都满足上面的式子为 0 时,即:
$$ \frac{K_{e} }{K} \cdot \frac{1}{N} - \frac{T_{i} }{T_{\text{all} } } = 0 $$- 此时每个非0专家被路由的次数比例为
$$ \frac{T_{i} }{T_{\text{all} } } = \frac{K_{e} }{K} \cdot \frac{1}{N} $$ - 此时,总的非0专家被路由总次数比例为
$$\frac{K_{e} }{K}$$ - 结合每个 Token 路由共 \(K\) 个专家,此时每个 Token 对应的非0专家次数为:
$$\frac{K_{e} }{K} \times K = K_e$$ - 每个 Token 对应的 0 计算专家次数为:
$$ K - K_e $$ - 注:对 0 计算专家,我们不要求每个专家都均衡的被路由,仅仅考虑整体满足比例约束即可
- 原因:非0计算专家是等价的,计算是完全一致的,都是 identity 操作!!
- 此时每个非0专家被路由的次数比例为
- 上述更新规则采用了控制理论中的 PID 控制器(比例-积分-微分控制器)(Bennett, 1993),确保第 \(i\) 个专家的 token 分配收敛到其目标比例
- 与固定的偏置增量 (2024a) 相比,这种机制提高了 softmax 路由器概率分布在专家数量扩展时的鲁棒性
- 值得注意的是,论文将零计算专家排除在偏置更新之外 ,因为它们的恒等性质只需要一个全局约束 ,当所有 FFN 专家达到其期望的 token 比例时,该约束会自动满足
- 问题:如何理解?
- 根据经验,大 Batch Size 和 \(\mu\) 的衰减计划(decay schedule)提高了预算控制的稳定性,而小 Batch Size 可能需要降低更新频率
- 在预训练期间,论文跟踪了激活专家的平均数量和标准差(图 2(b) 和 2(c))
- 结果表明,在经过大约 20B token 的调整后,所有层中的平均专家数量收敛到期望值,波动小于 1%
- 但标准差持续保持在相对较高的水平,表明模型在不同 token 间分配了显著不同的计算资源
- 注:关于动态路由的详细统计和案例研究,请参阅附录 A.1
- 补充 图 3:
- (a) 在匹配的计算预算下,比较带有/不带有零计算专家的模型的验证损失曲线
- 基线(
top-k=8,蓝色)每个 token 固定激活 6B 参数,而零专家变体(top-k=12,橙色)动态激活 4.2B-7.0B 参数,但保持 8 个 FFN 专家的期望(波动小于 1%) - 一致的损失降低证明了零计算专家的有效性
- 基线(
- (b) LongCat-Flash 训练期间激活的 FFN 专家的平均数量
- 平均数量始终保持在大约 8 左右,对应于期望的 27B 激活参数
- (c) 激活的 FFN 专家的标准差增长到 3,表明不同 token 间激活参数存在显著变异性
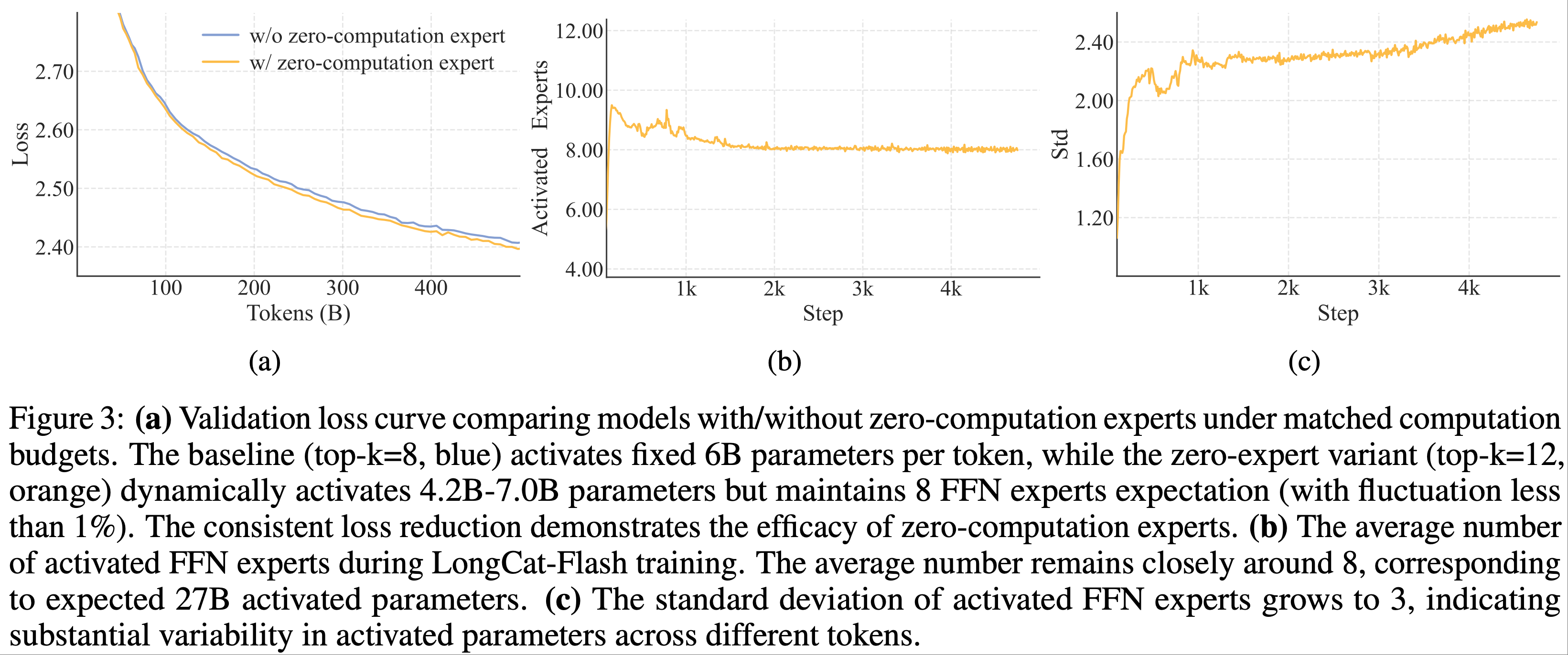
- (a) 在匹配的计算预算下,比较带有/不带有零计算专家的模型的验证损失曲线
Load Balance Control
- 高效的 MoE 训练需要 FFN 专家之间的鲁棒负载均衡
- 公式 (2) 在语料库级别强制执行平衡,论文进一步引入了设备级负载均衡损失 (DeepSeek-2025) 以进一步防止 EP 组(Expert Parallelism groups)之间的极端序列级不平衡
- 论文做出了必要的努力来适应零计算专家,具体来说:假设所有 \(N\) 个 FFN 专家被分为 \(D\) 个组,每组包含 \(G=\frac{N}{D}\) 个专家,该损失可以表示为:
$$
\begin{align}
\mathcal{L}_{\text{ LB} } &=\alpha\sum_{j=1}^{D+1}f_{j}P_{j}, \tag{3} \\
P_{j} &=\frac{1}{T}\sum_{i\in\text{Group}_{j} }\sum_{t=1}^{T}R(x_{t})_{i},
\tag{4} \\
f_{j} &=\begin{cases}
\dfrac{D}{K_{e}T}\sum_{t=1}^{T}\mathbb{I}(\text{token } t \text{ selects Group}_{j}), & \text{if } 1\leq j\leq D, \\
\dfrac{1}{(K-K_{e})T}\sum_{t=1}^{T}\mathbb{I}(\text{token } t \text{ selects zero-computation experts}), & \text{if } j = D+1,
\end{cases} \tag{5}
\end{align}
$$- \(\alpha\) 是平衡因子
- \(T\) 是微批次(micro batch)中的 token 数量
- \(\mathbb{I}\) 是指示函数
- 理解(与 DeepSeek-V3 类似,比 DeepSeek-V3 设计复杂一些):
- 每次计算最小化 损失 \(\mathcal{L}_{\text{ LB} }\) 时,都可以看做是一个求解约束优化问题的过程
- 约束优化问题为:
- 求解约束优化问题时,系数 \(f_{j}\) 可以看做是固定值(是每个序列的统计值,不同序列该值不同)
- 变量是 \(P_{j}\) 满足一定约束(详情参考 DeepSeek-V3)
$$ \sum_j P_j=1 $$ - 直观上看,最小化 \(\sum_{j=1}^{D+1}f_{j}P_{j}\) 的解就是让概率 \(P_{j}\) 随着 \(f_j\) 变化, \(f_j\) 越小,则 \(P_j\) 应该越大
- 这样才能才能满足最小化 \(\sum_{j=1}^{D+1}f_{j}P_{j}\)
- 从梯度上看
$$ \frac{\partial \mathcal{L}_{\text{ LB} }}{\partial P_{j}} = \alpha f_{j} $$- 对于 \(f_{j}\) 越大的组,其概率 \(P_j\) 下降的越多
- 进一步理解:\(P_j\) 下降是通过调整模型 router 参数实现的,这会导致参数更新后下一轮中真实统计值 \(f_j\) 下降,最终会收敛到一个大家的真实分配统计值 \(f_j\) 都差不多相同的地方(这也就实现了所谓的均衡),此时有:
$$ \dfrac{D}{K_{e}T} \beta_j^\text{non-0} = \dfrac{1}{(K-K_{e})T} \beta_j^\text{0} $$- \(\beta_j^\text{non-0}\) 表示 Token 选择某一个非0计算专家组的次数比例
- \(\beta_j^\text{0}\) 表示 Token 选择0计算专家组的次数比例
- 于是有单个非0组与0组的比例为:
$$ \frac{\beta_j^\text{non-0}}{\beta_j^\text{0}} = \frac{K_e}{D(K-K_e)}$$ - 进一步有,整体非0组与0组的比例为:
$$ \sum_j\frac{\beta_j^\text{non-0}}{\beta_j^\text{0}} = \frac{K_e}{K-K_e}$$
- 精巧的设计:上文对每个非 0 专家组使用的是
$$\dfrac{D}{K_{e}T}\sum_{t=1}^{T}\mathbb{I}(\text{token } t \text{ selects Group}_{j}), \text{if } 1\leq j\leq D$$- 而不是:
$$\dfrac{\color{red}{1}}{K_{e}T}\sum_{t=1}^{T}\mathbb{I}(\text{token } t \text{ selects Group}_{j}), \text{if } 1\leq j\leq D$$ - 这里故意放大了 非0计算专家组的 \(f_{j}\) 就是想要让最终总的非0专家数与0计算专家数的比例为: \(\frac{K_{e} }{K-K_{e} }\) ,具体逻辑参见对损失函数梯度的理解
- 而不是:
- 在损失中,论文将所有零计算专家分配到一个额外的组,并对每组中的频率取平均
- 通过调整 \(f_{j}\) 的系数,论文确保当损失收敛时,FFN 专家与零计算专家的比率接近 \(\frac{K_{e} }{K-K_{e} }\)
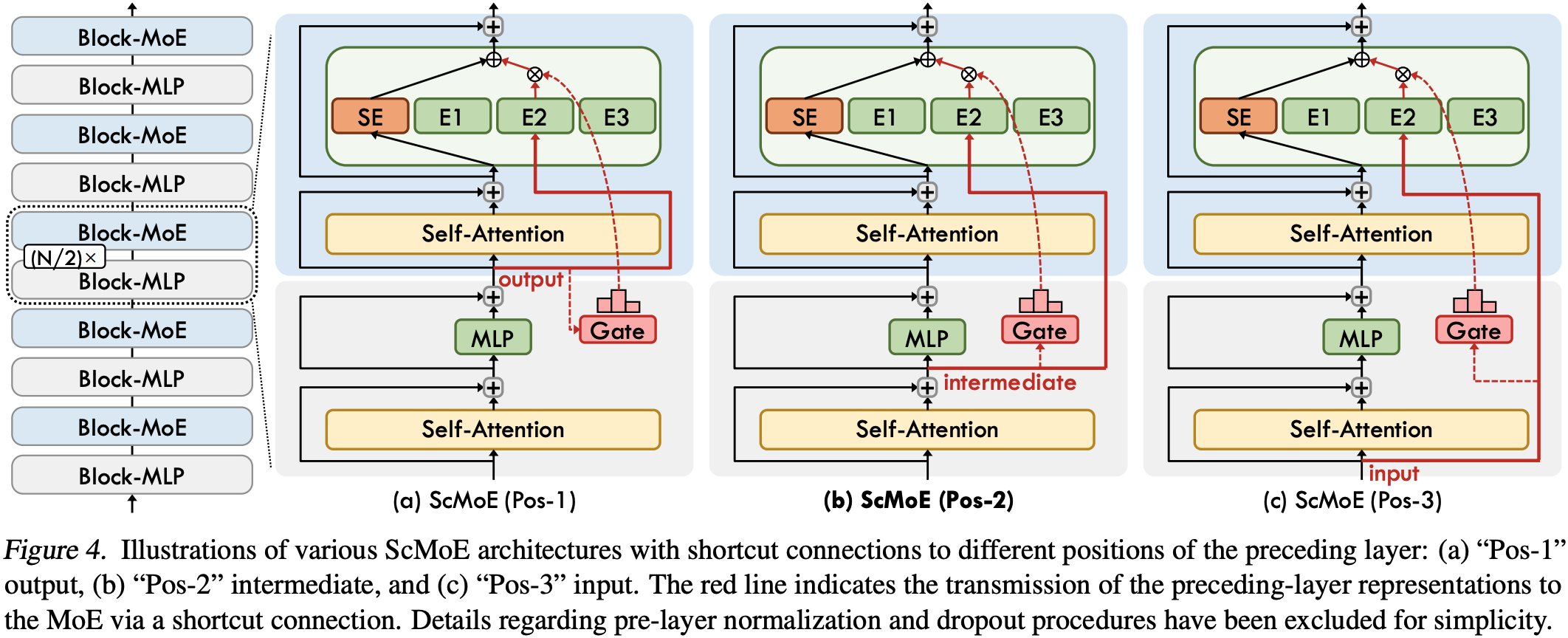
Shortcut-Connected MoE
- 论文最初的架构采用了 MoE 和 Dense FFN 块的交错拓扑(interleaved topology)
- 该设计已通过实证研究得到广泛验证,表现出与领先的共享专家模型 (2022, 2024a) 相当的性能
- 但大规模 MoE 模型的效率在很大程度上受到通信开销的限制
- 在传统的执行范式中,专家并行(Expert Parallelism, EP)强加了一个顺序工作流:一个集合操作(collective operation)必须首先将 token 路由到其指定的专家,然后才能开始计算
- 这种通信延迟成为瓶颈,导致设备利用率不足并限制整体系统吞吐量
- 共享专家架构试图通过将通信与单个专家的计算重叠来缓解这个问题 ,但它们的效率受到该单个专家较小计算窗口的限制
- 论文通过采用快捷连接混合专家(Shortcut-connected MoE, ScMoE)架构 (2024) 来克服这一限制
- ScMoE 引入了一个跨层快捷方式(cross-layer shortcut),重新排序了执行流水线
- 这一关键创新允许前一个块的 Dense FFN 与当前 MoE 层的分发/组合(dispatch/combine)通信并行执行,创造了比共享专家设计更实质性的重叠窗口
- 此外,该架构设计选择通过以下关键发现得到验证
- 首先,ScMoE 结构不会损害模型质量
- 如图 4 所示,论文的架构与没有 ScMoE 的基线的训练损失曲线几乎相同,证实了这种重新排序的执行不会损害模型性能
- 在多种设置下观察到一致的结果,包括一个带有 MLA 的 2.4B-16B MoE 模型、一个带有 MHA(多头注意力)(2017) 的 3B-20B 模型,以及带有 GQA(分组查询注意力)(2023) 的 15B-193B 模型
- 重要的是,这些发现表明 ScMoE 的稳定性和益处与注意力机制的选择是正交的
- 问题:这里的不损害模型质量相对于哪种结构来说的?
- 回答:应该是 MoE 和 Dense FFN 块的交错拓扑结构
- 补充问题:那现在的设计在每个 Layer 中多了一个 Dense FFN 块吧
- 其次,ScMoE 架构为训练和推理带来了显著的系统级效率提升
- 对于大规模训练:扩大的重叠窗口允许前一个块的计算与 MoE 层中的分发和组合通信阶段完全并行,这是通过沿 token 维度将操作划分为细粒度块(fine-grained chunks)来实现的
- 对于高效推理:ScMoE 实现了单批次重叠(Single Batch Overlap)流水线,与 DeepSeek-V3 等领先模型相比,将理论上的每输出 token 时间(Time-Per-Output-Token, TPOT)减少了近 50%
- 此外,它允许并发执行不同的通信模式: Dense FFN 的节点内张量并行(Tensor Parallelism, TP)通信(通过 NVLink)可以与节点间专家并行(Expert Parallelism, EP)通信(通过 RDMA)完全重叠,从而最大化总网络利用率
- 首先,ScMoE 结构不会损害模型质量
- 总之,ScMoE 在不牺牲模型质量的情况下提供了显著的性能提升
- 这些效率增益不是通过权衡实现的,而是经过严格验证的、质量中立的架构创新的直接结果
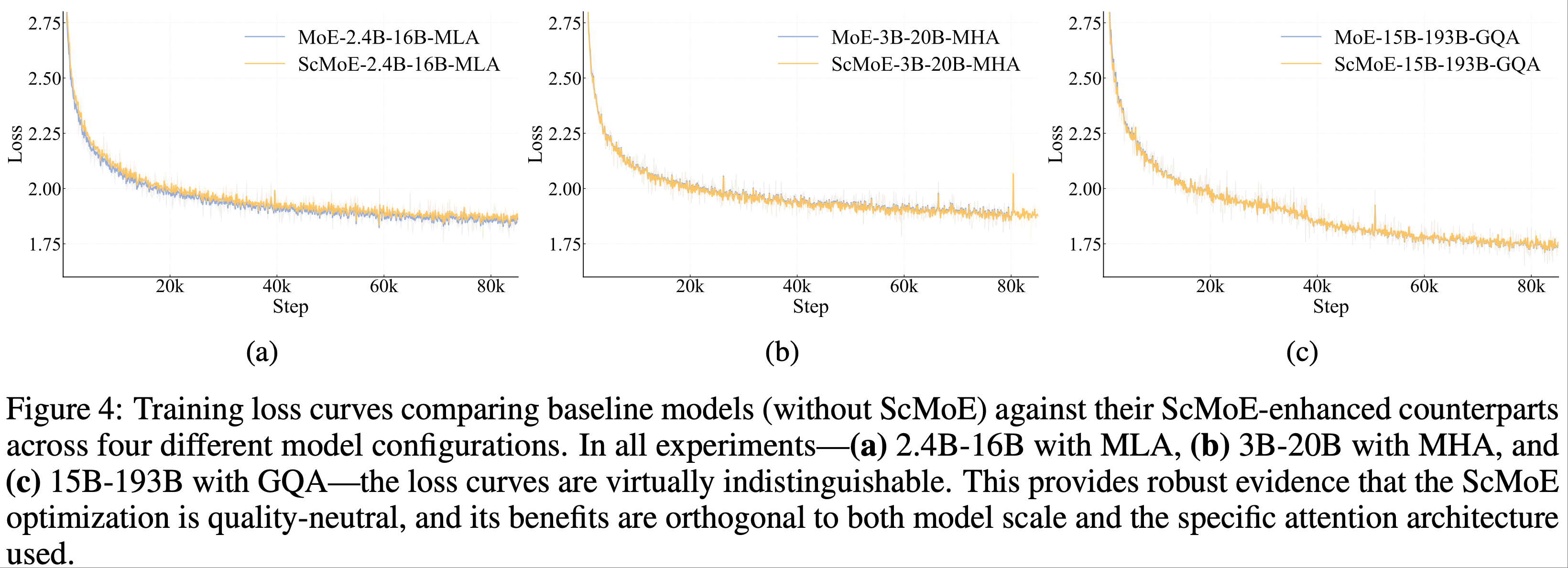
- 这些效率增益不是通过权衡实现的,而是经过严格验证的、质量中立的架构创新的直接结果
Variance Alignment Design for Scalability
- 在小规模下表现出色的架构设计,随着模型规模的扩大可能会变得次优,反之亦然 ,这使得初始设计选择不可靠
- 通过广泛的实验和理论分析,论文确定特定模块中的方差失配(variance misalignment)是导致这种差异的关键因素 ,这可能在扩展过程中导致不稳定和性能下降
- 为了应对这一挑战,论文为 MLA 和 MoE 块提出了方差对齐技术
Scale-Correction for MLA
- LongCat-Flash 采用了改进的多头潜在注意力(Multi-head Latent Attention, MLA)机制 (2024a),它结合了尺度校正因子 \(\alpha_{q}\) 和 \(\alpha_{kv}\) 以解决不对称低秩分解(asymmetric low-rank factorization)中固有的方差不平衡问题
- 论文整合了这些校正因子的完整数学公式如下:
$$
\begin{aligned}
c^Q_{t} &= \color{red}{\alpha_{q}} W^{DQ} h_{t} \in \mathbb{R}^{d_{q} }, \\
c^{KV}_{t} &= \color{red}{\alpha_{kv}} W^{DKV} h_{t} \in \mathbb{R}^{d_{kv} }, \\
q^{C}_{t,i} &= W^{UQ} c^Q_{t}, \\
k^{C}_{t,i} &= W^{UK} c^{KV}_{t}, \\
v_{t,i} &= W^{UV} c^{KV}_{t}, \\
q^{R}_{t,i} &= \text{RoPE}(W^{QR} c^Q_{t}), \\
k^{R}_{t} &= \text{RoPE}(W^{KR} h_{t}), \\
q_{t,i} &= [q^{C}_{t,i}; q^{R}_{t,i}], \\
k_{t,i} &= [k^{C}_{t,i}; k^{R}_{t}], \\
o_{t,i} &= \text{Attention}(q_{t,i}, k_{1:t,i}, v_{1:t,i}), \\
u_{t} &= W^{O} [o_{t,1}; o_{t,2}; \ldots; o_{t,n_{h} }],
\end{aligned}
\tag{6}
$$- \(h_{t} \in \mathbb{R}^{d_{\text{model} } }\) 是输入隐藏状态
- 每个头 \(i\) 的最终查询(query)和键(key)通过连接一个内容部分(C)和一个旋转部分(R)形成
- 注:作为对照,下面是原始的 MLA 结构:

- 引入 \(\alpha_{q}\) 和 \(\alpha_{kv}\) 解决了查询/键向量分量之间基本的方差失配问题
- 在初始化时,它们的方差与其源维度成正比: \(\sigma^{2}(q_{t}^{C})\) , \(\sigma^{2}(q_{t}^{R}) \propto d_{q}\) 和 \(\sigma^{2}(k_{t}^{C}) \propto d_{kv}\)
- 相比之下,旋转键分量 \(k_{t}^{R}\) 的方差与完整模型维度成正比: \(\sigma^{2}(k_{t}^{R}) \propto d_{\text{model} }\)
- 当 \(d_{q}\) , \(d_{kv}\) , 和 \(d_{\text{model} }\) 变化时,这种维度差异导致初始化时的注意力分数不稳定,导致模型缩放期间性能下降且不可预测
- 论文的解决方案是重新缩放低秩路径分量,使其最终方差与参考尺度对齐,论文使用完整模型维度作为参考。这是通过定义缩放因子来实现的:
$$
\alpha_{q}=\left( \frac{d_{\text{model} } }{d_{q} } \right)^{0.5} \quad \text{and} \quad \alpha_{kv}=\left( \frac{d_{\text{model} } }{d_{kv} } \right)^{0.5}.
\tag{7}
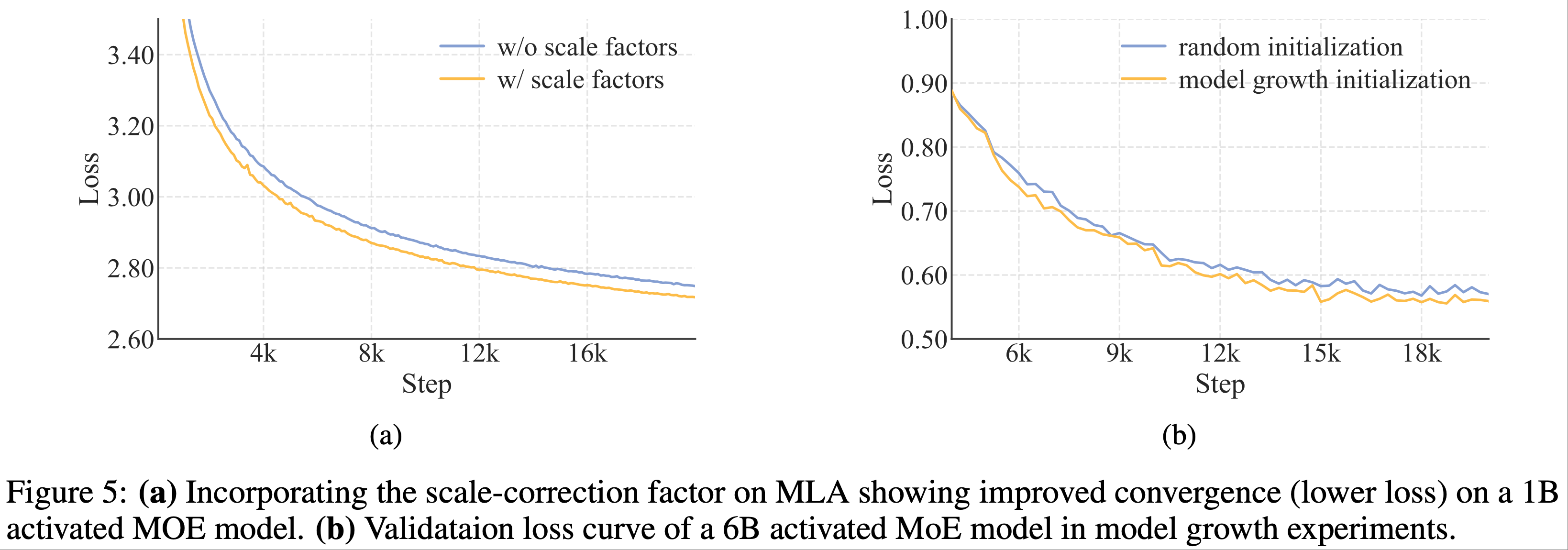
$$ - 这种尺度不变的校正(scale-invariant correction)中和了方差失配,确保它们对于注意力计算是良态的(well-conditioned)。论文的实验表明,这种方法提高了模型性能,如图 4(a) 所示
Variance Compensation for Experts Initialization
- LongCat-Flash 采用了来自 DeepSeek-MoE (2024a) 的细粒度专家策略,该策略将每个专家分割成 \(m\) 个更细粒度的专家,以增强组合灵活性和知识专门化
- 但论文观察到这种设计的性能对其他架构选择(例如,专家数量、
top-k、 \(m\) )很敏感
- 但论文观察到这种设计的性能对其他架构选择(例如,专家数量、
- 为了解决这个问题,论文提出了一种方差补偿机制,以抵消由专家分割引起的初始化方差减少。该机制将一个缩放因子 \(\gamma\) 应用于专家的聚合输出,公式如下:
$$
\text{MoE}(x_{t})=\gamma \left( \sum_{i=1}^{mN} g_{i} \cdot E_{i}(x_{t}) \right),
\tag{8}
$$- \(g_{i}\) 是路由器在 \(mN\) 个细粒度专家上的输出
- \(N\) 表示分割前的专家总数
- 公式 (8) 中的缩放因子 \(\gamma\) 是通过量化两个主要方差减少来源得出的:
- 1)门控稀释(Gating Dilution) :将每个原始的 \(N\) 个专家分解为 \(m\) 个更细粒度的专家,将专家总数扩展到 \(mN\)
- 这种扩展迫使 softmax 门控将其概率质量分布在更大的专家池上,按比例减小单个门控值 \(g_{i}\) 的大小。因此,输出方差大约减少了 \(m\) 倍
- 2)维度减少(Dimensional Reduction) :每个细粒度专家的中间隐藏维度( \(d_{\text{expert_inter} }\) )减少了 \(m\) 倍
- 假设参数初始化均匀,单个专家的输出方差也减少了 \(m\) 倍
- 1)门控稀释(Gating Dilution) :将每个原始的 \(N\) 个专家分解为 \(m\) 个更细粒度的专家,将专家总数扩展到 \(mN\)
- 为了在初始化时保持 MoE 层的输出方差(与分割前的基线匹配), \(\gamma\) 必须补偿这两种效应
- 因此,组合的方差补偿因子是 \(\gamma = \sqrt{m \cdot m} = m\)
- 补充 图 5:
- (a) 在 MLA 上加入尺度校正因子显示了在 1B 激活的 MoE 模型上改进的收敛性(更低的损失)
- (b) 模型增长实验中一个 6B 激活的 MoE 模型的验证损失曲线
Model Information
- Tokenizer
- LongCat-Flash 采用字节对编码(Byte-Pair Encoding, BPE)(1999, 2015) 进行分词
- 论文的分词器是在一个涵盖网页、书籍、源代码等的全面多语言语料库上训练的,确保了强大的跨域性能
- 在继承 GPT-4 的预分词框架的同时,论文引入了以下修改:
- (1) 增强的中日韩(CJK)字符分割以改进中文文本处理
- (2) 独立的数字分词以提升数学能力
- 词汇表大小优化为 131,072 个 token,在计算效率和语言覆盖范围之间取得了有效平衡
- Multi-Token Prediction
- 为了提升推理效率,论文集成了多 token 预测(Multi-Token Prediction, MTP)(2024) 作为辅助训练目标
- 问题:辅助训练目标的话,是提升效果吧?
- 为了获得最佳推理性能,论文使用单个 Dense 层而不是 MoE 层作为 MTP 头(MTP head)
- 经验观察显示 MTP 损失快速收敛,促使论文在训练管道中期策略性地引入 MTP 训练,以平衡模型性能和预测准确性
- MTP 头在评估中实现了 >90% 的接受率(表 5)
- 问题:具体评估了多少个?

- 为了提升推理效率,论文集成了多 token 预测(Multi-Token Prediction, MTP)(2024) 作为辅助训练目标
- LongCat-Flash 模型配置 (Model Configurations) :
- 包含 28 层(不包括 MTP 层),隐藏状态维度为 6144
- 每个 MLA 块使用 64 个注意力头,每个头的维度为 128,以实现性能-效率的平衡权衡
- Following DeepSeek-V3 (DeepSeek-2025),KV 压缩维度设置为 512,查询压缩维度设置为 1536
- Dense 路径中的 FFN 采用 12288 个中间维度,而每个 FFN 专家使用 2048 个维度
- MLA 块和 FFN 块中的缩放因子遵循第 2.3.1 节的方法
- 每层包含 512 个 FFN 专家和 256 个零计算专家,每个 token 精确激活 12 个专家(从两种类型中选择)
- LongCat-Flash 总参数量为 560B,根据上下文每个 token 激活 18.6B 到 31.3B 参数,平均激活约 27B 参数
Pre-Training
- LongCat-Flash 的预训练遵循三阶段课程:
- (1) 论文使用约 20T token、序列长度为 8192 的数据训练模型,以建立一个强大的基础模型
- (2) 使用数万亿数据进一步增强推理和编码能力
- (3) 通过在长上下文语料库上进行训练,将上下文长度扩展到 128k
- 每个阶段都实施了量身定制的数据策略,并辅以严格的去污染程序以防止测试集泄露
- 为了优化可扩展性,论文引入了超参数迁移和模型增长策略,显著提高了模型规模增大时的性能
- 鉴于大规模训练中固有的不稳定性挑战,论文识别并实施了多种有效技术来增强训练稳定性
Training Strategy
Hyperparameter Transfer
- LongCat-Flash 采用基于宽度缩放 (2024) 的超参数迁移策略来高效训练大规模模型,该方法包括:
- (1) 在较小的代理模型上确定最优超参数
- (2) 通过理论驱动的缩放规则将这些配置迁移到目标模型
- 迁移机制的核心是宽度缩放因子
$$ s = n_{\text{target} } / n_{\text{proxy} }$$- 其中 \(n\) 是模型的隐藏维度
- 论文特别采用了标准参数化的 “Adam LR Full Align” 规则
- 这些规则规定了如何调整代理模型的最优初始化方差 (\(\sigma^{2}\)) 和学习率 (\(\eta\)) 以适应目标架构
- 实际的迁移规则总结在表 1 中
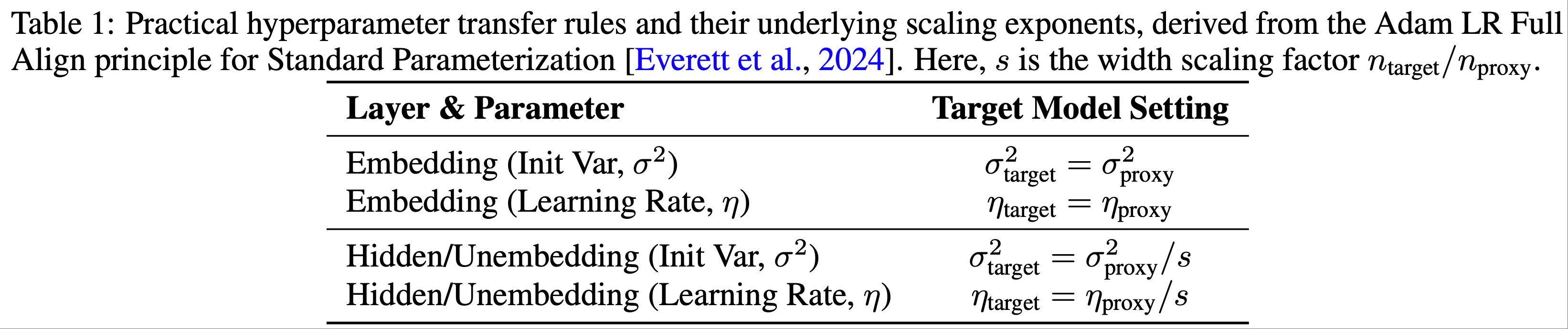
- 遵循此方法,论文的训练涉及以下步骤:
- 1)论文基于计算效率和迁移性能之间的权衡分析,将宽度缩放因子 \(s\) 设为 8,代理模型配置为宽度 768
- 2)然后论文在代理模型上执行全面的超参数搜索,以确定最优的层特定初始化方差 (\(\sigma_{\text{proxy} }^{2}\)) 和学习率 (\(\eta_{\text{proxy} }\))
- 3)代理模型的最优超参数按照表 1 中详述的规则迁移到目标模型
- 所有其他架构属性(深度、稀疏性和批大小)在此迁移过程中保持不变
- 论文进行了全面的实验来验证此方法的有效性
- 结果表明,该方法在为大规模模型训练确定最优超参数(初始化方差和学习率)时显著降低了计算成本,同时建立了一个稳健的、理论基础的模型缩放框架
Model Growth Initialization
- LongCat-Flash 采用模型增长作为其初始化策略,从一个在数百亿 token 上预训练的半规模模型开始
- 在现有的模型增长方法 (2015; 2024; 2023a; 2022; 2023b; 2019) 中,论文采用层堆叠技术 (2024; 2023) 来扩展参数并提升性能
- 暂时忽略嵌入和反嵌入过程,整个过程表述如下:
$$\begin{split}
L_{\text{small} } &= l_{1} \circ l_{2} \circ \cdots \circ l_{n} \\
L_{\text{target} } &= \underbrace{L_{\text{small} } \circ L_{\text{small} } \circ \cdots \circ L_{\text{small} } }_{r}
\end{split}$$- \(l_{i}\) 表示模型中第 \(i\) 层的变换
- \(r\) 表示扩展率
- \(L_{\text{small} }\) 表示从小模型 token 嵌入到最终隐藏状态的变换
- \(L_{\text{target} }\) 表示通过堆叠 \(r\) 个小模型副本构建的目标(大)模型的变换(论文的架构使用 \(r=2\) )
- 通过大量实验,论文一致观察到,通过模型增长初始化的模型表现出一个特征性的损失轨迹:
- 初始损失增加,随后加速收敛,最终性能超过随机初始化的基线
- 图 4(b) 展示了论文 6B 激活模型实验中的一个代表性案例,证明了模型增长初始化的优势
- 论文推测这种改进源于两个协同因素:
- (1) 较小模型的更快收敛可能为缩放训练提供更高质量的参数初始化
- (2) 增长操作可能作为防止参数崩溃的隐式正则化
- 实验证据进一步表明,过度优化前代模型可能会对目标模型的 token 效率产生负面影响 ,这表明需要明智地选择增长时机
- 对于 LongCat-Flash 初始化,论文
- 首先,训练一个与目标模型架构相同的 14 层模型 ,在初始数据段上使用随机初始化
- 然后,将训练好的模型堆叠以创建 28 层检查点,保留所有训练状态 ,包括来自前代模型的样本计数器和学习率调度
Training Stability
- 论文从三个角度增强 LongCat-Flash 的训练稳定性:路由器稳定性、激活稳定性和优化器稳定性
Router Stability
- 训练 MoE 模型的一个基本挑战是路由器稳定性,它源于两种竞争梯度之间的张力:
- 语言建模 (language modeling,LM) 损失,驱动专家专业化(expert specialization)(将 token 分配给最合适的专家),
- 辅助负载平衡 (auxiliary load balancing,LB) 损失,强制路由均匀性(routing uniformity)(将 token 均匀分布在专家之间)
- 当 LB 梯度占主导地位时,所有专家的路由器参数会趋于相似 ,导致无论输入 token 如何,路由决策都是均匀的
- 这抵消了条件计算的好处,并严重降低了模型性能
- 为了诊断和控制这种行为,论文提出了一个包含两个关键指标的监控框架:
- 路由器权重相似度 (Router Weight Similarity) :测量专家权重向量 \(\{w_{i}\}\) 之间的平均成对余弦相似度
- 高相似度直接表明负载平衡损失过度占主导地位
- 梯度范数比 (\(R_{g}\)) (Gradient Norm Ratio) :量化两种损失对批次平均专家概率向量 \(\vec{P}\) 的相对影响:
$$
R_{g} = \frac{|\alpha \nabla_{\vec{P} } \mathcal{L}_{\text{LB} }|_{2} }{|\nabla_{\vec{P} } \mathcal{L}_{\text{LM} }|_{2} },
$$- 其中 \(\mathcal{L}_{\text{LB} }\) 是在没有系数 \(\alpha\) 的情况下计算的负载平衡损失
- 路由器权重相似度 (Router Weight Similarity) :测量专家权重向量 \(\{w_{i}\}\) 之间的平均成对余弦相似度
- 在此框架的指导下,论文建立了设置超参数 \(\alpha\) 的实用指南
- 原则是确保负载平衡项充当正则化器,而不压倒 LM 损失
- 论文建议选择一个系数,使 \(R_{g}\) 保持在一个较小的阈值以下(例如, \(R_{g} < 0.1\) )
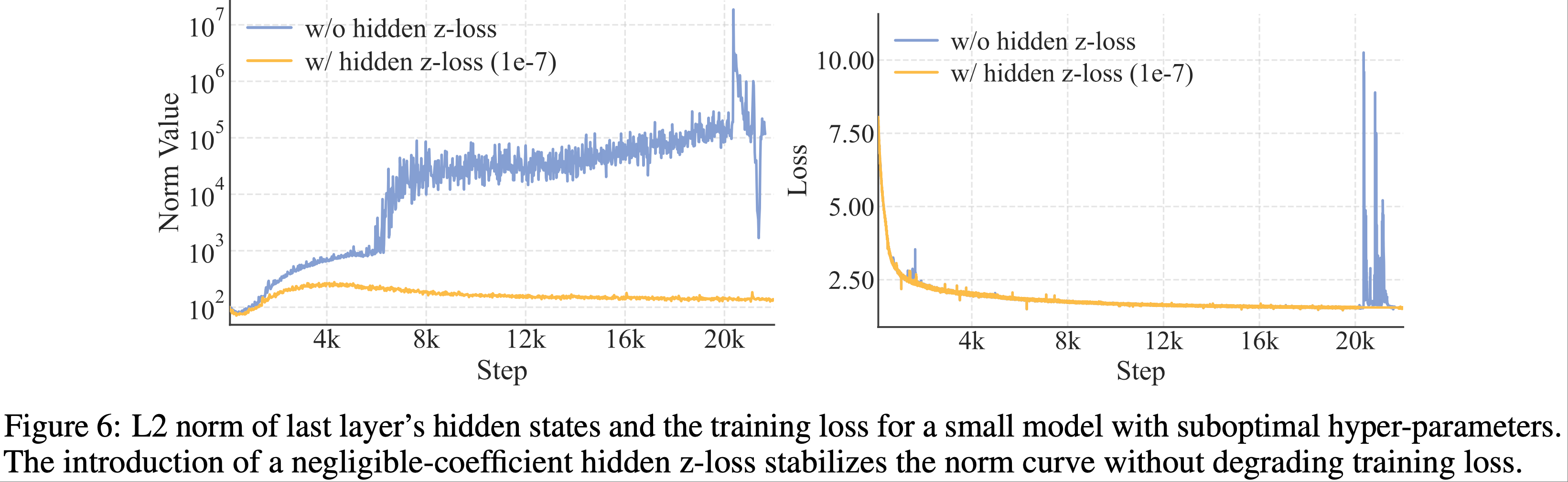
Activation Stability via Hidden z-loss
- 受 router z-loss (2022) 的启发,论文设计了隐藏 z-loss 来规避 LLM 训练期间普遍出现的大规模激活现象 (2024)
- 注:在原论文中 ST-MoE: Designing Stable and Transferable Sparse Expert Models, arXiv 2022, Google,提出了一种名为 router z-loss 的辅助损失函数,用于稳定 MoE 路由的训练:
$$ L_{z}(x) = \frac{1}{B} \sum_{i=1}^B \left( \log \sum_{j=1}^N e^{x_j^{(i)}} \right)^2$$- 可以使用
torch.logsumexp(x)来实现上述括号中的算子
- 可以使用
- 注:在原论文中 ST-MoE: Designing Stable and Transferable Sparse Expert Models, arXiv 2022, Google,提出了一种名为 router z-loss 的辅助损失函数,用于稳定 MoE 路由的训练:
- 通过经验观察,论文发现这种大规模激活与训练期间严重的损失尖峰相关,而损失尖峰与优化不稳定性和潜在的性能下降有关
- 隐藏 z-loss 主要用于抑制幅度极大的元素:
$$
\mathcal{L}_{Z} = \frac{\lambda}{T} \sum_{t=1}^{T} \left( \log \sum_{i=1}^{|x_{t}|} \exp(\text{abs}(x_{t}^{i})) \right)^{2},
$$- \(\lambda\) 是加权此损失的系数
- \(|x_{t}|\) 是隐藏大小
- \(\text{abs}(*)\) 表示绝对值函数
- 如图 6 所示,论文发现一个非常小的损失系数可以显著抑制大规模激活现象,而不会影响训练损失,从而降低了 BF16 训练期间出现数值错误的风险
On the Practical Configuration of Adam’s Epsilon
- 随着模型规模的增加,Adam 优化器中的 epsilon (\(\varepsilon\)) 参数(传统上被视为确保数值稳定性的次要常数)成为一个关键的超参数
- OLMo 等人 (2024) 证明,将其设置为
1e-8相比默认值1e-5能产生更优的结果,这种敏感性增强主要源于两个因素:- (1) 大规模模型通常采用较小的参数初始化
- (2) 它们在训练期间使用更大的批大小
- 当使用默认的 \(\varepsilon\) 值时,参数的大小可能与梯度二阶矩的典型规模相当甚至超过,从而破坏优化器的自适应机制
- 如图 7 所示,论文跟踪梯度均方根 (RMS) 范数 (2019) 的经验分析揭示了两个关键发现:
- (1) 阈值效应:当 \(\varepsilon\) 接近观测到的梯度 RMS 范数时,会发生显著的性能下降;
- (2) 下界稳定性:一旦 \(\varepsilon\) 降低到此临界阈值以下,进一步减小对模型性能的影响可以忽略不计
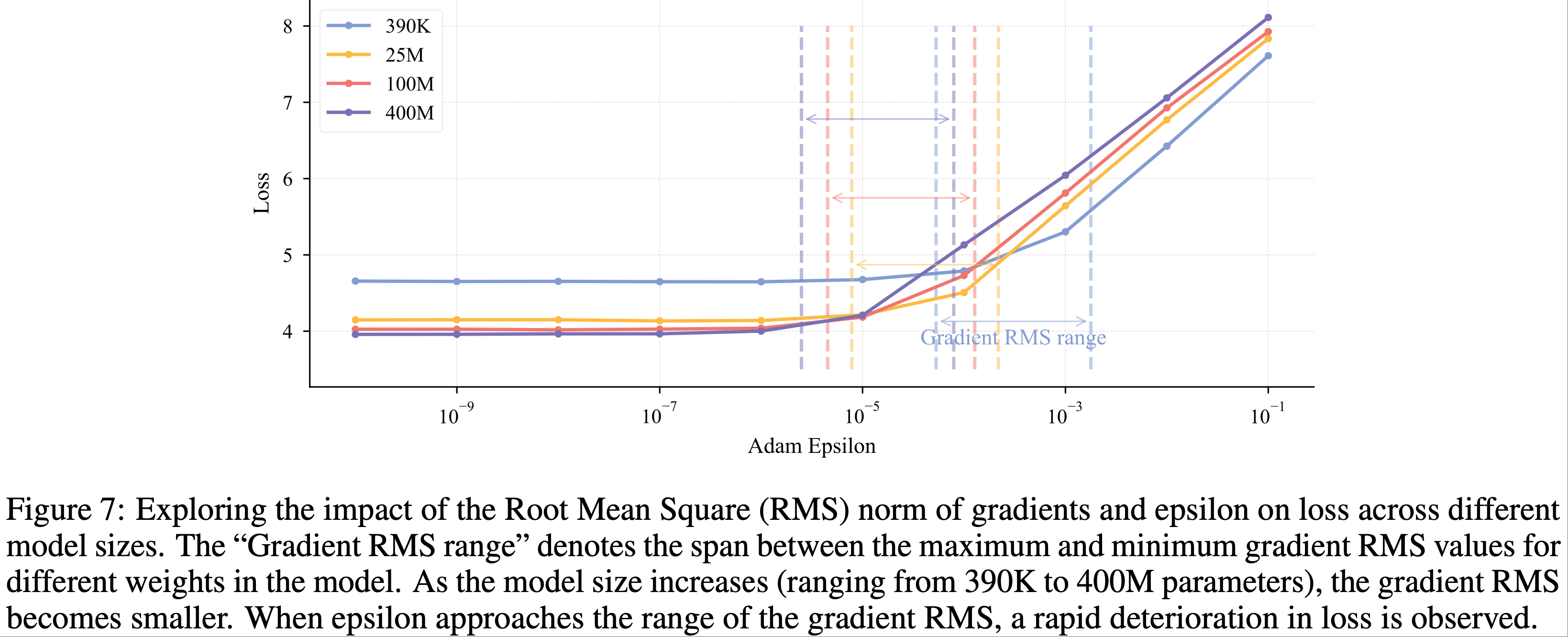
- 因此,论文建议将 \(\varepsilon\) 设置为一个较小的值(比预期的梯度 RMS 范数小几个数量级)
- 在 LongCat-Flash 中,论文采用 \(\varepsilon=1e-16\) ,此配置在保持优化器自适应特性的同时确保了数值稳定性
General Pre-Training
- 论文首先进行通用预训练阶段以确保模型的整体能力,设计了一个多阶段流程以确保数据质量和多样性。主要阶段包括:
- 内容提取 (Content Extraction) 论文使用定制版本的 trafilatura (2021) 处理通用网络内容,并使用专用流程处理 STEM 材料,以正确解析公式、代码和表格等复杂元素
- 质量过滤 (Quality Filtering) 采用两步过滤方法。初始分类器清除明显低质量的文档,随后基于流畅度和内容完整性等指标进行更细粒度的筛选
- 去重 (Deduplication) 论文应用高效的 MinHash 实现进行大规模去重,并辅以识别和处理重复网络模板的策略,以实现更准确的文档级去重
- 最终的数据混合过程采用两阶段调度,逐步增加高质量推理数据(例如 STEM 和代码)的比例
- 阶段 1 (Stage 1) :对于通用数据,论文采用实例级(instance-level)数据混合策略,平衡数据质量和多样性
- 如 SampleMix (2025) 所述,即使用质量和多样性分数计算初始采样分布,并基于细粒度的领域和写作风格标签进一步调整分布倾向
- 冗余的低价值领域(例如广告、体育、招聘)被降采样,而富含推理的领域(例如科学)被升采样
- 阶段 2 (Stage 2) :在此阶段,论文优先考虑 reasoning-intensive 领域,STEM 和代码占最终混合数据的 70%
- 初步实验表明,通用领域数据的突然减少会暂时降低模型能力
- 因此,论文实施渐进的代码比例增加 ,并通过在外部验证集上持续监控困惑度来指导 ,以确保平稳过渡而不损害通用性能
- 阶段 1 (Stage 1) :对于通用数据,论文采用实例级(instance-level)数据混合策略,平衡数据质量和多样性
Reasoning and Coding Enhancement
- 为了进一步增强模型的推理和编码能力,并为后续的后训练建立具有巨大潜力的强大基础模型,论文利用通过预训练数据检索和数据合成相结合生成的高质量相关数据,进行了一个中期训练阶段(mid-training stage)
- 引入了系统的合成数据工作流程,通过三个关键机制优化数据质量和多样性:
- (1) 知识图谱遍历和节点组合(Knowledge graph traversal and node combination)以确保概念复杂性和领域覆盖;
- (2) 多阶段迭代细化(Multi-stage iterative refinement)以逐步提高难度级别和思维链 (CoT) 推理质量;
- (3) 双模态生成和验证(Dual-modality generation and verification)(文本和计算)以保证数学准确性和解决方案有效性
- 结合基于规则和基于模型的过滤器进行了仔细的质量控制,最终数据集包含数千亿 token
Long Context Extension
- 论文实施了两阶段上下文长度扩展策略,以满足后续长上下文推理和智能体训练的要求
- 在第一阶段,使用 80B 训练 token 将上下文窗口从 8k 扩展到 32k token,并将 RoPE 的基频率 (2024) 从 1,000,000 提高到 5,000,000
- 在第二阶段,论文通过额外的 20B token 将其进一步扩展到 128k token,将基频率增加到 10,000,000
- 训练语料库建立在自然产生的长文本数据之上,例如高质量的书籍和小说
- 论文还开发了一种系统方法来组织仓库级源代码,以提高模型的长上下文能力
- 论文精心挑选了高质量的代码仓库,并应用多阶段过滤过程来移除非文本内容、构建产物和自动生成的代码,最终形成了一个用于长上下文预训练的精选的 20B token 数据集
- 为了确保模型的通用能力在长度扩展期间保持稳定,论文采用了与主预训练阶段相同的数据混合策略 ,并在此混合基础上增加了 25% 的长上下文数据 ,以增强模型的长上下文性能
Decontamination
- 论文对所有训练数据执行严格的去污染,以防止常见基准测试测试集的数据泄露
- 对于网络和代码数据,论文移除包含与预定义测试集有任何 13-gram 重叠的文档
- 对于合成数据和问答对,论文采用基于 BGE-m3 (2024) 嵌入的语义相似度的更严格策略
- 如果文档满足以下任一标准,则被丢弃:
- (1) 与任何测试用例的语义相似度得分 \(> 0.9\) ;
- 问题:如何评估,样本一一比较的复杂度是不是太高了
- 回答:实际上可能只针对不分特定的数据集做去重,其实复杂度还可以接受?
- (2) 词汇重叠(通过稀疏嵌入测量)结合相似度得分在 0.7 到 0.9 之间
- (1) 与任何测试用例的语义相似度得分 \(> 0.9\) ;
Evaluation
- 本节介绍了对 LongCat-Flash 基础模型的全面评估,包括方法和结果
Evaluation Benchmarks and Configurations
- 模型评估涵盖四个核心能力:通用任务、通用推理、数学推理和编码。用于评估的基准包括:
- 通用任务 (General Tasks) :MMLU (2021a), MMLU-Pro (2024b), C-Eval (2023), 和 CMMLU (2023a)
- 推理任务 (Reasoning Tasks) :GPQA (2023), SuperGPQA (M-A-P Team, ByteDance., 2025), BBH (2023), PIQA (2019), DROP (2019), CLUEWSC (2020), 和 WinoGrande (2019)
- 数学任务 (Math Tasks) :GSM8K (2021), MATH (2021b)
- 编码任务 (Coding Tasks) :MBPP+ (2024b), HumanEval+ (2023), MultiPL-E (2022), 和 CRUXEval (2024)
- 论文将 LongCat-Flash 基础模型与 SOTA 开源基础 MoE 模型进行比较,包括 DeepSeek-V3.1 Base (DeepSeek-2025), Llama-4-Maverick Base (Meta AI, 2025), 和 Kimi-K2 Base (MoonshotAI, 2025)
- 为确保公平性,所有模型都在相同的流水线和配置下进行评估。对于无法复现的少数结果,论文直接采用公开报告中的指标,并在表 2 中明确标注。评估设置如下:
- 通用/推理/数学任务:使用少样本提示 (few-shot prompts) 指导输出格式
- 性能通过准确率或 F1 分数衡量
- HumanEval+ 和 MBPP+:遵循 OpenAI 推荐设置 (2021)
- MultiPL-E:遵循 BigCode Evaluation Harness (Ben 2022)
- CRUXEval:遵循官方配置,采用 2-shot 示例
- 通用/推理/数学任务:使用少样本提示 (few-shot prompts) 指导输出格式
Evaluation Results
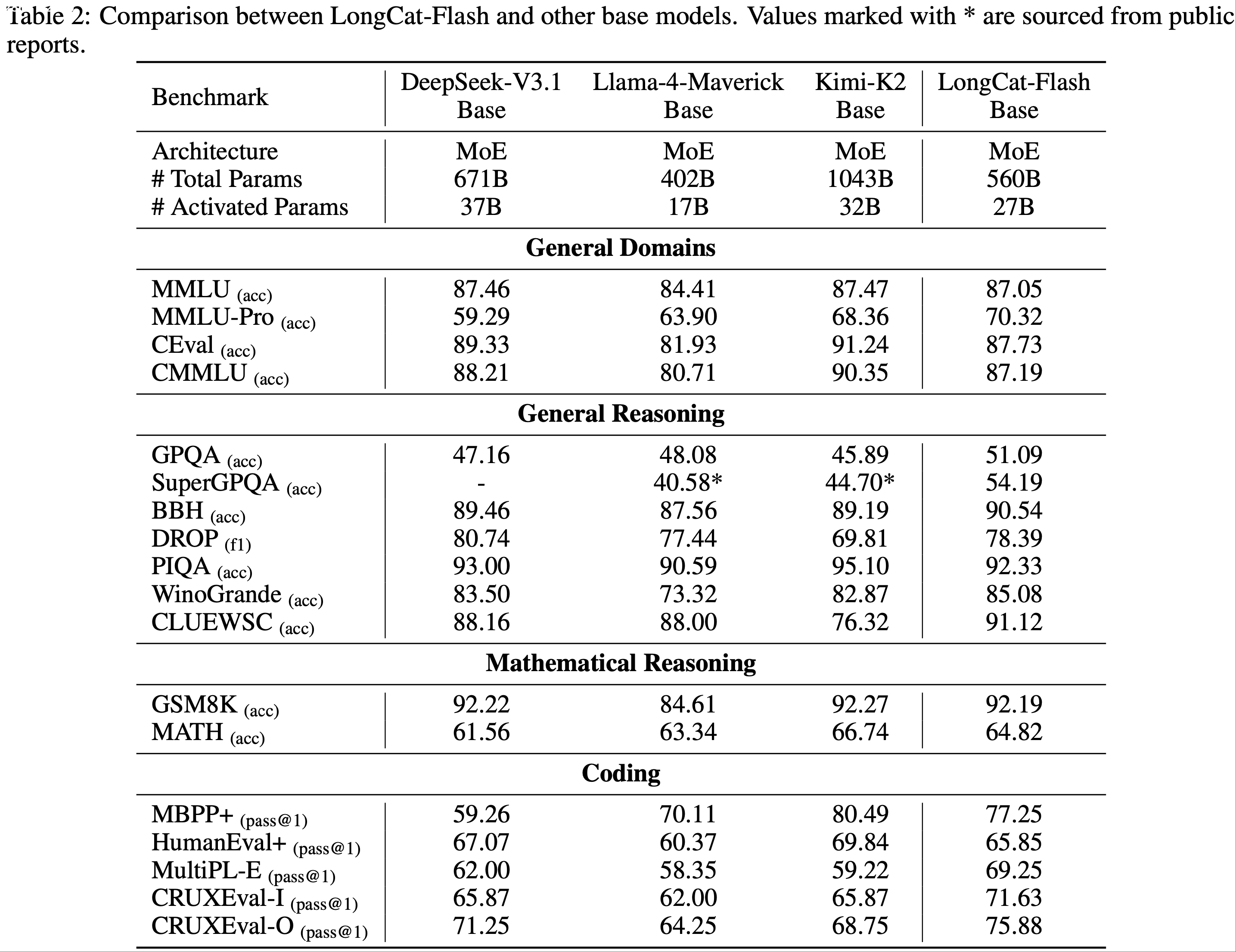
- 表 2 展示了跨不同基准的评估结果
- LongCat-Flash Base 模型在激活/总参数量更紧凑的情况下,实现了与最先进基础模型相当的性能
- Llama-4-Maverick 的激活和总参数更少,但 LongCat-Flash Base 在几乎所有基准测试上都超过了它
- 对比分析表明,LongCat-Flash Base 在所有领域都匹配了 DeepSeek-V3.1 Base 的性能(但前者参数更少)
- 虽然两个模型在通用任务上表现相似,但 LongCat-Flash Base 在 MMLU-Pro 基准(包含具有挑战性的问题)上表现出显著优势
- 对于推理任务,LongCat-Flash Base 获得了更高的平均分
- 在数学和编码任务中,它在大多数基准测试上优于 DeepSeek-V3.1 Base,仅在 CRUXEval 和 MultiPL-E 上观察到微小的性能差距
- 与 Kimi K2 Base 相比,LongCat-Flash Base 在通用任务上表现略低,但在推理、数学和编码任务上达到持平或更优
- 这些结果共同强调了 LongCat-Flash Base 的参数效率,因为它在大多数评估基准上提供了与更大模型相当或更优的性能
Post-Training
- 论文采用了一个常规的多阶段后训练框架来增强基础模型在多个领域的性能,范围涵盖复杂的推理、编码和智能体工具使用任务,以及通用能力
- 在此过程中,论文观察到,高质量问题集的有限可用性是所有领域的一个显著瓶颈
- 在后续小节中,论文将介绍从论文的后训练方法中得出的关键见解,分为三个不同的阶段:
- (1) 推理与编码
- (2) 智能体工具使用
- (3) 通用能力
Reasoning and Coding
Mathematics
- 为了生成高质量和新颖的问题,论文使用了一种角色扮演(persona)(2024) 和自我指导(self-instruct)(2022) 范式
- 这个过程由一个全面的数学框架指导,涵盖从初级到高级的主题
- 论文利用一组多样化的数学相关“专家”角色来提出问题,引导 LLM 合成涵盖代表性不足学科的查询
- 每个查询的结构旨在引发 CoT 推理,在生成的答案中促进逐步解决问题
- 角色策划和答案验证的细节如下:
- 角色策划 (Persona Curation) :这些角色从多个来源构建:论文从高质量预训练数据中生成它们,从现有的数学查询中衍生它们,并整合来自 Persona Hub 的相关集合
- 每个角色都根据其 STEM 学科进行系统性标注
- 为了确保最大的多样性并与论文的学科框架保持一致 ,论文使用 MinHash 算法来选择最终的角色集用于查询生成
- 答案验证 (Answer Verification) :论文采用一个两阶段过程来确保合成解决方案的准确性:
- 角色策划 (Persona Curation) :这些角色从多个来源构建:论文从高质量预训练数据中生成它们,从现有的数学查询中衍生它们,并整合来自 Persona Hub 的相关集合
- 论文从多个来源汇集了多样化的编码查询,包括公共数据集、从 GitHub 代码片段 (2024b) 和编码相关论坛生成的查询,以及使用代码进化指导(Code Evol-Instruct)方法 (2024) 演化而来的查询
- 数据分布根据主题多样性和难度进行平衡
- 论文训练一个模型来选择清晰、一致、正确且具有足够解释细节的查询,并实施一个过滤流程来消除包含乱码内容、重复模式或逻辑错误的回答
- 论文构建了涵盖演绎、假设和归纳推理的逻辑推理数据集,其中包括诸如 LogicPro (2025)、PODA (2025b) 和斑马谜题(Zebra-style logic puzzles)等任务
- 为了管理难度,论文首先使用 Pass@k 指标进行初步平衡,然后过滤掉高级思维模型也失败的棘手问题
- 论文还将多项选择题转换为填空题格式 ,以减轻随机猜测
- 对回答的评估侧重于四个关键领域:
- (1) 最终答案的正确性;
- (2) 推理的完整性和清晰度;
- (3) 避免过度重复;
- (4) 语言使用的一致性
Agentic Tool Use
- 论文将智能体任务定义为通过系统性的环境交互来解决复杂问题
- 在这种范式中,模型必须迭代分析现有信息,并确定何时需要与环境交互
- 在智能体工具利用框架内,环境由具有不同特征的用户和工具组成
- 用户作为一个自主的信息提供实体,没有上游或下游依赖关系 ,但表现出不愿被打扰和非自发的信息披露
- 问题:如何理解用户这个角色?
- 回答:这是在模拟现实世界的用户,用以定义现实环境问题
- 因此,模型必须最小化用户查询,同时在必要时采用策略性提问技巧以引出最精确的信息
- 工具可以被高频广泛调用,但表现出复杂的相互依赖性
- 从这个角度来看,除了领域特定专业知识(如高级编程能力或数学计算),论文将任务难度升级归因于三个因素:
- 信息处理复杂度 (Information processing complexity) 模型必须进行复杂的推理过程,以整合信息并将其转换为所需组件
- 工具集复杂度 (Tool set complexity) 通过基于工具间依赖关系将工具集建模为有向图,复杂度可以通过图的节点基数和边密度来量化表征
- 用户交互复杂度 (User interaction complexity) 模型必须学会以最低频率进行多轮策略性提问,适应各种对话风格、沟通意愿水平和信息披露模式,从而在确保充分获取信息的同时促进有效的用户交互
- 基于这些见解,论文构建了一个多智能体数据合成框架,通过系统地解决智能体训练关键的三个复杂度维度来生成高质量、具有挑战性的任务:
- (1) 工具集复杂度
- (2) 信息处理复杂度
- (3) 用户交互复杂度
- 该框架包含以下专门智能体:
- 用户画像智能体 (UserProfileAgent) 除了生成包含个人信息和偏好的基本用户画像外,论文还进一步实施了对用户对话风格、沟通意愿水平和信息披露模式的控制,以更准确地模拟真实用户交互场景,同时增强任务复杂度
- 工具集智能体 (ToolSetAgent) 为了最大化数据多样性并防止对特定场景的过拟合,论文采用了类似于 Kimi-K2 (2025) 的方法,枚举了 40 个不同的领域,随后利用模型枚举了 1600 个应用
- 基于这些应用,论文构建了 80,000 个模拟工具,形成了一个广泛的工具图
- 通过随机游走方法,论文从这个综合工具图中系统地采样具有预定节点数量的子图,从而通过节点数量控制工具图复杂度
- 指令智能体 (InstructionAgent) 推理的难度在以下维度上量化:约束复杂度、推理点数量和推理链长度
- 该模型需要基于 ToolSetAgent 提取的工具集生成全面描述完整任务的指令
- 环境智能体 (EnvironmentAgent) 论文根据 UserProfileAgent 和 InstructionAgent 生成的内容增强环境信息,包括项目细节、位置 specifics、时间参数和气象条件
- 此外,论文为项目和位置引入混淆元素以进一步增加推理复杂度
- 评分标准智能体 (RubricAgent) 论文基于各种任务相关信息构建了一套全面的具体检查清单
- 在最终评估时,考虑到智能体任务固有的长上下文特性,论文采用滑动窗口方法评估整个轨迹,持续更新检查清单项目的完成状态
- 验证智能体 (ValidatorAgent) 和 去重智能体 (DeduplicatorAgent) 论文从多个角度检查最终任务的质量,并删除任何过于相似的任务
- 这个过程确保论文拥有一套多样化且高质量的任务集
- 利用这些高质量、具有挑战性的任务,论文进一步进行严格的回答选择,以构建具有适当数量的冷启动训练集,揭示多样化的模式并保持高探索能力
- 论文还仔细选择了这些生成任务的一个子集用于进一步的后训练过程,以确保每个任务都值得大量探索
General Capability
Instruction-following
- 论文策划了单轮和多轮指令遵循数据集,具有不同级别的约束复杂度和数量
- 对于多约束查询 ,论文采纳了 Ye 等 (2025) 的见解,过滤掉语义质量低或约束冲突的查询
- 对于不同的查询类型,论文采用可验证规则、基于模型的验证和定制策略来确保回答满足所有约束
- 此外,论文汇编了针对挑战性任务的批评(critique)数据集,以增强模型的批判性思维能力 (2025c)
- 论文观察到某些约束类型本质上难以遵循,使得直接生成有效的查询-答案对不可靠
- 为了解决这个问题,论文提出了一种反向提示生成策略:从保证满足约束的预定义答案生成查询
Long Context
- 为了使模型能够在复杂、冗长的上下文中识别和分析相关信息,论文开发了三种类型的长序列数据集:阅读理解、基于表格的问答和定制设计的任务
- 为了促进长序列中显著信息的学习,论文在数据构建中聚合了主题相关的上下文片段
- 论文特别增强了模型的多跳推理、多轮对话和复杂计算能力
- 为了减轻在遇到不完整上下文时的幻觉,论文优化了模型的拒绝能力,从而提高了其对知识边界和局限性的认识
Safety
- 基于 Mu 等 (2024) 的框架并与论文内部内容指南保持一致,论文制定了一个内容安全策略,将查询分类为超过 40 个不同的安全类别,对应五种响应类型:遵守(comply)、遵守并带指南(comply with guideline)、软拒绝(soft refuse)、软拒绝并带指南(soft refuse with guideline) 或 硬拒绝(hard refuse)
- 明确的标准确保每种响应类型都有一致、符合安全标准的响应
- 该系统通过两个阶段作为一个上下文感知的数据合成器运行:
- (1) 查询分类:来自不同来源(开放域语料库、内部业务风险报告、政府问答和对抗性大语言模型合成的红队内容)的查询使用自动化标签和人工验证进行分类
- (2) 响应映射与优化:分类后的查询被映射到响应类型,并生成优化的、特定类型的响应,这些响应在作为训练目标之前经过人工评估
Evaluation
- 论文在后训练后对 LongCat-Flash 进行了全面而严格的评估
- 具体来说,论文评估了其在多个维度的能力,包括通用领域、指令遵循、数学推理、通用推理以及编码和智能体任务
Evaluation Benchmarks and Configurations
- 评估采用以下基准:
- 通用领域 (General Domains): MMLU (2023a), MMLU-Pro (2024b), ArenaHard (2024a), CEval (2023), 和 CMMLU (2023a)
- 指令遵循 (Instruction Following): IFEval (2023), COLLIE (2024), 和 Meeseeks (2025a)。Meeseeks 通过一个迭代反馈框架评估模型在多轮场景中的指令遵循能力,该框架模拟了真实的人与 LLM 交互,使模型能够基于每轮的失败进行自我纠正,更好地反映现实世界的使用模式
- 数学推理 (Mathematical Reasoning): MATH500 (2023), AIME24 (MAA, 2024), AIME25 (MAA, 2025), 和 BeyondAIME (ByteDance-Seed, 2025)
- 通用推理 (General Reasoning): GPQA-diamond (2024), DROP (2019), ZebraLogic (2025), 和 GraphWalks (OpenAI, 2025a)
- 编码 (Coding): Humaneval+ (2023, 2024c), MBPP+ (2024c), LiveCodeBench (2024.08-2025.05) (2025), SWE-Bench-Verified (2024), 和 TerminalBench (Team, 2025a)
- 智能体工具使用 (Agentic Tool Use): \(\tau^{2}\)-Bench (2025) 和 AceBench (2025)
- 智能体工具使用补充:论文还开发了一个高质量的专有基准 VitaBench,利用美团的全面现实业务场景来系统评估模型解决复杂现实世界任务的能力
- 在 VitaBench 中,为了全面评估模型的泛化智能体能力,论文特意策划了跨领域的日常场景,并明确描述了工具间的依赖关系,避免提供广泛的领域特定策略
- 论文的基准强调三个关键的复杂度维度:工具集复杂度(以密集工具图为特征,平均每个任务超过 30 个可用工具)、推理复杂度和用户交互复杂度(以具有挑战性的用户角色为特征,评估模型平均每个任务超过 60 个交互轮次)
- VitaBench 完整的基准数据集,连同详细的构建方法和全面的结果分析,将在后续工作中完全发布
- 论文还评估了 LongCat-Flash 的安全性能。具体来说,论文对四个主要风险类别进行了评估:
- 有害 (Harmful) :暴力、仇恨言论、侮辱、骚扰和欺凌、自残和自杀、成人内容等
- 犯罪 (Criminal) :非法活动、未成年人违规、极端恐怖主义和暴力等
- 错误信息 (Misinformation) :错误信息和虚假信息、不安全做法、幻觉等
- 隐私 (Privacy) :隐私侵犯、侵权等
- 在每个类别中,构建了足够数量的私有测试查询,随后进行了全面的人工审查,以确保其分类的准确性和质量的可靠性
- 论文将 LongCat-Flash 的聊天版本与几个当代的非思维(non-thinking)聊天模型进行了比较,包括 DeepSeek-V3.1 (DeepSeek-2025), Qwen3-235B-A22B (2507 版本) (2025), Kimi-K2 (MoonshotAI, 2025), GPT-4.1 (OpenAI, 2025b), Claude4-Sonnet (Anthropic, 2025), 和 Gemini2.5-Flash (2025)
- 对于闭源模型,论文通过其官方 API 进行评估
- 对于支持思维和非思维两种模式的模型(Qwen3-235B-A22B, Gemini2.5-Flash, 和 Claude4-Sonnet),论文明确配置这些模型在非思维模式下运行以进行公平比较
- 对于每个基准类别,论文采用以下专门的指标和设置:
- 通用领域基准 (General domain benchmarks): 论文使用准确率(accuracy)作为评估指标
- 与依赖精确匹配(EM)进行正确性判断的原始基准不同,论文采用一个评分模型来评估模型响应是否与参考答案一致
- 由于论文的评分模型能识别语义正确但文本不完全匹配的答案,报告的值可能略高于原始文档记录
- 指令遵循基准 (Instruction following benchmarks): 论文基于指令规则设计正则表达式来验证合规性
- 此外,还采用了基于规则和基于模型的答案跨度提取工具来支持此评估
- 数学推理基准 (Mathematical reasoning benchmarks): 论文对 MATH500 应用上述评分模型,对 AIME 相关基准采用 \(10\) 次运行的平均 EM 分数
- 问题:这里的 EM 分数是什么?是最终答案的完全匹配吗?
- 注:EM(Exact Match)是大模型评测中的 “精确匹配率”:模型输出与标准答案在字符 or Token 层面完全一致的样本占比,常用作问答、信息抽取、文本生成等任务的严格度量
- EM 分数一般取值 0–1(或百分比),越高越好
- 注:由于单次评估模型效果可能会波动,所以常见的方案是用同一个数据集多次评估模型
- 问题:这里的 EM 分数是什么?是最终答案的完全匹配吗?
- 通用推理基准 (General reasoning benchmarks): 论文对 GPQA-diamond 应用评分模型,计算 DROP 的 F1 分数,对 ZebraLogic 采用基于规则的匹配,并按照其 128k 上下文长度子集的官方实现使用精度(precision)指标
- 编码基准 (Coding benchmarks):
- 如果模型的响应在沙箱环境中通过所有测试用例或匹配特定状态,则每个问题得分为 1,否则为 0
- 最终得分是所有问题的平均值
- 论文采用 OpenAI 提供的脚本来评估 Humaneval+ 和 MBPP+,并使用其他基准的官方脚本
- 具体来说,对于 SWE-Bench-Verified,论文使用 R2E-Gym (Openhands scraffold),运行限制为 100 次迭代进行评估(DeepSeek V3.1 除外,使用 Openhands)
- 对于 Terminal-Bench,论文使用 Terminus 框架和直接提示进行评估
- 如果模型的响应在沙箱环境中通过所有测试用例或匹配特定状态,则每个问题得分为 1,否则为 0
- 通用领域基准 (General domain benchmarks): 论文使用准确率(accuracy)作为评估指标
- 智能体工具使用基准 (Agentic tool use benchmarks): 论文利用官方基准框架以确保公平性和可重现性
- 对于 AceBench,论文使用直接提示而非函数调用
- 对于论文提出的 VitaBench ,考虑到智能体任务固有的长上下文特性,论文采用滑动窗口机制来系统评估整个执行轨迹中的任务完成状态,促进对单个检查清单组件完成状态的持续更新
Evaluation Results
- 如表 3 详述,论文的全面评估表明 LongCat-Flash 是一个强大且多才多艺的模型
- LongCat-Flash 在不同领域始终展现出领先的性能,通常在广泛的一系列挑战性任务中优于当代模型,且激活参数相对较少
- 接下来的分析详细介绍了其在不同维度上的卓越能力
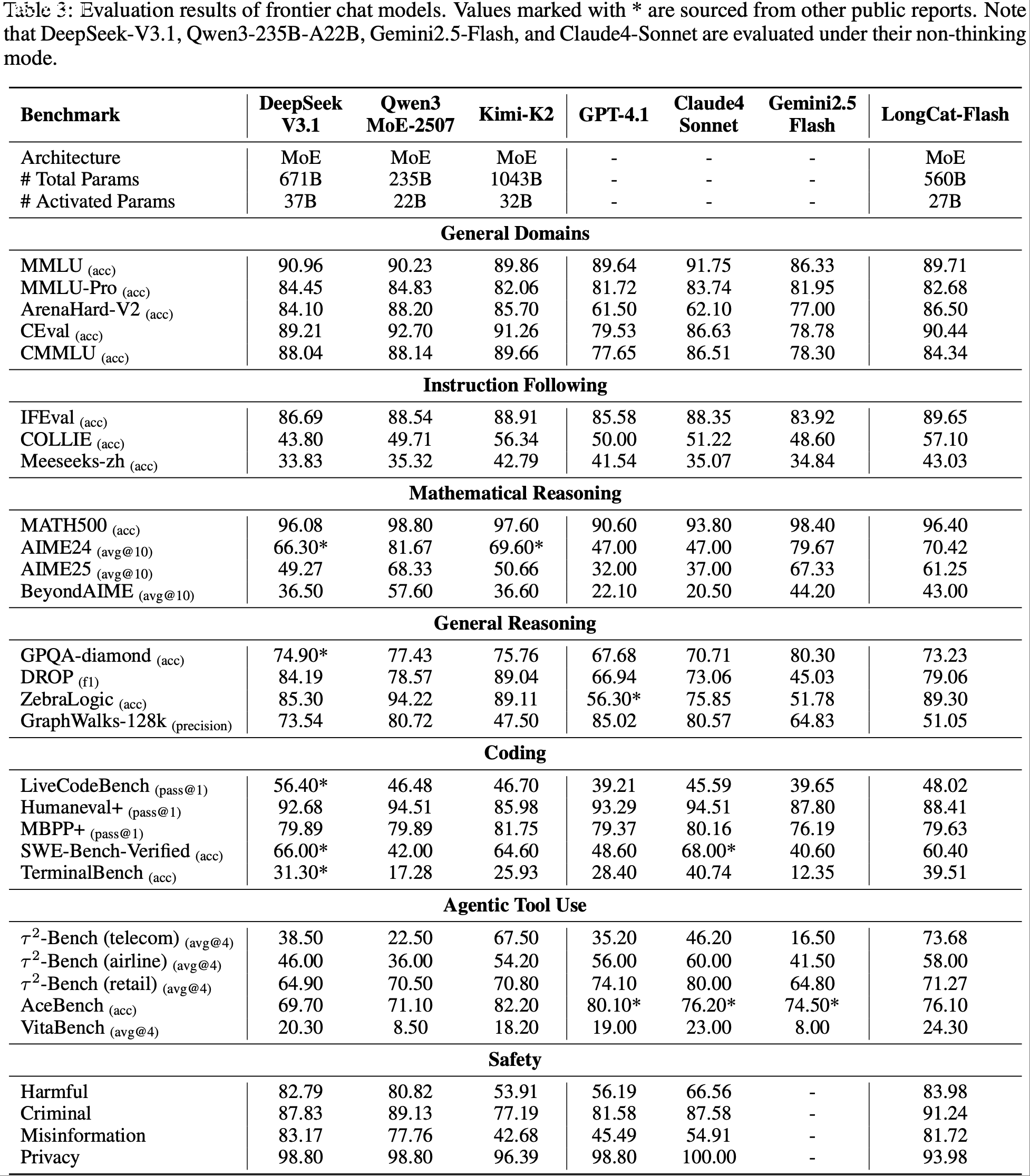
- 通用领域 (General Domains) 在通用领域知识方面,LongCat-Flash 表现出强大而全面的性能
- 它在 ArenaHard-V2 上取得了 86.50 的优秀分数,在所有评估模型中排名第二,展示了其在具有挑战性的 head-to-head 比较中的强大能力
- 在基础基准测试上,它仍然具有高度竞争力,在 MMLU 上得分 89.71,在 CEval 上得分 90.44
- 这些结果与领先模型相当,并且值得注意的是,这是在比 DeepSeek-V3.1 和 Kimi-K2 等竞争对手更少参数的情况下实现的,表明了高效率
- 指令遵循 (Instruction Following) LongCat-Flash 展现了 SOTA 指令遵循能力
- 它在 IFEval 上取得了最高分 89.65,优于所有其他模型,并展示了在遵循复杂和细致入微的指令方面卓越的可靠性
- 此外,它在 COLLIE (57.10) 和 Meeseeks-zh (43.03) 上获得了最佳分数,强调了其在英语和中文中多样化和具有挑战性的指令集上的卓越熟练度
- 数学推理 (Mathematical Reasoning) 在数学推理方面,LongCat-Flash 显示出强大而先进的能力
- 虽然其在 MATH500 上的分数 (96.40) 非常有竞争力,但其优势在更复杂的竞赛级基准测试中尤为明显
- 它在 AIME25 (61.25) 和 BeyondAIME (43.00) 上提供了优秀、顶级的成绩,在这些具有挑战性的领域中名列性能最佳的模型之一
- 这突显了其进行复杂、多步逻辑推理和问题解决的高级能力
- 通用推理 (General Reasoning) 对于通用推理任务,LongCat-Flash 的表现也很扎实
- 它在结构化逻辑推理方面表现出非凡的优势,在 ZebraLogic 上取得了 89.30 的分数,跻身顶级竞争者之列
- 它还在阅读理解基准 DROP 上获得了有竞争力的分数 79.06
- 相反,其在 GPQA-diamond (73.23) 和 GraphWalks (51.05) 上的结果表明了进一步改进的机会,特别是在增强其在极长上下文中分析结构化数据的能力方面
- 编码 (Coding) LongCat-Flash 在编码领域展现出了有前途且有能力的形象
- 其突出表现在 TerminalBench 上,取得了 39.51 的分数,排名第二,展示了在实用的、智能体命令行任务方面的卓越熟练度
- 它在 SWE-Bench-Verified 基准测试中也具有竞争力,得分为 60.4
- 在基础的代码生成任务上,如 Humaneval+ 和 MBPP+,其表现扎实,但未来仍有优化潜力以与领先模型看齐
- 智能体工具使用 (Agentic Tool Use) LongCat-Flash 在使用智能体工具使用领域展现出明显优势,在 \(\tau^{2}\)-Bench 上显著优于其他模型,即使与参数更多的模型相比也是如此
- 在高度复杂的场景中,它在 VitaBench 上取得了最高分 24.30,展示了在复杂场景中的强大能力
- 安全性 (Safety) LongCat-Flash 在识别和减轻风险方面整体表现出色,特别是在有害(Harmful)和犯罪(Criminal)领域
Training Infrastructures
- 论文训练基础设施(Training Infrastructures)的核心设计原则是 可扩展性与精确性 (scalability with precision)
- 论文开发了一种系统化的方法来验证算子精度,并将在线静默数据损坏(Silent Data Corruption, SDC)检测嵌入到空闲计算阶段,以最小化数值错误
- 为保证可重现性并确保小规模实验与全规模训练之间结果一致,论文在所有计算和通信算子中强制执行确定性(determinism)。这使得任何训练步骤的多次重新运行都能实现比特级对齐的损失值
- 在确保正确性后,论文专注于加速训练效率
- 挂钟时间(Wall-clock time)对于快速算法迭代至关重要,然而单个加速器的能力有限
- 注:Wall-clock time(墙上时钟时间)的说明:
- Wall-clock time 是从任务开始到结束在现实世界中流逝的实际时间,等同于你看墙上挂钟或手表所感知的时间,也常称作 real-world time、elapsed real time 或 wall time;
- (主要区别于 CPU 时间)Wall-clock time 包含所有等待时间,如 I/O、进程调度延迟、锁等待等,反映用户实际等待时长
- 注:Wall-clock time(墙上时钟时间)的说明:
- 因此,论文将训练扩展到数万个加速器上,面临着可扩展性和稳定性方面的挑战
- 通过模型-系统协同设计、多维并行以及全自动的故障检测和恢复,论文实现了接近线性的扩展和 98.48% 的可用性,在 30 天内完成了训练
Numerical Precision Control and Fault Detection
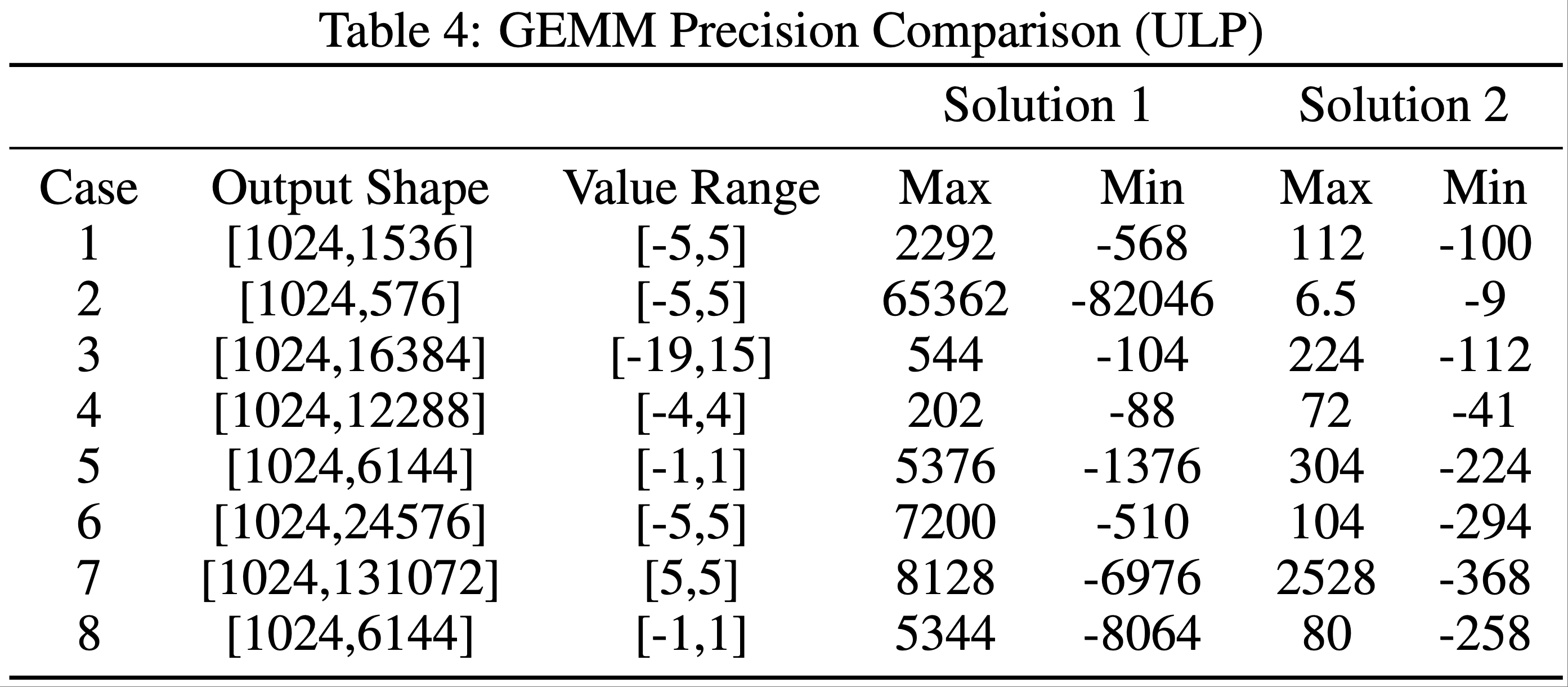
ULP Evaluation
- 浮点误差受多种因素影响,甚至在同一厂商不同代的加速器之间也会有所不同
- 为量化和减轻这些误差,论文采用 ULP(Unit in the Last Place,最小精度单位)作为度量标准,其中 ULP 误差衡量了加速器 BF16 结果与 CPU FP32 真实值之间的偏差
- 零 ULP 误差表示完美精度,而值越大表示精度越差
- 论文收集了训练中使用的所有算子类型和形状,并比较它们的 ULP 误差
- 表 4 显示了两种解决方案之间 GEMM 的 ULP 误差
SDC Detection Mechanism
- SDC 故障在大规模训练中通常不可避免,并且会通过改变数据而严重降低模型性能,且系统不会发出警告
- 为解决此问题,论文实现了一种高效的片上原地算子重计算机制
- 具体来说,论文发现 FlashAttention 梯度(FlashAttention Gradients, FAG)的反向计算对 SDC 最敏感,因为它同时混合了张量和向量计算
- 重计算结果之间的比特差异指示了潜在的 SDC 风险。检测计算在计算流(compute streams)内进行编排,重计算间隔可手动调整,从而在检测覆盖范围和计算成本之间实现灵活的权衡
- 值得注意的是,算子精度控制对于确保模型准确性是必要的,但还不够
- 使用不同算子实现的实验可能显示训练损失差异在 1e-3~1e-4 范围内,但在基准测试中却表现出大于 5 个百分点(pp)的变化
- 成本效益地评估算子精度误差对模型性能的影响仍然是一个开放的挑战
Kernel Optimization for Determinism and Performance
- 确定性(Determinism)是计算正确性的黄金标准,它消除了浮点误差作为实验变量
- 但实现确定性通常会带来显著的性能开销
- 论文通过内核重新设计来解决这个问题,在 LongCat-Flash 的整个训练过程中保持确定性的计算和通信
Deterministic FAG
- 默认的 FAG 实现是非确定性的,因为 \(dQ\) 、\(dK\) 和 \(dV\) 沿不同维度进行归约(reduce),其中原子加法(atomic addition)缺乏顺序保持性
- 论文开发了一种高效的确定性 FAG 内核,使用有限的额外工作空间以确定性顺序累加分块(tiles)
- 通过协同优化,包括双缓冲流水线(double-buffer pipelining)、调整后的分块调度(tuned tiling schedules)和负载均衡,论文的实现达到了原始确定性版本性能的 1.6 倍,非确定性版本的 0.95 倍,在确定性和效率之间取得了平衡
Deterministic ScatterAdd
- 反向传播(backward passes)中的 ScatterAdd 对于梯度聚合至关重要,但存在输入-输出操作数计数不匹配的问题。默认实现在单个计算单元内强制顺序执行,导致高达 50 倍的减速
- 论文提出了一种分层归约算法(hierarchical reduction algorithm),在所有可用处理器上并行化梯度聚合,实现了与非确定性版本相当的性能
Optimized Grouped GEMM
- 考虑到其高计算量但相对于密集 GEMM 较低的计算密度,分组 GEMM(Grouped GEMM)的性能至关重要。论文通过以下方式对其进行优化:
- (1) 双缓冲流水线(Double-buffer pipelining)以重叠计算、内存 I/O 和收尾操作(epilogue);
- (2) 对角线分块(Diagonal tiling)以减轻 L2 缓存冲突;
- (3) 通过计算单元限制控制 HBM 带宽,以重叠分组 GEMM 与分发/组合(dispatch/combine)通信
- 这些优化比默认版本带来了 5%-45% 的加速
Fused GemmAdd
- 梯度累积过程中的 \(dw\) 计算遭受带宽瓶颈的限制
- 论文将 FP32 加法融合到 GEMM 的收尾操作(epilogue)中,避免了中间写回(intermediate write-backs),并将加法隐藏在分块 GEMM 流水线中
- 这显著减少了延迟,并消除了由 BF16 数据转换为 HBM 引起的精度损失,在融合的 GroupedGemmAdd 基准测试上实现了 3.12 倍到 3.86 倍的加速
- 此外,论文重新实现了 I/O 密集型内核(例如 MoE 层的置换/逆置换,permute/unpermute),集成了丢弃 Token (drop-token)和处理零计算专家(zero-computation experts)等功能,确保了确定性和性能
Distributed Strategy for Large-scale Training
- 训练架构以专家并行组(Expert Parallelism Groups, EP)为中心,每个组包含 32 个加速器
- 在一个 EP 组内,注意力层采用上下文并行(Context Parallelism, CP=8)而不是张量并行(Tensor Parallelism, TP)以最小化通信开销,而 FFN 层使用 EP 分区而不使用 TP
- 多个 EP 组在流水线并行(Pipeline Parallelism, PP)和数据并行(Data Parallelism, DP)维度上进行扩展
- 采用专家并行(EP)是为了减少静态内存使用,包括权重和优化器状态
- 但 EP inherently 引入了昂贵的分发(dispatch)和组合(combine)通信操作
- 为缓解此问题,LongCat-Flash 采用了 ScMoE 结构,该结构使得分发/组合通信能够通过单个批次中更多的计算来重叠
- 此外,MoE 层沿 Token 维度被分成两个块(chunks)。这些子块实现了两个目标:
- (1) 与密集 FFN 计算重叠
- (2) 彼此之间相互重叠(参见图 8)
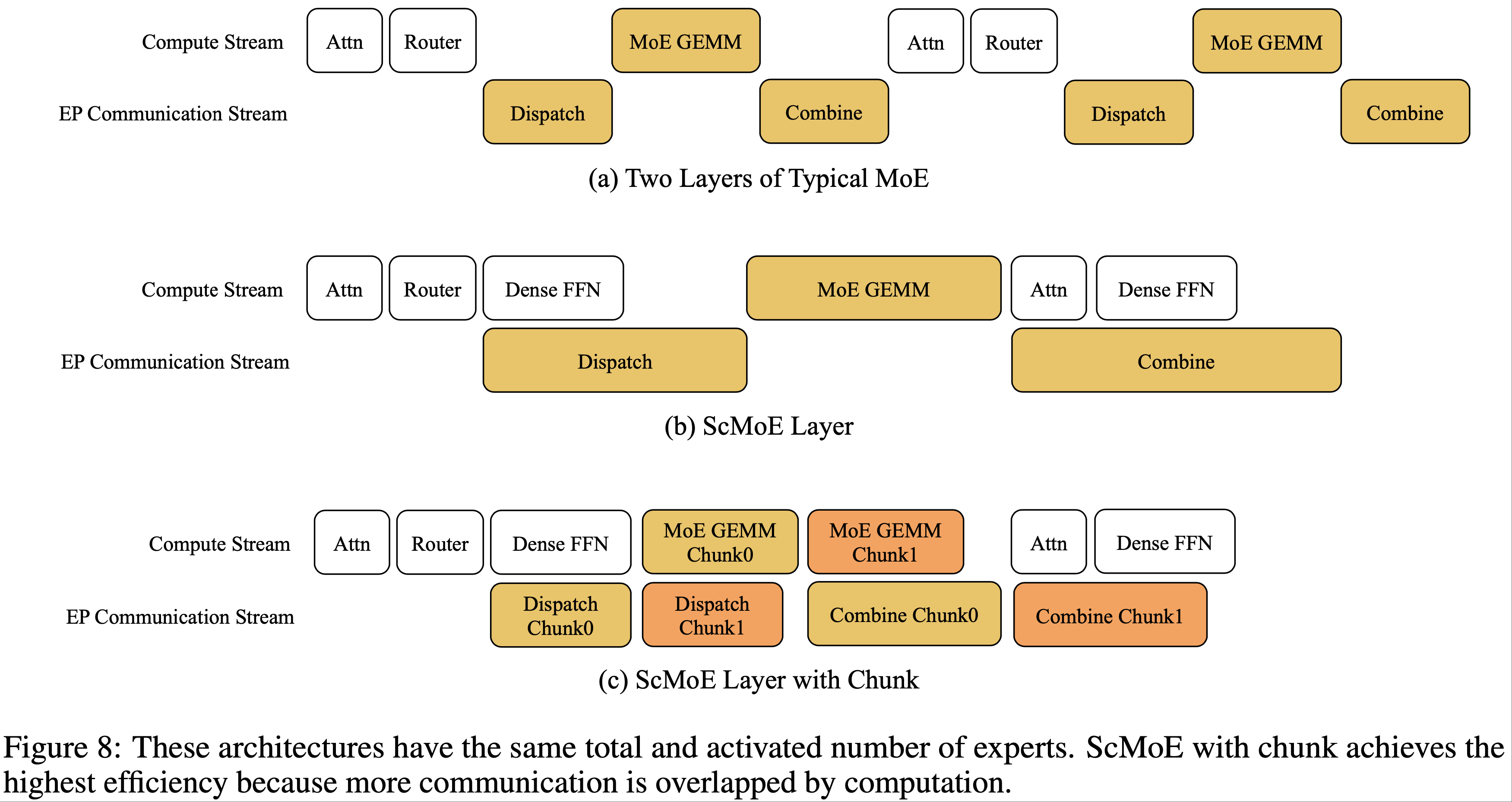
- 但 EP inherently 引入了昂贵的分发(dispatch)和组合(combine)通信操作
- 对于分发/组合通信,有两种优化策略:
- (1) 在节点内和节点间使用带流水线的 all-gather/reduce-scatter 内核;
- (2) 优化的 all-to-all 内核
- 原生的 all-to-all 将本地数据大小扩展了
top-k倍,增加了通过每个加速器 200Gb/s 的 RDMA 网络的流量 - 此外,由于拥塞控制不足,all-to-all 的性能不稳定
- 论文选择具有确定性的流水线式 all-gather/reduce-scatter 作为主要解决方案,在 ScMoE 架构下,非重叠的分发/组合通信时间比例从 25.3% 降至 8.4%
- 原生的 all-to-all 将本地数据大小扩展了
- 现有的流水线策略(例如 1F1B、交错式 1F1B(interleaved-1F1B)、零气泡 Zero-bubble (2023))存在流水线阶段间内存使用不平衡的问题
- 为此,论文采用了 V-ZB 算法 (2024),该算法平衡了所有阶段的内存使用,并将 LongCat-Flash 训练中的峰值内存减少到 60GB 以下
- 此外,论文启用了来自零气泡(zero bubble)的后验证策略(post-validation strategy),实现了理论上的零气泡
- 一个关键的改进是在优化器状态回滚(rollback)期间,用上一步的备份数据替换逆操作(inverse operations),保持了数值的比特级对齐
Reliability and Observability
- 可靠性由贡献给最终训练轨迹的时间比例(可用性,Availability)来衡量,其中不可用时间包括故障恢复以及最后一次检查点与故障发生之间浪费的时间
- 异步检查点(Asynchronous checkpointing)将训练停滞时间减少到 2~4 秒,允许更高的检查点频率并最小化故障引起的损失
- 结合在线关键日志过滤、优化初始化和全自动化,恢复时间减少到 <10 分钟
- 这些机制实现了 98.48% 的可用性,所有 20 次故障均无需手动干预即可自动处理
- 可观测性(Observability)将细粒度和粗粒度性能分析(profiling)与指标平台相结合
- 细粒度的 PyTorch Profiler 时间线支持分布式、感知并行的协同分析,以识别流水线并行中的“气泡”(bubbles)和跨秩(inter-rank)通信等待
- 粗粒度监控增加了对落后节点(stragglers)的低开销运行时分析
- 指标平台跟踪损失、权重、梯度和激活,以便快速评估模型状态
Inference and Deployment
- LongCat-Flash 采用了模型-系统协同设计(model-system co-design),这对其实现高吞吐量和低延迟起到了重要作用
- 本节重点介绍论文其中一个部署集群中实施的推理优化,阐述了同时提升系统吞吐量并将 H800 上的延迟显著降低至 100 TPS 的方法
- 首先,介绍与模型架构协同设计的并行推理架构
- 其次,在推理架构之后,描述了量化(quantization)和自定义内核(custom kernel)等优化方法
- 最后,论文介绍了部署策略和性能结果
Model-Specific Inference Optimization
- 为实现高效的推理系统,必须解决两个关键挑战:
- (1) 计算与通信的编排(orchestration)
- (2) KV 缓存(KV cache)的 I/O 和存储
- 对于第一个挑战,现有方法通常利用三种常规粒度的并行性:
- 算子级重叠(operator-level overlap) ,如 NanoFlow (2025);
- 专家级重叠(expert-level overlap) ,以 EPS-MoE (2025) 为代表;
- 层级重叠(layer-level overlap) ,如 DeepSeek-V3 TBO(Two Batch Overlap)(Team, 2025b) 所示
- LongCat-Flash 的 ScMoE 架构引入了第四个维度(模块级重叠(module-level overlap)),为此论文设计了 SBO(Single Batch Overlap)调度策略来同时优化延迟和吞吐量
- 对于第二个挑战,KV 缓存的 I/O 和存储,LongCat-Flash 通过其注意力机制和 MTP 结构的架构创新来减少有效的 I/O 开销
Computation and Communication Orchestration(计算与通信编排)
- LongCat-Flash 的结构天然具有计算-通信重叠(computation-communication overlap)的特性,这是在保持生成吞吐量的同时实现更低延迟的关键
- 论文精心设计了单批次重叠(Single Batch Overlap, SBO),这是一个四阶段的流水线执行过程,利用模块级重叠来充分发挥 LongCat-Flash 的潜力,如图 9 所示
- SBO 与 TBO 的不同之处在于它将通信开销隐藏在一个批次内
- 在 SBO 中
- 阶段 1 需要单独执行,因为 MLA 的输出是后续阶段的输入
- 阶段 2,论文将 all-to-all 分发(dispatch)与 Dense 前馈网络(Dense FFN)和注意力层 0(Attn 0,即 QKV 投影)重叠,这种重叠至关重要,因为通信开销过大,促使论文拆分注意力过程
- 阶段 3 独立执行 MoE 通用矩阵乘法(GEMM)
- 此阶段的延迟将受益于宽专家并行(wide EP)部署策略
- 在阶段 4,论文将注意力层 1(Attn 1,即核心注意力和输出投影)和 Dense 前馈网络与 all-to-all 组合(combine)重叠
- 这种编排有效缓解了通信开销,确保了 LongCat-Flash 的高效推理
- 此外,在宽 EP 部署方案下,ScMoE 架构通过 GPUDirect RDMA (Choquette, 2022) 促进了节点内 NVLink 带宽利用和节点间 RDMA 通信的重叠,从而提高了整体带宽效率
- ScMoE 中的 Dense 前馈网络具有相对较大的中间维度,因此采用张量并行(TP)部署以最小化内存占用,这分别需要在 Dense 前馈网络之前和之后进行 all-gather 和 reduce-scatter 通信
- 为减少此通信开销,论文开发了自定义内核,并采用 TP2 或 TP4 而不是 TP8
Speculative Decoding
- LongCat-Flash 采用多 Token 预测(MTP)作为推测解码(speculative decoding)的草稿模型(draft model)
- 论文的优化框架源于对推测解码加速公式的系统性分解,正如 Sadhukhan 等人 (2025) 所提到的:
$$
\frac{T_{Avg}^{SD} }{T_{T} }=\frac{1}{\Omega(\gamma,\alpha)}\left(\frac{\gamma \cdot T_{D} }{T_{T} }+\frac{T_{V}(\gamma)}{T_{T} }\right),
$$- \(T_{Avg}^{SD}, T_{T}, T_{D}\) 分别表示推测解码、目标模型(target model)和草稿模型(draft model)的每 Token 预期延迟
- \(\gamma\) 表示一个解码步骤中的草稿 Token 数量
- \(\Omega(\gamma,\alpha)\) 是给定步骤 \(\gamma\) 和接受率(acceptance rate) \(\alpha\) 的预期接受长度
- \(T_{V}(\gamma)\) 是目标验证(target verification)的预期延迟
- 论文的方法针对三个关键因素:
- 预期接受长度 \(\Omega(\gamma,\alpha)\) ,它与草稿 Token 的接受率 \(\alpha\) 正相关
- 为最大化接受率 \(\alpha\) ,论文采用 MTP
- 在后期预训练阶段集成单个 MTP 头,在测试集上实现了约 90% 的接受率
- 草稿与目标成本比 \(\gamma\frac{T_{D} }{T_{T} }\) ,这主要由目标模型和草稿模型的结构决定
- 正如 Liu 等人 (2024d) 所指出的,平衡草稿质量和速度至关重要
- 为在保持相当接受率的同时最小化生成开销,LongCat-Flash 采用了参数减少的轻量级 MTP 架构
- 论文的实验(表 5)表明,对 MTP 头使用单个 Dense 层优化了这种权衡,在延迟方面优于 ScMoE 层
- 目标验证与解码成本比 \(\frac{T_{V}(\gamma)}{T_{T} }\)
- 为降低此比率,论文采用了 C2T 方法 (2025),使用一个分类模型在验证前过滤掉不太可能被接受的 Token
- 预期接受长度 \(\Omega(\gamma,\alpha)\) ,它与草稿 Token 的接受率 \(\alpha\) 正相关
Reducing KV Cache
- 为了平衡性能和效率,LongCat-Flash 的注意力机制采用了具有 64 个头的 MLA,这减少了注意力组件的计算负载,同时实现了卓越的 KV 缓存压缩,从而减轻了存储和带宽压力
- 这对于编排 LongCat-Flash 的流水线至关重要,如图 9 所示,模型总是存在一个无法与通信重叠的注意力计算
- 具体来说,MLA 吸收方法中类似 MQA 的结构在 m 维度(64 个头)上共享 KV,与 WGMMA 指令的形状对齐,以实现最大的硬件利用率
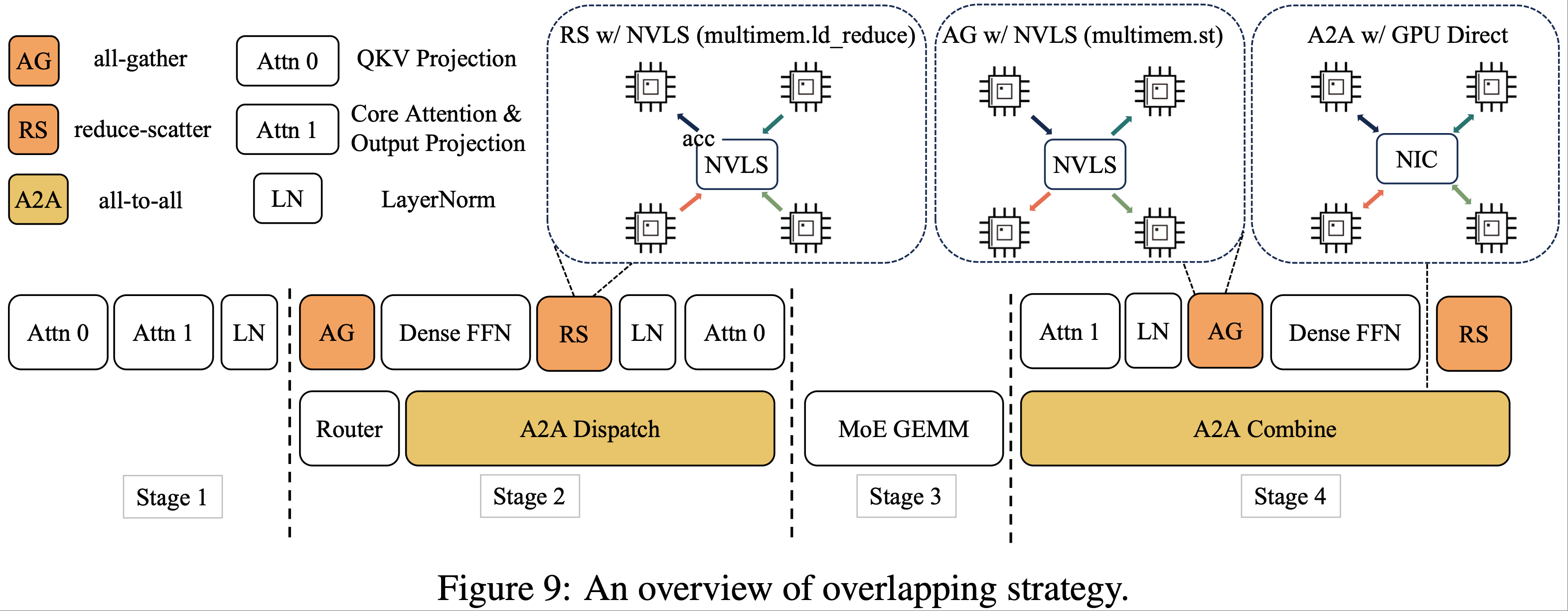
System-Wide Inference Techniques
Minimize Schedule Overhead
- LLM 推理系统中的解码阶段可能因内核启动开销而变得受启动限制(launch-bound)
- 引入推测解码后,这个问题更加严重——特别是对于 LongCat-Flash 的轻量级 MTP,验证内核和草稿前向传播的单独调度会带来显著的开销
- 为缓解此问题,采用了 TVD 融合策略(TVD fusing strategy),将目标前向(Target forward)、验证(Verification)和草稿前向(Draft forward)融合到单个 CUDA 图(CUDA graph)中
- 为了进一步提高 GPU 利用率,论文实现了一个重叠调度器(overlapped scheduler)
- 然而,实验结果表明,LongCat-Flash 前向传播的低延迟使得单步预调度策略不足以完全消除调度开销
- 如图 10 所示,论文引入了一个多步重叠调度器(multi-step overlapped scheduler),在单个调度迭代中启动多个前向步骤的内核
- 这种方法有效地将 CPU 调度和同步隐藏在 GPU 前向过程中,确保持续的 GPU 占用率
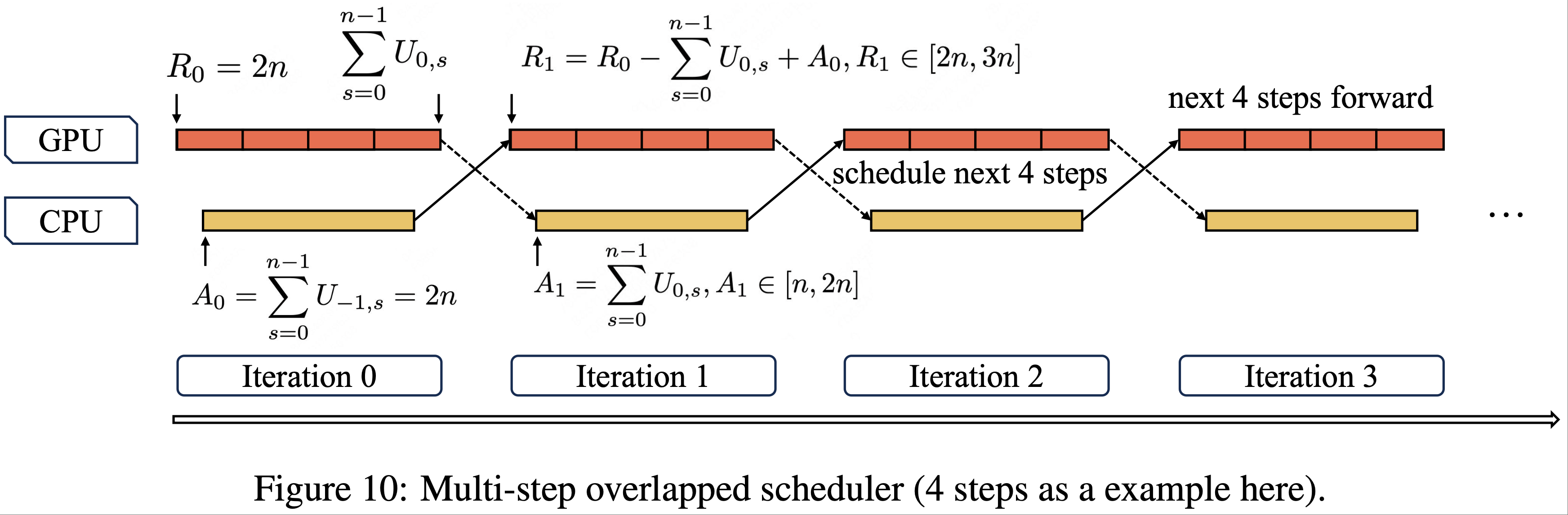
- 这种方法有效地将 CPU 调度和同步隐藏在 GPU 前向过程中,确保持续的 GPU 占用率
- 在多步重叠调度器中,论文需要在没有先前迭代中推测解码接受长度先验知识的情况下,为多个未来步骤动态预分配 KV 缓存槽(KV cache slots)
- 一个重要的问题是,多步重叠调度是否会导致不同的 KV 缓存分配
- 论文用 \(MTP=1\) 和步数 \(n=4\) 来说明这一点
- 令 \(R_{i}\) 表示 GPU 第 \(i\) 次迭代前向传播期间可用的 KV 条目数,因此 \(R_{0} = (MTP+1) \times n = 2n\)
- \(U_{i,s} \in [1, 2]\) 表示第 \(i\) 次迭代中第 \(s\) 步的接受长度,初始值 \(U_{-1,s} = 2\)
- 然后,当 GPU 执行第 \(i\) 次迭代的前向计算时,调度器基于第 \((i-1)\) 次前向迭代中的接受长度预分配第 \((i+1)\) 次前向迭代所需的 KV 缓存槽,其中 \(A_{i}\) 表示分配的 KV 缓存槽。形式化地:
$$
\begin{align}
A_{i} = \sum_{s=0}^{n-1} U_{i-1,s},\ i \geq 0 \\
R_{i} = R_{i-1} - \sum_{s=0}^{n-1} U_{i-1,s} + A_{i-1},\ i \geq 1
\end{align}
$$ - 通过归纳,论文得到闭式表达式:
$$
R_{i} = 4n - \sum_{s=0}^{n-1} U_{i-1,s},\ i \geq 1
$$ - 这意味着:
$$
R_{i} \in [2n, 3n],\ i \geq 1
$$ - 通过数学归纳法,这确保了即使不知道当前迭代的接受长度,也能为下一次迭代安全地分配 KV 缓存,同时保证了分配的 KV 缓存大小的收敛性
Custom Kernel
- LLM 推理的自回归(autoregressive)特性带来了独特的效率挑战
- 预填充阶段(prefilling phase)是计算受限的(compute-bound),像分块预填充(chunk-prefill)(2023) 这样的方法可以规范化数据以实现最优处理
- 相反,由于流量模式导致的小批量且不规则的 Batch Size ,解码阶段通常是内存受限的(memory-bound),这会损害内核性能
- 因此,优化这些特定情况对于最小化每输出 Token 时间(Time-Per-Output-Token, TPOT)至关重要
- MoE GEMM
- 现有的库,如 DeepGEMM (2025a),将模型权重映射到与 k/n 维度对齐的右侧矩阵(B,在 AxB=C 中),而输入激活(input activations)则成为映射到 m/k 维度的左侧矩阵,其中 m 表示 Token 数量
- 这种传统方法在 Token 数量低于 m 的 64 元素最小值时需要填充(padding)
- 为了解决这种低效问题,论文利用了 SwapAB (2025) 技术:将权重视为左侧矩阵,激活视为右侧矩阵
- 通过利用 n 维度的灵活 8 元素粒度,SwapAB 最大限度地提高了张量核心利用率
- 通信内核
- 推理系统利用 NVLink Sharp 的硬件加速广播(multimem.st)和交换机内归约(multimem.ld_reduce)来最小化数据移动和流多处理器(SM)占用,如图 9 所示
- 通过使用内联 PTX 汇编(inline PTX assembly),reduce-scatter 和 all-gather 内核实现了高效的数据传输
- 这些内核支持 GPU 间均匀和非均匀的 Token 分布,并且在 4KB 到 96MB 的消息大小上始终优于 NCCL (NVIDIA) 和 MSCCL++ (2025),仅使用 4 个线程块(thread blocks)
Quantization
- LongCat-Flash 采用与 DeepSeek-V3 相同的量化方案,使用细粒度分块量化(fine-grained block-wise quantization):激活值按 \([1,128]\) 块进行量化,权重按 \([128,128]\) 块进行量化
- 此外,为了实现最优的性能-精度权衡,论文基于两种方法应用了分层混合精度量化(layer-wise mixed-precision quantization):
- 第一种方案遵循论文在 FPTQ (2023b) 和 Super-Expert (2025) 中的方法,论文观察到某些线性层(特别是 Downproj)的输入激活值具有达到 \(10^{6}\) 的极端幅值
- 第二种方案涉及逐层计算分块 FPS 量化误差(包括相对误差和绝对误差),这揭示了特定专家层中存在显著的量化误差
- 通过取两种方案的交集,论文实现了显著的精度提升
Deployment and Performance
- 为了实现预填充(prefilling)和解码(decoding)阶段的独立优化,采用了 PD 分离架构(PD-Disaggregated architecture)
- 此设计中的一个关键挑战是将 KV 缓存从预填充节点传输到解码节点的开销
- 为了缓解这个问题,论文实现了分层传输(layer-wise transmission),这在高 QPS(每秒查询数)工作负载下显著降低了首 Token 时间(Time-To-First-Token, TTFT)
- 对于预填充和解码节点,最小部署单元由 2 个节点组成,每个节点配备 16 个 H800-80GB GPU
- 同时,采用宽 EP(wide EP)部署,并使用 DeepEP (2025b) 来最小化通信开销
- 此外,论文修改了 DeepEP 和 EPLB(专家并行负载均衡器,Expert Parallelism Load Balancer)以支持零计算专家(zero-computation experts),零计算专家的输出可以在无需通信的情况下获得
- 表 6 比较了 LongCat-Flash 与 DeepSeek-V3(DeepSeek-V3-profile 来自 DeepSeek (2025a),DeepSeek-V3-blog 来自 DeepSeek (2025b))的吞吐量和延迟,其中 TGS(每秒每 GPU Token 数,token per GPU per second)表示每个设备的生成吞吐量(数值越高表示成本越低),TPS/u(每秒每用户 Token 数,tokens per second per user)表示单个用户的生成速度(数值越高越好)
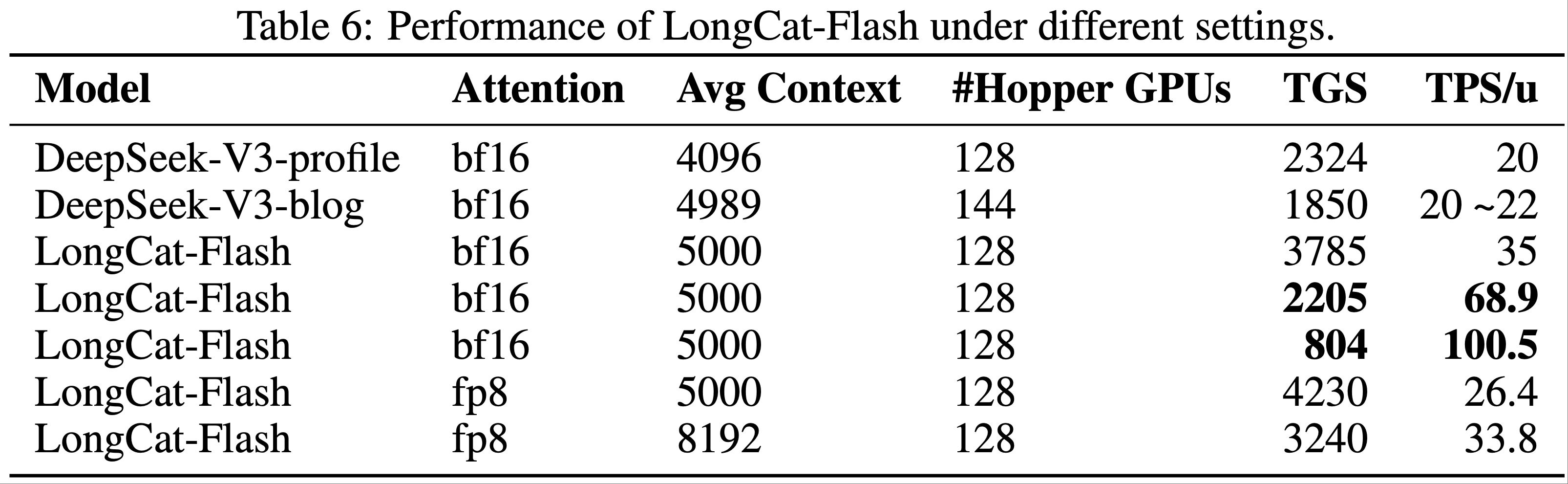
- 在测试过程中,使用给定序列长度下的稳态生成吞吐量进行计算。LongCat-Flash 在不同的序列长度下实现了更高的生成吞吐量和更快的生成速度
- 在基于 ReACT (2023) 模式的 Agent 应用中,完成单个任务需要多轮模型交互,其中交互延迟直接影响用户体验。对典型智能体调用模式的分析揭示了模型输出对不同速度的要求:
- 推理内容(用户可见):由认知过程(cognitive processes)和解释(explanations)组成,必须匹配人类阅读速度(约 20 个 Token /秒)
- 动作命令(用户不可见):结构化数据,如函数名和参数,通常为 30~100 个 Token ,但直接影响工具调用启动时间——要求尽可能高的速度
- 针对此场景,LongCat-Flash 对动作命令实现了近 100 个 Token /秒的生成速度
- 在 H800 GPU 每小时成本为 2 美元的假设下,这相当于每百万输出 Token 的价格为 0.7 美元
- 这种性能将单轮工具调用延迟限制在一秒以内,从而显著增强了智能体应用的交互性
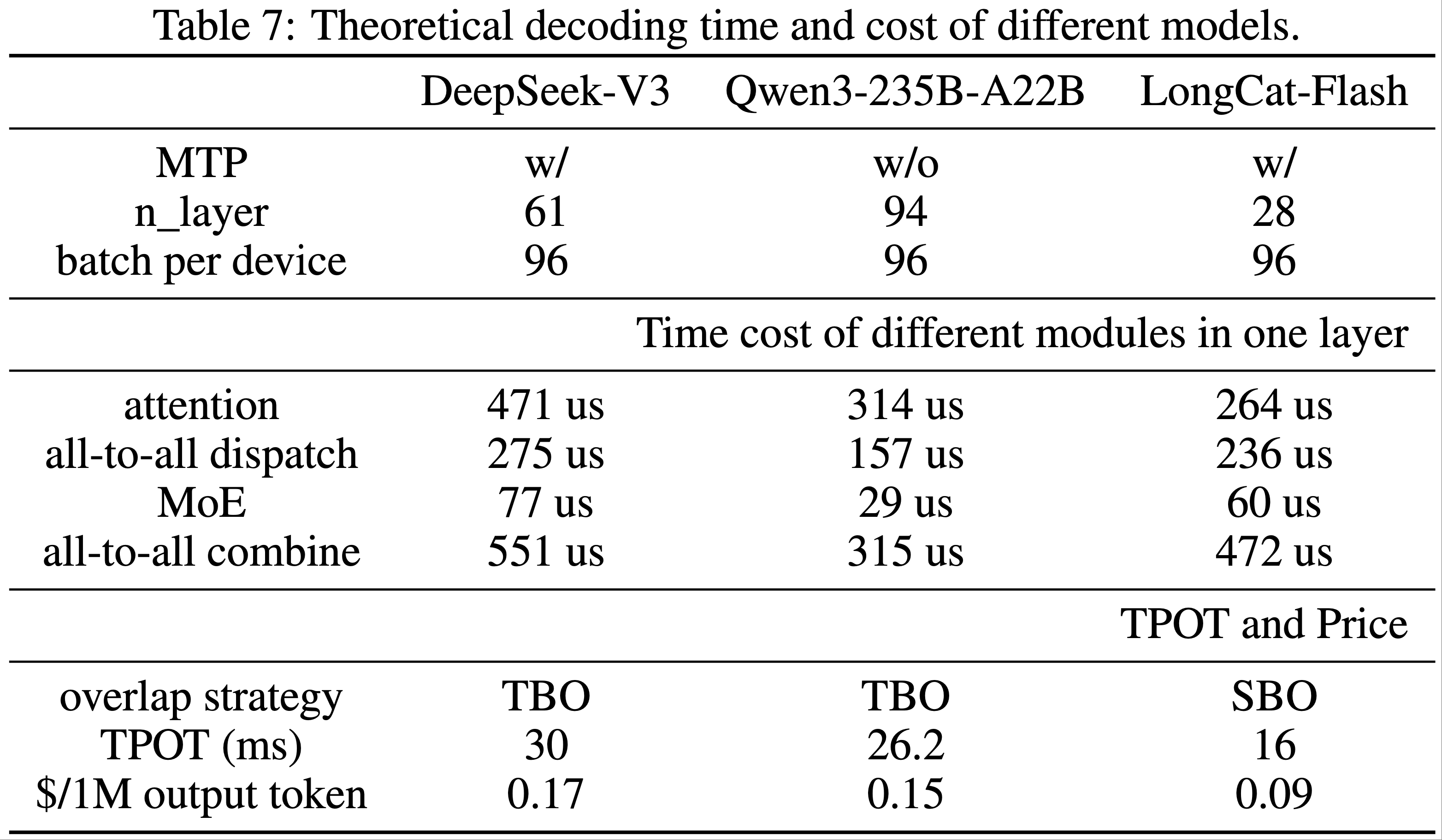
Theoretical Performance
- 图 9 显示,LongCat-Flash 的延迟主要由三个组成部分决定:
- MLA:其时间消耗无法通过增加 EP 数量来减少
- All-to-all 分发/组合:两者都受单设备 Batch Size和 topk 的限制
- MoE:其在内存受限区域(memory-bound region)的时间消耗随着 EP 数量的增加而减少
- 假设 EP 数量为 128,MLA 对 DeepSeek-V3 和 LongCat-Flash 使用数据并行(DP),GQA 对 Qwen3-235B-A22B 使用 TP4(因为它有 4 个 kv 头),每设备 Batch Size 为 96
- 实际上,Qwen-235B-A22B 的 GQA 特性导致其 KV 缓存的内存占用相对较高,在实践中难以达到每 GPU 96 的 Batch Size
- 此处假设其可以达到该值仅用于理论分析的目的
- 正如 (Li, 2025) 所指出的,FlashMLA 在 NVIDIA H800 SXM5 GPU 上可以达到 660 TFlops;Zhao 等人 (2025b) 表明 DeepEP 带宽可以达到 40GB/s
- 这两个指标都用于论文的计算
- 假设每个 H800 的成本为每小时 2 美元
- 考虑 MTP=1 且接受率为 80%,我们可以计算 DeepSeek-V3、Qwen3-235B-A22B 和 LongCat-Flash 每一层各个模块的理论时间消耗和成本,如表 7 所列
- 对于本身不支持 MTP 的 Qwen3-235B-A22B,论文假设采用具有相当接受率的推测采样策略(speculative sampling strategy)
- 在此配置下,采用 SBO 的 LongCat-Flash 的理论极限 TPOT 可以表示为:
$$
\text{TPOT} = \frac{\text{TPL} \times n_{\text{layer} } }{\text{batch per device} \times \text{MTP} \times \text{acceptance rate} }
$$ - 其中 TPL 表示每层时间成本(time cost per layer)
- 在 Batch Size 96 下测得的值约为 TPOT = 26 ms,大约是理论值的 61.5%,与 DeepSeek-V3(约 64%)相当。测量值与理论速度之间的差距主要来自小算子的开销和通信带宽的损失
- 论文应用相同的方法计算了 DeepSeek-V3 和 Qwen3-235B-A22B 在 TBO 调度下的 TPOT 和生成成本的理论极限
- 从表 7 可以观察到,通过模型系统协同设计,LongCat-Flash 在吞吐量和延迟方面都实现了显著的理论改进
- 从表 7 可以观察到,通过模型系统协同设计,LongCat-Flash 在吞吐量和延迟方面都实现了显著的理论改进
- 此外,论文观察到关于 LongCat-Flash 的两个关键见解:
- (1) LongCat-Flash 不仅暴露了 all-to-all 通信和 MoE 计算,还暴露了一个 MLA 计算。因此,在相同的 Batch Size 下,LongCat-Flash 的每层时间比 DeepSeek-V3 略长
- 然而,由于其层数显著减少,LongCat-Flash 实现了更低的总体延迟
- (2) LongCat-Flash 的第二个 MLA 与 all-to-all 组合重叠
- 这意味着在解码阶段,LongCat-Flash 可以在不显著增加延迟的情况下,将序列长度增加到一定程度
- (1) LongCat-Flash 不仅暴露了 all-to-all 通信和 MoE 计算,还暴露了一个 MLA 计算。因此,在相同的 Batch Size 下,LongCat-Flash 的每层时间比 DeepSeek-V3 略长
附录 A
A.1 Statistics and Case Studies of Dynamic Routing
- 图 11 显示了 LongCat-Flash Base Model 在不同Benchmarks中平均激活的前馈网络专家(activated FFN experts)数量
- 存在一种一致的计算偏好(computational bias):英语 Token 比中文和数学 Token 获得了更多的计算资源
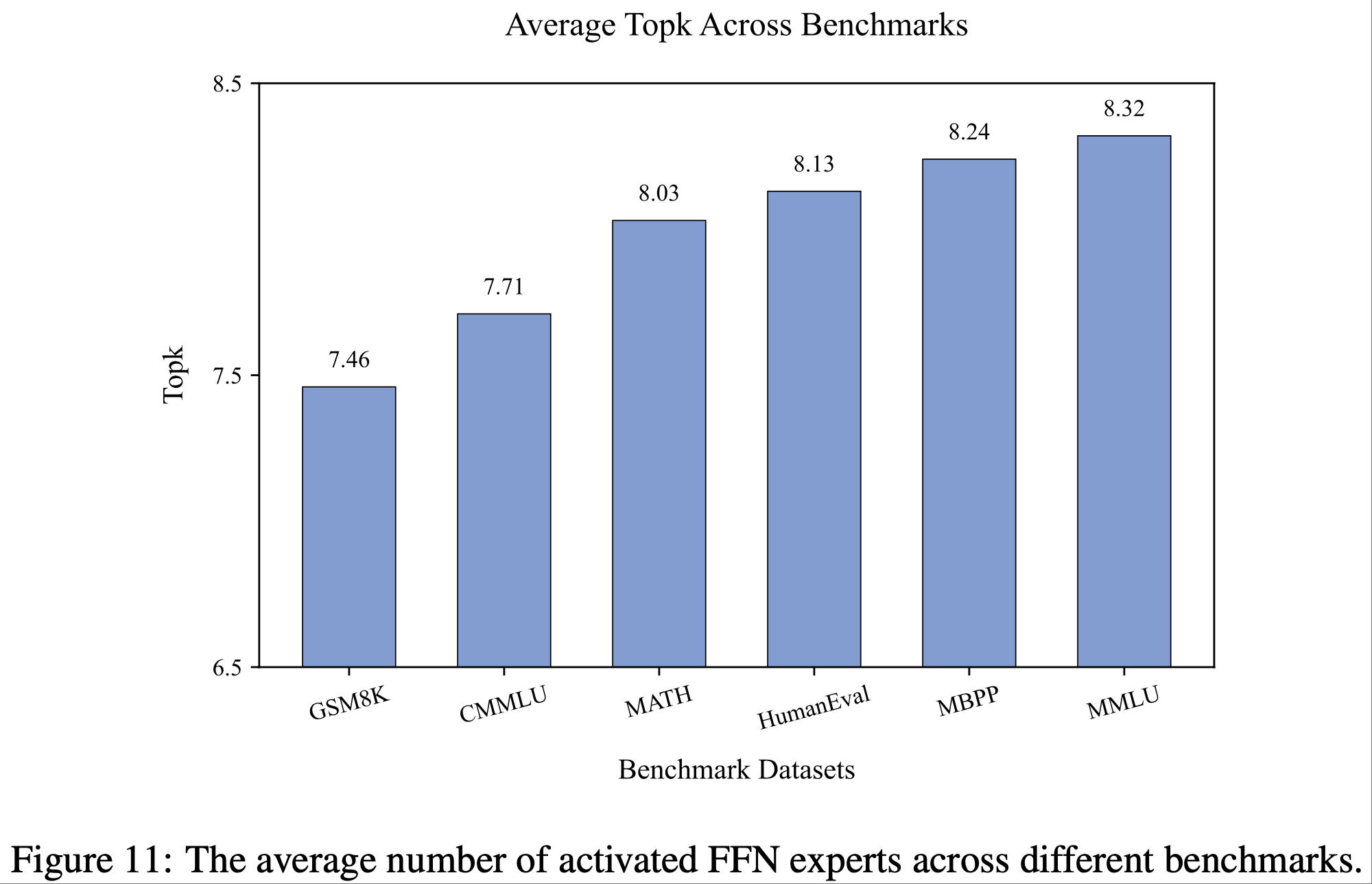
- 存在一种一致的计算偏好(computational bias):英语 Token 比中文和数学 Token 获得了更多的计算资源
- 论文在表 8 中展示了几个案例在不同层(layers)的更详细的专家选择情况
- 这些案例揭示了不同层之间专家选择模式(patterns of expert selection)的差异
- 在第一层(Layer 1),功能词(function words)(包括冠词、连词、介词)、数字和标点符号(punctuation marks) consistently 获得较少的计算资源
- 相比之下,最后一层(Layer 28)与第一层相比,表现出较少专门化的特征分配(specialized feature allocation),尽管仍然存在可识别的模式
- 例如,在中文文本案例中,标点符号前的 Token 往往被分配较少的计算资源
- 论文假设浅层(shallow layers)优先根据 Token 内部语义(token-internal semantics)进行资源分配,而深层(deeper layers)则根据预测复杂性(predictive complexity)动态调整资源,这可能反映了从局部特征处理(local feature processing)到全局预测优化(global prediction optimization)的层次化过渡(hierarchical transition)





























/CL4LLM-Survey-Table1.png)
/CL4LLM-Survey-Figure1.png)
/CL4LLM-Survey-Figure2.png)
/CL4LLM-Survey-Table2.png)
/CL4LLM-Survey-Figure3.png)