LEARN:Llm-driven knowlEdge Adaptive RecommeNdation
- 参考链接:
整体思路说明
- 当前推荐系统问题 :主要依赖 ID embedding 来捕捉用户与 item 之间的潜在关联。然而,这种方法忽视了 item 文本描述中丰富的语义信息 ,导致性能欠佳和泛化能力不足
- LLM :LLM 具备理解与推理文本内容的能力,为推荐系统的进步提供了新的可能
- 论文提出了一种 LLM-based 知识自适应推荐框架(Llm-driven knowlEdge Adaptive RecommeNdation,LEARN):
- 通过协同融合开放世界知识与协作知识(synergizes open-world knowledge with collaborative knowledge)来解决这一问题
- 针对计算复杂度问题,论文采用预训练的LLM作为 item 编码器,并冻结其参数以避免灾难性遗忘(catastrophic forgetting),从而保留开放世界知识
- 为了弥合开放世界与协作领域之间的鸿沟,论文设计了一种双塔结构(twin-tower structure),以推荐任务为监督目标,并适配实际工业应用需求
- 通过在真实工业级大规模数据集上的实验和在线A/B测试 ,论文验证了该方法的有效性。此外,论文在六个 Amazon 评论数据集上取得了 SOTA 性能,进一步证明了LEARN的优越性
Introduction and Discussion
- 近年来, LLM 展现出卓越的能力并快速发展,如何将其开放的领域知识和强大的逻辑推理能力引入推荐系统(RS)成为学术界和工业界关注的焦点。
- 当前的推荐系统严重依赖独立的 ID Embedding,并侧重于基于历史交互捕捉用户与 item 的潜在关联。这种方法忽略了 item 文本描述中的语义信息,难以泛化到未见数据,导致工业冷启动场景和长尾用户推荐中的性能不佳。此外,与计算机视觉(CV)和自然语言处理(NLP)领域不同,推荐系统中基于 ID Embedding 的建模方法难以开发出适用于下游任务和子场景的预训练模型。
- 为了改善当前推荐系统的泛化能力,已有研究尝试利用文本信息或结合LLM生成文本预测,例如用户兴趣(Ren等, 2024)、 next item 信息(Li等, 2023)和推荐理由(Zhang等, 2023b)。
- 先前关于LLM与推荐系统结合的研究通常遵循一种统一策略,论文称之为“Rec-to-LLM”适配(adaptation)
- 该策略将推荐领域的 user-item 交互数据(目标领域)转换为LLM开放世界领域(源领域)的文本格式,如图1所示
- 具体而言,这些方法设计任务特定的提示(prompt),将推荐数据转化为对话形式,并采用 next token 预测损失,使输入组织和目标任务与LLM预训练阶段对齐。
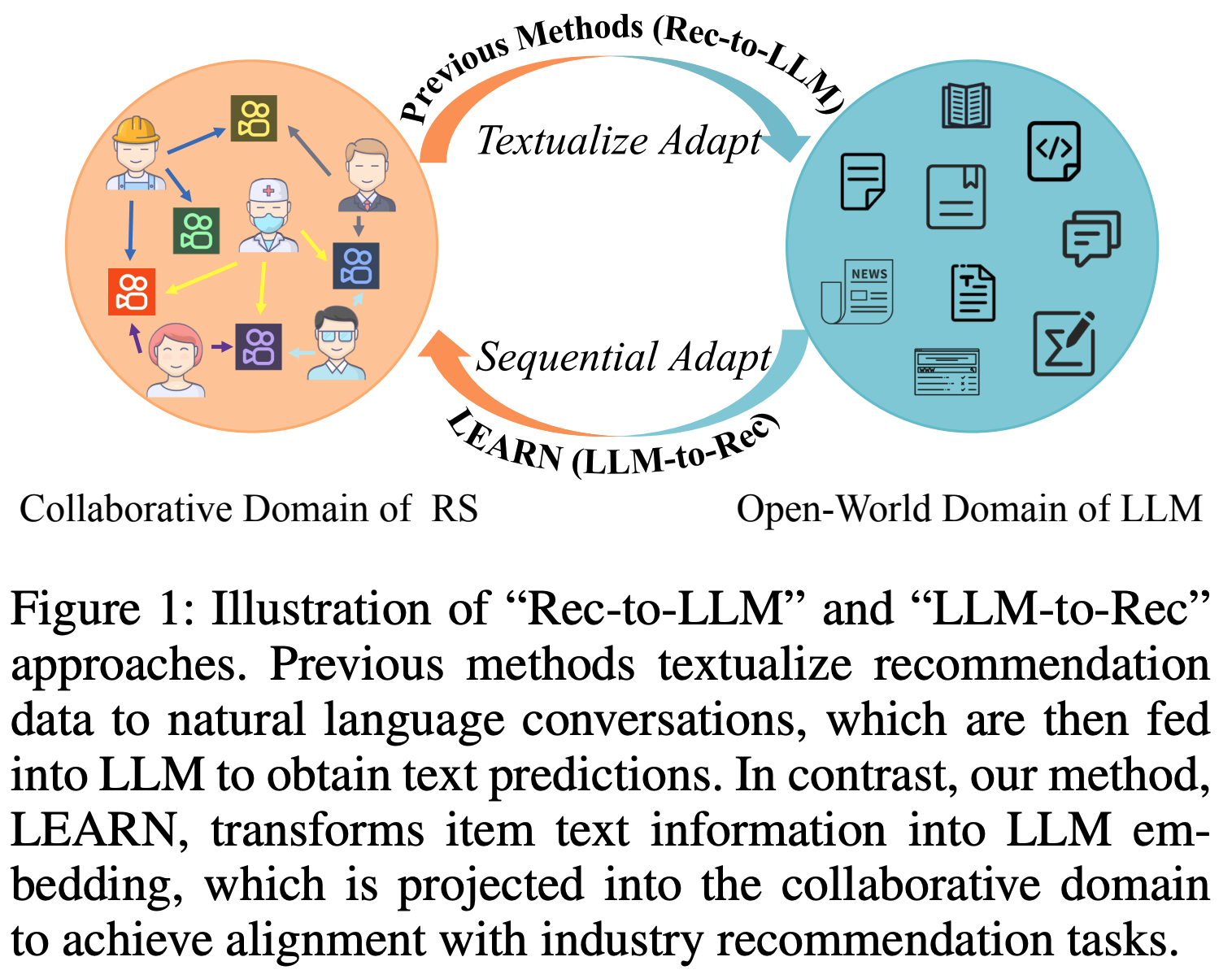
- 然而,论文的实证研究表明,“Rec-to-LLM”适配在真实工业应用中未能带来实际效益。这种低效性源于该方法的固有缺陷:
- 计算复杂度高 :由于LLM的输入长度限制(2K至128K)和计算复杂性,在工业场景中无法负担对文本化交互数据进行推理或微调
- 例如,在论文的短视频平台中,用户平均每周与近800个短视频交互,因此用LLM处理数月内的全局用户历史交互数据会带来巨大的计算负担。
- 灾难性遗忘 :用推荐数据微调LLM会导致开放世界知识的灾难性遗忘(catastrophic forgetting),因为推荐系统的协作知识与LLM的开放世界知识之间存在显著领域差距。
- 目标不对齐 :LLM的训练目标与推荐任务的不匹配进一步限制了已有方法的性能。
- 计算复杂度高 :由于LLM的输入长度限制(2K至128K)和计算复杂性,在工业场景中无法负担对文本化交互数据进行推理或微调
- 为克服上述限制,论文提出了一种基于语言模型的知识自适应推荐方法(LEARN) ,旨在协同融合LLM的开放世界知识与推荐系统的协作知识。与“Rec-to-LLM”适配不同,论文的方法遵循“LLM-to-Rec”适配(如图1所示),将LLM作为内容提取器,并以推荐任务为训练目标。
- LEARN框架由用户塔(User Tower)和 item 塔(Item Tower)组成,二者均包含内容提取模块(Content EXtraction,CEX)和偏好对齐模块(Preference ALignment,PAL)
- 内容提取模块(CEX) :为降低处理大规模用户历史交互的计算开销,CEX模块采用预训练LLM作为 item 编码器而非用户偏好编码器。为避免开放世界知识的灾难性遗忘,论文在训练阶段冻结LLM参数
- 偏好对齐模块(PAL) :为弥合开放世界与协作领域之间的鸿沟,论文设计了PAL模块,并采用推荐任务的自监督训练目标指导模型优化。LEARN生成的用户和 item 嵌入将作为在线排序模型的输入。
- 为验证方法在工业实践中的有效性,论文从真实推荐场景中构建了大规模数据集,并通过在线A/B测试进行评估。同时,论文在六个 Amazon 评论数据集(Ni等, 2019)上进行了实验,与已有方法进行公平对比。实验结果表明,LEARN在六个数据集的三项指标中均达到最先进性能,尤其在Recall@10上平均提升13.95%
- 论文的主要贡献如下:
- 提出LEARN框架,高效地将LLM的开放世界知识聚合到推荐系统中。
- 提出CEX和PAL模块,解决LLM的灾难性遗忘问题,并通过推荐任务弥合开放世界与协作领域的鸿沟。
- 在工业级数据集和在线A/B测试中验证了方法的实用性。
- 在六个公共数据集上取得最先进性能,Recall@10平均提升13.95%。
相关工作(直译,包含引用信息)
基于内容的推荐
- 传统推荐系统主要基于 ID Embedding,其泛化能力有限。为此,大量研究通过深化对用户和 item 内容的理解来增强推荐系统的泛化能力
- Wu等人(2020)为新闻推荐任务构建了大规模文本数据集MIND,推动了文本内容理解对推荐系统影响的研究
- 随后,多项研究利用BERT模型(Devlin等, 2018)改进内容理解,例如ZESRec(Ding等, 2021)、UniRec(Hou等, 2022)和TBIN(Chen等, 2023)采用预训练BERT模型作为编码器提取 item 文本描述的内容嵌入
- RecFormer(Li等, 2023)结合掩码语言模型损失(MLM)和对比损失,并重新设计分词器以编码 item 的文本信息
- 除文本信息外,部分方法还尝试将视觉信息融入推荐模型,例如SimRec和MAKE(Wang等, 2023)采用CLIP(Radford等, 2021)和MoCo(He等, 2020)提取图像特征,MoRec(Yue等, 2023)和MISSRec(Wang等, 2023)则利用ResNet(He等, 2016)和ViT(Dosovitskiy等, 2020)在序列推荐中融入 item 图像内容。
基于LLM的推荐
- 由于LLM在文本理解和常识推理上的强大能力,越来越多的研究探索如何将其整合到推荐系统中(Fan等, 2023; Lin等, 2023a)
- 第一类方法冻结LLM参数 ,将其直接作为推荐器
- 部分研究(Li等, 2023; Zhang等, 2023b; Yue等, 2023; Xi等, 2023)设计任务特定提示构建推荐对话,并利用ChatGPT生成候选 item ;
- RLMRec(Ren等, 2023)则通过ChatGPT生成用户/ item 画像
- 第二类方法在推荐领域的特定文本数据集上微调LLM
- LlamaRec(Yue等, 2023)以 item 标题为文本数据,通过排序分数优化LLM;
- TALLRec(Bao等, 2023b)提出两阶段微调框架,并采用LoRA(Hu等, 2021)进行少样本推荐;
- LLARA(Liao等, 2023)将LLM提示与 ID Embedding 结合,对齐LLM与序列推荐器;
- ReLLa(Lin等, 2023b)提出检索增强的指令微调方法,并在混合数据集上微调Vicuna(Chiang等, 2023)。
- 上述研究均将推荐系统的 user-item 交互数据适配为LLM的文本对话格式,并利用LLM的训练损失微调模型。这些方法将数据和任务从推荐领域(目标领域)迁移到LLM领域(源领域),因此论文称之为“Rec-to-LLM”方法。
方法
模型架构
- 给定按时间顺序排列的用户历史交互记录,交互序列根据特定时间戳分为两段:第一段是历史交互序列 \( U^{hist} \),第二段是目标序列 \( U^{tar} \)。历史交互和目标交互的长度分别记为 \( H \) 和 \( T \)。论文提出LEARN框架,旨在从历史交互中捕捉用户兴趣,并预测用户可能感兴趣的 next item。LEARN框架由用户塔(User Tower)和 item 塔(Item Tower)组成,如图2所示
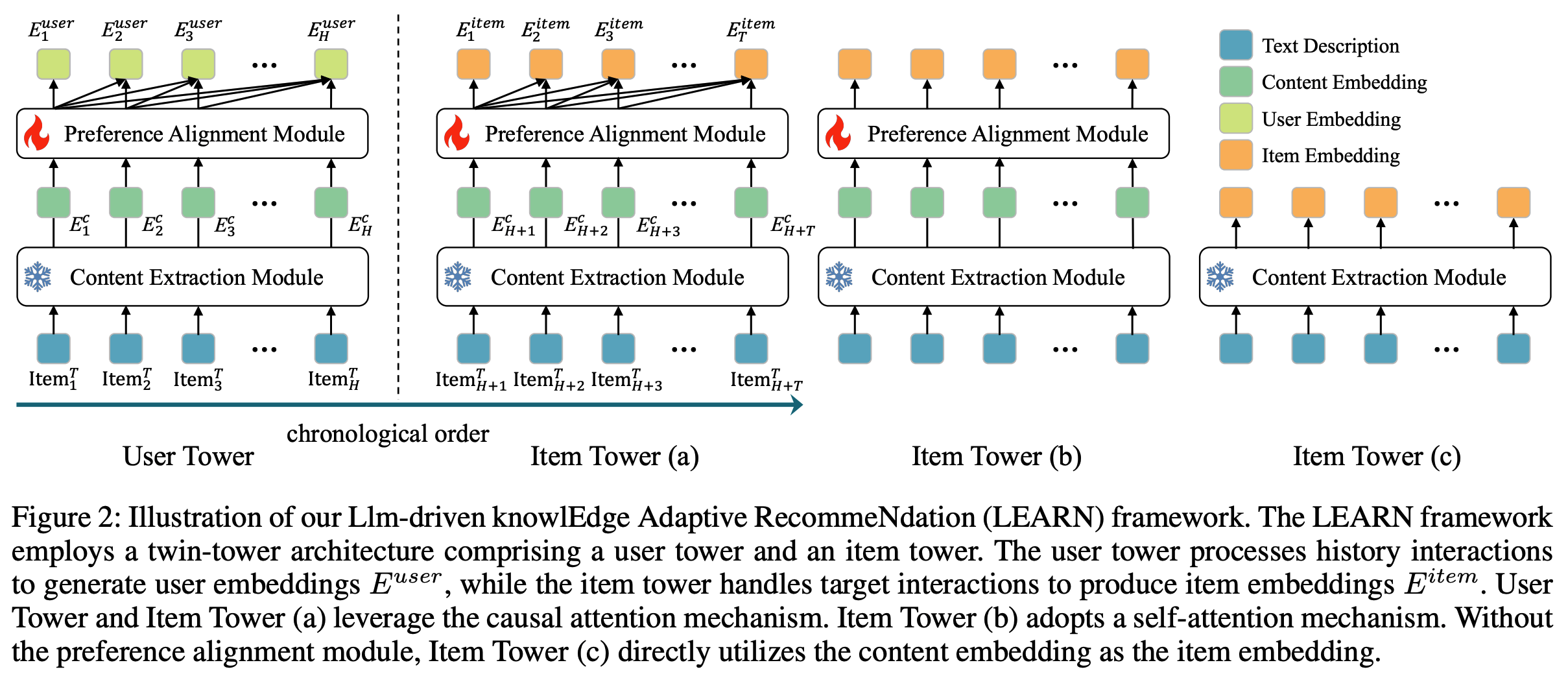
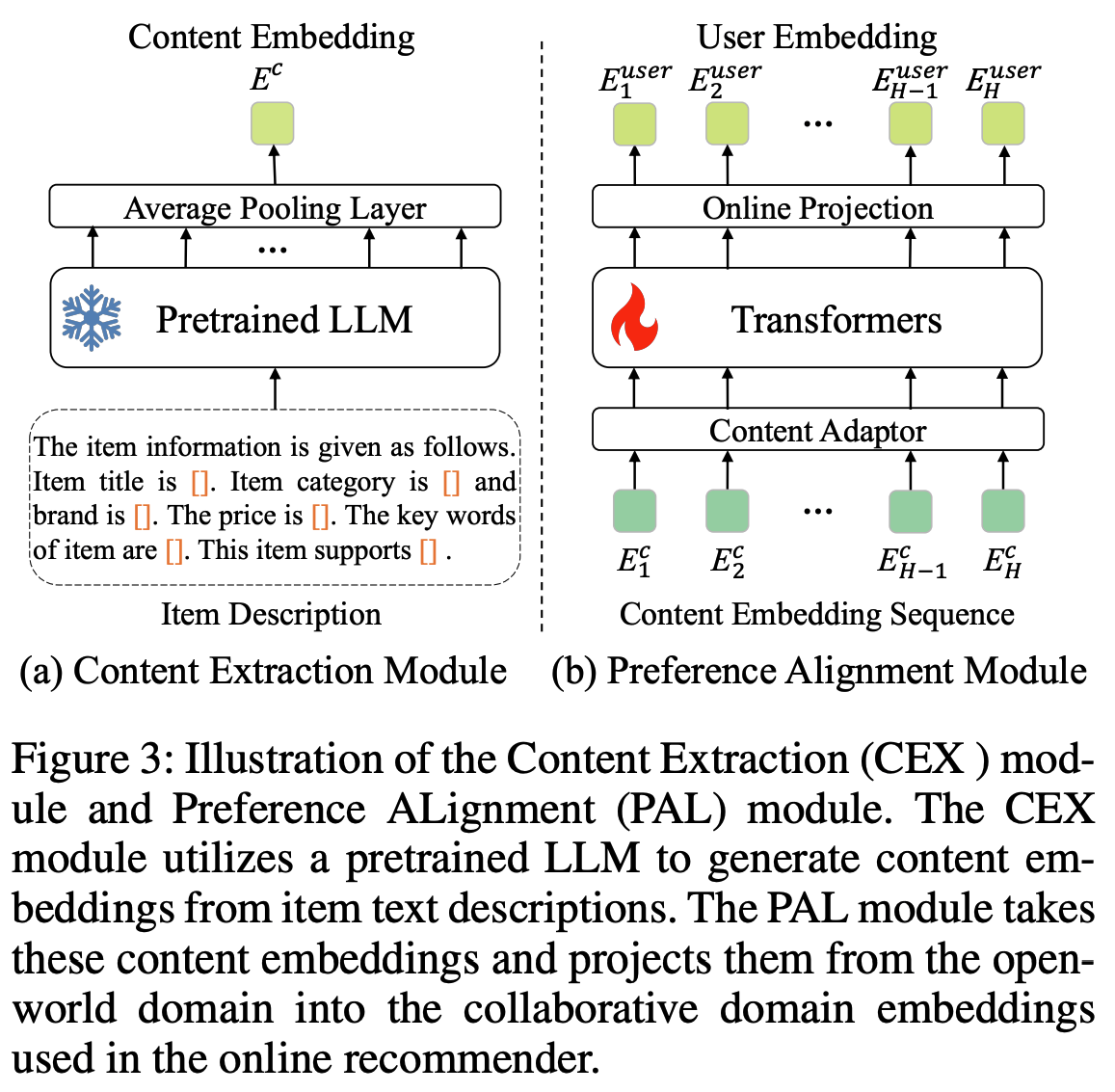
- 用户塔 :用户塔包含内容提取(Content EXtraction, CEX)模块和偏好对齐(Preference ALignment, PAL)模块,如图3所示
- 用户塔的输入 :与用户交互的历史 item 序列。每个 item 根据图3所示的提示模板进行文本描述。提示设计非常简洁,以有效评估文本描述的信息量
- CEX模块 :使用预训练的 LLM 和一个平均池化层处理这些 item 描述,生成内容嵌入 \( E^c \)。在训练过程中,预训练LLM的参数保持冻结状态,最终解码器层的隐藏状态作为输出嵌入,随后送入池化层,如图3(a)所示。对于整个历史交互序列 \( U^{hist} \),CEX模块将每个 item 的文本描述转换为内容嵌入 \( E^c \),形成内容嵌入序列。每个 item 由CEX模块独立处理
- 偏好对齐(PAL)模块 :基于内容嵌入序列捕捉用户偏好,并输出用户嵌入。PAL模块首先通过内容适配器进行维度转换,随后采用12层Transformer作为主干网络,其配置与BERT-base模型(Devlin等, 2018)一致。该Transformer专门设计用于学习隐含的 item 关系并建模用户偏好。与BERT的双向注意力机制不同,论文的模块采用因果注意力机制(causal attention),仅关注过去的 item ,以符合用户偏好的时序特性。Transformer的输出嵌入通过在线投影层进一步处理,生成用户嵌入 \( E^{user} \in \mathbf{R}^{64} \),直接用于图5所示的在线电商推荐系统
- item 塔 :item 塔处理 item 内容的文本描述,并输出适用于推荐领域的 item 嵌入 \( E^{item} \)。如图2所示,论文提出了三种 item 塔变体:
- item 塔(a) 采用与用户塔相同的因果注意力机制。
- item 塔(b) 采用自注意力机制(self-attention),每个 item 仅关注自身内容。尽管存在这一差异,两种变体的模型架构相同,且与用户塔共享权重。
- item 塔(c) 直接使用内容嵌入 \( E^c \) 作为 item 嵌入 \( E^{item} \),以“Rec-to-LLM”方式指导用户偏好学习。
- 在训练阶段,item 塔(a)将整个用户目标序列 \( U^{tar} \) 作为输入,而 item 塔(b)和 item 塔(c)独立处理单个 item。在推理阶段,所有三种变体均以单个 item 为输入,独立生成 item 嵌入。根据表5的结果,item 塔(a)因其性能优势被选为默认配置
训练目标
- 为了弥合LLM开放世界领域的内容嵌入与推荐系统协作领域 user/item 嵌入之间的差距,论文将训练目标与在线排序模型对齐。在在线推荐系统中,排序模型计算用户嵌入与所有候选 item 嵌入之间的相似度,相似度最高的前k个 item 被视为用户可能感兴趣的内容。因此,论文采用自监督对比学习机制建模用户偏好,与在线推荐系统的目标一致。该方法最大化用户嵌入与相关 item 嵌入之间的相似度,同时最小化与无关 item 的相似度
- 论文从用户历史序列中采样用户嵌入,从同一用户的目标序列中采样 item 嵌入,构建正样本对。同一批次中其他用户的目标 item 嵌入被采样为负样本。为充分利用用户交互并捕捉用户长期兴趣,论文采用密集全动作损失(dense all action loss)。从历史序列中采样 \( N_h \) 个用户嵌入,从目标序列中采样 \( N_t \) 个 item 嵌入,从而构建 \( N_h \times N_t \) 个正样本对以应用密集全动作损失。默认情况下,\( N_h \) 和 \( N_t \) 均设置为10
采样策略
- 尽管在构建工业数据集时已根据行为重要性对 item 进行了采样,但由于训练资源限制,用户序列长度仍然过长。为此,论文在训练阶段设计了两阶段采样策略:
- 第一阶段 :从完整用户历史/目标交互中随机采样,作为用户塔的输入,确保建模用户兴趣的数据无偏。
- 第二阶段 :构建正负样本对时,采用加权采样策略,优先选择近期交互的 item。历史/目标序列中第 \( i \) 个 item 的权重 \( \tilde{w}_i \) 计算如下:
$$
\tilde{w}_i = \frac{w_i}{\max(w)}, \quad \text{ Where } \quad w_i = \log(\alpha + i \cdot \frac{\beta - \alpha}{N - 1}).
$$- 超参数 \( \alpha \) 和 \( \beta \) 分别设置为10和10000,\( N \) 为第一阶段采样的用户历史/目标交互长度
- 通过这种策略,模型能够更有效地捕捉用户当前兴趣,提升推荐性能
Experiments
Experiment Setup
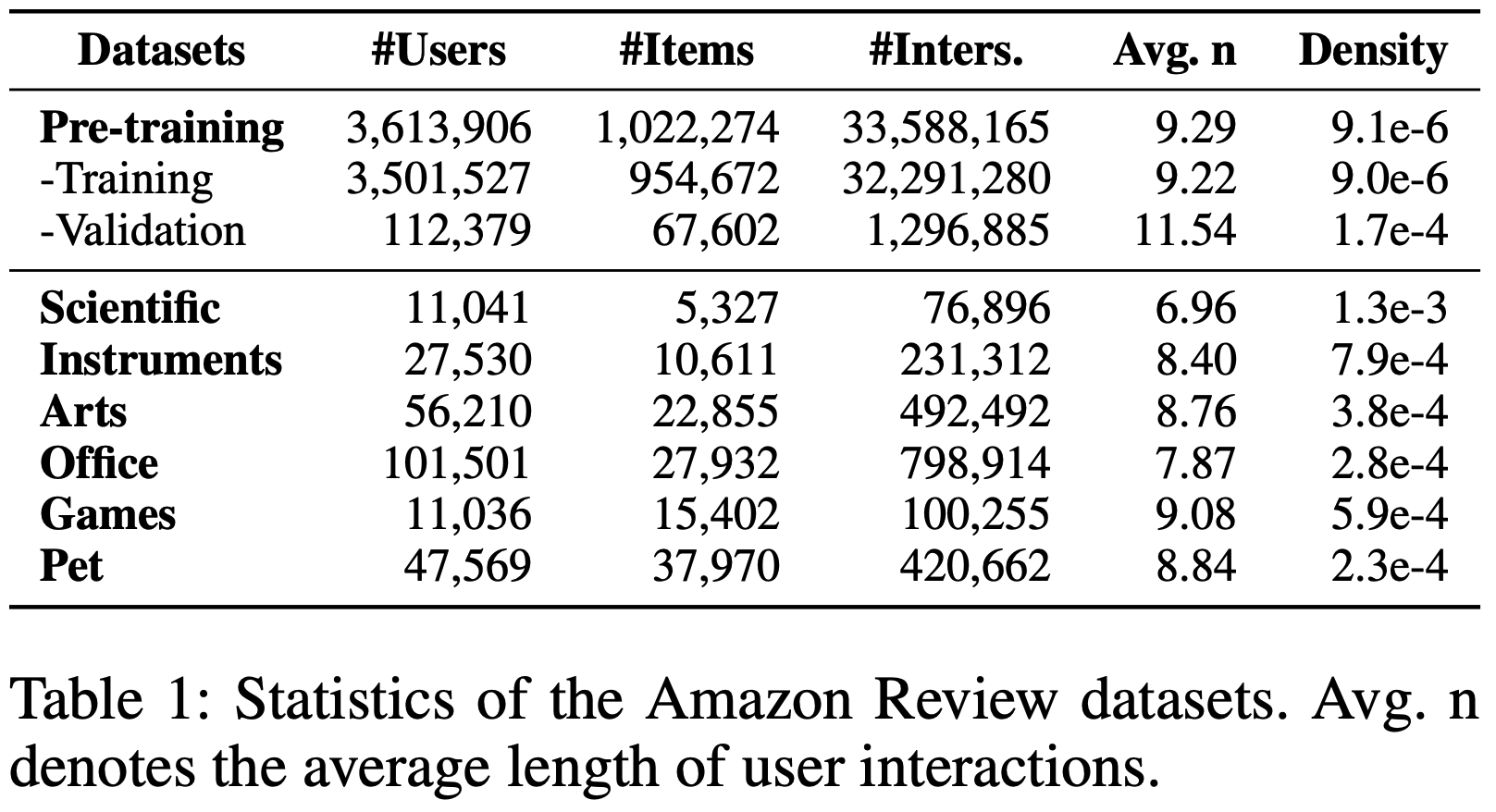
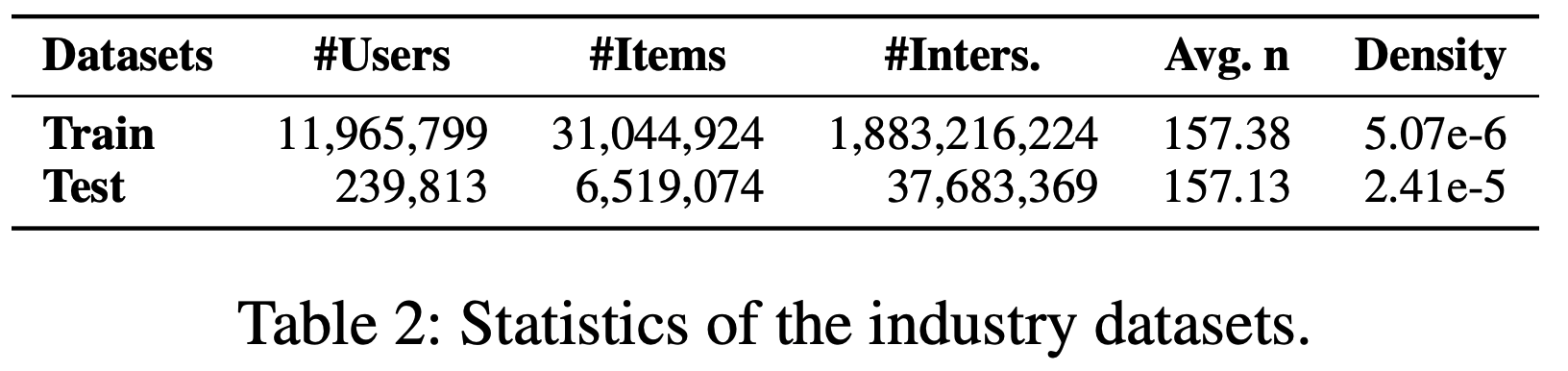
- 数据集 :为了工业应用,论文从短视频应用的电商平台构建了一个大规模的实际推荐数据集。该工业数据集包含从2022年6月到2023年4月共10个月内1200万用户与3100万商品的交互记录。前9个月的交互数据作为历史数据,最后1个月的交互数据作为目标数据。论文收集了六类信息(标题、类别、品牌、价格、关键词、属性)来构成商品描述。为了公平比较,论文采用了广泛使用的Amazon Review数据集,并遵循RecFormer的设置。选取七个类别作为预训练数据,另外六个类别作为微调数据以评估论文的方法。商品描述由三类信息(标题、类别、品牌)构成。公开数据集和工业数据集的统计信息分别如表1和表2所示
- 实现细节 :论文采用Baichuan2-7B作为 LLM 来提取商品文本描述的内容嵌入,因其在中文和英文文本理解上的强大能力。训练阶段冻结LLM的参数。所有实验默认采用AdamW优化器和余弦调度器。对于工业数据集,由于内存限制,训练批次大小设为240,用户历史交互和目标交互长度分别设为80和40,训练轮次为10。评估指标采用Top50和Top100的命中率(H@50、H@100)和召回率(R@50、R@100)。对于Amazon Review数据集,预训练阶段批次大小为1024,微调阶段为16,学习率分别为5e-5和2e-5。预训练和微调的训练轮次分别为20和200。论文遵循RecFormer的评估设置,采用留一策略进行评估,使用NDCG@10(N@10)、Recall@10(R@10)和MRR三个指标以确保公平比较。由于Amazon Review数据集的交互序列长度有限,论文在LEARN的训练阶段未采用任何采样策略
在Amazon Review数据集上的性能
- 整体性能 :为了验证方法的有效性,论文在Amazon Review数据集上的性能如表3所示。论文将LEARN与三类方法进行比较:仅ID方法(GRU4Rec、SASRec、BERT4Rec、RecGURU)、ID-文本方法(FDSA、S³-Rec)和纯文本方法(ZESRec、UniSRec、RecFormer)。论文的方法在仅ID、ID-文本和纯文本方法中均取得了显著提升。具体而言,与 SOTA RecFormer相比,LEARN在Scientific、Instruments、Arts、Office、Games和Pet数据集上的Recall@10分别提升了10.08%、17.87%、5.39%、10.41%、29.45%和10.50%。RecFormer采用掩码语言建模(MLM)损失和两阶段微调过程,而LEARN仅通过 user-item 对比损失在单阶段微调中实现显著性能提升,进一步证明了论文框架的有效性。论文还按照RecFormer的设置进行了零样本实验(仅预训练阶段)
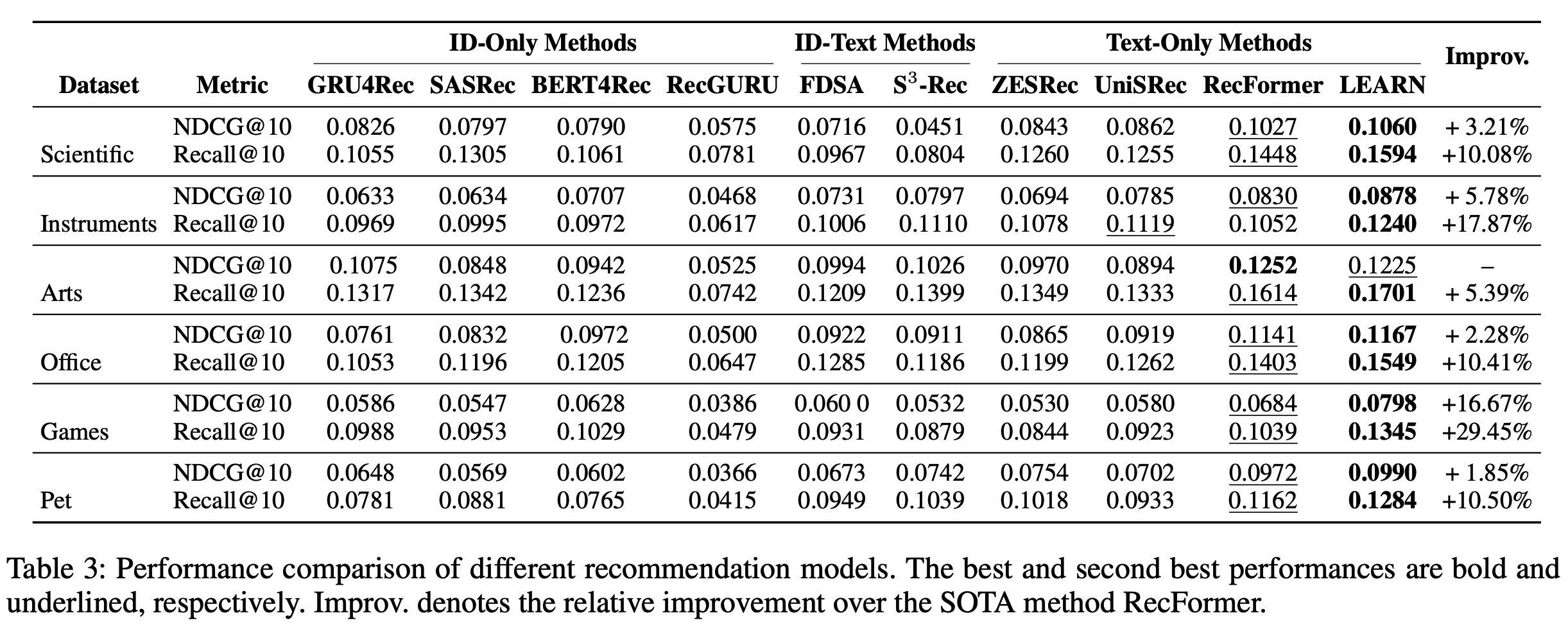
- 图4结果显示,LEARN框架可以作为预训练推荐模型,在下游子场景中表现优异
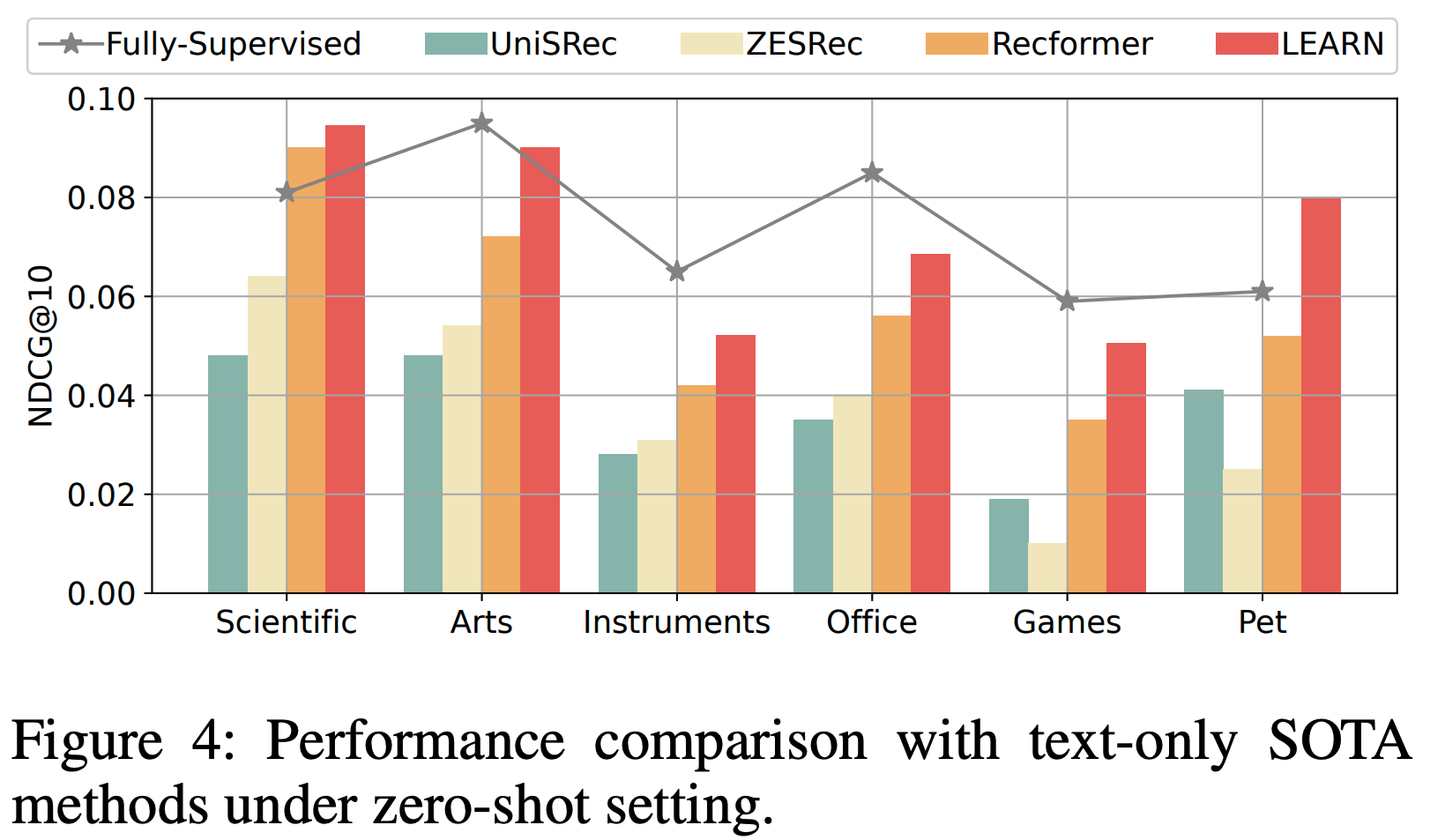
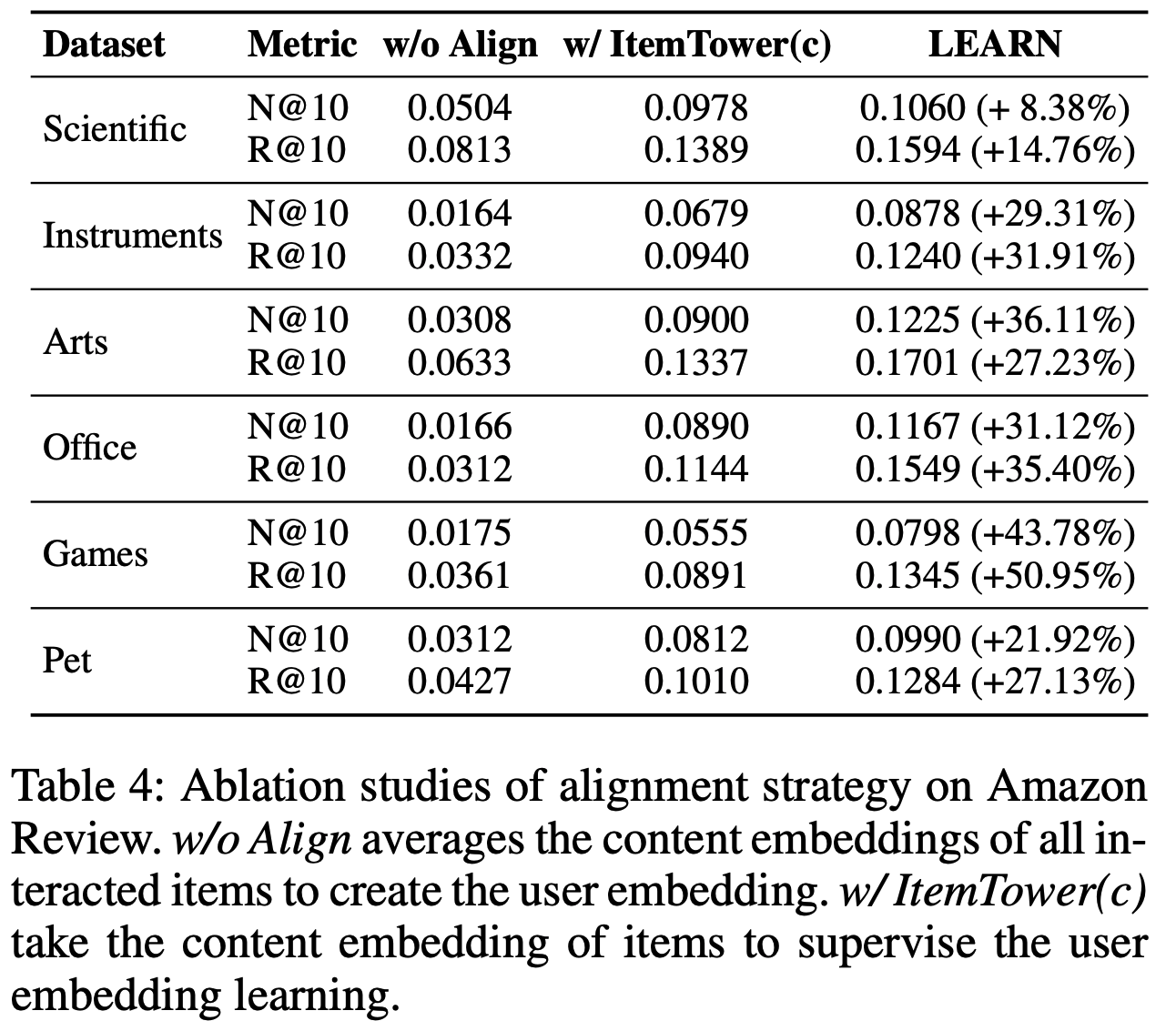
- 消融研究 :论文性能提升的核心在于推荐系统协作域与LLM开放域之间存在显著差距。通过将 user-item 交互作为对齐目标,将内容嵌入转换为用户/商品嵌入,可以有效弥合这一差距。表4展示了论文的发现。首先,论文通过平均用户交互商品的内容嵌入生成用户嵌入,并直接使用商品的内容嵌入作为商品嵌入(称为“w/o Align”)。由于LLM与推荐域之间缺乏对齐,其性能极差,验证了论文的假设。其次,论文采用LLM生成的内容嵌入作为对齐目标(ItemTower(c)),通过将推荐域转换为LLM域实现对齐(与之前工作的“Rec-to-LLM”方法一致)。实验表明,ItemTower(c)性能低于LEARN,因为推荐知识的特性未在LLM开放域中充分体现。相比之下,LEARN通过将源域投影到目标域空间,更贴合推荐分布的复杂性,从而提升性能。值得注意的是,在Amazon Review数据集中,由于留一设置,ItemTower(a)与ItemTower(b)等效
在工业数据集上的性能
- 消融研究 :为了验证模型设计的合理性,论文在实际工业场景构建的大规模数据集上进行了消融实验。如表5所示,“w/o Align”因LLM与推荐域之间的显著差距表现最差。在对齐策略中,采用ItemTower(a)的LEARN性能最佳,其次是ItemTower(b),ItemTower(c)最差。ItemTower(a)通过序列到序列对齐更好地捕捉用户长期兴趣,而ItemTower(c)的“Rec-to-LLM”对齐性能较差,与Amazon Review数据集的结论一致。由于用户交互序列长达十个月以上,论文采用式(1)的样本加权策略,与随机采样相比,H@100和R@100分别提升了7.13%和7.18%
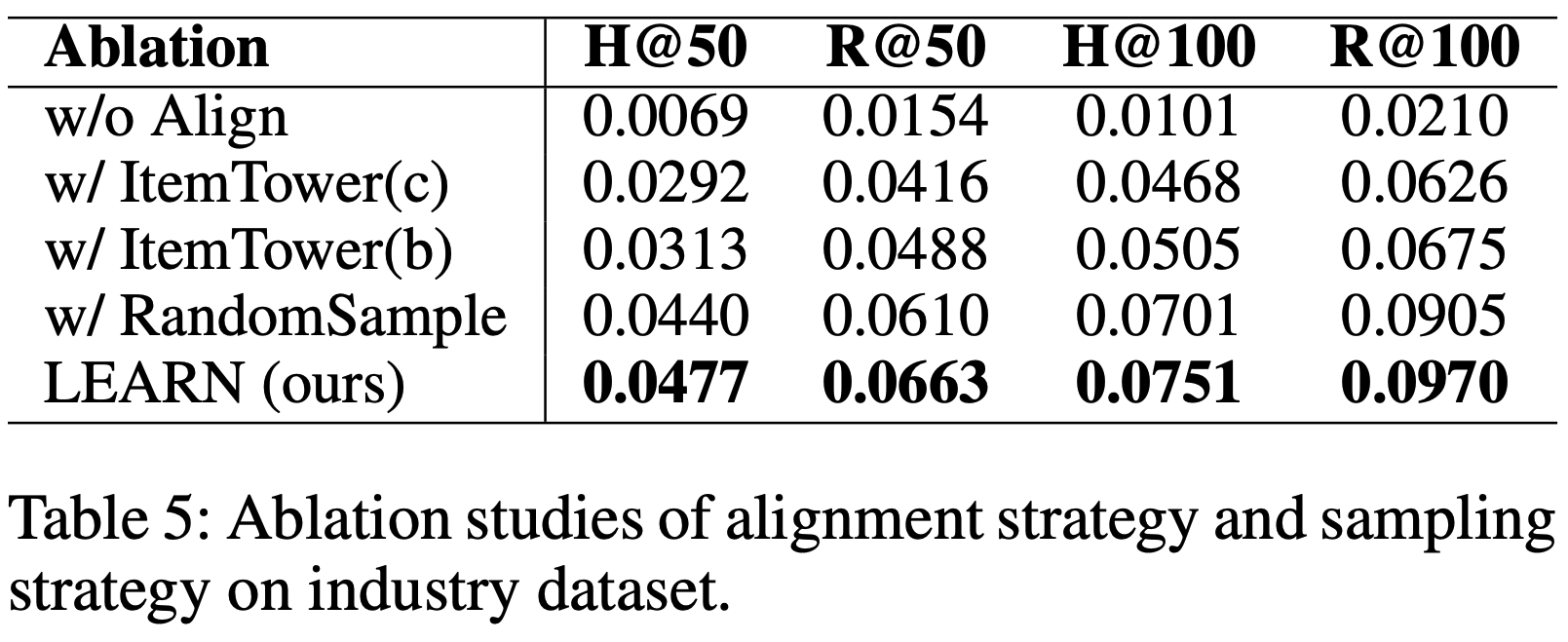
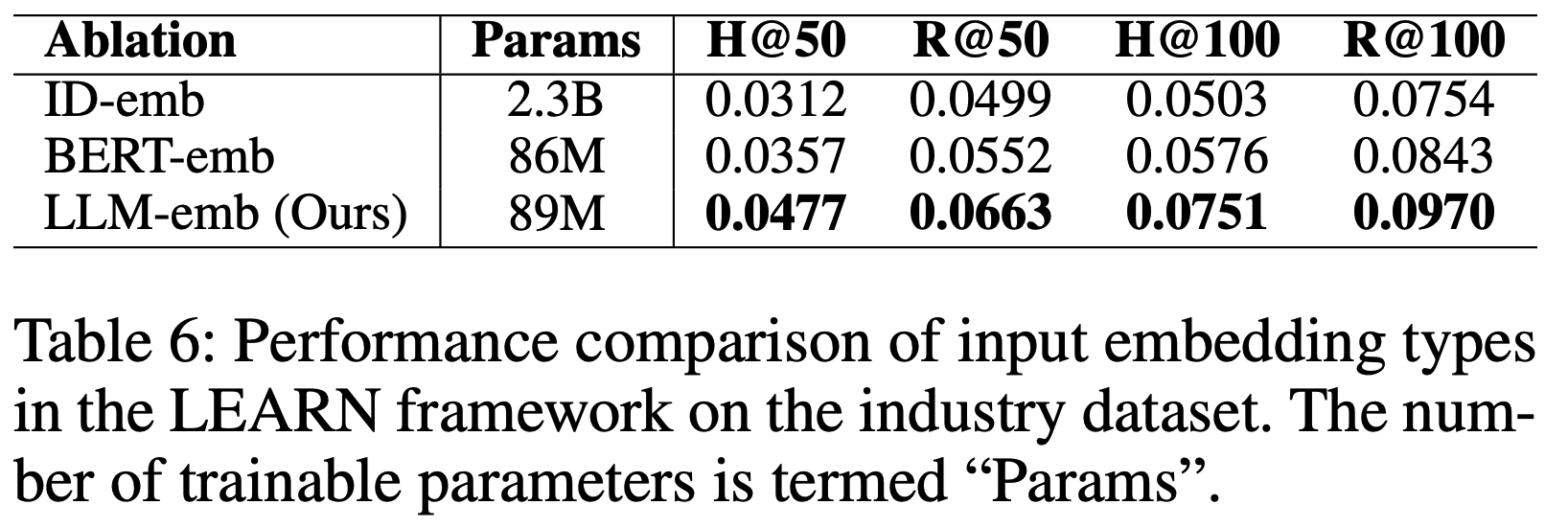
- ID Embedding 与内容嵌入对比 :鉴于 ID Embedding 在语义表示和泛化上的局限性,论文探索了在大规模工业场景中替代 ID Embedding 的可行性。论文采用三种商品表示方法:可学习的 ID Embedding 、从预训练BERT和LLM提取的冻结内容嵌入。 ID Embedding 维度设为64以匹配在线系统。表6显示,基于LLM的内容嵌入相比 ID Embedding 显著提升了性能,H@100从0.0504提升至0.0751(提升49.01%);相比BERT嵌入,LEARN进一步提升了30.38%。这表明LLM嵌入因训练于大规模文本语料而蕴含更丰富的信息,为替代 ID Embedding 提供了可行方向
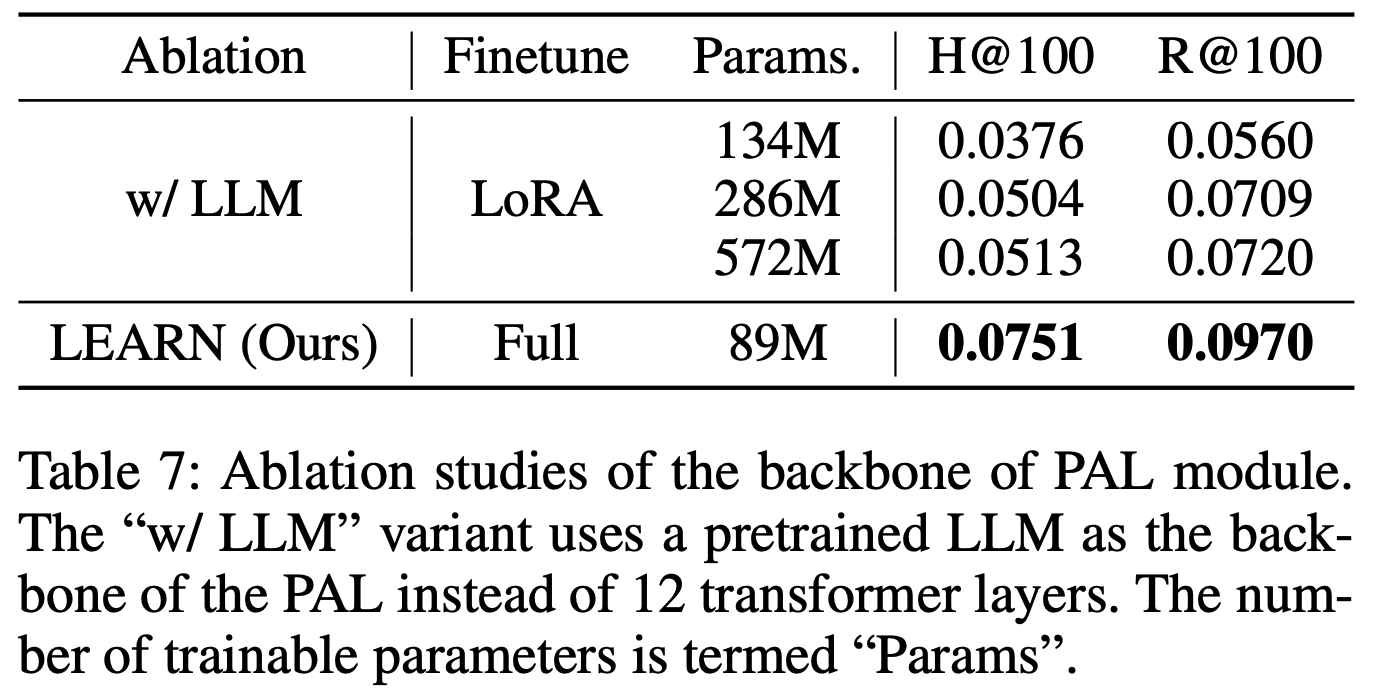
- PAL模块消融研究 :考虑到LLM在文本理解和常识推理上的优势,论文尝试用预训练LLM(Baichuan2-7B)替换PAL模块中从头训练的Transformer层。为避免遗忘开放域知识,论文采用LoRA微调LLM,并调整可训练参数量。如表7所示,随着可训练参数从134M增至572M,“w/ LLM”变体性能从0.0376提升至0.0513,但仍低于LEARN(采用12层Transformer)。由于LLM的冻结参数远多于LoRA可训练参数,原始特征(基于开放域和下一词预测损失)主导了混合特征,导致其无法达到最优性能
在线A/B实验
- 论文在拥有4亿日活跃用户(DAU)的短视频平台的排序模型上进行了在线A/B测试。自2024年1月起,论文的方法已部署在短视频信息流广告场景中
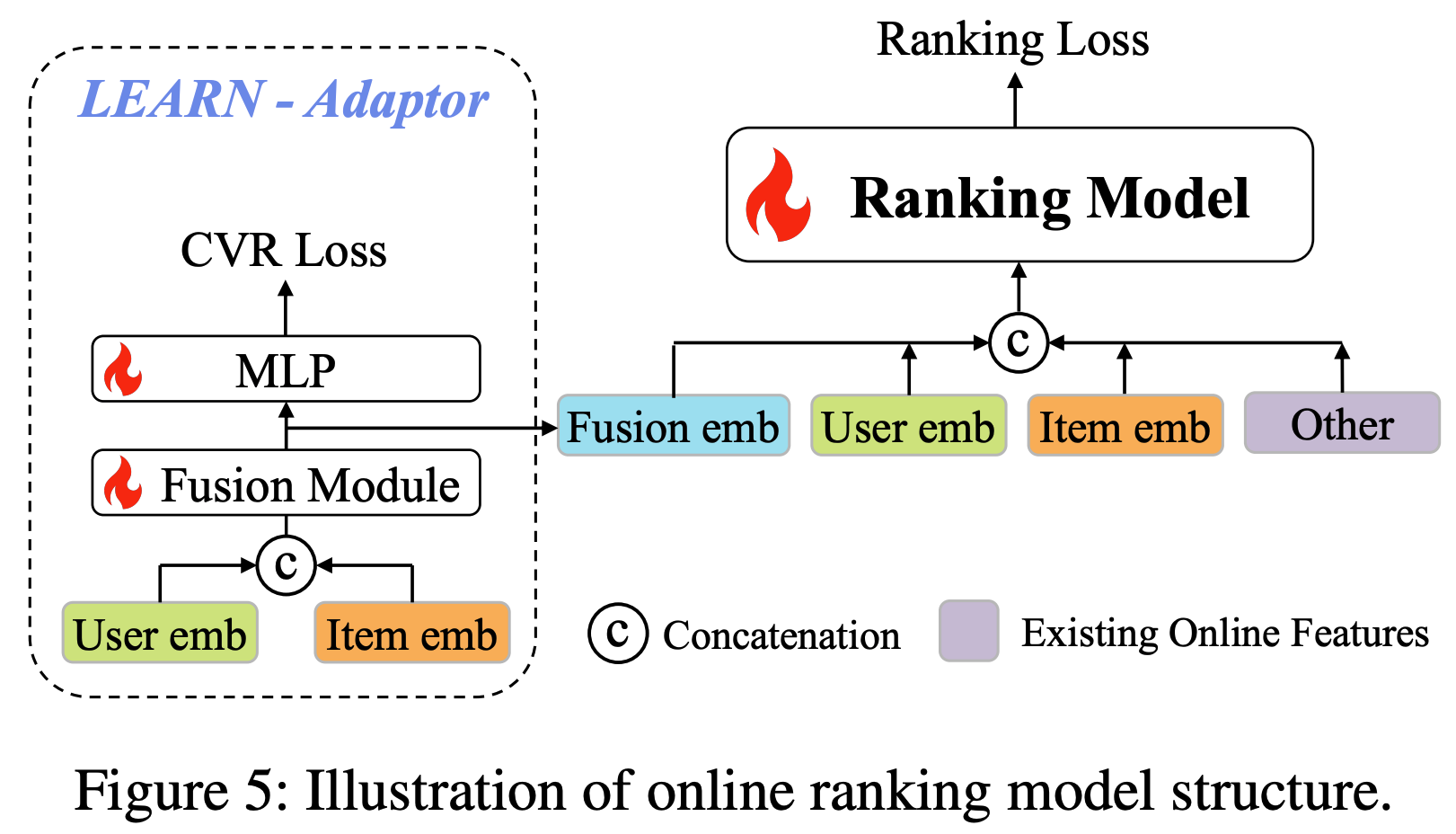
- 带LEARN适配器的排序模型 :为了更好地将LEARN生成的用户和商品嵌入与在线排序模型对齐,论文在基线模型上引入了LEARN适配器。如图5所示,基线模型包含原始排序模型(输入为现有在线特征)。LEARN适配器模块通过融合模块(两个线性层)和MLP,将用户和商品嵌入聚合为融合嵌入(基于CVR损失)。融合嵌入与LEARN的用户/商品嵌入及现有在线特征拼接后输入排序模型
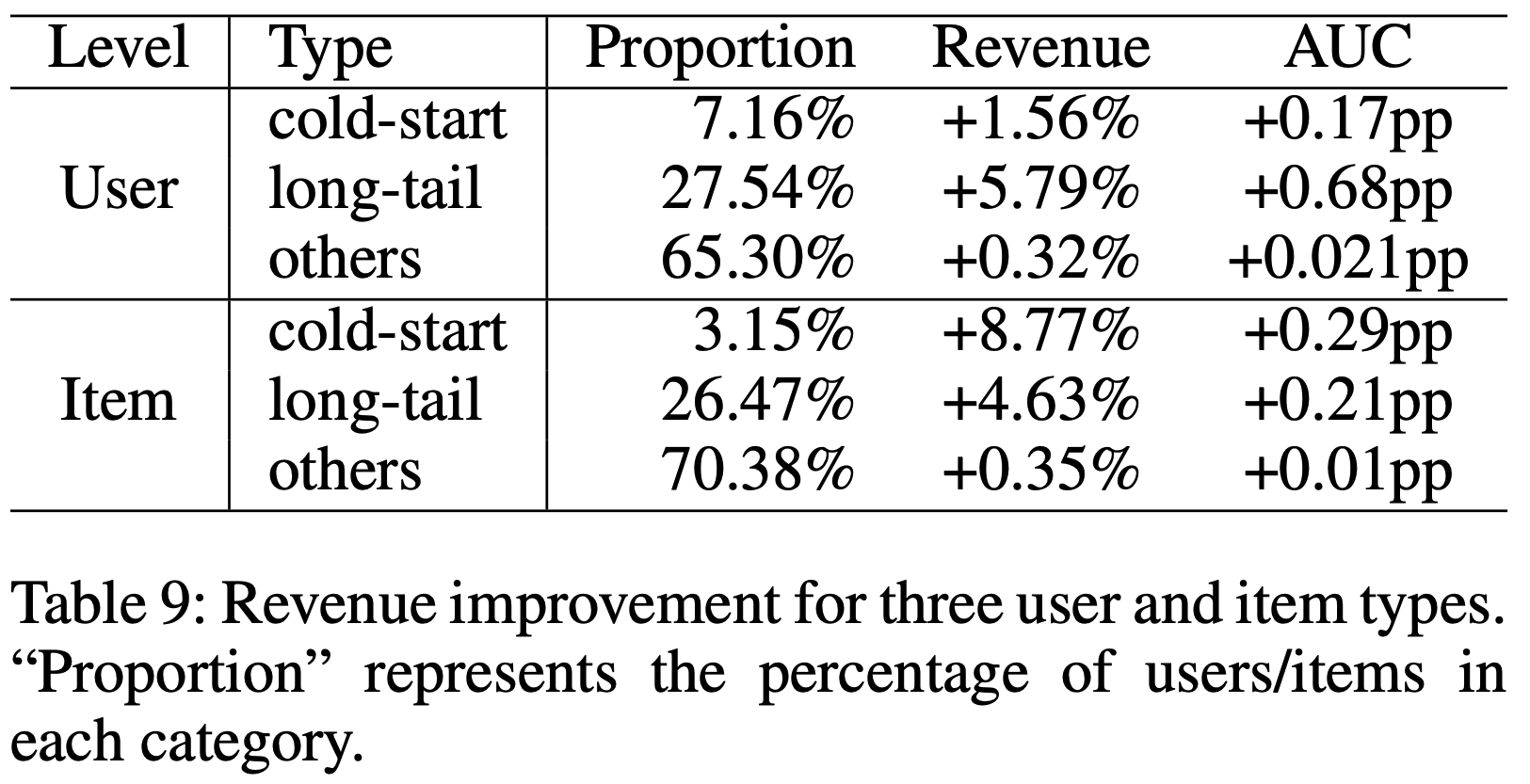
- AUC评估 :论文在短视频应用电商平台的十亿级数据集上进行了AUC评估。采用UAUC和WUAUC指标以更准确评估每用户的排序性能。如表8所示,论文的方法优于基线模型,UAUC和WUAUC分别提升0.84和0.76个百分点。这一提升归功于LEARN框架的泛化能力,能够有效捕捉长尾用户兴趣。进一步分析显示(表9),LEARN对冷启动和长尾用户及商品的性能提升尤为显著,验证了其在稀疏交互数据上的泛化能力

结论
- 论文探讨了如何将 LLM 与推荐系统相结合,并提出了LEARN框架以实现显著的商业效益。LEARN框架包含内容提取(CEX)和偏好对齐(PAL)模块。CEX模块利用预训练的LLM为每个项目提取内容嵌入,而PAL模块将这些嵌入从开放世界领域投影到推荐领域的用户/项目嵌入中。在工业数据集和公开的Amazon Review数据集上取得的领先性能,证明了论文的LEARN框架具有卓越的表现