整体总结性说明
- 样本组织思路:基本思路是将样本按照用户组织,具体来说,将同一用户的天粒度样本组织为同一条样本,同时通过掩码机制保证不会出现训练时数据/特征穿越问题
- 输入信息 Token 化(未详细说明 Token 化的方案)
输入信息Token化:我们将样本信息拆分成一个个Token。其中对于User Profile每一个特征都表示为一个Token,对于用户行为,则将每一个具体行为对应的item ID以及多个side info的Embedding表征拼接在一起再通过非线形映射组装成一个Token。同理,对于每一个曝光,我们则将item ID、对应的side info、交叉特征、时空等Context信息拼接在一起组成一Token
- HSTU架构使用
采用HSTU架构统一建模多个序列:我们利用HSTU架构针对Token化的输入进行统一编码,对比原方法,我们对每一层的输入都做了额外的LayerNorm以保证深层次训练的稳定性,考虑到不同与传统的LLM,我们的数据可以分组为多种类型的Token,因此,我们将LayerNorm拓展为Group LayerNorm,针对不同类别的Token采用不同的LayerNorm参数,以实现不同语义空间下Token的对齐
美团外卖的历史Scaling路径
- 历史Scaling路径
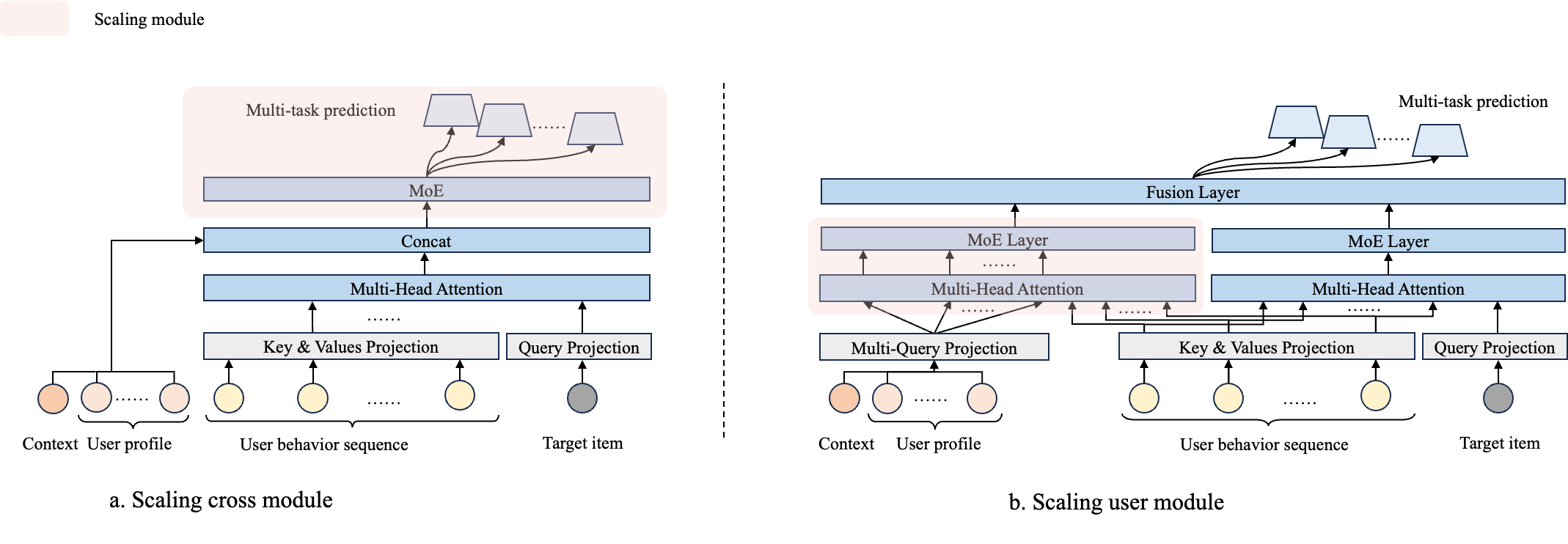
- 粉色框部分是之前的 Scaling 主要模块
特征处理
- 保留全部 DLRM 特征
- User Profile:用户统计信息,购买次数等
- Context:广告位,时间等
- UBS(User Behaviour Sequence):用户历史点击、曝光序列,包含每个 item(商家) 及其 Side Info
- Target item:待打分的商家,包含商家ID、Side Info 以及基于统计的交叉特征信息
- 注:博客中给出了丢弃交叉特征后,性能损失 CTR_GAUC -1.25pp;CTCVR_GAUC -0.91pp
- 按照用户压缩数据:将同一用户的天粒度样本组织为同一条样本,同时通过掩码机制(后续介绍)保证不会出现训练时数据/特征穿越问题
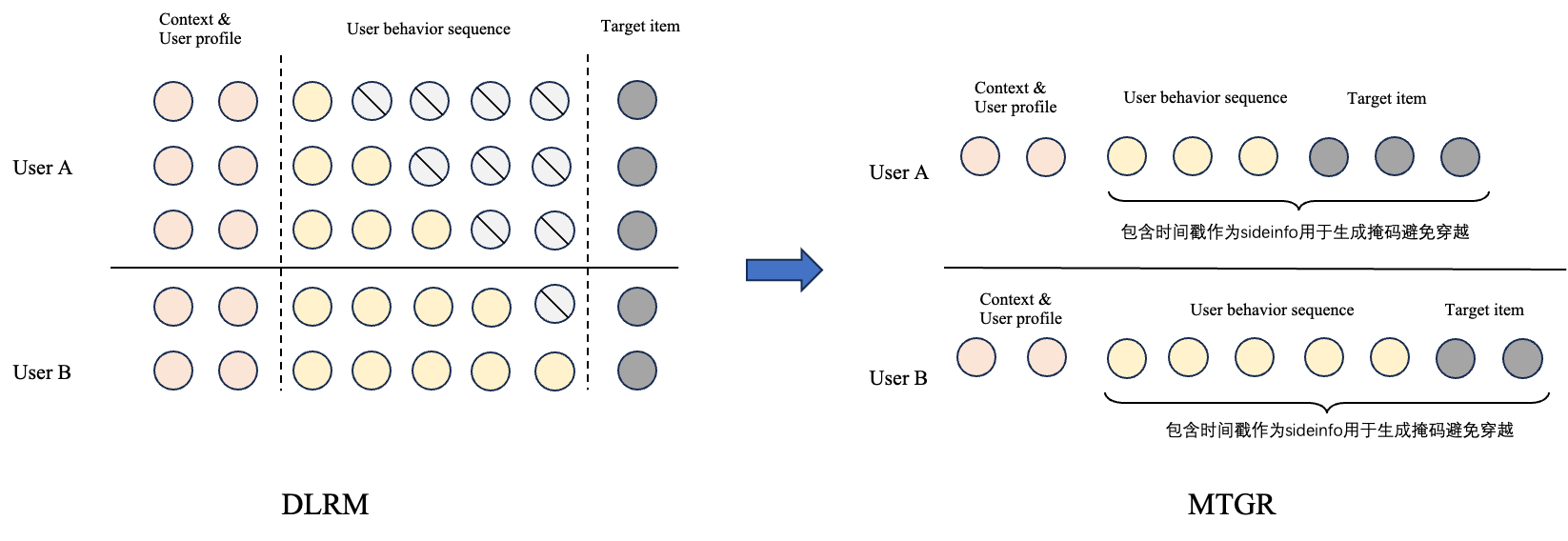
- 问题:按照用户压缩样本数据后会导致模型数据分布发生变化,减少模型对活跃用户的重视程度吗?
- 回答:不会,因为后文会提到,每个原始样本还是有一个自己的损失,总的样本损失数还是没有变化的
模型结构
- 整体架构如下所示:
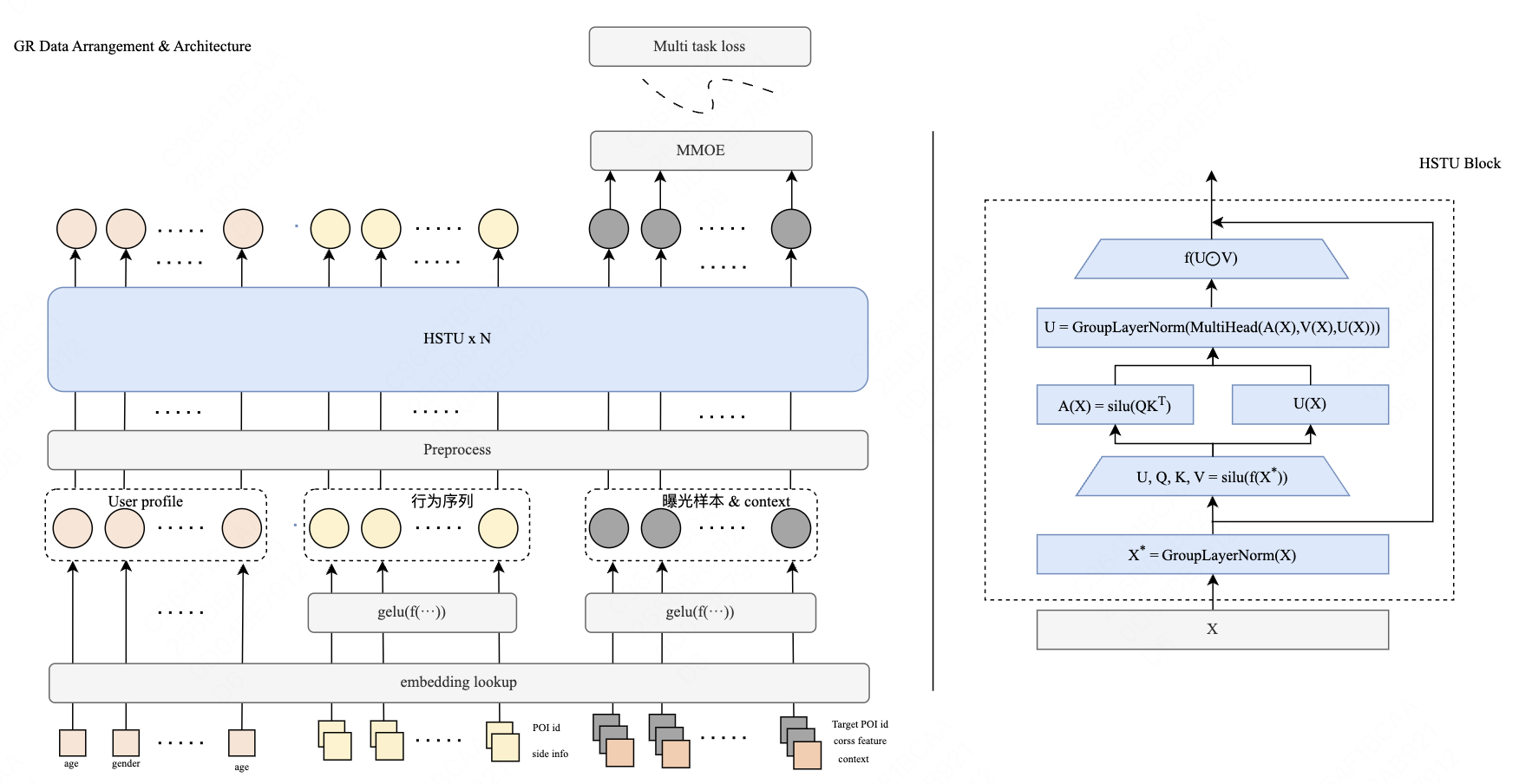
- 输入特征 Token 化:
- User Profile:每一个特征都表示为一个Token
- 问题:是否都是离散特征,直接就是 Token化的?
- UBS:对每一个行为 item,将其 item ID,以及 多个 Side Info 的 Embedding 表征拼接在一起,然后通过非线形映射映射成一个Token(理解:每个 item 输出一个离散 Token)
- 问题:非线性映射如何将连续向量映射成 Token?使用类似 CodeBook 机制吗?
- 每一个候选目标,将其 item ID、对应的side info、交叉特征、时空等 Context 信息拼接在一起组成 Token
- 补充原文描述:
我们将样本信息拆分成一个个Token。其中对于User Profile每一个特征都表示为一个Token,对于用户行为,则将每一个具体行为对应的item ID以及多个side info的Embedding表征拼接在一起再通过非线形映射组装成一个Token。同理,对于每一个曝光,我们则将item ID、对应的side info、交叉特征、时空等Context信息拼接在一起组成一Token
- User Profile:每一个特征都表示为一个Token
- 使用HSTU架构,并做以下改进
- 使用 GroupLayerNorm 层替换原始 HSTU 中的 Norm 层(Group的含义是针对不同类别的 Token 采用不同的 LayerNorm 参数)
- 在每一层输入时增加 GroupLayerNorm(注:增加 GroupLayerNorm 可提升0.17pp~0.18pp 的GAUC)
- 混合动态掩码机制(注:使用掩码机制可提升 0.12pp~0.16pp 的GAUC):
- 历史静态特征:包括 User Profile + 用户历史行为序列(User History Sequence),完全互相可见
- 当日实时行为序列(Real-Time Sequence):使用 Casual Mask 机制
- 目标 item(Targets):按照用户压缩组织样本后,这里会有多个 item,一方面要求 item 看不到发生于自己之前的当日实时行为序列,同时看不到自己之前的 Target item 信息(Casual Mask)
- 掩码机制的详细示意图如下(注:其中示意图的括号有点歪,按照颜色来区分更准确):
实时行为/曝光样本按照时间近至远进行排列:最近发生的曝光样本可以看到全部的实时行为,但较早发生的曝光样本只能看到部分实时行为
对于Target 1,因为它出现的时间较晚,因此它可以看到全部的User Profile & Sequence以及Real-Time Sequence;对于Target 2,有一部分Real-Time Sequence出现在其之前,因此它只能看到部分Real-Time Sequence
- HSTU 最终输出的利用:
- 任务建模:实际上使用的是 HSTU 编码后的 embedding 信息直接进行 多任务训练(CTR,CVR等)
- 注意:多个 targets 可以同时建模(一个样本包含多个 Target item 头,每个头都对应之前的一个曝光样本)每个头又会被分为多个任务
附录:生成式体现在哪里?
- 唯一体现生成式的地方是 Token 化特征后,Item 训练有 Casual Mask 的机制,变相在当日实时 Item 和 Target Item 上都实现了类似 Next Item Prediction 的感觉了
- Casual Mask 部分的序列不长(同一天内同一个用户的曝光数不会特别多),更像是一个 Prefix LM 架构
- 实际上生成式的体现很弱,甚至像是没有,但是确实拿到了 Scaling Law 的效果
附录:Scaling Law效果如何?
- Scaling Law实验结果
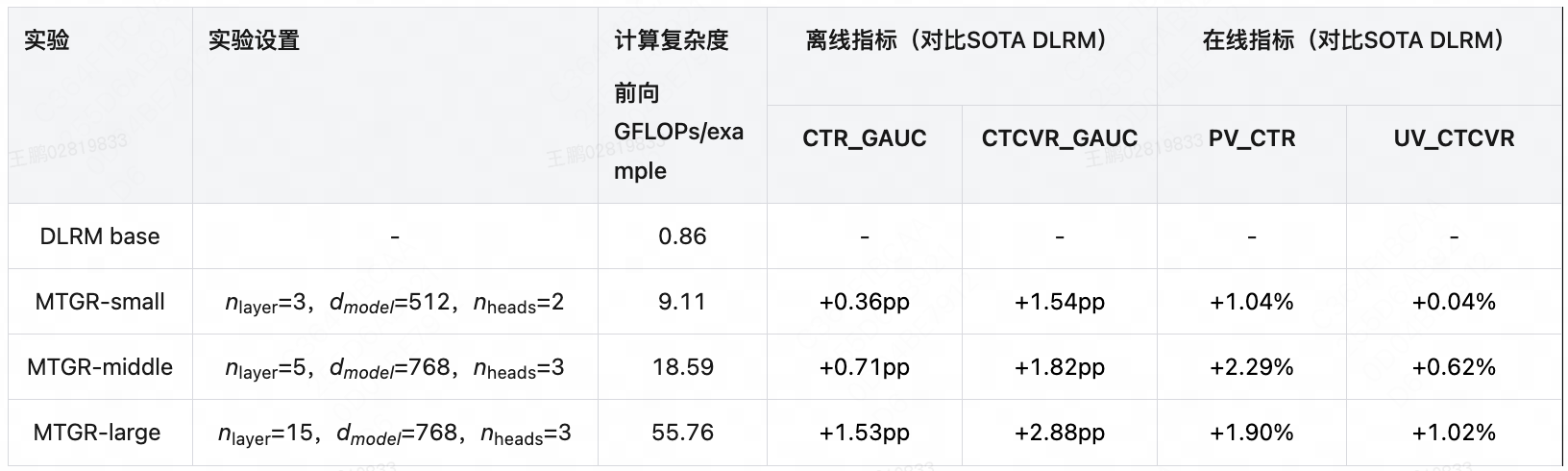
- 实际上效果有点微弱,虽然随着模型增大,效果一直在涨,但涨幅非常有限