LUM: large user model
整体思路
- LLM :自回归大型语言模型(LLMs)的成功主要归功于其可扩展性,通常被称为“扩展规律”(Scaling Law)
- LLM for RS :目前大量工作的思路是将推荐系统(RecSys)任务重新表述为生成问题来适应 LLMs
- 这种端到端生成推荐(End-to-End Generative Recommendation,E2E-GR)方法往往优先考虑理想化目标(idealized goals)
- 牺牲了传统基于深度学习的推荐模型(DLRMs)在特征、架构和实践方面提供的实际优势
- 这种理想化目标与实际需求之间的差距引入了一些挑战和限制,阻碍了工业推荐系统中扩展规律的应用
- 论文方案 :论文提出了一种大型用户模型(large user model,LUM),通过一个三步范式(three-step paradigm)解决这些限制
- 做到满足工业环境的严格要求
- 合理复用历史 DLRMs 的特征工程
- 释放 Scaling Law 在推荐系统上的潜力
- 离线+在线实验
- 离线:实验表名,LUM 在性能上优于 SOTA 的 DLRMs 和 E2E-GR 方法,此外,LUM 展现出卓越的可扩展性,当模型参数扩展到70亿时,性能持续提升
关于 LUM 提出的背景和一些讨论
- LLMs 显示出 Scaling Law,推荐系统(RecSys)领域也在积极探索利用类似 Scaling Law 的潜力
- 早期研究指出,工业中广泛使用的传统基于深度学习的推荐模型(DLRMs)并未展现出与LLMs相同水平的可扩展性(Liu 等, 2020)。这种差异可以归因于生成模型与判别模型之间的根本区别
- 生成模型需要更大的容量来有效捕捉数据的复杂联合概率分布 \(p(x,y)\)
- 判别模型(如传统的 DLRMs)则专注于建模更简单的条件概率 \(p(y|x)\)
- 因此,增加计算资源对判别模型的性能提升效果较弱(Chen 等, 2018; Li 等, 2020; Chen 等, 2021)
- 一些研究尝试 将推荐系统中召回和排序任务重新表述为生成任务 ,以模仿生成模型,具体来说,这是通过将用户行为序列(User Behavior Sequences,UBS)作为语料库,并以端到端的方式在“next-item prediction”任务上训练 Transformer 架构来实现的(Chen 等, 2018; Li 等, 2020)
- 端到端生成推荐方法(E2E-GRs)往往过度强调理想化目标,从而忽视了 DLRMs 在特征、架构和实践中的固有优势。这种建模范式中理想化目标与实际实现之间的差距,随后引发了一系列挑战和限制
- (1) 生成训练与判别应用之间的不一致性:尽管 E2E-GRs 擅长捕捉数据中的复杂模式和分布,但在应用于特定判别任务(如点击率预测,其中校准能力和排序能力至关重要)时,往往表现出局限性(Wang 等, 2020)
- 这种差异源于生成模型对数据生成过程的固有关注,而非精确的预测结果
- 尽管生成模型擅长捕捉数据的固有分布,但它们可能无法始终满足判别应用的严格要求,这些应用需要高水平的准确性和特异性(Li 等, 2020; Chen 等, 2021; Chen 等, 2021)
- (2) 效率挑战:在工业环境中,连续流式训练对高效率的需求,以及在线实时推理对低延迟的严格要求,为 E2E-GRs 的直接实施带来了重大挑战
- 即使部署可行,这些效率限制仍会阻碍这些端到端模型的可扩展性(后文第5.4节会继续讨论)
- (3) 缺乏灵活性: E2E-GRs 在适应业务需求的动态变化方面表现出明显的局限性,具体而言,整合新型行为数据(如退款行为或与新场景相关的行为)是一 item重大挑战
- E2E-GRs 的固有结构要求,对输入模式的任何修改(包括新增元素)都会触发对整个模型重新训练的需求。这种刚性不仅增加了新特征整合的复杂性,还对系统的适应性施加了重大限制
- 在工业环境中,快速灵活地响应变化条件通常至关重要,而从头开始重新训练模型既耗时又耗费资源,从而降低了 E2E-GRs 的实用性
- (4) 有限的兼容性: E2E-GRs 使用原始 UBS 和 Transformer 架构构建。这种方法固有地限制了它们与现有工业知识(如显式特征工程和 DLRMs 的参数继承)的兼容性
- 这些 E2E-GRs 在开发阶段与工业环境中的实际部署之间往往存在显著的性能差距(第5.3节)。这种差距在在线模型经过多年甚至数十年优化的应用中尤为明显。这一差异凸显了需要更强大的整合策略,以弥合理论进展与实际应用之间的差距
- (1) 生成训练与判别应用之间的不一致性:尽管 E2E-GRs 擅长捕捉数据中的复杂模式和分布,但在应用于特定判别任务(如点击率预测,其中校准能力和排序能力至关重要)时,往往表现出局限性(Wang 等, 2020)
- 论文重新思考了一个关键问题:如何在工业环境中有效利用生成模型来解锁 Scaling Law?
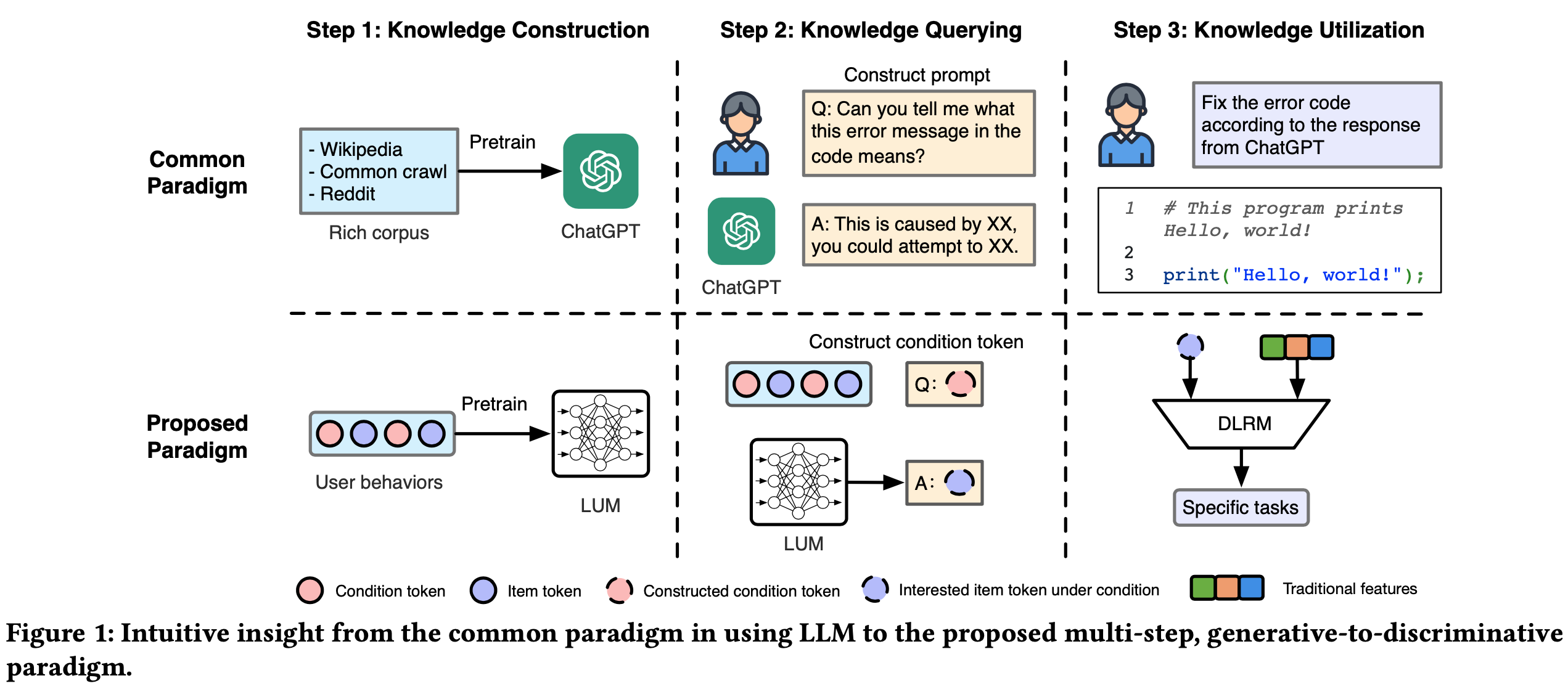
- 这一问题促使论文重新审视使用 LLMs 的常见范式(图1),具体而言,传统 LLM 的范式是:
- LLMs 首先在大量数据上以生成方式进行训练,使其能够吸收广泛的知识
- 终端用户(End-users)随后通过多样化的 prompts 与这些模型交互,提出问题(可以同时做多个领域的知识问答)
- 终端用户使用 LLM 的返回做决策(注:原文中称该决策为informed decision,可以直接翻译为有见识/学问的决策)
- LLMs的这种 multi-step, generative-to-discriminative 特性为在实际应用中利用生成模型提供了基础框架
- 基于这一见解,论文提出了一种用于工业用途的大型用户模型(LUM)的三步训练范式。这些步骤如下(见图1):
- Step 1:知识构建 引入 LUM,通过生成学习进行预训练(基于 Transformer 架构)。该模型捕捉用户兴趣和物品之间的协作关系,从而构建一个全面的知识库
- Step 2:知识查询 在此阶段,LUM 通过预定义的与用户特定信息相关的问题进行查询,提取 relevant insights
- 直观上,这一过程可以基本概念化为一种“prompt engineering”,专门设计用于引出广泛的知识
- Step 3:知识利用 LUM 在 Step 2 中获得的输出作为补充特征 ,被整合到传统的 DLRMs 中,以增强其预测准确性和决策能力
- 这一问题促使论文重新审视使用 LLMs 的常见范式(图1),具体而言,传统 LLM 的范式是:
- 总体而言,我们可以从三步范式中获益:
- (1) 在 Step 1 中,LUM 的生成学习能够探索扩展规律,这对提升模型性能至关重要
- (2) 论文范式的解耦设计消除了连续流式训练或服务的限制(进使用 prompt engineering 提取知识了)
- 这种分离便于为 LUM 实施缓存策略,从而缓解效率限制
- (3) Step 3 确保 DLRMs 能够满足实时学习、灵活性和兼容性的要求
- 这是通过将先前学习的 LUM 与 DLRMs 整合来实现的,从而增强了它们对动态环境的适应性,并确保与现有系统的无缝集成
- 另一个挑战是如何有效地将 Step 1 中学习到的数据联合分布 \(p(x,y)\) 迁移到下游判别任务中
- 理想情况下,LUM 中封装的用户知识应与目标判别任务具有显著相关性
- 为了实现这一点,论文为 UBS 引入了一种新颖的 token 化策略,其中每个物品被扩展为两个不同的 token :** condition token 和物品 token **(图2和第4.1.1节)
- 随后,论文将 UBS 的自回归学习过程从“next-item prediction”重新定义为“next-condition-item prediction”。通过这一重新表述,我们可以在 Step 2 过程中通过指定各种条件,将相关知识从 LUM 无缝 trigger 到判别任务中
- 最终结果说明:
- 离线+在线实验
- LUM 展现出与 LLMs 相似的 Scaling Law(PS:能够成功扩展到70亿参数,同时保持一致的性能提升)
相关工作(直译)
基于深度学习的推荐模型
- 传统的 DLRMs 通常采用深度神经网络,可以大致分为两大类:
- (1) Retrieval-Oriented Models :这些模型主要专注于为用户召回最相关的物品。它们通常采用双塔架构,如EDB(Bernard 等, 2018),或序列模型,如SASRec(Krizhevsky 等, 2013)、BERT4Rec(Zhang 等, 2019)和GRU4Rec(B),以有效捕捉用户与物品之间的相关性
- (2) CTR(Click-Through Rate)预估模型 :这类模型旨在预测点击率。许多模型采用嵌入+多层感知机(MLP)架构。一些工作(如DeepFM(Chen 等, 2019)和xDeepFM(Wang 等, 2019a))旨在构建更复杂的交互信号,而其他工作(包括DIN(Yang 等, 2019)、DIEN(Xu 等, 2019)、SIM(Song 等, 2020a)和 TWIN(Choi 等, 2019))则探索了 UBS 的重要性。尽管这些方法在推荐系统中取得了显著改进,但它们通常无法随着计算资源的增加而扩展,并且未能充分利用大型基础模型的进展
生成推荐模型
- 为了研究扩展规律,一些研究尝试类 LLM 架构,并通过端到端方式在 next-item prediction 任务上构建自回归 Transformer(Cheng 等, 2019; Wang 等, 2020b)
- 然而,如前文所述,这些方法往往做出强烈且理想化的假设(strong and idealized),忽视了传统 DLRMs 在特征、架构和实践中的优势。这导致这些模型在应用于工业环境时出现一系列问题和限制
- 论文提出了一种基于 LUM 的三步范式来解决这些限制。值得注意的是,也有工作尝试通过端到端(E2E)或多步训练利用 LLMs 中的开放世界知识构建基于内容的推荐模型(Chen 等, 2019; Chen 等, 2021b; Zhang 等, 2019; Xue 等, 2019)。然而,这些研究超出了论文当前研究的范围。论文的重点是开发一种可扩展的模型,捕捉协同过滤信号而非内容信号
- 吐槽一下:这篇论文的引用咋都是22年以前的?
推荐系统基础只是
传统深度推荐模型(DLRMs)
- 在推荐系统(RecSys)中,主要任务分为两类:召回和排序。论文以搜索场景为例进行讨论,但所提出的方法同样适用于其他工业应用场景
- 问题定义:给定用户 \(u \in \mathcal{U}\) 、物品 \(i \in \mathcal{I}\) 和搜索词 \(s \in \mathcal{S}\)
- 召回任务 :该任务的目标是从候选池中筛选出与用户 \(u\) 在查询 \(s\) 下的偏好相匹配的物品子集
- 传统召回任务通常采用双塔架构,包括 user-query 塔 \(UEnc\) 和物品塔 \(IEnc\)(这些塔可以由任何合适的神经网络结构(如多层感知机MLP)组成)
- user-query 塔将用户 \(u\) 和搜索词 \(s\) 编码为统一嵌入向量 \(\boldsymbol{e}_{us}^{\prime} = UEnc(us)\)
- 物品塔则为物品 \(i\) 生成嵌入向量 \(\boldsymbol{e}_{i}^{\prime} = IEnc(i)\)
- 最后,通过对比学习技术优化这两个塔的表示
- 排序任务 :排序任务的目标是预测用户 \(u\) 在特定查询 \(s\) 下点击物品 \(i\) 的概率
- 其数学形式为:
$$\hat{y} = f(u,i,s)$$- \(\hat{y}\) 表示预测的 CTR
- \(f\) 为 Embedding+MLP 架构
- 其数学形式为:
- 召回任务 :该任务的目标是从候选池中筛选出与用户 \(u\) 在查询 \(s\) 下的偏好相匹配的物品子集
基于“next-item prediction”的端到端生成推荐(E2E-GRs)
- 在 E2E-GRs 中,给定用户 \(u\) 的用户行为序列(UBS) \(B_u = \{i_1, i_2, …, i_L\}\)(其中 \(L\) 为序列长度),“next-item prediction”框架假设物品 \(i_k\) 出现的概率依赖于其之前的物品 \(\{i_1, i_2, …, i_{k-1}\}\)。因此,整个 UBS 的似然可以表示为:
$$ p(i_1, i_2, …, i_L) = \prod_{j=1}^{L} p(i_j | i_1, i_2, …, i_{j-1}) $$- E2E-GRs 的自回归学习目标是优化分布 \(p_{\theta}(i_1, i_2, …, i_L)\),这一方法通常被称为“next-item prediction”
LUM 方法整体介绍
Step 1:通过预训练 LUM 构建知识
Tokenization
- 论文将 UBS 的自回归建模从 “next-item prediction” 转变为 “next-condition-item prediction” 范式
- 序列 \(B_u\) 中的任意 item \(i\) 被分解为两个不同的 token:condition token 和 item token
- UBS 可以表示为交替 token 的序列:\(\{c_1, i_1, c_2, i_2, …, c_L, i_L\}\),其中 \(c_k\) 表示与 item \(i_k\) 相关联的 condition token(如图2所示)
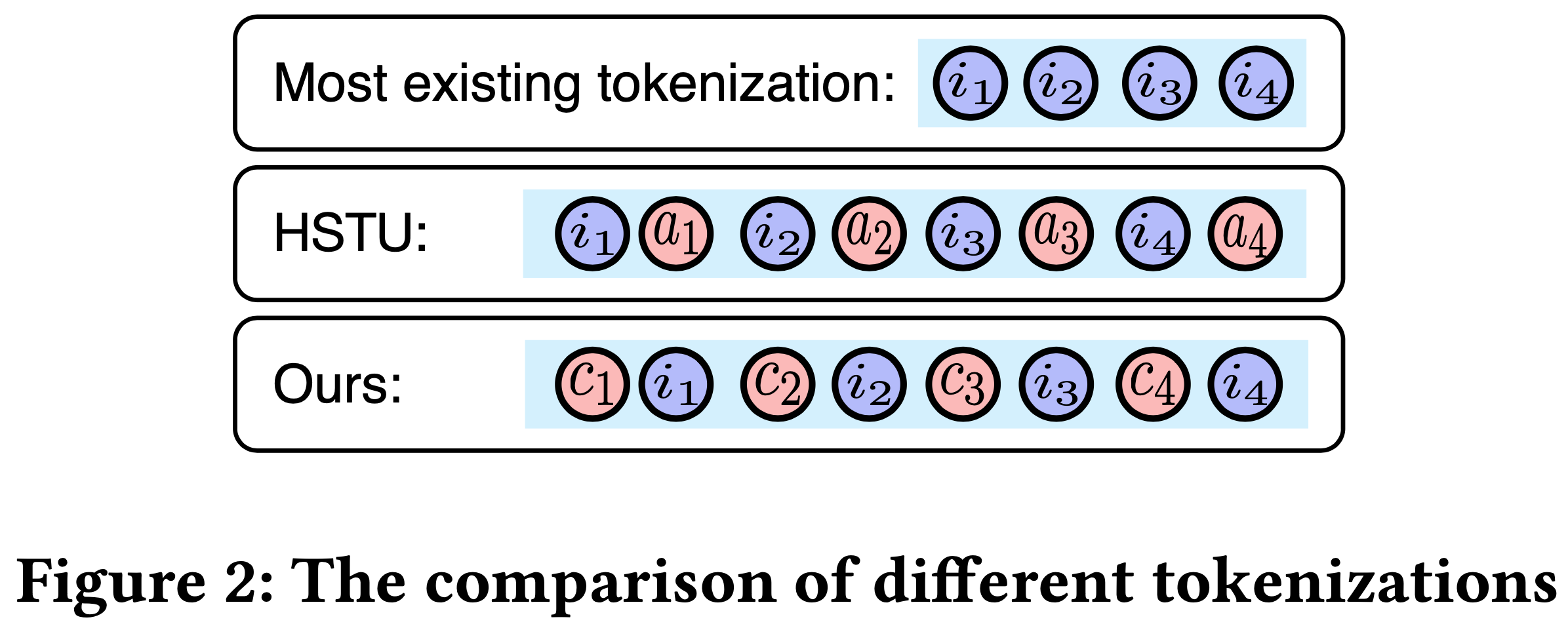
- 举例 :用户的行为可能涉及多个场景(如推荐和搜索场景)中的 item 交互。此时,condition token \(c_i\) 可以定义为场景 token,从而捕捉 item \(i\) 所处的特定环境。这种方法有助于细致理解用户在不同场景中的偏好和行为
- 论文方法与 HSTU 等方法引入了额外的动作 token 的形式不同
- HSTU 中,任意 item被扩展为 <item, action>,其中动作 \(a_k\) 与前面的(preceding) item \(i_k\) 相关联,而非后面的(subsequent) item(如图2所示)
- HSTU 的策略无法基于不同条件预测 next item,也难以捕捉用户在不同方面的偏好
LUM 整体架构
- LUM 的整体框架如图3(a)所示,采用分层结构,包含一个 Token Encoder 和一个 User Encoder
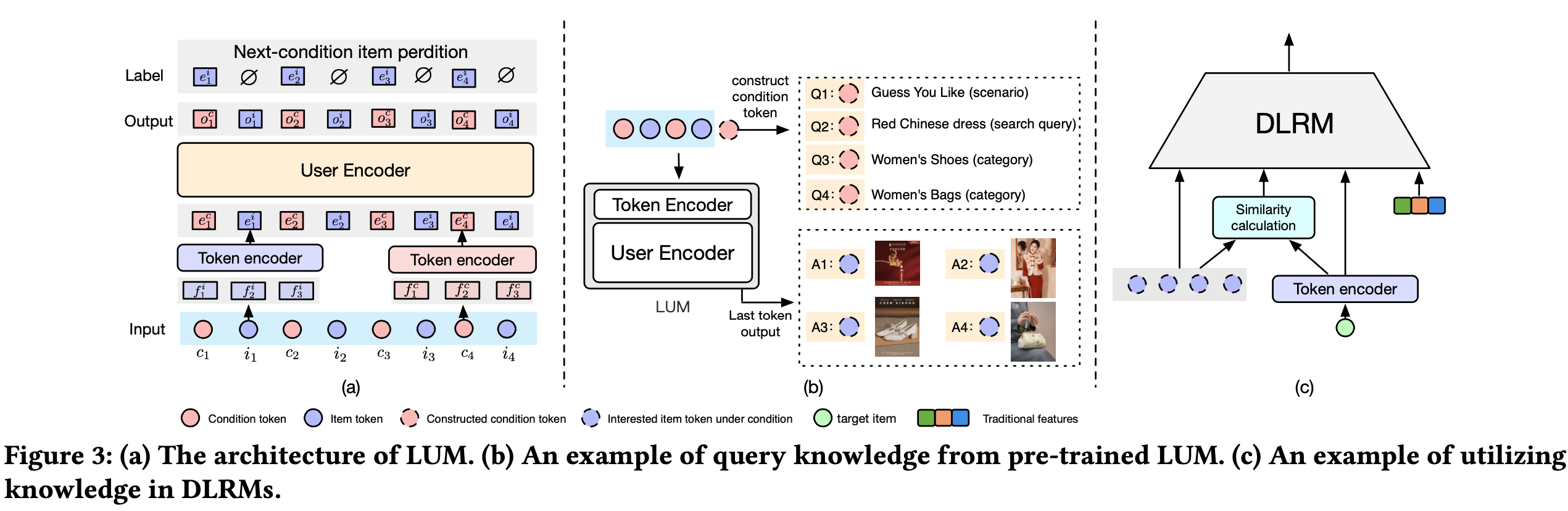
- Token Encoder :LUM 的输入 token 具有异质性,主要分为两类:condition token \(c\) 和 item token \(i\)
- 单个 token 可能携带多种属性特征(例如 item token 的ID、统计和内容特征)
- Token Encoder 旨在将这些异质输入统一为 token 嵌入
- 具体过程是先将每个 token 的特征或嵌入拼接,再通过投影层将其整合到共同的表示空间中。数学上,这一转换可表示为:
$$
e^t = \text{proj}(\text{concat}(f_1^t; f_2^t; f_3^t; …)), \quad t \in \{i, c\}
$$- \(f_k^t\) 表示 item token \(i\) 或 condition token \(c\) 的特征,其中\(t \in \{i, c\}\)
- 注意:一个 token 只能是 item token \(i\) 或 condition token \(c\) 中的一种,不能同时属于两种 token
- \(e^t\) 为生成的 token 嵌入
- \(\text{proj}\) 表示线性投影层
- \(f_k^t\) 表示 item token \(i\) 或 condition token \(c\) 的特征,其中\(t \in \{i, c\}\)
- User Encoder :User Encoder 用于捕捉用户偏好和 item间的协同信息
- 输入 token 序列 \(\{c_1, i_1, c_2, i_2, …, c_L, i_L\}\) 通过 Token Encoder 表示为 \(\{e_1^c, e_1^i, e_2^c, e_2^i, …, e_L^c, e_L^i\}\)
- 如图3(a)所示,User Encoder 使用传统的自回归 Transformer 架构处理这些嵌入,最终输出为 \(o_k^c\),封装了输入序列的整合信息
Next-condition-item Prediction
- “next-condition-item prediction”关注在给定特定条件下预测 next item
- 注:这种方法仅对 condition token 的输出应用自回归损失以推断 next item。因此,next-condition-item prediction 的自回归似然可表示为:
$$
p(c_1, i_1, c_2, i_2, …, c_L, i_L) = \prod_{l=1}^L p(i_l | c_1, i_1, c_2, i_2, …, i_{l-1}, c_l)
$$
- 注:这种方法仅对 condition token 的输出应用自回归损失以推断 next item。因此,next-condition-item prediction 的自回归似然可表示为:
- 为优化工业应用中的 \(p_\theta(c_1, i_1, c_2, i_2, …, c_L, i_L)\),本研究采用了 InfoNCE 损失函数并引入了 packing 策略
- InfoNCE 损失 :在工业应用中,item的词表可能达到数十亿,直接计算所有 item的生成概率是不现实的。为解决这一问题,本研究使用InfoNCE损失预测next-condition item。其数学表达式为:
$$
\text{Loss} = -\sum_{l=1}^L \log \left( \frac{\exp(\text{sim}(o_{l-1}^c, e_l^i))}{\exp(\text{sim}(o_{l-1}^c, e_l^i)) + \sum_{k=1}^K \exp(\text{sim}(o_{l-1}^c, e_k^i))} \right)
$$- \(\text{sim}\) 为相似度函数
- \(o_{l-1}^c\) 是自回归序列中 token \(e_{t-1}^c\) 对应的 Transformer 输出
- 对于任意 item \(i\),同一批次中的其他 item作为负样本,\(K\) 为负样本数量,\(e_k^i\) 为第 \(k\) 个负 item 的嵌入
- 注意:应用 InfoNCE 损失以后,不需要面对过大的词汇表了,仅关注 \(K\) 个负样本就行
- packing 策略 :在实际应用中,用户行为序列的长度差异显著,大多数序列长度远小于预设的最大长度。若单独处理每个序列,计算效率较低。受GPT系列打包策略的启发,本研究将多个 UBS 合并为单一序列,以充分利用序列长度
Step 2:基于给定条件查询知识
- 在 Step 1 中,论文构建了联合概率分布 \(p(c_1, i_1, c_2, i_2, …, c_L, i_L)\),Step 2 是从这一分布中提取相关知识
- 原文4.1.1节的分词方法支持在不同条件下查询知识,给定查询条件 \(c_q\),可以计算条件概率 \(p(i_q | c_1, i_1, c_2, i_2, …, c_L, i_L, c_q)\),以确定用户对 item \(i_q\) 的兴趣(如图3(b)所示)
- 这种触发条件知识的方法在生成模型与判别任务之间架起了桥梁,从而提升了工业应用的效果。以下是不同 condition token 的应用示例:
- 示例1 :若 condition token 为场景(scenario) token,模型可推断用户在不同场景中的兴趣
- 示例2 :若 condition token 为搜索场景中的 query token,模型可基于不同搜索查询推断用户兴趣
- 示例3 :若 condition token 为类别(category) token,模型可判断用户在不同类别中的兴趣
- LUM 允许在 \(\{f_1^c; f_2^c; f_3^c; …\}\) 加入额外条件特征来同时考虑多种条件
- 即加入 Token Encoder 的输入中,从而编码上指定条件信息
- 实验表明,整合多样条件能显著提升性能(见原文5.3节)
- 本质上,这一过程可视为一种“prompt engineering”,旨在激发广泛的知识
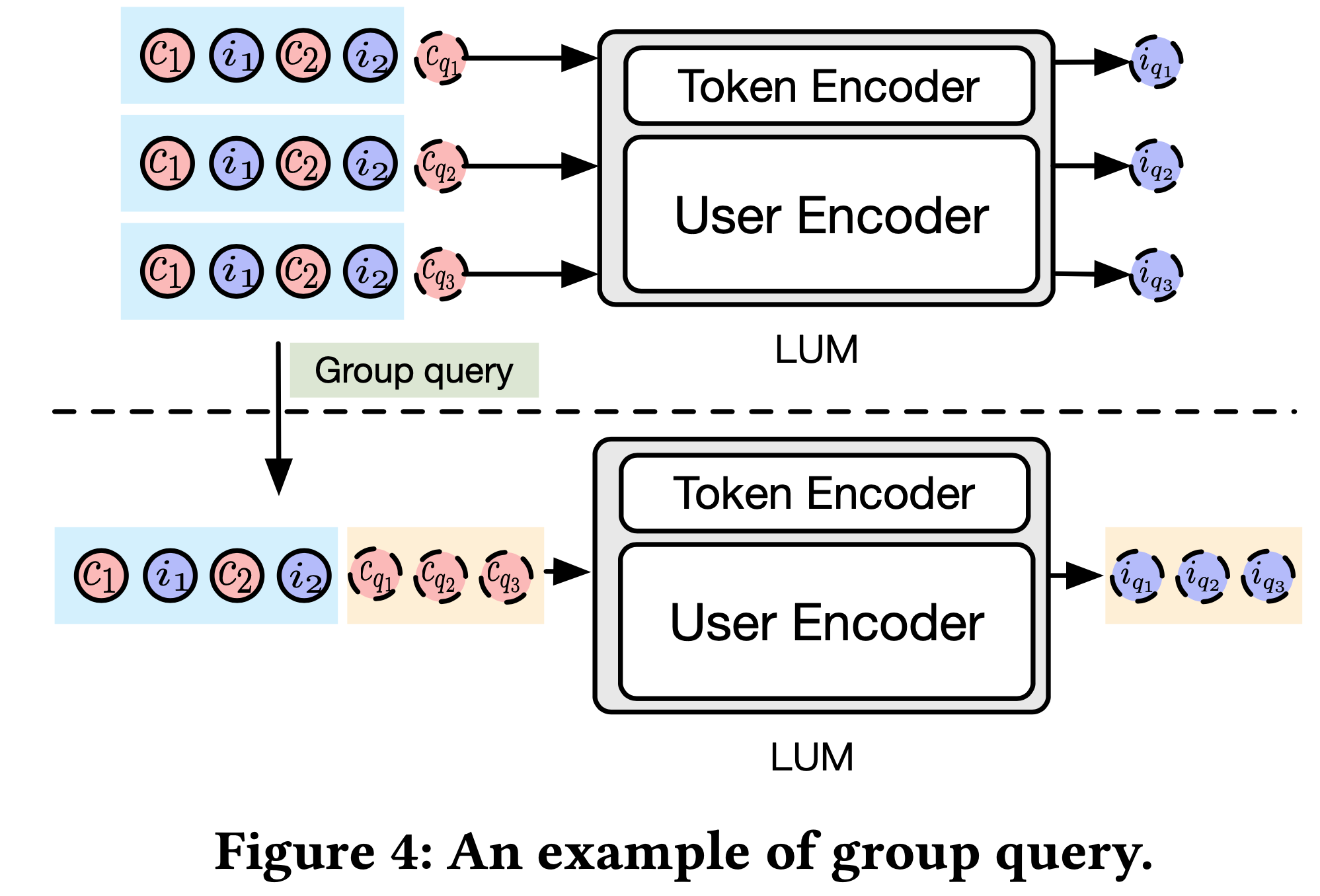
- 分组查询以提升效率 : 由于单个用户可能涉及多个查询(均基于同一 UBS),单独处理这些查询会导致效率低下
- 在实际场景中,用户数量可能达到数十亿, <user, query> 对的数量会急剧增加
- 为解决这一问题,本研究引入了分组查询策略以提升计算效率
- 如图4所示,所有查询被拼接为单一序列,表示为 \(p(i_{q_1}, i_{q_2}, … | c_1, i_1, c_2, i_2, …, c_L, i_L, c_{q_1}, c_{q_2}, …)\)
- 为确保推理过程准确且高效,采用掩码机制防止不同查询条件 \(c_{q_j}\) 间的注意力交互。这种方法使得不同查询的公共前缀 \(\{c_1, i_1, c_2, i_2, …, c_L, i_L\}\) 仅需计算一次,同时支持在不同条件下查询 item \(i_{q_j}\)
- 实验表明,分组查询策略可将推理速度提升78%(见5.3节)
Step 3:DLRM中的利用知识
- 在 Step 2 完成后,论文获得了一组 \(N\) 个 next-condition item \(\{i_{q_1}, i_{q_2}, …, i_{q_N}\}\),其对应输出为 \(o_{q_n}^i\)
- 注:每个 item \(i \in I\) 通过 Token Encoder(4.1.2节)生成嵌入 \(e_i^i\),在经过 User Encoder 最终生成 \(o_{i}^i\)
- 问题: \(o_{i}^i\) 是没有损失函数的,为什么可以直接使用?是不是应该使用 \(o_{i}^c\) 才合理?
- 为增强现有DLRM,本研究提出两种策略(如图3(c)所示):
- 直接特征融合 :将输出 \(o_{q_n}^i\) 和目标 item \(i\) 的嵌入 \(e_i^i\) 作为固定附加特征整合到 DLRM 中
- 通过相似度匹配兴趣 :计算目标 item \(i\) 与用户兴趣的相似度 \(\text{sim}(o_{q_n}^i, e_i^i)\)(如公式2所示),以量化目标 item 与上下文的匹配程度
- 形式上,对于召回任务,双塔模型可重构为:
$$
e_{us}^r = \text{UEnc}(us, \{o_{q_1}^i, o_{q_2}^i, …, o_{q_N}^i\}), \quad e_i^r = \text{IEnc}(i, e_i^i)
$$ - 对于排序任务,排序模型可表示为:
$$
\hat{y} = f(u, i, s, \{o_{q_n}^i, \text{sim}(o_{q_n}^i, e_i^i) | n=1, …, N\}, e_i^i)
$$ - 这一框架有效整合了上下文信息和 item嵌入,提升了推荐系统中召回和排序的性能
讨论
- 基于 LUM 的三步范式解决了原文第1节提到的四个限制:
- 解决限制1(生成训练与判别应用之间的不一致性) :通过生成到判别的设计,Step 1 构建联合分布 \(p(c_1, i_1, c_2, i_2, …, c_L, i_L)\),Step 2 通过“next-condition-item prediction”触发相关知识,Step 3 进行判别学习以满足应用需求
- 解决限制2(效率挑战) : Step 3 的模型训练和服务天然支持工业应用的高效需求,且 Step 1 和 Step 2 的计算成本较低,因其结果可预计算和存储
- 解决限制3(缺乏灵活性) :业务需求的动态变化可通过 Step 3 灵活处理,同时这些需求可统一为 condition token,支持 LUM 的持续训练以适应新需求
- 解决限制4(有限的兼容性) : Step 3 的DLRM主干可设置为在线模型,便于利用现有工业知识,并持续受益于DLRM技术的进步
Experiments
Experiment Setup
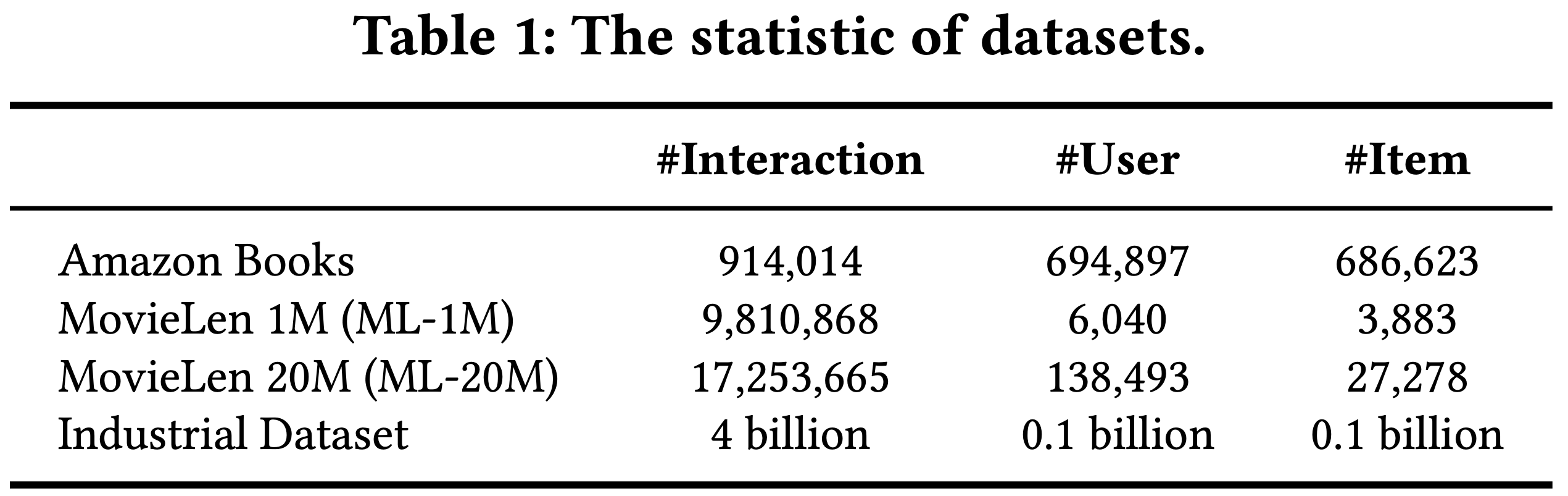
数据集 :本研究使用了三个公共数据集和一个工业数据集来评估所提出的 LUM 方法的性能。公共数据集包括两个基准数据集:MovieLens(包含1M和20M两个子集)和 Amazon Books[23, 25]。工业数据集来自淘宝电商平台。这些数据集的统计信息如表1所示
基线模型 :为了全面评估 LUM 的性能,论文将其与多种 SOTA 模型进行比较
- 对于传统的召回模型,论文使用基于双塔架构的 EDB[9]
- 对于传统的排序模型,论文考虑了 DIN[26]、DIEN[25]、SIM[16]和 TWIN[3]
- 此外,论文还比较了 LUM 与端到端生成推荐方法(E2E-GRs),特别是 HSTU[23]
- 论文还纳入了传统的序列推荐模型 SASRec[10]作为基线,该模型采用 Transformer 架构建模用户行为序列(UBS)
训练细节 :为了确保公平比较,论文遵循以下训练配置
- 默认情况下,论文为 Transformer 风格的模型(包括 LUM、HSTU 和 SASRec)保持相似的配置,以确保模型规模可比,其他 DLRMs 的配置根据其原始论文的建议设置
- 所有模型均使用相同的特征集从头开始训练
- 公共数据集的序列长度设置为 256,工业数据集的序列长度设置为 4096
- 对于 LUM,在公共数据集的排序任务中,Step 3 的 DLRM 主干配置为 SIM;在召回任务中配置为 EDB(一种双塔结构)
- 工业数据集的主干设置为当前生产环境中部署的在线模型(理解:使用当前线上部署模型去推理工业数据集)
推荐任务性能
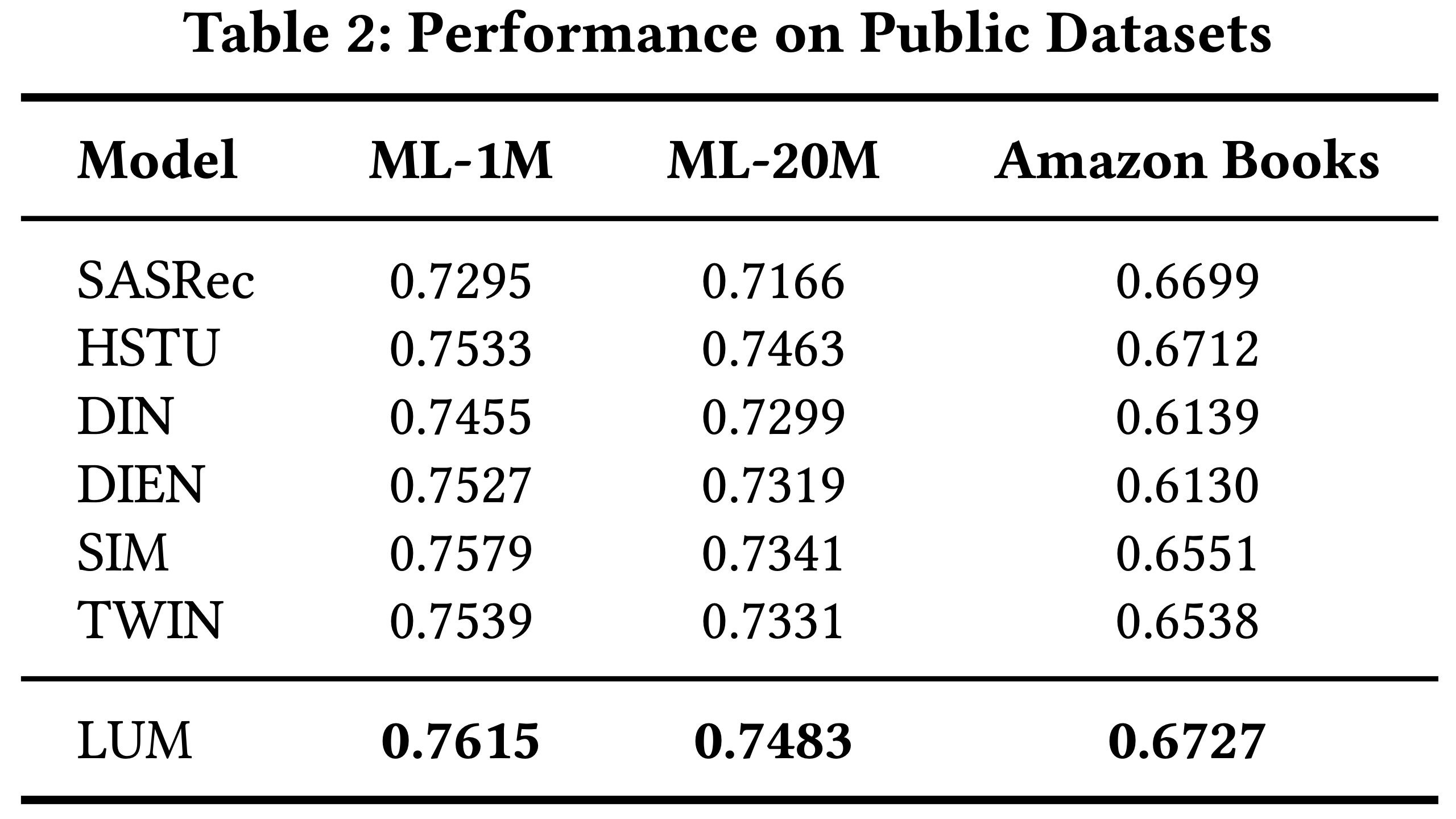
- 公共数据集上的性能 :论文首先在公共数据集上评估 LUM 的性能,性能指标为 AUC
- 结果如 表2 所示。从结果可以看出,LUM 在所有数据集上均实现了显著提升,这表明基于三步范式的 LUM 能够有效捕捉广泛的用户兴趣并提升 DLRMs 的预测准确性
- 注:Note 0.001 absolute AUC gain is regarded as significant for the ranking task
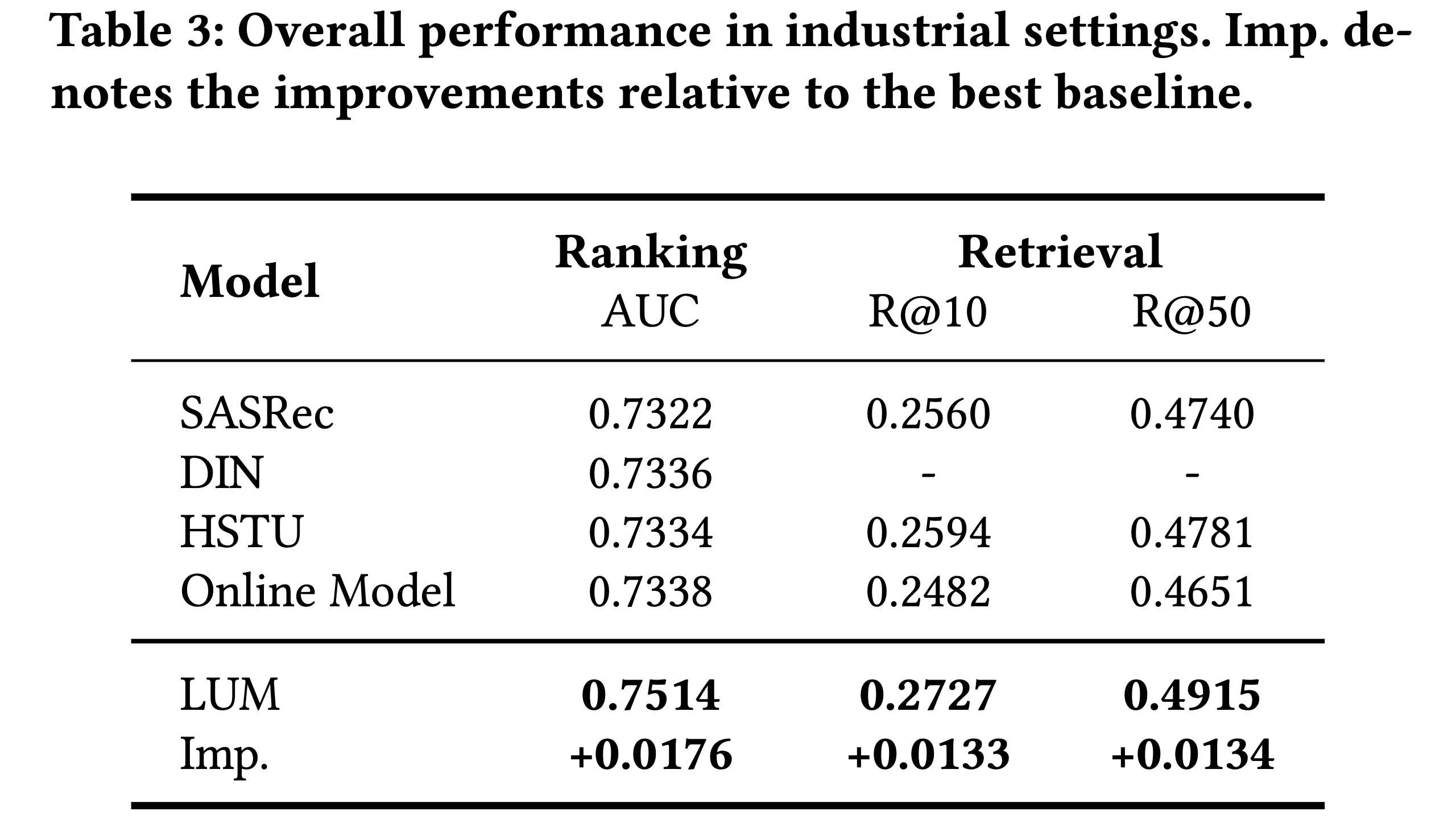
- 工业环境中的性能 :本节论文比较 LUM 与 DLRMs 和 E2E-GRs 在工业环境中的性能
- 基线使用论文应用中的在线模型,排序任务采用 Embedding+MLP 架构,召回任务采用双塔架构
- 排序任务评估指标是 AUC,召回任务评估指标是 Recall@K(R@K)
- 对于 LUM,Step 3 的DLRM主干也设置为在线模型
- 论文还纳入了传统 SOTA DLRMs(SASRec[10] 和 DIN[26])和 E2E-GR(HSTU[23])作为基线进行比较
- 所有模型使用相同的特征集,序列长度设置为4096,并从头开始训练
- 结果如表3所示。LUM 相对于最佳基线实现了显著提升,AUC 提高了 +0.0176,R@10 提高了 +0.0133,R@50 提高了 +0.0134。这些提升主要归功于论文提出的生成-判别设计范式
有效性评估
- 本节论文探讨基于三步范式的 LUM 的优势
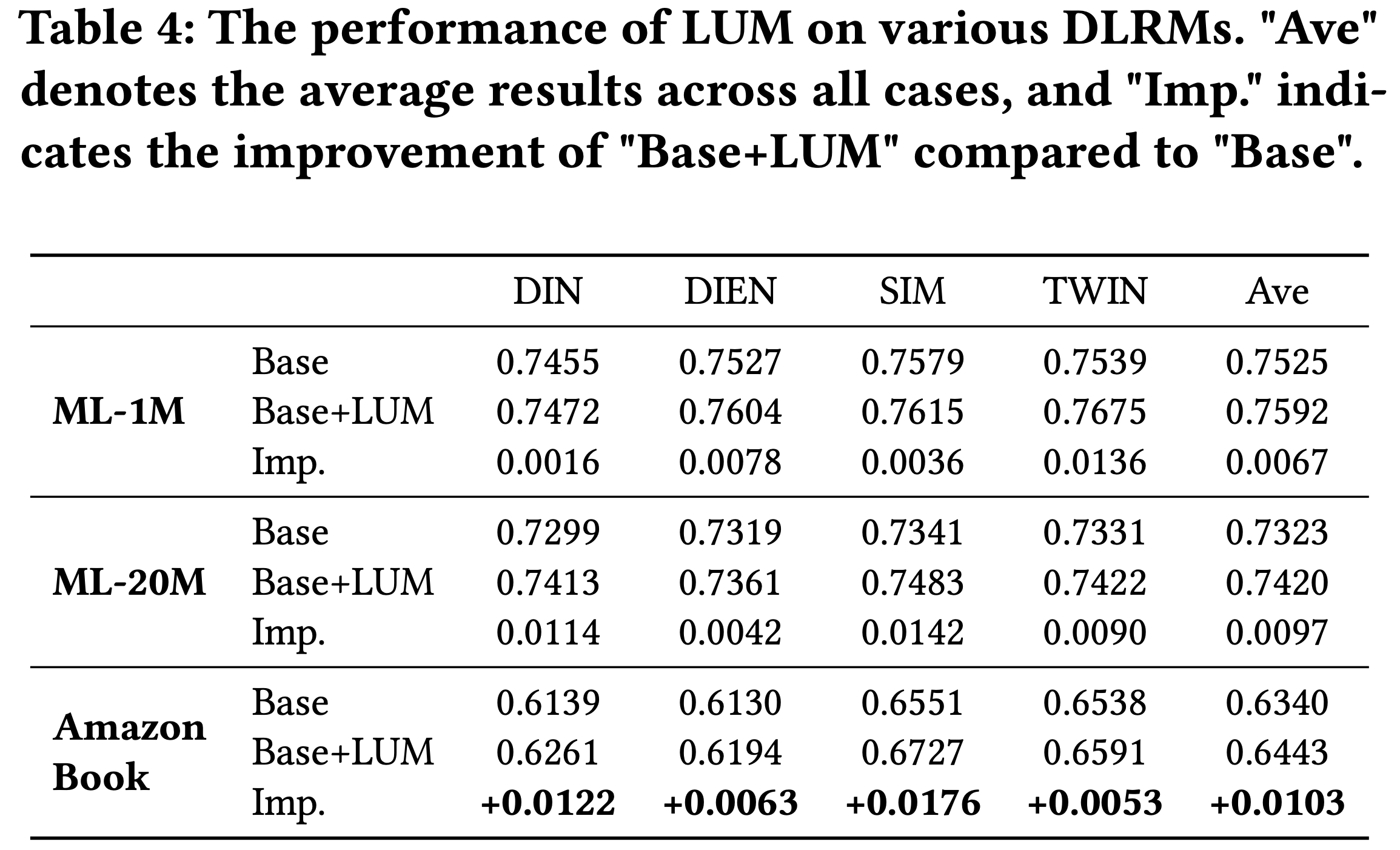
- 对多种 DLRMs 的影响 :由于论文的范式采用解耦设计,LUM 可以在 Step 3 中与任何 DLRM 集成。为了评估 LUM 的有效性,论文比较了原始 DLRMs(记为Base)和增强后的 DLRMs(记为Base+ LUM)在排序任务上的性能
- 结果如 表4 所示。结果表明,在 LUM 的辅助下,所有方法的性能均显著提升,提升幅度从 +0.0053 到 +0.0176 不等。这些发现凸显了 LUM 在提升多种 DLRMs 预测准确性方面的通用性和有效性
- 结果如 表4 所示。结果表明,在 LUM 的辅助下,所有方法的性能均显著提升,提升幅度从 +0.0053 到 +0.0176 不等。这些发现凸显了 LUM 在提升多种 DLRMs 预测准确性方面的通用性和有效性
- 工业应用中 warming up 设置的影响 :在工业应用中,在线模型通常包含复杂的特征工程,并每天在数十亿数据上持续训练
- 现有的 E2E-GRs 往往忽略这些在线模型的知识,这对其性能提出了挑战,尤其是在在线模型已开发数年甚至数十年的应用中
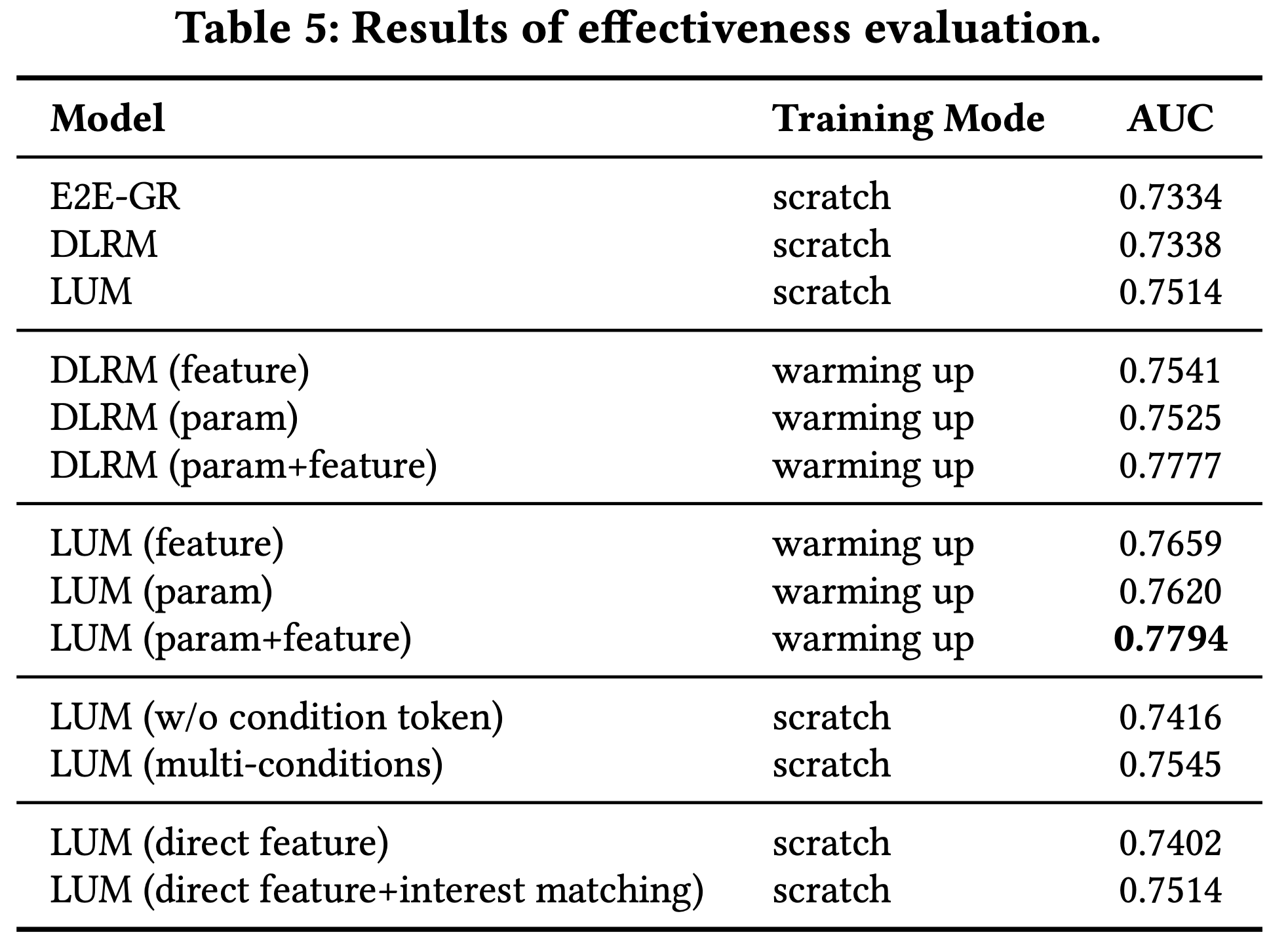
- LUM 具有出色的兼容性,可以在 warming up 设置下训练。本节论文通过实现 LUM 的多个版本,并与 E2E-GR(HSTU)和DLRM(在线模型)进行比较,探讨这种兼容性的影响。性能指标为工业数据集上的 AUC
- 结果如表5所示(“scratch”表示使用相同特征集从头训练的模型,“feature”表示使用复杂特征工程,“param”表示从持续训练的在线模型初始化参数)
- 从表5可以得出以下结论:
- (1) 与 LUM 相比,warming up 设置下的模型(包括 LUM(feature)、 LUM(param)和 LUM(feature+param))在AUC上实现了显著提升,幅度从+0.0106到+0.028。这表明利用在线模型的现有知识具有重要价值
- (2) 尽管HSTU在scratch设置下优于DLRM,但与DLRM(param+feature)相比仍存在较大性能差距(0.7334 vs. 0.7777)。这凸显了与在线模型兼容的重要性。E2E-GRs 的有限兼容性可能阻碍其在真实应用中的实际部署
- 提出的分词策略的影响 :论文评估了提出的分词策略的有效性
- 论文开发了 LUM(w/o condition token),并在 表5 中给出AUC
- 结果显示,与 LUM(w/o condition token)相比,LUM 通过给定条件更好地理解 UBS,从而实现了更好的性能
- 论文还评估了使用多条件(如场景条件和搜索词条件)的效果,记为 LUM(multi-conditions)
- 从 表5 可以看出,添加更多条件可以进一步提升性能
- 知识利用的影响 :论文评估了 Step 3 中知识利用的不同策略
- 结果如表5所示。“direct feature”和“interest matching”分别对应原文第4.3节中详细描述的知识利用策略
- LUM(direct feature)和 LUM(direct feature + interest matching)均显著优于DLRM,证明了所提策略的有效性
- 打包和分组查询的影响 :打包和分组查询旨在加速 Step 1 和 Step 2 的处理
- 表6展示了这些策略在工业环境中的效率提升,Step 1 和 Step 2 的处理速度分别提高了82%和78%
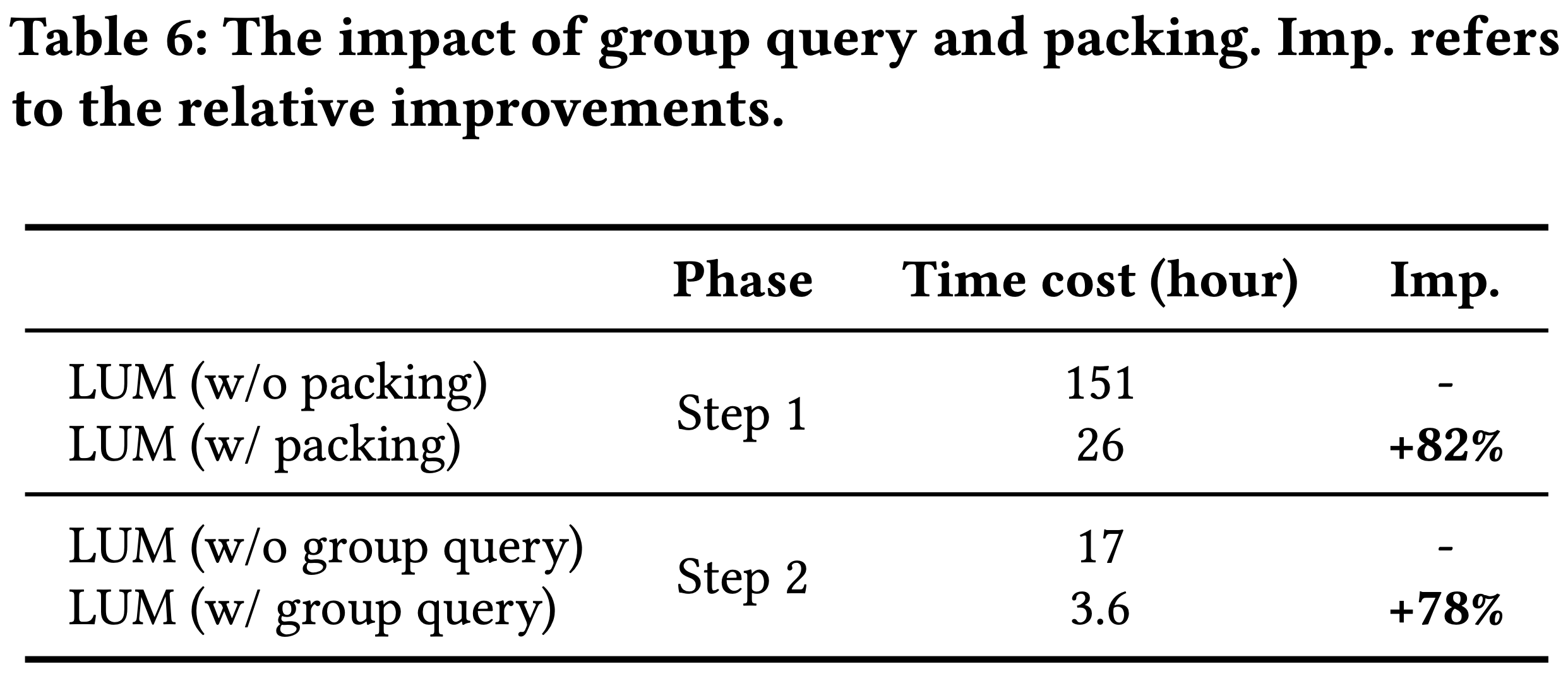
- 表6展示了这些策略在工业环境中的效率提升,Step 1 和 Step 2 的处理速度分别提高了82%和78%
效率评估
- 训练效率(Training Efficiency) :图5(a)展示了不同模型在工业环境中一天数据的训练时间成本
- 对于 E2E-GR,论文遵循HSTU[23]的优化方法,从展示级训练到用户级
- 对于DLRM,论文使用应用中的在线模型作为基线
- 对于 LUM,DLRM主干也设置为在线模型
- 由于 LUM 的 Step 1 和 Step 2 可以预处理(4.4节),因此在 Step 3 训练下游模型时不计入其时间成本
- 序列长度设置为4096,LUM 和 E2E-GR 的模型规模从0.5亿到140亿参数不等
- 所有模型在128个GPU上训练
- 最高时间成本设置为24小时,因为实际中的持续训练要求模型在此时间内处理每日数据
- LUM 的训练时间成本与DLRM相近,并且由于其解耦的三步范式,对模型规模不敏感,这一特性在工业环境中解锁了训练时的扩展潜力
- 相比之下,E2E-GR 比 LUM 慢12倍到98倍
- 所有 E2E-GR 模型(不同规模)均未满足在24小时内完成训练的要求
- 为了匹配 LUM 的吞吐量,E2E-GR 需要12倍到98倍的GPU;为了满足24小时要求,需要2倍到18倍的GPU
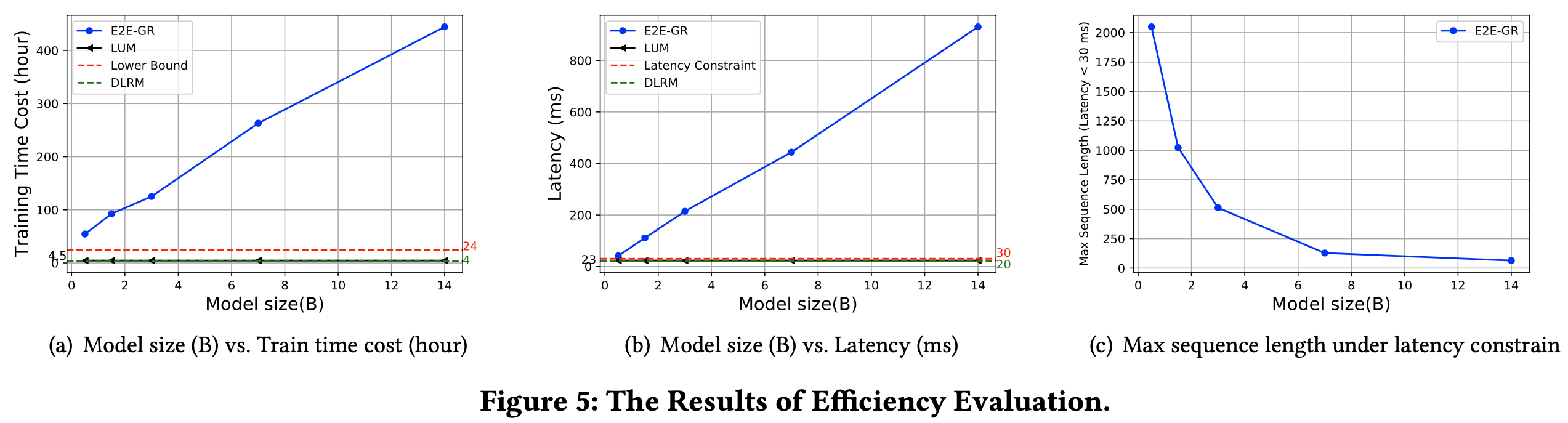
- Serving 效率(Serving Efficiency) :图5(b)和(c)展示了不同模型在线服务时的延迟
- 对于 E2E-GR,论文遵循 HSTU 的 M-FALCON 实现[23]
- DLRM 设置为在线模型,同时也是 LUM 的主干排序模型
- LUM 的 Step 3 需要评估 Serving 延迟(Step 1 和 Step 2 可以预计算(第4.4节)
- 在图5(b)中,序列长度设置为4096,LUM 和 E2E-GR 的模型规模从 0.5亿 到 140亿 参数不等
- 延迟约束设置为小于30毫秒(ms),在论文的案例中,排序候选数量约为100
- 总体而言,LUM 的延迟与模型规模无关,使得我们可以扩展 LUM 而不违反延迟约束。相反,即使对于小型模型(0.5亿参数),E2E-GR 也无法提供及时响应(小于30 ms)
- 为了进一步研究,论文尝试减少 E2E-GR 的序列长度以满足延迟约束(图5(c))。遗憾的是,在使用140亿参数模型时,满足延迟约束(<30 ms)的最大序列长度仅为64,远低于典型设置(在论文的案例中缩小了64倍)
- 这些结果表明,尽管 E2E-GR 在离线性能上可能表现出扩展性,但由于延迟约束,大规模模型在工业环境中的实际应用受到严重限制。相比之下,LUM 的解耦架构确保了延迟性能的一致性,使其成为实时工业应用中更可行和可扩展的解决方案
LUM 的扩展性
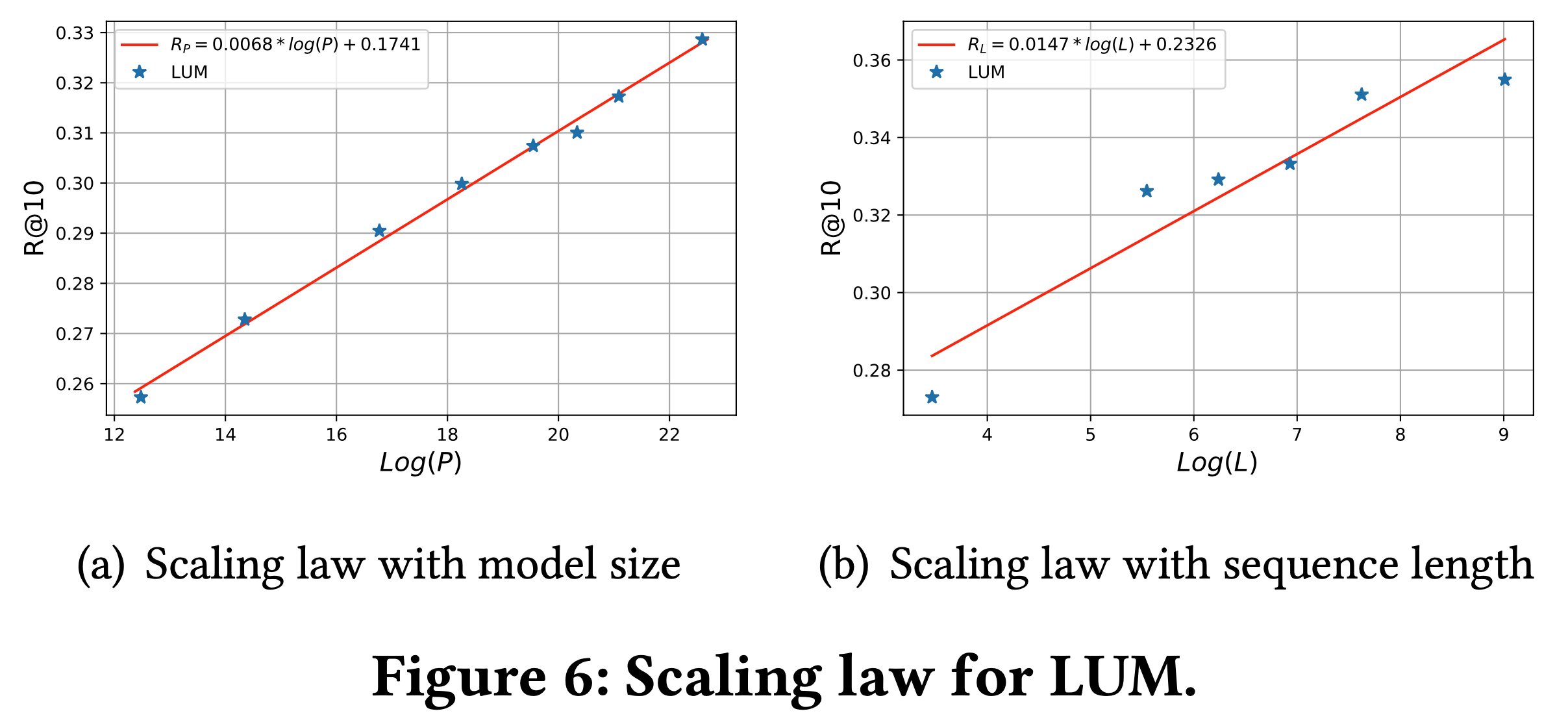
- 遵循 Improving language understanding by generative pretraining 和 Language models are unsupervised multitask learners 的协议,论文检验 LUM 是否遵循类似的 Scaling Law,论文重点评估模型参数和序列长度的扩展性
- 对于模型参数,为了评估模型参数的影响,论文保持序列长度为4096,训练模型规模从1900万到70亿参数不等
- 对于序列长度,为了评估序列长度的影响,论文在固定参数规模为3亿的情况下,训练序列长度从256到8192不等的模型
- 结果如图6所示,论文观察到明显的幂律扩展趋势,与之前的研究一致[17, 18, 23]。幂律扩展规律可以表示为:
$$
R_{P} = 0.0068 \cdot \log(P) + 0.1741 \\
R_{L} = 0.0147 \cdot \log(L) + 0.2326
$$- \(R_{P}\) 和 \(R_{L}\) 分别表示不同模型规模和序列长度下的 R@10 指标,\(P\) 表示模型规模,\(L\) 表示序列长度
- 这些结果证实了 LUM 的强大扩展性,表明增加模型规模和序列长度可以持续提升模型性能。这一发现凸显了 LUM 在扩展时实现更高性能的潜力,使其成为大规模工业应用的有前景的方法
在线结果
- 为了评估 LUM 在工业环境中的有效性,论文将其部署在中国最大的电商平台淘宝的搜索广告系统中
- 如原文第4.4节所述,评估过程包括以下关键步骤:
- (1) 离线阶段,论文首先预训练 LUM,并在各种条件下 pre-triggered 必要的知识
- (2) 存储 LUM 在 Step 2 生成的响应,以便在线服务时直接使用。这种预计算有助于满足实时工业应用中的严格延迟约束
- (3) 最后,论文进行了在线A/B实验测试 LUM 在排序任务中的表现。关键性能指标 CTR(点击率)和 RPM(每千次展示收入)分别显著提升了 2.9% 和 1.2%,这些发现凸显了 LUM 的实际效益,证明了其在大规模电商平台中提升用户参与度和业务成果的能力