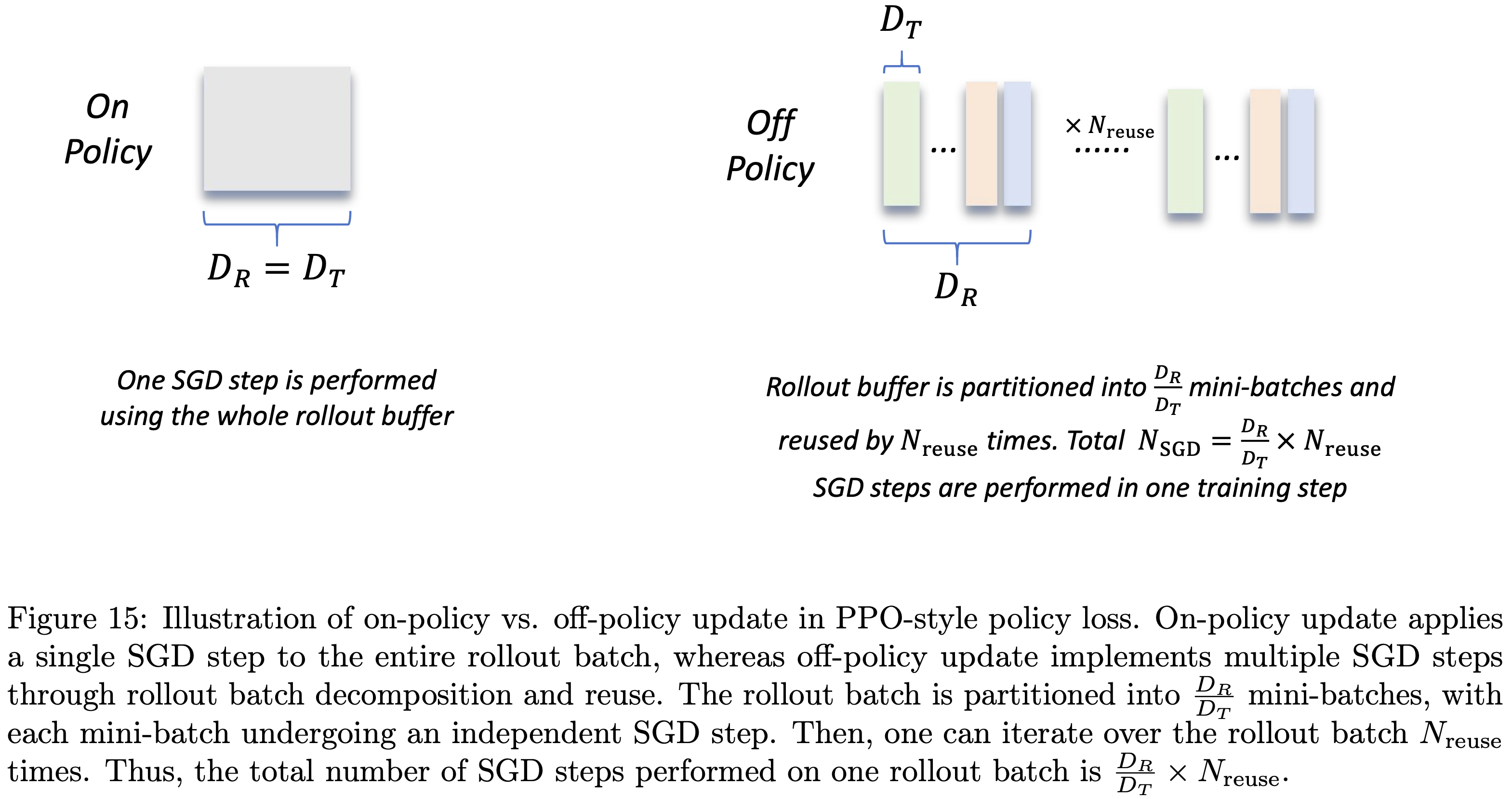
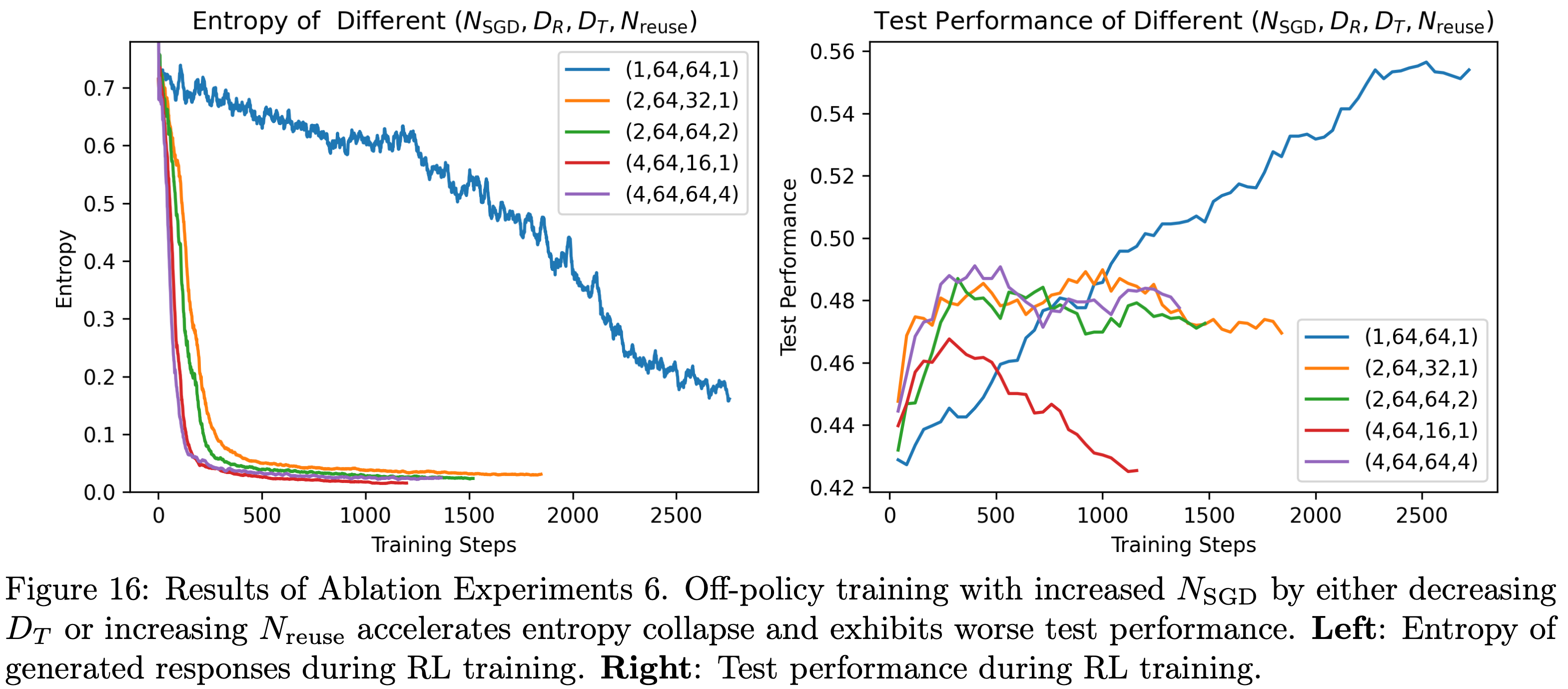
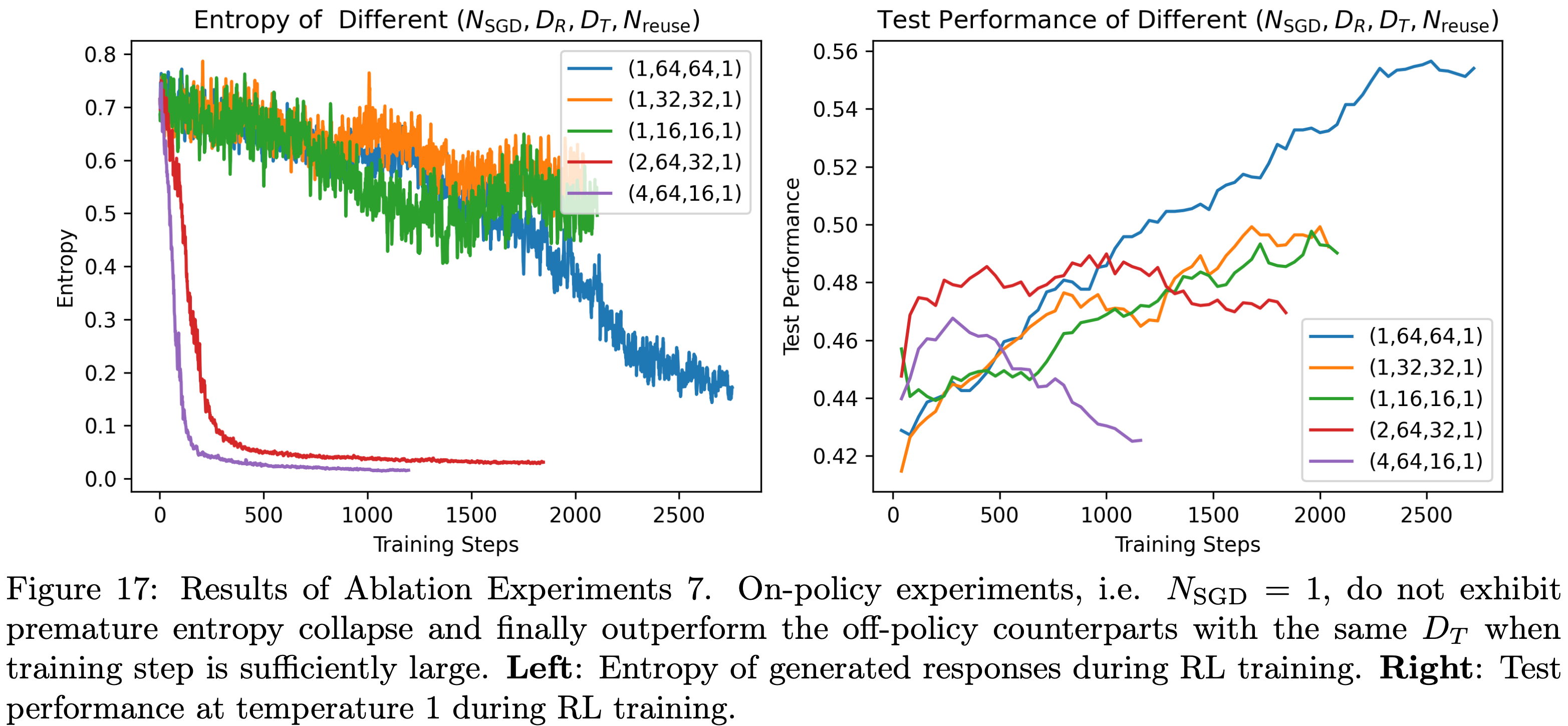
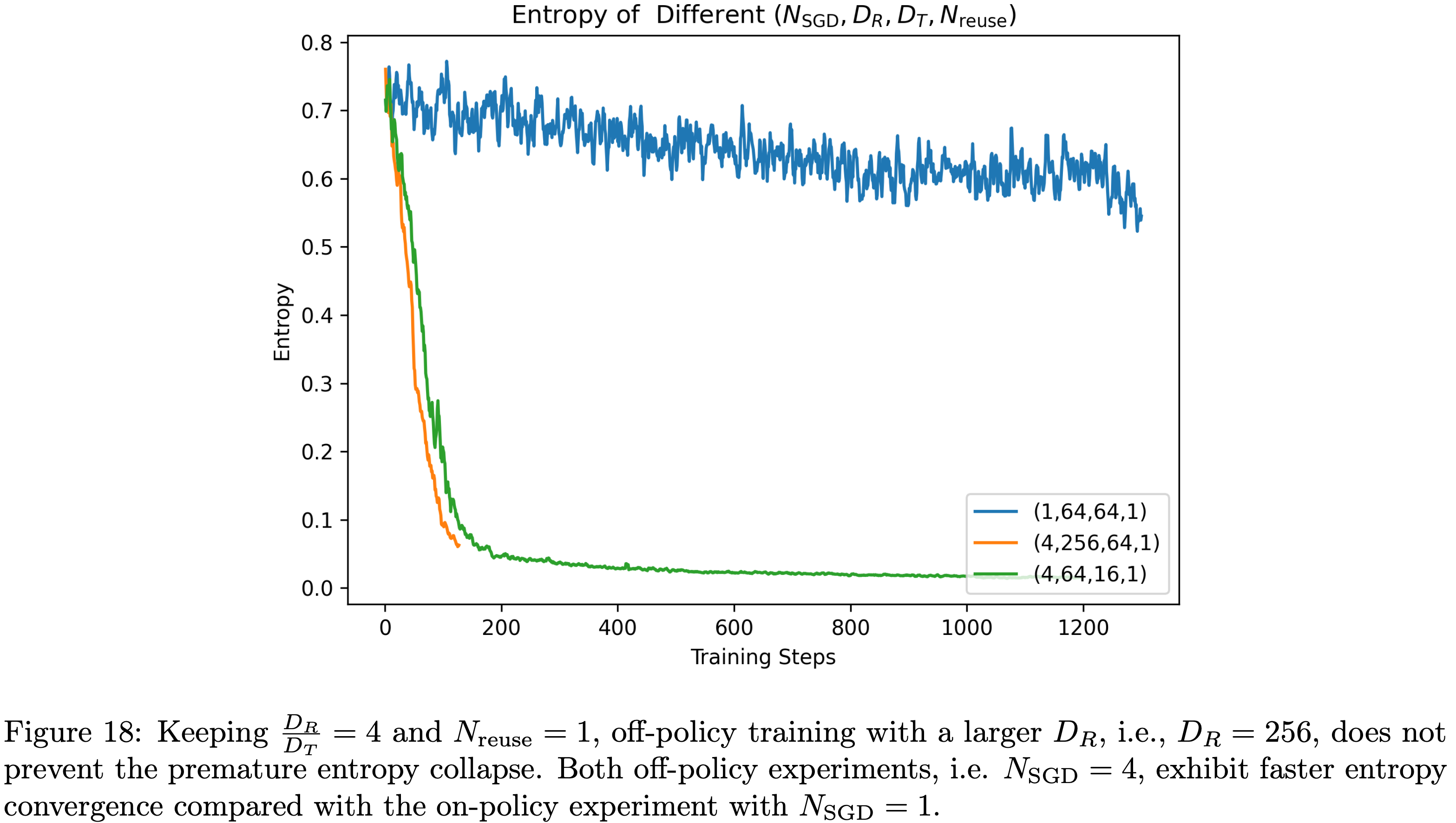
注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体内容总结:
- 论文提出了一个能够生成和验证数学证明的模型 DeepSeekMath-V2(基于 DeepSeek-V3.2-Exp-Base 开发)
- 训练模型识别自身推理中的问题,并激励它们在最终确定输出之前解决这些问题
- 论文超越了基于最终答案的奖励的局限性,迈向可 Self-Verification 的数学推理
- 论文的迭代训练过程(交替改进验证能力和利用这些能力来增强生成),创建了一个可持续的循环,其中每个组件都推动另一个组件前进
- 关键技术贡献包括:
- (1) 训练了一个准确且可信的 LLM-based 数学 Proof Verifier
- (2) 使用元验证来大幅减少幻觉问题并确保验证质量
- (3) 激励 Proof Generator 通过 Self-Verification 来最大化证明质量
- (4) 扩展验证计算量以自动标记日益难以验证的新证明,从而在没有人工标注的情况下改进 Verifier
- DeepSeekMath-V2 在竞赛数学中表现出强大的性能,在 IMO-ProofBench 指标上处于第一梯队
- 在包括 IMO 2025 和 CMO 2024 在内的高中竞赛中获得了金牌分数,并在本科生 Putnam 2024 竞赛中获得了接近满分的成绩
- 意义:这项工作确立了 LLM 可以为复杂推理任务发展有意义的自我评估能力
- 背景 & 问题提出:
- LLM 在数学推理领域取得了显著进展(该领域不仅是 AI 的重要测试基准,若进一步突破,更可能对科学研究产生深远影响)
- 当前方案:通过 RL 对推理过程进行 scaling,并以正确的最终答案为奖励信号,LLMs 在一年内实现了性能飞跃:
- 从最初的表现不佳,到如今在AIME(美国数学邀请赛)、HMMT(哈佛-麻省理工数学竞赛)等定量推理竞赛中达到性能饱和(saturating)状态
- 以上这种方法存在根本性局限:
- 追求更高的最终答案准确率,无法解决一个核心问题:正确答案并不意味着正确的推理过程
- 此外,定理证明(theorem proving)等诸多数学任务,要求严格的分步推导(step-by-step derivation),而不是仅输出数值答案,这使得“以最终答案为奖励”的机制完全不适用
- 为突破深度推理的极限,作者认为有必要对数学推理的完整性(comprehensiveness)与严谨性(rigor) 进行验证
- 自验证(self-verification)对于缩放测试时计算量(test-time compute)尤为重要,尤其是在处理无已知解的开放问题(open problems)时
- 针对可自验证数学推理这一目标,作者开展了以下研究:
- 1)验证器(verifier):训练一个 LLM-based 精准且可信(accurate and faithful)verifier,用于定理证明任务
- 2)证明生成器(Proof Generator):以该 Verifier 作为奖励模型(reward model),训练一个 Proof Generator
- 并激励 Generator 在最终定稿前,自主识别并解决其证明过程中的尽可能多的问题;
- 3)为避免 Generator 性能提升后出现“生成-验证差距(generation-verification gap)”,作者提出通过 scale verification compute,自动标注新的“难验证证明(hard-to-verify proofs)”,并以此构建训练数据,进一步迭代优化 verifier
- 理解:这里的生成-验证差距是指 Verifier 的能力已经无法验证 Generator 生成的结果
- 最终模型 DeepSeekMath-V2 展现出强大的定理证明能力:
- 在 2025 年国际数学奥林匹克(IMO 2025)和 2024 年中国数学奥林匹克(CMO 2024)中斩获金牌级分数(gold-level scores);
- With scaled test-time compute,在 2024 年普特南数学竞赛(Putnam 2024)中取得 118/120 的近乎满分成绩
- 尽管仍有大量工作亟待推进,但这些结果表明:可自验证数学推理是一条可行的研究方向 ,有望助力开发更具能力的数学 AI 系统
Introduction and Discussion
- 数学推理的常规强化学习方法涉及根据 LLM 预测的定量推理问题的最终答案是否与真实答案匹配来对其进行奖励 (2025)
- 这种方法足以让前沿的 LLM 在主要评估最终答案的数学竞赛(如 AIME 和 HMMT)中达到饱和
- 上述奖励机制有两个根本性的局限性
- 它是推理正确性的一个不可靠代理(Proxy)(模型可能通过有缺陷的逻辑或幸运的错误得出正确答案)
- 它不适用于定理证明任务 ,在这类任务中,问题可能不需要产生数值形式的最终答案,而严格的推导是主要目标
- 使用这种最终答案奖励在定量推理问题上进行训练的 LLM ,仍然经常产生数学上无效或逻辑上不一致的自然语言证明
- 且这种训练方法并不能自然地发展模型验证证明有效性的能力
- 它们表现出很高的假阳性率,即使证明包含明显的逻辑缺陷,也常常声称不正确的证明是有效的
- 自然语言定理证明中缺乏生成-验证差距阻碍了进一步的改进
- 为了解决这个问题,论文提议在 LLM 中开发证明验证能力
- 论文的方法基于以下几个关键观察:
- 人类即使没有参考解决方案也能识别证明中的问题
- 这在处理开放性问题时是至关重要的能力
- 当进行了扩展的验证努力也无法识别出任何问题时,证明有效的可能性更高
- 识别有效问题所需的努力可以作为证明质量的代理,这可以用来优化证明生成
- 人类即使没有参考解决方案也能识别证明中的问题
- 作者相信可以训练 LLM 在没有参考解决方案的情况下识别证明问题,且这样的 Verifier 将实现一个迭代改进循环:
- (1) 使用验证反馈来优化证明生成
- (2) 扩展验证计算来自动标注新的难以验证的证明,从而创建训练数据以改进 Verifier 本身
- (3) 使用这个增强的 Verifier 来进一步优化证明生成
- 一个可靠的 Proof Verifier 使论文能够教导 Proof Generator 像 Verifier 那样评估证明
- 这使得 Proof Generator 能够迭代地完善其证明,直到它无法再识别或解决任何问题。本质上,论文让模型明确地意识到其奖励函数,并使其能够通过深思熟虑的推理而不是盲目的试错来最大化这个奖励
- 基于 DeepSeek-V3.2-Exp-Base (2025),论文开发了 DeepSeekMath-V2 ,这是一个针对自然语言定理证明进行优化的 LLM ,展示了可 Self-Verification 的数学推理能力
- 论文的模型能够评估并迭代地改进其自身的证明
- 在包括 IMO 2025 和 CMO 2024 在内的顶级高中数学竞赛中取得了金牌级别的表现
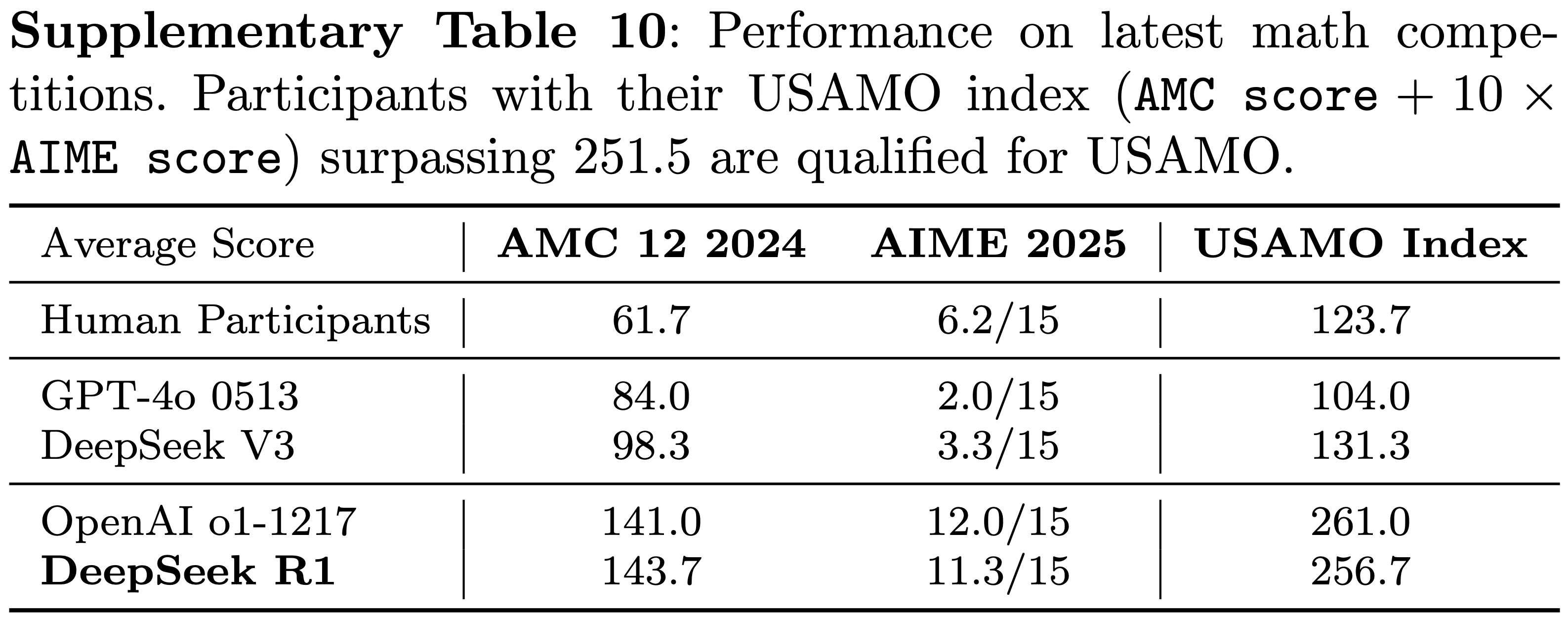
- 在 Putnam 2024 本科数学竞赛中,它取得了 118/120 的分数,超过了人类参与者的最高分 \(90\)(https://kskedlaya.org/putnam-archive/putnam2024stats.html)
Method
Proof Verification
Training a Verifier to Identify Issues and Score Proofs
- 论文为证明评估制定了高级评估标准 \(\mathcal{I}_{v}\)(见附录 A.2),目标是训练一个 Verifier 根据这些标准来评估证明,这反映了数学专家的评估过程
- 理解:这里说的高级评估标准 \(\mathcal{I}_{v}\) 就是 Verifier 的 Prompt
- 具体来说,给定一个问题 \(X\) 和一个证明 \(Y\), Verifier \(\pi_{\boldsymbol{\varphi} }(\cdot|X,Y,\mathcal{I}_{v})\) 被设计为生成一个证明分析,该分析首先总结识别出的问题(如果有的话),然后根据三个级别分配分数:
- 1 表示完整且严谨的证明,所有逻辑步骤都清晰合理;
- 0.5 表示整体逻辑合理但存在小错误或省略细节的证明;
- 0 表示包含致命逻辑错误或关键漏洞的根本性缺陷证明
- 附录 A.2 提供的 Prompt 大致中文含义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#### 说明
你的任务是评估问题解决方案的质量 问题可能要求证明一个陈述,或者要求一个 答案。如果需要找到答案,解决方案 应该呈现答案,并且也应该是该答案有效的 严格证明
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为 1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为 0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为 0
- 此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
请仔细推理并分析下方解决方案的质量, 并在你的最终回复中呈现解决方案质量的 详细评估,然后是你的评分。因此,你的回复 应遵循以下格式:
以下是我对解决方案的评估:
... // 你的评估在此处。你需要详细呈现 解决方案的关键步骤或你对其正确性 存疑的步骤,并明确分析每个步骤是否准确:对于正确的步骤,解释你最初为何怀疑其正确性 以及它们为何确实是正确的;对于错误的步骤, 解释错误的原因以及该错误对解决方案的影响
根据我的评估,最终总体得分应为:
\boxed{...} // 其中...应为根据上述标准得出的 最终总体得分(0、0.5或1,且不能是其他内容)
以下是你的任务输入:
#### 问题
{问题}
#### 解决方案
{证明}
Curating Cold Start RL Data
- 论文通过以下过程构建了初始训练数据:
- 1)论文从 Art of Problem Solving (AoPS) 竞赛中爬取问题,优先选择数学奥林匹克、团队选拔测试以及 2010 年后明确要求证明的问题,总计 17,503 个问题
- 此问题集记为 \(\mathcal{D}_{p}\)
- 2)论文使用 DeepSeek-V3.2-Exp-Thinking 的一个变体生成候选证明
- 由于该模型未针对定理证明进行优化,并且倾向于产生简洁但容易出错的输出,论文提示它在多轮中迭代地完善其证明,以提高全面性和严谨性
- 3)论文随机抽样了不同问题类型(例如,代数和数论)的证明,并由数学专家根据上述评估标准对每个证明进行评分
- 注意:这个数据集的数据是数学专家标注的,所以很厉害,后续会用做 Ground Truth 数据集
- 1)论文从 Art of Problem Solving (AoPS) 竞赛中爬取问题,优先选择数学奥林匹克、团队选拔测试以及 2010 年后明确要求证明的问题,总计 17,503 个问题
- 这个过程产生了一个初始的强化学习数据集
$$ \mathcal{D}_{v}=\{(X_{i},Y_{i},s_{i})\} $$- 其中每个项目包含一个问题 \(X_{i}\)、一个证明 \(Y_{i}\) 和一个整体证明分数 \(s_{i}\in\{0,0.5,1\}\)
- 理解:Verifier 的训练流程可以总结为:
- 第一步:对待解决的问题 Query \(X_{i}\),使用 Generator 生成证明过程 \(Y_{i}\)
- 第二步:使用数学专家对这些 证明过程 \(Y_{i}\) 进行检验,给出一个对 Generator 相应的评分 \(s_{i}\),得到最终数据集
$$ \mathcal{D}_{v}=\{(X_{i},Y_{i},s_{i})\} $$ - 第三步:基于上述数据集使用强化学习训练一个 Verifier
RL Objective
- 基于一个在数学和代码相关推理数据上进行 SFT 的 DeepSeek-V3.2-Exp-SFT 版本,论文使用两个奖励组件通过强化学习训练模型以产生证明分析:
- 格式奖励 \(R_{\text{format} }\): 一个指示函数,强制模型生成识别出的问题摘要和证明分数,通过检查最终响应是否包含关键短语 “Here is my evaluation of the solution.” 以及紧随 “Based on my evaluation, the final overall score should be.” 之后的 \boxed{} 内的分数
- 分数奖励 \(R_{\text{score} }\): 基于预测分数 \(s^{\prime}_{i}\) 与标注分数 \(s_{i}\) 接近程度的奖励:
$$R_{\text{score} }(s^{\prime}_{i},s_{i})=1-|s^{\prime}_{i}-s_{i}| \tag{1}$$
- 训练 Verifier 的强化学习目标是:
$$\max_{\pi_{\varphi} }\mathbb{E}_{(X_{i},Y_{i},s_{i})\sim\mathcal{D}_{v},(V^{\prime}_{i},s^{\prime}_{i})\sim\pi_{\varphi}(\cdot|X_{i},Y_{i})} \left[R_{\text{format} }(V^{\prime}_{i})\cdot R_{\text{score} }(s^{\prime}_{i},s_{i})\right] \tag{2}$$- 其中 \(V^{\prime}_{i}\) 表示 Verifier 的最终响应,\(s^{\prime}_{i}\) 是从中提取的证明分数
- 理解:要求格式一定正确,且分数越接近越好
Introducing Meta-Verification to Review Proof Analyses
- 第 2.1.1 节中描述的方法通过强化学习训练证明验证,以使预测的证明分数与专家标注对齐,但没有直接监督问题本身
- 这造成了一个关键的漏洞:在训练期间评估有缺陷的证明(其中 \(s_{i}<1\))时, Verifier 可以通过预测正确的分数同时幻觉出不存在的问题来获得全部奖励,这破坏了其可信度
- 理解:这里是说,错误可以有千百种,所以评估 Generator 出现错误的问题时,Verifier 可能会对齐分数,然后幻觉出一些 Generator 的回复没有的错误;(这是因为 Verifier 的 RL 奖励只监督了分数而不是问题本身导致的)
- 为了解决这个问题,论文引入了元验证 (meta-verification) :
- 一个次要的评估过程,用于评估 Verifier 识别出的问题是否确实存在,以及这些问题是否根据评估标准 \(\mathcal{I}_{v}\) 在逻辑上证明了预测的证明分数是合理的
- 完整的元验证标准 \(\mathcal{I}_{mv}\) 在附录 A.3 中详细说明
- 理解:这里说的元验证标准 \(\mathcal{I}_{mv}\) 就是 Meta-Verifier 的 Prompt
- 论文训练了一个专用的 Meta-Verifier 使用强化学习来执行此评估
- 通过将 Meta-Verifier 的反馈纳入 Verifier 训练,我们可以提高 Verifier 问题识别的忠实度
- A.3 的内容(Meta-Verification)大致含义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72你被提供了一个"问题"、"解决方案"和"解决方案评估", 你需要评估这个"解决方案评估"是否合理
首先,"解决方案评估"是通过使用以下规则提示 Verifier 来评估"解决方案"质量而生成的(这些不是你的规则):
'''
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为0
- 此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
'''
接下来,我将介绍你分析"解决方案评估"质量 的规则:
1. 你的任务是分析"解决方案评估"。你不需要 解决"问题",也不需要严格评估"解决方案" 是否准确。你的唯一任务是严格遵循以下规则 来评估"解决方案评估"是否合理
2. 你需要从三个方面分析"解决方案评估"的内容:
步骤重述:在"解决方案评估"中,可能会重述"解决方案" 的某些行为。你需要回到"解决方案"的原始文本, 检查"解决方案"是否实际具有"解决方案评估"中 提到的这些行为
缺陷分析:"解决方案评估"可能会指出"解决方案"中的 错误或缺陷。你需要仔细分析提到的错误和缺陷 是否确实有效
表达分析:"解决方案评估"的表达是否准确
分数分析:"解决方案评估"给出的最终分数是否与其 发现的缺陷相匹配。你需要根据上面给出的 评分规则进行分析
3. 最重要的部分是**缺陷分析** :在这部分中, 你的核心任务是检查 "解决方案评估" 中指出的 "解决方案" 的错误或缺陷是否合理。换句话说, "解决方案评估" 中关于 "解决方案" 的任何正面内容, 无论是否合理,都不在你的评估范围之内
- 例如:如果 "解决方案评估" 说 "解决方案" 中的某个 结论是正确的,但实际上这个结论是错误的, 那么你不需要关心这一点。"解决方案评估" 认为 正确的所有部分都不属于你的评估范围
- 具体来说:如果 "解决方案评估" 认为 "解决方案" 完全准确,没有发现任何错误或缺陷,那么无论 "解决方案" 本身是否实际准确,即使存在明显错误,你仍应认为其对错误的分析是合理的
**重要的是** ,对于 "解决方案评估" 发现的缺陷, 你需要同时分析两点:
- 这个缺陷是否实际存在
- "解决方案评估" 对这个缺陷的分析是否准确
这两个方面构成了缺陷分析
4. 关于**表达分析** ,如果 "解决方案评估" 中存在某些 表达错误,即使是细节上的小错误,你也需要 识别它们。但是,请注意,将 "解决方案" 中的 错误步骤识别为正确步骤不构成**表达错误**
在实践中,表达错误包括但不限于:
- 如果 "解决方案评估" 将 "解决方案" 中的某些推理步骤 识别为不正确,那么它不能进一步指出依赖于这些推理步骤的后续结论是错误的,而只能指出 后续结论 "没有得到严格证明"
- "解决方案评估" 中的拼写错误和计算错误
- 对 "解决方案" 内容的不准确重述
5. 最后,你需要在输出中呈现你对 "解决方案评估" 的 分析,并根据以下规则评定其质量:
首先,如果 "解决方案评估" 发现的缺陷中至少有一个 是不合理的,那么你只需要进行**缺陷分析** :
- 如果 "解决方案评估" 发现的所有缺陷都是不合理的, 那么你应该将其评定为\\(0\\)
- 如果 "解决方案评估" 发现的部分缺陷是合理的, 部分是不合理的,那么你的评分应为\\(0.5\\)
接下来,如果 "解决方案评估" 没有指出任何错误或 缺陷,或者评估发现的所有缺陷都是合理的, 那么你应该做以下事情:
- 分析 "解决方案评估" 中是否存在 "表达错误" (**表达分析**)或者 "解决方案评估" 是否根据 "解决方案评估" 的规则给出了错误的分数(**分数分析**)。如果是,你应该将 "解决方案评估" 评定为\\(0.5\\);如果不是,你的评分应为\\(1\\)
你的输出应遵循以下格式:
以下是我对"解决方案评估"的分析:
... // 你的分析在此处
根据我的分析,我将"解决方案评估"评定为:
\boxed{...} // 其中...应为根据上述标准对 "解决方案评估" 的数值评分(0、0.5或1,且不能是其他内容)
---
以下是你的任务输入:
#### 问题
{问题}
#### 解决方案
{证明}
#### 解决方案评估
{证明分析}
Meta-Verifier Training Process
- 1)论文按照第 2.1.1 节获得了一个初始 Verifier \(\pi_{\varphi}\)
- 2)数学专家根据 \(\mathcal{I}_{mv}\) 对 Verifier 响应的质量进行评分,创建数据集
$$ \mathcal{D}_{mv}=\{(X_{i},Y_{i},V_{i},ms_{i})\}$$- 其中 \(V_{i}\) 是对证明 \(Y_{i}\) 的分析,\(ms_{i}\in\{0,0.5,1\}\) 是专家标注的质量分数
- 理解:这里也有数学专家参与,给出的数据是明确的标签
- 3)论文训练了一个 Meta-Verifier \(\pi_{\eta}(\cdot|X,Y,V,\mathcal{I}_{mv})\) 来分析 Verifier 的证明分析 \(V\)
- Meta-Verifier 生成一个在分析本身中发现的问题摘要,然后是一个质量分数,用于衡量 Verifier 分析的准确性和合理性
- 强化学习目标:遵循与 Verifier 训练相同的结构,具有格式和分数奖励
- 理解:Meta-Verifier 也是通过强化学习训练的
- 使用训练好的 Meta-Verifier \(\pi_{\eta}\),论文通过将元验证反馈整合到奖励函数中来增强 Verifier 训练 :
$$R_{v}=R_{\text{format} }\cdot R_{\text{score} }\cdot R_{\text{meta} }\tag{3}$$- 其中 \(R_{\text{meta} }\) 是来自 Meta-Verifier 的质量分数
- 论文在验证数据集 \(\mathcal{D}_{v}\) 和元验证数据集 \(\mathcal{D}_{mv}\) 上训练了增强的 Verifier ,在 \(\mathcal{D}_{mv}\) 上使用与训练 Meta-Verifier 相同的奖励机制
- 最终的模型可以执行证明验证和元验证任务
- 在 \(\mathcal{D}_{v}\) 的一个验证 split 上, Verifier 证明分析的平均质量分数(由 Meta-Verifier 评估)从 \(0.85\) 提高到 \(0.96\),同时保持了相同的证明分数预测准确率
- 理解:Meta-Verifier 的训练流程可以总结为:
- 第一步:对待解决的问题 Query \(X_{i}\),使用 Generator 生成证明过程 \(Y_{i}\)
- 第二步:使用已经训练好的 Verifier 给这些证明打分 \(V_{i}\)
- 第三步:使用数学专家对这些 Verifier 的质量进行检验,给出一个对 Verifier 相应的评分 \(ms_{i}\),得到最终数据集
$$ \mathcal{D}_{mv}=\{(X_{i},Y_{i},V_{i},ms_{i})\}$$ - 第四步:基于上述数据集使用强化学习训练一个 Meta-Verifier
Proof Generation
Training a Generator for Theorem Proving
- 以 Verifier \(\pi_{\varphi}\) 作为生成式奖励模型(generative reward model),论文训练一个 Proof Generator \(\pi_{\theta}(\cdot|X)\),其强化学习目标为:
$$\max_{\pi_{\theta} }\mathbb{E}_{X_{i}\sim\mathcal{D}_{p},Y_{i}\sim\pi_{\theta}(\cdot|X_{i})}[R_{Y}] \tag{4}$$ - 其中 \(R_{Y}\) 是由 \(\pi_{\varphi}(\cdot|X_{i},Y_{i},\mathcal{I}_{v})\) 产生的证明分数
- 理解:这里说的 \(\mathcal{I}_{v}\) 是前文说的 高级评估标准,也就是 Verifier 的 Prompt
Enhancing Reasoning via Self-Verification
- 当 Proof Generator 无法一次性生成完全正确的证明时(对于来自 IMO 和 CMO 等竞赛的具有挑战性的问题来说,这很常见),迭代验证和细化可以改善结果
- 这包括使用外部 Verifier 分析证明,并提示 Generator 解决识别出的问题
- 然而,论文观察到一个关键的限制:
- 当提示在一次性中既生成又分析其自身证明时, Generator 倾向于声称正确,即使外部 Verifier 很容易识别出缺陷
- 换句话说,虽然 Generator 可以基于外部反馈来改进证明,但它未能像专用 Verifier 那样严格地评估自己的工作
- 这一观察激励论文赋予 Proof Generator 真正的验证能力
- 在训练期间,论文提示 Proof Generator \(\pi_{\theta}\) 生成一个证明 \(Y\),然后是一个自我分析 \(Z\),该分析遵循与 Verifier 相同的格式和标准 \(L_{t}\)(见附录 A.1)
- 论文将自我分析中预测的证明分数记为 \(s^{\prime}\)
- 理解: \(s^{\prime}\) 是自己给自己打的分
- 为了确保忠实的自我评估,论文使用 Verifier \(\pi_{\varphi}\) 来评估这两个部分:
- 证明 \(Y\) 获得分数 \(R_{Y}=s\),自我分析 \(Z\) 获得元验证分数 \(R_{\text{meta} }(Z)=ms\)
- 奖励函数结合了这些评估:
$$ R = R_{\text{format} }(Y, Z)\cdot(\alpha\cdot R_{Y}+\beta\cdot R_{Z}) \tag{5} $$- 理解:\(R_{Y}=s\) 表示验证分数,是根据 Verifier 模型输出 \(Y\) 得到的验证器输出分数,也就是 \(R_{Y}\) 是 \(\pi_{\varphi}(\cdot|X_{i},Y_{i},\mathcal{I}_{v})\) 的输出
$$ R_{Z} = R_{\text{score} }(s^{\prime}, s)\cdot R_{\text{meta} }(Z) \tag{6} $$ - 理解:\(R_{\text{meta} }(Z)=ms\) 表示元验证分数,是 Meta-Verifier 模型输出的元验证分数,\(R_{\text{meta} }(Z)=ms\) 是 \(\pi_{\eta}(\cdot|X,Y,V,\mathcal{I}_{mv})\) 的输出
- 注:\(s’\) 是 Generator Self-Verification 生成的分数;\(s\) 是 Verifier 输出的分数
- 理解:\(R_{Y}=s\) 表示验证分数,是根据 Verifier 模型输出 \(Y\) 得到的验证器输出分数,也就是 \(R_{Y}\) 是 \(\pi_{\varphi}(\cdot|X_{i},Y_{i},\mathcal{I}_{v})\) 的输出
- 进一步分析:
- \(R_{\text{format} }(Y,Z)\) 验证证明和自我分析都遵循指定的格式
- \(R_{\text{score} }(s^{\prime},s)\) 奖励准确的自我评估
- 这里希望 Generator 生成的 Self-Verification 给分越接近 Verifier 越好,即 Verifier 的输出 \(s’\) 对 Generator 的影响不仅仅在 \(R_Y=s\) 上,还在 \(R_{\text{score} }(s^{\prime},s)\) 上
- 论文设置 \(\alpha=0.76\) 和 \(\beta=0.24\)
- 这种奖励结构创建了以下激励:
- 忠实地承认错误比虚假地声称正确更受奖励
- 最高的奖励来自于产生正确的证明并准确认识到其严谨性
- Proof Generator 获得高奖励的一个好策略是在最终确定响应之前,尽可能多地识别和解决问题
- 附录 A.1 的 Prompt 大致含义是:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41你的任务是解决给定的问题。问题可能要求你 证明一个陈述,或者要求一个答案。如果需要 找到答案,你应该提出答案,并且 你的最终解决方案也应该是该答案有效的 严格证明
你对问题的最终解决方案应该非常 全面且易于理解,将根据以下评估说明 进行评分:
'''txt
以下是评估问题解决方案质量的说明 问题可能要求证明一个陈述,或者 要求一个答案。如果需要找到答案, 解决方案应该呈现答案,并且也应该是 该答案有效的严格证明
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为0
此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
'''
事实上,你已经具备了自己评估解决方案的 能力,因此期望你仔细推理如何 解决给定问题,根据说明评估你的方法, 并通过修复已识别的问题来改进你的解决方案, 直到你无法取得进一步进展
在你的最终回复中,你应该呈现问题的详细解决方案, 然后是对该解决方案的评估
- 为了给出好的最终回复,你应该尽力 根据上述评估说明找出自己(部分)解决方案中 的潜在问题,并尽可能多地修复它们
- 一个好的最终回复应该忠实地呈现你的 进展,包括你能给出的最佳解决方案, 以及对该解决方案的忠实评估
- 只有当你无法在解决方案中找到任何问题时, 才应将其评分为1
- 如果你确实注意到解决方案中的一些问题但 尽了最大努力仍无法解决,在最终回复中 忠实地呈现这些问题完全没有问题
- 最差的最终回复是提供错误的解决方案却撒谎 说它是正确的,或者在没有仔细检查错误的 情况下声称它是正确的。更好的版本应该 忠实地识别解决方案中的错误。记住!你不能作弊! 如果你作弊,论文会知道,你将受到惩罚!
你的最终回复应遵循以下格式:
#### 解决方案 // 你的最终解决方案应以这个完全相同的 markdown标题开始
... // 你对该问题的最终解决方案在此处。你应该尽力 根据上述评估说明优化解决方案的质量, 然后在此处定稿
#### 自我评估 // 你对自己上述解决方案的评估 应以这个完全相同的markdown标题开始
以下是我对解决方案的评估: // 你的分析应以 这个完全相同的短语开始
... // 你的评估在此处。你需要详细呈现 解决方案的关键步骤或你对其正确性 存疑的步骤,并明确分析每个步骤是否准确: 对于正确的步骤,解释你最初为何怀疑其正确性 以及它们为何确实是正确的;对于错误的步骤, 解释错误的原因以及该错误对解决方案的影响 你应该忠实地分析你的解决方案。例如, 如果你的最终解决方案存在问题,你应该 指出来
根据我的评估,最终总体得分应为:
\boxed{ {...} } // 其中...应为根据上述评估说明得出的 最终总体得分(0、0.5或1,且不能是其他内容) 你只有在仔细重新检查自己的解决方案后才应 得出这个分数
以下是你的任务输入:
#### 问题
{问题}
Synergy Between Proof Verification and Generation
- Proof Verifier 和 Generator 创建了一个协同循环:
- Verifier 改进了 Generator ,而随着 Generator 的改进,它产生了新的证明,这些证明挑战了 Verifier 当前的能力
- 这些具有挑战性的案例(Verifier 可能在单次尝试中未能识别出问题)成为增强 Verifier 本身的有价值的训练数据
- 为了重新训练和改进 Verifier ,论文需要为新生成的证明标注正确性数据
- 手动标注虽然直接,但随着问题变得 harder 和错误变得更加细微,变得越来越耗时
- 为了提高标注效率,论文为每个证明生成多个 Verifier 分析,以便为人工审查浮现潜在问题
- 从这个人工智能辅助的标注过程中,论文认识到两个事实,使得将自动化水平向前推进一步是可行的:
- 1)扩展 Verifier 样本增加了在有缺陷的证明中捕捉到真实问题的概率
- 2)审查 Verifier 识别出的问题正是元验证 ,这比从头开始识别问题更容易
- 元验证对于 LLM 掌握来说也更具样本效率
automated labeling
- 基于这些观察,论文开发了以下自动标注(automated labeling)流程 :
- 1)对于每个证明,生成 \(n\) 个独立的验证分析
- 2)对于报告问题(分数为 0 或 0.5)的分析,生成 \(m\) 个元验证评估以验证识别出的问题
- 如果大多数元评估确认了其发现,则认为一个分析是有效的
- 3)对于每个证明,论文检查分配最低分数的分析
- 如果至少有 \(k\) 个这样的分析被认为是有效的,则该证明被标记为该最低分数
- 如果在所有验证尝试中均未识别出合法问题,则该证明被标记为 1
- 否则,该证明被丢弃或转给人类专家进行标注
- 在论文的最后两次训练迭代中,这个完全自动化的流程完全取代了人工标注
- 注意:作者做过质量检查,确认自动化标签与专家判断吻合良好
- 理解:这里提供了一种自动标注的方法,通过非常严格的验证来保证结果信号的准确性
Experiments
Training Settings
- 论文采用 GRPO (2024) 进行强化学习,迭代地优化证明验证(Proof Verification)和生成能力(Generation Capabilities)
- 在每次迭代中,首先优化 Proof Verification(即优化 Proof Verifier)
- Proof Generator 从 Verifier Checkpoint 初始化,并针对证明生成进行优化
- 从第二次迭代开始, Proof Verifier 使用一个通过拒绝微调(Rejection Fine-tuning)整合了前一次迭代的验证和生成能力的 Checkpoint 进行初始化
Evaluation Benchmarks
- 论文在以下定理证明基准上评估论文最终的 Proof Generator :
- 内部 CNML 级别问题 (In-House CNML-Level Problems)
- 91 个定理证明问题,涵盖代数 (13)、几何 (24)、数论 (19)、组合数学 (24) 和不等式 (11),其难度与中国国家高中数学联赛 (Chinese National High School Mathematics League, CNML) 的问题相当
- 竞赛问题 (Competition Problems)
- IMO 2025 (6 个问题): 国际数学奥林匹克 (International Mathematical Olympiad),面向大学预科学生的全球顶级数学竞赛
- CMO 2024 (6 个问题): 中国数学奥林匹克 (China Mathematical Olympiad),中国的全国锦标赛
- Putnam 2024 (12 个问题): 威廉·洛厄尔·普特南数学竞赛 (The William Lowell Putnam Competition),北美本科生的杰出数学竞赛
- ISL 2024 (31 个问题): IMO 预选题 (The IMO Shortlist),由参赛国提出并由问题选拔委员会考虑可能纳入 IMO 2024 的问题集合
- IMO-ProofBench (60 个问题): 由 DeepThink IMO-Gold (2025) 背后的 DeepMind 团队开发,该基准 (2025) 分为基础集 (30 个问题,IMO 预选到 IMO 中等难度) 和高级集 (30 个具有挑战性的问题,模拟完整的 IMO 考试,难度高达 IMO 困难级别)
Evaluation Results
One-Shot Generation
- 论文首先评估模型在没有迭代优化的情况下生成正确证明的能力
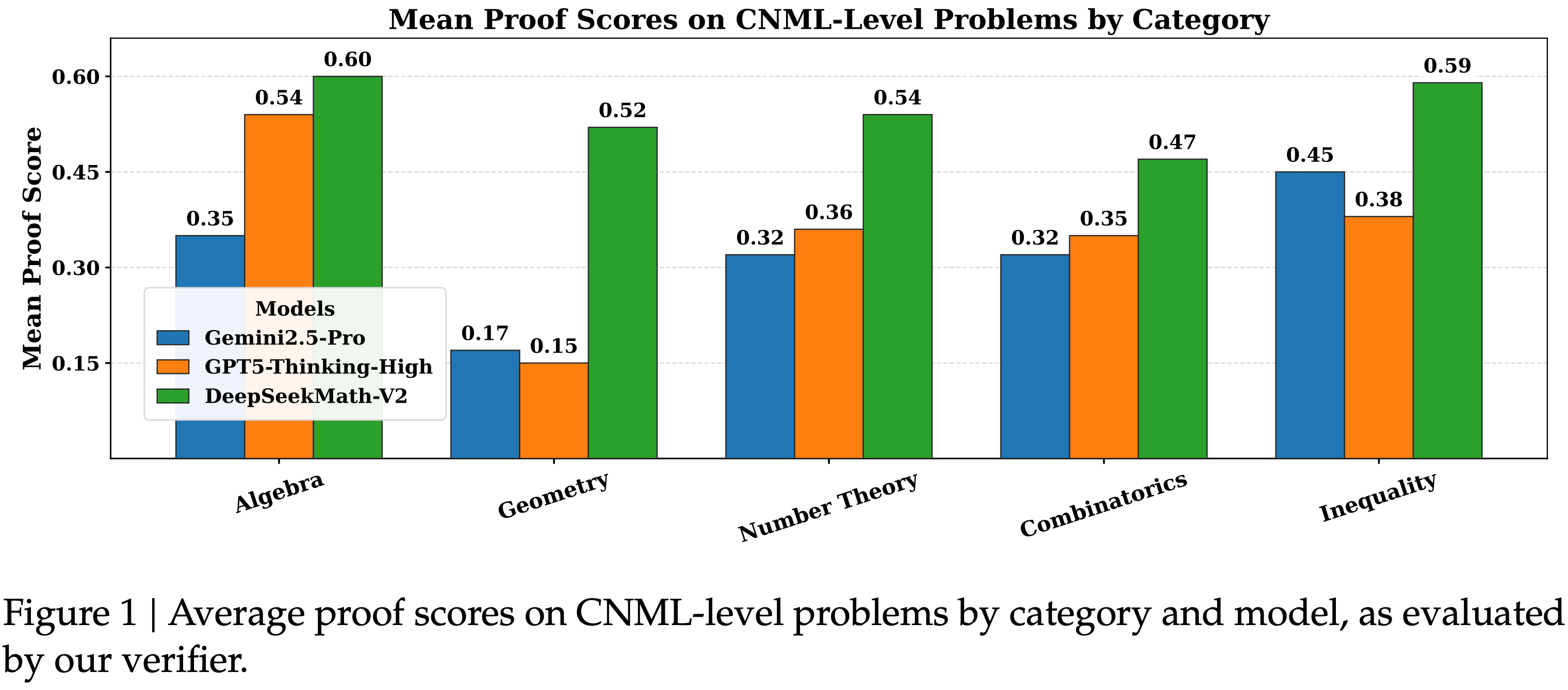
- 在内部问题上,论文为每个评估模型对每个问题生成 8 个证明样本
- 证明正确性通过论文最终 Verifier 生成的 8 个验证分析进行多数投票来衡量
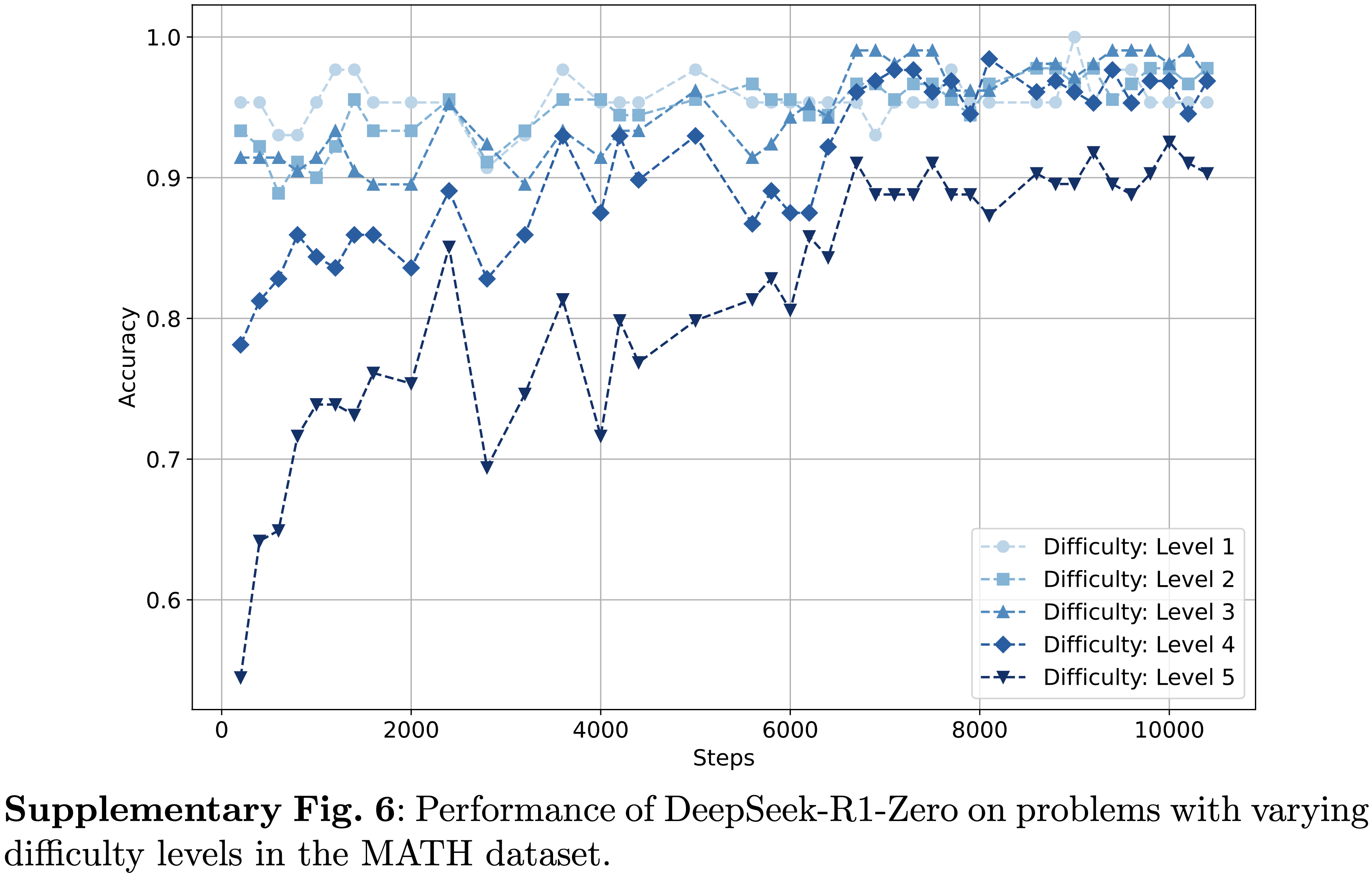
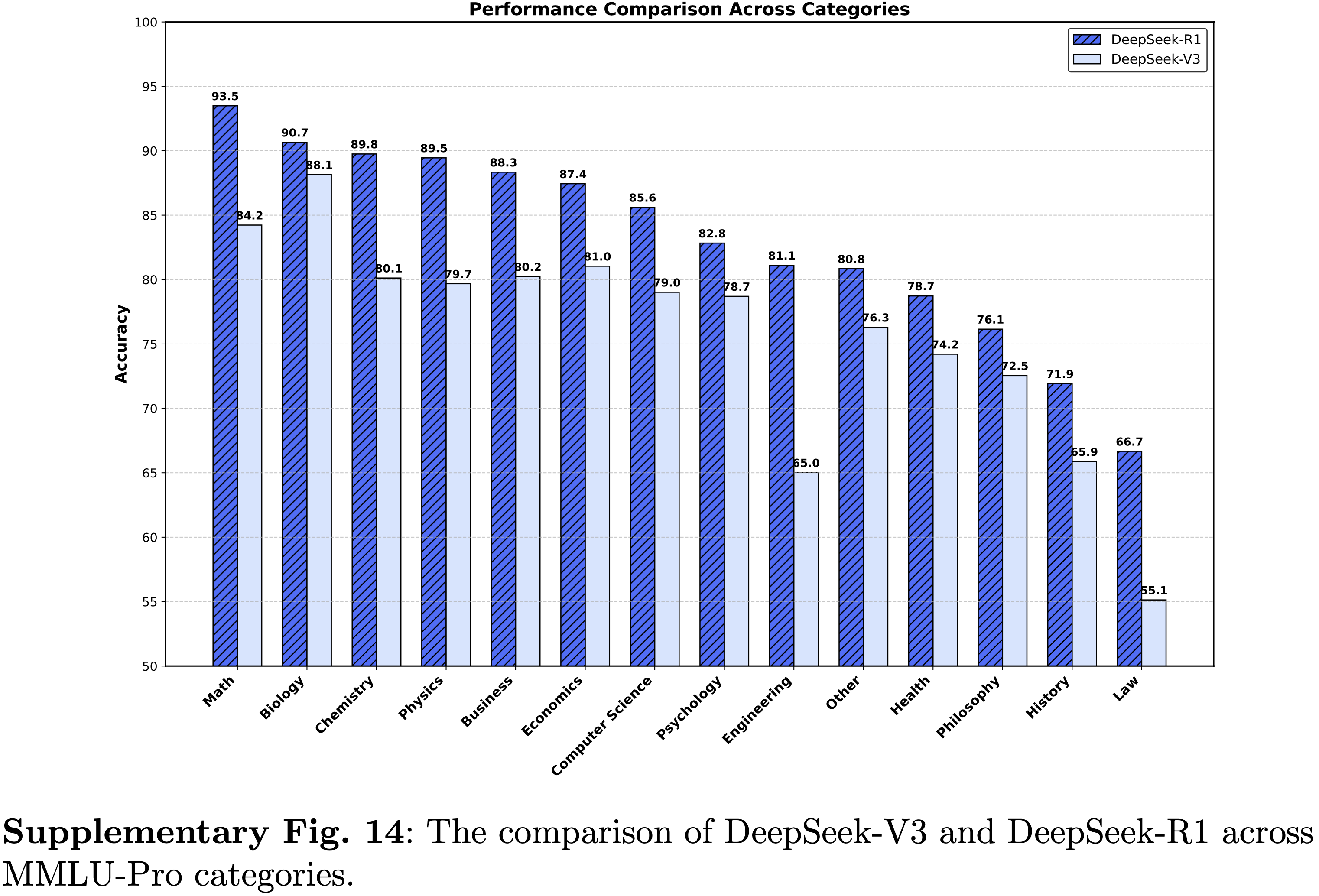
- 如图 1 所示,在 CNML 级别问题的所有类别中(代数、几何、数论、组合数学和不等式)DeepSeekMath-V2 始终优于 GPT-5-Thinking-High (OpenAI, 2025) 和 Gemini 2.5-Pro (DeepMind, 2025),展示了跨领域的卓越定理证明能力
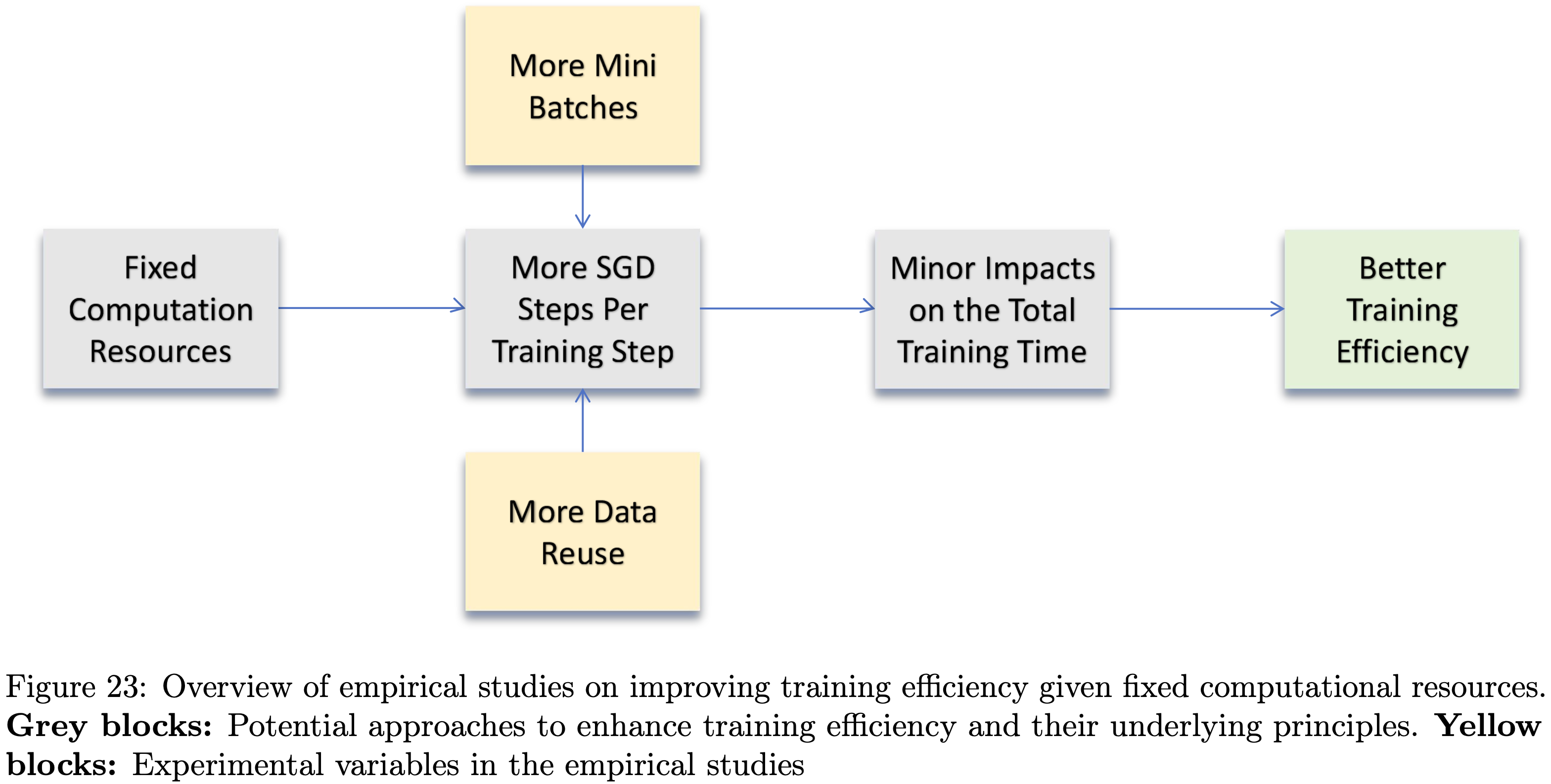
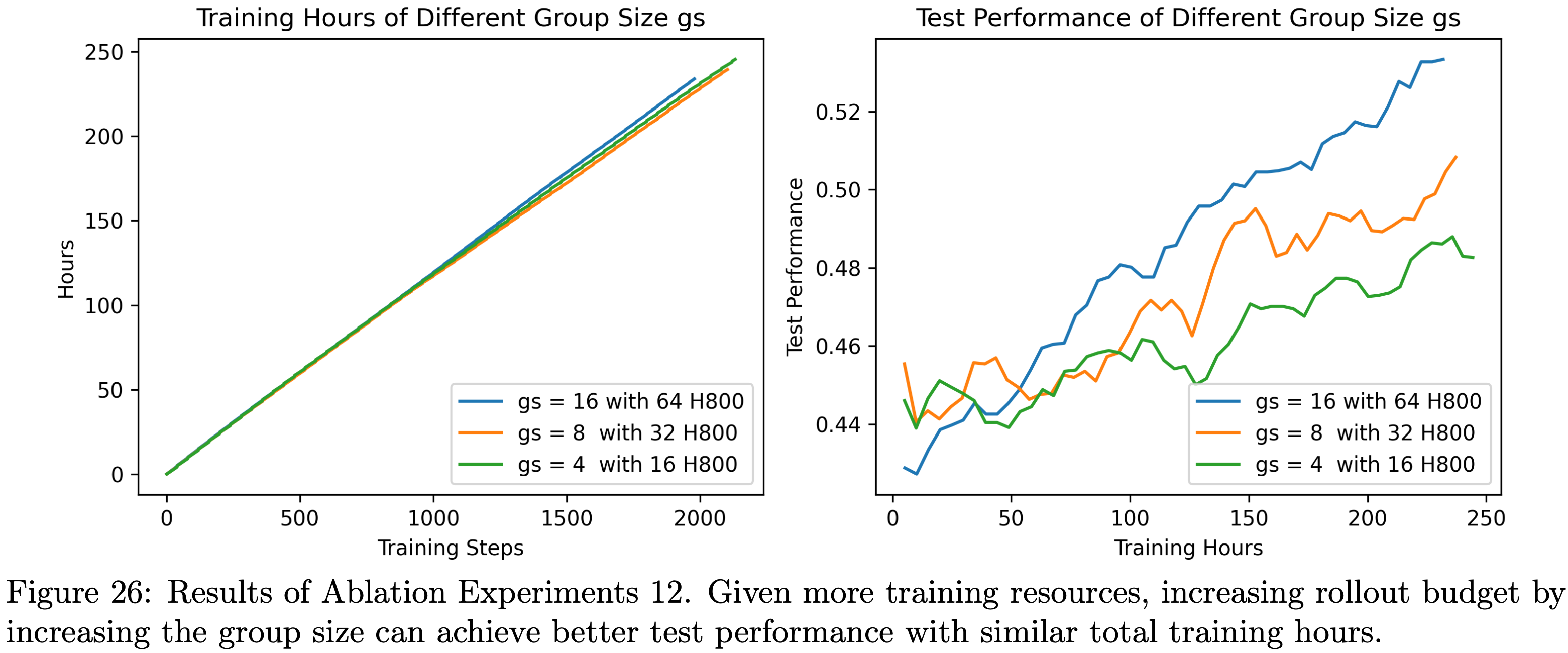
Sequential Refinement with Self-Verification
- 对于来自 IMO 和 CMO 等竞赛的具有挑战性的问题,模型通常无法在 128K 的标记限制内单次生成全面且严谨的证明
- 当这种情况发生时,论文的 Proof Generator 通过 Self-Verification 认识到其证明无效,但缺乏足够的上下文长度来单次解决所有已识别的问题
- 为了探索扩展上下文和 Self-Verification 如何提高证明质量,论文评估了通过 Self-Verification 进行顺序优化的方法
- 先生成一个带有自我分析的证明
- 然后迭代地使用其先前的输出来重新提示 Generator (优化提示见附录 A.4),使其能够解决已识别的问题
- 以上过程持续进行,直到 Generator 给自己分配了完美分数或达到最大顺序尝试次数
- 图 2 展示了在 IMO 预选题 2024 问题上通过顺序优化带来的证明质量改进
- 对于每个问题,论文启动了 32 个独立的优化线程
- 证明是否正确通过最终 Verifier 生成的 32 个验证分析进行多数投票来衡量
- 论文在图 2 中报告了两个指标:
- (1)
Pass@1:每个线程最终证明的平均分数 - (2)
Best@32:每个问题的最佳证明的分数,通过所有线程中自我分配的分数进行选择- 自我选择的最佳证明获得了显著高于线程平均值的验证分数,证明了论文的 Generator 准确评估证明质量的能力
- 此外,随着最大顺序尝试次数的增加,
Pass@1显著提高,表明 Self-Verification 有效地指导了迭代改进- 这些结果证实,论文的 Generator 能够可靠地区分高质量和有缺陷的证明,并利用这种自我意识来系统地改进其数学推理
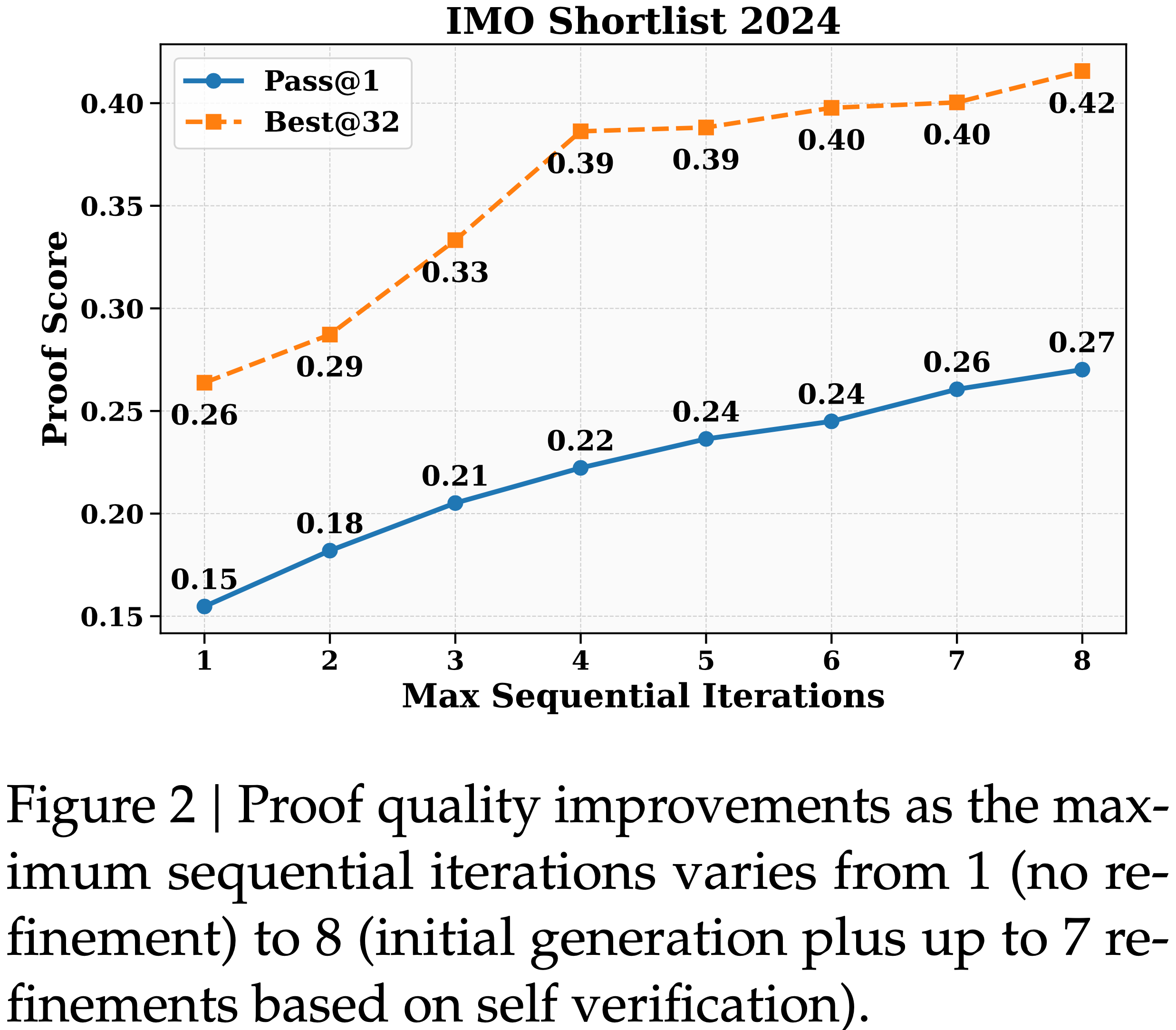
- 这些结果证实,论文的 Generator 能够可靠地区分高质量和有缺陷的证明,并利用这种自我意识来系统地改进其数学推理
- (1)
High-Compute Search
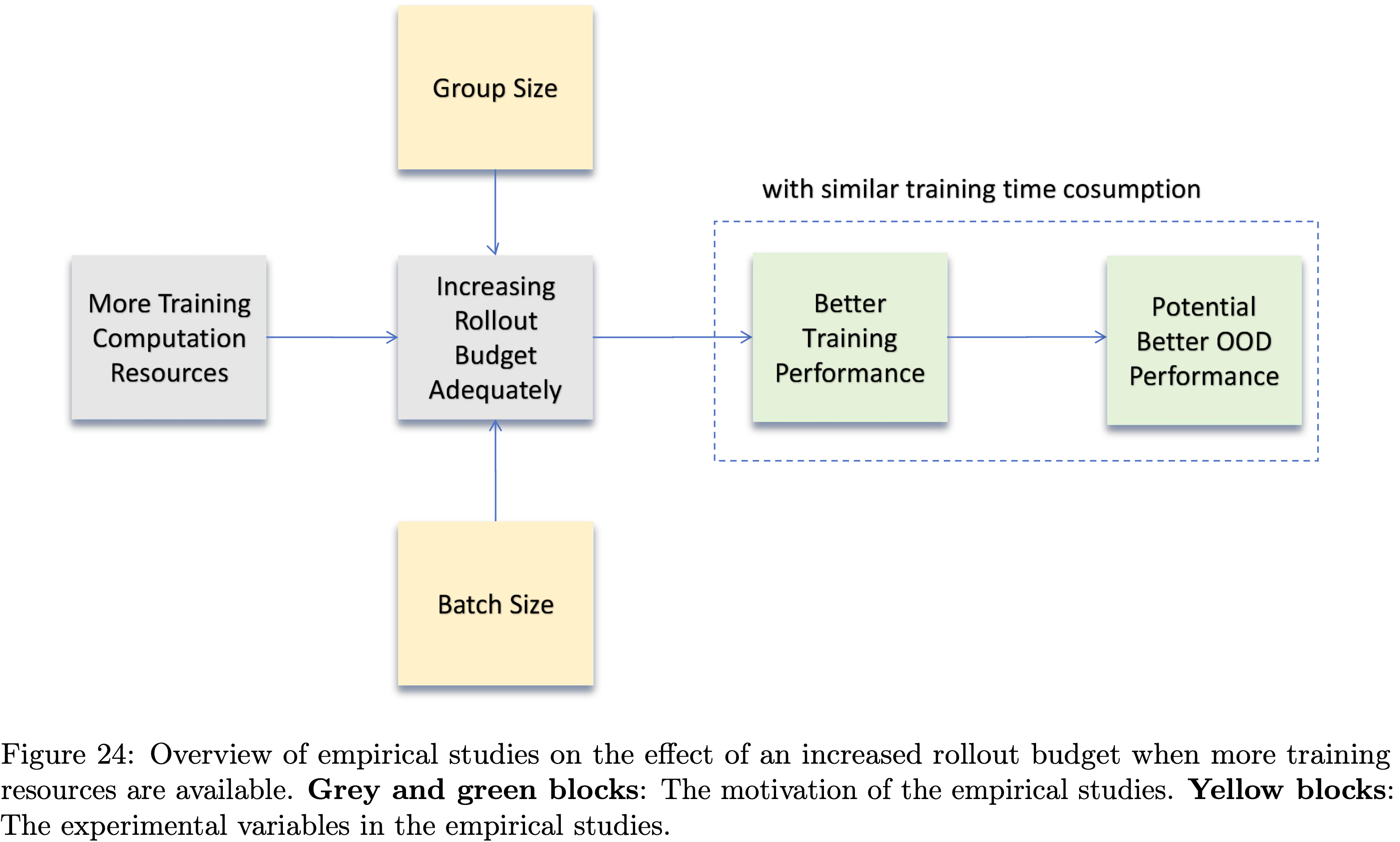
- 为了解决最具挑战性的问题,论文扩展了验证和生成的计算量,使用广泛的验证来识别细微的问题,并通过并行生成来探索多样化的证明策略
- 论文的方法详细描述如下(注意:这里是重头戏,论文最重要的核心技巧):
- 第一步:为每个问题维护一个候选证明池,初始化为 64 个证明样本
- 第二步:为每个样本生成 64 个验证分析
- 第三步:(每次优化迭代中)根据平均验证分数选择 64 个得分最高的证明
- 第四步:将每个选出的证明与 8 个随机选择的分析配对(这里优先选择那些识别出问题(分数为 0 或 0.5)的分析)
- 第五步:针对每个证明-分析(proof-analysis)对,重新生成一个优化后的证明,然后用该证明更新候选池
- 问题:这里更新候选池时,会删除原始的证明分析对吗?
- 迭代终止条件:此过程最多持续 16 次迭代,或者直到一个证明成功通过所有 64 次验证尝试,表明对其正确性有很高的置信度
- 所有实验均使用单一模型,即论文最终的 Proof Generator ,它同时执行证明生成和验证
- 注意:没有使用 Verifier,Verifier 仅在训练 Proof Generator 时使用
- 为了验证论文的结果,数学专家评估了得分最高的证明
- 如表 1 所示,论文的方法解决了 IMO 2025 的 6 个问题中的 5 个,以及 CMO 2024 的 4 个问题并对另一个问题获得了部分分数,在这两个顶尖的高中竞赛中均达到了金牌表现

- 如表 1 所示,论文的方法解决了 IMO 2025 的 6 个问题中的 5 个,以及 CMO 2024 的 4 个问题并对另一个问题获得了部分分数,在这两个顶尖的高中竞赛中均达到了金牌表现
- 在 Putnam 2024 这项杰出的本科生数学竞赛中,论文的模型完全解决了 12 个问题中的 11 个,并在剩余的问题上出现了小错误,得分 118/120,超过了人类最高分 90 分
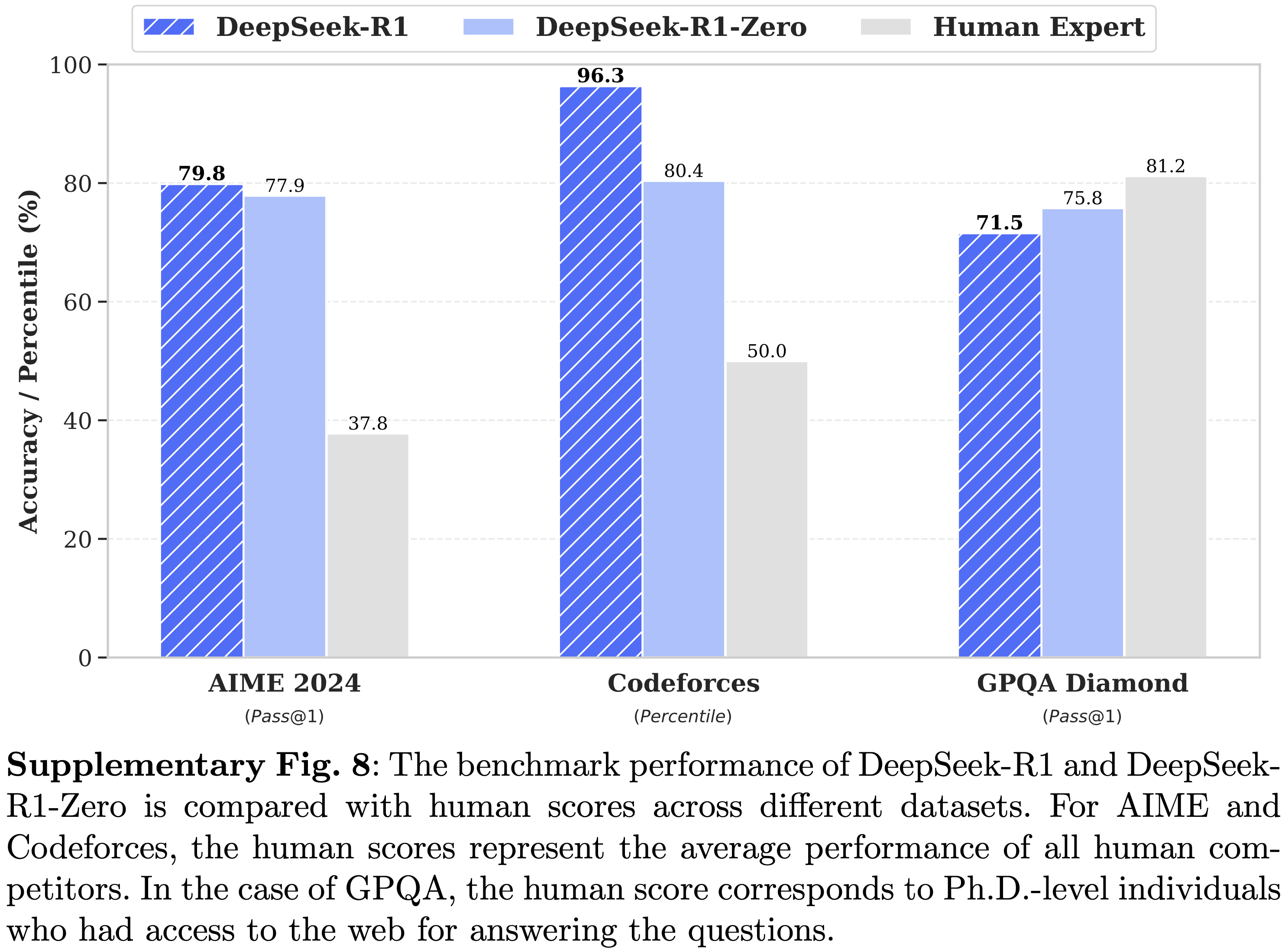
- 图 3 显示了在 IMO-ProofBench 上的结果
- 论文的方法在基础集上优于 DeepMind 的 DeepThink (IMO Gold),在高级集上保持竞争力,同时显著优于所有其他基线
- 论文观察到最难的 IMO 级别问题对论文的模型来说仍然具有挑战性
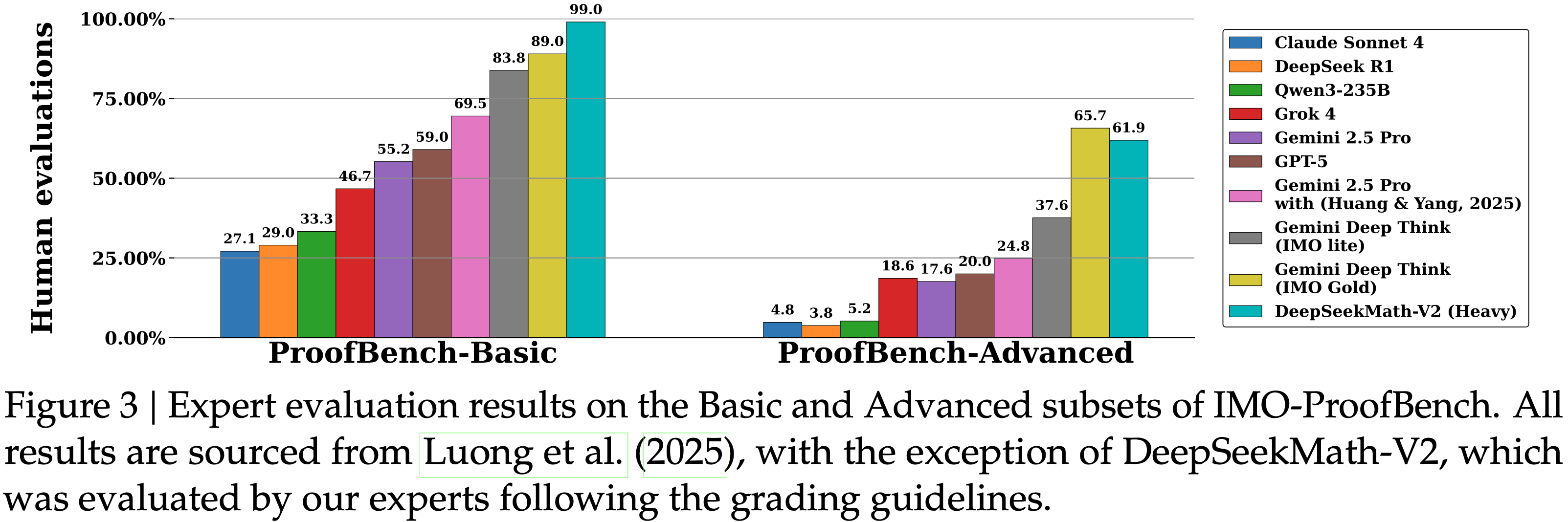
- 值得注意的是,对于未完全解决的问题,论文的 Generator 通常能识别其证明中的真正问题,而完全解决的问题则通过了所有 64 次验证尝试
- 这表明我们可以成功地训练 LLM-based Verifier 来评估先前被认为难以自动验证的证明
- 通过在 Verifier 指导下扩展测试时计算量,论文的模型解决了需要人类参赛者花费数小时努力的问题
Related Work
- 推理模型 (OpenAI, 2024; 2025) 在一年内就使 AIME 和 HMMT 等定量推理基准饱和了,这种快速进步部分归因于明确的评估标准:
- 如果只关心最终答案,那么定量推理很容易验证
- 但这种最终答案指标不适用于定理证明,后者通常不需要数值答案,但要求严谨的逐步推导
- 非正式的数学证明长期以来一直被认为难以自动验证,缺乏可靠的方法来评估证明的正确性;最近的发展表明这个障碍可能是可以克服的
- 像 Gemini-2.5 Pro 这样的模型已经展现出一定程度的 Self-Verification 能力,可以优化自己的解决方案以提高质量 (2025)
- DeepMind 内部的 DeepThink 变体 (2025) 使用纯自然语言推理在 IMO 2025 上获得了金牌表现,表明 LLM-based 复杂证明验证是可行的
- 最近的研究已经开始探索推理模型是否能够评估证明,无论是否有参考解决方案 (2025; 2025),并显示出有希望的结果
- 在这项工作中,论文开源了 DeepSeekMath-V2 和论文的训练方法,作为迈向可 Self-Verification 的数学推理的具体步骤,展示了模型如何学习验证和改进自己的证明
- 像 Lean (de 2015) 和 Isabelle (Paulson, 1994) 这样的证明助手提供了一种可靠的方法来验证证明
- 证明必须用形式化语言编写,但一旦编译完成,正确性就得到保证
- AlphaProof (AlphaProof and teams, 2024; 2024; 2025),一个专用于形式化证明搜索的系统,在 IMO 2024 上获得了银牌级别的表现,但需要密集的计算
- 虽然利用非正式推理来指导形式化证明生成已被广泛探索 (2023),但最近的推理模型极大地提高了非正式推理的质量,使得这种指导更加有效
- 像 DeepSeek-Prover-V2 (2025) 和 Seed-Prover (2025) 这样的系统现在可以在相同的计算预算内产生更多有效的形式化证明,其中 Seed-Prover 在 IMO 2025 上解决了 6 个问题中的 5 个
- 特别说明,这些成果是在没有专门针对定理证明任务优化非正式推理组件的情况下实现的
- 作者相信推进自然语言定理证明将极大地有益于形式化推理,并希望为开发真正可靠的数学推理系统做出贡献,这些系统利用非正式的洞察力和形式化的保证来推进数学研究
附录:Prompt Templates
A.1. Proof Generation Prompt
原始英文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43Your task is to solve a given problem. The problem may ask you to prove a statement, or ask for an answer. If finding an answer is required, you should come up with the answer, and your final solution should also be a rigorous proof of that answer being valid.
Your final solution to the problem should be exceptionally comprehensive and easy-to-follow, which will be rated according to the following evaluation instruction:
'''txt
Here is the instruction to evaluate the quality of a solution to a problem. The problem may ask for a proof of statement, or ask for an answer. If finding an answer is required, the solution should present the answer, and it should also be a rigorous proof of that answer being valid.
Please evaluate the solution and score it according to the following criteria:
- If the solution is completely correct, with all steps executed properly and clearly demonstrated, then the score is 1
- If the solution is generally correct, but with some details omitted or minor errors, then the score is 0.5
- If the solution does not actually address the required problem, contains fatal errors, or has severe omissions, then the score is 0
Additionally, referencing anything from any paper does not save the need to prove the reference. It's okay IF AND ONLY IF the solution also presents a valid proof of the reference argument(s); otherwise, if the solution omits the proof or if the proof provided is not completely correct, the solution should be scored according to the criteria above, and definitely not with a score of 1
'''
In fact, you already have the ability to rate your solution yourself, so you are expected to reason carefully about how to solve a given problem, evaluate your method according to the instruction, and refine your solution by fixing issues identified until you can make no further progress.
In your final response, you should present a detailed solution to the problem followed by your evaluation of that solution.
- To give a good final response, you should try your best to locate potential issues in your own (partial) solution according to the evaluation instruction above, and fix them as many as you can.
- A good final response should just faithfully present your progress, including the best solution you can give, as well as a faithful evaluation of that solution.
- Only when you fail to locate any issues in your solution should you score it with 1.
- If you do notice some issues in your solution but fail to resolve them with your best efforts, it's totally ok to faithfully present the issues in your final response.
- The worst final response would provide a wrong solution but lie that it's correct or claim that it's correct without careful error checking. A better version should faithfully identify errors in the solution. Remember! You CAN'T cheat! If you cheat, we will know, and you will be penalized!
Your final response should be in the following format:
## Solution // Your final solution should start with this exact same markdown title
... // Your final solution to the problem here. You should try your best to optimize the quality of your solution according to the evaluation instruction above before finalizing it here.
## Self Evaluation // Your evaluation of your own solution above should start with this exact same markdown title
Here is my evaluation of the solution: // Your analysis should start with this exact same phrase
... // Your evaluation here. You are required to present in detail the key steps of the solution or the steps for which you had doubts regarding their correctness, and explicitly analyze whether each step is accurate: for correct steps, explain why you initially doubted their correctness and why they are indeed correct; for erroneous steps, explain the reason for the error and the impact of that error on the solution. You should analyze your solution faithfully. E.g., if there are issues in your final solution, you should point it out.
Based on my evaluation, the final overall score should be:
\boxed{ {...} } // where ... should be the final overall score (0, 0.5, or 1, and nothing else) based on the evaluation instruction above. You should reach this score ONLY AFTER careful RE-examination of your own solution above
---
Here is your task input:
## Problem
{question}基本含义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41你的任务是解决给定的问题。问题可能要求你 证明一个陈述,或者要求一个答案。如果需要 找到答案,你应该提出答案,并且 你的最终解决方案也应该是该答案有效的 严格证明
你对问题的最终解决方案应该非常 全面且易于理解,将根据以下评估说明 进行评分:
'''txt
以下是评估问题解决方案质量的说明 问题可能要求证明一个陈述,或者 要求一个答案。如果需要找到答案, 解决方案应该呈现答案,并且也应该是 该答案有效的严格证明
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为0
此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
'''
事实上,你已经具备了自己评估解决方案的 能力,因此期望你仔细推理如何 解决给定问题,根据说明评估你的方法, 并通过修复已识别的问题来改进你的解决方案, 直到你无法取得进一步进展
在你的最终回复中,你应该呈现问题的详细解决方案, 然后是对该解决方案的评估
- 为了给出好的最终回复,你应该尽力 根据上述评估说明找出自己(部分)解决方案中 的潜在问题,并尽可能多地修复它们
- 一个好的最终回复应该忠实地呈现你的 进展,包括你能给出的最佳解决方案, 以及对该解决方案的忠实评估
- 只有当你无法在解决方案中找到任何问题时, 才应将其评分为1
- 如果你确实注意到解决方案中的一些问题但 尽了最大努力仍无法解决,在最终回复中 忠实地呈现这些问题完全没有问题
- 最差的最终回复是提供错误的解决方案却撒谎 说它是正确的,或者在没有仔细检查错误的 情况下声称它是正确的。更好的版本应该 忠实地识别解决方案中的错误。记住!你不能作弊! 如果你作弊,论文会知道,你将受到惩罚!
你的最终回复应遵循以下格式:
#### 解决方案 // 你的最终解决方案应以这个完全相同的 markdown标题开始
... // 你对该问题的最终解决方案在此处。你应该尽力 根据上述评估说明优化解决方案的质量, 然后在此处定稿
#### 自我评估 // 你对自己上述解决方案的评估 应以这个完全相同的markdown标题开始
以下是我对解决方案的评估: // 你的分析应以 这个完全相同的短语开始
... // 你的评估在此处。你需要详细呈现 解决方案的关键步骤或你对其正确性 存疑的步骤,并明确分析每个步骤是否准确: 对于正确的步骤,解释你最初为何怀疑其正确性 以及它们为何确实是正确的;对于错误的步骤, 解释错误的原因以及该错误对解决方案的影响 你应该忠实地分析你的解决方案。例如, 如果你的最终解决方案存在问题,你应该 指出来
根据我的评估,最终总体得分应为:
\boxed{ {...} } // 其中...应为根据上述评估说明得出的 最终总体得分(0、0.5或1,且不能是其他内容) 你只有在仔细重新检查自己的解决方案后才应 得出这个分数
以下是你的任务输入:
#### 问题
{问题}
A.2. Proof Verification Prompt
原始英文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27## Instruction
Your task is to evaluate the quality of a solution to a problem. The problem may ask for a proof of statement, or ask for an answer. If finding an answer is required, the solution should present the answer, and it should also be a rigorous proof of that answer being valid.
Please evaluate the solution and score it according to the following criteria:
- If the solution is completely correct, with all steps executed properly and clearly demonstrated, then the score is 1
- If the solution is generally correct, but with some details omitted or minor errors, then the score is 0.5
- If the solution does not actually address the required problem, contains fatal errors, or has severe omissions, then the score is 0
- Additionally, referencing anything from any paper does not save the need to prove the reference. It's okay IF AND ONLY IF the solution also presents a valid proof of the reference argument(s); otherwise, if the solution omits the proof or if the proof provided is not completely correct, the solution should be scored according to the criteria above, and definitely not with a score of 1
Please carefully reason out and analyze the quality of the solution below, and in your final response present a detailed evaluation of the solution's quality followed by your score. Therefore, your response should be in the following format:
Here is my evaluation of the solution:
... // Your evaluation here. You are required to present in detail the key steps of the solution or the steps for which you had doubts regarding their correctness, and explicitly analyze whether each step is accurate: for correct steps, explain why you initially doubted their correctness and why they are indeed correct; for erroneous steps, explain the reason for the error and the impact of that error on the solution.
Based on my evaluation, the final overall score should be:
\boxed{...} // where ... should be the final overall score (0, 0.5, or 1, and nothing else) based on the above criteria
---
Here is your task input:
## Problem
{question}
## Solution
{proof}基本含义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#### 说明
你的任务是评估问题解决方案的质量 问题可能要求证明一个陈述,或者要求一个 答案。如果需要找到答案,解决方案 应该呈现答案,并且也应该是该答案有效的 严格证明
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为0
- 此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
请仔细推理并分析下方解决方案的质量, 并在你的最终回复中呈现解决方案质量的 详细评估,然后是你的评分。因此,你的回复 应遵循以下格式:
以下是我对解决方案的评估:
... // 你的评估在此处。你需要详细呈现 解决方案的关键步骤或你对其正确性 存疑的步骤,并明确分析每个步骤是否准确:对于正确的步骤,解释你最初为何怀疑其正确性 以及它们为何确实是正确的;对于错误的步骤, 解释错误的原因以及该错误对解决方案的影响
根据我的评估,最终总体得分应为:
\boxed{...} // 其中...应为根据上述标准得出的 最终总体得分(0、0.5或1,且不能是其他内容)
以下是你的任务输入:
#### 问题
{问题}
#### 解决方案
{证明}
A.3. Meta-Verification Prompt
原始英文:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73You are given a "problem", "solution", and "solution evaluation", and you need to assess the whether this "solution evaluation" is reasonable.
First, "solution evaluation" is generated to evaluate the quality of the "solution", by prompting a verifier with the rules below (these are not your rules):
'''
Please evaluate the solution and score it according to the following criteria:
- If the solution is completely correct, with all steps executed properly and clearly demonstrated, then the score is 1
- If the solution is generally correct, but with some details omitted or minor errors, then the score is 0.5
- If the solution does not actually address the required problem, contains fatal errors, or has severe omissions, then the score is 0
Additionally, referencing anything from any paper does not save the need to prove the reference. It's okay IF AND ONLY IF the solution also presents a valid proof of the reference argument(s); otherwise, if the solution omits the proof or if the proof provided is not completely correct, the solution should be scored according to the criteria above, and definitely not with a score of 1
'''
Next, I will introduce the rules for you to analyze the quality of the "solution evaluation":
1. Your task is to analyze the "solution evaluation". You do not need to solve the "problem", nor do you need to strictly assess whether the "solution" is accurate. Your only task is to strictly follow the rules below to evaluate whether the "solution evaluation" is reasonable.
2. You need to analyze the content of the "solution evaluation" from three aspects:
Step Restatement: In the "solution evaluation", certain behaviors of the "solution" may be restated. You need to return to the original text of the "solution" and check whether the " solution" actually has these behaviors mentioned in the " solution evaluation".
Defect Analysis: "solution evaluation" may point out errors or defects in the "solution". You need to carefully analyze whether the mentioned errors and defects are indeed valid.
Expression Analysis: Whether the "solution evaluation"'s expressions are accurate.
Score Analysis: Whether the final score given by the "solution evaluation" matches the defects it found. You need to analyze according to the scoring rules given above.
3. The most important part is **defect analysis** :In this part, your core task is to check whether the errors or defects of the "solution" pointed out in the "solution evaluation" are reasonable. In other words, any positive components about the "solution" in the "solution evaluation", regardless of whether they are reasonable, are not within your evaluation scope.
- For example: If the "solution evaluation" says that a certain conclusion in the "solution" is correct, but actually this conclusion is incorrect, then you do not need to care about this point. All parts that the "solution evaluation" considers correct do not belong to your evaluation scope.
- Specifically: If the "solution evaluation" believes that the " solution" is completely accurate and has not found any errors or defects, then regardless of whether the "solution" itself is actually accurate, even if there are obvious errors, you should still consider its analysis of errors to be reasonable.
**Importantly**, for defects found by the "solution evaluation", you need to analyze two points simultaneously:
- whether this defect actually exists
- whether the "solution evaluation"'s analysis of this defect is accurate
These two aspects constitute the analysis of defects.
4. About **expression analysis**, if there are certain expression errors in the "solution evaluation", even minor errors in details, you need to identify them. However, please note that identifying incorrect steps in the "solution" as correct steps does not constitute an **expression error**.
In practice, expression errors include but are not limited to:
- If the "solution evaluation" identifies some reasoning step(s) in the "solution" as incorrect, then it cannot further indicate that subsequent conclusion(s) depending on those reasoning step(s) are wrong, but can only indicate that subsequent conclusion(s) are "not rigorously demonstrated."
- Typos and calculation errors made by "solution evaluation"
- Inaccurate restatement of content from "solution"
5. Finally, you need to present your analysis of the "solution evaluation" in your output and also rate its quality based on the rules below:
First, if there is at least one unreasonable defect among the defects found by the "solution evaluation", then you only need to do **defect analysis** :
- If all defects found by the "solution evaluation" are unreasonable, then you should rate it with \\(0\\)
- If some defects found by the "solution evaluation" are reasonable and some are unreasonable, then your rating should be \\(0.5\\)
Next, if the "solution evaluation" points out no errors or defects, or all defects found by the evaluation are reasonable, then you should do the following things:
- Analyze whether "expression errors" exist in the "solution evaluation" (**expression analysis**) or whether "solution evaluation" gives a wrong score according to the rules for " solution evaluation" (**score analysis**). If yes, you should rate the "solution evaluation" with \\(0.5\\); if no, your rating should be \\(1\\)
Your output should follow the format below:
Here is my analysis of the "solution evaluation":
... // Your analysis here.
Based on my analysis, I will rate the "solution evaluation" as:
\boxed{...} // where ... should be a numerical rating of the " solution evaluation" (0, 0.5, or 1, and nothing else) based on the criteria above.
---
Here is your task input:
## Problem
{question}
## Solution
{proof}
## Solution Evaluation
{proof analysis}中文含义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69你被提供了一个"问题"、"解决方案"和"解决方案评估", 你需要评估这个"解决方案评估"是否合理
首先,"解决方案评估"是通过使用以下规则提示 Verifier 来评估"解决方案"质量而生成的(这些不是你的规则):
请根据以下标准评估解决方案并评分:
- 如果解决方案完全正确,所有步骤都执行得当 并清晰展示,则得分为1
- 如果解决方案大体正确,但有一些细节 被省略或有小错误,则得分为0.5
- 如果解决方案实际上没有解决所要求的问题, 包含致命错误,或有严重遗漏,则 得分为0
此外,引用任何论文中的任何内容都不能免除 证明该引用的需要。仅当且仅当 解决方案同时提供了引用论证的有效证明时 才可以;否则,如果解决方案省略了证明或 提供的证明不完全正确,则 解决方案应根据上述标准评分, 且绝对不能得1分
接下来,我将介绍你分析"解决方案评估"质量 的规则:
1. 你的任务是分析"解决方案评估"。你不需要 解决"问题",也不需要严格评估"解决方案" 是否准确。你的唯一任务是严格遵循以下规则 来评估"解决方案评估"是否合理
2. 你需要从三个方面分析"解决方案评估"的内容:
步骤重述:在"解决方案评估"中,可能会重述"解决方案" 的某些行为。你需要回到"解决方案"的原始文本, 检查"解决方案"是否实际具有"解决方案评估"中 提到的这些行为
缺陷分析:"解决方案评估"可能会指出"解决方案"中的 错误或缺陷。你需要仔细分析提到的错误和缺陷 是否确实有效
表达分析:"解决方案评估"的表达是否准确
分数分析:"解决方案评估"给出的最终分数是否与其 发现的缺陷相匹配。你需要根据上面给出的 评分规则进行分析
3. 最重要的部分是**缺陷分析** :在这部分中, 你的核心任务是检查"解决方案评估"中指出的 "解决方案"的错误或缺陷是否合理。换句话说, "解决方案评估"中关于"解决方案"的任何正面内容, 无论是否合理,都不在你的评估范围之内
- 例如:如果"解决方案评估"说"解决方案"中的某个 结论是正确的,但实际上这个结论是错误的, 那么你不需要关心这一点。"解决方案评估"认为 正确的所有部分都不属于你的评估范围
- 具体来说:如果"解决方案评估"认为"解决方案" 完全准确,没有发现任何错误或缺陷,那么无论 "解决方案"本身是否实际准确,即使存在明显错误, 你仍应认为其对错误的分析是合理的
**重要的是** ,对于"解决方案评估"发现的缺陷, 你需要同时分析两点:
- 这个缺陷是否实际存在
- "解决方案评估"对这个缺陷的分析是否准确
这两个方面构成了缺陷分析
4. 关于**表达分析** ,如果"解决方案评估"中存在某些 表达错误,即使是细节上的小错误,你也需要 识别它们。但是,请注意,将"解决方案"中的 错误步骤识别为正确步骤不构成**表达错误**
在实践中,表达错误包括但不限于:
- 如果"解决方案评估"将"解决方案"中的某些推理步骤 识别为不正确,那么它不能进一步指出依赖于这些推理步骤的后续结论是错误的,而只能指出 后续结论"没有得到严格证明"
- "解决方案评估"中的拼写错误和计算错误
- 对"解决方案"内容的不准确重述
5. 最后,你需要在输出中呈现你对"解决方案评估"的 分析,并根据以下规则评定其质量:
首先,如果"解决方案评估"发现的缺陷中至少有一个 是不合理的,那么你只需要进行**缺陷分析** :
- 如果"解决方案评估"发现的所有缺陷都是不合理的, 那么你应该将其评定为\\(0\\)
- 如果"解决方案评估"发现的部分缺陷是合理的, 部分是不合理的,那么你的评分应为\\(0.5\\)
接下来,如果"解决方案评估"没有指出任何错误或 缺陷,或者评估发现的所有缺陷都是合理的, 那么你应该做以下事情:
- 分析"解决方案评估"中是否存在"表达错误" (**表达分析**)或者"解决方案评估"是否根据 "解决方案评估"的规则给出了错误的分数 (**分数分析**)。如果是,你应该将"解决方案评估" 评定为\\(0.5\\);如果不是,你的评分应为\\(1\\)
你的输出应遵循以下格式:
以下是我对"解决方案评估"的分析:
... // 你的分析在此处
根据我的分析,我将"解决方案评估"评定为:
\boxed{...} // 其中...应为根据上述标准对"解决方案评估" 的数值评分(0、0.5或1,且不能是其他内容)
-
以下是你的任务输入:
#### 问题
{问题}
#### 解决方案
{证明}
#### 解决方案评估
{证明分析}
A.4. Proof Refinement Prompt
原始英文:
1
2
3
4
5
6
7
8
9
10
11{proof_generation_prompt}
## Candidate Solution(s) to Refine
Here are some solution sample(s) along with their correctness evaluation(s). You should provide a better solution by solving issues mentioned in the evaluation(s), or by re- using promising ideas mentioned in the solution sample(s), or by doing both.
{proof}
{proof analyses}
## Final Instruction
Your final response should follow the format above, including a '## Solution' section followed by a '## Self Evaluation' section基本含义:
1
2
3
4
5
6
7
8
9
10
11{证明生成提示词}
#### 待改进的候选解决方案
以下是一些解决方案样本及其正确性评估 你应该通过解决评估中提到的问题,或重新使用 解决方案样本中提到的有前景的想法,或两者兼施, 来提供更好的解决方案
{证明}
{证明分析}
#### 最终说明
你的最终回复应遵循上述格式,包括一个 '## 解决方案'部分,后跟一个'## 自我评估' 部分


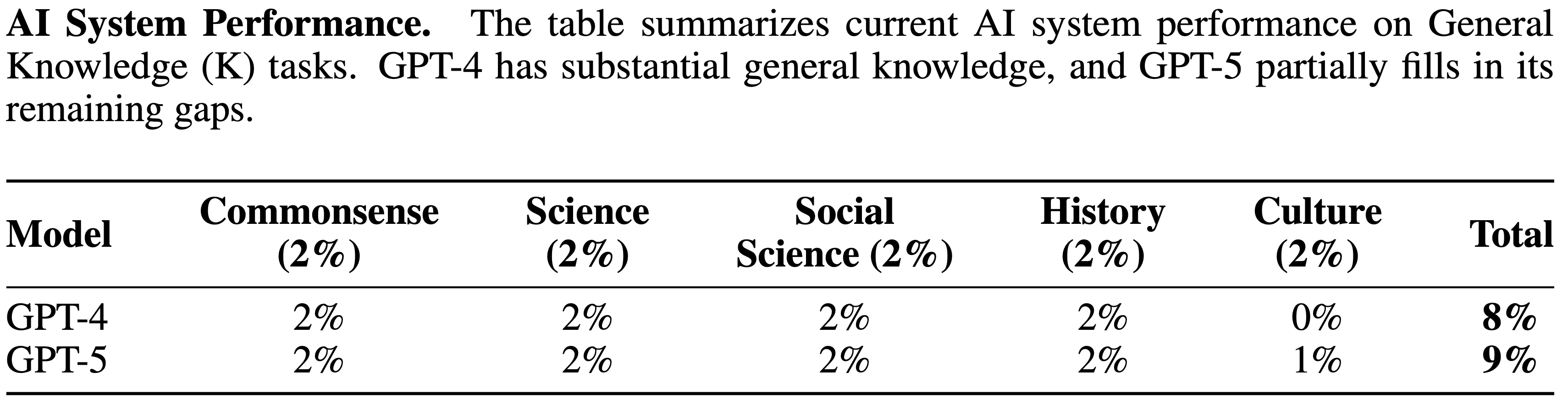

 tasks. GPT-4’s difficulty with token-level understanding, its small context window, and its imprecise working memory limit its ability to analyze substrings of words, to read long documents, and to carefully proofread text. GPT-5 addresses these issues.")

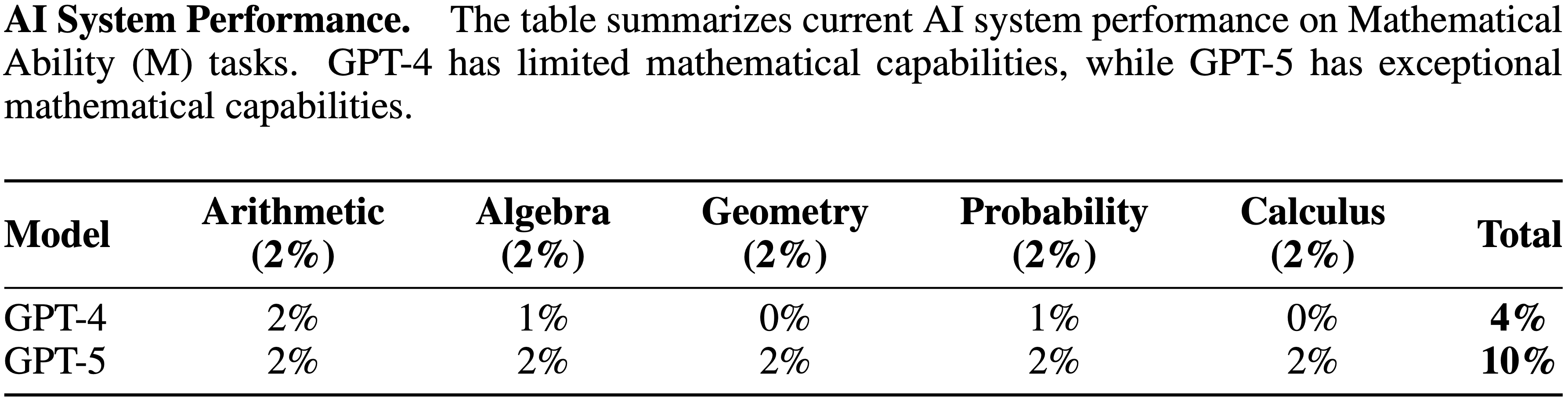
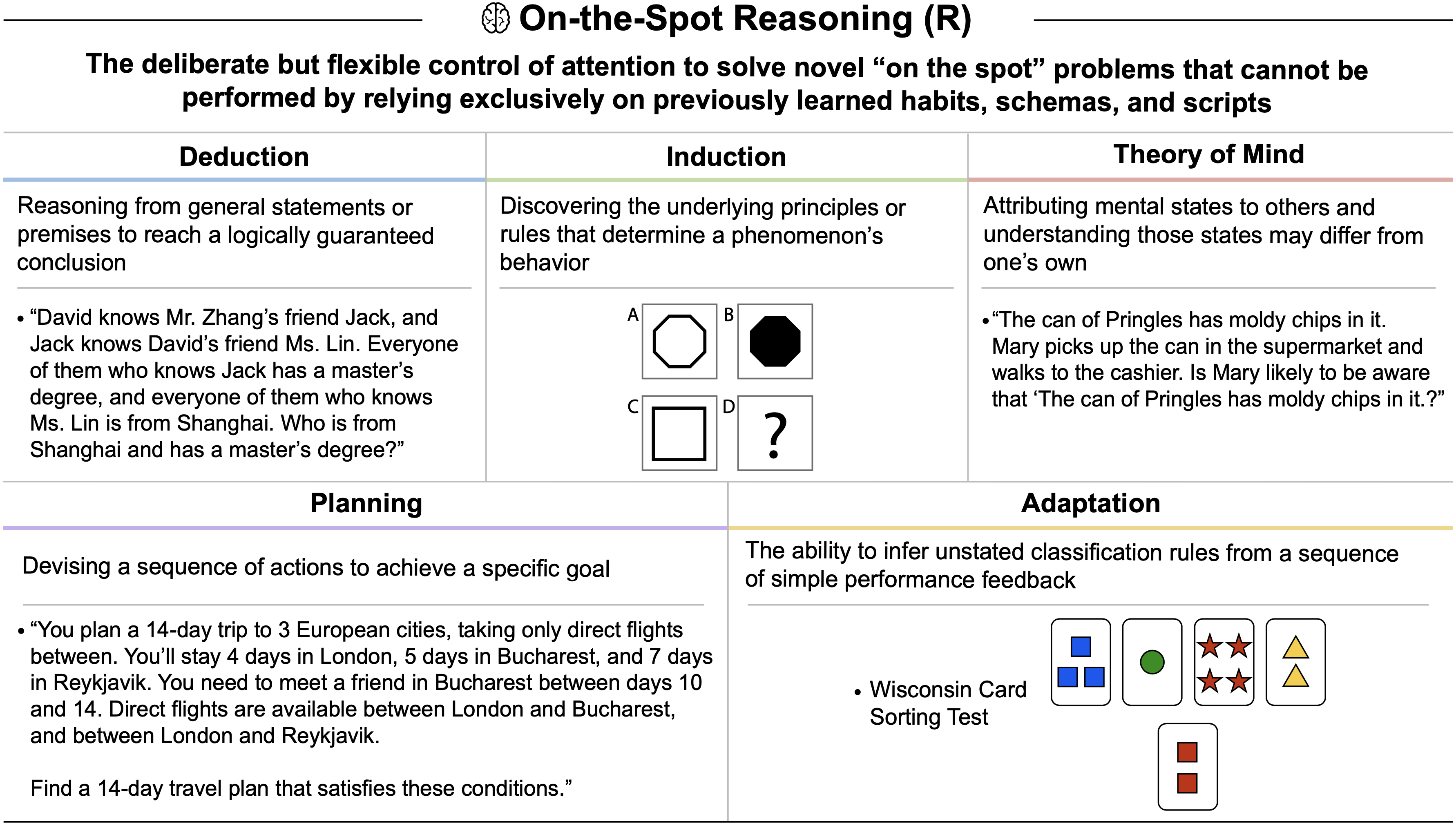
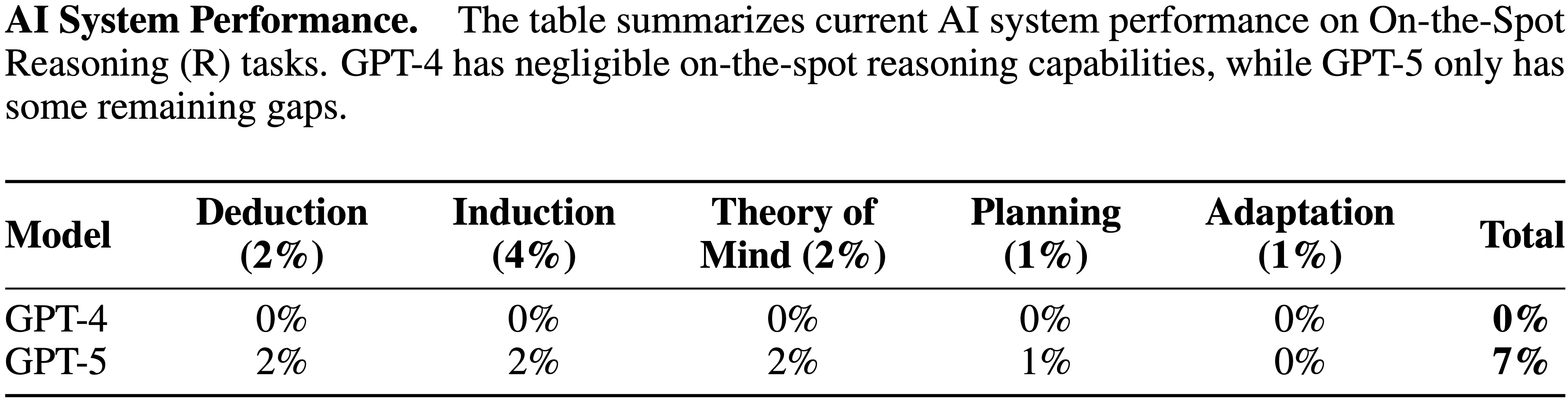
 tasks. While the raw Textual Working Memory score appears similar between GPT-4 and GPT-5 in this battery, improvements in managing long contexts are also reflected in the Document Level Reading Comprehension score within the Reading and Writing (RW) ability.")




 显示了在 Fox (2024) 基准测试上测试的压缩比(真实文本 Token 数量 / 模型使用的视觉 Token 数量);图 (b) 显示了在 OmniDocBench (2025) 上的性能比较;DeepSeek-OCR 在使用最少视觉 Token 的端到端模型中实现了 SOTA 性能")


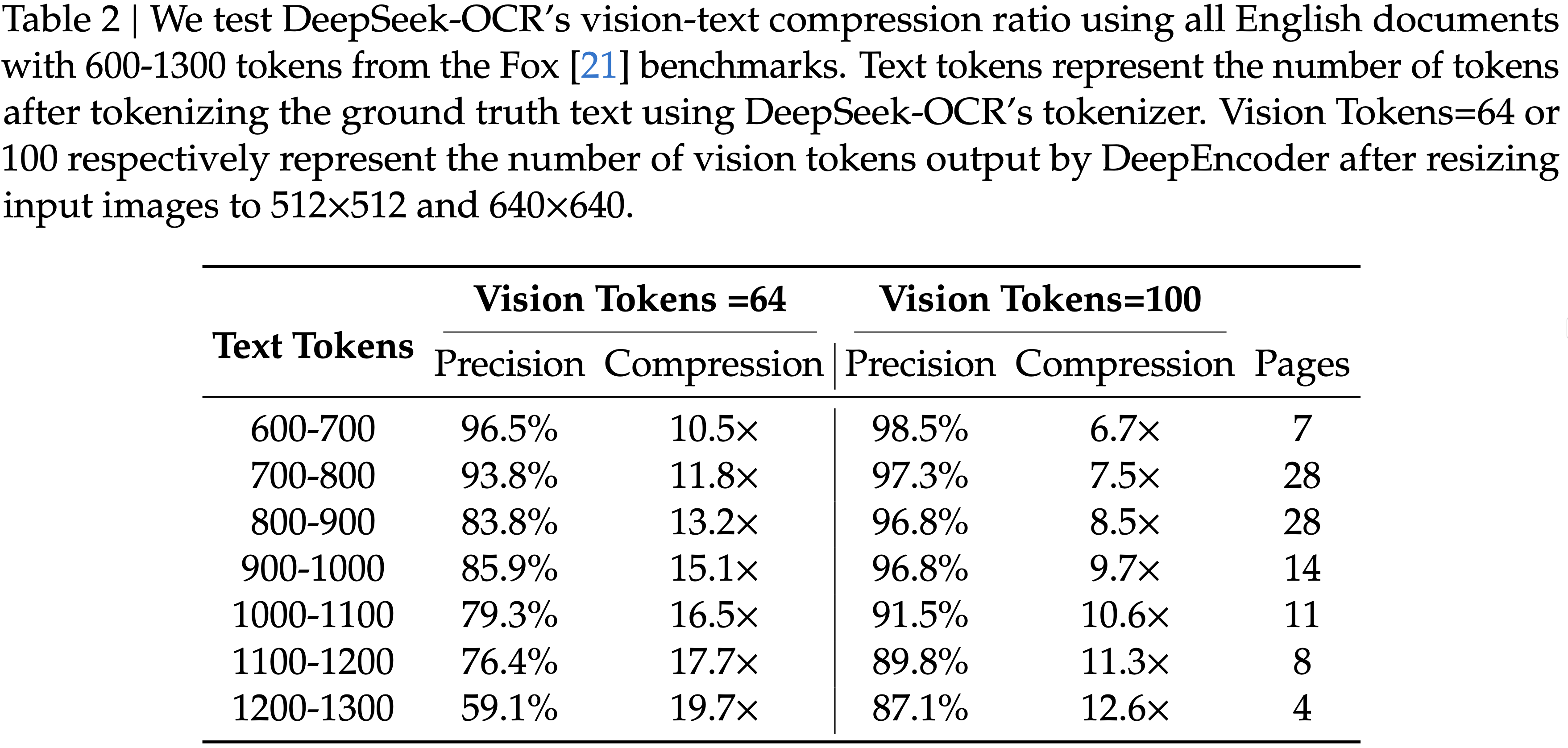
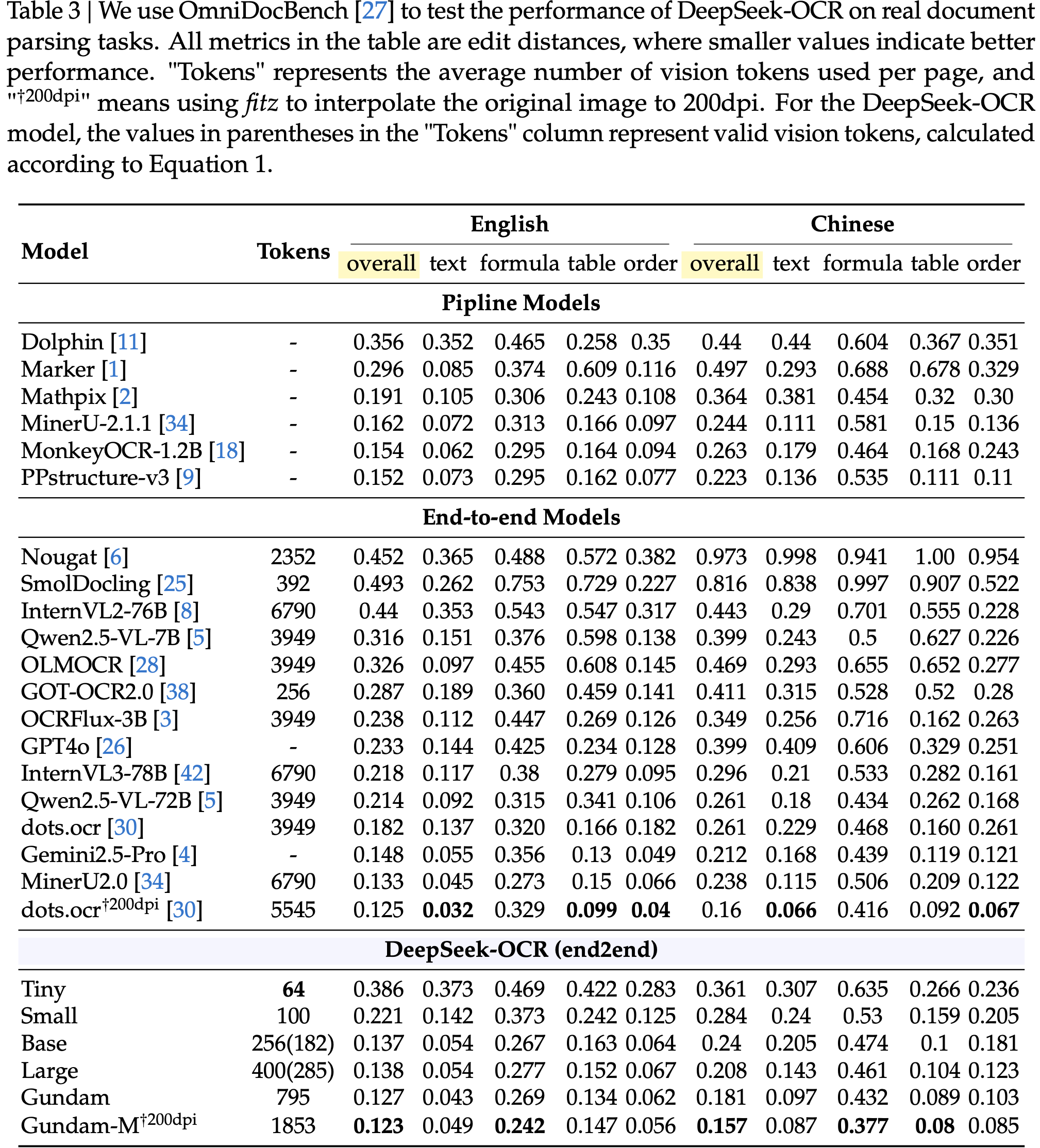
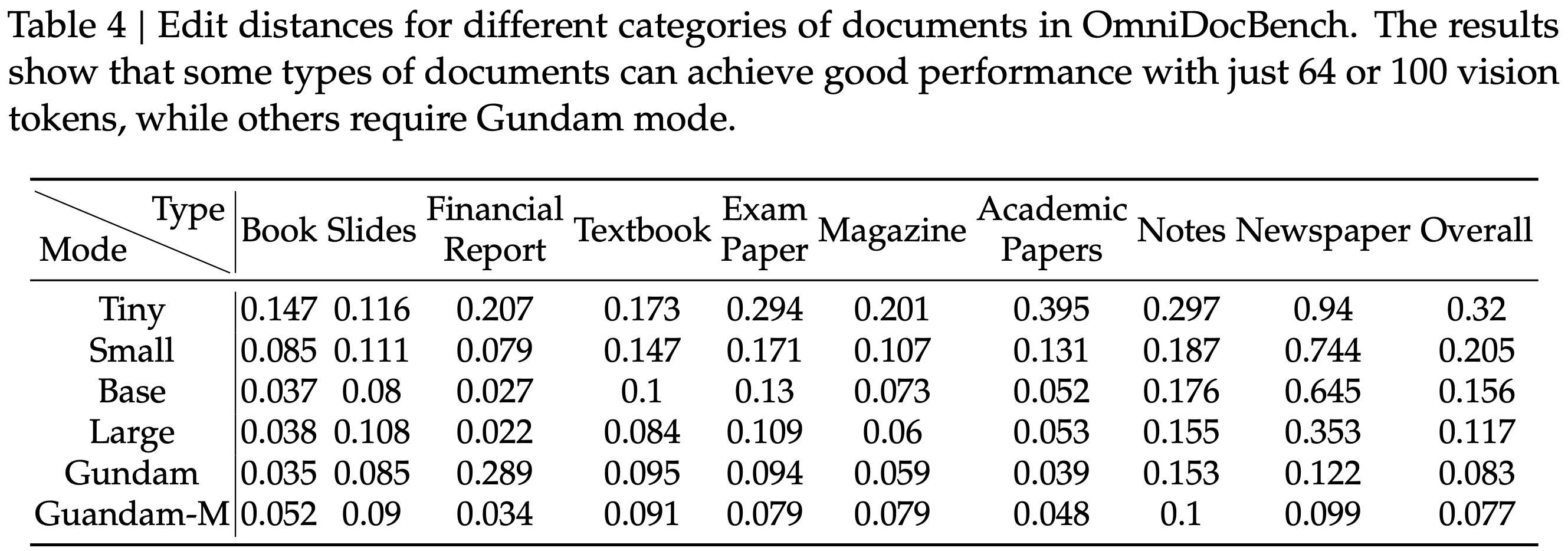
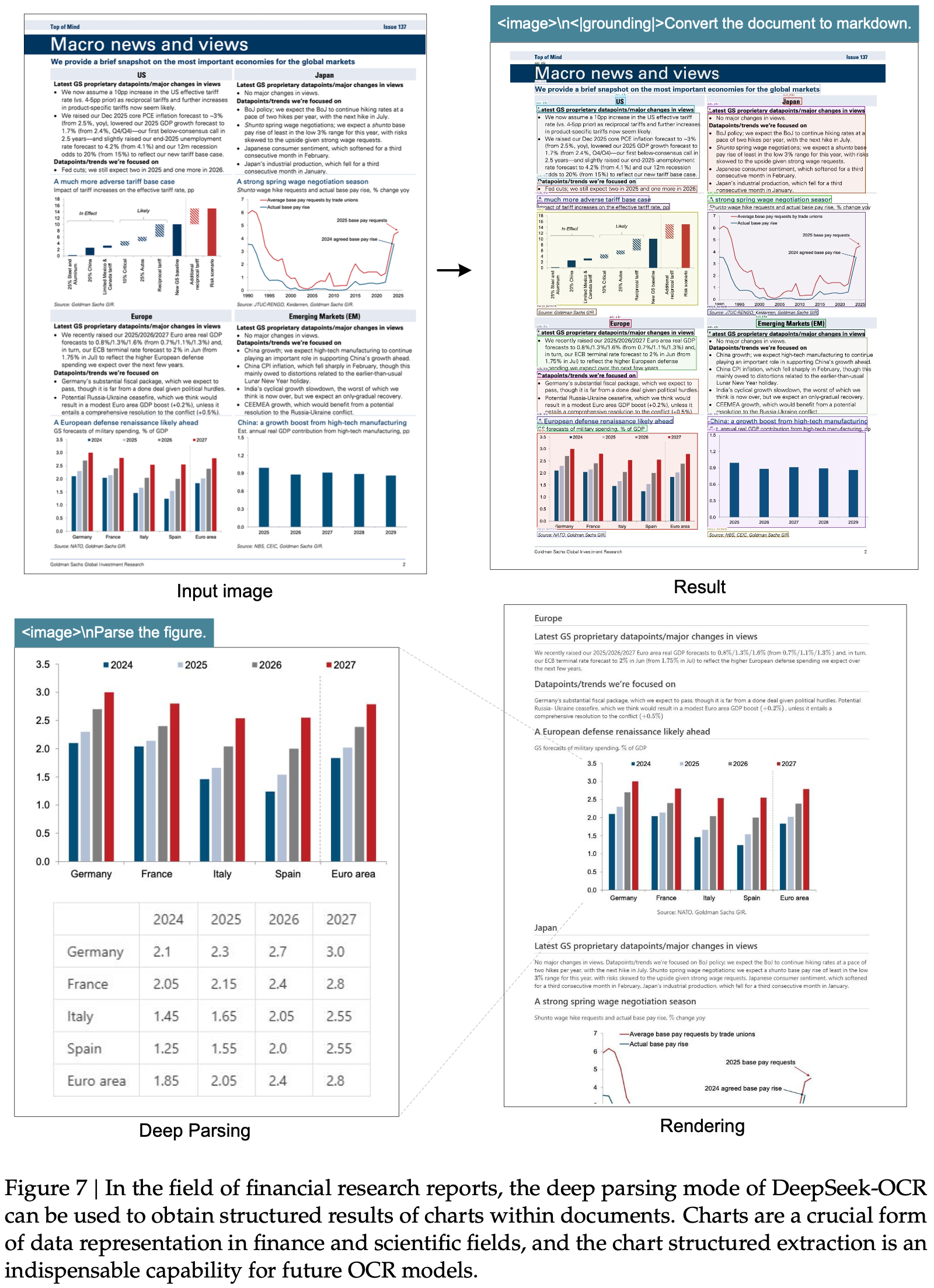


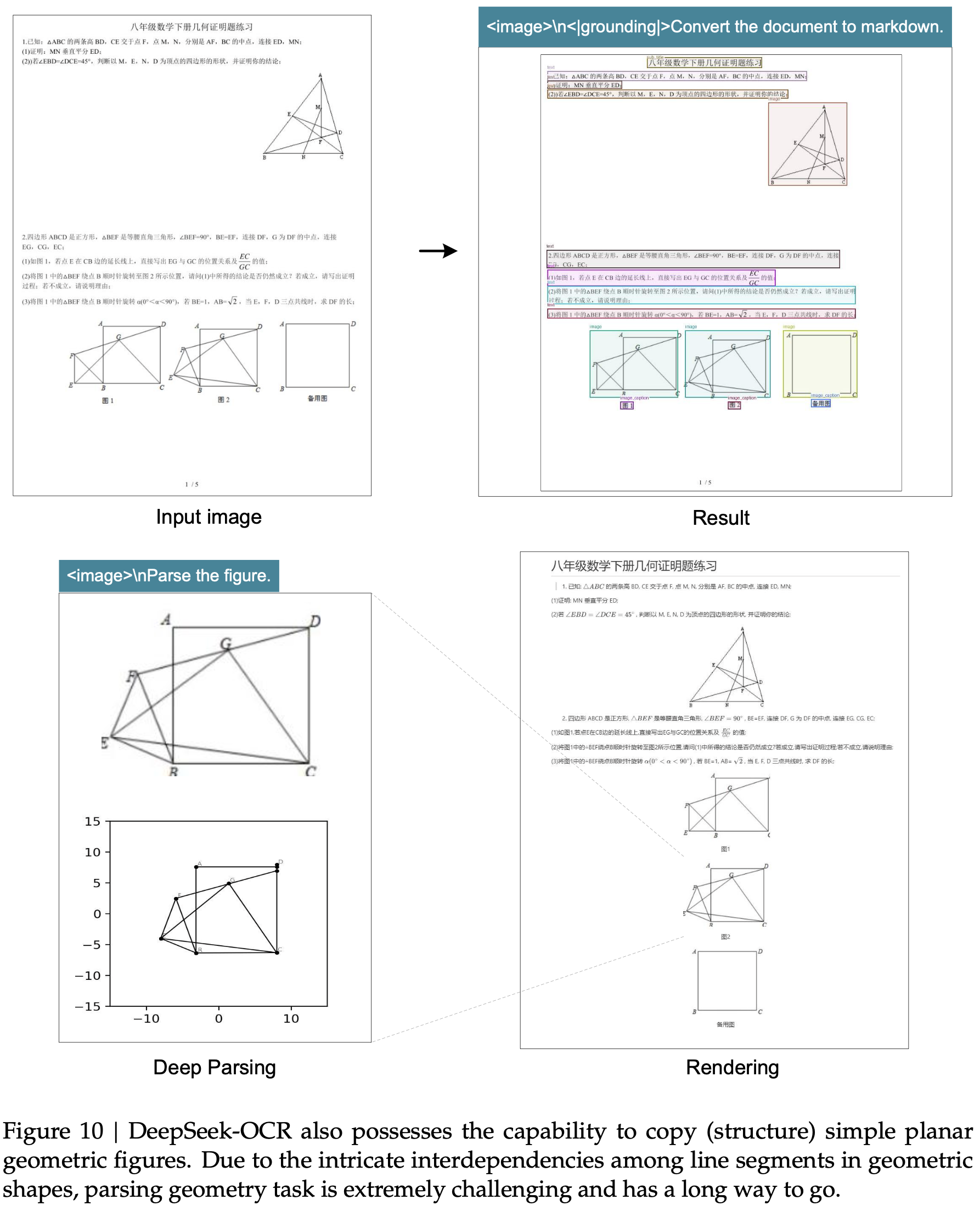




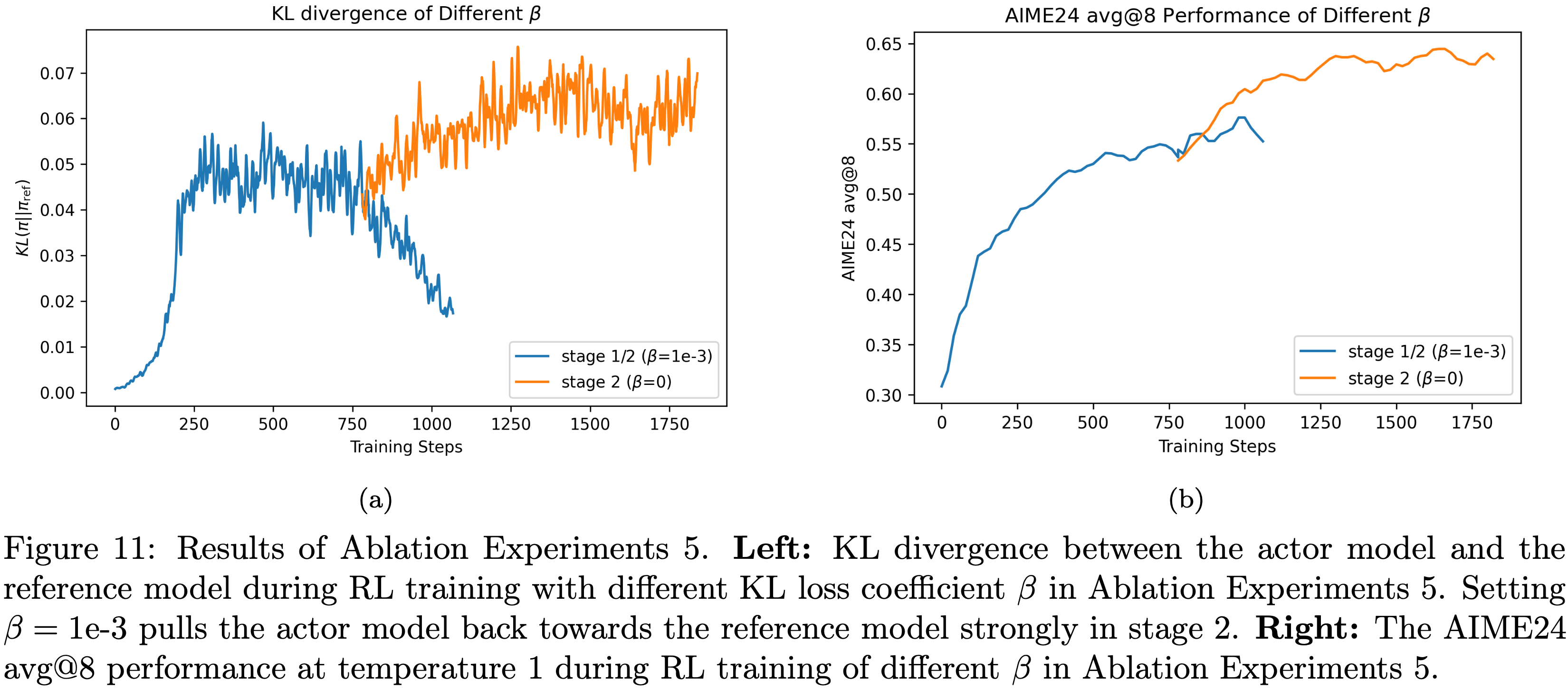
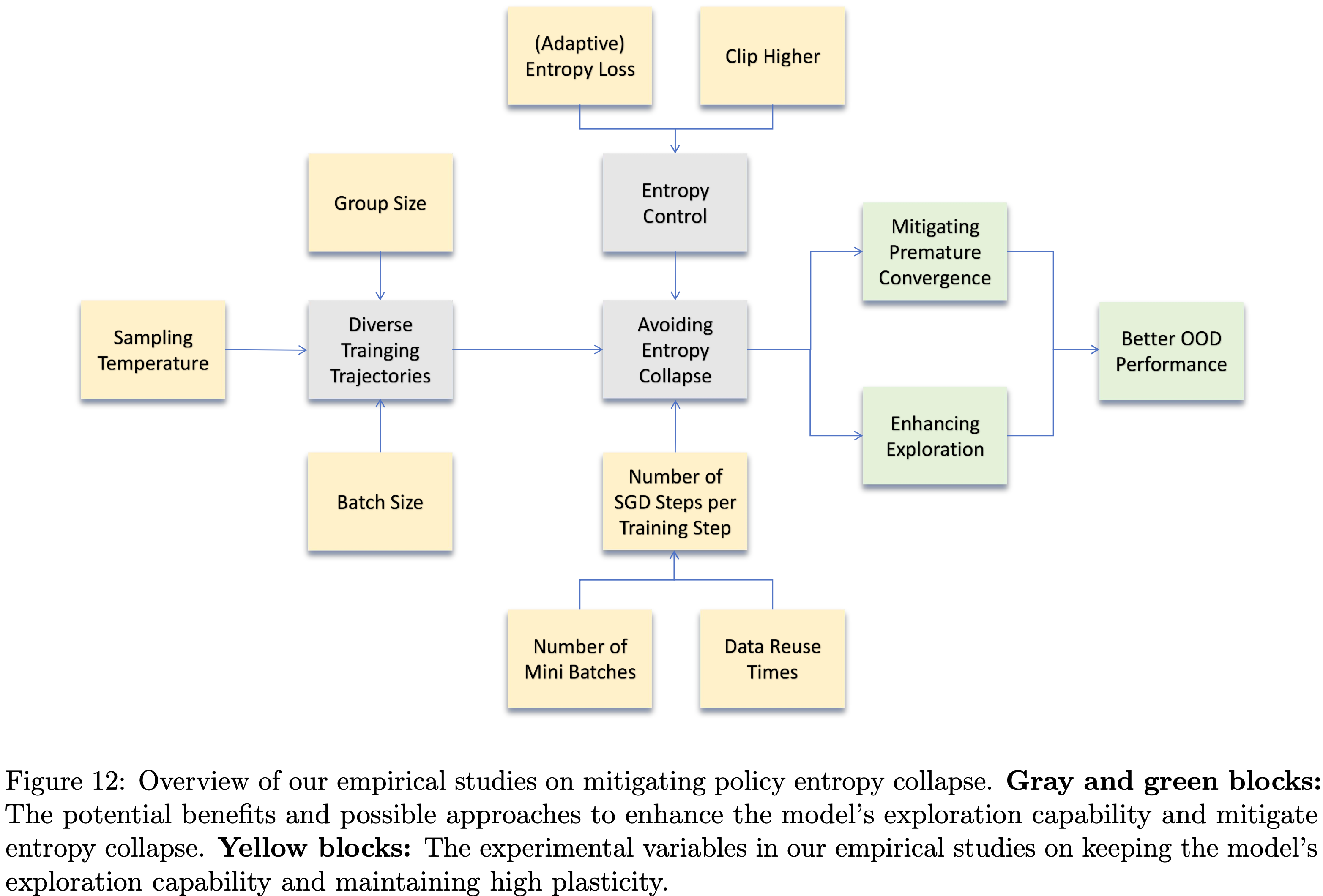
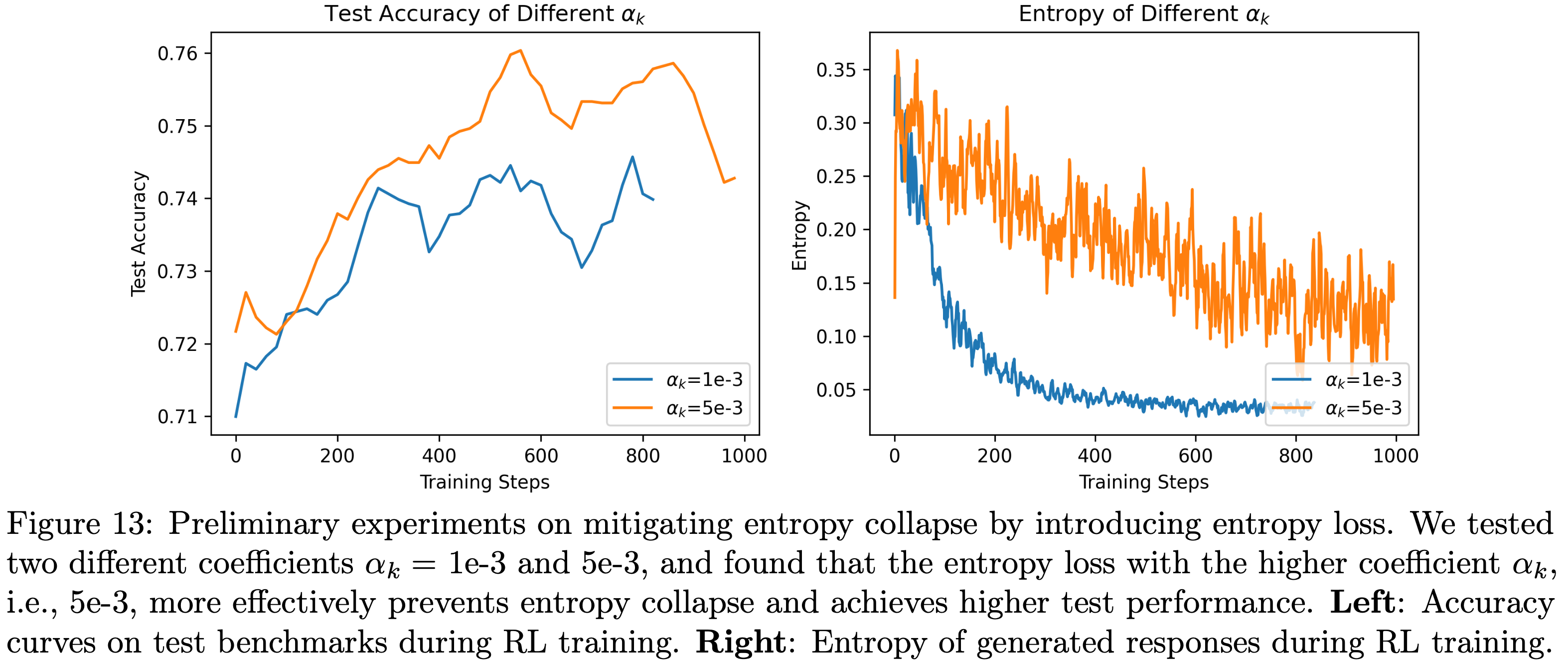
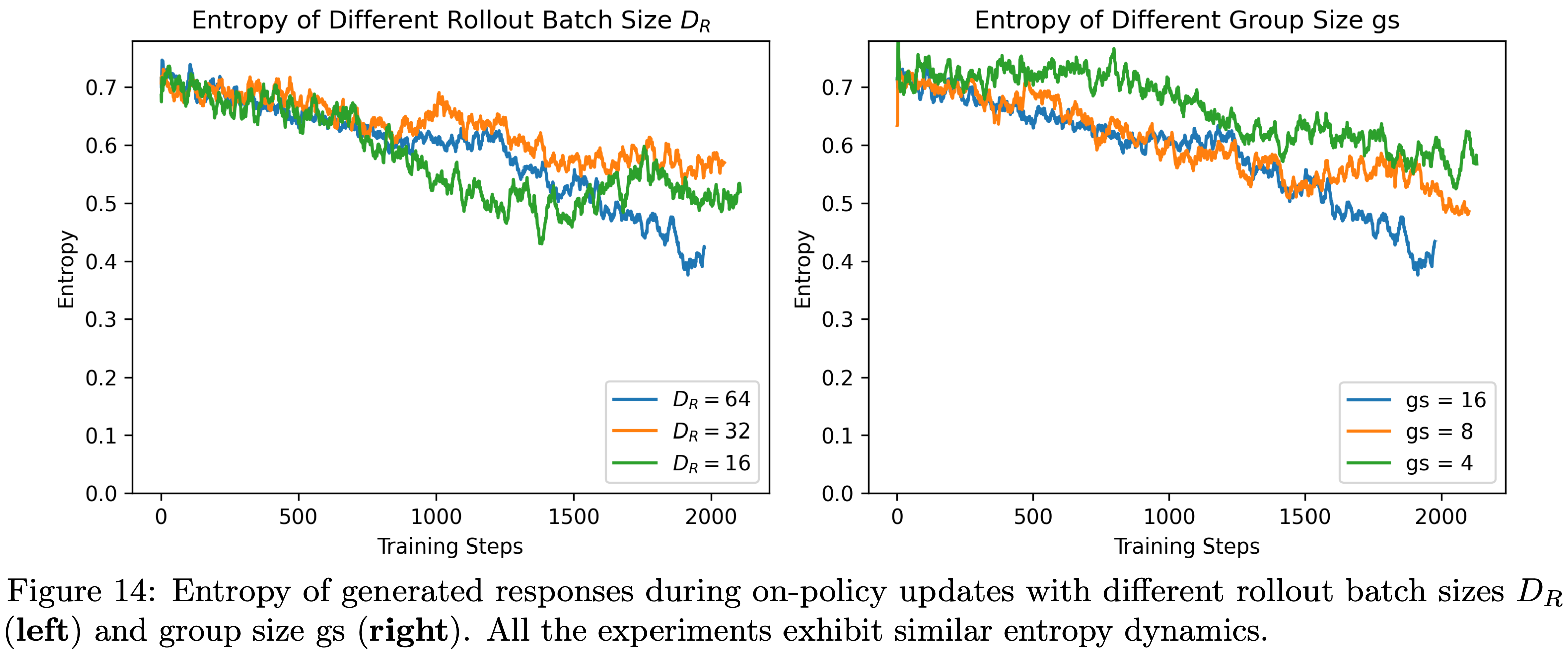
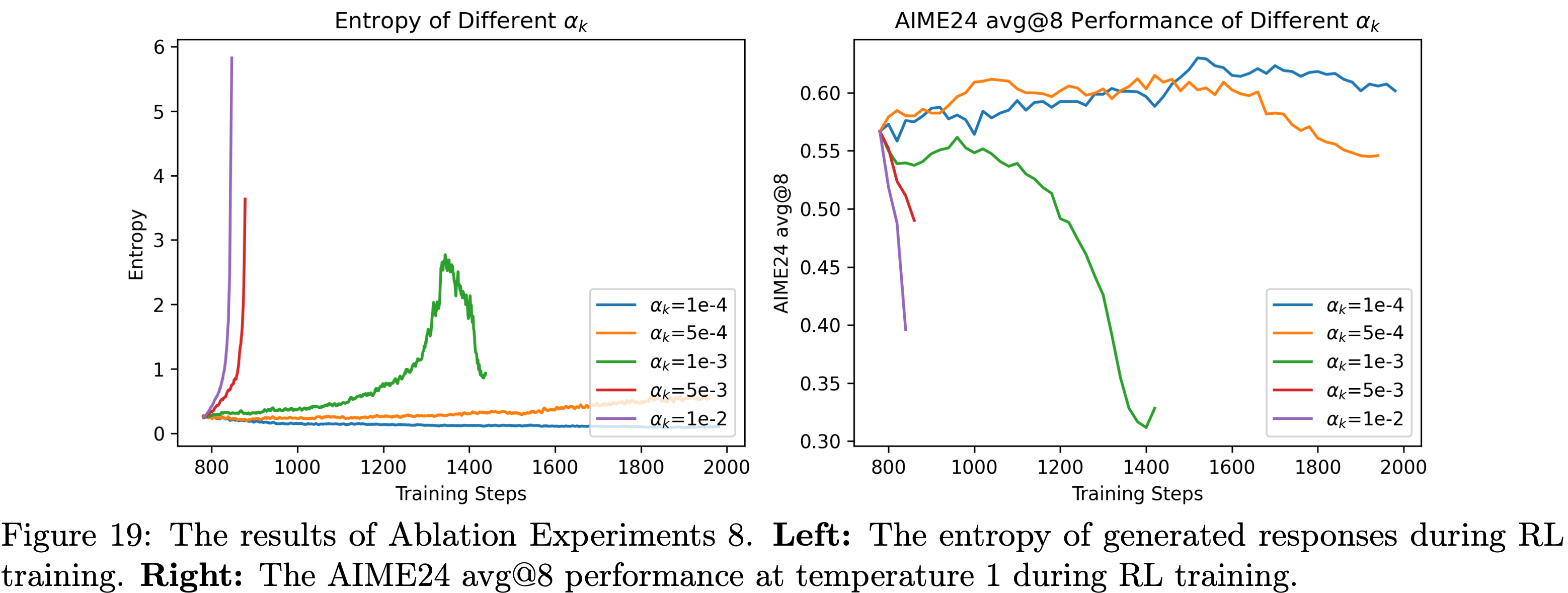
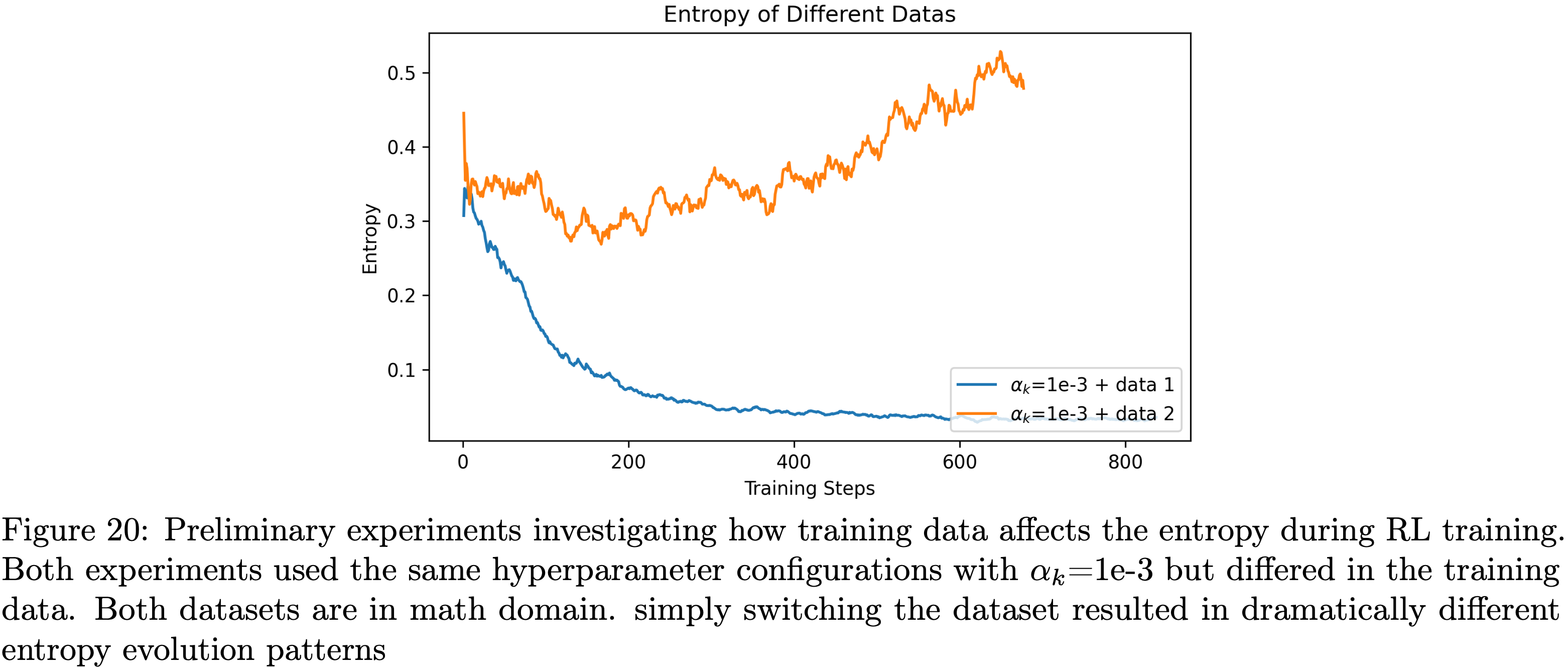
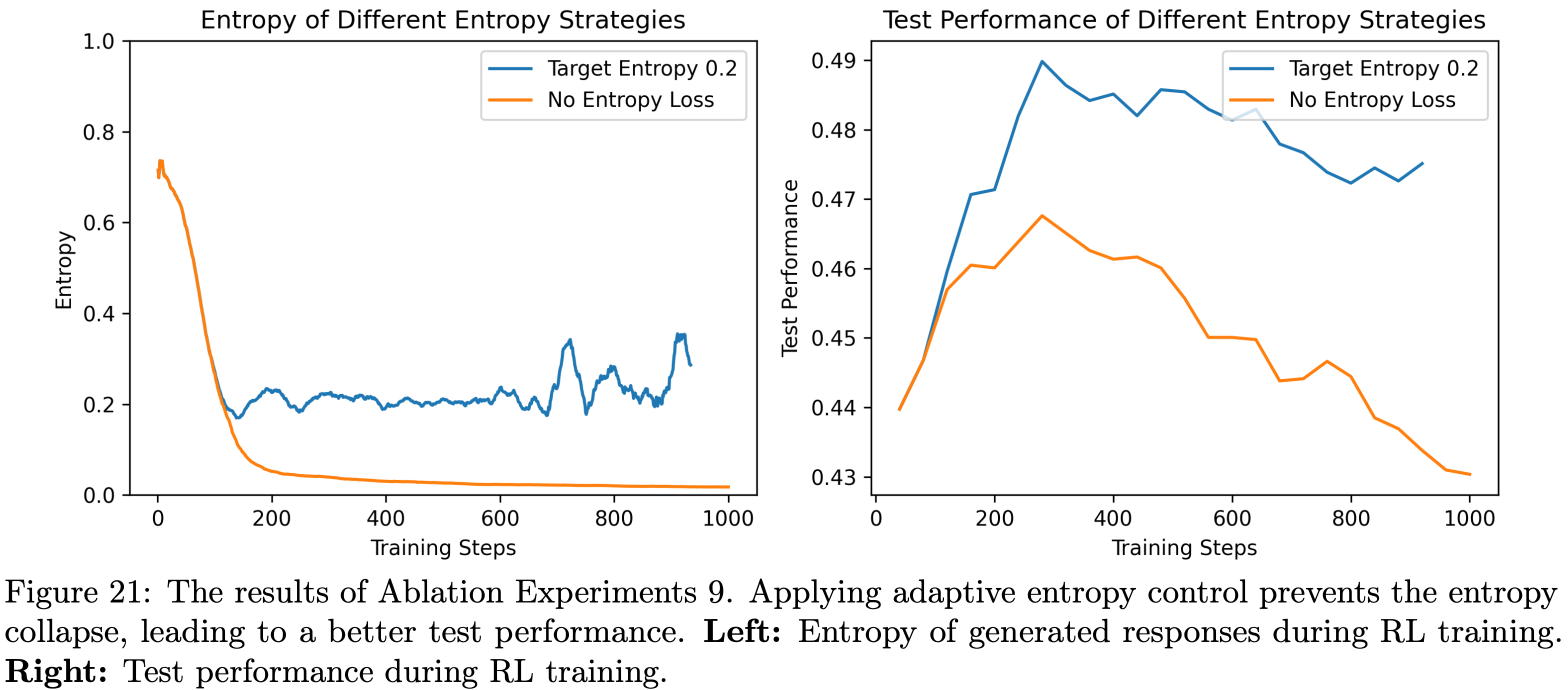
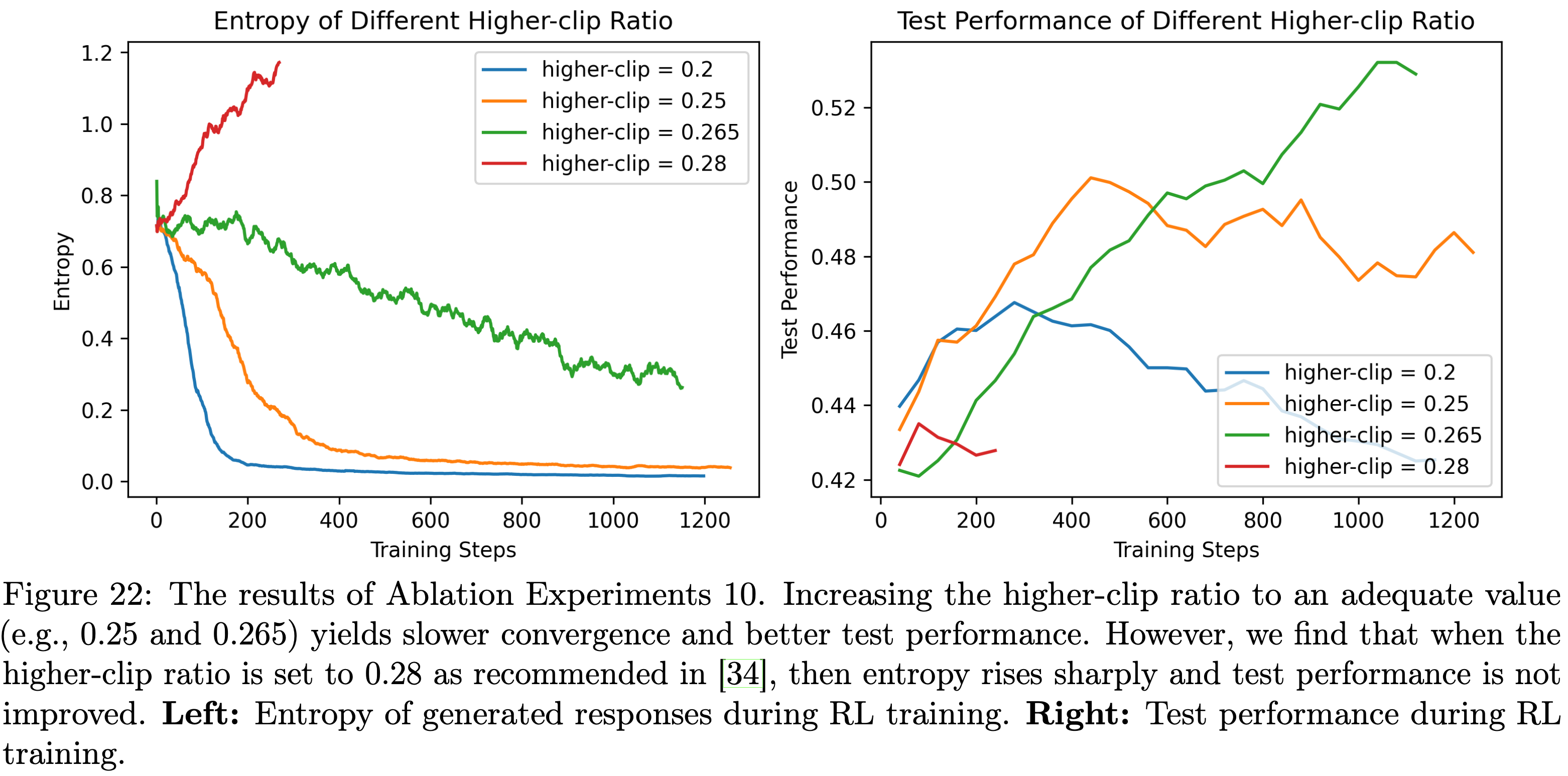
,大约为 -1.38")
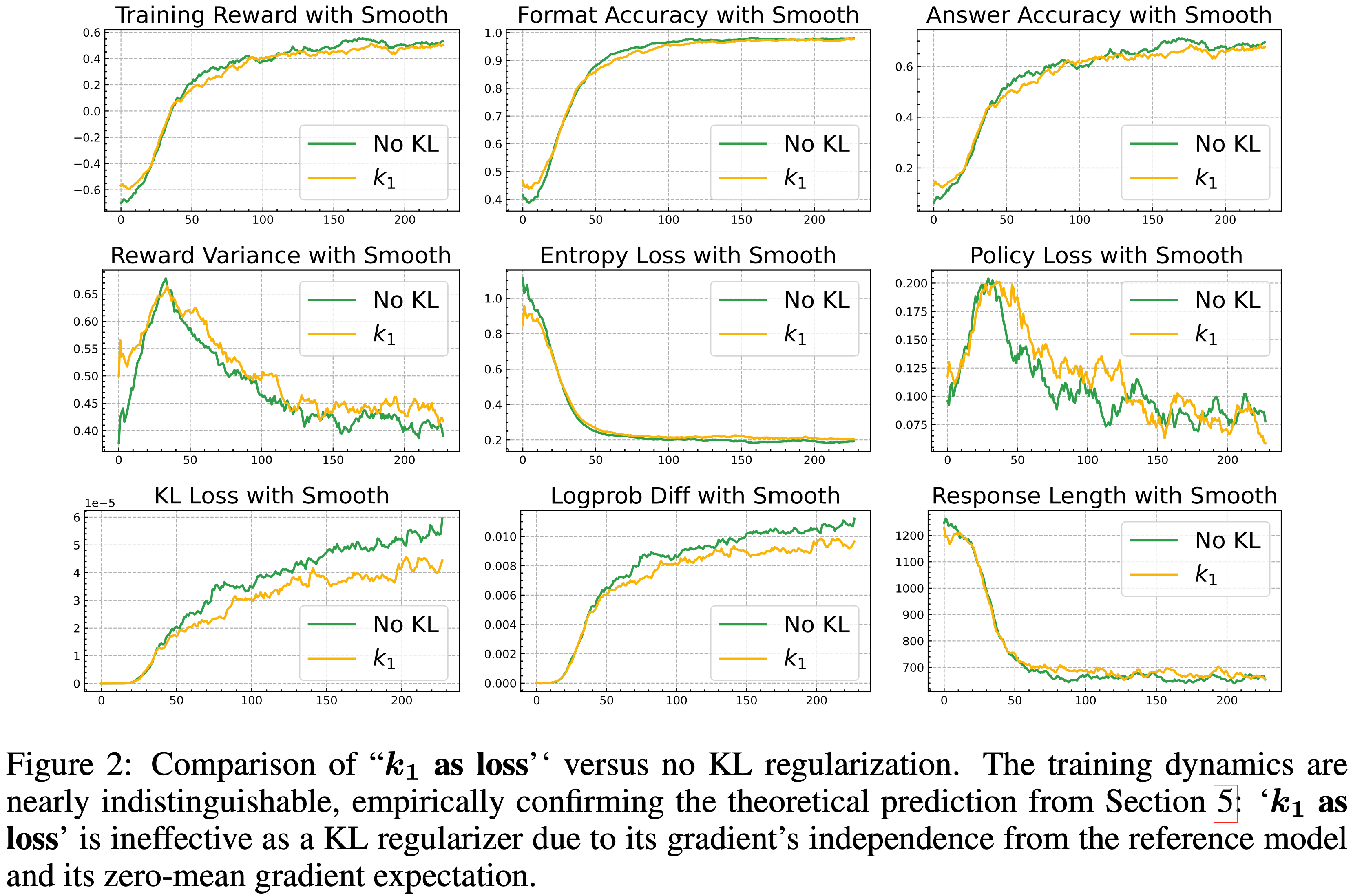
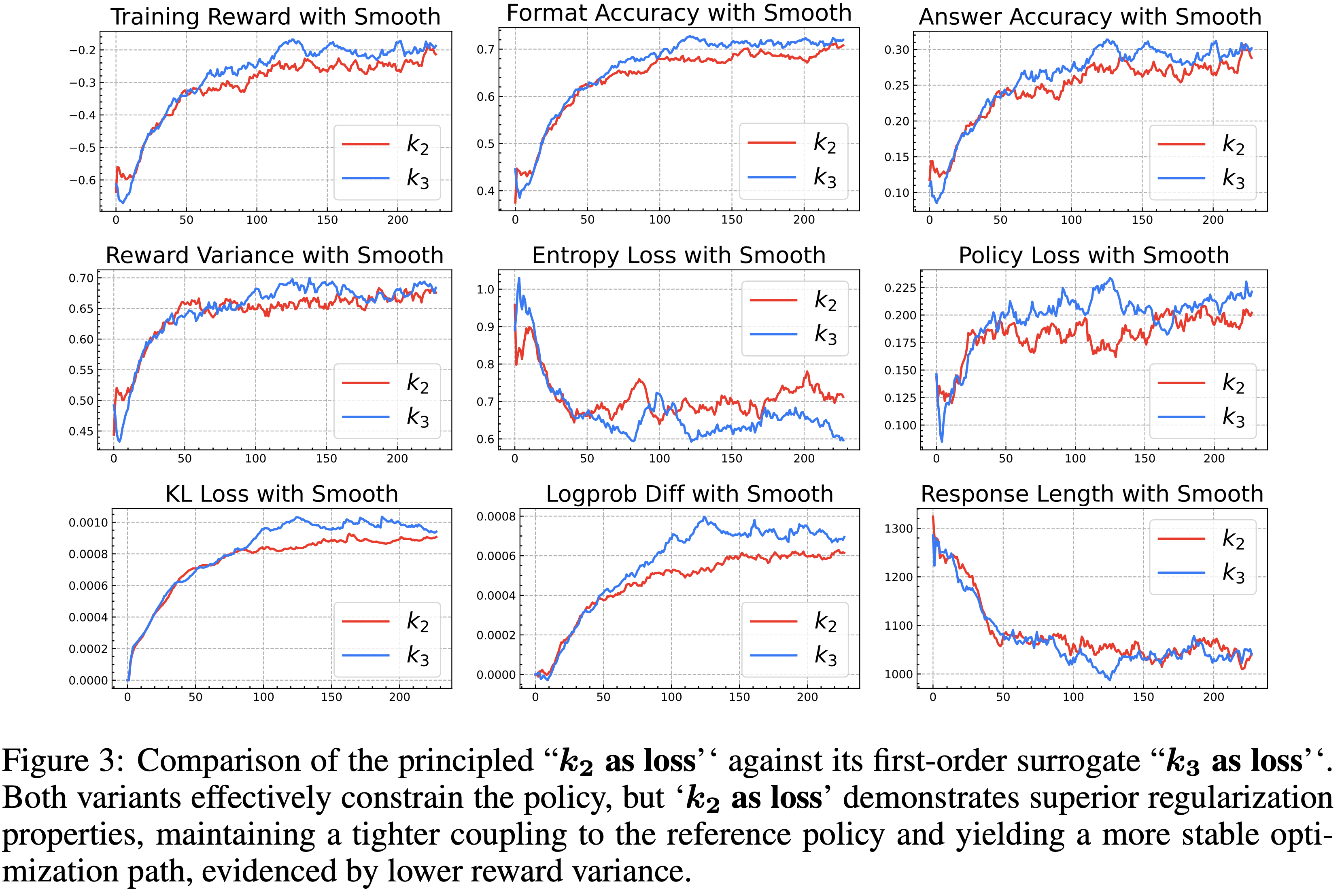
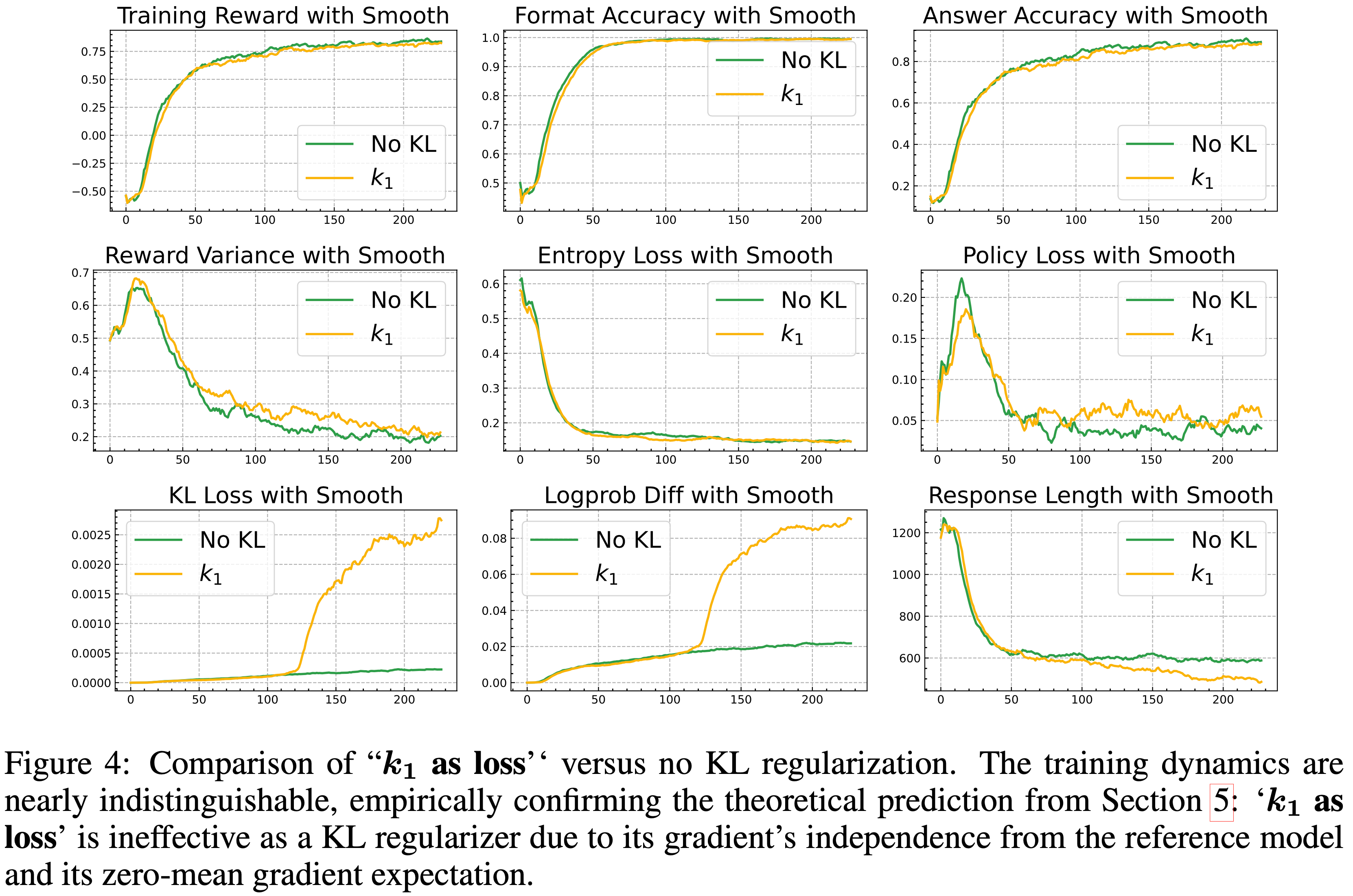
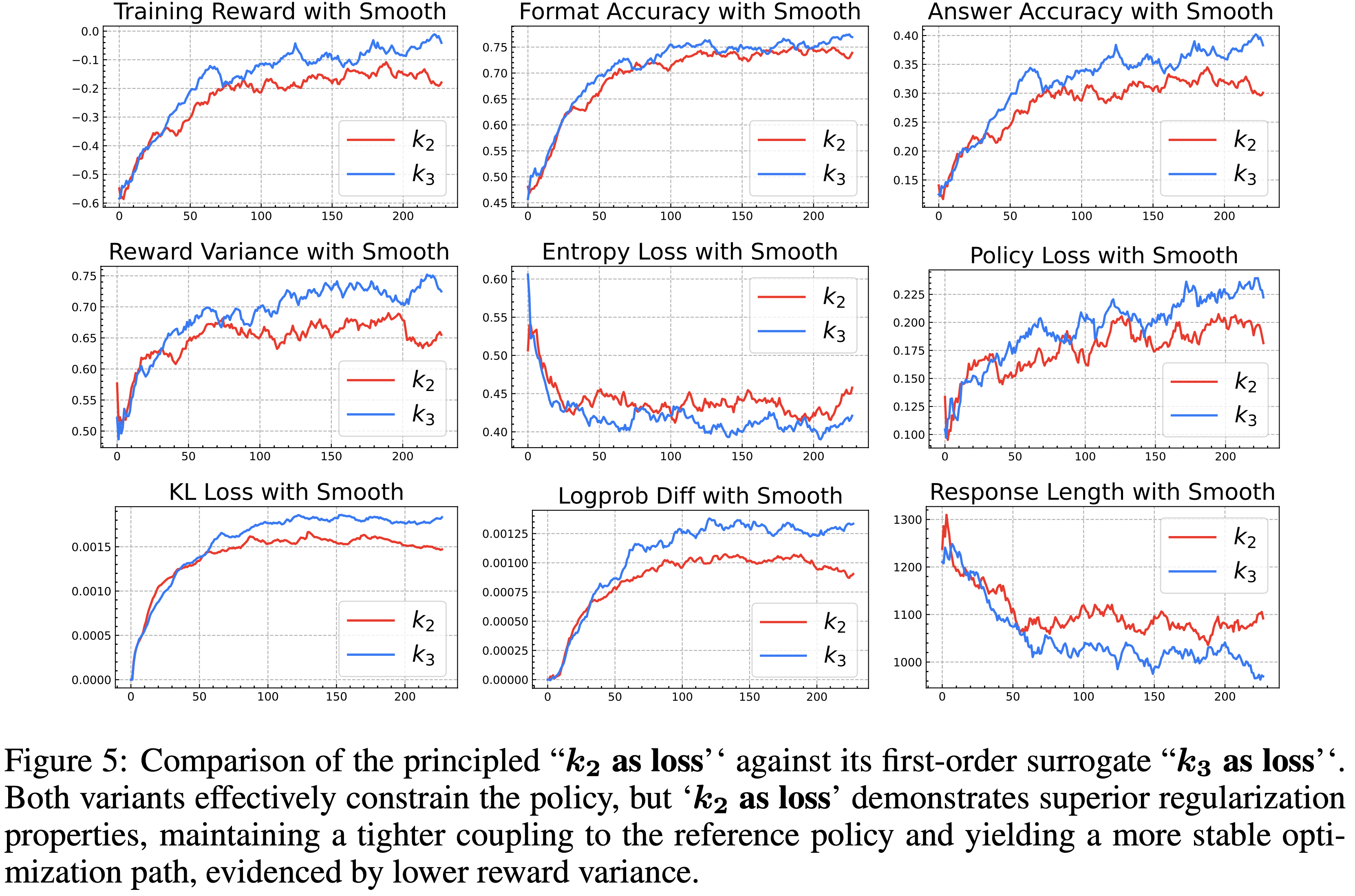
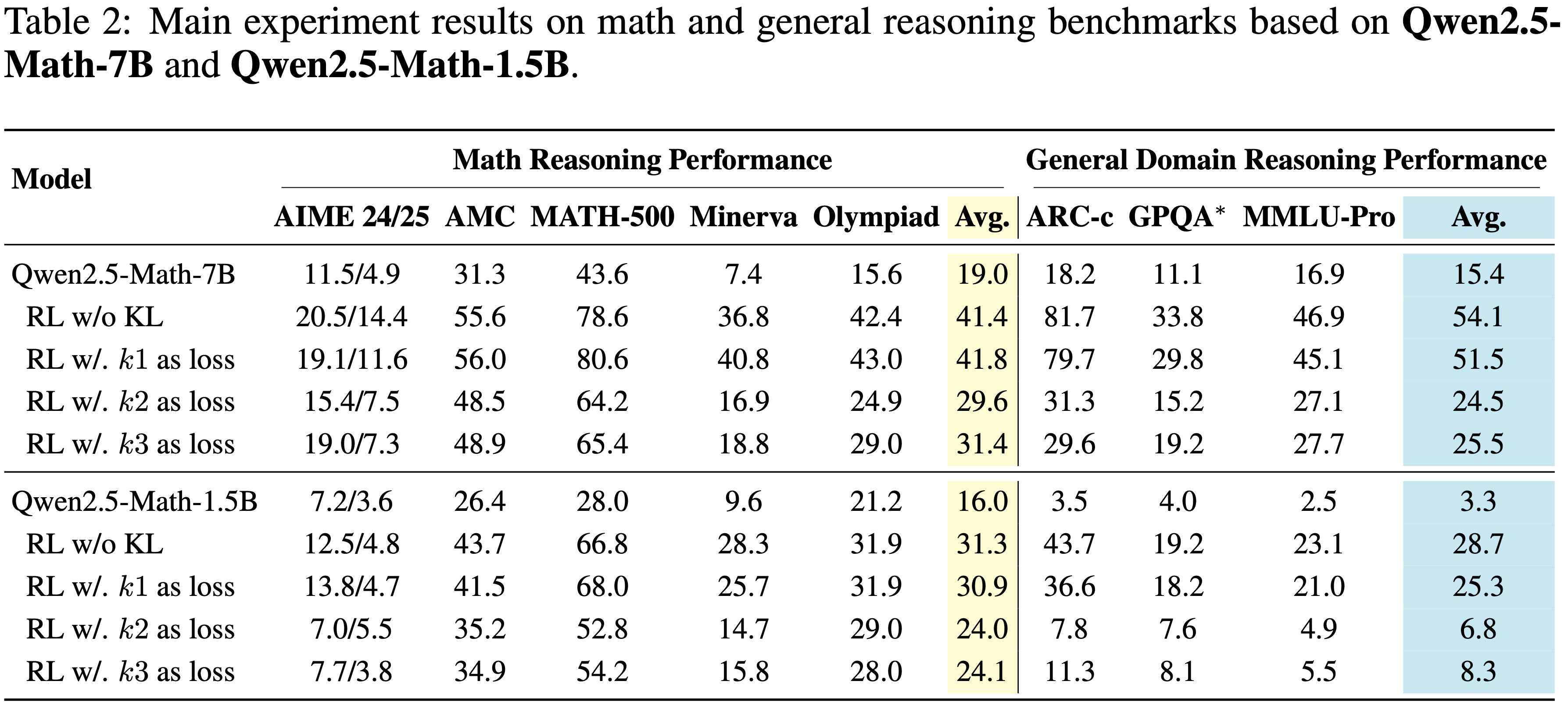
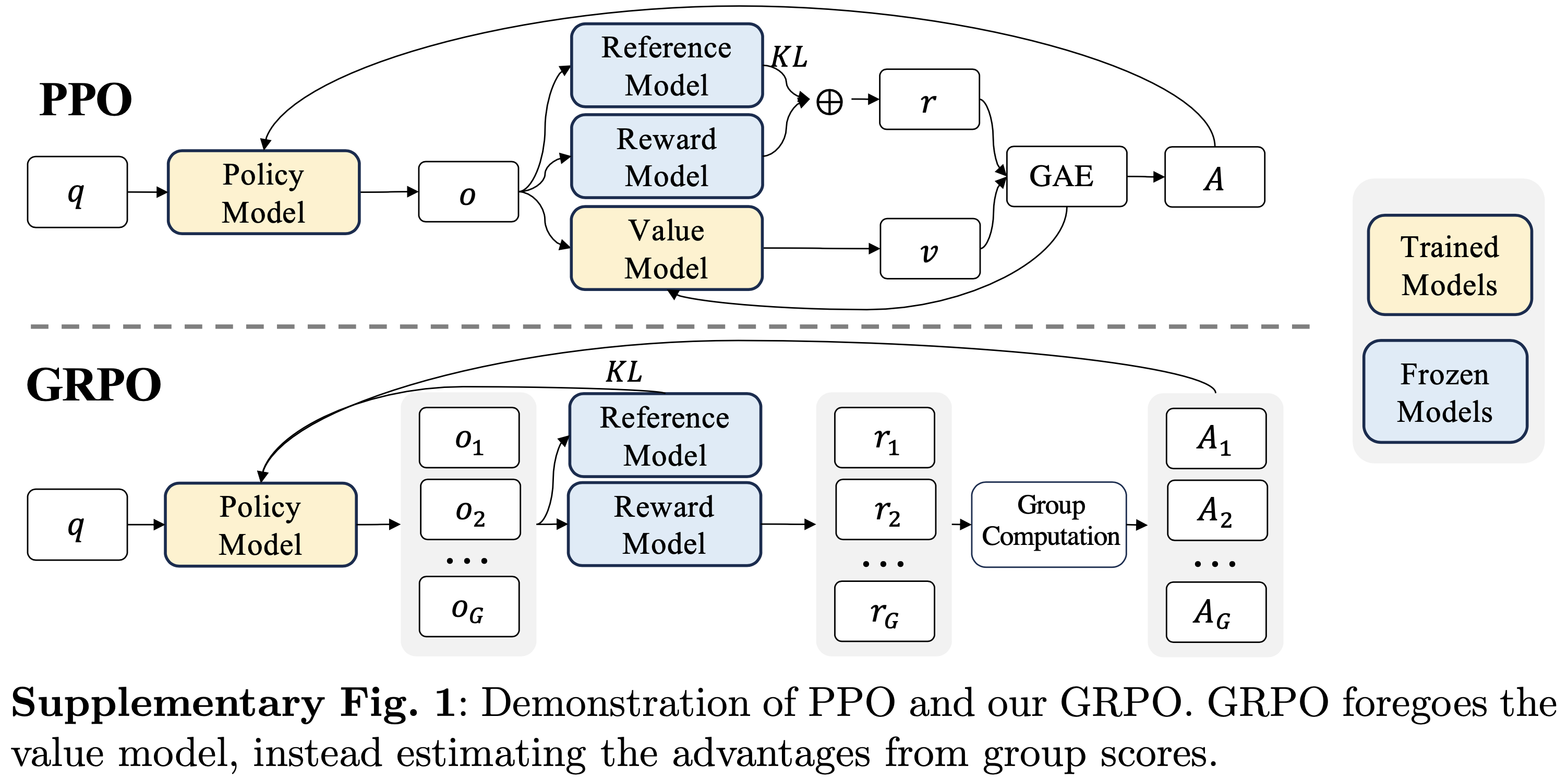
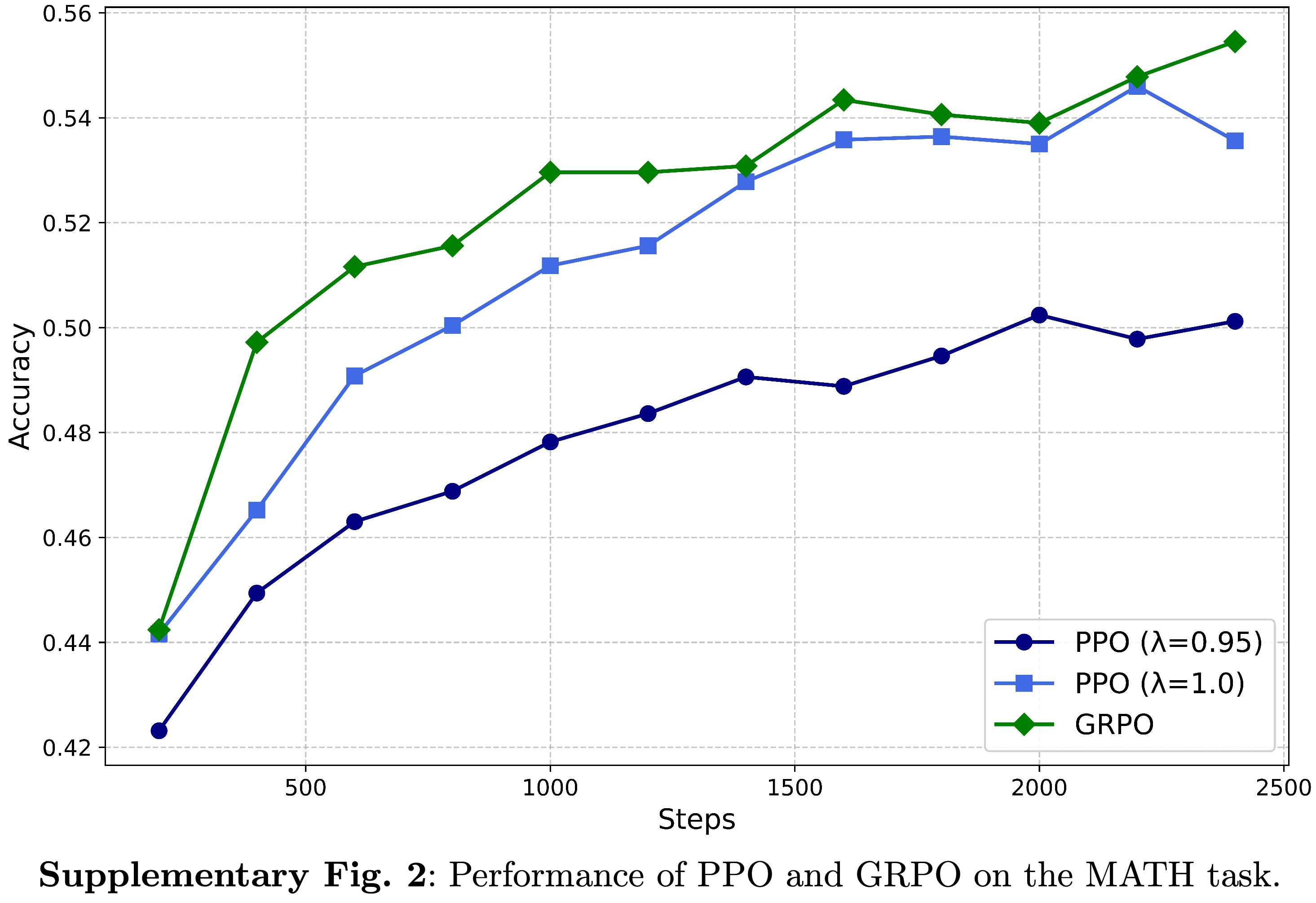


奖励的实验结果")