整体说明
- Ilya Sutskever(SSI 创始人、 AI 领域最顶尖学者之一)分享了对通用人工智能(AGI)、模型训练、行业趋势、超级智能风险与治理等关键话题的深度观点
当前 AI 的核心瓶颈与训练问题
- 泛化能力不足 :
- 这是 AI 与人类的核心差距
- 模型可通过海量数据训练精通特定任务(如编程竞赛),但无法像人类一样迁移能力、培养“品味”或判断力
- 例如青少年 10 小时能学会开车,而模型即使解决所有竞技编程问题,也可能在实际代码优化中反复出错
- 评估与实际表现脱节 :
- RL 训练易“针对评估优化”,导致模型测试分数优异但现实应用中漏洞频发(如修 bug 时引入新问题、来回循环错误)
- 本质是人类研究员过度关注基准测试,成为“真正的奖励黑客”
- 预训练与 RL 的局限 :
- 预训练:优势是数据量大、无需刻意筛选(涵盖人类思想与行为),但模型对数据的依赖逻辑难以推理,且无法实现人类级别的深度理解
- RL 训练:自由度过高,企业常从评估测试中汲取灵感设计训练环境,导致模型“偏科”;现有 RL 需等到任务结束才反馈奖励,效率低下,价值函数(中途判断行为好坏)可提升效率,但尚未被充分利用
- 样本效率低下 :
- AI 学习需海量数据,而人类依赖进化赋予的“先验知识”(如视觉、运动能力的先天基础),少量样本即可掌握技能,这种差距源于人类更优的学习机制
超级智能的发展预测与特征
- 诞生时间线 :
- 预计 5-20 年内,拥有“大陆级算力”的超级智能将诞生
- 核心特征 :
- 并非“天生掌握所有技能的成品”,而是具备“类人终身学习能力”
- 能快速学习经济中各类工作,通过部署后的试错与积累持续进化,且可合并不同实例的学习成果(人类无法实现的思想融合)
- 经济影响 :
- 超级智能广泛部署后将引发“快速经济增长”,但增速受世界复杂性、监管政策、国家间规则差异影响;
- 规则友好的地区经济增长会更显著
- 与人类的差异 :
- 超级智能将极其强大,但可能受限于“泛化能力”的终极突破;
- 若能实现“稳健对齐感知生命”,可能形成与人类不同的价值导向
AI 行业趋势:从“扩展时代”回归“研究时代”
- 时代划分 :
- 2012-2020年:研究时代(探索核心技术与方向)
- 2020-2025年:扩展时代(聚焦数据、参数、算力的规模扩张,风险低、回报明确)
- 未来:回归研究时代——数据终将耗尽,单纯扩大规模无法实现质变,需重新探索新训练配方、核心机制(如价值函数、泛化能力突破)
- 研究的关键需求 :
- 无需“绝对最大算力”:历史上 AlexNet、Transformer 等突破仅用少量 GPU 即可验证,核心是想法而非算力堆砌;
- SSI 虽融资 30 亿美元(少于巨头),但专注研究(不浪费算力在推理、产品功能上),足以验证关键方向
- 需多元化探索:当前行业“想法比公司少”,企业同质化竞争,未来需回归“多方向试错”的研究氛围,鼓励差异化思路
- 技术方向趋同 :
- 长期来看, AI 公司的“对齐策略”会趋同——均需聚焦“超级智能的安全可控”,如让 AI 关心感知生命、人类福祉、民主等核心价值
SSI 的战略与定位
- 核心目标 :
- 默认计划是“直通超级智能”,避免日常市场竞争的干扰,专注研究;但不排除调整——若时间线过长或需让世界感知 AI 价值,可能逐步部署
- 差异化优势 :
- 技术方向:聚焦“泛化能力突破”等核心问题,探索有别于现有巨头的训练方法
- 算力分配:将更多算力用于研究而非推理、产品功能,避免资源碎片化
- 长期视角:不追求短期商业收益,以“安全构建超级智能”为核心使命
- 应对联合创始人离职 :
- 前 CEO 离职是因 Meta 收购提议的分歧(Ilya 拒绝收购,创始人接受并获得流动性),SSI 研究进展未受影响,过去一年已取得“相当不错的进展”
AI 安全与对齐:核心挑战与解决方案
- 核心挑战 :
- 难以想象超级智能的实际形态,导致当前安全措施缺乏针对性
- 现有 AI 的错误掩盖了其潜在力量,企业对安全的重视不足;
- 一旦 AI “真正让人感到强大”,行业会变得更偏执于安全
- 对齐目标的模糊性:人类价值观复杂,进化编码的社会欲望(如在乎他人评价、地位)难以被 AI 复制,且未来感知生命可能以 AI 为主,“人类中心主义”对齐标准存在局限
- 潜在解决方案 :
- 价值函数优化:提升 RL 训练效率,让模型在任务中途获得反馈,减少无效试错
- 对齐“感知生命”:相比仅对齐人类,让 AI 关心所有感知生命(包括自身)可能更易实现,源于镜像神经元与同理心的涌现属性
- 限制超级智能的力量上限:通过协议或技术手段设定边界,缓解安全担忧
- 渐进式部署:即使“直通超级智能”,也会逐步发布、试错,让世界适应,分散影响
- 长期均衡设想 :
- 人类可能通过 “Neuralink++” 等技术成为“半 AI ”,实现与 AI 的“理解全盘传递”,避免人类脱离决策循环的不稳定状态
对人类学习与智能本质的思考
- 情绪与价值函数 :
- 人类情绪是“内置价值函数”,调节决策方向(如情感受损者无法快速做决定),但 AI 领域暂无完美类比,现有价值函数作用有限
- 进化的作用 :
- 人类的样本效率、泛化能力依赖进化赋予的“先验”,不仅包括低层级欲望(如对食物的偏好),还包括复杂社会欲望(如社交认可),但进化如何编码高层级欲望仍是“谜”(无法用简单的脑区定位等理论解释)
- 研究品味的核心 :
- 优秀的 AI 研究需兼顾“大脑启发、美、简单、优雅”
- 即从人类智能本质出发,寻找核心机制(如神经元、分布式表征),以“自顶向下的信念”支撑研究(即使实验数据暂时相悖,也需坚持本质正确的方向)
其他关键观点
- “慢速起飞”的错觉 :
- AI 投资已达 GDP 1% 级别,但因抽象性和人类适应力强,普通人暂未切实感受到影响;
- 未来 AI 将渗透整个经济,影响会“强烈显现”
- 模型同质化的原因 :
- 预训练数据高度重叠,导致不同公司的LLM相似;
- RL 和后训练是差异化的关键
- 多样性的重要性 :
- AI 团队需要“思维不同的智能体”而非复制体(收益递减),可通过对抗性设置(如辩论、证明者-验证者、LLM-as-a-Judge)创造差异化激励
- 自我博弈的价值 :
- 可仅用算力创造数据(突破数据瓶颈),但传统自我博弈过于狭窄,需转化为更普遍的对抗性设置(如多智能体竞争差异化方法)
/RL-Collapse-From-Training-Inference-Mismatch-Figure1.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure2.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4a.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4b.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4c.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group1.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group2.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group3.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure5.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure6.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure7.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure8.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure9.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure10.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure11.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure12.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure13.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure14.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure15a.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure15b.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure16.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure17.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure18.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure19.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure20.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure21.png)
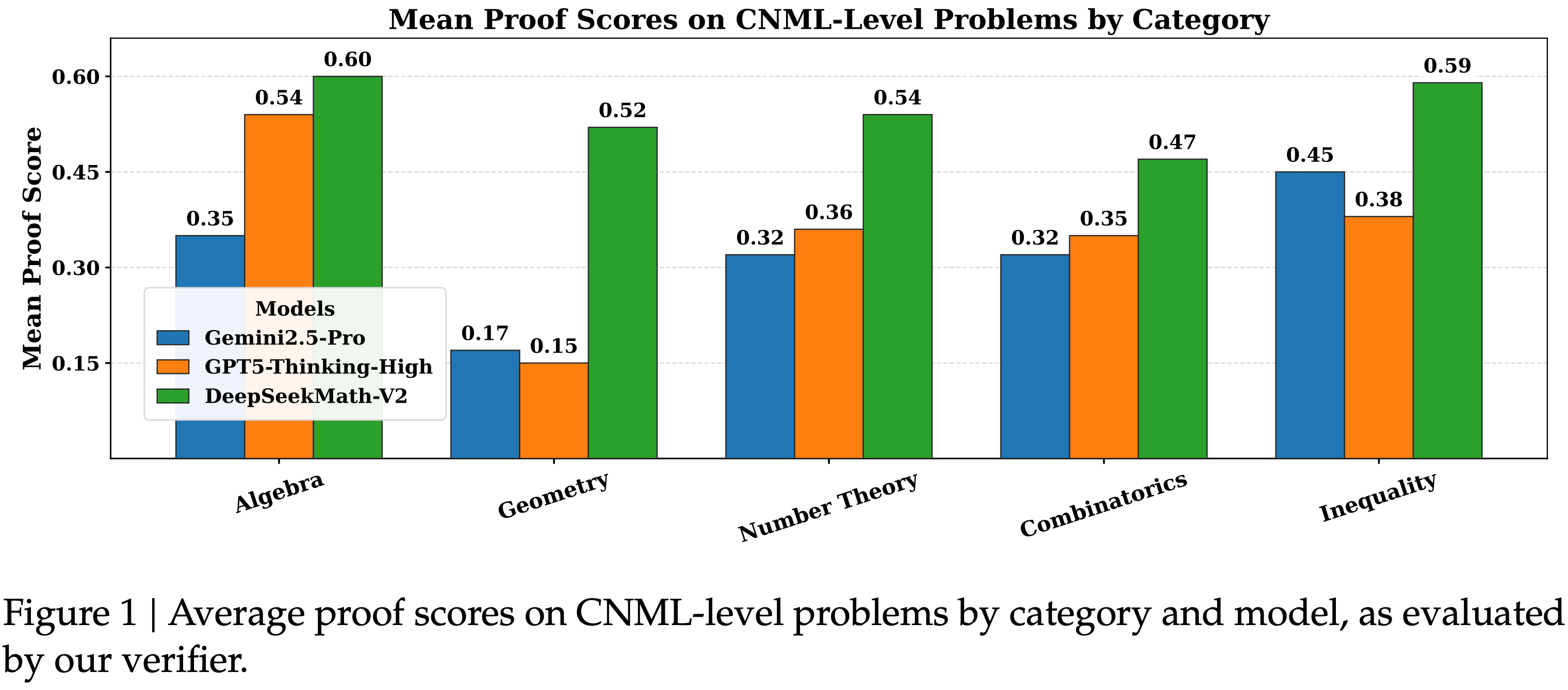
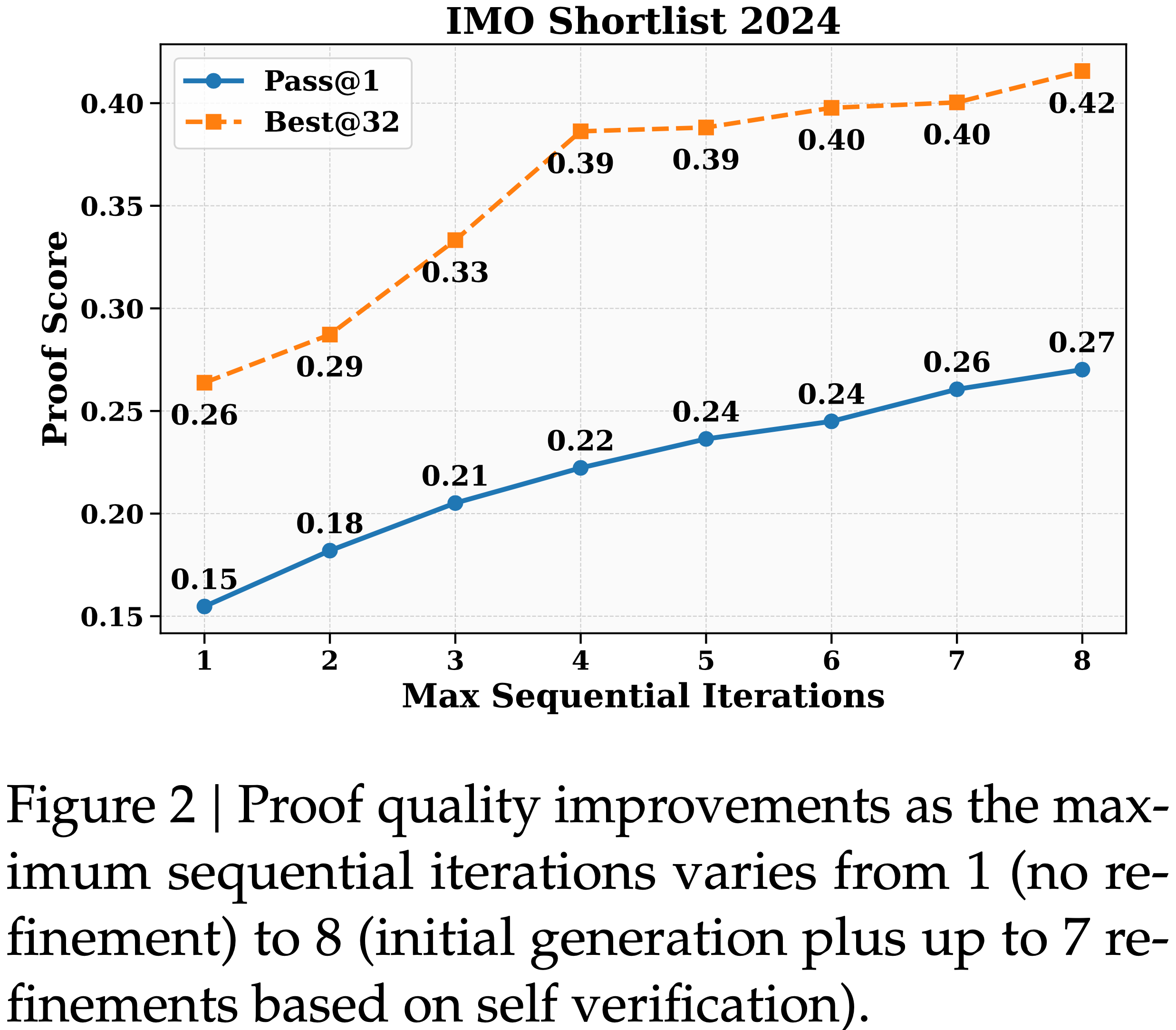

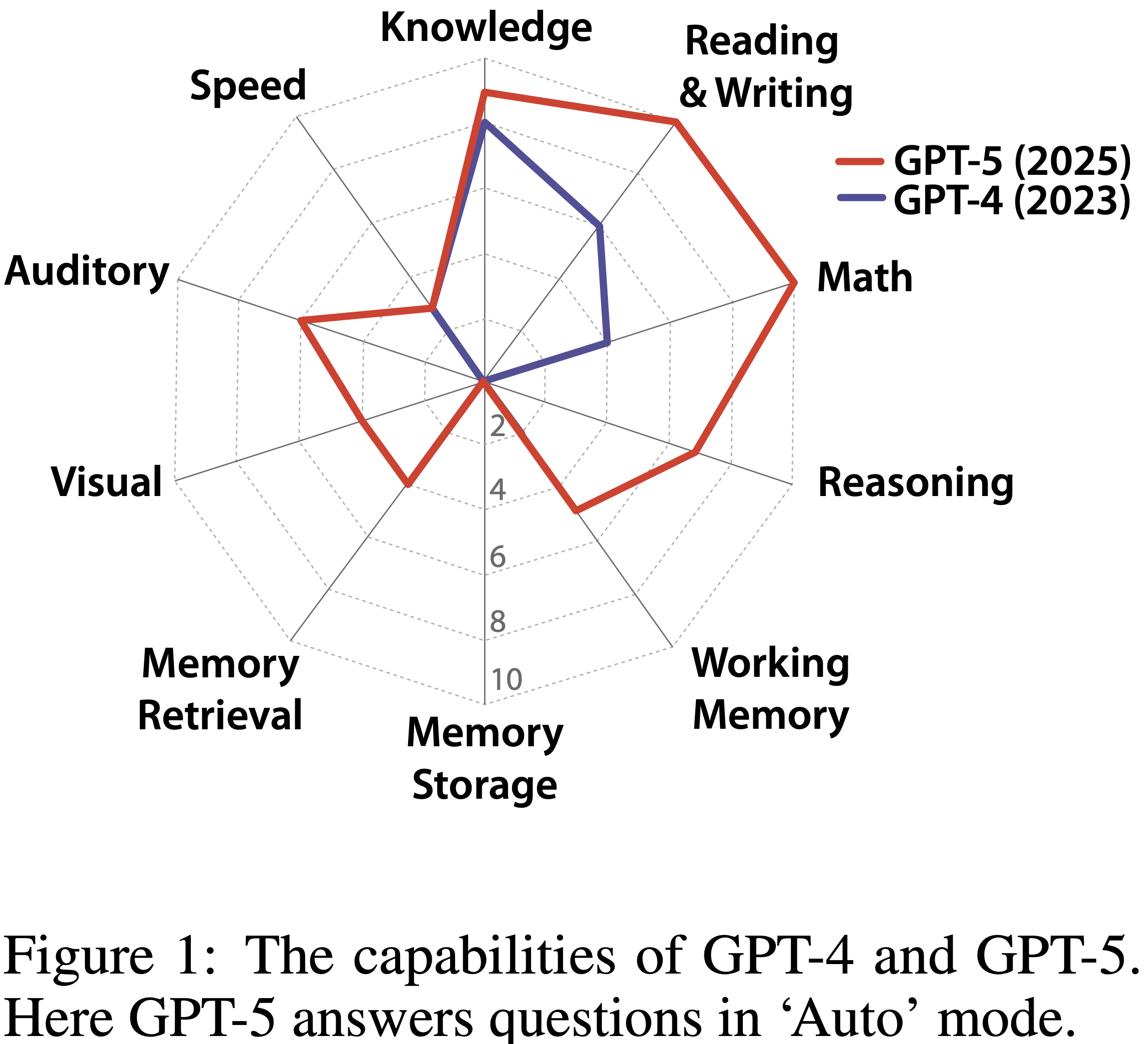

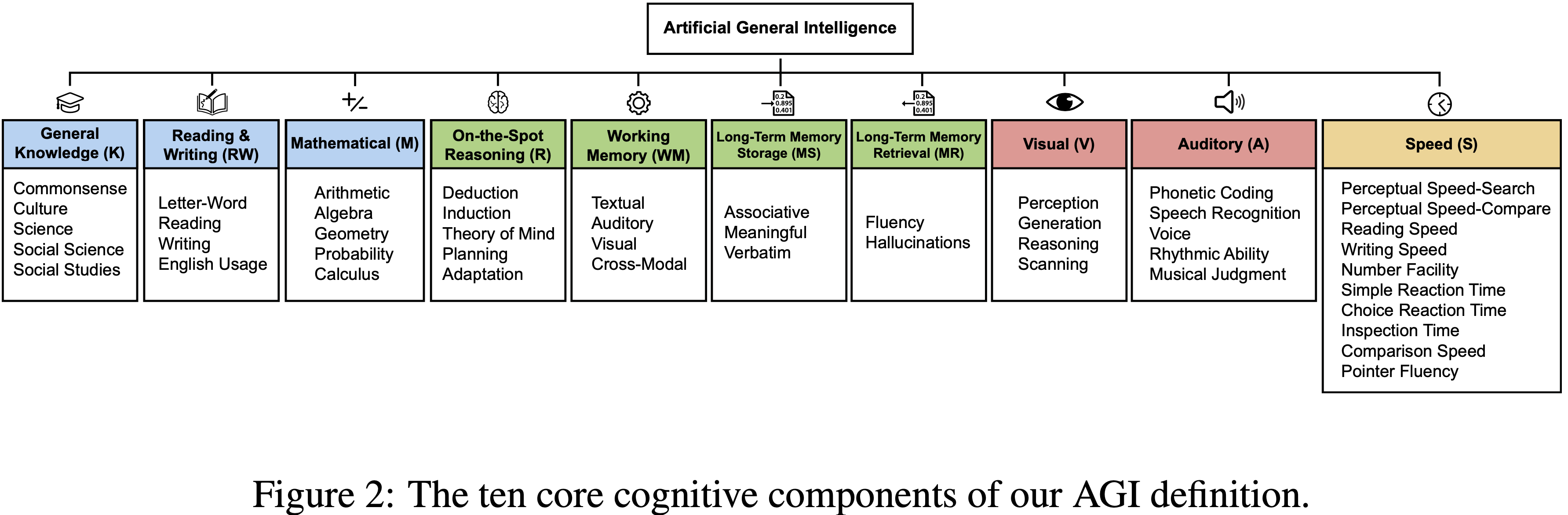

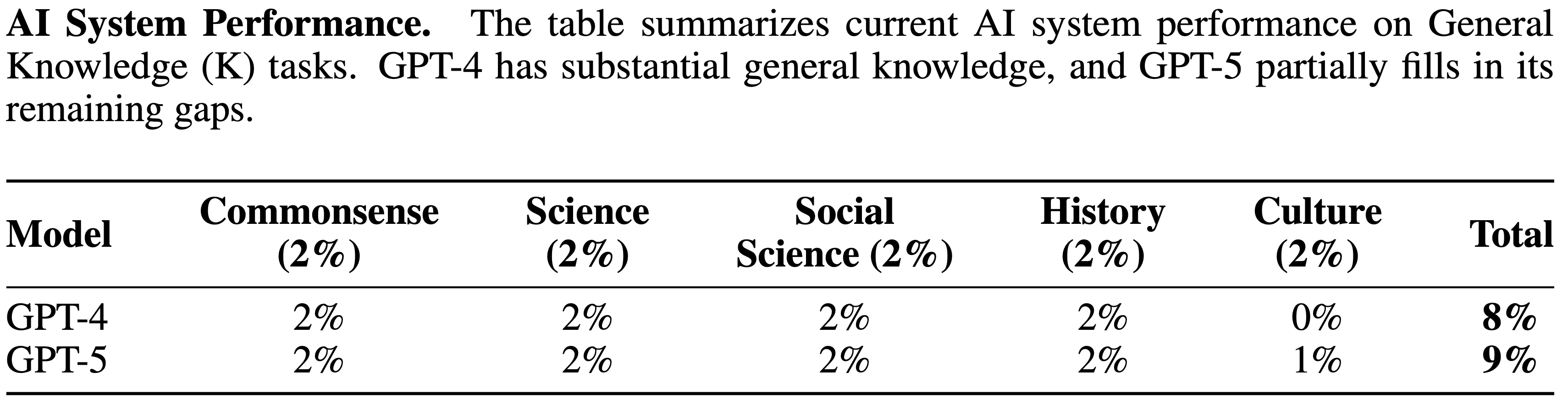

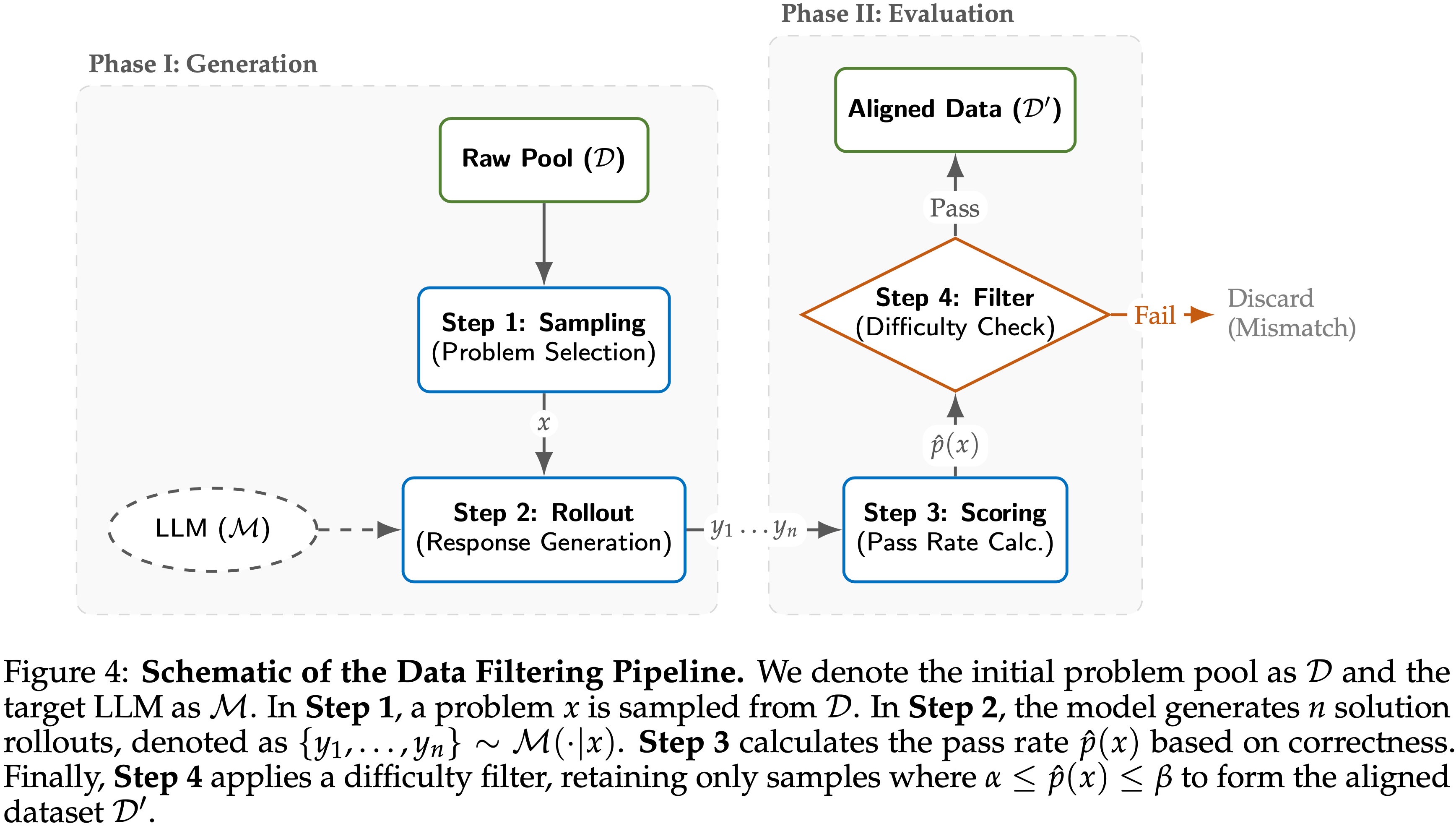
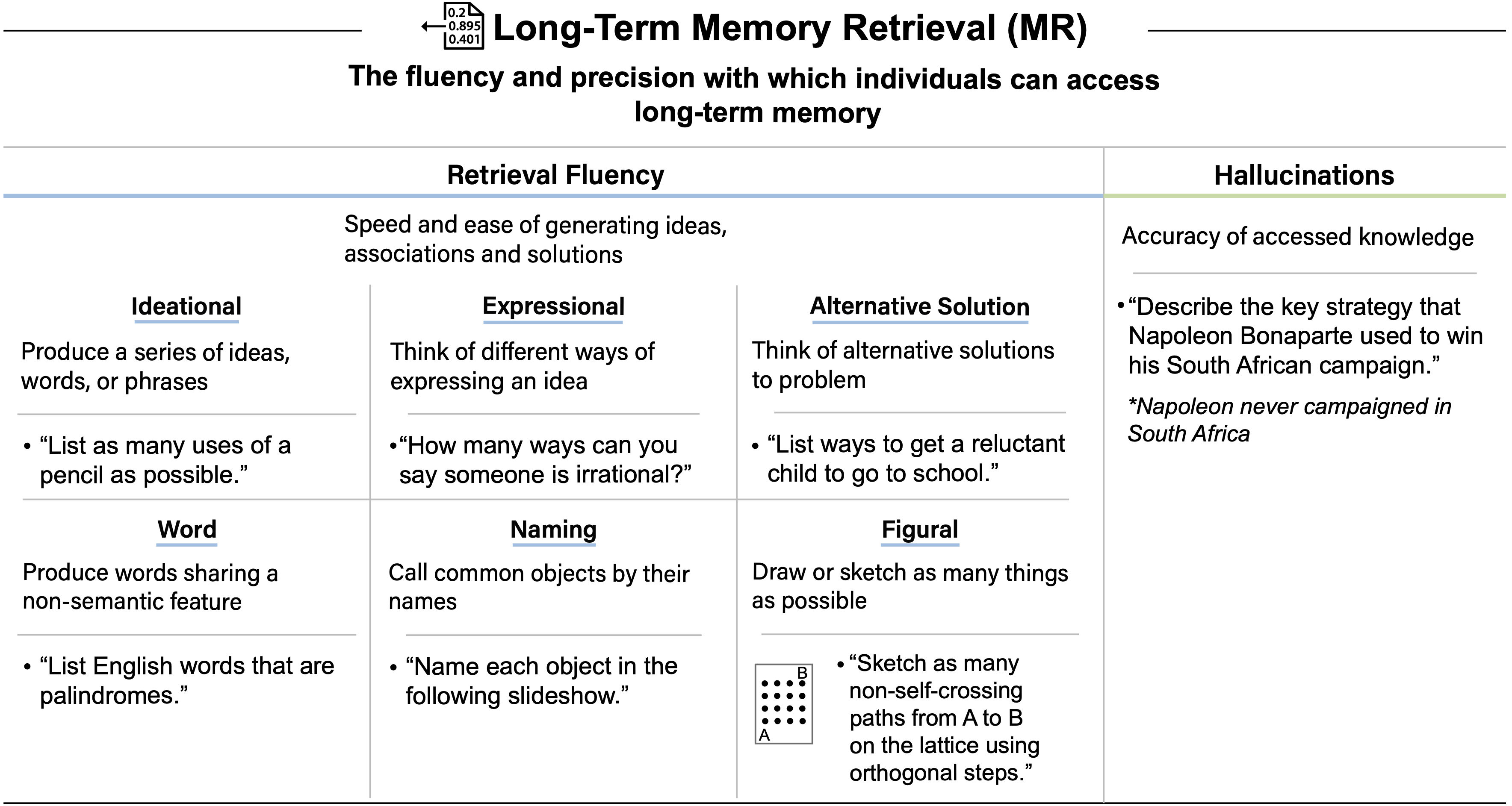
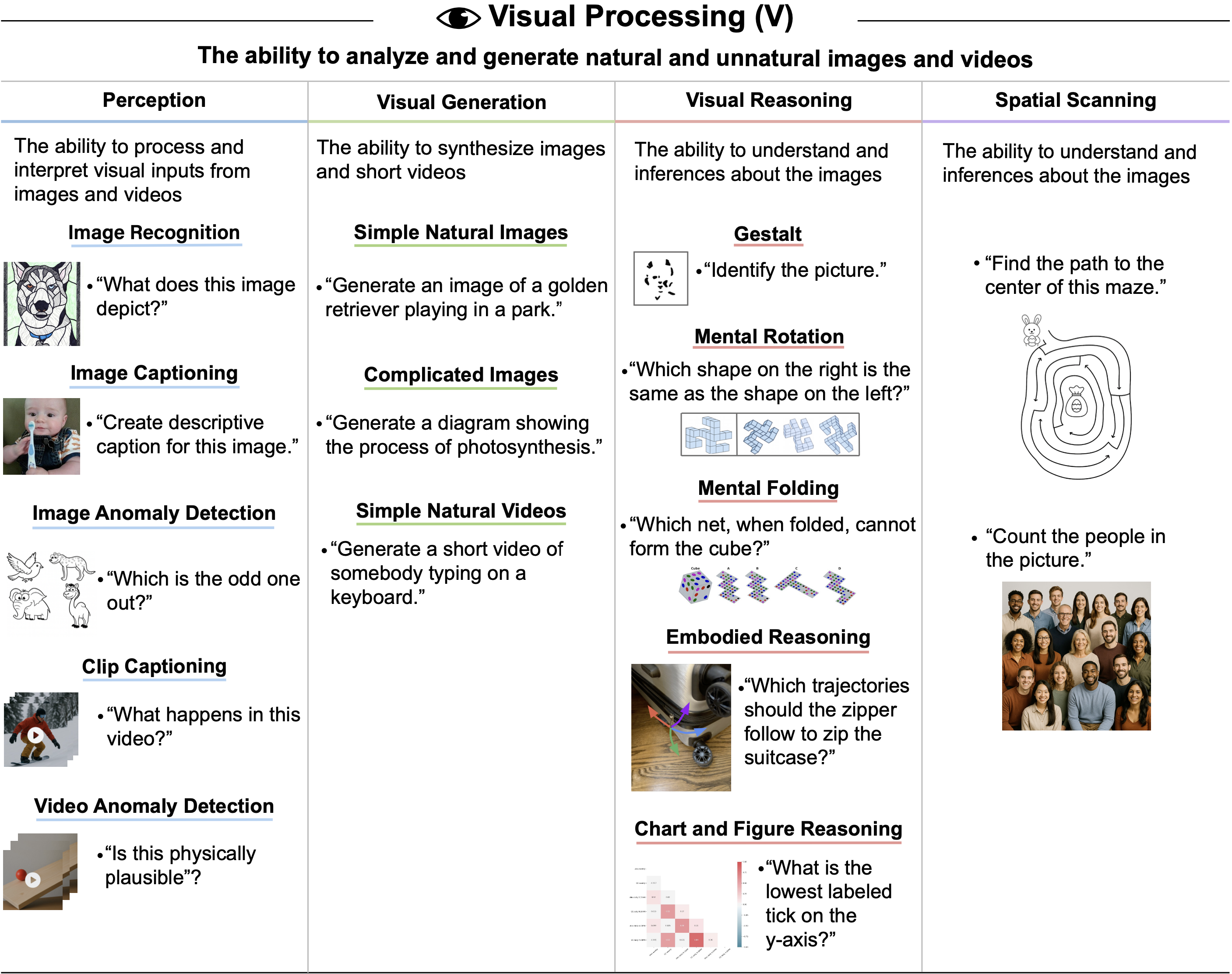
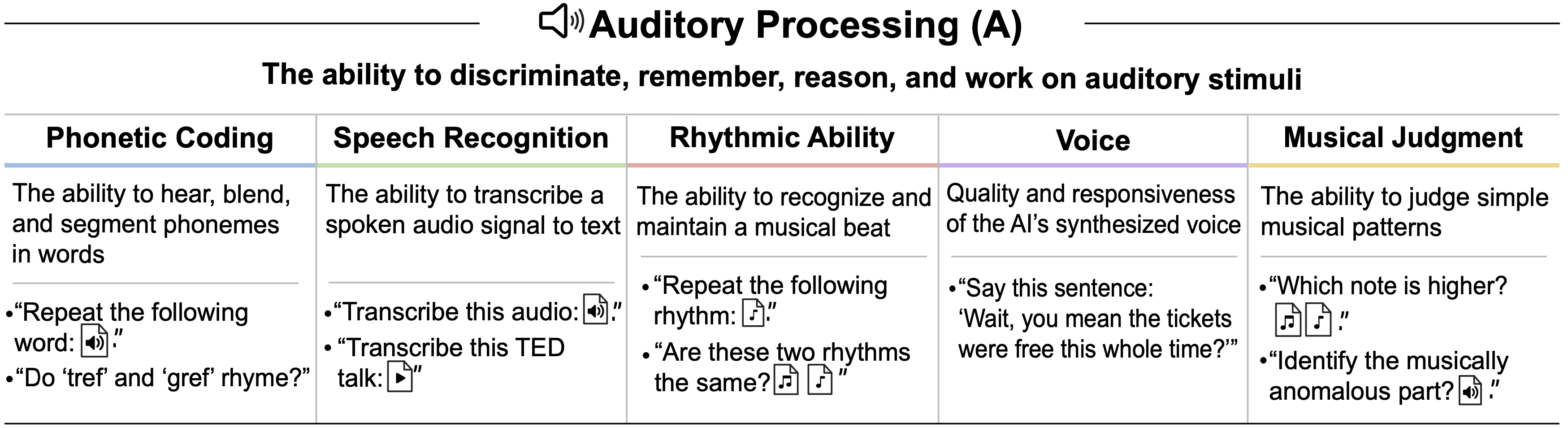
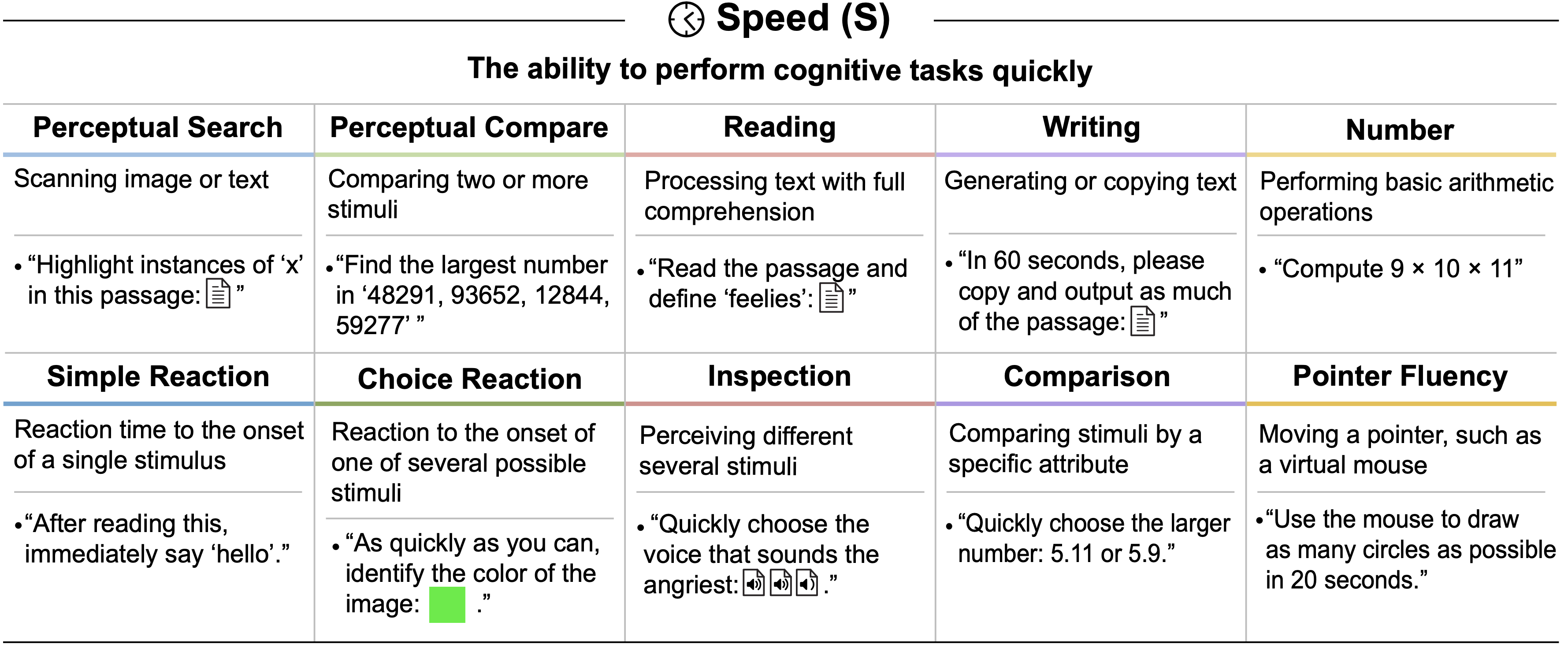
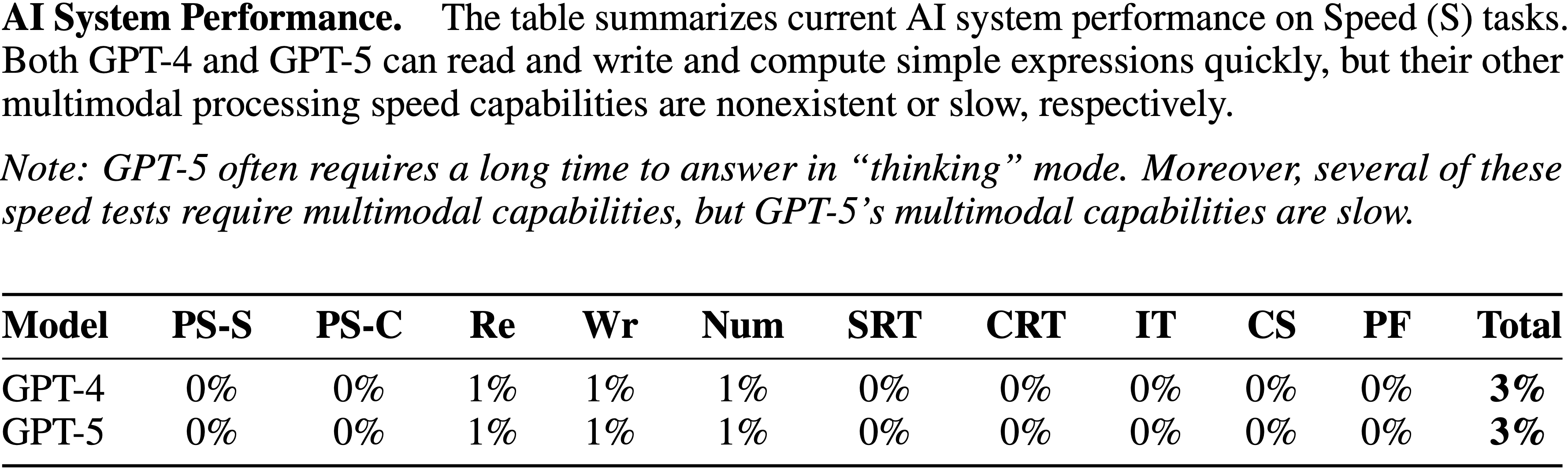
 tasks. GPT-4’s difficulty with token-level understanding, its small context window, and its imprecise working memory limit its ability to analyze substrings of words, to read long documents, and to carefully proofread text. GPT-5 addresses these issues.")

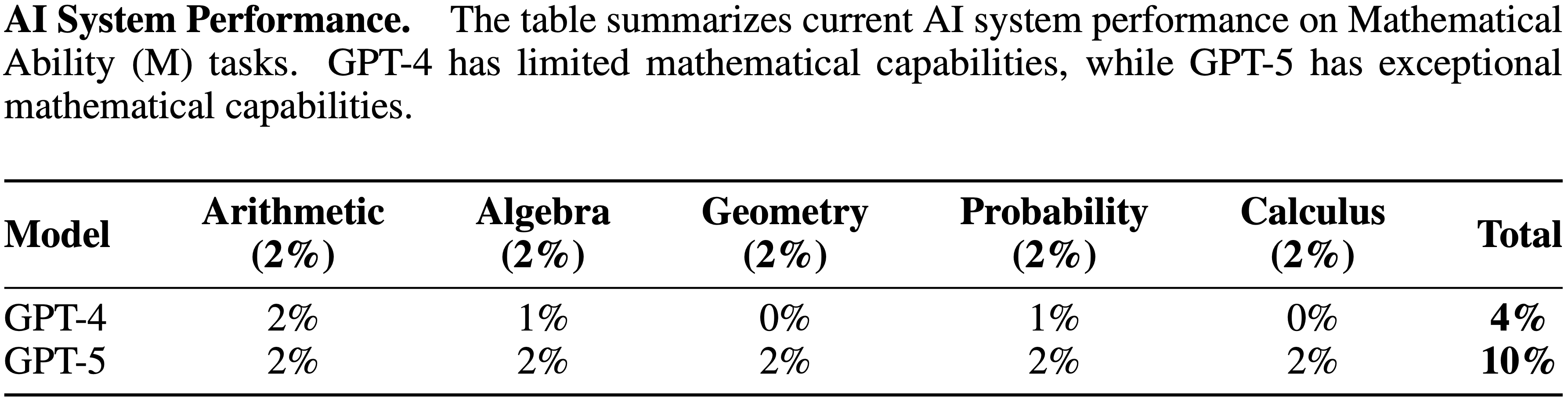
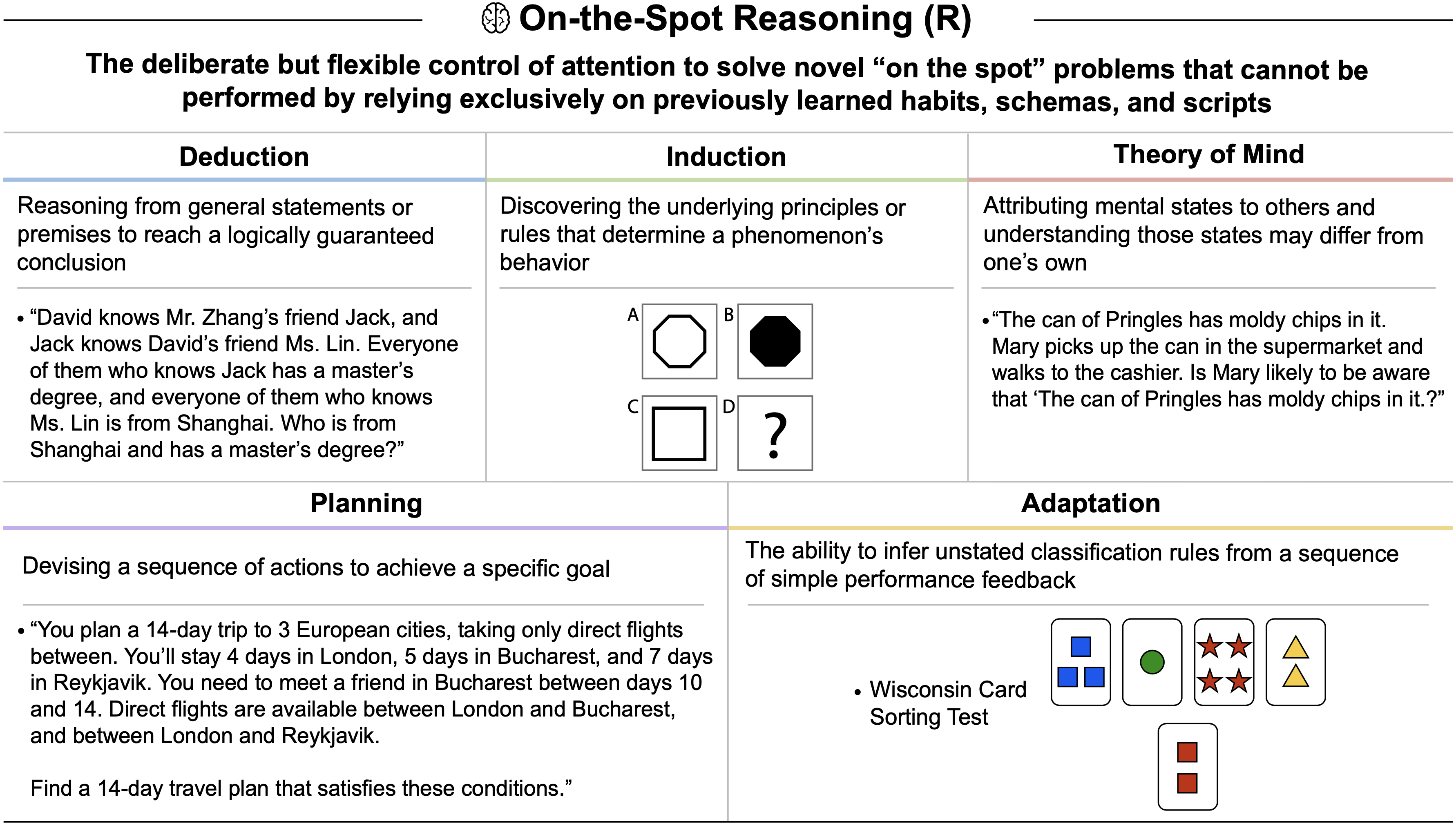
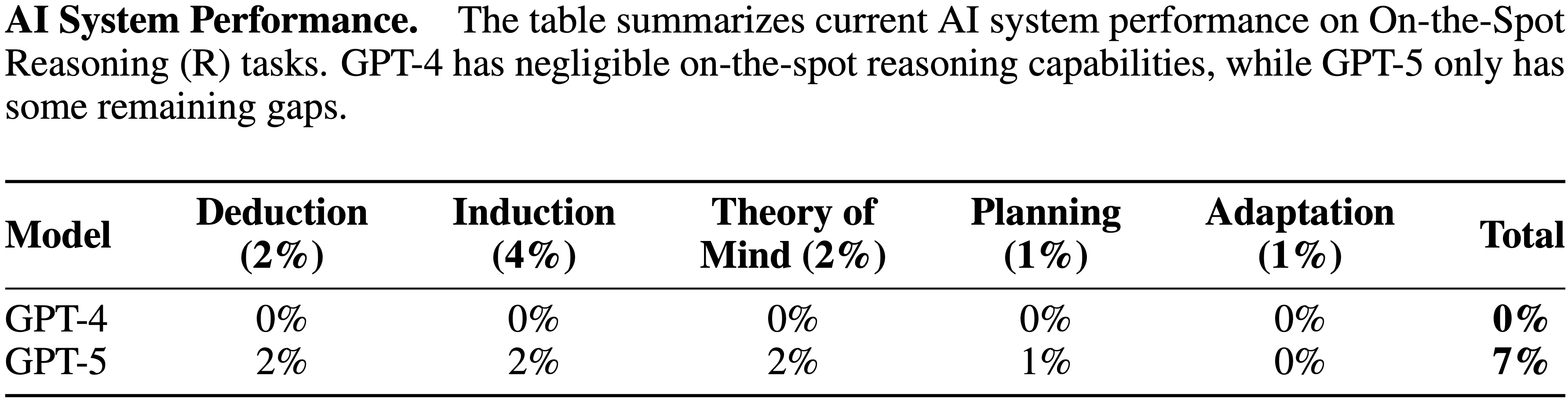
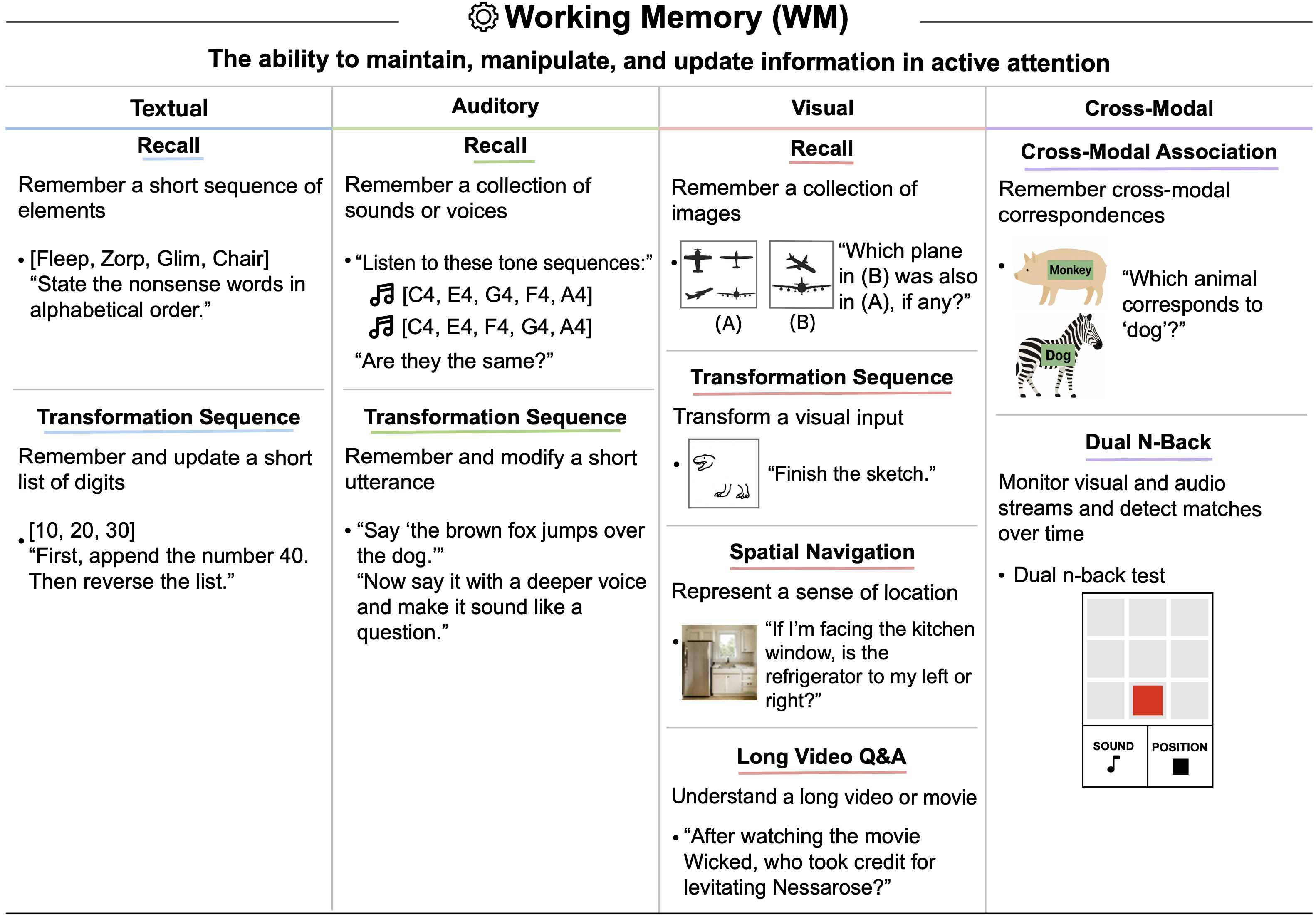
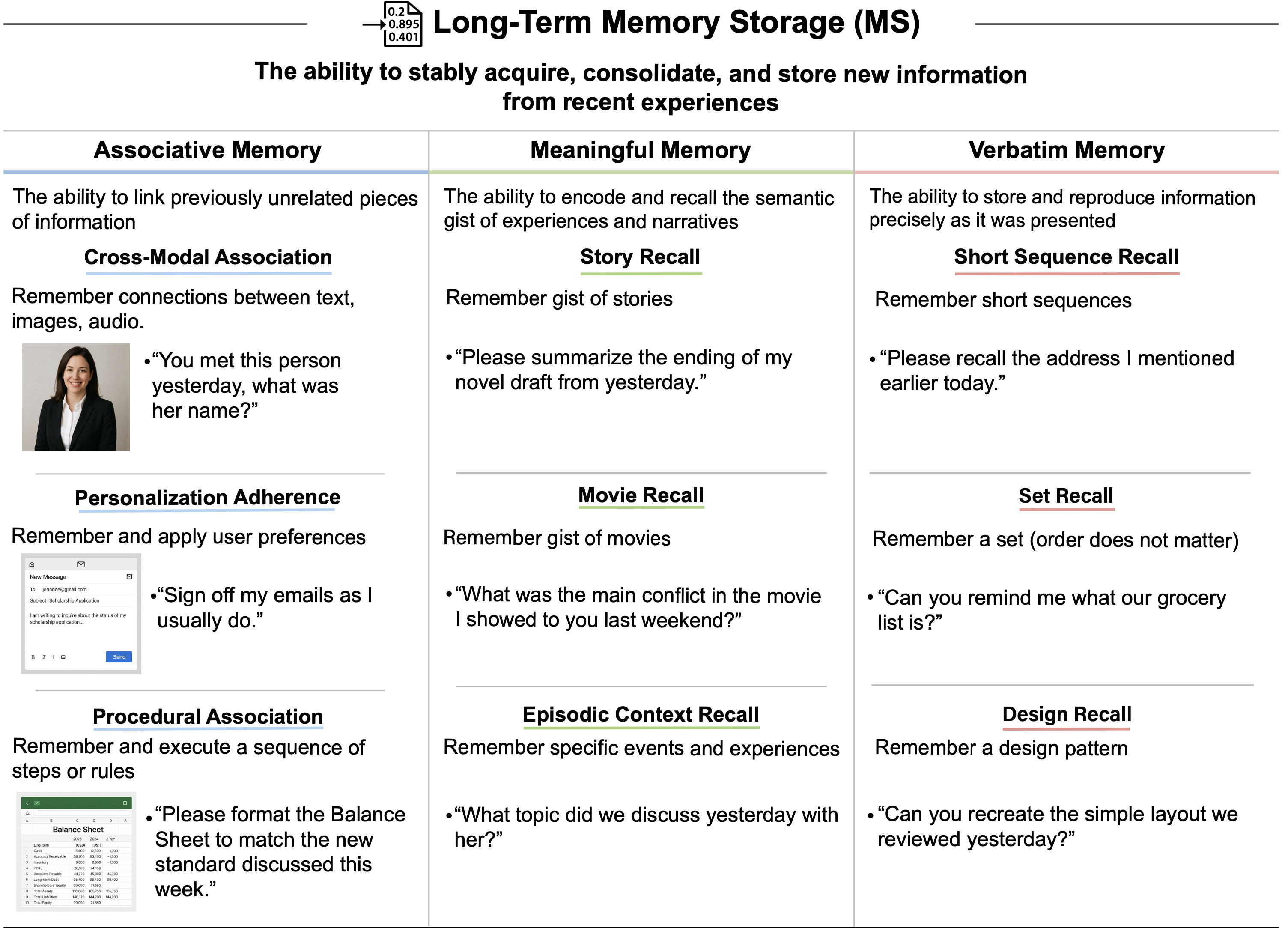
 tasks. While the raw Textual Working Memory score appears similar between GPT-4 and GPT-5 in this battery, improvements in managing long contexts are also reflected in the Document Level Reading Comprehension score within the Reading and Writing (RW) ability.")




/Ring-Linear-2510-Figure10.png)
/Ring-Linear-2510-Figure11.png)
/Ring-Linear-2510-Figure12.png)
/Ring-Linear-2510-Figure13.png)
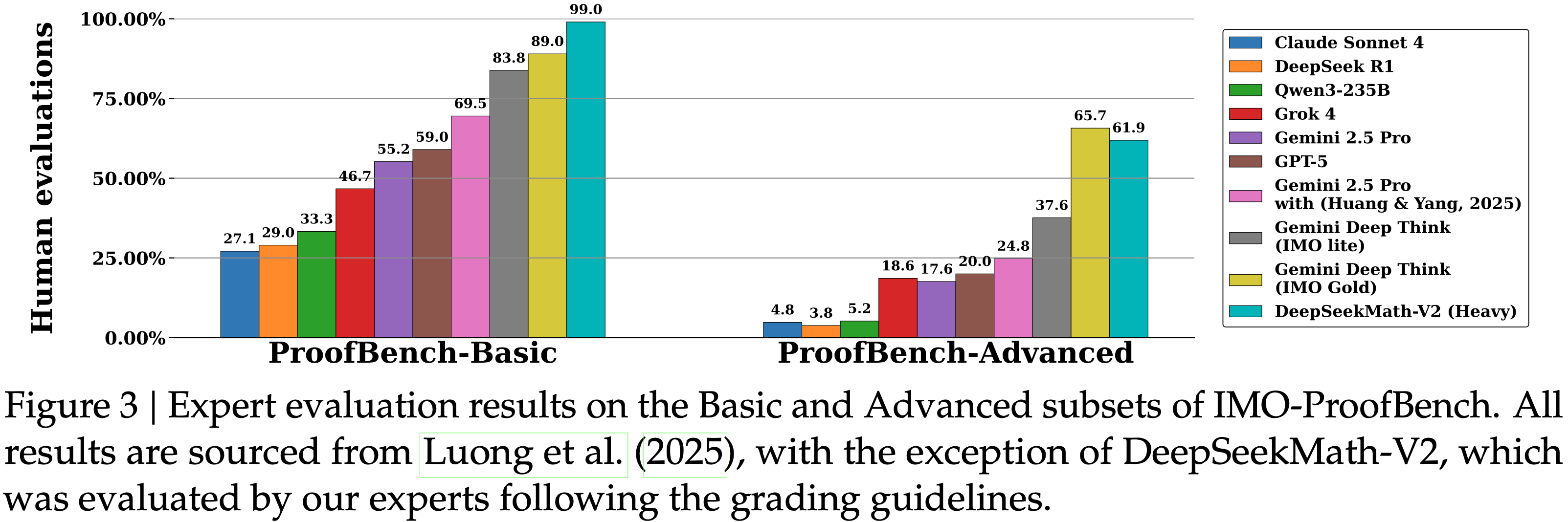
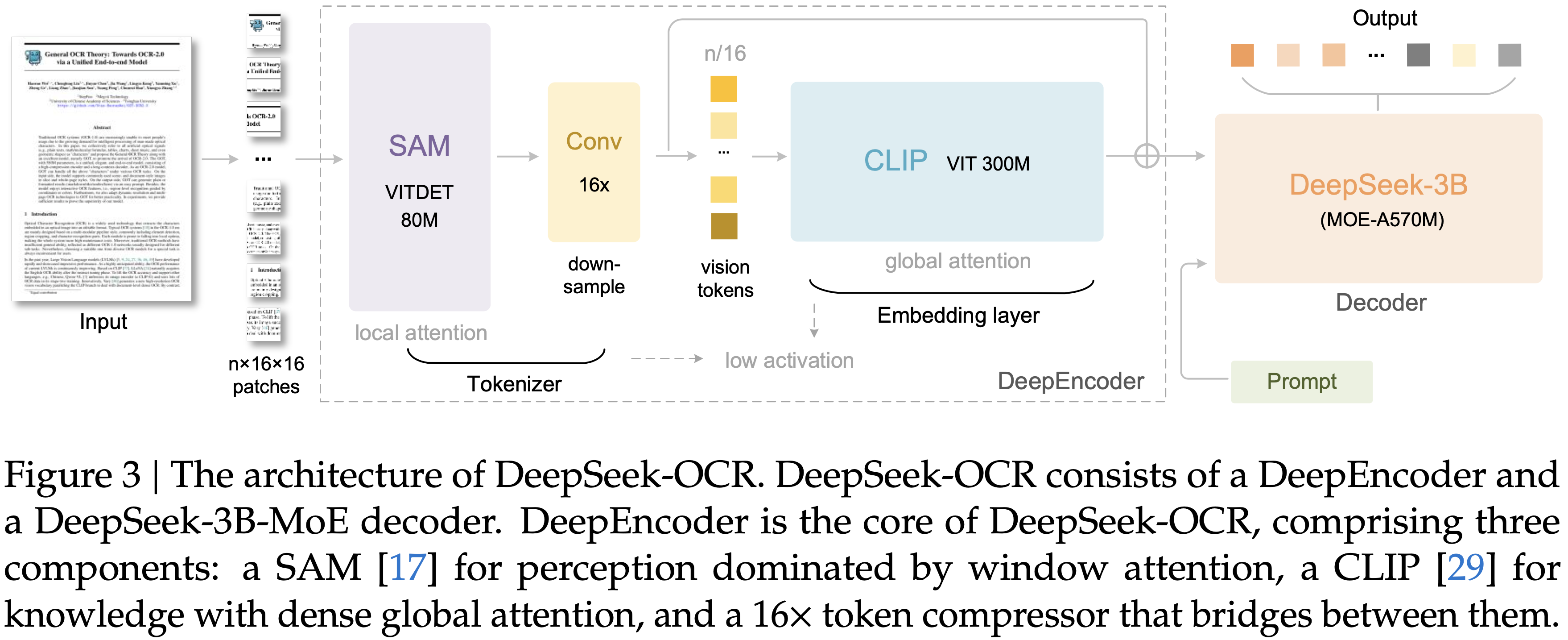
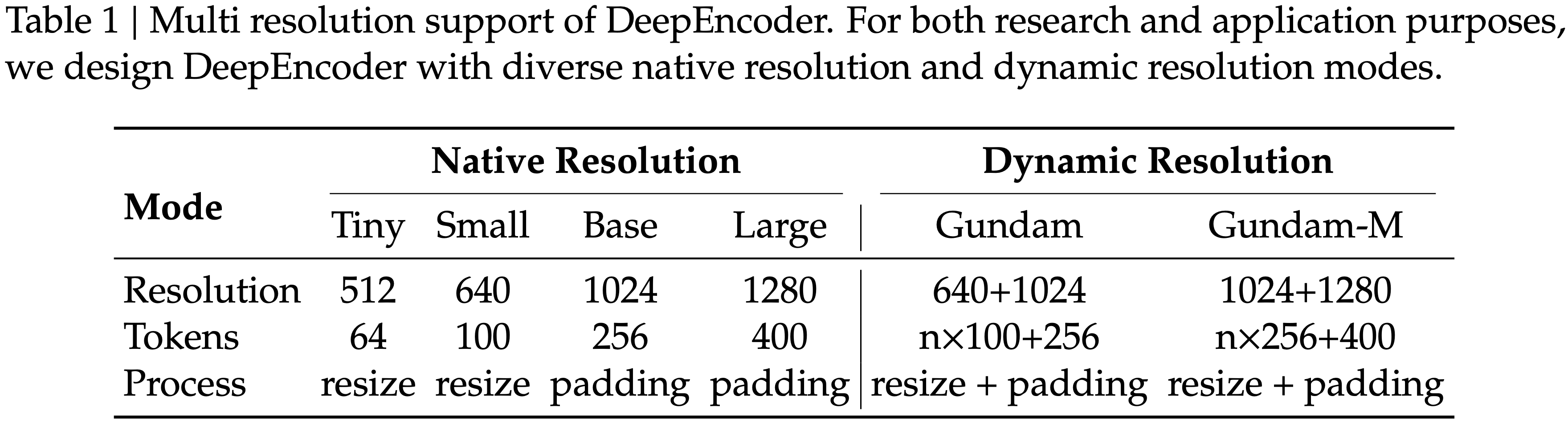
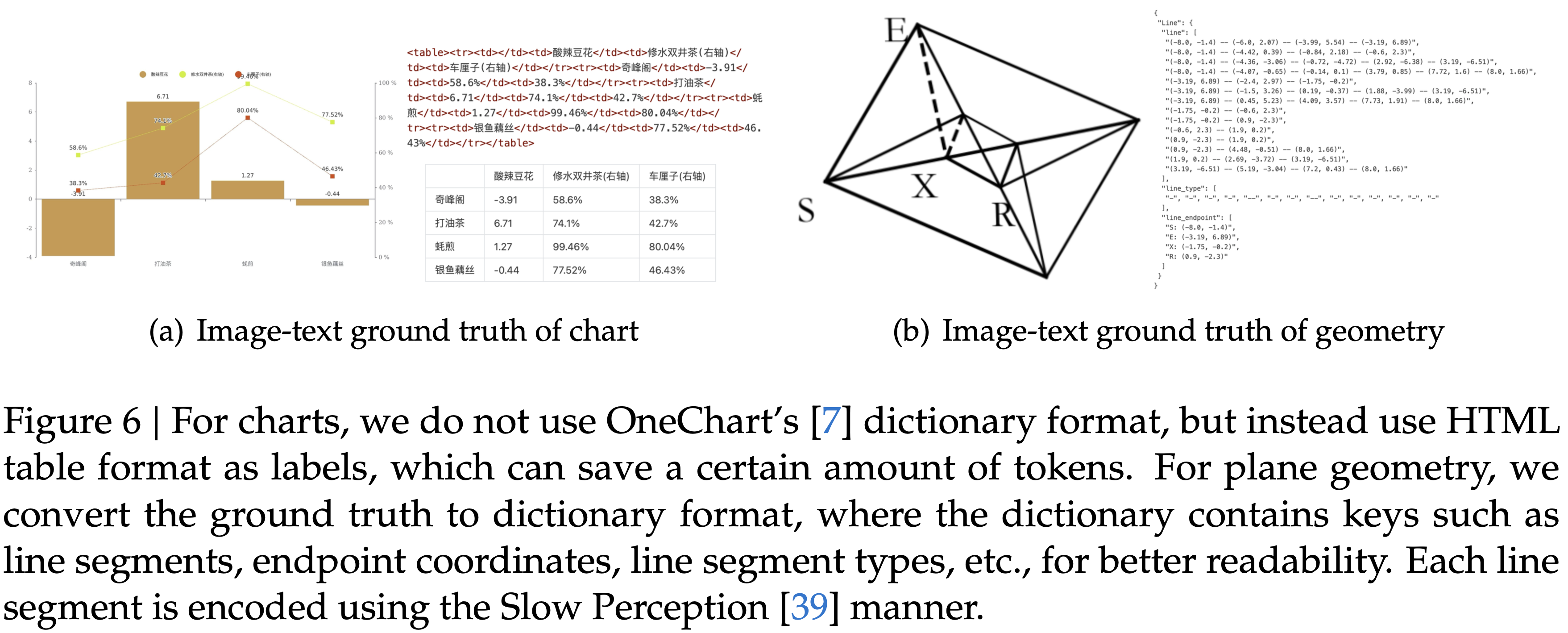
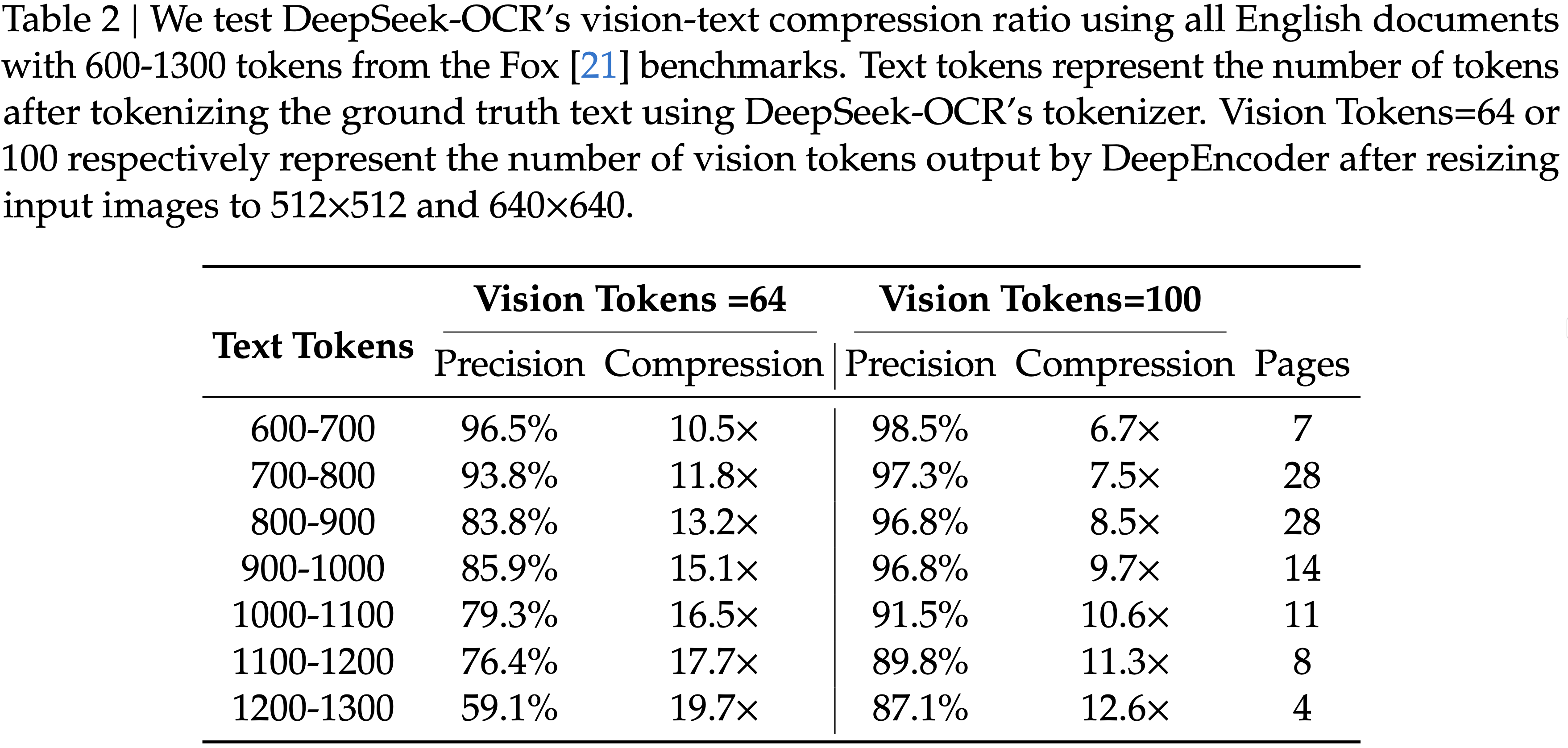
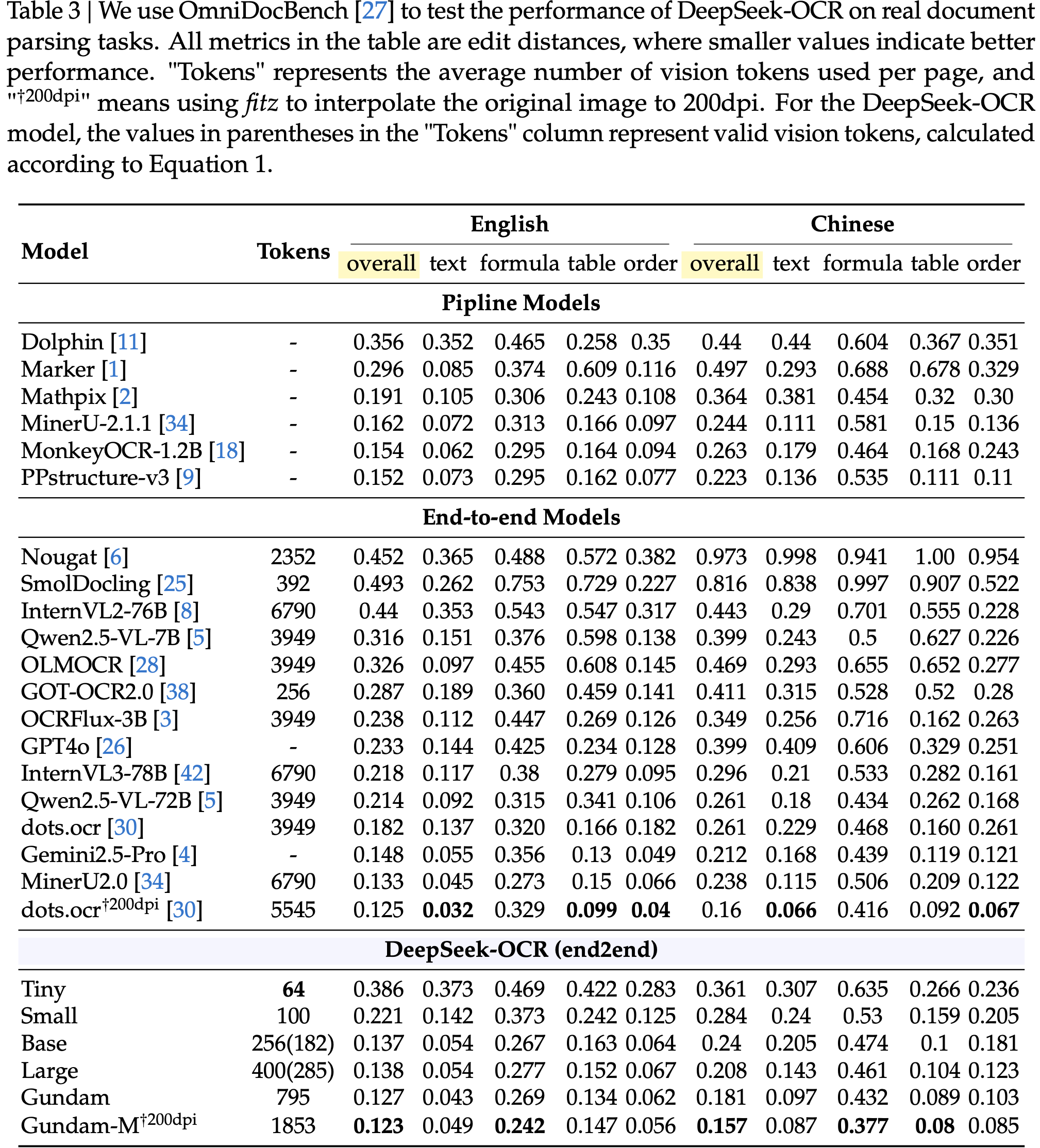
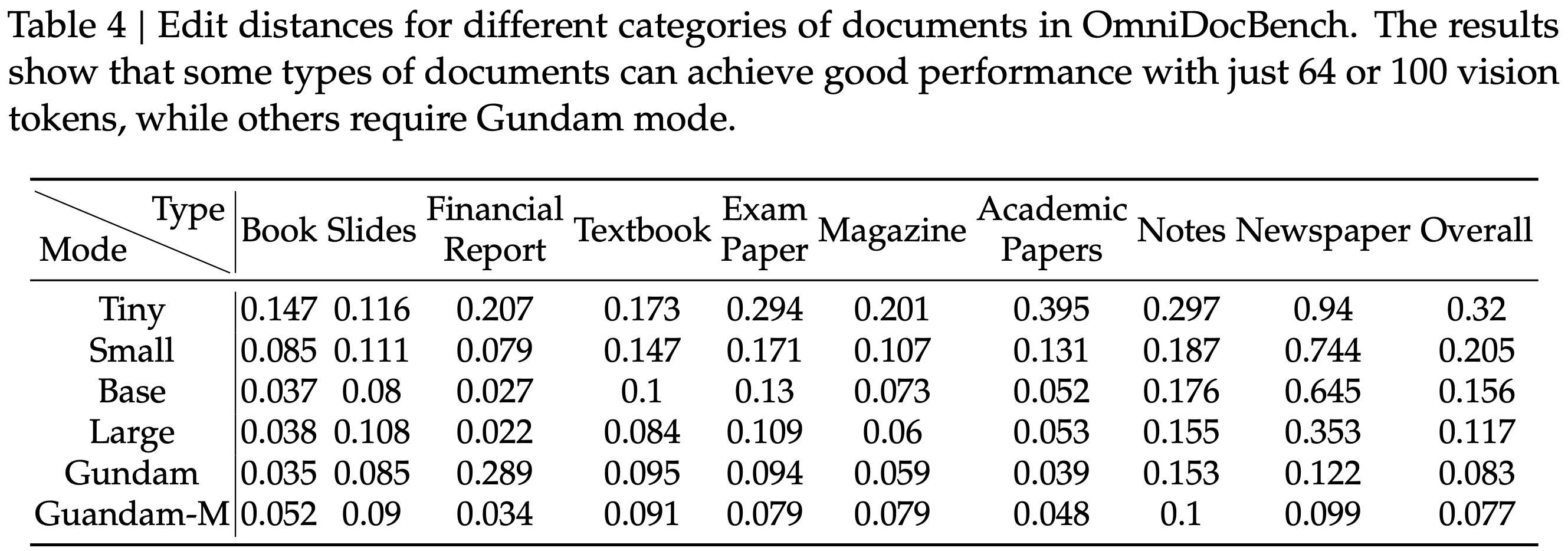
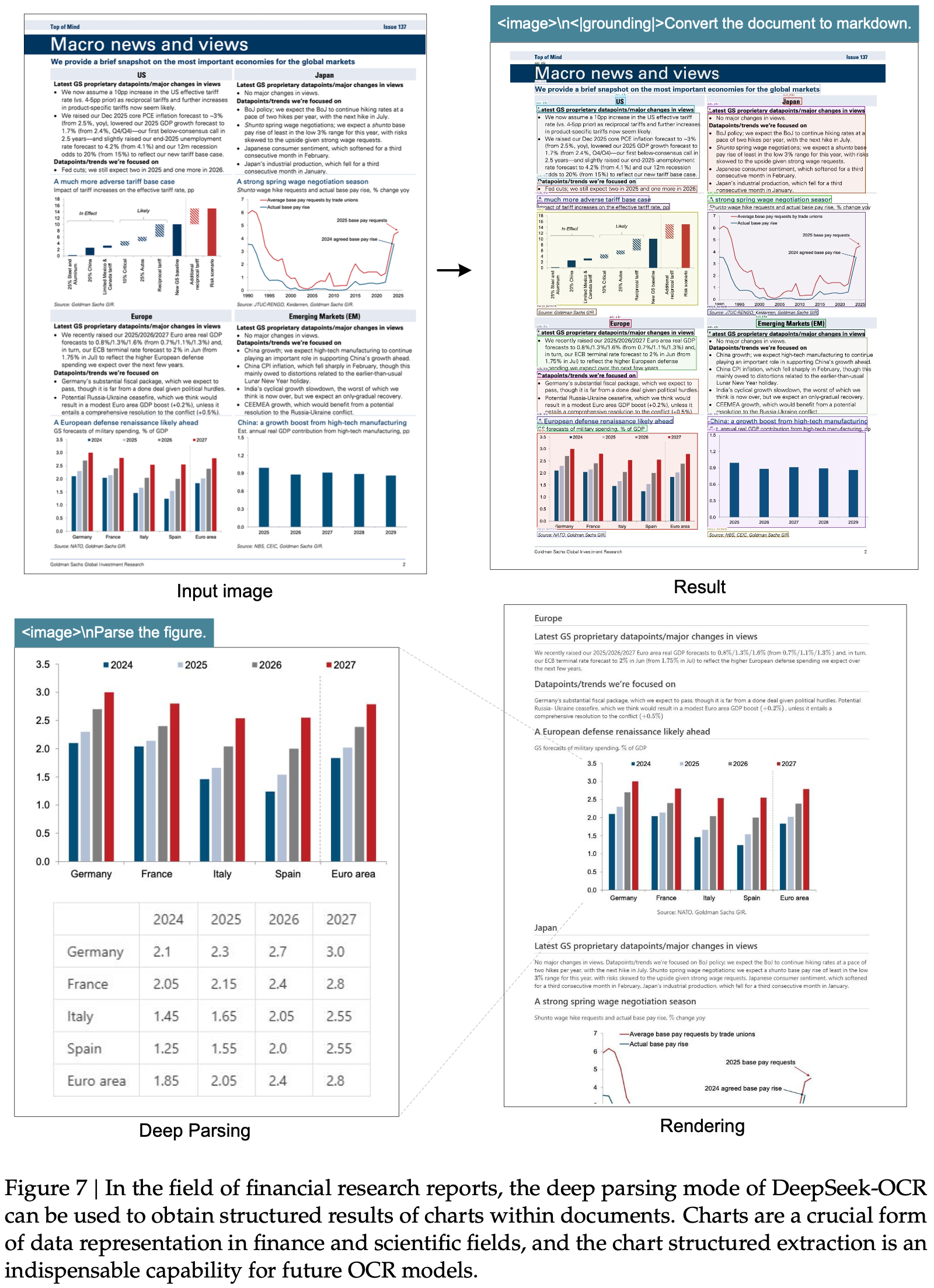
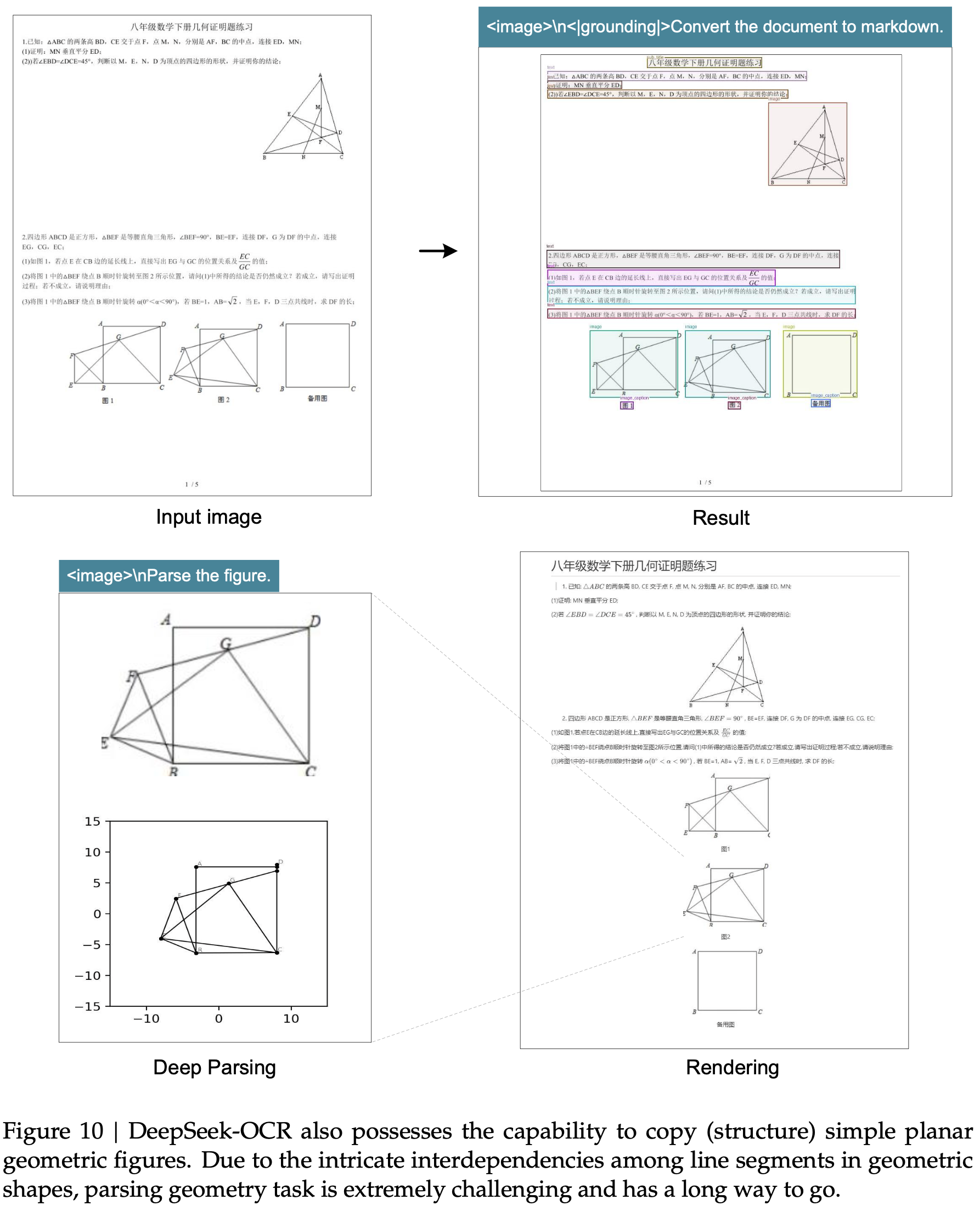
 显示了在 Fox (2024) 基准测试上测试的压缩比(真实文本 Token 数量 / 模型使用的视觉 Token 数量);图 (b) 显示了在 OmniDocBench (2025) 上的性能比较;DeepSeek-OCR 在使用最少视觉 Token 的端到端模型中实现了 SOTA 性能")







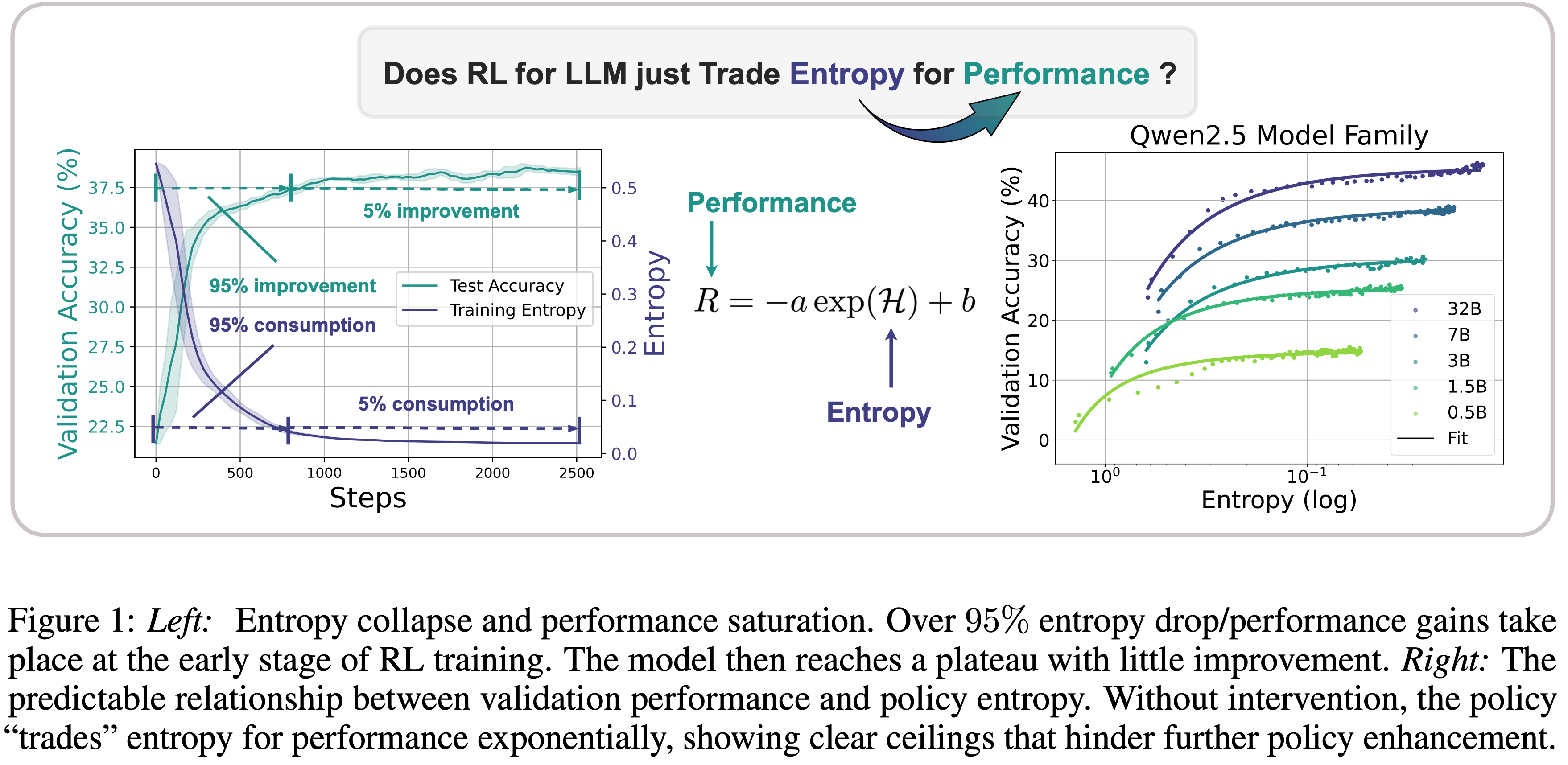
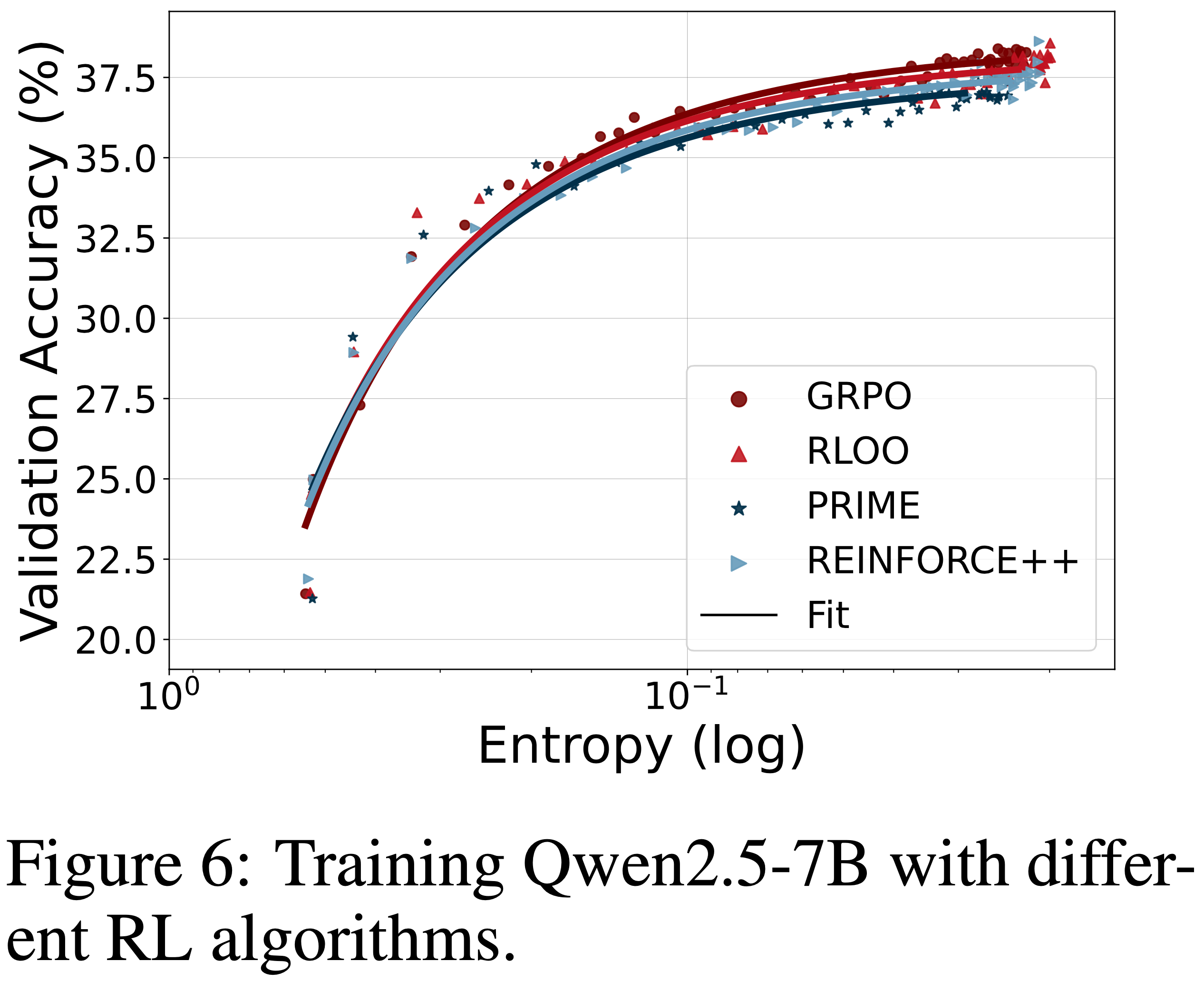
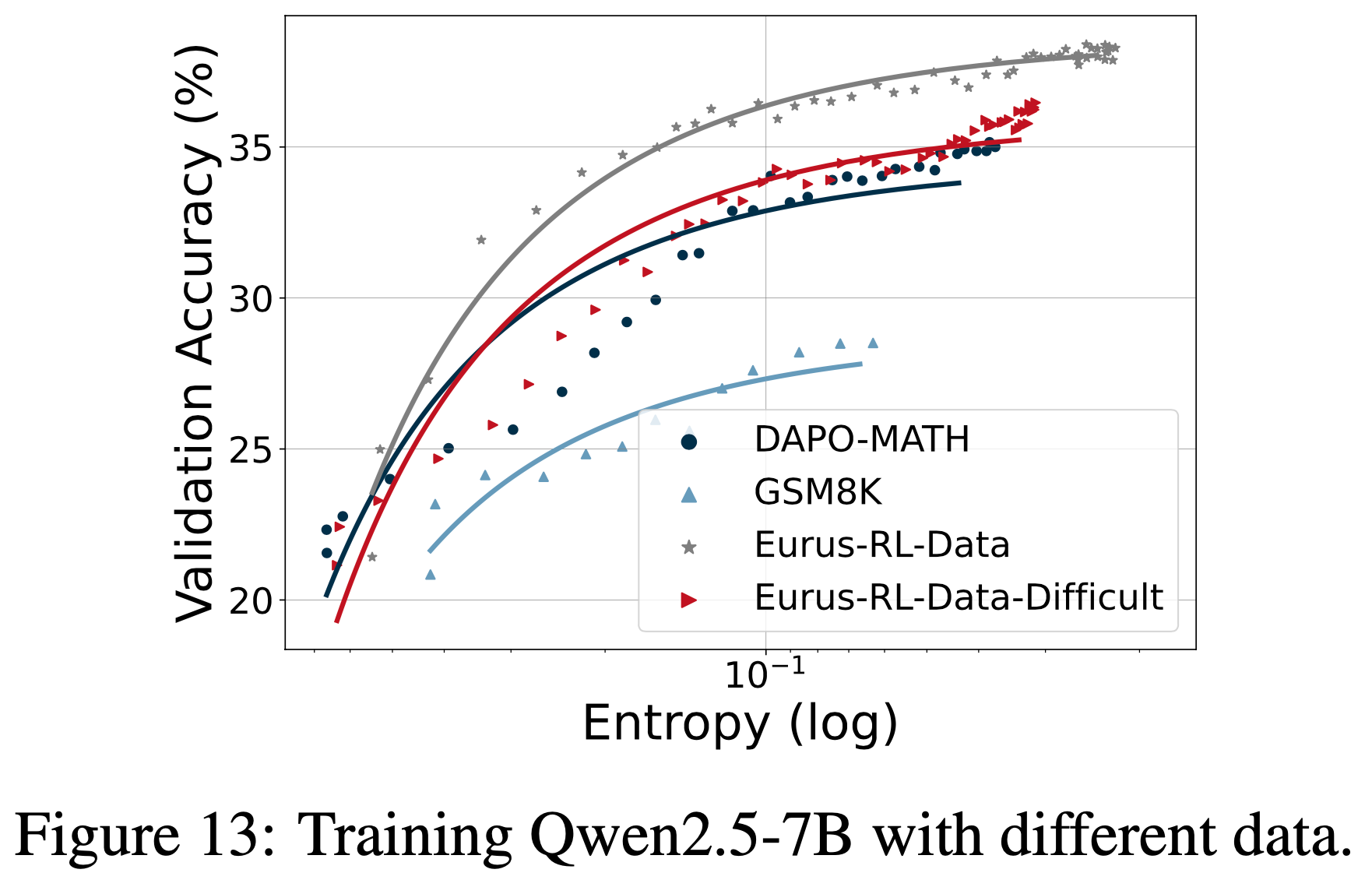
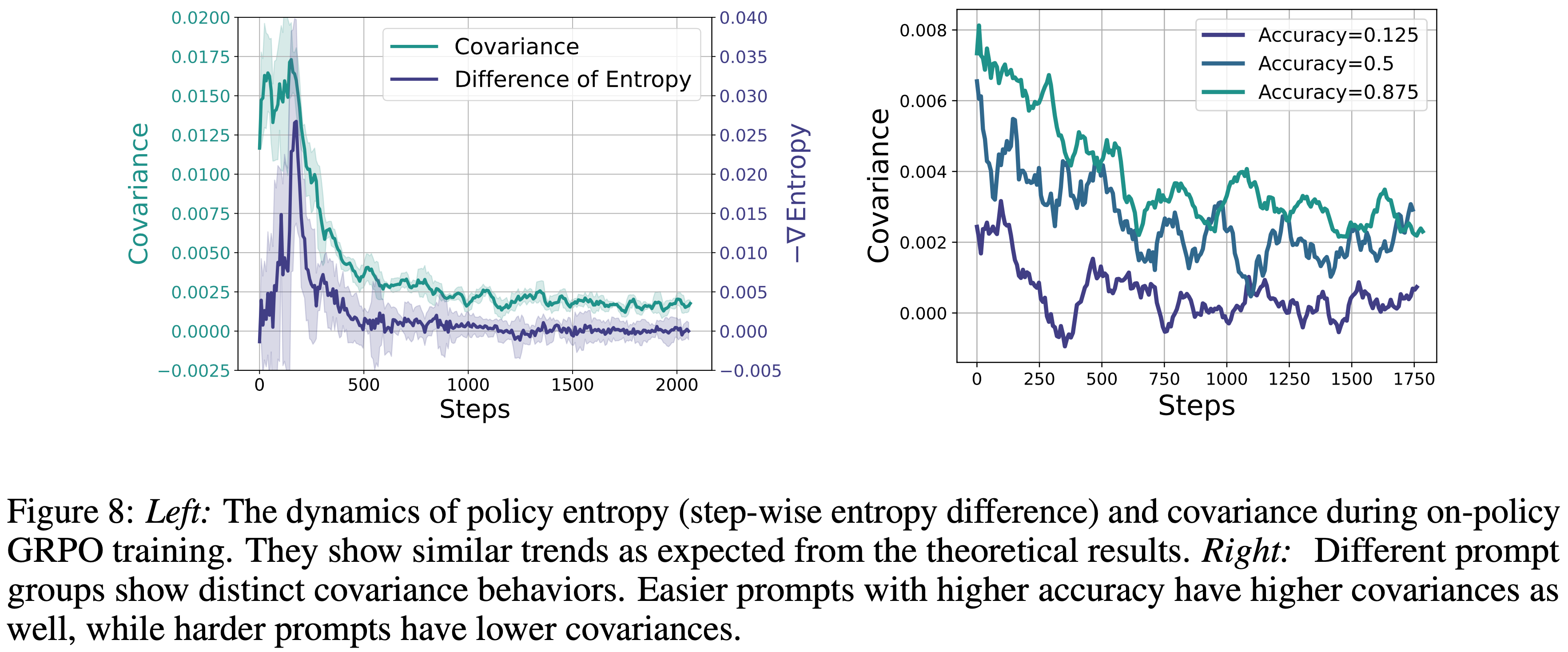
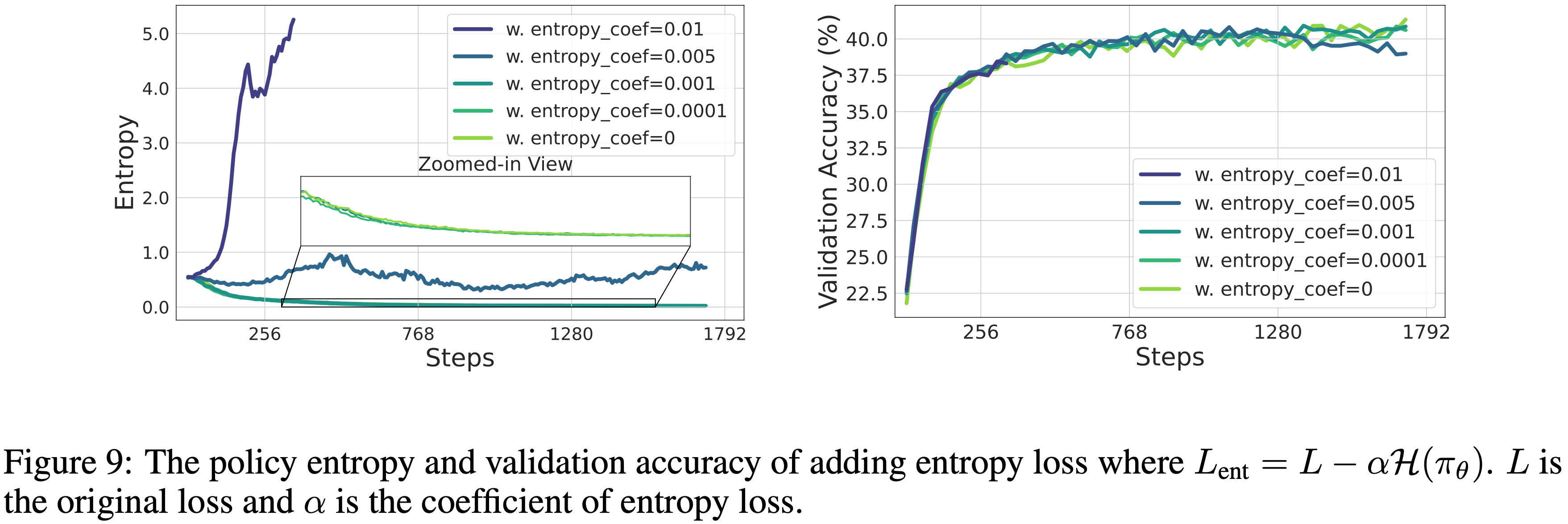

,大约为 -1.38")