BERT之前
Word2Vec的缺点
- 多义词问题 : 传统的Word Embedding无法识别多义词
- 确切的说是所有词的固定表征的方式(静态方式)的缺点
- 所谓静态指的是训练好之后每个单词的表达就固定住了
从Word Embedding到ELMo
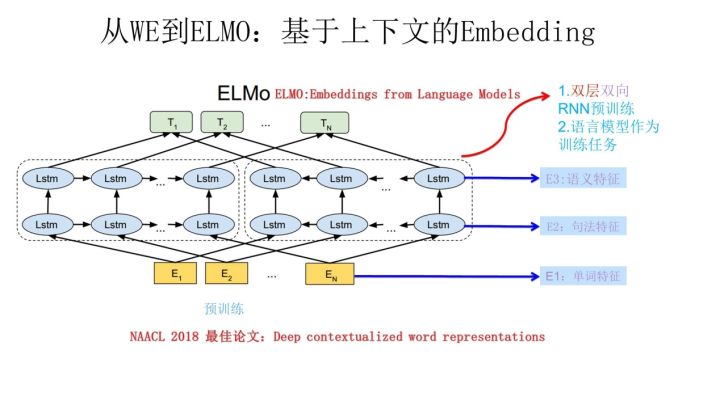
ELMo, Embedding from Language Models
根据当前上下文对Word Embedding动态调整的思路
- ELMo 论文原文: NAACL 2018 Best Paper, Deep contextualized word representations
- ELMo的本质思想:
- 事先用语言模型学好一个单词的Word Embedding,此时多义词无法区分
- 实际使用Word Embedding的时候,单词已经具备了特定的上下文了,这个时候我可以根据上下文单词的语义去调整单词的Word Embedding表示
- 这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题了
- ELMo是典型的两阶段训练过程: 预训练 + 特征融合?
- 第一个阶段是利用语言模型进行预训练
- 第二阶段通过基于特征融合的方式训练
- ELMo预训练过程示意图
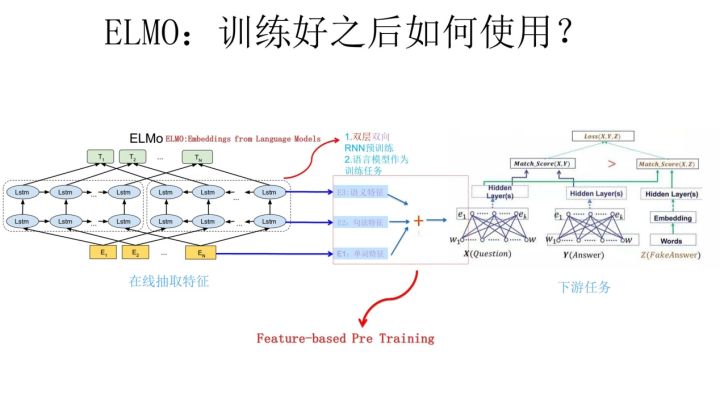
- ELMo预训练后如何处理下游任务?
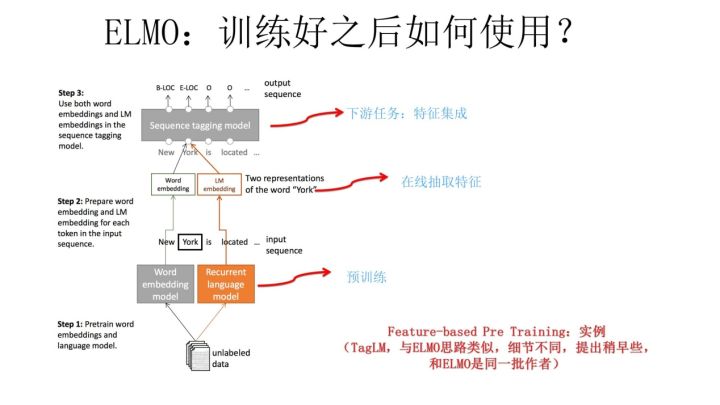
- 预训练训练完成后, 模型训练时使用在线特征抽取,和特征集成的方式对词向量在不同的上下文中进行不同的修正,从而区分多义词
补充知识: 下游任务
下游任务包括很多, 整体上可以分为四大类
序列标注
- 分词
- POS Tag
- NER
- 语义标注
- …
分类任务
- 文本分类
- 情感计算
- …
句子关系判断
- Entailment
- QA
- 自然语言推理
- …
机器翻译
- 机器翻译
- 文本摘要
- …
预训练模型
- 预训练模型是什么?
- 预训练模型是指在训练结束是结果比较好的一组权重值,研究人员分享出来供他人使用,基于这些预训练好的权重可以提升我们的模型训练速度和精度
- 预训练模型能够成功的本质是我们假设预训练模型足够好, 能学到句子的所有信息(包括序列信息等)
- 两阶段预训练模型如何处理下游任务?
- 预训练与下游任务无关
- 预训练阶段是预训练模型自己选择相应的NLP任务,然后让模型在学习处理这些任务的途中实现参数的训练
- 比如BERT选择的就是MLM(屏蔽语言模型)和NSP(Next Sentence Predition, 下一个句子预测)两个任务来做预训练
- 不同的下游任务往往需要修改第二阶段中的模型结构等
- 为适应不同的下游任务, 第二阶段可能使用不同结构, 比如添加Softmax层等方式
- 预训练与下游任务无关
ELMo的优缺点
- 优点:
- 很好的解决了多义词问题,而且效果非常好
- 采用上下文来训练词(从上下文预测单词, 上文称为Context-before, 下文称为Context-after)
- 缺点:
- 特征提取器没有使用新贵Transformer, 而是传统的LSTM, 特征抽取能力不足
从Word Embedding到GPT
GPT, Generative Pre-Training
- ELMo的训练方法和图像领域的预训练方法对比,模式不同, ELMo使用的是基于特征融合的预训练方法
- GPT使用的预训练方法则是在NLP领域开创了和图像领域一致的预训练方法基于Fine-tuning的模式
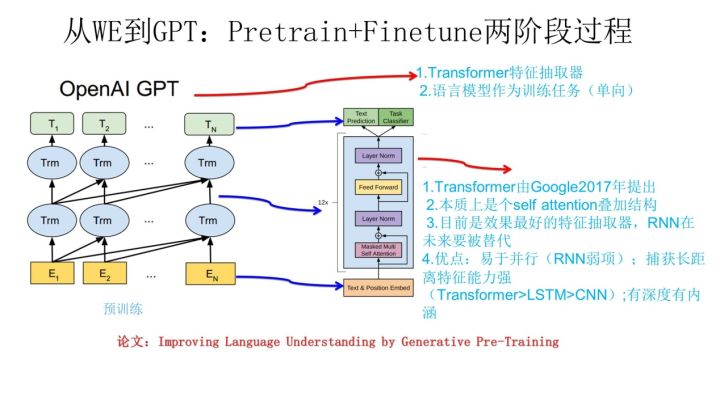
- GPT也采用两阶段过程: 预训练 + Fine-tuning
- 第一个阶段是利用语言模型进行预训练
- 第二阶段通过Fine-tuning的模式训练
- GPT预训练后如何处理下游任务?
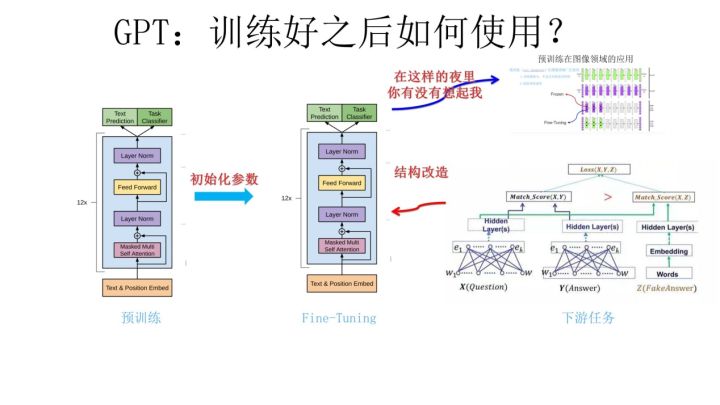
- 一些下游任务的Fine-tuning结构
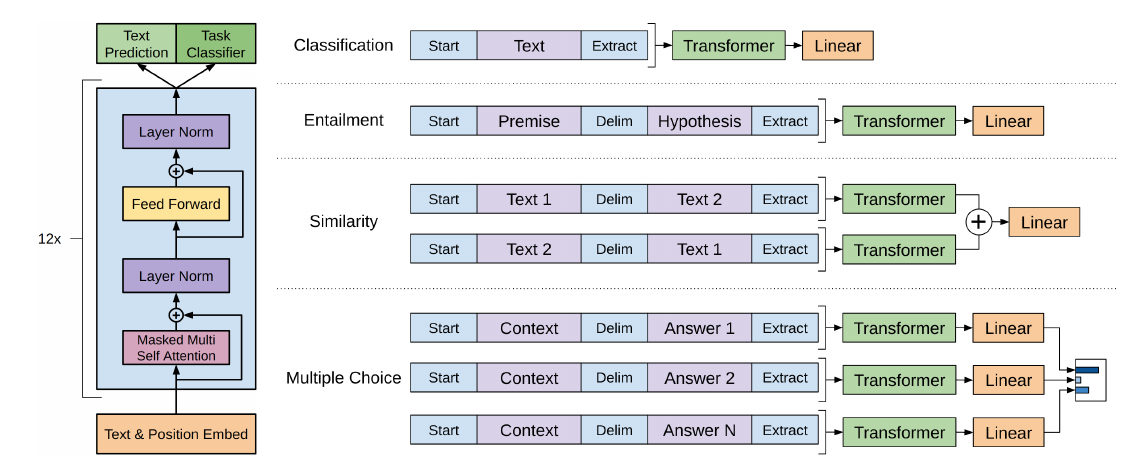
GPT的优缺点
- 优点:
- 特征提取器是Transformer,不是RNN, 所以特征提取效果好
- 缺点
- GPT使用的是单向语言模型 : 也就是说只用到了上文来预测词
- 词嵌入时没有单词的下文, 失去了很多信息
BERT结构和原理
下面的讲解都将按照原论文的思路讲解
- BERT(Bidirectional Encoder Representations from Transformers), 原文 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 下图是BERT与GPT和ELMo对比的结构图
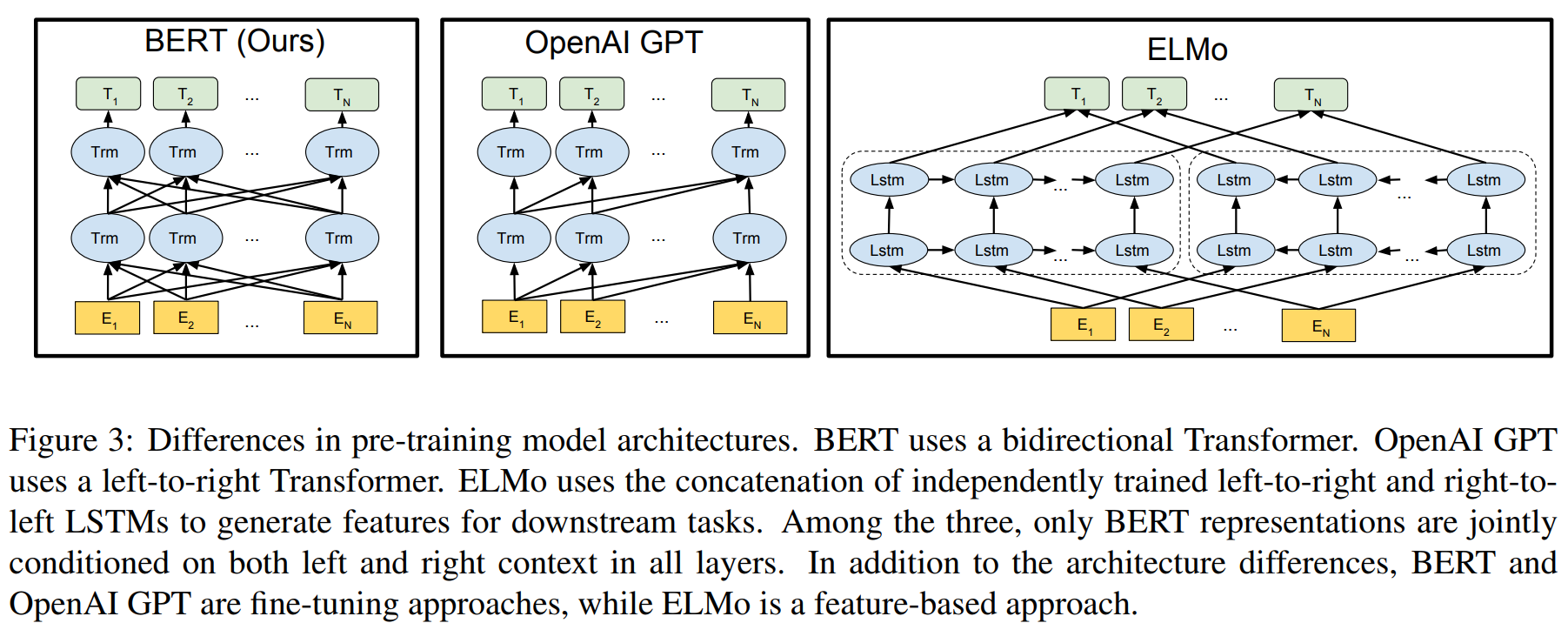
- 图中的每个
Trm组件就是一个 Transformer 的Encoder部分,也就是下图中的左半部分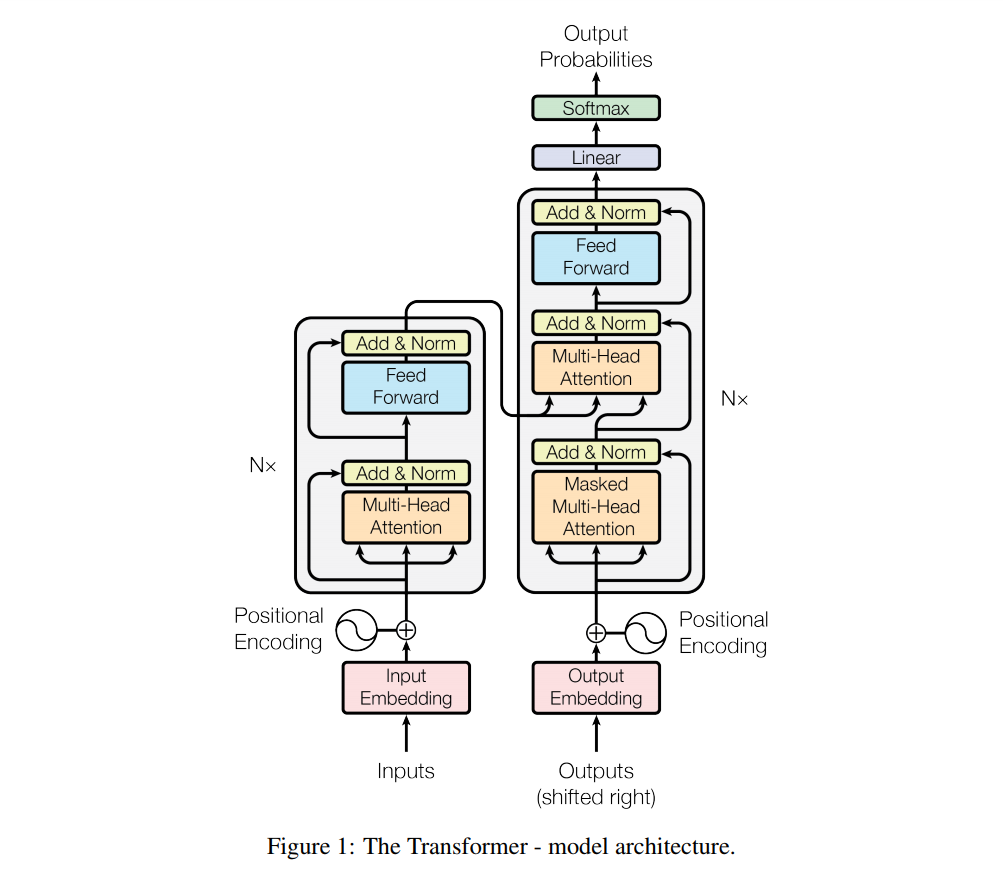
- 图中的每个
BERT的特点
- 一体化特征融合的双向(Bidirectional)语言模型
- 利用语言的双向信息
- GPT是单向语言模型, 只能利用一个方向的信息
- ELMo也是双向语言模型,但是 ELMo实际上是两个方向相反的单向语言模型的拼接, 融合特征的能力比BERT那种一体化的融合特征方式弱
- 特征提取器:
- 使用Transformer(实际上使用的是Transformer的Encoder部分, 图中每个)
- 预训练任务:
- 屏蔽语言模型(MLM, Masked Language Model) + 相邻句子判断(NSP, Next Sentence Prediction)两个任务的多任务训练目标
- 训练数据量:
- 超大规模的数据训练使得BERT结果达到了全新的高度
- 可以使用BERT作为词嵌入(Word2Vec)的转换矩阵, 实现比其他词嵌入模型更好的结果
输入表示
- 输入结构图
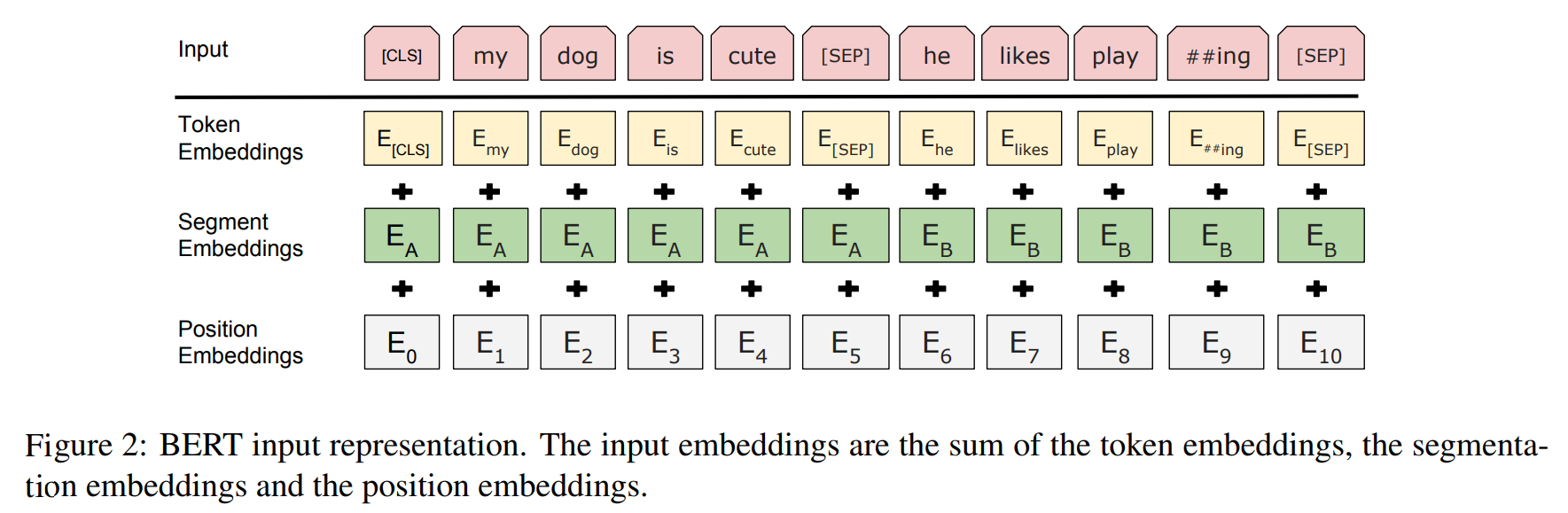
- BERT输入是一个512维的编码向量, 是三个嵌入特征的单位和
WordPiece嵌入
- 对应图中的Token Embedding
- WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡
- 举例: 原文中 “playing” 被拆分成了 “play” 和 “##ing” 两部分
Segment Embedding
分割嵌入
- 对应图中的Segment Embedding
- 用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)
- 对于句子对,第一个句子的特征值是0,第二个句子的特征值是1, 从而模型可以表达出词出现在前一个句子还是后一个句子
Position Embedding
位置嵌入
- 对应图中的 Position Embedding
- 位置嵌入是指将单词的位置信息编码成特征向量
- 这是继承自论文Google Brain, NIPS 2017: Attention Is All You Need中, 文章中的Transformer架构没有使用RNN,不能编码位置信息,就是在进入Attention前使用了 词嵌入 + 位置嵌入 的方式让模型能够表达位置信息的
预训练
- 通常预训练是指在训练阶段让模型去解决自然语言任务, 从而训练完成后得到可移植到其他模型(或者当前模型)使用的参数(包括词向量等)
- BERT的预训练使用了两个NLP任务: MLM + NSP
- BERT预训练和使用概览:
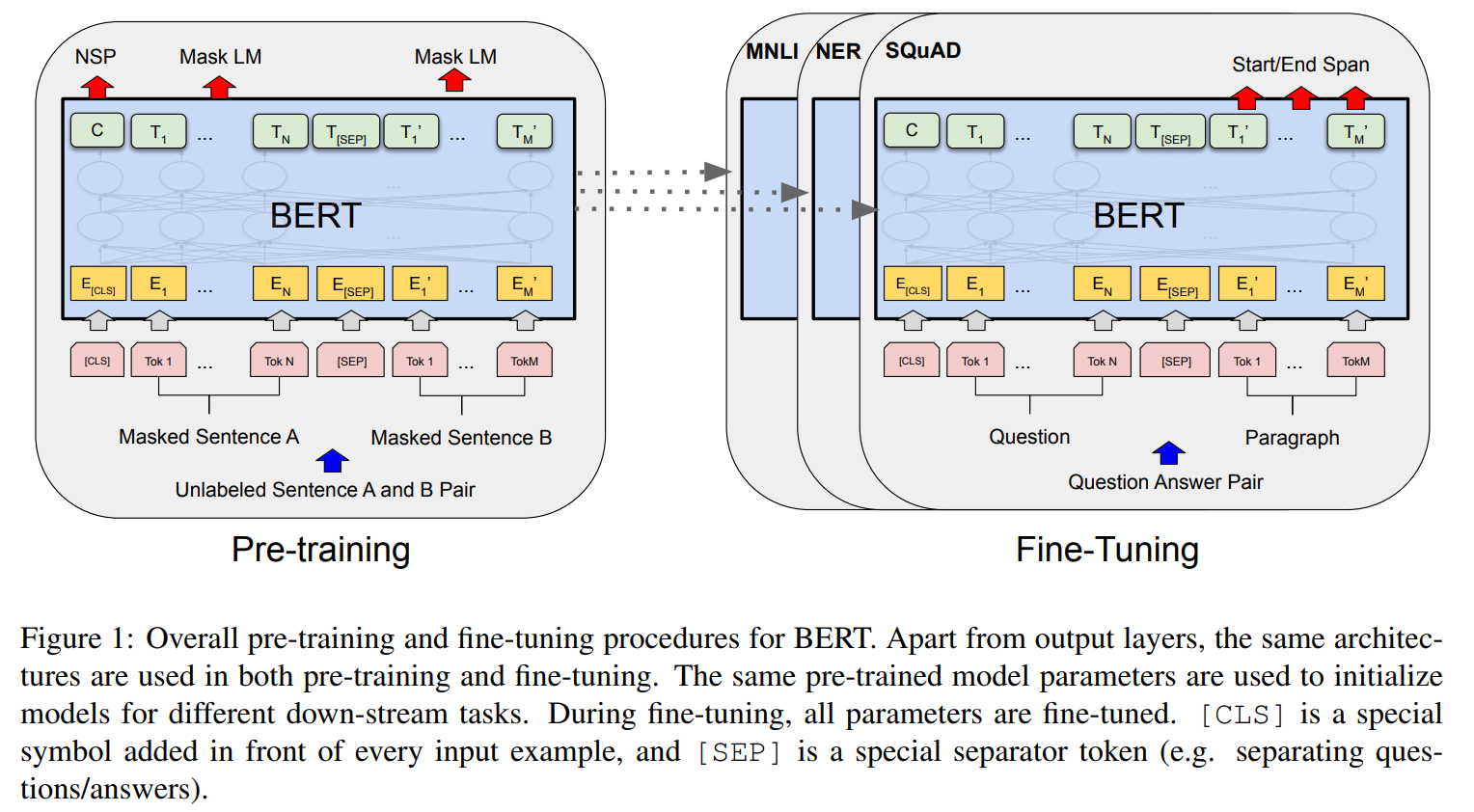
- 从上图可以看出, BERT的预训练包含了两方面的任务, NSP和 MLM
- 实验证明, MLM 优于标准的 LTR(left-to-right)语言模型(OpenAI GPT 使用的就是这个)
屏蔽语言模型(MLM)
Masked Language Model
- Masked Language Model(MLM)核心思想取自Wilson Taylor在1953年发表的一篇论文“Cloze Procedure”: A New Tool for Measuring Readability
- 在训练的时候随机从输入预料上屏蔽(Mask)掉一些单词,然后通过的上下文预测该单词(“完形填空”)
- 传统的语言模型是Left-to-Right(LTR)或者是Right-to-Left(RTL)的, 和 RNN 结构匹配
- MLM 的性质 和 Transformer 的结构匹配
- BERT实验中, 有15%的WordPiece Token句子会被屏蔽掉, 在屏蔽的时候,又有不同的概率
- 如果已经选中(15%概率)要屏蔽
my dog is hairy中的hairy, 那么我们的处理方式是:- 80%:
my dog is hairy -> my dog is [MASK] - 10%:
my dog is hairy -> my dog is apple - 10%:
my dog is hairy -> my dog is hairy - 防止句子中的某个Token 100%都会被mask掉,那么在Fine-tuning的时候模型就会有一些没有见过的单词
- 加入随机Token的原因是因为Transformer要保持对每个输入Token的分布式表征,否则模型就会记住这个[MASK]是 Token “hairy”
- 错误单词带来的负面影响: 一个单词被随机替换掉的概率只有 \(15% \times 10% = 1.5%\) 这个负面影响其实是可以忽略不计的
- 80%:
- 另外: 文章指出每次只预测15%的单词,因此模型收敛的比较慢
为什么使用MLM
- 因为效果好,解释就是MLM更符合Transformer的结构
- 论文中的实验结果:
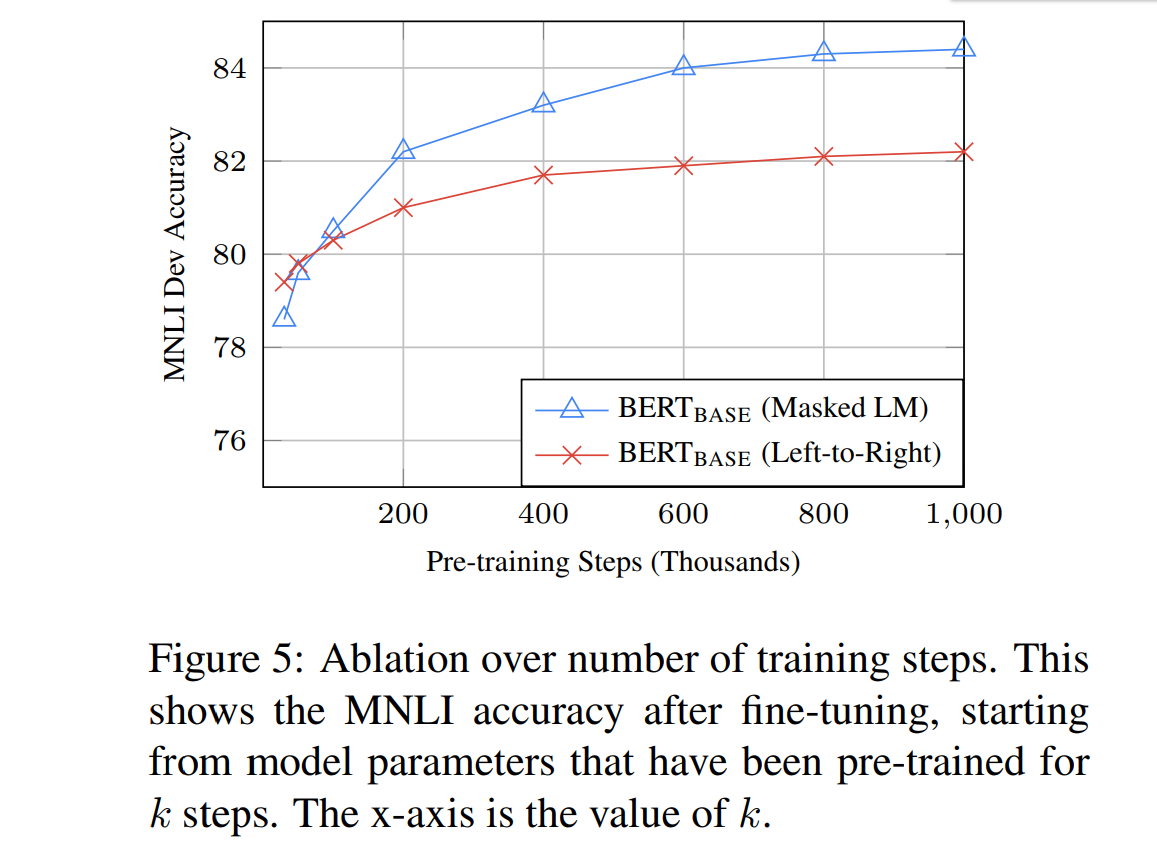
- MNLI(Multi-Genre Natural Language Inference)是多类型自然语言推理任务, 是一个大规模的众包蕴含分类任务, 给定一个句子,目标是预测第二句相对与第一句是一个蕴含语句, 矛盾语句, 还是中性语句
- 从图中可以看出,在MNLI任务中, MLM预训练 + MNLI Fine-tuning 的效果明显优于 LTR预训练 + MNLI Fine-tuning 的效果
相邻句子预测(NSP)
Next Sentence Prediction
- NSP 的任务是判断句子B是否是句子A的下文
- 图中的[CLS]符号就是用于分类的, 如果是的话输出’IsNext‘,否则输出’NotNext‘
- 训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的
- 举例来说:
- Input =
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] - Label =
IsNext - Input =
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] - Label =
NotNext
- Input =
Fine-tuning 处理下游任务
Fine-tining, 中文也称为微调
下图是BERT在不同任务的的微调方法
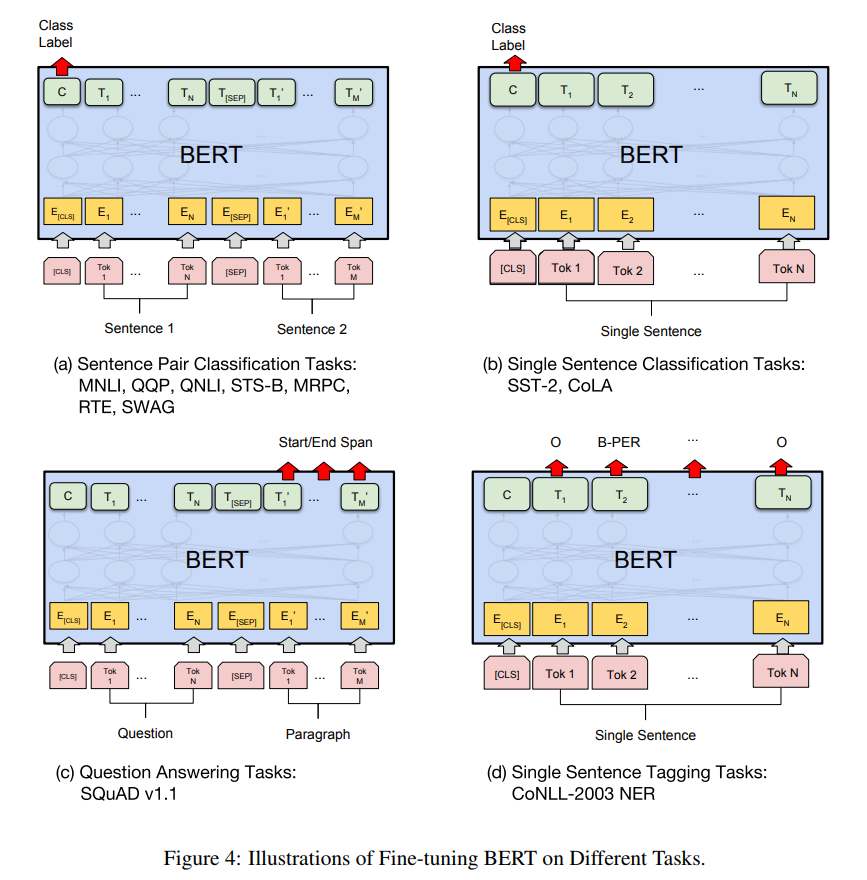
第二阶段,Fine-Tuning阶段,这个阶段的做法和GPT是一样的。当然,它也面临着下游任务网络结构改造的问题,在改造任务方面Bert和GPT有些不同
- 句子类关系任务: 和GPT一样,增加起始和终结符号,输出部分Transformer最后一层每个单词对应部分都进行分类即可
- 除了生成任务外, 其他任务Bert都涉及到了
BERT的使用
- Google公开了两个不同规模的 BERT模型:
- ** \(BERT_{BASE}\) ** : 110M模型参数
- ** \(BERT_{LARGE}\) ** : 340M模型参数
- 同时公开了两个模型在大规模数据预训练后的参数集合, 供开发者下载和使用
基于BERT的新秀
- Token仍然使用词, 但是MLM屏蔽时选择屏蔽短语或者实体
ERNIE from Baidu
- 参考文章: [ERNIE: Enhanced Representation through Knowledge Integration]
- 核心思想:
- 用先验知识来加强预训练模型(考虑实体,短语等级别的屏蔽)
- 在BERT的预训练阶段, MLM模型中屏蔽一个实体(Entity)或者短语(Phrase)而不是屏蔽一个字(Word)
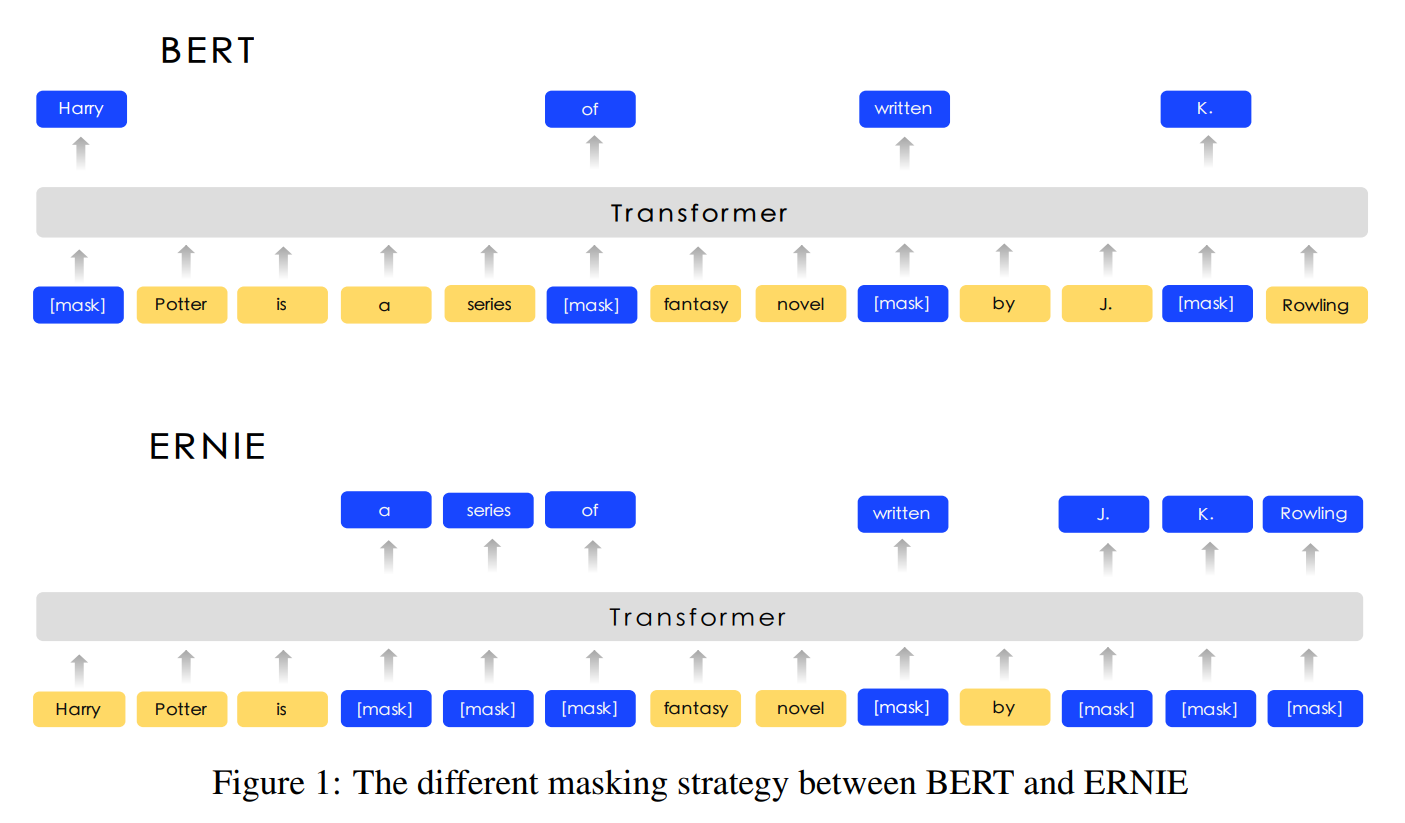
- 文中提出三种级别的屏蔽方式

- 基本级别(Basic-level)
- 实体级别(Entity-level)
- 短语级别(Phrase-level)
实验对比
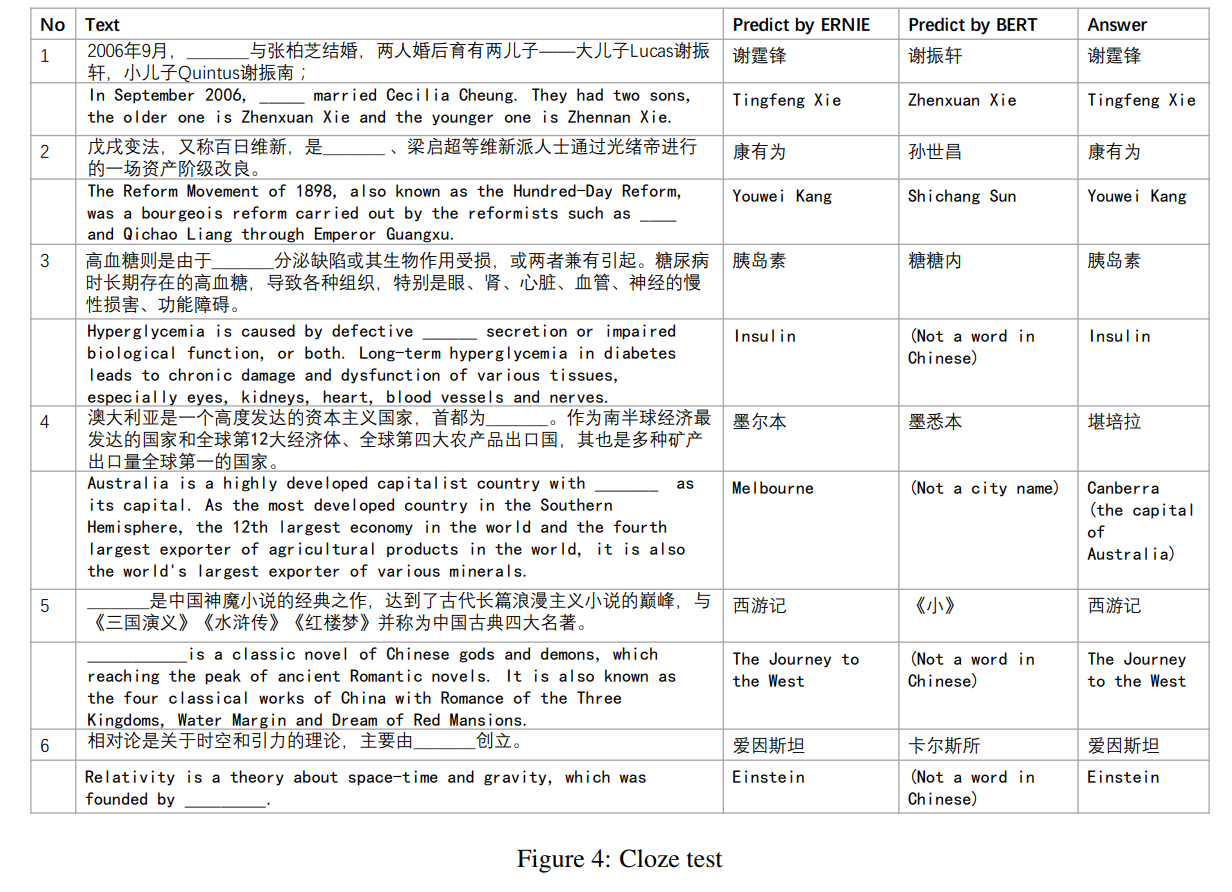
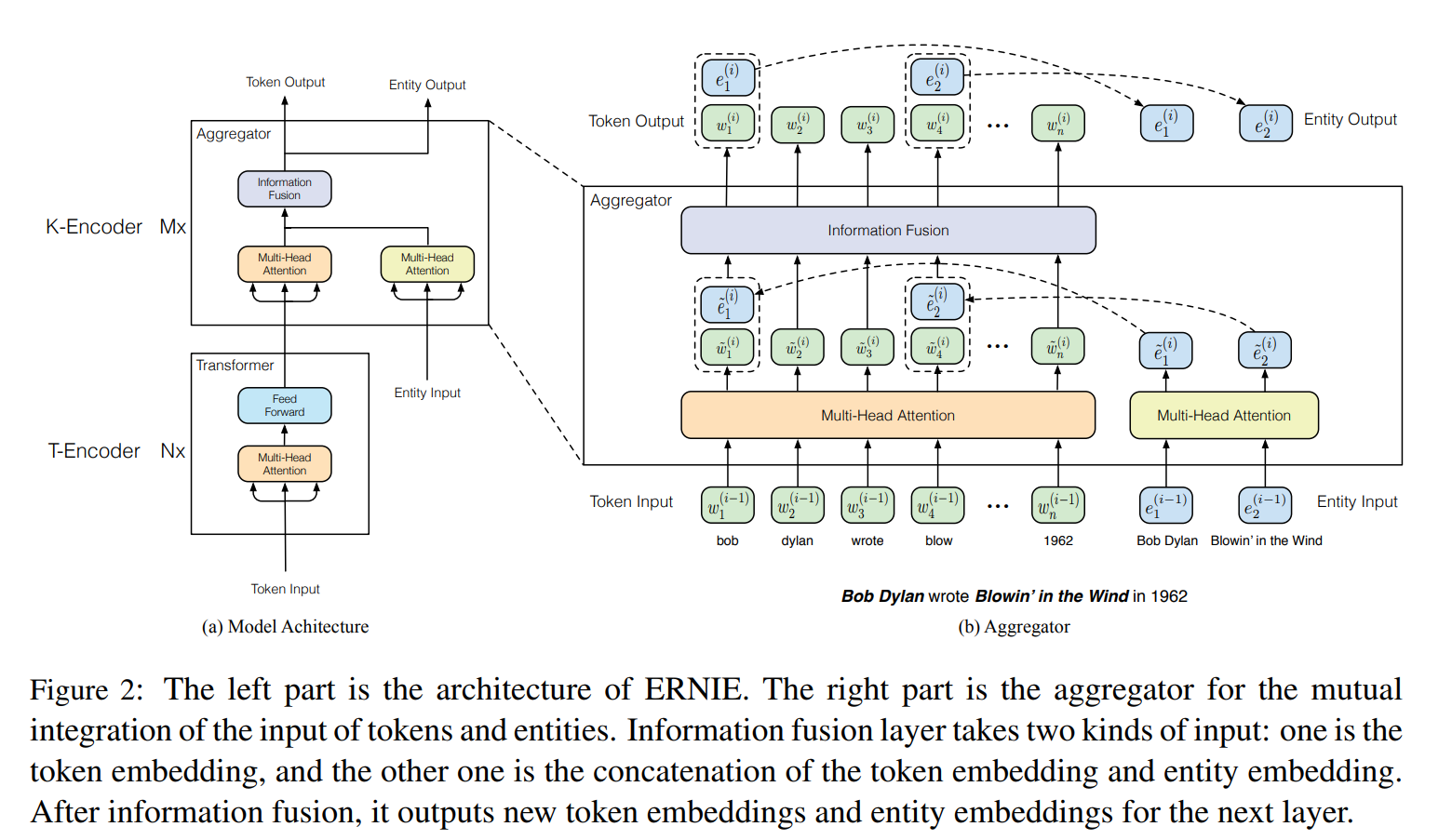
ERINE from THU
- 参考文章: ERNIE: Enhanced Language Representation with Informative Entities
- 核心思想:
- 利用先验知识来加强预训练模型(引入知识图谱)
- 提出了将知识纳入语言表达模型的方法
- 使用知识聚合器(Knowledgeable aggregator)和预训练任务 dEA, 更好的融合来自文本和知识图谱的异构信息
- 知识信息
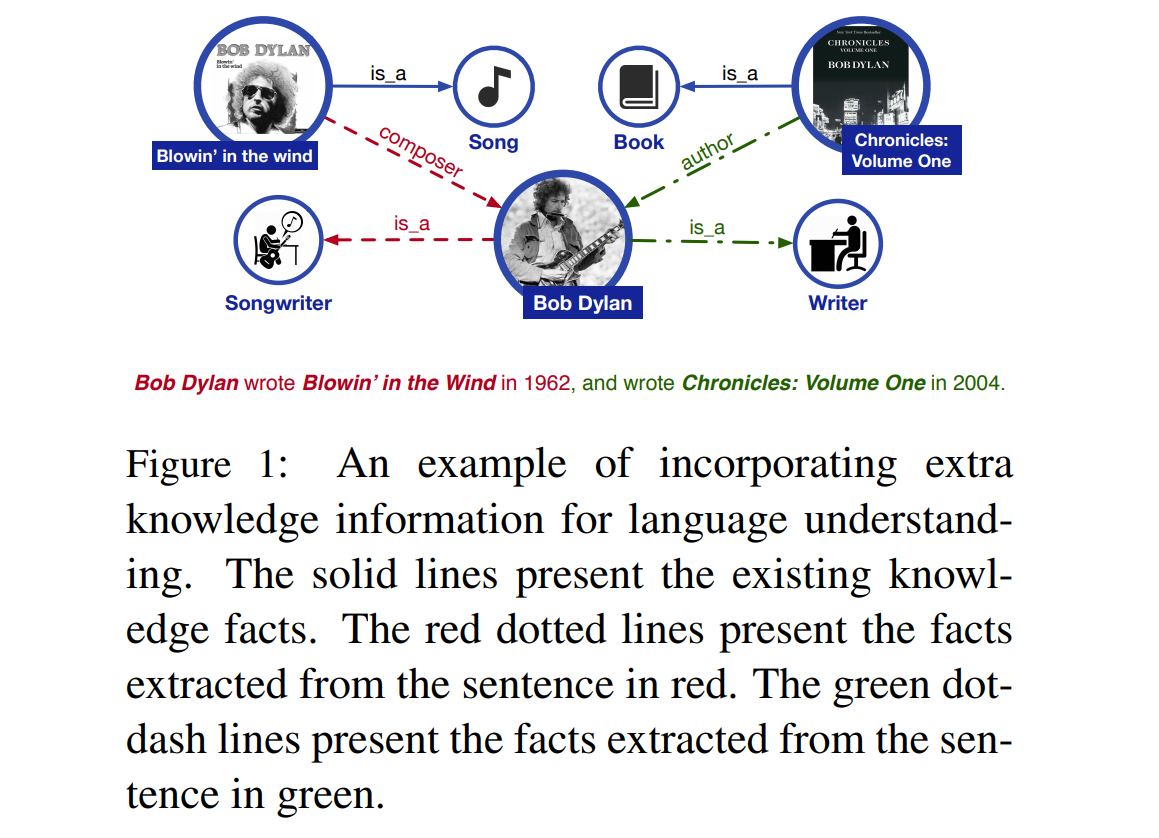
- 模型架构