注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体说明:
- 作者发现:Window Attention 提供了一个部分解决方案,但当初始 Token 被排除时,其性能会急剧下降(这些 Token 作为“Attention Sink”的作用很重要)
- 本文提出了一个简单而高效的框架 StreamingLLM,使 LLM 能够在无需微调的情况下处理无限长度的文本
- 通过将 Attention Sink 与 Recent Token 结合,StreamingLLM 可以高效地对多达 4M Token 的文本进行建模
- 论文还进一步通过实验证实,使用专用的 Sink Token 预训练模型可以改善流式性能
- StreamingLLM 首次将 LLM 的预训练窗口大小与其实际文本生成长度解耦,为 LLM 的流式部署铺平了道路
- 第一个问题提出:在流式(streaming)应用(如多轮对话)中部署 LLM 是迫切需要的,但面临两大挑战
- 挑战一:在解码阶段,缓存先前 Token 的键和值状态(KV)会消耗大量内存
- 挑战二:popular LLM 无法泛化到比训练序列长度更长的文本
- 第二个问题提出:Window Attention 是一种自然的方法,仅缓存最近的 KV,但论文发现当文本长度超过缓存大小时,该方法会失效
- Insight:作者观察到一个有趣的现象,即 Attention Sink :
- 保留(Keeping)初始 Token(initial Token)的 KV 会大幅恢复 Window Attention 的性能
- 注:Window Attention 会丢失最初的 Token 信息(窗口外),而刻意保留初始 Token 的 KV 能大幅提升模型性能
- 论文证明了 Attention Sink 的出现是由于对初始 Token 的 Strong 注意力分数 ,即使它们在语义上并不重要
- 注:Attention Sink 的定义应该是 无论初始 Token 与语言建模任务的相关性如何,都有大量的注意力分数分配给了初始 Token
- 方案:StreamingLLM
- StreamingLLM 是一个高效的框架,使经过有限长度注意力窗口训练的 LLM 能够无需任何微调即可泛化到无限序列长度
- StreamingLLM 能够使 Llama-2、MPT、Falcon 和 Pythia 在高达 4M Token 甚至更多的文本上实现稳定高效的语言建模
- 论文的其他发现,在预训练期间添加一个占位符 Token 作为专用的 Attention Sink 可以进一步改善流式部署
- 在流式设置中,StreamingLLM 相比滑动窗口重计算基线实现了高达 22.2 倍的加速
Introduction and Discussion
- LLM (2018; 2020; 2022; OpenAI, 2023; 2023a, 2023b) 正变得无处不在,驱动着许多自然语言处理应用,如对话系统 (2022; 2023; 2023)、文档摘要 (2020; 2023a)、代码补全 (2021; 2023) 和问答 (2023)
- 为了释放预训练 LLM 的全部潜力,它们应该能够高效且准确地执行长序列生成
- 例如,一个理想的聊天机器人助手应该能够在长达数日的对话内容上稳定工作
- 但对于 LLM 来说,泛化到比其预训练长度更长的序列是非常具有挑战性的,例如 Llama-2 的 4K (2023b)
- 为了释放预训练 LLM 的全部潜力,它们应该能够高效且准确地执行长序列生成
- 原因是 LLM 在预训练期间受到注意力窗口的限制
- 尽管在扩展此窗口大小 (2023; 2023; 2023) 以及改进长输入的训练 (2022; 2023) 和推理 (2022; 2023; 2023; 2021; 2023b) 效率方面付出了大量努力,可接受的序列长度本质上仍然是有限的 ,这不允许持久部署
- 论文介绍了 LLM 流式应用的概念,并提出了一个问题:论文能否在不牺牲效率和性能的情况下,为无限长度的输入部署 LLM?
- 当将 LLM 应用于无限输入流时,会出现两个主要挑战:
- 1)在解码阶段,基于 Transformer 的 LLM 会缓存所有先前 Token 的键和值状态(KV),如图 1 (a) 所示,这可能导致过多的内存使用和不断增加的解码延迟 (2022)
- 2)现有模型的长度外推能力有限,即当序列长度超过预训练期间设置的注意力窗口大小时,它们的性能会下降 (2023; 2022)
- 一种直观的方法,称为 Window Attention (2020)(图 1 b),仅维护最近 Token 的 KV 状态的固定大小滑动窗口
- 虽然它在缓存初始填满后确保了恒定的内存使用和解码速度,但一旦序列长度超过缓存大小,模型就会崩溃,即即使只是驱逐第一个 Token 的 KV ,如图 3 所示
- 另一种策略是带重计算的滑动窗口(如图 1 c 所示),它为每个生成的 Token 重建最近 Token 的 KV 状态
- 虽然它提供了强大的性能,但由于需要在其窗口内计算二次注意力,这种方法明显更慢,使其对于现实世界的流式应用不切实际
- 为了理解 Window Attention 的失败原因,论文发现了自回归 LLM 的一个有趣现象:无论初始 Token 与语言建模任务的相关性如何,都有大量的注意力分数分配给了初始 Token ,如图 2 所示
- 论文称这些 Token 为“ Attention Sink ”
- 尽管它们缺乏语义重要性,却收集了显著的注意力分数
- 论文将原因归咎于 Softmax 操作,它要求所有上下文 Token 的注意力分数总和为一
- 因此,即使当前查询在许多先前的 Token 中没有强匹配项,模型仍然需要将这些不需要的注意力值分配到某处,以便总和为一
- 初始 Token 成为汇聚 Token 背后的原因是直观的:
- 由于自回归语言建模的性质,初始 Token 对几乎所有后续 Token 都是可见的,这使得它们更容易被训练成 Attention Sink
- 基于上述见解,论文提出了 StreamingLLM,一个简单高效的框架,使经过有限注意力窗口训练的 LLM 能够无需微调即可处理无限长度的文本
- StreamingLLM 利用了 Attention Sink 具有高注意力值这一事实,保留它们可以保持注意力分数分布接近正常
- 因此,StreamingLLM 只需保留 Attention Sink Token 的 KV(仅需 4 个初始 Token 就足够)以及滑动窗口的 KV,以锚定注意力计算并稳定模型的性能
- 通过 StreamingLLM,包括 Llama-2 (2023b)、MPT (Team, 2023)、Falcon (2023) 和 Pythia (2023) 在内的模型可以可靠地对 4M Token 进行建模,甚至可能更多
- 与唯一可行的基线——带重计算的滑动窗口相比,StreamingLLM 实现了高达 22.2 倍的加速,实现了 LLM 的流式使用
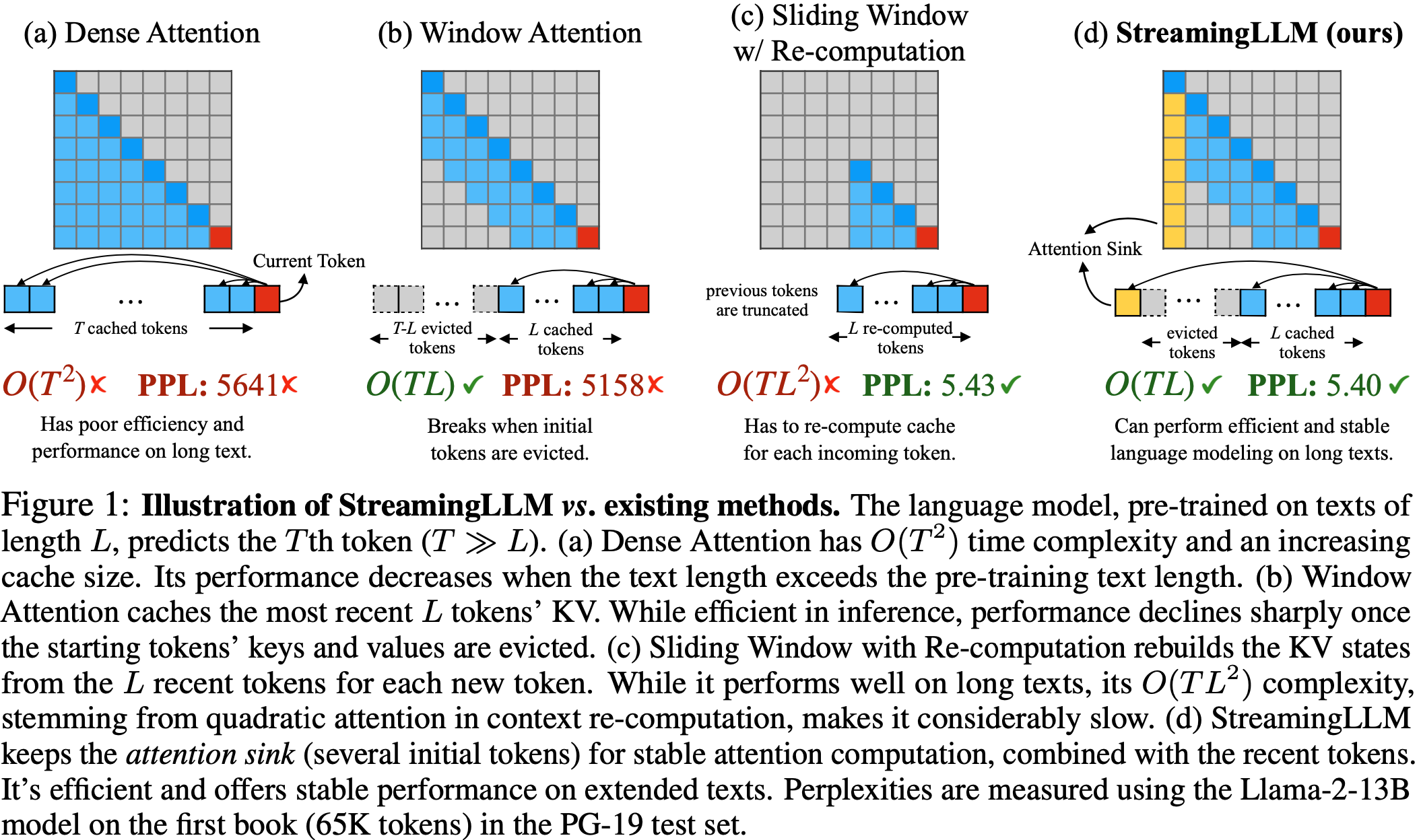
- 图 1: StreamingLLM 与现有方法的示意图 在长度为 \(L\) 的文本上预训练的语言模型预测第 \(T\) 个 Token (\(T\gg L\))
- (a) Dense Attention 具有 \(O(T^{2})\) 的时间复杂度和不断增长的缓存大小
- 当文本长度超过预训练文本长度时,其性能下降
- (b) Window Attention 缓存最近 \(L\) 个 Token 的 KV
- 虽然在推理中高效,但一旦起始 Token 的键和值被驱逐,性能就会急剧下降
- (c) 带重计算的滑动窗口(Sliding Window with Re-computation)为每个新 Token 从 \(L\) 个最近 Token 重建 KV 状态
- 虽然它在长文本上表现良好,但其 \(O(TL^{2})\) 的复杂度(源于上下文重计算中的二次注意力)使其相当慢
- (d) StreamingLLM 保留 Attention Sink (几个初始 Token )以进行稳定的注意力计算,并结合了最近 Token
- 在扩展文本上高效且提供稳定的性能
- 困惑度是使用 Llama-2-13B 模型在 PG-19 测试集中第一本书(65K Token )上测量的
- (a) Dense Attention 具有 \(O(T^{2})\) 的时间复杂度和不断增长的缓存大小
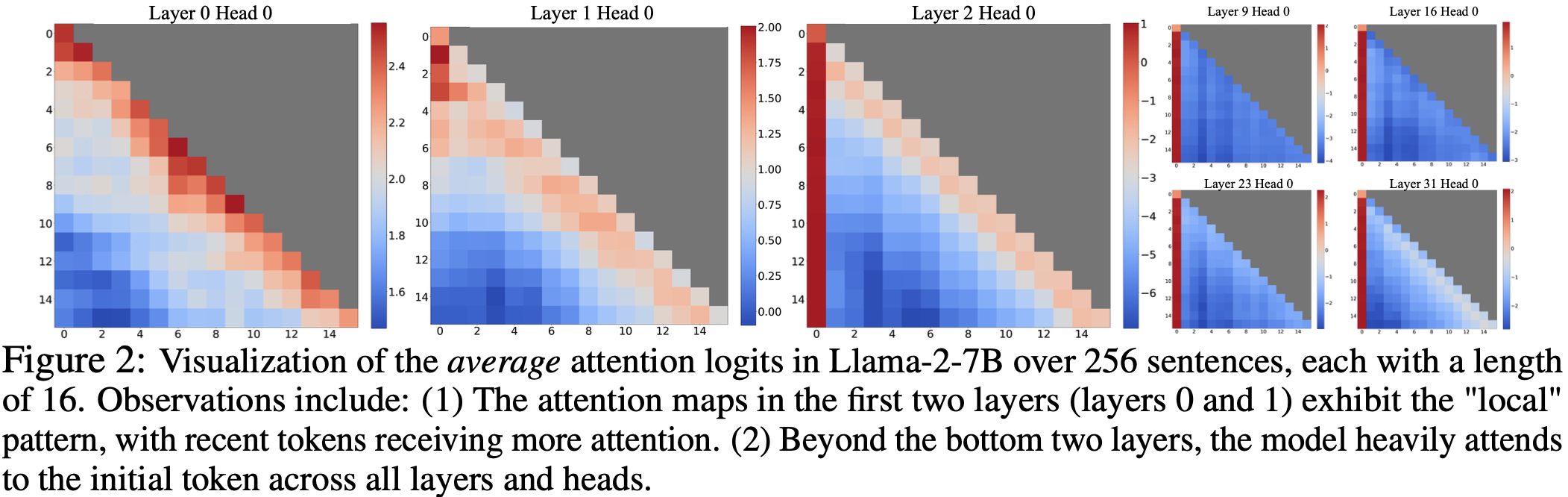
- 图 2: Llama-2-7B 在 256 个句子上的平均注意力对数概率可视化,每个句子长度为 16。观察包括:
- (1) 前两层(第 0 层和第 1 层)的注意力图呈现出“局部”模式,最近 Token 获得更多注意力
- (2) 在底部两层之上,模型在所有层和头中都严重关注(heavily attends)初始 Token
StreamingLLM
The Failure of Window Attention and Attention Sinks
- 虽然 Window Attention 技术在推理过程中提供了效率,但它导致了极高的语言建模困惑度
- 该模型的性能不适合部署在 流式应用 (streaming applications) 中
- 论文使用 Attention Sink 的概念来解释 Window Attention 的失败,这为 StreamingLLM 提供了灵感
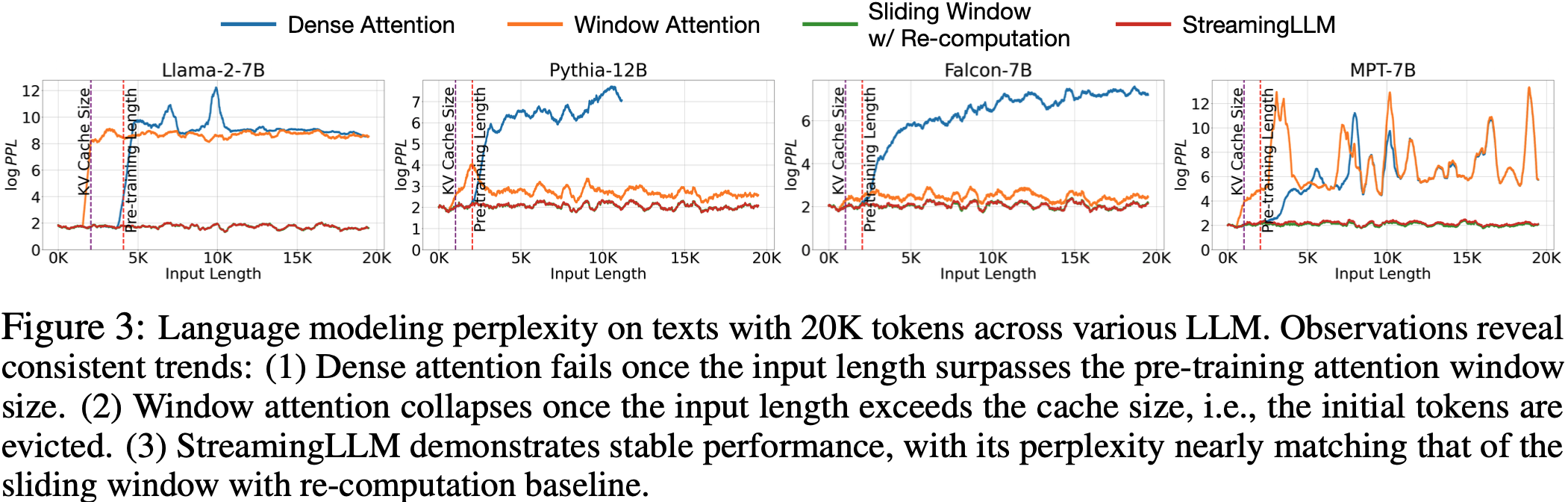
- 识别困惑度激增点 (Identifying the Point of Perplexity Surge) 图 3 显示了在 20K Token 文本上的语言建模困惑度
- 当文本长度超过 缓存 (cache) 大小时,由于排除了初始 Token ,困惑度会急剧上升
- 这表明,初始 Token ,无论它们与预测 Token 的距离如何,对于维持 LLM 的稳定性都至关重要
Why do LLMs break when removing initial tokens’ KV?
- 论文在图 2 中可视化了 Llama-2-7B 和模型所有层和头中的注意力图
- 论文发现,除了底部两层之外(注:这里的底部两层是最开始的两层),模型在所有层和头上都持续关注初始 Token
- 这意味着:移除这些初始 Token 的 KV 将移除 SoftMax 函数(公式 1)注意力计算中分母的相当一部分
- 这种改变导致注意力分数的分布发生显著变化,偏离了正常推理环境下的预期
$$\text{SoftMax}(x)_{i}=\frac{e^{x_{i} } }{e^{x_{1} }+\sum_{j=2}^{N}e^{x_{j} } },\quad x_{1}\gg x_{j},j\in 2,\ldots,N \tag{1}$$ - 对于初始 Token 在语言建模中的重要性,有两种可能的解释:
- (1) 它们的语义至关重要
- (2) 模型学习到了对其绝对位置的偏好
- 为了区分这两种可能性,论文进行了实验(表 1),其中前四个 Token 被替换为换行符 Token “\n”
- 观察结果表明,模型仍然显著关注这些初始的换行符 Token
- 此外,重新引入它们可以将语言建模困惑度恢复到与拥有原始初始 Token 相当的水平
- 这表明起始 Token 的绝对位置(而非其语义价值)具有更重要的意义
LLMs attend to Initial Tokens as Attention Sinks(LLM 将初始 Token 视为 Attention Sink )
- 为了解释为什么无论它们与语言建模的语义相关性如何,模型都不成比例地关注初始 Token,论文引入了 “Attention Sink” 的概念
- SoftMax 函数(公式 1)的性质阻止所有被关注的 Token 具有零值
- 这要求在所有层的所有头中从其他 Token 聚合一些信息,即使当前的 Embedding 已经有足够的 self-contained 信息用于预测
- 因此,模型倾向于将不必要的注意力值转储到特定的 Token 上
- 在量化异常值领域也进行了类似的观察 (2023; 2023),这导致了提出 SoftMax-Off-by-One (Miller, 2023) 作为潜在的补救措施
- 图 3:各种 LLM 在 20K Token 文本上的语言建模困惑度。观察结果显示了一致的趋势:
- (1) 一旦输入长度超过预训练注意力窗口大小, Dense Attention 就会失败
- (2) 一旦输入长度超过缓存大小,即初始 Token 被逐出(evicted), Window Attention 就会崩溃
- (3) StreamingLLM 表现出稳定的性能,其困惑度几乎与带重计算的滑动窗口 (sliding window with re-computation) 基线相匹配
- 为什么各种自回归 LLM,如 Llama-2、MPT、Falcon 和 Pythia,都一致地将初始 Token 作为它们的 Attention Sink,而不是其他 Token ?(Why do various autoregressive LLMs, such as Llama-2, MPT, Falcon, and Pythia, consistently focus on initial tokens as their attention sinks, rather than other tokens?)
- 论文的解释很简单:由于自回归语言建模的顺序性质,初始 Token 对所有后续 Token 都是可见的,而后来的 Token 仅对有限的后续 Token 集合可见
- 因此,初始 Token 更容易被训练成为 Attention Sink,捕获不必要的注意力
- 论文注意到,LLM 通常被训练为使用多个初始 Token 作为 Attention Sink,而不仅仅是一个
- 如图 2 所示,引入四个初始 Token 作为 Attention Sink,足以恢复 LLM 的性能
- 只添加一个或两个则无法实现完全恢复
- 作者认为这种模式的出现是因为这些模型在预训练期间没有在所有输入样本中包含一致的起始 Token
- 尽管 Llama-2 确实在每个段落前加上一个
<s>Token ,但这发生在文本分块(text chunking)之前 ,导致第零个位置大多被随机 Token 占据- 问题:如何理解这里的 text chunking 会影响第一个
<s>Token ?
- 问题:如何理解这里的 text chunking 会影响第一个
- 这种缺乏统一起始 Token 的情况导致模型使用几个初始 Token 作为 Attention Sink
- 如图 2 所示,引入四个初始 Token 作为 Attention Sink,足以恢复 LLM 的性能
- 论文假设,通过在所有训练样本的开头加入一个稳定的可学习 Token ,它可以单独作为一个专门的 Attention Sink,从而无需多个初始 Token 来确保一致的流式处理
- 论文将在第 3.3 节验证这一假设
Rolling KV Cache with Attention Sinks
- 为了在已训练的 LLM 中启用 LLM 流式处理,论文提出了一种简单的方法,可以在不进行任何模型微调的情况下恢复 Window Attention 的困惑度
- 方法:除了当前的滑动窗口 Token 之外,论文在注意力计算中重新引入了几个起始 Token 的 KV
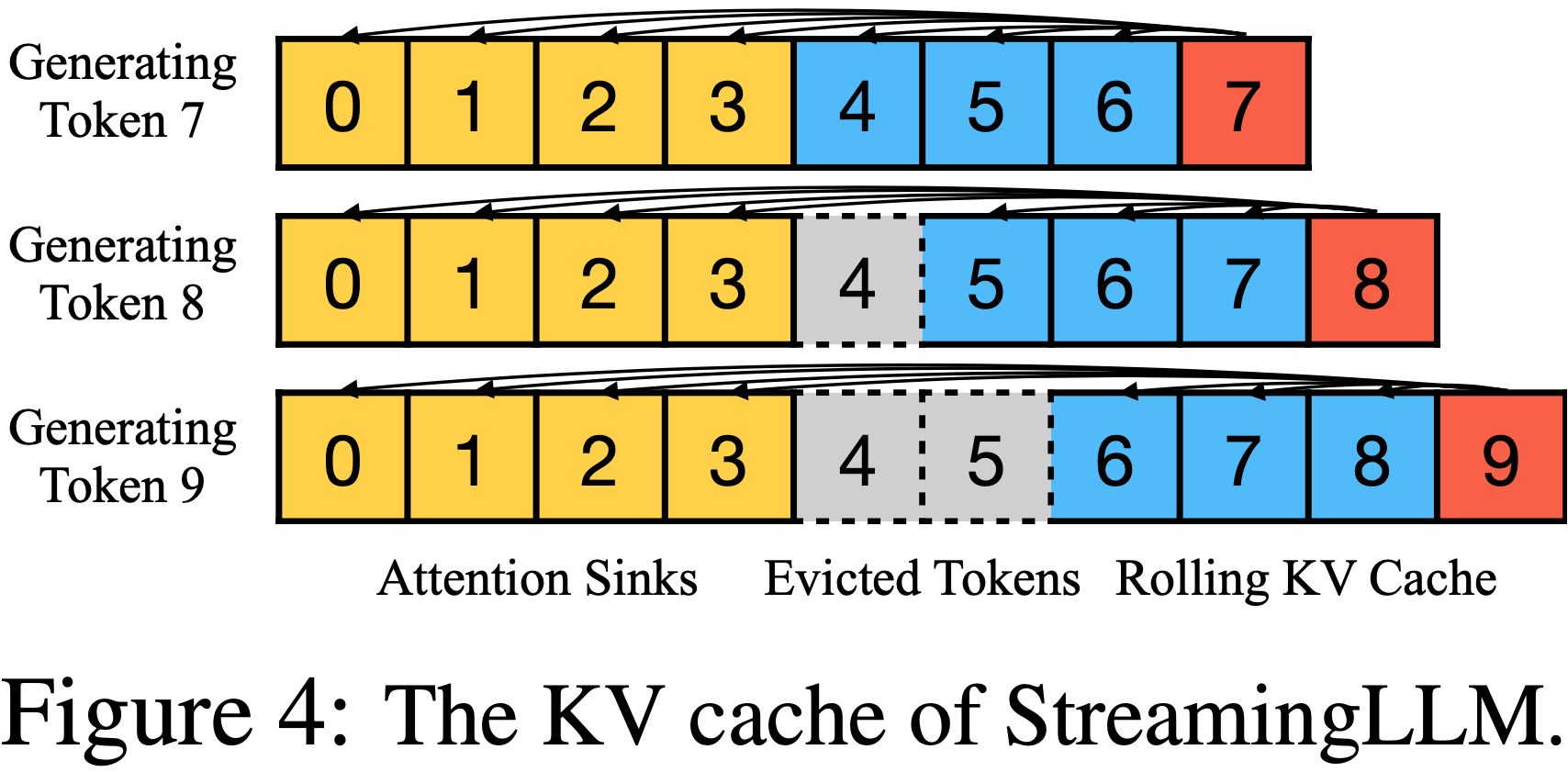
- StreamingLLM 中的 KV 缓存概念上可以分为两部分,如图 4 所示:
- (1) Attention Sink (四个初始 Token ) 稳定注意力计算;
- (2) 滚动 KV 缓存 (Rolling KV Cache) 保留最近的 Token ,这对语言建模至关重要
- StreamingLLM 的设计是通用的,可以无缝集成到任何使用相对位置编码的自回归语言模型中,例如 RoPE (2021) 和 ALiBi (2022)
- 在确定相对距离并向 Token 添加位置信息时,StreamingLLM 关注的是 缓存内 的位置(within the cache),而不是 原始文本中 的位置
- 这种区别对 StreamingLLM 的性能至关重要
- 例如,如果当前缓存(图 4)有 Token [0, 1, 2, 3, 6, 7, 8] 并且正在解码第 9 个 Token ,则分配的位置是 [0, 1, 2, 3, 4, 5, 6, 7],而不是原始文本中的位置 [0, 1, 2, 3, 6, 7, 8, 9]
- 问题:直观上看,怎么觉得这样反而会出现问题?因为原始文本中的真实相对位置信息被修改了
- 问题:直观上看,怎么觉得这样反而会出现问题?因为原始文本中的真实相对位置信息被修改了
- 对于像 RoPE 这样的编码
- 论文在引入旋转变换 之前 缓存 Token 的键 (Keys)
- 然后在每个解码阶段,论文对滚动缓存中的键应用位置变换
- 另一方面,与 ALiBi 集成更直接
- 这里,对注意力分数应用连续线性偏置,而不是 ‘跳跃’ 偏置
- 这种在缓存内分配位置 Embedding 的方法对 StreamingLLM 的功能至关重要,确保模型即使在其预训练注意力窗口大小之外也能高效运行
- 表 1:
- Window Attention 在长文本上表现不佳
- 当论文重新引入最初的四个 Token 以及最近的 1020 个 Token (对应表中 4+1020) 时,困惑度得以恢复
- 将原始的四个初始 Token 替换为换行符 Token “n” (对应表中 4”n”+1020) 实现了 comparable 困惑度恢复
- 缓存配置 x+y 表示添加 x 个初始 Token 和 y 个最近 Token
- 困惑度是在 PG19 测试集中第一本书(65K Token )上测量的

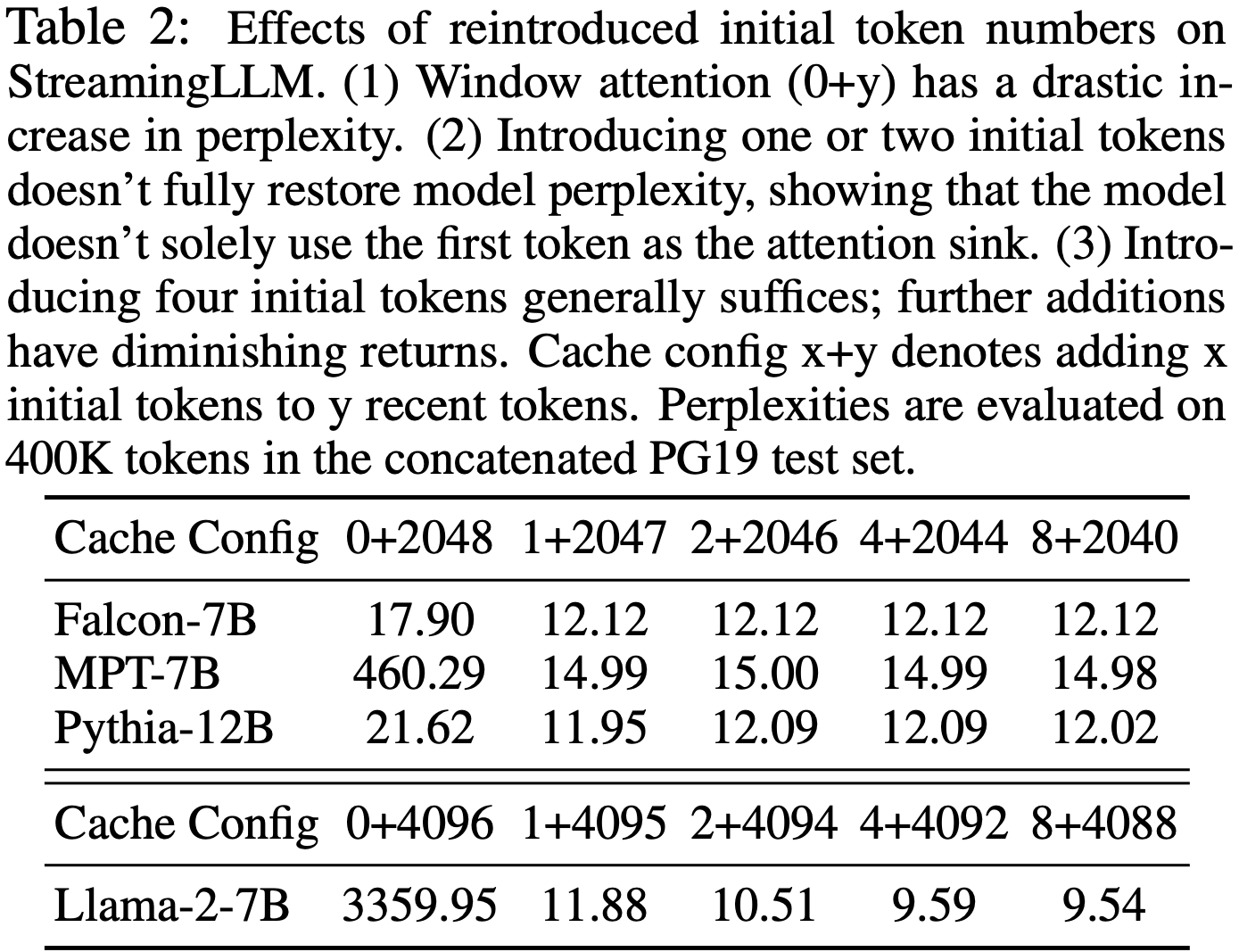
- 表 2:重新引入的初始 Token 数量对 StreamingLLM 的影响
- (1) Window Attention (0+y) 的困惑度急剧增加
- (2) 引入一个或两个初始 Token 不能完全恢复模型困惑度,表明模型不仅仅使用第一个 Token 作为 Attention Sink
- (3) 引入四个初始 Token 通常就足够了;进一步添加收益递减
- 缓存配置 x+y 表示将 x 个初始 Token 添加到 y 个最近 Token
- 困惑度是在 concatenated PG19 测试集中的 400K Token 上评估的
Pre-Training LLMs with Attention Sinks
- 如第 3.1 节所述,模型过度关注多个初始 Token 的一个重要原因是缺乏一个指定的 Sink Token 来卸载过多的注意力分数
- 因此,模型无意中使用了全局可见的 Token ,主要是初始 Token ,作为 Attention Sink
- 一个潜在的补救措施可以是故意加入一个全局可训练的 Attention Sink Token ,表示为 “Sink Token”,它将作为不必要注意力分数的储存库
- 或者,用像 SoftMax-off-by-One (2023) 这样的变体替换传统的 SoftMax 函数,
$$\text{SoftMax}_{1}(x)_{i}=\frac{e^{x_{i} } }{1+\sum_{j=1}^{N}e^{x_{j} } } \tag{2}$$
- 它不要求所有上下文 Token 上的注意力分数总和为 1,可能也是有效的
- 注意 SoftMax\(_1\) 相当于在注意力计算前添加一个具有全零键和值特征的 Token
- 问题:因为全是零,所以各种 Attention 的加权平均后均等价于没有增加该 Token
- 论文将此方法称为 “Zero Sink“ 以符合论文的框架
- 注意 SoftMax\(_1\) 相当于在注意力计算前添加一个具有全零键和值特征的 Token
- 为了验证,论文在相同设置下从头开始预训练了三个具有 160M 参数的语言模型
- 第一个模型使用标准的 SoftMax 注意力 (Vanilla)
- 第二个模型用 SoftMax\(_1\)(Zero Sink)替换了常规的注意力机制
- 第三个模型在所有训练样本前添加了一个可学习的占位符 Token (Sink Token)
- 如表 3 所示,Zero Sink 在某种程度上缓解了 Attention Sink 问题,但模型仍然依赖其他初始 Token 作为 Attention Sink
- 引入 Sink Token 在稳定注意力机制方面非常有效
- 只需将此 Sink Token 与最近的 Token 配对就足以稳定模型的性能,并且最终的评估困惑度甚至略有改善
- 鉴于这些发现,论文建议在所有样本中使用 Sink Token 来训练未来的 LLM,以优化流式部署
- 表 3:比较在预训练期间使用标准注意力、前置零 Token 和可学习 Sink Token
- 为了确保稳定的流式困惑度,标准模型需要几个初始 Token
- 虽然 Zero Sink 显示出轻微改进,但它仍然需要其他初始 Token
- 若使用可学习 Sink Token 训练的模型,仅添加 Sink Token 就显示出稳定的流式困惑度
- 缓存配置 \(x\)+\(y\) 表示添加 \(x\) 个初始 Token 和 \(y\) 个最近 Token
- 困惑度是在 PG19 测试集中第一个样本上评估的(问题:1 个样本就够评估困惑度了?)

Experiments
- 论文使用四个近期主流的模型家族来评估 StreamingLLM:Llama-2 (2023b)、MPT (2023)、Pythia (2023) 和 Falcon (2023)
- Llama-2、Falcon 和 Pythia 采用了 RoPE (2021)
- MPT 采用了 ALiBi (2022)
- RoPE 和 ALiBi 是近期研究中两种最具影响力的位置编码技术
- 论文多样化的模型选择确保了研究结果的有效性和鲁棒性
- 论文将 StreamingLLM 与已建立的基线方法进行比较,例如 Dense Attention、 Window Attention 以及带重计算的滑动窗口方法(Sliding Window with Re-computation)
- 在所有后续使用 StreamingLLM 的实验中,除非另有说明,论文默认使用四个初始 Token 作为 Attention Sink
Language Modeling on Long Texts Across LLM Families and Scales
- 论文首先使用 Concatenated PG19 (2020) 测试集评估 StreamingLLM 的语言建模困惑度(Perplexity),该测试集包含 100 本长书籍
- 对于 Llama-2 模型,缓存大小设置为 2048,而对于 Falcon、Pythia 和 MPT 模型,则设置为 1024
- 这是预训练窗口大小的一半,选择此值是为了增强可视化清晰度
- 图 3 表明
- 在跨越 20K Token 的文本上,StreamingLLM 在困惑度方面可以与 Oracle 基线(带重计算的滑动窗口)相媲美
- 当输入长度超过其预训练窗口时, Dense Attention 技术会失败;
- 当输入长度超过缓存大小时, Window Attention 技术会因初始 Token 被逐出而表现不佳
- 在图 5 中,论文进一步证实了 StreamingLLM 可以可靠地处理异常长的文本,涵盖超过 4M 个 Token ,跨越一系列模型家族和规模
- 这包括 Llama-2 [7,13,70]B、Falcon [7,40]B、Pythia-[2,8,6,9,12]B 和 MPT-[7,30]B
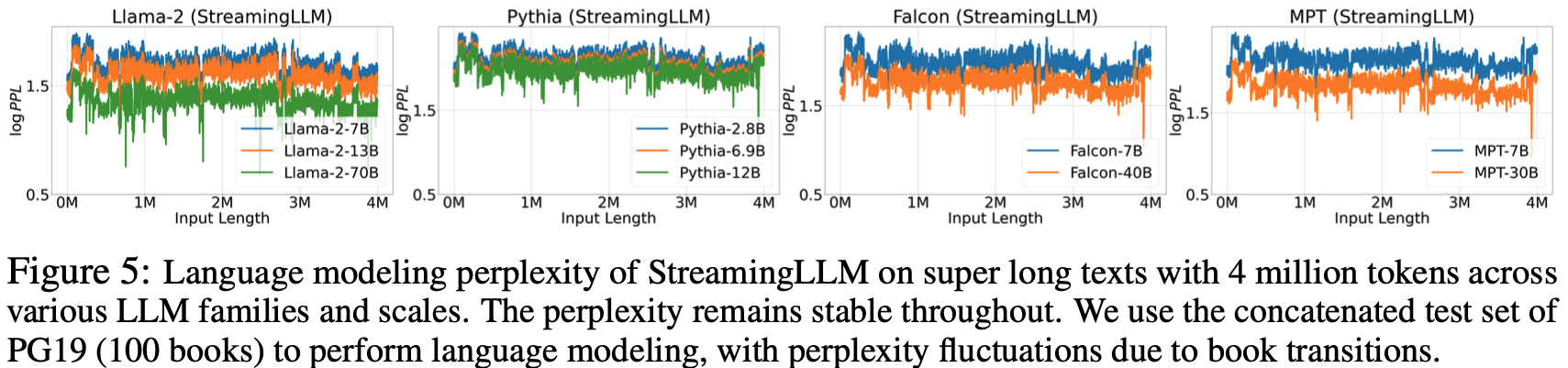
- 这包括 Llama-2 [7,13,70]B、Falcon [7,40]B、Pythia-[2,8,6,9,12]B 和 MPT-[7,30]B
Results of Pre-Training with a Sink Token
- 为了验证论文在所有预训练样本中引入一个 Sink Token 可以改进流式 LLM 的建议,论文在相同条件下训练了两个语言模型,每个模型有 160M 参数
- 一个模型遵循原始训练设置
- 另一个在每个训练样本的开头加入了一个 Sink Token
- 论文的实验使用了 Pythia-160M (2023) 代码库并遵循其训练方法
- 论文在一个 8xA6000 NVIDIA GPU 服务器上使用去重后的 Pile (2020) 数据集训练模型
- 除了将训练批大小减少到 256 之外,论文保留了所有 Pythia 训练配置,包括学习率调度、模型初始化和数据集排列
- 两个模型都训练了 143,000 步
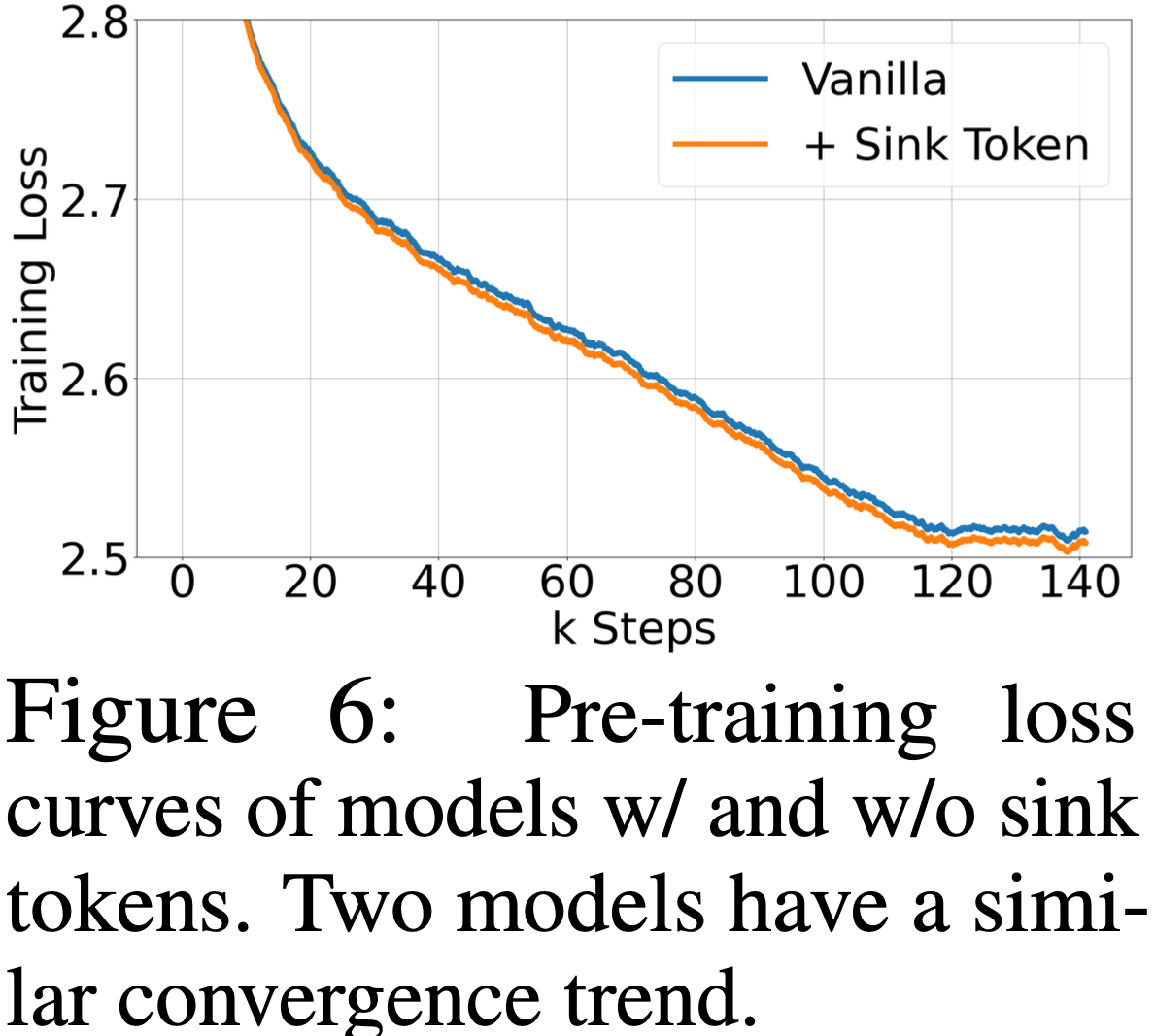
- 收敛性与正常模型性能 (Convergence and Normal Model Performance)
- 在预训练期间包含一个 Sink Token 对模型收敛性以及后续在一系列 NLP 基准测试中的性能没有负面影响
- 如图 6 所示,原始模型与使用 Sink Token 训练的模型表现出相似的收敛动态
- 论文在七个不同的 NLP 基准测试上评估这两个模型,包括 ARC-[Challenge, Easy] (2018)、HellaSwag (2019)、LAMBADA (2016)、OpenbookQA (2018)、PIQA (2020) 和 Winogrande (2019)
- 如表 4 所示,使用 Sink Token 预训练的模型与使用原始方法训练的模型表现相似

- 流式性能 (Streaming Performance)
- 如表 3 所示,使用传统方法训练的模型与使用 Sink Token 增强的模型在流式困惑度上存在差异
- 原始模型需要添加多个 Token 作为 Attention Sink 以维持稳定的流式困惑度
- 使用 Sink Token 训练的模型仅使用该 Sink Token 就能达到令人满意的流式性能
- 注:其实原始训练方法需要 4 个 Token 这个事情,表 3 不够明显,表 2 MPT-7B 更明显
- 如表 3 所示,使用传统方法训练的模型与使用 Sink Token 增强的模型在流式困惑度上存在差异
- 注意力可视化 (Attention Visualization)
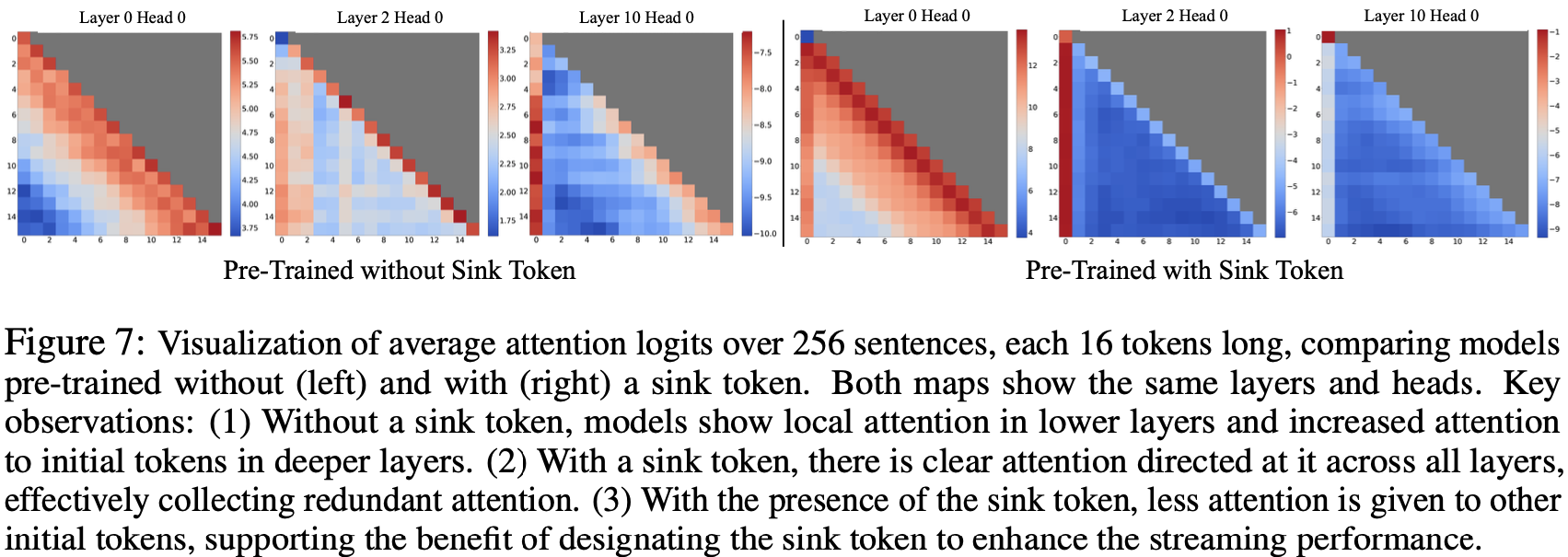
- 图 7 对比了使用和不使用 Sink Token 预训练的模型的注意力图
- 没有 Sink Token 的模型,类似于 Llama-2-7B(图 2),在浅层显示局部注意力,在深层则关注初始 Token
- 相比之下,使用 Sink Token 训练的模型在所有层和头中都持续关注 Sink ,表明存在有效的注意力卸载机制
- 这种对 Sink 的 Strong 关注,加上对其他初始 Token 注意力的减少,解释了 Sink Token 在提升模型流式性能方面的有效性
Results on Streaming Question Answering with Instruction-tuned Models
- 为了展示 StreamingLLM 在现实世界中的适用性,论文使用指令微调(Instruction-tuned)的 LLM 模拟多轮问答,这在现实场景中很常见
- 论文首先将 ARC-[Challenge, Easy] 数据集中的所有问答对拼接起来,将连续的流输入到 Llama-2-[7,13,70]B-Chat 模型中,并使用精确匹配(Exact Match)准则评估每个答案位置上的模型补全情况
- 如表 5 所示,
- Dense Attention 会导致内存不足(Out-of-Memory, OOM)错误,表明它不适合此设置
- Window Attention 方法虽然运行高效,但由于输入长度超过缓存大小时会产生随机输出,导致准确率低下
- StreamingLLM 表现出色,能高效处理流式格式,其准确率与 One-shot、Sample-by-sample 的基线准确率相当
- 为了突出一个更适合 StreamingLLM 的场景,论文引入了一个数据集 StreamEval,其灵感来源于 LongEval (2023) 基准测试
- 如图 8 所示
- 与 LongEval 在长跨度设置上使用单一查询不同,论文每提供 10 行新信息就查询一次模型
- 每个查询的答案始终在 20 行之前,这反映了现实世界中问题通常与近期信息相关的实例
- 问题:从图 8 中看,查询间隔是 20 行,一定会超过窗口吗?

- 如图 9 所示
- 采用 StreamingLLM 的 LLM 即使在输入长度接近 120K Token 时也能保持合理的准确率
- Dense Attention 和 Window Attention 分别在达到预训练文本长度和 KV 缓存大小时失败
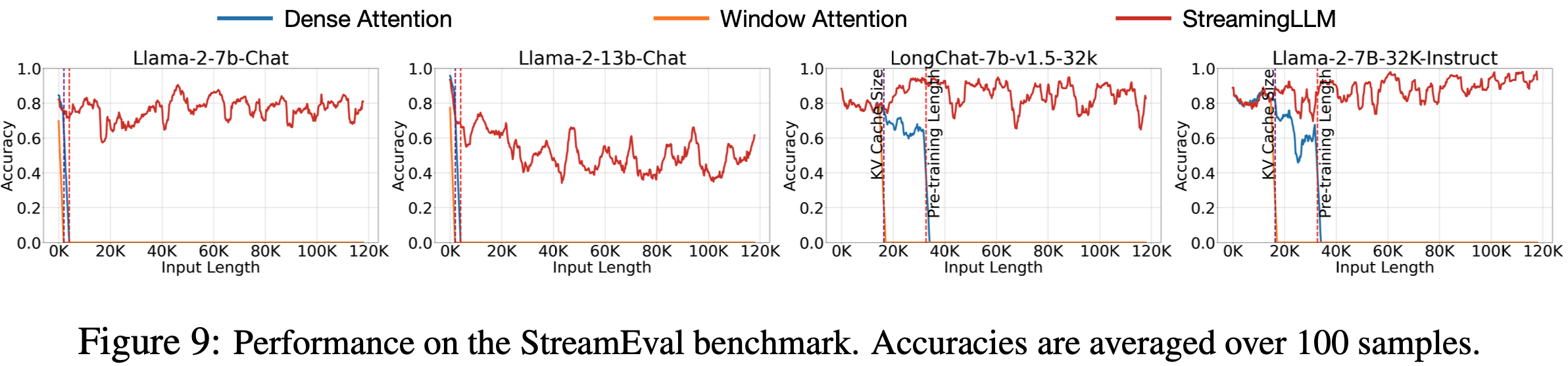
- 论文使用了两个上下文扩展模型,LongChat-7b-v1.5-32k (2023) 和 Llama-2-7B-32K-Instruct (2023),以表明 StreamingLLM 可以与上下文扩展技术互补
- 在 StreamingLLM 中,上下文扩展意味着扩大流式 LLM 的最大缓存大小,从而能够捕获更广泛的局部信息
Ablation Studies
- 初始 Token 数量 (Numbers of Initial Tokens)
- 在表 2 中,论文通过消融实验研究了添加不同数量的初始 Token 与 Recent Token 对流式困惑度的影响
- 结果表明,仅引入一个或两个初始 Token 是不够的,而四个初始 Token 的阈值似乎就足够了,后续增加 Token 数量带来的效果微乎其微
- 这一结果证明了论文在 StreamingLLM 中引入 4 个初始 Token 作为 Attention Sink 的选择是合理的
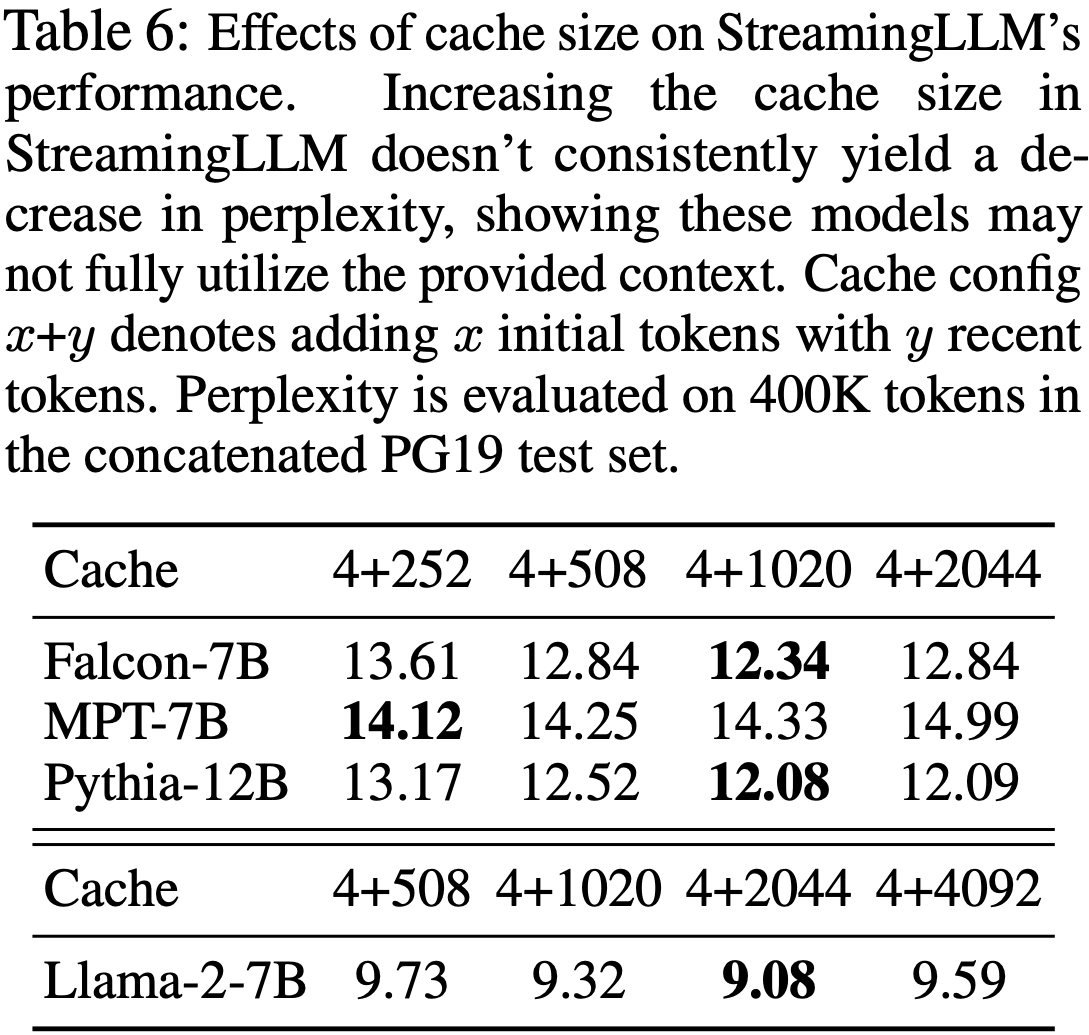
- 缓存大小 (Cache Sizes)
- 在表 6 中,论文评估了缓存大小(Cache Size, Attention Window Size)对 StreamingLLM 困惑度的影响
- 与直觉相反 ,增加缓存大小并不会持续降低语言建模的困惑度
- 这种不一致性表明了一个潜在的局限性,即这些模型可能无法最大化利用它们接收到的整个上下文信息
- 未来的研究工作应致力于增强这些模型更好利用广泛上下文的能力
Efficiency Results
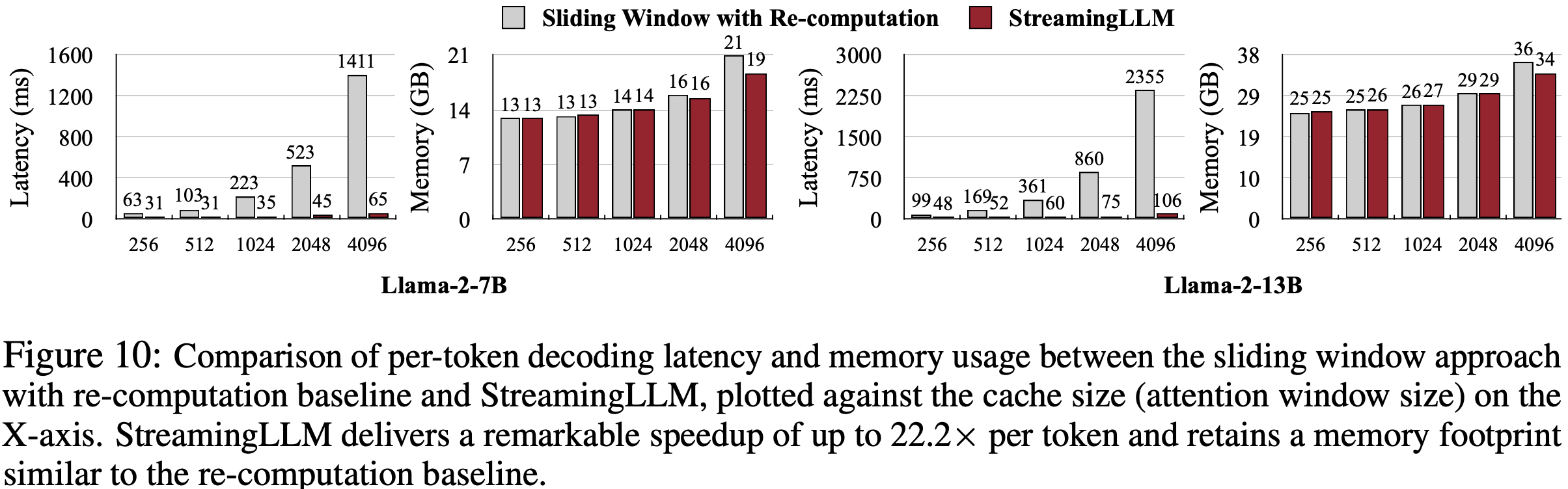
- 论文将 StreamingLLM 的解码延迟(Decoding Latency)和内存使用量与带重计算的滑动窗口基线进行了基准测试,带重计算的滑动窗口 是唯一具有可接受质量的基线
- 两种方法均使用 Huggingface Transformers (2020) 库实现,并在单个 NVIDIA A6000 GPU 上使用 Llama-2-7B 和 Llama-2-13B 模型进行测试
- 如图 10 所示
- 随着缓存大小(Attention Window Size)的增加 ,StreamingLLM 的解码速度呈线性增长
- 而带重计算的滑动窗口基线的解码延迟呈二次方增长
- StreamingLLM 实现了令人印象深刻的加速,每个 Token 的加速比高达 \(22.2\times\)
- 且 StreamingLLM 仍保持了与重计算基线一致的内存占用
- 注意:这里仅仅考虑效率,具体模型性能指标见前面的其他图
补充:Related Work
- 关于将 LLM 应用于长文本已经进行了广泛的研究,主要集中在三个领域:
- 长度外推(Length Extrapolation)
- 上下文窗口扩展(Context Window Extension)
- 改进 LLM 对长文本的利用(Improving LLMs’ Utilization of Long Text)
- 虽然看似相关,但值得注意的是,一个方向的进展并不一定导致另一个方向的进展
- 例如,扩展 LLM 的上下文大小并不能提高模型在上下文大小之外的性能,而且这两种方法都不能确保有效利用长上下文
- 论文的 StreamingLLM 框架主要属于第一类(长度外推),即 LLM 被应用于显著超过预训练窗口大小的文本,甚至可能是无限长度
- 论文不扩展 LLM 的注意力窗口大小,也不增强模型对长文本的记忆和使用能力
- 后两个类别与论文的重点正交,并且可以与论文的技术结合
- 长度外推(第一类)旨在使在较短文本上训练的语言模型能够在测试时处理较长的文本
- 一个主要的研究方向是针对 Transformer 模型开发相对位置编码方法,使其能够在训练窗口之外运行
- 其中一项工作是 Rotary Position Embeddings (RoPE) (2021),它在每个注意力层中转换查询和键以整合相对位置信息
- 后续研究 (2022; 2023) 表明其在超过训练窗口的文本上表现不佳
- 另一种方法 ALiBi (2022) 根据查询和键之间的距离对注意力分数进行偏置,从而引入相对位置信息
- 虽然这显示出改进的外推能力,但论文在 MPT 模型上的测试突显了当文本长度远大于训练长度时会出现崩溃
- 当前的方法尚未实现无限长度外推,导致没有现有的 LLM 适合流式应用
- 上下文窗口扩展(第二类)侧重于扩展 LLM 的上下文窗口,使其能够在一个前向传递中处理更多 Token
- 一条主要的工作线解决了训练效率问题
- 考虑到训练期间注意力计算的二次复杂度,开发长上下文 LLM 既是计算挑战也是内存挑战
- 解决方案范围从系统优化的 FlashAttention (2022; Dao, 2023)(加速注意力计算并减少内存占用)到近似注意力(Approximative attention)方法 (2020a; 2020; 2020; 2020),这些方法以模型质量换取效率
- 最近,关于使用 RoPE 扩展预训练 LLM 的工作激增 (2023;),涉及位置插值和微调
- 但所有上述技术仅将 LLM 的上下文窗口扩展到有限的程度 ,这未能达到论文处理无限输入的主要关注点
- 一条主要的工作线解决了训练效率问题
- 改进 LLM 对长文本的利用(第三类)优化 LLM 以更好地捕获和使用上下文中的内容,而不是仅仅将它们作为输入
- 正如 (2023) 和 (2023) 所强调的,前述两个方向的成功并不一定能转化为对长上下文的胜任利用
- 解决 LLM 内部对长上下文的有效使用仍然是一个挑战
- 论文的工作集中于稳定地利用最近 Token ,实现 LLM 的无缝流式应用
附录 A:Discussions
- 应用 (Applications)
- StreamingLLM 特别适合流式应用,例如多轮对话,其中持续运行而不严重依赖大量内存或历史数据至关重要
- 例如,在 LLM-based 日常助手应用中,StreamingLLM 使模型能够在较长时间内无缝运行
- 它基于最近的交互生成响应,从而避免了频繁刷新缓存的需要
- 传统方法可能需要在对话长度超过训练长度时重置缓存,导致丢失最近的上下文,或者可能需要根据最近的文本历史重新计算键值状态,这可能效率低下
- StreamingLLM 特别适合流式应用,例如多轮对话,其中持续运行而不严重依赖大量内存或历史数据至关重要
- 局限性 (Limitations)
- 虽然 StreamingLLM 提高了 LLM 在流式上下文中的效率,但它并没有扩展模型的上下文窗口或增强其长期记忆能力
- 如章节 C 中详述,模型仅限于在其当前缓存的范围内运行
- StreamingLLM 不适合需要长期记忆和广泛数据依赖性的任务,例如长文档问答和摘要
- 但它在仅需要短期记忆的场景中表现出色 ,例如日常对话和短文档问答,其优势在于能够根据最近的上下文生成连贯的文本,而无需刷新缓存
- 更广泛的社会影响 (Broader Societal Impacts)
- StreamingLLM 显著提高了 LLM 的效率和可访问性,使其在各个部门的使用民主化
- 通过在对话代理等应用中实现不间断的快速交互,StreamingLLM 改善了用户体验,尤其是在需要固定长度模型的场景中
- 这一进步使得对话更加无缝和具有上下文感知能力,可能惠及教育、医疗保健和客户服务等行业
- StreamingLLM 在处理过程中的效率降低了计算负载,符合对环境可持续 AI 技术的需求
- 这一方面对于在技术资源有限的地区推广先进的 AI 工具至关重要
- 但 StreamingLLM 的潜在负面影响与通用语言模型相关的风险类似,例如错误信息和生成有偏见内容的风险
- 必须通过强有力的道德准则和保障措施来解决这些风险
- 虽然 StreamingLLM 具有语言模型共有的一些风险,但其在提升用户体验、 democratizing AI 访问和促进可持续性方面的积极贡献是值得注意的
- 这些好处强调了负责任地部署和合乎道德地使用该技术的重要性
- StreamingLLM 显著提高了 LLM 的效率和可访问性,使其在各个部门的使用民主化
附录 B:Additional Related Works
- 稀疏 Transformer (Sparse Transformers)
- 关于高效 Transformer 模型的文献主要集中于降低自注意力机制的计算和内存复杂性
- 一项相关的工作是通过将注意力范围限制在固定的、预定义的模式来稀疏化注意力矩阵,例如局部窗口或固定步长的块模式 (2022)
- Sparse Transformer (2019) 引入了注意力矩阵的稀疏分解,将注意力的计算复杂度降低到 \(O(n\sqrt{n})\)
- LongFormer (2020) 将扩张的局部 Window Attention 与任务驱动的全局注意力相结合
- Extended Transformer Construction (ETC) Ainslie 等 (2020) 提出了一种新颖的全局-局部注意力机制,包含四种注意力模式:全局到全局、局部到局部、局部到全局和全局到局部
- 基于 ETC,BigBird (2020a) 提出了另一种线性复杂度的注意力替代方案,利用全局 Token、局部滑动 Window Attention 和随机注意力
- 但这些方法有几个局限性
- 一:Sparse Transformer 和 ETC 需要为特定的块稀疏矩阵乘法变体定制 GPU 内核
- 二:LongFormer、ETC 和 BigBird 都依赖于全局注意力模式,这不适合自回归语言模型
- 三:这些方法与预训练模型不兼容,需要从头开始重新训练
- 相比之下,论文的方法使用标准的 GPU 内核易于实现,并且与使用 Dense Attention 的预训练自回归语言模型兼容,这些模型在 NLP 社区中普遍存在
- 这种兼容性提供了显著的优势,允许利用现有的预训练模型而无需任何微调
- 关于高效 Transformer 模型的文献主要集中于降低自注意力机制的计算和内存复杂性
- 同期工作 (Concurrent Works)
- 论文的研究与 Han 等人的工作同时进行,他们对语言模型长度泛化失败进行了理论研究,确定了三个分布外因素
- 受此分析启发,他们的方法采用“\(\Lambda\)”形注意力模式并重新配置位置编码距离以增强 LLM 中的长度泛化
- 这种方法与论文的方法有相似之处
- 但论文的工作揭示了“Attention Sink”现象,即 Transformer 模型倾向于将高注意力分数分配给语义较小的初始 Token
- 这一现象超出了长度泛化失败的范围,表明 Transformer 模型中存在一个更普遍的问题
- 论文不仅在自回归语言模型中观察到这种“Attention Sink”行为,而且在编码器 Transformer(如 BERT,见章节 H)和视觉 Transformer (ViTs) Darcet 等 (2023) 中也观察到,表明其在 Transformer 架构中更广泛地存在
- 为了缓解“Attention Sink”现象,论文建议在预训练期间引入一个可学习的 Sink Token ,并通过广泛的消融研究支持论文的发现
- 与此同时,Darcet 等人在视觉 Transformer 中观察到类似的注意力集中在随机背景 patch Token 上的现象,称为“寄存器(registers)”
- 这些寄存器充当全局图像信息的存储库
- 他们的解决方案是添加专用的“寄存器” Token ,旨在平衡注意力分布
- “Attention Sink”与此概念类似
- 在论文的论文中,“Attention Sink” 是初始 Token ,不成比例地吸引后续 Token 的注意力
- 在预训练期间引入专用的 Sink Token 可以防止模型不适当地使用内容 Token 作为 Attention Sink ,从而实现更有效的注意力分布
- 但存在一个关键区别:视觉 Transformer 中的“寄存器”在中间层充当全局信息持有者,而论文的“Attention Sink”在自回归模型中作为初始 Token 定位
- 这种位置差异表明,注意力计算中的 softmax 函数可能在 Attention Sink 的出现中扮演更基本的角色
- 论文的研究与 Han 等人的工作同时进行,他们对语言模型长度泛化失败进行了理论研究,确定了三个分布外因素
附录 C:Accuracy on StreamEval with Increasing Query-Answer Line Distance(行距增加时的精确率)
- 为了评估 StreamingLLM 对扩展输入的处理能力,论文在 StreamEval 上评估了 Llama-2-7B-32K-Instruct 模型,重点关注不同缓存配置下不同的查询-答案行距
- 在 StreamEval 中,每行包含 23 个 Token ,使得行距相当于 Token 距离的 \(23\times\) 行距
- 准确率是通过对 100 个样本的结果取平均值计算的,每个样本包含 100 个查询
- 表 7 说明
- 当查询和答案之间的 Token 距离在缓存大小之内时,StreamingLLM 保持准确率
- 但随着该距离增加,准确率会降低,并在最终超过缓存容量时降至零
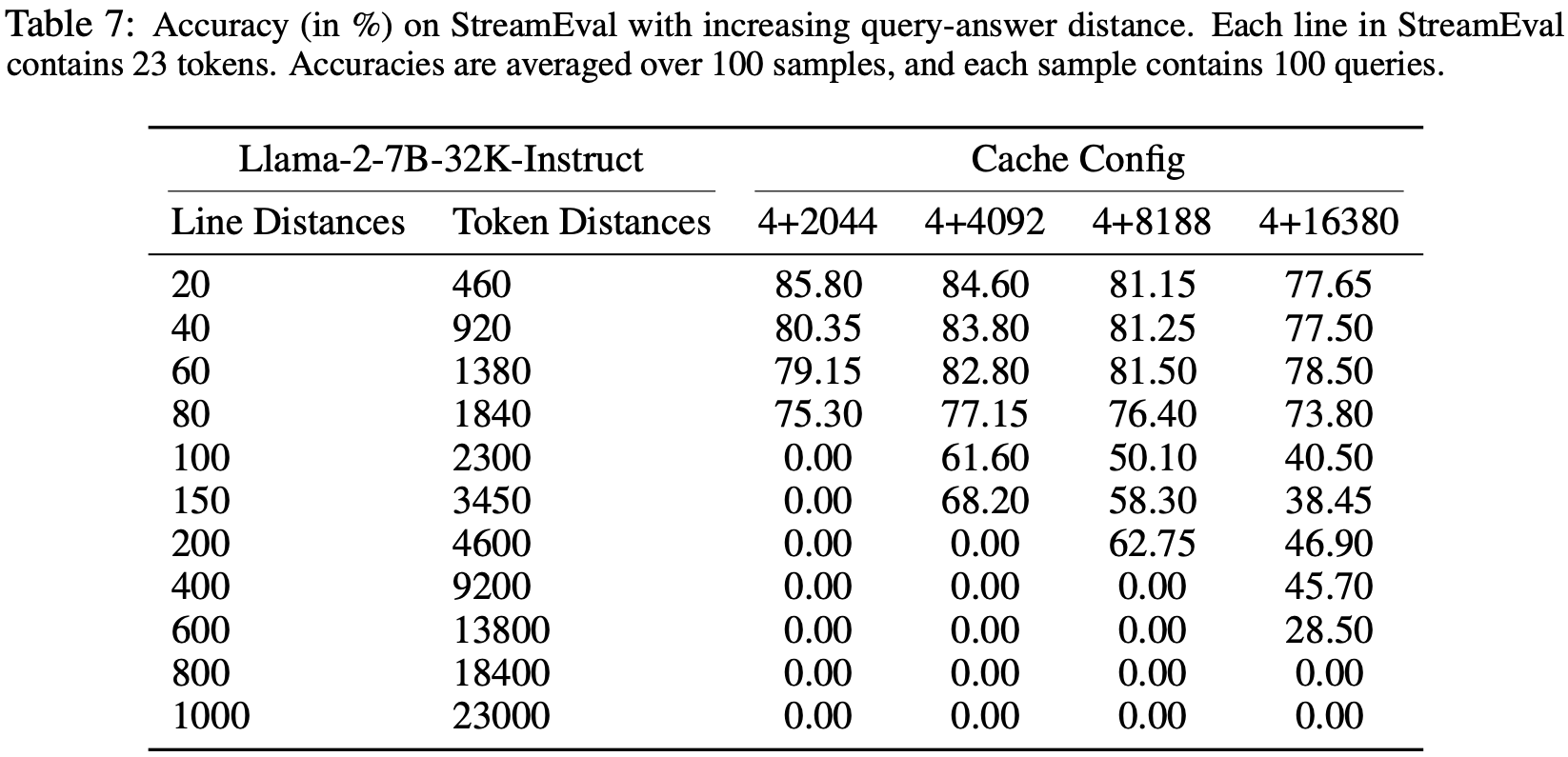
- 这些结果表明,虽然 StreamingLLM 在基于最近上下文生成连贯文本方面是有效的,但它不能扩展语言模型的上下文长度
- 这些结果也强调了当前语言模型中一个更广泛的挑战:它们无法充分利用缓存中的上下文信息,这一发现与 Liu 等人的观察结果一致
附录 D:Long-Range Benchmark Evaluation
- 论文使用 Llama-2-7B-chat 模型(最大上下文长度 4k)在 Long-Bench Bai 等 (2023) 上评估了 StreamingLLM,该基准包含三个关键 NLP 任务:
- 单文档问答 NarrativeQA Kocisky 等 (2017) 和 Qasper Dasigi 等 (2021)
- 多文档问答 HotpotQA Yang 等 (2018) 和 2WikiMQA Ho 等 (2020)
- 摘要 GovReport Huang 等 (2021), MultiNews Fabbri 等 (2019)
- LongBench 为 Llama-2-7B-chat 模型设置了默认的最大序列长度 3,500 个 Token ,从中间截断以保留开头和结尾信息(各 1,750 个 Token )
- 表 8 显示,使用 4+3496 缓存配置的 StreamingLLM 表现不如 truncation 基线,这可能是由于丢失了关键的初始输入提示信息
- 但将 Attention Sink 数量调整为 1750 可以将性能恢复到文本截断基线的水平
- 这些结果证实了章节 C 中的发现,表明 StreamingLLM 的有效性取决于其缓存中的信息,其缓存内性能与文本截断基线相当

- 问题:这里的 truncation 基线是指直接保留 前后 1750 个 Token 吗?
- 回答:是的,与 StreamingLLM 1750+1750 的最大区别在于,StreamingLLM 1750+1750 的位置信息是缓存窗口内部的,不是真实文本中的
- 从表 8 中可知,两者的模型效果差不多
附录 E:在较长序列上 Llama-2-7B 的注意力可视化 (Llama-2-7B Attention Visualization on Longer Sequences)
- 图 2 使用短序列(长度为 16)可视化了 Llama-2-7B 的注意力图,以便清晰展示
- 论文在图 11 中进一步可视化了 Llama-2-7B 在较长序列(长度为 128)上的注意力
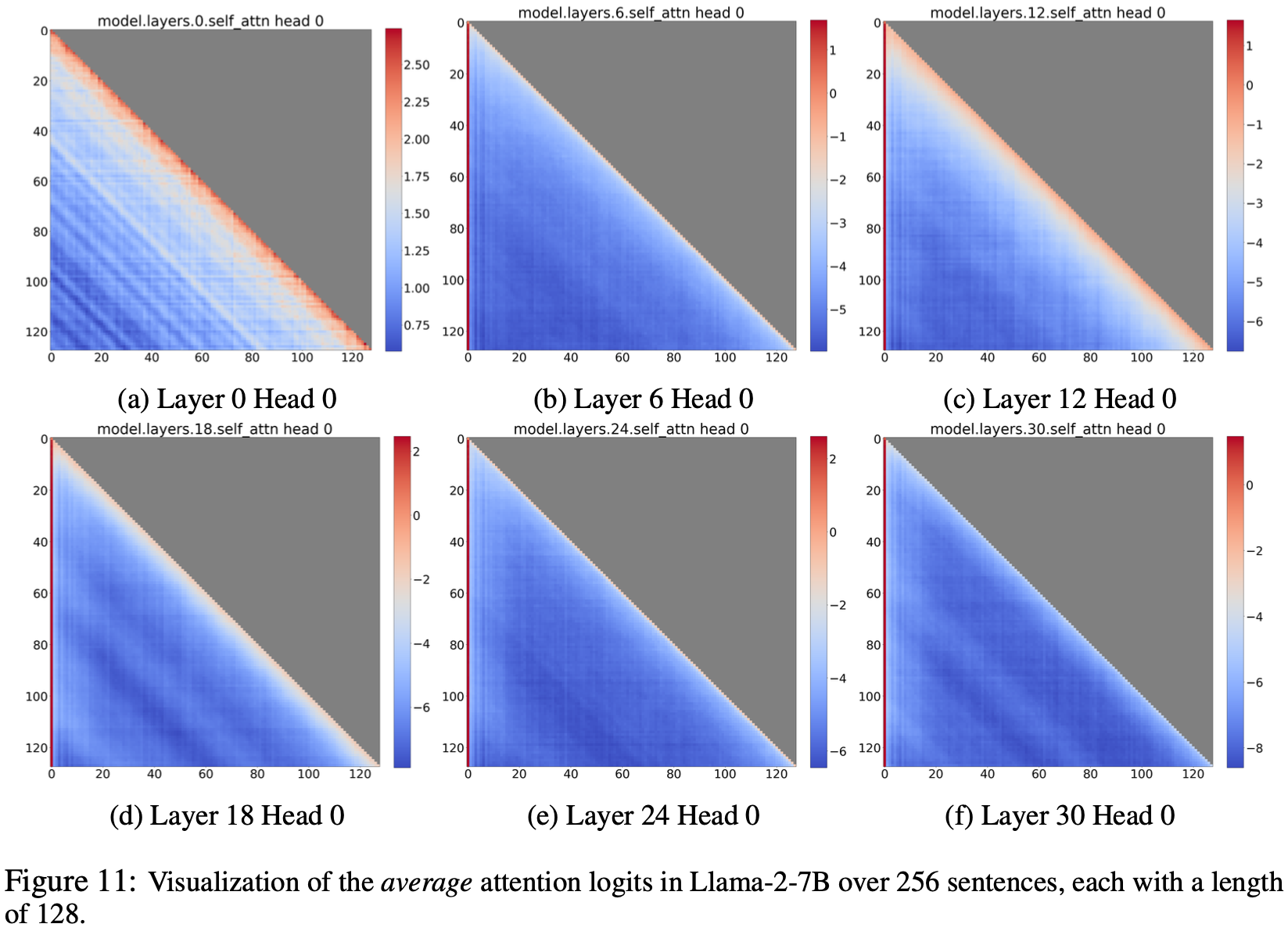
- 论文发现短序列上的观察结果在较长序列上也成立
- 即在大多数层中,无论初始 Token 与序列中其余 Token 之间的距离如何,初始 Token 的注意力分数远高于序列中其余 Token 的注意力分数
- 因为序列越长, Attention Sink 的分数在热力图上的显示就越细
- 论文在章节 F 中使用不同的方法进一步分析了较长序列(长度为 4096)上的注意力分布
- 补充观察:从图上看,仍然是输入的浅层(低层)上关注局部注意力,深层关注 Sink Token
附录 F:Qualitative Analysis of Attention Sinks in Long Inputs
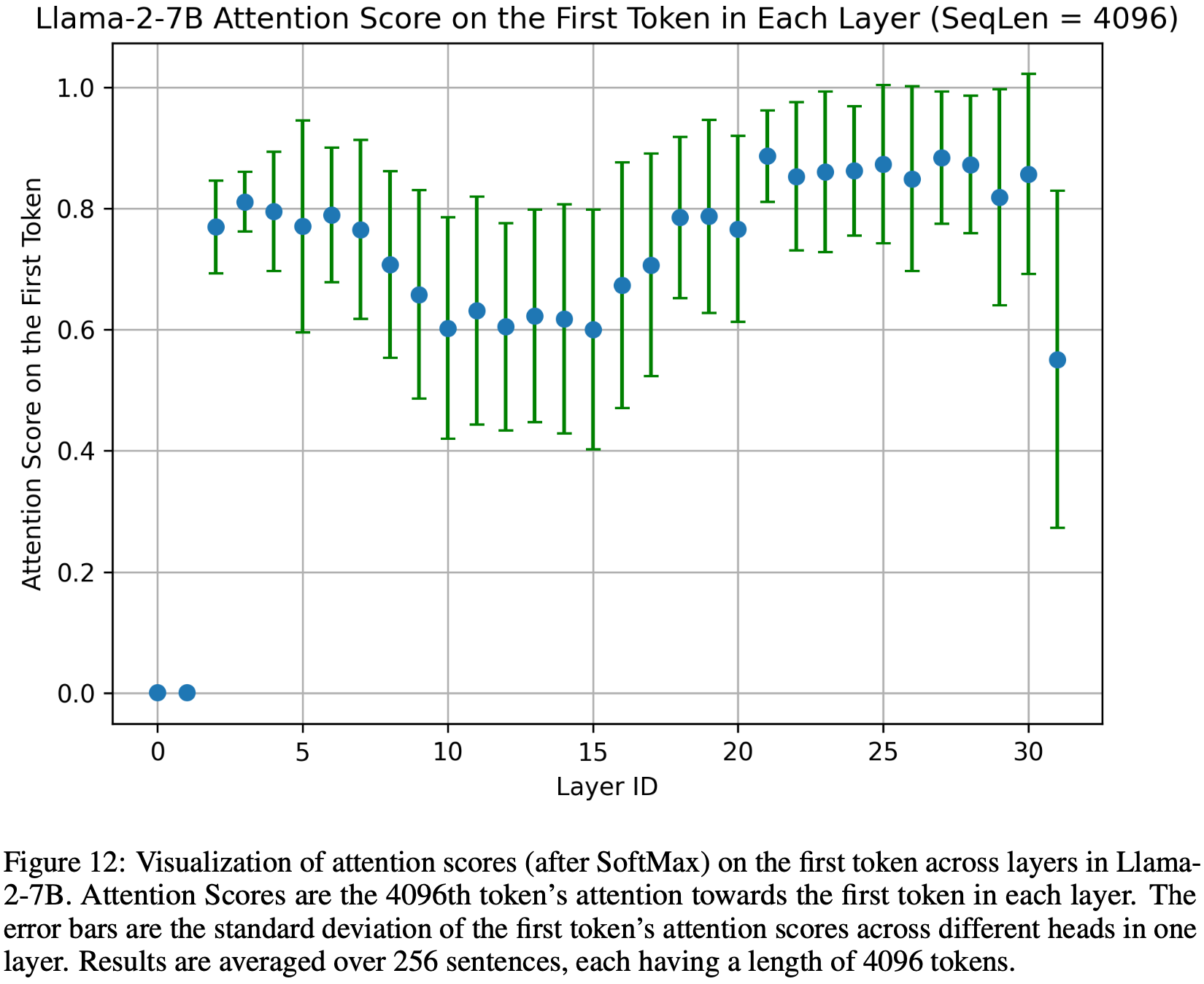
- 图 2 和图 13 使用短序列说明了 Attention Sink 现象以便清晰展示
- 扩展此分析,图 12 展示了在长输入(序列长度为 4096)中指向第一个 Token 的注意力分数(经过 SoftMax 后)的分布
- 论文对 256 个序列的注意力分数取平均值,每个序列包含 4096 个 Token ,绘制数据表示第 4096 个 Token 在每个层中对初始 Token 的注意力分配
- 第一个 Token 的注意力分数显著高,通常超过总注意力的一半,除了最底部的两个层(最浅的两层)
- 这一观察经验性地证实了大多数层和头对第一个 Token 的偏好关注,无论序列中其他 Token 的距离如何
- 这种趋势强调了序列中初始 Token 的关键作用,因为移除它们会由于 SoftMax 函数分母的大部分被移除而对语言模型性能产生巨大影响

附录 G:Llama-2-70B 注意力可视化 (Llama-2-70B Attention Visualization)
- 图 2 展示了 Llama-2-7B 的注意力可视化,论文在图 13 中进一步可视化了 Llama-2-70B 的注意力
- 论文发现对 Llama-2-7B 的观察结果在 Llama-2-70B 上也成立,
- 其中在大多数层中,初始 Token 的注意力分数远高于其余 Token 的注意力分数
附录 H:Attention Sinks in Encoder Transformers
- 在论文中,论文主要探讨了在自回归、 Decoder-only 语言模型(如 GPT 和 Llama)中观察到的 Attention Sink 现象
- 基于章节 3.1 的见解,论文提出这一现象可能扩展到其他 Transformer 架构,包括编码器模型,如 BERT Devlin 等 (2019) 和 ViT Dosovitskiy 等 (2021)
- 这一假设源于这些模型共享相似的 Transformer 结构并使用 SoftMax 注意力机制
- 为了证实论文的假设,论文分析了 BERT-base-uncased 的注意力模式
- 如图 14 所示
- BERT-base-uncased 表现出 Attention Sink 现象,其特征是在大多数层中分配给 [SEP] Token 的注意力分数不成比例地高
- 这表明模型始终依赖无处不在的 [SEP] Token 作为注意力的焦点
- Darcet 等人的同期研究在视觉 Transformer 中识别出类似的注意力尖峰,归因于随机背景补丁 Token 充当全局图像信息的“寄存器”
- 作者认为这些“寄存器”类似于论文观察到的 Attention Sink 现象,表明这是所有 Transformer 模型的普遍特征
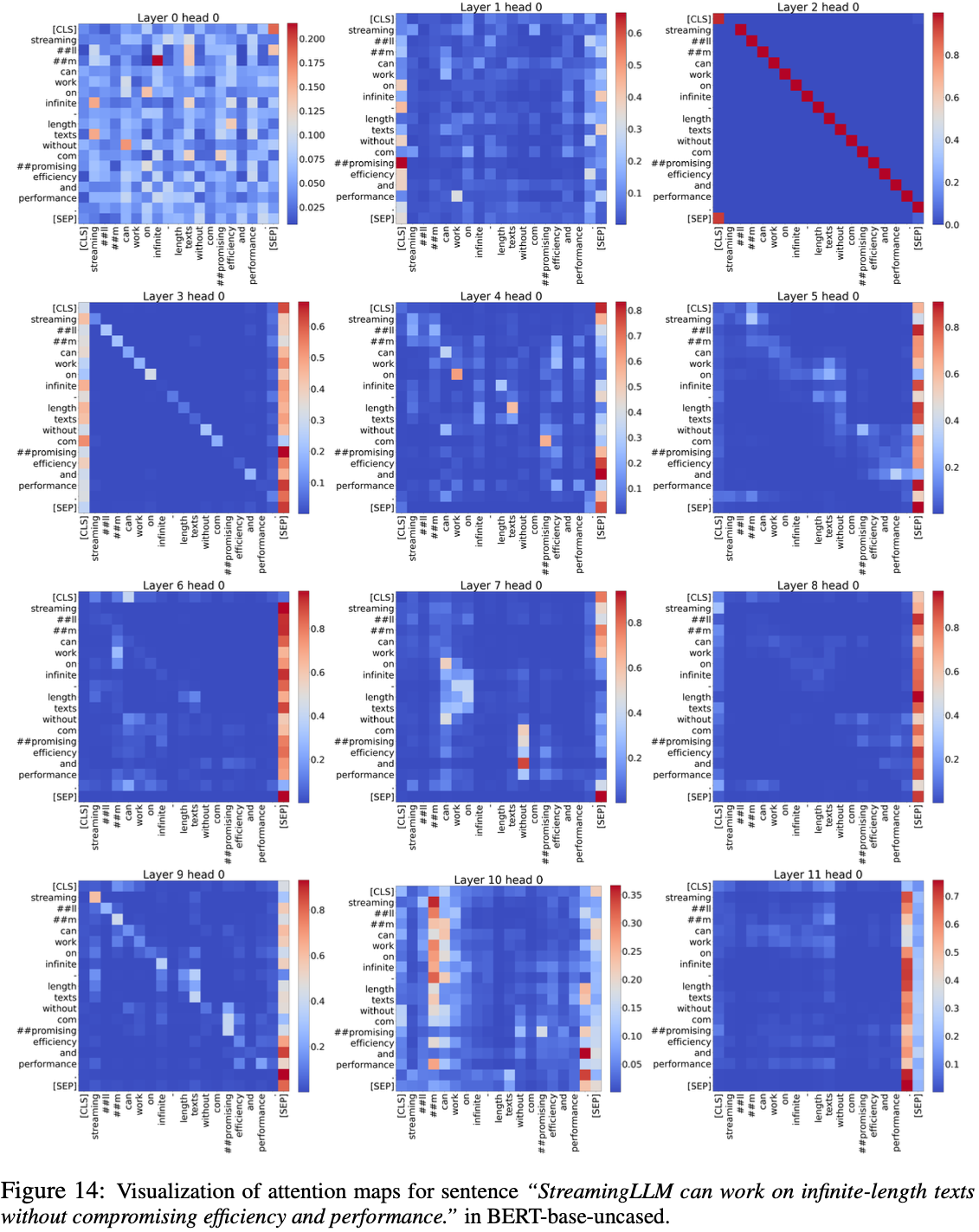
- BERT-base-uncased 表现出 Attention Sink 现象,其特征是在大多数层中分配给 [SEP] Token 的注意力分数不成比例地高
附录 I:Using More Sink Tokens in the Pre-Training Stage
- 章节 3.3 说明,在预训练阶段加入单个专用的 Sink Token 不会影响模型性能,可通过将 Attention Sink 集中到一个 Token 上来增强流式性能
- 本节深入探讨在预训练期间添加额外的 Sink Token 是否能够进一步优化预训练语言模型的性能
- 如图 15 所示,论文的实验表明,在预训练期间加入一个或两个 Sink Token,预训练损失曲线与基线(原始)模型非常相似
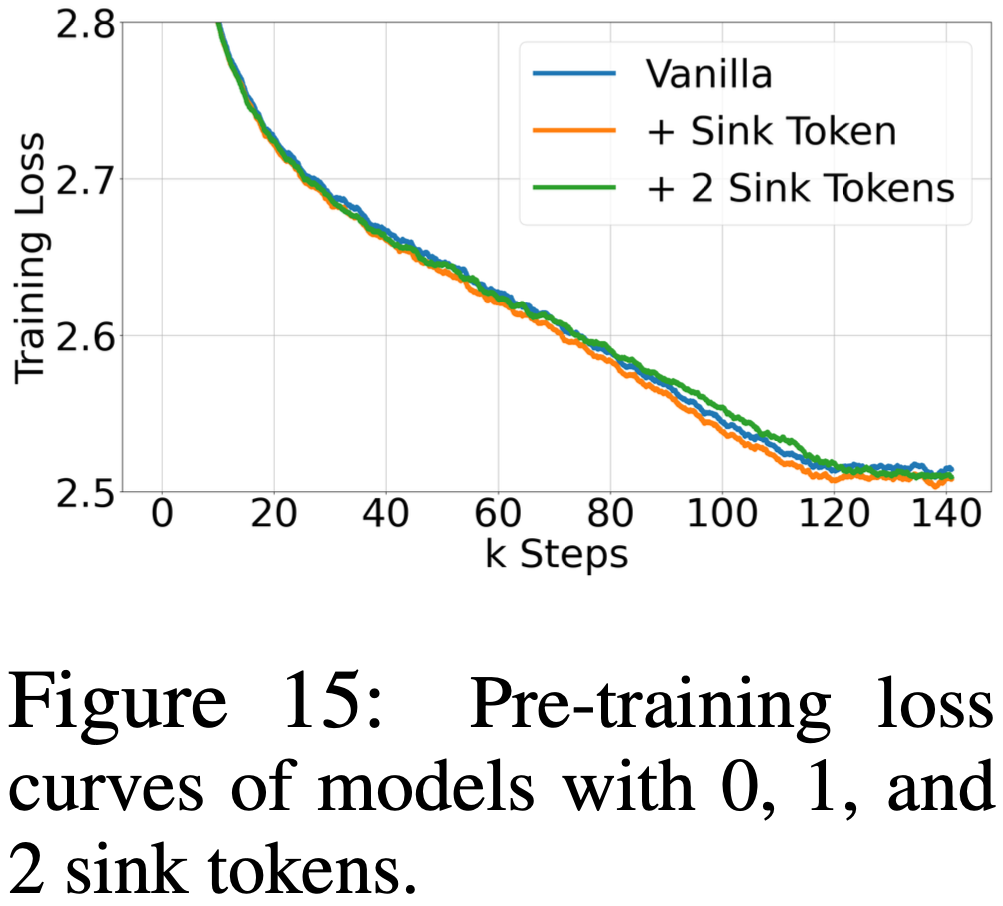
- 但如表 9 详述,引入第二个 Sink Token 在大多数基准任务中并未产生实质性的性能改进
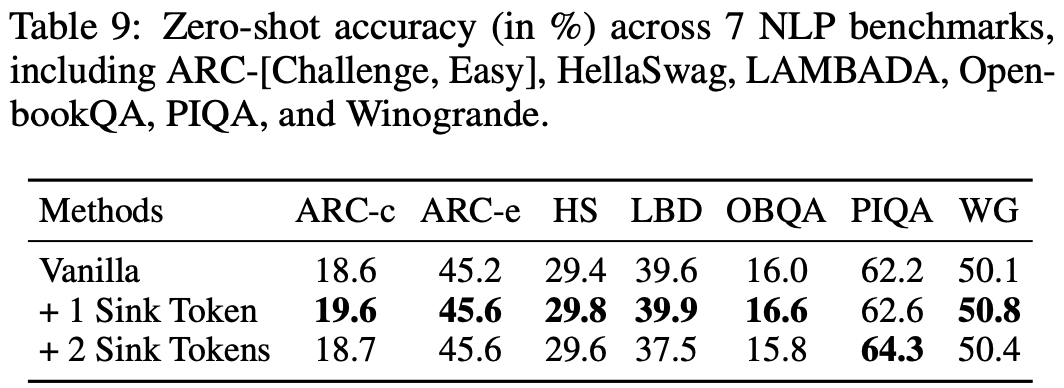
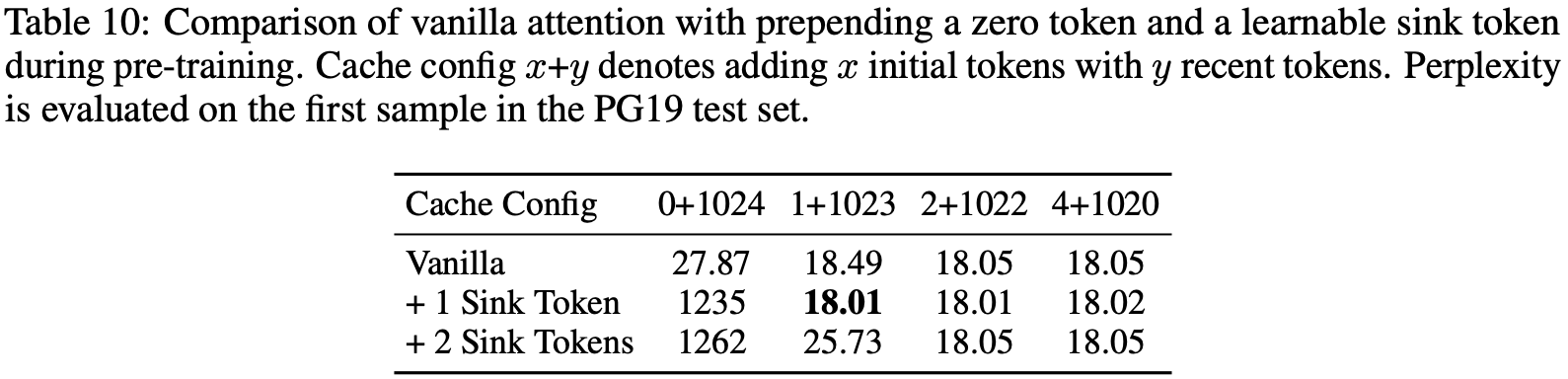
- 进一步分析,如表 10 所示,显示包含额外的 Sink Token 并不会增强流式性能(理解:这里的额外指的主要是多余一个的部分?)
- 模型似乎依赖两个 Sink Token 来维持稳定的流式性能
- 这些发现表明,单个 Sink Token 足以改善流式性能,添加更多 Sink Token 并不会带来整体语言模型性能的进一步提升
- 这与视觉 Transformer (ViT) Darcet 等 (2023) 中的发现形成对比,在 ViT 中发现多个“寄存器”是有益的
- 表 10: 预训练期间添加零 Token 和可学习 Sink Token 与原始注意力的比较
- 缓存配置 \(x\)+\(y\) 表示添加 \(x\) 个初始 Token 和 \(y\) 个最近 Token
- 困惑度在 PG19 测试集的第一个样本上评估