本文主要介绍 LLM 的 Tokenization(一些研究文献也叫作 Tokenize)
Tokenization 技术分类
- 分词(Tokenization),有些地方也称为词元化,用于将文本进行切分,以便于语言模型能够理解和使用
- Tokenization 技术有三种粒度:Word-level Tokenization、Character-level Tokenization 和 Sub-word Tokenization
Word-level Tokenization(Word 粒度)
- 按照单词为最小单位进行分词来进行分词,每个单词是一个 token
- 优点:
- 每个 token 都是完整的单词,能准确表达语义(理解:模型学到的embedding就是当前单词的),便于理解和处理
- 缺点:
- 词表一般会很大,比如英文中各种词语变化非常大,词表动辄超过 10W+
- 容易遇到 OOV(未登录词)问题
- 对新词语或者拼写错误词语敏感,比如“MAGA”等近期新出的词语就无法识别到
Character-level Tokenization(Char 粒度)
- 按照字符来进行分词,每个字符是一个 token
- 优点:
- 无 OOV 问题,且任何的新词都能被拆解到字符粒度
- 词表固定,且词表很小(就几十个很少的字符集合),占用存储少
- 缺点:
- 相同句子长度下 token 太多,导致模型训练和推理慢
- 单个字符无法表达语义,学出来的 embedding 也难以对应到语义上,比如 “Queen” 和 “King” 就很难被联系起来
Sub-word Tokenization(Subword 粒度)
- 介于 Word-level 和 Character-level 之间,可以灵活地将一个单词拆分成一个或多个有语义信息的部分,比如 “tokenization” 可以拆为 “token”+”ization”,而 “love” 则不需要拆分,能够在减少 OOV 和 表达语义之间做 Trade-off
- Sub-word Tokenization 包括 BPE,WordPiece,Unigram 等
- BPE(Byte-Pair Encoding) ,即字节对编码,是一种 Tokenize 算法。其核心思想在于将最常出现的子词对合并,直到词汇表达到预定的大小时停止(实际上该方法本质是一种压缩算法,最早1994年提出,被用于通用数据压缩)
- 特别说明 :Byte-Pair Encoding 中的 Byte 不是字节的意思,可以理解为编码的最小单位,一般是字符级别(这里很容易误解)
- BPE 的缺点 :由于 BPE 是字符级别,直接使用 BPE 可能导致词表过大
- 理解:一个字符可能包含很多个字节,比如 UTF-8(Unicode编码的一种)是一种变长的编码方式,它可以使用 1 到 4 个字节来表示一个字符(理论上 4 个字节可以表示所有语言的所有字符);对于英文,通常 1 个字符 1 个字节,但对于汉字,通常使用 2 到 3 个字节,由于中文的字符空间过大,所以直接使用 BPE 可能导致词表过大
- BBPE(Byte-level BPE) ,BBPE 是 BPE 的一个变体,与 BPE 的唯一区别是,BPE 是字符级别,BBPE 是字节级别,特别适用于中文,日文等基础字符过于庞大的语言编码,BBPE 会使用 “_”作为每个字第一个 Byte 的前缀来指示单词边界,从而识别
- WordPiece 是 Google 提出的一种方法,没有公开的实现,其实现逻辑较为复杂,与 BPE 类似,但是每次合并子词时不是按照出现频率最高的词对,而是其他策略(Google是使用模型来预估词对出现的概率),比如 HuggingFace 上的一个实现是使用一个计算公式计算优先级 \(Score_{<A,B>} = \frac{Count_{A}}{Count_{A} \times Count_{B}}\),然后按照优先级选择合并的词对
- 公开资料显示:WordPiece 的目标是寻找最大化(分词训练集数据)似然的分词组合
- 大名鼎鼎的 BERT 使用的就是 WordPiece 分词方法
- Unigram ,又名 ULM(Unigram Language Model) :先初始化一个巨大的词汇表 ,再逐渐删除出现概率低的词汇(会从词汇表中挑出使得 loss 增长最小的 10%~20% 的词汇),直到词汇表打到预定的大小时停止
- BPE(Byte-Pair Encoding) ,即字节对编码,是一种 Tokenize 算法。其核心思想在于将最常出现的子词对合并,直到词汇表达到预定的大小时停止(实际上该方法本质是一种压缩算法,最早1994年提出,被用于通用数据压缩)
- 缺点:
- 需要提前使用一些特定的算法,按照不同的文本训练集/分词方法进行分词,可能导致不同模型的分词结果不同
- 每个模型需要增加一个自己的分词词表和分词函数(不同词表分词流程不同),以确保其他开发者可以使用
- 优点:
- 能准确控制词表大小,可大可小
- 相对 Char 粒度分词,每个 Token 的语义相对独立,在词表数量足够的情况下,单个token不会大规模重复语义
- 相对 Word 粒度分词,出现 OOV 的概率大大降低
分词的一般流程
- 一个分词算法的目标是实现编码和解码
- 常见的分词算法包括三个函数功能:
- 词表生成 :对给定数据进行编码生成
- 编码 :根据词表,对给定句子进行编码,输出为 token 列表
- 解码 :根据词表,给定 token 列表,输出句子
BPE 词表生成过程
- BPE 的词表生成函数的输入输出 :
- 输入 :训练数据 \(\mathcal{D}\)
- 输出 :词表(BPE的词表是有序的合并规则集合)
- BPE 生成词表的执行步骤如下:
- 第一步:初始化词汇表 vacab :将训练数据 \(\mathcal{D}\) 中的文本拆分为字符级别的词汇表并统计字符出现次数
- 注:单词的结尾使用一个特殊字符来表示
/w,后续处理过程中该字符与其他字符等价处理
- 注:单词的结尾使用一个特殊字符来表示
- 第二步:统计频率 :统计所有相邻词汇对的出现频数并记录(注意:这一步是所有相邻的词汇都要统计)
- 第三步:合并最频繁的字符对 :将频数最高的词汇对 \(<v_1,v_2>\) 合并为一个新的词汇 \(v_{\text{new}}\),并更新词汇表
- 假设:原始词汇表频次统计次数为 \(v_1:count_1\),\(v_2:count_2\),而 \(v_3 = <v_1,v_2>\) 出现的频次是 \(count_3\),
- 更新方式:增加一个新的词汇 \(v_3: count_3\),减少 \(<v_1,v_2>\) 对应的次数,更新结果为:\(v_1:count_1-count_3\),\(v_2:count_2-count_3\),若更新后的频数值为0,则该词汇可以从词表中永久删除了
- 问题:可能出现新的词汇已经在词汇表中了吗?此时如何处理?
- 回答:是可能出现的,相当于不同路径生成了同一个词汇,此时一般可以选择跳过更新或者将频数增加到新的词汇上,同时减少子词汇的频数
如果更注重词汇表的稳定性和避免不必要的合并,那么跳过合并可能是较好的选择;如果希望更准确地反映子词的出现频率,以便在后续处理中更好地权衡不同子词的重要性,那么更新词频则更为合适。在一些实际的 BPE 实现中,也可能会综合考虑这两种方式,或者根据一些特定的条件来动态决定采取哪种处理方式
- 回答:是可能出现的,相当于不同路径生成了同一个词汇,此时一般可以选择跳过更新或者将频数增加到新的词汇上,同时减少子词汇的频数
- 第四步:重复第二步和第三步 ,直到触发终止条件,终止条件一般有:
- 词汇表达到预定的词汇表大小:迭代过程中词汇表会越来越大,可以给定确定的词汇表大小
- 迭代次数达到最大值
- 第一步:初始化词汇表 vacab :将训练数据 \(\mathcal{D}\) 中的文本拆分为字符级别的词汇表并统计字符出现次数
BPE 编码过程
- 根据词表,对输入文本进行编码,生成 token 序列
- 具体流程
- 根据词表和有序的合并规则集合,对输入文本进行编码
- 由于合并规则是有序的,所以按照规则即可实现固定的编码,相同文本编码一定是相同的
- 实际上,在词表中加入权重分后,不需要任何其他文件(规则隐含在权重分中),可以使用贪心的方式编码
- 首先轮询一遍,搜索所有的相邻编码 A 和 B 并尝试合并,如果合并结果 AB 在词表中(这里的词表可以使用有序词表,会加快匹配效率),则取出 AB 的权重分(注意,这里先不合并)
- 轮询一遍以后分两种情况
- 如果没有任何候选 AB 在词表中,则结束,编码完成
- 否则,对所有候选的匹配 AB 按照权重分进行倒序排列,选择得分最高的匹配 AB 执行合并操作(注意,一个句子可以同时匹配多个完全相同的地方)
- 另一种不需要权重分的贪心编码方式:
- 直接从第一个字符开始,贪心匹配从第一个字符为初始起点的,最大满足长度的匹配(不需要权重分,只需要词表即可)
- 代码示例,来自github.com/boyu-ai/Hands-on-NLP
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49ordered_vocabulary = {key: x for x, key in enumerate(vocabulary)}
sentence = "nanjing beijing"
print(f"输入语句:{sentence}")
tokens = sentence.split(' ')
tokenized_string = []
for token in tokens:
key = token+'_'
splits = list(key)
#用于在没有更新的时候跳出
flag = 1
while flag:
flag = 0
split_dict = {}
#遍历所有符号进行统计
for i in range(len(splits)-1):
#组合两个符号作为新的符号
current_group = splits[i]+splits[i+1]
if current_group not in ordered_vocabulary:
continue
if current_group not in split_dict:
#判断当前组合是否在词表里,如果是的话加入split_dict
split_dict[current_group] = ordered_vocabulary[current_group]
flag = 1
if not flag:
continue
#对每个组合进行优先级的排序(此处为从小到大)
group_hist=[(k, v) for k, v in sorted(split_dict.items(),\
key=lambda item: item[1])]
#优先级最高的组合
merge_key = group_hist[0][0]
new_splits = []
i = 0
# 根据优先级最高的组合产生新的分词
while i < len(splits):
if i+1>=len(splits):
new_splits.append(splits[i])
i+=1
continue
if merge_key == splits[i]+splits[i+1]:
new_splits.append(merge_key)
i+=2
else:
new_splits.append(splits[i])
i+=1
splits=new_splits
tokenized_string+=splits
print(f"分词结果:{tokenized_string}")
BPE 解码过程
- 根据词表,对输出token进行解码,生成文本
- 具体流程
- 解码比较简单,按照token直接从词表查询原始字符值,添加到文本后面即可
其他说明
- BPE 在对中英文处理时,方式不同,英文时,需要先按照空格进行切分,然后再进行词表生成,中文则不需要进行切分
- 理解:英文需要切分的原因是为了防止出现
"e y"这种包含空格的 token 吗? - 问题:实际上也可以包含吧?感觉不一定会影响效果(注:目前是不包含的)
- 理解:英文需要切分的原因是为了防止出现
- OpenAI 统计 GPT3 和 GPT4 分词数量的在线链接OpenAI Tokenizer
- ChatGPT-BPE编码过程实例(from OpenAI Tokenizer)
- 实例1
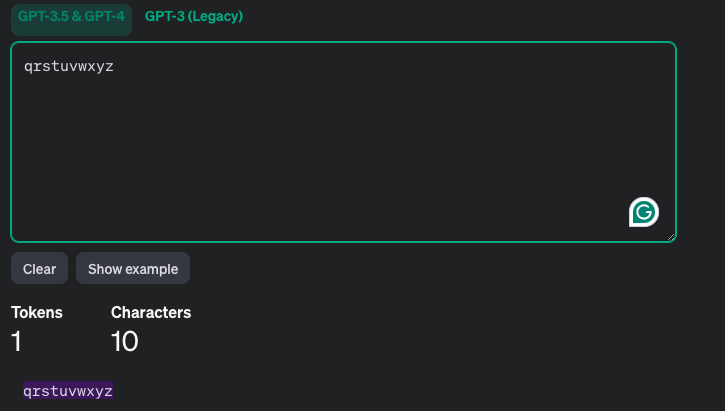
- 实例2
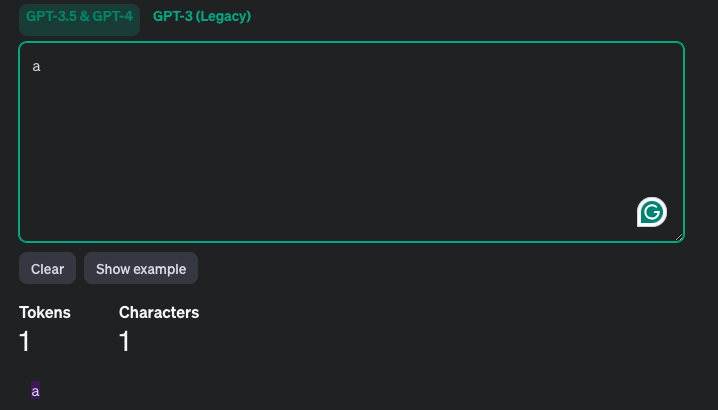
- 实例3
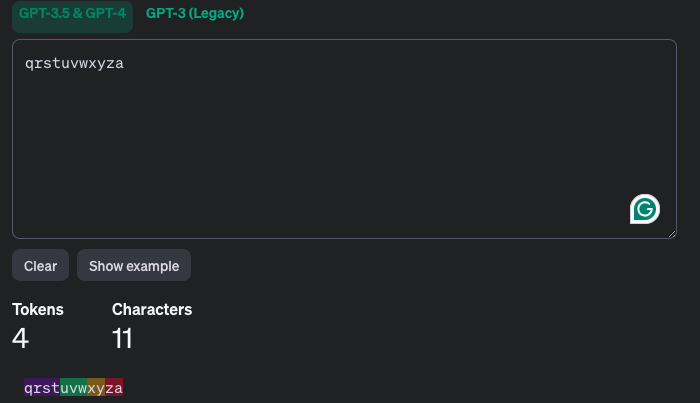
- 以上实例1-3说明:
- BPE编码不是从最长的 token 开始搜索,否则实例3的编码应该是2个 token 才对
- BPE编码也不是为了保证将每一个句子编码成最少的 token 数量(但原始算法的基本思想是所有训练数据上,尽量压缩 token 数量,减少存储)
- 实例1
附录:扩展词表的方法
- 参考链接:自定义构造Tokenizer
附录:分词器比较
- 常用分词器有:SentencePiece 和 Tiktoken
对比维度 SentencePiece Tiktoken 公司 Google OpenAI 设计目标和使用场景 通用分词工具 OpenAI 专为 GPT 系列模型设计 分词算法 支持多种算法,如 BPE、Unigram 等 BPE 算法 词表特点 词表可根据数据集和任务训练,可调整大小和内容 针对 GPT 系列模型预先训练好,用户无法直接训练或修改 性能和效率 性能和效率受算法选择和词表大小影响,某些情况下训练和分词速度可能较慢 分词速度快,能高效计算文本token数量 - SentencePiece 是 Google 开源的一个分词工具库,包含以下优点:
- SentencePiece 使用特殊的符号来转义空格,可以精确区分
love you !和love you!两个句子中!前的空格 - 高效实现了如 BPE 和 ULM 等分词方法,且自动将语料先转换为 Unicode 编码(注意这里不是 UTF-8),再输入分词算法,这样可以解决中文没有空格的问题
- 理解(待确定):Unicode 编码中文时是以字为单位的,比如你对应
U+4F60,可以从U+准确识别每个文字开头? - 一些文章中提到,中文字符是在进行 BBPE 算法时,需要先将中文经过 UTF-8 变成字节,然后再经过 Unicode 统一编码成字符,最后再进行分词表构造
- 理解(待确定):Unicode 编码中文时是以字为单位的,比如你对应
- SentencePiece 使用特殊的符号来转义空格,可以精确区分
- Tiktoken 的使用讲解:NLP(五十四)tiktoken的使用
- 注:Llama1 和 Llama2 使用 SentencePiece,Llama3 开始使用 Tiktoken 了
- 两种分词器的使用 Demo,分别展示 SentencePiece 和 Tiktoken 从指定数据构造词表、加载词表、编码和解码的全过程:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39import sentencepiece as spm
import tiktoken
# 数据文件构造
data = [
"This is a sample sentence.",
"Another sample sentence for testing."
]
with open('data.txt', 'w', encoding='utf-8') as f:
for line in data:
f.write(line + '\n')
# SentencePiece 使用 Demo
# 构造 SentencePiece 词表
spm.SentencePieceTrainer.train(input='data.txt', model_prefix='sp_model', vocab_size=100)
# 加载 SentencePiece 词表
sp = spm.SentencePieceProcessor()
sp.load('sp_model.model')
# 编码和解码
text = "This is a test."
sp_encoded = sp.encode(text)
sp_decoded = sp.decode(sp_encoded)
print("SentencePiece 编码结果:", sp_encoded)
print("SentencePiece 解码结果:", sp_decoded)
# Tiktoken 使用 Demo
# 对于 Tiktoken,我们使用预训练的 cl100k_base 编码
# 这里不需要构造词表,直接加载预训练编码
encoding = tiktoken.get_encoding("cl100k_base")
# 还可以选择其他编码方式,不同模型使用不同的编码方式,可以调用函数对应抽取到编码方式
# print(tiktoken.encoding_for_model('gpt-3.5-turbo'))
# 编码和解码
tiktoken_encoded = encoding.encode(text)
tiktoken_decoded = encoding.decode(tiktoken_encoded)
print("Tiktoken 编码结果:", tiktoken_encoded)
print("Tiktoken 解码结果:", tiktoken_decoded)
附录:transformers.AutoTokenizer 的使用
tokenizer.tokenize() 处理单文本
- tokenize 处理单文本示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22from transformers import AutoTokenizer
# Tokenizer 加载,根据路径下的文件初始化自身,路径下会包含:
# # tokenizer.json(包含词表)
# # tokenizer_config.json(包含 tokenizer_class(可以按照需要自己实现并提 PR 到 transformers 库) 和 special_token 等信息)
# # special_tokens_map.json(通常与 tokenizer_config.json 中的内容重复,可选,可被类初始化时读取使用),special_token 包含 bos,eos,pad,unk 四个,是模型必须指定的,有时候也实现在 tokenizer_config.json 等文件中
# # vocab.json (词表信息,可选,可被类初始化时读取使用)
tokenizer = AutoTokenizer.from_pretrained("model_name")
text = "Hello world! This is a test."
# 单行分词
tokens = tokenizer.tokenize(text)
print("Tokens:", tokens) # 这里输出的可能是 类似 ['Hello', ',', 'Ġworld', '!', 'ĠThis', 'Ġis', 'Ġa', 'Ġtest', '.'] 的结果(分词器里面使用 'Ġ'(Unicode 字符 U+0120,带点空格)在这里表示普通空格(U+0020))
# 注:这一步中,如果是BBPE 分词,且输入是中文甚至可能看起来像是乱码,因为常见的 BBPE 分词方式会先将中文转换成 UTF-8 编码后再进行分词
# 转换为索引 IDs
ids = tokenizer.convert_tokens_to_ids(tokens)
print("IDs:", ids) # 这里输出具体索引(int 类型的数字列表)
# 解码验证,将 IDs 解码为原始文本
decoded = tokenizer.decode(ids)
print("解码结果:", decoded) # 与原始输出文本 text 一致
tokenizer() 批量处理文本
tokenizer(text)实际上是tokenizer.__call__(text)的简写,是最常用、最完整的文本编码方法tokenizer(text)函数包含以下步骤:- 1)分词 :将文本拆分成 Tokens(注意: Token 不是 ID,不是整数)
- 2)映射 :将 Toke ns 转换为对应的 IDs
- 3)添加特殊标记 :如[CLS], [SEP], [PAD]等
- 4)填充和截断 :处理长度不一致的问题,需指定参数
- 5)返回张量 :转换为 PyTorch/TensorFlow 张量,注意返回的是 ID 列表,不是 Token 列表
tokenizer(text)函数参数较多,重点需要关注的如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def __call__(
self,
text: Union[str, List[str], List[str], List[List[str]], None] = None, # 待编码的单条文本或文本列表;若为 List[str] 类型,表示已按词切分
text_pair: Optional[Union[str, List[str], List[str], List[List[str]]]] = None, # 与 text 配对的第二条文本(或列表),用于需要“句子对”输入的任务,如 NLI、QA
text_target: Union[str, List[str], List[str], List[List[str]], None] = None, # 作为“标签/目标”的单条文本或文本列表,用于 seq2seq 等需对目标序列编码的场景
text_pair_target: Optional[
Union[str, List[str], List[str], List[List[str]]]
] = None, # 与 text_target 配对的第二条目标文本(或列表)
add_special_tokens: bool = True, # 是否在输出中自动添加特殊符号(如 [CLS]、[SEP])
padding: Union[bool, str, PaddingStrategy] = False, # 是否/如何填充:True/False、'longest'、'max_length' 或 "do_not_pad"(PaddingStrategy 枚举)
truncation: Union[bool, str, TruncationStrategy, None] = None, # 是否/如何截断:True/False、'only_first'、'only_second'、"longest_first" 或 "do_not_truncate"(TruncationStrategy 枚举)
max_length: Optional[int] = None, # 允许的最大序列长度;超出则按 truncation 策略处理
stride: int = 0, # 滑动窗口截断时,相邻片段间的重叠 token 数
is_split_into_words: bool = False, # 表明输入 text 是否已经按词切分(List[str]),此时不重新分词
pad_to_multiple_of: Optional[int] = None, # 将序列长度填充到指定值的整数倍(常见于 TensorRT / 优化内核)
padding_side: Optional[str] = None, # 显式指定填充方向:'left' 或 'right';默认采用 tokenizer 配置
return_tensors: Optional[Union[str, TensorType]] = None, # 返回张量类型:'np'、'pt'、'tf' 等 TensorType 枚举;None 则返回 Python 列表
return_token_type_ids: Optional[bool] = None, # 是否返回 token_type_ids(区分句子对);None 时按模型默认
return_attention_mask: Optional[bool] = None, # 是否返回 attention_mask;None 时按模型默认
return_overflowing_tokens: bool = False, # 是否返回因截断被溢出的 token 列表
return_special_tokens_mask: bool = False, # 是否返回特殊符号掩码(1 表示特殊 token,0 表示普通 token)
return_offsets_mapping: bool = False, # 是否返回每个 token 对应原始文本的 (start, end) 字符偏移
return_length: bool = False, # 是否返回编码后序列长度
verbose: bool = True, # 遇到警告/异常时是否打印详细信息
**kwargs,
) -> BatchEncoding: # BatchEncoding 对象支持字典索引和属性访问
tokenizer() 参数说明(按常用程度排序)
- text :必填参数,要分词的文本数据
- 支持类型:单个字符串(如
"Hello world")、字符串列表(如["Hello, World", "你好,你好"])、嵌套字符串列表(如[["Hello, World", "你好,你好"], ["Hi,你好吗?", "谢谢你"]],仅部分模型支持) - 说明:当传入列表时,会自动批量处理;嵌套列表通常用于处理“文本对”场景,需结合
padding等参数使用
- 支持类型:单个字符串(如
- padding :控制是否填充(补全)序列到相同长度,可选值如下:
False/None:不填充(默认值),每个序列保留原始长度True/"longest":填充到批量中最长序列的长度 ,此时"max_length"指定了也不会使用"max_length":填充到max_length参数指定的长度(需同时设置max_length)"do_not_pad":等价于False- 说明:填充时使用分词器的
pad_token(默认通常是<pad>),填充位置由padding_side控制(默认右侧)
- truncation :控制是否截断过长的序列,可选值如下:
False/None:不截断(默认值),若序列长度超过max_length会(理解:不能截断,又不能超过max_length,矛盾了,必须报错)True/"longest_first":截断到max_length(需指定max_length),优先截断最长的序列(批量场景)"only_first":仅截断输入文本对中的第一个文本(如 premise)"only_second":仅截断输入文本对中的第二个文本(如 hypothesis)"do_not_truncate":等价于False- 说明:截断时默认从右侧截断(由
truncation_side控制)
- max_length :指定序列的最大长度
- 类型:整数(int)
- 说明:需与
padding(设为"max_length")或truncation(设为True等)配合使用;- 若不指定,默认使用分词器的
model_max_length(通常是模型支持的最大输入长度,如 512、1024 等)
- 若不指定,默认使用分词器的
- return_tensors :指定返回的张量类型
- 可选值:
None(默认)、"pt"(PyTorch 张量)、"tf"(TensorFlow 张量)、"np"(NumPy 数组)、"jax"(JAX 张量) - 说明:默认返回普通 Python 列表;指定后返回对应框架的张量,可直接传入模型训练/推理
- 可选值:
- return_attention_mask :是否返回注意力掩码
- 类型:布尔值(bool),默认
True - 说明:注意力掩码用于告诉模型哪些 token 是真实文本(值为 1),哪些是填充的 pad token(值为 0);若设为
False,返回结果中不包含attention_mask键
- 类型:布尔值(bool),默认
- return_token_type_ids :是否返回 token 类型 ID(用于区分文本对)
- 类型:布尔值(bool),默认值由模型决定(如 BERT 类模型默认
True,GPT 类模型默认False) - 说明:文本对场景(如
text = (sent1, sent2))中,token_type_ids 用 0 标识第一个文本的 token,1 标识第二个文本的 token;单文本场景中全为 0 - 注意:亲测,很多现代 GPT 模型中,即使设置
return_token_type_ids=True,输出都全 0 了
- 类型:布尔值(bool),默认值由模型决定(如 BERT 类模型默认
- add_special_tokens :是否添加模型所需的特殊 token
- 类型:布尔值(bool),默认
True - 说明:特殊 token 包括
cls_token(如<cls>)、sep_token(如<sep>)、bos_token(如<s>)、eos_token(如</s>)等,不同模型的特殊 token 不同;设为False则仅返回原始分词结果,不添加任何特殊 token
- 类型:布尔值(bool),默认
- return_offsets_mapping :是否返回 token 在原始文本中的偏移量(起始/结束索引)
- 类型:布尔值(bool),默认
False - 说明:返回的
offsets_mapping是一个列表,每个元素为(start, end)元组,对应每个 token 在原始文本中的字符位置(可用于实体标注、文本对齐等任务)
- 类型:布尔值(bool),默认
- return_length :是否返回每个序列的原始长度(未填充/未截断前)
- 类型:布尔值(bool),默认
False - 说明:返回的
length列表包含每个序列在处理前的实际长度,便于后续计算有效 token 数
- 类型:布尔值(bool),默认
- padding_side :填充方向
- 可选值:
"right"(默认,右侧填充)、"left"(左侧填充) - 说明:部分模型(如 GPT 类)可能需要左侧填充,需根据模型要求设置
- 可选值:
- truncation_side :截断方向
- 可选值:
"right"(默认,右侧截断)、"left"(左侧截断) - 说明:根据任务需求调整,例如处理历史对话时可能需要左侧截断旧对话
- 可选值:
- stride :截断时的重叠长度(用于长文本分段处理)
- 类型:整数(int),默认 0
- 说明:当文本长度超过
max_length时,截断后保留前一段序列的stride个 token,避免丢失上下文(如长文档分类、问答任务)
- return_overflowing_tokens :是否返回截断后溢出的 token 组成的额外序列
- 类型:布尔值(bool),默认
False - 说明:结合
stride使用,长文本会被分成多个重叠的子序列,返回所有子序列及对应的overflow_to_sample_mapping(映射子序列到原始样本的索引)
- 类型:布尔值(bool),默认
- allow_multiple_sentences :是否允许单个文本包含多个句子(通过标点/换行分隔)
- 类型:布尔值(bool),默认
True - 说明:部分分词器支持自动拆分多句子,但通常不影响核心分词逻辑,保持默认即可
- 类型:布尔值(bool),默认
- verbose :是否输出详细日志
- 类型:布尔值(bool),默认
True - 说明:设为
False可关闭警告信息(如序列长度超过模型最大长度的警告)
- 类型:布尔值(bool),默认
简单的返回结果示例
- 示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62from transformers import AutoTokenizer
model_path = "path_to_model"
# 初始化分词器(以 BERT 为例)
tokenizer = AutoTokenizer.from_pretrained(model_path)
# 1. 基础用法(单文本)
text = "Hello, world! This is a test."
inputs = tokenizer(
text,
padding=True,
truncation=True,
max_length=10,
return_tensors="pt"
)
print(type(inputs)) # <class 'transformers.tokenization_utils_base.BatchEncoding'>
print(inputs.keys()) # 输出:dict_keys(['input_ids', 'attention_mask'])
print(inputs["input_ids"].shape) # 输出:torch.Size([1, 9])
# 文本对用法(如句子相似度),仅在 BERT RoBERTa 等模型中可以使用,其他模型会输出 inputs_pair["token_type_ids"],但是包含的值都是 0
text_pair = ("I like cats.", "I love dogs.")
inputs_pair = tokenizer(
text_pair,
padding="max_length",
max_length=5,
return_token_type_ids=True,
return_tensors="np"
)
print(inputs_pair.keys()) # 输出:dict_keys(['input_ids', 'token_type_ids', 'attention_mask'])
print(inputs_pair["input_ids"].shape) # 输出:(2, 5)
print(inputs_pair["token_type_ids"]) # 在 BERT RoBERTa 等模型中,0 对应第一个句子,1 对应第二个句子;现代大模型一般都是 0
# 输出:
# [[0 0 0 0]
# [0 0 0 0]]
# 长文本分段(带重叠)
long_text = "This is a very long text that exceeds the max length. We need to split it into chunks with overlap."
inputs_long = tokenizer(
long_text,
max_length=10,
truncation=True,
stride=3,
return_overflowing_tokens=True,
return_offsets_mapping=True
)
print(inputs_long.keys()) # 输出:dict_keys(['input_ids', 'attention_mask', 'offset_mapping', 'overflow_to_sample_mapping'])
print(type(inputs_long)) # <class 'transformers.tokenization_utils_base.BatchEncoding'>
print(len(inputs_long["input_ids"])) # 输出:3
print(inputs_long["input_ids"])
# 输出:
# [
# [3031, 472, 358, 2481, 2093, 3402, 524, 159, 369, 156],
# [159, 369, 156, 5041, 112, 1769, 1838, 408, 11694, 574],
# [408, 11694, 574, 1394, 48782, 537, 30033, 112]
# ]
# 批量处理多条文本
texts = ["你好", "世界", "深度学习"]
encoded_batch = tokenizer(texts)
print(encoded_batch.keys()) # 输出:dict_keys(['input_ids', 'attention_mask'])
print(encoded_batch["input_ids"]) # [[135], [487], [18834]]
其他更多完整详细示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
from transformers import AutoTokenizer
MODEL = "path_to_model"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
# 故意构造 3 条长度差异很大的句子
raw_texts = [
"Hello world!",
"This is a much longer sentence, designed to exceed the usual 8 ~ 12 token budget.",
"Hi"
]
def group_title(title):
print(f"\n{title}")
def pretty_print(enc):
print("input_ids :", enc["input_ids"])
if "attention_mask" in enc:
print("attention_mask :", enc["attention_mask"])
if "token_type_ids" in enc:
print("token_type_ids :", enc["token_type_ids"])
if "overflowing_tokens" in enc:
print("overflowing_tokens:", enc["overflowing_tokens"])
print("-" * 50)
# 默认:不 padding 也不 truncation -> 长度各异的 list
group_title("默认:padding=False, truncation=None")
enc = tokenizer(raw_texts)
pretty_print(enc)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# 只 padding 不 truncation -> 长度一致,无截断
group_title("只 padding(最长)不 truncation")
enc = tokenizer(raw_texts, padding=True)
pretty_print(enc)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# 只 truncation 不 padding -> 超过 max_length 被截断,仍返回 list
group_title("只 truncation=True 不 padding, max_length=12")
enc = tokenizer(raw_texts, truncation=True, max_length=12)
pretty_print(enc)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# padding + truncation -> 固定长度,超长截断,不足填充
group_title("padding + truncation, max_length=16")
enc = tokenizer(raw_texts, padding=True, truncation=True, max_length=16)
pretty_print(enc)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# 返回 PyTorch 张量(必须 padding,否则长度不同会抛错)
group_title("return_tensors='pt' 必须配合 padding")
enc = tokenizer(raw_texts, padding=True, truncation=True, max_length=16, return_tensors="pt")
print("input_ids 形状:", enc["input_ids"].shape)
print("attention_mask 形状:", enc["attention_mask"].shape)
print("类型:", type(enc["input_ids"]))
# 按照窗口拆分成多个 chunks,stride + return_overflowing_tokens 演示滑动窗口
group_title("stride=4 + return_overflowing_tokens 截断窗口")
long_text = "This is a very long sentence that will be split into overlapping chunks."
enc = tokenizer(long_text, truncation=True, max_length=10, stride=4, return_overflowing_tokens=True, return_offsets_mapping=True)
print("共返回片段数:", len(enc["input_ids"]))
for idx, (ids, off) in enumerate(zip(enc["input_ids"], enc["offset_mapping"])):
print(f"片段 {idx}: tokens={ids}")
print(f"offsets={off}")
print("-" * 30)
# padding='max_length' 强制 pad 到 max_length
group_title("padding='max_length' 强制 32")
enc = tokenizer(raw_texts, padding='max_length', max_length=32)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# pad_to_multiple_of 演示 8 的倍数填充
group_title("pad_to_multiple_of=8, 填充到最小符合要求的 8 的倍数,比 21 大的倍数是 24")
enc = tokenizer(raw_texts, padding=True, pad_to_multiple_of=8)
print("每条长度:", [len(ids) for ids in enc["input_ids"]])
# tokenizer 类属性:默认最大长度 & 截断策略
group_title("tokenizer 默认属性")
print("tokenizer.model_max_length :", tokenizer.model_max_length) # 从原始模型文件中读取
print("tokenizer.truncation_side :", tokenizer.truncation_side)
print("tokenizer.padding_side :", tokenizer.padding_side)
# 其他:如 tokenizer.vocab_size 等
# 默认:padding=False, truncation=None
# input_ids : [[20769, 3121, 224], [3156, 597, 483, 2799, 6991, 14941, 235, 7605, 533, 15890, 494, 15299, 444, 247, 8581, 444, 240, 241, 10539, 14517, 237], [23383]]
# attention_mask : [[1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1]]
# --------------------------------------------------
# 每条长度: [3, 21, 1]
#
# 只 padding(最长)不 truncation
# input_ids : [[20769, 3121, 224, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3], [3156, 597, 483, 2799, 6991, 14941, 235, 7605, 533, 15890, 494, 15299, 444, 247, 8581, 444, 240, 241, 10539, 14517, 237], [23383, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3]]
# attention_mask : [[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
# --------------------------------------------------
# 每条长度: [21, 21, 21]
#
# 只 truncation=True 不 padding, max_length=12
# input_ids : [[20769, 3121, 224], [3156, 597, 483, 2799, 6991, 14941, 235, 7605, 533, 15890, 494, 15299], [23383]]
# attention_mask : [[1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1]]
# --------------------------------------------------
# 每条长度: [3, 12, 1]
#
# padding + truncation, max_length=16
# input_ids : [[20769, 3121, 224, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3], [3156, 597, 483, 2799, 6991, 14941, 235, 7605, 533, 15890, 494, 15299, 444, 247, 8581, 444], [23383, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3]]
# attention_mask : [[1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]
# --------------------------------------------------
# 每条长度: [16, 16, 16]
#
# return_tensors='pt' 必须配合 padding
# input_ids 形状: torch.Size([3, 16])
# attention_mask 形状: torch.Size([3, 16])
# 类型: <class 'torch.Tensor'>
#
# stride=4 + return_overflowing_tokens 截断窗口
# 共返回片段数: 2
# 片段 0: tokens=[3156, 597, 483, 2606, 2218, 14941, 649, 1253, 621, 11819]
# offsets=[(0, 4), (4, 7), (7, 9), (9, 14), (14, 19), (19, 28), (28, 33), (33, 38), (38, 41), (41, 47)]
# ------------------------------
# 片段 1: tokens=[649, 1253, 621, 11819, 1519, 44984, 48907, 237]
# offsets=[(28, 33), (33, 38), (38, 41), (41, 47), (47, 52), (52, 64), (64, 71), (71, 72)]
# ------------------------------
#
# padding='max_length' 强制 32
# 每条长度: [32, 32, 32]
#
# pad_to_multiple_of=8
# 每条长度: [24, 24, 24]
#
# tokenizer 默认属性
# tokenizer.model_max_length : 131072
# tokenizer.truncation_side : right
# tokenizer.padding_side : right
常见注意事项
- 建议批量处理,而不是单条处理
- 大批量处理时注意内存使用
- 不同模型有不同的最大长度限制,模型配置中会包含
- 某些模型会自动添加特殊标记,也可以自己预设标记:
1
tokenizer.pad_token = tokenizer.eos_token # 设置填充token
附录:transformers.AutoTokenizer.decode 的使用
tokenizer.decode用于将模型输出的 token ID 序列(或 token 索引序列)反向解码为自然语言文本- 会自动处理 token 间的拼接逻辑(如去除 subword 分隔符、恢复原始词汇),屏蔽底层 tokenization 细节(如 BPE、WordPiece 等子词切分的拼接)
函数签名:
1
2
3
4
5
6
7def decode(
self,
token_ids: Union[int, List[int], "np.ndarray", "torch.Tensor", "tf.Tensor"],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: Optional[bool] = None,
**kwargs,
) -> str:需要注意:
- 解码结果依赖于 tokenizer 的训练数据和切分规则(如 BPE 切分的词汇可能需要特殊拼接逻辑),需确保解码使用的 tokenizer 与编码(tokenizer.encode)时一致;
- 对于包含填充 token(PAD)的 input_ids,建议设置
skip_special_tokens=True或指定padding_token_id,避免解码出无效的填充文本;
参数说明
token_ids:必选,对应编码时的input_ids,需要解码的 token ID 序列,支持两种输入形式:- 单个整数(单个 token ID),例如
101、2023; - 整数列表/张量(多个 token ID 组成的序列),例如
[101, 2054, 2182, 102]、torch.tensor([101, 3845, 102]),也支持批量输入(如二维张量,shape 为[batch_size, seq_len])- 注意:这里的批量不是 list 形式,必须是一个张量才行
- 单个整数(单个 token ID),例如
skip_special_tokens:布尔值,默认False- 设为
True时,解码过程中会自动跳过所有特殊 token(如[CLS]、[SEP]、[PAD]、[MASK]等,具体取决于 tokenizer 的配置); - 设为
False时,会保留所有特殊 token 原样输出(例如解码结果可能包含"<s>" "<pad>"等标记) - 实际使用中通常设为
True,以获取干净的自然语言文本
- 设为
clean_up_tokenization_spaces:布尔值,默认True- 设为
True时,会自动清理解码后文本中多余的空格(如 subword 拼接后残留的空格、特殊 token 移除后的空字符); - 设为
False时,保留 token 拼接后的原始空格布局(可能出现连续空格或不合理空格) - 注:
clean_up_tokenization_spaces参数的必要性已大大降低,亲测这个参数为True或False的结果是一样的,多个特殊的字符串测试没有例外
- 设为
padding_token_id:整数,默认使用 tokenizer 配置中的 padding_token_id(如[PAD]对应的 ID)- 当
input_ids中包含填充 token ID 时,可通过该参数指定需要忽略的填充 ID,避免解码出[PAD]对应的文本标记
- 当
stop_at_eos:布尔值,默认False(部分 tokenizer 版本默认 True,需结合具体库版本确认)- 设为
True时,解码过程中遇到eos_token_id会立即终止,仅返回eos_token_id之前的文本; - 设为
False时,会完整解码input_ids中的所有 token ID,包括eos_token_id之后的内容
- 设为
使用示例
- 使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 基础解码(跳过特殊 token):
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
input_ids = [101, 2054, 2182, 2003, 1996, 3014, 102] # 包含 [CLS](101)和 [SEP](102)
text = tokenizer.decode(input_ids, skip_special_tokens=True)
print(text) # 输出:"i love this movie"(自动去除特殊 token 并拼接子词)
# 保留特殊 token:
text = tokenizer.decode(input_ids, skip_special_tokens=False)
print(text) # 输出:"[CLS] i love this movie [SEP]"
# 解码批量输入(二维张量):
import torch
batch_input_ids = torch.tensor([[101, 2054, 102], [101, 2182, 102]])
batch_text = tokenizer.decode(batch_input_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
print(batch_text) # 输出批量文本(具体格式取决于 tokenizer,通常为列表或拼接字符串)
decode() vs batch_decode()
tokenizer.decode()和tokenizer.batch_decode()的核心区别是 处理输入的维度和场景tokenizer.decode()用于解码「单个序列」的input_ids,无批量优化tokenizer.batch_decode()用于批量解码「多个序列」的input_ids,有批量优化,比循环调用decode()更高效- 本质是「单样本」与「多样本」的适配差异
- 输入要求:
decode()仅接受 1维输入 :- 支持
list[int](如[101, 2054, 3110, ...])、1D Tensor、1D numpy数组,若传入2D数据会直接报错
- 支持
batch_decode()仅接受 2维输入 :- 支持
list[list[int]](如[[101, 2054], [101, 3110]])、2D Tensor、2D numpy数组,自动处理批量样本
- 支持
- 输出情况:
decode()输出单个字符串(str);batch_decode()输出字符串列表(list[str])
- 两者用相同参数解码时,结果应该一致
附录:中英文 Tokenization 编码效率对比
注:本文以 Qwen3 编码方式为例,且只是简单的粗糙对比,不严谨
分别尝试了将文本从中文翻译为英文和从英文翻译为中文两种方式(翻译工作由 豆包完成),代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50from transformers import AutoTokenizer
import sys
model_name = "/Users/jiahong/Workspace/IdeaProjects/Torch/LLaMA-Factory/model/Qwen3-0.6B/"
tokenizer = AutoTokenizer.from_pretrained(model_name)
print("Chinese to English")
print("Chinese")
prompt_c = """xxx"""
print(f"{len(prompt_c)} 字, 存储 {sys.getsizeof(prompt_c)-49} B") # 49 是对象的固定存储部分
token_c = tokenizer.tokenize(prompt_c)
print(f"len of tokens: {len(token_c)}, {len(prompt_c)/len(token_c)} 字/token")
print("English")
prompt_e = """xxx"""
print(f"{len(prompt_e.split(' '))} 单词, {sys.getsizeof(prompt_e)-49} B, len: {len(prompt_e)}")
token_e = tokenizer.tokenize(prompt_e)
# print(token_e)
print(f"len of tokens: {len(token_e)}, {len(prompt_e)/len(token_e)} B/token, {len(prompt_e.split(' '))/len(token_e)} words/token")
print("="*30)
print("English to Chinese")
print("Chinese")
prompt_c = """xxx"""
print(f"{len(prompt_c)} 字, 存储 {sys.getsizeof(prompt_c)-49} B")
token_c = tokenizer.tokenize(prompt_c)
# print(token_c)
print(f"len of tokens: {len(token_c)}, {len(prompt_c)/len(token_c)} 字/token")
print("English")
prompt_e = """xxx"""
print(f"{len(prompt_e.split(' '))} 单词, {sys.getsizeof(prompt_e)-49} B, len: {len(prompt_e)}")
token_e = tokenizer.tokenize(prompt_e)
print(f"len of tokens: {len(token_e)}, {len(prompt_e)/len(token_e)} B/token, {len(prompt_e.split(' '))/len(token_e)} words/token")
# Chinese to English
# Chinese
# 2514 字, 存储 5053 B
# len of tokens: 1784, 1.4091928251121075 字/token
# English
# 1611 单词, 21073 B, len: 10524
# len of tokens: 2239, 4.700312639571237 B/token, 0.7195176418043769 words/token
# ==============================
# English to Chinese
# Chinese
# 2061 字, 存储 4147 B
# len of tokens: 1421, 1.450387051372273 字/token
# English
# 814 单词, 10739 B, len: 5357
# len of tokens: 1223, 4.3802125919869175 B/token, 0.6655764513491415 words/token结论(以 Qwen3 的编码方式为例):
- 中文:约 1.5 字/token
- 英文:约 0.7 words/token,且大约合 4.5 B/token
- 编码效率上看,汉译英时,中文优于英文(0.8:1);英译汉时,则英文较优(1.16:1)
有趣的是,汉译英和英译汉的效率差异很大:
- 汉译英时,1 个单词大概对应 1.56 个中文字
- 英译汉时,1 个单词大概对应 2.53 个中文字
- 解释:不翻译别人,自由发挥的情况下,文字使用效率是最高的
附录:新增 Token 的方法
- 可以对 HuggingFace 模型添加新的 Token,添加 Token 的类型可以有两种
- 特殊 Token(Special Token):
- Special Token 是具有特定语义或结构作用的标记,常用于向模型指示文本的结构、任务类型或特殊信息
- Special Token 会保证原子性 (Atomicity) : Special Token 永远不会被分词器拆分成更小的 subword 或字符,它们作为一个整体被识别
- 通常可通过两种方式添加:
- 通过
tokenizer.add_special_tokens()方法添加(推荐使用)- 接受一个字典,如
{'additional_special_tokens': ['<NEW_TOKEN>']}
- 接受一个字典,如
- 通过
tokenizer.add_tokens()并设置参数special_tokens=True来添加
- 通过
- 在解码时,通常可以选择跳过这些 Special Token(使用
skip_special_tokens=True) - Special Token 添加后,词表中显示它的属性为
"special": true
- 常规 Token (Regular Token):
- Regular Token 指的是模型训练过程中常见的词汇、词片段(subword)或字符,它们在自然语言文本中出现,主要用于表示文本内容
- 主要通过
tokenizer.add_tokens()方法添加- 新添加的 Token 会被加入到词汇表中,从现有词汇表的末尾开始分配新的索引
- 如果添加的 Token 是一个完整的词汇,它通常不会被分词器拆分 ,但如果它本身就是 subword 的一部分,则会按照分词器的逻辑处理
- 如果一个新词汇被添加,分词器在遇到该词时会优先使用该新词汇作为一个整体
- 常规 Token 添加后,词表中显示它的属性为
"special": false
- 特殊 Token(Special Token):
- 此外,如果在模型预训练时已经增加了
<mask_id>还可以手动添加(已测试没问题):- 直接修改
tokenizer.json中的字段- 分别修改
<mask_id_xx>为指定 Token 文本,比如<start_think> - 映射关系一般有两个地方
- 一个是
"added_tokens"中的 ID 映射 - 另一个是词表中的映射关系(一般也在
"tokenizer.json"的"model"->"vocab"中)
- 一个是
- 分别修改
- 直接修改
新增 Token 对模型嵌入层的影响
- 无论是哪种方式添加了 Token,都必须调用
model.resize_token_embeddings(len(tokenizer))来调整模型的词嵌入层 (Embedding Layer) 大小,使其与新的词汇表大小匹配,否则新增的 Token 无法被模型正确处理 - Special Tokens 通常会被赋予特定的嵌入初始化方式(例如部分模型对特殊 tokens 有默认初始化逻辑),而普通 tokens 的嵌入则可能随机初始化
修改文件的方式添加 Special Token
- 不建议使用这种方式,建议通过代码动态添加并
save_pretrained的方式持久化到文件中 - 手动修改文件容易出错,比如 Special Token 的添加,除了词表外,还需要修改
special_tokens_map.json文件, 否则tokenizer不会将其识别为 Special Token- 注:部分模型也可以将 “special_tokens_map” 作为一个 key 放到
tokenizer.json中?
- 注:部分模型也可以将 “special_tokens_map” 作为一个 key 放到
tokenizer.add_special_tokens() 函数使用及对比
tokenizer.add_special_tokens()接受一个字典对象作为参数,且字典的 key 必须在tokenizer.SPECIAL_TOKENS_ATTRIBUTES中- 在 Hugging Face 的
tokenizers库中,tokenizer.SPECIAL_TOKENS_ATTRIBUTES是分词器类(如 PreTrainedTokenizer)的一个内置属性,它定义了 “特殊 token 类型” 的标准名称集合- 注意:不同版本可能写作
SPECIAL_TOKENS_ATTRIBUTES或类似属性,本质一致 - 常见配置为:
['bos_token', 'eos_token', 'unk_token', 'sep_token', 'pad_token', 'cls_token', 'mask_token', 'additional_special_tokens'] - “additional_special_tokens” 用于添加自定义的 Special Token
- 注意:不同版本可能写作
- 使用
tokenizer.add_special_tokens()添加 与tokenizer.add_tokens(..., special_tokens=True)的区别:- Special Token 是否会出现在
special_tokens_map.json文件 和tokenizer_config.json的"additional_special_tokens"字段中?tokenizer.add_tokens(..., special_tokens=True)方式添加的不会出现tokenizer.add_special_tokens()方式添加的则会出现
- 两者都会出现在
tokenizer_config.json的"added_tokens_decoder"中 - 说明:
add_special_tokens(标准用法)会将新添加的 Token 关联到分词器的任何标准特殊 Token 属性,而add_tokens(..., special_tokens=True)不会add_tokens(..., special_tokens=True)添加后只能在词表中找到索引,其他地方看不到
- Special Token 是否会出现在
- 添加 Special Token 的示例:
1
2
3
4
5print(tokenizer.special_tokens_map) # 可能输出为:{'bos_token': '<bos>', 'eos_token': '<eos>', 'unk_token': '<unk>', 'pad_token': '<pad>'}
tokenizer.add_special_tokens({"additional_special_tokens": ["<llm_assistant>", "<llm_user>"]})
print(tokenizer.special_tokens_map) # 可能输出为:{'bos_token': '<bos>', 'eos_token': '<eos>', 'unk_token': '<unk>', 'pad_token': '<pad>', 'additional_special_tokens': ['<llm_assistant>', '<llm_user>']}
# 注意:tokenizer.add_tokens(["<longcat_assistant>", "<longcat_system>"], special_tokens=True) 方式添加的 Special Token 不会出现在 special_tokens_map 中
新增 Special Token 与解码注意事项
- 特别注意:推理引擎解码时,一般会默认会自动跳过所有 Special Token
- 在定义 Special token 时需要非常小心
- 工具调用等场景中,会依赖工具调用相关的 Token 的明文文本做工具解析(例如
<tool_call>等) - 因此需要设置为这部分 Token 为 Regular Token (配置方式为:
tokenizer.json中设置"special": false)
- 工具调用等场景中,会依赖工具调用相关的 Token 的明文文本做工具解析(例如
- 必须设置为 Regular Token 的 Token 有:
- tool 调用回复相关的 Token
- thinking 相关的 Token
新增 Special Token 的初始化
- 新增 Token 的训练可能不太充足,可考虑使用已有 Token 的 embedding 来进行初始化
- 常用方式:使用添加 Token 前的编码 Token(可能为多个)对应的 embedding 均值作为添加 Token 后的 embedding 初始值
- 比如新增
'<think>'作为 Special Token,这个 Token 在原来的场景里面可能是编码为['<', 'think', '>']这三个 Token 的,此时可以使用 这三个 Token embedding 的均值作为新 Token 的 embedding 初始值 - 注:这种方式对于有语义的 Special Token 可能有一定帮助(比如
assistant:或<assistant:>等),但是对于非常特殊的非语义 Token 理论上没有帮助,如ACBD34或<ACBD34>等) - 亲测:这种方法得到的结果可能持平甚至负向,原因是提前保留的
<mask_id_xx>对应的 Embedding 其实已经被训练过了(压低出现的概率),这里替换可能反而会影响结果
- 比如新增
- 初始化流程(以 HF 格式的模型为例):
- 在
model.safetensors.index.json中 找到 embedding 层变量和 LM Head 层变量所在的safetensors文件 - 读取对应文件,检索到对应的 embedding 并修改(注意:一定要两个层的参数都修改)
- 注:可能部分模型上该 embedding 参数和 LM Head 层参数是共享的?
- 在
- 已有模型,修改初始化值的代码示例(一般来说续修改 embedding 层 和 LM Head 层):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 以使用旧 Token ID embedding 的均值初始化为例
from safetensors.torch import load_file, save_file
from transformers import AutoTokenizer
import torch
# 新旧路径加载 Tokenizer
tokenizer_base = AutoTokenizer.from_pretrained('/path_to_old_base_tokenizer/') # 不包含新 Special Token
tokenizer_new = AutoTokenizer.from_pretrained('/path_to_new_tokenizer/') # 包含新 Special Token
# 指定需要修改的文件
# # 对于多文件存储的大模型参数,需要在 model.safetensors.index.json 中找到 Embedding 层参数或者 LM Head 层参数所在的路径
st_path_base = '/path_to_old_base_safetensors/model_xx-of-xx.safetensors' # 随机初始化/原始初始化的模型权重
st_path_new = '/path_to_new_safetensors/model_xx-of-xx.safetensors' # 待写入路径,写入后包含自定义初始化的 embedding 的结果
# 从原来的 safetensors 文件路径读取数据,得到一个字典数据 dict[name, weight]
safetensors_weights = load_file(st_path_base)
# # print weights for debug
# for name, weight in safetensors_weights.items():
# print(name, weight.shape)
# 从上面的打印结果中查找对应的权重名称并抽取出对应的值,也可以写个 for 循环,逐个修改
weight_name = '$LM_Head_name or $Embedding_name'
embedding_layer_weight = safetensors_weights[weight_name]
# 待替换的 Special Token
# # 注意肯定是不存在于 tokenizer_base 中但新定义到 tokenizer_new 中的新 Token
# # 这种 Special Token 使用第一个 tokenizer_base 编码一般是编码为几个 Token 的组合,但使用 tokenizer_new 时一般是编码为一个整体(跟新修改的 ID 对齐)
new_special_tokens = [3,5,18] # 这里只是一个示例,需要修改为自己的;也可以使用 文本而不是 ID,下面的脚本对应修改即可
for new_token_id in new_special_tokens:
token_text = tokenizer_new.decode([new_token_id]) # 抽取原始文本,也可提前定义
old_token_ids = tokenizer_base(token_text).input_ids # 使用旧的 tokenizer 编码新的样本
# print(token_text, new_token_id, old_token_ids) # 可打印看看 Token 对应情况
new_embedding = torch.mean(safetensors_weights[weight_name][old_token_ids], dim=0) # 按照旧 Token ID 检索向量并做平均
# print(new_token_id, "old == new: ", torch.equal(embedding_layer_weight[new_token_id], new_embedding)) # 打印日志,纯新的 Token 不应该相等,旧的则应该相等(因为旧的两者 ID 都只有一个且相同)
safetensors_weights[weight_name][new_token_id] = new_embedding # 核心代码,替换 Token embedding
# 将 safetensors 对象写入新的目标路径
save_file(safetensors_weights, st_path_new)
附录:新增 Special Token 初始化的讨论
- 纯新增的 Special Token 确实可以考虑使用一些特殊的初始化操作,比如使用 Embedding 的均值
- 非纯新增的 Special Token (使用预留的
<mask_1>等转换而来), 理论上在预训练中会被训练到:- 即使
<mask_1>等 token 永远没出现在语料库中,也会参与训练,因为训练时是整个词表参与的,Softmax 保证了每次都会训练到所有 Embedding - 理解:为了压低语料库中不存在的 Token (如
<mask_1>)出现的概率(监督学习目标输出其他正常 Token),也需要学习<mask_1>等 Token 的 Embedding 的
- 即使
- 思考:使用预留的
<mask_1>等转换 Special Token,特别是 Special Token 没有太明确的明文语义时,不应该随便替换 Special Token 的 Embedding- 因为替换后得到的可能是很奇怪的无语义 Embedding,反而丢失了原始
<mask_1>在预训练中学到的 Embedding(这个 Embedding 可以保证这个 Special Token 以较低的概率出现) - 进一步的理解:如果替换 Embedding,也不建议使用原始 Token 文字使用旧 词表编码的结果
- 因为特意设计作为非常特殊用途的,非语义的 Special Token,理论上就是 Special 的,一般来说不应该含有语义(其文本形式应该可以为任意值),这时候使用 旧词表的编码结果来初始化是奇怪的,打破了这种特殊的 Special Token 没有语义的设定
- 因为替换后得到的可能是很奇怪的无语义 Embedding,反而丢失了原始