注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 整体总结:
- PEFT 为定制 LLM/VLLM 以适应下游任务提供了一种高效的解决方案,但当模型规模庞大且任务多样时,其成本仍然很高
- 论文训练了一个参数生成器来映射提示-权重对,可以通过处理未标注的任务提示为新颖任务生成定制化的权重
- 本论文的方法可以在几秒内将未标注的任务提示直接转换为 LoRA 权重更新
- 这种无需进一步微调的提示到权重的范式,为高效定制 LLM 和 VLLM 开辟了一条新的研究方向
- PEFT 方法降低了定制 LLM 的成本,但仍需为每个下游数据集单独运行优化过程
- 注:参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,包括 LoRA(Low-Rank Adaptation),P-tuning 等
- 论文提出了 Drag-and-Drop LLMs(DnD) ,这是一种 prompt-conditioned 参数生成器 ,通过将少量未标注的任务提示直接映射到 LoRA 权重更新,从而消除逐任务(per-task training)的训练
- 一个轻量级文本编码器将每批 Prompt 蒸馏为条件 Embedding ,随后通过级联的超卷积(cascaded hyper-convolutional)解码器将其转换为完整的 LoRA 矩阵集合
- 在多样化的 prompt-checkpoint 对上进行训练后,DnD 能在几秒内生成任务特定的参数,实现以下优势:
- 1)相比全参数微调,开销降低高达 12,000 倍;
- 2)在未见过的常识推理、数学、编程和多模态基准测试中,平均性能比最强的训练 LoRA 提升高达 30%
- 3)即使从未见过目标数据或标签,也能实现强大的跨领域泛化能力
- 论文的结果表明,prompt-conditioned 参数生成是一种可行的替代梯度下降适配的方法,能够快速定制 LLM
Introduction and Discussion
- GPT-4、Llama 2/3、Qwen2.5 和 DeepSeek 等 LLMs 凭借其互联网规模的预训练和 Transformer 架构,迅速成为当代自然语言处理乃至更广泛人工智能领域的核心 (2021; 2024; 2025; 2024)
- 这种预训练使单个模型在数学、编程、推理甚至多模态理解方面具备广泛的 零样本(Zero-Shot) 能力 (2023; 2021; 2022; 2021)
- 然而,实际部署很少止步于零样本使用,而是需要反映内部数据、领域术语或定制响应风格的任务特定行为
- 参数高效微调(PEFT)旨在通过插入一小部分可训练权重(最突出的是 LoRA 的低秩适配器)来满足这一需求 (2022)
- 尽管 LoRA 通过冻结模型参数保持可训练参数和存储开销较小,但其实际时间成本仍然很高:
- 例如,使用 LoRA 适配最轻量的 0.5B 参数 Qwen2.5 仍需占用 4 块 A100 GPU 半天时间 (2024)
- 此外,每个下游用户或数据集都需要独立的优化运行,这在 PEFT 大规模部署时迅速成为计算瓶颈
- 论文观察到,LoRA 适配器仅仅是其训练数据的函数 :梯度下降将基础权重“拖拽(drags)”至任务特定最优值(图 1)
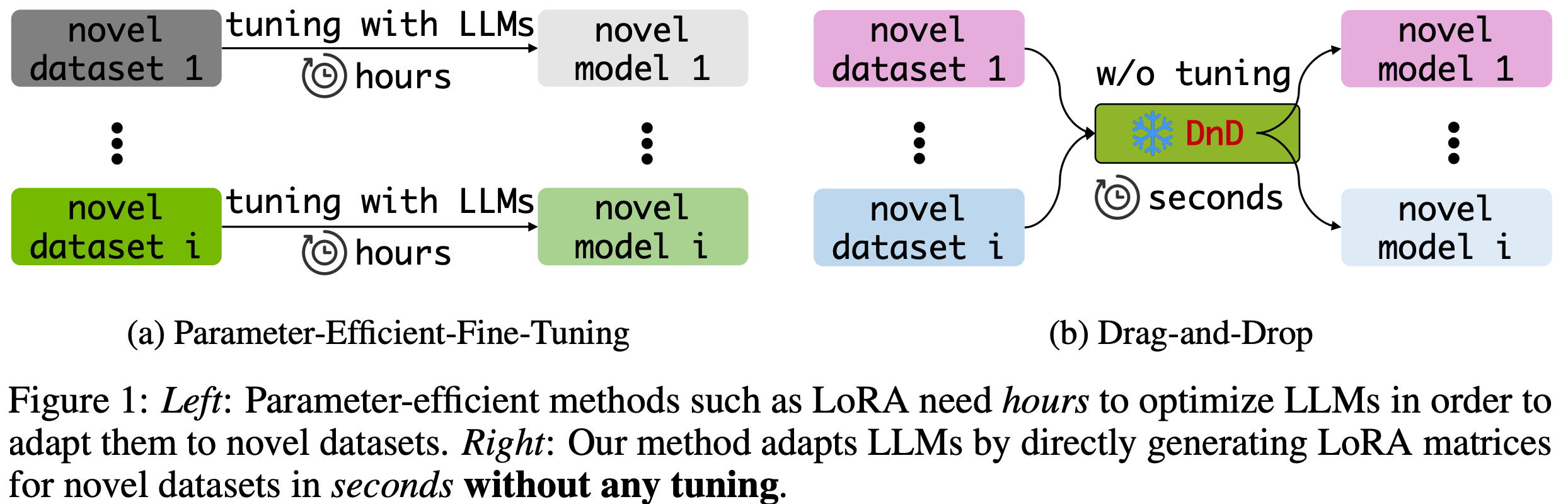
- 如果能直接学习从提示到权重的映射,就可以完全绕过梯度下降
- 早期的参数生成研究表明,超网络可以在几分钟内合成数十亿参数 (2022; 2022; 2024; 2024; 2024),但它们要么忽略任务条件,要么使用简单的二元嵌入
- 近期的进展使这一目标成为可能
- RPG(2025)是最早基于任务信息进行条件生成(并在单次传递中生成整个分类器)的方法之一
- 该方法在零样本情况下对未见过的图像类别达到了与从头训练相当的效果,但将这种成功迁移到语言领域带来了新的挑战
- 首先,语言提示比 RPG 中使用的二进制嵌入具有更高数量级的语义变化
- 因此,一个实用的生成器必须能够接收丰富的任务描述并保留其细微差别
- 其次,实际应用中的 LLM 可能面临数百种异构工作负载(heterogeneous workloads),因此条件机制必须能够优雅地扩展,同时以高保真度注入特定于任务的线索
- 问题:这里的异构工作负载是指什么?
- 首先,语言提示比 RPG 中使用的二进制嵌入具有更高数量级的语义变化
- 这些挑战催生了对一种紧凑而富有表现力的表示的需求,这种表示既要能捕捉输入文本的显著特征,又要能引导超网络走向 LoRA 权重空间的相应区域
- 论文接下来介绍的方法正是为解决这一核心挑战而设计的
- 论文提出了 Drag-and-Drop LLMs(DnD) ,这是一种基于提示条件的超生成器(hyper-generator),能够在几秒钟内将少量未标记的任务提示转换为完整的 LoRA 适配器 ,消除了任何特定于任务的优化
- DnD 采用现成的轻量级文本编码器 ,将给定的提示批次压缩为条件 Embedding ,然后通过级联超卷积解码器将其扩展为每个 transformer 层的 LoRA 更新
- 在常识推理、数学、代码生成和多模态基准测试中,DnD 将适配开销降低了高达 12,000 倍,同时与最强的训练 LoRA 相比,在未见过的数据集上性能提升高达 30%,并且能够从 0.5B 参数无缝迁移到 7B 参数的骨干模型
- 通过将经典的“data -> gradients -> weights”循环压缩为单个前向步骤,DnD 挑战了梯度下降对于模型特化不可或缺的观念,并开辟了一条新的道路,其中权重本身成为一种新的数据模态和基于简洁任务描述的生成目标
- 论文的主要贡献如下:
- 提出新的 LLM 适配范式 :论文将 LoRA 适配视为从新数据集的原始提示直接生成特定于任务的权重,并通过可扩展的超生成器实现这种映射,这比传统调优效率高得多
- 设计了实用架构 :一个冻结的文本编码器与超卷积解码器相结合,能够生成大规模参数,同时将适配开销降低四个数量级
- 完成了全面评估 :在推理、数学、编码和多模态任务上的实验显示,在未见过的数据集上零样本性能提升高达 30%,并且在不同模型大小之间实现平滑迁移,突出了 DnD 令人印象深刻的效率和多功能性
Drag-and-Drop Your LLMs
Preliminary
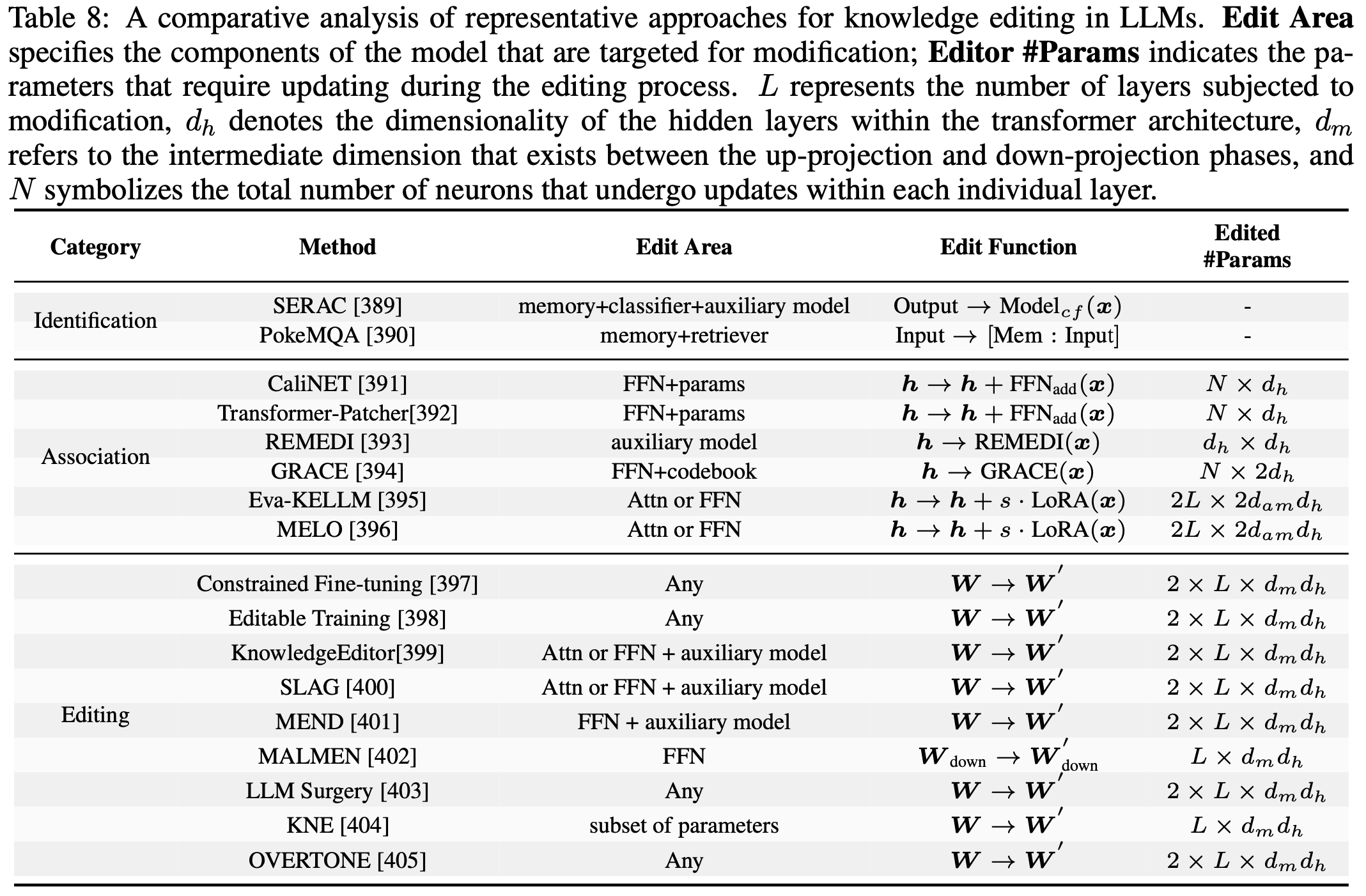
- 参数高效微调(Parameter-Efficient Fine-Tuning) :参数高效微调(PEFT)通过仅引入和调整少量额外参数,同时冻结原始模型权重来节省训练成本
- 这种方法已应用于 LLM 和其他基础模型,尤其是以低秩适应(LoRA)形式,例如 LLaMA (2024) 和 Stable Diffusion (2022)
- 其优化过程可表示为:
$$
\min_{A,B}\mathcal{L}(W_0 + BA, \mathcal{D}), \tag{1}
$$- 其中 \( W_0 \) 是冻结的原始权重矩阵
- 低秩矩阵 \( B \in \mathbb{R}^{d \times r} \) 和 \( A \in \mathbb{R}^{r \times k} \)(\( r \ll \min(d,k) \))是唯一的可训练参数
- \( \mathcal{D} \) 表示微调数据集
- 根据公式 1,LoRA 使用数据 \( \mathcal{D} \) 作为原材料,通过优化驱动获得权重空间偏移 \( \Delta W = BA \),从而使 \( \Delta W \) 与 \( \mathcal{D} \) 强关联
- 参数生成(Parameter generation) :这种方法将模型或训练权重视为数据,旨在无需传统训练即可合成高性能神经网络参数
- 近期进展如 COND P-DIFF (2024)、RPG (2024)、SANE (2024) 和 ORAL (2025) 通过引入条件机制实现了可控生成,允许为简单数据集生成初步个性化参数
- 参数生成过程与 PEFT 有根本共性:条件作为原材料,参数生成器提供驱动力以生成具有特定属性的目标权重
- 一个问题仍然存在:论文能否利用参数生成有效地“拖放(drag-and-drop)”LLM 的权重,使其更适合给定的新任务?
- 通过“拖放(drag-and-drop)”,论文类比于一种简单、无需调优的过程,直接生成任务特定权重 ,类似于无需进一步配置即可将文件拖放至目标位置
- 关键挑战(Key challenges) :在回答上述问题前,论文分析潜在挑战:
- 挑战 1 :如何为参数生成器配备有效的“拖放”能力?
- 生成器应生成能有效使 LLM 适应特定任务的参数
- 挑战 2 :如何在不进行任务特定训练的情况下实现适配?
- 传统 PEFT 方法通常需要在新任务上训练,但论文能否通过直接生成参数而无需目标任务的任何微调来达到可比性能?
- 挑战 3 :如何使拖放功能用户友好且易于访问?
- 生成机制应简单直观,以促进广泛采用和实际部署
- 挑战 1 :如何为参数生成器配备有效的“拖放”能力?
Overview of DnD
- 为解决上述挑战,论文提出如图 2 所示的 DnD
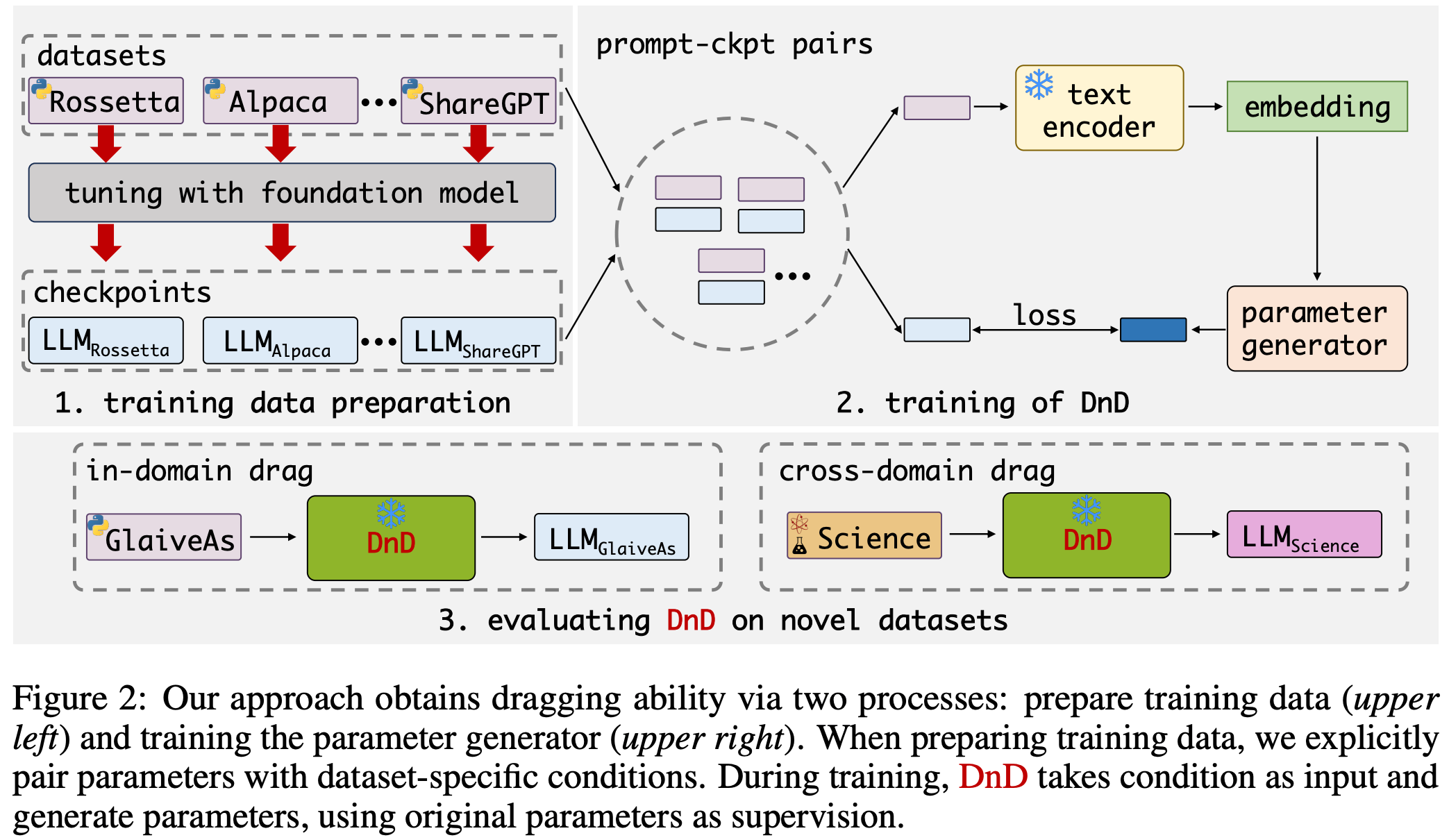
- training data preparation :
- 作为准备,论文首先在各种数据集上训练并保存 LoRA 适配器
- training of DnD :
- 为开发“拖放”能力,论文的方法应了解参数与数据集的关联
- 因此,论文随机将收集的检查点与其训练数据中的提示批次配对
- 问题:为什么是随机配对?
- 回答:真实 label 应该是严格对齐数据和 checkpoint 的,这里指的随机不是随便做不相关的组合,而是对一个模型 checkpoint,随机采样采样训练出该模型的数据中的某些 Prompt 样本,这里的核心是保证模型一定时由对应的数据训练出来的
- 预训练的文本编码器从提示中提取嵌入,并将其馈送至论文的参数生成器
- 生成器采用级联纯卷积解码器块的简单架构(详见第 2.5 节和附录 A.3)
- 论文使用生成参数与原始 tokenized 模型权重之间的均方误差(MSE)损失优化生成器
- 注:这里是指让生成参数尽量能拟合原始 tokenized 模型权重
- 在推理时,论文在领域内和跨领域场景中评估方法:
- 只需将新数据集(训练中未见)的提示输入 DnD,即可通过单次前向传递获得定制模型参数
Data Preparation of DnD
- 检查点收集(Checkpoint collection) :论文收集跨数据集的检查点作为多样化监督,以赋予 DnD 能力
- 收集过程遵循先前的参数生成工作 (2024; 2024):训练指定周期,随后在每次迭代时保存检查点(更多细节见附录 A.1)
- 提示的作用(The role of prompts) :近期研究 (2025; 2024) 表明,不同数据集的样本表现出独特特征,即样本可视为特定数据集(任务)的“指纹”
- 基于此观察,论文使用数据样本(提示)作为其各自数据集(任务)的代理
- 为建立数据-参数映射,论文结合用于训练这些检查点的数据集中的提示
- 这些提示包含数据集特定特征,使生成器能够推断不同任务中模型的适当“拖拽”方向
- 提示-检查点配对(Prompt-checkpoint pairing) :基于上述分析,下一个重要问题是:如何利用这些元素在训练中为 DnD 配备“拖放”能力?
- 给定数据集 \( P \),论文首先将其划分为不重叠的提示批次 \([p_1, \cdots, p_i, \cdots, p_I]\)。该数据集训练后的 LLM 检查点记为 \( M = [m_1, \cdots, m_j, \cdots, m_J] \)。论文随机选取一批提示和对应的检查点。该过程可形式化为:
$$
[p_1, \cdots, p_i, \cdots, p_I] \xrightarrow{\text{随机选取} } \{p_i, m_j\} \xleftarrow{\text{随机选取} } [m_1, \cdots, m_j, \cdots, m_J], \tag{2}
$$- 其中 \(\{p_i, m_j\}\) 作为参数生成器训练的配对。提示 \( p_i \) 和检查点 \( m_j \) 分别作为输入和监督
- 给定数据集 \( P \),论文首先将其划分为不重叠的提示批次 \([p_1, \cdots, p_i, \cdots, p_I]\)。该数据集训练后的 LLM 检查点记为 \( M = [m_1, \cdots, m_j, \cdots, m_J] \)。论文随机选取一批提示和对应的检查点。该过程可形式化为:
Prompt Embedding
- 对于每批提示,论文使用开源文本编码器提取嵌入作为参数生成器的输入。提取过程可形式化表示为:
$$
c_i = \operatorname{Encoder}(p_i, \theta), \tag{3}
$$- 其中 \(\operatorname{Encoder}(\cdot, \cdot)\) 表示由 \( \theta \) 参数化的嵌入提取函数,\( c_i \) 表示与提示 \( p_i \) 对应的提取嵌入
- 默认情况下,论文采用基于编码器的语言模型架构 (2019) 进行提示嵌入
- 在实验部分,论文进一步探索并定量评估其他嵌入方法,包括 word2vec 表示 (2014)、编码器-解码器架构 (2020) 和解码器专用语言模型 (2024)
Training and Inference of DnD
Structure of parameter generator
- 与基于扩散的参数生成方法(2024, 2024, 2025)不同,论文采用超卷积解码器(hyper-convolutional decoder)来学习输入提示与参数之间的映射
- 这种设计主要考虑了效率,因为 Decoder-only 结构在 LLM 中已显示出其优越性(2023, 2024, 2024, 2025)
- 论文在右侧部分(图 3)展示了解码器的模块细节

- 论文假设输入提示嵌入的维度为 \([B, N, L, C]\),其中 \(B\)、\(N\)、\(L\) 和 \(C\) 分别表示批大小(batch size)、提示批长度(即提示数量)、序列长度(sequence length)和隐藏维度(hidden dimension)
- 级联卷积块(cascaded convolutional blocks)将提示嵌入转换为与 tokenized 权重相匹配的维度
- 这里,论文将最后一个块的输出记为 \([B, N_w, L_w, C_w]\)
Learning objective
- 学习目标很简单:论文计算参数生成器最后一个块的输出与相应的 tokenized 检查点(checkpoint)之间的均方误差(Mean Squared Error, MSE)损失
- 与 RPG(2025)类似,论文将每一层的参数 tokenized 为非重叠的片段并进行填充,确保检查点具有一致的形状 \([B, N_w, L_w, C_w]\)
- 形式上,论文将均方误差损失写为:
$$
\text{prompt embeddings} \xrightarrow{\text{parameter generator} } L_{MSE} \xleftarrow{\text{tokenization} } \text{corresponding checkpoints}. \tag{4}
$$
Inference
- 论文期望参数生成器开发有效的“拖放”能力,尤其是对训练中未见过的新数据集或任务
- 因此,评估主要关注新数据集的性能
- 推理过程包括四个步骤:
- 1) 从新数据集中采样提示;
- 2) 从这些提示中提取嵌入;
- 3) 将嵌入输入参数生成器;
- 4) 在新数据集上评估生成的参数
- 为全面展示方法的“拖放”能力,论文检查领域内(如常识到常识)和跨领域(如常识到科学)场景的性能
Experiments
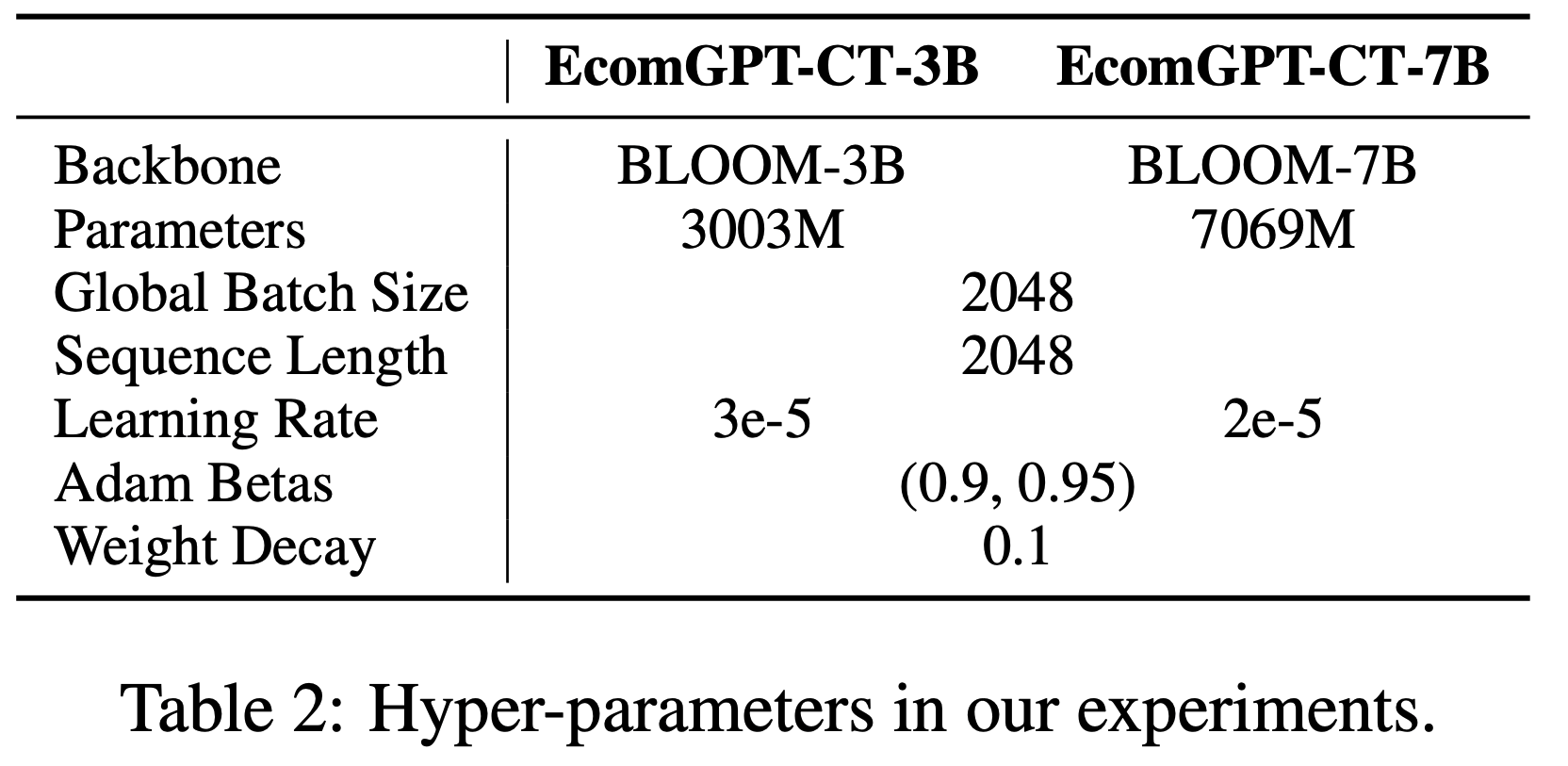
Implementation details
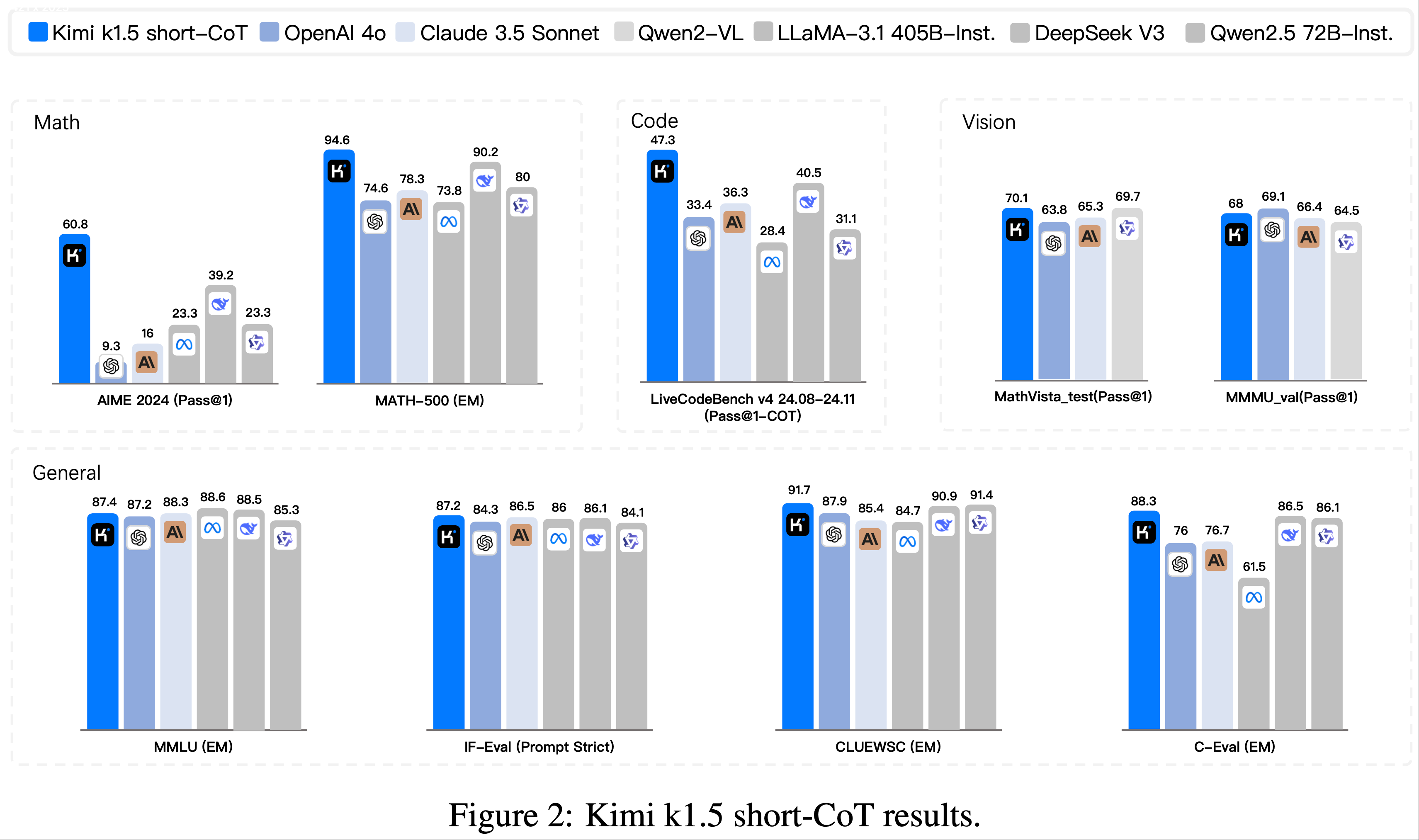
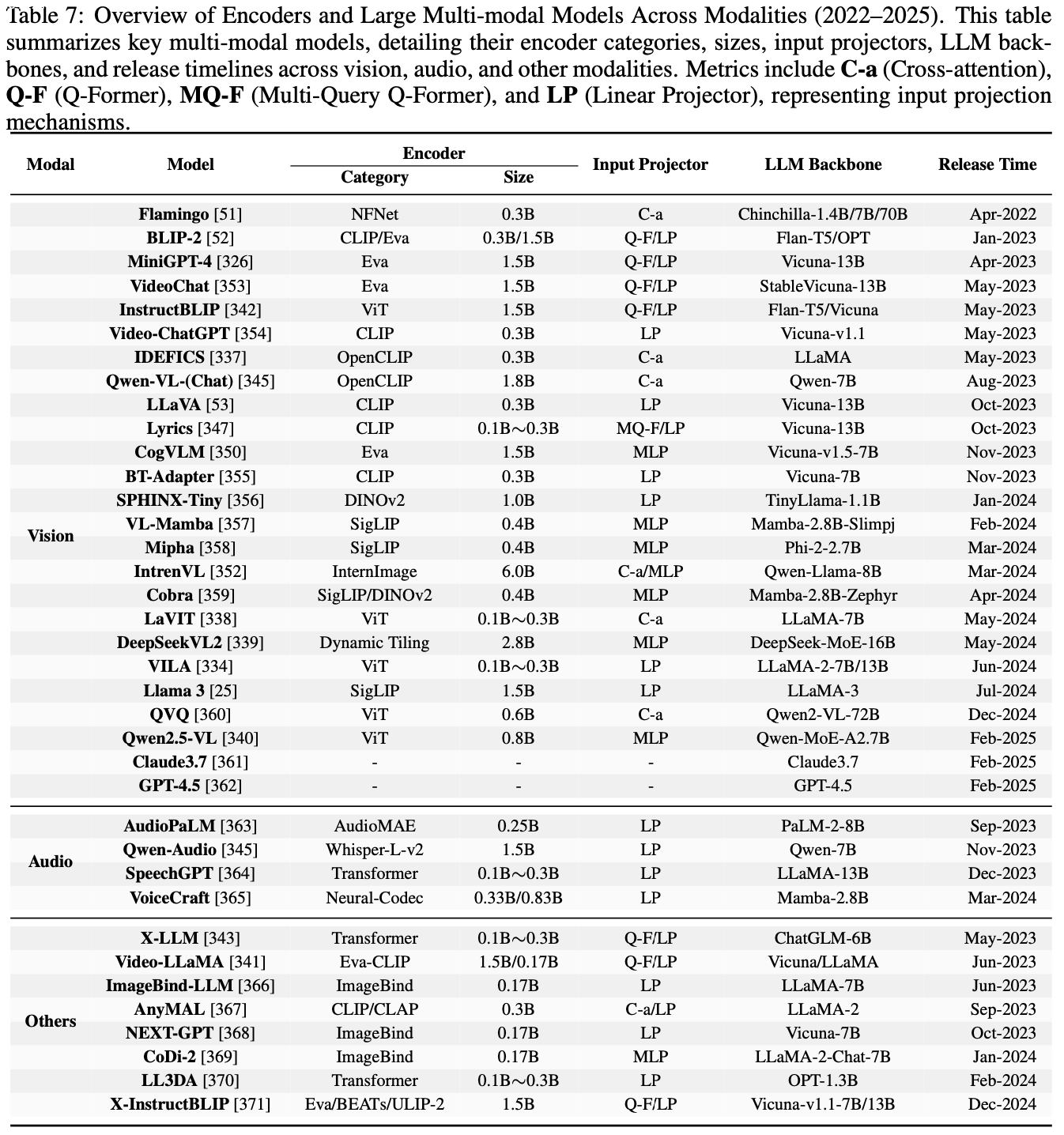
- 论文选择 Qwen2.5 (2024) 系列作为基础模型,并在常识推理、代码生成、数学和多模态任务上进行实验
- 下表列出了每个任务涉及的模型规模和数据集详情

- 默认的文本编码器为 Sentence-BERT (2019),提示批次的长度在常识推理、数学、代码生成和多模态任务中分别设置为 128、64、64 和 32
- 其他超参数设置请参考附录 A.1
Common Sense Reasoning
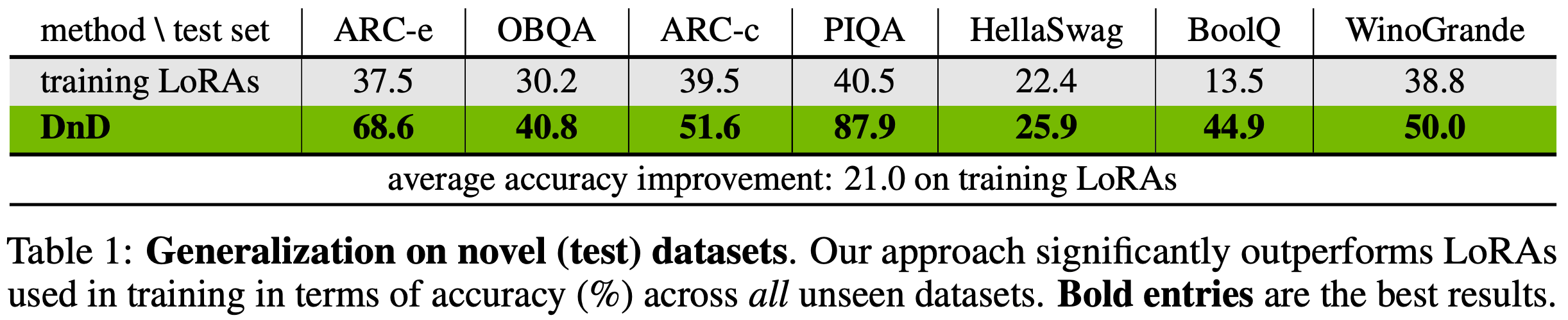
- 评估设置 (Evaluating setting) :论文使用 LoRA (2022) 在七个常识推理数据集上微调 Qwen2.5-0.5B,并将检查点保存为训练数据
- 在表 1 的每一列中,论文将指定数据集作为测试集(即不用于训练),并在其他数据集的 LoRA 上训练 DnD
- 在表 1 的每一列中,论文将指定数据集作为测试集(即不用于训练),并在其他数据集的 LoRA 上训练 DnD
- 分析 (Analysis) :表 1 报告了训练 LoRA 和生成 LoRA 的平均准确率。从结果中可以看出以下几点:
- 1) 论文的方法在未见数据集上始终优于用于训练的 LoRA,表明它能够通过条件将 LLM 参数“拖放”到任务特定的分布中
- 2) 这种“拖放”能力在不同数据集上均成立,显示出对各种数据输入的强鲁棒性
- 跨领域拖放 (Cross-domain Drag-and-Drop) :为了进一步探索 DnD 的零样本能力,论文不仅在推理中使用领域内未见数据集,还将其在科学数据集 (2023) 上测试
- 生成的参数与科学数据集上的训练 LoRA 进行比较
- 从表 2 可以看出,DnD 超越了其训练 LoRA 的平均准确率,表明论文的方法能够将 LLM 参数“拖放”到跨领域任务(即从常识推理到科学任务)

Generalization to Coding, Math, and Multimodal Tasks
- 为了验证论文的方法在更复杂场景中的适用性,论文还将 DnD 应用于代码生成、数学和多模态任务。实验结果和发现如下
- 代码生成 (Coding) :
- 与常识推理任务类似,论文在七个代码数据集上使用 LoRA 微调 Qwen2.5-1.5B,并将检查点保存为训练数据
- 评估在 HumanEval (2021) 基准上进行,使用 pass@k (2021) 分数(k = 1, 5, 10)
- 需要注意的是,无论是 LoRA 微调模型还是 DnD,在训练中均未见过该基准的任何样本
- 因此,论文直接在 HumanEval 上测试训练 LoRA 和生成的 LoRA。从表 3 可以得出以下结论:
- 1)论文的方法取得了显著结果,平均 pass@1 = 15.1,pass@5 = 26.7,pass@10 = 30.9
- 2)尽管训练 LoRA 在测试集上表现不佳,DnD 仍然获得了良好的性能
- 这表明它并非简单地记忆训练中见过的参数,而是学会了根据条件为未见数据集生成适配的参数
- 数学 (Math) :论文在六个数学数据集上微调 Qwen2.5-1.5B 并保存检查点
- 采用 gsm8K (2021) 和 MATH (2021) 作为基准,以准确率为评估指标
- 表 3 中的结果与常识推理和代码任务的结果一致,凸显了论文的方法在广泛场景中的优越性

- 多模态 (Multimodal) :上述结果验证了论文的方法在文本模态中的有效性,接下来,论文探索其更广泛的潜力,将其扩展到其他模态
- 论文在 MathV360K (2024) 上微调 Qwen2.5-VL-3B (2025),保存检查点,并使用 Math-Vision (2024) 和 Math-Vista (2024) 进行评估
- 表 3 的结果显示,DnD 在多模态任务中表现良好,表明论文的方法可以适配文本以外的模态,并具有广阔的应用潜力
- 总结 (Takeaway) :基于上述结果和比较,DnD 是一个高性能的零样本学习器,具有强鲁棒性和广泛适用性,这体现在其相对于训练数据的显著改进以及在各种场景中的优异表现
- 接下来,论文将继续探索论文提出的方法的更多有趣特性
Ablation Studies
- 本节主要探索论文方法的一系列有趣特性
- 对于实验中涉及的不同设置,论文将在附录 B.3 中详细报告
- 除非特别说明,论文使用 ARC-c 作为测试集,其他常识推理数据集用于训练
What types of data will help Drag-and-Drop LLMs better?
- 如第 2.3 节所述,论文使用提示作为条件来驱动 DnD
- 当条件类型变化时(例如答案),这种“拖放”能力是否仍然有效?
- 论文通过将条件类型更改为提示(Prompt)、提示 + 答案(Prompt + Answer)及其混合(Mix)(提示 : 答案 = 4 : 1)进行消融研究,结果如表 4a 所示

- 可以观察到,提示 + 答案组的性能出人意料地较差
- 作者得出结论,这是因为常识推理数据集中的答案缺乏多样性(例如 A/B/C/D),将其与提示结合可能会损害数据集特定的表示
- 这会阻碍生成器区分不同数据集并生成特定参数
- 因此,论文建议不要单独使用答案作为条件
- 然而,对于答案更复杂和多样化的任务,结论可能不同 ,论文在附录 B.3 中展示了这些任务的结果
How does the choice of condition extractor affect DnD’s performance?(condition extractor 的影响)
- 论文的默认条件提取器是 Sentence-BERT (2019),但探索其他模型的潜力也很有趣
- 为了确保全面比较,论文包括经典的 word2vec 方法 Glove (2014)、默认的仅编码器 Sentence-BERT (2019)、编码器-解码器模型 T5 (2020) 和 Decoder-only Qwen2.5-7B (2024)
- 表 4b 的结果揭示了以下几点:
- 1)即使是 Glove 等传统方法也能帮助 DnD 获得良好的结果,表明论文的方法可以适配多种文本编码器
- 2)Qwen2.5-7B 的表现不如预期,可能有两个原因:
- 首先,其庞大的规模限制了每次迭代中与参数配对的条件数量,导致对未见数据集的感知能力较差(类似结论可以从附录 B.3 的实验中得到)
- 其次,Qwen2.5-7B 的 Decoder-only 架构可能会限制条件的多样性,因为它将提示编码为答案
What property of training data equips our method with drag-and-drop ability?(哪些 Training 数据属性赋予论文的方法“拖放”能力?)
- 默认情况下,论文在多个数据集上训练并在 1 个未见数据集上测试
- 本节通过减少训练集数量并在更多数据集上测试来探索 DnD 的鲁棒性
- 训练-测试集安排为:6-1、4-3、3-4 和 2-5
- 生成的参数与训练 LoRA 在未见数据集上的平均准确率进行比较,并报告其平均准确率提升(表 4c)
- 可以观察到:
- 1)通常情况下,更多的训练数据集会带来更好的性能提升
- 这是预期的,因为更多数据确保了条件-参数关联的更好覆盖,从而为未见数据带来更好的鲁棒性
- 2)当训练样本较少时,DnD 无法将 LLM 参数“拖放”到未见数据集
- 随着用于训练的数据集减少,DnD 的平均提升也相应下降
- 在 2-5 的情况下,它几乎无法超越训练 LoRA
- 我们可以得出结论,DnD 需要基本的训练样本量来学习条件-参数关联
- 1)通常情况下,更多的训练数据集会带来更好的性能提升
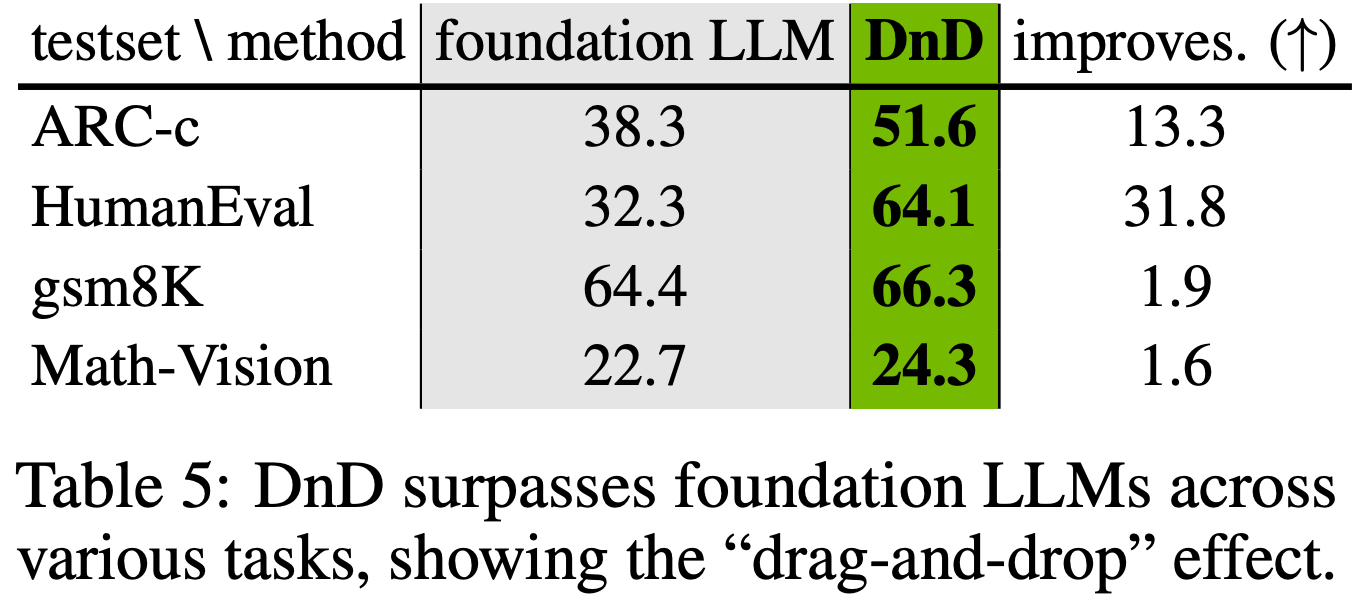
How does DnD’s performance compared with foundation LLMs?
- 考虑到大规模预训练 LLM 通常需要大量计算,在小规模下游数据集上微调可能会损害其在未见测试集上的零样本性能
- 意识到这一现象后,论文在所有实验任务中将 DnD 生成的权重性能与基础 LLM 进行比较
- 理解:即比较实用 DnD 后,基础模型效果能提升多少
- 具体来说,对于基础 LLM,论文采用 Qwen2.5-0.5B 进行常识推理,1.5B 进行数学和代码生成,Qwen2.5-VL-3B 进行多模态任务
- 表 5 的结果再次显示了论文方法的优越性:
- DnD 在所有任务中均优于基础 LLM。其“拖放”能力可以生成任务特定的参数,性能优于经过大量预训练的基础 LLM
- DnD 在所有任务中均优于基础 LLM。其“拖放”能力可以生成任务特定的参数,性能优于经过大量预训练的基础 LLM
Open Explorations and Analysis
Condition-Parameter Pairing
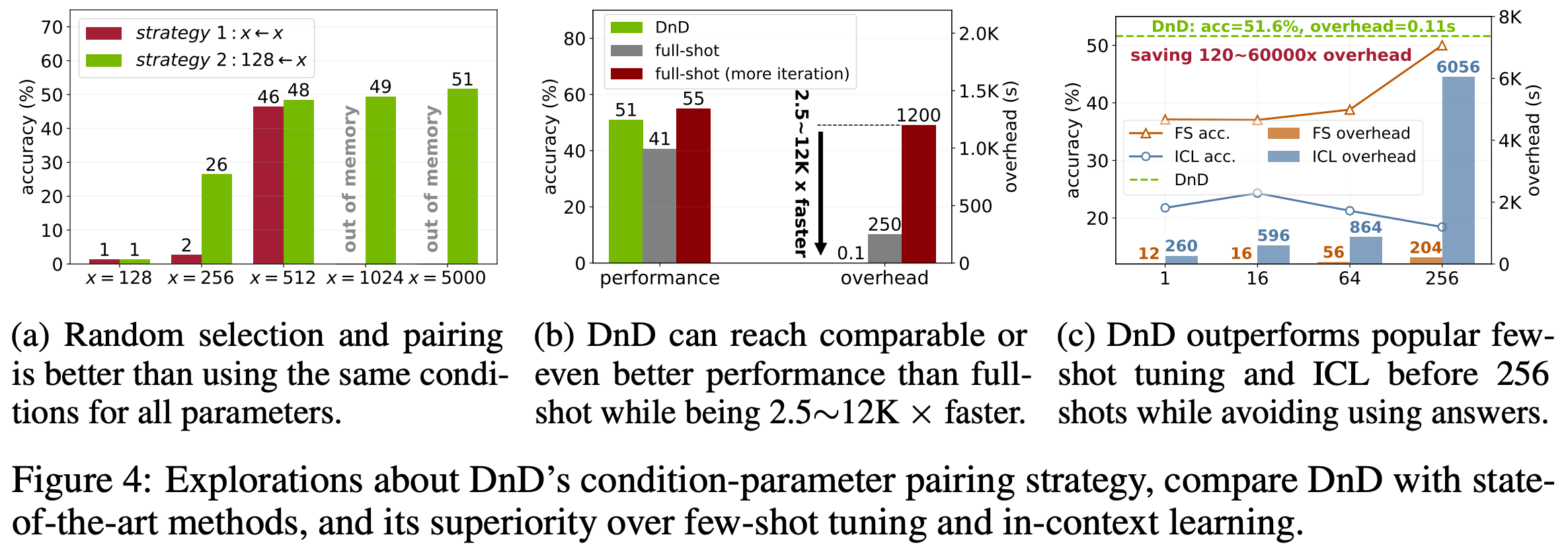
- 本节探索第 2.3 节中介绍的其他配对策略对性能的影响。论文测试了两种条件配对策略:
- 策略 1 :固定提示总数为 128、256、512、1024、2048、5000,并在每次迭代中使用所有这些提示与参数配对(\(x \gets x\))
- 策略 2 :固定每次迭代中提示批次的长度为 128,并从 128、256、512、1024、2048、5000 候选提示中随机选择这些提示(128 \(\gets x\))
- 基于图 4a 的结果,我们可以得出以下结论:
- 1)在条件数量有限的情况下,DnD 无法泛化到未见数据,因为它几乎无法学习关于条件-参数映射的全面知识
- 2)随着条件数量的增加,策略 2 的性能迅速提升,因为 DnD 暴露于足够多的条件-参数对中。这表明策略 2 可能有助于 DnD 高效收敛
- 3)策略 1 需要更多条件才能达到与策略 2 相当的性能。在条件数量较多时,策略 1 会遇到内存不足的问题。每次迭代中相同条件与参数的配对可能会阻碍 DnD 将条件与特定数据集关联。综上所述,策略 2 在模型泛化性、收敛速度和内存消耗方面均优于 策略 1。这些结论与表 4c 的发现一致:训练数据的多样性赋予论文的方法“拖放”能力
DnD vs full-shot tuning
- 本节在准确率和开销方面将 DnD 与全量微调(full-shot tuning)进行比较
- 具体来说,论文测试了 ARC-c 微调的 LoRA(约 75 次迭代,详见附录 A.4)在 ARC-c 测试集上的全量性能
- 由于 LoRA 的性能可能随着迭代次数的增加而提升,论文还在 ARC-c 上微调 LoRA 300 次迭代并测试其性能
- 这些结果与 零样本 DnD 的结果在图 4b 中进行了比较:
- 1)使用适度微调的检查点进行训练时,DnD 已经取得了比全量微调更好的结果。这展示了 DnD 令人印象深刻的 零样本 能力,甚至超越了 全量微调
- 2)DnD 的效率极高,性能优于全量微调的同时,速度提升了 2500 倍
- 此外,随着训练的继续,尽管全量微调表现更好,但论文的方法与其性能差距极小,同时效率提升了 12,000 倍
- 理解:
- 仅训练一轮的 全参数微调效果不如 DnD
- 训练很多轮的 全参数微调效果比 DnD 好,但没有好很多
- 注:DnD 的速度极快,且比仅训练一轮的全参数微调效果好很多
Efficiency analysis of DnD
- 除了全量微调外,上下文学习(in-context learning,ICL) 和少样本微调(few-shot tuning,FS) 也是 LLM 微调中的流行方法
- 在图 4c 中,论文通过实验研究了它们的性能-效率权衡。可以得出以下几点观察:
- 1) 当样本较少时,ICL 和 FS 的结果较差,但随着样本增加,它们的开销也会上升
- 2) DnD 在样本数达到 256 之前,能以可忽略的开销获得比 FS 和 ICL 更好的性能
- 3) 值得注意的是,少样本和 ICL 都使用答案来指导 LLM 以获得更好的性能。相反,DnD 仅依赖 128 个未标注的提示。基于上述结果,论文预计 DnD 是一个强大且高效的零样本学习器
Scalability of DnD
- 本节探索 DnD 的可扩展性
- 由于常识推理任务较为简单,0.5B 模型已足够,论文专注于数学和代码生成任务,同时将基础模型规模从 1.5B 增加到 7B
- 论文使用第 3.3 节中的原始数学和代码数据集,数学任务使用 gsm8K 进行评估,代码任务使用更难的基准 LiveCodeBench (2024) 进行评估
- 论文在表 6 中报告了数学任务的准确率和代码任务的 pass@1。可以观察到:
- 1)在 7B 模型设置下,DnD 在两个任务中始终优于训练 LoRA,突显了其对更大基础 LLM 的卓越可扩展性
- 2)在更难的代码基准上,DnD 保持了优于训练 LoRA 的性能,即平均 pass@1 提升 = 20.3。这表明 DnD 能够泛化到更复杂的基准,显示出广阔的应用潜力和鲁棒性

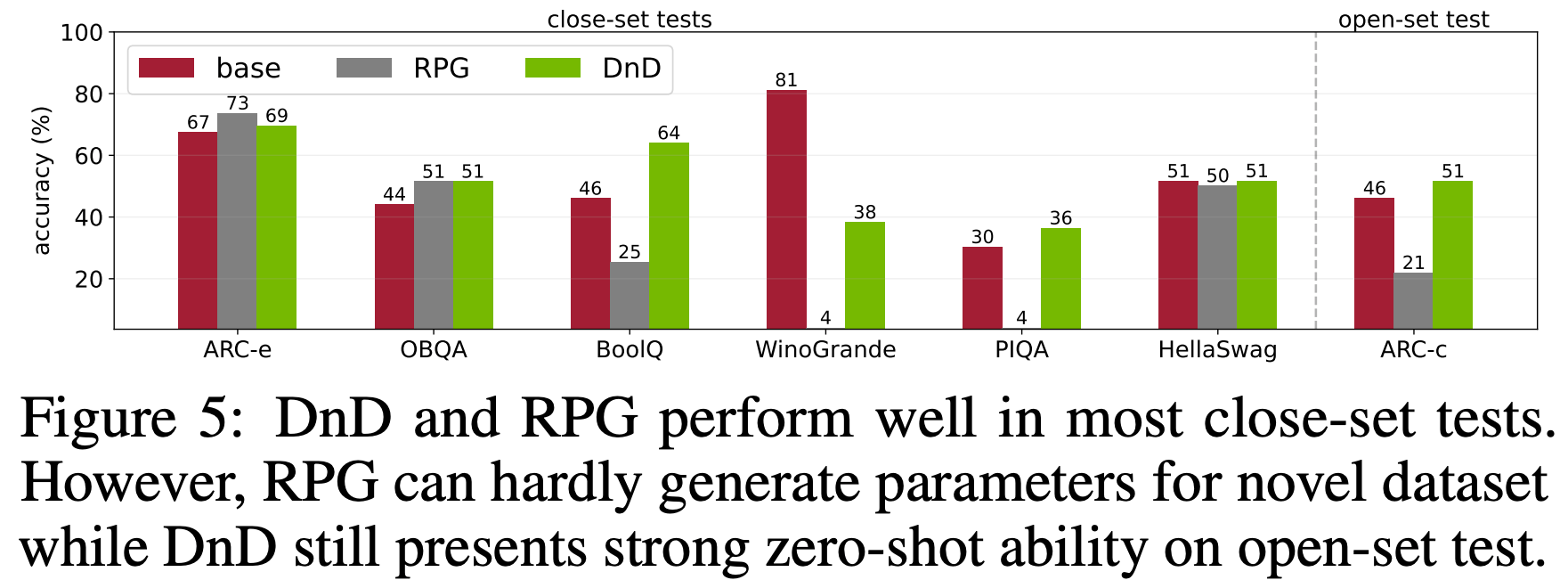
Comparisons with previous methods
- 论文将论文的方法与最新的参数生成方法 RPG (2025) 进行比较。论文在两种场景中探索两种方法的性能:
- 闭集生成:生成训练中见过的参数
- 开集生成:为未见数据集生成参数
- 图 5 显示两种方法在闭集生成中表现良好,但 RPG 在开集生成中失败,表明论文的设计(以提示为条件,条件-参数配对)对未见数据集具有一定的鲁棒性和泛化性
Visualization for the effect of drag-and-drop
- 本节在图 6 中可视化原始参数和生成参数
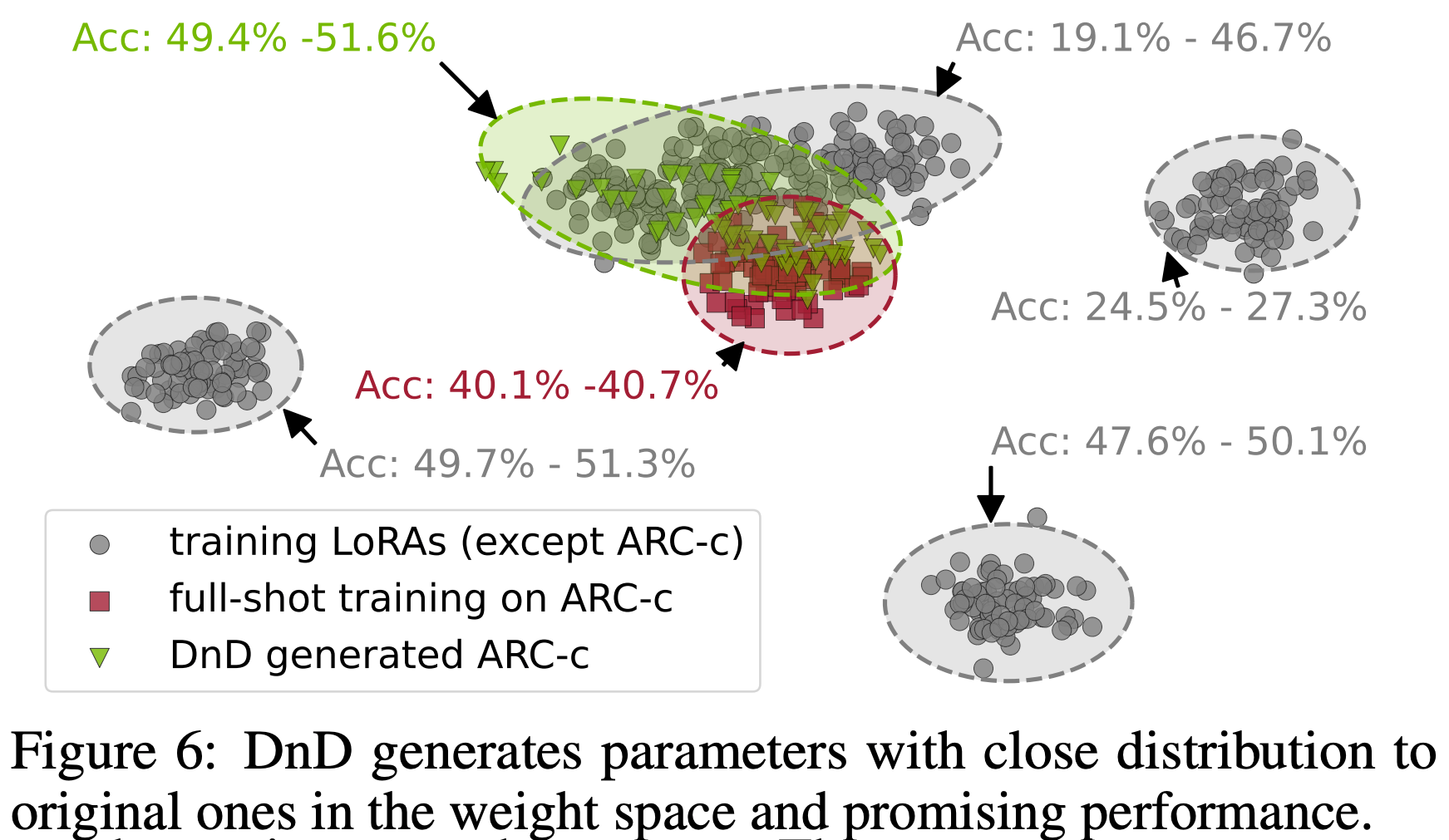
- 可以看出,原始参数在权重空间中表现出多样化的模式,形成不同的簇
- 此外,即使接近目标数据集(即 ARC-c)微调的参数,也可能存在较大的性能差距(即 19.1% 对比 40.7%)
- 在训练了这些具有不同特征的模型后,DnD 能够以零样本方式为目标数据集生成参数
- 生成的参数在权重空间中接近原始参数,甚至性能优于全量微调(即 51.6% 对比 40.7%)。这生动地展现了“拖放”效果
Related Works
Parameter-Efficient-Fine-Tuning (PEFT)
- LLM 的规模迅速扩大,使得全参数微调成本越来越高
- 为了解决这一问题,低秩适应(LoRA)(2022) 被提出,利用 LLM 固有的稀疏性,通过优化两个低秩矩阵而非原始权重,大幅降低了微调成本
- 随后出现了多种 LoRA 变体,如 DoRA (2024)、LoRA+ (2024)、VeRA (2024) 和 DyLoRA (2023)
- 但它们都有一个潜在缺陷:需要对每个新数据集进行模型参数微调,因此缺乏通用性
- 随着模型规模的扩大和训练数据的增加,这仍然会带来额外的成本
Parameter generation
- 参数生成以模型检查点为训练目标,旨在生成高性能参数,包括训练中见过和未见的数据集
- 先前的工作 (2016; 2011; 2013; 2016) 专注于学习参数分布,但难以重建原始模型的性能
- 随着扩散模型的发展,超表示 (2022; 2022; 2024) 和 p-diff (2024) 使用潜在扩散架构生成高性能参数
- 借助 Mamba (2024) 和适当的标记化策略,RPG (2025) 可以在几分钟内生成 2 亿参数
- 关于条件生成,COND P-DIFF (2024)、Tina (2024) 和 ORAL (2025) 探索了文本控制的参数生成方法
- RPG 甚至在 CIFAR-10 (2009) 的二元嵌入分类任务上为未见数据集生成参数
- 但这些方法在更复杂的任务上难以保持优异的零样本能力,阻碍了参数生成更广阔的应用潜力
- 本论文的方法以未见数据集中的提示为条件,更好地捕捉参数与数据集的关联,能够为未见数据集生成有效的参数
附录
- 详情见原文
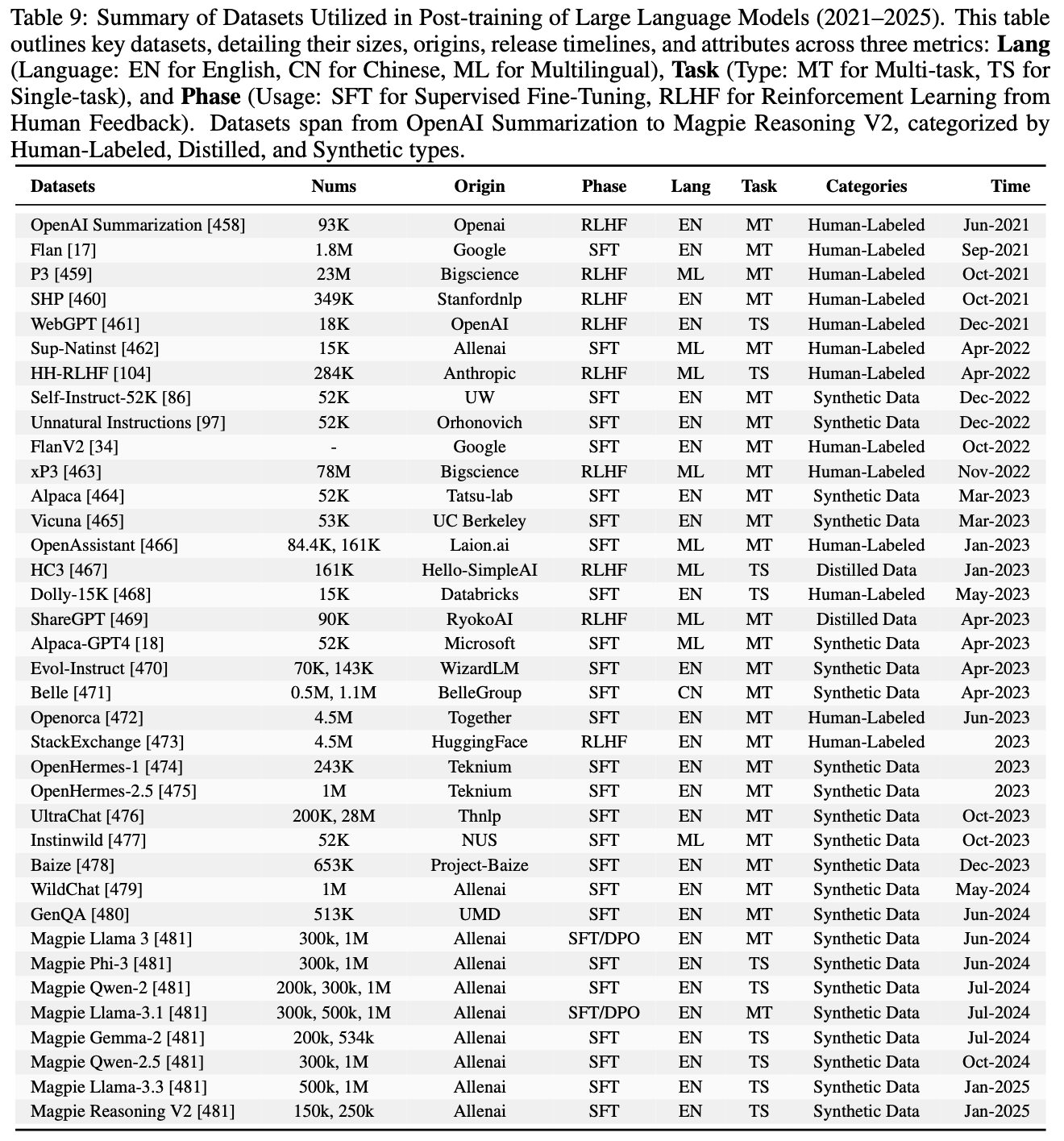
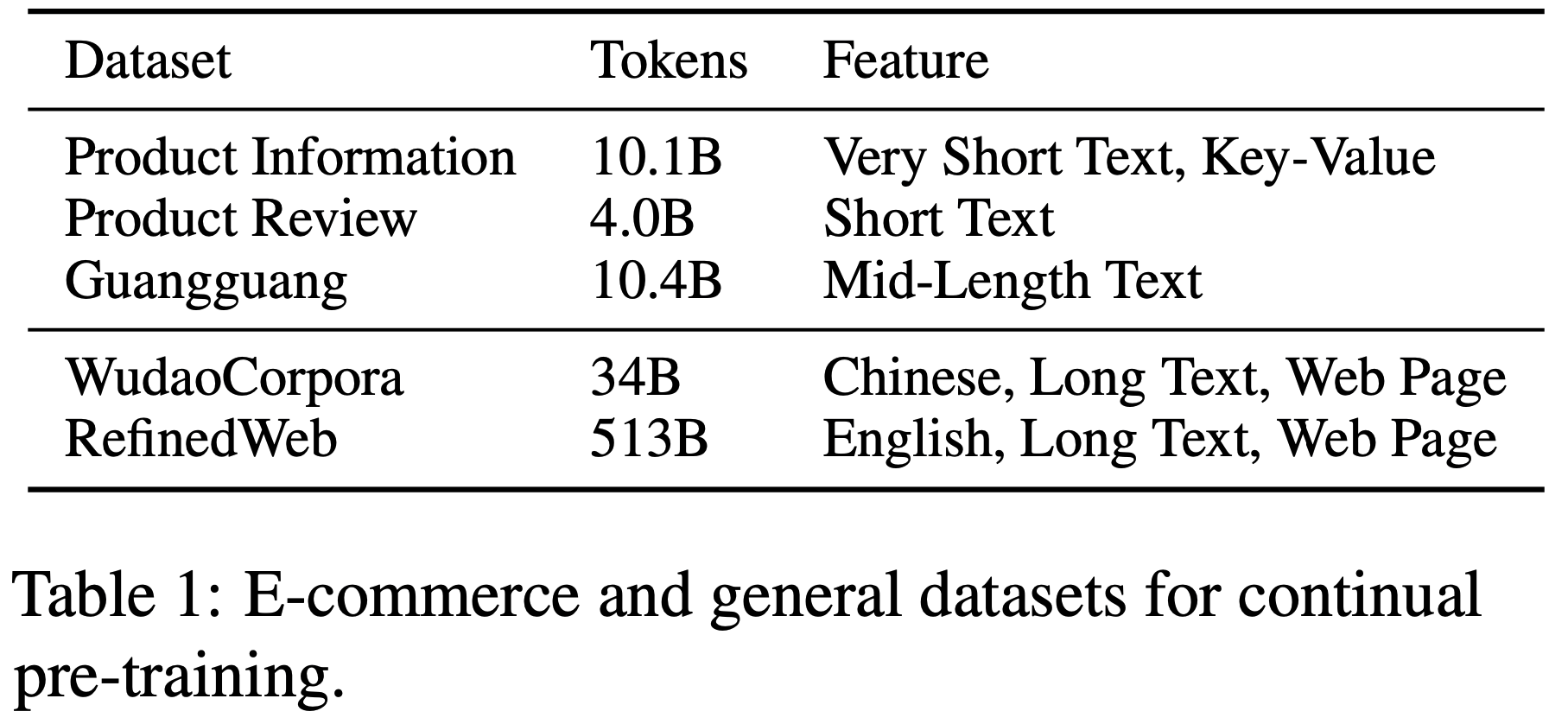
/CL4LLM-Survey-Table1.png)
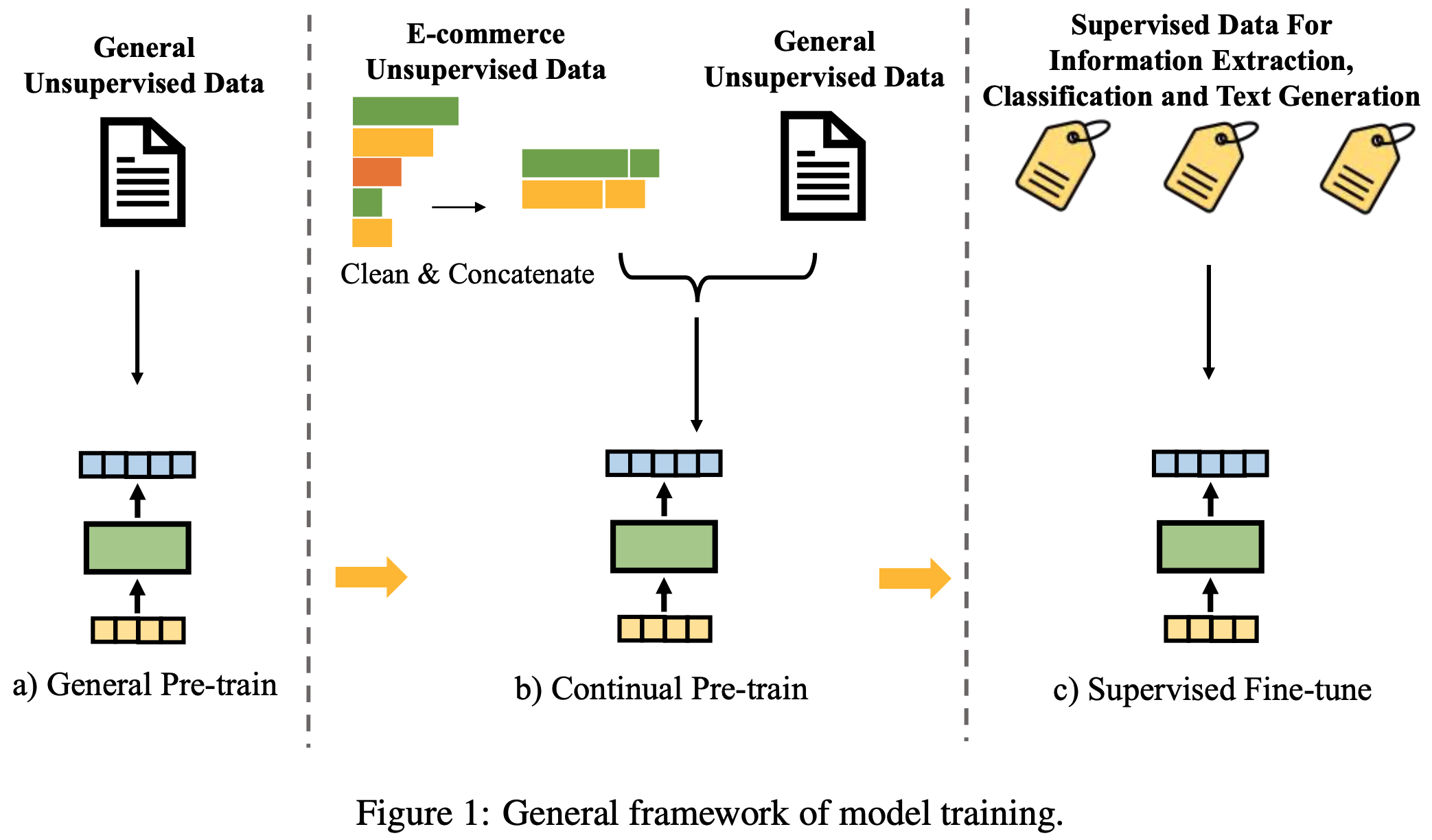
/CL4LLM-Survey-Figure1.png)
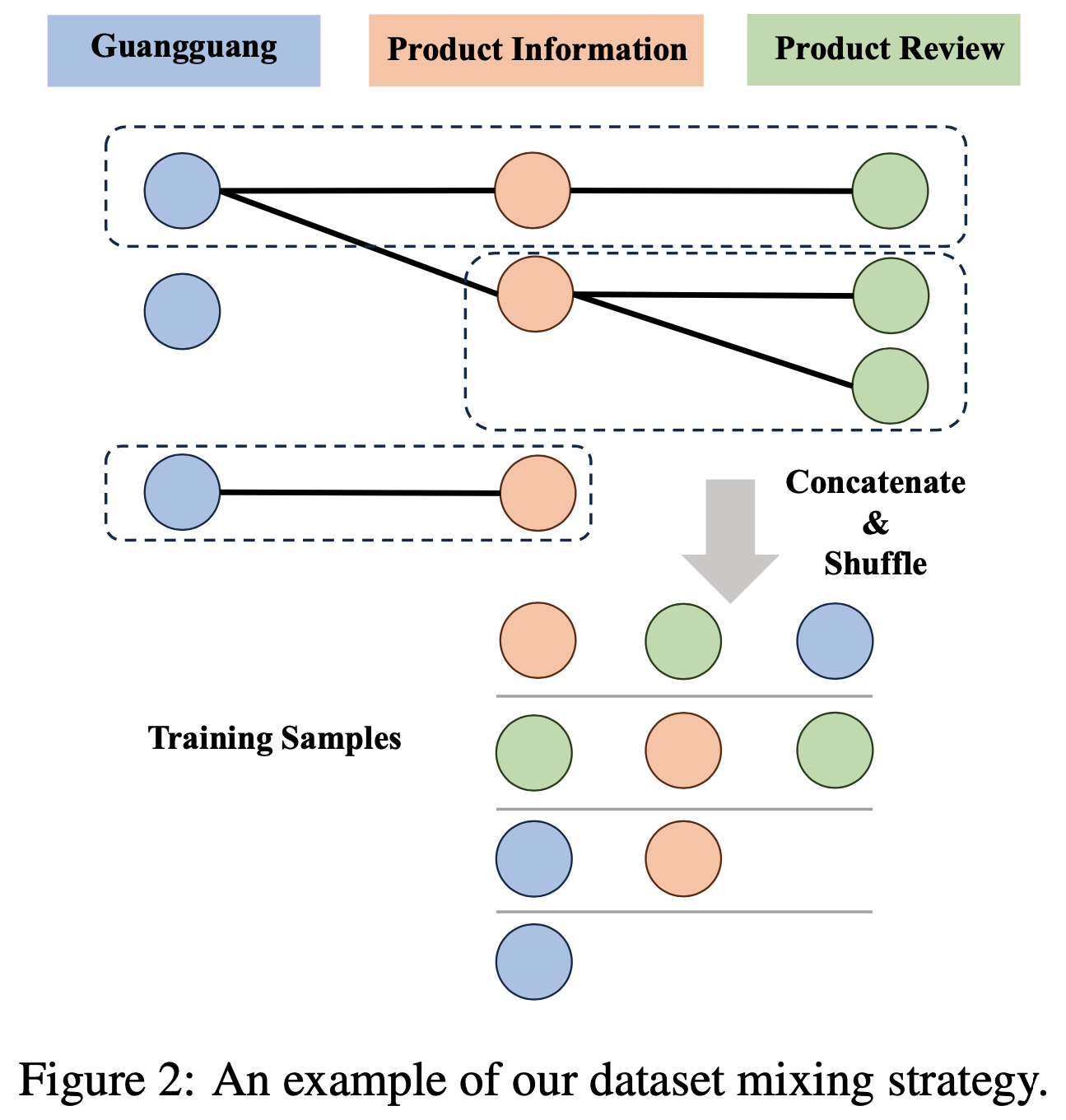
/CL4LLM-Survey-Figure2.png)
/CL4LLM-Survey-Table2.png)
/CL4LLM-Survey-Figure3.png)
/EverGreenQA-Figure1.png)
/EverGreenQA-Table10.png)
/EverGreenQA-Table2.png "注:加权 F1 值通常是对每个类别的 F1 值进行加权平均,权重通常是每个类别的样本数量")
/EverGreenQA-Table3.png "表3展示的数字是常青性(EG)和不确定性(UC,困惑度和熵越大越不确定)的相关性,数字越大越相关")
/EverGreenQA-Table4.png)
/EverGreenQA-Table5.png)
/EverGreenQA-Table6.png)
/EverGreenQA-Table7.png)
/EverGreenQA-Table8.png)
/EverGreenQA-Table1.png)
/EverGreenQA-Table9.png)
/EverGreenQA-Table11.png)


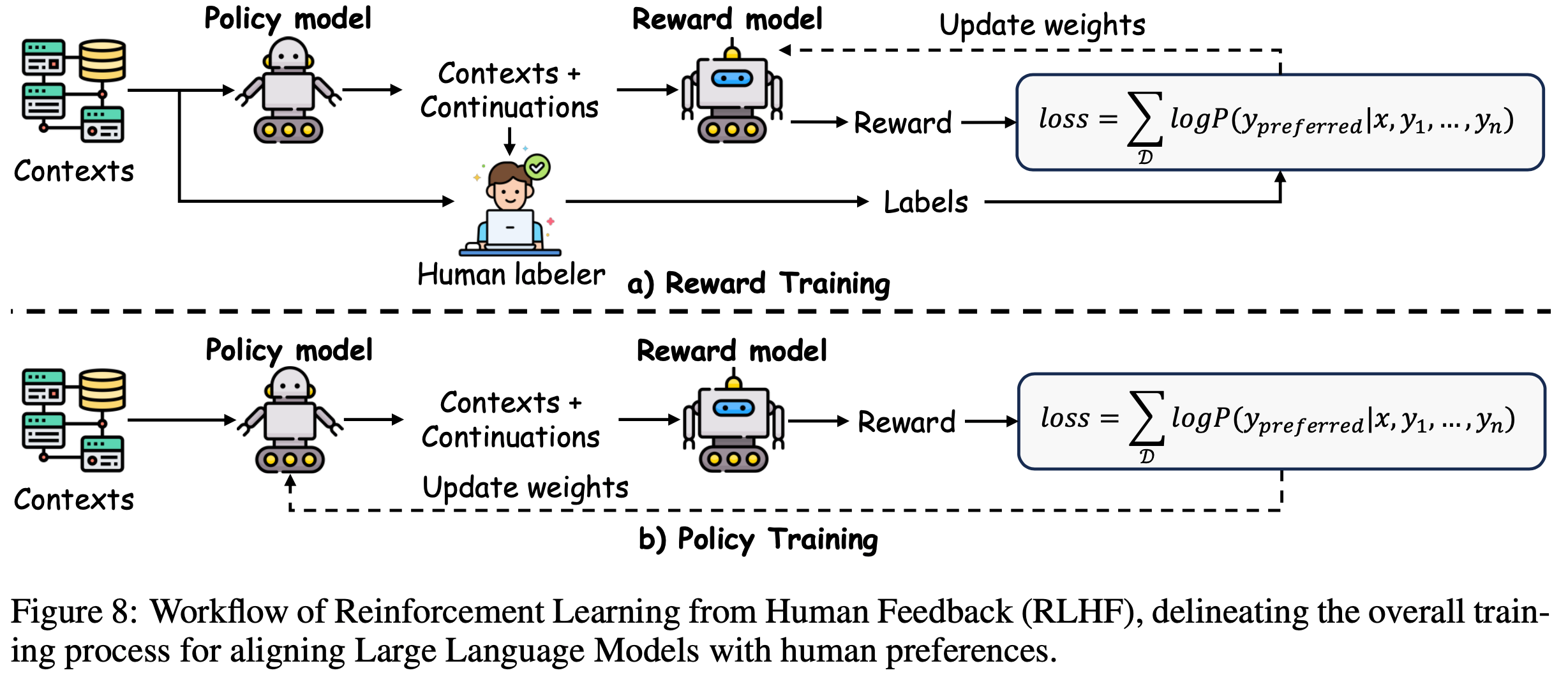
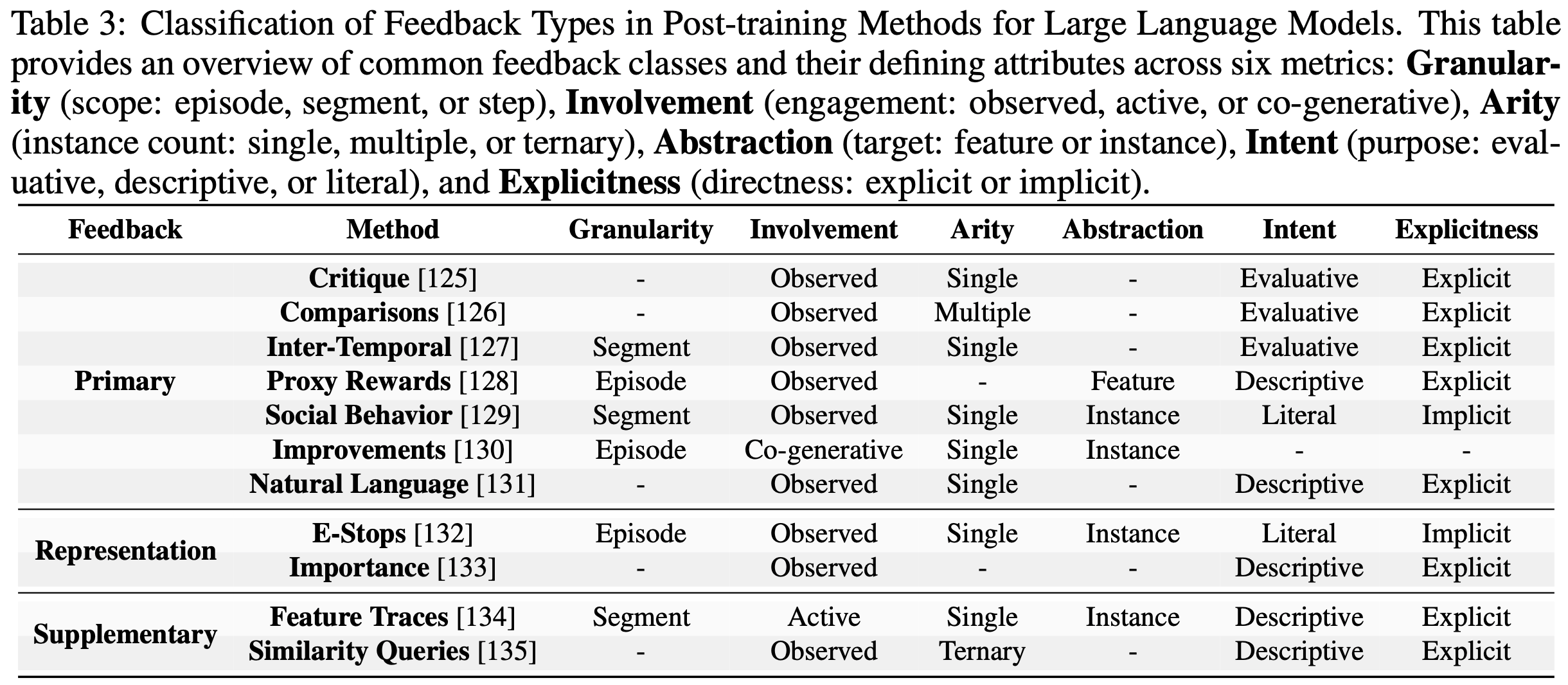
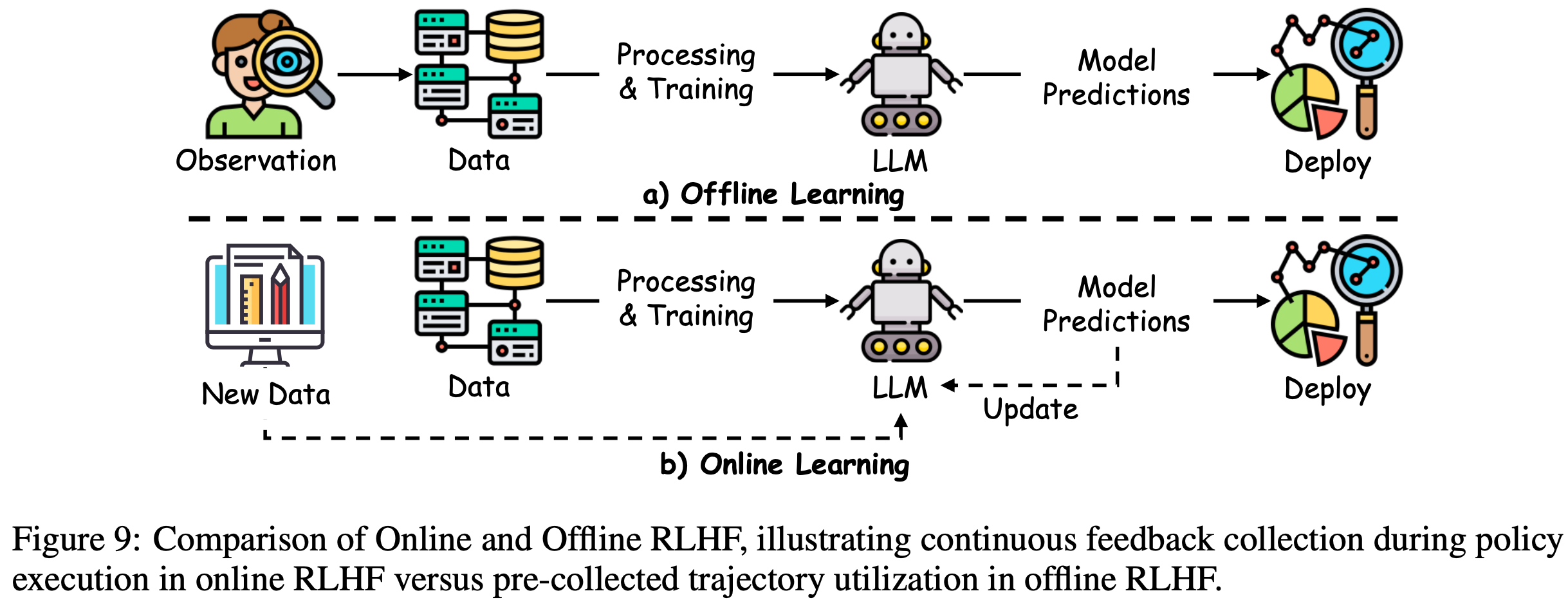
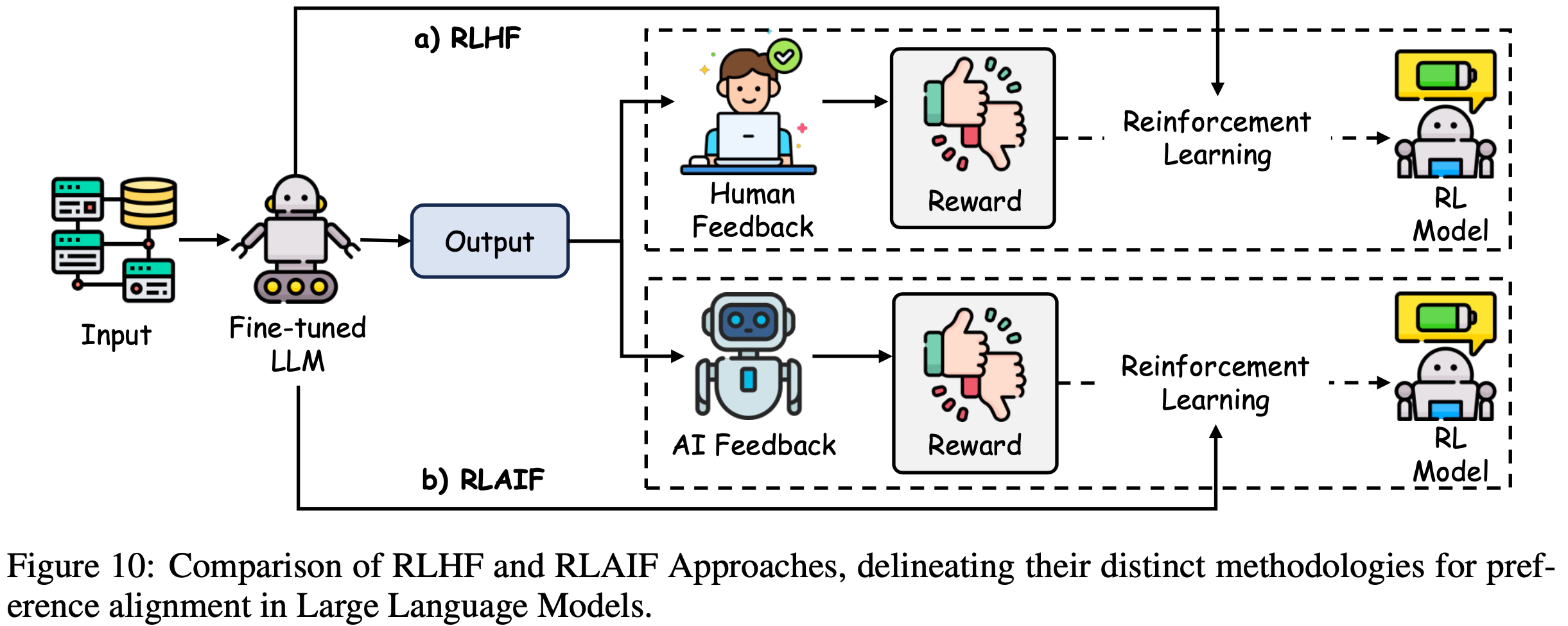
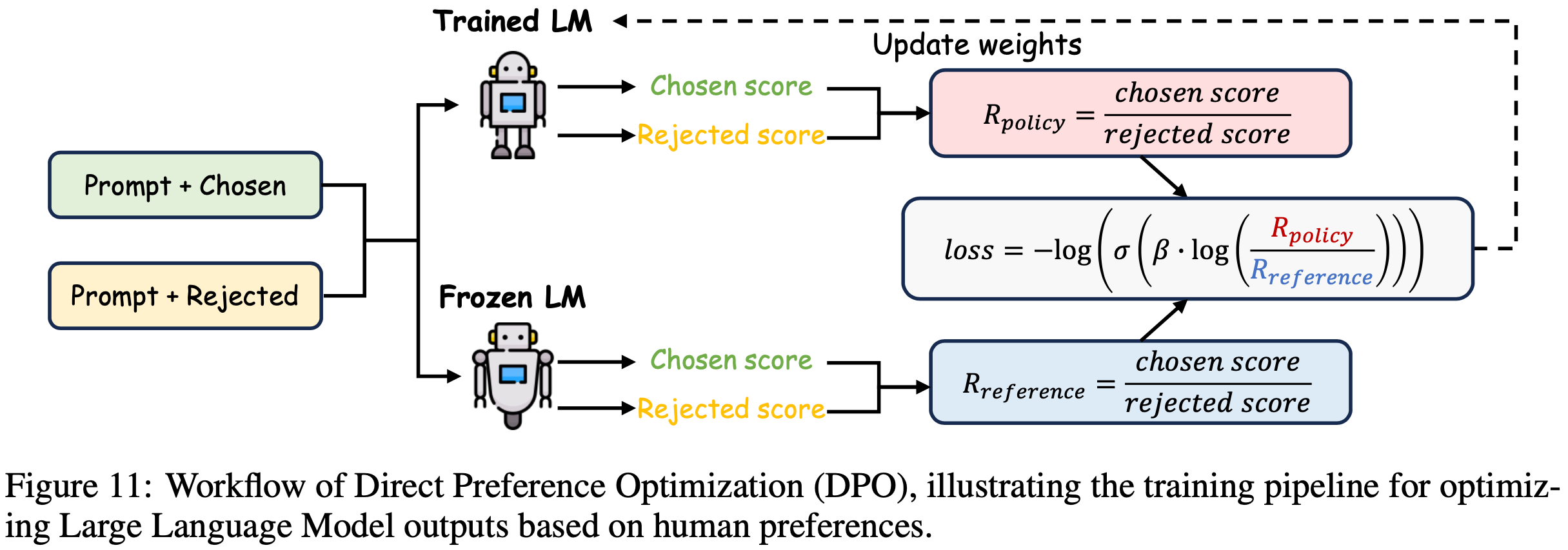
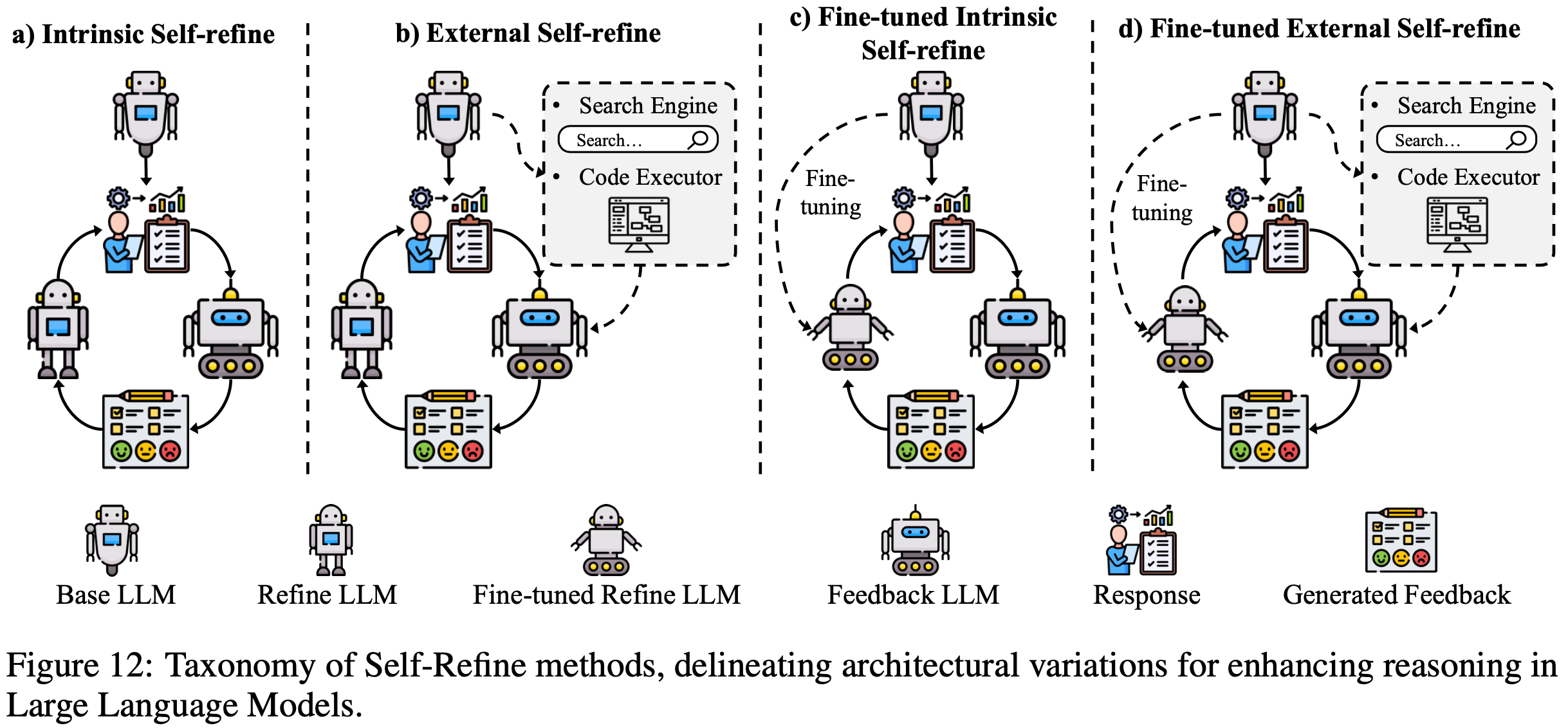
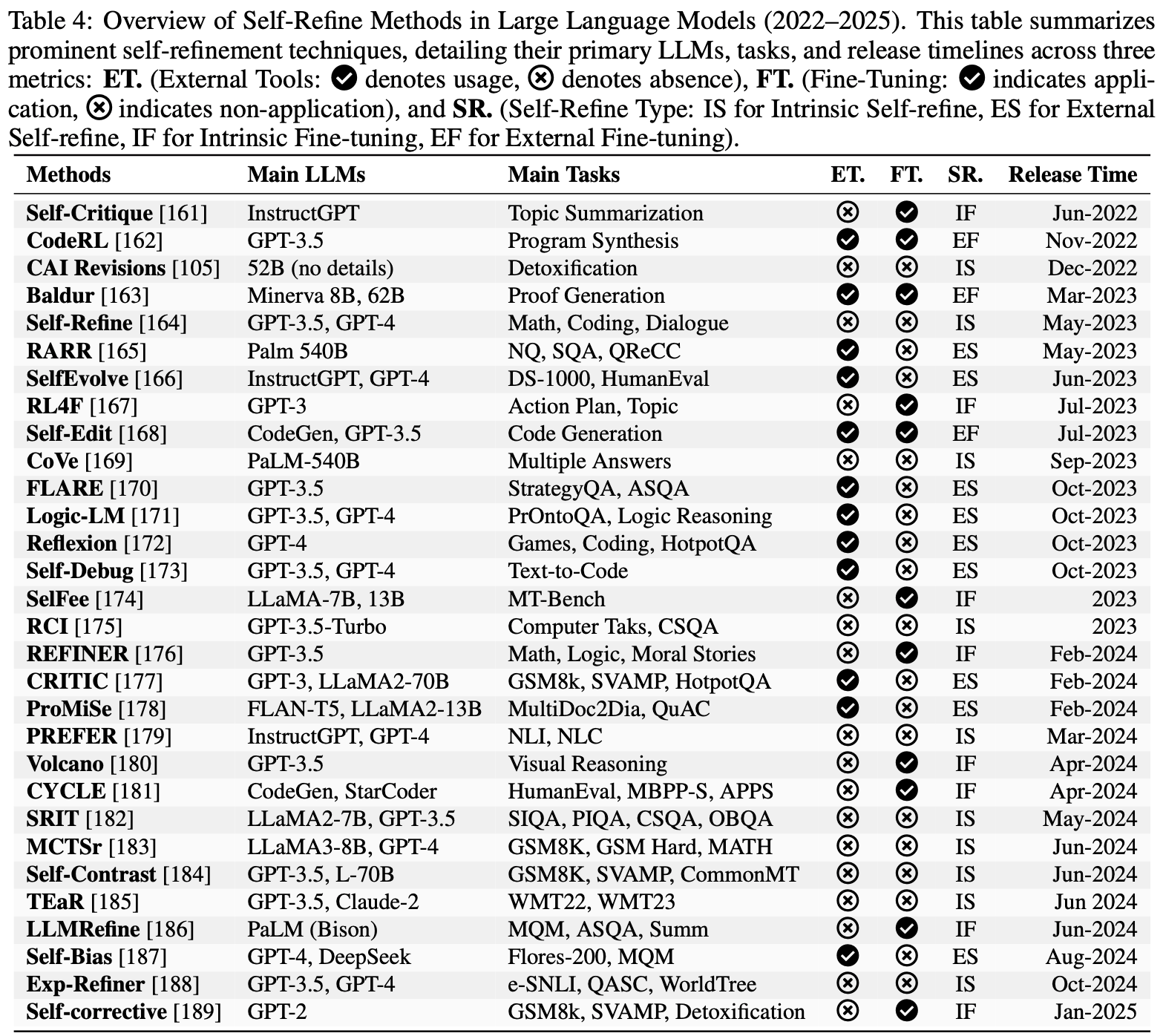
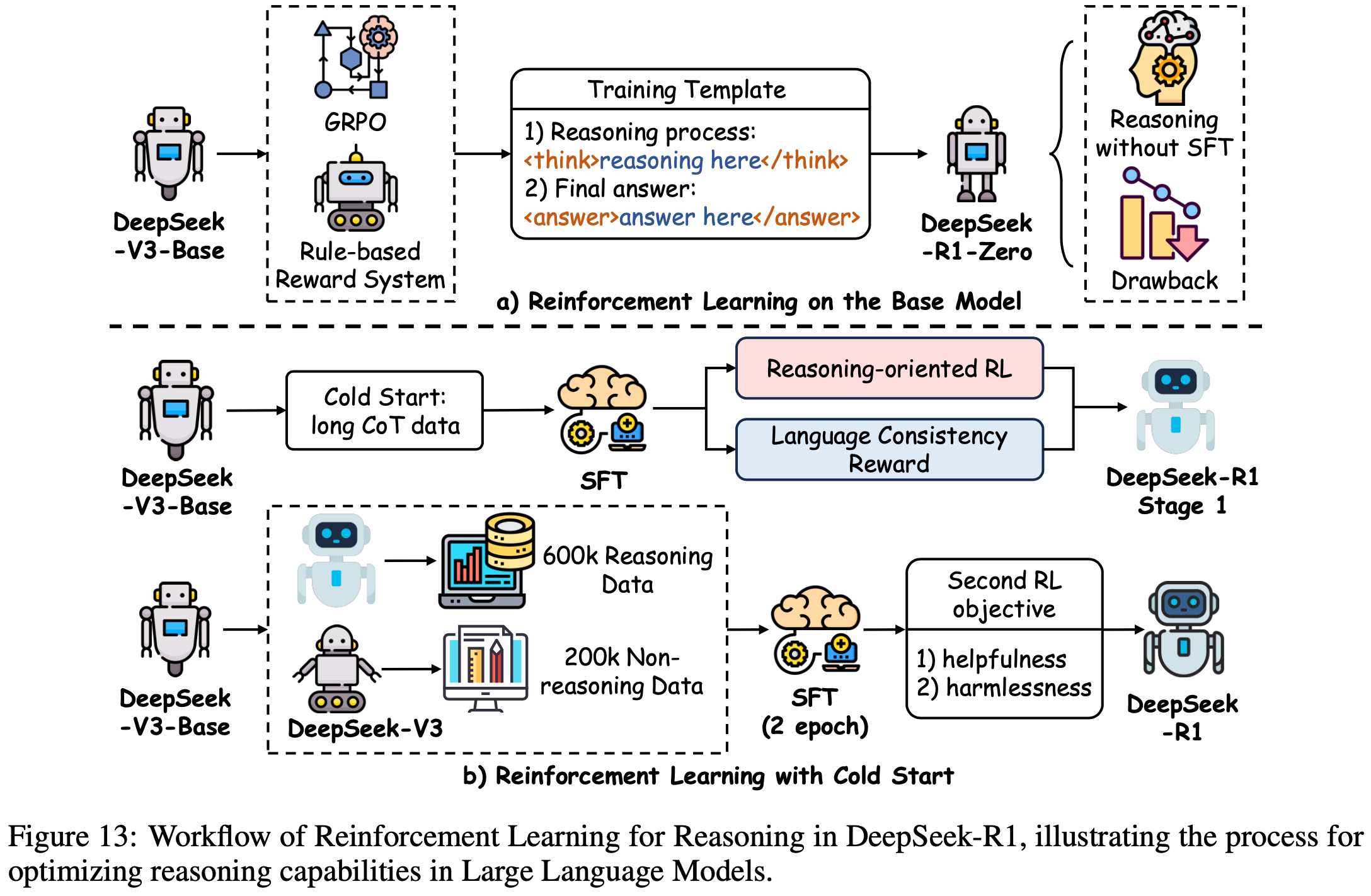
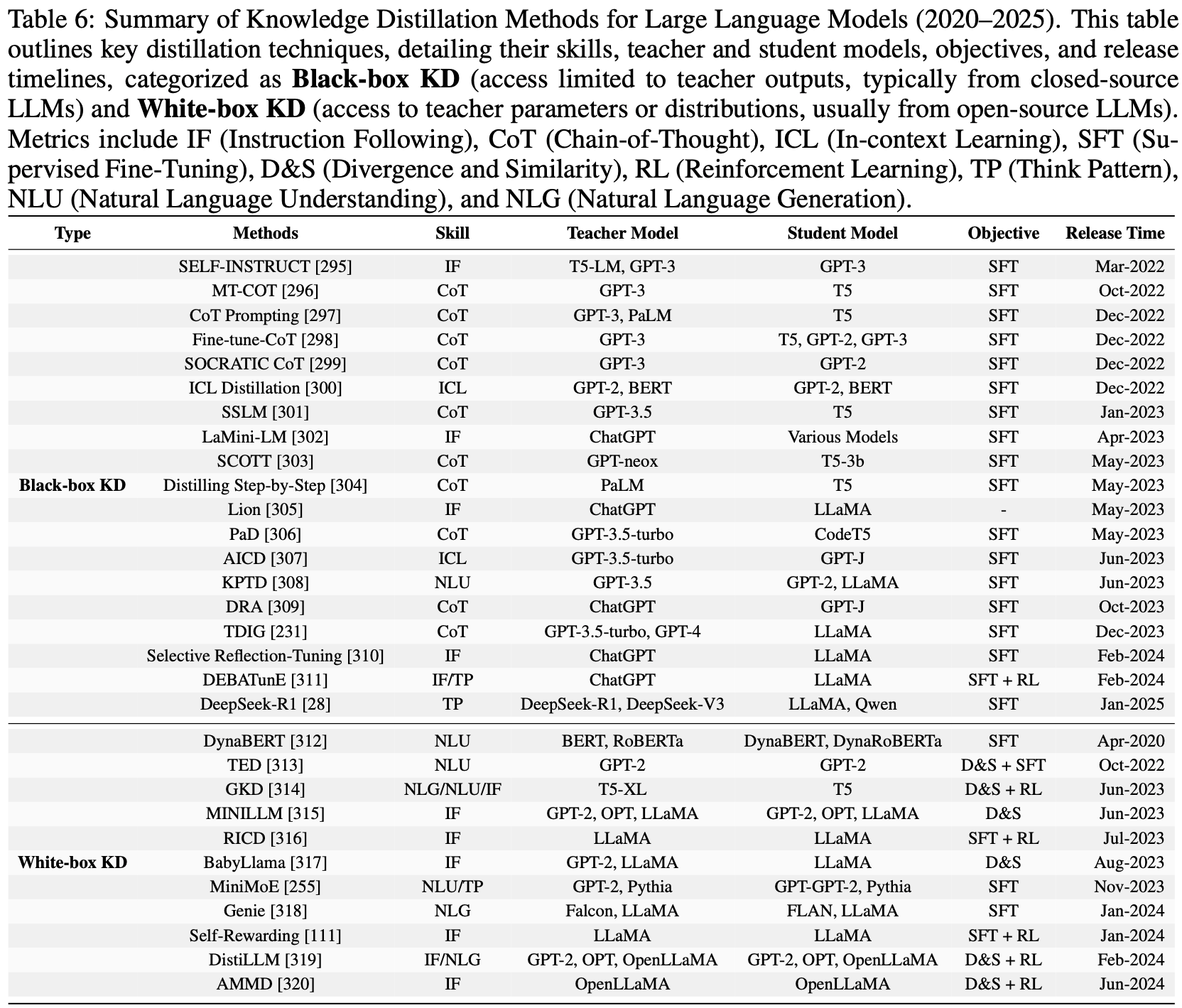
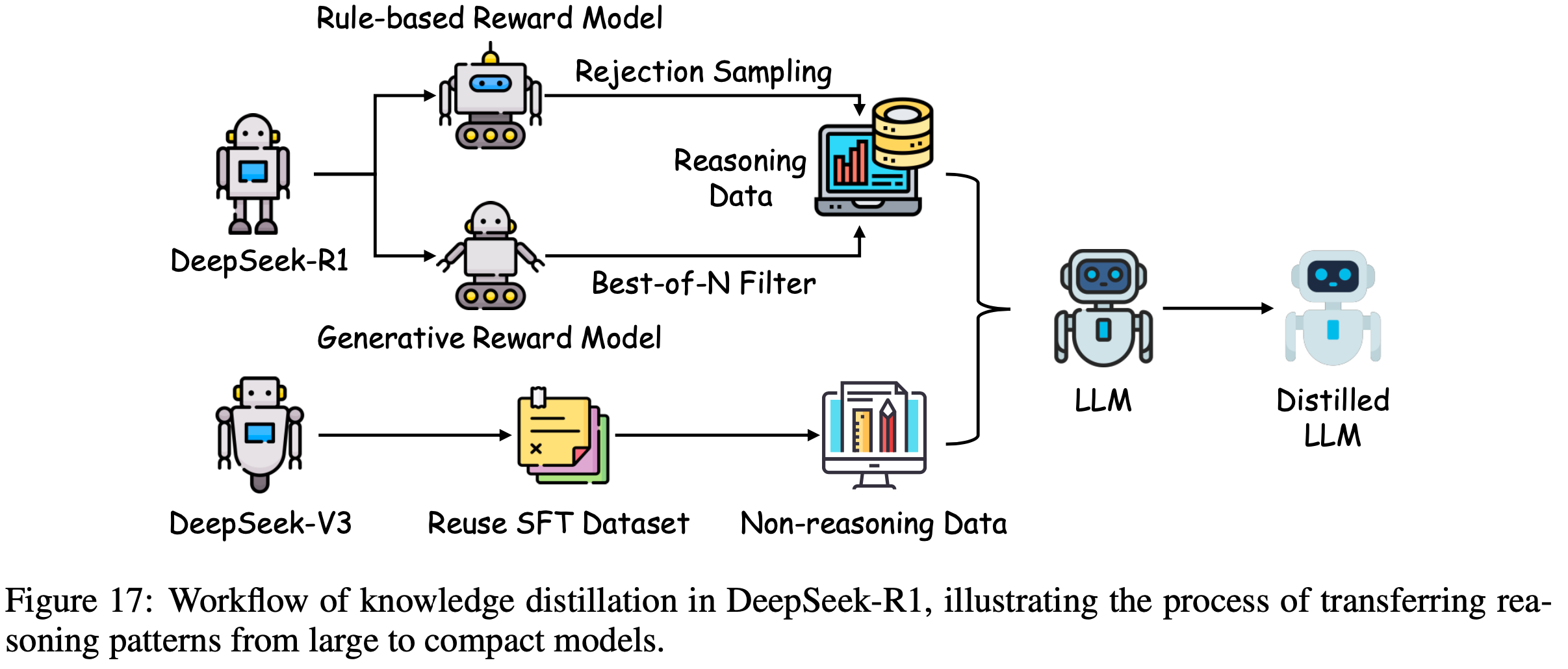
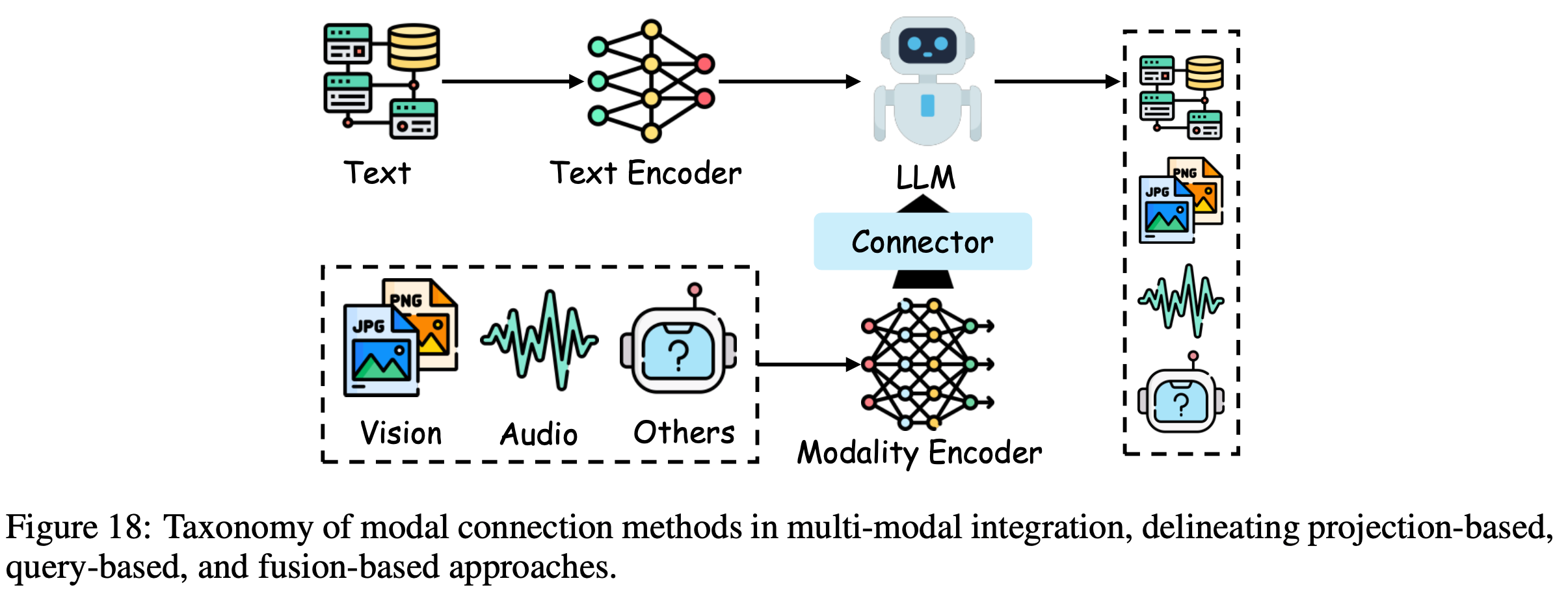
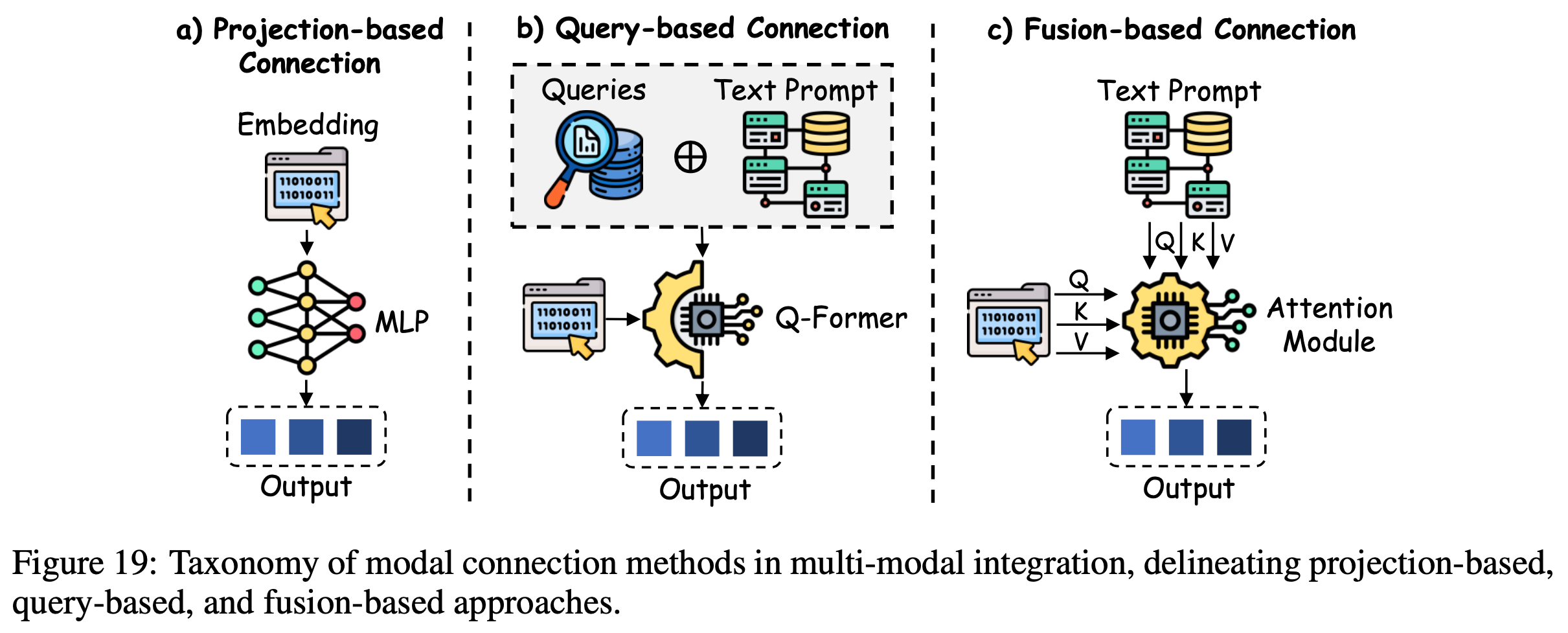


/FinPythia-Figure1.png)
/FinPythia-Table1.png)
/FinPythia-Table2.png)
/FinPythia-Table3.png)
/FinPythia-Table4.png)
/FinPythia-Figure2.png)
/FinPythia-Table5.png)
/FinPythia-Table6.png)
/Pile-Dataset.png "图片来源:[4个大语言模型训练中的典型开源数据集——华为云开发者联盟](https://zhuanlan.zhihu.com/p/680925832)")
/FinPythia-Figure3.png)
/FinPythia-Figure5.png)
/FinPythia-Figure4.png)
/FinPythia-Figure7.png)
/FinPythia-Figure6.png)
/FinPythia-Figure8.png)
/FinPythia-Figure9.png)