本文不定期更新
模型的一般使用流程
- init
- fit(x_train, y_train)
- predict(x_test)
模型输出预测概率
- 方法名称: predict_proba(x_test)
- 该方法对于预测时使用概率或者分数的算法来说直接返回概率值,对于不能返回概率的类来说一般返回交叉验证结果的平均值等
- NB: 概率值
- LR: 逻辑回归的分数
- SVM: 交叉验证生成的平均值, 这里的结果与predict预测结果可能有偏差
关于参数
- 待补充
为DataFrame的某一列实行OneHot编码
基本实现思路:
实现代码:
1 | from sklearn.preprocessing import OneHotEncoder |
从文件读取:
1 | jq [参数] 'filter_statement' [json_file_name] |
参数 用于指定输出形式等'filter_statement' 表示过滤器表达式,可以用于访问 Json 对象内部的字段json_file_name 表示 Json 文件名或从标准输入读取
1 | cat data.json | jq 'filter_statement' |
-c/--compact-output:-r/--raw-output:-C:.:输出整个输入 JSON,用于格式化美化echo '{"name":"Alice"}' | jq '.'. 效果一致.字段名:提取对象字段值.父字段.子字段 链式访问echo '{"user":{"name":"Bob"}}' | jq '.user.name'.字段名?:null,不报错.[索引]:.[起始:] 取切片.[起始:结束] 取区间echo '["a","b","c"]' | jq '.[1]'(取第二个元素).[]:echo '["x","y"]' | jq '.[]'(每行输出一个元素).[]?:|:
echo '{"users":[{"name":"A"},{"name":"B"}]}' | jq '.users[] | .name'1 | "A" |
,:
echo '{"a":1,"b":2}' | jq '.a, .b'1 | 1 |
A // B:
A 为 null 或 空时,取 Becho '{"name":null}' | jq '.name // "Unknown"'keys:获取对象的键名列表,或数组的索引列表
echo '{"x":1,"y":2}' | jq 'keys'1 | [ |
length:返回数组长度、字符串长度或对象键的数量
echo '{"name":null}' | jq 'length'1 | 1 |
map(过滤器):对数组每个元素应用过滤器,返回新数组
echo '[1,2,3]' | jq 'map(. * 2)'(每个元素的值翻倍)1 | [ |
select(条件):按条件过滤元素,保留满足条件的结果
echo '[{"age":20},{"age":30}]' | jq '.[] | select(.age > 25)'1 | { |
sort_by(字段):按指定字段对数组排序
echo '[{"age":30},{"age":20}]' | jq 'sort_by(.age)'1 | [ |
构造新 JSON
1 | # 提取指定字段并重组 |
条件判断与修改
1 | # 年龄大于25则标记为成年 |
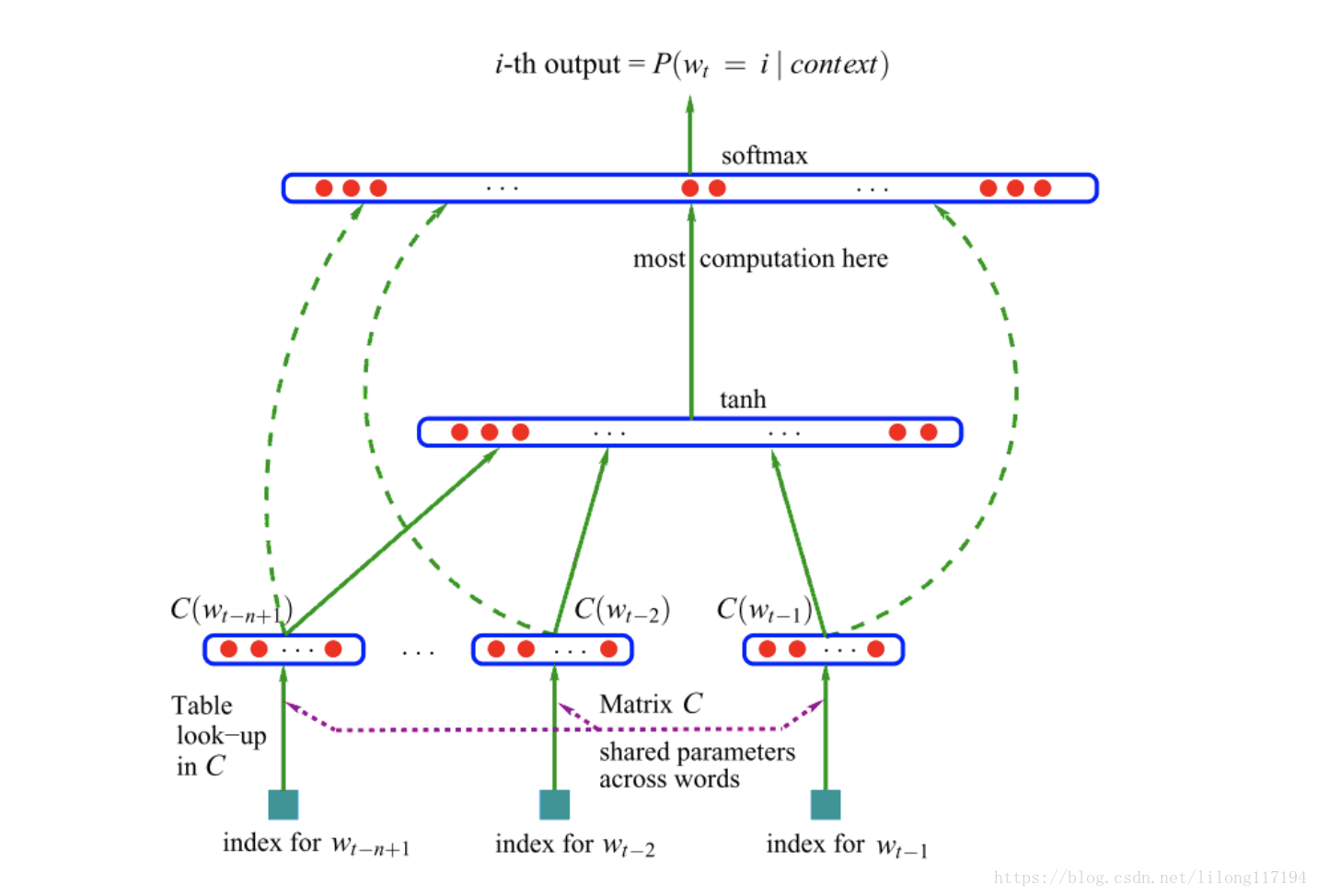
词嵌入的发展,NNLM,CBOW,skip-gram
词嵌入(Word Embedding)也称为词向量(Word2Vec): 指的是将词转换成向量的形式
“where” 作为例子来了解子词是如何产生的“<”和“>”以区分作为前后缀的子词“<wh>” “whe” “her” “ere” “<re>”以及特殊子词“<where>”下面是一些模型的详细介绍
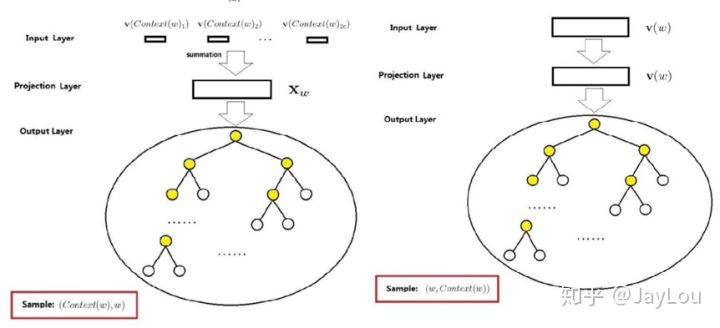
sum,而不是拼接)
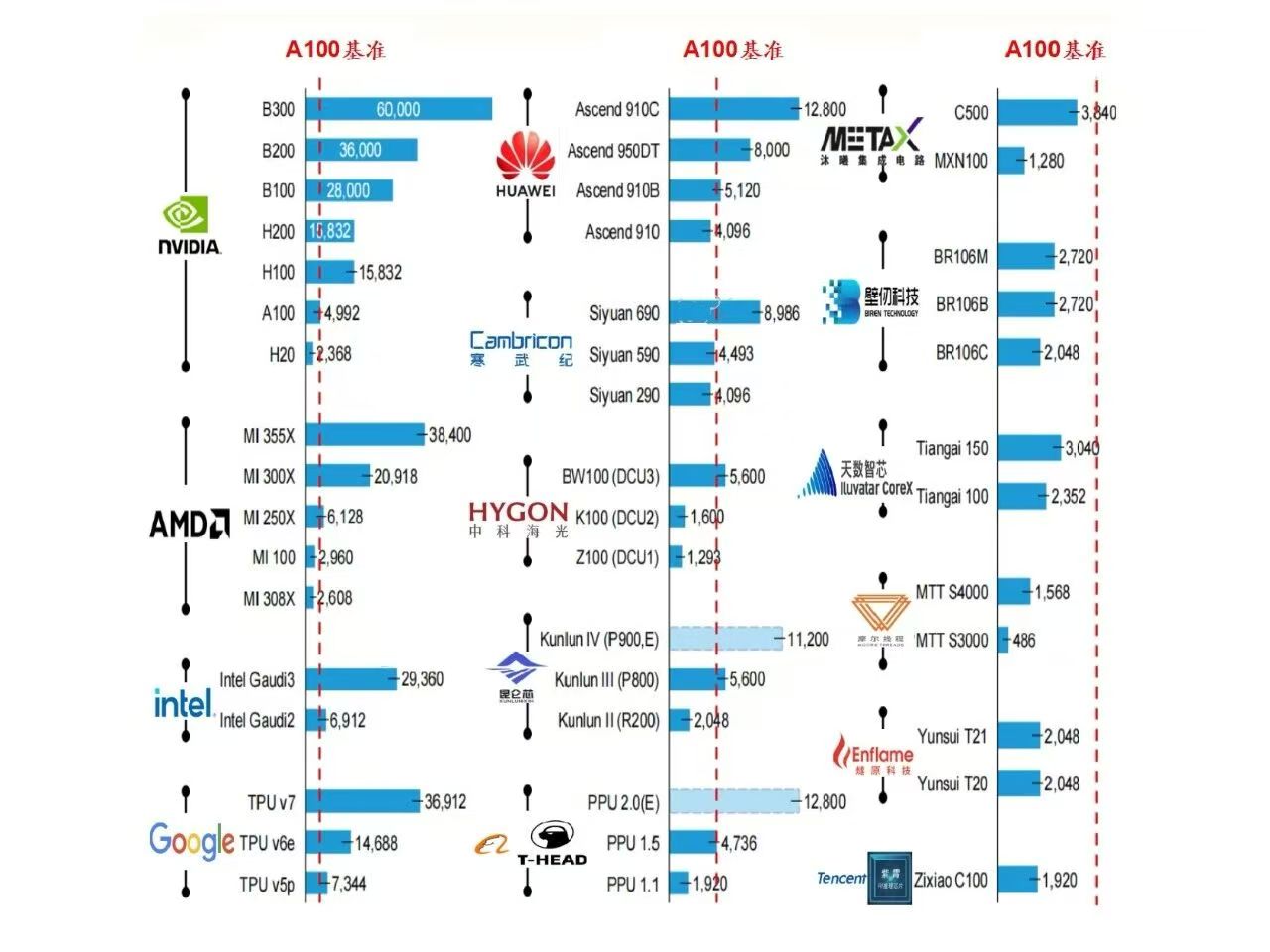
| 型号 | 发布时间 | 架构 | 主要身份 / 卖点 | 备注 |
|---|---|---|---|---|
| H100 | 2022 年 Q3 | Hopper | 首款 Hopper 架构旗舰,取代 A100 | 80 GB HBM3,989 TFLOPS FP16,是 2022 年的“卡皇” |
| H800 | 2023 年 Q1 | Hopper | 中国特供“缩水版 H100” | 带宽砍到 2 TB/s,算力基本保留 |
| H200 | 2023-11-13 | Hopper | H100 的“显存升级版” | 141 GB HBM3e + 4.8 TB/s,推理速度大约 2×H100 |
| H20 | 2023-11 | Ampere(部分文献亦标为 Hopper 降规) | 中国特供“再缩水版”,算力只有 H100 的 1/7 | 96 GB HBM3、148 TFLOPS FP16,对标昇腾 910B |
Topic Suggestions for Millions of Repositories

(Readme preprocessing and cleanup)
(Generate candidate topics)
(Eliminate noisy topics)
请教师兄Other features we used were occurrence of user names, n-gram size of a phrase, length of a phrase, and numeric content within a phrase.)(Score Topics)
The second approach we tried uses the average tf-idf scores of individual words in a phrase weighted by the phrase frequency (if it’s more than one word long) and n-gram size.
(Canonicalize topics)
使用内部词典规范主题形式(Use an in-house dictionary to suggest canonical form of topics)
解决文字层面的差别和变化等,比如下面四个主题
neural-network
neural-networks
neuralnetwork
neuralnetworks
(Eliminate near similar topics)
用基于Jaccard相似性评分的贪心算法(Greedy approach using Jaccard similarity scoring)
motivation:在得到Top-N的主题后,有些主题其实很相似,虽然都有用,但是他们只是在不同粒度描述了同一个主题而已,因此我们需要删除一些重复的,比如下面的例子
machine learning
deep learning
general-purpose machine learning
machine learning library
machine learning algorithms
distributed machine learning
machine learning framework
deep learning library
support vector machine
linear regression
method: 两个短语的相似性计算使用的是基于词的Jaccard相似性(两个短语的差集与并集的比值,因为它对较短的短语很有效,而且分数是[0-1]的,很方便设置阈值(thresholds)),用贪心算法,如果两个主题相似,去除分数较低的那一个,上面的例子去除相似主题后的结果是:
machine learning
deep learning
support vector machine
linear regression
Note: 他们都是struct类型的
type StringHeader struct {
Data uintptr
Len int
}type SliceHeader struct {
Data uintptr
Len int
Cap int
}[]byte("string")
string([]byte{1,2,3})注意:这种实现会有拷贝操作
答案是自己实现指针转换(也可用反射实现头部转换),省去复制数据部分,同时注意这种实现后底层的数据不能再更改了,不然容易引发错误
func String2Slice(s string) []byte {
sp := *(*[2]uintptr)(unsafe.Pointer(&s))
bp := [3]uintptr{sp[0], sp[1], sp[1]}
return *(*[]byte)(unsafe.Pointer(&bp))
}
func BytesToString(b []byte) string {
return *(*string)(unsafe.Pointer(&b))
}func Slice2String(b []byte) (s string) {
pbytes := (*reflect.SliceHeader)(unsafe.Pointer(&b))
pstring := (*reflect.StringHeader)(unsafe.Pointer(&s))
pstring.Data = pbytes.Data
pstring.Len = pbytes.Len
return
}
func String2Slice(s string) (b []byte) {
pbytes := (*reflect.SliceHeader)(unsafe.Pointer(&b))
pstring := (*reflect.StringHeader)(unsafe.Pointer(&s))
pbytes.Data = pstring.Data
pbytes.Len = pstring.Len
pbytes.Cap = pstring.Len
return
}本文先给出Go语言中struct类型作为函数参数传入的例子,然后给出总结
1 | func changeValue(person Person){ |
注意:struct类型与切片传值方式不同而与数组相同
关于切片与数组的区别,这里给出定义和传值等使用上的区别,最后给出总结
1 | var arr [2]byte |
1 | arr := [2]byte{1,2} |
1 | var sli []byte |
1 | sli := make([]byte, 5) |
1 | package main |
切片传入时是按照引用传递的,加上指针甚至可以修改引用(内存地址)本身
比如下面的代码会是的传入的引用重新指向nil指针:
1 | func changeSlicePoint(p *[]byte){ |
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
1 | $ hexo new "My New Post" |
More info: Writing
1 | $ hexo server |
More info: Server
1 | $ hexo generate |
More info: Generating
1 | $ hexo deploy |
More info: Deployment