本文介绍LightGBM的一些特性和并行实现方法
LightGBM vs XGBoost
- 树结点切分方式不同:
- XGBoost树节点切分是 Level-wise
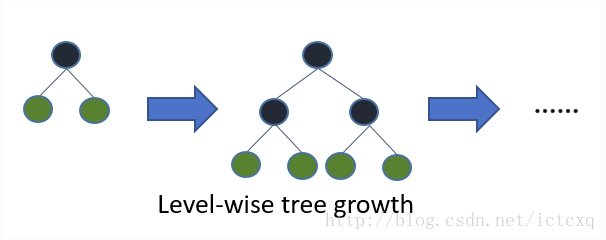
- LightGBM树节点切分是 Leaf-wise
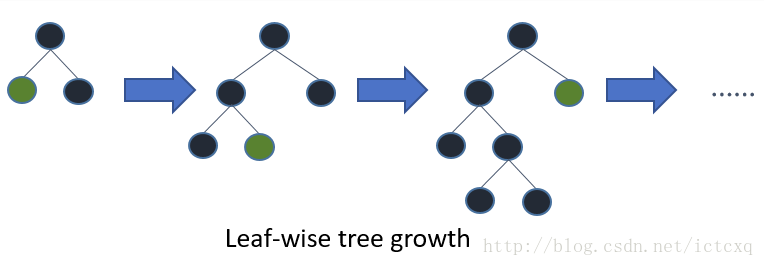
- XGBoost树节点切分是 Level-wise
- LightGBM直接支持类别特征 ,对类别特征不必进行 One-Hot 处理
- 实现方面:
- 直方图算法(近似切分算法)最初由LightGBM提出,后来的XGBoost算法也实现了直方图算法
- XGBoost的近似搜索算法和LightGBM的直方图算法不同
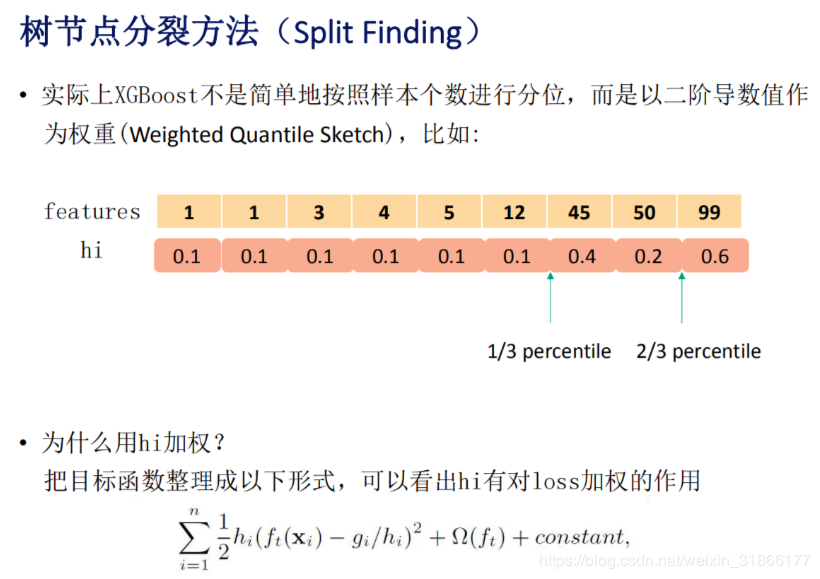
- XGBoost的近似搜索算法是保存所有样本的二阶梯度,用分位数确定划分方法,他的分割点是可以直接通过计算总的样本梯度和和分位数点得到的.
* LightGBM算法是将所有样本放进对应的桶中,并以当前桶作为划分点,计算左右桶的最大增益,它的最优点是遍历所有的桶才能得到的.
- XGBoost的近似搜索算法是保存所有样本的二阶梯度,用分位数确定划分方法,他的分割点是可以直接通过计算总的样本梯度和和分位数点得到的.
- LightGBM 通信优化 比 XGBoost 做得好
- 这里有亲身体验: XGBoost使用多个处理器时,有时候处理器数量增加训练速度不增加,甚至反而变慢,
xgboost.XGBClassifier
- 这里有亲身体验: XGBoost使用多个处理器时,有时候处理器数量增加训练速度不增加,甚至反而变慢,
- LightGBM 使用了 GOSS(Gradient-based One-Side Sampling) 来做采样算法
- GOSS 是通过区分不同梯度的实例,保留较大梯度实例同时对较小梯度随机采样的方式减少计算量,从而达到提升效率的目的
- GOSS 算法流程 :
- 根据样本的梯度将样本降序排序
- 保留前 \(a \ (0 < a < 1)\) 比例大小的数据样本,作为数据子集 \(Z_1\),也就是保留 \(a * len(all\_samples)\) 的数据样本
- 对于剩下的数据的样本,随机采样获得大小为 \(b \ (0 < b < 1)\) 的数据子集 \(Z_2\),也就是采样 \(b * len(all\_samples)\) 的数据样本
- 计算信息增益时对采样的 \(Z_2\) 样本的梯度数据乘以 \((1-a)/b\) (目的是不改变原数据的分布)
- GOSS的思想是,梯度大的实例正常使用,梯度小的实例就通过采样实现部分拟合总体的方法(拟合时不改变原来的分布,除以采样率就行了)
- LightGBM 使用了 EFB (Exclusive Feature Bundling)
- EFB 通过特征捆绑的方式减少特征维度(其实是降维技术)的方式,提升计算效率
- 通常被捆绑的特征都是互斥的(一个特征值为0,一个特征值不为0), 这样两个特征捆绑起来也不会造成信息丢失
- 当两个特征不是完全互斥时,可以用一个指标对特征不互斥程度进行评估,称为冲突比率
- 冲突比率较小时,我们可以将他们捆绑而不太影响训练结果
- EFB 算法流程:
- 将特征按照非零值的个数进行排序
- 计算不同特征之间的冲突比率
- 遍历每个特征并尝试合并特征,使冲突比率最小化
- LightGBM 的内存优化
- XGBoost 中 需要对每个特征进行预排序(注意:这里不能在算是XGBoost的缺点了,后来的XGBoost也实现了这个直方图算法,不需要预排序了)
- LightGBM使用直方图算法替代了预排序
LightGBM的优点
- 相对XGBoost:
- 速度快 (GOSS, EFB, Histogram等)
- 内存少 (XGBoost中排序)
- 精度高(效果不明显, 与XGBoost相当, 本人测试, 实际使用中有时候不如XGBoost, 可能是参数调节的问题)
缺点
- 虽然官方一再强调LightGBM的精度不比XGBoost低,而且可能超过XGBoost,但是实践中, LightGBM除了比XGBoost快以外, 精度方面没什么优势, 甚至精度还不如XGBoost(注意: 也可能是我调参技术不行)
- 问题: 为什么某些数据集上出现LightGBM比XGBoost精度差的情况?
- 回答: (个人理解)因为GOSS和EFB会带来一定的精度损失
总结
- LightGBM = XGBoost + Histogram + GOSS + EFB
- XGBoost: 不同于XGBoost的, 树节点切分不同, LightGBM使用了 Leaf-wise 的生长策略
- Histogram:
- Histogram方法牺牲了一定的精度,但是作者强调了在实验中精度降低并不多
- 开始的XGBoost使用的是预先排序的方式, 后来在 XGBoost 中也实现了Histogram
- LightGBM 对 Histogram 算法进一步加速
- 一个叶子节点的 Histogram 可以直接由父节点的Histogram和兄弟节点的Histogram做差得到, 一般情况下,构造Histogram需要遍历该叶子上的所有数据,通过该方法,只需要遍历Histogram的k个捅, 速度提升了一倍
- GOSS: 对于梯度小的样本, 使用采样部分代替总体的方法省时间
- EFB: 互斥特征捆绑,提升计算效率
- LightGBM 真正做到了把并行做到极致
- 特征并行: 在不同的机器在不同的特征集合上分别寻找最优的分割点, 然后再机器间同步最优的分割点.
- 数据并行: 让不同的机器先在本地构造直方图, 然后进行全局的合并,然后在合并的直方图上寻找最优的分割点.
- LightGBM 支持类别特征
- 无需将类别特征 One-Hot
- 问题: 为什么XGBoost也使用了直方图,但是速度依然比较慢?
- 直方图算法的实现有两种:
- 1)全局构造 ,在树的构造过程中只建立一次直方图, 每次分裂都从缓存的直方图中寻找分裂点
- 2)局部构造 ,每次树分裂到一层的时候就建立一次直方图
- XGBoost使用的是局部构造的方式, 所以速度会较慢
- 直方图算法的实现有两种: