显卡性能详细天梯图
- 显卡性能天梯图(截止到 24 年底):

- H100 SXM 和 H100 性能不一致的原因主要是接口不同导致的,SXM 英伟达设计的一种集成到主板上的接口,支持更大功率,能发挥的显卡性能也更好
- 图中没有显示的常见显卡简单说明:
- H800 是 H100 的替代卡,通过降低互联带宽(从 H100 的 900GB/s 降至 450GB/s)规避出口限制,但算力仍达行业顶尖水平
- 23 年腾讯开始使用
- H20 是 25年新发布的 H100 限制版芯片,目前有 96G 和 141G 版本,带宽 4TB/s (高于 H100 的 3.35TB/s) 性能大概只有
- H800 是 H100 的替代卡,通过降低互联带宽(从 H100 的 900GB/s 降至 450GB/s)规避出口限制,但算力仍达行业顶尖水平
AI 相关显卡对比
- 注意:本图来自网络(不一定符合真实情况)
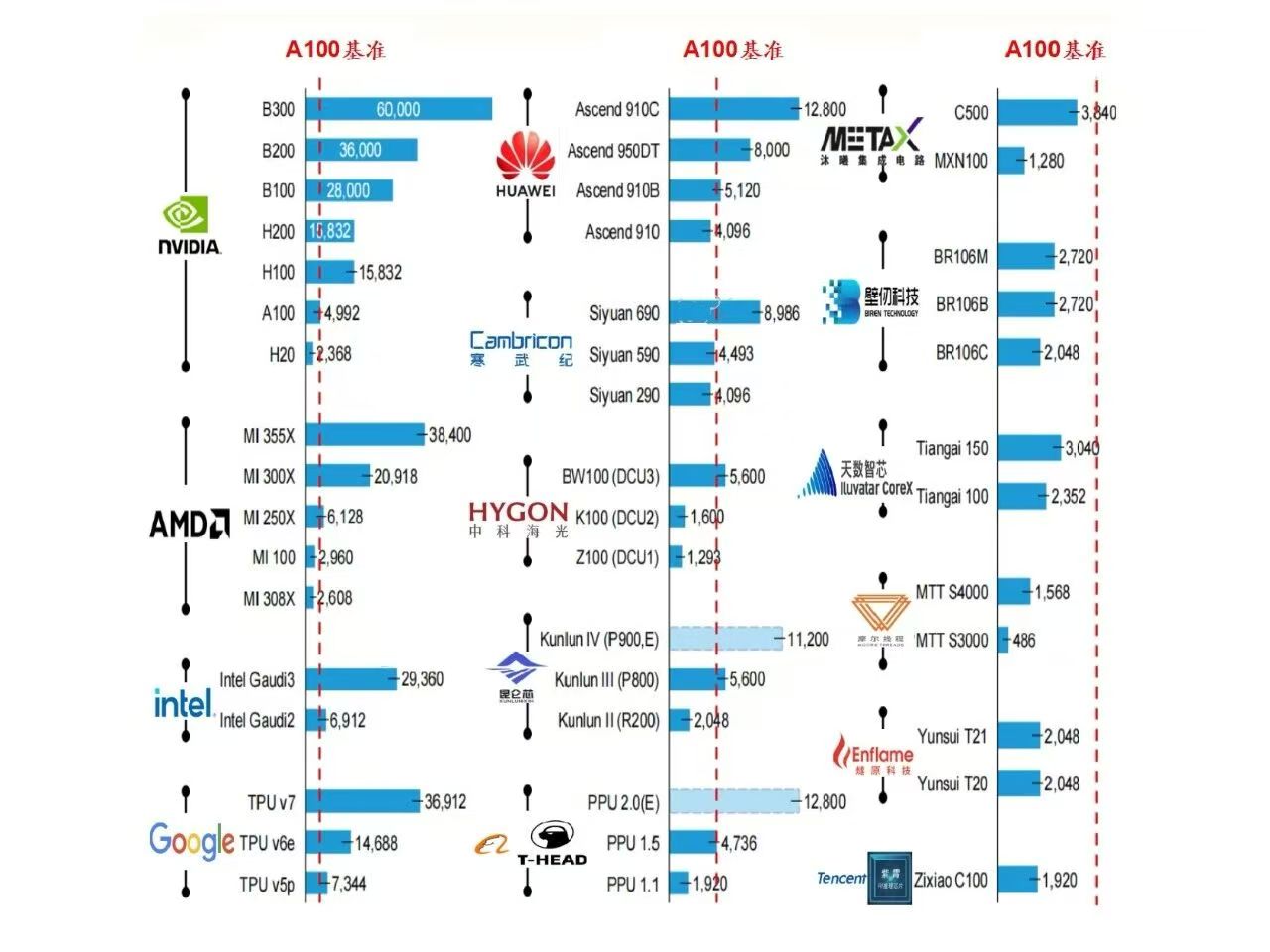
- 文字总结:
- 华为
- Ascend 910C:A100 的 2.56 倍
- Ascend 950DT:A100 的 1.6 倍
- Ascend 910B:A100 的 1.026 倍
- Ascend 910:A100 的 0.82 倍
- 寒武纪
- Siyuan 690:A100 的 1.8倍
- Siyuan 590:A100 的 0.9 倍
- Siyuan 290:A100 的 0.82倍
- 海光
- BW100(DCU3):A100 的 1.12 倍
- K100(DCU2):A100 的 0.32 倍
- Z100(DCU1):A100 的 0.26倍
- 沐曦
- C500:A100 的 0.77 倍
- MXN100:A100 的 0.26 倍
- 壁仞
- BR106M/BR106B:A100 的 0.54 倍
- BR106C:A100 的 0.41 倍
- 摩尔线程
- MTT S4000:A100 的 0.31 倍
- MTT S3000:A100 的 0.1倍。
- 华为
主要显卡对照记录
- 主要显卡对照记录表格
型号 发布时间 架构 主要身份 / 卖点 备注 H100 2022 年 Q3 Hopper 首款 Hopper 架构旗舰,取代 A100 80 GB HBM3,989 TFLOPS FP16,是 2022 年的“卡皇” H800 2023 年 Q1 Hopper 中国特供“缩水版 H100” 带宽砍到 2 TB/s,算力基本保留 H200 2023-11-13 Hopper H100 的“显存升级版” 141 GB HBM3e + 4.8 TB/s,推理速度大约 2×H100 H20 2023-11 Ampere(部分文献亦标为 Hopper 降规) 中国特供“再缩水版”,算力只有 H100 的 1/7 96 GB HBM3、148 TFLOPS FP16,对标昇腾 910B - 注:H20 虽官方 PPT 仍写 Hopper,但算力/显存规格与 H100/H200 差距过大,业内多视为“Ampere 时代”最后一款中国特供卡
- H910 系列显卡
- 亲自测试结论:
- 910B 约是 H800 的 1/4
- 910C 约是 H800 的 1/3?
- 亲自测试结论:
附录:GPU、NPU 和 TPU 辨析
- NPU(Neural Processing Unit,神经网络处理器)是专门为加速人工智能和深度学习任务设计的硬件芯片
- NPU 采用针对神经网络算法优化的指令集和硬件结构,如高效矩阵乘法单元、低精度数据处理能力,能以低功耗实现高性能计算,支持边缘智能,可在本地处理数据
- NPU 主要应用于智能手机、智能安防、自动驾驶、医疗等领域,如手机 AI 拍照、实时人脸识别等
- 华为的升腾 910B 就是 NPU
- TPU(Tensor Processing Unit,张量处理单元)是谷歌为加速机器学习工作负载,特别是 TensorFlow 框架下的深度学习任务而定制开发的专用集成电路
- TPU 采用定制化架构,针对张量运算优化,有高效矩阵乘法单元和专用内存结构,能在较低功耗下实现极高计算性能
- TPU 主要应用于大规模数据中心的深度学习训练和推理任务
- GPU(Graphics Processing Unit,图形处理器)是一种专门用于处理图形和图像相关运算的微处理器
- GPU 拥有大量流处理器,可并行处理多个线程,最初用于图形渲染,如游戏中的3D场景渲染等
- 因 GPU 强大的并行计算能力,也广泛应用于深度学习、科学计算、影音编辑和渲染等领域