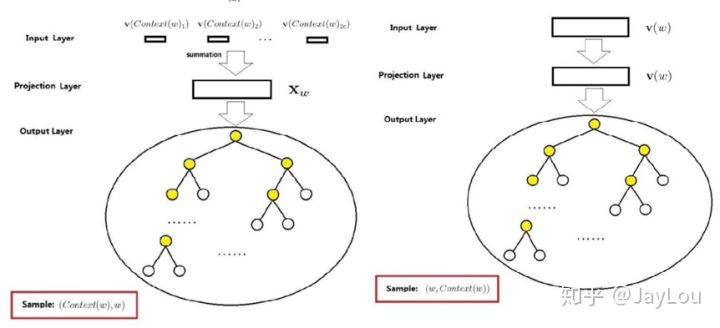
自定义的HashKey类
什么样的自定义类可以用作HashMap的Key?
- 实现了HashCode方法和equals方法的类
作为Key后的对象有什么要求?
- 该对象的值不能再修改,否则将导致containsKey找不到已经存储的Key
- 注意,Key值被修改后是无论如何都找不到的,因为hash对象变化导致hash方式变了
- 能正确找到hash桶的对象与目标对象(修改后的值)不相等
- 与对象与目标对象(修改后的值)相等的对象找不到正确的Hash桶
- 除非将修改的值改回来
拓展
- 如果是使用TreeMap,则不是考虑hashCode方法,而是其他方法