注:本文包含 AI 辅助创作
- 参考链接:
Paper Summary
- 总结:
- 之前的经验:模型性能的提升通常是以牺牲探索能力为代价的(降低熵),熵坍缩限制了性能的提升
- 在大量没有熵干预的 RL 训练中:策略熵在训练早期阶段急剧下降,收敛到一个过于自信的策略模型
- 本文尝试解决 LLM 推理的 RL 中策略熵崩溃的挑战
- 本文基于对熵的详细分析,引入了两种简单的正则化技术 ,Clip-Cov 和 KL-Cov ,来直接管理高协方差的 Token ,从而抵消熵崩溃
- 本文提出,实践时,在熵 \(\mathcal{H}\) 和下游性能 \(R\) 之间存在一个关系(经验定理)
$$ R = - a \exp \mathcal{H} + b $$- \(a, b\) 是拟合系数
- 注:策略性能和策略熵是负相关关系,最高性能是:
$$ (\mathcal{H} = 0,\quad R = - a + b) $$ - 论文观点:RL 训练过程中,管理熵是必要的
- 个人理解:这里的拟合公式在很多场景不一定成立,部分场景中,训练过程中熵会 下降->提升->下降,性能却持续在提升
- 但这里的设定也有一定的道理,若 RL 训练再提升
pass@1的效果时,一般就是变得越来越自信的过程,此时熵肯定会逐步下降
- 但这里的设定也有一定的道理,若 RL 训练再提升
- 作者推导: 策略熵的变化 是由 Action 概率和 Logits 变化之间的协方差驱动的
- 当使用类似策略梯度(Policy Gradient-like)的算法时,该协方差与其 Advantage 成正比
- 意味着,具有高 Advantage 的高概率 Action 会减少策略熵 ,而具有高 Advantage 的低概率 Action 则会增加策略熵
- 理解:鼓励高概率 Action 会减少熵,鼓励低概率 Action 会增加熵(大家概率都相等时熵最大)
- 实验结果:协方差项和熵差的值完全匹配
- 注:协方差项在训练过程中大多保持正值,所以策略熵会单调递减
- 本文通过限制高协方差 Token 的更新来激励控制熵,提出了两种简单而有效的技术,即 Clip-Cov 和 KL-Cov
- 分别对具有高协方差的 Token 进行裁剪和应用 KL 惩罚
- 实验结果:Clip-Cov 和 KL-Cov 正则化鼓励探索,从而帮助策略摆脱熵崩溃并获得更好的下游性能
Introduction and Discussion
- LLM RL 的核心问题:策略熵的减少
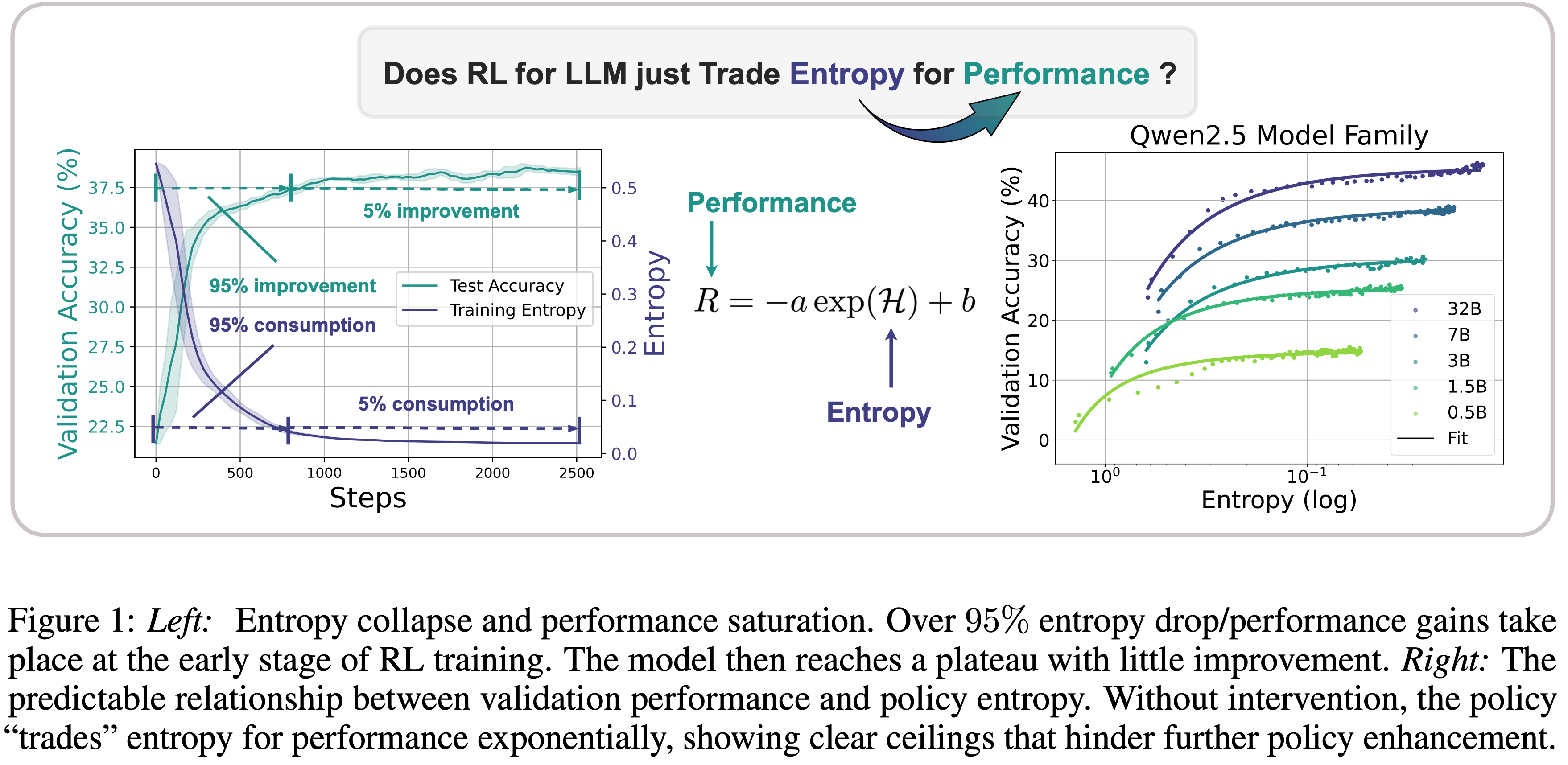
- 如 图 1 所示:
- 左图:熵崩溃与性能饱和
- 超过 \(95%\) 的熵降/性能增益发生在 RL 训练的早期阶段
- 模型随后达到一个平台期,几乎没有改进
- 右图:验证性能与策略熵之间的可预测关系
- 在没有干预的情况下,策略和熵的兑换关系是指数的
- 在没有干预的情况下,策略和熵的兑换关系是指数的
- 左图:熵崩溃与性能饱和
- 传统 RL 中:会有大量方法延缓熵降低的过程
- 对于 LLM RL,策略熵的典型行为在很大程度上仍未得到充分研究
- 作者从广泛的实验中发现了一个有趣且一致的模式:
- 策略熵在几个训练步骤内急剧下降到接近 0,表明策略变得极其确定
- 导致策略无法探索新路径导致性能平台期,验证性能同时也难以提升
- 作者进一步推导:
- 在没有熵干预(如熵损失或 KL 正则化)的情况下,下游性能完全可以由策略熵预测,拟合的曲线是一个简单的指数函数 (如图 1 所示)
$$ R = - a \exp \mathcal{H} + b$$- 从这个式子中可以看到,基本上,策略正以可预测的方式用不确定性(熵)来换取奖励
- 在没有熵干预(如熵损失或 KL 正则化)的情况下,下游性能完全可以由策略熵预测,拟合的曲线是一个简单的指数函数 (如图 1 所示)
- 关键的推论:
- (1) 如同缩放定律(Scaling Laws)(2020; 2022),给定策略模型和训练数据,探索-利用曲线是预先确定的
- 可以在 RL 的早期阶段预测策略性能,并根据小模型预测大模型的性能(OpenAI, 2024b)(第 2.4 节)
- (2) 这个方程表明策略性能的上限也是确定的,随着策略熵的耗尽
$$ \mathcal{H} = 0,\quad \bar{R} = - a + b $$- 此外,简单地应用熵正则化方法被证明是无效的(第 4.1 节)
- (1) 如同缩放定律(Scaling Laws)(2020; 2022),给定策略模型和训练数据,探索-利用曲线是预先确定的
- 作者从广泛的实验中发现了一个有趣且一致的模式:
- 为什么策略熵会单调递减?
- 第一:对于像 LLM 这样的 Softmax 策略,两个连续步骤之间的熵变化与 Action 的对数概率和相应 Logit 变化的协方差成正比 (2025)
- 第二:在类似策略梯度 和 类似自然策略梯度(Natural Policy Gradient-like)(2001)的算法下,Logit 差值与 Action Advantage 成正比
- 理解:具有高 Advantage 和高概率的 Action 会减少策略熵,而具有高 Advantage 的低概率 Action 则会增加熵
- 训练过程中的观察:
- 在早期阶段,策略在训练数据上表现出高协方差,暗示策略的置信度是良好校准的(2022),因此可以安全地利用高置信度的轨迹,加强信念并最小化熵(2025; 2025; 2025)
- 随着训练的进行,协方差逐渐下降但仍保持正值,持续将策略熵拉得更低
- 结论:高协方差对可扩展的 RL 是有害的
- 目标:限制高协方差 Token 的步长
- 方法: Clip-Cov 和 KL-Cov,替代代理损失中的裁剪和 PPO-KL 方法(2017b)
- Clip-Cov 随机选择一小部分具有正协方差的 Token 并 Detach 其梯度
- KL-Cov 对具有最大协方差的 Token 应用 KL 惩罚
The Predictable “Collapse” of Policy Entropy,策略熵的“可预测”崩溃
- takeaway
- 在没有干预(例如,熵或 KL 正则化)的情况下,策略熵在 RL 期间以可预测的方式换取奖励,详细关系见 图 1 和前面的分析
- 在没有干预(例如,熵或 KL 正则化)的情况下,策略熵在 RL 期间以可预测的方式换取奖励,详细关系见 图 1 和前面的分析
Preliminaries
- 本文考虑在可验证任务(如数学和编码)上使用 RL 微调 LLM(能避免奖励破解)
- 给定输入 Prompt \(\pmb{x}\),一个 LLM \(\pi_{\theta}\) 自回归地生成输出序列 \(\pmb{y}\),该序列由 \(T\) 个 Token \(\{y_{1},\dots ,y_{t},\dots ,y_{T}\}\) 组成
- 使用 RL 来优化 LLM 策略,以最大化从验证器接收的累积奖励 \(r\):
$$\max_{\theta}J(\theta):= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(x)}[r(y)] \tag {1}$$- \(\mathcal{D}\) 是训练分布
- 为了优化目标函数,通常使用策略梯度算法进行梯度估计:
$$\nabla_{\theta}J(\theta) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(x)}\left[\sum_{t = 0}^{T}\nabla_{\theta}\log \pi_{\theta}(y_{t}|y_{< t})A_{t}\right] \tag {2}$$- \(A_{t}\) 是当前 Action 的 Advantage,在不同的 RL 算法中有不同的实现
- REINFORCE:
$$A_t = r(\pmb{y})$$ - 为缩小方差:GRPO 为每个 prompt 采样 \(K\) 个 Response,并按如下方式估计优势:
$$
A_t = \frac{r(\pmb{y}) - \text{mean}\left(r\left(\pmb{y}^{1:K}\right)\right)}{\text{std}\left(r\left(\pmb{y}^{1:K}\right)\right)} \tag {3}
$$ - 为处理 off-policy 数据并约束策略更新的大小:PPO 提出优化一个替代损失函数:
$$
L(\theta) = \mathbb{E}_{t}\left[\min \left(\frac{\pi_{\theta}(y_{t}|\pmb{y}_{< t})}{\pi_{\theta_{\text{old} } }(y_{t}|\pmb{y}_{< t})} A_{t},\text{clip}\left(\frac{\pi_{\theta}(y_{t}|\pmb{y}_{< t})}{\pi_{\theta_{\text{old} } }(y_{t}|\pmb{y}_{< t})},1 - \epsilon ,1 + \epsilon\right)A_{t}\right)\right] \tag {4}
$$
- REINFORCE:
- \(A_{t}\) 是当前 Action 的 Advantage,在不同的 RL 算法中有不同的实现
Policy entropy
- 策略熵量化了 Agent 所选择动作中固有的可预测性或随机性
- 给定策略模型 \(\pi_{\theta}\) 和训练数据集 \(\mathcal{D}\),测量策略模型在训练数据上的平均 Token 级熵,其定义如下:
$$
\mathcal{H}(\pi_{\theta},\mathcal{D}) = -\mathbb{E}_{\mathcal{D},\pi_{\theta} }\left[\log \pi_{\theta}(y_t|\pmb{y}_{< t})\right] = -\frac{1}{|\mathcal{D}|}\sum_{x\in \mathcal{D} }\frac{1}{|\pmb{y}|}\sum_{t = 1}^{|\pmb{y}|}\mathbb{E}_{y_t\sim \pi_\theta}\left[\log \pi_\theta (y_t|\pmb{y}_{< t},x)\right] \tag {5}
$$ - 这种熵量化了策略在当前 prompts 上的不确定性水平,并被最大熵 RL 广泛采用作为正则化项 (2008; 2017, 2018)
- 在实践中,我们一般从训练数据集中随机采样的每个 prompt 批次计算熵
Settings
- 涵盖 4 个模型家族和 11 个基础模型(0.5-32B 参数),在 8 个公开基准上评估的可验证任务领域(数学和编码),以及 4 种 RL 算法
Models
- 采用的模型跨越 4 个模型家族和 11 个广泛使用的开源基础模型
- Qwen2.5 家族(Qwen2.5-0.5B, 1.5B, 3B, 7B, 32B)(2025)
- Mistral 家族(Mistral-7B-v0.3 (2023), Mistral-Nemo-Base-2407 (MistralAI-NeMo), Mistral-Small-3.1-24B-Base-2501 (MistralAI-Small-3))
- LLaMA 家族(LLaMA3.2-3B (Meta-Llama-3.2), LLaMA3.1-8B (Meta, 2024))
- DeepSeek-Math-7B-Base(2024)
Tasks and datasets
- 主要关注具有可验证奖励的数学和编码问题
- 由于模型家族之间初始推理能力的固有差异,使用不同难度的数据来训练模型以稳定 RL 过程(详细信息见附录 A)中找到
- 在下游性能评估中使用相同的数据以保持一致性
- 数学任务,包括 MATH500(2021),AIME 2024(2024),AMC(2024),OlympiadBench(2024)和 OMNI-MATH(2024)
- 编码任务,Eurus-2-RL-Code(2025)和 KodCode(2025)的测试集
RL training
- 从基础模型开始 RL,遵循“Zero”设置(DeepSeek-2025),使用 veRL 框架(2024)
- RL 算法,采用了 GRPO(2024),REINFORCE++(2025)和 PRIME(2025)
- 超参数:
- 对策略模型使用 \(5 \times 10^{- 7}\) 的学习率
- 对 PRIME 中的隐式 PRM(2025)使用 \(10^{- 6}\) 的学习率
- 策略和 PRM 都使用 256 的 Batch Size 和 128 的 Micro-Batch Size
- Rollout 阶段收集 512 个 Prompt
- 每个 Prompt 有 8 个采样的 Response
- 参考 KL 散度系数设置为 0
- 策略损失(方程 4)中的 \(\epsilon\) 是 0.2
- 过滤掉所有 Response 都正确或都错误的 Prompt
A First Glance: Entropy Collapse and Performance Saturation
- 所有实验中观察到一个一致的模式:
- 策略熵在训练一开始就急剧下降,并单调地降至接近零
- 策略的验证性能呈现相反的趋势,在训练开始时迅速上升,然后饱和在某个水平
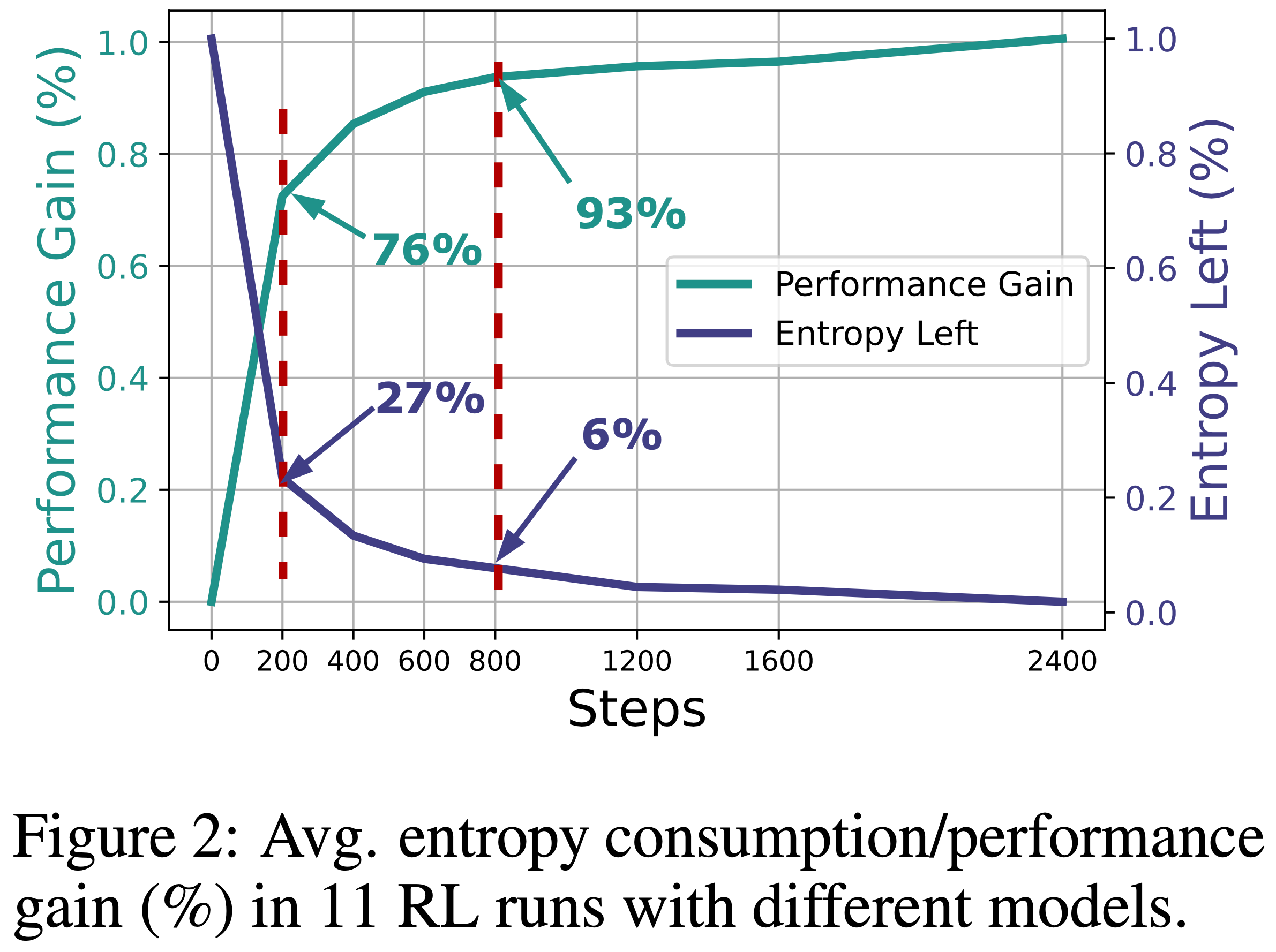
- 图 2 展示了在 11 个不同模型的 2400 步梯度步骤的 RL 运行中,平均归一化熵消耗/性能增益的百分比
- 可以看到,\(73%\) 的熵消耗和 \(76%\) 的性能增益仅发生在前 200 个梯度步骤(训练的 1/12),而前 800 个(1/3)步骤占了超过 \(93%\) 的性能增益和 \(94%\) 的熵损失
- 超过 2/3 的训练步骤产生的回报是微乎其微的
Fitting the Curves between Entropy and Performance,拟合熵与性能之间的曲线
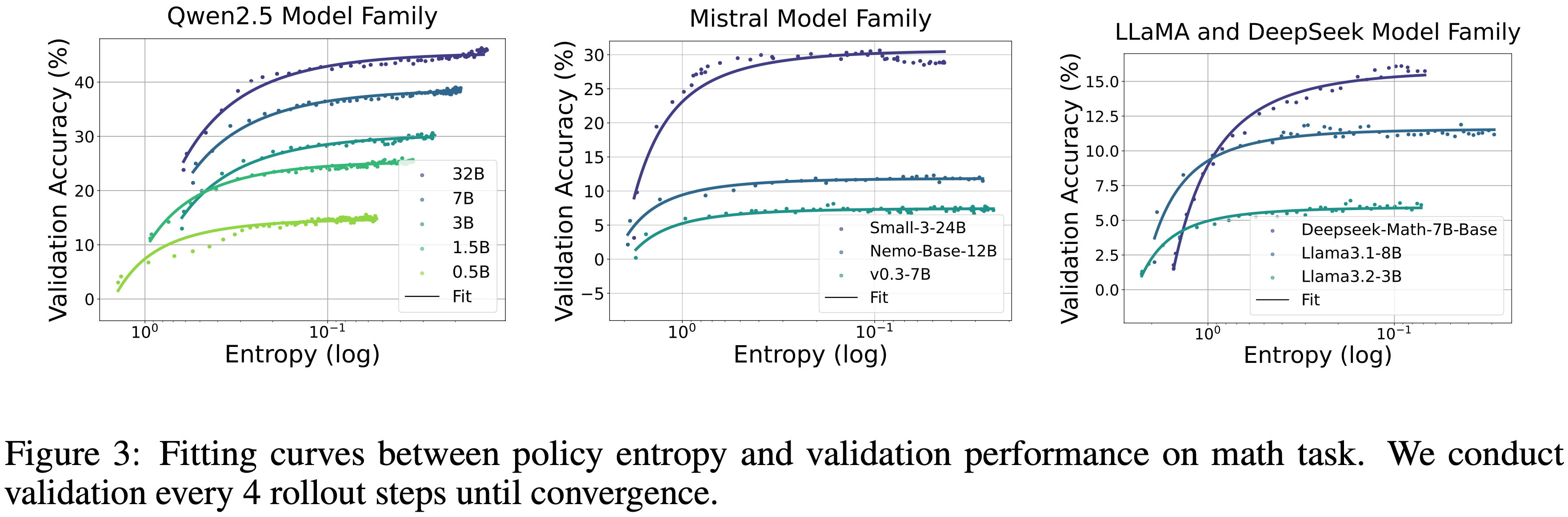
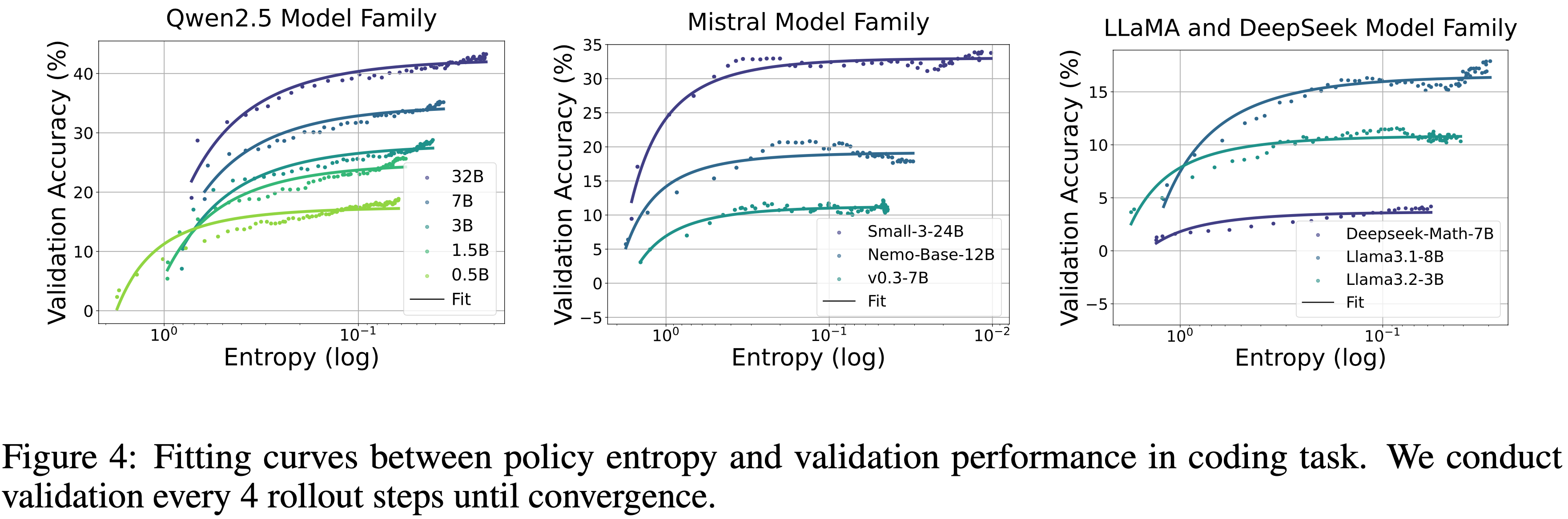
- 通过广泛的实验发现下游性能(准确率)和熵可以用指数函数拟合:
$$R = -a\exp (\mathcal{H}) + b \tag {6}$$- \(R\) 代表验证性能,\(\mathcal{H}\) 是熵
- 不同模型家族使用 GRPO 的拟合结果如图 3 和图 4 所示
- 拟合曲线精确地描述了在所有进行的实验中性能-熵的关系,这些实验涵盖了各种大小、家族和不同任务的模型
- 仅需 2 个系数即可拟合超过 200 个数据点的曲线,显示出高度的规律性(对 Instruct 模型 和使用不同数据集训练的拟合结果可以见附录 B)
Predicting late stage from early stage
- 公式 6 可以精确地拟合策略熵和验证性能之间的曲线,这种拟合的一个直接应用是利用高熵数据点的观察结果来预测低熵时的策略性能
- 为了验证函数形式可以在 RL 训练的早期阶段应用,可以更进一步,在有限的训练步数内拟合函数,并使用拟合出的函数来预测最终性能
- 以 Qwen2.5 家族为例,仅使用前 36 个训练步骤来拟合带有系数 \(a\) 和 \(b\) 的函数形式
- 使用这个函数,对后续 200 个训练步骤进行提前预测
- 如图 5 所示,对于数学和编码任务,在预测期间实现了 \(0.9%\) 和 \(1.2%\) 的平均均方根误差,最终性能的 RMSE 分别为 \(0.5%\) 和 \(1.9%\)
- 这表明策略的后期性能可以在训练早期进行估计,而无需运行整个 RL 过程
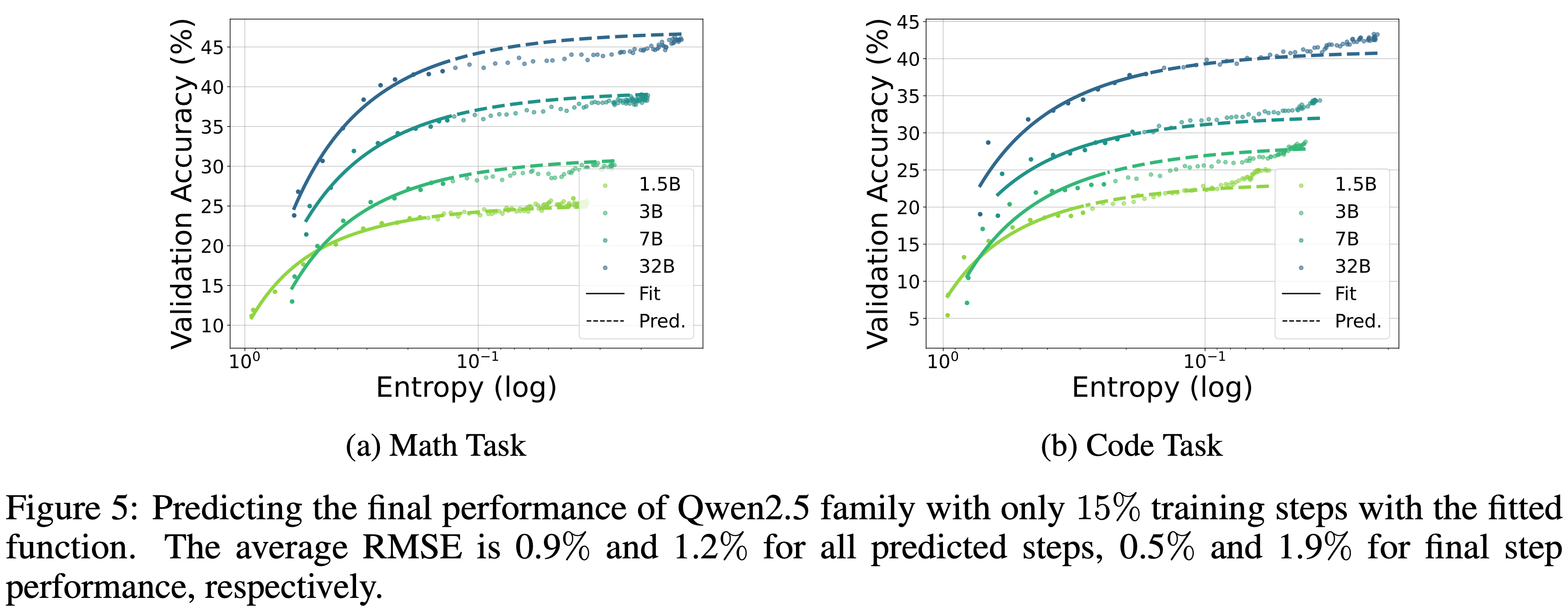
- 这表明策略的后期性能可以在训练早期进行估计,而无需运行整个 RL 过程
Understanding the Coefficients,系数理解
The coefficients are algorithm-irrelevant,系数与算法无关
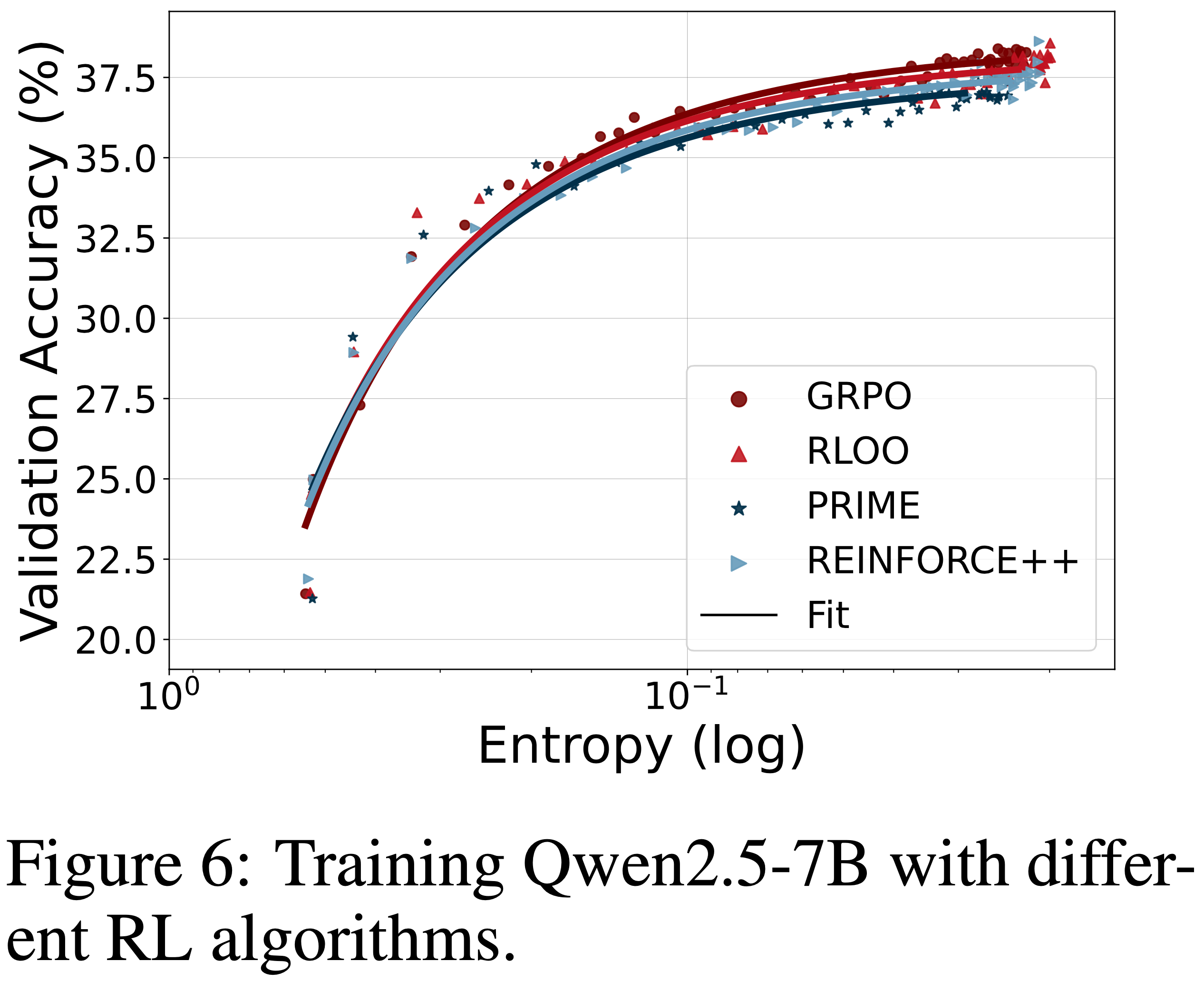
- 研究了不同的 RL 算法是否会影响拟合函数
- 图 6 绘制了使用 GRPO,RLOO 和 PRIME 的拟合曲线
- 尽管这些算法应用了不同的 Advantage 估计方法,但它们并不影响拟合的熵-性能函数
- 表明系数 \(a, b\) 反映了策略模型和训练数据的一些内在属性
Predicting coefficients when scaling parameters,在扩展参数时预测系数
- 通过对方程求导,得到
$$ \frac{dR}{d\mathcal{H}} = - a\exp (\mathcal{H}) $$- 这意味着 \(a\) 是模型将熵转换为下游性能的速率
- \(- a + b\) 是模型在熵完全耗尽时能达到的最大验证分数
- \(a, b\) 应该与模型大小相关,其中更大的模型可以更有效地将熵转化为奖励,并达到更高的性能
- 在 Qwen2.5 模型家族上(它们具有相似的架构并经历了相似的训练过程)
- 图 7 绘制了模型参数数量(不含嵌入)与数学和编码任务上的 \(a, b\) 的关系图
- 可以观察到 \(a\) 和 \(b\) 都随着策略大小的变化而以对数线性率平滑变化
- 作者观点(除了数学和代码外的其他场景存疑):
- 基于较小模型的训练动态来推断较大模型的系数,将可预测性扩展到模型大小的维度
- 一旦作者训练同一家族内的较小模型并获得其系数,就能够预测较大 LM 通过 RL 训练的最终性能,而无需实际训练它们
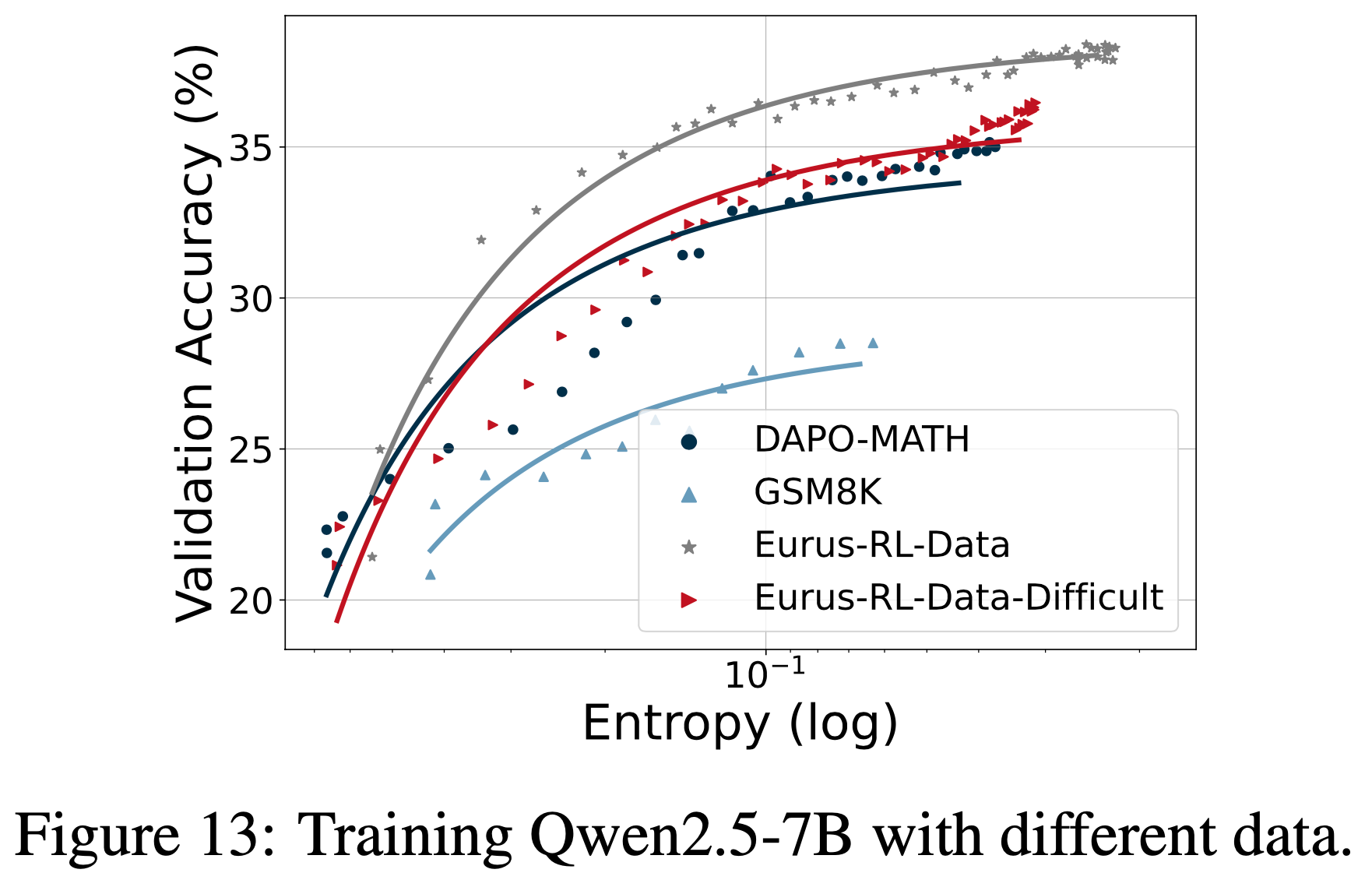
- 图 13 还说明了系数与训练数据相关
Discussion
The predictability,可预测性
- 目前为止已经建立了
- (1)策略性能与熵之间
- (2)公式中系数与模型大小之间的可预测性
- 作者认为:这类似与传统 LLM 预训练中的 Scaling Law
The ceiling
- 有一个激烈的讨论质疑 RL 是否仅仅引出了预训练中已学到的潜在行为,因此无法突破基础模型的天花板(2025)
- 本文结果有条件地支持这一说法,即如果策略熵减少,天花板不仅存在,而且可以预测
- 作者认为:
- 设定天花板的不是 RL 的内在限制,而是 LLM 的熵机制导致了这一结果
- LLM 提供了强大的策略先验,但其输出分布也被收窄了,这可能会阻碍 RL 期间的探索潜力
Dynamics Analysis of Policy Entropy
- TAKEAWAY
- (1) 对于包括 LLM 在内的 softmax 策略,策略熵的变化由 log 概率与 Action logits 变化之间的协方差决定
- (2) 对于策略梯度和自然策略梯度,logits 的变化与 Action 优势成正比,这意味着高协方差会导致策略熵迅速下降,正如在用于 LLM 推理的 RL 中观察到的那样
Entropy Dynamics of Softmax Policy,Softmax 策略的熵 Dynamics
- 对于步骤 \(k\),计算一次参数更新前后的熵差,即 \(\mathcal{H}(\pi_{\theta}^{k + 1})\) 和 \(\mathcal{H}(\pi_{\theta}^{k})\) 的差
- 首先考虑 LLM 的一个内在属性,即它们是 softmax 策略,这意味着策略由下式参数化:
$$\pi_{\theta}(a|s) = \frac{\exp(z_{s,a})}{\sum_{a^{\prime}\in \mathcal{A} }\exp(z_{s,a^{\prime} })} \tag {7}$$- \(s\sim d_{\pi_{\theta} }\) 和 \(a\sim \pi_{\theta}^{k}(|s)\) 分别表示状态和 Action
- \(z_{s,a}\) 是在给定状态 \(s\) 下 Action \(a\) 的输出 logit
- 对于任何 softmax 策略,有以下引理:
- 首先考虑 LLM 的一个内在属性,即它们是 softmax 策略,这意味着策略由下式参数化:
- Lemma1(Entropy difference of softmax policy) (证明见附录 E.2)
- 假设策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,其中每个状态-动作对 \((s,a)\) 与一个单独的 logit 相关联
$$ z_{s,a} = \theta_{s,a} $$- 理解:这里的 \(z_{s,a}\) 是 softmax 前的 logits 值
- 则在给定状态 \(s\) 下,两步之间策略熵的差在一阶近似下满足
$$
\begin{align}
\mathcal{H}(\pi_{\theta}^{k + 1}) - \mathcal{H}(\pi_{\theta}^{k}) &\approx \mathbb{E}_{s\sim d_{\pi_{\theta} } }\left[\mathcal{H}(\pi_{\theta}^{k + 1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s)\right] \\
&\approx \mathbb{E}_{s\sim d_{\pi_{\theta} } }\left[-Cov_{a\sim \pi_{\theta}^{k}(|s)}\left(\log \pi_{\theta}^{k}(a|s),z_{s,a}^{k + 1} - z_{s,a}^{k}\right)\right]
\end{align}
$$- \(z_{s,a}^{k+1} - z_{s,a}^{k}\) 是步骤 \(k\) 和步骤 \(k + 1\) 之间输出 logits 的变化
- 该引理表明:策略熵的变化近似等于 Action 的原始 log 概率与 logits 变化的负协方差
- 也就是说:当一个 Action \(a\) 在更新前从策略获得高概率,并且其相应的 logit 在更新后也在增加时,它将降低策略熵
- 理解:高概率的 Action,更新后变得更大了,协方差是正的,负的协方差是负的,也就是熵在减少
- 假设策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,其中每个状态-动作对 \((s,a)\) 与一个单独的 logit 相关联
Entropy Dynamics under Policy Gradient / Natural Policy Gradient Algorithms,策略梯度 / 自然策略梯度算法下的熵 Dynamics
- 从引理 1 可知,输出 logits 的 step-wise 差异 \(z_{s,a}^{k + 1} - z_{s,a}^{k}\) 会导致熵的变化,这与所使用的具体训练算法有关
- 本节进一步推导策略梯度和自然策略梯度算法下的 logits 变化
- 假设通过策略梯度更新 Actor 策略,那么
$$ z_{s,a}^{k + 1} - z_{s,a}^{k} = -\eta \cdot \nabla_{z}J(\theta)$$- \(J(\theta)\) 表示目标函数
- \(\eta\) 表示学习率
- \(\nabla_{z}J(\theta)\) 用公式 2 计算:
$$\nabla_{\theta}J(\theta) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(x)}\left[\sum_{t = 0}^{T}\nabla_{\theta}\log \pi_{\theta}(y_{t}|y_{< t})A_{t}\right] \tag {2}$$
- 假设通过策略梯度更新 Actor 策略,那么
- 有以下命题:
- Proposition 1 (Difference of policy logits in vanilla policy gradient) (证明见附录 E.3)
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并使用公式 2 通过梯度回传以学习率 \(\eta\) 进行更新,则两步之间 \(z_{s,a}\) 的差满足
$$z_{s,a}^{k + 1} - z_{s,a}^{k} = \eta \pi_{\theta}(a\mid s)A(s,a)$$ - 将命题 1 应用于引理 1,可以进一步用以下定理 1 描述熵的变化:
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并使用公式 2 通过梯度回传以学习率 \(\eta\) 进行更新,则两步之间 \(z_{s,a}\) 的差满足
- Theorem 1 (Entropy change under policy gradient)
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并且 \(\pi_{\theta}\) 通过 vanilla 策略梯度更新,则在给定状态 \(s\) 下,两步之间策略熵的差满足
$$\mathcal{H}(\pi_{\theta}^{k + 1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s)\approx -\eta \cdot Cov_{a\sim \pi_{\theta}^{k}(\cdot |s)}\left(\log \pi_{\theta}^{k}(a|s),\pi_{\theta}^{k}(a|s)\cdot A(s,a)\right)$$ - 定理 1 揭示了策略熵在策略梯度方法下如何变化
- 直观地说:如果一个 Action \(a\) 同时获得高/低概率和高/低优势,则会降低熵,反之亦然
- 在早期阶段,策略在训练数据上表现出高协方差,这意味着策略的置信度是良好校准的 (well-calibrated) (2022),因此可以安全地利用高置信度的轨迹,强化信念并最小化熵 (2025; 2025; 2025)
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并且 \(\pi_{\theta}\) 通过 vanilla 策略梯度更新,则在给定状态 \(s\) 下,两步之间策略熵的差满足
- Liu (2025) 对自然策略梯度进行了推导,在下面给出结论
- Theorem 2 (Entropy change under natural policy gradient) (证明见附录 E.4)
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并且 \(\pi_{\theta}\) 通过自然策略梯度 (2001) 更新,则在给定状态 \(s\) 下,两步之间策略熵的差满足
$$\mathcal{H}(\pi_{\theta}^{k + 1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s)\approx -\eta \cdot Cov_{a\sim \pi_{\theta}^{k}(\cdot |s)}\left(\log \pi_{\theta}^{k}(a|s),A(s,a)\right)$$
- 令 Actor 策略 \(\pi_{\theta}\) 是一个表格型 softmax 策略,并且 \(\pi_{\theta}\) 通过自然策略梯度 (2001) 更新,则在给定状态 \(s\) 下,两步之间策略熵的差满足
- Conclusion
- 从定理 1 和定理 2 中可获得直观的 Insight:
- 如果当前策略下的 Action 概率 \(P(a)\) 与相应优势值 \(A(a)\) 之间存在强正相关,则会降低熵
- 当前就是这个情况偏多,所以平均而言,这些更新会导致策略熵降低
- 如果(仅仅是假设) 当前策略下的 Action 概率 \(P(a)\) 与相应优势值 \(A(a)\) 负相关,则会增加熵
- 如果当前策略下的 Action 概率 \(P(a)\) 与相应优势值 \(A(a)\) 之间存在强正相关,则会降低熵
- 从定理 1 和定理 2 中可获得直观的 Insight:
Empirical Verification
- 前面的理论分析提供了通过策略梯度算法优化 softmax 策略时影响策略熵的因素的 Insight
- 本节通过实验来验证理论结论,特别是定理 1
Setting
- 在 Qwen2.5-7B 上应用带有策略梯度的 GRPO,即在没有 PPO 代理损失(理解:Clip 损失)的情况下进行 on-policy 学习
- 在此背景下,采用 bandit 设置(多臂老虎机形式),其中 Prompt \(x\) 是状态,整个 Response \(y\) 是 Action,那么协方差项变为:
$$Cov_{a\sim \pi_{\theta}(\cdot |s)}\left(\log \pi_{\theta}(a\mid s),\pi_{\theta}(a\mid s)\cdot A(s,a)\right) = Cov_{y\sim \pi_{\theta}(\cdot |x)}\left(\log \pi_{\theta}(y\mid x),\pi_{\theta}(y\mid x)\cdot A(y,x)\right) \tag {8}$$ - 在训练期间,计算每个 Prompt 的分组协方差,并在一批 Prompts 上取平均
- 进一步用 Response 的长度对 log 概率进行归一化,得到
$$\log \pi_{\theta}(\pmb {y}\mid \pmb {x}) = \frac{1}{|\pmb{y}|}\sum_{t = 1}^{|\pmb{y}|}\log \pi_{\theta}(y_t\mid \pmb{y}_{< t},\pmb {x}) \tag {9}$$- 理解:如果不进行归一化,会导致序列越长的 Response,\(\log \pi_{\theta}(\pmb {y}\mid \pmb {x})\) 越小
Experiment Results
- 本节记录了基于上述推导的两个关键指标 \(Cov(\cdot)\) 和 \(\mathcal{H}(\pi_{\theta})\) 在整个训练期间的情况,并试图分析它们的关系和动态
- 1)\(Cov(\cdot)\) 和 \(-d(\mathcal{H})\) 动态之间的相似性
- 根据定理 1,有理论结果 \(-d(\mathcal{H}) \propto Cov(\cdot)\)
- 如图 8 左侧所示
- \(-d(\mathcal{H})\) 和 \(Cov(\cdot)\) 的经验曲线表现出高度相似的动态,为定理提供了强有力的实证支持
- 在训练的早期阶段,熵 \(\mathcal{H}\) 迅速下降,伴随着相对较大且为正的 \(Cov(\cdot)\)
- 随着 RL 训练的进行,熵衰减减慢,\(Cov(\cdot)\) 稳定在较低水平,反映了策略的逐渐收敛
- 其他发现: \(Cov(\cdot)\) 在整个训练过程中保持正值,从而导致熵持续下降
- 2)不同难度样本间 \(Cov(\cdot)\) 动态的变化
- 利用基于分组的采样策略,根据训练样本的准确率对其难度进行分类
- 图 8 右侧展示了三个难度组的协方差曲线,其中较低的准确率表示较高的难度
- 观察结果: \(Cov(\cdot)\) 对于较难的样本往往幅度较小,这与直觉相符:
- 当模型难以学习时,高概率的 Action 并不总是与较高的预期回报可靠地关联
- 对于较简单的样本,模型更自信且校准得更好,\(Cov(\cdot)\) 往往更高,表明 Action 概率与优势估计之间的一致性更强
- 图 8:
- 左图:在 on-policy GRPO 训练期间策略熵( step-wise 熵差)和协方差的动态变化
- 与理论结果预期相似的趋势:两者变化几乎同步
- 右图:不同的 Prompt 组表现出不同的协方差行为
- 准确率较高的简单 Prompt 具有较高的协方差
- 准确率较低的较难 Prompt 具有较低的协方差
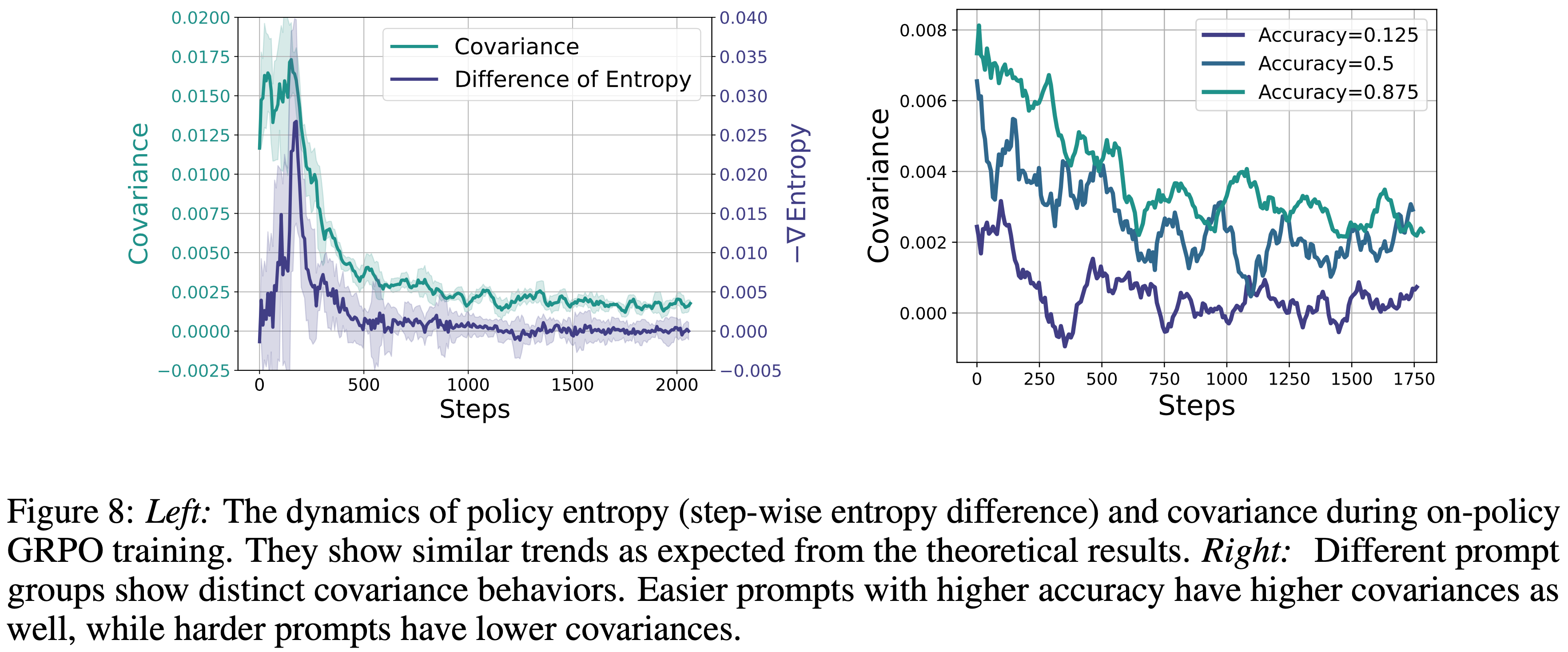
- 左图:在 on-policy GRPO 训练期间策略熵( step-wise 熵差)和协方差的动态变化
Entropy Control by Covariance Regularization,通过协方差正则化控制熵
- TAKEAWAY
- 可以通过限制高协方差 Token 的更新来控制策略熵,例如,裁剪 (Clip-Cov) 或应用 KL 惩罚 (KL-Cov)
- 这些简单的技术可以防止策略熵崩溃,从而促进探索
Effect of Entropy Regularization
- RL 文献中控制策略熵的一种常见方法是应用熵损失 (entropy loss) (2017b)
- 本节进行实验看看这对 LLM 是否有效
- 图 9 展示了添加熵损失的结果,如图所示:
- 熵损失对系数高度敏感
- 小的系数对熵影响不大 (0.0001, 0.001)
- 大的系数会导致熵爆炸 (0.01),注:这里熵爆炸的原因是模型只往熵小的方向优化了
- 将系数设置为 0.005 成功地稳定了策略熵,但它的表现并没有优于其他基线
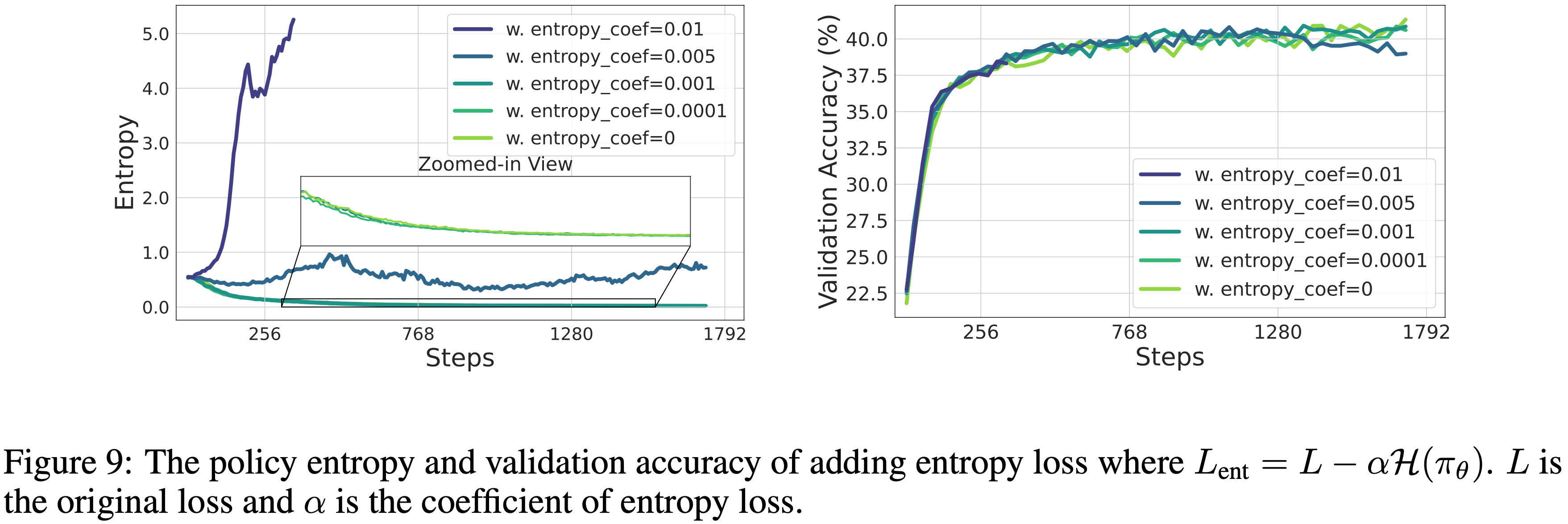
- 熵损失对系数高度敏感
- 图 10 中展示了通过调整策略模型和参考模型之间的 KL 惩罚来控制熵的结果
- 参考 KL 实现了稳定的熵值,但它未能改善策略,反而导致性能下降
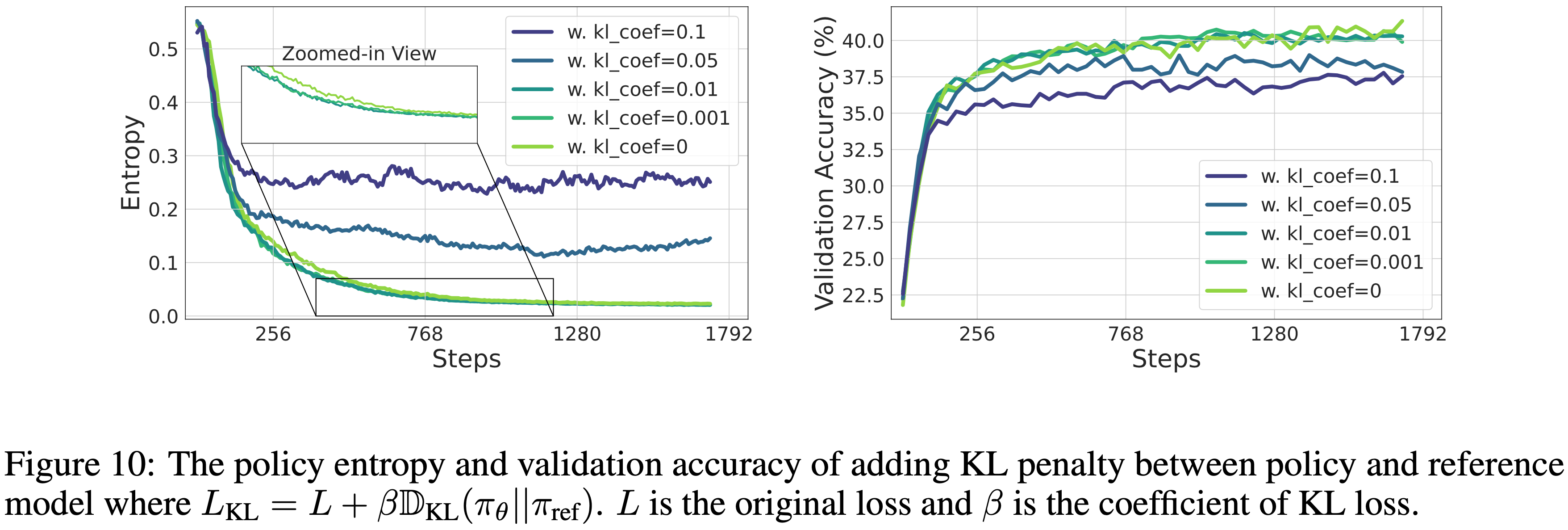
- 参考 KL 实现了稳定的熵值,但它未能改善策略,反而导致性能下降
- 从传统 RL 中直接采用熵正则化技术难以解决 LLM 的熵瓶颈
- 这些正则化项要么对超参数敏感 (2025),要么会降低策略性能
- 所以,最近的大多数工作也不包含它们 (2025; 2025; 2025; 2025)
Suppressing Tokens with High Covariances,抑制高协方差的 Token
- 已知策略熵动态与 Action 概率和优势之间的协方差密切相关
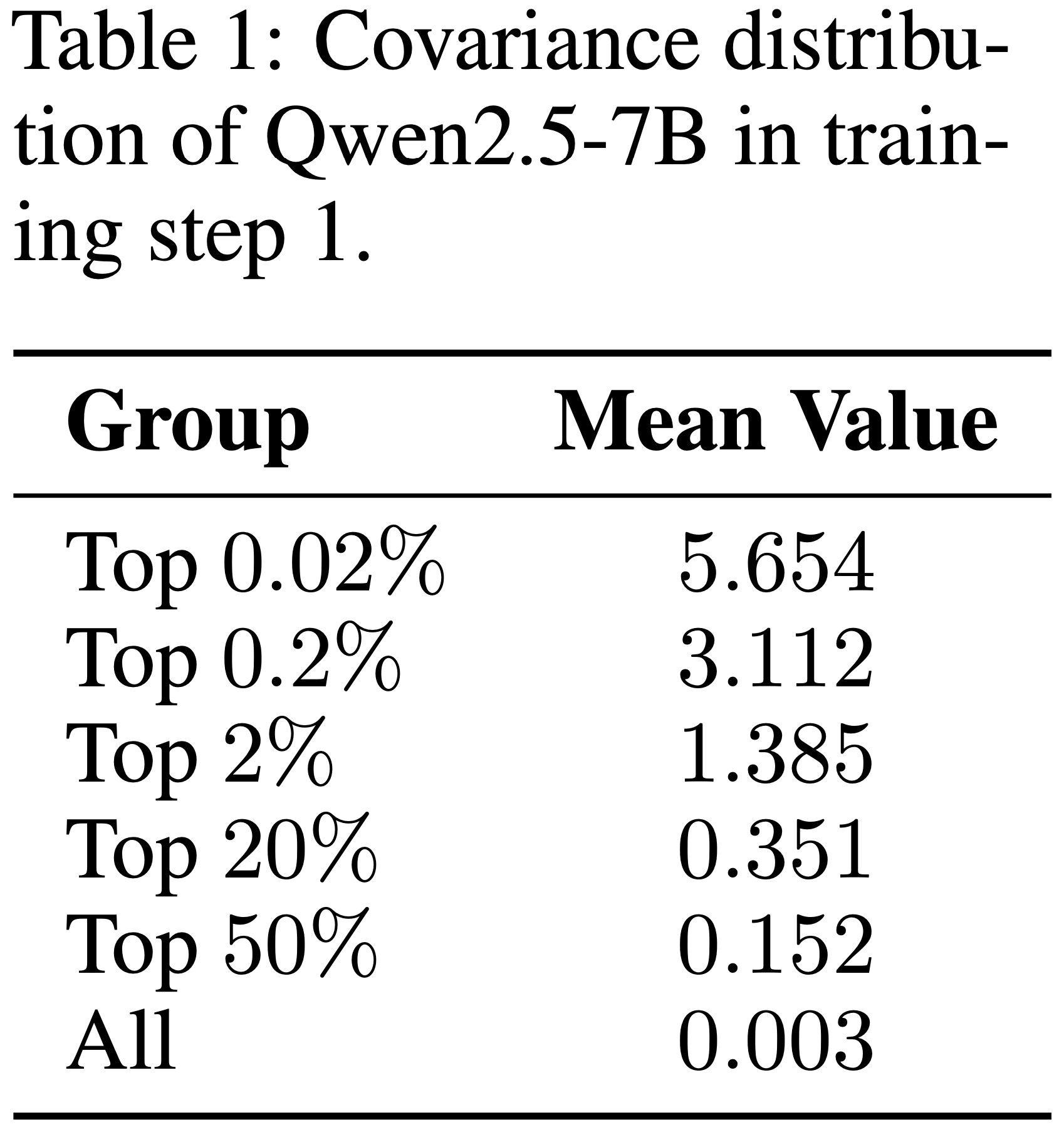
- 如表 1 所示,一小部分 Token 表现出极高的协方差,远远超过平均值
- 也就是说这些离群的 Token 在引发熵崩溃中起主导作用
- 为了减轻它们的不利影响,可以它们对策略损失的贡献施加约束
- 在 RL 文献中,PPO 的两个变体使用裁剪或 KL 惩罚来约束策略更新 (2017b),防止过于激进的变化
- 受这些方法的启发,本文提出了两种简单而有效的协方差感知方法:Clip-Cov 和 KL-Cov 来实现这一目标
- 自然策略梯度很少用于 LLM 的后训练,因为它需要耗时的二阶优化
- 但它引入的以 KL 距离为约束的目标函数与 TRPO (2015) 和 PPO 有着相似的理念
- 本节稍后将定理 2 应用于像 PPO 这样的算法
- 假设有 \(N\) 个 Rollout Token,\(\pi_{\theta}(y_{i})\) 表示策略模型在给定其相应前缀的情况下对 Token \(y_{i}\) 的输出概率
- 根据定理 2,首先定义 Token 级别的 log 概率与优势之间的中心化叉积为:
$$Cov(y_{i}) = (\log \pi_{\theta}(y_{i}) - \frac{1}{N}\sum_{j = 1}^{N}\log \pi_{\theta}(y_{j}))\cdot (A(y_{i}) - \frac{1}{N}\sum_{j = 1}^{N}A(y_{j})) \tag {10}$$- \(Cov\) 是 \(N\) 个 Rollout 中每个 Token 的协方差
- 理解:根据协方差的定义公式得到上述公式:
- 总体协方差
$$
\text{Cov}(X,Y) = \boldsymbol{E}\big[(X-\boldsymbol{E}X)(Y-\boldsymbol{E}Y)\big] = \boldsymbol{E}(XY)-\boldsymbol{E}(X)\boldsymbol{E}(Y)
$$ - 离散样本协方差
$$
\text{Cov}(X,Y) = \frac{1}{n-1}\sum_{i=1}^n (x_i-\bar{x})(y_i-\bar{y})
$$
- 总体协方差
- 其期望就是定理 2 中的协方差
- 根据定理 2,首先定义 Token 级别的 log 概率与优势之间的中心化叉积为:
Clip-Cov
- 在 Clip-Cov 策略中,按如下方式从策略梯度更新中裁剪出一小部分高协方差的 Token
- 通过公式 10 计算后,根据协方差值随机选择 \(r\cdot N\) 个高协方差的 Token:
$$I_{\text{clip} } = I\sim \text{Uniform}(i\mid Cov(y_{i})\in [\omega_{\text{low} },\omega_{\text{high} }]),[r\cdot N]) \tag {11}$$- \(I\) 是索引的缩写
- \(r\) 表示裁剪比例
- \(\omega_{\text{low} },\omega_{\text{high} }\) 是两个预定义的协方差边界,分别设置
- 两者都设置得远高于平均协方差 (\(>500\times\))
- 问题:只需要下界 \(\omega_{\text{low} }\) 就够了吧,为什么需要上界 \(\omega_{\text{high} }\)
- 所选索引的 Token 将 Detach 策略梯度(Mask 梯度),即:
$$
L_{\text{clip-Cov} }(\theta) =
\begin{cases}
\mathbb{E}_t\left[\frac{\pi_{\theta}(y_t|\mathbf{y}_{< t})}{\pi_{\theta_{\text{old} } }(y_t|\mathbf{y}_{< t})} A_t\right], & t\notin I_{\text{clip} }\\
0, & t\in I_{\text{clip} }
\end{cases}
\tag {12}
$$- \(t\) 是一个 Rollout Response 中的第 \(t\) 个 Token,并且每个 \(t\) 唯一对应于 \(N\) 中的一个索引 \(i\)
KL-Cov
- KL-Cov 策略更简单
- 首先计算公式 10 中的协方差
- 然后排序并选择协方差排在前 \(k\) 比例的 Token:
$$I_{\text{KL} } = \{i\mid \text{Rank}(Cov(y_i))\leq k\cdot N\} \tag {13}$$- 这里的 \(k\) 表示将受到 KL 惩罚的 Token 比例,且 \(k\ll 1\)
- 最后对选定的 Token 施加 KL 惩罚(当前策略与 Rollout 策略之间的 KL 散度),策略损失计算如下:
$$
L_{\text{KL-Cov} }(\theta) =
\begin{cases}
\mathbb{E}_t\left[\frac{\pi_{\theta}(y_t|\mathbf{y}_{< t})}{\pi_{\theta_{\text{old} } }(y_t|\mathbf{y}_{< t})} A_t\right], & t\notin I_{\text{KL} }\\
\mathbb{E}_t\left[\frac{\pi_{\theta}(y_t|\mathbf{y}_{< t})}{\pi_{\theta_{\text{old} } }(y_t|\mathbf{y}_{< t})} A_t - \beta \mathbb{D}_{\text{KL} }(\pi_{\theta_{\text{old} } }(y_t|\mathbf{y}_{< t})||\pi_{\theta}(y_t|\mathbf{y}_{< t}))\right], & t\in I_{\text{KL} }
\end{cases}
\tag {14}$$- 其中 \(\beta\) 是控制 KL 惩罚权重的系数
- 在代码清单 1 中展示了伪代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def compute_policy_loss(old_log_prob , log_prob , advantages , select_ratio, method, **args):
ratio = exp(log_prob - old_log_prob) pg_losses1 = -ratio * advantages
# calculate token wise centered cross - product
covs = (log_prob - log_prob.mean()) * (advantages - advantages.mean ())
select_num = int(select_ratio * len(pg_losses1))
if method == "clip_cov":
pg_losses2 = -clip(ratio, args["clip_range_lb"], args["clip_range_ub"]) * advantages
# randomly select index to be detached
clip_idx = random_select(covs[covs > args["cov_lb"] & covs < args["cov_ub"]], num=select_num)
pg_losses1[clip_idx].detach_() + pg_losses2[clip_idx].detach_()
pg_loss = maximum(pg_losses1 , pg_losses2).mean()
if method == "kl_cov":
kl_coef = args["kl_coef"]
kl_penalty = (log_prob - old_log_prob).abs()
# pg_losses = pg_losses1 + kl_coef * kl_penalty
# find out index with highest conviriance
select_idx = topk(covs, k=select_num, largest=True)
# apply KL penalty of these samples
pg_losses1[select_idx] += kl_coef * kl_penalty[select_idx]
pg_loss = pg_losses1.mean()
return pg_loss
Experiments
Settings
- 在数学任务上训练 Qwen2.5 模型,使用 DAPOMATH 数据集 (2025) 进行训练
- 在每个 Rollout 步骤中
- 为一批 256 个 Prompt 中的每一个采样 8 个 Response
- 温度为 1
- 对收集到的 Response 执行 8 次策略更新(8 个 Off-policy 步骤)
- 过滤掉全对或全错的 Prompt
- 测试数据集包括 MATH500, AIME 2024, AIME 2025 (2024), AMC, OMNI-MATH, OlympiadBench 和 Minerva (2022)
- 在评估期间,将 AIME 和 AMC 的 Rollout 温度设置为 0.6,而对所有其他测试集使用贪心解码
- 对于基线,比较原始 GRPO 和带有 Clip-higher 的 GRPO(将 PPO 损失中的上限阈值 \(\epsilon\) 调整为 0.28)
- 本文超参
- 在 Clip-Cov 中:
- 裁剪比例 \(r\) 为 \(2 \times 10^{- 4}\)
- \(\omega_{\text{low} } = 1\)
- \(\omega_{\text{high} } = 5\)
- 对于 KL-Cov
- \(k\) 对于 Qwen2.5-7B 和 32B 分别设置为 \(2 \times 10^{- 3}\) 和 \(2 \times 10^{- 4}\)
- KL 系数 \(\beta\) 设置为 1
- 最大生成长度为 8192
- 在 Clip-Cov 中:
Results and analysis
- 表 2 中展示实验结果,可以看到两种方法在所有基准测试中都取得了不俗的提升
- 与 GRPO 相比,本文方法在 7B 模型上平均高出 \(2.0%\),在 32B 模型上平均高出 \(6.4%\)
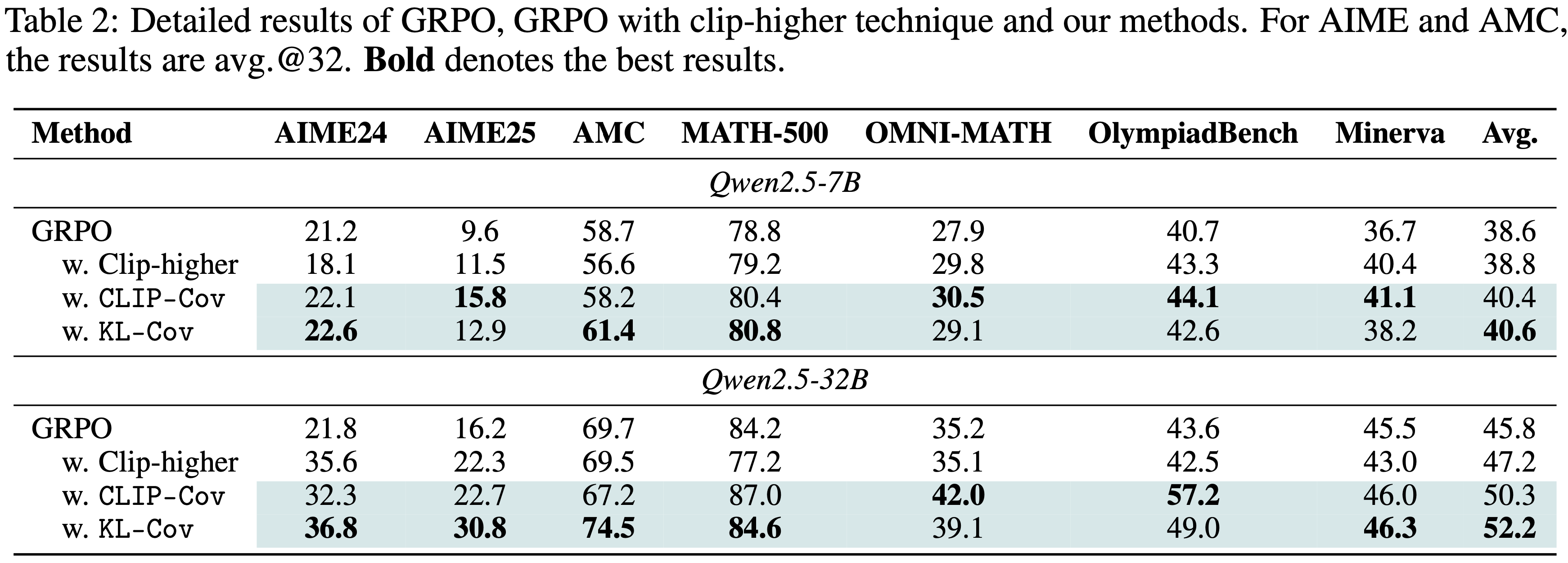
- 与 GRPO 相比,本文方法在 7B 模型上平均高出 \(2.0%\),在 32B 模型上平均高出 \(6.4%\)
- 如图 11 所示,本文方法能够在整个训练过程中维持相当高的熵水平
- 当基线的熵达到平稳期且无法再被消耗时,KL-Cov 方法仍然保持着高出 \(10\times\) 以上的熵水平
- 策略模型的 Response 长度稳步增加,其在测试集上的表现持续超越基线
- 这表明:模型能够在训练期间更“自由地”探索,通过 RL 学习到更好的策略
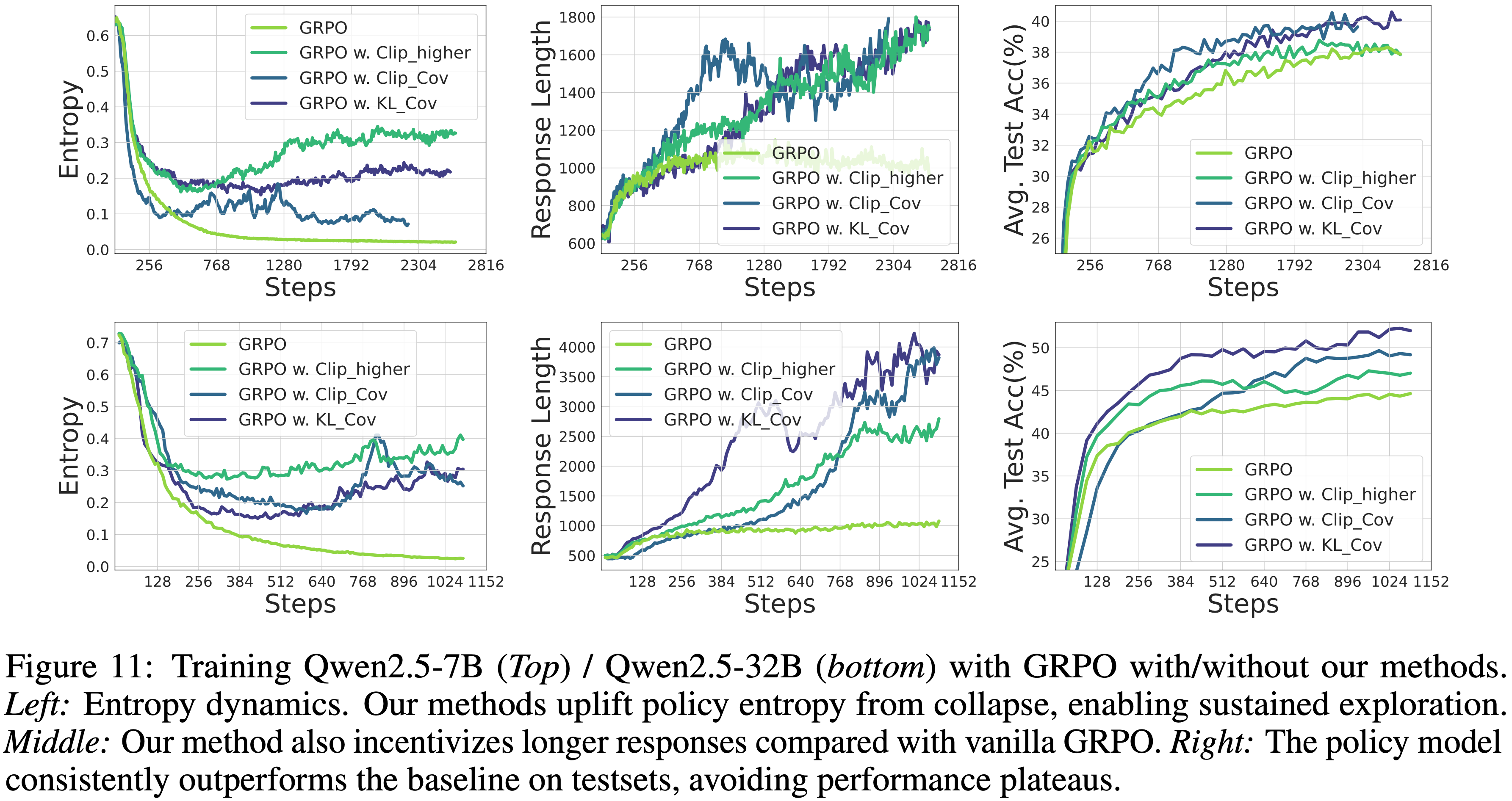
- 对比 clip-higher
- clip-higher 技术也可以在训练早期增加熵并带来性能提升,但它逐渐变得不稳定,性能出现饱和并下降
- 本文方法在整个训练过程中获得了更稳定的熵曲线,最终取得了比基线更显著的改进
- 注:本文方法在更大的 Qwen2.5-32B 上产生了更显著的收益
- 在最具挑战性的基准 AIME24 和 AIME25 上,本文方法相比 GRPO 分别实现了 \(15.0%\) 和 \(14.6%\) 的提升
- 作者推断这是因为 32B 模型相比 7B 模型具有更大的预训练潜力
- 一旦由熵崩溃引起的“探索诅咒(exploration curse)”被解除,32B 模型就能够探索更多样化和更高质量的策略
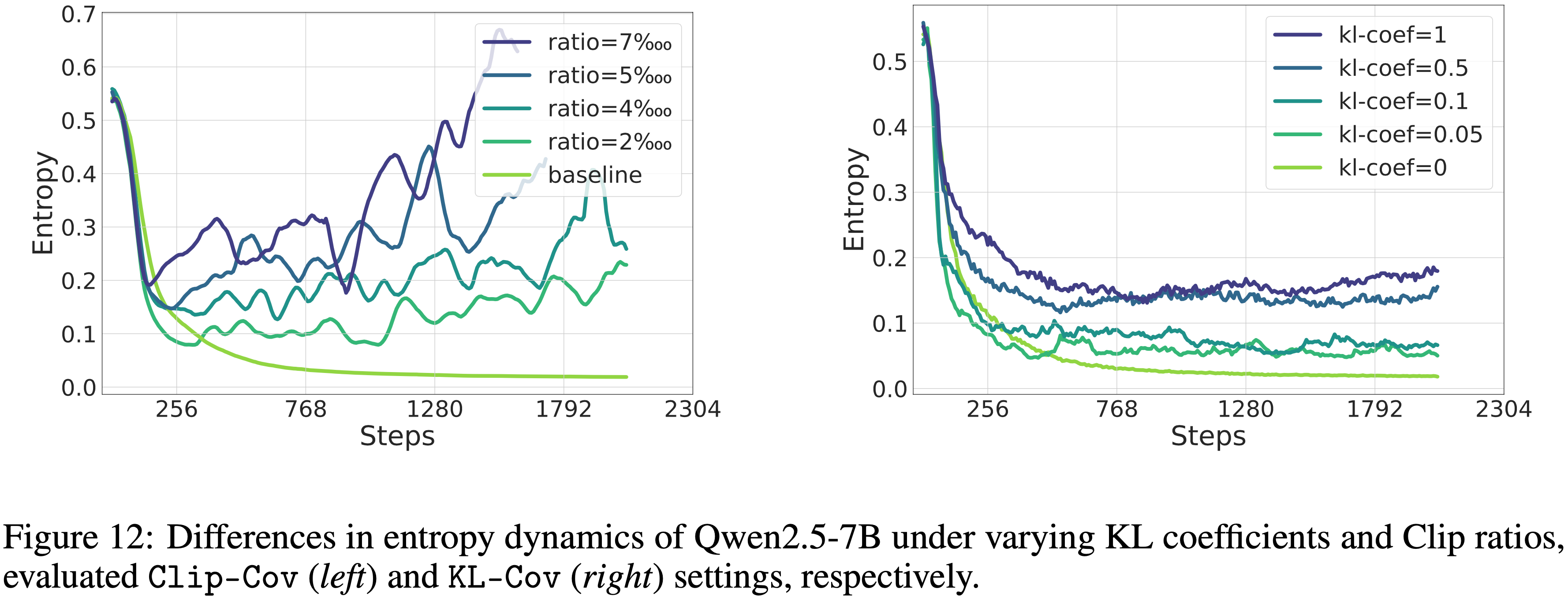
Get Policy Entropy Controlled,控制策略熵
- 本节评估本文方法控制策略熵的能力
- 图 12 所示
- 对于 Clip-Cov,策略熵的水平可以通过调整裁剪样本的比例来调节,裁剪的样本越多,熵越高
- 对于 KL-Cov,可以通过控制 KL 系数 \(\beta\) 来调节熵,即 KL 惩罚的权重,系数越大,熵越高
- KL-Cov 达到了比 Clip-Cov 更稳定的熵曲线,这可能更有利于稳定训练过程
- 不同场景下熵的最优值仍然是一个悬而未决的问题,但本文方法表明,可以简单地调整超参数来控制策略熵,从而能够引导熵并使模型更有效地探索
- 不同场景下熵的最优值仍然是一个悬而未决的问题,但本文方法表明,可以简单地调整超参数来控制策略熵,从而能够引导熵并使模型更有效地探索
Discussion
Connection with clip-higher
- 主要基线方法 clip-higher (2025) 也可以激励更高的策略熵,这种技术与本文方法具有相似的功能
- 通过提高重要性采样比率的上升阈值
- 1)clip-higher 包含了更多低概率的 Token 用于策略更新
- 2)上升阈值仅影响具有正优势的 Token
- 上述两点意味着 clip-higher 实际上是在梯度计算中添加了更多低协方差 (低概率,高优势 ,平均协方差约为 \(0.03\))的 Token
- 通过提高重要性采样比率的上升阈值
- 本文方法更进一步,直接使用协方差作为阈值,从而更精确地控制熵
The philosophy of entropy control,熵控制的理念
- 策略熵对超参数设置很敏感
- 本文方法只干预了极小部分的 Token(\(10^{- 4}\) 到 \(10^{- 3}\)),却完全改变了熵曲线
- 这意味着少数“关键 (pivotal)” Token 对于 LLM 的熵至关重要
- 注:目前没有观察到干预的熵与模型性能之间的关系
- 是否存在一个最优的熵值来平衡探索和训练稳定性仍然是一个待解决问题
补充:Related Work
Policy entropy in reinforcement learning
- 熵源于信息论,为管理利用与探索的权衡提供了一种有原则的机制
- 熵正则化 RL ,也称为最大熵 RL (maximum entropy RL) (2008; 2009),在奖励中采用正则化项来鼓励高熵 Action
- 这个正则化项被广泛地继承在 RL 算法中 (2015, 2016; 2017a; 2017, 2018),并被视为一种必需品
- 在用于 LLM 的 RL 中,关于是否应该保留熵正则化存在不同意见 (2022; 2024; 2025; 2025)
- 本文实验表明,控制熵是必要的,但可以设计比熵损失更好的目标
Predictability of reinforcement learning for reasoning language models,用于推理语言模型的 RL 的可预测性
- 这项工作的第一部分揭示了用于 LLM 推理的 RL 的可预测性
- LLM 的发展很大程度上受到神经缩放定律的指导,该定律将模型性能与计算预算、模型大小和训练数据量联系起来 (2017; 2020; 2022)
- 通过对较小模型进行缩放实验,可以准确预测较大模型的损失和任务性能
- 在 RL 中,Hilton 等人 (2023); Rybkin 等人 (2025) 研究了非 LLM 模型上策略性能与计算量的缩放行为,但用于 LLM 的 RL 的可预测性还有待研究
- Gao 等人 (2022) 提出根据 LLM 上 RL 中的 KL 散度来预测奖励分数,用于模拟代理奖励模型的过优化效应
- 这项工作与作者的结论一致,因为:
- 1)可验证的奖励消除了代理奖励模型与真实情况之间的差距
- 2)KL 散度与策略熵之间的相似性
- 这项工作与作者的结论一致,因为:
Reinforcement learning for LLMs
- RL 已成为 LLM 后训练的主要方法 (2022; 2024; 2023; 2025; 2023)
- 最近的工作通过使用具有可验证奖励的 RL 在增强 LLM 的推理能力方面取得了进一步的突破 (OpenAI, 2024a; 2024; DeepSeek-2025; 2025),引起了研究界的极大关注 (2025; 2025; 2025; 2025)
- 目前仍然缺乏对用于 LLM 的 RL 底层机制的系统研究,这是本文的主要目标
附录 A:Training Details for Different Models
- 由于不同模型家族之间初始推理能力的固有差异,本文使用不同难度的数据来训练模型,以稳定 RL 过程
- 对于数学任务
- 训练:
- 使用 Eurus-2-RL-Math (2025) 训练 Qwen 家族和 Mistral-24B 模型
- 其他模型家族则使用 GSM8K (2021) 进行训练
- 评估:
- 使用 MATH500 (2021)、AIME 2024 (2024)、AMC (2024)、OlympiadBench (2024) 和 OMNI-MATH (2024) 进行评估
- 训练:
- 对于代码任务
- 使用 AceCode (2025)、Eurus-2-RL-Code (2025) 和 Kodcode\(^{3}\) 训练 Qwen 家族和 Mistral-24B 模型
- 对于数学任务
附录 B:More Fitting Results
- 并未看到新增的结果
附录 C:Fitting Results of Training with Different Dataset,使用不同数据集训练的拟合结果
- 图 13:在不同数据上训练 Qwen2.5-7B
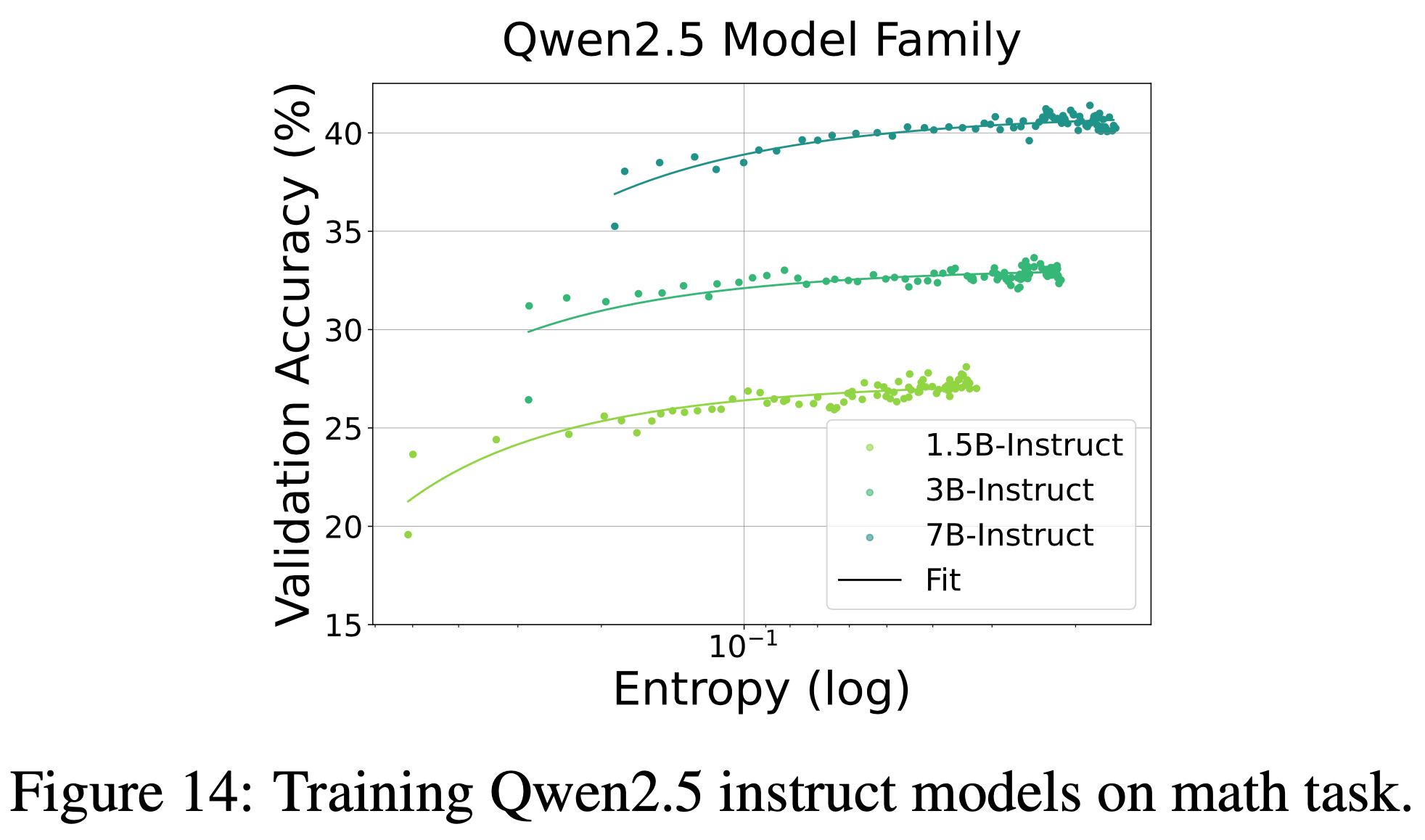
附录 D:Fitting Results of Instruct Models, Instruct 模型 的拟合结果
- 本节在 Instruct 模型 上进行了拟合实验,拟合函数在本文实验中仍然有效,在此展示拟合结果
- 图 14:在数学任务上训练 Qwen2.5 Instruct 模型
附录 E:Proof
E.1 Useful Lemmas
- 引理 2 (Softmax 函数的导数)
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a’} } = \mathbf{1}\{a = a’\} - \pi_{\theta}(a’ | s)
$$ - 引理 3 (给定状态 \(s\) 的优势函数期望)
$$
\begin{aligned}
\mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [A^{\pi_{\theta} }(s, a)] &= \mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [Q^{\pi_{\theta} }(s, a) - V^{\pi_{\theta} }(s)] \\
&= \mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [Q(s, a)] - \mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [V(s)] \\
&= V(s) - V(s) \\
&= 0
\end{aligned}
$$ - 补充:引理 2 的证明
- 将策略 \(\pi_{\theta}(a|s)\) 取对数,将除法转换为减法:
$$
\log \pi_{\theta}(a | s) = \log \left( \frac{\exp(z_{s,a})}{\sum_{j} \exp(z_{s,j})} \right) = z_{s,a} - \log \left( \sum_{j} \exp(z_{s,j}) \right)
$$- 注:这里 \(z_{s,a} = \theta_{s,a}\),且分母中的求和 \(\sum_{j} \exp(z_{s,j})\) 是不依赖于特定动作 \(a\) 的,它是对所有动作 \(j\) 的logits求和(通常称为配分函数,log-partition function)
- 对参数 \(\theta_{s,a’}\) 求导(需要考虑两种情况:当 \(a’\) 等于 \(a\) 时,以及当 \(a’\) 不等于 \(a\) 时)
- 情况 1:\(a’ = a\)
- 此时,导数作用于分子中的特定项 \(z_{s,a}\)
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a} } = \frac{\partial z_{s,a} }{\partial \theta_{s,a} } - \frac{\partial}{\partial \theta_{s,a} } \log \left( \sum_{j} \exp(z_{s,j}) \right)
$$ - 由于 \(z_{s,a} = \theta_{s,a}\),第一项的导数为 \(1\)。对于第二项,根据复合函数求导法则(链式法则):
$$
\begin{align}
\frac{\partial}{\partial \theta_{s,a} } \log \left( \sum_{j} \exp(z_{s,j}) \right) &= \frac{1}{\sum_{j} \exp(z_{s,j})} \cdot \frac{\partial}{\partial \theta_{s,a} } \left( \sum_{j} \exp(z_{s,j}) \right) \\
&= \frac{1}{\sum_{j} \exp(z_{s,j})} \cdot \exp(z_{s,a}) \\
&= \frac{\exp(z_{s,a})}{\sum_{j} \exp(z_{s,j})} \\
&= \pi_{\theta}(a | s)
\end{align}
$$ - 因此,当 \(a’ = a\) 时:
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a} } = \color{red}{1 - \pi_{\theta}(a | s)}
$$
- 此时,导数作用于分子中的特定项 \(z_{s,a}\)
- 情况 2:\(a’ \neq a\)
- 此时,导数作用于分母中的某个特定项 \(z_{s,a’}\),而分子第一项 \(z_{s,a}\) 对 \(\theta_{s,a’}\) 的导数为 \(0\)
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a’} } = 0 - \frac{\partial}{\partial \theta_{s,a’} } \log \left( \sum_{j} \exp(z_{s,j}) \right)
$$ - 同样地,计算第二项:
$$
\begin{align}
\frac{\partial}{\partial \theta_{s,a’} } \log \left( \sum_{j} \exp(z_{s,j}) \right) &= \frac{1}{\sum_{j} \exp(z_{s,j})} \cdot \frac{\partial}{\partial \theta_{s,a’} } \left( \sum_{j} \exp(z_{s,j}) \right) \\
&= \frac{1}{\sum_{j} \exp(z_{s,j})} \cdot \exp(z_{s,a’}) \\
& = \frac{\exp(z_{s,a’})}{\sum_{j} \exp(z_{s,j})} \\
&= \pi_{\theta}(a’ | s)
\end{align}
$$ - 因此,当 \(a’ \neq a\) 时:
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a’} } = 0 - \pi_{\theta}(a’ | s) = \color{red}{-\pi_{\theta}(a’ | s)}
$$
- 此时,导数作用于分母中的某个特定项 \(z_{s,a’}\),而分子第一项 \(z_{s,a}\) 对 \(\theta_{s,a’}\) 的导数为 \(0\)
- 合并表达式 :
- 上述两种情况可以合并为一个紧凑的形式,使用指示函数 \(\mathbf{1}\{a = a’\}\)(当 \(a = a’\) 时值为1,否则为0):
$$
\frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a’} } = \mathbf{1}\{a = a’\} - \pi_{\theta}(a’ | s)
$$
- 上述两种情况可以合并为一个紧凑的形式,使用指示函数 \(\mathbf{1}\{a = a’\}\)(当 \(a = a’\) 时值为1,否则为0):
- 情况 1:\(a’ = a\)
- 将策略 \(\pi_{\theta}(a|s)\) 取对数,将除法转换为减法:
E.2 Proof for Lemma 1
- 引理 1 :设 Actor 策略 \(\pi_{\theta}\) 是一个表格型 (tabular) softmax 策略,则在两个连续步骤之间,给定状态 \(s\) 的信息熵之差满足
$$
\mathcal{H}(\pi_{\theta}^{k+1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s) \approx -\text{Cov}_{a \sim \pi_{\theta}^{k}(\cdot|s)} \left( \log \pi_{\theta}^{k}(a|s), z_{s,a}^{k+1} - z_{s,a}^{k} \right)
$$ - 证明 adapted from (Liu, 2025)
- 在表格型 softmax 策略中,每个状态-动作对 \((s, a)\) 都与一个独立的 logit 参数 \(z_{s,a} = \theta_{s,a}\) 相关联
- 假设通过 \(z^{k+1} = z^{k} + \eta \cdot \nabla J(\pi_{\theta})\) 来更新 logits \(z\)
- 由于 \(\eta\) 相对较小,利用泰勒展开的一阶近似,有
$$
\mathcal{H}(\pi_{\theta}^{k+1} | s) \approx \mathcal{H}(\pi_{\theta}^{k} | s) + \langle \nabla \mathcal{H}(\pi_{\theta}^{k} | s), (z^{k+1} - z^{k}) \rangle
$$
- 然后需要推导出 \(\nabla \mathcal{H}(\pi_{\theta}^{k} | s)\) 是什么
- 根据 \(\mathcal{H}\) 的定义,有
$$
\begin{aligned}
\nabla_{\theta} \mathcal{H}(\pi_{\theta} | s) &= \nabla_{\theta} \mathcal{H}(\pi_{\theta}(\cdot | s)) \\
&= \nabla_{\theta} \left( -\mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [\log \pi_{\theta}(a | s)] \right) \\
&= -\mathbb{E}_{a \sim \pi_{\theta}(\cdot|s)} [\nabla_{\theta} \log \pi_{\theta}(a | s) + \log \pi_{\theta}(a | s) \nabla_{\theta} \log \pi_{\theta}(a | s)] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} [\log \pi_{\theta}(a | s) \nabla_{\theta} \log \pi_{\theta}(a | s)]
\end{aligned}
$$
- 根据 \(\mathcal{H}\) 的定义,有
- 于是得到 内积 \(\langle \nabla_{\theta} \mathcal{H}(\theta^{k} | s), (z^{k+1} - z^{k}) \rangle\) 为:
$$
\begin{aligned}
\langle \nabla_{\theta} \mathcal{H}(\theta^{k} | s), (z^{k+1} - z^{k}) \rangle &= -\langle \mathbb{E}_{a \sim \pi(\cdot|s)} [\log \pi_{\theta}(a | s) \nabla_{\theta} \log \pi_{\theta}(a | s)], (\theta^{k+1} - \theta^{k}) \rangle \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s) \langle \nabla_{\theta} \log \pi_{\theta}(a | s), \theta^{k+1} - \theta^{k} \rangle \right] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s) \left( \sum_{a’ \in \mathcal{A} } \frac{\partial \log \pi_{\theta}(a | s)}{\partial \theta_{s,a’} } \cdot (\theta_{s,a’}^{k+1} - \theta_{s,a’}^{k}) \right) \right] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s) \left( \sum_{a’ \in \mathcal{A} } (\mathbf{1}\{a = a’\} - \pi(a’ | s)) \cdot (\theta_{s,a’}^{k+1} - \theta_{s,a’}^{k}) \right) \right] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s) \left( (\theta_{s,a}^{k+1} - \theta_{s,a}^{k}) - \sum_{a’ \in \mathcal{A} } \pi(a’ | s)(\theta_{s,a’}^{k+1} - \theta_{s,a’}^{k}) \right) \right] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s)(\theta_{s,a}^{k+1} - \theta_{s,a}^{k}) \right] + \mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s) \cdot \mathbb{E}_{a’ \sim \pi(\cdot|s)} \left[ \theta_{s,a’}^{k+1} - \theta_{s,a’}^{k} \right] \right] \\
&= -\mathbb{E}_{a \sim \pi(\cdot|s)} \left[ \log \pi_{\theta}(a | s)(\theta_{s,a}^{k+1} - \theta_{s,a}^{k}) \right] + \mathbb{E}_{a \sim \pi(\cdot|s)} [\log \pi_{\theta}(a | s)] \cdot \mathbb{E}_{a’ \sim \pi(\cdot|s)} \left[ \theta_{s,a’}^{k+1} - \theta_{s,a’}^{k} \right] \\
&= -\text{Cov}_{a \sim \pi(\cdot|s)} \left( \log \pi(a | s), \theta^{k+1} - \theta^{k} \right) \\
&= -\text{Cov}_{a \sim \pi(\cdot|s)} \left( \log \pi(a | s), z^{k+1} - z^{k} \right)
\end{aligned}
$$- 注:上面的推到用到了 Cov 的公式:
$$
\begin{align}
\mathrm{Cov}(X,Y)
&= \boldsymbol{E}\big[(X-\boldsymbol{E}X)(Y-\boldsymbol{E}Y)\big] \\
&= \boldsymbol{E}(XY)-\boldsymbol{E}(X)\boldsymbol{E}(Y)
\end{align}
$$
- 注:上面的推到用到了 Cov 的公式:
E.3 Proof for Proposition 1
- 命题 1 :设 Actor 策略 \(\pi_{\theta}\) 是表格型 softmax 策略,并使用公式 2 进行更新,则 \(z_{s,a}\) 在两个连续步骤之间的差满足
$$
z_{s,a}^{k+1} - z_{s,a}^{k} = \eta \cdot \pi_{\theta}(a | s) \cdot A(s, a)
$$ - 证明 :
- 在表格型 softmax 策略中,每个状态-动作对 \((s, a)\) 都与一个独立的 logit 参数 \(z_{s,a} = \theta_{s,a}\) 相关联
- 通过梯度回溯,\(z_{s,a}\) 通过 \(z_{s,a}^{k+1} = z_{s,a}^{k} + \eta \cdot \nabla_{\theta_{s,a} } J(\theta)\) 进行更新,因此有
$$
\begin{aligned}
z_{s,a}^{k+1} - z_{s,a}^{k} &= \eta \cdot \nabla_{\theta_{s,a} } J(\theta) \\
&= \eta \cdot \mathbb{E}_{a’ \sim \pi_{\theta}(\cdot|s)} \left[ \nabla_{\theta_{s,a} } \log \pi_{\theta}(a’ | s) \cdot A(s, a’) \right] \\
&= \eta \cdot \mathbb{E}_{a’ \sim \pi_{\theta}(\cdot|s)} \left[ \underbrace{\frac{\partial \log \pi_{\theta}(a’ | s)}{\partial \theta_{s,a} } }_{\text{Lemma 2} } \cdot A(s, a’) \right] \\
&= \eta \cdot \sum_{a’ \in \mathcal{A} } [\pi_{\theta}(a’ | s) \cdot (\mathbf{1}\{a = a’\} - \pi_{\theta}(a | s)) \cdot A(s, a’)] \\
&= \eta \cdot \pi_{\theta}(a | s) \cdot \left[ (1 - \pi_{\theta}(a | s)) \cdot A(s, a) - \sum_{a’ \in \mathcal{A}, a’ \neq a} \pi_{\theta}(a’ | s) \cdot A(s, a’) \right] \\
&= \eta \cdot \pi_{\theta}(a | s) \cdot \left[ A(s, a) - \underbrace{\sum_{a’ \in \mathcal{A} } \pi_{\theta}(a’ | s) \cdot A(s, a’)}_{\text{Lemma 3} } \right] \\
&= \eta \cdot \pi_{\theta}(a | s) \cdot [A(s, a) - 0] \\
&= \eta \cdot \pi_{\theta}(a | s) \cdot A(s, a)
\end{aligned}
$$
E.4 Proof for Theorem 2
- 定理 2 :设 Actor 策略 \(\pi_{\theta}\) 是表格型 softmax 策略,并且 \(\pi_{\theta}\) 通过自然策略梯度进行更新,则在两个连续步骤之间,给定状态 \(s\) 的信息熵之差满足
$$
\mathcal{H}(\pi_{\theta}^{k+1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s) \approx -\eta \cdot \text{Cov}_{a \sim \pi_{\theta}^{k}(\cdot|s)} \left( \log \pi_{\theta}^{k}(a|s), A(s, a) \right)
$$ - 证明 :
- 根据引理 1,首先推导自然策略梯度中 logits \(z\) 的差
- 从 (2021) 中了解到,当通过梯度回溯使用自然策略梯度更新策略时,\(z_{s,a}^{k+1} - z_{s,a}^{k}\) 满足,
$$
z_{s,a}^{k+1} - z_{s,a}^{k} = \eta \cdot A(s, a)
$$ - 将其应用于引理 1,有
$$
\mathcal{H}(\pi_{\theta}^{k+1}|s) - \mathcal{H}(\pi_{\theta}^{k}|s) \approx -\eta \cdot \text{Cov}_{a \sim \pi_{\theta}^{k}(\cdot|s)} \left( \log \pi_{\theta}^{k}(a|s), A(s, a) \right)
$$