注:本文包含 AI 辅助创作
- 参考链接:
- 原始博客链接:A Definition of AGI, 202510
Paper Summary
- 由于当前缺乏对 AGI 的具体定义,导致我们模糊了当今 Specialized AI 与人类水平认知(human-level cognition)之间的差距
- 论文引入了一个可量化的(quantifiable)框架,将 AGI 定义为匹配一位受过良好教育的成年人的认知广度(cognitive versatility)和熟练程度
defining AGI as matching the cognitive versatility and proficiency of a well-educated adult.
- To operationalize this,论文将方法建立在 Cattell-Horn-Carroll(CHC) 理论之上(the most empirically validated model of human cognition)
- 注:operationalize 是 “将抽象概念转化为可观察、可测量的具体操作或指标的行为/过程”,名词形式为:operationalization
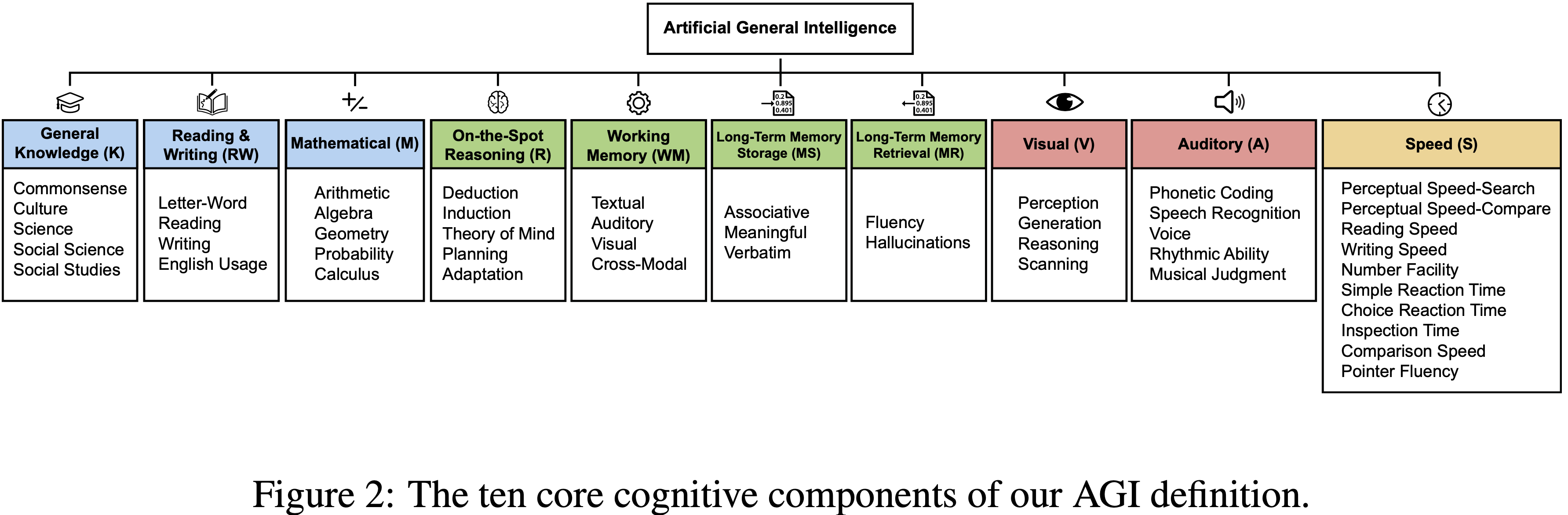
- 该框架将通用智能分解为十个核心认知领域
- 包括推理、记忆和感知(reasoning, memory, and perception)
- 并采用成熟的人类心理评估(established human psychometric batteries)来评估 AI 系统
- 注意:“psychometric batteries” 是心理学领域的专有名词,即 “心理测量成套量表”,是由多个相关的标准化测试组成的组合,用于全面评估个体的心理特质(如认知能力、人格特征等)
- 论文应用此框架揭示了当代模型高度“不均衡(jagged)”的认知 profile
- 虽然当前的 AI 系统在 knowledge-intensive domains 表现出色,但在基础认知机制(foundational cognitive machinery)上存在严重缺陷,特别是长期记忆存储
- 论文的 AGI Score具体量化了其快速进展,也说明了在实现 AGI 之前,我们距离 AGI 仍存在的巨大差距
- 注:GPT-4 得分为 27%,GPT-5 得分为 58%
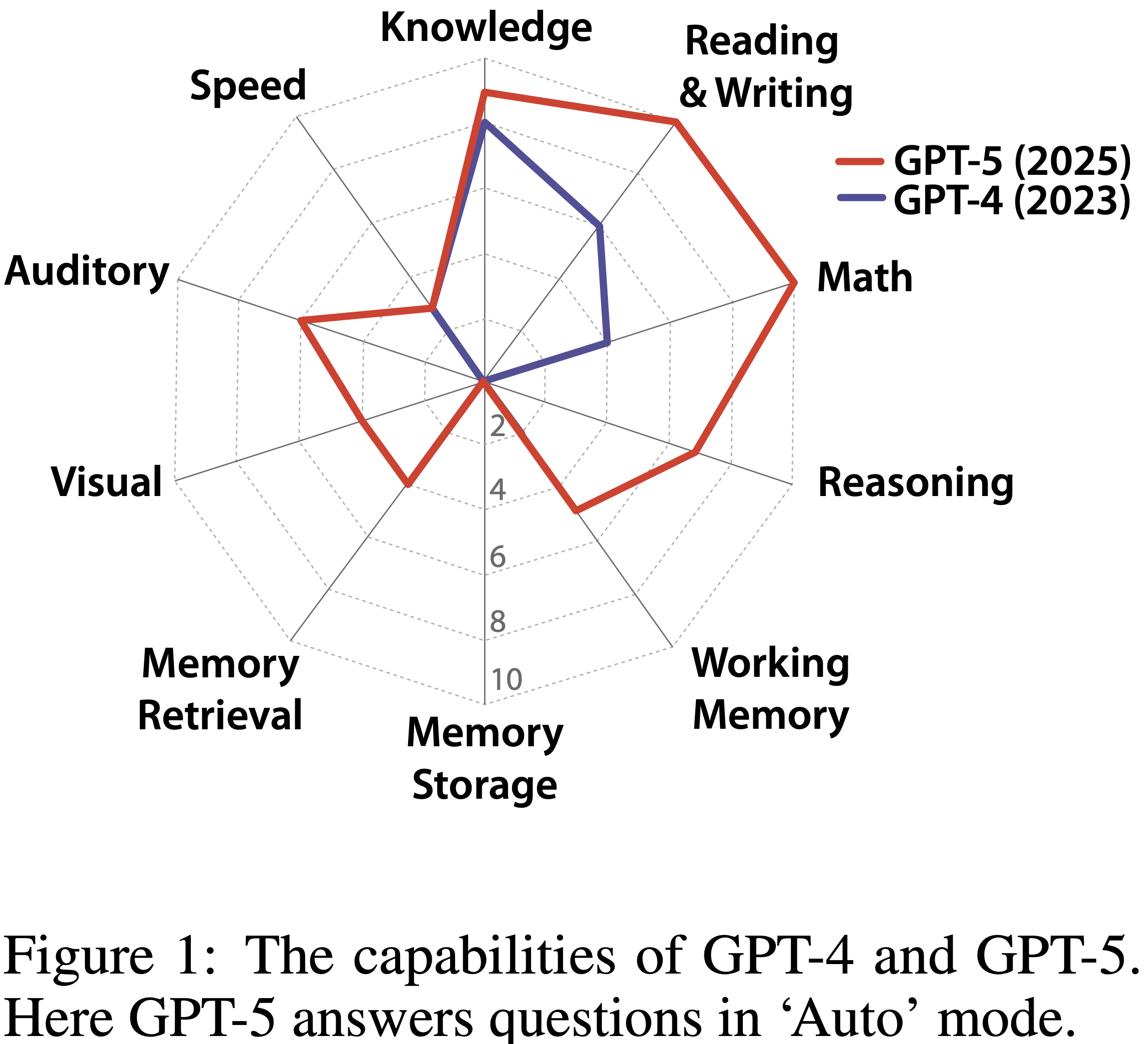
- 注:GPT-4 得分为 27%,GPT-5 得分为 58%
Introduction and Discussion
AGI 可能成为人类历史上最重要的技术发展,然而这个术语本身仍然令人沮丧地模糊不清,像一个不断移动的 goalpost(球门柱)
- 随着专用 AI 系统掌握了曾被认为需要人类智能的任务(从数学到艺术)“AGI”的标准也在不断变化
- 这种模糊性引发了无益的争论,阻碍了关于我们距离 AGI 还有多远的讨论,并最终模糊了当今 AI 与 AGI 之间的差距
论文提供了一个全面的、可量化的框架,以消除这种模糊性
论文的框架旨在具体说明以下非正式定义:
- AGI 是一种能够匹配或超越一位受过良好教育的成年人的认知广度和熟练程度的 AI
AGI is an AI that can match or exceed the cognitive versatility and proficiency of a well-educated adult.
- AGI 是一种能够匹配或超越一位受过良好教育的成年人的认知广度和熟练程度的 AI
这个定义强调,通用智能不仅需要特定领域的专业表现,还需要具有人类认知特征的技能广度和深度(breadth (versatility) and depth (proficiency) of skill)
To operationalize this definition,论文必须参考唯一现存的通用智能实例:人类
- 人类认知并非单一的能力,而是一个由许多经过进化磨练的独特能力组成的复杂架构
- 这些能力使论文具有非凡的适应性和对世界的理解能力
为了系统地研究 AI 系统是否拥有这种能力谱系,论文将论文的方法建立在 Cattell-Horn-Carroll(CHC)认知能力理论 (1993; 2009; 2018; 2023;) 之上
- 这是 the most empirically validated model of human intelligence
- CHC 理论主要源于对一个多世纪以来各种认知能力测试的迭代因子分析的综合
- 在 20 世纪 90 年代末到 21 世纪初,几乎所有主要的临床、个体施测的人类智能测试都迭代转向了明确或隐含基于 CHC 模型测试设计蓝图的测试修订版 (2010; 2018)
- CHC 理论提供了一个人类认知的层次分类图谱
- 它将通用智能分解为不同的广泛能力和众多的狭窄能力(例如归纳、联想记忆或空间扫描(induction, associative memory, or spatial scanning))
- 对 CHC 框架的优点和局限性感兴趣的读者可以参考进一步的学术讨论 (2019; 2019)
数十年的心理测量(psychometric)研究产生了大量专门设计用于隔离和测量个体中这些不同认知成分的 battery of tests
论文的框架将这种方法应用于 AI 评估
- 论文不只依赖可能通过补偿策略(compensatory strategies)解决的通用任务,而是系统地研究 AI 系统是否拥有人类所具有的底层 CHC narrow abilities
- 为了确定一个 AI 是否具有受过良好教育的成年人的认知广度和熟练度,论文用用于测试人类的 gauntlet of cognitive battery 来测试该 AI 系统
- 理解:gauntlet 字面意思是 长手套,这里应该是指 一系列严苛的测试
- 这种方法用具体的测量取代了模糊的智能概念,产生了一个标准化的“AGI Score”(0% to 100%),其中 100% 代表 AGI
应用此框架是具有发人深省的(revealing)
- 通过测试支撑人类认知的基本能力(其中许多对人类来说似乎很简单),论文发现当代 AI 系统大约能解决其中一半的这些通常简单的评估
- 这表明,尽管在复杂基准测试上表现不错,但当前的 AI 缺乏许多对人类类似通用智能至关重要的核心认知能力
- 当前的 AI 总体上比受过良好教育的人类更狭窄(narrower) ,但在某些特定任务上要聪明得多
该框架包含十个核心认知成分,源自 CHC 的广泛能力,并赋予同等权重(10%),以优先考虑广度并覆盖认知的主要领域:
- 通用知识 (General Knowledge, K): 对世界事实理解的广度,包括常识、文化、科学、社会科学和历史
The breadth of factual understanding of the world, encompassing commonsense, culture, science, social science, and history
- 阅读与写作能力 (Reading and Writing Ability, RW): 消费和产出书面语言的熟练度,从基本解码到复杂理解、写作和用法
Proficiency in consuming and producing written language, from basic decoding to complex comprehension, composition, and usage.
- 数学能力 (Mathematical Ability, M): 跨算术、代数、几何、概率和微积分的数学知识和技能的深度
The depth of mathematical knowledge and skills across arithmetic, algebra, geometry, probability, and calculus.
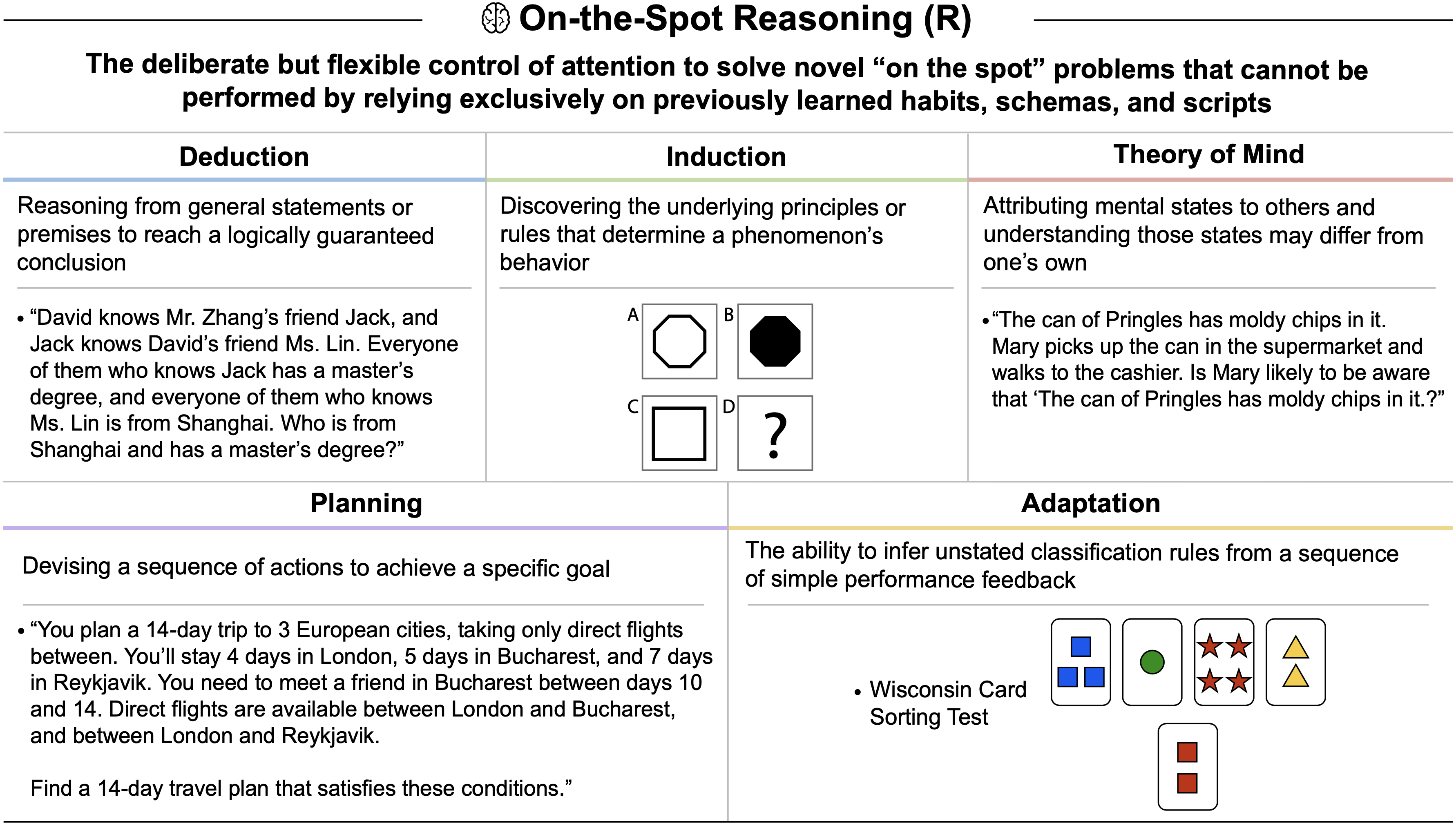
- 即时推理 (On-the-Spot Reasoning, R): 灵活控制注意力以解决新颖问题的能力,不完全依赖先前学习的图式,通过演绎和归纳进行测试
The flexible control of attention to solve novel problems without relying exclusively on previously learned schemas, tested via deduction and induction.
- 工作记忆 (Working Memory, WM): 在文本、听觉和视觉模态中维持和操纵活跃注意力中信息的能力
The ability to maintain and manipulate information in active attention across textual, auditory, and visual modalities.
- 长期记忆存储 (Long-Term Memory Storage, MS): 持续学习新信息(联想性、意义性和逐字性)的能力
The capability to continually learn new information (associative, meaningful, and verbatim).
- 长期记忆提取 (Long-Term Memory Retrieval, MR): 访问存储知识的流畅性和精确性,包括避免虚构(幻觉)的关键能力
The fluency and precision of accessing stored knowledge, including the critical ability to avoid confabulation (hallucinations).
- 视觉处理 (Visual Processing, V): 感知、分析、推理、生成和扫描视觉信息的能力
The ability to perceive, analyze, reason about, generate, and scan visual information
- 听觉处理 (Auditory Processing, A): 辨别、识别和创造性处理听觉刺激的能力,包括语音、节奏和音乐
The capacity to discriminate, recognize, and work creatively with auditory stimuli, including speech, rhythm, and music.
- 速度 (Speed, S): 快速执行简单认知任务的能力,包括感知速度、反应时间和处理流畅性
The ability to perform simple cognitive tasks quickly, encompassing perceptual speed, reaction times, and processing fluency
- 通用知识 (General Knowledge, K): 对世界事实理解的广度,包括常识、文化、科学、社会科学和历史
这种可操作化提供了一个整体的、多模态(文本、视觉、听觉)的评估,作为一个严格的诊断工具,以 pinpoint 当前 AI 系统的优势和深刻弱点
This operationalization provides a holistic and multimodal (text, visual, auditory) assessment, serving as a rigorous diagnostic tool to pinpoint the strengths and profound weaknesses of current AI systems

Scope
- 论文的定义不是自动评估也不是数据集,而是指定了一大套范围明确的任务,用于测试特定的认知能力
- AI 是否能解决这些任务可以由任何人手动评估,并且人们可以使用当时可用的最佳评估来补充他们的测试
- 这使得论文的定义比固定的自动 AI 能力数据集更广泛、更稳健
- 论文的定义侧重于受过良好教育的个体经常具备的能力,而不是所有受过良好教育的个体综合知识和技能的超人集合(superhuman aggregate)
- 因此,论文的 AGI 定义是 about human-level AI,not economylevel AI;
- 论文测量的是认知能力,而不是专业的经济上有价值的技能
- 论文的测量也不是自动化或经济扩散的直接预测指标(automation or economic diffusion)
- 论文将高级 AI 的经济测量留给其他工作
- 论文特意关注核心认知能力,而不是身体能力,如运动技能(motor skills)或触觉感知(tactile sensing),因为论文寻求测量心智的能力(capabilities of the mind),而不是其执行器(actuators)或传感器(sensors)的质量
AGI Overview of Abilities Needed for AGI
- 论文概述了一个通过 adopting and adapting Cattell-Horn-Carroll 人类智能理论来评估 AGI 的框架
- 该框架将通用智能分解为十个核心认知组成(广泛能力)和众多的狭窄认知能力
- 解决与这些能力相对应的所有任务意味着 AGI Score 为 100%
- 接下来将介绍每个认知能力的全面列表
General Knowledge, K
- 社会大多数成员熟悉或足够重要以至于大多数成年人接触过的知识
- 常识 (Commonsense): 关于世界如何运作的大量共享的、显而易见的背景知识
- 科学 (Science): 自然和物理科学的知识
- 社会科学 (Social Science): 对人类行为、社会和制度的理解
- 历史 (History): 对过去事件和物体的知识
- 文化 (Culture): 文化素养和意识
阅读与写作能力 (Reading and Writing Ability, RW)
- 捕捉一个人用于消费和产出书面语言的所有陈述性知识和程序性技能
- 字母-单词能力 (Letter-Word Ability): 识别字母和解码单词的能力
- 阅读理解 (Reading Comprehension): 在阅读过程中理解连贯语篇的能力
- 写作能力 (Writing Ability): 以清晰的思路、组织性和良好的句子结构进行写作的能力
- 英语用法知识 (English Usage Knowledge): 关于英语写作中大写、标点、用法和拼写的知识
数学能力 (Mathematical Ability, M):
- 数学知识和技能的深度和广度
- 算术 (Arithmetic): 使用基本运算操作数字并解决文字问题
- 代数 (Algebra): 对符号及其组合规则的研究,以表达一般关系并求解方程
- 几何 (Geometry): 对形状、空间、大小、位置和距离的研究
- 概率 (Probability): 通过将 0 到 1 的数字分配给事件来量化不确定性
- 微积分 (Calculus): 关于变化和累积的数学
即时推理 (On-the-Spot Reasoning, R)
- deliberate 但灵活地控制注意力以解决新颖的“即时”问题,这些问题不能仅仅依靠先前学习的习惯、图式和脚本来执行
- 演绎 (Deduction): 从一般性陈述或前提进行推理,以得出逻辑上必然的结论
- 归纳 (Induction): 发现决定现象行为的潜在原理或规则
- 心理理论 (Theory of Mind): 将心理状态归因于他人,并理解这些状态可能与自己不同
- 规划 (Planning): 设计一系列行动以实现特定目标
- 适应 (Adaptation): 从一系列简单的表现反馈中推断未阐明的分类规则的能力
Working Memory, WM
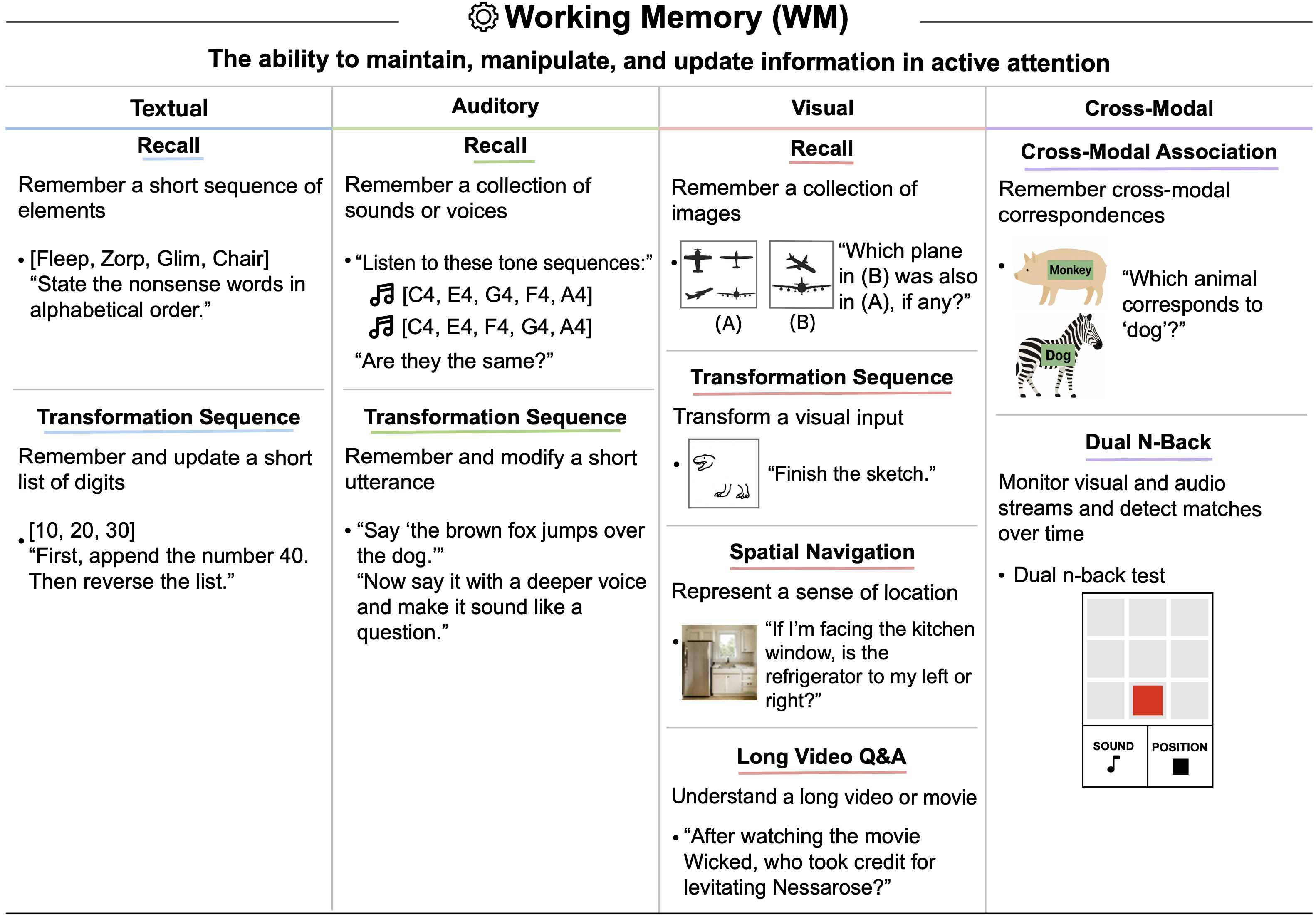
- 在活跃注意力中维持、操纵和更新信息的能力,通常称为短期记忆(short-term memory)
- 文本工作记忆 (Textual Working Memory): 保持和操纵以文本方式呈现的言语信息序列的能力
- 回忆 (Recall): 记住一个短序列元素(数字、字母、单词和无意义词)并回答关于它们的基本问题的能力
- 转换序列 (Transformation Sequence): 记住并更新一个短数字列表或数字列表,遵循一系列操作的能力
- 听觉工作记忆 (Auditory Working Memory): 保持和操纵听觉信息的能力,包括语音、声音和音乐
- 回忆 (Recall): 记住一组声音、话语和音效并回答关于它们的基本问题的能力
- 转换序列 (Transformation Sequence): 记住并修改一个短话语,应用各种变换的能力
- 视觉工作记忆 (Visual Working Memory): 保持和操纵视觉信息的能力,包括图像、场景、空间布局和视频
- 回忆 (Recall): 记住一组图像并回答关于它们的基本问题的能力
- 转换序列 (Transformation Sequence): 遵循一系列操作变换视觉输入的能力
- 空间导航记忆 (Spatial Navigation Memory): 在环境中表示位置感的能力
- 长视频问答 (Long Video Q&A): 观看长视频或电影(长达三小时)并回答关于其基本问题的能力
- 跨模态工作记忆 (Cross-Modal Working Memory): 维持和修改跨不同模态呈现的信息的能力
- 文本工作记忆 (Textual Working Memory): 保持和操纵以文本方式呈现的言语信息序列的能力
长期记忆存储 (Long-Term Memory Storage, MS)
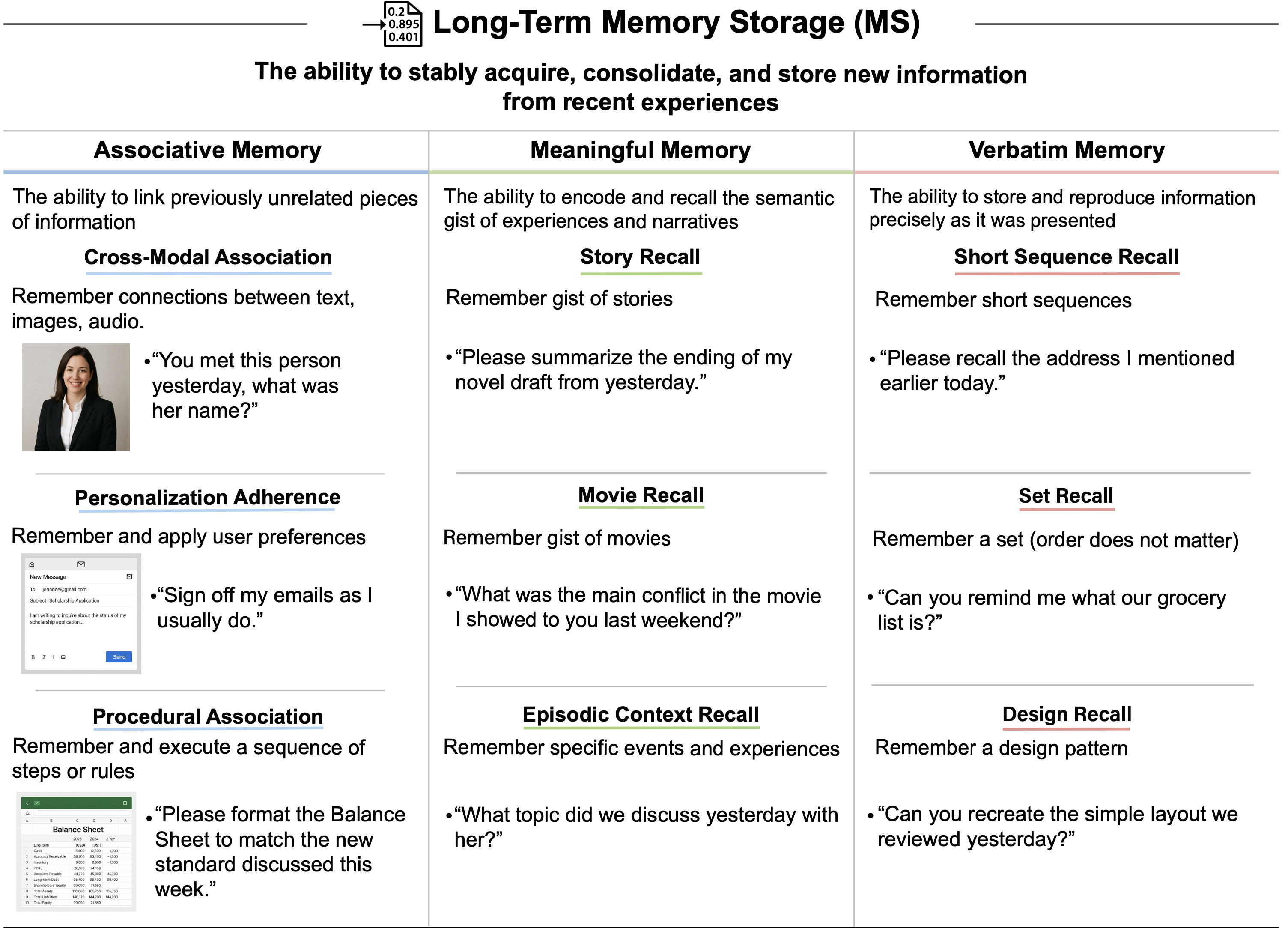
- 稳定地获取、巩固和存储来自近期经验的新信息的能力
- 联想记忆 (Associative Memory): 将先前不相关的信息片段联系起来的能力
- 跨模态联想 (Cross-Modal Association): 在两个先前不相关的刺激之间形成联系的能力,使得随后呈现其中一个刺激能够激活对另一个刺激的回忆
- 个性化遵循 (Personalization Adherence): 将特定规则、偏好或修正与不同的交互上下文相关联,并随着时间的推移一致地、无需提示地应用它们的能力
- 程序性联想 (Procedural Association): 获取并保留一系列相关联的步骤或规则(一个程序),并在被提示程序名称时执行它们的能力
- 意义记忆 (Meaningful Memory): 记住叙事和其他形式的语义相关信息的能力
- 故事回忆 (Story Recall): 记住故事要点的能力
- 电影回忆 (Movie Recall): 记住电影要点的能力
- 情景上下文回忆 (Episodic Context Recall): 记住特定事件或经历,包括其上下文(“什么、哪里、何时以及如何”)的能力
- 逐字记忆 (Verbatim Memory): 精确回忆所呈现信息的能力,需要精确编码特定序列、集合或设计,通常独立于信息的意义
- 短序列回忆 (Short Sequence Recall): 在延迟后精确回忆短文本序列的能力
- 集合回忆 (Set Recall): 回忆一个集合的能力(回忆顺序无关紧要)
- 设计回忆 (Design Recall): 回忆视觉信息的空间排列和结构的能力
- 联想记忆 (Associative Memory): 将先前不相关的信息片段联系起来的能力
长期记忆提取 (Long-Term Memory Retrieval, MR)
- 个体访问长期记忆的流畅性和精确性
- 提取流畅性 (Retrieval Fluency, Fluency): 基于存储知识生成想法、联想和解决方案的速度和容易程度
- 观念流畅性 (Ideational Fluency): 这是快速产生与特定条件、类别或对象相关的一系列想法、单词或短语的能力
- 表达流畅性 (Expressional Fluency): 这是快速思考表达一个想法的不同方式的能力
- 替代解决方案流畅性 (Alternative Solution Fluency): 这是快速思考一个实际问题的几种替代解决方案的能力
- 词语流畅性 (Word Fluency): 这是快速产生共享一个非语义特征的单词的能力
- 命名敏捷性 (Naming Facility): 这是快速用名称称呼常见物体的能力
- 图形流畅性 (Figural Fluency): 这是快速绘制或勾画尽可能多的事物的能力
- 提取精确性 (Retrieval Precision, Hallucinations): 访问知识的准确性,包括避免虚构(幻觉)的关键能力
- 提取流畅性 (Retrieval Fluency, Fluency): 基于存储知识生成想法、联想和解决方案的速度和容易程度
视觉处理 (Visual Processing, V)
- 分析和生成自然与非自然图像和视频的能力
- 感知 (Perception): 准确解释和理解视觉输入的能力
- 图像识别 (Image recognition): 对常见物体、地点或面部表情的图像进行分类的能力,包括扭曲的图像
- 图像描述 (Image captioning): 为图像的视觉内容生成简洁的、类人的文本描述的能力
- 图像异常检测 (Image anomaly detection): 包括检测图像中是否存在异常,或物体缺少什么
- 片段描述 (Clip captioning): 为短视频片段的视觉内容生成简洁的、类人的文本描述的能力
- 视频异常检测 (Video anomaly detection): 检测短视频片段是否异常或不合情理的能力
- 视觉生成 (Visual Generation): 合成图像和短视频的能力
- 视觉推理 (Visual Reasoning): 使用空间逻辑和视觉抽象来解决问题和做出推断的能力
- 空间扫描 (Spatial Scanning): 视觉探索复杂视野的速度和准确性
- 感知 (Perception): 准确解释和理解视觉输入的能力
听觉处理 (Auditory Processing, A)
- 辨别、记忆、推理和创造性处理听觉刺激的能力,这些刺激可能包括音调和语音单元
- 语音编码 (Phonetic Coding): 清晰听辨音素、将声音混合成单词以及将单词分割成部分、声音或音素的能力
- 语音识别 (Speech Recognition): 将口语音频信号转录成相应文本序列的能力
- 语音 (Voice): AI 合成语音的质量和响应能力
- 自然语音 (Natural speech): 说出听起来自然而非机械的句子或段落的能力
- 自然对话 (Natural conversation): 保持对话流畅性,没有长时间延迟或过度中断的能力
- 节奏能力 (Rhythmic Ability): 识别和保持音乐节拍的能力,包括再现节奏、检测节奏之间的差异以及通过演奏或哼唱同步
- 音乐判断 (Musical Judgment): 辨别和判断音乐中简单模式的能力
Speed, S
- 快速执行简单认知任务的能力
- 感知速度-搜索 (Perceptual Speed-Search): 扫描视觉或文本字段以查找特定目标的速度
- 感知速度-比较 (Perceptual Speed-Compare): 比较两个或多个刺激以识别相似性或差异的速度
- 阅读速度 (Reading Speed): 在完全理解的情况下处理文本的速度
- 写作速度 (Writing Speed): 生成或复制文本的速度
- 数字敏捷性 (Number Facility): 执行基本算术运算的速度和准确性
- 简单反应时 (Simple Reaction Time): 对单个预期刺激做出反应所需的时间
- 选择反应时 (Choice Reaction Time): 当呈现几个可能刺激中的一个时做出正确反应所需的时间
- 检查时间 (Inspection Time): 感知视觉或听觉刺激之间细微差异的速度
- 比较速度 (Comparison Speed): 对两个刺激在特定属性上做出判断比较所需的时间
- 指针流畅性 (Pointer Fluency): 移动指针(例如虚拟鼠标)的速度和准确性
General Knowledge, K
- 通用知识是指社会大多数成员所熟悉或足够重要以至于大多数成年人都接触过的知识

- Assessment Details:关于如何具体评估通用知识能力的更多细节,请参见 附录 A
阅读与写作能力 (Reading and Writing Ability, RW)
- 阅读与写作能力捕捉了一个人用于理解和生成书面语言的所有陈述性知识和程序性技能

- Assessment Details:关于如何具体评估阅读和写作能力的更多细节,请参见 附录 B
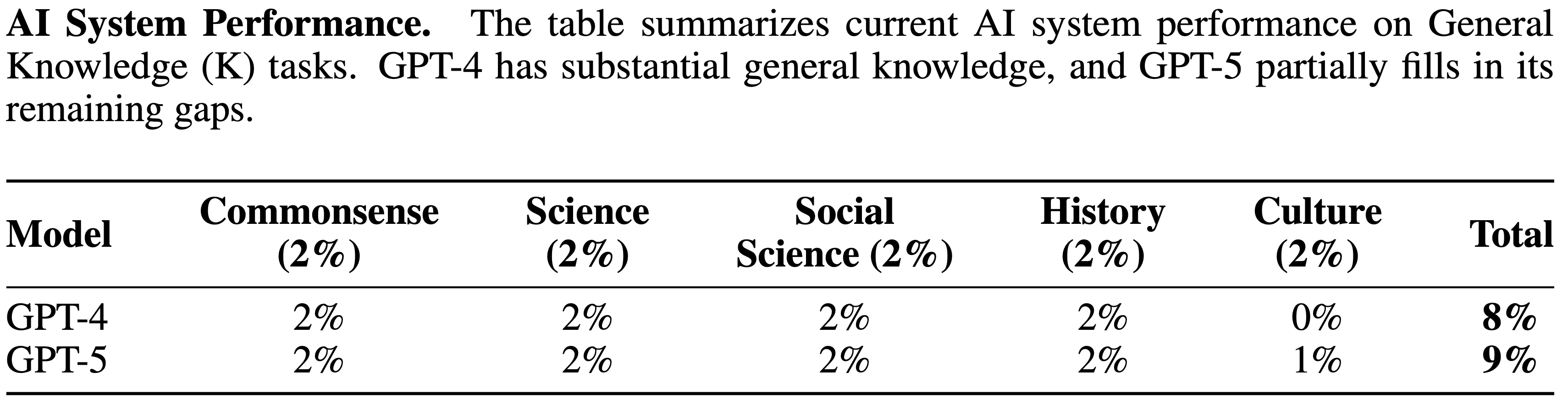
- AI System Performance. 该表总结了当前 AI 系统在阅读与写作能力任务上的表现
- GPT-4 在词元级别理解上的困难、其较小的上下文窗口以及不精确的工作记忆限制了其分析单词子串、阅读长文档和仔细校对文本的能力
- GPT-5 解决了这些问题
 tasks. GPT-4’s difficulty with token-level understanding, its small context window, and its imprecise working memory limit its ability to analyze substrings of words, to read long documents, and to carefully proofread text. GPT-5 addresses these issues.")
Mathematical Ability, M
- 数学能力指数学知识的深度和广度以及数学技能

- Assessment Details:关于如何具体评估数学能力的更多细节,请参见 附录 C
- AI System Performance. 该表总结了当前 AI 系统在数学能力 (M) 任务上的表现
- GPT-4 的数学能力有限,而 GPT-5 具有卓越的数学能力
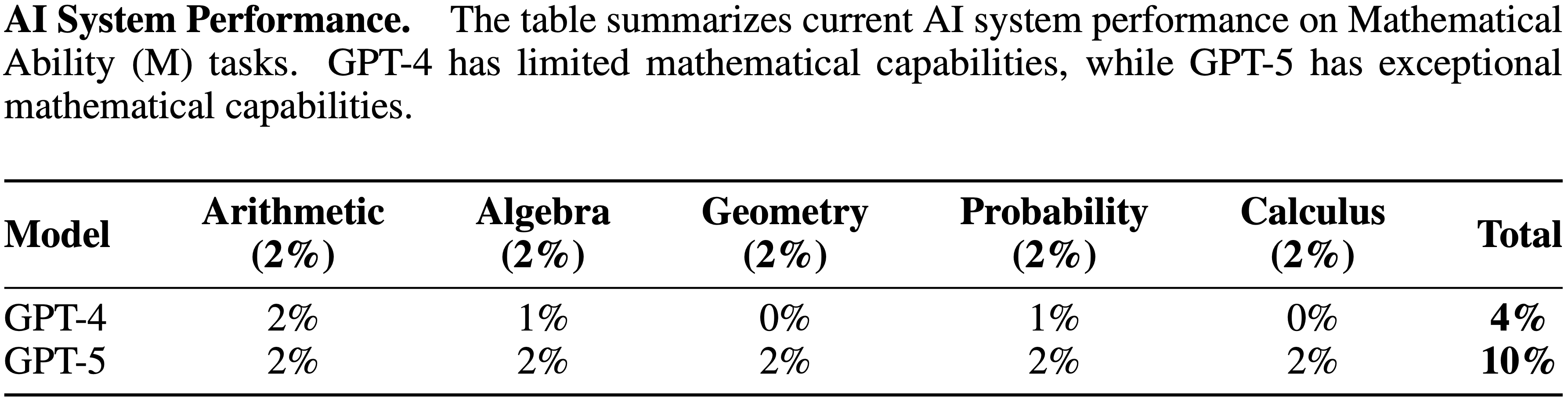
- GPT-4 的数学能力有限,而 GPT-5 具有卓越的数学能力
On-the-Spot Reasoning, R
- The deliberate but flexible control of attention to solve novel “on the spot”(即时性)problems that cannot be performed by relying exclusively on previously learned habits, schemas, and scripts
- Assessment Details:关于如何具体评估即时推理能力的更多细节,请参见 附录 D
- AI System Performance. 该表总结了当前 AI 系统在即时推理能力任务上的表现
- GPT-4 的即时推理能力可忽略不计,GPT-5 仅填补了部分剩余空白
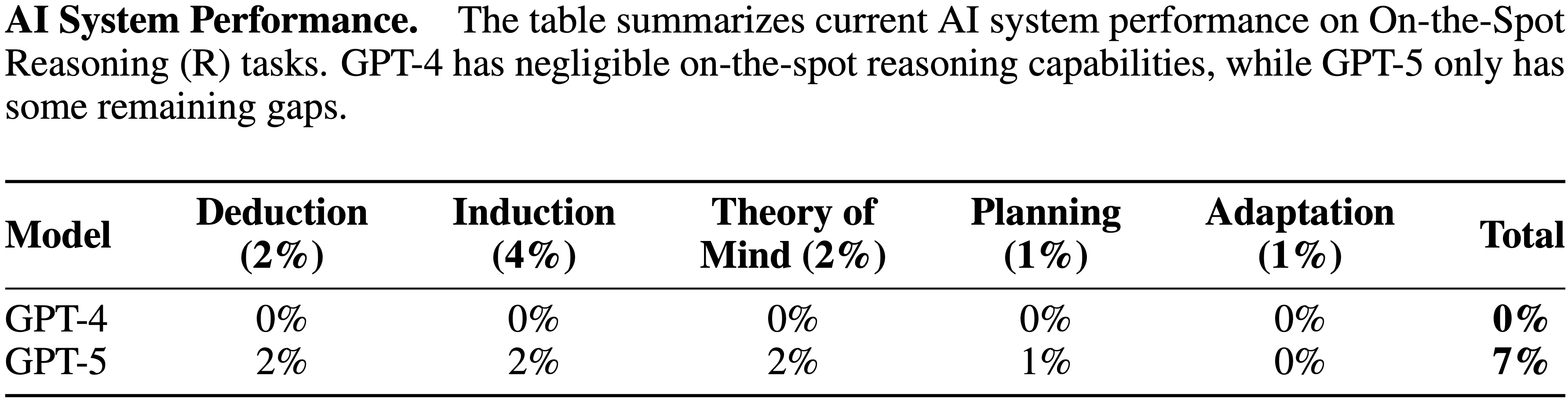
- GPT-4 的即时推理能力可忽略不计,GPT-5 仅填补了部分剩余空白
Working Memory, WM
- Working Memory 在主动注意中保持、操纵和更新信息的能力
- Assessment Details:关于如何具体评估工作记忆能力的更多细节,请参见附录 E
- AI System Performance. 该表总结了当前 AI 系统在 Working Memory 任务上的表现
- 虽然在此测试组合中,GPT-4 和 GPT-5 的原始文本工作记忆分数看起来相似,但在处理长上下文方面的改进也反映在阅读与写作能力中的文档级阅读理解分数中
 tasks. While the raw Textual Working Memory score appears similar between GPT-4 and GPT-5 in this battery, improvements in managing long contexts are also reflected in the Document Level Reading Comprehension score within the Reading and Writing (RW) ability.")
- 虽然在此测试组合中,GPT-4 和 GPT-5 的原始文本工作记忆分数看起来相似,但在处理长上下文方面的改进也反映在阅读与写作能力中的文档级阅读理解分数中
Long-Term Memory Storage, MS
- The ability to stably acquire, consolidate, and store new information from recent experiences
- Assessment Details:请参见附录 F

- 目前的 AI 暂时没有 Long-Term Memory Storage 的能力
Long-Term Memory Retrieval, MR
- 个体访问长期记忆的流畅性和精确性(The fluency and precision with which individuals can access long-term memory)
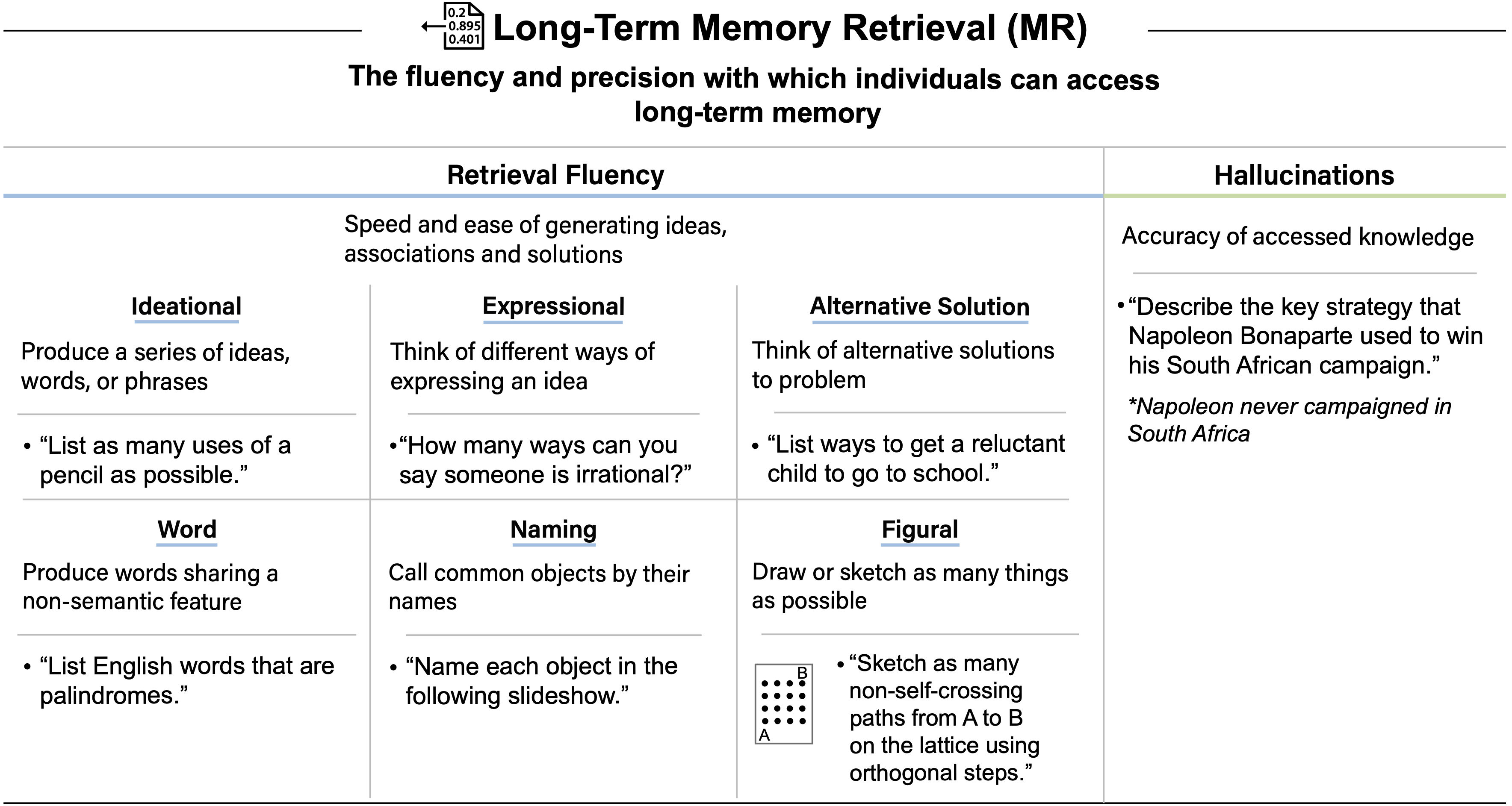
- Assessment Details:关于如何具体评估长期记忆检索能力的更多细节,请参见 附录 G
- AI System Performance. 该表总结了当前 AI 系统在长期记忆检索任务上的表现
- GPT-4 和 GPT-5 都能从其参数中快速检索许多概念,但它们都经常产生幻觉

- GPT-4 和 GPT-5 都能从其参数中快速检索许多概念,但它们都经常产生幻觉
Visual Processing, V
- 视觉处理分析和生成自然与非自然图像和视频的能力
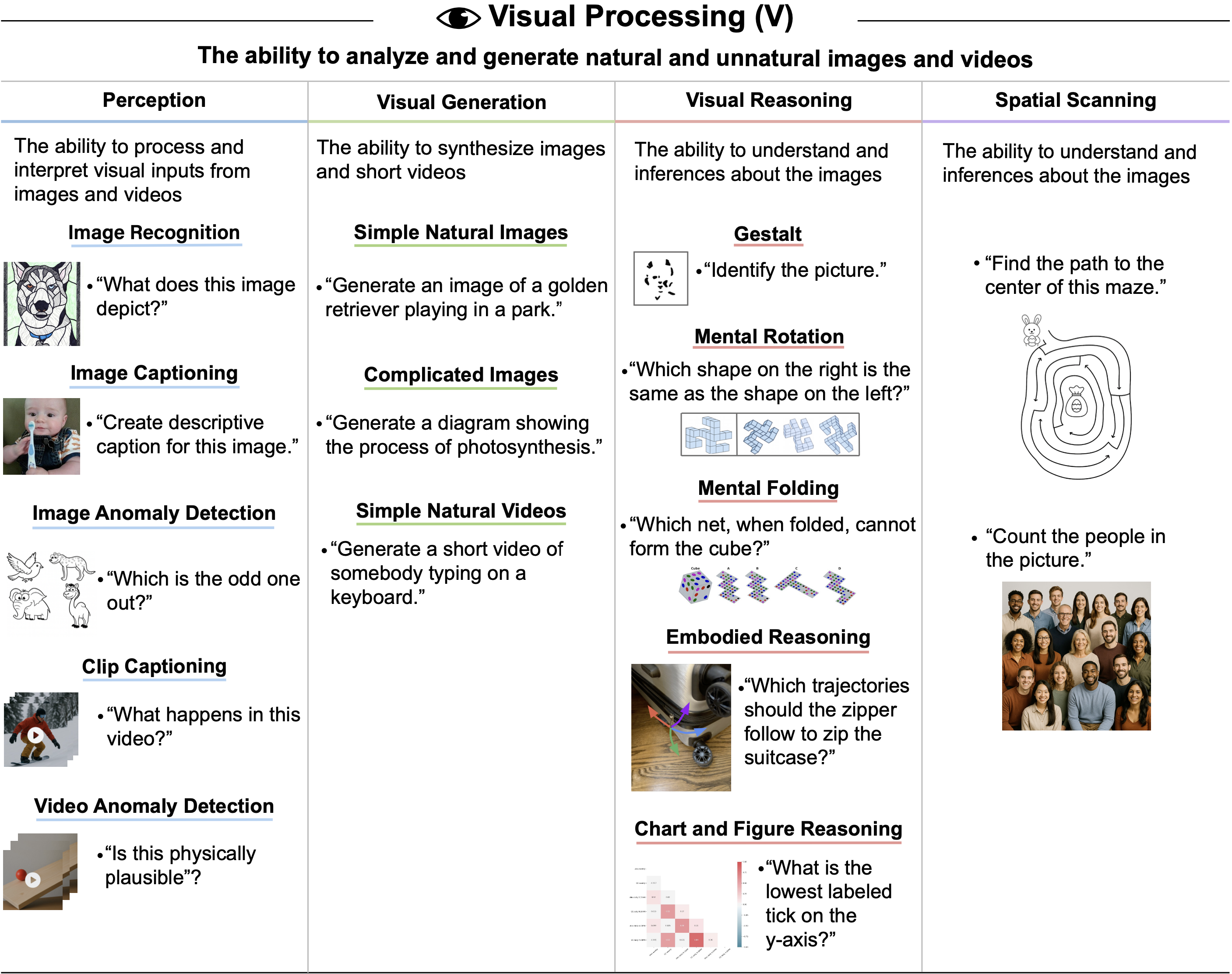
- Assessment Details:关于如何具体评估视觉处理能力的更多细节,请参见附录 H
- AI System Performance. 该表总结了当前 AI 系统在视觉处理任务上的表现
- GPT-4 没有感知或生成图像的能力,而 GPT-5 具有明显但不完整的视觉处理能力

- GPT-4 没有感知或生成图像的能力,而 GPT-5 具有明显但不完整的视觉处理能力
Auditory Processing, A
- 听觉处理辨别、记忆、推理和处理听觉刺激的能力
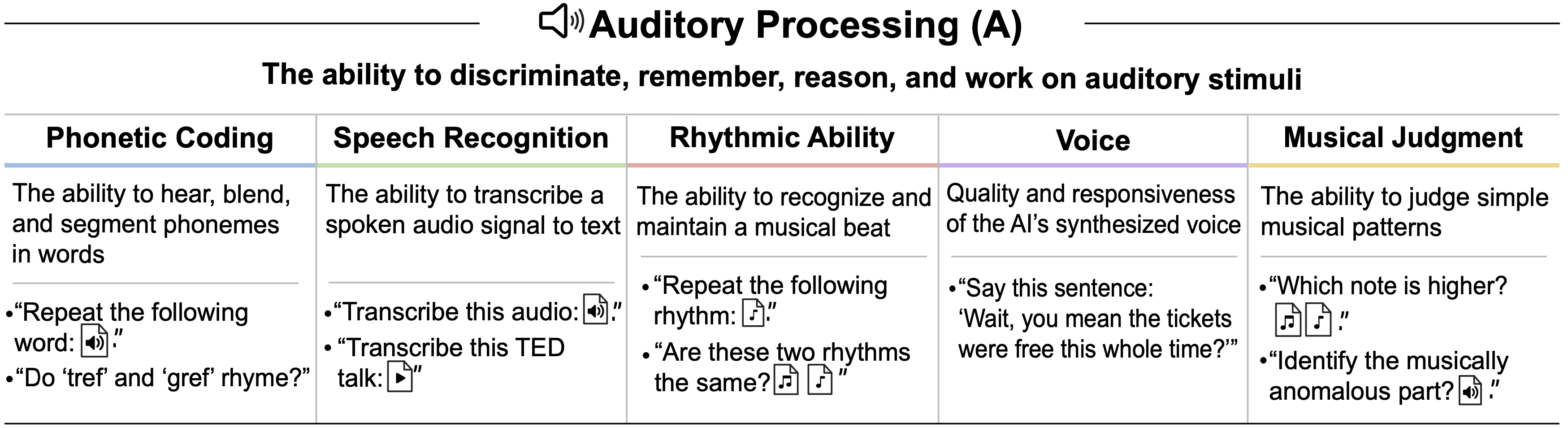
- Assessment Details:关于如何具体评估听觉处理能力的更多细节,请参见 附录 I
- AI System Performance. 该表总结了当前 AI 系统在听觉处理任务上的表现
- GPT-4 没有音频处理能力,而 GPT-5 的能力明显但不完整

- GPT-4 没有音频处理能力,而 GPT-5 的能力明显但不完整
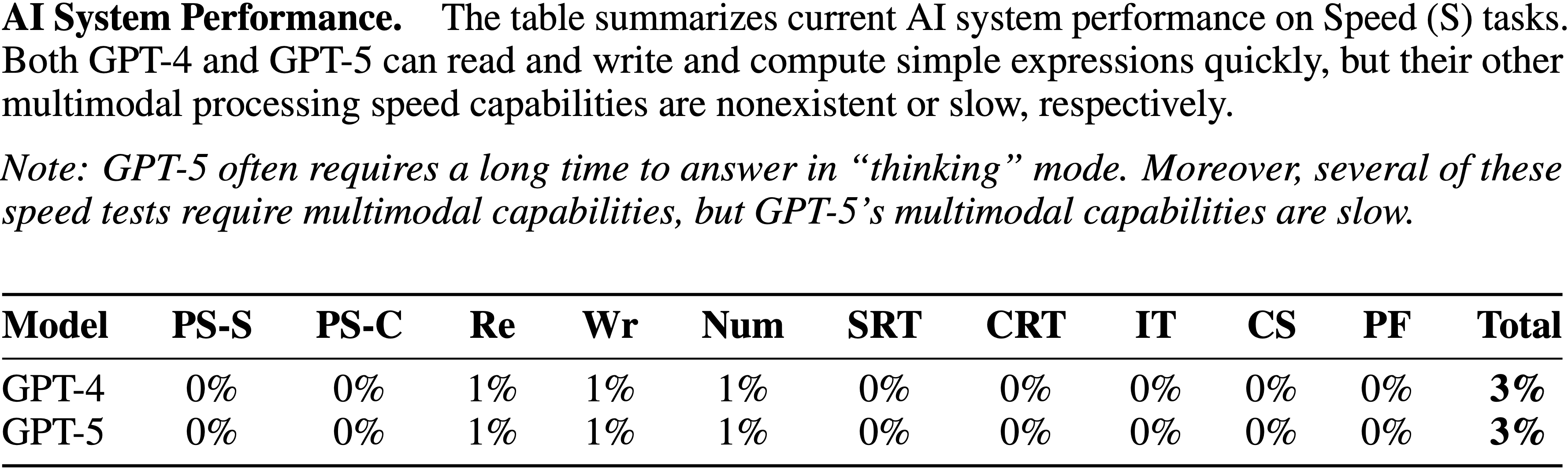
Speed, S
- 快速执行认知任务的能力
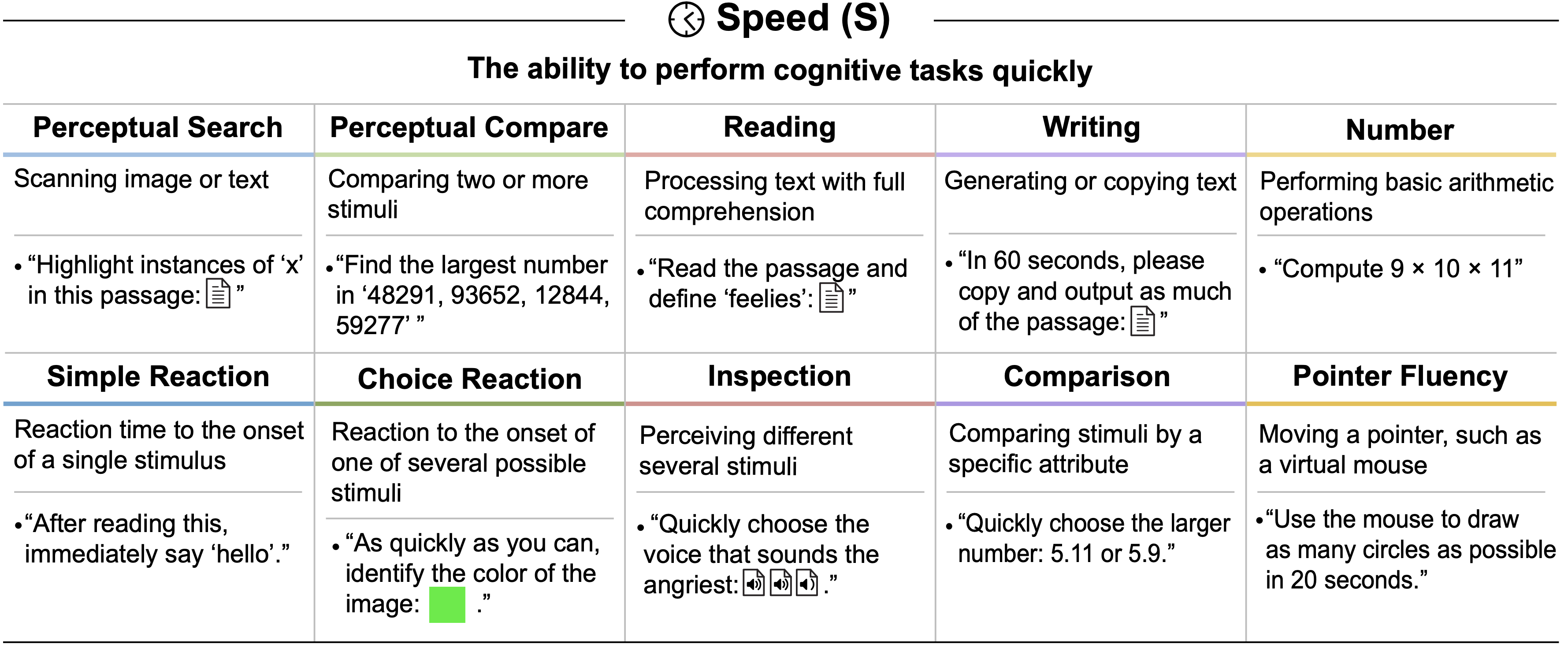
- Assessment Details:关于如何具体评估速度能力的更多细节,请参见 附录 J
- AI System Performance. 该表总结了当前 AI 系统在速度任务上的表现
- GPT-4 和 GPT-5 都能快速阅读、书写和计算简单表达式,但它们的其他多模态处理速度能力分别不存在或较慢
- 注意:GPT-5 在”思考”模式下通常需要很长时间才能回答。此外,其中一些速度测试需要多模态能力,但 GPT-5 的多模态能力速度较慢
Discussion
- 本框架提供了一种结构化、可量化的方法来评估 AGI ,超越了狭隘的、专业化的基准测试,转向评估认知能力的广度(通用性)和深度(熟练度)(the breadth (versatility) and depth (proficiency) of cognitive capabilities)
- 通过借鉴 CHC 理论启发的十个核心认知领域来具体化 AGI,我们可以系统地诊断当前 AI 系统的优势和深刻弱点
- 估算的 AGI 分数既说明了该领域的快速进展,也表明了在实现人类水平通用智能之前仍存在的巨大差距
“不均衡”的 AI 能力与关键瓶颈 (Jagged AI Capabilities and Crucial Bottlenecks)
- 该框架的应用揭示了当代 AI 系统表现出高度不均衡或“不均衡”的认知特征
- 虽然模型在利用海量训练数据的领域(例如通用知识 (K)、阅读与写作 (RW) 和数学能力 (M))表现出很高的熟练度,但它们同时在基础的认知机制上存在严重的缺陷
- 这种不均衡的发展突显了阻碍 AGI 发展路径的特定瓶颈
- 长期记忆存储 (Long-Term Memory Storage, MS) 或许是最显著的瓶颈,当前模型的得分接近 0%
- 如果没有持续学习的能力,AI 系统就会遭受“健忘症”的困扰,这限制了它们的实用性,迫使 AI 在每次交互中重新学习上下文
- 类似地,视觉推理方面的缺陷限制了 AI 智能体与复杂数字环境交互的能力
能力扭曲与通用性的幻觉 (Capability Contortions and the Illusion of Generality)**
- 当前 AI 能力的不均衡特征常常导致“能力扭曲”,即某些领域的优势被用来弥补其他领域的深刻弱点
- 这些变通方法掩盖了潜在的局限性,并可能创造出一种脆弱的通用能力幻觉
- 工作记忆与长期存储 (Working Memory vs. Long-Term Storage) :
- 一个突出的扭曲是依赖巨大的上下文窗口(工作记忆,WM)来弥补长期记忆存储 (MS) 的缺失
- 实践者使用这些长上下文来管理状态和吸收信息(例如,整个代码库)
- 但这种方法效率低下、计算成本高昂,并且可能使系统的注意力机制超载
- 它最终无法扩展到需要数天或数周累积上下文的任务
- 长期记忆系统可能采用模块的形式(例如,LoRA 适配器 (2021)),该模块持续调整模型权重以整合经验
- 一个突出的扭曲是依赖巨大的上下文窗口(工作记忆,WM)来弥补长期记忆存储 (MS) 的缺失
- 外部搜索与内部检索 (External Search vs. Internal Retrieval) :
- 长期记忆检索 (Long-Term Memory Retrieval, MR) 的不精确性(表现为幻觉或虚构)通常通过集成外部搜索工具来缓解,这个过程被称为检索增强生成 (Retrieval-Augmented Generation, RAG)
- 但这种对 RAG 的依赖是一种能力扭曲,它掩盖了 AI 记忆中两个不同的潜在弱点
- 首先,它弥补了无法可靠访问 AI 庞大但静态的参数化知识的能力
- 其次,也是更关键的是,它掩盖了动态的、经验性记忆的缺失
- 这种经验性记忆是一种用于长时间尺度上的私人交互和不断演变的上下文的持久、可更新的存储库
- 虽然 RAG 可以适用于私人文档,但其核心功能仍然是从数据库中检索事实
- 这种依赖性可能成为 AGI 的根本性弱点,因为它不能替代真正学习、个性化和长期上下文理解所需的整体性、集成化的记忆
- 将这些扭曲误认为是真正的认知广度,可能会导致对 AGI 何时到来的错误评估
- 这些扭曲也可能误导人们认为智能过于不均衡而无法被系统地理解
引擎类比 (The Engine Analogy)
- 论文对智能的多方面看法暗示了一个与高性能引擎的类比,其中整体智能是“马力”(2000)
- 人工心智,就像引擎一样,最终受限于其最薄弱的组件
- 参见图 3 以理解这些能力之间的关系
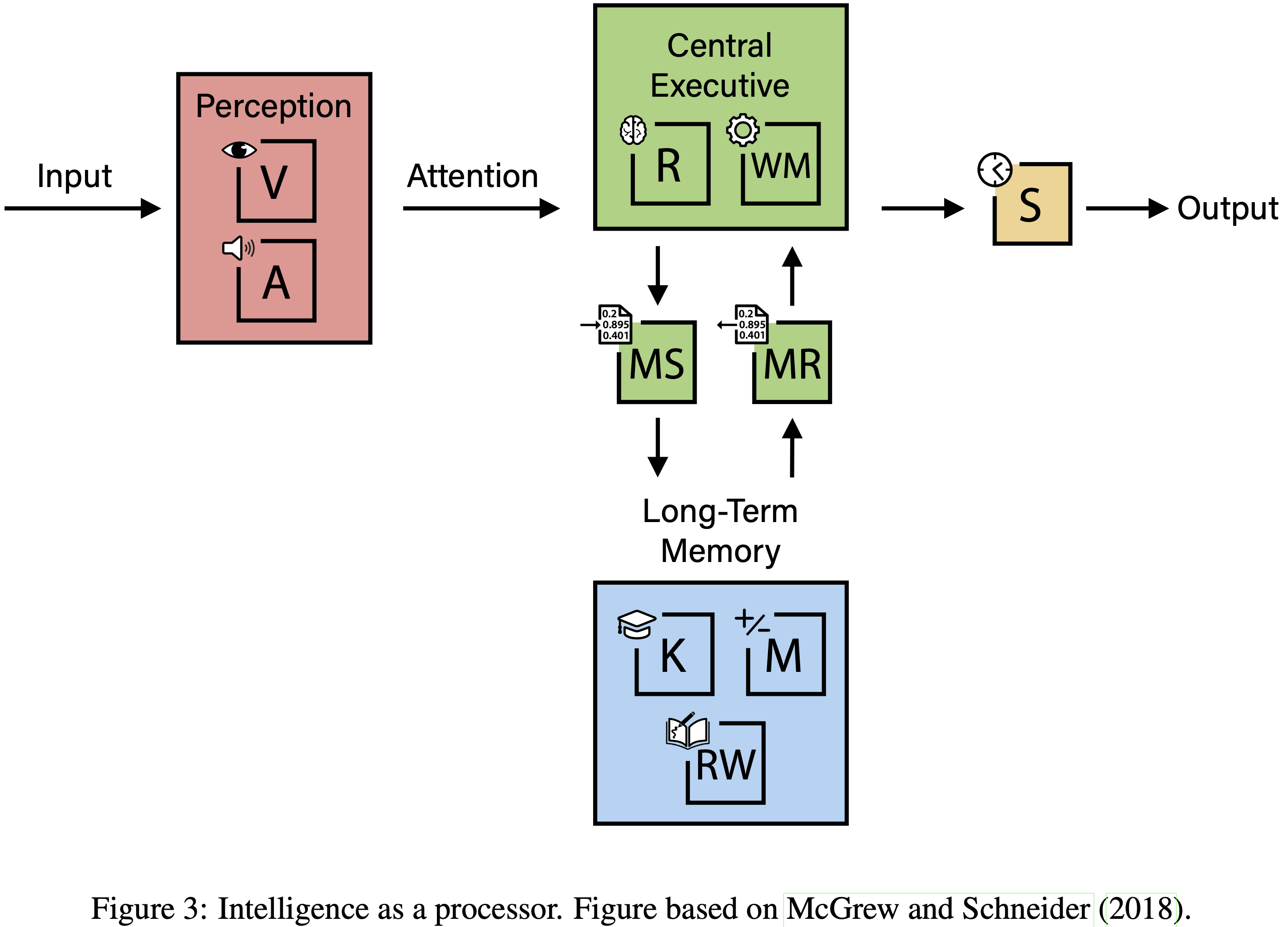
- 目前,AI“引擎”的几个关键部件存在严重缺陷。这严重限制了系统的整体“马力”,无论其他组件可能被优化到何种程度
- 本框架识别了这些缺陷,以指导论文的评估以及论文距离 AGI 还有多远
社交智能 (Social Intelligence)
- 人际交往技能体现在这些广泛能力中,比如:
- 认知共情体现在 K 的“常识”窄能力中
- 面部情绪识别对于在 V 的“图像描述”中达到熟练是必要的
- 心智理论在即时推理 (R) 中进行了测试
认知能力的相互依存性 (Interdependence of Cognitive Abilities)
- 虽然本框架将智能分解为十个不同的轴进行测量,但必须认识到这些能力是深度相互依存的
- 复杂的认知任务很少孤立地使用单个领域
- 例如
- 解决高级数学问题需要数学能力 (M) 和即时推理 (R)
- 心智理论问题需要即时推理 (R) 以及通用知识 (K)
- 图像识别涉及视觉处理 (V) 和通用知识 (K)
- 理解一部电影需要整合听觉处理 (A)、视觉处理 (V) 和工作记忆 (WM)
- 因此,各种窄能力测试组合测试了认知能力的组合,反映了通用智能的集成性质
Contamination(这里在强调数据污染下的刷榜行为)
- 有时 AI 公司通过在与目标测试高度相似或完全相同的数据上进行训练来“刷高(juice)”其数字
- 注:“juice” 是口语化的动词用法,结合语境表示 “人为抬高、美化(数据或指标)”,带有一定的贬义,指通过不正当或取巧的方式让数字看起来更漂亮
- 为防止这种情况,评估者应在微小的分布偏移下(例如,重新表述问题)评估模型性能,或者在相似但不同的问题上进行测试
Solving the Dataset vs. Solving the Task
- 论文的具体化(operationalization)依赖于任务规范
- 论文偶尔会用特定的数据集来详细说明这些任务规范,并且通常将它们视为解决任务的必要条件而非充分条件
- 此外,解决论文的说明性示例并不意味着任务已解决,因为论文的示例集合并非详尽无遗
- 自动评估默认不足以覆盖其目标现象 (2019),因此与现有的自动评估相比,论文的具体化更有可能具有鲁棒性并经受住时间的考验
- 由于论文将定义建立在一系列任务集合的基础上,而不是严重依赖特定的现有数据集,我们可以使用当时可用的最佳测试来测试 AI 系统
Ambiguity Resolution,歧义消解
- 具体化中的测试组合具有不同的精确度水平
- 然而,描述和示例应该足够清晰,以便人们可以自己给 AI 系统评分
- 因此,不同的人可以给出他们自己对 AGI 分数的估计,并且人们可以决定他们是否认为评分者的判断合理
Related Work
- Ilic 和 Gignac (2024) 以及 Ren 等人 (2024) 发现各种 AI 系统的能力与预训练计算量高度相关
- Gignac 和 Szodorai (2024) 讨论了人类心理测量学和测试 AI 系统的智能
- Turing (1950) 认为图灵测试可以指示通用能力
- Marcus 等人 (2016) 讨论了需要超越图灵测试以捕捉智能的多维性质
- Morris 等人 (2023) 阐述了基于性能百分位数的 AGI 级别
- Legg 和 Hutter (2007) 讨论了通用机器智能的各种测试
Limitations
- 首先,论文对智能的概念化并非详尽无遗
- 它刻意排除了某些能力,例如在加德纳多元智能理论 (1993) 等替代框架中提出的动觉能力
- 其次,论文的说明性示例是特定于英语语言的,并非文化无关的
- 未来的研究可能涉及将这些测试适应不同的语言和文化背景
- 此外,论文的具体化具有固有的约束
- 通用知识 (K) 测试必然是选择性的,并未评估所有可能的学科领域的全部广度
- 100% 的 AGI 分数代表了一个在这些测试维度上达到精通水平的“高度熟练”的受过良好教育的个体,而不是指拥有大学学位的意义上的受过良好教育
- 而且,虽然论文采用的评分权重对于定量测量是必要的,但它们代表了众多可能配置中的一种
- 论文给予每个广泛能力相等的权重 (10%) 以优先考虑广度,但更具自由裁量权的加权方案也可能是合理的
- 结果取决于这些方法论选择,未来的工作可以探索替代的任务集合和加权方案
- 最后,虽然汇总的 AGI 分数是为了方便起见,但它可能具有误导性
- 简单的求和可能会掩盖瓶颈能力中的关键失败
- 例如,一个 AGI 分数为 90% 但在长期记忆存储 (MS) 上为 0% 的 AI 系统将因某种形式的“健忘症”而功能受损,尽管总分很高,但其能力受到严重限制
- 因此,论文建议报告 AI 系统的认知特征,而不仅仅是其 AGI 分数
Definitions of Related Concepts
- 某些具有战略意义的 AI 类型可能在 AGI 之前或之后出现
- 以下是一些特别值得注意的 AI 类型:
- 1)大流行病 AI (Pandemic AI) 是一种能够设计并生产新的、具有传染性和毒力的病原体,从而可能引发大流行病的 AI (2024; 2025)
- 2)网络战 AI (Cyberwarfare AI) 是一种能够针对关键基础设施(例如,能源电网、金融系统、国防网络)设计和执行复杂的、多阶段的网络攻击行动的 AI
- 3)自我维持 AI (Self-Sustaining AI) 是一种能够自主无限期运行、获取资源并维护其自身存在的 AI
- 4)AGI 是一种能够匹配或超越受过良好教育的成年人的认知通用性和熟练度的 AI
- 5)递归 AI (Recursive AI) 是一种能够独立进行整个 AI 研发生命周期,从而在没有人类输入的情况下创造出显著更先进的 AI 系统的 AI
- 注:递归 AI 消除了对人类研究人员的需求,并“闭合(closes the loop)”了 AI 研发的循环,使得在没有人类科学输入的情况下能够实现快速、递归的能力提升(一种“智能递归(intelligence recursion)”(2025)),并可能潜在地导致 超级智能
- 6)超级智能 (Superintelligence) 是一种在所有重要领域都大大超过人类认知表现的 AI (2014)
- 7)替代性 AI (Replacement AI) 是一种能更有效、更经济地执行几乎所有任务,从而使人类劳动力在经济上过时的 AI
- 注:替代性 AI 是关于经济规模的 AI,并且与 AGI 不同,它包含体力任务
- 论文的 AGI 定义是关于人类水平的 AI,而不是具有经济价值的 AI,也不是经济规模的 AI
- 据报道,OpenAI 和 Microsoft 认为 AGI 是能够产生 1000 亿美元利润的 AI (2024)
- 论文不将 AGI 与具有经济价值的 AI 混为一谈,因为像 iPhone 这样的狭窄技术尽管不具备通用智能,也能产生数十亿美元的经济价值
Barriers to AGI:实现 AGI 的障碍
- 实现 AGI 需要解决各种重大挑战,举例如下:
- 机器学习社区旨在衡量 抽象推理(abstract reasoning) 的 ARC-AGI 挑战体现在即时推理(On-the-Spot Reasoning) (R) 任务中
- Meta 创建包含直观物理理解的 世界模型(world models) 的尝试体现在视频异常检测任务 (V) 中
- 空间导航(spatial navigation)记忆 (WM) 的挑战反映了李飞飞初创公司 World-Labs 的一个核心目标
- 幻觉(hallucinations) (MR) 和 持续学习(continual learning) (MS) 的挑战也需要得到解决
- 这些重大障碍使得在未来一年内达到 100% 的 AGI 分数不太可能
附录:待补充
- 附录主要是一些测评示例,详情见原始论文