注:本文包含 AI 辅助创作
- 参考链接:
- 原始博客:Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization, 202503, SYSU
- 原始论文1:Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization, ICLR 2026 under review
- 原始论文2(arXiv):Rethinking KL Regularization in RLHF: From Value Estimation to Gradient Optimization, 20251006, SYSU
- 最早时作者在知乎上讨论:k2 loss就是比k3 loss好!以及GRPO_off-policy
Paper Summary
- 整体评价:
- 本文详细分析了 RLHF 中的 KL 正则化(KL regularization)
- 本文最早在知乎上讨论,后续逐步被作者整理为 博客和论文,目前在投 ICLR 2026(Under Review)
- 本文的工作早在博客时期就已经被 REINFORCE++ 论文引用,并作为依据切换 GRPO 中的 k3 Loss 为 k2 Loss
- 作者在论文中添加了实验,实验结果验证了这些理论上的区别
- 总结:作者的工作为实现 KL 正则化提供了一个清晰且理论坚实的基础,是非常值得读的一篇文章
- 本博客前的主流观点(以 GRPO 为代表):
- 主流观点主要将 KL正则化视为一种 Value 估计(value estimation)问题,因此优先选择那些能最小化 KL 项数值方差的估计器
- 当这些 KL 项在优化过程中被用作正则化损失(regularization loss) 时,这种基于价值的视角从根本上说是错误的(注:因为此时应该关注梯度的无偏性而不是数值本身的无偏性)
- 作者的工作:
- 分析 \(k_{n}\) in reward 和 \(k_{n}\) as loss 两种实现方式的联系和区别
- 先以 \(k_{1}\) as loss 的情况作为反例,论证 Value 估计视角的错误
- 然后证明传统的 \(k_{1}\) in reward 和 \(k_{2}\) as loss 公式在梯度上是等价的,并且代表了反向 KL 正则化(reverse KL regularization, RKL)的方法
- 最后分析 \(k_{3}\) as loss 这样的流行替代方案,揭示了它们作为有偏近似(biased approximations)的本质,并指出了它们在 off-policy implementation 中一个常见但关键的缺陷
- 分析 \(k_{n}\) in reward 和 \(k_{n}\) as loss 两种实现方式的联系和区别
- 作者的主要贡献有三个方面:
- A Gradient-Centric(以梯度为中心) Framework for KL Regularization
- 重新审视 RLHF 中的 KL 正则化,将焦点从 Value 估计转移到梯度优化
- 使用 \(k_{1}\) as loss 作为一个强有力的反例,展示了即使是一个无偏的 Value 估计器也可能产生完全无效的优化信号,从而论证了这种视角转变的必要性
- 识别 Principled KL 实现方法:Identification of Principled KL Implementations
- 证明了传统的 \(k_{1}\) in reward 公式正确地实现了 KL 梯度
- 进一步确立了一个先前未被认识到的关键等价性:\(k_{1}\) in reward 在梯度上与 \(k_{2}\) as loss 等价
- 这一发现巩固了两者作为 KL 正则化在理论上的合理选择
- 替代实现和修正方案:Analysis of Alternative Implementations and a Practical Correction
- 分析流行的替代方法,表明:
- \(k_{3}\) as loss (在 GRPO 中使用)是 Principled 梯度的一个有偏一阶近似(biased first-order approximation),导致正则化较弱或潜在的不稳定性
- 指出了一个在 off-policy algorithms 中的常见陷阱:
- 陷阱描述: \(k_{n}\) as loss 方法通常在实现时没有进行正确的重要性采样(importance sampling)
- 本文作者为这种偏差提供了一个 Principled 修正方案
- 分析流行的替代方法,表明:
- A Gradient-Centric(以梯度为中心) Framework for KL Regularization
- 注:原始论文使用红色的 \(\pi_{\color{red}{\theta}}\) 表示可训练的策略(携带梯度),并使用普通黑色字体 \(\pi_{\theta}\) 表示其数值相同、但 Detached 快照(不携带梯度)
- 注:原始文章中全文均使用 红色和黑色(普通字体)来区分是否携带梯度
- 这里后续考虑使用特殊的说明(红色和黑色来替代其实并不合适,使用特殊符号修饰一下最好,比如 \(\hat{\theta}\),但为了方便,后续本文也先继续沿用)
- 注:原始文章中部分地方用的不对(应该红色的地方没有红色等问题),本文会针对性进行修复
Introduction and Discussion
- RLHF 通过 KL 散度惩罚项来约束其与初始参考模型(reference model)的偏差
- KL 项是 RLHF 的核心组成部分,但其在 RLHF 中的实现方式仍然基于一种过时且从根本上来说不恰当的视角:视为一个 Value 估计问题
- 目前的主流观点(2020)通过 Numerical Value 估计的视角来对待 KL 散度
- 具体做法:
- 选择像 \(k_{1}, k_{2}, k_{3}\) 这样的蒙特卡洛估计器
- 目标是使其作为 KL 值估计器的偏差和方差最小化
- 这种观点的问题:
- 这种观点将 \(k_{1}\) 定性为无偏但高方差,\(k_{2}\) 为有偏但低方差,并将 \(k_{3}\) 推崇为“最优”选择,声称其在分布相近时具有低方差和无偏性
- 但当这些估计器被用作 RLHF 目标中的正则化项(regularization term)时,这种以价值为中心的观点从根本上来说是错误的
- 正确理解:
- 正则化损失的目标不是提供一个精确的 Numerical Value 估计,而是产生一个正确的优化信号
- 这个信号是一个能有效将策略约束回参考模型的梯度
- 作者通过一个基于梯度的分析来挑战这一传统智慧,证明一个无偏的 Value 估计器也可能导致一个完全无效的优化信号,反之亦然
- 正则化损失的目标不是提供一个精确的 Numerical Value 估计,而是产生一个正确的优化信号
- 具体做法:
- 简单总结:作者通过对 KL 损失进行系统的、基于梯度的分析来解决这些问题
- 建立一个统一的框架,将两种风格联系起来:
- 风格1:“以数学项 \(k_{n}\) 作为分离系数 \(k_{n}\) in reward ”
- 风格2:“作为直接损失函数(’ \(k_{n}\) as loss** ”
- 然后通过检查其等效梯度系数来分析任何实现
- 1)以 \(k_{1}\) as loss 的情况作为反例,来论证 Value 估计视角的错误
- 2)证明传统的 \(k_{1}\) in reward 和 \(k_{2}\) as loss 公式在梯度上是等价的,并且代表了反向 KL 正则化的 Principled 方法
- 3)分析了像 \(k_{3}\) as loss 这样的流行替代方案,揭示了它们作为有偏近似(biased approximations)的本质,并指出了它们在 off-policy implementation 中一个常见但关键的缺陷
- 建立一个统一的框架,将两种风格联系起来:
Related Work
KL Value Estimation
- KL 散度的期望通常是难以处理的,因此通常通过蒙特卡洛采样来估计
- 先前的分析主要将这些估计器作为值估计器进行评估(2020),将 \(k_{1}\) 描述为无偏但高方差,\(k_{2}\) 为有偏但低方差,而 \(k_{3}\) 则为“最优的”、低方差且无偏的选择
- 本文的工作:
- 作者首先挑战了 \(k_{3}\) 作为值估计器所声称的优越性,表明其宣称的特性在实际环境中往往不成立
- 更重要的是,当这些估计器被用于 RLHF 的正则化时,这种强调是错误的
- 作者表明,以梯度为中心的视角至关重要:从值估计中得出的结论并不一定能转化为有效的优化
RLHF Methods
- OpenRLHF(2024)是第一个使用 vLLM(2023)来加速 RLHF 训练中 Rollout 阶段的框架,并整合了多种使 RLHF 训练更稳定的技术
- 此后的一些训练框架,包括 Verl(2024)、slime(2025)和 ROLL(2025)
- 这些框架主要支持 PPO(2022)及其变体,专注于提高训练稳定性,特别是解决训练 Critic 模型时遇到的挑战
- VAPO(2025)提出预训练 Critic 模型以缓解这些问题,而 GRPO 和 Reinforce++ 则主张完全移除它,从而实现更大的 Actor 模型扩展
- 大多数 RLHF 方法都包含了 KL 损失,尽管最近一些基于规则的奖励算法,如 DAPO,建议移除 KL 损失以提升性能
- Prof(2025a)通过周期性地重置参考模型解决了性能问题,并帮助证明了 KL 损失在防止过拟合和确保长期训练稳定性方面仍然起着至关重要的作用
- 特别地,Prof 中使用的 KL 损失正是作者在本文中提出并倡导的 \(k_{2}\) as loss
KL Loss in RLHF
- 在奖励中引入 KL 惩罚的做法主要基于 OpenAI InstructGPT 论文(2022),该论文有效地将对数比率项作为策略得分函数(score function)的系数,尽管没有给出正式的证明
- 早期的工作(2019)注意到了将 KL 项加到奖励中与加到损失中等价的潜力,但这并未得到正式证明
- 最近,在 DeepSeek-R1(2025)等有影响力的模型中使用的 GRPO 方法(2024),因采用直接作为 KL 损失的项 \(k_{3}\) 而受到关注
- 这一选择的理由是引用了(2020)及其声称的 \(k_{3}\) 是一个“无偏估计器”的说法,这例证了将有偏的值估计原则转移到损失设计中的错误做法,这也是本文作者正在解决的核心问题
Preliminary
Value Estimation of KL Divergence
- 从分布 \(q(x)\) 到参考分布 \(p(x)\) 的 KL 散度定义为:
$$D_{\text{KL} }(q\parallel p) = \mathbb{E}_{x\sim q}\left[\log \frac{q(x)}{p(x)}\right] \tag {1}$$ - 由于这个期望通常是难以处理的,因此通过蒙特卡洛样本来估计
- 给定重要性比率
$$ \delta (x) = p(x) / q(x)$$- 注意:这个比例跟 KL 期望的目标的分子分母是相反的
- 期望内项的常见估计器包括:
$$
\begin{align}
k_{1}(x) &= -\log \delta (x) \\
k_{2}(x) &= \frac{1}{2}\left(\log \delta (x)\right)^{2} \\
k_{3}(x) &= \delta (x) - 1 - \log \delta (x)
\end{align}
$$ - 除了第 2 节中提到的性质外,估计器 \(k_{3}\) 尤其值得注意,它旨在降低高方差
- 尽管当分布 \(p\) 和 \(q\) 接近时 \(k_{3}\) 可能很有效,但声称 \(k_{3}\) 是一个“严格更好的估计器”(2020)在一般情况下并不成立
- 当分布的支撑集或尾部差异显著时,\(k_{3}\) 可能会出现严重偏差和无限方差的潜在问题
- 因此,\(k_{3}\) 的应用需要仔细验证某些假设
- 关于这些统计不稳定性的详细分析,以及反例支持,请参见附录 I
RLHF
- RLHF 的目标:
- 微调一个策略(Actor 模型) \(\pi_{\color{red}{\theta}}\),使其对 Prompt \(x\) 生成的 Response \(y\) 能够最大化源自人类偏好的奖励 \(r(x,y)\)
- 纯粹的最大化奖励可能会导致 Reward Hacking 以及偏离可信的 SFT 策略的分布漂移
- 为了抵消 Reward Hacking 或 分布漂移 这一点,RLHF 增加了一个 KL 惩罚损失,将策略正则化(regularizes)到一个固定的参考模型 \(\pi_{\text{ref} }\)
$$\begin{align} \mathcal{J}_{\text{RLHF} }(\color{red}{\theta}) &= \underbrace{\mathbb{E}_{x\sim D,y\sim \pi_{\color{red}{\theta}}(\cdot|x)}\left[r(x,y)\right]}_{\text{Reward Maximization Term} } - \beta \underbrace{D_{\text{KL} }\left(\pi_{\color{red}{\theta}}(\cdot|x)\parallel\pi_{\text{ref} }(\cdot|x)\right)}_{\text{KL Regularization Term} } \\
\quad &= \mathcal{J}_{\text{Reward} }(\color{red}{\theta}) - \beta \mathcal{J}_{\text{KL} }(\color{red}{\theta}) \end{align} \tag {2}$$- \(\mathcal{D}\) 是 Prompt 分布
- \(y\) 是从分离的快照(detached snapshot)策略 \(\pi_{\theta}\)(在采样时数值上等于 \(\pi_{\color{red}{\theta}}\))上 On-policy 采样的
- \(\beta\) 权衡了奖励最大化和与 \(\pi_{\text{ref} }\) 的偏离
A Unified Framework for KL Regularization in RLHF
- 大多数 RLHF 算法优化的是与公式 (2) 相同的高层目标,但它们的具体实现却大相径庭
- 为了系统地分析这些差异,作者建立了一个统一的框架,将该目标分解为其核心组成部分,并对不同的 KL 实现风格进行分类
- 作者给出的 约定(Convention)
- 在本文作者的分析中,用 \(\pi_{\color{red}{\theta}}\) 表示携带梯度的可训练策略,并遵循标准的 Bandit 设置
- 样本 \(y\) 是从一个分离的且数值上相同的快照策略 \(\pi_{\theta}(\cdot |x)\) 中抽取的,在当前迭代中进行评估;
- 梯度仅通过 \(\pi_{\color{red}{\theta}}\) 传播
- 所有乘以得分函数 \(\nabla_{\color{red}{\theta}} \log \pi_{\color{red}{\theta}}(y|x)\) 的标量系数都被视为是分离的(detached)
- 在本文作者的分析中,用 \(\pi_{\color{red}{\theta}}\) 表示携带梯度的可训练策略,并遵循标准的 Bandit 设置
- 补充:关于 Bandit Setting 的解释:
To simplify analysis of core gradient properties, we model the entire response \(y\) as a single action. Our derivations therefore operate on the joint probability \(\pi(y|x)\) of the sequence, rather than the token-level probabilities used in standard sequential PPO.
- 为了简化,将整个回复建模为一个 Action,所以推导均在联合概率分布 \(\pi(y|x)\) 上,而不是 Token-level 的概率分布上
Core Components of The RLHF Objective
- 实际的 RLHF 目标由通过蒙特卡洛采样估计的两个部分组成
Reward Maximization
- 主要目标是最大化期望奖励
- 这个目标的梯度通常使用得分函数估计器(score function estimator)(1992)来估计,其详细推导见附录 B:
$$\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{reward} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}[r(x,y)\cdot \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)] \tag {3}$$ - 实际的实现会用 Shaped 优势信号(shaped advantage signal)替换原始奖励 \(r(x,y)\)
- 具体的 Shaped 技术详见附录 A
KL Regularization
- RLHF 通过 RKL 将 Actor 模型正则化到参考模型:
$$ \begin{align}
\mathcal{J}_{\text{KL} }(\color{red}{\theta}) &= \mathbb{E}_{x\sim \mathcal{D} }\left[D_{\text{KL} }(\pi_{\color{red}{\theta}}(\cdot |x)| \pi_{\text{ref} }(\cdot |x))\right] \\
&= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\color{red}{\theta}}(\cdot |x)}\left[\log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x)\right]
\end{align} \tag {4}
$$- 上述期望是在当前策略下计算的,因此 On-policy 蒙特卡洛估计(on-policy Monte Carlo estimation)是一个自然的选择
- 在实现中,通过代理项 \(k_{n}\) 来优化这个目标,这些代理项的形式借鉴自值估计器
- 期望是使用从分离的快照策略 \(\pi_{\theta}\)(在采样时数值上等于 \(\pi_{\color{red}{\theta}}\))中抽取的样本来评估的。有两种主要的公式:
- 1)\(k_{n}\) as a Detached Coefficient ( \(k_{n}\) in reward) :将 \(k_{n}\) 视为得分函数的一个分离的系数权重
$$\mathcal{J}_{k_{n}\text{ in reward} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\color{red}{\theta}}(\cdot |x)}\left[\underbrace{k_{n}\left(\pi_{\theta}(y|x),\pi_{\text{ref} }(y|x)\right)}_{\text{detached coefficient} }\cdot \log \pi_{\color{red}{\theta}}(y|x)\right] \tag {5}$$- 一个典型的选择是
$$ k_{1}(y|x) = \log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x) $$
- 一个典型的选择是
- 2)\(k_{n}\) as a Direct Loss ( \(k_{n}\) as loss) :将 \(k_{n}\) 视为一个独立的损失,梯度直接通过它传播
$$ \mathcal{J}_{k_{n}\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[k_{n}\big(\pi_{\color{red}{\theta}}(y|x),\pi_{\text{ref} }(y|x)\big)\right] \tag {6}$$- 常见的选择包括 下面两个
$$
\begin{align}
k_{2}(y|x) &= \frac{1}{2}\big(\log \frac{\pi_{\color{red}{\theta}}(y|x)}{\pi_{\text{ref} }(y|x)}\big)^{2} \\
k_{3}(y|x) &= \frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)} -1 - \log \frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)}
\end{align}
$$ - \(k_n\) as loss 的梯度是直接通过 \(k_{n}\) 计算的,没有显式的得分函数项,然而正如作者将在第 5 节中证明的,在 On-policy 条件下,它与 in reward 的梯度是匹配的
- 并且在 On-policy 采样下, \(k_{1}\) in reward 和 \(k_{2}\) as loss 是 RKL 目标的梯度等价实现(参见附录 C 的完整证明)
- 常见的选择包括 下面两个
- 1)\(k_{n}\) as a Detached Coefficient ( \(k_{n}\) in reward) :将 \(k_{n}\) 视为得分函数的一个分离的系数权重
KL Integration Forms And Algorithm Mapping
- KL 公式的选择决定了它如何与奖励目标整合
组合形式 vs. 解耦形式(Combined vs. Decoupled Forms)
- 由于 \(k_{n}\) in reward 使用与奖励目标相同的得分函数,其系数可以合并到奖励系数中以产生组合形式(Combined Form),这也是 in reward 名称的由来:
$$\mathcal{L}_{\text{combined} }(\color{red}{\theta}) = -\mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(r(x,y) - \beta k_{n}\left(\pi_{\theta}(y|x),\pi_{\text{ref} }(y|x)\right)\right)\cdot \log \pi_{\color{red}{\theta}}(y|x)\right] \tag {7}$$ - 相比之下, \(k_{n}\) as loss 则需要一种具有独立损失形式的解耦形式(Decoupled form):
$$\mathcal{L}_{\text{decoupled} }(\color{red}{\theta}) = -\mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[r(x,y)\cdot \log \pi_{\color{red}{\theta}}(y|x)\right] + \beta \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[k_{n}\left(\pi_{\color{red}{\theta}}(y|x),\pi_{\text{ref} }(y|x)\right)\right] \tag {8}$$ - 解耦形式也可以与 \(k_{n}\) in reward 一起使用,通过分离两个得分函数项
- 在 Off-policy 更新中,组合形式中的合并系数 \(r - \beta k_{n}\) 必须使用重要性采样(importance sampling, IS)进行修正
- 当与 PPO 结合时,这种修正通过裁剪的代理目标(clipped surrogate objective) \(\pi_{\color{red}{\theta}} / \pi_{\theta_{k} }\) 自动继承
- as loss 的实现也明确要求应用 IS 和 PPO 裁剪(Cliping),但这些在实践中常常被忽略(参见附录 G)
定位 PPO 和 GRPO(Positioning PPO and GRPO)
- 该框架可以定位主要算法,总结于表 1
- PPO 是在组合形式中使用 \(k_{1}\) in reward 的典型例子
- \(k_{1}\) in reward 与 PPO 配对时,继承 IS/Cliping
- GRPO 则是在解耦形式中使用“” \(k_{3}\) as loss 的典型例子
- 需要显式的 IS/Cliping,实践中常被省略

- 需要显式的 IS/Cliping,实践中常被省略
- PPO 是在组合形式中使用 \(k_{1}\) in reward 的典型例子
Gradient-based Analysis of KL Implementations
- 在 RLHF 中,应根据梯度属性而非值的准确估计来选择 KL 正则化器
- 本节工作:
- Step1: 使用 \(k_{1}\) as loss 作为反例,说明采用 without auditing the induced gradients 的估计器会导致无效的更新
adopting estimators without auditing the induced gradients can lead to vacuous updates
- Step2: 推导出 RKL 的主要代理损失,并证明
- 1)\(k_{3}\) as loss 是其一阶近似
- 2)在 on-policy 设置下,\(k_{n}\) as loss 和 \(k_{n^{\prime} }\) in reward 通常是梯度等价的,并且可以相互转换
,大约为 -1.38")
- Step1: 使用 \(k_{1}\) as loss 作为反例,说明采用 without auditing the induced gradients 的估计器会导致无效的更新
- 图 1: 展示了 KL 正则化梯度系数的比较
- 每条曲线显示了乘以 Score Function \(\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\) 的标量系数 \(c(x,y)\)
- 以 \(\log \pi_{\theta}(y|x)\) 为 X 轴绘制
- 其中 \(\pi_{\text{ref} }(y|x) = 0.25\) (垂直虚线)
- Principled 实现 (\(k_{1}\) in reward 或 \(k_{2}\) as loss) 产生
$$ c = \log (\pi_{\color{red}{\theta}} / \pi_{\text{ref} }) $$- 这是在 log-probability 中的 Linear restoring force
- \(k_{3}\) as loss 使用
$$ c = 1 - \pi_{\text{ref} } / \pi_{\color{red}{\theta}}$$- 这是 \(-\log \delta\) 在 \(\delta = \pi_{\text{ref} } / \pi_{\color{red}{\theta}} = 1\) 处的一阶泰勒代理:
- 当 \(\log \pi_{\color{red}{\theta}}\) 很大 \((\pi_{\color{red}{\theta}}\gg \pi_{\text{ref} })\) 时它是松弛的
- 当 \(\log \pi_{\color{red}{\theta}}\) 很小 \((\pi_{\color{red}{\theta}}\ll \pi_{\text{ref} })\) 时它可能会爆炸
- 这是 \(-\log \delta\) 在 \(\delta = \pi_{\text{ref} } / \pi_{\color{red}{\theta}} = 1\) 处的一阶泰勒代理:
- 朴素的 \(k_{1}\) as loss 给出 \(c\equiv 1\),在期望中产生一个零均值、无正则化作用的梯度
- 每条曲线显示了乘以 Score Function \(\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\) 的标量系数 \(c(x,y)\)
反例 (The Counterexample: Why \(k_{1}\) as loss Fails)
- 本工作的一个核心教训是,值估计的优良属性不会自动转化为有效的优化损失
- 使用 \(k_{1}\) as loss 的情况提供了一个清晰的反例:
- 尽管 \(k_{1}\) 是 KL 值的无偏估计量,但作为强制执行 KL 约束的损失,它是无效的
- 考虑使用从 detached snapshot \(y\sim \pi_{\theta}(\cdot |x)\) 进行的 on-policy 采样的直接损失公式:
$$\mathcal{J}_{k_1\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot |x)}\big[\log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x)\big] \tag {9}$$ - 由于 \(\pi_{\text{ref} }\) 不依赖于 \(\color{red}{\theta}\),其项在微分后消失,剩下:
$$\nabla_{\color{red}{\theta}}\mathcal{J}_{k_1\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim D,y\sim \pi_{\theta}(\cdot |x)}\big[\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\big] \tag {10}$$ - 结果揭示了一个根本性缺陷:梯度完全独立于参考策略 \(\pi_{\text{ref} }\)
- 因此,它不携带任何 KL 正则化信号
- 根据引理 C.2 中的零均值 Score 恒等式,该梯度的期望恰好为零
- 注:正是 REINFORCE (1992) 等 Policy Gradient 中减去 Baseline 的底层机制
- 因此,在蒙特卡洛实践中,该项仅注入零均值噪声,这会增大梯度方差并可能破坏学习的稳定性
- 这个反例是决定性的:一个“无偏的值估计器”可能产生无用的优化信号
- 它直接挑战了这样一种错误假设 :良好的值估计属性足以设计有效的 KL 损失
- 而这种假设已隐含地激发了一些最近的实现,例如 GRPO
- 它直接挑战了这样一种错误假设 :良好的值估计属性足以设计有效的 KL 损失
The Principled KL Loss in RLHF: \(k_{1}\) in Reward \(\Leftrightarrow\) \(k_{2}\) as loss
- 本节推导了方程 (4) 中 Reverse KL 目标的精确 on-policy 梯度,并将其用作设计代理 KL 损失的参考梯度,将乘积规则和对数导数技巧应用于 RKL(见附录 C)可得:
$$\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{RKL} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D} }\left[\sum_{y}\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)\left(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)} +1\right)\right] \tag {11}$$ - 根据引理 C.2 中的零均值 Score 恒等式,项 \(+1\) 在期望中消失,从而得到 Policy Gradient 的实际形式:
$$\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{RKL} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[ \underbrace{\left(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)}\right)}_{\text{k1 (detached) coefficient}}\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {12}$$- 任何 Principled KL 正则化损失都应在期望中重现这个目标梯度
- 定理 5.1 表明,两个结构上不同的代理损失可以精确地做到这一点
定理 5.1 (Principled RKL 代理损失的 On-policy 梯度等价性)
- 令 \(\pi_{\theta}\) 为可训练策略 \(\pi_{\color{red}{\theta}}\) 的一个 detached snapshot,其参数在梯度评估时一致
- 对于从 \(\pi_{\theta}(\cdot |x)\) 以 on-policy 方式采样的样本 \(y\),以下目标具有与方程 (12) 中目标相同的期望梯度:
$$\mathcal{J}_{k_{1}\text{ in }reward}(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\Bigg[\underbrace{\Big(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)}\Big)}_{\text{k1 (detached) coefficient}}\log \pi_{\color{red}{\theta}}(y|x)\Big] \tag{13}$$
$$ \mathcal{J}_{k_{2}\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\Big[\frac{1}{2}\Big(\log \frac{\pi_{\color{red}{\theta}}(y|x)}{\pi_{\text{ref} }(y|x)}\Big)^{2}\Big] \tag {14}$$
- 证明梗概 (完整证明见附录 C)
- 对于方程 (13),它可以恢复方程 (12),因为项 \(k_{1}\) 是一个乘以 \(\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}\) 的 detached 标量
- 对于方程 (14),微分得到
$$\nabla_{\color{red}{\theta}}\frac{1}{2}\left(\log \frac{\pi_{\color{red}{\theta}} }{\pi_{\text{ref} } }\right)^{2} = \left(\log \frac{\pi_{\theta} }{\pi_{\text{ref} } }\right)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}$$ - 所以这里的 \(k_{2^{\prime} }\) 就是 \(k_{1}\),并且方程 (71) 中的通用 \(k_{n^{\prime} }\) 解公式也会产生与方程 (12) 相同的系数
- 理解:这里的 \(k_{2^{\prime} }\) 是表示 \(k_{2}\) 的导数(梯度)
- 因此,这里得到一个重要结论:
- 传统的 \(k_{1}\) in reward(如 PPO/REINFORCE 中所用)和新提出的 \(k_{2}\) as loss 是在 on-policy 采样下 RKL 正则化的 Principled 、梯度等价且可互换的实现
- 对于 off-policy 更新,需要显式的 Importance Sampling 和 PPO clip,如附录 G 中所讨论
\(k_{2}\) as loss 的一阶近似(First-Order Approximation): \(k_{3}\) as loss \(\Leftrightarrow\) \(k_{3^{\prime} }\) in reward
- \(k_{3}\) as loss 的表达式如下:
$$\mathcal{J}_{k_{3}\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)} -\log \frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)} -1\right] \tag {15}$$- 其中期望是对来自 detached snapshot \(\pi_{\theta}\) 的 on-policy 样本求得的
- 对 \(k_{3}\) as loss 取梯度得到等效系数 \(k_{3^{\prime} }\),并可以得到损失形式的 \(k_{n^{\prime} }\) in reward :
$$\nabla_{\color{red}{\theta}}\mathcal{J}_{k_{3}\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\Bigg[\underbrace{\left(1 - \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}\right)}_{\substack{k_{3^{\prime} }\text{ (detached) coefficient} } }\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\Bigg] = \nabla_{\color{red}{\theta}}\mathcal{J}_{k_{3^{\prime} }\text{ in reward} }(\color{red}{\theta}) \tag {16}$$ - 令
$$ \delta = \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}$$ - 第 5.2 节中的 Principled \(k_{1}\) in reward 和 “\(k_{3}\) in reward” 共享相同的 Score Function,但它们的标量系数不同:
- Principled \(k_{1}\) in reward or \(k_{2}\) as loss :
$$ \underbrace{-\log\delta}_{\text{(detached) coefficient} }.\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)$$ - Approximation \(k_{3}\) as loss or \(k_{3^\prime}\) in reward :
$$ \underbrace{-\left(\delta -1\right)}_{\text{(detached) coefficient} }.\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x) \tag {17}$$
- Principled \(k_{1}\) in reward or \(k_{2}\) as loss :
泰勒陷阱 (Taylor trap)
- 在 \(\delta = 1\) 附近,恒等式 \(\log \delta = (\delta - 1) + \mathcal{O}((\delta - 1)^{2})\) 意味着 \(\color{blue}{- \log \delta} \approx \color{red}{1 - \delta}\)
- 因此,\(\color{red}{1 - \delta}\) 仅是主要系数 \(\color{blue}{- \log \delta}\) 的一阶代理
- 超过一阶的失配导致了三个具体问题(形式化陈述见附录 E)
- 为了可视化,系数曲线绘制在图 1 中,代码在附录 H 中
- 代理系数 \(\color{red}{1 - \delta}\) 替代 Principled 系数 \(\color{blue}{- \log \delta}\) 时可能遇到的三个具体问题:
- 1)Bias
- 对于所有 \(\delta \neq 1, \ \color{red}{1 - \delta} \neq \color{blue}{- \log \delta}\) ,有:
- 相对于真实的 RKL 梯度,更新方向是有偏的
- 对于所有 \(\delta \neq 1, \ \color{red}{1 - \delta} \neq \color{blue}{- \log \delta}\) ,有:
- 2)病态不对称性 (Pathological asymmetry) :这两个系数在 \(\delta = 1\) 附近一致,但在尾部表现非常不同:
- 过覆盖 (Over-coverage) \((\delta \rightarrow 0)\) :
- \(\delta \rightarrow 0\) 时
- \(\color{blue}{- \log \delta} \rightarrow +\infty\) (强大的、持续的恢复力,可对模型添加更多惩罚)
- \(\color{red}{1 - \delta} \rightarrow 1\) (饱和),产生弱得多的正则化器
- 这在 RLHF 训练后期,当 \(\pi_{\color{red}{\theta}} > \pi_{\text{ref} }\) 时常发生,使得 \(k_{3^{\prime} }\) 的约束更弱
- \(\delta \rightarrow 0\) 时
- 欠覆盖 (Under-coverage) \((\delta \rightarrow \infty)\) :
- \(\delta \rightarrow \infty\) 时,\(\color{blue}{- \log \delta}\) 仅对数级衰减,但 \(\color{red}{1 - \delta} \rightarrow -\infty\) 快得多,引发爆炸性更新
- 过覆盖 (Over-coverage) \((\delta \rightarrow 0)\) :
- 3)统计不稳定性 (Statistical instability)
- 在 \(y\sim \pi_{\theta}(\cdot |x)\) 下:
$$
\mathbb{E}[\delta ] = 1 \\
\text{Var}[\color{red}{1 - \delta} ] = \mathbb{E}[(\delta -1)^{2}] = \chi^{2}(\pi_{\text{ref} }||\pi_{\theta})$$- 即卡方散度,这是出了名的不稳定
- 随机梯度继承了这种高方差
- 在 \(y\sim \pi_{\theta}(\cdot |x)\) 下:
- 1)Bias
Pratical Recommendations(作者给出的经验建议)
- 基于本文以梯度为中心的分析,作者为在 RLHF 中实现 KL 正则化损失提供以下实用建议,最后两点将在附录 G 和附录 F 中讨论:
建议1:Do not use \(k_{1}\) as a loss
- Do not use \(k_{1}\) as a loss
- 其期望梯度为零,且独立于参考模型,不提供正则化信号,仅提供噪声
建议2:优先选择 \(k_{1}\) in reward 或 \(k_{2}\) as loss 以保证理论上的合理性
- Prefer \(k_{1}\) in reward’ or \(k_{2}\) as loss’ for theoretical soundness
- 在 on-policy 设置中,这两种表述是梯度等价的,并能正确实现 RKL 目标。它们是 KL 正则化的主要默认选择(详细证明见附录 C)
建议3:理解 \(k_{3}\) as loss 是 \(k_{2}\) as loss 的有偏一阶近似
- 原始标题:Understand the properties of \(k_{3}\) as loss
- 这种表述应被视为 \(k_{2}\) as loss 的有偏一阶近似(形式化分析见附录附录 E)
- 尽管其在策略高概率区域较弱的正则化强度在某些场景下可能带来实际好处,但实践者应意识到它在理论上偏离了真实的 KL 梯度,并且在策略概率较低时可能导致病态更新的可能性
建议4:纠正 Off-policy 偏差
- Correct for off- policy bias
- 在像 PPO 这样的 off-policy 设置中使用任何 \(k_{n}\) as loss 表述时,对 KL 项本身应用 Importance Sampling 校正至关重要
- 忽略这一点会引入系统性偏差
- \(k_{n}\) in reward 的组合方法自然避免了这个问题
- 详细的讨论和作者提出的修正方案见附录 G
建议5:考虑有界替代方案以增强稳定性
- Consider bounded alternatives for enhanced stability
- 如果要求最大稳定性,特别是在策略更新幅度较大的情况下,产生有界梯度系数的替代方案可能是有益的
- 例如,基于 MSE 的惩罚,如 MiniMax-01 损失,会产生一个边界在 \([- 1,1]\) 内的系数
- 这里推导和性质详见附录 F
Experiments
- 作者在一个数学推理任务上进行了受控的 GRPO 实验,以检验第 5 节中的梯度分析
- 作者的实验设计隔离了不同 KL 表述的影响,使作者能够:
- (i) 验证 \(k_{1}\) as loss 不提供适当的正则化项
- (ii) 比较 Principled \(k_{2}\) as loss 与其一阶代理 \(k_{3}\) as loss
- 作者将大规模实验放在附录 K,下游 Benchmark 性能放在附录 L
Setup and Baselines
Dataset Construction
- 作者使用 OpenR1-Math-220k 的一个精选子集,主要由 NuminaMath 1.5 Prompts 组成
- 推理轨迹由强模型 Deepseek-R1 生成,并通过 MathVerify 进行格式和正确性过滤
- 问题:RL 训练为什么需要其他模型的推理轨迹?
- 删除长度大于 2048 个 token 的序列,得到了 7.3K 个具有高质量 off-policy 推理轨迹的 Prompts
RL Configuration
- 为了隔离每个 KL 项的梯度属性,作者采用了完全的 on-policy 训练配置:
- Rollout 批大小为 32
- 每个 Prompt 生成 8 个 Response
- 更新批大小为 256
- 采样温度为 1.0
- 使用正则表达式计算格式奖励
- 使用 Math-Verify 计算准确率奖励
- Actor 模型为 Qwen2.5-Math-1.5B (2024)
- 关闭了熵损失(系数为 0)
- 为所有带有 KL 正则化的损失设置 \(\beta = 0.5\)
Key Results
\(k_{1}\) as loss:没有限制效果,仅添加了一些噪音
- 图 2 中显示的实证结果有力地支持了作者对 \(k_{1}\) as loss 的理论分析
- 正如第 5 节中推导的那样,这个损失项的梯度对于正则化来说存在根本性缺陷:
- 首先,它完全独立于参考策略 \(\pi_{\text{ref} }\) ;
- 其次,它在 on-policy 样本上的期望恰好为零
- 在实践中,此项等同于向梯度中添加一个缩放的 Score Function
$$ \beta \cdot \nabla_{\color{red}{\theta}} \log \pi_{\color{red}{\theta}} $$ - 虽然这不改变预期的更新方向,但它注入了零均值噪声,从而增加了梯度方差
- 这与 REINFORCE 中使用 Baseline 的方差减少技术的作用相反
- 图 2 中可以观察到:\(k_{1}\) as loss 与无 KL 正则化的比较,两条训练曲线几乎相同,证实了理论预测:
- \(k_{1}\) as loss 作为一个 KL 正则化器是无效的
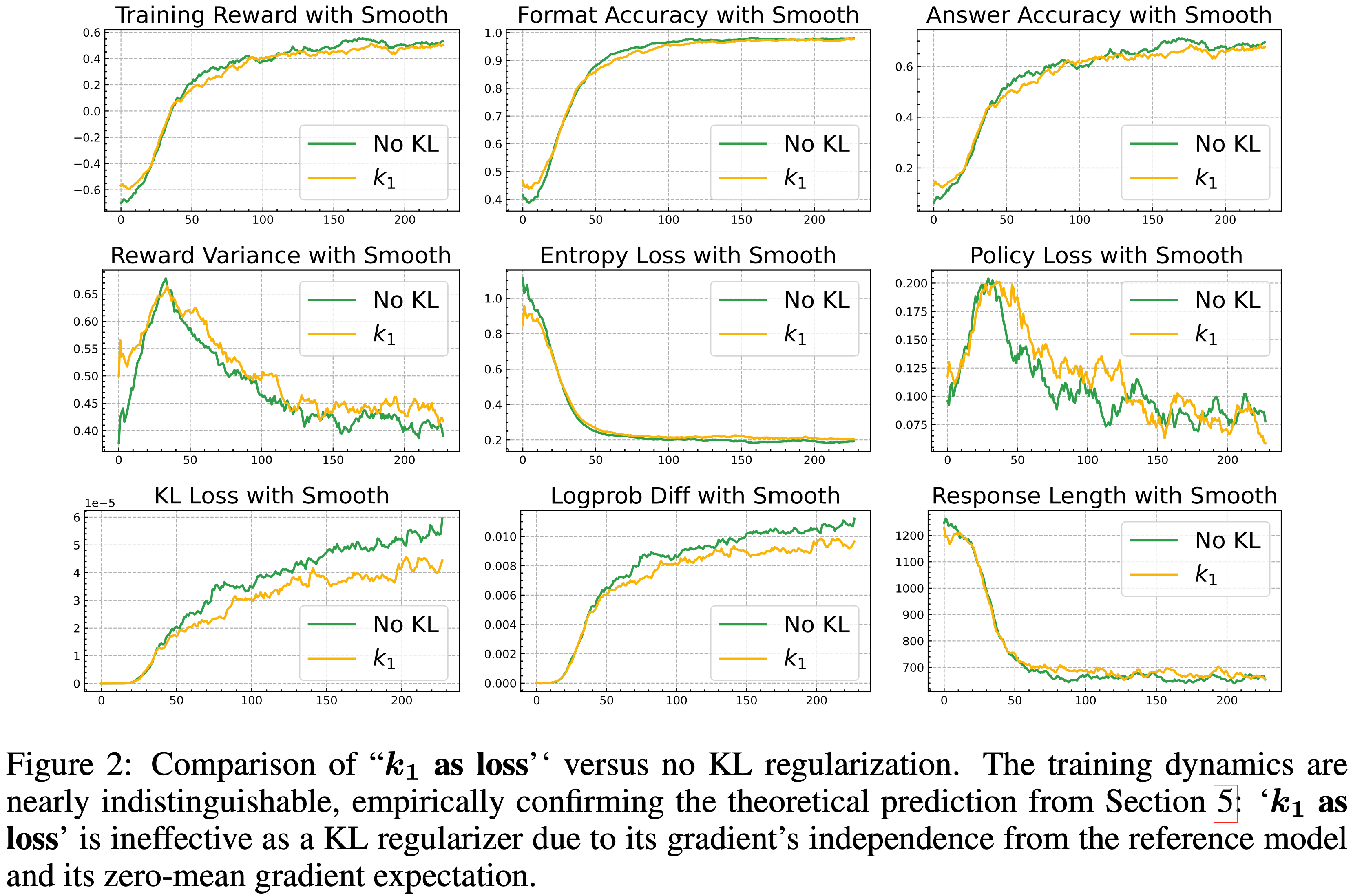
- \(k_{1}\) as loss 作为一个 KL 正则化器是无效的
- 正如第 5 节中推导的那样,这个损失项的梯度对于正则化来说存在根本性缺陷:
- 图 2 中得到的结论:
- 对 \(k_{1}\) as loss 的理论预期是:其性能最多与没有 KL 惩罚时相当,并且由于增加的方差阻碍优化,其性能可能会更差
- 注:作者的实验结果中,\(k_{1}\) as loss 的训练轨迹与没有 KL 的基线几乎无法区分,完全落在这个预测的结果范围内
- 这一观察提供了令人信服的证据,表明应避免使用 \(k_{1}\) as loss ,因为它对正则化无益,同时可能对训练的稳定性构成风险
\(k_{2}\) as loss VS \(k_{3}\) as loss: \(k_{2}\) as loss 表现更好
- 在图 3 中,作者比较了 Principled \(k_{2}\) as loss 与其近似 \(k_{3}\) as loss
- 两种方法都成功地正则化了策略;
- 与图 2 的交叉对比显示,它们的奖励曲线相对于无 KL 的基线被抑制,证实了 KL 惩罚积极地约束了优化过程,使其更接近参考模型
- 两种变体都正则化了策略,而 Principled \(k_{2}\) as loss 表现出一些优势
- \(k_{2}\) as loss 提供了更高的训练稳定性和更强的正则化,体现在更低的奖励方差和 Response 长度方差,这表明优化 Landscape 更平滑
- 理解:\(k_{2}\) as loss 训练曲线的 Training Reward(左上)确实波动会稍微更小一些,但是其实也没有小很多
- \(k_{2}\) as loss 还与参考策略保持更紧密的耦合,具有更小的 Actor-Reference 概率差距(参见“Logprob Diff with Smooth”)和略高的熵,这表明 \(k_{2}\) as loss 在保持稳定的同时保留了更多的探索能力
- 这些实证观察与其作为 RKL 目标正确代理损失的角色相符
- \(k_{2}\) as loss 提供了更高的训练稳定性和更强的正则化,体现在更低的奖励方差和 Response 长度方差,这表明优化 Landscape 更平滑
- 相比之下, \(k_{3}\) as loss 是一个一阶代理,施加的约束较弱,导致更大的概率差距和更低的熵
- 尽管当需要在后期进行较弱的约束时, \(k_{3}\) as loss 可能是一个可行的选择,但作者的结果表明,\(k_{2}\) as loss 为稳定、有效的正则化提供了一条更健壮、更 Principled 途径
- 从图 3 中可以观察到:
- Principled \(k_{2}\) as loss 与其一阶代理 \(k_{3}\) as loss 两种变体都有效地约束了策略,但 \(k_{2}\) as loss 表现出更优的正则化特性,与参考策略保持更紧密的耦合,并产生更稳定的优化路径,更低的奖励方差证明了这一点
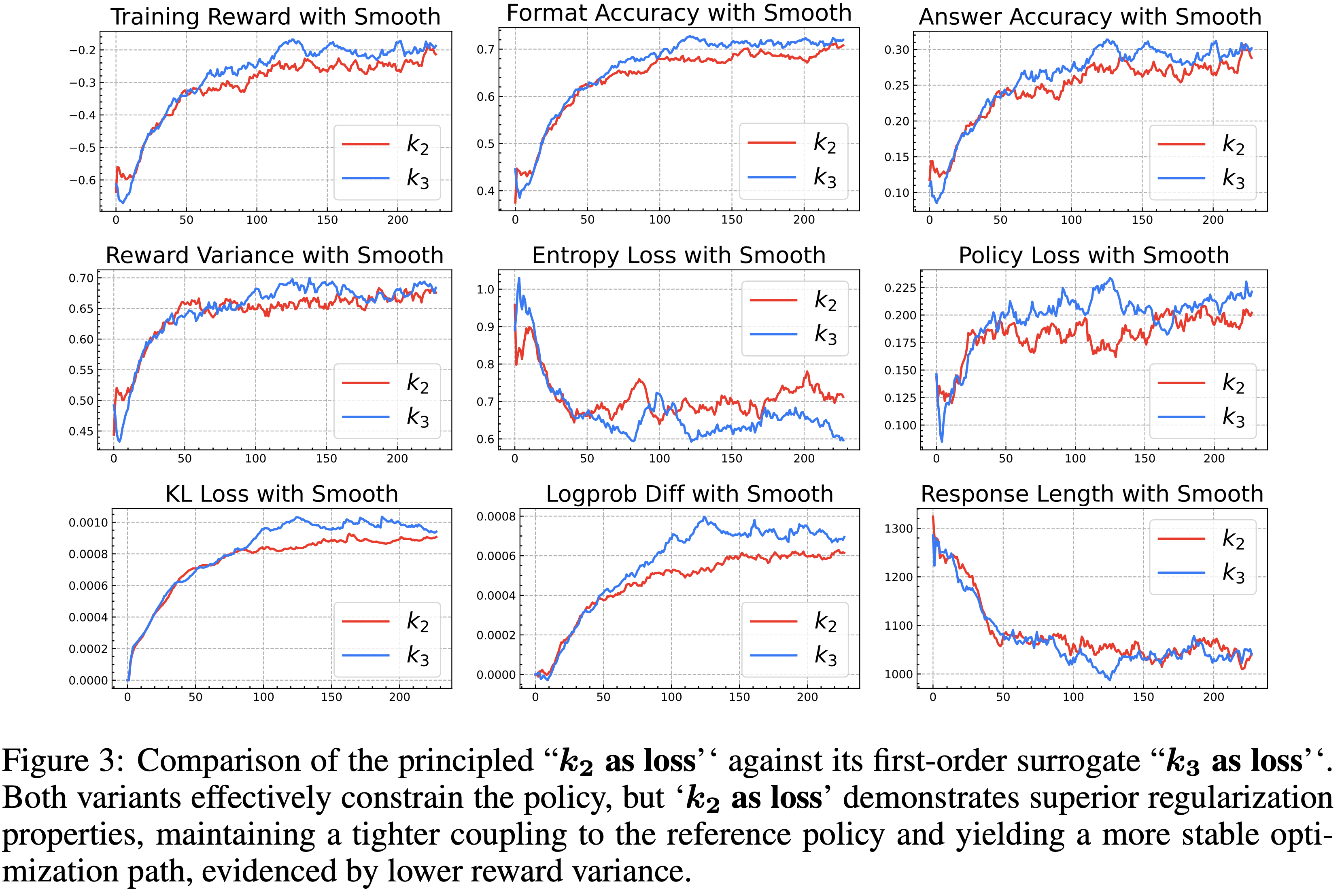
- Principled \(k_{2}\) as loss 与其一阶代理 \(k_{3}\) as loss 两种变体都有效地约束了策略,但 \(k_{2}\) as loss 表现出更优的正则化特性,与参考策略保持更紧密的耦合,并产生更稳定的优化路径,更低的奖励方差证明了这一点
附录 A:Detailed Implementation of RLHF Methods
- 在典型的 RLHF 训练步骤中,作者从数据集 \(\mathcal{D}\) 中抽取 \(N\) 个 Prompt
$$\{x^{(i)}\}_{i = 1}^{N}$$ - 对于每个 Prompt \(x^{(i)}\),作者采样 \(G\) 个回复(来自 Detached 当前策略)
$$ y^{(i,1)},\ldots ,y^{(i,G)}\sim \pi_{\theta}(\cdot |x^{(i)})$$ - 与同一个 Prompt 关联的 \(G\) 个回复形成一个组,而完整的 minibatch 包含 \(N\times G\) 个 Prompt-Response 对
- 训练时使用红色的 \(\pi_{\color{red}{\theta}}\) 表示可训练的策略(携带梯度),并使用普通黑色字体 \(\pi_{\theta}\) 表示其数值相同、但 Detached 快照(不携带梯度)
- 注:原始文章中全文均使用 红色和黑色(普通字体)来区分是否携带梯度
- 这里后续考虑使用特殊的说明(红色和黑色来替代其实并不合适,使用特殊符号修饰一下最好,比如 \(\hat{\theta}\),但为了方便,后续本文也先继续沿用)
Baseline Subtraction and Normalization
- 由 REINFORCE (1992) 提出,减去一个与动作无关的基线不会改变期望的策略梯度(无偏;见公式 (34)),并且通常会降低方差,加速收敛
- 考虑以下应用于标量信号 \(r\) 的基线算子:
$$
\begin{align}
f_{\text{group-bl} }(r) = r - \text{mean}_{\text{group} }(r) \tag{18}\\
f_{\text{batch-bl} }(r) = r - \text{mean}_{\text{batch} }(r) \tag {19}
\end{align}
$$- 理解:这里的 \(\text{-bl}\) 应该是 Baseline 的简称,表示减去一个 基线(Baseline)的方案
- 在实践中,也可能会使用归一化,归一化不是无偏的,但可以通过控制奖励信号的尺度来提高数值稳定性:
$$
\begin{align}
f_{\text{BN} }(r) = \frac{r - \text{mean}_{\text{batch} }(r)}{\text{std}_{\text{batch} }(r)} \tag {20}\\
f_{\text{GN} }(r) = \frac{r - \text{mean}_{\text{group} }(r)}{\text{std}_{\text{group} }(r)} \tag {21}
\end{align}
$$
How Common Algorithms Shape the Reward Signal
- 令 \(r_{\text{raw} }(x,y)\) 表示在应用任何 shaping 之前的、来自奖励模型的原始得分
- 以下变体在如何后处理 \(r_{\text{raw} }\) 上有所不同:
$$
\begin{align}
\text{REINFORCE: } & r(x,y) = f_{\text{BN} }(r_{\text{raw} }(x,y)) \tag {23} \\
\text{PPO/REINFORCE++ : } & r(x,y) = f_{\text{BN} }(r_{\text{raw} }(x,y))\tag {24} \\
\text{GRPO: } & r(x,y) = f_{\text{GN} }(r_{\text{raw} }(x,y))\tag {25} \\
\text{Dr-GRPO: } & r(x,y) = f_{\text{group-bl} }(r_{\text{raw} }(x,y)) \tag {26} \\
\text{REINFORCE++ baseline: } & r(x,y) = f_{\text{BN} }\Big(f_{\text{group-bl} }(r_{\text{raw} }(x,y))\Big) \tag {27}
\end{align}
$$
KL 正则化损失的整合 (Integration of the KL Regularization Loss)
- 上述变换仅塑造了奖励信号,KL 正则化项通常以两种方式之一被整合:
- (i) 组合形式 (Combined Form) (\(k_{n}\) in reward):由 REINFORCE/PPO 方法使用
- 首先形成一个组合的奖励信号:
$$A_{\text{combined} }(x,y) = r_{\text{raw} }(x,y) - \beta k_{1}\Big(\pi_{\theta}(y|x),\pi_{\text{ref} }(y|x)\Big),$$ - 然后对这个组合信号 \(A_{\text{combined} }\) 应用基线/归一化,之后再乘以得分函数
- 首先形成一个组合的奖励信号:
- (ii) 解耦形式 (Decoupled Form) (\(k_{n}\) as loss):由 GRPO 方法使用
- KL 惩罚项(形式如下)作为一个单独的、未归一化的损失项进行优化,与由成形奖励 \(r(x,y)\) 驱动的策略梯度损失相加
$$k_{n}(\pi_{\color{red}{\theta}}(\cdot |x),\pi_{\text{ref} }(\cdot |x))$$
- KL 惩罚项(形式如下)作为一个单独的、未归一化的损失项进行优化,与由成形奖励 \(r(x,y)\) 驱动的策略梯度损失相加
- (i) 组合形式 (Combined Form) (\(k_{n}\) in reward):由 REINFORCE/PPO 方法使用
Complete On-Policy Objectives(完整 On-Policy 目标)for REINFORCE/PPO and GRPO
- 理解:本节给出的是不考虑归一化等操作下 REINFORCE/PPO and GRPO 等方法的 On-policy 原始最优目标(即最大化原始奖励目标)
- REINFORCE/PPO(蒙特卡洛 minibatch):
$$
\begin{align}
\mathcal{L}_{\text{REINFORCE/PPO,MC} }(\color{red}{\theta}) = -\frac{1}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}\Big\{A(x^{(i)},y^{(i,j)})\log \pi_{\color{red}{\theta}}(y^{(i,j)}\mid x^{(i)})\Big\} \tag{28}\\
\text{where } A(x,y) = f_{\text{BN} }\Big(r_{\text{raw} }(x,y) - \beta k_{1}\Big(\pi_{\theta}(y\mid x),\pi_{\text{ref} }(y\mid x)\Big)\Big\} \tag {29}
\end{align}
$$- 这里,\(k_{1}\) 项使用 Detached 概率进行评估,这与策略梯度框架中它作为得分函数的系数是一致的
- GRPO(蒙特卡洛 minibatch):
$$
\begin{align}
\mathcal{L}_{\text{GRPO,MC} }(\color{red}{\theta}) = -\frac{1}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}\left\{r(x^{(i)},y^{(i,j)})\log \pi_{\color{red}{\theta}}(y^{(i,j)}\mid x^{(i)})\right\} +\frac{\beta}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}k_{3}\Big(\pi_{\color{red}{\theta}}(y^{(i,j)}\mid x^{(i)}),\pi_{\text{ref} }(y^{(i,j)}\mid x^{(i)})\Big)
\end{align} \tag {30}
$$- 在这种解耦形式中,Shaped 奖励 \(r(x,y)\) 驱动策略梯度项,而 KL 惩罚是一个单独的损失,梯度通过 \(k_{3}(\cdot)\) 内部的 \(\pi_{\color{red}{\theta}}\) 直接传播
- Remark
- 原始 RL 算法 是本节给出的是不考虑归一化等操作下的 On-policy 原始最优目标(即最大化原始奖励目标)
- Reward Shaping 优化方法1:基线减法是一种无偏的方差缩减技术
- Reward Shaping 优化方法2:归一化是一种有偏但通常对实际稳定性至关重要的启发式方法
- 问题:为什么说 归一化 是有偏的呢?
- 回答:因为 归一化 相当于让模型更倾向于某些 Group 或者 Batch 了,改变了本该有的权重
- 理解:但归一化从另一个视角来看,是让每个 Group 的 advantage 方差一样,本质是让不同 Group 变得公平了,可以抹平一些因为 Prompt 不同带来的差异性问题(比如一些 Prompt 的输出 Rewards 差异就是本身偏小一个量级的,归一化(除以
std)本身可以修正回来)
- 理解:但归一化从另一个视角来看,是让每个 Group 的 advantage 方差一样,本质是让不同 Group 变得公平了,可以抹平一些因为 Prompt 不同带来的差异性问题(比如一些 Prompt 的输出 Rewards 差异就是本身偏小一个量级的,归一化(除以
- 补充一个个人理解:
- 如果考虑到我们的目标是最大化所有 Prompt 的累计 Reward(等价于期望 Reward),则这种做法会导致原始目标有偏
- 如果考虑到我们的目标是给定一个 Prompt 下,让这个 Prompt 回复的 Reward 最大化 ,则做不做 归一化 都不算有有偏
- 两者都是重要的工程细节,但一般在简化的理论分析中被省略了
附录 B:策略梯度推导:奖励最大化 (Policy Gradient Derivation for Reward Maximization)
- 本节提供了奖励最大化目标的策略梯度的详细推导
- 作者阐明了真实目标、其梯度和替代损失函数之间的区别,并遵循严格的符号约定,其中 \(\color{red}{\theta}\) 表示需要进行微分的变量,而 \(\theta\) 表示 Detached 参数,例如在采样分布中的参数
The Objective Function(目标函数推导)
- RL 的目标是找到策略 \(\pi_{\color{red}{\theta}}\) 的参数 \(\color{red}{\theta}\),以最大化期望奖励:
$$
\mathcal{J}_{\text{reward} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\color{red}{\theta}}(\cdot |x)}[r(x,y)] = \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}[r(x,y)\cdot \pi_{\color{red}{\theta}}(y|x)] \tag {31}
$$- 假设标准的正则条件,允许交换微分和期望算子的顺序
Policy Gradient Derivation(策略梯度推导)
- 使用对数导数技巧计算目标函数 \(\mathcal{J}_{\text{reward} }(\color{red}{\theta})\) 的梯度
- 注意区分 \(\color{red}{\theta}\) 和 \(\theta\):
$$
\begin{align}
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{reward} }(\color{red}{\theta}) &= \nabla_{\color{red}{\theta}}\mathbb{E}_{x\sim \mathcal{D} }\sum_{y}[r(x,y)\cdot \pi_{\color{red}{\theta}}(y|x)] \\
\qquad &= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}[r(x,y)\cdot \nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)] \\
\qquad &= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}\left[r(x,y)\cdot \pi_{\theta}(y|x)\cdot \frac{\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)}{\pi_{\color{red}{\theta}}(y|x)}\right] \\
\qquad &= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}\pi_{\theta}(y|x)[r(x,y)\cdot \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)] \\
\qquad &= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}[r(x,y)\cdot \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)]
\end{align} \tag {32}
$$- 注:其实这就是策略梯度法的核心推导公式
- 在第三行和第四行中,\(\pi_{\theta}\) 代表当前策略的概率值,在应用对数链式法则时被视为常数因子,而 \(\pi_{\color{red}{\theta}}\) 是被微分的函数
- 最后一行将梯度表示为来自 \(\pi_{\theta}\) 的样本的期望,其中采样过程本身被视为没有梯度路径
附录 C:Formal Proof of the Principle KL Regularization
- 本节提供了一个正式的、逐步的推导,表明:
- 在假设 (A1)-(A4) 下,真实的 KL 散度目标和两个常见的替代目标 \(k_{1}\) in reward 和 \(k_{2}\) as loss 具有相同的期望梯度
- 作者使用策略的两个数值相同的副本:
- 一个携带梯度的 \(\pi_{\color{red}{\theta}}(\cdot |x)\),及其 Detached 对应物 \(\pi_{\theta}(\cdot |x)\)
- 标记为 \(\color{red}{\theta}\) 的参数携带梯度;
- 黑色的 \(\theta\) 表示 Detached 参数
- 采样度量、分母以及乘以梯度项的标量系数总是通过使用 \(\pi_{\theta}\) 而被视为 Detached
- 一个携带梯度的 \(\pi_{\color{red}{\theta}}(\cdot |x)\),及其 Detached 对应物 \(\pi_{\theta}(\cdot |x)\)
C.1 Assumptions and Notation
- 令 \(\mathcal{D}\) 为关于 \(x\) 的数据分布,\(\pi_{\text{ref} }(\cdot |x)\) 为固定的参考策略,\(\pi_{\color{red}{\theta}}(\cdot |x)\) 为可微的策略,所有对数均为自然对数
- (A1) 对于每个 \(x\),函数 \(y\mapsto \pi_{\color{red}{\theta}}(y|x)\) 是一个有效的概率质量/密度函数:在其支撑集上 \(\pi_{\color{red}{\theta}}(y|x) > 0\),在 \(\color{red}{\theta}\) 上可微,并且归一化和为 1,即
$$ \sum_{y}\pi_{\color{red}{\theta}}(y|x) = 1 \text{ or } \int \pi_{\color{red}{\theta}}(y|x)dy = 1 $$ - (A2) 期望/求和与微分可交换是有效的
- (A3) 数据分布 \(\mathcal{D}\) 和参考策略 \(\pi_{\text{ref} }\) 不依赖于 \(\color{red}{\theta}\)
- (A4) KL 散度是良定义的:对于所有 \(x\) 和所有在 \(\pi_{\theta}(\cdot |x)\) 支撑集中的 \(y\),作者有 \(\pi_{\text{ref} }(y|x) > 0\)
- (A1) 对于每个 \(x\),函数 \(y\mapsto \pi_{\color{red}{\theta}}(y|x)\) 是一个有效的概率质量/密度函数:在其支撑集上 \(\pi_{\color{red}{\theta}}(y|x) > 0\),在 \(\color{red}{\theta}\) 上可微,并且归一化和为 1,即
Notation
- \(\pi_{\theta}\) 表示 \(\pi_{\color{red}{\theta}}\) 的 Detached 副本,在当前迭代步数值相等
- 关于 \(y\) 的期望是在 \(y\sim \pi_{\theta}(\cdot |x)\) 下取的(除非另有说明)
C.2 Fundamental Identities
Lemma C.1 Log-derivative identity with detached denominator (对数导数恒等式)
- 对于任意固定的 \(x\) 和任意满足 \(\pi_{\color{red}{\theta}}(y|x) > 0\) 的 \(y\)
$$
\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x) = \frac{\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)}{\pi_{\theta}(y|x)} \tag {33}
$$
证明
- 根据链式法则,有:
$$\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}} = (\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}) / \pi_{\color{red}{\theta}}$$ - 将分母替换为其数值相等、 Detached 副本 \(\pi_{\theta}\),在保持数值值的同时,明确了无梯度路径
Lemma C.2 Zero-mean score
- 对于任意固定的 \(x\)
$$
\mathbb{E}_{y\sim \pi_{\color{red}{\theta}}(\cdot |x)}[\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)] = 0 \tag {34}
$$- 理解:这是得分函数的性质
证明
- 使用引理 C.1,
$$
\sum_{y}\pi_{\color{red}{\theta}}(y|x)\frac{\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)}{\pi_{\color{red}{\theta}}(y|x)} = \sum_{y}\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x) = \nabla_{\color{red}{\theta}}\sum_{y}\pi_{\color{red}{\theta}}(y|x) = \nabla_{\color{red}{\theta}}(1) = 0 \tag {35}
$$
Corollary C.0.1(Score-function reweighting)
- 推论 C.0.1 (得分函数重加权) :对于任意关于 \(\color{red}{\theta}\) Detached 函数 \(z(y,x)\)
$$
\begin{align}
\sum_{y}\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)z(y,x) &= \sum_{y} \pi_{\theta}(y |x) \cdot z(y,x) \cdot \frac{1}{\pi_{\theta}(y |x)} \nabla_{\color{red}{\theta}} \pi_{\color{red}{\theta}}(y|x) \\
&= \mathbb{E}_{y\sim \pi_{\theta}(\cdot |x)}[z(y,x)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)]
\end{align}
\tag {36}
$$- 注:强调一下,这里要求 \(z(y,x)\) 与 \(\color{red}{\theta}\) 无关
Corollary C.0.2 (Baseline invariance)
- 推论 C.0.2 (基线不变性,Baseline invariance) :对于任意关于 \(\color{red}{\theta}\) Detached 函数 \(b(x)\)
$$
\mathbb{E}_{y\sim \pi_{\color{red}{\theta}}(\cdot |x)}[b(x)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)] = b(x)\cdot \mathbb{E}_{y\sim \pi_{\color{red}{\theta}}(\cdot |x)}[\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)] = 0 \tag {37}
$$- 理解:这个是策略梯度法推导基线过程中的常用基础概念
- 因此,将一个 Detached 、与动作无关的基线 \(b(x)\) 添加到任何系数中,不会改变期望梯度
C.3 Derivation of the True KL Gradient(真实 KL 梯度的推导)
- KL 散度目标为:
$$
\mathcal{J}_{\text{KL} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D} }\left[\sum_{y}\pi_{\color{red}{\theta}}(y|x)\log \frac{\pi_{\color{red}{\theta}}(y|x)}{\pi_{\text{ref} }(y|x)}\right] \tag {38}
$$ - Step 1 (Differentiate under the expectation,在期望内微分)
- 根据 (A2),梯度算子可以被移入期望和求和内部
- Step 2 (Apply product rule, 应用乘积法则)
- 对于每个 \(y\),分子部分的梯度为(应用乘积法则):
$$
\begin{align}
\nabla_{\color{red}{\theta}}\big[\pi_{\color{red}{\theta}}(y|x)\log \pi_{\color{red}{\theta}}(y|x)\big] &= (\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}})\log \pi_{\theta} + \pi_{\theta}\cdot \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}} \\ \qquad
&= (\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}})\log \pi_{\theta} + \pi_{\theta}\cdot \frac{1}{\pi_{\theta}}\cdot \nabla_{\color{red}{\theta}} \pi_{\color{red}{\theta}} \\
&= (\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}})(\log \pi_{\theta} + 1).
\end{align}\tag {39}
$$ - 根据 (A3),参考项的梯度为
$$\nabla_{\color{red}{\theta}}[- \pi_{\color{red}{\theta}}(y|x)\log \pi_{\text{ref} }(y|x)] = - (\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x))\log \pi_{\text{ref} }(y|x)$$
- 对于每个 \(y\),分子部分的梯度为(应用乘积法则):
- Step 3 (Collect terms, 合并项)
- 合并项后可得到一个带有 Detached 系数的表达式(减法变分母):
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{KL} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D} }\left[\sum_{y}\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)\left(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)} +1\right)\right] \tag {40}
$$
- 合并项后可得到一个带有 Detached 系数的表达式(减法变分母):
- Step 4 (Apply score-function reweighting,应用得分函数重加权)
- 使用推论 C.0.1,其中 Detached 系数为 与 \(\color{red}{\theta}\) 梯度无关的 \(z(y,x)\)
$$ z(y,x):= \log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)} +1$$- 于是有:
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{KL} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)} +1\right)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {41}
$$
- 于是有:
- 使用推论 C.0.1,其中 Detached 系数为 与 \(\color{red}{\theta}\) 梯度无关的 \(z(y,x)\)
- Step 5 (Simplify using the zero-mean score property,使用得分零均值性质简化)
- 根据引理 C.2,\(+1\) 项的期望为零,得到最终 Standard 梯度:
$$
\begin{align}
\color{red}{\text{Final Standard Gradient :}}& \\
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{KL} }(\color{red}{\theta}) &= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)}\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right]
\end{align} \tag {42}
$$
- 根据引理 C.2,\(+1\) 项的期望为零,得到最终 Standard 梯度:
C.4 The Gold Standard:\(k_{1}\) in reward \(\Leftrightarrow k_{2}\) as loss
Surrogate 1:\(k_{1}\) in reward
- 具体如下:
$$
\mathcal{J}_{k_1\text{ in rewards} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)}\right)\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {43}
$$- 由于系数 Detached ,其梯度与公式 (42) 相同(最终 Standard 梯度)
Surrogate 2:\(k_{2}\) as loss
- 具体公式如下:
$$
\mathcal{J}_{k_2\text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\frac{1}{2}\left(\log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x)\right)^2\right] \tag {44}
$$ - 根据链式法则,并为了清晰起见,展示得到的标量乘子为其 Detached 副本:
$$
\begin{align}
\nabla_{\color{red}{\theta}}\mathcal{J}_{k_2\text{ as loss} }(\color{red}{\theta}) &= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[(\log \pi_{\theta}(y|x) - \log \pi_{\text{ref} }(y|x))\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right] \\
&= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[(\log \frac{\pi_{\theta}(y|x)}{\pi_{\text{ref} }(y|x)})\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right]
\end{align}
\tag {45}
$$- 注意系数 Detached ,所以这也与公式 (42) 相同(最终 Standard 梯度)
C.5 Conclusion and Implementation Guidance
- 在假设 (A1)-(A4) 下,真实的 KL 目标和两个替代目标共享相同的期望梯度,由公式 (42) 给出,需要注意的是这种等价性基于以下关键约定
- Sampling Measure :样本从一个 Detached 策略 \(y\sim \pi_{\theta}(\cdot |x)\) 中抽取(通常是 vLLM)
- Detached 系数 :乘以得分函数的尺度系数被视为 Detached
- 应用推论 C.0.2,可以添加任何 Detached 基线 \(b(x)\) 以降低方差
- 梯度路径 (Gradient Path) :梯度仅通过明确由 \(\color{red}{\theta}\) 参数化的项传播
Implementation Notes
- 对于单个 on-policy 样本 \(y\sim \pi_{\theta}(\cdot |x)\):
- \(k_{1}\) in reward:
- 为了最小化 \(\mathcal{J}_{\text{KL} }\),定义权重(Detached)
$$ \text{weight} := \log \pi_{\theta}(y|x) - \log \pi_{\text{ref} }(y|x) $$ - 对下面的损失上执行梯度下降步骤即是对 \(\mathcal{J}_{\text{KL} }\) 进行下降:
$$ \text{Loss} := \text{weight} \cdot \log \pi_{\color{red}{\theta}}(y|x) $$ - 对下面的损失上执行梯度下降步骤即是对 \(\mathcal{J}_{\text{KL} }\) 进行提升(提升 KL 散度有啥意义?这里应该是作为 \(\text{loss} = L_{\text{reward}} - \beta L_{\text{KL}}\) 的用法吧):
$$ \text{Loss} :=- \text{weight} \cdot \log \pi_{\color{red}{\theta}}(y|x) $$
- 为了最小化 \(\mathcal{J}_{\text{KL} }\),定义权重(Detached)
- \(k_{2}\) as loss:
- 为了最小化 \(\mathcal{J}_{\text{KL} }\),可以:
- 定义对数比率:
$$ \text{log-ratio} := \log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x) $$ - 然后损失为:
$$\text{Loss} := \frac{1}{2}\left(\text{log-ratio}\right)^{2} $$
- Remarks
- (i) 对于连续空间,用积分替换求和,只要密度在其支撑集上为正,证明不变
- (ii) 等价性需要 on-policy 采样
- 如果样本是从一个旧的策略 \(\pi_{\text{old} }\) 中抽取的,精确的修正需要在期望内部使用重要性权重
$$\rho (x,y) = \frac{\pi_{\color{red}{\theta}}(y|x)}{\pi_{\text{old} }(y|x)}$$
- 如果样本是从一个旧的策略 \(\pi_{\text{old} }\) 中抽取的,精确的修正需要在期望内部使用重要性权重
附录 D:Surrogate Objective: Full-Vocabulary vs. Monte Carlo
- 本节形式化了理论策略梯度目标与其实际 minibatch 实现之间的联系
- 本文作者详细说明了两个关键的估计器:
- 1)全词表损失 (full-vocabulary loss) :精确的,但计算上不可行
- 2)蒙特卡洛损失 (Monte Carlo, MC) :无偏的、实用的近似估计
Conventions and gradient paths(一些约定和梯度路径)
- 1)可训练的策略 \(\pi_{\color{red}{\theta}}\) 携带梯度
- 其在当前迭代步数值相同、 Detached 快照记为 \(\pi_{\theta}\)
- 2)所有乘以得分函数的标量都 Detached :
- 奖励 \(r(x,y)\),任何 KL 导出的项 \(k_{n}(\cdot)\),以及它们的组合 \(r(x,y) - \beta k_{n}(\cdot)\)
- 注:附录 D 的前几个小节主要在讨论 \(k_{n}\) in reward 的情况,最后会再给出一个 \(k_{n}\) as loss 的分析
- 3)梯度仅通过 \(\log \pi_{\color{red}{\theta}}(y|x)\) 流动
- 系数 \(c(x,y)\) 内的所有内容都 Detached
- 4)这里继续采用正文中使用的命名:
- 奖励(Detached)系数,\(k_{n}\)(Detached)系数,以及组合形式系数
- 本文作者使用一个通用的、 Detached 标量系数 \(c(x,y)\) 来表达目标,它可以有多种形式:
$$
c(x, y) \in \left\{
\begin{array}{lr}
r(x, y) & \text{reward (detached) coefficient} \\
k_n(\pi_\theta(y|x), \pi_{\text{ref}}(y|x)) & k_n \text{ (detached) coefficient} \\
r(x, y) - \beta k_n(\pi_\theta(y|x), \pi_{\text{ref}}(y|x)) & \text{combined form coefficient}
\end{array}
\right\} \tag{46}
$$- 即:\(c(x,y) \text{ 可以是 } r(x,y) \text{ 或 } k_n(\cdot) \text{ 或 } r(x,y) - \beta k_n(\cdot)\)
- 问题:\(c(x, y) = k_n(\pi_\theta(y|x), \pi_{\text{ref}}(y|x))\) 是不是应该加负号?
- 一个典型的 KL 选择是
$$
k_{1}(y|x) = \log \pi_{\color{red}{\theta}}(y|x) - \log \pi_{\text{ref} }(y|x) \tag {47}
$$
Policy gradient in expectation form (with baseline)(带基线的策略梯度期望形式)
- 对于总体目标
$$\mathcal{J}_{\text{true} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\color{red}{\theta}}(\cdot |x)}[c(x,y)]$$ - 首先我们有下面这个带 Detached 分母的对数导数恒等式
$$
\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x) = \frac{\nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y|x)}{\pi_{\theta}(y|x)} \tag {48}
$$ - 在结合一个 Detached 、与动作无关的基线 \(b(x)\),于是得到无偏的策略梯度为
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{true} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[(c(x,y) - b(x))\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {49}
$$- 注:这一步依赖于在 \(y\sim \pi_{\theta}(\cdot |x)\) 下证明的得分零均值性质(公式 (34)),确保 \(b(x)\) 不会改变期望梯度
Population surrogate loss(总体替代损失)
- 一个其负梯度恢复公式 (49) 的替代损失是
$$
\mathcal{L}_{\text{sur} }(\color{red}{\theta}) = -\mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[(c(x,y) - b(x))\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {50}
$$- 问题:为什么要加上负号?
- 回答:因为这里不是用于恢复 (49) 的,而是恢复 (49) 的负梯度
Two interchangeable mini-batch implementations(可互换的实现)
- 作者提供公式 (50) 的两个等价的 minibatch 估计器
- 第一个 :通过对所有动作求和,使用 Detached 采样权重,计算离散动作空间 \(\mathcal{V}\) 上的精确内层期望
$$
\mathcal{L}_{\text{sur,Full} }(\color{red}{\theta}) = -\frac{1}{N}\sum_{i = 1}^{N}\sum_{y^{(i)}\in \mathcal{V} }\pi_{\theta}\big(y^{(i)}\mid x^{(i)}\big)\left(c(x^{(i)},y^{(i)}) - b(x^{(i)})\right)\log \pi_{\color{red}{\theta}}\big(y^{(i)}\mid x^{(i)}\big) \tag {51}
$$- 这里需要注意:
- “Detached 权重”表示梯度不通过 \(\pi_{\theta}\) 流动
- 得分路径仅通过 \(\log \pi_{\color{red}{\theta}}\)
- 这里本质是原始 RL 中对所有可能的动作进行积分来准确衡量期望的方式
- 这里需要注意:
- 第二个 :用独立同分布的 on-policy 样本替换这个内层求和,得到在给定 minibatch Prompt 条件下的无偏估计
$$
\mathcal{L}_{\text{sur,MC} }(\color{red}{\theta}) = -\frac{1}{N}\sum_{i = 1}^{N}\frac{1}{G}\sum_{j = 1}^{G}\left(c(x^{(i)},y^{(i,j)}) - b(x^{(i)})\right)\log \pi_{\color{red}{\theta}}\big(y^{(i,j)}\mid x^{(i)}\big)\\
\text{where } \quad y^{(i,j)}\sim \pi_{\theta}(\cdot |x^{(i)}) \tag {52}
$$- 在公式 (52) 中,\(\{y^{(i,j)}\}_{j = 1}^{G}\) 是从 Detached 快照 \(\pi_{\theta}(\cdot |x^{(i)})\) 中独立同分布采样得到的
- 增加 \(G\) 可以在保持无偏性的同时降低方差
- 第一个 :通过对所有动作求和,使用 Detached 采样权重,计算离散动作空间 \(\mathcal{V}\) 上的精确内层期望
Unbiasedness and practical considerations
- 对于任意固定的 \(x^{(i)}\) 和函数 \(f\),均有
$$
\mathbb{E}_{\{y^{(i,j)}\}_{j = 1}^{G}\text{i.i.d.}\sim \pi_{\theta}(\cdot |x^{(i)})}\left[\frac{1}{G}\sum_{j = 1}^{G}f\big(y^{(i,j)}\big)\right] = \sum_{y^{(i)}\in \mathcal{V} }\pi_{\theta}\big(y^{(i)}\mid x^{(i)}\big)f\big(y^{(i)}\big) \tag {53}
$$ - 因此其期望等于原始按照词表加和的情况:
$$ \mathbb{E}\big[\mathcal{L}_{\text{sur,MC} }\mid \{x^{(i)}\} \big] = \mathcal{L}_{\text{sur,Full} }$$ - 在实践中,MC 估计是标准做法
- 因为:对于 LLM 来说,由于 GPU 内存限制,计算整个词表表上的 \(r(x,y)\) 或 \(k_{n}(\cdot)\) 是不可行的
\(k_{n}\) in reward 外的另一种解耦形式:\(k_{n}\) as loss
- 注:附录 D 的前几个小节主要在讨论 \(k_{n}\) in reward 的情况
- 除了通过系数 \(c(x,y)\) 整合 KL 外,还可以添加一个单独的、仅惩罚项的损失,该损失直接通过对数比率进行微分
- 令 \(\psi_{n}:\mathbb{R}\to \mathbb{R}\) 是可微的
- 例如,\(\psi_{1}(t) = t\),\(\psi_{2}(t) = \frac{1}{2} t^{2}\)
- 注:不能是 \(\psi_{3}(t)\)
- 定义
$$
\mathcal{L}_{k_{n}\text{ as loss,MC} }(\color{red}{\theta}) = -\frac{1}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}\psi_{n}\big(\log \pi_{\color{red}{\theta}}\big(y^{(i,j)}\big|x^{(i)}\big) - \log \pi_{\text{ref} }\big(y^{(i,j)}\big|x^{(i)}\big)\big) \tag {54}
$$ - 其梯度呈现得分函数形式
$$
\nabla_{\color{red}{\theta}}\mathcal{L}_{k_{n}\text{ as loss,MC} }(\color{red}{\theta}) = -\frac{1}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}\psi_{n}^{\prime}(\cdot)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}\big(y^{(i,j)}\big|x^{(i)}\big) \tag {55}
$$- 其中 \((\cdot)\) 表示公式 (54) 中的对数比率 (log-ratio)
- 注:\(\pi_\text{ref}\) 并没有完全消失,还在 \(\psi_{n}^{\prime}(\cdot)\) 中
- 这里上撇号(prime)表示对标量参数的微分:
$$
\psi_{n}^{\prime}(t)\triangleq \frac{\text{d} }{\text{d}t}\psi_{n}(t) \tag {56}
$$- 在 on-policy 采样下,在当前迭代步评估标量系数 \(\psi_{n}^{\prime}(\cdot)\)(即将其视为 Detached ),会得到正文中建立的梯度等价性(见第 5.2 节中的定理和附录 C)
- 一个常见的选择 \(\psi_{2}(t) = \frac{1}{2} t^{2}\) 恢复了平方对数比率惩罚
- 此时,总目标即为
$$ \mathcal{L}_{\text{reward,MC} } - \beta \cdot \mathcal{L}_{k_{n}\text{ as loss,MC} }$$- 其中 \(\pi_{\text{ref} }\) 是固定的且 Detached
- 注:即使求梯度后(公式 (55)),\(\pi_\text{ref}\) 也不会完全消失,还在 \(\psi_{n}^{\prime}(\cdot)\) 中,这跟 KL 与 \(\pi_\text{ref}\) 有关的判断能对齐
附录 E:对 \(\mathbf{k}_{3}\) as loss 梯度替代目标的 Formal 分析
- 本节提供了支撑第 5.3 节的正式分析,证明 \(k_{3}\) as loss 公式作为主要逆向 KL 梯度的 一阶、有偏的替代目标
- 首先在 on-policy 采样下推导其梯度等价的 in-reward 系数,然后剖析其三个核心缺陷:
- 局部偏差、全局不对称性和统计不稳定性
- 在整个过程中,作者固定一个 Prompt \(x\),并考虑从可训练策略 \(\pi_{\color{red}{\theta}}\) 的 Detached 快照中 on-policy 采样的样本 \(y \sim \pi_{\theta}(\cdot |x)\),这里将概率比定义为:
$$
\delta (y):= \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)} \tag {57}
$$ - 作者的分析比较了由 \(k_{3}\) as loss 诱导的系数与主要 RKL 梯度系数 \(c^{*}(y) = - \log \delta (y)\)
- 注:所有乘以得分函数 \(\nabla_{\color{red}{\theta}} \log \pi_{\color{red}{\theta}}(y|x)\) 的标量系数均被视为 Detached
\(k_{3}\) as loss 的梯度等价系数
- \(k_{3}\) as loss 目标由下式给出:
$$
\mathcal{J}_{k_3 \text{ as loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)} -1 - \log \frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)}\right] \tag {58}
$$ - 微分并在 Detached 快照处评估得到的标量乘子,得到:
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{k_3\text{ as }\text{loss} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(1 - \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}\right)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {59}
$$- 从公式 (58) 到 (59) 的推导详情见附录
- 这证实了 \(k_{3}\) as loss(在 on-policy 采样下)梯度等价于一个 in-reward 更新,其 Detached 系数为:
$$
c_{3^{\prime} }(y):= 1 - \delta (y) \tag {60}
$$ - 也就是说 \(k_{3}\) as loss 的等价 in reward 形式,即 \(k_{3}^{\prime}\) in reward 目标形式为:
$$
\mathcal{J}_{k_3^{\prime}\text{ in }\text{reward} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(1 - \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}\right)\log \pi_{\color{red}{\theta}}(y|x)\right] \tag {61}
$$ - 接下来,本节主要分析这个代理 \(c_{3^{\prime} }\) 与主要目标 \(c^{*} = - \log \delta\) 相比的缺陷
Lemma E.1 (First-order agreement and second-order bias,一阶一致性和二阶偏差)
- 代理 \(1 - \delta\) 是主要系数 \(- \log \delta\) 在 \(\delta = 1\) 附近的一阶泰勒近似
- 近似误差(偏差)是二阶的:
$$
\text{Bias}(\delta) = (- \log \delta) - (1 - \delta) = \frac{1}{2} (\delta -1)^{2} - \frac{1}{3} (\delta -1)^{3} + O((\delta -1)^{4}) \tag {62}
$$ - Proof sketch
- 通过在 \(r = 1\) 处展开 \(- \log \delta\) 的泰勒级数并减去项 \((1 - \delta)\) 得到此结果
Lemma E.2 (One-sided domination and asymmetric tails, 单边支配和不对称尾部)
- 对于所有 \(\delta > 0\),代理是一个严格的下界,\(1 - \delta \leq - \log \delta\),且仅在 \(\delta = 1\) 时取等
- 注:这里的不等式源于基本性质 \(\log \delta \leq \delta - 1\)
- 它们的尾部行为是病态的不对称的:
- 过覆盖 (Over-coverage) \((\delta \rightarrow 0^{+})\):
- 代理提供一个弱的、饱和的恢复力
$$\lim_{\delta \rightarrow 0^{+} }(1 - \delta) = 1$$ - 主要系数提供一个无界的惩罚
$$\lim_{\delta \rightarrow 0^{+} }(- \log \delta) = +\infty$$
- 代理提供一个弱的、饱和的恢复力
- 欠覆盖 (Under-coverage) \((\delta \rightarrow \infty)\):
- 代理诱导一个激进的、线性爆炸的惩罚
$$ \lim_{\delta \rightarrow \infty}(1 - \delta) = -\infty $$ - 主要系数的惩罚仅呈对数增长
$$ \lim_{\delta \rightarrow \infty}(- \log \delta) = -\infty $$
- 代理诱导一个激进的、线性爆炸的惩罚
- 过覆盖 (Over-coverage) \((\delta \rightarrow 0^{+})\):
Theorem E.1 (Variance equals chi-squared divergence,方差等于卡方散度)
- 假设 \(\sup (\pi_{ref}(\cdot |x)) \subseteq \sup (\pi_{\color{red}{\theta}}(\cdot |x))\),代理系数 \(c_{3^{\prime} }\) 在 on-policy 采样分布下的均值为零,其方差恰好是卡方散度:
$$
\mathbb{E}_{y\sim \pi_{\color{red}{\theta}} }[1 - \delta (y)] = 0 \\ \text{Var}_{y\sim \pi_{\color{red}{\theta}} }[1 - \delta (y)] = \chi^{2}(\pi_{ref}(\cdot |x)\parallel \pi_{\color{red}{\theta}}(\cdot |x)) \tag {63}
$$- 如果支撑集条件被违反,则方差是无穷大
- 注:卡方散度比 KL 散度更不稳定(在 \(Q(x)\) 极小时,卡方散度很容易出现爆炸)
- 卡方散度是被 \(\frac{1}{Q}\) 修饰的,当 \(Q(x)\) 减小时,是线性增长
- KL 散度是被 \(\log \frac{1}{Q}\) 修饰的,当 \(Q(x)\) 减小时,对数增长就慢很多
- Proof sketch
$$\begin{array}{r}{\mathbb{E}[\delta ] = \sum_{y}\pi_{\color{red}{\theta}}(y|x)\frac{\pi_{\text{ref} }(y|x)}{\pi_{\color{red}{\theta}}(y|x)} = 1} \end{array}$$- 因此 \(\mathbb{E}[1 - r] = 0\)
- 然后方差恒等式直接由 \(\chi^{2}(p\parallel q)\) 的定义得出
推论 E.1.1 (Implication for stochastic gradient variance) 对随机梯度方差的影响
- 由 \(k_{3}\) as loss 诱导的随机梯度项的方差直接受卡方散度控制(如上文所述,这是一个以不稳定著称的度量):
$$
\mathbb{E}\left[\left| (1 - \delta (y))\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right|^{2}\right] = \mathbb{E}\left[(1 - \delta (y))^{2}\left| \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x)\right|^{2}\right] \tag {64}
$$
Conclusion
- \(k_{3}\) as loss 公式并未实现真实的 RKL 梯度
- \(k_{3}\) as loss 提供了一个一阶代理 \((c_{3^{\prime} } = 1 - \delta)\)
- \(k_{3}\) as loss 代理仅在策略非常接近参考策略时 \((\delta \approx 1)\) 才是准确的
- \(k_{3}\) as loss 病态的尾部行为和高方差(与卡方散度相关)引入了 \(k_{1}\) in reward 或 \(k_{2}\) as loss 公式中不存在的优化挑战
- 要根据梯度属性(而不仅仅是其作为值估计器的特性)来选择正则化损失的关键重要性
附录 F:(MiniMax-01 surrogate loss)Derivation of an Alternative Regularizer: The MiniMax-01 Loss from MSE Distance(推导得到替代正则化项)
- 作为 KL 正则化的替代方案,本附录推导了 MiniMax-01 损失 (2025)
- 注:这个损失的目标就已经变化了,不是原始的 KL 散度的,目标是 MSE 了
- 接下来将证明它源于均方误差 (Mean Squared Error, MSE) 目标,并且符合本文以梯度为中心的框架
- 我们遵循已建立的 on-policy 约定:
- \(\pi_{\color{red}{\theta}}\) 是可训练的策略,\(\pi_{\theta}\) 是其 Detached 快照(在当前迭代步数值相等)
- 所有乘以得分函数的标量系数在反向传播期间都被视为 Detached
Objective of MiniMax-01 surrogate loss
- 我们最小化策略与参考模型之间的全词表 MSE:
$$
\mathcal{J}_{\text{MSE} }(\color{red}{\theta}) = \mathbb{E}_{x\sim \mathcal{D} }\left[\frac{1}{2}\sum_{y}\left(\pi_{\color{red}{\theta}}(y\mid x) - \pi_{\text{ref} }(y\mid x)\right)^{2}\right] \tag {65}
$$- 注意:这已经不是 KL 散度了
On-policy gradient of MiniMax-01 surrogate loss
- 对公式 (65) 关于 \(\color{red}{\theta}\) 求导,在 Detached 快照 \(\pi_{\theta}\) 处评估标量乘子(作者的标准 on-policy 约定),并转换为得分函数形式,得到:
$$
\begin{align}
\nabla_{\color{red}{\theta}}\mathcal{J}_{\text{MSE} }(\color{red}{\theta}) &= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}\left[\frac{1}{2}\nabla_{\color{red}{\theta}}(\pi_{\color{red}{\theta}}(y|x) - \pi_{\text{ref} }(y|x))^{2}\right]\\
&= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}\underbrace{\left(\pi_{\theta}(y\mid x) - \pi_{\text{ref} }(y\mid x)\right)}_{\text{detached coefficient} } \nabla_{\color{red}{\theta}}\pi_{\color{red}{\theta}}(y\mid x)\\
&= \mathbb{E}_{x\sim \mathcal{D} }\sum_{y}\pi_{\theta}(y\mid x)\underbrace{\left(\pi_{\theta}(y\mid x) - \pi_{\text{ref} }(y\mid x)\right)}_{\text{detached coefficient} } \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y\mid x)\\
&= \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot \mid x)}\left[\left(\pi_{\theta}(y\mid x) - \pi_{\text{ref} }(y\mid x)\right)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y\mid x)\right]
\end{align} \tag {66}
$$- 最后一行揭示了 MSE 正则化诱导出一个得分函数更新,其标量系数是概率差 \(\pi_{\theta} - \pi_{\text{ref} }\)
- 注意:这里跟之前的推导有本质差异,本身没有对数,也不是之前的 \(\log\frac{\pi_{\text{ref}}}{\pi_{\theta}}\) 形式
MiniMax-01 surrogate loss (Monte Carlo)
- 使用一个 on-policy 采样器,为每个 Prompt 抽取 \(G\) 个回复 \(y^{(i,j)}\sim \pi_{\theta}(\cdot \mid x^{(i)})\),其负梯度能恢复公式 (66) 的无偏 minibatch 替代目标为
$$
\mathcal{L}_{\text{MSE},\text{MC}(\text{MinMax-01})}(\color{red}{\theta}) = -\frac{1}{NG}\sum_{i = 1}^{N}\sum_{j = 1}^{G}\left(\pi_{\theta}(y^{(i,j)}\mid x^{(i)}) - \pi_{\text{ref} }(y^{(i,j)}\mid x^{(i)})\right)\log \pi_{\color{red}{\theta}}(y^{(i,j)}\mid x^{(i)}) \tag {67}
$$ - 这与作者 Principled KL 实现共享相同的 in-reward 得分函数结构:
- 系数 Detached ,并且梯度仅通过 \(\log \pi_{\color{red}{\theta}}\) 流动
Key properties and implications of MiniMax-01 surrogate loss
- 1)有界梯度系数 (Bounded gradient coefficient)
- 由于 \(0\leq \pi_{\color{red}{\theta}}(y\mid x),\pi_{\text{ref} }(y\mid x)\leq 1\),系数满足 \(-1\leq \pi_{\color{red}{\theta}}(y\mid x) - \pi_{\text{ref} }(y\mid x)\leq 1\)
- 这种有界性增强了针对大规模或病态更新的稳定性,与 KL 使用的无界对数比率形成对比(见图 1)
- 这支持了作者在第 5 节中的建议,即在稳定性至关重要时考虑有界替代方案
- 2)概率空间中的对称性 (Symmetry in probability space)
- 与逆向 KL 的对数惩罚相比,MSE 惩罚关于概率差是对称的,在策略发散时提供更保守的修正
- 3)Off-policy 兼容性 (Off- policy compatibility)
- 由于其 in-reward 形式带有 Detached 系数,该头部完全兼容重要性采样和裁剪,遵循与附录 G 中相同的修正规则
- Remark
- 与作者的 KL 分析一致,公式 (66) 是通过在 Detached 快照 \(\pi_{\theta}\)(on-policy)处评估标量乘子得到的
- 这使所有正则化项都保持在统一的 \(k_{n}\) 乘以得分函数的视角下,并能够对其诱导的更新动态进行直接的、同类比较
附录 G:Off-Policy Correction for KL Regularization,KL 正则化的 Off-policy 修正
- 许多 RLHF 实现都存在一个微妙但关键的 Off-policy 偏差,特别是当 KL 项以 “as loss” 的方式实现时
- 这种公式只有在 On-policy 采样下才具有正确的梯度
- 对于 Off-policy 更新,它们需要显式的重要性采样和 PPO 式裁剪
- 省略这些步骤会系统地使更新产生偏差,并破坏训练稳定性
- 本节提供了符合本文以梯度为中心框架的 Principled 修正
G.1 From On-Policy to Off-Policy Gradients, 从 On-policy 梯度到 Off-policy 梯度
- 我们在策略梯度视角下进行操作,其中更新由一个 detached 系数 \(c(x,y)\) 驱动,该系数乘以得分函数, On-policy 梯度估计器为:
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{c}(\color{red}{\theta}) = \mathbb{E}_{x\sim D,y\sim \pi_{\color{red}{\theta}}(.|x)}\left[c(x,y)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y\mid x)\right] \tag {68}
$$- 其中 \(\pi_{\color{red}{\theta}}\) 是在梯度评估时数值上等于 \(\pi_{\color{red}{\theta}}\) 的 detached 快照
- 对于从行为策略 \(y\sim \pi_{\theta_{k} }(\cdot \mid x)\) 抽取的样本,一个无偏的 Off-policy 估计器需要 IS,假设行为策略对采样数据具有支持 \((\pi_{\theta_{k} }(y\mid x) > 0)\):
$$
\nabla_{\color{red}{\theta}}\mathcal{J}_{c}(\color{red}{\theta}) = \mathbb{E}_{x\sim D,y\sim \pi_{\theta_{k} }(\cdot |x)}\left[\frac{\pi_{\color{red}{\theta}}(y\mid x)}{\pi_{\theta_{k} }(y\mid x)} c(x,y)\nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y\mid x)\right] \tag {69}
$$
- PPO 的目标函数中,使用如下携带梯度的比率来修正
$$ \rho_{k}(\color{red}{\theta}) = \frac{\pi_{\color{red}{\theta}}(y|x)}{\pi_{\theta_{k} }(y|x)}$$- 其中梯度仅流过分子
- 替换这个 detached IS 权重,并采用裁剪的替代目标以降低方差
- 对于任何 detached 系数 \(c(x,y)\) ,要最大化的裁剪目标为:
$$
\mathcal{J}_{c,\text{clipped} }(\color{red}{\theta}) = \mathbb{E}_{x\sim D,y\sim \pi_{\theta_{k} }(\cdot |x)}\left[\min \left(\rho_{k}(\color{red}{\theta})c(x,y), \text{clip}\left(\rho_{k}(\color{red}{\theta}),1 - \epsilon ,1 + \epsilon\right)c(x,y)\right)\right] \tag {70}
$$
G.2 Correcting \(k_{n}\) as Loss by Converting to an In Reward Head(通过转换为“in reward” Head 来修正“\(k_{n}\) as loss”)
- \(k_{n}\) as loss 仅在 On-policy 时具有正确的梯度
- 要使 \(k_{n}\) as loss 适用于 Off-policy 使用,必须首先将其转换为其梯度等效的 in reward 形式
- 这是通过定义一个 detached 系数 \(k_{n^{\prime} }(x,y)\) 来实现的,该系数重现了原始 loss 的 On-policy 梯度
- 对于一个可微的惩罚项 \(k_{n}(\pi_{\color{red}{\theta}}(y|x),\pi_{\text{ref} }(y|x))\) ,该 \(k_{n}\) in reward 的系数是其关于策略对数概率的导数,在当前 detached 快照处求值:
$$
k_{n^{\prime} }(\pi_{\color{red}{\theta}}(y|x),\pi_{\text{ref} }(y|x)):= \frac{\partial}{\partial\log\pi_{\color{red}{\theta}} } k_{n}(\pi_{\color{red}{\theta}}(y|x),\pi_{\text{ref} }(y|x))\bigg|_{\log \pi = \log \pi_{\theta}(y|x)} \tag {71}
$$ - 作者的 约定
- 1)呈现的目标是用于最大化
- 2)实现若最小化一个 loss,应对这些表达式取负
- 例如,最小化 \(-\mathcal{J}_{\text{combined} }\) 或 \(-(\mathcal{J}_{\text{reward} } - \beta \mathcal{J}_{\text{KL} })\)
附录 H:Visualization of KL Regularization Gradient Coefficients,KL 正则化梯度系数的可视化
- 为了可视化第 5 节讨论的理论论点,本节提供了用于生成图 1 的 Python 代码
- 该图比较了不同的标量系数的行为,这些系数乘以策略的得分函数作为给定 token 的 Actor 对数概率的函数
$$ \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}(y|x) $$ - 这些系数分别来自各自的 KL 正则化 Loss:\(k_{1}\) in erward、 \(k_{2}\) as loss 、\(k_{3}\) as loss以及 MiniMax-01 loss
- 该可视化清晰地对比了源自 \(k_{1}\) in erward / \(k_{2}\) as loss 的 Principled 系数的稳定、线性行为与一阶近似 \(k_{3}\) as loss 的非对称行为
- 正如正文中所论述的,\(k_{3}\) 代理在过度采样 token 时趋于饱和,而在欠采样 token 时趋于爆炸的倾向
- 以下代码使用 ‘matplotlib’ 和 ‘torch’ 生成该图
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62import torch
import matplotlib.pyplot as plt
# --- Plotting Style ---
plt.style.use('seaborn-v0_8-whitegrid')
plt.rcParams.update({
"text.usetex": False, # Disable LaTeX rendering
"font.family": "serif", # Use a generic serif font
"font.serif": ["Times New Roman"], # Specify Times New Roman as the serif font
"font.size": 14,
"axes.labelsize": 16,
"legend.fontsize": 12,
"xtick.labelsize": 12,
"ytick.labelsize": 12,
})
# --- Data Generation ---
log_pi_actor = torch.linspace(-5, 0, steps=400)
pi_actor = torch.exp(log_pi_actor)
pi_ref_val = 0.25
log_pi_ref = torch.log(torch.tensor(pi_ref_val))
# --- Coefficients Calculation ---
coeff_k1_loss = torch.ones_like(log_pi_actor)
coeff_k1_reward = log_pi_actor - log_pi_ref
coeff_k3_loss = 1 - pi_ref_val / pi_actor
coeff_minimax = pi_actor - pi_ref_val
# --- Plotting ---
plt.figure(figsize=(10, 6.5))
plt.plot(log_pi_actor, coeff_k1_reward,
label=r'$\\log\\pi_{\\theta} - \\log\\pi_{\\text{ref}}$ ($k_1$ in reward / $k_2$ as loss) - Principled',
color='#808000', linewidth=3, zorder=10)
plt.plot(log_pi_actor, coeff_k3_loss,
label=r'$1 - \\pi_{\\text{ref}}/\\pi_{\\theta}$ ($k_{3^{\\prime}}$ in reward / $k_3$ as loss) - Biased Approximation',
color='Firebrick', linestyle='--', linewidth=2)
plt.plot(log_pi_actor, coeff_minimax,
label=r'$\\pi_{\\theta} - \\pi_{\\text{ref}}$ (MiniMax-01)',
color='RoyalBlue', linestyle='-.', linewidth=2)
plt.plot(log_pi_actor, coeff_k1_loss,
label=r'$1$ ($k_1$ as loss) - Zero Expected Gradient',
color='Gray', linestyle=':', linewidth=2)
plt.axvline(x=log_pi_ref.item(), color='black', linestyle='--', linewidth=1,
label=r'$\\log\\pi_{\\theta} = \\log\\pi_{\\text{ref}}$')
plt.xlabel(r'Actor Log-Probability: $\\log \\pi_{\\theta}(y|x)$')
plt.ylabel(r'Coefficient of Score Function')
plt.title(r'Comparison of KL Regularization Coefficients ($\\pi_{\\text{ref}}=0.25$)', fontsize=18)
plt.legend(loc='upper left')
plt.ylim(-4, 4)
plt.xlim(-5, 0)
plt.tight_layout()
plt.savefig('comparison_kl_regularization_coefficients.png', dpi=300, bbox_inches='tight')
plt.show()
附录 I:On the Statistical Instability of the \(k_{3}\) Value Estimator, 论 \(k_{3}\) 值估计器的统计不稳定性
I.1 The Strict Precondition for Unbiasedness,无偏性的严格前提条件
- 回顾一下无偏的定义:如果一个估计器的期望等于真实值,则该估计器是无偏的
- 对于 \(k_{3}\) ,其期望为:
$$
\mathbb{E}_{q}[k_{3}] = \mathbb{E}_{q}[\delta (x) - 1 - \log \delta (x)] = (\mathbb{E}_{q}[\delta (x)] - 1) + D_{KL}(q \parallel p)
$$ - 要使 \(k_{3}\) 无偏,必须满足条件 \(\mathbb{E}_{q}[\delta (x)] = 1\)
- 注:这里有 \(\delta (x) = \frac{p(x)}{q(x)}\)
- 如果 \(p\) 关于 \(q\) 是绝对连续的 \((p\ll q)\) ,即 \(p\) 的支持集必须包含在 \(q\) 的支持集内 ,则满足此条件
- \(p\) 的支持集必须包含在 \(q\) 的支持集内 的本质是:\(p\) 有值(概率大于 0)的地方,\(q\) 也要有值(概率大于 0),否则积分积不到这部分,导致期望 \(\mathbb{E}_{q}[\delta (x)]\) 不为 1
- 有限的 KL 散度 \((D_{KL}(q \parallel p)< \infty)\) 条件不足以保证无偏性
- 例如,设 \(q\) 是 \([0,1]\) 上的均匀分布,\(p\) 是 \([0,2]\) 上的均匀分布
- KL 散度 \(D_{KL}(q \parallel p) = \int_{0}^{1} 1 \cdot \log (\frac{1}{0.5}) dx = \log 2\) ,是有限的
- 然而,\(\mathbb{E}_{q}[r(x)] = \int_{0}^{1} 1 \cdot \frac{p(x)}{q(x)} dx = \int_{0}^{1} \frac{0.5}{1} dx = 0.5\)
- 因此估计器期望为 \(\mathbb{E}_{q}[k_{3}] = (0.5 - 1) + \log 2 = \log 2 - 0.5\) ,是有偏的
- 例如,设 \(q\) 是 \([0,1]\) 上的均匀分布,\(p\) 是 \([0,2]\) 上的均匀分布
补充:\(\mathbb{E}_{q}[\delta (x)] = 1\) 的严格证明
- 证明目标:当 \(p\) 的支持集包含在 \(q\) 的支持集内(即 \(p \ll q\))时,证明:
$$
\mathbb{E}_{q}[\delta(x)] = 1
$$ - 以下是证明过程:
- 定义重要性权重为:
$$
\delta(x) = \frac{p(x)}{q(x)}.
$$ - 其在分布 \( q(x) \) 下的期望为:
$$
\mathbb{E}_{q}[\delta(x)] = \int q(x) \cdot \frac{p(x)}{q(x)} , dx = \int p(x) , dx
$$ - 假设 \( p \) 的支持集包含在 \( q \) 的支持集内
- 即对于所有 \( x \) 满足 \( p(x) > 0 \),都有 \( q(x) > 0 \),从而 \(\frac{p(x)}{q(x)}\) 几乎处处有定义且有限
- 由于 \( p \) 是一个概率密度函数,满足归一化条件:
$$
\int p(x) , dx = 1
$$ - 因此有:
$$
\mathbb{E}_{q}[\delta(x)] = 1
$$- 证毕
- 注:在 LLM 的场景,一般都是满足 \(p\) 的支持集必须包含在 \(q\) 的支持集内 的
I.2 Infinite Variance and the Chi-Squared Divergence,无限方差和卡方散度
- \(k_{3}\) 的方差主要由重要性比率的二阶矩 \(\mathbb{E}_{q}[\delta (x)^{2}]\) 决定
- 这一项直接与卡方散度相关
- 当 \(p\ll q\) 时,恒等式成立:
$$ \chi^{2}(p \parallel q) = \mathbb{E}_{q}[(\delta (x) - 1)^{2}] = \mathbb{E}_{q}[\delta (x)^{2}] - 1$$- 如果 \(p\) 关于 \(q\) 不是绝对连续的 \((p\ll q)\) ,则 \(\chi^{2}(p \parallel q)\) 被定义为无穷大
- 因此
- 如果 \(\mathbb{E}_{q}[\delta (x)^{2}]\) 是无穷大,那么 \(k_{3}\) 的方差将是无穷大
- 如果 \(p\ll q\) 或者 \(p\ll q\) 但 \(q\) 的尾部明显轻于 \(p\) 的尾部,就会发生这种情况
- \(\mathbb{E}_{q}[\delta (x)^{2}]\) 的发散是导致不稳定的主要原因
- \(\text{Var}(k_{3})\) 的有限性在技术上也需要 \(\mathbb{E}_{q}[(\log \delta (x))^{2}]\) 的有限性
I.3 The Gaussian Case and an Empirical Demonstration,高斯分布情况与实证演示
对于两个高斯分布 \(p \sim \mathcal{N}(\mu_p, \sigma_p^2)\) 和 \(q \sim \mathcal{N}(\mu_q, \sigma_q^2)\):
- 当且仅当 \(\sigma_q^2 > \sigma_p^2 / 2\) 时,\(k_3\) 的方差是有限的
这个条件说明,采样分布 \(q\) 必须相对于参考分布 \(p\) 足够“宽”
对于具有协方差矩阵 \(\Sigma_p\) 和 \(\Sigma_q\) 的多变量高斯分布,此条件可以推广
- 计算 \(\mathbb{E}_q[r(x)^2]\) 需要积分两个高斯概率密度之比
- 为了使该积分收敛 (进而方差有限),要求矩阵 \(2\Sigma_q - \Sigma_p\) 是正定的
如下面的实证所示,用一个窄的高斯分布 \(q(x)\) \((\sigma_q = 0.2)\) 来估计相对于标准高斯分布 \(p(x)\) \((\sigma_p = 1)\) 的 KL 散度,就违反了该条件,因为 \(0.2^2 \not> 1^2 / 2\)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65import torch
import torch.distributions as dist
# p: reference distribution, q: sampling distribution
p = dist.Normal(loc=0, scale=1)
q = dist.Normal(loc=0.1, scale=0.2) # A narrow distribution where Var[k3] is infinite
# Sample from the narrow distribution q
x = q.sample(sample_shape=(10_000,))
# Ground truth KL divergence D_KL(q || p)
true_kl = dist.kl_divergence(q, p)
# Compute the log-ratio log(p(x)/q(x))
log_r = p.log_prob(x) - q.log_prob(x)
r = torch.exp(log_r)
# Define estimators
k1 = -log_r
k2 = log_r.pow(2) / 2
k3 = r - 1 - log_r
# --- Code to generate output ---
print(f"True KL Divergence: {true_kl:.4f}\\n")
print("Estimator | Sample Mean | Sample Std. Dev.")
print("------------------|---------------|------------------")
estimators = {"k1": k1, "k2": k2, "k3": k3}
for name, k in estimators.items():
mean = k.mean()
std = k.std()
print(f"{name:<17} | {mean:>13.4f} | {std:>16.4f}")
# --- Actual Output 1 ---
# True KL Divergence: 1.1344
#
# Estimator | Sample Mean | Sample Std. Dev.
# ------------------|---------------|------------------
# k1 | 1.1272 | 0.6912
# k2 | 0.8742 | 0.6006
# k3 | 0.8136 | 8.8244
# --- Actual Output 2 ---
# True KL Divergence: 1.1344
#
# Estimator | Sample Mean | Sample Std. Dev.
# ------------------|---------------|------------------
# k1 | 1.1336 | 0.6611
# k2 | 0.8611 | 0.5210
# k3 | 0.6817 | 4.1082
# --- Actual Output 3 ---
# True KL Divergence: 1.1344
#
# Estimator | Sample Mean | Sample Std. Dev.
# ------------------|---------------|------------------
# k1 | 1.1348 | 0.6709
# k2 | 0.8689 | 0.4968
# k3 | 0.6595 | 1.4925
# --- Actual Output 4 ---
# True KL Divergence: 1.1344
#
# Estimator | Sample Mean | Sample Std. Dev.
# ------------------|---------------|------------------
# k1 | 1.1256 | 0.6962
# k2 | 0.8758 | 0.6263
# k3 | 0.9772 | 26.7379Listing 2: 当采样分布 \(\mathbf{q}(\mathbf{x})\) 过窄时,说明 \(k_{3}\) 值估计量高方差的代码
结果生动地说明了这个问题
- \(k_3\) 的样本标准差比 \(k_1\) 的大数倍
- 并且几次重复实验表明,\(k_3\) 的数值不稳定性明显比 \(k_1\) 和 \(k_2\) 更严重
- \(k_3\) 的样本均值与真实 KL 值之间的巨大差距并非估计量偏差,而是巨大的抽样误差,这是具有极大或无穷大方差的估计量的特征
·* 这表明需要数量不切实际的大样本量才能使估计可靠地收敛,使得 \(k_3\) 在此类场景中成为一个不可靠的选择
附录 J:Group Normalization Stability Issues(Group Norm 的稳定性讨论)
- GRPO 执行每个 Prompt 的组归一化:
- 对于一个具有 \(G\) 个 Response 和奖励 \(\mathbf{r} = \{r_{1},\ldots ,r_{G}\}\) 的 Prompt,其优势 (advantage) 为:
$$A_{i} = \frac{r_{i} - \text{mean}_{\text{group} }(\mathbf{r})}{\text{std}_{\text{group} }(\mathbf{r})}. \tag {78}$$
- 对于一个具有 \(G\) 个 Response 和奖励 \(\mathbf{r} = \{r_{1},\ldots ,r_{G}\}\) 的 Prompt,其优势 (advantage) 为:
Stability issue
- 当组内方差非常小时 (例如,\(\mathbf{r} = [0.99999, 1.00001, 0.99999, 1.00001]\) ),归一化可能会急剧放大微小的数值差异
- 对于上面的例子,得到的优势值大约为 \([- 0.8660, 0.8660, - 0.8660, 0.8660]\) (使用无偏样本标准差),这会将近乎恒定的奖励转变为大幅度的更新,从而破坏优化过程的稳定性
Proposed solution
- 裁剪标准差以防止病态放大:
$$
\begin{align}
A_{i} &= \frac{r_{i} - \text{mean}_{\text{group} }(\mathbf{r})}{\text{clip_std}_{\text{group} }(\mathbf{r})} \\
\text{clip_std}_{\text{group} }(\mathbf{r}) &= \text{max}\big(\text{min}(\text{std}_{\text{group} }(\mathbf{r}),\text{std}_{\text{max} }),\text{std}_{\text{min} }\big) \tag {79}
\end{align}
$$- 其中,\(\text{std}_{\text{min} } > 0\) 是一个小的下限,用于防止当方差崩溃时归一化过程产生爆炸性数值
- \(\text{std}_{\text{max} }\) 则用于避免当方差异常大时归一化不足
- 在实践中,将 \(\text{std}_{\text{min} }\) 设置为一个相对于奖励尺度较小的常数 (例如,\(10^{- 1}\) ) 可能是有效的
Why this matters beyond binary rewards
- RLVR 中的二元 0/1 奖励有时可以缓解极端情况
- 但更通用的回归奖励模型(例如使用 Bradley-Terry (BT) 损失训练的模型)通常会产生连续的分数,这些分数在简单或非常难的 Prompt 上可能会高度集中 (例如,接近 0 或 1)
- 在这种情况下,即使奖励被限制在 \([0,1]\) 区间内,组内标准差也可能任意小,并且除非使用方差下限 (或裁剪),否则组归一化将会过度放大微小的差异
- 因此,标准差裁剪不仅对于数值稳定性很重要,而且对于避免在奖励预测饱和时过度放大噪声也很重要
Remark
- 对于限制在 \([0,1]\) 区间内的奖励分数,\(\operatorname {std}(\mathbf{r})< 1\) 总是成立,但在实践中它可能比 1 小几个数量级
- 方差越小,组归一化的放大效应就越强
- 裁剪 \(\operatorname {std}_{\text{group} }(\mathbf{r})\) 可以在方差适中时保持预期的尺度不变性 ,同时防止方差崩溃时出现不稳定性
附录 K:Large Scale Experiment
Figure 4 比较了 \(k_1\) as loss 与无 KL 正则化的情况
- 训练动态几乎无法区分,这实证地证实了第 5 节的理论预测:由于\(k_1\) as loss的梯度独立于参考模型且其梯度期望为零均值,因此它作为 KL 正则化器是无效的
- 在更大规模 7B 模型上的实证结果(图 4)进一步证实了作者对 \(k_1\) as loss 的理论分析
- 如第 5 节所述,该 loss 项的梯度从根本上不适合正则化:
- 它独立于参考策略 \(\pi_{\text{ref} }\) ,并且在 On-policy 采样下的期望恰好为零
- 在实践中,这相当于注入一个缩放的得分函数
$$\beta \cdot \nabla_{\color{red}{\theta}}\log \pi_{\color{red}{\theta}}$$- 它引入了零均值但可能高方差的噪声
- 尽管预期的更新方向保持不变,但增加的梯度方差偶尔会在单个更新步骤中产生大的偏差
- 这一现象清晰地反映在实验曲线中
- 如 KL Loss 和 Logprob Diff 所示,在 \(k_1\) as loss 下的 Actor 模型不仅未能更接近参考模型,反而在后期阶段漂移得更远
- 两种设置的轨迹最初是对齐的,但 \(k_1\) as loss 变体突然发散,表明出现了由方差引起的剧烈波动
- 尽管最终的任务级性能(例如,奖励/准确率)大致相似,但实现这样的结果需要高得多的 KL 量级,这最终是低效的,并且没有提供有意义的正则化
- 简而言之,在更大的模型规模上应用 \(k_1\) as loss 不仅无效,而且适得其反,因为它会破坏训练稳定性并削弱与参考模型的对齐
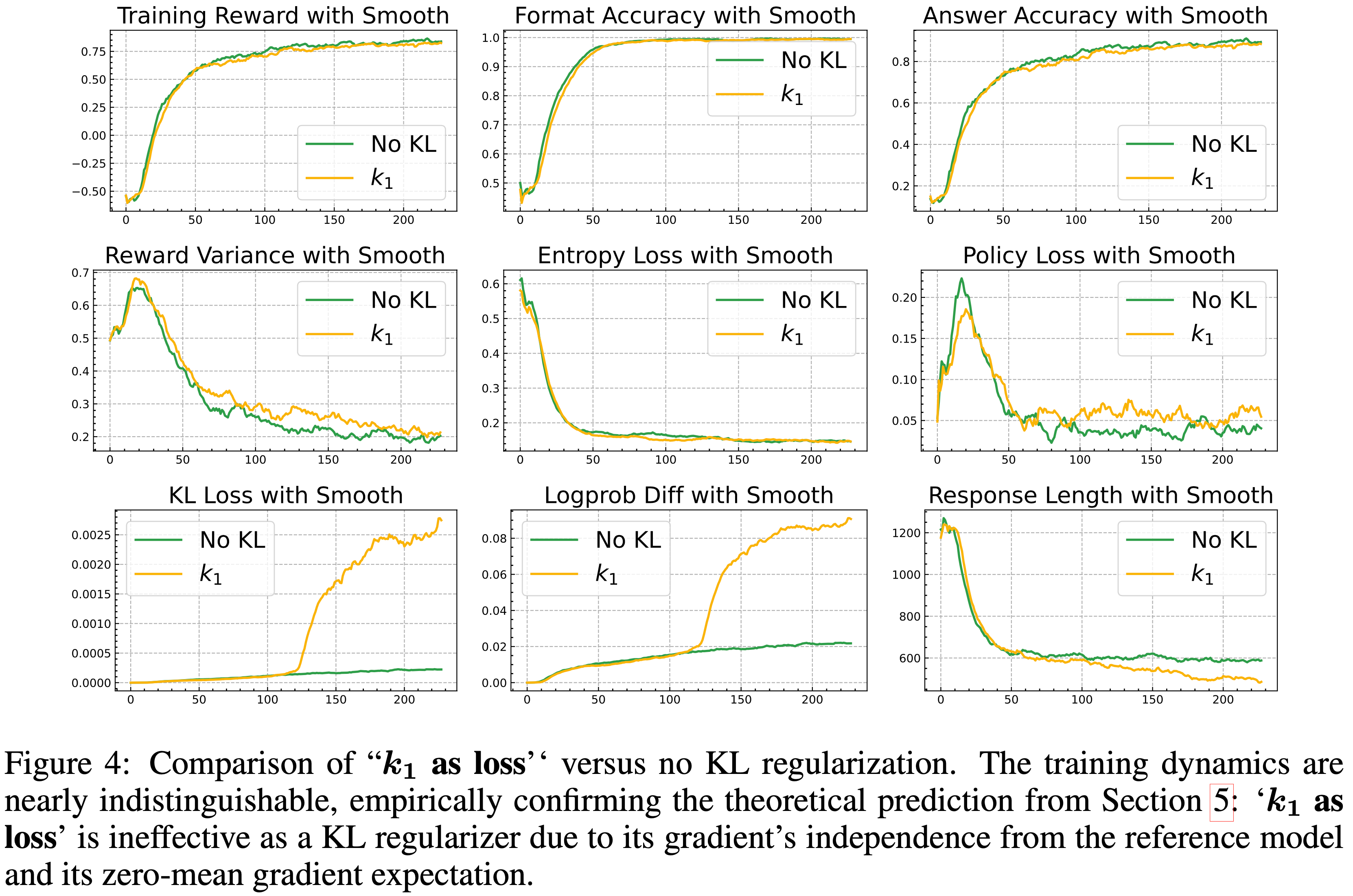
- 简而言之,在更大的模型规模上应用 \(k_1\) as loss 不仅无效,而且适得其反,因为它会破坏训练稳定性并削弱与参考模型的对齐
- 如第 5 节所述,该 loss 项的梯度从根本上不适合正则化:
Figure 5 比较了 Principled \(k_2\) as loss 与其一阶近似 \(k_3\) as loss
- 两种变体都有效地约束了策略
- \(k_2\) as loss 展示了更优的正则化特性,保持了与参考策略更紧密的耦合,并产生了更稳定的优化路径,表现为更低的奖励方差
- 在 7B 规模模型上的实证结果(图 5)突出了 \(k_2\) as loss 和 \(k_3\) as loss 的对比行为
- 在相同的系数下, \(k_2\) as loss 施加了明显更强的约束:
- \(k_2\) as loss 的 KL Loss 和 Logprob Diff 曲线都持续低于 \(k_3\) as loss 的曲线,表明 Actor 更接近参考模型
- \(k_3\) as loss 在训练中往往发散得更厉害 ,这可以从更高的 KL 量级和更大的对数概率差异中看出
- 会不会是可通过调整学习率修改回来的?
- 这种发散进一步反映在 Response 长度上,\(k_3\) 产生更短且更多变的输出,表明对生成的控制较弱
- 尽管 \(k_3\) as loss 在训练早期和中期有时会获得更高的奖励和准确率,但这种优势是以不稳定性为代价的
- 问题:看着图 5 第一行的三个图,都是 \(k_3\) 的分数更高啊!
- 在 \(k_3\) as loss 下,奖励方差和策略损失显著更高,表明其较弱的约束允许优化过程中出现更大的波动
- 尽管 \(k_3\) as loss 在训练早期和中期有时会获得更高的奖励和准确率,但这种优势是以不稳定性为代价的
- \(k_2\) as loss 提供了更稳定的训练轨迹,保持了较低的方差,并使策略与参考保持紧密对齐
- 这些结果表明,在更大的模型规模上, \(k_2\) as loss 是实现一致且受控正则化的更有效选择,而 \(k_3\) as loss 尽管有暂时的性能提升,但冒着更大的漂移和不稳定性风险
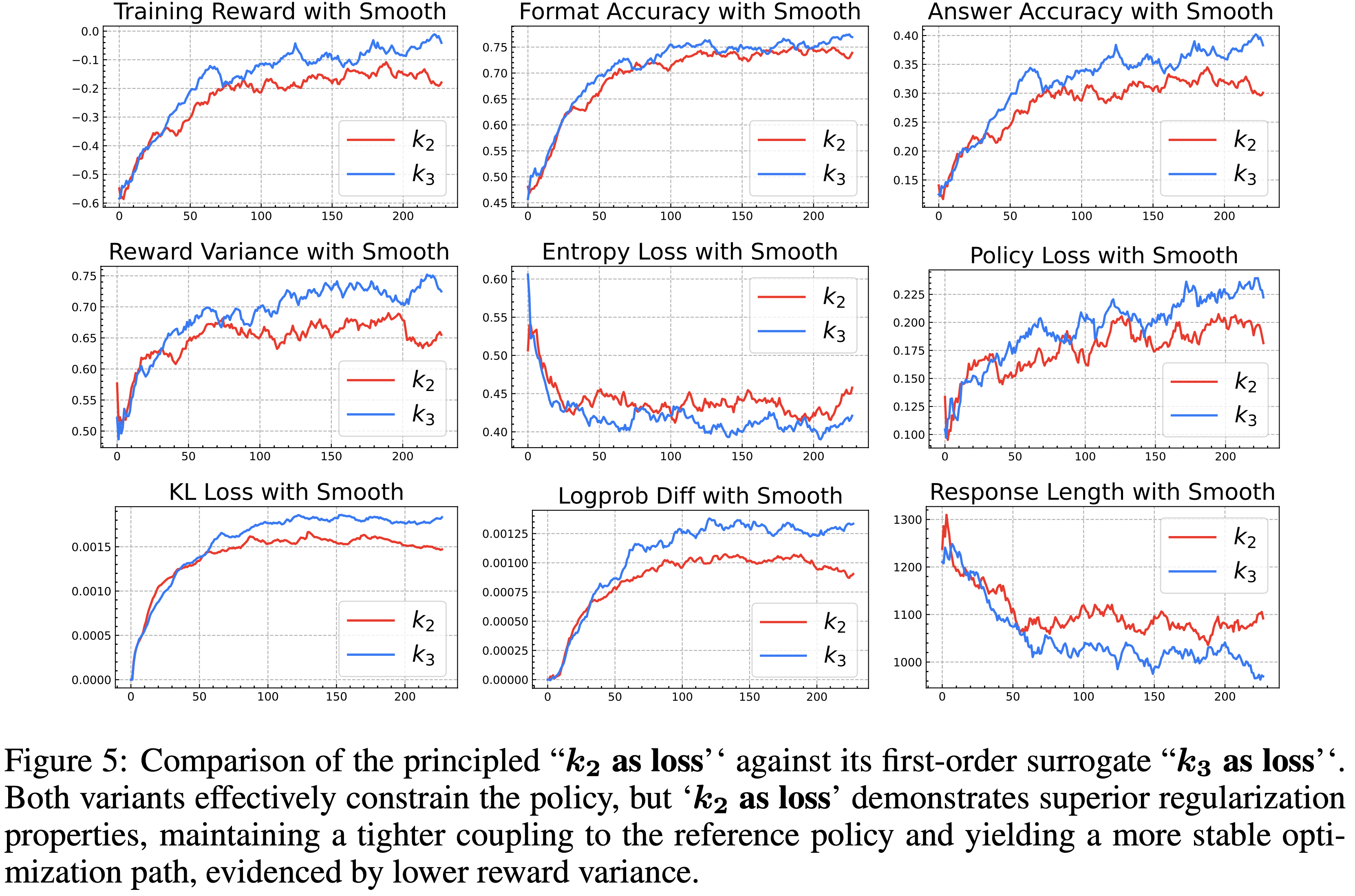
- 在相同的系数下, \(k_2\) as loss 施加了明显更强的约束:
- 两种变体都有效地约束了策略
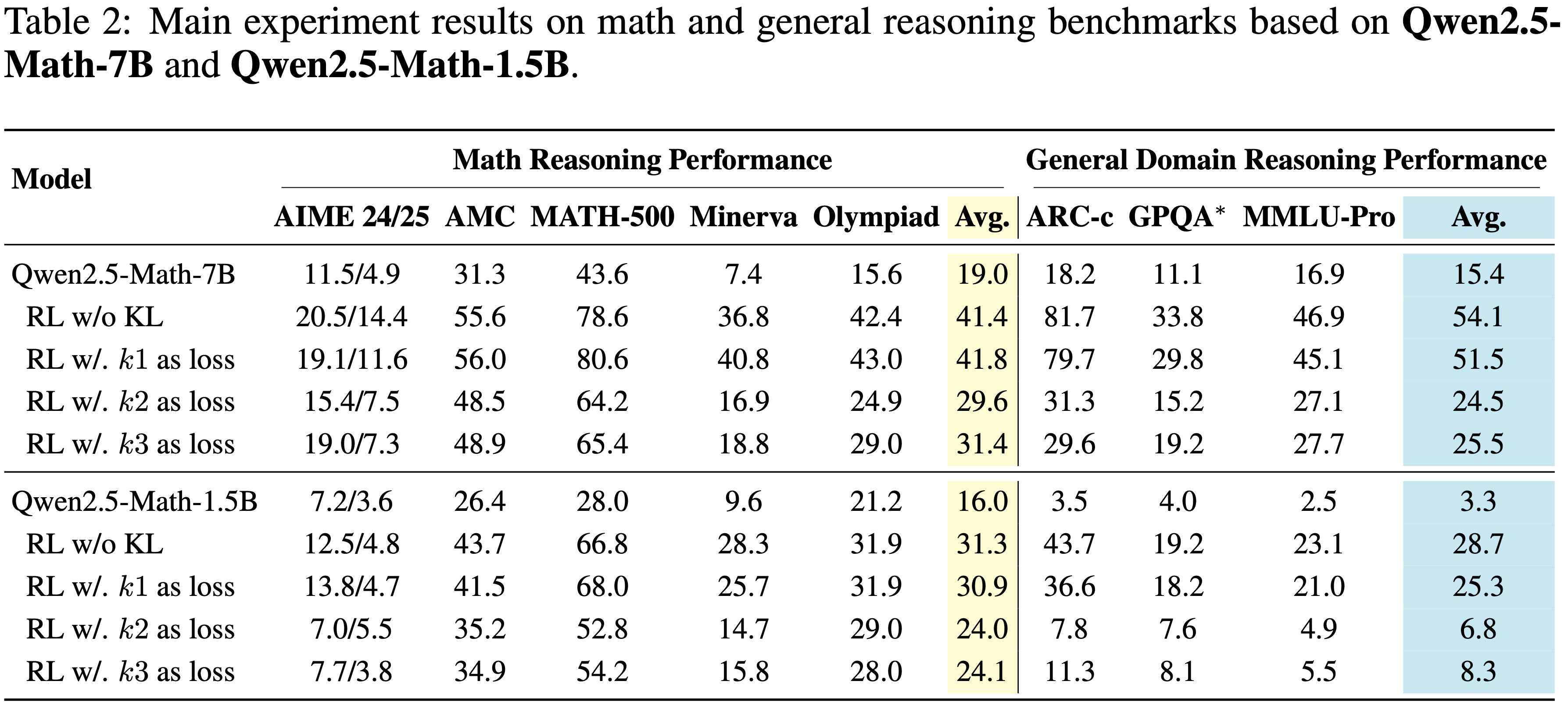
附录 L:Downstream Benchmark Performance
- 在数学和通用推理基准上的主要结果总结在表 2 中
- 在 7B 和 1.5B 模型上出现了一些一致的模式
- First,使用 \(k_1\) as loss 的设置并未提供显著的正则化益处
- 这与作者的理论分析一致,该分析表明其期望梯度为零,因此未能约束 Actor 相对于参考模型
- 实验上,在数学和通用领域任务中,其性能仍然非常接近 “无 KL 的 RL” 基线,这表明 \(k_1\) as loss 作为正则化器是无效的
- Second,在相同系数下, \(k_2\) as loss 和 \(k_3\) as loss 的行为存在显著差异
- \(k_2\) as loss 对 Actor 施加了更严格的约束:
- 模型保持更接近参考策略,但这种更紧密的耦合是以性能大幅下降为代价的,这在数学推理(例如,AIME (2024)、AMC (2024)、MATH-500 (2021))和通用推理基准(例如,ARC-c (2018)、GPQA (2024)、MMLU-Pro (2024))上都有所反映
- \(k_3\) as loss 施加了较弱的约束,允许模型漂移更多,这在训练动态中也可以观察到(更高的 KL 和对数概率差异)
- 尽管在最终基准分数上 , \(k_3\) as loss 看起来略好于 \(k_2\) as loss ,但其更具发散性的行为凸显了有效正则化的缺失和更大的不稳定性
- 分数高了,是不是也说明应该被使用呢?
- 尽管在最终基准分数上 , \(k_3\) as loss 看起来略好于 \(k_2\) as loss ,但其更具发散性的行为凸显了有效正则化的缺失和更大的不稳定性
- \(k_2\) as loss 对 Actor 施加了更严格的约束:
- 综合来看,这些结果证实了作者的理论预期:
- \(k_1\) as loss不起约束作用
- \(k_2\) as loss 施加了更强且僵化的正则化,抑制了整体性能
- \(k_3\) as loss ,尽管限制性较弱,但允许过度发散,可能导致训练不稳定
- First,使用 \(k_1\) as loss 的设置并未提供显著的正则化益处
- Table 2: 基于 Qwen2.5-Math-7B 和 Qwen2.5-Math-1.5B 在数学和通用推理基准上的主要实验结果
附录 M:Statement on the Use of Large Language Models
- 作者仅将 LLMs 用于语言润色和编辑
- 所有相关工作检索、算法设计和理论推导均由作者完成
附录 N:Impact
- 本文作者提出的 \(k_{2}\) as loss 公式已被合并到 OpenRLHF 中,并已被 Reinforce++ 采用和引用
- Prorl 也将其与参考模型的周期性重置相结合
- 通过提供一种梯度正确、适用于 Off-policy 的 KL 正则化处理方法,作者的工作澄清了长期存在的歧义,并为构建稳定、有效且可重现的 RLHF 系统提供了实用指导
附录:补充 \(k_3\) as loss 梯度推导
- 目标:推导公式 (58) 到公式 (59) 的过程
- 公式 (58) 是 \(k_3\) as loss 的目标函数:
$$
\mathcal{J}_{k_3\text{ as loss} }(\theta) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)} -1 - \log \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}\right] \tag {58}
$$ - 为了简化符号,固定一个 prompt \(x\) 和一个从策略 \(\pi_{\theta}(\cdot|x)\) 中采样的输出 \(y\),定义概率比:
$$
\delta = \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}.
$$ - 对于这个特定的样本 \((x, y)\),公式 (58) 中括号内的项(记作 \(L\))可以写作:
$$
L = \delta - 1 - \log \delta
$$ - 我们的目标是计算梯度 \(\nabla_{\theta} L\)。这里的关键是,\(\delta\) 依赖于 \(\pi_{\theta}(y|x)\),因此也依赖于 \(\theta\)
第一步:将 \(L\) 表达为 \(\log \pi_{\theta}(y|x)\) 的函数
- 为了更方便地求导,将 \(\delta\) 和 \(\log \delta\) 用 \(\log \pi_{\theta}\) 表示
- 注意,\(\pi_{\text{ref} }(y|x)\) 是与 \(\theta\) 无关的常数
$$
\begin{align}
\delta = \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)} = \exp\left(\log \pi_{\text{ref} }(y|x) - \log \pi_{\theta}(y|x)\right) \\
\log \delta = \log \pi_{\text{ref} }(y|x) - \log \pi_{\theta}(y|x)
\end{align}
$$ - 因此,\(L\) 可以重写为:
$$
L = \exp\left(\log \pi_{\text{ref} }(y|x) - \log \pi_{\theta}(y|x)\right) - 1 - \left(\log \pi_{\text{ref} }(y|x) - \log \pi_{\theta}(y|x)\right)
$$
第二步:对 \(L\) 求梯度
- 现在对 \(\theta\) 求导
- 令 \(z = \log \pi_{\theta}(y|x)\),则 \(L\) 是 \(z\) 的函数,根据链式法则:
$$
\nabla_{\theta} L = \frac{dL}{dz} \cdot \nabla_{\theta} \log \pi_{\theta}(y|x)
$$ - 计算 \(\frac{dL}{dz}\):
$$
\frac{dL}{dz} = \frac{d}{dz} \left[ \exp\left(\log \pi_{\text{ref} } - z\right) - 1 - (\log \pi_{\text{ref} } - z) \right]
$$ - 分别对各项求导:
- 对第一项 \(\exp(\log \pi_{\text{ref} } - z)\) 求导:
$$
\frac{d}{dz} \exp(\log \pi_{\text{ref} } - z) = \exp(\log \pi_{\text{ref} } - z) \cdot (-1) = -\exp(\log \pi_{\text{ref} } - z)
$$- 注意
$$ \exp(\log \pi_{\text{ref} } - z) = \frac{\pi_{\text{ref} } }{\pi_{\theta} } = \delta$$ - 所以这一项的导数是 \(-\delta\)
- 注意
- 对第二项常数 \(-1\) 求导为 \(0\)
- 对第三项 \(-(\log \pi_{\text{ref} } - z) = -\log \pi_{\text{ref} } + z\) 求导为 \(+1\)
- 对第一项 \(\exp(\log \pi_{\text{ref} } - z)\) 求导:
- 因此:
$$
\frac{dL}{dz} = -\delta + 1 = 1 - \delta.
$$
第三步:得到梯度表达式
- 将 \(\frac{dL}{dz}\) 代回链式法则中,得到单个样本的梯度贡献:
$$
\nabla_{\theta} L = (1 - \delta) \cdot \nabla_{\theta} \log \pi_{\theta}(y|x)
$$ - 根据公式 (58),整个目标函数的梯度是此梯度的期望
- 在计算这个期望时,样本 \(y\) 是从 \(\pi_{\theta}(\cdot|x)\) 中采样的,并且按照惯例,系数 \((1-\delta)\) 在梯度计算中被视为 detached(即不计算其对 \(\theta\) 的依赖,只作为一个常数系数)
- 最终得到:
$$
\nabla_{\theta}\mathcal{J}_{k_{3}\text{ as loss} }(\theta) = \mathbb{E}_{x\sim \mathcal{D},y\sim \pi_{\theta}(\cdot |x)}\left[\left(1 - \frac{\pi_{\text{ref} }(y|x)}{\pi_{\theta}(y|x)}\right)\nabla_{\theta}\log \pi_{\theta}(y|x)\right] \tag {59}
$$
- 最终得到:
- 证毕