混合精度 (Automatically Mixed Precision, AMP)
数字类型
FP32
- FP32,Single-precision floating-point
- 4B, 32位,符号位1位,指数位8位,尾数位23位
- 符号位:用于表示数值的正负
- 指数位:用于表示数值的范围
- 尾数位(Fraction):也称为小数位,用于表示数值的精度
- 数字表达范围: \([-3e^{38},-1e^{-45}] \bigcup [1e^{-45}, 3e^{38}]\)
- 下溢精度: \(1e^{-38}\)
FP16
- FP16,Half-precision floating-point
- 2B, 16位,符号位1位,指数位5位,尾数位10位
- 数字表达范围: \([-65504,-5.9e^{-8}] \bigcup [5.9e^{-8}, 65504]\)
- 下溢精度: \(5.9e^{-8}\)
BF16
- BF16,Brain Floating Point
- 2B,16位,符号位1位,指数位8位,尾数位7位
- 数字表达范围: \([−3e^{38}, -9.2^{-41}],[9.2^{-41}, 3e^{38}]\)
- 下溢精度: \(9.2^{-41}\)
FP32 vs FP16
- 能表达的数字范围和精度远小于FP32
- 浮点数都有个上下溢问题:
- 上/下溢出:FP16 的表示范围不大,非常容易溢出
- 超过 \(6.5e^4\) 的数字会上溢出变成 inf,小于 \(5.9e^{-8}\) 的数字会下溢出变成 0
FP16 vs BF16
- 都是2B存储
- BF16指数位更多:可以表示更大范围的数值
- FP16尾数位更多:可以表示更精确的数值,如果都是小数值,用FP16更好
- 注意:下溢精度不等于精度,下溢精度与指数关系更大
混合精度训练
- 最早论文:Mixed precision training
- 作者:百度,英伟达
- 一次迭代过程
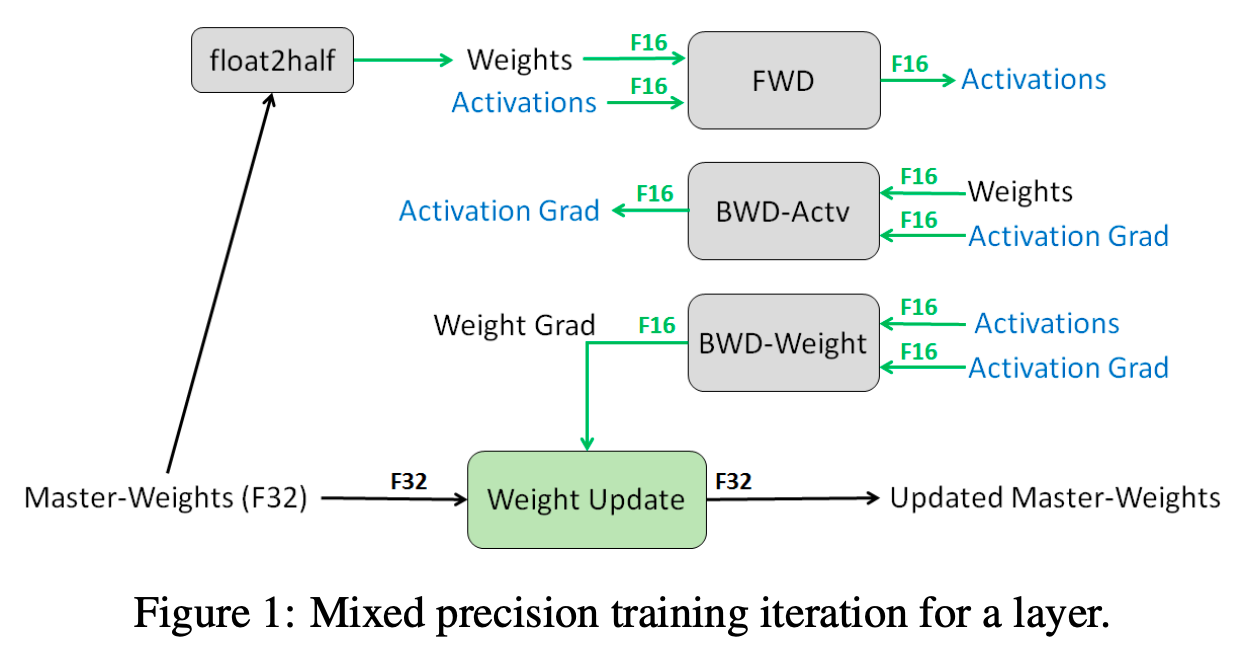
- 基本思路:保持原始参数还是fp32的情况下,将计算梯度等所有流程都使用fp16进行,节省内存/显存的同时提升训练速度
- fp16会损失精度,所以在过程中需要用到scaling操作
- 混合精度训练的优点
- 减少显存占用:FP16 的显存占用只有 FP32 的一半,这使得我们可以用更大的 batch size;
- 混合精度训练下,需要存储的变量为:FP16的梯度,FP16的参数,FP32的参数;好像并没有减少显存啊?
- 加速训练:使用 FP16,模型的训练速度几乎可以提升 1 倍
- 减少显存占用:FP16 的显存占用只有 FP32 的一半,这使得我们可以用更大的 batch size;
- FP16的下溢值这么大,梯度一般都很小,为什么能存储梯度?
- 通过loss scaling技术,对loss进行缩放(放大很多倍)可以确保梯度不会下溢,在更新时转换成FP32再unscale回去即可(需要FP32)
- FP32有什么用?(为什么不能只使用fp16呢?)
- 防止FP16导致误差过大:将模型权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差。
- 为了节省存储和加快训练速度,特别是大模型时代,越来越重要
混合精度的使用
- 更新最新参考资料:由浅入深的混合精度训练教程