spark 从 DataFrame 中读取 Array 类型的列
- 代码示例
1
2
3
4dataFrame.rdd.map(row => {
val vectorCol = row.getAs[Seq[Double]]("VectorCol")
vectorCol.toArray
}).collect().foreach(println)
整体讨论
《Muon is Scalable for LLM Training》 Paper Summary
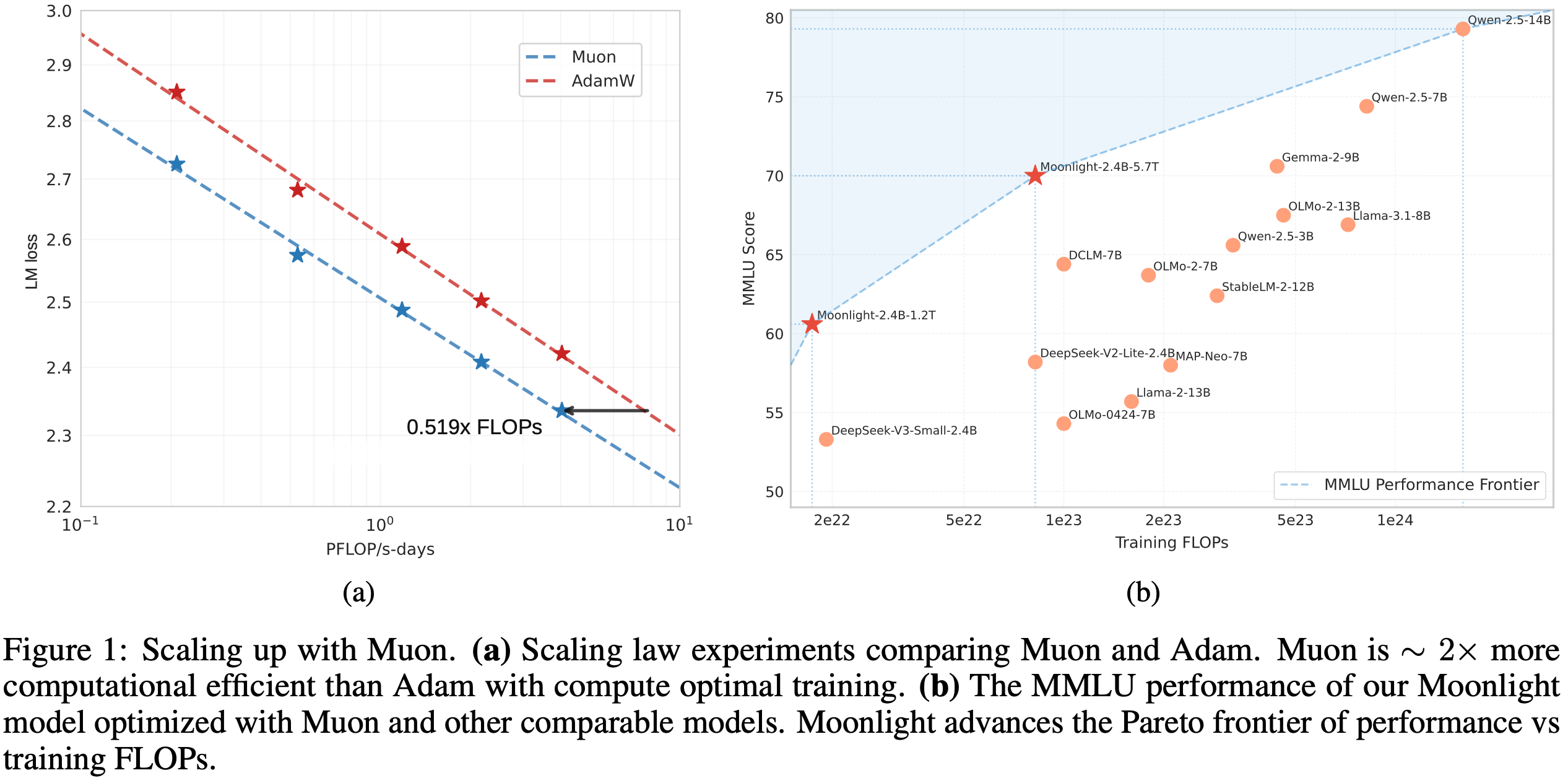
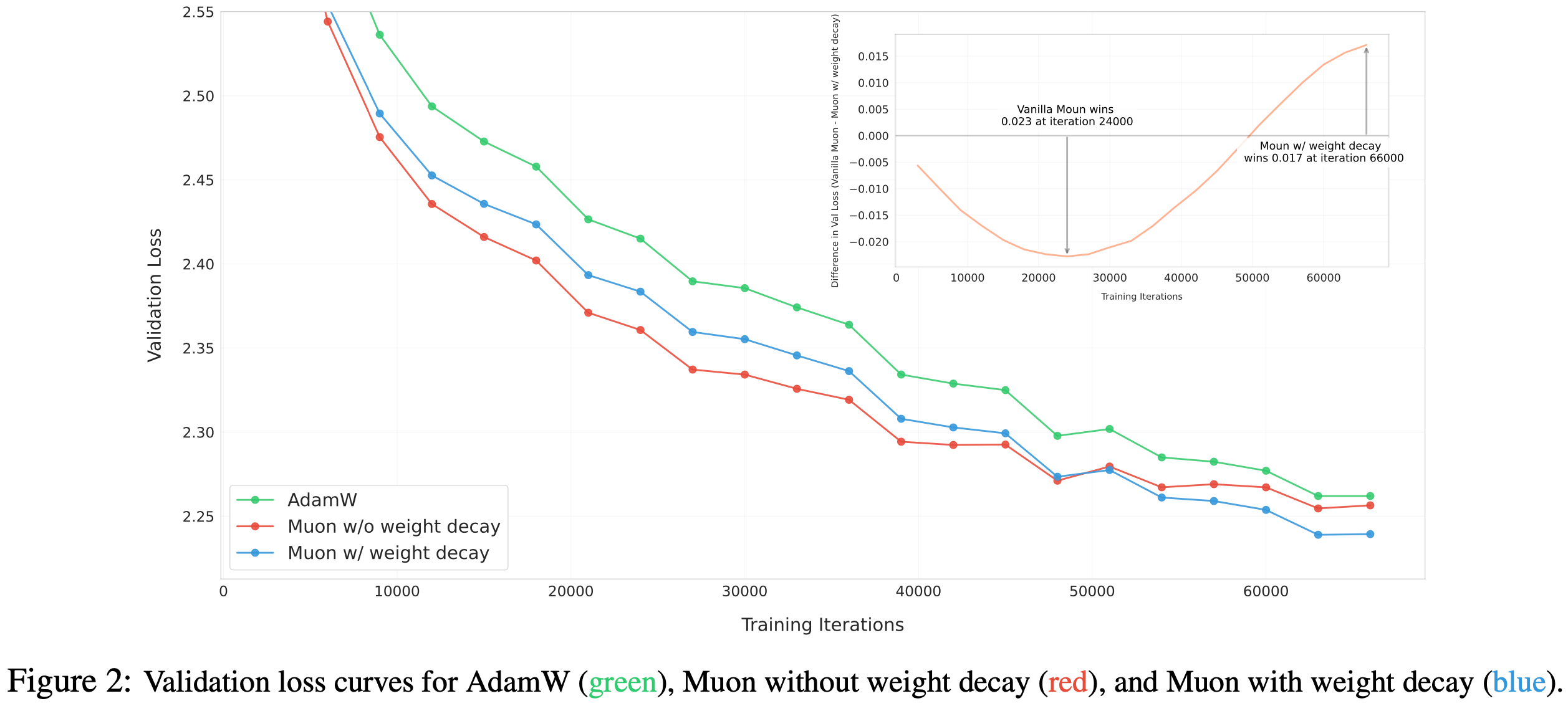
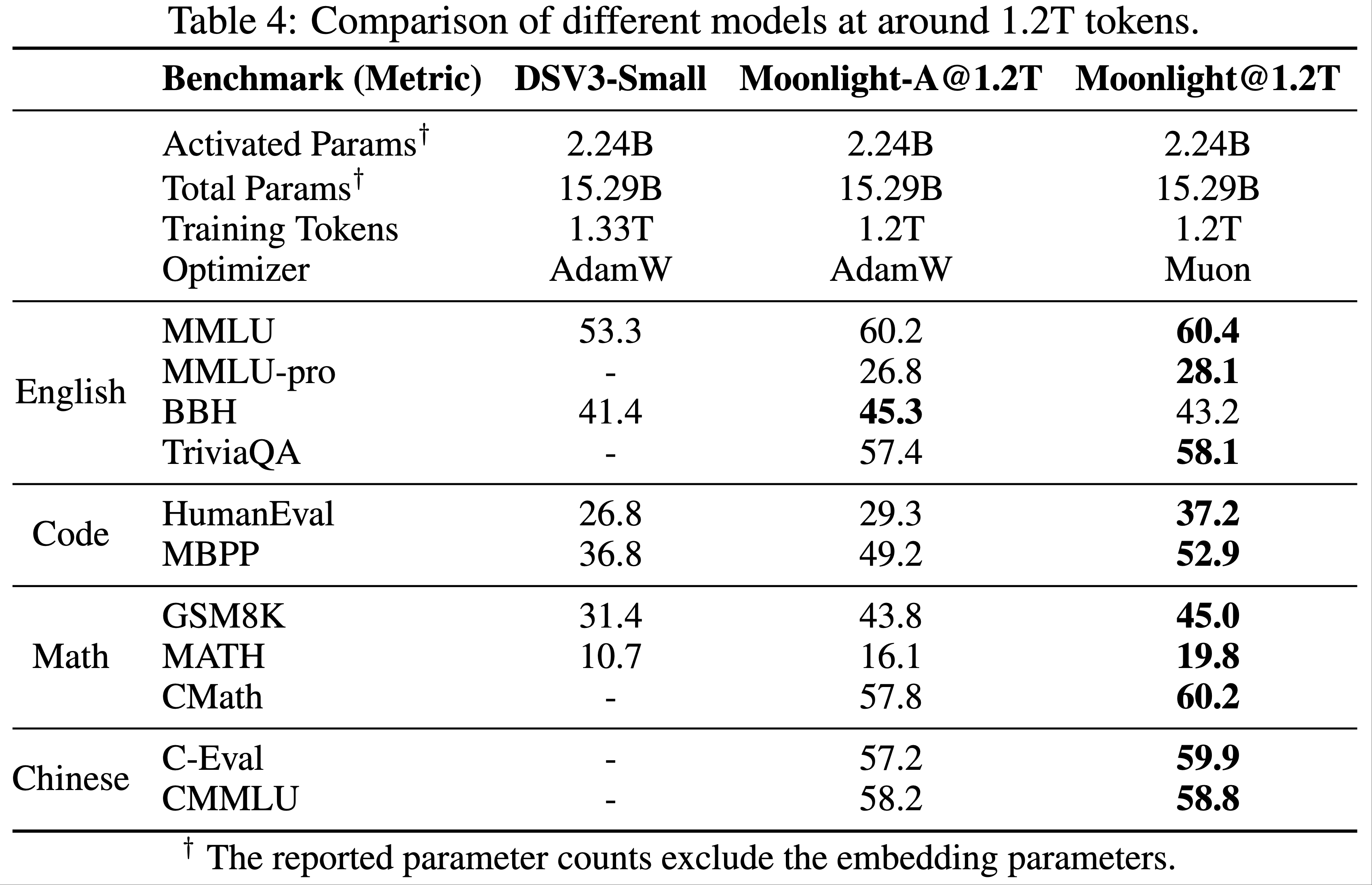
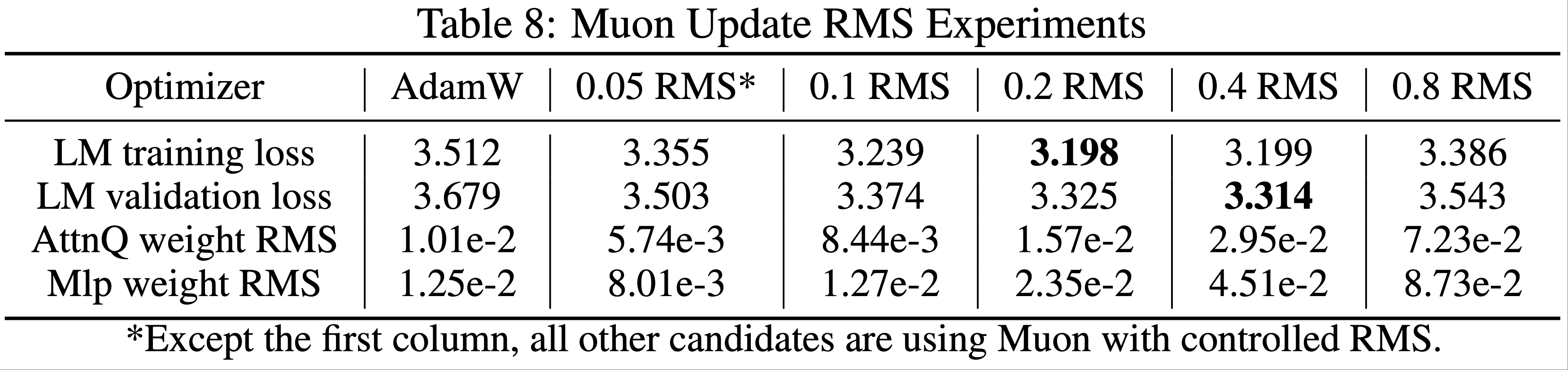
Muon 优化器 Muon(2024)是一种针对矩阵参数优化的神经网络优化器
在迭代步 \( t \) 时,给定当前权重 \(\mathbf{W}_{t-1}\)、动量 \(\mu\)、学习率 \(\eta_t\) 和目标函数 \(\mathcal{L}_t\),Muon 的更新规则如下:
$$
\begin{split}
\mathbf{M}_t &= \mu\mathbf{M}_{t-1} + \nabla\mathcal{L}_t(\mathbf{W}_{t-1}) \\
\mathbf{O}_t &= \text{Newton-Schulz}(\mathbf{M}_t)^{\mathrm{i} } \\
\mathbf{W}_t &= \mathbf{W}_{t-1} - \eta_t\mathbf{O}_t
\end{split} \tag{1}
$$
Newton-Schulz 迭代的矩阵正交化(Newton-Schulz Iterations for Matrix Orthogonalization) :公式1通过迭代过程计算
M.norm(),定义如下:1 | # Pytorch code |
范数约束下的最速下降法(Steepest Descent Under Norm Constraints)
d_model x vocab_size维度大小)吧?Based on Megatron-LM’s sophisticated parallel strategies, e.g. Tensor-Parallel (TP), Pipeline Parallel (PP), Expert Parallel (EP) and Data Parallel (DP), the communication workload of ZeRO-1 can be reduced from gathering all over the distributed world to only gathering over the data parallel group.







smoothing_function 传入一些平滑策略来解决问题1 | from nltk.translate.bleu_score import sentence_bleu # 评估句子 |
* BLEU 倾向于精确率,对于短的(已经有惩罚了)、精确匹配的句子可能给出高分,但可能忽略了语义的完整性或流畅性
* 更多的参考翻译通常会提高 BLEU 分数
* BLEU 在单句评估上指标不太稳定(修改单个单词可能出现非常大的变化),更适合评估整个语料库的平均表现rouge-score 库)rouge-score 是一个常用的 Python 库,用于计算 ROUGE 分数 1 | from rouge_score import rouge_scorer |
method0(): 无平滑 (No smoothing)method1(): 添加epsilon计数 (Add epsilon counts)method2(): 添加1到分子和分母 (Add 1 to both numerator and denominator)method3(): NIST 几何序列平滑 (NIST geometric sequence smoothing)前言:RWKV 作为挑战 Transformer 架构的国人开源项目,有前景,本文先简单介绍,有时间回来详细补课
注:本文包含 AI 辅助创作
Paper Summary
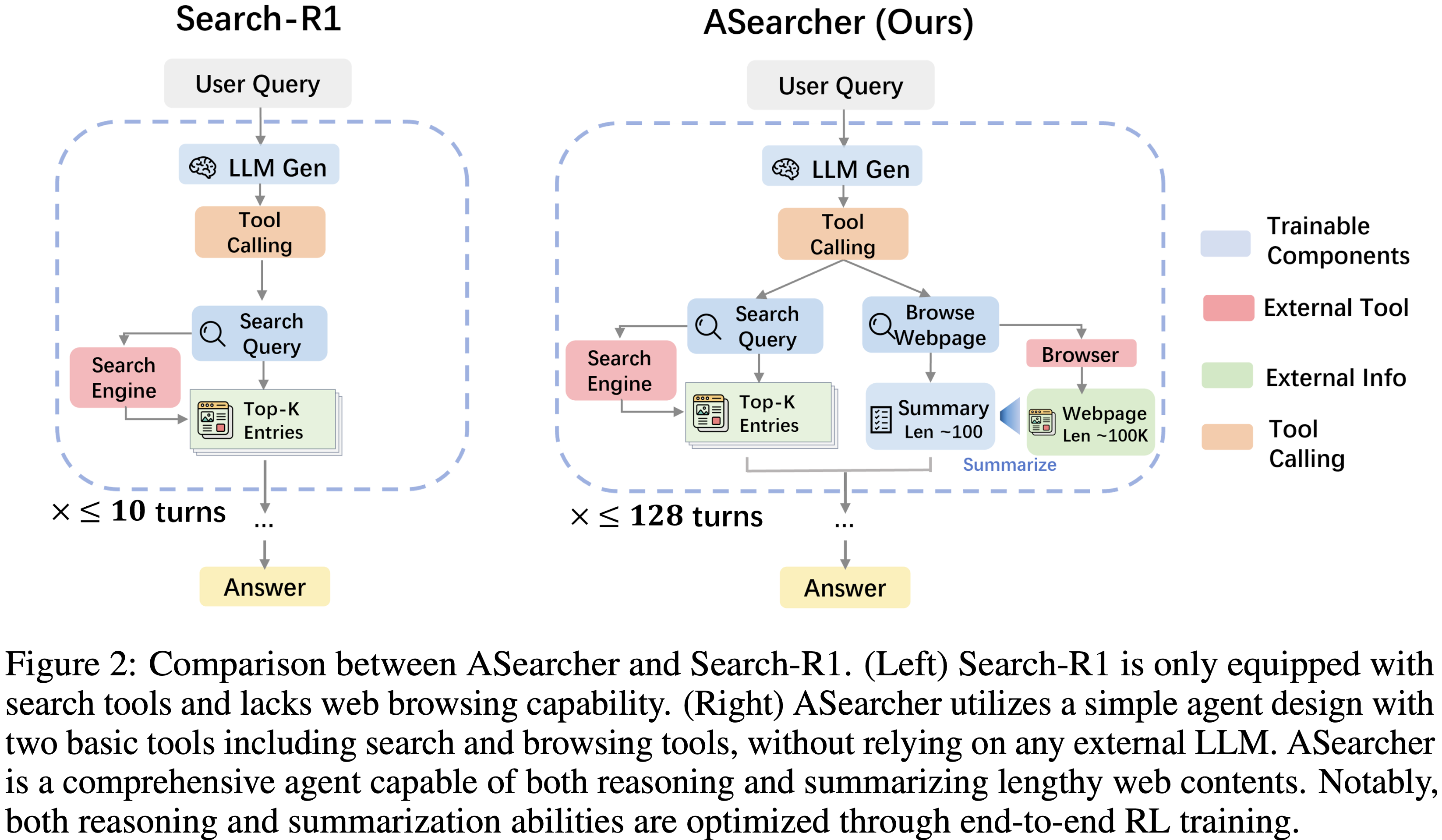
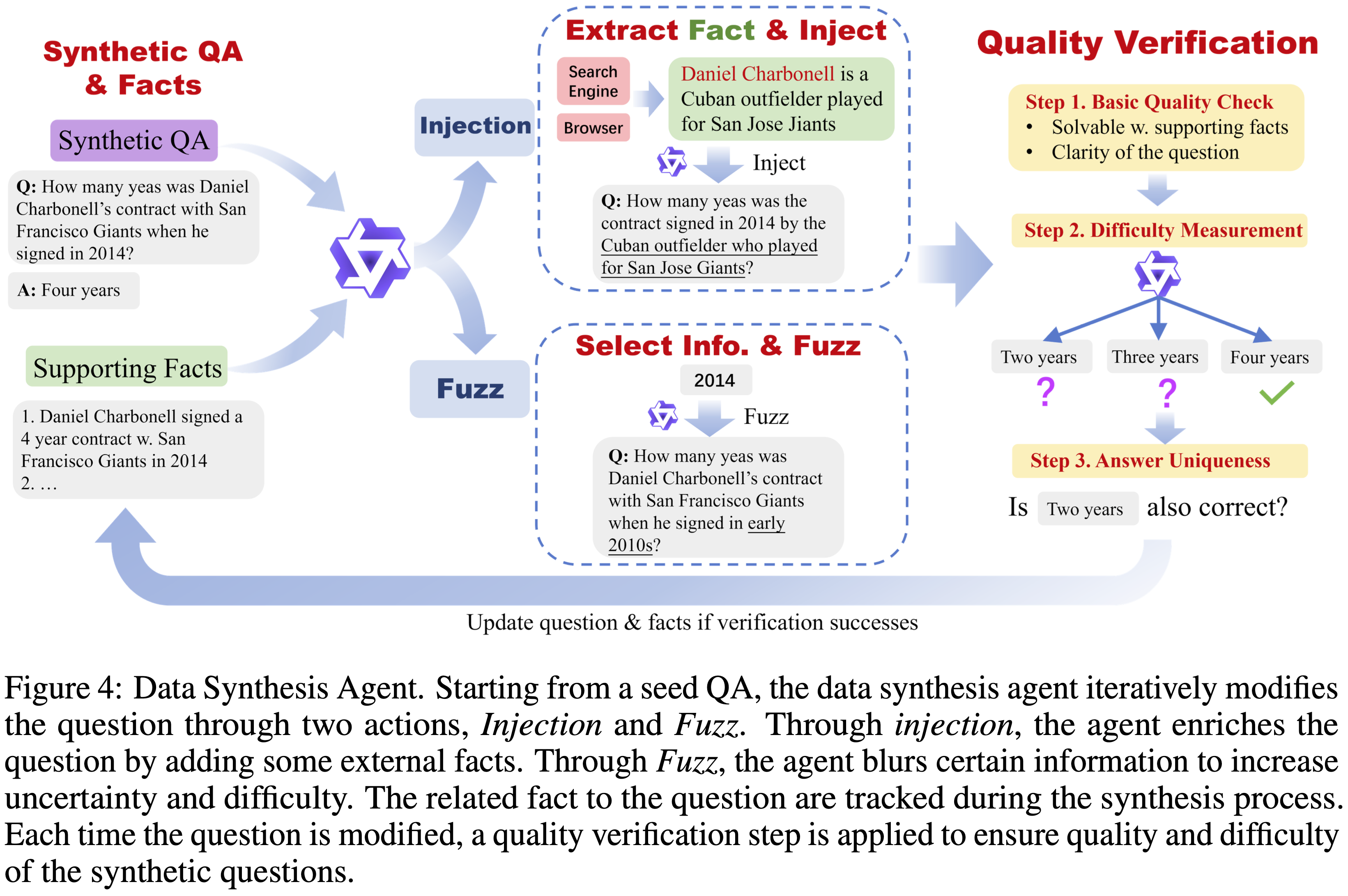
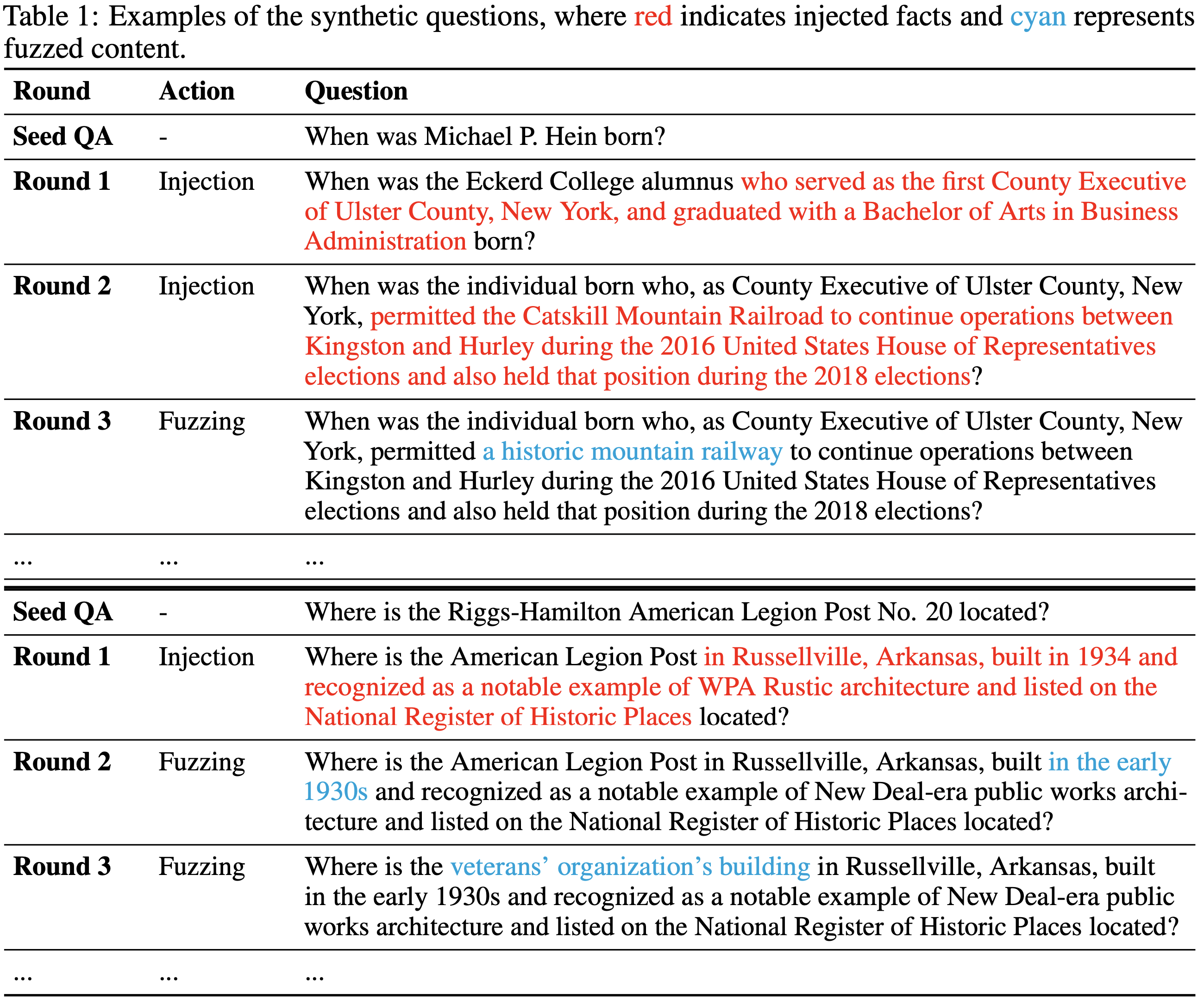
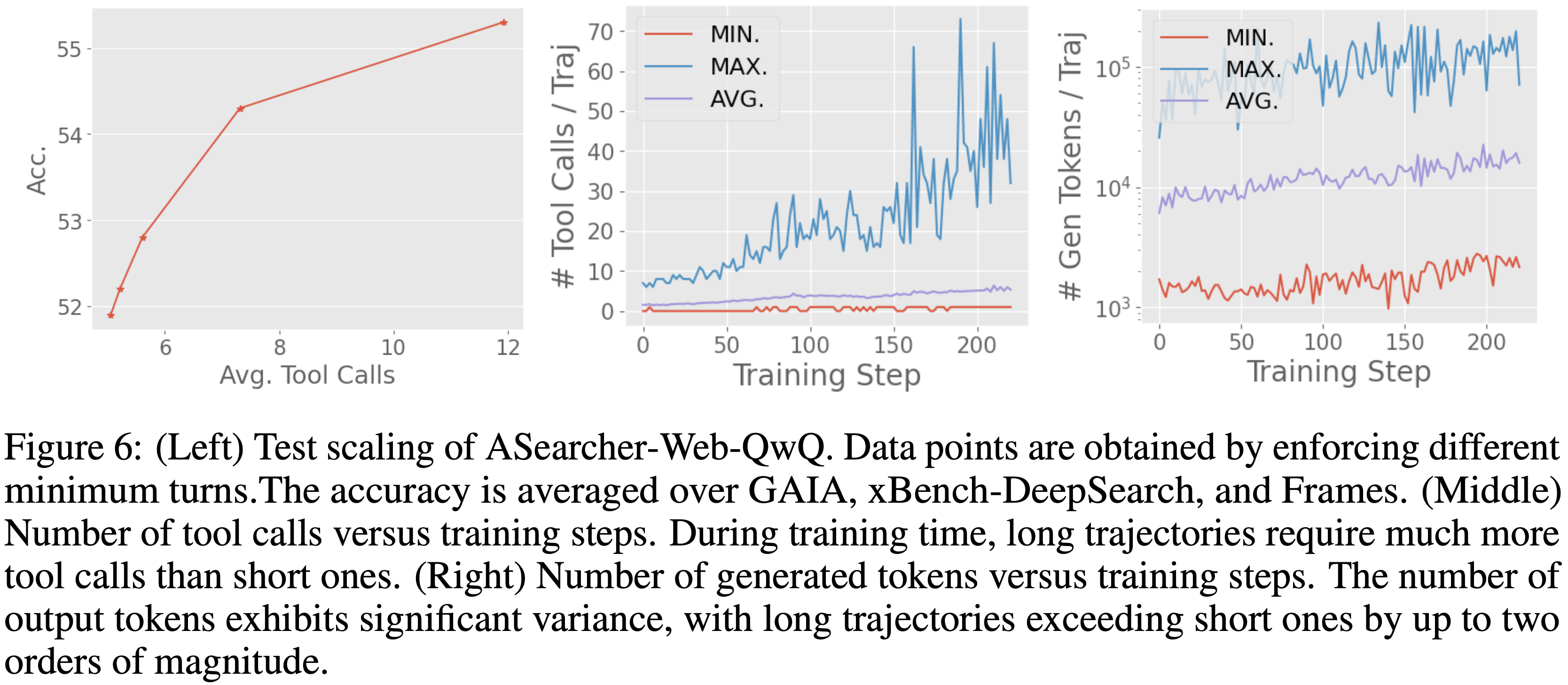
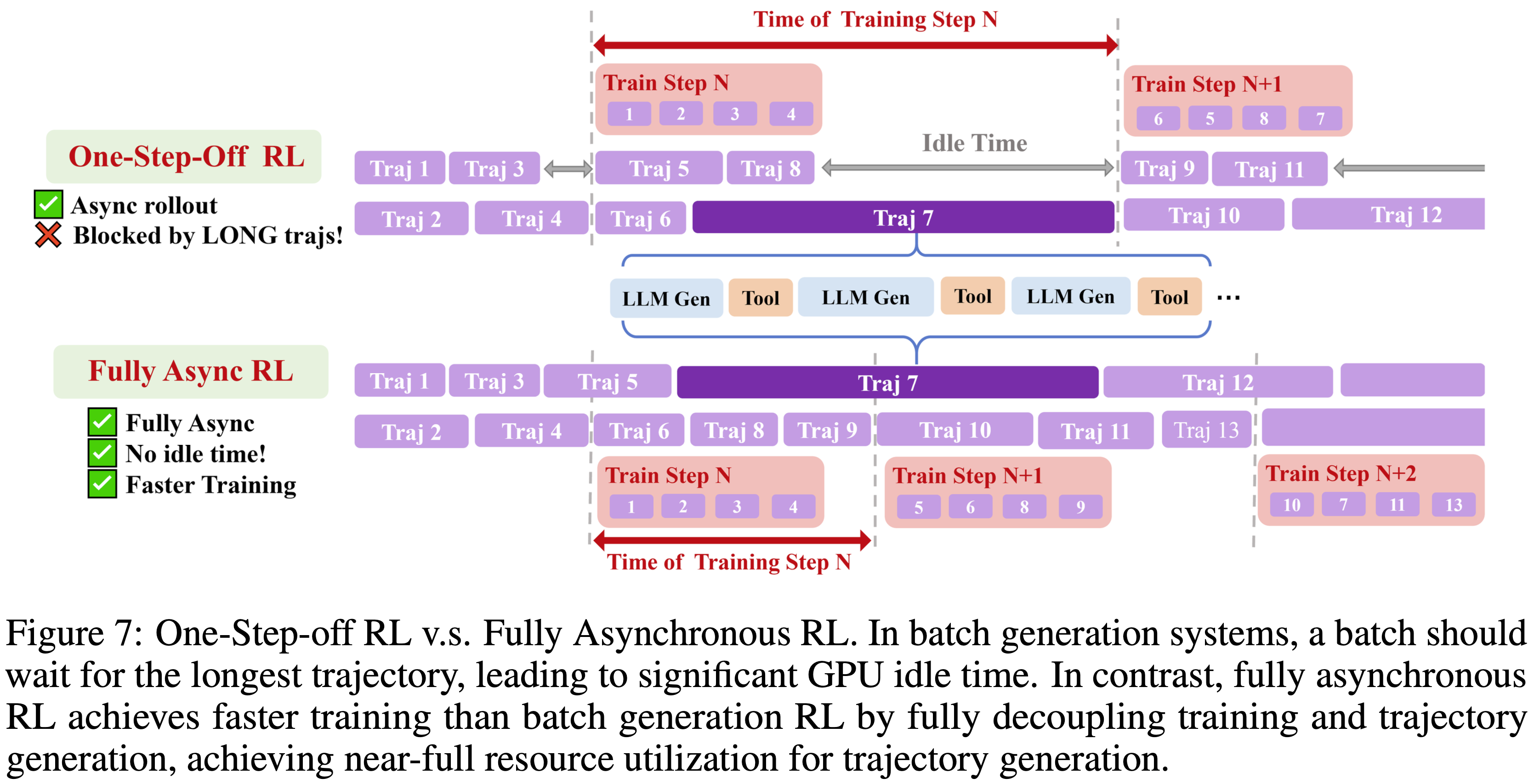
<search> search query </search>
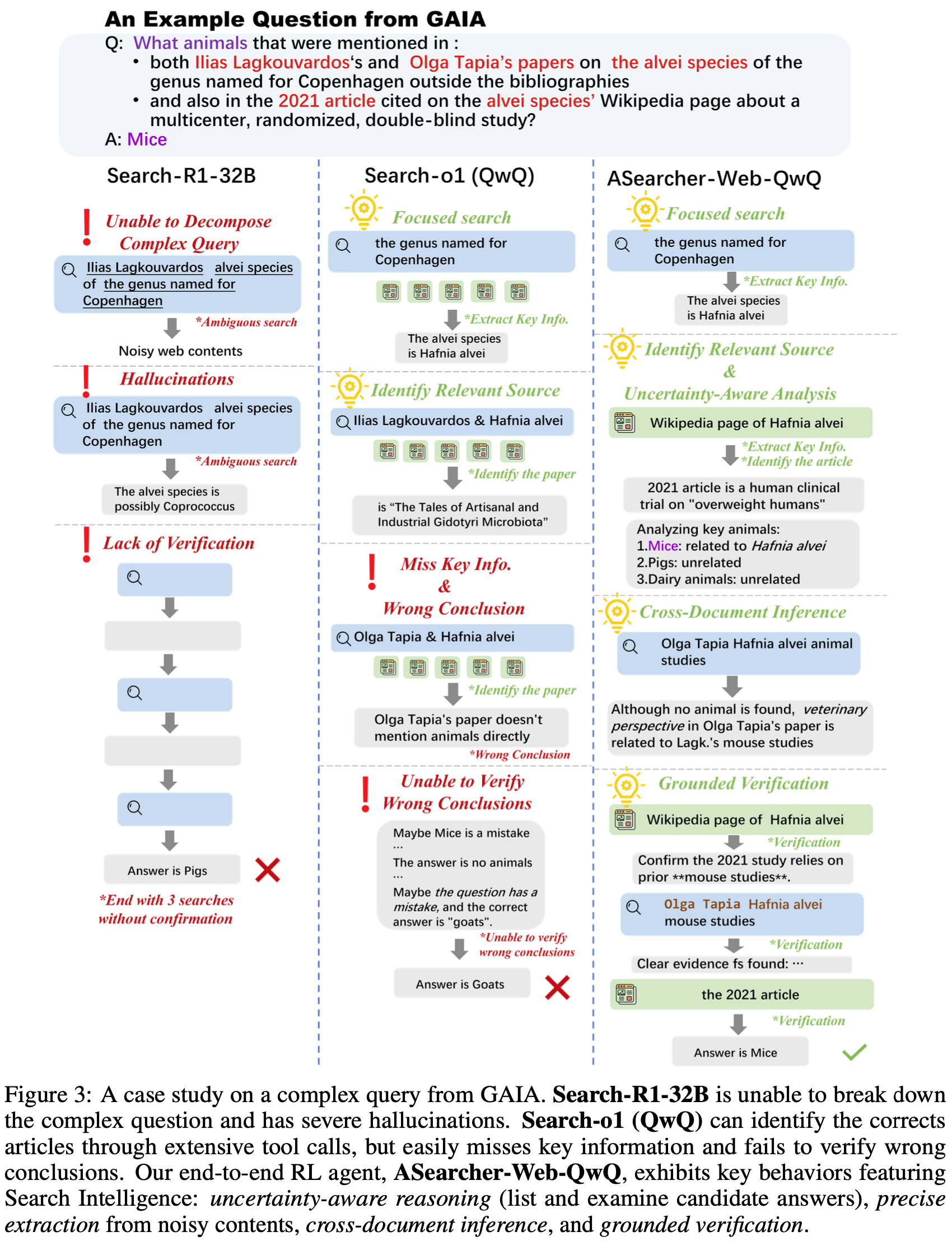
中均有提及,且同时出现在维基百科 “alvei 物种” 词条所引用的、一篇关于多中心、随机、双盲研究的 2021 年文章中的动物有哪些?")
简单介绍
前置讨论
注:本文包含 AI 辅助创作
Paper Summary
temperature=0.6 和 top-\(p\) 值 0.95,允许最大生成 16,384 个 Token




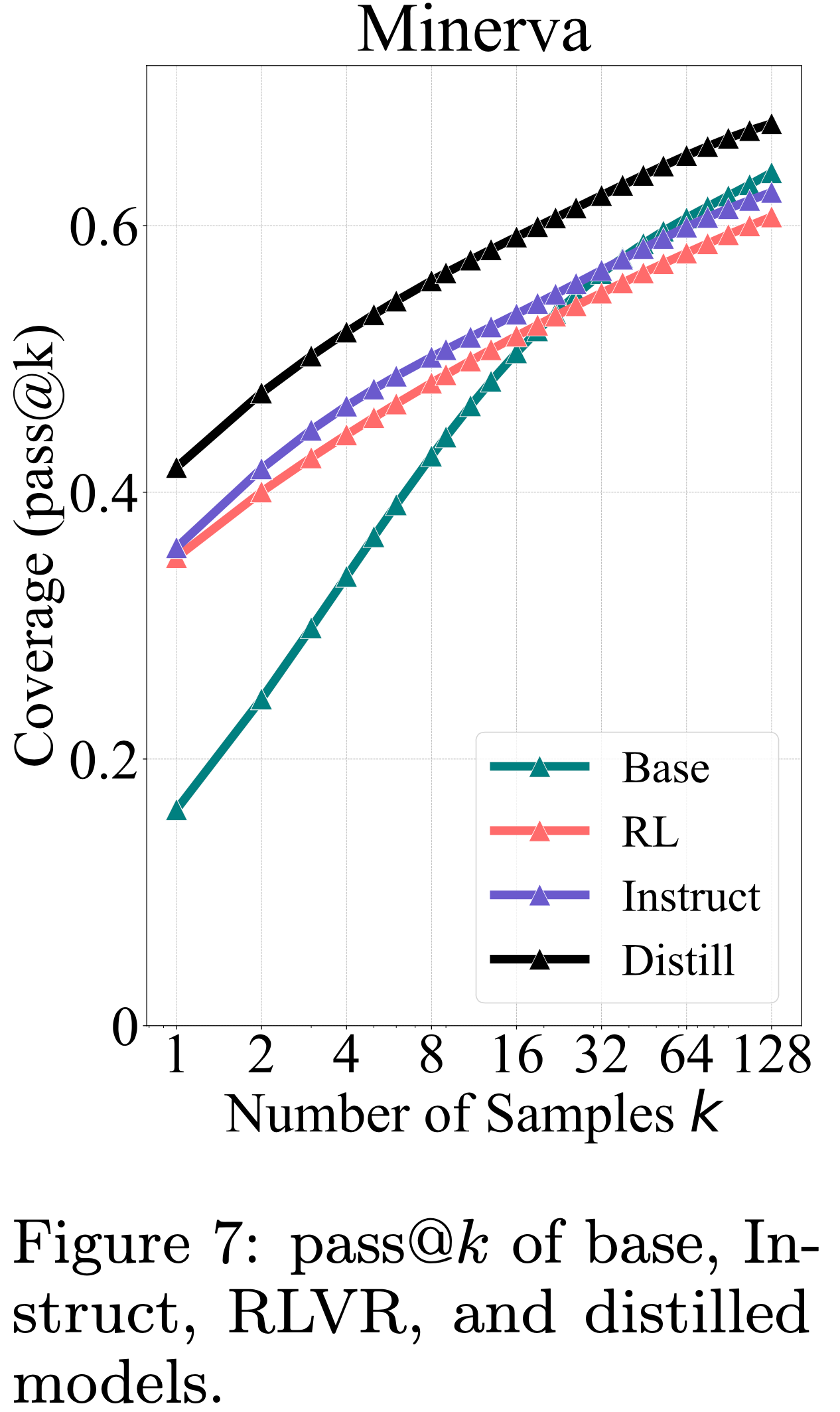
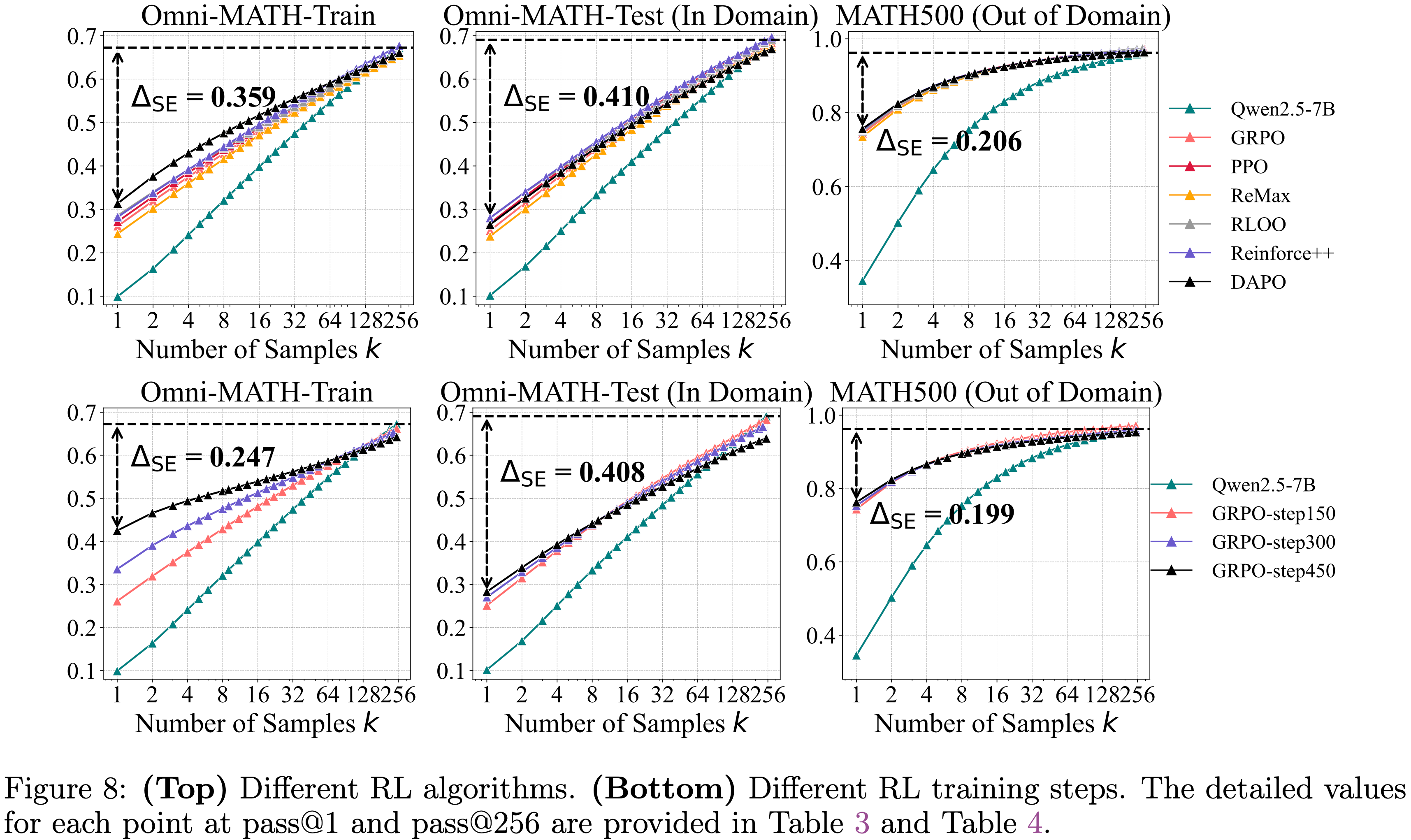
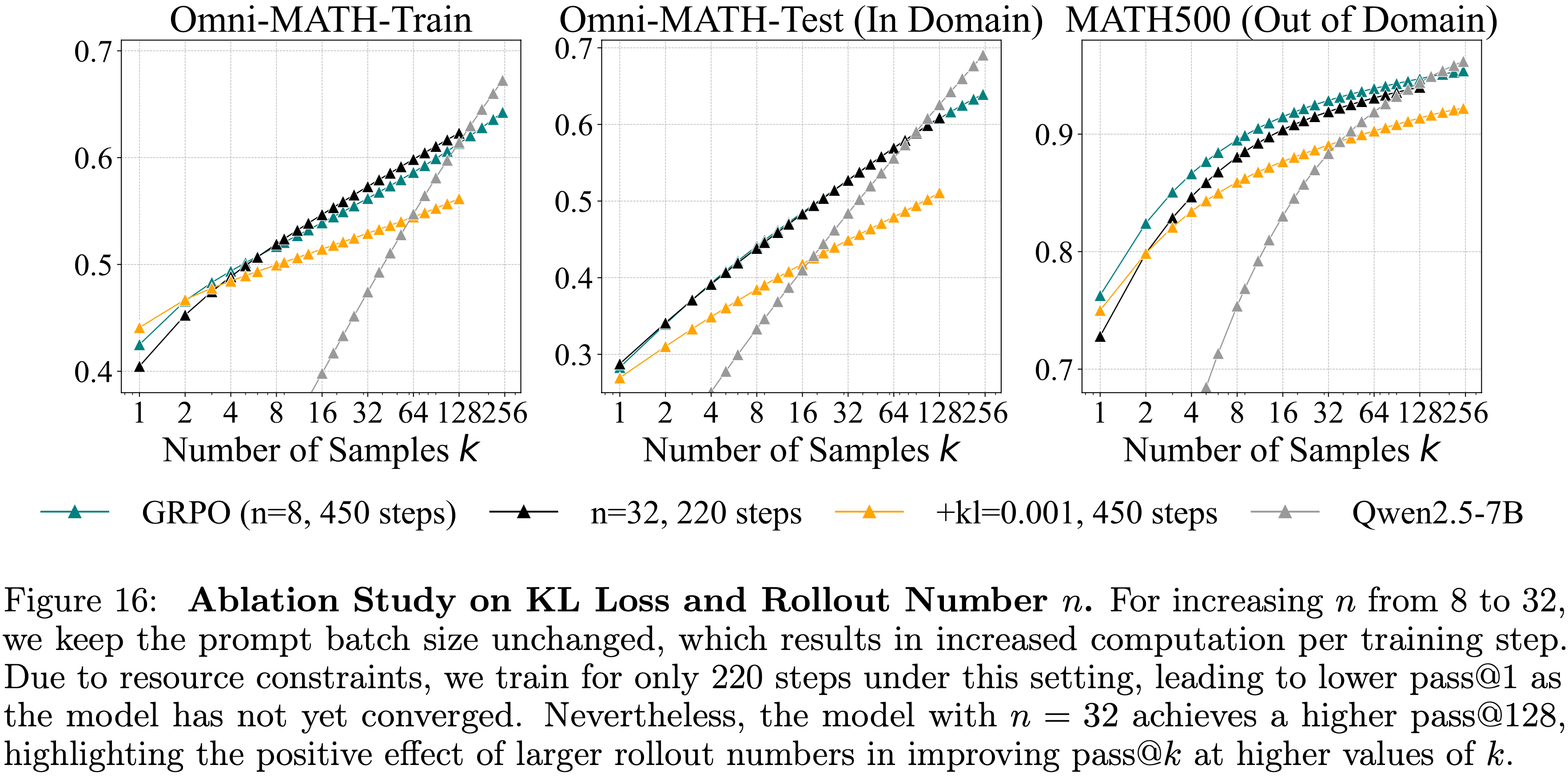
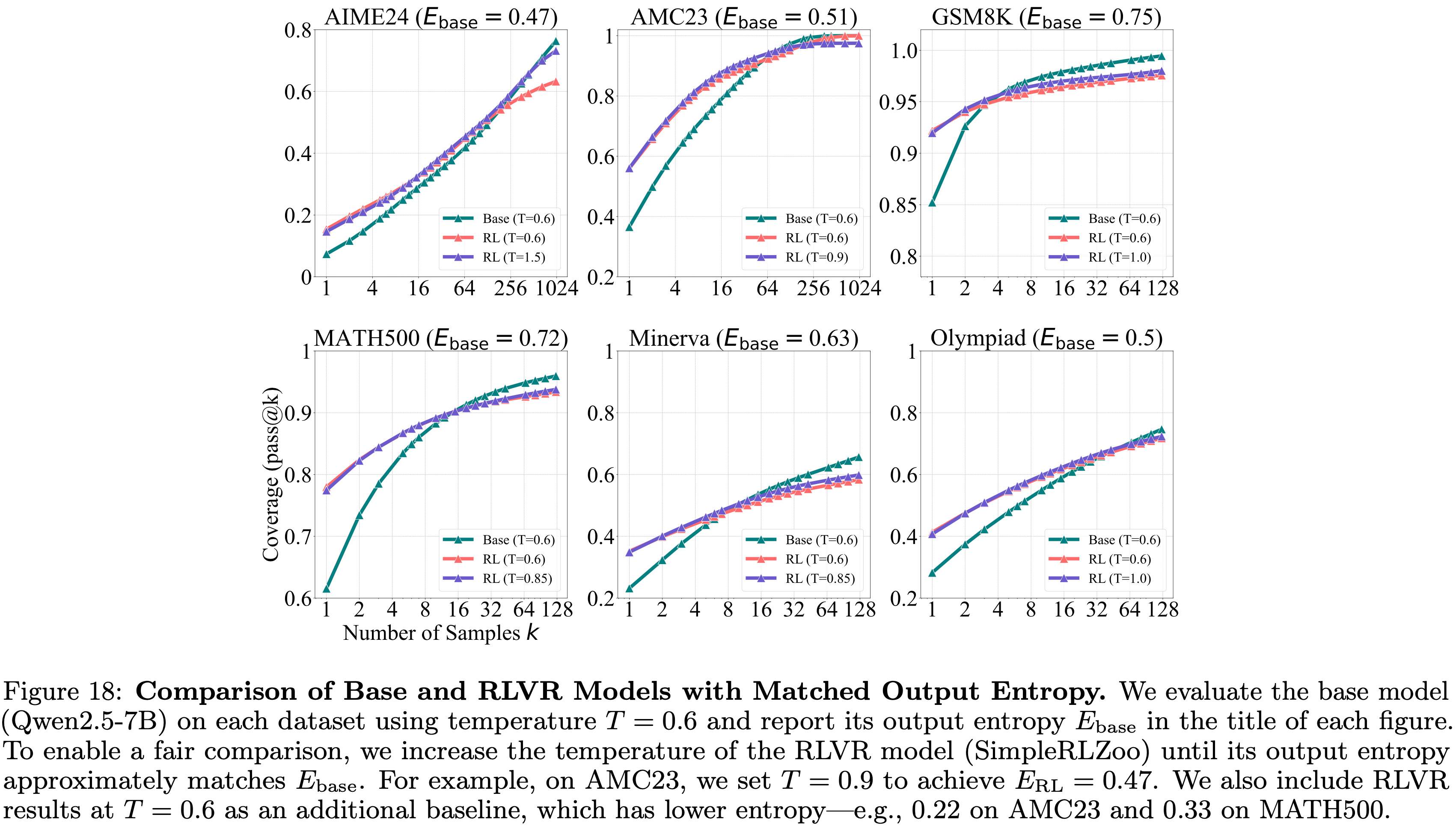










注:本文包含 AI 辅助创作
Paper Summary
<chosen,rejected> 对用于标准的 DPO 训练,分为两方面构建损失:
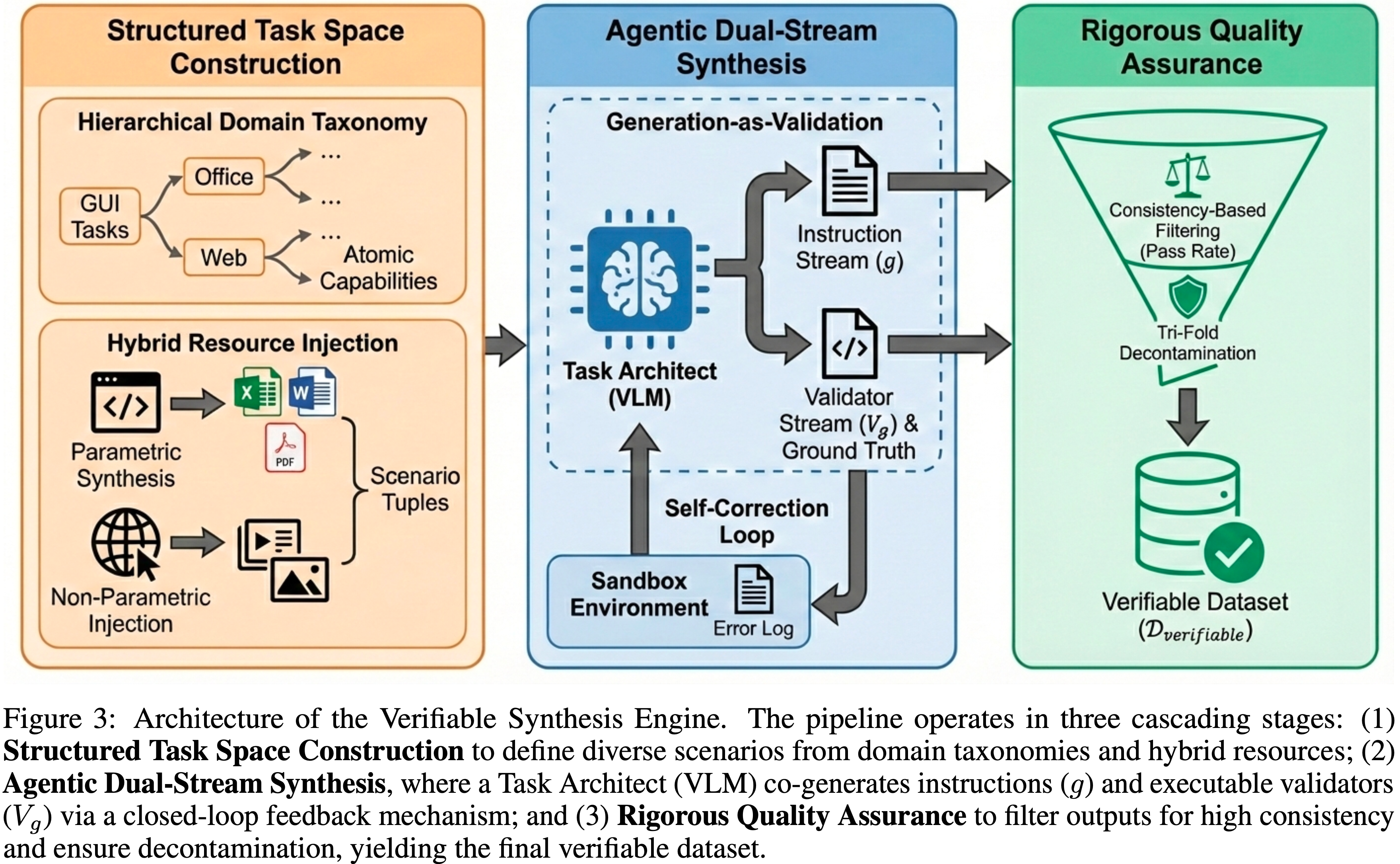
/usr/share/x11/xkb/symbols/pc 的定义,以解决符号冲突(例如,US布局中的 < 与 > 的shift状态错误),确保智能体的符号意图与最终实现的字符输入严格匹配wait 原语允许智能体处理异步UI渲染,而 terminate 作为正式信号来结束任务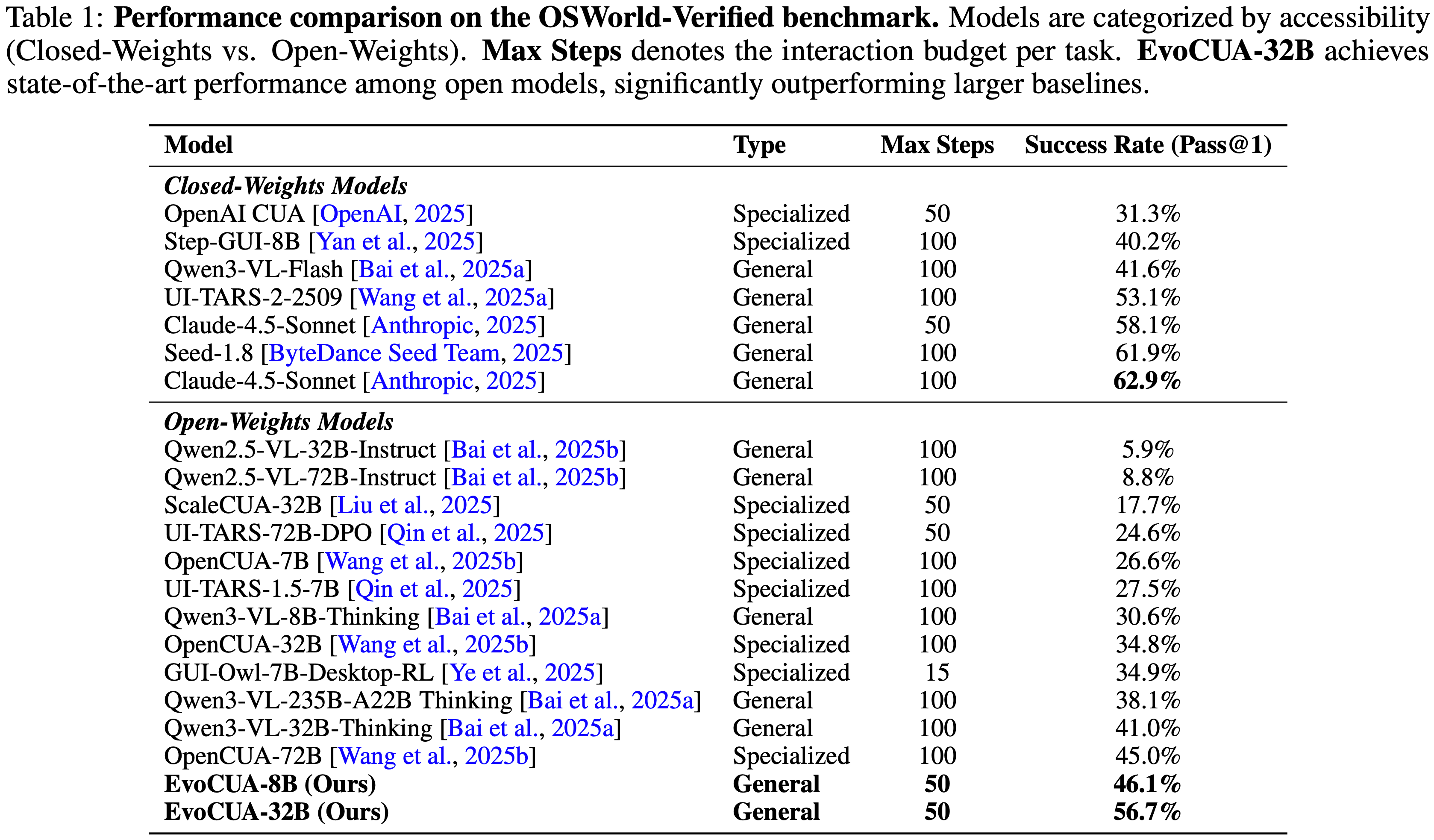



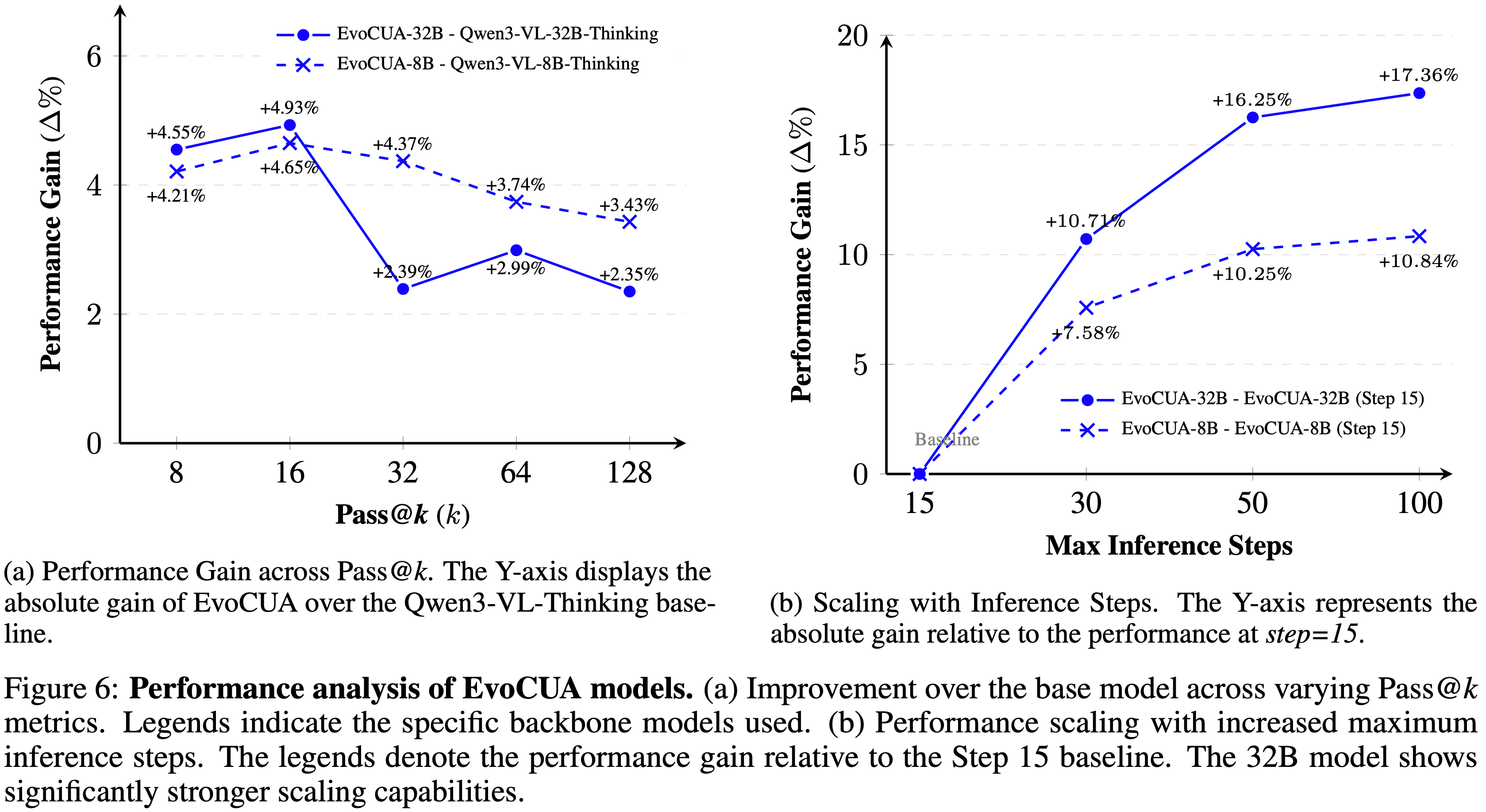
Pass@k 在智能体任务与标准 LLM 基准测试中的作用至关重要Pass@k 仅衡量模型内部能力的多样性Pass@k 具有双重目的:temperature=0),由于这些系统扰动,成功率也会表现出方差
computer_use 函数并指定特定的行动及其相应参数来与环境交互 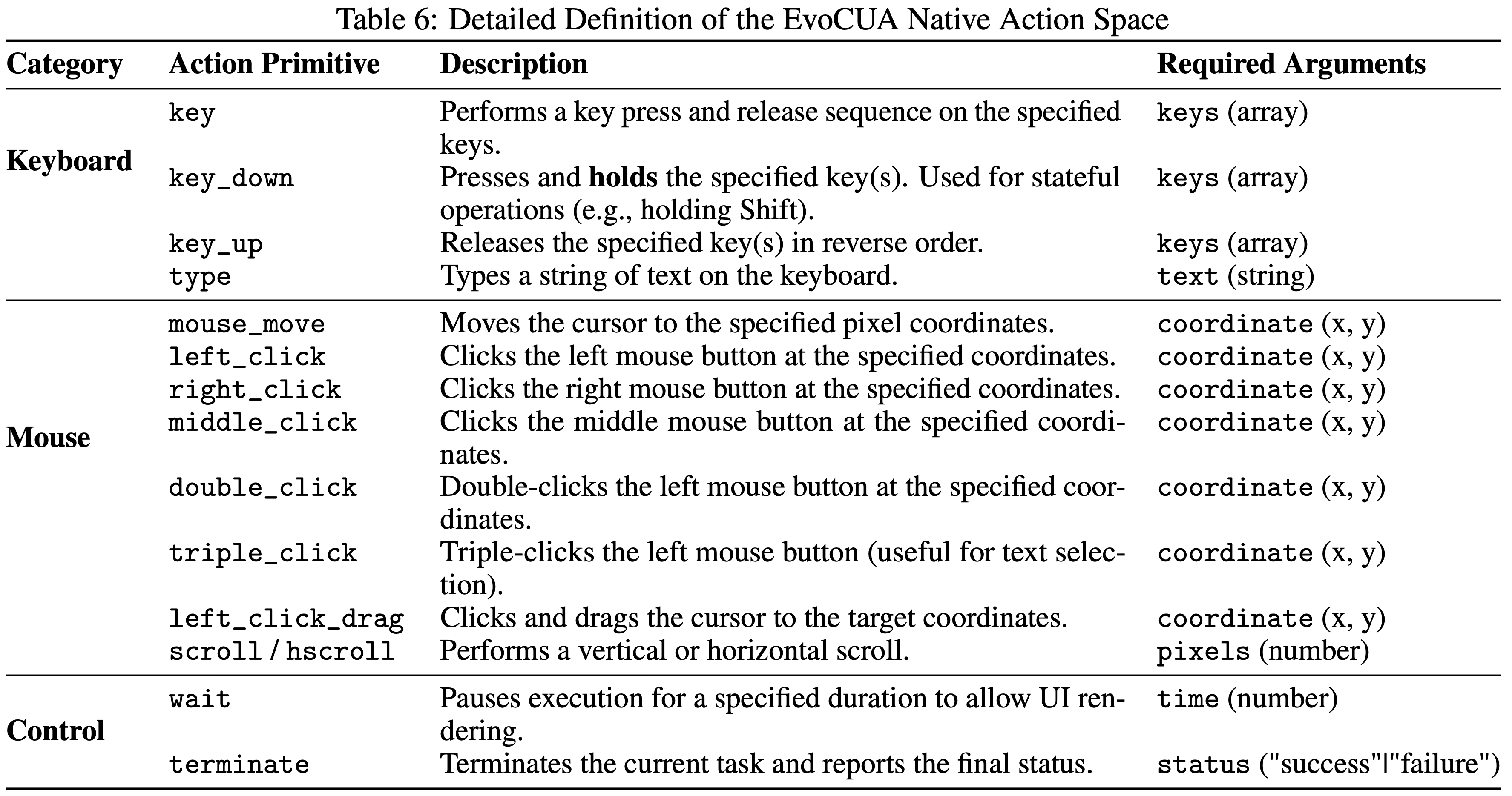
analysis_reason(先前失败的根本原因)注入到提示上下文中

 用户指令与 Agent 计划之间的清晰对齐,Step1 中推理面板显示 Agent 对指令的明确转述(“找到最大值... 放置在 G 列中”),验证了论文合成数据中的目标基础机制;(b) 推理与原子键盘行动之间的精确对应,Step2: 对齐了原子动作分别按键实现 `Max` 的输入")
 验证对于图形用户界面操作至关重要的复杂有状态原语(Shift+Click), Step 9: ;(d) 验证终止逻辑以确保任务完整性")
key_down: shift \(\rightarrow\) click \(\rightarrow\) key_up: shift 序列