UNet最早应用与图像分割领域,目前随着Diffusion模型的应用,使用越来越广泛
最早的UNet
最早的UNet网络是用作图片分割的,其输入是572x572像素,并且输出一个较小尺寸(388x388)的分割图,UNet架构图如下:
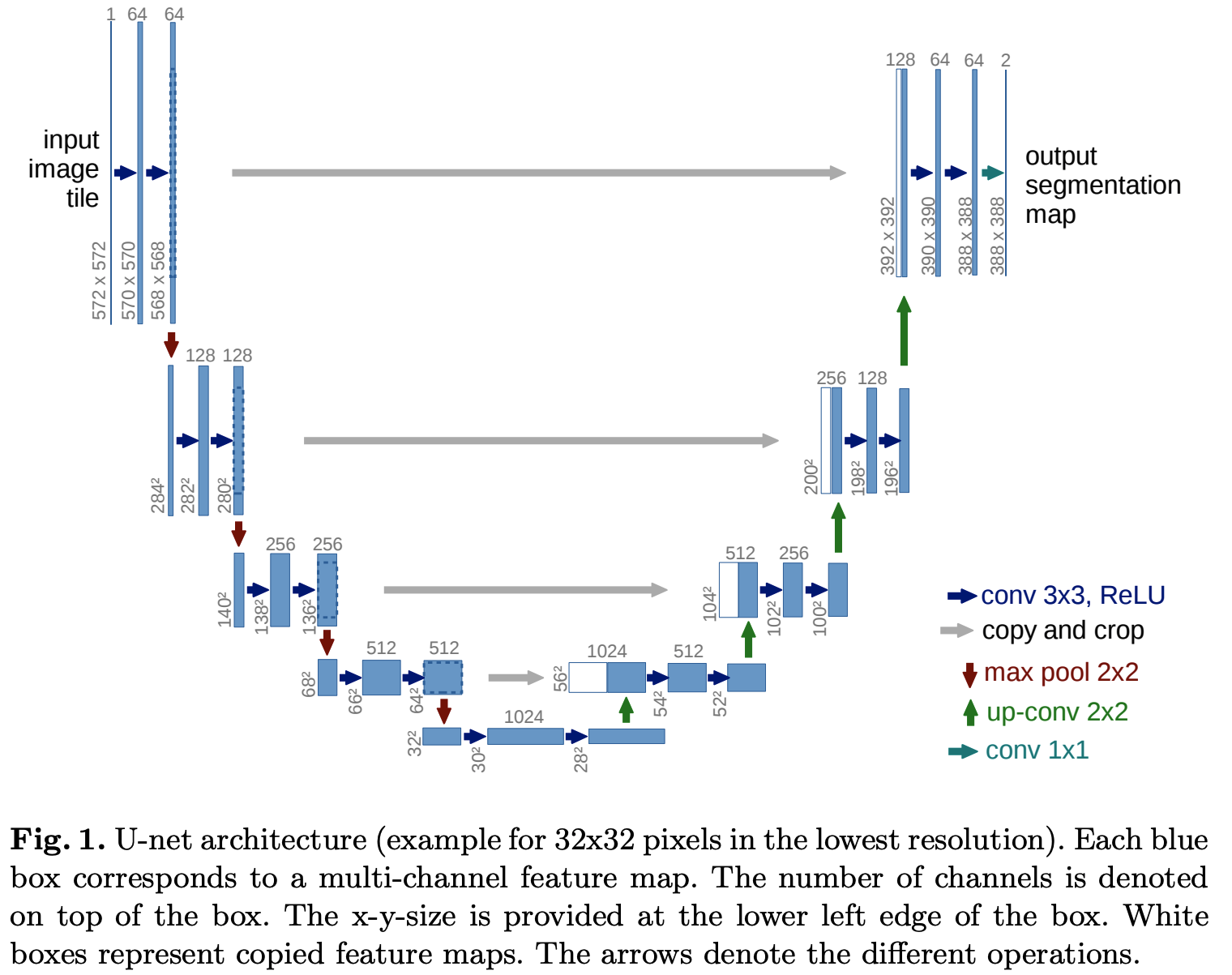
可以按照编码器-解码器思想来理解UNet
编码器部分:
- 可以看到,原始的UNet网络没有用Padding,所以每次卷积(3x3的卷积)后,图片尺寸(长和宽)会缩小2,在实际实现时,可以使用Padding,保证卷积的输入和输出图片尺寸不变
- 在编码过程中,Max Pooling操作和卷积操作使得样本长和宽逐步缩小(输入尺寸是572x572,编码结果最小尺寸为28x28),卷积输出通道逐步增加的(输入Channel为1,编码结果最大增加到1024)
解码器部分:
核心组件是上卷积:up-conv 2x2,该网络将通道减少为原来的 \(\frac{1}{2}\),同时将尺寸变化成原来的2倍,实际实现时,是通过上采样+带padding的卷积实现扩大尺寸为原来的两倍的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class up_conv(nn.Module):
"""
Up Convolution Block
"""
def __init__(self, in_ch, out_ch):
super(up_conv, self).__init__()
self.up = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.Conv2d(in_ch, out_ch, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_ch),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.up(x)
return x跳跃连接:在每次进行上卷积以后,都将编码器的中间结果Clip并Concat过来
最终输出维度是388x388的,通道数为2
Diffusion模型中的UNet
- 一个简单的Conditional Diffusion实现代码:github.com/TeaPearce/Conditional_Diffusion_MNIST
- 以下内容参考自:扩散模型U-Net可视化理解
- 整体框架图示:
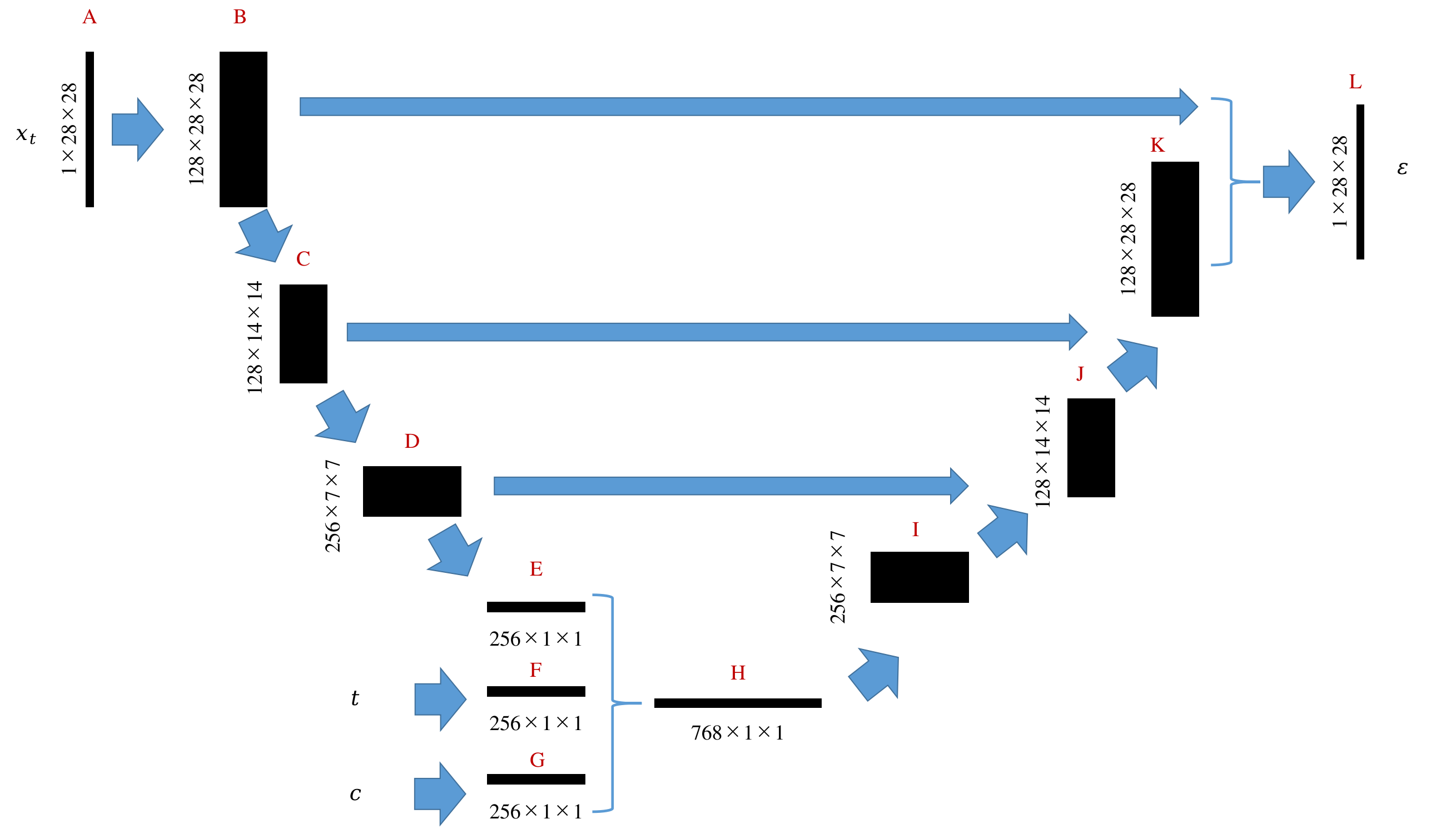
- 架构图解读:
扩散模型中的U-net结构如上图所示,1X28X28表示通道数为1,长宽为28的图片。在实际训练中不是一个三阶张量而是一个四阶张量128X1X28X28,其中128表示批处理数,即128张图片同时在GPU上完成一次训练迭代
整个计算流程如下:输入图片(A)被提取出128张特征图(B),经过第一次下采样图像缩小一半(C),经过第二次下采样图像进一步缩小为一半(D),经过平均池化得到一个向量(E),这个向量包含了图片中的所有必要特征信息。至此,输入图片已被编码。除了图片以外,时间标签、其他条件变量也可使用全链接网络进行编码,得到两个向量(F和G),为了确保后续上采样顺利,E、F、G的长度应当相同。接下来,将E、F、G合并为一个更长的向量H。H经过上采用不断恢复出I、J、K直到L。L即为最终期望输出的噪声图。用这个噪声图即可实现对图片的去噪 - 时间片和条件信息是在编码完成后加入的,且加入时先Embedding,再将Embedding向量Concat添加到图片编码结果上
- 整体框架图示: