注:本文包含 AI 辅助创作
- 参考链接:
- 官网主页:Megatron Core User Guide
- GitHub开源地址:github.com/NVIDIA/Megatron-LM
- Megatron 系列目前公认的三篇核心论文如下,它们分别对应了张量并行、3D 并行 与 序列并行/激活重计算优化 三大阶段:
- 第一篇:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism, arXiv 2019, NVIDIA
- 核心贡献:提出 张量并行(Tensor Parallelism) ,将 Transformer 的 Attention 头与 FFN 权重按列/按行切分,实现层内模型并行,首次在 GPU 集群上训练出 8.3 B 参数的 GPT-2 模型
- 第二篇:Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM, SC 2021, NVIDIA
- 核心贡献:提出 3D 并行(数据 + 张量 + 流水线),并给出 interleaved 1F1B 流水线调度,显著降低流水线气泡;在 3072 块 A100 上训练出 530 B 参数的 GPT-3 级模型,GPU 利用率达到 76 %
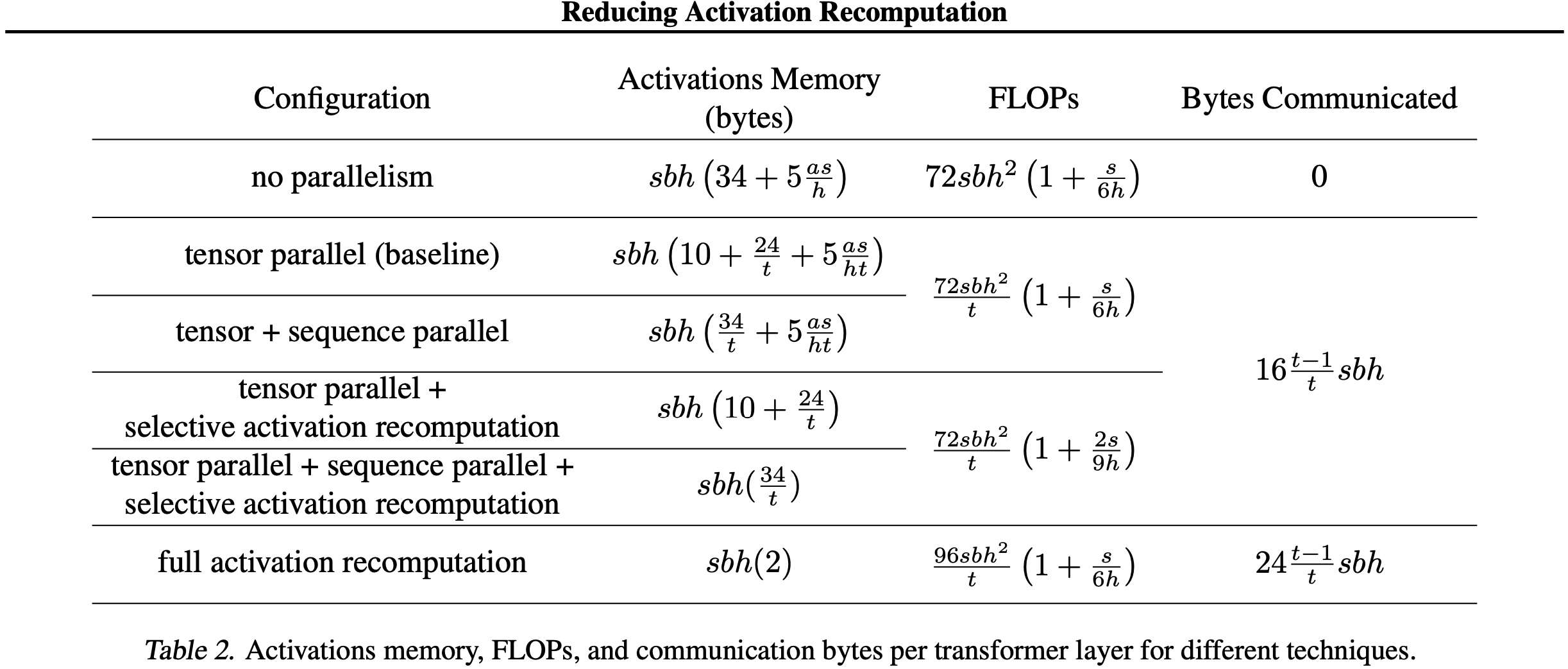
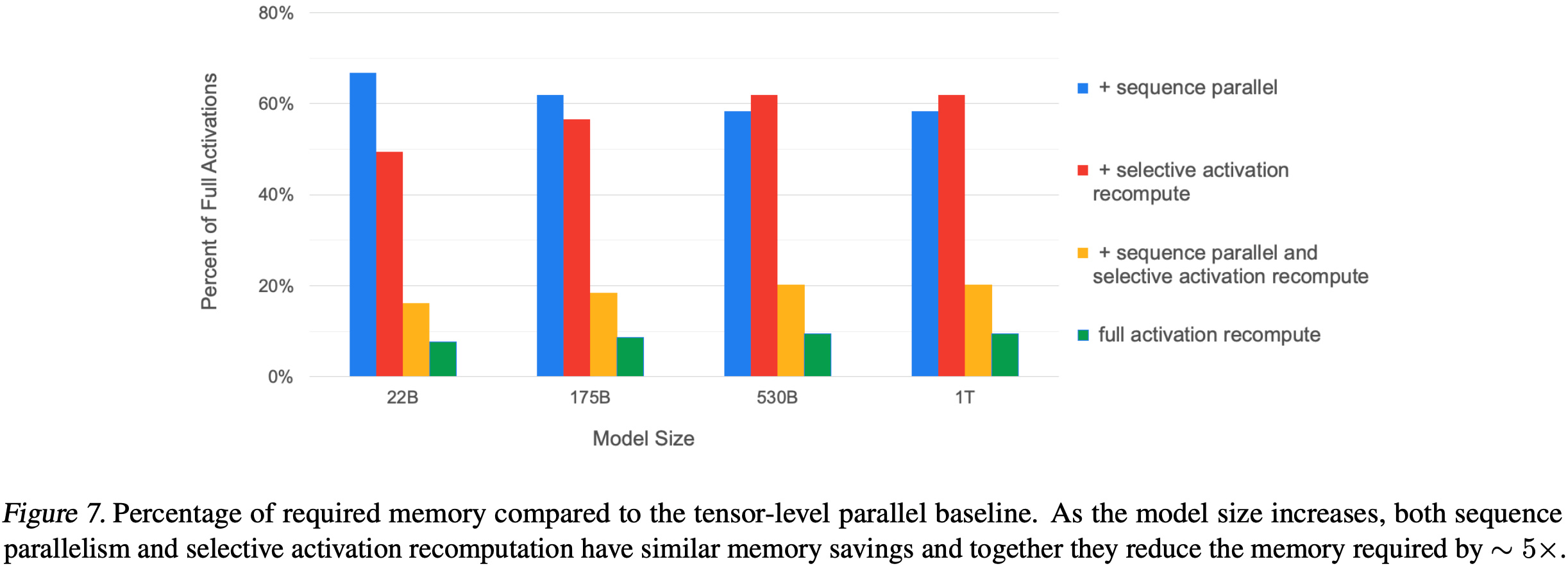
- 第三篇:Reducing Activation Recomputation in Large Transformer Models, MLSys 2023, NVIDIA
- 核心贡献:提出 序列并行(Sequence Parallelism) 与 选择性激活重计算 ,将激活显存占用再降 3–5 倍,支持更长序列与更大批训练;与 Flash-Attention 思想互补,现已成为 Megatron-Core 默认配置
- 以上三篇即社区常说的“Megatron 三篇论文”,覆盖了从单层切分、多层多维并行到显存优化的完整技术路线,本文介绍第一篇论文
Paper Summary
- 整体总结:
- 本文是 Megatron-LM原始论文解读-第一篇
- 论文的核心贡献:提出 张量并行(Tensor Parallelism) ,将 Transformer 的 Attention 头与 FFN 权重按列/按行切分,实现层内模型并行,首次在 GPU 集群上训练出 8.3 B 参数的 GPT-2 模型
- 论文通过对现有 PyTorch Transformer 实现仅进行少量修改来实现模型并行,成功突破了传统的单 GPU 单模型训练的限制
- 论文在 512 块 NVIDIA V100 GPU 上使用 8 路模型并行高效训练了高达 8.3B 参数的基于 Transformer 的模型,并在整个应用中实现了高达 15.1 PetaFLOPs 的持续性能
- 论文表明,对于 BERT 模型,随着模型规模的增长,类 BERT 模型中 Layer Normalization 的位置对准确率的提升至关重要
- 论文研究了模型规模对下游任务准确率的影响,在下游任务上取得了远超现有水平的结果,并在 WikiText103、LAMBADA 和 RACE 数据集上建立了新的最佳结果(SOTA)
- 非常值得称赞的是:论文开源了论文的代码,以支持未来基于模型并行 Transformer 的研究工作
- 背景 & 问题提出:
- Transformer 模型推动了 NLP 技术发展,但内存限制,导致超大型模型的训练难度极大
- 方法内容:
- 论文提出了训练超大型 Transformer 模型的技术,并实现了一种简单、高效的层内模型并行(intra-layer model parallel)方法,该方法能够训练具有数十亿参数的 Transformer 模型
- 本方法不需要新的编译器或库修改,与流水线模型并行(pipeline model parallelism)相互独立且互补,完全可以通过在原生 PyTorch 中插入少量通信操作来实现
- 论文通过使用 512 个 GPU 训练出高达 8.3B 参数的 Transformer 模型验证了该方法的有效性
- 与单个GPU基准(可持续 39 TeraFLOPs,达到峰值浮点运算的 30%)相比,论文在整个应用中实现了 15.1 PetaFLOPs 的性能,扩展效率为76%
- \({39 \times 512 / 1000}{39} \approx 76%\)
- 为了证明 LLM 能进一步推动技术发展,论文训练了一个与 GPT-2 类似的 8.3B 参数 Transformer 语言模型和一个与 BERT 类似的 3.9B 参数模型
- 论文发现,对于类 BERT 模型,随着模型规模的增长, Layer Normalization的位置对性能提升至关重要
- 使用 GPT-2 模型,论文在 WikiText103 数据集和 LAMBADA 数据集上取得了最佳结果
- WikiText103 数据集:困惑度为 10.8(之前最佳困惑度为 15.8)
- LAMBADA 数据集:准确率为 66.5%(之前最佳准确率为63.2%)
- 使用 BERT 模型,论文在在 RACE 数据集上取得了最佳结果
- RACE 数据集:准确率为 90.9%(之前最佳准确率为 89.4%)
Introduction and Discussion
- NLP 正在快速发展,部分原因是可用计算资源和数据集规模的增加
- 丰富的计算资源和数据使得通过无监督预训练(unsupervised pretraining)训练越来越大的语言模型成为可能(2018;2019)
- 实证证据表明,更大的语言模型在文章补全、问答和自然语言推理等 NLP 任务中更有用(2019;2019)
- 近期研究显示,在下游自然语言任务上对这些预训练语言模型进行微调(finetuning),可以取得最佳结果(2018;2017;2016;2019b;)
- 模型规模的增长超出了现代处理器的内存限制,需要额外的内存管理技术,如激活检查点(activation checkpointing)(2016)
- ADAM 等广泛使用的优化算法(optimization algorithms)需要为每个参数额外分配内存来存储动量(momentum)和其他优化器状态,这限制了可有效训练的模型规模
- 几种模型并行(model parallelism)方法通过对模型进行分区来克服这一限制,使得权重及其相关的优化器状态无需同时驻留在处理器上,比如:
- GPipe(2018)和 Mesh-Tensorflow(2018)提供了不同类型的模型并行框架
- 但它们需要重写模型,并依赖仍在开发中的自定义编译器和框架
- 论文使用层内模型并行(intra-layer model-parallelism)实现了一种简单高效的模型并行方法
- 论文利用基于 Transformer 的语言模型的固有结构,实现了一种简单的模型并行方案,该方案能在 PyTorch 中高效训练,无需自定义 C++ 代码或编译器
- 这种方法与 GPipe(2018)等方法所倡导的基于流水线的模型并行相互独立
- 为了证明论文方法的可扩展性,论文建立了一个基准:在单个 NVIDIA V100 32GB GPU 上训练 1.2B 参数的模型,可持续 39 TeraFLOPs
- 这相当于 DGX-2H 服务器中配置的单个 GPU 理论峰值浮点运算的 30%,因此是一个很强的基准
- 通过 8路 模型并行在 512 个 GPU 上训练 8.3B 参数的模型,论文在整个应用中实现了高达 15.1 PetaFLOPs 的持续性能
- 与单GPU情况相比,这一扩展效率为76%
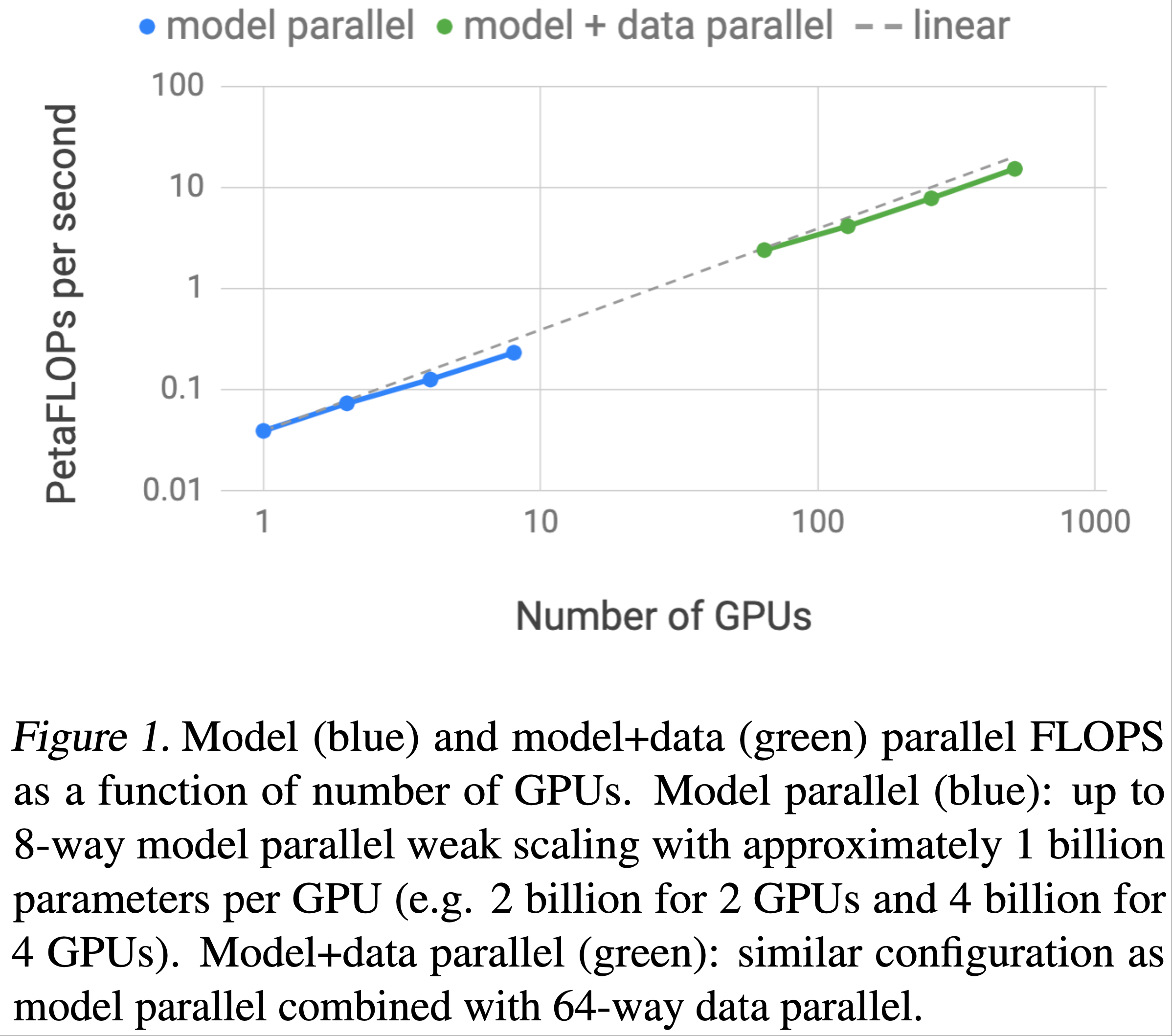
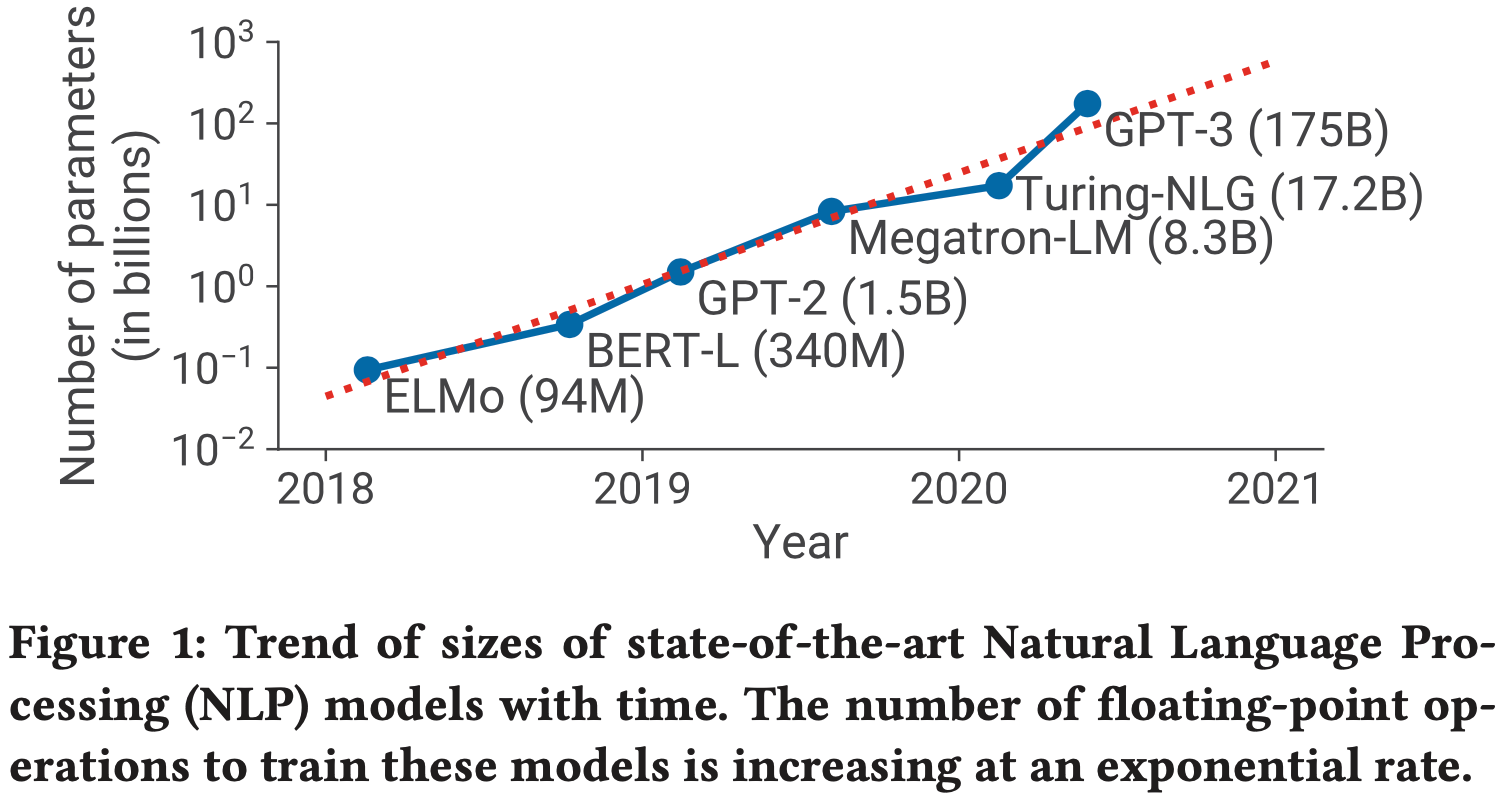
- 图1显示了更详细的扩展结果
- 为了分析模型规模扩展对准确率的影响:
- 论文训练了从左到右的 GPT-2(2019)语言模型和 BERT(2018)双向 Transformer,并在多个下游任务上对它们进行了评估
- 论文发现,现有 BERT 架构会随着规模的增加而导致模型性能下降
- 论文通过重新排列 Transformer 层中的 Layer Normalization 和残差连接(residual connection)克服了这一挑战,并表明通过这种修改,下游任务在开发集上的结果会随着模型规模的增加而单调提升
- 论文的模型在 WikiText103 测试集、LAMBADA 的完形填空预测准确率(cloze-style prediction accuracy)和 阅读理解 RACE 数据集上取得了最佳结果
- 论文训练了从左到右的 GPT-2(2019)语言模型和 BERT(2018)双向 Transformer,并在多个下游任务上对它们进行了评估
- 总结来看:论文的贡献如下:
- 通过对现有 PyTorch Transformer 实现仅进行少量有针对性的修改,实现了一种简单高效的模型并行方法
- 对模型和数据并行技术进行了深入的实证分析,并证明了在 512 个 GPU 上的扩展效率高达 76%
- 论文实验表名:对于类 BERT 模型,随着模型规模的增长, Layer Normalization 的位置对准确率的提升至关重要
- 论文证明:模型规模的扩展会提高 GPT-2(研究到 8.3B 参数)和 BERT(研究到 3.9B 参数)模型的准确率
- 展示了论文的模型在测试集上取得了最佳结果:WikiText103的困惑度(10.8 ppl)、LAMBADA 的准确率(66.5%)和 RACE 的准确率(90.9%)
- 开源了论文的代码以及训练和评估流水线,地址为 github.com/NVIDIA/Megatron-LM
Background and Challenges
Neural Language Model Pretraining
- 预训练语言模型已成为 NLP 研究人员工具包中不可或缺的一部分
- 利用大型语料库预训练来学习稳健的语言神经表征是过去十年中一个活跃的研究领域
- 预训练和迁移语言神经表征的早期例子表明,预训练的词嵌入表(word embedding tables)比从头学习的词嵌入表能更好地提升下游任务结果(2013;2014;2010)
- 后来的研究通过学习和迁移能捕捉单词上下文表征(contextual representations)的神经模型推进了这一领域(2016;2018;2017;2019)
- 近期的相关研究(2016;2018;2019b;)进一步基于这些思想,不仅迁移语言模型来提取上下文单词表征,还在下游任务上对语言模型进行端到端微调
- 通过这些工作,技术发展已经从仅迁移词嵌入表发展到迁移整个数十亿参数的语言模型
- 这种方法的发展使得需要能够高效大规模运行并满足日益增长的计算需求的硬件、系统技术和框架
- 论文的工作旨在提供必要的工具,以推动这一趋势向前迈出又一步
Transformer Language Models and Multi-Head Attention
- 当前 NLP 研究趋势是使用 Transformer 模型(2017),因为它们具有更高的准确率和计算效率
- 原始 Transformer 结构被设计为机器翻译架构,它使用 Encoder 和 Decoder 两部分将输入序列转换为另一个输出序列
- 近期利用 Transformer 进行语言建模的研究(如BERT(2018)和GPT-2(2019))根据其需求仅使用 Encoder 或 Decoder
- 本研究探讨了 Decoder 架构 GPT-2 和 Encoder 架构 BERT
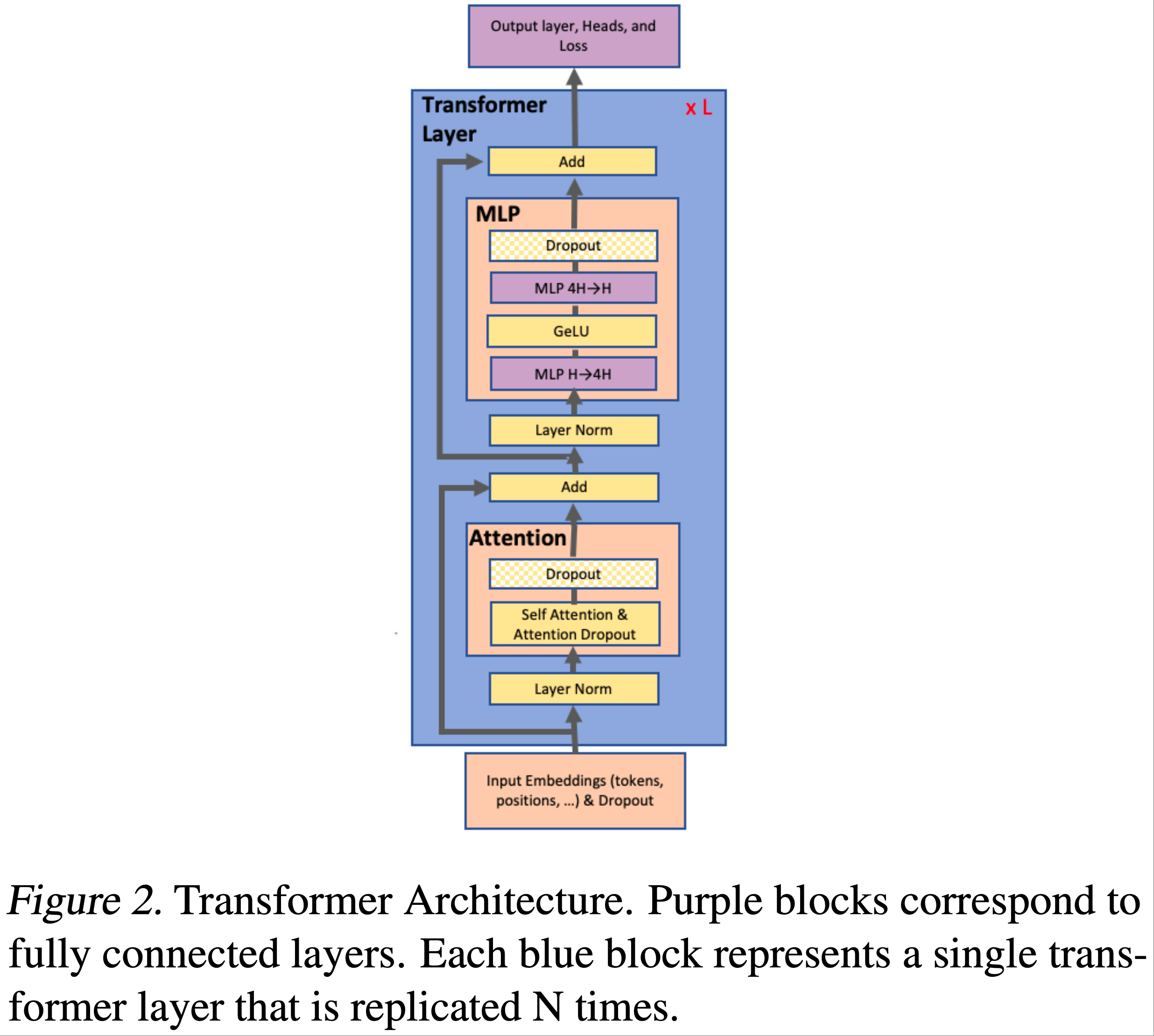
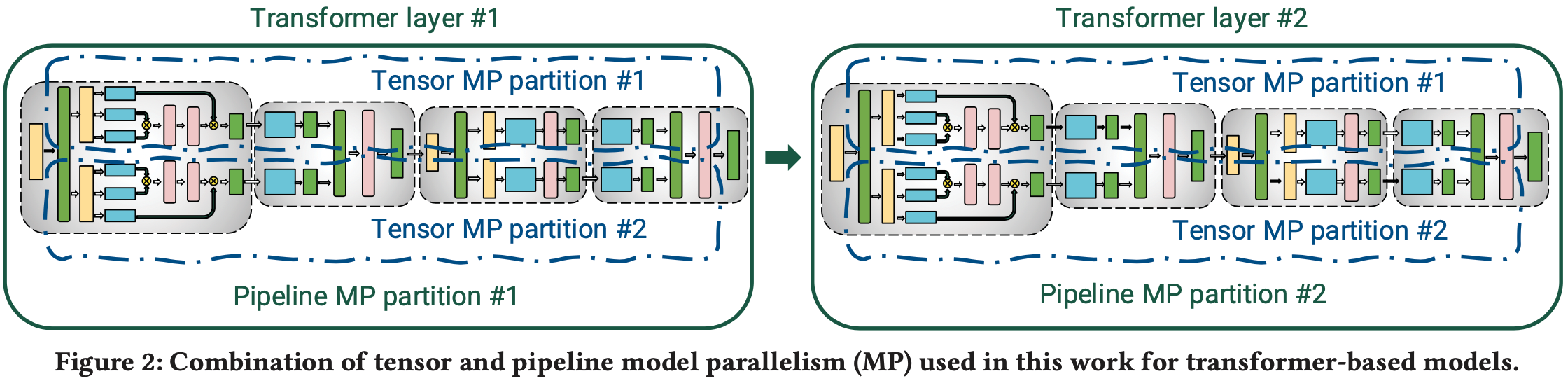
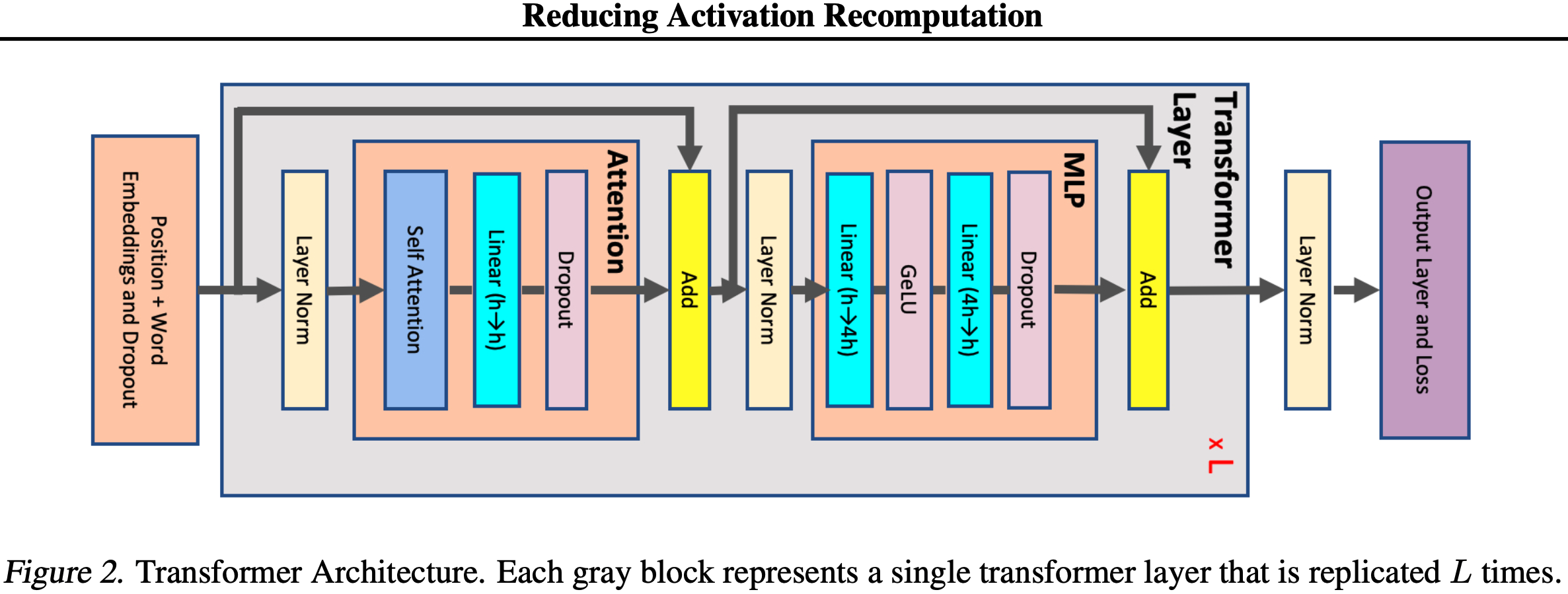
- 图2显示了论文使用的模型示意图
- 有关模型架构的详细描述,论文建议读者参考先前的研究(2017;2018;2019)
- 特别地,GPT-2 和 BERT都使用 GeLU(2016)非线性激活函数和 Layer Normalization (2016),并 将其应用于多头注意力(multi-head attention)和前馈层(feed forward layers)的输入,而原始 Transformer (2017)使用 ReLU 非线性激活函数,并将 Layer Normalization 应用于输出
Data and Model Parallelism in Deep Learning
- 将深度神经网络训练扩展到多个硬件加速器有两种核心范式:数据并行(data parallelism)(1990)和模型并行(model parallelism)
- 数据并行是将训练小批量(minibatch)分配到多个工作节点(workers)
- 模型并行是将模型的内存使用和计算分配到多个工作节点
- 通过与可用工作节点数量成比例地增加批量大小(即弱扩展),可以观察到训练数据吞吐量接近线性扩展
- 但大批量训练会给优化过程带来复杂性,可能导致准确率下降或收敛时间延长,从而抵消训练吞吐量增加带来的好处(2017)
- 进一步的研究(2017;2017;2019)开发了缓解这些影响的技术,并缩短了大型神经网络的训练时间
- 为了进一步扩展训练,相关研究(2016)将数据并行与激活检查点相结合 :
- 在反向传播(backward pass)中重新计算激活(activations),而不在前向传播(forward pass)中存储它们,以减少内存需求
- 以上这些技术在处理问题规模上有一个根本限制:模型必须完全适合单个工作节点
- 随着 BERT 和 GPT-2 等语言模型规模和复杂性的增加,神经网络已经接近现代硬件加速器的内存容量
- 解决这一问题的一种方法是使用参数共享(parameter sharing)来减少模型的内存占用(2019),但这会限制模型的整体容量
- 论文的方法是利用模型并行将模型分配到多个加速器上
- 这不仅减轻了内存压力,还独立于微批量(microbatch)大小增加了并行性
- 在模型并行中,还有两种进一步的范式:分层流水线并行(layer-wise pipeline parallelism)和更通用的分布式张量计算(distributed tensor computation)
- 在流水线模型并行中,一组操作在一个设备上执行,然后将输出传递到流水线中的下一个设备,在那里执行另一组操作
- 一些方法(2018;2018)将参数服务器(parameter server)(2014)与流水线并行结合使用,但这些方法存在不一致问题
- TensorFlow 的 GPipe 框架(2018)通过使用同步梯度下降(synchronous gradient decent)克服了这一不一致问题
- GPipe 需要额外的逻辑来处理这些通信和计算操作的高效流水线,并且会受到流水线气泡(pipeline bubbles)的影响而降低效率,或者需要修改优化器本身,从而影响准确率
- 分布式张量计算是一种独立且更通用的方法,它将张量操作分配到多个设备上,以加速计算或增加模型规模
- FlexFlow(2018)是一个协调这种并行计算的深度学习框架,它提供了一种选择最佳并行策略的方法
- Mesh-TensorFlow(2018)引入了一种在 TensorFlow(2015)中指定通用分布式张量计算类别的语言
- 用户在该语言中指定并行维度,然后使用适当的集合原语(collective primitives)编译生成的图
- 在流水线模型并行中,一组操作在一个设备上执行,然后将输出传递到流水线中的下一个设备,在那里执行另一组操作
- 论文利用与 Mesh-TensorFlow 中类似的见解,并利用 Transformer 注意力头(attention heads)计算中的并行性来并行化论文的 Transformer 模型
- 论文没有为模型并行实现框架和编译器,而是仅对现有 PyTorch Transformer 实现进行了少量有针对性的修改
- 论文的方法简单,不需要任何新的编译器或代码重写,并且可以通过插入一些简单的原语来完全实现,如下一节所述
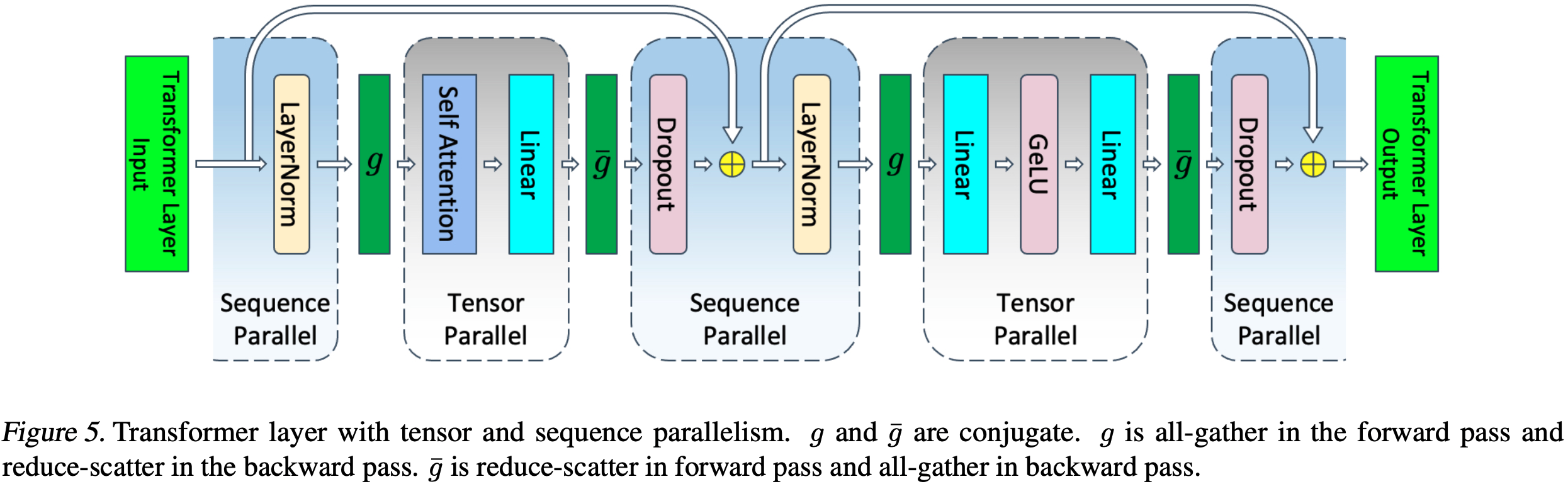
Model Parallel Transformer s
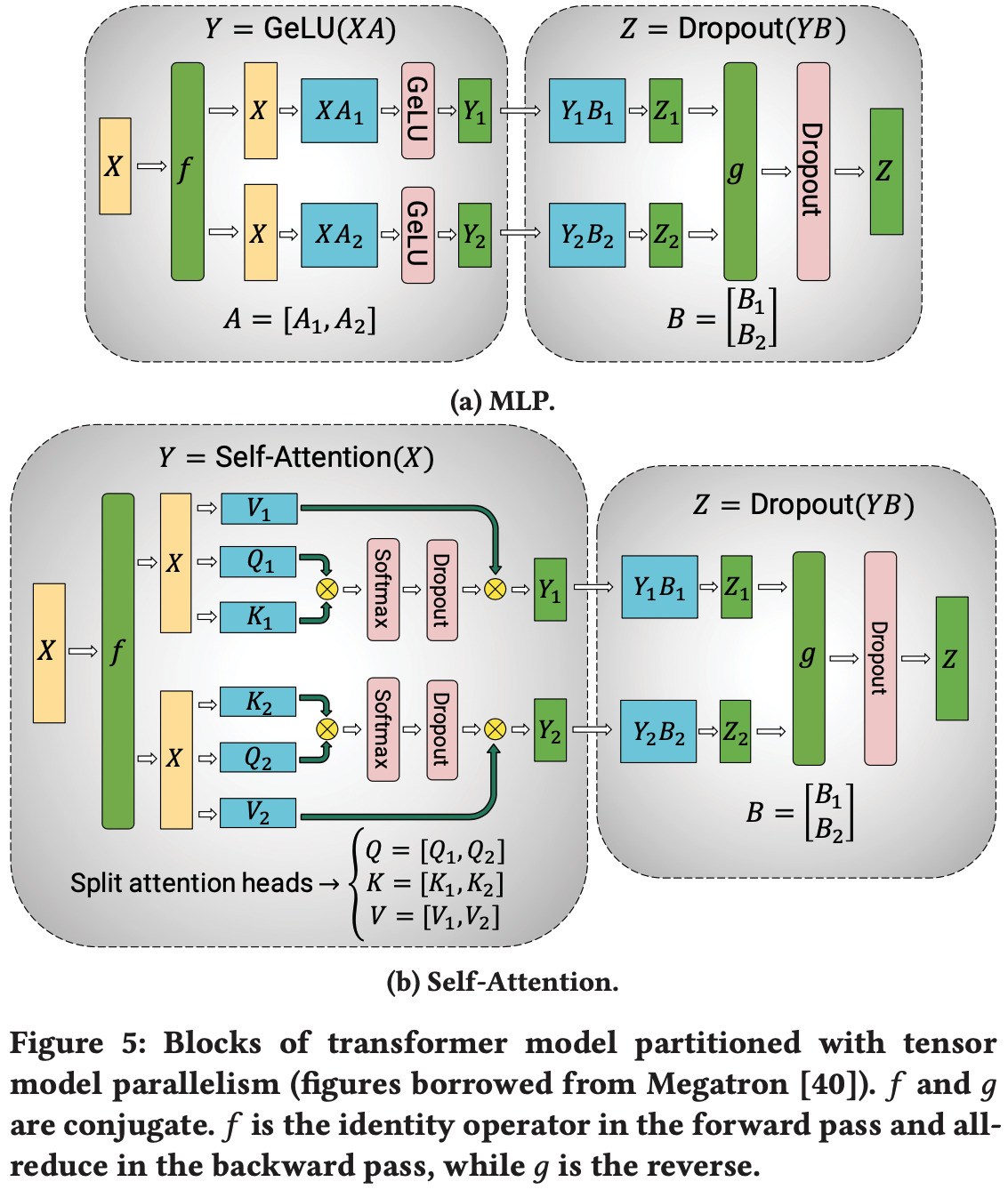
论文利用 Transformer 网络的结构,通过添加一些同步原语(synchronization primitives),实现了一种简单的模型并行方案
如图2所示:一个 Transformer 层由一个自注意力块(self attention block)和一个两层的多层感知器(multi-layer perceptron, MLP)组成
- 论文分别在这两个块中引入模型并行
首先详细介绍 MLP 块
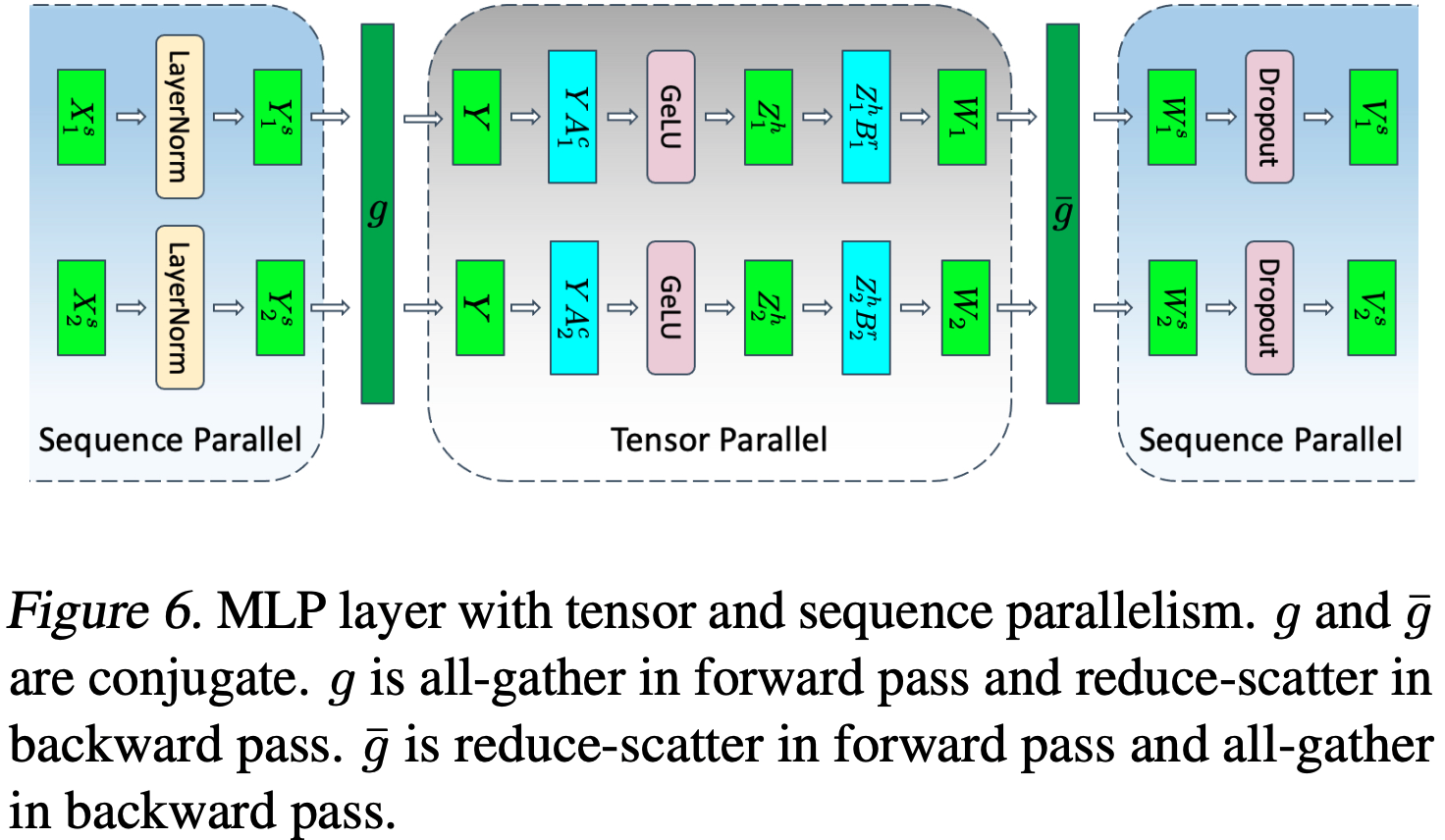
- MLP 块的第一部分是一个通用矩阵乘法(general matrix multiplication, GEMM),后跟一个 GeLU 非线性激活函数:
$$Y=GeLU(X A) \tag{1}$$ - 并行化 GEMM 的一种方法是将权重矩阵 \(A\) 按行拆分,将输入 \(X\) 按列拆分,如下所示:
$$X=\left[X_{1}, X_{2}\right], A=\left[\begin{array}{l}A_{1} \\ A_{2}\end{array}\right] \tag{2}$$ - 这种划分将导致
$$ Y=GeLU(X_{1} A_{1}+X_{2} A_{2}) $$ - 由于 GeLU 是一个非线性函数
$$ GeLU(X_{1} A_{1}+X_{2} A_{2}) \neq GeLU(X_{1} A_{1})+GeLU(X_{2} A_{2})$$ - 因此这种方法需要在 GeLU 函数之前设置一个同步点
- MLP 块的第一部分是一个通用矩阵乘法(general matrix multiplication, GEMM),后跟一个 GeLU 非线性激活函数:
另一种方法是将 \(A\) 按列拆分 \(A=[A_{1}, A_{2}]\)
这种划分允许 GeLU 非线性激活函数独立应用于每个划分的 GEMM 输出:
$$\left[Y_{1}, Y_{2}\right]=\left[GeLU\left(X A_{1}\right), GeLU\left(X A_{2}\right)\right]$$这一方法的优势在于消除了同步点
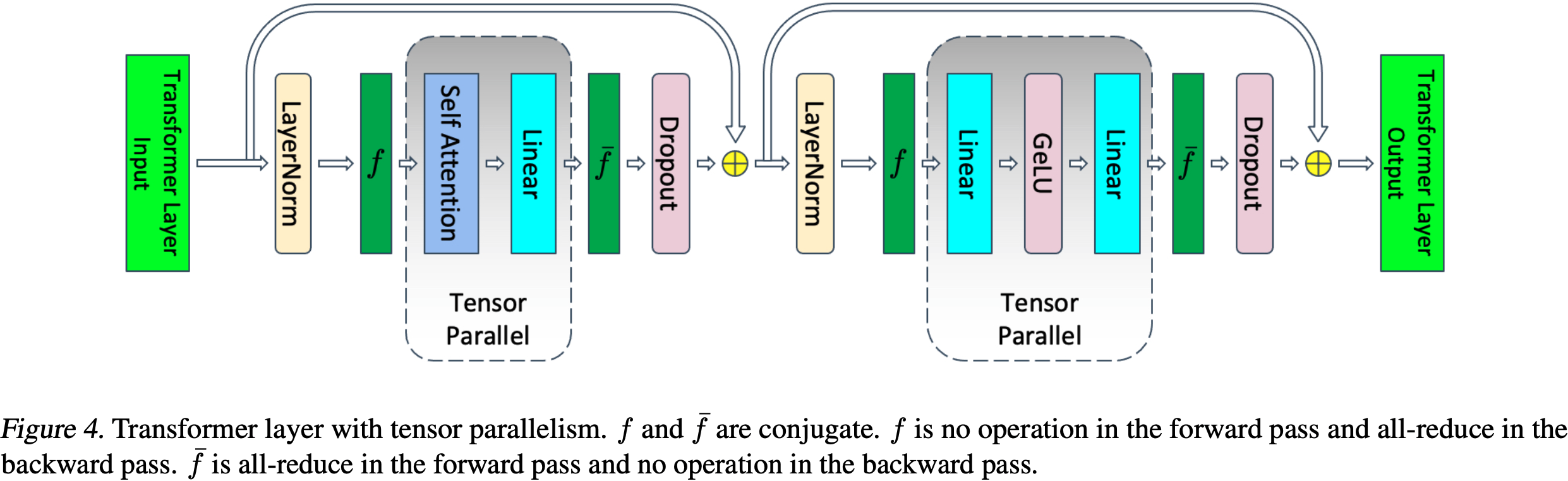
论文以这种列并行的方式划分第一个 GEMM,并将第二个 GEMM 按行拆分,使其可以直接接收 GeLU 层的输出,而无需任何通信(如图3a所示)
然后,第二个 GEMM 的输出在多个 GPU 之间进行归约(reduce),之后再传递到 dropout 层
这种方法将 MLP 块中的两个 GEMM 都拆分到多个 GPU 上,并且在正向传播中只需要一个 \(g\) 算子,在反向传播中只需要一个全归约(all-reduce)( \(f\) 算子)
- 这两个算子是共轭的,可以用 PyTorch 中的几行代码实现
例如, \(f\) 算子的实现如下:
1
2
3
4
5
6class f(torch.autograd.Function):
def forward(ctx, x):
return x
def backward(ctx, gradient):
all_reduce(gradient)
return gradient\(g\) 与 \(f\) 类似,只是在正向传播中执行全归约,在反向传播中执行恒等操作
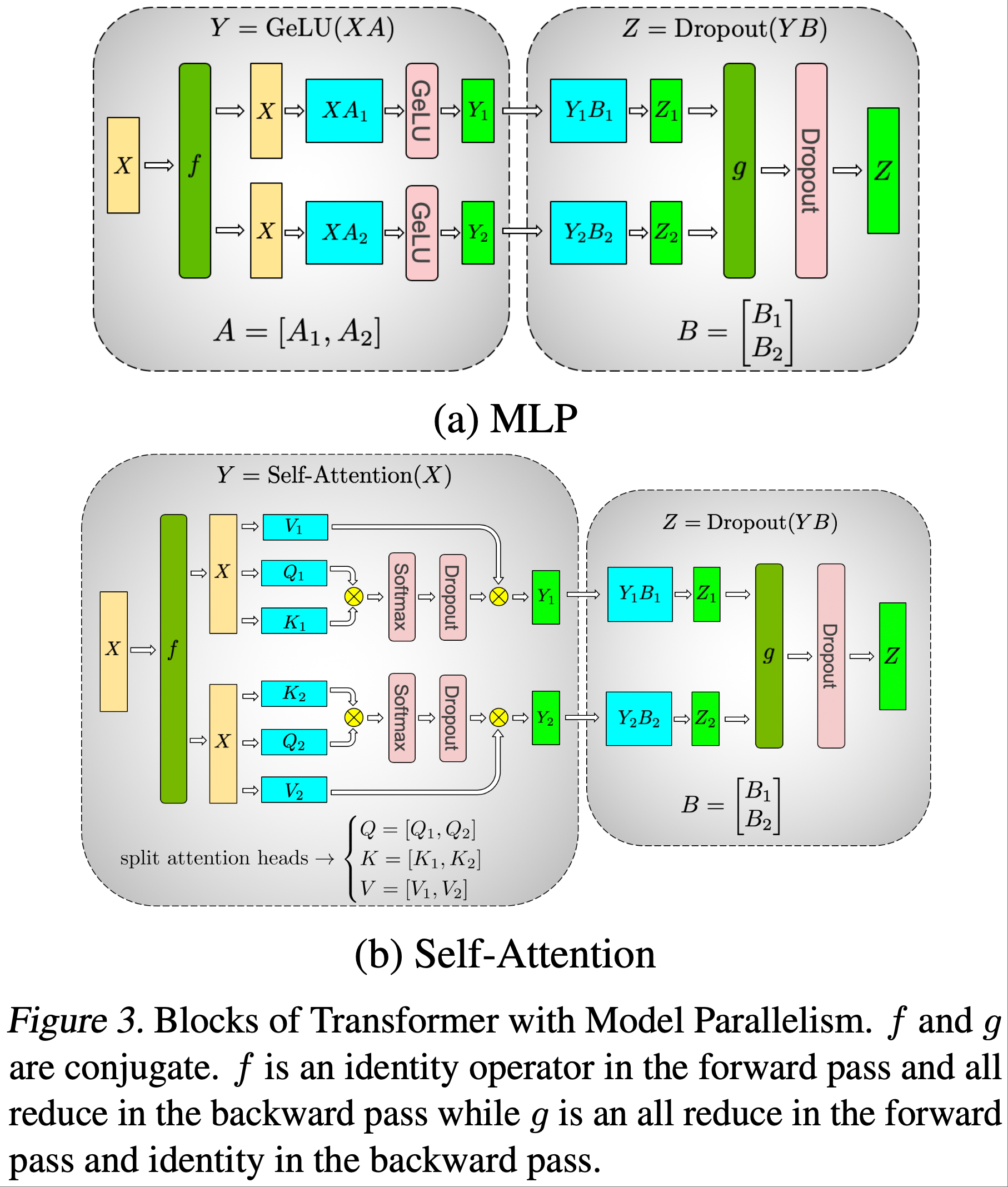
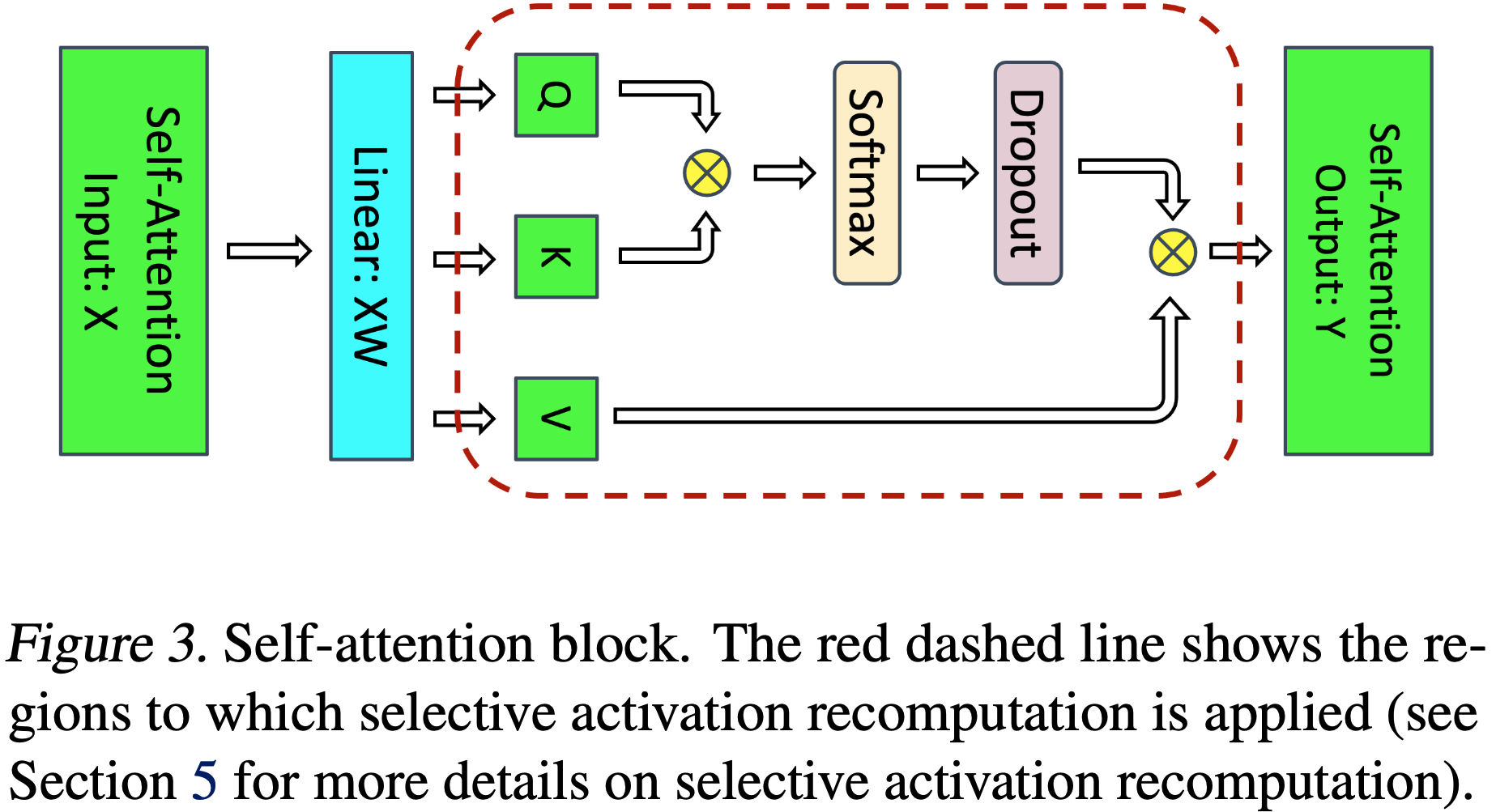
如图3b所示
- 对于自注意力块,利用多头注意力操作中固有的并行性 ,将与 \(K\)、 \(Q\) 和 \(V\) 相关的 GEMM 以列并行的方式划分 ,这样每个注意力头对应的矩阵乘法都在单个 GPU 上本地完成
- 这使得我们可以将每个注意力头的参数和计算负载分配到多个 GPU 上,并且不需要立即通信就能完成自注意力计算
- 自注意力之后的输出线性层(output linear layer)的 GEMM 按行并行化,可以直接接收并行注意力层的输出,无需 GPU 之间的通信
- 这种针对 MLP 层和自注意力层的方法融合了两组 GEMM,消除了它们之间的同步点,从而实现了更好的扩展性
- 这使得论文能够在一个简单的 Transformer 层中,仅在正向传播和反向传播中各使用两次全归约来执行所有 GEMM(见图4)
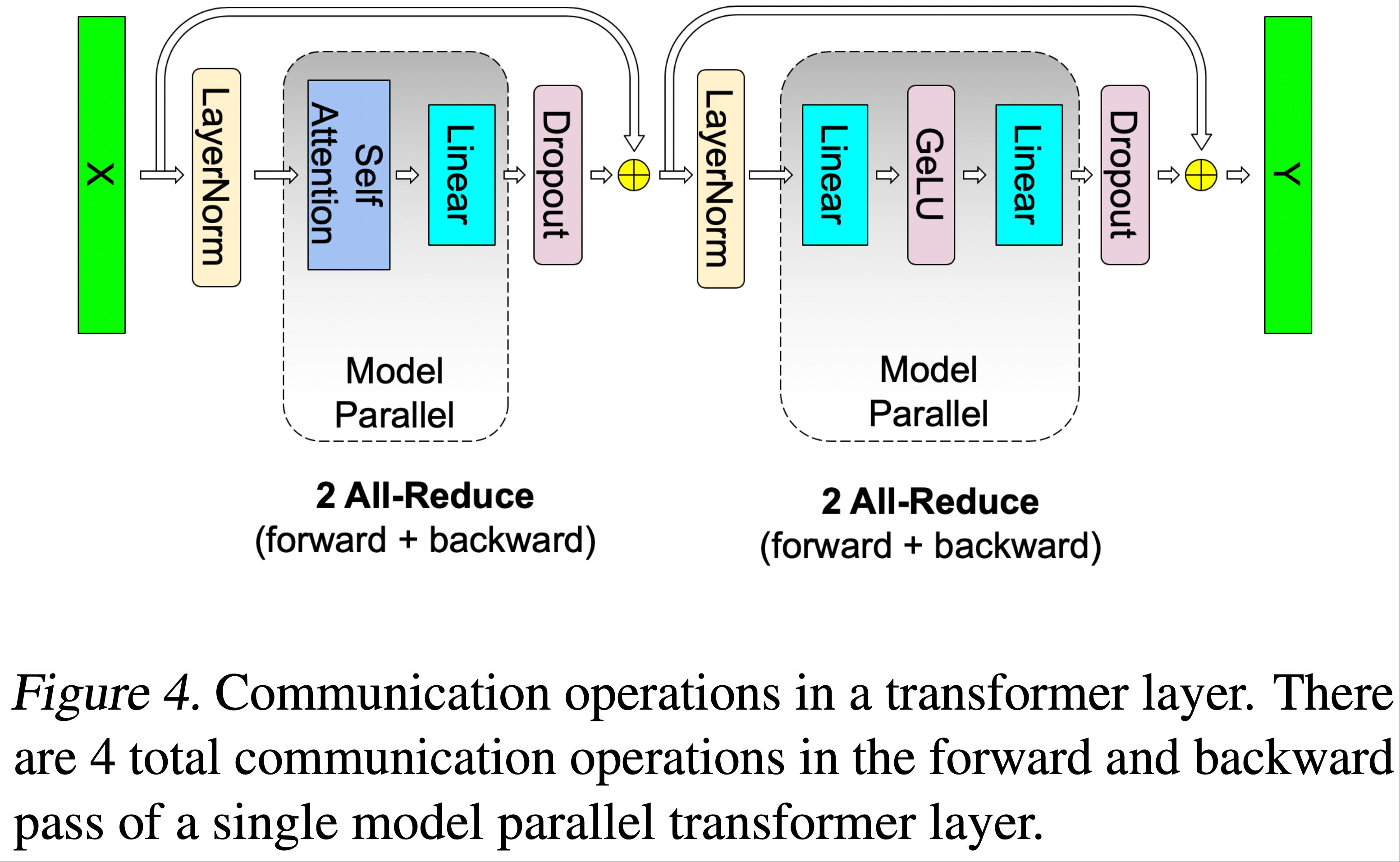
Transformer 语言模型的 Output Embedding 维度为隐藏层大小( \(H\) )乘以词汇表大小( \(v\) )
- 现代语言模型的词汇表大小通常在数万个 token 量级(例如,GPT-2 使用的词汇表大小为 50257),因此并行化 Output Embedding 的 GEMM 是有益的
- 但在 Transformer 语言模型中, Output Embedding 层与 Input Embedding 层共享权重,这需要对两者都进行修改
- 对于 Input Embedding 权重矩阵 \(E_{H \times v}\) 沿词汇表维度按列拆分:
$$ E=[E_{1}, E_{2}]$$- 由于每个分区现在只包含一部分嵌入,因此在 Input Embedding 之后需要一个 \(g\) 算子
- 对于 Output Embedding :
- 一种方法是执行下面的并行 GEMM 以获得 logits
$$ [Y_{1}, Y_{2}]=[X E_{1}, X E_{2}] $$- 然后添加一个全收集(all-gather)操作 $$ Y = \text{all-gather}([Y_{1}, Y_{2}])$$
- 再将结果传递给交叉熵损失函数(cross-entropy loss function)
- 但这种情况下,全收集操作将传递 \(b \times s \times v\) 个元素( \(b\) 是批大小, \(s\) 是序列长度),由于词汇表大小很大,这一数据量非常庞大
- 为了减少通信量,论文将并行 GEMM 的输出 \([Y_{1}, Y_{2}]\) 与交叉熵损失融合,这将维度减少到 \(b \times s\)
- 传递标量损失而不是 logits 大大减少了通信量,提高了论文模型并行方法的效率
- 一种方法是执行下面的并行 GEMM 以获得 logits
论文的模型并行方法在很大程度上可以概括为旨在减少通信并使 GPU 保持计算受限(compute bound)的技术
论文选择在多个 GPU 上复制计算,而不是让一个 GPU 计算 dropout、 Layer Normalization 或残差连接的一部分,然后将结果广播到其他 GPU
具体来说:
- 论文在每个 GPU 上维护 Layer Normalization 参数的副本
- 并对模型并行区域的输出执行 dropout 和 残差连接
- 然后将其作为输入馈送到下一个模型并行区域
- 问题:如何理解这里的每个 GPU 独立维持 Layer Normalization 参数的副本?
为了优化模型,论文允许每个模型并行工作节点优化自己的一组参数
- 由于所有值要么在 GPU 上本地存储,要么在 GPU 上复制,因此在这种形式中不需要通信更新后的参数值
关于混合模型并行与数据并行以及随机数生成的处理,论文在附录B中提供了更多细节
总之,如上所述,论文的方法易于实现,只需要在正向传播和反向传播中添加少量额外的全归约操作
- 它不需要编译器,并且与 GPipe(2018)等方法所倡导的流水线模型并行相互独立且互补
Setup
- 预训练语言理解模型是自然语言处理和语言理解中的核心任务
- 语言建模有多种形式,论文重点关注 GPT-2(2019)(一种基于 Transformer 的从左到右生成式语言模型)和 BERT(2018)(一种基于掩码语言模型的双向 Transformer 模型)
- 论文在以下部分解释这些模型的配置,并建议读者参考原始论文以获取更多细节
Training Dataset
- 为了收集具有长期依赖关系的大型多样化训练集,论文聚合了几个最大的语言建模数据集
- 论文创建的聚合数据集包括 Wikipedia(2018)、CC-Stories(2018)、RealNews(2019)和 OpenWebtext(2019)
- 为了避免训练集数据泄露到下游任务中
- 移除了 WikiText103 测试集(2016)中存在的 Wikipedia 文章
- 还移除了 CC-Stories 语料库中因预处理 artifacts 引入的不必要换行
- 对于 BERT 模型,论文在训练数据集中包含了 BooksCorpus(2015),但由于该数据集与 LAMBADA 任务重叠,因此在 GPT-2 训练中排除了该数据集
- 论文合并了所有数据集,然后做了以下操作:
- 从聚合数据集中过滤掉内容长度小于 128 个 token 的所有文档
- (聚合数据集中可能存在重复的相似内容),论文使用局部敏感哈希(locality-sensitive hashing, LSH)对 Jaccard 相似度大于 0.7 的内容进行去重
- 最终的聚合语料库包含 174 GB 的去重文本
Training Optimization and Hyperparameters
- 为了高效训练论文的模型,论文利用混合精度训练(mixed precision training)和动态损失缩放(dynamic loss scaling),以充分利用 V100 的Tensor Core(2017;2018)
- 使用简单的正态分布初始化权重 \(W\) :
$$ W \sim N(0,0.02)$$ - 在残差层(residual layers)之前立即按下面的比例缩放权重:
$$ \frac{1}{\sqrt{2 N} } $$- 其中 \(N\) 是由自注意力和 MLP 块组成的 Transformer 层数
- 使用带权重衰减(weight decay)(2019)的 Adam 优化器(2014),其中 \(\lambda=0.01\)
- 使用全局梯度范数裁剪(global gradient norm clipping)为 1.0,以提高大型模型训练的稳定性
- dropout 率均设置为 0.1
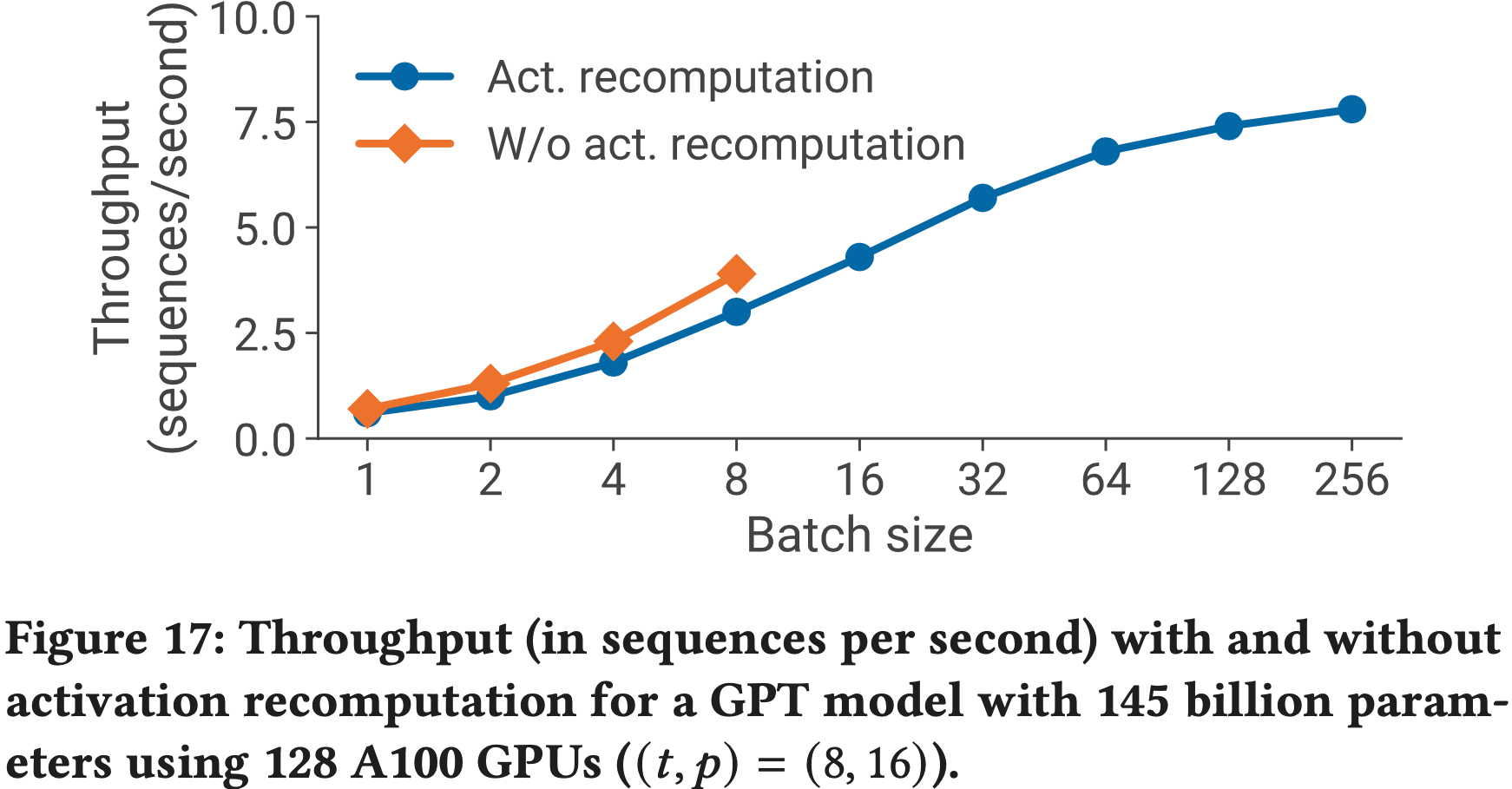
- 在每个 Transformer 层之后使用激活检查点(2016)
- 对于 GPT-2 模型
- 所有训练都使用 1024 个子词单元(subword units)的序列
- 批大小为 512
- 共训练 300K 次迭代
- 初始学习率为 1.5e-4(3k 次迭代的预热期(warmup period))
- 剩余的 297K 次迭代中遵循单周期余弦衰减(single cycle cosine decay)至最小学习率 1e-5
- 对于 BERT 模型
- 在很大程度上遵循(2019)中描述的训练过程
- 论文使用原始 BERT 词典,词汇表大小为 30522
- 按照(2019)的建议,用句子顺序预测(sentence order prediction)替换了下一句预测(next sentence prediction)头,并使用(2019)的全词 n-gram 掩码(whole word n-gram masking)
- 批大小设置为 1024
- 学习率为 1.0e-4
- 在 10k 次迭代中预热,然后在 2M 次迭代中线性衰减
- 其他训练参数与(2018)保持一致
Experiments
- 论文所有的实验都使用了多达 32 台 DGX-2H 服务器(总共 512 块 Tesla V100 SXM3 32GB GPU)
- 论文的基础设施针对多节点深度学习应用进行了优化,服务器内部的 GPU 之间通过 NVSwitch 实现 300 GB/秒 的带宽,服务器之间通过每台服务器配备的 8 个 InfiniBand 适配器实现 100 GB/秒 的互联带宽
Scaling Analysis
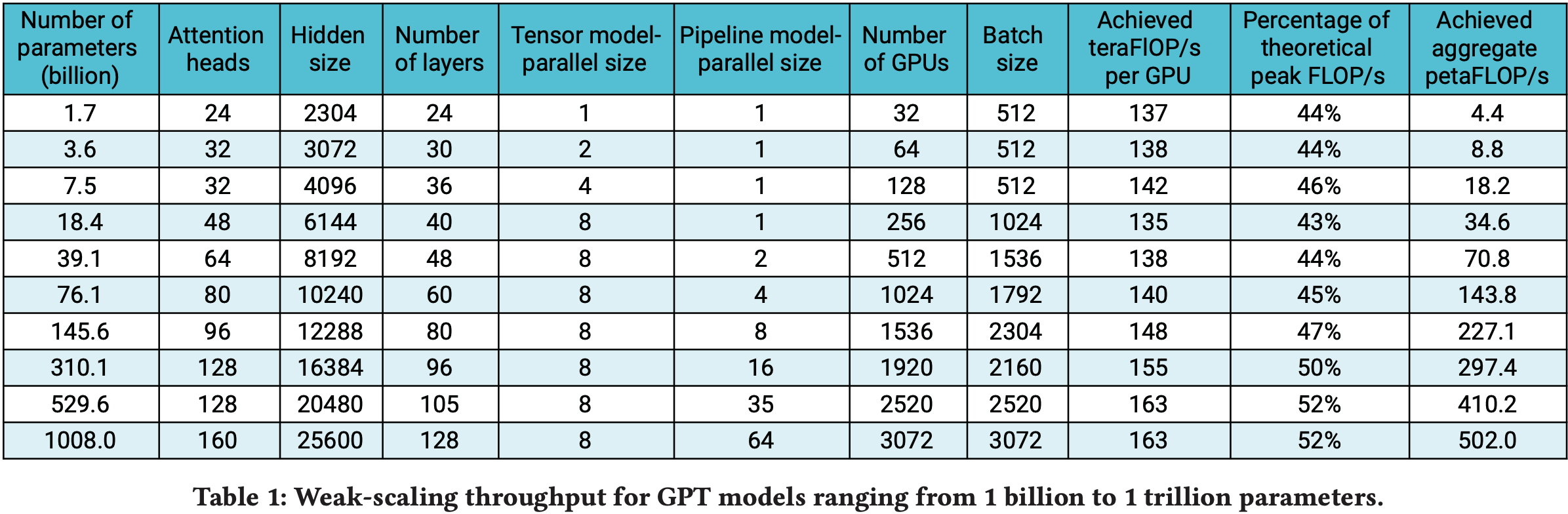
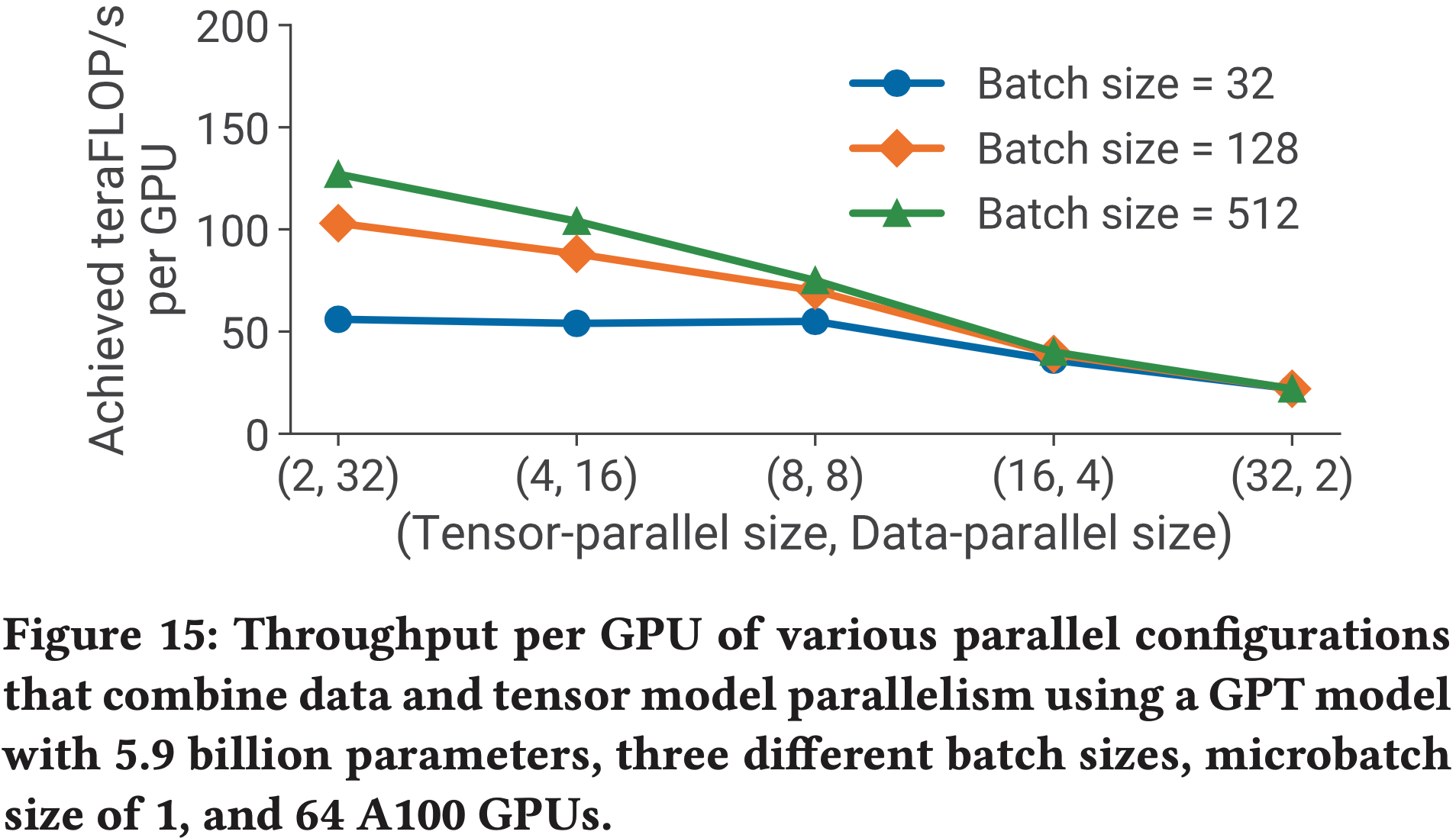
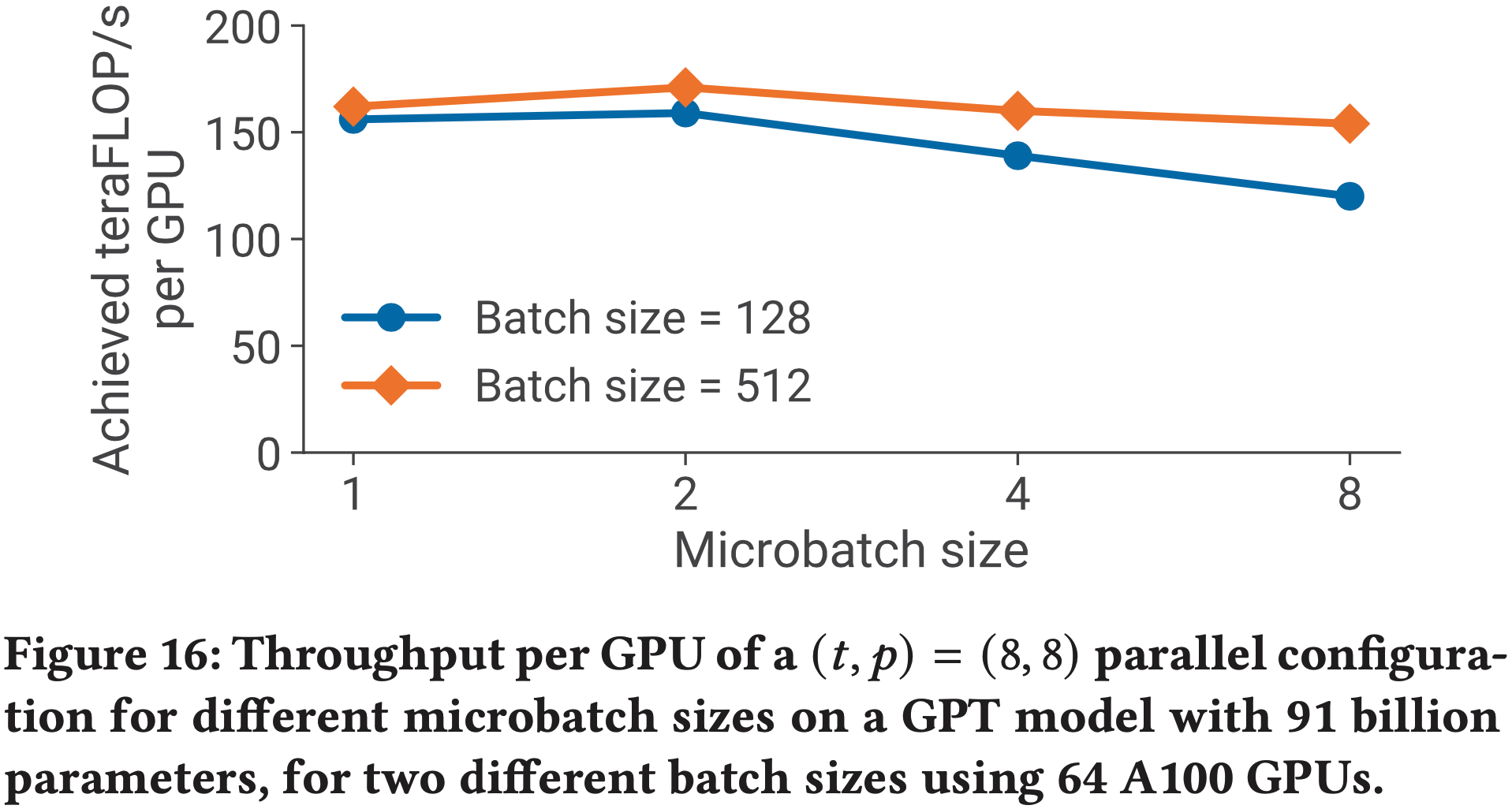
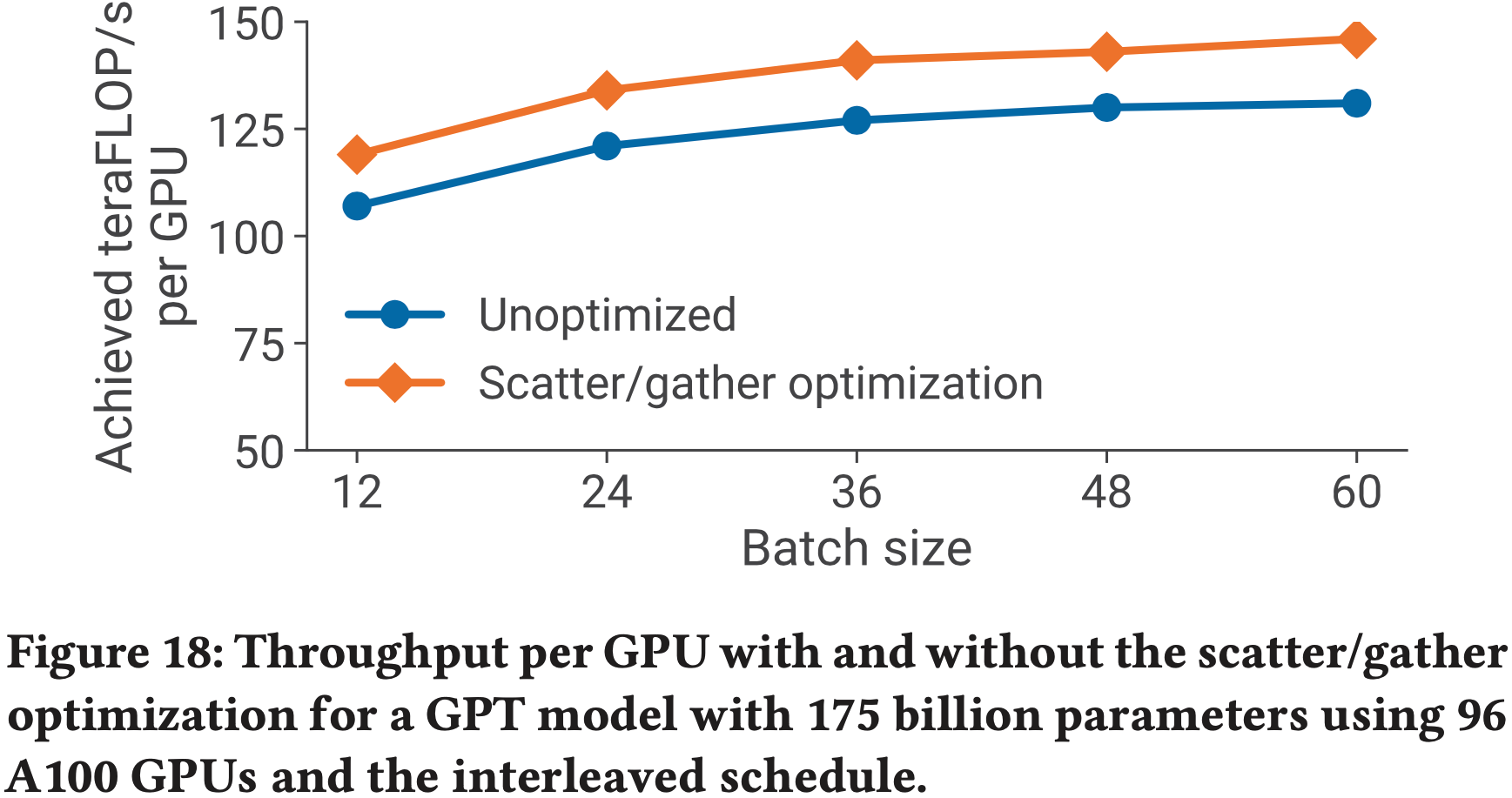
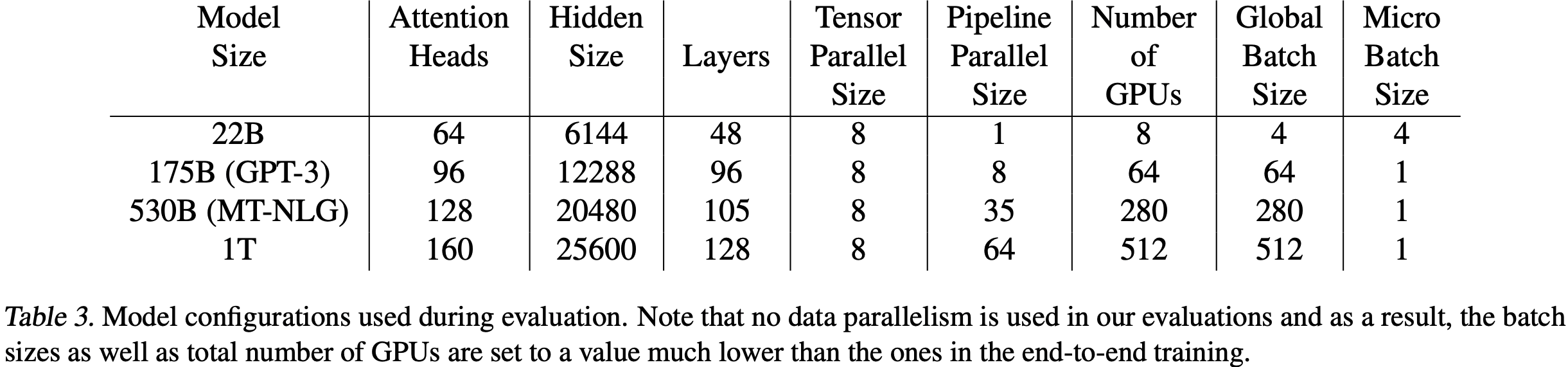
- 为了测试论文实现方案的可扩展性,论文考虑了四组参数的 GPT-2 模型,详情见表1
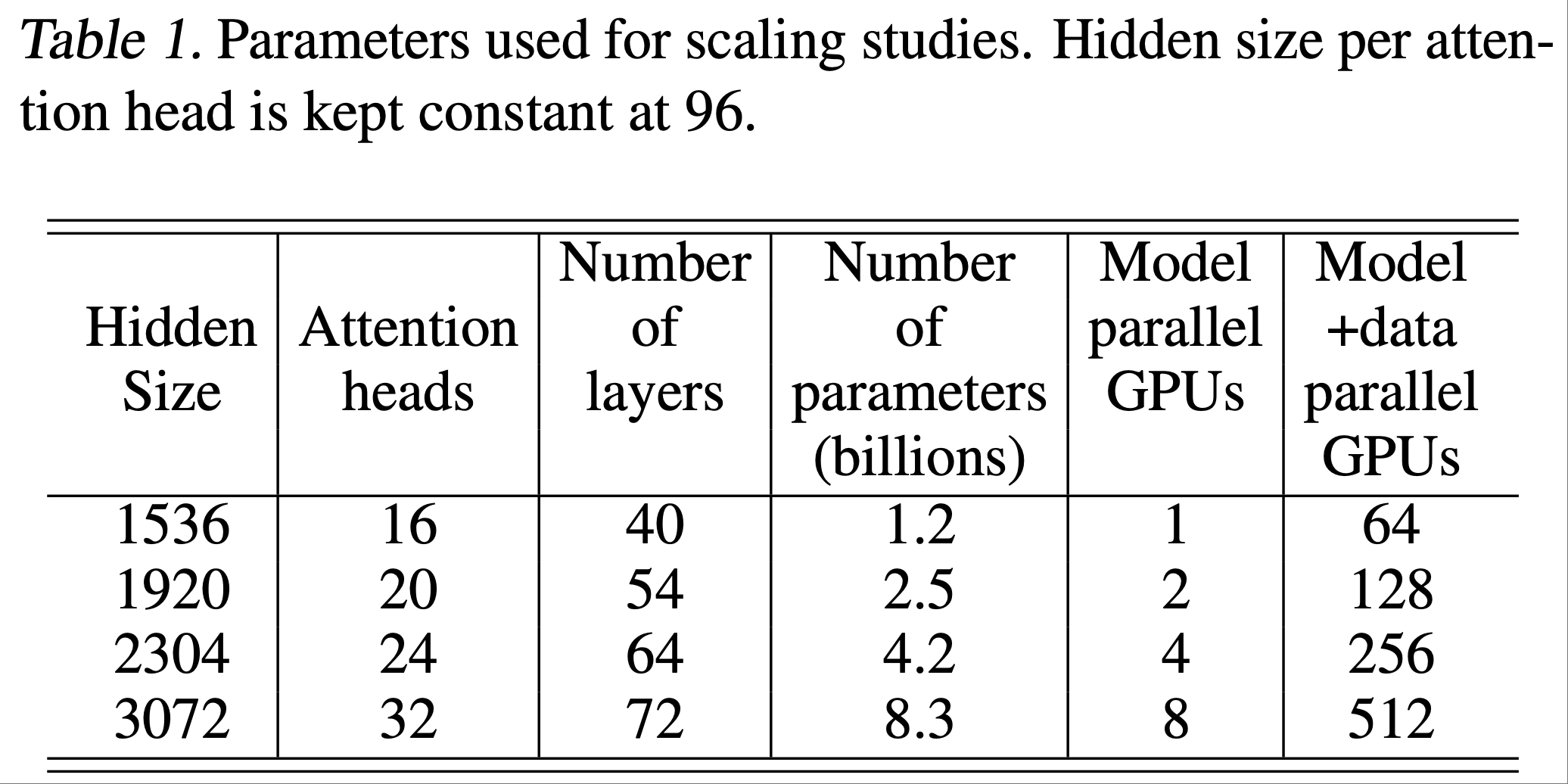
- 为了使自注意力层中的通用矩阵乘法(GEMM)大小保持一致,每个注意力头的隐藏层大小固定为 96,通过调整注意力头数和层数来获得参数规模从 1B 到 8B 的配置
- 1.2B 参数的配置可以在单个 GPU 上运行,而 8B 参数的模型则需要 8 路模型并行(8 块 GPU)
- 将原始词汇表大小从 50257 填充为 51200,原因如下:
- 为了使 logit 层的通用矩阵乘法(GEMM)更高效,每个 GPU 上的词汇表大小最好是 128 的倍数
- 论文的模型并行最多为 8 路,因此论文将词汇表填充为可被 \(128 \times 8 = 1024\) 整除的大小,最终填充后的词汇表大小为 51200
- 论文研究了模型并行和模型+数据并行两种扩展性
- 对于模型并行扩展性,所有配置都使用固定的批大小 8
- 数据并行扩展对于训练许多 SOTA 模型是必要的,这些模型通常使用更大的全局批大小
- 在模型+数据并行的情况下,论文所有实验的全局批大小都固定为 512,这对应于 64 路数据并行
Model and Data Parallelism
- 本节展示模型并行和模型+数据并行情况下,相对于模型参数的弱扩展性
- 弱扩展性通常通过扩展批大小来实现,但这种方法无法解决训练无法在单个 GPU 上运行的大型模型的问题,而且会导致大批量训练的收敛性下降
- 论文不同,在这里使用弱扩展性来训练原本无法实现的更大模型
- 所有扩展性数据的基准是表1中的第一种配置(1.2B 参数)在单个 GPU 上的运行情况
- 这是一个很强的基准,因为它在整个训练过程中达到了 39 TeraFLOPs,相当于 DGX-2H 服务器中单个 GPU 理论峰值浮点运算的 30%
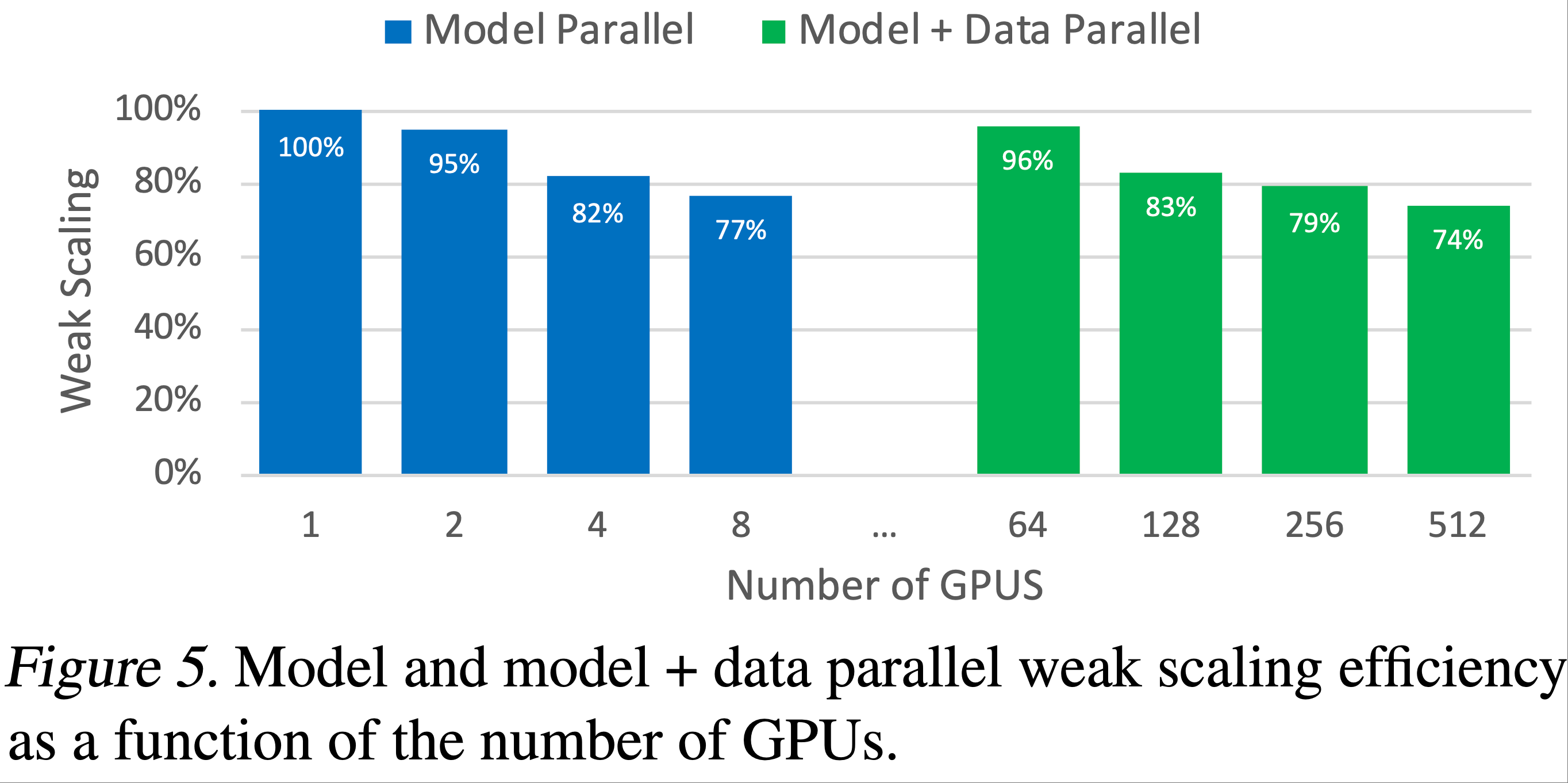
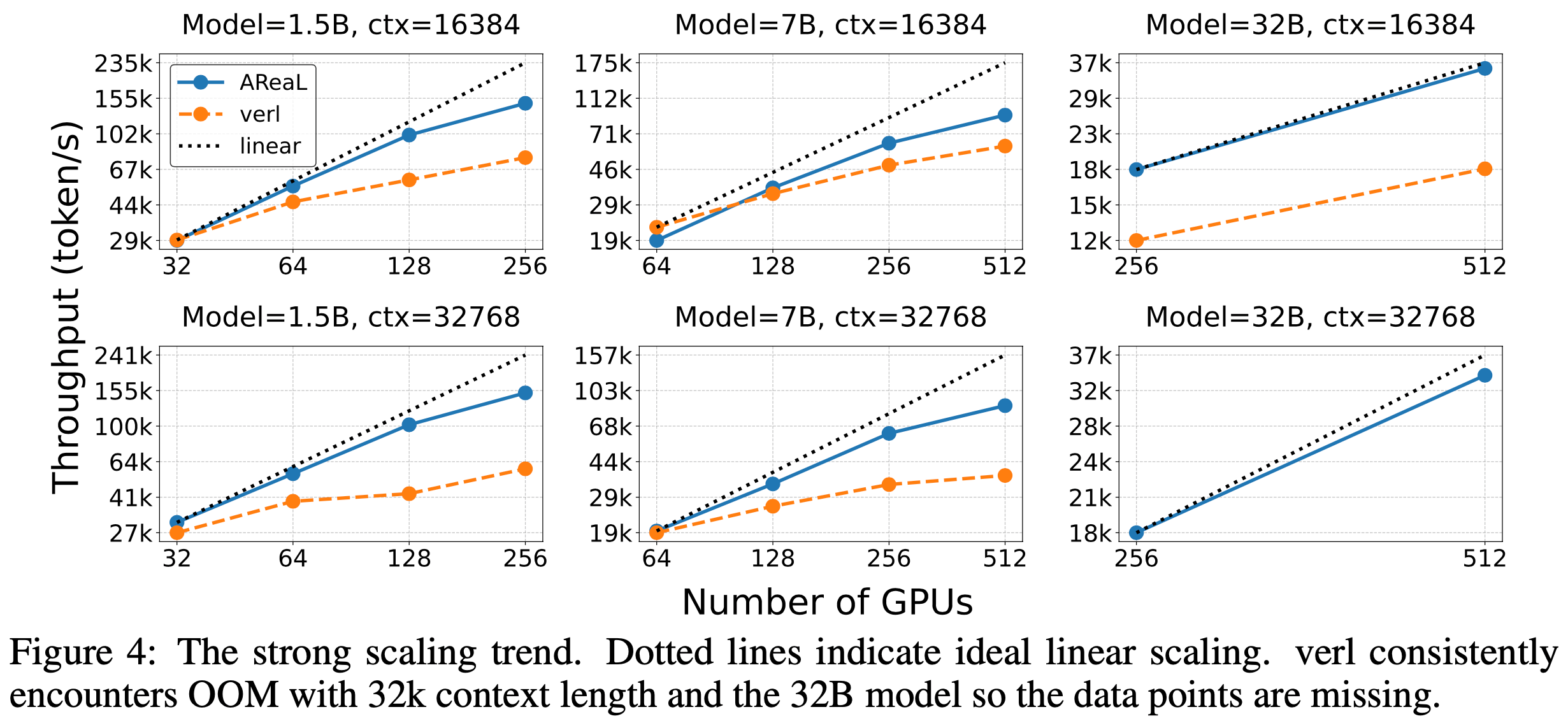
- 图5显示了模型并行和模型+数据并行的扩展性数值:论文在两种设置下都观察到了优异的扩展性。例如,
- 8.3B 参数的模型在 8 路(8 块 GPU)模型并行下实现了 77% 的线性扩展效率
- 模型+数据并行由于需要额外的梯度通信,扩展性数值略有下降
- 但即使是在 512 块 GPU 上运行的最大配置(8.3B 参数),相对于 1.2B 参数在单个 GPU 上的强基准配置,论文也实现了 74% 的线性扩展效率
- 更多扩展性分析见附录D
Language Modeling Results Using GPT-2
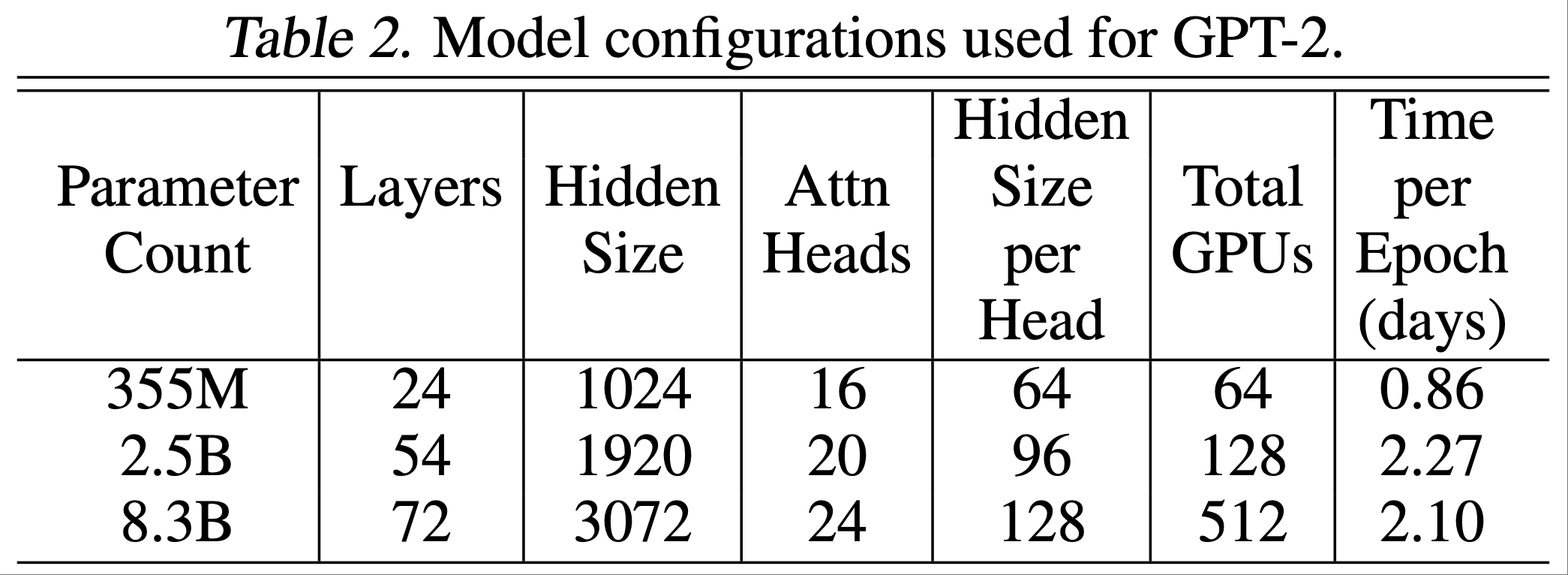
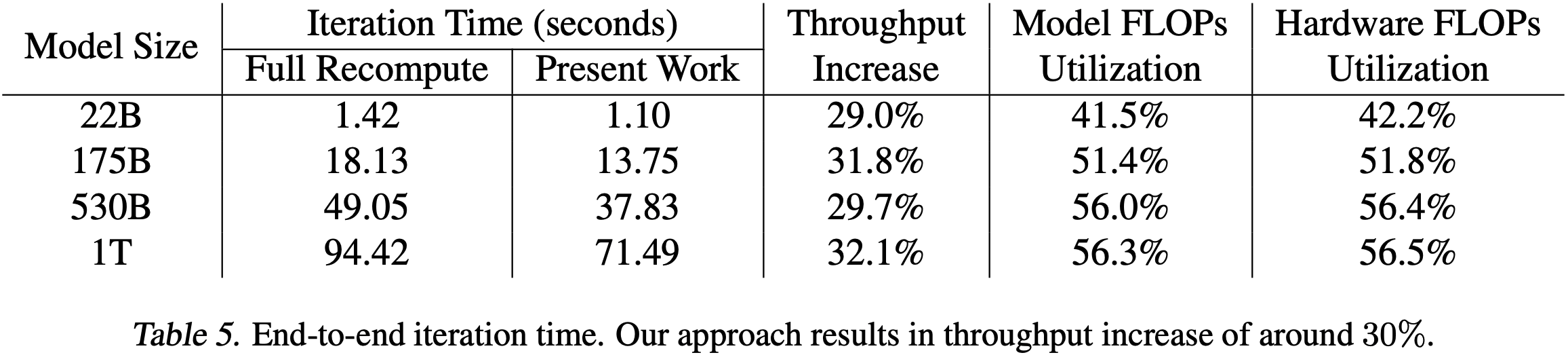
为了证明大型语言模型能进一步推动技术发展,论文考虑训练表2中列出的不同规模和配置的 GPT-2 模型
- 355M 参数的模型与 BERT-Large 模型(2018)的规模和配置相当
- 2.5B 参数的模型比之前最大的 GPT-2 模型更大,而据论文所知,8.3B 参数的模型比任何已训练的从左到右的 Transformer 语言模型都要大
论文使用第4节中描述的流程来训练和评估论文的语言模型
表2还列出了完成一个 epoch 所需的时间,一个 epoch 相当于 68507 次迭代
- 例如, 8.3B 参数的模型在 512 块 GPU 上,每个 epoch 大约需要两天
- 与表1中用于扩展性研究的配置相比:
- 2.5B 参数的模型是相同的
- 8.3B 参数的模型有 24 个注意力头(而不是 32 个)
- 355M 参数的模型比之前的任何模型都小,但仍使用 64 块 GPU 进行训练,因此每个 epoch 的时间短得多
图6显示了验证集困惑度(perplexity)随迭代次数的变化
- 随着模型规模的增加,验证集困惑度降低, 8.3B 参数的模型达到 9.27 的验证集困惑度
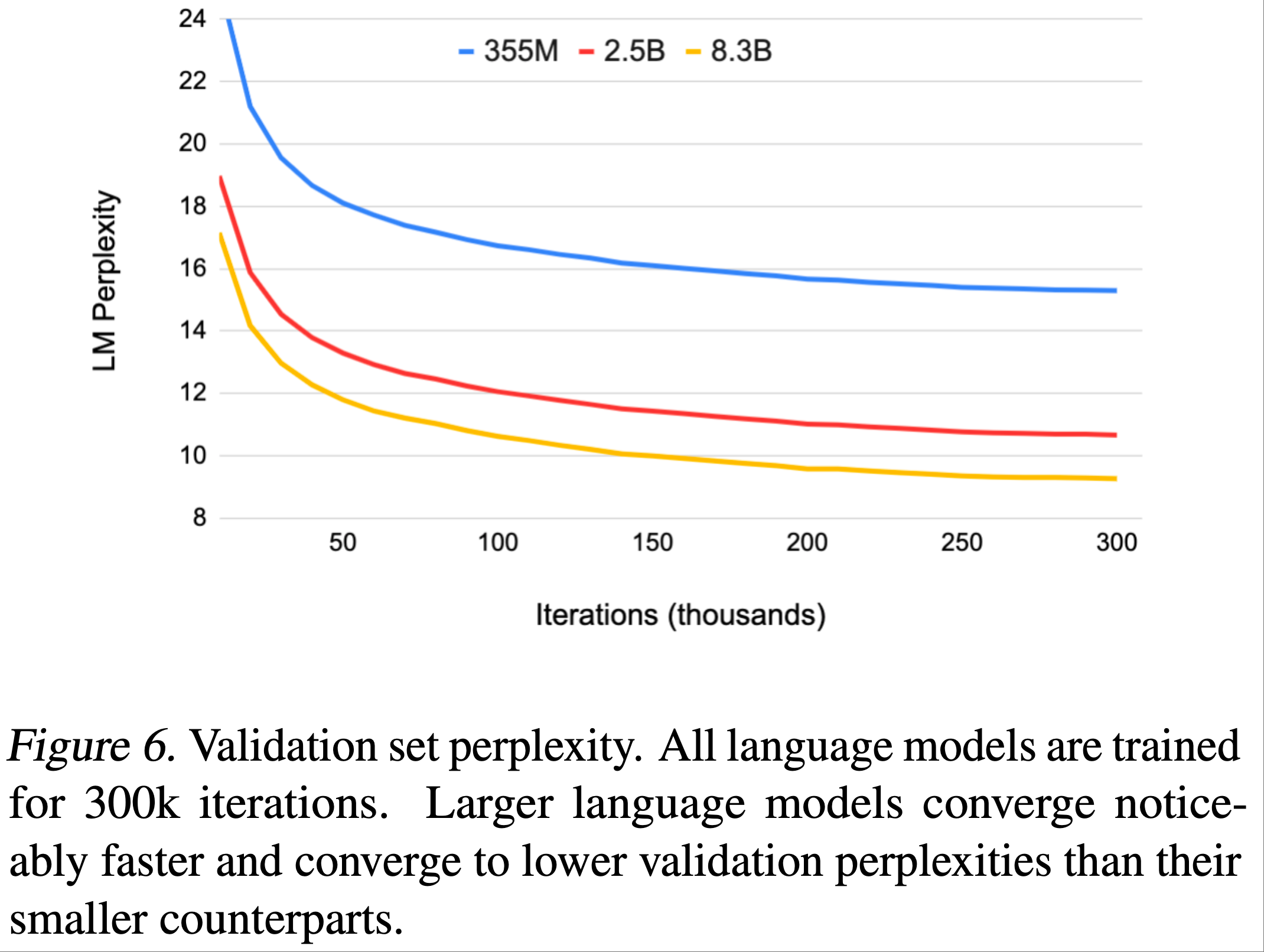
- 随着模型规模的增加,验证集困惑度降低, 8.3B 参数的模型达到 9.27 的验证集困惑度
表3报告了训练后的模型在 LAMBADA 和 WikiText103 数据集上的零样本评估结果
- 有关评估方法的更多细节,请参见附录E
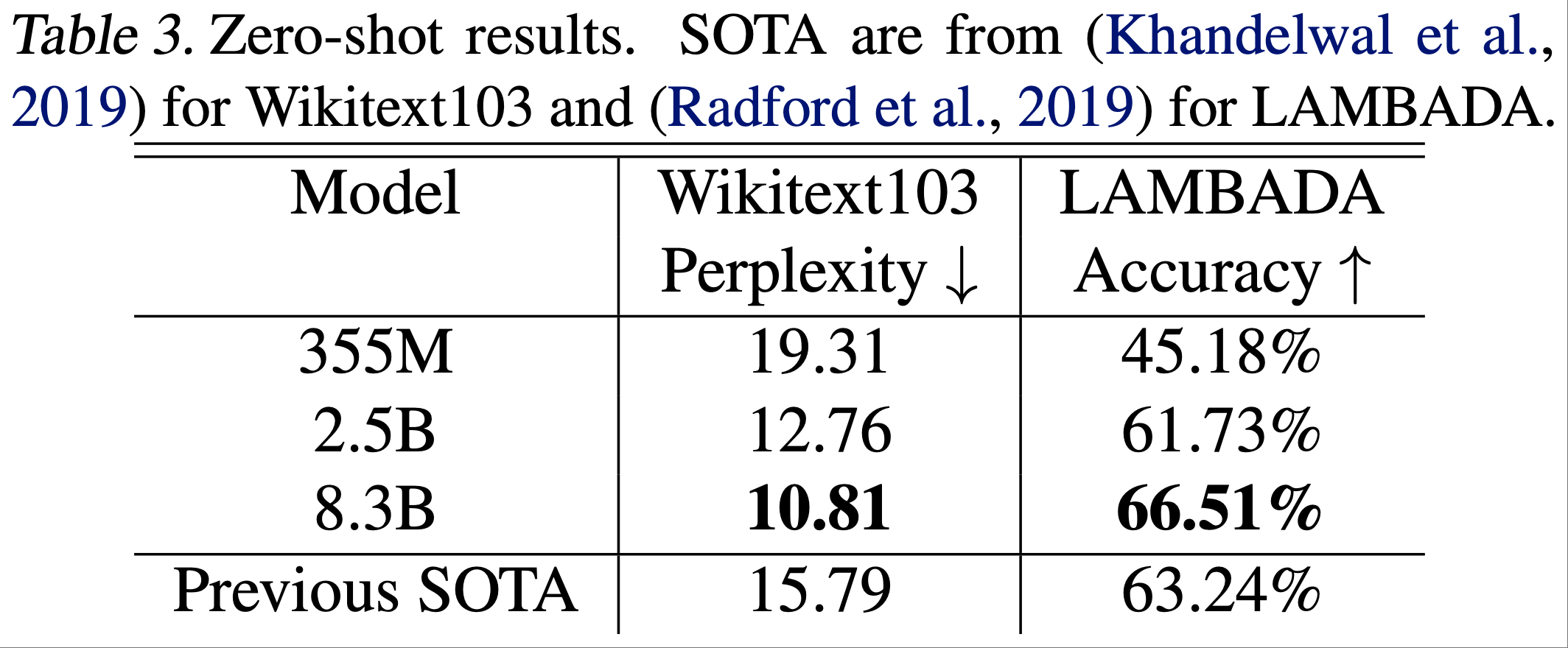
- 有关评估方法的更多细节,请参见附录E
论文观察到,随着模型规模的增加,WikiText103 上的困惑度降低,LAMBADA 上的完形填空准确率(cloze accuracy)提高
- 论文的 8.3B 参数模型在 WikiText103 测试集上实现了 10.81 的调整后困惑度,达到了最佳水平
- 8.3B 参数的模型在 LAMBADA 任务上的准确率为 66.51%,同样超过了之前的完形填空准确率结果
- 附录C 中包含了 8.3B 参数模型生成的样本
最近,微软的研究人员与 NVIDIA 合作,使用 Megatron 训练了一个 17B 参数的 GPT-2 模型,称为 Turing-NLG(微软,2020),并表明随着模型规模的扩大,准确率进一步提高,凸显了更大模型的价值
为了确保论文的训练数据中不包含任何测试集数据
- 论文计算了测试集中的 8-grams 在训练集中出现的百分比,就像之前的工作(2019)所做的那样
- WikiText103 测试集的重叠率最多为 10.8%,LAMBADA 测试集(2016)的重叠率最多为 1.4%
- WikiText103 测试集与 WikiText103 训练集的重叠率已经达到 9.09%(2019)
- 由于这些结果与之前的工作一致,论文有信心训练数据中没有无意中包含任何测试数据的文档
Bi-directional Transformer Results Using BERT
- 在本节中,论文将论文的方法应用于类 BERT(BERT-style)的 Transformer 模型,并研究模型扩展对多个下游任务的影响
- 先前的工作(2019)发现,当模型规模超过 336M 参数的 BERT-large 时,会出现意想不到的模型性能下降
- 为了解决这种下降,该工作的作者(2019)引入了参数共享,并表明他们的模型比原始 BERT 模型的扩展性好得多
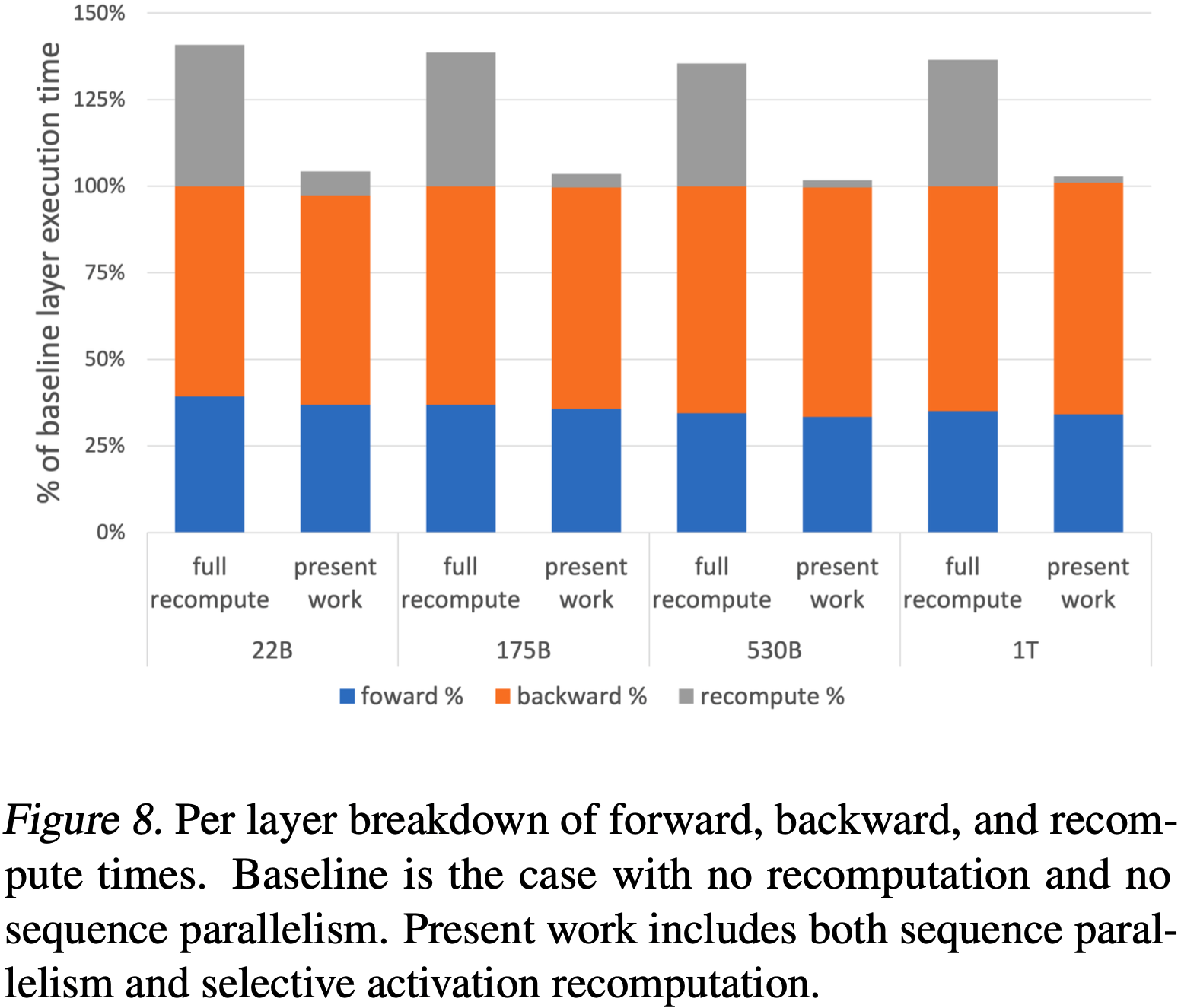
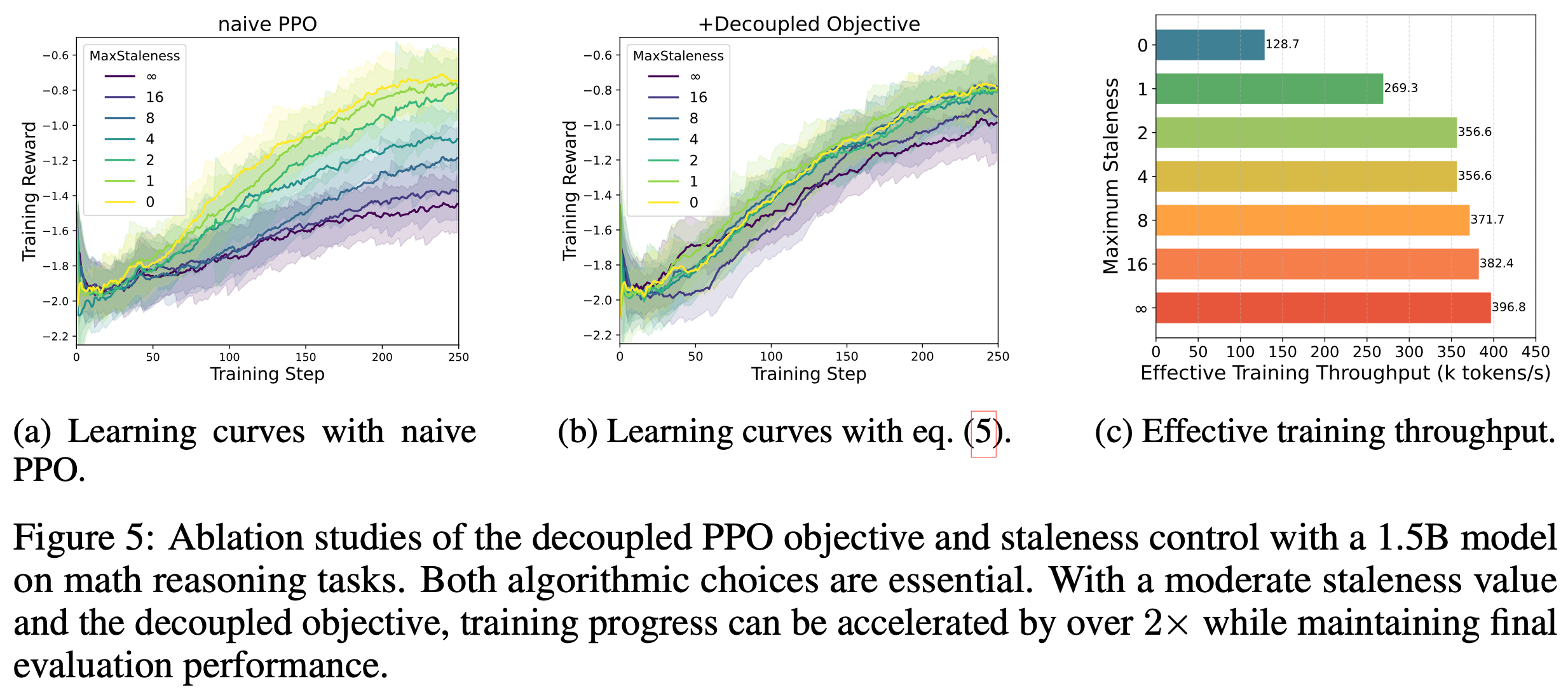
- 论文进一步研究了这种现象,并通过实证证明,如图7所示,重新排列 Layer Normalization 和残差连接(residual connections)的顺序,对于使类 BERT 模型能够扩展到超过 BERT-Large 的规模至关重要
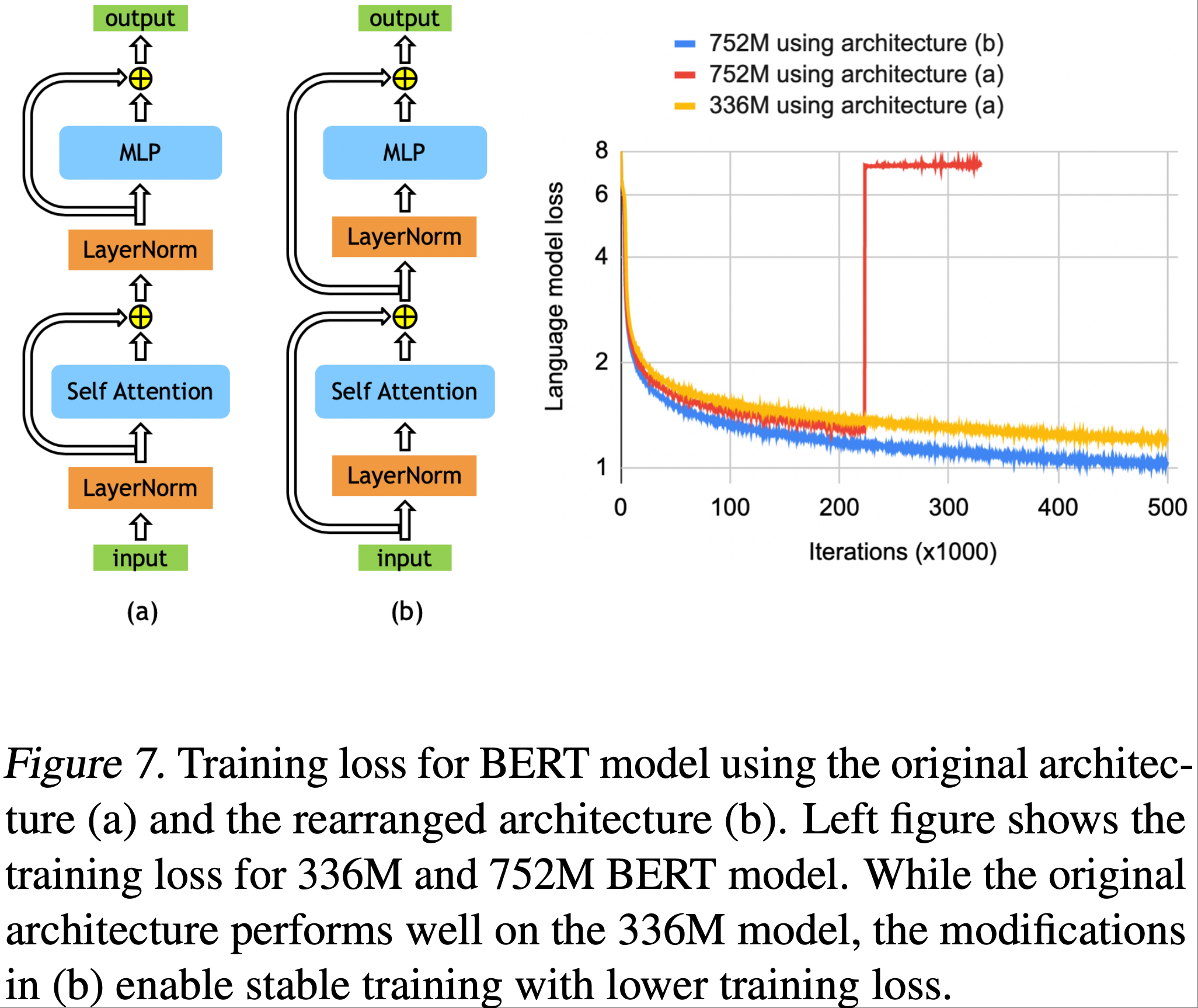
- 图7中的架构(b)消除了使用原始BERT架构(a)时观察到的不稳定性,并且具有更低的训练损失
- 据论文所知,论文是第一个报告这种修改能够训练更大 BERT 模型的研究
- 使用图7(b)中的架构修改,论文考虑了表4中详细列出的三种情况
- 336M 参数的模型与 BERT-large 的规模相同
- 1.3B 参数的模型与之前被证明比 336M 参数的 BERT-large 模型结果更差的 BERT-xlarge 配置相同(2019)
- 论文通过同时增加隐藏层大小和层数,将 BERT 模型进一步扩展到 3.9B 参数的情况
- 在所有情况下,每个注意力头的隐藏层大小都固定为 64
- 336M 和 1.3B 参数的模型训练了 2M 次迭代,而 3.9B 参数的模型训练了 1.5M 次迭代,目前仍在训练中
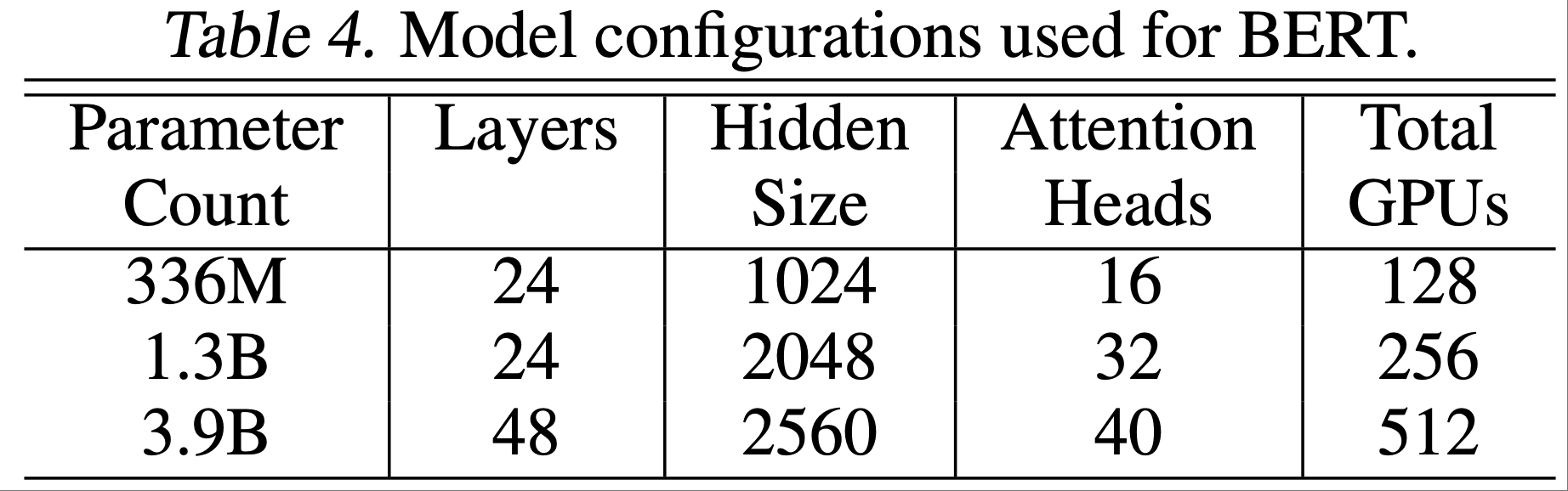
- 在 3% 的保留集上,336M、1.3B和 3.9B 参数的模型分别实现了 1.58、1.30 和 1.16 的验证集困惑度 ,随着模型规模的增加而单调下降
- 论文在多个下游任务上对训练后的模型进行微调,包括 GLUE 基准(2019)中的 MNLI 和 QQP,斯坦福问答数据集(2016;2018)中的 SQuAD 1.1 和 SQuAD 2.0,以及阅读理解 RACE 数据集(2017)
- 微调时,论文遵循(2019b)中的相同流程
- 论文首先对批大小和学习率进行超参数调优
- 获得最佳值后,论文报告 5 个不同随机种子初始化的开发集结果的中值
- 每个模型和任务使用的超参数见附录A
- 表5显示了 MNLI、QQP、SQuAD 1.1 和 SQuAD 2.0 的开发集结果,以及 RACE 的测试集结果
- 对于 RACE 的测试集结果,论文首先使用开发集找到在 5 个随机种子上给出中值分数的检查点,然后报告该检查点在测试集上的结果
- 论文还报告了 SQuAD 开发集和 RACE 测试集的 5 路集成(ensemble)结果
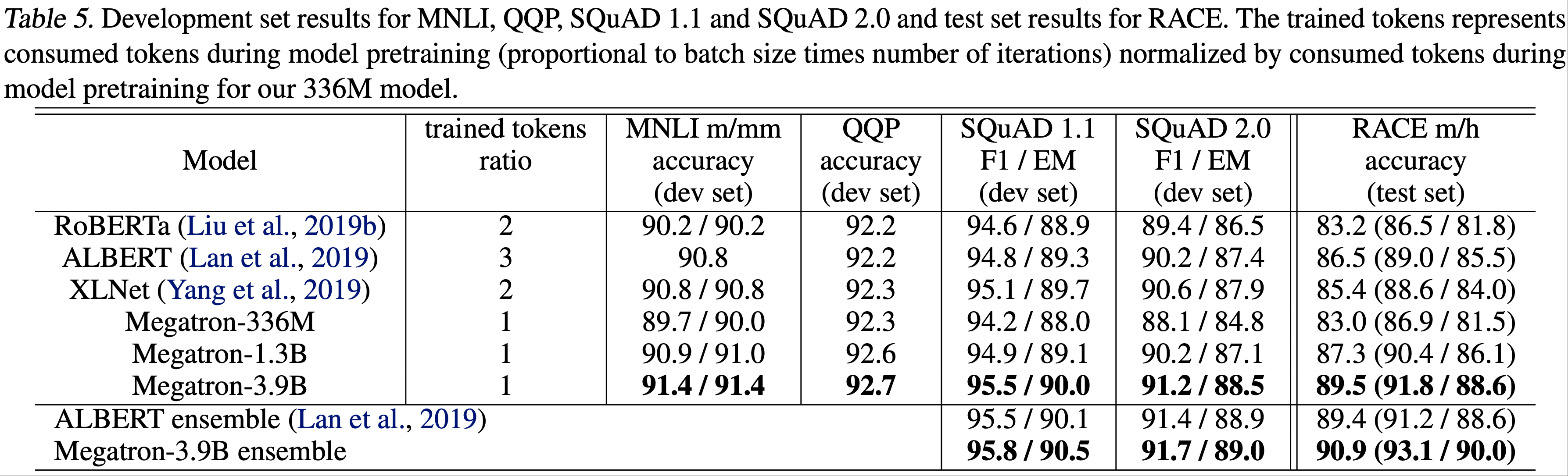
- 从表5中论文观察到:
- (a)随着模型规模的增加,所有情况下的下游任务性能都有所提高;
- (b)论文的 3.9B 参数模型在开发集上建立了比其他基于 BERT 的模型更好的最佳结果;
- (c)论文的 3.9B 参数模型在 RACE 测试集上同时实现了单模型和集成模型的最佳结果
Future Work
- 未来的工作有几个方向
- 继续扩大预训练规模是一个很有前景的研究方向,这将进一步考验现有的深度学习硬件和软件
- 为了实现这一点,需要提高优化器的效率和减少内存占用
- 此外,训练超过16B 参数的模型将需要比 DGX-2H 服务器的16块GPU更多的内存
- 对于此类模型,混合层内和层间模型并行以及节点间模型并行将更合适
- 其他三个研究方向包括:
- (a)预训练不同的模型系列(XLNet、T5);
- (b)评估大型模型在更多更困难和更多样化的下游任务(如生成式问答、摘要和对话)上的性能;
- (c)使用知识蒸馏(knowledge distillation)从这些大型预训练教师模型(teacher models)中训练小型学生模型(student models)
- 继续扩大预训练规模是一个很有前景的研究方向,这将进一步考验现有的深度学习硬件和软件
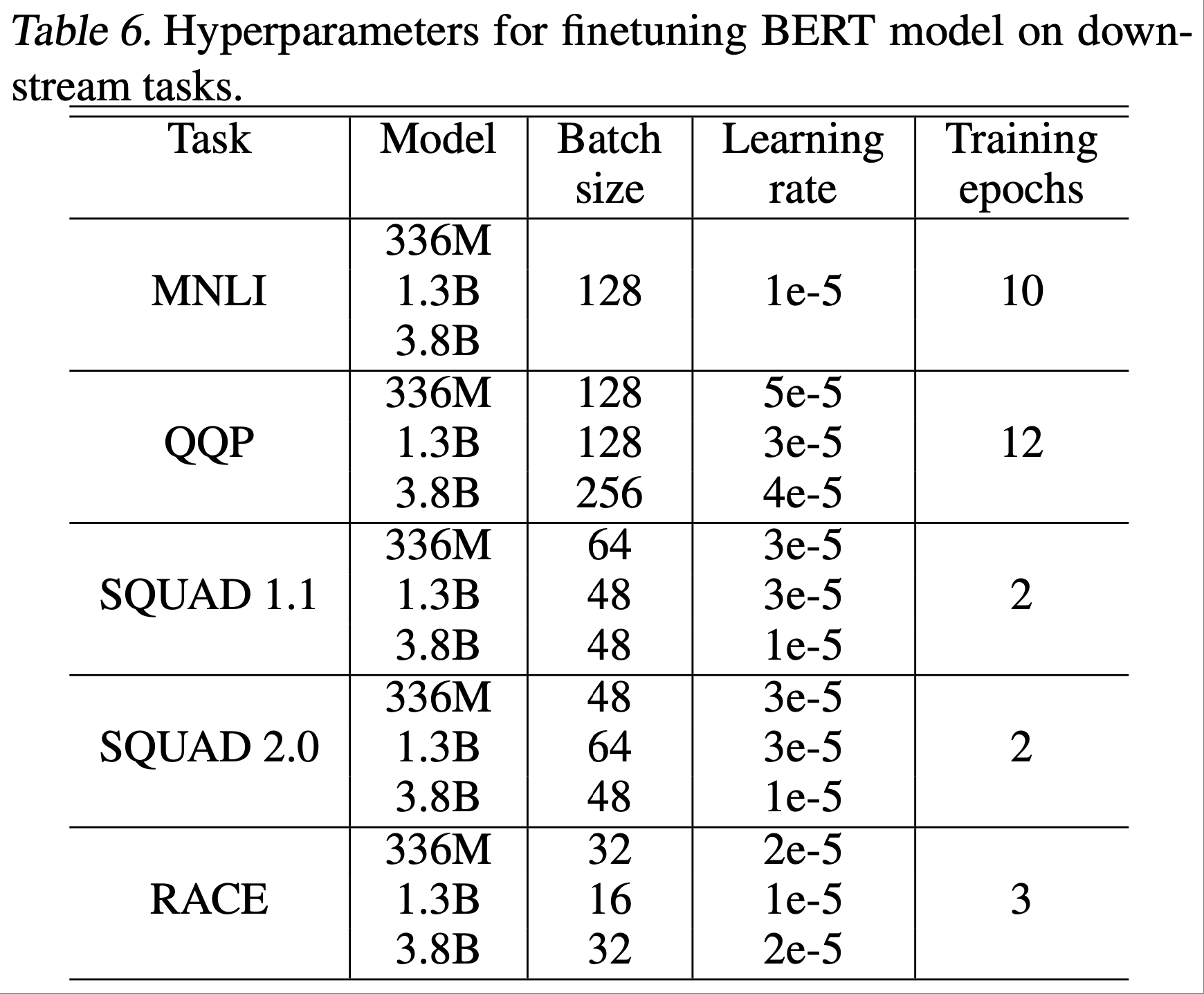
A. BERT Finetuning Hyperparameters
- 表6展示了每个模型和任务在微调过程中使用的超参数
B. Model Parallel Supplementary Material
在本节中,论文将详细介绍混合模型并行与数据并行以及随机数生成的处理方法
B.1 Hybrid Model and Data Parallelism
- 模型并行与数据并行是相互独立的,因此我们可以同时使用这两种方法,在合理的时间内训练大型模型
- 图8展示了用于混合模型并行与数据并行的 GPU 分组方式
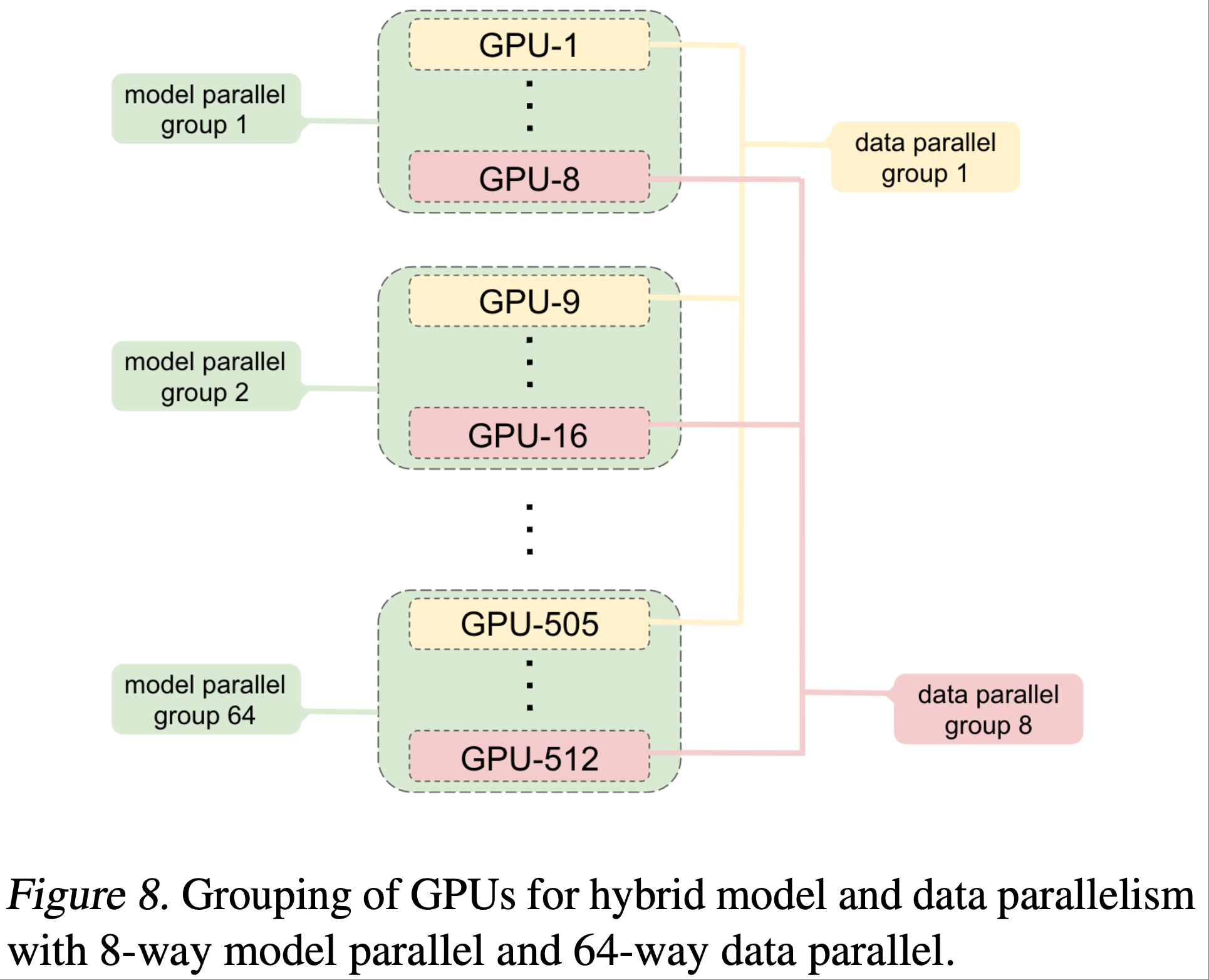
- 同一服务器内的两块或多块 GPU 组成模型并行组(例如图8中的 GPU 1 至 8),这些 GPU 共同分布运行一个模型实例
- 其余的 GPU(可能位于同一服务器内,但更常见的是位于其他服务器中)运行额外的模型并行组
- 每个模型并行组中处于相同位置的 GPU(例如图8 中的 GPU 1、9、……、505)组成数据并行组,因此数据并行组内的所有GPU都持有相同的模型参数
- 在反向传播过程中,论文并行运行多个梯度全归约(gradient all-reduce)操作,以在每个不同的数据并行组内归约权重梯度
- 所需的 GPU 总数是模型并行组数与数据并行组数的乘积
- 例如,对于 8.3B 参数的模型,论文每个模型并行组使用 8 块 GPU,并采用 64 路数据并行,因此总共需要 512 块 GPU
- 所有通信都是在 PyTorch 中通过 Python 调用 NCCL 实现的
- 每个模型并行组内的 GPU 在组内所有 GPU 之间执行全归约操作
- 对于数据并行,每个全归约操作都在每个模型并行组中的一块 GPU 之间进行
B.2 Model Parallel Random Number Generation
- 诸如 dropout 等利用随机数生成的技术是现代深度学习训练中的重要组成部分
- Transformer 在模型并行区域之外的残差连接之前以及模型并行区域内的自注意力块中都有 dropout 层
- 由于一些 dropout 层位于模型并行区域内,而另一些则不在,因此论文需要谨慎处理随机数生成,以确保 dropout 正常工作
- 为了在模型并行工作节点之间同步残差连接 dropout,论文在训练开始时使用相同的种子初始化随机数生成器
- 这使得所有模型并行工作节点的 dropout 模式完全相同
- 然而,模型并行区域内的 dropout 应该为每个工作节点生成不同的随机模式,以实现整个操作的随机性
- 为了实现这一点,论文为模型并行区域内的 dropout 维护一个单独的随机数生成器
- 每个模型并行工作节点的这个随机数生成器都有唯一的种子
C. Text Samples
- 本节展示了 Megatron-LM 使用上下文提示生成的一些文本样本
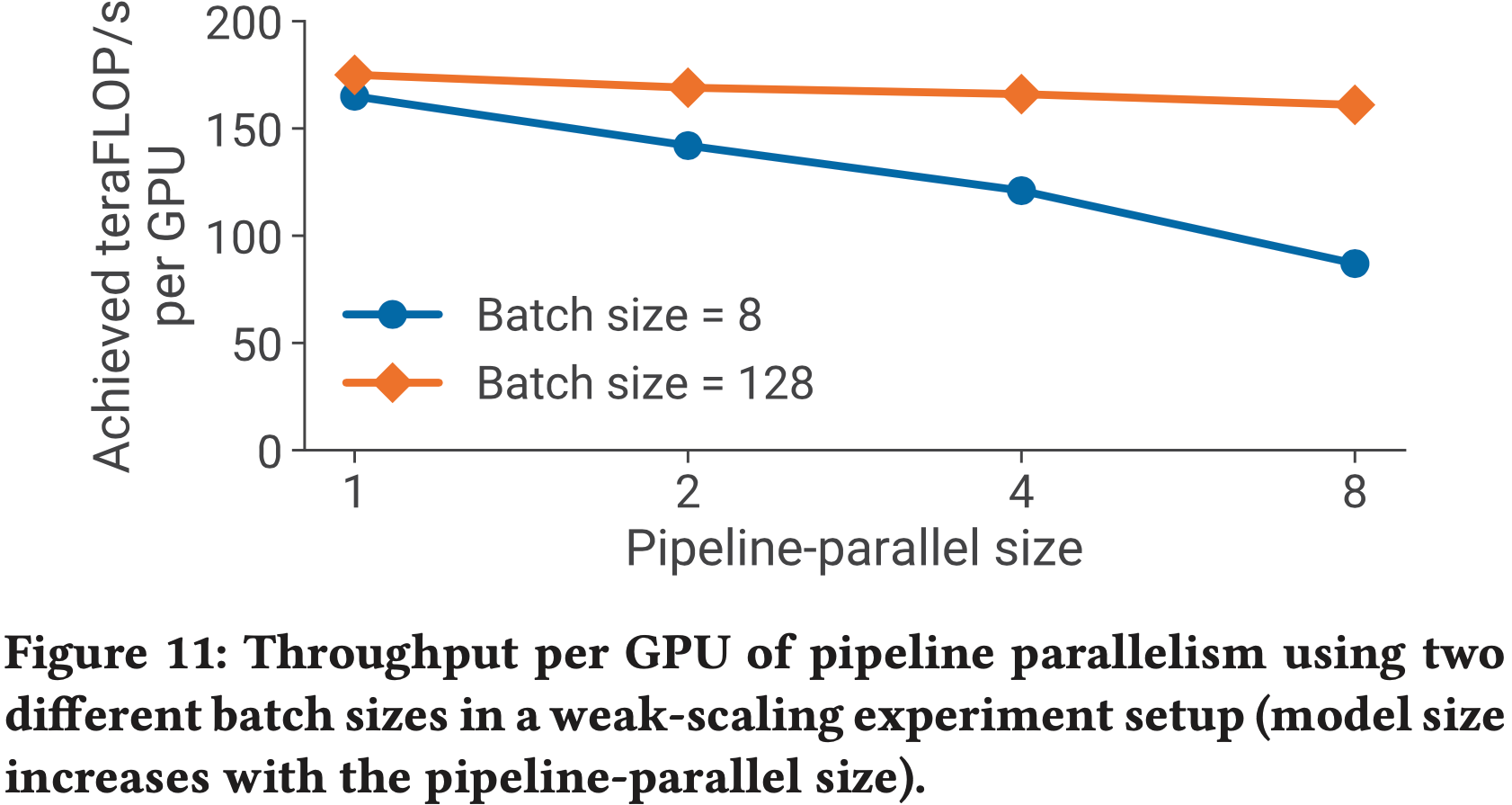
D. Further Scaling Analysis
- 在本节中,论文研究注意力头数对扩展性结果的影响
- 论文还展示了 1.2B 参数模型的强扩展性结果
D.1 Attention Heads and Scaling
- 本节研究注意力头数对模型并行扩展性的影响
- 为此,论文考虑 8.3B 参数配置(采用8路模型并行),并将注意力头数从 16 调整到 32
- 结果如表7所示
- 随着注意力头数的增加 ,自注意力层内的一些通用矩阵乘法(GEMMs)会变小 ,自注意力 softmax 中的元素数量也会增加
- 这导致扩展性效率略有下降
- 未来的研究在设计平衡模型速度和准确率的大型 Transformer 模型时,应注意这个超参数

- 随着注意力头数的增加 ,自注意力层内的一些通用矩阵乘法(GEMMs)会变小 ,自注意力 softmax 中的元素数量也会增加
D.2 Strong Scaling
- 论文的模型并行主要是为了能够训练规模超过单个 GPU 内存的模型,但它也可以在不增加批大小的情况下加速较小模型的训练
- 为了衡量这种加速效果,论文训练了一个固定的 1.2B 参数模型
- 论文使用每次迭代 8 个样本的固定批大小,并通过模型并行增加 GPU 数量
- 结果如表8所示
- 使用两块GPU可使训练速度提高 64%
- 超过这个数量后,论文看到收益递减,因为每个 GPU 的计算量减少,内存带宽和通信开销开始占据主导地位

E. 使用 WikiText103 和 LAMBADA 评估语言模型(Evaluating Language Models Using WikiText103 and LAMBADA)
- 在本节中,论文详细介绍了 WikiText103 数据集(2016)和 LAMBADA 数据集(2016)上完形填空式预测准确率的评估方法
E.1 Wikitext103 困惑度(Wikitext103 Perplexity)
- WikiText103 困惑度是过去几年中被广泛研究的评估标准,困惑度是语料库平均交叉熵的指数(2011)。是语言模型的自然评估指标,因为语言模型表示整个句子或文本的概率分布:
$$\text{PPL}=\exp \left(-\frac{1}{T_{o} } \sum_{t}^{T} \log P(t | 0: t-1)\right) \tag{4}$$ - 为了计算式(4)中的困惑度
- 论文根据子词词汇表对 WikiText103 测试语料库进行分词,并对每个 token \([0, T]\) 的交叉熵损失求和
- 然后,论文通过原始分词方案中的 token 数量 \(T_{0}\) 对交叉熵损失进行归一化
- WikiText103 测试语料库已经过预处理,采用单词级分词,先前的研究使用这种分词来计算困惑度
- 为了在公平的环境下与先前的研究比较论文模型的困惑度,论文必须通过原始 token 数量 \(T_{0}\) 进行归一化,而不是输入到论文模型中的实际分词数据的 token 数量 \(T\)
- 这种预分词还会在文本中引入训练数据中不存在的 artifacts
- 为了缓解这种分布不匹配,论文首先使用可逆的去分词器对 WikiText103 测试数据集进行预处理,以去除与标点符号和空格相关的各种 artifacts
- \(T_{0}\) 的值是在这种预处理之前计算的
- 对于WikiText103的测试集, \(T_{o}=245566\) , \(T=270329\)
- 论文还必须对困惑度计算进行一项特定于 Transformer 的修改
- 与基于 RNN 的语言模型不同, Transformer 在固定的窗口输入大小上运行
- 因此,它们无法完全计算 \(P(t | 0: t-1)\) ,只能计算 \(P(t | t-w: t-1)\) ,其中 \(w\) 是论文的上下文大小:1024 个 token
- 但为数据集中的每个 token 计算这个值的成本过高,因为论文必须对 \(w\) 大小的上下文进行大约 \(T\) 次评估
- 为了高效地评估论文的模型,论文采用了一种称为重叠评估(overlapping evaluation)的折中方法,每次滑动窗口前进一定的重叠量 \(o\) ,只计算窗口最后 \(o\) 个 token 的交叉熵损失
- 在论文的实验中,论文使用 32 的重叠量 \(o\) ,并以这种方式对所有滑动窗口计算损失
E.2 LAMBADA Cloze Accuracy
- 处理长期上下文的能力对于 SOTA 语言模型至关重要,也是长文本生成和基于文档的问答等问题的必要前提
- 像 LAMBADA 这样的完形填空式数据集旨在衡量模型在这些类型的长期上下文中运行和推理的能力
- 完形填空式阅读理解使用单词 token 的上下文 \(x=x_{1: t}\) ,其中一个 token \(x_{j}\) 被掩码;
- 模型的目标是正确预测缺失的第 \(j\) 个 token
- 为了准确预测缺失的 token,模型需要深入理解周围的上下文以及在这种上下文中应如何使用语言
- LAMBADA 使用完形填空式阅读理解来测试生成式从左到右语言模型,它构建了 45 个句子的示例,其中上下文 \(x_{t}\) 的最后一个单词被掩码
- 论文的模型使用子词单元,因此在 LAMBADA 评估中,论文使用原始的、未处理的 LAMBADA 数据集,并要求论文的模型预测组成单词 token 的多个子词token
- 论文使用教师强制(teacher forcing),只有当所有输出预测都正确时,才认为答案正确
- 这种形式与原始的单词 token 预测任务等效


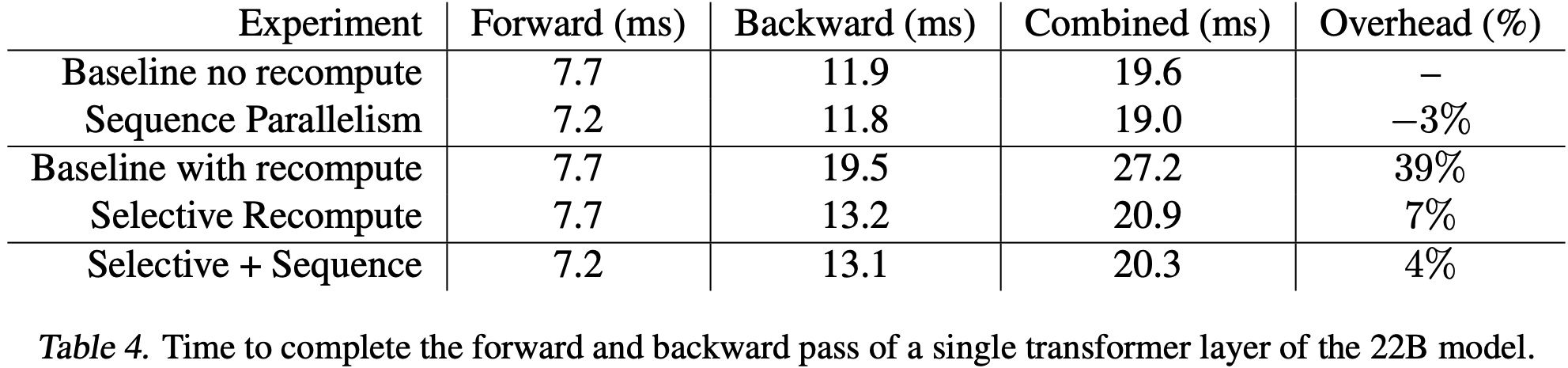
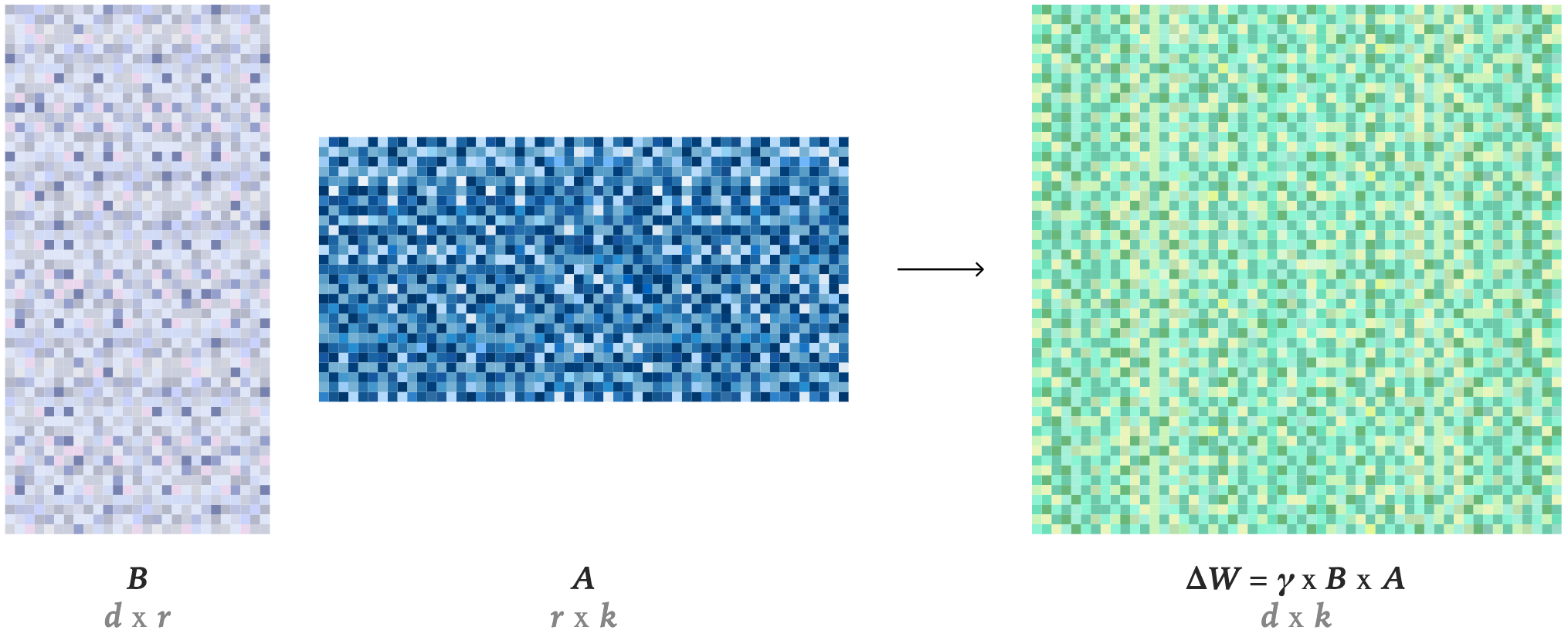
中,高 Rank LoRA 在一个数据集上的性能优于 FullFT,在另一个数据集上则表现较差;由于 Training Dynamics 或泛化行为的差异,LoRA 在不同数据集上的性能可能存在一定的随机波动")

与 FullFT(实线)之间存在持续的差距;右图:最终损失随批量大小变化的曲线显示,LoRA 因批量大小增加而产生的损失 penalty 更大")
的性能显著低于仅应用于 MLP 层的 LoRA(MLP-Only LoRA),且在 MLP 层应用 LoRA 的基础上再增加注意力层的 LoRA,也无法进一步提升性能;这种现象在 Dense 模型(Llama-3.1-8B)和稀疏 MoE 模型(Qwen3-30B-A3B-Base)中均存在")

和 MATH(右图)数据集上的学习率与最终奖励(准确率)关系图")

上的基准分数;右图展示了训练过程中思维链(CoT)长度的变化,这可以作为模型学习推理能力的一个指标")
的学习曲线差异;左图为学习曲线,右图为 Rank 16 和 Rank 256 对应的学习曲线差异(随时间增大);奇怪的是,在最初几步,该差异为负值(尽管数值很小),因此图中未显示这部分曲线")





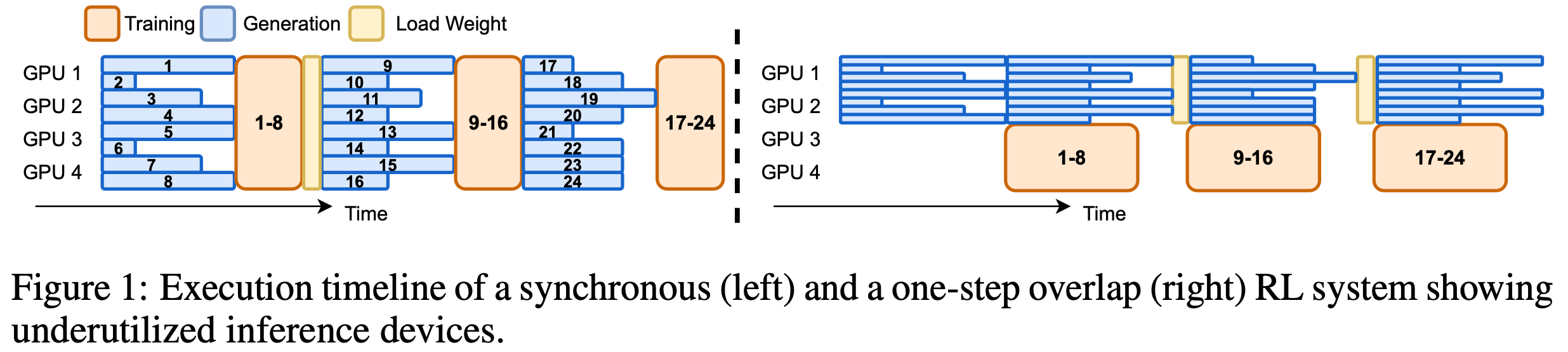
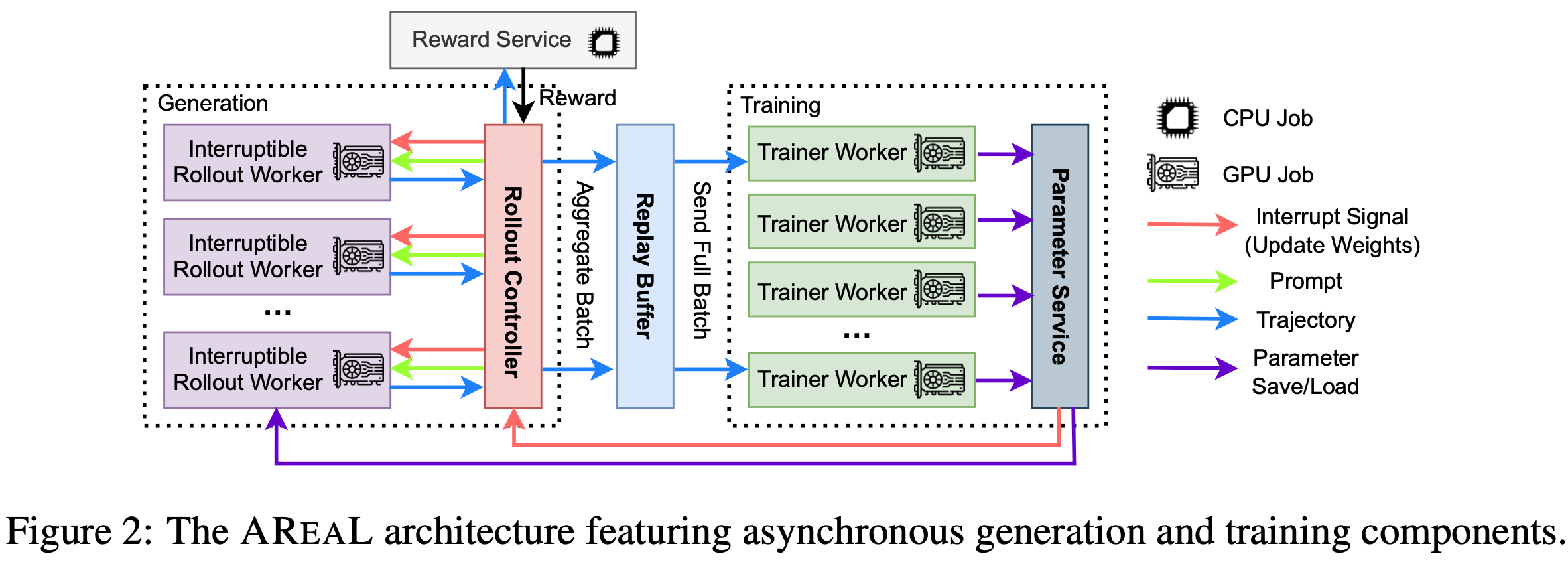
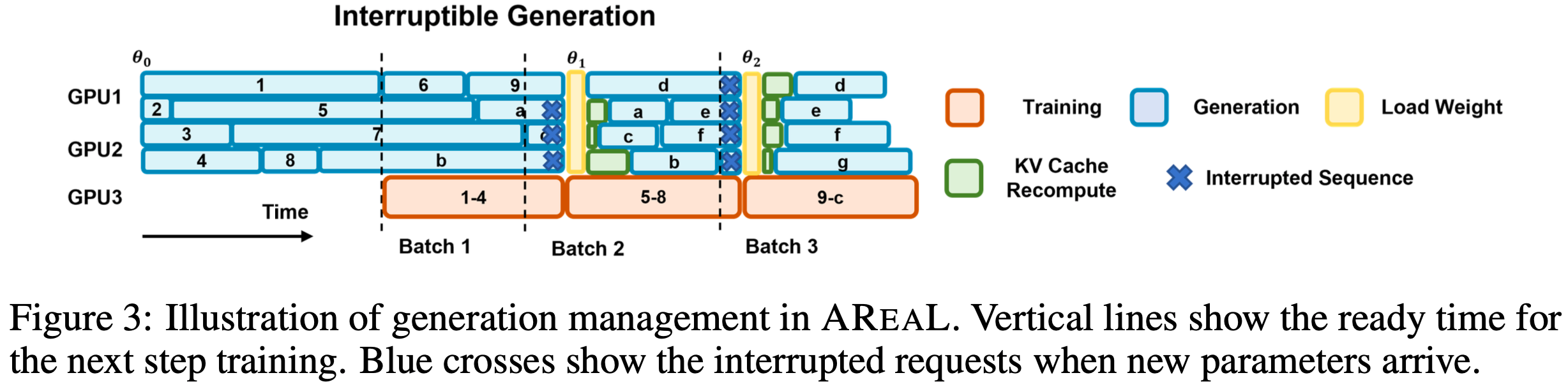
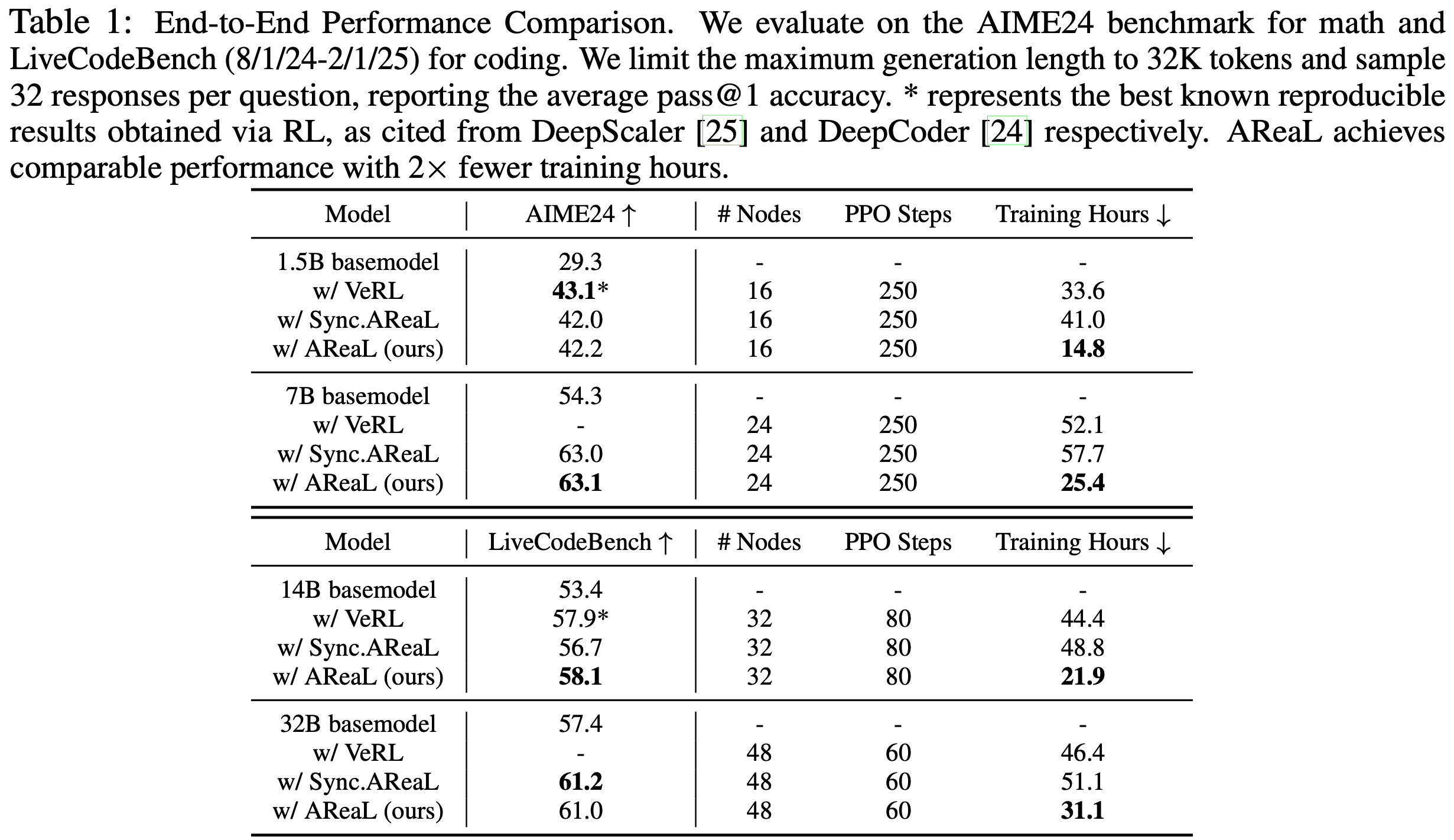

 score as training progresses. At step 180, context length is extended to 32K. The best 32K checkpoint is used for inference-time scaling to 64K, achieving 60.6% LCB—matching o3-mini’s performance.")



 > Baby, there ain't no mountain high enough.
Ain't no context long enough.
— Inspired by Marvin Gaye & Tammi Terrell
> Baby, there ain't no mountain high enough.
Ain't no context long enough.
— Inspired by Marvin Gaye & Tammi Terrell.")

, trainer workers process them asynchronously. At the end of an iteration, trainers broadcast their weights to samplers.")