注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:(AutoRubric)Auto-Rubric: Learning to Extract Generalizable Criteria for Reward Modeling, 20251020, Alibaba & Ant Group
- GitHub 源码:github.com/modelscope/RM-Gallery
- 注:从作者的代码实现中可以看到,同时有中文和英文两个版本
- HuggingFace 数据集: huggingface.co/datasets/agentscope-ai/Auto-Rubric
- 亲测本文开源的 General Rubrics 在各种 Reward Model Benchmarks 中均有不错的表现
- 特别是和 BT RM 融合以后,在各种 Reward Model Benchmark 上能拿到超出 BT RM 的结果
Paper Summary
- 整体总结:
- 论文介绍了一个新颖的、Training-free 框架(Auto-Rubric)
- Auto-Rubric 成功地解决了奖励建模中性能、数据效率和可解释性之间的关键权衡
- 认知迭代:论文的工作表明,人类偏好背后的核心标准可以自动提炼成一个紧凑的(compact)、可泛化的、非冗余的 “Theme-Tips” Rubrics 集
- 这种方法的有效性值得注意的发现:
- 仅使用 70 个偏好对(源数据的 1.5%),提取的 Rubrics 使 Qwen3-8B 模型能够超越专门的、完全训练的奖励模型
- 在 RewardBench2 上为免训练方法设定了新的最先进水平
- 核心观点:通过将焦点从不透明的 Reward model learning 转移到透明的 Rubric learning ,可以为 LLM 对齐开辟一条更具可扩展性、更高效、更可信的路径
- 评价:
- 论文通过一种非常严谨的理论化方法自动生成 Rubric,直观上看起来很 Make sense
- 论文的在各种评估基准上的分数特别高,是因为论文是 pairwise 的(同时输入两个 Response 判断分数),不是 pointwise 的
- 特别说明:亲测本文开源的 General Rubrics 在各种 Reward Model Benchmarks 中均有不错的表现,特别是和 BT RM 融合以后,在各种 Reward Model Benchmark 上能拿到超出 BT RM 的结果
- 论文介绍了一个新颖的、Training-free 框架(Auto-Rubric)
- 问题提出:
- 奖励模型对于将 LLM 与人类价值观对齐至关重要,但其发展受限于昂贵的偏好数据集和较差的解释性
- 虽然近期的 Rubric-based 方法提供了透明度,但它们通常缺乏系统性的质量控制和优化 ,导致可扩展性与可靠性之间存在权衡
- 论文通过一个新颖、无需训练 (training-free) 的框架来解决这些局限性
- 该框架建立在一个关键假设之上:支撑人类偏好的评估 Rubric 在不同 Query 间展现出显著的泛化能力(evaluation rubrics underlying human preferences exhibit significant generalization ability across di- verse queries)
- 这一特性实现了卓越的数据效率
- 论文的方法是两阶段的:
- 首先通过一个验证引导的 Propose-Evaluate-Revise 流程推断出高质量的、针对特定 Query 的 Rubric
- 然后通过最大化信息论编码率(information-theoretic coding rate) ,将这些细粒度的 Rubric 泛化成一个紧凑、非冗余的核心集合
- 最终的输出是一个可解释的、层次化的 “主题-要点(Theme-Tips)” Rubric 集合
- 该框架建立在一个关键假设之上:支撑人类偏好的评估 Rubric 在不同 Query 间展现出显著的泛化能力(evaluation rubrics underlying human preferences exhibit significant generalization ability across di- verse queries)
- 大量实验证明了该框架卓越的数据效率和性能
- 关键的是(Critically),仅使用 70 个偏好对(源数据的 1.5%),论文的方法还能使像 Qwen3-8B 这样的小模型胜过专门的、经过充分训练的同类模型
- 这项工作开创了一条可扩展、可解释且数据高效的奖励建模路径
Introduction and Discussion
- RLHF 是使 LLM 与人类价值观对齐的强大范式 (2022)
- 如图 1 所示,RLHF 的核心是一个奖励模型,它在大量的人类偏好数据集上进行训练,作为人类判断的代理 (2023; 2025)
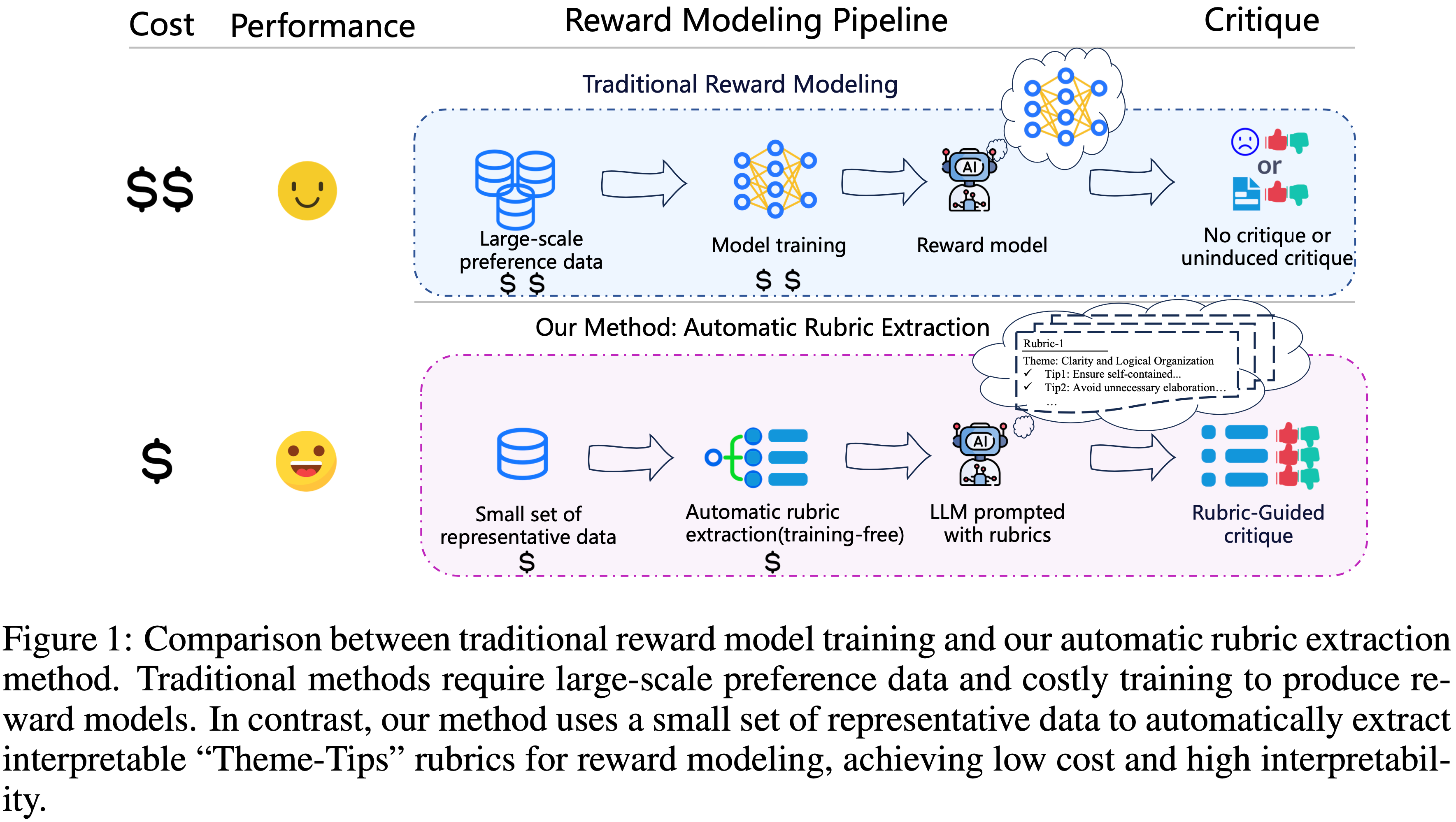
- However,这种方法从根本上受到数据获取成本高昂以及奖励模型的“黑盒”性质的限制 (2025)
- 这种解释性的缺乏不仅阻碍了我们诊断故障的能力,也增加了“Reward Hacking”的风险 (2025),即模型以非预期的方式利用代理奖励
- 为了解决这些缺点,使用明确标准的 Rubric-based 评估作为一种更透明的替代方案得到了关注
- Rubric 是一套明确的、人类可读的标准,例如事实准确性和内容组织良好,可以有效地将其作为“LLM-as-a-Judge”范式的 Prompt 的一部分
- 早期方法依赖于专家定义的(expert-defined) Rubric (2024) 或大规模众包标注(large-scale crowd annotations)(2022)
- 早期方法有限的可扩展性促使研究转向自动化的 Rubric 生成 (2025; 2025)
- 这些方法产生的 Rubric 常常存在噪声、冗余(redundancy)以及与人类偏好不一致(misalignment with human preferences)的问题,原因是缺乏验证机制
- Consequently,在可扩展性与保真度之间产生了根本性的矛盾 ,这构成了 Rubric-based 评估更广泛采用的主要瓶颈
- 为了化解这一矛盾(tension),论文提出了一个新的框架,用于使用少量偏好数据自动生成和精炼高质量的评估 Rubric
- 论文的工作建立在一个关键假设之上:支撑人类偏好的评估 Rubric 在不同 Query 间展现出显著的泛化能力
- For Example,人类通常更喜欢对不同 Query 给出更具逻辑性、组织良好且基于事实的回答
- 论文的目标不是学习一个不透明的奖励函数,而是明确地推断出支配人类选择的基本原理,即 Rubric
- 这代表了从典型的奖励模型学习到Rubric 学习的根本性转变,这一对比在图 1 中进行了直观总结
- 为了实现这一新范式,论文的方法通过两个阶段运作:
- 针对特定 Query 的 Rubric 生成(Query-Specific Rubric Generation)
- 针对特定 Query 的 Rubric 生成采用迭代的 Propose-Evaluate-Revise 循环,将 Rubric 生成视为一个约束优化问题,确保每个 Rubric 都经过其判别能力的验证
- 与 Query 无关的 Rubric 聚合(Query-Agnostic Rubric Aggregation)
- 与 Query 无关的 Rubric 聚合使用一种 信息论选择(information-theoretic selection) 算法
- 将从大量经过验证的细粒度 Rubric 池中提炼出一个紧凑的、层次化结构的 Rubric,论文称之为 “Theme-Tips” Rubric
- 这个 Rubric 包含高层主题和相应的可操作要点
- 与 Query 无关的 Rubric 聚合使用一种 信息论选择(information-theoretic selection) 算法
- 针对特定 Query 的 Rubric 生成(Query-Specific Rubric Generation)
- 论文的主要贡献如下:
- 一种数据高效、无需训练的自动化 Rubric 提取框架(A data-efficient, training-free framework for automated rubric extraction)
- 论文的两阶段 Propose-Evaluate-Revise 和信息论选择机制仅使用典型偏好数据的一小部分就实现了 SOTA 性能
- 开源的 Rubric 数据集(Open-source rubric datasets)
- 论文发布了从偏好数据推断出的、与 Query 无关的 Rubric 公共数据集,以促进可解释对齐的研究
- 一种新颖的 Rubric 分析框架(A novel rubric analysis framework)
- 论文引入了一种通过覆盖率、精确度和贡献度指标来剖析 Rubric 效用的定量方法,为评估过程提供了更深入的见解
- 在奖励建模基准测试上的最先进性能(State-of-the-art performance on reward modeling benchmarks)
- 论文的方法在四个基准测试上持续改进了基础 LLM
- Notably,论文在 RewardBench2 上的性能为无需训练的方法设定了新的最先进水平,论文 Rubric 增强的 Qwen3-235B 和 Qwen3-8B 在多个基准上优于许多专门的、经过充分训练的奖励模型
- 一种数据高效、无需训练的自动化 Rubric 提取框架(A data-efficient, training-free framework for automated rubric extraction)
Methodology
- Overview 论文的框架系统地从少量人类偏好样本中推断出一套通用的、可解释的评估 Rubric
- 论文的方法论被结构化为几个阶段,从细粒度开始以最大化数据效率
- Step1:将 Rubric 学习公式化为传统奖励建模的替代方案
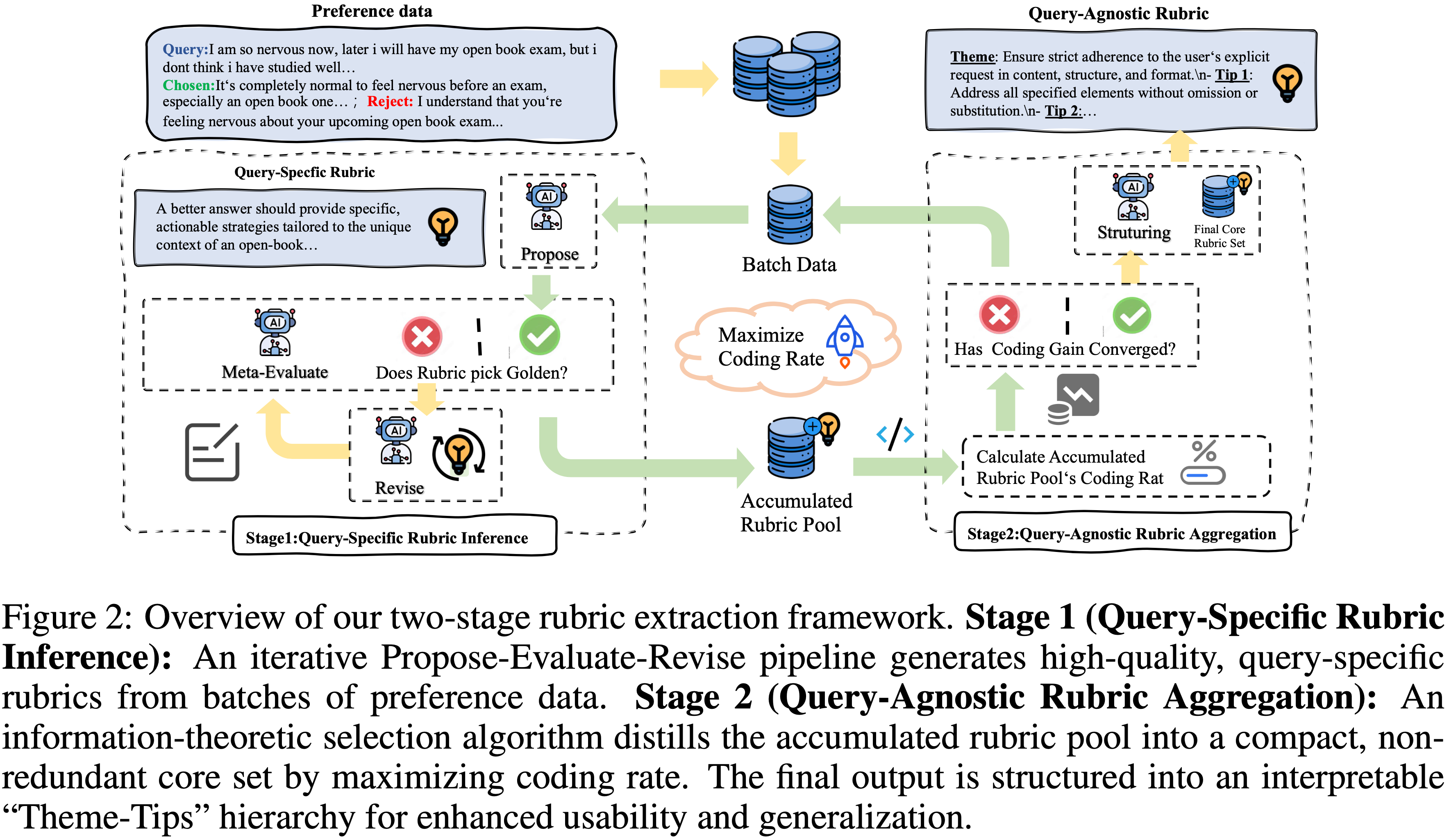
- Step2:在初始生成阶段,处理一小批种子数据,通过一个以验证为中心的循环为每个偏好对推断出高保真的(high-fidelity)、针对特定 Query 的 Rubric,如图 2 所示
- Step3:使用信息论方法,将这些细粒度 Rubric 聚合成一个紧凑的、与 Query 无关的集合
- Step4:论文引入一个定量框架来分析最终集合中每个 Rubric 的效用和贡献
Formulation
- 从人类偏好(human preferences)中学习的传统方法是训练一个参数化的奖励模型
- 给定一个偏好数据集 \(\mathcal{D}=\{(x_{i},y^{+}_{i},y^{-}_{i})\}^{N}_{i=1}\)
- 目标是学习一个标量奖励函数 \(r_{\theta}(x,y)\),该函数为偏好的回答分配更高的分数
- 这通常使用 Bradley-Terry 模型 (1952) 进行优化,其中偏好的概率被建模为:
$$P(y^{+}_{i}\succ y^{-}_{i}|x_{i})=\sigma(r_{\theta}(x_{i},y^{+}_{i})-r_{\theta}(x_{i},y^{-}_{i})) \tag{1}$$- 目标是通过最大化数据集的似然对数来找到最优参数 \(\theta\)
- 虽然有效,但这个过程产生了一个不透明的奖励函数 \(r_{\theta}\)
- 一个“黑盒”,对为何一个回答优于另一个提供的洞察有限
- 这种解释性的缺乏阻碍了故障诊断和信任
- 为了克服这些挑战,论文的工作尝试从 奖励模型学习(Reward Model Learning) 到 Rubric 学习(Rubric Learning) 的范式转变
- 论文的目标不是优化一个难以理解的函数的参数 \(\theta\),而是直接推断出最能解释 \(\mathcal{D}\) 中偏好的、明确的、人类可读的 Rubric 集合 \(R\)
- 论文的优化问题仍然是:
$$R^{*}_{\text{task} }=\arg\max_{R}\sum_{i=1}^{N}\mathbb{I}[\text{eval}_{R}(x_{i},y ^{+}_{i},y^{-}_{i})=\text{correct}] \tag{2}$$
- However,评估函数 \(\text{eval}_{R}(\cdot)\) 不再是一个参数化模型,而是一个由 \(R\) 中的自然语言 Rubric 引导的透明推理过程
- 在实践中(In practice),这个评估函数是通过向一个大语言模型 Prompt Query 、候选回答和 Rubric 集合 \(R\),并要求其做出偏好判断来实现的
- 直接求解方程 2 中的 \(R_{\text{task} }\) 是难以处理的,因为它需要在极其庞大且非结构化的自然语言规则空间中进行搜索
- 为了使这个问题可处理,论文引入了一个实用的两阶段框架,该框架从少量样本中自动化生成和聚合 Rubric,具体如下所述
Query-Specific Rubric Generation
- 论文的框架不是需要一个大规模数据集,而是从细粒度开始,通过处理一小批种子数据来为每个单独的偏好对 \((x_{i},y^{+}_{i},y^{-}_{i})\) 推断出高质量的 Rubric
- 这个过程的核心是一个迭代的 Propose-Evaluate-Revise 循环,它强调验证以确保 Rubric 质量
- 形式上,对于单个偏好对的过程始于一个提案模型(proposal model) \(\mathcal{M}_{\text{propose} }\) 提出一个初始的 Rubric 集合:
$$R^{(0)}_{i}\leftarrow\mathcal{M}_{\text{propose} }(x_{i},y^{+}_{i},y^{-}_{i}) \tag{3}$$- 在每次迭代 \(t\),一个评估模型 \(\mathcal{M}_{\text{evaluate} }\) 通过做出判断来验证当前的 Rubric 集合 \(R^{(t)}_{i}\):
$$y^{(t)}_{\text{pred} }\leftarrow\mathcal{M}_{\text{evaluate} }(x_{i},y^{+}_{i},y^ {-}_{i},R^{(t)}_{i})\tag{4}$$- 这个验证步骤是必要的,充当质量关口
- 理解:这里可以验证之前生成的 Rubric 集合是否能够准确评判原始 Response 的好坏
- 如果预测与真实偏好不匹配 (\(y^{(t)}_{\text{pred} }\neq y^{+}_{i}\)),失败的 Rubric 集合 \(R^{(t)}_{i}\) 被用作负反馈
- 然后,一个修订模型 \(\mathcal{M}_{\text{revise} }\) 产生一个改进的(Rubrics)集合:
$$R^{(t+1)}_{i}\leftarrow\mathcal{M}_{\text{revise} }(x_{i},y^{+}_{i},y^{-}_{i},R^ {(t)}_{i})\tag{5}$$
- 然后,一个修订模型 \(\mathcal{M}_{\text{revise} }\) 产生一个改进的(Rubrics)集合:
- 这个验证步骤是必要的,充当质量关口
- 这种迭代精炼会持续进行,直到验证成功或达到最大迭代次数 \(E_{\text{max} }\)
- 理解:这里被迭代优化的对象是 Rubrics 集合,随着迭代的进行,Rubrics 集合会越来越好
- 在每次迭代 \(t\),一个评估模型 \(\mathcal{M}_{\text{evaluate} }\) 通过做出判断来验证当前的 Rubric 集合 \(R^{(t)}_{i}\):
- Finally,对于每个样本 \((x_{i},y^{+}_{i},y^{-}_{i})\)(这里 \(i\) 表示样本索引)
- 论文生成一个针对特定 Query 的 Rubric 集合 \(R^{*}_{i}\),它捕捉了该特定实例最相关的评估标准
- 这个过程填充了一个庞大的候选 Rubric 池 :
$$ \mathcal{R}_{\text{pool} }=\bigcup_{i=1}^{N}R^{*}_{i} $$
Query-Agnostic Rubric Aggregation(Query 无关的聚合)
- 虽然初始生成阶段产生了一个丰富的、高质量的、针对特定 Query 的 Rubric 池 \(\mathcal{R}_{\text{pool} }\),但这个集合本身是不够的
- 它本质上是冗余的(例如,同样的潜在 Rubric 以许多略微不同的措辞表达)并且是碎片化的(许多 Rubric 对其源 Query 过于特定,难以广泛使用)
- Therefore,一个与 Query 无关的聚合阶段至关重要
- 主要目标是提炼一个最小但全面的 Rubric 核心集合,以增强对未见 Query 的泛化性和可转移性
- 这通过从原始的、针对特定 Query 的池中识别并合并最基本和重复出现的评估 Rubric 来实现
- 为了实现这一点,论文选择一个能最大化信息增益的子集,确保高的语义覆盖率同时最小化冗余
- 从几何角度看,这等同于选择一组能够张成最大可能体积的嵌入向量,这个过程自然会惩罚冗余的向量(Geometrically, this is equivalent to selecting a set of embedding vectors that span the largest possible volume, a process that naturally penalizes redundant (i.e., near-collinear) vectors)
- 论文的选择标准是 最大化编码率(coding rate) (2020),并直接实现了这一原则
- 编码率是一个定义在 Rubric 嵌入 \(\mathbf{E}_{R}\in\mathbb{R}^{d\times|R|}\) 上的信息论度量:
$$\mathcal{C}(\mathbf{E}_{R},\varepsilon)=\frac{1}{2}\log\det\left(\mathbf{I}+ \frac{1}{\varepsilon^{2}|R|}\mathbf{E}_{R}^{\top}\mathbf{E}_{R}\right) \tag{6}$$- 其中 \(\mathcal{C}\in\mathbb{R}\),\(\varepsilon>0\) 控制压缩与保真度之间的权衡
- 最大化此函数等同于最大化 Rubric 嵌入向量所张成的体积,从而促进多样性
- 优化问题是找到核心集合 \(R_{\text{core} }\):
$$R_{\text{core} }^{*}=\arg\max_{R\subseteq R_{\text{pool} },|R|\leq m}\mathcal{C}(\mathbf{E}_{R},\varepsilon) \tag{7}$$- 其中 \(m\) 是 Rubric 集合的期望大小
- 由于这个问题是 NP 难的,论文采用一种贪心算法,迭代选择能提供最高边际信息增益的 Rubric
- 从一个空集 \(R_{0}=\emptyset\) 开始,在每一步 \(k\),论文添加 Rubric \(r_{k+1}\),使得:
$$r_{k+1}=\arg\max_{r\in\mathcal{R}_{\text{pool} }\setminus R_{k} }\left[\mathcal{C }(\mathbf{E}_{R_{k}\cup\{r\} },\varepsilon)-\mathcal{C}(\mathbf{E}_{R_{k} },\varepsilon)\right] \tag{8}$$- 理解:每次都添加使得增益最大的 Rubric
- 从一个空集 \(R_{0}=\emptyset\) 开始,在每一步 \(k\),论文添加 Rubric \(r_{k+1}\),使得:
- 编码率是一个定义在 Rubric 嵌入 \(\mathbf{E}_{R}\in\mathbb{R}^{d\times|R|}\) 上的信息论度量:
- 这个过程持续进行直到收敛,收敛由一个提前停止标准确定:
- 编码率的边际增益必须连续若干次低于最小阈值 (\(\tau_{\min}\)) 以确保核心集合的信息内容已经饱和
- Finally,选出的核心集由一个 structuring LLM 组织成论文可解释的 “Theme-Tips” 层次结构
- 注:这一步也通过 Prompt 大模型来实现,详细 Prompt 见附录 H
- 这一步的目标:通过 Prompt 让 LLM 帮忙生成结构化的 Rubric,这一步已经与 Query 无关了
- 输入:一批 Rubric
- 输出:符合指定要求的,“Theme-Tips” 层次结构的 几条总结性 Rubric
- 问题:附录中 Prompt 中没有给模型展示输入 Rubrics
- 回答:看了一下源码,作者源码中的内容跟这个 Prompt 不完全一致(是包含了所有 Rubric 的),详情见 OpenJudge/openjudge/generator/iterative_rubric/categorizer.py
- 这个两阶段框架可以被视为一个在线学习过程(online learning process)
- 其中新的偏好数据批次被用来生成更多针对特定 Query 的 Rubric,这些 Rubric 反过来迭代地精炼和扩展与 Query 无关的核心集合,从而实现高样本效率
- 论文流程每个阶段使用的具体 Prompt 详见附录 H
A Framework for Rubric Analysis
- 为确保最终的 Rubric 集合不仅性能优越,而且健壮且结构良好,论文引入了一个定量分析框架
- 这个框架是论文方法论的核心部分,使论文能够剖析最终集合 \(R_{\text{task} }\) 中每个单独 Rubric 的效用
- 通过评估每个 Rubric 在三个关键维度上的表现,我们可以验证聚合过程的有效性,并对评估机制获得更深入的见解
- 对于每个 Rubric \(r_{j}\in R_{\text{task} }\),论文定义以下指标:
- 覆盖率 (Coverage): 该 Rubric 能提供判别信号测试样本的比例(此指标衡量 Rubric 的通用性和适用性)
$$\text{Coverage}(r_{j})=\frac{1}{|D_{\text{test} }|}\sum_{i\in D_{\text{test} } }\mathbb{I}[\text{eval}_{\{r_{j}\} }(x_{i},y_{i}^{+},y_{i}^{-})\neq\text{tie}]\tag{9}$$ - 精确度 (Precision): 给定 Rubric 提供了判别信号,其判断与真实偏好一致的条件概率(衡量了 Rubric 的可靠性)
$$\text{Precision}(r_{j})=P(\text{eval}_{\{r_{j}\} }\text{ is correct}|\text{eval }_{\{r_{j}\} }\neq\text{tie})\tag{10}$$ - 贡献度 (Contribution): Rubric 对全集性能的边际影响,通过移除它时整体准确率的下降来度量(量化了 Rubric 的独特价值和非冗余性)
$$\text{Contribution}(r_{j})=\text{Acc}(R_{\text{task} })-\text{Acc}(R_{\text{task} }\setminus\{r_{j}\})\tag{11}$$
- 覆盖率 (Coverage): 该 Rubric 能提供判别信号测试样本的比例(此指标衡量 Rubric 的通用性和适用性)
- 这个分析框架对于验证论文的方法产生了一组互补的 Rubric 至关重要,这些 Rubric 平衡了通用、高覆盖率的 Rubric 与专门、高精确度的 Rubric
Experiment
- 在本节中,论文进行了一系列实验来验证论文框架的核心贡献
- 论文的目标是证明其:
- (1) 在标准奖励建模基准测试上的最先进性能;
- (2) 通过快速收敛所体现的高数据效率;
- (3) 以及通过论文新颖的分析方法所验证的、能够生成高价值、可解释的 Rubrics 的能力
Experimental Setting
Datasets
- 论文从两个偏好数据集中提取 Rubrics:
- (1) HelpSteer3-Preference (2025) 提供了一个涵盖四个领域(通用、STEM、代码、多语言)的开放的人工标注偏好数据集
- 论文专注于通用领域进行 Rubrics 提取
- (2) UltraFeedback-Binarized (2024) 包含由 GPT-4 在诸如 helpfulness 和 honesty 等 Rubrics 上评分的 Prompt 和模型完成结果
- (1) HelpSteer3-Preference (2025) 提供了一个涵盖四个领域(通用、STEM、代码、多语言)的开放的人工标注偏好数据集
Baselines
- 论文将论文的方法与三类基线进行比较:
- (1) 基础模型 (Base Models) :使用各种 LLM 进行零样本评估,不使用任何 Rubrics
- (2) 上下文学习 (In-Context Learning, ICL) (2022):使用相同的 \(k=5\) 个示例提示基础模型以进行偏好评估
- (3) 基于训练的奖励模型 (Training-based Reward Models) :一套全面的最先进模型,包括 ArmoRM(2024)、J1(2025)、R3(2025)、RM-R1(2025) 和 Skywork-Reward-V2(2025a)
Evaluation Benchmarks
- 论文在涵盖多个领域的四个标准基准上进行了评估:
- RewardBench (2024)、RewardBench2 (2025)、RM-Bench (2025b)、JudgeBench (2025)
Models
- 论文的 Training-free 框架在整个 Rubrics 构建阶段(包括 Propose、Evaluate、Revise 和 Structuring)都使用 Qwen3-32B(2025)
- 论文进一步分析了所得 Rubrics 在一系列 LLM 之间的泛化能力,发现由 Qwen3-32B 生成的 Rubrics 表现出最强的跨模型适用性(见附录 C)
- 详细的实验设置和实施细节见附录 B
Main Results
State-of-the-Art Performance Across Benchmarks
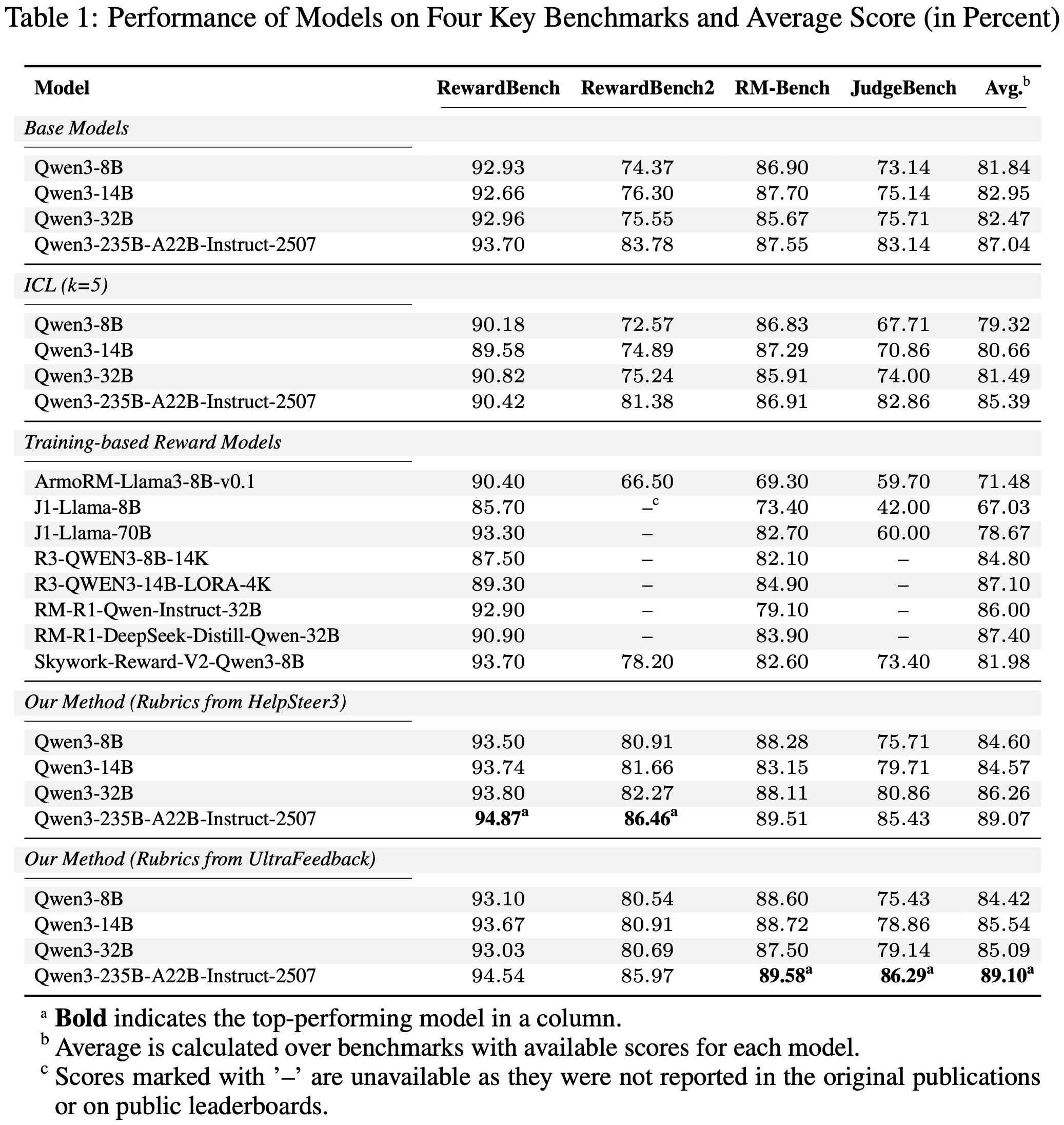
- 论文的框架展示了 SOTA 性能,在四个评估基准上均获得了最高分(详见表 1)
- Specifically,论文的 Qwen3-235B 模型:
- 在 RewardBench 上达到了最高分 94.87%
- 在 RewardBench2 上达到 86.46%
- 在 RM-Bench 上达到 89.58%
- 在 JudgeBench 上达到 86.29%
- 这一广泛成功突显了所提取 Rubrics 的鲁棒性和普遍适用性
Consistent Improvement Across Model Scales(跨模型规模时,体现了一的改进)
- 如表 1 所示,经过 Rubric 增强的模型持续优于其基础版本,在 Qwen3-14B (+2.59%)、Qwen3-32B (+3.79%) 上观察到了显著的准确率平均增益
- Notably,论文的方法使较小的模型能够实现卓越的性能
- 例如,论文基于 Rubrics 指导的 Qwen3-8B 不仅在 RewardBench2 上超越了专门的、完全训练的 Skywork-Reward-V2-Qwen3-8B (80.91% vs. 78.20%),而且在 RM-Bench 上也显示出明显的优势 (88.28% vs. 82.60%)
- 证明了其增强效果并不局限于单一基准
Robustness Across Rubric Source Datasets(跨 Rubric 源数据集表现了鲁棒性)
- 该框架的泛化能力很强,从人工标注的 HelpSteer3 和 AI 标注的 UltraFeedback 中推导出的 Rubrics 都产生了具有竞争力的、 SOTA 结果
- 尽管 Qwen3-235B 上的平均得分几乎相同 (89.07% vs. 89.10%),但每组 Rubrics 在不同的基准上表现出色
- HelpSteer3 在 RewardBench/RewardBench2 上表现更好
- UltraFeedback 在 RM-Bench/JudgeBench 上表现更好
- 这证明了该框架从人类和 AI 标注中都捕捉到了基本的偏好模式
Data Efficiency and Convergence Analysis
- 论文工作的一个核心主张是,在显著的数据效率下实现高性能
- 论文通过分析信息论选择过程的收敛性来证明这一点
- 该过程从包含 4,626 个样本的 HelpSteer3 训练数据集中迭代地抽取批次大小为 \(B=10\) 的偏好对
- 论文的框架采用了一种早停机制,当编码率的边际增益连续 \(p_{\text{patience} }=2\) 次低于 \(\tau_{\min}=0.002\) 时,信息论选择过程终止
- 每个偏好对最多经历 \(E_{\text{max} }=10\) 轮的 Propose-Evaluate-Revise 循环以确保 Rubrics 质量
- 图 3 提供了这种效率的直接证据,论文将其归因于论文的选择过程从少量样本中快速识别出了一个全面且非冗余的 Rubrics 集
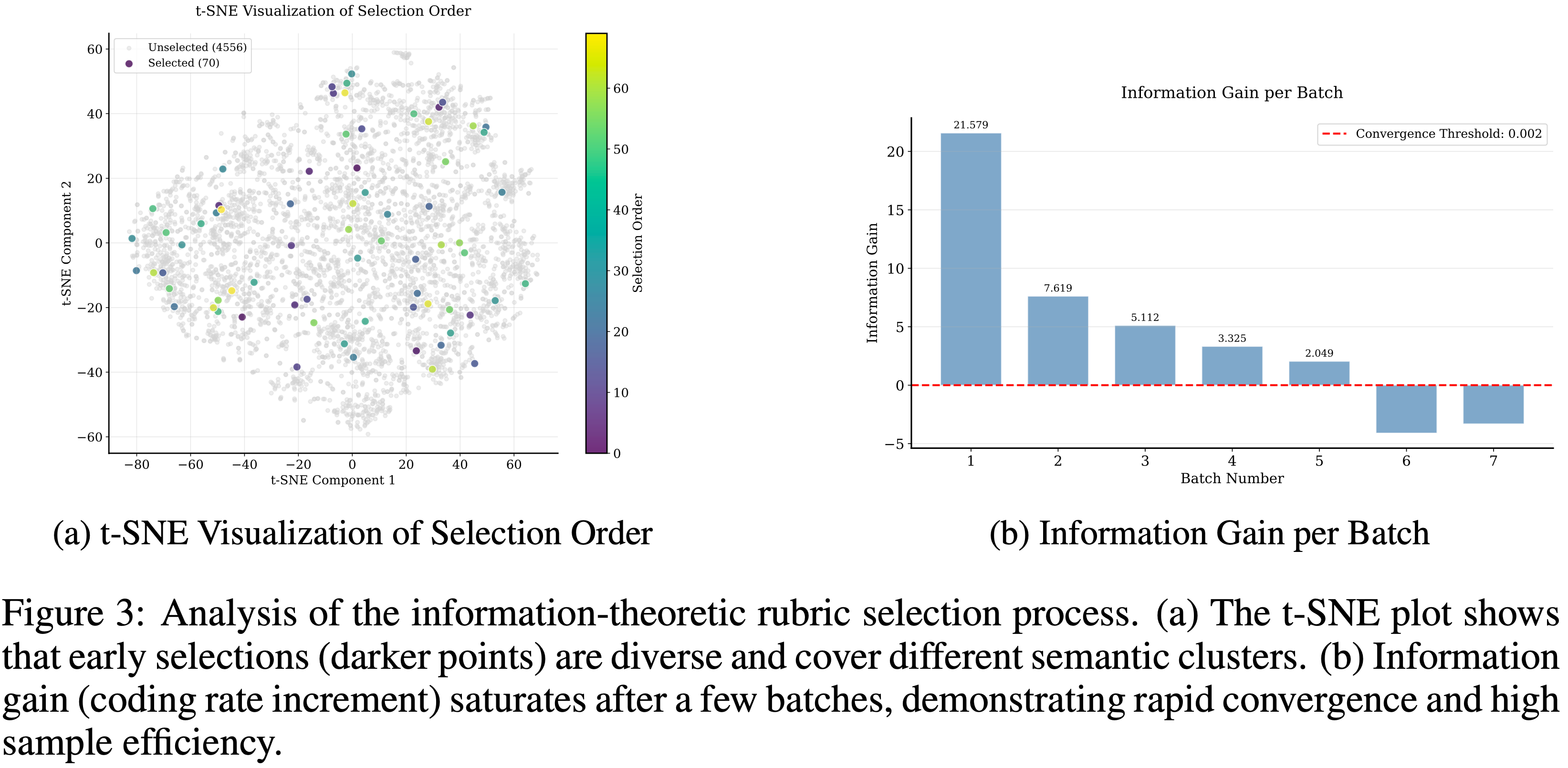
- 图 3a 中的 t-SNE 可视化追踪了 Rubrics 的选择顺序,表明论文的算法积极地促进了语义多样性
- 早期选择的 Rubrics(颜色较深)广泛分布在不同的聚类中,这表明框架优先覆盖整个语义空间,而不是选择相似、冗余的 Rubrics
- 这确保了每个新 Rubric 都提供新颖的信息,从而最大化从每个样本中提取的价值
- 关于迭代精炼动态的额外分析见附录 D,显示了在不同数据集上的快速收敛
- 这种效率在图 3b 的信息增益图中得到了量化
- 编码率的增量在前几个批次中最高,然后迅速减少
- 论文的早停机制在 7 次迭代后停止了该过程,确认可以从数据集中非常小的部分捕捉到偏好的核心 Rubrics
- 总共只处理了 70 个样本 (源数据的 1.5%),就提炼出了最终的、紧凑的 \(k = 5\) 步的 “Theme-Tips” Rubrics
- 注意:这里的 \(k\) 在前文 3.3 节中有定义,\(k\) 是迭代步骤,也是 Rubric 的数量
Ablation Studies
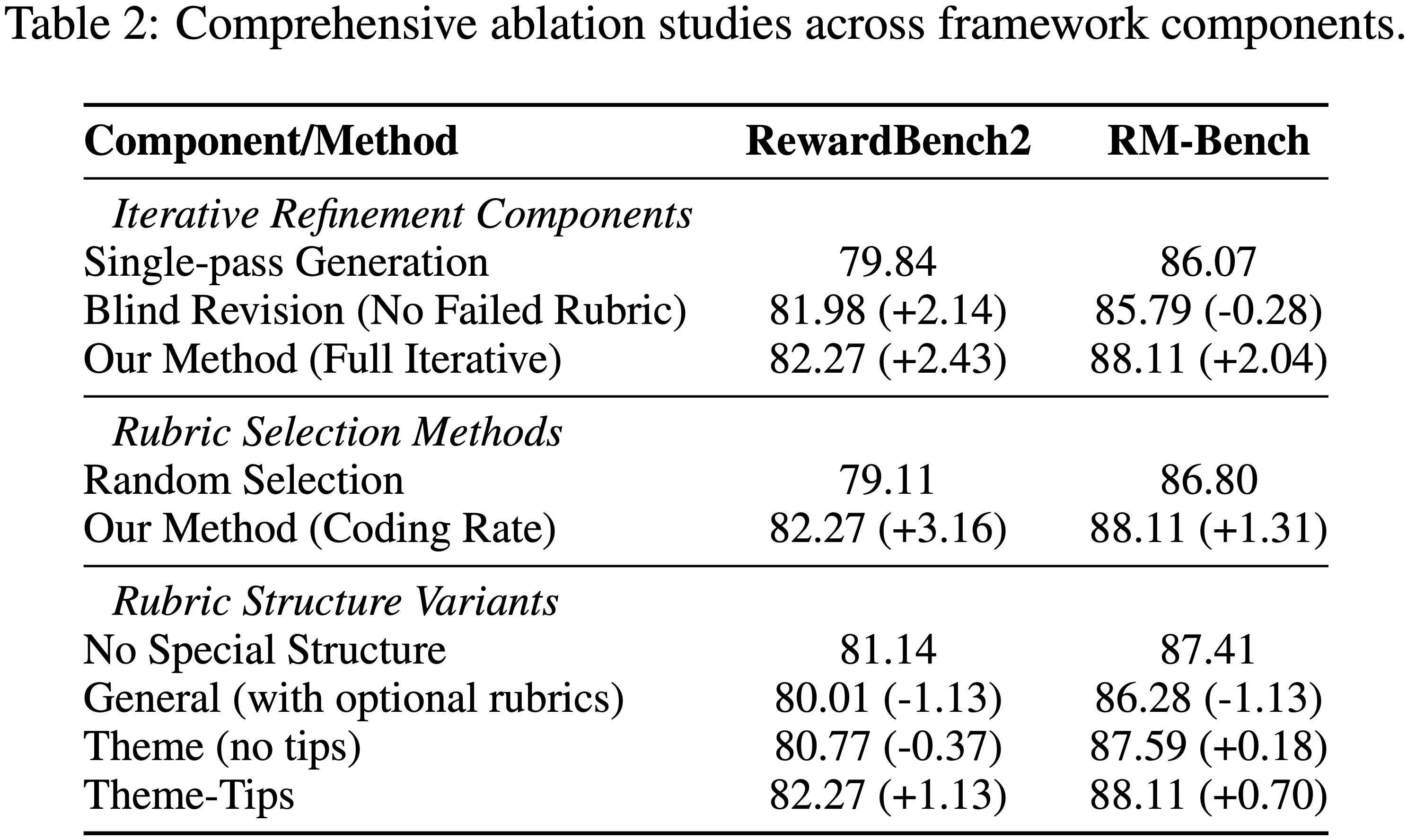
- 论文进行了消融研究,以分离论文框架中每个核心组件的贡献,详见表 2:
- (1) Query 特定 Rubrics 的迭代精炼
- (2) Rubrics 子集的信息论选择
- (3) Rubrics 的最终层次化结构
- (4) 跨模型泛化能力
Iterative Refinement
- 论文通过将论文完整的反馈驱动方法与两个基线进行比较,来测试迭代精炼过程的必要性:
- 基线一:无精炼的单次生成 (Single-pass Generation without refinement)
- 基线二:在没有失败 Rubrics 的情况下迭代的盲目修订 (Blind Revision)
- 完整的迭代 Propose-Evaluate-Revise 过程在 Rubrics 评估和修订的帮助下,在 RewardBench2 上比单次生成高出 +2.43%,在 RM-Bench 上高出 +2.04%
- 这证实了验证驱动的反馈循环对于可靠地提高 Rubric 质量至关重要
Rubric Selection Strategy
- 此项消融研究验证了论文的信息论选择策略与随机选择基线相比的优越性
- 论文方法的优越性非常显著:
- 论文的编码率最大化策略在 RewardBench2 上比随机选择高出 +3.16%,在 RM-Bench 上高出 +1.31%
- 理解:那岂不是没有这个选择策略的话,效果还不如原始的基础模型?
- 这种显著的性能差距证实,基于效率和多样性的选择对于从大量候选池中构建强大且非冗余的 Rubrics 集至关重要
- 论文的编码率最大化策略在 RewardBench2 上比随机选择高出 +3.16%,在 RM-Bench 上高出 +1.31%
Hierarchical Structure
- 论文通过将论文的层次化 “Theme-Tips” 结构与更扁平的变体(包括非结构化列表)进行比较,分析了 Rubrics 组织对评估器性能的影响
- 与扁平列表相比, “Theme-Tips” 格式在 RewardBench2 上的准确率提高了 +1.13%,这表明通用 Rubrics(主题)和具体指导(要点)之间的平衡是有效应用 Rubrics 的关键
Exceptional Cross-Model Generalization(优秀的跨模型泛化)
- 为了进一步验证论文提取的 Rubrics 的普适性,论文进行了严格的跨模型评估(完整细节见附录 C,图 4)
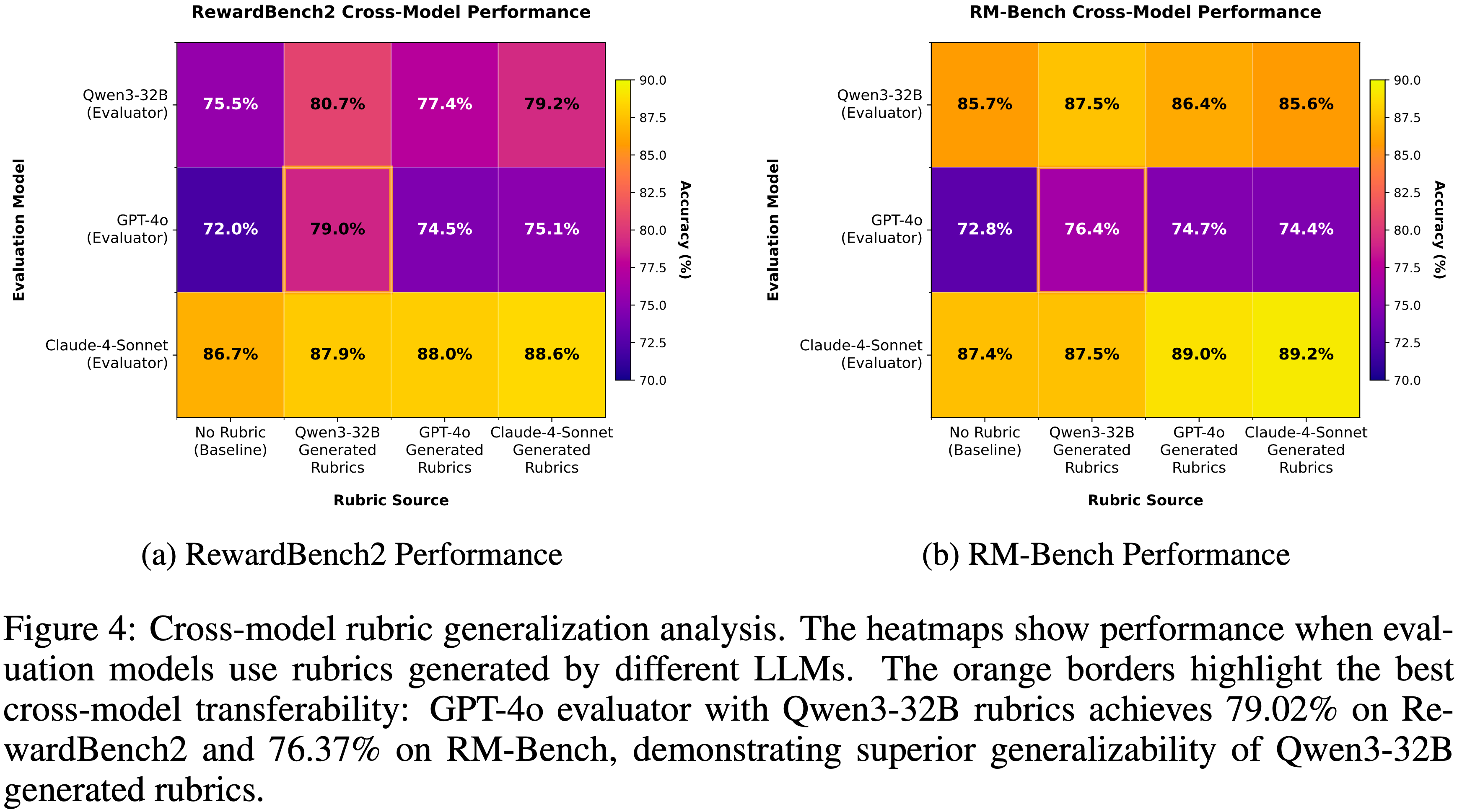
- 结果表明,论文的框架生成的 Rubrics 不仅在其原生模型族内有效,而且表现出很强的可移植性
- 最值得注意的是(Most notably),当将 Qwen3-32B 生成的 Rubrics 应用于 GPT-4o 时,其在 RewardBench2 上的性能从基线的 71.96% 跃升至 79.02%
- 这一发现提供了强有力的证据,表明论文的方法捕捉到了基本且可迁移的评估 Rubrics,而不是模型特定的捷径或风格偏见
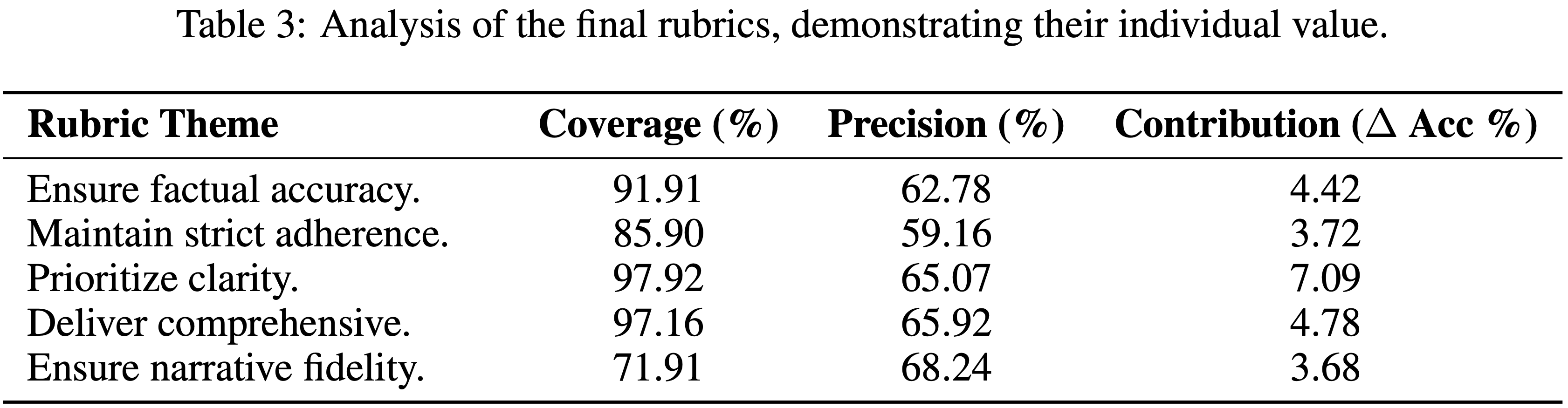
Analysis of Core Rubrics
- 为了验证论文的框架生成了高价值、可解释的数据,论文将第 3.4 节方法中定义的分析框架应用于最终提取的 Rubrics 集
- 这使论文能够量化每个 Rubric 的效用,并证明最终集合由互补的、非冗余的 Rubrics 组成
- 如表 3 所示
- 像 “优先考虑清晰度 (Prioritize clarity)” 这样的基础 Rubric 表现出极高的覆盖率 (97.92%) 和贡献度(如果移除会导致 7.09% 的准确率下降),作为评估的基础
- In Contrast,像 “确保叙事保真度 (Ensure narrative fidelity)” 这样的专业 Rubric 覆盖率较低 (71.91%)
- 但具有最高的精确度 (68.24%),能有效处理更广泛的 Rubrics 可能忽略的特定场景
- 每个 Rubric 显著的贡献度分数验证了论文的信息论选择成功地产生了一个非冗余的集合,其中每个元素都发挥着关键作用
- 此分析证实论文不仅仅是在生成 Rubrics,而是在生成高质量、结构化的评估知识
- 从不同数据集提取的完整 Rubrics 集合见附录 G
补充:Related Work
LLM-as-a-Judge Evaluation
- 使用 LLM 作为自动评估器的范式前景广阔,但受到严重可靠性挑战的破坏
- 早期工作识别了表面层面的偏差,如位置效应和冗长效应 (2023),而最近的研究揭示了更深层次的不对齐:
- LLM 评判者会系统性地优先考虑风格质量而非事实准确性和安全性 (2025)
- 后续工作试图通过校准技术或开发专门的评判模型来缓解这些问题 (2025; 2023; 2023)
- However,这些方法通常解决的是偏差的表征而非其根本原因:不透明且隐式的判断过程(an opaque and implicit judgment process)
- 论文的框架通过用明确的、可验证的 Rubric 结构替代这种隐式判断,提供了一个更根本的解决方案
- 这使得潜在的 Rubric 透明化,从而能够直接缓解此类偏差
Rubric-Based Reward Modeling
- 基于 Rubric 方法的发展揭示了 Rubric 生成与有效 Rubric 优化之间始终存在的差距
- 早期方法 (2024) 依赖于静态的、专家编写的 Rubric
- 这些 Rubric 虽然可解释,但基本上不可扩展
- 为了克服这一限制,近期工作使用思维链推理和模板化提示等方法来自动化 Rubric 提取 (2025; 2025)
- However,这些自动化方法通常会产生一个未经提炼、常常相互冲突的混乱规则语料库,并且许多方法仍然与昂贵的参数化训练绑定 (2025; 2024)
- 论文的工作在无需训练的范式下解决了这一完整生命周期,引入了一个系统化框架,以从最少的数据中提出、精炼、选择 Rubric 并将其结构化为连贯的、可泛化的层次结构(propose, refine, select, and structure rubrics into coherent, generalizable hierarchies from minimal data.)
附录 A:The Use of Large Language Models
- 后续写我们可以参考本节的写法
- 在准备本手稿期间,论文利用了多个 LLM 来协助语言编辑和文本润色 (吐槽:为什么要用这么多?)
- 包括 Google 的 Gemini、阿里巴巴的 Qwen 和 Anthropic 的 Claude
- 这些模型的作用严格限于增强手稿的清晰度、语法正确性、流畅性和风格一致性
- 具体任务包括:优化句子结构、为提高可读性提出替代措辞建议、以及统一各部分的术语和语气
- 这些模型生成或建议的所有输出都经过了仔细评估、严格修改,并最终由作者批准
- 作者对最终手稿的科学内容、准确性和完整性承担全部责任
附录 B:Experiment Setting Details
- Implementation details.
- 论文的 Rubric 提取流程以批次大小 \( B=10 \) 处理数据
- 每个样本的 Propose-Evaluate-Revise 循环最多运行 \( E_{\text{max} }=10 \) 个 Epoch
- 当编码率 (coding rate) 的边际增益连续 \( p_{\text{patience} }=2 \) 次迭代低于阈值 \( \tau_{\text{min} }=0.002 \) 时,信息论选择 (information-theoretic selection) 过程终止
- 最终的核心集 (core set) 被结构化为 \( k=5 \) 步 “Theme-Tips” Rubrics
- 为了评估,论文使用准确率作为主要指标,并根据每个基准测试的稳定性采用定制化的投票策略(例如,RewardBench2 使用 voting@10,RewardBench 和 JudgeBench 使用 voting@5,RM-Bench 使用 voting@1),以平衡结果的可靠性与计算效率
- 附录 E 中提供了关于投票次数与性能之间权衡的全面测试时缩放 (test-time scaling) 分析
附录 C:Analysis on the Generalizability of Model-Generated Rubrics
- 为了为论文的框架选择最优的 LLM,论文分析了三个领先模型生成的评估 Rubrics 的泛化性:
- Qwen3-32B、GPT-4o 和 Claude-4-Sonnet
- 论文分别对每个模型作为评估器的性能进行了基准测试,包括基线条件(无 Rubric)以及在使用这三个生成器中每一个生成的 Rubrics 指导下的情况
- 图 4 中的结果揭示了 Rubric 质量和跨模型效用方面的清晰模式
- 这些发现证实了两个要点
- 第一,在所有场景中,应用模型生成的 Rubric 都比基线提供了显著的性能提升
- 第二,and more critically,Qwen3-32B 生成的 Rubrics 表现出最强的泛化性
- 这在跨模型测试中最为明显;
- 例如,Qwen3-32B 的 Rubric 将 GPT-4o 在 RewardBench2 上的性能提升至 0.7902 ,并且显著高于使用其自身 Rubric 达到的分数 (0.7453)
- 虽然 Claude-4-Sonnet 始终保持最高的绝对分数,证明其本身是一个强大的独立评估器,但 Qwen3-32B 的 Rubrics 为 其他 模型提供的卓越且一致的性能提升 ,使其成为为论文主要实验生成一套稳健、普遍适用的 Rubrics 的明确选择
- 问题:结论是使用 Qwen3-32B 得到的效果最好(这其实有点奇怪)
附录 D:Query-Specific Accuracy Improvement Analysis
- 为了进一步理解论文 Rubric 提取框架的学习动态,论文分析了实验中使用的两个数据集在不同训练 Epoch 上的 Query-specific 准确率改进情况
- 图 5 展示了随着论文的迭代优化过程生成和优化 Rubrics,准确率的渐进提升
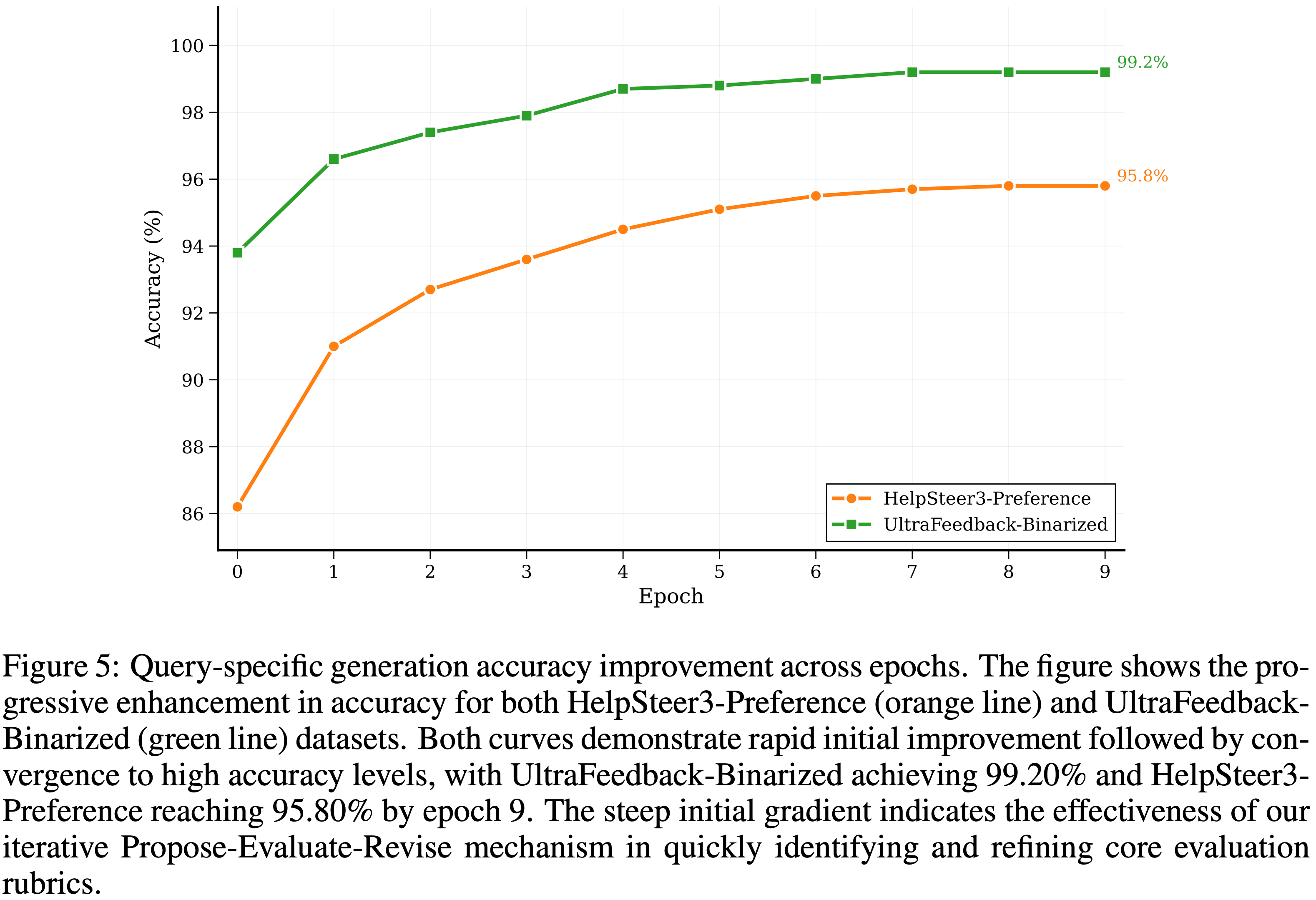
- 结果揭示了关于论文框架学习动态的几个关键见解:
- 快速初始收敛 (Rapid Initial Convergence).
- 两个数据集都在最初的 2-3 个 Epoch 表现出陡峭的准确率提升,HelpSteer3-Preference 从 86.1% 跃升至 92.7%( Epoch 0 到 2),UltraFeedback-Binarized 从 93.9% 提升至 97.4%
- 这种快速的初始改进证明了论文的迭代优化过程在快速识别支配人类偏好的基本评估 Rubrics 方面的有效性
- 数据集特定特性 (Dataset-Specific Characteristics).
- UltraFeedback-Binarized 始终达到更高的准确率水平和更快的收敛速度,在 Epoch 9 时达到 99.20%,而 HelpSteer3-Preference 则为 95.80%
- 这种差异可能反映了不同的标注方法:
- HelpSteer3 是基于人工标注的,自然包含更多主观差异
- UltraFeedback 是基于 GPT-4 打分的,可能表现出更一致的模式
- 收敛稳定性 (Convergence Stability).
- 两条曲线在 Epoch 6 后都表现出饱和行为,后续迭代的改进微乎其微
- 这验证了论文的自适应停止机制,并表明支配人类偏好的核心评估 Rubrics 可以在有限数量的优化循环中被有效捕获
- 跨数据集验证 (Cross-Dataset Validation).
- 尽管存在不同的领域、标注方法和偏好分布,但两个数据集一致的改进模式支持了论文关于 Rubric 收敛的核心假设
- 即:潜在的评估 Rubrics 表现出相似的优化动态,证实了论文方法的泛化性
- 尽管存在不同的领域、标注方法和偏好分布,但两个数据集一致的改进模式支持了论文关于 Rubric 收敛的核心假设
- 快速初始收敛 (Rapid Initial Convergence).
附录 E:Test-time Scaling Analysis
- 为了评估论文 Rubric-based 评估框架的鲁棒性和稳定性,论文研究了在 RewardBench2 上进行测试时推理时,性能如何随着投票数的增加而扩展
- 这项分析为计算成本与评估可靠性之间的权衡提供了关键见解
- 一致的性能优势 (Consistent Performance Advantage).
- 图 6 表明,论文的 Rubric 增强方法在所有投票策略中都保持着相对于基础模型 6-7 个百分点的优势
- 这种系统性的改进表明,论文提取的 Rubrics 提供了基本的评估能力,这些能力与集成投票 (ensemble voting) 的益处是正交的 ,从而产生了附加的性能增益

- 低投票数下的快速收敛 (Rapid Convergence with Low Voting Numbers).
- 两种方法在从 voting@1 扩展到 voting@5 时都显示出最显著的改进,此后收益递减
- 这种模式表明,集成投票的主要好处可以用相对适度的计算开销来捕获
- 对于实际部署,voting@5 到 voting@10 似乎提供了性能与效率之间的最佳平衡
- 在困难案例上的卓越性能 (Superior Performance on Challenging Cases).
- 图 6 为论文框架的有效性提供了特别令人信服的证据
- 在 Ties subset 上(代表最具挑战性的评估场景,基础模型难以做出决定性判断)论文的 Rubric 增强方法显示出约 20 个百分点(improvements of approximately 20 percentage points)的显著提升
- 这种巨大的差距突显了明确 Rubrics 在恰恰最需要的地方提供区分能力的关键作用
- 问题:其实 RewardBench2 的 Ties 这个数据集上波动较大,只有 50 多个分组样本
- 平台行为和计算效率 (Plateau Behavior and Computational Efficiency).
- 两张图都展示了超过 voting@10 后的平台行为,表明额外的计算投入带来的回报是边际的
- 这一发现具有重要的实际意义:论文的框架以适度的集成大小实现了接近最优的性能,使其在保持高评估质量的同时,对于实际部署具有计算效率
- 跨难度级别的鲁棒性 (Robustness Across Difficulty Levels).
- 整体准确率和 Ties subset 准确率的一致性性能模式表明,论文的 Rubrics 提供了强大的评估能力,能够在不同难度级别上有效扩展
- 这种鲁棒性对于实际应用至关重要,因为评估系统必须可靠地处理多样化的 Query 类型和模糊案例
附录 F:Detailed Experimental Analysis
- 为了全面了解论文框架的有效性,论文在多个基准测试和评估维度上进行了详细分析
- 本节考察论文的 Rubric 指导方法在哪些方面提供了最显著的价值,重点关注具有挑战性的评估场景和特定领域的性能模式
Cross-Benchmark Performance Analysis
- 论文的详细分析涵盖了两个互补的基准测试,它们共同提供了 Rubric 有效性的全面视图:
- RM-Bench(允许论文检查不同难度级别样本的性能)和 RewardBench2(提供包括挑战性边缘案例在内的多样化评估维度)
RM-Bench: Difficulty-Stratified Analysis(难度分层分析)
- 论文在 RM-Bench 上进行了分层分析,以了解论文的 Rubrics 在不同难度级别上的表现(表 4)
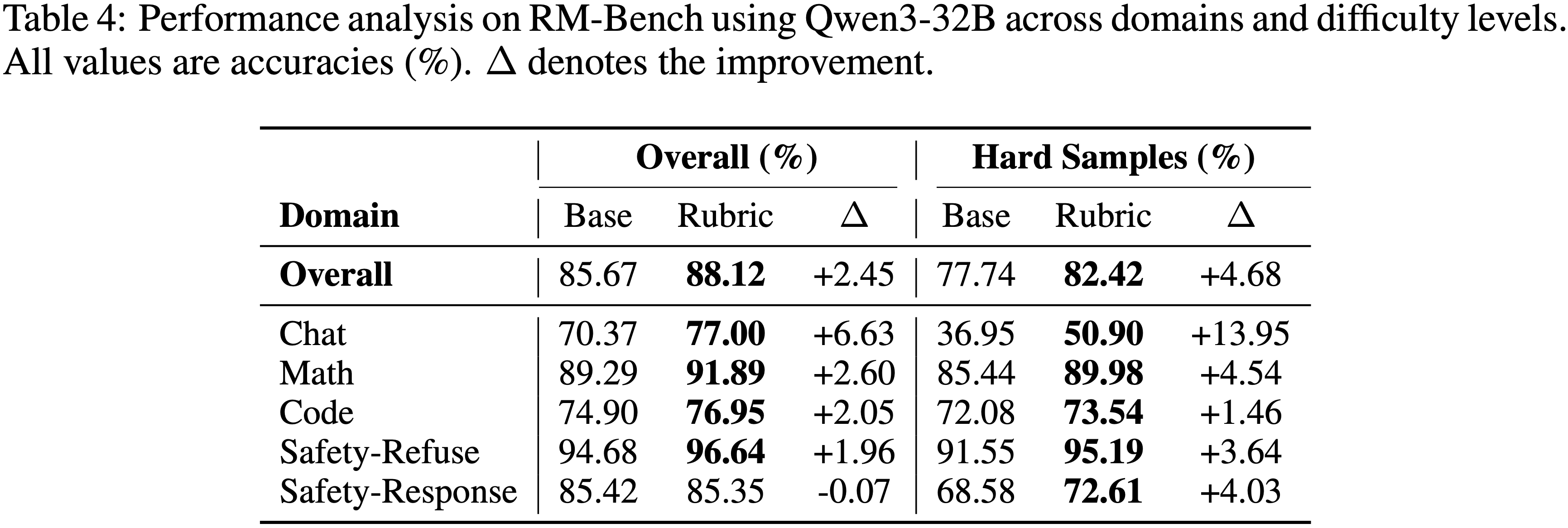
- 结果揭示了一个清晰且一致的模式:论文的 Rubrics 擅长解决最具挑战性的案例,在这些案例中基础模型难以做出准确的偏好判断
- 难度分层分析显示,困难样本从 Rubric 指导中获益更多 (+4.68%),相比于整体改进 (+2.45%)
- 这种在困难案例上 2 倍的放大效应表明,论文的 Rubrics 恰恰在最需要的地方(即隐含评估 Rubrics 不足的场景),提供了关键的区分能力
- 领域特定模式进一步阐明了论文框架有针对性的优势
- 聊天 (Chat) 领域表现出最显著的改进(困难样本上 +13.95%),突显了论文的 Rubrics 在著名的具有主观性的对话评估领域的有效性,其中细微的判断 Rubrics 至关重要
- 在 数学 (Math) (+4.54%) 和 安全-拒绝 (Safety-Refuse) (+3.64%) 领域也观察到了显著的提升,展示了在多样化推理和安全场景中的广泛适用性
RewardBench2: 评估维度分析 (Evaluation Dimension Analysis)
- 为了补充论文以难度为中心的 RM-Bench 分析,论文在 RewardBench2 上检查了跨不同评估维度的性能(表 5)
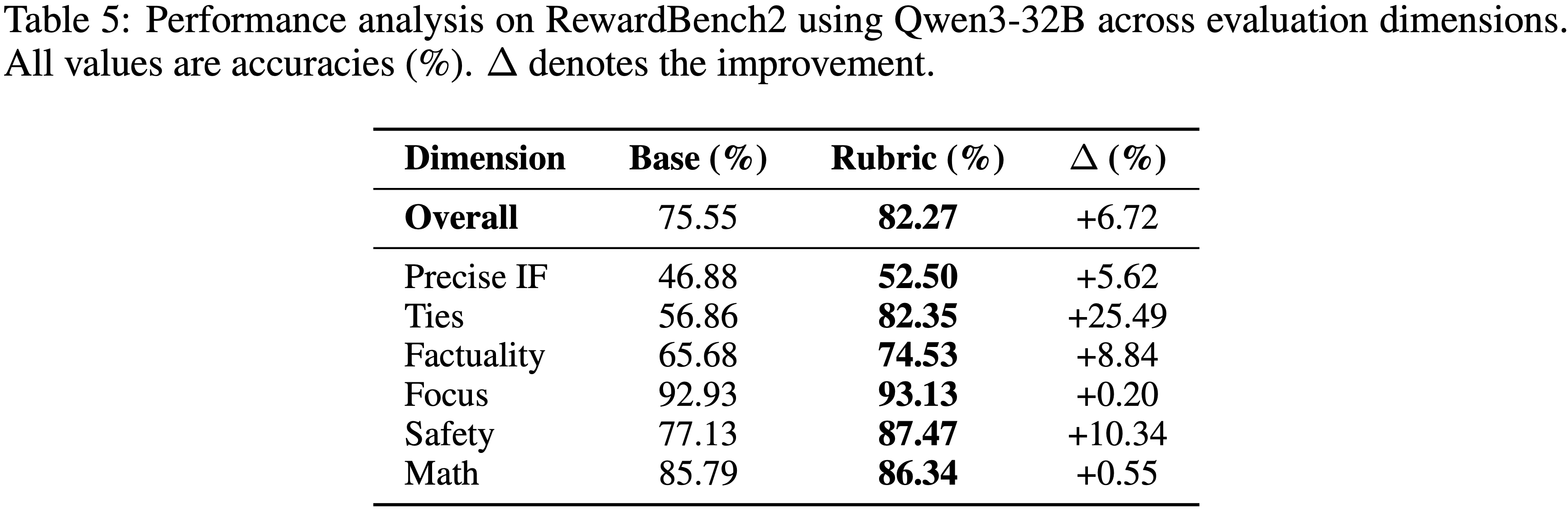
- RewardBench2 提供了一个更具挑战性和全面性的评估设置,使论文能够理解 Rubric 指导的评估在不同类型的评估 Rubrics 中在哪些方面提供了最显著的优势
- 结果显示,在所有评估维度上都有一致且显著的改进,论文的 Rubrics 实现了令人瞩目的整体改进 +6.72%(从 75.55% 到 82.27%)
- 在具有挑战性的基准测试上取得的这一显著提升,证明了论文框架在多样化评估场景中的强大有效性
- 最重要的发现是 平局 (Ties) 子集的显著改进 (+25.49%),从 56.86% 跃升至 82.35%
- 这一显著提升代表了最具挑战性的评估场景(即基础模型难以做出决定性判断的情况)并突显了明确 Rubrics 在模糊案例中提供的关键区分能力
- 安全 (Safety) 领域也显示出显著的增强 (+10.34%),证明了论文的 Rubrics 在需要仔细平衡多个竞争因素的微妙安全考量方面的有效性
- 重要的是,即使在基础模型已经取得良好表现的领域也显示出了有意义的改进:
- 事实性 (Factuality) 提升了 +8.84%,精确指令遵循 (Precise IF) 提升了 +5.62%
- 这种模式表明,论文的 Rubrics 在整个评估难度范围内(从具有挑战性的边缘案例到已确立的领域)都提供了价值,证实了论文方法的广泛适用性和鲁棒性
附录 G:Extracted Rubric Collections
- 本节展示了论文的框架从不同数据集和实验配置中提取的完整的 Query 无关 (query-agnostic) Rubrics 集合
- 这些 Rubrics 展示了从论文的信息论选择 (information-theoretic selection) 和主题归纳 (thematic induction) 过程中产生的结构化 “Theme-Tips” 层次结构
HelpSteer3-Preference Dataset Rubrics
- 以下 Rubrics 是从 HelpSteer3-Preference 数据集提取的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34**主题 1: 事实准确性与规范一致性 (Theme 1: Factual Accuracy and Canonical Consistency)**
**主题 (Theme):** 确保回答中的事实准确性、规范一致性,并避免编造或幻觉 (hallucination)
* **Tip 1:** 对于关于_Undertale_ 的 Query ,确保所有角色动机和游戏机制与已确立的背景设定 (lore) 一致,避免推测性或矛盾的断言
* **Tip 2:** 讨论历史里程碑(如早期有声同步卡通)时,正确地将 "Steamboat Willie"(而非 "My Old Kentucky Home")归为里程碑,以保持可靠性
* **Tip 3:** 在涉及_Hogwarts_ 学生的回答中,仅包含背景设定中描绘的、具有学术准确成就的学生,排除教授或非学生人物
* **Tip 4:** 避免编造苏美尔文本或虚构的调查链接;相反,在必要时承认缺失的上下文并请求澄清,特别是对于小众文化引用
**主题 2: 严格遵守提示要求 (Theme 2: Strict Adherence to Prompt Requirements)**
**主题 (Theme):** 严格遵守提示的结构、格式和明确的用户要求
* **Tip 1:** 当要求提供一个单词时,提供恰好一个单词,避免冗余或额外建议,如需要最小输出的回答
* **Tip 2:** 对于要求 100 个项目的提示,即使主题宽泛,也要提供完整的列表,并主动选择一个相关的主题来满足数量要求
* **Tip 3:** 在口号 (tagline) 创作中,直接融入核心技术优势,如 "距离对冲击的影响 (distance at impact)",避免模糊或冗余的措辞,以免削弱产品相关性
* **Tip 4:** 当提示要求单词 "scenery" 后跟冒号和一个单词术语时,遵循这种确切的句法结构,不得有任何偏差
**主题 3: 清晰度与结构化组织 (Theme 3: Clarity and Structured Organization)**
**主题 (Theme):** 优先考虑清晰度、简洁性和结构化组织,以增强可读性和直接性
* **Tip 1:** 对于 "谢谢 (Thank you)" 的提示,用简洁的致谢和进一步的提问邀请来回应,避免假设用户是学生或律师
* **Tip 2:** 总结建立 dropshipping agent 业务的步骤时,使用项目符号或编号列表来逻辑地呈现关键点,并避免幻觉信息
* **Tip 3:** 在有关存款保险委员会 (deposit insurance boards) 的审计结果中,用精确、可操作的条目构建回答,并以强调影响的简明摘要结尾
* **Tip 4:** 解释语法正确性时,避免使用粗体文本或不必要的标点等过度格式,保持直接专业的语气
**主题 4: 全面且详细的分析 (Theme 4: Comprehensive and Detailed Analysis)**
**主题 (Theme):** 提供全面、详细且主题连贯的叙述或分析,完全解决所有提示要素
* **Tip 1:** 解释 CFA Institute Investment Foundations® 证书时,包含课程、资格、考试形式、备考资源、益处和持续教育,并提供具体示例
* **Tip 2:** 在奇幻故事回答中,融入丰富的叙事细节、鲜明的角色发展以及身临其境的世界构建,如生动的场景和动态的互动
* **Tip 3:** 在讨论与税收成比例的立法机构时,全面概述其机制、影响、数据收集、代表配额、公平问题和宪法考量
* **Tip 4:** 对于恐怖动漫场景,使用 INT/EXT.(内景/外景)指示,强调氛围张力,并描述生物细节,如菱形尾巴和变色龙状头部,以符合动漫风格
**主题 5: 叙事与上下文保真度 (Theme 5: Narrative and Contextual Fidelity)**
**主题 (Theme):** 确保叙事和上下文保真度,保持角色动态、语气和世界构建的一致性
* **Tip 1:** 在涉及 Jade 角色的回答中,保持她权威但专业的语气,避免与已确立行为相矛盾的敌对转变
* **Tip 2:** 对于以 KikoRiki 中的 Emily 为主角的故事,保持她作为恶作剧者的角色,并在描述她变形成 Rosa 失败以及橙色后端出错时融入异想天开的语气
* **Tip 3:** 在延续关于使用尿布而非如厕训练的叙事时,保持一种有趣、适合儿童的语气,避免与原主题相矛盾
* **Tip 4:** 在治疗性角色扮演场景中,优先通过对话和确认深入参与患者的想象世界,而不是使用临床检查清单
UltraFeedback-Binarized Dataset Rubrics
- 以下 Rubrics 是从 UltraFeedback-Binarized 数据集提取的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39**主题 1: 事实准确性与领域特定知识 (Theme 1: Factual Accuracy and Domain-Specific Knowledge)**
**主题 (Theme):** 答案必须事实准确,并基于正确的领域特定知识,避免误解、逻辑错误或推测性假设
* **Tip 1:** 正确且精确地应用科学、技术或数学原理(例如,重力、正则表达式语法、Pig Latin 规则)
* **Tip 2:** 避免延续错误的前提(例如,鸟类产生种子),并澄清生物学或概念上的不准确性
* **Tip 3:** 使用经过验证的数据、正确的引用和准确的术语(例如,Azure 工作流、MLA 格式、产品设计细节)
* **Tip 4:** 面对模糊性时,寻求澄清而不是做出无根据的假设
* **Tip 5:** 在翻译中保留原始信息,不添加、省略或扭曲含义
**主题 2: 明确要求满足 (Theme 2: Explicit Requirement Fulfillment)**
**主题 (Theme):** 答案必须直接满足用户在结构、内容和格式方面的明确要求,严格遵守所有陈述的约束
* **Tip 1:** 遵循规定的结构元素(例如,开场白、问题框架、章节顺序)
* **Tip 2:** 遵守格式规则(例如,LaTeX、APA、SQL 模式限制、电话号码模式)
* **Tip 3:** 处理多部分 Query 的每个组成部分(例如,示例、解释、代码、引用)
* **Tip 4:** 仅使用正确技术上下文内的有效函数、库或命令(例如,Streamlit、PL/pgSQL)
* **Tip 5:** 仅使用允许的来源提取或生成响应(例如,确切的文本片段、背景段落)
**主题 3: 清晰度与逻辑组织 (Theme 3: Clarity and Logical Organization)**
**主题 (Theme):** 答案必须通过结构良好、简洁、逻辑清晰的组织推理,提供清晰度、连贯性和完整性
* **Tip 1:** 提供分步解释,使推理过程透明且可验证
* **Tip 2:** 保持语法正确性,并保留原始语言或格式惯例
* **Tip 3:** 避免不必要的阐述、冗余或分散核心任务的无关细节
* **Tip 4:** 确保回答是自包含的,无需外部上下文即可理解
* **Tip 5:** 使用精确的连接词和描述性语言来保持翻译或解释的保真度
**主题 4: 深度与上下文相关性 (Theme 4: Depth and Contextual Relevance)**
**主题 (Theme):** 答案必须通过整合具体示例、可操作的策略和上下文相关性来展示深度和丰富性
* **Tip 1:** 包含具体、场景特定的例证(例如,AR 游戏机制、文化项目指标)
* **Tip 2:** 提供具有技术细节的实用实施指南(例如,iOS 框架、OpenGL 代码)
* **Tip 3:** 将抽象概念与现实世界应用联系起来(例如,文学中的象征意义、市场进入中的 ESG 因素)
* **Tip 4:** 展示进展或转变(例如,习惯养成计划、历史上的科学影响)
* **Tip 5:** 通过覆盖多个维度并提供细致入微的分析,平衡广度和深度
**主题 5: 伦理责任与用户一致性 (Theme 5: Ethical Responsibility and User Alignment)**
**主题 (Theme):** 答案必须在其方法和语气上优先考虑伦理责任、用户一致性和功能性效用
* **Tip 1:** 主动重构可能具有冒犯性或有害的术语,以保持尊重的沟通
* **Tip 2:** 专注于可操作的解决方案,而不是简单否定或过于理论化的回答
* **Tip 3:** 根据用户的角色、目标或身份定制建议(例如,英国律师、开发者、教育者)
* **Tip 4:** 在旨在互动时,通过清晰的邀请或后续提示鼓励参与
* **Tip 5:** 通过置信度指标或对结论的明确理由来增强透明度
附录 H:Prompt Templates
Rubric Generation Prompt(Figure 7: Prompt for generating query-specific rubrics.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29## Overview
You are an expert rubric writer for open-ended question.
Your job is to generate a self-contained set of evaluation criteria ("rubrics") for choosing a better answer from candidate answers to a given query.
Rubrics can cover aspects such as factual correctness, depth of reasoning, clarity, completeness, style, helpfulness, and common pitfalls.
Each rubric item must be fully selfcontained so that non-expert readers need not consult any external information.
I will give you:
1. the query(maybe contains history messages)
2. candidate answers
3. which answer is better than others
4. critics by the human experts, and you need to carefully read the critics provided by human experts and summarize the rubrics.
NOTE: The number of rubrics should be LESS THAN OR EQUAL TO {number}
## Query
{query}
## Candidate Answers
<answer_1>{answer_1}</answer_1>
<answer_2>{answer_2}</answer_2>
## Better Answer
Answer {preference} is better than others.
## Critics
<critic>{critic}</critic>
## Output Format Requirements
<rubrics>your rubrics without index</rubrics>Rubric Evaluation Prompt(Figure 8: Prompt for rubric-based pairwise evaluation.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24## Task Description
I will provide you with a set of rubrics, along with the current query and two responses.
These rubrics are the primary basis for selecting the best answer.
You must follow the steps specified in the Evaluation Process when conducting your evaluation process.
## Rubrics
{rubrics}
## Process
1. Confirm the task scenario of the current query and select the corresponding evaluation rubrics.
2. Identify the best response that meets the most selected rubrics.
## Query
{query}
## Response A
{response_a}
## Response B
{response_b}
## Output Requirement
Please choose the better response. Response "A", "B", or "tie" within the tags.
<preference>A/B/tie</preference>- 理解:让模型判断当前的回复 A 和 B 哪个更符合 Rubric
Rubric Revision Prompt(Figure 9: Prompt for revising query-specific rubrics based on evaluation feedback.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41## Overview
You are an expert rubric writer for open-ended question.
A selfcontained set of evaluation criteria ("rubrics") is needed for choosing a better answer from candidate answers to a given query.
Since the rubrics generated in the previous round failed to correctly select a better answer, you need to revise the rubrics.
rubrics can cover aspects such as factual correctness, depth of reasoning, clarity, completeness, style, helpfulness, and common pitfalls.
Each rubric item must be fully self-contained so that non-expert readers need not consult any external information.
I will give you:
1. the query(maybe contains history messages)
2. candidate answers
3. which answer is better than others
4. critics by the human experts, and you need to carefully read the critics provided by human experts and summarize the rubrics.
5. previous round rubrics that should to be improved
NOTE: The number of rubrics should be LESS THAN OR EQUAL TO {number}
## Query
{query}
## Candidate Answers
<answer_1>
{answer_1}
</answer_1>
<answer_2>
{answer_2}
</answer_2>
## Better Answer
Answer {preference} is better than others.
## Previous Round rubrics
<rubric_1>
{previous_rubric_1}
</rubric_1>
## Output Format Requirements
Note: Ensure all outputs are placed within the tags like <tag>...</tag> as required!!!
<rubrics>
your improved rubrics without index
</rubrics>- 问题:人类专家的 Critics 是怎么来的?生成过程需要人类专家参与吗?
Rubric Structuring Prompt(Figure 10: Prompt for structuring the core rubric set into a ”Theme-Tips” hierarchy.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40## Task Description
Your task is to generate a set of evaluation rubrics to identify the best answer, based on the suggestions for determining from the examples.
I will give you some examples, and every example contains the query and suggestion which has been verified to help select the best answer.
## Requirements
- Rubrics must be fully self-contained so that non-expert readers need not consult any external information.
- Each rubric should assess an independent dimension and be noncontradictory with others.
- Rubrics ensure that the overall judgment remains aligned and consistent for all examples.
- The number of rubrics should be LESS THAN OR EQUAL TO 5. The number of tips for each rubric should be LESS THAN OR EQUAL TO 5.
- Must strictly adhere to the Rubrics Format.
## Rubric Format
Each rubric consists of two parts:
- Theme: A concise and clear statement that captures the core focus of the rubric, and must be **necessary** for all queries with no assumption.
- Tips: Multiple bullet points that expand on or supplement the rubric and only focuses on some specific queries.
Here is an example of a rubric:
Theme: [Concise theme statement]
-Tip 1:
-Tip 2:
-Tip 3:
-(Optional: More tips as needed)
## Process
1. Based on the query and suggestions of each example, summarize the rubric of each example.
2. summarize the rubrics of each example, taking care to strictly adhere to the Requirements.
NOTE: The number of rubrics should be LESS THAN OR EQUAL TO 5. The number of tips for each rubric should be LESS THAN OR EQUAL TO 5.
## Output Format Requirements
<rubrics>
Theme: [Concise theme statement]
-Tip 1: [Specific tip for certain queries]
-Tip 2: [Another specific tip]
-Tip 3: [Additional tip if needed]
Theme: [Another theme statement]
-Tip 1: [Related tip]
-Tip 2: [Another tip]
</rubrics>- 目标:通过 Prompt 让 LLM 帮忙生成结构化的 Rubric,这一步已经与 Query 无关了
- 输入:一批 Rubric
- 输出:符合指定要求的,结构化的 几条总结性 Rubric
- 问题:Prompt 中没有给模型展示需要 Structuring 的 Rubric 吗?
- 回答:看了一下源码,作者源码中的内容跟这个 Prompt 不完全一致(是包含了所有 Rubric 的),详情见 OpenJudge/openjudge/generator/iterative_rubric/categorizer.py
- 目标:通过 Prompt 让 LLM 帮忙生成结构化的 Rubric,这一步已经与 Query 无关了