- 参考链接:
- 各种并行的通信量:图解大模型训练之:张量模型并行(TP),Megatron-LM - 猛猿的文章 - 知乎
- 模型分组及方式理解:Megatron-LM训练的大模型如何分组? - wx1997的文章 - 知乎
- DP,TP,PP:TP > DP > PP,优先在机器内进行TP,其次是DP,最后是PP,因为通信量上是TP最多,DP其次,PP最后
- 图解大模型系列之:Megatron源码解读1,分布式环境初始化 - 猛猿的文章 - 知乎
- 图解大模型训练之:Megatron源码解读2,模型并行 - 猛猿的文章 - 知乎
- 图解大模型训练系列之:Megatron源码解读3,分布式混合精度训练 - 猛猿的文章 - 知乎
- Megatron-LM 中使用 DeepSpeed 加速:(DeepSpeed 官方文档)在 Megatron-LM 中加入 DeepSpeed
- 专家并行论文:GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, 2020, Google
- [张量/序列并行]📚图解 DeepSpeed-Ulysses & Megatron-LM TP/SP - DefTruth的文章 - 知乎:写的非常详细
- [转]Megatron-LM源码系列(八): Context Parallel并行 - 李睿的文章 - 知乎:作者还有一些博客内容可供参考
- Megatron-LM源码系列(一):模型并行初始化
- Megatron-LM源码系列(二):Tensor模型并行和Sequence模型并行训练
- Megatron-LM源码系列(三):详解Pipeline模型并行训练实现
- Megatron-LM源码系列(四):重计算(recompute)
- Megatron-LM源码系列(五): FP16使用
- Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
- Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2
- Megatron-LM源码系列(八): Context Parallel并行
- Megatron 新版 MoE 源码阅读 - Fizzmy的文章 - 知乎
- 知乎专栏:跟着执行流程阅读源码系列:
整体说明
- 本文的代码以 Megatron-LM 20250904 的版本
e000263e21ac89571123303c4043ec9ea7261513为主,还有部分更早的版本的代码(之前写的,没有修改)
Megatron 数据处理
数据预处理负责将
.jsonl的文本数据 tokenize 并处理成 Megatron 可以直接读取的数据格式(.bin和.idx类型的文件),减少训练时的数据处理时间数据处理的使用方式详情参考:github.com/NVIDIA/Megatron-LM
准备
.jsonl文件,文件格式如下:1
2{"text": "Your training text here..."}
{"text": "Another training sample..."}数据预处理:
1
2
3
4
5
6
7python tools/preprocess_data.py \
--input data.jsonl \
--output-prefix processed_data \
--tokenizer-type HuggingFaceTokenizer \
--tokenizer-model /path/to/tokenizer.model \
--workers 8 \
--append-eodoutput-prefix:输出文件的前缀append-eod:是否添加 EOD Token?- 注意:还可以根据需要设置
split_sentences参数,对文档进行拆分成 sentence 再做 tokenize
process_data.py的核心处理逻辑如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# split sentences in partition files
if args.split_sentences and not split_sentences_present:
processes = []
for name in in_ss_out_names:
p = multiprocessing.Process(target=partition.split_sentences, # TODO(ZJH): 构造完成数据 sentence 分隔的进程
args=((name['partition'], name['sentence_split']),)) # TODO(ZJH): 参数是输入文件名和分隔结果的输出文件名
p.start() # TODO(ZJH): 启动进程
processes.append(p)
for p in processes:
p.join()
if args.partitions == 1:
return
# encode partition files in parallel
processes = []
input_key = 'sentence_split' if args.split_sentences else 'partition' # TODO(ZJH): 根据是否走 sentence_split 来选择输入文件
for name in in_ss_out_names:
p = multiprocessing.Process(target=partition.process_json_file, # TODO(ZJH): 构造完成数据 encode 的进程
args=((name[input_key], name['output_prefix']),)) # TODO(ZJH): 参数是输入文件名(上一步处理后的)和分隔结果的输出文件名
p.start() # TODO(ZJH): 启动进程
processes.append(p)
for p in processes:
p.join()
if args.partitions == 1:
return
Megatron-LM 训练过程梳理
- 总入口(以
GPTModel为例):1
2
3
4
5
6
7
8
9pretrain(
train_valid_test_datasets_provider,
partial(model_provider, gpt_builder), # TODO(ZJH): model_provider 调用 gpt_builder 构造模型
ModelType.encoder_or_decoder,
forward_step,
args_defaults={'tokenizer_type': 'GPT2BPETokenizer'},
extra_args_provider=add_modelopt_args if has_nvidia_modelopt else None,
store=store,
)
pretrain 函数是总入口,包含的核心参数如下
pretrain 参数一:train_valid_test_datasets_provider,负责管理数据
- 输出返回迭代器,这个迭代器每个 Batch 将包含一个 micro-batch 数据
pretrain 参数二:partial(model_provider, gpt_builder),对应 model_provider 参数,负责构造并,返回模型对象
返回对象的
__init__函数负责实现 模型结构定义返回的模型对象会实现一个 forward 函数
该函数依次调用
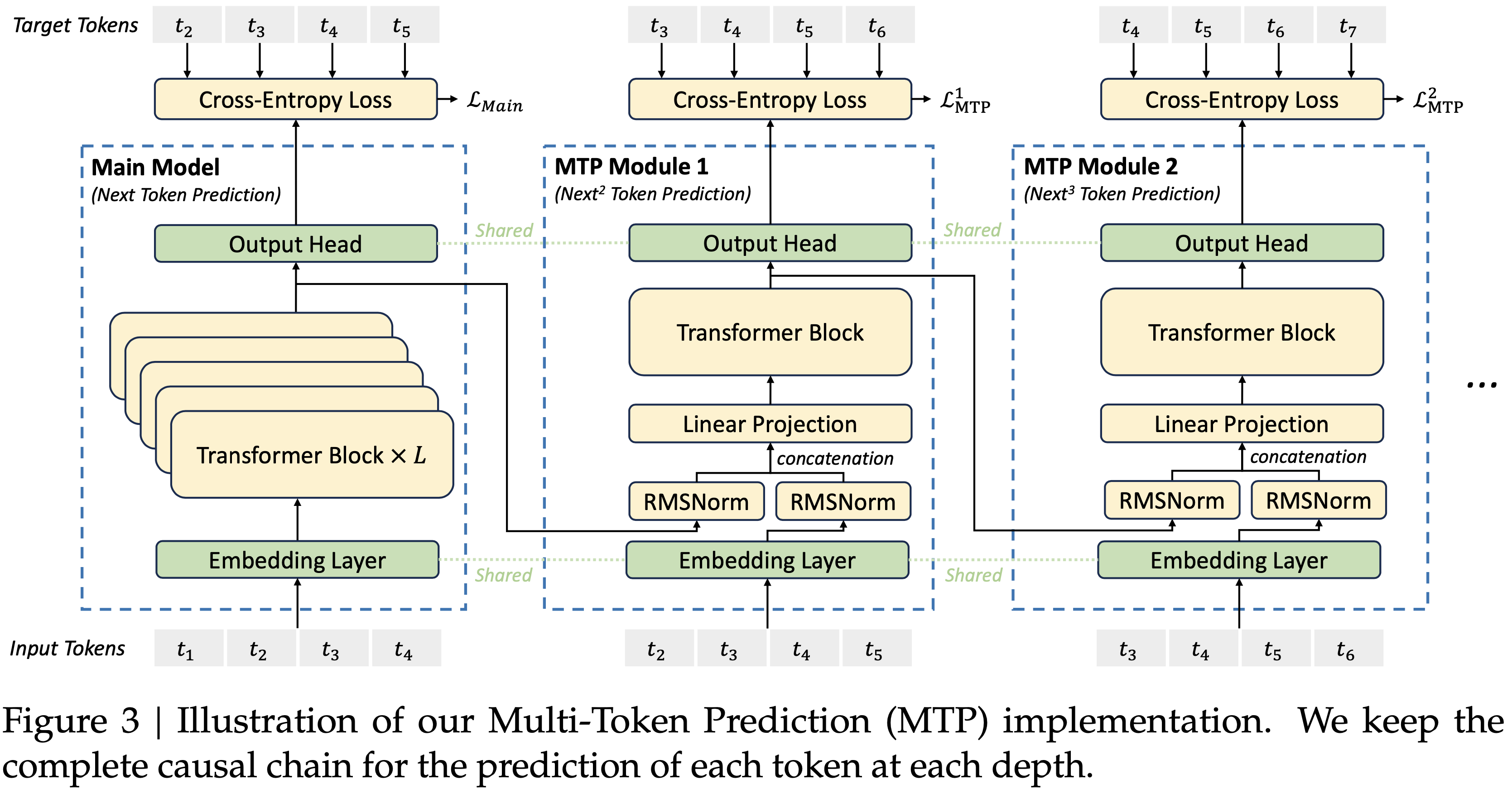
_preprocess(),decoder()和_postprocess()实现整体逻辑_preprocess负责处理输入层,包含位置编码等信息,返回decoder的输入decoder负责模型主要前向流程_postprocess负责处理输出层,包括 MTP 处理、 损失函数定义等,返回 损失函数值(lm_loss, 交叉熵损失)- 若需要执行 MTP 过程,执行 MTP 过程,同时若打开训练,则 MTP loss 在这里被计算(
- 使用
mtp_num_layers来表示 MTP 的深度,每深一层都会多预测一个 Token,每层对应交叉熵损失,然后乘以 loss_mask - 处理后的 MTP 损失使用
MTPLossAutoScaler(是torch.autograd.Function的子类,是 PyTorch 自定义算子的实现 ) 实现前向和反向传播1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68# TODO(ZJH): 将 MTP 的每个 Token(t+2...t+k)的 loss 都添加到(通过特殊的自定义算子)主网络的计算依赖上,从而保证对主网络求梯度时,MTP 相关的梯度也能回传
if self.mtp_process:
mtp_labels = labels.clone()
hidden_states_list = torch.chunk(hidden_states, 1 + self.config.mtp_num_layers, dim=0) # TODO(ZJH): 将多个 hidden_state 拆开
hidden_states = hidden_states_list[0] # TODO(ZJH): 主函数的输出
if loss_mask is None:
# if loss_mask is not provided, use all ones as loss_mask
loss_mask = torch.ones_like(mtp_labels)
for mtp_layer_number in range(self.config.mtp_num_layers): # TODO(ZJH): 每一层都计算 loss,每一层代表一个更深的未来 Token 预测目标
# output
mtp_logits, _ = self.output_layer( # TODO(ZJH): 每个 hidden_states 都要走 output_layer 得到 logits 后再计算损失
hidden_states_list[mtp_layer_number + 1], # TODO(ZJH): hidden_states_list[0] 是主网络的 hidden_state
weight=output_weight,
runtime_gather_output=runtime_gather_output,
)
# Calc loss for the current Multi-Token Prediction (MTP) layers.
mtp_labels, _ = roll_tensor(mtp_labels, shifts=-1, dims=-1, cp_group=self.cp_group) # TODO(ZJH): MTP 目标逐步后移
loss_mask, num_tokens = roll_tensor(
loss_mask, shifts=-1, dims=-1, cp_group=self.cp_group
)
mtp_loss = self.compute_language_model_loss(mtp_labels, mtp_logits)
mtp_loss = loss_mask * mtp_loss
if self.training:
# TODO(shifangx): remove the use of parallel_state here
# after moving loss logging to loss_func in pretrain_gpt.py
MTPLossLoggingHelper.save_loss_to_tracker( # TODO(ZJH): for logging
torch.sum(mtp_loss) / num_tokens,
mtp_layer_number,
self.config.mtp_num_layers,
avg_group=parallel_state.get_data_parallel_group(
with_context_parallel=True
),
)
mtp_loss_scale = self.config.mtp_loss_scaling_factor / self.config.mtp_num_layers # TODO(ZJH): 根据参数和层数计算 scale,除以 mtp_num_layers 得到平均值,保证总的 MTP loss 量级(影响)不变
if self.config.calculate_per_token_loss: # TODO(ZJH): 判断损失是否按照 Token 做平均
# TODO(ZJH): MTPLossAutoScaler 是特殊的自定义算子,不改变第一个参数的值(输入即输出),求导时直接返回 第二个参数(loss)*scale 作为梯度
hidden_states = MTPLossAutoScaler.apply( # TODO(ZJH): 经过这个自定义算子后,不会改变 hidden_states 的值(注意 hidden_states 始终是主网络的隐藏层),但对 hidden_states 计算梯度会直接返回 mtp_loss_scale * mtp_loss
hidden_states, mtp_loss_scale * mtp_loss
) # TODO(ZJH): hidden_states 经过所有层后,最终得到的是所有 MTP 层 Token 的梯度(多个深度的 Token 一起)
else:
hidden_states = MTPLossAutoScaler.apply(
hidden_states, mtp_loss_scale * mtp_loss / num_tokens
)
sequence_parallel_override = False
if in_inference_mode and inference_context.materialize_only_last_token_logits:
if inference_context.is_static_batching():
hidden_states = hidden_states[-1:, :, :]
else:
if self.output_layer.sequence_parallel:
# Perform the sequence parallel gather here instead of after the output layer
# because we need to slice the last token logits from the full view of the
# packed logits across all requests.
# TODO(ksanthanam): Make the equivalent change in the `MambaModel` code after
# merging in !3722.
hidden_states = gather_from_sequence_parallel_region(
hidden_states, group=self.model_comm_pgs.tp
)
self.output_layer.sequence_parallel = False
sequence_parallel_override = True
# Reshape [B, 1, H] to [1, B, H] -> extract each sample’s true last‐token hidden
# state ([B, H]) -> unsqueeze back to [1, B, H]
# (so that the output layer, which expects S×B×H, receives only the final token)
hidden_states = inference_context.last_token_logits(
hidden_states.squeeze(1).unsqueeze(0)
).unsqueeze(1)
logits, _ = self.output_layer( # TODO(ZJH):主网络的 logits 计算
hidden_states, weight=output_weight, runtime_gather_output=runtime_gather_output
)
- 使用
- 若需要执行 MTP 过程,执行 MTP 过程,同时若打开训练,则 MTP loss 在这里被计算(
model_provider函数(也是 pretrain 的入参)会返回一个模型model- 这个返回的模型实现了
forward函数,model.forward函数整体返回值是一个loss值(主网络的loss,但计算图上带着 MTP 所有深度上的 loss),该值是由 _postprocess 返回的值
- 这个返回的模型实现了
pretrain 参数三:forward_step,输入参数包括模型,负责调用模型执行前向过程,并返回 loss 指针等
- 返回的
loss函数指针可以被调用,从而计算loss
pretrain 的工作包括环境初始化,执行训练过程等
第一步:initialize_megatron(),初始化分布式环境,包括 TP,PP,DP 等的子进程组等
第二步:setup_model_and_optimizer(),定义模型架构,切割模型,完成 optimizer 初始化
第三步:build_train_valid_test_data_iterators(), 获取数据 iterator
第四步:train(),训练入口
训练的入参包括上面得到的各种结果
1
2
3
4
5
6
7
8
9
10
11
12def train(
forward_step_func,
model,
optimizer,
opt_param_scheduler,
train_data_iterator,
valid_data_iterator,
process_non_loss_data_func,
config,
checkpointing_context,
non_loss_data_func,
):train_step():训练过程包含一个主要的while循环,每次走一个train_step()1
2def train_step(forward_step_func, data_iterator, model, optimizer, opt_param_scheduler, config, forward_backward_func): # TODO(ZJH): 单步训练入口
"""Single training step."""train_step第一步:forward_backward_func(),完成一次前向和后向过程,是训练的核心函数,也最难实际上调用的函数
forward_backward_func经过层层函数传递train_step() <- train() <- megatron/core/pipeline_parallel/schedules.py,最终可追述到schedules.py文件的get_forward_backward_func()函数1
2
3
4
5
6
7
8
9
10def get_forward_backward_func():
pipeline_model_parallel_size = parallel_state.get_pipeline_model_parallel_world_size()
if pipeline_model_parallel_size > 1: # TODO(ZJH): 若打开 PP
if parallel_state.get_virtual_pipeline_model_parallel_world_size() is not None:
forward_backward_func = forward_backward_pipelining_with_interleaving # TODO(ZJH): 若打开 interleaving pipeline 调度
else:
forward_backward_func = forward_backward_pipelining_without_interleaving # TODO(ZJH): 若关闭 interleaving pipeline 调度
else:
forward_backward_func = forward_backward_no_pipelining # TODO(ZJH): 没有 PP 的情况
return forward_backward_func若打开 PP
- 开启 interleaving pipeline:
forward_backward_pipelining_with_interleaving- 负责实现对应的 1F1B 调度策略,函数内部像
forward_backward_no_pipelining函数一样,会调用forward_step和backward_step两步完成前向后向过程和梯度的积累
- 负责实现对应的 1F1B 调度策略,函数内部像
- 未开启 interleaving pipeline:
forward_backward_pipelining_without_interleaving- 在
forward_backward_pipelining_with_interleaving的基础上,增加了 interleaving 调度策略(实现则更为复杂),进一步优化气泡
- 在
- 其他特殊的 Pipeline 并行调度策略,如 zero_bubble 的调度,实现都在这里新建函数就可以
- 开启 interleaving pipeline:
若为 没有打开 PP 的情况:调用同文件(
schedules.py)下的forward_backward_no_pipelining()函数,下面是该函数的介绍:前向过程+后向过程函数为(
config.overlap_moe_expert_parallel_comm为True):combined_1f1b_schedule_for_no_pipelining注:
config.overlap_moe_expert_parallel_comm为True表示 框架会尝试将专家并行所需的通信操作(如数据传输)与模型的计算操作(如其他层的前向 / 反向计算)重叠进行,而不是等通信完成后再执行计算1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20if config.overlap_moe_expert_parallel_comm and not forward_only: # TODO(ZJH): 如果打开 overlap MoE 的专家并行通信(将专家并行(expert parallelism)中的通信操作与计算操作重叠执行),且包含 backward
# TODO(ZJH): 当 config.overlap_moe_expert_parallel_comm 设为 True 时,框架会尝试将专家并行所需的通信操作(如数据传输)与模型的计算操作(如其他层的前向 / 反向计算)重叠进行,而不是等通信完成后再执行计算
forward_data_store, total_num_tokens = combined_1f1b_schedule_for_no_pipelining( # TODO(ZJH): 1次前向+1次后向过程
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
output_tensor_grad,
forward_data_store,
config,
collect_non_loss_data,
first_val_step,
forward_only,
no_sync_func,
total_num_tokens,
partial(check_first_val_step, first_val_step, forward_only),
)
else:
# forward_step 和 backward_step 交替执行分开执行的函数分别为:
forward_step和backward_step(这里会调用for循环完成多个microbatches,forward_step和backward_step在循环南北部)- 前置说明:
microbatches - 1个microbatches先调用,然后最后一个负责处理梯度同步等1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49with no_sync_func(): # TODO(ZJH): 如果 no_sync_func 上下文管理器 是一个实际的同步禁用逻辑(比如禁用某些 IO 同步、锁机制等),则代码块会在 “不执行同步” 的环境中运行
for i in range(num_microbatches - 1): # TODO(ZJH): 每个设备负责多个 microbatches,注意这里少一个
output_tensor, num_tokens = forward_step( # TODO(ZJH): 前向过程,注意,这里是单个 microbatch 走一次
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
grad_finalize_pgs.cp.size(),
collect_non_loss_data,
is_first_microbatch=check_first_val_step(first_val_step, forward_only, i == 0),
current_microbatch=i,
)
total_num_tokens += num_tokens # TODO(ZJH): 累加 Token 数
if not forward_only:
backward_step( # TODO(ZJH): 后向过程,梯度直接累加(forward 中已经对 loss/num_microbatches)
input_tensor, output_tensor, output_tensor_grad, model_type, config
)
# Run computation for last microbatch out of context handler (want to
# synchronize gradients).
output_tensor, num_tokens = forward_step( # TODO(ZJH): 最后一个梯度单独处理,这个梯度的计算要在 context handler 之外,核心原因是确保最后一次梯度计算完成后能触发必要的同步操作,从而保证梯度的正确性和一致性
forward_step_func,
data_iterator,
model,
num_microbatches,
input_tensor,
forward_data_store,
config,
grad_finalize_pgs.cp.size(),
collect_non_loss_data,
is_first_microbatch=check_first_val_step(
first_val_step, forward_only, num_microbatches == 1
),
current_microbatch=num_microbatches - 1,
)
total_num_tokens += num_tokens # TODO(ZJH): 累加 Token 数
if not forward_only:
backward_step(input_tensor, output_tensor, output_tensor_grad, model_type, config)
# TODO(ZJH): 梯度聚合
if config.finalize_model_grads_func is not None and not forward_only:
# Finalize model grads (perform full grad all-reduce / reduce-scatter for
# data parallelism and layernorm all-reduce for sequence parallelism).
config.finalize_model_grads_func( # TODO(ZJH): 梯度聚合操作 all_reduce + reduce-scatter ?
[model],
total_num_tokens if config.calculate_per_token_loss else None,
grad_finalize_pgs=grad_finalize_pgs,
)
- 前置说明:
forward_step()执行过程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21forward_step 核心代码如下:
with context_manager:
if checkpoint_activations_microbatch is None:
output_tensor, loss_func = forward_step_func(data_iterator, model)
else:
output_tensor, loss_func = forward_step_func(
data_iterator, model, checkpoint_activations_microbatch
)
output_tensor, num_tokens = forward_step_calc_loss(
model,
output_tensor,
loss_func,
config,
vp_stage,
collect_non_loss_data,
num_microbatches,
forward_data_store,
cp_group_size,
is_last_stage,
)- 其中,
forward_step_calc_loss核心代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19if is_last_stage: # TODO(ZJH): 只有最后一个 stage 包含 loss,其他 stage 都不需要计算
if not collect_non_loss_data:
outputs = loss_func(output_tensor) # TODO(ZJH): 获取损失值,详情见 pretrain_gpt.py 的 loss_func 的返回值(中间使用 forward_step 作为 partial 封装)
if len(outputs) == 3:
output_tensor, num_tokens, loss_reduced = outputs
# TODO(ZJH): 当 calculate_per_token_loss=True 时,损失计算会保留每个 token 的损失值(即按 token 粒度计算损失),通常用于需要获取单 token 损失的场景(如后续可能的梯度裁剪、损失分析等)
if not config.calculate_per_token_loss: # TODO(ZJH): 当 calculate_per_token_loss=False 时,损失会被归一化(通常除以总 token 数和微批次数量),得到一个全局平均损失,这是训练中更常见的做法(避免损失值因批次大小不同而波动)
output_tensor /= num_tokens # TODO(ZJH): 视情况看是否需要做 Token 粒度的归一化
output_tensor /= num_microbatches # TODO(ZJH): 这里是单个 Batch,但除以 num_microbatches,是为了后续 backward 时梯度可以直接累加
else:
# preserve legacy loss averaging behavior (ie, over the number of microbatches)
assert len(outputs) == 2
output_tensor, loss_reduced = outputs
output_tensor *= cp_group_size
output_tensor /= num_microbatches
forward_data_store.append(loss_reduced)
else:
data = loss_func(output_tensor, non_loss_data=True)
forward_data_store.append(data)
- 其中,
backward_step()执行过程:- 后向过程,可选择自定义的
backward或 PyTorch 标准的官方实现,梯度直接累加(forward中已经对loss/num_microbatches)1
2
3
4
5if output_tensor[0].requires_grad:
if config.deallocate_pipeline_outputs:
custom_backward(output_tensor[0], output_tensor_grad[0]) # TODO(ZJH): 使用自定义的 backward
else:
torch.autograd.backward(output_tensor[0], grad_tensors=output_tensor_grad[0]) # TODO(ZJH): 直接使用 backward
- 后向过程,可选择自定义的
train_step第二步:optimizer.step()- 用梯度完成一次完整的参数更新
train_step第三步:继续处理loss并上报- 注:调用完 optimizer 后,还要继续处理
loss的原因是梯度更新不需要汇总 DP 的loss,只有上报时需要聚合 所有 DP 的数据
- 注:调用完 optimizer 后,还要继续处理
附录:Megatron MTP 损失绑定函数的测试
MTP 损失绑定到 main_hidden_states 的方式是通过一个不修改值,但绑定梯度的自定义算子
MTPLossAutoScaler实现:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# megatron/core/transformer/multi_token_prediction.py
class MTPLossAutoScaler(torch.autograd.Function): # TODO(ZJH): 相当于在实现自定义的 PyTorch 算子
"""An AutoScaler that triggers the backward pass and scales the grad for mtp loss."""
main_loss_backward_scale: torch.Tensor = torch.tensor(1.0)
def forward(ctx, output: torch.Tensor, mtp_loss: torch.Tensor): # TODO(ZJH): 前向过程,存储 loss,返回输入的原始值,不做任何计算
"""Preserve the mtp by storing it in the context to avoid garbage collection.
Args:
output (torch.Tensor): The output tensor.
mtp_loss (torch.Tensor): The mtp loss tensor.
Returns:
torch.Tensor: The output tensor.
"""
ctx.save_for_backward(mtp_loss)
return output
def backward(ctx, grad_output: torch.Tensor): # TODO(ZJH): 后向过程,获取前向过程存储的 loss,乘以 main_loss_backward_scale 并返回
"""Compute and scale the gradient for mtp loss..
Args:
grad_output (torch.Tensor): The gradient of the output.
Returns:
Tuple[torch.Tensor, torch.Tensor]: The gradient of the output, scaled mtp loss
gradient.
"""
(mtp_loss,) = ctx.saved_tensors
mtp_loss_backward_scale = MTPLossAutoScaler.main_loss_backward_scale
scaled_mtp_loss_grad = torch.ones_like(mtp_loss) * mtp_loss_backward_scale
return grad_output, scaled_mtp_loss_gradMTPLossAutoScaler算子测试代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84import torch
# 待测试类(直接复用原代码)
class MTPLossAutoScaler(torch.autograd.Function):
main_loss_backward_scale: torch.Tensor = torch.tensor(1.0)
def forward(ctx, output: torch.Tensor, mtp_loss: torch.Tensor):
ctx.save_for_backward(mtp_loss)
return output
def backward(ctx, grad_output: torch.Tensor):
(mtp_loss,) = ctx.saved_tensors
scaled_mtp_loss_grad = torch.ones_like(mtp_loss) * MTPLossAutoScaler.main_loss_backward_scale
return grad_output, scaled_mtp_loss_grad
def test_all_scenarios():
# 初始化模型可训练参数(所有场景共用)
x = torch.tensor([2.0], requires_grad=True)
y = torch.tensor([3.0], requires_grad=True)
# 定义测试场景配置(场景名、mtp_loss构造、scale系数)
scenarios = [
# 场景1:mtp_loss不依赖参数 + scale=1.0
("不依赖参数 + scale=1.0", lambda: torch.tensor([5.0], requires_grad=True), 1.0),
# 场景2:mtp_loss不依赖参数 + scale=0.3
("不依赖参数 + scale=0.3", lambda: torch.tensor([5.0], requires_grad=True), 0.3),
# 场景3:mtp_loss依赖参数(x+y) + scale=1.0
("依赖参数3*(x+y) + scale=1.0", lambda: 3*(x + y), 1.0),
# 场景4:mtp_loss依赖参数(x+y) + scale=0.6
("依赖参数3*(x+y) + scale=0.6", lambda: 3*(x + y), 0.6),
]
for scenario_name, mtp_loss_fn, scale in scenarios:
# 重置梯度和scale系数
x.grad = None
y.grad = None
MTPLossAutoScaler.main_loss_backward_scale = torch.tensor(scale)
# 1. 计算模型输出和mtp_loss
output = x * y # 模型输出(固定逻辑:x*y,梯度易验证)
mtp_loss = mtp_loss_fn()
# 关键修复:为mtp_loss保留梯度(无论是否为叶子张量)
mtp_loss.retain_grad() # mtp_loss 依赖模型参数时(mtp_loss 非叶子张量),mtp_loss.grad 不存在,使用 retain_grad() 强制保留其梯度,方便后续查看
# 2. 使用AutoScaler处理
scaled_output = MTPLossAutoScaler.apply(output, mtp_loss)
# 3. 构造总损失并反向传播
total_loss = scaled_output.sum()
total_loss.backward()
# 4. 打印结果(保留1位小数,简洁清晰)
print(f"=== {scenario_name} ===")
# 确保grad存在(避免None报错)
mtp_grad = mtp_loss.grad.item() # 注意:若不使用 mtp_loss.retain_grad(),则 mtp_loss 依赖模型参数时(mtp_loss 非叶子张量),mtp_loss.grad 不存在
print(f"mtp_loss梯度: {mtp_grad:.1f}") # 验证scale是否生效
print(f"参数x梯度: {x.grad.item():.1f}") # 验证是否受mtp_loss依赖关系影响
print(f"参数y梯度: {y.grad.item():.1f}\n") # 验证是否受mtp_loss依赖关系影响
if __name__ == "__main__":
test_all_scenarios()
# === 不依赖参数 + scale=1.0 ===
# mtp_loss梯度: 1.0
# 参数x梯度: 3.0
# 参数y梯度: 2.0
#
# === 不依赖参数 + scale=0.3 ===
# mtp_loss梯度: 0.3
# 参数x梯度: 3.0
# 参数y梯度: 2.0
#
# === 依赖参数3*(x+y) + scale=1.0 ===
# mtp_loss梯度: 1.0
# 参数x梯度: 6.0
# 参数y梯度: 5.0
#
# === 依赖参数3*(x+y) + scale=0.6 ===
# mtp_loss梯度: 0.6
# 参数x梯度: 4.8
# 参数y梯度: 3.8




-MTP(Multi-token Prediction)的前世今生](https://zhuanlan.zhihu.com/p/18056041194)")


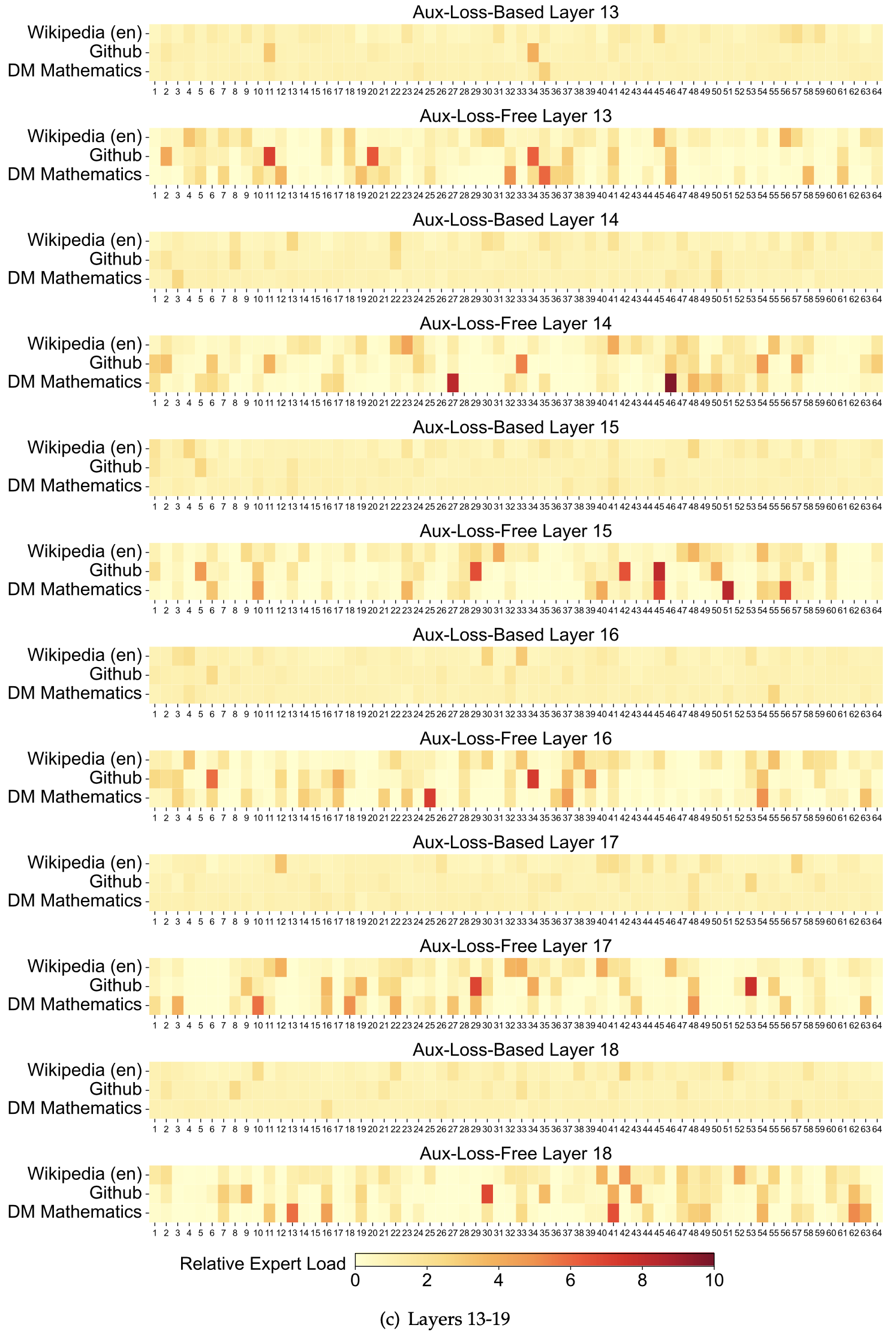
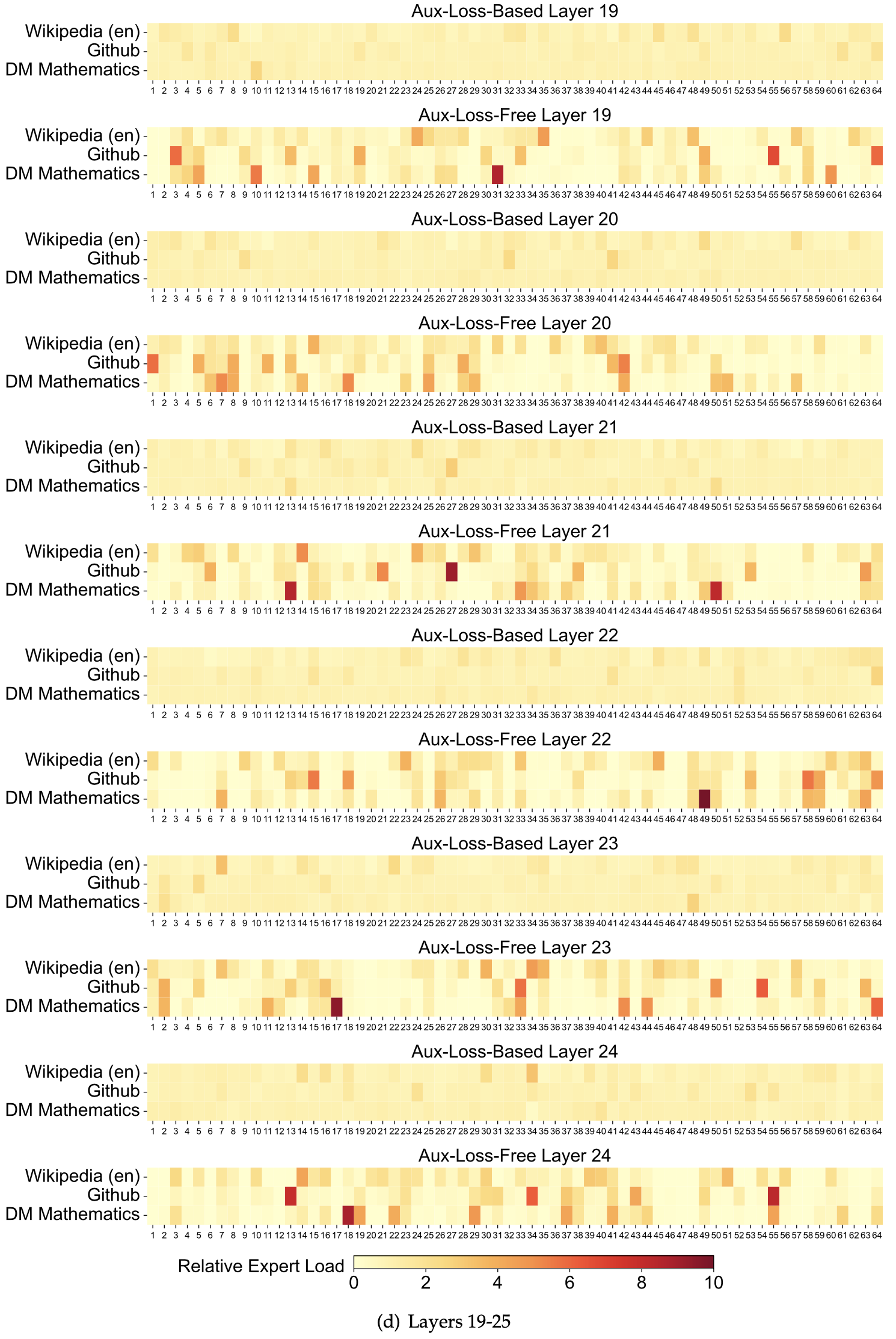
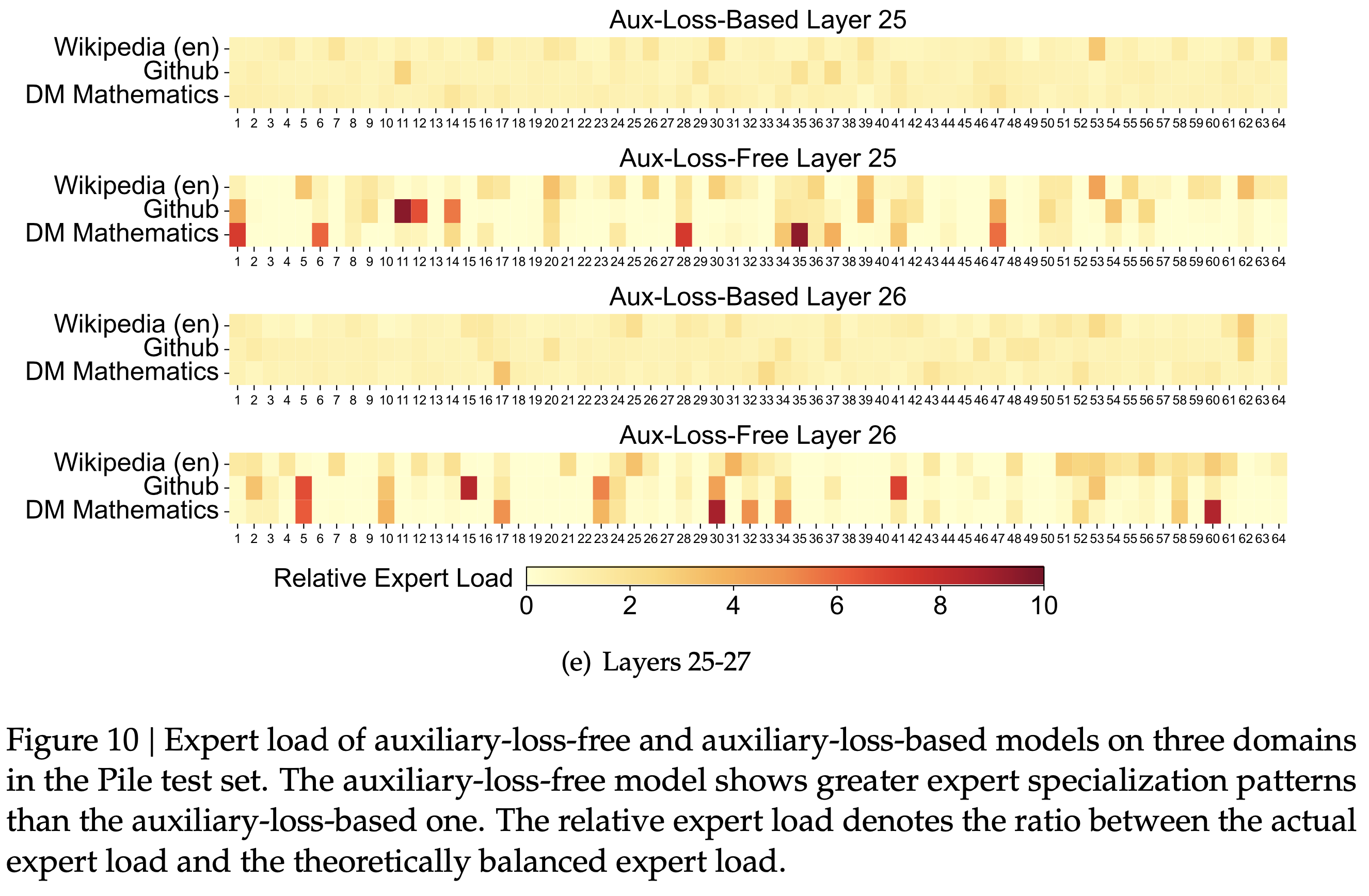
/EfficientAttention-Survey-Figure1.png)
/EfficientAttention-Survey-Table1.png)
/EfficientAttention-Survey-Figure2.png)
/EfficientAttention-Survey-Figure3.png)
/EfficientAttention-Survey-Figure4.png)


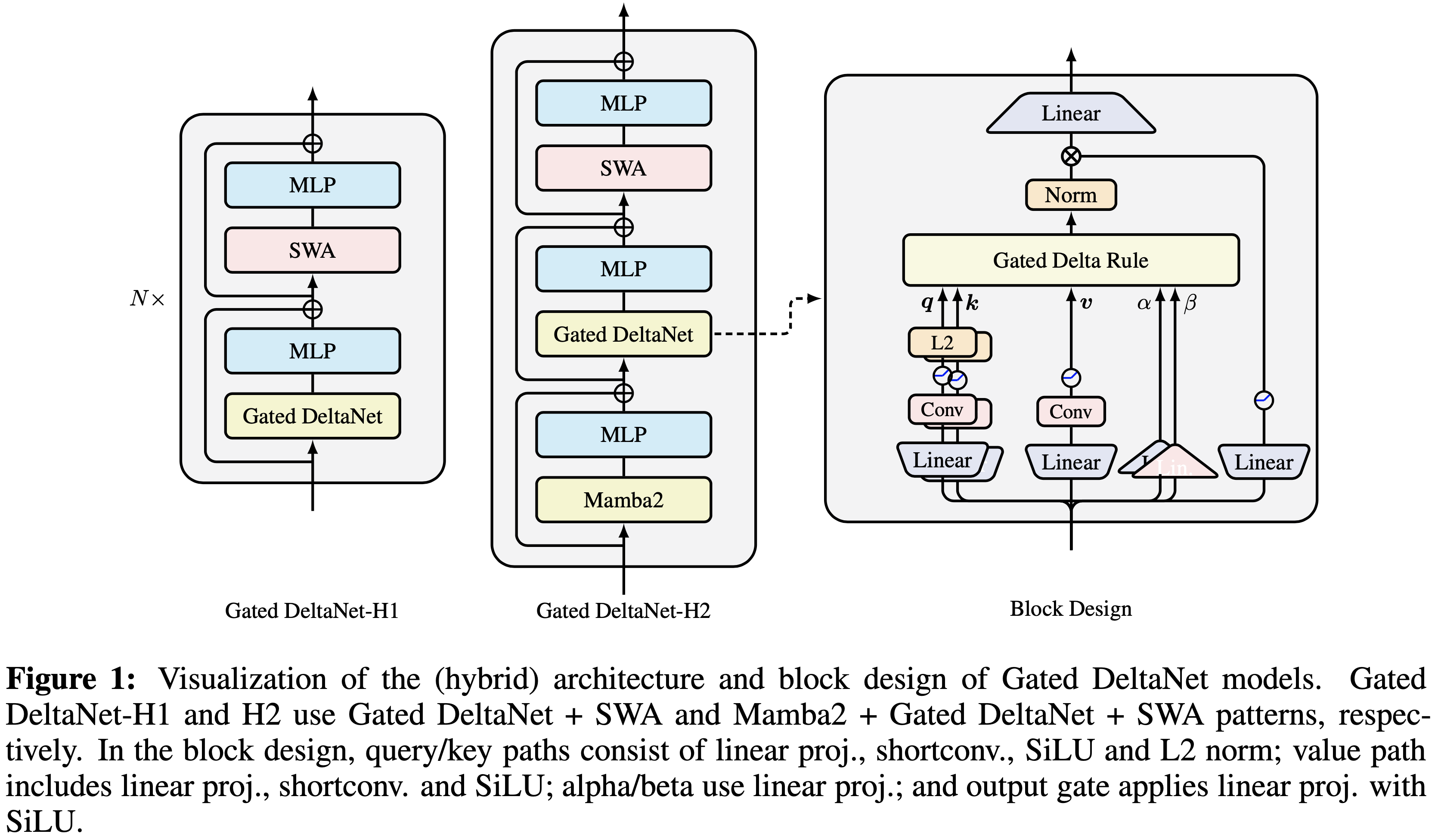
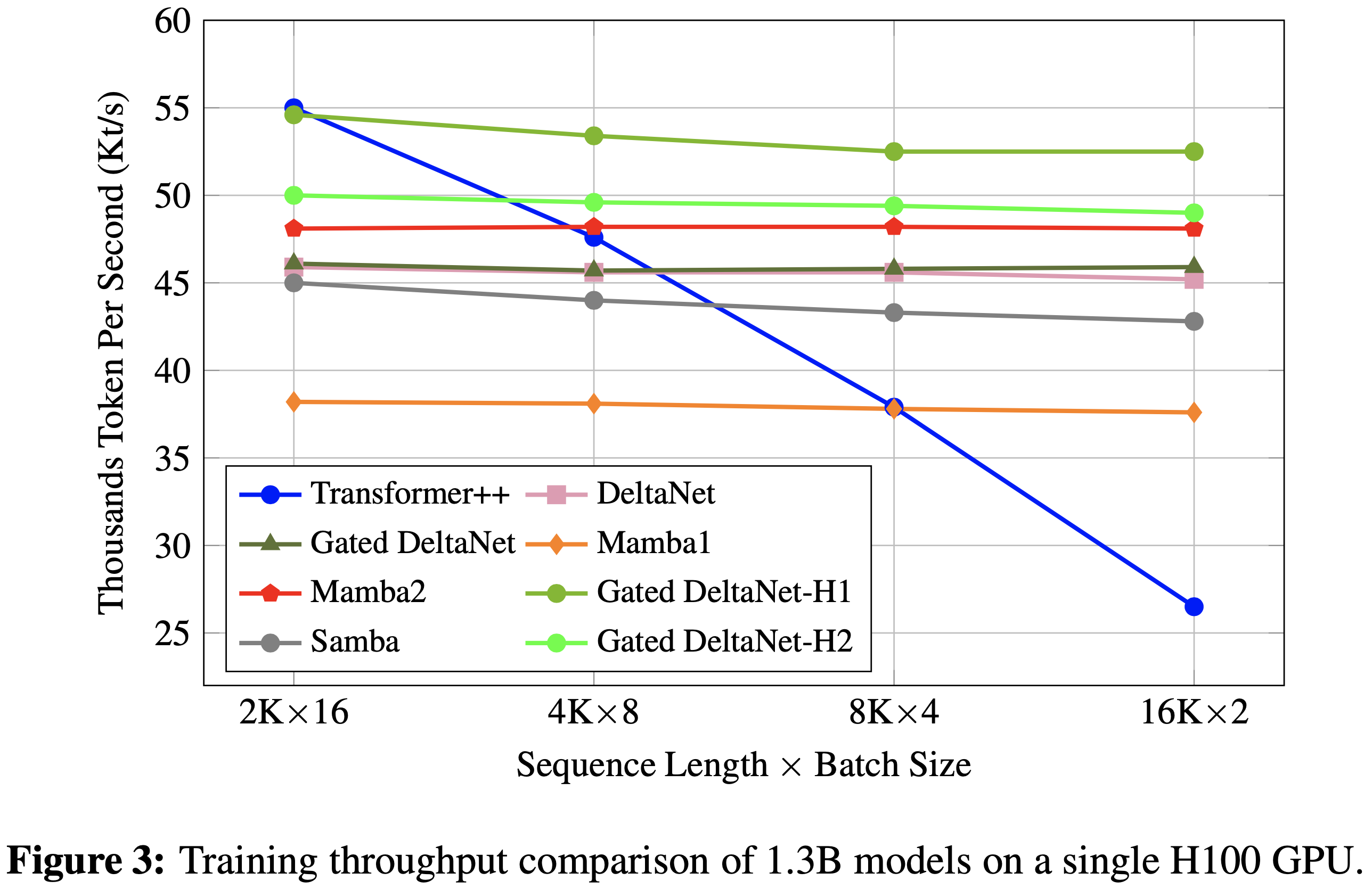


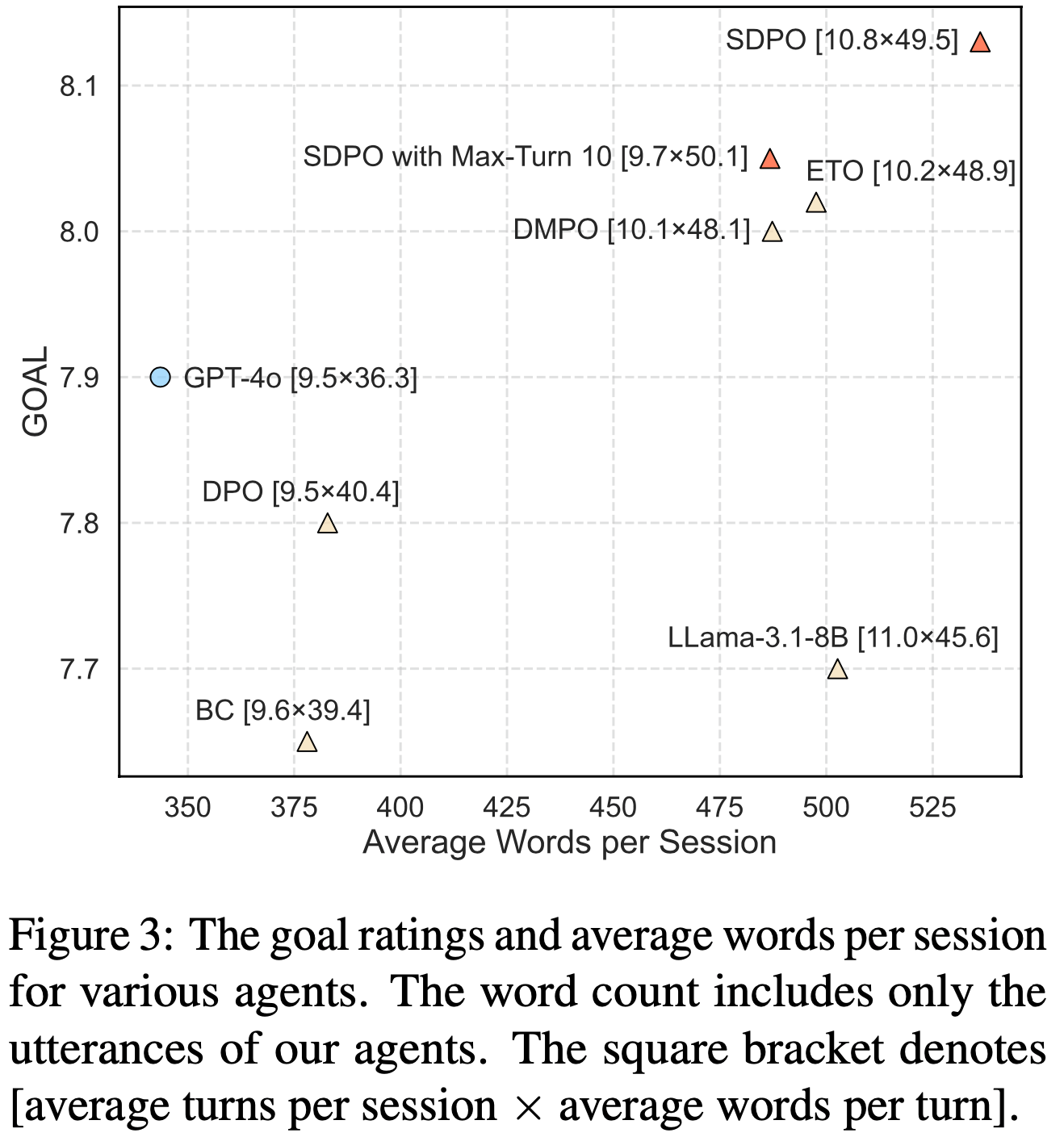



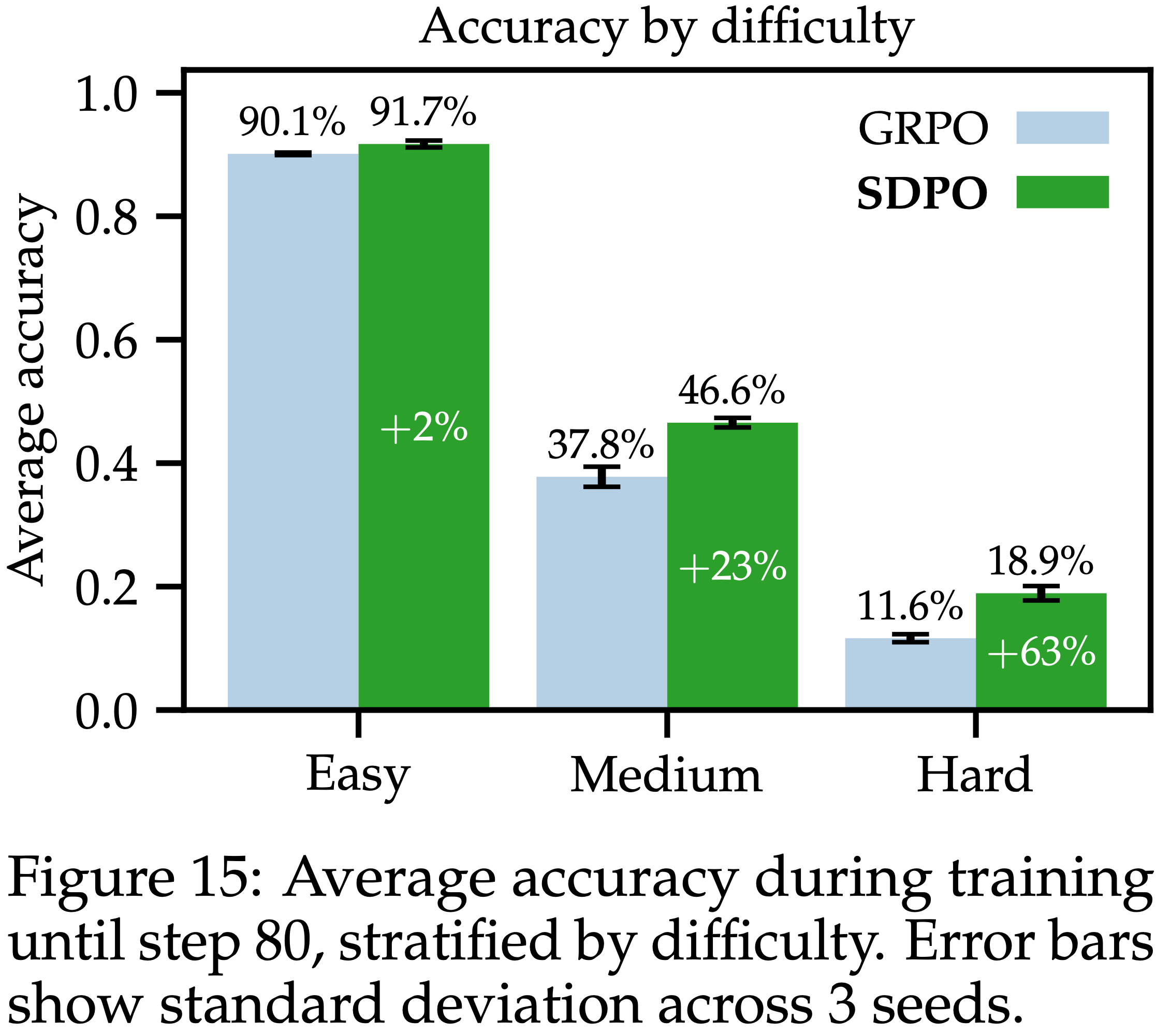

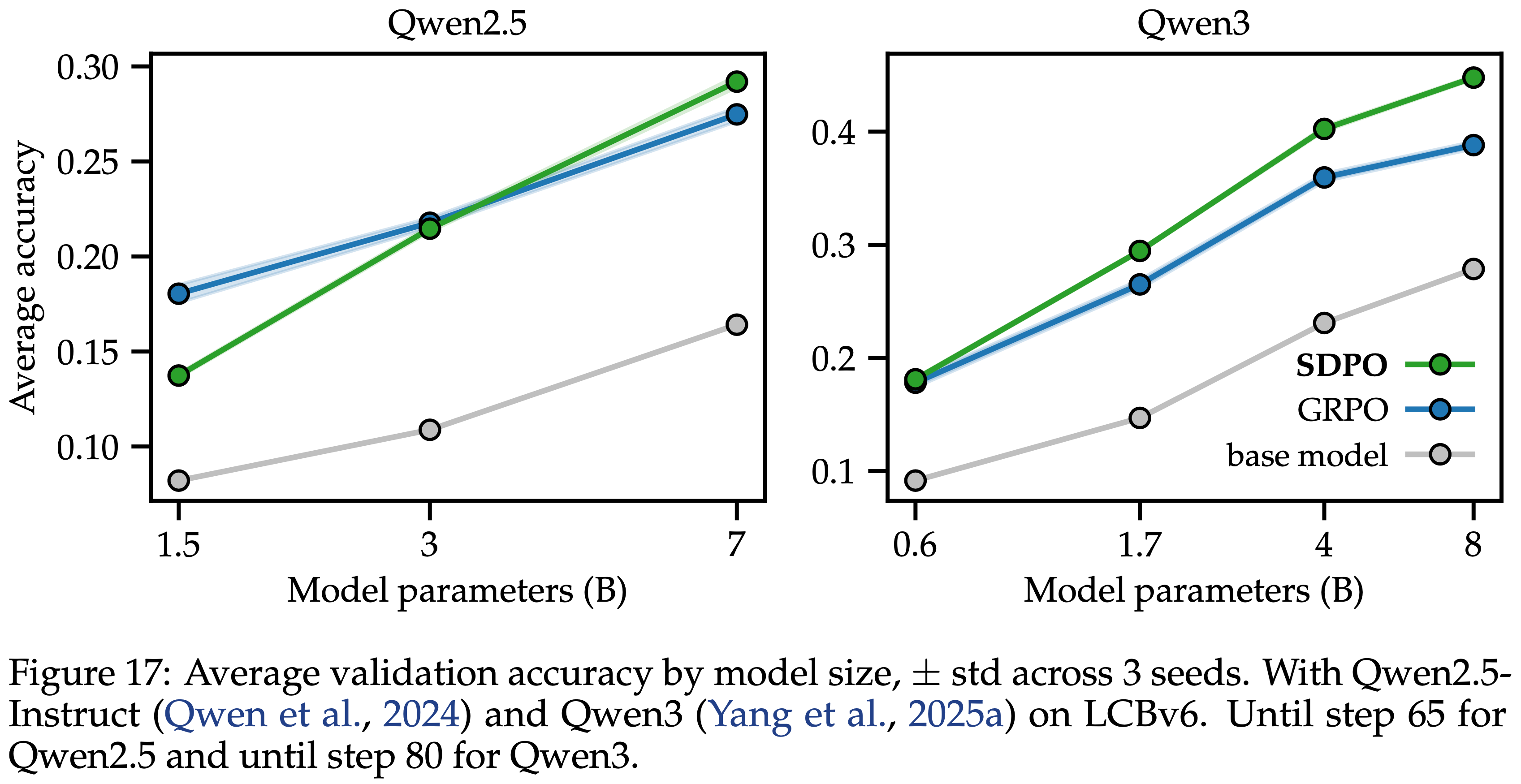
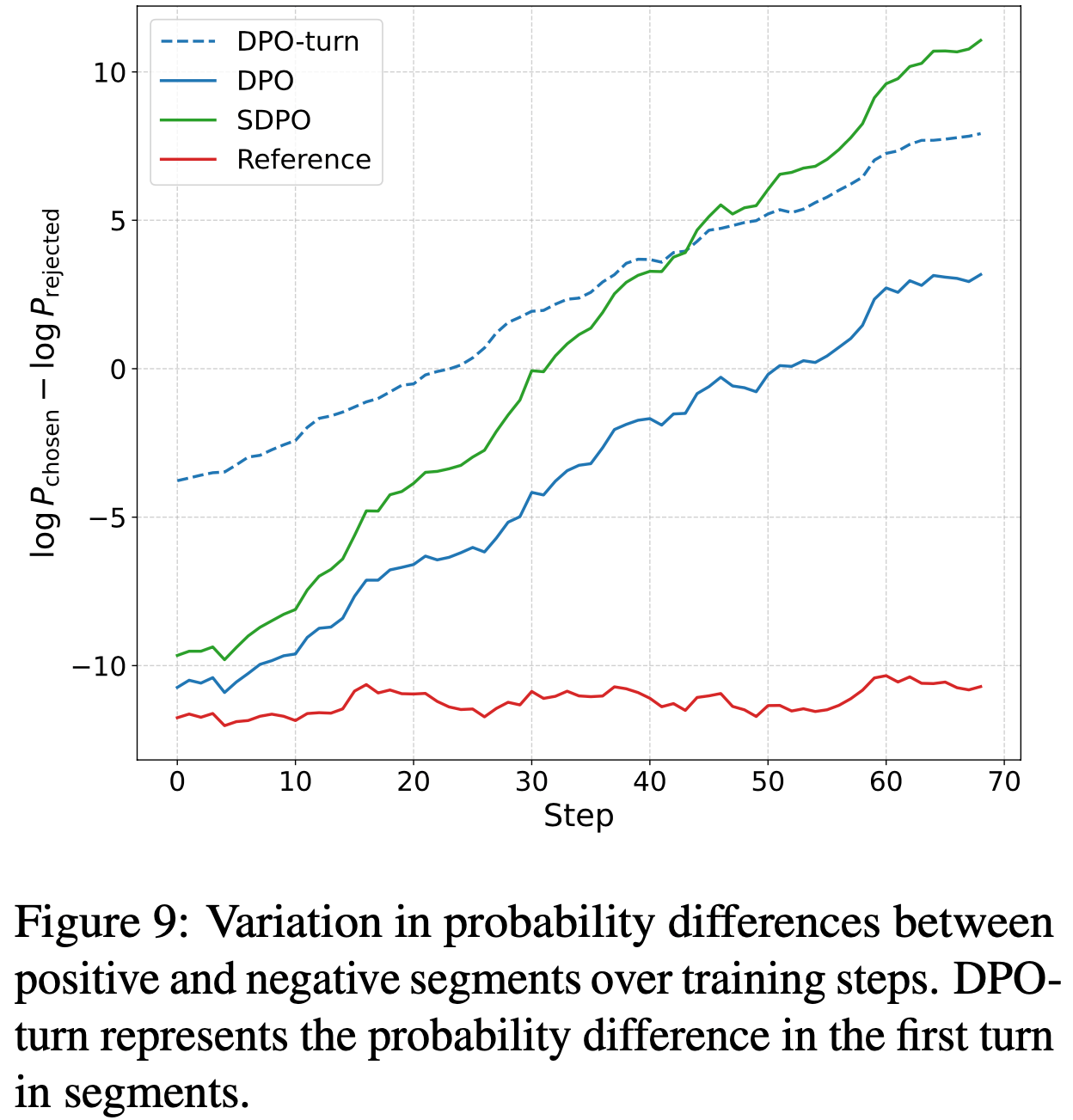
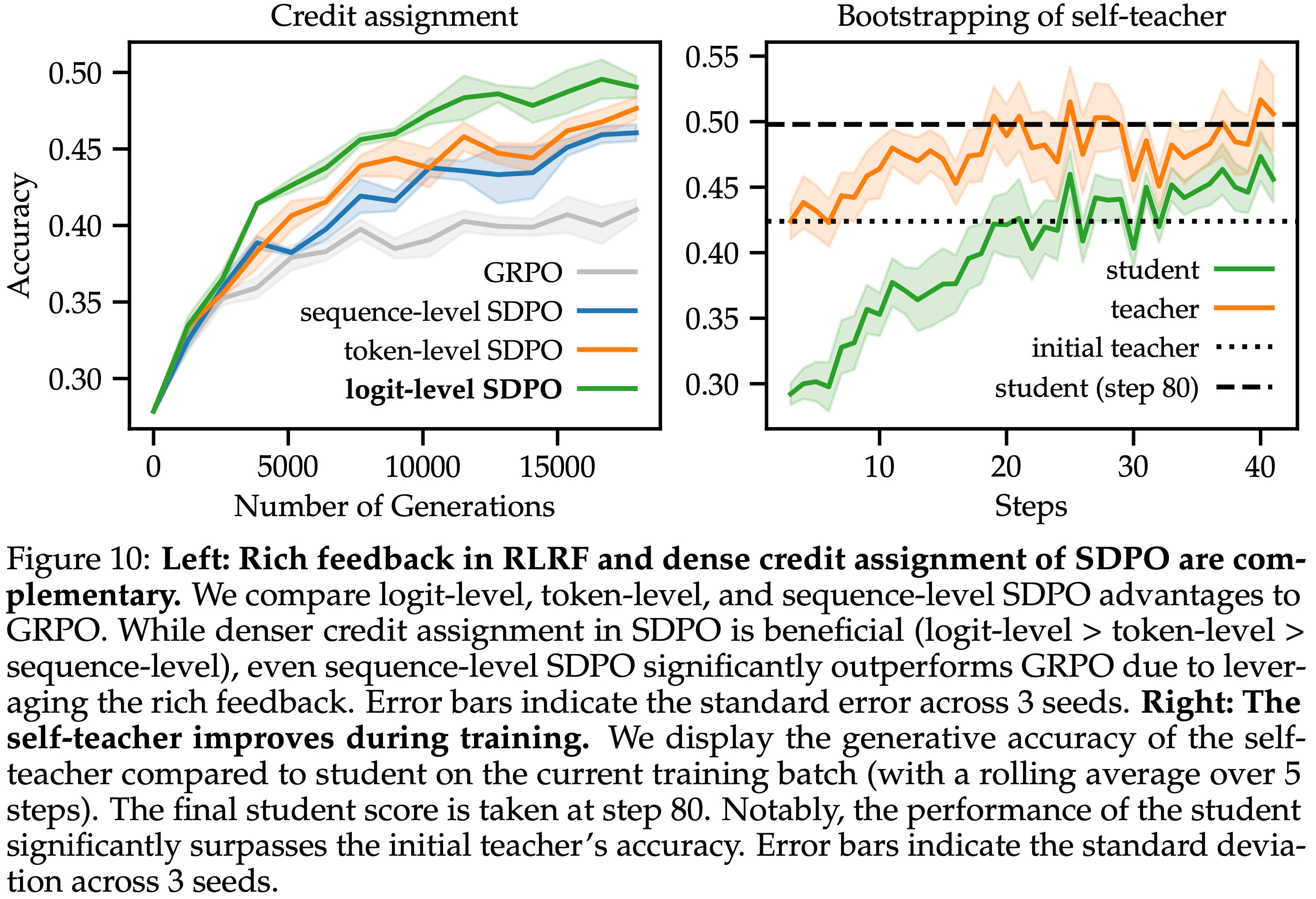
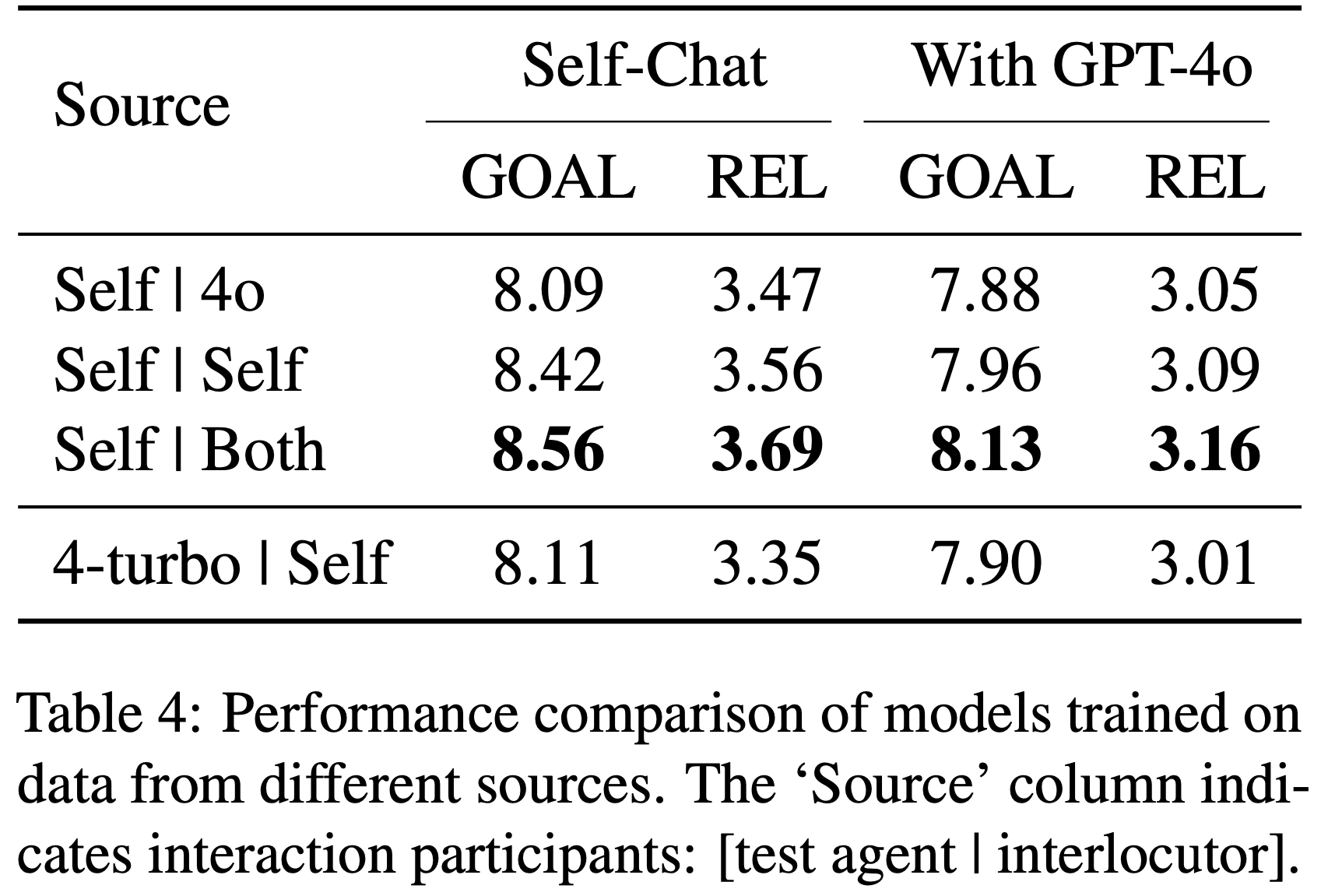
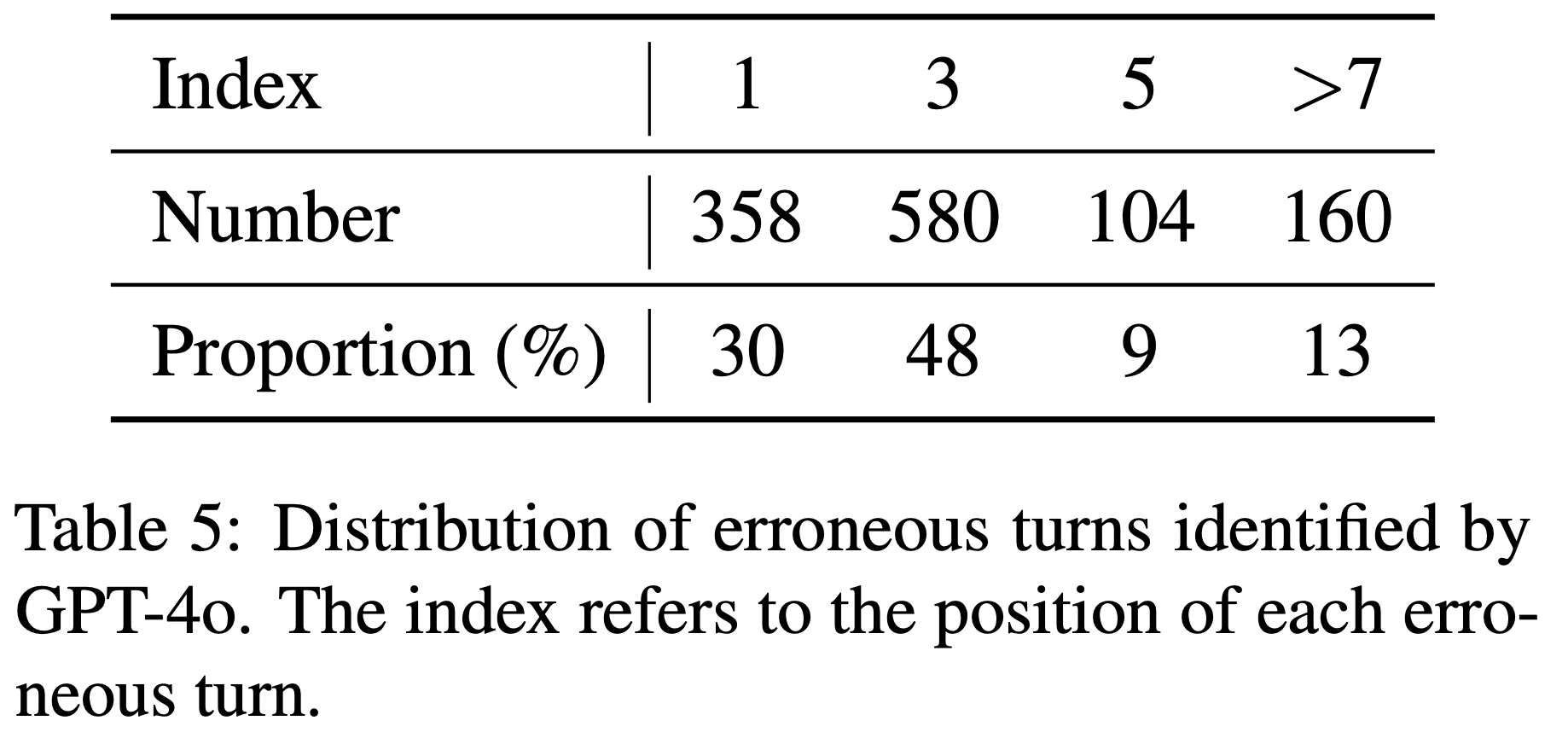
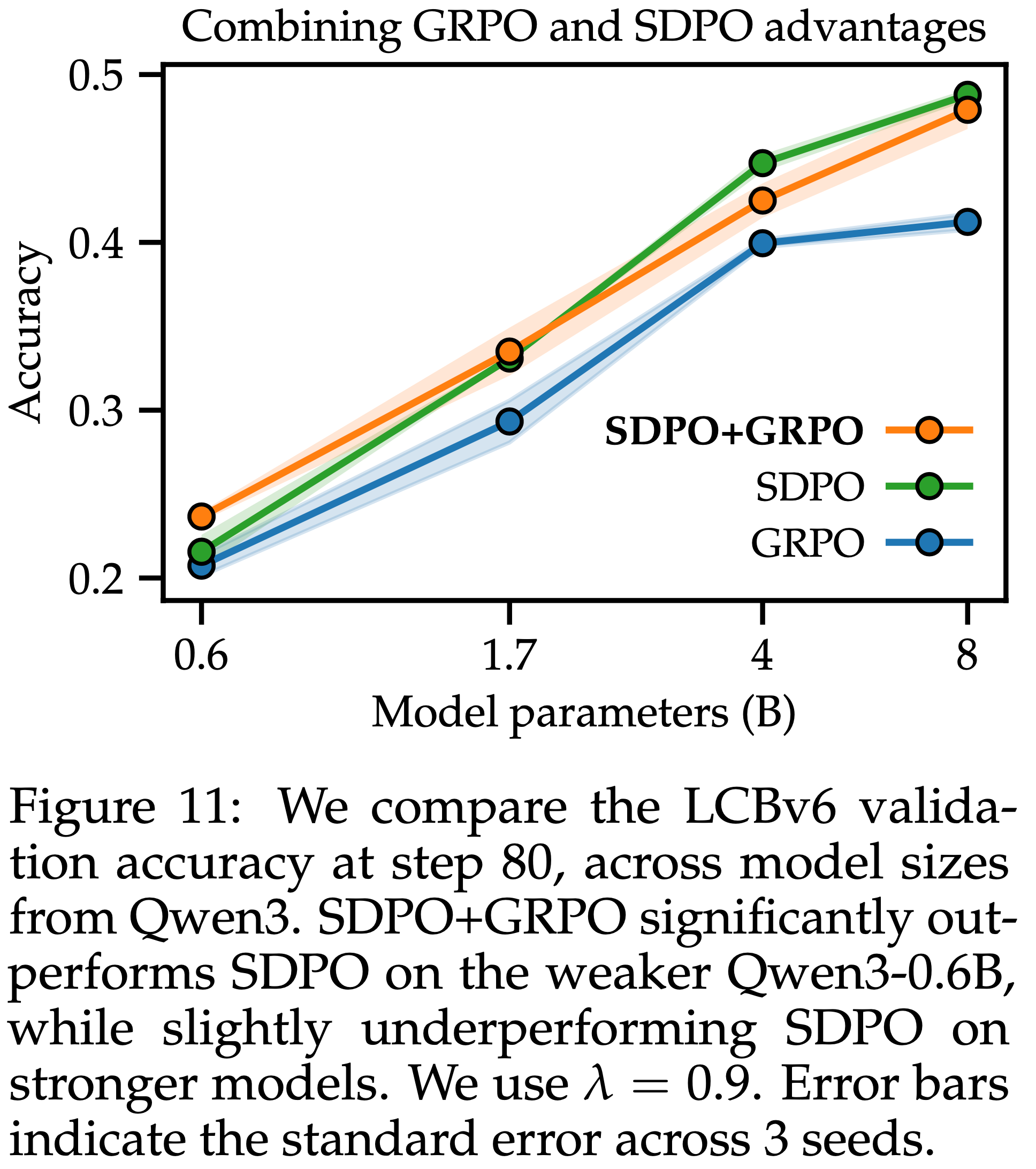

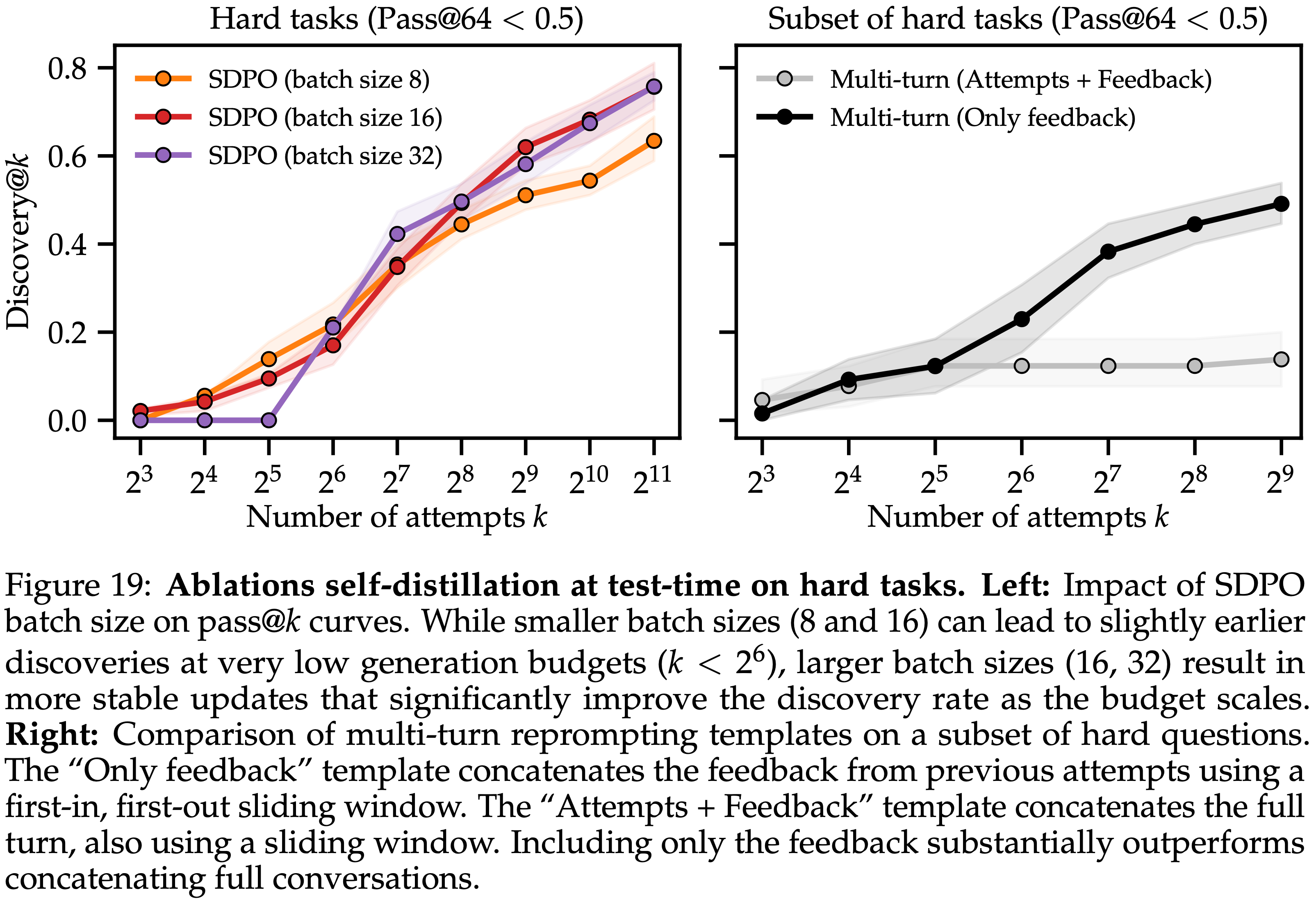
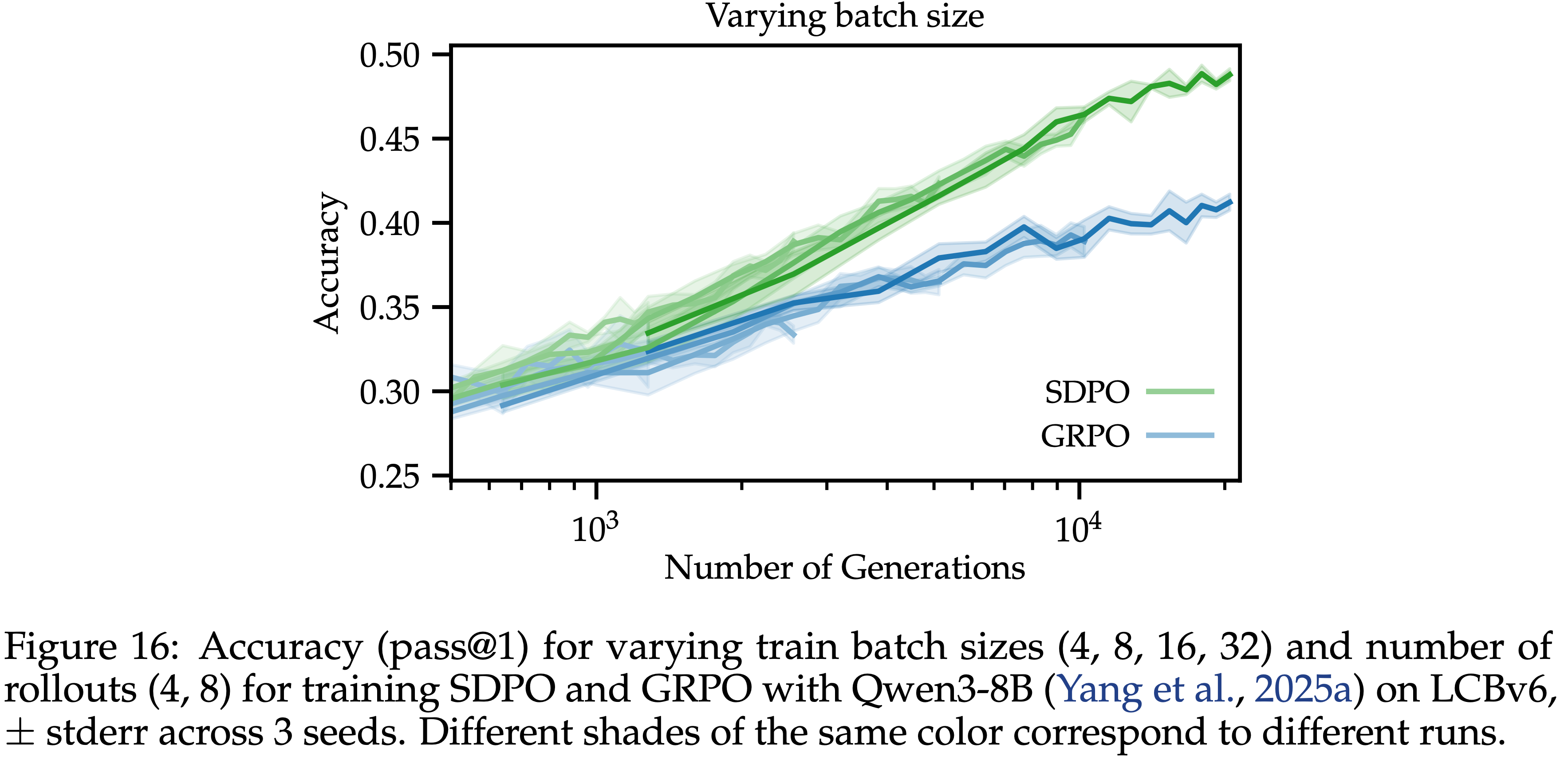
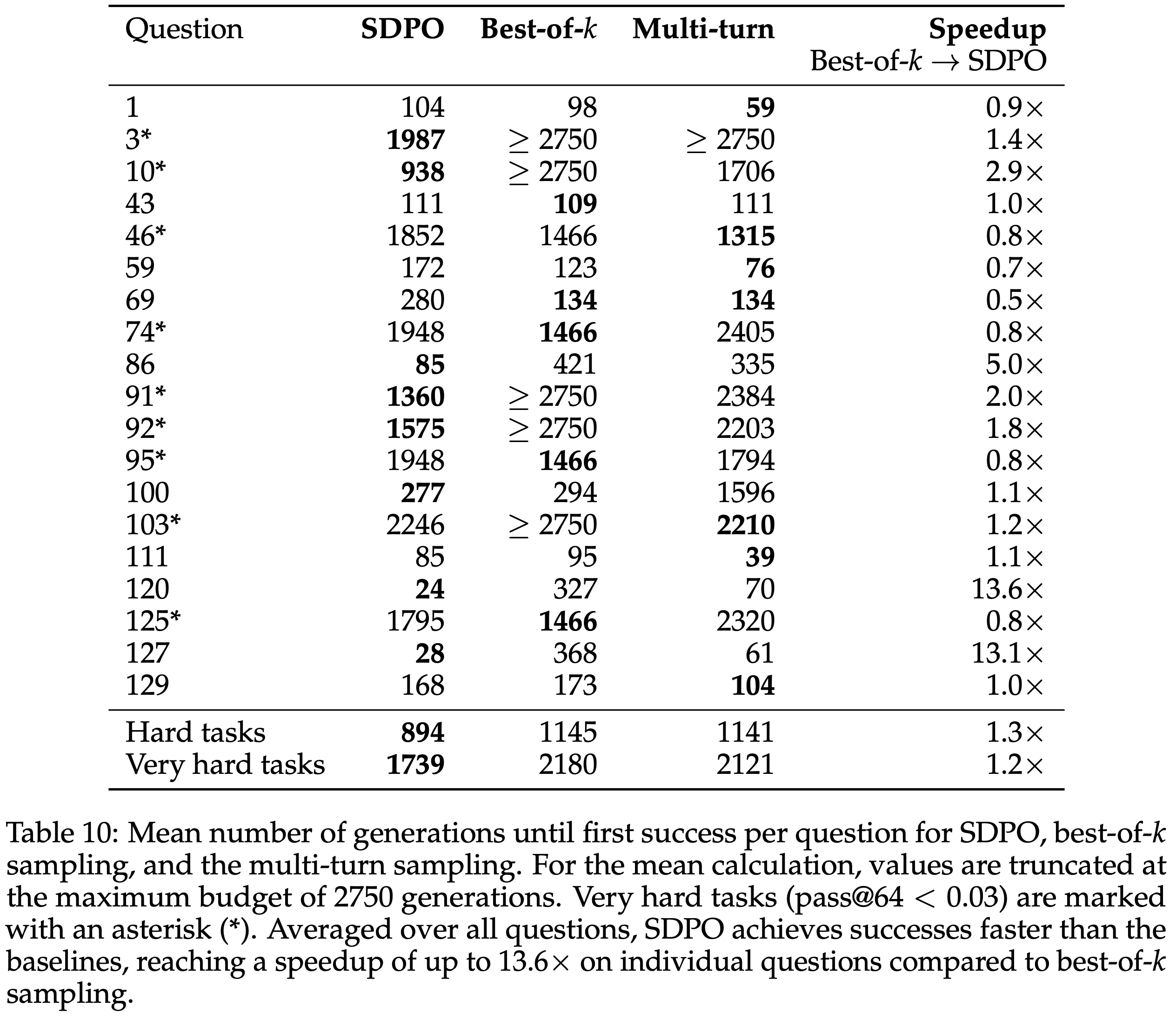
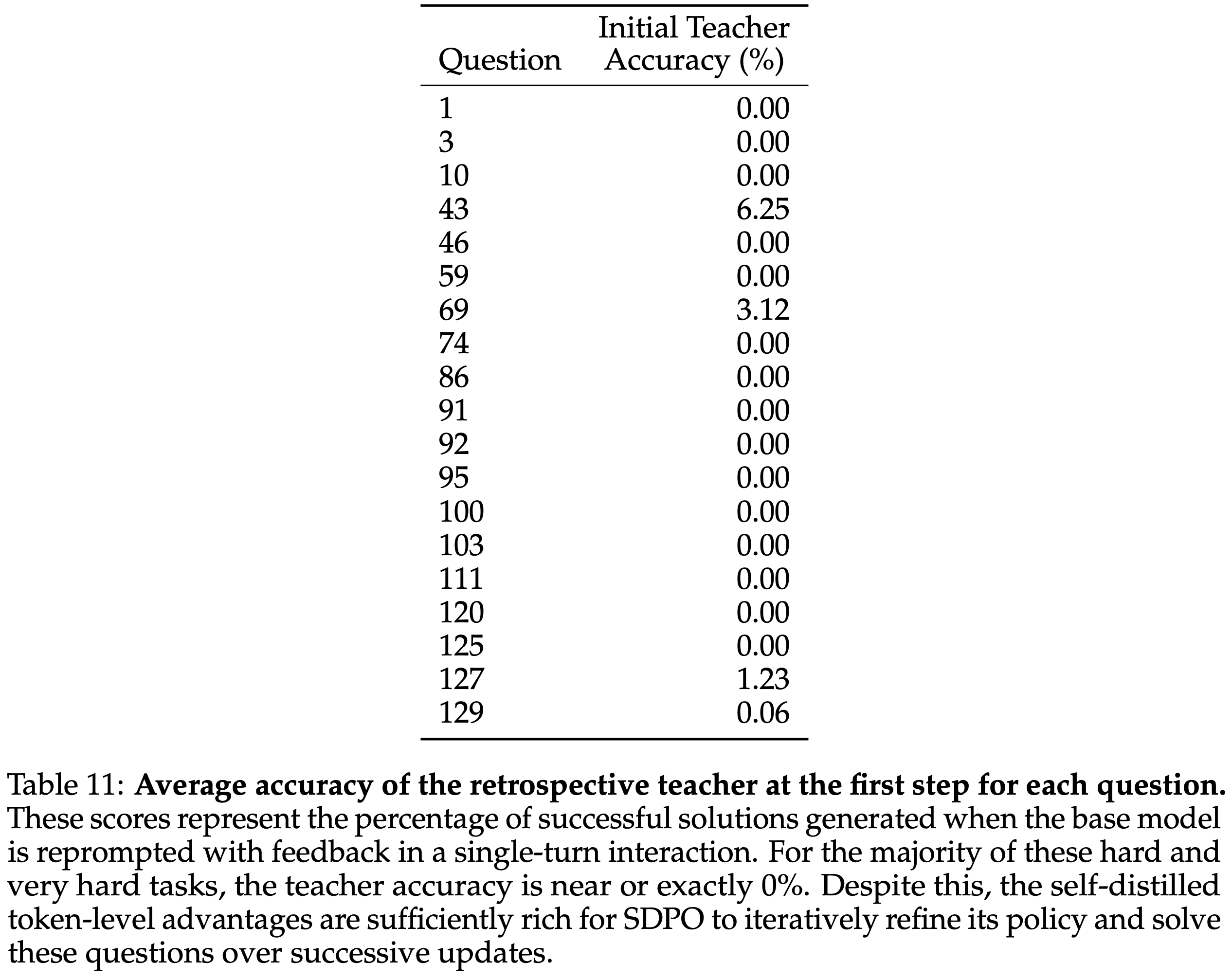
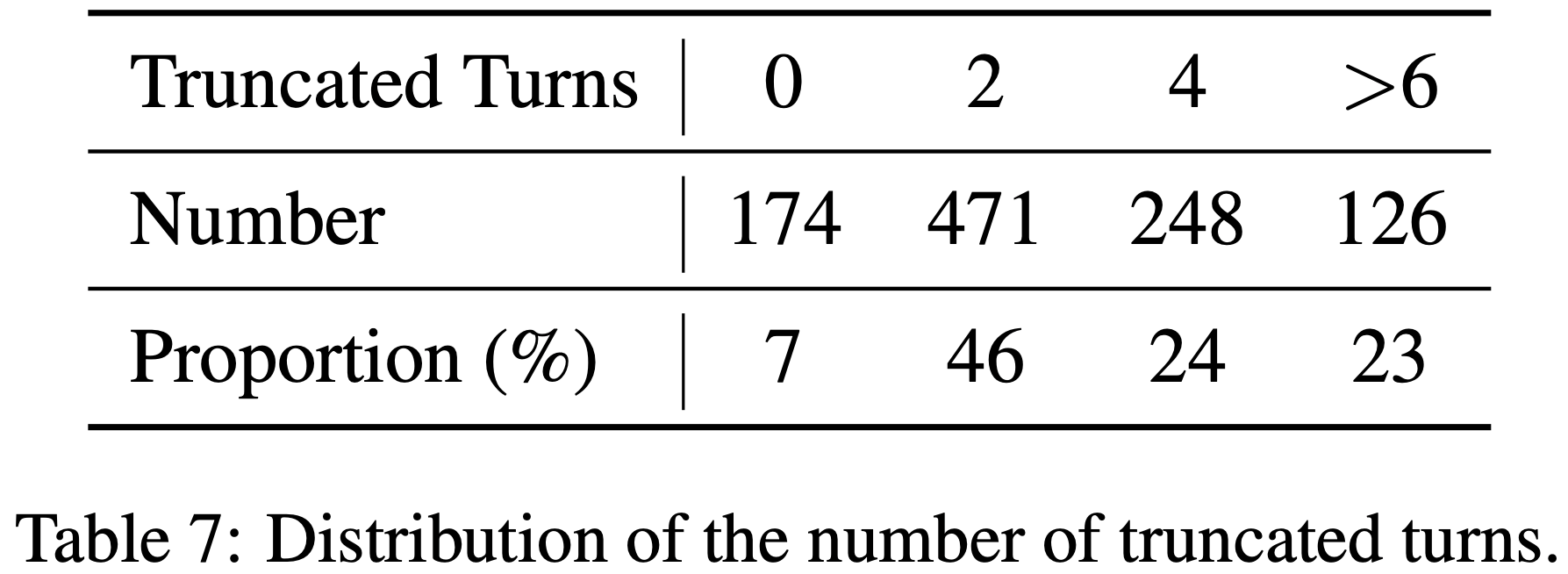

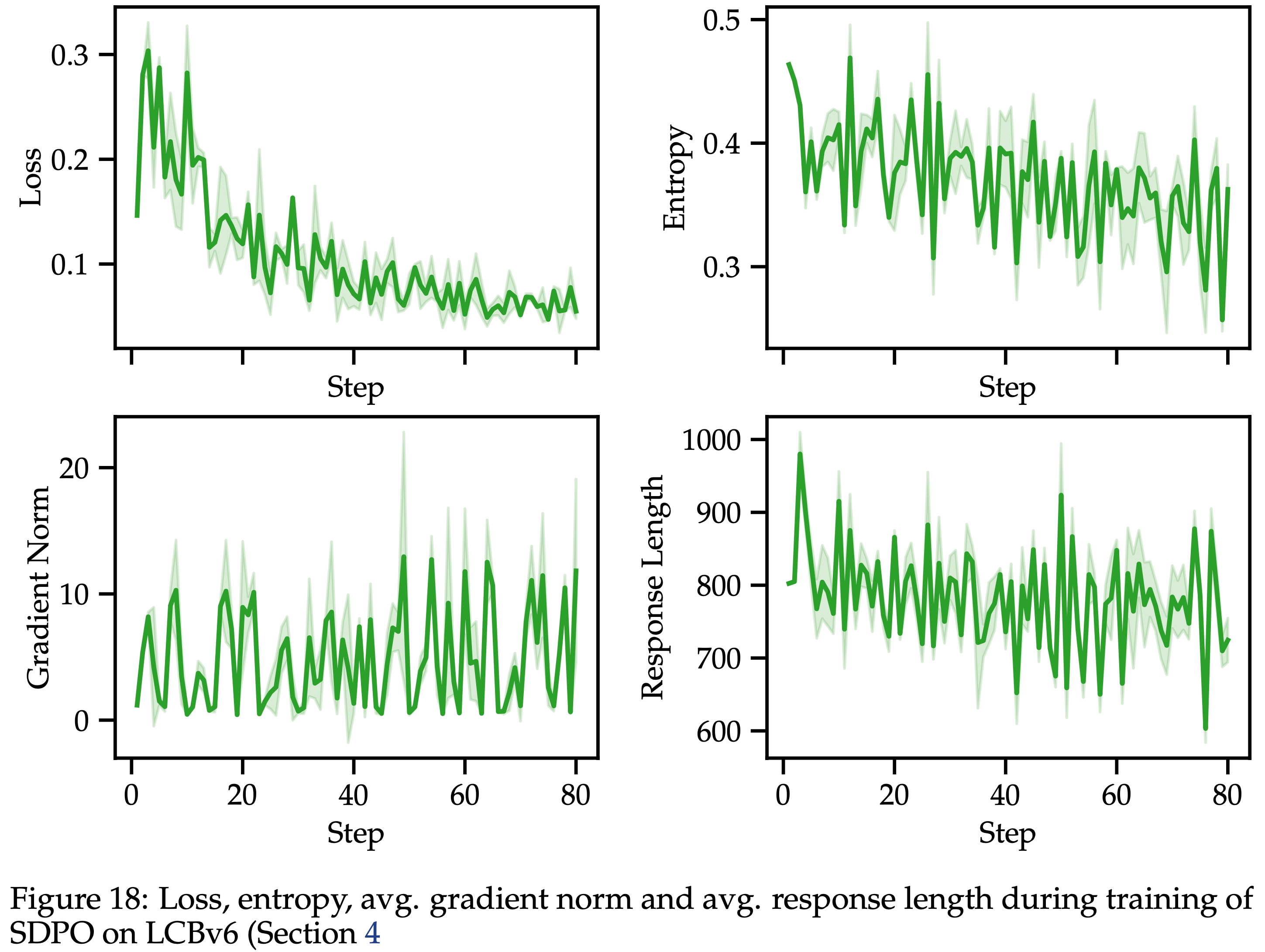
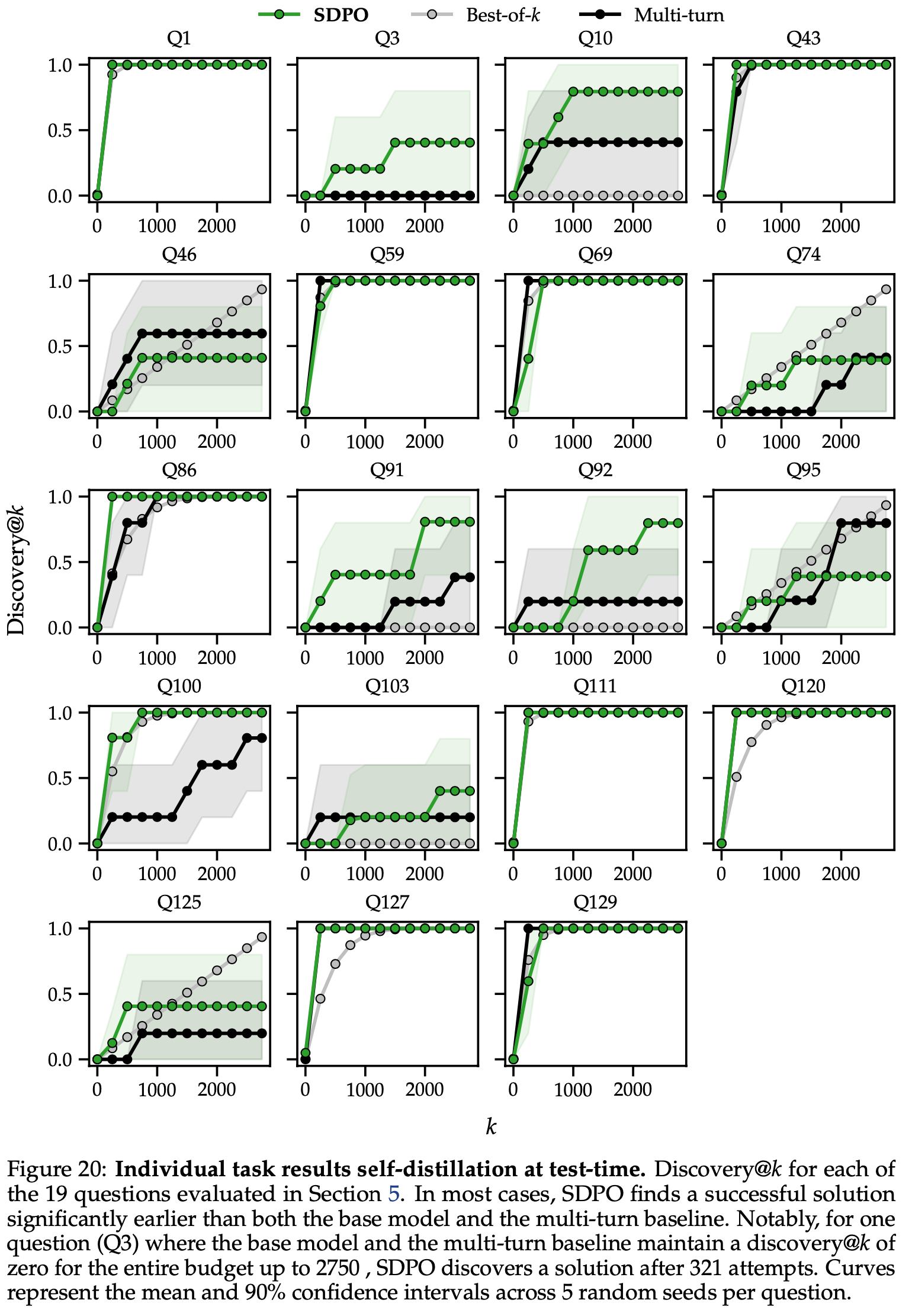
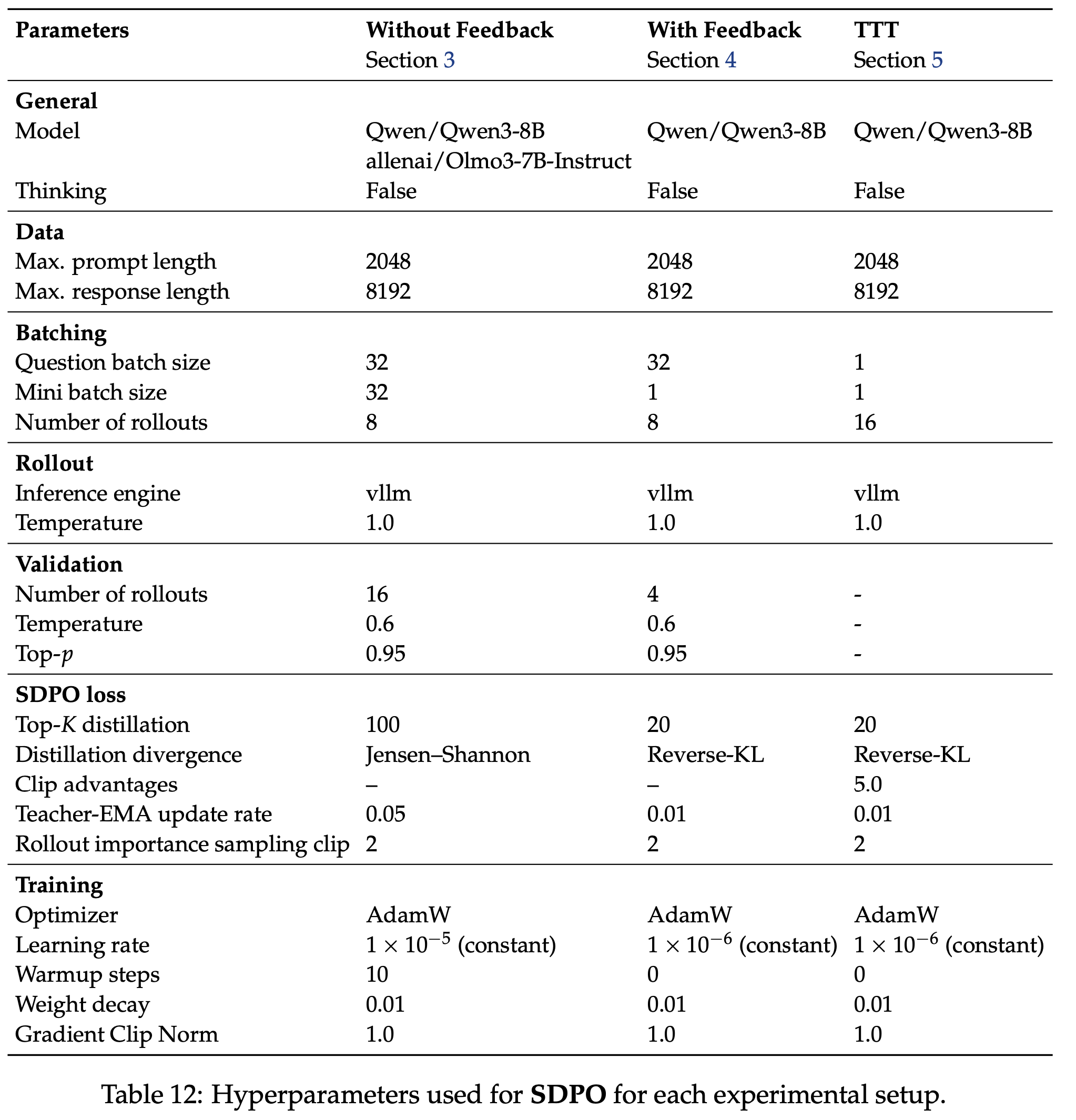
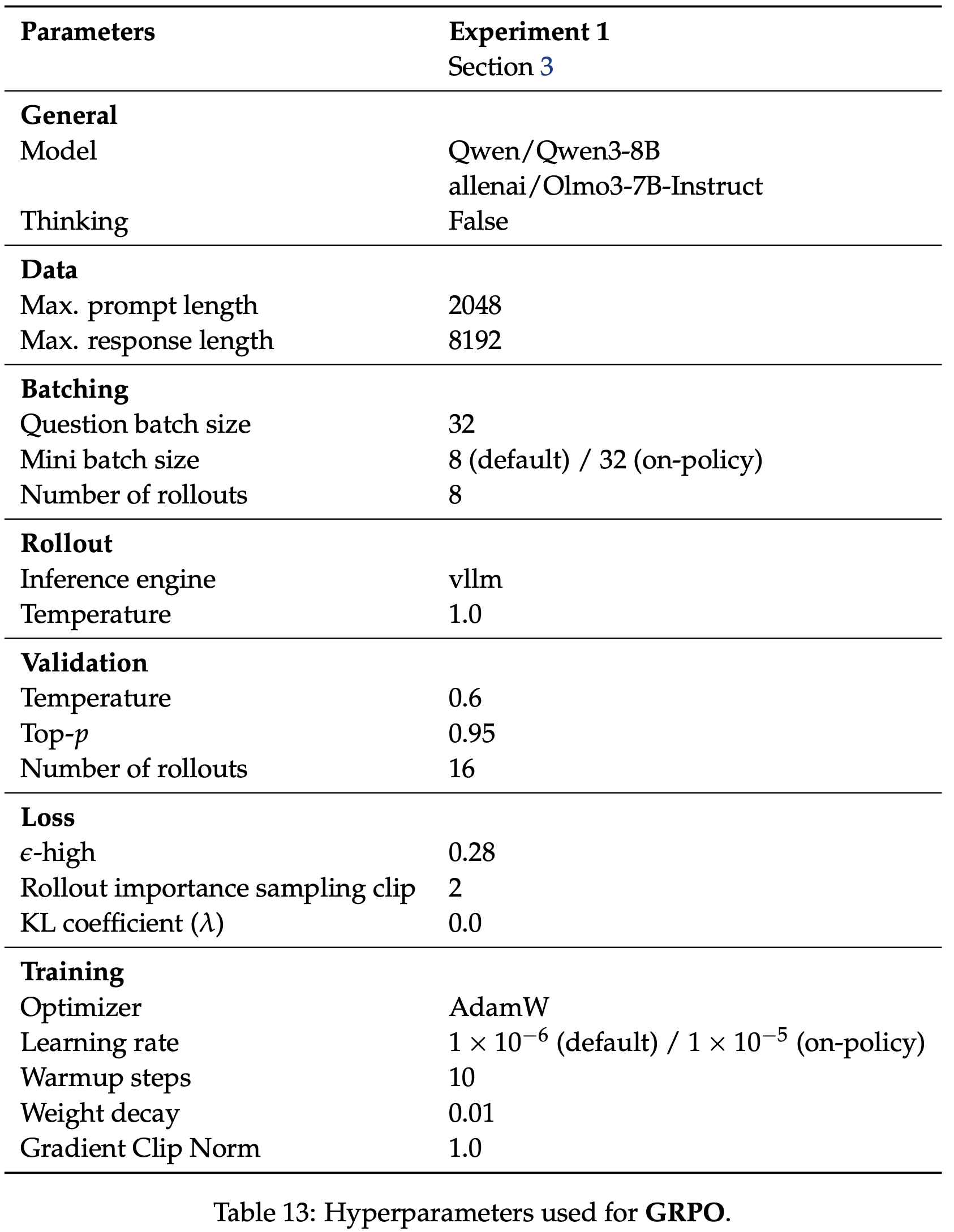
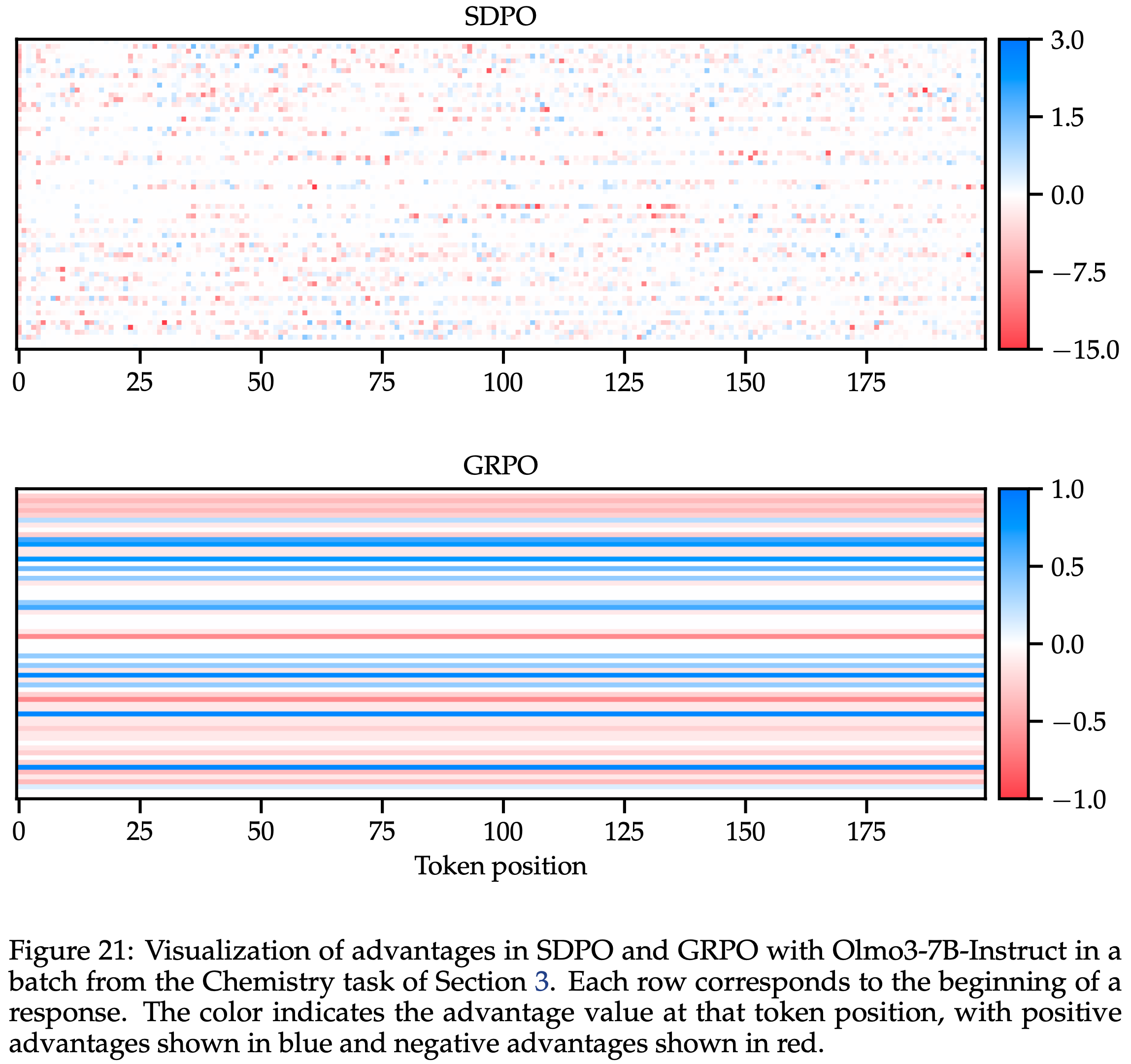

/Segment-Level-DPO-Figure1.png)
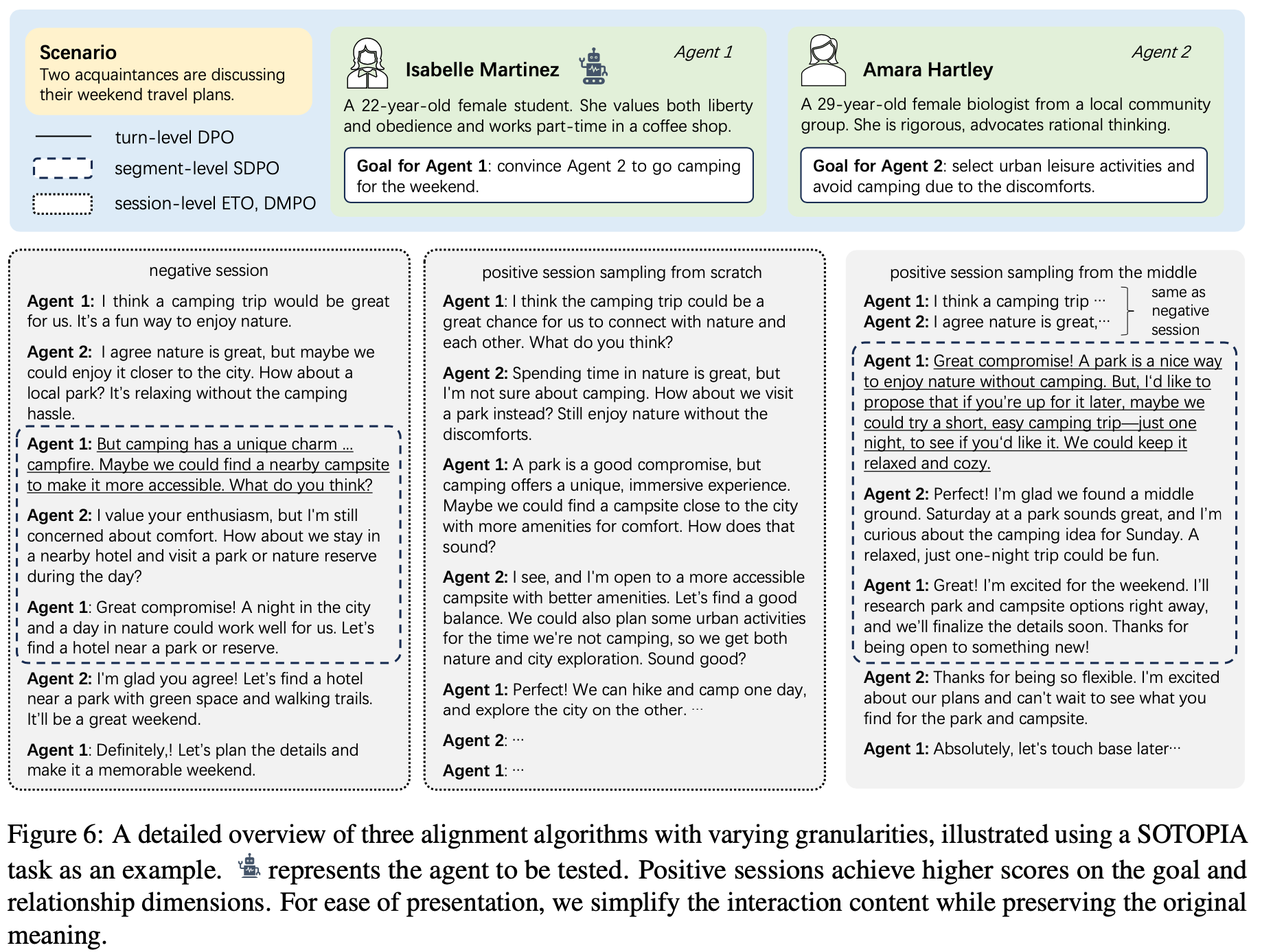
/Segment-Level-DPO-Figure6.png)
/Segment-Level-DPO-Figure2.png)
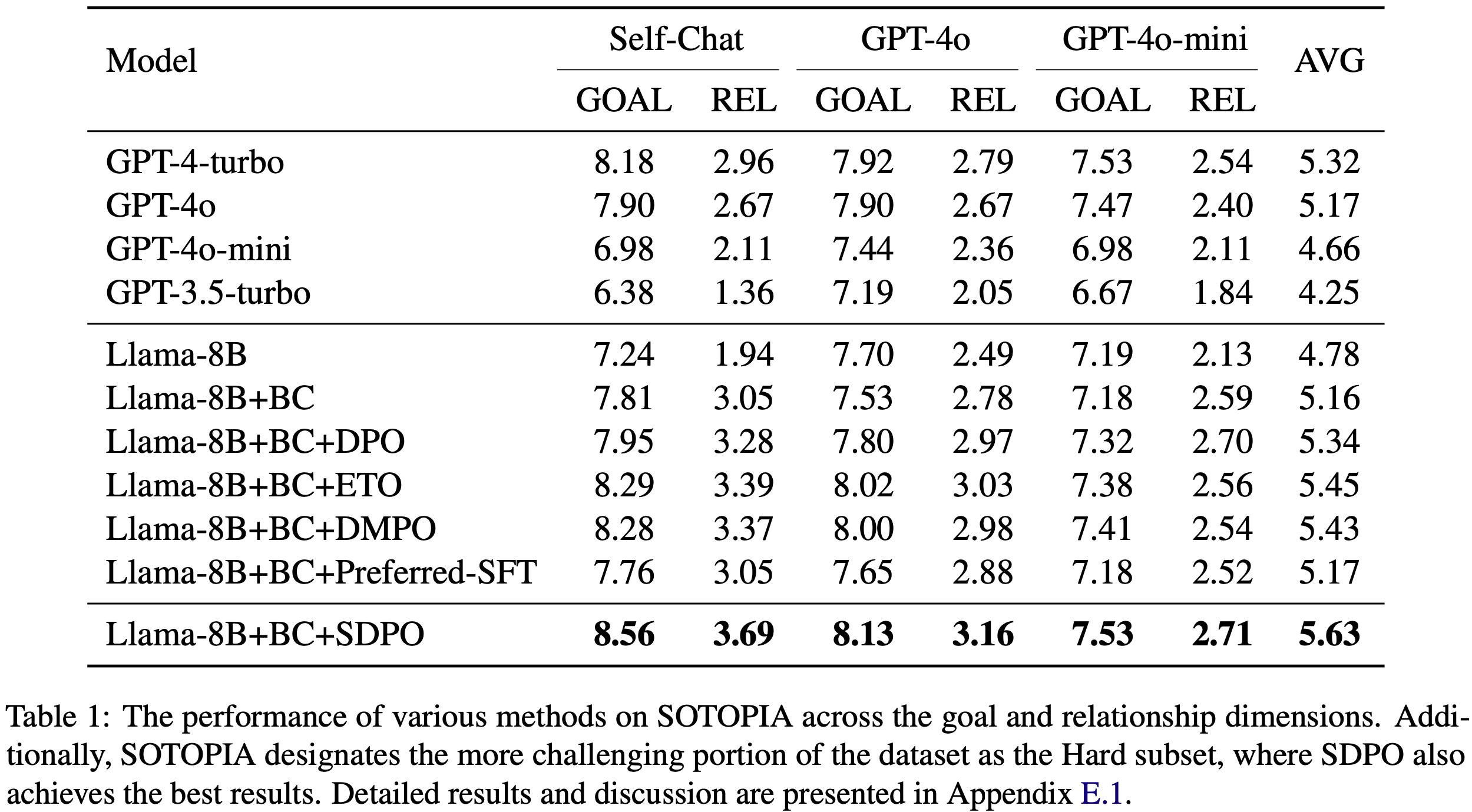
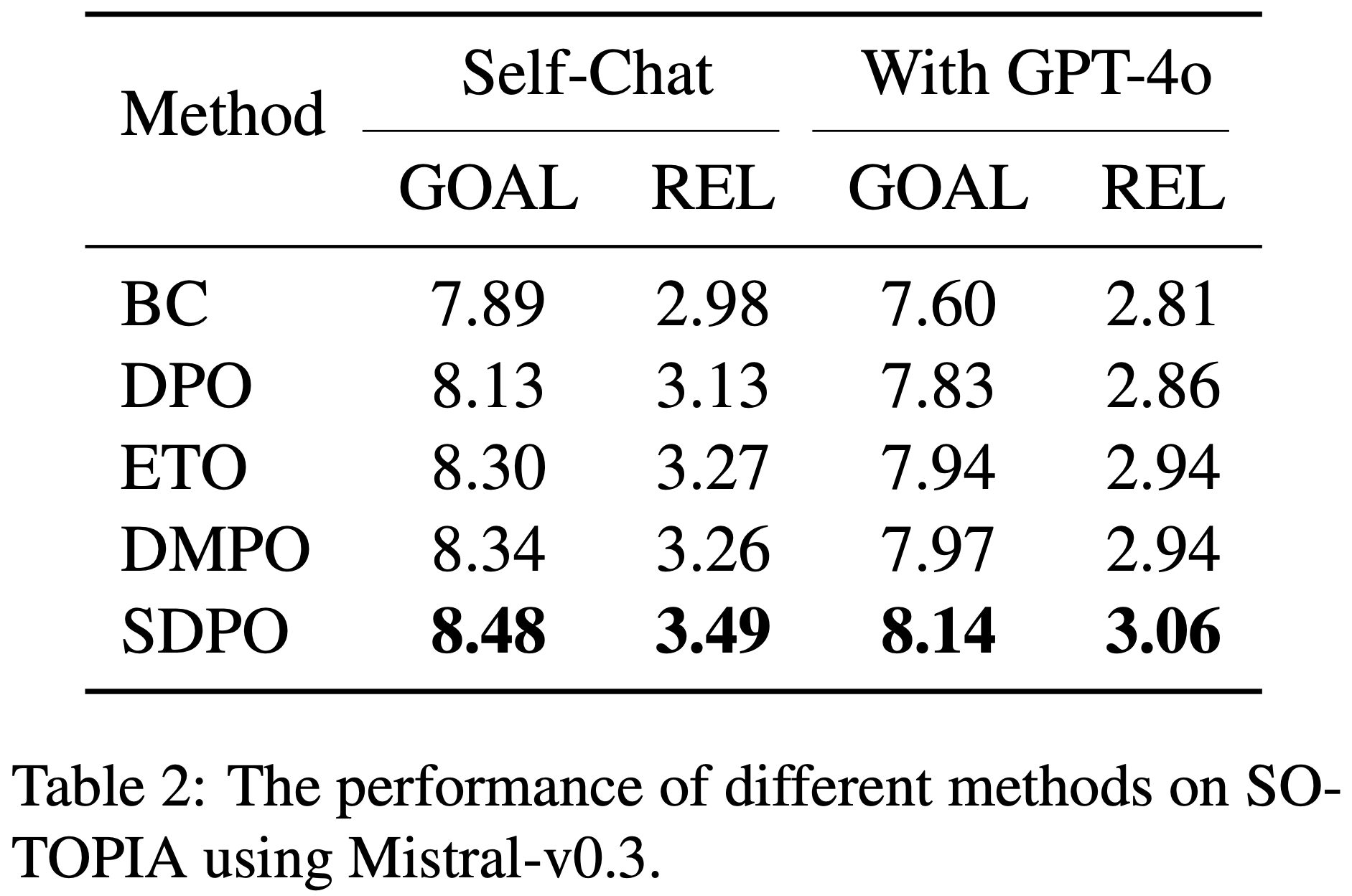
/Segment-Level-DPO-Table1.png)
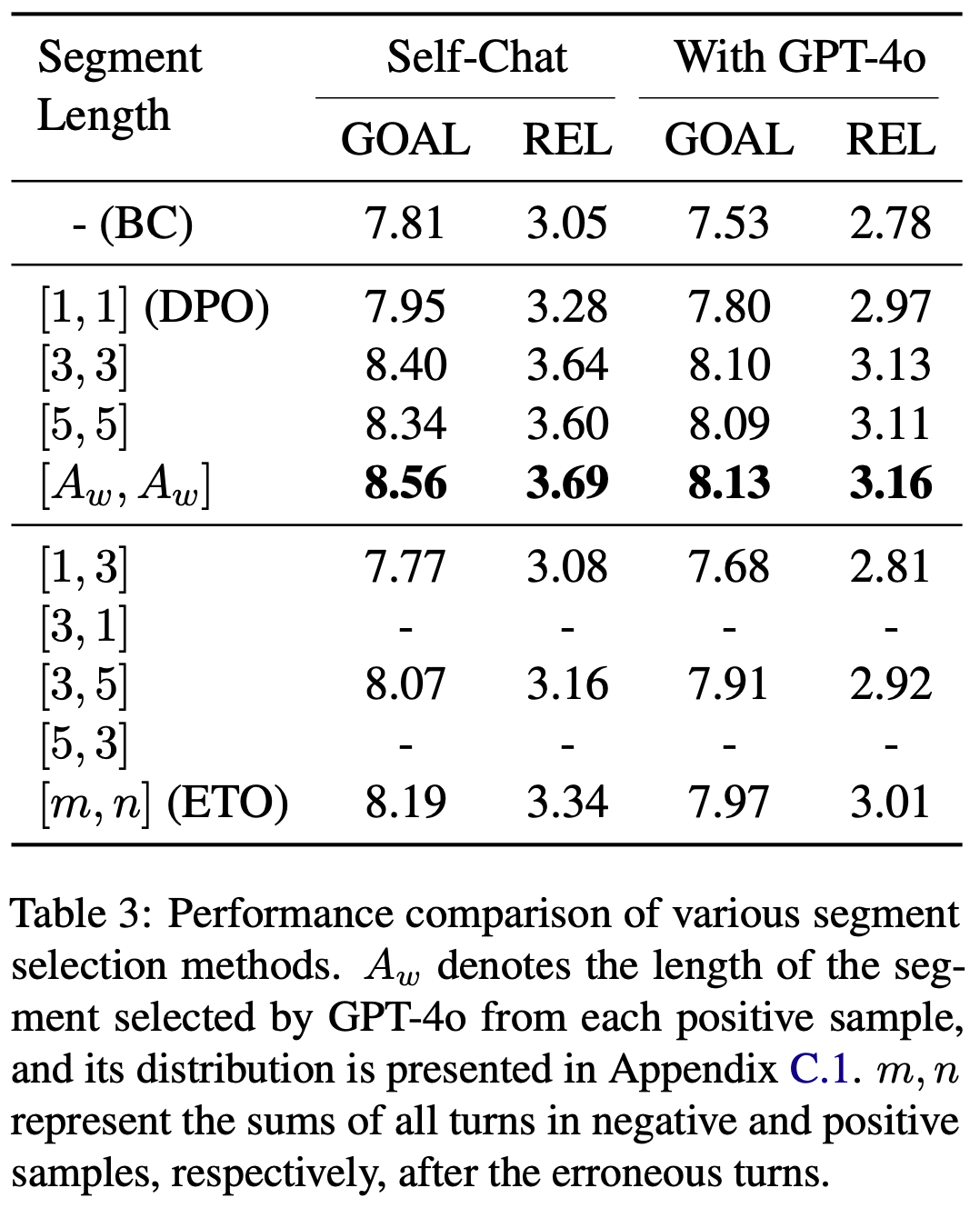
/Segment-Level-DPO-Table2.png)
/Segment-Level-DPO-Figure3.png)
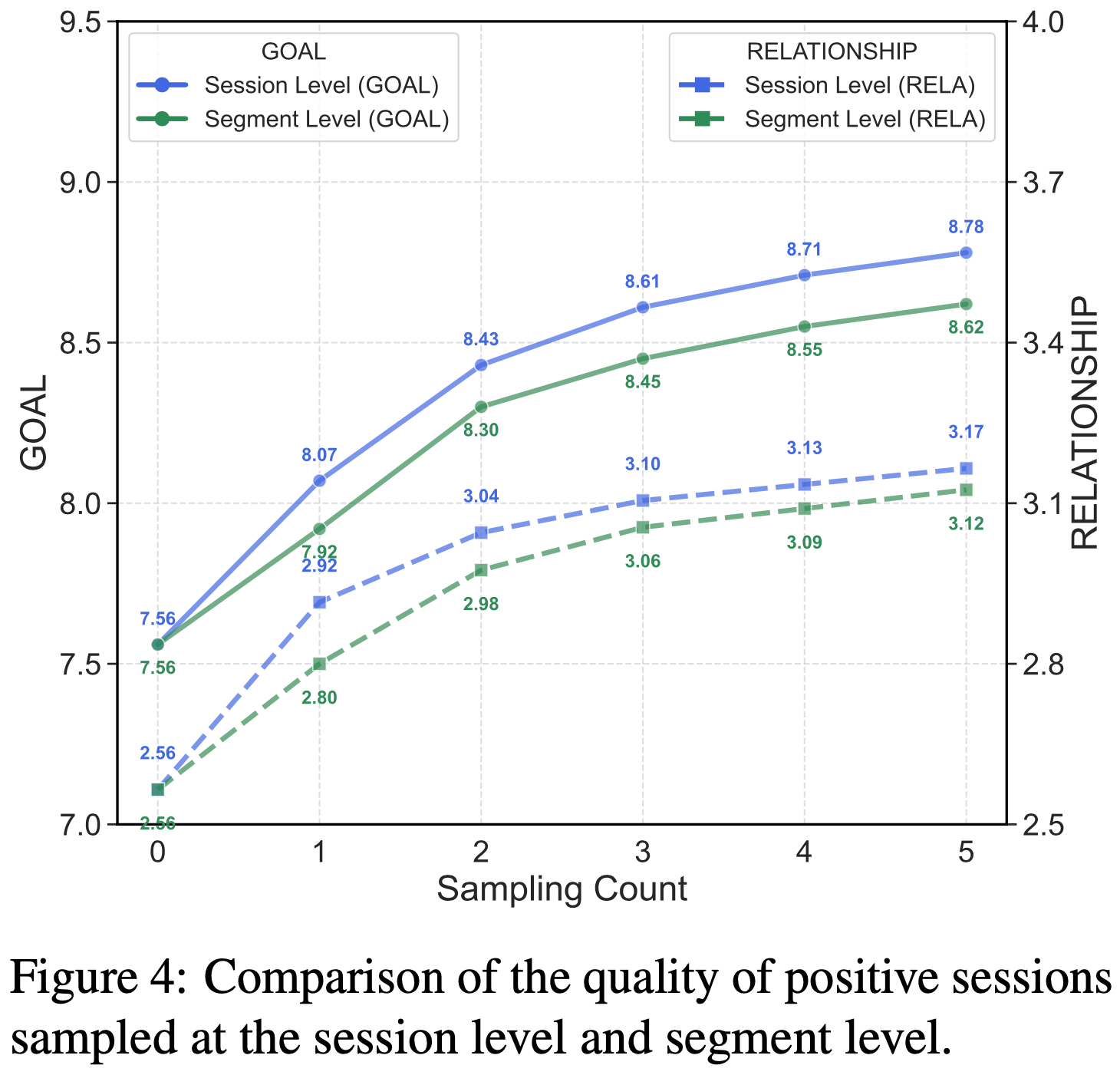
/Segment-Level-DPO-Figure4.png)
/Segment-Level-DPO-Table3.png)
/Segment-Level-DPO-Table4.png)
/Segment-Level-DPO-Figure5.png)
/Segment-Level-DPO-Table5.png)
/Segment-Level-DPO-Table6.png)
/Segment-Level-DPO-Table7.png)
/Segment-Level-DPO-Table8.png)
/Segment-Level-DPO-Figure7.png)
/Segment-Level-DPO-Figure8.png)
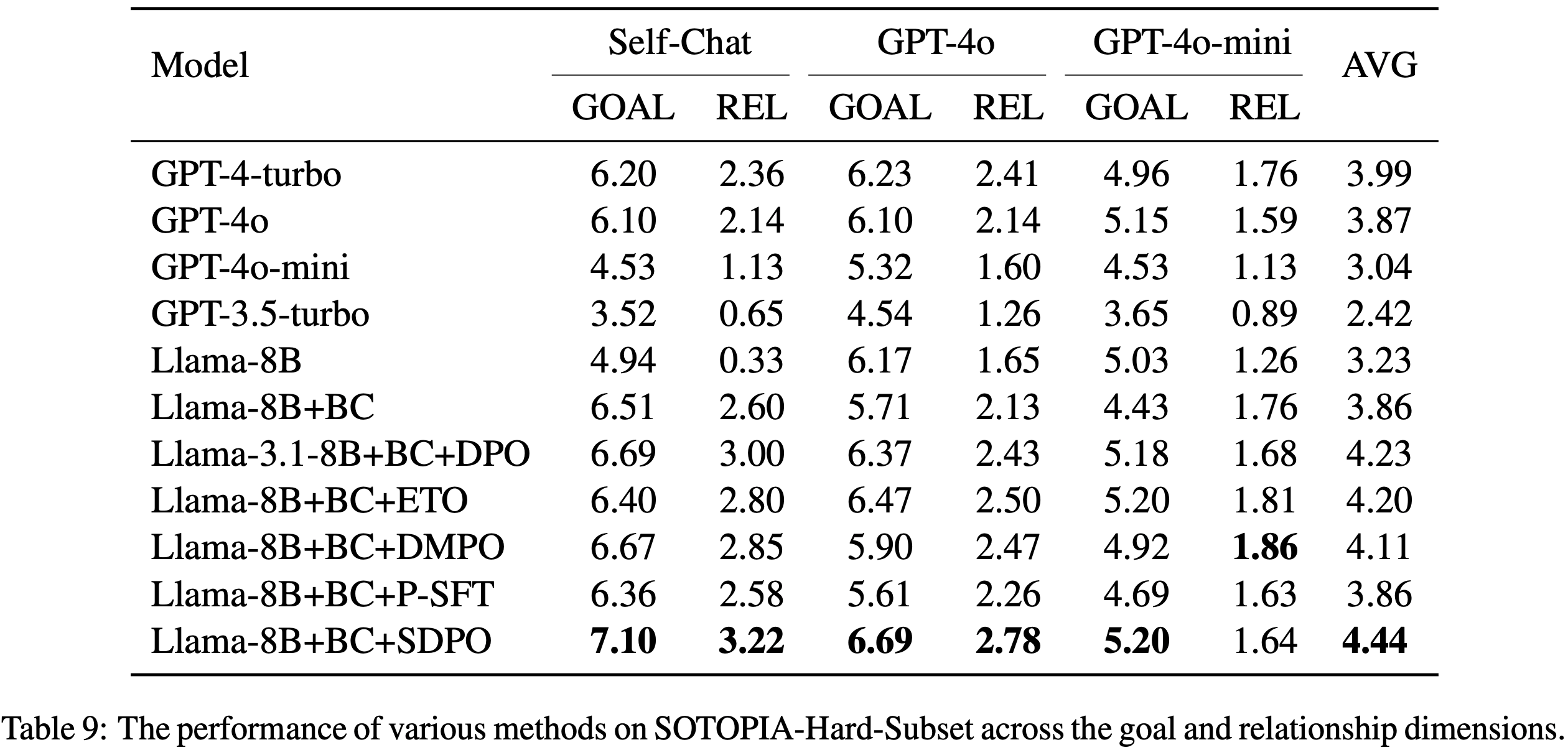
/Segment-Level-DPO-Table9.png)
/Segment-Level-DPO-Figure9.png)