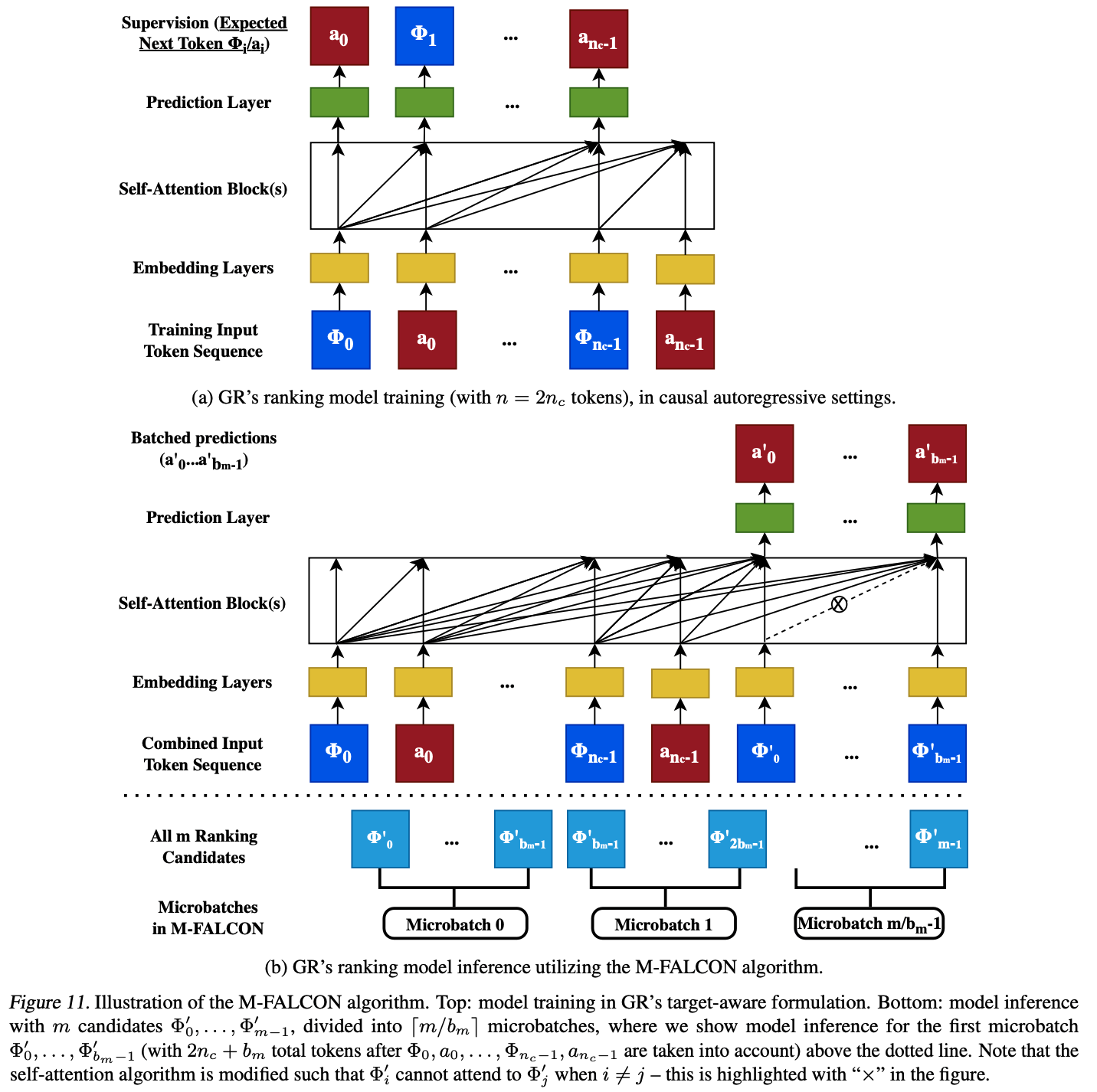
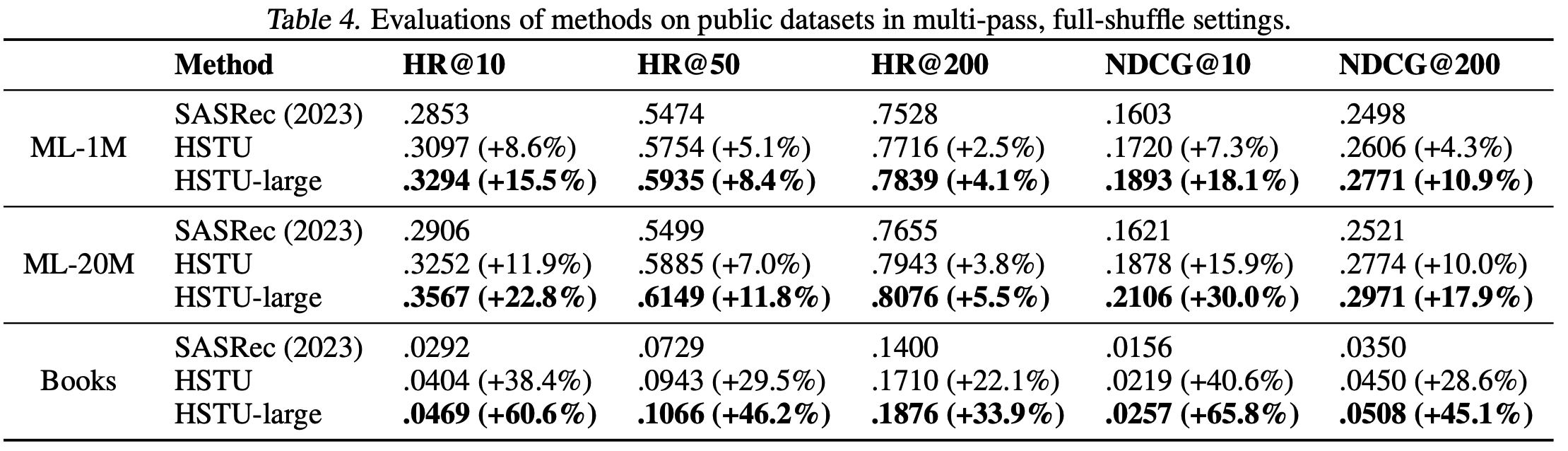
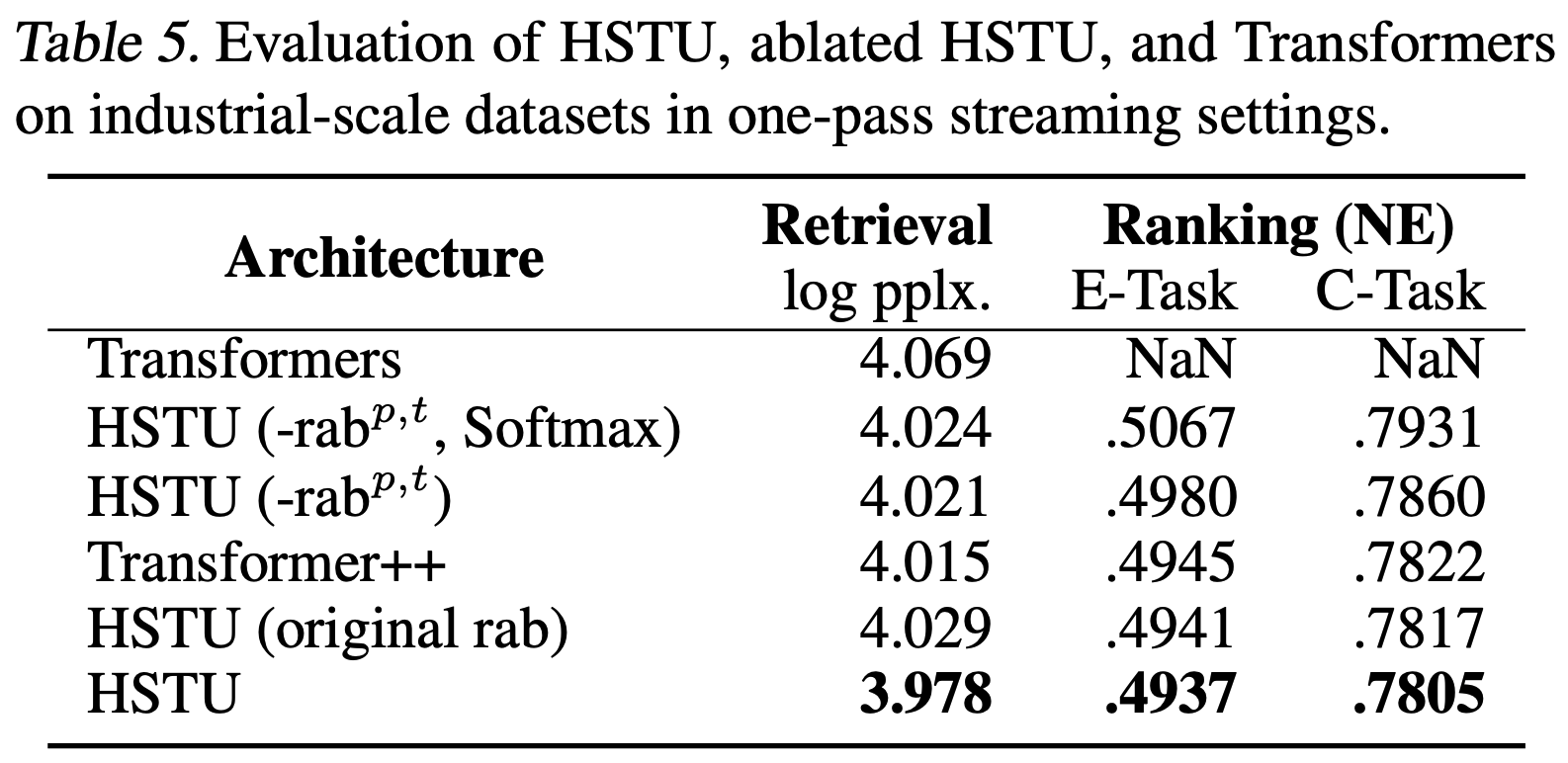
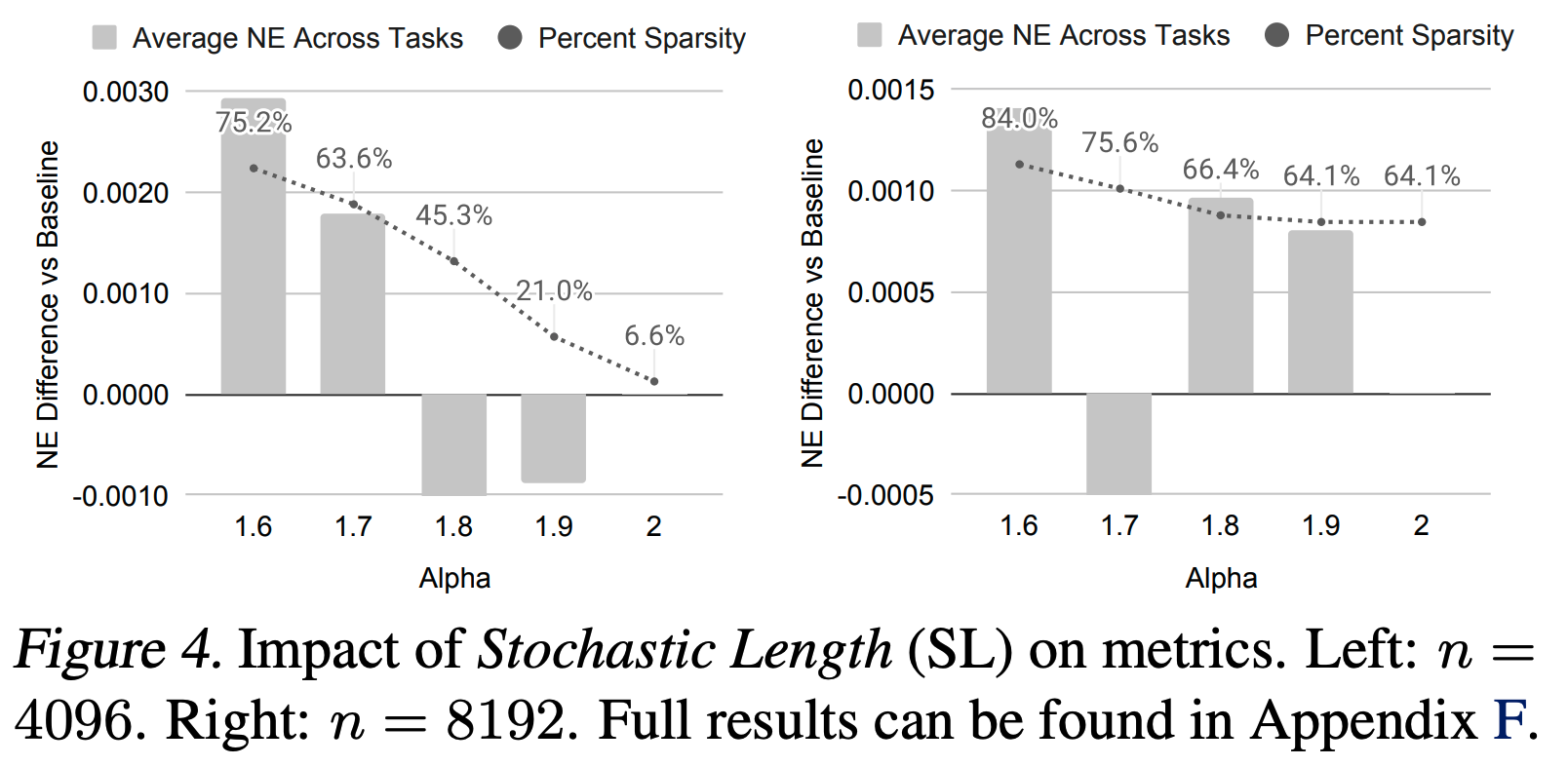
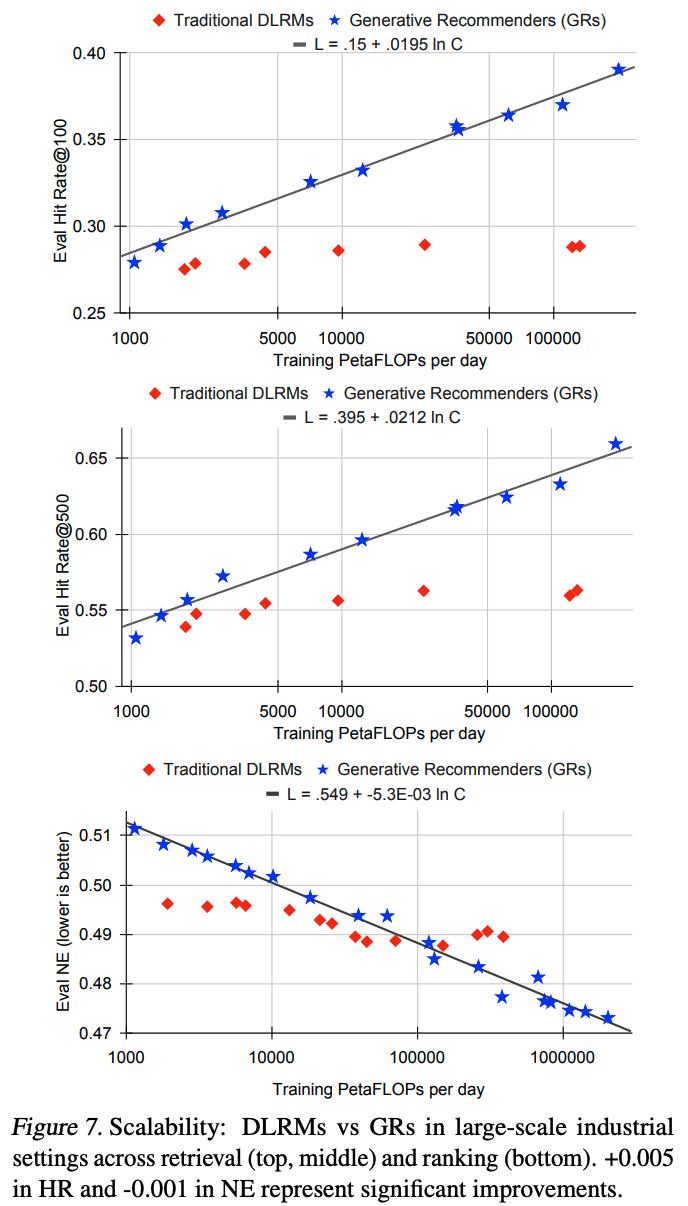
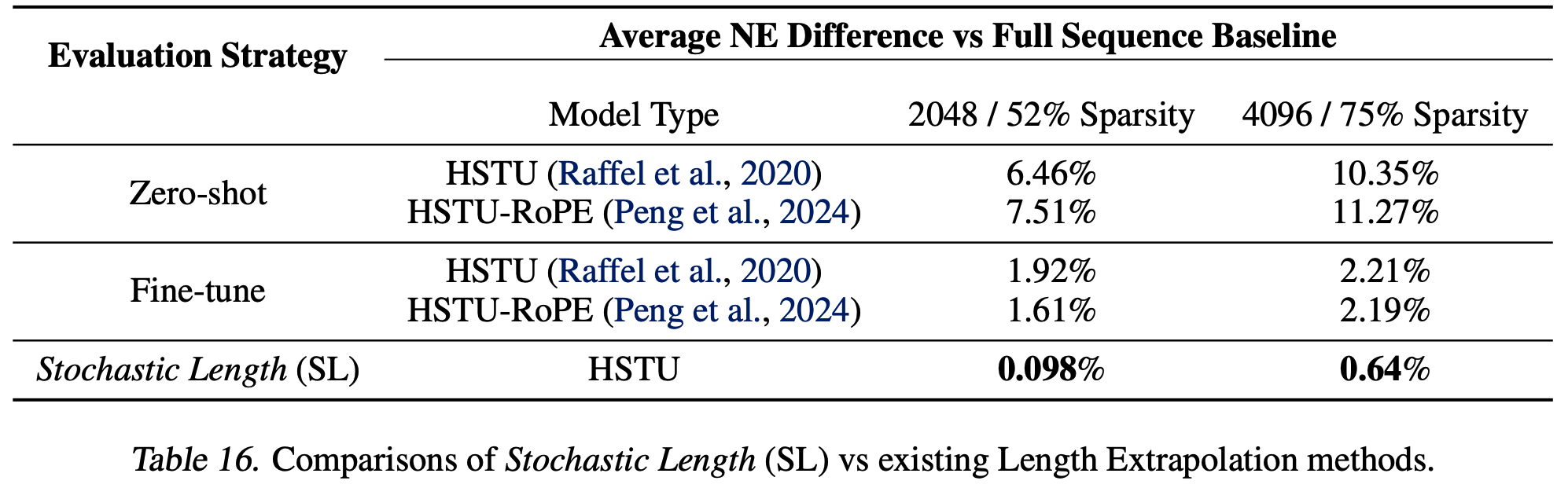
Cascaded Organized Bi-Represented generAtive retrieval, COBR
整体思路
- 现有召回方案的问题 :生成模型能够直接从用户交互序列中预测 item ID,但现有方法难以达到 sequential Dense 召回技术的建模精度(原因是量化、序列建模等阶段的分离导致严重的信息损失),整合生成式与 Dense 召回方法仍是一个关键挑战
- 论文提出一种生成式召回方法COBRA(Cascaded Organized Bi-Represented generAtive retrieval):
- 核心亮点 :通过级联过程(Cascading Process)创新性地整合 Sparse 语义 ID 与 Dense 向量,提升召回准确性和多样性
- 具体思路 :交替生成 Sparse 语义 ID 与 Dense 向量这两种表示,先生成 Sparse ID ,再将其作为条件辅助生成 Dense 向量(Sparse ID 是 Dense 向量的生成条件)
- 训练时 :端到端训练实现了 Dense Representation 的动态优化,同时捕捉 user-item 交互中的语义信息与协同信号
- 推理时 :COBRA 采用 Coarse-to-Fine的策略,首先生成 Sparse ID,再通过生成模型将其细化为 Dense 向量
- 论文还提出了 BeamFusion 方法,结合 Beam Search 与最近邻分数(Nearest Neighbor Scores)以提升推理灵活性与推荐多样性
- 实验 :离线+在线实验
一些讨论
- 序列推荐(Sequential Recommendation)方法,利用用户交互的时序特性提升推荐性能。SASRec 和 BERT4Rec 等模型证明了序列模型在捕捉用户行为模式上的有效性
- 生成模型可直接基于用户行为序列预测目标 item(与传统序列推荐方法不同)
- 生成模型能处理复杂的 user-item 交互,并具备推理和小样本学习(few-shot learning)等新兴能力,显著提升推荐准确性与多样性
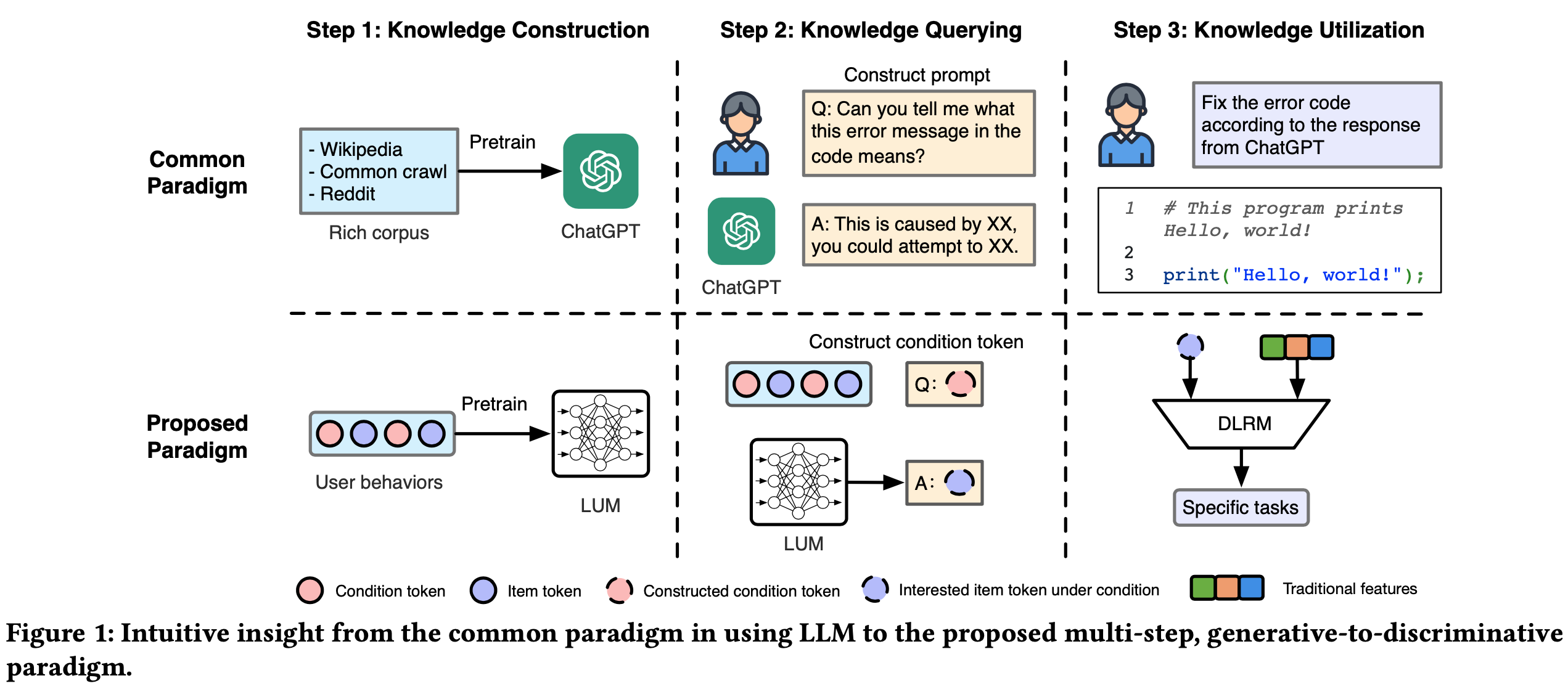
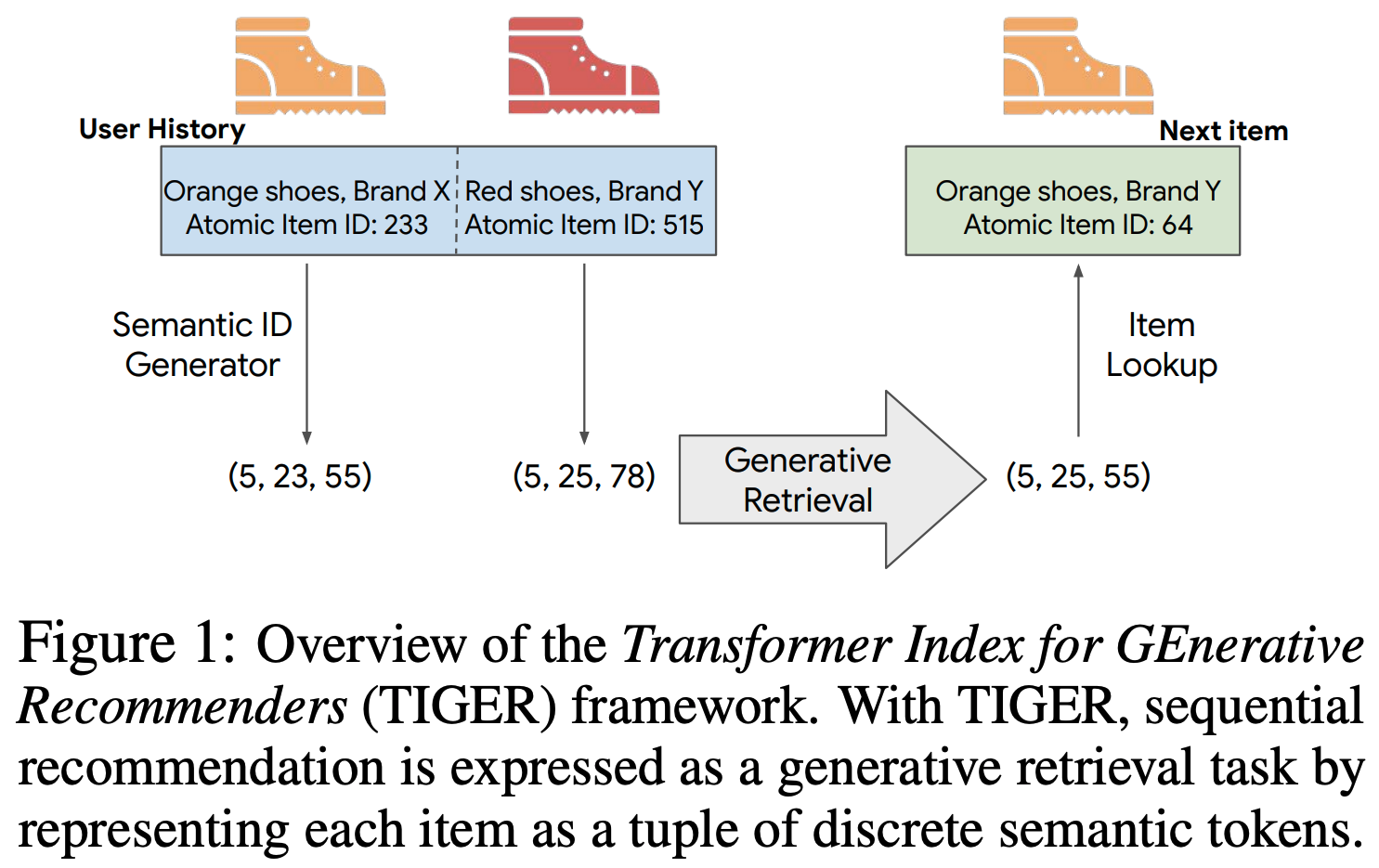
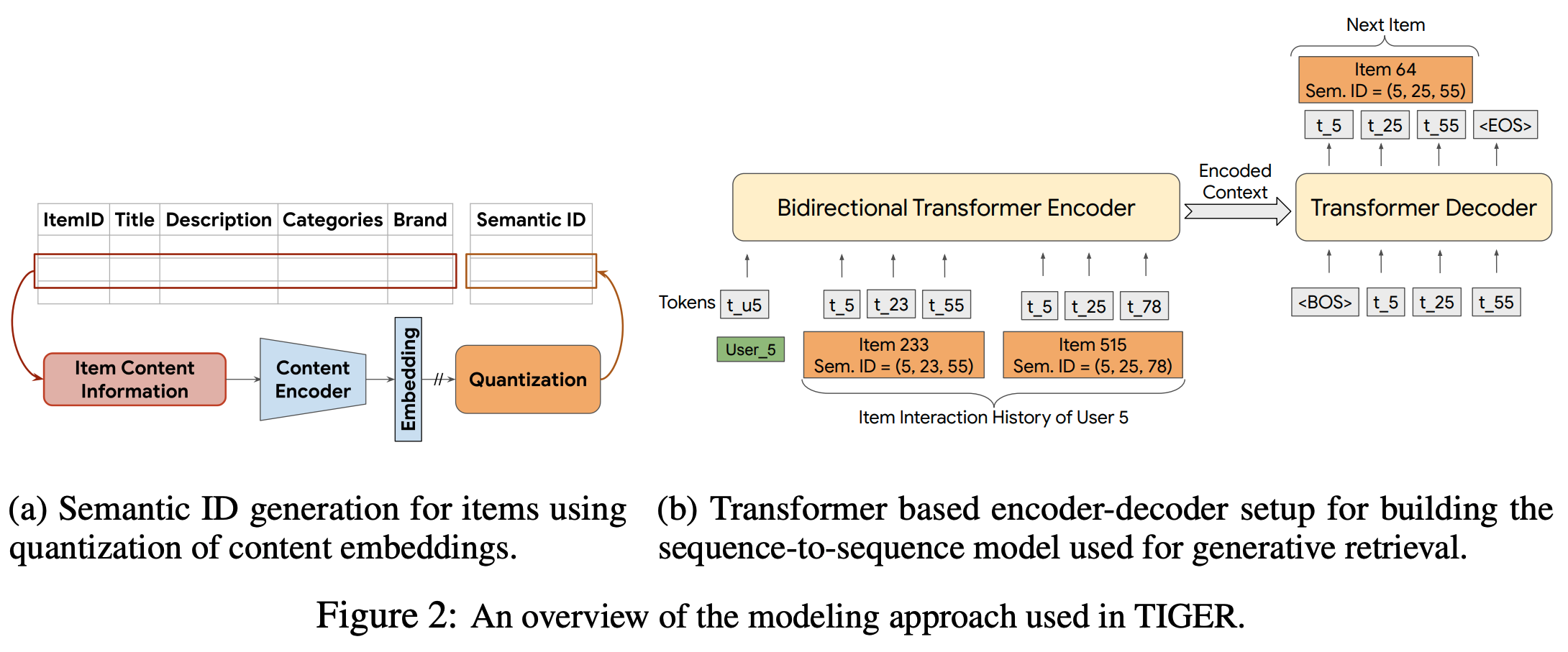
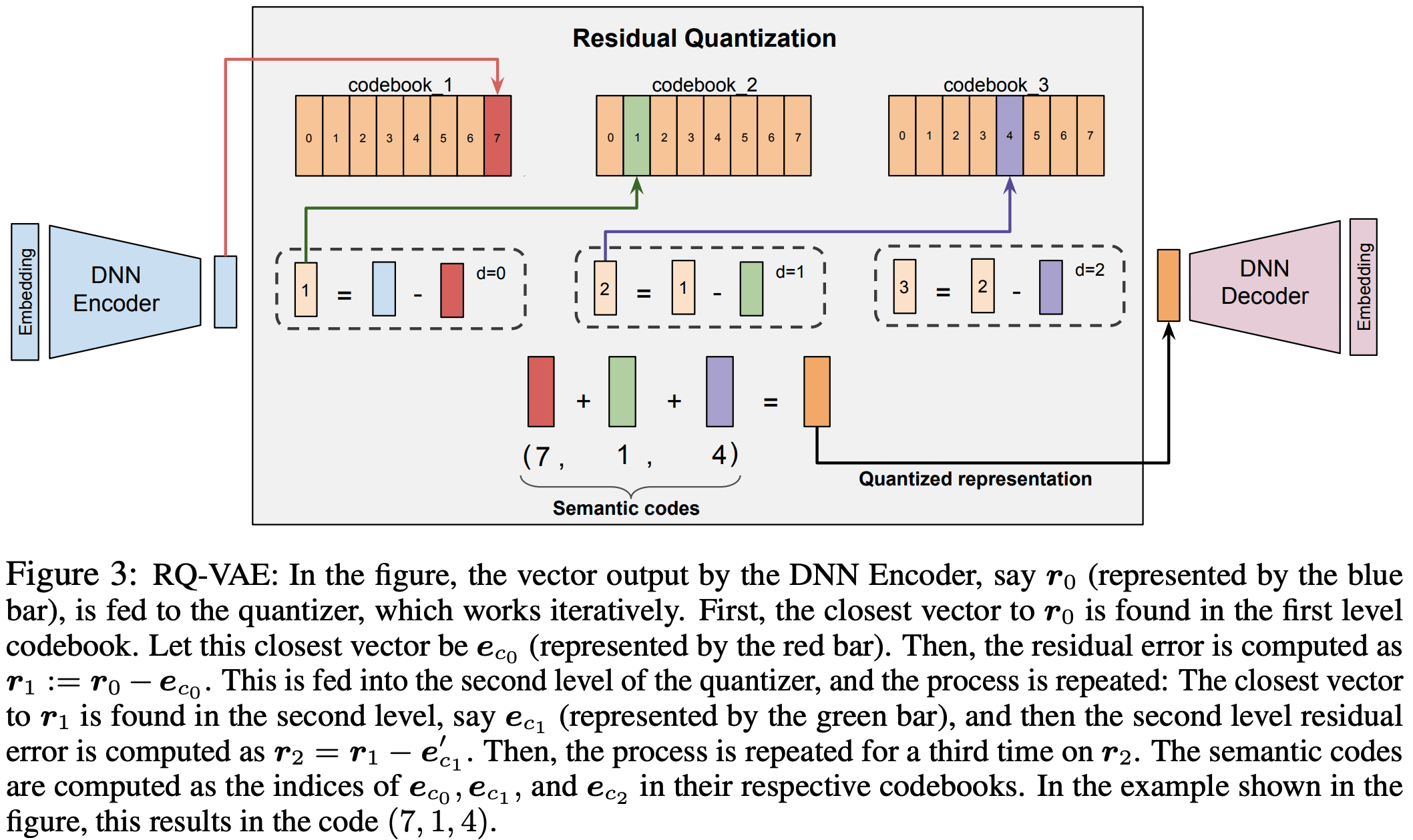
- TIGER 是生成式推荐领域的开创性工作。如图1(左下)所示,TIGER利用残差量化变分自 Encoder (RQ-VAE)将 item 内容特征编码为分层语义 ID,使模型能在语义相似 item 间共享知识和 Embedding(不是独立的 item Embedding)
- 除 TIGER 外,其他方法也探索了生成模型与推荐系统的融合
- LC-Rec 通过一系列对齐任务将语义与协同信息结合;
- ColaRec 从预训练推荐模型中获得(deriving)生成式标识符,整合协同过滤信号与内容信息;
- IDGenRec 利用大语言模型生成独特、简洁且语义丰富的文本标识符,在零样本(zero-shot)场景中展现出强大潜力
- 现有生成式推荐方法的挑战 :(相比序列 Dense 召回方法的挑战)
- 问题 :序列 Dense 召回方法依赖每个 item 的 Dense 嵌入,具有高准确性和鲁棒性,但需要大量存储和计算资源;生成式方法高效,却常难以建模细粒度相似性
- 理解:细粒度相似性指的是一些 item 的统计信息相似,但是 ID 完全不想关?
- 解决思路 :为有效结合两种召回范式的优势,论文提出 COBRA(协同生成式与 Dense 召回的框架),图1(右)展示了 COBRA 中级联 Sparse-Dense Representation 的结构
- 该方法通过交替生成 Sparse ID 与 Dense 向量的级联生成式召回框架,缓解了基于 ID 方法固有的信息损失
- 具体实现 :COBRA 的输入是由用户交互历史中 item 的 Sparse ID 和 Dense 向量组成的级联表示(Cascaded Representations)序列
- 训练时,Dense Representation 通过端到端的对比学习目标进行学习
- 先生成 Sparse ID 再生成 Dense Representation ,降低了 Dense Representation 的学习难度并促进两种表示间的相互学习
- 推理时,COBRA 采用 Coarse-to-Fine 生成过程:
- 先生成 Sparse ID 以捕获 item 的高层类别特征 ,随后将该 ID 追加至输入序列并反馈至模型中以预测捕捉细粒度细节的 Dense 向量 ,从而实现更精准的个性化推荐
- 此外,为确保灵活推理,论文引入 BeamFusion 采样技术,结合 Beam Search 与最近邻分数,确保召回 item 的多样性可控
- 与仅依赖 Sparse ID 的 TIGER 不同,COBRA 同时利用了 Sparse 与 Dense Representation 的优势
- 训练时,Dense Representation 通过端到端的对比学习目标进行学习
- 问题 :序列 Dense 召回方法依赖每个 item 的 Dense 嵌入,具有高准确性和鲁棒性,但需要大量存储和计算资源;生成式方法高效,却常难以建模细粒度相似性
- 论文的主要贡献如下:
- 提出 COBRA 框架 :交替生成 Sparse 语义 ID 与 Dense 向量,将 Dense Representation 融入 ID 序列,补充了基于 ID 方法的信息损失;以 Sparse ID 为条件生成 Dense 向量,降低了 Dense Representation 的学习难度
- 端到端训练的可学习 Dense Representation :COBRA 利用原始 item 数据作为输入,通过端到端训练生成 Dense Representation。不同于静态嵌入,COBRA 的 Dense 向量是动态学习的,能捕捉语义信息与细粒度细节
- Coarse-to-Fine 生成过程 :推理时,COBRA 先生成 Sparse ID,再将其反馈至模型生成优化的 Dense Representation,提升向量的细粒度。此外,论文提出 BeamFusion 以实现灵活多样的推荐
- 实验 :离线+在线
相关工作(直译)
- 序列 Dense 推荐 :序列 Dense 推荐系统利用用户交互序列学习用户与 item 的 Dense Representation [8, 15, 21],捕捉长期偏好与短期动态[25, 51, 22, 10]
- 早期模型如 GRU4Rec[14]使用循环神经网络(RNN)[49]捕捉用户行为的时间依赖性
- Caser[39]将序列视为“图像”,应用卷积神经网络(CNN)[36]提取空间特征
- Transformer 相关模型如 SASRec[18]和 BERT4Rec[37]显著推动了该领域发展,这些模型采用自注意力机制捕捉复杂用户行为,其中 SASRec 专注于自回归任务,BERT4Rec侧重双向上下文建模
- PinnerFormer[30]和 FDSA[52]等更先进的模型通过利用 Transformer 进行长期行为建模与特征整合,进一步提升了用户表示
- ZESRec[8]、UniSRec[15]和 RecFormer[21]等近期工作通过融合文本特征和对比学习技术,强调了跨领域可迁移性,RecFormer 尤其通过双向 Transformer 统一了语言理解与序列推荐
- 生成式推荐 :生成模型在各领域的普及推动了推荐系统从判别式向生成式模型的范式转变[17, 44, 26, 27, 42, 46]。生成模型直接生成 item 标识符而非计算每个 item 的排序分数[11, 34, 38, 54]
- P5[11]将多种推荐任务转化为自然语言序列,通过独特训练目标和提示为推荐补全提供通用框架
- TIGER[33]首创将生成式召回应用于推荐,利用残差量化自 Encoder 创建语义丰富的索引标识符,随后由基于Transformer的模型从用户历史中生成 item 标识符
- LC-Rec[53]通过额外对齐任务将语义标识符与协同过滤技术结合以增强效果
- IDGenRec[38]将生成式系统与大语言模型结合,生成独特且语义 Dense 的文本标识符,在零样本场景中表现优异
- SEATER[34]通过平衡的k叉树结构索引保持语义一致性,并结合对比与多任务学习优化
- ColaRec[45]对齐基于内容的语义空间与协同交互空间以提升推荐效果
- 以上现有的生成式方法仍面临挑战,例如:
- 基于离散 ID 的方法:可能缺乏细粒度细节并存在信息损失 ,限制其准确捕捉用户偏好的能力[48]
- 依赖自然语言的方法:可能难以将语言表达与推荐任务需求对齐 ,导致性能欠佳[25]
- 为解决以上这些问题,LIGER[48]提出结合生成式与 Dense 召回优势的混合模型,同时生成 Sparse ID 与 Dense Representation ,将其视为同一对象粒度的互补表示
- 该混合方法在一定程度上缩小了生成式与 Dense 召回间的差距;
- 但 LIGER 的 ID 与 Dense Representation 共享相同粒度,且 Dense Representation 是预训练且固定的。因此,如何更灵活地结合生成式与 Dense 召回仍是待探索的开放问题
COBRA框架方法
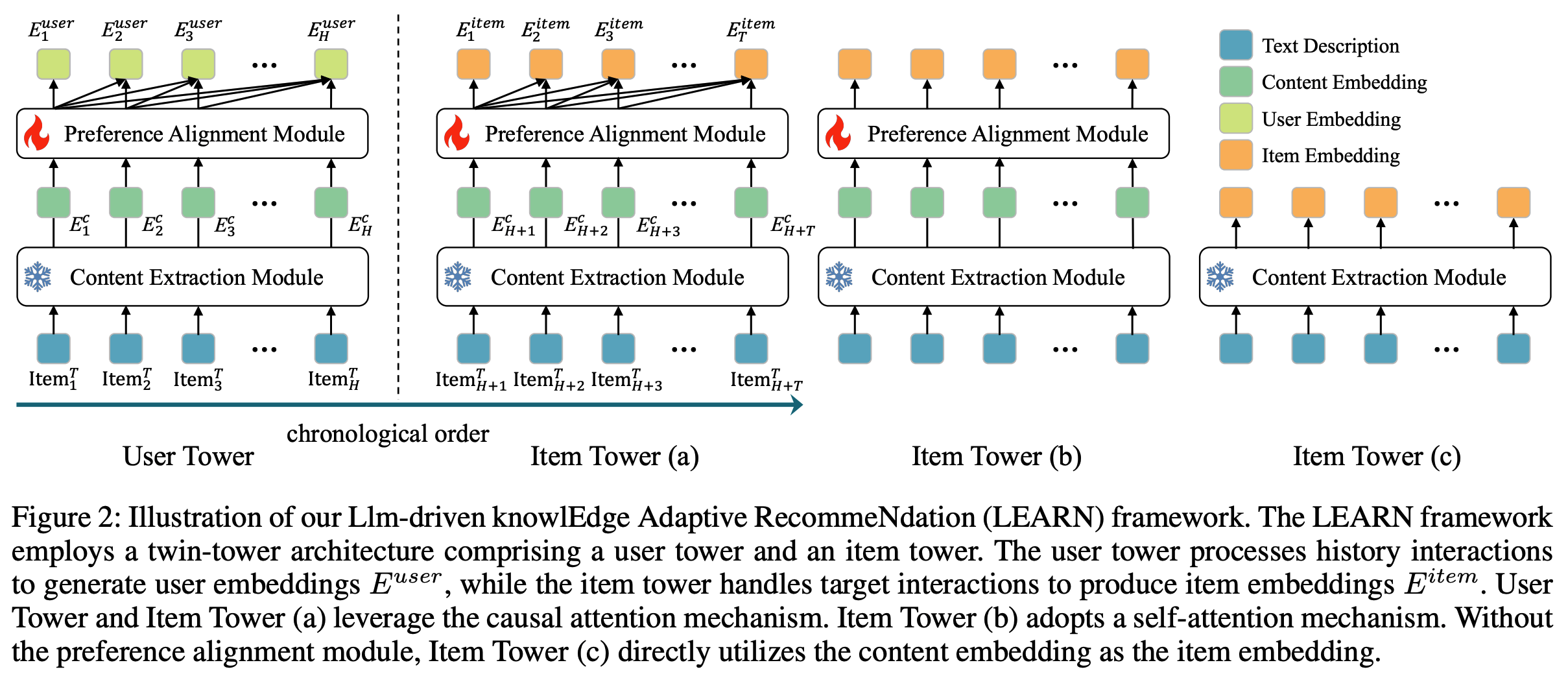
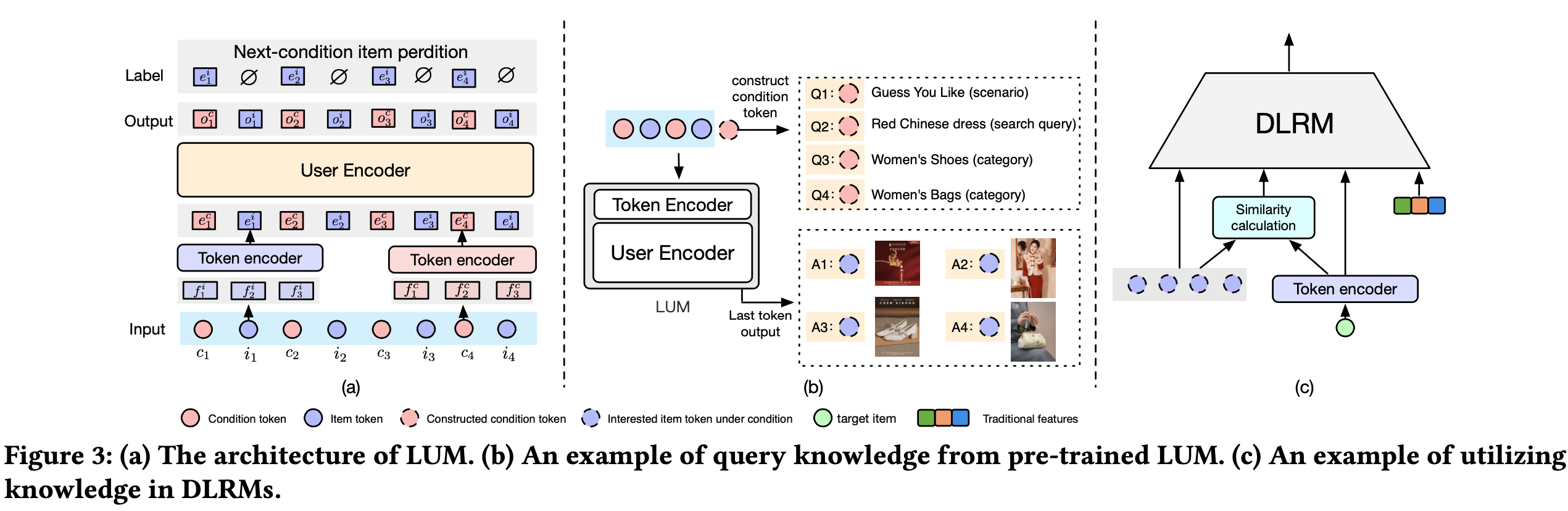
- 本节介绍 COBRA(Cascaded Organized Bi-Represented generAtive Retrieval)框架,该框架通过级联 Sparse-Dense Representation 和 Coarse-to-Fine 生成过程提升推荐性能。图2展示了 COBRA 的整体框架
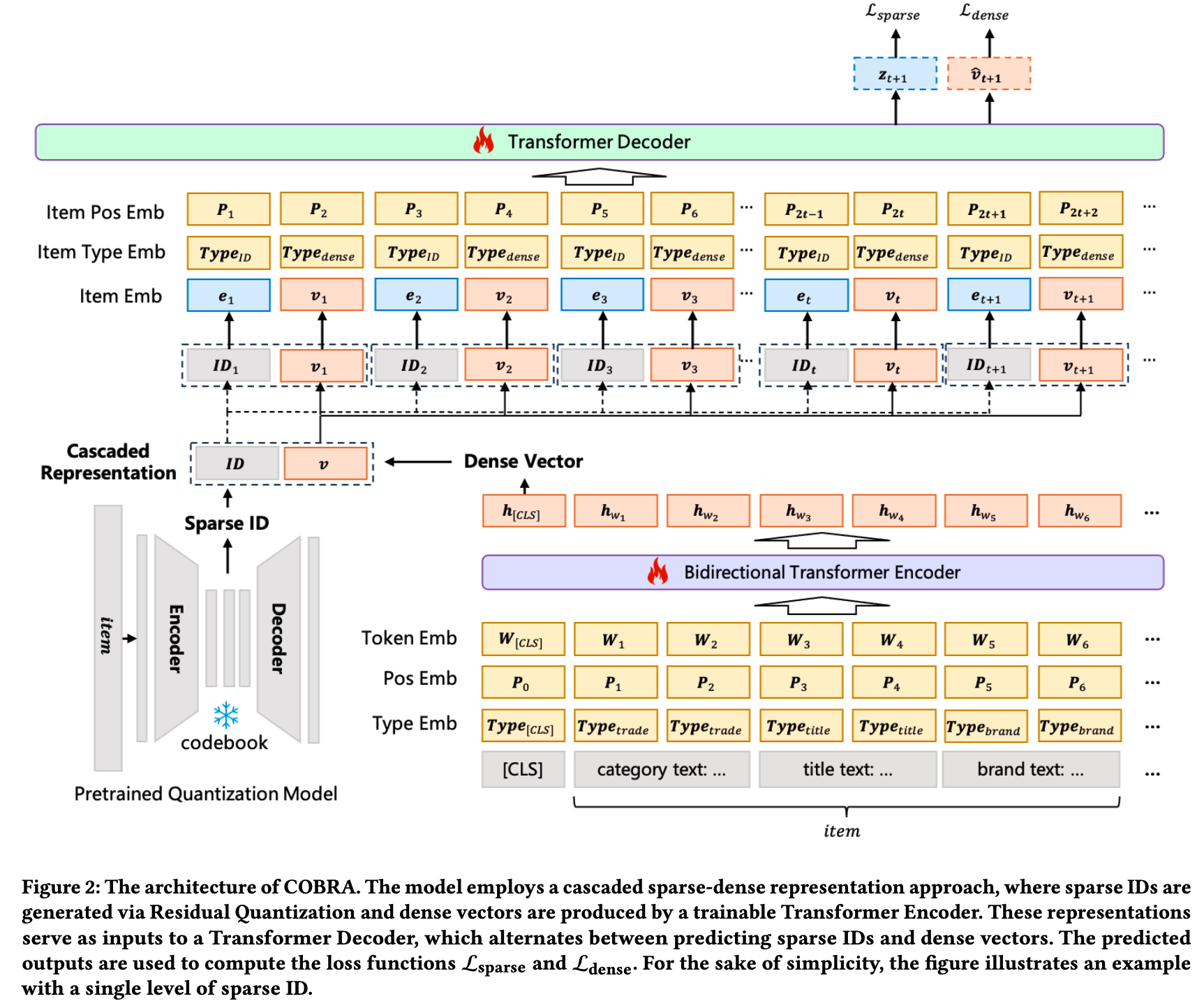
Sparse-Dense Representation
Sparse 表示
- COBRA 使用残差量化变分自 Encoder (RQ-VAE)生成 Sparse ID,灵感来源于 TIGER[33]的方法。对于每个 item ,提取其属性生成文本描述,将其嵌入 Dense 向量空间并量化生成 Sparse ID。这些 ID 捕捉 item 的类别本质,为后续处理奠定基础
- 注:为简洁起见 ,后续方法描述假设 Sparse ID 仅包含单层,但该方法可轻松扩展至多层场景
Dense Representation
- 端到端可训练的 *Dense Encoder * :用于对 item 文本内容进行编码(可捕捉细粒度的属性信息)
- 每个 item 的属性被展平为文本句子,前缀为 [CLS] token,并输入基于 Bidirectional Transformer 的文本 Encoder Encoder
- Dense Representation \(\mathbf{v}_{t}\) 从 [CLS] token 对应的输出中提取,捕捉 item 文本内容的细粒度细节
- 如图2下半部分所示,论文加入位置 Embedding 和类型 Embedding 以建模序列中 token 的位置和上下文。这些 Embeddings 以加法方式与 token Embedding 结合,增强模型区分不同 token 及其在序列中位置的能力
- 注:文中未指明类型(type) Embedding是什么
Cascaded Representation
- 思路 :Cascaded Representation(级联表示)将 Sparse ID 和 Dense 向量整合到统一的生成模型中
- 具体方案 :对于每个 item,论文将其 Sparse ID \( ID_{t}\) 和 Dense 向量 \(\mathbf{v}_{t}\) 组合为级联表示 \(( ID_{t},\mathbf{v}_{t})\)
- 该方法结合两种表示的优势,提供更全面的 item 表征:Sparse ID 通过离散约束提供稳定的类别基础,而 Dense 向量保持连续特征分辨率,确保模型同时捕捉高层语义和细粒度细节
序列建模(Sequential Modeling)
概率分解(Probabilistic Decomposition)
- 思路 :目标 item 的概率分布建模分为两个阶段,利用 Sparse 和 Dense Representation 的互补优势
- 具体方案 :COBRA 不直接基于历史交互序列 \(S_{1:t}\) 预测 next item \(s_{t+1}\),而是分别预测 Sparse ID \( ID_{t+1}\) 和 Dense 向量 \(\mathbf{v}_{t+1}\):
$$P( ID_{t+1},\mathbf{v}_{t+1}|S_{1:t})=P( ID_{t+1}|S_{1:t})P(\mathbf{v}_{t+1}| ID_{t+1},S_{1:t})$$- \(P( ID_{t+1}|S_{1:t})\) 表示基于历史序列 \(S_{1:t}\) 生成 Sparse ID \( ID_{t+1}\)的概率,捕捉下一个 item 的类别本质;
- \(P(\mathbf{v}_{t+1}| ID_{t+1},S_{1:t})\) 表示在给定 Sparse ID \( ID_{t+1}\) 和历史序列 \(S_{1:t}\) 下生成 Dense 向量 \(\mathbf{v}_{t+1}\) 的概率,捕捉下一个 item 的细粒度细节
- 这种分解使 COBRA 能够同时利用 Sparse ID 提供的类别信息和 Dense 向量捕捉的细粒度细节
- 注:论文中未明确,但根据上下文信息可以推测 \(s_{t}\) 的定义为 \(s_{t} = ( ID_{t},\mathbf{v}_{t})\)
统一生成模型的序列建模(Sequential Modeling with a Unified Generative Model)
- 使用基于 Transformer 架构的统一生成模型做序列建模,有效捕捉 user-item 交互中的序列依赖关系:
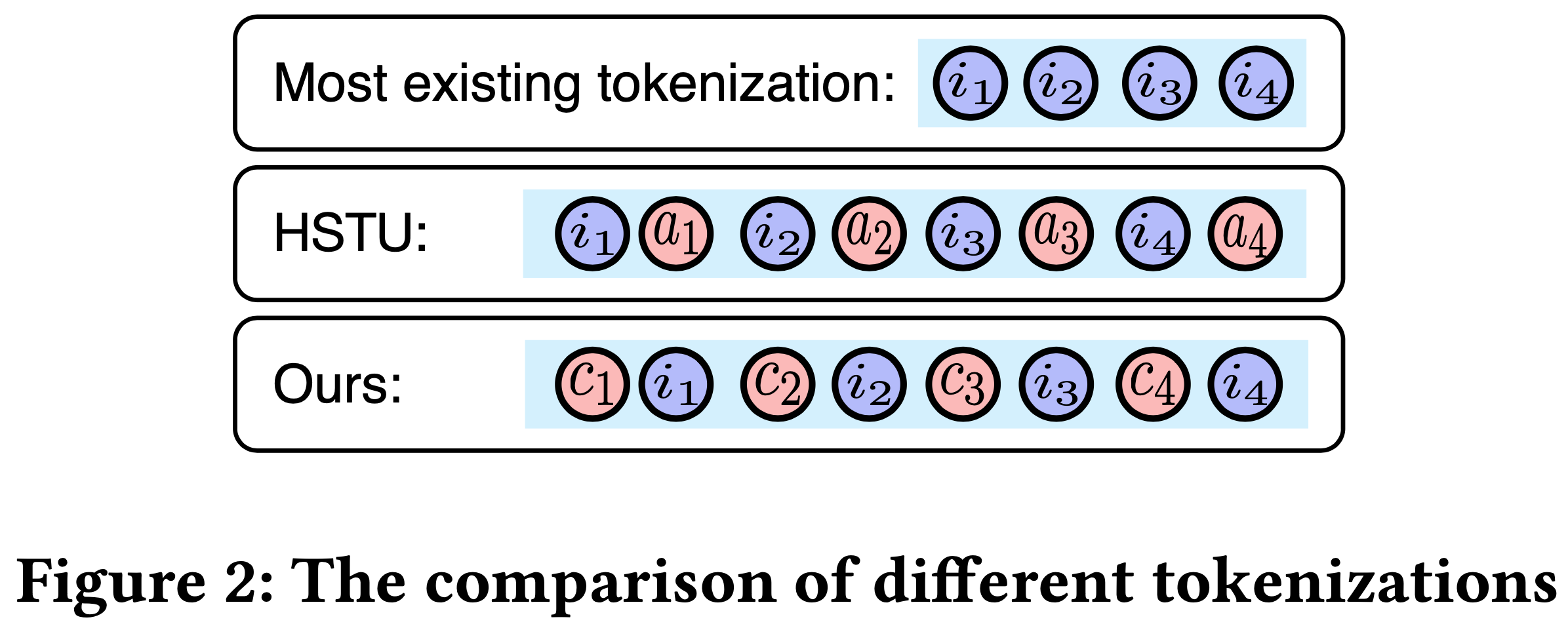
- Transformer 接收级联表示的输入序列,每个 item 由其 Sparse ID 和 Dense 向量表示
- Sparse ID 嵌入 :Sparse ID \( ID_{t}\)通过嵌入层转换为 Dense 向量空间:\(\boldsymbol{e}_{t}=\textbf{Embed}( ID_{t})\)。该 Embedding \(\boldsymbol{e}_{t}\) 与 Dense 向量 \(\mathbf{v}_{t}\) 拼接形成模型在每一步的输入:
$$\mathbf{h}_{t}=[\boldsymbol{e}_{t};\mathbf{v}_{t}]$$ - Transformer建模 :论文的Transformer Decoder 模型包含多层,每层具有自注意力机制和前馈网络
- 如图2上半部分所示, Decoder 的输入序列由级联表示组成
- 为增强序列和上下文信息建模,这些表示加入了 item 位置和类型 Embedding
- 为简洁起见,后续数学公式聚焦于级联序列表示,省略位置和类型嵌入的显式 token
- Decoder 处理这一增强的输入,生成用于预测后续 Sparse ID 和 Dense 向量的上下文表示
- Sparse ID 预测 :给定历史交互序列\(S_{1:t}\),为预测 Sparse ID \( ID_{t+1}\),Transformer的输入序列为:
$$S_{1:t}=[\mathbf{h}_{1},\mathbf{h}_{2},\ldots,\mathbf{h}_{t}]=[\boldsymbol{e}_{1},\mathbf{v}_{1},\boldsymbol{e}_{2},\mathbf{v}_{2},\ldots,\boldsymbol{e}_{t},\mathbf{v}_{t}]$$- 其中每个 \(\mathbf{h}_{i}\) 是第 \(i\) 个 item 的 Sparse ID 嵌入和 Dense 向量的拼接
- Transformer 处理该序列生成上下文表示,随后用于预测下一个 Sparse ID 和 Dense 向量。Transformer Decoder 处理序列 \(S_{1:t}\),生成向量序列\(\mathbf{y}_{t}=\textbf{TransformerDecoder}(S_{1:t})\)。Sparse ID 预测的logits通过下式得到:
$$\mathbf{z}_{t+1}=\textbf{SparseHead}(\mathbf{y}_{t})$$- 其中 \(\mathbf{z}_{t+1}\) 表示预测 Sparse ID \( ID_{t+1}\) 的logits
- Dense 向量预测 :为预测 Dense 向量\(\mathbf{v}_{t+1}\),Transformer的输入序列为:
$$\tilde{S}_{1:t}=[S_{1:t},\boldsymbol{e}_{t+1}]=[\boldsymbol{e}_{1},\mathbf{v}_{1},\boldsymbol{e}_{2},\mathbf{v}_{2},\ldots,\boldsymbol{e}_{t},\mathbf{v}_{t},\boldsymbol{e}_{t+1}]$$- Transformer Decoder 处理\(\tilde{S}_{1:t}\),输出预测的 Dense 向量:
$$\hat{\mathbf{v} }_{t+1}=\textbf{TransformerDecoder}(\tilde{S}_{1:t})$$
- Transformer Decoder 处理\(\tilde{S}_{1:t}\),输出预测的 Dense 向量:
端到端训练(End-to-End Training)
- 在 COBRA 中,端到端训练过程旨在联合优化 Sparse 和 Dense Representation 预测。训练过程由组合损失函数控制,该函数结合了 Sparse ID 预测损失和 Dense 向量预测损
- Sparse ID 预测损失 \(\mathcal{L}_{\textrm{Sparse} }\) 确保模型能够基于历史序列 \(S_{1:t}\) 熟练预测下一个 Sparse ID:
$$\mathcal{L}_{\textrm{Sparse} }=-\sum_{t=1}^{T-1}\log\left(\frac{\exp(\mathbf{z}_{t+1}^{ ID_{t+1} })}{\sum_{j=1}^{C}\exp(\mathbf{z}_{t+1}^{j})}\right)$$- \(T\) 是历史序列的长度
- \( ID_{t+1}\) 是时间步 \(t+1\) 交互 item 对应的 Sparse ID
- \(\mathbf{z}_{t+1}^{ ID_{t+1} }\) 表示 Transformer Decoder 在时间步 \(t+1\) 生成的真实 Sparse ID \( ID_{t+1}\)的预测 logit
- \(C\) 表示所有 Sparse ID 的集合
- 注:Sparse ID 预测损失本质是个交叉熵损失函数
- Dense 向量预测损失 \(\mathcal{L}_{\textrm{Dense} }\) 聚焦于优化 Dense 向量,使其能够区分相似和不相似的 item,损失定义为:
$$\mathcal{L}_{\textrm{Dense} }=-\sum_{t=1}^{T-1}\log\frac{\exp(\cos(\hat{\mathbf{v} }_{t+1}\cdot\mathbf{v}_{t+1}))}{\sum_{item_{j}\in\textrm{Batch} }\exp(\cos(\hat{\mathbf{v} }_{t+1},\mathbf{v}_{item_{j} }))}$$- \(\hat{\mathbf{v} }_{t}\) 是预测的 Dense 向量
- \(\mathbf{v}_{t}\) 是正样本的真实 Dense 向量
- \(\mathbf{v}_{j}\) 表示批次内 item 的 Dense 向量
- \(\cos(\hat{\mathbf{v} }_{t+1}\cdot\mathbf{v}_{t+1})\) 表示预测和真实 Dense 向量之间的余弦相似度,较高的余弦相似度表明向量在方向上更相似,这对于准确的 Dense 向量预测是理想的
- Dense 向量由端到端可训练的 Encoder Encoder生成,该 Encoder 在训练过程中优化,确保 Dense 向量动态调整并适应推荐任务的特定需求
- 注:Dense 向量预测损失本质是个 InfoNCE
- 总体损失函数为:
$$\mathcal{L}=\mathcal{L}_{\textrm{Sparse} }+\mathcal{L}_{\textrm{Dense} }$$ - 双目标损失函数实现了平衡的优化过程,模型在 Sparse ID 的引导下动态优化 Dense 向量。这种端到端训练方法同时捕捉高层语义和特征级信息,联合优化 Sparse 和 Dense Representation 以获得卓越性能
- 问题:图2中的 上层 Bidirectional Transformer 和 (Casual) Transformer Decoder 是同时训练的吗?
- 看起来是的,这也是论文所说的端到端训练
Coarse-to-Fine Generation
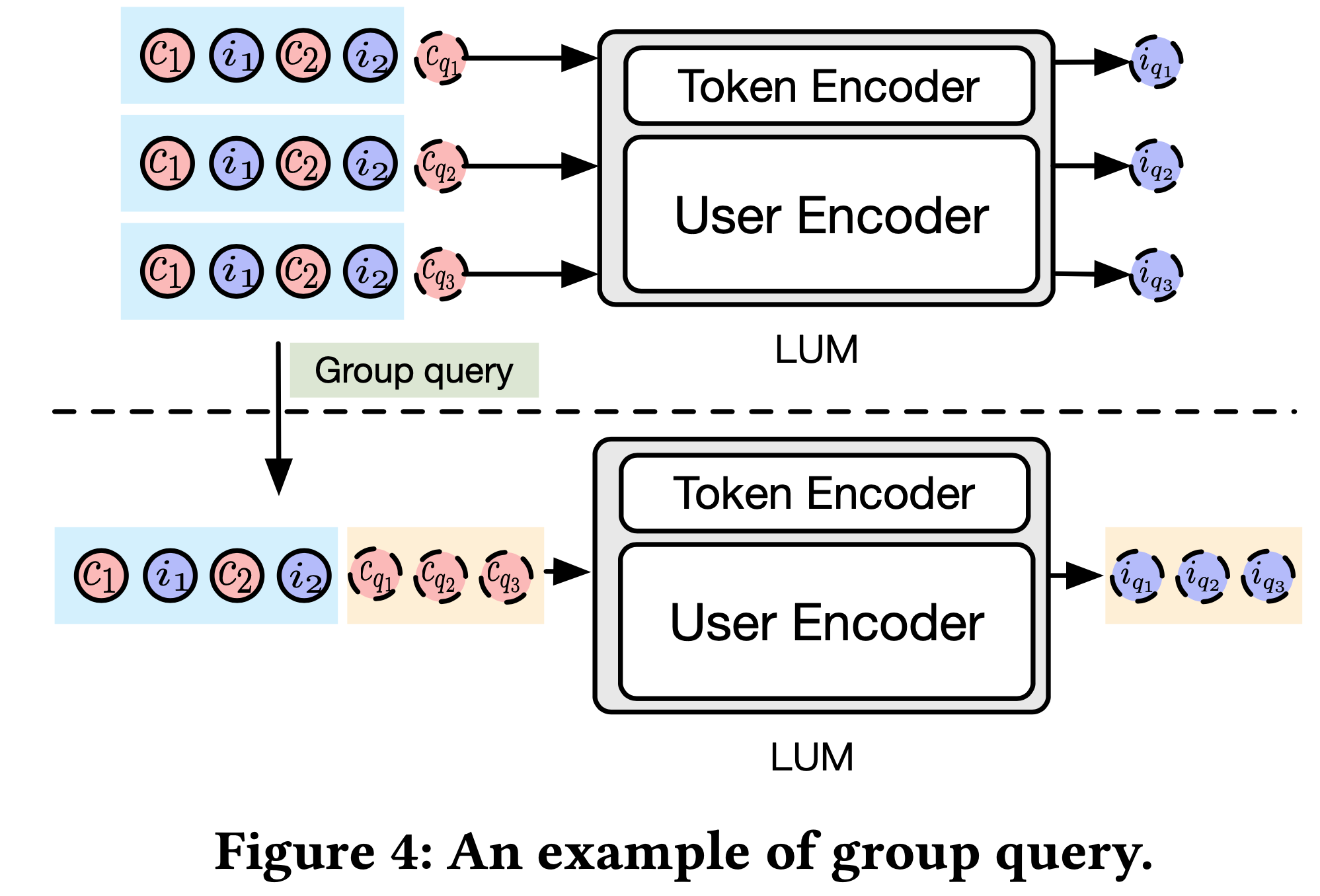
- 在推理阶段,COBRA 实现 Coarse-to-Fine 生成过程,依次生成 Sparse ID 并级联优化 Dense 向量(如图3所示)
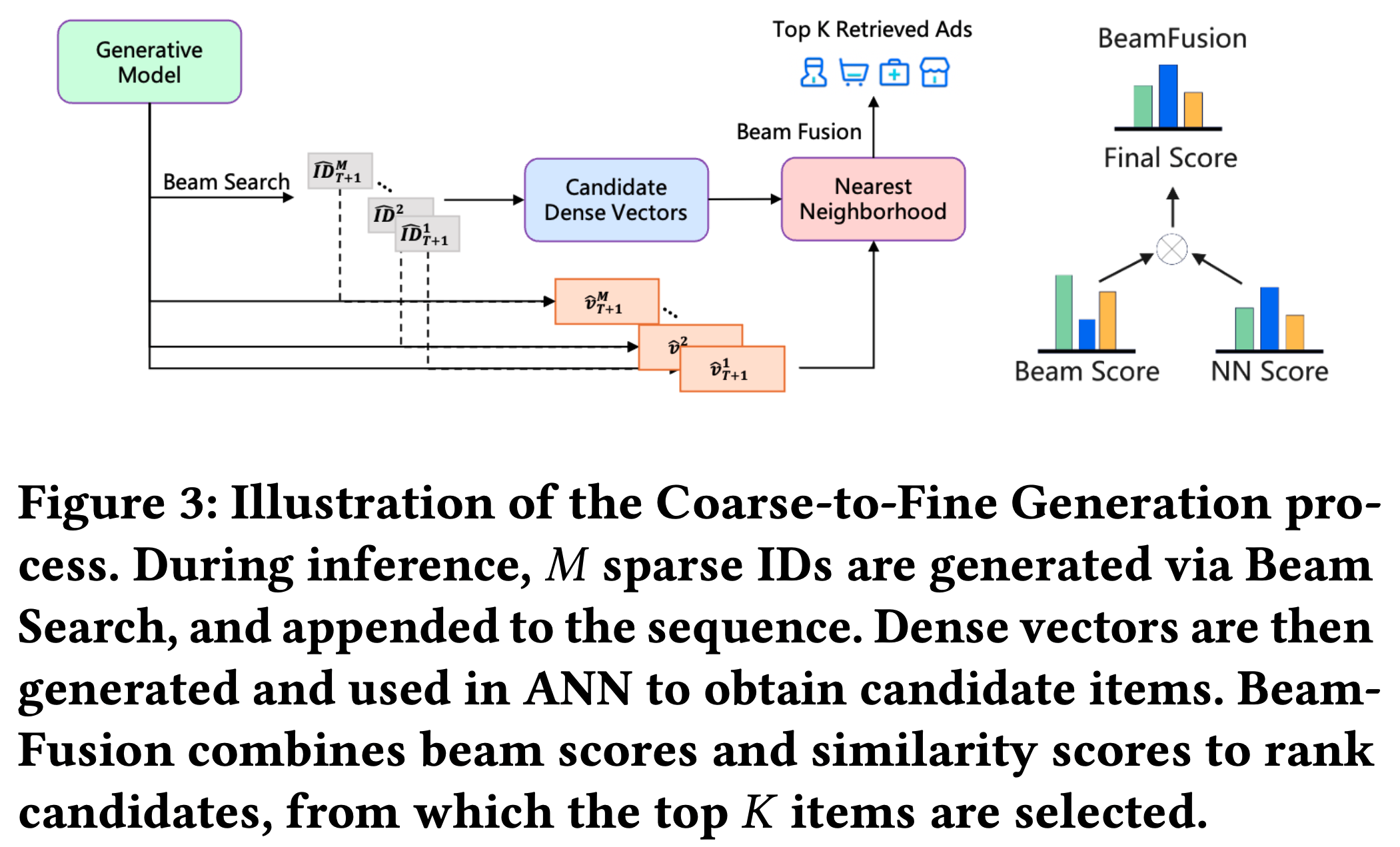
- COBRA 中的 Coarse-to-Fine 生成过程旨在捕捉 user-item 交互的类别本质和细粒度细节。该过程包含两个主要阶段:
- Sparse ID 生成 :给定用户序列 \(S_{1:T}\),论文利用 Transformer Decoder 建模的 ID 概率分布 \(\hat{\textit{ ID } }_{T+1}\sim P(t_{T+1}|S_{1:T})\),并采用 Beam Search 算法得到前 \(M\) 个 ID:
$$\{\hat{\textsf{ ID } }^{k}_{T+1}\}_{k=1}^{M}=\textrm{BeamSearch}(\textbf{TransformerDecoder}(\textrm{S}_{1:T}),M)$$- \(k\in\{1,2,\ldots,M\}\)
- 每个生成的 ID 关联一个 Beam 分数 \(\phi_{\hat{\textsf{ ID } }^{k}_{T+1} }\)
- Dense 向量精细化(Dense Vector Refinement) :每个生成的 Sparse ID \(\hat{\textsf{ ID } }^{k}_{T+1}\) 随后转换为嵌入并追加到先前的级联序列嵌入 \(\textrm{S}_{1:T}\) 中,然后生成对应的 Dense 向量 \(\mathbf{\hat{v}}^{k}_{T+1}\):
$$\mathbf{\hat{v}}^{k}_{T+1}=\textbf{TransformerDecoder}(\{\textrm{S}_{1:T},\textbf{Embed}(\hat{\textsf{ ID } }^{k}_{T+1})\})$$ - ANN 搜索候选 item :对每一个 Sparse ID \(\hat{\textsf{ ID } }^{k}_{T+1}\),论文使用近似最近邻(ANN)搜索检索前 \(N\) 个候选 item :
$$\mathcal{A}_{k}=\textrm{ANN}(\hat{\textsf{ ID } }^{k}_{T+1},C(\hat{\textsf{ ID } }^{k}_{T+1}),N)$$- \(C(\hat{\textsf{ ID } }^{k}_{T+1})\) 是与 Sparse ID \(\hat{\textsf{ ID } }^{k}_{T+1}\) 关联的候选 item 集合
- \(N\) 表示要召回的 top item 数量
- 理解:这里的 ANN 搜索是为 Beam Search 生成的每一个 \(k\),即 Sparse ID \(\hat{\textsf{ ID } }^{k}_{T+1}\) 都生成一个候选集合 \(\mathbf{\hat{v}}^{k}_{T+1}\)
- 注:这里原论文未给出 ANN 的具体方法(是否与 Dense 向量 \(\mathbf{\hat{v}}^{k}_{T+1}\) 有关还未知)
- BeamFusion 机制合并结果 :为实现精度和多样性的平衡,论文为每个 Sparse ID 对应的 item 设计全局可比分数。该分数能反映不同 Sparse ID 之间的差异以及同一 Sparse ID 下 item 间的细粒度差异。为此,论文提出 BeamFusion 机制:
$$\Phi^{(\mathbf{\hat{v}}^{k}_{T+1},\hat{\textsf{ ID } }^{k}_{T+1},\mathbf{a})}=\textrm{Softmax}(\tau\phi_{\hat{\textsf{ ID } }^{k}_{T+1} })\times\textrm{Softmax}(\psi\cos(\mathbf{\hat{v}}^{k}_{T+1},\mathbf{a}))$$- \(\mathbf{a}\) 表示候选 item(理解:文章未明确说明,但通过上下文可推测:\(\mathbf{a} \in \mathcal{A}_{k}\))
- \(\tau\) 和 \(\psi\) 是系数
- \(\phi_{\hat{\textsf{ ID } }^{k}_{T+1} }\)表示 Beam Search 过程中获得的 Beam 分数
- 最后,基于 BeamFusion 分数对所有候选 item 排序 ,并选择前 \(K\) 个 item 作为最终推荐:
$$\mathcal{R}=\textrm{TopK}\left(\bigcup_{k=1}^{M}\mathcal{A}_{k},\Phi,K\right)$$- \(\mathcal{R}\) 表示最终推荐集合
- TopK 表示选择具有最高 BeamFusion 分数的前 \(K\) 个 item 的操作
相关实验(离线+在线)
- 数据:公开数据集 + 工业数据集
- 指标:重点关注 COBRA 在提升推荐准确性和多样性方面的能力
- 实验方式:离线 + 在线
公开数据集实验
数据集与评估指标
- 采用 Amazon 产品评论数据集[13,29](注:该数据集是推荐任务的经典基准)
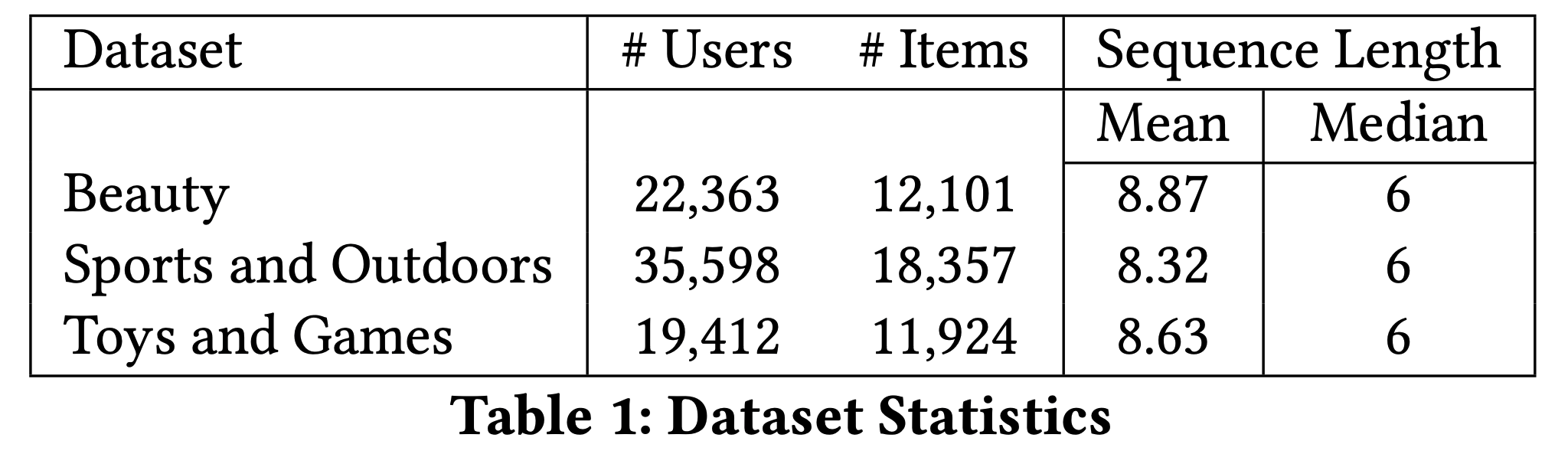
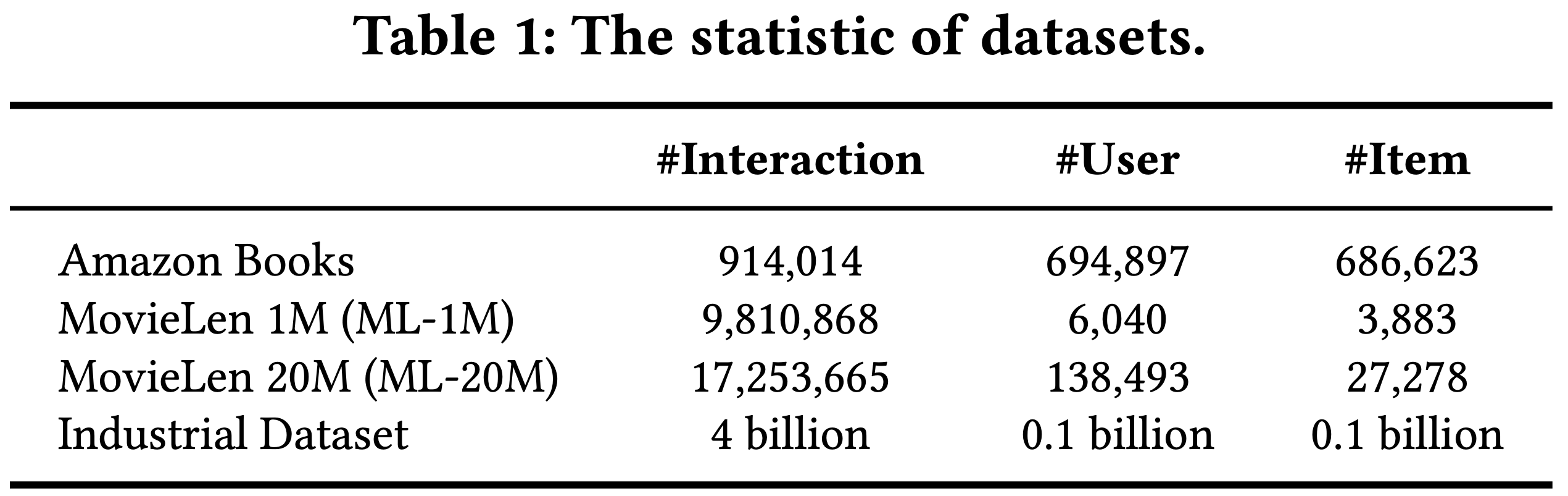
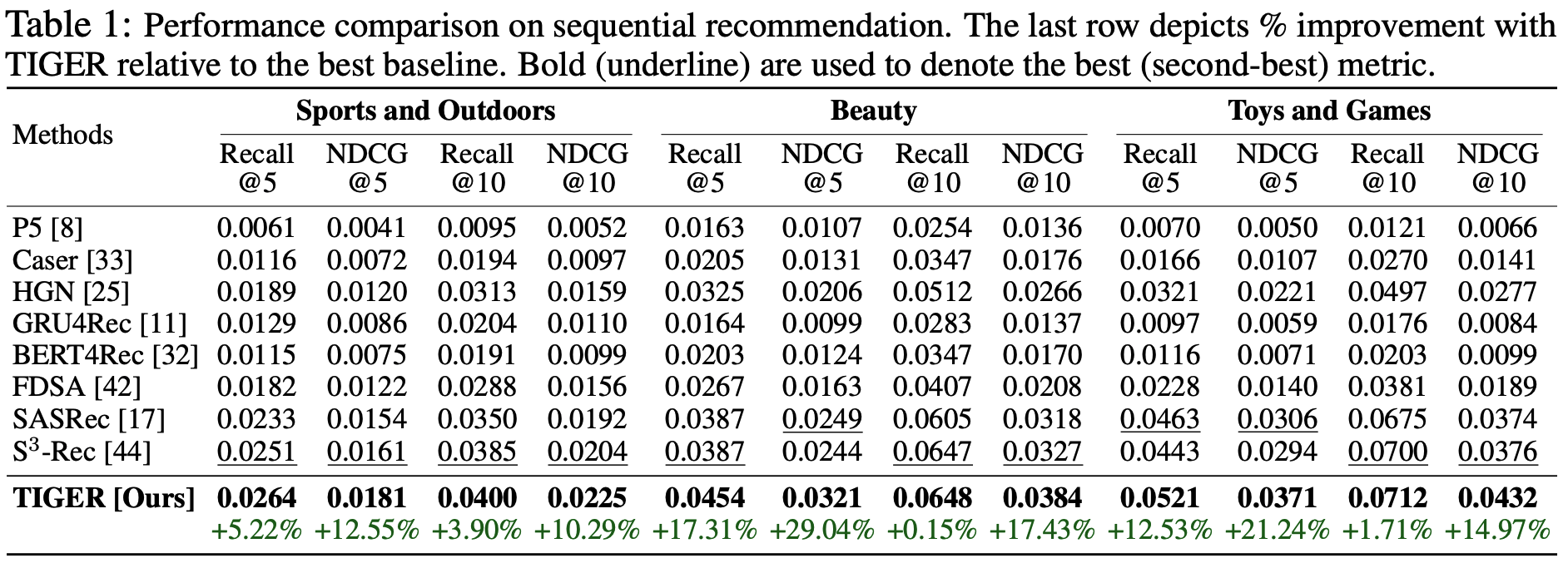
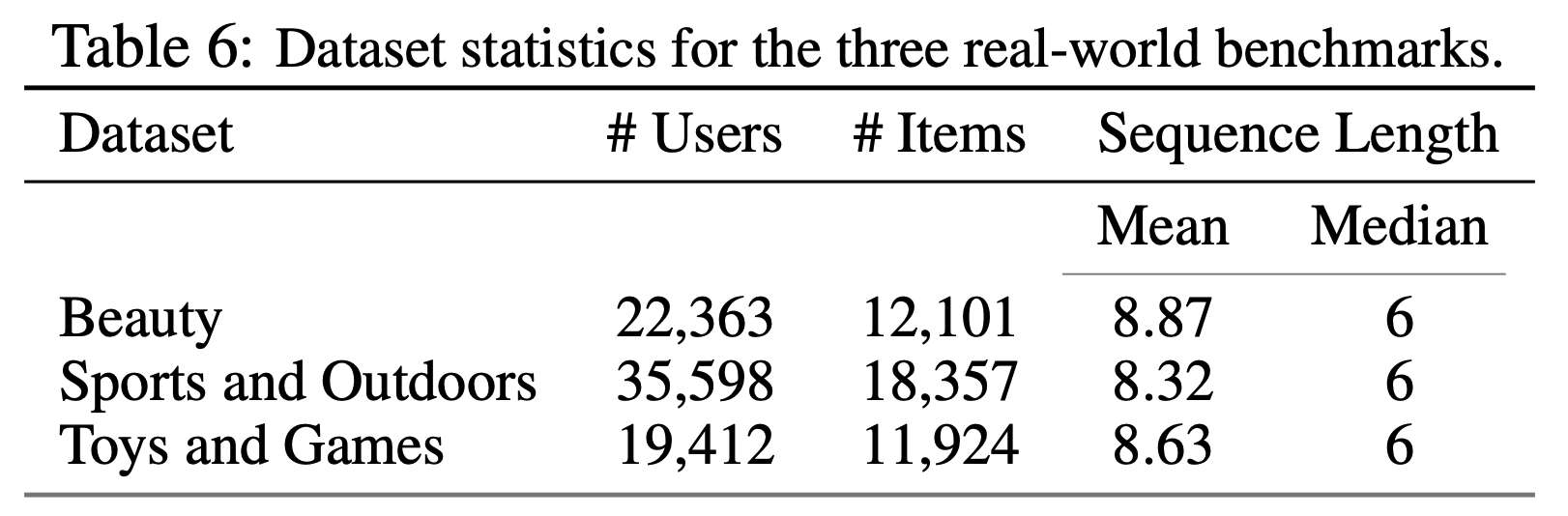
- 该数据集包含从 1996年5月 至 2014年9月 收集的产品评论及相关元数据。论文选取了三个特定子集:”Beauty”、”Sports and Outdoors”和”Toys and Games”
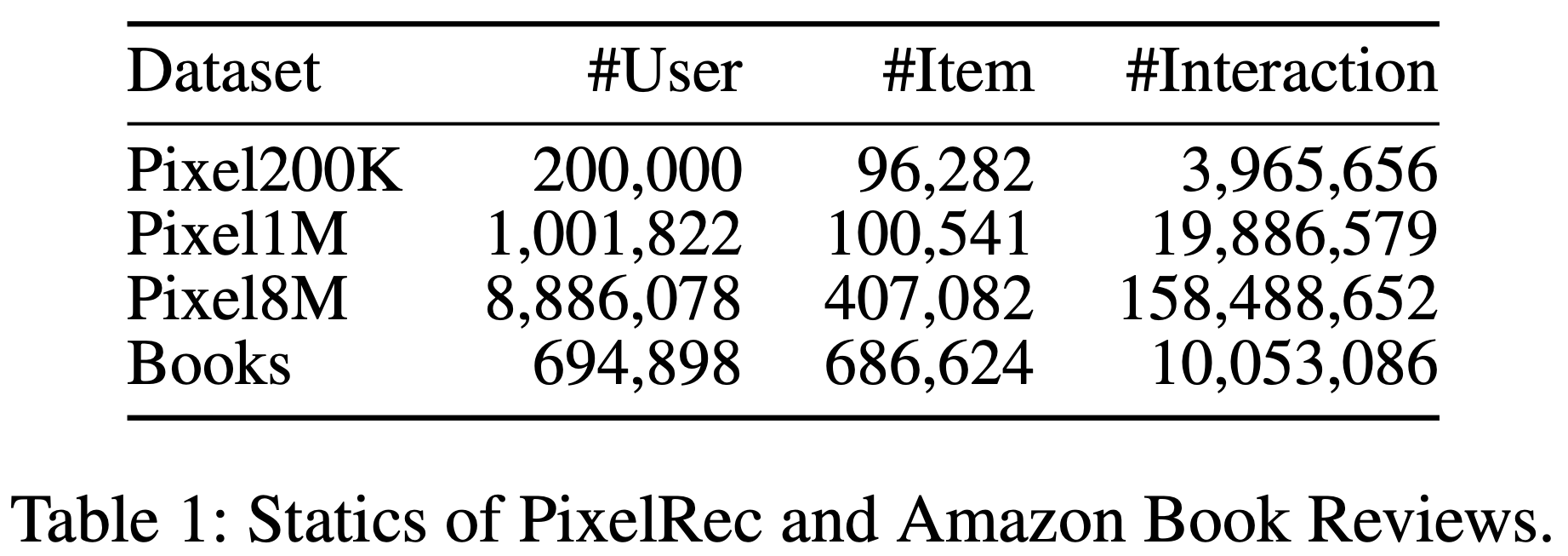
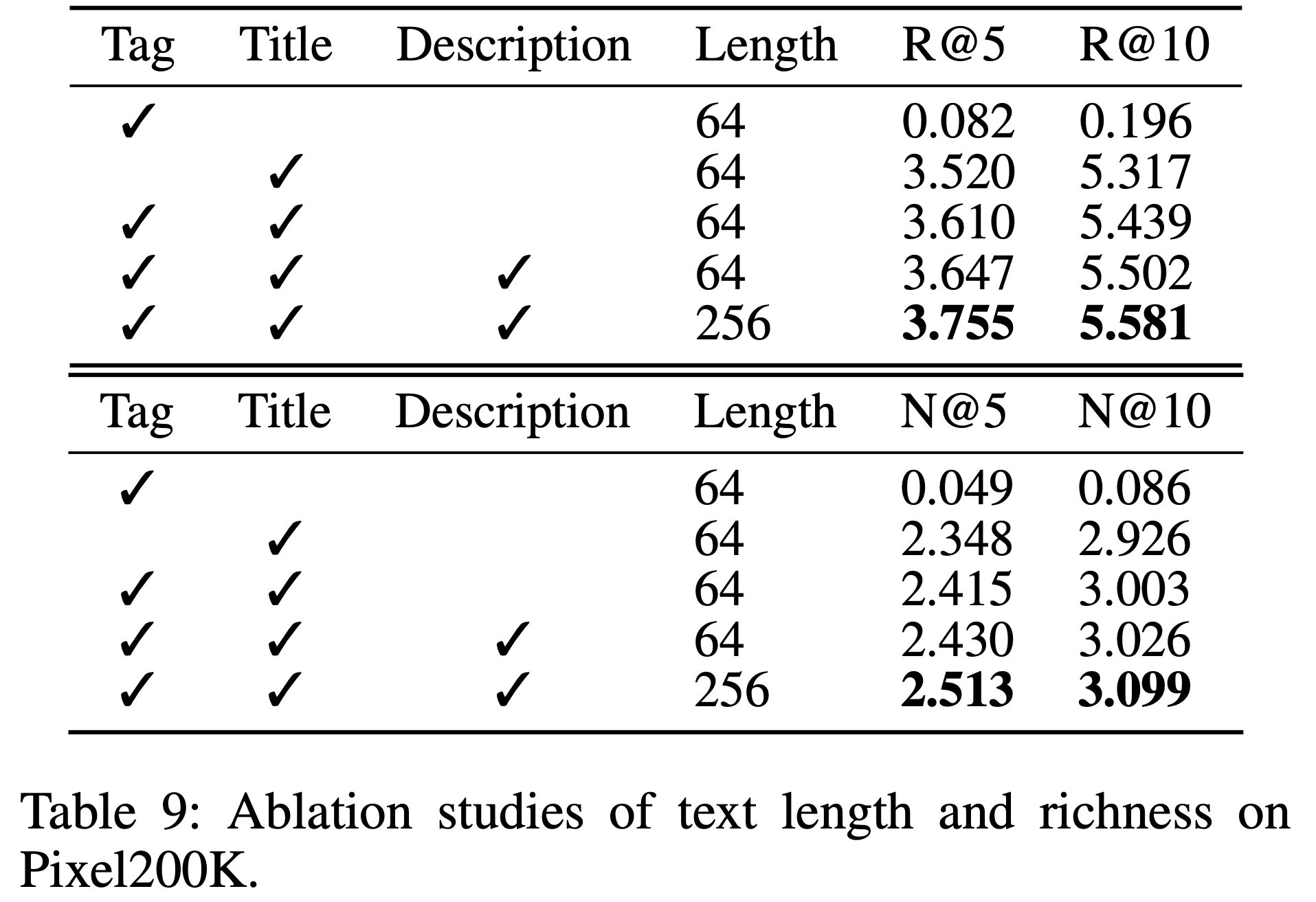
- 对于每个子集,论文利用标题、价格、类别和描述等属性构建 item 嵌入。为确保数据质量,论文应用了5-core过滤处理,剔除了交互次数少于5次的 item 和用户。数据集统计信息详见表1
- 为评估推荐准确性和排序质量,论文采用 Recall@K(准确性)和 NDCG@K(排序质量)指标,其中 \(K=5\) 和 \(K=10\)
基线方法
- 为全面评估 COBRA 的性能,论文将其与以下 SOTA 推荐方法进行比较(这些方法代表了多种推荐技术,包括序列 Dense 推荐和生成式推荐):
- P5[11]:将推荐任务转化为自然语言序列
- Caser[39]:使用卷积层捕捉序列模式
- HGN[28]:通过分层门控网络建模用户长短期兴趣
- GRU4Rec[14]:利用门控循环单元建模用户行为
- SASRec[18]:基于 Transformer 的模型,用于捕捉长期依赖关系
- FDSA[52]:自注意力模型,用于 item 特征转移
- BERT4Rec[37]:结合双向自注意力与掩码目标函数
- S³-Rec[55]:通过对比学习提升推荐效果
- TIGER[33] :使用 RQ-VAE 编码 item 内容特征,并利用 Transformer 进行生成式召回
实现细节
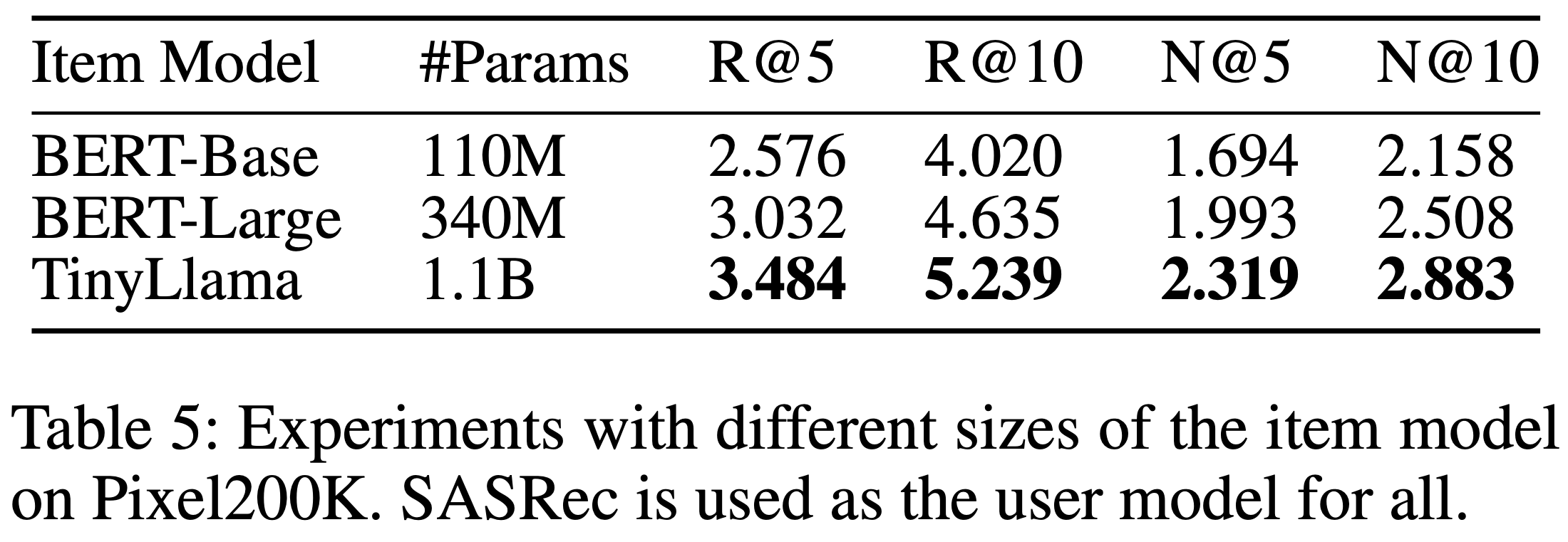
- 论文采用与 TIGER 类似的语义 ID 生成方法,但与其配置不同,论文使用 3 层语义 ID 结构,每层对应 Codebook 大小为32
- 这些语义 ID 通过 T5 模型生成
- 理解:这里原文表达有误,应该是需要从 item 文本描述中提取 Embedding,再进入 RQ-VAE 编码为离散 Code(也就是语义 ID),TIGER 中也使用了 Sentence-T5 作为第一步的文本编码器的
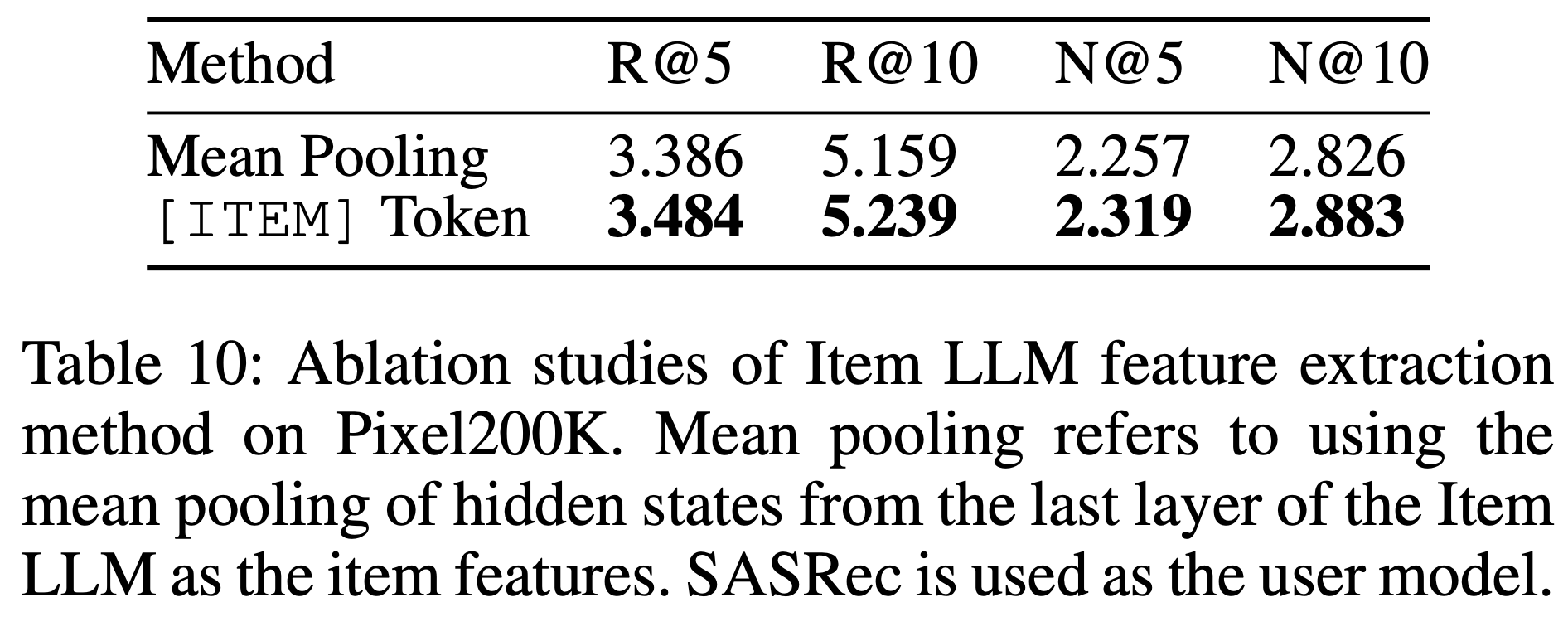
- COBRA 采用轻量级架构实现,包含 1 层 Encoder 和 2 层 Decoder
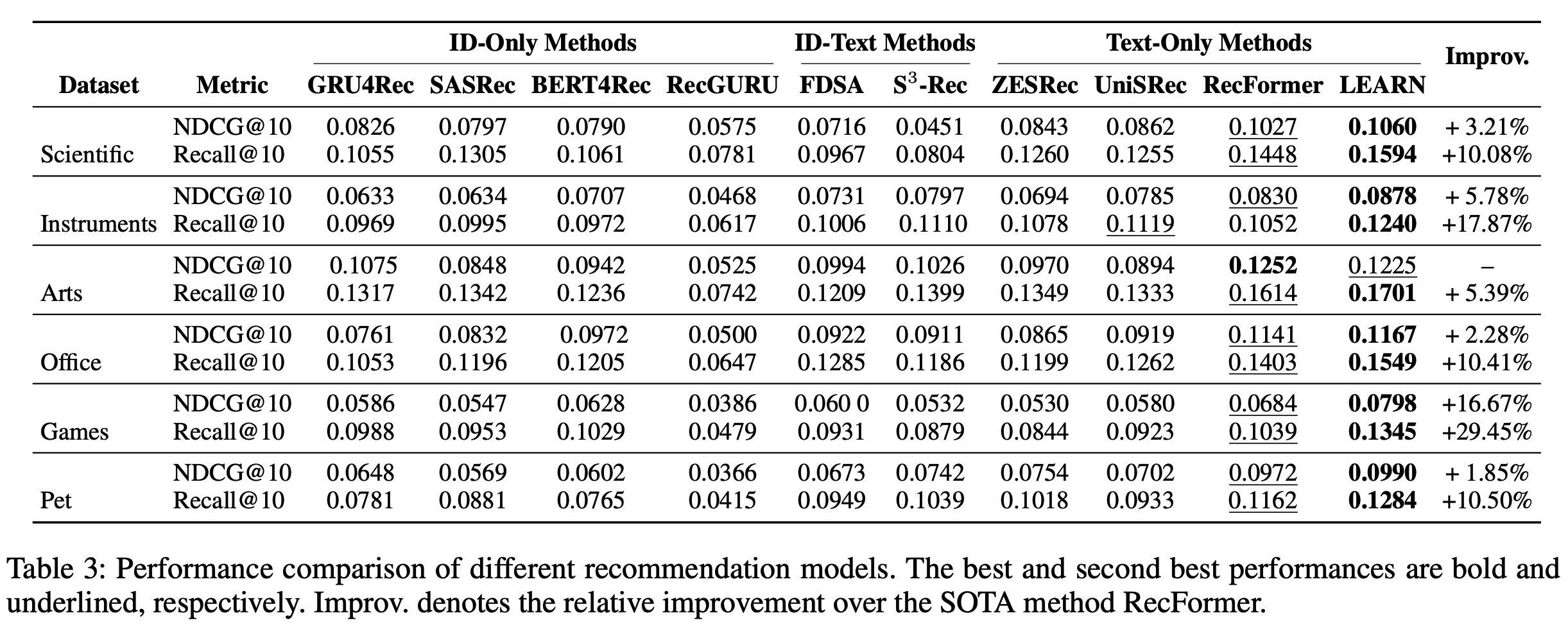
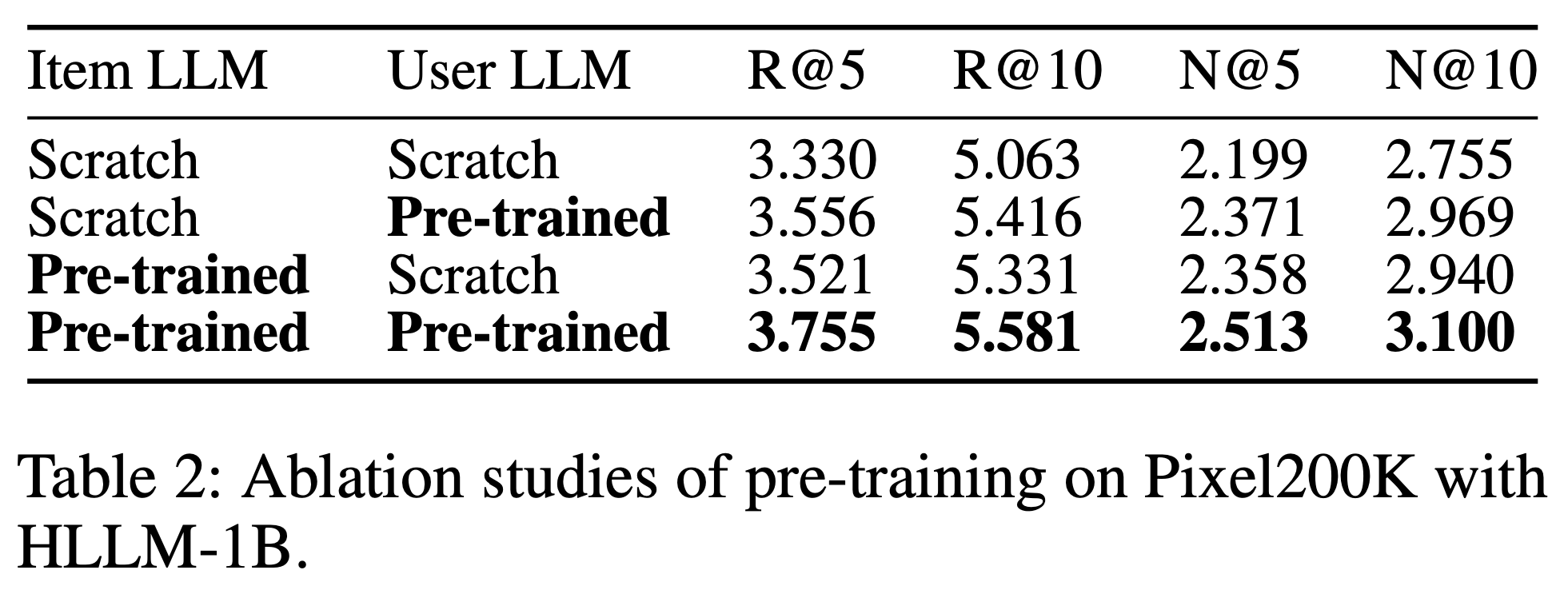
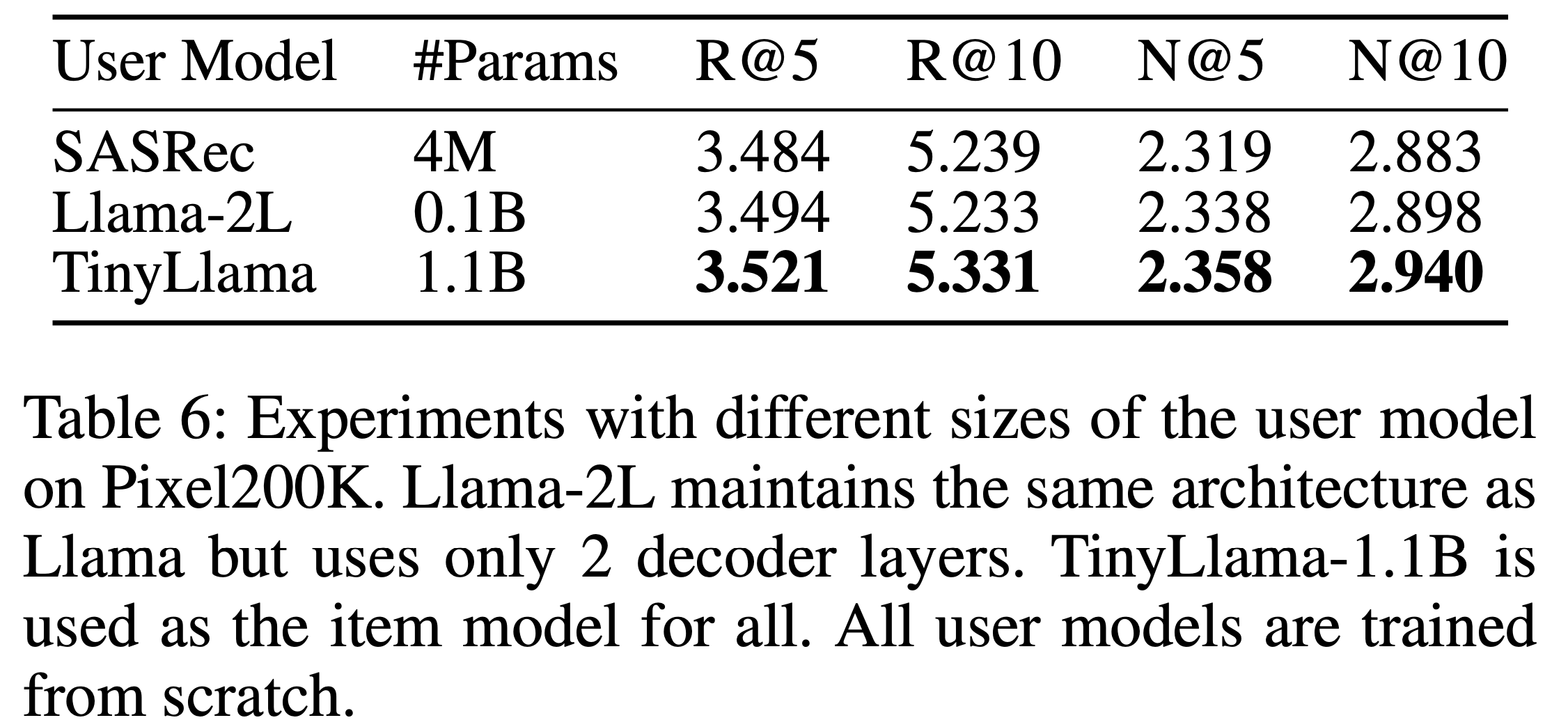
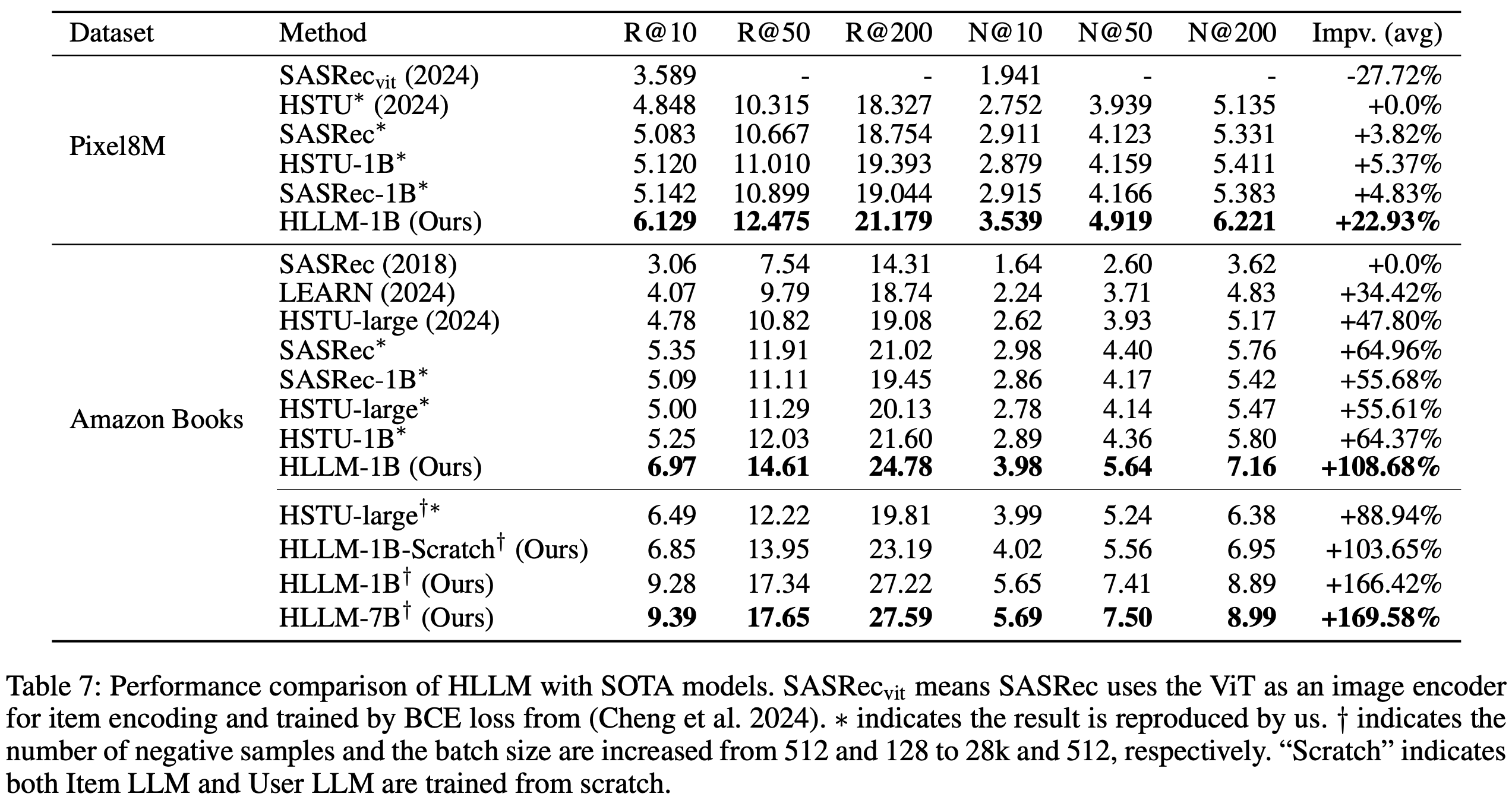
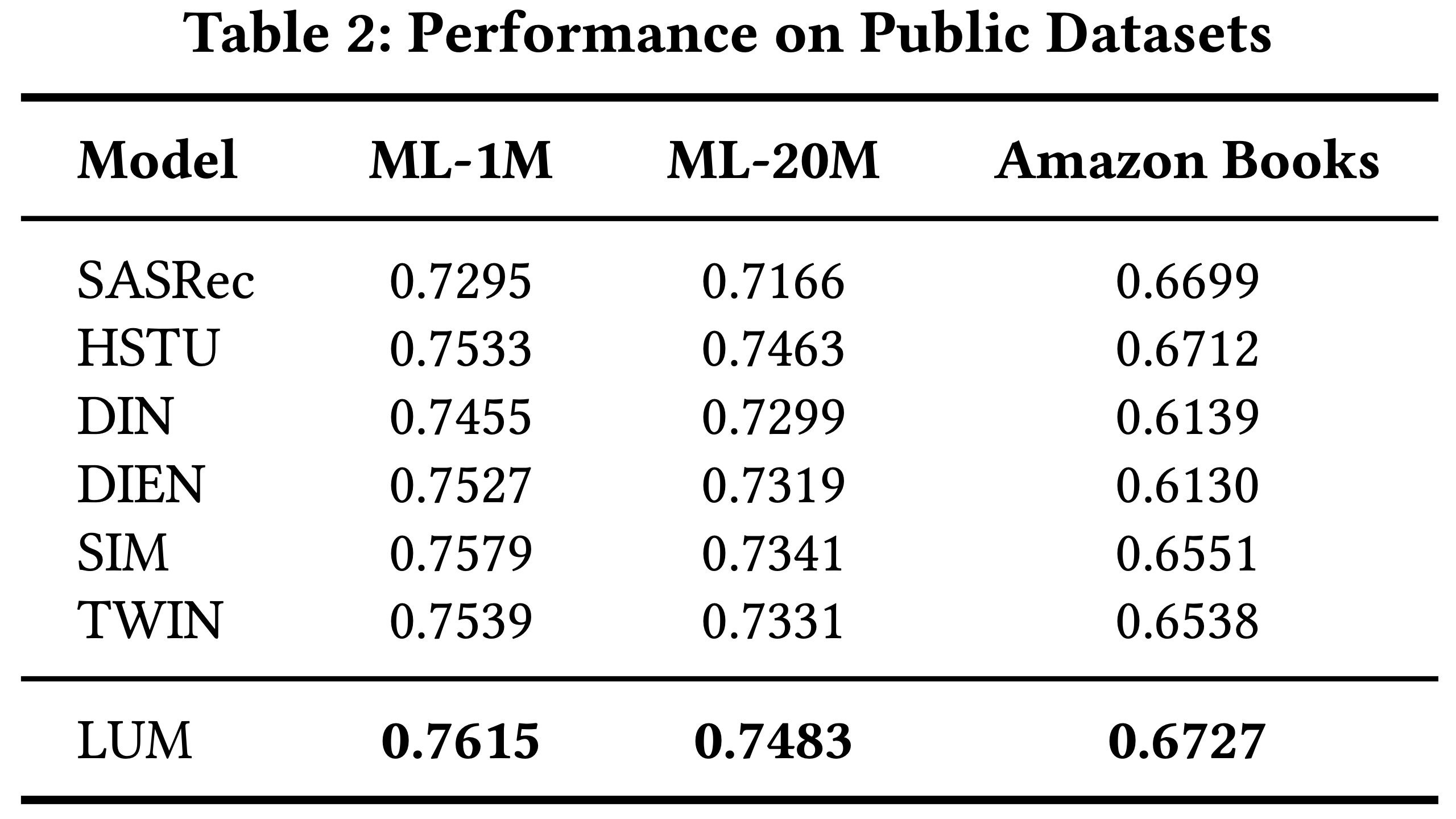
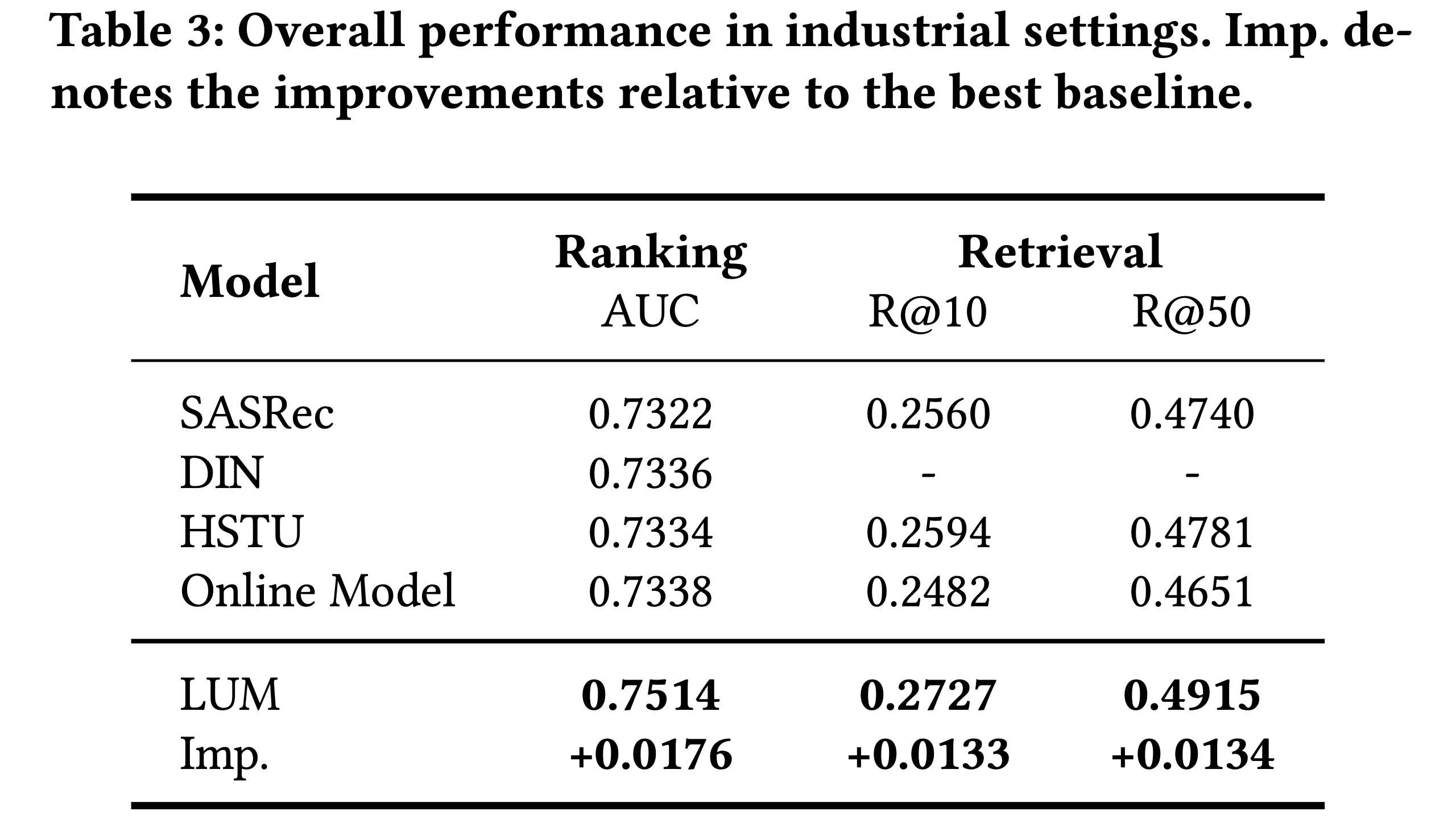
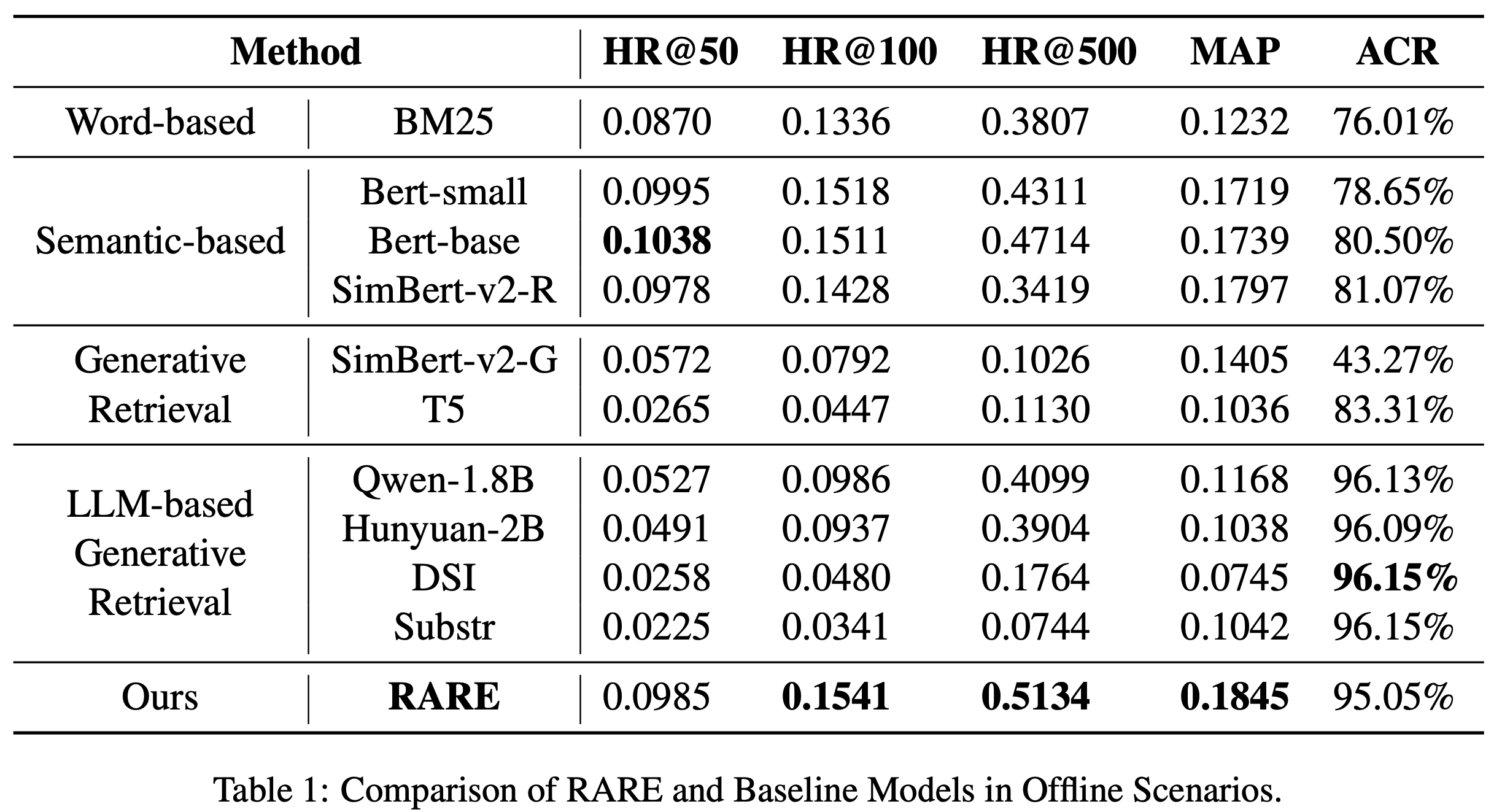
结果
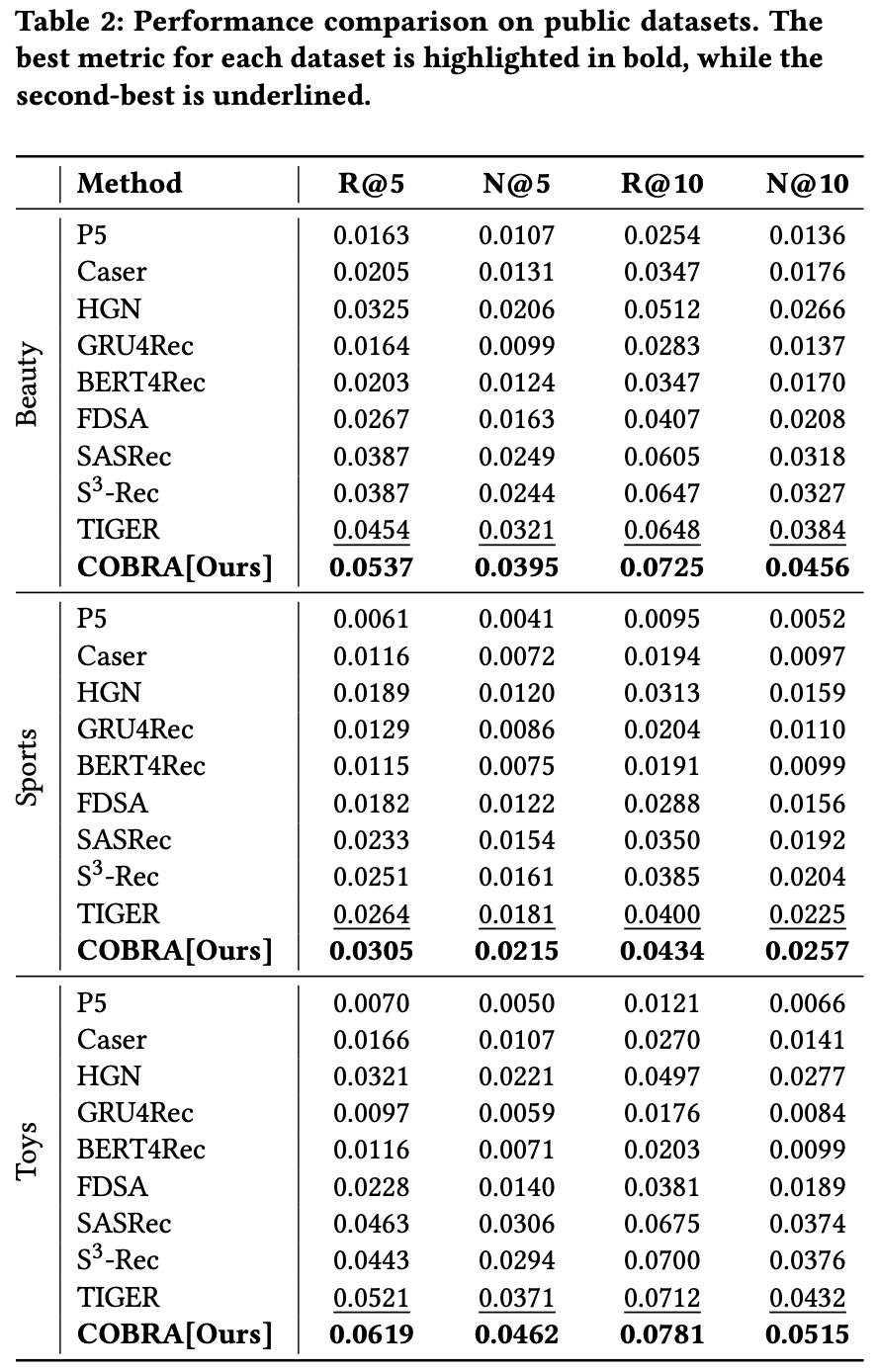
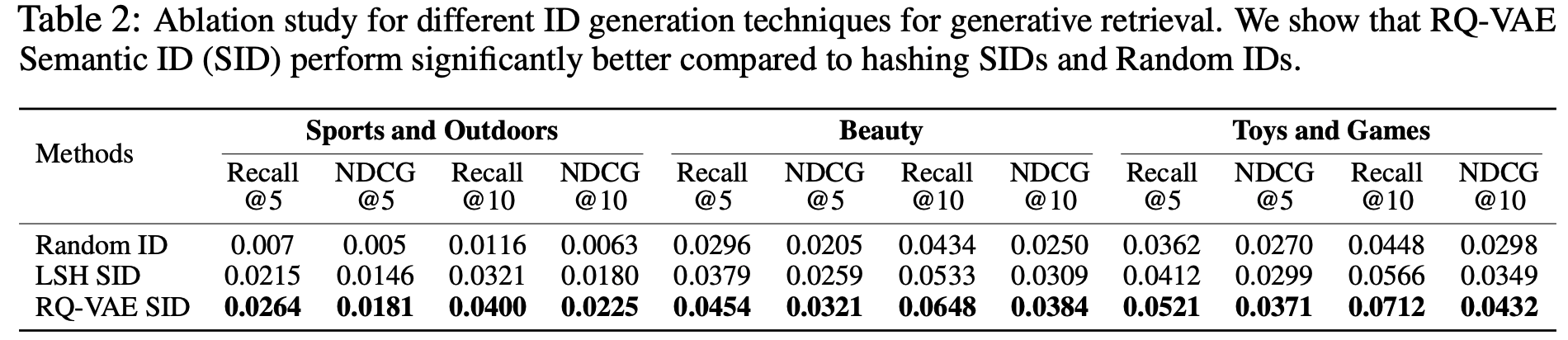
- 如表2所示,COBRA 在各项指标上均超越所有基线模型
工业规模实验(Industrial-scale Experiments)
数据集与评估指标
- 在百度工业数据集上进行实验,该数据集源自百度广告平台的用户交互日志,涵盖列表页、双栏和短视频等多种推荐场景
- 数据集包含500万用户和200万广告,全面反映了真实世界的用户行为和广告内容
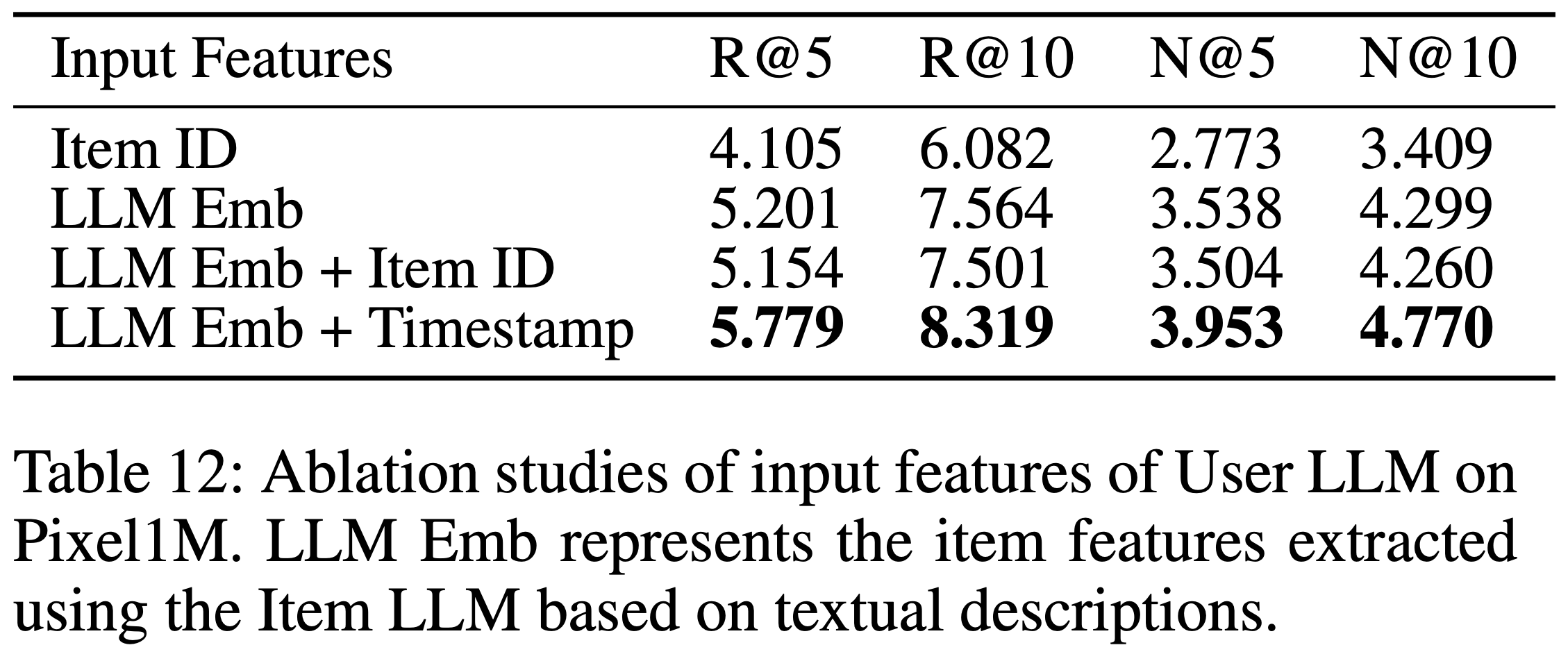
- 广告和广告主通过标题、行业标签、品牌和活动文本等属性表示,这些属性被处理并编码为两层 Sparse ID 和 Dense 向量,捕捉粗粒度和细粒度语义信息。这种双重表示使 COBRA 能够有效建模用户偏好和 item 特征
- 数据集分为两部分: \(D_{\text{train} }\) 和 \(D_{\text{test} }\)
- 训练集 \(D_{\text{train} }\) 包含前60天的用户交互日志,覆盖该期间的推荐内容交互
- 测试集 \(D_{\text{test} }\) 构建自 \(D_{\text{train} }\) 之后一天的日志,作为评估模型性能的基准
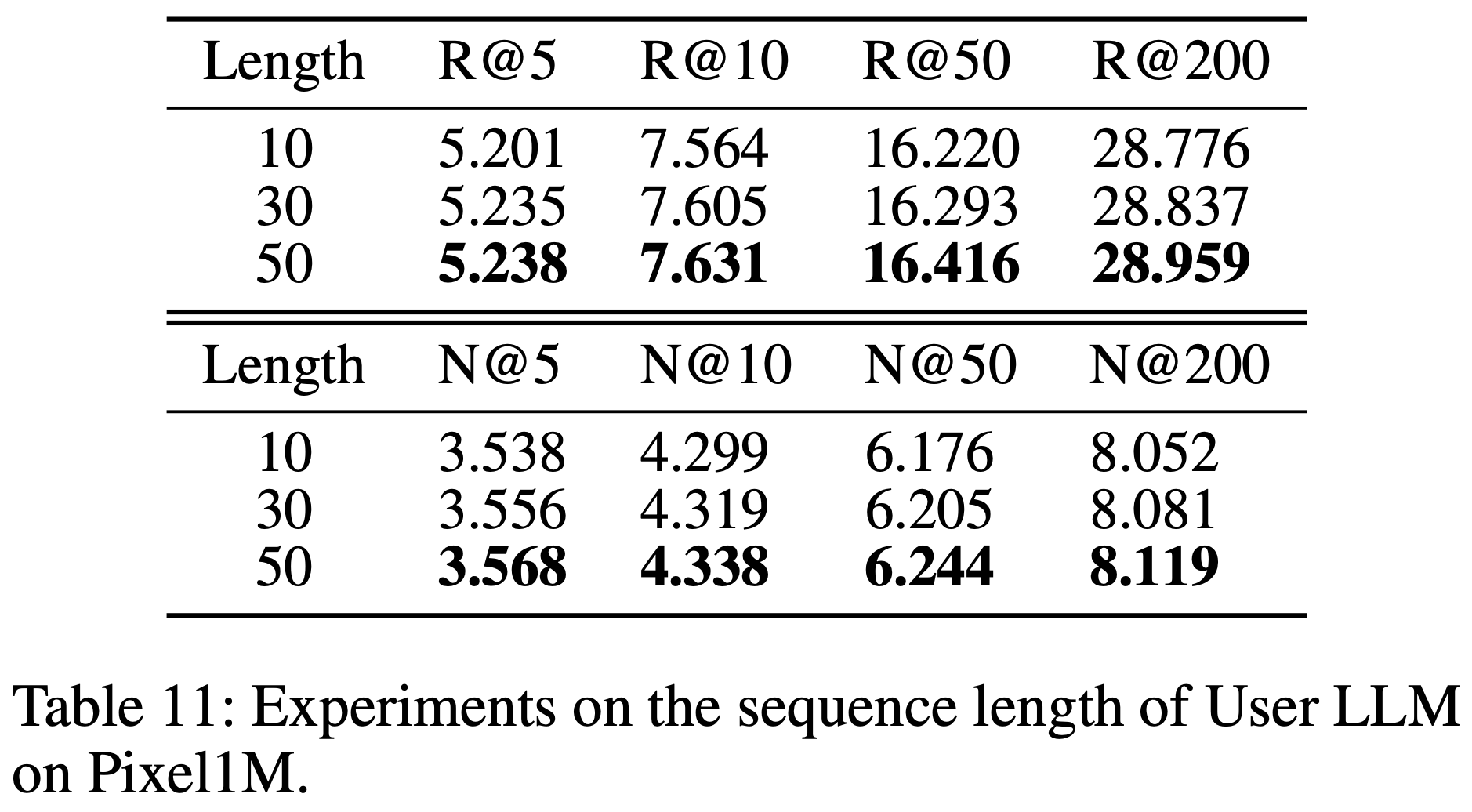
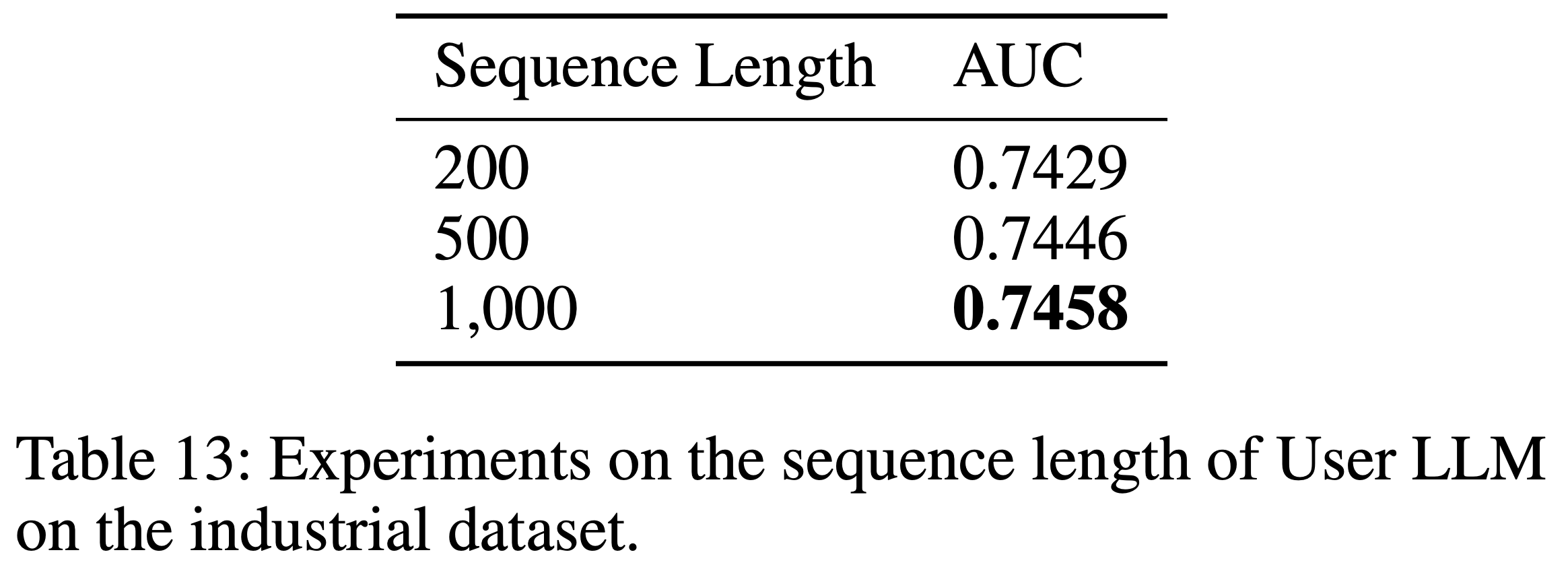
- 离线评估采用 Recall@K 指标,测试 \(K \in \{50,100,200,500,800\}\),该指标衡量模型在不同阈值下准确召回推荐内容的能力
基线方法
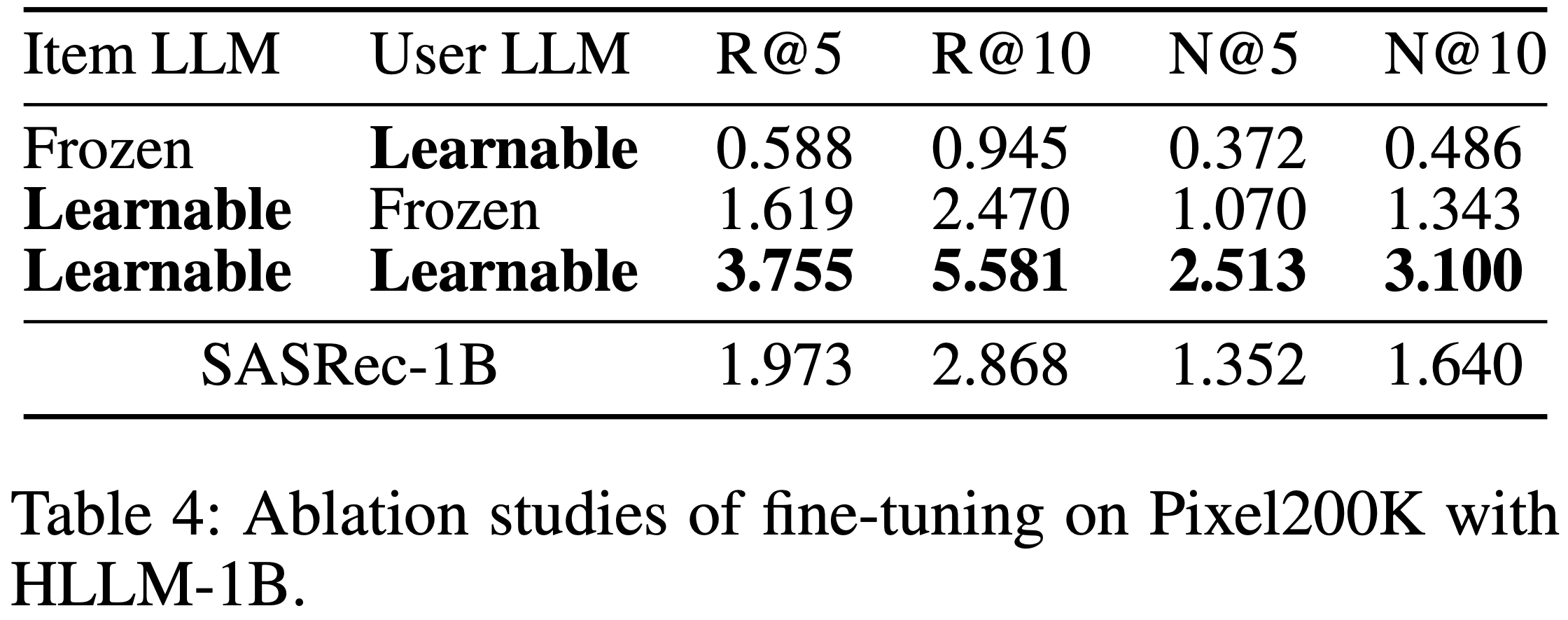
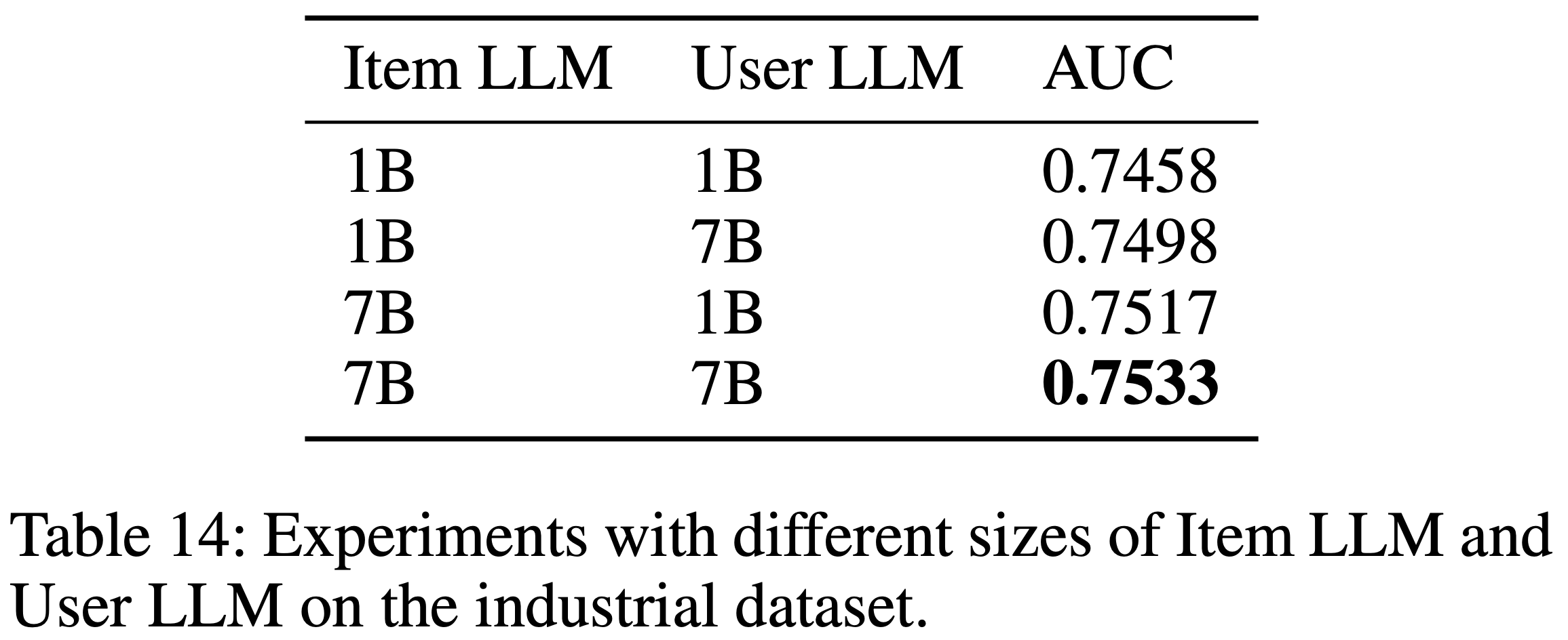
- 论文将 COBRA 与其变体进行比较:
- COBRA w/o ID :移除 Sparse ID,仅依赖 Dense 向量。该变体类似于 RecFormer[21],使用轻量级 Transformer 进行序列建模
- COBRA w/o Dense :移除 Dense 向量,仅使用 Sparse ID。由于 ID 的粗粒度特性,该变体采用类似 TIGER[33]的生成式召回方法,利用语义 ID 进行召回
- COBRA w/o BeamFusion :移除 BeamFusion 模块,使用 top-1 Sparse ID 和最近邻召回获取 top-\(k\) 结果
实现细节
- COBRA 基于 Transformer 架构实现
- Encoder 将广告文本处理为序列,随后由 Sparse ID 头部预测2层语义 ID,配置为 \(32 \times 32\)
- 变体 COBRA w/o Dense 采用 3 层语义 ID ( \(256 \times 256 \times 256\) ),以更细粒度地建模广告
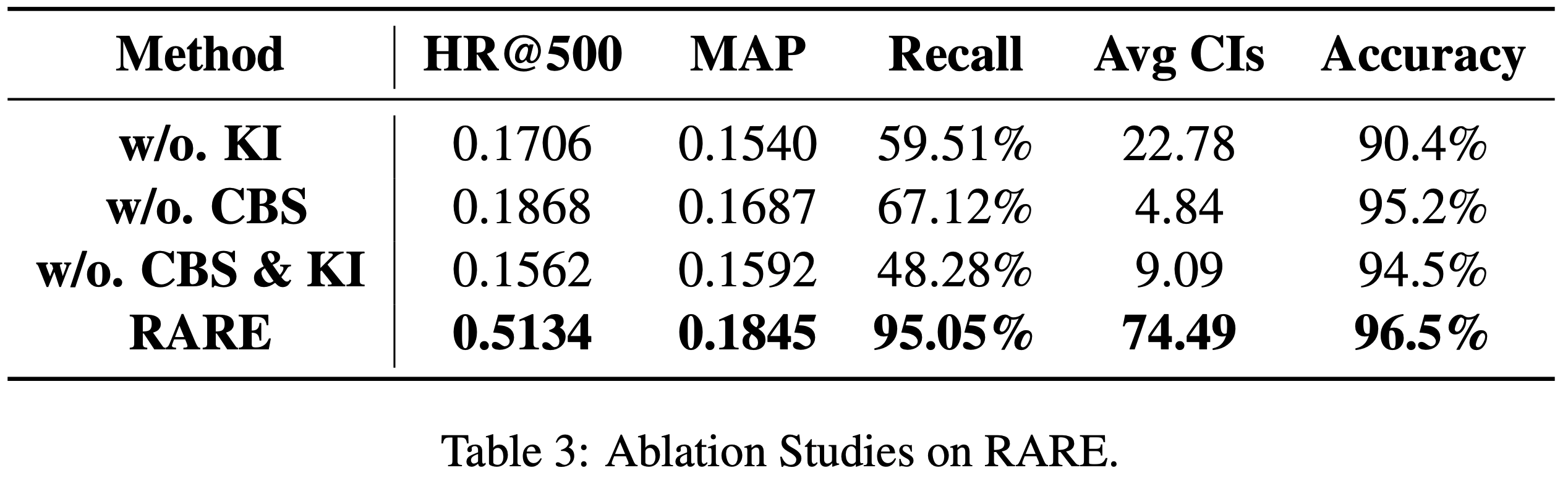
结果
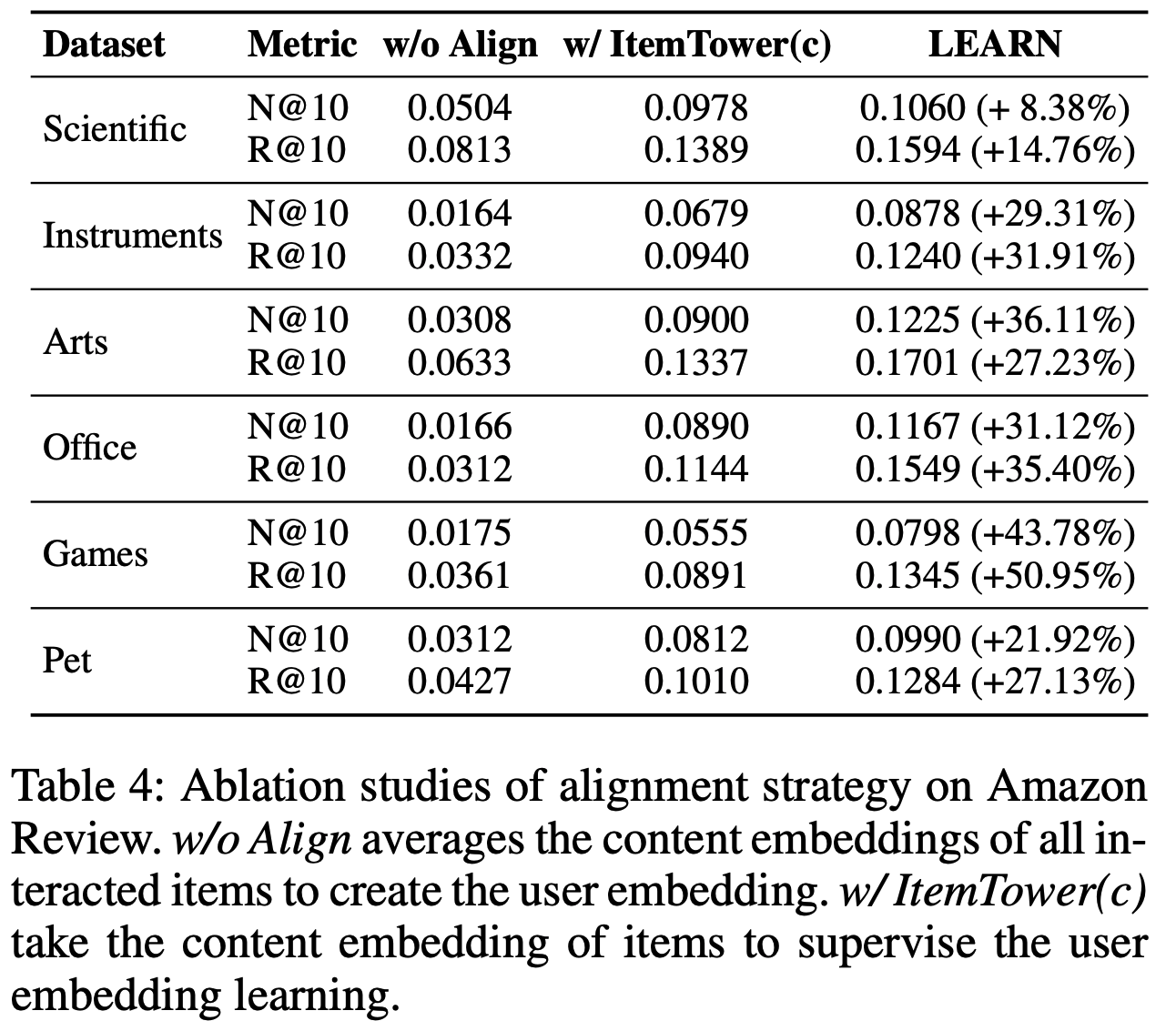
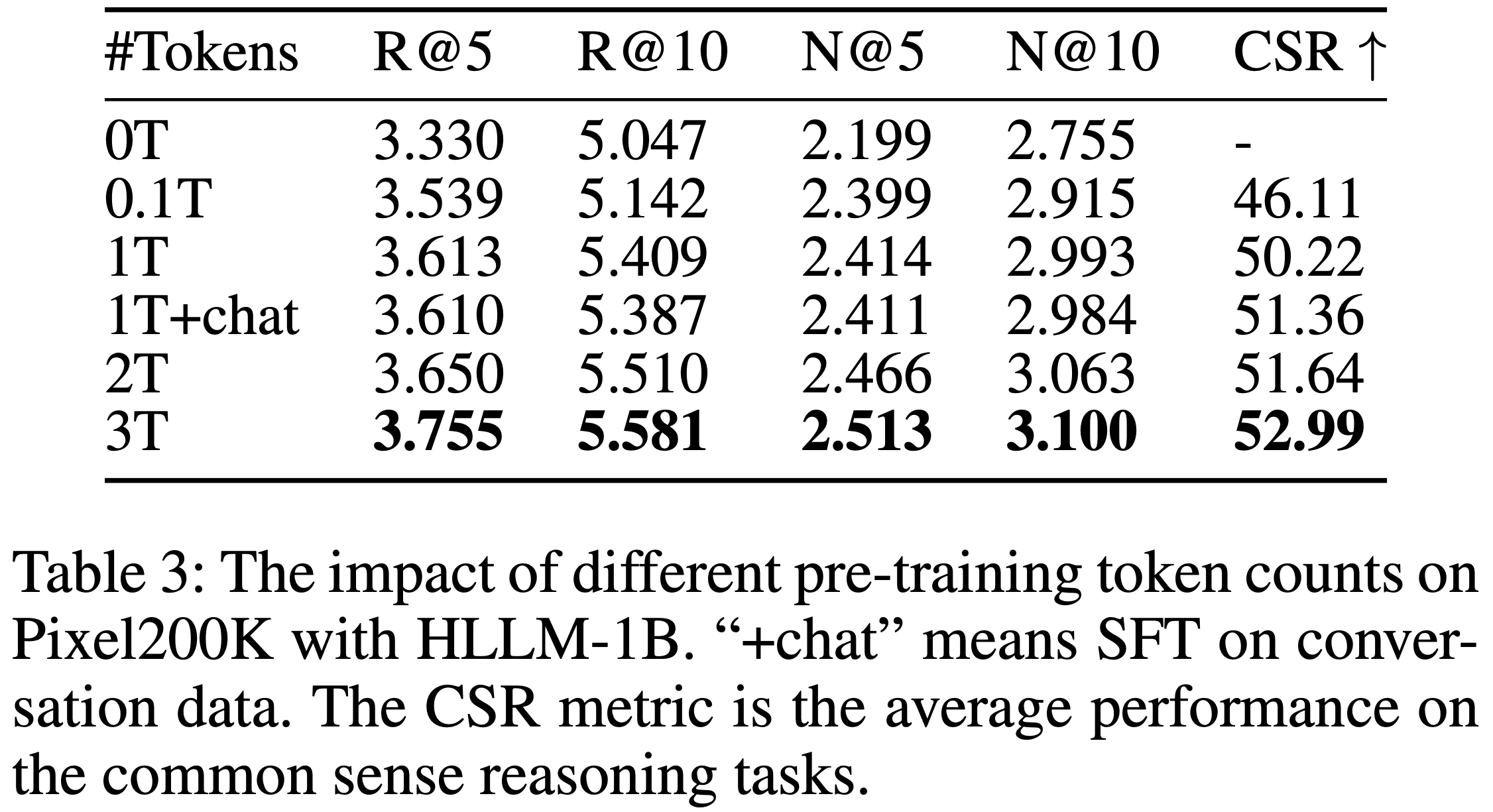
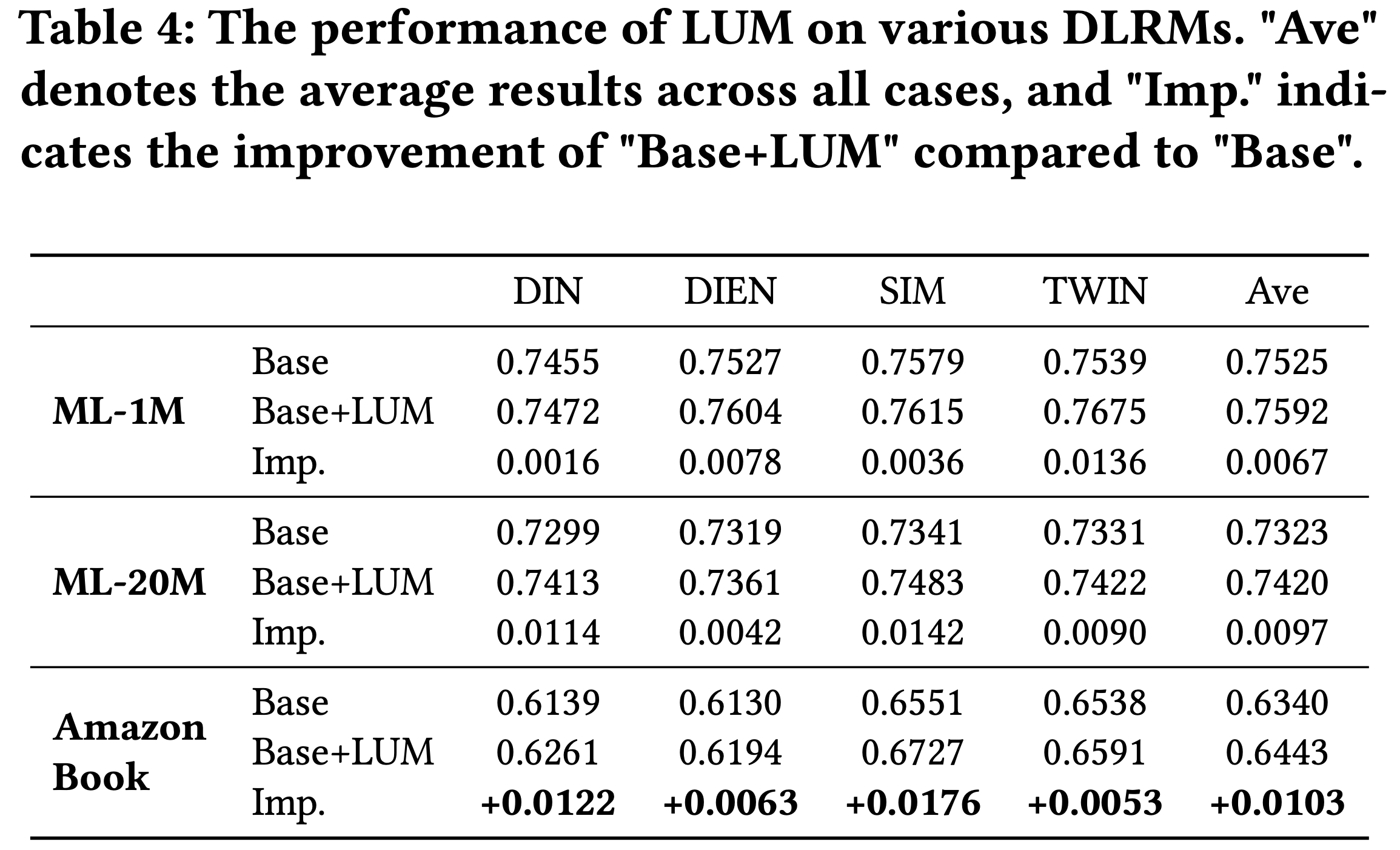
- 如表3所示,COBRA 在所有评估指标上均优于其变体
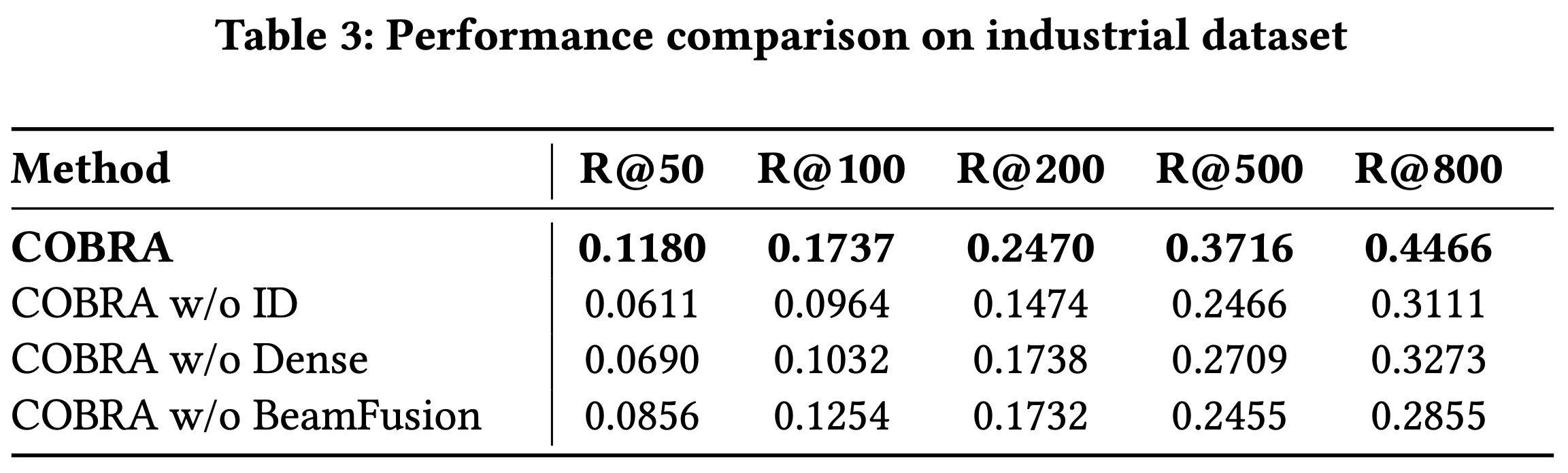
- 值得注意的是,在较小的 \(K\) 值时,缺少 Dense 或 Sparse 表示会导致更明显的性能下降,这凸显了级联表示对于实现粒度和精度的重要性。相反,随着召回规模 \(K\) 的增加,BeamFusion 的性能优势愈发明显,证明了其在工业召回系统中的有效性
- 结果进一步凸显了特定组件的贡献:
- 移除 Sparse ID(COBRA w/o ID)导致召回率下降 26.7%至41.5%,表明语义分类的关键作用
- 移除 3 层语义 ID(COBRA w/o Dense)导致性能下降 30.3%至48.3%,说明细粒度建模的重要性
- 移除 BeamFusion 导致召回率下降 27.5%至36.1%,强调了其在 Sparse ID 内部和 Sparse ID 之间的信息整合的重要性
进一步分析
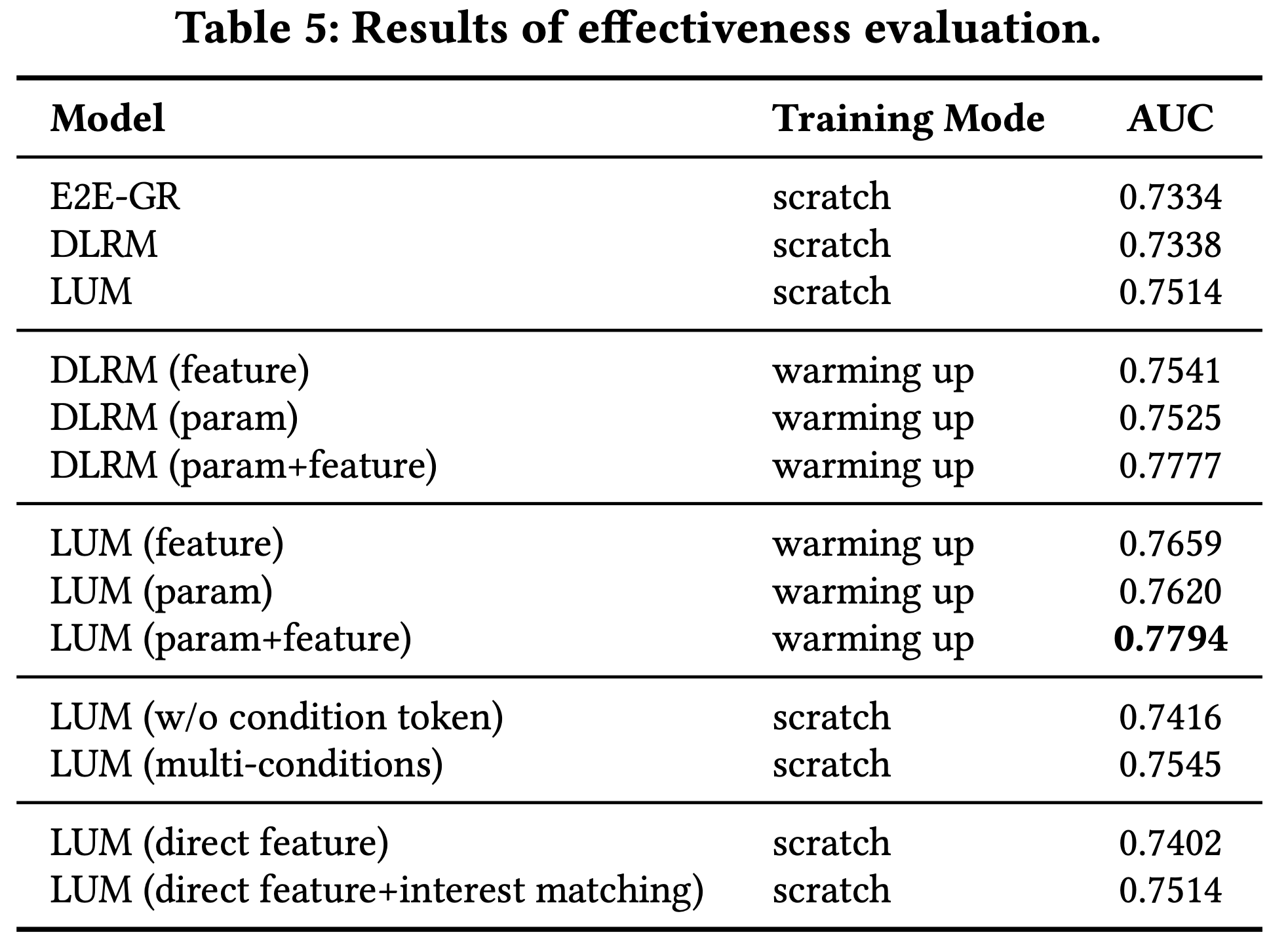
表示学习分析
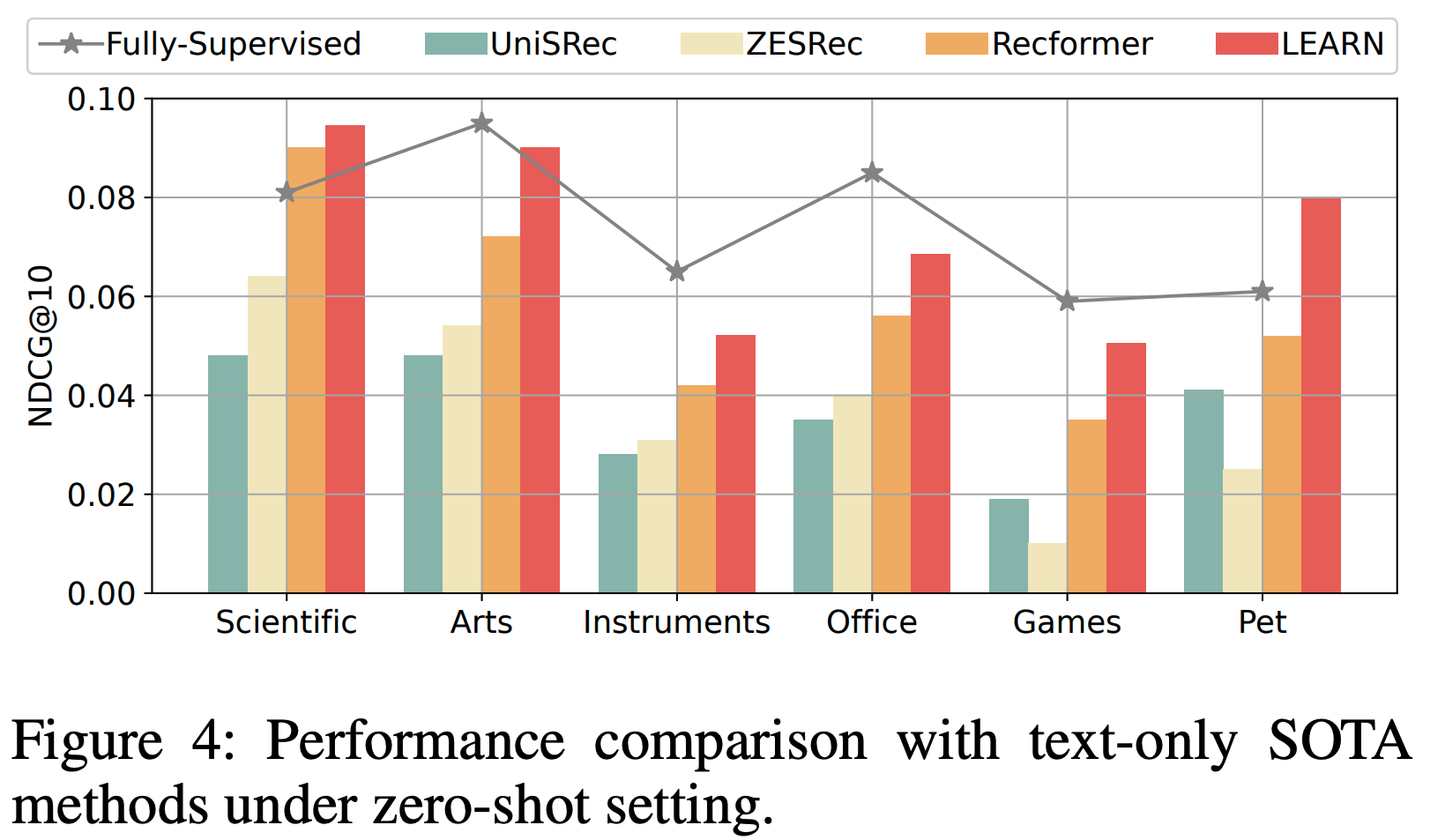
- 为评估 COBRA 模型的表示学习能力,论文构建了广告 Dense 嵌入的相似度矩阵,如图4所示
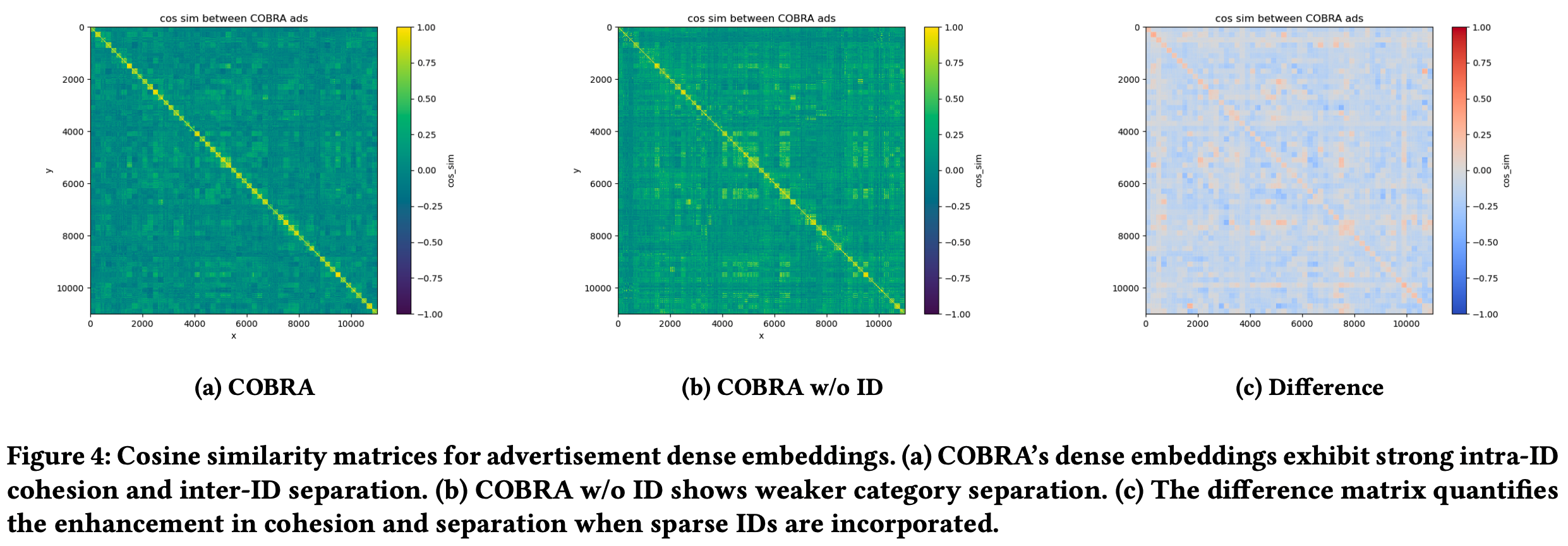
- 图4相关结论:
- 图4a:COBRA 模型展现出显著的 ID 内凝聚性(intra-ID cohesion) 和 ID 间分离性(inter-ID separation) ,表明其 Dense 嵌入能够有效捕捉 item 细节特征,同时保持类别内的语义一致性
- 图4b:无 Sparse ID 的模型变体显示出较弱的类别分离性,凸显了 Sparse ID 在保持语义结构中的重要性
- 图4c:差异矩阵定量验证了 Sparse ID 对增强内聚性和分离性的作用
- 通过 t-SNE 将广告嵌入分布可视化,进一步验证 COBRA 嵌入的效果。随机采样 10,000 个广告后,可观察到不同类别的明显聚类中心。图5显示广告按类别有效聚类,表明类别内的强内聚性。紫色、青色、浅绿色和深绿色聚类分别主要对应小说、游戏、法律服务和服装类广告,表明广告表示有效捕捉了语义信息

召回-多样性平衡
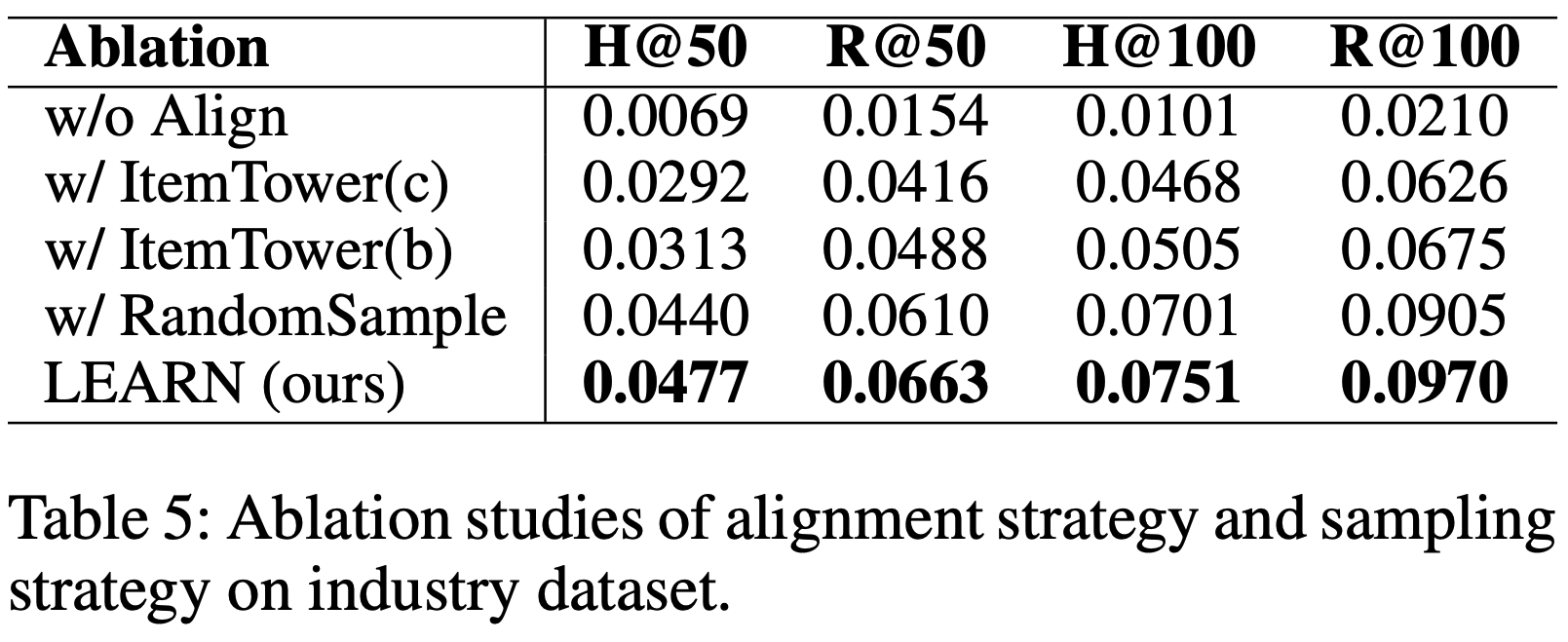
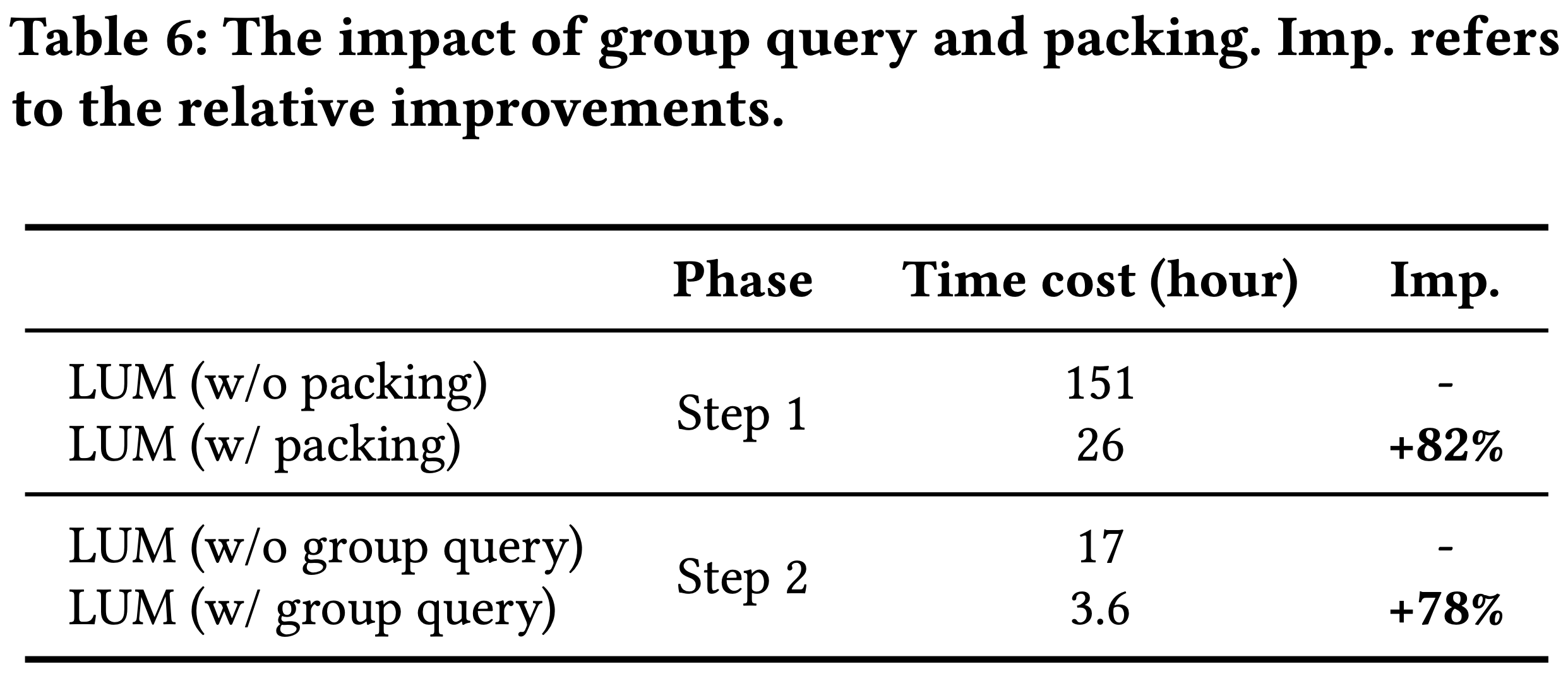
- 在推荐系统的召回阶段,平衡准确性和多样性是一项挑战,为分析 COBRA 的这种权衡,论文研究了召回-多样性曲线(recall-diversity curves)
- 该曲线描述了在固定 \(\phi=16\) 时,Recall@2000 和多样性指标如何随 BeamFusion 机制中的系数 \(\tau\) 变化
- 如图6所示,增加 \(\tau\) 通常会导致多样性下降
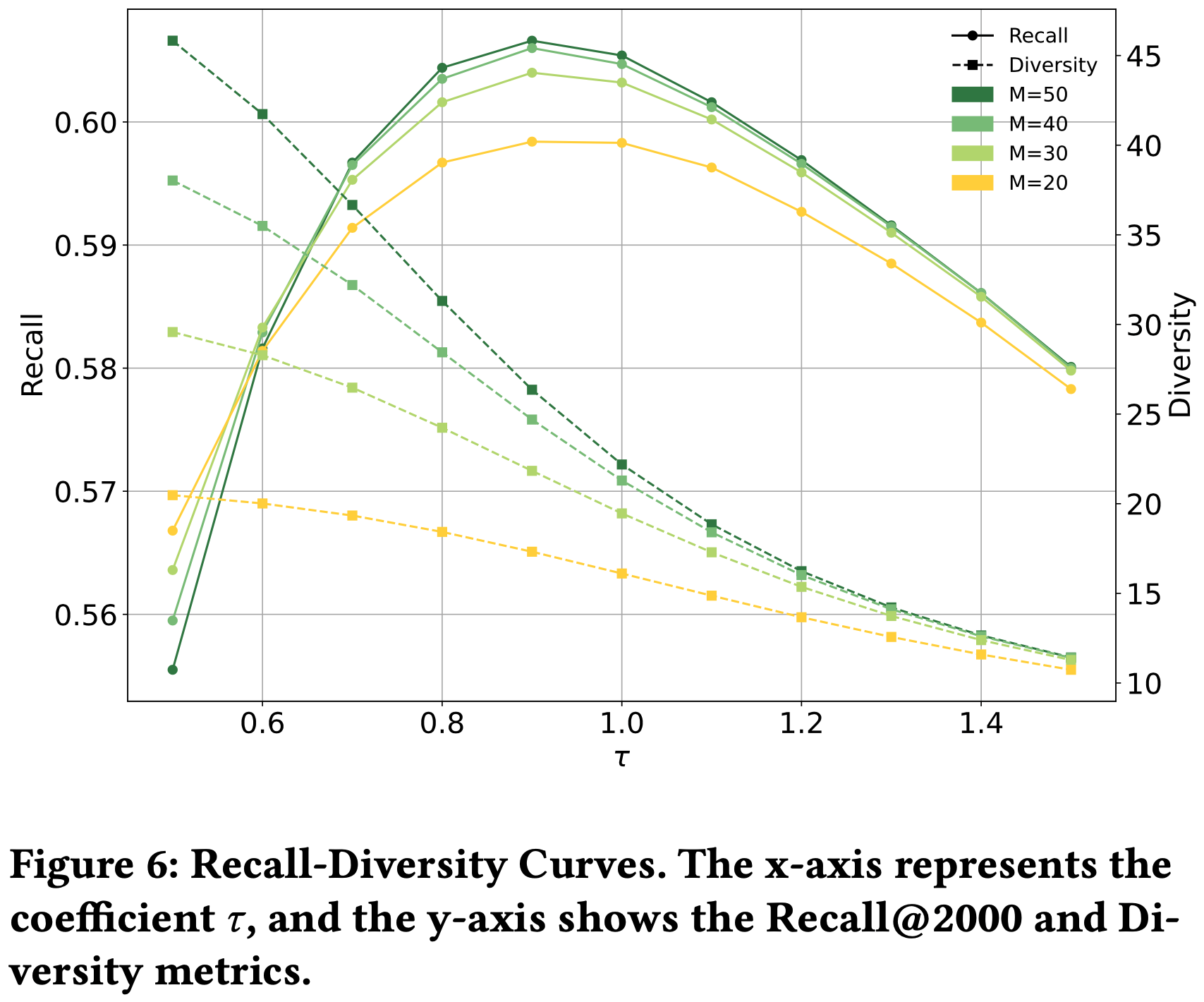
- COBRA 在 \(\tau=0.9\) 和 \(\phi=16\) 时达到召回与多样性的最佳平衡,此时模型在保持高准确性的同时确保推荐 item 覆盖足够多样的集合
- 多样性指标定义 :召回 item 中不同 ID 的数量,反映模型避免冗余和为用户提供更广泛选择的能力
- 通过精细控制 \(\tau\) 和 \(\phi\),实现业务目标
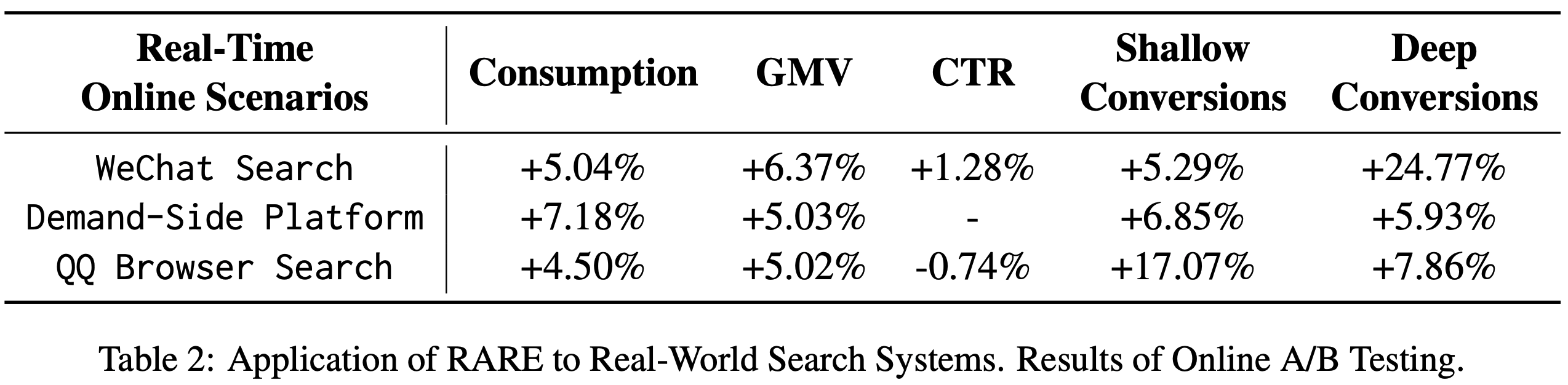
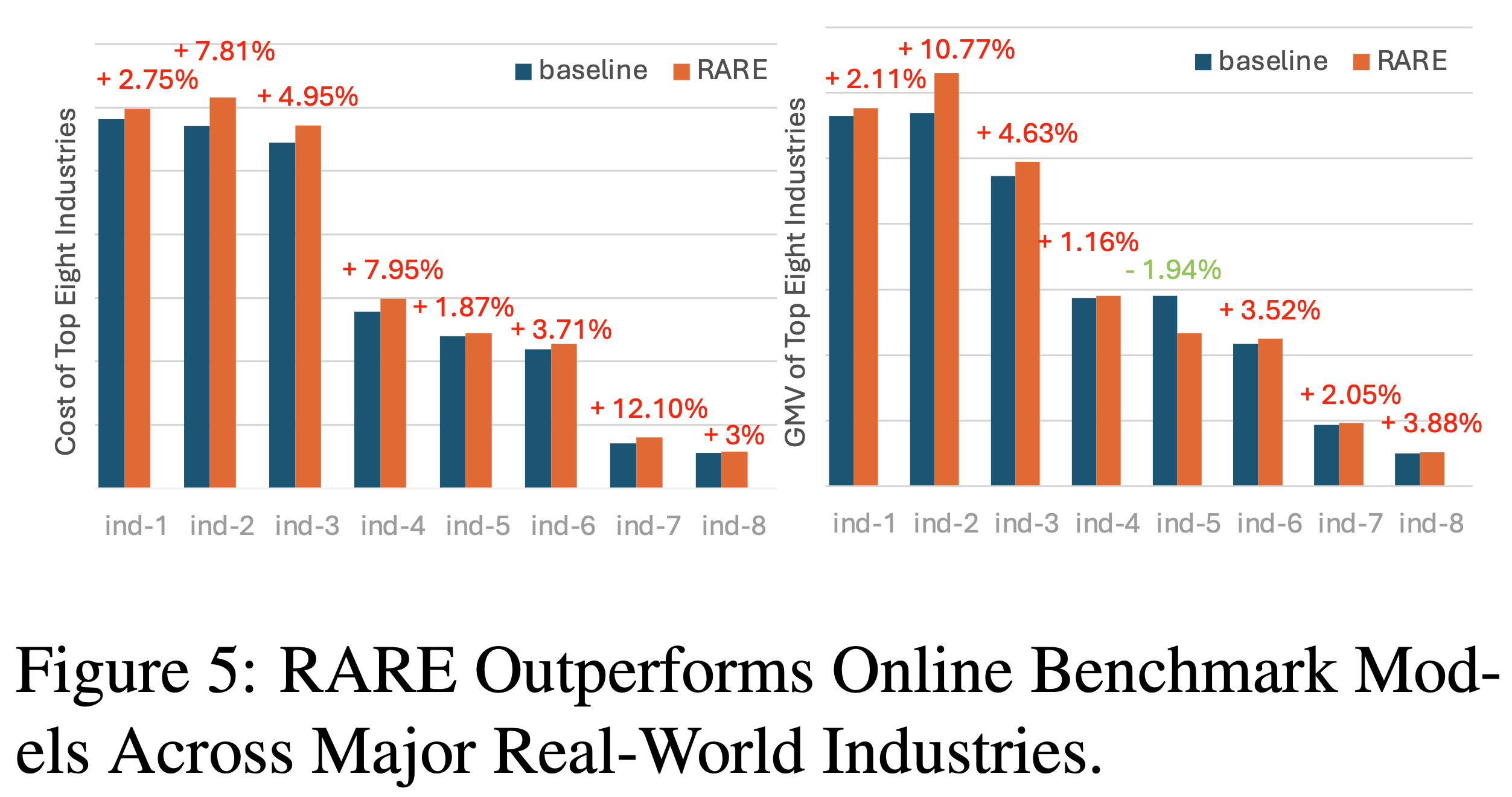
在线结果
- 论文于 2025年1月 在百度工业数据集上进行了在线A/B测试
- 测试覆盖 10% 的用户流量 ,确保统计显著性(ensuring statistical significance)
- 主要评估指标 :转化率(用户参与度)和用户平均收入(ARPU,经济价值)
- 在论文策略覆盖的领域中,COBRA 实现 转化率+3.60%,ARPU+4.15%





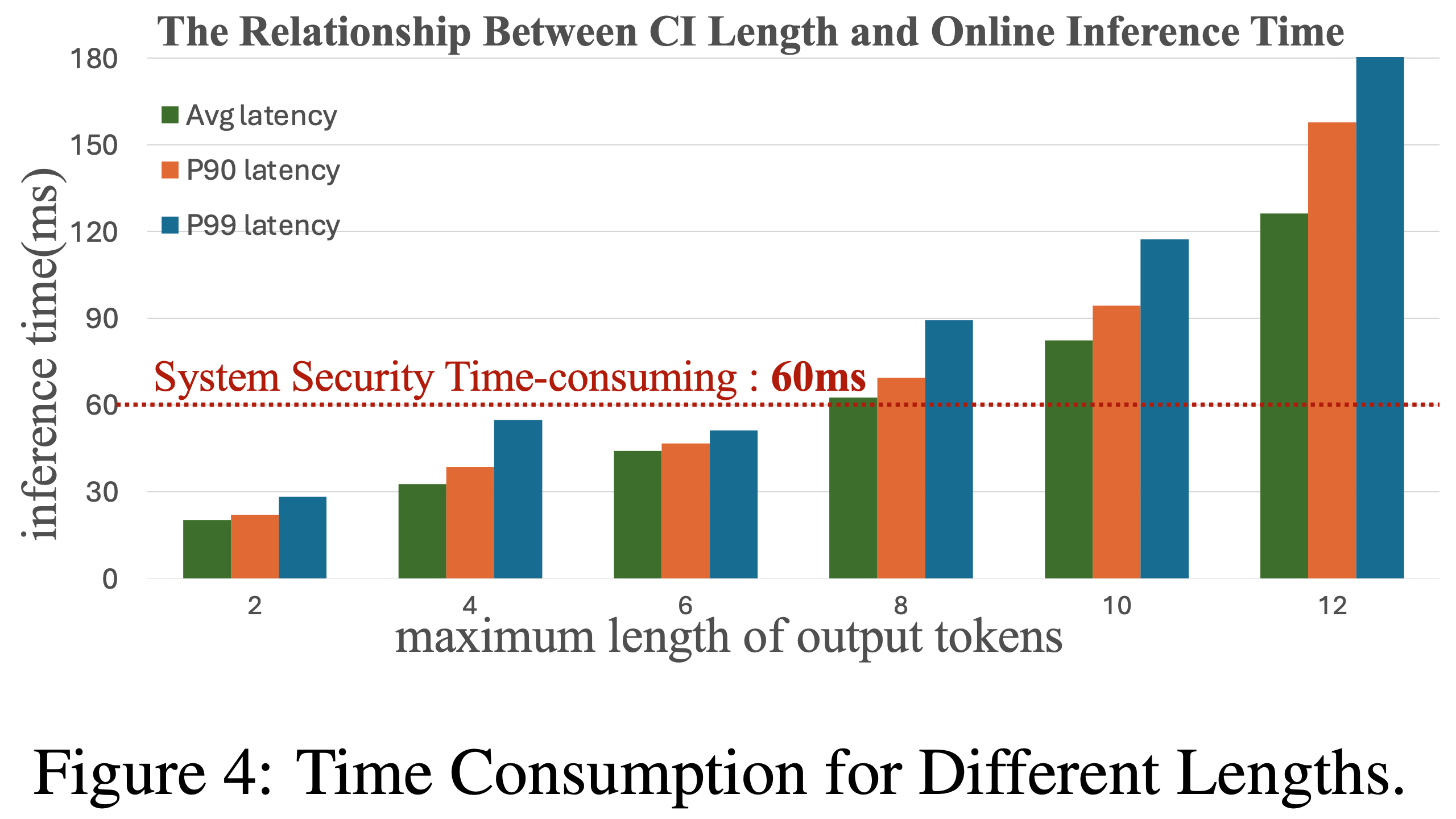








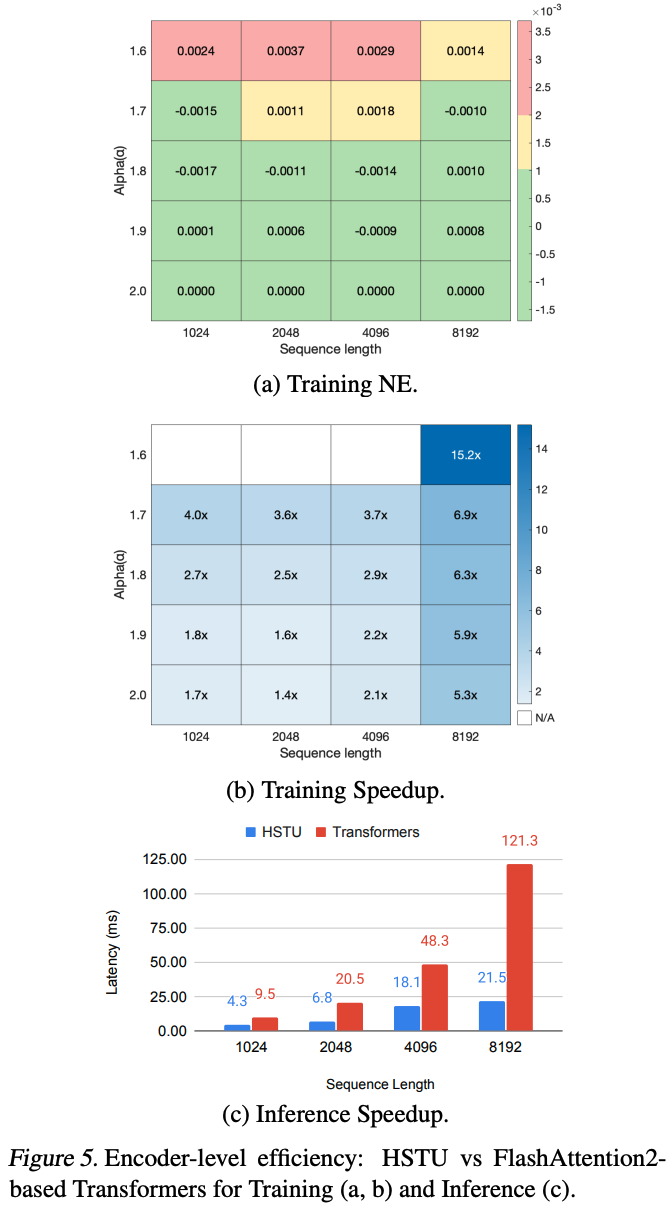
算法对序列sparse度的影响(如 \alpha=1.6 时sparse度达80.5%)")