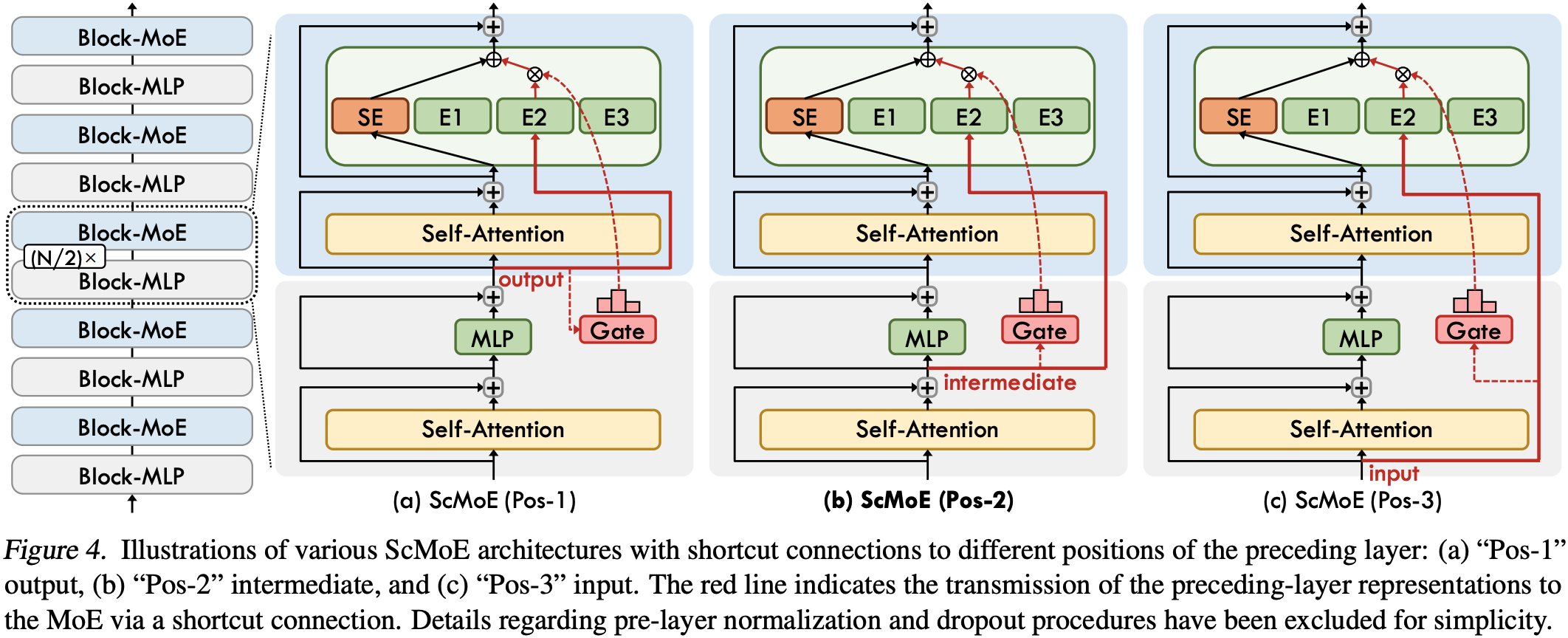
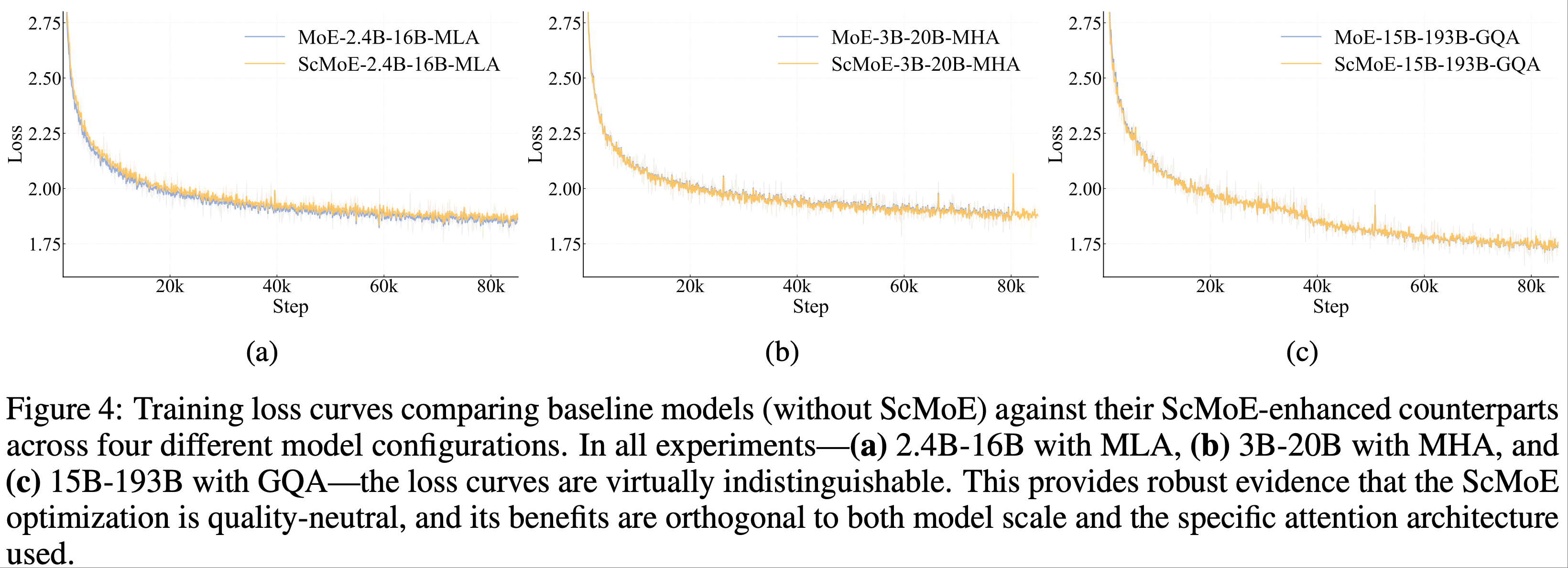
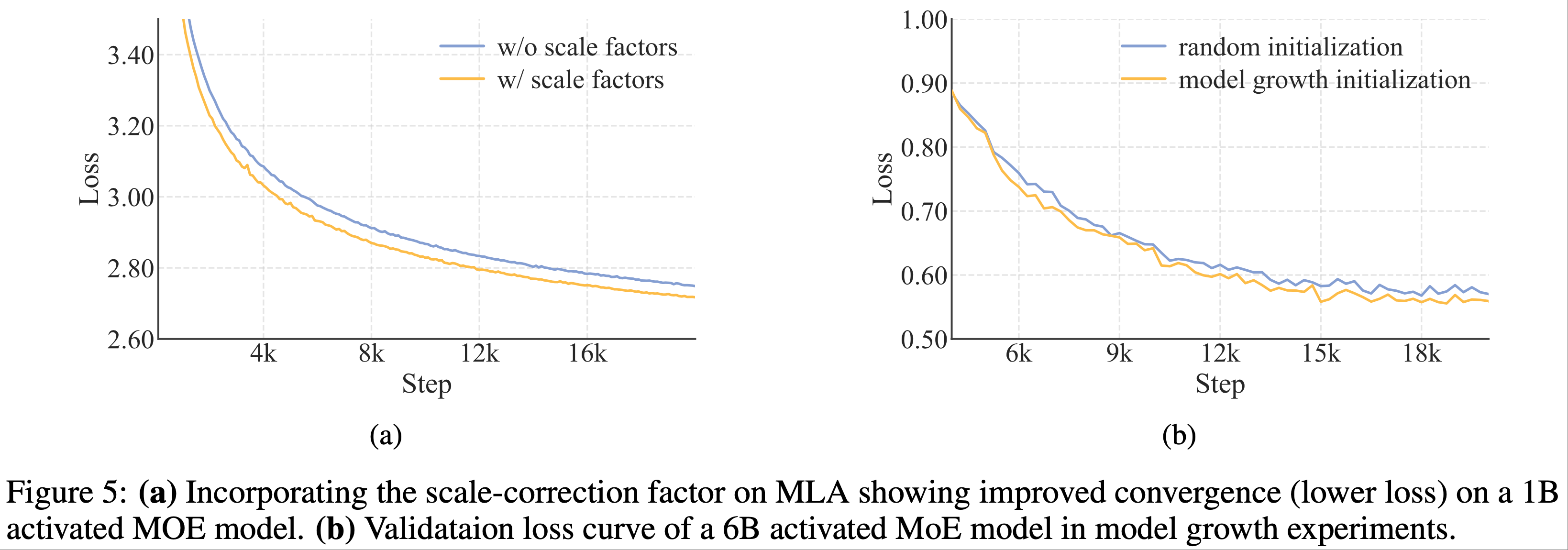
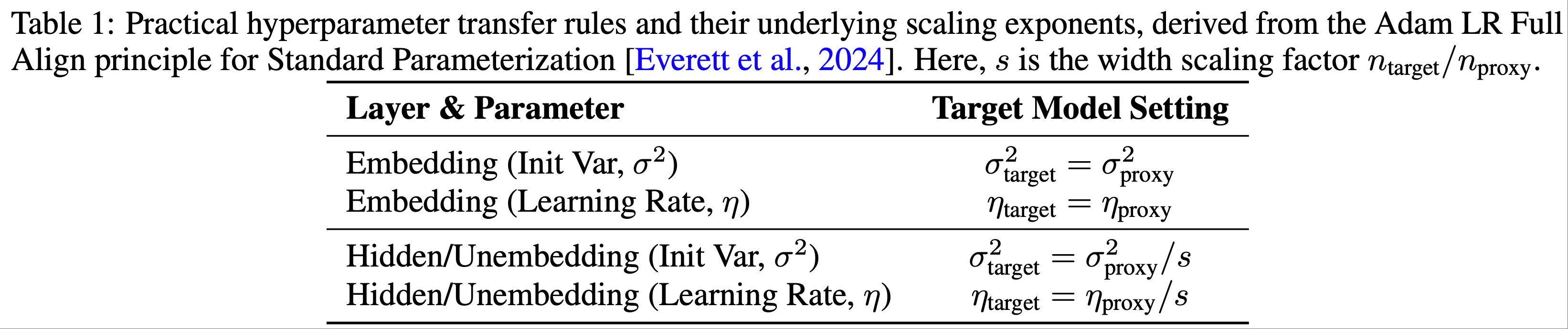
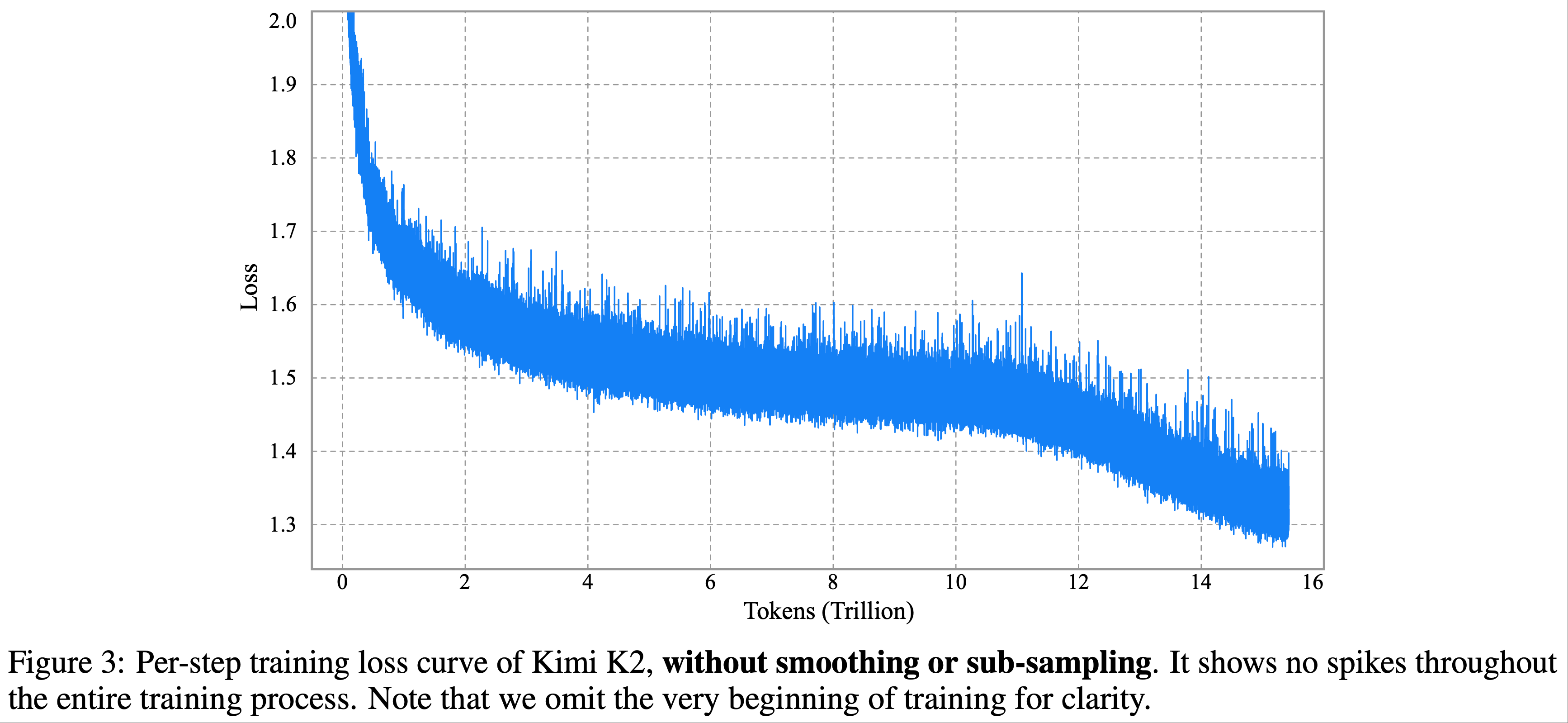
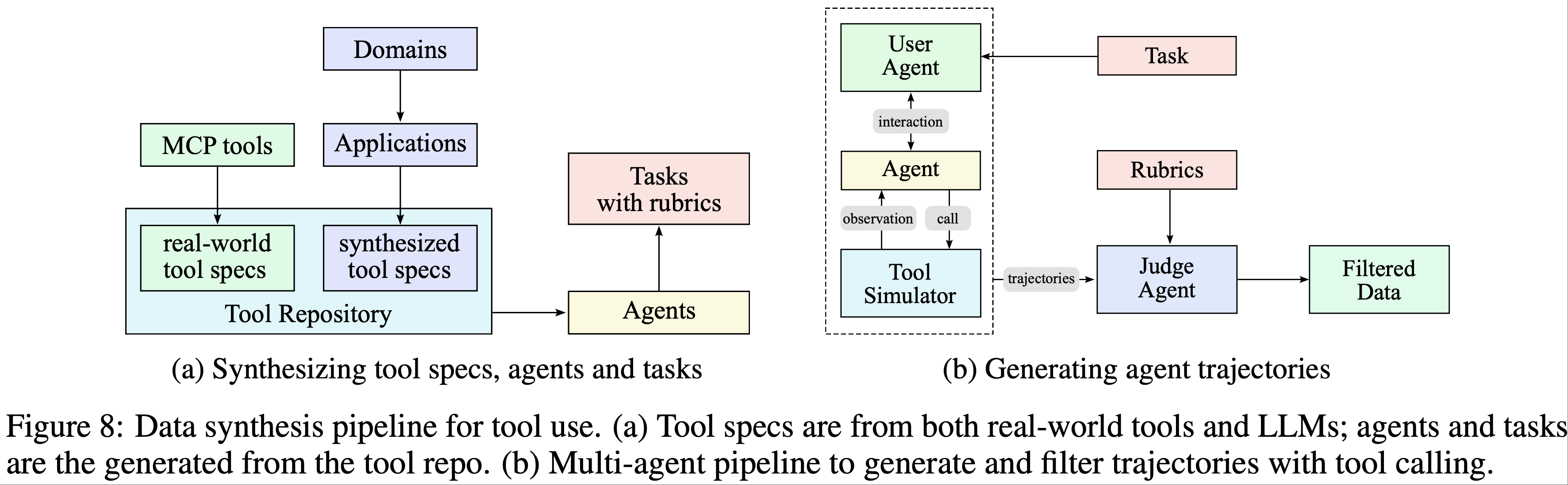
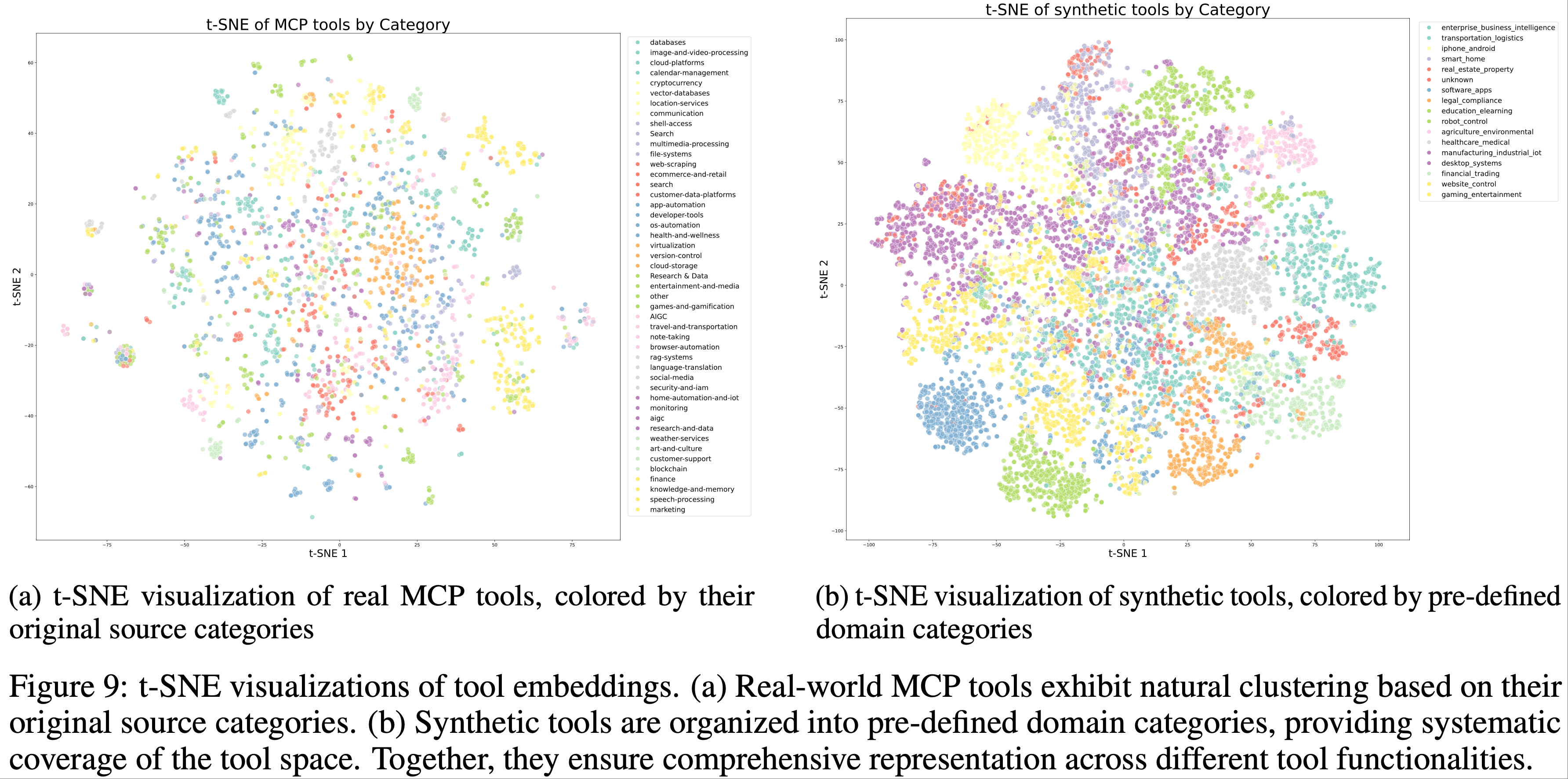
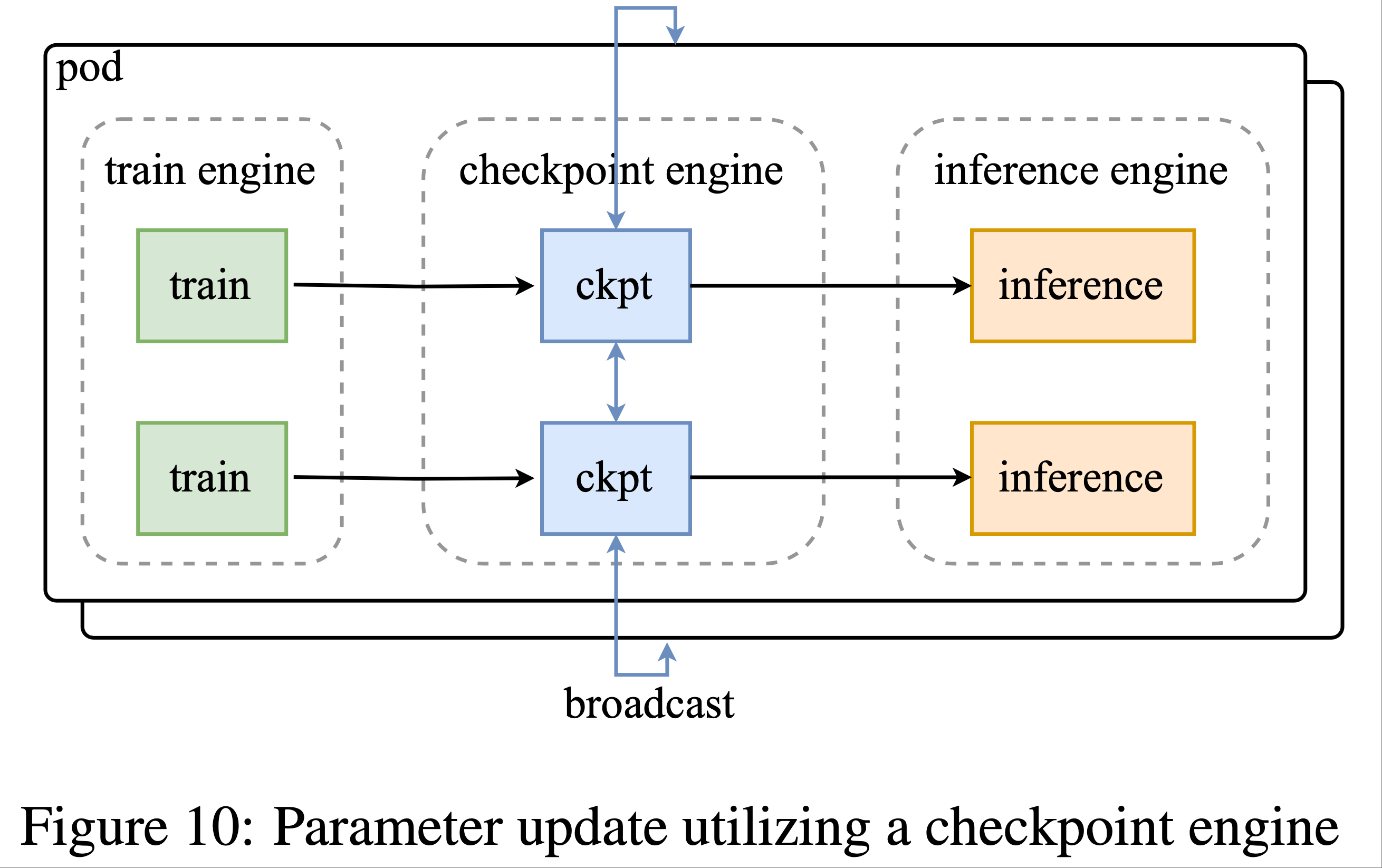
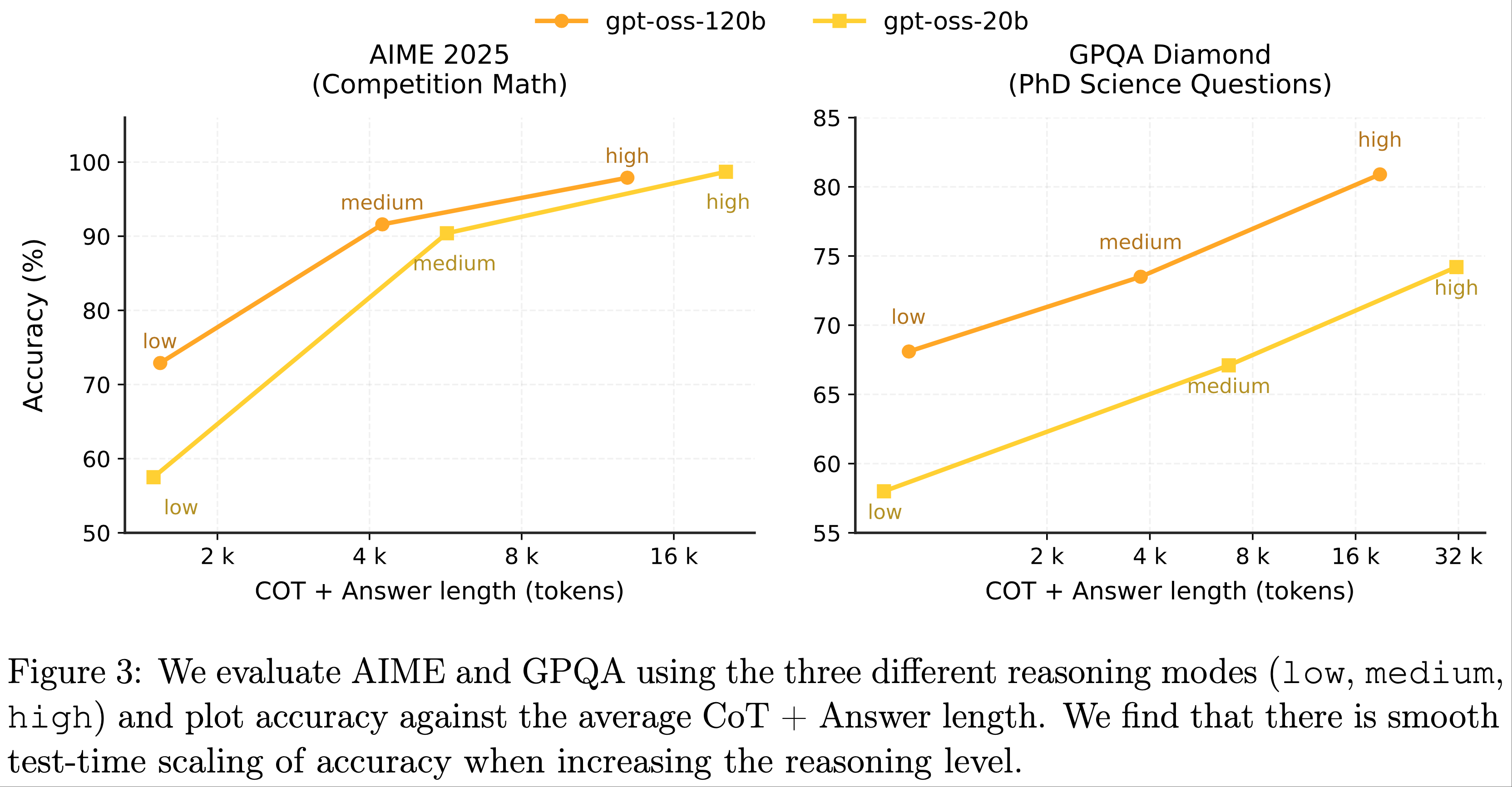
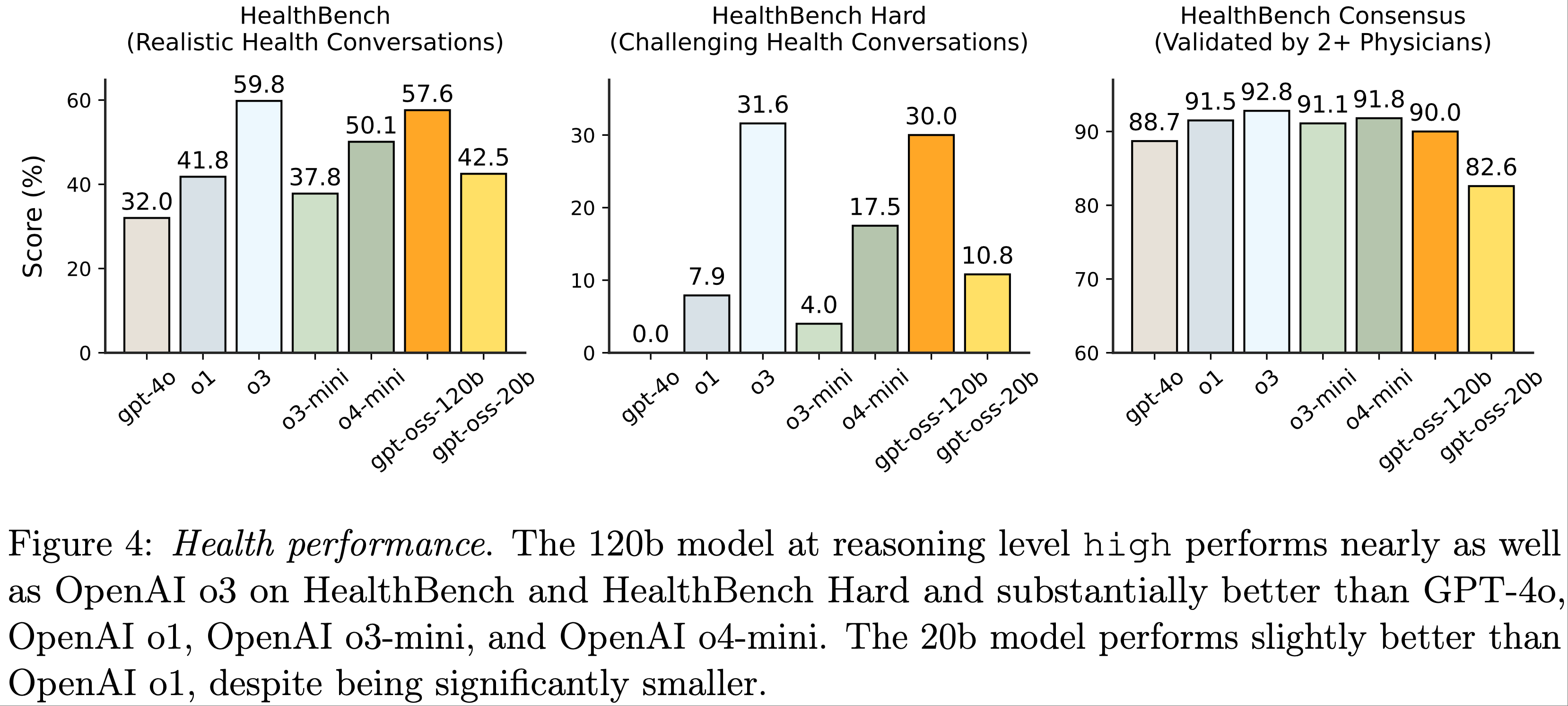
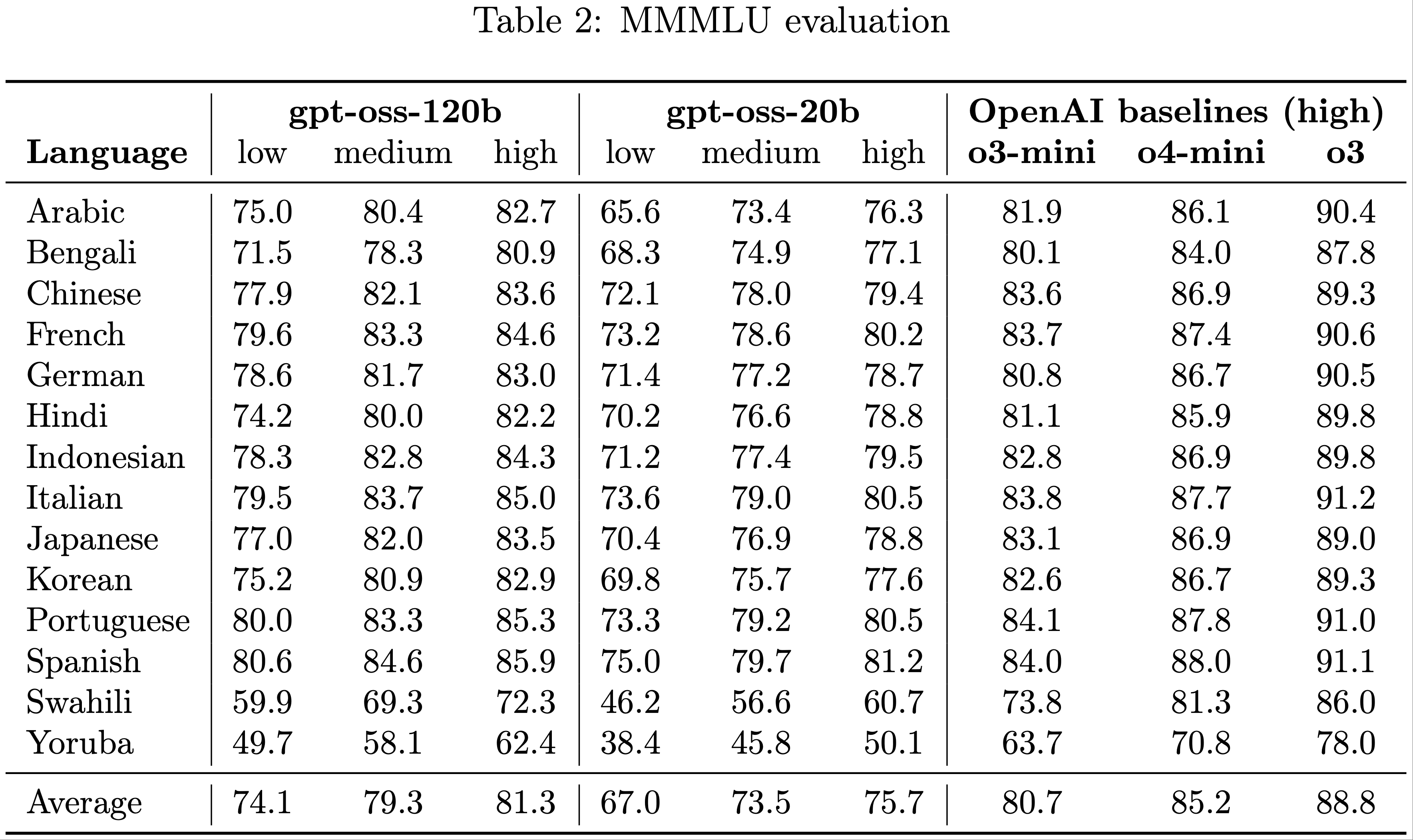
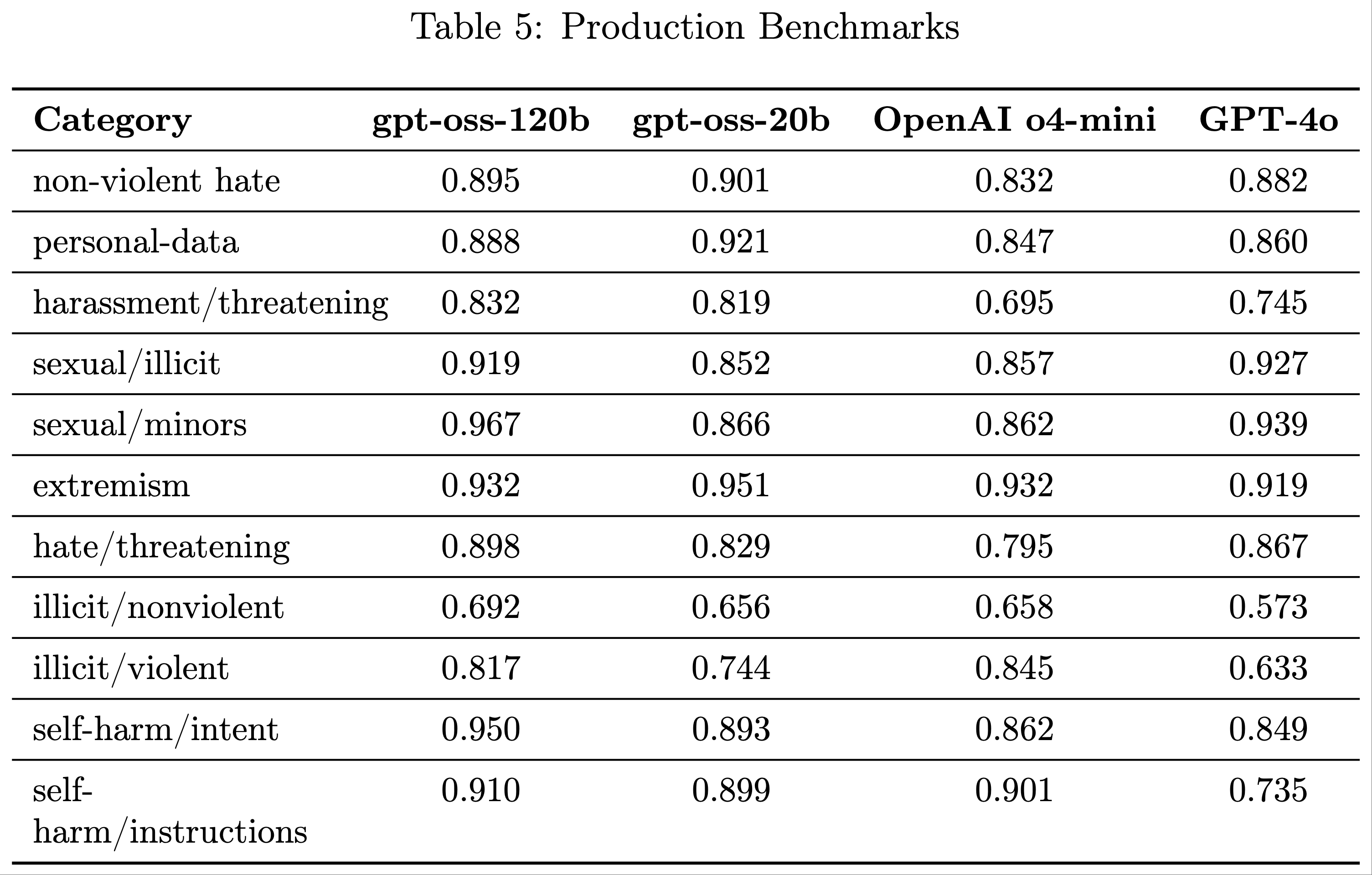
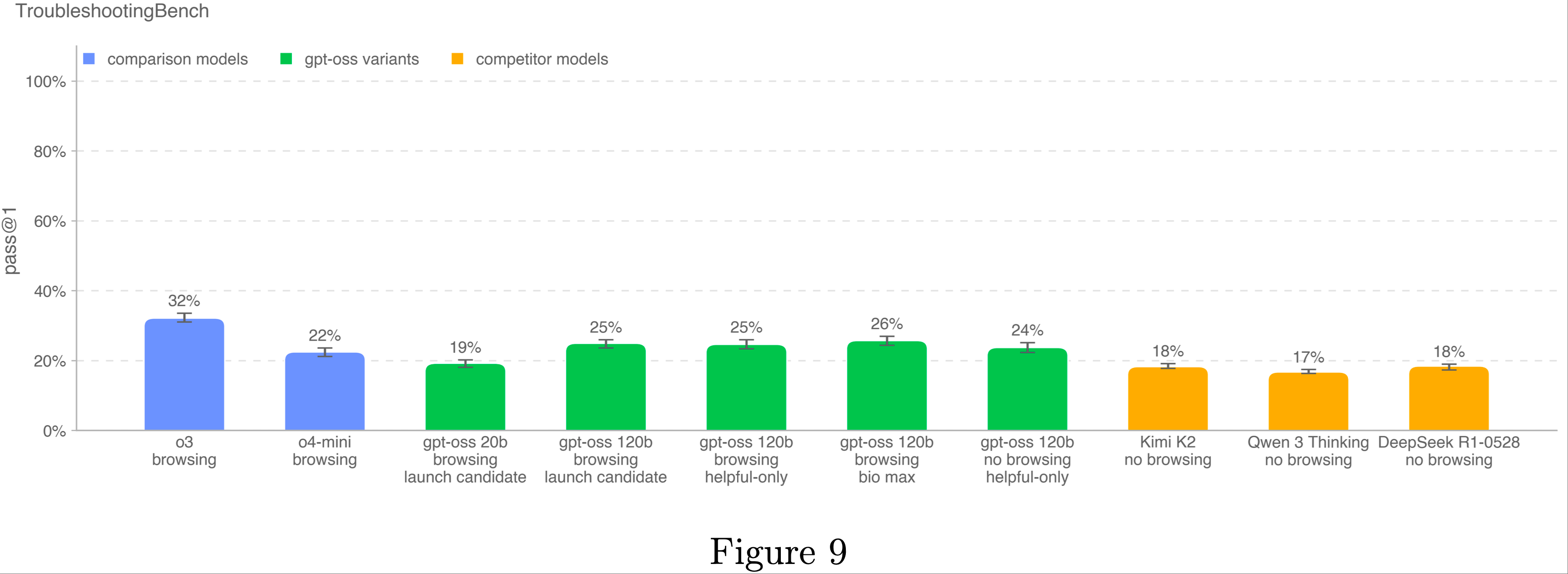
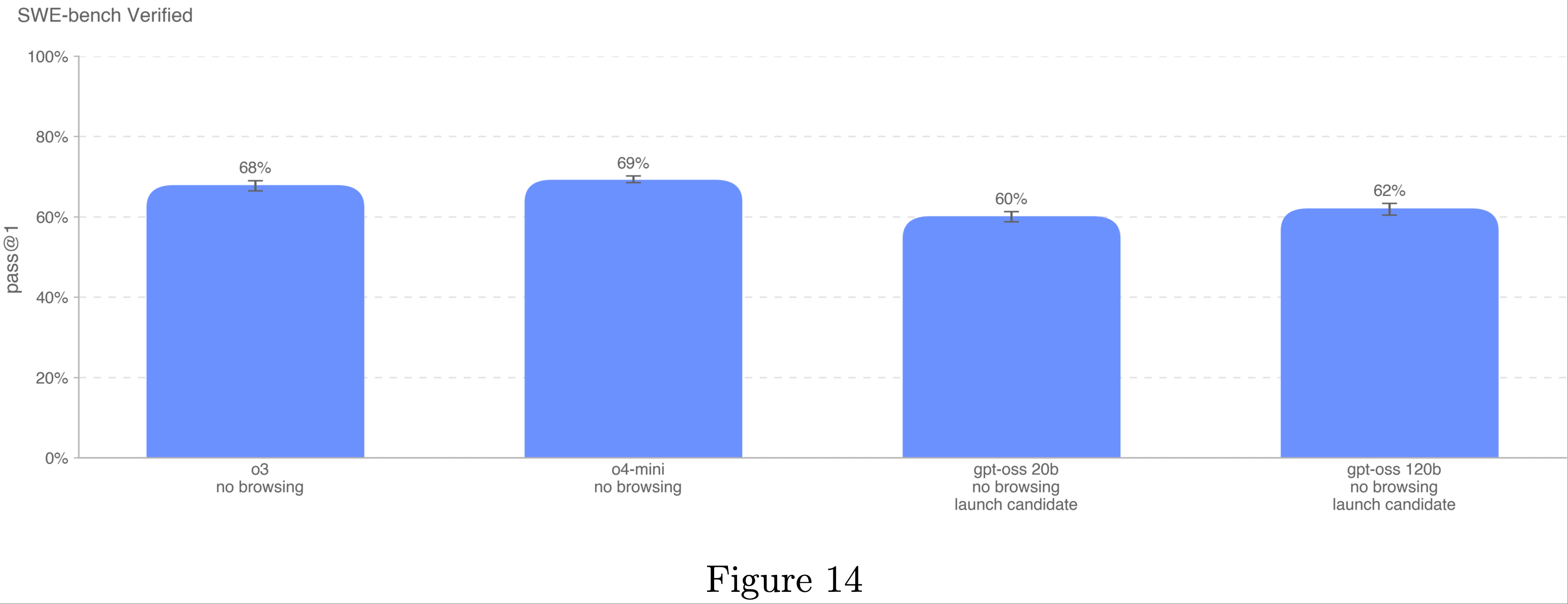
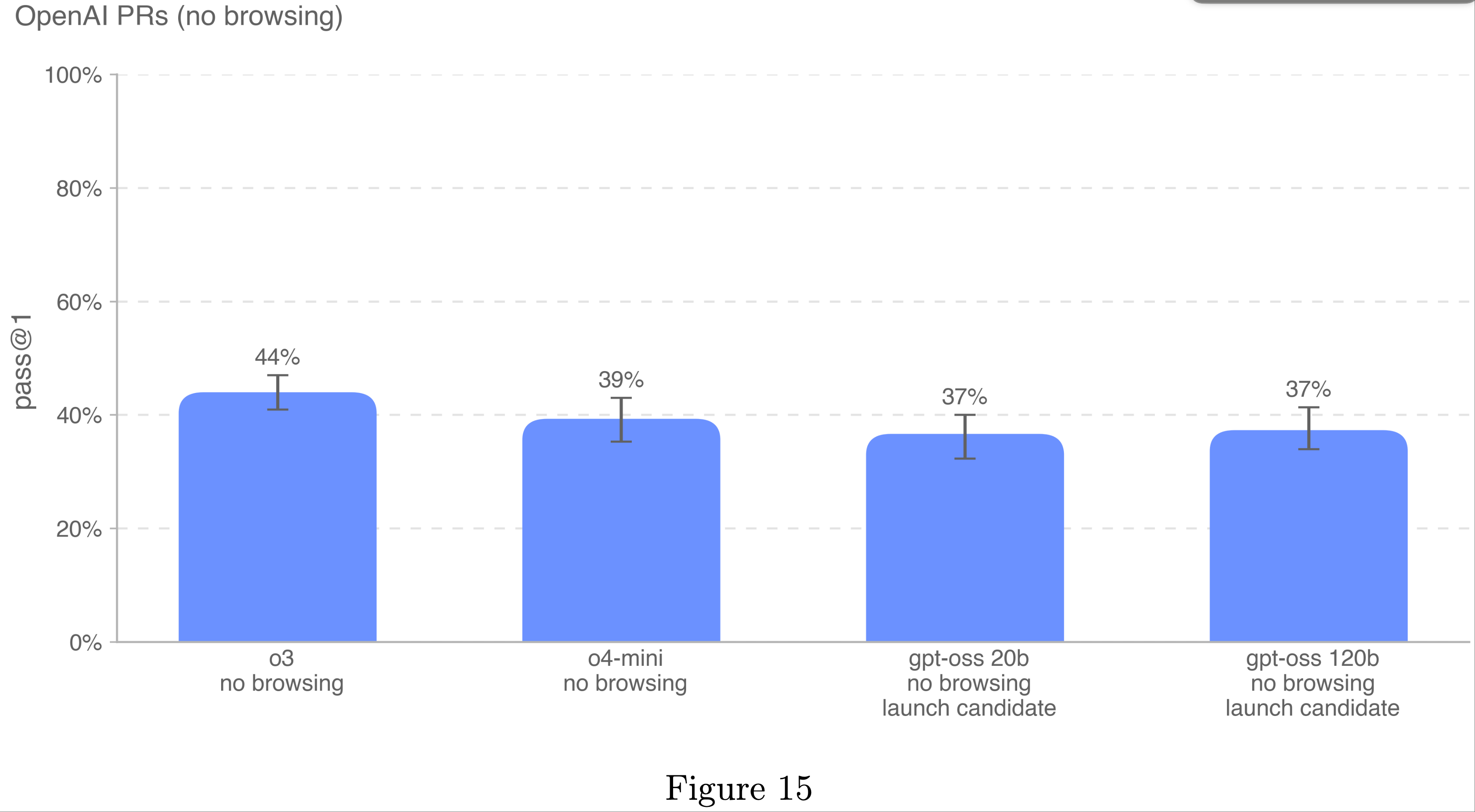
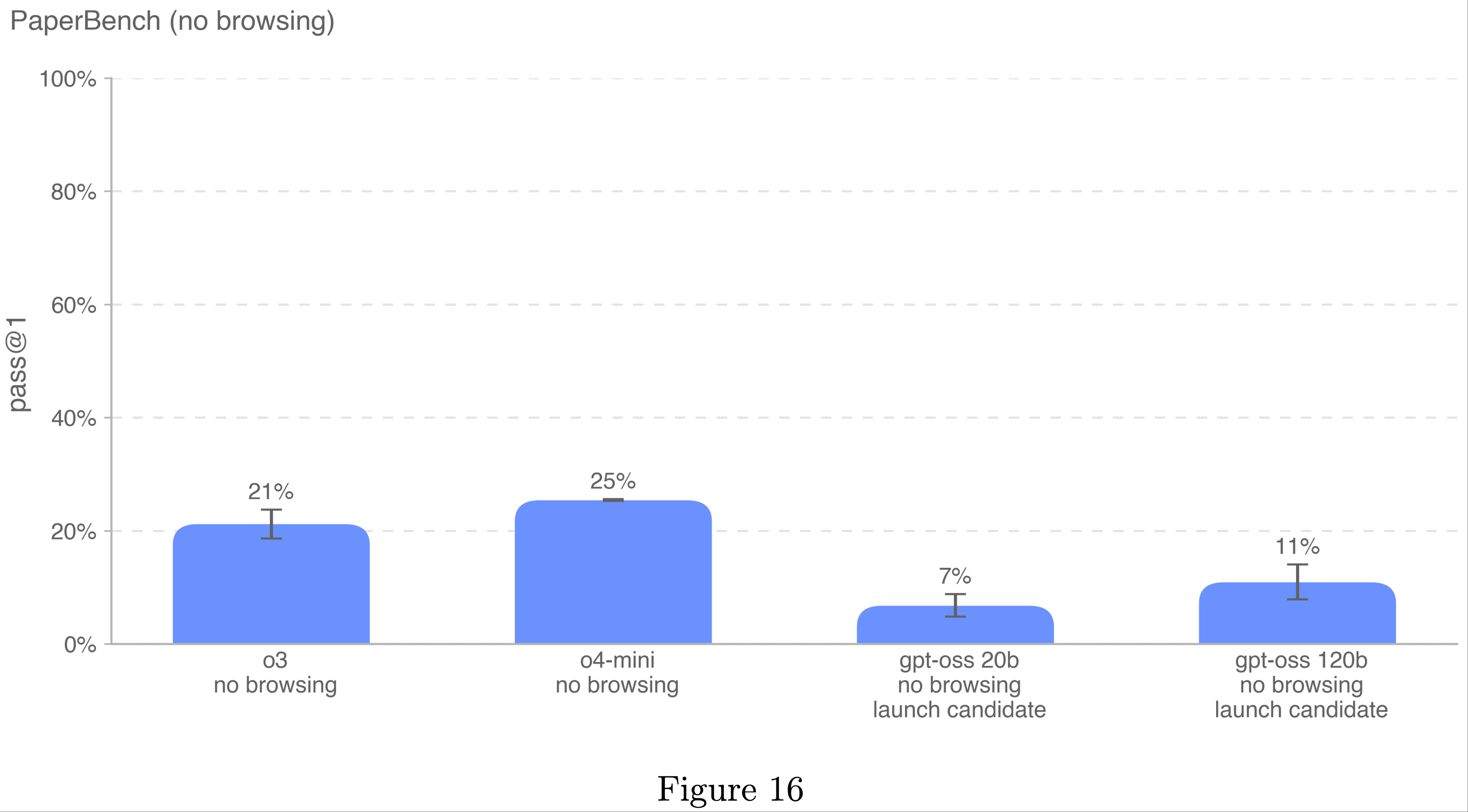
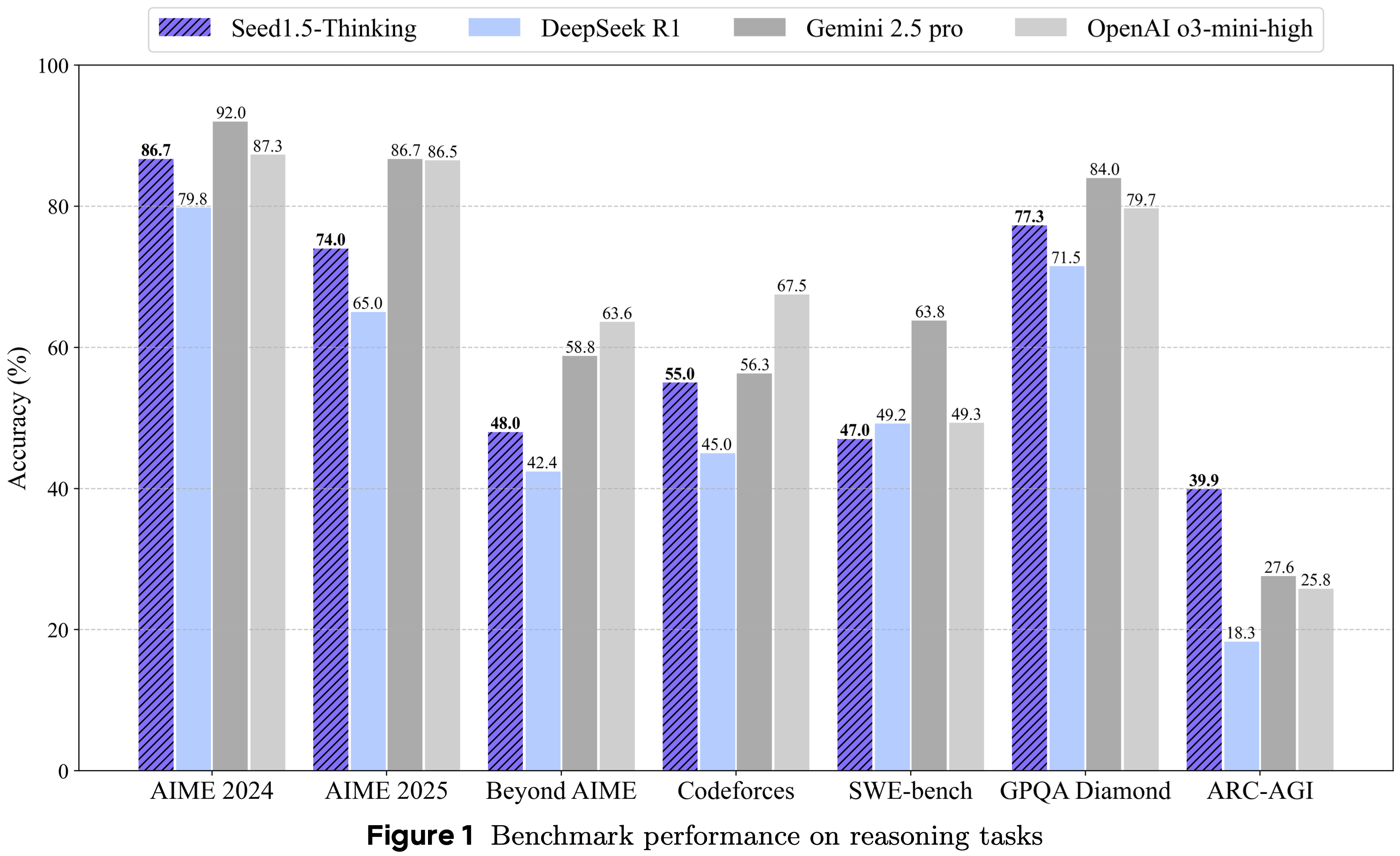
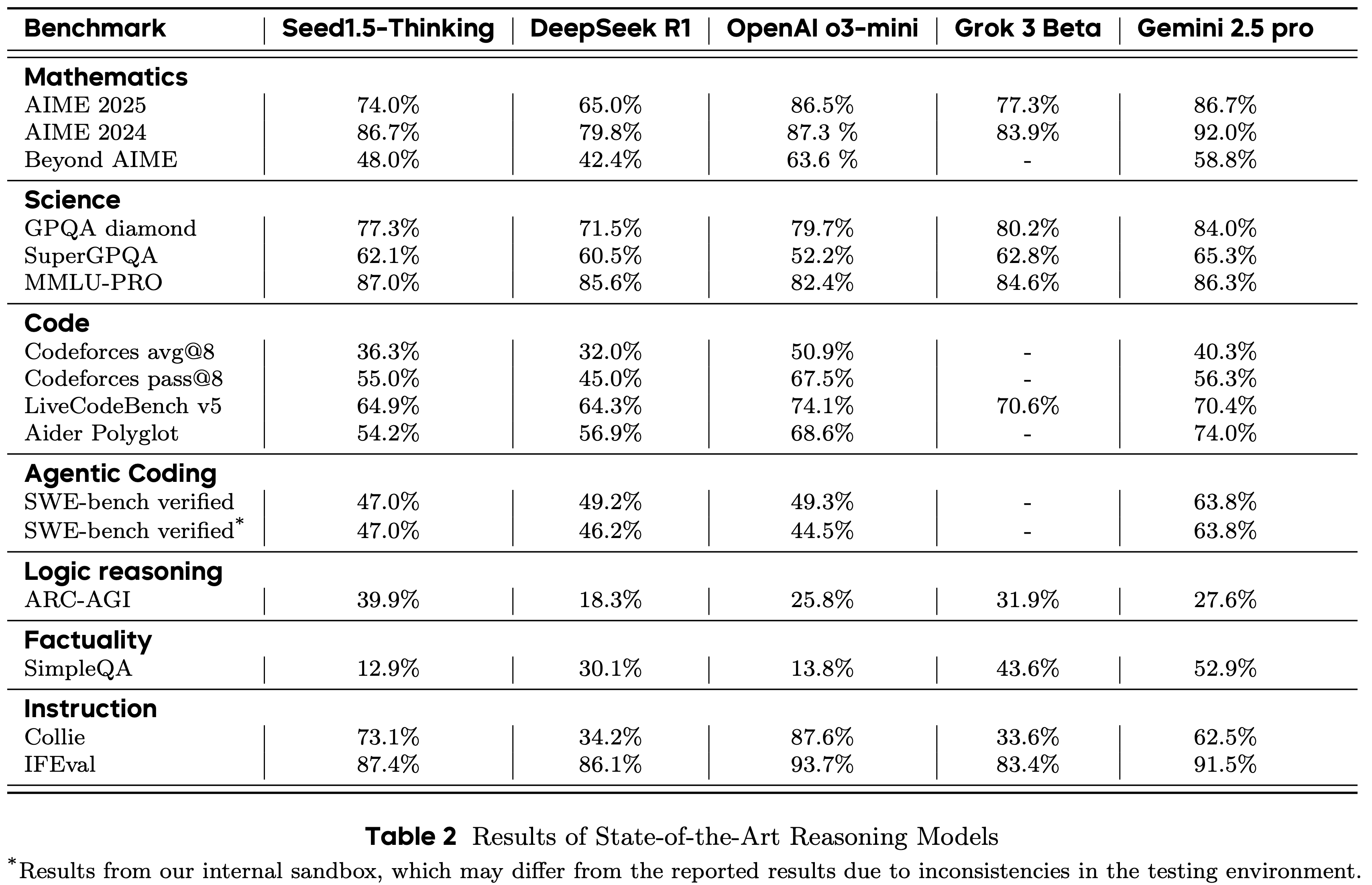
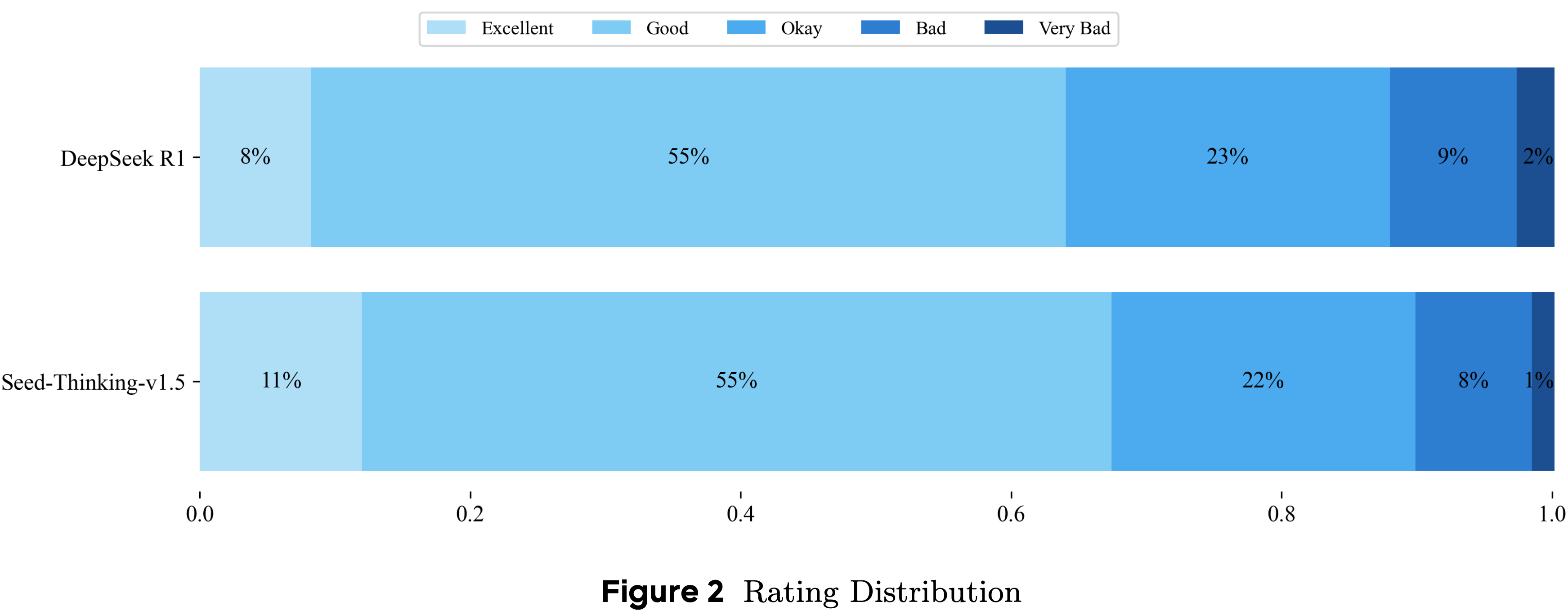
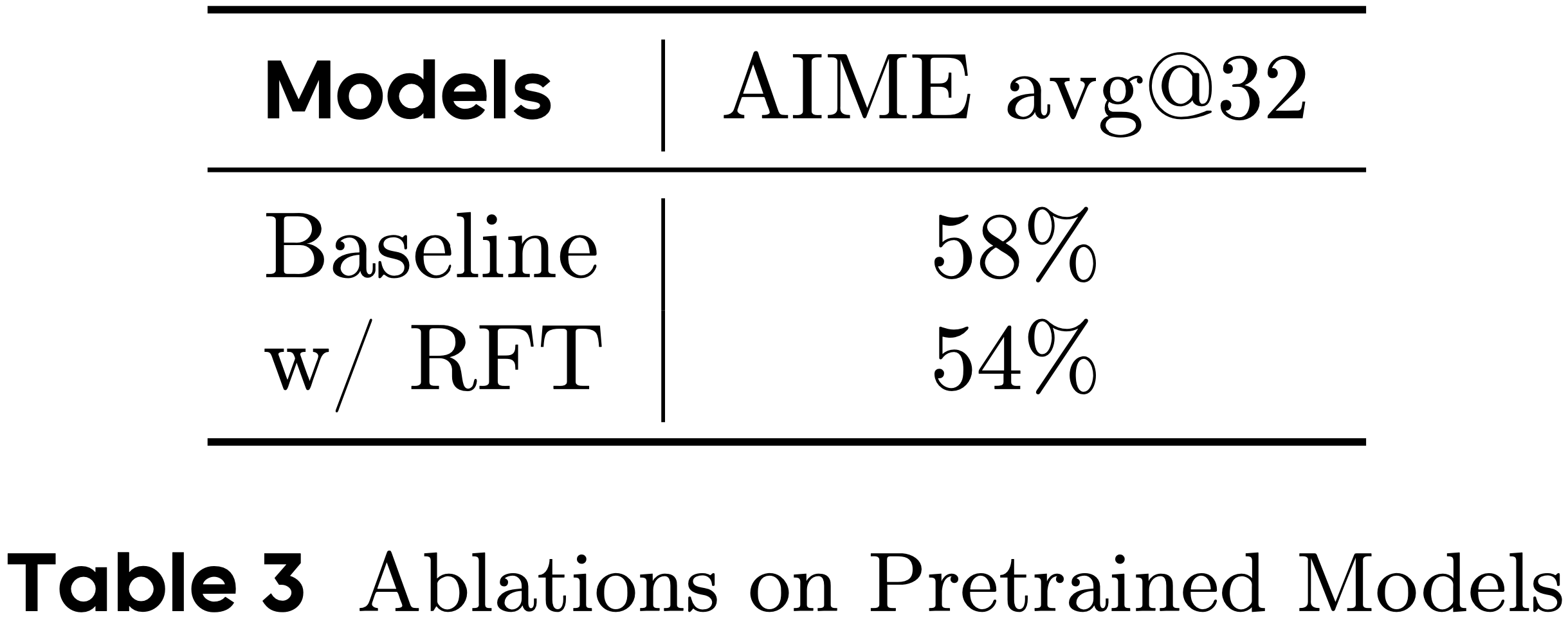
整体总结
- 整个访谈主要围绕 AGI 的实现路径展开,主要内容是 LLM 和 Agent
- 本文主要记录 姚顺雨的核心观点
- 姚顺雨的 AI 哲学:
- 姚顺雨的思考贯穿一条主线:从“工具思维”到“系统思维”
- 他不将 AI 视为孤立模型,而是语言、推理、环境、任务、交互、组织的复杂系统
- 他的研究始终围绕“如何构建能泛化、能创造、能组织的智能体”,并坚信未来属于那些敢于重新定义问题、重新设计交互的创新者
姚顺雨的人生轨迹
- 15 到 19 年在清华姚班,19 到 24 年在普林斯顿,24 年毕业进的 OpenAI
- 注:姚班的传统是偏理论计算机科学
- 18 年,按照姚班的传统,去了国外(MIT),跟的是吴佳俊学长
- 19 年做过第一个 LLM Agent CALM
- 博士期间的工作:包括 Language Agent 领域的 ReAct、Reflexion、思维树,然后包括 Digital Automation(数字自动化)
听报告过程中的核心观点和笔记
- 用 GPT 不要用 BERT
- 任务或环境非常重要
- 姚顺雨觉得自己第一个比较重要的工作就是 WebShop(2022)
- ReAct的重点是 Prompting,但姚顺雨觉得很重要,做模型会做不过 OpenAI,但是用模型,还有机会
- 问题:如果别人不让你用呢?
- 目前的 Agent 架构都类似于 ReAct,就是先思考再决策一个 Action(简单但有用)
- Agent 的定义:
- 从 NLP 的角度来说,Agent 是相对于一个能够去和外界进行交互的 语言模型,比如说使用计算器、使用互联网或者使用这些 tool
- 从 AI 的更大背景来说,Agent 可以是任何可以去做自我决策、和环境交互、然后 optimize reward(让它的奖励变大)的这样的系统
- 为什么是 LM 的 Agent?
- 语言模型提供了一个足够强的先验,这个先验使得你可以推理,而推理又可以在不同环境间泛化
- Agent的历史
- 第一波:1980 年代的符号主义,遍历所有可能的规则
- 第二波:Deep RL,以 AlphaGo 为代表,但领域上仍然不能泛化
- 所能解决的环境都是虚拟的,能无限次尝试的
- 第三波:LLM 这波,能预训练并且能够泛化了
- Agent 能力分类(没有确定的 taxonomy):
- 第一种:基于使用工具的能力,coding 能力、上网的能力、使用计算机的能力等
- 第二种:LLM 本身的能力,处理多模态的能力、处理 long context 的能力,reasoning 能力
- 姚顺雨最看重的是:处理 context 的能力,或者说 memory 的能力,然后基于它去做 life-long learning 或者 online learning 的能力
- Coding 是最重要的环境之一,但有些现实环境是 API 不能代表的,改造所有的车(Agent)比改造所有的路(现实环境,只有一个 frontend)简单,所以最终的 Agent 可能是 API 和现实环境的 frontend 都能操作
- 关于是否真的泛化了?
- 首先,lilian weng 好像说过一句话:maybe the ultimate generalization is to overfit the reality,如果真的是拟合了整个世界,那是否泛化就不重要了
- 其次,姚顺雨认为真的是泛化,因为能够 Reasoning,“思考” 这个技能本身的迁移就是泛化,之前的下棋或者其他任务,都是学到了环境信息,而现在的思考是通用的(都可以像语言一样去思考),可以算是泛化
- 补充:泛化是指之前只能对每个任务创造不同的模型,现在一个模型可以解决多个任务,且任务之间是可以一定程度迁移的(当然,迁移不一定成功,且与任务本身的性质有关)
- 27 年出现能自己操作 Web 的 AI?
- 不确定,现在的模型缺的是 Context 和被定义好的问题,而不是 Reasoning 的能力
- 做 WebShop 这个工作的时候,其实当时最困难的一点就是说我怎么去定义 reward。实际上我认为做任何的 RL task,最难的部分其实是怎么定义 Reward
- Reward 应该基于结果而不是过程
- Reward 应该是基于规则或者是白盒的 reward,而不是一个黑盒的 reward
- Math 和 Coding 成功的关键:
- 基于结果而不是过程的 Reward
- 有一个非常清晰的、基于规则的 reward,而不是基于奇怪的人或者模型偏好的 reward
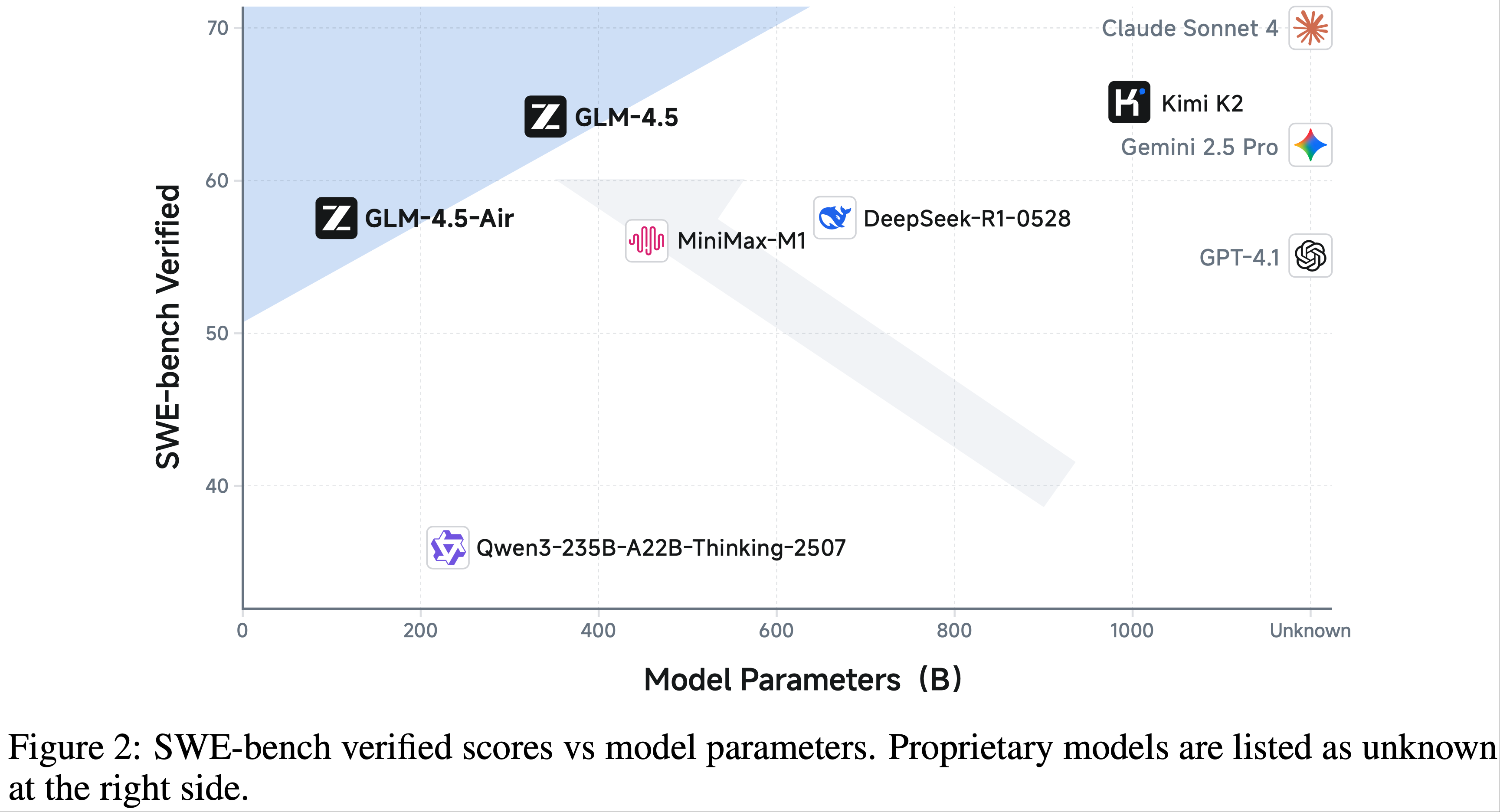
- 姚顺雨在做 SWE-bench 等时,也在重视这样的 falvor
- 人和 AI 看待认为的难度是不一样的,人会觉得电销简单,编程很难,但 AI 相反
- 小的 Agent 创业公司应该重视在使用模型上创新(interface),而不是在模型本身能力创新(这方面很难做过其他大公司)
- 大公司容易 focus on 自己的主业上,这个是小公司的机会
- Arc是什么?Adept 是什么?MindOS, Genspark 呢?
我觉得 Arc 是一个好的尝试,就是说你可以基于现在的一个任务,去在线生成一个最符合这个情境和你的个性和这个任务的一个前端,然后你可以让这个东西对不同的事情做得很不一样。我觉得这是一个很显然值得探索的方向。但这个事情显然也很难
- 数据飞轮:
- 目前可能 Midjourney 是做起来了的,依赖人的反馈来做数据训练,逐步增强自己
- 如果自己是 Cursor 公司的 CEO,一定会做 fine-tune,但不一定做 pre-training
- 在 fundamental research 上,比较重要的方向是 memory,intrinsic reward,和 multi-agent
- intrinsic reward 指什么?内在的 reward?没有外在的奖励,是从内部来?感觉说的是一些环境提供的奖励,但是用了内在奖励这个词语而已,用错了?
因为直到你证明的那一刻,你是没有任何外在 reward 的,你也没有获奖,你也没有做任何事情,没有人给你任何 feedback,你需要自己给自己一个 feedback。那这个事情是所有 innovator 最重要的事情,无论你是艺术家、还是科学家、还是文学家、还是任何创作者
很多创新者,他为什么能够在没有外在激励的情况下,去做很多事情?他是有个自己内在的价值观或者激励。然后这个事情其实我觉得 AI 或者 neuroscience 已经研究了很久很多年。从某种程度上来说,婴儿是有这样的一个基于好奇心或者自我的 reward 的。就是你会发现很多婴儿他会玩这些玩具,他会用嘴咬这样一个东西或者干别的。那你你说他获得什么 reward 了吗?他也没有升职加薪,他也没有获得钱,他没有这些外在激励,他就是好奇。他就是说,如果我做这个事情,那我会有什么样的感觉?这个感觉如果是新的,那我可以学习。
但当你长大之后,你有了一个基于语言或者基于推理或者基于文字的对世界的一个理解。就这个世界是怎么运作的?我怎么才能开一个公司?我怎么才能升职?我怎么才能做各种各样的事情?你在玩的不是一个物理游戏,而是一个文字游戏。那在这个文字游戏里面,你当然也有这样的内在激励,但好像又很不一样。我觉得这是现在的一个挑战,就是说传统的 AI,他比如说你去玩迷宫或者你去玩一些机器人的仿真,他可以定义出来一些比如基于世界模型或者基于各种各样人婴儿时候的这些 motivation 这样的内在激励。但当你在玩一个文字游戏的时候,你怎么去做一个内在激励?这似乎又变得很不一样了。
- intrinsic reward 指什么?内在的 reward?没有外在的奖励,是从内部来?感觉说的是一些环境提供的奖励,但是用了内在奖励这个词语而已,用错了?
- 两个重点:innovator 和 organization
- 其实就是 OpenAI 对 AGI 的 Level 4 和 Level 5
- 目前模型不能创造价值的原因是缺少 Context (这里是跟人作比较的,人有记忆(不一定能用文字写下来),模型没有)
- 人之所以能泛化是因为推理?
- 可以寻找哪些事情是人能做,机器不能做的,但是不能要求机器解决问题的方式和人完全一样
- Agent 不一定要像人,Agent 是一个 utility problem,很多问题不像人更有价值
- 即使是 GPT-1 的作者,也不是坚信 GPT 这个方向的,当时 OpenAI 坚持的人主要是 Ilya
- 后面还会有新的 scaling dimension 出现,比如 long-term memory 和 multi-agent
- 为什么 coding 和 math 容易泛化?
- 我觉得只是因为它是最早开始做的事情,而它最早开始做是因为它比较简单。就是说它有一个很好的 reward,然后它不需要一个环境,它就是 reasoning
- 个人理解:
- 首先不敢苟同前面是因为最早做,更多是因为这两个方向的数据多,模型预训练时看的多,且奖励纯粹,不容易发生 Reward hacking 等
- 其次,我认为这个不是更容易泛化,本质还是预训练看的多了
- 多次提到第一性原理(回归事情的本质,多问为什么)
- OpenAI 的一个护城河可能是记录用户的历史,这样能提升用户粘性
- 冯·诺依曼生前写的最后一本书叫做《The Computer and the Brain》,其中有一句话:
essentially, the environment is always the most outer part of the memory hierarchy
- 人类的长期记忆应该是书本这些持久化的环境信息
- long context 是一个实现 long-term memory 的方式,但可能还有别的方式
- 衡量 Agent 的指标应该是价值,而不是类似于考试、代码等,现实世界更多是无法定义的
- 最终我觉得 AGI 是个系统的话,它需要有 intelligence,它需要有环境,它还需要有 user context,或者对 user understanding
- 书籍《智能简史》
语言是人类为“泛化”而发明的最本质工具
- 语言的真正价值不在于表达,而在于泛化能力(generalization)
- 人类通过语言可以跨越具体经验,进行抽象、推理、学习和协作,从而应对从未见过的新任务
- 相比图像、语音等数据,语言是人类创造的、最具通用性的工具,是通往AGI(通用人工智能)的关键
AI 主线已进入“下半场”:从方法创新转向任务与环境定义
- 博文《The Second Half》的核心观点:AI的“上半场”是模型训练与方法突破,下半场是任务设计与环境构建
- 当前瓶颈不再是模型能力(如 scaling law 已证明通用性),而是如何定义有真实价值、可衡量、可泛化的任务
- 研究重心应从“如何训练模型”转向“如何使用模型”,即从“training”转向“using”
Agent 的本质是“推理+交互”
- Agent 不是简单的自动化脚本,而是能与环境交互、基于推理做出决策的系统
- 传统 Agent(如 AlphaGo)依赖强化学习在封闭环境中优化奖励,但无法泛化
- 语言 Agent(Language Agent)的核心突破是通过语言推理实现跨任务泛化 ,例如 ReAct 框架中的“思考-行动”循环
ReAct是Agent范式的关键转折
- ReAct(Reasoning + Acting)证明了语言推理能显著提升Agent在新环境中的表现
- 它打破了“必须为每个任务设计专用模型”的旧范式,实现了简单、通用、可迁移的方法
- 其成功在于:用语言作为推理媒介,使 Agent能“像人一样思考” ,而非仅靠模式匹配
任务与环境的设计比模型架构更重要
- 好的任务应具备:
- 基于结果而非过程的奖励(如代码是否通过测试,而非是否“写得优雅”);
- 清晰、可计算、非黑盒的reward机制(避免被“奖励黑客”利用);
- 真实世界价值(如 WebShop 模拟真实购物,SWE-bench 模拟真实代码修复)
- 他批评当前 AI 研究过度依赖“考试式”任务(如选择题、问答),而忽视真实复杂场景
泛化已实现,且源于“推理”而非“记忆”
- 当前大模型已具备跨任务泛化能力 ,例如在数学上训练的 RL 可提升创意写作能力
- 这种泛化不是因为数据量大,而是因为语言推理能力的迁移
- 他提出:“终极泛化可能是对现实的过拟合“,如果AI能处理一切现实任务,泛化与过拟合的界限将消失
Agent 的未来演进路径:从个体到组织
- OpenAI的五级分类(聊天 -> 推理 -> 代理 -> 创新 -> 组织)揭示了 Agent 的演进方向:
- Level 3(Agent) :能使用工具、与环境交互;
- Level 4(Innovator) :具备长期记忆与内在奖励机制,能自主探索;
- Level 5(Organizer) :多Agent协作,形成组织,解决复杂系统问题
- 未来关键能力:
- 长期记忆(long-term memory);
- 内在奖励(intrinsic reward)——如好奇心、掌控感;
- 多 Agent 协作(multi-agent systems)
创业公司的机会在于“交互方式创新”而非模型能力
- 模型能力将趋于同质化(“溢出”),真正的壁垒是交互设计
- 成功产品如 Cursor、Arc、Perplexity,都不是简单复制 ChatGPT,而是创造了新的交互范式(如 IDE 内嵌、动态前端生成)
- 他强调:“AI 的未来不是 ChatGPT 的延伸,而是新 Super App 的诞生。”
数据飞轮的形成需要“对齐的奖励机制”
- 多数公司尚未形成真正的数据飞轮,因为缺乏可量化的、与商业价值对齐的反馈信号
- 成功案例:Midjourney 通过用户点赞形成清晰 reward,驱动模型迭代
- 对于客服、写作等任务,需定义新指标,如 pass@k(k 次都成功的概率),而非仅 pass@1
长期记忆是解锁AI实用性的关键
- 当前AI的瓶颈不是推理能力,而是缺乏上下文(context)
- 人类的价值在于能积累“分布式上下文”(如办公室政治、老板偏好),而AI无法获取
- 解决方案:构建长期记忆系统 ,可能通过long context、embedding或外部存储实现
- 他引用冯·诺依曼:“环境本身就是记忆层级的最外层”,AI需学会从世界中“读取”记忆
内在奖励是实现“创新者” Agent 的核心
- 人类创新者(如爱因斯坦)能在无外部奖励下持续工作,因其有内在动机(好奇心、使命感)
- AI 若要成为“创新者”,必须发展自驱动的学习机制 ,如基于预测误差的好奇心模型
- 这是通往 ASI(超级智能)的必经之路
AI 与人类的关系:互补而非替代
- AI不应一味“像人”,而应在需要的地方像人,在能超越的地方超越人
- 如开车:AI 可基于规则优化,无需模仿人类;
- 如职场协作:AI需理解人情世故,更“像人”
- 未来 AI 可能是非拟人化的系统(如平台、工具),而非“数字人”
Agent 生态将走向多元化,而非中心化垄断
- 他反对“单极世界”(如 OpenAI 垄断一切),认为未来将是多形态、多交互方式的Agent生态
- 可能形态包括:
- 拟人化朋友(情感陪伴);
- 分布式Agent网络(信息中介);
- 组织级Agent系统(企业自动化)
- 技术趋势是中心化(大模型)与去中心化(用户数据、本地 Agent)并存
对 AI 研究者的建议:追求“方法-任务契合”
- 伟大研究往往源于特定任务激发通用方法(如 Transformer 源于翻译)
- 他采取逆向路径:先构想通用方法,再寻找能证明其价值的任务
- 关键是找到 method-task fit ,即方法与任务的完美匹配
最关键的“Bet”:相信“不同的 Super App” 存在
- 他最核心的信念是:未来将出现与 ChatGPT 完全不同的、革命性的交互形态
- 正如互联网初期无法预见微信,AI时代也将诞生尚未想象的 Super App
- 因此,创业者和研究者应大胆探索非共识的交互方式 ,而非局限于现有范式
附录:个人思考
- 是否认为制造一些很通用的能力,并注入模型,模型就能学会这些能力,后面我们强调模型的能力而不是领域
- 比如模型的组合函数能力,比如模型的算数能力等
- 奖励方面:是否实际上自己有一个终极的目标就够了,不需要太多奖励,然后世界模型做好,使用 RL,AGI 就成功了?
- AI 的终极目标:能做最前沿的科学研究

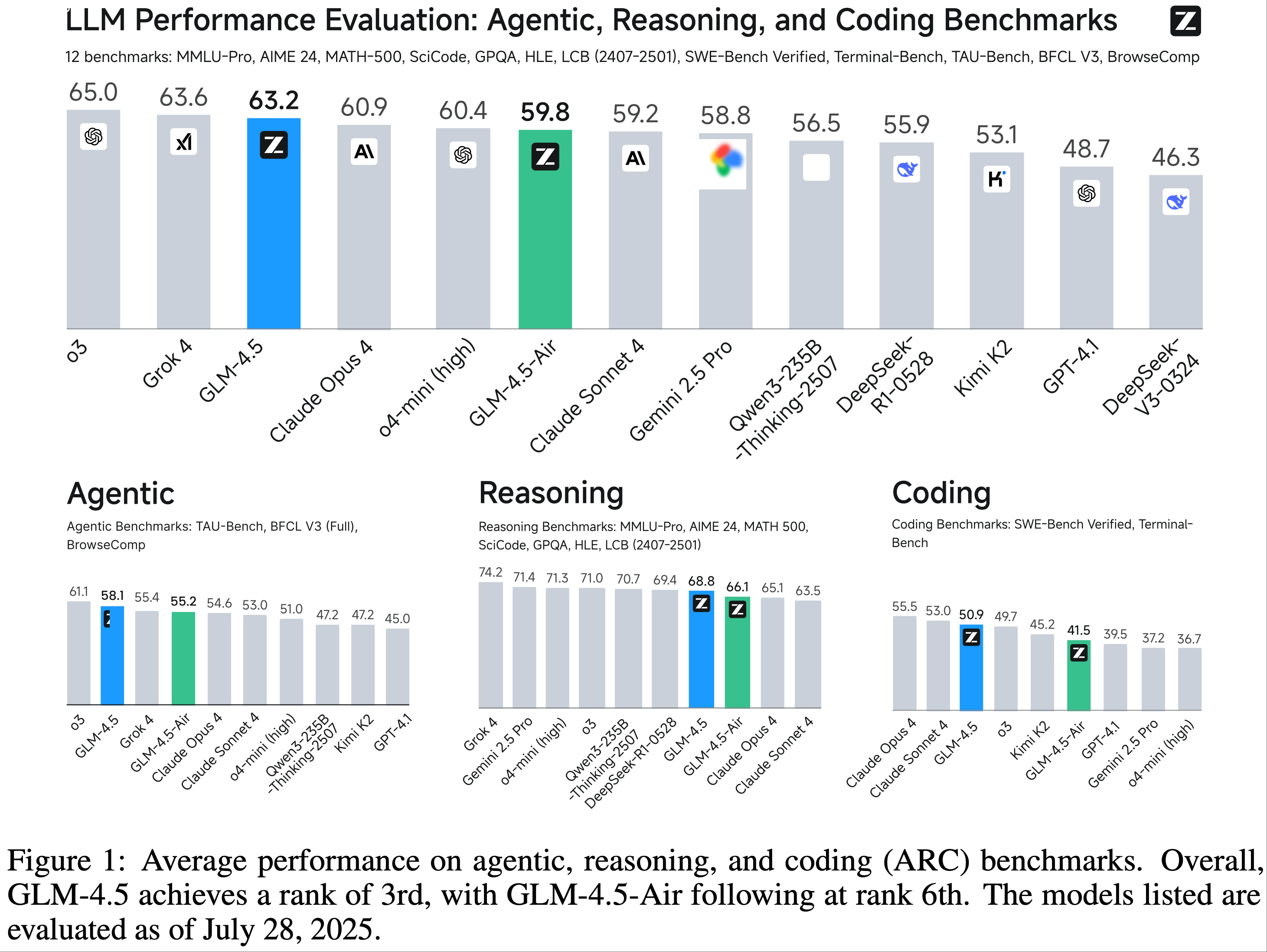
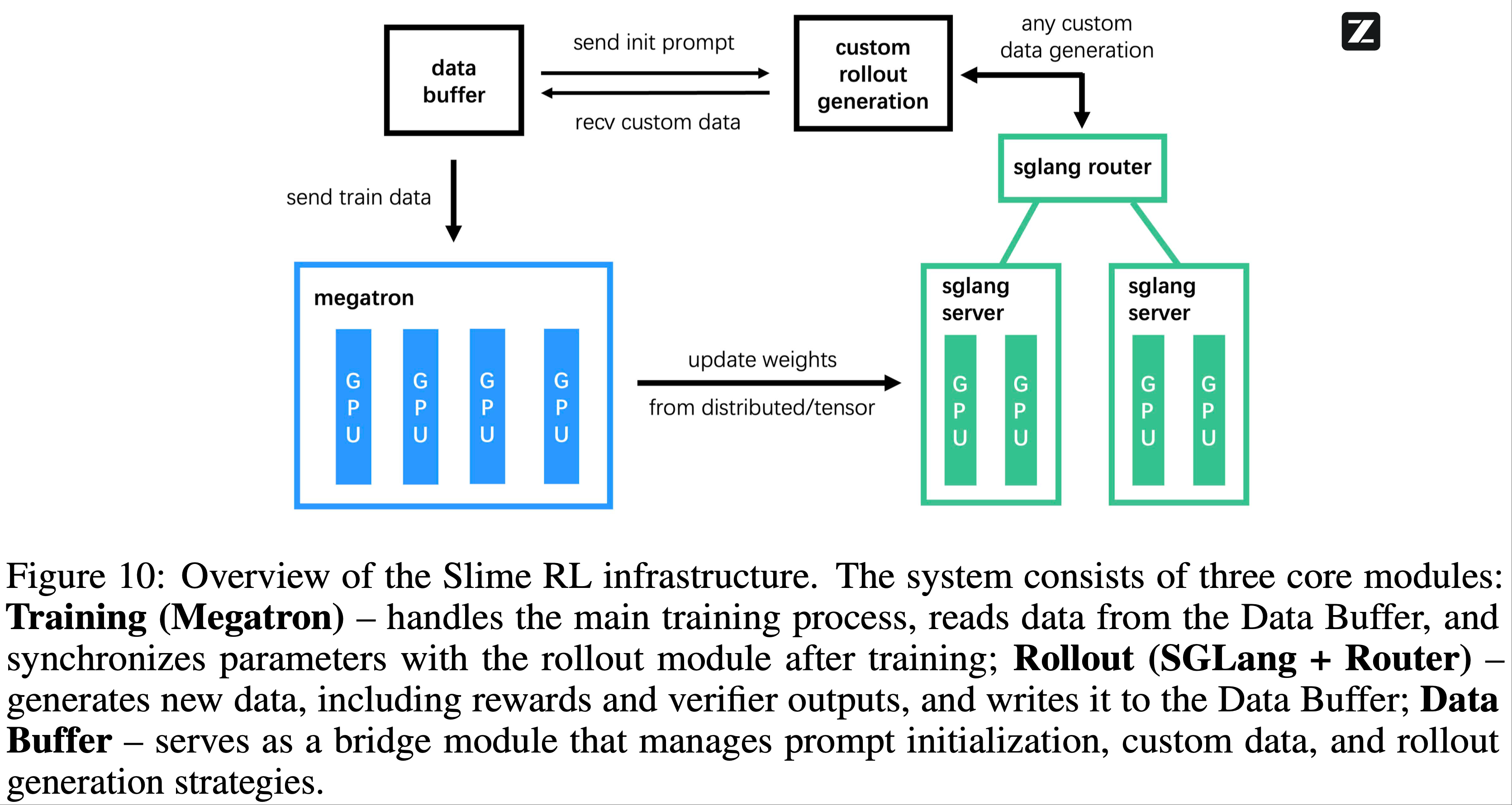
)-Figure1.png)
)-Figure2.png)
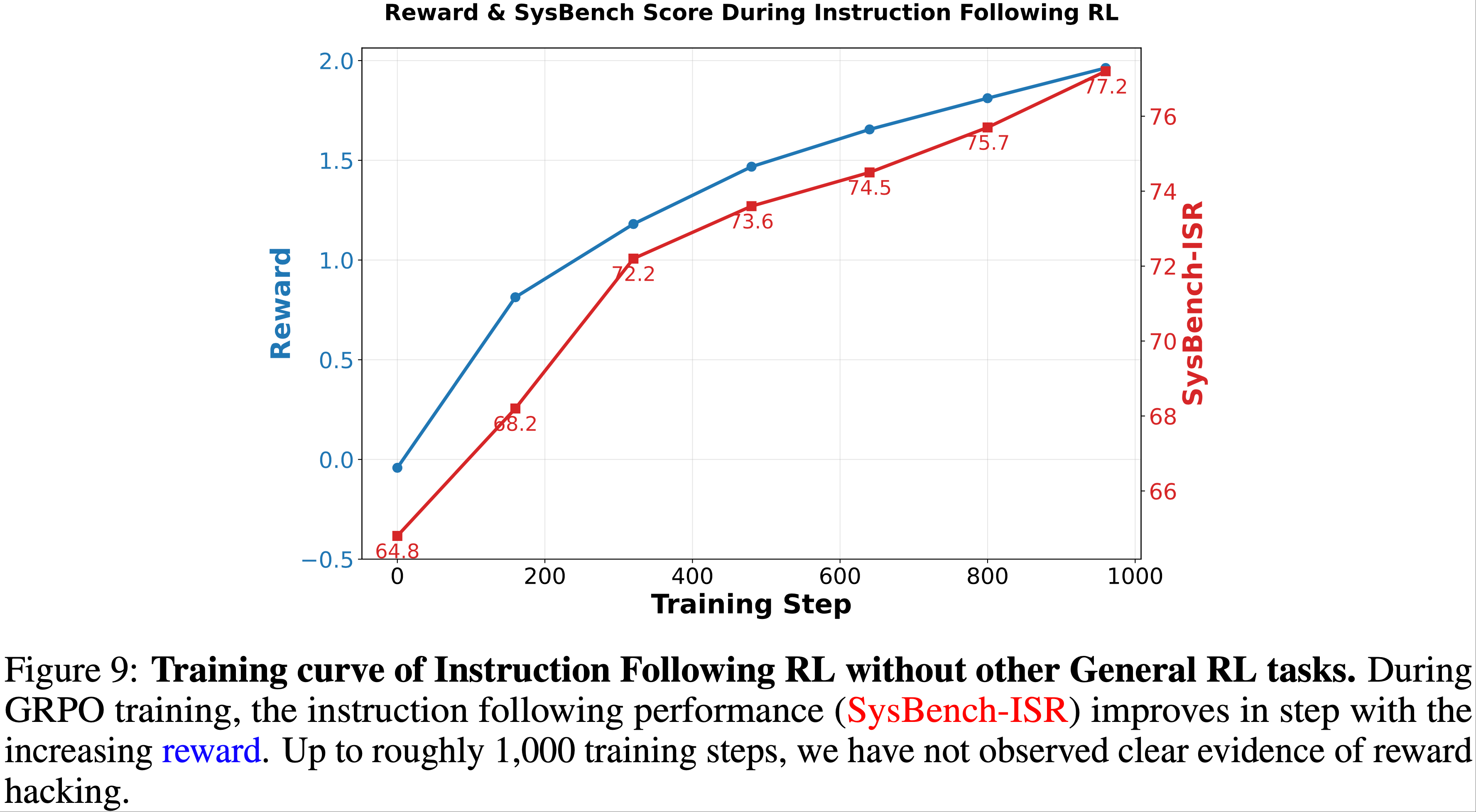
)-Figure3.png)
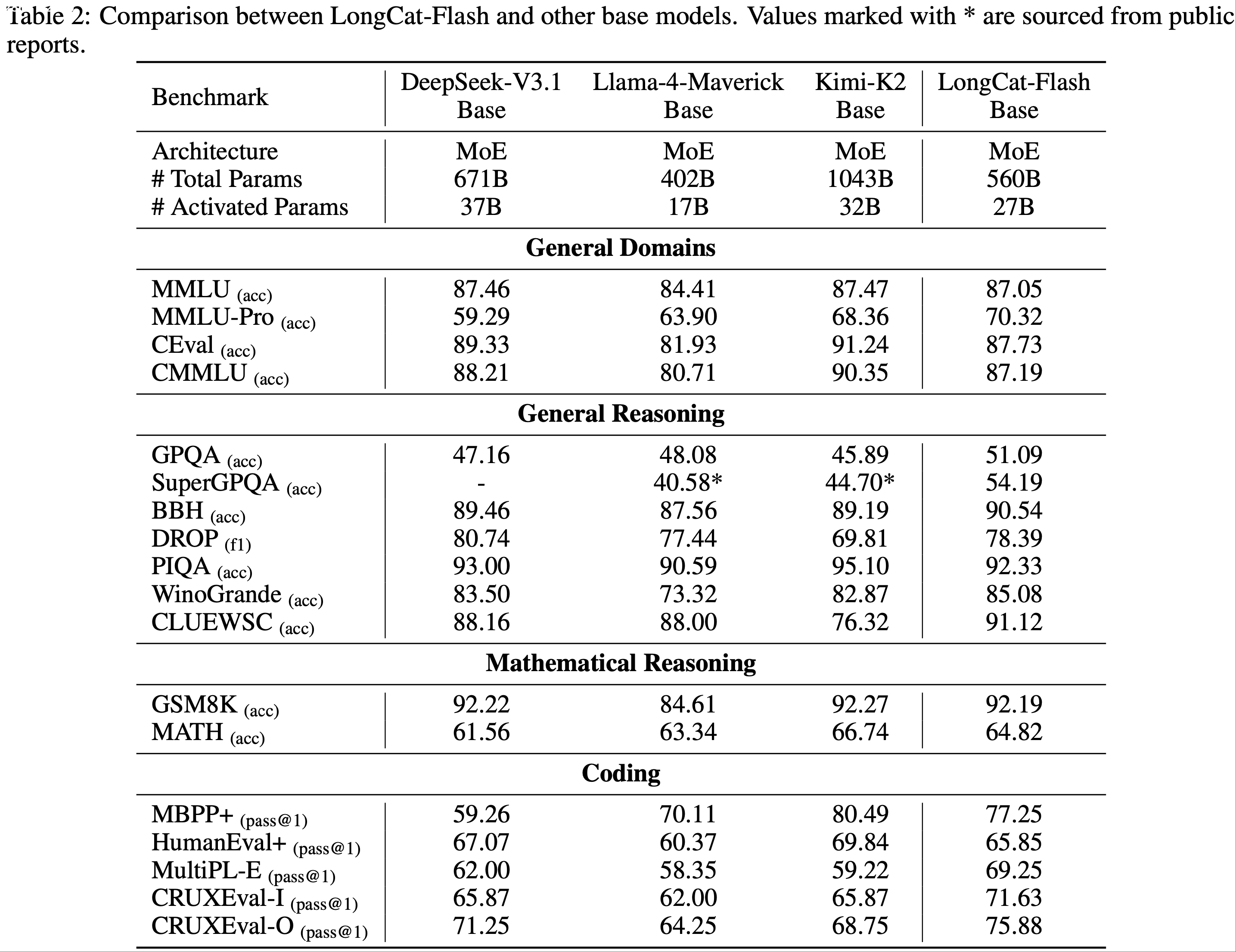
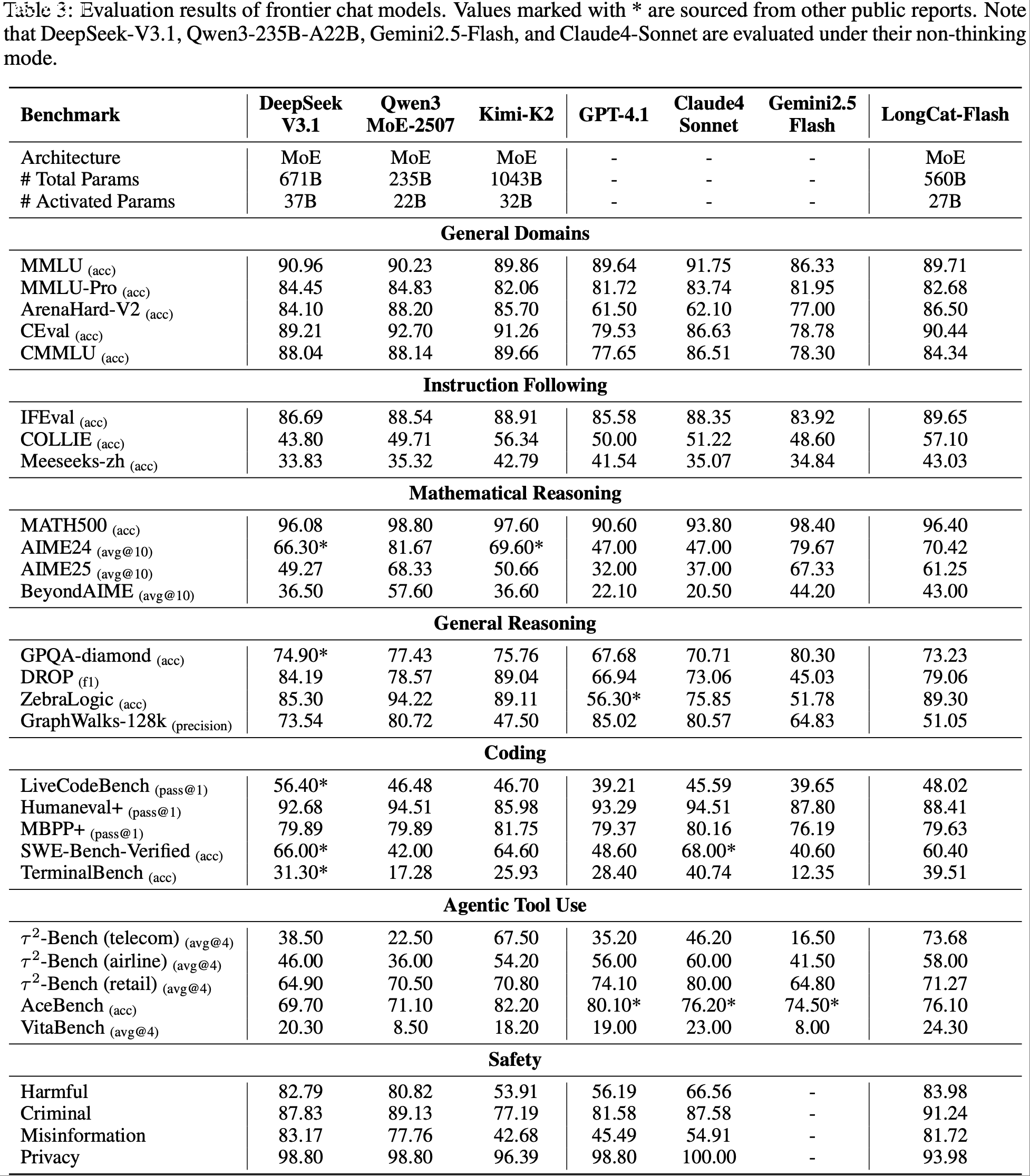
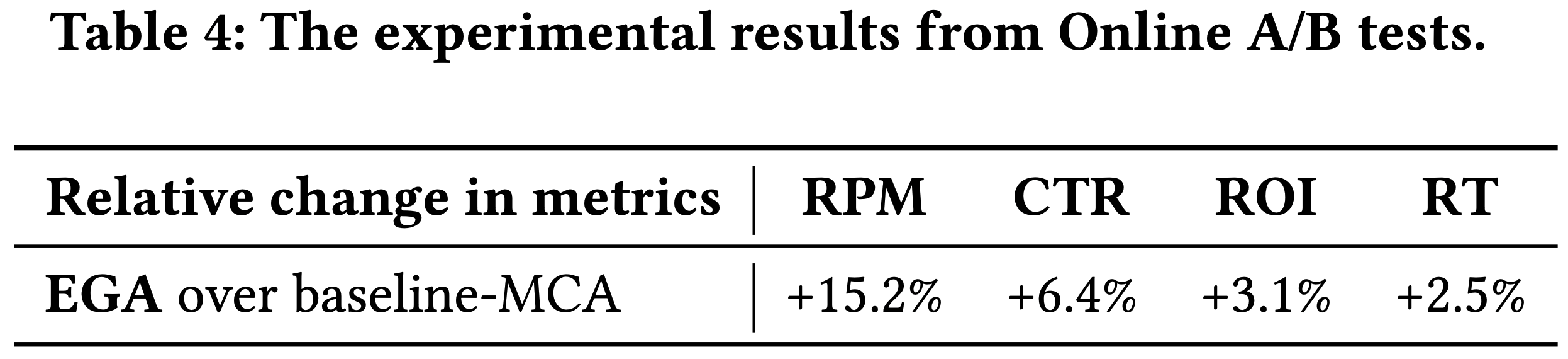
)-Table1.png)
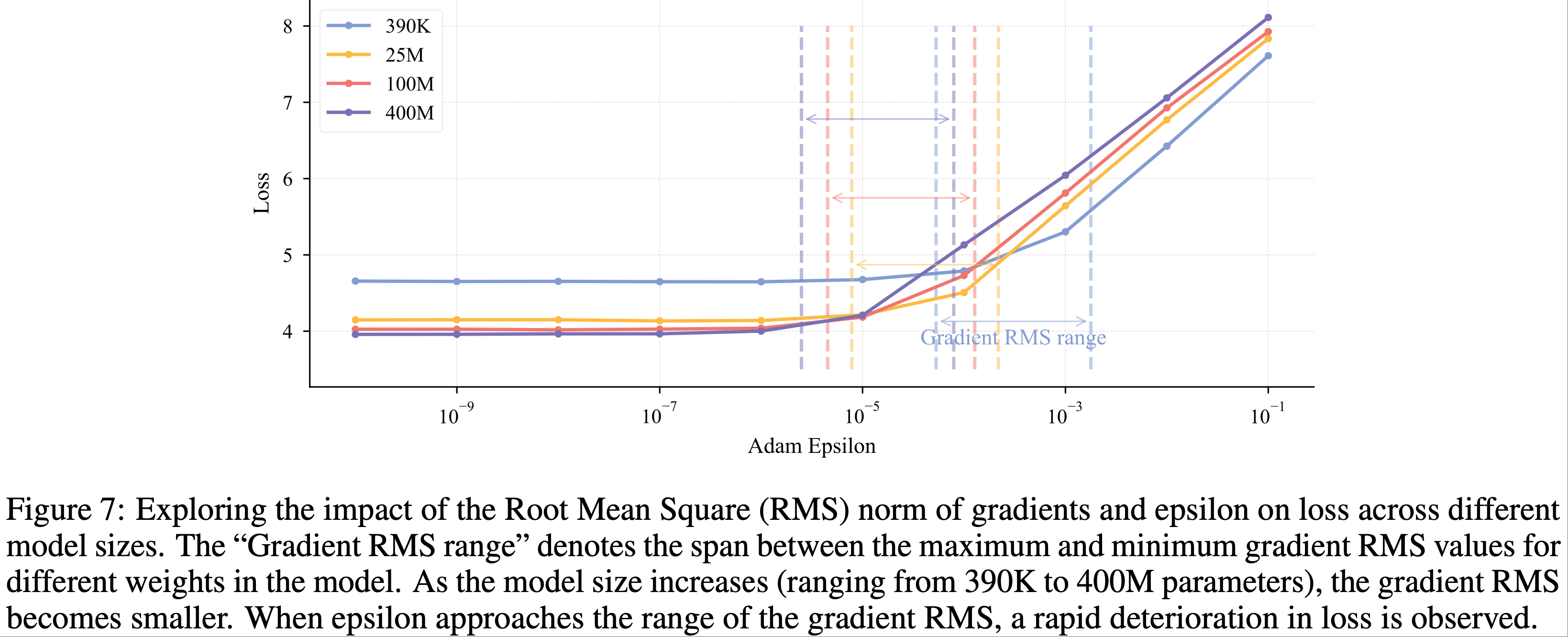
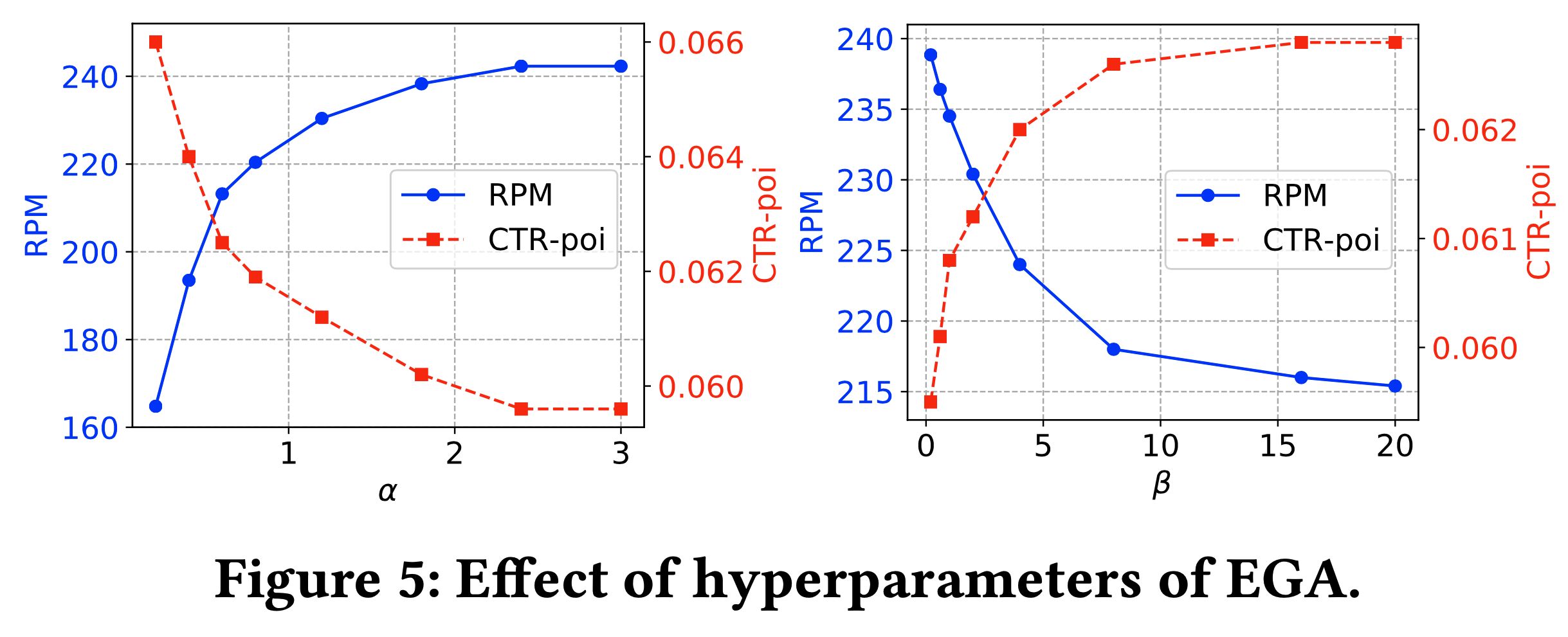
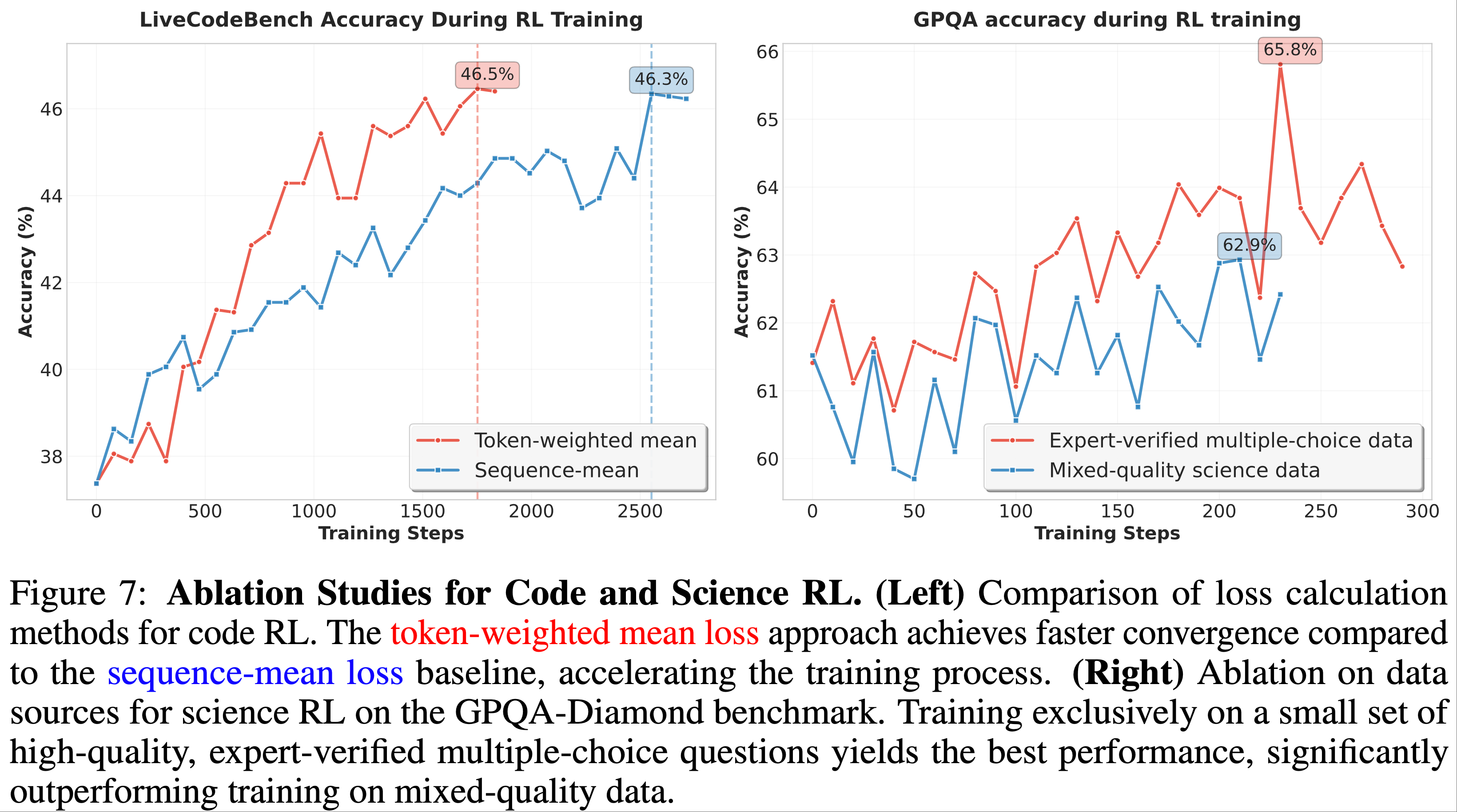
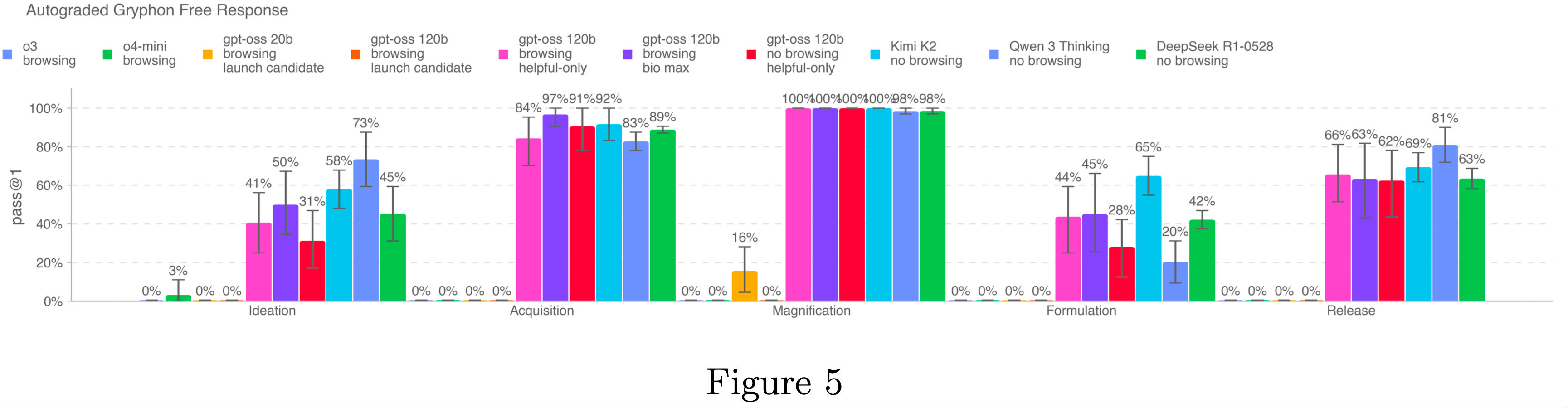
)-Figure5.png)
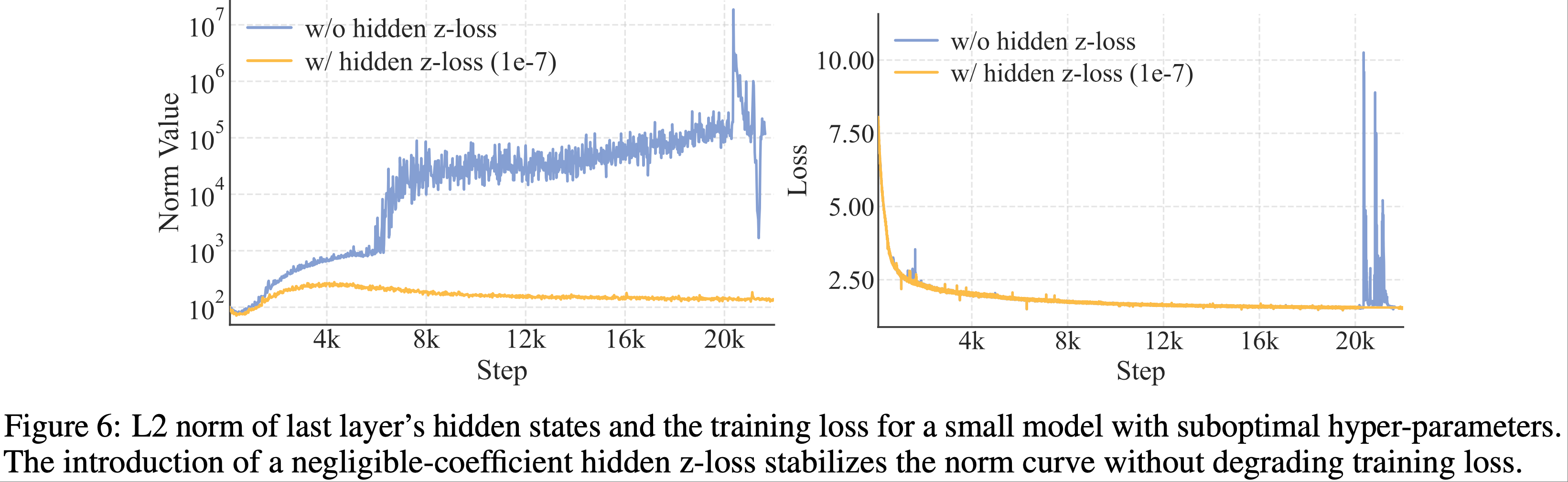
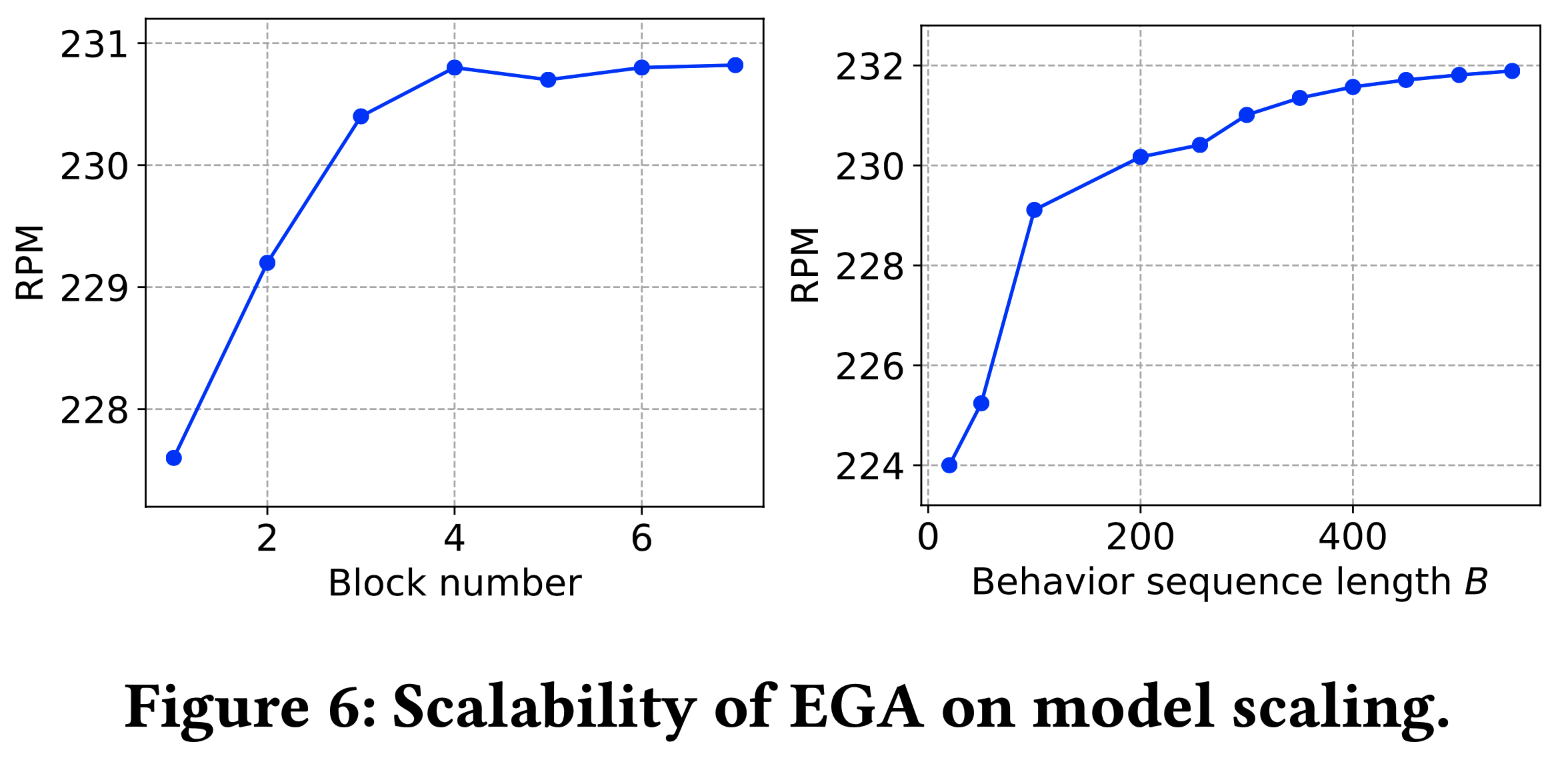
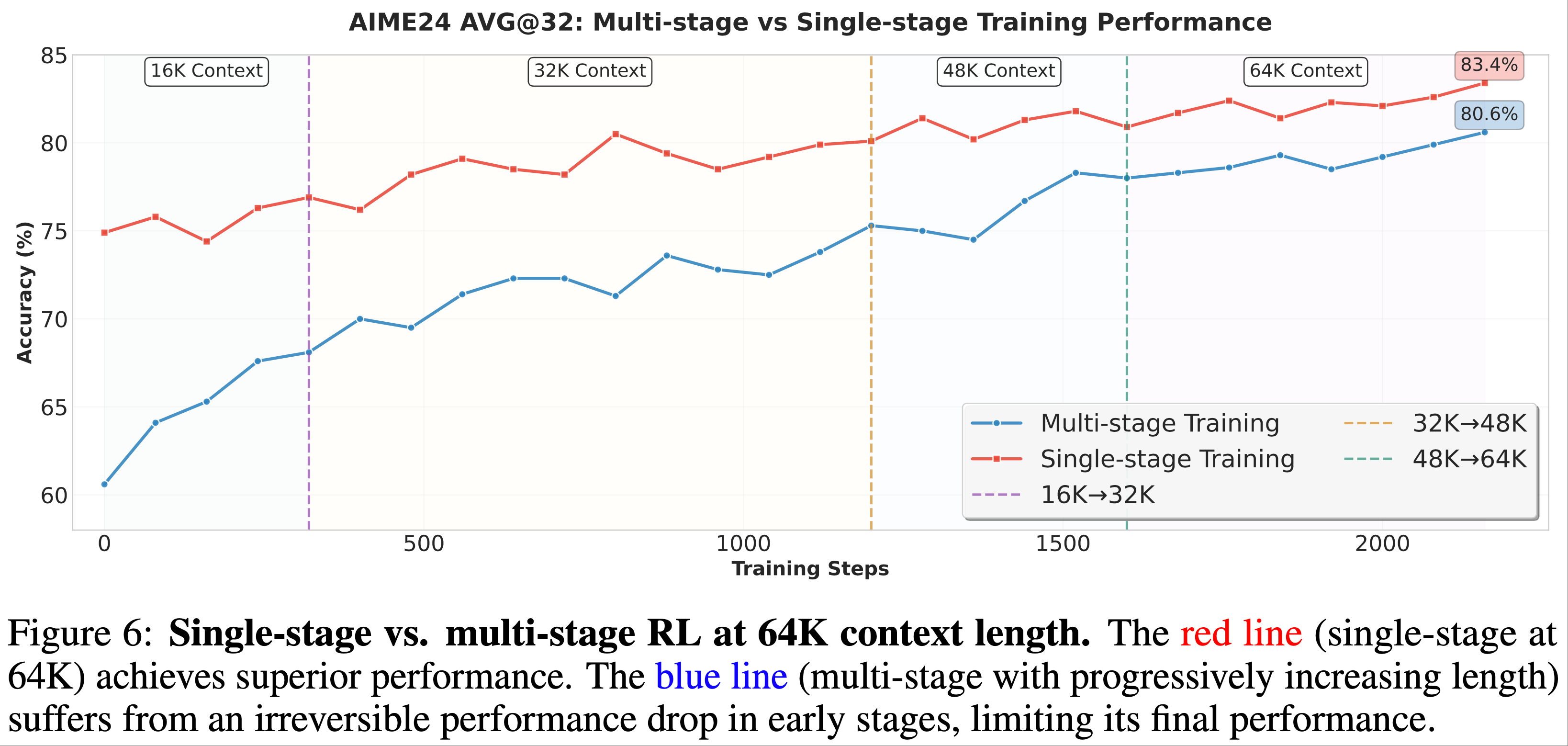
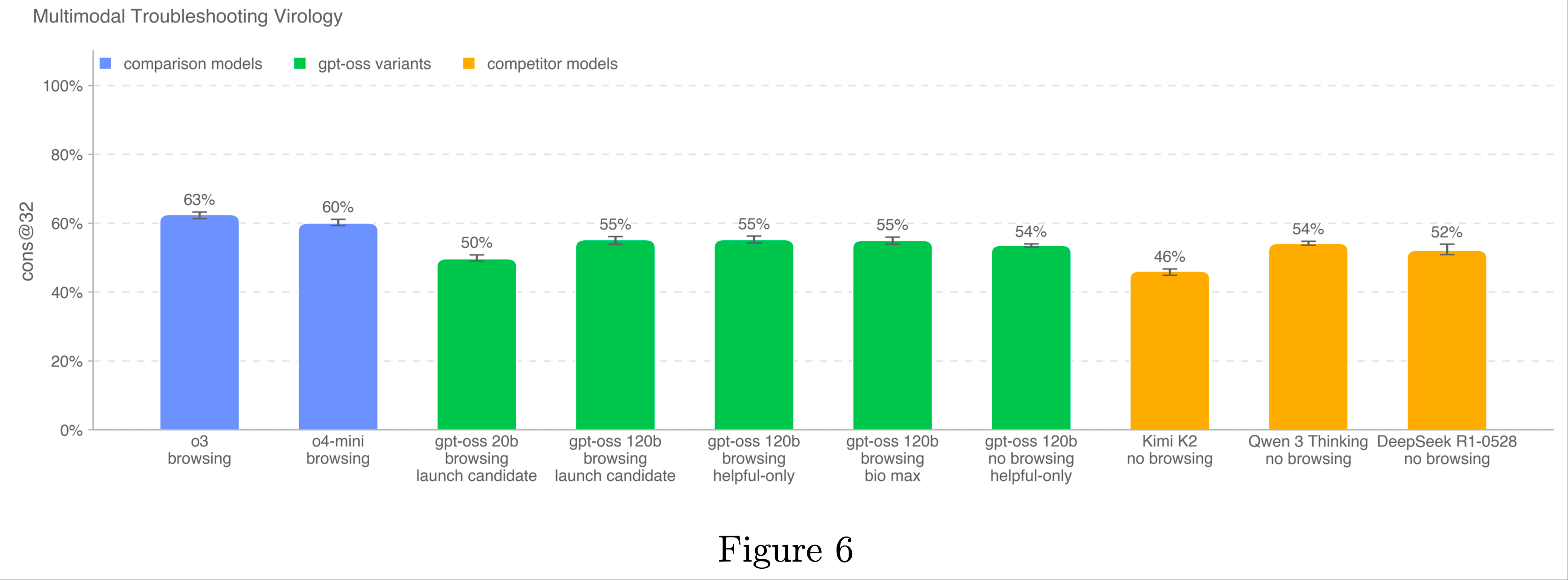
)-Figure6.png)