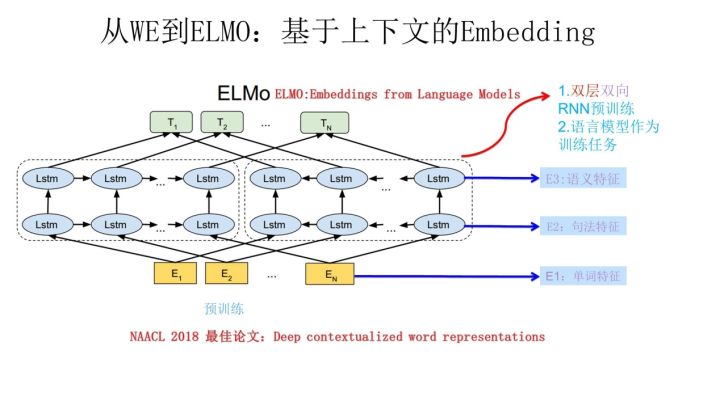
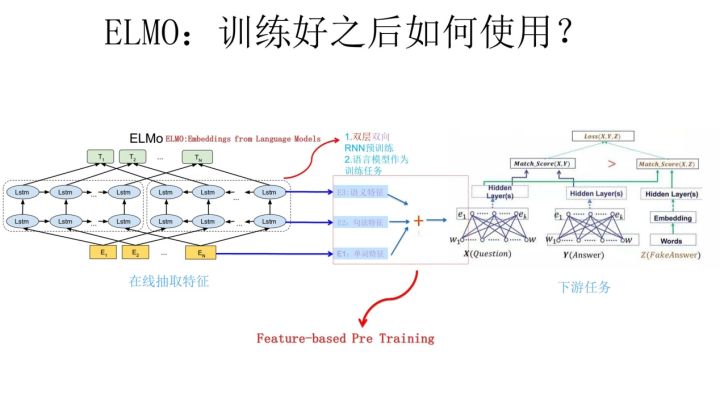
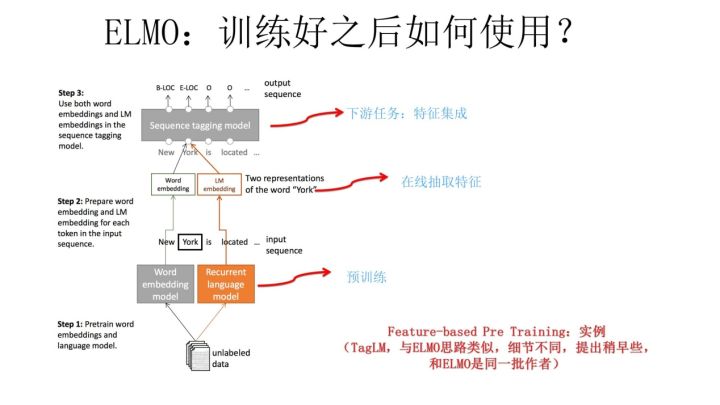
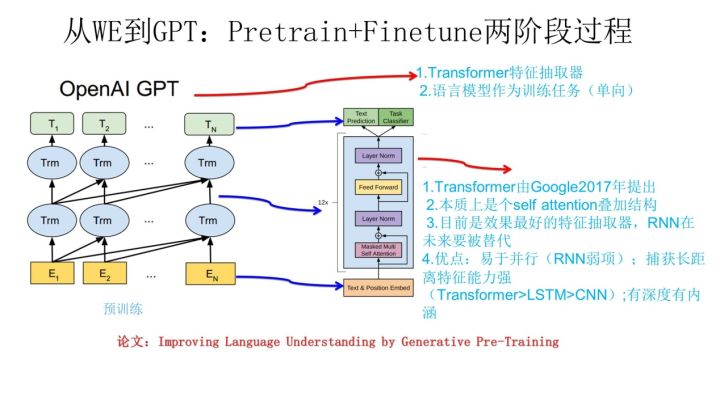
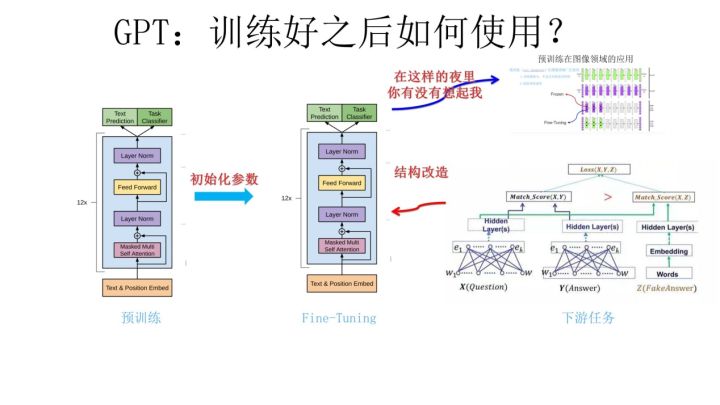
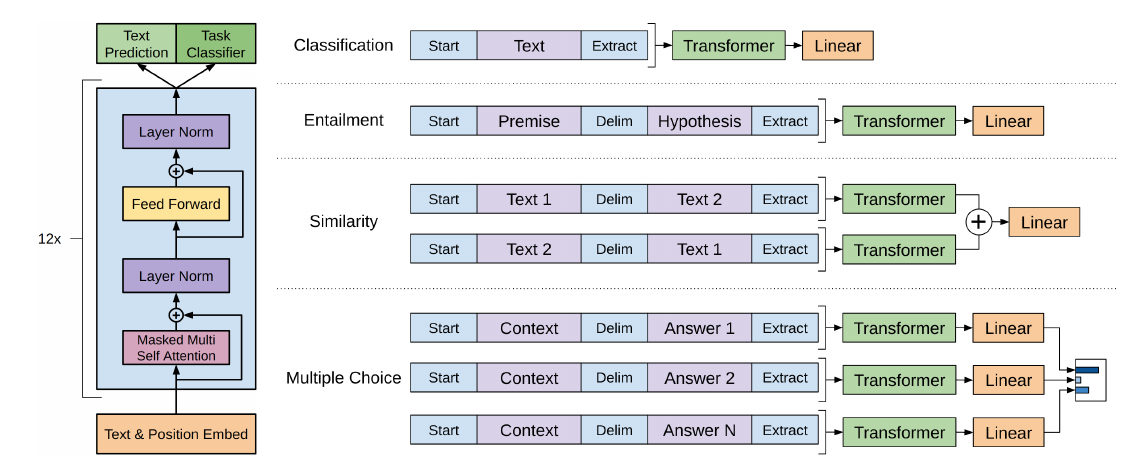
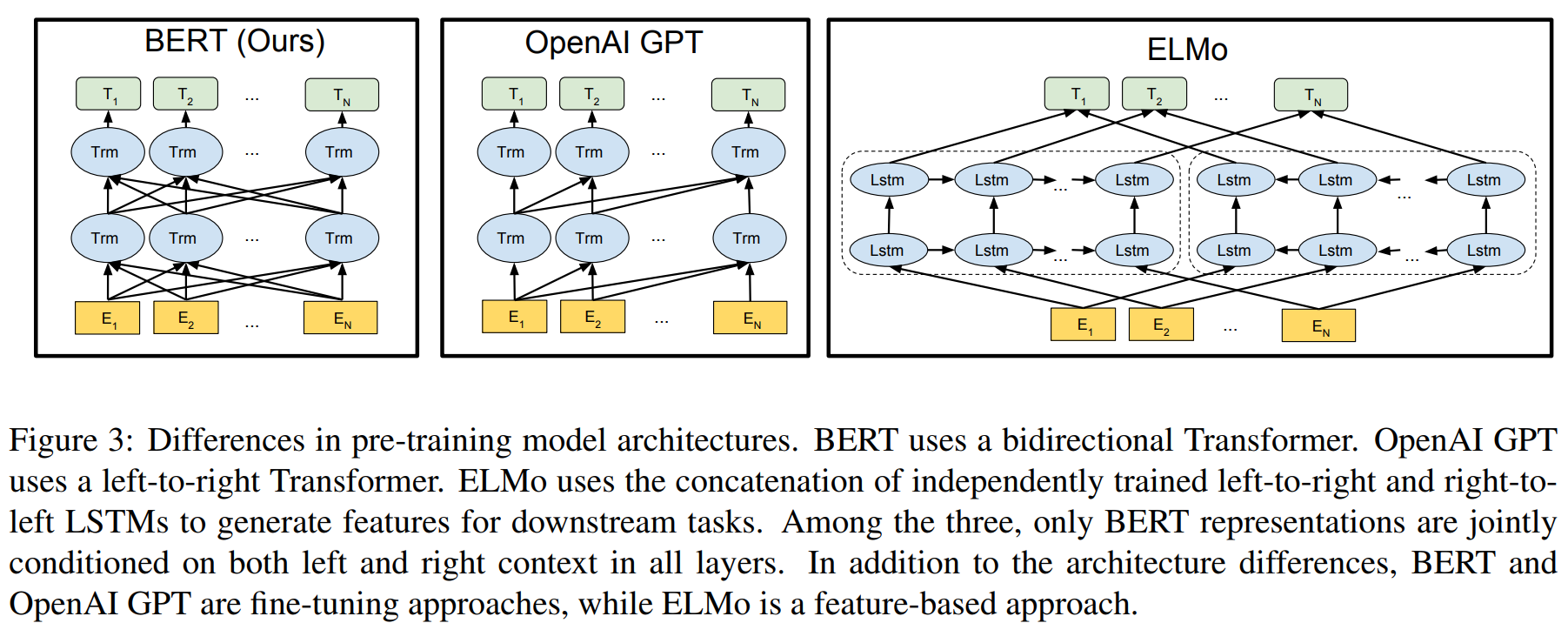
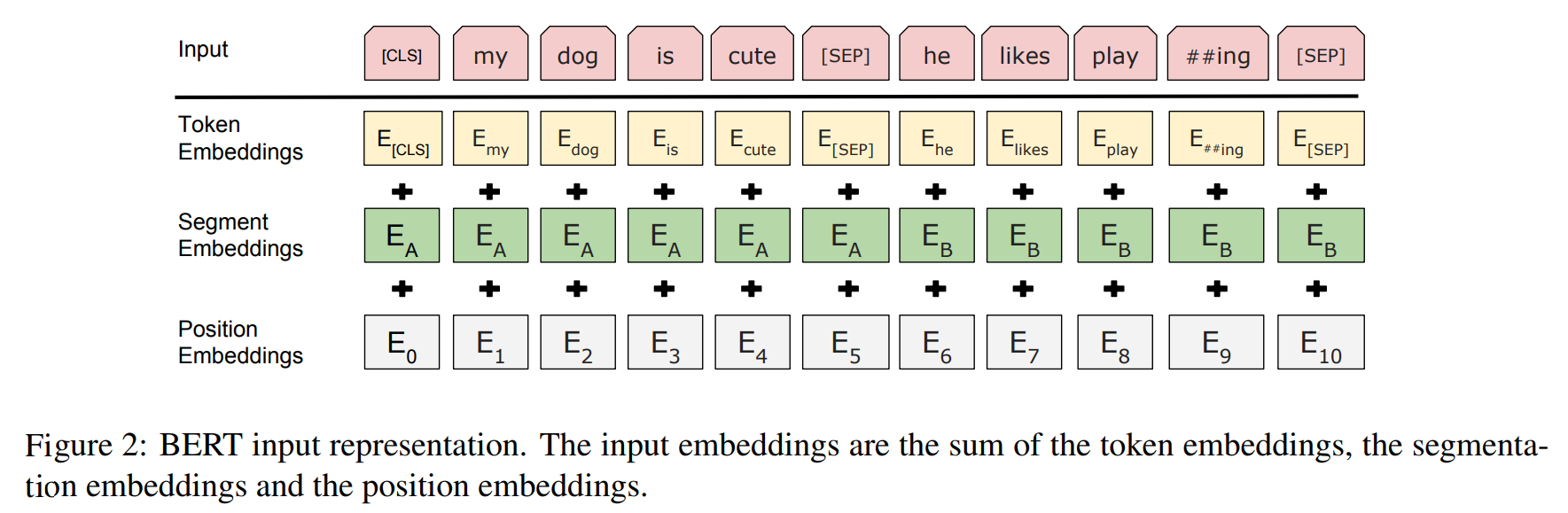
整体说明
- 本文示例使用 AI 辅助生成,Prompt 为:
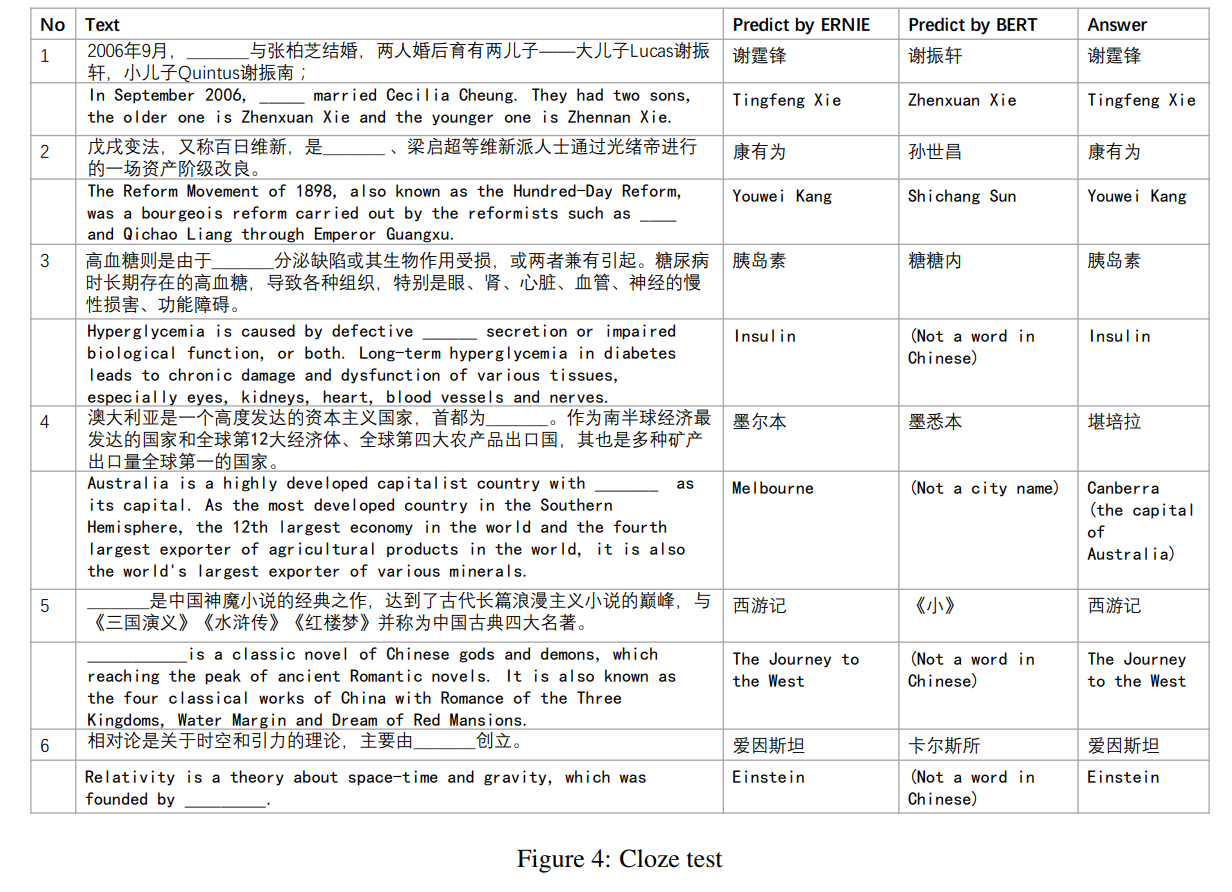
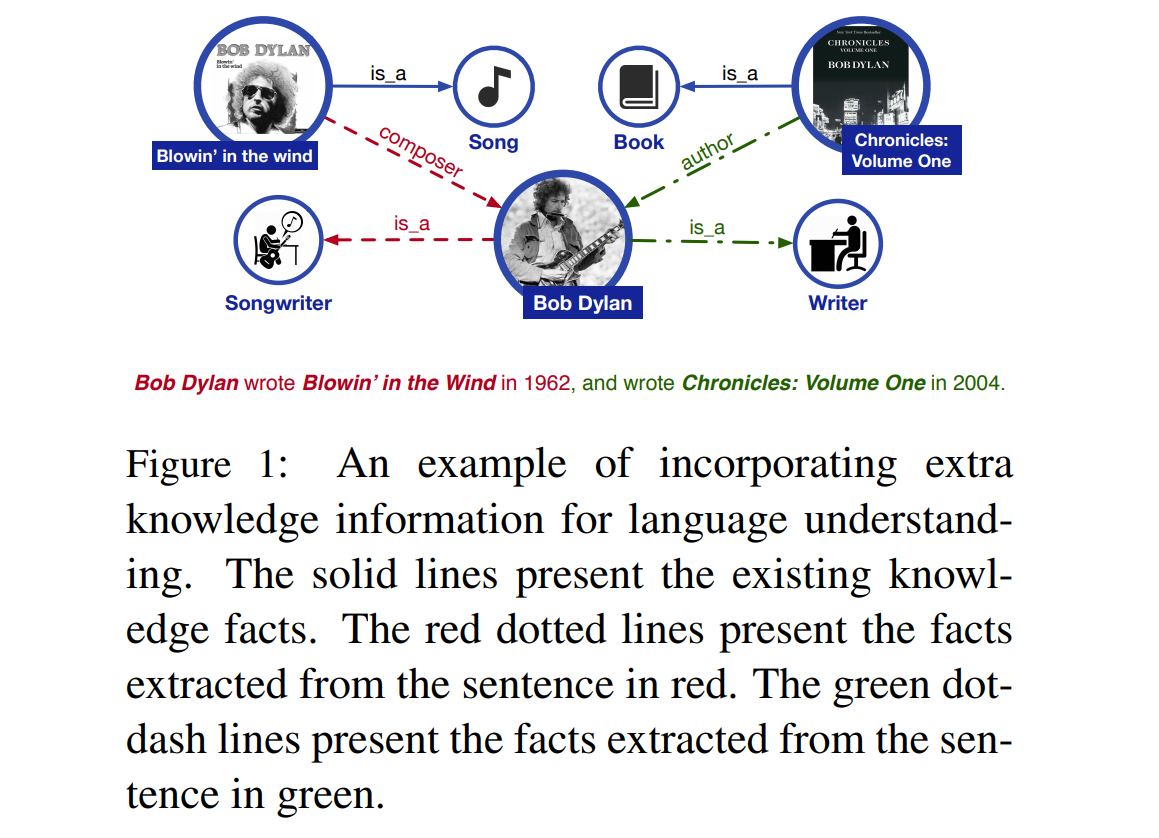
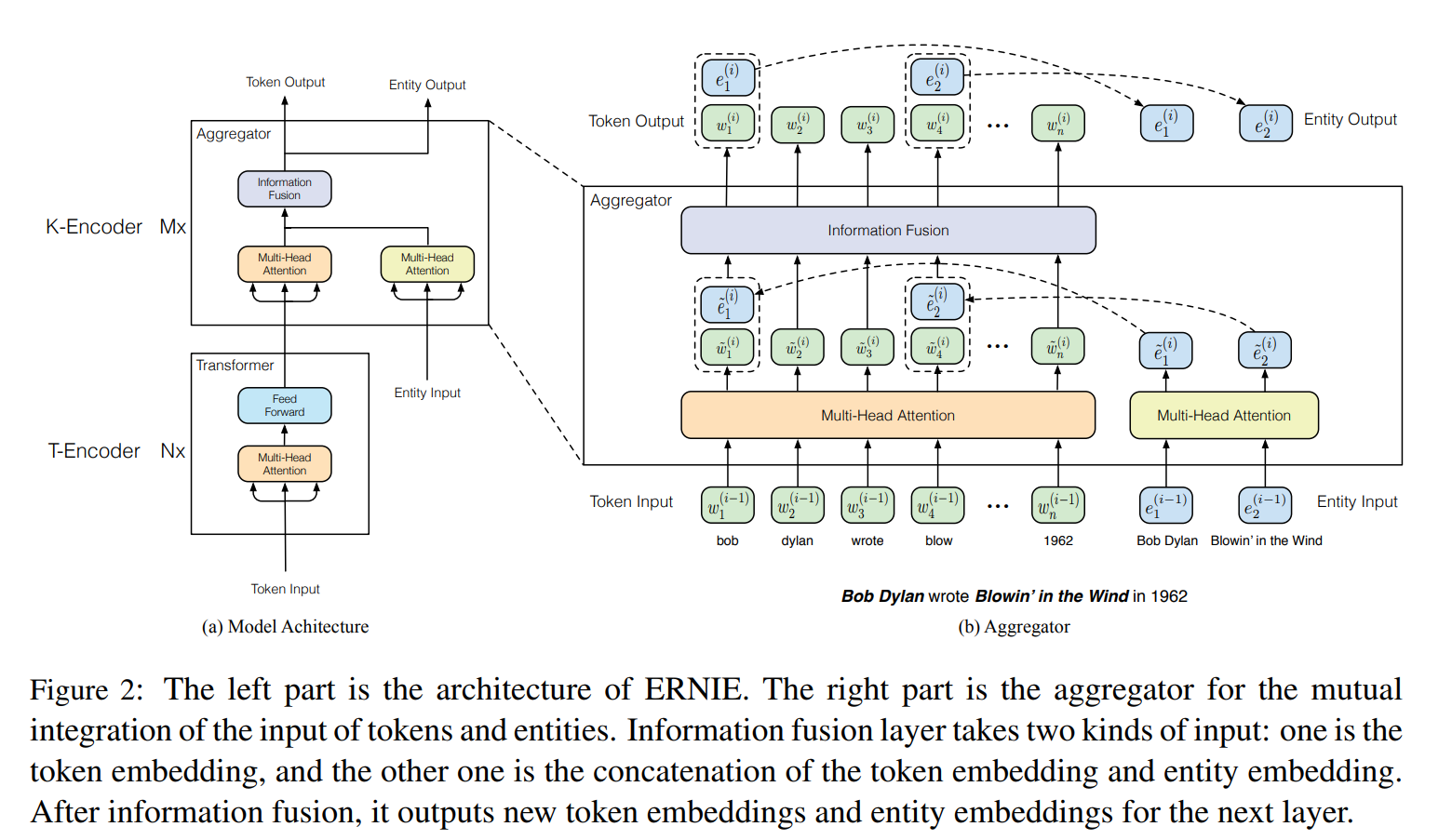
1
2
3
4
5写一个多线程 python 代码,从一个文件读取数据,然后逐行进行处理,加载为 json 后从中读取 'input' 字段并在前后添加 '```',处理完成后写入另一个文件中,要求如下:
1. 处理过程中实时打印处理进度
2. 要求不使用 queue 等高级的包,用原生的 Python 和 threading 包实现即可
3. 要求写入文件顺序和原始文件的顺序相同
4. 由于文件很大,且执行过程中可能会随时中断,请用一个文件维护完成情况(完整写入文件才算完成),保证可以随时重启(指定参数 resume=True 时则从中断处启动,否则从头开始重新执行)
多线程可中断文件逐行处理示例
- 代码示例,仅修改
process_line即可使用:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276import threading
import json
import os
import signal
import sys
from typing import Optional
import traceback
class MultiThreadFileProcessor:
def __init__(self, input_file: str, output_file: str, progress_file: str = "progress.txt", num_threads: int = 4):
"""
初始化文件处理器
Args:
input_file: 输入文件路径
output_file: 输出文件路径
progress_file: 进度记录文件路径
num_threads: 线程数量
"""
self.input_file = input_file
self.output_file = output_file
self.progress_file = progress_file
self.num_threads = num_threads
# 用于线程同步的锁
self.task_lock = threading.Lock()
self.result_lock = threading.Lock()
self.write_lock = threading.Lock()
# 所有待处理的行
self.all_lines = []
# 当前要分配的任务索引
self.current_task_index = 0
# 存储处理结果的字典
self.results = {}
# 已完成的行号集合
self.completed_lines = set()
# 下一个要写入的行号
self.next_write_line = 0
# 总行数
self.total_lines = 0
# 处理完成的行数
self.processed_count = 0
# 输出文件句柄
self.output_handle = None
# 停止标志(用于优雅退出)
self.stop_flag = threading.Event()
# 注册信号处理器
signal.signal(signal.SIGINT, self.signal_handler)
signal.signal(signal.SIGTERM, self.signal_handler)
def signal_handler(self, signum, frame):
"""处理 Ctrl+C 和终止信号"""
print("\n\n收到中断信号,正在优雅退出...")
print("已处理的数据会保存,可以使用 resume=True 继续")
self.stop_flag.set() # 设置停止标志
def load_progress(self) -> set:
"""加载进度文件,返回已完成的行号集合"""
if os.path.exists(self.progress_file):
with open(self.progress_file, 'r') as f:
completed = set(int(line.strip()) for line in f if line.strip())
return completed
return set()
def save_progress(self, line_num: int):
"""保存进度到文件"""
with open(self.progress_file, 'a') as f:
f.write(f"{line_num}\n")
f.flush()
def process_line(self, line: str) -> str:
"""
处理单行数据
Args:
line: 原始行数据
Returns:
处理后的数据
"""
try:
data = json.loads(line.strip())
if 'input' in data:
data['input'] = f"```{data['input']}```"
return json.dumps(data, ensure_ascii=False)
except json.JSONDecodeError as e:
print(f"\nJSON解析错误: {e}, 原始数据: {line[:100]}")
return line.strip()
def get_next_task(self) -> Optional[tuple]:
"""
获取下一个待处理的任务(线程安全)
Returns:
(行号, 行内容) 或 None(无任务)
"""
with self.task_lock:
# 检查停止标志
if self.stop_flag.is_set():
return None
# 跳过已完成的任务
while self.current_task_index < len(self.all_lines):
line_num, line = self.all_lines[self.current_task_index]
self.current_task_index += 1
if line_num not in self.completed_lines:
return (line_num, line)
else:
# 已完成的任务也计入进度
self.processed_count += 1
return None
def worker(self):
"""工作线程函数 - 动态获取任务"""
try:
while not self.stop_flag.is_set():
# 获取下一个任务
task = self.get_next_task()
if task is None:
break # 没有任务了或收到停止信号
line_num, line = task
# 处理数据
processed = self.process_line(line)
# 检查是否需要停止
if self.stop_flag.is_set():
# 将未写入的结果放回(不保存进度)
break
# 将结果存储到字典中
with self.result_lock:
self.results[line_num] = processed
self.processed_count += 1
# 实时打印进度
progress = (self.processed_count / self.total_lines) * 100
print(f"\r处理进度: {self.processed_count}/{self.total_lines} ({progress:.2f}%) | 待写入: {len(self.results)}", end='', flush=True)
# 尝试写入文件(按顺序)
self.try_write_results()
except Exception as e:
print(f"\n线程 {threading.current_thread().name} 发生错误: {e}")
traceback.print_exc()
self.stop_flag.set() # 发生错误时通知其他线程停止
def try_write_results(self):
"""尝试按顺序写入结果到文件"""
if self.stop_flag.is_set():
return # 如果收到停止信号,不再写入
with self.write_lock:
# 按顺序写入所有可以写入的行
while self.next_write_line in self.results:
line_num = self.next_write_line
with self.result_lock:
content = self.results.pop(line_num)
# 写入文件
self.output_handle.write(content + '\n')
self.output_handle.flush() # 确保写入磁盘
# 保存进度
self.save_progress(line_num)
# 更新下一个要写入的行号
self.next_write_line += 1
def process(self, resume: bool = False):
"""
主处理函数
Args:
resume: 是否从中断处继续
"""
# 如果不是恢复模式,清空输出文件和进度文件
if not resume:
if os.path.exists(self.output_file):
os.remove(self.output_file)
if os.path.exists(self.progress_file):
os.remove(self.progress_file)
self.completed_lines = set()
self.next_write_line = 0
else:
# 加载已完成的行
self.completed_lines = self.load_progress()
self.next_write_line = len(self.completed_lines)
print(f"从第 {self.next_write_line} 行继续处理...")
# 读取所有行
print("正在读取文件...")
with open(self.input_file, 'r', encoding='utf-8') as f:
self.all_lines = [(i, line) for i, line in enumerate(f)]
self.total_lines = len(self.all_lines)
print(f"文件总行数: {self.total_lines}")
print(f"已完成行数: {len(self.completed_lines)}")
print(f"待处理行数: {self.total_lines - len(self.completed_lines)}")
if len(self.completed_lines) >= self.total_lines:
print("所有行已处理完成!")
return
# 打开输出文件(追加模式)
self.output_handle = open(self.output_file, 'a', encoding='utf-8')
try:
# 创建并启动线程(设置为守护线程)
threads = []
for i in range(self.num_threads):
thread = threading.Thread(target=self.worker, name=f"Worker-{i}")
thread.daemon = False # 不设置为守护线程,以便优雅退出
threads.append(thread)
thread.start()
# 等待所有线程完成
for thread in threads:
thread.join()
# 检查是否是被中断的
if self.stop_flag.is_set():
print(f"\n程序被中断")
print(f"已完成 {self.next_write_line} 行的处理和写入")
print(f"使用 resume=True 可以继续处理")
else:
# 确保所有结果都已写入
self.try_write_results()
print(f"\n处理完成! 输出文件: {self.output_file}")
except KeyboardInterrupt:
print("\n\n检测到键盘中断...")
self.stop_flag.set()
# 等待线程退出(最多等待5秒)
for thread in threads:
thread.join(timeout=5)
print(f"已完成 {self.next_write_line} 行的处理和写入")
finally:
# 关闭输出文件
if self.output_handle:
self.output_handle.close()
print("输出文件已安全关闭")
# 使用示例
if __name__ == "__main__":
# 创建处理器实例
processor = MultiThreadFileProcessor(
input_file="input.jsonl",
output_file="output.jsonl",
progress_file="progress.txt",
num_threads=4
)
# 从头开始处理
# processor.process(resume=False)
# 从中断处继续
processor.process(resume=True)