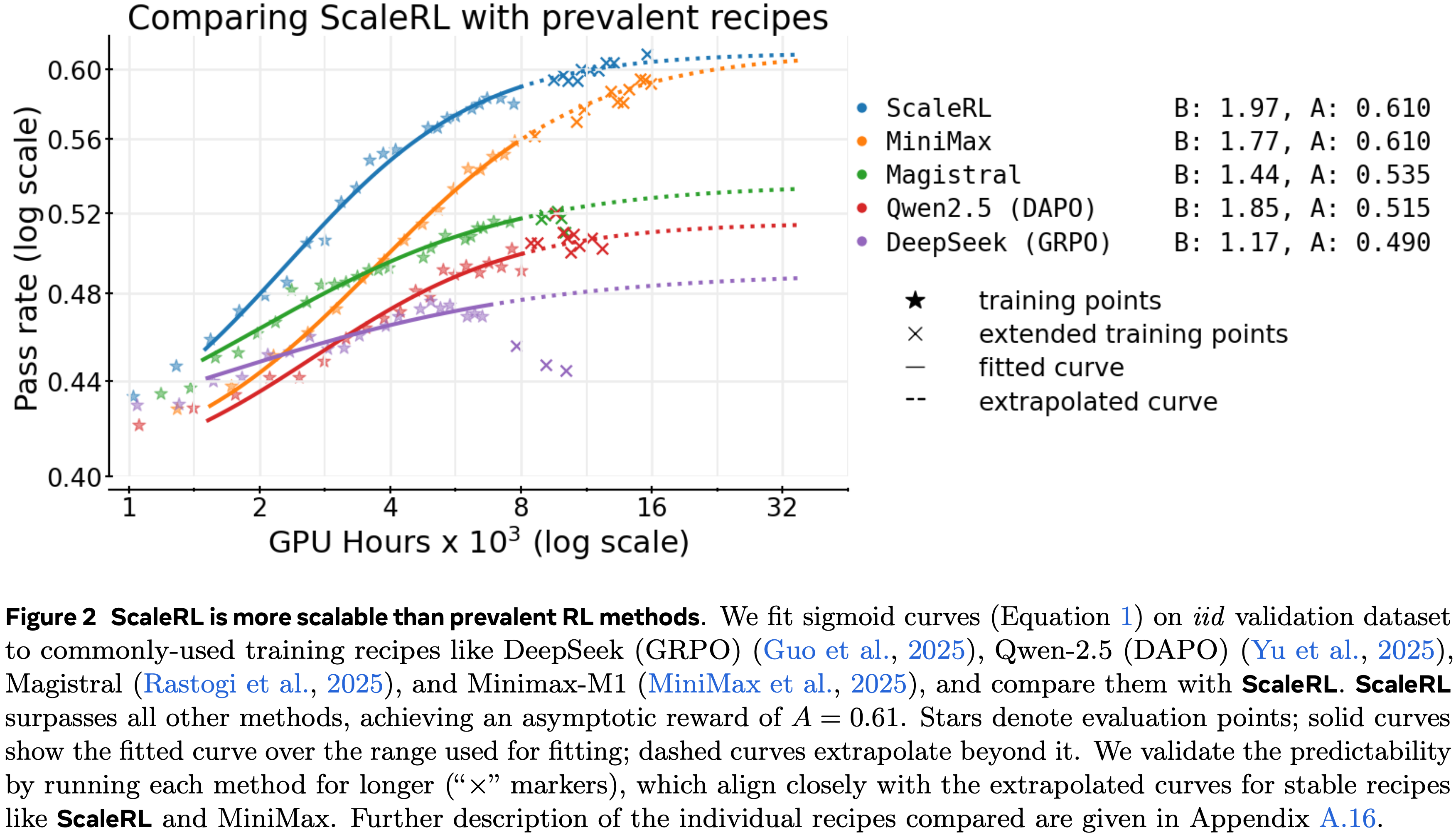
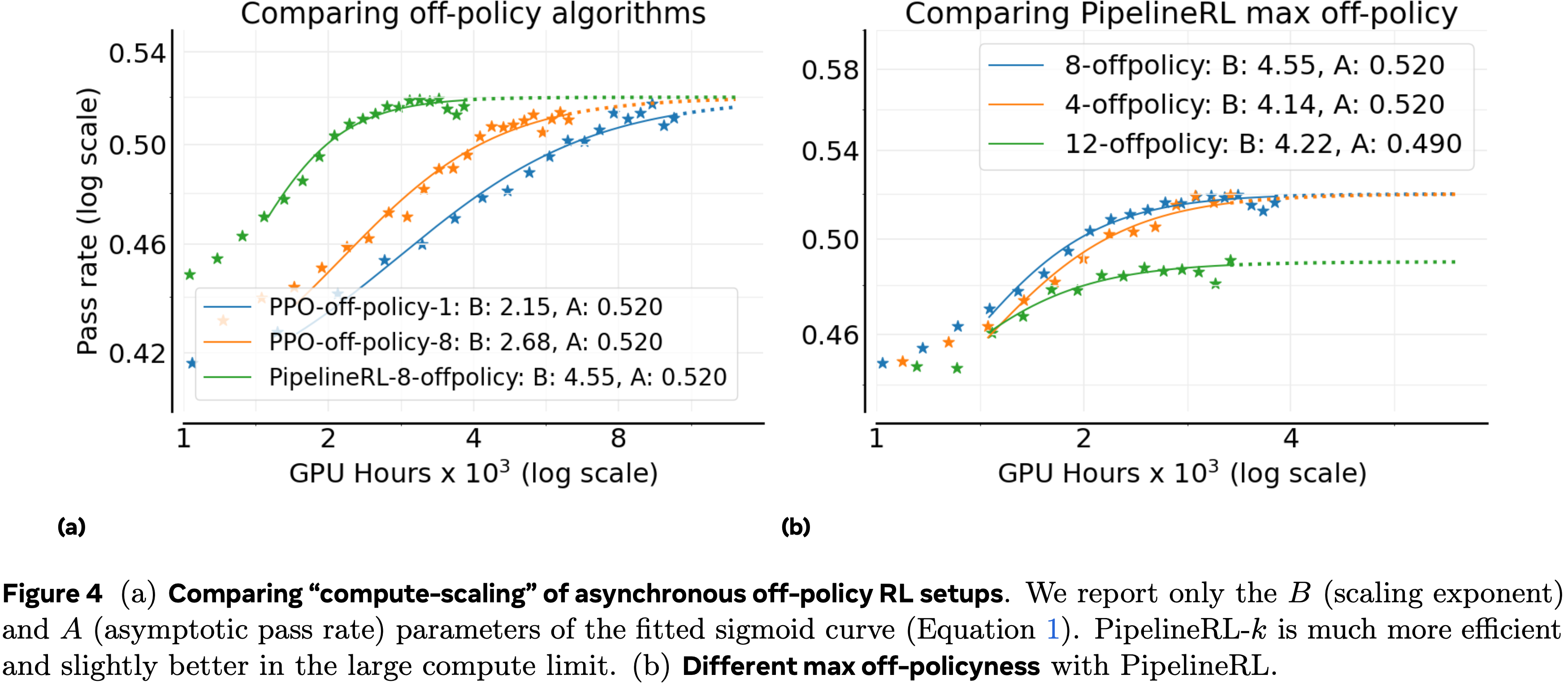
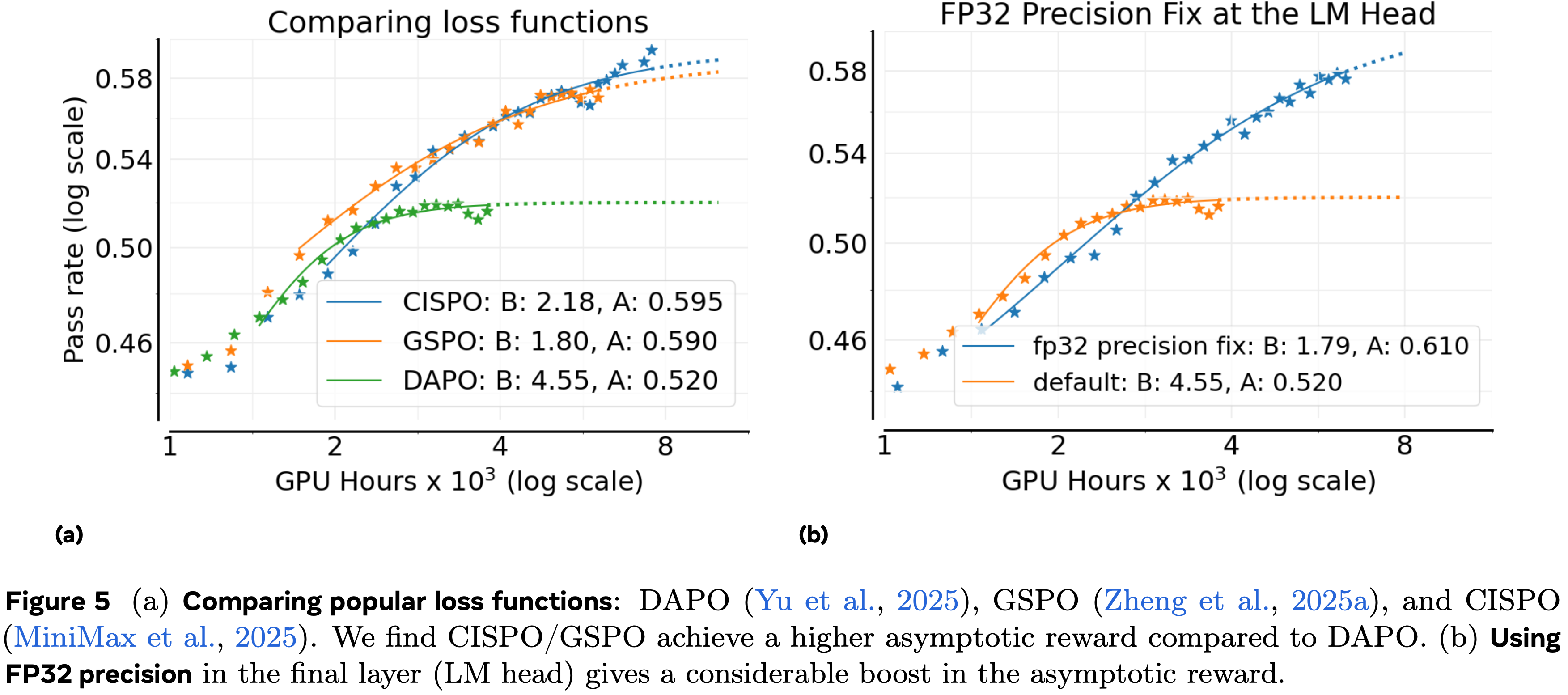
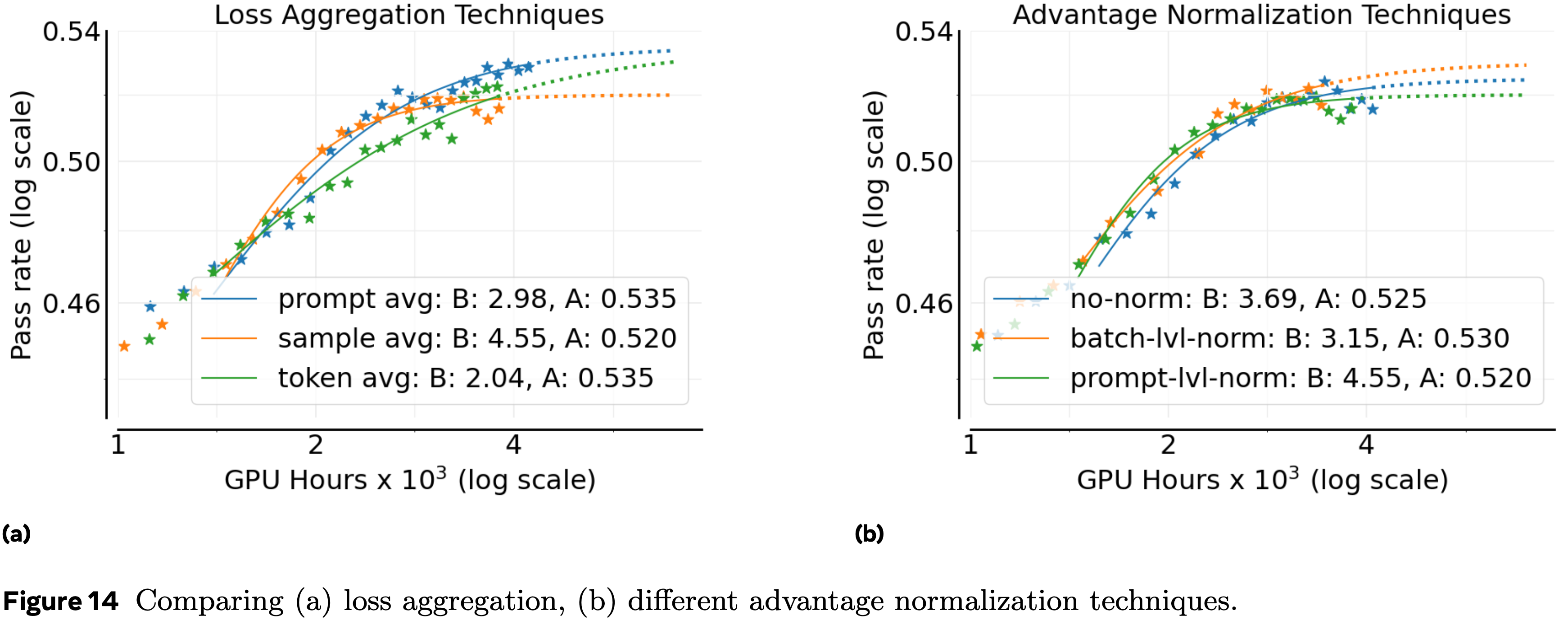
注:本文包含 AI 辅助创作
- 参考链接:
- 原始论文:EvoCUA Technical Report, Meituan, 20260122
- Github:github.com/meituan/EvoCUA
- Huggingface:huggingface.co/meituan/EvoCUA-32B-20260105
- OSWorld:os-world.github.io/
- 原作者解读:美团EvoCUA技术报告解读
Paper Summary
- 对论文的评价和关键认知:
- 论文是研究生同学的作品,实现了 CUA 方向的开源 SOTA,有非常丰富的数据生产经验和 Sense,值得深读
- 虽然没有使用太多 PPO 等高大上的技术,但从文章里面可以看到作者的工作逻辑是非常严谨的,也做的非常深入,靠的是比较全面的调研、深入思考和工程实践能力拿到的最终效果,值得参考
- 论文的核心认知:
- 先对模型注入广泛的原子能力,再通过后续的训练将原子能力串起来,思路与之前的 \(f(g(x))\) 论文类似
- 数据的质量需要高度保证(去噪非常重要),高质量的数据对应高质量的模型,理解:Garbage in,Garbage out
- 根据数据的深入分析,构建时识别第一个分叉点,目标是构造
<chosen,rejected>对用于标准的 DPO 训练,分为两方面构建损失:- 范式1:
- Rejected:旧的错误步骤
- Chosen:新合成的正确步骤,针对步骤 \(t^*\) 动作纠正,用最优的 Chosen 响应 \((z_{w},a_{w})\) 替换 Rejected 的错误 \((z_{l},a_{l})\)
- 范式2:
- Rejected:之前盲目继续的样本
- Chosen:反思样本,针对步骤 \(t^* + 1\),对错误步骤进行改进(其他更优模型或高温),而不是盲目继续(之前的轨迹会盲目继续)
- 这里相当于让模型开始反思,从错误中反思重新开始的方式,最终模型能学会思考
- 范式1:
- RFT 和 DPO 数据要使用 On-policy 的
- 论文整体再次体现了数据为王的思路
- 问题提出:
- 原生计算机使用智能体 (Native Computer-use Agents,CUA) 的发展代表了多模态 AI 领域的重大飞跃
- 但其潜力目前受限于静态数据扩展的约束
- 现有范式主要依赖于对静态数据集的被动模仿,难以捕捉长时程计算机任务中固有的复杂因果动态
- 论文介绍了 EvoCUA,一个原生计算机使用智能体模型
- 与静态模仿不同,EvoCUA 将数据生成和策略优化整合到一个自我维持的演进循环中
- 为了缓解数据稀缺问题,论文开发了一个可验证的合成引擎,能够自主生成多样化的任务并附带可执行的验证器
- 为了实现大规模经验获取,论文设计了一个可扩展的基础设施,能够编排数以万计的异步沙箱 Rollout
- 基于这些海量轨迹,论文提出了一种迭代演进学习策略,以有效地将这些经验内化
- 该机制通过识别能力边界来动态调控策略更新,即强化成功的例程,同时通过错误分析和自我纠正将失败轨迹转化为丰富的监督信号
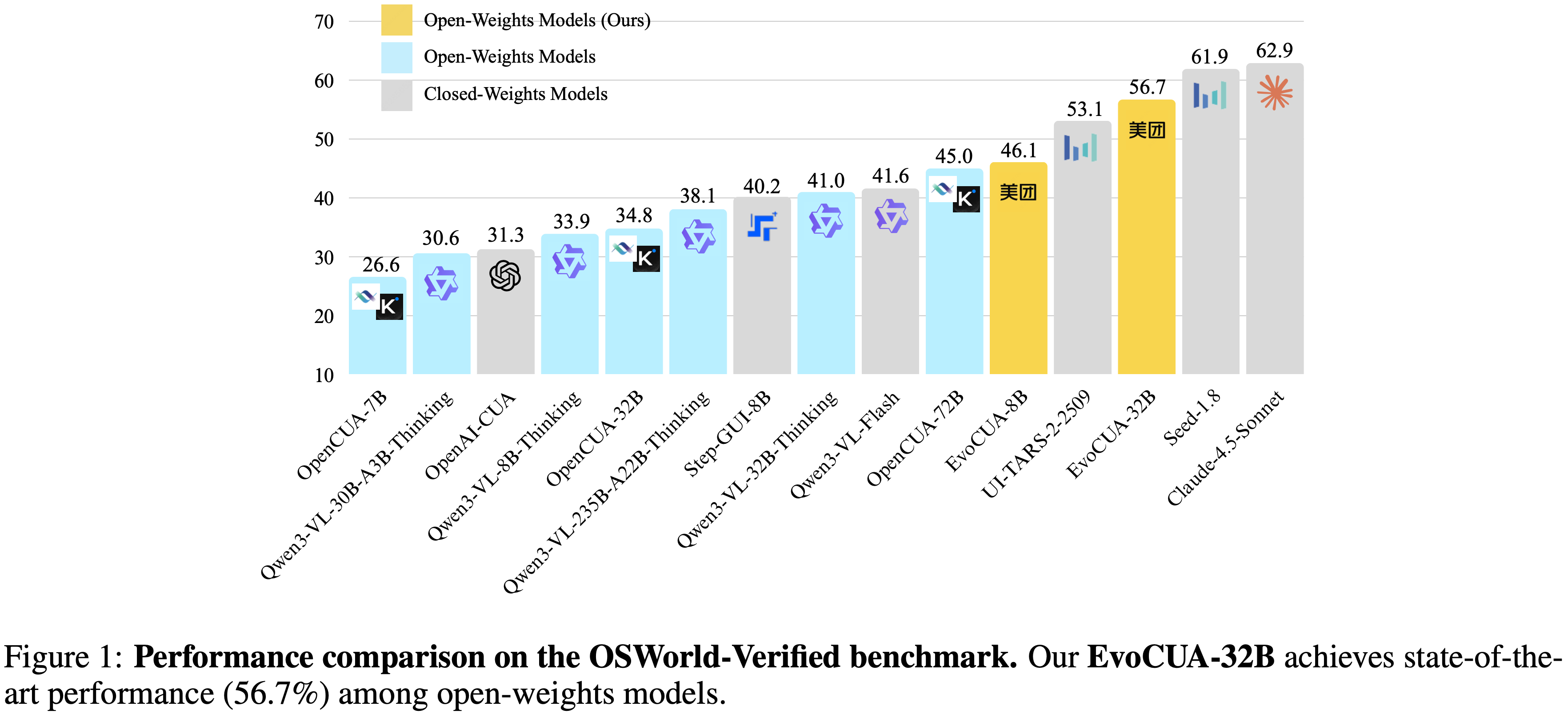
- 在 OSWorld 基准测试上的实证评估表明,EvoCUA 取得了 \(56.7%\) 的成功率,建立了新的开源 state-of-the-art
- EvoCUA 显著优于先前最好的开源模型 OpenCUA-72B (\(45.0%\)),并超越了领先的闭源权重模型,如 UI-TARS-2 (\(53.1%\))
- 论文的结果强调了该方法的泛化能力:
- 通过从经验中学习驱动的演进范式,在不同规模的基座模型上都能带来持续的性能提升,为推进原生智能体能力建立了一条稳健且可扩展的路径
- 通过从经验中学习驱动的演进范式,在不同规模的基座模型上都能带来持续的性能提升,为推进原生智能体能力建立了一条稳健且可扩展的路径
Introduction and Discussion
- 能够掌握图形用户界面 (GUIs) 的通才(generalist)智能体的开发,代表了通向人工通用智能的关键里程碑
- 与专用工具不同,这些智能体必须感知复杂的视觉上下文,并在异构应用程序中执行长时程工作流,有效地模拟人机交互
- 最近的原生视觉语言模型 (VLMs) 已成功地将感知和动作集成到端到端架构中 (2025a, 2025),但实现人类水平的可靠性仍然是一个重大挑战
- 尽管 UI-TARS-2 (2025a) 和 OpenCUA (2025b) 等 SOTA 模型的,已经建立了基础架构,但进一步的进展越来越受到一个关键瓶颈的限制:依赖静态数据集进行扩展的收益递减
- 现有的扩展定律主要局限于对固定的、非交互式数据集的被动模仿,无法捕捉现实世界计算机使用中固有的因果反馈
- 克服这一限制需要一个范式转变,即从通过静态轨迹进行数据扩展,转变为通过大规模交互式 Rollout 进行经验扩展
- 动态经验比静态文本提供了更丰富的监督信号,包含了环境反馈以及来自成功和失败的关键 Insight
- However,将原始交互转化为自我改进的学习循环存在三个主要挑战:
- 1)可验证的数据合成(Verifiable data synthesis) :
- 仅仅合成文本 Query 通常会导致幻觉,智能体会为不可行的任务生成看似合理的计划
- 因此,需要一个稳健的框架来确保生成的 Query 严格基于可解决的状态,符合可验证奖励的原则
- 2)可扩展的交互基础设施(Scalable interaction infrastructure) :
- 高吞吐量的经验生产需要一个统一系统,将大规模环境模拟与高性能强化学习相结合,以支持持续、异步的交互
- 3)高效的训练方案(Efficient training recipe) :
- 给定一个大规模的交互空间,无限制的探索在计算上是不可行的
- 有效的学习需要一种遵循策略的方法,模仿人类学习动态:巩固已掌握的例程(routines),同时集中关注智能体在成功和失败之间摇摆的边界任务
- 1)可验证的数据合成(Verifiable data synthesis) :
- 为了解决这些问题,本报告介绍了 EvoCUA ,一个原生计算机使用智能体,它通过从经验中学习驱动的演进范式应对这些挑战
- 如图 2 所示,通过将可验证合成、高吞吐量基础设施和演进优化相统一,EvoCUA 建立了一个自我维持的循环,持续将合成计算转化为高质量的智能体能力
- 如图 2 所示,通过将可验证合成、高吞吐量基础设施和演进优化相统一,EvoCUA 建立了一个自我维持的循环,持续将合成计算转化为高质量的智能体能力
- 论文的核心贡献有三方面:
- 可验证合成引擎 (Verifiable Synthesis Engine)
- 为了克服数据瓶颈同时确保严格的环境基础,论文首先提出了一个合成引擎,能够 自主生成多样化任务及其可执行验证器(executable validators)
- 超越纯文本生成,论文分析原子能力以合成自包含的任务定义
- 这种“生成即验证(Generation-as-Validation)”的方法消除了自然语言奖励的模糊性,为智能体提供精确的、确定性的监督信号
- 可扩展交互基础设施 (Scalable Interaction Infrastructure)
- 为了支持所需的大规模经验扩展,论文构建了一个高性能基础设施,集成了大规模沙箱环境
- 这个系统不仅仅是轨迹生成,它充当一个动态训练场,提供策略优化所必需的实时反馈和状态转换
- 通过架构一个完全异步的 Rollout 机制,论文将模拟与模型更新解耦,使系统能够编排数万个并发的交互会话
- 通过从经验中学习的演进范式 (Evolving Paradigm via Learning from Experience)
- 论文引入了一个以从经验中学习为中心的迭代训练范式,以确保效率
- 该过程始于一个注重多样性的冷启动,以 建立稳健的先验
- 随后,通过持续的环境探索,模型对比成功与失败的轨迹,以巩固有效模式并纠正错误
- 这个动态反馈循环将累积的经验转化为模型参数,产生一个精确而稳健的执行策略
- 可验证合成引擎 (Verifiable Synthesis Engine)
- 实证评估表明,EvoCUA 在 OSWorld 基准测试上 (2024) 取得了 state-of-the-art 成功率 \(56.7%\),显著超越了之前的开源 SOTA,OpenCUA-72B (45.0%) (2025b),并超过了领先的闭源模型 UI-TARS-2 (53.1%) (2025a)
- 此外,演进式经验学习范式被证明是一条可泛化的路径,在不同大小的多个基座模型上带来了一致的增益
Preliminaries
- 在介绍论文的 EvoCUA 之前,论文在下文中提供 CUA 的基本任务定义
- 形式上,CUA 可以看作是一个具有显式推理的部分可观测马尔可夫决策过程 (POMDP) (1998),它通过可验证任务合成和策略优化的协同演进循环进行优化
POMDP
- 给定一个自然语言指令 \(g\),交互过程被建模为一个元组 \((S, A, \mathcal{Z}, \mathcal{O}, \mathcal{P}, \mathcal{R}_{syn})\)
- 其中 \(S\), \(A\), \(Z\), \(\mathcal{O}\), \(\mathcal{P}\), 和 \(\mathcal{R}_{syn}\) 分别表示状态空间、动作空间、思维空间、观测、转移核和奖励函数
- 细节如下所示:
- 状态空间 \((S)\) (State Space) :
- 环境被建模为具有底层计算机系统状态 \(s_t \in S\),包括应用程序状态、系统配置和隐式的系统级上下文
- 智能体无法直接观测到这个状态,智能体感知到从该状态渲染出的视觉观测(对应于时间 \(t\) 的屏幕图像)
$$ I_t \triangleq \mathrm{Render}(s_t) \in \mathbb{R}^{H \times W \times 3} $$- \(H\), \(W\) 分别表示屏幕截图的高度和宽度
- 渲染的屏幕截图 \(I_t\) 是智能体观察环境的唯一感知接口
- 智能体无法直接观测到这个状态,智能体感知到从该状态渲染出的视觉观测(对应于时间 \(t\) 的屏幕图像)
- 环境被建模为具有底层计算机系统状态 \(s_t \in S\),包括应用程序状态、系统配置和隐式的系统级上下文
- 观测 \((O)\) (Observation) :
- 在步骤 \(t\),智能体接收原始视觉观测 \(o_t \in \mathcal{O}\),其中
$$ o_t \triangleq I_t \in \mathbb{R}^{H \times W \times 3} $$ - 为了解决部分可观测性,论文定义了交互历史
$$h_t = \{g, o_0, z_0, a_0, \ldots , o_{t-1}, z_{t-1}, a_{t-1}\}$$- 它作为智能体决策过程的条件上下文
- 在实际实现中,为了防止上下文窗口溢出,论文遵循 (2025b, 2025a) 执行上下文工程策略
- 论文将视觉历史限制为最近的五张屏幕截图,并使用结构化的内心独白和动作表示来压缩文本历史,以平衡性能和 token 效率
- 在步骤 \(t\),智能体接收原始视觉观测 \(o_t \in \mathcal{O}\),其中
- 动作空间 \((A)\) (Action Space) :
- 论文定义了一个统一的原生动作空间 \(A\),它包含基于坐标的鼠标事件 \(A_{\mathrm{mouse} }\)、键盘输入 \(A_{\mathrm{keyboard} }\) 以及用于管理任务执行流的特殊控制 \(A_{\mathrm{control} }\) 原语
- 形式上,论文定义
$$A = A_{\mathrm{mouse} } \cup A_{\mathrm{keyboard} } \cup A_{\mathrm{control} }$$
- 思维空间 \((Z)\) (Thought Space) :
- 论文将推理过程显式地建模为内部思维空间 \(Z\)
- 在每个步骤 \(t\),智能体在执行动作之前生成一个自然语言推理痕迹(Reasoning Trace) \(z_t \in Z\)
- 它作为智能体内部的中间认知状态,用于将后续的物理动作基于当前的视觉上下文
- 策略 \((\pi_\theta)\) (Policy) :
- 智能体遵循一个参数化的策略
$$ \pi_\theta (z_t, a_t \mid h_t, o_t)$$- 该策略控制推理和动作选择
- 在每个步骤 \(t\),策略首先生成一个基于当前交互上下文的推理痕迹 \(z_t\),随后基于生成的推理选择一个可执行动作 \(a_t\)
- 这种顺序生成确保动作执行以显式推理为条件
- 智能体遵循一个参数化的策略
- 转移 \((\mathcal{P})\) (Transition) :
- 环境状态根据状态转移核 \(\mathcal{P}(s_{t + 1} \mid s_t, a_t)\) 演化,它捕捉底层计算机系统响应执行的物理动作 \(a_t\) 的 Dynamics
- 给定更新后的状态 \(s_{t + 1}\),后续的视觉观测被渲染为 \(I_{t + 1} = \text{Render}(s_{t + 1})\)
- 可验证奖励 \((\mathcal{R}_{syn})\) (Verifiable Reward (Rsyn)) :
- 监督通过可验证合成机制基于执行正确性建立
- 对于 给定的指令 \(g\) ,合成引擎提供一个 可执行的验证器(validator) \(V_g\) ,用于评估任务目标是否满足
- 注意:每个指令都有不同的 Validator
- 论文基于终止环境状态定义一个稀疏的、二元的、指令条件的奖励:
$$ \mathcal{R}_{syn}(s_T; g) \triangleq \mathbb{I}[V_g(s_T) = \text{True}]$$- 其中 \(s_T\) 表示 Episode 终止时的环境状态
- 这种奖励公式提供了结果级别的监督,无需中间标注
- 状态空间 \((S)\) (State Space) :
Objective
- 论文不将训练数据视为静态数据集,而是将其概念化为一个动态分布,该分布根据当前策略快照 \(\pi_{\mathrm{old} }\) 进行自适应参数化
- 优化目标 \(J(\theta)\) 被制定为最大化在:由合成引擎 \(\mathcal{T}_{syn}\) 编排的耦合课程上的验证率
Theoretical Objective
- 形式上,论文的目标是最大化在一个任务分布上的期望成功率,该分布根据当前策略的能力 \((\pi_{\mathrm{old} })\) 自适应地演进:
$$J(\theta) = \mathbb{E}_{(g,V_g)\sim \mathcal{T}_{\pi_{\mathrm{old} } }(\cdot |\pi_{\mathrm{old} })}\left[\mathbb{E}_{\tau \sim \pi_\theta (\cdot |g)}[\mathcal{R}_{syn}(s_T;g)]\right],$$- 其中 \(\mathcal{T}_{syn}(\cdot |\pi_{\mathrm{old} })\) 表示合成引擎的分布,它根据智能体的性能动态调整任务复杂性和多样性
- 论文使用 \(\tau \sim \pi_{\theta}(\cdot |g)\) 表示在指令 \(g\) 下在环境 Dynamics \(\mathcal{P}\) 中执行策略 \(\pi_{\theta}\) 所诱导出的轨迹
- 理解:这里的 \(s_T\) 是 轨迹 \(\tau\) 中的最后一个状态(终止状态)
Empirical Approximation
- 由于上述期望没有闭式解,论文通过大规模蒙特卡洛估计进行经验近似
- 可扩展的交互基础设施维护一个临时的经验池 \(\mathcal{B}\),它聚合了高吞吐量的新鲜交互轨迹流:
$$\mathcal{B} = \{(\tau ,V_g)\mid \tau \sim \pi_{\mathrm{old} }(\cdot |g),(g,V_g)\sim \mathcal{T}_{syn}\} ,$$- 其中 \(\pi_{\mathrm{old} }\) 表示驱动成千上万个异步沙箱的策略快照
- 通过使用从 \(\mathcal{B}\) 中采样的批次持续更新 \(\theta\),论文有效地闭合了可验证合成、大规模执行和策略优化之间的循环
- 注意:上面的公式表示了经验包括了 轨迹 \(\tau\) 和验证器 \(\V_g\)
Verifiable Synthesis Engine
- 本节介绍一个可验证合成引擎,它专注于克服固有的局限性
- 例如 Reward Hacking ,以及缺乏精确的训练信号
- 与被动数据收集不同,基于该引擎,我们可以实现在“Generation-as-Validation”范式上的操作,如图 3 所示
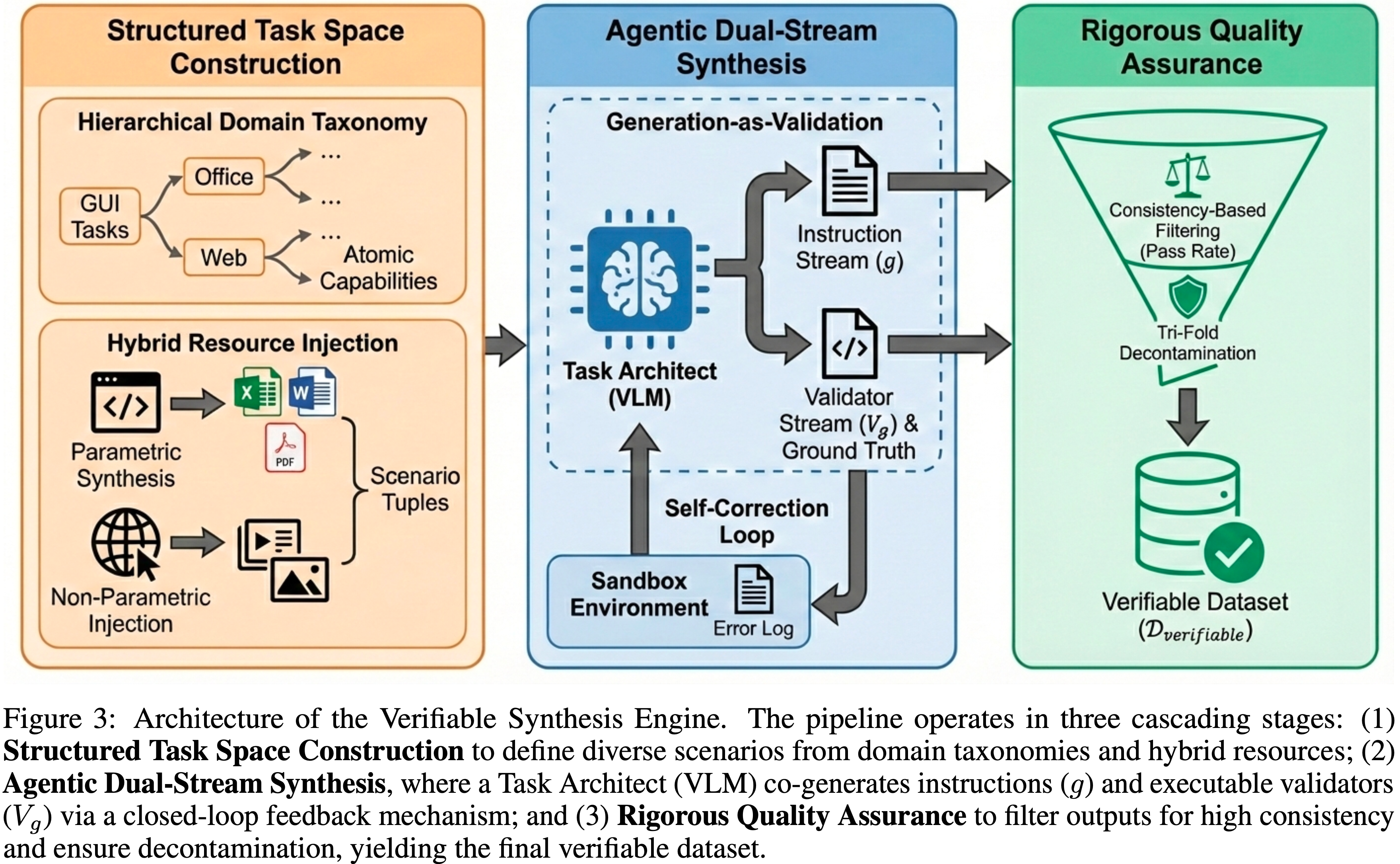
- 形式上,给定一个合成指令 \(g\),引擎必须共同生成一个确定性的、可执行的验证器 \(V_g\)
- 这确保了奖励信号 \(\mathcal{R}_{syn}(s_T; g)\) 源自对最终环境状态的严格验证,从而绕过了语义匹配的模糊性
- 该架构组织成三个级联模块:结构化任务空间构建、智能体双流合成和严格的质量保证
Structured Task Space Construction
- 为确保合成分布 \(\mathcal{T}_{syn}\) 捕捉真实世界计算机使用的复杂性,论文首先建立一个分解为域和资源的结构化任务空间
Hierarchical Domain Taxonomy
- 作者认为原子能力本质上是可转移的,并能组合形成复杂任务
- 在此原则指导下,论文系统地分类核心桌面应用程序(例如,Web 浏览器、Excel、Word),并将用户行为分解为原子能力
- 这种正交分解使智能体能够通过原始技能的重组泛化到多样化的场景
- 例如,Excel 中的财务分析任务被分解为子技能,如公式操作、数据排序和图表生成
- 利用分层域分类法,论文合成了涵盖多样化用户角色 (2024) 的广泛任务场景,以确保数据多样性
- 合成的场景范围从教育工作者设计讲座幻灯片到算法工程师进行技术文献调研
Hybrid Resource Injection
- 为了弥合模拟与现实的差距,论文对环境的初始状态实施了一种混合策略:
- 参数化合成 (Parametric synthesis) :
- 对于结构化数据(例如,产品销售数据),论文利用基于代码的生成器,通过参数化变量(如名称、价格和日期)来批量生成文档(Word, Excel, PDF)
- 这确保了数值和布局的高度可变性
- 非参数化注入 (Non-parametric injection) :
- 为了减轻合成模板的单调性,论文注入公共互联网数据(例如,图像、音频、复杂幻灯片)
- 这迫使智能体处理真实世界文件中固有的视觉噪声和结构多样性
- 参数化合成 (Parametric synthesis) :
Agentic Dual-Stream Synthesis(双流合成)
- 核心合成过程被建模为一个基于 ReAct 的智能体工作流 (2022)
- 给定一个采样的场景元组(角色,能力,资源),一个基座 VLM 作为任务架构师(Architect)执行双流生成:
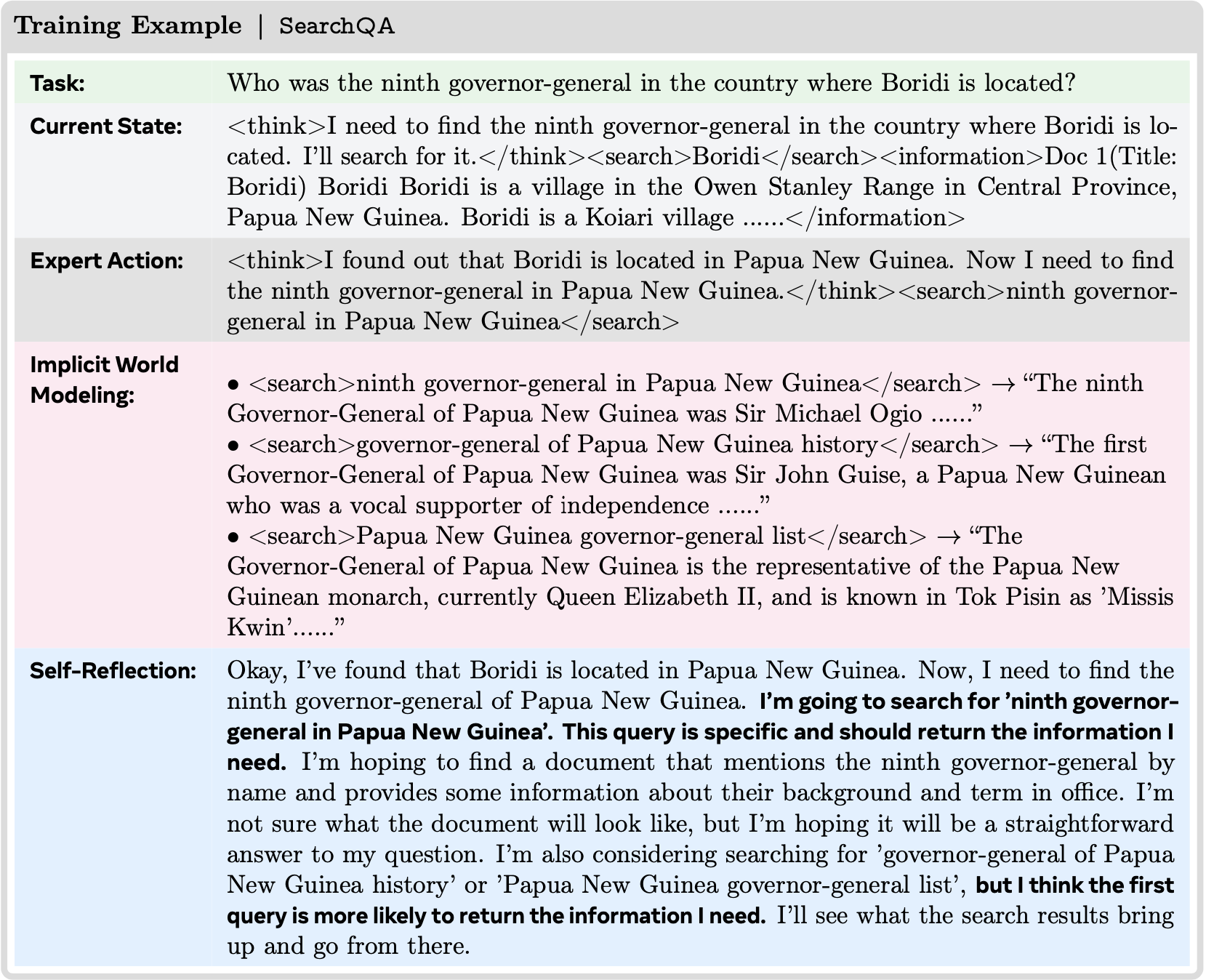
- 1)指令流 (g) (Instruction stream) :架构师基于特定的资源上下文制定一个自然语言 Query ,确保用户意图清晰且可实现
- 2)验证器流 \((V_{g})\) (Validator stream) :同时,架构师生成真值 (GT) 以及相应的可执行评估器代码
- 这段代码定义了任务的精确成功条件 (2025)
- 为了确保可执行性,论文强制执行一个闭环反馈机制
- 生成的代码立即在一个真实的沙箱环境中执行
- 执行结果(包括成功运行的输出文件,以及失败执行(例如,语法错误、API 不匹配)产生的错误消息)被反馈给模型,用于评估 GT 文件和评估器的质量
- 这个过程迭代多轮,直到执行成功并通过质量检查
- 为了进一步增强稳定性,论文将频繁使用的验证逻辑抽象成一个标准化工具库
- 最后,有效的元组被格式化为一个标准化的 JSON 结构,与 OSWorld 等现有基准测试兼容
Rigorous Quality Assurance
- 最后阶段通过一个严格的协议过滤原始合成的配对 \(\{(g, V_g)\}\),以消除误报(幻觉的成功)、漏报和数据泄露
Consistency-based filtering
- 论文部署一个参考计算机使用智能体,在合成任务上执行沙箱 Rollout
- 论文对数据纳入设定了高标准
- 首先,由于参数配置异常等问题而无法完成 Rollout 的任务,会将错误消息返回给基于 ReAct 的智能体工作流进行修改
- 其次,对于成功 Rollout 的任务,论文使用奖励模型和评估器计算通过率
- 在论文的分层域分类法组织下,论文对 奖励模型和评估器 这两个来源通过率存在显著差异的任务进行人工抽查
- 对于人工检查发现评估器明显失败导致误报或漏报的情况,论文优化基于 ReAct 的智能体工作流以缓解这些问题
- 最后,论文保留那些通过沙箱 Rollout、奖励模型和人工检查交叉验证的任务
Tri-fold decontamination:三重去污染
- 合成数据生成有效地缓解了高质量轨迹的稀缺性,但它引入了数据泄漏的风险,因为强大的模型可能会无意中从其庞大的预训练语料库中复制基准测试内容
- 为了防止指标虚高并确保论文实验洞察的有效性,论文执行了严格的去污染:
- (1) 语义去污染,使用 LLM-based 过滤移除与基准测试 Query 语义等效的指令;
- (2) 配置去污染,修剪在某些域内具有相同应用程序初始化设置的任务;
- (3) 评估器去污染,验证生成的执行成功条件和真值文件与现有评估脚本没有重叠
- 通过这条流水线,论文已成功将可验证训练数据扩展到 数万个实例 ,有效打破了人工数据整理的瓶颈
Scalable Interaction Infrastructure
- 从静态数据扩展到演进式经验学习,需要对基础设施能力进行根本性转变
- 论文的主动学习范式与被动训练流程不同,需要一个高吞吐量的“健身房(gymnasium)”,能够大规模地持续生成多样化、交互式的反馈
- 为了应对大规模强化学习中固有的异构性、高并发性和严格会话隔离等挑战,论文开发了一个统一的环境沙箱平台
- 如图 4 所示,该平台是 EvoCUA 的基石,每天编排数十万个沙箱会话,处理数百万个交互请求,并保持工业级的稳定性
Architecture and Abstractions
- 为了管理多样化交互任务的复杂性,该平台围绕两个核心抽象进行架构:Tools 和 Clusters
- Tools:
- 一个工具封装了模拟环境的不可变定义,包括版本控制的系统镜像和暴露的交互 API
- 该平台目前支持数百种不同的环境类型,从通用基准测试到专门的智能体环境
- 这种设计将环境迭代与实验解耦,确保了向后兼容性和可复现性
- 集群 (动态扩展单元) (Clusters (Dynamic Scaling Units))
- 集群代表工具的运行时实例,是环境扩展的基本单位
- 通过指定工具类型和配置资源配额,用户可以为不同的工作负载即时提供定制化的环境服务
- 这种抽象允许基础设施动态扩展环境实例(从少量调试会话到数万个并发训练节点)而不会产生资源争用或交叉污染
High-Throughput Orchestration(编排)
- 支持大规模探索的能力取决于论文的微服务架构的效率,该架构专门设计用于消除 I/O 瓶颈并实现快速的环境扩展
- 基于反应器模式,基础设施依赖于一个异步网关服务以实现非阻塞 I/O
- 该服务实现了每分钟数十万请求量级的路由吞吐量
- 通过将控制平面(生命周期管理)与数据平面(环境交互)解耦,网关防止了长时间运行的环境执行阻塞关键的路由逻辑
- 与网关相辅相成,分布式调度器专为极致的弹性而设计,负责管理海量沙箱镜像的生命周期
- 利用分布式分片和资源池化,调度器实现了高效的节点调度
- 更重要的是,它支持突发扩展能力,能在一分钟内启动数万个沙箱实例
- 这种快速实例化确保了环境扩展严格匹配 On-Policy 强化学习的训练需求,最大限度地减少了策略更新与经验收集之间的延迟
- 最终,这个弹性的 Scheduling backbone 使基础设施能够稳定地维持超过 10 万个并发沙箱
High-Fidelity Environment Instantiation(高保真环境实例化)
- 为了支持计算机使用任务的严格要求,论文实现了一个混合虚拟化架构,将 QEMU-KVM 虚拟机封装在 Docker 容器内
Hybrid virtualization,混合虚拟化
- 虽然 Docker 提供了与论文的编排层的兼容性,但内部执行依赖于带有 KVM 硬件加速的 QEMU
- 论文构建了一个定制的 QEMU 启动序列,明确禁用了非必需的外围设备,同时优化了 I/O 性能
- 这种嵌套设计确保了严格的内核级隔离(当智能体执行任意代码时,这对安全性至关重要),同时为 GUI 渲染和 I/O 操作保持了近乎原生的性能
Deterministic environment calibration(校准)
- 论文基于 Ubuntu 22.04 构建了一个定制的操作系统镜像,以解决模拟环境与现实部署之间的差距,并实现了特定的内核和用户空间补丁:
- 输入确定性 (HID补丁) (Input determinism (HID patching)) :
- 标准虚拟化通常存在键位映射冲突
- 论文在 xkb 内核级别校准了人机接口设备映射
- 具体来说,论文修改了
/usr/share/x11/xkb/symbols/pc的定义,以解决符号冲突(例如,US布局中的<与>的shift状态错误),确保智能体的符号意图与最终实现的字符输入严格匹配
- 渲染一致性 (Rendering consistency) :
- 为了防止办公软件中的布局偏移误导视觉智能体,论文将一套全面的专有字体直接注入到系统字体缓存(fc-cache)中
- 这保证了文档的渲染效果与其原生版本完全相同
- 运行时稳定性 (Runtime stability) :
- 镜像通过系统级代理配置进行了加固,以解决网络不稳定的问题,并预安装了xsel和qpdf等依赖项,以消除剪贴板操作和PDF处理过程中的常见运行时错误
- 输入确定性 (HID补丁) (Input determinism (HID patching)) :
Evolving Paradigm via Learning from Experience
- 为了弥合原子模仿与通用问题解决之间的鸿沟,论文提出了通过从经验中学习的演进范式
- 该范式从静态数据扩展转向动态能力演进循环
- 该过程被构建为三个递进阶段:有监督的冷启动以建立行为先验,拒采样微调以通过自适应扩展巩固成功经验,以及强化学习以纠正失败并通过交互探索复杂动态
Cold-Start
- 为了使用强大的行为先验初始化策略 \(\pi_{\mathrm{init} }\) ,论文构建了一个数据集 \(\mathcal{D}_{\mathrm{prior} }\) ,其中包含展示精确执行和连贯推理的轨迹
- 论文首先形式化地定义了统一动作和思考空间,以确立智能体的结构边界,随后利用这些定义来合成并格式化基于现实环境的交互数据
Unifying the Action Space(A)
- 论文实现了语义动作映射 (Semantic Action Mapping),以构建一个统一动作空间
$$ \mathcal{A} = \mathcal{A}_{\mathrm{mouse} } \cup \mathcal{A}_{\mathrm{keyboard} } \cup \mathcal{A}_{\mathrm{control} }$$- 如附录 A 所示
- 论文将原始事件流分为两个主要部分:
- 物理交互 (\(\mathcal{A}_{\mathrm{mouse} } \cup \mathcal{A}_{\mathrm{keyboard} }\)) (Physical Interaction) :
- 这部分包括基于坐标的鼠标事件和键盘输入
- 为了支持复杂的多步骤操作,论文实现了一个状态化交互机制 (Stateful Interaction mechanism)
- 通过将离散的按键操作分解为 key_down 和 key_up 事件,策略可以维护复杂任务所需的活动状态(例如,按住 Shift 键进行多选)
- 控制原语 (\(\mathcal{A}_{\mathrm{control} }\)) (Control Primitives) :
- 论文引入了元动作来管理与物理 I/O 不同的执行流程
- 具体来说,
wait原语允许智能体处理异步UI渲染,而terminate作为正式信号来结束任务
- 物理交互 (\(\mathcal{A}_{\mathrm{mouse} } \cup \mathcal{A}_{\mathrm{keyboard} }\)) (Physical Interaction) :
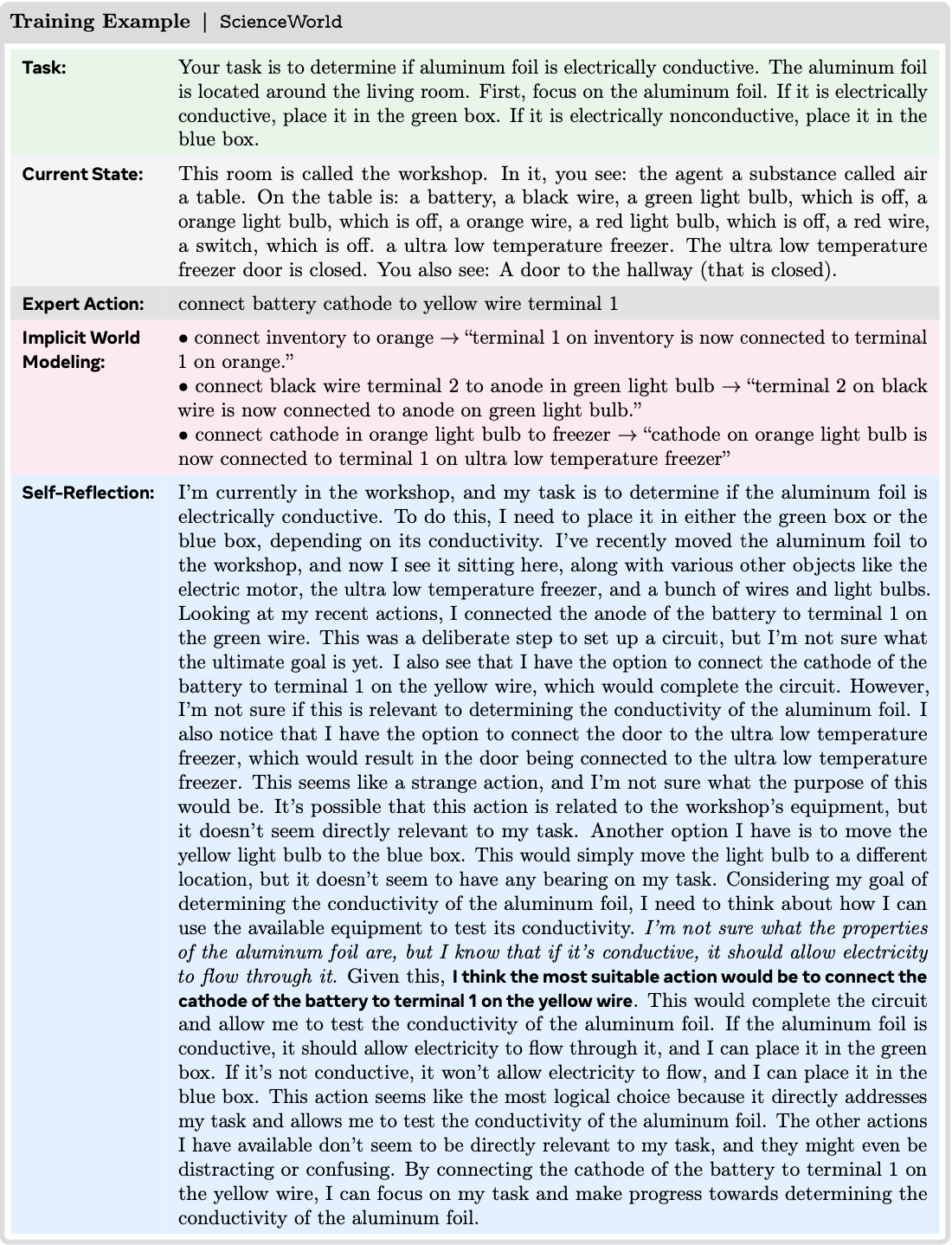
Structuring the Thought Space(Z)
- 为了实现可解释和稳健的决策,论文为潜在思考空间 \(Z\) 定义了一个推理模式 (Reasoning Schema)
- 该模式强加了一种结构化格式,以确保推理过程与执行逻辑严格一致:
- 目标澄清 (\(z_{0}\)) (Goal Clarification) :
- 在初始步骤 (\(t = 0\)),要求智能体明确转述用户的目标
- 这澄清了模糊的指令,并为后续规划过程奠定了基础
- 观察一致性 (\(z_{\mathrm{obs} }\)) (Observation Consistency) :
- 为了最小化幻觉 (hallucination),推理轨迹必须包含关键视觉元素的简洁摘要
- 论文 强制要求此文本摘要与实际观察到的状态之间存在严格的语义一致性
- 自我验证 (\(z_{\mathrm{check} }\)) (Self-Verification) :
- 在发出最终终止信号之前,提示智能体执行辅助交互步骤(例如,检查文件状态),以视觉方式确认执行结果与用户指令相符
- 反思与纠正 (\(z_{\mathrm{reflect} }\)) (Reflection and Correction) :
- 论文利用失败的 Rollout 进行错误纠正。在识别出失败轨迹中的关键错误步骤后,论文将环境恢复到错误发生前的状态
- 为了考虑沙箱的非确定性,论文严格筛选恢复的环境与原始轨迹之间的状态一致性
- 从这个有效的恢复状态出发,论文使用高温采样来诱导自我纠正,生成成功的补救路径
- 推理增强终止 (\(z_{T}\)) (Reasoning-Augmented Termination) :
- 为了防止模型对终止标签过拟合,终止动作必须严格以前面的推理轨迹为条件
- 该轨迹要求智能体明确综合视觉证据来证明任务完成,确保决策基于逻辑而非记忆的模式
- 目标澄清 (\(z_{0}\)) (Goal Clarification) :
- 基于这些形式化的定义,论文通过在模块化框架内利用基础视觉语言模型(例如,Qwen3-VL、OpenCUA)来合成先验数据集 \(\mathcal{D}_{\mathrm{prior} }\)
- 至关重要的是,为了确保推理与动作之间的一致性,论文采用了一种事后推理生成策略 (Hindsight Reasoning Generation strategy)
- 将真实执行路径视为已知的未来信息,论文事后生成解释所观察动作的推理轨迹 \(z_{t}\) ,从而用连贯的认知链来增强物理轨迹
Training Details
- 对于模型训练,论文将这些多轮轨迹分解为单轮样本
- 为了平衡信息密度与内存限制,输入上下文仅为最近五个步骤保留完整的多模态细节(截图、推理和动作),而较早的历史信息则被压缩为纯文本的语义动作
- 训练损失仅针对当前步骤的推理和动作进行计算
- 最后,为了保留通用的基础能力,论文融入了多样化的通用数据混合,涵盖 STEM、OCR、视觉基础理解和基于文本的推理
- 这些通用数据的数量与分解后的单轮轨迹样本规模保持平衡
Qualitative Analysis
- 论文合成了符合此模式的轨迹数据
- 经过冷启动训练后,定性分析证实智能体有效地掌握了原子能力,如附录 D 所示
- 但在复杂场景中仍存在关键的稳健性差距
- 虽然智能体可以执行标准的长流程工作流,但在边界案例中表现出脆弱性
- 为了应对这些限制,论文进入下一阶段:内化可扩展、高质量的经验
Rejection Sampling Fine-Tuning(RFT)
- 拒采样微调 (Rejection Sampling Fine-Tuning (RFT)) (2024) 的目标是通过仅从高质量、成功的执行中学习,来巩固智能体解决任务的能力
- 这个过程包括两个关键组成部分:通过动态计算高效生成成功轨迹,以及对它们进行去噪以最大化信噪比
Dynamic Compute Budgeting
- 为了在计算限制下优化高质量经验的生成,论文提出了动态计算预算
- 该机制不是均匀分配 Rollout 资源,而是根据智能体当前对每个特定任务的熟练程度来调整探索预算
- 论文建立一个层次化的预算谱(hierarchical budget spectrum)
$$ \mathcal{K} = \{k_{1},\ldots ,k_{n}\}$$- 并配以递减的成功率阈值
$$ \Lambda = \{\tau_{1},\ldots ,\tau_{n}\}$$- 理解:过滤用的成功率阈值为什么是逐步递减的,是因为这里的成功率是跟前面的预算一一对齐的,推测预算是逐步减少的,故而对应的成功率也会逐渐减小
- 对于从合成引擎 \(\mathcal{T}_{\mathrm{syn} }\) 抽取的给定任务 Query \(g\) ,系统识别满足充分条件的最优 Rollout 预算 \(K^{*}\) :
$$K^{*} = k_{i^{*} }\quad \mathrm{where}\quad i^{*} = \min \{i\mid \mathrm{SR}(k_{i})\geq \tau_{i}\} \tag{1}$$- \(\mathrm{SR}(k_{i})\) 表示使用预算 \(k_{i}\) 观察到的通过率
- 该策略有效地剪除了高效解决的任务,并将计算能力集中在边界 Query 上,即策略表现出高方差的任务
- 并配以递减的成功率阈值
Step-Level Denoising
- 虽然成功的 Rollout 展示了模型的能力,但它们通常包含显著的噪音
- 论文使用一个评估模型 (judge model) 来分析轨迹并屏蔽冗余步骤
- 这种过滤对于不可行的任务尤其重要;
- 对于这些任务,论文移除所有中间动作,并严格保留推理轨迹和最终的终止失败动作
- 这个过程将原始数据精炼为高质量监督信号,然后将其汇总到经验池 \(B\) 中
- 通过这个生成和过滤流程,论文将高保真经验池 \(B\) 扩展到数万条轨迹
- 论文将这些特定领域的经验与平衡的通用多模态数据语料库交错混合,以防止灾难性遗忘
Reinforcement Learning
- 虽然 RFT 巩固了智能体能做什么 ,但它 并不显式地纠正其错误
- 为了扩展能力边界,论文采用 RL 从失败中学习,并通过在线交互进行探索
- 由于状态不对齐,标准的轨迹级偏好优化不适合长流程任务
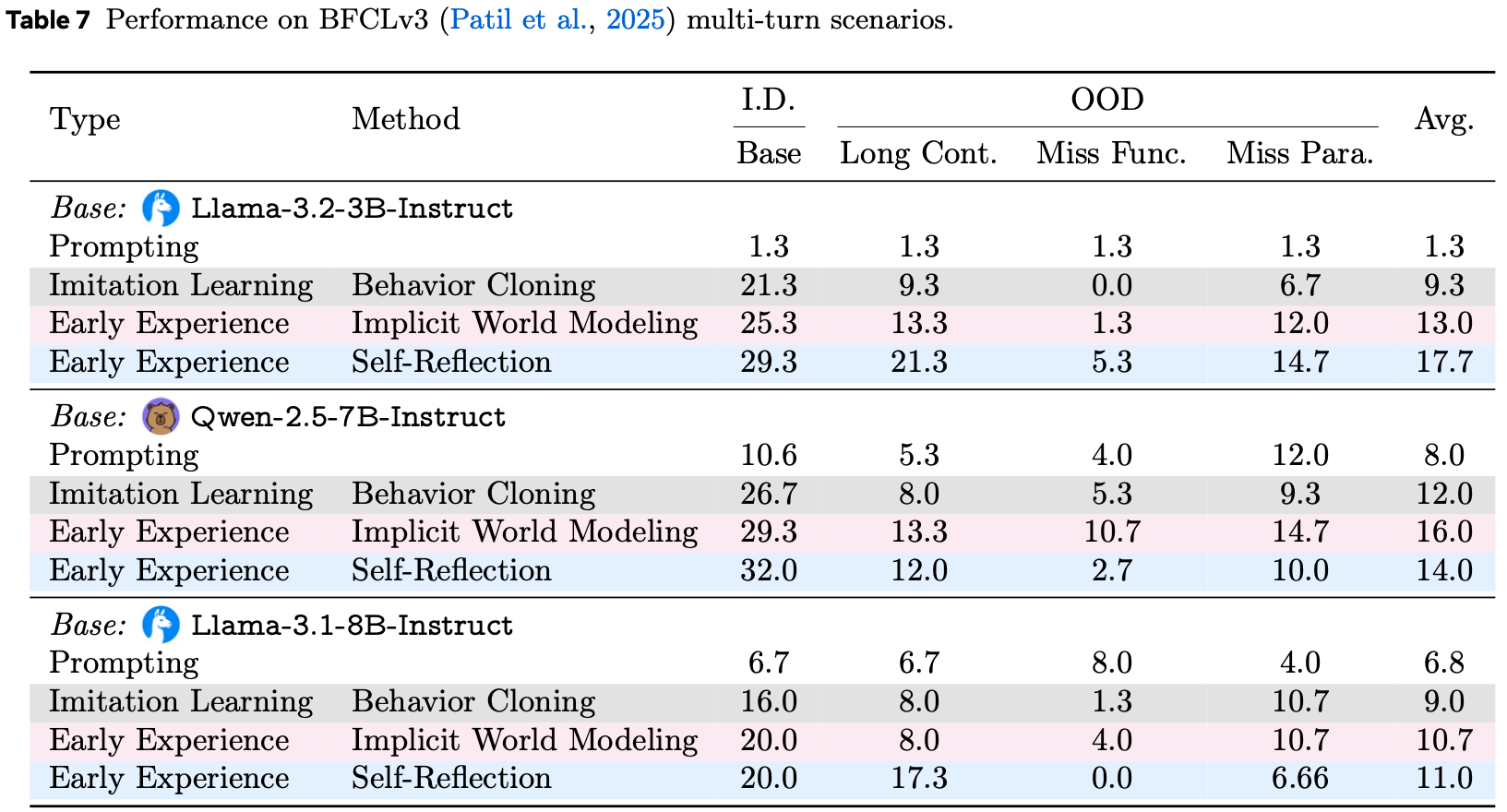
- 论文转而提出了一种步骤级直接偏好优化策略 (Step-Level Direct Preference Optimization strategy) (2024),该策略针对图5所示的关键分叉点 (Critical Forking Points)
Causal Deviation Discovery,因果偏差发现
- 给定一个失败的 Rollout \(\tau^{- }\) 和一个成功的参考轨迹 \(\tau^{+}\) (从相同或语义等价的任务中检索),论文采用参考引导诊断机制 (Reference-Guided Diagnosis mechanism)
- 论文将 关键偏差步骤 \(t^{*}\) 识别为第一个时间戳 ,在该时间戳处,尽管环境状态在功能上保持等效,但智能体的动作偏离了参考
- 这隔离了导致智能体离开最优解流形的特定响应 \((z_{t^{*} }^{- },a_{t^{*} }^{- })\)
- 注意:这里只是识别到了关键错误步骤
Structured Preference Construction
- 识别出关键错误 \((z_{l},a_{l}) = (z_{l}^{*},a_{l}^{*})\) 后,论文构建偏好对以提供全面的监督
- 范式1:动作纠正 (在步骤 \(t^*\)) (Paradigm I: Action Correction (At Step \(t^*\)))
- 目标是用最优的 Chosen 响应 \((z_{w},a_{w})\) 替换 Rejected 的错误 \((z_{l},a_{l})\)
- 论文通过基于窗口的参考对齐(通过 VLM 语义匹配从 \(\tau^+\) 迁移思考和动作)或基于视觉的合成(当不存在对齐时,通过通用模型合成新的轨迹)来获得 \((z_{w},a_{w})\)
- 范式2:反思与恢复 (在步骤 \(t^* +1\)) (Paradigm II: Reflection and Recovery (At Step \(t^* +1\)))
- 为了提高稳健性,论文处理错误发生后的立即状态 \((t^* +1)\)
- 论文将智能体的盲目继续视为 Rejected 样本
- 对于 Chosen 样本 ,论文合成一个反思轨迹 (Reflection Trace)
- 智能体被训练为停止并生成一个推理链,而不是盲目行动
- 该推理链:(1) 观察意外的屏幕状态 并 (2) 制定补救计划
- 理解:
- 范式1:
- Rejected:旧的错误步骤
- Chosen:新合成的正确步骤,针对步骤 \(t^*\) 动作纠正,用最优的 Chosen 响应 \((z_{w},a_{w})\) 替换 Rejected 的错误 \((z_{l},a_{l})\)
- 范式2:
- Rejected:之前盲目继续的样本
- Chosen:反思样本,针对步骤 \(t^* + 1\),对错误步骤进行改进(其他更优模型或高温),而不是盲目继续(之前的轨迹会盲目继续)
- 这里相当于让模型开始反思,从错误中反思重新开始的方式,最终模型能学会思考
- 范式1:
Optimization Objective
- 论文使用直接偏好优化 (Direct Preference Optimization (DPO)) 来优化策略 \(\pi_{\theta}\)
- 与论文策略根据历史 \(h_{t}\) 和观察 \(o_{t}\) 生成推理轨迹 \(z\) 和动作 \(a\) 的公式一致,损失函数定义为:
$$\mathcal{I}(\theta) = -\mathbb{E}_{(h_t,a_t,(z,a)_w,(z,a)_l)\sim \mathcal{D} }\left[\log \sigma \left(\beta \log \frac{\pi_{\theta}(z_w,a_w|h_t,a_t)}{\pi_{\mathrm{ref} }(z_w,a_w|h_t,a_t)} -\beta \log \frac{\pi_{\theta}(z_l,a_l|h_t,a_t)}{\pi_{\mathrm{ref} }(z_l,a_l|h_t,a_t)}\right)\right]. \tag{2}$$ - 通过使用这些结构化偏好迭代更新策略,EvoCUA 不断扩展其能力边界,有效地将短暂的交互经验转化为稳健的模型参数
- 总之,演进式经验学习范式为增强智能体可靠性建立了一个严格的循环
- 通过协同结合拒采样微调来巩固基本执行模式,以及强化学习来纠正复杂、长尾场景中的错误,EvoCUA 迭代地将可扩展的合成经验转化为策略参数
- 这种双重机制确保智能体不仅在标准任务上稳定性能,而且在边界条件下显著提高了稳健性和泛化能力,从而实现更稳定和通用的计算机使用能力
Evaluation
- 本节对 EvoCUA 进行全面实证评估
- 论文的分析聚焦于三个关键维度:
- (1) 在线智能体能力 (Online Agentic Capability),评估在真实环境中的长程交互;
- (2) 离线定位 (Offline Grounding),评估细粒度的 UI 元素理解;
- (3) 通用 VLM 能力 (General VLM Capabilities),确保保留通用的多模态推理能力
Experimental Setup
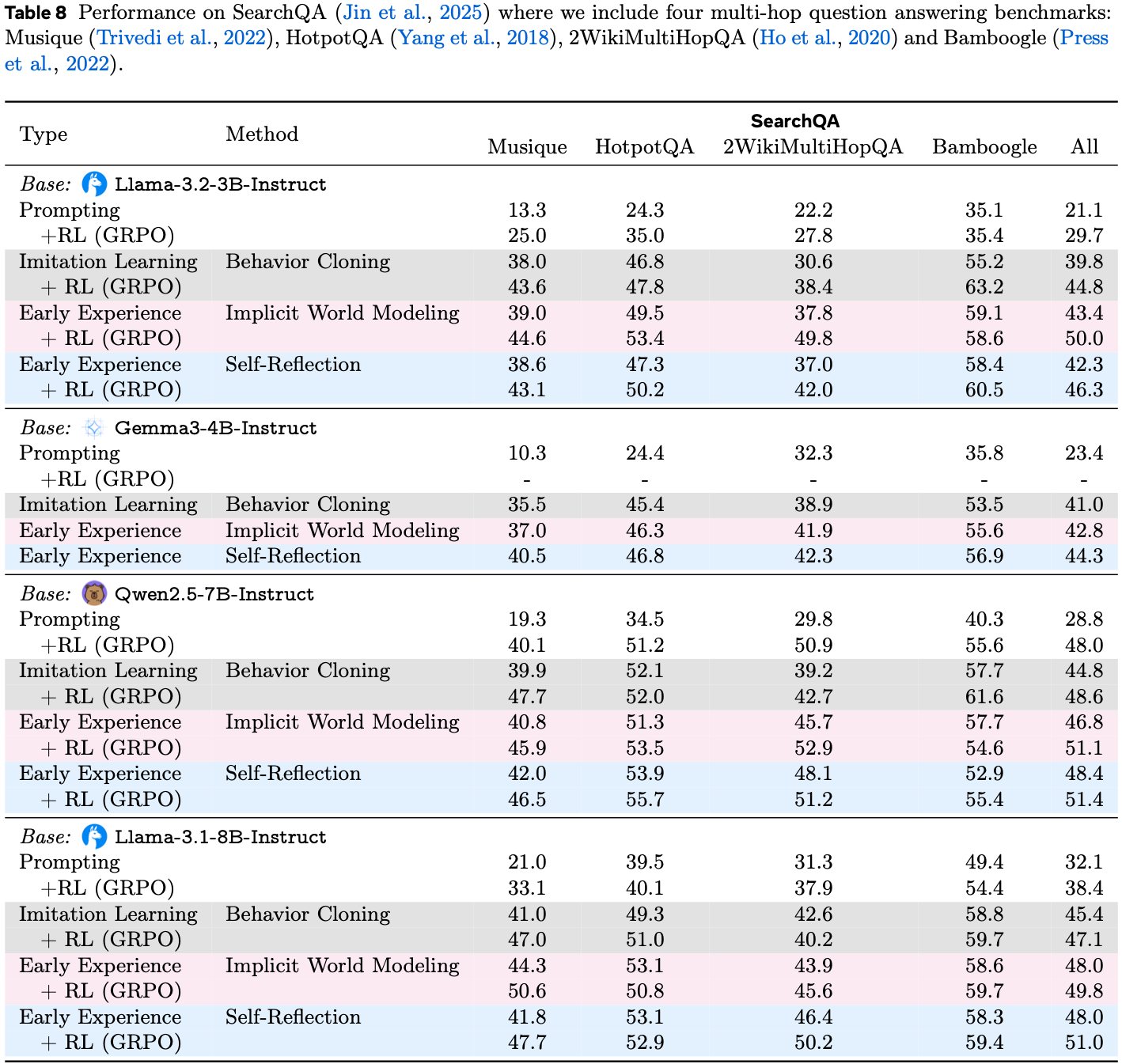
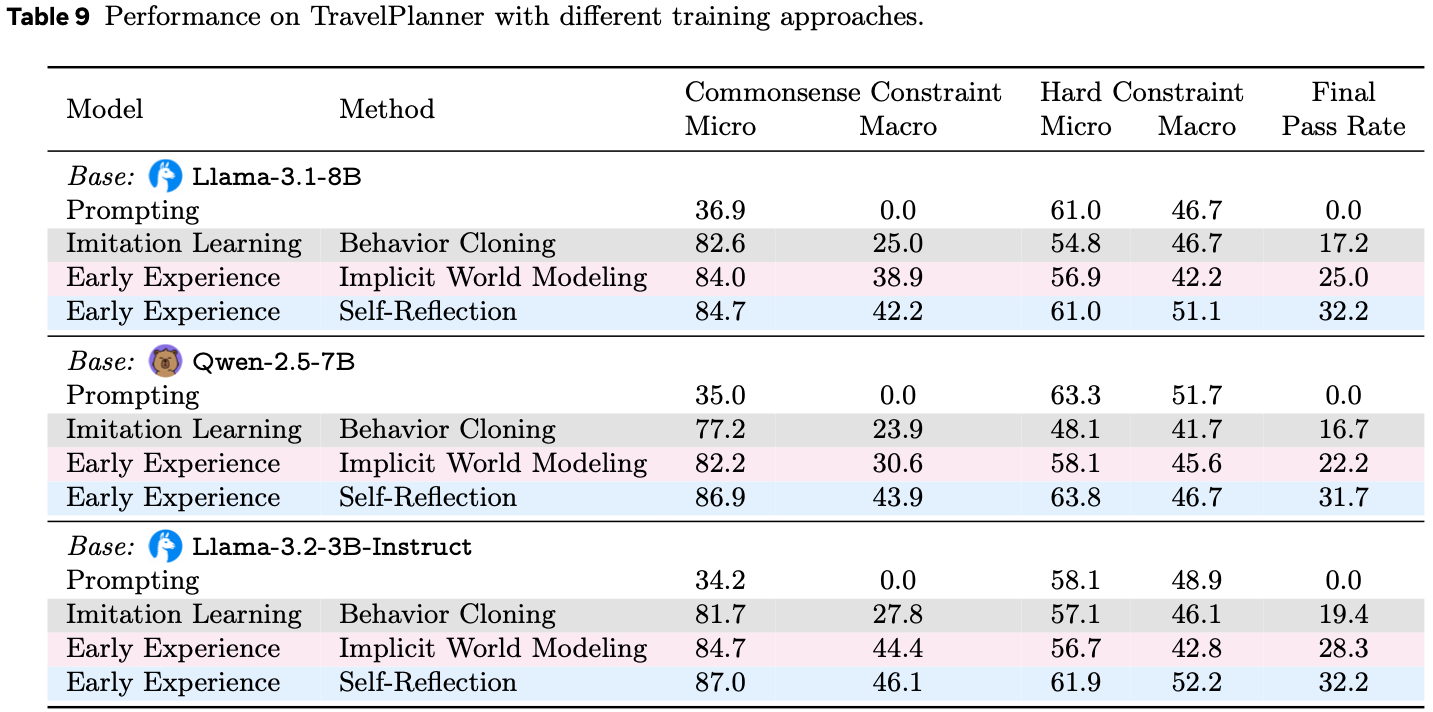
- 为了超越静态模仿,论文采用统一的训练流程,该流程始于一个轻量级的冷启动 (cold start) 阶段,使用约 1k 条高质量轨迹来建立完整的动作空间和结构化的推理模式
- 随后,模型进入一个结合经验生成与策略优化的持续迭代优化循环
- 在这个演化阶段,论文通过从大规模拒绝采样中收集成功轨迹、应用步级降噪,同时通过从错误中提取的偏好学习和在真实环境中的在线探索来混合优化策略,逐步扩展训练分布
- 整个过程由一个 pass@k 引导的动态计算策略驱动,该策略自动将计算资源集中在更难的问题上,并为表现不佳的领域合成补充数据,确保跨迭代的持续能力增长
- 论文通过在 Qwen3-VL-Thinking (2025a) (8B, 32B) 和 OpenCUA (2025b) (7B, 32B, 72B) 基础模型上进行后训练,在不同规模上验证了论文的方法
Main Results
Online Agent Evaluation
- 论文在 OSWorld 基准测试上评估 EvoCUA,该基准是开放式计算机使用任务的代表性测试平台
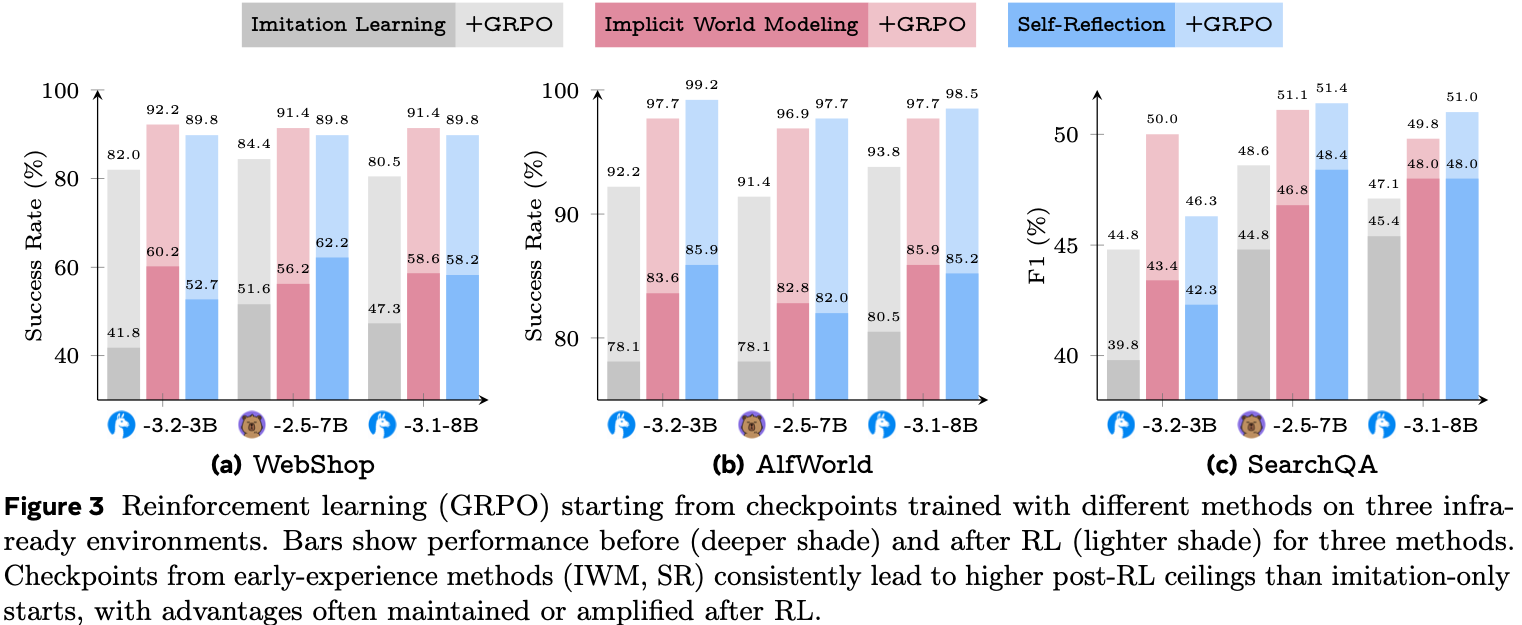
- 如表 1 总结所示,论文的结果突显了所提出方法的有效性:
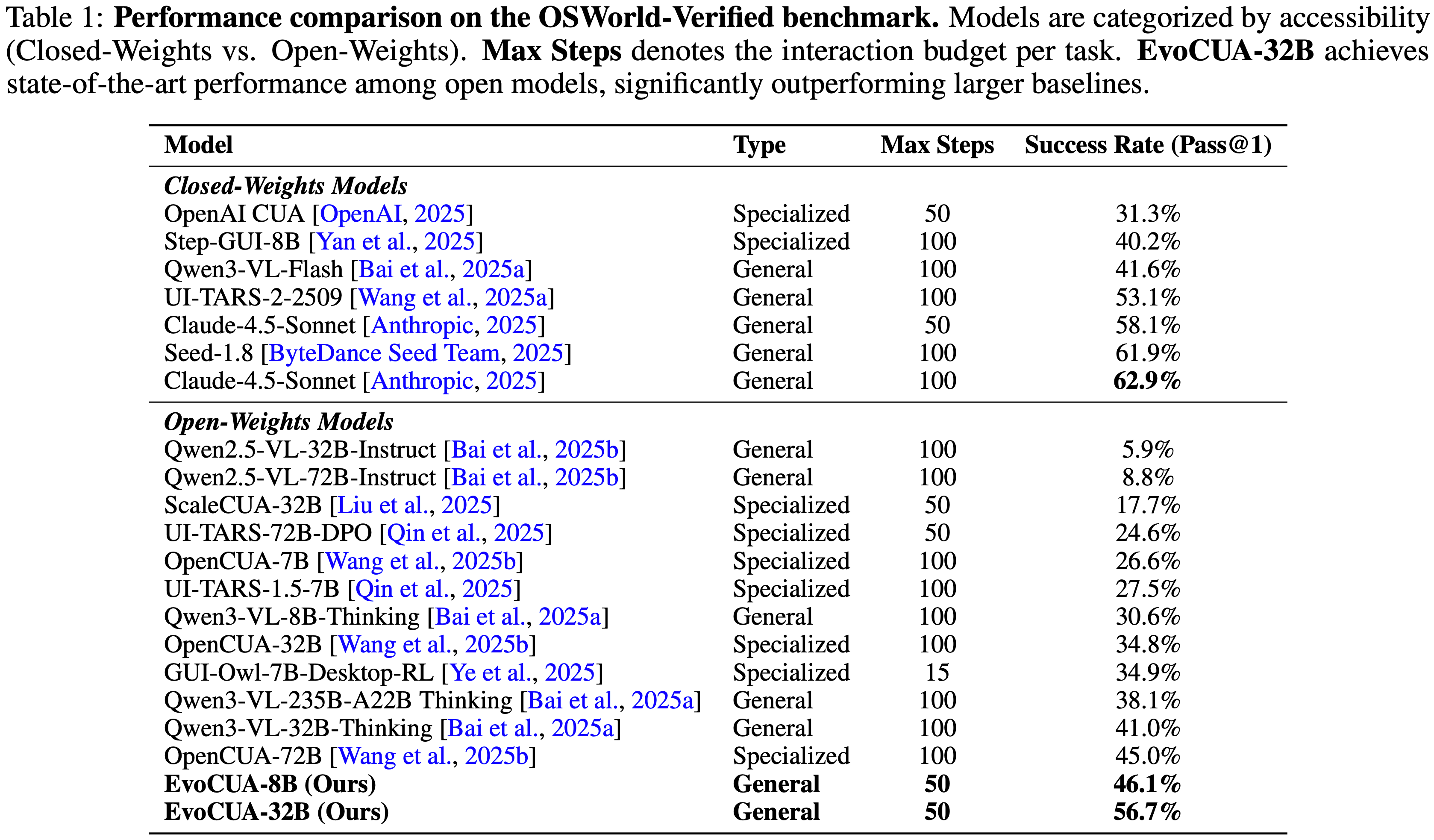
- ** SOTA 开放权重性能 (State-of-the-Art Open-Weights Performance)**
- 论文的主要模型 EvoCUA-32B,基于 Qwen3-VL-32B-Thinking (2025a) 主干微调,达到了 \(56.7%\) 的成功率
- 这一性能在所有评估的开放权重模型中位列第一
- 显著改进与效率 (Significant Improvements & Efficiency)
- EvoCUA-32B 相比之前的开源最先进模型 OpenCUA-72B (45.0%) 取得了 \(+11.7%\) 的绝对提升,相比其基础模型提升了 \(+15.1%\)
- 值得注意的是,这些结果是在严格的 50 步限制下实现的,而基线模型通常需要 100 步预算才能达到峰值性能,这表明论文模型具有更优的执行精度
- 与闭源权重前沿模型竞争 (Competitive with Closed-Weights Frontiers)
- EvoCUA-32B 有效地缩小了与闭源权重模型的差距
- 最显著的是,它以 \(+3.6%\) 的优势超过了强大的闭源权重基线 UI-TARS-2-2509 (53.1%)
- 在相同的步数限制下,EvoCUA-32B 与行业领先的 Claude-4.5-Sonnet (58.1%) 之间的性能差距缩小到仅 \(1.4%\)
- 扩展效率与训练优势 (Scaling Efficiency & Training Superiority)
- 论文方法的有效性延伸到了更小的模型规模
- EvoCUA-8B 达到了 \(46.1%\) 的成功率,超越了像 OpenCUA-72B 这样的专用 72B 参数模型
- 与 Step-GUI-8B (2025) 的直接对比尤其具有启发性:
- 尽管两个模型都从相同的 Qwen3-VL-8B 主干初始化,但 EvoCUA-8B 取得了 \(+5.9%\) 的更高成功率 (46.1% 对比 40.2%)
- 这严格隔离了论文演化经验学习范式的贡献,确认了论文的数据合成和 RL 策略从相同的基础架构中释放了显著更大的潜力
Offline Grounding(定位)and General Capabilities
- 论文评估 EvoCUA 在两个关键维度的性能:
- 细粒度 GUI 定位 (ScreenSpot-v2 (2024), ScreenSpot-Pro (2025), OSWorld-G (2025))
- 通用多模态鲁棒性 (MMMU (2024), MMMU-Pro (2025), MathVista (2024), MMStar (2024), OCRBench (2024))
- 表 2 总结了不同模型规模和主干的结果
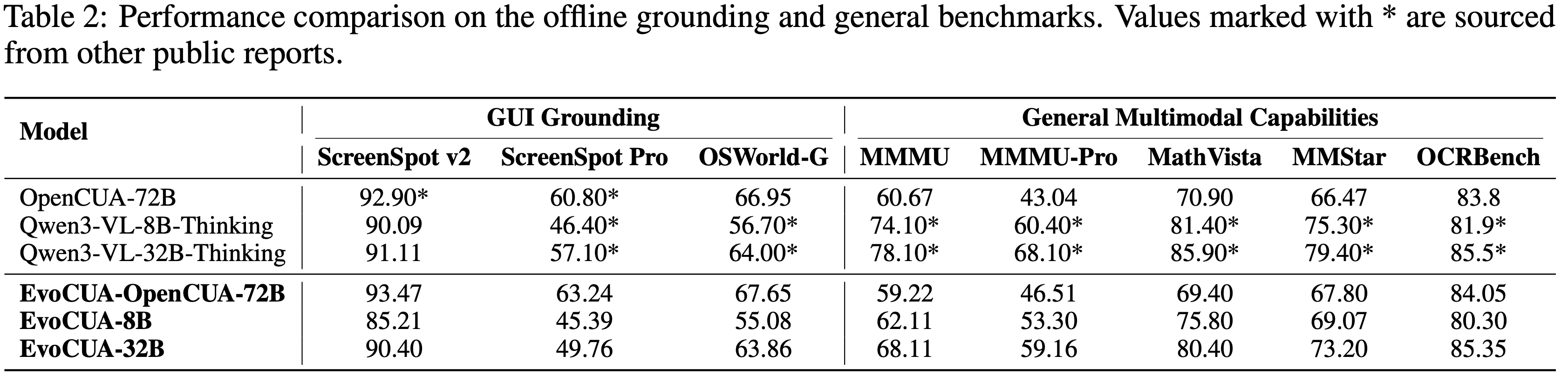
Analysis
- 论文观察到根据使用的基础模型的不同而有不同的行为
- 对于 OpenCUA-72B 主干,论文的后训练策略在定位和通用基准测试中都保持了性能持平或略有提升(例如,保持 MMMU 分数同时提升 OSWorld-G)
- 这种稳定性证实,当数据分布一致时,论文的训练方法能有效保留基础模型的知识
- 与 Qwen3-VL-32B-Thinking 基线相比,EvoCUA-32B 变体在特定指标上表现出性能下降,尤其是在 ScreenSpot-Pro 和 MMMU 上
- 论文将这种性能下降主要归因于数据分布和模式的差异
- 由于时间限制,用于微调 EvoCUA 的通用数据集直接采用了来自 OpenCUA-72B 变体实验的数据集
- 然而,这个数据集是“非思考型”的,与 Qwen3-VL-32B-Thinking 模型的“思考型”分布存在显著不匹配
- 论文进一步分析了 Qwen3-VL-32B-Thinking 和 EvoCUA 在通用基准测试上的输出长度
- 结果显示,与 Qwen3-VL-32B-Thinking 相比,EvoCUA 的 Token 数量显著减少 (2,514 vs 3,620),同时输出风格也发生了转变
Conclusion
- 在 OpenCUA 主干上的一致性能验证了论文训练策略的有效性
- 在基于 Qwen3-VL-Thinking 的变体中观察到的性能下降主要归因于通用数据分布和模式的转变
- 未来版本的 EvoCUA 模型将纳入升级的基于“思考”的通用数据集
- 这种对齐有望解决当前的差异,并进一步提高模型的泛化性能
Ablation Study
- 为了严格验证 EvoCUA 中每个组件的贡献,论文进行了广泛的消融研究
- 论文使用了两个不同的基础模型,Qwen3-VL-32B-Thinking 和 OpenCUA-72B,以证明论文特定模块的效力以及演化经验学习范式的普适性
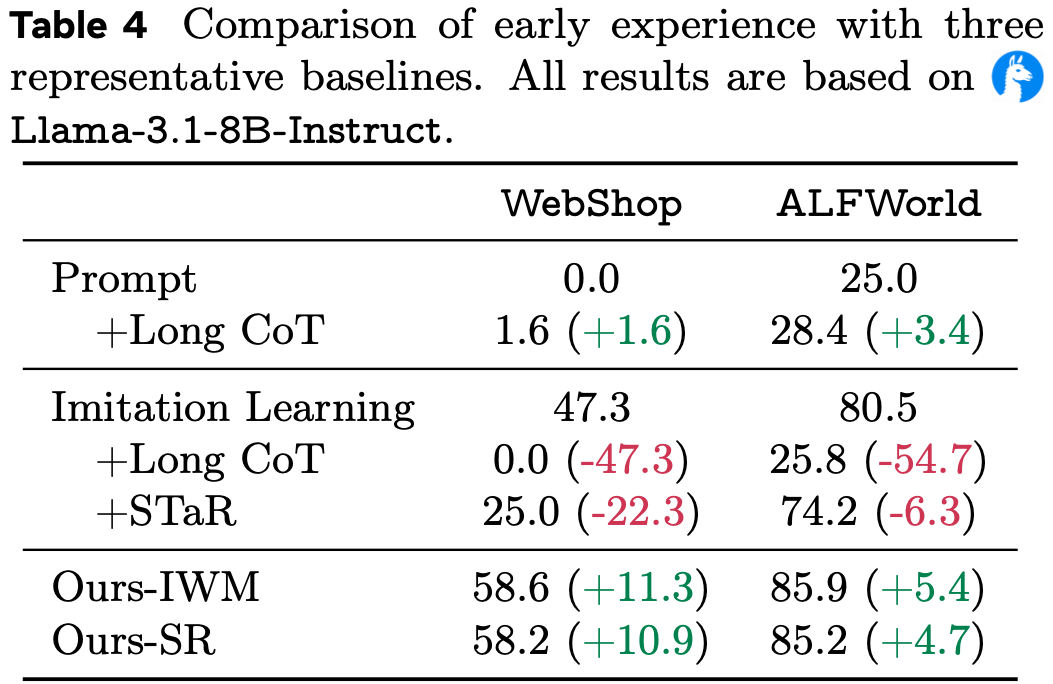
Component Analysis on EvoCUA-32B
- 论文采用 Qwen3-VL-32B-Thinking 作为基础检查点,以剖析来自统一动作空间、冷启动、拒绝微调和 RL 的累积收益
- 如表 3 所示,演化循环的每个阶段都带来了显著的单调改进

- 统一动作空间与冷启动的影响 (Impact of Action Space & Cold Start)
- 论文首先通过受控单变量实验量化了统一动作空间的影响,将标准的 SFT 基线与一个包含论文精确定义动作的 SFT 变体进行比较
- 统一动作空间的明确表述提供了 +4.84% 的基础增益
- 通过进一步在合成的高质量轨迹上进行冷启动训练来注入行为先验,论文观察到额外的 \(+2.62%\) 增益
- 这验证了用结构化动作模式和连贯推理模式为基础模型奠定基础是进行有效大规模经验学习的前提
- 论文首先通过受控单变量实验量化了统一动作空间的影响,将标准的 SFT 基线与一个包含论文精确定义动作的 SFT 变体进行比较
- 演化学习的效力 (Efficacy of Evolutionary Learning (RFT & DPO))
- 过渡到主动学习阶段,拒绝微调通过巩固成功经验将性能显著提升了 \(+3.13%\)
- 随后,通过 DPO 明确解决失败模式,论文实现了 \(+3.21%\) 的显著改进,突显了学习“不应该做什么”与学习成功惯例同等重要
- Crucially,对整个演化循环执行额外的迭代(再叠加一轮 RFT 和 DPO)带来了进一步的 \(+1.90%\) 增益
- 这种持续收益证实了论文范式的自我维持特性,模型通过递归合成和纠正迭代地精炼其能力边界
Generalizability on OpenCUA-72B
- 为了验证论文方法的普适性,论文将相同的范式应用于更大的 OpenCUA-72B 模型
- 如表 4 详述,演化经验学习范式在不同模型规模上带来了一致的增益

- OpenCUA-72B 上的结果与论文在 Qwen3-VL 上的发现相呼应,DPO \((+3.02%)\) 和 RFT \((+3.69%)\) 贡献显著
- 有趣的是,论文观察到纯 RFT(叠加 3 轮,没有明确的冷启动)实现了 \(+8.12%\) 的显著增益,如表 5 所示
- 这表明,对于一个足够强大的基础模型,仅凭合成引擎和可扩展的交互基础设施就可以驱动巨大的能力改进,甚至无需显式注入先验

- 这表明,对于一个足够强大的基础模型,仅凭合成引擎和可扩展的交互基础设施就可以驱动巨大的能力改进,甚至无需显式注入先验
- 此外,OpenCUA-72B 采用了标准的 pyautogui 格式
- 这个动作空间本身支持有状态操作(例如 shift+click)并且没有明显的功能缺陷
Scaling Analysis
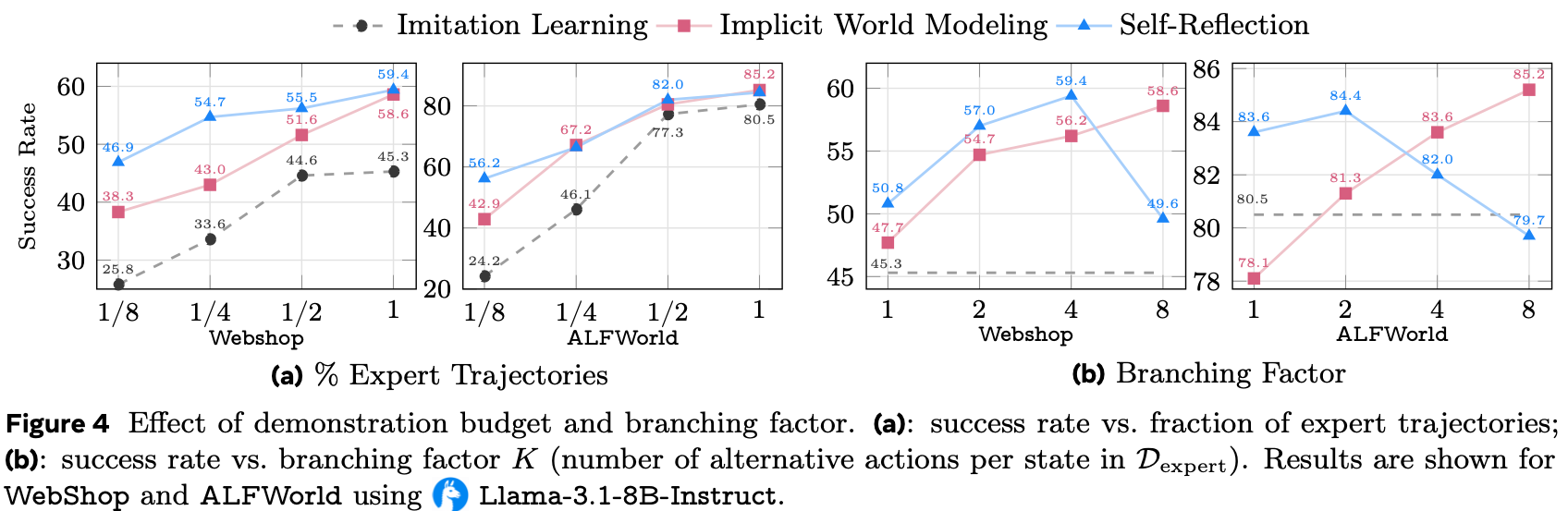
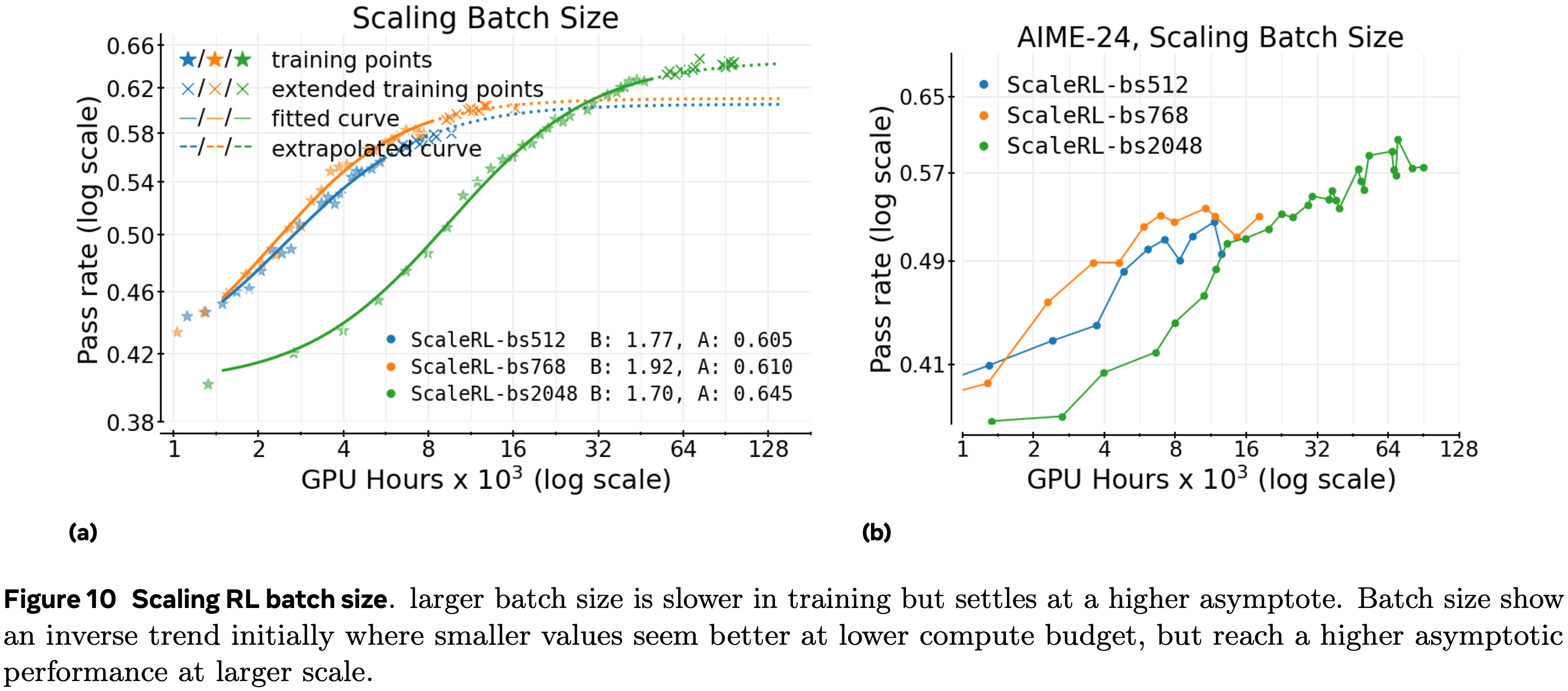
- 论文通过分析在不同 Pass@k 值、最大推理步数和数据量下的性能增益 \((\Delta %)\) 来研究 EvoCUA 的可扩展性
Scaling with Pass@k
- 在图 6a 中,在所有 Pass@k 指标上,EvoCUA 相对于基础模型 (Qwen3-VL-Thinking) 保持了稳定的性能领先
- 如图 6a 所示,32B 模型保持了正向增益,在 \(k = 16\) 时达到峰值 \(+4.93%\),即使是在更高的 \(k\) 值时也保持显著优势
- 这种持续的性能差距表明,论文优化动作空间和推理先验的训练策略从根本上提升了模型的性能上限
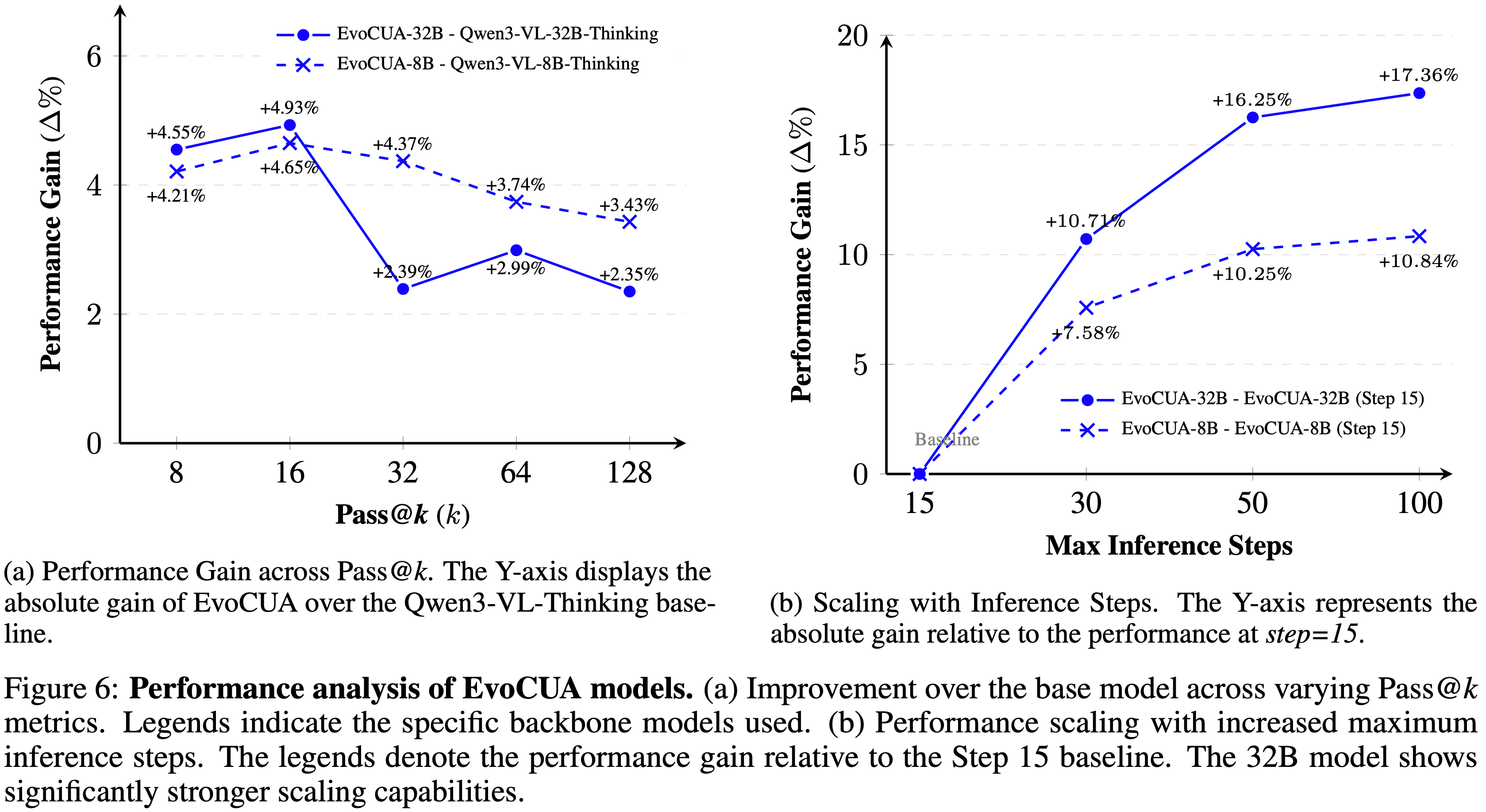
Scaling with Max Steps
- 在图 6b 中,论文观察到随着最大步数限制的增加,性能稳步提升
- 将推理能力从 15 步增加到 50 步带来了一致的增益,32B 模型相比基线提升了 \(+16.25%\)
- 超过 50 步后,改进速度放缓,这主要是由于当前训练分布中超过 50 步的轨迹稀缺
Experience Scaling
- 论文在 RFT 上进行了经验扩展实验
- 具体来说,论文在 OpenCUA-72B 模型的一个早期迭代上进行了消融研究,省略了冷启动和 DPO 阶段,以专注于多轮 RFT
- 如表 5 所示,相对于基线的性能增益如下:
- Round 1:在 2 万样本上独立训练,带来 +2.61 个百分点的增益
- Round 2:在 22.6 万样本上迭代训练,从第一轮的检查点初始化,将增益提高到 +6.79 个百分点
- Round 3:在三轮 RFT 迭代聚合的 100 万样本上训练 OpenCUA-72B 基础模型,实现了 +8.12 个百分点的改进
- 论文的分析突显了数据规模、 Off-Policy 分布和信噪比之间的关键权衡
- 随着模型能力随规模提升,对噪声的容忍度降低,这为现有的迭代方法创造了瓶颈
- 但至关重要的是,作者仍然相信只要数据质量、策略对齐和信噪比得到有效优化,进一步的扩展是可以持续的
Environmental Uncertainty and Evaluation
- 区分
Pass@k在智能体任务与标准 LLM 基准测试中的作用至关重要- 在传统文本生成中,“环境”(即提示)是静态且确定性的;
- 此时,
Pass@k仅衡量模型内部能力的多样性
- 此时,
- GUI 环境中引入了固有的环境随机性
- 系统延迟、网络波动和细微渲染变化等因素意味着相同的动作序列可能产生不同的状态转换
- 在传统文本生成中,“环境”(即提示)是静态且确定性的;
- 因此,在这种背景下,
Pass@k具有双重目的:- 它不仅评估模型的生成多样性,还评估其对抗环境噪声的鲁棒性
- 论文观察到,即使采用确定性采样(
temperature=0),由于这些系统扰动,成功率也会表现出方差- 这一发现突显了纯数据扩展的一个关键局限性
- 为了实现人类级别的可靠性,未来的研究必须优先考虑环境扩展,扩展环境多样性和建模动态不确定性,以确保在现实世界系统中的鲁棒性
Discussions
- 基于总计超过 100 万加速器小时的上千次独立实验,论文将关于原生计算机使用智能体训练动态的观察归纳为四个关键维度
- 维度1:经验的双重性 (The Dual Nature of Experiences) :论文的分析表明,成功和失败轨迹的信噪比存在根本性差异,需要不同的处理策略
- 成功轨迹 (Success trajectories) :由模型生成的轨迹代表已知知识,其特点是噪声低但信息增益有限
- 虽然最终结果正确,但步级冗余构成了主要的噪声源
- 如果不积极过滤这些低效步骤,模型会变得脆弱,导致诸如动作别名(对单一状态输出冲突动作)和循环重复(无休止点击相同坐标)等现象
- 因此,有效过滤是多轮拒绝采样微调的前提
- 失败轨迹 (Failure trajectories) :相反,失败轨迹是高噪声但高信息的
- 它们描绘了模型的能力边界,并包含了当前策略无法处理的边界情况
- 虽然原始失败数据噪声太大无法直接学习,但识别关键错误步骤可以用于构建偏好对
- 这将失败的尝试转化为用于边界对齐的高价值来源
- 成功轨迹 (Success trajectories) :由模型生成的轨迹代表已知知识,其特点是噪声低但信息增益有限
- 维度2:基础约束与初始化 (Foundational Constraints and Initialization) :初始化阶段极大地影响了智能体的潜在性能
- 动作空间的完备性 (Completeness of action space) :动作空间的全面定义是前提
- 缺少高效操作(例如,三连击、基于 Shift 的快捷键)会导致特定任务(例如复杂的电子表格编辑)实际上无法解决
- 与正确的初始定义相比,事后添加动作空间是低效的
- 以模式为中心的冷启动 (Pattern-centric cold start) :冷启动阶段应优先考虑模式多样性而非数据量
- 论文观察到,轻量级的冷启动足以建立潜在的对齐(奠定动作空间并稳定输出格式)
- 重度的冷启动通常会产生较高的监督指标,但会创建一个后期更难精炼的检查点
- 轻量级初始化,随后进行严格的拒绝采样和偏好优化,始终能产生更优的最终性能
- 动作空间的完备性 (Completeness of action space) :动作空间的全面定义是前提
- 维度3:迭代优化的动态 (Dynamics of Iterative Optimization) :计算机使用任务本质上是长程的,通常需要数十次交互回合,为此进行优化需要严格遵守特定的动态属性
- On-Policy 的必然性 (The on-policy imperative) :论文强调在迭代学习期间使用严格 On-Policy 数据的必要性
- 作者推测 Off-Policy 数据会扰乱监督期间建立的优化向量的主方向
- 一旦模型的权重由于分布偏移而偏离最优流形,恢复正确的优化路径在计算上是不可行的
- 终止的不对称性 (Termination asymmetry) :终止动作的分布是最关键的控制变量
- 论文观察到一个明显的不对称性:模型在识别失败方面收敛迅速,而识别成功则需要精心校准的正样本密度
- 成功信号的过度集中会导致过早终止,而不足则阻止智能体停止
- 自我纠正与未来潜力 (Self-correction and future potential) :为了减轻长程任务中的错误累积,论文利用专注于状态检查和反思的偏好优化
- 通过针对智能体未能感知错误的步骤,论文增强了鲁棒性
- 这些改进表明,逻辑上的演进是过渡到在线强化学习,其中先进的信用分配机制可以进一步优化复杂多步环境中的性能
- On-Policy 的必然性 (The on-policy imperative) :论文强调在迭代学习期间使用严格 On-Policy 数据的必要性
- 维度4:可视化驱动的诊断与迭代 (Visualization-Driven Diagnosis and Iteration) :作者认为,在长程任务中实现 SOTA 性能需要的不仅仅是算法新颖性;它需要一个透明的调试基础设施
- 论文开发了一套全面的轨迹分析和可视化工具套件,作为论文演化循环的“眼睛”
- 这些工具在三个关键阶段发挥了关键作用:
- 合成的质量保证 (Quality Assurance for Synthesis) :它们使论文能够将合成样本与其真实状态一起可视化,从而能够在论文的合成引擎中的“幻觉验证器”或可执行逻辑错误污染训练池之前快速识别它们
- 冷启动数据构建 (Cold-Start Data Construction) :通过可视化对比不同基础模型的轨迹特征,论文识别出更优的推理模式和动作序列
- 这指导了论文高质量冷启动数据集的整理,确保智能体学习鲁棒的行为先验而非嘈杂的模仿
- 用于精炼的失败分析 (Failure Analysis for Refinement) :论文的 Pass@k 差异分析工具聚合了同一 Query 的成功和失败轨迹
- 这种细粒度的比较帮助论文精确识别特定的失败模(例如坐标漂移或推理-动作错位),直接指导论文步级策略优化的设计以纠正这些特定弱点
Future Work on Online Agentic RL
- RLVR (2025) 已成为提升模型可靠性、泛化性和性能的关键框架
- 在此基础上,论文未来的工作旨在探索基于 GUI 的智能体任务中的在线智能体强化学习
- 受限于时间,论文尚未进行足够的模型训练和全面的基准评估
- 因此,本节的后续部分将首先深入分析训练-推理差异问题,然后讨论推进这项工作的未来研究方向
(Training-Inference Discrepancy in Trajectory-Level Training)
- 诸如 GRPO (2024) 等算法已被证明在广泛的推理任务上有效
- 这些算法为单个 Query 收集一组轨迹,计算轨迹组内的优势函数,并以轨迹粒度进行训练
- 但轨迹级训练会在 GUI 任务中引起训练-推理差异
- 在 Rollout 阶段,GUI 模型并不保留所有完整的上下文信息,而只保留最近步骤的完整信息(包括截图、推理和动作),而更早的历史信息被压缩为纯文本语义动作
- 如果直接使用最终步骤的轨迹进行训练,模型将无法学习中间步骤的监督信号
Step-Level Policy Optimization
- 为了解决轨迹级训练中的训练-推理差异,论文提出一种简单而有效的策略优化算法,即步级策略优化 (Step-Level Policy Optimization, STEPO)
- 对于一个长度为 \(T\) 的轨迹 \(\tau\),每一步 \(t\in \{1,2,\ldots ,T\}\) 包含 \(K_{t}\) 个 Token
- 论文将步骤 \(t\) 中的第 \(k\) 个 Token 表示为 \(x_{t,k}\) \((k\in \{1,2,\dots,K_t\})\),步骤 \(t\) 的完整 Token 序列表示为 \(x_{t} = (x_{t,1},x_{t,2},\ldots ,x_{t,K_{t} })\)
- 对于轨迹集合 \(\mathcal{T} = \{\tau_{1},\tau_{2},\ldots ,\tau_{n}\}\),第 \(i\) 个轨迹中步骤 \(t\) 的位置 \(k\) 的 Token 表示为 \(x_{i,t,k}\)
- 对于每个问题 \(q\),类似于 GRPO,STEPO 从策略 \(\pi_{\theta_{\mathrm{old} } }\) 采样一组轨迹 \(G\):\(\{\tau_{1},\tau_{2},\ldots ,\tau_{n}\}\),并计算轨迹组内的优势:
$$\hat{A}_i = \frac{R_i - \mathrm{mean}(\{R_j\}_{j = 1}^G)}{\mathrm{std}(\{R_j\}_{j = 1}^G)} \tag{3}$$- 其中 \(R_{i}\) 表示轨迹 \(\tau_{i}\) 的奖励
- 随后,将每个轨迹 \(\tau_{i}\) 对应的优势值 \(\hat{A}_{i}\) 均匀分配给该轨迹包含的所有步骤,即:
$$\hat{A}_{i,t} = \frac{\hat{A}_i}{ T_i}, \quad t\in \{1,2,\ldots ,T_i\} , \tag{4}$$- 其中 \(T_{i}\) 表示轨迹 \(\tau_{i}\) 包含的步骤数
- 同一步骤内的所有 Token 共享该步骤对应的优势值 \(\hat{A}_{i,t}\)
- 在此基础上,论文使用所有步级样本进行模型训练
- STEPO 算法的优化目标可表示为:
$$\begin{array}{rl} {\mathcal{I}_{\mathrm{STEPO} }(\theta) = \mathbb{E}_{[q\sim P(Q),\{\tau_i\}_{i = 1}^G\sim \pi_{\theta_{\mathrm{old} } }(\mathcal{T}|q)]}} {\frac{1}{G}\sum_{i = 1}^{G}\sum_{t = 1}^{T_i}\frac{1}{K_t}\sum_{k = 1}^{K_t}\{\min [r_{i,t,k}(\theta)\hat{A}_{i,t},\mathrm{clip}(r_{i,t,k},1 - \epsilon_{\mathrm{low} },1 + \epsilon_{\mathrm{high} })\hat{A}_{i,t}] - \beta \mathbb{D}_{KL}(\pi_{\theta}| \pi_{\mathrm{ref} })\} ,} \end{array} \tag{5}$$- \(r_{i,t,k}(\theta)\) 表示重要性采样比率:
$$r_{i,t,k}(\theta) = \frac{\pi_{\theta}(\tau_{i,t,k}|q,\tau_{i,t,k})}{\pi_{\theta_{\mathrm{old} } }(\tau_{i,t,k}|q,\tau_{i,t,k})}, \tag{6}$$ - \(\epsilon\) 表示剪裁参数
- \(\mathbb{D}_{KL}\) 表示 KL 惩罚项
- \(\beta\) 控制 KL 散度正则化强度
- \(r_{i,t,k}(\theta)\) 表示重要性采样比率:
- 通过将轨迹的优势值均匀分配给其包含的所有步骤,该策略实现了两个核心优化效果:
- 首先,它驱使高优势值轨迹以更少的步骤完成任务,从而减少冗余的执行步骤;
- 其次,它促使低优势值轨迹扩展探索步骤数,从而提高任务完成率。通过步级策略优化机制,STEPO 可以有效规避训练-推理差异问题
Experiments and Analysis
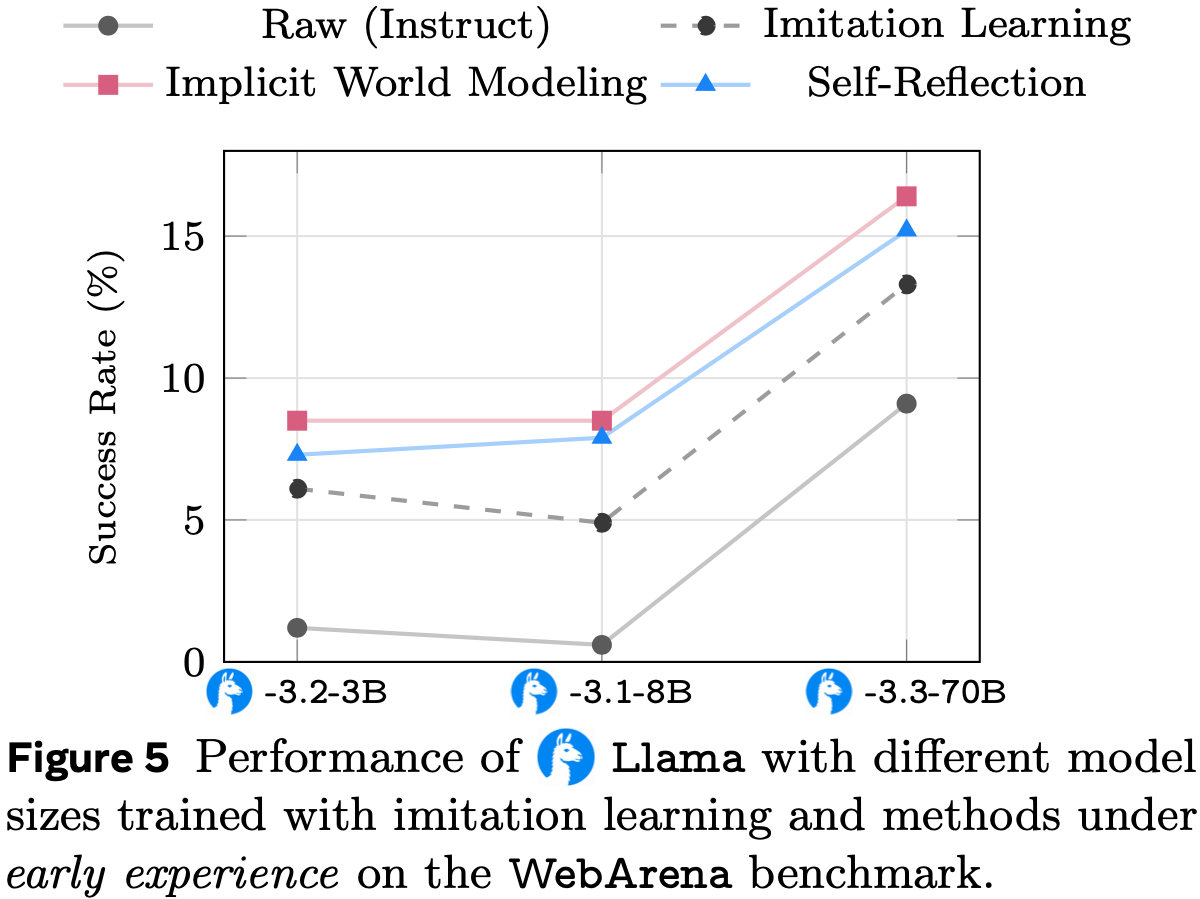
- 为了阐明训练-推理差异的影响并验证 STEPO 的有效性,论文在 OpenCUA-32B 模型上进行了在线 RL 训练
- 如图 7 所示,STEPO 的训练性能显著优于使用最终轨迹训练的 GRPO,这充分证实了 STEPO 的有效性
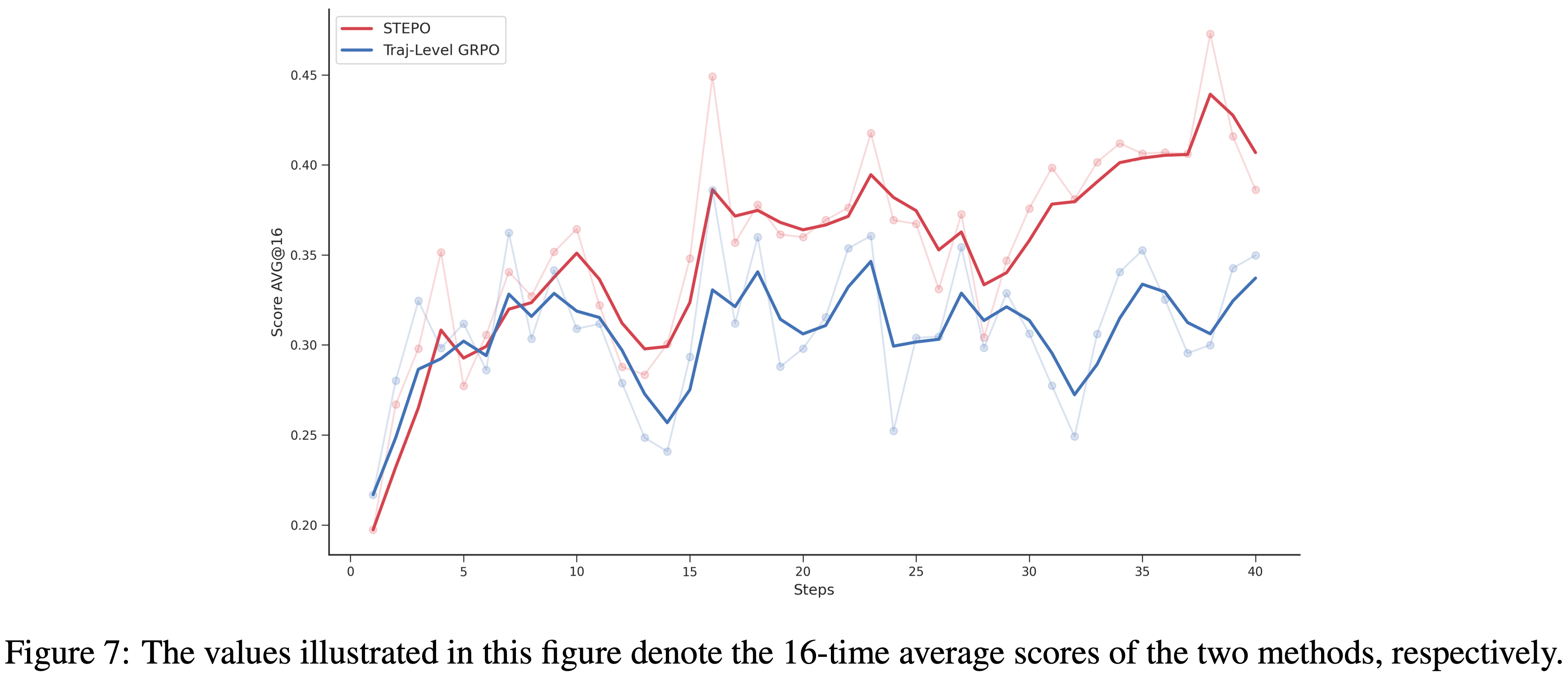
- 然而,STEPO 存在训练成本高的问题,因为策略模型的更新次数显著倍增
- 因此,论文猜测步级训练的要求可能在不同的训练阶段并不一致,仅训练特定的关键步骤也可能达到与训练所有步骤相当的性能
- 未来,论文将探索扩大在线 RL 规模以及开发更有效的 RL 训练方案等方向
Related Work
Foundation VLMs and Computer Use Capabilities
- 大型视觉语言模型的格局已迅速发展以支持复杂的智能体任务
- 专有的前沿模型,最著名的是 Claude 4.5 Sonnet (2025) 和 Seed 1.8 (2025),设定了行业标准,在零样本指令跟随和长程规划方面展示了人类级别的熟练度
- 在开放权重领域,Qwen3-VL (2025a) 已成为一个强大的主干,引入了下一代动态分辨率和增强的 OCR 能力
- EvoCUA 直接建立在 Qwen3-VL 架构之上,通过专门的演化后训练课程对其进行增强,以超越通用预训练的限制
Generalist GUI Agents and Benchmarks
- 为了评估在线智能体性能,OSWorld (2024) 和 OSWorld 是主要的测试平台
- OpenCUA (2025b) 凭借 AgentNet 数据集建立了一个关键的基础,而 SOTA 工作如 UI-TARS-2 (2025a) 和 Step-GUI (2025) 分别利用了多轮 RL 和逐步视觉推理
- 与这些重度依赖演示的方法不同,EvoCUA 利用自主合成的、可验证的经验来降低标注成本,同时在 OSWorld 排行榜上实现了更优的性能
Visual Grounding and Action Execution
- 精确的 GUI 定位是原生计算机使用的基石
- 早期的方法如 Aguvis (2024) 奠定了基础,而最近的模型如 ShowUI (2025) 和 UGround (2024) 专门针对高分辨率布局优化了视觉-语言-动作架构
- EvoCUA 从这些专门用于定位的架构中汲取见解,以在高层次规划优化之前建立鲁棒的执行原语
From Imitation to Learning from Experience
- 训练范式正在从行为克隆 (Behavior Cloning, BC) 向强化学习转变
- 标准算法如 PPO (2017) 已被 UI-TARS-2 (2025a) 成功适配于多轮 GUI 交互,但最近的研究专注于激励推理能力
- 这一转变由 DeepSeek-R1 (2025) 和 DeepSeekMath (2024) 开创,它们引入了 RLVR 范式
- 他们证明了 RL 可以在没有密集过程监督的情况下隐式验证复杂的推理链
- Feng 等人 (2025) 提出了组内优化 (Group-in-Group optimization) 以稳定此类训练
- Zhang 等人 (2025) 探索了通过无奖励的“早期经验”进行学习
- EvoCUA 通过一个可验证的合成引擎解决了数据稀缺瓶颈,从而推进了这一方向,该引擎自主产生可扩展的、基于真实值验证的合成数据
- 这一基础实现了论文通过经验学习的演化范式,这是一个自我维持的循环,通过在大规模可验证合成轨迹上进行拒绝采样和偏好学习,迭代地增强智能体能力
Conclusion
- 论文提出了一个通过经验学习的演化范式开发的原生计算机使用智能体 EvoCUA,详尽展示了将合成计算转化为高质量训练信号的有效性
- 可验证的合成
- 可扩展的交互基础设施相结合
- 在 OSWorld 基准测试上,EvoCUA 达到了 \(56.7%\) 的成功率
- 注:当前的开源模型与领先的闭源权重系统或人类级别的可靠性之间仍然存在性能差距
- 这种差异突显了仅从合成痕迹进行离线学习的局限性
- 为了解决这个问题,作者的中心对在线强化学习上
- 目前作者已经在初步尝试,作者初步调查确定了主动环境交互是进一步改进的关键驱动力,奖励累积的持续上升趋势证明了这一点
- 未来的作者的工作将侧重于系统地扩展这个在线演化边界,旨在弥合剩余的差距,实现完全自主的计算机使用能力
附录 A:A Unified Action Space
- 下表详细说明了在 EvoCUA 中实现的统一原生行动空间 \(\mathcal{A}\)
- Agent 通过调用
computer_use函数并指定特定的行动及其相应参数来与环境交互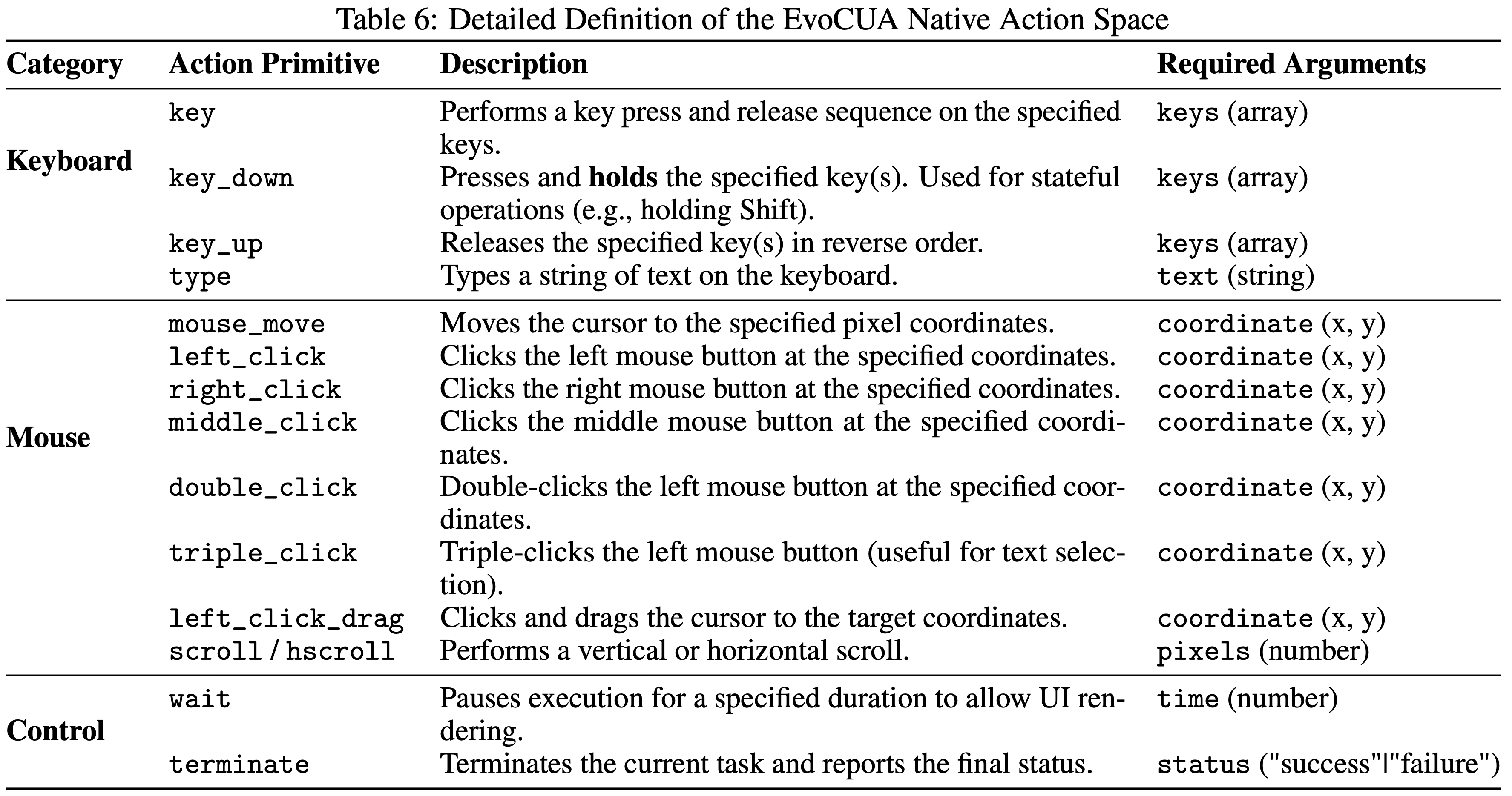
附录 B:Cold Start: Hindsight Reasoning Generation(事后推理生成)
- 为了为监督式冷启动阶段构建高质量数据,论文将原始的物理交互轨迹转化为增强了明确认知链的训练样本
- 论文采用事后推理生成 (Hindsight Reasoning Generation) 策略来实现这一点
- 通过将真实执行路径视为已知的未来信息,论文利用一个通用模型来回溯性地生成解释所观察行动的推理轨迹 \((z_{t})\),从而在认知和执行之间建立因果对齐
- 生成过程由一系列强制执行论文思维空间 \((Z)\) 中所定义结构模式的、上下文感知的提示模板驱动
- 根据执行阶段的不同,生成逻辑调整如下:
- 1)目标澄清 \((z_{0})\) 在轨迹的初始步骤 \((t = 0)\),推理生成的重点是解决歧义并建立全局计划
- 上下文 (Context) :为通用模型提供用户指令、初始屏幕截图和第一个可执行代码块
- 生成逻辑 (Generation Logic) :论文使用一个强制要求第一人称视角的特定模板。模型必须明确陈述当前环境状态、澄清任务目标、并阐述一个高层次计划(例如,“我需要打开浏览器来搜索…”),然后证明所采取的具体行动是合理的。这确保了后续的物理执行基于清晰的意图
- 2)观察一致性 \((z_{obs})\) 对于中间步骤,目标是保持视觉观察和推理轨迹之间的语义一致性
- 上下文 (Context) :模型分析从前一个状态到当前状态的转换
- 生成逻辑 (Generation Logic) :提示指令模型识别环境中“发生了什么变化”,并解释“为什么需要这个行动”来推进工作流
- 语义抽象 (Semantic Abstraction) :为了防止过拟合于特定的屏幕分辨率,提示明确限制生成内容,避免提及原始像素坐标
- 相反,引导模型从语义上描述目标 UI 元素(例如,“点击‘文件’菜单”而非“点击 (100, 200)”),确保推理对不同布局变化保持鲁棒性
- 3)反思与纠正 \((z_{reflect})\) 对于涉及错误恢复(“恢复”轨迹)的轨迹,论文实现了一个专门的反思机制 (Reflection Mechanism)
- 上下文 (Context) :当处理从失败中恢复的轨迹片段时,合成引擎将特定的
analysis_reason(先前失败的根本原因)注入到提示上下文中 - 生成逻辑 (Generation Logic) :模型被强制要求以专用的标头开始思维轨迹:“反思:”
- 它必须回顾性地分析失败原因(例如,“反思:我意识到我之前点击图标的尝试失败了,因为…”)
- 自我纠正 (Self-Correction) :在反思之后,模型必须自然地过渡到一个纠正后的计划(例如,“现在我将尝试一种不同的方法…”),从而有效地将自我纠正的逻辑内化到训练数据中
- 上下文 (Context) :当处理从失败中恢复的轨迹片段时,合成引擎将特定的
- 4)推理增强的终止 \((z_{T})\) 为了缓解过早或延迟停止的问题,终止行动基于严格的视觉验证过程
- 上下文 (Context) :生成在轨迹的最后一步触发
- 生成逻辑 (Generation Logic) :要求通用模型根据初始指令评估最终屏幕截图
- 它必须在发出最终终止信号之前,生成一个提供任务完成(或失败)视觉证据的推理轨迹
- 这确保了 Agent 的终止决策是基于逻辑验证,而不是记忆的轨迹长度
- 1)目标澄清 \((z_{0})\) 在轨迹的初始步骤 \((t = 0)\),推理生成的重点是解决歧义并建立全局计划
- Algorithm 1:

附录 C:Algorithm for DPO
- 在本节中,论文介绍步骤级直接偏好优化 (Step-Level Direct Preference Optimization, DPO) 的算法实现
- 该方法侧重于两个核心过程:关键错误识别和偏好对构建
- 算法 2 详细说明了论文如何从失败轨迹中识别关键分岔点 (Critical Forking Points) ,并为行动纠正和反思两者构建配对数据

附录 D:Trajectory Analysis and Visualization
- 为了实现 Agent 行为的细粒度诊断并严格验证论文合成生成的经验质量,论文开发了 EvoCUA 轨迹检查器 (EvoCUA Trajectory Inspector)
- 该可视化系统允许论文逐帧检查 Agent 的视觉观察 \((o_{t})\)、内部推理轨迹 \((z_{t})\) 和可执行代码行动 \((a_{t})\) 之间的对齐情况
- 论文使用一个来自电子表格领域的代表性合成任务来说明该系统的实用性:“找到每行的最大值并将其放置在 G 列中” 这个长视程任务是一个验证论文合成引擎逻辑一致性的严格测试平台
- 图 8 展示了这些关键时间戳的可视化
 用户指令与 Agent 计划之间的清晰对齐,Step1 中推理面板显示 Agent 对指令的明确转述(“找到最大值... 放置在 G 列中”),验证了论文合成数据中的目标基础机制;(b) 推理与原子键盘行动之间的精确对应,Step2: 对齐了原子动作分别按键实现 `Max` 的输入")
 验证对于图形用户界面操作至关重要的复杂有状态原语(Shift+Click), Step 9: ;(d) 验证终止逻辑以确保任务完整性")
- 解读:
- 步骤 9(\(t=9\)):有状态交互
- 此视图验证了统一行动空间 (Unified Action Space)
- 合成真实情况需要一个有状态操作(Shift-选择)
- 检查器确认 Agent 正确执行了
key_down: shift\(\rightarrow\)click\(\rightarrow\)key_up: shift序列
- 步骤 15(\(t=15\)):已验证的终止
- 最后一帧验证了推理增强的终止模式 (Reasoning-Augmented Termination schema)
- 工具突出显示 Agent 生成了视觉证据(“我可以看到… 最大值列… 已计算”)来证明成功的终止状态是合理的
- 步骤 9(\(t=9\)):有状态交互