注:本文包含 AI 辅助创作
- 参考链接:
- 技术报告链接:LongCat-Flash-Thinking-2601 Technical Report, 20260123, Meituan LongCat
- 上一版技术报告链接:LongCat-Flash-Thinking Technical Report, 20250922, Meituan LongCat
- 体验地址:longcat.ai
- HuggingFace:huggingface.co/meituan-longcat/LongCat-Flash-Thinking-2601
- GitHub:github.com/meituan-longcat/LongCat-Flash-Thinking-2601
Paper Summary
- LongCat-Flash-Thinking-2601 是美团继 25年9月底 LongCat-Flash-Thinking 后的第二个推理模型
- 统一的端到端训练流程训练,强调针对支持长程、交互驱动的智能体推理设计
- 定位:560B-A26B(平均值),具备卓越 Agentic 推理能力的开源 MoE 推理模型,在 Agentic 搜索、Agentic 工具使用和工具集成推理上,均达到了开源模型中 Top 性能
- LongCat-Flash-Thinking-2601 的核心创新如下:
- (i) 一个可扩展的环境构建和多领域强化学习框架,能够稳定地习得可泛化的智能体技能
- (ii) 一个鲁棒的智能体训练流程,通过基于课程的强化学习系统地纳入现实世界的环境噪声
- (iii) 一种 Heavy Thinking 模式,通过联合扩展推理宽度和深度,实现有效的测试时推理扩展
- 更详细的说明:
- 为了优化长尾、偏态生成和多轮 Agentic 交互,并在横跨 20 多个领域的超过 10,000 个环境中实现稳定训练,作者系统地扩展了异步强化学习框架 DORA,以实现稳定高效的大规模多环境训练
- 此外,认识到现实世界任务本质上是嘈杂的,作者对现实世界的噪声模式进行了系统性分析和分解,并设计了针对性的训练流程,明确地将此类不完美性纳入训练过程,从而提高了现实世界应用中的鲁棒性
- 为了进一步提升复杂推理任务的性能,作者引入了 Heavy Thinking 模式 (Heavy Thinking mode),该模式通过密集的并行思考联合扩展推理深度和宽度,从而实现有效的测试时扩展
Introduction and Discussion
- 最近的推理模型进展在数学和编程等复杂任务上取得了快速进步,在某些情况下甚至超越了顶尖人类专家 (DeepSeek-AI,2025,2025,Anthropic,2025,Google,2025)
- 随之自然产生的下一个问题是:如何将这种复杂的问题解决能力应用于解决复杂的现实生活任务,以及如何将复杂的问题解决能力扩展到更广阔的范围?
- 随着内在推理能力接近其极限,作者发现 与外部环境的交互成为推动进一步进步的关键机制 (MoonshotAI,2025,DeepSeek-AI,2025)
- 从这个角度来看,Agentic 推理可以被理解为通过自适应地与外部环境交互来解决复杂问题的能力
- 除了内部思考之外,高级的 Agentic 推理能力要求模型决定何时以及如何与环境交互,并有效地整合环境反馈以维持和推进推理过程
- 通过这种方式,推理和交互自然地交织并相互增强,共同促成更通用、更强大的问题解决行为 (MiniMax,2025)
- 然而,实现这种 Agentic 推理能力对现有模型和训练流程构成了重大挑战
- Agentic 任务通常涉及长视野轨迹、异构环境和长尾交互动态,这对数据管理、环境构建、强化学习策略以及贯穿预训练到后训练阶段的系统级基础设施提出了新的要求
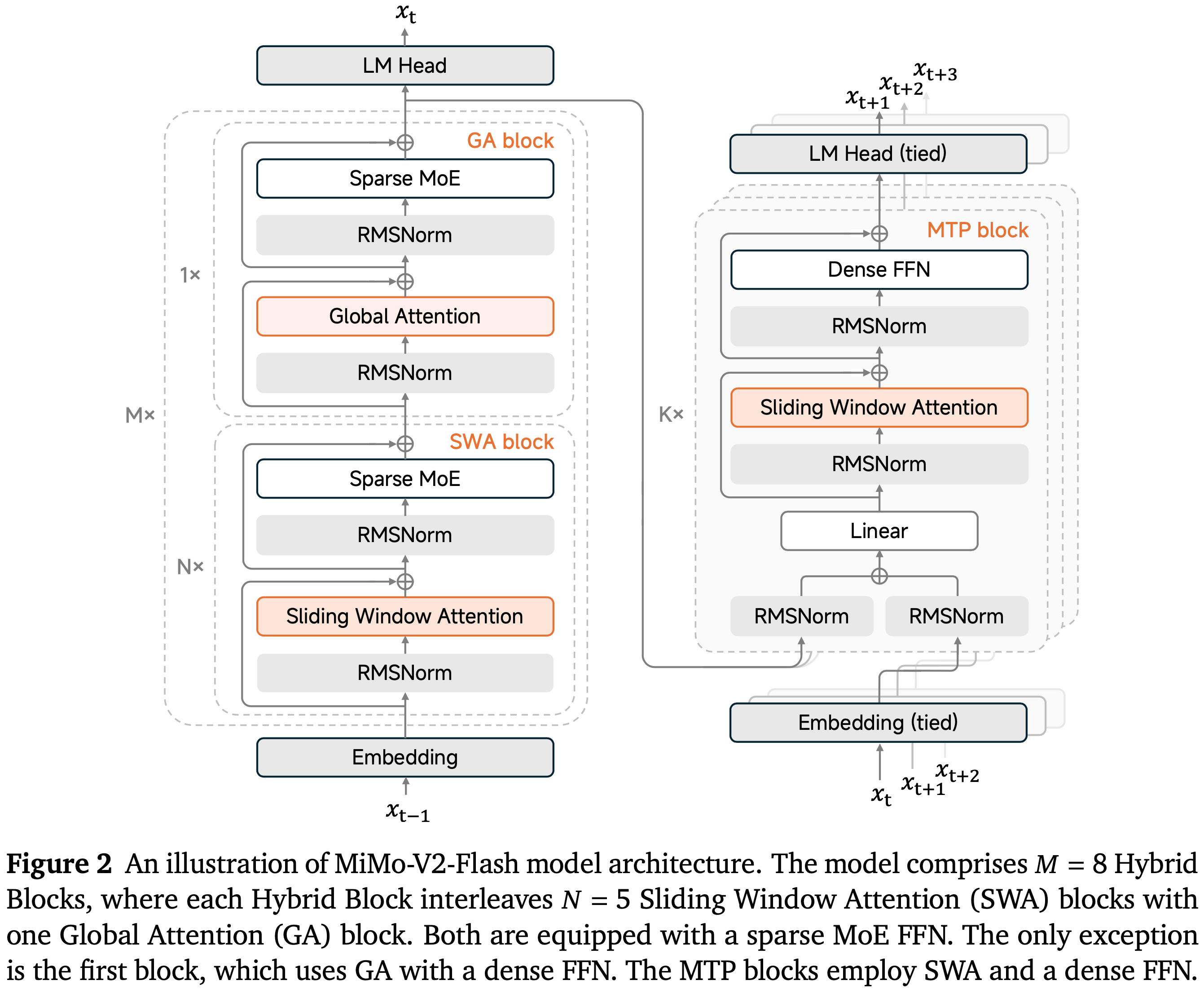
- LongCat-Flash-Thinking-2601 是一个强大且高效的 MoE 推理模型
- 总参数为 560B,平均每个 Token 激活参数为 27B,具备强大的 Agentic 推理能力
- LongCat-Flash-Thinking-2601 的预训练大体遵循了 LongCat-Flash-Chat 的方案 (2025a),保留了原始数据分布以维持有竞争力的一般推理性能
- 在此基础上,作者通过精心设计的 Mid-training 阶段进一步将模型扩展至大规模 Agentic 推理
- 与传统推理相比,Agentic 行为通常涉及具有主动性工具调用的长视野轨迹
- 但这种交互模式在现实世界语料库中极其稀缺,因为大部分数据主要由自然语言构成
- 所以原始模型对 Agentic 交互动态大多不熟悉,导致在强化学习阶段探索效率低下
- 为了解决这一挑战,作者在 Mid-training 中让模型接触中等规模的合成结构化 Agentic 轨迹,为 Agentic 推理行为提供了强有力的初始化
- 与传统推理相比,Agentic 行为通常涉及具有主动性工具调用的长视野轨迹
- 在后训练中,作者专注于高效扩展强化学习计算以提高 Agentic 推理能力
- 除了搜索和代码等特定 Agentic 场景外,作者进一步将跨任务和环境的泛化识别为高级 Agentic 行为的核心特征
- 这种能力主要通过与多样化环境的交互获得,因此这些环境充当了学习场
- 为此,作者设计了一个自动化环境扩展流程,以构建覆盖超过 20 个领域的复杂多样化环境,同时严格保持可执行性和可验证性
- 由于所生成的环境在领域和难度上都表现出显著的异质性,对它们进行训练需要仔细协同设计训练策略和基础设施支持,以确保稳定有效的多领域环境学习
- 为了在这种设置下支持大规模 Agentic 强化学习,作者扩展了多版本异步训练系统 DORA,以实现多达 32,000 个环境并发执行的可扩展且稳定的训练
- 但泛化到现实世界设置仍然极具挑战性
- 因为现实世界环境本质上 imperfect
- 为了弥合理想化训练设置与现实世界部署之间的差距,作者系统分析了现实世界噪声,并设计了一个自动化流程,逐步将多类型、多级别的环境不完美性纳入多领域环境训练过程
- 除了搜索和代码等特定 Agentic 场景外,作者进一步将跨任务和环境的泛化识别为高级 Agentic 行为的核心特征
- 为了进一步将推理能力推至超越现有极限,LongCat-Flash-Thinking-2601 集成了一个 ** Heavy Thinking 模式 (Heavy Thinking Mode)** ,该模式能够实现有效的推理测试时扩展
- 该模式将具有挑战性的问题解决分解为互补的阶段,共同扩展推理的宽度和深度,使模型能够探索多样化的解决路径,同时逐步完善其推理
- 注意:这里为 Heavy Thinking Mode 引入了一个额外的强化学习阶段,以增强模型聚合和完善中间推理结果的能力,从而进一步提高有效性
- 在保持一般推理基准测试强竞争力的同时,LongCat-Flash-Thinking-2601 在广泛的 Agentic 基准测试中取得了开源模型中 state-of-the-art 的性能,同时展现出对分布外现实世界 Agentic 场景的强大泛化能力
- LongCat-Flash-Thinking-2601 在 BrowseComp 上达到 \(73.1%\),在 RWSearch 上达到 \(77.7%\),在 \(\tau^2\)-Bench 上达到 \(88.2%\),在 VitaBench 上达到 \(29.3%\),使其成为 Agentic 搜索和 Agentic 工具使用任务的领先开源模型
- 作者的三个核心贡献:
- 环境扩展与多领域环境训练 (Environment Scaling and Multi-Domain Environment Training)
- 开发了一个可扩展的环境构建和任务生成框架,以产生大量高质量、可执行且可验证的 Agentic 环境
- 在此基础上,作者扩展了异步强化学习基础设施,以支持稳定高效的多领域环境训练,从而能够在不同领域中学习到可泛化的 Agentic 技能
- 嘈杂环境下的鲁棒 Agentic 训练 (Robust Agentic Training under Noisy Environments)
- 为了解决现实世界环境固有的非理想性,作者系统分析了环境噪声的主要来源,并设计了一个自动化流程,将多类型、多级别的噪声注入训练环境
- 采用基于课程 (curriculum-based) 的强化学习策略逐步增加噪声复杂性,从而在不完美条件下显著提高鲁棒性和性能
- 用于测试时扩展的 Heavy Thinking 模式 (Heavy Thinking Mode for Test-Time Scaling)
- 引入了 Heavy Thinking 模式,该模式通过联合扩展推理宽度和深度,实现有效的推理测试时扩展
- 通过并行轨迹探索和迭代推理精炼,该模式进一步提升了在具有挑战性的推理和 Agentic 任务上的性能
- 环境扩展与多领域环境训练 (Environment Scaling and Multi-Domain Environment Training)
Pre-Training
- 作者的模型建立在 LongCat-Flash-Chat 的预训练方案之上 (2025a),继承了其数据分布以保留强大的通用语言和推理能力
- 超越传统推理,Agentic 行为通常涉及具有主动性工具调用的长视野轨迹,这带来了两个额外的挑战:
- (i) 对长上下文建模效率的需求大幅增加
- (ii) 现实世界中大规模 Agentic 轨迹的稀缺性
- 为了应对 Agentic 推理对长上下文的需求,作者采用了一个分阶段的 Mid-training 过程,逐步增加上下文长度,分配 500B 个 Token 给 32K/128K 阶段,并额外分配 40B 个 Token 给 256K 阶段
- 由于如果没有已具备基本 Agentic 行为能力的模型,大规模强化学习本身通常是低效且不稳定的,因此作者选择在此阶段让模型接触中等规模的 Agentic 数据
- 为了缓解现实世界 Agentic 轨迹的稀缺性,作者构建了一个混合数据合成流程来收集和构建 Agentic 训练数据
- 此外,作者基于任何预训练检查点预测 Mid-training 阶段的最优超参数,这一设计专门旨在最小化寻找最佳配置的计算成本
- 遵循原始的 Mid-training 方案以保留一般推理能力 (2025a, 2025),作者进一步用结构化 Agentic 轨迹 (2026) 增强数据分布
- 由于大规模、高质量的 Agentic 数据(特别是涉及推理、规划和交互的长视野轨迹)极其稀缺,作者构建了一个混合数据合成框架来填补这一空白
- 具体来说,作者的框架借鉴了两个互补来源:
- 非结构化文本和可执行环境,分别对应文本驱动合成和环境驱动合成
- 非结构化文本提供了广泛的语义和任务多样性
- 可执行环境确保了逻辑一致性和可执行性
- 为了显式加强规划能力(这是 Agentic 推理的一个核心组成部分,难以从现有数据中获取),作者进一步设计了一个专门的、以规划为中心的数据构建策略
- 非结构化文本和可执行环境,分别对应文本驱动合成和环境驱动合成
- 如图 2 所示,使用这种增强的 Mid-training 方案训练的模型展现出优越的 Agentic 能力边界,这体现在 \(\tau^2\)-Bench 上更大的
pass@k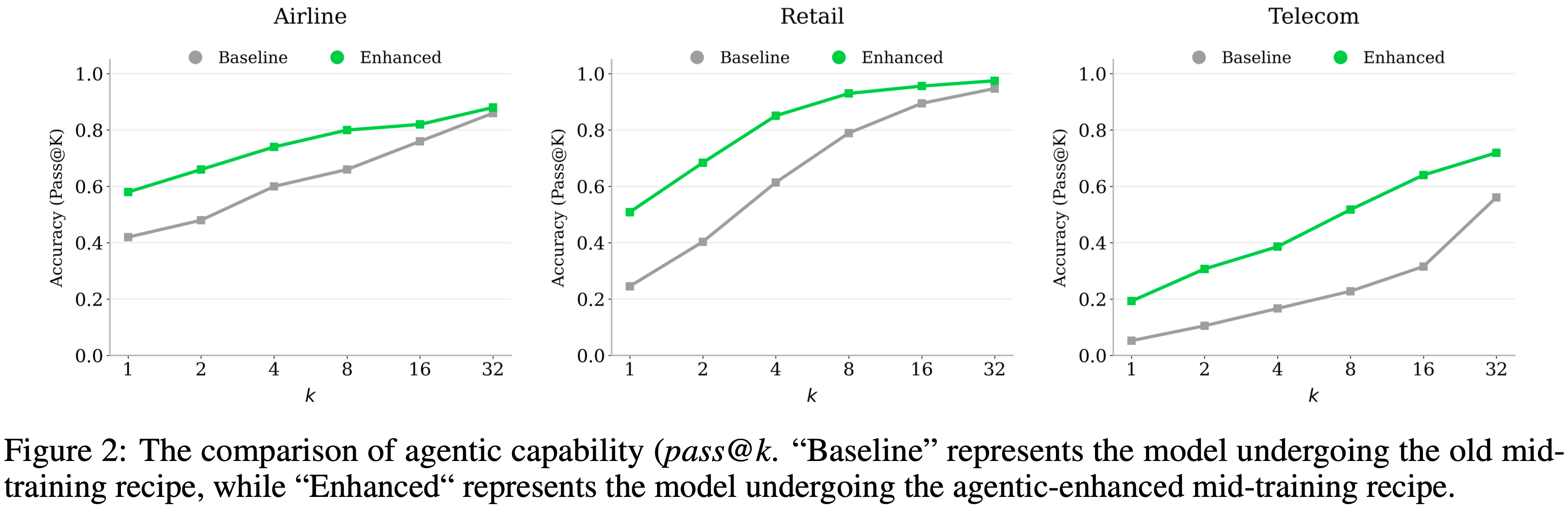
Text-driven synthesis
- 大规模文本语料库包含丰富的隐性过程知识,例如教程、指令和多步骤问题解决工作流
- 作者利用这一特性,通过以下流程挖掘并将这些潜在过程重构成显式的 Agentic 交互轨迹:
- 文本过滤与工具提取 (Text Filtering & Tool Extraction) :作者策略性地识别出展现丰富、多步骤工作流的文本片段
- 从这些片段中,作者定义潜在函数并提取相应的函数调用列表,将隐式过程转化为显式的工具模式
- 合成与精炼 (Synthesis & Refinement) :作者将抽象的工作流和原始文本转化为具体的、多轮次的用户-Agent 交互
- 为了确保数据集的鲁棒性和广度,作者应用了广泛的 Agentic 模式多样性增强和严格的质量过滤,确保最终的轨迹覆盖各种交互场景和任务领域
- 文本过滤与工具提取 (Text Filtering & Tool Extraction) :作者策略性地识别出展现丰富、多步骤工作流的文本片段
- 为了进一步提高合成轨迹的结构复杂性,作者应用了两种基于分解的增强:
- 工具分解 (Tool Decomposition) :从简单的工具调用轨迹开始,作者迭代地将部分工具参数隐藏到环境中
- 相应地,作者合成模型交互以提取这些参数,逐步构建更复杂的轨迹
- 推理分解 (Reasoning Decomposition) :对于模型输出中的每个动作步骤,作者生成多个替代候选方案,并用这些替代方案替换原始动作
- 然后作者合成模型推理步骤以选择最合适的候选,将轨迹转化为反映 Agent 跨多个步骤进行推理的决策过程
- 工具分解 (Tool Decomposition) :从简单的工具调用轨迹开始,作者迭代地将部分工具参数隐藏到环境中
Environment-grounded synthesis
- 除了文本衍生的轨迹,作者也直接从可执行环境构建 Agentic 数据,以保证逻辑正确性和执行一致性
- 作者为收集的工具集实现轻量级 Python 环境,并通过受控的工具链采样和执行验证生成轨迹:
- 环境构建与依赖建模 (Environment Construction & Dependency Modeling) :基于现有的工具定义,作者实现轻量级、可验证的 Python 环境
- 作者显式地建模工具间的逻辑依赖关系,构建一个有向图,其中节点代表工具,边代表参数依赖
- 这种结构让我们能够系统地采样不同复杂性和深度的工具调用链
- 逆向合成与执行验证 (Reverse-Synthesis & Execution Verification) :作者从依赖图中采样有效的工具执行路径,并采用逆向工程方法合成与所选工具链相符的用户模拟器系统提示
- 重点:通过执行代码并验证环境数据库的最终状态来验证每个轨迹的正确性
- 这确保了合成数据基于实际执行逻辑
- 重点:通过执行代码并验证环境数据库的最终状态来验证每个轨迹的正确性
- 环境构建与依赖建模 (Environment Construction & Dependency Modeling) :基于现有的工具定义,作者实现轻量级、可验证的 Python 环境
Planning-Oriented Data Augmentation
- 作者观察到 Agentic 推理关键依赖于规划能力,该能力控制着模型如何分解复杂目标、探索替代方案并确定中间决策
- 但这种以规划为中心的行为在现有数据中代表性不足,并且难以大规模获取
- 为了在 Mid-training 中显式加强这种能力,作者设计了一种针对性的数据构建策略,将现有轨迹转化为以规划为中心的决策过程
- 第一类数据专注于合成有效的问题分解轨迹,并配对正确的初始动作选择,为从粗到细的规划和早期决策制定提供监督
- 第二类数据从完整的交互轨迹开始,通过在每个决策步骤生成多个替代候选方案来进一步丰富它们
- 然后训练模型对这些候选方案进行推理和选择,将原本线性的轨迹转化为结构化的多步骤决策过程
Scaling Reinforcement Learning
- 通过强化学习进行后训练已成为激发更强推理能力的主要方法
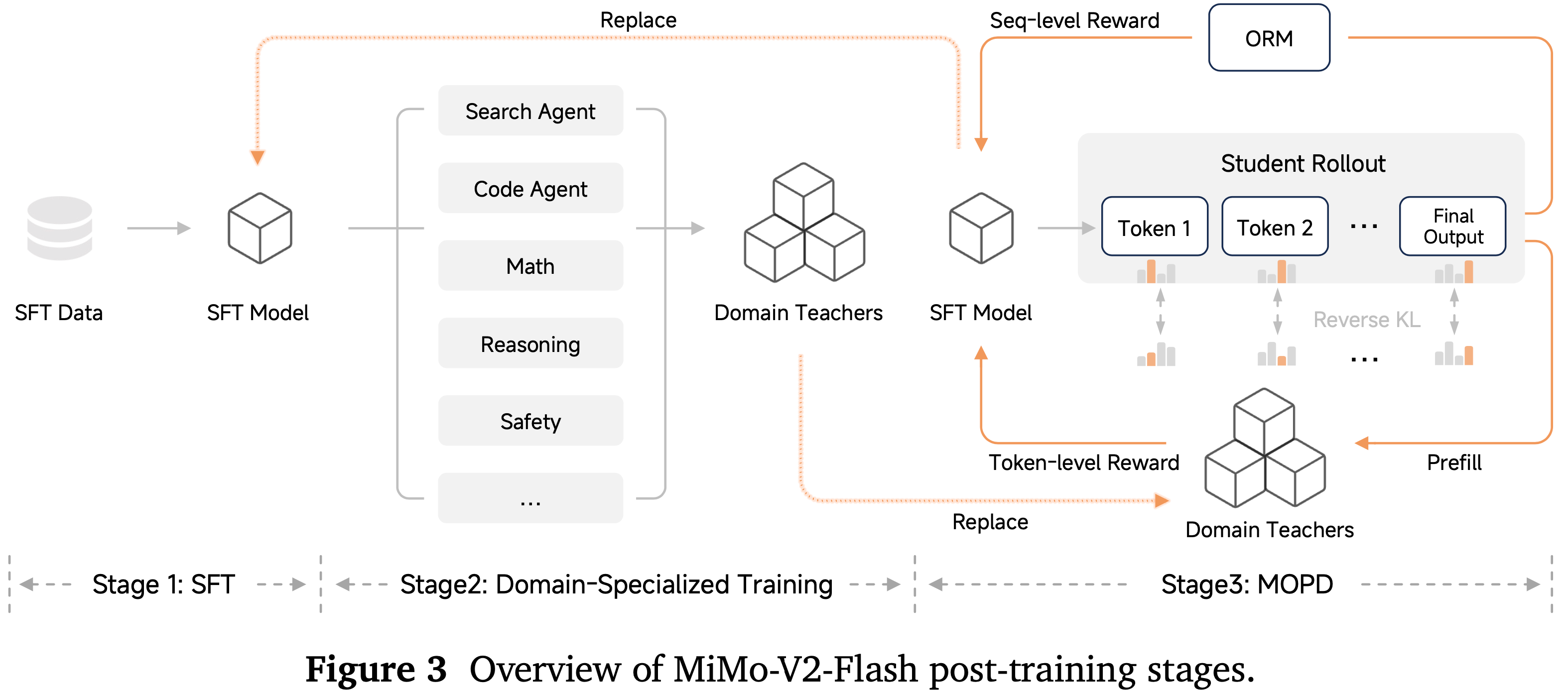
- 遵循 LongCat-Flash-Thinking (2025b),作者采用了一个统一的多领域后训练流程,其中领域专家模型首先在一个共享框架下训练,然后通过模型级和数据级合并整合为一个通用模型
- 具有智能体(agentic)推理能力的强化学习需要:
- (i) 精心准备的训练设置,包括可扩展的环境构建、高质量的冷启动数据和良好校准的 RL 任务集;
- (ii) 一个能够维持高吞吐量、异步、长尾的多轮 Rollout 的专用基础设施;
- (iii) 能够在异构领域和不同难度级别下保持稳定和有效的专用训练策略
- 本节将介绍一个系统性流程,以应对这些挑战并实现可扩展的智能体强化学习
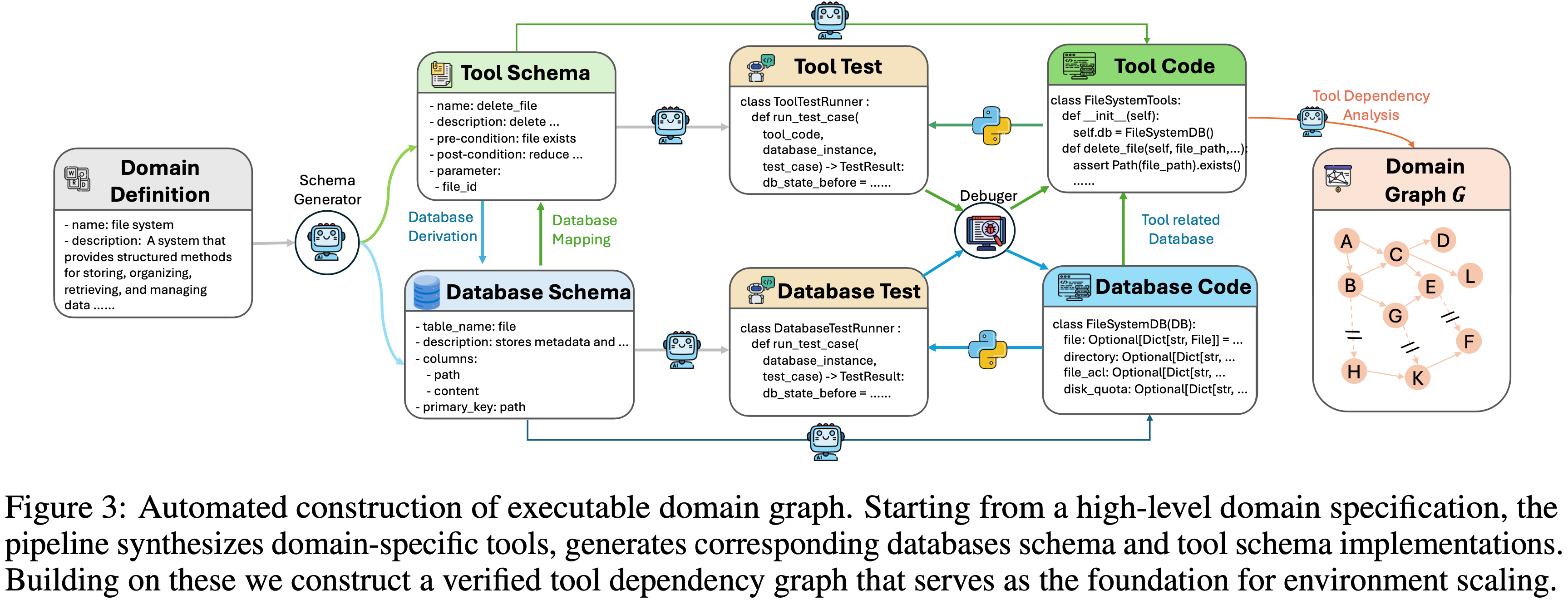
- 图 3:可执行领域图的自动化构建
- 从高层领域规范开始,该流程合成领域特定工具,生成相应的数据库模式和工具模式实现
- 在此基础上,作者构建一个经过验证的工具依赖图,作为环境扩展的基础
RL Preparation
- 在进行大规模强化学习之前,需要几个必要的准备步骤
- 标准强化学习依赖于两个核心组件:
- (i) 一个展现了基本任务相关行为的、良好初始化的策略(policy);
- (ii) 一个能够实现稳定有效学习的、有原则的训练任务集
- 除了这些共享组件之外,智能体强化学习还需要一个可靠且可扩展的环境基础来支持长视野、交互驱动的训练
Environment
- 传统推理在很大程度上是无环境的,主要在内部语言空间内运作
- 环境是智能体系统的一个决定性组成部分,因为它们直接决定了智能体能够感知什么、如何与外部系统交互以及在世界上哪些动作是可执行的
- 作者特别介绍了智能体任务中两种特别具有挑战性的环境类型:智能体编码和智能体工具使用
Code Sandbox
- 对于每个编码任务,智能体必须在可执行的代码沙箱中操作,并实时与各种终端工具交互
- 这种设置带来了两个主要挑战:
- 需要高效的大规模资源调度
- 工具和执行环境的异构性
- 在大规模训练中,沙箱系统必须同时确保灵活性和鲁棒性
- 为了解决这些挑战,作者设计了一个可扩展的执行沙箱系统,提供统一的工具接口和高吞吐量的交互
- 为了处理现实世界代码执行设置的异构性,作者将常用工具(包括搜索、文件读写、代码编辑和 shell 执行)整合到一个标准化的环境接口中
- 为了进一步支持大规模训练,作者实现了一个高并发沙箱调度器,异步地供应和回收沙箱实例,将任务分配给工作节点,并并行执行数千个沙箱,从而消除了环境启动和阻塞开销对关键训练路径的影响
Agentic Tool-Use Environment
- 高级智能体推理能力的核心特征是泛化性,即在已知环境中获得有效行为并将其可靠地迁移到先前未见过的环境中的能力
- 为了训练这种泛化的智能体,作者认为可迁移的智能体推理能力应源于接触多样化的工具集和交互模式
- 虽然设计一个能够完全捕捉现实世界工具使用复杂性的单一元环境是不可行的,但作者发现一个足够多样化的环境集合可以提供一个基础,从而实现可迁移和可泛化的工具使用行为
- 然而,在实践中,构建这样的环境存在不小的挑战,因为不同领域对交互接口、执行机制和评估标准提出了不同的要求
- 作者设计了一个完全自动化的流程,将高层领域规范转换为可执行图
- 如图 3 所示,该流程从领域定义中合成领域特定工具集,并将它们的功能抽象为具有明确工具-数据库映射的统一数据库模式
- 基于这个模式级规范,它然后自动生成数据库实现和相应的工具代码
- 为了确保正确性和鲁棒性,生成的代码通过单元测试和辅助调试智能体进行验证
- 在实践中,该流程在将模式级设计转换为完全可执行的工具实现方面,成功率超过 \(95%\)
- 最后,作者从经过验证的工具集构建工具依赖图,作为后续环境构建和扩展的基础
- 使用作者的自动化流程,作者构建了一个涵盖超过20个领域的领域特定工具图集合 \(\mathcal{G}\)
- 每个工具图 \(G \in \mathcal{G}\) 包含超过60个工具,这些工具组织在一个密集的依赖图中,并配有相应的可执行、工具特定的数据库模式实现,为大规模探索和多样化环境构建提供了足够的结构复杂度
- 接下来,作者介绍基于领域图构建可执行环境的流程
- 给定一个领域特定的工具图 \(G\),作者首先从中采样一个中等规模的工具链 \(s_1 \subset G\)
- 先前选择的工具的采样概率会逐渐降低,以促进任务多样性
- 对于 \(s_1\) 中的每个工具,作者顺序实例化相应的数据库状态,确保所有所需的工具依赖关系都得到完全满足
- 在构建了与工具关联的数据库之后,作者自动生成一个基于此工具链的任务
- 采样的 \(s_1\) 作为生成任务的可执行工具链
- 为了减轻潜在的人工先验偏见,任务生成器被限制为仅使用完整的工具链,而没有任何刻意的任务设计
- 具体来说,每个生成的任务包含三个部分:
- (i) 任务描述
- (ii) 用户画像
- (iii) 评估标准 (Evaluation Rubrics)
- 为了确保可靠的监督,评估标准通过多轮一致性检查进行验证,保证任何可执行工具链都能被接受为正确解决方案,并且不正确或不完整的轨迹会被一致地拒绝
- 作者注意到任务难度来自两个互补的方面:交互复杂性和环境复杂性
- 交互复杂性通过合成多样化的用户提示 (prompts) 来保证,这些提示需要不同程度的澄清、规划和多步交互,鼓励模型进行丰富且自适应的智能体行为
- 环境复杂性使用底层工具图的结构特性来量化,包括涉及的工具节点数量以及它们之间的连接密度
- 增加环境复杂性的自然方法是通过从 \(G\) 中引入额外的工具节点,将初始工具链 \(s_1\) 扩展为一个更大的子图 \(\mathcal{R}(s_1)\),同时维护它们的数据库实例
- 值得注意的是,在此扩展之后,生成的环境可能还包含多个有效的可执行工具链
- 然而,随着子图的增长,维护跨工具的数据库一致性变得越来越具有挑战性
- 特别是,由于工具依赖图施加的约束,不受控制地引入额外的工具节点可能触发一系列先前未满足的依赖关系,需要大量的数据库扩充和维护大量辅助工具节点
- 一旦在这种扩展下数据库状态变得不一致,工具调用可能产生不可预测的结果,导致即使有效的工具轨迹也执行失败
- 这可能导致正确的解决方案被错误地判定为失败,从而在训练中引入有偏差的负奖励
- 为了缓解这个问题,作者不是盲目地注入随机工具,而是通过扩展可执行工具链来扩展环境
- 具体来说,从 \(s_1\) 开始,作者在工具图上执行广度优先搜索 (BFS) 风格的扩展,并且仅当一个新工具节点的所有依赖项都已由先前实例化的工具(其数据库状态已被完全构建)满足时,才添加该节点。这种受控的扩展策略让我们能够在保持可执行性和可靠监督的同时,逐步增加环境复杂性
- 通过这种受控的图扩展,作者将 \(s_{1}\) 扩展为一个更复杂的子图 \(\mathcal{R}(s_{1})\)
- 作者将生成的环境表示为 \(\mathcal{E}_{1} = \mathcal{R}(s_{1})\)
- 令 \(\mathcal{D}_{1} = G\backslash \mathcal{E}_{1}\) 表示对于 \(\mathcal{E}_{1}\) 剩余的未使用工具节点
- 一个进一步的设计选择是是否初始化另一个种子可执行工具链 \(s_{2}\subseteq \mathcal{D}_{1}\),并将其扩展为 \(\mathcal{R}(s_{2})\) 来构造环境:
$$\mathcal{E}_2 = \mathcal{R}(s_1)\bigcup \mathcal{R}(s_2),$$
- 这进一步增加了环境复杂性,作者基于以下因素做出这个决定:
- (i) 当前环境的结构复杂度 \(c(\mathcal{E}_1)\)
- (ii) 从剩余图中识别新有效工具链的难度 \(g(\mathcal{D}_1)\)
- (iii) 剩余未使用节点的数量 \(|\mathcal{D}_1|\)
- 具体来说,给定当前环境:
$$\mathcal{E}_n = \bigcup_{i = 1}^n\mathcal{R}(s_i),$$ - 作者将剩余未使用的工具集定义为 \(\mathcal{D}_n = G\backslash \mathcal{E}_n\),并以概率从 \(\mathcal{D}_n\) 中采样一个新的种子链 \(s_{n + 1}\):
$$p = f(c(\mathcal{E}_n),g(\mathcal{D}_n),|\mathcal{D}_n|),$$- 其中 \(g(\mathcal{D}_n)\) 通过一个强大的求解器从 \(\mathcal{D}_n\) 中发现一个替代有效工具链所需的尝试次数来度量,而 \(f(\cdot)\) 是一个单调决策函数,控制环境增长过程
- 在实践中,当 \(p > \tau\) 时,其中 \(\tau\) 是预定义的阈值,作者从 \(\mathcal{D}_n\) 初始化一个新的种子黄金工具链 \(s_{n + 1}\),并将其扩展为 \(\mathcal{R}(s_{n + 1})\)
- 为了确保最低水平的环境复杂性,作者进一步引入了回退机制
- 如果生成的扩展 \(\mathcal{E}_n\) 仅包含少量工具节点,作者从 \(G\) 中随机采样一个中等大小的额外工具链,并将其合并到环境中,同时确保数据库与当前工具链的一致性
- 这保证了每个构建的环境至少包含20个工具,为有意义的智能体交互和探索提供了足够的结构复杂性
- 这种自动环境构建策略让我们能够在保持可靠监督信号的同时,逐步扩展环境复杂性,从而实现稳定有效的大规模智能体强化学习
Initial Policy
- 冷启动阶段在初始化后续强化学习阶段的策略方面起着关键作用
- 冷启动的主要目标不是优先考虑在标准基准测试上的即时收益,而是为有效的大规模探索做好准备
- 高质量的冷启动策略必须展现出多样化的推理模式和稳定的交互格式,确保后续的 RL 阶段可以高效进行,同时保留通用思维能力
- 因此,作者从更根本的角度评估冷启动模型,重点关注以下两个方面:
- (1) 其在 RL 阶段指定任务上的熟练程度
- (2) 通过人工定性检查评估的其推理路径的多样性
- 虽然作者报告标准基准测试上的
pass@k性能以衡量基础推理能力,但这仅作为参考,而非主要优化目标
- 因此,作者从更根本的角度评估冷启动模型,重点关注以下两个方面:
- 冷启动训练的一个主要挑战在于构建高质量的数据,这些数据能有效引导模型产生智能体行为
- 对于某些领域,如数学、通用编码和智能体代码任务,现实世界中存在大规模数据源
- 在这些情况下,作者从现有来源中收集和组装轨迹,核心挑战在于严格的质量控制和可执行性验证
- 然而,对于大多数智能体任务,如搜索和工具使用,高质量的实境轨迹基本上是不可用的
- 因此,作者依赖于精心设计的数据合成流程来构建冷启动轨迹
- 接下来作者将详细描述如何针对不同的智能体能力实例化这两种互补的策略
- 对于某些领域,如数学、通用编码和智能体代码任务,现实世界中存在大规模数据源
General Thinking
- 智能体能力需要强大的思考能力作为基础,作者设计了一个严格的数据过滤流程来构建高质量的 通用思考数据
- 具体来说,作者采用了一种由困惑度 (Perplexity, PPL) 引导的 K-Center-Greedy (KCG) 选择算法 (2018; 2023; 2023)
- 现有的基于 PPL 的过滤方法要么忽略序列长度,要么对整个序列平均 PPL (2025; 2025b),这 会掩盖局部困难 Token 并丢弃信息丰富的样本
- 为了解决这个问题,作者引入了滑动窗口 PPL,它计算序列中所有 512-Token 窗口的平均 PPL 的最大值 ,从而捕捉模型的峰值不确定性,而不会被全局平均所稀释
- 理解:
- 对于一个模型来说(作者指待训练模型),PPL 约小说明拟合的越好,PPL 越大,说明信息量越多;
- 部分子序列上的 PPL 差异可能是很大的,所以 子序列 PPL 很大时,值得留下来,故而做了一个加权
- 理解:
- 在 KCG 选择期间,作者根据 候选样本的滑动窗口 PPL 分数来加权 它与当前已选集合之间的距离
- 这种设计同时捕获了两个互补的目标:KCG 保留了对原始数据分布的覆盖 ,而滑动窗口 PPL 则强调了暴露模型当前推理能力差距的样本
- 使用这个流程,作者从一个大语料库中下采样了 210K 个通用思考样本
- 在此子集上训练的模型在多个推理基准测试中优于在全语料库上训练的模型
- General Thinking 的补充:
- 核心:这是一种结合 K-Center-Greedy (KCG) 算法和 滑动窗口困惑度(Sliding-Window PPL) 的数据选择策略。具体步骤如下:
- 滑动窗口困惑度计算
- 对于一个长度为 \( L \) 的文本序列,定义滑动窗口大小为 512 个 token,计算每个窗口内的平均困惑度(PPL),并取所有窗口中的最大值作为该样本的“滑动窗口困惑度”:
$$
\text{PPL}_{\text{slide} }(s) = \max_{i=1}^{L-511} \frac{1}{512} \sum_{t=i}^{i+511} -\log P(w_t \mid w_{ < t})
$$- 其中 \( P(w_t \mid w_{ < t}) \) 是模型在给定前文条件下预测当前 token 的概率
- 对于一个长度为 \( L \) 的文本序列,定义滑动窗口大小为 512 个 token,计算每个窗口内的平均困惑度(PPL),并取所有窗口中的最大值作为该样本的“滑动窗口困惑度”:
- K-Center-Greedy 选择算法
- 在 KCG 选择过程中,每个候选样本 \( s \) 与当前已选集合 \( S \) 的距离由滑动窗口困惑度加权:
$$
\text{dist}_{\text{weighted} }(s, S) = \text{PPL}_{\text{slide} }(s) \times \min_{s’ \in S} d(s, s’)
$$- 其中 \( d(s, s’) \) 是样本间的表示距离(比如通过 Sentence-BERT 编码的余弦距离)
- 在 KCG 选择过程中,每个候选样本 \( s \) 与当前已选集合 \( S \) 的距离由滑动窗口困惑度加权:
- 选择目标
- KCG 算法选择能够最大化覆盖原始数据分布的样本,而 滑动窗口困惑度 则 强调那些当前模型在局部推理上存在困难的样本 ,两者的结合实现了:
- 分布覆盖(Diversity)
- 困难样本挖掘(Difficulty-Aware Selection)
- 该方法从大规模语料库中筛选出 210K 条高质量通用推理样本,显著提升了推理任务的性能
- KCG 算法选择能够最大化覆盖原始数据分布的样本,而 滑动窗口困惑度 则 强调那些当前模型在局部推理上存在困难的样本 ,两者的结合实现了:
- 注意:在 LongCat 报告中提到的 滑动窗口 PPL 是基于 正在被训练的 LongCat-Flash-Thinking-2601 模型自身 来计算的,而不是外部模型
- 1)模型自身对候选样本进行前向推理
- 2)计算每个 512 token 窗口内的平均负对数似然(即局部 PPL)
- 3)取所有窗口中的 最大值 作为该样本的“滑动窗口 PPL”
- 目的:用当前模型自身的困惑度峰值来标识“局部推理困难”的样本,从而在 KCG 采样时给予更高权重,实现困难感知的数据选择
Agentic Coding
- 对于智能体编码任务,大规模的软件开发平台提供了丰富的实境轨迹来源
- 但从这些来源收集的原始轨迹通常是有噪声的、部分错误的或不可复现的 ,确保它们的可靠性和可执行性成为一个关键挑战
- 为了解决这个问题,作者为*代码交互轨迹 *构建了一个严格的筛选流程
- 作者要求所有保留的轨迹在可复现的环境中都是完全可执行和可验证的 ,并且 只保留那些在保留现有功能的同时正确解决了目标问题的轨迹
- 为了进一步避免学习到虚假行为,作者应用了 细粒度的动作级过滤,移除错误的、冗余的或推测性操作(speculative operations,即对正确解决问题无益的)
- 为了保留在实际调试过程中常见的长期推理模式,作者通过压缩早期步骤,保留涉及长且迭代调试的轨迹,从而在没有长度约束的情况下保持长期代码推理
Agentic Search
- 对于智能体搜索能力,构建高质量的轨迹需要显式地建模多步证据收集和完整条件验证,同时避免基于部分信息的虚假捷径
- 这种结构化的推理轨迹在现实世界的搜索日志中很少见
- 作者构建了合成的推理轨迹,这些轨迹优先考虑正确性、推理完整性以及针对捷径行为的鲁棒性
- 作者应用严格的过滤来确保轨迹质量,移除琐碎案例,并强制使用一致的推理和工具使用格式
- 为了避免捷径学习,例如基于部分证据的幸运猜测,作者要求轨迹包含对 Query 中指定的所有条件的显式验证
- 作者通过压缩早期步骤,进一步保留了涉及长且迭代探索的轨迹,从而在没有长度约束的情况下保留长期推理
- 作者通过重用后续强化学习阶段中的 Rollout 轨迹来扩展数据收集并增加行为多样性
Agentic Tool-Use
- 对于智能体通用工具使用能力,主要挑战在于对跨异构工具和数据库(具有不同模式和依赖结构)的复杂、有状态的交互进行建模
- 这样的环境和交互轨迹也难以从现实世界来源获得或标准化
- 作者在环境扩展流程之上构建了一个可扩展的数据合成流程
- 通过联合定义领域(jointly defining domains)、工具模式、数据库状态和任务目标,并在结构化工具依赖关系的基础上生成多步任务,以模拟覆盖 33 个代表性领域的现实工具使用环境
- 了确保多样性,作者明确地在三个方面促进可变性:领域覆盖范围、轨迹结构和交互长度
- 每个任务允许多种不同的正确工具调用轨迹,交互范围从短对话到长多轮执行,涵盖了广泛的任务难度和行为模式
- 为了确保数据质量,所有合成的轨迹都使用基于标准 (Rubric-based) 的结果验证和轮次级质量控制进行严格过滤
- 只有正确达到目标最终状态的轨迹才会被保留
- 在这些轨迹中,作者应用 Turn-level 损失掩码 ,从损失计算中排除低质量的轮次(例如失败的工具调用或格式违规),确保模型只从正确的动作中学习,同时保留完整的交互上下文
RL Task Set
- 在强化学习中,环境定义了智能体可以做什么,而任务集则决定了智能体被训练去做什么
- 它们共同塑造了智能体如何探索环境、分配计算并通过重复 Rollout 来改进其策略
- 一个设计良好的任务集应该既有信息量又有适当的复杂度 ,以便它能够提供有效的学习信号,而不会过于琐碎或难以解决
- 常见的做法是首先构建一个多样化的环境集合,并配以跨多个领域和难度级别的任务指令,然后通过评估模型的通过率来评估任务的适用性
- 基于这个信号,选择那些既非轻易可解决也非极其困难的任务用于强化学习
- 但不同领域的训练任务可用性差异很大
- 对于一些领域,如编码,已经存在大量复杂且高质量的任务,可以直接收集和整理
- 对于智能体搜索和工具使用等领域,合适的任务稀缺或不存在现成可用的形式,使得直接收集不足
- 作者引入了有原则的合成流程(principled synthesis pipelines),为智能体搜索和工具使用场景构建涵盖多种复杂级别的任务集
Agentic Search
- 作者确定了表征搜索问题的两个基本难度因素:
- (i) 对关系实体链的多跳推理
- (ii) 在多个模糊约束下对单个实体的推理
- 大多数复杂的搜索任务可以看作是这两个因素的组合或迭代细化
- Graph-based QA Synthesis :
- 为了建模多跳推理难度,作者通过一个系统性流程构建基于图的 Question-Answer 任务,该流程从维基百科实体构建关系图并生成具有挑战性的推理问题
- 首先从维基百科中提取低频实体作为初始种子节点,然后通过从现有实体集中采样、检索它们的维基百科页面,并结合相关实体及其对应关系,迭代扩展图,直到达到预定义的大小阈值
- 图构建完成后,采样多个固定大小的连通子图,并用它们生成 Question-Answer 对
- 在问题生成过程中,作者利用大语言模型创建与子图信息对应的问题,然后故意混淆显式细节,如数值、实体名称、地理位置和时间 Token ,以最大化推理复杂性
- 为了确保整个流程的质量和正确性,作者在关键步骤(包括实体关系提取、问题生成和混淆)采用 LLM-as-a-judge 方法以保持基准准确性
- 最后,对于每个生成的 Question-Answer 对,作者利用基于智能体的方法来识别其他潜在正确答案并评估其有效性,只保留那些原始答案正确且所有其他识别的潜在答案都不正确的配对
- 为了建模多跳推理难度,作者通过一个系统性流程构建基于图的 Question-Answer 任务,该流程从维基百科实体构建关系图并生成具有挑战性的推理问题
- Agent-based QA Synthesis :
- 为了建模由模糊性驱动的难度,作者提出了一个可扩展、高效的数据合成流程,其中多智能体协作交互由有限状态机 (FSM) 编排
- 在此框架内,一个实体提取智能体识别代表性的长尾实体并提取其显著属性,作为合成问题的基础事实
- 一个问题合成智能体利用这些属性的随机抽样来制定定制化问题
- 为了确保精确性,一个验证智能体利用搜索和浏览工具严格验证基础事实是否满足问题中指定的所有约束,从而减轻实体-问题不匹配的风险
- 对于每个经过验证的问题,答案生成智能体利用搜索和浏览工具生成候选答案
- 判断智能体评估这些候选答案与预定义基础事实之间的一致性
- 当判断智能体识别出一个非基础事实但仍满足验证标准的答案时,它表示存在多答案冲突
- 为了解决这个问题,系统会随机加入基础事实实体的额外属性,并触发问题重新合成,以确保其唯一性
- 该流程促进了跨多个领域多样化、高质量的问答对的高吞吐量生成
- 此外,它还实现了一个基于答案生成智能体准确性指标的自动难度分级机制
Agentic Tool-Use
- 对于智能体工具使用,作者的任务集直接通过第 3.1.1 节描述的环境扩展流程构建
- 每个合成的环境自然地定义了一个独立的任务,而这样的环境集合构成了最终的任务集
Scalable Asynchronous Agentic RL Framework
- 与标准推理任务等单轮场景相比,智能体训练涉及与可变环境 (ENV) 或工具的多轮交互,这对强化学习基础设施提出了新的挑战
- 在典型的多轮 Rollout 阶段,它反复交错进行 LLM 生成、环境执行和奖励评估,以构建用于强化学习训练的最终轨迹
- 在这种情况下,轨迹不仅具有长尾分布且偏斜,还涉及不可预测和延迟不均衡的环境交互,这导致在批处理设置下设备利用率不足 (2025; 2025c; 2025a)
- 此外,作者的生产集群由中端加速器组成,特别是仅有大约 60GB 的可用设备内存
- 硬件约束及其软件生态系统对实现稳定且可扩展的智能体强化学习训练构成了重大挑战
- 为了解决这些问题,作者扩展了作者的多版本异步训练系统 DORA (Dynamic ORchestration for Asynchronous Rollout) (2025c),以全面支持多轮智能体场景下的大规模强化学习训练
- 如图 5 所示,作者的控制器采用生产者-消费者架构,包括 RolloutManager(管理 Rollout 阶段)、SampleQueue(控制样本陈旧度)和 Trainer(管理 Experience-Maker 和训练阶段)
- 这些组件运行在不同的节点上,主要负责通过远程过程调用 (RPC) 进行逻辑控制和协调,而在 CPU 或加速器上运行的 Worker 执行实际任务
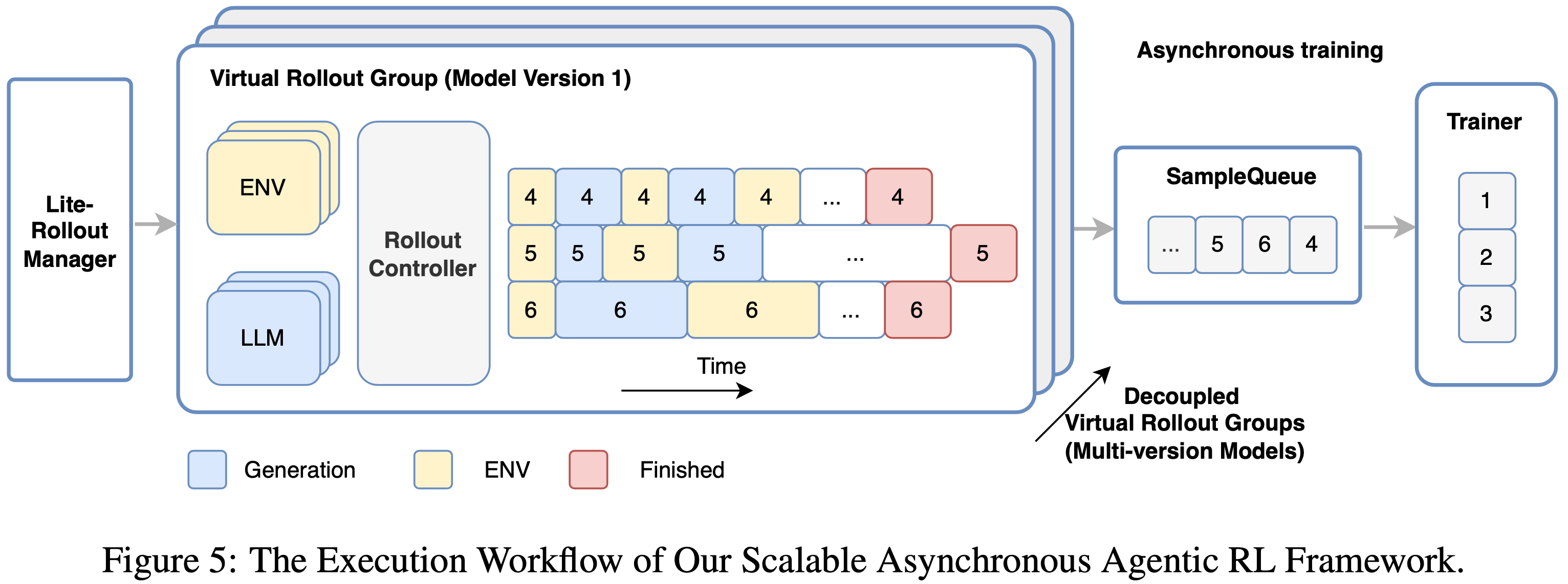
- 这些组件运行在不同的节点上,主要负责通过远程过程调用 (RPC) 进行逻辑控制和协调,而在 CPU 或加速器上运行的 Worker 执行实际任务
- 作者提出了几项关键技术,以实现高效、可扩展且稳定的智能体强化学习训练
- 全流式异步 Pipeline (Fully Streaming Asynchronous Pipeline)
- 为了最小化智能体设置下的设备闲置时间,作者基于流式 RPC (2025c) 引入了全流式异步 Pipeline ,既在 Rollout 过程内部,也在 Rollout 和训练之间
- 在 RolloutManager 内的 Rollout 循环中,作者移除了批处理屏障,使 LLM 生成、环境执行和奖励计算能够在远程 Worker 上以单个样本的粒度执行
- 这防止了加速器在等待批处理 ENV 调用完成时闲置
- 为了进一步解决训练稳定性与长尾生成问题,作者的 DORA 系统支持多版本异步训练,由不同模型版本生成的轨迹在完成后会立即入队
- 在一个步骤内,作者的多版本生成实例继续使用多个先前的模型版本进行 Rollout,而 Trainer 可以在满足其条件时立即启动训练,或者在训练设备闲置时弹性扩展额外的生成实例以获得免费的额外吞吐量
- 扩展至大规模智能体训练 (Scaling to Large-scale Agentic Training)
- 作者的算法设置需要大量环境,例如,多达 32,000 个环境在大约 400 台物理机器上运行,涉及数千个加速器
- 然而,这些环境之间的密集交互在横向扩展时会导致 RolloutManager 出现单机瓶颈,因为每次交互通常只涉及少量 CPU 操作
- 为了解决这个问题
- 首先,将原始设计分解为一个轻量级 RolloutManager(管理全局控制元数据)和多个 RolloutController(每个都以数据并行方式管理一个虚拟 Rollout 组的生命周期)
- 一个虚拟 Rollout 组由多个轨迹和相关的物理机器(包括生成实例和环境实例)组成
- 然后,为了在作者的生产作业中灵活调度大规模环境,作者扩展了 PyTorch RPC 框架 (2023),以提供 CPU-空闲感知的远程函数调用和对象实例化
- 此扩展允许在任意或空闲的机器上实例化和执行远程环境,从而实现大规模环境的高效部署
- 首先,将原始设计分解为一个轻量级 RolloutManager(管理全局控制元数据)和多个 RolloutController(每个都以数据并行方式管理一个虚拟 Rollout 组的生命周期)
- 带有 CPU 交换的预填充-解码分离 (PD Disaggregation with CPU Swapping)
- 为了在作者的加速器上高效生成拥有 560B 参数的 MoE 模型 LongCat-Flash-Thinking-2601,作者在解码时采用了高度的专家并行以及图级编译
- 但在多轮智能体训练中,频繁到来的长上下文请求会导致专家并行组内的工作负载不均衡:分配给较长上下文的 rank 消耗不成比例的计算和通信带宽,成为性能瓶颈
- 理解:较长上下文的机器需要更多的计算资源和通信带宽
- 为了解决这个问题,作者在强化学习训练中引入了预填充-解码 (Prefill-Decode, PD) 分离 (2024; 2024),如图 6 所示
- 对于生成实例,作者在不同的设备组上部署预填充节点和解码节点,允许解码执行图在不被新到达请求的预填充工作负载中断的情况下运行
- 这防止了生成效率的下降,并在多轮 Rollout 期间保持了高吞吐量
- 但PD 分离引入了额外的挑战,包括 KV 缓存传输开销以及当解码节点上的设备上 KV 缓存不足时(特别是在作者的加速器上)昂贵的重新计算开销
- 为了缓解 KV 缓存传输成本,作者在块级别聚合 KV 缓存块,并启用 PD 节点之间的异步传输
- 对于生成实例,作者在不同的设备组上部署预填充节点和解码节点,允许解码执行图在不被新到达请求的预填充工作负载中断的情况下运行
- 作者呢允许 之前块与后续块的计算重叠,以最小化 KV-cache 传输的开销
- 为了避免由于设备上 KV-cache 内存不足导致的重计算,作者进一步引入了 驻留于 CPU 的 KV-cache,它能根据需要动态地换入和换出 KV-cache 块
- 这一设计消除了因设备上 KV-cache 容量不足而导致的重计算开销,并有助于在我们的加速器上维持高吞吐量
- 为了避免由于设备上 KV-cache 内存不足导致的重计算,作者进一步引入了 驻留于 CPU 的 KV-cache,它能根据需要动态地换入和换出 KV-cache 块
- 全流式异步 Pipeline (Fully Streaming Asynchronous Pipeline)
- 总体而言,作者的 agentic RL 训练框架在 560B 模型上实现了工业规模的强大性能和稳定性,支持数以万计的加速器和环境
- 根据生产作业的运行时统计,我们的请求负载率在整個 rollout 过程中大约为 63%
- 这一指标量化了长尾请求对生成吞吐量的影响,数值越高表示利用率越好
- 在训练期间没有达到完全的请求负载率
- 因为作者限制新请求使用较旧的模型版本,以控制平均陈旧性,这牺牲了一定的效率
- 此外,在可能包含多次负载均衡操作的单个步骤内,作者采用了两阶段策略:在首次负载均衡之前的初始 rollout 阶段,当没有长尾生成时,允许每个设备有较高的请求数(例如 8 个),随后将每个设备的请求数限制在一个最优水平(例如 4 个),以避免重计算并提高生成效率
- 未来,作者计划采用更乐观的陈旧性控制策略,并探索对陈旧性敏感的稳定性技术,以实现更高效的异步训练
- 总之,作者的多版本异步训练系统 DORA,在涵盖不同场景的生产作业中,比同步训练快 2 到 4 倍
- 根据生产作业的运行时统计,我们的请求负载率在整個 rollout 过程中大约为 63%
RL Training Strategy
- 强化学习已成为持续提升模型推理能力的核心机制,传统上,RL 训练策略主要侧重于在相对同质的任务分布和单步 rollout 下,稳定策略优化、提高样本效率以及管理探索-利用权衡
- 在这些设置中,任务难度差异可能很大,导致训练样本的学习价值高度不平衡
- 除了课程学习,作者在每个训练步骤内动态分配 rollout 预算,以有效利用有限的计算和训练时间预算,将学习资源集中在高价值的任务上
- 为了进一步提高训练效果,我们还将验证 (verification) 建模为辅助任务,以支持生成并加速优化
- 当扩展到 agentic 设置时,强化学习面临着由多轮交互和不可预测的环境反馈所带来的新挑战,这对模型的有效上下文长度提出了严格的要求
- 为了解决这个问题,作者引入了一种 上下文管理 (context management) 策略,使模型能够在有限的上下文窗口下支持长视界轨迹,同时保留最具信息量的上下文
- 当进一步扩展到 agentic 工具使用场景时,训练问题变得更具挑战性,如前所述, 泛化性和鲁棒性 在此设置中尤为重要
- 为了促进泛化性,agentic 工具使用环境来自作者的环境扩展 (environment scaling) 流程
- 单个批次中的任务可能跨越不同领域的异构环境,这加剧了训练的不稳定性和不平衡性
- 通过精心协同设计训练策略和基础设施支持,作者大规模地执行了高效且稳定的 多领域环境训练 (multi-domain environment training)
- 泛化到现实世界设置仍然具有挑战性,因为现实世界环境本身是不完美的
- 为了提高鲁棒性,我们明确地将环境不完美性纳入训练过程,使模型能够在非理想条件下学习具有韧性的行为
- 这些设计共同形成了一个统一的训练策略,能够实现稳定、高效且可扩展的 agentic 强化学习
- 为了促进泛化性,agentic 工具使用环境来自作者的环境扩展 (environment scaling) 流程
General Training Strategy
- 在大规模强化学习中,训练集涵盖难度差异很大的任务
- 对所有任务进行朴素的均匀处理通常会导致学习效率低下
- 作者设计了一套应用于作者所有强化学习方案的训练策略
- 具体来说,引入 课程学习 (curriculum learning) 以逐步增加任务难度,应用 动态预算分配 (dynamic budget allocation) 以将计算集中在当前模型状态下信息量最大的任务上
- 作者还将 自验证 (self-verification) 作为辅助任务纳入,以进一步提高优化效率和效果
Training Objective
- 采用 组序列策略优化 (Group Sequence Policy Optimization, GSPO) 作为训练目标,因为它在 MoE 模型上的经验有效性,并为长视界 agentic 轨迹提供了更稳定的序列级优化
- 给定一个输入 \(x\),作者从旧策略 \(\pi_{\theta_{\mathrm{old} } }\) 采样一组 \(G\) 个轨迹 \(\{y_{i}\}_{i = 1}^{G}\) 并优化:
$$\mathcal{J}_{\mathrm{GSPO} }(\theta) = \mathbb{E}_{x\sim \mathcal{D},\{y_{i}\}_{i = 1}^{G}\sim \pi_{\theta_{\mathrm{old} } }(\cdot |x)}\left[\frac{1}{G}\sum_{i = 1}^{G}\min \left(s_{i}(\theta)\hat{A}_{i},\mathrm{clip}(s_{i}(\theta),1 - \epsilon ,1 + \epsilon)\hat{A}_{i}\right)\right], \quad (1)$$- 其中 \(\epsilon\) 是裁剪阈值
- 遵循 Zheng 等人 (2025) 的工作,作者采用基于组 (group-based) 的优势估计,并基于归一化似然在序列级别定义重要性比率 \(s_{i}(\theta)\)
- 作者主要依赖结果导向的监督 ,并放宽对长轨迹的惩罚 ,允许在训练过程中自然地出现有效的策略
Curriculum Learning
- 为了提高学习效果,作者采用了一种课程学习策略,逐步构建训练过程
- 具体来说,作者的课程沿着两个互补的轴组织:任务难度和能力需求
- 任务难度 使用 在优化前估计的模型通过率 来量化,其中较低的通过率表示更具挑战性的任务
- 根据任务主要调用的 智能体能力 (如基本工具调用、多步规划或自主决策)来表征任务
- 理解:这里不同任务需要的智能体能力侧重是不一样的
- Curriculum Learning Pipeline:
- 在早期训练阶段,作者优先考虑那些更容易学习的任务 ,或者 优先考虑那些暴露了智能体在解决更难任务时预计会自主重用的能力的任务
- 随着训练的进行,作者逐渐转向那些难度更大且需要更高级智能体能力组合的任务
- 这种二维课程使模型能够首先获得可重用的智能体技能,然后组合它们来解决日益复杂的问题
- 经验表明,这种课程策略提高了整体任务通过率,并在最具挑战性的任务上产生了特别显著的收益
- 作者在智能体设置下的分析表明,这些改进源于三个主要因素:
- 工具使用泛化 (Tool-use generalization) :从较简单任务(如工具选择和约束处理)中获得的技能能有效地迁移到更复杂的场景,显著减少了工具调用失败
- 交互效率 (Interaction efficiency) :对任务指令的更好理解使得内部推理更加彻底,减少了冗余的澄清或不必要的工具调用,从而减少了交互轮次
- 规划能力 (Planning capability) :对多个约束(如时间、地点和实体)的增强联合推理使得任务能够以更少的纠正迭代更直接地完成
Dynamic Budget Allocation
- 作者在训练批次内进一步应用动态预算分配,以 优先考虑在当前模型状态下提供更高学习价值的任务
- 作者观察到, 难度与模型当前能力相匹配的任务在固定的 Rollout 预算下会产生显著更高的学习收益
- 现有的大规模强化学习流程通常为所有任务分配统一的 Rollout 预算
- 最近的研究开始探索自适应 Rollout 分配 (2025),但大多数方法依赖于预定义的价值函数
- 但随着模型能力在训练过程中持续演化,这个假设会失效,导致提供最有信息量的学习信号的任务集合也相应发生变化
- 为了解决这个问题,作者提出了一种动态 Rollout 预算分配策略,以适应模型的实时训练状态
- 具体来说,作者通过监控实时训练指标 \(\mathbf{m}_{t}\)(例如,通过率)来量化当前策略 \(\pi_{\theta_{t} }\) 的能力
- 作者通过一个动态价值函数将特定任务 \(\tau_{i}\) 和 \(\mathbf{m}_{t}\) 映射起来:
$$v_{i,t} = V(\tau_{i}\mid \pi_{\theta_{t} },\mathbf{m}_{t}) \quad (2)$$- 其中 \(v_{i,t}\) 表示任务 \(\tau_{i}\) 的估计价值,表征了模型在任务空间上演化的偏好分布
- 基于这个价值估计,作者采用一种基于堆 (heap-based) 的贪心算法来计算 Rollout 分配,以最大化当前训练批次的总体学习价值
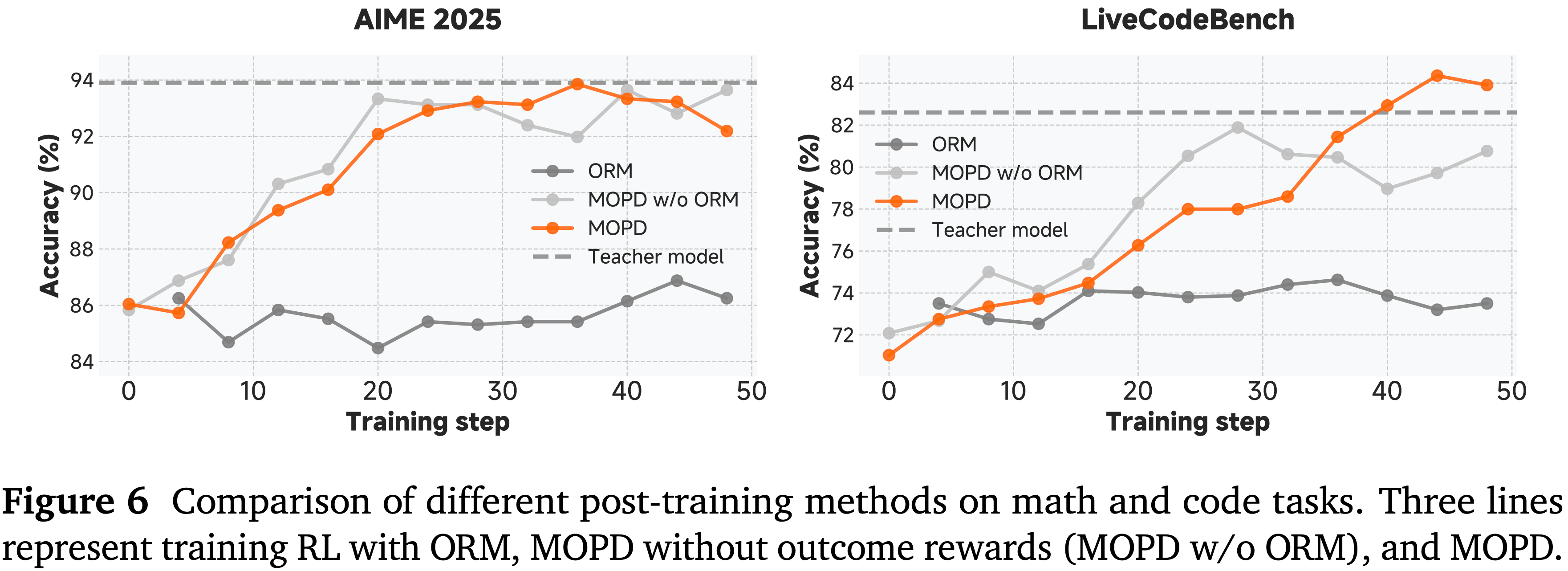
Self-Verification
- 除了将模型仅用作生成的行为者策略 (Actor Policy) 外,作者还额外利用模型作为验证器 (verifier) 来评估其自身在线策略 (on-policy) 轨迹的质量
- 作者观察到一个显著的不对称性:即使是能够生成高质量轨迹的高级推理模型 ,也常常难以在没有显式基础事实信号的情况下可靠地评估这些轨迹的正确性
- 这让我们能显式地增强模型的自我验证能力 ,并将其用作辅助信号,以提高其在特定领域的推理能力
- 具体来说,作者引入了在线策略自我验证作为强化学习过程中动态激活的训练阶段
- 当 生成器表现出停滞或收敛到局部最优的迹象时 ,作者触发一个验证阶段 ,在此阶段模型评估其自身的 Rollout 轨迹
- 与生成相比 ,验证是一个相对更容易的任务 ,并且通常产生更高的奖励
- 为了进一步增强自我验证的有效性,作者采用了一种定制的训练方案
- 具体来说,作者确保验证重点针对具有挑战性的案例,并且验证的影响与相应生成轨迹的质量相关联,使得辅助信号鼓励生成的忠实改进,而不是退化的捷径行为
- 经验表明,引入在线策略自我验证作为辅助任务可以加速模型收敛,从而提高生成性能
Agentic Specific Strategy
- 在智能体场景中,交互模式自然地从单轮生成转变为模型推理和工具调用交错的多轮轨迹
- 随着任务复杂性的增加,交互轮次数量和工具响应长度都会增长,使得总上下文长度变化很大且通常难以控制
- 在实践中,这经常导致上下文窗口溢出、推理链被截断以及任务执行不完整
- 因此,在有限上下文窗口下,有效的上下文管理成为使用工具的强化学习的必要组成部分
Context Management
- 作者设计了一种混合上下文管理策略,以在有限上下文窗口下支持长期轨迹
- 现有的智能体模型主要采用两种策略进行上下文管理:
- 基于摘要的管理 (Summary-based Management) :
- 当累积上下文长度超过预定义的 Token 阈值时,历史工具调用结果会被提炼成一个简洁的摘要,以替换原始上下文,保持上下文连续性
- 基于 ReSum (2025) 的框架,作者使用模型本身作为摘要工具,并用不同的 Token 阈值进行了一系列对比实验,最终确定了 80K Token 为最优阈值(更多细节见附录 B)
- 此外,为了增强模型的摘要性能,作者合成了一个包含 15K 个样本的高质量数据集,专门用于冷启动阶段
- 实证结果表明,这带来了大约 3% 的准确率提升
- 基于丢弃的管理 (Discard-based Management) :
- 当上下文长度超过预定义阈值时,模型将丢弃全部或部分历史上下文,然后基于截断的上下文恢复或重新启动生成过程
- 遵循 DeepSeek-V3.2 (DeepSeek-2025) 的做法,作者在工作中采用了全部丢弃 (discard-all) 策略
- 基于摘要的管理 (Summary-based Management) :
- 结合上述两种策略,作者设计了一种针对智能体推理量身定制的混合上下文管理方法
- 具体来说,作者首先在上下文窗口超过作者预定义的 80K Token 限制时应用基于摘要的压缩
- 当交互超过最大轮数时 ,作者触发全部丢弃重置 ,并使用从原始问题衍生的初始化系统和用户提示重新启动生成
- 作者在 BrowseComp 基准 (2025) 上评估了这三种策略
- 如图 7 所示,在不同的计算预算下,上下文管理通过使模型能够扩展测试时计算资源,带来了显著的性能提升
- 混合策略在大多数情况下优于其他两种,并在整个实验中表现出最高的效率,从 \(55.8%\) 开始,峰值达到 \(73.1%\)
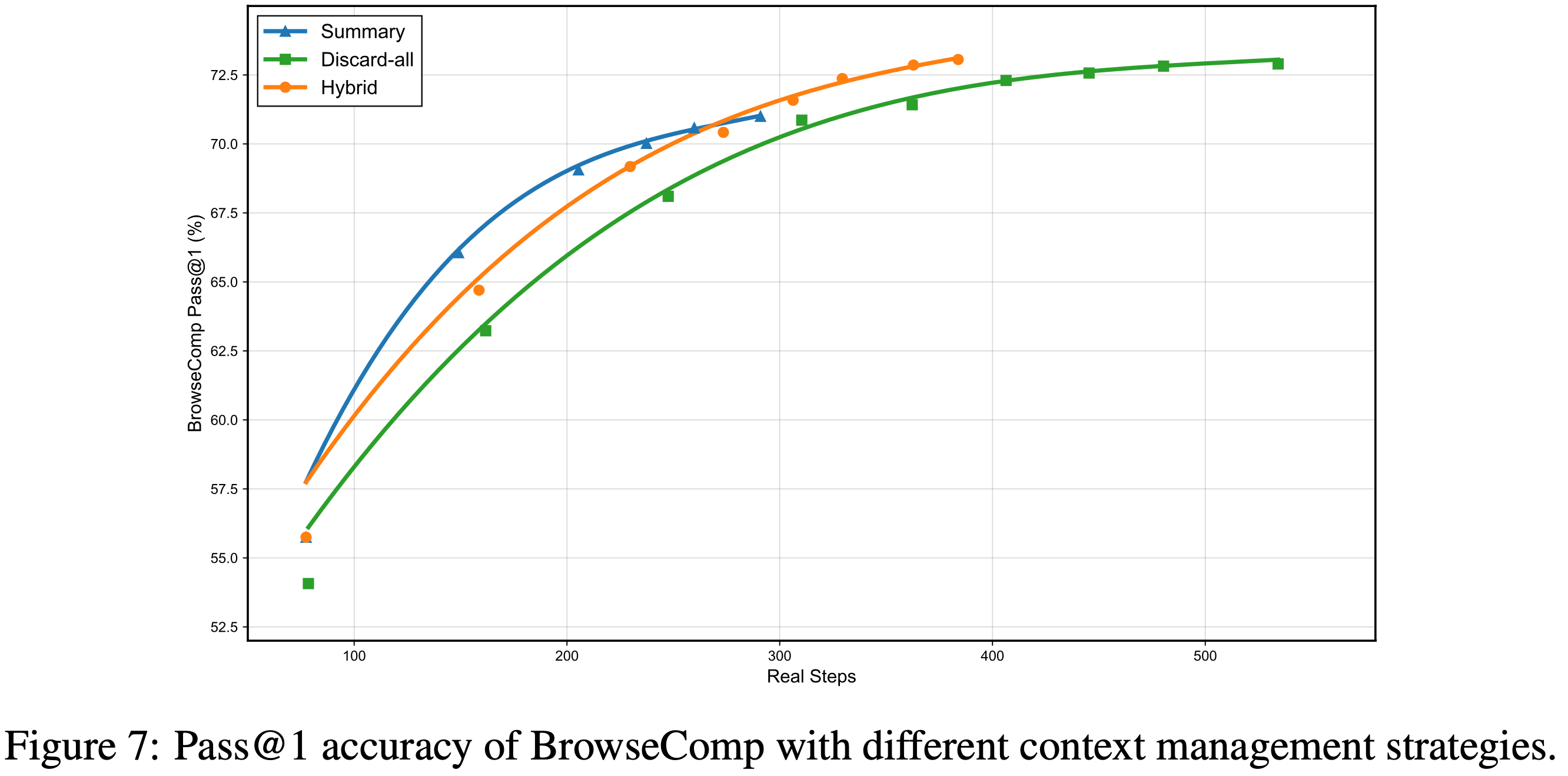
- 混合策略在大多数情况下优于其他两种,并在整个实验中表现出最高的效率,从 \(55.8%\) 开始,峰值达到 \(73.1%\)
- 这种优越性能源于压缩和重置之间的动态切换,由上下文窗口和交互轮次约束控制,在关键推理上下文保留和计算开销控制之间实现了良好的权衡
- 此外,作者采用了一种渐进的丢弃调度,逐步增加丢弃阈值,允许更困难的样本逐渐增加推理步骤数
Training Strategy with Scaled Environment
- 引入扩展环境进一步提升了强化学习的复杂性,超越了工具增强设置
- 在这个阶段,作者在跨越多个领域且表现出高度异质性的环境上进行了大规模训练
- 作者期望在这种多样化的环境上进行训练能够鼓励模型获得可迁移的智能体行为,这些行为可以泛化到领域特定模式之外
- 这种异质性在算法和系统层面都带来了新的挑战:
- 训练过程必须同时保持跨领域泛化能力,确保在高度多样化的任务分布下稳定优化,并在长尾且不均衡的环境工作负载下保持高效
- 为了应对这些挑战,作者采用了一种多领域环境训练范式,在每次训练批次内联合优化不同的环境
- 为了确保稳定性和可扩展性,作者需要共同设计训练策略和作者的异步基础设施
- 受环境扩展构建过程的启发,作者注意到现实世界的环境本质上是不完美的,因此,作者在训练期间显式地引入了环境噪声,以提高对异构和不可靠环境反馈的鲁棒性
Multi-Domain Environment Training
- 为了提高跨环境泛化能力和训练稳定性,作者采用了一种多领域环境训练策略,在每次训练批次内联合优化不同的环境
- 通过环境扩展,作者构建了数以万计跨越超过20个领域的环境,提供了对异构交互模式的广泛覆盖
- 在此设置下进行训练引入了不小的系统挑战
- 具体来说,为了保持训练稳定性,有必要确保所有领域对整体训练过程的贡献相当,同时防止任何一个训练批次被少数几个领域主导
- 这个算法约束显著降低了作者 DORA 系统的效率,因为它打破了异步设计原则:
- Trainer 可能被迫等待缓慢或罕见的长尾领域产生足够的样本,而较快的领域则积累过多的 Rollout 轨迹,导致调度气泡和设备利用率不足。为了缓解这个问题,作者支持为不同的数据类型和领域配置单独的过采样比率
- 在实践中,作者增加了更具挑战性或低吞吐量领域的 Rollout 配额,使它们能够贡献足够的样本而不阻塞整个流程,而较快的领域则以较低的有效速率进行采样
- 这种设计放宽了严格的每批平衡约束,同时利用 DORA 保持了异步训练的高吞吐量特性,并且在训练阶段仍然保持了大致平衡的数据混合,并保证了训练收敛
- 为了确保在此训练设置下动态预算分配与作者的异步基础设施的兼容性,作者根据每个任务的历史通过率为其引入了一个过采样系数
- 成功率较低的任务被分配更高的过采样系数,有效地将更多的 Rollout 预算分配给更具挑战性的任务
- 具体来说,每个任务根据其过采样系数被复制为多个组,每个组在训练期间独立计算优势
- 这种设计近似于动态预算分配,同时保留了 DORA 简单且完全异步的调度行为,以最小的系统复杂性实现了动态 Token 预算控制
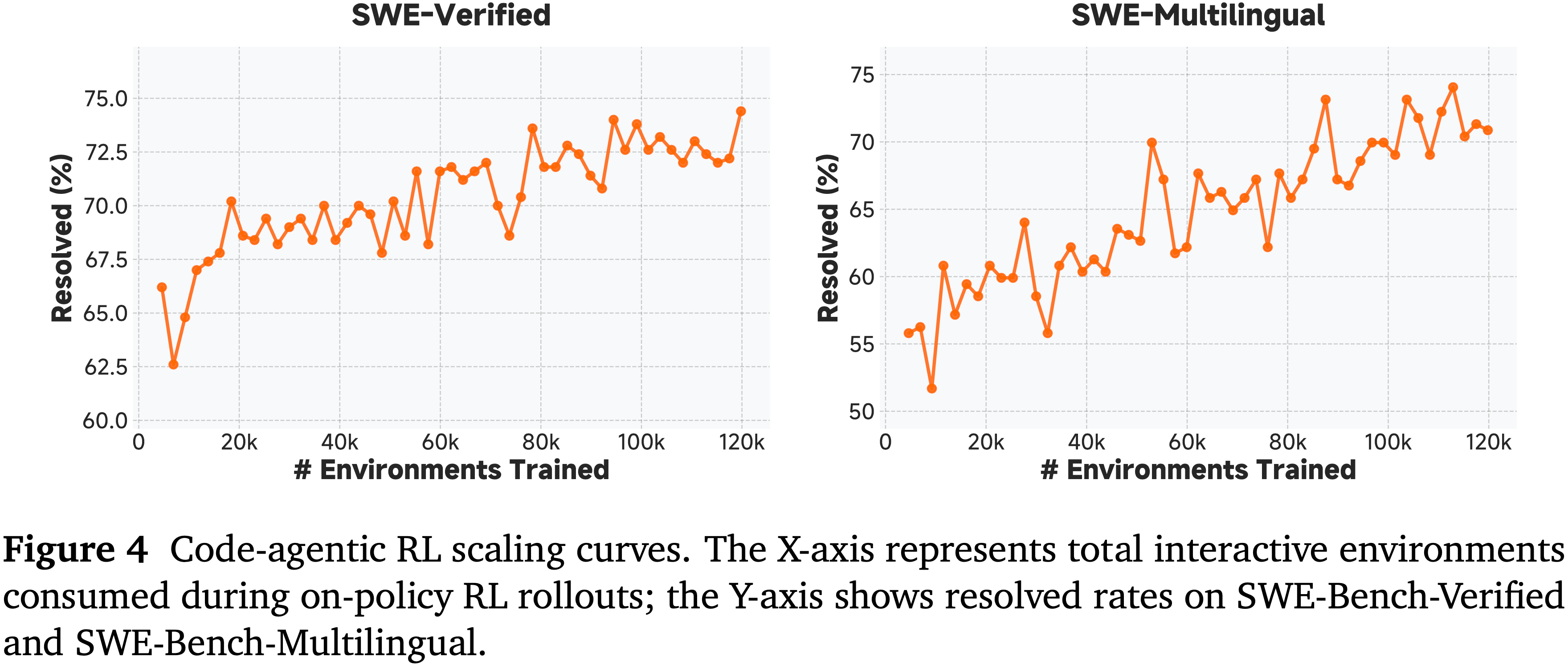
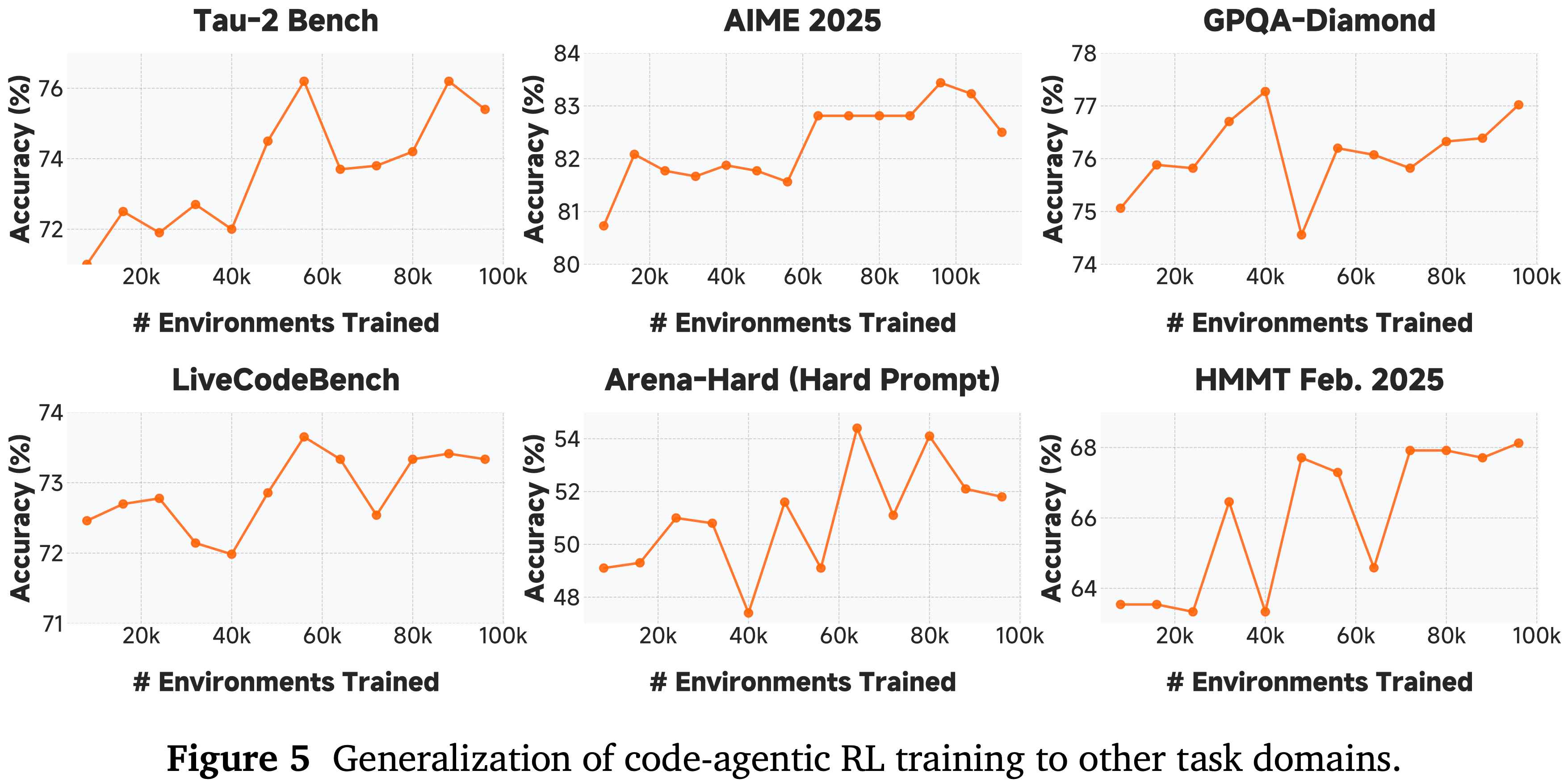
- 作者在图 8 中展示了 LongCat-Flash-Thinking-2601 的训练奖励曲线,并在图 9 中展示了在不同训练步骤下智能体基准测试的相应性能
- 图 8 中的训练奖励表现出稳定且一致的上升趋势,表明作者的算法-基础设施协同设计有效地确保了大规模训练的稳定性
- 图 9 中智能体基准测试的性能展示了跨多个基准测试的强大泛化能力,这验证了作者环境合成流程的有效性
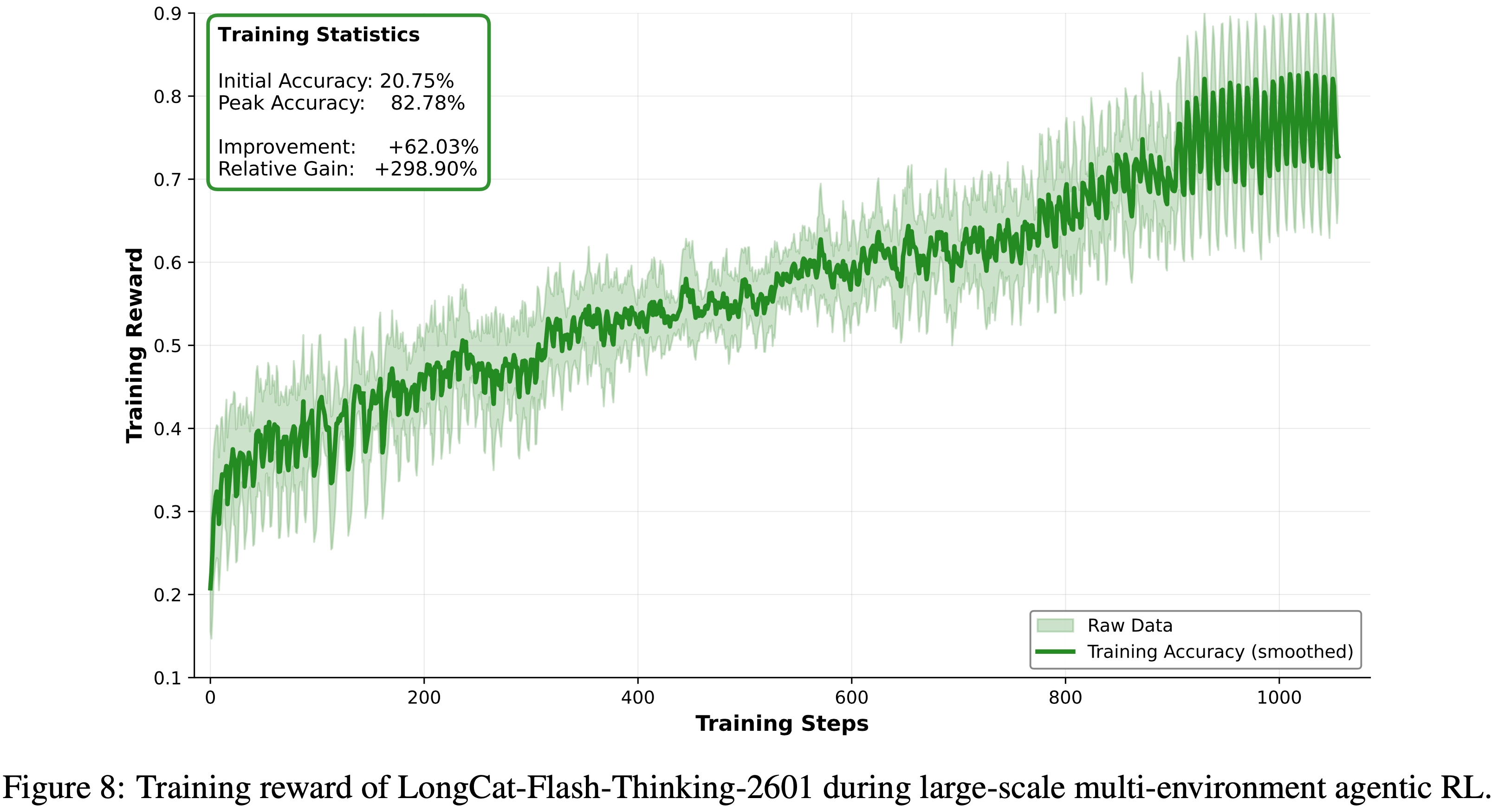
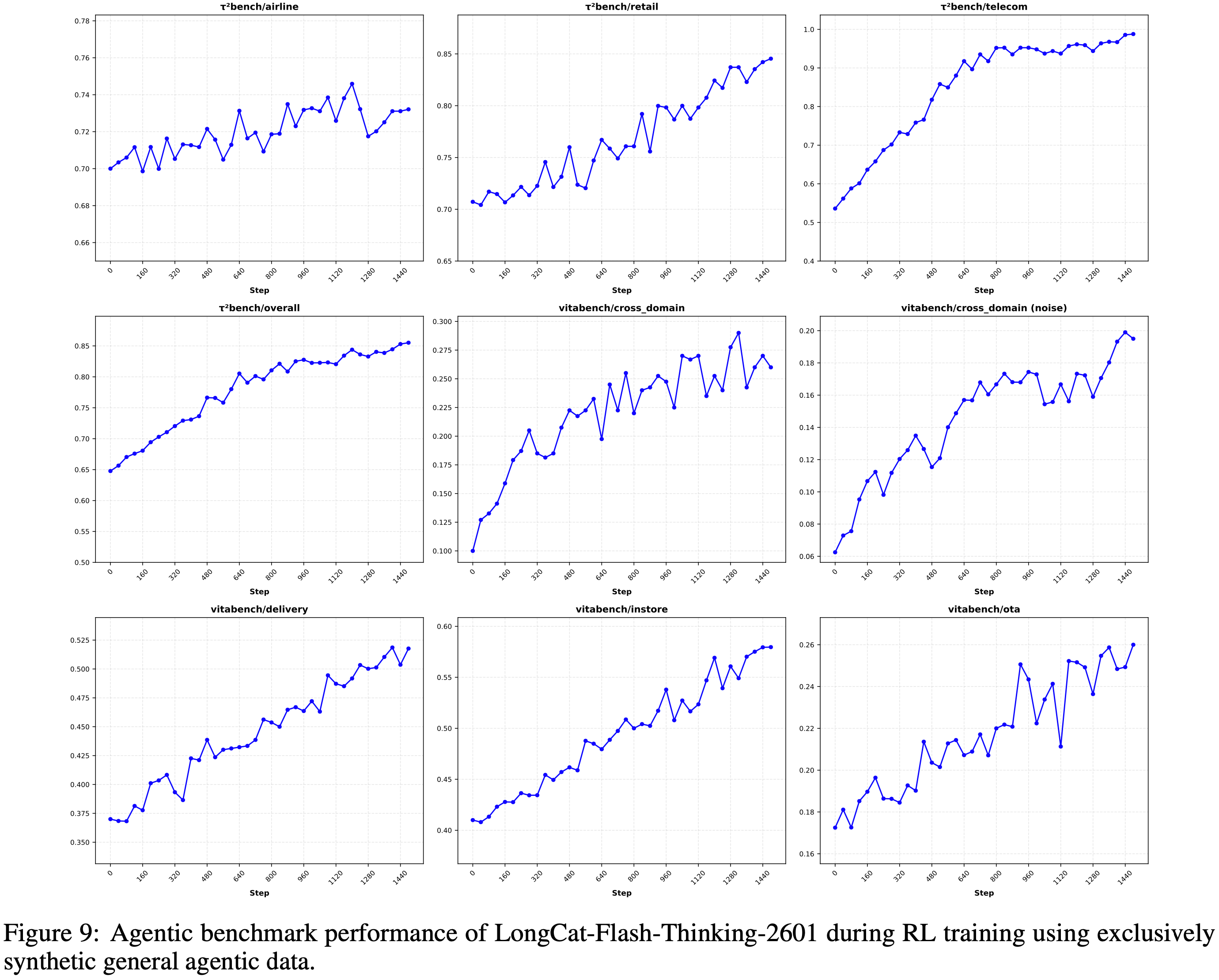
- 经验表明,多领域环境训练在环境中实现了更高的平均任务完成率,尤其是在最具挑战性的环境上改进显著
- 此外,该模型在随机生成的环境中获得了强大的性能,表现出强大的泛化能力
Robust RL
- 作者明确地将环境缺陷纳入训练过程 ,以提高鲁棒性
- 现有的智能体模型在部署到先前未见过的或不完美的环境中时,性能会显著下降
- 这个问题主要源于当前智能体训练范式中的一个常见假设:智能体通常使用精心策划的指令进行训练,并与稳定、受控良好的环境交互
- 相比之下,现实世界的环境本质上是不完美的
- 用户表现出多样化的交互风格和不可预测的行为,而工具可能因各种外部因素而失败、返回有噪声的输出或产生不完整的结果
- 作者不是假设训练期间环境是理想化的并依赖智能体事后适应,而是系统地分析现实世界的噪声 ,并设计一个自动化流程 ,明确地将环境缺陷纳入训练过程
- 为了避免引入不可靠或误导性的奖励信号,作者确保注入的缺陷不会使任务变得不可解,而是增加交互过程的难度和随机性
- 具体来说,我们为现实世界 agentic 场景中的两种主要交互噪声源建模:
- 指令噪声 (instruction noise) :捕捉用户交互模式的模糊性和可变性;
- 工具噪声 (tool noise) :模拟外部工具的执行失败、不一致响应和部分结果
- 在 agentic 强化学习过程中,作者使用基于课程学习 (curriculum-based) 的策略逐步引入这些噪声
- 将 agentic 模型的鲁棒性衡量为同一任务在完美环境与不完美环境之间的性能差距
- 从轻微的扰动开始,随着模型在当前水平上表现出足够的鲁棒性,逐渐增加噪声的难度和多样性
- 这种自适应过程确保了训练保持信息性而非压倒性,并避免了在过度嘈杂的环境中进行低效探索
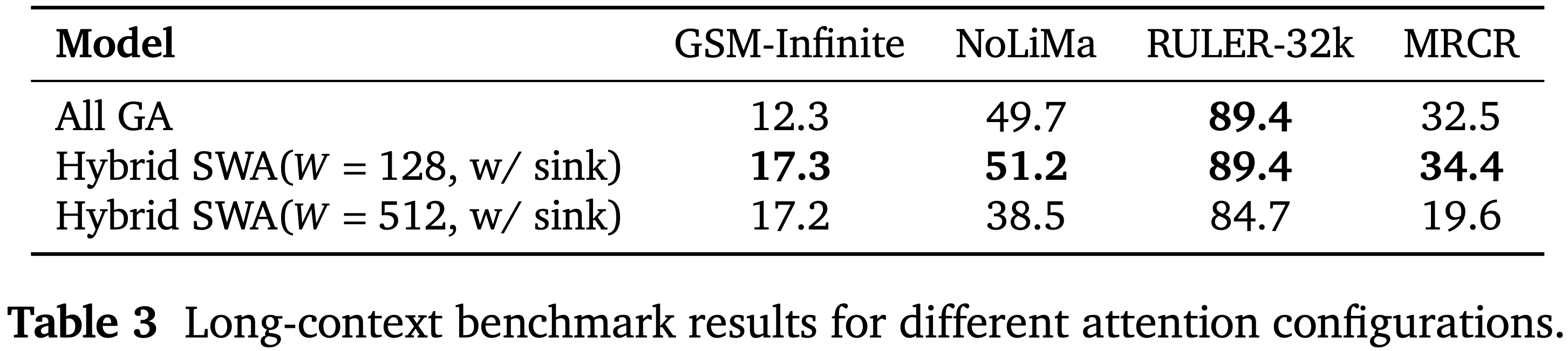
- 表 1 展示了在不完美环境下的鲁棒训练策略的消融研究结果
- 结果表明,引入噪声的训练在标准 agentic 基准测试上取得了相当甚至略好的性能,同时在噪声和不完美的条件下产生了显著的性能提升
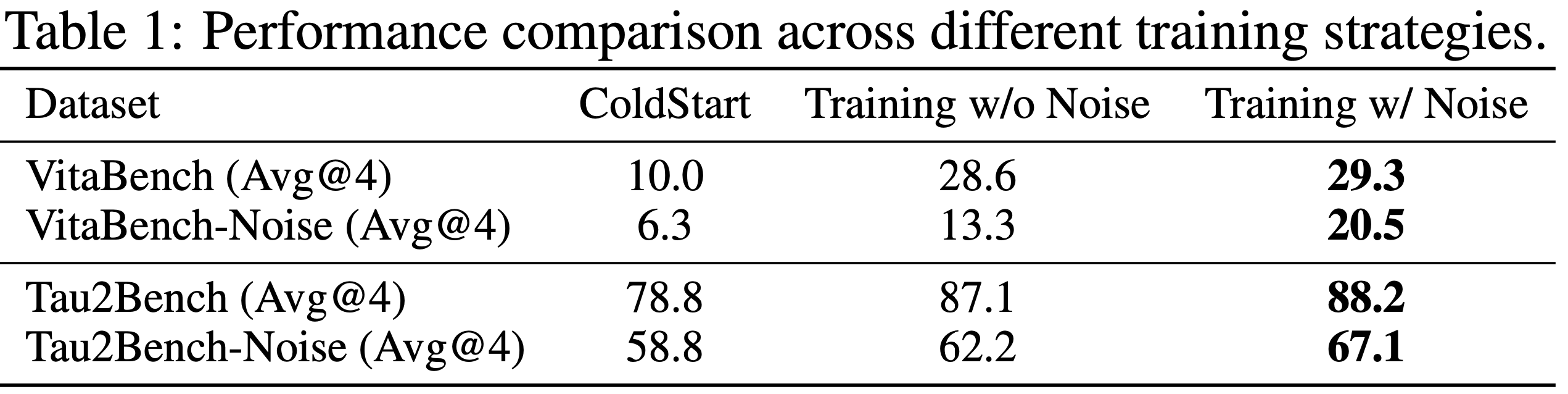
- 结果表明,引入噪声的训练在标准 agentic 基准测试上取得了相当甚至略好的性能,同时在噪声和不完美的条件下产生了显著的性能提升
Test-Time Scaling Through Heavy Thinking
- 测试时扩展 (Test-time scaling, TTS) 已成为通过在推理阶段扩展计算来提高模型在复杂推理任务上性能的一种有效范式
- 最新进展表明,通过结合自反思的长思维链来增加推理深度,可以让模型迭代地优化其推理过程 (2024, 2025, 2025)
- 与此同时,诸如自一致性(self-consistency)和蒙特卡洛树搜索 (Monte Carlo Tree Search, MCTS) 等方法则沿宽度维度扩展计算,探索多个推理轨迹以更好地逼近模型的推理边界
- 一些前沿模型引入了 Heavy Thinking (2025, 2025a, 2025, 2025),其目标是在测试时联合扩展推理的深度和宽度
- 经验上,这些模式的表现超过了仅扩展深度或宽度的策略
- 但此类 Heavy Thinking 的具体实现细节大多未公开,限制了其可复现性和系统性研究
- 为了进一步释放推理能力并突破现有的性能天花板,作者提出了一个简单有效的 Heavy Thinking 框架,将测试时计算分解为两个互补的阶段:
- 并行推理(parallel reasoning)和 Heavy Thinking
- 如图 10 所示
- 在第一阶段,作者允许一个思考模型并行执行生成,产生多个候选推理轨迹以扩展探索的广度
- 在第二阶段,作者利用一个总结模型对这些轨迹进行反思性推理,综合它们的中途推理和结果以得出最终决策
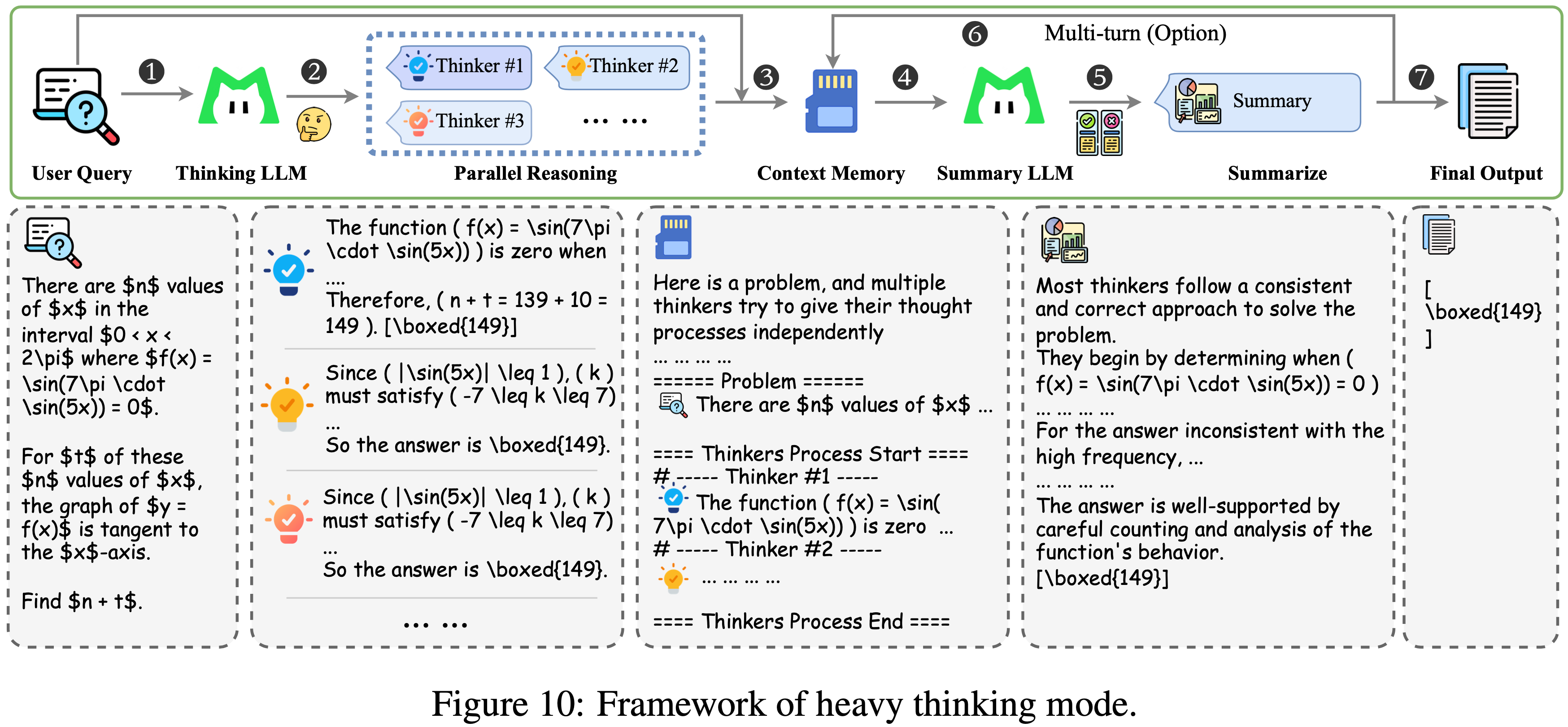
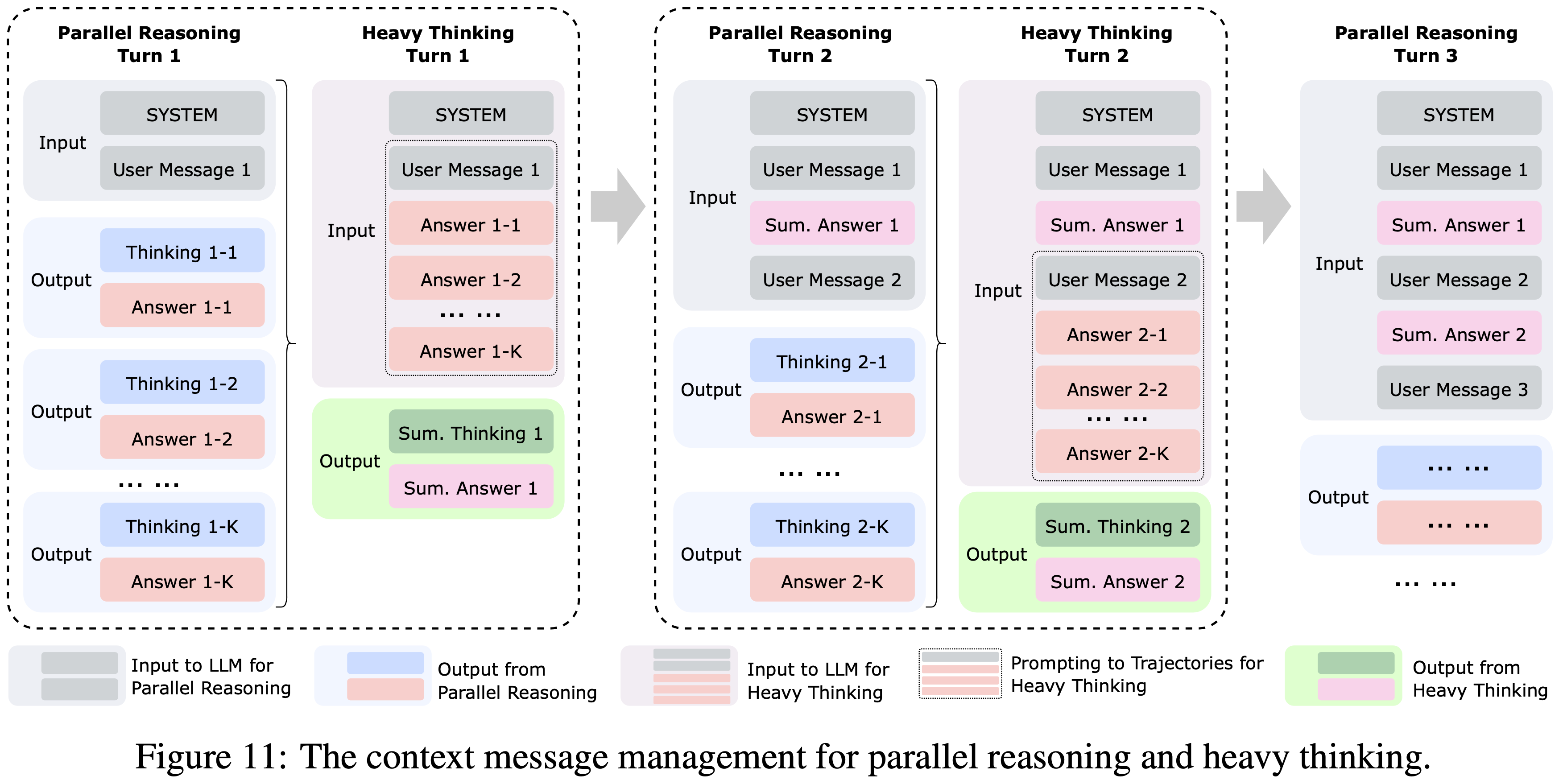
- 为了支持工具使用和多轮对话场景,作者还引入了一个上下文记忆模块来存储消息历史
- 如图 11 所示
- 在每一轮中,总结模型将接收来自并行推理阶段的历史消息以感知上下文
- 作者设计了一个特定的提示模板来组织当前轮次并行轨迹的排列(仅保留答案内容),并引导总结模型生成最终响应,其目的是聚合或优化从并行推理阶段得出的答案
- 作者还约束总结模型的最终输出响应,以保持与并行推理阶段的风格和格式一致,使得总结模型的响应能够与消息历史直接拼接
- 值得注意的是,思考模块和总结模块可以共享相同的模型参数,也可以实例化为不同的模型
- 为了进一步提升性能,作者还引入了一个专门针对总结阶段设计的额外 RL 阶段
- 经验上,作者发现 Heavy Thinking 在多种设置下都有效,包括长思维链推理、工具集成推理和完全的工具使用(agentic tool-use)场景
- 通过允许测试时计算在推理深度和宽度上自适应地扩展, Heavy Thinking 的表现始终优于自一致性(self-consistency),并且随着测试时计算预算的增加,其性能优势变得愈发显著
Evaluation
Benchmarks and Configurations
- 作者的评估涵盖模型能力的五个方面:
- Mathematical Reasoning
- Agentic Search
- Agentic Tool Use
- General Reasoning
- Coding
Mathematical Reasoning
- 作者使用标准的奥林匹克级基准测试来评估数学推理,包括 AIME 2025、HMMT 2025 (February) (2025) 和 IMO-AnswerBench (2025)
- 此外,还引入了 AMO-Bench (2025)(这是现有奥林匹克级基准测试中最具挑战性的数据集)
- 包含由人类专家设计的 50 个问题,并提供中英文版本,便于分析跨语言数学推理
- 作者发布了 AMO-Bench 的英文版和评估脚本
- 由于这些数据集规模有限,作者报告 Avg@k 指标,IMO-AnswerBench 使用 \(k = 4\),其他所有数学基准使用 \(k = 16\)
- 作者主要关注工具集成推理(Tool-integrated Reasoning, TIR)的性能,注意:此处工具指代码执行
- 对于支持代码执行的外部模型,作者在评估时启用此功能
- 对于不支持代码的模型,作者报告其官方结果或它们不使用工具时的性能
Agentic Search
- 作者在 BrowseComp (2025) 和 BrowseComp-ZH (2025) 上评估智能体搜索能力,并报告启用和未启用上下文管理两种设置下的结果
- 注:对于 BrowseComp-zh,作者发现原始标注存在一些错误,并手动修正了 24 个案例的答案
- 作者尝试在作者的智能体搜索框架下复现开源和闭源模型在这些基准测试上报告的结果
- 但作者观察到性能持续低于报告的数字,对于外部模型,作者使用其官方报告的结果
- 理解:这里确实花了时间后没法复现这部分分数(猜测与模型的某些配置有关,Infra 和评估同学不够给力?)
- 但作者观察到性能持续低于报告的数字,对于外部模型,作者使用其官方报告的结果
- 为了实现对搜索能力的公平且受控的比较,作者另外构建了 RWSearch(这是一个具有挑战性的智能体搜索基准)
- 包含 200 个需要复杂推理和多步骤信息检索的现实世界搜索 Query
- 所有模型都在未启用上下文管理的情况下在 RWSearch 上进行评估,以确保公平比较
Agentic Tool-Use
- 作者在 \(\tau^{2}\)-Bench (2025)、VitaBench (2025)、\(\tau^{2}\)-Noise、Vita-Noise 和随机复杂任务(Random Complex Tasks)上评估智能体工具使用能力
- 对于 \(\tau^{2}\)-Bench,作者观察到默认的用户模拟器(user simulator)偶尔会表现出异常行为,给评估带来不可控的噪声
- 为了解决这个问题,作者将原始模拟器替换为 GPT-4.1 并相应地调整提示策略 (2025, 2025b, 2025)
- 对于 \(\tau^{2}\)-Bench 的航空子集,作者进一步发现了一些标注和环境问题,可能导致虚假失败和不可靠的评估 (2025, 2025b, 2025)
- 作者在一个固定且清理过的航空子集版本上评估所有模型,其中 19 个有问题案例得到了修正
- 所有以上这些修改都已公开发布以确保可复现性
- 对于 VitaBench,作者更新了评估设置,将验证器模型(verifier model)升级到最强的公开可用版本,并采用更严格的评估标准,从而进一步提高基准测试的可靠性
- 作者已公开发布 VitaBench 的这个更新版本
- \(\tau^{2}\)-Noise、Vita-Noise 和随机复杂任务的构建和评估协议
- \(\tau^{2}\)-Noise 和 Vita-Noise :为了评估智能体推理能力的鲁棒性,作者系统分析了现实世界环境中观察到的偏差,并设计了一个自动噪声注入 Pipeline (noise injection pipeline),可以将逼真的噪声注入任意基准测试
- 基于此 Pipeline ,作者重复随机地将噪声注入 \(\tau^{2}\) 和 Vita 基准测试以构建 \(\tau^{2}\)-Noise 和 Vita-Noise,并报告多次噪声实例化的平均性能
- 随机复杂任务 (Random Complex Tasks) :为了评估智能体推理能力的泛化性,作者引入了一种新的评估协议,即随机复杂任务
- 随机复杂任务建立在一个自动任务合成过程之上,该过程受作者环境扩展 Pipeline 的启发,随机生成跨多种场景的复杂、可执行且可验证的智能体任务
- 对于每次评估运行,作者随机抽样超过 4 个领域的 100 个多样且复杂的任务,并计算 Avg@4 分数
- 为确保可靠性,作者重复进行三次独立运行的评估,并报告各次运行的平均结果
- \(\tau^{2}\)-Noise 和 Vita-Noise :为了评估智能体推理能力的鲁棒性,作者系统分析了现实世界环境中观察到的偏差,并设计了一个自动噪声注入 Pipeline (noise injection pipeline),可以将逼真的噪声注入任意基准测试
- 作者将发布噪声注入 Pipeline ,并将随机复杂任务集成到一个开放的评估平台中,以支持未来的可复现性和基准测试
General QA
- 作者在 GPQA-Diamond (2023) 和 HLE (2025) 上评估通用推理,它们涵盖了广泛的知识密集型和推理密集型任务
- 对于 GPQA-Diamond,作者报告 Avg@16 以减少抽样随机性引入的方差
- 对于 HLE,由于作者的模型是纯文本的,作者报告其在纯文本子集上的结果,并确保所有比较模型遵循相同的设置
- 作者注意到 HLE 的结果对提示模板和评分模型很敏感
- 为确保公平比较,所有模型都使用官方 HLE 推荐的提示模板进行评估,并使用官方 o3-mini 评分模型和模板进行评分
Coding
- 作者在两种设置下评估代码能力:Code Reasoning 和 Agentic Coding
- 对于代码推理,作者使用 LiveCodeBench (2025)、OJBench (2025) 和 OIBench (2025)
- 对于 LiveCodeBench,作者评估 2408-2505 子集,覆盖最近的两个版本,包含 454 个问题, 作者报告 LiveCodeBench 的 Avg@4
- 对于 OJBench 和 OIBench,由于评估成本和思考模型所需的长推理轨迹,作者报告 Pass@1
- 对于智能体编码,作者使用 SWE-bench Verified,这是软件工程智能体的标准基准
- 作者采用第三方智能体框架 R2E-Gym 作为执行主干
- 为确保正确性,作者手动清理并修复了原始基准测试中的少量 Docker 镜像,主要是由于库升级引入的依赖不匹配问题,保证所有标准补丁(gold patches)都是可执行的
Main Results
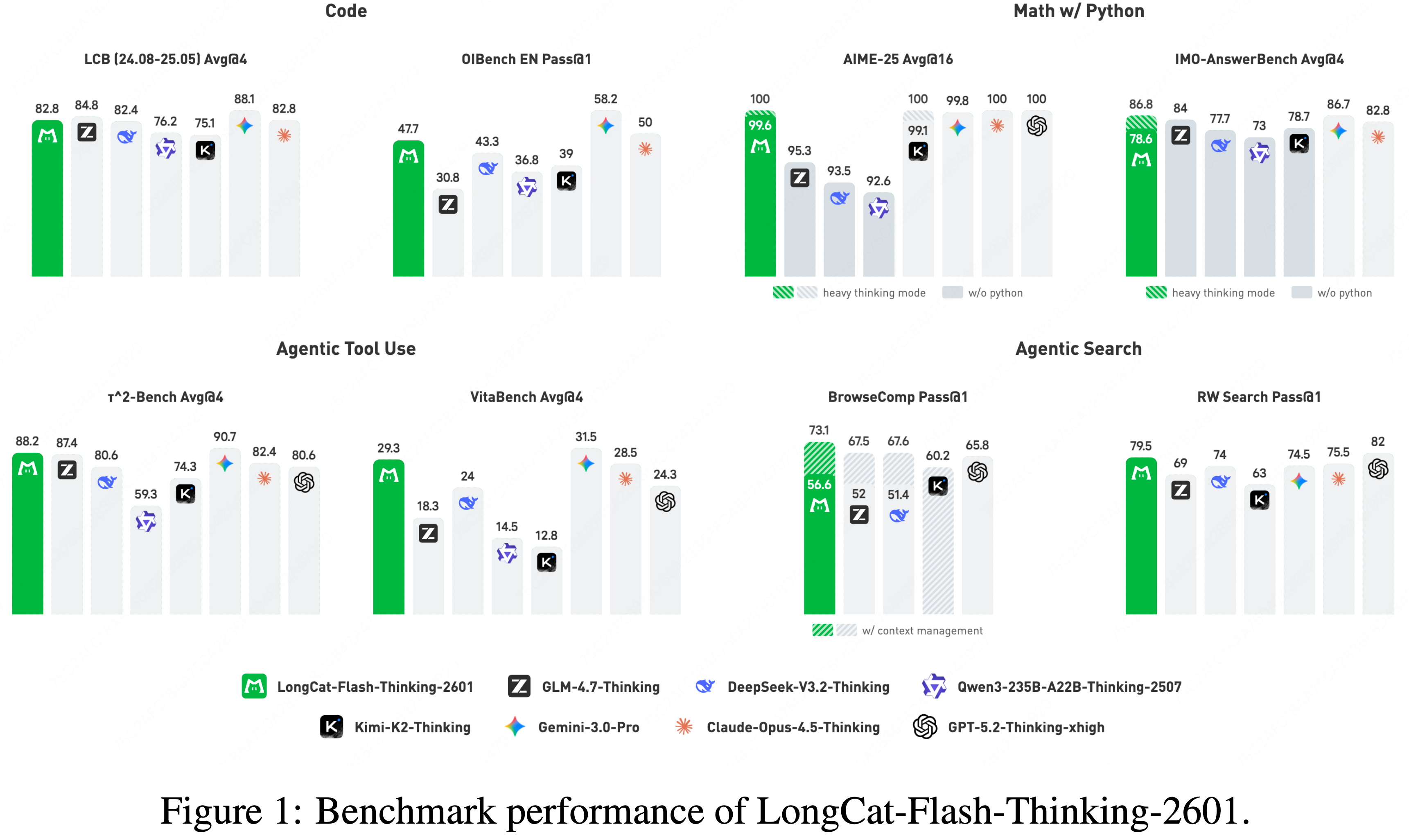
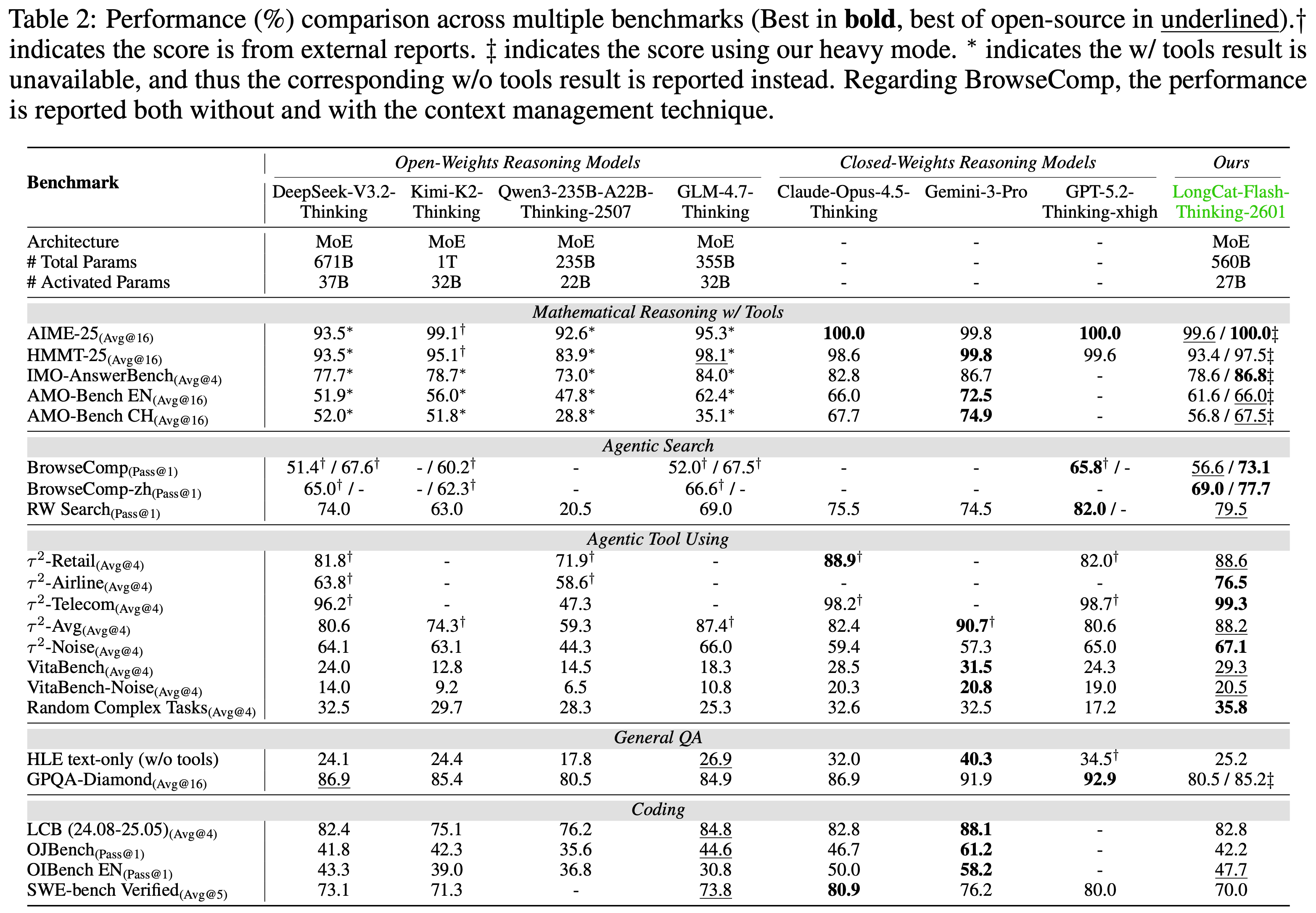
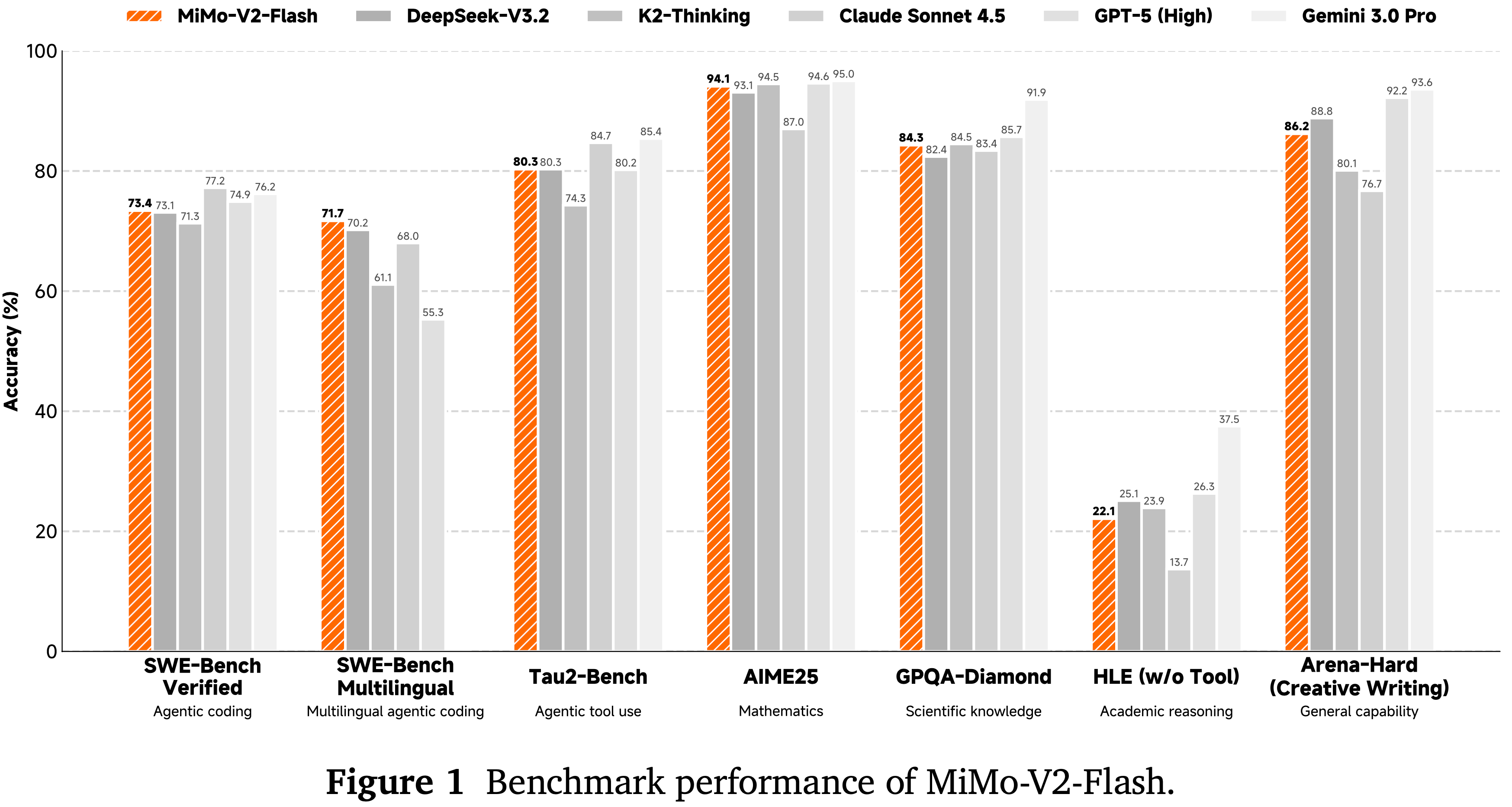
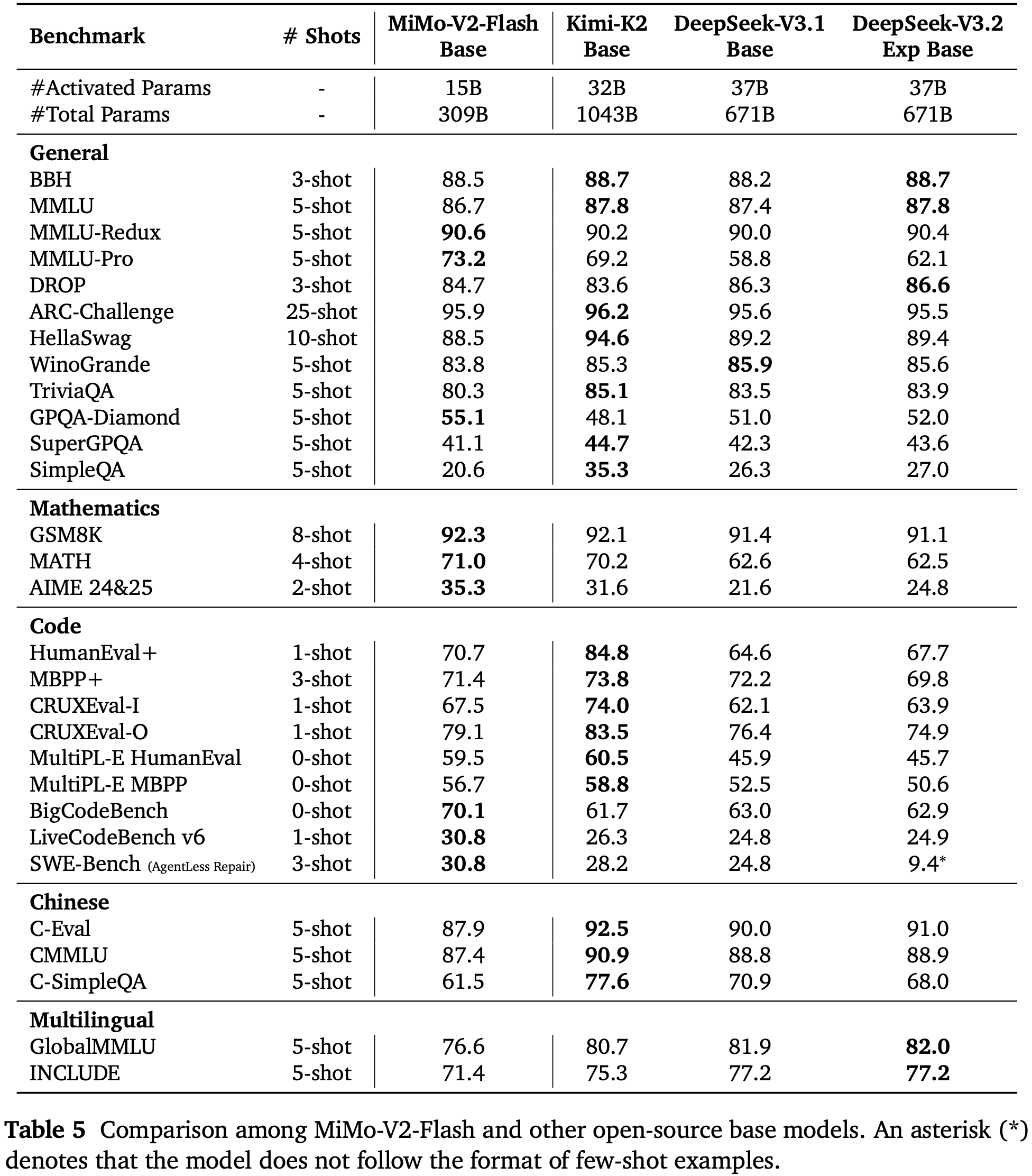
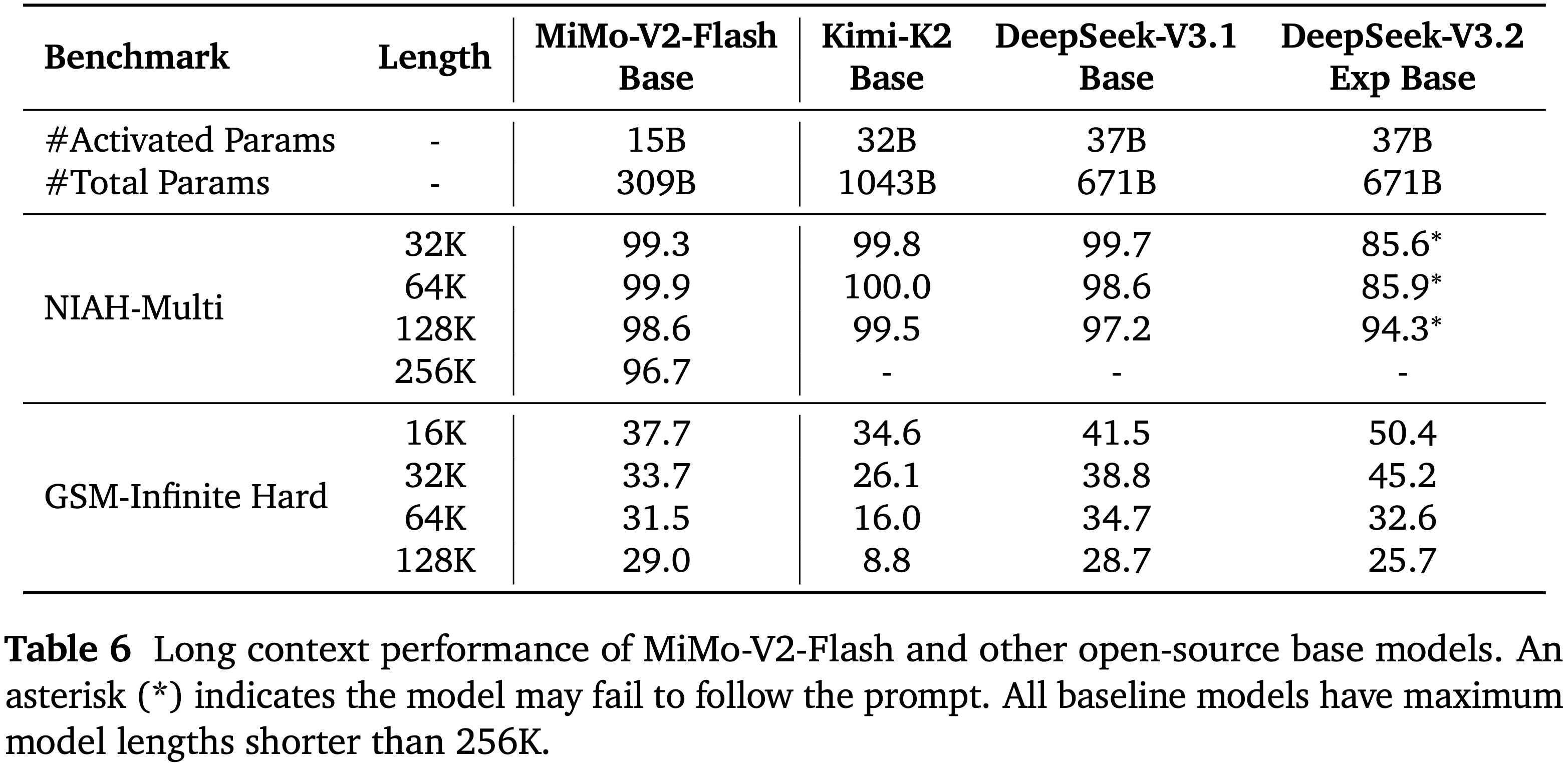
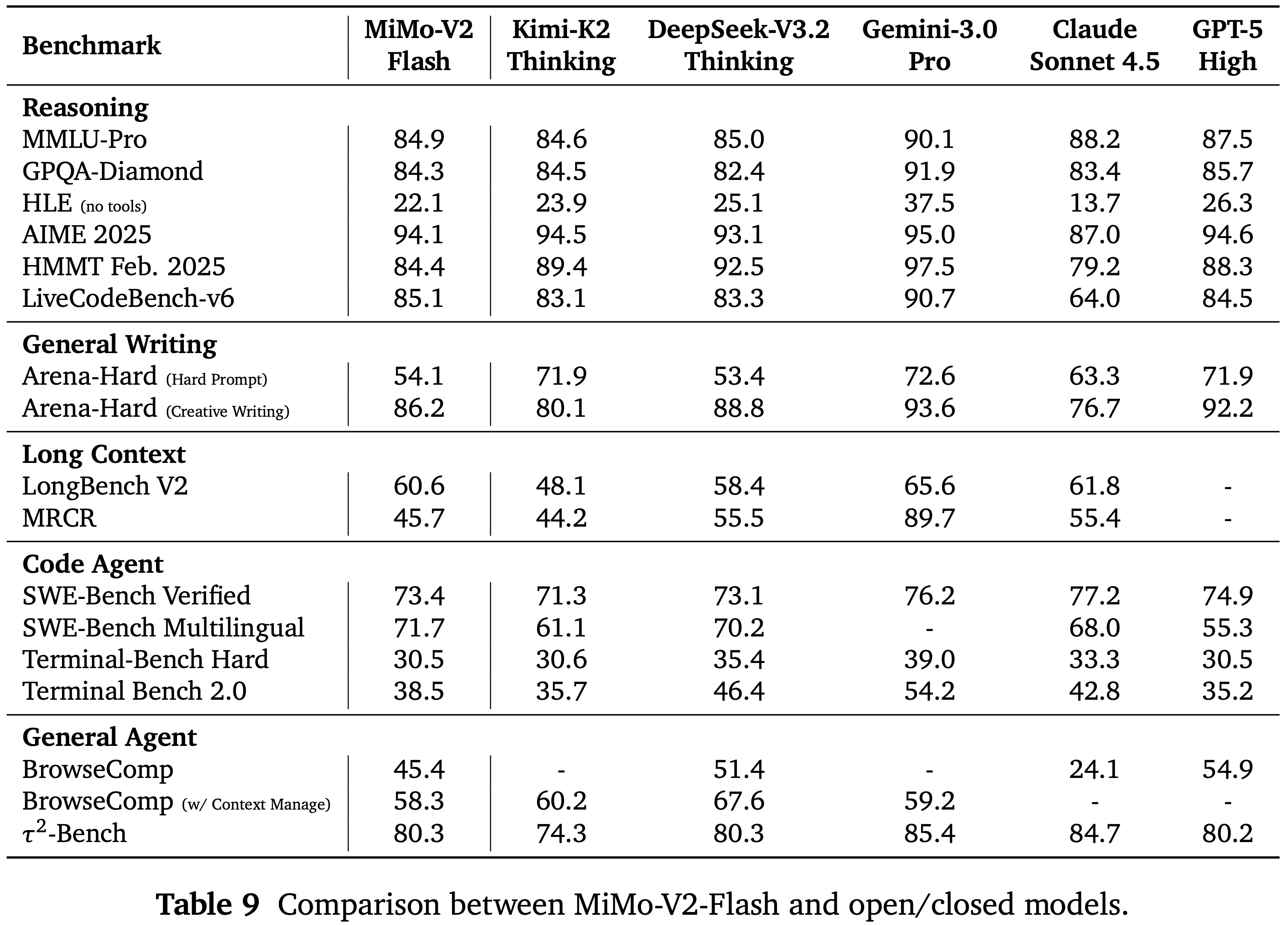
- 如表 2 所示,作者将 LongCat-Flash-Thinking-2601 与几个先进的开源权重和闭源权重推理模型进行了比较
- 开源权重模型包括 DeepSeek-V3.2-Thinking (2025)、Kimi-K2-Thinking (2025)、Qwen3-235B-A22B-Thinking-2507 (2025) 和 GLM-4.7-Thinking (2025)
- 闭源权重模型包括 Claude-Opus-4.5-Thinking (2025)、Gemini-3-Pro (2025) 和 GPT-5.2-Thinking-xhigh (2025b)
- 在一套全面的基准测试中,LongCat-Flash-Thinking-2601 在传统推理任务上取得了极具竞争力的性能,并在智能体推理能力方面展现出强大优势
- 除非另有说明,推理均使用温度 \(= 1.0\),top-\(k = -1\),top-\(p = 1.0\) 进行
- 除非另有说明,推理均使用温度 \(= 1.0\),top-\(k = -1\),top-\(p = 1.0\) 进行
Mathematical Reasoning
- 在具有挑战性的数学推理基准测试上,LongCat-Flash-Thinking-2601 展现出强大的工具集成推理能力,并始终达到第一梯队的性能
- 当启用 Heavy Thinking 模式(heavy mode)时,LongCat-Flash-Thinking-2601 达到了与领先闭源模型相当的性能
- 启用 Heavy Thinking 模式的 LongCat-Flash-Thinking-2601 在 AIME-2025 上获得了满分,在 IMO-AnswerBench 上取得了 86.8 分的领先成绩,并在 AMO-Bench 上取得了开源的领先结果
- 在 AMO-Bench (EN) 上略逊于最强的闭源模型,LongCat-Flash-Thinking-2601 仍然是表现最好的开源模型
- LongCat-Flash-Thinking-2601 在 AMO-Bench 的英文版和中文版上表现出相当的性能,表明其在非英语环境下也具有先进的数学推理和工具使用能力
Agentic Search
- LongCat-Flash-Thinking-2601 在 BrowseComp 和 BrowseComp-ZH 上都达到了领先的性能
- 启用上下文管理后,它在 BrowseComp 上达到 73.1 分,在 BrowseComp-ZH 上达到 77.7 分,超越了所有评估的模型
- 在 RWSearch 上——这是一个为评估现实世界复杂搜索场景而设计的私有基准测试,LongCat-Flash-Thinking-2601 取得了 79.5 分,仅次于 GPT-5.2-Thinking
Agentic Tool-Use
- LongCat-Flash-Thinking-2601 在开源模型中展示了领先的智能体工具使用能力
- 在 \(\tau^2\)-Bench 和 VitaBench 上取得了强劲的性能,包括在它们的噪声增强变体上的竞争性结果
- 模型在任意生成工具的随机复杂任务上取得了领先的结果
- 这些结果表明模型对现实世界环境噪声具有很强的鲁棒性,并对先前未见过的任务分布具有出色的泛化能力
General QA
- LongCat-Flash-Thinking-2601 在通用问答基准测试上保持了强劲的性能
- 在 HLE 的纯文本子集上获得了 25.2 分,在 Heavy Thinking 模式下在 GPQA-Diamond 上获得了 85.2 分
- 接近开源模型的最佳结果
Coding
- LongCat-Flash-Thinking-2601 在代码推理和智能体编码基准测试上都展现了有竞争力的性能
- 在 LiveCodeBench 系列的算法问题解决任务上,位居开源模型前列
- 在更难的基准测试如 OJBench 和 OIBench 上,作者的模型分别取得了开源模型的第二好和最佳性能
- 注:与 GLM-4.7 相比,LongCat-Flash-Thinking-2601 以显著更低的推理成本实现了相似的性能,每个问题大约需要 45k 个 token,而 GLM-4.7 需要 57k 个 token
- 在 SWE-bench Verified 上,LongCat-Flash-Thinking-2601 在开源模型的第一梯队中表现具有竞争力,进一步验证了其在现实世界软件工程任务中的能力
One More Thing: Zig-Zag Attention Design
- 长上下文效率(Long-context Efficiency)已成为现代大型语言模型日益严峻的挑战
- 越来越长的推理轨迹趋势对标准的全注意力(Full Attention)构成了根本性限制,其二次方复杂度对于长上下文智能体训练和推理来说很快变得难以使用
- 而且在 Heavy Thinking 模式中,由于同时解码多个并行推理轨迹,推理延迟被进一步放大,使得高效的注意力机制变得更加不可或缺
- 现有的方法,包括稀疏和线性注意力方法 (2025),试图通过降低注意力的计算复杂度来缓解这个问题
- 但这些方法通常需要大量的重新训练来使模型适应新的注意力架构,这引入了相当多的额外计算开销和工程成本
- 为了解决这一限制,作者探索了一种实验性的高效注意力设计,并同时发布了一个开源模型 LongCat-Flash-Thinking-ZigZag
- 作者提出了 Zigzag Attention,一种稀疏注意力机制(sparse attention mechanism),使得现有的全注意力模型可以在 Mid-training 期间高效地转换为稀疏变体
- 这种转换仅产生可忽略的开销,同时允许模型高效地扩展到超长上下文,支持高达 1M 个 token 的序列长度
- Zigzag Attention (2026) 结合了 MLA 和流式稀疏注意力 (Streaming Sparse Attention, SSA) (2024),实现了计算量随完整上下文长度呈次二次方(sub-quadratically)扩展
- 对于每个 Query token \(h_t\),注意力被限制在一个固定的键值 token 集合中,该集合包括
- (i) 最近 token 的局部窗口
- (ii) 序列开头的一小组初始 token
- 形式上,注意力输出计算如下:
$$
u_{t} = \mathrm{Attn}(h_{t},\{h_{s}\mid s\in [t - W,t]\cup [0,B)\} ,
$$- 其中 \(W\) 表示局部上下文窗口大小,\(B\) 表示保留的前缀 token 数量
- 与全注意力相比,这种设计显著降低了计算和内存复杂度,同时保留了短期上下文和全局锚点
- 对于每个 Query token \(h_t\),注意力被限制在一个固定的键值 token 集合中,该集合包括
Zigzag Connectivity
- Zigzag Attention 采用了一种层级交错的稀疏化策略
- 大约 \(50%\) 的全注意力层被替换为 SSA 层,而剩余的层保留基于 MLA 的全注意力
- 这种层级的稀疏性避免了通常由头部级稀疏化引入的计算不平衡和 GPU 线程分歧,从而实现更高效的硬件利用率
- 每个 SSA 层内的注意力是稀疏且局部的,但全局信息通过跨层组合得以保留
- 通过交替稀疏注意力层和全注意力层,信息可以在多层之间跨越远距离位置传播,沿着序列形成一条锯齿形的连接路径
- 因此,尽管存在每层的稀疏性,长距离依赖关系仍然可以访问
Zigzag Integration
- Zigzag Attention 通过结构化的稀疏化过程在 Mid-training 阶段引入
- 1)作者使用一个校准过的数据集来估计预训练模型中注意力层的相对重要性
- 2)重要性得分最低的那部分层被替换为 SSA 层
- 稀疏化之后,模型继续进行长上下文的持续 Mid-training ,同时结合基于 YaRN 的位置编码扩展,从而实现高达 1M token 的上下文长度
- 实践中,作者采用块大小为 128,一个 Sink block 和七个局部块(local block),使得每层的有效注意力跨度达到 1,024 个 token
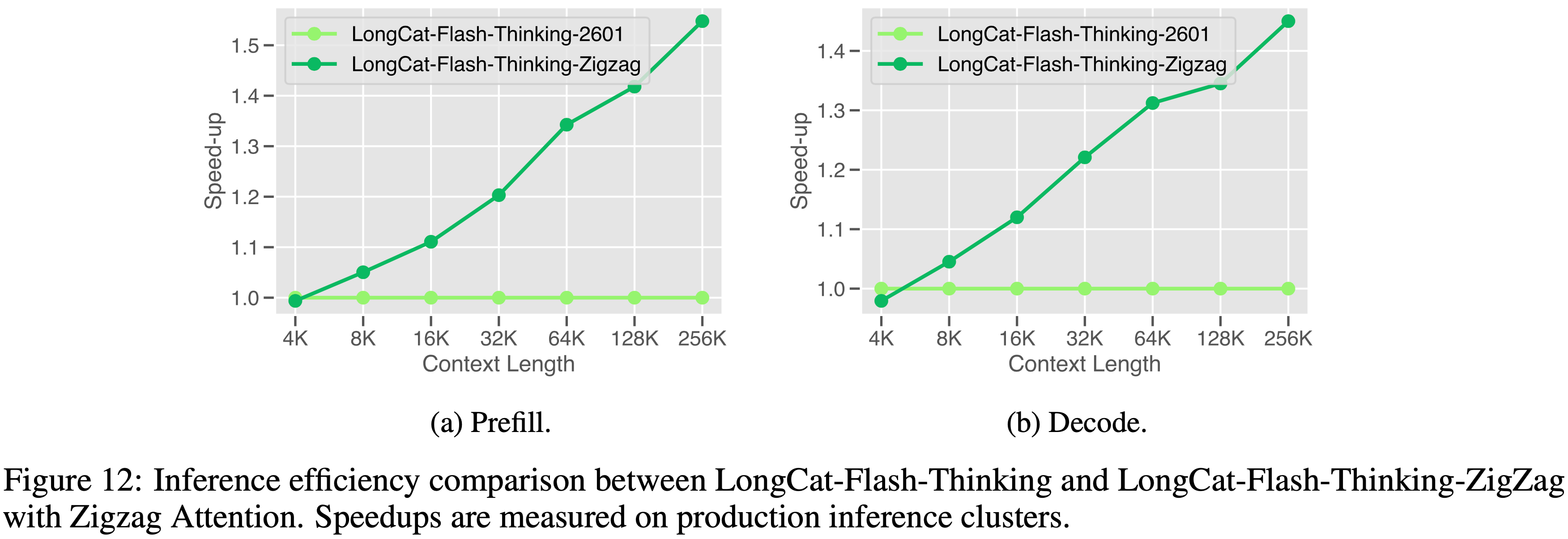
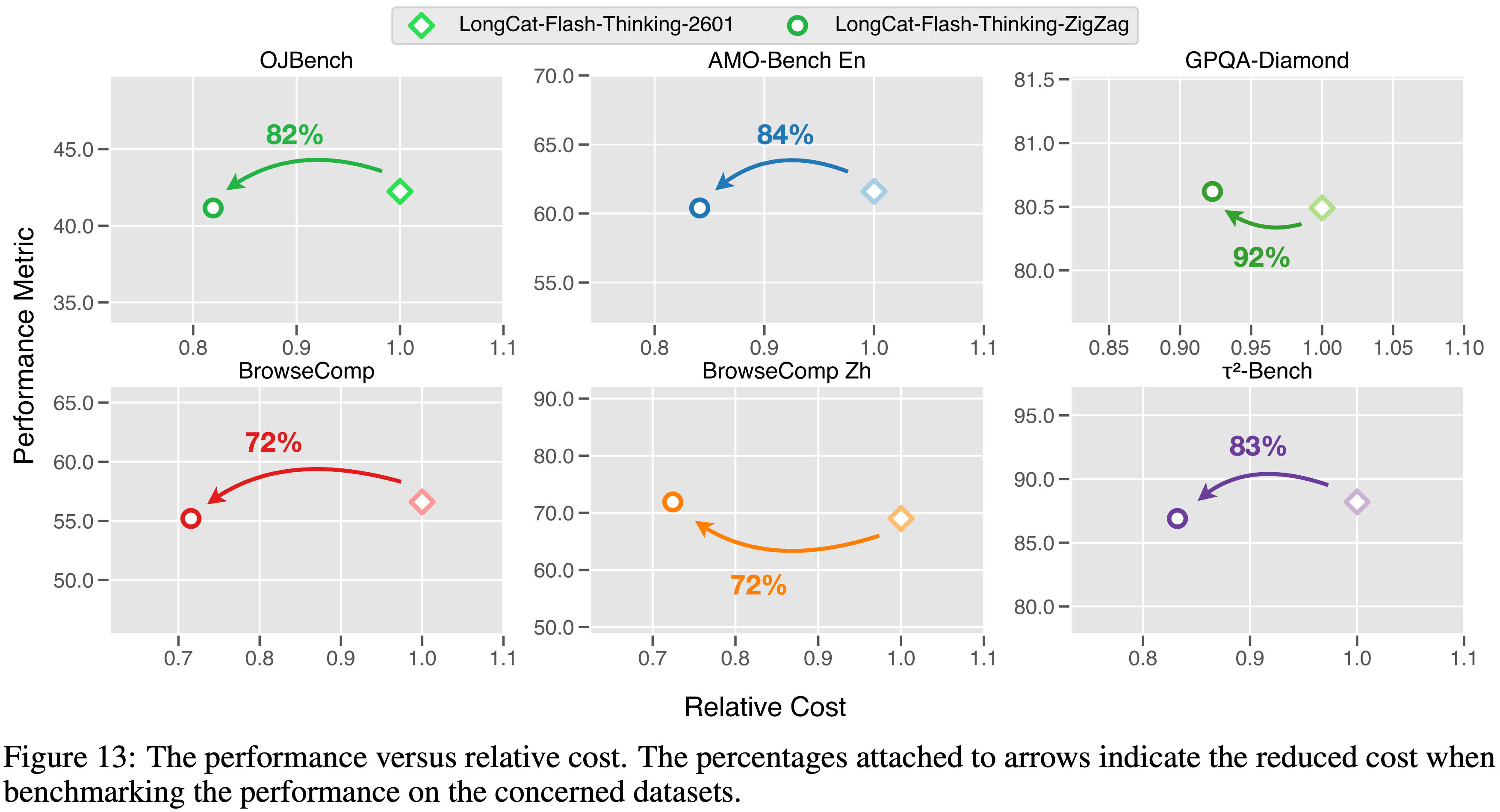
- 将大约一半的全注意力层替换为 Zigzag Attention 可带来约 1.5 倍的端到端推理加速,如图 12 所示,同时在基准测试中保持了推理性能和智能体能力
结合 YaRN
- 为了解锁处理更长上下文的能力,作者将这些方法配置与 YaRN (2024) 结合,使得 LongCat-Flash-Thinking-ZigZag 能够外推至处理高达 1M 个 token
- 除此之外,作者还提供了模型中涉及的一些关键参数
- 块大小为 128,Sink block 数量为 1,局部块数量为 7,总计 1,024 个 token
- LongCat-Flash-Thinking-ZigZag 在性能和速度之间取得了良好的平衡,图 13 简要展示了它如何提高效率的同时保持竞争力的性能
附录 A:Optimal Hyperparameter Prediction
- 在大型规模的 Mid-training 中,有效识别最优超参数是一个核心挑战,因为搜索空间巨大且计算成本高昂
- 为了应对这一挑战,作者提出了一种新颖的最优超参数预测方法,该方法专门设计用于最小化寻找最佳配置的计算成本
- 作者的方法包括两个关键步骤:
- 超参数映射 (Hyperparameter Mapping): 作者使用不同的超参数训练小型模型,利用验证损失和 FLOPS 将最优超参数映射到它们的计算成本(见图 14),从而深入了解配置如何影响训练效率和性能
- 超参数预测 (Hyperparameter Prediction): 对于一个给定的持续训练检查点,作者使用验证损失来估算等效计算成本,即从零开始在持续训练数据上达到相同损失所需的计算量,然后基于此估算和实际计算负载来预测最优超参数
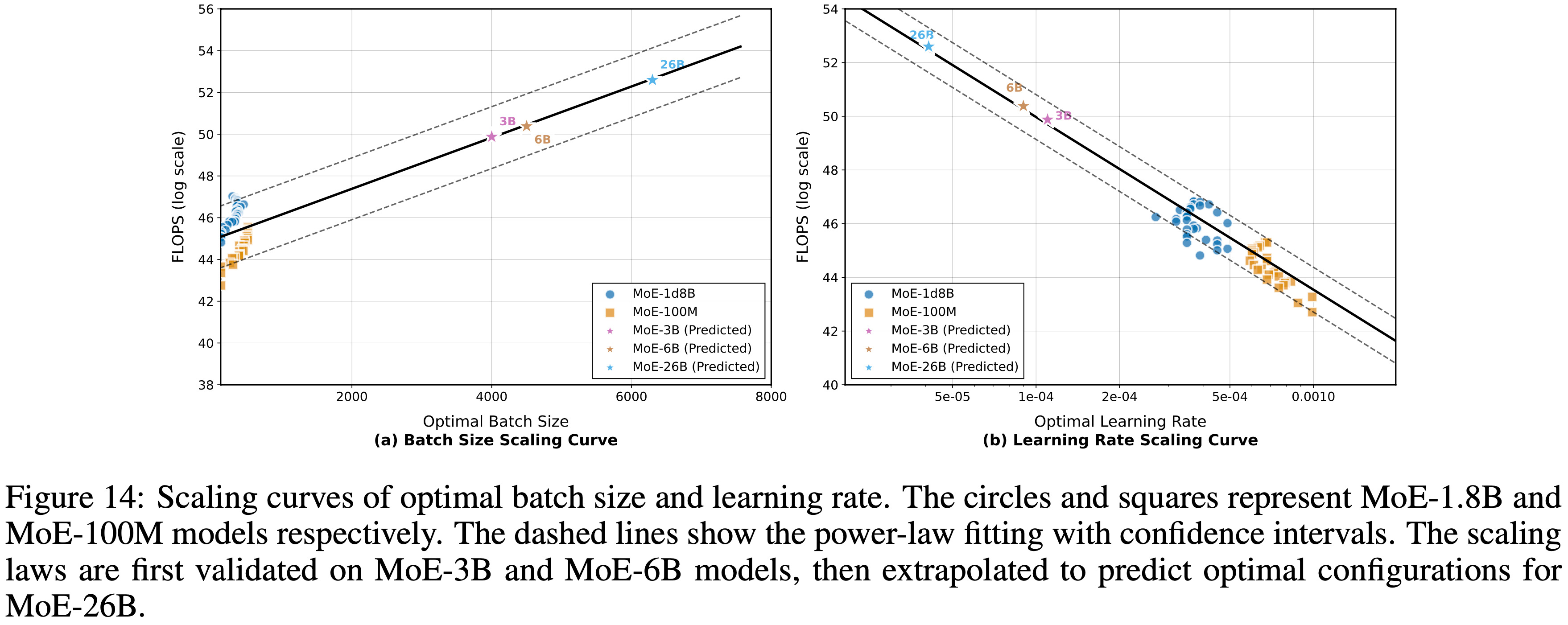
- 通过这种方法,作者能够预测出可实现高效持续训练的最优超参数,以最小的计算开销提高模型性能
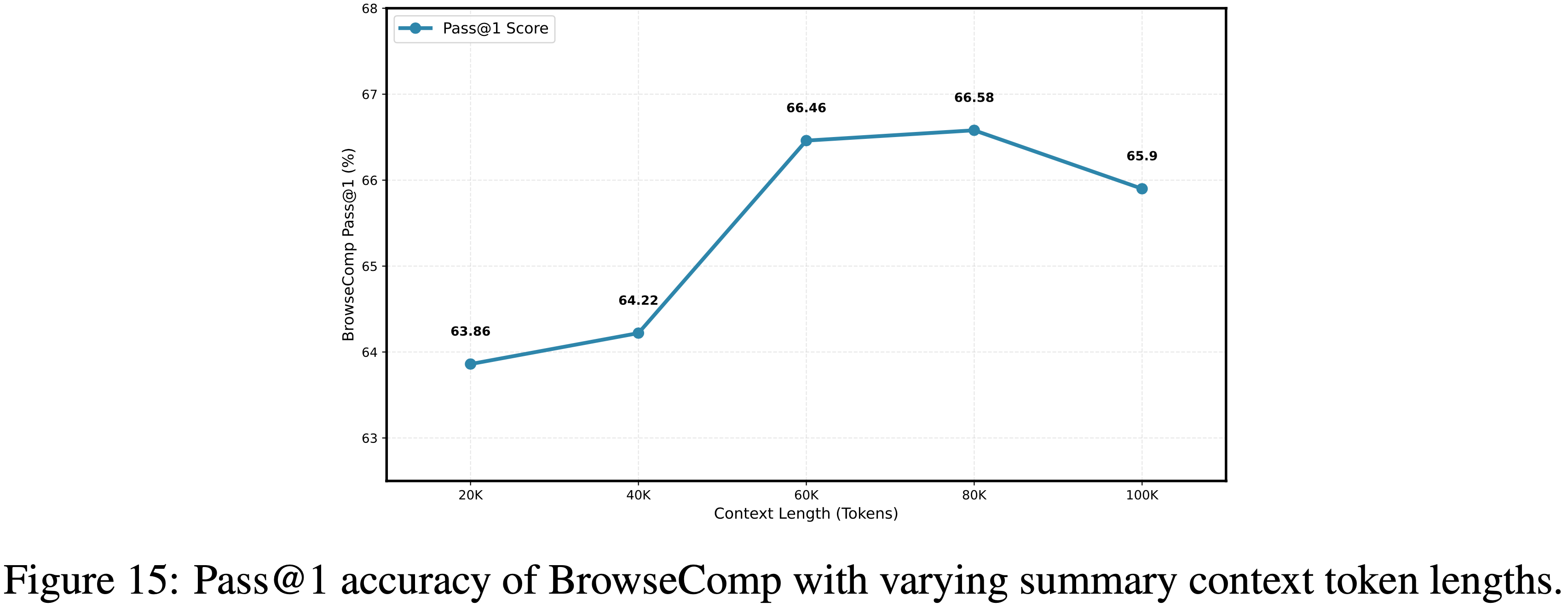
附录 B:Token Threshold Context Management Performance Evaluation
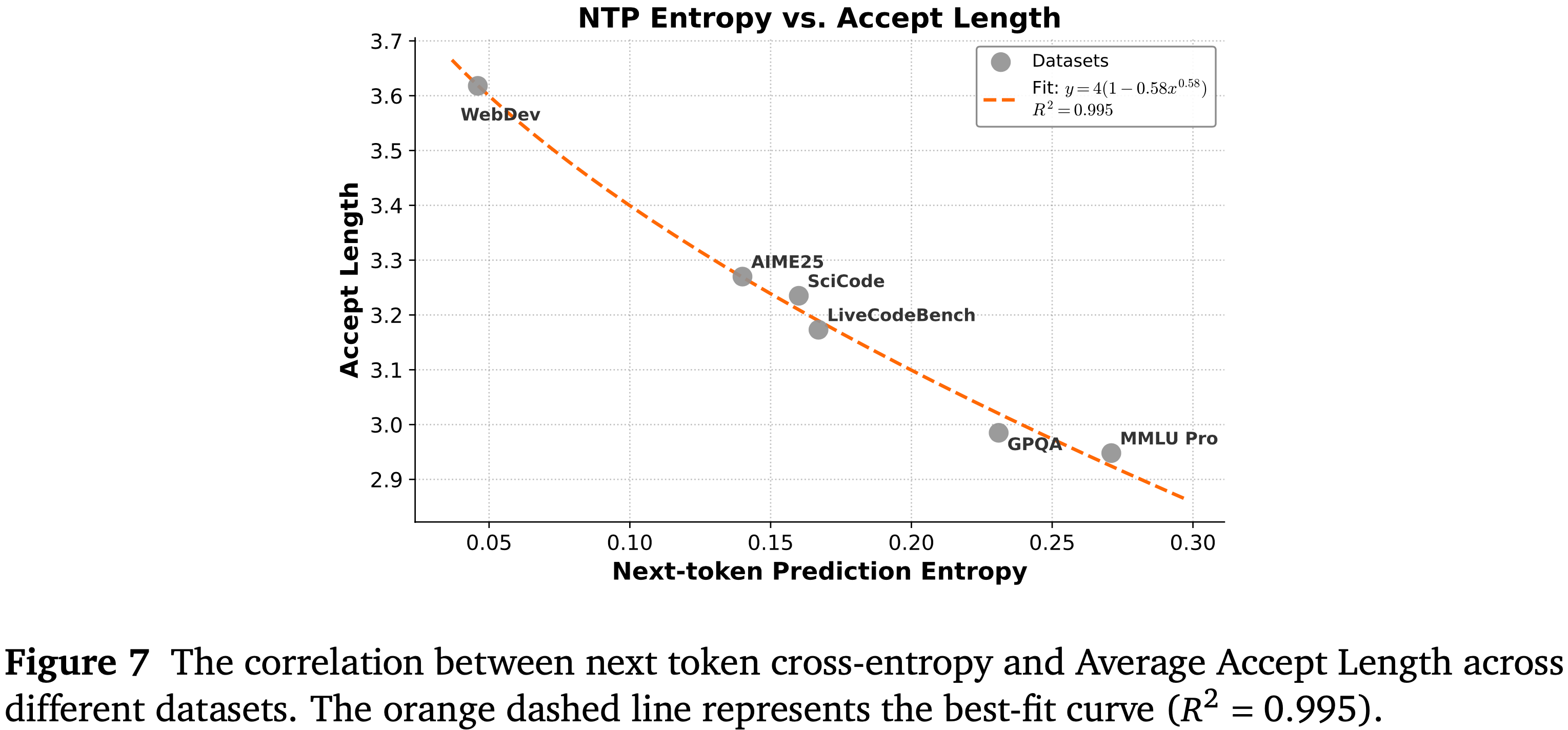
- 如图 15 所示,作者评估了在不同摘要上下文 Token 长度下 BrowseComp 的 Pass@1 准确率,最大上下文轮次限制为 500
- 准确率从 20K Token 时的 \(63.86%\) 稳步上升至 80K Token 时达到峰值 \(66.58%\),然后在 100K Token 时降至 \(65.9%\)
- 这确定了 80K 是基于摘要的上下文管理的最优上下文长度,因此在所有后续实验中,作者将 80K 上下文长度固定为摘要触发的阈值

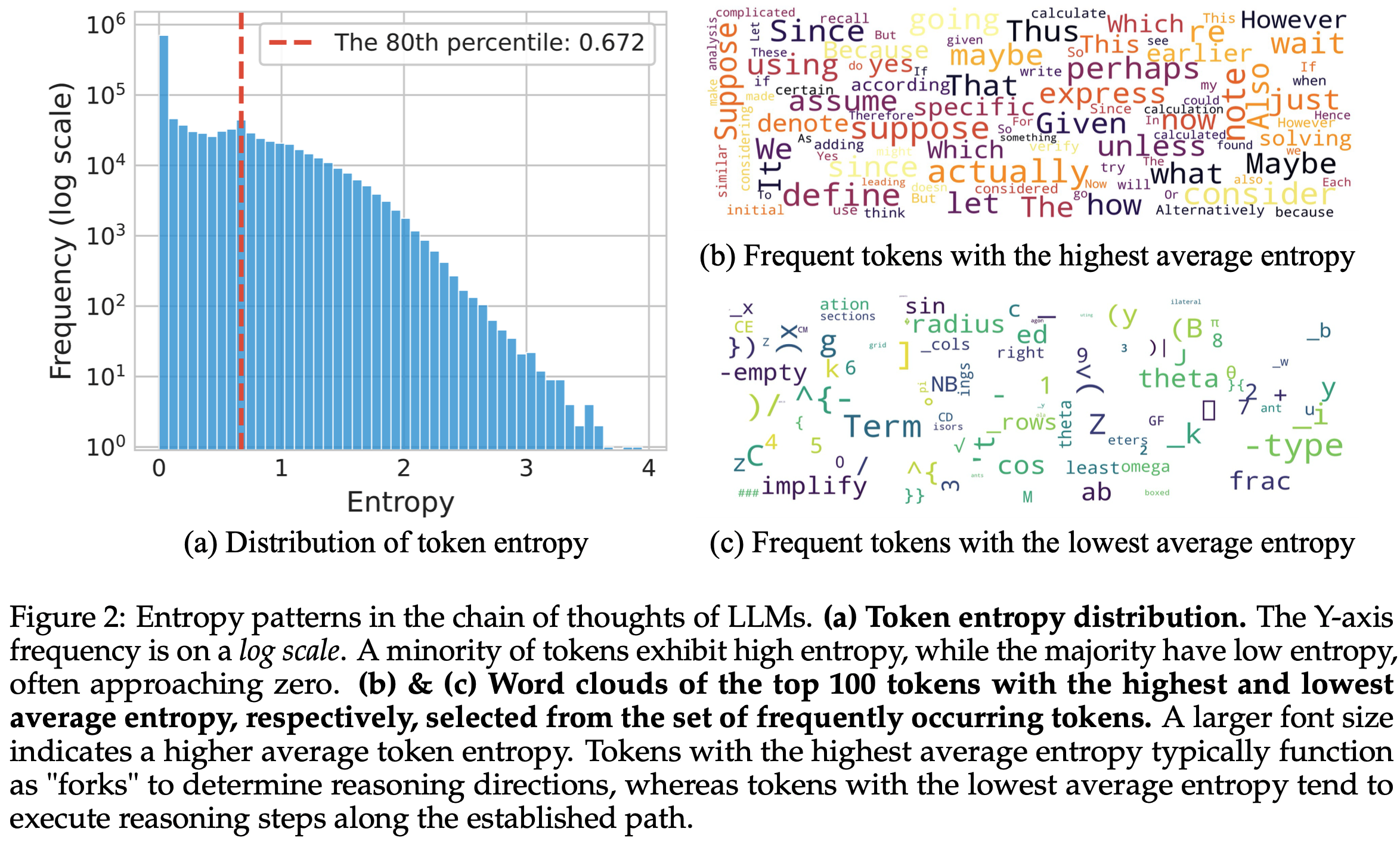
:模型 RLVR 训练 Step 16 后,与基础模型(Step 0)的重合度为98.62%,与最终 RLVR 模型的重合度为 86.71%")






/RL-Collapse-From-Training-Inference-Mismatch-Figure1.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure2.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4a.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4b.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure4c.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group1.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group2.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure3.4-Group3.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure5.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure6.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure7.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure8.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure9.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure10.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure11.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure12.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure13.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure14.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure15a.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure15b.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure16.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure17.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure18.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure19.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure20.png)
/RL-Collapse-From-Training-Inference-Mismatch-Figure21.png)