注:本文包含 AI 辅助创作
Paper Summary
- 整体总结:
- 本文从信息论的视角看 Self-Distillation
- 分析表名:Self-Distillation 的有效性 取决于信息如何提供给模型 ,以及模型如何将不确定性纳入其推理过程
- Self-Distillation 通过鼓励模型产生更高置信度的答案 来重塑模型的推理行为
- 这种效应能够实现更紧凑的推理,并在任务覆盖有限时快速提高领域内性能
- 当任务覆盖范围广时,它会变得不那么有效,甚至可能损害 OOD 性能
- 背景 & 问题提出:
- 背景:Self-Distillation 是 LLM 的一种有效的后训练范式
- 特点:通常在缩短推理轨迹的同时提升性能
- 问题提出:
- 在数学推理中,Self-Distillation 会减少响应长度,同时降低性能
- 本文将这种性能下降归因于 Epistemic Verbalization (epistemic verbalization) 的抑制
- 即对模型在推理过程中表达不确定性的行为的抑制
- 背景:Self-Distillation 是 LLM 的一种有效的后训练范式
- 实验 Insight:
- 让 Teacher 依赖于丰富的信息会抑制不确定性表达
- 这能够在有限的任务覆盖度下实现快速的领域内优化,但会损害 OOD 性能
- 因为未见过的(unseen)问题往往受益于表达不确定性并进行相应调整
- 在 Qwen3-8B、DeepSeek-Distill-Qwen-7B 和 Olmo3-7B-Instruct 上,性能下降高达 40%
- 让 Teacher 依赖于丰富的信息会抑制不确定性表达
- 结论:暴露适当水平的不确定性对于稳健的推理至关重要 ,并强调了优化推理行为的重要性 ,而不仅仅是强化正确的答案轨迹
Introduction and Discussion
- Self-Distillation 的定义:
- (2022) 使用同一模型的两个实例:
- 实例1:依赖于真实解决方案作为 Teacher
- 实例2:无法访问解决方案的实例
- Teacher 为 无法访问解决方案的实例 生成的响应提供信息丰富的奖励信号
- (2022) 使用同一模型的两个实例:
- Self-Distillation 与 RLVR 等后训练方法相结合,可以实现高效的性能提升 (2025; 2026;)
- 在诸如代理环境 (agentic environments) 和科学推理等领域显示出尤为显著的改进,特别是在 In-domain 评估 Setting 下
- 先前工作的实验观察:性能随着响应长度的减少而提高,这表明 Self-Distillation 促进了更简洁和有效的推理
- 问题提出:
- Self-Distillation 方法应用于数学推理任务时,发生了显著不同的现象
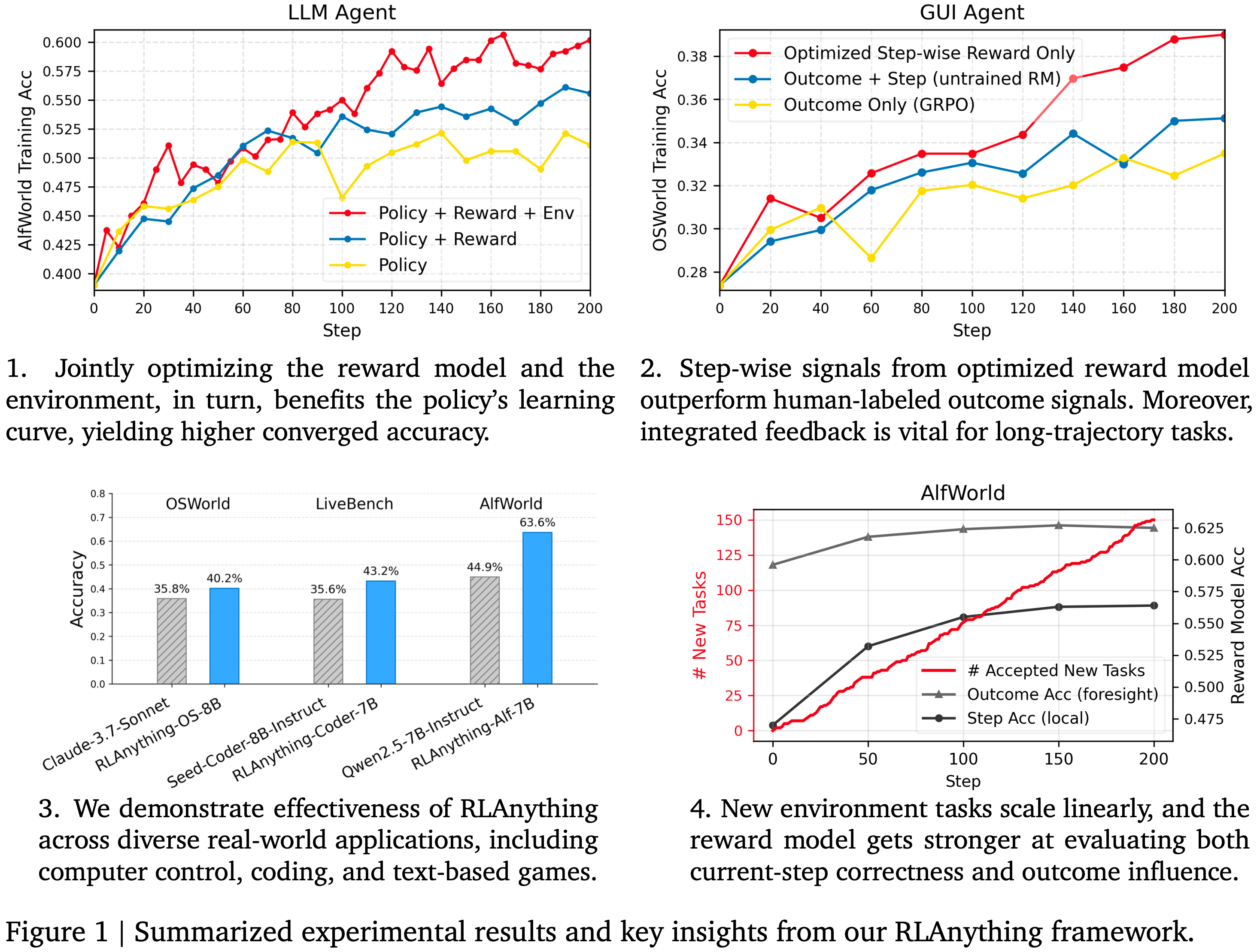
- 图 1 比较了代表性 Self-Distillation 算法 SDPO 在化学领域 (a) 和数学领域 (b) 的效果
- 在化学领域,与 GRPO 相比, Self-Distillation 显著减少了响应长度,同时快速提高了性能
- 在数学领域,尽管响应长度随着训练进行而持续减少,但性能却显著下降,这与之前的发现相反
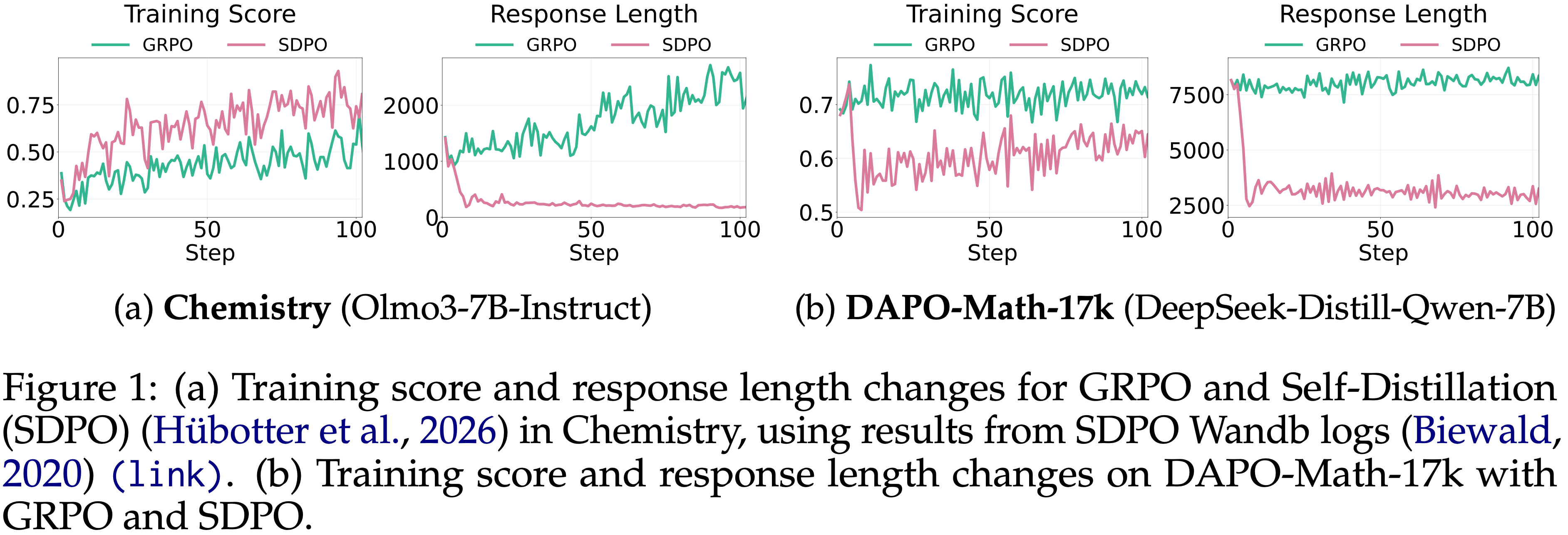
- 这引出了一个问题:“为什么即使模型被训练成朝着正确答案移动,性能有时反而会下降?”
”Why does performance sometimes degrade despite the model being trained to move toward the correct answer?”
- 本文分析结论:
- 提供给 Teacher 的上下文信息越丰富,其生成的推理就越简洁和自信,不确定性表达显著减少,尤其是在数学推理中,性能会下降
- 作者将这种影响归因于 Epistemic Verbalization (2026) 的抑制
- 即对 模型明确地表达并将不确定性纳入其推理过程 的能力的抑制
- 理解:本文的 Epistemic Verbalization 含义可以理解为是不确定性 Token
- 像 DeepSeek-R1 (2025b) 这样强大的推理模型经常使用像“Wait”或“Hmm”这样的 Token 来表达不确定性
- 这些表达可能不会直接推进推理,但移除它们会丢弃推理路径可能有缺陷的重要信号,导致显著的性能下降 (2026)
- Self-Distillation 何时以及为何会抑制 Epistemic Verbalization ?
- 本文确定了两个关键因素: 信息丰富度 和 任务覆盖度
- 信息丰富度:
- 当 Teacher 依赖于更丰富的信息(如正确的解决方案)时,它产生的推理轨迹几乎不表达不确定性
- 从而鼓励学生模型 (student) 模仿一种自信的推理风格,这种风格预设了在推理时无法获得的信息
- 当 Teacher 依赖于更丰富的信息(如正确的解决方案)时,它产生的推理轨迹几乎不表达不确定性
- 任务覆盖度:
- 任务覆盖度有限时,这种压缩使得能够快速进行领域内优化
- 随着覆盖度的增加,训练中对 Epistemic Verbalization 的消除会干扰跨多样化任务的优化,从而在更具挑战性或之前未见过的(unseen)问题上降低性能
- 结果表明:
- 即使训练目标忠实地引导模型走向正确的推理轨迹,所产生的推理风格也可能会悄然转变,从而损害泛化能力
- 标准目标不会惩罚对 Epistemic Verbalization 的抑制,但会对 OOD 性能产生负面影响
- 这表明:
- 后训练目标不仅要考虑答案的正确性 ,还要考虑激发和保留具有不确定性意识的推理行为
- 即使训练目标忠实地引导模型走向正确的推理轨迹,所产生的推理风格也可能会悄然转变,从而损害泛化能力
Preliminaries
Self-Distillation
- 定义:
- \(x\in \mathcal{X}\) 表示一个输入
- \(y = (y_{1},\ldots ,y_{T})\) 表示由语言模型 \(\pi_{\theta}\) 生成的一个序列
- 该模型定义了一个自回归分布
$$ \pi_{\theta}(y|x) = \prod_{t = 1}^{T}\pi_{\theta}(y_{t}\mid x,y_{< t})$$ - 在 Self-Distillation 中,同一个模型在不同的条件上下文下既充当学生又充当教师
- 学生首先生成一个序列 \(y\sim \pi_{\theta}(\cdot \mid x)\)
- 教师策略是通过让模型依赖于一个更丰富的上下文 \(c\) 来获得的,该上下文提供了关于输入的额外信息(例如,解决方案、环境反馈或其他辅助信号):
$$ \pi_{\theta}^{T}(\cdot \mid x,c) = \pi_{\theta}(\cdot \mid x,c) $$
- 训练过程最小化学生和教师下一个 Token 分布之间的散度:
$$\mathcal{L}_{\text{SD} }(\theta) = \sum_{t}\text{KL}(\pi_{\theta}(\cdot \mid x,y_{< t})\parallel \text{stopgrad}(\pi_{\theta}(\cdot \mid x,c,y_{< t}))) \tag {1}$$- 这个目标鼓励学生匹配教师在更丰富上下文下的预测,使模型能够通过提炼训练时可用的信息来改进,而无需外部教师
- 理解:
- 这里主要强调目标,通过对上述目标求导可证明,上述目标的梯度本质等价于 On-Policy Distillation(RL)形式
- 但在实现时 RL 仅针对当前采样到的 Token 进行更新,OPD 则会针对每个 Token 位置上,全词表上(或 Student Top-\(K\) 的)候选 Token 进行更新
- 也就是说,这个目标可以被解释为 密集奖励策略梯度 :
$$
r_n = \log p_T(\hat{y}_n) - \log p_S(\hat{y}_n)
$$- 简单理解:将原始目标设置为 KL 散度,然后按照当前策略采样并展开成对数相减形式即可看到 Thinking Machines 的 OPD 博客中给出的形式
- 详细证明见 (SDPO)Reinforcement Learning via Self-Distillation, 20260128 & 20260216, ETH Zurich & Max Planck Institute for Intelligent Systems & MIT & Stanford 的附录 B.1 部分(本人解读博客:NLP——LLM对齐微调-SDPO)
- 这里主要强调目标,通过对上述目标求导可证明,上述目标的梯度本质等价于 On-Policy Distillation(RL)形式
Key Characteristics of Math Reasoning
- 在 LLM 中,数学推理可以被视为一种自我贝叶斯推理 (self-Bayesian reasoning)
- 其中每一步都仅基于问题和之前生成的 Token 进行生成,模型迭代地更新其对中间假设的信念(belief) (2026)
- 数学推理涵盖了算术、代数、几何、文字题和逻辑模式识别等多种任务,使得评估基准常常因组合和推理深度的变化而相对于训练数据属于 OOD
- 关于任务覆盖度、其对性能的影响以及这如何将数学与其他领域区分开来的更深入讨论,请参见第 6 节
- 在这个过程中,对 \(y\) 的语言化不确定性(称为 Epistemic Verbalization (epistemic verbalization) (2026))可以作为一种信息丰富的信号,而不仅仅是风格上的冗余
- 如图 2(a) 所示,没有这种信号的推理可能导致模型过早地固守错误的假设,且纠正机会有限,而 Epistemic Verbalization 则有助于维持替代假设并支持逐步减少不确定性

- 如图 2(a) 所示,没有这种信号的推理可能导致模型过早地固守错误的假设,且纠正机会有限,而 Epistemic Verbalization 则有助于维持替代假设并支持逐步减少不确定性
- 在 Self-Distillation 中, Teacher 可以访问更丰富的上下文 \(c\),使其能够生成带有强提示和最小化不确定性表达的推理轨迹
- 这会带来更简洁的响应 ,但可能会阻碍学生模型执行具有不确定性意识的推理的能力
- 因此,激进的长度约束和过度自信的推理风格 有可能不仅消除了不必要的冗长内容 ,也消除了有价值的认知信号 (尤其是在参数知识有限的小模型中 )
- 关键的挑战是:
- 过滤掉非信息性内容,同时保留能够实现迭代信念修正的认知表达 ,而不是盲目地压缩推理过程
LLM Reasoning Behavior Under Richer Information,更丰富信息下的 LLM 推理行为
- 为了形式化条件上下文的信息量,本文将 \(c\) 提供的关于目标序列 \(y\) 的信息定义为条件互信息
$$I(y;c\mid x) = H(y\mid x) - H(y\mid x,c), \tag {2}$$- 条件互信息 \(I(y;c\mid x)\) 捕捉了在给定额外上下文 \(c\) 后,关于 \(y\) 的不确定性的减少量
- 使用 DAPO-Math-17k 数据集 (2025) 和 DeepSeek-R1-Distill-Qwen-7B (2025b) 基础模型
- 选择 100 个问题,在这些问题上,基础模型在 8 次 Rollout 中的准确率介于 0.125 和 0.5 之间
- 定义:
- \(s\) 表示完整解决方案(包括在
<think>标签中的思维链) - \(s_{\text{th} }\) 表示移除了
<think>内容的解决方案 - \(\tilde{y}\) 表示之前在全解决方案指导下生成的响应
- \(s\) 表示完整解决方案(包括在
- 本文比较了模型在四种条件信息递增的生成设置下的响应:
- (1) 无引导生成 (Unguided generation):
$$ c = \emptyset $$- 此时 \(I(y;c\mid x) = 0\)
- (2) 解决方案引导生成 (Solution-guided generation):
$$ c = s $$- 提供最大引导,并产生最大的 \(I(y;c\mid x)\)
- (3) 解决方案引导生成(无 think 内容)(Solution-guided generation (without think contents)):
$$c = s_{\text{\think} }$$- 由于 \(s_{\text{\think} }\) 是 \(s\) 的一个严格信息子集,于是有
$$ I(y;s_{\text{\think} }\mid x)\leq I(y;s\mid x) $$
- 由于 \(s_{\text{\think} }\) 是 \(s\) 的一个严格信息子集,于是有
- (4) 重生成条件生成 (Regeneration-conditioned generation):
$$ c = \tilde{y} $$- 其中 \(\tilde{y}\) 是在设置 (2) 下生成的,于是有:
$$ I(y;\tilde{y}\mid x)\leq I(y;s\mid x) $$- 理解:文章中没有非常明确这里的 \(\tilde{y}\) 具体是如何生成的,但这里应该是基于 Setting 2 中的完整方案,再让模型重新生成一次得到的结果,目前推测这个结果应该是也包含 Thinking 信息的
- 其中 \(\tilde{y}\) 是在设置 (2) 下生成的,于是有:
- (1) 无引导生成 (Unguided generation):
- 这些设置引出了以下关于条件互信息的排序:
$$\underbrace{I(y;c\mid x)}_{(1)} = 0< \underbrace{I(y;s_{\text{\think} }\mid x)}_{(3)}\leq \underbrace{I(y;\tilde{y}\mid x)}_{(4)}\leq \underbrace{I(y;s\mid x)}_{(2)} \tag {3}$$
Prompts
Prompts 用于无引导和解决方案引导设置的提示词如下
对于重生成,本文使用了与 Hübottter 等 (2026) 相同的提示词
Prompt for unguided generation:
1
2{question}
Please reason step by step, and put your final answer within \boxed{}.Regeneration prompt (followed the prompt in Hübottter et al. (2026))
1
2
3
4{question}
Please reason step by step, and put your final answer within \boxed{}.
Correctsolution: {previously correct solution}
Correctly solve the original question.- 理解:Regeneration 时,给出标准答案,再让模型解决问题
Epistemic tokens, Epistemic Token
- Following Kim 等 (2026),本文作者定义了一组 10 个认知性标记(Epistemic Markers)作为不确定性外化可能发生区域的实用指标:
$$ \mathcal{T} = \{\text{wait, hmm, perhaps, maybe, actually, alternatively, seems, might, likely, check}\} $$ - 本文测量一个响应 \(y\) 的 Epistemic Token 数量为
$$ E(y) = \sum_{t \in \mathcal{T} } \text{count}(t, y) $$
Results
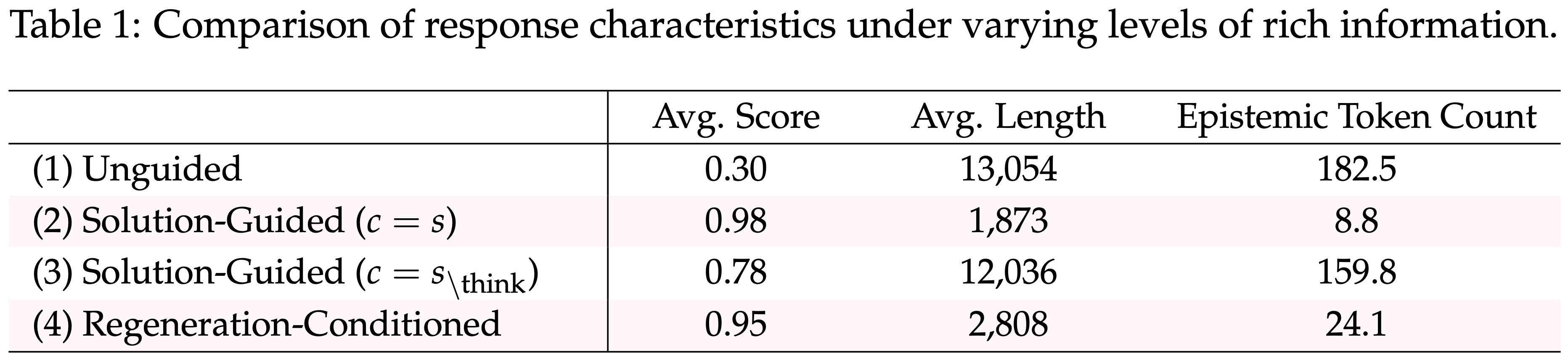
- 分析不同形式的解决方案引导如何影响模型的推理行为
- 比较四种设置下的平均响应长度 \(\mathbb{E}[L(y)]\)、模型分数和 Epistemic Token 数量 \(\mathbb{E}[E(y)]\)
- 如表 1 所示,这两个量都随着 \(I(y; c \mid x)\) 的增加而单调递减:
$$\mathbb{E}[L(y)]\Big|_{(1)} > \mathbb{E}[L(y)]\Big|_{(3)} > \mathbb{E}[L(y)]\Big|_{(4)} > \mathbb{E}[L(y)]\Big|_{(2)}, \tag {4}$$- 并且对于 \(\mathbb{E}[E(y)]\) 也是如此
- 证实了更丰富的条件信息会导致更简洁和自信的推理
- 无引导生成 \((c = \emptyset)\) 产生了明显更长的响应和最高的 Epistemic Token 数量
- 当在 (2) 中提供完整解决方案 \(s\) 时,模型以高置信度遵循给定的推理轨迹,其简洁输出可以看作是 \(s\) 中基本推理的压缩表示
- 在 (3) 中,移除
<think>部分仅保留 \(s_{\backslash \text{\think} }\) (13,054 个响应 Token 中的 640 个)- \(\mathbb{E}[L(y)]\) 和 \(\mathbb{E}[E(y)]\) 都再次向无引导水平增加,反映了显著的信息损失
- (4) 依赖于重生成的响应 \(\tilde{y}\),产生了中间值(低于 (3) 但高于 (2))
- 表明 \(\tilde{y}\) 保留了完整解决方案的大部分信息结构
- 详细的每个 Token 的分解见附录 A.1.1
Takeaway 1: Information Richness and Epistemic Verbalization
- 随着条件上下文 \(c\) 变得越来越信息丰富且直接有用,LLM 生成的答案更加自信,并且认知性不确定性表达更少
Supervised Finetuning with Self-Distillation,使用 Self-Distillation 进行 SFT
- 问题提出:在高 \(I(y; c \mid x)\) 下对 Epistemic Verbalization 的抑制仅仅是风格上的变化,还是对推理能力有切实的影响
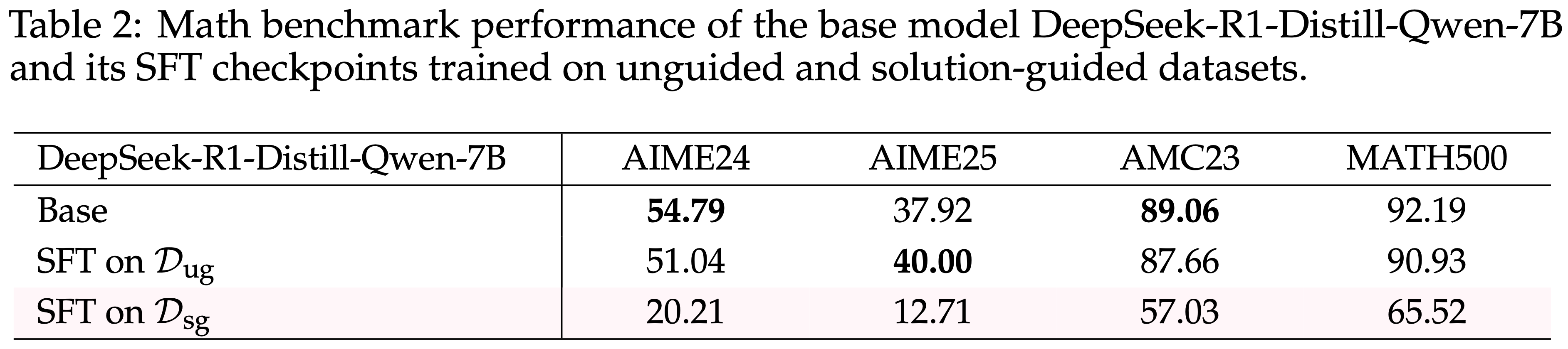
- 为了验证这一点,本文使用 DeepSeek-R1-Distill-Qwen-7B (2025a) 在两个数据集上进行了 Off-policy Self-Distillation(即 SFT)
- 每个数据集包含 800 个正确响应:
- \(\mathcal{D}_{\text{ug} }\):无引导响应 \((c = \emptyset)\),具有高 \(\mathbb{E}[E(y)]\) 和 \(\mathbb{E}[L(y)] \approx 12k\) Token
- \(\mathcal{D}_{\text{sg} }\):解决方案引导响应 \((c = s)\),具有低 \(\mathbb{E}[E(y)]\) 和 \(\mathbb{E}[L(y)] \approx 2k\) Token
- 每个数据集包含 800 个正确响应:
- 两个数据集都由完全正确的轨迹组成;关键区别在于训练信号的认知密度
- 本文在多个数学基准上评估了得到的检查点(每个数据集的示例在作者的博客:Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? 中展示)
- 本文在多个数学基准上评估了得到的检查点(每个数据集的示例在作者的博客:Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs? 中展示)
- 如表 2 所示,数据集由正确答案组成
- 在 \(\mathcal{D}_{\text{sg} }\) 上训练导致了所有基准上的显著性能下降
- 在 \(\mathcal{D}_{\text{ug} }\) 上训练则没有产生显著的性能变化
- 这种不对称性产生的原因是
- 解决方案引导的响应之所以简洁,正是因为外部上下文 \(s\) 的存在
- 在没有 \(s\) 的情况下将它们用作 SFT 目标,迫使模型模仿一种预设了推理时无法获得的信息的推理风格,从而有效地抑制了支持自主探索和错误修正的 Epistemic Token
- 这些结果与 Kim 等 (2026) 一致,该研究表明抑制 Epistemic Verbalization 会显著降低推理性能
Epistemic Suppression and Reasoning Performance
- 即使在正确的轨迹上进行训练,过度抑制 Epistemic Verbalization 也可能严重损害推理性能
On-Policy Self-Distillation
- On-Policy Self-Distillation (2026;) 中,模型从自教师提供的奖励信号中学习,该教师可以访问正确的解决方案,并基于当前策略的响应
- 具体做法:
- 在 DAPO-Math-17k 数据集 (2025) 上,使用 Qwen3-8B (2025) 和 DeepSeek-R1-Distill-Qwen-7B (2025b) 作为基础模型,比较了 GRPO 和基于 Self-Distillation 的强化学习 (Reinforcement Learning via Self-Distillation, SDPO) (Hü2026)
- 关于 Olmo-3-7B-Instruct (2025) 的附加结果见附录 D.2
- 对于每个模型,跟踪训练得分和响应长度,以及在两个标准数学基准 AIME24 和 AMC23 上的 OOD 性能
- 将教师策略固定为初始策略,而不是使用移动目标 ,因为这能获得更好的性能 (关于比较见第 5.4 节)
- 在 DAPO-Math-17k 数据集 (2025) 上,使用 Qwen3-8B (2025) 和 DeepSeek-R1-Distill-Qwen-7B (2025b) 作为基础模型,比较了 GRPO 和基于 Self-Distillation 的强化学习 (Reinforcement Learning via Self-Distillation, SDPO) (Hü2026)
- On-Policy Self-Distillation 的行为取决于两个因素:
- (i) 基础模型已经表现出的认知口头化程度
- (ii) 条件上下文 \(c\) 的丰富程度
- 为了厘清这些因素,本文在两种设置下比较了 GRPO 和 SDPO:
- \(c = s\)(完整解决方案)
- \(c = s_{\text{\think} }\)(去除
<think>内容的解决方案)
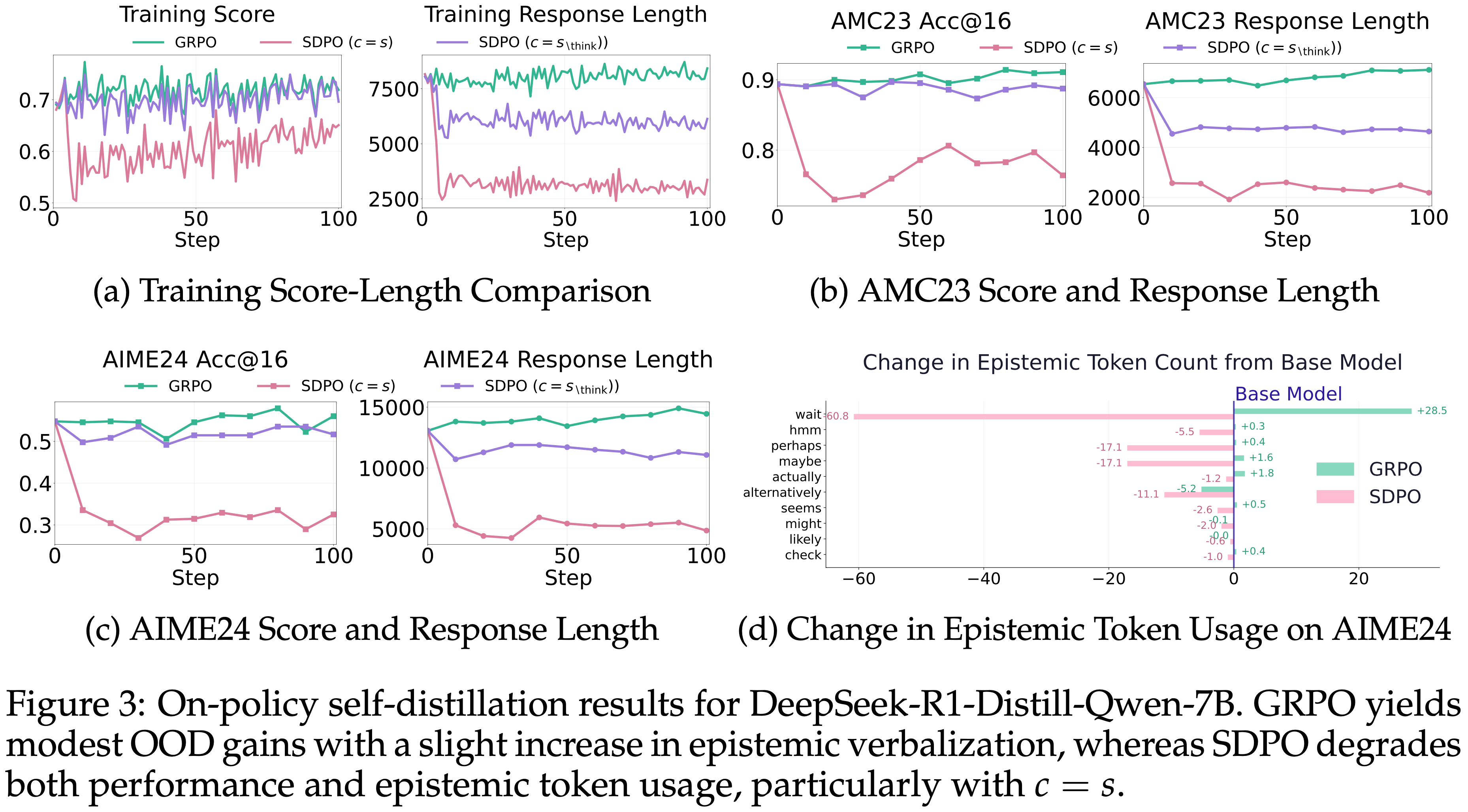
DeepSeek-R1-Distill-Qwen-7B
- DeepSeek-R1-Distill-Qwen-7B 是一个代表性的高推理能力模型
- DeepSeek-R1-Distill-Qwen-7B 以其在
<think>标签内生成大量 Epistemic Verbalization 和产生长响应而闻名,实现了强大的推理性能
- DeepSeek-R1-Distill-Qwen-7B 以其在
Training Performance
- 如图 4a 所示
- GRPO 训练略微增加了 \(\mathbb{E}[L(y)]\),同时得分略有提高
- 采用 \(c = s\) 的 SDPO
- \(\mathbb{E}[L(y)]\) 和得分都出现急剧的初始下降,然后性能逐渐恢复
- 但在整个训练过程中仍低于 GRPO
- 采用 \(c = s_{\text{\think} }\) 的 SDPO
- \(\mathbb{E}[L(y)]\) 的下降幅度减弱,得分轨迹接近 GRPO
- 这与第 3 节讨论的 \(I(y; c \mid x)\) 与认知抑制之间的关系一致
OOD Evaluation - AIME24, AMC23
- 与训练趋势一致:
- GRPO 在两个 OOD 基准测试上都取得了适度的提升(图 3b 和 3c),同时 \(\mathbb{E}[L(y)]\) 略有增加
- AIME24: \(54.7 \rightarrow 56.0\)
- AMC23: \(89.3 \rightarrow 91.1\)
- 采用 \(c = s\) 的 SDPO 显著降低了性能
- AIME24 上约 \(40%\)
- AMC23 上约 \(15%\)
- 采用 \(c = s_{\backslash \text{\think} }\) 的 SDPO 缓解了性能下降
- 但性能仍低于基础模型
- 但性能仍低于基础模型
- GRPO 在两个 OOD 基准测试上都取得了适度的提升(图 3b 和 3c),同时 \(\mathbb{E}[L(y)]\) 略有增加
Reasoning Pattern
- 图 3d 展示了训练后模型的 Epistemic Token 计数
- GRPO 增加了 \(\mathbb{E}[E(y)]\),而 SDPO 则更激进地抑制了它,这与作者在整个分析中观察到的认知抑制与性能下降之间的相关性一致
- 回顾 \(\mathbb{E}[E(y)]\) 是 Epistemic Token Count
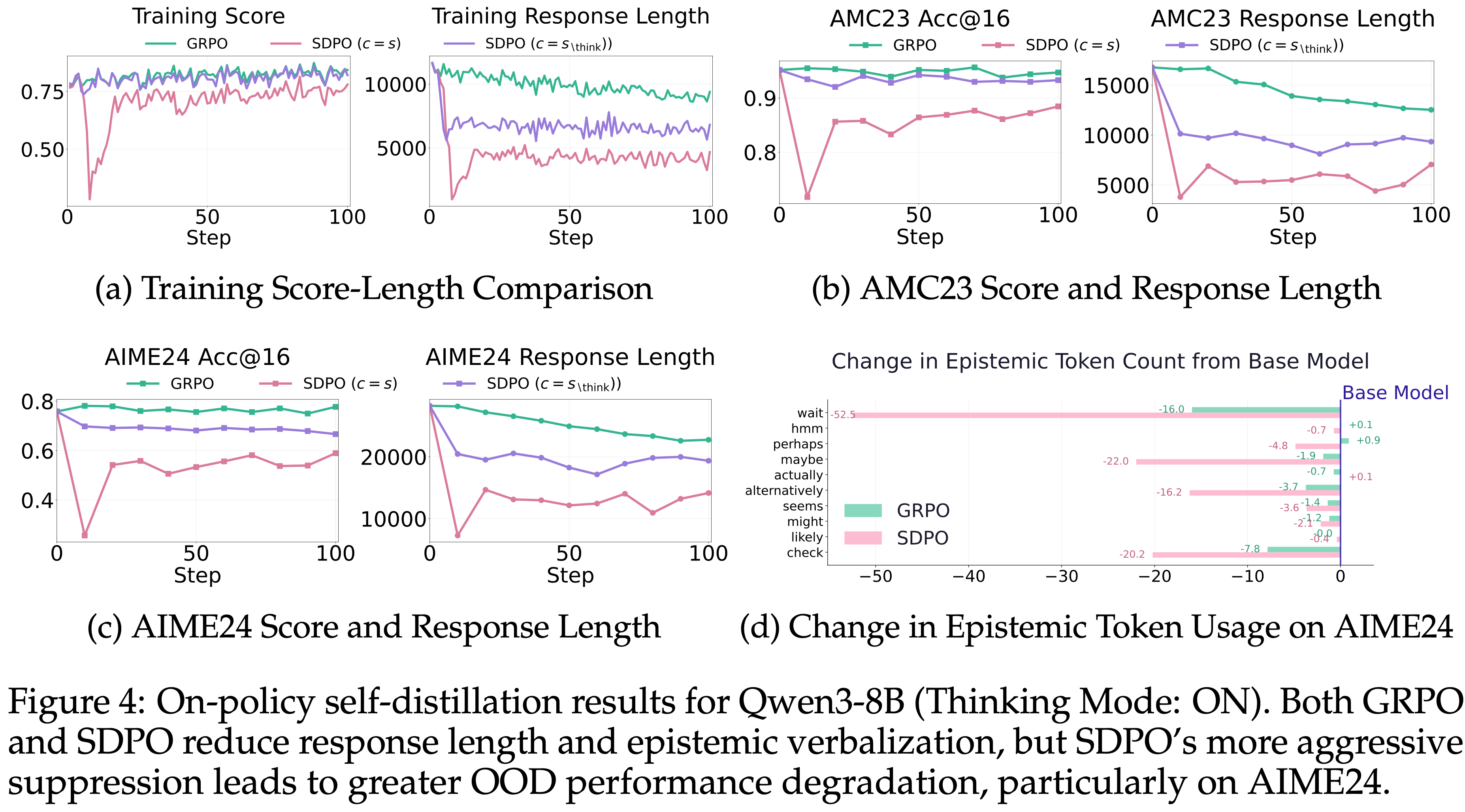
Qwen3-8B (Thinking Mode: ON)
- 启用思考模式后,Qwen3-8B 最初生成的响应非常长,甚至比 DeepSeek-R1-Distill-Qwen-7B 还要长,同时伴随着大量的 Epistemic Token
- 详情见附录 A.1.2 所示
Training Performance
- 如图 4a 所示
- 在 GRPO 和 SDPO 下,\(\mathbb{E}[L(y)]\) 均有所下降
- 其中 SDPO 表现出更大的下降幅度和相应的更大性能下降
- Notably,\(\mathbb{E}[L(y)]\) 首先急剧下降,然后略有上升
- 由于教师策略被固定为参考策略,将响应缩短约 \(900\) 个 Token 会降低 \(c\) 的信息量,即减小 \(I(y; c \mid x)\)
- 随着上下文信息量减少,模型通过增加 Epistemic Verbalization 来补偿,导致长度部分恢复
- 问题:这里的教师策略是参考策略的话,训练过程中教师策略应该是不变的,这时候为什么 \(c\) 的信息量会减小?大约减少 900 个 Token 的数字是从哪里看出来的(图 4 中给出的长度降幅都远远高于 900 个 Token)?
- 其中 SDPO 表现出更大的下降幅度和相应的更大性能下降
- 在 GRPO 和 SDPO 下,\(\mathbb{E}[L(y)]\) 均有所下降
OOD Evaluation - AIME24, AMC23
- 这种差距在 OOD 基准测试上变得更加明显:
- GRPO 在 \(\mathbb{E}[L(y)]\) 逐渐下降的同时保持了基本稳定的性能
- SDPO 则降至基础模型以下,尤其是在 \(c = s\) 的情况下
- GRPO 和采用 \(c = s_{\backslash \text{\think} }\) 的 SDPO 达到了相当的训练性能
- 但它们的 OOD 结果却出现分歧,尤其是在更具挑战性的 AIME24 上(AIME23 上还好)
- 采用 \(c = s_{\backslash \text{\think} }\) 的 SDPO 随着训练的进行表现出逐渐的性能下降
Reasoning Pattern
- GRPO 和 SDPO 两种方法相对于基础模型都降低了 \(\mathbb{E}[E(y)]\),但 SDPO 更为激进
- 这表明 Qwen3-8B 最初产生的 Epistemic Verbalization 比必要的更多
- 虽然两种方法都减轻了这种冗余,但过于激进的抑制可能会移除携带有用推理信息的认知信号
Qwen3-8B (Thinking Mode: OFF)
- 当 Qwen3-8B 在不使用思考模式的情况下使用时,
<think>标签不存在,只比较 \(c = s\)- Qwen3-8B 最初产生的响应要短得多,并且表现出显著降低的性能
- GRPO 通过促进 Epistemic Verbalization (如附录 D.1 所示)迅速增加了 \(\mathbb{E}[L(y)]\),快速达到了高训练得分
- SDPO 减少了 \(\mathbb{E}[L(y)]\) 并且改进速度慢得多
- 如图 5b 所示,训练得分略有增加,但 AIME24 上的测试性能略有下降 \((0.25 \rightarrow 0.23)\)
- 这进一步说明了 Self-Distillation 下认知抑制的代价
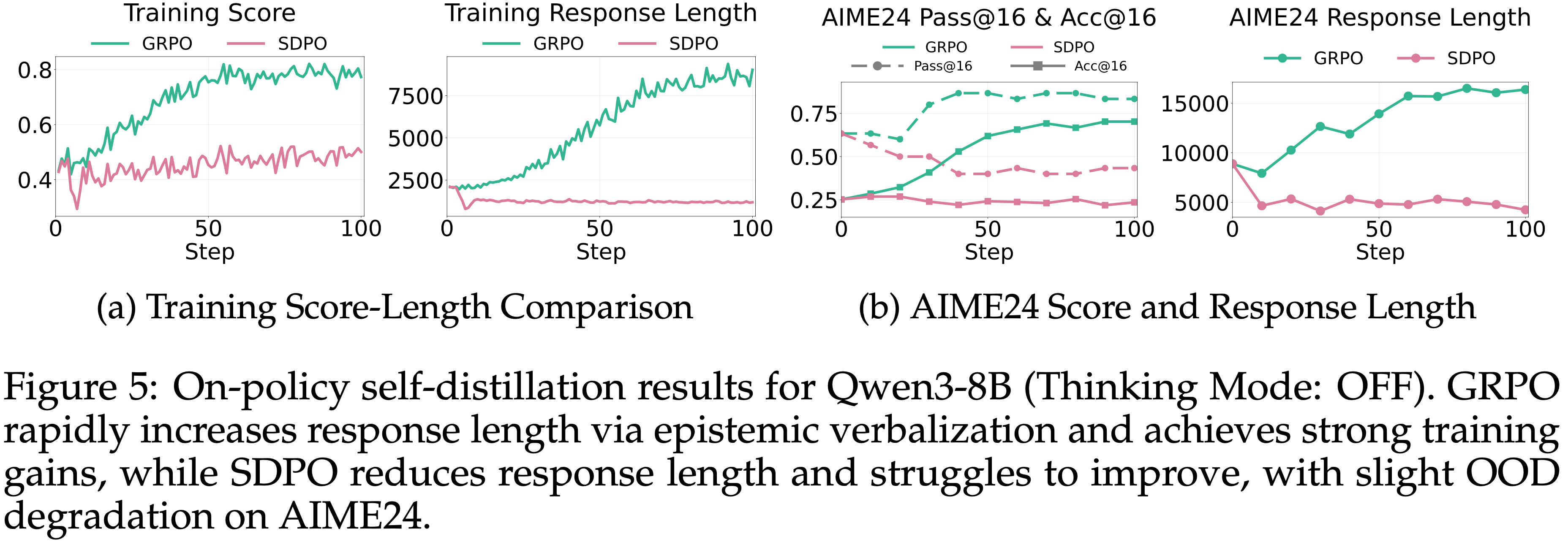
Takeaway 3: Epistemic Verbalization Changes and Performance in On-Policy Self-Distillation
- 随着教师上下文 \(c\) 变得信息更丰富, On-Policy Self-Distillation 会减少 Epistemic Verbalization 并缩短响应
- 这种效应因基础模型最初表达的不确定性水平而异
- 理解(初始模型的长度和 Epistemic Verbalization 等决定了使用 不同算法训练时观察到的 现象):
- 如原始 Qwen3-8B (Thinking Mode: ON) 生成的响应非常长,且包含大量的 Epistemic Token
- 此时训练 GRPO/SDPO 都会缩短长度,且 GRPO 和 采用 \(c = s_{\backslash \text{\think} }\) 的 SDPO 的分数差不多
- Qwen3-8B (Thinking Mode: OFF) 则回答很短
- 此时训练 GRPO 会提升长度,而 采用 \(c = s_{\backslash \text{\think} }\) 的 SDPO 则会降低长度
- 如原始 Qwen3-8B (Thinking Mode: ON) 生成的响应非常长,且包含大量的 Epistemic Token
- 理解(初始模型的长度和 Epistemic Verbalization 等决定了使用 不同算法训练时观察到的 现象):
Ablation Study: Fixed vs. Moving Target Teacher,固定 Teacher 模型 or 滑动 Teacher 模型
- 在朴素的 On-Policy Self-Distillation 中,教师和学生共享一个持续更新的策略
- 此时教师是一个移动目标,可能引入训练不稳定性 (2026; 2026)
- 为了缓解这个问题,SDPO 使用 EMA 平滑的教师(EMA 率:0.05)
- 进一步的实验发现,将 EMA 率设置为 0.0(即固定教师为初始策略)能获得更好的性能(注:第 5 节遵循此设置)
- 图 6: DeepSeek-R1-Distill-Qwen-7B 的固定教师与移动目标教师对比
- 即使缓慢的 EMA 更新(率 0.05)也会通过反馈循环放大认知抑制,导致比固定教师更严重的性能下降
- 图 6a 显示了在训练期间更新教师时的额外比较结果
- 即使是缓慢的更新(例如,率 0.05)也会导致响应长度更急剧的减少,从而导致更大的性能下降
- 这可以解释为 Self-Distillation 中的一个反馈循环:
- 模型被训练产生越来越自信的输出,当使用同一个模型的 checkpoint 作为教师时,它会产生更自信的响应 ,从而在迭代中放大这种效应
- 个人理解1:这个理解应该不对,个人理解应该是这样的:
- 模型训练过程中本来就是越来越自信的,这个现象其实说明收敛快,并不一定是坏事
- 个人理解2:从另一个视角看,持续变化的 Teacher 会导致目标(Teacher)一直在变化,不利于模型(Student)收敛,这类似 DQN 中最早面临的问题(使用的 Target Q 可缓解这个问题),所以 OPSD 中 实验发现这一设置有助于稳定训练
- 个人理解3:使用初始的策略作为 Teacher,能隐式起到正则化作用,防止模型过度偏离初始策略 (观点来自 OPSD 中)
- 个人理解1:这个理解应该不对,个人理解应该是这样的:
- 模型被训练产生越来越自信的输出,当使用同一个模型的 checkpoint 作为教师时,它会产生更自信的响应 ,从而在迭代中放大这种效应
- 问题(推测):如果 Teacher 不随着 Student 策略变化,那么 Teacher 的上限太明显了
- 建议考虑以一定的间隔或较小的 EMA 更新参数(比如间隔 100 步或 EMA 系数=0.01 等),类似 DQN 中 Target Q 的实现,这样才能打开 Teacher 的上限
- 但需要特别注意训练稳定性以及对原始策略的偏离程度(比如加一个 KL 散度来缓解,或者第一步更新前的策略给与固定高权重?)
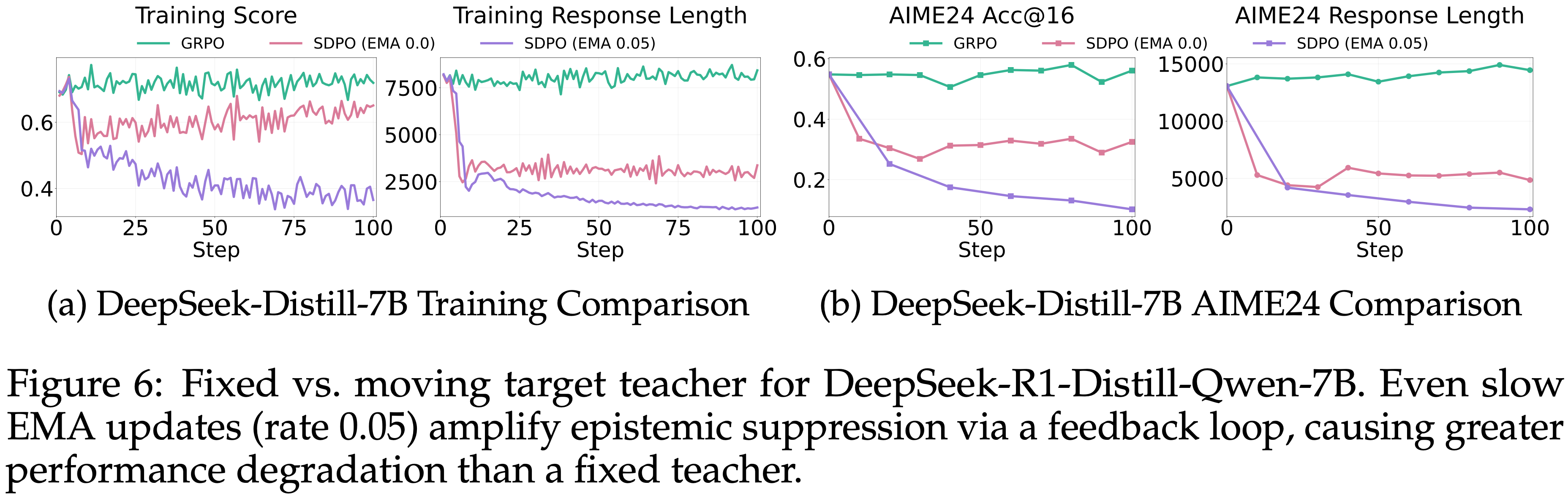
- 关于学习率和 top-k logits 的进一步消融研究见附录 E
Relationship Between Task Coverage, Epistemic Verbalization and Generalization Ability,任务覆盖 & Epistemic Verbalization 与泛化能力的关系
- 上述分析可知,不论 Off-policy 还是 On-policy Setting
- Self-Distillation 都会一致地产生更自信的响应,并降低了 \(\mathbb{E}[E(y)]\)
- 问题:Off-policy 的 Self-Distillation 是什么?
- 回答:是第 4 节开头提到的 SFT,在 SFT 上,也观察到了类似 \(\mathbb{E}[E(y)]\) 降低的现象
- 这与 Hübottter 等 (2026) 的发现一致,该报告指出 SDPO 学会了简洁地推理:
- 在科学问答(化学、物理、生物学和材料科学)(2024)、工具使用 (2023) 和 LiveCodeBench v6 (2025) 上,SDPO 在产生更短输出、更少认知标记的同时,实现了比 GRPO 更高的准确率
- Self-Distillation 都会一致地产生更自信的响应,并降低了 \(\mathbb{E}[E(y)]\)
- 在这些领域中, Self-Distillation 抑制了 Epistemic Verbalization ,同时提高了性能
- 关键问题提出:为什么相同的机制在数学聚焦 Setting 中会导致性能下降?
- 本文作者推测答案在于训练分布和评估分布之间任务覆盖的差异
Comparison of Task Coverage
- 为了验证这个 hypothesis,作者比较了 SDPO 优于 GRPO 的设置与本文实验设置的数据集特征
- 如表 3 所示
- 化学数据集虽然规模庞大,但仅来自六种主要问题类型
- 这些类型主要在表面细节上有所不同,而非底层结构
- LiveCodeBench v6 包含多样化的问题,但总共只有 131 个
- 在训练期间使用相同的训练/评估划分进行重复暴露
- DAPO-Math-17k 让模型接触到 14,000 个不同的问题
- 由于重复采样,在 100 步中抽取到 25,600 个样本中的 78%
- 问题:如何理解这里的 重复采样和 78%?
- 涵盖了广泛且不重叠的问题类型,并且评估是在未见过的的问题类型上进行的

- 由于重复采样,在 100 步中抽取到 25,600 个样本中的 78%
- 化学数据集虽然规模庞大,但仅来自六种主要问题类型
Relationship Between Task Coverage and Learning Performance
- 为了进一步研究任务覆盖与泛化之间的相互作用,本文改变了来自 DAPO-Math-17k 的训练问题数量
$$|\mathcal{D}| \in \{1, 8, 64, 128, 512\}$$- 并使用 GRPO 和 SDPO 进行训练
- 所有实验均使用 Qwen3-8B(Thinking Mode OFF)
Training Logs
- GRPO 和 SDPO 随着 \(|\mathcal{D}|\) 的变化展现出不同的训练动态
- SDPO
- 当 \(|\mathcal{D}|\leq 128\) 时 ,SDPO 在减少 \(\mathbb{E}[L(y)]\) 的同时快速达到高分
- 表明在小型任务集上 SDPO 具有更高的训练效率
- 当 \(|\mathcal{D}| = 512\) 时 ,相对于 GRPO,\(\mathbb{E}[L(y)]\) 的进一步减少开始损害训练得分 ,(图 7 左数第三个图))
- 当 \(|\mathcal{D}|\leq 128\) 时 ,SDPO 在减少 \(\mathbb{E}[L(y)]\) 的同时快速达到高分
- GRPO 的 \(\mathbb{E}[L(y)]\) 则随着 \(|\mathcal{D}|\) 的增加而逐渐增加
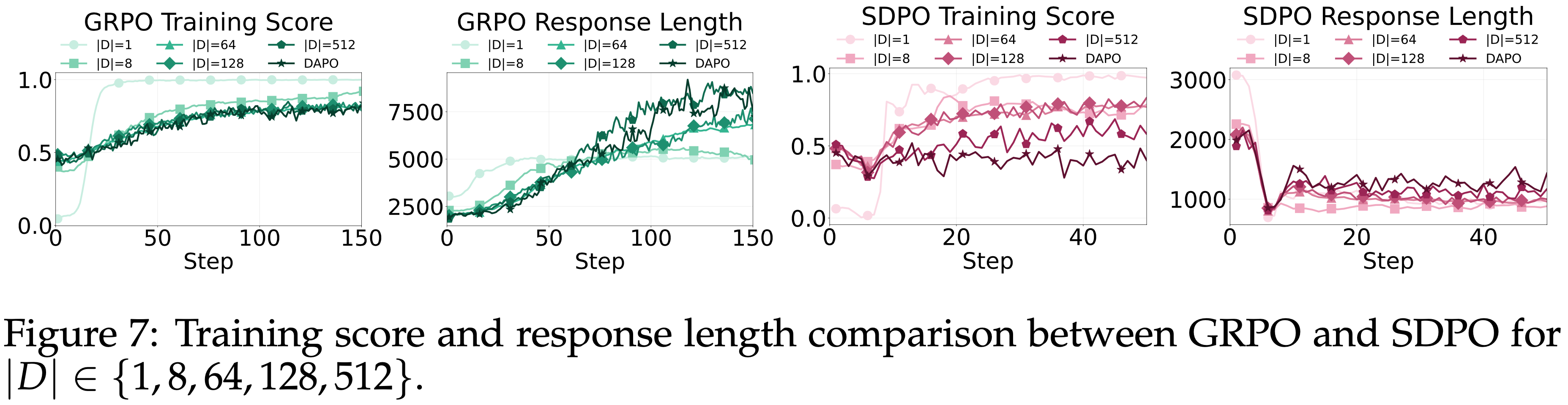
- SDPO
- 这种差异可以通过任务覆盖来解释
- 随着 \(|\mathcal{D}|\) 的增长,模型必须适应更广泛的推理模式
- GRPO 通过增加 \(\mathbb{E}[E(y)]\) 来解决这个问题,使模型能够表达更大的不确定性并相应地调整其推理
- SDPO 则鼓励自信、简洁的响应——这在任务覆盖较小时有效,但当问题集变得更大、更多样化时则会受限
OOD Evaluation - AIME24, MATH500
- GRPO 和 SDPO 之间的区别在 OOD 基准测试(图 8)上变得更加明显
- 在 GRPO 下,性能随 \(|\mathcal{D}|\) 的增大而稳定提升:
- \(|\mathcal{D}| = 1\) 时收敛迅速但很快停止改进
- 较大的 \(|\mathcal{D}|\) 则产生逐渐更高的最终得分
- 伴随着 \(\mathbb{E}[L(y)]\) 的增加
- 在 SDPO 下:
- 较小的 \(|\mathcal{D}|\) 导致更严重的 OOD 性能下降
- 即使在最大的 \(|\mathcal{D}|\)(DAPO Setting)下,SDPO 的性能仍然低于基础模型
- 理解:图中的 SDPO DAPO 实验组即全量数据的场景
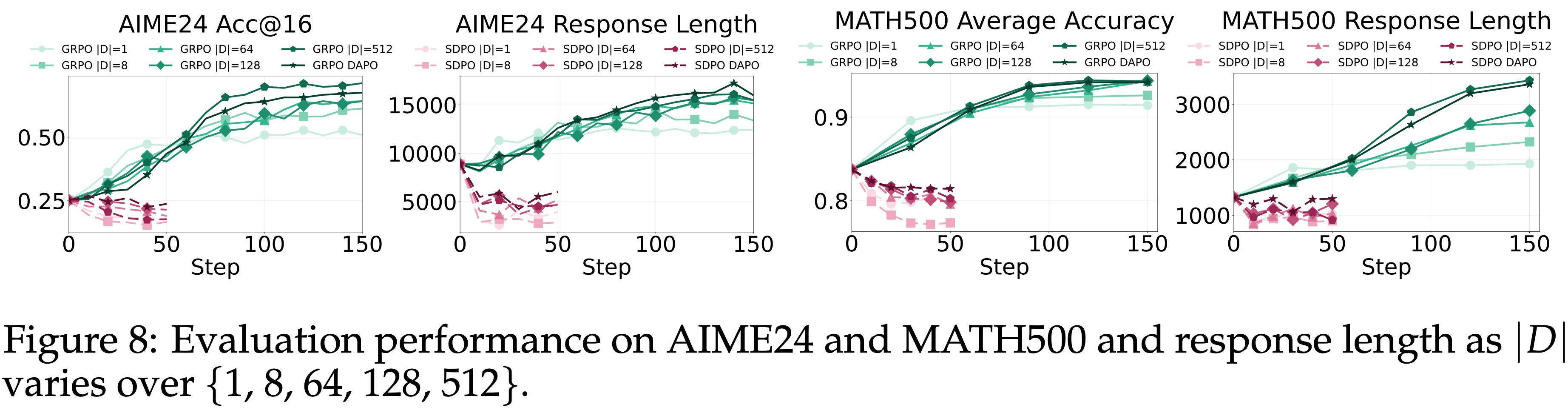
- 理解:图中的 SDPO DAPO 实验组即全量数据的场景
- 在 GRPO 下,性能随 \(|\mathcal{D}|\) 的增大而稳定提升:
- 示例推理模式见附录 A.2
Takeaway 4: Epistemic Verbalization Depends on Task Generalization
- Epistemic Verbalization 的价值随泛化需求的增加而增加:
- 对于熟悉、重复的任务(小 \(|\mathcal{D}|\)),Epistemic Verbalization 在很大程度上是多余的,可以为了效率而移除
- 随着任务多样性的增长,Epistemic Verbalization 变得越来越重要
附录 A:Additional Analysis of Epistemic Tokens Count
A.1 LLM Reasoning Behavior Under Richer Information,更丰富信息下的 LLM 推理行为
A.1.1 Per-Token Analysis of Epistemic Verbalization,Epistemic Verbalization 的逐 Token 分析
- 在第 3 节的表 1 中,本文比较了每个 Response 中十个 Epistemic Token 的平均数量
- 图 9 进一步扩展了这一分析,展示了在不同程度的条件信息下,每个单独 Token 的平均每 Response 计数如何变化
- 当检查每个 Token 的计数时,所有 Token 都表现出一致的趋势:
$$
\mathbb{E}[E(y)]\bigg|_{(1)} > \mathbb{E}[E(y)]\bigg|_{(3)} > \mathbb{E}[E(y)]\bigg|_{(4)} > \mathbb{E}[E(y)]\bigg|_{(2)},
$$- 其中像
wait、maybe和perhaps这样的 Token 尤其突出
- 其中像
- 当检查每个 Token 的计数时,所有 Token 都表现出一致的趋势:
- 图 9: 四种生成设置下 Epistemic Token 使用情况的逐 Token 细分
- 每个条形图表示每个 Response 中单个 Epistemic Token 的平均出现次数
- 所有 Token 都遵循与总体趋势相同的顺序,其中
wait、maybe和perhaps在不同设置下表现出最大的变化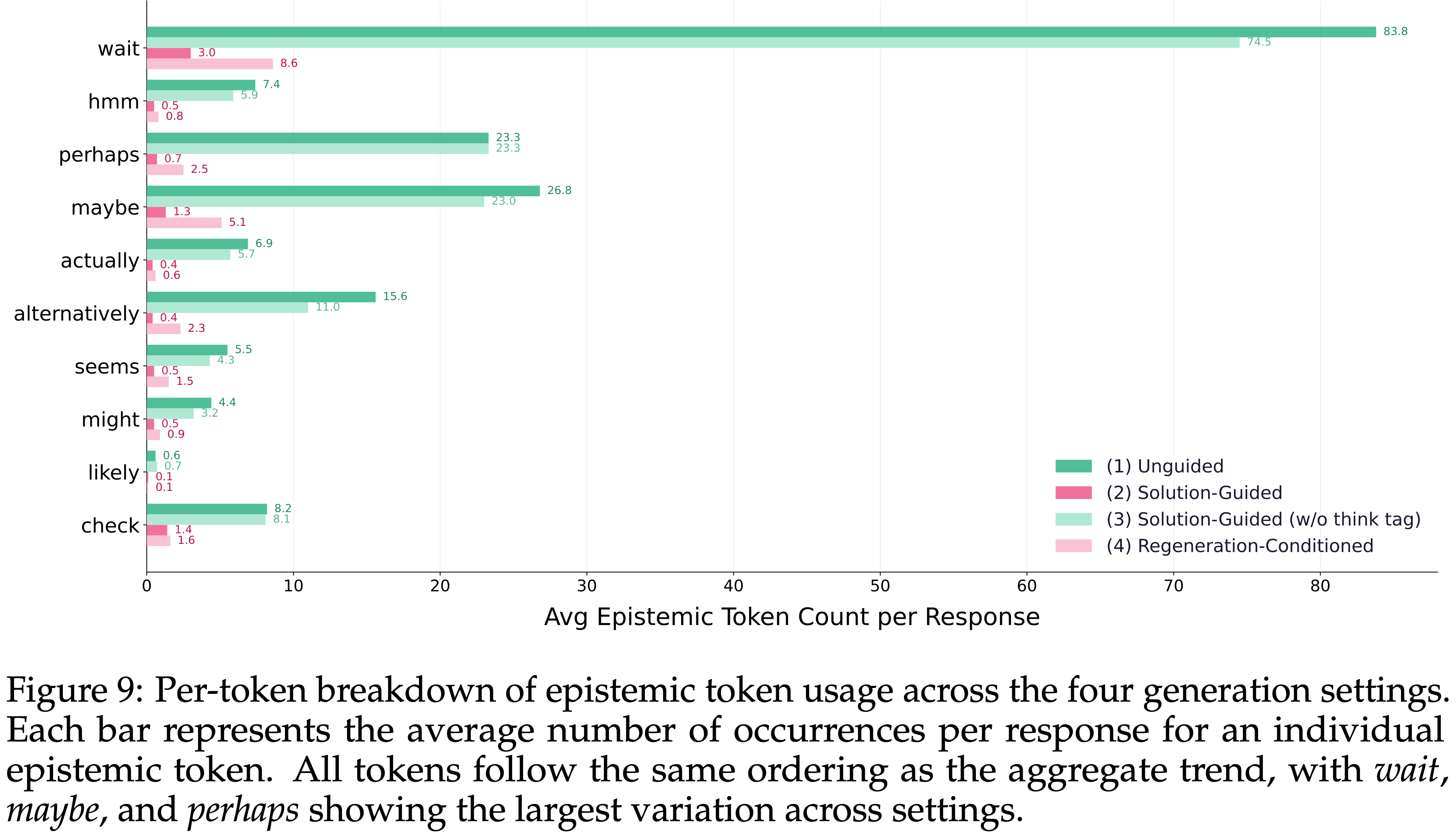
A.1.2 Comparison of Epistemic Token Usage Across Models,不同模型间 Epistemic Token 使用情况的比较
- 继第 3 节中对 DeepSeek-R1-Distill-Qwen-7B (DeepSeek-Distill-7B) 的分析之后
- 这里进一步比较了三种设置下的 Epistemic Token 使用情况:
- DeepSeek-Distill-7B
- 启用思考模式的 Qwen3-8B
- 禁用思考模式的 Qwen3-8B
- 这里进一步比较了三种设置下的 Epistemic Token 使用情况:
- 如图 10 所示
- DeepSeek-Distill-7B 和启用思考模式的 Qwen3-8B 产生的 Epistemic Token 数量都远多于禁用思考模式的 Qwen3-8B
- 虽然这两个启用思考的模型在表达不确定性方面有相似的趋势,但它们在偏好的 Epistemic Token 上有所不同
- 例如:
- DeepSeek-Distill-7B 经常使用
wait,并且使用perhaps和maybe的频率相当 - Qwen3-8B 使用
perhaps相对较少,更倾向于使用maybe - Qwen3-8B 使用
alternatively和check的频率远高于 DeepSeek-Distill-7B,并且总体上在其推理中嵌入了更多的不确定性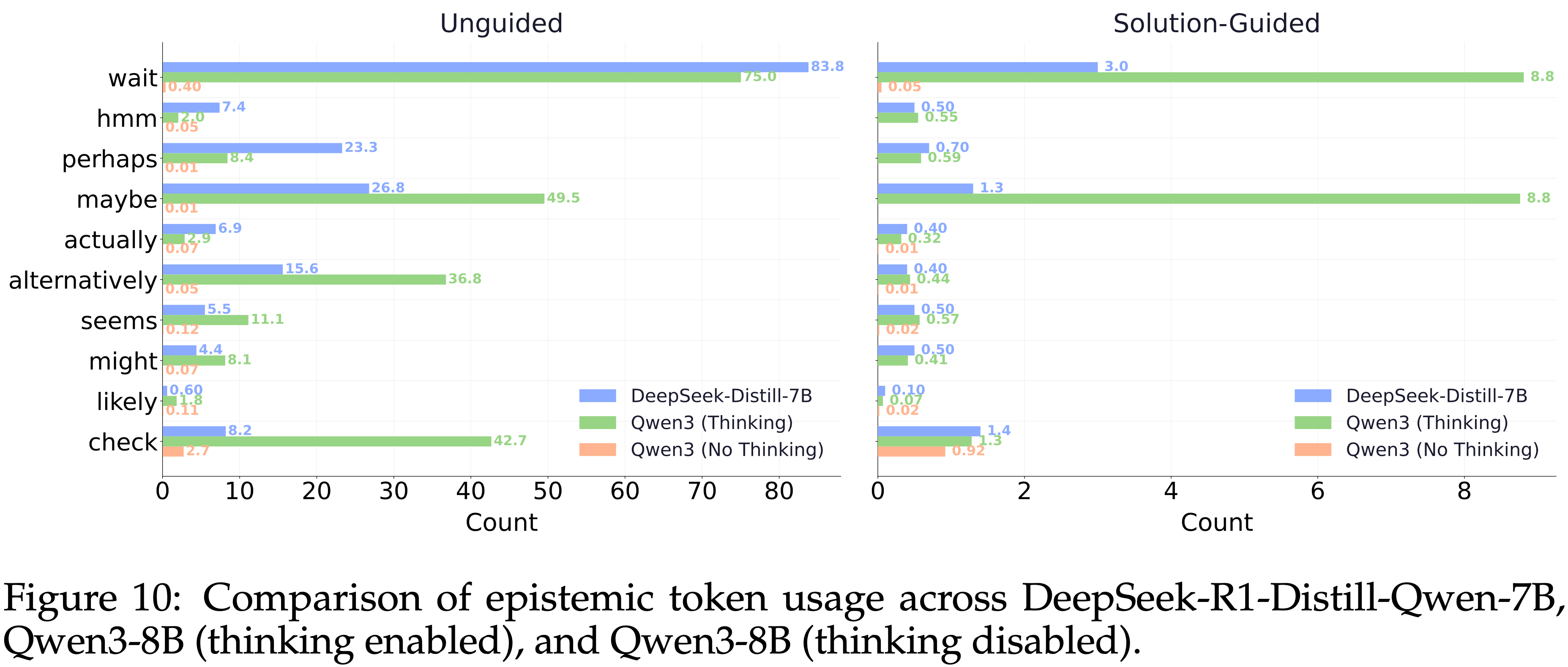
- DeepSeek-Distill-7B 经常使用
- 例如:
- Extending 第 3 节的讨论,还可观察到
- 在 Solution-Guided 生成下,Qwen3-8B 生成的 Epistemic Token 远少于 Unguided 生成
- 在所有三种设置中 Epistemic Token 数量从大到小依次为:
- 启用思考模式的 Qwen3-8B 产生的 Epistemic Token 最多
- 其次是 DeepSeek-Distill-7B
- 最后是禁用思考模式的 Qwen3-8B
Relationship Between Task Coverage and Learning Performance, 任务覆盖与学习性能之间的关系
- 为了对第 6.2 节图 8 中的结果进行更深入的分析,本文比较了六种训练配置下 AIME24 上相对于基础模型的 Epistemic Token 计数的变化:
- 交叉供 6 种:GRPO 和 SDPO,每种配置下 \(|D| \in \{1, 64, 512\}\)
- 图 11 显示
- GRPO:Epistemic Token 使用量 在增加
- \(|D|\) 越大,Epistemic Token 使用量增加越多
- SDPO:Epistemic Token 使用量 在减少
- \(|D|\) 越大,Epistemic Token 使用量减少越少
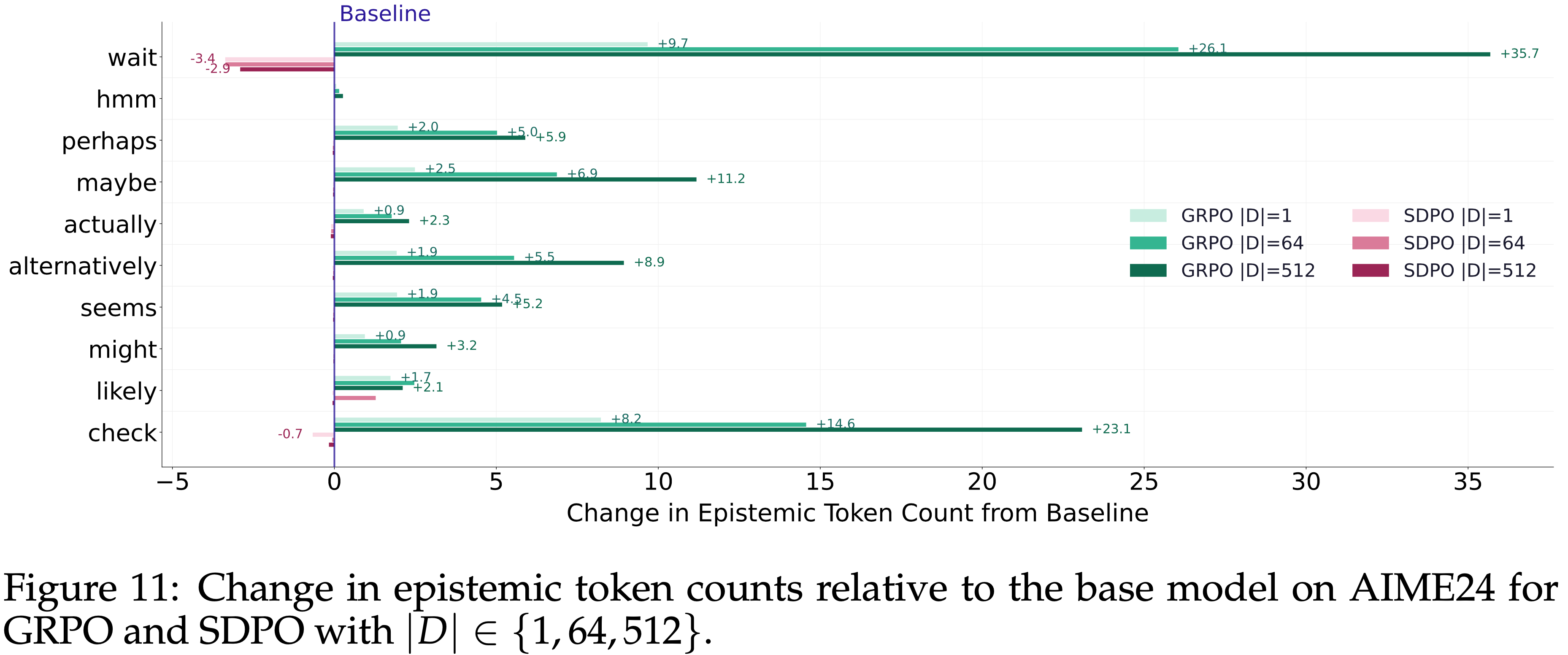
- \(|D|\) 越大,Epistemic Token 使用量减少越少
- GRPO:Epistemic Token 使用量 在增加
- 问题:相对之前的 图 3 ,为什么 图 11 这里 SDPO Epistemic Token 使用量减少的幅度这么小?
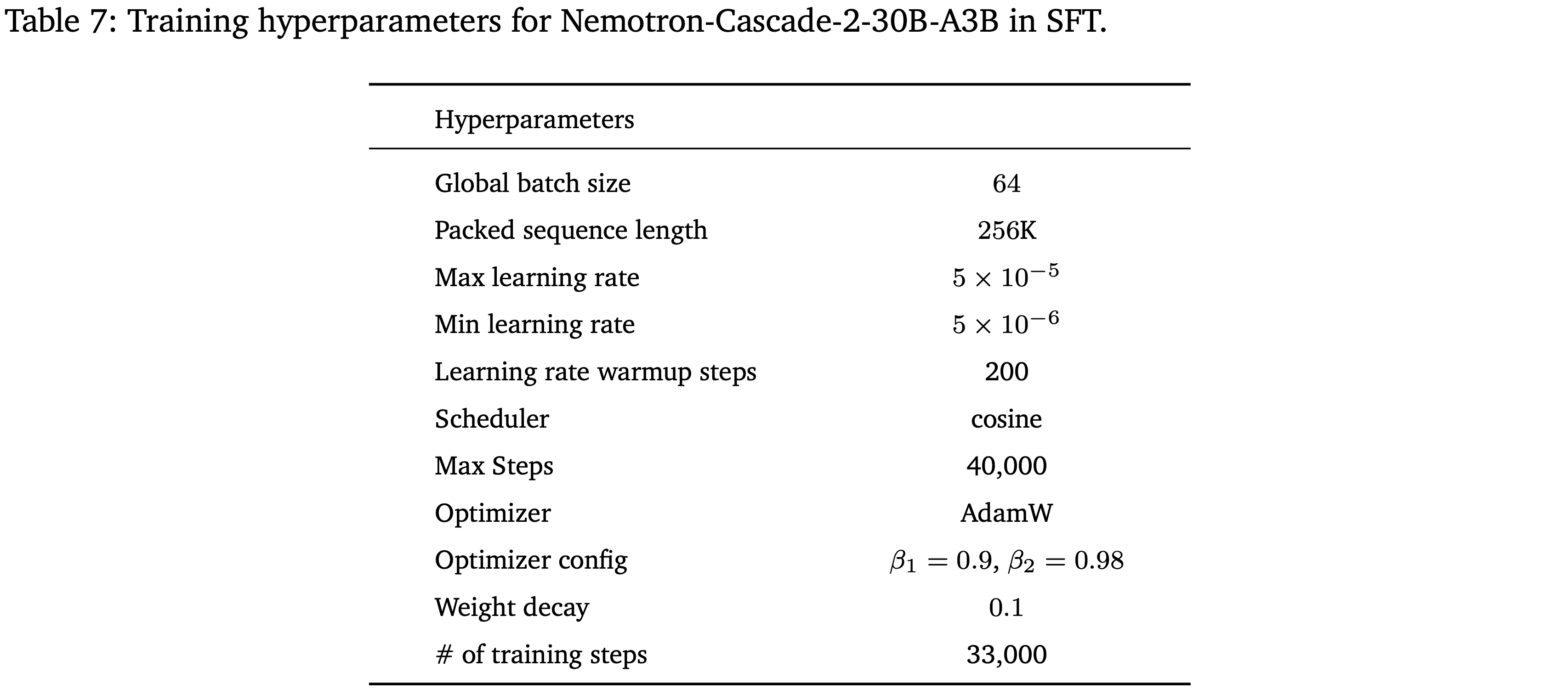
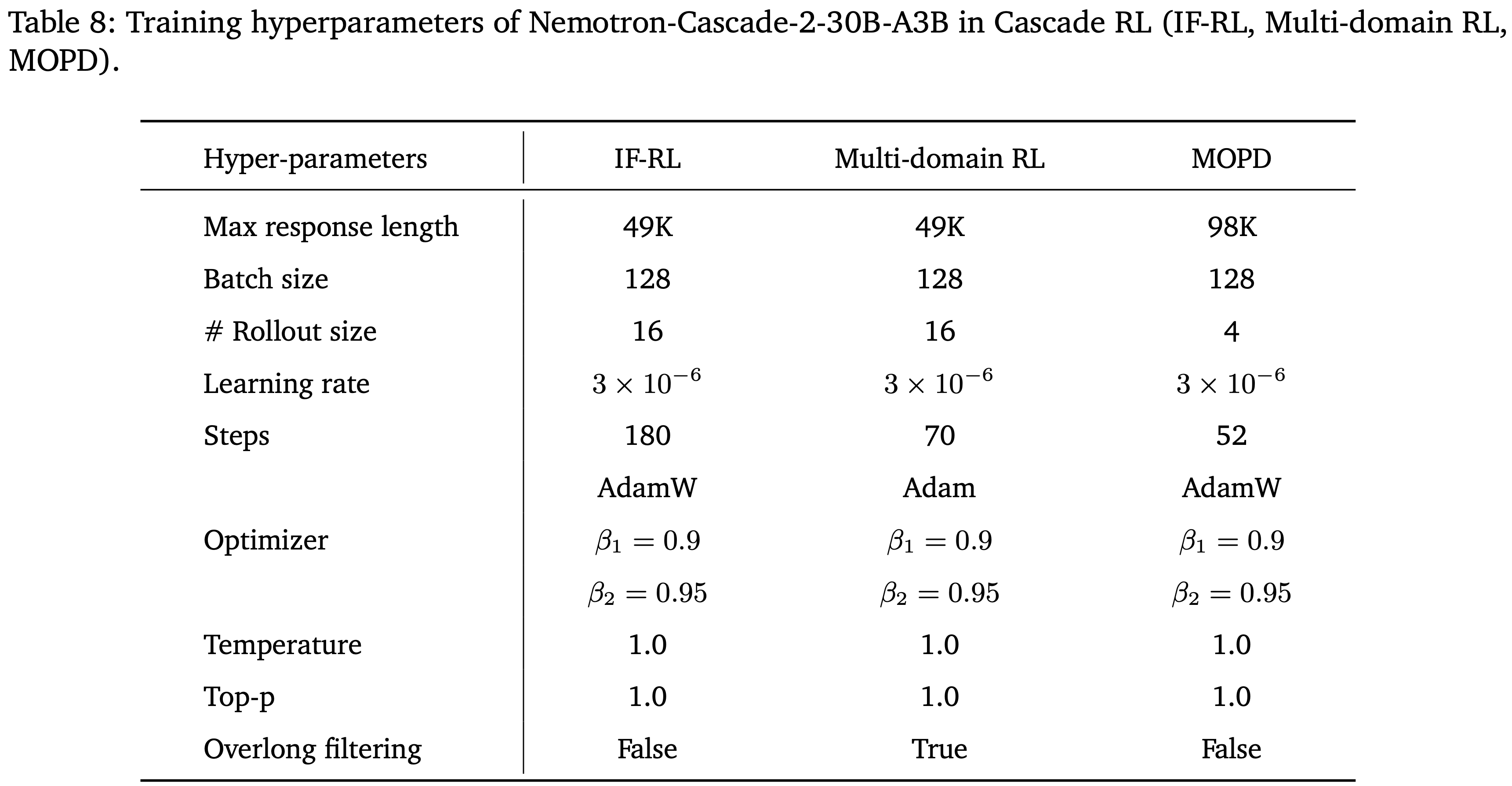
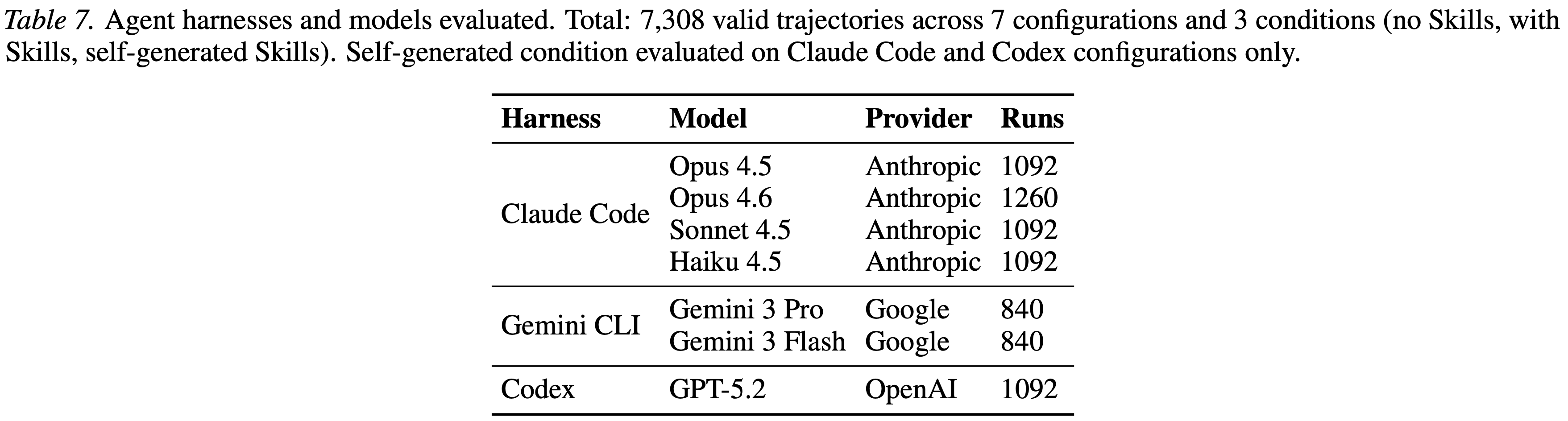
附录 B:Experimental Details
Training
对于 GRPO 和 SDPO 训练
- 本文在 SDPO 实现 github.com/lasgroup/SDPO 的基础上进行了构建,并额外加入了 DAPO-Math-17k 数据集
原始的 DAPO-Math-17k 数据集使用以下 Prompt 格式:
1
Solve the following math problem step by step. The last line of your response should be of the form Answer: $Answer (without quotes) where $Answer is the answer to the problem. \n\n{question}\nRemember to put your answer on its own line after "Answer:".
本文将其替换为更简单的格式(因为观察到这种格式能持续获得更高的评估性能):
1
{question}\nPlease reason step by step, and put your final answer within \boxed{boxed}.
对于奖励验证,使用了
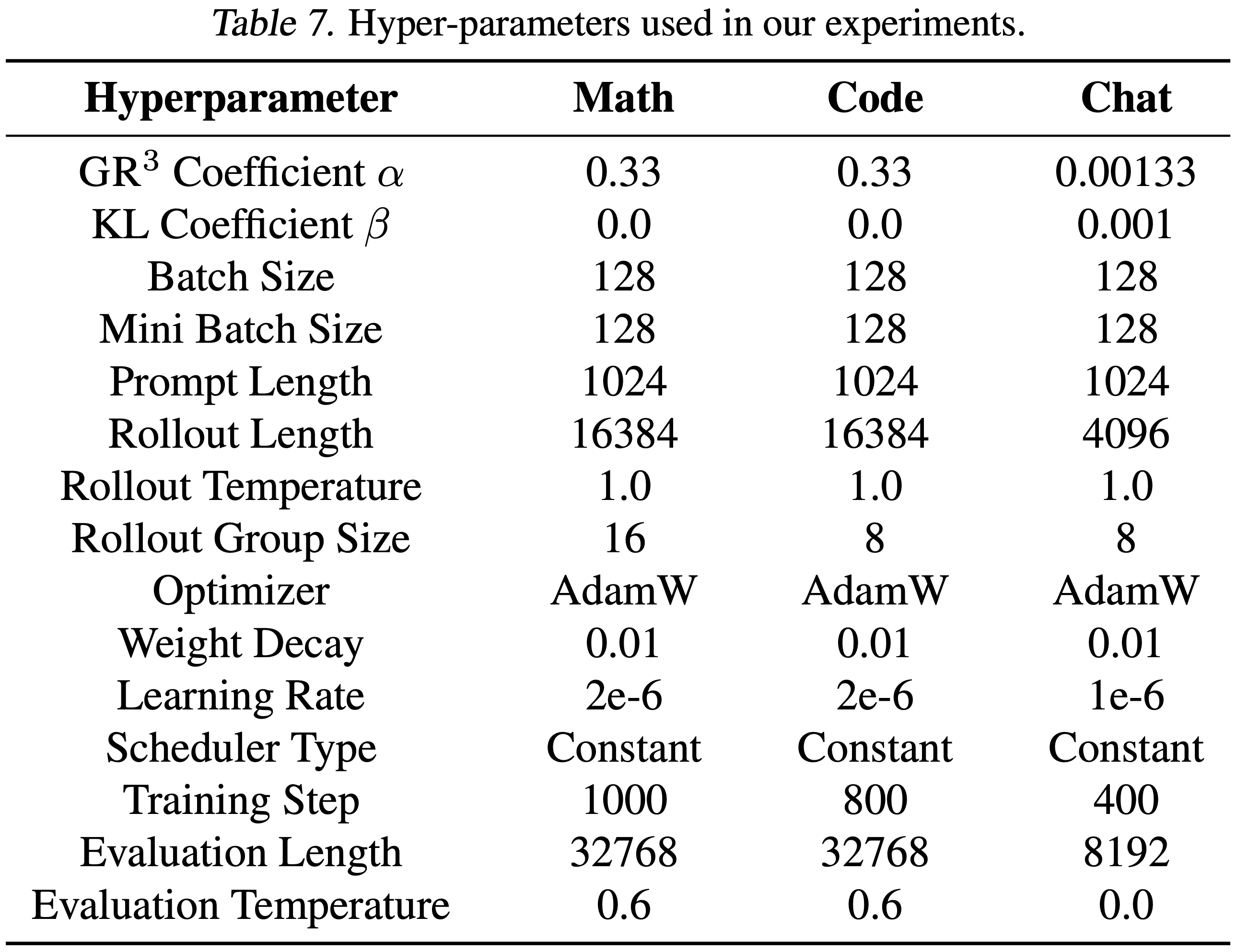
vert框架中的评分函数,该函数从\boxed{}表达式中提取答案,并通过精确匹配和数学等价性检查(使用math-verify,改编自 EleutherAI 的lmevaluation-harness(2024))来验证其正确性GRPO 和 SDPO 训练的超参数列在表 4、5 和 6 中
- 对于图 8 中关于任务覆盖与学习性能之间关系的实验,由于使用了更小的训练问题集,本文将问题批次大小减少到了 64
表 4: GRPO 和 SDPO 共享的通用超参数

表 5: GRPO 特定超参数

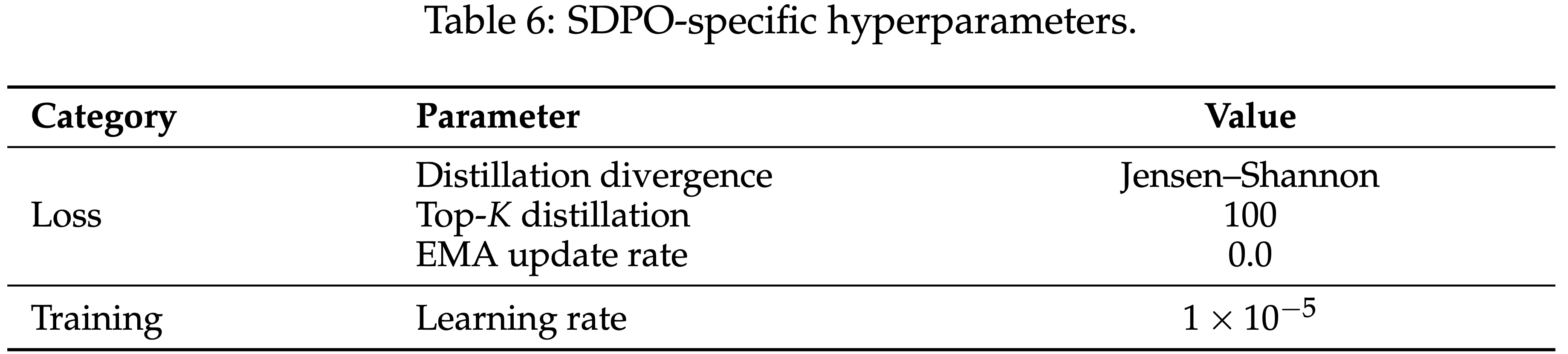
表 6: SDPO 特定超参数,从表 6 的超参数可以看出,训练时:
- 训练的损失是 Jensen-Shannon 距离,且仅使用了 Top-100 Token 计算距离
- 同时 EMA 为 0 表示 Teacher 模型固定不动
Evaluation
- 使用表 7 中列出的超参数评估所有模型,这些设置遵循了每个模型官方文档中的推荐设置
Chat Templates for Different Model Series
这里总结了几种开源权重语言模型家族使用的 Chat Template 格式
- 每个模型系列使用不同的特殊 Token 和结构来区分用户和 Assistant 的对话轮次
- 在整个过程中,本文使用相同的数学问题作为示例 Prompt
DeepSeek-R1-Distill-7B
1
2<begin_of_sentence></User>Find the largest possible real part of [(75 + 117)z + \text{frac}(96 + 144i)(z)] where z is a complex number with |z| = 4
Please reason step by step, and put your final answer within \boxed{}.<|Assistant|><think>Qwen3-8B (Thinking Mode: ON)
1
2
3
4<|im_start|>user
Find the largest possible real part of [((75 + 117)z + \text{frac}(96 + 144i)(z)] where $z$ is a complex number with $|z| = 4$
Please reason step by step, and put your final answer within \boxed{}.<|im_end|>
<|im_start|>assistantQwen3-8B (Thinking Mode: OFF)
1
2
3
4
5
6<|im_start|>user
Find the largest possible real part of [((75 + 117)z + \text{frac}(96 + 144i)(z)] where $z$ is a complex number with $|z| = 4$
Please reason step by step, and put your final answer within \boxed{}.<|im_end|>
<|im_start|>assistant
<think>
</think>- 注:这是 Qwen3 的创新设计,使用
<think>\n</think>来表示这里没有任何思考内容
- 注:这是 Qwen3 的创新设计,使用
OLMo-3-7B-Instruct
1
2
3
4
5
6<|im_start|>system
You are a helpful function-calling AI assistant. You do not currently have access to any functions.<functions></functions><|im_end|>
<|im_start|>user
Find the largest possible real part of \[((75 + 117)z + \text{frac}(96 + 144i)(z)\] where $z$ is a complex number with $|z| = 4$
Please reason step by step, and put your final answer within \\boxed{}.<|im_end|>
<|im_start|>assistant
附录 C:Comparison with OPSD
- 最近,OPSD (2026) 展示了通过 Self-Distillation 在数学推理中的性能提升,特别是在 Qwen3 系列上
- 差异一:模型 Setting 差异
- 本文的 Setting :学生和教师都启用或都禁用 思考模式
- OPSD 的 Setting :采用了一种混合配置,其中 学生禁用思考模式 ,教师启用思考模式
- 正如本文的实验也证实的那样
- 启用思考模式会产生更长且带有更多 Epistemic Token 的 Response,这使得这种混合设置的功能更类似于传统的教师-学生蒸馏,尽管使用的是同一个底层模型
- 注:这种配置本质上仅限于像 Qwen3 这样支持切换思考模式的模型家族,其他的模型并不支持(其实已经不能算是同一个模型了)
- 差异二:训练 Token 差异
- (为了训练效率)OPSD 并不在整个学生 Response 上进行训练
- OPSD 只关注一个前缀(默认为 1024 个 Token)
- 注:OPSD 中(附录 B 中),不是只关注 1024 的前缀,而是在生成时就特意只生成了 1024 个
- 理解:传统的 RL 中不能这样做(这是 OPD 专有的优点)
- 在 OPD 场景中,不需要 Rollout 结束就可以有奖励(来源于 Teacher)
- 在传统 RL 场景,一般是需要 Rollout 结束才能得到 Reward 反馈的
- 理解:传统的 RL 中不能这样做(这是 OPD 专有的优点)
- 本文使用的 SDPO 则是所有 Response 上都训练的
- (为了训练效率)OPSD 并不在整个学生 Response 上进行训练
- 差异三:微调方式
- 本文 SDPO:基于
verl(2024) 执行全量微调 - OPSD:使用基于
trl(2020) 的 LoRA 微调
- 本文 SDPO:基于
- 差异四:其他超参数差异
- 本文 SDPO:Batch Size 256,学习率 1e-5
- OPSD:Batch Size 32,学习率 1e-6
- OPSD 有更高的训练效率(BS 更小),但每一步的参数更新更小
- 注:学习率本该是全量微调上更小的,这里更多是与 BS 有关
- 图 12: Qwen3-1.7B 中 OPSD 混合蒸馏与本文同质 Chat Template 设置的训练动态
- (a) 在混合(Hybrid)设置下
- 启用思考的教师最初提高了学生性能,但随着时间的推移收益发生逆转
- 同质设置显示出持续下降的趋势
- (b) 同质(Homogeneous)设置中的 Response 长度和 Epistemic Token 使用情况
- (a) 在混合(Hybrid)设置下
- 在 Qwen3-1.7B 的混合设置和前缀学习下,如图 12a(橙色线)所示
- 观察到一个有趣的训练动态:
- 在早期阶段,启用思考的教师驱动学生生成更长的 Response,并提高了性能,展示了混合蒸馏在训练早期的有效性
- 但随着训练的进行,Response 长度逐渐减少,同时伴随着性能的相应下降
- 在本文的同质设置(如图 12b 所示,学生和教师都启用了思考模式)下,性能持续下降
- Response 长度和 Epistemic Token 计数也稳步下降,这与本文之前的分析一致
- 观察到一个有趣的训练动态:
- 问题遗留:
- 这种针对 Qwen3 系列的混合蒸馏设置代表了一个有趣的研究方向,具有其独特的训练动态
- 例如,为什么性能会先提升后下降,以及这是否源于推理行为的变化或 Chat Template 的不匹配
- 深入探究这个现象超出了本工作的范围,留待未来探索
- 这种针对 Qwen3 系列的混合蒸馏设置代表了一个有趣的研究方向,具有其独特的训练动态
附录 D:More On-Policy Self-Distillation Results
D.1 Qwen3-8B (Thinking Mode: OFF)
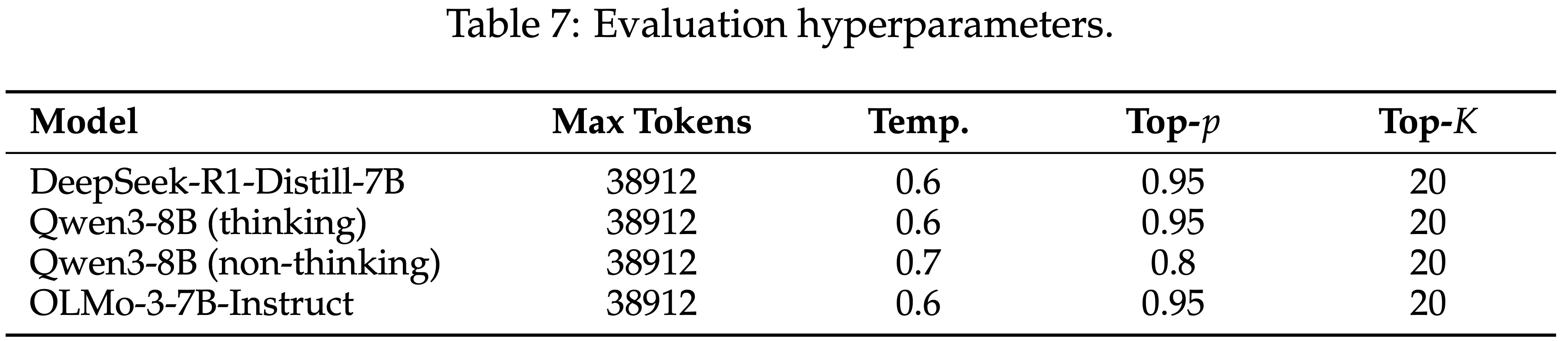
- 作为第 5.3 节图 5 的扩展,本节额外比较了 AMC23 的评估分数和 AIME24 上 Epistemic Token 使用量的变化
- 如图 13 所示
- GRPO 显著增加了 Response 长度,并在两个基准测试上都带来了显著的性能提升
- SDPO 表现出不同的趋势:
- 在 AMC23 上,
acc@16从 0.67 增加到 0.73,同时 Response 长度减少约一半 - 在 AIME24 上,
acc@16从 0.25 略微下降到 0.23,pass@16下降更显著
- 在 AMC23 上,
- 在 AMC23 上,SDPO 以更短的 Response 实现了约 6 个百分点的提升,而 GRPO 则以更长的 Response 为代价获得了约 36 个百分点的更大提升
- 在保持合理 Response 长度的同时实现大的性能提升仍然是一个开放的挑战
- 在保持合理 Response 长度的同时实现大的性能提升仍然是一个开放的挑战
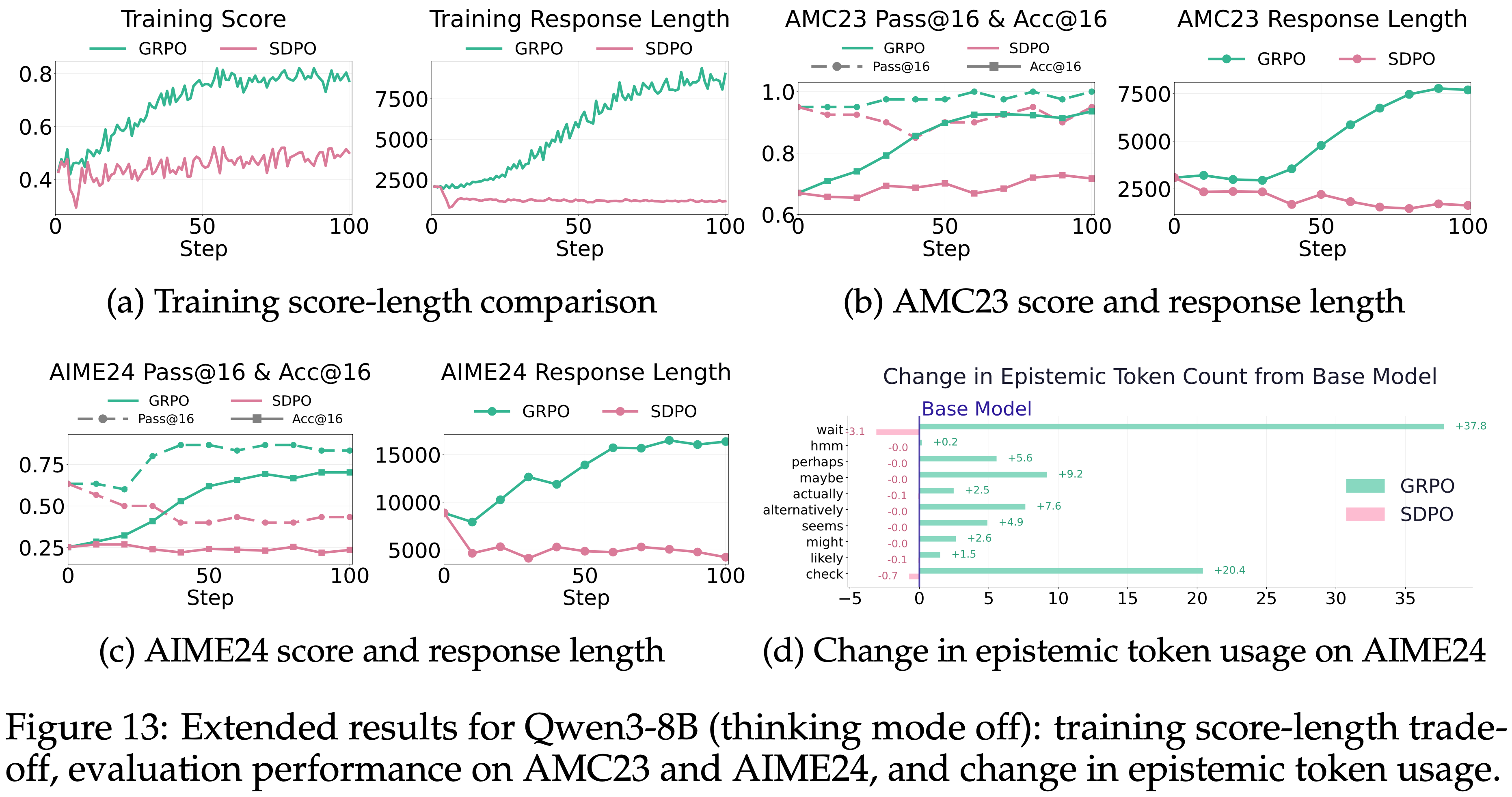
D.2 Olmo-3-7B-Instruct
- 除了 DeepSeek-R1-Distill-Qwen-7B 和 Qwen3-8B,本文进一步在另一个模型家族 OLMo-3-7B-Instruct 上评估了 On-Policy Self-Distillation
- 如图 14 所示,与本文之前的分析一致,SDPO 也降低该模型上的推理性能,OOD 评估分数降至基础模型之下
- 证实了作者的发现并非模型依赖的,反映了跨不同模型家族的推理行为的稳健特征
- 证实了作者的发现并非模型依赖的,反映了跨不同模型家族的推理行为的稳健特征
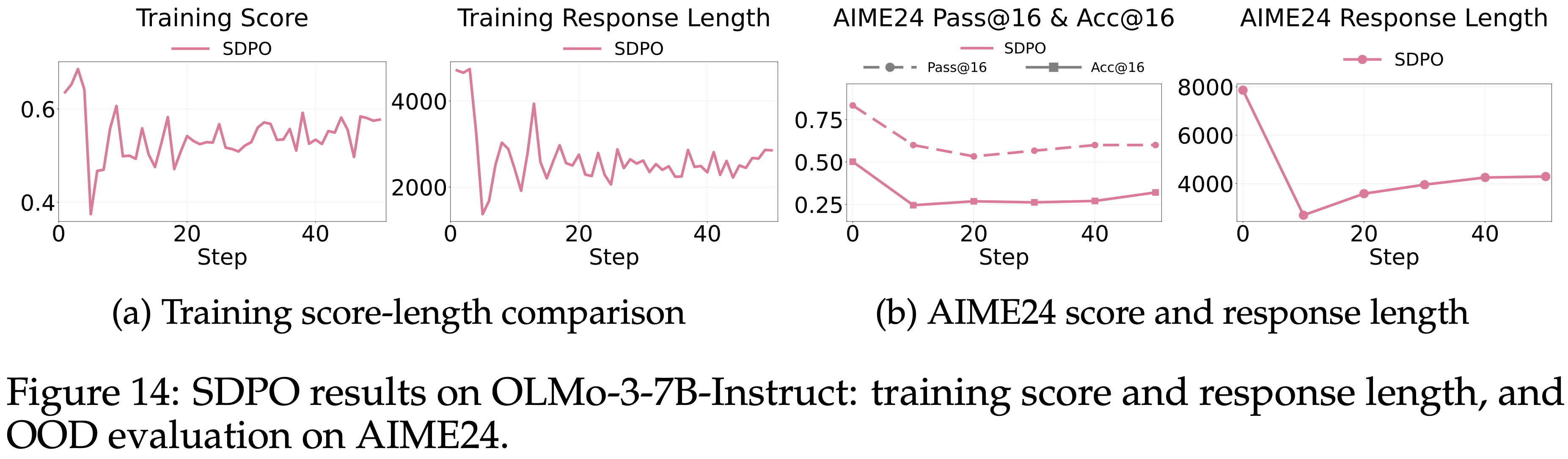
D.3 Pass@16 Score
- 除了图 3b、3c、4b 和 4c 中显示的 DeepSeek-Distill-7B 和 Qwen3-8B(thinking mode enabled)的
acc@16分数外- 本文还在图 15 中报告了
pass@16分数
- 本文还在图 15 中报告了
- GRPO 和 SDPO 在
pass@16上的差距:- DeepSeek-Distill-7B 大于 Qwen3-8B
- 并且在更难的基准测试(AIME24)上比 AMC23 上更为明显
- 问题:如何理解 GRPO 和 SDPO 在
pass@16上的差距,DeepSeek-Distill-7B 大于 Qwen3-8B 这件事情?- 简单理解:
- 模型方面,一个理解是 DeepSeek-Distill-7B 的不确定性更低一些,长度更短一些,受 SDPO 的影响也更小?
- 难度方面,一方面是越难的题目可能对 Epistemic Token 的数量要求就更高些,另一方面也可能更多是 OOD 导致的?
- 简单理解:
附录 E:More Ablation Study
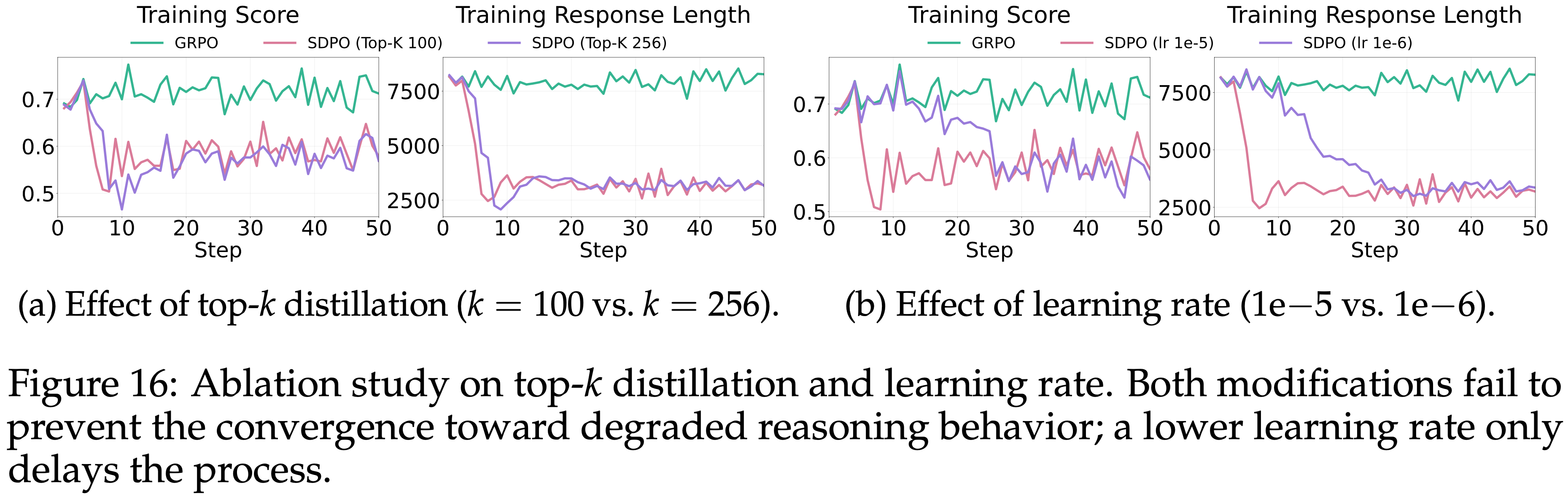
- 为了检查各种训练超参数对 Self-Distillation 行为的影响,本文通过改变 top-\(k\) 蒸馏参数和学习率进行了额外的实验
- 问题:这里的 top-\(k\) 参数是什么?
- 如图 16a 所示
- 将 top-\(k\) 从 100 增加到 256 在训练动态或最终性能上没有产生显著差异
- 如图 16b 所示
- 将学习率从 1e-5 降低到 1e-6 仅仅是减缓了性能下降的速度
- 模型最终收敛到相同的推理行为

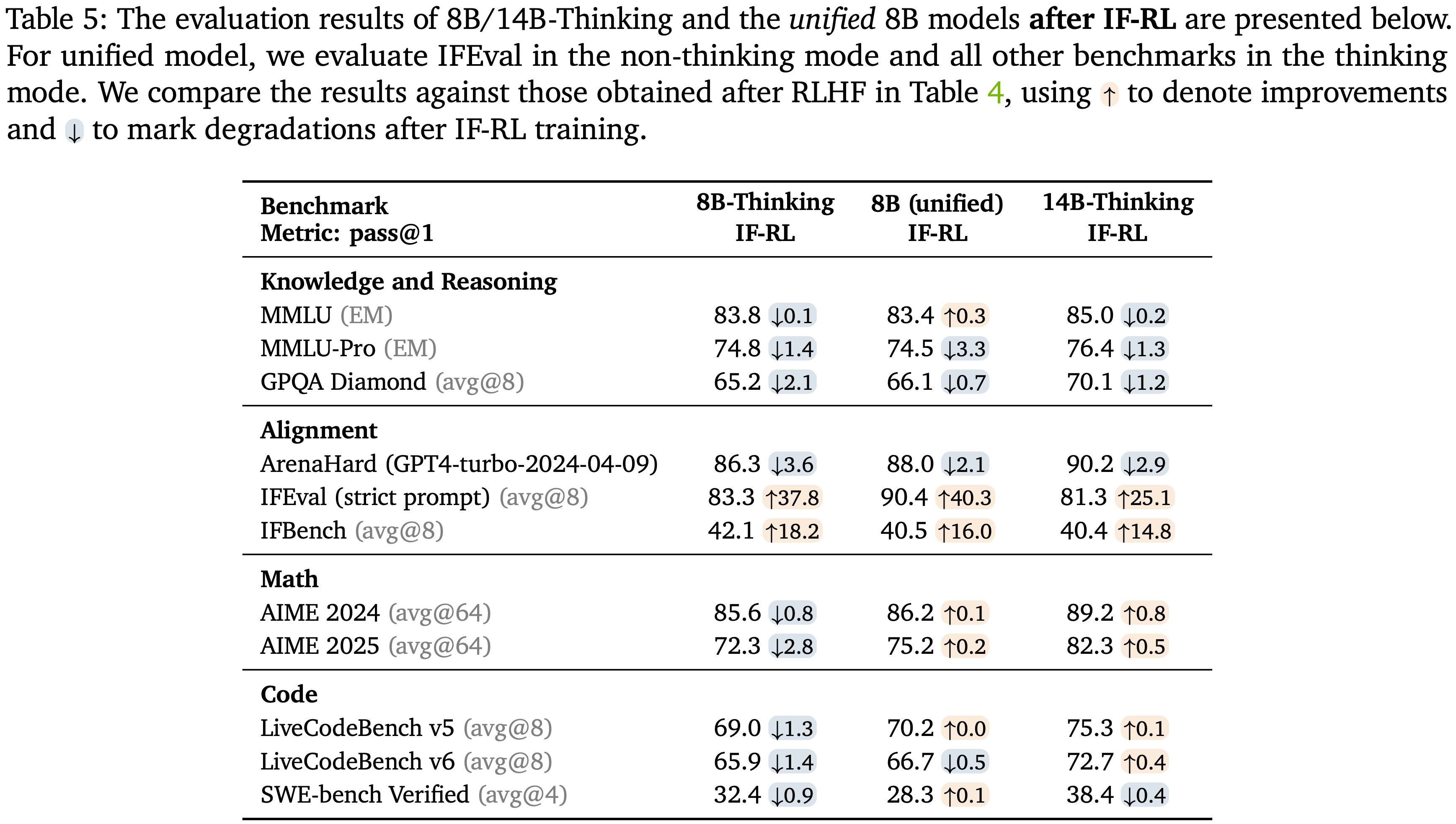
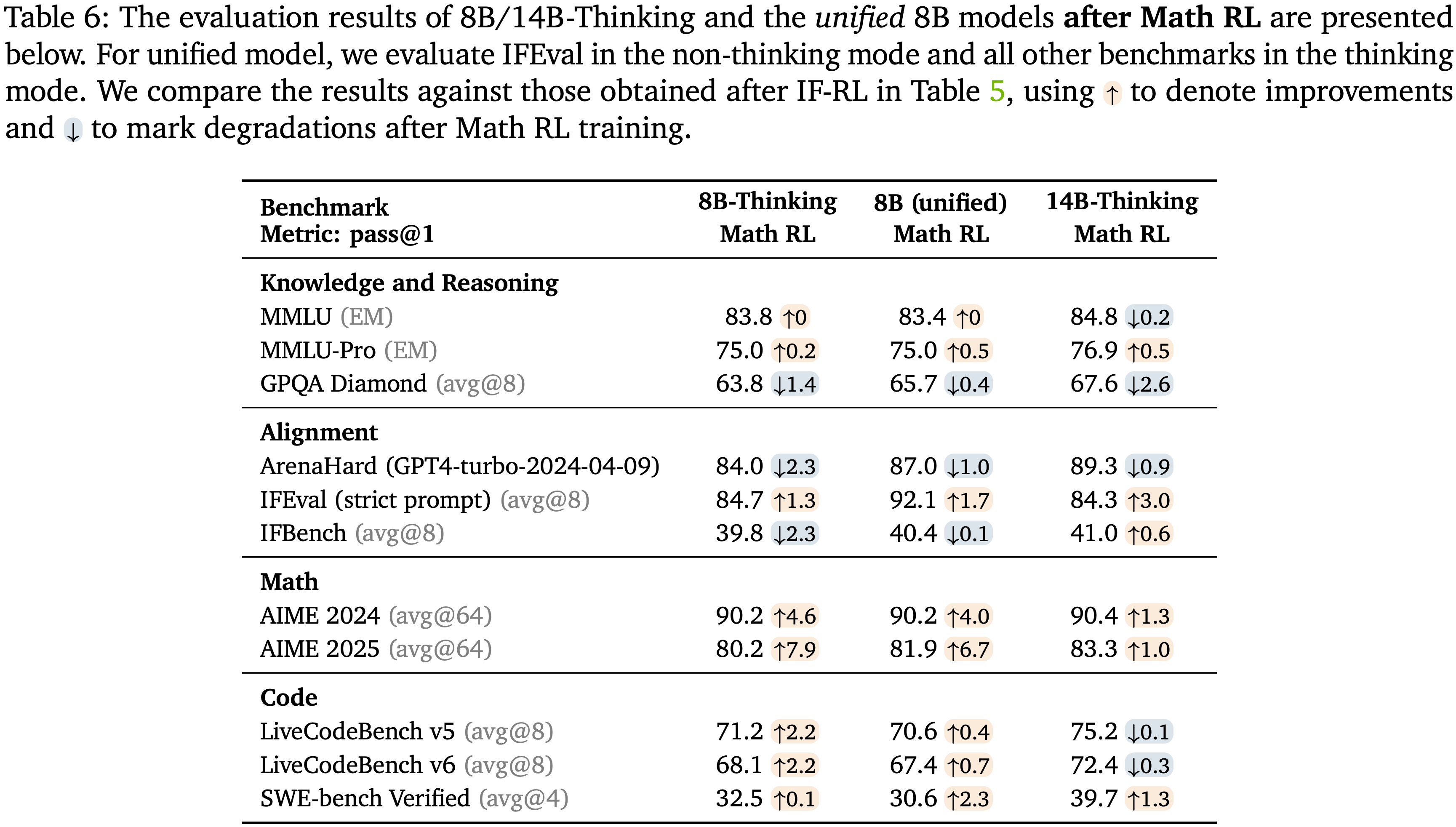
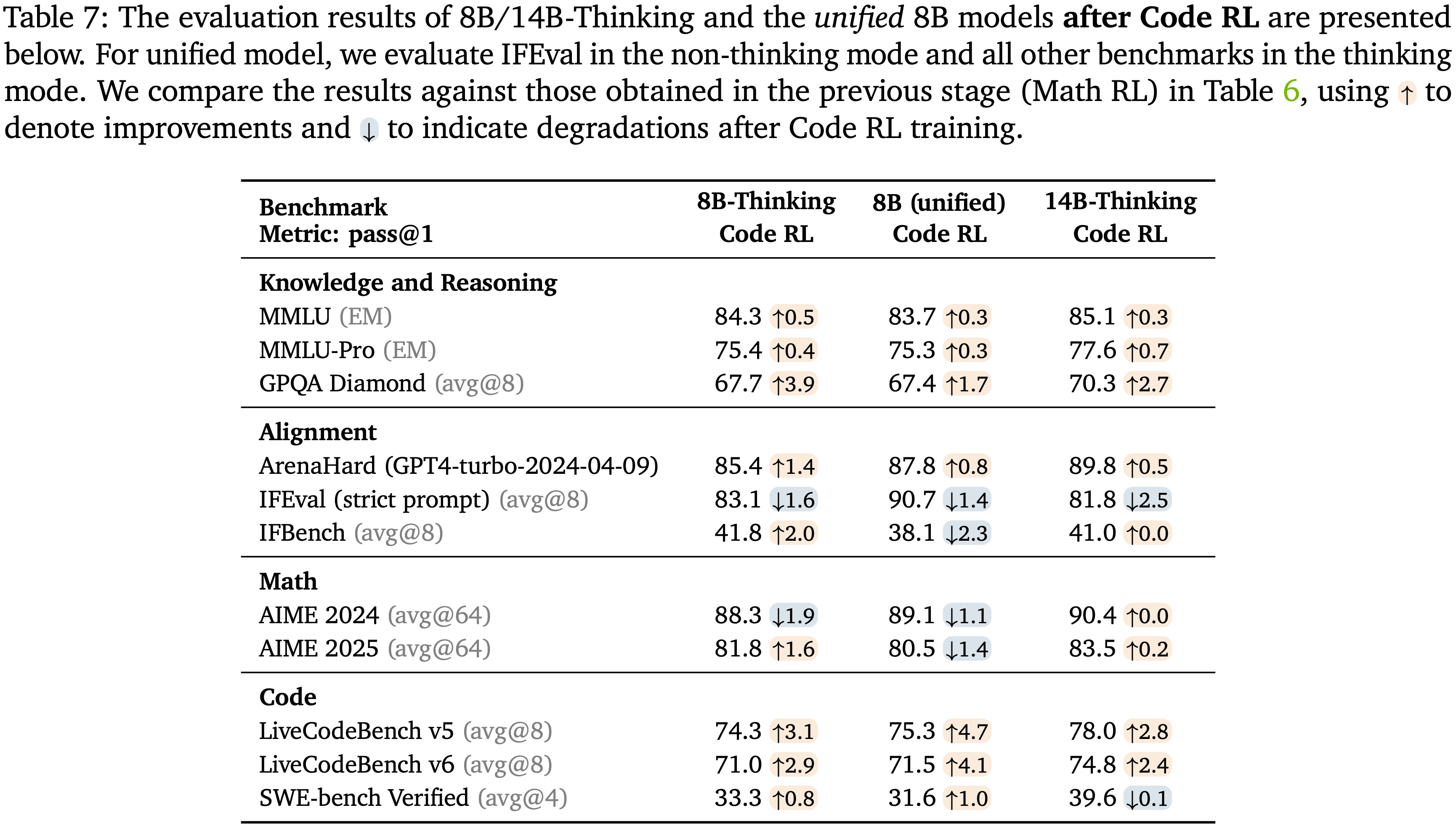
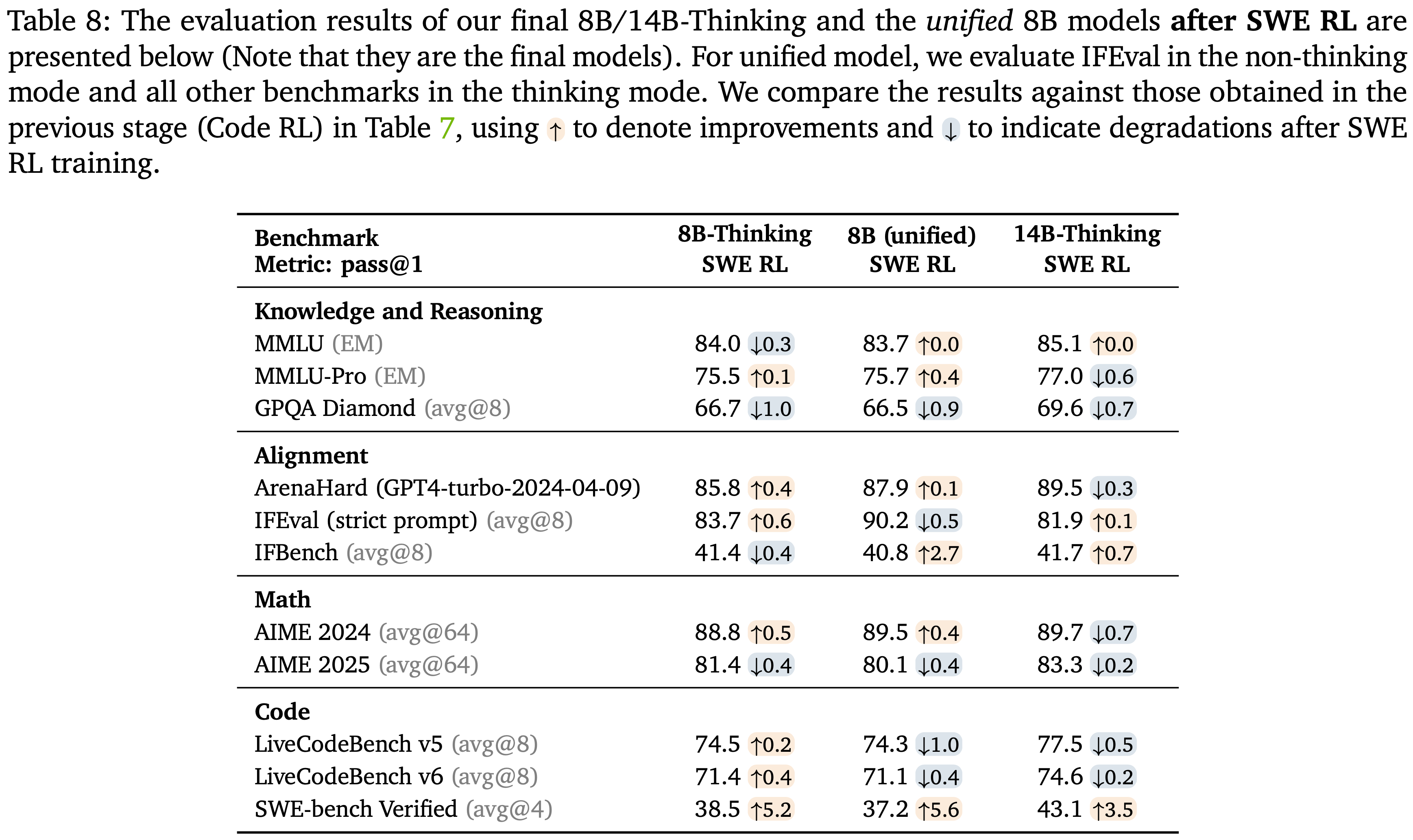







;reward clipping(2);token-level dynamic sampling(3);多阶段训练(4)")



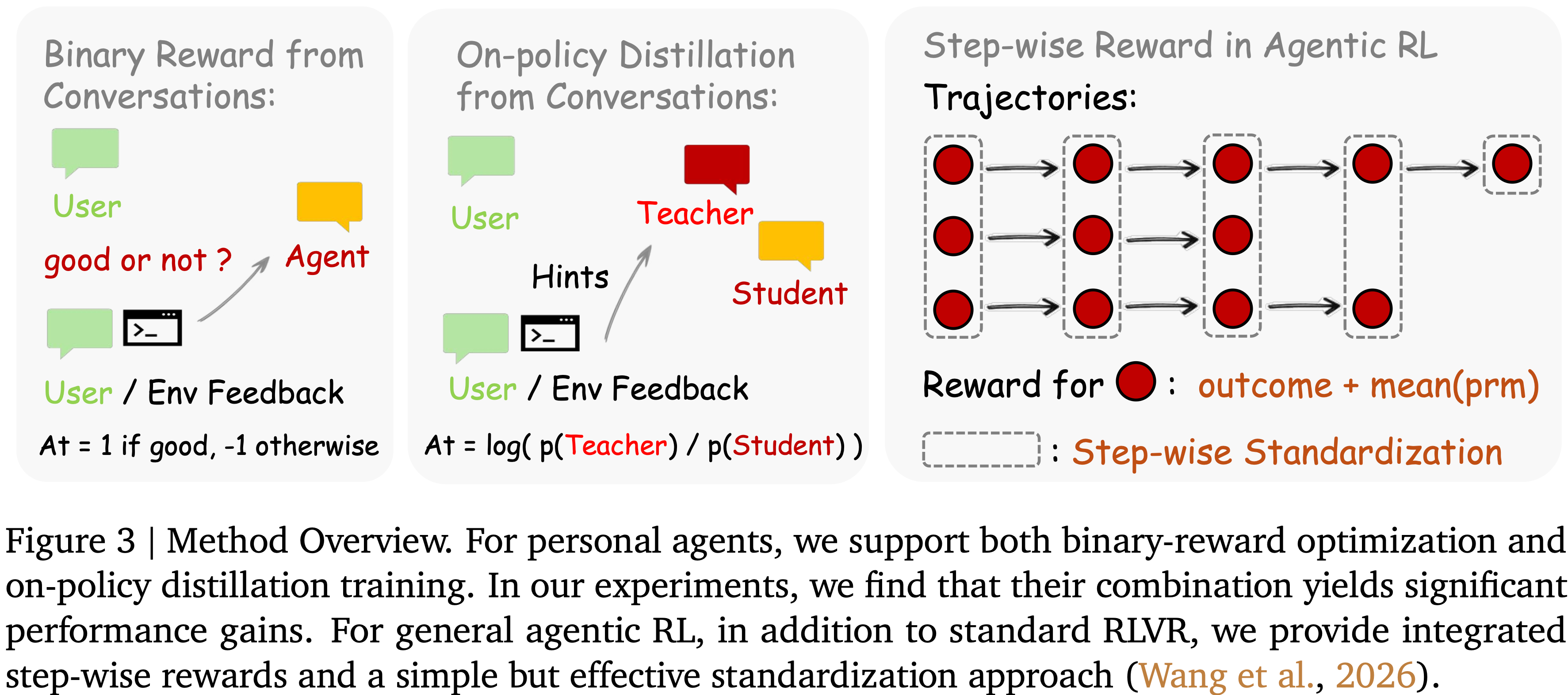
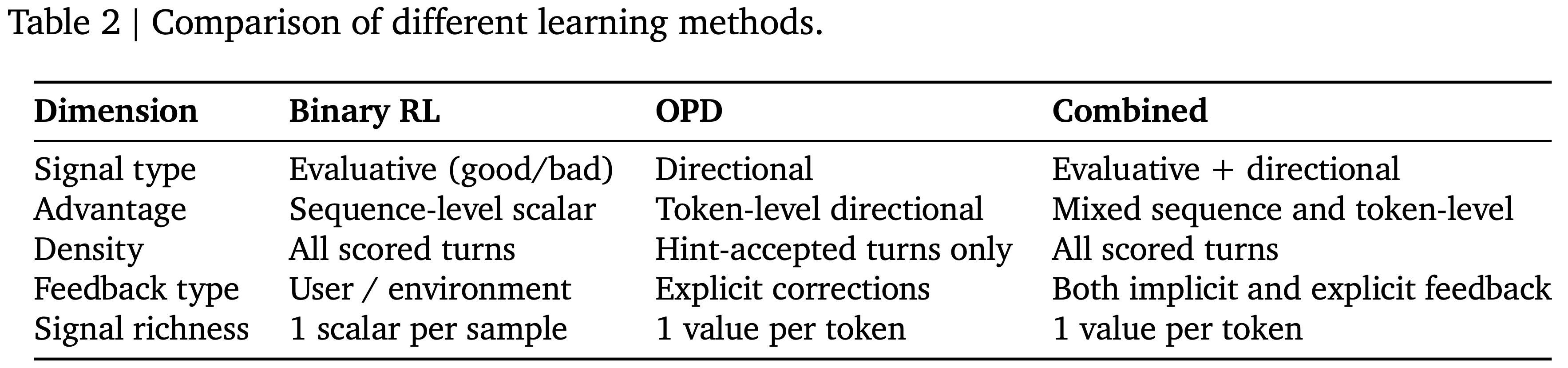
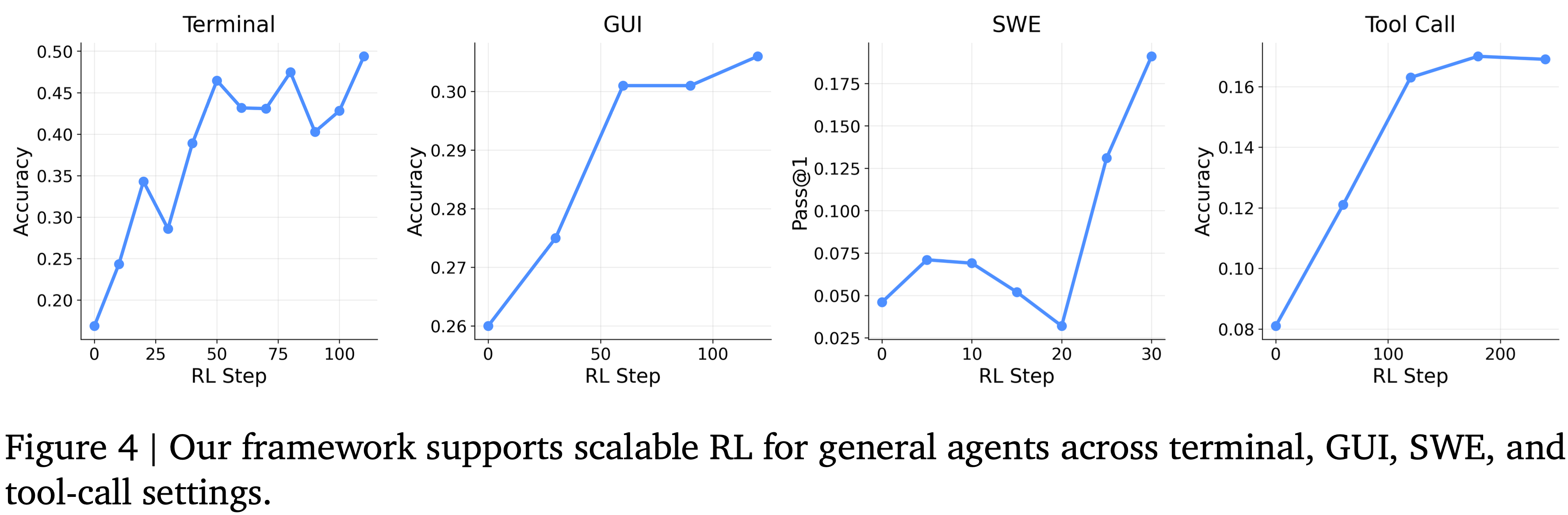


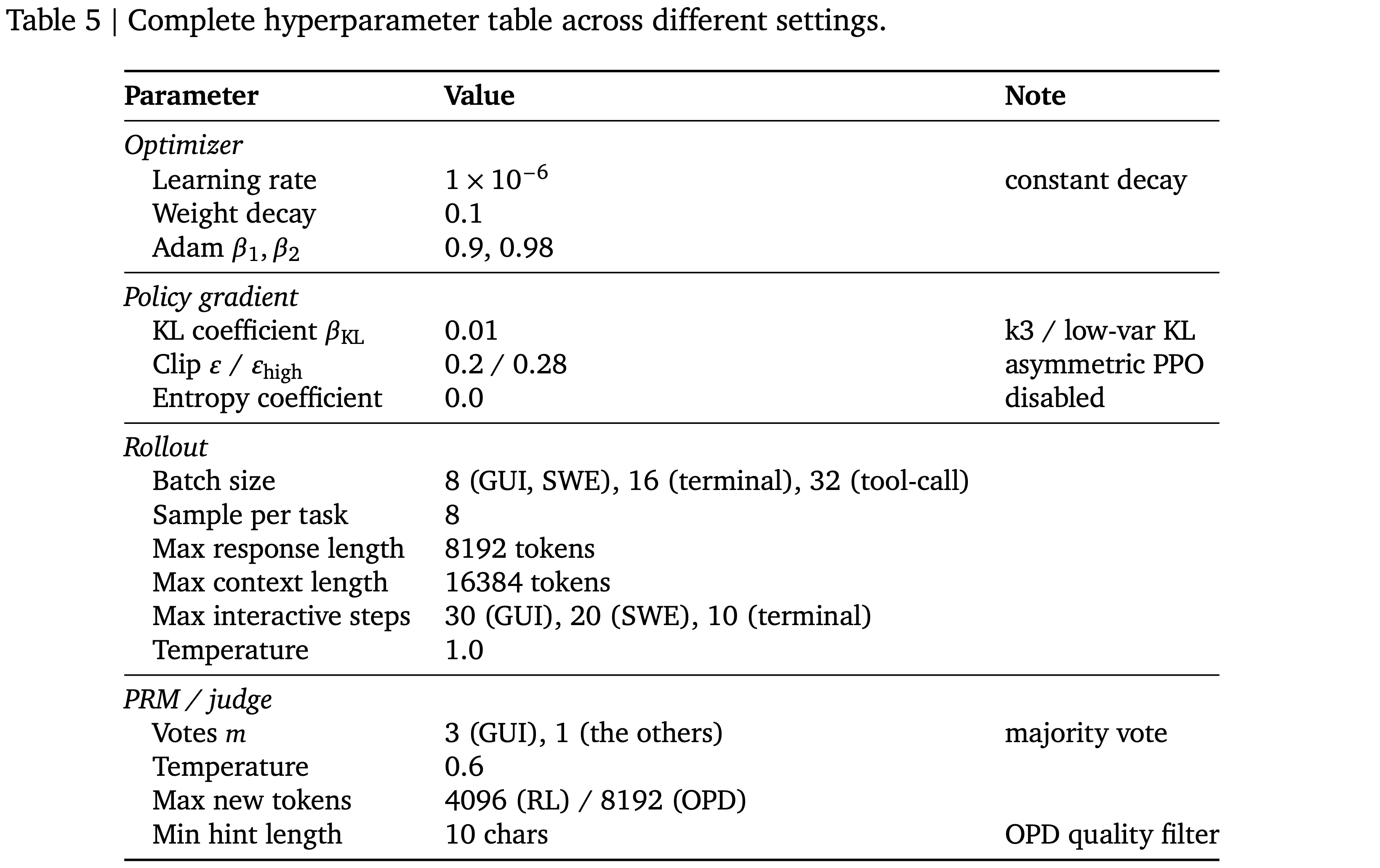






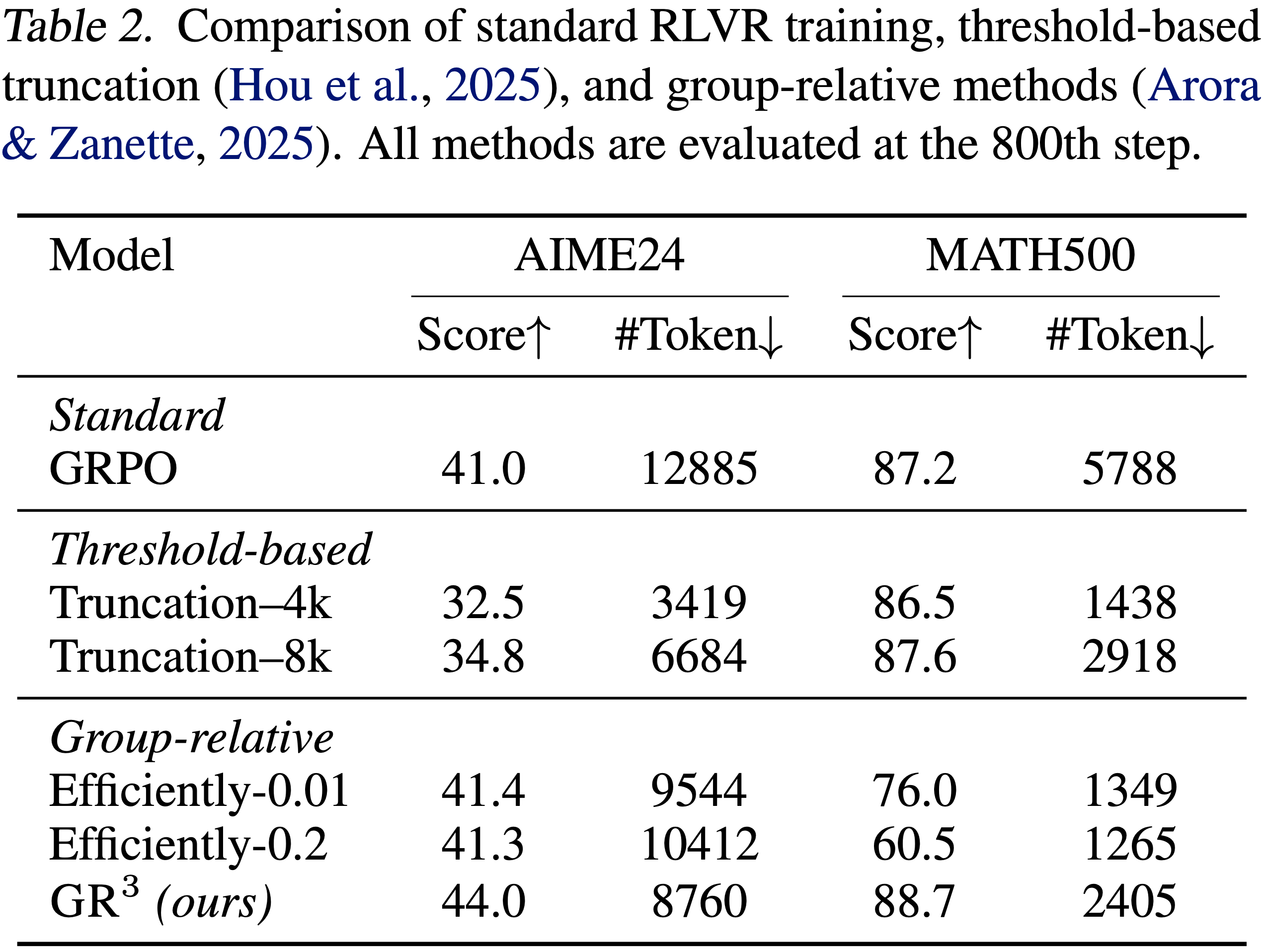
")