本文主要介绍LLaMA-Factory项目训练和微调大模型的笔记
- 参考链接:
数据集准备
LLaMA-Factory 支持两种格式的文件,分别是 Alpaca 格式和 ShareGPT 格式
Alpaca示例(名称来源:alpaca是“羊驼”,llama是“大羊驼”)
1
2
3
4
5
6
7
8
9
10
11
12[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]ShareGPT示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16[
{
"id": "对话ID", // 可选
"conversations": [
{
"from": "human",
"value": "用户消息"
},
{
"from": "gpt",
"value": "助手回复"
},
// 后续交替对话...
]
}
]
最佳实践:参照示例增加自定义数据集
参照
data/文件夹下的其他.json文件,准备自己的数据集,存储格式为json,命名为diy_train_data_name.json在
data/dataset_info.json文件中增加一个dict对象,示例如下:1
2
3
4
5
6
7
8
9
10
11"diy_train_data_name": {
"file_name": "your_data_name.json",
"file_sha1": "xxx", // 可选
"columns": {
"prompt": "prompt_key",
"query": "input_key", // 可选
"response": "output_key/response_key",
"system": "system_key", // 可选
"history": "history_key" // 可选
}
}- 其中
file_sha1是文件的SHA1码,生成方式可参考生成、查看文件的MD5、SHA1、SHA2、SHA3值 | 文件的哈希(hash)值生成- 这个码随便写好像也能保证数据集在网页版中被加载和看到,但是错误的SHA1码是否能正常训练未测试【TODO】
- 其中
命令行微调
- 修改指定文档中的
.yaml文件 - 按照 README.md 文档执行命令
网页版LLaMA微调简单流程
启动web_ui
- 启动web_ui的命令
1
2unset http_proxy https_proxy all_proxy # 关闭代理
python -m llmtuner.webui.interface
训练
- 从
base_path加载base模型到内存,变量命名为model- 如果要量化,记得配置量化选项,配置量化选项后可减少显存占用
- 定义PEFT配置
peft_config- 最常用的PEFT手段就是LoRA
- 基于
model和peft_config,生成peft_model - 生成数据集,并指定数据集对
peft_model进行微调训练 - 训练完成后,保存模型参数到指定peft模型路径
peft_path(这一步只会保存微调参数,不会保存base模型参数)
推理
- 从
base_path加载base模型到内存,变量命名为model- 这里要求与训练配置完全一致(包括量化选项等配置必须一致)
- 从
peft_path加载PEFT模型到内存- 这一步需要将
model和peft_path作为参数传入
- 这一步需要将
- 构造生成配置
generation_config,配置可参考NLP——LLM推理时的生成方式 - 调用
model.generate()函数- 传入
input信息和生成配置generation_config,得到Response
- 传入
附录:记一个从ckpt加载训练的错误
- 错误参考:LaMA-Factory/issues/7868:无法从中间checkpoint恢复SFT训练 #7868
- 解决方案:手动下载 transformers 源码重新安装
pip install . - 注意:由于重新安装后版本号依赖无法对齐了,直接执行运行和推理命令可能会报错,此时需要在命令前加上
DISABLE_VERSION_CHECK=1来跳过版本检查
附录:Qwen3 微调后不会输出停止 token
- 相关问题链接:LLaMA-Factory/issues/589:基于预训练后的模型进行指令微调,预测时停不下来 #589
Qwen-7B-Base 的分词器词表里没有 chatml 模板里的一些字符,所以会导致这种问题,因此应该避免使用 chatml 模板对 base 模型做微调。
- 最终解法:LLaMA-Factory/issues/7943:Qwen3 not stopping generation after lora finetuning #7943
Try setting the eos token in the tokenizer config to <|endoftext|> and using default template if you are fine-tuning base model using lora https://huggingface.co/Qwen/Qwen3-4B-Base/blob/main/tokenizer_config.json#L232
- 理解:Qwen3-Base模型中没有
<|im_end|>,训练时应该使用<|endoftext|>,但是Qwen3-Base模型的tokenizer_config.json中定义了"eos_token":"<|im_end|>"(而default 模板在原始模型定义了eos_token时是不会修改原始模型的eos_token的),所以,需要手动改成"eos_token":"<|endoftext|>"- 其他解法1:是修改 template 代码实现修改(比如基于
default写一个新的模版,配置replace_eos=True并使用stop_words=["<|endoftext|>"],此时会使用template的stop_words的第一个值赋值上去,用于主动修改替换值,但是改模型更合适 - 其他解法2:直接删除原始模型中的
eos_token字段应该也可行,此时模版会自动修改为<|endoftext|>(详情见template.py中的fix_special_tokens函数)
- 其他解法1:是修改 template 代码实现修改(比如基于
- 问题:为什么无法学习
<|im_end|>,使用 tokenizer 命名可以编码<|im_end|>啊!
- 理解:Qwen3-Base模型中没有
- 注:在使用 instruct 的 Qwen,模型时,直接使用 qwen 模板即可,不会出现上述问题
附录:Tokenizer的结束符号由什么确定?
- 一方面,模型的
tokenizer_config.json等文件会影响结束符号eos_token_id,另一方面,针对不同的template,Tokenizer 的结束符号还会被修改- 以 SFT 为例,该修改发生在
sft/workflow.py的get_template_and_fix_tokenizer函数中,对于配置了replace_eos=True的模板,会使用template的stop_words的第一个值赋值上去
- 以 SFT 为例,该修改发生在
附录:Qwen3 聊天模板的使用
- Qwen3-Base模型中无法识别
<|im_end|>token,如果需要使用模型自带的模板训练,需要将Qwen3-Base模型的tokenizer_config.json相关字段(chat_template和eos_token中的<|im_end|>替换为<|endoftext|> - 经过上述修改以后,可以使用模型的聊天模板进行对话
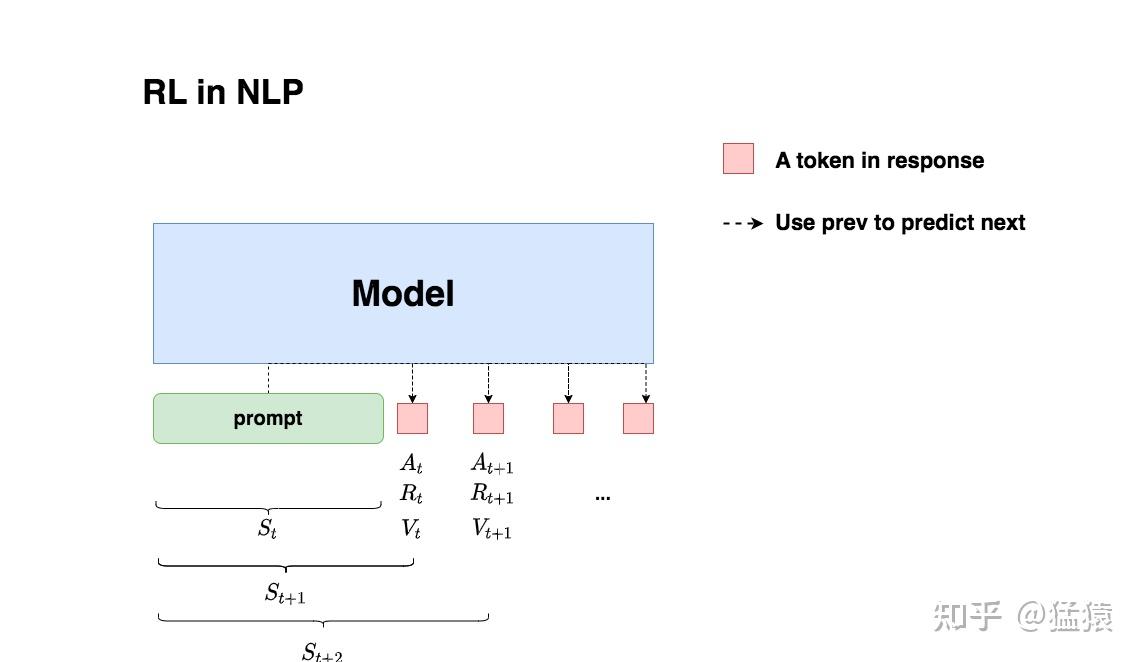
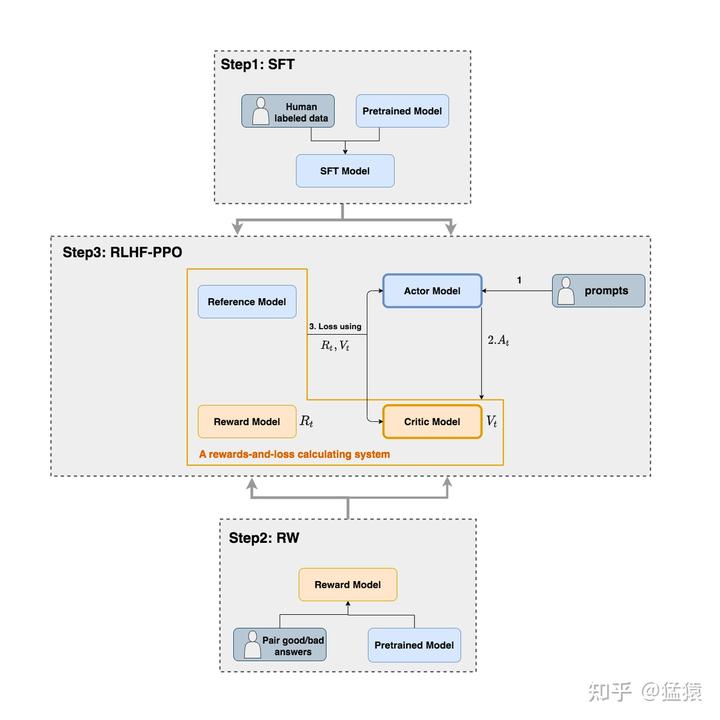
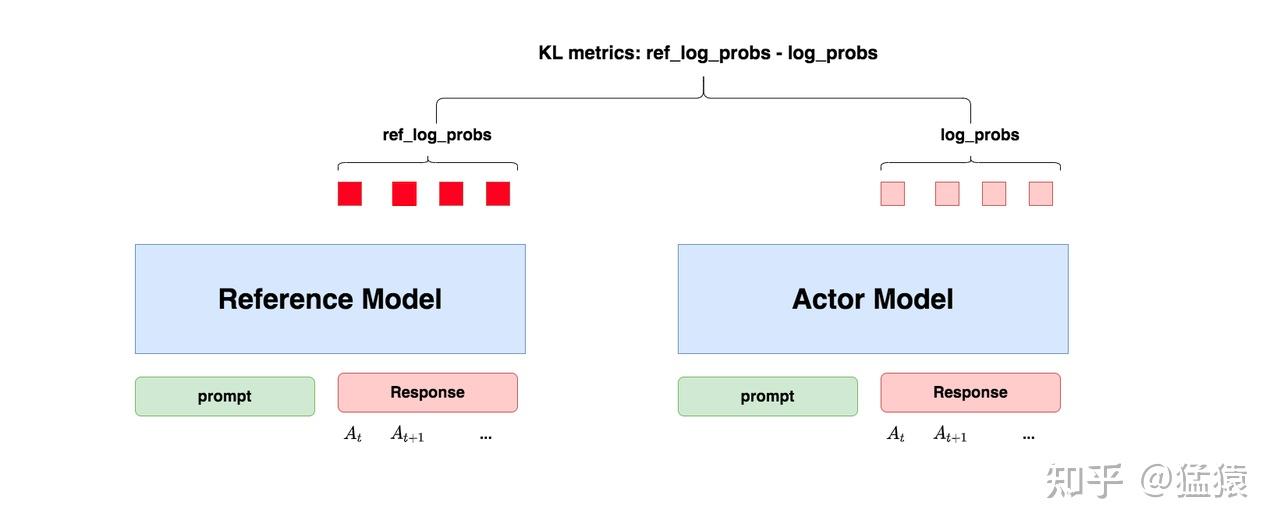
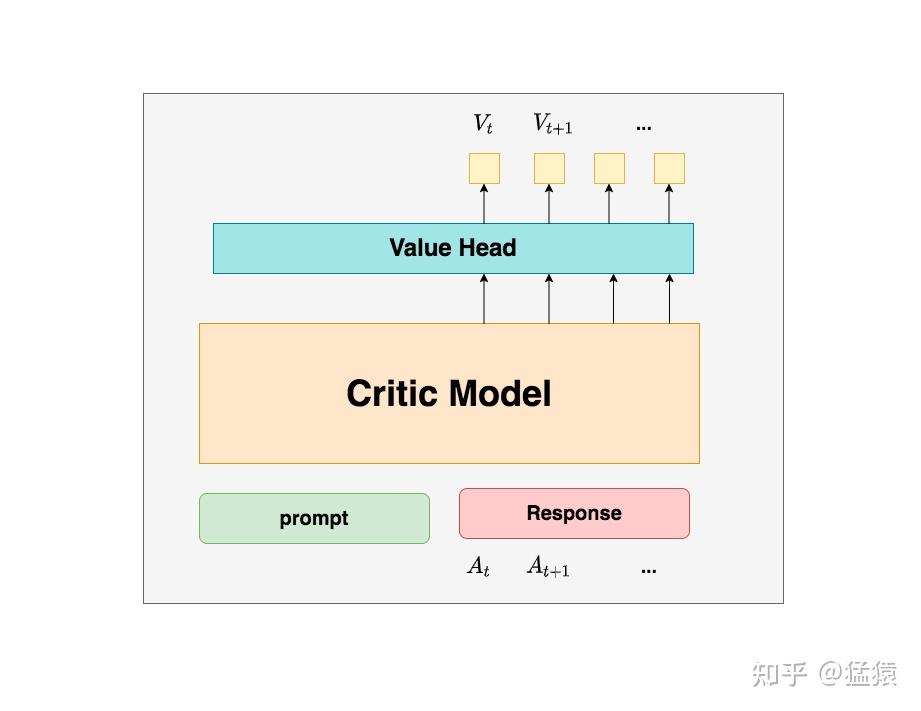
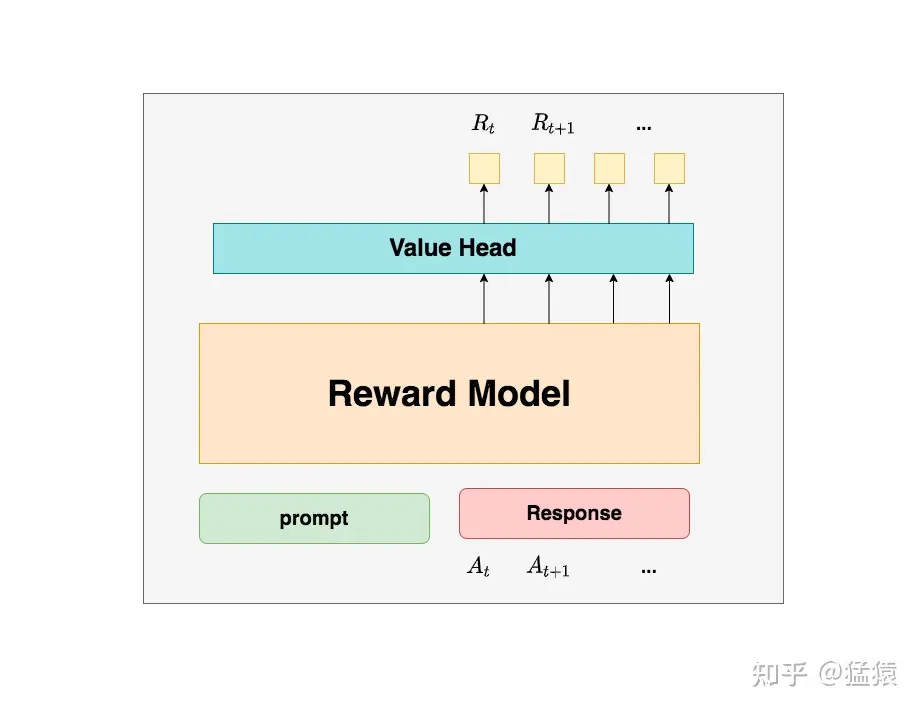
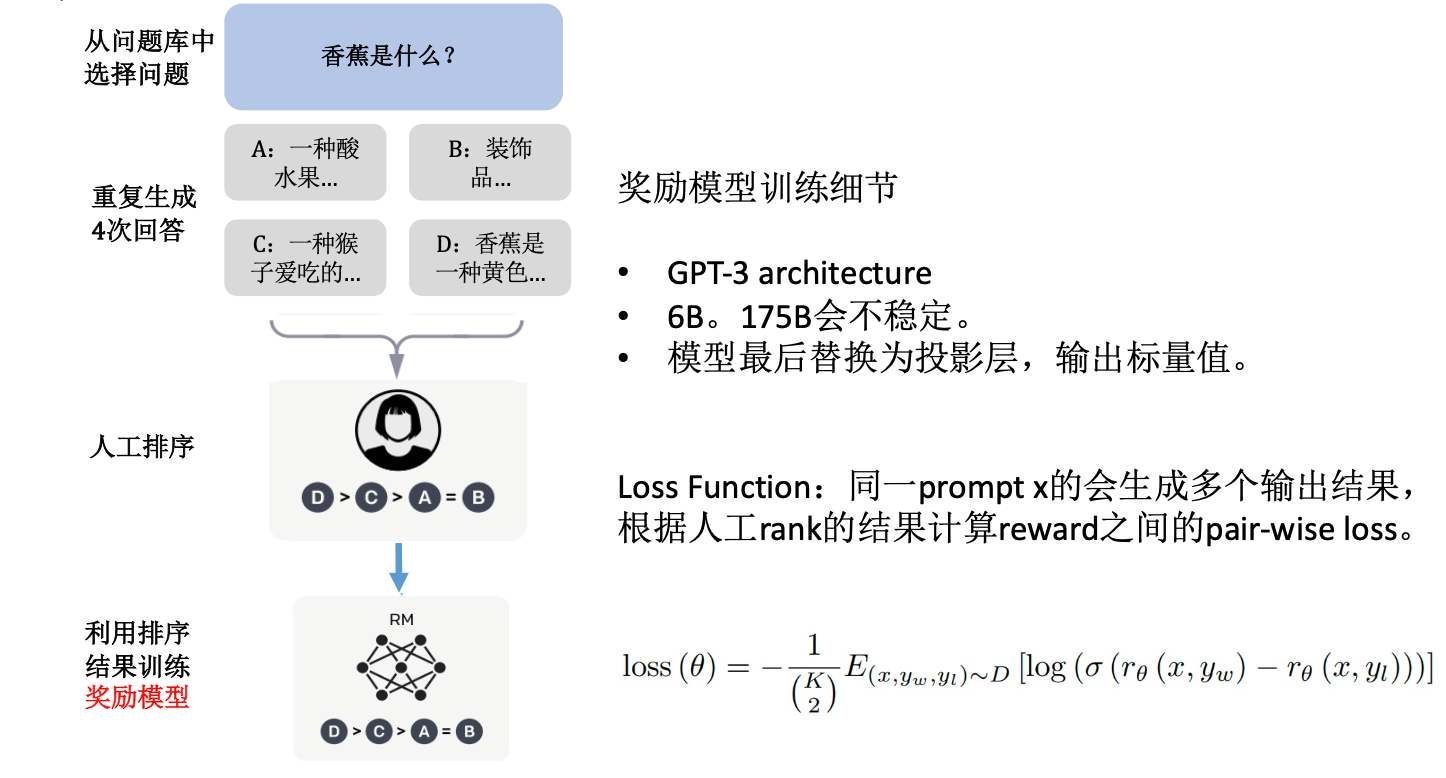
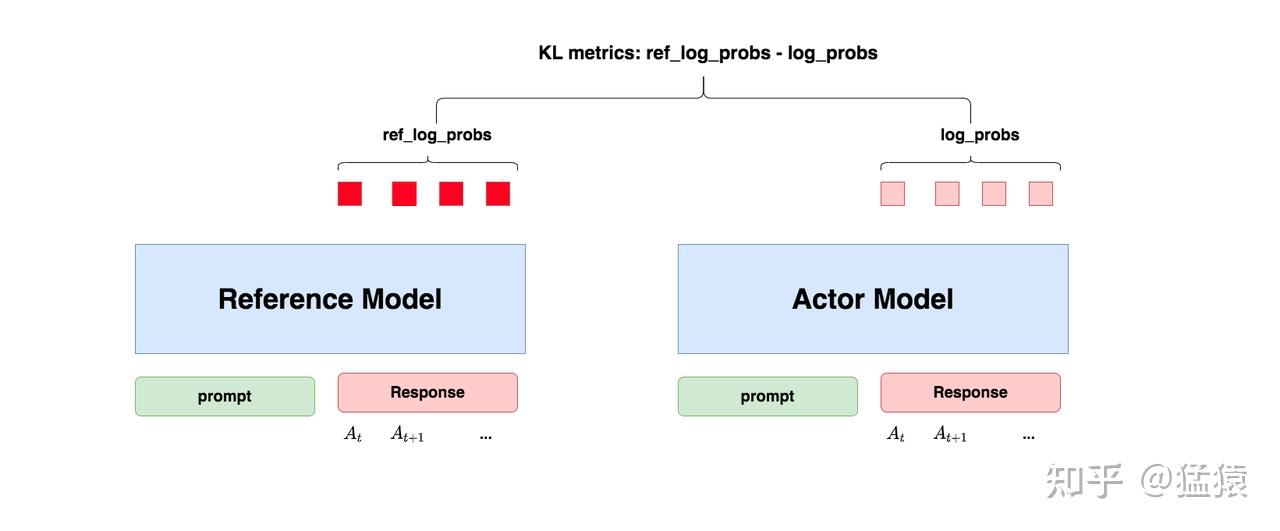

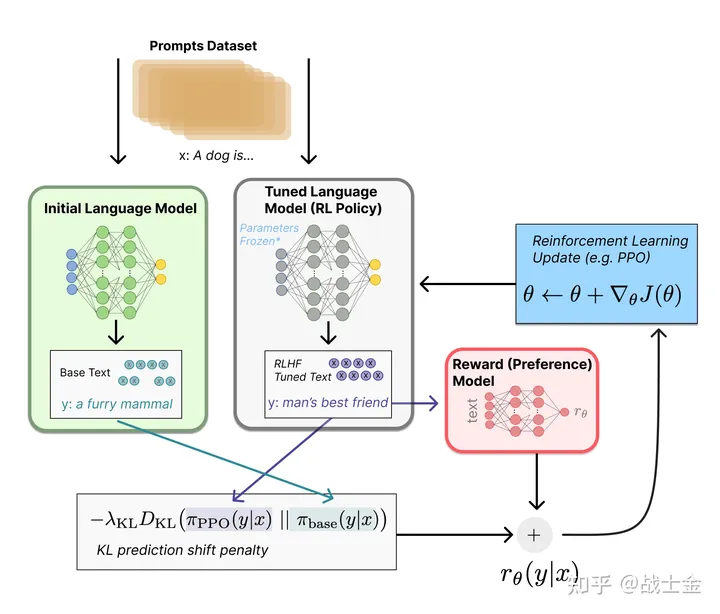
")
")
")





/Algorithm1.png)
/Figure2.png)
/Figure3.png)
/Figure4.png)
/Figure6.png)
/Figure7.png)
/Figure8.png)
/Figure9.png)
/Figure10.png)
/Figure11.png)
/Figure12.png)
/Figure13.png)
/Figure14.png)
/Figure15.png)
/Figure16.png)
/Figure17.png)
/Figure18.png)
/Figure19.png)
/Table4.png)