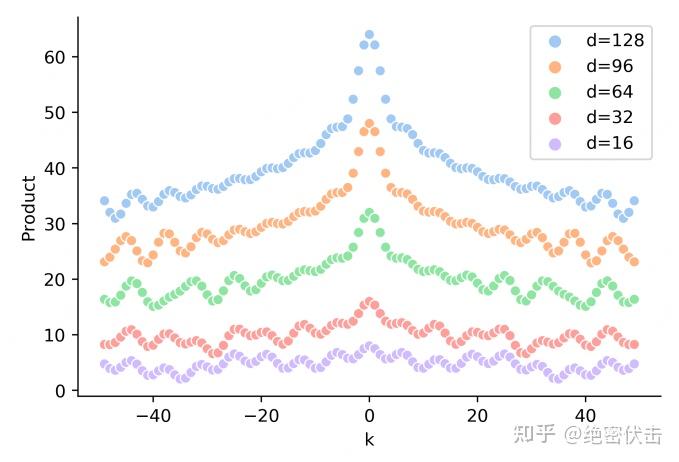
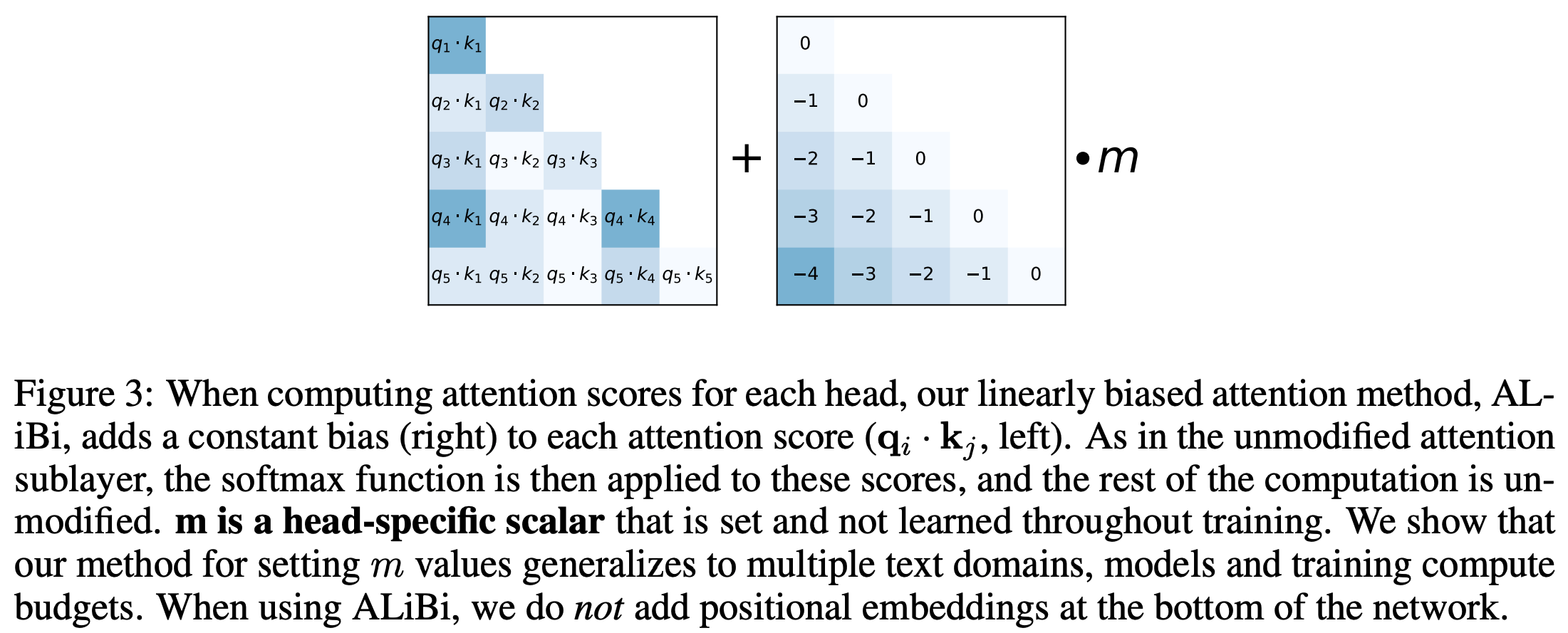
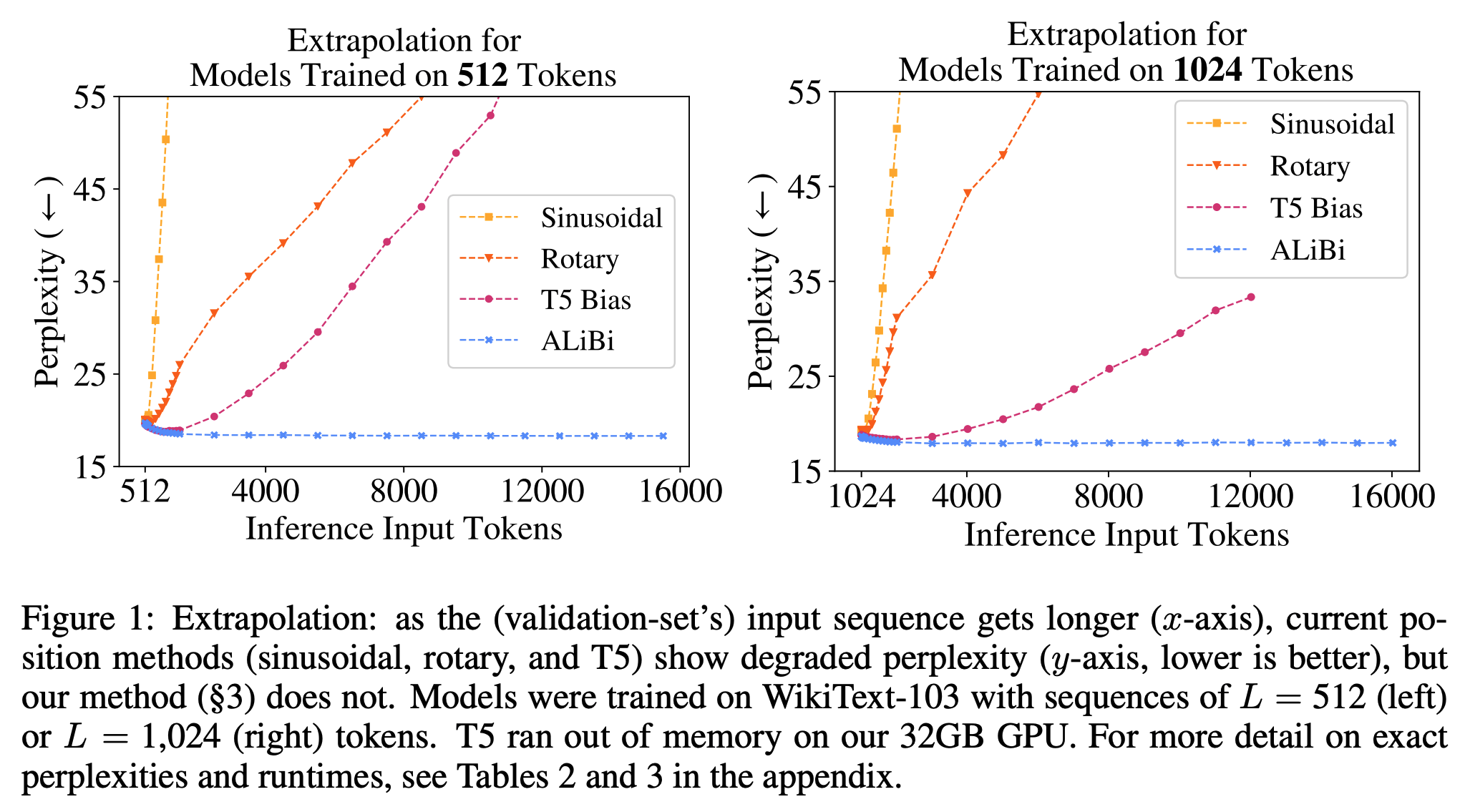
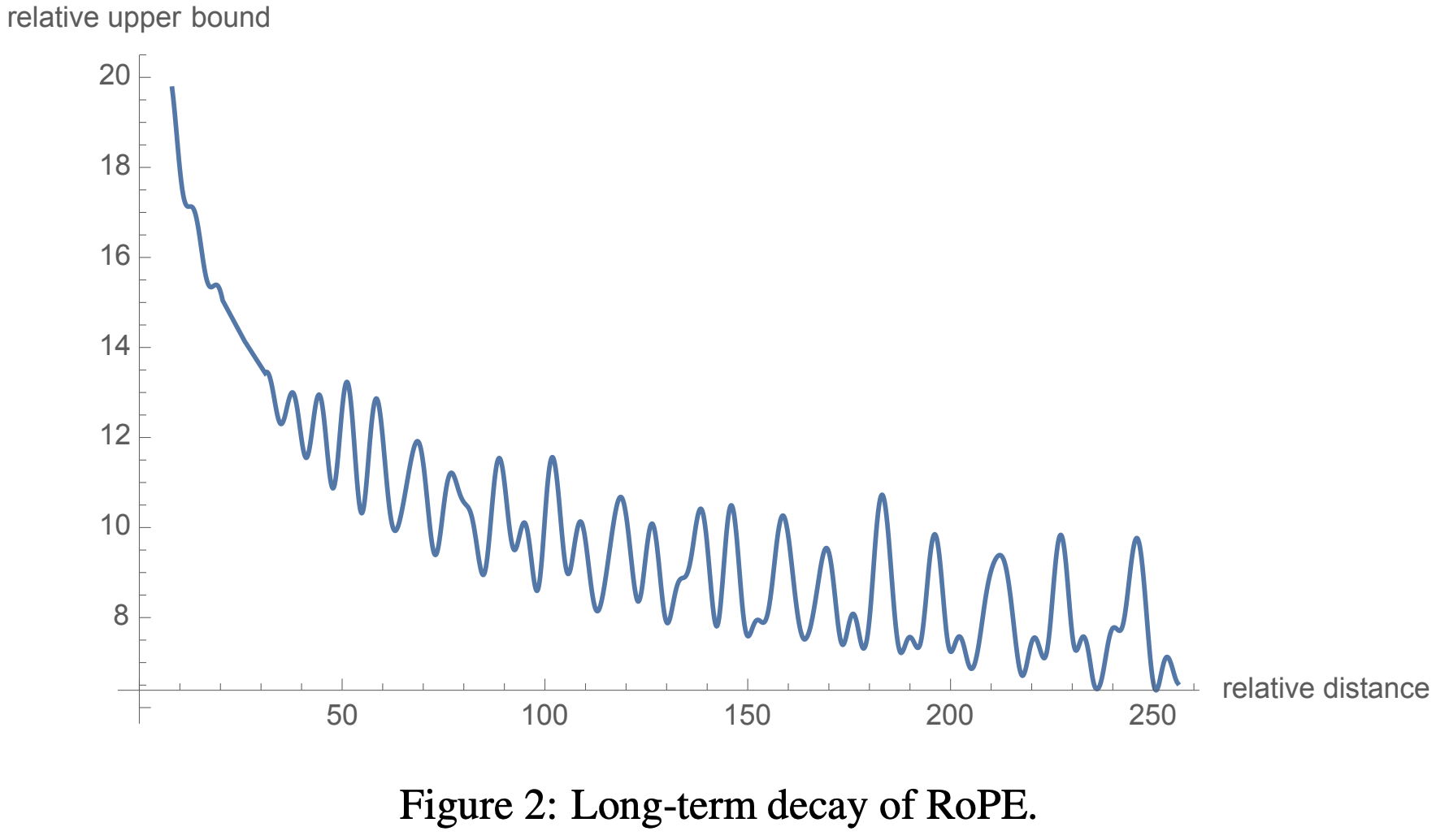
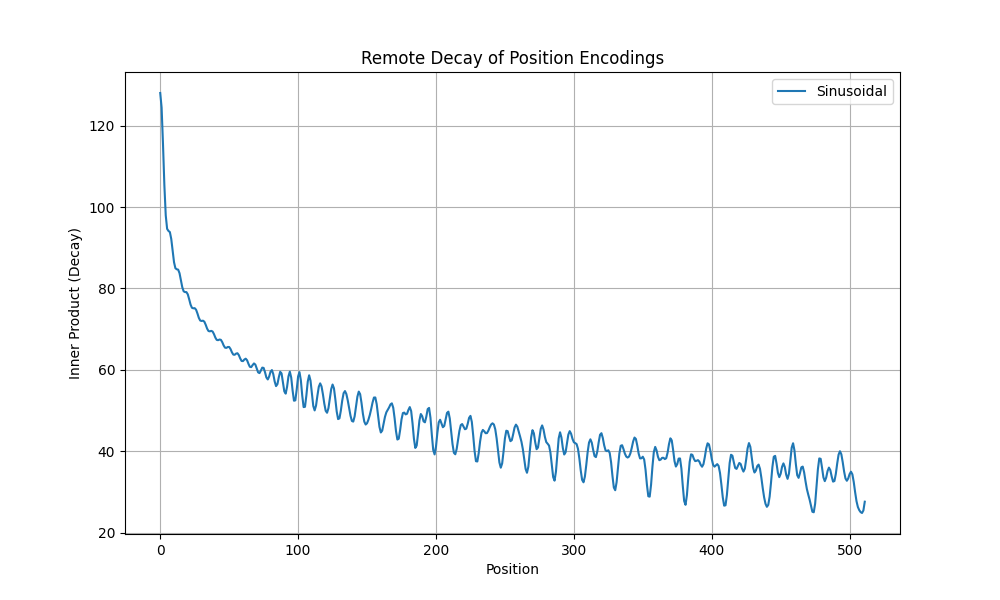
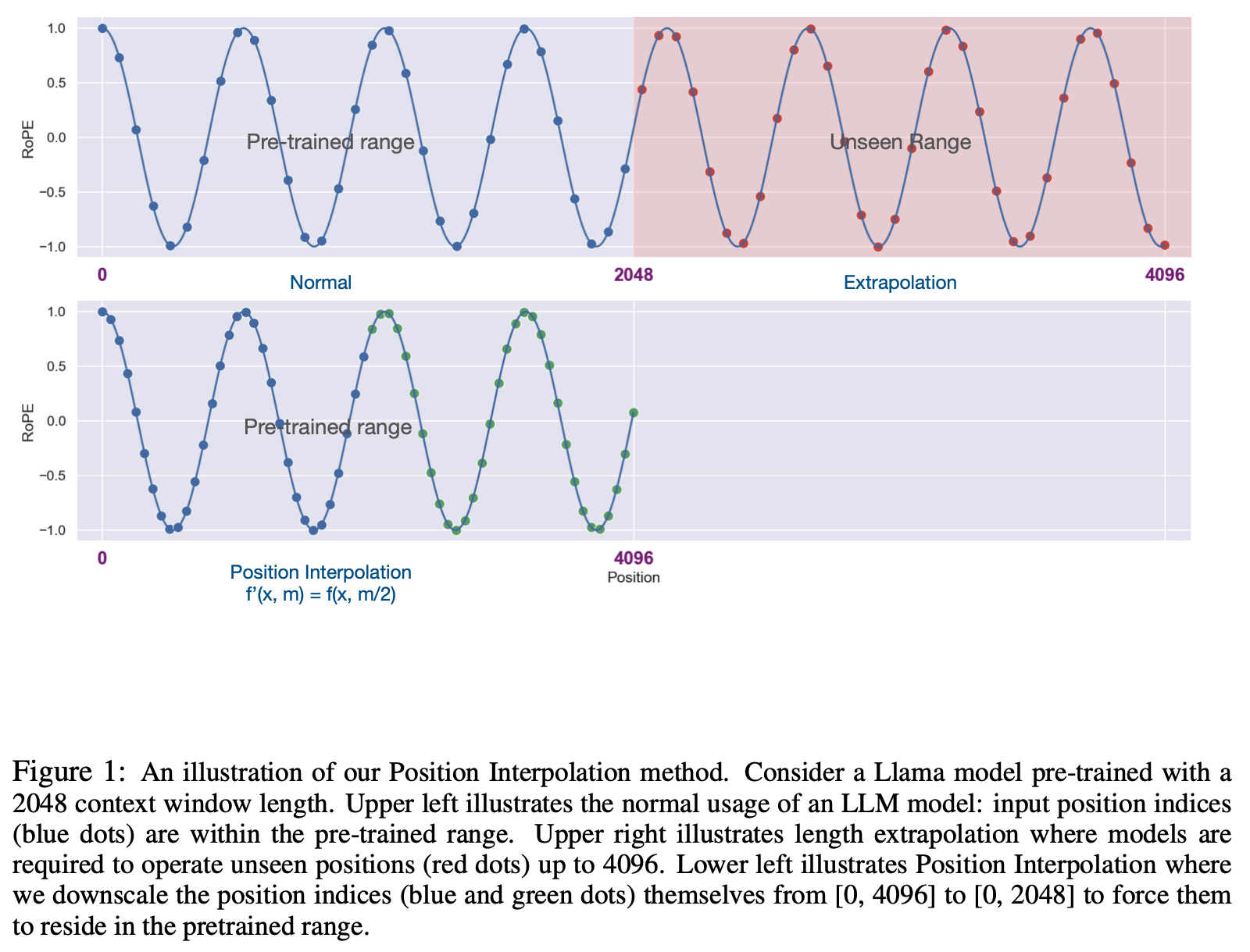
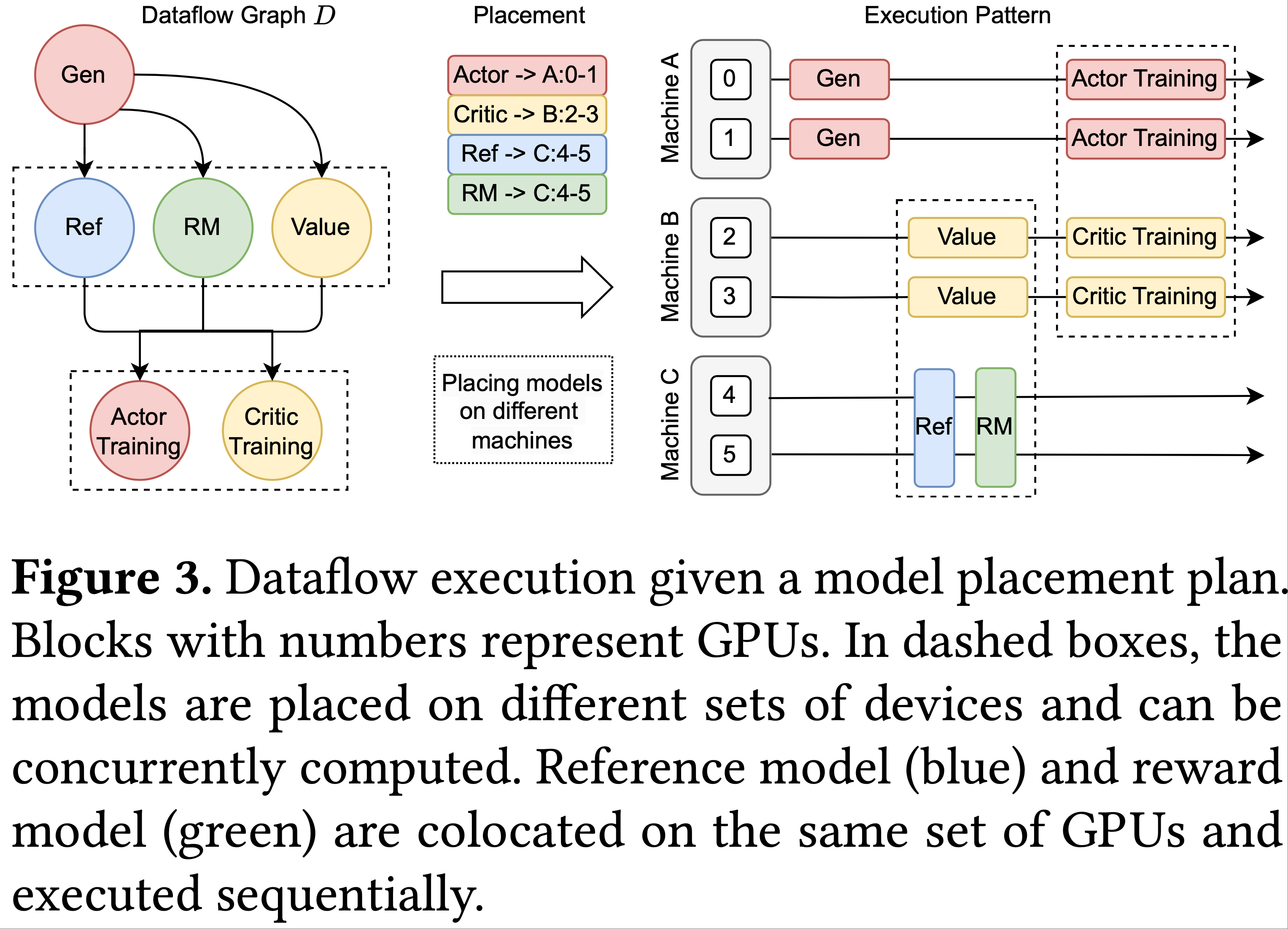
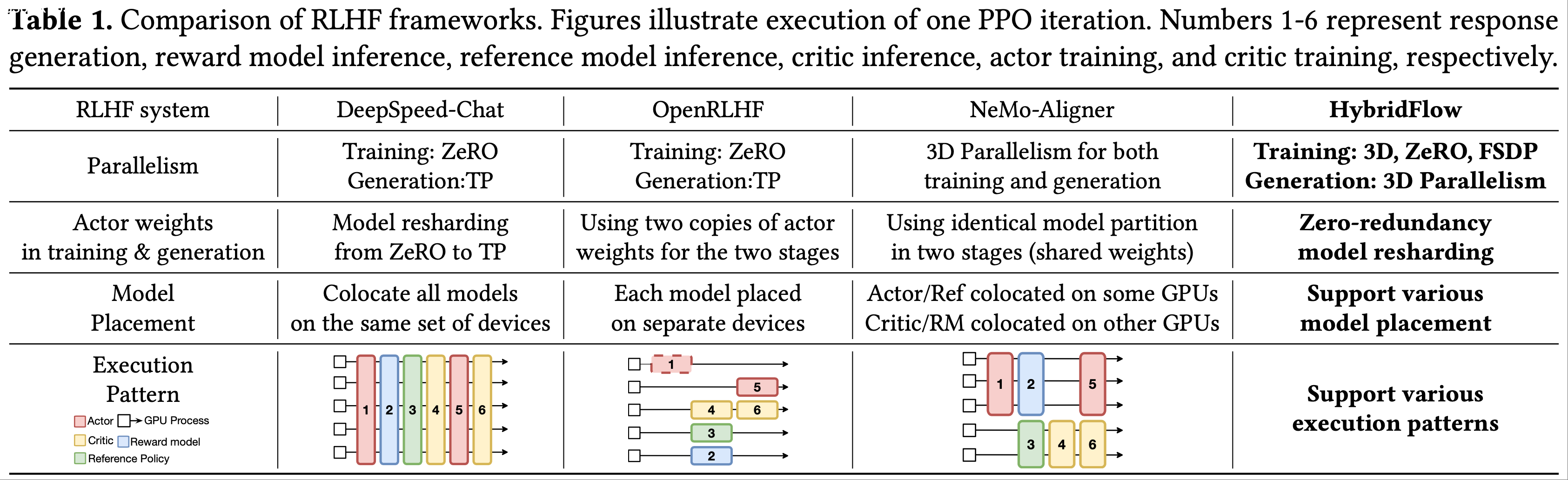
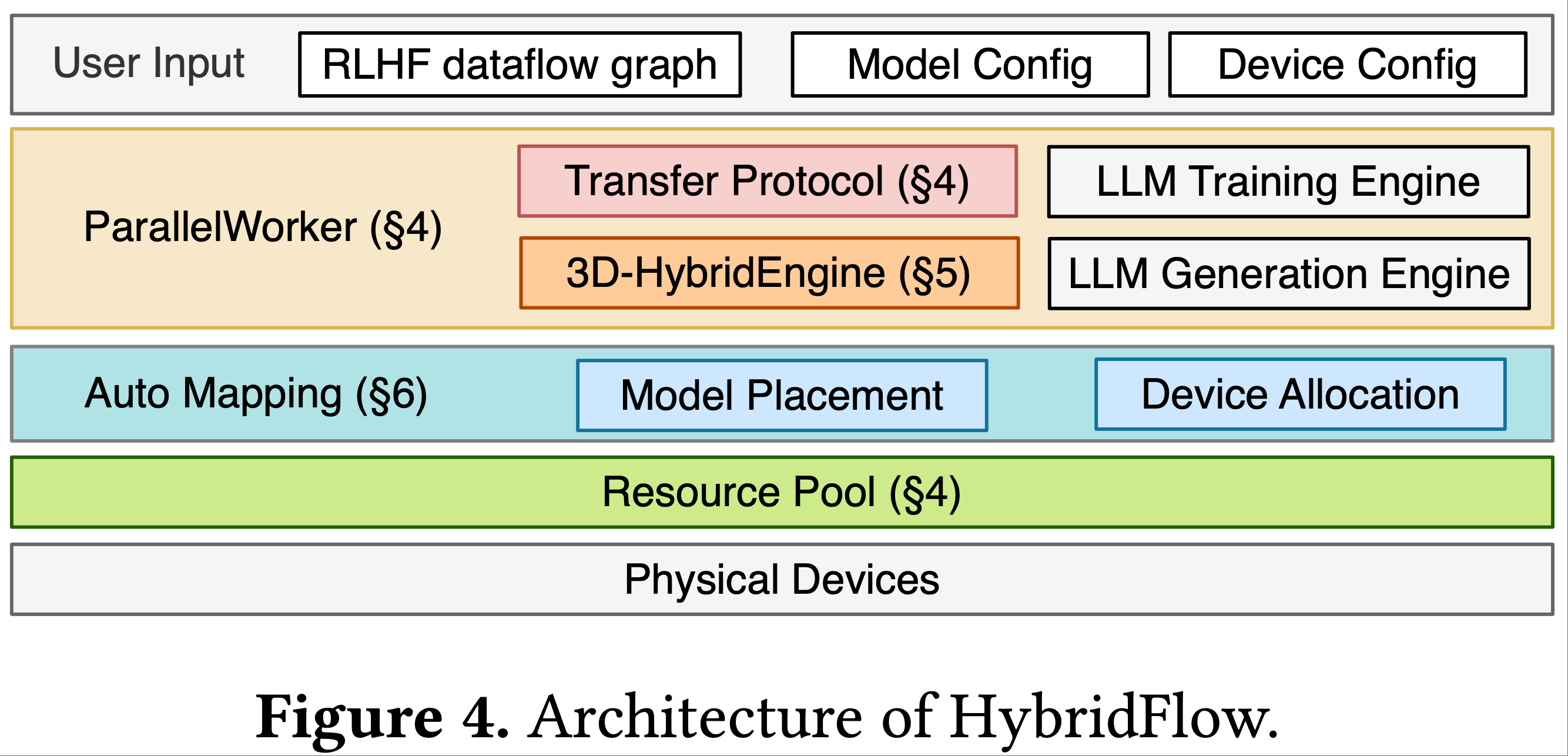
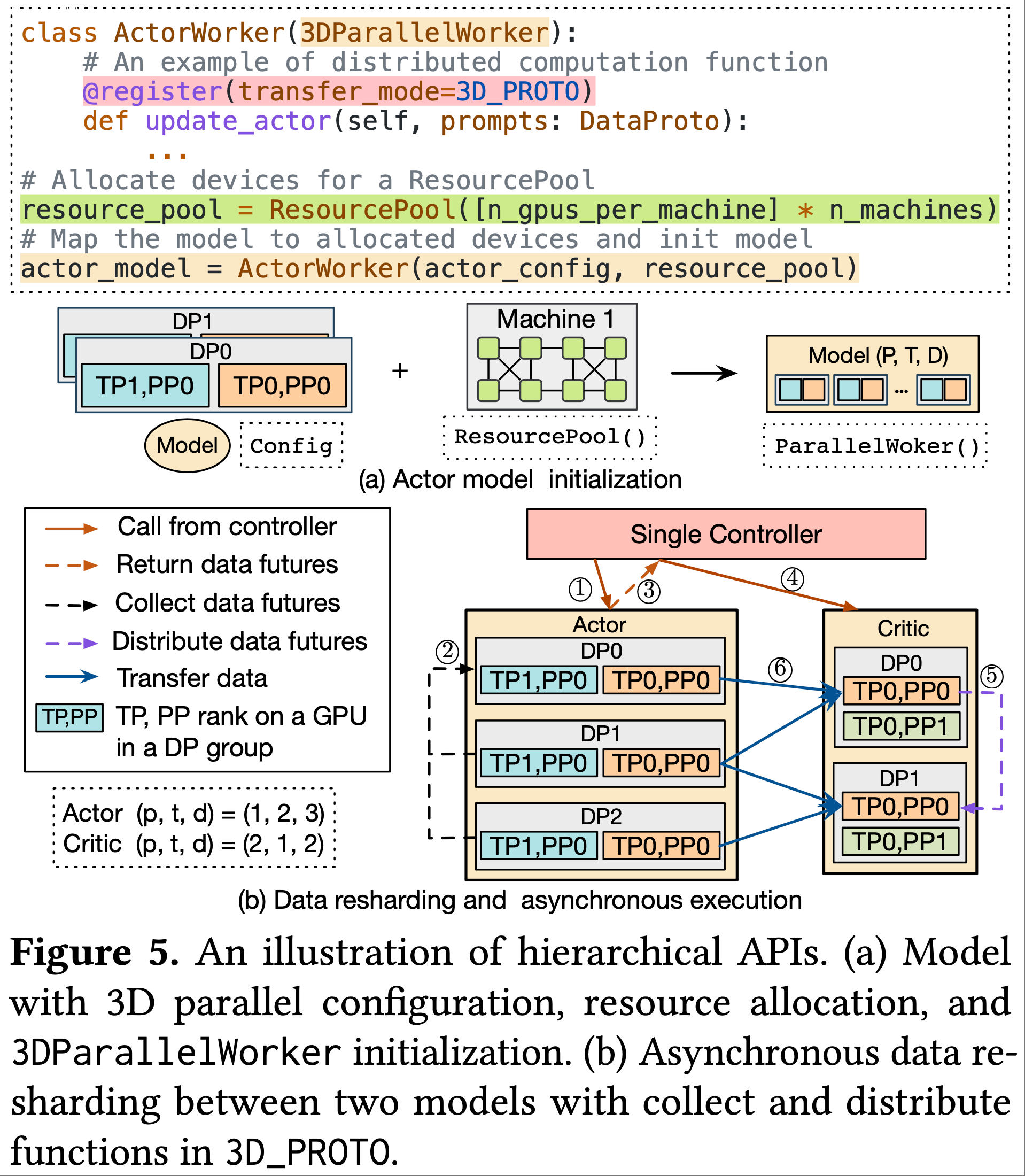
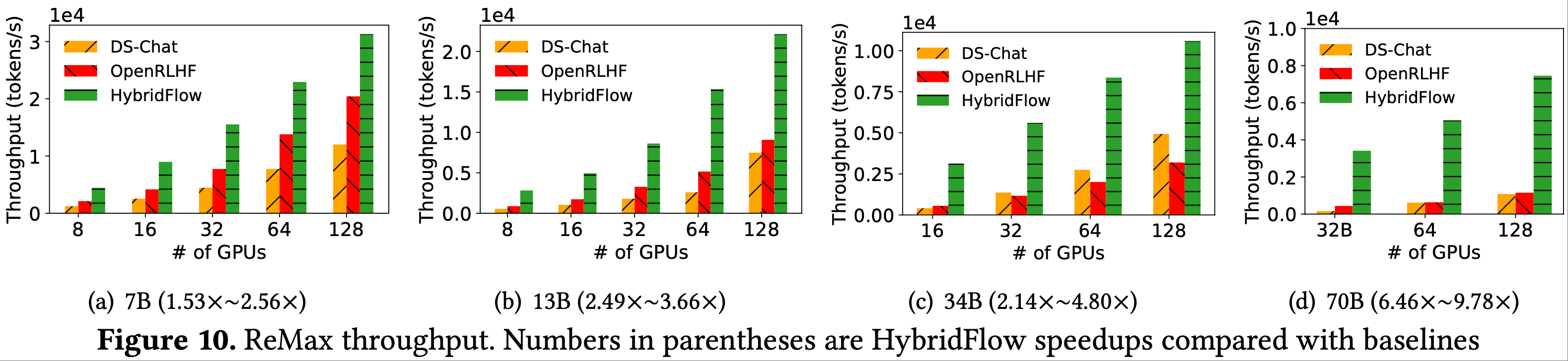
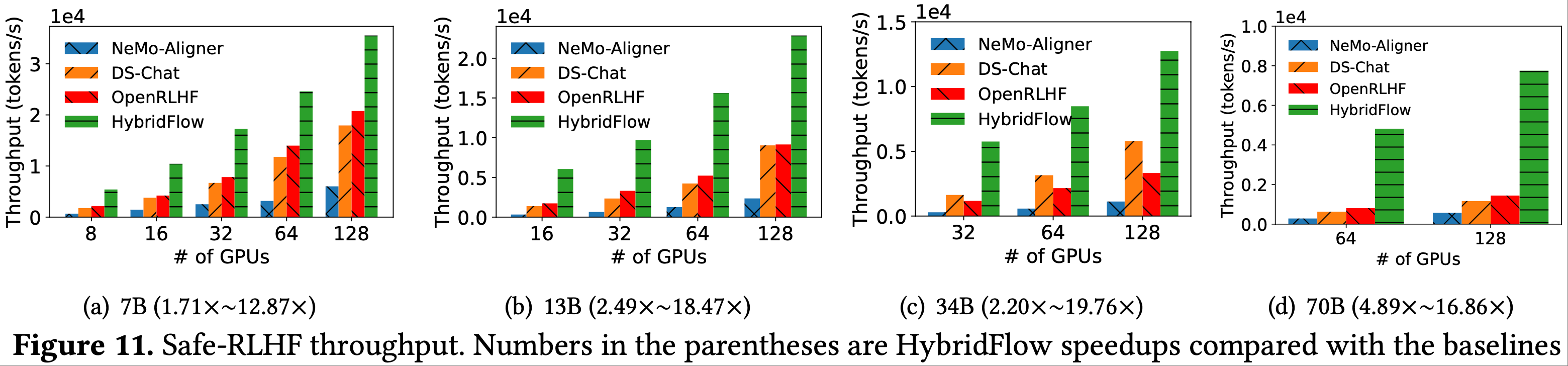
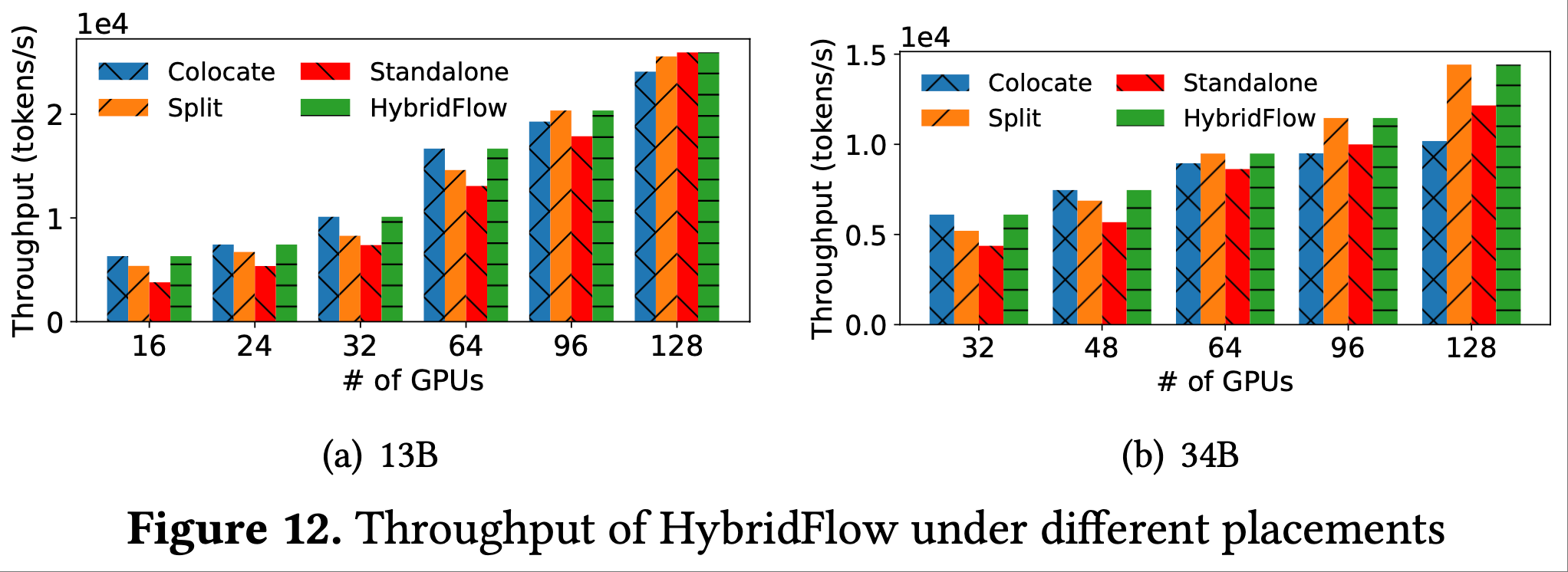
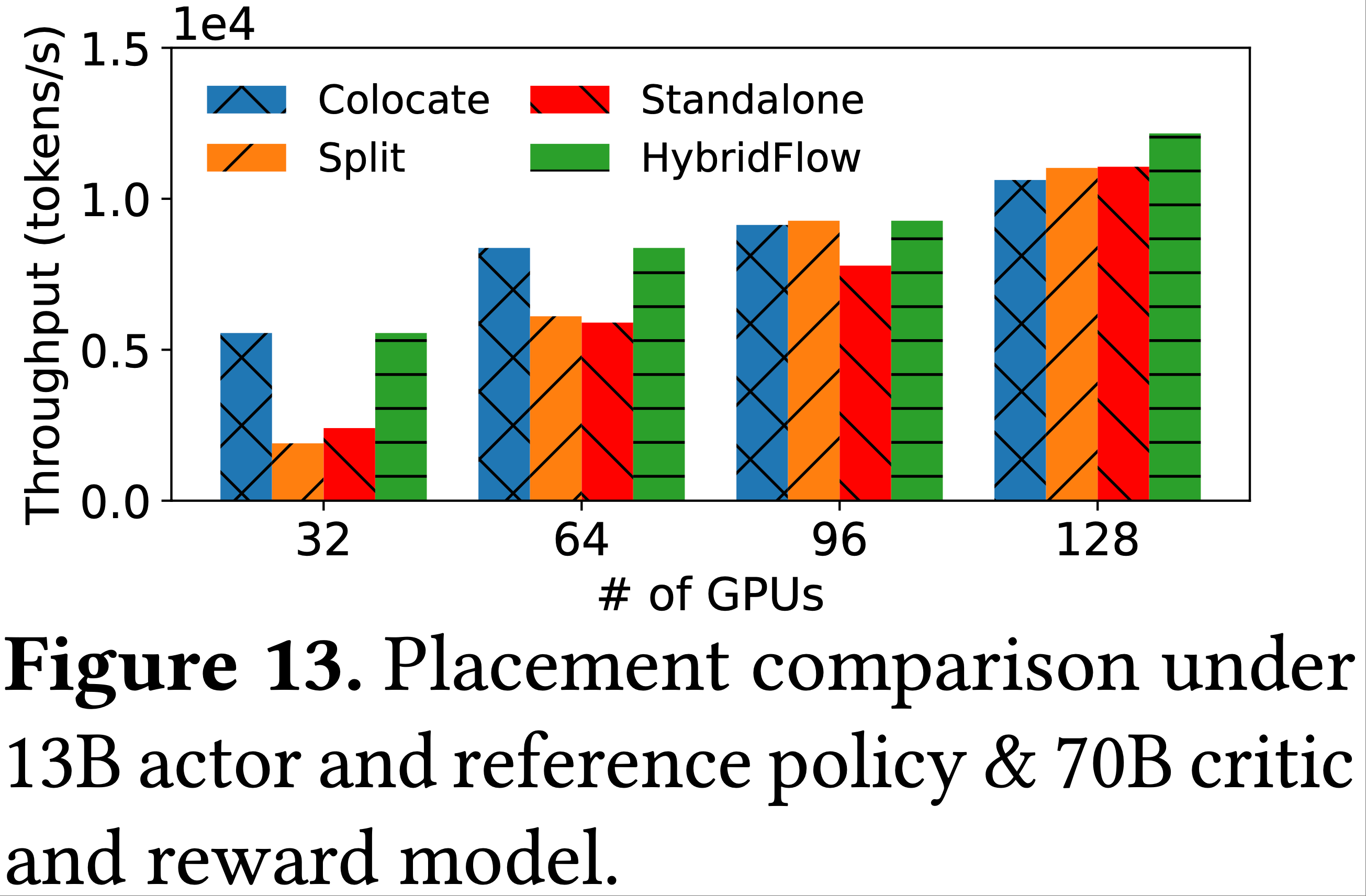
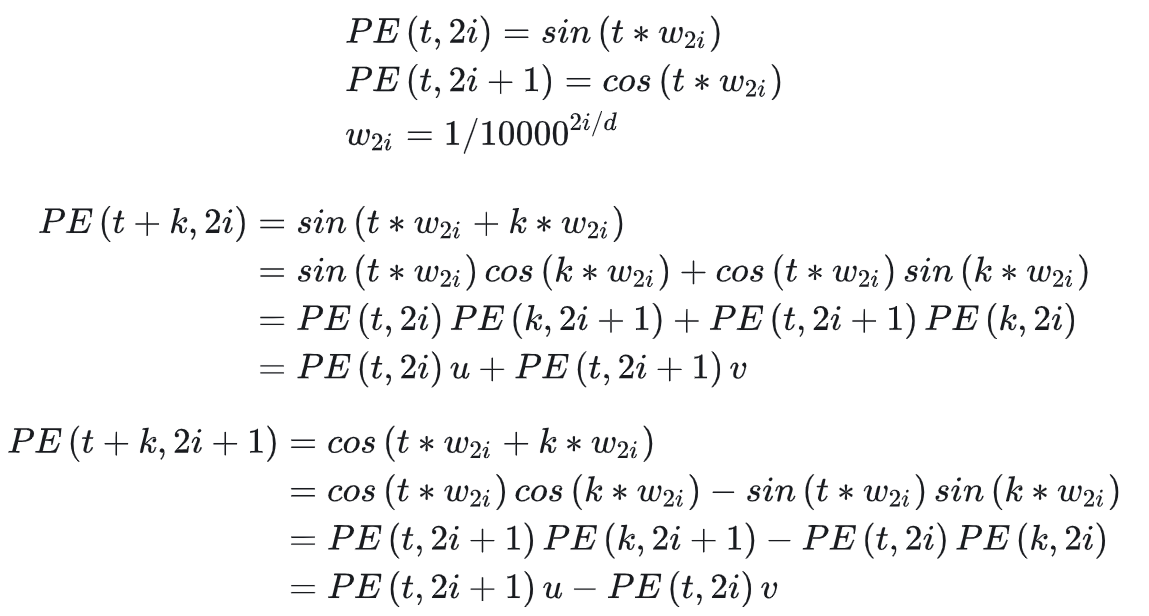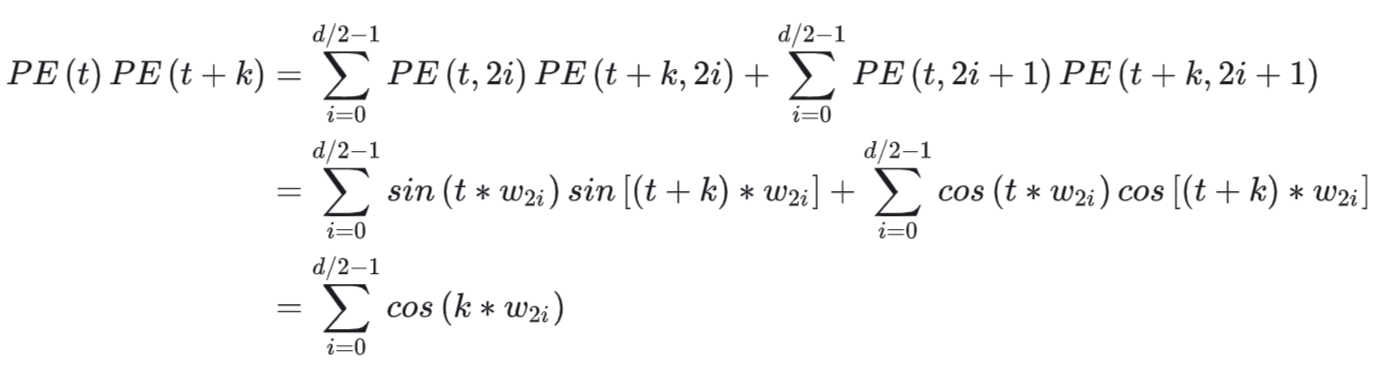本文主要介绍基于 Ollama 的 DeepSeek-R1 本地部署
安装 Ollama
- 在 ollama官网 下载安装即可
- ollama 是一个类 Docker 的大模型管理工具
安装 DeepSeek-R1 模型
安装命令(以下命令会自动安装7B版本,即DeepSeek-R1-Distill-Qwen-7B)
1
ollama run deepseek-r1
更多镜像可参考:ollama.com/library
基于 ChatBox 的可视化交互
- 下载并安装:chatboxai.app
- 点击设置选择指定本地模型即可启动
ollama API 调用
参考链接:
- 官方:ollama/docs/api.md
- 博客:DeepSeek R1本地化部署以及API调用 - 数字梦想家的文章 - 知乎,包含使用ollama API和OpenAI API等方法
API 调用 Demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173def http_api_demo():
import requests
import json
# Ollama 服务器的地址
OLLAMA_URL = "http://localhost:11434/api/generate"
# 要调用的模型名称
MODEL_NAME = "deepseek-r1:latest"
# 要发送的提示文本
prompt = "你好,DeepSeek!请求解方程x^3+x^2+x-3=0"
# 请求的 payload
payload = {
"model": MODEL_NAME,
"prompt": prompt,
"stream": False # 设置为 False 以获取完整的响应
}
# 发送 POST 请求
response = requests.post(OLLAMA_URL, json=payload)
# 检查响应状态码
if response.status_code == 200:
# 解析响应内容
response_data = response.json()
print("模型响应:", response_data.get("response"))
else:
print(f"请求失败,状态码: {response.status_code}")
print("响应内容:", response.text)
def ollama_api_stream_demo():
import requests # 使用 requests 库调用 Ollama 的 API
import json
# Ollama 的 API 地址
url = "http://localhost:11434/api/chat"
# 请求数据
data = {
"model": "deepseek-r1:latest", # 使用的模型
"messages": [
{
"role": "system",
"content": "你是一个专业人士,每次回答前请先说“解:”"
},
{
"role": "user",
"content": "9.9和9.11哪个更大?"
}
],
"stream": True # 启用流式响应
}
# 发送 POST 请求
response = requests.post(
url,
json=data,
stream=True # 启用流式接收
)
# 打印结果
print("模型返回的内容:")
for line in response.iter_lines():
if line: # 过滤掉空行
# 解析 JSON 数据
chunk = json.loads(line.decode('utf-8'))
if "message" in chunk and "content" in chunk["message"]:
print(chunk["message"]["content"], end='', flush=True) # 逐步打印内容
def ollama_api_demo():
import requests # 使用 requests 库调用 Ollama 的 API
import json
# Ollama 的 API 地址
url = "http://localhost:11434/api/chat"
# 请求数据
data = {
"model": "deepseek-r1:latest", # 使用的模型
"messages": [
{
"role": "system",
"content": "你是一个专业人士,每次回答前请先说“解:”"
},
{
"role": "user",
"content": "9.9和9.11哪个更大?"
}
],
"stream": False # 禁用流式响应
}
# 发送 POST 请求
response = requests.post(
url,
json=data
)
# 检查响应状态
if response.status_code == 200:
# 解析 JSON 数据
result = response.json()
if "message" in result and "content" in result["message"]:
print("模型返回的内容:")
print(result["message"]["content"]) # 打印完整内容
else:
print(f"请求失败,状态码:{response.status_code}")
print(response.text) # 打印错误信息
def openai_api_demo():
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# required but ignored
api_key='ollama',
)
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': '9.9和9.11哪个更大?',
},
{
'role': 'system',
'content': '你是一个专业人士,每次回答前请先说“解:”',
}
],
model='deepseek-r1:latest',
temperature=0.0, # 可以根据需要调整温度值,决定生成的随机性程度
)
# 打印结果
print("模型返回的内容:")
print(chat_completion.choices[0].message.content)
def openai_api_stream_demo():
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# required but ignored
api_key='ollama',
)
# 启用流式响应
stream = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': '9.9和9.11哪个更大?',
},
{
'role': 'system',
'content': '你是一个专业人士,每次回答前请先说“解:”',
}
],
model='deepseek-r1:latest',
temperature=0.0, # 可以根据需要调整温度值,决定生成的随机性程度
stream=True, # 启用流式响应
)
# 打印结果
print("模型返回的内容:")
for chunk in stream:
if chunk.choices[0].delta.content: # 检查是否有内容
print(chunk.choices[0].delta.content, end='', flush=True) # 逐步打印内容
# openai_api_demo()
# openai_api_stream_demo()
ollama_api_stream_demo()
# ollama_api_demo()多线程调用 Demo
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76import requests
import json
from concurrent.futures import ThreadPoolExecutor, as_completed
def ollama_api_demo(message):
# Ollama 的 API 地址
url = "http://localhost:11434/api/chat"
# 请求数据
data = {
"model": "deepseek-r1:latest", # 使用的模型
# "model": "llama3.2:latest",
"messages": [
{
"role": "system",
"content": "你是一个专业人士,每次回答前请先说“解:”"
},
{
"role": "user",
"content": message
}
],
"stream": False # 禁用流式响应
}
# 发送 POST 请求
response = requests.post(
url,
json=data
)
# 检查响应状态
if response.status_code == 200:
# 解析 JSON 数据
result = response.json()
if "message" in result and "content" in result["message"]:
return result["message"]["content"] # 返回完整内容
else:
return f"请求失败,状态码:{response.status_code}\n{response.text}" # 返回错误信息
def parallel_ollama_api_demo(messages):
with ThreadPoolExecutor() as executor:
# 提交任务到线程池
futures = [executor.submit(ollama_api_demo, message) for message in messages]
# 等待所有任务完成并获取结果
results = []
for future in as_completed(futures):
try:
result = future.result()
results.append(result)
except Exception as e:
results.append(f"任务执行出错: {e}")
return results
if __name__ == "__main__":
# 示例消息列表
messages = [
"9.9和9.11哪个更大?",
# "Python 和 Java 哪个更适合初学者?",
# "解释一下量子计算的基本概念。"
]
import time
x = time.time()
# 并行调用 API
results = parallel_ollama_api_demo(messages)
# 打印结果
for i, result in enumerate(results):
print(f"结果 {i+1}:")
print(result)
print("-" * 40)
y = time.time()
print("time(s):", y-x)如果想要设定
temperature等参数,可以在结构体中增加option参数,按照字典传入即可,比如,可以如下实现仅返回长度为 20 的 token1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44def ollama_api_demo():
import requests # 使用 requests 库调用 Ollama 的 API
import json
# Ollama 的 API 地址
url = "http://localhost:11434/api/chat"
# 请求数据
data = {
"model": "deepseek-r1:latest", # 使用的模型
"messages": [
{
"role": "system",
"content": "你是一个专业人士,每次回答前请先说“解:”"
},
{
"role": "user",
"content": "9.9和9.11哪个更大?"
}
],
"options": {
"temperature": 0.7,
"top_p": 0.8,
"num_predict": 20 # 仅返回20个 token 长度
},
"stream": False # 禁用流式响应
}
# 发送 POST 请求
response = requests.post(
url,
json=data
)
# 检查响应状态
if response.status_code == 200:
# 解析 JSON 数据
result = response.json()
if "message" in result and "content" in result["message"]:
print("模型返回的内容:")
print(result["message"]["content"]) # 打印完整内容
else:
print(f"请求失败,状态码:{response.status_code}")
print(response.text) # 打印错误信息