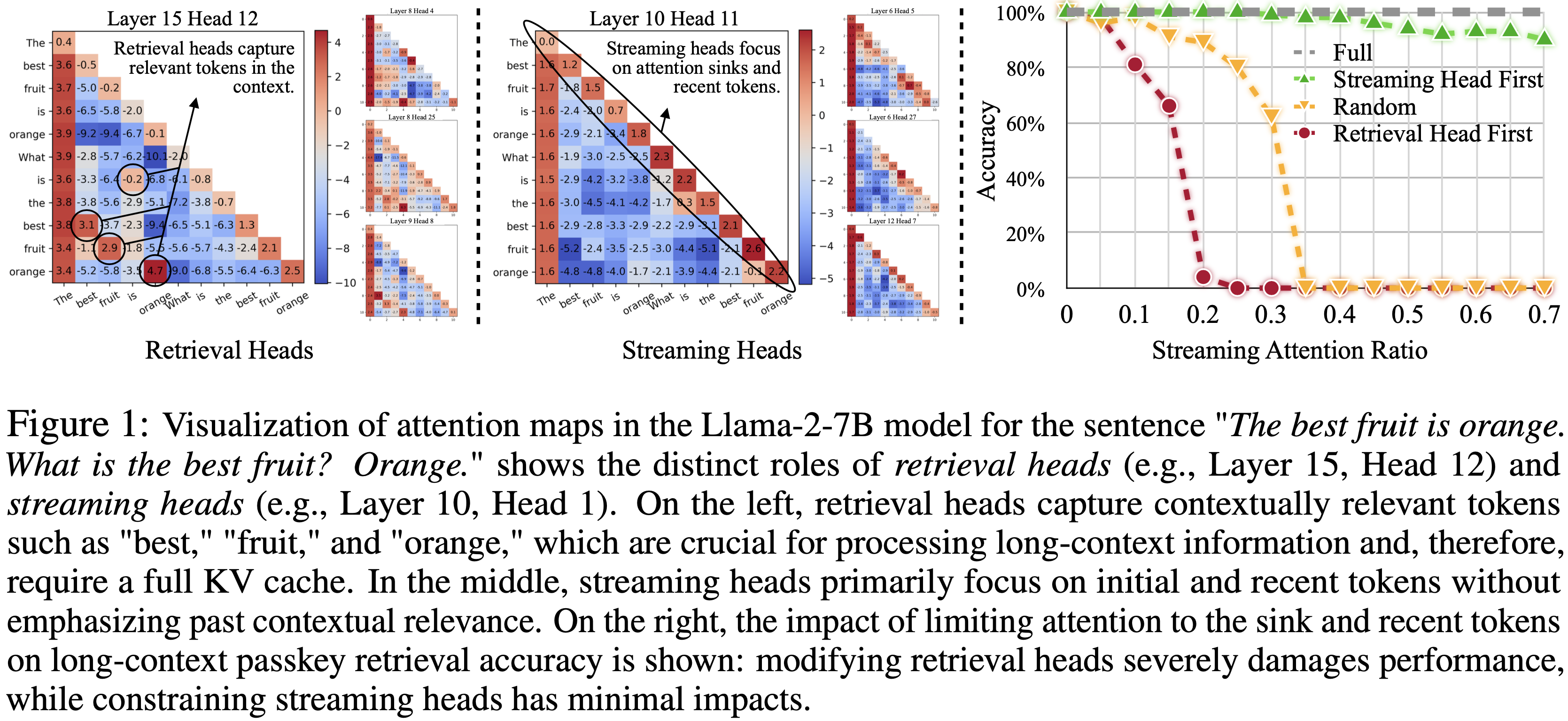
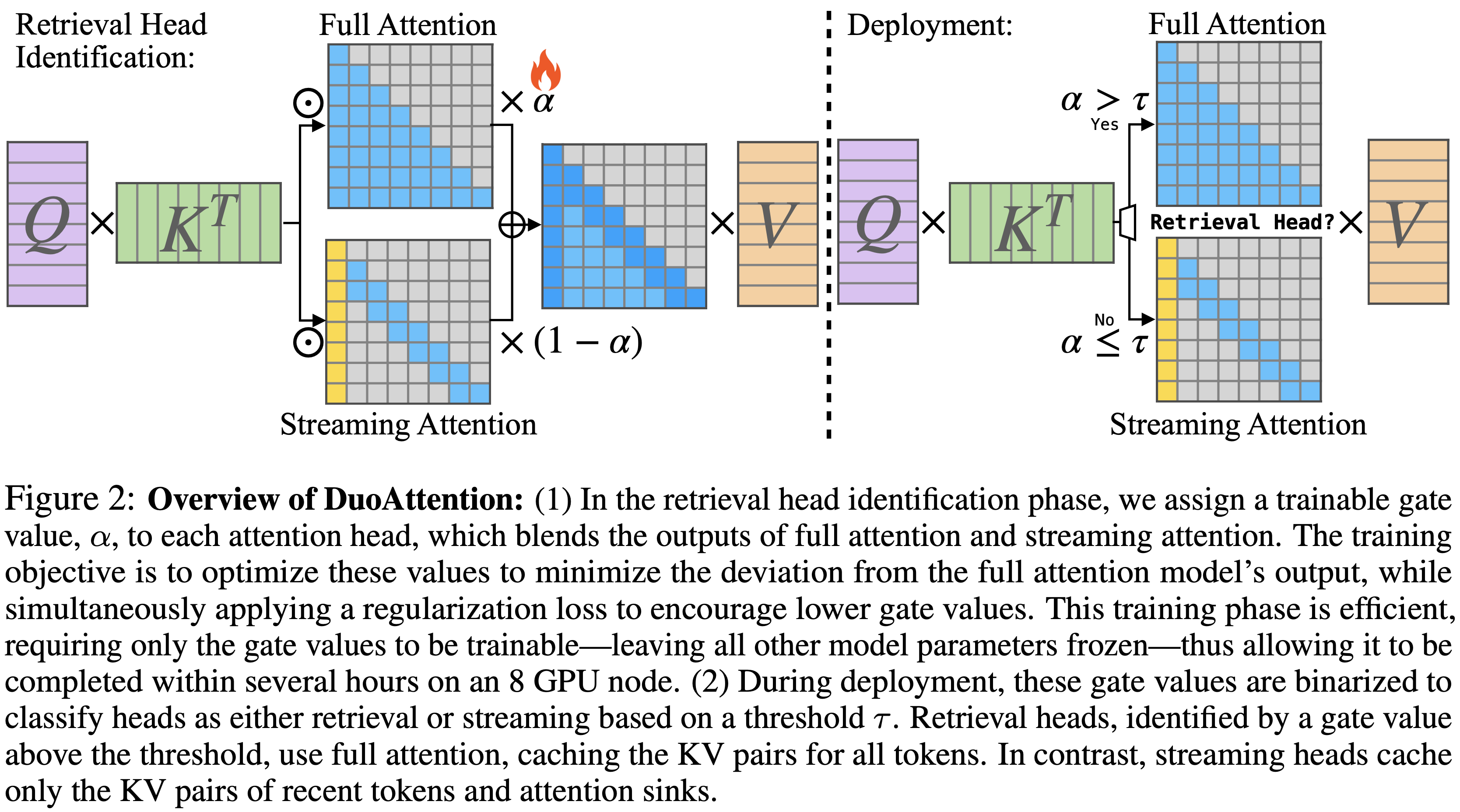
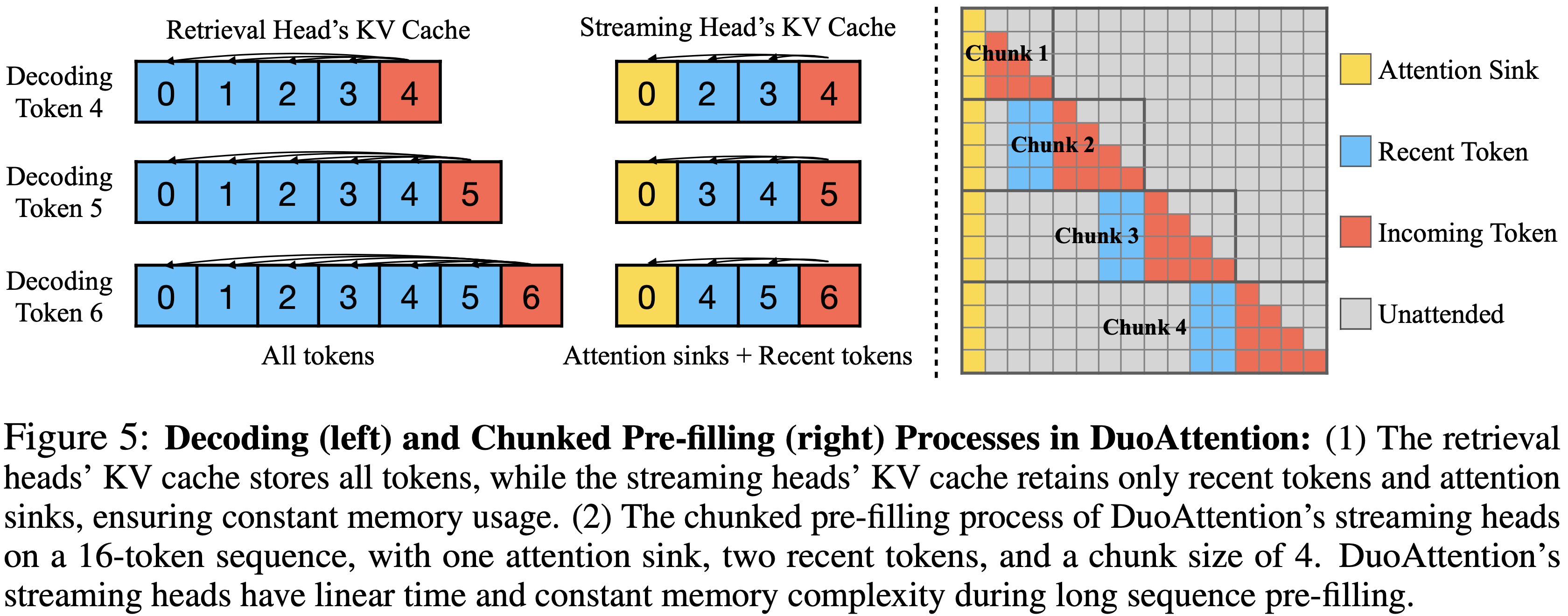
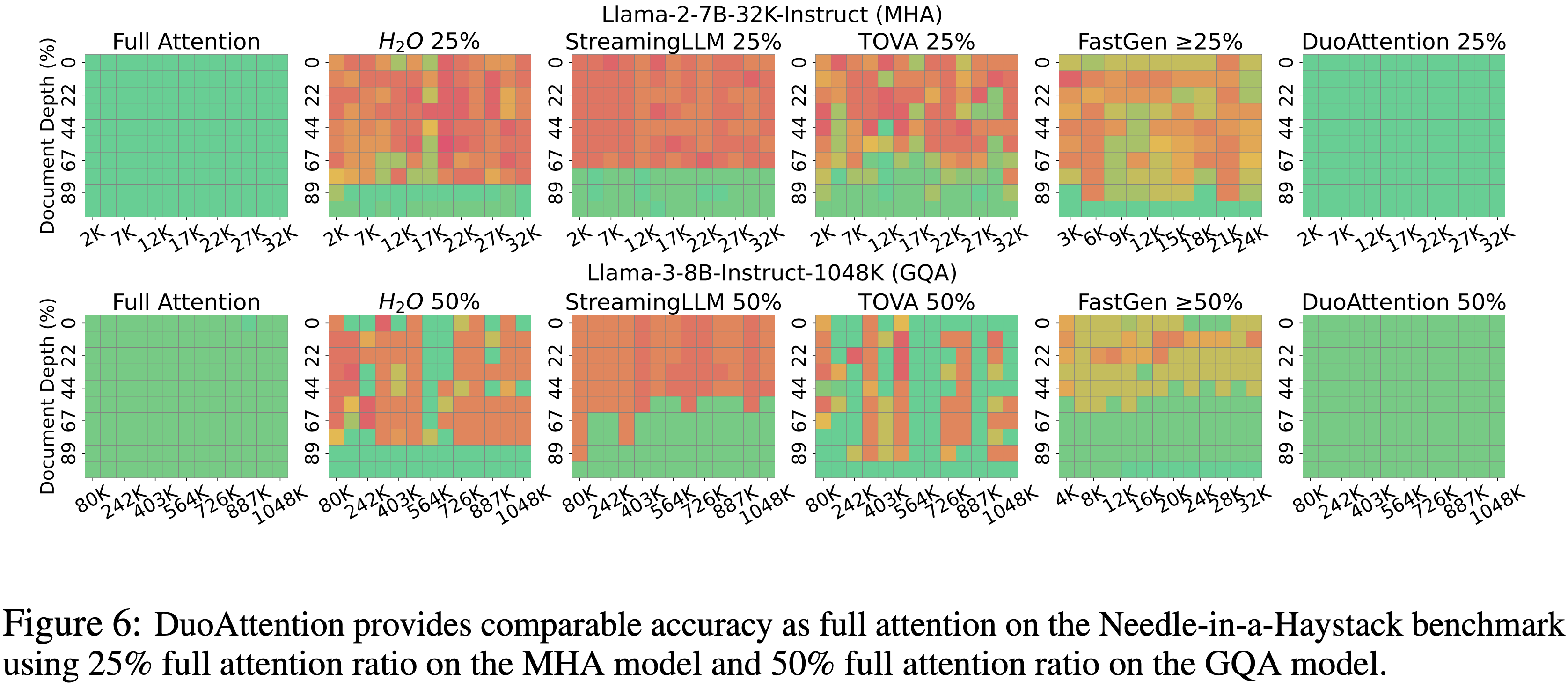
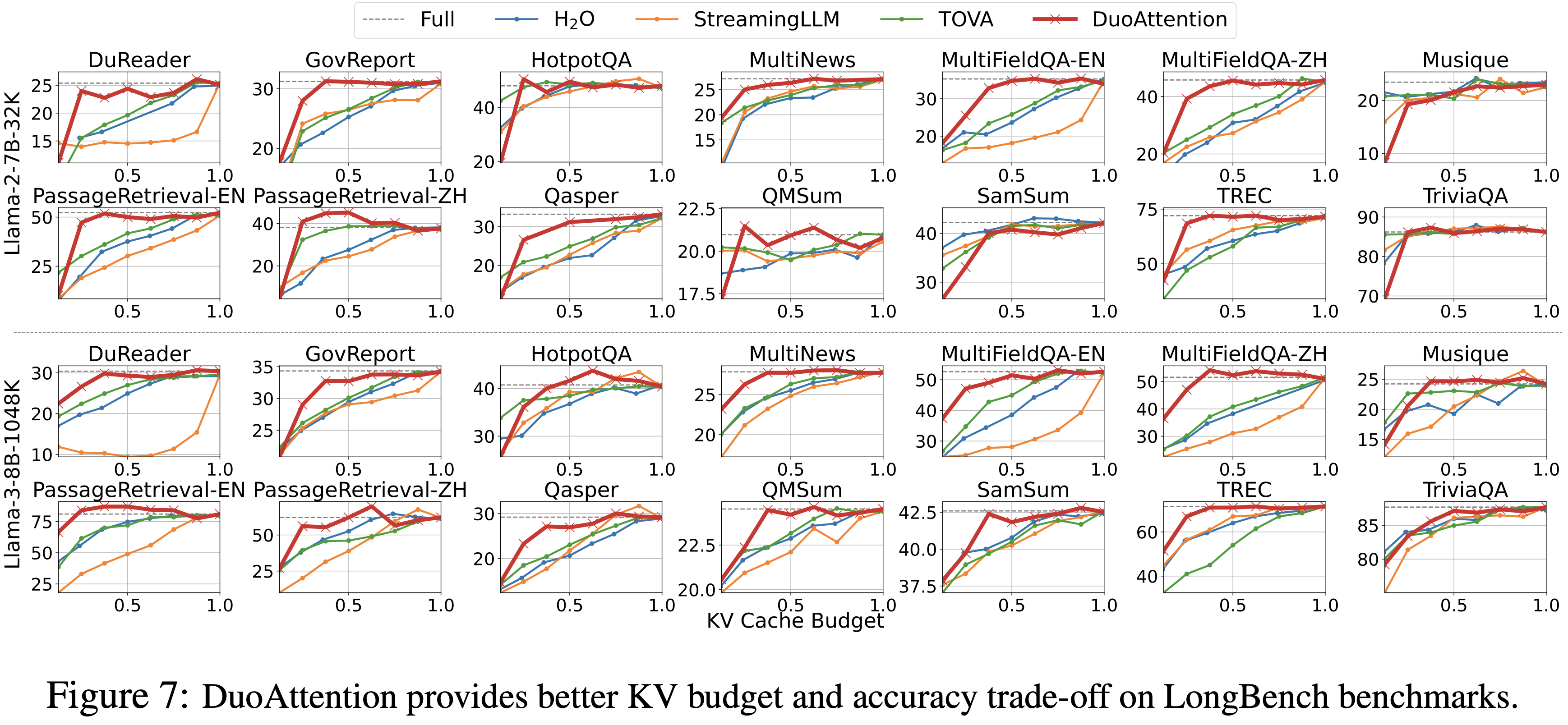
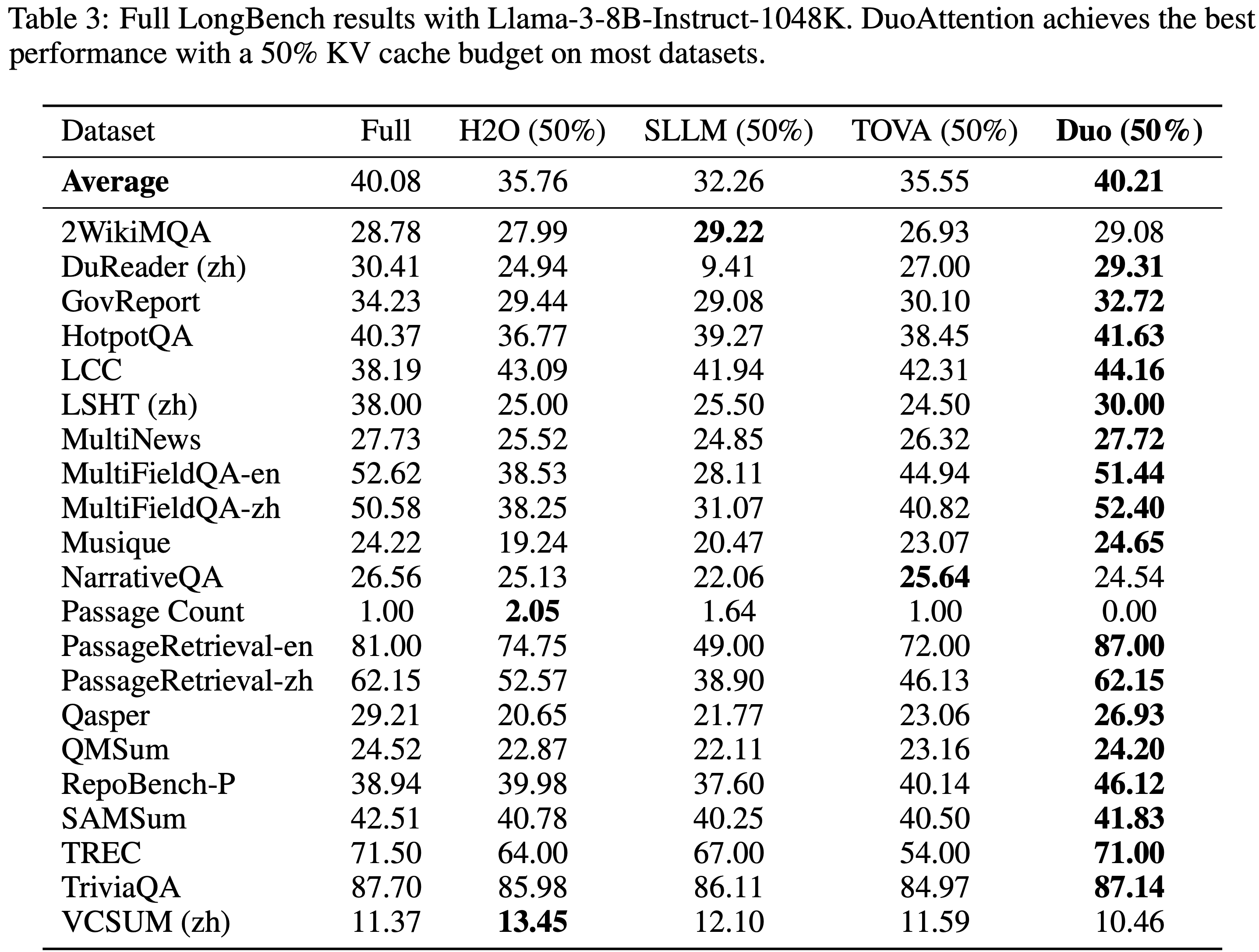
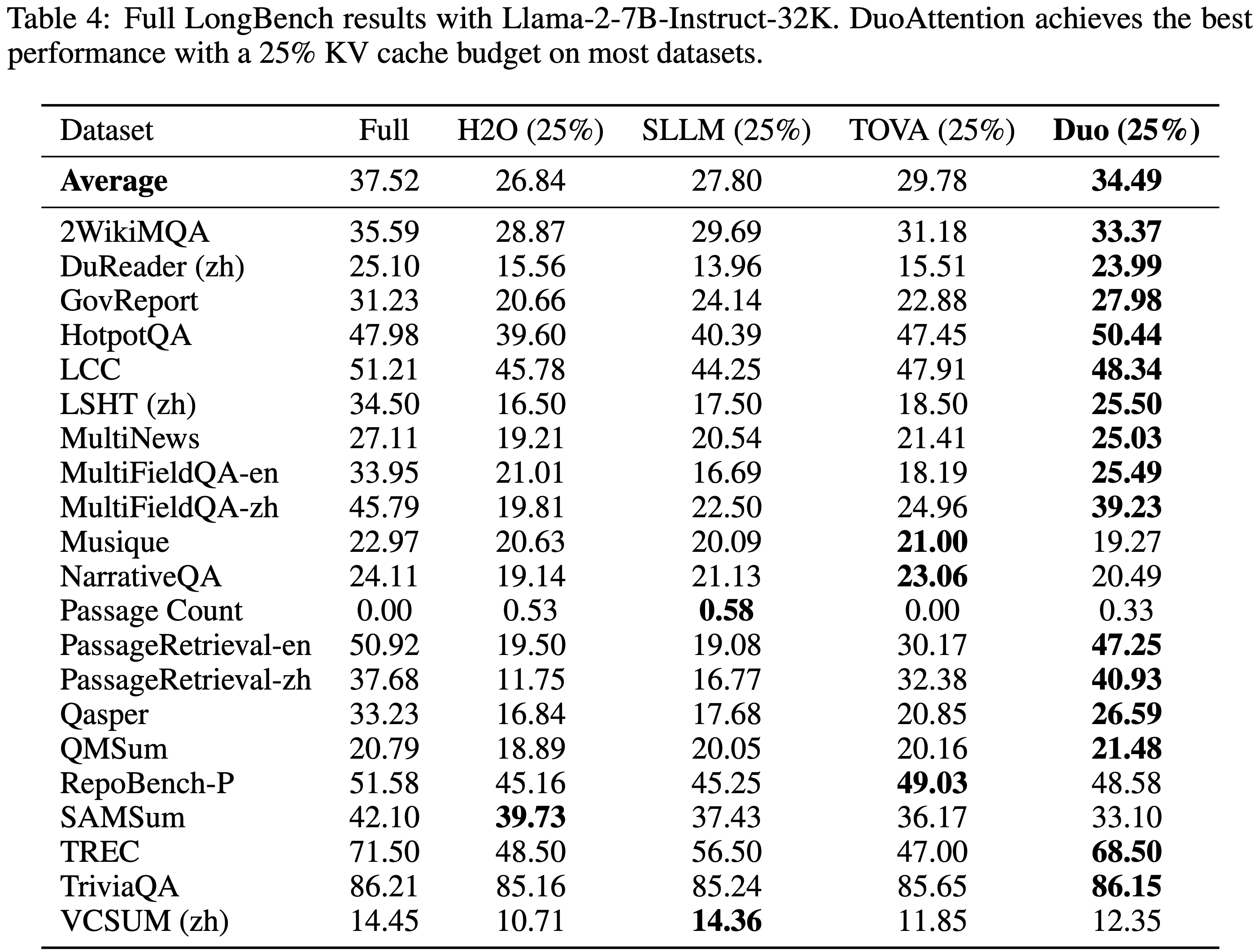
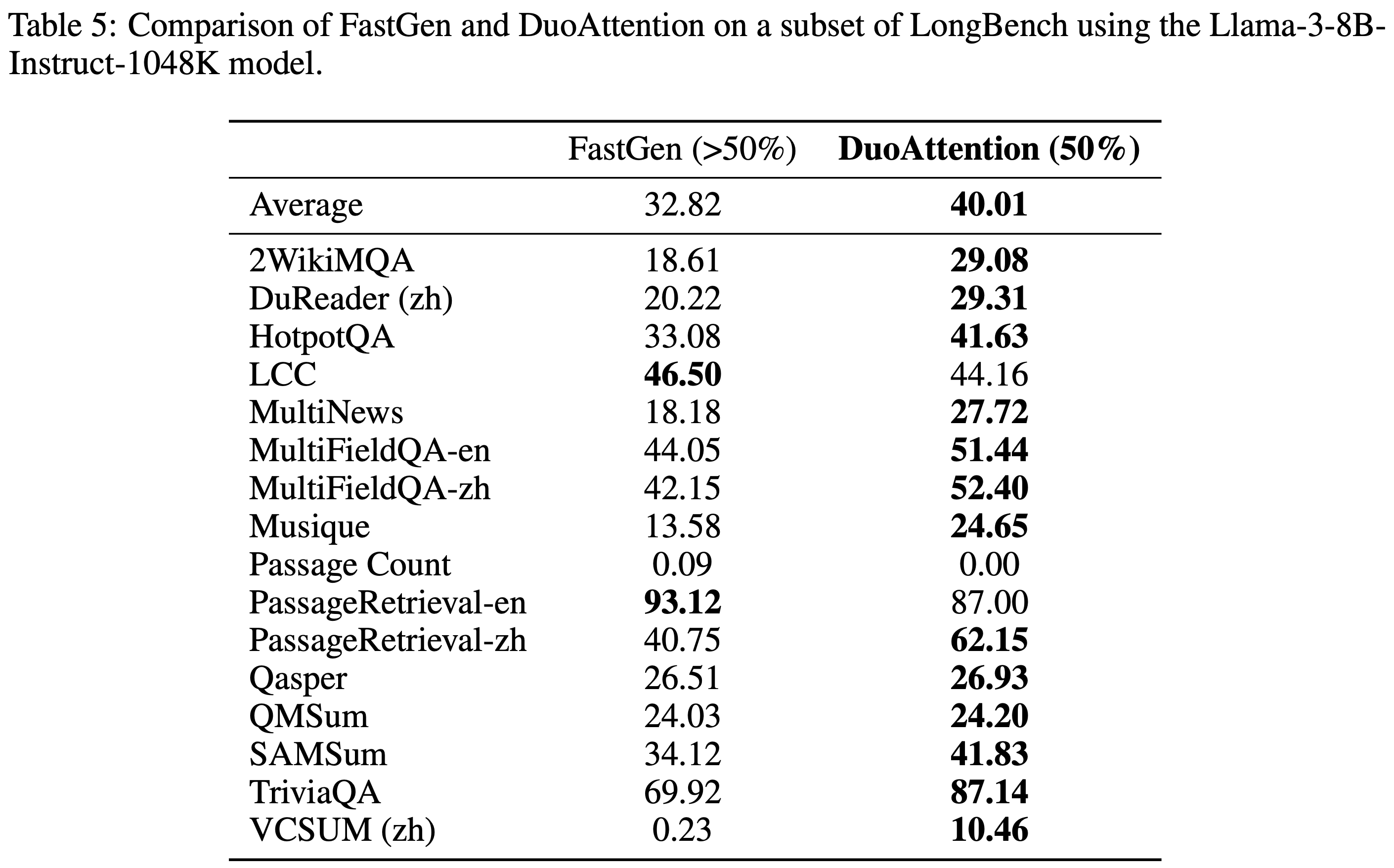
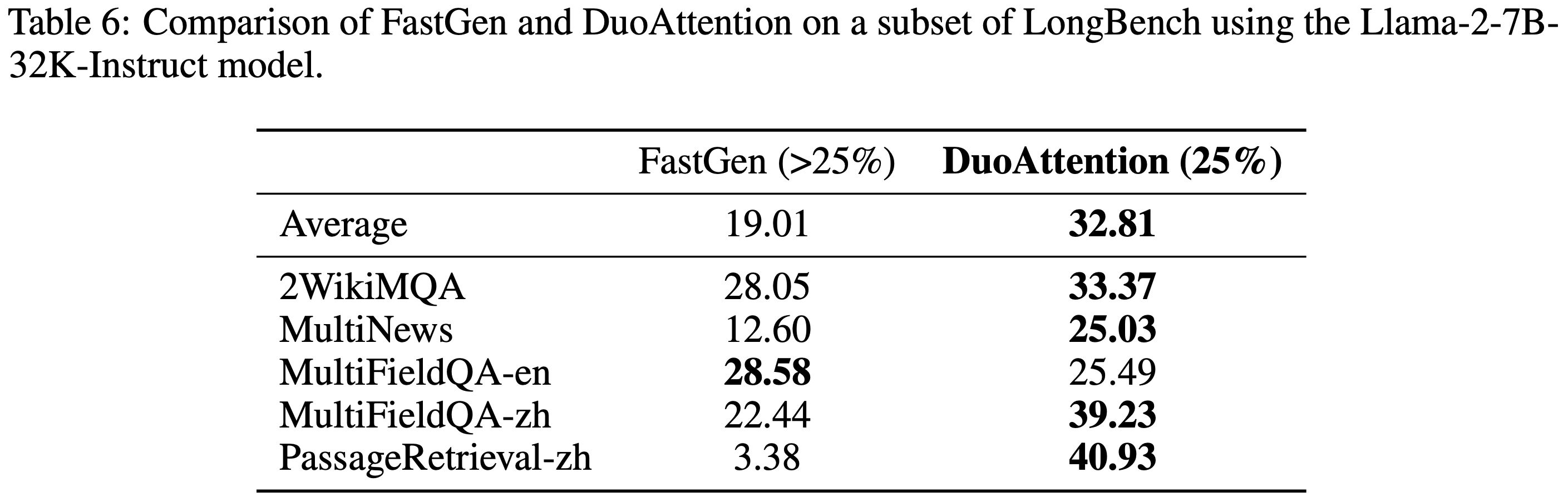
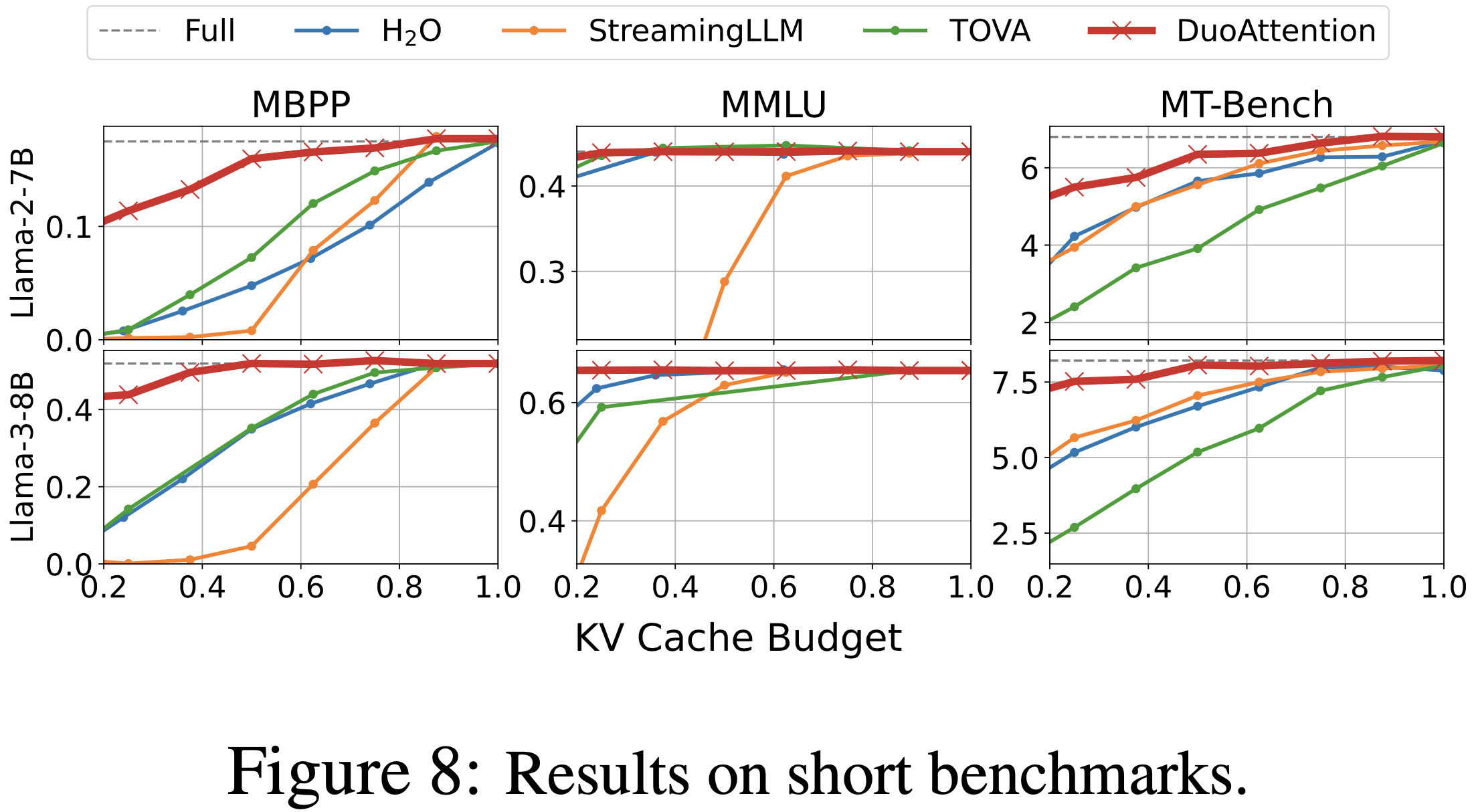
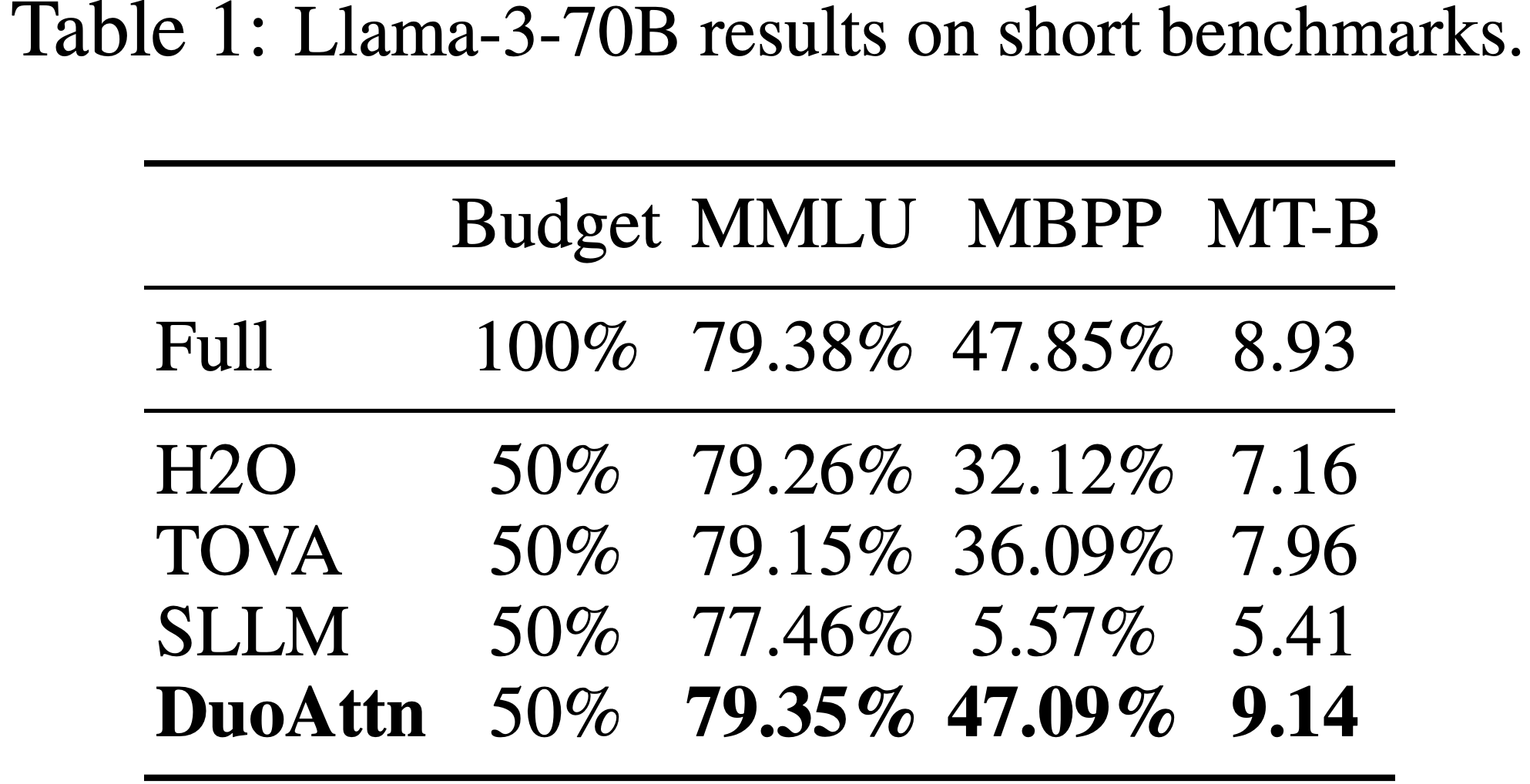
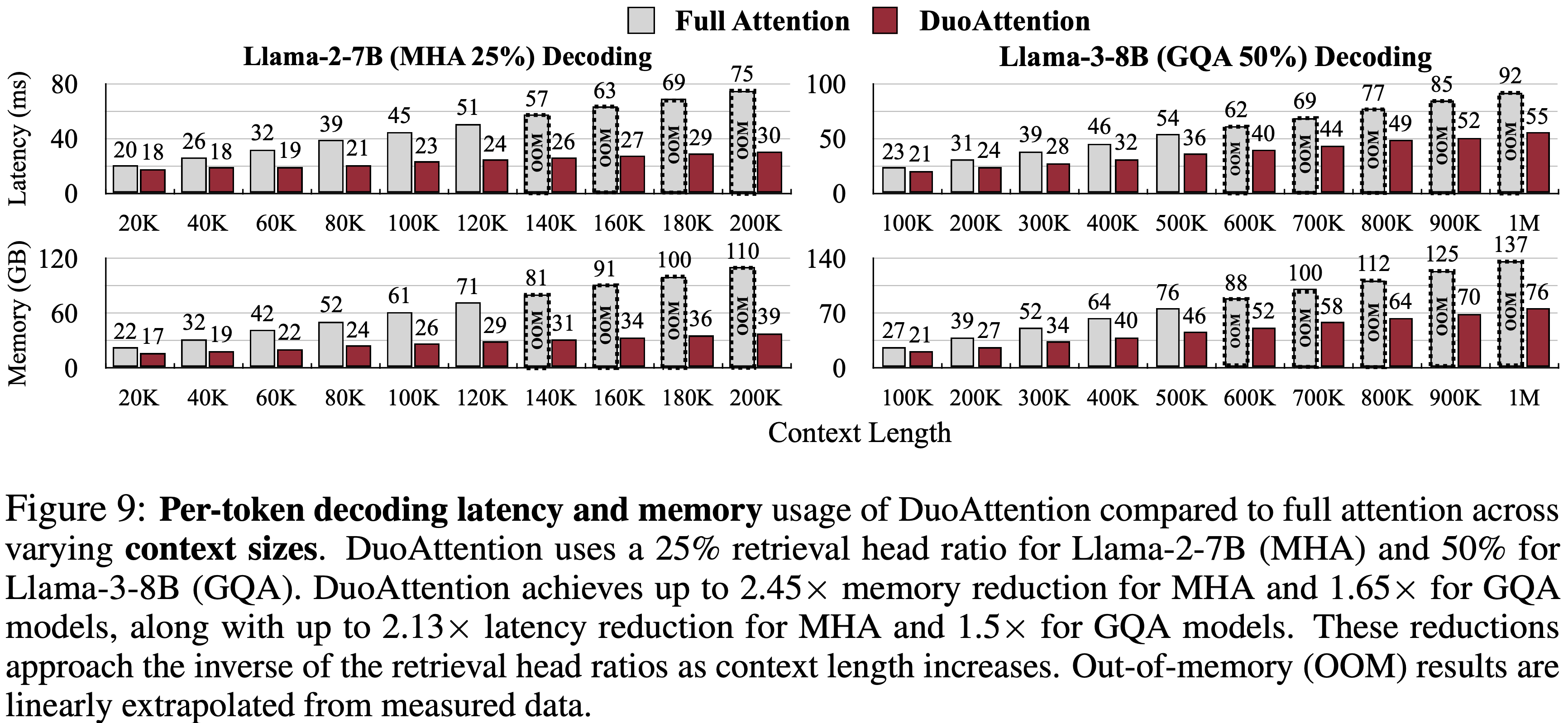
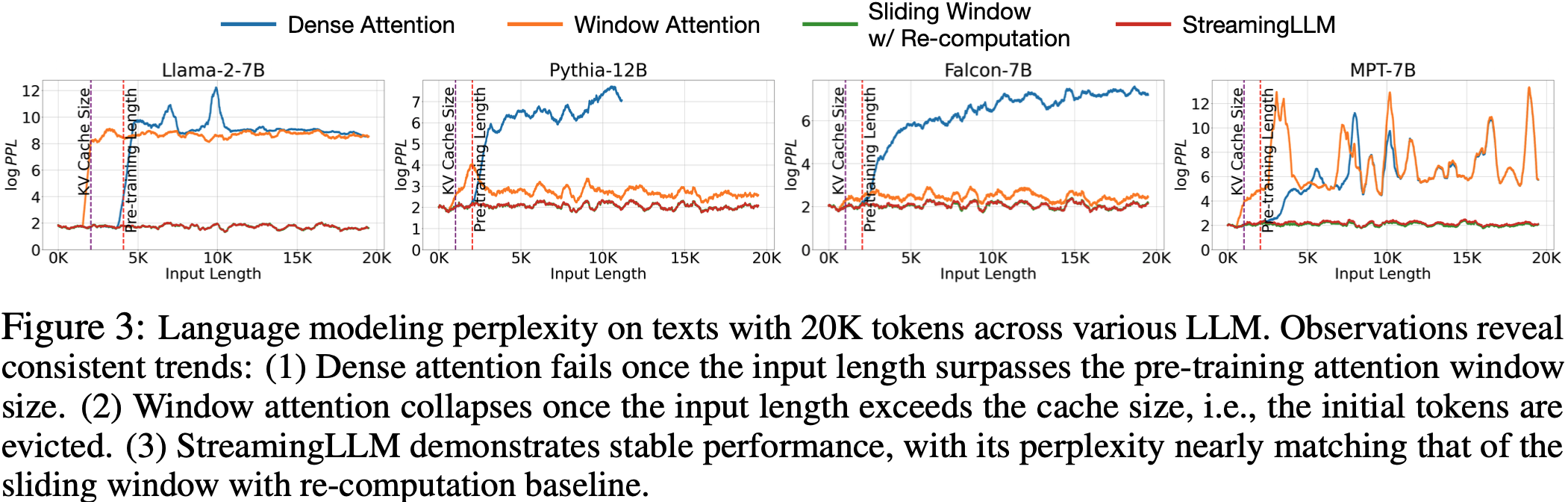
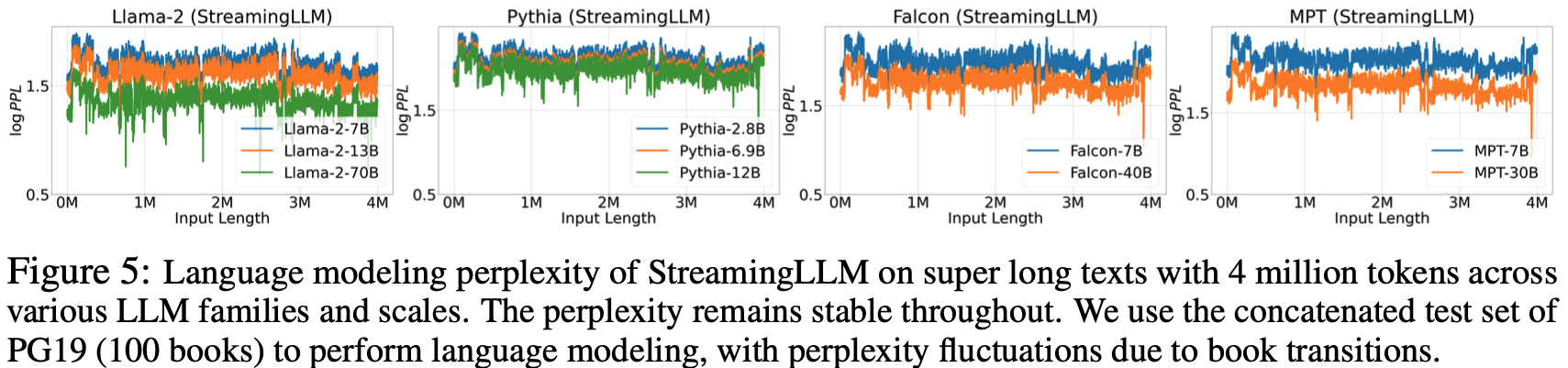
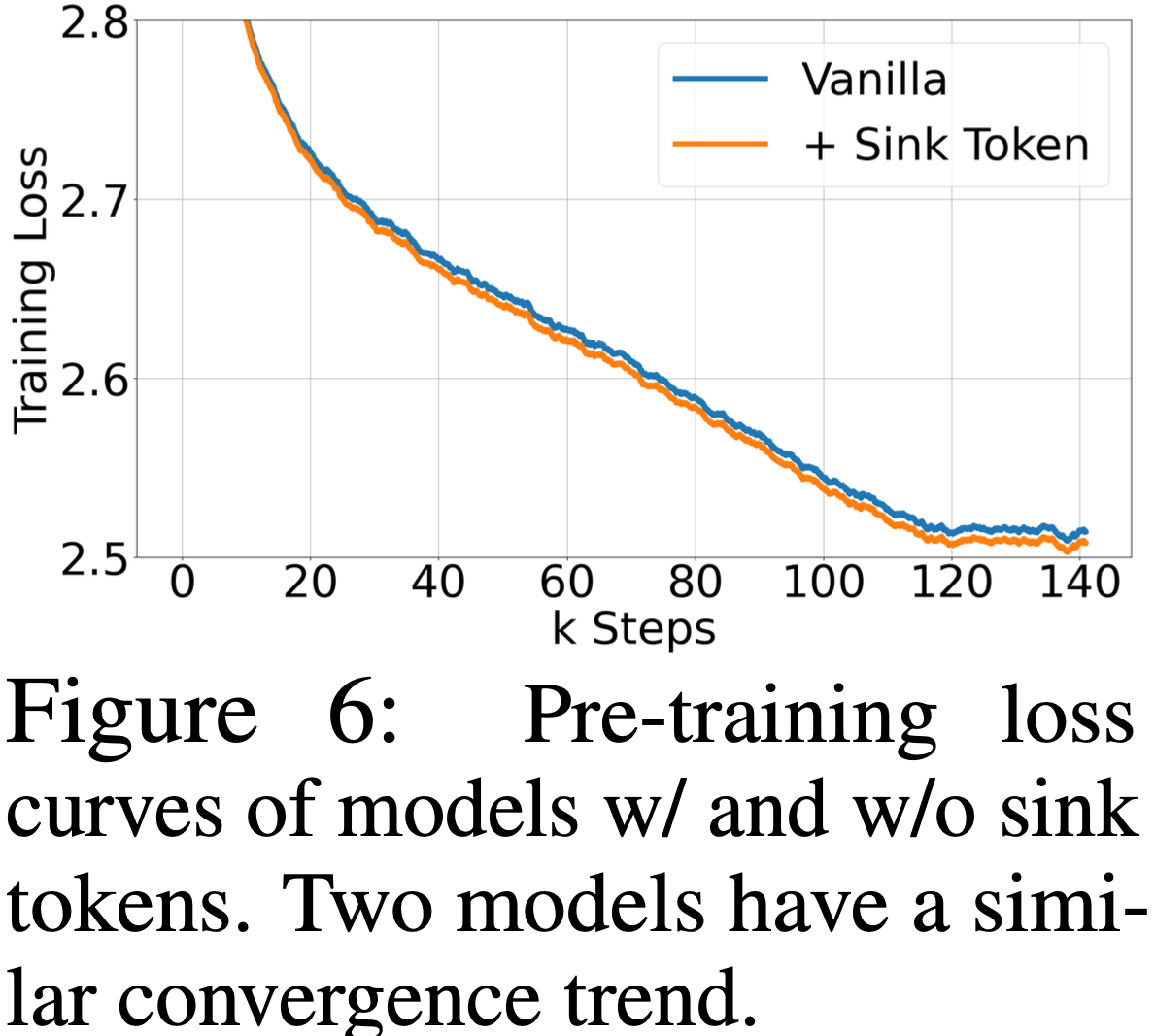
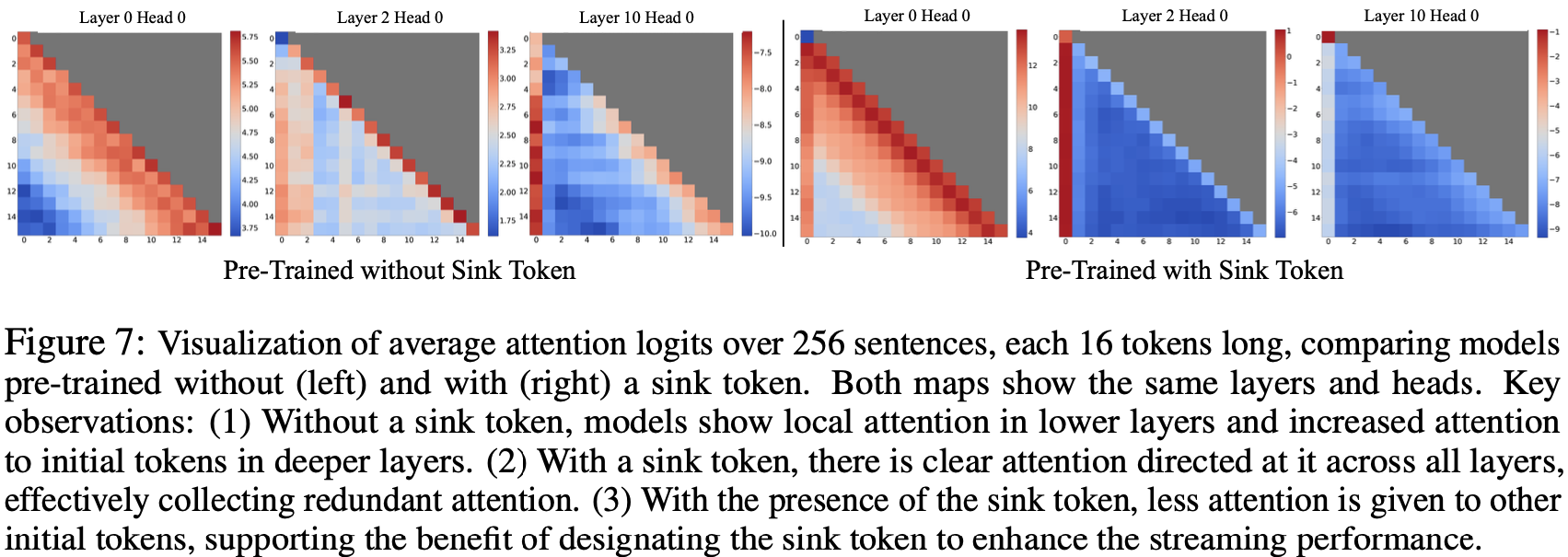
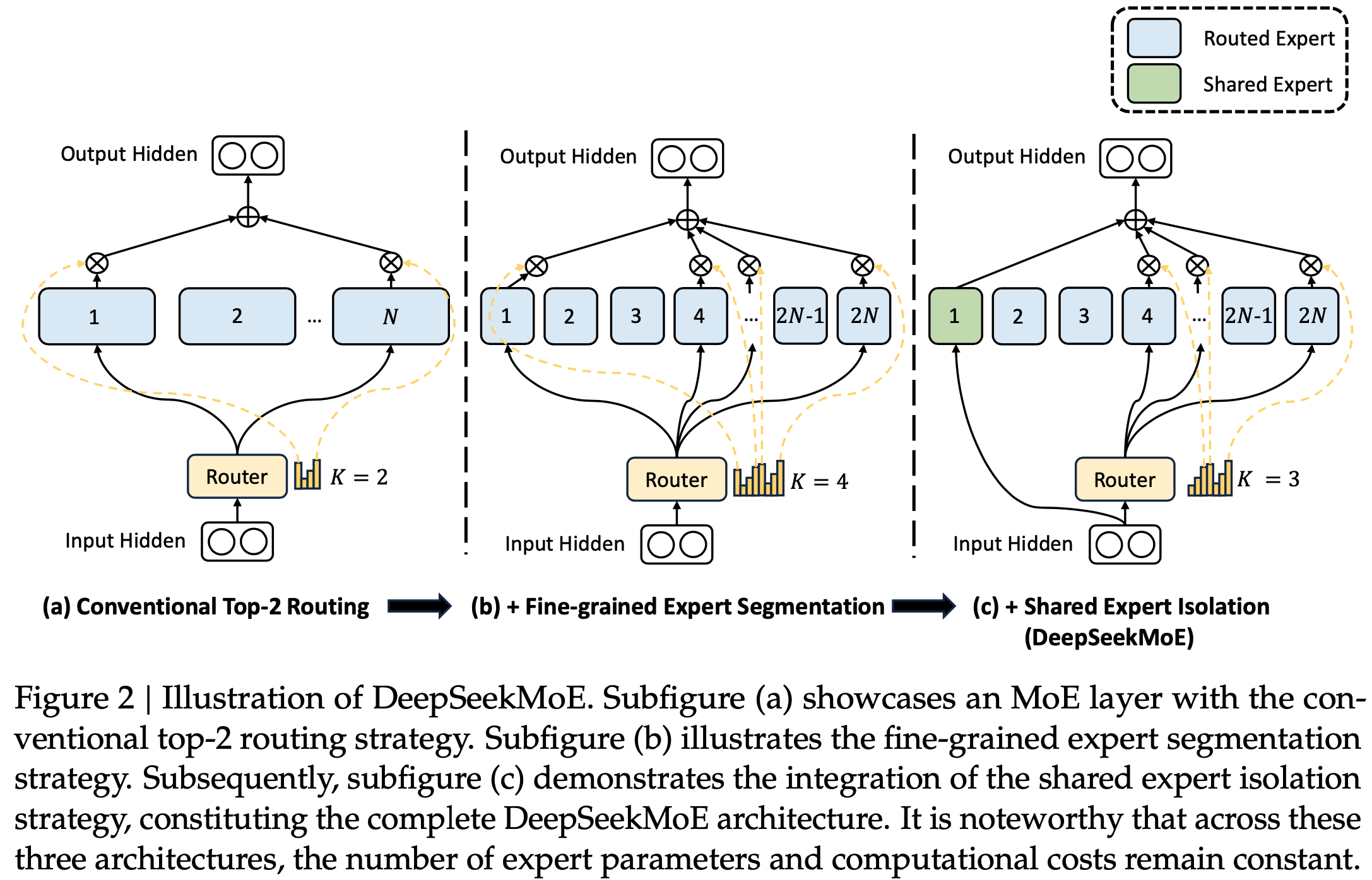
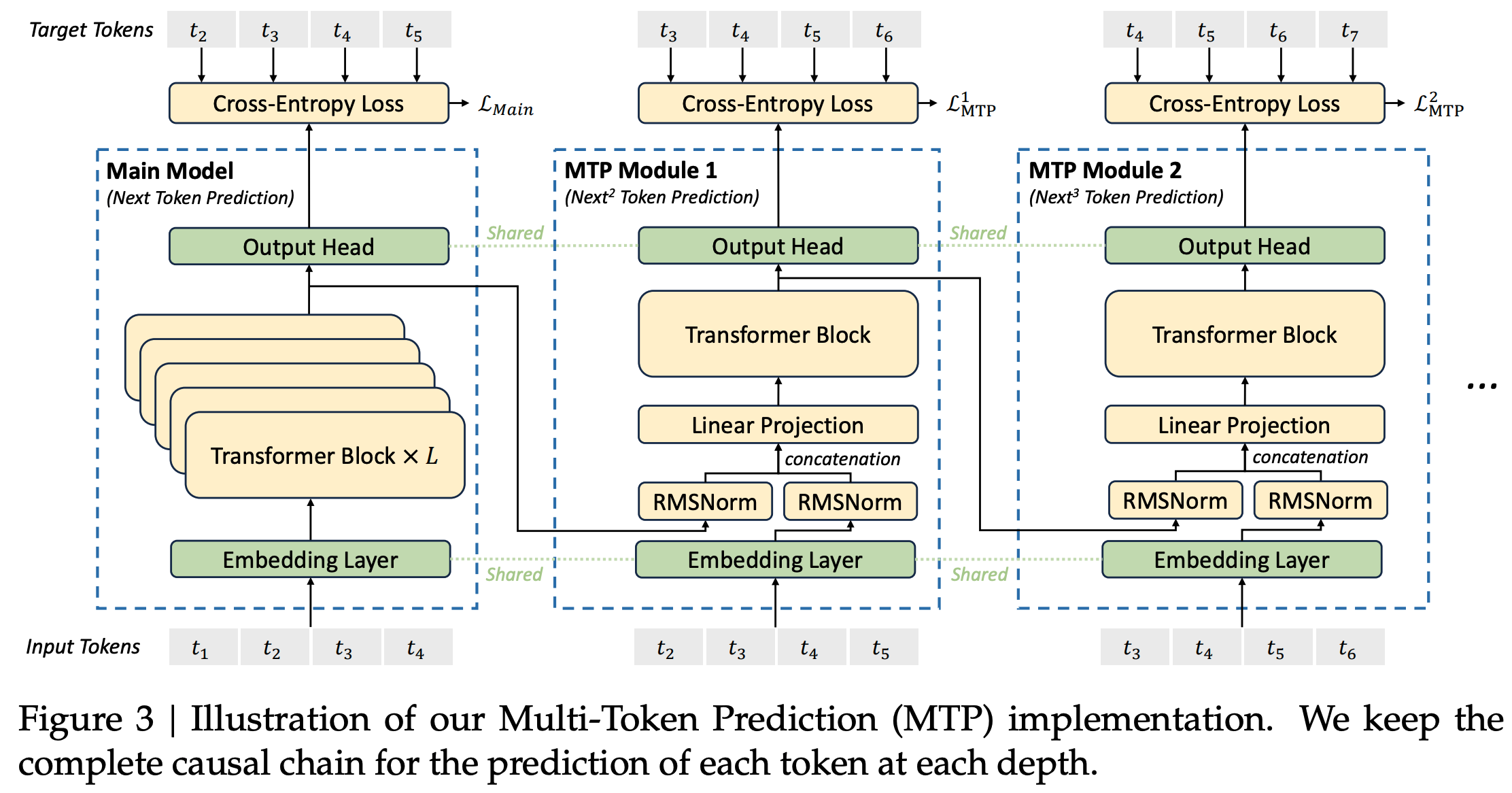
- 参考链接:hydra.cc/docs/intro
整体说明
- Hydra 是一个开源的 Python 框架 ,旨在简化复杂应用程序的配置管理
- Hydra 的核心功能是能够通过组合动态创建分层配置 ,并且可以通过配置文件和命令行轻松覆盖这些配置
- Hydra 的名字来源于神话中的九头蛇(Hydra) ,象征着它能够轻松地使用不同配置运行多个相似的作业(即 Multirun 功能),这在机器学习和科学实验中尤其有用
- Hydra 的主要特点总结如下
- 分层配置 (Hierarchical Configuration): 配置可以从多个独立的配置文件组合而成
- 命令行覆盖 (Command-Line Overrides): 能够通过命令行参数轻松修改配置的任何部分
- 多任务运行 (Multirun): 使用一个命令就能运行多次实验,每次实验使用不同的配置组合
- 配置快照 (Configuration Snapshots): 自动保存每次运行的完整配置,确保结果的可复现性
- 工作目录管理 (Working Directory Management): 每次运行都会在
outputs/或multirun/目录下创建一个以日期和时间命名的新目录,将运行结果和日志隔离
- Hydra 常常和 omegaconf 包一起使用
Hydra 安装
通过
pip安装hydra-core:1
pip install hydra-core --upgrade
- 依赖的
omegaconf包会自动安装
- 依赖的
常用示例(必会)
文件结构
1
2
3
4
5
6
7
8
9
10
11
12tree
.
├── config
│ ├── color
│ │ ├── blue.yaml
│ │ └── green.yaml
│ ├── config.yaml
│ ├── config2.yaml
│ └── person
│ ├── alice.yaml
│ └── bob.yaml
└── hydra_demo.py./config/color/blue.yaml文件内容1
2favorite_color: blue
time: 10./config/color/green.yaml文件内容1
favorite_color: green
./config/person/alice.yaml文件内容1
2name: Alice
age: 30./config/person/bob.yaml文件内容1
2name: Bob
age: 25config/config2.yaml文件内容:1
name_aux: 100
config/config.yaml文件内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14# 定义到 defaults 的一定是配置文件,没有配置文件会出错,索引方式见下图
defaults:
# - _self_ # 放到最前面则用下面的默认参数覆盖当前文件定义(比如 person:name:0)
- person: alice # 索引 ./person/alice.yaml,也可以被参数覆盖
- color: blue # 索引 ./blue/blue.yaml,直接效果与 - color/blue 等价,但 - color/blue 覆盖参数需要使用 `+`,不建议使用
- person@aux_person: bob # 索引 ./person/bob.yaml,同时重命名为 aux_person,后续通过 "aux_person" 替换 ”person" 作为引用
- config2 # 直接引用同步目录下的其他文件,相关字段会被 config2.yaml 更新
- _self_ # 放到最后则用当前文件定义覆盖前面的默认参数(比如 person:name:0)
# 可以在这里添加其他全局配置
full_name: "${person.name} Li" # 全局参数,要等到所有解析完成才解析这里,所以不用担心先后顺序,这个总是最后执行的
modes: ??? # ??? 的变量比较特殊,在通过命令行传入该参数值前,无法直接使用,否则会报错:omegaconf.errors.MissingMandatoryValue: Missing mandatory value: modes
person:
name: "lilian" # 当前文件定义参数,是否覆盖引入的默认值与 `_self_` 的位置有关
ENV_PATH: ${oc.env:PATH} # 读取环境变量 $PATH,环境变量不存在会出错hydra_demo.py文件内容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import hydra
from omegaconf import OmegaConf
import json
def main(cfg):
print("===== to yaml =====:")
print(OmegaConf.to_yaml(cfg))
print("===== parse to json =====:")
dict_obj = OmegaConf.to_container(cfg, resolve=True)
json_str = json.dumps(dict_obj, indent=4, ensure_ascii=False)
print(json_str)
if __name__ == '__main__':
main()执行命令1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36python hydra_demo.py
# ===== to yaml =====:
# person:
# name: lilian
# age: 30
# color:
# favorite_color: blue
# time: 10
# aux_person:
# name: Bob
# age: 25
# name_aux: 100
# full_name: ${person.name} Li
# modes: ???
# ENV_PATH: ${oc.env:PATH}
#
# ===== parse to json =====:
# {
# "person": {
# "name": "lilian",
# "age": 30
# },
# "color": {
# "favorite_color": "blue",
# "time": 10
# },
# "aux_person": {
# "name": "Bob",
# "age": 25
# },
# "name_aux": 100,
# "full_name": "lilian Li",
# "modes": "???",
# "ENV_PATH": "/Users/jiahong/.nvm/versions/node/v12.14.0/bin:/usr/local/opt/node@16/bin:/Users/jiahong/anaconda3/envs/torch_py310/bin:/Users/jiahong/anaconda3/condabin:/usr/local/bin:/System/Cryptexes/App/usr/bin:/usr/bin:/bin:/usr/sbin:/sbin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/local/bin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/bin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/appleinternal/bin"
# }执行命令2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38python hydra_demo.py +new_name=Joey person=bob color.time=15
# ===== to yaml =====:
# person:
# name: lilian
# age: 25
# color:
# favorite_color: blue
# time: 15
# aux_person:
# name: Bob
# age: 25
# name_aux: 100
# full_name: ${person.name} Li
# modes: ???
# ENV_PATH: ${oc.env:PATH}
# new_name: Joey
#
# ===== parse to json =====:
# {
# "person": {
# "name": "lilian",
# "age": 25
# },
# "color": {
# "favorite_color": "blue",
# "time": 15
# },
# "aux_person": {
# "name": "Bob",
# "age": 25
# },
# "name_aux": 100,
# "full_name": "lilian Li",
# "modes": "???",
# "ENV_PATH": "/Users/jiahong/.nvm/versions/node/v12.14.0/bin:/usr/local/opt/node@16/bin:/Users/jiahong/anaconda3/envs/torch_py310/bin:/Users/jiahong/anaconda3/condabin:/usr/local/bin:/System/Cryptexes/App/usr/bin:/usr/bin:/bin:/usr/sbin:/sbin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/local/bin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/bin:/var/run/com.apple.security.cryptexd/codex.system/bootstrap/usr/appleinternal/bin",
# "new_name": "Joey"
# }
Multi-run:启动多个配置运行
启动方式:
1
2
3# 两种启动方式等价
python my_app.py --multirun db=mysql,postgresql schema=warehouse,support,school
python my_app.py -m db=mysql,postgresql schema=warehouse,support,school- 以上启动会生成6份任务,且串行执行
使用
--multirun启动的任务配置记录在multirun/文件夹下(单任务启动方式的记录在outputs/下)
Multi-run 的高阶用法
通过覆盖
hydra.sweeper.param实现启动多个任务1
2
3
4
5hydra:
sweeper:
params:
db: mysql,postgresql
schema: warehouse,support,school启动命令:
1
2
3
4
5python my_app.py -m db=mysql
# [2021-01-20 17:25:03,317][HYDRA] Launching 3 jobs locally
# [2021-01-20 17:25:03,318][HYDRA] #0 : db=mysql schema=warehouse
# [2021-01-20 17:25:03,458][HYDRA] #1 : db=mysql schema=support
# [2021-01-20 17:25:03,602][HYDRA] #2 : db=mysql schema=school
日志文件说明
每次执行命令后都会按照时间生成日志文件
1
2
3
4
5
6
7$ tree outputs/2024-09-25/15-16-17
outputs/2024-09-25/15-16-17
├── .hydra
│ ├── config.yaml
│ ├── hydra.yaml
│ └── overrides.yaml
└── my_app.logconfig.yaml: A dump of the user specified configurationhydra.yaml: A dump of the Hydra configurationoverrides.yaml: The command line overrides usedmy_app.log: A log file created for this run- 用 Python 文件命令的日志文件,记录被
@hydra.main注解过的函数中的log对象输出1
2
3
4
5
6
7
8
9
10
11
12
13import logging
log = logging.getLogger(__name__)
def main(config):
log.info("Info level message")
log.debug("Debug level message") # 若输出日志的等级包含 debug,则这句话也会输出到日志文件
pass
if __name__ == '__main__':
log.info("out info") # 不会输出到日志文件中(因为不在 `@hydra.main` 注解过的函数中)
main()
- 用 Python 文件命令的日志文件,记录被
特别需要注意的点
- 参数覆盖规则:
- 传入的参数 > 后定义的参数 > 先定义的参数
- 传入参数的规则:
- 被覆盖的参数必须是存在的,如
name=Joe要求name已经存在,若不存在则会报错 - 不存在的参数就需要使用
+增加参数,如+name=Joe(少用) - 如果存在的参数上使用
+name=Joe也会出现错误(不可以同时出现两个相同的 key) - 注:由于传入的参数会影响生效的子配置文件,自配置文件的参数配置命名上可能不同,所以参数的判定有一定的复杂性
- 被覆盖的参数必须是存在的,如
- 对于子配置可以使用动态方式添加(
+),但建议使用defaults关键字定义,方便管理,定义后可以被正常覆盖(不再需要+)
附录:使用 Structured Config
在新增加文件的情况下,也可以使用 Python 类定义对象实现类似
yaml文件的效果(不常用)示例(无需任何
yaml文件配置):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20from dataclasses import dataclass
import hydra
from hydra.core.config_store import ConfigStore
class MySQLConfig:
host: str = "localhost"
port: int = 3306
cs = ConfigStore.instance()
# Registering the Config class with the name 'config'.
cs.store(name="config", node=MySQLConfig)
def my_app(cfg: MySQLConfig) -> None:
if cfg.port == 80:
print("Is this a webserver?!")
if __name__ == "__main__":
my_app()- 等价于有了
config.yaml配置文件,写入了下面的信息1
2
3# config.yaml
'host': 'localhost'
'port': 3306
- 等价于有了
更高阶的层级示例(参考自:https://hydra.cc/docs/tutorials/structured_config/hierarchical_static_config/):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30from dataclasses import dataclass
import hydra
from hydra.core.config_store import ConfigStore
class MySQLConfig:
host: str = "localhost"
port: int = 3306
class UserInterface:
title: str = "My app"
width: int = 1024
height: int = 768
class MyConfig:
db: MySQLConfig = field(default_factory=MySQLConfig)
ui: UserInterface = field(default_factory=UserInterface)
cs = ConfigStore.instance()
cs.store(name="config", node=MyConfig)
def my_app(cfg: MyConfig) -> None:
print(f"Title={cfg.ui.title}, size={cfg.ui.width}x{cfg.ui.height} pixels")
if __name__ == "__main__":
my_app()更多详情参考:
附录:运行时文件工作路径获取
- 使用 Python 命令获取,详情见原始路径
- 参考链接:https://hydra.cc/docs/tutorials/basic/running_your_app/working_directory/
附录:调试参数配置情况
- 在命令中添加
--cfg job等来输出自己的配置job: 个人配置参数生效情况,包括命令行传入的参数,这里是最终生效参数情况hydra: Hydra’s configall: The full config, which is a union of job and hydra. 二者融合
- 参考链接:https://hydra.cc/docs/tutorials/basic/running_your_app/debugging/