RARE: Real-time Ad REtrieval framework
- 参考链接:
整体思路
- 现有的 LLM-based 的召回(retrieval,一些地方也称为检索)方法通过生成 numeric 或 content-based DocIDs 来检索 docs/ads
- 问题 :1)DocIDs 与文档之间的 one-to-few 映射关系;2)耗时的内容提取过程
- 两个问题共同导致语义效率低下,限制了其在大规模语料库中的扩展性
- 注:在本文的写作中,会使用 文档(docs)或者 广告(ads)替代检索目标,而不是普通推荐系统中的 item
- 论文提出了一种实时广告召回(Real-time Ad REtrieval,RARE)框架,该框架利用 LLM 生成的文本作为中间语义表示,直接从 Query 中实时召回广告
- 论文将这些中间语义表示称为商业意图 ,Commercial Intentions (CIs),本质上就是 LLM 输出的剪短的文本
- CIs 是由注入商业知识的定制化(Customized)LLM 生成的(有领域相关性)
- 每个 CI 对应多个广告,从而形成一个轻量级且可扩展的 CIs 集合
- 离线和在线实验验证了 RARE
- 离线:在 4 个主要场景上超过 10 个基线
- 在线 :Consumption+5.04%, GMV+6.37%, CTR+1.28%,Shallow Conversions+5.29%
一些讨论
- 传统召回 :广告系统分召回和排序两个模块,其中召回召回模型常常采用两阶段流程,1)从 Query 中提取关键词;2)利用这些关键词获取广告
- 问题 :现有的两阶段召回方法放大了用户 Query 与人工选择关键词之间的差异,导致大量漏检问题(missed retrieval issues)
- 解决方案 :query-ad 单阶段(直接从Query 到 广告)方法通过直接召回广告解决了漏检问题,但由于推理能力和领域知识的限制,仍难以深入理解商业意图(Commercial Intentions)
- LLM-based 的召回 :大多数 LLM-based 的召回方法(Lin等,2025)首先通过训练模型将文档与其标识符(DocIDs)关联,构建文档索引。在召回阶段,模型处理 Query 并生成相应的 DocIDs(Li等,2023a)
- DSI(Tay等,2022)使用 numeric IDs 表示文档,建立用户 Query 与 numeric IDs 之间的连接;
- LTRGR(Li等,2023b)则提取文档内容(如标题和正文)表示文档,实现从用户 Query 到文档的检索
- 使用复杂的 DocIDs 存在以下缺陷 :
- 第一,由于 DocIDs 与候选之间的 one-to-few 映射关系,推理效率较低(Wang等,2023b),难以在大规模场景中实现实时生成;
- 第二,仅用复杂 DocIDs 表示文档或广告无法充分发挥 LLM 在商业意图挖掘和高级文本生成方面的能力,从而阻碍了对广告商意图的有效探索;
- 第三,其泛化能力较差。当新候选出现时,通常需要重新训练模型或更新 FM-index (Ferragina and Manzini, 2000) 以适应其 DocIDs,难以及时更新或删除候选
- 关键问题提出 :由于广告召回需要实时获取与用户商业意图匹配的大规模广告集合,现有语义效率低下的 DocIDs 在实际任务中既不实用也不适用。因此,利用 LLM 强大的语义能力设计更有效的语义标记索引,并开发更全面的端到端架构,已成为一项关键挑战
- 论文开发了一种名为 RARE 的实时LLM生成广告召回框架。该框架利用 LLM 生成的商业意图(CIs)作为中间语义表示,直接连接 Query 与广告,而非依赖人工选择的关键词或复杂文档标识符,具体方法为:
- 离线为广告生成 CIs,构建索引 :RARE 首先使用注入知识的LLM(离线)为语料库中的广告生成 CIs ,随后筛选出一组有限但全面的 CIs,并构建一个动态索引 ,将这些 CIs 以 one-to-many 的关系映射到对应的广告
- 理解:相对之前的区别是:为候选广告生成 CIs 而不是 DocIDs
- 在线为 Query 生成 CIs,实时召回 :接收到 Query 时,RARE 利用定制化 LLM(在线)实时生成 CIs,并从预构建的索引中召回对应的广告
- 离线为广告生成 CIs,构建索引 :RARE 首先使用注入知识的LLM(离线)为语料库中的广告生成 CIs ,随后筛选出一组有限但全面的 CIs,并构建一个动态索引 ,将这些 CIs 以 one-to-many 的关系映射到对应的广告
- 关键创新 :在于利用定制化 LLM 生成的 CIs 作为中间语义 DocIDs,链接 Query 与广告
- 定制化 LLM 通过对基础 LLM 进行知识注入(knowledge injection)和格式微调(format fine-tuning)开发而成
- 知识注入可融入领域特定信息以增强广告领域的专业性;
- 格式微调则确保LLM仅输出 CIs 并提升解码效率
- CIs 定义为关键词的聚合,由定制化LLM基于广告相关材料生成。与现有精心设计的 DocIDs 相比,CIs 充分利用了LLM的文本生成能力。CIs 与广告之间的 one-to-many 对应关系使得解码过程极为高效
- 问题:为什么 one-to-many 能带来高效的解码?
- 回答:这里是跟 one-to-few 而言的(TIGER 中就属于 one-to-few),他们要实时生成隐空间语义 ID,且多个语义 ID 才对应一个实际的广告,但 one-to-many 相当于生成的 CI 可直接检索很多个广告(离线会构建索引:让一个 CI 对应很多广告)
- 对于新广告 ,RARE 可通过 constrained beam search 生成 CIs,无需重新训练模型
- 传统 query-keyword-ads 范式中的关键词竞价可能引发 index manipulation 问题。与关键词不同,CIs 由具备世界知识和商业专业知识的LLM生成,能够更好地挖掘广告和 Query 背后的商业意图
- 定制化 LLM 通过对基础 LLM 进行知识注入(knowledge injection)和格式微调(format fine-tuning)开发而成
- 论文的主要贡献如下:
- (1)提出了一种名为 RARE 的新型端到端生成召回框架,实现实时召回
- 注:文章中说是首个在百万级数据库上实现实时召回的 LLM 生成架构研究,但忽略了 TIGER?
- (2)提出了一种知识注入与格式微调方法,使基础LLM能够挖掘广告商和用户的深层商业意图,并以 CIs 形式表达
- (3)实现了在线部署 LLM-based 的召回服务
- (4)离线+在线实验
- (1)提出了一种名为 RARE 的新型端到端生成召回框架,实现实时召回
相关工作(直译)
- 广告召回 :传统广告召回(Zhao和Liu,2024;Wang等,2023c)通常遵循 query-keyword-ads 架构,即 Query 召回关键词,再通过关键词拉取广告。该方法包括基于词(word-based)和基于语义(semantic-based)的方法
- Word-based Methods(Ramos等,2003;Robertson等,2009)解析用户 Query 获取关键词,并使用倒排索引召回候选广告;
- Semantic-based Methods(Ramos等,2003;Yates等,2021)则利用双编码器在共享语义空间中获取 Query 和关键词的嵌入,实现基于语义相似性的召回
- 这些方法依赖人工选择关键词,导致大量漏检问题。相比之下,Generative LLM 召回方法(Sun等,2024;Lin等,2024;Tang等,2023b)使用 DocIDs 表示广告,LLM 在接收 Query 时直接生成候选广告对应的 DocID
- Generative LLMs Retriever :生成式召回利用 LLM 的生成能力构建端到端召回模型
- 部分方法(如DSI(Tay等,2022)、NCI(Wang等,2022)、TIGER(Rajput等,2024)以文档ID为生成目标 ,实现 Query 对文档/广告的召回。这些方法利用LLM学习文档/广告与其ID的对应关系,直接生成相关文档/广告的 ID 以完成召回
- 其他方法(如SEAL(Bevilacqua等,2022)和LTRGR(Li等,2023b)则以文档内容为中介实现文档召回,通过FM索引生成文档中出现的片段,辅助 Query 到文档的召回。MINDER(Li等,2023)采用伪 Query 和文档内容进行召回,但显著增加了索引量,不适用于候选集较大的场景
- 语义 DocIDs :LLM生成召回通常使用 DocIDs 执行 Query 到文档的召回任务
- 现有 DocIDs 主要包括 numeric IDs 和文档内容。例如,TIGER中的 numeric IDs 表示为离散语义标记的元组;LTRGR中的文档内容则由文档内预定义序列组成。然而,这些方法使用的语义标记为类ID特征,解码效率较低 ,因为每个DocID仅对应少量候选。对于新候选文档或广告,需重新训练模型或重建FM索引以获取其 DocIDs,难以及时更新或删除广告
RARE 方法整体介绍
- 如图1所示,论文提出了一种新颖的端到端生成式召回架构,专为在线召回设计,命名为实时广告召回(RARE)
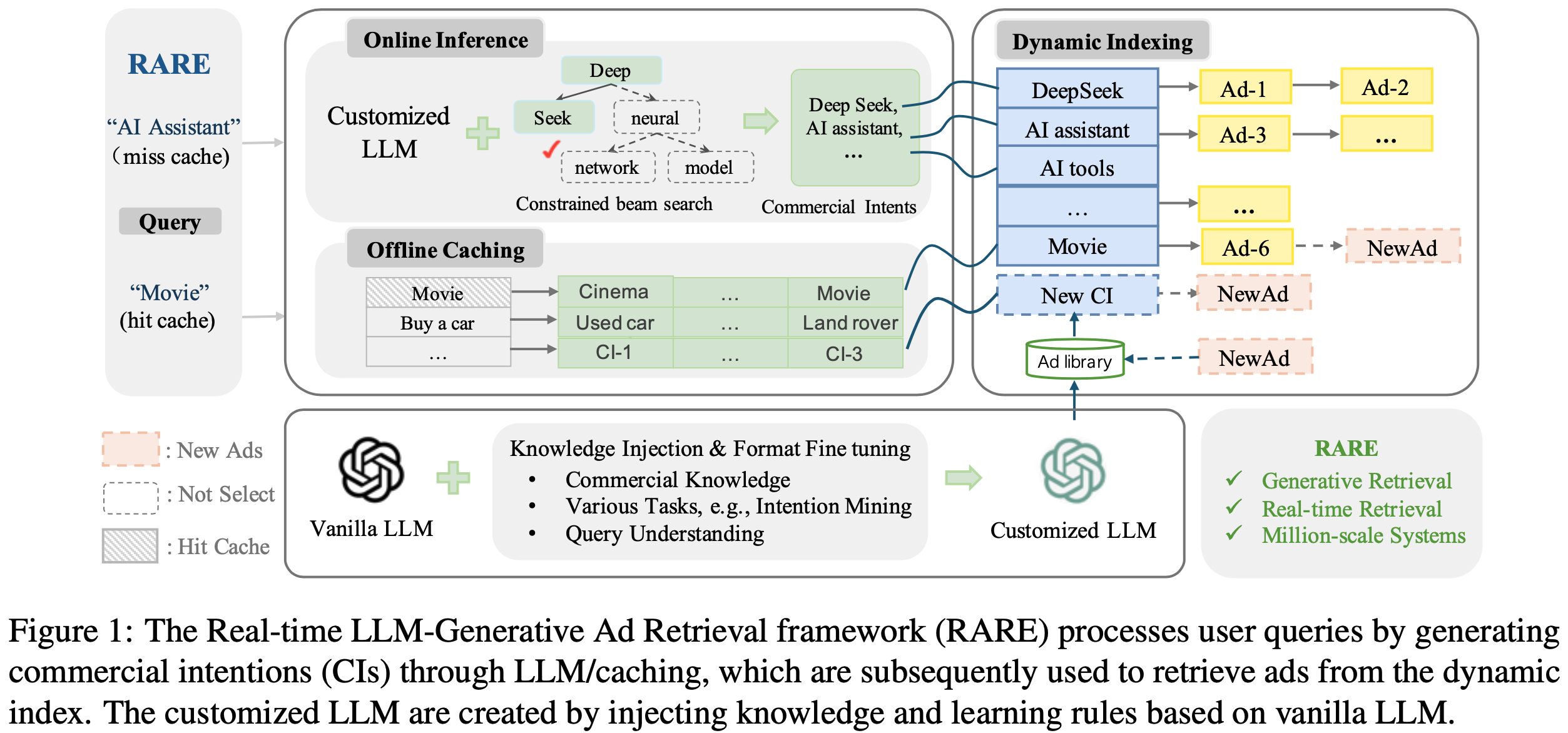
- RARE 有效缩短了链路结构,使广告能够突破关键词竞价的限制,帮助广告主获取更精准的流量
- 问题:如何理解“突破关键词竞价的限制”?
- 图2给出了 RARE 与传统召回方法的一个对比:
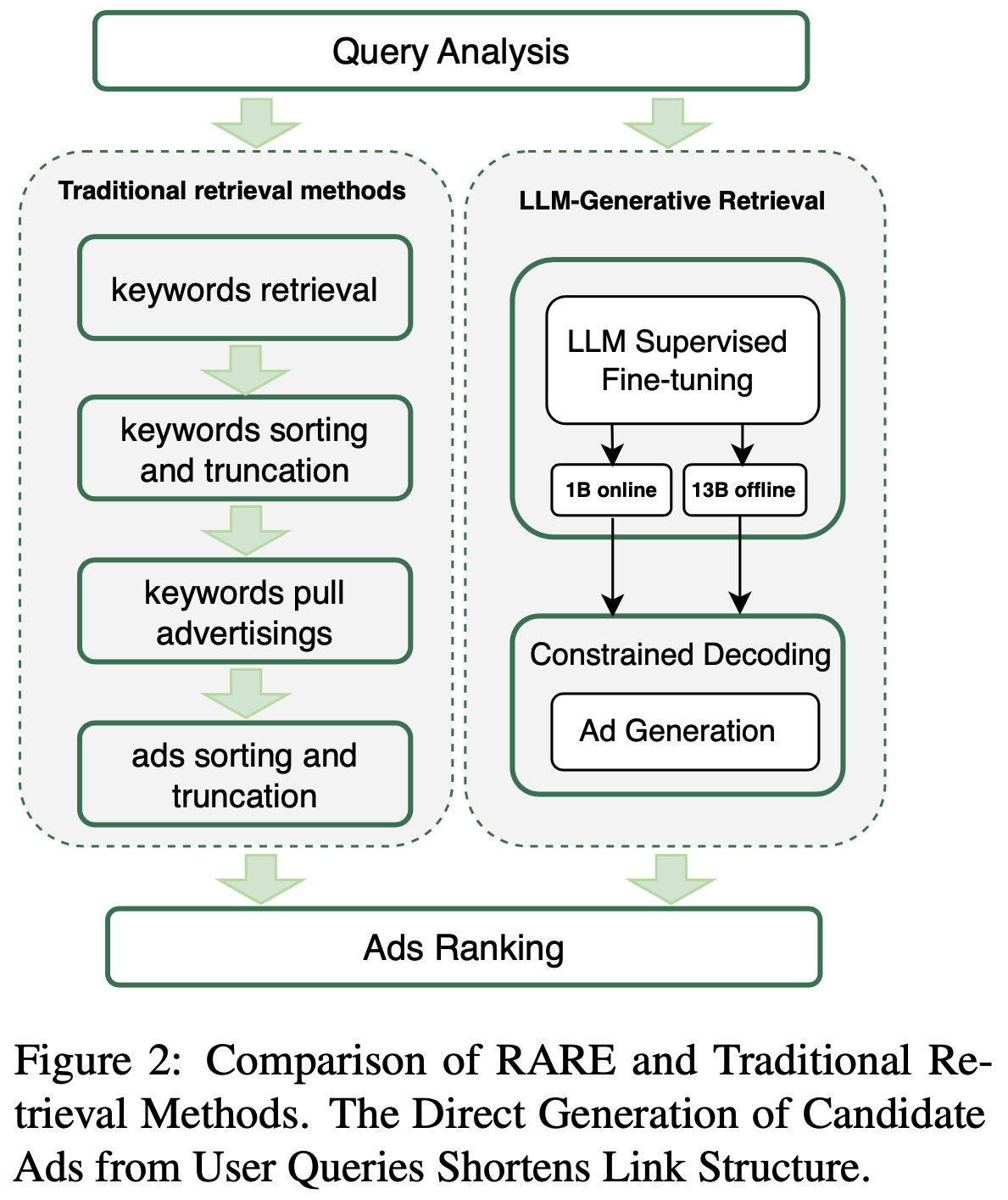
端到端生成式架构
- 当接收到用户 Query 时,RARE 首先生成对应的具有特定语义的文本,即商业意图(CIs),随后利用这些 CIs 召回最终的广告
- CIs 到广告的索引构建过程以及召回流程如下:
- 索引构建(Indexing) :RARE 首先生成整个广告库的 CIs 并确定商业意图集合,随后构建 CIs 到广告的倒排索引
- 对于后续新增的广告,基于当前商业意图集合进行约束推理 ,确保每个新候选广告能够准确更新至索引中
- 值得注意的是,CIs 是由定制化 LLM 生成的具有特定语义的文本,用于挖掘广告的商业意图。具体实现细节将在 3.3节 讨论
- 召回流程(Retrieval) :基于离线缓存和在线推理,为 Query 实时生成 CIs
- 高频 Query 的 CIs 会被存储在缓存中,当 Query 到达时,RARE 首先检查当前 Query 是否匹配缓存条目
- 若匹配,则直接使用对应的 CIs 获取广告;
- 否则,RARE 会使用定制化 LLM 结合 constrained beam search 进行实时推理(具体实现细节将在原文 3.4节 介绍)
- 高频 Query 的 CIs 会被存储在缓存中,当 Query 到达时,RARE 首先检查当前 Query 是否匹配缓存条目
- 索引构建(Indexing) :RARE 首先生成整个广告库的 CIs 并确定商业意图集合,随后构建 CIs 到广告的倒排索引
定制化 LLM
- 为了挖掘广告和用户 Query 背后的深层意图,论文通过知识注入和格式微调两个阶段对基础 LLM 进行定制化
- 阶段1:知识注入 :此阶段旨在将广告领域的专业知识注入基础 LLM 中,使其能够理解广告和用户 Query 的商业意图。知识数据包括 Query 意图挖掘、广告意图挖掘以及广告词购买等任务。知识注入过程可形式化表示为:
$$
\theta^{\prime}=h(\theta,K),
$$- 函数 \( h \) 以 LLM 模型参数 \( \theta \) 和广告知识数据 \( K \) 为输入 ,输出更新后的模型参数 \( \theta^{\prime} \)
- 新参数 \( \theta^{\prime} \) 用于生成预测结果,即:
$$
y=P(y|x;\theta^{\prime}).
$$
- 阶段2:格式微调 :在具备商业知识的 LLM 基础上,此阶段专注于优化生成 CIs 的格式并提升其多样性。格式微调的训练数据来自真实线上数据,并进行了必要的格式调整。格式微调的生成损失如下:
$$
L(\theta)=\frac{1}{N}\sum_{i=1}^{N}\sum_{t=1}^{T_{i} }logp(y_{i,t}|y_{i<t},x_{i};\theta),
$$- 微调数据集为 \( D=(x_{i},y_{i})_{i=1}^{N} \),\( x_{i} \) 为输入序列,\( y_{i} \) 为目标输出序列
- 概率 \( p(\cdot) \) 是由参数为 \( \theta \) 的模型基于 \( x_{i} \) 和已生成词 \( y_{i < t} \) 预测的概率
- 问题:\(x_i\) 是历史序列吗?\(y_i\) 和 \(x_i\) 都是广告吗?
- 定制化LLM显著增强了其理解和提取广告与用户 Query 意图的能力。它将广告压缩并总结至商业意图空间、聚类相似的广告,从而减少同质化召回,提升在线和离线的召回性能
索引构建
- 论文使用定制化 LLM 生成广告的商业意图(CIs),随后构建 CIs 到广告的倒排索引
- 商业意图(CIs) :CIs 是由定制化 LLM 生成的简短文本 ,用于描述用户或广告的商业意图。给定包含广告信息(如标题、描述等)的提示,定制化 LLM 会生成对应的 CIs。例如,对于广告标题“新款智能手机限时优惠”,生成的 CIs 可能包括“智能手机促销”、“限时折扣”和“电子产品优惠”
- 动态索引 :CIs 与广告之间是 one-to-many 的关系 ,即一个 CI 可能对应多个广告。论文基于这种关系构建动态索引,支持高效召回。对于新增广告 ,RARE 通过约束推理生成其 CIs,无需重新训练模型或更新索引结构
高效推理
- 高效推理对于从数百万候选集中实时召回至关重要,因为搜索广告对召回时间有严格要求
- constrained beam search :本工作采用 constrained beam search 算法生成商业意图(CIs),确保模型输出限定在预定义的 CIs 集合内
- 论文开发了基于 CUDA 的 constrained beam search 实现,并将其与 LLM 推理过程集成,支持并行生成 Beam size 的 CIs,从而提升解码效率
- 此外,在 constrained beam search 框架中引入了截断功能,允许丢弃低分单标记以提升模型输出的准确性。具体约束过程如 图3 所示(新的广告加入时,为其生成对应的 CIs,然后将其加入到这些 CIs 的检索列表中,注意,从图1中看还可以加入新的 CIs)
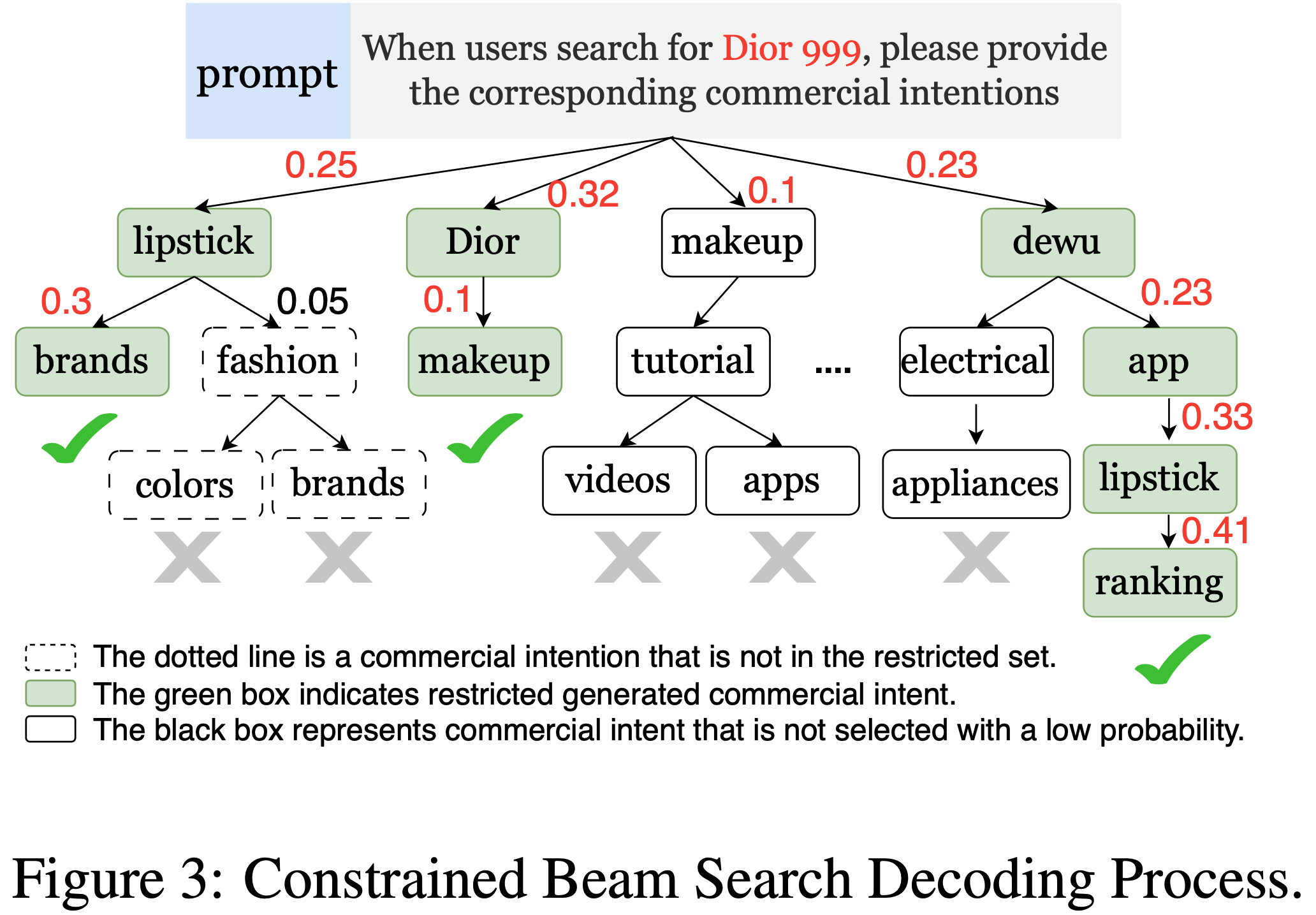
- 缓存技术 :搜索系统呈现显著的长尾效应 ,其中 5% 的 Query 占据了总 Query 请求的 60%
- 为了提升推理效率,论文对这些高频 Query 进行离线推理和存储 ,当用户提交 Query 时,系统首先检查离线缓存
- 若命中,则立即返回结果;
- 否则,由推理服务处理请求
- 为了提升推理效率,论文对这些高频 Query 进行离线推理和存储 ,当用户提交 Query 时,系统首先检查离线缓存
- 离线处理对时间要求较低,因此论文使用 13B 规模的 LLM 处理这些 Query。在线推理有严格的时延要求(通常在毫秒级完成),因此使用 1B 规模的小模型
- 通过缓存数百万头部 Query 的离线结果,论文能够减少 70% 的在线机器消耗,不仅降低推理时间,还提升了头部 Query CIs 的质量
相关实验和讨论
Experiment Setup
- 训练数据集 :为了使基础LLM具备商业知识,论文使用了商业知识和合成数据。原始数据来自真实在线日志,通过开源LLM执行 Query 意图挖掘和广告意图挖掘等任务生成最终合成数据。格式微调主要涉及 Query 和广告的商业意图(CIs),这些数据来自真实在线交互,并按固定规则组合。详情参见附录A的表4
- 评估数据集 :为了评估模型效果,论文从真实场景中收集了一天内头部 Query 及其对应点击广告的数据。清洗后,得到5,000条 Query 和150,000条广告作为基准数据,每条 Query 最多包含 1,000 个候选广告
- 基线方法 :论文将 RARE 与 10 种竞争基线方法进行比较,涵盖四大类别,包括基于关键词的 BM25、基于语义的 BERT、基于生成的 T5 以及 LLM-based 的 Qwen 等
- BM25 :将 Query 分割为词项并计算相关性得分,最终累加得到文本相似度结果
- BERT-small :使用 4 层 Transformer 网络,隐藏层大小为 768,参数约 52.14M
- BERT-base :使用 12 层 Transformer 网络,隐藏层大小为 768,共 12 个头,参数约 110M
- SimBert-v2-R :结合生成与召回能力的模型,用于计算句子向量
- T5 :基于生成的强基线,通过大量在线点击 Query 和关键词微调
- DSI :使用语义ID进行召回的典型方法
- Qwen-1.8B 和 Hunyuan-2B :参数规模与 RARE 相近的模型,通过格式微调确保仅生成 CIs
- 评估指标 :
- 广告覆盖率(ACR, Ad Coverage Rate) :在广告检索中,ACR表示覆盖率,即召回广告的请求占总请求的比例。如公式5所示,AdPV表示召回广告的请求数量,PV表示总请求数量
$$ ACR = AdPV / PV \tag{5} $$ - 命中率(HR@K, Hit Ratio) :如公式6所示,GT表示候选广告的真实集合,Hits@K表示在检索结果的前K个候选中属于真实集合的相关广告数量
$$ HR@K = \frac{Hits@K}{|GT|} \tag{6} $$ - 平均精度均值(MAP, Mean Average Precision) :是所有查询的平均精度(AP)的均值,如公式7所示
$$ MAP = \frac{\sum_{q \in Q} AP_q}{|Q|} \tag{7} $$ - 平均精度(AP, Average Precision) :如公式8所示
$$ AP_q = \frac{1}{|\Omega_q|} \sum_{i \in \Omega_q} \frac{\sum_{j \in \Omega_q} h(p_{qj} < p_{qi}) + 1}{p_{qi} } \tag{8} $$- \(\Omega_q\) 表示 ground-truth results
- \(p_{qj}\) 表示广告 \(ad_j\) 在生成列表中的位置
- \(p_{qj} < p_{qi}\) 表示广告 \(ad_j\) 在列表中排在广告 \(ad_i\) 之前
- 理解:对 ground-truth results 中的任意一个位置 \(p_{qi}\),希望出现在它前面的广告中,包含在 ground-truth results 中的数量越多越好;
- 举例1:最完美的情况是所有 ground-truth results 都排在最前面,则该值为 1
- 举例2:最极端的情况,如果有些 ground-truth results 的广告排在了最后,则该值非常小
- 广告覆盖率(ACR, Ad Coverage Rate) :在广告检索中,ACR表示覆盖率,即召回广告的请求占总请求的比例。如公式5所示,AdPV表示召回广告的请求数量,PV表示总请求数量
- 实现细节
- 使用 Hunyuan 作为主干模型,参数包括 1B-Dense-SFT 和 13B-Dense-SFT
- 离线缓存使用13B模型,Beam Search 大小为 256,温度系数为 0.8,最大输出长度为 6
- 在线推理使用1B模型,Beam Search 大小为 50,温度系数为 0.7,最大输出长度为 4,确保延迟在 60ms 内
- 新广告的 CIs 每小时更新索引 ,整个 CIs 集合每月更新一次 ,并定期注入新商业知识
实验结果
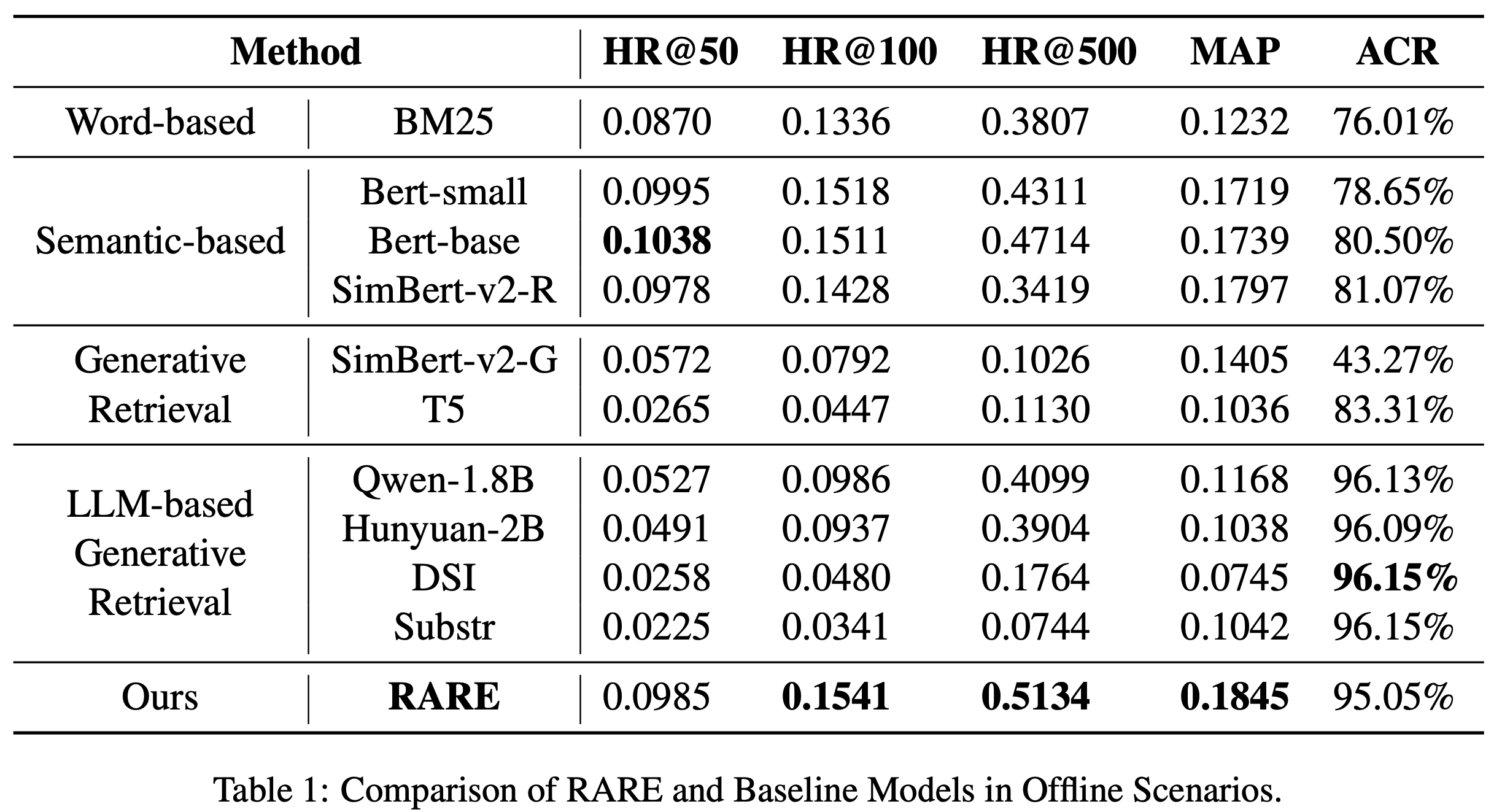
离线评估
- 表1展示了 RARE 与 10 种基线方法在工业评估数据集上的对比结果。RARE 在 HR@500 和 MAP 上表现优异,同时保持高 ACR,表明其能够理解用户搜索意图并优化广告投放。其 ACR 超过90%,HR@500的高值验证了其召回高商业价值广告的能力
消融研究
- 论文通过两种消融研究分析各组件贡献:
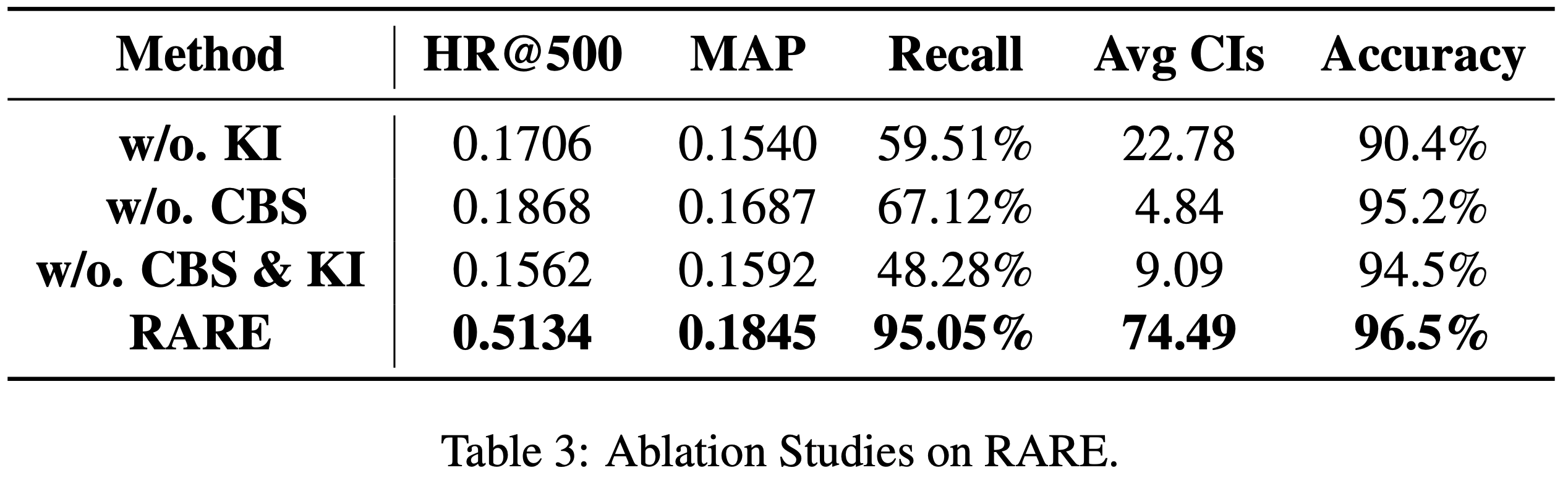
- 表3展示了 RARE 在不同设置下的广告召回结果:
- w/o. KI(无知识注入):召回率仅为 59.51%,显著低于 RARE 的95.05%
- w/o. CBS(无 constrained beam search ):平均 CIs 数量仅为 4.84,显著低于 RARE 的 74.49
- w/o. CBS & KI :HR@500、MAP 和 ACR 均为最低
- 注:附录C 的表5通过案例定性分析了各组件的作用
在线A/B测试
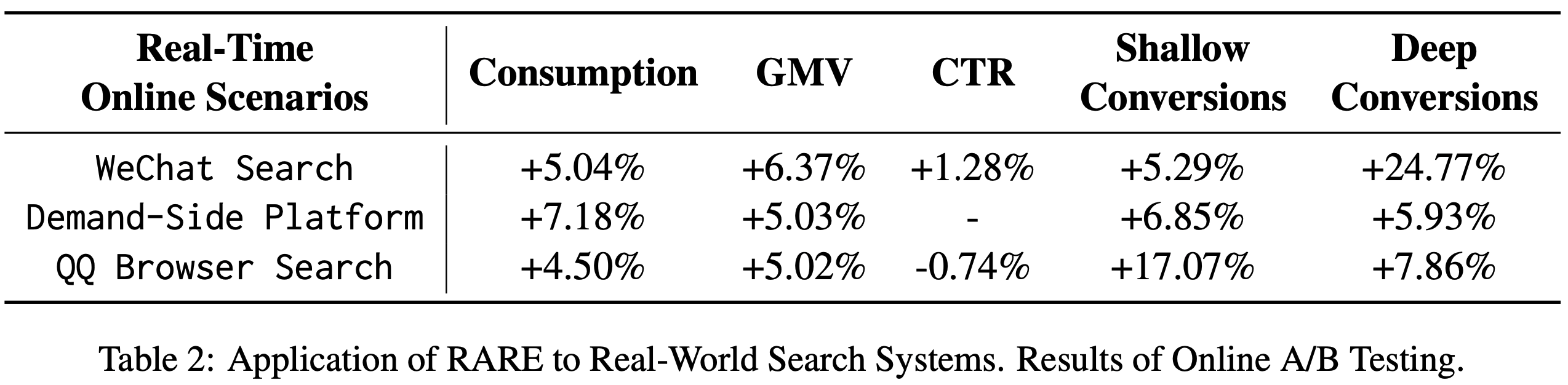
- 论文将 RARE 应用于腾讯三个在线召回场景(每日请求数十亿):
- 微信搜索(WTS) :消费提升5.04%,GMV提升6.37%,CTR提升1.28%,浅层转化提升5.29%,深层转化显著提升24.77%
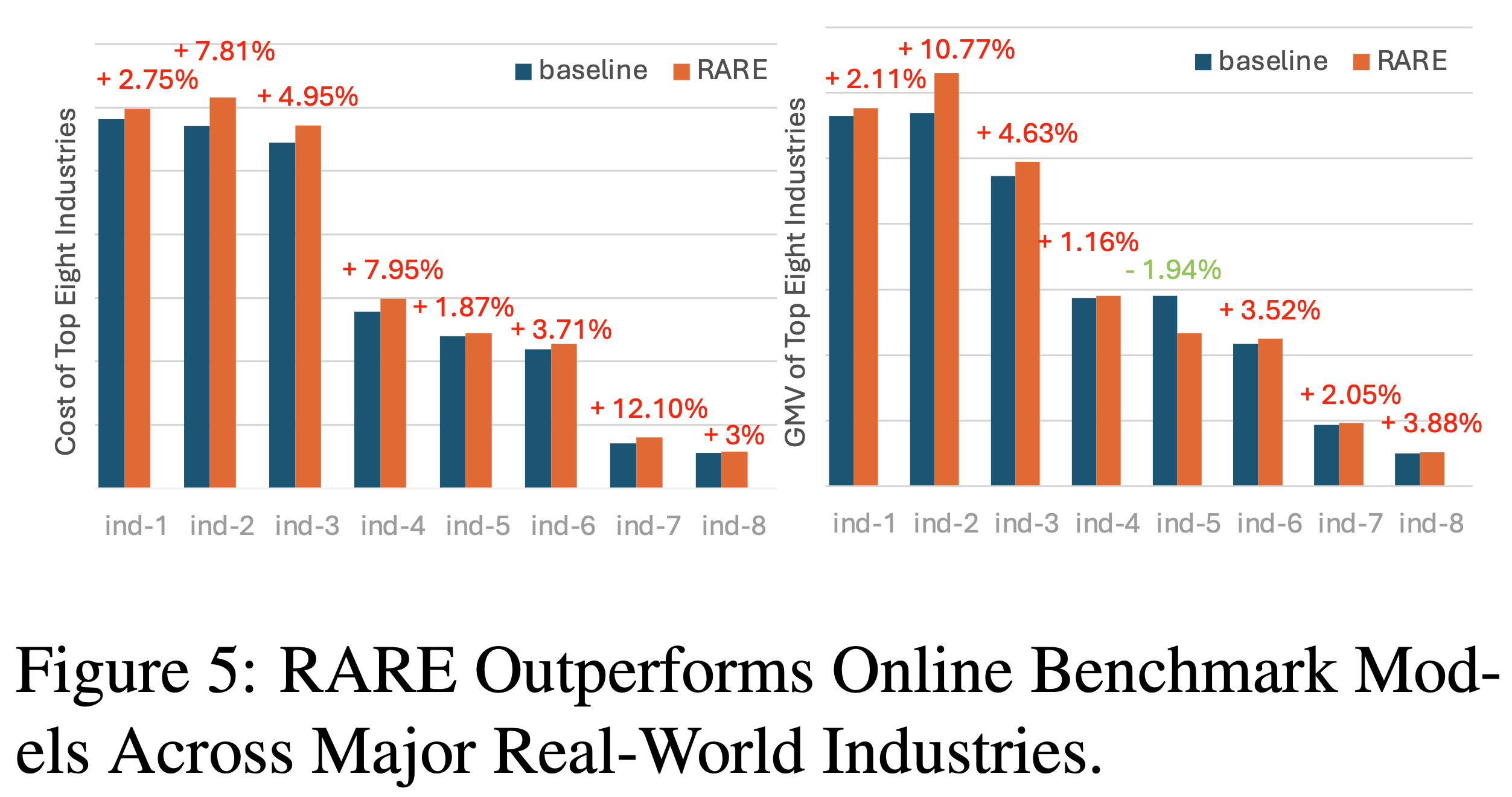
- 需求方平台(DSP)和QQ浏览器搜索(QBS) :也观察到显著收益(表2),图5进一步展示了 RARE 在八大行业的有效性
在线推理支持
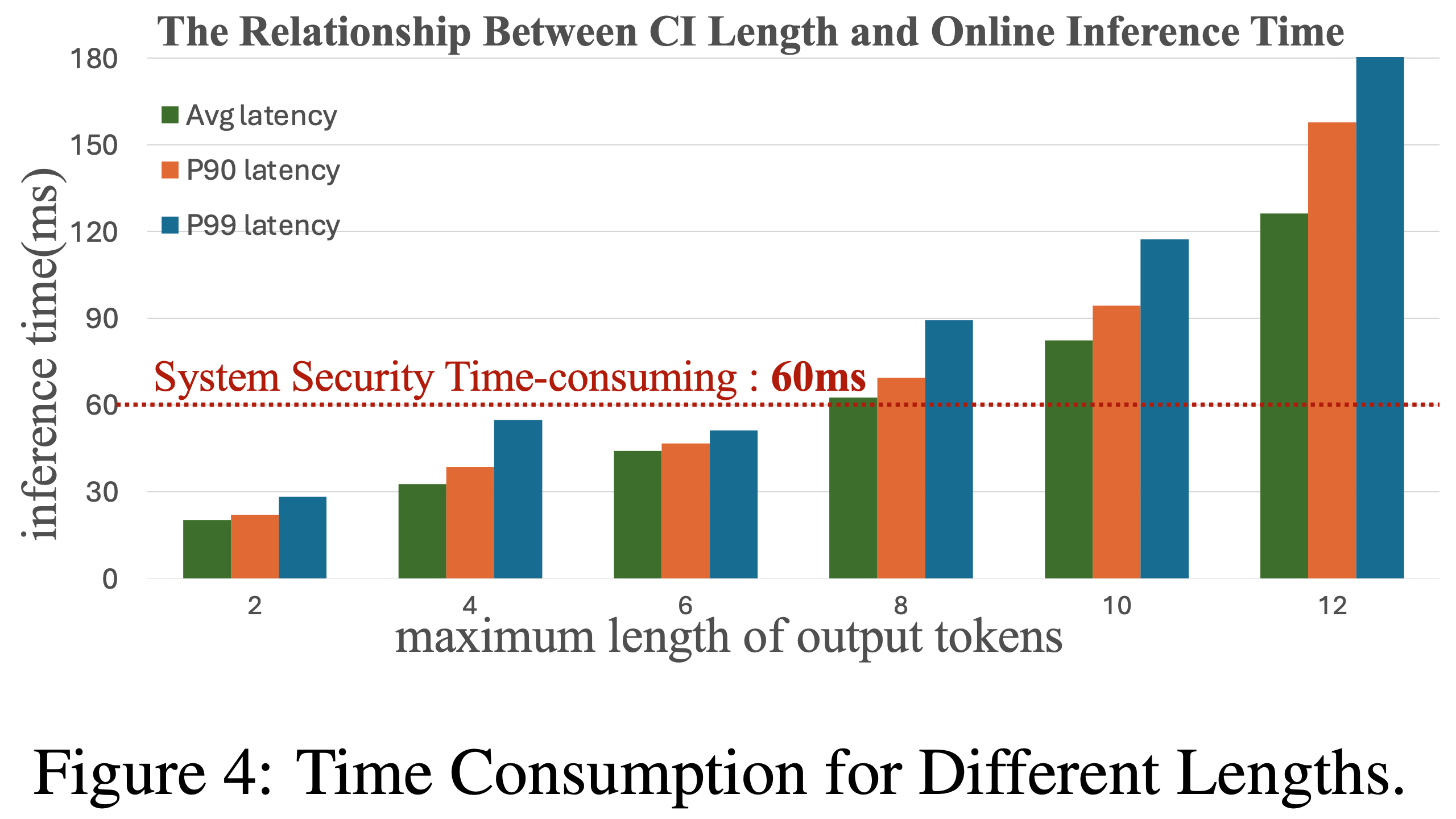
- 图4显示了实时在线推理中不同输出长度的时间消耗。CIs 平均词数为3,确保满足安全阈值。论文开发了专用GPU集群(数百台L40),量化模型至FP8精度,每台L40支持约30 QPS,缓存命中率达65%,显著降低了计算成本
附录A 微调数据
- 本节主要介绍微调数据的细节。定制化 LLM 的微调包括两个阶段:知识注入和格式微调
- 知识注入阶段的微调数据主要包括 Query 意图挖掘、广告意图挖掘和广告词购买。我们将包含广告和用户信息的提示输入开源LLM(如ChatGPT),获取包含丰富推理过程与指导信息的输出,随后将这些数据作为知识注入Hunyuan模型,在微调阶段注入大量数据(规模达数十万或数百万)可能导致LLM丢失通用知识与推理能力,因此本阶段仅针对每项任务精选2,000条实例。表4详细展示了这两个阶段的微调数据
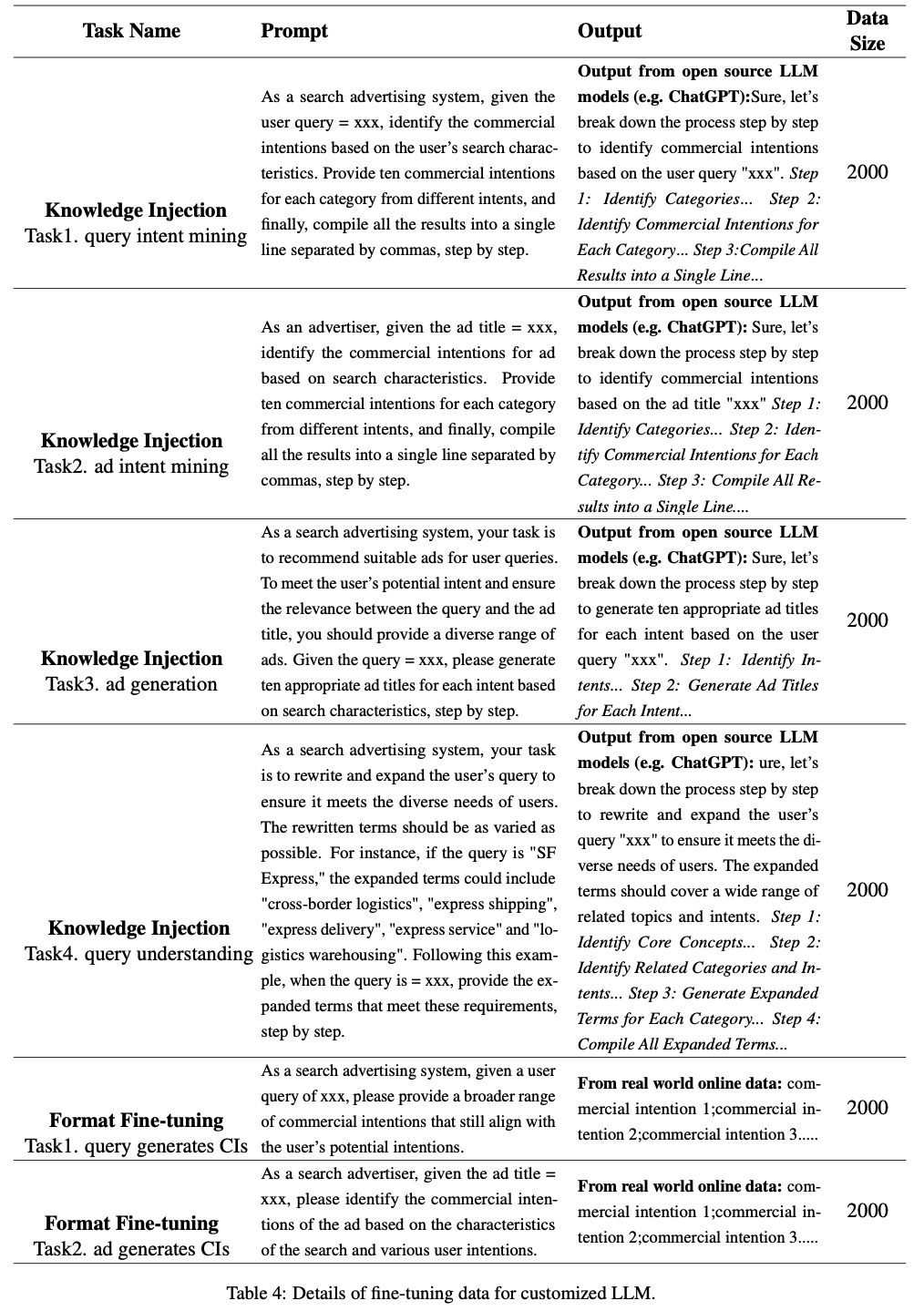
附录B 相关工作
- 束搜索(Beam Search) :作为一种启发式搜索的解码策略, Beam Search 已被广泛应用于多项研究。例如,DSI使用 Beam Search 生成排序后的候选文档列表,TIGER通过 Beam Search 一次性生成多个候选商品ID。早在数年前,seq2seq 与 constrained Beam Search 的结合已在实体链接和文档检索任务中实现了效果与效率的双赢。例如GENRE[3]将 constrained Beam Search 应用于文档检索任务并达到SOTA性能
- Query-关键词-广告架构(Query-kwds-ads Architecture) :传统 Query -关键词-广告方法存在两大缺陷:
- (1) 关键词由广告主手动选择,质量参差不齐,可能导致匹配范围过宽或过窄,造成流量匹配效率低下;
- (2) 广告主常购买大量关键词,导致关键词反转后的广告检索效率受损,给系统带来沉重负担
- 相比之下,商业意图(CIs)由注入领域知识的LLM生成,能更精准体现广告主意图并与相关流量匹配,既带来经济效益,也保障系统长期健康运行
- 基于编码器的LLM检索器(Encoder-based LLMs Retriever) :基于编码器的检索器利用LLM的语义能力获取文本嵌入[9]。例如:
- cpt-text[21]通过对比学习从头训练GPT-3[5],生成高质量文本嵌入;
- GTR[22]基于 T5 模型[23]微调获得文本向量表示;
- NoteLLM[26]则通过新增训练任务和修改 LLM 结构实现文本-图像嵌入
附录C 定性分析
- 表5 通过实例直观分析了 RARE 各组件的作用

- 观察 表5 可知:
- (1) 零样本 LLM 缺乏对提示的推理过程,仅依赖对 Query 的表层理解,导致大量低质案例;
- (2) 知识注入阶段教会 LLM 如何推理,使其能分步分析 Query 、提供商业意图并判断相关性,但多样性不足;
- (3) 格式微调阶段指导模型遵循规则的同时生成更多样化结果,由于训练数据多来自线上,商业意图较丰富,但自由生成过程限制了意图数量;
- (4) 引入受限解码(constrained decoding)能在保证相关性和多样性的同时显著增加商业意图数量